ANALYSIS-RESILIENCE-AND-ANONYMITY
| Field | Value |
|---|---|
| Name | [Analysis] Resilience and Anonymity |
| Slug | 195 |
| Status | raw |
| Category | Informational |
| Editor | Alexander Mozeika [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-08-25 |
Introduction
In order to guide a design of the Blend Network, this document summarises parameters (and results of analysis) of the leader election process, communication on trees and inference of relative stake. In addition to this, we considered sampling of linear trees and derived conditions under which results for communication on trees can be used. Also, we analysed the probability of linking a sender node to its message which allows us to quantify the “unlinkability of block proposer.” All these parameters (and results) were used to design (and implement) the “calculator” which can be used to quantify resilience and anonymity of communication in the Blend Network.
Finally, in this document we also analysed strategies which can be used to reduce anonymity failure and statistical properties of number of time-slots between two consecutive blocks in Cryptarchia.
Analysis
Leader election process
The leader election process is organised into epochs and each epoch is divided into time-slots.

One epoch of the leader election process. Node participates in the leader election at time-slots . The (binary) outcome of this lottery, where 0/1 corresponds to lost/won, is either observed (numbers in square brackets) or unobserved.
The leader election process has the following parameters
| Parameter | Description | Value/Range |
|---|---|---|
| Number of nodes | | |
| | Number of time-slots per epoch | |
| | Fraction of time-slots with at least one winner | |
| | The duration of a single time-slot | s |
Sampling of Linear Trees
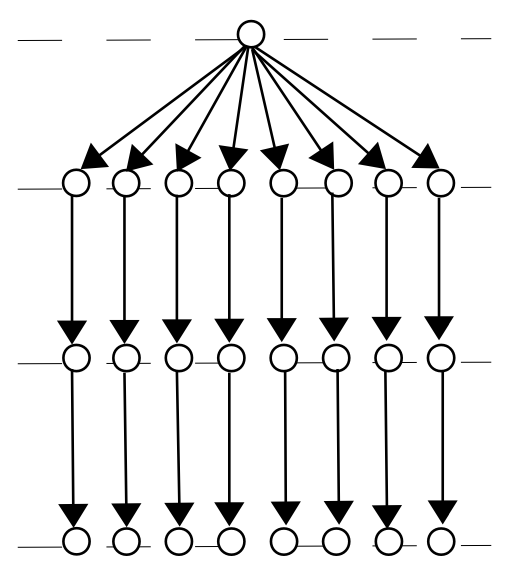
Communication on Linear Trees. A message is sent from a root node through communication paths where each path has nodes.
The number of nodes in linear tree design is , where is the number of paths and is the number of nodes in each path excluding the sender node. In the linear tree design, one node is the sender node and the other nodes are mix nodes.
We assume that in each epoch of the protocol there are sender nodes, labelled by the set . Each of the sender nodes sample nodes from the population of nodes (labeled by the set ). The total number of nodes involved in communication is .
We assume that each sender node samples nodes, independently from other nodes, using sampling without replacement. A node among the nodes sampled from just by chance can also appear in other random subsets of nodes.
The result of the sampling process described above can be represented by the following random factor-graph:
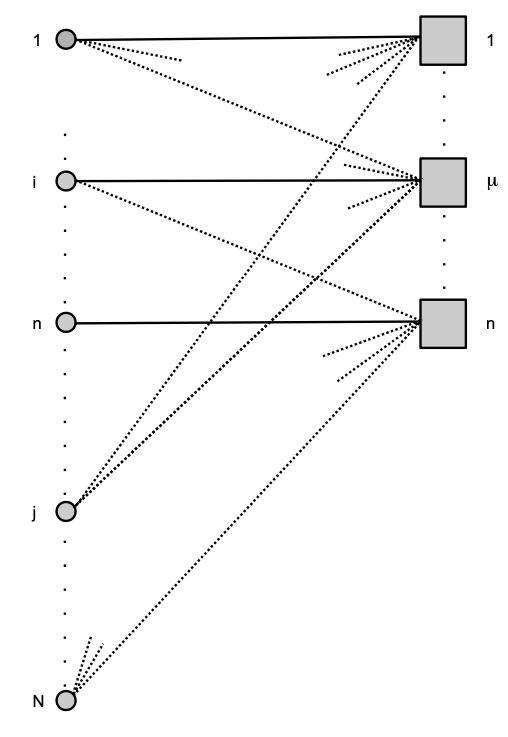
The random factor-graph generated by sampling of subsets of nodes, represented by factors (squares), from the set of all nodes represented by (filled) circles. If a node is a member of a subset then this is represented by an edge on this graph. Each node in the subset of , , is a member of at least of these subsets. Here .
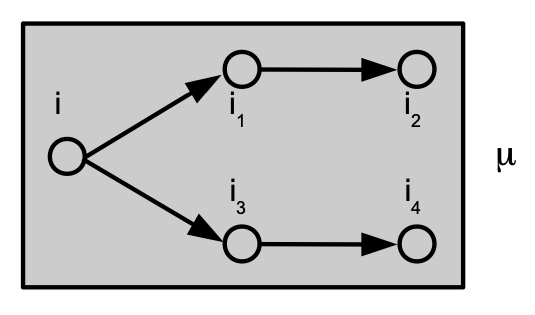
Structure of a factor in the random factor graph associated with sampling of linear trees. Here . Node , associated with , is a sending a message to nodes and via the mix nodes and .
Connectivity of a node is the number of random edges connecting this nodes to factors labelled by the set . The connectivity of a node is the number of linear trees that appears in. The connectivity is a random number from the binomial distribution
with parameters and .
The probability that a node has more than one random connection , i.e. the prob. that a mix node participates in more than one subset of mix nodes used in linear trees, for is given by the sum
where with .
We note that and for , i.e. the probability is monotonic increasing function of for . Furthermore, the probability is monotonic increasing function of , i.e. increasing the number of nodes , , in the linear tree sampled by each sender node in increases probability that a node in has more than one random connection.
The probability is computed using the following parameters
| Parameter | Description | Value/Range |
|---|---|---|
| | Number of nodes | |
| | Number of sender nodes | |
| | Number of nodes in a linear tree | |
Communication on Linear Trees
We consider the following communication system
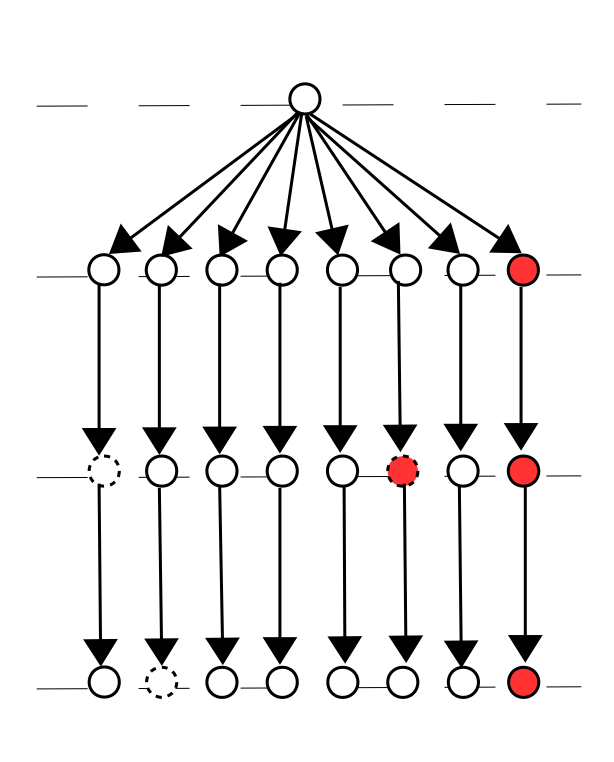
Communication on Linear Trees. A message is sent from a node through communication paths where each path has nodes. A node could be faulty (circle with dashed boundary), or adversarial (red circle). The presence of faulty node leads to communication failures. The presence of adversarial nodes could lead to communication and anonymity failures.
We assume that nodes in the population are “faulty” (faulty node is unable to relay a message) and the probability that a node is faulty is .
We assume that nodes in the population are “adversarial” (adversarial nodes are controlled by an adversary which can make nodes faulty, use them for traffic analysis, etc.) and the probability that a node is adversarial is .
If a path contains at least one faulty node then communication failure occurred.
If a path does not have any faulty nodes then this path is functioning.
If all paths have a communication failure then broadcast failure occurred.
The probability of broadcast failure is given by
We note that is the site percolation threshold of random regular graph (RRG) with connectivity C, i.e. for the RRG becomes disconnected with high probability as . The latter suggests if our model of the network is RRG then for the fraction of faulty nodes the communication is not possible with high probability in .
If all nodes in a communication path are non-faulty then this is a functioning communication path.
If there is at least one functioning communication paths where all nodes are adversarial, then adversary has opportunity to cause anonymity failure.
The probability of anonymity failure is given by
If there is at least one adversarial node in each functioning communication paths then the adversary has an opportunity to cause broadcast failure. The probability of adversarial broadcast failure is given by
The probabilities , and are computed the following parameters
| Parameter | Description | Value/Range | |
|---|---|---|---|
| | Fraction of faulty nodes | | |
| | Fraction of adversarial nodes | | |
| | Number of communication paths | | |
| | Number of nodes in a communication path | |
The code which computes above probabilities is given below
def Prob_b(K, L, qF):
"""
Compute the probability of broadcast failure.
Formula: (1 - (1 - qF)^L)^K
"""
return (1 - (1 - qF) ** L) ** K
def Prob_ab(K, L, qF, qA):
"""
Compute the probability of adversarial broadcast failure.
Formula: (1 - ((1 - qF)^L * (1 - qA)^L))^K - (1 - (1 - qF)^L)^K
"""
term1 = (1 - qF) ** L
term2 = (1 - qA) ** L
return (1 - (term1 * term2)) ** K - (1 - term1) ** K
def Prob_a(K, L, qF, qA):
"""
Compute the probability of anonymity failure.
Formula: 1 - (1 - ((1 - qF)^L * qA^L))^K
"""
term1 = (1 - qF) ** L
term2 = qA ** L
return 1 - (1 - (term1 * term2)) ** K
Inference of relative stake
The adversary observes the leader election process of a node with the relative stake .
In time-slots, the adversary is able to observe fraction of wins in observations. The probability of observing the election outcome of a node is . For adversary uses the “naive” estimator of the true relative stake . For large , the probability that is given by
In the above, is the lottery function with parameter , and , where is the fraction of observed time-slots such that slots are observed on average.
The probability can be interpreted as adversarial “confidence” and the parameter as “accuracy”. An example of the above probability is given below
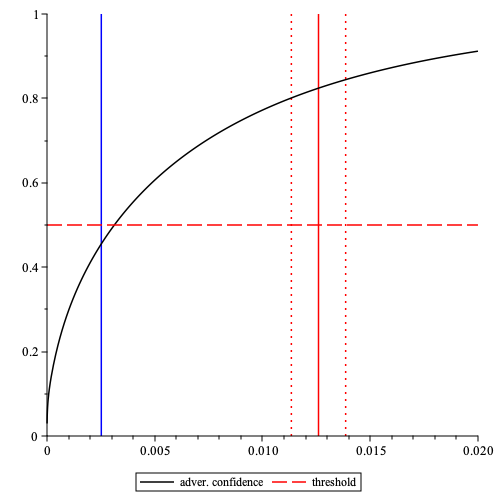
The probability that inferred relative stake , i.e. adversarial “confidence”, as a function of true relative stake obtained in time-slots (this value is used in Cardano) when the fraction of slots is observed. Here the probability that stake of a node with the true stake (the max. stake in the Bitcoin network), represented by a red vertical line, is inferred with an “accuracy” within the fraction of relative stake , represented by red vertical dotted lines, is approx. . The red dashed horizontal line corresponds to the threshold . The blue vertical line at is the result of dividing the stake among the nodes.
The probability , i.e. adversarial “confidence,” is computed using the following parameters:
| Parameter | Description | Value/Range |
|---|---|---|
| | Number of slots per epoch | |
| | Fraction of non-empty slots | |
| | Relative stake of a node | |
| | “Accuracy” parameter | |
| | Fraction of observed time-slots | |
The code which computes adversarial “confidence” is given below
def phi(alpha, f):
return 1 - (1 - f) ** alpha
def dphi(alpha, f):
return -((1 - f) ** alpha) * log(1 - f)
def Prob2(alpha, epsilon, T, q):
sqrt2 = sqrt(2.0)
phi_alpha = phi(alpha, f)
# Denominator term
denominator = (
erf((phi_alpha - 1) * sqrt2 / (2 * sqrt(phi_alpha * (1 - phi_alpha) / (T * q))))
- erf(phi_alpha * sqrt2 / (2 * sqrt(phi_alpha * (1 - phi_alpha) / (T * q))))
)
# Numerator term
numerator = -2.0 * erf(
sqrt2 * epsilon / (2 * sqrt(phi_alpha * (1 - phi_alpha) / (T * q)))
)
# Final result
return numerator / denominator
# Compute epsilon = dphi(alpha) * alpha * gamma
epsilon = dphi(alpha, f) * alpha * gamma
# Compute Prob2
Prob2_result = Prob2(alpha, epsilon, T, q)
The probability can also compute the (minimum) number of time-slots, , such that , for some . Here is the time needed by an adversary to achieve “confidence” greater than . The code which computes is given below
T0 = T # One epoch
T1 = 730 * T # 10 years
dT = 10**3 # Step size
if Prob2_t < delta:
# Increase T until Prob2_result >= delta
t = T0
while t <= T1 and Prob2_t < delta:
Prob2_t = Prob2(alpha, epsilon, t, result3)
t += dT
else:
# Decrease T until Prob2_result <= delta
t = T
while t >= 100 and Prob2_t > delta:
Prob2_t = Prob2(alpha, epsilon, t, result3)
t -= dT
Adversarial Confidence as a Measure of Statistical “Noise”
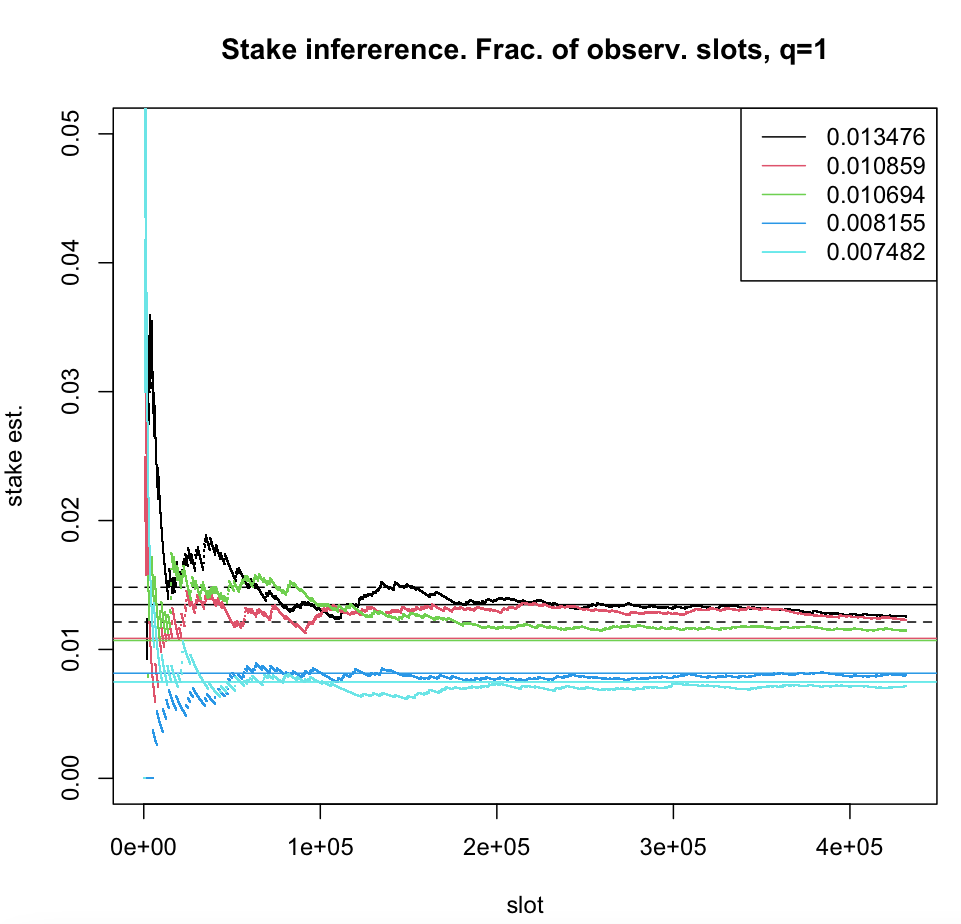
The probability , where is the (average) number of time-slots observed by adversary in one epoch, can be seen as a measure of the magnitude of “noise” which prevents accurate measurements of the relative stake . One source of this noise is the actual (stochastic) leader election process and the other is the sampling (or “observation”), controlled by parameter , of the latter by an adversary. For , i.e. all time-slots are observed, and leader election process is the only source of noise. In this regime, for a given accuracy (), the relative stake can be inferred with high confidence as can be seen in the figure below
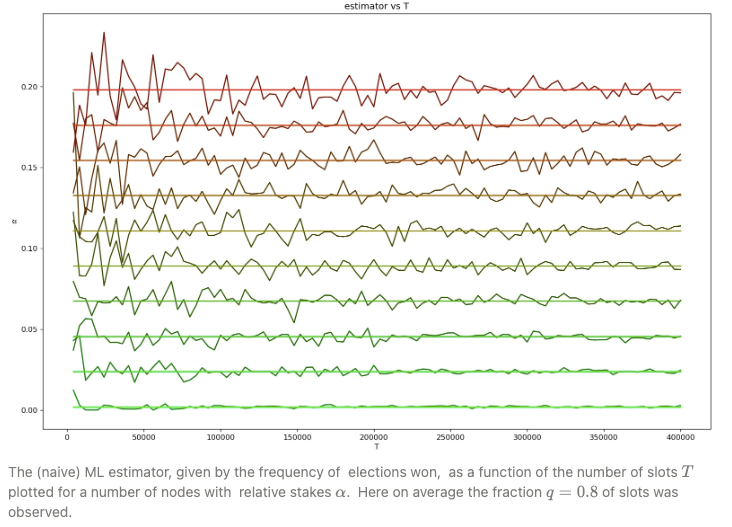
The (relative) stake estimator , computed in one epoch of leader election process, plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. For a node with the stake the prob. , where , (fraction of observed time-slots) and (number of time-slots in one epoch). The boundaries of the interval for are represented by dashed horizontal lines.
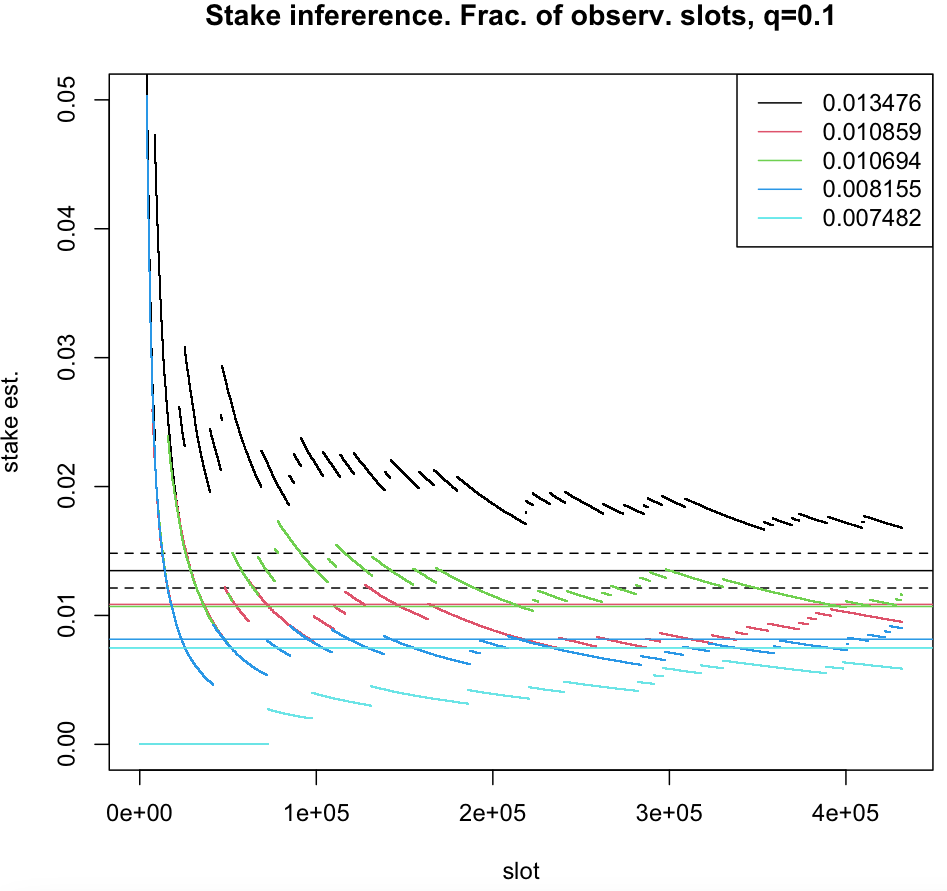
For , sampling becomes an additional source of noise interfering with measurements done by adversary. Here, for a given accuracy, the confidence deteriorates as (see figures below).
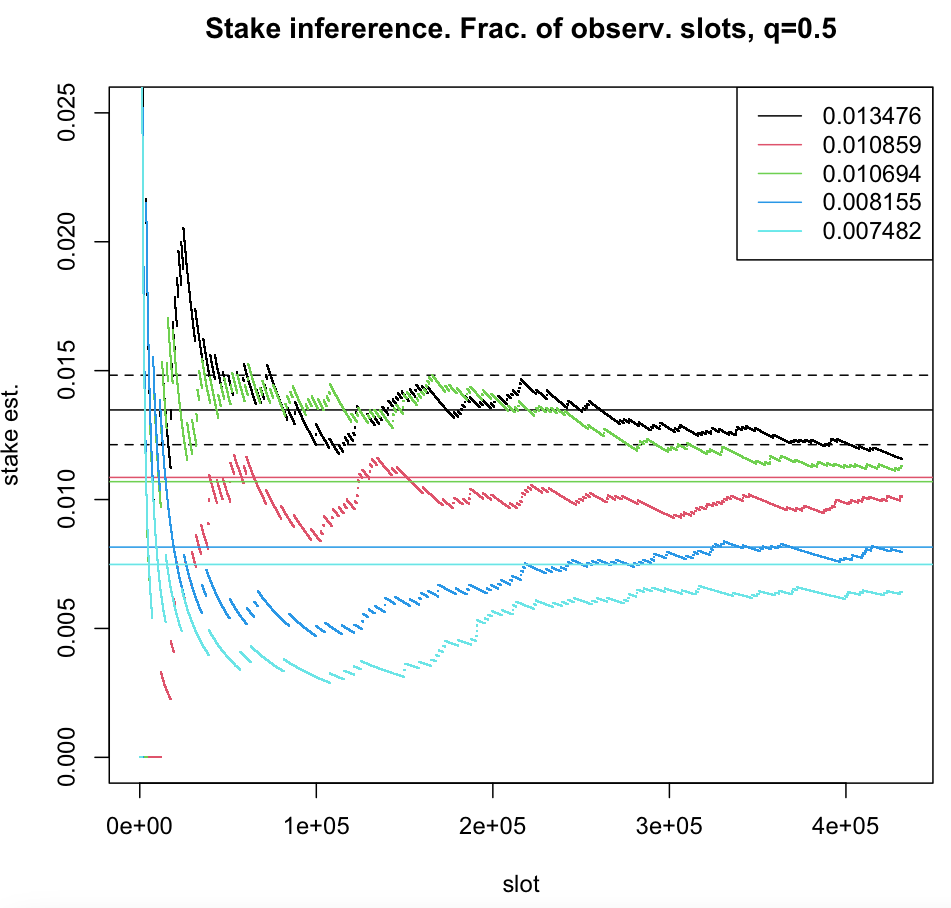
The (relative) stake estimator , computed in one epoch of the leader election process, plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. For a node with the stake the prob. , where , (fraction of observed time-slots) and (number of time-slots in one epoch). The boundaries of the interval for are represented by dashed horizontal lines.
The (relative) stake estimator , computed in one epoch of leader election process, plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. For a node with the stake the prob. , where , (fraction of observed time-slots) and (number of time-slots in one epoch). The boundaries of the interval for are represented by dashed horizontal lines.
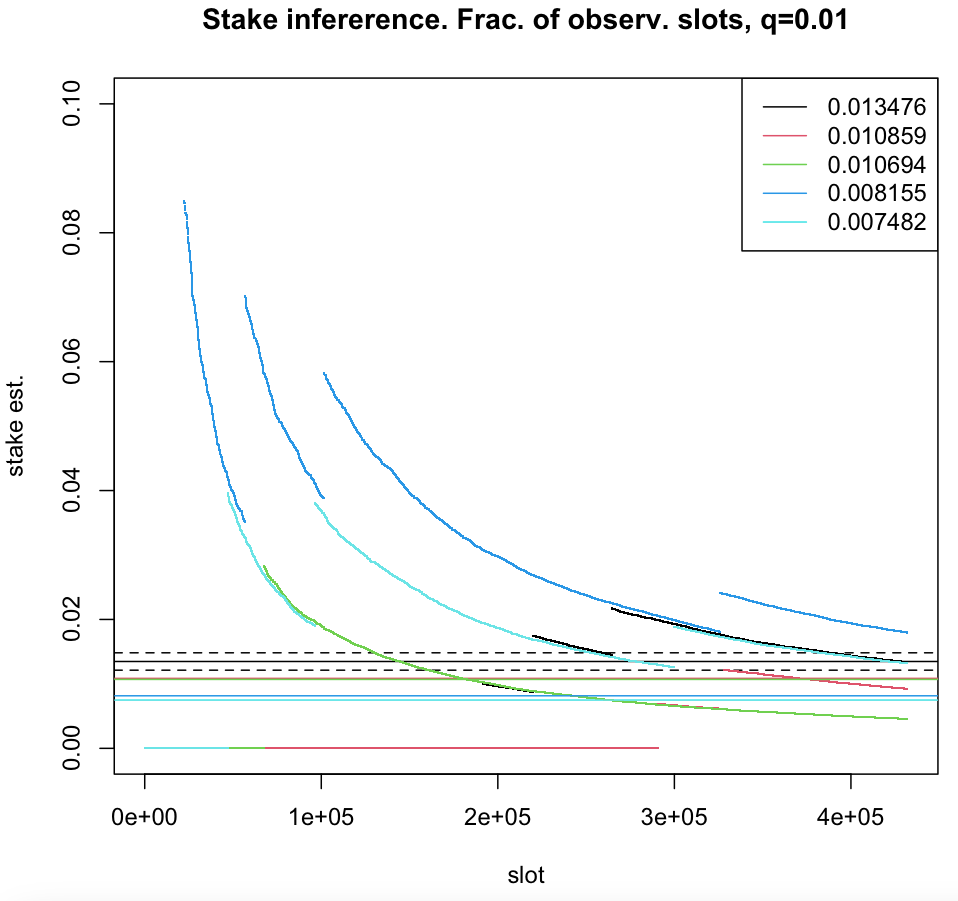
The (relative) stake estimator , computed in one epoch of leader election process, plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. For a node with the stake the prob. , where , (fraction of observed time-slots) and (number of time-slots in one epoch). The boundaries of the interval for are represented by dashed horizontal lines.
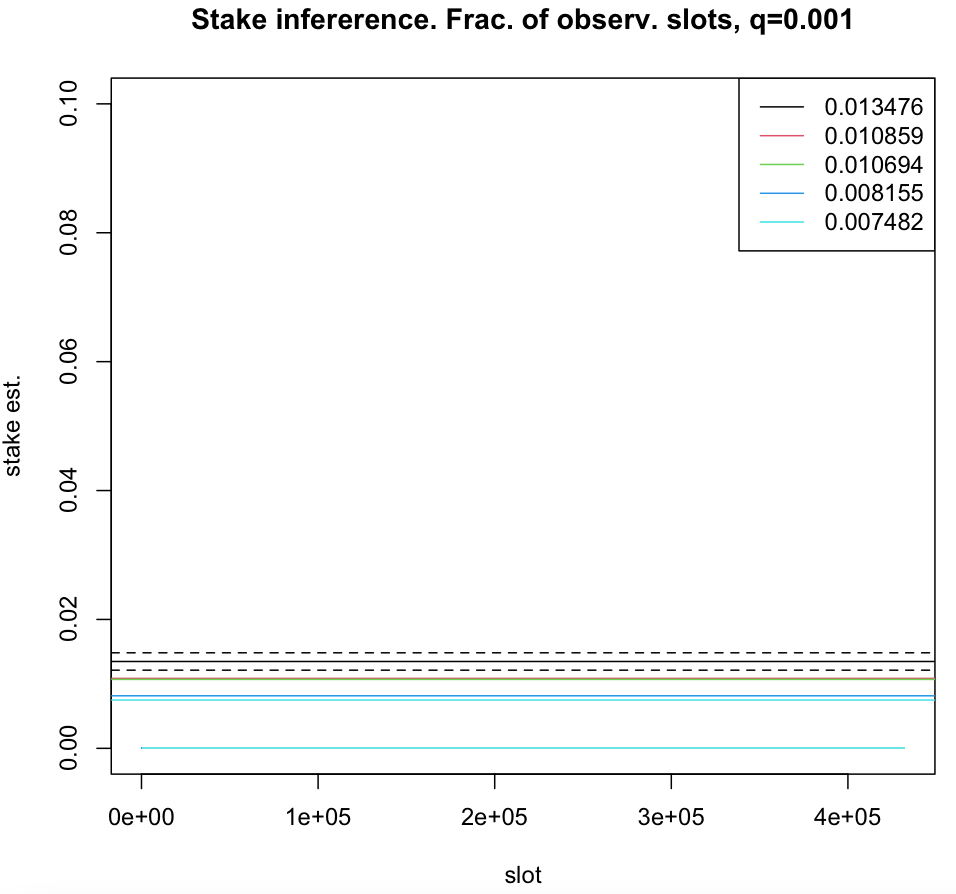
The (relative) stake estimator , computed in one epoch of leader election process, plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. For a node with the stake the prob. , where , (fraction of observed time-slots) and (number of time-slots in one epoch). The boundaries of the interval for are represented by dashed horizontal lines.
Let us define a function which compares properties of inference for and as follows
We note that above is when , i.e. no sampling noise, and is growing when (see figure below). Hence, above can be seen as “amplitude” of the sampling noise.
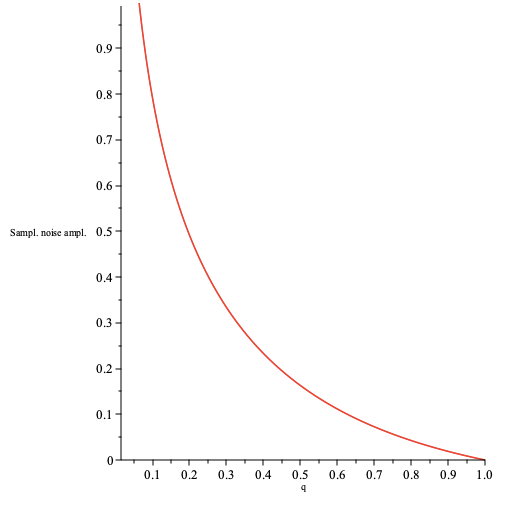
plotted as function of for and .
The Unlinkability of Block Proposers
We assume that node wins the election and broadcasts message to the network using linear trees. We assume that in the network the sender node has neighbouring nodes. Message is first sent to the neighbouring nodes then, via the latter, to the rest of the network. A node in the neighbourhood , where , is adversarial with the prob. . The prob. that at least one node in is adversarial is .
If has at least one adversarial neighbour and anonymity failure occurred then the message can linked to the sender node . We note that just occurrence of the anonymity failure alone is not sufficient to link to and at least one compromised node is also needed in . Furthermore, an adversary may need not one but at least compromised nodes in . The probability of the latter is given by the binomial
We note that the case one adversarial node in is recovered by setting in the above. The probability of above event, given that won the election, is the product of two probabilities
We note that in above we assumed that , i.e. there are no faulty nodes in the network. The probability above is an upper bound for a scenario with faulty nodes. Since for , the prob. of anonymity failure is an upper bound on the above prob. If node has (relative) stake then the prob. of node winning is , where is thelottery function. Hence, the prob. that the message , sent by the winning node , can be linked to is given by
The prob. that message can not be linked to the sender is
Hence the prob. that any message sent by node can be linked to in elections is given by
For the above prob. to be greater than some threshold (for example ) the number of elections has to satisfy the following inequality
The minimum for which above inequality holds , which is the RHS of the above, is computed using the following parameters
| Parameter | Description | Value/Range |
|---|---|---|
| | Prob. threshold | |
| | Fraction of non-empty slots | |
| | Relative stake of a node | |
| | Node neighbourhood size | |
| | Number of adver. nodes threshold | |
| | Fraction of adversarial nodes | |
| | Number of communication paths | |
| | Number of nodes per communication path | |
The code which computes is given below
def phi(alpha, f):
return 1 - (1 - f) ** alpha
def calculate_t(qA, L, K, alpha, f, C, nA, theta):
#compute prob. Pa
x = 1 - pow(qA, L)
Pa = (1 - pow(x, K))
#compute prob. Pan
p = 1 - qA
Pan = 0
for n in range(nA, C + 1):
Pan += comb(C, n) * (p ** (C - n)) * (qA ** n)
#compute prod. of prob.
Prob = Pan * Pa
#compute t
numerator = log(1 - theta)
denominator = log(1 - phi(alpha, f) * Prob)
t = ceil(numerator / denominator)
return t
Design of the “Calculator”
Here we combine the results for leader election process, sampling of linear trees, broadcasting on linear trees and inference of relative stake to design a calculator which takes parameters of the latter and computes properties of a node related to the resilience and anonymity of communication. The calculator has the following modules:
PDF attachment: Modules.pdf
The dependencies between modules can be represented as the following diagram
PDF attachment: Flowchart.pdf
Using above diagram of dependencies a first and later versions of the calculator were implemented as an online app. The input and output of the most recent version is presented below. The app is available in the repository.
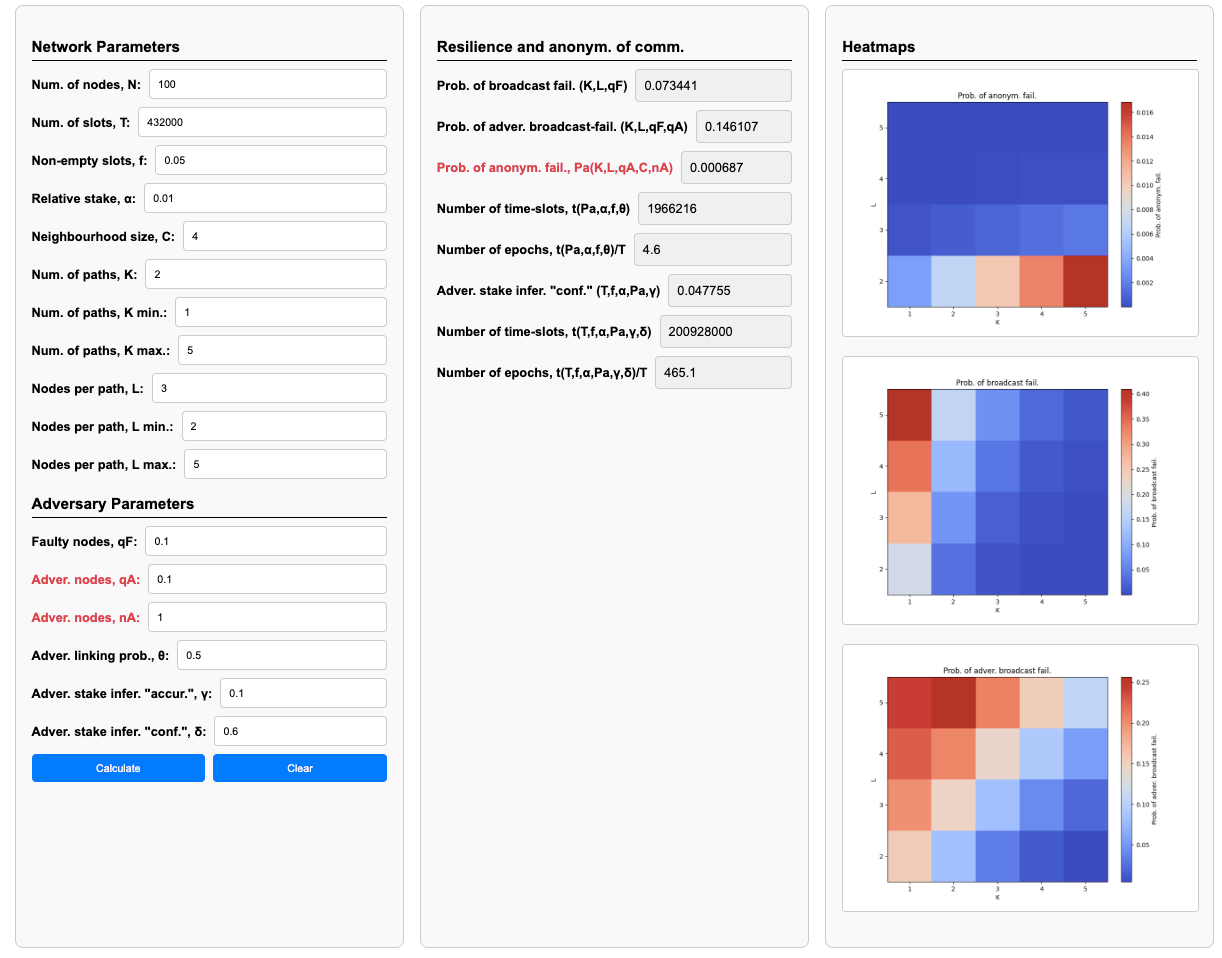
Strategies to Reduce Anonymity Failure
Let us assume that a node won at time of the election process and it broadcasts a message to the network using linear trees. Furthermore, assume that the neighbourhood of this node has at least one adversarial node. Conditioned that these two assumptions are true, the probability of anonymity failure is given by
Above corresponds to a scenario when a node at time sends a message through paths of length (see figure) constructed from nodes sampled (with replacement) from the set of network nodes . Here and is, respectively, the fraction of faulty and adversarial nodes in the network.
For , i.e. a message is sent through one path, the probability of anonymity failure is given by
We note that in above is the prob. that path is functional and is the prob. that every single node on this path is adversarial. Hence is the prob. that either the path is not functional or at least one node in the path is not adversarial.
Now let us assume that node sends the same message (or different messages) through different paths of length at times (see figure below)
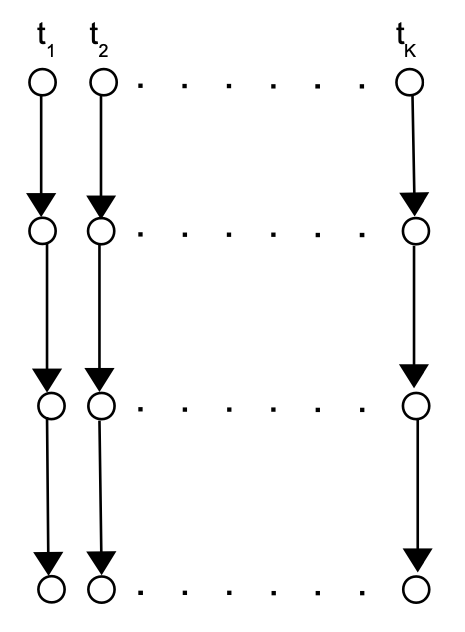
Communication on Linear Trees. Node sends a message at times . Each time a different, sampled randomly (with replacement) from , communication path of nodes is used.
After sending the first message at time the prob. of anonymity failure is , after sending the second message at time the prob. of anonymity failure is , etc. Thus after sending the last message at time the prob. anonymity failure is , i.e. the same as sending a message through paths simultaneously. We note that for fixed the prob. is monotonic increasing function of and hence is monotonic increasing function of the number of sent messages as can be seen in the figure below.
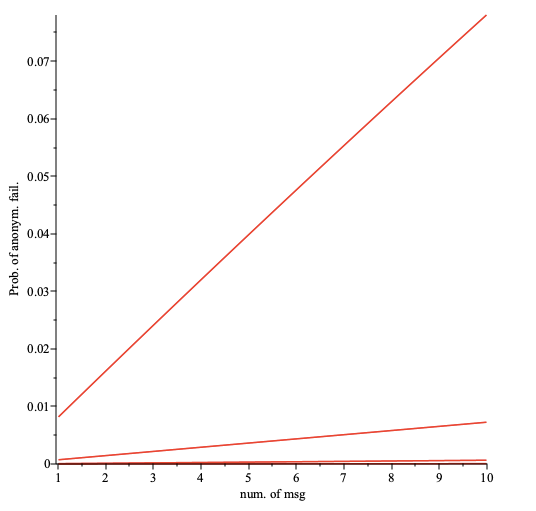
The prob. of anonymity failure as a function of the number of sent messages plotted for the number of nodes per path (top to bottom). Here the fraction of faulty nodes is and the fraction of adversarial nodes is .
Furthermore, the probability that no anonymity failure occurred after sending messages is given by
From above, it follows that for we have
Hence the probability that no anonymity failure occurred is much larger if the number of messages sent is much less than . Equivalently, the probability of anonymity failure is much smaller if the number of messages sent is much less than .
We now consider the prob. of broadcast failure
which is a monotonic decreasing function of when is fixed. Hence is monotonic decreasing function of the number of sent messages as can be seen in the figure below.
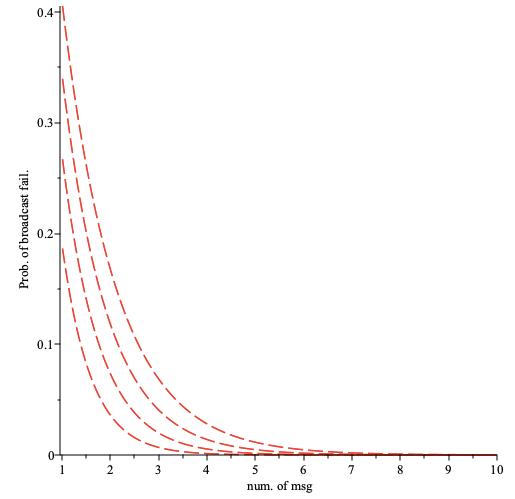
The prob. of broadcast failure as a function of the number of sent messages plotted for the number of nodes per path (bottom to top). Here the fraction of faulty nodes is .
We note that the probability of adversarial broadcast-failure behaves in a similar way as can be seen in the figure below
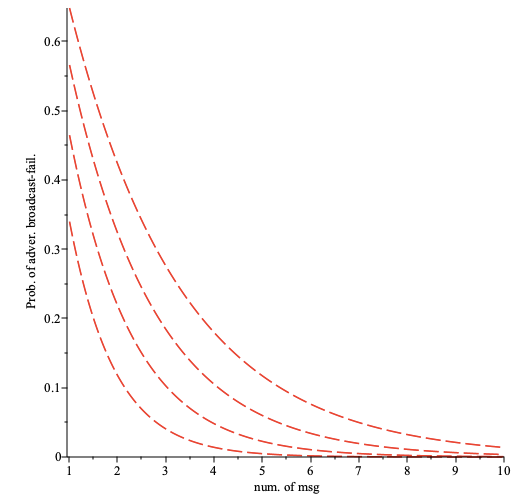
The prob. of adversarial broadcast-failure as a function of the number of sent messages plotted for the number of nodes per path (bottom to top). Here the fraction of faulty nodes is and the fraction of adversarial nodes is .
The number of nodes used for broadcasting of messages is , i.e. grows linearly with the number of messages .
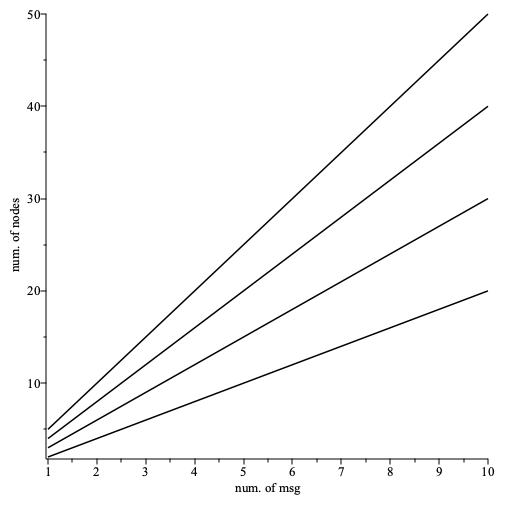
The number of nodes used in broadcasting as a function of the number of sent messages plotted for the number of nodes per path (bottom to top).
We note that
is the probability that the first occurrence of a successful broadcast requires sending messages. We note that above is generalisation of the Geometric prob. distribution.
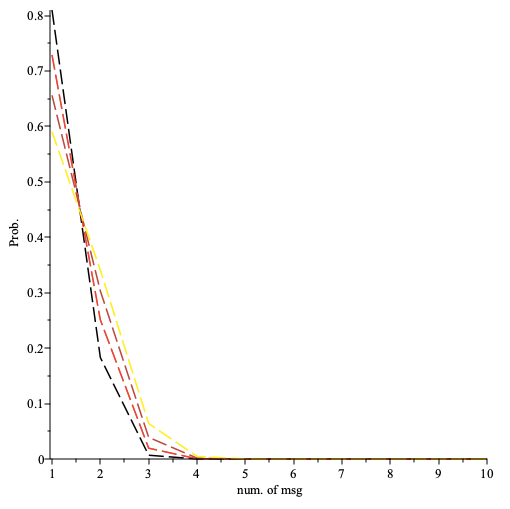
The probability that the first occurrence of a successful broadcast requires sending number of messages () plotted for the number of nodes per path (black, red, orange,yellow). Here the fraction of faulty nodes is .
From the above, it follows that
is the prob. that the first occurrence of a successful broadcast requires sending more than messages.
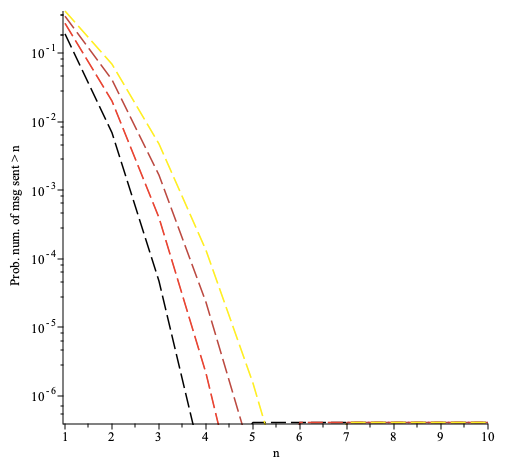
The prob. that the first occurrence of broadcast requires sending more than messages as a function of plotted for the number of nodes per path (bottom to top). Here the fraction of faulty nodes is .
In a similar manner, we obtain the probability
that the first occurrence of anonymity failure requires sending messages.
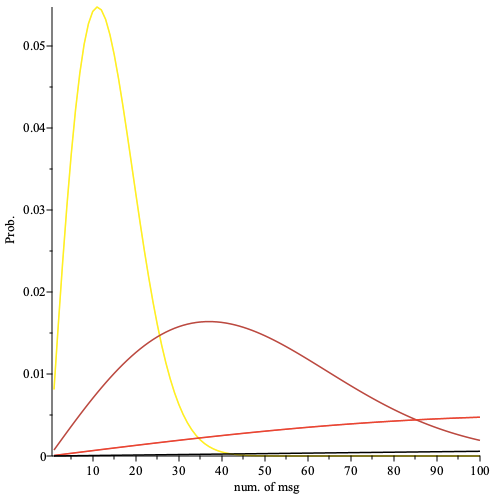
The prob. that the first occurrence of anonymity failure requires sending number of messages () plotted for the number of nodes per path (yellow, orange, red, black). Here the fraction of faulty nodes is and the fraction of adversarial nodes is .
From the above, it follows that
is the prob. that the first occurrence of anonymity failure requires sending less than messages.
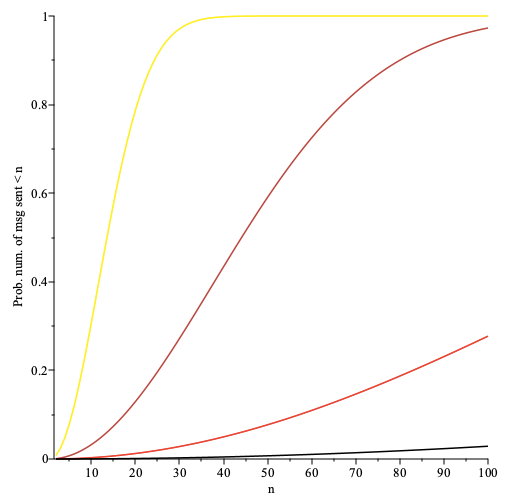
The prob. that the first occurrence of anonymity failure requires sending less than messages as a function of plotted for the number of nodes per path (top to bottom). Here the fraction of faulty nodes is and the fraction of adversarial nodes is .
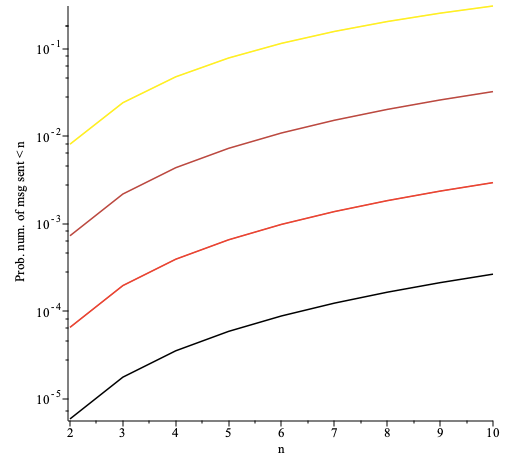
The prob. that the first occurrence of anonymity failure requires sending less than messages as a function of plotted for the number of nodes per path (top to bottom). Here the fraction of faulty nodes is and the fraction of adversarial nodes is .
Analysis of Latency
We consider a network constructed from nodes. We assume that a message sent from node , via nodes of , to the network using the broadcast method of communication. The message is delayed at the node by the amount of time, at the node by the amount of time, etc. Furthermore, a message traveling between the nodes and is delayed by due to the latency of broadcast on used for communication.
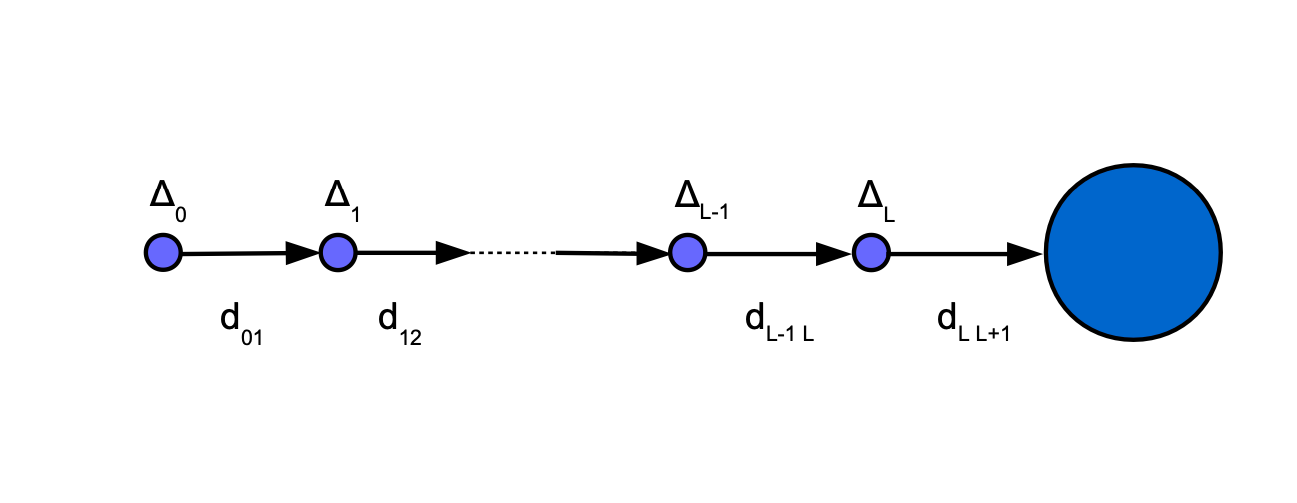
A message is sent by node to the network via nodes using the broadcast mode of communication. Here nodes are represented by blue circles and is represented by large blue circle.
Assuming that the message was successfully broadcasted by the last node to the network , the total delay is given by . We note that for and we have a simple upper bound
We note that we have equality in the above when and , i.e. all delays are the same.
Assuming that sender node monitors, via observation of broadcasts on , how a message is propagated along the path, the sender node sends first messages and if this message is not broadcasted to after some time, for example after time , it will send a second message and if this message is not broadcasted it send a third message, etc. We note that a worst case scenario of above strategy is when the 1st message “travels” to the last node , but is not broadcasted to the network . Then nodes send a 2nd message and again this message is not broadcasted by the last node, etc. Assuming that the -th message is broadcasted by the last node to , gives us that the total delay in the sequential scenario is at most
if the delay on each -th path, i.e. the value of , is known exactly.
Furthermore, we have the following inequality
where and . We can assume that and .
We note that when messages are sent simultaneously and if at least one of them is successfully broadcasted by a last node to the network , then the total delay is at most
if the delay on each -th path, i.e. the value of , is known exactly. Furthermore, for and we have the following inequality
From the above, it follows that in the worst case the latency of sequential communication is times the latency of synchronous communication.
Let us assume that , and sender node is not delaying messages. The latter gives us the upper bound on latency in synchronous communication and for the upper bound on latency of sequential communication.
The Number of Time-Slots Between Two Consecutive Blocks
In the leader election process the probability of winning a slot is and the number of time-slots per epoch is . Assuming that winning a slots results in generation of a valid block, the number of time-slots between two consecutive blocks, , follow the geometric distribution
where . Follows from above that the average of is , i.e. on average we expected to see a next block after time-slots. The probability that is greater than the average is given by
For , the above gives us . Furthermore, the maximum of observed in time-slots (approximately) follows the distribution
where .
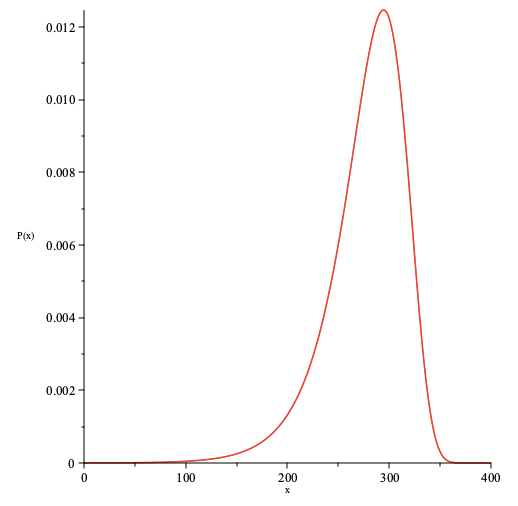
The probability distribution as a function of plotted for and .
We note that the mode of is at and hence the typical value of the maximum of observed in time-slots for is . The prob. that the maximum of observed in time-slots for is greater than can be computed with high accuracy from simulations and is as suggested by the simulation data tabulated below.
| Num. of samples | Prob. |
|---|---|
| | |
| | |
| | |
| | |
The histogram of the maximum of obtained in one such simulation is presented below
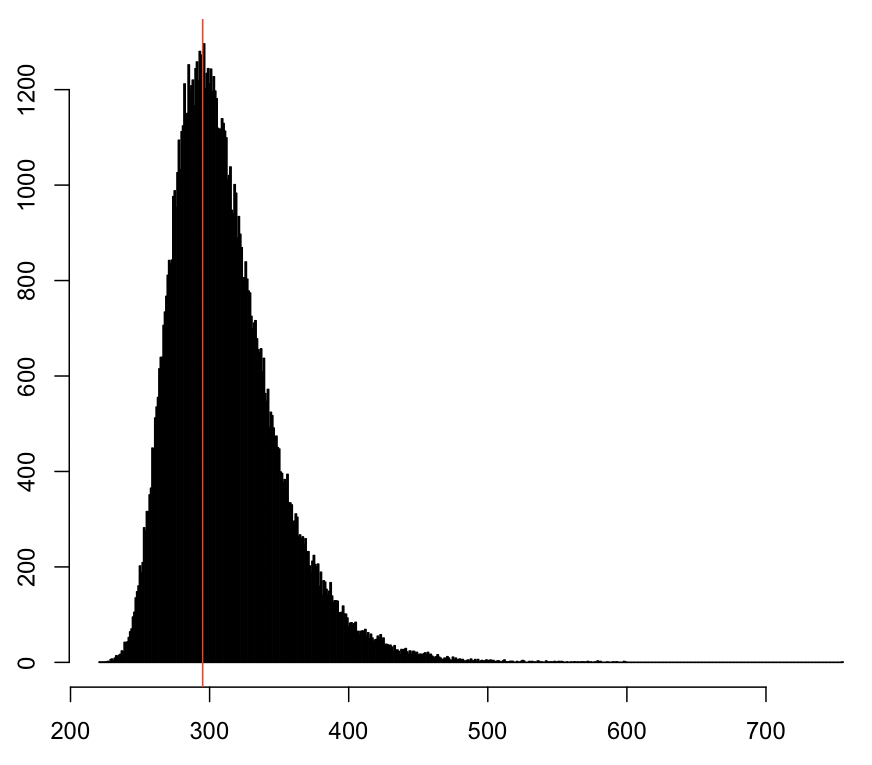
This histogram of the maximum number of time-slots between two consecutive blocks, , obtained in simulations of one epoch with and . The red vertical line corresponds to the typical value of . Here estimating the prob. that gives us the value of .
Bibliography
Svante Janson. (2009). On percolation in random graphs with given vertex degrees. Electron. J. Probab. 14: 86 - 118. https://doi.org/10.1214/EJP.v14-603
Gordon, L., Schilling, M. F. and Waterman, M. S. (1986). An extreme value theory for long head runs. Probability Theory and Related Fields 72: 279-287. https://doi.org/10.1007/BF00699107