Logos LIP Index
An IETF-style index of Logos-managed LIPs across Storage, Messaging, Blockchain, AnonComms, and Research sections. Use the filters below to jump straight to a specification.
About
The Logos LIP Index collects specifications maintained by Logos Research across Messaging, Blockchain, Storage, and AnonComms. Each RFC documents a protocol, process, or system in a consistent, reviewable format.
This site is generated with mdBook from the repository: logos-co/logos-lips.
Contributing
- Open a pull request against the repo.
- Add or update the RFC in the appropriate component folder.
- Include clear status and category metadata in the RFC header table.
If you are unsure where a document belongs, open an issue first and we will help route it.
We keep RFCs in Markdown within this repository; updates happen through pull requests.
Links
- Logos Research: https://vac.dev
- IETF RFC Series: https://www.rfc-editor.org/
- Repository: https://github.com/logos-co/logos-lips
Messaging LIPs
Logos Messaging builds a family of privacy-preserving, censorship-resistant communication protocols for web3 applications.
Contributors can visit Messaging LIPs for new Messaging specifications under discussion.
Core
Core messaging delivery specifications.
Core
Core messaging delivery raw specifications.
RELAY-SHARDING
| Field | Value |
|---|---|
| Name | Waku v2 Relay Sharding |
| Slug | 178 |
| Status | raw |
| Type | RFC |
| Category | core |
| Tags | waku/core |
| Editor | Daniel Kaiser [email protected] |
| Contributors | Simon-Pierre Vivier [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
48600b5— Migrate logos-messaging/specs into docs/messaging/ (#315)
Abstract
This document describes ways of sharding the Waku relay topic, allowing Waku networks to scale in the number of content topics.
Note: Scaling in the size of a single content topic is out of scope for this document.
Background and Motivation
Unstructured P2P networks are more robust and resilient against DoS attacks compared to structured P2P networks). However, they do not scale to large traffic loads. A single libp2p gossipsub mesh, which carries messages associated with a single pubsub topic, can be seen as a separate unstructured P2P network (control messages go beyond these boundaries, but at its core, it is a separate P2P network). With this, the number of Waku relay content topics that can be carried over a pubsub topic is limited. This prevents app protocols that aim to span many multicast groups (realized by content topics) from scaling.
This document specifies three pubsub topic sharding methods (with varying degrees of automation), which allow application protocols to scale in the number of content topics. This document also covers discovery of topic shards.
Named Sharding
Note: As of 2025-07-24 freely named sharding has been deprecated from all Waku implementations. It is still described here as background for static and automatic sharding.
Named sharding offers apps to freely choose pubsub topic names. It is RECOMMENDED for App protocols to follow the naming structure detailed in 23/WAKU2-TOPICS. With named sharding, managing discovery falls into the responsibility of apps. For this reason it is NOT RECOMMENDED that app protocols and Waku implementations make use of named sharding.
From an app protocol point of view, a subscription to a content topic waku2/xxx on a shard named /mesh/v1.1.1/xxx would look like:
subscribe("/waku2/xxx", "/mesh/v1.1.1/xxx")
Static Sharding
Static sharding is an extension of named sharding that offers a set of shards with fixed names. Assigning content topics to specific shards is up to app protocols, but the discovery of these shards is managed by Waku. This is the RECOMMENDED default format for shards chosen by an app protocol.
Static shards are managed in shard clusters of 1024 shards per cluster. Waku static sharding can manage shard clusters. Each shard cluster is identified by its index (between and ).
It is RECOMMENDED that, for simplification of configuration and various APIs,
all app-level protocols only interact with cluster and shard
and never the fully-formed pubsub topic,
which is a concern internal to the Waku implementation.
A specific shard cluster is either globally available to all apps, specific for an app protocol, or reserved for automatic sharding (see next section).
Note: This leads to shards for which Waku manages discovery.
App protocols can either choose to use global shards, or app specific shards.
Like the IANA ports, shard clusters are divided into ranges:
| index (range) | usage |
|---|---|
| 0 - 15 | reserved |
| 16 - 65535 | app-defined networks |
The informational RFC WAKU2-RELAY-STATIC-SHARD-ALLOC lists the current index allocations.
The global shard with index 0 and the "all app protocols" range are treated in the same way, but choosing shards in the global cluster has a higher probability of sharing the shard with other apps. This offers k-anonymity and better connectivity, but comes at a higher bandwidth cost.
Since the introduction of the Waku Network, it is RECOMMENDED that apps choose a cluster + shard within the defined range for that network.
The name of the pubsub topic corresponding to a given static shard is specified as
/waku/2/rs/<cluster_id>/<shard_number>,
an example for the 2nd shard in the global shard cluster:
/waku/2/rs/0/2.
Note: Because all shards distribute payload defined in 14/WAKU2-MESSAGE via protocol buffers, the pubsub topic name does not explicitly add
/prototo indicate protocol buffer encoding. We usersto indicate these are relay shard clusters; further shard types might follow in the future.
From an app point of view, a subscription to a content topic waku2/xxx on a static shard would look like:
subscribe("/waku2/xxx", 16, 43)
for shard 43 of the Status app (which has allocated index 16).
Discovery
Waku v2 supports the discovery of peers within static shards, so app protocols do not have to implement their own discovery method.
Nodes add information about their shard participation in their WAKU2-ENR. Having a static shard participation indication as part of the ENR allows nodes to discover peers that are part of shards via 33/WAKU2-DISCV5 as well as via DNS.
Note: In the current version of this document, sharding information is directly added to the ENR. (see Ethereum ENR sharding bit vector here Static relay sharding supports 1024 shards per cluster, leading to a flag field of 128 bytes. This already takes half (including index and key) of the ENR space of 300 bytes. For this reason, the current specification only supports a single shard cluster per node. In future versions, we will add further (hierarchical) discovery methods. We will update WAKU2-ENR accordingly, once this RFC moves forward.
This document specifies two ways of indicating shard cluster participation.
The index list SHOULD be used for nodes that participante in fewer than 64 shards,
the bit vector representation SHOULD be used for nodes participating in 64 or more shards.
Nodes MUST NOT use both index list (rs) and bit vector (rsv) in a single ENR.
ENRs with both rs and rsv keys SHOULD be ignored.
Nodes MAY interpret rs in such ENRs, but MUST ignore rsv.
Index List
| key | value |
|---|---|
rs | <2-byte shard cluster index> | <1-byte length> | <2-byte shard index> | ... | <2-byte shard index> |
The ENR key is rs.
The value is comprised of
- a two-byte shard cluster index in network byte order, concatenated with
- a one-byte length field holding the number of shards in the given shard cluster, concatenated with
- two-byte shard indices in network byte order
Example:
| key | value |
|---|---|
rs | 16u16 | 3u8 | 13u16 | 14u16 | 45u16 |
This example node is part of shards 13, 14, and 45 in the Status main-net shard cluster (index 16).
Bit Vector
| key | value |
|---|---|
rsv | <2-byte shard cluster index> | <128-byte flag field> |
The ENR key is rsv.
The value is comprised of a two-byte shard cluster index in network byte order concatenated with a 128-byte wide bit vector.
The bit vector indicates which shards of the respective shard cluster the node is part of.
The right-most bit in the bit vector represents shard 0, the left-most bit represents shard 1023.
The representation in the ENR is inspired by Ethereum shard ENRs),
and this).
Example:
| key | value |
|---|---|
rsv | 16u16 | 0x[...]0000100000003000 |
The [...] in the example indicates 120 0 bytes.
This example node is part of shards 13, 14, and 45 in the Status main-net shard cluster (index 16).
(This is just for illustration purposes, a node that is only part of three shards should use the index list method specified above.)
Automatic Sharding
Autosharding is an extension of static sharding,
where shards can automatically be selected based on content topic.
This is only possible in cases where there exists a clear definition of a "network" combining multiple shards
with a predefined cluster ID and number of shards in the network (number_of_shards_in_network).
An example is the Waku Network.
To use autosharding,
the shards corresponding to the network definition MUST be numbered from 0 and monotonously increase to number_of_shards_in_network - 1.
The Waku Network SHOULD be considered the default destination for all app-level protocols.
In cases where the Waku Network is not used but autosharding is desired,
the default number of shards in a network SHOULD be considered 1.
When using autosharding, shards (pubsub topics) MUST be computed from content topics with the procedure below.
Algorithm
Hash using Sha2-256 the concatenation of
the content topic application field (UTF-8 string of N bytes) and
the version (UTF-8 string of N bytes).
The shard to use is the modulo of the hash by the number of shards in the network.
Example
| Field | Value | Hex |
|---|---|---|
application | "myapp" | 0x6d79617070 |
version | "1" | 0x31 |
network shards | 8 | 0x8 |
- SHA2-256 of
0x6d7961707031is0x8e541178adbd8126068c47be6a221d77d64837221893a8e4e53139fb802d4928 0x8e541178adbd8126068c47be6a221d77d64837221893a8e4e53139fb802d4928MOD8equals0- The shard to use has index 0
Content Topics Format for Autosharding
Content topics MUST follow the format in 23/WAKU2-TOPICS.
In addition, a generation prefix MAY be added to content topics.
When omitted default values are used.
Generation default value is 0.
- The full length format is
/{generation}/{application-name}/{version-of-the-application}/{content-topic-name}/{encoding} - The short length format is
/{application-name}/{version-of-the-application}/{content-topic-name}/{encoding}
Example
- Full length
/0/myapp/1/mytopic/cbor - Short length
/myapp/1/mytopic/cbor
Generation and scaling
The generation number monotonously increases and indirectly refers to the total number of shards of a defined network.
In order to scale,
each subsequent generation of a defined network can define a larger number_of_shards_in_network,
with the content topics only sharded to the number of shards defined for the corresponding generation of the network.
Generational autosharding MUST be clearly defined for each generation of a network.
For example, consider a specific network defined as the 2 shards 0 and 1 in cluster 32.
This will automatically be assumed to be generation 0 of this network.
All content topics in the format /myapp/1/mytopic/cbor defined for apps on this network will be autosharded to 1 of these 2 shards.
If in future the specifiers of this network want to scale the network to 4 shards (i.e. shards 0 to 3 on cluster 32),
they MUST define a generation 1 version of the network with number_of_shards_in_network = 4.
New content topics for apps on generation 1 of this network MUST be prefixed in the format /1/myapp/1/mytopic/cbor to be autosharded into all 4 shards.
Legacy generation 0 content topics will still only be autosharded into the original 2 shards.
Topic Design
Content topics have 2 purposes: filtering and routing.
Filtering is done by changing the {content-topic-name} field.
As this part is not hashed, it will not affect routing (shard selection).
The {application-name} and {version-of-the-application} fields do affect routing.
Using multiple content topics with different {application-name} field has advantages and disadvantages.
It increases the traffic a relay node is subjected to when subscribed to all topics.
It also allows relay and light nodes to subscribe to a subset of all topics.
Problems
Hot Spots
Hot spots occur (similar to DHTs), when a specific mesh network (shard) becomes responsible for (several) large multicast groups (content topics). The opposite problem occurs when a mesh only carries multicast groups with very few participants: this might cause bad connectivity within the mesh.
The current autosharding method does not solve this problem.
Note: Automatic sharding based on network traffic measurements to avoid hot spots in not part of this specification.
Discovery
For the discovery of automatic shards this document specifies two methods (the second method will be detailed in a future version of this document).
The first method uses the discovery introduced above in the context of static shards.
The second discovery method will be a successor to the first method, but is planned to preserve the index range allocation. Instead of adding the data to the ENR, it will treat each array index as a capability, which can be hierarchical, having each shard in the indexed shard cluster as a sub-capability. When scaling to a very large number of shards, this will avoid blowing up the ENR size, and allows efficient discovery. We currently use 33/WAKU2-DISCV5 for discovery, which is based on Ethereum's discv5. While this allows to sample nodes from a distributed set of nodes efficiently and offers good resilience, it does not allow to efficiently discover nodes with specific capabilities within this node set. Our research log post explains this in more detail. Adding efficient (but still preserving resilience) capability discovery to discv5 is ongoing research. A paper on this has been completed, but the Ethereum discv5 specification has yet to be updated. When the new capability discovery is available, this document will be updated with a specification of the second discovery method. The transition to the second method will be seamless and fully backwards compatible because nodes can still advertise and discover shard memberships in ENRs.
Security/Privacy Considerations
See WAKU2-ADVERSARIAL-MODELS, especially the parts on k-anonymity. We will add more on security considerations in future versions of this document.
Receiver Anonymity
The strength of receiver anonymity, i.e. topic receiver unlinkablity,
depends on the number of content topics (k), as a proxy for the number of peers and messages, that get mapped onto a single pubsub topic (shard).
For named and static sharding this responsibility is at the app protocol layer.
Copyright
Copyright and related rights waived via CC0.
References
- 11/WAKU2-RELAY
- Unstructured P2P network
- 33/WAKU2-DISCV5
- WAKU2-ENR
- 23/WAKU2-TOPICS
- Ethereum ENR sharding bit vector
- Ethereum discv5 specification
- Research log: Waku Discovery
- WAKU2-RELAY-STATIC-SHARD-ALLOC
- 14/WAKU2-MESSAGE
- 64/WAKU2-NETWORK
WAKU-LIGHTPUSH
| Field | Value |
|---|---|
| Name | Waku Light Push |
| Slug | 176 |
| Status | raw |
| Type | RFC |
| Category | core |
| Editor | Zoltan Nagy [email protected] |
| Contributors | Hanno Cornelius [email protected], Daniel Kaiser [email protected], Oskar Thorén [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
48600b5— Migrate logos-messaging/specs into docs/messaging/ (#315)
previous version: /vac/waku/lightpush/2.0.0-beta1 19/WAKU2-LIGHTPUSH
Protocol identifier: /vac/waku/lightpush/3.0.0
Motivation and Goals
Light nodes with short connection windows and limited bandwidth wish to push messages to other nodes in the Waku network to request message services.
A common use case is to request that the service node publish the message to an 11/WAKU2-RELAY pubsub-topic.
Additionally, there is sometimes a need for confirmation that a message has been received "by the network"
(here, at least one node).
WAKU-LIGHTPUSH is a request/response protocol for this.
Payloads
syntax = "proto3";
message LightPushRequest {
string request_id = 1;
// 10 Reserved for future `request_type`. Currently, RELAY is the only available service.
optional string pubsub_topic = 20;
WakuMessage message = 21;
}
message LightPushResponse {
string request_id = 1;
uint32 status_code = 10; // has value 200 in case of success, see appendix
optional string status_desc = 11;
optional uint32 relay_peer_count = 12; // number of peers, the message is successfully relayed to
}
Message Relaying
Nodes that respond to LightPushRequest SHOULD
- either relay the encapsulated message via 11/WAKU2-RELAY protocol on the specified
pubsub_topic - or perform another requested service.
Services beyond [11/WAKU2-RELAY](https://github.com/logos-co/logos-lips/blob/master/docs/messaging/core/stable/11/relay.md) are yet to be defined.
Depending on the network configuration, the lightpush client may not need to provide pubsub_topic (WAKU2-RELAY-SHARDING).
If the node is unable to perform the request for some reason, it SHOULD return an error code in LightPushResponse.
Once the relay is successful, the relay_peer_count will indicate the number of peers that the node has managed to relay the message to. It's important to note that this number may vary depending on the node subscriptions and support for the requested pubsub_topic. The client can use this information to either consider the relay as successful or take further action, such as switching to a lightpush service peer with better connectivity.
The field
relay_peer_countmay not be present or has the value zero in case of error or in other future use cases, where no relay is involved.
Examples of possible error codes
| Result | Code | Note |
|---|---|---|
| SUCCESS | 200 | Successfull push, response's relay_peer_count holds the number of peers the message is pushed. |
| BAD_REQUEST | 400 | Wrong request payload. |
| PAYLOAD_TOO_LARGE | 413 | Message exceeds certain size limit, it can depend on network configuration, see status_desc for details. |
| UNSUPPORTED_PUBSUB_TOPIC | 421 | Requested push on pubsub_topic is not possible as the service node does not support it. |
| TOO_MANY_REQUESTS | 429 | DOS protection prevented this request as the current request exceeds the configured request rate. |
| INTERNAL_SERVER_ERROR | 500 | status_desc holds explanation of the error. |
| NO_PEERS_TO_RELAY | 503 | Lightpush service is not available as the node has no relay peers. |
The list of error codes is not complete and can be extended in the future.
Security Considerations
Since this can introduce an amplification factor, it is RECOMMENDED for the node relaying to the rest of the network to take extra precautions. Therefore Waku applies or will apply:
- DOS protection through request rate limitation on the service itself.
- message rate limiting via 17/WAKU2-RLN-RELAY, applied via network membership subscription.
These features are under development.
Future work
- Add support attaching RLN proof for the message requested to be relayed.
- Add support for other request types.
- Incentivization of the service
Copyright
Copyright and related rights waived via CC0.
References
WAKU-MIX
| Field | Value |
|---|---|
| Name | Waku Mix |
| Slug | 177 |
| Status | raw |
| Type | RFC |
| Category | core |
| Editor | Prem Chaitanya Prathi [email protected] |
| Contributors | Akshaya Mani [email protected], Hanno Cornelius [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
48600b5— Migrate logos-messaging/specs into docs/messaging/ (#315)
Tags
waku/core-protocol
Abstract
The document describes libp2p mix integration into waku. This integration provides higher anonymity for users publishing or querying for messages to/from the Waku network.
This document covers integration of mix with lightpush and store protocols.
Both of these are request-response based protocols that follow a service-user and a service-provider model.
A node that initiates the request is a service-user/client whereas a node that replies to the request is the service-provider/service-node.
This document also covers the aspect of relay nodes acting as mix nodes.
Background / Rationale / Motivation
Waku protocols have weak sender/originator anonymity as explained in Waku Privacy and Anonymity Analysis. Without further anonymization, it is easy to analyze the network traffic and determine the originator of messages published into the network. Topic interests of a user can be identified by analyzing Store query messages sent by a user. Same applies for topic subscriptions via Filter protocol.
Mix protocol allows libp2p nodes to send messages without revealing the sender's identity (peer ID, IP address) to intermediary mix nodes or the recipient/destination.
Anonymity is achieved by using the Sphinx packet format, which encrypts and routes messages through a series of mix nodes before reaching the recipient.
By integrating the mix protocol into the waku network, we can improve the anonymity for publishers and store query users.
Each waku relay node SHOULD be acting as a mix node that forms an overlay mix network.
This network of mix nodes SHALL relay mix messages anonymously to the recepient.
Anonymity of Filter users is not addressed by this document.
Terminology
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in RFC2119.
Theory / Semantics
Waku Mix creates an overlay network of all the Waku nodes that support the mix protocol.
Nodes with mix protocol mounted SHOULD advertise that they support mix protocol via their their chosen discovery method.
They MAY do so by updating their ENR and using one of the ENR based discovery methods.
Nodes that want higher anonymity while publishing a message via lightpush or performing a store query SHOULD use the mix protocol to route their messages to the destination.
Sender Node that would like to use mix protocol SHOULD discover enough mix nodes so that there is always a healthy pool of mix nodes available for selection.
The pool size of mix nodes SHOULD be large enough for the mixing to be effective.
We RECOMMEND a pool size of at least 100 mix nodes for the mixing to be effective.
The serialized Waku Message MUST be the payload in the sphinx packet.
To allow acknowledgments from the service-node while preserving sender anonymity, Single Use Reply Blocks or anonymous replies as specified in the original sphinx paper SHALL be used.
A node that sends messages using mix MAY use two redundant paths to have better reliability of the message being delivered.
It is up to the higher-layer mixed protocol to deduplicate redundant messages received in this way.
Node Roles
Mix protocol defines 3 roles for the nodes in the mix network - sender, exit, intermediary.
- An
sendernode is the originator node of a message, i.e a node that wishes to publish/query messages to/from the waku network. - An
exitnode is responsible for delivering messages to destination peer in the network. - An
intermediarynode is responsible for forwarding a mix packet to the next mix node in the path.
A Waku relay node SHOULD by default have mix intermediary and exit node roles in the network.
The implementation MAY provide a configuration to disable a node from acting as an intermediary\exit node.
Any waku node that wishes to publish/query messages via mix from the waku network MUST act as a sender node.
Resource-restricted/Edge nodes with short connection windows MUST only act as sender nodes and cannot function as intermediaries or exit nodes.
ENR updates
Each waku node that supports the mix intermediary or exit role SHOULD indicate the same in its discoverable ENR.
The following fields MUST be set as part of the discoverable ENR of a mix waku node:
- The
bit 5in the waku2 ENR key is reserved to indicatemixsupport. This bit MUST be set to true to indicatemixsupport. - A new field
mix-keySHOULD be set to theed25519 public keywhich is used for sphinx encryption.
Adding these fields to the ENR may cause the ENR size to cross the 300 byte limit especially in case a node supports multiple transports. This limitation will have to be addressed in future.
Discovery
Mix protocol provides better anonymity when a sender node has a sufficiently large pool of mix nodes to do path selection. This moves the problem into discovery domain and requires the following from discovery mechanisms:
- It is important for nodes to be able to discover as many nodes as possible quickly. This becomes especially important for edge nodes that come online just to publish/query messages for a short period of time.
- The discovery mechanism MUST be unbiased and not biased toward specific subsets (e.g., nodes that are topologically closer).
- It is important to have the most recent online status of the nodes so that mix paths that are selected are not broken which lead to reliability issues.
Point-3 above can be mitigated partially by choosing redundant mix paths for the same message by the sender node. This may not be an effective solution as it increases the overall bandwidth usage.
Spam Protection
Mix protocol in waku network SHOULD have rate-limiting/spam protection to handle scenarios such as below:
- Any node can generate a mix packet and publish into the mix network. Hence there needs to be some validation as to who is allowed to publish and whether the user is within allowed rate-limits.
- Any node can intentionally generate paths which are broken and send messages into the mix network.
- An attacker can spawn a huge number of mix nodes so that user behaviour is observed in order to determine traffic patterns and deanonymize users.
There is a need to enforce rate-limits and spam protect the mix network. The rate-limiting and spam protection shall be addressed as part of future work.
Tradeoffs
Using mix protocol for publishing and querying messages adds certain overhead which is primarily the delay in delivering message to the destination.
The overall additional delay D depends on the following params:
- path length
L - delay added by each intermediary node
dm - connection establishment time
dc - processing delay
dp
Delay overhead can be calculated as D = L * (dm + dc +dp)
Future Work
- Integration of waku relay with mix.
- Spam protection of mix overlay network.
- Alternative way to communicate mix-public-key in order to overcome ENR size limitations.
Copyright
Copyright and related rights waived via CC0.
References
WAKU-RENDEZVOUS
| Field | Value |
|---|---|
| Name | Waku Rendezvous discovery |
| Slug | 179 |
| Status | raw |
| Type | RFC |
| Category | core |
| Editor | Prem Chaitanya Prathi [email protected] |
| Contributors | Simon-Pierre Vivier [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
48600b5— Migrate logos-messaging/specs into docs/messaging/ (#315)
Abstract
This document describes the goal, strategy, usage, and changes to the libp2p rendezvous protocol by Waku.
Rendezvous is one of the discovery methods that can be used by Waku. It supplements Discovery v5 and Waku peer exchange.
Background and Rationale
Waku needs discovery mechanism(s) that are both rapid and robust against attacks. Fully centralised discovery (such as DNS lookup) may be fast but is not secure. Fully decentralised discovery (such as discv5) may be robust, but too slow for some bootstrapping use cases Rendezvous provides a limited, balanced solution that trades off some robustness for speed. It's meant to complement not replaced fully decentralised discovery mechanisms, like discv5
By combining rendezvous with Discv5 and 34/WAKU2-PEER-EXCHANGE, Waku nodes can more quickly reach a meaningful set of peers than by relying on a single discovery method.
Semantics
Waku rendezvous extends the libp2p rendezvous semantics by using WakuPeerRecord instead of the standard libp2p PeerRecord.
This allows nodes to advertise additional Waku-specific metadata beyond what is available in the standard libp2p peer record.
Specifications
Libp2p Protocol identifier: /vac/waku/rendezvous/1.0.0
Wire Protocol
Nodes advertise their information through WakuPeerRecord, a custom peer record structure designed for Waku rendezvous.
Since this is a customPeerRecord, we define a private multicodec value of 0x300000 as per multicodec table.
The WakuPeerRecord is defined as follows:
WakuPeerRecord fields:
peer_id: The libp2p PeerId of the node.seqNo: The time at which the record was created or last updated (Unix epoch, seconds).multiaddrs: A list of multiaddresses for connectivity.mix_public_key: The Mix protocol public key (only present for nodes supporting Mix).
Encoding: WakuPeerRecord is encoded as a protobuf message. The exact schema is:
message WakuPeerRecord {
string peer_id = 1;
uint64 seqNo = 2;
repeated string multiaddrs = 3;
optional bytes mix_public_key = 4;
}
When a node discovers peers through rendezvous, it receives the complete WakuPeerRecord for each peer, allowing it to make informed decisions about which peers to connect to based on their advertised information.
Namespace Format
The rendezvous namespaces used to register and request peer records
MUST be in the format rs/<cluster-id>/<capability>.
<capability> is a string representing the individual capability for which a discoverable Waku peer record is registered.
The Waku peer record is separately registered against each capability for which discovery is desired.
The only defined capability for now is mix, representing Waku Mix support.
For example, a Waku peer record for a node supporting mix protocol in cluster 1 will be registered against a namespace: rs/1/mix.
This allows for discovering peers with specific capabilities within a given cluster.
Currently, this is used for Mix protocol discovery where the capability field specifies mix.
Refer to RELAY-SHARDING for cluster information.
Registration and Discovery
Every Waku Relay node SHOULD be initialized as a rendezvous point.
Each relay node that participates in discovery MUST register with random rendezvous points at regular intervals. The RECOMMENDED registration interval is 10 seconds.
All relay nodes participating in rendezvous discovery SHOULD advertise their information using WakuPeerRecord. For nodes supporting the Mix protocol, the mix_public_key field MUST be included.
All advertised records MUST conform to the WakuPeerRecord definition.
It is RECOMMENDED that rendezvous points expire registrations after 1 minute (60 seconds TTL) to keep discovered peer records limited to those recently online.
At startup, every Waku node supporting Mix SHOULD discover peers by sending requests to random rendezvous points for the Mix capability namespace.
It is RECOMMENDED a maximum of 12 peers be requested each time. This number is sufficient for good GossipSub connectivity and minimizes the load on rendezvous points.
Operational Recommendations
It is RECOMMENDED that bootstrap nodes participate in rendezvous discovery and that other discovery methods are used in conjunction and continue discovering peers for the lifetime of the local node.
For resource-constrained devices or light clients, a client-only mode MAY be used where nodes only query for peers without acting as rendezvous points themselves and without advertising their own peer records.
Future Work
The protocol currently supports advertising Mix-specific capabilities (Mix public keys) through WakuPeerRecord.
Future enhancements could include:
- Extending
WakuPeerRecordto advertise other Waku protocol capabilities (Relay, Store, Filter, Lightpush, etc.) - Supporting shard-based namespaces (e.g.,
rs/<cluster-id>/<shard>) for general relay peer discovery without capability filtering - Batch registration support allowing nodes to register across multiple namespaces in a single request
Copyright
Copyright and related rights waived via CC0.
References
WAKU-STORE-SYNC
| Field | Value |
|---|---|
| Name | Waku Store Synchronization |
| Slug | 181 |
| Status | raw |
| Type | RFC |
| Category | core |
| Editor | Simon-Pierre Vivier [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
48600b5— Migrate logos-messaging/specs into docs/messaging/ (#315)
Abstract
This document describes a strategy to keep 13/WAKU2-STORE nodes synchronised, using a combination of 13/WAKU2-STORE queries and the WAKU-SYNC protocol.
Background / Rationale / Motivation
Message propagation in 10/WAKU2 networks is not perfect. Even with peer-to-peer reliability mechanisms, a certain amount of routing losses are always expected between Waku nodes. For example, nodes could experience brief, undetected disconnections, undergo restarts in order to update software, or suffer losses due to resource constraints.
Whatever the source of the losses, this affects applications and services relying on the message routing layer. One such service is the 13/WAKU2-STORE protocol that allows nodes to cache historical 14/WAKU2-MESSAGEs from the routing layer, and provision these to clients. Using Waku Store Sync, 13/WAKU2-STORE can remain synchronised and reach eventual consistency despite occasional losses on the routing layer.
Scope:
Waku Store Sync aims to provide a way for 13/WAKU2-STORE nodes to compare and retrieve differences with other 13/WAKU2-STORE nodes, in order to remedy messages that might have been missed or lost on the routing layer.
It seeks to cover the following loss scenarios:
- Short-term offline periods, for example due to a restart or short-term node maintenance
- Occasional message losses that occur during normal operation, due to short-term instability, churn, etc.
For the purposes of this document,
we define short-term offline periods as no more than 1 hour
and occasional message losses as no more than 20% of total routed messages.
It does not aim to address recovery after long-term offline periods, or to address massive message losses due to extraordinary circumstances, such as adversarial behaviour. Although Store Sync could perhaps work in such cases, it's not optimised or designed for catastrophic loss recovery. Large scale recovery falls beyond the scope of this document. We provide further recommendations for reasonable parameter defaults below.
Theory / Semantics
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “NOT RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in RFC 2119.
A 13/WAKU2-STORE node with Store Sync enabled:
- MAY use Store Resume to recover messages after detectable short-term offline periods
- MUST use Waku Sync to maintain consistency with other nodes and recover occasional message losses
Store Resume
Store Sync nodes MAY use Store Resume to fill the gap in messages for any short-term offline period.
Such a node SHOULD keep track of its last online timestamp.
It MAY do so by periodically storing the current timestamp on disk while online.
After a detected offline period has been resolved,
or at startup,
a Store Sync node using Store Resume SHOULD select another 13/WAKU2-STORE node using any available discovery mechanism.
We RECOMMEND that this to be a random node.
Next, the Store Sync node SHOULD perform a 13/WAKU2-STORE query
to the selected node for the time interval since it was last online.
Messages returned by the query are then added to the local node storage.
It is RECOMMENDED to limit the time interval to a maximum of 6 hours.
Waku Sync
Even while online, Store Sync nodes may occasionally miss messages. To remedy any such losses and to achieve eventual consistency, Store Sync nodes MUST mount WAKU2-SYNC protocol to detect and exchange differences with other Store Sync nodes. As described in that specification, WAKU2-SYNC consists of two sub-protocols. Both sub-protocols MUST be used by Store Sync nodes in the following way:
reconciliationMUST be used to detect and exchange differences between 14/WAKU2-MESSAGEs cached by the 13/WAKU2-STORE nodetransferMUST be used to transfer the actual content of such differences. Messages received viatransferMUST be cached in the same archive backend where the 13/WAKU2-STORE node caches messages received via normal routing.
Periodic syncing
Store Sync nodes SHOULD periodically trigger WAKU2-SYNC.
We RECOMMEND syncing at least once every 5 minutes with 1 other Store Sync peer.
The node MAY choose to sync more often with more peers
to achieve faster consistency.
Any peer selected for Store Sync SHOULD be chosen at random.
Discovery of other Store Sync peers falls outside the scope of this document. For simplicity, a Store Sync node MAY assume that any other 13/WAKU2-STORE peer supports Store Sync and attempt to trigger a sync operation with that node. If the sync operation then fails (due to unsupported protocol), it could continue attempting to sync with other 13/WAKU2-STORE peers on a trial-and-error basis until it finds a suitable Store Sync peer.
Sync window
For every WAKU2-SYNC operation,
the Store Sync node SHOULD choose a reasonable window of time into the past
over which to sync cached messages.
We RECOMMEND a sync window of 1 hour into the past.
This means that the syncing peers will compare
and exchange differences in cached messages up to 1 hour into the past.
A Store Sync node MAY choose to sync over a shorter time window to save resources and sync faster.
A Store Sync node MAY choose to sync over a longer time window to remedy losses over a longer period.
Copyright
Copyright and related rights waived via CC0.
References
WAKU-SYNC
| Field | Value |
|---|---|
| Name | Waku Sync |
| Slug | 182 |
| Status | raw |
| Type | RFC |
| Category | core |
| Editor | Simon-Pierre Vivier [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
48600b5— Migrate logos-messaging/specs into docs/messaging/ (#315)
Abstract
This specification explains WAKU-SYNC
which enables the synchronization of messages between nodes storing sets of 14/WAKU2-MESSAGEs.
Specification
Waku Sync consists of two libp2p protocols: reconciliation and transfer.
The Reconciliation protocol finds differences in sets of messages.
The Transfer protocol is used to exchange the differences found with other peers.
The end goal being that peers have the same set of messages.
Terminology
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in RFC2119.
Reconciliation
Libp2p Protocol identifier: /vac/waku/reconciliation/1.0.0
The reconciliation protocol finds the differences between two sets of 14/WAKU2-MESSAGE on different nodes.
It assumes that each 14/WAKU2-MESSAGE maps to a uniquely identifying SyncID,
which is maintained in an ordered set within each node.
An ordered set of SyncIDs is termed a Range.
This implies that any contiguous subset of a Range is also a Range.
In other words, the reconciliation protocol allows two nodes to find differences between Ranges of SyncIDs,
which would map to an equivalent difference in cached 14/WAKU2-MESSAGEs.
These terms, the wire protocol and message flows are explained below.
Wire protocol
Reconcilation payload
Nodes participating in the reconciliation protocol exchange encoded RangesData messages.
The RangesData structure represents a complete reconciliation payload:
| Field | Type | Description |
|---|---|---|
| cluster | varint | Cluster ID of the sender |
| shards | seq[varint] | Shards supported by the sender |
| ranges | seq[Range] | Sequence of ranges |
The cluster and shards fields
represent the sharding elements as defined in RELAY-SHARDING.
The ranges field contain a sequence of ranges for reconciliation.
We identify the following subtypes:
Range
A Range represents a representation of the bounds, type and, optionally, an encoded representation of the content of a range.
| Field | Type | Description |
|---|---|---|
| bounds | RangeBounds | The bounds of the range |
| type | RangeType | The type of the range |
| Option(content) | Fingerprint OR ItemSet | Optional field depending on type. If set, possible values are a Fingerprint of the range, or the complete ItemSet in the range |
RangeBounds
RangeBounds defines a Range by two bounding SyncID values, forming a time-hash interval:
| Field | Type | Description |
|---|---|---|
| a | SyncID | Lower bound (inclusive) |
| b | SyncID | Upper bound (exclusive) |
The lower bound MUST be strictly smaller than the upper bound.
SyncID
A SyncID consists of a message timestamp and hash to uniquely identify a 14/WAKU2-MESSAGE.
| Field | Type | Description |
|---|---|---|
| timestamp | varint | Timestamp of the message (nanoseconds) |
| hash | seq[Byte] | 32-byte message hash |
The timestamp MUST be the time of message creation and the hash MUST follow the deterministic message hashing specification. SyncIDs MUST be totally ordered by timestamp first, then by hash to disambiguate messages with identical timestamps.
RangeType
A RangeType indicates the type of content encoding for the Range:
| Type | Value | Description |
|---|---|---|
| Skip | 0 | Range has been processed and content field is empty |
| Fingerprint | 1 | Range is encoded in content field as a 32-byte Fingerprint |
| ItemSet | 2 | Range is encoded in content field as an ItemSet of SyncIDs |
Fingerprint
A Fingerprint is a compact 32-byte representation of all message hashes within a Range.
It MUST be implemented as an XOR of all contained hashes,
extracted from the SyncIDs present in the Range.
Fingerprints allow for efficient difference detection without transmitting complete message sets.
ItemSet
An ItemSet contains a full representation of all SyncIDs within a Range
and a reconciliation status:
| Field | Type | Description |
|---|---|---|
| elements | seq[SyncID] | Sequence of SyncIDs in the Range |
| reconciled | bool | Whether the Range has been reconciled |
Payload encoding
We can now define a heuristic for encoding the RangesData payload.
All varints MUST be encoded according to the specified varint encoding procedure.
Concatenate each of the following, in order:
- Encode the cluster ID as a varint
- Encode the number of shards as a varint
- For each shard, encode the shard as a varint and concatenate it to the previous
- Encode the
ranges, according to "Delta encoding for Ranges".
Varint encoding
All variable integers (varints) MUST be encoded as little-endian base 128 variable-length integers (LEB128) and MUST be minimally encoded.
Delta encoding for Ranges
The ranges field contain a sequence of Ranges.
It can be delta encoded as follows:
For each Range element, concatenate the following:
- From the
RangeBounds, select only theSyncIDrepresenting the upper bound of that range. Inclusive lower bounds are omitted because they are always the same as the exclusive upper bounds of the previous range. The first range is always assumed to have a lower boundSyncIDof0(both thetimestampandhashare0). - Delta encode the selected
SyncIDby comparing it to the previous ranges'SyncIDs. The first range'sSyncIDwill be fully encoded, as described in that section. - Encode the
RangeTypeas a single byte and concatenate it to the delta encodedSyncID. - If the
RangeTypeis:- Skip: encode nothing more
- Fingerprint: encode the 32-byte fingerprint
- ItemSet:
- Encode the number of elements as a varint
- Delta encode the item set, according to "Delta encoding for ItemSets"
Delta encoding for sequential SyncIDs
Sequential SyncIDs can be delta encoded to minimize payload size.
Given an ordered sequence of SyncIDs:
- Encode the first timestamp in full
- Delta encode subsequent timestamps, i.e., encode only the difference from the previous timestamp
- If the timestamps are identical, encode a
SyncIDhashdelta as follows: 3.1. Compared to the previous hash, truncate the hash up to and including the first differentiating byte 3.2. Encode the number of bytes in the truncated hash (as a single byte) 3.3. Encode the truncated hash
See the table below as an example:
| Timestamp | Hash | Encoded Timestamp (diff from previous) | Encoded Hash (length + all bytes up to first diff) |
|---|---|---|---|
| 1000 | 0x4a8a769a... | 1000 | - |
| 1002 | 0x351c5e86... | 2 | - |
| 1002 | 0x3560d9c4... | 0 | 0x023560 |
| 1003 | 0xbeabef25... | 1 | - |
Delta encoding for ItemSets
An ItemSet is delta encoded as follows:
Concatenate each of the following, in order:
- From the first
SyncID, encode the timestamp in full - From the first
SyncID, encode the hash in full - For each subsequent
SyncID:- Delta encode the timestamp, i.e., encode only the difference from the previous
SyncID's timestamp - Append the encoded hash in full
- Delta encode the timestamp, i.e., encode only the difference from the previous
- Encode a single byte for the
reconciledboolean (0 or 1)
Reconciliation Message Flow
The reconciliation message flow is triggered by an initiator with an initial RangesData payload.
The selection of sync peers
and triggers for initiating a reconciliation is out of scope of this document.
The response to a RangesData payload is another RangesData payload, according to the heuristic below.
The syncing peers SHOULD continue exchanging RangesData payloads until all ranges have been processed.
The output of a reconciliation flow is a set of differences in SyncIDs.
These could either be SyncIDs present in the remote peer and missing locally,
or SyncIDs present locally but missing in the remote peer.
Each sync peer MAY use the transfer protocol to exchange the full messages corresponding to these computed differences,
proactively transferring messages missing in the remote peer.
Initial Message
The initiator
- Selects a time range to sync
- Computes a fingerprint for the entire range
- Constructs an initial
RangesDatapayload with:- The initiator's cluster ID
- The initiator's supported shards
- A single range of type
Fingerprintcovering the entire sync period - The fingerprint for this range
- Delta encodes the payload
- Sends the payload using libp2p length-prefixed encoding
Responding to a RangesData payload
Each syncing peer performs the following in response to a RangesData payload:
The responder:
- Receives and decodes the payload
- If shards and cluster match, processes each range:
- If the received range is of type
Skip, ignores it. - If the received range is of type
Fingerprint, computes the fingerprint over the local matching range- If the local fingerprint matches the received fingerprint, includes this range in the response as type
Skip - If the local fingerprint does not match the received fingerprint:
- If the corresponding range is small enough, includes this range in the response as type
ItemSetwith allSyncIDs - If the corresponding range is too large, divide it into subranges.
For each subrange, if the range is small enough, includes it in the response as type
ItemSetwith allSyncIDs. If the subrange is too large, includes it in the response as typeFingerprint.
- If the corresponding range is small enough, includes this range in the response as type
- If the local fingerprint matches the received fingerprint, includes this range in the response as type
- If the received range is of type
ItemSet, compares it to the local items in the corresponding range- If there are any differences between the local and remote items, adds these as part of the output of the
reconciliationprocedure. At this point, the syncing peers MAY start to exchange the full messages corresponding to differences using thetransferprotocol. - If the received
ItemSetis not marked asreconciledby the remote peer, includes the corresponding local range in the response as typeItemSet. - If the received
ItemSetis marked asreconciledby the remote peer, includes the corresponding local range in the response as typeSkip.
- If there are any differences between the local and remote items, adds these as part of the output of the
- If the received range is of type
- If shards or cluster don't match:
- Responds with an empty payload
- Delta encodes the response
- Sends the response using libp2p length-prefixed encoding
This process continues until the syncing peer crafts an empty response, i.e., when all ranges have been processed and reconciled by both syncing peers and there are no differences left.
Transfer Protocol
Libp2p Protocol identifier: /vac/waku/transfer/1.0.0
Once the reconciliation protocol starts finding differences in SyncIDs,
the transfer protocol MAY be used to exchange actual message contents between peers.
A node using transfer SHOULD proactively send 14/WAKU2-MESSAGEs missing in the remote party.
Nodes SHOULD only accept incoming transfers from peers for which they have an active reconciliation session.
The SyncIDs corresponding to messages received via transfer,
MUST be added to the corresponding Range tracked by the reconciliation protocol.
The transferpayload MUST follow the wire specification below.
Wire specification
syntax = "proto3";
package waku.sync.transfer.v1;
import "waku/message/v1/message.proto";
message WakuMessageAndTopic {
// Full message content and associated pubsub_topic as value
optional waku.message.v1.WakuMessage message = 1;
optional string pubsub_topic = 2;
}
Implementation Suggestions
The flexibility of the protocol implies that much is left to the implementers. What will follow is NOT part of the specification. This section was created to inform implementations.
Cluster & Shards
To prevent nodes from synchronizing messages from shard they don't support, cluster and shards information has been added to each payload. On reception, if two peers don't share the same set of shards the sync is aborted.
Parameters
Two useful parameters to add to your implementation are partitioning count and the item set threshold.
The partitioning count is the number of time a range is split. A higher value reduces round trips at the cost of computing more fingerprints.
The item set threshold determines when item sets are sent instead of fingerprints. A higher value sends more items which means higher chance of duplicates but reduces the amount of round trips overall.
Storage
The storage implementation should reflect the context. Most messages that will be added will be recent and removed messages will be older ones. When differences are found some messages will have to be inserted randomly. It is expected to be a less likely case than time based insertion and removal. Last but not least it must be optimized for fingerprinting as it is the most often used operation.
Sync Interval
Ad-hoc syncing can be useful in some cases but continuous periodic sync minimize the differences in messages stored across the network. Syncing early and often is the best strategy. The default used in Nwaku is 5 minutes interval between sync with a range of 1 hour.
Sync Window
By default we offset the sync window by 20 seconds in the past. The actual start of the sync range is T-01:00:20 and the end T-00:00:20 in most cases. This is to handle the inherent jitters of GossipSub. In other words, it is the amount of time needed to confirm if a message is missing or not.
Peer Choice
Wrong peering strategies can lead to inadvertently segregating peers and reduce sampling diversity. Nwaku randomly select peers to sync with for simplicity and robustness.
More sophisticated strategies may be implemented in future.
Security/Privacy Considerations
Nodes using WAKU-SYNC are fully trusted.
Message hashes are assumed to be of valid messages received via Waku Relay or Light push.
Further refinements to the protocol are planned to reduce the trust level required to operate. Notably by verifying messages RLN proof at reception.
Copyright
Copyright and related rights waived via CC0.
References
WAKU2-INCENTIVIZATION
| Field | Value |
|---|---|
| Name | Incentivization for Waku Light Protocols |
| Slug | 175 |
| Status | raw |
| Type | RFC |
| Category | core |
| Tags | incentivization |
| Editor | Sergei Tikhomirov [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
48600b5— Migrate logos-messaging/specs into docs/messaging/ (#315)
Abstract
This document describes an approach to incentivization of Waku request-response protocols. Incentivization is necessary for economically sustainable growth of Waku. In an incentivized request-response protocol, only eligible (e.g., paying) clients receive the service. Clients include eligibility proofs in their requests.
Eligibility proofs are designed to be used in multiple Waku protocols, such as Store, Lightpush, and Filter. Lightpush is planned to become the first Waku protocol with an incentivization component. In particular, a Lightpush client will be able to publish messages without their own RLN membership. Instead, the client would pay the server for publishing the client's message using the server's RLN proof. We will discuss a proof-of-concept implementation of this incentivization component in a later section.
Background / Rationale / Motivation
Decentralized protocols require incentivization to be economically sustainable. While some aspects of a P2P network can successfully operate in a tit-for-tat model, we believe that nodes that run the protocol in good faith need to be tangibly rewarded. Motivating servers to expand resources on handling clients' requests allows us to scale the network beyond its initial altruism-based phase.
Incentivization is not necessarily limited to monetary rewards. Reputation may also play a role. For Waku request-response (i.e., client-server) protocols, we envision a combination of monetary and reputation-based incentivization. See a write-up on incentivization for our high-level reasoning on the topic.
Theory / Semantics
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “NOT RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in RFC 2119.
Consider a request-response protocol with two roles: a client and a server. A server MAY indicate to a client that it expects certain eligibility criteria to be met. In that case, a client MUST provide a valid eligibility proof as part of its request.
Forms of eligibility proofs include:
- Proof of payment: for paid non-authenticated requests. A proof of payment, in turn, may also take different forms, such as a transaction hash or a ZK-proof. In order to interpret a proof of payment, the server needs information about its type.
- Proof of membership: for services for a predefined group of users. An example use case: an application developer pays in bulk for their users' requests. A client then prove that they belong to the user set of that application. Rate limiting in Waku RLN Relay is based on a similar concept.
- Service credential: a proof of membership in a set of clients who have prepaid for the service (which may be considered a special case of proof of membership).
Upon a receiving a request:
- the server SHOULD check if the eligibility proof is included and valid;
- if that proof is absent or invalid, the server SHOULD send back a response with a corresponding error code and an error description;
- if the proof is valid, the server SHOULD send back the response that the client has requested.
Note that the protocol does not ensure atomicity. It is technically possible for a server to fail to respond to an eligible request (in violation of the protocol). Addressing this issue is left for future work.
Wire Format Specification / Syntax
A client includes an EligibilityProof in its request.
A server includes an EligibilityStatus in its response.
syntax = "proto3";
message EligibilityProof {
optional bytes proof_of_payment = 1; // e.g., a txid
// may be extended with other eligibility proof types, such as:
//optional bytes proof_of_membership = 2; // e.g., an RLN proof
}
message EligibilityStatus {
optional uint32 status_code = 1;
optional string status_desc = 2;
}
We include the other_eligibility_proof field in EligibilityProof to reflect other types of eligibility proofs that could be added to the protocol later.
Implementation in Lightpush (PoC version)
This Section describes a proof-of-concept (PoC) implementation of incentivization in the Lightpush protocol. Note: this section may later be moved to Lightpush RFC.
Lightpush is one of Waku's request-response protocols.
A Lightpush client sends a request to the server containing the message to be published to the Waku network on the client's behalf.
A Lightpush server responds to indicate whether the client's message was successfully published.
See 19/WAKU2-LIGHTPUSH for the definitions of PushRequest and PushResponse.
The PoC Lightpush incentivization makes the following simplifying assumptions:
- the client knows the server's on-chain address
A(likely on an L2 network); - the client and the server have agreed on a constant price
pper published message.
To publish a message, the client:
- pays
pto the server's addressAwith an on-chain transaction; - waits until the transaction is confirmed with identifier
txid; - includes
txidin the request as a proof of payment.
It is the server's responsibility to keep track of the txids from prior requests and to make sure they are not reused.
Note that txid may not always be practical as proof of payment due to on-chain confirmation latency.
To address this issue, future versions of the protocol may involve bulk payments, that is, paying for multiple requests in one transaction.
In that scheme, after a bulk payment is made, the client will not have to face on-chain latency for each new prepaid request.
Wire Format Specifications for Lightpush PoC incentivization
Request
We extend PushRequest to include an eligibility proof:
message PushRequest {
string pubsub_topic = 1;
WakuMessage message = 2;
// numbering gap left for non-eligibility-related protocol extensions
+ optional bytes eligibility_proof = 10;
}
An example of usage with txid as a proof of payment:
PushRequest push_request {
pubsub_topic: "example_pubsub_topic"
message: "example_message"
eligibility_proof: {
proof_of_payment: 0xabc123 // txid for the client's payment
// eligibility proofs of other types are not included
};
}
Response
We extend the PushResponse to indicate the eligibility status:
message PushResponse {
bool is_success = 1;
// Error messages, etc
string info = 2;
+ EligibilityStatus eligibility_status = 3;
}
Example of a response if the client is eligible:
PushResponse response_example {
is_success: true
info: "Request successful"
eligibility_status: {
status_code: 200
status_desc: "OK"
}
}
Example of a response if the client is not eligible:
PushResponse response_example {
is_success: false
info: "Request failed"
eligibility_status: {
status_code: 402
status_desc: "PAYMENT_REQUIRED"
}
}
Security/Privacy Considerations
Eligibility proofs may reveal private information about the client. In particular, a transaction identifier used as a proof of payment links the client's query to their on-chain activity. Potential countermeasures may include using one-time addresses or ZK-based privacy-preserving protocols.
Limitations and Future Work
This document is intentionally simplified in its initial version. It assumes a shared understanding of prices and the blockchain addresses of servers. Additionally, the feasibility of paying for each query is hindered by on-chain fees and confirmation delays.
We will address these challenges as the specification evolves alongside the corresponding PoC implementation. The following ideas will be explored:
- Batch Payment: instead of paying for an individual query, the client would make a consolidated payment for multiple messages.
- Price Negotiation: rather than receiving prices off-band, the client would engage in negotiation with the server to determine costs.
- Dynamic Pricing: the price per message would be variable, based on the total size (in bytes) of all received messages.
- Subscriptions: the client would pay for a defined time period during which they can query any number of messages, subject to DoS protection.
Copyright
Copyright and related rights waived via CC0.
References
normative
- A high-level incentivization outline
- 19/WAKU2-LIGHTPUSH (for Lightpush-specific sections)
informative
RFCs of request-response protocols:
RFCs of Relay and RLN-Relay:
WAKU2-RLN-CONTRACT
| Field | Value |
|---|---|
| Name | Waku2 RLN Contract Specification |
| Slug | 180 |
| Status | raw |
| Type | RFC |
| Category | core |
| Tags | waku/core-protocol |
| Editor | Sergei Tikhomirov [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
48600b5— Migrate logos-messaging/specs into docs/messaging/ (#315)
Abstract
This document describes membership management within the Rate-Limiting Nullifer (RLN) smart contract, specifically addressing:
- membership-related contract functionality;
- suggested parameter values for the initial mainnet deployment;
- contract governance and upgradability.
Background
Rate-Limiting Nullifier (RLN) is a Zero-Knowledge (ZK) based gadget used for privacy-preserving rate limiting in Waku. The RLN smart contract (referred to as "the contract" hereinafter) is the central component of the RLN architecture. The contract stores the membership set, which contains all current memberships. Users interact with the contract to manage their memberships and obtain the necessary data for proof generation and verification.
Message transmission is handled by Waku RLN Relay nodes. RLN Relay nodes verify the validity of messages according to RLN requirements and do not relay invalid messages. For the full specification of RLN Relay, see 17/WAKU2-RLN-RELAY.
Currently, this document focuses solely on membership-related functionality. It might later evolve into a comprehensive contract specification. As of August 2024, RLN is deployed only on Sepolia testnet (source code). This document aims to outline the path to its mainnet deployment.
Contract overview
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “NOT RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in RFC 2119.
The contract MUST provide the following membership-related functionalities (hereinafter, functionalities):
- register a membership;
- extend a membership;
- erase a membership;
- withdraw a deposit.
A membership holder is a role that grants special privileges in the context of membership management.
Each membership MUST have exactly one holder.
The holder role MUST be assigned at membership registration time to the sender
(msg.sender in Solidity semantics) of the registration transaction.
The sender of the registration SHOULD have an RLN identity_commitment created.
For more information on identity_commitment creation,
see 32/RLN-V1.
Membership registration MAY be initiated by a different entity from the one that controls the RLN identity_secret,
which is associated with the respective RLN identity_commitment.
Therefore, the holder role MAY be assigned to a blockchain address that is not derived from the identity_secret.
The contract SHOULD verify that the identity_commitment is valid.
If the identity_commitment is not checked or validated,
the contract MAY be exploited using malicious or malformed inputs.
When authorizing membership-related requests,
the contract MUST distinguish between the holder and non-holders,
and MAY also implement additional criteria.
The contract MUST support transactions sent directly from externally-owned accounts (EOA). The contract MAY support transactions sent via a chain of contract calls, in which case the last contract in the call chain MAY be designated as the membership holder. The contract MAY also support meta-transactions sent via paymasters or relayers, which MAY require additional authentication-related logic.
Contract parameters and their RECOMMENDED values for the initial mainnet deployment are as follows:
| Parameter | Symbol | Value | Units |
|---|---|---|---|
| Epoch length | t_{ep} | 600 | seconds |
| Maximum total rate limit of all memberships in the membership set | R_{max} | 160000 | messages per epoch |
| Minimum rate limit of one membership | r_{min} | 20 | messages per epoch |
| Maximum rate limit of one membership | r_{max} | 600 | messages per epoch |
| Membership active state duration | A | 180 | days |
| Membership grace period duration | G | 30 | days |
Membership price for 1 message per epoch for period A | p_u | 0.05 | USD |
| Accepted tokens | DAI |
The pricing function SHOULD be linear in the rate limit per epoch.
Note: epoch length means the same as period as defined in 17/WAKU2-RLN-RELAY.
This specification uses the term "epoch length" instead of "period" to avoid confusion with "grace period".
Membership lifecycle
Any existing membership MUST always be in exactly one of the following states:
- Active;
- GracePeriod;
- Expired;
- ErasedAwaitsWithdrawal;
- Erased.
The duration of each state MUST include the start timestamp.
The duration of each state MUST exclude the end timestamp.
For example, if a membership is registered at time 0,
and the active state duration A = 5,
the membership is considered to be Active at timestamps 0, 1, 2, 3, and 4.
At timestamp 5, the membership is considered to be in GracePeriod.
graph TD;
NonExistent --> |"register"| Active;
Active -.-> |"time A passed"| GracePeriod;
GracePeriod ==> |"extend"| Active;
GracePeriod -.-> |"time G passed"| Expired;
GracePeriod ==> |"erase"| ErasedAwaitsWithdrawal;
Expired --> |"erase"| ErasedAwaitsWithdrawal;
Expired --> |"reused by a new membership"| ErasedAwaitsWithdrawal;
ErasedAwaitsWithdrawal ==> |"withdraw"| Erased;
Different line types denote the types of state transitions:
| Line type | Triggered by | Requirements |
|---|---|---|
Thick (==) | Transaction | MUST be initiable by the membership holder and MUST NOT be initiable by other users. |
Thin (--) | Transaction | MAY be initiable by any user. |
Dotted (-.-) | Time progression | MAY be applied lazily. |
Transaction-triggered state transitions MUST be applied immediately.
When handling a membership-specific transaction, the contract MUST:
- check whether the state of the involved membership is up-to-date;
- if necessary, update the membership state;
- process the transaction in accordance with the updated membership state.
Memberships MUST be included in the membership set according to the following table:
| State | Included in the membership set |
|---|---|
| Active | Yes |
| GracePeriod | Yes |
| Expired | Yes |
| ErasedAwaitsWithdrawal | No |
| Erased | No |
The holder role MUST NOT be transferable to a different blockchain address. A user MAY use one blockchain address to manage multiple memberships. A user MAY use one Waku node1 to manage multiple memberships.
No Waku implementation supports managing multiple memberships from one node (as of August 2024).
Contract functionalities
Availability of functionalities[^2] MUST be as follows:
| Active | GracePeriod | Expired | ErasedAwaitsWithdrawal | Erased | |
|---|---|---|---|---|---|
| Extend the membership | No | Yes (holder only) | No | No | No |
| Erase the membership | No | Yes (holder only) | Yes | No | No |
| Withdraw the deposit | No | No | No | Yes (holder only) | No |
[^2] Note: Sending a message is not present in this table because it is part of the RLN Relay protocol and not the contract. For completeness, we note that the membership holder MUST be able to send a message if their membership is Active, in GracePeriod, or Expired. Sending messages with Expired memberships is allowed, because the inclusion (Merkle) proof that the holder provides to RLN Relay only proves that the membership belongs to the membership set, and not that membership's state.
Register a membership
Membership registration is subject to the following requirements:
- The holder MUST specify the requested rate limit
rof a new membership at registration time2. - Registration MUST fail if
r < r_{min}orr > r_{max}. - To register a membership, the holder MUST make a tranasction that locks up a deposit in the contract.
- The amount of the deposit MUST depend on the specified rate limit.
- In case of a successful registration:
- the new membership MUST become Active;
- the new membership MUST have an active state duration
A > 0and a grace period durationG >= 0; - the current total rate limit MUST be incremented by the rate limit of the new membership.
Reusing the rate limit of Expired memberships
The rate limits are defined as follows:
R_{active}is the total rate limit of all Active memberships;R_{grace_period}is the total rate limit of all GracePeriod memberships;R_{expired}is the total rate limit of all Expired memberships.
The free rate limit that is available without reusing the rate limit of Expired memberships is defined as follows:
R_{free} = R_{max} - R_{active} - R_{grace_period} - R_{expired}
Membership registration is additionally subject to the following requirements:
- If
r <= R_{free}, the new membership MUST be registered (assuming all other necessary conditions hold).- The new membership MAY erase one or multiple Expired memberships and reuse their rate limit.
- If
r > R_{free}:- if
r > R_{free} + R_{expired}, registration MUST fail; - if
r <= R_{free} + R_{expired}, the new membership SHOULD be registered by reusing some Expired memberships.
- if
- The sender of the registration transaction MAY specify a list of Expired memberships to be erased and their rate limit reused.
- If any of the memberships in the list are not Expired, the registration MUST fail.
- If the list is not provided, the contract MAY use any criteria to select Expired memberships to reuse (see Implementation Suggestions).
- If the list is not provided, the registration MAY fail even if the membership set contains Expired membership that, if erased, would free up sufficient rate limit.
- If a new membership A erases an Expired membership B to reuse its rate limit:
- membership B MUST become ErasedAwaitsWithdrawal;
- the current total rate limit MUST be decremented by the rate limit of membership B;
- the contract MUST take all necessary steps to ensure that the holder of membership B can withdraw their deposit later.
A user-facing application SHOULD suggest default rate limits to the holder (see Implementation Suggestions).
Extend a membership
Extending a membership is subject to the following conditions:
- The extension MUST fail if the membership is in any state other than GracePeriod.
- The membership holder MUST be able to extend their membership.
- Any user other than the membership holder MUST NOT be able to extend a membership.
- After an extension, the membership MUST become Active.
- After an extension, the membership MUST stay Active for time
g + A, wheregis the remaining time of the GracePeriod after the extension, andAis this membership's active state duration. - The extended membership MUST retain its original parameters, including active state duration
Aand grace period durationG, even if the global default values of such parameters for new memberships have been changed.
Withdraw the deposit
Deposit withdrawal is subject to the following conditions:
- The membership holder MUST be able to withdraw their deposit.
- Any user other than the membership holder MUST NOT be able to withdraw its deposit.
- A deposit MUST be withdrawn in full.
- A withdrawal MUST fail if the membership is not in ErasedAwaitsWithdrawal.
- A membership MUST become Erased after withdrawal.
Governance and upgradability
At initial mainnet deployment, the contract MUST have an Owner. The Owner MUST be able to change the values of all contract parameters. The updated parameter values MUST apply to all new memberships. The parameters of existing memberships MUST NOT change if the Owner updates global parameters. The contract MAY restrict extensions for memberships created before the latest parameter update.
The Owner MUST be able to pause any of the functionalities (see definition above).
At some point, the Owner SHOULD renounce their privileges, and the contract becomes immutable. If further upgrades are necessary, a new contract SHOULD be deployed, and the membership set SHOULD be migrated.
Implementation Suggestions
Membership Set Implementation
The membership set MAY be implemented as a Merkle tree, such as an Incremental Merkle Tree (IMT).
Choosing Which Expired Memberships to Reuse
When registering a new membership, the contract needs to decide which Expired memberships, if any, to reuse. The criteria for this selection can vary depending on the implementation.
Key considerations include:
- To minimize gas costs, it's better to reuse a single high-rate membership rather than multiple low-rate ones.
- To encourage timely deposit withdrawals, it's better to reuse memberships that have been Expired for a long time.
Considerations for User-facing Applications
User-facing applications SHOULD suggest one or more rate limits (tiers) to simplify user selection among the following RECOMMENDED options:
20messages per epoch as low-tier;200messages per epoch as mid-tier;600messages per epoch as high-tier.
User-facing applications SHOULD save membership expiration timestamps in a local keystore during registration, and notify the user when their membership is about to expire.
Q&A
Why can't I withdraw a deposit from an Active membership?
The rationale for this limitation is to prevent a usage pattern where users make deposits and withdrawals in quick succession.
Such a pattern could lead to network instability and should be carefully considered if deemed desirable.
Why can't I extend an Active membership?
Memberships can only be extended during GracePeriod. Extending an Active membership is not allowed. The rationale is to make possible parameter changes that the contract Owner might make (e.g., for security reasons) applicable to most memberships.
What if I don't extend my membership within its GracePeriod?
If the membership is not extended during its GracePeriod,
it becomes Expired and can be erased at any time.
Users are expected to either extend their membership on time to avoid this risk,
or erase them and withdraw their deposit.
Can I send messages when my membership is Expired?
An Expired membership allows sending messages for a certain period. The RLN proof that message senders provide to RLN Relay nodes does not prove the state of the membership, only its inclusion in the membership set.
Expired memberships are not immediately erased from the membership set. An Expired membership is erased in the following scenarios:
- the holder erases it to withdraw the deposit;
- a new membership erases it to free up rate limit during registration;
- a public function is called that erases Expired memberships from the given list.
Once in Erased or ErasedAwaitsWithdrawal state, the membership can no longer be used to send messages.
Will my deposit be slashed if I exceed the rate limit?
This specification does not include slashing. The deposit's current purpose is purely to protect the network from denial-of-service attacks through bandwidth capping.
Do I need an extra deposit to extend my membership?
Membership extension requires no additional deposit. The opportunity cost of locked-up capital and gas fees for extension transactions make extensions non-free, which is sufficient for the initial mainnet deployment.
Why this particular epoch length?
Epoch length is a global parameter defined in the contract. Rate limits are defined in terms of the maximum allowed messages per epoch.
There is a trade-off between short and long epochs.
Longer epochs accommodate short-term usage peaks better,
but they increase memory requirements for RLN Relay nodes.
An epoch length of 10 minutes was chosen as a reasonable middle ground.
Each message contains a nullifier that proves its validity in terms of RLN.
Each RLN Relay node must store a nullifier log for the current epoch in memory.
A nullifier plus metadata is 128 bytes per message.
With a 10-minute epoch, a high-tier user with a 1 message per second rate limit generates up to 600 * 128 / 1024 = 75 KiB of nullifier log data per epoch.
This equates to, approximately:
73 MiBfor 1000 users;732 MiBfor 10 thousand users.
Why is there a cap on the total rate limit?
Total network bandwidth is a limited resource.
To avoid overstretching the network's capabilities for the initial mainnet deployment,
we define a cap R_{max} on the total rate limit.
Why is there a minimum rate limit?
The minimum rate limit r_{min} prevents an attack where a large number of tiny memberships cause membership set bloat.
Why is there a maximum rate limit?
The maximum rate limit r_{max} prevents any single actor from consuming an excessive portion of the total available rate limit.
However, it is still possible for an attacker to register multiple Ethereum addresses, and occupy a significant portion of the total rate limit through several memberships.
Are there bulk discounts for high-rate memberships?
For the initial mainnet deployment, no bulk discounts are offered. Membership price is linearly proportional to its rate limit. We choose this pricing scheme for simplicity. Future work may explore alternative pricing schemes that balance efficiency with centralization risk.
Why only accept DAI?
When choosing a token to accept, we considered the following criteria:
- a stablecoin, as USD-denominated pricing is familiar for users and requires no oracle;
- popular with high liquidity;
- decentralized;
- reasonably good censorship-resistance.
Based on these criteria, we chose DAI for the initial mainnet deployment. Other tokens may be added in the future.
Security / Privacy Considerations
Issuing membership-specific transactions, such as membership extensions and deposit withdrawals, publicly associates a membership with an Ethereum address. However, this association does not compromise the privacy of the relayed messages, as the protocol does not require the sender to disclose their specific membership to RLN Relay nodes.
To generate an RLN proof, a message sender must obtain a proof that their membership belongs to the membership set. This proof can be requested directly from the contract. Requesting the proof through a third-party RPC provider could compromise the sender's privacy, as the provider might link the requester's Ethereum address, their RLN membership, and the corresponding API key.
Copyright
Copyright and related rights waived via CC0.
References
Core
Core messaging delivery draft specifications.
10/WAKU2
| Field | Value |
|---|---|
| Name | Waku v2 |
| Slug | 10 |
| Status | draft |
| Type | RFC |
| Category | core |
| Editor | Hanno Cornelius [email protected] |
| Contributors | Sanaz Taheri [email protected], Hanno Cornelius [email protected], Reeshav Khan [email protected], Daniel Kaiser [email protected], Oskar Thorén [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-08 —
c0ef3b9— Cleanup: rewrite specs-repo links in pre-existing messaging specs (#316) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-04-15 —
34aa3f3— Fix links 10/WAKU2 (#153) - 2025-04-09 —
cafa04f— 10/WAKU2: Update (#125) - 2024-11-20 —
ff87c84— Update Waku Links (#104) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-02-01 —
8e14d58— Update waku2.md - 2024-02-01 —
6cf68fd— Update waku2.md - 2024-02-01 —
6734b16— Update waku2.md - 2024-01-31 —
356649a— Update and rename WAKU2.md to waku2.md - 2024-01-27 —
550238c— Rename README.md to WAKU2.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-26 —
d6651b7— Update README.md - 2024-01-25 —
6e98666— Rename README.md to README.md - 2024-01-25 —
9b740d8— Rename waku/10/README.md to waku/specs/standards/core/10-WAKU2/README.md - 2024-01-24 —
330c35b— Create README.md
Abstract
Waku is a family of modular peer-to-peer protocols for secure communication. The protocols are designed to be secure, privacy-preserving, censorship-resistant and being able to run in resource-restricted environments. At a high level, it implements Pub/Sub over libp2p and adds a set of capabilities to it. These capabilities are things such as: (i) retrieving historical messages for mostly-offline devices (ii) adaptive nodes, allowing for heterogeneous nodes to contribute to the network (iii) preserving bandwidth usage for resource-restriced devices
This makes Waku ideal for running a p2p protocol on mobile devices and other similar restricted environments.
Historically, it has its roots in 6/WAKU1, which stems from Whisper, originally part of the Ethereum stack. However, Waku acts more as a thin wrapper for Pub/Sub and has a different API. It is implemented in an iterative manner where initial focus is on porting essential functionality to libp2p. See rough road map (2020) for more historical context.
Motivation and Goals
Waku, as a family of protocols, is designed to have a set of properties that are useful for many applications:
1.Useful for generalized messaging.
Many applications require some form of messaging protocol to communicate between different subsystems or different nodes. This messaging can be human-to-human, machine-to-machine or a mix. Waku is designed to work for all these scenarios.
2.Peer-to-peer.
Applications sometimes have requirements that make them suitable for peer-to-peer solutions:
- Censorship-resistant with no single point of failure
- Adaptive and scalable network
- Shared infrastructure
3.Runs anywhere.
Applications often run in restricted environments, where resources or the environment is restricted in some fashion. For example:
- Limited bandwidth, CPU, memory, disk, battery, etc.
- Not being publicly connectable
- Only being intermittently connected; mostly-offline
4.Privacy-preserving.
Applications often have a desire for some privacy guarantees, such as:
- Pseudonymity and not being tied to any personally identifiable information (PII)
- Metadata protection in transit
- Various forms of unlinkability, etc.
5.Modular design.
Applications often have different trade-offs when it comes to what properties they and their users value. Waku is designed in a modular fashion where an application protocol or node can choose what protocols they run. We call this concept adaptive nodes.
For example:
- Resource usage vs metadata protection
- Providing useful services to the network vs mostly using it
- Stronger guarantees for spam protection vs economic registration cost
For more on the concept of adaptive nodes and what this means in practice, please see the 30/ADAPTIVE-NODES spec.
Specification
The keywords “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in 2119.
Network Interaction Domains
While Waku is best thought of as a single cohesive thing, there are three network interaction domains:
(a) gossip domain (b) discovery domain (c) request/response domain
Protocols and Identifiers
Since Waku is built on top of libp2p, many protocols have a libp2p protocol identifier. The current main protocol identifiers are:
/vac/waku/relay/2.0.0/vac/waku/store-query/3.0.0/vac/waku/filter/2.0.0-beta1/vac/waku/lightpush/2.0.0-beta1
This is in addition to protocols that specify messages, payloads, and recommended usages. Since these aren't negotiated libp2p protocols, they are referred to by their RFC ID. For example:
- 14/WAKU2-MESSAGE and 26/WAKU-PAYLOAD for message payloads
- 23/WAKU2-TOPICS and 27/WAKU2-PEERS for recommendations around usage
There are also more experimental libp2p protocols such as:
/vac/waku/waku-rln-relay/2.0.0-alpha1/vac/waku/peer-exchange/2.0.0-alpha1
The semantics of these protocols are referred to by RFC ID 17/WAKU2-RLN-RELAY and 34/WAKU2-PEER-EXCHANGE.
Use of libp2p and Protobuf
Unless otherwise specified, all protocols are implemented over libp2p and use Protobuf by default. Since messages are exchanged over a bi-directional binary stream, as a convention, libp2p protocols prefix binary message payloads with the length of the message in bytes. This length integer is encoded as a protobuf varint.
Gossip Domain
Waku is using gossiping to disseminate messages throughout the network.
Protocol identifier: /vac/waku/relay/2.0.0
See 11/WAKU2-RELAY specification for more details.
For an experimental privacy-preserving economic spam protection mechanism, see 17/WAKU2-RLN-RELAY.
See 23/WAKU2-TOPICS for more information about the recommended topic usage.
Direct use of libp2p protocols
In addition to /vac/waku/* protocols,
Waku MAY directly use the following libp2p protocols:
- libp2p ping protocol with protocol id
/ipfs/ping/1.0.0
for liveness checks between peers, or to keep peer-to-peer connections alive.
- libp2p identity and identity/push with protocol IDs
/ipfs/id/1.0.0
and
/ipfs/id/push/1.0.0
respectively, as basic means for capability discovery. These protocols are anyway used by the libp2p connection establishment layer Waku is built on. We plan to introduce a new AnonComms capability discovery protocol with better anonymity properties and more functionality.
Transports
Waku is built in top of libp2p, and like libp2p it strives to be transport agnostic. We define a set of recommended transports in order to achieve a baseline of interoperability between clients. This section describes these recommended transports.
Waku client implementations SHOULD support the TCP transport. Where TCP is supported it MUST be enabled for both dialing and listening, even if other transports are available.
Waku nodes running in environments that do not allow the use of TCP directly, MAY use other transports.
A Waku node SHOULD support secure websockets for bidirectional communication streams, for example in a web browser context.
A node MAY support unsecure websockets if required by the application or running environment.
Discovery Domain
Discovery Methods
Waku can retrieve a list of nodes to connect to using DNS-based discovery as per EIP-1459. While this is a useful way of bootstrapping connection to a set of peers, it MAY be used in conjunction with an ambient peer discovery procedure to find other nodes to connect to, such as Node Discovery v5. It is possible to bypass the discovery domain by specifying static nodes.
Use of ENR
WAKU2-ENR
describes the usage of EIP-778 ENR (Ethereum Node Records)
for Waku discovery purposes.
It introduces two new ENR fields, multiaddrs and
waku2, that a Waku node MAY use for discovery purposes.
These fields MUST be used under certain conditions, as set out in the specification.
Both EIP-1459 DNS-based discovery and Node Discovery v5 operate on ENR,
and it's reasonable to expect even wider utility for ENR in Waku networks in the future.
Request/Response Domain
In addition to the Gossip domain, Waku provides a set of request/response protocols. They are primarily used in order to get Waku to run in resource restricted environments, such as low bandwidth or being mostly offline.
Historical Message Support
Protocol identifier*: /vac/waku/store-query/3.0.0
This is used to fetch historical messages for mostly offline devices. See 13/WAKU2-STORE spec specification for more details.
There is also an experimental fault-tolerant addition to the store protocol that relaxes the high availability requirement. See 21/WAKU2-FAULT-TOLERANT-STORE
Content Filtering
Protocol identifier*: /vac/waku/filter/2.0.0-beta1
This is used to preserve more bandwidth when fetching a subset of messages. See 12/WAKU2-FILTER specification for more details.
LightPush
Protocol identifier*: /vac/waku/lightpush/2.0.0-beta1
This is used for nodes with short connection windows and limited bandwidth to publish messages into the Waku network. See 19/WAKU2-LIGHTPUSH specification for more details.
Other Protocols
The above is a non-exhaustive list, and due to the modular design of Waku, there may be other protocols here that provide a useful service to the Waku network.
Overview of Protocol Interaction
See the sequence diagram below for an overview of how different protocols interact.
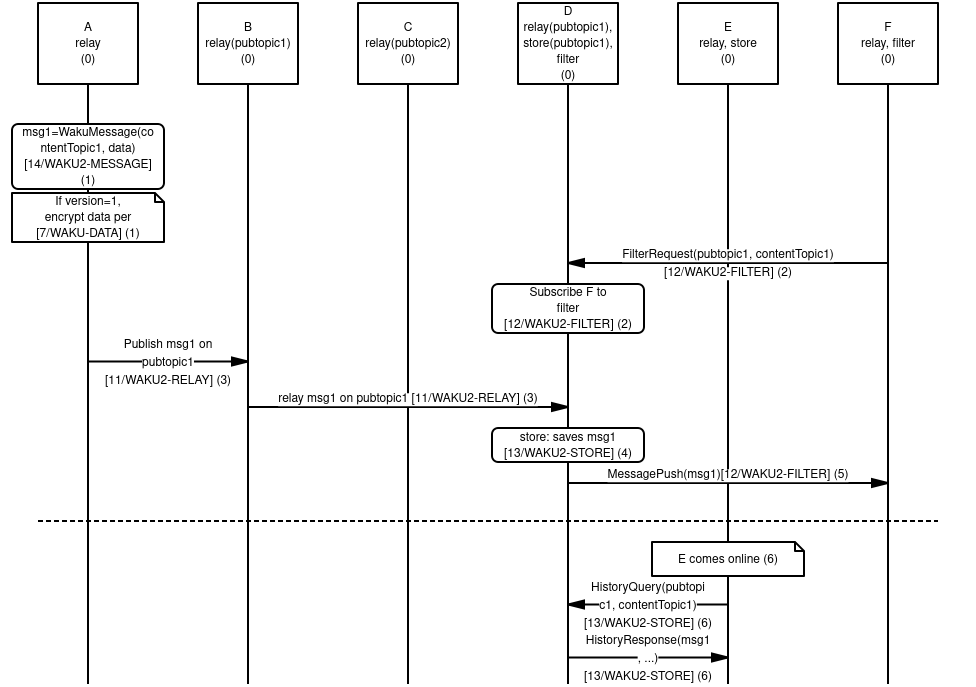
-
We have six nodes, A-F. The protocols initially mounted are indicated as such. The PubSub topics
pubtopic1andpubtopic2is used for routing and indicates that it is subscribed to messages on that topic for relay, see 11/WAKU2-RELAY for details. Ditto for 13/WAKU2-STORE where it indicates that these messages are persisted on that node. -
Node A creates a WakuMessage
msg1with a ContentTopiccontentTopic1. See 14/WAKU2-MESSAGE for more details. If WakuMessage version is set to 1, we use the 6/WAKU1 compatibledatafield with encryption. See 7/WAKU-DATA for more details. -
Node F requests to get messages filtered by PubSub topic
pubtopic1and ContentTopiccontentTopic1. Node D subscribes F to this filter and will in the future forward messages that match that filter. See 12/WAKU2-FILTER for more details. -
Node A publishes
msg1onpubtopic1and subscribes to that relay topic. It then gets relayed further from B to D, but not C since it doesn't subscribe to that topic. See 11/WAKU2-RELAY. -
Node D saves
msg1for possible later retrieval by other nodes. See 13/WAKU2-STORE. -
Node D also pushes
msg1to F, as it has previously subscribed F to this filter. See 12/WAKU2-FILTER. -
At a later time, Node E comes online. It then requests messages matching
pubtopic1andcontentTopic1from Node D. Node D responds with messages meeting this (and possibly other) criteria. See 13/WAKU2-STORE.
Appendix A: Upgradability and Compatibility
Compatibility with Waku Legacy
6/WAKU1 and Waku are different protocols all together. They use a different transport protocol underneath; 6/WAKU1 is devp2p RLPx based while Waku uses libp2p. The protocols themselves also differ as does their data format. Compatibility can be achieved only by using a bridge that not only talks both devp2p RLPx and libp2p, but that also transfers (partially) the content of a packet from one version to the other.
See 15/WAKU-BRIDGE for details on a bidirectional bridge mode.
Appendix B: Security
Each protocol layer of Waku provides a distinct service and is associated with a separate set of security features and concerns. Therefore, the overall security of Waku depends on how the different layers are utilized. In this section, we overview the security properties of Waku protocols against a static adversarial model which is described below. Note that a more detailed security analysis of each Waku protocol is supplied in its respective specification as well.
Primary Adversarial Model
In the primary adversarial model, we consider adversary as a passive entity that attempts to collect information from others to conduct an attack, but it does so without violating protocol definitions and instructions.
The following are not considered as part of the adversarial model:
- An adversary with a global view of all the peers and their connections.
- An adversary that can eavesdrop on communication links between arbitrary pairs of peers (unless the adversary is one end of the communication). Specifically, the communication channels are assumed to be secure.
Security Features
Pseudonymity
Waku by default guarantees pseudonymity for all of the protocol layers
since parties do not have to disclose their true identity
and instead they utilize libp2p PeerID as their identifiers.
While pseudonymity is an appealing security feature,
it does not guarantee full anonymity since the actions taken under the same pseudonym
i.e., PeerID can be linked together and
potentially result in the re-identification of the true actor.
Anonymity / Unlinkability
At a high level, anonymity is the inability of an adversary in linking an actor to its data/performed action (the actor and action are context-dependent). To be precise about linkability, we use the term Personally Identifiable Information (PII) to refer to any piece of data that could potentially be used to uniquely identify a party. For example, the signature verification key, and the hash of one's static IP address are unique for each user and hence count as PII. Notice that users' actions can be traced through their PIIs (e.g., signatures) and hence result in their re-identification risk. As such, we seek anonymity by avoiding linkability between actions and the actors / actors' PII. Concerning anonymity, Waku provides the following features:
Publisher-Message Unlinkability:
This feature signifies the unlinkability of a publisher
to its published messages in the 11/WAKU2-RELAY protocol.
The Publisher-Message Unlinkability
is enforced through the StrictNoSign policy due to which the data fields
of pubsub messages that count as PII for the publisher must be left unspecified.
Subscriber-Topic Unlinkability: This feature stands for the unlinkability of the subscriber to its subscribed topics in the 11/WAKU2-RELAY protocol. The Subscriber-Topic Unlinkability is achieved through the utilization of a single PubSub topic. As such, subscribers are not re-identifiable from their subscribed topic IDs as the entire network is linked to the same topic ID. This level of unlinkability / anonymity is known as k-anonymity where k is proportional to the system size (number of subscribers). Note that there is no hard limit on the number of the pubsub topics, however, the use of one topic is recommended for the sake of anonymity.
Spam protection
This property indicates that no adversary can flood the system
(i.e., publishing a large number of messages in a short amount of time),
either accidentally or deliberately, with any kind of message
i.e. even if the message content is valid or useful.
Spam protection is partly provided in 11/WAKU2-RELAY
through the scoring mechanism
provided for by GossipSub v1.1.
At a high level,
peers utilize a scoring function to locally score the behavior
of their connections and remove peers with a low score.
Data confidentiality, Integrity, and Authenticity
Confidentiality can be addressed through data encryption whereas integrity and authenticity are achievable through digital signatures. These features are provided for in 14/WAKU2-MESSAGE (version 1)` through payload encryption as well as encrypted signatures.
Security Considerations
Lack of anonymity/unlinkability in the protocols involving direct connections
including 13/WAKU2-STORE and 12/WAKU2-FILTER protocols:
The anonymity/unlinkability is not guaranteed in the protocols like 13/WAKU2-STORE
and 12/WAKU2-FILTER where peers need to have direct connections
to benefit from the designated service.
This is because during the direct connections peers utilize PeerID
to identify each other,
therefore the service obtained in the protocol is linkable
to the beneficiary's PeerID (which counts as PII).
For 13/WAKU2-STORE,
the queried node would be able to link the querying node's PeerID
to its queried topics.
Likewise, in the 12/WAKU2-FILTER,
a full node can link the light node's PeerIDs to its content filter.
Appendix C: Implementation Notes
Implementation Matrix
There are multiple implementations of Waku and its protocols:
Below you can find an overview of the specifications that they implement as they relate to Waku. This includes Waku legacy specifications, as they are used for bridging between the two networks.
| Spec | nim-waku (Nim) | go-waku (Go) | js-waku (Node JS) | js-waku (Browser JS) |
|---|---|---|---|---|
| 6/WAKU1 | ✔ | |||
| 7/WAKU-DATA | ✔ | ✔ | ||
| 8/WAKU-MAIL | ✔ | |||
| 9/WAKU-RPC | ✔ | |||
| 10/WAKU2 | ✔ | 🚧 | 🚧 | ✔ |
| 11/WAKU2-RELAY | ✔ | ✔ | ✔ | ✔ |
| 12/WAKU2-FILTER | ✔ | ✔ | ||
| 13/WAKU2-STORE | ✔ | ✔ | ✔* | ✔* |
| 14/WAKU2-MESSAGE) | ✔ | ✔ | ✔ | ✔ |
| 15/WAKU2-BRIDGE | ✔ | |||
| 16/WAKU2-RPC | ✔ | |||
| 17/WAKU2-RLN-RELAY | 🚧 | |||
| 18/WAKU2-SWAP | 🚧 | |||
| 19/WAKU2-LIGHTPUSH | ✔ | ✔ | ✔** | ✔** |
| 21/WAKU2-FAULT-TOLERANT-STORE | ✔ | ✔ |
*js-waku implements 13/WAKU2-STORE as a querying node only. **js-waku only implements 19/WAKU2-LIGHTPUSH requests.
Recommendations for Clients
To implement a minimal Waku client, we recommend implementing the following subset in the following order:
- 10/WAKU2 - this specification
- 11/WAKU2-RELAY - for basic operation
- 14/WAKU2-MESSAGE - version 0 (unencrypted)
- 13/WAKU2-STORE - for historical messaging (query mode only)
To get compatibility with Waku Legacy:
- 7/WAKU-DATA
- 14/WAKU2-MESSAGE - version 1 (encrypted with
7/WAKU-DATA)
For an interoperable keep-alive mechanism:
- libp2p ping protocol, with periodic pings to connected peers
Appendix D: Future work
The following features are currently experimental, under research and initial implementations:
Economic Spam Resistance:
We aim to enable an incentivized spam protection technique
to enhance 11/WAKU2-RELAY by using rate limiting nullifiers.
More details on this can be found in 17/WAKU2-RLN-RELAY.
In this advanced method,
peers are limited to a certain rate of messaging per epoch and
an immediate financial penalty is enforced for spammers who break this rate.
Prevention of Denial of Service (DoS) and Node Incentivization:
Denial of service signifies the case where an adversarial node
exhausts another node's service capacity (e.g., by making a large number of requests)
and makes it unavailable to the rest of the system.
DoS attack is to be mitigated through the accounting model as described in 18/WAKU2-SWAP.
In a nutshell, peers have to pay for the service they obtain from each other.
In addition to incentivizing the service provider,
accounting also makes DoS attacks costly for malicious peers.
The accounting model can be used in 13/WAKU2-STORE and
12/WAKU2-FILTER to protect against DoS attacks.
Additionally, this gives node operators who provide a useful service to the network an incentive to perform that service. See 18/WAKU2-SWAP for more details on this piece of work.
Copyright
Copyright and related rights waived via CC0.
References
12/WAKU2-FILTER
| Field | Value |
|---|---|
| Name | Waku v2 Filter |
| Slug | 12 |
| Status | draft |
| Type | RFC |
| Category | core |
| Editor | Hanno Cornelius [email protected] |
| Contributors | Dean Eigenmann [email protected], Oskar Thorén [email protected], Sanaz Taheri [email protected], Ebube Ud [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-03-25 —
e8a3f8a— 12/WAKU2-FILTER: Update (#119) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-02-01 —
e4d8f27— Update and rename FILTER.md to filter.md - 2024-01-27 —
046a3b7— Rename WAKU2-FILTER.md to FILTER.md - 2024-01-27 —
57124a7— Rename README.md to WAKU2-FILTER.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-25 —
940d795— Rename waku/12/README.md to waku/rfcs/standards/core/12/README.md - 2024-01-22 —
420adf1— Vac RFC index initial structure
Protocol identifiers:
- filter-subscribe:
/vac/waku/filter-subscribe/2.0.0-beta1 - filter-push:
/vac/waku/filter-push/2.0.0-beta1
Abstract
This specification describes the 12/WAKU2-FILTER protocol,
which enables a client to subscribe to a subset of real-time messages from a Waku peer.
This is a more lightweight version of 11/WAKU2-RELAY,
useful for bandwidth restricted devices.
This is often used by nodes with lower resource limits to subscribe to full Relay nodes and
only receive the subset of messages they desire,
based on content topic interest.
Motivation
Unlike the 13/WAKU2-STORE protocol for historical messages, this protocol allows for native lower latency scenarios, such as instant messaging. It is thus complementary to it.
Strictly speaking, it is not just doing basic request-response, but performs sender push based on receiver intent. While this can be seen as a form of light publish/subscribe, it is only used between two nodes in a direct fashion. Unlike the Gossip domain, this is suitable for light nodes which put a premium on bandwidth. No gossiping takes place.
It is worth noting that a light node could get by with only using the 13/WAKU2-STORE protocol to query for a recent time window, provided it is acceptable to do frequent polling.
Semantics
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in 2119.
Content filtering
Content filtering is a way to do
message-based filtering.
Currently the only content filter being applied is on contentTopic.
Terminology
The term Personally identifiable information (PII) refers to any piece of data that can be used to uniquely identify a user. For example, the signature verification key, and the hash of one's static IP address are unique for each user and hence count as PII.
Protobuf
syntax = "proto3";
// Protocol identifier: /vac/waku/filter-subscribe/2.0.0-beta1
message FilterSubscribeRequest {
enum FilterSubscribeType {
SUBSCRIBER_PING = 0;
SUBSCRIBE = 1;
UNSUBSCRIBE = 2;
UNSUBSCRIBE_ALL = 3;
}
string request_id = 1;
FilterSubscribeType filter_subscribe_type = 2;
// Filter criteria
optional string pubsub_topic = 10;
repeated string content_topics = 11;
}
message FilterSubscribeResponse {
string request_id = 1;
uint32 status_code = 10;
optional string status_desc = 11;
}
// Protocol identifier: /vac/waku/filter-push/2.0.0-beta1
message MessagePush {
WakuMessage waku_message = 1;
optional string pubsub_topic = 2;
}
Filter-Subscribe
A filter service node MUST support the filter-subscribe protocol to allow filter clients to subscribe, modify, refresh and unsubscribe a desired set of filter criteria. The combination of different filter criteria for a specific filter client node is termed a "subscription". A filter client is interested in receiving messages matching the filter criteria in its registered subscriptions.
Since a filter service node is consuming resources to provide this service, it MAY account for usage and adapt its service provision to certain clients.
Filter Subscribe Request
A client node MUST send all filter requests in a FilterSubscribeRequest message.
This request MUST contain a request_id.
The request_id MUST be a uniquely generated string.
Each request MUST include a filter_subscribe_type, indicating the type of request.
Filter Subscribe Response
When responding to a FilterSubscribeRequest,
a filter service node SHOULD send a FilterSubscribeResponse
with a requestId matching that of the request.
This response MUST contain a status_code indicating if the request was successful
or not.
Successful status codes are in the 2xx range.
Client nodes SHOULD consider all other status codes as error codes and
assume that the requested operation had failed.
In addition,
the filter service node MAY choose to provide a more detailed status description
in the status_desc field.
Filter matching
In the description of each request type below,
the term "filter criteria" refers to the combination of pubsub_topic and
a set of content_topics.
The request MAY include filter criteria,
conditional to the selected filter_subscribe_type.
If the request contains filter criteria,
it MUST contain a pubsub_topic
and the content_topics set MUST NOT be empty.
A 14/WAKU2-MESSAGE matches filter criteria
when its content_topic is in the content_topics set
and it was published on a matching pubsub_topic.
Filter Subscribe Types
The filter-subscribe types are defined as follows:
SUBSCRIBER_PING
A filter client that sends a FilterSubscribeRequest with
filter_subscribe_type set to SUBSCRIBER_PING,
requests that the filter service node SHOULD indicate if it has any active subscriptions
for this client.
The filter client SHOULD exclude any filter criteria from the request.
The filter service node SHOULD respond with a success status_code
if it has any active subscriptions for this client
or an error status_code if not.
The filter service node SHOULD ignore any filter criteria in the request.
SUBSCRIBE
A filter client that sends a FilterSubscribeRequest with
filter_subscribe_type set to SUBSCRIBE
requests that the filter service node SHOULD push messages
matching this filter to the client.
The filter client MUST include the desired filter criteria in the request.
A client MAY use this request type to modify an existing subscription
by providing additional filter criteria in a new request.
A client MAY use this request type to refresh an existing subscription
by providing the same filter criteria in a new request.
The filter service node SHOULD respond with a success status_code
if it successfully honored this request
or an error status_code if not.
The filter service node SHOULD respond with an error status_code and
discard the request if the FilterSubscribeRequest
does not contain valid filter criteria,
i.e. both a pubsub_topic and a non-empty content_topics set.
UNSUBSCRIBE
A filter client that sends a FilterSubscribeRequest with
filter_subscribe_type set to UNSUBSCRIBE
requests that the service node SHOULD stop pushing messages
matching this filter to the client.
The filter client MUST include the filter criteria
it desires to unsubscribe from in the request.
A client MAY use this request type to modify an existing subscription
by providing a subset of the original filter criteria
to unsubscribe from in a new request.
The filter service node SHOULD respond with a success status_code
if it successfully honored this request
or an error status_code if not.
The filter service node SHOULD respond with an error status_code and
discard the request if the unsubscribe request does not contain valid filter criteria,
i.e. both a pubsub_topic and a non-empty content_topics set.
UNSUBSCRIBE_ALL
A filter client that sends a FilterSubscribeRequest with
filter_subscribe_type set to UNSUBSCRIBE_ALL
requests that the service node SHOULD stop pushing messages
matching any filter to the client.
The filter client SHOULD exclude any filter criteria from the request.
The filter service node SHOULD remove any existing subscriptions for this client.
It SHOULD respond with a success status_code if it successfully honored this request
or an error status_code if not.
Filter-Push
A filter client node MUST support the filter-push protocol to allow filter service nodes to push messages matching registered subscriptions to this client.
A filter service node SHOULD push all messages
matching the filter criteria in a registered subscription
to the subscribed filter client.
These WakuMessages
are likely to come from 11/WAKU2-RELAY,
but there MAY be other sources or protocols where this comes from.
This is up to the consumer of the protocol.
If a message push fails,
the filter service node MAY consider the client node to be unreachable.
If a specific filter client node is not reachable from the service node
for a period of time,
the filter service node MAY choose to stop pushing messages to the client and
remove its subscription.
This period is up to the service node implementation.
It is RECOMMENDED to set 1 minute as a reasonable default.
Message Push
Each message MUST be pushed in a MessagePush message.
Each MessagePush MUST contain one (and only one) waku_message.
If this message was received on a specific pubsub_topic,
it SHOULD be included in the MessagePush.
A filter client SHOULD NOT respond to a MessagePush.
Since the filter protocol does not include caching or fault-tolerance,
this is a best effort push service with no bundling
or guaranteed retransmission of messages.
A filter client SHOULD verify that each MessagePush it receives
originated from a service node where the client has an active subscription
and that it matches filter criteria belonging to that subscription.
Adversarial Model
Any node running the WakuFilter protocol
i.e., both the subscriber node and
the queried node are considered as an adversary.
Furthermore, we consider the adversary as a passive entity
that attempts to collect information from other nodes to conduct an attack but
it does so without violating protocol definitions and instructions.
For example, under the passive adversarial model,
no malicious node intentionally hides the messages
matching to one's subscribed content filter
as it is against the description of the WakuFilter protocol.
The following are not considered as part of the adversarial model:
- An adversary with a global view of all the nodes and their connections.
- An adversary that can eavesdrop on communication links between arbitrary pairs of nodes (unless the adversary is one end of the communication). In specific, the communication channels are assumed to be secure.
Security Considerations
Note that while using WakuFilter allows light nodes to save bandwidth,
it comes with a privacy cost in the sense that they need to
disclose their liking topics to the full nodes to retrieve the relevant messages.
Currently, anonymous subscription is not supported by the WakuFilter, however,
potential solutions in this regard are discussed below.
Future Work
Anonymous filter subscription:
This feature guarantees that nodes can anonymously subscribe for a message filter
(i.e., without revealing their exact content filter).
As such, no adversary in the WakuFilter protocol
would be able to link nodes to their subscribed content filers.
The current version of the WakuFilter protocol does not provide anonymity
as the subscribing node has a direct connection to the full node and
explicitly submits its content filter to be notified about the matching messages.
However, one can consider preserving anonymity through one of the following ways:
- By hiding the source of the subscription i.e., anonymous communication. That is the subscribing node shall hide all its PII in its filter request e.g., its IP address. This can happen by the utilization of a proxy server or by using Tor
Note that the current structure of filter requests
i.e., FilterRPC does not embody any piece of PII, otherwise,
such data fields must be treated carefully to achieve anonymity.
- By deploying secure 2-party computations in which the subscribing node obtains the messages matching a content filter whereas the full node learns nothing about the content filter as well as the messages pushed to the subscribing node. Examples of such 2PC protocols are Oblivious Transfers and one-way Private Set Intersections (PSI).
Copyright
Copyright and related rights waived via CC0.
Previous versions
References
Informative
12/WAKU2-FILTER
| Field | Value |
|---|---|
| Name | Waku v2 Filter |
| Slug | 12 |
| Status | draft |
| Type | RFC |
| Category | core |
| Editor | Hanno Cornelius [email protected] |
| Contributors | Dean Eigenmann [email protected], Oskar Thorén [email protected], Sanaz Taheri [email protected], Ebube Ud [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-21 —
a00f16e— chore: mdbook fixes (#265) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-03-25 —
e8a3f8a— 12/WAKU2-FILTER: Update (#119) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-02-05 —
d41f106— Update filter.md - 2024-02-05 —
8436a31— Update and rename README.md to filter.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-25 —
420a51b— Rename waku/rfcs/core/12/previous-versions00/README.md to waku/rfcs/standards/core/12/previous-versions00/README.md - 2024-01-25 —
755fea9— Rename waku/12/previous-versions/00/README.md to waku/rfcs/core/12/previous-versions00/README.md - 2024-01-22 —
420adf1— Vac RFC index initial structure
WakuFilter is a protocol that enables subscribing to messages that a peer receives.
This is a more lightweight version of WakuRelay
specifically designed for bandwidth restricted devices.
This is due to the fact that light nodes subscribe to full-nodes and
only receive the messages they desire.
Content filtering
Protocol identifier*: /vac/waku/filter/2.0.0-beta1
Content filtering is a way to do message-based
filtering.
Currently the only content filter being applied is on contentTopic. This
corresponds to topics in Waku v1.
Rationale
Unlike the store protocol for historical messages, this protocol allows for
native lower latency scenarios such as instant messaging. It is thus
complementary to it.
Strictly speaking, it is not just doing basic request response, but performs sender push based on receiver intent. While this can be seen as a form of light pub/sub, it is only used between two nodes in a direct fashion. Unlike the Gossip domain, this is meant for light nodes which put a premium on bandwidth. No gossiping takes place.
It is worth noting that a light node could get by with only using the store
protocol to query for a recent time window, provided it is acceptable to do
frequent polling.
Design Requirements
The effectiveness and reliability of the content filtering service
enabled by WakuFilter protocol rely on the high availability of the full nodes
as the service providers.
To this end, full nodes must feature high uptime
(to persistently listen and capture the network messages)
as well as high Bandwidth (to provide timely message delivery to the light nodes).
Security Consideration
Note that while using WakuFilter allows light nodes to save bandwidth,
it comes with a privacy cost in the sense that they need to disclose their liking
topics to the full nodes to retrieve the relevant messages.
Currently, anonymous subscription is not supported by the WakuFilter, however,
potential solutions in this regard are sketched below in Future Work
section.
Terminology
The term Personally identifiable information (PII) refers to any piece of data that can be used to uniquely identify a user. For example, the signature verification key, and the hash of one's static IP address are unique for each user and hence count as PII.
Adversarial Model
Any node running the WakuFilter protocol i.e.,
both the subscriber node and the queried node are considered as an adversary.
Furthermore, we consider the adversary as a passive entity
that attempts to collect information from other nodes to conduct an attack but
it does so without violating protocol definitions and instructions.
For example, under the passive adversarial model,
no malicious node intentionally hides the messages matching
to one's subscribed content filter as it is against the description
of the WakuFilter protocol.
The following are not considered as part of the adversarial model:
- An adversary with a global view of all the nodes and their connections.
- An adversary that can eavesdrop on communication links between arbitrary pairs of nodes (unless the adversary is one end of the communication). In specific, the communication channels are assumed to be secure.
Protobuf
message FilterRequest {
bool subscribe = 1;
string topic = 2;
repeated ContentFilter contentFilters = 3;
message ContentFilter {
string contentTopic = 1;
}
}
message MessagePush {
repeated WakuMessage messages = 1;
}
message FilterRPC {
string requestId = 1;
FilterRequest request = 2;
MessagePush push = 3;
}
FilterRPC
A node MUST send all Filter messages (FilterRequest, MessagePush)
wrapped inside a FilterRPC this allows the node handler
to determine how to handle a message as the Waku Filter protocol
is not a request response based protocol but instead a push based system.
The requestId MUST be a uniquely generated string. When a MessagePush is sent
the requestId MUST match the requestId of the subscribing FilterRequest
whose filters matched the message causing it to be pushed.
FilterRequest
A FilterRequest contains an optional topic, zero or more content filters and
a boolean signifying whether to subscribe or unsubscribe to the given filters.
True signifies 'subscribe' and false signifies 'unsubscribe'.
A node that sends the RPC with a filter request and subscribe set to 'true'
requests that the filter node SHOULD notify the light requesting node of messages
matching this filter.
A node that sends the RPC with a filter request and subscribe set to 'false'
requests that the filter node SHOULD stop notifying the light requesting node
of messages matching this filter if it is currently doing so.
The filter matches when content filter and, optionally, a topic is matched.
Content filter is matched when a WakuMessage contentTopic field is the same.
A filter node SHOULD honor this request, though it MAY choose not to do so. If it chooses not to do so it MAY tell the light why. The mechanism for doing this is currently not specified. For notifying the light node a filter node sends a MessagePush message.
Since such a filter node is doing extra work for a light node, it MAY also account for usage and be selective in how much service it provides. This mechanism is currently planned but underspecified.
MessagePush
A filter node that has received a filter request SHOULD push all messages that
match this filter to a light node. These WakuMessage's
are likely to come from the
relay protocol and be kept at the Node, but there MAY be other sources or
protocols where this comes from. This is up to the consumer of the protocol.
A filter node MUST NOT send a push message for messages that have not been requested via a FilterRequest.
If a specific light node isn't connected to a filter node for some specific period of time (e.g. a TTL), then the filter node MAY choose to not push these messages to the node. This period is up to the consumer of the protocol and node implementation, though a reasonable default is one minute.
Future Work
Anonymous filter subscription:
This feature guarantees that nodes can anonymously subscribe for a message filter
(i.e., without revealing their exact content filter).
As such, no adversary in the WakuFilter protocol would be able to link nodes
to their subscribed content filers.
The current version of the WakuFilter protocol does not provide anonymity
as the subscribing node has a direct connection to the full node and
explicitly submits its content filter to be notified about the matching messages.
However, one can consider preserving anonymity through one of the following ways:
- By hiding the source of the subscription i.e., anonymous communication. That is the subscribing node shall hide all its PII in its filter request e.g., its IP address. This can happen by the utilization of a proxy server or by using Tor
Note that the current structure of filter requests i.e.,
FilterRPC does not embody any piece of PII, otherwise,
such data fields must be treated carefully to achieve anonymity.
- By deploying secure 2-party computations in which the subscribing node obtains the messages matching a content filter whereas the full node learns nothing about the content filter as well as the messages pushed to the subscribing node. Examples of such 2PC protocols are Oblivious Transfers and one-way Private Set Intersections (PSI).
Copyright
Copyright and related rights waived via CC0.
References
13/WAKU2-STORE
| Field | Value |
|---|---|
| Name | Waku Store Query |
| Slug | 13 |
| Status | draft |
| Type | RFC |
| Category | core |
| Editor | Hanno Cornelius [email protected] |
| Contributors | Dean Eigenmann [email protected], Oskar Thorén [email protected], Aaryamann Challani [email protected], Sanaz Taheri [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-04-15 —
1b8b2ac— Add missing status to 13/WAKU-STORE (#149) - 2025-02-03 —
a60a2c4— 13/WAKU-STORE: Update (#124) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-08-05 —
eb25cd0— chore: replace email addresses (#86) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-02-01 —
755be94— Update and rename STORE.md to store.md - 2024-01-27 —
3baed07— Rename README.md to STORE.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-25 —
51e2879— Create README.md
Abstract
This specification explains the WAKU2-STORE protocol,
which enables querying of 14/WAKU2-MESSAGEs.
Protocol identifier*: /vac/waku/store-query/3.0.0
Terminology
The term PII, Personally Identifiable Information, refers to any piece of data that can be used to uniquely identify a user. For example, the signature verification key, and the hash of one's static IP address are unique for each user and hence count as PII.
Wire Specification
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in RFC2119.
Design Requirements
The concept of ephemeral messages introduced in 14/WAKU2-MESSAGE affects WAKU2-STORE as well.
Nodes running WAKU2-STORE SHOULD support ephemeral messages as specified in 14/WAKU2-MESSAGE.
Nodes running WAKU2-STORE SHOULD NOT store messages with the ephemeral flag set to true.
Payloads
syntax = "proto3";
// Protocol identifier: /vac/waku/store-query/3.0.0
package waku.store.v3;
import "waku/message/v1/message.proto";
message WakuMessageKeyValue {
optional bytes message_hash = 1; // Globally unique key for a Waku Message
// Full message content and associated pubsub_topic as value
optional waku.message.v1.WakuMessage message = 2;
optional string pubsub_topic = 3;
}
message StoreQueryRequest {
string request_id = 1;
bool include_data = 2; // Response should include full message content
// Filter criteria for content-filtered queries
optional string pubsub_topic = 10;
repeated string content_topics = 11;
optional sint64 time_start = 12;
optional sint64 time_end = 13;
// List of key criteria for lookup queries
repeated bytes message_hashes = 20; // Message hashes (keys) to lookup
// Pagination info. 50 Reserved
optional bytes pagination_cursor = 51; // Message hash (key) from where to start query (exclusive)
bool pagination_forward = 52;
optional uint64 pagination_limit = 53;
}
message StoreQueryResponse {
string request_id = 1;
optional uint32 status_code = 10;
optional string status_desc = 11;
repeated WakuMessageKeyValue messages = 20;
optional bytes pagination_cursor = 51;
}
General Store Query Concepts
Waku Message Key-Value Pairs
The store query protocol operates as a query protocol for a key-value store of historical messages,
with each entry having a 14/WAKU2-MESSAGE
and associated pubsub_topic as the value,
and deterministic message hash as the key.
The store can be queried to return either a set of keys or a set of key-value pairs.
Within the store query protocol,
the 14/WAKU2-MESSAGE keys and
values MUST be represented in a WakuMessageKeyValue message.
This message MUST contain the deterministic message_hash as the key.
It MAY contain the full 14/WAKU2-MESSAGE and
associated pubsub topic as the value in the message and
pubsub_topic fields, depending on the use case as set out below.
If the message contains a value entry in addition to the key,
both the message and pubsub_topic fields MUST be populated.
The message MUST NOT have either message or pubsub_topic populated with the other unset.
Both fields MUST either be set or unset.
Waku Message Store Eligibility
In order for a message to be eligible for storage:
- it MUST be a valid 14/WAKU2-MESSAGE.
- the
timestampfield MUST be populated with the Unix epoch time, at which the message was generated in nanoseconds. If at the time of storage thetimestampdeviates by more than 20 seconds either into the past or the future when compared to the store node’s internal clock, the store node MAY reject the message. - the
ephemeralfield MUST be set tofalse.
Waku message sorting
The key-value entries in the store MUST be time-sorted by the 14/WAKU2-MESSAGE timestamp attribute.
Where two or more key-value entries have identical timestamp values,
the entries MUST be further sorted by the natural order of their message hash keys.
Within the context of traversing over key-value entries in the store,
"forward" indicates traversing the entries in ascending order,
whereas "backward" indicates traversing the entries in descending order.
Pagination
If a large number of entries in the store service node match the query criteria provided in a StoreQueryRequest,
the client MAY make use of pagination
in a chain of store query request and response transactions
to retrieve the full response in smaller batches termed "pages".
Pagination can be performed either in a forward or backward direction.
A store query client MAY indicate the maximum number of matching entries it wants in the StoreQueryResponse,
by setting the page size limit in the pagination_limit field.
Note that a store service node MAY enforce its own limit
if the pagination_limit is unset
or larger than the service node's internal page size limit.
A StoreQueryResponse with a populated pagination_cursor indicates that more stored entries match the query than included in the response.
A StoreQueryResponse without a populated pagination_cursor indicates that
there are no more matching entries in the store.
The client MAY request the next page of entries from the store service node
by populating a subsequent StoreQueryRequest with the pagination_cursor
received in the StoreQueryResponse.
All other fields and query criteria MUST be the same as in the preceding StoreQueryRequest.
A StoreQueryRequest without a populated pagination_cursor indicates that
the client wants to retrieve the "first page" of the stored entries matching the query.
Store Query Request
A client node MUST send all historical message queries within a StoreQueryRequest message.
This request MUST contain a request_id.
The request_id MUST be a uniquely generated string.
If the store query client requires the store service node to include 14/WAKU2-MESSAGE values in the query response,
it MUST set include_data to true.
If the store query client requires the store service node to return only message hash keys in the query response,
it SHOULD set include_data to false.
By default, therefore, the store service node assumes include_data to be false.
A store query client MAY include query filter criteria in the StoreQueryRequest.
There are two types of filter use cases:
- Content filtered queries and
- Message hash lookup queries
Content filtered queries
A store query client MAY request the store service node to filter historical entries by a content filter. Such a client MAY create a filter on content topic, on time range or on both.
To filter on content topic,
the client MUST populate both the pubsub_topic and content_topics field.
The client MUST NOT populate either pubsub_topic or
content_topics and leave the other unset.
Both fields MUST either be set or unset.
A mixed content topic filter with just one of either pubsub_topic or
content_topics set, SHOULD be regarded as an invalid request.
To filter on time range, the client MUST set time_start, time_end or both.
Each time_ field should contain a Unix epoch timestamp in nanoseconds.
An unset time_start SHOULD be interpreted as "from the oldest stored entry".
An unset time_end SHOULD be interpreted as "up to the youngest stored entry".
If any of the content filter fields are set,
namely pubsub_topic, content_topic, time_start, or time_end,
the client MUST NOT set the message_hashes field.
Message hash lookup queries
A store query client MAY request the store service node to filter historical entries by one or more matching message hash keys. This type of query acts as a "lookup" against a message hash key or set of keys already known to the client.
In order to perform a lookup query,
the store query client MUST populate the message_hashes field with the list of message hash keys it wants to lookup in the store service node.
If the message_hashes field is set,
the client MUST NOT set any of the content filter fields,
namely pubsub_topic, content_topic, time_start, or time_end.
Presence queries
A presence query is a special type of lookup query that allows a client to check for the presence of one or more messages in the store service node, without retrieving the full contents (values) of the messages. This can, for example, be used as part of a reliability mechanism, whereby store query clients verify that previously published messages have been successfully stored.
In order to perform a presence query,
the store query client MUST populate the message_hashes field in the StoreQueryRequest with the list of message hashes
for which it wants to verify presence in the store service node.
The include_data property MUST be set to false.
The client SHOULD interpret every message_hash returned in the messages field of the StoreQueryResponse as present in the store.
The client SHOULD assume that all other message hashes included in the original StoreQueryRequest but
not in the StoreQueryResponse is not present in the store.
Pagination info
The store query client MAY include a message hash as pagination_cursor,
to indicate at which key-value entry a store service node SHOULD start the query.
The pagination_cursor is treated as exclusive
and the corresponding entry will not be included in subsequent store query responses.
For forward queries,
only messages following (see sorting) the one indexed at pagination_cursor
will be returned.
For backward queries,
only messages preceding (see sorting) the one indexed at pagination_cursor
will be returned.
If the store query client requires the store service node to perform a forward query,
it MUST set pagination_forward to true.
If the store query client requires the store service node to perform a backward query,
it SHOULD set pagination_forward to false.
By default, therefore, the store service node assumes pagination to be backward.
A store query client MAY indicate the maximum number of matching entries it wants in the StoreQueryResponse,
by setting the page size limit in the pagination_limit field.
Note that a store service node MAY enforce its own limit
if the pagination_limit is unset
or larger than the service node's internal page size limit.
See pagination for more on how the pagination info is used in store transactions.
Store Query Response
In response to any StoreQueryRequest,
a store service node SHOULD respond with a StoreQueryResponse with a requestId matching that of the request.
This response MUST contain a status_code indicating if the request was successful or not.
Successful status codes are in the 2xx range.
A client node SHOULD consider all other status codes as error codes and
assume that the requested operation had failed.
In addition,
the store service node MAY choose to provide a more detailed status description in the status_desc field.
Filter matching
For content filtered queries,
an entry in the store service node matches the filter criteria in a StoreQueryRequest if each of the following conditions are met:
- its
content_topicis in the requestcontent_topicsset and it was published on a matchingpubsub_topicOR the requestcontent_topicsandpubsub_topicfields are unset - its
timestampis larger or equal than the requeststart_timeOR the requeststart_timeis unset - its
timestampis smaller than the requestend_timeOR the requestend_timeis unset
Note that for content filtered queries, start_time is treated as inclusive and
end_time is treated as exclusive.
For message hash lookup queries,
an entry in the store service node matches the filter criteria if its message_hash is in the request message_hashes set.
The store service node SHOULD respond with an error code and discard the request if the store query request contains both content filter criteria and message hashes.
Populating response messages
The store service node SHOULD populate the messages field in the response
only with entries matching the filter criteria provided in the corresponding request.
Regardless of whether the response is to a forward or backward query,
the messages field in the response MUST be ordered in a forward direction
according to the message sorting rules.
If the corresponding StoreQueryRequest has include_data set to true,
the service node SHOULD populate both the message_hash and
message for each entry in the response.
In all other cases,
the store service node SHOULD populate only the message_hash field for each entry in the response.
Paginating the response
The response SHOULD NOT contain more messages than the pagination_limit provided in the corresponding StoreQueryRequest.
It is RECOMMENDED that the store node defines its own maximum page size internally.
If the pagination_limit in the request is unset,
or exceeds this internal maximum page size,
the store service node SHOULD ignore the pagination_limit field and
apply its own internal maximum page size.
In response to a forward StoreQueryRequest:
- if the
pagination_cursoris set, the store service node SHOULD populate themessagesfield with matching entries following thepagination_cursor(exclusive). - if the
pagination_cursoris unset, the store service node SHOULD populate themessagesfield with matching entries from the first entry in the store. - if there are still more matching entries in the store
after the maximum page size is reached while populating the response,
the store service node SHOULD populate the
pagination_cursorin theStoreQueryResponsewith the message hash key of the last entry included in the response.
In response to a backward StoreQueryRequest:
- if the
pagination_cursoris set, the store service node SHOULD populate themessagesfield with matching entries preceding thepagination_cursor(exclusive). - if the
pagination_cursoris unset, the store service node SHOULD populate themessagesfield with matching entries from the last entry in the store. - if there are still more matching entries in the store
after the maximum page size is reached while populating the response,
the store service node SHOULD populate the
pagination_cursorin theStoreQueryResponsewith the message hash key of the first entry included in the response.
Security Consideration
The main security consideration while using this protocol is that a querying node has to reveal its content filters of interest to the queried node, hence potentially compromising their privacy.
Adversarial Model
Any peer running the WAKU2-STORE protocol, i.e.
both the querying node and the queried node, are considered as an adversary.
Furthermore,
we currently consider the adversary as a passive entity that attempts to collect information from other peers to conduct an attack but
it does so without violating protocol definitions and instructions.
As we evolve the protocol,
further adversarial models will be considered.
For example, under the passive adversarial model,
no malicious node hides or
lies about the history of messages as it is against the description of the WAKU2-STORE protocol.
The following are not considered as part of the adversarial model:
- An adversary with a global view of all the peers and their connections.
- An adversary that can eavesdrop on communication links between arbitrary pairs of peers (unless the adversary is one end of the communication). Specifically, the communication channels are assumed to be secure.
Future Work
-
Anonymous query: This feature guarantees that nodes can anonymously query historical messages from other nodes i.e., without disclosing the exact topics of 14/WAKU2-MESSAGE they are interested in. As such, no adversary in the
WAKU2-STOREprotocol would be able to learn which peer is interested in which content filters i.e., content topics of 14/WAKU2-MESSAGE. The current version of theWAKU2-STOREprotocol does not provide anonymity for historical queries, as the querying node needs to directly connect to another node in theWAKU2-STOREprotocol and explicitly disclose the content filters of its interest to retrieve the corresponding messages. However, one can consider preserving anonymity through one of the following ways: -
By hiding the source of the request i.e., anonymous communication. That is the querying node shall hide all its PII in its history request e.g., its IP address. This can happen by the utilization of a proxy server or by using Tor. Note that the current structure of historical requests does not embody any piece of PII, otherwise, such data fields must be treated carefully to achieve query anonymity.
- By deploying secure 2-party computations in which the querying node obtains the historical messages of a certain topic, the queried node learns nothing about the query. Examples of such 2PC protocols are secure one-way Private Set Intersections (PSI).
- Robust and verifiable timestamps: Messages timestamp is a way to show that
the message existed prior to some point in time.
However, the lack of timestamp verifiability can create room for a range of attacks,
including injecting messages with invalid timestamps pointing to the far future.
To better understand the attack,
consider a store node whose current clock shows
2021-01-01 00:00:30(and assume all the other nodes have a synchronized clocks +-20seconds). The store node already has a list of messages,(m1,2021-01-01 00:00:00), (m2,2021-01-01 00:00:01), ..., (m10:2021-01-01 00:00:20), that are sorted based on their timestamp. An attacker sends a message with an arbitrary large timestamp e.g., 10 hours ahead of the correct clock(m',2021-01-01 10:00:30). The store node placesm'at the end of the list,(m1,2021-01-01 00:00:00), (m2,2021-01-01 00:00:01), ..., (m10:2021-01-01 00:00:20), (m',2021-01-01 10:00:30). Now another message arrives with a valid timestamp e.g.,(m11, 2021-01-01 00:00:45). However, since its timestamp precedes the malicious messagem', it gets placed beforem'in the list i.e.,(m1,2021-01-01 00:00:00), (m2,2021-01-01 00:00:01), ..., (m10:2021-01-01 00:00:20), (m11, 2021-01-01 00:00:45), (m',2021-01-01 10:00:30). In fact, for the next 10 hours,m'will always be considered as the most recent message and served as the last message to the querying nodes irrespective of how many other messages arrive afterward.
A robust and verifiable timestamp allows the receiver of a message to verify that a message has been generated prior to the claimed timestamp. One solution is the use of open timestamps e.g., block height in Blockchain-based timestamps. That is, messages contain the most recent block height perceived by their senders at the time of message generation. This proves accuracy within a range of minutes (e.g., in Bitcoin blockchain) or seconds (e.g., in Ethereum 2.0) from the time of origination.
Copyright
Copyright and related rights waived via CC0.
Previous versions
References
13/WAKU2-STORE
| Field | Value |
|---|---|
| Name | Waku v2 Store |
| Slug | 13 |
| Status | draft |
| Type | RFC |
| Category | core |
| Editor | Simon-Pierre Vivier [email protected] |
| Contributors | Dean Eigenmann [email protected], Oskar Thorén [email protected], Aaryamann Challani [email protected], Sanaz Taheri [email protected], Hanno Cornelius [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-02-03 —
a60a2c4— 13/WAKU-STORE: Update (#124) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-08-05 —
eb25cd0— chore: replace email addresses (#86) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-02-01 —
755be94— Update and rename STORE.md to store.md - 2024-01-27 —
3baed07— Rename README.md to STORE.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-25 —
51e2879— Create README.md
Abstract
This specification explains the 13/WAKU2-STORE protocol
which enables querying of messages received through the relay protocol and
stored by other nodes.
It also supports pagination for more efficient querying of historical messages.
Protocol identifier*: /vac/waku/store/2.0.0-beta4
Terminology
The term PII, Personally Identifiable Information, refers to any piece of data that can be used to uniquely identify a user. For example, the signature verification key, and the hash of one's static IP address are unique for each user and hence count as PII.
Design Requirements
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in RFC2119.
Nodes willing to provide the storage service using 13/WAKU2-STORE protocol,
SHOULD provide a complete and full view of message history.
As such, they are required to be highly available and
specifically have a high uptime to consistently receive and store network messages.
The high uptime requirement makes sure that no message is missed out
hence a complete and intact view of the message history
is delivered to the querying nodes.
Nevertheless, in case storage provider nodes cannot afford high availability,
the querying nodes may retrieve the historical messages from multiple sources
to achieve a full and intact view of the past.
The concept of ephemeral messages introduced in
14/WAKU2-MESSAGE affects 13/WAKU2-STORE as well.
Nodes running 13/WAKU2-STORE SHOULD support ephemeral messages as specified in
14/WAKU2-MESSAGE.
Nodes running 13/WAKU2-STORE SHOULD NOT store messages
with the ephemeral flag set to true.
Adversarial Model
Any peer running the 13/WAKU2-STORE protocol, i.e.
both the querying node and the queried node, are considered as an adversary.
Furthermore,
we currently consider the adversary as a passive entity
that attempts to collect information from other peers to conduct an attack but
it does so without violating protocol definitions and instructions.
As we evolve the protocol,
further adversarial models will be considered.
For example, under the passive adversarial model,
no malicious node hides or
lies about the history of messages
as it is against the description of the 13/WAKU2-STORE protocol.
The following are not considered as part of the adversarial model:
- An adversary with a global view of all the peers and their connections.
- An adversary that can eavesdrop on communication links between arbitrary pairs of peers (unless the adversary is one end of the communication). In specific, the communication channels are assumed to be secure.
Wire Specification
Peers communicate with each other using a request / response API. The messages sent are Protobuf RPC messages which are implemented using protocol buffers v3. The following are the specifications of the Protobuf messages.
Payloads
syntax = "proto3";
message Index {
bytes digest = 1;
sint64 receiverTime = 2;
sint64 senderTime = 3;
string pubsubTopic = 4;
}
message PagingInfo {
uint64 pageSize = 1;
Index cursor = 2;
enum Direction {
BACKWARD = 0;
FORWARD = 1;
}
Direction direction = 3;
}
message ContentFilter {
string contentTopic = 1;
}
message HistoryQuery {
// the first field is reserved for future use
string pubsubtopic = 2;
repeated ContentFilter contentFilters = 3;
PagingInfo pagingInfo = 4;
}
message HistoryResponse {
// the first field is reserved for future use
repeated WakuMessage messages = 2;
PagingInfo pagingInfo = 3;
enum Error {
NONE = 0;
INVALID_CURSOR = 1;
}
Error error = 4;
}
message HistoryRPC {
string request_id = 1;
HistoryQuery query = 2;
HistoryResponse response = 3;
}
Index
To perform pagination,
each WakuMessage stored at a node running the 13/WAKU2-STORE protocol
is associated with a unique Index that encapsulates the following parts.
digest: a sequence of bytes representing the SHA256 hash of aWakuMessage. The hash is computed over the concatenation ofcontentTopicandpayloadfields of aWakuMessage(see 14/WAKU2-MESSAGE).receiverTime: the UNIX time in nanoseconds at which theWakuMessageis received by the receiving node.senderTime: the UNIX time in nanoseconds at which theWakuMessageis generated by its sender.pubsubTopic: the pubsub topic on which theWakuMessageis received.
PagingInfo
PagingInfo holds the information required for pagination.
It consists of the following components.
pageSize: A positive integer indicating the number of queriedWakuMessages in aHistoryQuery(or retrievedWakuMessages in aHistoryResponse).cursor: holds theIndexof aWakuMessage.direction: indicates the direction of paging which can be eitherFORWARDorBACKWARD.
ContentFilter
ContentFilter carries the information required for filtering historical messages.
contentTopicrepresents the content topic of the queried historicalWakuMessage. This field maps to thecontentTopicfield of the 14/WAKU2-MESSAGE.
HistoryQuery
RPC call to query historical messages.
- The
pubsubTopicfield MUST indicate the pubsub topic of the historical messages to be retrieved. This field denotes the pubsub topic on whichWakuMessages are published. This field maps totopicIDsfield ofMessagein11/WAKU2-RELAY. Leaving this field empty means no filter on the pubsub topic of message history is requested. This field SHOULD be left empty in order to retrieve the historicalWakuMessageregardless of the pubsub topics on which they are published. - The
contentFiltersfield MUST indicate the list of content filters based on which the historical messages are to be retrieved. Leaving this field empty means no filter on the content topic of message history is required. This field SHOULD be left empty in order to retrieve historicalWakuMessageregardless of their content topics. PagingInfoholds the information required for pagination. ItspageSizefield indicates the number ofWakuMessages to be included in the correspondingHistoryResponse. It is RECOMMENDED that the queried node defines a maximum page size internally. If the querying node leaves thepageSizeunspecified, or if thepageSizeexceeds the maximum page size, the queried node SHOULD auto-paginate theHistoryResponseto no more than the configured maximum page size. This allows mitigation of long response time forHistoryQuery. In the forward pagination request, themessagesfield of theHistoryResponseSHALL contain, at maximum, thepageSizeamount ofWakuMessagewhoseIndexvalues are larger than the givencursor(and vise versa for the backward pagination). Note that thecursorof aHistoryQueryMAY be empty (e.g., for the initial query), as such, and depending on whether thedirectionisBACKWARDorFORWARDthe last or the firstpageSizeWakuMessageSHALL be returned, respectively.
Sorting Messages
The queried node MUST sort the WakuMessage based on their Index,
where the senderTime constitutes the most significant part and
the digest comes next, and
then perform pagination on the sorted result.
As such, the retrieved page contains an ordered list of WakuMessage
from the oldest messages to the most recent one.
Alternatively, the receiverTime (instead of senderTime)
MAY be used to sort messages during the paging process.
However, it is RECOMMENDED the use of the senderTime
for sorting as it is invariant and
consistent across all the nodes.
This has the benefit of cursor reusability i.e.,
a cursor obtained from one node can be consistently used
to query from another node.
However, this cursor reusability does not hold when the receiverTime is utilized
as the receiver time is affected by the network delay and
nodes' clock asynchrony.
HistoryResponse
RPC call to respond to a HistoryQuery call.
- The
messagesfield MUST contain the messages found, these are 14/WAKU2-MESSAGE types. PagingInfoholds the paging information based on which the querying node can resume its further history queries. ThepageSizeindicates the number of returned Waku messages (i.e., the number of messages included in themessagesfield ofHistoryResponse). Thedirectionis the same direction as in the correspondingHistoryQuery. In the forward pagination, thecursorholds theIndexof the last message in theHistoryResponsemessages(and the first message in the backward paging). Regardless of the paging direction, the retrievedmessagesare always sorted in ascending order based on their timestamp as explained in the sorting messagessection, that is, from the oldest to the most recent. The requester SHALL embed the returnedcursorinside its nextHistoryQueryto retrieve the next page of the 14/WAKU2-MESSAGE. Thecursorobtained from one node SHOULD NOT be used in a request to another node because the result may be different.- The
errorfield contains information about any error that has occurred while processing the correspondingHistoryQuery.NONEstands for no error. This is also the default value.INVALID_CURSORmeans that thecursorfield ofHistoryQuerydoes not match with theIndexof any of theWakuMessagepersisted by the queried node.
Security Consideration
The main security consideration to take into account while using this protocol is that a querying node have to reveal their content filters of interest to the queried node, hence potentially compromising their privacy.
Future Work
- Anonymous query: This feature guarantees that nodes
can anonymously query historical messages from other nodes i.e.,
without disclosing the exact topics of 14/WAKU2-MESSAGE
they are interested in.
As such, no adversary in the
13/WAKU2-STOREprotocol would be able to learn which peer is interested in which content filters i.e., content topics of 14/WAKU2-MESSAGE. The current version of the13/WAKU2-STOREprotocol does not provide anonymity for historical queries, as the querying node needs to directly connect to another node in the13/WAKU2-STOREprotocol and explicitly disclose the content filters of its interest to retrieve the corresponding messages. However, one can consider preserving anonymity through one of the following ways:- By hiding the source of the request i.e., anonymous communication. That is the querying node shall hide all its PII in its history request e.g., its IP address. This can happen by the utilization of a proxy server or by using Tor. Note that the current structure of historical requests does not embody any piece of PII, otherwise, such data fields must be treated carefully to achieve query anonymity.
- By deploying secure 2-party computations in which the querying node obtains the historical messages of a certain topic, the queried node learns nothing about the query. Examples of such 2PC protocols are secure one-way Private Set Intersections (PSI).
- Robust and verifiable timestamps:
Messages timestamp is a way to show that the message existed
prior to some point in time.
However, the lack of timestamp verifiability can create room for a range of attacks,
including injecting messages with invalid timestamps pointing to the far future.
To better understand the attack,
consider a store node whose current clock shows
2021-01-01 00:00:30(and assume all the other nodes have a synchronized clocks +-20seconds). The store node already has a list of messages,(m1,2021-01-01 00:00:00), (m2,2021-01-01 00:00:01), ..., (m10:2021-01-01 00:00:20), that are sorted based on their timestamp. An attacker sends a message with an arbitrary large timestamp e.g., 10 hours ahead of the correct clock(m',2021-01-01 10:00:30). The store node placesm'at the end of the list,
(m1,2021-01-01 00:00:00), (m2,2021-01-01 00:00:01), ..., (m10:2021-01-01 00:00:20),(m',2021-01-01 10:00:30).
Now another message arrives with a valid timestamp e.g.,
(m11, 2021-01-01 00:00:45).
However, since its timestamp precedes the malicious message m',
it gets placed before m' in the list i.e.,
(m1,2021-01-01 00:00:00), (m2,2021-01-01 00:00:01), ..., (m10:2021-01-01 00:00:20), (m11, 2021-01-01 00:00:45), (m',2021-01-01 10:00:30).
In fact, for the next 10 hours,
m' will always be considered as the most recent message and
served as the last message to the querying nodes irrespective
of how many other messages arrive afterward.
A robust and verifiable timestamp allows the receiver of a message to verify that a message has been generated prior to the claimed timestamp. One solution is the use of open timestamps e.g., block height in Blockchain-based timestamps. That is, messages contain the most recent block height perceived by their senders at the time of message generation. This proves accuracy within a range of minutes (e.g., in Bitcoin blockchain) or seconds (e.g., in Ethereum 2.0) from the time of origination.
Copyright
Copyright and related rights waived via CC0.
References
15/WAKU-BRIDGE
| Field | Value |
|---|---|
| Name | Waku Bridge |
| Slug | 15 |
| Status | draft |
| Type | RFC |
| Category | core |
| Editor | Hanno Cornelius [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-01-28 —
c3d5fe6— 15/WAKU2-BRIDGE: Update (#113) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-02-01 —
d637b10— Update and rename BRIDGE.md to bridge.md - 2024-01-27 —
4bf2f6e— Rename README.md to BRIDGE.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-25 —
f883f26— Create README.md
Abstract
This specification describes how 6/WAKU1 traffic can be used with 10/WAKU2 networks.
Wire Format
The keywords “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in 2119.
A bridge requires supporting both Waku versions:
Publishing Packets
Packets received on 6/WAKU1 networks SHOULD be published just once on 10/WAKU2 networks. More specifically, the bridge SHOULD publish this through 11/WAKU2-RELAY (PubSub domain).
When publishing such packet,
the creation of a new Message with a new WakuMessage as data field is REQUIRED.
The data and
topic field, from the 6/WAKU1 Envelope,
MUST be copied to the payload and content_topic fields of the WakuMessage.
See 14/WAKU2-MESSAGE
for message format details.
Other fields such as nonce, expiry and
ttl will be dropped as they become obsolete in 10/WAKU2.
Before this is done, the usual envelope verification still applies:
- Expiry & future time verification
- PoW verification
- Size verification
Bridging SHOULD occur through the 11/WAKU2-RELAY, but it MAY also be done on other 10/WAKU2 protocols (e.g. 12/WAKU2-FILTER). The latter is however not advised as it will increase the complexity of the bridge and because of the Security Considerations explained further below.
Packets received on 10/WAKU2 networks,
SHOULD be posted just once on 6/WAKU1 networks.
The 14/WAKU2-MESSAGE contains only the payload and
contentTopic fields.
The bridge MUST create a new 6/WAKU1 Envelope and
copy over the payload and contentFilter
fields to the data and topic fields.
Next, before posting on the network,
the bridge MUST set a new expiry, ttl and do the PoW nonce calculation.
Security Considerations
As mentioned above,
a bridge will be posting new 6/WAKU1 envelopes,
which requires doing the PoW nonce calculation.
This could be a DoS attack vector, as the PoW calculation will make it more expensive to post the message compared to the original publishing on 10/WAKU2 networks. Low PoW setting will lower this problem, but it is likely that it is still more expensive.
For this reason, it is RECOMMENDED to run bridges independently of other nodes, so that a bridge that gets overwhelmed does not disrupt regular Waku v2 to v2 traffic.
Bridging functionality SHOULD also be carefully implemented so that messages do not bounce back and forth between the 10/WAKU2 and 6/WAKU1 networks. The bridge SHOULD properly track messages with a seen filter, so that no amplification occurs.
Copyright
Copyright and related rights waived via CC0.
References
17/WAKU2-RLN-RELAY
| Field | Value |
|---|---|
| Name | Waku v2 RLN Relay |
| Slug | 17 |
| Status | draft |
| Type | RFC |
| Category | core |
| Editor | Alvaro Revuelta [email protected] |
| Contributors | Oskar Thorén [email protected], Aaryamann Challani [email protected], Sanaz Taheri [email protected], Hanno Cornelius [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-11-20 —
776c1b7— rfc-index: Update (#110) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-08-05 —
eb25cd0— chore: replace email addresses (#86) - 2024-06-06 —
5064ded— Update 17/WAKU2-RLN-RELAY: Proof Size (#44) - 2024-05-28 —
7b443c1— 17/WAKU2-RLN-RELAY: Update (#32) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-02-01 —
244ea55— Update and rename RLN-RELAY.md to rln-relay.md - 2024-01-27 —
7bcefac— Rename README.md to RLN-RELAY.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-26 —
1ed5919— Update README.md - 2024-01-25 —
4b3b4e3— Create README.md
Abstract
This specification describes the 17/WAKU2-RLN-RELAY protocol,
which is an extension of 11/WAKU2-RELAY
to provide spam protection using Rate Limiting Nullifiers (RLN).
The security objective is to contain spam activity in the 64/WAKU-NETWORK by enforcing a global messaging rate to all the peers. Peers that violate the messaging rate are considered spammers and their message is considered spam. Spammers are also financially punished and removed from the system.
Motivation
In open and anonymous p2p messaging networks, one big problem is spam resistance. Existing solutions, such as Whisper’s proof of work, are computationally expensive hence not suitable for resource-limited nodes. Other reputation-based approaches might not be desirable, due to issues around arbitrary exclusion and privacy.
We augment the 11/WAKU2-RELAY protocol
with a novel construct of RLN
to enable an efficient economic spam prevention mechanism
that can be run in resource-constrained environments.
Specification
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in 2119.
Flow
The messaging rate is defined by the period
which indicates how many messages can be sent in a given period.
We define an epoch as unix_time / period .
For example, if unix_time is 1644810116 and we set period to 30,
then epoch is (unix_time/period) = 54827003.
NOTE: The
epochrefers to the epoch in RLN and not Unix epoch. This means a message can only be sent every period, where theperiodis up to the application.
See section Recommended System Parameters
for the RECOMMENDED method to set a sensible period value depending on the application.
Peers subscribed to a spam-protected pubsubTopic
are only allowed to send one message per epoch.
The higher-level layers adopting 17/WAKU2-RLN-RELAY
MAY choose to enforce the messaging rate for WakuMessages
with a specific contentTopic published on a pubsubTopic.
Setup and Registration
A pubsubTopic that is spam-protected requires subscribed peers to form a RLN group.
- Peers MUST be registered to the RLN group to be able to publish messages.
- Registration MAY be moderated through a smart contract deployed on the Ethereum blockchain.
Each peer has an RLN key pair denoted by sk
and pk.
- The secret key
skis secret data and MUST be persisted securely by the peer. - The state of the membership contract
SHOULD contain a list of all registered members' public identity keys i.e.,
pks.
For registration,
a peer MUST create a transaction to invoke the registration function on the contract,
which registers its pk in the RLN group.
- The transaction MUST transfer additional tokens to the contract to be staked.
This amount is denoted by
staked_fundand is a system parameter. The peer who has the secret keyskassociated with a registeredpkwould be able to withdraw a portionreward_portionof the staked fund by providing valid proof.
reward_portion is also a system parameter.
NOTE: Initially
skis only known to its owning peer however, it may get exposed to other peers in case the owner attempts spamming the system i.e., sending more than one message perepoch.
An overview of registration is illustrated in Figure 1.
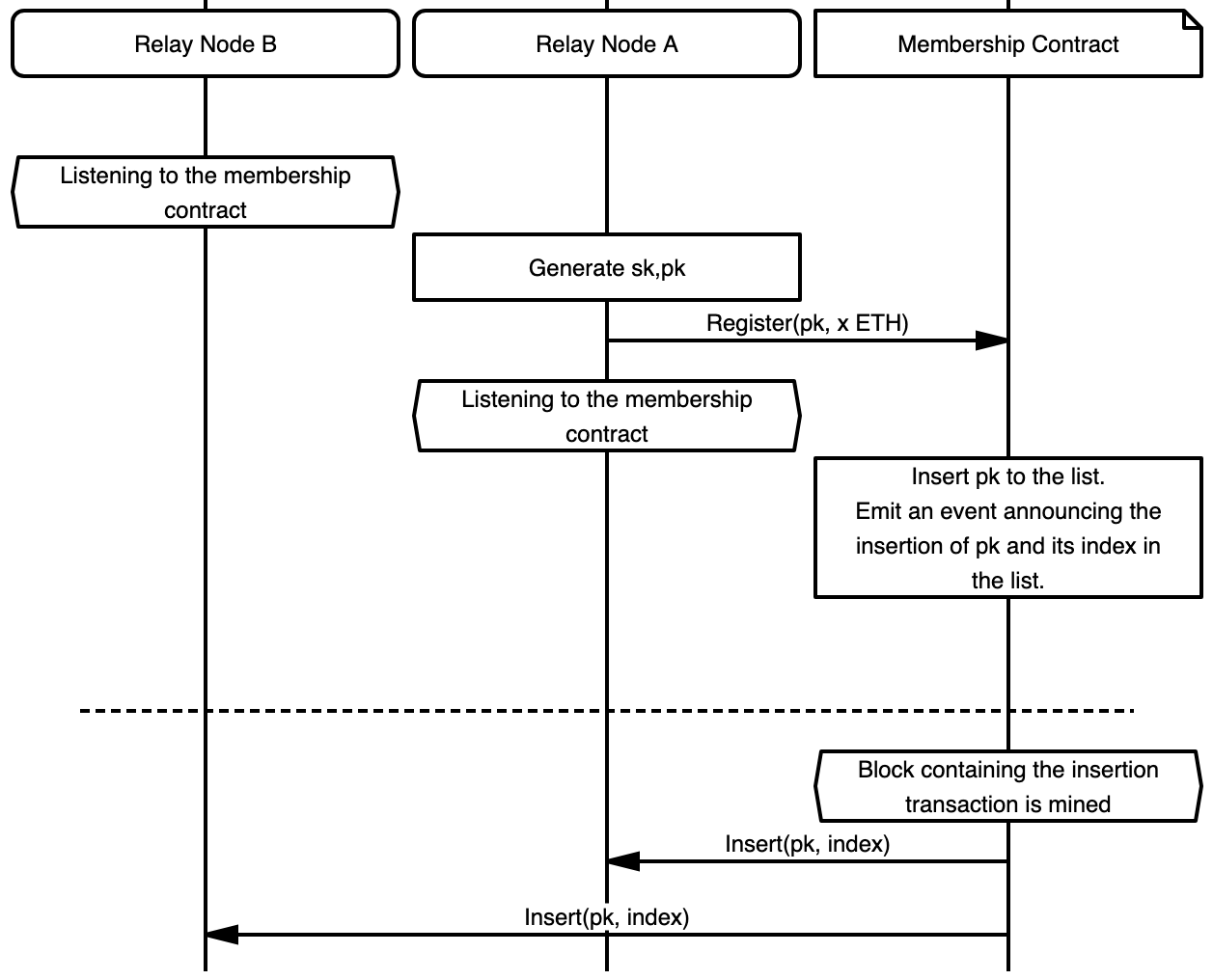
Publishing
To publish at a given epoch, the publishing peer proceeds
based on the regular 11/WAKU2-RELAY protocol.
However, to protect against spamming, each WakuMessage
(which is wrapped inside the data field of a PubSub message)
MUST carry a RateLimitProof with the following fields.
Section Payload covers the details about the type and
encoding of these fields.
- The
merkle_rootcontains the root of the Merkle tree. - The
epochrepresents the current epoch. - The
nullifieris an internal nullifier acting as a fingerprint that allows specifying whether two messages are published by the same peer during the sameepoch. - The
nullifieris a deterministic value derived fromskandepochtherefore any two messages issued by the same peer (i.e., using the samesk) for the sameepochare guaranteed to have identicalnullifiers. - The
share_xandshare_ycan be seen as partial disclosure of peer'sskfor the intendedepoch. They are derived deterministically from peer'sskand currentepochusing Shamir secret sharing scheme.
If a peer discloses more than one such pair (share_x, share_y) for the same epoch,
it would allow full disclosure of its sk and
hence get access to its staked fund in the membership contract.
- The
prooffield is a zero-knowledge proof signifying that:
- The message owner is the current member of the group i.e.,
the peer's identity commitment key,
pk, is part of the membership group Merkle tree with the rootmerkle_root. share_xandshare_yare correctly computed.- The
nullifieris constructed correctly. For more details about the proof generation check RLN The proof generation relies on the knowledge of two pieces of private information i.e.,skandauthPath. TheauthPathis a subset of Merkle tree nodes by which a peer can prove the inclusion of itspkin the group.
The proof generation also requires a set of public inputs which are:
the Merkle tree root merkle_root, the current epoch, and
the message for which the proof is going to be generated.
In 17/WAKU2-RLN-RELAY,
the message is the concatenation of WakuMessage's payload filed and
its contentTopic i.e., payload||contentTopic.
Group Synchronization
Proof generation relies on the knowledge of Merkle tree root merkle_root and
authPath which both require access to the membership Merkle tree.
Getting access to the Merkle tree can be done in various ways:
-
Peers construct the tree locally. This can be done by listening to the registration and deletion events emitted by the membership contract. Peers MUST update the local Merkle tree on a per-block basis. This is discussed further in the Merkle Root Validation section.
-
For synchronizing the state of slashed
pks, disseminate such information through apubsubTopicto which all peers are subscribed. A deletion transaction SHOULD occur on the membership contract. The benefit of an off-chain slashing is that it allows real-time removal of spammers as opposed to on-chain slashing in which peers get informed with a delay, where the delay is due to mining the slashing transaction.
For the group synchronization,
one important security consideration is that peers MUST make sure they always use
the most recent Merkle tree root in their proof generation.
The reason is that using an old root can allow inference
about the index of the user's pk in the membership tree
hence compromising user privacy and breaking message unlinkability.
Routing
Upon the receipt of a PubSub message via 11/WAKU2-RELAY protocol,
the routing peer parses the data field as a WakuMessage and
gets access to the RateLimitProof field.
The peer then validates the RateLimitProof as explained next.
Epoch Validation
If the epoch attached to the WakuMessage is more than max_epoch_gap,
apart from the routing peer's current epoch,
then the WakuMessage MUST be discarded and considered invalid.
This is to prevent a newly registered peer from spamming the system
by messaging for all the past epochs.
max_epoch_gap is a system parameter
for which we provide some recommendations in section Recommended System Parameters.
Merkle Root Validation
The routing peers MUST check whether the provided Merkle root
in the RateLimitProof is valid.
It can do so by maintaining a local set of valid Merkle roots,
which consist of acceptable_root_window_size past roots.
These roots refer to the final state of the Merkle tree
after a whole block consisting of group changes is processed.
The Merkle roots are updated on a per-block basis instead of a per-event basis.
This is done because if Merkle roots are updated on a per-event basis,
some peers could send messages with a root that refers to a Merkle tree state
that might get invalidated while the message is still propagating in the network,
due to many registrations happening during this time frame.
By updating roots on a per-block basis instead,
we will have only one root update per-block processed,
regardless on how many registrations happened in a block, and
peers will be able to successfully propagate messages in a time frame
corresponding to roughly the size of the roots window times the block mining time.
Atomic processing of the blocks are necessary so that even if the peer is unable to process one event, the previous roots remain valid, and can be used to generate valid RateLimitProof's.
This also allows peers which are not well connected to the network
to be able to send messages, accounting for network delay.
This network delay is related to the nature of asynchronous network conditions,
which means that peers see membership changes asynchronously, and
therefore may have differing local Merkle trees.
See Recommended System Parameters
on choosing an appropriate acceptable_root_window_size.
Proof Verification
The routing peers MUST check whether the zero-knowledge proof proof is valid.
It does so by running the zk verification algorithm as explained in RLN.
If proof is invalid then the message MUST be discarded.
Spam detection
To enable local spam detection and slashing,
routing peers MUST record the nullifier, share_x, and share_y
of incoming messages which are not discarded i.e.,
not found spam or with invalid proof or epoch.
To spot spam messages, the peer checks whether a message
with an identical nullifier has already been relayed.
- If such a message exists and its
share_xandshare_ycomponents are different from the incoming message, then slashing takes place. That is, the peer uses theshare_xandshare_yof the new message and theshare'_xandshare'_yof the old record to reconstruct theskof the message owner. Theskthen MAY be used to delete the spammer from the group and withdraw a portionreward_portionof its staked funds. - If the
share_xandshare_yfields of the previously relayed message are identical to the incoming message, then the message is a duplicate and MUST be discarded. - If none is found, then the message gets relayed.
An overview of the routing procedure and slashing is provided in Figure 2.
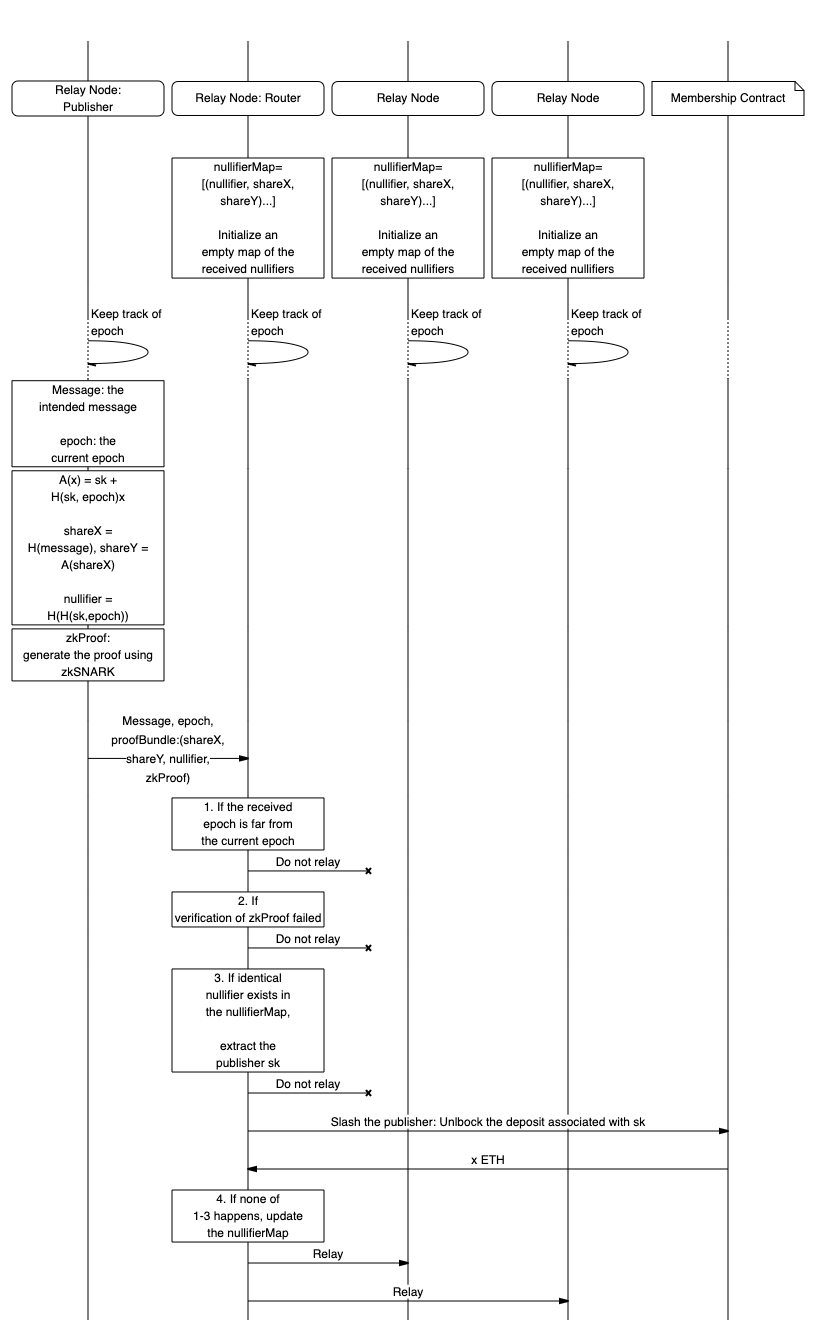
Payloads
Payloads are protobuf messages implemented using protocol buffers v3.
Nodes MAY extend the 14/WAKU2-MESSAGE
with a rate_limit_proof field to indicate that their message is not spam.
syntax = "proto3";
message RateLimitProof {
bytes proof = 1;
bytes merkle_root = 2;
bytes epoch = 3;
bytes share_x = 4;
bytes share_y = 5;
bytes nullifier = 6;
}
message WakuMessage {
bytes payload = 1;
string content_topic = 2;
optional uint32 version = 3;
optional sint64 timestamp = 10;
optional bool ephemeral = 31;
RateLimitProof rate_limit_proof = 21;
}
WakuMessage
rate_limit_proof holds the information required to prove that the message owner
has not exceeded the message rate limit.
RateLimitProof
Below is the description of the fields of RateLimitProof and their types.
| Parameter | Type | Description |
|---|---|---|
proof | array of 256 bytes uncompressed or 128 bytes compressed | the zkSNARK proof as explained in the Publishing process |
merkle_root | array of 32 bytes in little-endian order | the root of membership group Merkle tree at the time of publishing the message |
share_x and share_y | array of 32 bytes each | Shamir secret shares of the user's secret identity key sk . share_x is the Poseidon hash of the WakuMessage's payload concatenated with its contentTopic . share_y is calculated using Shamir secret sharing scheme |
nullifier | array of 32 bytes | internal nullifier derived from epoch and peer's sk as explained in RLN construct |
Recommended System Parameters
The system parameters are summarized in the following table, and the RECOMMENDED values for a subset of them are presented next.
| Parameter | Description |
|---|---|
period | the length of epoch in seconds |
staked_fund | the amount of funds to be staked by peers at the registration |
reward_portion | the percentage of staked_fund to be rewarded to the slashers |
max_epoch_gap | the maximum allowed gap between the epoch of a routing peer and the incoming message |
acceptable_root_window_size | The maximum number of past Merkle roots to store |
Epoch Length
A sensible value for the period depends on the application
for which the spam protection is going to be used.
For example, while the period of 1 second i.e.,
messaging rate of 1 per second, might be acceptable for a chat application,
might be too low for communication among Ethereum network validators.
One should look at the desired throughput of the application
to decide on a proper period value.
Maximum Epoch Gap
We discussed in the Routing section that the gap between the epoch
observed by the routing peer and
the one attached to the incoming message
should not exceed a threshold denoted by max_epoch_gap.
The value of max_epoch_gap can be measured based on the following factors.
- Network transmission delay
Network_Delay: the maximum time that it takes for a message to be fully disseminated in the GossipSub network. - Clock asynchrony
Clock_Asynchrony: The maximum difference between the Unix epoch clocks perceived by network peers which can be due to clock drifts.
With a reasonable approximation of the preceding values,
one can set max_epoch_gap as
max_epoch_gap
where period is the length of the epoch in seconds.
Network_Delay and Clock_Asynchrony MUST have the same resolution as period.
By this formulation, max_epoch_gap indeed measures the maximum number of epochs
that can elapse since a message gets routed from its origin
to all the other peers in the network.
acceptable_root_window_size depends upon the underlying chain's average blocktime,
block_time
The lower bound for the acceptable_root_window_size SHOULD be set as
Network_Delay MUST have the same resolution as block_time.
By this formulation,
acceptable_root_window_size will provide a lower bound
of how many roots can be acceptable by a routing peer.
The acceptable_root_window_size should indicate how many blocks may have been mined
during the time it takes for a peer to receive a message.
This formula represents a lower bound of the number of acceptable roots.
Copyright
Copyright and related rights waived via CC0.
References
11/WAKU2-RELAY- 64/WAKU-NETWORK
- RLN
- 14/WAKU2-MESSAGE
- RLN documentation
- Public inputs to the RLN circuit
- Shamir secret sharing scheme used in RLN
- RLN internal nullifier
19/WAKU2-LIGHTPUSH
| Field | Value |
|---|---|
| Name | Waku v2 Light Push |
| Slug | 19 |
| Status | draft |
| Type | RFC |
| Category | core |
| Editor | Hanno Cornelius [email protected] |
| Contributors | Daniel Kaiser [email protected], Oskar Thorén [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-08 —
c0ef3b9— Cleanup: rewrite specs-repo links in pre-existing messaging specs (#316) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-11-20 —
ff87c84— Update Waku Links (#104) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-02-01 —
c88680a— Update and rename LIGHTPUSH.md to lightpush.md - 2024-01-27 —
f9efd29— Rename README.md to LIGHTPUSH.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-25 —
c90013b— Create README.md
Protocol identifier: /vac/waku/lightpush/2.0.0-beta1
Motivation and Goals
Light nodes with short connection windows and limited bandwidth wish to publish messages into the Waku network. Additionally, there is sometimes a need for confirmation that a message has been received "by the network" (here, at least one node).
19/WAKU2-LIGHTPUSH is a request/response protocol for this.
Payloads
syntax = "proto3";
message PushRequest {
string pubsub_topic = 1;
WakuMessage message = 2;
}
message PushResponse {
bool is_success = 1;
// Error messages, etc
string info = 2;
}
message PushRPC {
string request_id = 1;
PushRequest request = 2;
PushResponse response = 3;
}
Message Relaying
Nodes that respond to PushRequests MUST either
relay the encapsulated message via 11/WAKU2-RELAY protocol
on the specified pubsub_topic,
or forward the PushRequest via 19/LIGHTPUSH on a WAKU2-DANDELION
stem.
If they are unable to do so for some reason,
they SHOULD return an error code in PushResponse.
Security Considerations
Since this can introduce an amplification factor, it is RECOMMENDED for the node relaying to the rest of the network to take extra precautions. This can be done by rate limiting via 17/WAKU2-RLN-RELAY.
Note that the above is currently not fully implemented.
Copyright
Copyright and related rights waived via CC0.
References
31/WAKU2-ENR
| Field | Value |
|---|---|
| Name | Waku v2 usage of ENR |
| Slug | 31 |
| Status | draft |
| Type | RFC |
| Category | core |
| Editor | Franck Royer [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-04-15 —
5a3e844— Chore/move repo into logos co (#312) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-10-16 —
e4f5f28— Update WAKU-ENR: Move to Draft (#180)
Abstract
This specification describes the usage of the ENR (Ethereum Node Records) format for 10/WAKU2 purposes. The ENR format is defined in EIP-778 [3].
This specification is an extension of EIP-778, ENR used in Waku MUST adhere to both EIP-778 and 31/WAKU2-ENR.
Motivation
EIP-1459 with the usage of ENR has been implemented [1] [2] as a discovery protocol for Waku.
EIP-778 specifies a number of pre-defined keys. However, the usage of these keys alone does not allow for certain transport capabilities to be encoded, such as Websocket. Currently, Waku nodes running in a browser only support websocket transport protocol. Hence, new ENR keys need to be defined to allow for the encoding of transport protocol other than raw TCP.
Usage of Multiaddr Format Rationale
One solution would be to define new keys such as ws to encode the websocket port of a node.
However, we expect new transport protocols to be added overtime such as quic.
Hence, this would only provide a short term solution until another specification would need to be added.
Moreover, secure websocket involves SSL certificates. SSL certificates are only valid for a given domain and ip, so an ENR containing the following information:
- secure websocket port
- ipv4 fqdn
- ipv4 address
- ipv6 address
Would carry some ambiguity: Is the certificate securing the websocket port valid for the ipv4 fqdn? the ipv4 address? the ipv6 address?
The 10/WAKU2 protocol family is built on the libp2p protocol stack. Hence, it uses multiaddr to format network addresses.
Directly storing one or several multiaddresses in the ENR would fix the issues listed above:
- multiaddr is self-describing and support addresses for any network protocol: No new specification would be needed to support encoding other transport protocols in an ENR.
- multiaddr contains both the host and port information, allowing the ambiguity previously described to be resolved.
Wire Format
multiaddrs ENR key
We define a multiaddrs key.
- The value MUST be a list of binary encoded multiaddr prefixed by their size.
- The size of the multiaddr MUST be encoded in a Big Endian unsigned 16-bit integer.
- The size of the multiaddr MUST be encoded in 2 bytes.
- The
secp256k1value MUST be present on the record;secp256k1is defined in EIP-778 and contains the compressed secp256k1 public key. - The node's peer id SHOULD be deduced from the
secp256k1value. - The multiaddresses SHOULD NOT contain a peer id except for circuit relay addresses
- For raw TCP & UDP connections details,
EIP-778 pre-defined keys SHOULD be used;
The keys
tcp,udp,ip(andtcp6,udp6,ip6for IPv6) are enough to convey all necessary information; - To save space,
multiaddrskey SHOULD only be used for connection details that cannot be represented using the EIP-778 pre-defined keys. - The 300 bytes size limit as defined by EIP-778 still applies; In practice, it is possible to encode 3 multiaddresses in ENR, more or less could be encoded depending on the size of each multiaddress.
Usage
Many connection types
Alice is a Waku node operator, she runs a node that supports inbound connection for the following protocols:
- TCP 10101 on
1.2.3.4 - UDP 20202 on
1.2.3.4 - TCP 30303 on
1234:5600:101:1::142 - UDP 40404 on
1234:5600:101:1::142 - Secure Websocket on
wss://example.com:443/ - QUIC on
quic://quic.example.com:443/ - A circuit relay address
/ip4/1.2.3.4/tcp/55555/p2p/QmRelay/p2p-circuit/p2p/QmAlice
Alice SHOULD structure the ENR for her node as follows:
| key | value |
|---|---|
tcp | 10101 |
udp | 20202 |
tcp6 | 30303 |
udp6 | 40404 |
ip | 1.2.3.4 |
ip6 | 1234:5600:101:1::142 |
secp256k1 | Alice's compressed secp256k1 public key, 33 bytes |
multiaddrs | len1 | /dns4/example.com/tcp/443/wss | len2 | /dns4/quic.examle.com/tcp/443/quic | len3 | /ip4/1.2.3.4/tcp/55555/p2p/QmRelay |
Where multiaddrs:
|is the concatenation operator,len1is the length of/dns4/example.com/tcp/443/wssbyte representation,len2is the length of/dns4/quic.examle.com/tcp/443/quicbyte representation.len3is the length of/ip4/1.2.3.4/tcp/55555/p2p/QmRelaybyte representation. Notice that the/p2p-circuitcomponent is not stored, but, since circuit relay addresses are the only one containing ap2pcomponent, it's safe to assume that any address containing this component is a circuit relay address. Decoding this type of multiaddresses would require appending the/p2p-circuitcomponent.
Raw TCP only
Bob is a node operator that runs a node that supports inbound connection for the following protocols:
- TCP 10101 on
1.2.3.4
Bob SHOULD structure the ENR for his node as follows:
| key | value |
|---|---|
tcp | 10101 |
ip | 1.2.3.4 |
secp256k1 | Bob's compressed secp256k1 public key, 33 bytes |
As Bob's node's connection details can be represented with EIP-778's pre-defined keys only,
it is not needed to use the multiaddrs key.
Limitations
Supported key type is secp256k1 only.
Support for other elliptic curve cryptography such as ed25519 MAY be used.
waku2 ENR key
We define a waku2 field key:
- The value MUST be an 8-bit flag field,
where bits set to
1indicatetrueand bits set to0indicatefalsefor the relevant flags. - The flag values already defined are set out below,
with
bit 7the most significant bit andbit 0the least significant bit.
| bit 7 | bit 6 | bit 5 | bit 4 | bit 3 | bit 2 | bit 1 | bit 0 |
|---|---|---|---|---|---|---|---|
undef | undef | undef | sync | lightpush | filter | store | relay |
- In the scheme above, the flags
sync,lightpush,filter,storeandrelaycorrelates with support for protocols with the same name. If a protocol is not supported, the corresponding field MUST be set tofalse. Indicating positive support for any specific protocol is OPTIONAL, though it MAY be required by the relevant application or discovery process. - Flags marked as
undefis not yet defined. These SHOULD be set tofalseby default.
Key Usage
- A Waku node MAY choose to populate the
waku2field for enhanced discovery capabilities, such as indicating supported protocols. Such a node MAY indicate support for any specific protocol by setting the corresponding flag totrue. - Waku nodes that want to participate in Node Discovery Protocol v5 [4], however,
MUST implement the
waku2key with at least one flag set totrue. - Waku nodes that discovered other participants using Discovery v5,
MUST filter out participant records that do not implement this field or
do not have at least one flag set to
true. - In addition, such nodes MAY choose to filter participants on specific flags
(such as supported protocols),
or further interpret the
waku2field as required by the application.
Copyright
Copyright and related rights waived via CC0.
References
33/WAKU2-DISCV5
| Field | Value |
|---|---|
| Name | Waku v2 Discv5 Ambient Peer Discovery |
| Slug | 33 |
| Status | draft |
| Type | RFC |
| Category | core |
| Editor | Daniel Kaiser [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-08 —
c0ef3b9— Cleanup: rewrite specs-repo links in pre-existing messaging specs (#316) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-04-29 —
5971166— Update discv5.md (#139) - 2024-11-20 —
87d4ff7— Workflow Fix: markdown-lint (#111) - 2024-11-20 —
dcc579c— Update WAKU2-PEER-EXCHANGE: Move to draft (#7) - 2024-11-20 —
ff87c84— Update Waku Links (#104) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-02-01 —
38d68ce— Update discv5.md - 2024-02-01 —
b8f8d20— Update and rename DISCV5.md to discv5.md - 2024-01-27 —
c6ef447— Rename README.md to DISCV5.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-25 —
037474d— Create README.md
Abstract
33/WAKU2-DISCV5 specifies a modified version of
Ethereum's Node Discovery Protocol v5
as a means for ambient node discovery.
10/WAKU2 uses the 33/WAKU2-DISCV5 ambient node discovery network
for establishing a decentralized network of interconnected Waku2 nodes.
In its current version,
the 33/WAKU2-DISCV5 discovery network
is isolated from the Ethereum Discovery v5 network.
Isolation improves discovery efficiency,
which is especially significant with a low number of Waku nodes
compared to the total number of Ethereum nodes.
Disclaimer
This version of 33/WAKU2-DISCV5 has a focus on timely deployment
of an efficient discovery method for 10/WAKU2.
Establishing a separate discovery network is in line with this focus.
However, we are aware of potential resilience problems
(see section on security considerations) and
are discussing
and researching hybrid approaches.
Background and Rationale
11/WAKU2-RELAY assumes the existence of a network of Waku2 nodes. For establishing and growing this network, new nodes trying to join the Waku2 network need a means of discovering nodes within the network. 10/WAKU2 supports the following discovery methods in order of increasing decentralization
- hard coded bootstrap nodes
DNS discovery(based on EIP-1459)34/WAKU2-PEER-EXCHANGE33/WAKU2-DISCV5(specified in this document)
The purpose of ambient node discovery within 10/WAKU2
is discovering Waku2 nodes in a decentralized way.
The unique selling point of 33/WAKU2-DISCV5 is its holistic view of the network,
which allows avoiding hotspots and allows merging the network after a split.
While the other methods provide either a fixed or local set of nodes,
33/WAKU2-DISCV5 can provide a random sample of Waku2 nodes.
Future iterations of this document will add the possibility
of efficiently discovering Waku2 nodes that have certain capabilities,
e.g. holding messages of a certain time frame
during which the querying node was offline.
Separate Discovery Network
w.r.t. Waku2 Relay Network
33/WAKU2-DISCV5 spans an overlay network separate from the
GossipSub
network 11/WAKU2-RELAY builds on.
Because it is a P2P network on its own, it also depends on bootstrap nodes.
Having a separate discovery network reduces load on the bootstrap nodes,
because the actual work is done by randomly discovered nodes.
This also increases decentralization.
w.r.t. Ethereum Discovery v5
33/WAKU2-DISCV5 spans a discovery network
isolated from the Ethereum Discovery v5 network.
Another simple solution would be taking part in the Ethereum Discovery network, and filtering Waku nodes based on whether they support WAKU2-ENR. This solution is more resilient towards eclipse attacks. However, this discovery method is very inefficient for small percentages of Waku nodes (see estimation). It boils down to random walk discovery and does not offer a O(log(n)) hop bound. The rarer the requested property (in this case Waku), the longer a random walk will take until finding an appropriate node, which leads to a needle-in-the-haystack problem. Using a dedicated Waku2 discovery network, nodes can query this discovery network for a random set of nodes and all (well-behaving) returned nodes can serve as bootstrap nodes for other Waku2 protocols.
A more sophisticated solution would be using Discv5 topic discovery. However, in its current state it also has efficiency problems for small percentages of Waku nodes and is still in the design phase (see here).
Currently, the Ethereum discv5 network is very efficient in finding other discv5 nodes, but it is not so efficient for finding discv5 nodes that have a specific property or offer specific services, e.g. Waku.
As part of our discv5 roadmap,
we consider two ideas for future versions of 33/WAKU2-DISCV5
- Discv5 topic discovery with adjustments (ideally upstream)
- a hybrid solution that uses both a separate discv5 network and a Waku-ENR-filtered Ethereum discv5 network
Semantics
33/WAKU2-DISCV5 fully inherits the discv5 semantics.
Before announcing their address via Waku2 discv5, nodes SHOULD check if this address is publicly reachable. Nodes MAY use the libp2p AutoNAT protocol to perform that check. Nodes SHOULD only announce publicly reachable addresses via Waku2 discv5, to avoid cluttering peer lists with nodes that are not reachable.
Wire Format Specification
33/WAKU2-DISCV5 inherits the discv5 wire protocol
except for the following differences
WAKU2-Specific protocol-id
Ethereum discv5:
header = static-header || authdata
static-header = protocol-id || version || flag || nonce || authdata-size
protocol-id = <b>"discv5"</b>
version = 0x0001
authdata-size = uint16 -- byte length of authdata
flag = uint8 -- packet type identifier
nonce = uint96 -- nonce of message
33/WAKU2-DISCV5:
kcode>
header = static-header || authdata
static-header = protocol-id || version || flag || nonce || authdata-size
protocol-id = <b>"d5waku"</b>
version = 0x0001
authdata-size = uint16 -- byte length of authdata
flag = uint8 -- packet type identifier
nonce = uint96 -- nonce of message
Suggestions for Implementations
Existing discv5 implementations
- can be augmented to make the
protocol-idselectable using a compile-time flag as in this feature branch of nim-eth/discv5. - can be forked followed by changing the
protocol-idstring as in go-waku.
Security Considerations
Sybil attack
Implementations should limit the number of bucket entries that have the same network parameters (IP address / port) to mitigate Sybil attacks.
Eclipse attack
Eclipse attacks aim to eclipse certain regions in a DHT. Malicious nodes provide false routing information for certain target regions. The larger the desired eclipsed region, the more resources (i.e. controlled nodes) the attacker needs. This introduces an efficiency versus resilience tradeoff. Discovery is more efficient if information about target objects (e.g. network parameters of nodes supporting Waku) are closer to a specific DHT address. If nodes providing specific information are closer to each other, they cover a smaller range in the DHT and are easier to eclipse.
Sybil attacks greatly increase the power of eclipse attacks, because they significantly reduce resources necessary to mount a successful eclipse attack.
Security Implications of a Separate Discovery Network
A dedicated Waku discovery network is more likely to be subject to successful eclipse attacks (and to DoS attacks in general). This is because eclipsing in a smaller network requires less resources for the attacker. DoS attacks render the whole network unusable if the percentage of attacker nodes is sufficient.
Using random walk discovery would mitigate eclipse attacks targeted at specific capabilities, e.g. Waku. However, this is because eclipse attacks aim at the DHT overlay structure, which is not used by random walks. So, this mitigation would come at the cost of giving up overlay routing efficiency. The efficiency loss is especially severe with a relatively small number of Waku nodes.
Properly protecting against eclipse attacks is challenging and raises research questions that we will address in future stages of our discv5 roadmap.
References
- 10/WAKU2
34/WAKU2-PEER-EXCHANGE- 11/WAKU2-RELAY
- WAKU2-ENR
- Node Discovery Protocol v5 (
discv5) discv5semantics.discv5wire protocoldiscv5topic discovery- libp2p AutoNAT protocol
EIP-1459GossipSub- Waku discv5 roadmap discussion
- discovery efficiency estimation
- implementation: Nim
- implementation: Go
Copyright
Copyright and related rights waived via CC0.
34/WAKU2-PEER-EXCHANGE
| Field | Value |
|---|---|
| Name | Waku2 Peer Exchange |
| Slug | 34 |
| Status | draft |
| Type | RFC |
| Category | core |
| Editor | Hanno Cornelius [email protected] |
| Contributors | Daniel Kaiser [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-08 —
c0ef3b9— Cleanup: rewrite specs-repo links in pre-existing messaging specs (#316) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-12-07 —
2b297d5— Update peer-exchange.md to fix a build error (#114) - 2024-11-20 —
87d4ff7— Workflow Fix: markdown-lint (#111) - 2024-11-20 —
dcc579c— Update WAKU2-PEER-EXCHANGE: Move to draft (#7)
Abstract
This document specifies a simple request-response peer exchange protocol. Responders send information about a requested number of peers. The main purpose of this protocol is providing resource restricted devices with peers.
Protocol Identifier
/vac/waku/peer-exchange/2.0.0-alpha1
Background and Motivation
It may not be feasible, on resource restricted devices, to take part in distributed random sampling ambient peer discovery protocols, such as 33/WAKU2-DISCV5. The Waku peer discovery protocol, specified in this document, allows resource restricted devices to request a list of peers from a service node. Network parameters necessary to connect to this service node COULD be learned from a static bootstrapping method or using EIP-1459: Node Discovery via DNS. The advantage of using Waku peer exchange to discover new peers, compared to relying on a static peer list or DNS discovery, is a more even load distribution. If a lot of resource restricted nodes would use the same service nodes as relay or store nodes, the load on these would be very high. Heavily used static nodes also add a centralized element. Downtime of such a node might significantly impact the network.
However, the resource efficiency of this protocol comes at an anonymity cost, which is explained in the Security/Privacy Considerations section. This protocol SHOULD only be used if 33/WAKU2-DISCV5 is infeasible.
Theory and Protocol Semantics
The keywords “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in 2119.
The peer exchange protocol, specified in this document, is a simple request-response protocol. As Figure 1 illustrates, the requesting node sends a request to a peer, which acts as the responder. The responder replies with a list of ENRs as specified in WAKU2-ENR. The multiaddresses used to connect to the respective peers can be extracted from the ENRs.

In order to protect its anonymity, the responder MUST NOT provide peers from its actively used peer list as this opens pathways to Neighbourhood Surveillance attacks, as described in the Security/Privacy Considerations Section. The responder SHOULD provide a set of peers that has been retrieved using ambient peer discovery methods supporting random sampling, e.g. 33/WAKU2-DISCV5. This both protects the responder's anonymity as well as helps distributing load.
To allow for fast responses, responders SHOULD retrieve peers unsolicited (before receiving a query) and maintain a queue of peers for the purpose of providing them in peer exchange responses. To get the best anonymity properties with respect to response peer sets, responders SHOULD use each of these peers only once.
To save bandwidth, and as a trade off to anonymity, responders MAY maintain a larger cache of exchange peers and randomly sample response sets from this local cache. The size of the cache SHOULD be large enough to allow randomly sampling peer sets that (on average) do not overlap too much. The responder SHOULD periodically replace the oldest peers in the cache. The RECOMMENDED options for the cache size are described in the Implementation Suggestions Section.
Requesters, in the context of the specified peer exchange protocol, SHOULD be resource restricted devices. While any node could technically act as a requester, using the peer exchange protocol comes with two drawbacks:
- reducing anonymity
- causing load on responder nodes
Wire Format Specification
syntax = "proto3";
message PeerInfo {
bytes enr = 1;
}
message PeerExchangeQuery {
uint64 num_peers = 1;
}
message PeerExchangeResponse {
repeated PeerInfo peer_infos = 1;
}
message PeerExchangeRPC {
PeerExchangeQuery query = 1;
PeerExchangeResponse response = 2;
}
The enr field contains a Waku ENR as specified in WAKU2-ENR.
Requesters send a PeerExchangeQuery to a peer.
Responders SHOULD include a maximum of num_peers PeerInfo instances into a response.
Responders send a PeerExchangeResponse to requesters
containing a list of PeerInfo instances, which in turn hold an ENR.
Implementation Suggestions
Discovery Interface
Implementations can implement the libp2p discovery interface:
Exchange Peer Cache Size
The size of the (optional) exchange peer cache discussed in
Theory and Protocol Semantics
depends on the average number of requested peers,
which is expected to be the outbound degree of the underlying
libp2p gossipsub
mesh network.
The RECOMMENDED value for this outbound degree is 6 (see parameter D in 29/WAKU2-CONFIG).
It is RECOMMENDED for the cache to hold at least 10 times as many peers (60).
The RECCOMENDED cache size also depends on the number of requesters a responder is expected to serve within a refresh cycle. A refresh cycle is the time interval in which all peers in the cache are expected to be replaced. If the number of requests expected per refresh cycle exceeds 600 (10 times the above recommended 60), it is RECOMMENDED to increase the cache size to at least a tenth of that number.
Security Considerations
Privacy and Anonymity
The peer exchange protocol specified in this document comes with anonymity and security implications. We differentiate these implications into the requester and responder side, respectively.
Requester
With a simple peer exchange protocol, the requester is inherently susceptible to both neighbourhood surveillance and controlled neighbourhood attacks.
To mount a neighbourhood surveillance attack, an attacker has to connect to the peers of the victim node. The peer exchange protocol allows a malicious responder to easily get into this position. The responder connects to a set of peers and simply returns this set of peers to the requester.
The peer exchange protocol also makes it much easier to get into the position required for the controlled neighbourhood attack: A malicious responder provides controlled peers in the response peer list.
More on these attacks may be found in our research log article.
As a weak mitigation the requester MAY ask several peers and select a subset of the returned peers.
Responder
Responders that answer with active mesh peers are more vulnerable to a neighbourhood surveillance attack. Responding with the set of active mesh peers allows a malicious requester to get into the required position more easily. It takes away the first hurdle of the neighbourhood surveillance attack: The attacker knows which peers to try to connect to. This increased vulnerability can be avoided by only responding with randomly sampled sets of peers, e.g. by requesting a random peer set via 33/WAKU2-DISCV5. (As stated in the Theory and Protocol Semantics Section, these peer sets SHOULD be retrieved unsolicitedly before receiving requests to achieve faster response times.)
Responders are also susceptible to amplification DoS attacks.
Requesters send a simple message request which causes responders to
engage in ambient peer discovery to retrieve a new random peer set.
As a mitigation, responders MAY feature a seen cache for requests and
only answer once per time interval.
The exchange-peer cache discussed in Theory and Protocol Semantics Section
also provides mitigation.
Still, frequent queries can tigger the refresh cycle more often.
The seen cache MAY be used in conjunction to provide additional mitigation.
Further Considerations
The response field contains ENRs as specified in WAKU2-ENR. While ENRs contain signatures, they do not violate the Waku relay no-sign policy, because they are part of the discovery domain and are not propagated in the relay domain. However, there might still be some form of leakage: ENRs could be used to track peers and facilitate linking attacks. We will investigate this further in our Waku anonymity analysis.
Copyright
Copyright and related rights waived via CC0.
References
- 33/WAKU2-DISCV5
- EIP-1459: Node Discovery via DNS
- WAKU2-ENR
- multiaddress
- libp2p discovery interface in nim
- libp2p discovery interface in javascript
- libp2p gossipsub
- 29/WAKU2-CONFIG
- Waku Relay Anonymity
- Waku relay no-sign policy
36/WAKU2-BINDINGS-API
| Field | Value |
|---|---|
| Name | Waku v2 C Bindings API |
| Slug | 36 |
| Status | draft |
| Type | RFC |
| Category | core |
| Editor | Richard Ramos [email protected] |
| Contributors | Franck Royer [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-02-28 —
cb56103— Update bindings-api.md - 2024-02-01 —
e9469d0— Update and rename BINDINGS-API.md to bindings-api.md - 2024-01-27 —
76e514a— Rename README.md to BINDINGS-API.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-25 —
6bd686d— Create README.md
Introduction
Native applications that wish to integrate Waku may not be able to use nwaku and its JSON RPC API due to constraints on packaging, performance or executables.
An alternative is to link existing Waku implementation as a static or dynamic library in their application.
This specification describes the C API that SHOULD be implemented by native Waku library and that SHOULD be used to consume them.
Design requirements
The API should be generic enough, so:
- it can be implemented by both nwaku and go-waku C-Bindings,
- it can be consumed from a variety of languages such as C#, Kotlin, Swift, Rust, C++, etc.
The selected format to pass data to and from the API is JSON.
It has been selected due to its widespread usage and easiness of use. Other alternatives MAY replace it in the future (C structure, protobuf) if it brings limitations that need to be lifted.
The API
General
WakuCallBack type
All the API functions require passing callbacks which will be executed depending on the result of the execution result. These callbacks are defined as
typedef void (*WakuCallBack) (const char* msg, size_t len_0);
With msg containing a \0 terminated string, and len_0 the length of this string.
The format of the data sent to these callbacks
will depend on the function being executed.
The data can be characters, numeric or json.
Status Codes
The API functions return an integer with status codes depending on the execution result. The following status codes are defined:
0- Success1- Error2- Missing callback
JsonMessage type
A Waku Message in JSON Format:
{
payload: string;
contentTopic: string;
version: number;
timestamp: number;
}
Fields:
payload: base64 encoded payload,waku_utils_base64_encodecan be used for this.contentTopic: The content topic to be set on the message.version: The Waku Message version number.timestamp: Unix timestamp in nanoseconds.
DecodedPayload type
A payload once decoded, used when a received Waku Message is encrypted:
interface DecodedPayload {
pubkey?: string;
signature?: string;
data: string;
padding: string;
}
Fields:
pubkey: Public key that signed the message (optional), hex encoded with0xprefix,signature: Message signature (optional), hex encoded with0xprefix,data: Decrypted message payload base64 encoded,padding: Padding base64 encoded.
FilterSubscription type
The criteria to create subscription to a light node in JSON Format:
{
contentFilters: ContentFilter[];
pubsubTopic: string?;
}
Fields:
contentFilters: Array ofContentFilterbeing subscribed to / unsubscribed from.topic: Optional pubsub topic.
ContentFilter type
{
contentTopic: string;
}
Fields:
contentTopic: The content topic of a Waku message.
StoreQuery type
Criteria used to retrieve historical messages
interface StoreQuery {
pubsubTopic?: string;
contentFilters?: ContentFilter[];
startTime?: number;
endTime?: number;
pagingOptions?: PagingOptions
}
Fields:
pubsubTopic: The pubsub topic on which messages are published.contentFilters: Array ofContentFilterto query for historical messages,startTime: The inclusive lower bound on the timestamp of queried messages. This field holds the Unix epoch time in nanoseconds.endTime: The inclusive upper bound on the timestamp of queried messages. This field holds the Unix epoch time in nanoseconds.pagingOptions: Paging information inPagingOptionsformat.
StoreResponse type
The response received after doing a query to a store node:
interface StoreResponse {
messages: JsonMessage[];
pagingOptions?: PagingOptions;
}
Fields:
messages: Array of retrieved historical messages inJsonMessageformat.pagingOption: Paging information inPagingOptionsformat from which to resume further historical queries
PagingOptions type
interface PagingOptions {
pageSize: number;
cursor?: Index;
forward: bool;
}
Fields:
pageSize: Number of messages to retrieve per page.cursor: Message Index from which to perform pagination. If not included and forward is set to true, paging will be performed from the beginning of the list. If not included and forward is set to false, paging will be performed from the end of the list.forward:trueif paging forward,falseif paging backward
Index type
interface Index {
digest: string;
receiverTime: number;
senderTime: number;
pubsubTopic: string;
}
Fields:
digest: Hash of the message at thisIndex.receiverTime: UNIX timestamp in nanoseconds at which the message at thisIndexwas received.senderTime: UNIX timestamp in nanoseconds at which the message is generated by its sender.pubsubTopic: The pubsub topic of the message at thisIndex.
Events
Asynchronous events require a callback to be registered.
An example of an asynchronous event that might be emitted is receiving a message.
When an event is emitted,
this callback will be triggered receiving a JSON string of type JsonSignal.
JsonSignal type
{
type: string;
event: any;
}
Fields:
type: Type of signal being emitted. Currently, onlymessageis available.event: Format depends on the type of signal.
For example:
{
"type": "message",
"event": {
"pubsubTopic": "/waku/2/default-waku/proto",
"messageId": "0x6496491e40dbe0b6c3a2198c2426b16301688a2daebc4f57ad7706115eac3ad1",
"wakuMessage": {
"payload": "TODO",
"contentTopic": "/my-app/1/notification/proto",
"version": 1,
"timestamp": 1647826358000000000
}
}
}
type | event Type |
|---|---|
message | JsonMessageEvent |
JsonMessageEvent type
Type of event field for a message event:
{
pubsubTopic: string;
messageId: string;
wakuMessage: JsonMessage;
}
pubsubTopic: The pubsub topic on which the message was received.messageId: The message id.wakuMessage: The message inJsonMessageformat.
waku_set_event_callback
extern void waku_set_event_callback(WakuCallBack cb){}
Register callback to act as event handler and receive application signals, which are used to react to asynchronous events in Waku.
Parameters
WakuCallBack cb: callback that will be executed when an async event is emitted.
Node management
JsonConfig type
Type holding a node configuration:
interface JsonConfig {
host?: string;
port?: number;
advertiseAddr?: string;
nodeKey?: string;
keepAliveInterval?: number;
relay?: boolean;
relayTopics?: Array<string>;
gossipsubParameters?: GossipSubParameters;
minPeersToPublish?: number
legacyFilter?: boolean;
discV5?: boolean;
discV5BootstrapNodes?: Array<string>;
discV5UDPPort?: number;
store?: boolean;
databaseURL?: string;
storeRetentionMaxMessages?: number;
storeRetentionTimeSeconds?: number;
websocket?: Websocket;
dns4DomainName?: string;
}
Fields:
All fields are optional.
If a key is undefined, or null, a default value will be set.
host: Listening IP address. Default0.0.0.0.port: Libp2p TCP listening port. Default60000. Use0for random.advertiseAddr: External address to advertise to other nodes. Can be ip4, ip6 or dns4, dns6. Ifnull, the multiaddress(es) generated from the ip and port specified in the config (or default ones) will be used. Default:null.nodeKey: Secp256k1 private key in Hex format (0x123...abc). Default random.keepAliveInterval: Interval in seconds for pinging peers to keep the connection alive. Default20.relay: Enable relay protocol. Defaulttrue.relayTopics: Array of pubsub topics that WakuRelay will automatically subscribe to when the node starts Default[]gossipSubParameters: custom gossipsub parameters. SeeGossipSubParameterssection for defaultsminPeersToPublish: The minimum number of peers required on a topic to allow broadcasting a message. Default0.legacyFilter: Enable Legacy Filter protocol. Defaultfalse.discV5: Enable DiscoveryV5. DefaultfalsediscV5BootstrapNodes: Array of bootstrap nodes ENRdiscV5UDPPort: UDP port for DiscoveryV5 Default9000store: Enable store protocol to persist message history DefaultfalsedatabaseURL: url connection string. Accepts SQLite and PostgreSQL connection strings Default:sqlite3://store.dbstoreRetentionMaxMessages: max number of messages to store in the database. Default10000storeRetentionTimeSeconds: max number of seconds that a message will be persisted in the database. Default2592000(30d)websocket: custom websocket support parameters. SeeWebsocketsection for defaultsdns4DomainName: the domain name resolving to the node's public IPv4 address.
For example:
{
"host": "0.0.0.0",
"port": 60000,
"advertiseAddr": "1.2.3.4",
"nodeKey": "0x123...567",
"keepAliveInterval": 20,
"relay": true,
"minPeersToPublish": 0
}
GossipsubParameters type
Type holding custom gossipsub configuration:
interface GossipSubParameters {
D?: number;
D_low?: number;
D_high?: number;
D_score?: number;
D_out?: number;
HistoryLength?: number;
HistoryGossip?: number;
D_lazy?: number;
GossipFactor?: number;
GossipRetransmission?: number;
HeartbeatInitialDelayMs?: number;
HeartbeatIntervalSeconds?: number;
SlowHeartbeatWarning?: number;
FanoutTTLSeconds?: number;
PrunePeers?: number;
PruneBackoffSeconds?: number;
UnsubscribeBackoffSeconds?: number;
Connectors?: number;
MaxPendingConnections?: number;
ConnectionTimeoutSeconds?: number;
DirectConnectTicks?: number;
DirectConnectInitialDelaySeconds?: number;
OpportunisticGraftTicks?: number;
OpportunisticGraftPeers?: number;
GraftFloodThresholdSeconds?: number;
MaxIHaveLength?: number;
MaxIHaveMessages?: number;
IWantFollowupTimeSeconds?: number;
}
Fields:
All fields are optional.
If a key is undefined, or null, a default value will be set.
d: optimal degree for a GossipSub topic mesh. Default6dLow: lower bound on the number of peers we keep in a GossipSub topic mesh Default5dHigh: upper bound on the number of peers we keep in a GossipSub topic mesh. Default12dScore: affects how peers are selected when pruning a mesh due to over subscription. Default4dOut: sets the quota for the number of outbound connections to maintain in a topic mesh. Default2historyLength: controls the size of the message cache used for gossip. Default5historyGossip: controls how many cached message ids we will advertise in IHAVE gossip messages. Default3dLazy: affects how many peers we will emit gossip to at each heartbeat. Default6gossipFactor: affects how many peers we will emit gossip to at each heartbeat. Default0.25gossipRetransmission: controls how many times we will allow a peer to request the same message id through IWANT gossip before we start ignoring them. Default3heartbeatInitialDelayMs: short delay in milliseconds before the heartbeat timer begins after the router is initialized. Default100millisecondsheartbeatIntervalSeconds: controls the time between heartbeats. Default1secondslowHeartbeatWarning: duration threshold for heartbeat processing before emitting a warning. Default0.1fanoutTTLSeconds: controls how long we keep track of the fanout state. Default60secondsprunePeers: controls the number of peers to include in prune Peer eXchange. Default16pruneBackoffSeconds: controls the backoff time for pruned peers. Default60secondsunsubscribeBackoffSeconds: controls the backoff time to use when unsuscribing from a topic. Default10secondsconnectors: number of active connection attempts for peers obtained through PX. Default8maxPendingConnections: maximum number of pending connections for peers attempted through px. Default128connectionTimeoutSeconds: timeout in seconds for connection attempts. Default30secondsdirectConnectTicks: the number of heartbeat ticks for attempting to reconnect direct peers that are not currently connected. Default300directConnectInitialDelaySeconds: initial delay before opening connections to direct peers. Default1secondopportunisticGraftTicks: number of heartbeat ticks for attempting to improve the mesh with opportunistic grafting. Default60opportunisticGraftPeers: the number of peers to opportunistically graft. Default2graftFloodThresholdSeconds: If a GRAFT comes before GraftFloodThresholdSeconds has elapsed since the last PRUNE, then there is an extra score penalty applied to the peer through P7. Default10secondsmaxIHaveLength: max number of messages to include in an IHAVE message, also controls the max number of IHAVE ids we will accept and request with IWANT from a peer within a heartbeat. Default5000maxIHaveMessages: max number of IHAVE messages to accept from a peer within a heartbeat. Default10iWantFollowupTimeSeconds: Time to wait for a message requested through IWANT following an IHAVE advertisement. Default3secondsseenMessagesTTLSeconds: configures when a previously seen message ID can be forgotten about. Default120seconds
Websocket type
Type holding custom websocket support configuration:
interface Websocket {
enabled?: bool;
host?: string;
port?: number;
secure?: bool;
certPath?: string;
keyPath?: string;
}
Fields:
All fields are optional.
If a key is undefined, or null, a default value will be set.
If using secure websockets support, certPath and
keyPath become mandatory attributes.
Unless selfsigned certificates are used,
it will probably make sense in the JsonConfiguration
to specify the domain name used in the certificate in the dns4DomainName attribute.
enabled: indicates if websockets support will be enabled Defaultfalsehost: listening address for websocket connections Default0.0.0.0port: TCP listening port for websocket connection (0for random, binding to443requires root access) Default60001, if secure websockets support is enabled, the default is6443“secure: enable secure websockets support DefaultfalsecertPath: secure websocket certificate pathkeyPath: secure websocket key path
waku_new
extern int waku_new(char* jsonConfig, WakuCallBack onErrCb){}
Instantiates a Waku node.
Parameters
char* jsonConfig: JSON string containing the options used to initialize a waku node. TypeJsonConfig. It can beNULLto use defaults.WakuCallBack onErrCb:WakuCallBack. Callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
- 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onErrCbcallback
waku_start
extern int waku_start(WakuCallBack onErrCb){}
Starts a Waku node mounting all the protocols that were enabled during the Waku node instantiation.
Parameters
WakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
- 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onErrCbcallback
waku_stop
extern int waku_stop(WakuCallBack onErrCb){}
Stops a Waku node.
Parameters
WakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
- 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onErrCbcallback
waku_peerid
extern int waku_peerid(WakuCallBack onOkCb, WakuCallBack onErrCb){}
Get the peer ID of the waku node.
Parameters
WakuCallBack onOkCb: callback to be executed if the function is succesfulWakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
onOkCbwill receive the base58 encoded peer ID, for exampleQmWjHKUrXDHPCwoWXpUZ77E8o6UbAoTTZwf1AD1tDC4KNP - 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onOkCboronErrCbcallback
waku_listen_addresses
extern int waku_listen_addresses(WakuCallBack onOkCb, WakuCallBack onErrCb){}
Get the multiaddresses the Waku node is listening to.
Parameters
WakuCallBack onOkCb: callback to be executed if the function is succesfulWakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
onOkCbwill receive a json array of multiaddresses. The multiaddresses arestrings. For example:
[
"/ip4/127.0.0.1/tcp/30303",
"/ip4/1.2.3.4/tcp/30303",
"/dns4/waku.node.example/tcp/8000/wss"
]
- 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onOkCbandonErrCbcallback
Connecting to peers
waku_add_peer
extern int waku_add_peer(char* address, char* protocolId, WakuCallBack onOkCb, WakuCallBack onErrCb){}
Add a node multiaddress and protocol to the waku node's peerstore.
Parameters
char* address: A multiaddress (with peer id) to reach the peer being added.char* protocolId: A protocol we expect the peer to support.WakuCallBack onOkCb: callback to be executed if the function is succesfulWakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
onOkCbwill receive the base 58 peer ID of the peer that was added. - 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onOkCboronErrCbcallback
waku_connect
extern int waku_connect(char* address, int timeoutMs, WakuCallBack onErrCb){}
Dial peer using a multiaddress.
Parameters
char* address: A multiaddress to reach the peer being dialed.int timeoutMs: Timeout value in milliseconds to execute the call. If the function execution takes longer than this value, the execution will be canceled and an error returned. Use0for no timeout.WakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
- 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onErrCbcallback
waku_connect_peerid
extern int waku_connect_peerid(char* peerId, int timeoutMs, WakuCallBack onErrCb){}
Dial peer using its peer ID.
Parameters
char* peerID: Peer ID to dial. The peer must be already known. It must have been added before withwaku_add_peeror previously dialed withwaku_connect.int timeoutMs: Timeout value in milliseconds to execute the call. If the function execution takes longer than this value, the execution will be canceled and an error returned. Use0for no timeout.WakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
- 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onErrCbcallback
waku_disconnect
extern int waku_disconnect(char* peerId, WakuCallBack onErrCb){}
Disconnect a peer using its peerID
Parameters
char* peerID: Peer ID to disconnect.WakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
- 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onErrCbcallback
waku_peer_cnt
extern int waku_peer_cnt(WakuCallBack onOkCb, WakuCallBack onErrCb){}
Get number of connected peers.
Parameters
WakuCallBack onOkCb: callback to be executed if the function is succesfulWakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
onOkCbwill receive the number of connected peers. - 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onOkCboronErrCbcallback
waku_peers
extern int waku_peers(WakuCallBack onOkCb, WakuCallBack onErrCb){}
Retrieve the list of peers known by the Waku node.
Parameters
WakuCallBack onOkCb: callback to be executed if the function is succesfulWakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
onOkCbwill receive a json array with the list of peers. This list has this format:
[
{
"peerID": "16Uiu2HAmJb2e28qLXxT5kZxVUUoJt72EMzNGXB47RedcBafeDCBA",
"protocols": [
"/ipfs/id/1.0.0",
"/vac/waku/relay/2.0.0",
"/ipfs/ping/1.0.0"
],
"addrs": [
"/ip4/1.2.3.4/tcp/30303"
],
"connected": true
}
]
- 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onOkCboronErrCbcallback
Waku Relay
waku_content_topic
extern int waku_content_topic(char* applicationName, unsigned int applicationVersion, char* contentTopicName, char* encoding, WakuCallBack onOkCb){}
Create a content topic string according to RFC 23.
Parameters
char* applicationNameunsigned int applicationVersionchar* contentTopicNamechar* encoding: depending on the payload, useproto,rlporrfc26WakuCallBack onOkCb: callback to be executed if the function is succesful
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
onOkCbwill receive the content topic formatted according to RFC 23:/{application-name}/{version-of-the-application}/{content-topic-name}/{encoding} - 1 - The operation failed for any reason.
- 2 - The function is missing the
onOkCbcallback
waku_pubsub_topic
extern int waku_pubsub_topic(char* name, char* encoding, WakuCallBack onOkCb){}
Create a pubsub topic string according to RFC 23.
Parameters
char* namechar* encoding: depending on the payload, useproto,rlporrfc26WakuCallBack onOkCb: callback to be executed if the function is succesful
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
onOkCbwill get populated with a pubsub topic formatted according to RFC 23:/waku/2/{topic-name}/{encoding} - 1 - The operation failed for any reason.
- 2 - The function is missing the
onOkCbcallback
waku_default_pubsub_topic
extern int waku_default_pubsub_topic(WakuCallBack onOkCb){}
Returns the default pubsub topic used for exchanging waku messages defined in RFC 10.
Parameters
WakuCallBack onOkCb: callback to be executed if the function is succesful
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
onOkCbwill get populated with/waku/2/default-waku/proto - 1 - The operation failed for any reason.
- 2 - The function is missing the
onOkCbcallback
waku_relay_publish
extern int waku_relay_publish(char* messageJson, char* pubsubTopic, int timeoutMs, WakuCallBack onOkCb, WakuCallBack onErrCb){}
Publish a message using Waku Relay.
Parameters
char* messageJson: JSON string containing the Waku Message asJsonMessage.char* pubsubTopic: pubsub topic on which to publish the message. IfNULL, it uses the default pubsub topic.int timeoutMs: Timeout value in milliseconds to execute the call. If the function execution takes longer than this value, the execution will be canceled and an error returned. Use0for no timeout.WakuCallBack onOkCb: callback to be executed if the function is succesfulWakuCallBack onErrCb: callback to be executed if the function fails
If the execution is successful, the result field contains the message ID.
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
onOkCbwill get populated with the message ID - 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onOkCboronErrCbcallback
waku_relay_enough_peers
extern int waku_relay_enough_peers(char* pubsubTopic, WakuCallBack onOkCb, WakuCallBack onErrCb){}
Determine if there are enough peers to publish a message on a given pubsub topic.
Parameters
char* pubsubTopic: Pubsub topic to verify. IfNULL, it verifies the number of peers in the default pubsub topic.WakuCallBack onOkCb: callback to be executed if the function is succesfulWakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
onOkCbwill receive a stringbooleanindicating whether there are enough peers, i.e.trueorfalse - 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onOkCboronErrCbcallback
waku_relay_subscribe
extern int waku_relay_subscribe(char* topic, WakuCallBack onErrCb){}
Subscribe to a Waku Relay pubsub topic to receive messages.
Parameters
char* topic: Pubsub topic to subscribe to. IfNULL, it subscribes to the default pubsub topic.WakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
- 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onErrCbcallback
Events
When a message is received,
a "message" event is emitted containing the message, pubsub topic,
and node ID in which
the message was received.
The event type is JsonMessageEvent.
For Example:
{
"type": "message",
"event": {
"pubsubTopic": "/waku/2/default-waku/proto",
"messageId": "0x6496491e40dbe0b6c3a2198c2426b16301688a2daebc4f57ad7706115eac3ad1",
"wakuMessage": {
"payload": "TODO",
"contentTopic": "/my-app/1/notification/proto",
"version": 1,
"timestamp": 1647826358000000000
}
}
}
waku_relay_unsubscribe
extern int waku_relay_unsubscribe(char* topic, WakuCallBack onErrCb)
Closes the pubsub subscription to a pubsub topic. No more messages will be received from this pubsub topic.
Parameters
char* pusubTopic: Pubsub topic to unsubscribe from. IfNULL, unsubscribes from the default pubsub topic.WakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
- 1 - The operation failed for any reason.
- 2 - The function is missing the
onErrCbcallback
waku_relay_topics
extern int waku_relay_topics(WakuCallBack onOkCb, WakuCallBack onErrCb)
Get the list of subscribed pubsub topics in Waku Relay.
Parameters
WakuCallBack onOkCb: callback to be executed if the function is succesfulWakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
onOkCbwill receive a json array of pubsub topics i.e["pubsubTopic1", "pubsubTopic2"] - 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onOkCboronErrCbcallback
Waku Filter
waku_filter_subscribe
extern int waku_filter_subscribe(char* filterJSON, char* peerID, int timeoutMs, WakuCallBack onOkCb, WakuCallBack onErrCb)
Creates a subscription to a filter full node matching a content filter..
Parameters
char* filterJSON: JSON string containing theFilterSubscriptionto subscribe to.char* peerID: Peer ID to subscribe to. The peer must be already known. It must have been added before withwaku_add_peeror previously dialed withwaku_connect_peer. UseNULLto automatically select a node.int timeoutMs: Timeout value in milliseconds to execute the call. If the function execution takes longer than this value, the execution will be canceled and an error returned. Use0for no timeout.WakuCallBack onOkCb: callback to be executed if the function is succesfulWakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
onOkCbwill receive the subscription details, for example:
{
"peerID": "....",
"pubsubTopic": "...",
"contentTopics": [...]
}
- 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onOkCboronErrCbcallback
Events
When a message is received,
a "message" event is emitted containing the message, pubsub topic,
and node ID in which the message was received.
The event type is JsonMessageEvent.
For Example:
{
"type": "message",
"event": {
"pubsubTopic": "/waku/2/default-waku/proto",
"messageId": "0x6496491e40dbe0b6c3a2198c2426b16301688a2daebc4f57ad7706115eac3ad1",
"wakuMessage": {
"payload": "TODO",
"contentTopic": "/my-app/1/notification/proto",
"version": 1,
"timestamp": 1647826358000000000
}
}
}
waku_filter_ping
extern int waku_filter_ping(char* peerID, int timeoutMs, WakuCallBack onErrCb){}
Used to know if a service node has an active subscription for this client
Parameters
char* peerID: Peer ID to check for an active subscription The peer must be already known. It must have been added before withwaku_add_peeror previously dialed withwaku_connect_peer.int timeoutMs: Timeout value in milliseconds to execute the call. If the function execution takes longer than this value, the execution will be canceled and an error returned. Use0for no timeout.WakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
- 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onErrCbcallback
waku_filter_unsubscribe
extern int waku_filter_unsubscribe(filterJSON *C.char, char* peerID, int timeoutMs, WakuCallBack onErrCb){}
Sends a requests to a service node to stop pushing messages matching this filter to this client. It might be used to modify an existing subscription by providing a subset of the original filter criteria
Parameters
char* filterJSON: JSON string containing theFilterSubscriptioncriteria to unsubscribe fromchar* peerID: Peer ID to unsubscribe from The peer must be already known. It must have been added before withwaku_add_peeror previously dialed withwaku_connect_peer.int timeoutMs: Timeout value in milliseconds to execute the call. If the function execution takes longer than this value, the execution will be canceled and an error returned. Use0for no timeout.WakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
- 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onOkCboronErrCbcallback
waku_filter_unsubscribe_all
extern int waku_filter_unsubscribe_all(char* peerID, int timeoutMs, WakuCallBack onOkCb, WakuCallBack onErrCb){}
Sends a requests to a service node (or all service nodes) to stop pushing messages
Parameters
char* peerID: Peer ID to unsubscribe from The peer must be already known. It must have been added before withwaku_add_peeror previously dialed withwaku_connect_peer. UseNULLto unsubscribe from all peers with active subscriptionsint timeoutMs: Timeout value in milliseconds to execute the call. If the function execution takes longer than this value, the execution will be canceled and an error returned. Use0for no timeout.WakuCallBack onOkCb: callback to be executed if the function is succesfulWakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
onOkCbwill receive an array with information about the state of each unsubscription attempt (one per peer)
[
{
"peerID": ....,
"error": "" // Empty if succesful
},
...
]
- 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onOkCboronErrCbcallback
Waku Legacy Filter
waku_legacy_filter_subscribe
extern int waku_legacy_filter_subscribe(char* filterJSON, char* peerID, int timeoutMs, WakuCallBack onErrCb){}
Creates a subscription in a lightnode for messages that matches a content filter
and optionally a PubSub topic.
Parameters
char* filterJSON: JSON string containing theLegacyFilterSubscriptionto subscribe to.char* peerID: Peer ID to subscribe to. The peer must be already known. It must have been added before withwaku_add_peeror previously dialed withwaku_connect_peer. UseNULLto automatically select a node.int timeoutMs: Timeout value in milliseconds to execute the call. If the function execution takes longer than this value, the execution will be canceled and an error returned. Use0for no timeout.WakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
- 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onErrCbcallback
Events
When a message is received,
a "message" event is emitted containing the message, pubsub topic,
and node ID in which the message was received.
The event type is JsonMessageEvent.
For Example:
{
"type": "message",
"event": {
"pubsubTopic": "/waku/2/default-waku/proto",
"messageId": "0x6496491e40dbe0b6c3a2198c2426b16301688a2daebc4f57ad7706115eac3ad1",
"wakuMessage": {
"payload": "TODO",
"contentTopic": "/my-app/1/notification/proto",
"version": 1,
"timestamp": 1647826358000000000
}
}
}
waku_legacy_filter_unsubscribe
extern int waku_legacy_filter_unsubscribe(char* filterJSON, int timeoutMs, WakuCallBack onErrCb){}
Removes subscriptions in a light node matching a content filter and,
optionally, a PubSub topic.
Parameters
char* filterJSON: JSON string containing theLegacyFilterSubscription.int timeoutMs: Timeout value in milliseconds to execute the call. If the function execution takes longer than this value, the execution will be canceled and an error returned. Use0for no timeout.WakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
- 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onErrCbcallback
Waku Lightpush
waku_lightpush_publish
extern int waku_lightpush_publish(char* messageJSON, char* topic, char* peerID, int timeoutMs, WakuCallBack onOkCb, WakuCallBack onErrCb){}
Publish a message using Waku Lightpush.
Parameters
char* messageJson: JSON string containing the Waku Message asJsonMessage.char* pubsubTopic: pubsub topic on which to publish the message. IfNULL, it uses the default pubsub topic.char* peerID: Peer ID supporting the lightpush protocol. The peer must be already known. It must have been added before withwaku_add_peeror previously dialed withwaku_connect_peer. UseNULLto automatically select a node.int timeoutMs: Timeout value in milliseconds to execute the call. If the function execution takes longer than this value, the execution will be canceled and an error returned. Use0for no timeout.WakuCallBack onOkCb: callback to be executed if the function is succesfulWakuCallBack onErrCb: callback to be executed if the function fails
Note: messageJson.version is overwritten to 0.
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
onOkCbwill receive the message ID - 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onOkCboronErrCbcallback
Waku Store
waku_store_query
extern int waku_store_query(char* queryJSON, char* peerID, int timeoutMs, WakuCallBack onOkCb, WakuCallBack onErrCb){}
Retrieves historical messages on specific content topics.
This method may be called with PagingOptions,
to retrieve historical messages on a per-page basis.
If the request included PagingOptions, the node
must return messages on a per-page basis and
include PagingOptions in the response.
These PagingOptions
must contain a cursor pointing to the Index from which a new page can be requested.
Parameters
char* queryJSON: JSON string containing theStoreQuery.char* peerID: Peer ID supporting the store protocol. The peer must be already known. It must have been added before withwaku_add_peeror previously dialed withwaku_connect_peer.int timeoutMs: Timeout value in milliseconds to execute the call. If the function execution takes longer than this value, the execution will be canceled and an error returned. Use0for no timeout.WakuCallBack onOkCb: callback to be executed if the function is succesfulWakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
onOkCbwill receive aStoreResponse. - 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onOkCboronErrCbcallback
waku_store_local_query
extern int waku_store_local_query(char* queryJSON, WakuCallBack onOkCb, WakuCallBack onErrCb){}
Retrieves locally stored historical messages on specific content topics.
This method may be called with PagingOptions,
to retrieve historical messages on a per-page basis.
If the request included PagingOptions, the node
must return messages on a per-page basis and
include PagingOptions in the response.
These PagingOptions
must contain a cursor pointing to the Index from which a new page can be requested.
Parameters
char* queryJSON: JSON string containing theStoreQuery.int timeoutMs: Timeout value in milliseconds to execute the call. If the function execution takes longer than this value, the execution will be canceled and an error returned. Use0for no timeout.WakuCallBack onOkCb: callback to be executed if the function is succesfulWakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
onOkCbwill receive aStoreResponse. - 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onOkCboronErrCbcallback
Encrypting messages
waku_encode_symmetric
extern int waku_encode_symmetric(char* messageJson, char* symmetricKey, char* optionalSigningKey, WakuCallBack onOkCb, WakuCallBack onErrCb){}
Encrypt a message using symmetric encryption and optionally sign the message
Parameters
char* messageJson: JSON string containing the Waku Message asJsonMessage.char* symmetricKey: hex encoded secret key to be used for encryption.char* optionalSigningKey: hex encoded private key to be used to sign the message.WakuCallBack onOkCb: callback to be executed if the function is succesfulWakuCallBack onErrCb: callback to be executed if the function fails
Note: messageJson.version is overwritten to 1.
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
onOkCbwill receive the encrypted waku message which can be broadcasted with relay or lightpush protocol publish functions. - 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onOkCboronErrCbcallback
waku_encode_asymmetric
extern int waku_encode_asymmetric(char* messageJson, char* publicKey, char* optionalSigningKey, WakuCallBack onOkCb, WakuCallBack onErrCb){}
Encrypt a message using asymmetric encryption and optionally sign the message
Parameters
char* messageJson: JSON string containing the Waku Message asJsonMessage.char* publicKey: hex encoded public key to be used for encryption.char* optionalSigningKey: hex encoded private key to be used to sign the message.WakuCallBack onOkCb: callback to be executed if the function is succesfulWakuCallBack onErrCb: callback to be executed if the function fails
Note: messageJson.version is overwritten to 1.
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
onOkCbwill receive the encrypted waku message which can be broadcasted with relay or lightpush protocol publish functions. - 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onOkCboronErrCbcallback
Decrypting messages
waku_decode_symmetric
extern int waku_decode_symmetric(char* messageJson, char* symmetricKey, WakuCallBack onOkCb, WakuCallBack onErrCb){}
Decrypt a message using a symmetric key
Parameters
char* messageJson: JSON string containing the Waku Message asJsonMessage.char* symmetricKey: 32 byte symmetric key hex encoded.WakuCallBack onOkCb: callback to be executed if the function is succesfulWakuCallBack onErrCb: callback to be executed if the function fails
Note: messageJson.version is expected to be 1.
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
onOkCbwill receive the decoded payload as aDecodedPayload.
{
"pubkey": "0x......",
"signature": "0x....",
"data": "...",
"padding": "..."
}
- 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onOkCboronErrCbcallback
waku_decode_asymmetric
extern int waku_decode_asymmetric(char* messageJson, char* privateKey, WakuCallBack onOkCb, WakuCallBack onErrCb){}
Decrypt a message using a secp256k1 private key
Parameters
char* messageJson: JSON string containing the Waku Message asJsonMessage.char* privateKey: secp256k1 private key hex encoded.WakuCallBack onOkCb: callback to be executed if the function is succesfulWakuCallBack onErrCb: callback to be executed if the function fails
Note: messageJson.version is expected to be 1.
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
onOkCbwill receive the decoded payload as aDecodedPayload.
{
"pubkey": "0x......",
"signature": "0x....",
"data": "...",
"padding": "..."
}
- 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onOkCboronErrCbcallback
DNS Discovery
waku_dns_discovery
extern int waku_dns_discovery(char* url, char* nameserver, int timeoutMs, WakuCallBack onOkCb, WakuCallBack onErrCb){}
Returns a list of multiaddress and enrs given a url to a DNS discoverable ENR tree
Parameters
char* url: URL containing a discoverable ENR treechar* nameserver: The nameserver to resolve the ENR tree url. IfNULLor empty, it will automatically use the default system dns.int timeoutMs: Timeout value in milliseconds to execute the call. If the function execution takes longer than this value, the execution will be canceled and an error returned. Use0for no timeout.WakuCallBack onOkCb: callback to be executed if the function is succesfulWakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
onOkCbwill receive an array objects describing the multiaddresses, enr and peerID each node found.
[
{
"peerID":"16Uiu2HAmPLe7Mzm8TsYUubgCAW1aJoeFScxrLj8ppHFivPo97bUZ",
"multiaddrs":[
"/ip4/134.209.139.210/tcp/30303/p2p/16Uiu2HAmPLe7Mzm8TsYUubgCAW1aJoeFScxrLj8ppHFivPo97bUZ",
"/dns4/node-01.do-ams3.wakuv2.test.statusim.net/tcp/8000/wss/p2p/16Uiu2HAmPLe7Mzm8TsYUubgCAW1aJoeFScxrLj8ppHFivPo97bUZ"
],
"enr":"enr:-M-4QCtJKX2WDloRYDT4yjeMGKUCRRcMlsNiZP3cnPO0HZn6IdJ035RPCqsQ5NvTyjqHzKnTM6pc2LoKliV4CeV0WrgBgmlkgnY0gmlwhIbRi9KKbXVsdGlhZGRyc7EALzYobm9kZS0wMS5kby1hbXMzLndha3V2Mi50ZXN0LnN0YXR1c2ltLm5ldAYfQN4DiXNlY3AyNTZrMaEDnr03Tuo77930a7sYLikftxnuG3BbC3gCFhA4632ooDaDdGNwgnZfg3VkcIIjKIV3YWt1Mg8"
},
...
]
- 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onOkCboronErrCbcallback
DiscoveryV5
waku_discv5_update_bootnodes
extern int waku_discv5_update_bootnodes(char* bootnodes, WakuCallBack onErrCb)`
Update the bootnode list used for discovering new peers via DiscoveryV5
Parameters
char* bootnodes: JSON array containing the bootnode ENRs i.e.["enr:...", "enr:..."]WakuCallBack onErrCb: callback to be executed if the function fails
Returns
int with a status code. Possible values:
- 0 - The operation was completed successfuly.
- 1 - The operation failed for any reason.
onErrCbwill be executed with the reason the function execution failed. - 2 - The function is missing the
onErrCbcallback
Copyright
Copyright and related rights waived via CC0.
64/WAKU2-NETWORK
| Field | Value |
|---|---|
| Name | Waku v2 Network |
| Slug | 64 |
| Status | draft |
| Type | RFC |
| Category | core |
| Editor | Hanno Cornelius [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-08 —
c0ef3b9— Cleanup: rewrite specs-repo links in pre-existing messaging specs (#316) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-04-15 —
5a3e844— Chore/move repo into logos co (#312) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-02-25 —
0277fd0— docs: update dead links in 64/Network (#133) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-07-09 —
77029a2— Add RLNv2 to TheWakuNetwork (#82) - 2024-05-10 —
e5b859a— Update WAKU2-NETWORK: Move to draft (#5)
Abstract
This specification describes an opinionated deployment of 10/WAKU2 protocols to form a coherent and shared decentralized messaging network that is open-access, useful for generalized messaging, privacy-preserving, scalable and accessible even to resource-restricted devices. We'll refer to this opinionated deployment simply as the public Waku Network, the Waku Network or, if the context is clear, the network in the rest of this document. All The Waku Network configuration parameters are listed here.
Theory / Semantics
Routing protocol
The Waku Network is built on the 17/WAKU2-RLN-RELAY routing protocol, which in turn is an extension of 11/WAKU2-RELAY with spam protection measures.
Network shards
Traffic in the Waku Network is sharded into eight 17/WAKU2-RLN-RELAY pubsub topics. Each pubsub topic is named according to the static shard naming format defined in WAKU2-RELAY-SHARDING with:
<cluster_id>set to1<shard_number>occupying the range0to7. In other words, the Waku Network is a 17/WAKU2-RLN-RELAY network routed on the combination of the eight pubsub topics:
/waku/2/rs/1/0
/waku/2/rs/1/1
...
/waku/2/rs/1/7
A node MUST use 66/WAKU2-METADATA
protocol to identify the <cluster_id> that every
inbound/outbound peer that attempts to connect supports.
In any of the following cases, the node MUST trigger a disconnection:
- 66/WAKU2-METADATA dial fails.
- 66/WAKU2-METADATA
reports an empty
<cluster_id>. - 66/WAKU2-METADATA
reports a
<cluster_id>different than1.
Roles
There are two distinct roles evident in the network, those of:
- nodes, and
- applications.
Nodes
Nodes are the individual software units using 10/WAKU2 protocols to form a p2p messaging network. Nodes, in turn, can participate in a shard as full relayers, i.e. relay nodes, or by running a combination of protocols suitable for resource-restricted environments, i.e. non-relay nodes. Nodes can also provide various services to the network, such as storing historical messages or protecting the network against spam. See the section on default services for more.
Relay nodes
Relay nodes MUST follow 17/WAKU2-RLN-RELAY to route messages to other nodes in the network for any of the pubsub topics defined as the Waku Network shards. Relay nodes MAY choose to subscribe to any of these shards, but MUST be subscribed to at least one defined shard. Each relay node SHOULD be subscribed to as many shards as it has resources to support. If a relay node supports an encapsulating application, it SHOULD be subscribed to all the shards servicing that application. If resource restrictions prevent a relay node from servicing all shards used by the encapsulating application, it MAY choose to support some shards as a non-relay node.
Bootstrapping and discovery
Nodes MAY use any method to bootstrap connection to the network, but it is RECOMMENDED that each node retrieves a list of bootstrap peers to connect to using EIP-1459 DNS-based discovery. Relay nodes SHOULD use 33/WAKU2-DISCV5 to continually discover other peers in the network. Each relay node MUST encode its supported shards into its discoverable ENR, as described in WAKU2-RELAY-SHARDING. The ENR MUST be updated if the set of supported shards change. A node MAY choose to ignore discovered peers that do not support any of the shards in its own subscribed set.
Transports
Relay nodes MUST follow 10/WAKU2 specifications with regards to supporting different transports. If TCP transport is available, each relay node MUST support it as transport for both dialing and listening. In addition, a relay node SHOULD support secure websockets for bidirectional communication streams, for example to allow connections from and to web browser-based clients. A relay node MAY support unsecure websockets if required by the application or running environment.
Default services
For each supported shard, each relay node SHOULD enable and support the following protocols as a service node:
- 12/WAKU2-FILTER to allow resource-restricted peers to subscribe to messages matching a specific content filter.
- 13/WAKU2-STORE to allow other peers to request historical messages from this node.
- 19/WAKU2-LIGHTPUSH to allow resource-restricted peers to request publishing a message to the network on their behalf.
- WAKU2-PEER-EXCHANGE to allow resource-restricted peers to discover more peers in a resource efficient way.
Store service nodes
Each relay node SHOULD support 13/WAKU2-STORE
as a store service node, for each supported shard.
The store SHOULD be configured to retain at least 12 hours of messages
per supported shard.
Store service nodes SHOULD only store messages
with a valid rate_limit_proof attribute.
Non-relay nodes
Nodes MAY opt out of relay functionality on any network shard and instead request services from relay nodes as clients using any of the defined service protocols:
- 12/WAKU2-FILTER to subscribe to messages matching a specific content filter.
- 13/WAKU2-STORE to request historical messages matching a specific content filter.
- 19/WAKU2-LIGHTPUSH to request publishing a message to the network.
- WAKU2-PEER-EXCHANGE to discover more peers in a resource efficient way.
Store client nodes
Nodes MAY request historical messages from 13/WAKU2-STORE
service nodes as store clients.
A store client SHOULD discard any messages retrieved from a store service node
that do not contain a valid rate_limit_proof attribute.
The client MAY consider service nodes returning messages
without a valid rate_limit_proof attribute as untrustworthy.
The mechanism by which this may happen is currently underdefined.
Applications
Applications are the higher-layer projects or platforms that make use of the generalized messaging capability of the network. In other words, an application defines a payload used in the various 10/WAKU2 protocols. Any participant in an application SHOULD make use of an underlying node in order to communicate on the network. Applications SHOULD make use of an autosharding API to allow the underlying node to automatically select the target shard on the Waku Network. See the section on autosharding for more.
RLN rate-limiting
The 17/WAKU2-RLN-RELAY protocol uses RLN-V2
proofs to ensure that a pre-agreed rate limit
of x messages every y seconds is not exceeded by any publisher.
While the network is under capacity,
individual relayers MAY choose to freely route messages without RLN proofs
up to a discretionary bandwidth limit,
after which messages without proofs MUST be discarded by relay nodes.
This bandwidth limit SHOULD be enforced using a bandwidth validation mechanism
separate from a RLN rate-limiting.
This implies that quality of service and
reliability is significantly lower for messages without proofs
and at times of high network utilization these messages may not be relayed at all.
RLN Parameters
The Waku Network uses the following RLN parameters:
rlnRelayUserMessageLimit=100: Amount of messages that a membership is allowed to publish per epoch. Configurable between0andMAX_MESSAGE_LIMIT.rlnEpochSizeSec=600: Size of the epoch in seconds.rlnRelayChainId=11155111: Network in which the RLN contract is deployed, aka Sepolia.rlnRelayEthContractAddress=0xCB33Aa5B38d79E3D9Fa8B10afF38AA201399a7e3: Network address where RLN memberships are stored.staked_fund=0: In other words, the Waku Network does not use RLN staking. Registering a membership just requires to pay gas.MAX_MESSAGE_LIMIT=100: Maximum amount of messages allowed per epoch for any membership. Enforced in the contract.max_epoch_gap=20: Maximum allowed gap in seconds into the past or future compared to the validator's clock.
Nodes MUST reject messages not respecting any of these parameters. Nodes SHOULD use Network Time Protocol (NTP) to synchronize their own clocks, thereby ensuring valid timestamps for proof generation and validation. Publishers to the Waku Network SHOULD register an RLN membership.
RLN Proofs
Each RLN member MUST generate and attach an RLN proof to every published message as described in 17/WAKU2-RLN-RELAY and RLN-V2. Slashing is not implemented for the Waku Network. Instead, validators will penalise peers forwarding messages exceeding the rate limit as specified for the rate-limiting validation mechanism. This incentivizes all relay nodes to validate RLN proofs and reject messages violating rate limits in order to continue participating in the network.
Network traffic
All payload on the Waku Network MUST be encapsulated in a 14/WAKU2-MESSAGE with rate limit proof extensions defined for 17/WAKU2-RLN-RELAY. Each message on the Waku Network SHOULD be validated by each relayer, according to the rules discussed under message validation.
Message Attributes
- The mandatory
payloadattribute MUST contain the message data payload as crafted by the application. - The mandatory
content_topicattribute MUST specify a string identifier that can be used for content-based filtering. This is also crafted by the application. See Autosharding for more on the content topic format. - The optional
metaattribute MAY be omitted. If present, will form part of the message uniqueness vector described in 14/WAKU2-MESSAGE. - The optional
versionattribute SHOULD be set to0. It MUST be interpreted as0if not present. - The mandatory
timestampattribute MUST contain the Unix epoch time at which the message was generated by the application. The value MUST be in nanoseconds. It MAY contain a fudge factor of up to 1 seconds in either direction to improve resistance to timing attacks. - The optional
ephemeralattribute MUST be set totrue, if the message should not be persisted by the Waku Network. - The optional
rate_limit_proofattribute SHOULD be populated with the RLN proof as set out in RLN Proofs. Messages with this field unpopulated MAY be discarded from the network by relayers. This field MUST be populated if the message should be persisted by the Waku Network.
Message Size
Any 14/WAKU2-MESSAGE published to the network
MUST NOT exceed an absolute maximum size of 150 kilobytes.
This limit applies to the entire message after protobuf serialization,
including attributes.
It is RECOMMENDED not to exceed an average size of 4 kilobytes
for 14/WAKU2-MESSAGE published to the network.
Message Validation
Relay nodes MUST apply gossipsub v1.1 validation to each relayed message and SHOULD apply all of the rules set out in the section below to determine the validity of a message. Validation has one of three outcomes, repeated here from the gossipsub specification for ease of reference:
- Accept - the message is considered valid and it MUST be delivered and forwarded to the network.
- Reject - the message is considered invalid, MUST be rejected and SHOULD trigger a gossipsub scoring penalty against the transmitting peer.
- Ignore - the message SHOULD NOT be delivered and forwarded to the network, but this MUST NOT trigger a gossipsub scoring penalty against the transmitting peer.
The following validation rules are defined:
Decoding failure
If a message fails to decode as a valid 14/WAKU2-MESSAGE, the relay node MUST reject the message. This SHOULD trigger a penalty against the transmitting peer.
Invalid timestamp
If a message has a timestamp deviating by more than 20 seconds
either into the past or the future
when compared to the relay node's internal clock,
the relay node MUST reject the message.
This allows for some deviation between internal clocks,
network routing latency and
an optional fudge factor when timestamping new messages.
Free bandwidth exceeded
If a message contains no RLN proof
and the current bandwidth utilization on the shard the message was published to
equals or exceeds 1 Mbps,
the relay node SHOULD ignore the message.
Invalid RLN epoch
If a message contains an RLN proof
and the epoch attached to the proof deviates by more than max_epoch_gap seconds
from the relay node's own epoch,
the relay node MUST reject the message.
max_epoch_gap is set to 20 seconds for the Waku Network.
Invalid RLN proof
If a message contains an RLN proof and the zero-knowledge proof is invalid according to the verification process described in RLN-V2, the relay node MUST ignore the message.
Rate limit exceeded
If a message contains an RLN proof
and the relay node detects double signaling
according to the verification process described in RLN-V2,
the relay node MUST reject the message
for violating the agreed rate limit of rlnRelayUserMessageLimit messages
every rlnEpochSizeSec second.
This SHOULD trigger a penalty against the transmitting peer.
Autosharding
Nodes in the Waku Network SHOULD allow encapsulating applications to use autosharding, as defined in WAKU2-RELAY-SHARDING by automatically determining the appropriate pubsub topic from the list of defined Waku Network shards. This allows the application to omit the target pubsub topic when invoking any Waku protocol function. Applications using autosharding MUST use content topics in the format defined in WAKU2-RELAY-SHARDING and SHOULD use the short length format:
/{application-name}/{version-of-the-application}/{content-topic-name}/{encoding}
When an encapsulating application makes use of autosharding the underlying node MUST determine the target pubsub topic(s) from the content topics provided by the application using the hashing mechanism defined in WAKU2-RELAY-SHARDING.
Copyright
Copyright and related rights waived via CC0.
References
- 10/WAKU2
- 17/WAKU2-RLN-RELAY
- 11/WAKU2-RELAY
- WAKU2-RELAY-SHARDING
- 66/WAKU2-METADATA
- EIP-1459 DNS-based discovery
- 33/WAKU2-DISCV5
- 12/WAKU2-FILTER
- 13/WAKU2-STORE
- 19/WAKU2-LIGHTPUSH
- 34/WAKU2-PEER-EXCHANGE
- 32/RLN-V1
- RLN-V2
- 14/WAKU2-MESSAGE
- gossipsub v1.1 validation
- WAKU2-RELAY-SHARDING
- The Waku Network Config
66/WAKU2-METADATA
| Field | Value |
|---|---|
| Name | Waku Metadata Protocol |
| Slug | 66 |
| Status | draft |
| Type | RFC |
| Category | core |
| Editor | Franck Royer [email protected] |
| Contributors | Filip Dimitrijevic [email protected], Alvaro Revuelta [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-07-31 —
4361e29— Add implementation recommendation for metadata (#168) - 2025-05-13 —
f829b12— waku/standards/core/66/metadata.md update (#148) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-04-17 —
d82eacc— Update WAKU2-METADATA: Move to draft (#6)
Abstract
This specification describes the metadata that can be associated with a 10/WAKU2 node.
Metadata Protocol
The keywords “MUST”, // List style “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “NOT RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in RFC 2119.
Waku specifies a req/resp protocol that provides information about the node's capabilities. Such metadata MAY be used by other peers for subsequent actions such as light protocol requests or disconnection.
The node that makes the request, includes its metadata so that the receiver is aware of it, without requiring another round trip. The parameters are the following:
clusterId: Unique identifier of the cluster that the node is running in.shards: Shard indexes that the node is subscribed to via11/WAKU2-RELAY.
Protocol Identifier
/vac/waku/metadata/1.0.0
Request
message WakuMetadataRequest {
optional uint32 cluster_id = 1;
repeated uint32 shards = 2;
}
Response
message WakuMetadataResponse {
optional uint32 cluster_id = 1;
repeated uint32 shards = 2;
}
Implementation Suggestions
Triggering Metadata Request
A node SHOULD proceed with metadata request upon first connection to a remote node. A node SHOULD use the remote node's libp2p peer id as identifier for this heuristic.
A node MAY proceed with metadata request upon reconnection to a remote peer.
A node SHOULD store the remote peer's metadata information for future reference. A node MAY implement a TTL regarding a remote peer's metadata, and refresh it upon expiry by initiating another metadata request. It is RECOMMENDED to set the TTL to 6 hours.
A node MAY trigger a metadata request after receiving an error response from a remote note
stating they do not support a specific cluster or shard.
For example, when using a request-response service such as 19/WAKU2-LIGHTPUSH.
Providing Cluster Id
A node MUST include their cluster id into their metadata payload. It is RECOMMENDED for a node to operate on a single cluster id.
Providing Shard Information
- Nodes that mount
11/WAKU2-RELAYMAY include the shards they are subscribed to in their metadata payload. - Shard-relevant services are message related services,
such as
13/WAKU2-STORE, 12/WAKU2-FILTER and19/WAKU2-LIGHTPUSHbut not34/WAKU2-PEER-EXCHANGE - Nodes that mount
11/WAKU2-RELAYand a shard-relevant service SHOULD include the shards they are subscribed to in their metadata payload. - Nodes that do not mount
11/WAKU2-RELAYSHOULD NOT include any shard information
Using Cluster Id
When reading the cluster id of a remote peer, the local node MAY disconnect if their cluster id is different from the remote peer.
Using Shard Information
It is NOT RECOMMENDED to disconnect from a peer based on the fact that their shard information is different from the local node.
Ahead of doing a shard-relevant request, a node MAY use the previously received metadata shard information to select a peer that support the targeted shard.
For non-shard-relevant requests, a node SHOULD NOT discriminate a peer based on medata shard information.
Copyright
Copyright and related rights waived via CC0.
References
Core
Core messaging delivery stable specifications.
2/MVDS
| Field | Value |
|---|---|
| Name | Minimum Viable Data Synchronization |
| Slug | 2 |
| Status | stable |
| Type | RFC |
| Category | core |
| Editor | Sanaz Taheri [email protected] |
| Contributors | Dean Eigenmann [email protected], Oskar Thorén [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-06-28 —
a5b24ac— fix_: broken image links (#81) - 2024-02-01 —
0253d53— Rename MVDS.md to mvds.md - 2024-01-30 —
70326d1— Rename MVDS.md to MVDS.md - 2024-01-27 —
472a7fd— Rename vac/rfcs/02/README.md to vac/02/MVDS.md - 2024-01-25 —
4362a7b— Create README.md
In this specification, we describe a minimum viable protocol for data synchronization inspired by the Bramble Synchronization Protocol (BSP). This protocol is designed to ensure reliable messaging between peers across an unreliable peer-to-peer (P2P) network where they may be unreachable or unresponsive.
We present a reference implementation1 including a simulation to demonstrate its performance.
Definitions
| Term | Description |
|---|---|
| Peer | The other nodes that a node is connected to. |
| Record | Defines a payload element of either the type OFFER, REQUEST, MESSAGE or ACK |
| Node | Some process that is able to store data, do processing and communicate for MVDS. |
Wire Protocol
Secure Transport
This specification does not define anything related to the transport of packets. It is assumed that this is abstracted in such a way that any secure transport protocol could be easily implemented. Likewise, properties such as confidentiality, integrity, authenticity and forward secrecy are assumed to be provided by a layer below.
Payloads
Payloads are implemented using protocol buffers v3.
syntax = "proto3";
package vac.mvds;
message Payload {
repeated bytes acks = 5001;
repeated bytes offers = 5002;
repeated bytes requests = 5003;
repeated Message messages = 5004;
}
message Message {
bytes group_id = 6001;
int64 timestamp = 6002;
bytes body = 6003;
}
The payload field numbers are kept more "unique" to ensure no overlap with other protocol buffers.
Each payload contains the following fields:
- Acks: This field contains a list (can be empty)
of
message identifiersinforming the recipient that sender holds a specific message. - Offers: This field contains a list (can be empty)
of
message identifiersthat the sender would like to give to the recipient. - Requests: This field contains a list (can be empty)
of
message identifiersthat the sender would like to receive from the recipient. - Messages: This field contains a list of messages (can be empty).
Message Identifiers: Each message has a message identifier calculated by
hashing the group_id, timestamp and body fields as follows:
HASH("MESSAGE_ID", group_id, timestamp, body);
Group Identifiers: Each message is assigned into a group
using the group_id field,
groups are independent synchronization contexts between peers.
The current HASH function used is sha256.
Synchronization
State
We refer to state as set of records for the types OFFER, REQUEST and
MESSAGE that every node SHOULD store per peer.
state MUST NOT contain ACK records as we do not retransmit those periodically.
The following information is stored for records:
- Type - Either
OFFER,REQUESTorMESSAGE - Send Count - The amount of times a record has been sent to a peer.
- Send Epoch - The next epoch at which a record can be sent to a peer.
Flow
A maximum of one payload SHOULD be sent to peers per epoch,
this payload contains all ACK, OFFER, REQUEST and
MESSAGE records for the specific peer.
Payloads are created every epoch,
containing reactions to previously received records by peers or
new records being sent out by nodes.
Nodes MAY have two modes with which they can send records:
BATCH and INTERACTIVE mode.
The following rules dictate how nodes construct payloads
every epoch for any given peer for both modes.
NOTE: A node may send messages both in interactive and in batch mode.
Interactive Mode
- A node initially offers a
MESSAGEwhen attempting to send it to a peer. This means anOFFERis added to the next payload and state for the given peer. - When a node receives an
OFFER, aREQUESTis added to the next payload and state for the given peer. - When a node receives a
REQUESTfor a previously sentOFFER, theOFFERis removed from the state and the correspondingMESSAGEis added to the next payload and state for the given peer. - When a node receives a
MESSAGE, theREQUESTis removed from the state and anACKis added to the next payload for the given peer. - When a node receives an
ACK, theMESSAGEis removed from the state for the given peer. - All records that require retransmission are added to the payload,
given
Send Epochhas been reached.
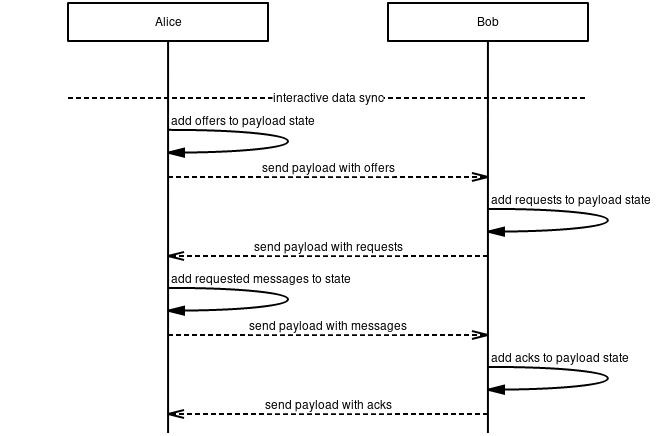
Figure 1: Delivery without retransmissions in interactive mode.
Batch Mode
- When a node sends a
MESSAGE, it is added to the next payload and the state for the given peer. - When a node receives a
MESSAGE, anACKis added to the next payload for the corresponding peer. - When a node receives an
ACK, theMESSAGEis removed from the state for the given peer. - All records that require retransmission are added to the payload,
given
Send Epochhas been reached.
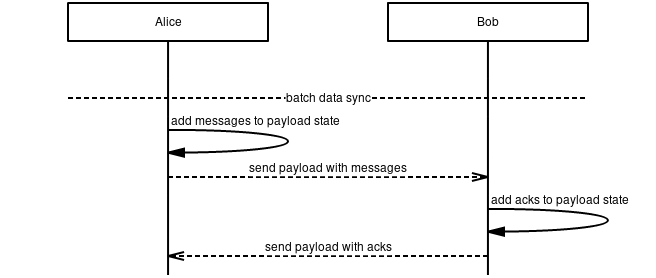
Figure 2: Delivery without retransmissions in batch mode.
NOTE: Batch mode is higher bandwidth whereas interactive mode is higher latency.
Retransmission
The record of the type Type SHOULD be retransmitted
every time Send Epoch is smaller than or equal to the current epoch.
Send Epoch and Send Count MUST be increased every time a record is retransmitted.
Although no function is defined on how to increase Send Epoch,
it SHOULD be exponentially increased until reaching an upper bound
where it then goes back to a lower epoch in order to
prevent a record's Send Epoch's from becoming too large.
NOTE: We do not retransmission
ACKs as we do not know when they have arrived, therefore we simply resend them every time we receive aMESSAGE.
Formal Specification
MVDS has been formally specified using TLA+: https://github.com/vacp2p/formalities/tree/master/MVDS.
Acknowledgments
- Preston van Loon
- Greg Markou
- Rene Nayman
- Jacek Sieka
Copyright
Copyright and related rights waived via CC0.
Footnotes
6/WAKU1
| Field | Value |
|---|---|
| Name | Waku v1 |
| Slug | 6 |
| Status | stable |
| Type | RFC |
| Category | core |
| Editor | Oskar Thorén [email protected] |
| Contributors | Adam Babik [email protected], Andrea Maria Piana [email protected], Dean Eigenmann [email protected], Kim De Mey [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-02-12 —
be052c8— Rename waku/standards/core/waku_legacy/6/waku1.md to waku/standards/legacy/6/waku1.md - 2024-02-12 —
7d83b3d— Rename waku/standards/core/6/waku1.md to waku/standards/core/waku_legacy/6/waku1.md - 2024-02-01 —
161b35a— Update and rename WAKU1.md to waku1.md - 2024-01-27 —
4c666c6— Create WAKU1.md - 2024-01-27 —
61f7641— Create WAKU0.md
This specification describes the format of Waku packets within the ÐΞVp2p Wire Protocol. This spec substitutes EIP-627. Waku is a fork of the original Whisper protocol that enables better usability for resource restricted devices, such as mostly-offline bandwidth-constrained smartphones. It does this through (a) light node support, (b) historic envelopes (with a mailserver) (c) expressing topic interest for better bandwidth usage and (d) basic rate limiting.
Motivation
Waku was created to incrementally improve in areas that Whisper is lacking in, with special attention to resource restricted devices. We specify the standard for Waku packets in order to ensure forward compatibility of different Waku clients, backwards compatibility with Whisper clients, as well as to allow multiple implementations of Waku and its capabilities. We also modify the language to be more unambiguous, concise and consistent.
Definitions
| Term | Definition |
|---|---|
| Batch Ack | An abbreviated term for Batch Acknowledgment |
| Light node | A Waku node that does not forward any envelopes through the Messages packet. |
| Envelope | Messages sent and received by Waku nodes. Described in ABNF spec waku-envelope |
| Node | Some process that is able to communicate for Waku. |
Underlying Transports and Prerequisites
Use of DevP2P
For nodes to communicate, they MUST implement devp2p and run RLPx. They MUST have some way of connecting to other nodes. Node discovery is largely out of scope for this spec, but see the appendix for some suggestions on how to do this.
This protocol needs to advertise the waku/1 capability.
Gossip based routing
In Whisper, envelopes are gossiped between peers. Whisper is a form of rumor-mongering protocol that works by flooding to its connected peers based on some factors. Envelopes are eligible for retransmission until their TTL expires. A node SHOULD relay envelopes to all connected nodes if an envelope matches their PoW and bloom filter settings. If a node works in light mode, it MAY choose not to forward envelopes. A node MUST NOT send expired envelopes, unless the envelopes are sent as a 8/WAKU-MAIL response. A node SHOULD NOT send an envelope to a peer that it has already sent before.
Maximum Packet Size
Nodes SHOULD limit the maximum size of both packets and envelopes. If a packet or envelope exceeds its limit, it MUST be dropped.
- RLPx Packet Size - This size MUST be checked before a message is decoded.
- Waku Envelope Size - Each envelope contained in an RLPx packet MUST then separately be checked against the maximum envelope size.
Clients MAY use their own maximum packet and envelope sizes.
The default values are 1.5mb for the RLPx Packet and 1mb for a Waku envelope.
Wire Specification
Use of RLPx transport protocol
All Waku packets are sent as devp2p RLPx transport protocol, version 51 packets. These packets MUST be RLP-encoded arrays of data containing two objects: packet code followed by another object (whose type depends on the packet code). See informal RLP spec and the Ethereum Yellow Paper, appendix B for more details on RLP.
Waku is a RLPx subprotocol called waku with version 0.
The version number corresponds to the major version in the header spec.
Minor versions should not break compatibility of waku,
this would result in a new major.
(Some exceptions to this apply in the Draft stage
of where client implementation is rapidly change).
ABNF specification
Using Augmented Backus-Naur form (ABNF) we have the following format:
; Packet codes 0 - 127 are reserved for Waku protocol
packet-code = 1*3DIGIT
; rate limits per packet
packet-limit-ip = 1*DIGIT
packet-limit-peerid = 1*DIGIT
packet-limit-topic = 1*DIGIT
; rate limits by size in bytes
bytes-limit-ip = 1*DIGIT
bytes-limit-peerid = 1*DIGIT
bytes-limit-topic = 1*DIGIT
packet-rate-limits = "[" packet-limit-ip packet-limit-peerid packet-limit-topic "]"
bytes-rate-limits = "[" bytes-limit-ip bytes-limit-peerid bytes-limit-topic "]"
pow-requirement-key = 0
bloom-filter-key = 1
light-node-key = 2
confirmations-enabled-key = 3
packet-rate-limits-key = 4
topic-interest-key = 5
bytes-rate-limits-key = 6
status-options = "["
[ pow-requirement-key pow-requirement ]
[ bloom-filter-key bloom-filter ]
[ light-node-key light-node ]
[ confirmations-enabled-key confirmations-enabled ]
[ packet-rate-limits-key packet-rate-limits ]
[ topic-interest-key topic-interest ]
[ bytes-limits-key bytes-rate-limits ]
"]"
status = status-options
status-update = status-options
confirmations-enabled = BIT
light-node = BIT
; pow is "a single floating point value of PoW.
; This value is the IEEE 754 binary representation
; of a 64-bit floating point number packed as a uint64.
; Values of qNAN, sNAN, INF and -INF are not allowed.
; Negative values are also not allowed."
pow = 1*DIGIT "." 1*DIGIT
pow-requirement = pow
; bloom filter is "a byte array"
bloom-filter = *OCTET
waku-envelope = "[" expiry ttl topic data nonce "]"
; List of topics interested in
topic-interest = "[" *10000topic "]"
; 4 bytes (UNIX time in seconds)
expiry = 4OCTET
; 4 bytes (time-to-live in seconds)
ttl = 4OCTET
; 4 bytes of arbitrary data
topic = 4OCTET
; byte array of arbitrary size
; (contains encrypted payload)
data = *OCTET
; 8 bytes of arbitrary data
; (used for PoW calculation)
nonce = 8OCTET
messages = 1*waku-envelope
; version of the confirmation packet
version = 1*DIGIT
; keccak256 hash of the envelopes batch data (raw bytes)
; for which the confirmation is sent
hash = *OCTET
hasherror = *OCTET
; error code
code = 1*DIGIT
; a descriptive error message
description = *ALPHA
error = "[" hasherror code description "]"
errors = *error
response = "[" hash errors "]"
confirmation = "[" version response "]"
; message confirmation packet types
batch-ack = confirmation
message-response = confirmation
; mail server / client specific
p2p-request = waku-envelope
p2p-message = 1*waku-envelope
p2p-request-complete = *OCTET
; packet-format needs to be paired with its
; corresponding packet-format
packet-format = "[" packet-code packet-format "]"
required-packet = 0 status /
1 messages /
22 status-update /
optional-packet = 11 batch-ack /
12 message-response /
126 p2p-request-complete /
126 p2p-request /
127 p2p-message
packet = "[" required-packet [ optional-packet ] "]"
All primitive types are RLP encoded. Note that, per RLP specification,
integers are encoded starting from 0x00.
Packet Codes
The packet codes reserved for Waku protocol: 0 - 127.
Packets with unknown codes MUST be ignored without generating any error, for forward compatibility of future versions.
The Waku sub-protocol MUST support the following packet codes:
| Name | Int Value |
|---|---|
| Status | 0 |
| Messages | 1 |
| Status Update | 22 |
The following message codes are optional, but they are reserved for specific purpose.
| Name | Int Value | Comment |
|---|---|---|
| Batch Ack | 11 | |
| Message Response | 12 | |
| P2P Request Complete | 125 | |
| P2P Request | 126 | |
| P2P Message | 127 |
Packet usage
Status
The Status packet serves as a Waku handshake and peers MUST exchange this packet upon connection. It MUST be sent after the RLPx handshake and prior to any other Waku packets.
A Waku node MUST await the Status packet from a peer before engaging in other Waku protocol activity with that peer. When a node does not receive the Status packet from a peer, before a configurable timeout, it SHOULD disconnect from that peer.
Upon retrieval of the Status packet, the node SHOULD validate the packet received and validated the Status packet. Note that its peer might not be in the same state.
When a node is receiving other Waku packets from a peer before a Status packet is received, the node MUST ignore these packets and SHOULD disconnect from that peer. Status packets received after the handshake is completed MUST also be ignored.
The Status packet MUST contain an association list containing various options. All options within this association list are OPTIONAL, ordering of the key-value pairs is not guaranteed and therefore MUST NOT be relied on. Unknown keys in the association list SHOULD be ignored.
Messages
This packet is used for sending the standard Waku envelopes.
Status Update
The Status Update packet is used to communicate an update of the settings of the node. The format is the same as the Status packet, all fields are optional. If none of the options are specified the packet MUST be ignored and considered a noop. Fields that are omitted are considered unchanged, fields that haven't changed SHOULD not be transmitted.
PoW Requirement Field
When PoW Requirement is updated, peers MUST NOT deliver envelopes with PoW lower than the PoW Requirement specified.
PoW is defined as average number of iterations, required to find the current BestBit (the number of leading zero bits in the hash), divided by envelope size and TTL:
PoW = (2**BestBit) / (size * TTL)
PoW calculation:
fn short_rlp(envelope) = rlp of envelope, excluding env_nonce field. fn pow_hash(envelope, env_nonce) = sha3(short_rlp(envelope) ++ env_nonce) fn pow(pow_hash, size, ttl) = 2**leading_zeros(pow_hash) / (size * ttl)
where size is the size of the RLP-encoded envelope,
excluding env_nonce field (size of short_rlp(envelope)).
Bloom Filter Field
The bloom filter is used to identify a number of topics to a peer without compromising (too much) privacy over precisely what topics are of interest. Precise control over the information content (and thus efficiency of the filter) may be maintained through the addition of bits.
Blooms are formed by the bitwise OR operation on a number of bloomed topics. The bloom function takes the topic and projects them onto a 512-bit slice. At most, three bits are marked for each bloomed topic.
The projection function is defined as a mapping from a 4-byte slice S to a 512-bit slice D; for ease of explanation, S will dereference to bytes, whereas D will dereference to bits.
LET D[*] = 0 FOREACH i IN { 0, 1, 2 } DO LET n = S[i] IF S[3] & (2 ** i) THEN n += 256 D[n] = 1 END FOR
A full bloom filter (all the bits set to 1)
means that the node is to be considered a Full Node and it will accept any topic.
If both topic interest and bloom filter are specified, topic interest always takes precedence and bloom filter MUST be ignored.
If only bloom filter is specified, the current topic interest MUST be discarded and only the updated bloom filter MUST be used when forwarding or posting envelopes.
A bloom filter with all bits set to 0 signals that the node is not currently interested in receiving any envelope.
Topic Interest Field
Topic interest is used to share a node's interest in envelopes with specific topics. It does this in a more bandwidth considerate way, at the expense of some metadata protection. Peers MUST only send envelopes with specified topics.
It is currently bounded to a maximum of 10000 topics. If you are interested in more topics than that, this is currently underspecified and likely requires updating it. The constant is subject to change.
If only topic interest is specified, the current bloom filter MUST be discarded and only the updated topic interest MUST be used when forwarding or posting envelopes.
An empty array signals that the node is not currently interested in receiving any envelope.
Rate Limits Field
Rate limits is used to inform other nodes of their self defined rate limits.
In order to provide basic Denial-of-Service attack protection, each node SHOULD define its own rate limits. The rate limits SHOULD be applied on IPs, peer IDs, and envelope topics.
Each node MAY decide to whitelist, i.e. do not rate limit, selected IPs or peer IDs.
If a peer exceeds node's rate limits, the connection between them MAY be dropped.
Each node SHOULD broadcast its rate limits to its peers
using the status-update packet.
The rate limits MAY also be sent as an optional parameter in the handshake.
Each node SHOULD respect rate limits advertised by its peers. The number of packets SHOULD be throttled in order not to exceed peer's rate limits. If the limit gets exceeded, the connection MAY be dropped by the peer.
Two rate limits strategies are applied:
- Number of packets per second
- Size of packets (in bytes) per second
Both strategies SHOULD be applied per IP address, peer id and topic.
The size limit SHOULD be greater or equal than the maximum packet size.
Light Node Field
When the node's light-node field is set to true,
the node SHOULD NOT forward Envelopes from its peers.
A node connected to a peer with the light-node field set to true
MUST NOT depend on the peer for forwarding Envelopes.
Confirmations Enabled Field
When the node's confirmations-enabled field is set to true,
the node SHOULD send message confirmations
to its peers.
Batch Ack and Message Response
Message confirmations tell a node that an envelope originating from it has been received by its peers, allowing a node to know whether an envelope has or has not been received.
A node MAY send a message confirmation for any batch of envelopes
received with a Messages packet (0x01).
A message confirmation is sent using Batch Ack packet (0x0B) or
Message Response packet (0x0C).
The message confirmation is specified in the ABNF specification.
The current version in the confirmation is 1.
The supported error codes:
1: time sync error which happens when an envelope is too old or was created in the future (typically because of an unsynchronized clock of a node).
The drawback of sending message confirmations is that it increases the noise in the network because for each sent envelope, a corresponding confirmation is broadcast by one or more peers.
P2P Request
This packet is used for sending Dapp-level peer-to-peer requests, e.g. Waku Mail Client requesting historic (expired) envelopes from the Waku Mail Server.
P2P Message
This packet is used for sending the peer-to-peer envelopes, which are not supposed to be forwarded any further. E.g. it might be used by the Waku Mail Server for delivery of historic (expired) envelopes, which is otherwise not allowed.
P2P Request Complete
This packet is used to indicate that all envelopes,
requested earlier with a P2P Request packet (0x7E),
have been sent via one or more P2P Message packets (0x7F).
The content of the packet is explained in the Waku Mail Server specification.
Payload Encryption
Asymmetric encryption uses the standard Elliptic Curve Integrated Encryption Scheme with SECP-256k1 public key.
Symmetric encryption uses AES GCM algorithm with random 96-bit nonce.
Packet code Rationale
Packet codes 0x00 and 0x01 are already used in all Waku / Whisper versions.
Packet code 0x02 and 0x03 were previously used in Whisper but
are deprecated as of Waku v0.4
Packet code 0x22 is used to dynamically change the settings of a node.
Packet codes 0x7E and 0x7F may be used to implement Waku Mail Server and
Client.
Without the P2P Message packet it would be impossible to deliver the historic envelopes,
since they will be recognized as expired, and
the peer will be disconnected for violating the Waku protocol.
They might be useful for other purposes
when it is not possible to spend time on PoW,
e.g. if a stock exchange will want to provide live feed about the latest trades.
Additional capabilities
Waku supports multiple capabilities. These include light node, rate limiting and bridging of traffic. Here we list these capabilities, how they are identified, what properties they have and what invariants they must maintain.
Additionally, there is the capability of a mailserver which is documented in its on specification.
Light node
The rationale for light nodes is to allow for interaction with waku on resource restricted devices as bandwidth can often be an issue.
Light nodes MUST NOT forward any incoming envelopes, they MUST only send their own envelopes. When light nodes happen to connect to each other, they SHOULD disconnect. As this would result in envelopes being dropped between the two.
Light nodes are identified by the light_node value in the Status packet.
Accounting for resources (experimental)
Nodes MAY implement accounting, keeping track of resource usage. It is heavily inspired by Swarm's SWAP protocol, and works by doing pairwise accounting for resources.
Each node keeps track of resource usage with all other nodes. Whenever an envelope is received from a node that is expected (fits bloom filter or topic interest, is legal, etc) this is tracked.
Every epoch (say, every minute or every time an event happens) statistics SHOULD be aggregated and saved by the client:
| peer | sent | received |
|---|---|---|
| peer1 | 0 | 123 |
| peer2 | 10 | 40 |
In later versions this will be amended by nodes communication thresholds, settlements and disconnect logic.
Upgradability and Compatibility
General principles and policy
The currently advertised capability is waku/1.
This needs to be advertised in the hello ÐΞVp2p packet.
If a node supports multiple versions of waku, those needs to be explicitly advertised.
For example if both waku/0 and waku/1 are supported,
both waku/0 and waku/1 MUST be advertised.
These are policies that guide how we make decisions when it comes to upgradability, compatibility, and extensibility:
-
Waku aims to be compatible with previous and future versions.
-
In cases where we want to break this compatibility, we do so gracefully and as a single decision point.
-
To achieve this, we employ the following two general strategies:
- a) Accretion (including protocol negotiation) over changing data
- b) When we want to change things, we give it a new name (for example, a version number).
Examples:
- We enable bridging between
shh/6andwaku/1until such a time as when we are ready to gracefully drop support forshh/6(1, 2, 3). - When we add parameter fields, we (currently) do so by accreting them in a list, so old clients can ignore new fields (dynamic list) and new clients can use new capabilities (1, 3).
- To better support (2) and (3) in the future, we will likely release a new version that gives better support for open, growable maps (association lists or native map type) (3)
- When we we want to provide a new set of packets that have different requirements, we do so under a new protocol version and employ protocol versioning. This is a form of accretion at a level above - it ensures a client can support both protocols at once and drop support for legacy versions gracefully. (1,2,3)
Backwards Compatibility
Waku is a different subprotocol from Whisper so it isn't directly compatible. However, the data format is the same, so compatibility can be achieved by the use of a bridging mode as described below. Any client which does not implement certain packet codes should gracefully ignore the packets with those codes. This will ensure the forward compatibility.
Waku-Whisper bridging
waku/1 and shh/6 are different DevP2P subprotocols,
however they share the same data format making their envelopes compatible.
This means we can bridge the protocols naively, this works as follows.
Roles:
- Waku client A, only Waku capability
- Whisper client B, only Whisper capability
- WakuWhisper bridge C, both Waku and Whisper capability
Flow:
- A posts envelope; B posts envelope.
- C picks up envelope from A and B and relays them both to Waku and Whisper.
- A receives envelope on Waku; B on Whisper.
Note: This flow means if another bridge C1 is active, we might get duplicate relaying for a envelope between C1 and C2. I.e. Whisper(<>Waku<>Whisper)<>Waku, A-C1-C2-B. Theoretically this bridging chain can get as long as TTL permits.
Forward Compatibility
It is desirable to have a strategy for maintaining forward compatibility
between waku/1 and future version of waku.
Here we outline some concerns and strategy for this.
- Connecting to nodes with multiple versions:
The way this SHOULD be accomplished is by negotiating the versions of subprotocols,
within the
hellopacket nodes transmit their capabilities along with a version. The highest common version should then be used. - Adding new packet codes: New packet codes can be added easily due to the available packet codes. Unknown packet codes SHOULD be ignored. Upgrades that add new packet codes SHOULD implement some fallback mechanism if no response was received for nodes that do not yet understand this packet.
- Adding new options in
status-options: New options can be added to thestatus-optionsassociation list in thestatusandstatus-updatepacket as options are OPTIONAL and unknown option keys SHOULD be ignored. A node SHOULD NOT disconnect from a peer when receivingstatus-optionswith unknown option keys.
Appendix A: Security considerations
There are several security considerations to take into account when running Waku. Chief among them are: scalability, DDoS-resistance and privacy. These also vary depending on what capabilities are used. The security considerations for extra capabilities, such as mailservers can be found in their respective specifications.
Scalability and UX
Bandwidth usage
In version 0 of Waku, bandwidth usage is likely to be an issue. For more investigation into this, see the theoretical scaling model described here.
Gossip-based routing
Use of gossip-based routing doesn't necessarily scale. It means each node can see an envelope multiple times, and having too many light nodes can cause propagation probability that is too low. See Whisper vs PSS for more and a possible Kademlia based alternative.
Lack of incentives
Waku currently lacks incentives to run nodes, which means node operators are more likely to create centralized choke points.
Privacy
Light node privacy
The main privacy concern with a light node is that it has to reveal its topic interests (in addition to its IP/ID) to its directed peers. This is because when a light node publishes an envelope, its directed peers will know that the light node owns that envelope (as light nodes do not relay other envelopes). Therefore, the directed peers of a light node can make assumptions about what envelopes (topics) the light node is interested in.
Mailserver client privacy
A mailserver client fetches archival envelopes from a mailserver through a direct connection. In this direct connection, the client discloses its IP/ID as well as the topics/ bloom filter it is interested in to the mailserver. The collection of such information allows the mailserver to link clients' IP/IDs to their topic interests and build a profile for each client over time. As such, the mailserver client has to trust the mailserver with this level of information.
Bloom filter privacy
By having a bloom filter where only the topics you are interested in are set, you reveal which envelopes you are interested in. This is a fundamental tradeoff between bandwidth usage and privacy, though the tradeoff space is likely suboptimal in terms of the Anonymity trilemma.
Privacy guarantees not rigorous
Privacy for Whisper / Waku haven't been studied rigorously for various threat models like global passive adversary, local active attacker, etc. This is unlike e.g. Tor and mixnets.
Topic hygiene
Similar to bloom filter privacy, if you use a very specific topic you reveal more information. See scalability model linked above.
Spam resistance
PoW bad for heterogeneous devices:
Proof of work is a poor spam prevention mechanism. A mobile device can only have a very low PoW in order not to use too much CPU / burn up its phone battery. This means someone can spin up a powerful node and overwhelm the network.
Censorship resistance
Devp2p TCP port blockable:
By default Devp2p runs on port 30303,
which is not commonly used for any other service.
This means it is easy to censor, e.g. airport WiFi.
This can be mitigated somewhat by running on e.g. port 80 or 443,
but there are still outstanding issues.
See libp2p and Tor's Pluggable Transport for how this can be improved.
Appendix B: Implementation Notes
Implementation Matrix
Recommendations for clients
Notes useful for implementing Waku mode.
1.Avoid duplicate envelopes
To avoid duplicate envelopes, only connect to one Waku node. Benign duplicate envelopes is an intrinsic property of Whisper which often leads to a N factor increase in traffic, where N is the number of peers you are connected to.
2.Topic specific recommendations
Consider partition topics based on some usage, to avoid too much traffic on a single topic.
Node discovery
Resource restricted devices SHOULD use EIP-1459 to discover nodes.
Known static nodes MAY also be used.
Changelog
Initial Release
- Add section on P2P Request Complete packet and update packet code table.
- Correct the header hierarchy for the status-options fields.
- Consistent use of the words packet, message and envelope.
- Added section on max packet size
- Complete the ABNF specification and minor ABNF fixes.
Version 1.1
Released June 09, 2020
- Add rate limit per bytes
Version 1.0
Released April 21,2020
- Removed
versionfrom handshake - Changed
RLPkeys from 48,49.. to 0,1.. - Upgraded to
waku/1
Version 0.6
Released April 21,2020
- Mark spec as Deprecated mode in terms of its lifecycle.
Version 0.5
Released March 17,2020
- Clarify the preferred way of handling unknown keys
in the
status-optionsassociation list. - Correct spec/implementation mismatch: Change RLP keys to be the their int values in order to reflect production behavior
Version 0.4
Released February 21, 2020.
- Simplify implementation matrix with latest state
- Introduces a new required packet code Status Code (
0x22) for communicating option changes - Deprecates the following packet codes: PoW Requirement (
0x02), Bloom Filter (0x03), Rate limits (0x20), Topic interest (0x21) - all superseded by the new Status Code (0x22) - Increased
topic-interestcapacity from 1000 to 10000
Version 0.3
Released February 13, 2020.
- Recommend DNS based node discovery over other Discovery methods.
- Mark spec as Draft mode in terms of its lifecycle.
- Simplify Changelog and misc formatting.
- Handshake/Status packet not compatible with shh/6 nodes; specifying options as association list.
- Include topic-interest in Status handshake.
- Upgradability policy.
topic-interestpacket code.
Version 0.2
Released December 10, 2019.
- General style improvements.
- Fix ABNF grammar.
- Mailserver requesting/receiving.
- New packet codes: topic-interest (experimental), rate limits (experimental).
- More details on handshake modifications.
- Accounting for resources mode (experimental)
- Appendix with security considerations: scalability and UX, privacy, and spam resistance.
- Appendix with implementation notes and implementation matrix across various clients with breakdown per capability.
- More details on handshake and parameters.
- Describe rate limits in more detail.
- More details on mailserver and mail client API.
- Accounting for resources mode (very experimental).
- Clarify differences with Whisper.
Version 0.1
Initial version. Released November 21, 2019.
Differences between shh/6 and waku/1
Summary of main differences between this spec and Whisper v6, as described in EIP-627:
- RLPx subprotocol is changed from
shh/6towaku/1. - Light node capability is added.
- Optional rate limiting is added.
- Status packet has following additional parameters: light-node, confirmations-enabled and rate-limits
- Mail Server and Mail Client functionality is now part of the specification.
- P2P Message packet contains a list of envelopes instead of a single envelope.
Copyright
Copyright and related rights waived via CC0.
Footnotes
Felix Lange et al. The RLPx Transport Protocol. Ethereum.
9/WAKU-RPC
| Field | Value |
|---|---|
| Name | Waku RPC API |
| Slug | 9 |
| Status | stable |
| Type | RFC |
| Category | core |
| Editor | Andrea Maria Piana [email protected] |
| Contributors | Dean Eigenmann [email protected], Oskar Thorén [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-02-12 —
5eb393f— Rename waku/legacy/9/rpc.md to waku/standards/legacy/9/rpc.md - 2024-02-12 —
9617146— Rename waku/standards/core/waku_legacy/9/waku2-rpc.md to waku/legacy/9/rpc.md - 2024-02-12 —
75705cd— Rename waku/standards/core/9/waku2-rpc.md to waku/standards/core/waku_legacy/9/waku2-rpc.md - 2024-02-01 —
e808e36— Create waku2-rpc.md
This specification describes the RPC API that Waku nodes MAY adhere to. The unified API allows clients to easily be able to connect to any node implementation. The API described is privileged as a node stores the keys of clients.
Introduction
This API is based off the Whisper V6 RPC API.
Wire Protocol
Transport
Nodes SHOULD expose a JSON RPC API
that can be accessed.
The JSON RPC version SHOULD be 2.0.
Below is an example request:
{
"jsonrpc":"2.0",
"method":"waku_version",
"params":[],
"id":1
}
Fields
| Field | Description |
|---|---|
jsonrpc | Contains the used JSON RPC version (Default: 2.0) |
method | Contains the JSON RPC method that is being called |
params | An array of parameters for the request |
id | The request ID |
Objects
In this section you will find objects used throughout the JSON RPC API.
Message
The message object represents a Waku message. Below you will find the description of the attributes contained in the message object. A message is the decrypted payload and padding of an envelope along with all of its metadata and other extra information such as the hash.
| Field | Type | Description |
|---|---|---|
sig | string | Public Key that signed this message |
recipientPublicKey | string | The recipients public key |
ttl | number | Time-to-live in seconds |
timestamp | number | Unix timestamp of the message generation |
topic | string | 4 bytes, the message topic |
payload | string | Decrypted payload |
padding | string | Optional padding, byte array of arbitrary length |
pow | number | The proof of work value |
hash | string | Hash of the enveloped message |
Filter
The filter object represents filters that can be applied to retrieve messages. Below you will find the description of the attributes contained in the filter object.
| Field | Type | Description |
|---|---|---|
symKeyID | string | ID of the symmetric key for message decryption |
privateKeyID | string | ID of private (asymmetric) key for message decryption |
sig | string | Public key of the signature |
minPow | number | Minimal PoW requirement for incoming messages |
topics | array | Array of possible topics, this can also contain partial topics |
allowP2P | boolean | Indicates if this filter allows processing of direct peer-to-peer messages |
All fields are optional, however symKeyID or privateKeyID must be present,
it cannot be both.
Additionally, the topics field is only optional when an asymmetric key is used.
Methods
waku_version
The waku_version method returns the current version number.
Parameters
none
Response
- string - The version number.
waku_info
The waku_info method returns information about a Waku node.
Parameters
none
Response
The response is an Object containing the following fields:
minPow[number] - The current PoW requirement.maxEnvelopeSize[float] - The current maximum envelope size in bytes.memory[number] - The memory size of the floating messages in bytes.envelopes[number] - The number of floating envelopes.
waku_setMaxEnvelopeSize
Sets the maximum envelope size allowed by this node.
Any envelopes larger than this size both incoming and outgoing will be rejected.
The envelope size can never exceed the underlying envelope size of 10mb.
Parameters
- number - The message size in bytes.
Response
- bool -
trueon success or an error on failure.
waku_setMinPoW
Sets the minimal PoW required by this node.
Parameters
- number - The new PoW requirement.
Response
- bool -
trueon success or an error on failure.
waku_markTrustedPeer
Marks a specific peer as trusted allowing it to send expired messages.
Parameters
- string -
enodeof the peer.
Response
- bool -
trueon success or an error on failure.
waku_newKeyPair
Generates a keypair used for message encryption and decryption.
Parameters
none
Response
- string - Key ID on success or an error on failure.
waku_addPrivateKey
Stores a key and returns its ID.
Parameters
- string - Private key as hex bytes.
Response
- string - Key ID on success or an error on failure.
waku_deleteKeyPair
Deletes a specific key if it exists.
Parameters
- string - ID of the Key pair.
Response
- bool -
trueon success or an error on failure.
waku_hasKeyPair
Checks if the node has a private key of a key pair matching the given ID.
Parameters
- string - ID of the Key pair.
Response
- bool -
trueorfalseor an error on failure.
waku_getPublicKey
Returns the public key for an ID.
Parameters
- string - ID of the Key.
Response
- string - The public key or an error on failure.
waku_getPrivateKey
Returns the private key for an ID.
Parameters
- string - ID of the Key.
Response
- string - The private key or an error on failure.
waku_newSymKey
Generates a random symmetric key and stores it under an ID. This key can be used to encrypt and decrypt messages where the key is known to both parties.
Parameters
none
Response
- string - The key ID or an error on failure.
waku_addSymKey
Stores the key and returns its ID.
Parameters
- string - The raw key for symmetric encryption hex encoded.
Response
- string - The key ID or an error on failure.
waku_generateSymKeyFromPassword
Generates the key from a password and stores it.
Parameters
- string - The password.
Response
- string - The key ID or an error on failure.
waku_hasSymKey
Returns whether there is a key associated with the ID.
Parameters
- string - ID of the Key.
Response
- bool -
trueorfalseor an error on failure.
waku_getSymKey
Returns the symmetric key associated with an ID.
Parameters
- string - ID of the Key.
Response
- string - Raw key on success or an error of failure.
waku_deleteSymKey
Deletes the key associated with an ID.
Parameters
- string - ID of the Key.
Response
- bool -
trueorfalseor an error on failure.
waku_subscribe
Creates and registers a new subscription to receive notifications for inbound Waku messages.
Parameters
The parameters for this request is an array containing the following fields:
- string - The ID of the function call, in case of Waku this must contain the value "messages".
- object - The message filter.
Response
- string - ID of the subscription or an error on failure.
Notifications
Notifications received by the client contain a message matching the filter. Below is an example notification:
{
"jsonrpc": "2.0",
"method": "waku_subscription",
"params": {
"subscription": "02c1f5c953804acee3b68eda6c0afe3f1b4e0bec73c7445e10d45da333616412",
"result": {
"sig": "0x0498ac1951b9078a0549c93c3f6088ec7c790032b17580dc3c0c9e900899a48d89eaa27471e3071d2de6a1f48716ecad8b88ee022f4321a7c29b6ffcbee65624ff",
"recipientPublicKey": null,
"ttl": 10,
"timestamp": 1498577270,
"topic": "0xffaadd11",
"payload": "0xffffffdddddd1122",
"padding": "0x35d017b66b124dd4c67623ed0e3f23ba68e3428aa500f77aceb0dbf4b63f69ccfc7ae11e39671d7c94f1ed170193aa3e327158dffdd7abb888b3a3cc48f718773dc0a9dcf1a3680d00fe17ecd4e8d5db31eb9a3c8e6e329d181ecb6ab29eb7a2d9889b49201d9923e6fd99f03807b730780a58924870f541a8a97c87533b1362646e5f573dc48382ef1e70fa19788613c9d2334df3b613f6e024cd7aadc67f681fda6b7a84efdea40cb907371cd3735f9326d02854",
"pow": 0.6714754098360656,
"hash": "0x17f8066f0540210cf67ef400a8a55bcb32a494a47f91a0d26611c5c1d66f8c57"
}
}
}
waku_unsubscribe
Cancels and removes an existing subscription. The node MUST stop sending the client notifications.
Parameters
- string - The subscription ID.
Response
- bool -
trueorfalse
waku_newMessageFilter
Creates a new message filter within the node. This filter can be used to poll for new messages that match the criteria.
Parameters
The request must contain a message filter as its parameter.
Response
- string - The ID of the filter.
waku_deleteMessageFilter
Removes a message filter from the node.
Parameters
- string - ID of the filter created with
waku_newMessageFilter.
Response
- bool -
trueon success or an error on failure.
waku_getFilterMessages
Retrieves messages that match a filter criteria and were received after the last time this function was called.
Parameters
- string - ID of the filter created with
waku_newMessageFilter.
Response
The response contains an array of messages or an error on failure.
waku_post
The waku_post method creates a waku envelope and propagates it to the network.
Parameters
The parameters is an Object containing the following fields:
symKeyID[string]optional- The ID of the symmetric key used for encryptionpubKey[string]optional- The public key for message encryption.sig[string]optional- The ID of the signing key.ttl[number] - The time-to-live in seconds.topic[string] - 4 bytes message topic.payload[string] - The payload to be encrypted.padding[string]optional- The padding, a byte array of arbitrary length.powTime[number] - Maximum time in seconds to be spent on the proof of work.powTarget[number] - Minimal PoW target required for this message.targetPeer[string]optional- The optional peer ID for peer-to-peer messages.
Either the symKeyID or the pubKey need to be present.
It can not be both.
Response
- bool -
trueon success or an error on failure.
Changelog
| Version | Comment |
|---|---|
| 1.0.0 | Initial release. |
Copyright
Copyright and related rights waived via CC0.
11/WAKU2-RELAY
| Field | Value |
|---|---|
| Name | Waku v2 Relay |
| Slug | 11 |
| Status | stable |
| Type | RFC |
| Category | core |
| Editor | Hanno Cornelius [email protected] |
| Contributors | Oskar Thorén [email protected], Sanaz Taheri [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-02-01 —
b346ad2— Update relay.md - 2024-02-01 —
0904a8b— Update and rename RELAY.md to relay.md - 2024-01-27 —
8ff46fa— Rename WAKU2-RELAY.md to RELAY.md - 2024-01-27 —
4c4591c— Rename README.md to WAKU2-RELAY.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-25 —
6874961— Create README.md
11/WAKU2-RELAY specifies a Publish/Subscribe approach
to peer-to-peer messaging with a strong focus on privacy,
censorship-resistance, security and scalability.
Its current implementation is a minor extension of the
libp2p GossipSub protocol
and prescribes gossip-based dissemination.
As such the scope is limited to defining a separate
protocol id
for 11/WAKU2-RELAY, establishing privacy and security requirements,
and defining how the underlying GossipSub is to be interpreted and
implemented within the Waku and cryptoeconomic domain.
11/WAKU2-RELAY should not be confused with libp2p circuit relay.
Protocol identifier: /vac/waku/relay/2.0.0
Security Requirements
The 11/WAKU2-RELAY protocol is designed to provide the following security properties
under a static Adversarial Model.
Note that data confidentiality, integrity, and
authenticity are currently considered out of scope for 11/WAKU2-RELAY and
must be handled by higher layer protocols such as 14/WAKU2-MESSAGE.
-
Publisher-Message Unlinkability: This property indicates that no adversarial entity can link a published
Messageto its publisher. This feature also implies the unlinkability of the publisher to its published topic ID as theMessageembodies the topic IDs. -
Subscriber-Topic Unlinkability: This feature stands for the inability of any adversarial entity from linking a subscriber to its subscribed topic IDs.
Terminology
Personally identifiable information (PII) refers to any piece of data that can be used to uniquely identify a user. For example, the signature verification key, and the hash of one's static IP address are unique for each user and hence count as PII.
Adversarial Model
- Any entity running the
11/WAKU2-RELAYprotocol is considered an adversary. This includes publishers, subscribers, and all the peers' direct connections. Furthermore, we consider the adversary as a passive entity that attempts to collect information from others to conduct an attack but it does so without violating protocol definitions and instructions. For example, under the passive adversarial model, no malicious subscriber hides the messages it receives from other subscribers as it is against the description of11/WAKU2-RELAY. However, a malicious subscriber may learn which topics are subscribed to by which peers. - The following are not considered as part of the adversarial model:
- An adversary with a global view of all the peers and their connections.
- An adversary that can eavesdrop on communication links between arbitrary pairs of peers (unless the adversary is one end of the communication). In other words, the communication channels are assumed to be secure.
Wire Specification
The PubSub interface specification
defines the protobuf RPC messages
exchanged between peers participating in a GossipSub network.
We republish these messages here for ease of reference and
define how 11/WAKU2-RELAY uses and interprets each field.
Protobuf definitions
The PubSub RPC messages are specified using protocol buffers v2
syntax = "proto2";
message RPC {
repeated SubOpts subscriptions = 1;
repeated Message publish = 2;
message SubOpts {
optional bool subscribe = 1;
optional string topicid = 2;
}
message Message {
optional string from = 1;
optional bytes data = 2;
optional bytes seqno = 3;
repeated string topicIDs = 4;
optional bytes signature = 5;
optional bytes key = 6;
}
}
NOTE: The various control messages defined for GossipSub are used as specified there. NOTE: The
TopicDescriptoris not currently used by11/WAKU2-RELAY.
Message fields
The Message protobuf defines the format in which content is relayed between peers.
11/WAKU2-RELAY specifies the following usage requirements for each field:
-
The
fromfield MUST NOT be used, following theStrictNoSignsignature policy. -
The
datafield MUST be filled out with aWakuMessage. See14/WAKU2-MESSAGEfor more details. -
The
seqnofield MUST NOT be used, following theStrictNoSignsignature policy. -
The
topicIDsfield MUST contain the content-topics that a message is being published on. -
The
signaturefield MUST NOT be used, following theStrictNoSignsignature policy. -
The
keyfield MUST NOT be used, following theStrictNoSignsignature policy.
SubOpts fields
The SubOpts protobuf defines the format
in which subscription options are relayed between peers.
A 11/WAKU2-RELAY node MAY decide to subscribe or
unsubscribe from topics by sending updates using SubOpts.
The following usage requirements apply:
-
The
subscribefield MUST contain a boolean, wheretrueindicates subscribe andfalseindicates unsubscribe to a topic. -
The
topicidfield MUST contain the pubsub topic.
Note: The
topicidrefering to pubsub topic andtopicIdrefering to content-topic are detailed in 23/WAKU2-TOPICS.
Signature Policy
The StrictNoSign option
MUST be used, to ensure that messages are built without the signature,
key, from and seqno fields.
Note that this does not merely imply that these fields be empty, but
that they MUST be absent from the marshalled message.
Security Analysis
- Publisher-Message Unlinkability:
To address publisher-message unlinkability,
one should remove any PII from the published message.
As such,
11/WAKU2-RELAYfollows theStrictNoSignpolicy as described in libp2p PubSub specs. As the result of theStrictNoSignpolicy,Messages should be built without thefrom,signatureandkeyfields since each of these three fields individually counts as PII for the author of the message (one can link the creation of the message with libp2p peerId and thus indirectly with the IP address of the publisher). Note that removing identifiable information from messages cannot lead to perfect unlinkability. The direct connections of a publisher might be able to figure out whichMessages belong to that publisher by analyzing its traffic. The possibility of such inference may get higher when thedatafield is also not encrypted by the upper-level protocols.
- Subscriber-Topic Unlinkability:
To preserve subscriber-topic unlinkability,
it is recommended by
10/WAKU2to use a single PubSub topic in the11/WAKU2-RELAYprotocol. This allows an immediate subscriber-topic unlinkability where subscribers are not re-identifiable from their subscribed topic IDs as the entire network is linked to the same topic ID. This level of unlinkability / anonymity is known as k-anonymity where k is proportional to the system size (number of participants of Waku relay protocol). However, note that11/WAKU2-RELAYsupports the use of more than one topic. In case that more than one topic id is utilized, preserving unlinkability is the responsibility of the upper-level protocols which MAY adopt partitioned topics technique to achieve K-anonymity for the subscribed peers.
Future work
- Economic spam resistance:
In the spam-protected
11/WAKU2-RELAYprotocol, no adversary can flood the system with spam messages (i.e., publishing a large number of messages in a short amount of time). Spam protection is partly provided by GossipSub v1.1 through scoring mechanism. At a high level, peers utilize a scoring function to locally score the behavior of their connections and remove peers with a low score.11/WAKU2-RELAYaims at enabling an advanced spam protection mechanism with economic disincentives by utilizing Rate Limiting Nullifiers. In a nutshell, peers must conform to a certain message publishing rate per a system-defined epoch, otherwise, they get financially penalized for exceeding the rate. More details on this new technique can be found in17/WAKU2-RLN-RELAY.
- Providing Unlinkability, Integrity and Authenticity simultaneously:
Integrity and authenticity are typically addressed through digital signatures and
Message Authentication Code (MAC) schemes, however,
the usage of digital signatures (where each signature is bound to a particular peer)
contradicts with the unlinkability requirement
(messages signed under a certain signature key are verifiable by a verification key
that is bound to a particular publisher).
As such, integrity and authenticity are missing features in
11/WAKU2-RELAYin the interest of unlinkability. In future work, advanced signature schemes like group signatures can be utilized to enable authenticity, integrity, and unlinkability simultaneously. In a group signature scheme, a member of a group can anonymously sign a message on behalf of the group as such the true signer is indistinguishable from other group members.
Copyright
Copyright and related rights waived via CC0.
References
14/WAKU2-MESSAGE
| Field | Value |
|---|---|
| Name | Waku v2 Message |
| Slug | 14 |
| Status | stable |
| Type | RFC |
| Category | core |
| Editor | Hanno Cornelius [email protected] |
| Contributors | Sanaz Taheri [email protected], Aaryamann Challani [email protected], Lorenzo Delgado [email protected], Abhimanyu Rawat [email protected], Oskar Thorén [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-08 —
c0ef3b9— Cleanup: rewrite specs-repo links in pre-existing messaging specs (#316) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-01-30 —
d5a9240— chore: removed archived (#283) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-04-09 —
8052808— 14/WAKU2-MESSAGE: Move to Stable (#120) - 2024-11-20 —
ff87c84— Update Waku Links (#104) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-08-05 —
eb25cd0— chore: replace email addresses (#86) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-02-01 —
8e70159— Update and rename MESSAGE.md to message.md - 2024-01-27 —
88df5d8— Rename README.md to MESSAGE.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-25 —
9cd48a8— Create README.md
Abstract
10/WAKU2 is a family of modular peer-to-peer protocols for secure communication. These protocols are designed to be secure, privacy-preserving, and censorship-resistant and can run in resource-restricted environments. At a high level, 10/WAKU2 implements a publish/subscribe messaging pattern over libp2p and adds capabilities.
The present document specifies the 10/WAKU2 message format. A way to encapsulate the messages sent with specific information security goals, and Whisper/6/WAKU1 backward compatibility.
Motivation
When sending messages over Waku, there are multiple requirements:
- One may have a separate encryption layer as part of the application.
- One may want to provide efficient routing for resource-restricted devices.
- One may want to provide compatibility with 6/WAKU1 envelopes.
- One may want encrypted payloads by default.
- One may want to provide unlinkability to get metadata protection.
This specification attempts to provide for these various requirements.
Semantics
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in 2119.
Waku Message
A WakuMessage is constituted by the combination of data payload and
attributes that, for example, a publisher sends to a topic and
is eventually delivered to subscribers.
The WakuMessage attributes are key-value pairs of metadata associated with a message.
The message data payload is the part of the transmitted WakuMessage
that is the actual message information.
The data payload is also treated as a WakuMessage attribute for convenience.
Message Attributes
-
The
payloadattribute MUST contain the message data payload to be sent. -
The
content_topicattribute MUST specify a string identifier that can be used for content-based filtering, as described in 23/WAKU2-TOPICS. -
The
metaattribute, if present, contains an arbitrary application-specific variable-length byte array with a maximum length limit of 64 bytes. This attribute can be utilized to convey supplementary details to various 10/WAKU2 protocols, thereby enabling customized processing based on its contents. -
The
versionattribute, if present, contains a version number to discriminate different types of payload encryption. If omitted, the value SHOULD be interpreted as version 0. -
The
timestampattribute, if present, signifies the time at which the message was generated by its sender. This attribute MAY contain the Unix epoch time in nanoseconds. If the attribute is omitted, it SHOULD be interpreted as timestamp 0. -
The
rate_limit_proofattribute, if present, contains a rate limit proof encoded as per 17/WAKU2-RLN-RELAY. -
The
ephemeralattribute, if present, signifies the transient nature of the message. For example, an ephemeral message SHOULD not be persisted by other nodes on the same network. If this attribute is set totrue, the message SHOULD be interpreted as ephemeral. If, instead, the attribute is omitted or set tofalse, the message SHOULD be interpreted as non-ephemeral.
Wire Format
The WakuMessage wire format is specified using protocol buffers v3.
syntax = "proto3";
message WakuMessage {
bytes payload = 1;
string content_topic = 2;
optional uint32 version = 3;
optional sint64 timestamp = 10;
optional bytes meta = 11;
optional bytes rate_limit_proof = 21;
optional bool ephemeral = 31;
}
An example proto file following this specification can be found here (vacp2p/waku).
Payload encryption
The WakuMessage payload MAY be encrypted.
The message version attribute indicates
the schema used to encrypt the payload data.
-
Version 0: The payload SHOULD be interpreted as unencrypted; additionally, it CAN indicate that the message payload has been encrypted at the application layer.
-
Version 1: The payload SHOULD be encrypted using 6/WAKU1 payload encryption specified in 26/WAKU-PAYLOAD. This provides asymmetric and symmetric encryption. The key agreement is performed out of band. And provides an encrypted signature and padding for some form of unlinkability.
-
Version 2: The payload SHOULD be encoded according to WAKU2-NOISE. The Waku Noise protocol provides symmetric encryption and asymmetric key exchange.
Any version value not included in this list is reserved for future specification.
And, in this case, the payload SHOULD be interpreted as unencrypted by the Waku layer.
Whisper/6/WAKU1 envelope compatibility
Whisper/6/WAKU1 envelopes are compatible with Waku messages format.
- Whisper/6/WAKU1
topicfield SHOULD be mapped to Waku message'scontent_topicattribute. - Whisper/6/WAKU1
datafield SHOULD be mapped to Waku message'spayloadattribute.
10/WAKU2 implements a publish/subscribe messaging pattern over libp2p.
This makes some Whisper/6/WAKU1 envelope fields redundant
(e.g., expiry, ttl, topic, etc.), so they can be ignored.
Deterministic message hashing
In Protocol Buffers v3, the deterministic serialization is not canonical across the different implementations and languages. It is also unstable across different builds with schema changes due to unknown fields.
To overcome this interoperability limitation, a 10/WAKU2 message's hash MUST be computed following this schema:
message_hash = sha256(concat(pubsub_topic, message.payload, message.content_topic, message.meta, message.timestamp))
If an optional attribute, such as meta, is absent,
the concatenation of attributes SHOULD exclude it.
This recommendation is made to ensure that the concatenation process proceeds smoothly
when certain attributes are missing and to maintain backward compatibility.
This hashing schema is deemed appropriate for use cases where a cross-implementation deterministic hash is needed, such as message deduplication and integrity validation. The collision probability offered by this hashing schema can be considered negligible. This is due to the deterministic concatenation order of the message attributes, coupled with using a SHA-2 (256-bit) hashing algorithm.
Test vectors
The WakuMessage hash computation (meta size of 12 bytes):
pubsub_topic = "/waku/2/default-waku/proto" (0x2f77616b752f322f64656661756c742d77616b752f70726f746f)
message.payload = 0x010203045445535405060708
message.content_topic = "/waku/2/default-content/proto" (0x2f77616b752f322f64656661756c742d636f6e74656e742f70726f746f)
message.meta = 0x73757065722d736563726574
message.timestamp = 0x175789bfa23f8400
message_hash = 0x64cce733fed134e83da02b02c6f689814872b1a0ac97ea56b76095c3c72bfe05
The WakuMessage hash computation (meta size of 64 bytes):
pubsub_topic = "/waku/2/default-waku/proto" (0x2f77616b752f322f64656661756c742d77616b752f70726f746f)
message.payload = 0x010203045445535405060708
message.content_topic = "/waku/2/default-content/proto" (0x2f77616b752f322f64656661756c742d636f6e74656e742f70726f746f)
message.meta = 0x000102030405060708090a0b0c0d0e0f101112131415161718191a1b1c1d1e1f202122232425262728292a2b2c2d2e2f303132333435363738393a3b3c3d3e3f
message.timestamp = 0x175789bfa23f8400
message_hash = 0x7158b6498753313368b9af8f6e0a0a05104f68f972981da42a43bc53fb0c1b27
The WakuMessage hash computation (meta attribute not present):
pubsub_topic = "/waku/2/default-waku/proto" (0x2f77616b752f322f64656661756c742d77616b752f70726f746f)
message.payload = 0x010203045445535405060708
message.content_topic = "/waku/2/default-content/proto" (0x2f77616b752f322f64656661756c742d636f6e74656e742f70726f746f)
message.meta = <not-present>
message.timestamp = 0x175789bfa23f8400
message_hash = 0xa2554498b31f5bcdfcbf7fa58ad1c2d45f0254f3f8110a85588ec3cf10720fd8
The WakuMessage hash computation (payload length 0):
pubsub_topic = "/waku/2/default-waku/proto" (0x2f77616b752f322f64656661756c742d77616b752f70726f746f)
message.payload = []
message.content_topic = "/waku/2/default-content/proto" (0x2f77616b752f322f64656661756c742d636f6e74656e742f70726f746f)
message.meta = 0x73757065722d736563726574
message.timestamp = 0x175789bfa23f8400
message_hash = 0x483ea950cb63f9b9d6926b262bb36194d3f40a0463ce8446228350bd44e96de4
Security Considerations
Confidentiality, integrity, and authenticity
The level of confidentiality, integrity, and
authenticity of the WakuMessage payload is discretionary.
Accordingly, the application layer shall utilize the encryption and
signature schemes supported by 10/WAKU2,
to meet the application-specific privacy needs.
Reliability of the timestamp attribute
The message timestamp attribute is set by the sender.
Therefore, because message timestamps aren’t independently verified,
this attribute is prone to exploitation and misuse.
It should not solely be relied upon for operations such as message ordering.
For example, a malicious actor can arbitrarily set the timestamp of a WakuMessage
to a high value so that it always shows up as the most recent message
in a chat application.
Applications using 10/WAKU2 messages’ timestamp attribute
are RECOMMENDED to use additional methods for more robust message ordering.
An example of how to deal with message ordering against adversarial message timestamps
can be found in the Status protocol,
see 62/STATUS-PAYLOADS.
Reliability of the ephemeral attribute
The message ephemeral attribute is set by the sender.
Since there is currently no incentive mechanism
for network participants to behave correctly,
this attribute is inherently insecure.
A malicious actor can tamper with the value of a Waku message’s ephemeral attribute,
and the receiver would not be able to verify the integrity of the message.
Copyright
Copyright and related rights waived via CC0.
References
- 10/WAKU2
- 6/WAKU1
- 23/WAKU2-TOPICS
- 17/WAKU2-RLN-RELAY
- 64/WAKU2-NETWORK
- protocol buffers v3
- 26/WAKU-PAYLOAD
- WAKU2-NOISE
- 62/STATUS-PAYLOADS
Core
Core messaging delivery deprecated specifications.
5/WAKU0
| Field | Value |
|---|---|
| Name | Waku v0 |
| Slug | 5 |
| Status | deprecated |
| Type | RFC |
| Category | core |
| Editor | Oskar Thorén [email protected] |
| Contributors | Adam Babik [email protected], Andrea Maria Piana [email protected], Dean Eigenmann [email protected], Kim De Mey [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-30 —
d5a9240— chore: removed archived (#283) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-01-31 —
9770963— Rename WAKU0.md to waku0.md - 2024-01-31 —
ac8fe6d— Rename waku/rfc/deprecated/5/WAKU0.md to waku/deprecated/5/WAKU0.md - 2024-01-27 —
61f7641— Create WAKU0.md
This specification describes the format of Waku messages within the ÐΞVp2p Wire Protocol. This spec substitutes EIP-627. Waku is a fork of the original Whisper protocol that enables better usability for resource restricted devices, such as mostly-offline bandwidth-constrained smartphones. It does this through (a) light node support, (b) historic messages (with a mailserver) (c) expressing topic interest for better bandwidth usage and (d) basic rate limiting.
Motivation
Waku was created to incrementally improve in areas that Whisper is lacking in, with special attention to resource restricted devices. We specify the standard for Waku messages in order to ensure forward compatibility of different Waku clients, backwards compatibility with Whisper clients, as well as to allow multiple implementations of Waku and its capabilities. We also modify the language to be more unambiguous, concise and consistent.
Definitions
| Term | Definition |
|---|---|
| Light node | A Waku node that does not forward any messages. |
| Envelope | Messages sent and received by Waku nodes. |
| Node | Some process that is able to communicate for Waku. |
Underlying Transports and Prerequisites
Use of DevP2P
For nodes to communicate, they MUST implement devp2p and run RLPx. They MUST have some way of connecting to other nodes. Node discovery is largely out of scope for this spec, but see the appendix for some suggestions on how to do this.
Gossip based routing
In Whisper, messages are gossiped between peers. Whisper is a form of rumor-mongering protocol that works by flooding to its connected peers based on some factors. Messages are eligible for retransmission until their TTL expires. A node SHOULD relay messages to all connected nodes if an envelope matches their PoW and bloom filter settings. If a node works in light mode, it MAY choose not to forward envelopes. A node MUST NOT send expired envelopes, unless the envelopes are sent as a mailserver response. A node SHOULD NOT send a message to a peer that it has already sent before.
Wire Specification
Use of RLPx transport protocol
All Waku messages are sent as devp2p RLPx transport protocol, version 51 packets. These packets MUST be RLP-encoded arrays of data containing two objects: packet code followed by another object (whose type depends on the packet code). See informal RLP spec and the Ethereum Yellow Paper, appendix B for more details on RLP.
Waku is a RLPx subprotocol called waku with version 0.
The version number corresponds to the major version in the header spec.
Minor versions should not break compatibility of waku,
this would result in a new major.
(Some exceptions to this apply in the Draft stage
of where client implementation is rapidly change).
ABNF specification
Using Augmented Backus-Naur form (ABNF) we have the following format:
; Packet codes 0 - 127 are reserved for Waku protocol
packet-code = 1*3DIGIT
; rate limits
limit-ip = 1*DIGIT
limit-peerid = 1*DIGIT
limit-topic = 1*DIGIT
rate-limits = "[" limit-ip limit-peerid limit-topic "]"
pow-requirement-key = 48
bloom-filter-key = 49
light-node-key = 50
confirmations-enabled-key = 51
rate-limits-key = 52
topic-interest-key = 53
status-options = "["
[ pow-requirement-key pow-requirement ]
[ bloom-filter-key bloom-filter ]
[ light-node-key light-node ]
[ confirmations-enabled-key confirmations-enabled ]
[ rate-limits-key rate-limits ]
[ topic-interest-key topic-interest ]
"]"
status = "[" version status-options "]"
status-update = status-options
; version is "an integer (as specified in RLP)"
version = DIGIT
confirmations-enabled = BIT
light-node = BIT
; pow is "a single floating point value of PoW.
; This value is the IEEE 754 binary representation
; of a 64-bit floating point number.
; Values of qNAN, sNAN, INF and -INF are not allowed.
; Negative values are also not allowed."
pow = 1*DIGIT "." 1*DIGIT
pow-requirement = pow
; bloom filter is "a byte array"
bloom-filter = *OCTET
waku-envelope = "[" expiry ttl topic data nonce "]"
; List of topics interested in
topic-interest = "[" *10000topic "]"
; 4 bytes (UNIX time in seconds)
expiry = 4OCTET
; 4 bytes (time-to-live in seconds)
ttl = 4OCTET
; 4 bytes of arbitrary data
topic = 4OCTET
; byte array of arbitrary size
; (contains encrypted message)
data = OCTET
; 8 bytes of arbitrary data
; (used for PoW calculation)
nonce = 8OCTET
messages = 1*waku-envelope
; mail server / client specific
p2p-request = waku-envelope
p2p-message = 1*waku-envelope
; packet-format needs to be paired with its
; corresponding packet-format
packet-format = "[" packet-code packet-format "]"
required-packet = 0 status /
1 messages /
22 status-update /
optional-packet = 126 p2p-request / 127 p2p-message
packet = "[" required-packet [ optional-packet ] "]"
All primitive types are RLP encoded. Note that, per RLP specification,
integers are encoded starting from 0x00.
Packet Codes
The message codes reserved for Waku protocol: 0 - 127.
Messages with unknown codes MUST be ignored without generating any error, for forward compatibility of future versions.
The Waku sub-protocol MUST support the following packet codes:
| Name | Int Value |
|---|---|
| Status | 0 |
| Messages | 1 |
| Status Update | 22 |
The following message codes are optional, but they are reserved for specific purpose.
| Name | Int Value | Comment |
|---|---|---|
| Batch Ack | 11 | |
| Message Response | 12 | |
| P2P Request | 126 | |
| P2P Message | 127 |
Packet usage
Status
The Status message serves as a Waku handshake and peers MUST exchange this message upon connection. It MUST be sent after the RLPx handshake and prior to any other Waku messages.
A Waku node MUST await the Status message from a peer before engaging in other Waku protocol activity with that peer. When a node does not receive the Status message from a peer, before a configurable timeout, it SHOULD disconnect from that peer.
Upon retrieval of the Status message, the node SHOULD validate the message received and validated the Status message. Note that its peer might not be in the same state.
When a node is receiving other Waku messages from a peer before a Status message is received, the node MUST ignore these messages and SHOULD disconnect from that peer. Status messages received after the handshake is completed MUST also be ignored.
The status message MUST contain an association list containing various options. All options within this association list are OPTIONAL, ordering of the key-value pairs is not guaranteed and therefore MUST NOT be relied on. Unknown keys in the association list SHOULD be ignored.
Messages
This packet is used for sending the standard Waku envelopes.
Status Update
The Status Update message is used to communicate an update of the settings of the node. The format is the same as the Status message, all fields are optional. If none of the options are specified the message MUST be ignored and considered a noop. Fields that are omitted are considered unchanged, fields that haven't changed SHOULD not be transmitted.
PoW Requirement update
When PoW is updated, peers MUST NOT deliver the sender envelopes with PoW lower than specified in this message.
PoW is defined as average number of iterations, required to find the current BestBit (the number of leading zero bits in the hash), divided by message size and TTL:
PoW = (2**BestBit) / (size * TTL)
PoW calculation:
#![allow(unused)] fn main() { fn short_rlp(envelope) = rlp of envelope, excluding env_nonce field. fn pow_hash(envelope, env_nonce) = sha3(short_rlp(envelope) ++ env_nonce) fn pow(pow_hash, size, ttl) = 2**leading_zeros(pow_hash) / (size * ttl) }
where size is the size of the RLP-encoded envelope,
excluding env_nonce field (size of short_rlp(envelope)).
Bloom filter update
The bloom filter is used to identify a number of topics to a peer without compromising (too much) privacy over precisely what topics are of interest. Precise control over the information content (and thus efficiency of the filter) may be maintained through the addition of bits.
Blooms are formed by the bitwise OR operation on a number of bloomed topics. The bloom function takes the topic and projects them onto a 512-bit slice. At most, three bits are marked for each bloomed topic.
The projection function is defined as a mapping from a 4-byte slice S to a 512-bit slice D; for ease of explanation, S will dereference to bytes, whereas D will dereference to bits.
LET D[*] = 0
FOREACH i IN { 0, 1, 2 } DO
LET n = S[i]
IF S[3] & (2 ** i) THEN n += 256
D[n] = 1
END FOR
A full bloom filter (all the bits set to 1)
means that the node is to be considered a Full Node and it will accept any topic.
If both Topic Interest and bloom filter are specified, Topic Interest always takes precedence and bloom filter MUST be ignored.
If only bloom filter is specified, the current Topic Interest MUST be discarded and only the updated bloom filter MUST be used when forwarding or posting envelopes.
A bloom filter with all bits set to 0 signals that the node is not currently interested in receiving any envelope.
Topic Interest update
This packet is used by Waku nodes for sharing their interest in messages with specific topics. It does this in a more bandwidth considerate way, at the expense of some metadata protection. Peers MUST only send envelopes with specified topics.
It is currently bounded to a maximum of 10000 topics. If you are interested in more topics than that, this is currently underspecified and likely requires updating it. The constant is subject to change.
If only Topic Interest is specified, the current bloom filter MUST be discarded and only the updated Topic Interest MUST be used when forwarding or posting envelopes.
An empty array signals that the node is not currently interested in receiving any envelope.
Rate Limits update
This packet is used for informing other nodes of their self defined rate limits.
In order to provide basic Denial-of-Service attack protection, each node SHOULD define its own rate limits. The rate limits SHOULD be applied on IPs, peer IDs, and envelope topics.
Each node MAY decide to whitelist, i.e. do not rate limit, selected IPs or peer IDs.
If a peer exceeds node's rate limits, the connection between them MAY be dropped.
Each node SHOULD broadcast its rate limits to its peers using the rate limits packet. The rate limits MAY also be sent as an optional parameter in the handshake.
Each node SHOULD respect rate limits advertised by its peers. The number of packets SHOULD be throttled in order not to exceed peer's rate limits. If the limit gets exceeded, the connection MAY be dropped by the peer.
Message Confirmations update
Message confirmations tell a node that a message originating from it has been received by its peers, allowing a node to know whether a message has or has not been received.
A node MAY send a message confirmation for any batch of messages received with a packet Messages Code.
A message confirmation is sent using Batch Acknowledge packet or Message Response packet. The Batch Acknowledge packet is followed by a keccak256 hash of the envelopes batch data.
The current version of the message response is 1.
Using Augmented Backus-Naur form (ABNF) we have the following format:
; a version of the Message Response
version = 1*DIGIT
; keccak256 hash of the envelopes batch data (raw bytes) for which the confirmation is sent
hash = *OCTET
hasherror = *OCTET
; error code
code = 1*DIGIT
; a descriptive error message
description = *ALPHA
error = "[" hasherror code description "]"
errors = *error
response = "[" hash errors "]"
confirmation = "[" version response "]"
The supported codes:
1: means time sync error which happens when an envelope is too old or
created in the future (the root cause is no time sync between nodes).
The drawback of sending message confirmations is that it increases the noise in the network because for each sent message, a corresponding confirmation is broadcast by one or more peers.
P2P Request
This packet is used for sending Dapp-level peer-to-peer requests, e.g. Waku Mail Client requesting old messages from the Waku Mail Server.
P2P Message
This packet is used for sending the peer-to-peer messages, which are not supposed to be forwarded any further. E.g. it might be used by the Waku Mail Server for delivery of old (expired) messages, which is otherwise not allowed.
Payload Encryption
Asymmetric encryption uses the standard Elliptic Curve Integrated Encryption Scheme with SECP-256k1 public key.
Symmetric encryption uses AES GCM algorithm with random 96-bit nonce.
Packet code Rationale
Packet codes 0x00 and 0x01 are already used in all Waku / Whisper versions.
Packet code 0x02 and 0x03 were previously used in Whisper but
are deprecated as of Waku v0.4
Packet code 0x22 is used to dynamically change the settings of a node.
Packet codes 0x7E and 0x7F may be used to implement Waku Mail Server and Client.
Without P2P messages it would be impossible to deliver the old messages,
since they will be recognized as expired,
and the peer will be disconnected for violating the Whisper protocol.
They might be useful for other purposes
when it is not possible to spend time on PoW,
e.g. if a stock exchange will want to provide live feed about the latest trades.
Additional capabilities
Waku supports multiple capabilities. These include light node, rate limiting and bridging of traffic. Here we list these capabilities, how they are identified, what properties they have and what invariants they must maintain.
Additionally there is the capability of a mailserver which is documented in its on specification.
Light node
The rationale for light nodes is to allow for interaction with waku on resource restricted devices as bandwidth can often be an issue.
Light nodes MUST NOT forward any incoming messages, they MUST only send their own messages. When light nodes happen to connect to each other, they SHOULD disconnect. As this would result in messages being dropped between the two.
Light nodes are identified by the light_node value in the status message.
Accounting for resources (experimental)
Nodes MAY implement accounting, keeping track of resource usage. It is heavily inspired by Swarm's SWAP protocol, and works by doing pairwise accounting for resources.
Each node keeps track of resource usage with all other nodes. Whenever an envelope is received from a node that is expected (fits bloom filter or topic interest, is legal, etc) this is tracked.
Every epoch (say, every minute or every time an event happens) statistics SHOULD be aggregated and saved by the client:
| peer | sent | received |
|---|---|---|
| peer1 | 0 | 123 |
| peer2 | 10 | 40 |
In later versions this will be amended by nodes communication thresholds, settlements and disconnect logic.
Upgradability and Compatibility
General principles and policy
These are policies that guide how we make decisions when it comes to upgradability, compatibility, and extensibility:
-
Waku aims to be compatible with previous and future versions.
-
In cases where we want to break this compatibility, we do so gracefully and as a single decision point.
-
To achieve this, we employ the following two general strategies:
- a) Accretion (including protocol negotiation) over changing data
- b) When we want to change things, we give it a new name (for example, a version number).
Examples:
- We enable bridging between
shh/6andwaku/0until such a time as when we are ready to gracefully drop support forshh/6(1, 2, 3). - When we add parameter fields, we (currently) do so by accreting them in a list, so old clients can ignore new fields (dynamic list) and new clients can use new capabilities (1, 3).
- To better support (2) and (3) in the future, we will likely release a new version that gives better support for open, growable maps (association lists or native map type) (3)
- When we we want to provide a new set of messages that have different requirements, we do so under a new protocol version and employ protocol versioning. This is a form of accretion at a level above - it ensures a client can support both protocols at once and drop support for legacy versions gracefully. (1,2,3)
Backwards Compatibility
Waku is a different subprotocol from Whisper so it isn't directly compatible. However, the data format is the same, so compatibility can be achieved by the use of a bridging mode as described below. Any client which does not implement certain packet codes should gracefully ignore the packets with those codes. This will ensure the forward compatibility.
Waku-Whisper bridging
waku/0 and shh/6 are different DevP2P subprotocols,
however they share the same data format making their envelopes compatible.
This means we can bridge the protocols naively, this works as follows.
Roles:
- Waku client A, only Waku capability
- Whisper client B, only Whisper capability
- WakuWhisper bridge C, both Waku and Whisper capability
Flow:
- A posts message; B posts message.
- C picks up message from A and B and relays them both to Waku and Whisper.
- A receives message on Waku; B on Whisper.
Note: This flow means if another bridge C1 is active, we might get duplicate relaying for a message between C1 and C2. I.e. Whisper(<>Waku<>Whisper)<>Waku, A-C1-C2-B. Theoretically this bridging chain can get as long as TTL permits.
Forward Compatibility
It is desirable to have a strategy for maintaining forward compatibility
between waku/0 and future version of waku.
Here we outline some concerns and strategy for this.
-
Connecting to nodes with multiple versions: The way this SHOULD be accomplished in the future is by negotiating the versions of subprotocols, within the
hellomessage nodes transmit their capabilities along with a version. As suggested in EIP-8, if a node connects that has a higher version number for a specific capability, the node with a lower number SHOULD assume backwards compatibility. The node with the higher version will decide if compatibility can be assured between versions, if this is not the case it MUST disconnect. -
Adding new packet codes: New packet codes can be added easily due to the available packet codes. Unknown packet codes SHOULD be ignored. Upgrades that add new packet codes SHOULD implement some fallback mechanism if no response was received for nodes that do not yet understand this packet.
-
Adding new options in
status-options: New options can be added to thestatus-optionsassociation list in thestatusandstatus-updatepacket as options are OPTIONAL and unknown option keys SHOULD be ignored. A node SHOULD NOT disconnect from a peer when receivingstatus-optionswith unknown option keys.
Appendix A: Security considerations
There are several security considerations to take into account when running Waku. Chief among them are: scalability, DDoS-resistance and privacy. These also vary depending on what capabilities are used. The security considerations for extra capabilities such as mailservers can be found in their respective specifications.
Scalability and UX
Bandwidth usage:
In version 0 of Waku, bandwidth usage is likely to be an issue. For more investigation into this, see the theoretical scaling model described here.
Gossip-based routing:
Use of gossip-based routing doesn't necessarily scale. It means each node can see a message multiple times, and having too many light nodes can cause propagation probability that is too low. See Whisper vs PSS for more and a possible Kademlia based alternative.
Lack of incentives:
Waku currently lacks incentives to run nodes, which means node operators are more likely to create centralized choke points.
Privacy
Light node privacy:
The main privacy concern with light nodes is that directly connected peers will know that a message originates from them (as it are the only ones it sends). This means nodes can make assumptions about what messages (topics) their peers are interested in.
Bloom filter privacy:
By having a bloom filter where only the topics you are interested in are set, you reveal which messages you are interested in. This is a fundamental tradeoff between bandwidth usage and privacy, though the tradeoff space is likely suboptimal in terms of the Anonymity trilemma.
Privacy guarantees not rigorous:
Privacy for Whisper / Waku haven't been studied rigorously for various threat models like global passive adversary, local active attacker, etc. This is unlike e.g. Tor and mixnets.
Topic hygiene:
Similar to bloom filter privacy, if you use a very specific topic you reveal more information. See scalability model linked above.
Spam resistance
PoW bad for heterogeneous devices:
Proof of work is a poor spam prevention mechanism. A mobile device can only have a very low PoW in order not to use too much CPU / burn up its phone battery. This means someone can spin up a powerful node and overwhelm the network.
Censorship resistance
Devp2p TCP port blockable:
By default Devp2p runs on port 30303,
which is not commonly used for any other service.
This means it is easy to censor, e.g. airport WiFi.
This can be mitigated somewhat by running on e.g. port 80 or 443,
but there are still outstanding issues.
See libp2p and Tor's Pluggable Transport for how this can be improved.
Appendix B: Implementation Notes
Implementation Matrix
Recommendations for clients
Notes useful for implementing Waku mode.
- Avoid duplicate envelopes:
To avoid duplicate envelopes, only connect to one Waku node. Benign duplicate envelopes is an intrinsic property of Whisper which often leads to a N factor increase in traffic, where N is the number of peers you are connected to.
- Topic specific recommendations -
Consider partition topics based on some usage, to avoid too much traffic on a single topic.
Node discovery
Resource restricted devices SHOULD use EIP-1459 to discover nodes.
Known static nodes MAY also be used.
Changelog
Version 0.6
Released April 21,2020
- Mark spec as Deprecated mode in terms of its lifecycle.
Version 0.5
Released March 17,2020
- Clarify the preferred way of handling unknown keys
in the
status-optionsassociation list. - Correct spec/implementation mismatch: Change RLP keys to be the their int values in order to reflect production behavior
Version 0.4
Released February 21, 2020.
- Simplify implementation matrix with latest state
- Introduces a new required packet code Status Code (
0x22) for communicating option changes - Deprecates the following packet codes:
PoW Requirement (
0x02), Bloom Filter (0x03), Rate limits (0x20), Topic interest (0x21) - all superseded by the new Status Code (0x22) - Increased
topic-interestcapacity from 1000 to 10000
Version 0.3
Released February 13, 2020.
- Recommend DNS based node discovery over other Discovery methods.
- Mark spec as Draft mode in terms of its lifecycle.
- Simplify Changelog and misc formatting.
- Handshake/Status message not compatible with shh/6 nodes; specifying options as association list.
- Include topic-interest in Status handshake.
- Upgradability policy.
topic-interestpacket code.
Version 0.2
Released December 10, 2019.
- General style improvements.
- Fix ABNF grammar.
- Mailserver requesting/receiving.
- New packet codes: topic-interest (experimental), rate limits (experimental).
- More details on handshake modifications.
- Accounting for resources mode (experimental)
- Appendix with security considerations: scalability and UX, privacy, and spam resistance.
- Appendix with implementation notes and implementation matrix across various clients with breakdown per capability.
- More details on handshake and parameters.
- Describe rate limits in more detail.
- More details on mailserver and mail client API.
- Accounting for resources mode (very experimental).
- Clarify differences with Whisper.
Version 0.1
Initial version. Released November 21, 2019.
Differences between shh/6 and waku/0
Summary of main differences between this spec and Whisper v6, as described in EIP-627:
- RLPx subprotocol is changed from
shh/6towaku/0. - Light node capability is added.
- Optional rate limiting is added.
- Status packet has following additional parameters: light-node, confirmations-enabled and rate-limits
- Mail Server and Mail Client functionality is now part of the specification.
- P2P Message packet contains a list of envelopes instead of a single envelope.
Copyright
Copyright and related rights waived via CC0.
Footnotes
Felix Lange et al. The RLPx Transport Protocol. Ethereum.
16/WAKU2-RPC
| Field | Value |
|---|---|
| Name | Waku v2 RPC API |
| Slug | 16 |
| Status | deprecated |
| Type | RFC |
| Category | core |
| Editor | Hanno Cornelius [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-04-16 —
8b552ba— chore: mark 16/WAKU2-RPC as deprecated (#30) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-02-01 —
87b56de— Update and rename RPC.md to rpc.md - 2024-01-27 —
9042acf— Rename README.md to RPC.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-25 —
8a53f24— Create README.md
Introduction
This specification describes the JSON-RPC API that Waku v2 nodes MAY adhere to. Refer to the Waku v2 specification for more information on Waku v2.
Wire Protocol
Transport
Nodes SHOULD expose an accessible
JSON-RPC API.
The JSON-RPC version SHOULD be 2.0. Below is an example request:
{
"jsonrpc":"2.0",
"method":"get_waku_v2_debug_info",
"params":[],
"id":1
}
Fields
| Field | Description |
|---|---|
jsonrpc | Contains the used JSON-RPC version (Default: 2.0) |
method | Contains the JSON-RPC method that is being called |
params | An array of parameters for the request |
id | The request ID |
Types
In this specification, the primitive types Boolean, String,
Number and Null, as well as the structured types Array and Object,
are to be interpreted according to the JSON-RPC specification.
It also adopts the same capitalisation conventions.
The following structured types are defined for use throughout the document:
WakuMessage
Refer to Waku Message specification for more information.
WakuMessage is an Object containing the following fields:
| Field | Type | Inclusion | Description |
|---|---|---|---|
payload | String | mandatory | The message payload as a base64 (with padding) encoded data string |
contentTopic | String | optional | Message content topic for optional content-based filtering |
version | Number | optional | Message version. Used to indicate type of payload encryption. Default version is 0 (no payload encryption). |
timestamp | Number | optional | The time at which the message is generated by its sender. This field holds the Unix epoch time in nanoseconds as a 64-bits integer value. |
ephemeral | Boolean | optional | This flag indicates the transient nature of the message. Indicates if the message is eligible to be stored by the store protocol, 13/WAKU2-STORE. |
Method naming
The JSON-RPC methods in this document are designed to be mappable to HTTP REST endpoints.
Method names follow the pattern <method_type>_waku_<protocol_version>_<api>_<api_version>_<resource>
<method_type>: prefix of the HTTP method type that most closely matches the JSON-RPC function. Supportedmethod_typevalues areget,post,put,deleteorpatch.<protocol_version>: Waku version. Currently v2.<api>: one of the listed APIs below, e.g.store,debug, orrelay.<api_version>: API definition version. Currently v1 for all APIs.<resource>: the resource or resource path being addressed
The method post_waku_v2_relay_v1_message, for example,
would map to the HTTP REST endpoint POST /waku/v2/relay/v1/message.
Debug API
Types
The following structured types are defined for use on the Debug API:
WakuInfo
WakuInfo is an Object containing the following fields:
| Field | Type | Inclusion | Description |
|---|---|---|---|
listenAddresses | Array[String] | mandatory | Listening addresses of the node |
enrUri | String | optional | ENR URI of the node |
get_waku_v2_debug_v1_info
The get_waku_v2_debug_v1_info method retrieves information about a Waku v2 node
Parameters
none
Response
WakuInfo- information about a Waku v2 node
get_waku_v2_debug_v1_version
The get_waku_v2_debug_v1_version method retrieves the version of a Waku v2 node
as a string.
The version SHOULD follow semantic versioning.
In case the node's current build is based on a git commit between semantic versions,
the retrieved version string MAY contain the git commit hash alone or
in combination with the latest semantic version.
Parameters
none
Response
string- represents the version of a Waku v2 node
Relay API
Refer to the Waku Relay specification for more information on the relaying of messages.
post_waku_v2_relay_v1_message
The post_waku_v2_relay_v1_message method publishes a message to be relayed on a
PubSub topic
Parameters
| Field | Type | Inclusion | Description |
|---|---|---|---|
topic | String | mandatory | The PubSub topic being published on |
message | WakuMessage | mandatory | The message being relayed |
Response
Bool-trueon success or an error on failure.
post_waku_v2_relay_v1_subscriptions
The post_waku_v2_relay_v1_subscriptions method subscribes a node to an array of
PubSub topics.
Parameters
| Field | Type | Inclusion | Description |
|---|---|---|---|
topics | Array[String] | mandatory | The PubSub topics being subscribed to |
Response
Bool-trueon success or an error on failure.
delete_waku_v2_relay_v1_subscriptions
The delete_waku_v2_relay_v1_subscriptions method unsubscribes a node from an array
of PubSub topics.
Parameters
| Field | Type | Inclusion | Description |
|---|---|---|---|
topics | Array[String] | mandatory | The PubSub topics being unsubscribed from |
Response
Bool-trueon success or an error on failure.
get_waku_v2_relay_v1_messages
The get_waku_v2_relay_v1_messages method returns a list of messages
that were received on a subscribed
PubSub topic
after the last time this method was called.
The server MUST respond with an error
if no subscription exists for the polled topic.
If no message has yet been received on the polled topic,
the server SHOULD return an empty list.
This method can be used to poll a topic for new messages.
Parameters
| Field | Type | Inclusion | Description |
|---|---|---|---|
topic | String | mandatory | The PubSub topic to poll for the latest messages |
Response
Array[WakuMessage] - the latestmessageson the polledtopicor an error on failure.
Relay Private API
The Private API provides functionality to encrypt/decrypt WakuMessage payloads
using either symmetric or asymmetric cryptography.
This allows backwards compatibility with Waku v1 nodes.
It is the API client's responsibility to keep track of the keys
used for encrypted communication.
Since keys must be cached by the client and
provided to the node to encrypt/decrypt payloads,
a Private API SHOULD NOT be exposed on non-local or untrusted nodes.
Types
The following structured types are defined for use on the Private API:
KeyPair
KeyPair is an Object containing the following fields:
| Field | Type | Inclusion | Description |
|---|---|---|---|
privateKey | String | mandatory | Private key as hex encoded data string |
publicKey | String | mandatory | Public key as hex encoded data string |
get_waku_v2_private_v1_symmetric_key
Generates and returns a symmetric key that can be used for message encryption and decryption.
Parameters
none
Response
String- A new symmetric key as hex encoded data string
get_waku_v2_private_v1_asymmetric_keypair
Generates and returns a public/private key pair that can be used for asymmetric message encryption and decryption.
Parameters
none
Response
KeyPair- A new public/private key pair as hex encoded data strings
post_waku_v2_private_v1_symmetric_message
The post_waku_v2_private_v1_symmetric_message method publishes a message
to be relayed on a PubSub topic.
Before being relayed, the message payload is encrypted using the supplied symmetric key. The client MUST provide a symmetric key.
Parameters
| Field | Type | Inclusion | Description |
|---|---|---|---|
topic | String | mandatory | The PubSub topic being published on |
message | WakuMessage | mandatory | The (unencrypted) message being relayed |
symkey | String | mandatory | The hex encoded symmetric key to use for payload encryption. This field MUST be included if symmetric key cryptography is selected |
Response
Bool-trueon success or an error on failure.
post_waku_v2_private_v1_asymmetric_message
The post_waku_v2_private_v1_asymmetric_message method publishes a message
to be relayed on a PubSub topic.
Before being relayed, the message payload is encrypted using the supplied public key. The client MUST provide a public key.
Parameters
| Field | Type | Inclusion | Description |
|---|---|---|---|
topic | String | mandatory | The PubSub topic being published on |
message | WakuMessage | mandatory | The (unencrypted) message being relayed |
publicKey | String | mandatory | The hex encoded public key to use for payload encryption. This field MUST be included if asymmetric key cryptography is selected |
Response
Bool-trueon success or an error on failure.
get_waku_v2_private_v1_symmetric_messages
The get_waku_v2_private_v1_symmetric_messages method decrypts and
returns a list of messages that were received on a subscribed
PubSub topic
after the last time this method was called.
The server MUST respond with an error
if no subscription exists for the polled topic.
If no message has yet been received on the polled topic,
the server SHOULD return an empty list.
This method can be used to poll a topic for new messages.
Before returning the messages, the server decrypts the message payloads using the supplied symmetric key. The client MUST provide a symmetric key.
Parameters
| Field | Type | Inclusion | Description |
|---|---|---|---|
topic | String | mandatory | The PubSub topic to poll for the latest messages |
symkey | String | mandatory | The hex encoded symmetric key to use for payload decryption. This field MUST be included if symmetric key cryptography is selected |
Response
Array[WakuMessage] - the latestmessageson the polledtopicor an error on failure.
get_waku_v2_private_v1_asymmetric_messages
The get_waku_v2_private_v1_asymmetric_messages method decrypts and
returns a list of messages that were received on a subscribed PubSub topic
after the last time this method was called.
The server MUST respond with an error
if no subscription exists for the polled topic.
If no message has yet been received on the polled topic,
the server SHOULD return an empty list.
This method can be used to poll a topic for new messages.
Before returning the messages, the server decrypts the message payloads using the supplied private key. The client MUST provide a private key.
Parameters
| Field | Type | Inclusion | Description |
|---|---|---|---|
topic | String | mandatory | The PubSub topic to poll for the latest messages |
privateKey | String | mandatory | The hex encoded private key to use for payload decryption. This field MUST be included if asymmetric key cryptography is selected |
Response
Array[WakuMessage] - the latestmessageson the polledtopicor an error on failure.
Store API
Refer to the Waku Store specification for more information on message history retrieval.
The following structured types are defined for use on the Store API:
StoreResponse
StoreResponse is an Object containing the following fields:
| Field | Type | Inclusion | Description |
|---|---|---|---|
messages | Array[WakuMessage] | mandatory | Array of retrieved historical messages |
pagingOptions | PagingOptions | conditional | Paging information from which to resume further historical queries |
PagingOptions
pagingOptions is an Object containing the following fields:
| Field | Type | Inclusion | Description |
|---|---|---|---|
pageSize | Number | mandatory | Number of messages to retrieve per page |
cursor | Index | optional | Message Index from which to perform pagination. If not included and forward is set to true, paging will be performed from the beginning of the list. If not included and forward is set to false, paging will be performed from the end of the list. |
forward | Bool | mandatory | true if paging forward, false if paging backward |
Index
Index is an Object containing the following fields:
| Field | Type | Inclusion | Description |
|---|---|---|---|
digest | String | mandatory | A hash for the message at this Index |
receivedTime | Number | mandatory | UNIX timestamp in nanoseconds at which the message at this Index was received |
ContentFilter
ContentFilter is an Object containing the following fields:
| Field | Type | Inclusion | Description |
|---|---|---|---|
contentTopic | String | mandatory | The content topic of a WakuMessage |
get_waku_v2_store_v1_messages
The get_waku_v2_store_v1_messages method retrieves historical messages
on specific content topics.
This method MAY be called with PagingOptions,
to retrieve historical messages on a per-page basis.
If the request included PagingOptions,
the node MUST return messages on a per-page basis and
include PagingOptions in the response.
These PagingOptions MUST contain a cursor pointing
to the Index from which a new page can be requested.
Parameters
| Field | Type | Inclusion | Description |
|---|---|---|---|
pubsubTopic | String | optional | The pubsub topic on which a WakuMessage is published |
contentFilters | Array[ContentFilter] | optional | Array of content filters to query for historical messages |
startTime | Number | optional | The inclusive lower bound on the timestamp of queried WakuMessages. This field holds the Unix epoch time in nanoseconds as a 64-bits integer value. |
endTime | Number | optional | The inclusive upper bound on the timestamp of queried WakuMessages. This field holds the Unix epoch time in nanoseconds as a 64-bits integer value. |
pagingOptions | PagingOptions | optional | Pagination information |
Response
StoreResponse- the response to aqueryfor historical messages.
Filter API
Refer to the Waku Filter specification for more information on content filtering.
Types
The following structured types are defined for use on the Filter API:
ContentFilter
ContentFilter is an Object containing the following fields:
| Field | Type | Inclusion | Description |
|---|---|---|---|
contentTopic | String | mandatory | message content topic |
post_waku_v2_filter_v1_subscription
The post_waku_v2_filter_v1_subscription method creates a subscription in a
light node for messages that matches a content filter
and, optionally, a PubSub topic.
Parameters
| Field | Type | Inclusion | Description |
|---|---|---|---|
contentFilters | Array[ContentFilter] | mandatory | Array of content filters being subscribed to |
topic | String | optional | Message topic |
Response
Bool-trueon success or an error on failure.
delete_waku_v2_filter_v1_subscription
The delete_waku_v2_filter_v1_subscription method removes subscriptions
in a light node matching a content filter and,
optionally, a PubSub topic.
Parameters
| Field | Type | Inclusion | Description |
|---|---|---|---|
contentFilters | Array[ContentFilter] | mandatory | Array of content filters being unsubscribed from |
topic | String | optional | Message topic |
Response
Bool-trueon success or an error on failure.
get_waku_v2_filter_v1_messages
The get_waku_v2_filter_v1_messages method returns a list of messages
that were received on a subscribed content topic
after the last time this method was called.
The server MUST respond with an
error
if no subscription exists for the polled content topic.
If no message has yet been received on the polled content topic,
the server SHOULD respond with an empty list.
This method can be used to poll a content topic for new messages.
Parameters
| Field | Type | Inclusion | Description |
|---|---|---|---|
contentTopic | String | mandatory | The content topic to poll for the latest messages |
Response
Array[WakuMessage] - the latestmessageson the polled contenttopicor an error on failure.
Admin API
The Admin API provides privileged accesses to the internal operations of a Waku v2 node.
The following structured types are defined for use on the Admin API:
WakuPeer
WakuPeer is an Object containing the following fields:
| Field | Type | Inclusion | Description |
|---|---|---|---|
multiaddr | String | mandatory | Multiaddress containing this peer's location and identity |
protocol | String | mandatory | Protocol that this peer is registered for |
connected | bool | mandatory | true if peer has active connection for this protocol, false if not |
get_waku_v2_admin_v1_peers
The get_waku_v2_admin_v1_peers method returns an array of peers
registered on this node.
Since a Waku v2 node may open either continuous or ad hoc connections,
depending on the negotiated protocol,
these peers may have different connected states.
The same peer MAY appear twice in the returned array,
if it is registered for more than one protocol.
Parameters
- none
Response
Array[WakuPeer] - Array of peers registered on this node
post_waku_v2_admin_v1_peers
The post_waku_v2_admin_v1_peers method connects a node to a list of peers.
Parameters
| Field | Type | Inclusion | Description |
|---|---|---|---|
peers | Array[String] | mandatory | Array of peer multiaddrs to connect to. Each multiaddr must contain the location and identity addresses of a peer. |
Response
Bool-trueon success or an error on failure.
Example usage
Store API
get_waku_v2_store_v1_messages
This method is part of the store API and
the specific resources to retrieve are (historical) messages.
The protocol (waku) is on v2, whereas the Store API definition is on v1.
1.get all the historical messages for content topic
"/waku/2/default-content/proto"; no paging required
Request
curl -d '{"jsonrpc":"2.0","id":"id","method":"get_waku_v2_store_v1_messages", "params":["", [{"contentTopic":"/waku/2/default-content/proto"}]]}' --header "Content-Type: application/json" http://localhost:8545
{
"jsonrpc": "2.0",
"id": "id",
"method": "get_waku_v2_store_v1_messages",
"params": [
"",
[
{"contentTopic": "/waku/2/default-content/proto"}
]
]
}
Response
{
"jsonrpc": "2.0",
"id": "id",
"result": {
"messages": [
{
"payload": dGVzdDE,
"contentTopic": "/waku/2/default-content/proto",
"version": 0
},
{
"payload": dGVzdDI,
"contentTopic": "/waku/2/default-content/proto",
"version": 0
},
{
"payload": dGVzdDM,
"contentTopic": "/waku/2/default-content/proto",
"version": 0
}
],
"pagingInfo": null
},
"error": null
}
2.get a single page of historical messages for content topic "/waku/2/default-content/proto";
2 messages per page, backward direction.
Since this is the initial query, no cursor is provided,
so paging will be performed from the end of the list.
Request
curl -d '{"jsonrpc":"2.0","id":"id","method":"get_waku_v2_store_v1_messages", "params":[ "", [{"contentTopic":"/waku/2/default-content/proto"}],{"pageSize":2,"forward":false}]}' --header "Content-Type: application/json" http://localhost:8545
{
"jsonrpc": "2.0",
"id": "id",
"method": "get_waku_v2_store_v1_messages",
"params": [
"",
[
{"contentTopic": "/waku/2/default-content/proto"}
],
{
"pageSize": 2,
"forward": false
}
]
}
Response
{
"jsonrpc": "2.0",
"id": "id",
"result": {
"messages": [
{
"payload": dGVzdDI,
"contentTopic": "/waku/2/default-content/proto",
"version": 0
},
{
"payload": dGVzdDM,
"contentTopic": "/waku/2/default-content/proto",
"version": 0
}
],
"pagingInfo": {
"pageSize": 2,
"cursor": {
"digest": "abcdef",
"receivedTime": 1605887187000000000
},
"forward": false
}
},
"error": null
}
3.get the next page of historical messages for content topic "/waku/2/default-content/proto",
using the cursor received above; 2 messages per page, backward direction.
Request
curl -d '{"jsonrpc":"2.0","id":"id","method":"get_waku_v2_store_v1_messages", "params":[ "", [{"contentTopic":"/waku/2/default-content/proto"}],{"pageSize":2,"cursor":{"digest":"abcdef","receivedTime":1605887187000000000},"forward":false}]}' --header "Content-Type: application/json" http://localhost:8545
{
"jsonrpc": "2.0",
"id": "id",
"method": "get_waku_v2_store_v1_messages",
"params": [
"",
[
{"contentTopic": "/waku/2/default-content/proto"}
],
{
"pageSize": 2,
"cursor": {
"digest": "abcdef",
"receivedTime": 1605887187000000000
},
"forward": false
}
]
}
Response
{
"jsonrpc": "2.0",
"id": "id",
"result": {
"messages": [
{
"payload": dGVzdDE,
"contentTopic": "/waku/2/default-content/proto",
"version": 0
},
],
"pagingInfo": {
"pageSize": 2,
"cursor": {
"digest": "123abc",
"receivedTime": 1605866187000000000
},
"forward": false
}
},
"error": null
}
Copyright
Copyright and related rights waived via CC0.
References
- JSON-RPC specification
- LibP2P Addressing
- LibP2P PubSub specification - topic descriptor
- Waku v2 specification
- IETF RFC 4648 - The Base16, Base32, and Base64 Data Encodings
Application
Application-level messaging specifications.
Application
Application-level messaging and chat raw specifications.
CHAT-FRAMEWORK
| Field | Value |
|---|---|
| Name | A modular framework for defining chat protocols |
| Slug | 239 |
| Status | raw |
| Type | RFC |
| Category | application |
| Tags | chat |
| Editor | Jazz Alyxzander [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-11 —
bb9d20b— chore: scope linting (#355) - 2026-06-04 —
022afcd— docs(messaging): move remaining specs from logos-messaging/specs (#346)
Abstract
This specification defines a modular communication protocol framework for describing chat protocols. It introduces abstraction boundaries, and a component model for describing chat protocol functionality.
Background / Rationale / Motivation
Chat protocols specifications can be long and dense documents. To fully describe a chat protocol there are many layers and operations which are required to be documented. This includes payloads, message transport, encryption as well as user level features such as account registration, typing indicators, content formatting.
With the vast amount of information required to maintain compatibility between applications - protocol documentation is either comprehensive which leads to large monolithic specifications or lacking the required details for interop between implementors. A suitable solution would provide both the specificity while also remaining lean and focused.
Theory / Semantics
This specification defines an abstract framework for building a chat protocol. Its purpose is to name the distinct components/phases, and define modular boundaries between them to promote reuse. The end result is that a chat protocol implementation can be described by listing its approach to 5 things.
The lifecycle of a protocol instance is divided into three phases:
- Discovery: How does a Sender learn of other clients.
- Initialization: How does a Recipient learn a client wants to communicate with them.
- Operation: How do participants exchange content.
and transport details are divided into 2 components:
- Delivery Service: How are payloads routed and delivered to a client.
- Framing Strategy: How are payloads encoded.
Defining these 5 parameters allows for chat protocol implementations to be fully defined, which allows clients from different applications to exchange messages. While also dividing documents by their focus area.
Abstract Transport
Delivery service
A Delivery Service (DS) is the service or method that distributes payloads to clients. A DS accepts payloads with a delivery_address and delivers them to all subscribers of that delivery_address. Protocols use delivery_addresses to establish delivery contracts between senders and recipients. The mapping of delivery_addresses to DS-level concepts is implementation-specific.
Requirements
- A DS MUST provide a method for clients to subscribe to messages from a delivery_address
- Payloads sent to a delivery_address are delivered by a DS to all subscribers of that delivery_address
- A DS SHOULD handle segmentation if the underling transport limits message sizes
- A DS MAY NOT guarantee message delivery
- A DS MAY NOT guarantee message ordering
- A DS MAY reject payloads
Framing Strategy
In this protocol framework, payloads from multiple protocols are potentially multiplexed over the same channel. This requires that clients are able to associate a given payload to a given instance of a protocol.
A framing strategy should define a common payload type as well as a method to determine which state machine a receiving client must use to decode it.
Protocol Phases
In order to exchange content clients must be able to learn of each others existence, gather the pre-requisite information/parameters and, remain synchronized over time.
The lifecycle of a protocol instance is divided into three phases, which are described by a corresponding protocol.
- Discovery Phase: Discovery Protocol
- Initialization Phase: Initialization Protocol
- Operation Phase: Conversation Protocol
sequenceDiagram
participant D as ???
participant S as Saro
participant R as Raya
Note over D,S: Discovery
D -->> S: <IntroBundle>
Note over R,S: Initialization
S ->> R: Invite
Note over R,S: Operation
loop
par
R->> S: Send Message
and
S->> R: Send Message
end
end
Discovery Protocol
A discovery protocol defines how clients gather the prerequisite information to contact another client.
The input requirements of the discovery protocol are not defined here, and largely determined by the desired user experience.
The output requirements of the discovery protocol are very implementation specific, and will depend on the initialization protocol requirements and DS chosen by the implementation. The data provided by the discovery protocol and required by the initialization protocol is called the IntroductionBundle.
- The discovery protocol MUST provide all data required for the initialization protocol.
Note: There is no requirement that the Discovery protocol be neither a complicated nor interactive process. Hypothetically If all required values to construct a IntroductionBundle could be statically defined, that would be sufficient for this definition.
Initialization Protocol
A initialization protocol specifies how two clients can initiate communication. The input to this process is the IntroductionBundle and the output is an established instance of a Conversation between the participants.
The core of an initialization protocol is a defined location and procedure for receiving initial messages.
Many chat protocols choose to define the initialization protocol within the conversation protocol. This tight coupling produces two negative artifacts.
- New conversation protocols must define and deploy there own initialization channels. Increasing overhead and adding complexity.
- Protocol upgrades then create partitions in the communication network, as older clients have no means of communicating with new clients.
Separating channel initialization from conversation flow allows multiple conversations to reuse the same initialization channel. This reduces effort for new conversation protocols, and is especially valuable when upgrading existing ones. Being independent the initialization pathway can persist across conversation versions. Even if an older client cannot parse new message types, it can still recognize their presence, adding observability.
Conversation Protocol
A conversation protocol defines how messages flow between participants, and subsequently determines the properties of that channel.
- A Conversation protocol MUST define the payloads it uses and how to handle them.
- A Conversation protocol SHOULD outline the cryptographic properties provided
- A Conversation protocol SHOULD describe bidirectional communication.
Copyright
Copyright and related rights waived via CC0.
CONTENTFRAME
| Field | Value |
|---|---|
| Name | Chat Content Frames |
| Slug | 240 |
| Status | raw |
| Type | RFC |
| Category | application |
| Editor | Jazzz [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-11 —
bb9d20b— chore: scope linting (#355) - 2026-06-04 —
022afcd— docs(messaging): move remaining specs from logos-messaging/specs (#346)
Abstract
This specification defines ContentFrame, a self-describing message format for decentralized chat networks.
ContentFrame wraps content payloads with metadata identifying their type and governing specification repository.
Using a (domain, tag) tuple, applications can uniquely identify message types and locate authoritative documentation for parsing unfamiliar content.
This approach enables permissionless innovation while maintaining the context needed for interoperability, allowing applications to gracefully handle messages from sources they don't explicitly know about.
Motivation
In an interoperable chat network, participants cannot be assumed to use the same software to send and receive messages. Users may employ different versions of the same application or different applications entirely. This heterogeneity creates a fundamental challenge: how can applications support extensible message types without prior knowledge of every possible format?
Two naive approaches each have significant drawbacks:
Developer-defined types would allow flexibility but create fragmentation.
When developers define their own message types, the context for parsing these messages remains tightly coupled to the software that created them.
Other applications receiving these messages lack the necessary context to interpret them correctly.
This leads to multiple definitions of basic types such as Text and Image that are not compatible across applications.
Fixed type systems would ensure universal understanding but restrict innovation. A predetermined set of message types eliminates ambiguity but adds friction for developers who want to extend functionality. In a permissionless, decentralized protocol, requiring centralized approval for new message types contradicts core design principles.
The core challenge is managing fragmentation in a decentralized protocol while preserving developer freedom to innovate.
Solution: A self-describing message format that encodes both the payload and the metadata needed to parse it. This approach directs application developers on how a message should be parsed while providing a clear path to learn about unfamiliar content types they encounter. By decoupling the encoded data from the specific software that created it, applications can gracefully handle messages from diverse sources without sacrificing extensibility.
Theory / Semantics
ContentFrame
A ContentFrame provides a self-describing format for payload types by encoding both the type identifier and its administrative origin. The core principle is that each payload should declare which entity is responsible for its definition and provide a unique type discriminator within that entity's namespace.
A ContentFrame consists of two key components:
- Domain: Points to a specification repository that defines and governs a collection of types
- Tag: A unique identifier within that domain that specifies which type the payload conforms to
Together, the tuple (domain, tag) serves two purposes:
- Identification: Uniquely identifies the payload type without ambiguity
- Discovery: Provides a path for developers to learn how to parse and support unfamiliar types
Benefits:
This approach provides several advantages for decentralized interoperability:
- No naming collisions: Developers can independently create types without coordinating with others, as each domain manages its own namespace
- Type reuse: Well-defined, established types can be shared across applications, reducing fragmentation
- Graceful extensibility: Applications encountering unknown types can direct developers to the authoritative specification
- Decentralized governance: No central authority is required to approve new types; domains manage their own specifications
By separating the "who defines this" (domain) from the "what is this" (tag), ContentFrame enables permissionless innovation while maintaining the context needed for interoperability.
Concept Mapping
The following diagram illustrates the relationship between ContentFrame components and their specifications:
flowchart TD
d[Domain ID] -->|references| D
D[Domain] -->|Defines| T[Tag]
T -->|References| Specification
Domain
A domain identifies the authority responsible for defining and governing a set of content types. By including the domain, receiving applications can locate the authoritative specification for a type, regardless of which application originally sent it.
Requirements:
- A domain MUST be a valid URL as defined in RFC 3986
- A domain MUST host or reference definitions for all content types within its namespace
- A domain SHOULD be a specification repository or index that developers can reference
Specification Format:
Domains are responsible for describing their types in whatever format is most appropriate. The only requirement is that the information needed to parse and understand each type is accessible from the domain URL.
Domain ID Mapping:
To minimize payload size, domains are mapped to integer identifiers.
Each domain is assigned a unique domain_id which is used in the wire format instead of the full URL.
- A
domain_idMUST be a positive integer value - A
domain_idMUST correspond to exactly one unique domain - The canonical mapping of
domain_idto domains can be found in Appendix A: Domains
Tag
A tag is a numeric identifier that uniquely specifies a content type within a domain's namespace. After resolving the domain and tag, application developers have all the information needed to locate the definition and parse the payload.
Requirements:
- A tag MUST be a positive integer value
- A tag MUST uniquely identify a single type within its domain
- Two payloads with the same
(domain, tag)tuple MUST conform to the same type specification - A tag's meaning MUST NOT change after it has been assigned within a domain
Domain Responsibility:
Each domain is responsible for:
- Assigning and managing tag values within its namespace
- Documenting how each tag maps to a type specification
- Ensuring tag assignments remain stable and unambiguous
Tags are scoped to their domain, meaning the same tag value can represent different types in different domains without conflict.
Wire Format Specification / Syntax
message ContentFrame {
uint32 domain_id = 1;
uint32 tag = 2;
bytes payload = 3;
}
Field Descriptions:
- domain_id: Identifies the domain that governs this content type
- tag: Identifies the specific content type within the domain's namespace
- payload: The encoded content data
All fields are required.
Implementation Suggestions
Tags to Specifications
Where possible, tag values should directly correspond to specification identifiers. Using specification IDs as tags removes the need to maintain a separate mapping between tags and specifications.
Fragmentation
This protocol allows multiple competing definitions of similar content types.
Having multiple definitions of Text or Image increases fragmentation between applications.
Where possible, reusing existing types will reduce burden on developers and increase interoperability.
Domains should focus on providing types unique to their service or use case.
Appendix A: Domains
![TODO] Find appropriate home for this registry.
Domain IDs are assigned sequentially on a first-come, first-served basis. New domains are added via pull request.
Registry Rules:
- A domain MUST only appear once in the table
- A domain MAY be updated by the original submitter if the repository has been moved
Registry:
| domain_id | specification repository |
|---|---|
| 1 | https://github.com/logos-co/logos-lips |
ConversationTypes
| Field | Value |
|---|---|
| Name | ConversationTypes |
| Slug | 236 |
| Status | raw |
| Type | RFC |
| Category | application |
| Editor | jazzz [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-14 —
7a2ff23— Add ConversationTypes Spec (#323)
Terminology
This specification uses the terminology outlined in CHAT_DEFS including:
- Content
- Frame
- Payload
Background
Building a messaging protocol requires solving the same set of problems repeatedly: how to structure messages, encrypt them, encode them for transport, and handle versioning across a decentralized network where you can't force clients to upgrade in lockstep.
Without a shared abstraction, each protocol re-solves these problems independently — producing incompatible implementations that resist interoperability and make coordinated upgrades expensive.
The hard problem: versioning in a decentralized network
In centralized systems, versioning is straightforward — the server dictates the protocol, and clients update or lose access. In a decentralized network, no such authority exists. Clients at different versions must coexist indefinitely, and any breaking change risks permanently fragmenting the network.
The conventional response is complex negotiation logic, semver schemes, and careful backwards-compatibility maintenance.
This creates a compounding burden: the older the protocol, the more legacy behavior implementors must carry.
Overview
This specification takes a different approach to the versioning problem. Rather than versioning protocols, we make them immutable. A ConversationType is a fixed contract — it never changes. When new functionality is needed, a new ConversationType is defined and participants rotate to it. This makes upgrades cheap, explicit, and coordination-free: clients that support a ConversationType can always communicate, and adding new capabilities never breaks existing ones.
ConversationTypes are the mechanism that makes this possible — a common framework for defining messaging protocols that is modular, immutable, and interoperable by design. ConversationTypes define protocol messages and their serialization, including message structures, encryption mechanisms, and encoding.
In this model, clients are expected to support multiple ConversationTypes simultaneously. Compatibility between clients is determined not by client version, but by the set of ConversationTypes each client supports.
Definitions
A ConversationType is a specification for full-duplex communication.
A Conversation is a software instance of that specification.
Scope
A Conversation can be considered a processor which converts between Content and Payloads. The scope of a ConversationType defines everything inside that boundary.
| In scope | Out of scope |
|---|---|
| Framing: how data is bundled into frames | Transport & routing: how payloads move between clients |
| Encryption: confidentiality and integrity of frames | Content schema: conversations are content-agnostic |
| Encoding: how frames are converted to bytes | Discovery & peer negotiation |
| Addressing: which delivery address a payload targets | Conversation initialization & bootstrapping |
| Membership & Administration |
High Level Operation
sequenceDiagram
participant A as Client
participant C as Conversation
A ->> C: Initializes
Note over A,C : Sending
A ->> C : Send(Content)
C -->> A : ret: List<(deliveryAddr, Payload)>
Note over A,C : Receiving
A ->> C : Receive(Payload)
C -->> A : ret: Content or None
Assumptions
Delivery Service
This specification assumes the existence of a Delivery Service(DS) responsible for routing payloads between clients. A ConversationType is always defined in the context of a DS with the following properties:
- A DS operates as a PubSub — it supports Publish and Subscribe functionality.
- A DS uses a
delivery addressto create broadcast domains. - A DS is not reliable — message delivery is not guaranteed.
Specification
- A ConversationType MUST define how to generate ConversationIds.
- A ConversationType MUST define how to assign
delivery addressesto Payloads. - A ConversationType MUST define how to generate Payloads.
- A ConversationType MUST define how to retrieve Content.
- A ConversationType MUST be immutable.
- A ConversationType MUST explicitly document all Frames required for interoperability.
- A ConversationType MUST NOT impose any requirements on Content structure.
- A ConversationType MUST NOT depend on the internal state of any other ConversationType.
ConversationIds
ConversationIds uniquely identify a Conversation instance on a client. Their primary role is routing — when an inbound Payload arrives, the client uses the ConversationId to determine which Conversation should process it.
Requirements:
- ConversationIds MUST be 128bits long.
- For every client, a ConversationId MUST reference one and only one Conversation.
Delivery Subscriptions
Delivery addresses define where a Conversation expects to receive inbound Payloads from the DS. They are defined by the ConversationType rather than the DS for two reasons:
First, delivery addresses have direct privacy implications — how messages are grouped and addressed can leak metadata about participants and group membership. The ConversationType is best positioned to reason about this, as it has full knowledge of the message structure and encryption scheme.
Second, the DS treats all Payloads as opaque bytes — it has no visibility into content, participants, or intent. The ConversationType, by contrast, understands the semantics of its messages and can make informed decisions about how to group and address them for delivery.
Requirements:
- A Conversation instance MUST define a static set of
delivery addressesto subscribe to during initialization.
Payload Generation & Content Retrieval
A Conversation exposes two conversions — one for each direction of communication. These are the core operations of a ConversationType and define how Content moves in and out of the protocol layer.
A single Content message MAY result in multiple Payloads, each with its own delivery address. This allows a ConversationType to fan out messages across multiple delivery addresses when required by its design.
An inbound Payload will either produce a single Content or nothing. The None case is intentional — not all Payloads are intended to surface content to the application. Some may be protocol-level messages handled internally by the Conversation.
Requirements:
- All Conversation instances MUST provide the following conversions:
Content -> list(DeliveryAddress, Payload)Payload -> Content | None
Immutability
A ConversationType is a fixed contract — once published it cannot be changed. This eliminates compatibility mismatches between clients: any two clients that support the same ConversationType can always interoperate, regardless of their implementation or version.
When new functionality is needed, a new ConversationType is defined. Existing ConversationTypes remain valid indefinitely.
Immutability applies to frame definitions and their semantics — not to the data carried within frames.
Because ConversationTypes are immutable, implementors do not need to manage breaking schema changes.
Any additions to stored state will be additive, removing the need for complex migrations, semver, or version tracking.
Requirements:
- A ConversationType MUST NOT be modified after publication.
- Any change that affects interoperability MUST be defined as a new ConversationType.
Frame Definitions
Frames are the typed data structures that a Conversation operates on internally. They sit between the raw Payload bytes and the Content exposed to the application — a Payload is decoded into a Frame, and either handled internally by the Conversation or converted to Content.
Each ConversationType defines its own set of Frames. Multiple ConversationTypes may reuse the same Frame definitions but there is no requirement to do so.
All Frames fall into one of three states when processed by a Conversation. Distinguishing between these states improves observability — a malformed Frame and an unrecognized Frame are different problems and should not be conflated:
- Valid — the Frame is well-formed and recognized.
- Invalid — the Frame is malformed or fails validation.
- Unsupported — the Frame is unrecognized by this Conversation instance.
Requirements:
- A ConversationType MUST explicitly document all Frames required for interoperability.
- A ConversationType MUST define how to distinguish between Valid, Invalid, and Unsupported frames.
- A ConversationType MUST explicitly tag all Frames intended for the application layer.
- A ConversationType SHOULD define an unambiguous parsing strategy for all Frames, including in the presence of errors.
- A Conversation MUST process all valid frames.
- A Conversation SHOULD notify clients when Unsupported Frames are received.
Encoding/Decoding
Encoding defines how Frames are serialized into Payload bytes for transport, and how inbound Payload bytes are deserialized back into Frames. Payloads are treated as opaque bytes by all other layers — only the Conversation itself is responsible for interpreting them.
Different ConversationTypes may use different encoding schemes. There is no requirement to share encoding procedures across ConversationTypes.
Requirements:
- A ConversationType MUST define how to encode Frames into Payloads.
- A ConversationType MUST define how to decode Payloads into Frames.
Implementation Suggestions
Logical "Chats"
App developers should maintain a logical separation between the user-facing message stream (a "chat") and the Conversation used to transport it. As ConversationTypes are immutable, the lifecycle of a "chat" may outlive the Conversation that carries it — particularly across Conversation Rotation. Applications that map a stable "ChatId" to a current ConversationId will handle rotation more gracefully.
Membership
One property which is determined by the ConversationType is the membership model. For clarity the ConversationType SHOULD define this clearly in the spec.
Is participant list fixed at initialization or can be changed? Who decides which participants are allowed to join? How does a participant join? These are all questions which would be helpful for implementors to know.
Conversation Rotation
Conversation Rotation is the process of migrating participants from one ConversationType to a new one. A new Conversation is initialized with the same membership and the existing Conversation is archived. This is the primary mechanism for accessing new functionality without breaking existing clients.
Protocol Naming
ConversationType names are for convenience only — they carry no semantic meaning and imply no protocol relationship, compatibility, or ordering. Similarly named ConversationTypes do not imply any relationship between them. Implementors MAY use a common prefix for organizational clarity.
Security Considerations
[TODO]
DANDELION
| Field | Value |
|---|---|
| Name | Waku v2 Dandelion |
| Slug | 166 |
| Status | raw |
| Type | RFC |
| Category | application |
| Tags | waku/anonymity |
| Editor | Daniel Kaiser [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
48600b5— Migrate logos-messaging/specs into docs/messaging/ (#315)
Abstract
This document specifies a deanonymization mitigation technique, based on Dandelion and Dandelion++, for Waku Relay. It mitigates mass deanonymization in the multi-node (botnet) attacker model, even when the number of malicious nodes is linear in the number of total nodes in the network.
Based on the insight that symmetric message propagation makes deanonymization easier, it introduces a probability for nodes to simply forward the message to one select relay node instead of disseminating messages as per usual relay operation.
Background and Motivation
Waku Relay, offers privacy, pseudonymity, and a first layer of anonymity protection by design. Being a modular protocol family Waku v2 offers features that inherently carry trade-offs as separate building blocks. Anonymity protection is such a feature. The Anonymity Trilemma states that an anonymous communication network can only have two out of low bandwidth consumption, low latency, and strong anonymity. Even when choosing low bandwidth and low latency, which is the trade-off that basic Waku Relay takes, better anonymity properties (even though not strong per definition) can be achieved by sacrificing some of the efficiency properties. WAKU2-DANDELION specifies one such technique, and aims at gaining the best "bang for the buck" in terms of efficiency paid for anonymity gain. WAKU2-DANDELION is based on Dandelion and Dandelion++.
Dandelion is a message spreading method, which, compared to other methods, increases the uncertainty of an attacker when trying to link messages to senders. Libp2p gossipsub aims at spanning a d-regular graph topology, with d=6 as the default value. Messages are forwarded within this (expected) symmetric topology, which reduces uncertainty when trying to link messages to senders. Dandelion breaks this symmetry by subdividing message spreading into a "stem" and a "fluff" phase.
In the "stem" phase, the message is sent to a single select relay node. With a certain probability, this message is relayed further on the "stem", or enters the fluff phase. On the stem, messages are relayed to single peers, respectively, while in fluff phase, messages are spread as per usual relay operation (optionally augmented by random delays to further reduce symmetry). The graph spanned by stem connections is referred to as the anonymity graph.
Note: This is an early raw version of the specification. It does not strictly follow the formally evaluated Dandelion++ paper, as we want to experiment with relaxing (and strengthening) certain model properties. In specific, we aim at a version that has tighter latency bounds. Further research suggests that Dandelion++'s design choices are not optimal, which further assures that tweaking design choices makes sense. We will refine design decisions in future versions of this specification.
Further information on Waku anonymity may be found in our Waku Privacy and Anonymity Analysis.
Theory and Functioning
WAKU2-DANDELION can be seen as an anonymity enhancing add-on to Waku Relay message dissemination, which is based on libp2p gossipsub. WAKU2-DANDELION subdivides message dissemination into a "stem" and a "fluff" phase. This specification is mainly concerned with specifying the stem phase. The fluff phase corresponds to Waku Relay, with optional fluff phase augmentations such as random delays. Adding random delay in the fluff phase further reduces symmetry in dissemination patterns and introduces more uncertainty for the attacker. Specifying fluff phase augmentations is out of scope for this document.
Note: We plan to add a separate specification for fluff phase augmentations. We envision stem and fluff phase as abstract concepts. The Dandelion stem and fluff phases instantiate these concepts. Future stem specifications might comprise: none (standard relay), Dandelion stem, Tor, and mix-net. As for future fluff specifications: none (standard relay), diffusion (random delays), and mix-net.
Messages relayed by nodes supporting WAKU2-DANDELION are either in stem phase or in fluff phase. We refer to the former as a stem message and to the latter as a fluff message. A message starts in stem phase, and at some point, transitions to fluff phase. Nodes, on the other hand, are in stem state or fluff state. Nodes in stem state relay stem messages to a single relay node, randomly selected per epoch for each incoming stem connection. Nodes in fluff state transition stem messages into fluff phase and relay them accordingly. Fluff messages are always disseminated via Waku Relay, by both nodes in stem state and nodes in fluff state.
Messages originated in the node (i.e. messages coming from the application layer of our node), are always sent as stem messages.
The stem phase can be seen as a different protocol, and messages are introduced into Waku Relay, and by extension gossipsub, once they arrive at a node in fluff state for the first time. WAKU2-DANDELION uses 19/WAKU2-LIGHTPUSH as the protocol for relaying stem messages.
There are no negative effects on gossipsub peer scoring, because Dandelion nodes in stem state still normally relay Waku Relay (gossipsub) messages.
Specification
Nodes supporting WAKU2-DANDELION MUST either be in stem state or in fluff state. This does not include relaying messages originated in , for which SHOULD always be in stem state.
Choosing the State
On startup and when a new epoch starts, node randomly selects a number between 0 and 1. If , for , the node enters fluff state, otherwise, it enters stem state.
New epochs start when unixtime (in seconds) ,
corresponding to 10 minute epochs.
Stem State
On entering stem state, nodes supporting WAKU2-DANDELION MUST randomly select two nodes for each pubsub topic from the respective gossipsub mesh node set. These nodes are referred to as stem relays. Stem relays MUST support 19/WAKU2-LIGHTPUSH. If a chosen peer does not support 19/WAKU2-LIGHTPUSH, the node SHOULD switch to fluff state. (We may update this strategy in future versions of this document.)
Further, the node establishes a map that maps each incoming stem connection to one of its stem relays chosen at random (but fixed per epoch). Incoming stem connections are identified by the Peer IDs of peers the node receives 19/WAKU2-LIGHTPUSH messages from. Incoming 19/WAKU2-LIGHTPUSH connections from peers that do not support WAKU2-DANDELION are identified and mapped in the same way. This makes the protocol simpler, increases the anonymity set, and offers Dandelion anonymity properties to such peers, too.
The node itself is mapped in the same way, so that all messages originated by the node are relayed via a per-epoch-fixed Dandelion relay, too.
While in stem state, nodes MUST relay stem messages to the respective stem relay. Received fluff messages MUST be relayed as specified in the fluff state section.
The stem protocol (19/WAKU2-LIGHTPUSH) is independent of the fluff protocol (Waku Relay). While in stem state, nodes MUST NOT gossip about stem messages, and MUST NOT send control messages related to stem messages. (An existing gossipsub implementation does not have to be adjusted to not send gossip about stem messages, because these messages are only handed to gossipsub once they enter fluff phase.)
Fail Safe
Nodes in stem state SHOULD store messages attached with a random timer between and . This time interval is chosen because
- we assume as an average per hop delay, and
- using will lead to an expected number of 5 stem hops per message.
If does not receive a given message via Waku Relay (fluff) before the respective timer runs out, will disseminate the message via Waku Relay.
Fluff State
In fluff state, nodes operate as usual Waku Relay nodes. The Waku Relay functionality might be augmented by a future specification, e.g. adding random delays.
Note: The Dandelion paper describes the fluff phase as regular forwarding. Since Dandelion is designed as an update to the Bitcoin network using diffusion spreading, this regular forwarding already comprises random delays.
Implementation Notes
Handling of the WAKU2-DANDELION stem phase can be implemented as an extension to an existing 19/WAKU2-LIGHTPUSH implementation.
Fluff phase augmentations might alter gossipsub message dissemination (e.g. adding random delays). If this is the case, they have to be implemented on the libp2p gossipsub layer.
Security/Privacy Considerations
Denial of Service: Black Hole Attack
In a black hole attack, malicious nodes prevent messages from being spread, metaphorically not allowing messages to leave once they entered. This requires the attacker to control nodes on all dissemination paths. Since the number of dissemination paths is significantly reduced in the stem phase, Dandelion spreading reduces the requirements for a black hole attack.
The fail-safe mechanism specified in this document (proposed in the Dandelion paper), mitigates this.
Anonymity Considerations
Attacker Model and Anonymity Goals
WAKU2-DANDELION provides significant mitigation against mass deanonymization in the passive scaling multi node model. in which the attacker controls a certain percentage of nodes in the network. WAKU2-DANDELION provides significant mitigation against mass deanonymization even if the attacker knows the network topology, i.e. the anonymity graph and the relay mesh graph.
Mitigation in stronger models, including the active scaling multi-node model, is weak. We will elaborate on this in future versions of this document.
WAKU2-DANDELION does not protect against targeted deanonymization attacks.
Non-Dandelion Peers
Stem relays receiving messages can either be in stem state or in fluff state themselves. They might also not support WAKU2-DANDELION, and interpret the message as classical 19/WAKU2-LIGHTPUSH, which effectively makes them act as fluff state relays. While such peers lower the overall anonymity properties, the Dandelion++ paper showed that including those peers yields more anonymity compared to excluding these peers.
Future Analysis
The following discusses potential relaxations in favour of reduced latency, as well as their impact on anonymity. This is still work in progress and will be elaborated on in future versions of this document.
Generally, there are several design choices to be made for the stem phase of a Dandelion-based specification:
- the probability of continuing the stem phase, which determines the expected stem lengh,
- the out degree in the stem phase, which set to 1 in this document (also in the Dandelion papers),
- the rate of re-selecting stem relays among all gossipsub mesh peers (for a given pubsub topic), and
- the mapping of incoming connections to outgoing connections.
Bound Stem Length
Choosing , WAKU2-DANDELION has an expected stem length of 5 hops, Assuming added delay per hop, the stem phase adds around 500ms delay on average.
There is a possibility for the stem to grow longer, but some applications need tighter bounds on latency.
While fixing the stem length would yield tighter latency bounds, it also reduces anonymity properties. A fixed stem length requires the message to carry information about the remaining stem length. This information reduces the uncertainty of attackers when calculating the probability distribution assigning each node a probability for having sent a specific message. We will quantify the resulting loss of anonymity in future versions of this document.
Stem Relay Selection
In its current version, WAKU2-DANDELION nodes default to fluff state if the random stem relay selection yields at least one peer that does not support 19/WAKU2-LIGHTPUSH (which is the stem protocol used in WAKU2-DANDELION. If nodes would reselect peers until they find peers supporting 19/WAKU2-LIGHTPUSH, malicious nodes would get an advantage if a significant number of honest nodes would not support 19/WAKU2-LIGHTPUSH. Even though this causes messages to enter fluff phase earlier, we choose the trade-off in favour of protocol stability and sacrifice a bit of anonymity. (We will look into improving this in future versions of this document.)
Random Delay in Fluff Phase
Dandelion and Dandelion++ assume adding random delays in the fluff phase as they build on Bitcoin diffusion. WAKU2-DANDELION (in its current state) allows for zero delay in the fluff phase and outsources fluff augmentations to dedicated specifications. While this lowers anonymity properties, it allows making Dandelion an opt-in solution in a given network. Nodes that do not want to use Dandelion do not experience any latency increase. We will quantify and analyse this in future versions of this specification.
We plan to add a separate fluff augmentation specification that will introduce random delays. Optimal delay times depend on the message frequency and patterns. This delay fluff augmentation specification will be oblivious to the actual message content, because Waku Dandelion specifications add anonymity on the routing layer. Still, it is important to note that Waku2 messages (in their current version) carry an originator timestamp, which works against fluff phase random delays. An analysis of the benefits of this timestamp versus anonymity risks is on our roadmap.
By adding a delay, the fluff phase modifies the behaviour of libp2p gossipsub, which Waku Relay builds upon.
Note: Introducing random delays can have a negative effect on peer scoring.
Stem Flag
While WAKU2-DANDELION without fluff augmentation does not effect Waku Relay nodes, messages sent by nodes that only support 19/WAKU2-LIGHTPUSH might be routed through a Dandelion stem without them knowing. While this improves anonymity, as discussed above, it also introduces additional latency and lightpush nodes cannot opt out of this.
In future versions of this specification we might
- add a flag to 14/WAKU2-MESSAGE indicating a message should be routed over a Dandelion stem (opt-in), or
- add a flag to 14/WAKU2-MESSAGE indicating a message should not be routed over a Dandelion stem (opt-out), or
- introducing a fork of 19/WAKU2-LIGHTPUSH exclusively used for Dandelion stem.
In the current version, we decided against these options in favour of a simpler protocol and an increased anonymity set.
Copyright
Copyright and related rights waived via CC0.
References
- Dandelion
- Dandelion++
- multi-node (botnet) attacker model
- Waku Relay
- Waku v2
- d-regular graph
- Anonymity Trilemma
- Waku Privacy and Anonymity Analysis.
- On the Anonymity of Peer-To-Peer Network Anonymity Schemes Used by Cryptocurrencies
- Adversarial Models
- 14/WAKU2-MESSAGE
- 29/WAKU-CONFIG
- 19/WAKU2-LIGHTPUSH
Introduction Bundle Encoding
| Field | Value |
|---|---|
| Name | introduction-bundle-encoding |
| Slug | 241 |
| Status | raw |
| Type | RFC |
| Category | application |
| Tags | core, encoding |
| Editor | Patryk [email protected], Jazzz [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-06-11 —
bb9d20b— chore: scope linting (#355) - 2026-06-04 —
022afcd— docs(messaging): move remaining specs from logos-messaging/specs (#346)
Abstract
This specification defines the encoding format for Introduction Bundles — the out-of-band information shared so that a remote party can initiate contact with the bundle publisher.
Background / Rationale / Motivation
Users need a way to share contact information across arbitrary channels (messaging apps, emails, QR codes, URLs, CLI terminals) without relying on a centralized directory. The Introduction Bundle provides the cryptographic material required to establish an encrypted conversation.
The encoding must be:
- Copy-paste safe across arbitrary text transports.
- Space-efficient for manual sharing.
- Version-aware to support protocol evolution.
Theory / Semantics
An Introduction Bundle is bound to a specific protocol version; its encoded form identifies the version unambiguously.
Why ASCII, Not Unicode
The encoded string consists entirely of printable ASCII. This is a natural consequence of the design rather than a defensive choice against Unicode:
- No human-readable content. The format contains a fixed prefix, a numeric version, and a binary-to-text encoded payload. These components do not require characters outside ASCII. Common binary-to-text encodings such as hex, base32, and base64 produce ASCII output.
- Encoding stability. Printable ASCII characters are represented identically in widely deployed text encodings such as UTF-8 and Latin-1, avoiding ambiguity in character interpretation across transports.
- Restricted visible alphabet. Limiting the character set reduces the risk of visually confusable or non-rendering characters during manual comparison, transcription, or copy-paste across different platforms, terminals, and fonts.
Delimiter Choice
The _ character is present in the alphabets of common binary-to-text
encodings (hex, base32, base64url) and may therefore appear inside the payload.
Parsers MUST split the encoded string on the first three _ characters;
everything after the third _ is the payload verbatim.
The underscore was chosen because it is a printable ASCII character that is
safe in URLs, filenames, and plain text without requiring escaping. Delimiters
outside this category (e.g., . or :) may require percent-encoding in
certain URL contexts, undermining the transport-safety goal.
Wire Format Specification / Syntax
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "NOT RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119.
Text Format
The Introduction Bundle is encoded as a single ASCII string:
logos_<namespace>_<version>_<payload>
| Field | Description |
|---|---|
logos | Fixed prefix. Identifies the string as a Logos protocol artifact. |
namespace | Domain identifier. Distinguishes bundle types. |
version | Protocol version number. Decimal integer, no leading zeros. |
payload | Binary-to-text encoded payload (version-specific). |
Fields are separated by _ (underscore).
V1
Parameters
| Parameter | Value |
|---|---|
namespace | chatintro |
version | 1 |
encoding | base64url, no padding |
payload | Protobuf-encoded IntroBundle |
Payload Encoding
V1 uses base64url without padding (RFC 4648 §5, padding
characters = omitted). This encoding was chosen for:
- URL safety without percent-encoding.
- ~33% size overhead (compared to ~100% for hex).
- Wide library support across languages.
Future versions MAY choose a different binary-to-text encoding.
Binary Payload
The payload is a Protocol Buffers (proto3) encoding of:
syntax = "proto3";
message IntroBundle {
bytes installation_pubkey = 1; // 32 bytes, X25519
bytes ephemeral_pubkey = 2; // 32 bytes, X25519
bytes signature = 3; // 64 bytes, XEdDSA
}
The encoding MUST use standard proto3 serialization. Canonical (deterministic) serialization is NOT REQUIRED; decoders MUST accept any valid proto3 encoding of the message.
Encoding Procedure
- Construct the
IntroBundleprotobuf message. - Serialize using proto3 encoding (~134 bytes).
- Encode as base64url without padding (~179 characters).
- Prepend the preamble with version prefix.
The resulting string is ~197 printable ASCII characters.
Security/Privacy Considerations
The signature prevents tampering but does not provide confidentiality. Bundles should be transmitted over channels appropriate for the user's threat model.
Copyright
Copyright and related rights waived via CC0.
References
- RFC 2119 — Key words for use in RFCs
- RFC 4648 §5 — Base 64 Encoding with URL and Filename Safe Alphabet
- CC0 — Creative Commons Zero Public Domain Dedication
MESSAGE-SEGMENTATION-AND-RECONSTRUCTION
| Field | Value |
|---|---|
| Name | Message Segmentation and Reconstruction |
| Slug | 243 |
| Version | 0.1 |
| Status | raw |
| Type | RFC |
| Category | application |
| Tags | segmentation |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-06-11 —
bb9d20b— chore: scope linting (#355) - 2026-05-28 —
557bfbd— docs(messaging): moved segmentation spec (#331)
Abstract
This specification defines an application-layer protocol for segmentation and reconstruction of messages carried over a transport/delivery service with a message-size limitation, when the original payload exceeds said limitation.
Applications partition the payload into multiple transport messages and reconstruct the original on receipt,
even when segments arrive out of order or up to a predefined percentage of segments are lost.
The protocol optionally uses Reed–Solomon erasure coding for fault tolerance.
All messages are wrapped in a SegmentMessageProto, including those that fit in a single segment.
Motivation
Many message transport and delivery protocols impose a maximum message size that restricts the size of application payloads. For example, Waku Relay typically propagates messages up to 150 KB as per 64/WAKU2-NETWORK - Message. To support larger application payloads, a segmentation layer is required. This specification enables larger messages by partitioning them into multiple envelopes and reconstructing them at the receiver. Erasure-coded parity segments provide resilience against partial loss or reordering.
Terminology
- original payload: the full application payload before segmentation.
- data segment: one of the partitioned chunks of the original message payload.
- parity segment: an erasure-coded segment derived from the set of data segments.
- segment message: a wire-message whose
payloadfield carries a serializedSegmentMessageProto. segmentSize: configured maximum size in bytes of each data segment'spayloadchunk (before protobuf serialization).
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "NOT RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119.
Wire Format
Each segmented message is encoded as a SegmentMessageProto protobuf message:
syntax = "proto3";
message SegmentMessageProto {
// Keccak256(original payload), 32 bytes
bytes entire_message_hash = 1;
// Data segment indexing
uint32 data_segment_index = 2; // zero-indexed sequence number for data segments
uint32 data_segment_count = 3; // number of data segments (>= 1)
// Segment payload (data or parity shard)
bytes payload = 4;
// Parity segment indexing
uint32 parity_segment_index = 5; // zero-based sequence number for parity segments
uint32 parity_segment_count = 6; // number of parity segments
// Segment type
bool is_parity = 7; // true for parity segments, false (default) for data segments
}
Field descriptions:
entire_message_hash: A 32-byte Keccak256 hash of the original complete payload, used to identify which segments belong together and verify reconstruction integrity.data_segment_index: Zero-indexed sequence number identifying this data segment's position (0, 1, 2, ..., data_segment_count - 1). Set only on data segments.data_segment_count: Total number of data segments the original message was split into. Set on every segment (data and parity).payload: The actual chunk of data or parity information for this segment.parity_segment_index: Zero-based sequence number for parity segments. Set only on parity segments.parity_segment_count: Total number of parity segments generated. Set on every segment (data and parity) when Reed–Solomon parity is used;0(default) otherwise.is_parity: Explicit segment type marker.false(default) for data segments;truefor parity segments.
A message is either a data segment (when is_parity == false) or a parity segment (when is_parity == true).
Validation
Receivers MUST enforce:
entire_message_hash.length == 32data_segment_count >= 1data_segment_count + parity_segment_count < maxTotalSegments- Data segments (
is_parity == false):data_segment_index < data_segment_count - Parity segments (
is_parity == true):parity_segment_count > 0ANDparity_segment_index < parity_segment_count
No other combinations are permitted.
A SegmentMessageProto with data_segment_count == 1 and data_segment_index == 0 is a valid single-segment data message: the payload field carries the entire original payload (see Sending).
Segmentation
Sending
To transmit a payload, the sender:
- MUST compute a 32-byte
entire_message_hash = Keccak256(original_payload). - MUST split the payload into one or more data segments,
each of size up to
segmentSizebytes. A payload of size ≤segmentSizeproduces a single data segment (data_segment_count == 1). - MUST pad the last segment to
segmentSizefor Reed-Solomon erasure coding (only if Reed-Solomon coding is enabled). - MAY use Reed–Solomon erasure coding at the predefined parity rate.
- MUST encode every segment as a
SegmentMessageProtowith:- The
entire_message_hash data_segment_count(total number of data segments, always set)- When Reed–Solomon parity is used,
parity_segment_count(total number of parity segments, set on every segment) - For data segments:
is_parity = false,data_segment_index - For parity segments:
is_parity = true,parity_segment_index - The raw payload data
- The
- Send each segment as an individual transport message according to the underlying transport service.
This yields a deterministic wire format: every transmitted payload is a SegmentMessageProto.
Receiving
Upon receiving a segmented message, the receiver:
- MUST validate each segment according to Wire Format -> Validation.
- MUST cache received segments.
- MUST attempt reconstruction once at least
data_segment_countdistinct segments (data and parity combined) have been received:- If all data segments are present, concatenate their
payloadfields indata_segment_indexorder. - Otherwise, recover the payload via Reed–Solomon decoding over the available data and parity segments.
- If all data segments are present, concatenate their
- MUST verify
Keccak256(reconstructed_payload)matchesentire_message_hash. On mismatch, the message MUST be discarded and logged as invalid. - Once verified, the reconstructed payload SHALL be delivered to the application.
Implementation Suggestions
Reed–Solomon
Implementations that apply parity SHALL use fixed-size shards of length segmentSize.
The reference implementation uses nim-leopard (Leopard-RS) with a maximum of 256 total shards.
Storage / Persistence
Segments may be persisted (e.g., SQLite) and indexed by entire_message_hash and by sender. Sender may be authenticated, this is out of scope of this spec.
Implementations SHOULD support:
- Duplicate detection and idempotent saves
- Completion flags to prevent duplicate processing
- Timeout-based cleanup of incomplete reconstructions
- Per-sender quotas for stored bytes and concurrent reconstructions
Configuration
segmentSize— maximum size in bytes of each data segment's payload chunk (before protobuf serialization). REQUIRED parameter, configurable by the client.parityRate— fraction of parity shards relative to data shards. Configurable by the client. Defaults to 0.125 (12.5%).maxTotalSegments— maximum number of total shards (data + parity) per message. Implementation-specific parameter, fixed. The reference implementation uses 256.
Reconstruction capability:
With the predefined parity rate, reconstruction is possible if all data segments are received or if any combination of data + parity totals at least data_segment_count (i.e., up to the predefined percentage of loss tolerated).
API simplicity:
Libraries SHOULD require only segmentSize from the application for normal operation.
Security Considerations
Privacy
entire_message_hash enables correlation of segments that belong to the same original message but does not reveal content.
To prevent this correlation, applications SHOULD encrypt each segment after segmentation (see Encryption).
Traffic analysis may still identify segmented flows.
Encryption
This specification does not provide confidentiality.
Applications SHOULD encrypt each segment after segmentation
(i.e., encrypt the serialized SegmentMessageProto prior to transmission),
so that entire_message_hash and other identifying fields are not visible to observers.
Integrity
Implementations MUST verify the Keccak256 hash post-reconstruction and discard on mismatch.
Denial of Service
To mitigate resource exhaustion:
- Limit total concurrent reconstructions and aggregate buffered bytes
- When sender identity is available, apply the same two limits per sender
- Enforce timeouts and size caps
- Validate segment counts (≤ 256)
- Consider rate-limiting at the transport layer (for example, via 17/WAKU2-RLN-RELAY on Waku)
Deployment Considerations
Overhead:
- Bandwidth overhead ≈ the predefined parity rate from parity (if enabled)
- Additional per-segment overhead ≤ 100 bytes (protobuf + metadata)
Network impact:
- Larger messages increase transport traffic and storage; operators SHOULD consider policy limits
Compatibility:
- Nodes that do not implement this specification cannot reconstruct any messages.
References
- 10/WAKU2 – Waku
- 11/WAKU2-RELAY – Relay
- 14/WAKU2-MESSAGE – Message
- 64/WAKU2-NETWORK
- nim-leopard – Nim bindings for Leopard-RS (Reed–Solomon)
- Leopard-RS – Fast Reed–Solomon erasure coding library
- RFC 2119 – Key words for use in RFCs to Indicate Requirement Levels
MESSAGING-API
| Field | Value |
|---|---|
| Name | Messaging API definition |
| Slug | 168 |
| Status | raw |
| Type | RFC |
| Category | application |
| Tags | reliability, application, api, protocol composition |
| Editor | Oleksandr Kozlov [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
cd783d4— adjust event defs to messaging-api implementation in logos-delivery (#333) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
48600b5— Migrate logos-messaging/specs into docs/messaging/ (#315)
Table of contents
- Table of contents
- Abstract
- Motivation
- Syntax
- API design
- The Messaging API
- The Validation API
- Security/Privacy Considerations
- Copyright
Abstract
This document specifies an Application Programming Interface (API) that is RECOMMENDED for developers of the WAKU2 clients to implement, and for consumers to use as a single entry point to its functionalities.
This API defines the RECOMMENDED interface for leveraging Logos Messaging protocols to send and receive messages. Application developers SHOULD use it to access capabilities for peer discovery, message routing, and peer-to-peer reliability.
Motivation
The accessibility of Logos Messaging protocols is capped by the accessibility of their implementations, and hence API. This RFC enables a concerted effort to draft an API that is simple and accessible, and provides an opinion on sane defaults.
The API defined in this document is an opinionated-by-purpose method to use the more agnostic WAKU2 protocols.
Syntax
The keywords “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in RFC2119.
API design
IDL
A custom Interface Definition Language (IDL) in YAML is used to define the Messaging API. Existing IDL Such as OpenAPI, AsyncAPI or WIT do not exactly fit the requirements for this API. Hence, instead of having the reader learn a new IDL, we propose to use a simple IDL with self-describing syntax.
An alternative would be to choose a programming language. However, such choice may express unintended opinions on the API.
Primitive types and general guidelines
- No
defaultmeans that the value is mandatory, meaning adefaultvalue implies an optional parameter. - Primitive types are
string,int,bool,byte,enumanduint - Complex pre-defined types are:
object: object and other nested types.array: iterable object containing values of all the same type. Syntax:array<T>whereTis the element type (e.g.,array<string>,array<byte>).result: an enum type that either contains a value or void (success), or an error (failure); The error is left to the implementor.error: Left to the implementor on whethererrortypes arestringorobjectin the given language.event_emitter: an object that emits events with specific event names and associated event data types.
- Usage of
resultis RECOMMENDED, usage of exceptions is NOT RECOMMENDED, no matter the language.
TODO: Review whether to specify categories of errors.
Language mappings
How the API definition should be translated to specific languages.
language_mappings:
typescript:
naming_convention:
- functions: "camelCase"
- variables: "camelCase"
- types: "PascalCase"
event_emitter: "Use EventEmitter object with `emit`, `addListener`, etc; with event name the string specified in IDL. For example. eventEmitter.emit('message_sent',...)"
nim:
naming_convention:
- functions: "camelCase"
- variables: "camelCase"
- types: "PascalCase"
event_emitter: TBD
Application
This API is designed for generic use and ease across all programming languages, for edge and core type nodes.
The Messaging API
api_version: "0.0.1"
library_name: "liblogosdelivery"
description: "Logos Messaging: a private and censorship-resistant message routing library."
Common
This section describes common types used throughout the API.
Note that all types in the API are described once in this document, in a single section. Types should just forward-reference other types when needed.
Common type definitions
types:
WakuNode:
type: object
description: "A node instance."
fields:
messageEvents:
type: MessageEvents
description: "The node's messaging event emitter"
healthEvents:
type: HealthEvents
description: "The node's health monitoring event emitter"
RequestId:
type: string
description: "A unique identifier for a request"
Init node
Init node type definitions
types:
NodeConfig:
type: object
fields:
mode:
type: string
constraints: [ "edge", "core" ]
default: "core" # "edge" for mobile and browser devices.
description: "The mode of operation of the node; 'edge' of the network: relies on other nodes for message routing; 'core' of the network: fully participate to message routing."
protocols_config:
type: ProtocolsConfig
default: TheWakuNetworkPreset
networking_config:
type: NetworkConfig
default: DefaultNetworkingConfig
eth_rpc_endpoints:
type: array<string>
description: "Eth/Web3 RPC endpoint URLs, only required when RLN is used for message validation; fail-over available by passing multiple URLs. Accepting an object for ETH RPC will be added at a later stage."
ProtocolsConfig:
type: object
fields:
entry_nodes:
type: array<string>
default: []
description: "Nodes to connect to; used for discovery bootstrapping and quick connectivity. enrtree and multiaddr formats are accepted. If not provided, node does not bootstrap to the network (local dev)."
static_store_nodes:
type: array<string>
default: []
# TODO: confirm behaviour at implementation time.
description: "The passed nodes are prioritised for store queries."
cluster_id:
type: uint
description: "The cluster ID for the network. Cluster IDs are defined in [RELAY-SHARDING](https://github.com/logos-co/logos-lips/blob/master/docs/messaging/core/raw/relay-sharding.md) and allocated in [RELAY-STATIC-SHARD-ALLOC](https://github.com/logos-co/logos-lips/blob/master/docs/messaging/informational/raw/relay-static-shard-alloc.md)."
auto_sharding_config:
type: AutoShardingConfig
default: DefaultAutoShardingConfig
description: "The auto-sharding config, if sharding mode is `auto`"
message_validation:
type: MessageValidation
description: "If the default config for TWN is not used, then we still provide default configuration for message validation."
default: DefaultMessageValidation
NetworkingConfig:
type: object
fields:
listen_ipv4:
type: string
default: "0.0.0.0"
description: "The network IP address on which libp2p and discv5 listen for inbound connections. Not applicable for some environments such as the browser."
p2p_tcp_port:
type: uint
default: 60000
description: "The TCP port used for libp2p, relay, etc aka, general p2p message routing. Not applicable for some environments such as the browser."
discv5_udp_port:
type: uint
default: 9000
description: "The UDP port used for discv5. Not applicable for some environments such as the browser."
AutoShardingConfig:
type: object
fields:
num_shards_in_cluster:
type: uint
description: "The number of shards in the configured cluster; this is a globally agreed value for each cluster."
MessageValidation:
type: object
fields:
max_message_size:
type: string
default: "150 KiB"
description: "Maximum message size. Accepted units: KiB, KB, and B. e.g. 1024KiB; 1500 B; etc."
# For now, RLN is the only message validation available
rln_config:
type: RlnConfig
# If the default config for TWN is not used, then we do not apply RLN
default: none
RlnConfig:
type: object
fields:
contract_address:
type: string
description: "The address of the RLN contract that exposes `root` and `getMerkleRoot` ABIs"
chain_id:
type: uint
description: "The chain ID on which the RLN contract is deployed"
epoch_size_sec:
type: uint
description: "The epoch size to use for RLN, in seconds"
Init node function definitions
functions:
createNode:
description: "Initialises a node instance"
parameters:
- name: nodeConfig
type: NodeConfig
description: "The node configuration."
returns:
type: result<WakuNode, error>
Init node predefined values
values:
DefaultNetworkingConfig:
type: NetworkConfig
fields:
listen_ipv4: "0.0.0.0"
p2p_tcp_port: 60000
discv5_udp_port: 9000
TheWakuNetworkPreset:
type: ProtocolsConfig
fields:
entry_nodes: [ "enrtree://AIRVQ5DDA4FFWLRBCHJWUWOO6X6S4ZTZ5B667LQ6AJU6PEYDLRD5O@sandbox.waku.nodes.status.im" ]
# On TWN, we encourage the usage of discovered store nodes
static_store_nodes: []
cluster_id: 1
auto_sharding_config:
type: AutoShardingConfig
fields:
num_shards_in_cluster: 8
message_validation: TheWakuNetworkMessageValidation
TheWakuNetworkMessageValidation:
type: MessageValidation
fields:
max_message_size: "150 KiB"
rln_config:
type: RlnConfig
fields:
contract_address: "0xB9cd878C90E49F797B4431fBF4fb333108CB90e6"
chain_id: 59141
epoch_size_sec: 600 # 10 minutes
# If not preset is used, autosharding on one cluster is applied by default
# This is a safe default that abstract shards (content topic shard derivation), and it enables scaling at a later stage
DefaultAutoShardingConfig:
type: AutoShardingConfig
fields:
num_shards_in_cluster: 1
# If no preset is used, we only apply a max size limit to messages
DefaultMessageValidation:
type: MessageValidation
fields:
max_message_size: "150 KiB"
rln_config: none
Init node extended definitions
mode:
If the mode set is edge, the initialised WakuNode SHOULD use:
- LIGHTPUSH as client
- FILTER as client
- STORE as client
- METADATA as client
- PEER-EXCHANGE as client
- P2P-RELIABILITY
If the mode set is core, the initialised WakuNode SHOULD use:
- RELAY
- LIGHTPUSH as service node
- FILTER as service node
- STORE as client
- METADATA as client and service node
- P2P-RELIABILITY
- DISCV5
- PEER-EXCHANGE as client and service node
- RENDEZVOUS as client and service node
edge mode SHOULD be used if node functions in resource restricted environment,
whereas core SHOULD be used if node has no strong hardware or bandwidth restrictions.
Messaging
Messaging type definitions
types:
MessageEnvelope:
type: object
fields:
content_topic:
type: string
description: "Content-based filtering field as defined in [TOPICS](https://lip.logos.co/messaging/draft/23/topics.html#content-topics)"
payload:
type: array<byte>
description: "The message data."
ephemeral:
type: bool
default: false
description: "Whether the message is ephemeral. Read at [ATTRIBUTES](https://lip.logos.co/messaging/stable/14/message.html#message-attributes)"
MessageReceivedEvent:
type: object
description: "Event emitted when a message is received from the network"
fields:
message_hash:
type: string
description: "Hash of the received message"
message:
type: MessageEnvelope
description: "The received message's payload and metadata"
MessageSentEvent:
type: object
description: "Event emitted when a message is sent to the network"
fields:
request_id:
type: RequestId
description: "The request ID associated with the sent message"
message_hash:
type: string
description: "Hash of the message that got sent to the network"
MessageErrorEvent:
type: object
description: "Event emitted when a message send operation fails"
fields:
request_id:
type: RequestId
description: "The request ID associated with the failed message"
message_hash:
type: string
description: "Optional property. Hash of the message that got error"
error:
type: string
description: "Error message describing what went wrong"
MessagePropagatedEvent:
type: object
description: "Confirmation that a message has been correctly delivered to some neighbouring nodes."
fields:
request_id:
type: RequestId
description: "The request ID associated with the propagated message in the network"
message_hash:
type: string
description: "Hash of the message that got propagated within the network"
MessageEvents:
type: event_emitter
description: "Event source for message-related events"
events:
"message_received":
type: MessageReceivedEvent
"message_sent":
type: MessageSentEvent
"message_error":
type: MessageErrorEvent
"message_propagated":
type: MessagePropagatedEvent
Messaging function definitions
functions:
send:
description: "Send a message through the network."
parameters:
- name: message
type: MessageEnvelope
description: "Parameters for sending the message."
returns:
type: result<RequestId, error>
Messaging extended definitions
A first message sent with a certain contentTopic SHOULD trigger a subscription for such contentTopic as described in the Subscriptions section.
The node uses P2P-RELIABILITY strategies to ensure message delivery.
Subscriptions
Subscriptions type definitions
types:
SubscriptionError:
type: object
description: "A content topic subscription-related operation failed synchronously and irremediably"
fields:
content-topic:
type: string
description: "Content topic that the node failed to subscribe to or unsubscribe from"
error:
type: string
description: "Error message describing what went wrong"
Subscriptions function definitions
functions:
subscribe:
description: "Subscribe to specific content topics"
parameters:
- name: contentTopics
type: Array<string>
description: "The content topics for the node to subscribe to."
returns:
type: result<void, array<SubscriptionError>>
unsubscribe:
description: "Unsubscribe from specific content topics"
parameters:
- name: contentTopics
type: Array<ContentTopic>
description: "The content topics for the node to unsubscribe from."
returns:
type: result<void, array<SubscriptionError>>
Subscriptions extended definitions
mode:
If the mode set is edge, subscribe SHOULD trigger set up a subscription using FILTER as client and P2P-RELIABILITY.
If the mode set is core, subscribe SHOULD trigger set up a subscription using RELAY and P2P-RELIABILITY.
This MAY trigger joining a new shard if not already set.
Only messages on subscribed content topics SHOULD be emitted by a MessageEvents event source, meaning messages received via RELAY SHOULD be filtered by content topics before emission.
error:
Only irremediable failures should lead to synchronously returning a subscription error for failed subscribe or unsubscribe operations.
Failure to reach nodes can be omitted, and should be handled via the health events; P2P-RELIABILITY SHOULD handle automated re-subscriptions and redundancy.
Examples of irremediable failures are:
- Invalid content topic format
- Exceeding number of content topics
- Node not started
- Already unsubscribed
- Other node-level configuration issue
Health
Health type definitions
types:
ConnectionStatus:
type: enum
values: [Disconnected, PartiallyConnected, Connected]
description: "Used to identify health of the operating node"
TopicHealth:
type: enum
values: [UNHEALTHY, MINIMALLY_HEALTHY, SUFFICIENTLY_HEALTHY, NOT_SUBSCRIBED]
description: "Used to identify health of a subscribed topic or shard"
EventConnectionStatusChange:
type: object
description: "Event emitted when the overall node connection status changes"
fields:
connection_status:
type: ConnectionStatus
description: "The node's new connection status"
EventContentTopicHealthChange:
type: object
description: "Event emitted when health of a subscribed content topic changes"
fields:
content_topic:
type: string
description: "The content topic whose health changed"
health:
type: TopicHealth
description: "The new health status of the content topic"
EventShardTopicHealthChange:
type: object
description: "Event emitted when health of a shard (pubsub topic) changes"
fields:
topic:
type: string
description: "The pubsub topic (shard) whose health changed"
health:
type: TopicHealth
description: "The new health status of the shard"
HealthEvents:
type: event_emitter
description: "Event source for health-related events."
events:
"connection_status_change":
type: EventConnectionStatusChange
"content_topic_health_change":
type: EventContentTopicHealthChange
"shard_topic_health_change":
type: EventShardTopicHealthChange
Health function definitions
TODO
Health extended definitions
EventConnectionStatusChange:
Disconnected indicates that the node has lost connectivity for message reception,
sending, or both, and as a result, it cannot reliably receive or transmit messages.
PartiallyConnected indicates that the node meets the minimum operational requirements:
it is connected to at least one peer with a protocol to send messages (LIGHTPUSH or RELAY),
one peer with a protocol to receive messages (FILTER or RELAY),
and one peer with STORE service capabilities,
although performance or reliability may still be impacted.
Connected indicates that the node is operating optimally,
with full support for message reception and transmission.
EventContentTopicHealthChange and EventShardTopicHealthChange:
NOT_SUBSCRIBED indicates that the node is not subscribed to the topic.
UNHEALTHY indicates that the node has no peers on the topic.
MINIMALLY_HEALTHY indicates that the node has at least one peer on the topic but has not reached the healthy threshold.
SUFFICIENTLY_HEALTHY indicates that the node has reached the healthy threshold of peers on the topic.
Debug
Debug function definitions
functions:
getAvailableNodeInfoIds:
description: "Returns a list of available node information identifiers. e.g., [ version, my_peer_id, metrics ]."
returns:
type: result<array<string>, error>
getNodeInfo:
description: "Returns the JSON formatted node's information that is requested. Expect single value or list results depending on requested information."
parameters:
- name: nodeInfoId
type: string
description: "Information identifier. The only supported values are the ones returned by getAvailableNodeInfoItems function."
returns:
type: result<string, error>
getAvailableConfigs:
description: "Returns a list of all available options, their description and default values."
returns:
type: string
The Validation API
WAKU2-RLN-RELAY is currently the primary message validation mechanism in place.
Work is scheduled to specify a validate API to enable plug-in validation. As part of this API, it will be expected that a validation object can be passed, that would contain all validation parameters including RLN.
In the time being, parameters specific to RLN are accepted for the message validation. RLN can also be disabled.
Security/Privacy Considerations
Copyright
Copyright and related rights waived via CC0.
OP-CHAN
| Field | Value |
|---|---|
| Name | OpChan Decentralized Forum |
| Slug | 171 |
| Status | raw |
| Type | RFC |
| Category | application |
| Tags | waku |
| Contributors | Jimmy Debe [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
48600b5— Migrate logos-messaging/specs into docs/messaging/ (#315)
Abstract
This document specifies the architecture of OpChan, a decentralized forum application. The specification is transport-agnostic, with Waku as the reference delivery mechanism.
Background
In a decentralized forum, content is hosted on multiple nodes, making it difficult for a user's post to be censored. Users own their post data, so data cannot be removed by a third party, and forum boards will not rely on moderators remaining active.
OpChan clients distribute content through a peer-to-peer network rather than relying on centralized server storage. OpChan supports ephemeral anonymous sessions using a locally generated ED25519 key pair for identity and signing. Additionally, OpChan supports wallet-backed identities and identity key delegation.
Terminology
- Channel: A discussion board or channel that hosts posts and moderation controls.
- Post: User content created within a forum.
- Comment: A reply to a
Postor otherComment(threaded discussion). - Participant: Any user able to publish or consume messages (anonymous or wallet-backed).
- Anonymous session: A client-generated ed25519 keypair used as identity for a user without a wallet identity.
Specification
The keywords "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119.
OpChan distributes forum content amongst peers using a publish-subscribe messaging layer. All messages are cryptographically signed using ED25519 keys generated by the client locally.
OpChan supports two types of messages, content and control messages. Content messages are user-generated content on the forum. The message types include the following:
- Channel: Includes the metadata information like name, description, and admins of a forum feed.
- Post: User content created within a channel.
- Comment: Users reply to a post or another comment.
- Vote: To cast upvote or downvote for a post or comment.
- User: Includes username, delegation proofs, and identities. See the Identity section for more information.
- Bookmark: A user bookmarking a post or comment.
Control messages consist of the user activity/interactions on the forum. This includes the management of the current forum state, permissions, and moderations. The message types include the following:
- Create Channel: The initial event of creating a new channel within the forum.
- Delegation Events: Channel admins granting or revoking channel rights.
- Moderation Events: Channel admins are able to hide, remove, pin/unpin a post or comment, promote new admins, and change the ownership of a channel.
Message Format
Each channel is assigned a unique topic identifier that clients MUST subscribe to in order to discover messages from that channel.
All messages MUST include the following envelope fields:
{
"id": "string",
"type": "CHANNEL_CREATED | POST_CREATED | COMMENT_CREATED | VOTE | BOOKMARK | MODERATION | DELEGATION",
"timestamp": "uint64"
"author": "string" // author public key or wallet address
"signature": "bytes" // ed25519 signature
"delegationProof": "bytes" // optional wallet signature authorizing the browser key
"body": object // The message content
}
Every message SHOULD be signed using signature owned by the publishing user.
Clients SHOULD verify the signature against the author public key and,
when present, verify delegationProof.
Signing Flow:
- Serialize
bodyfields in stable key order. - Construct signing bytes with:
type,timestamp,authorandbody. - Sign with the user's cryptographic keys,
signature, for the session.
Identity
There are two types of identities for users: anonymous session and wallet delegation. A wallet delegation MAY be an ENS (Ethereum Name Service) verified user. An anonymous session generates an ED25519 keypair locally with the client. The key is used to sign all messages and a username MAY be attached to the post or comments. An anonymous user SHOULD NOT be granted an admin role, create moderation events, or create a channel.
A wallet delegation is a user blockchain wallet's private key used to sign a message,
which is the delegationProof.
The delegationProof SHOULD be a short-lived message,
RECOMMENDED a few minutes to a few hours.
Once a delegationProof is generated,
the client SHOULD be able to sign messages,
without the need for repeated wallet prompts requesting to sign.
Delegation Flow
- The client generates a new
browserKey, which is an Ed25519 keypair. - The client generates a delegation request to authorize
browserKeyto sign. - The user's wallet signs the delegation request and
returns a
delegationProofwith an expiration timestamp,expiry. - The client stores the
delegationProof,browserKey, andexpiry.
A delegationProof could become revoked by the wallet owner or
after the expiry time.
If a wallet delegation is revoked,
clients SHOULD ignore subsequent messages from the revoked delegation key.
Moderation & Permissions
A post MAY have moderation message types assigned by the channel admin. The moderation types include:
HIDE: Hide a post or comment from the channel feed.REMOVE: Permanently remove a post or comment.PIN: Pin a post to the top of a channel feed or pin a comment to the top of a thread.UNPIN: Remove aPINfrom a post feed or comment thread.CHANGE_OWNERSHIP: Change theauthorof a post or comment.
Moderation messages MUST be signed by an admin,
who is recognized as the author of the channel.
Clients SHOULD validate the admin before applying moderation events locally.
User Flagging
Users MAY flag content for review by moderators.
A FLAG is user-initiated and distinct from admin moderation actions.
Flagged content SHOULD be queued for moderator review
but does not automatically result in content removal.
Relevance Score
A post can gain better visibility on the forum channel and the forum's search through the content relevance score. Clients with verified wallet identities MUST be favored over an anonymous session identity.
There are a few RECOMMENDED areas that collect points when calculating the relevance score of a post:
Basic points include the activities that each user is able to engage in.
- A channel has a score value of 15
- Each post within a channel has a score value of 10
- A base value if comments are present within a post boosts the relevance score by a value of 5
Engagement points include the different user activities for each post or comment.
- Each wallet delegation upvote adds a score value of 1.
- Each individual comment adds a score value of 0.5.
- The total number of posts multiplied by 0.5. The total number of upvotes multiplied by 0.1. These two values are added together.
For identity verification points, participants of posts or comments that use wallet-based identities, including an optional ENS, the score is boosted over the anonymous identities. If a participant has a verified ENS and a verified connected wallet, only the ENS multiplier SHOULD be applied.
- Participants who have a verified ENS name gain a value multiplier of 1.25(25%).
- For wallet connect participant the multiplier is 1.1(10%).
- For verified upvote participants the multiplier is 0.1.
- For verified comment participants the multiplier is 0.05.
There is a time decay that reduces the relevance score over time. The older a post or comment was made the lower its score.
Where
is the time-decay rate per day.There SHOULD be a moderation penalty that reduces the score when a post or
comment is moderated with a value of 0.5(50%).
This penalty is applied once a post is HIDDEN, REMOVED or flagged by users to be reviewed by a moderator.
Below is the final relevance score based on the RECOMMENDED points above:
Waku as Delivery Mechanism
This section describes how OpChan MAY use the Waku protocol as the delivery mechanism.
OpChan clients MAY use the 10/WAKU2 network for the distribution of forum content amongst peers. The messages are 14/WAKU-MESSAGE objects. Users SHOULD use the 19/WAKU2-LIGHTPUSH protocol to send messages to Waku nodes storing the forum's content.
Message routing and discovery are handled by 23/WAKU2-TOPICS.
Each channel is assigned a content_topic that clients MUST subscribe to
in order to discover messages from that channel.
Copyright
Copyright and related rights waived via CC0.
References
PRIVATE1
| Field | Value |
|---|---|
| Name | Private conversation |
| Slug | 242 |
| Status | raw |
| Type | RFC |
| Category | application |
| Editor | Jazz Alyxzander (@Jazzz) |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-11 —
bb9d20b— chore: scope linting (#355) - 2026-06-04 —
022afcd— docs(messaging): move remaining specs from logos-messaging/specs (#346)
Abstract
This specification defines PRIVATE1, a conversation protocol for establishing secure, full-duplex encrypted communication channels between two participants. PRIVATE1 provides end-to-end encryption with forward secrecy and post-compromise security using the Double Ratchet algorithm, combined with reliable message delivery via Scalable Data Sync (SDS) and efficient segmentation for transport-constrained environments.
The protocol is transport-agnostic and designed to support both direct messaging and as a foundation for group communication systems. PRIVATE1 ensures payload confidentiality, content integrity, sender privacy, and message reliability while remaining resilient to network disruptions and message reordering.
Background
Pairwise encrypted messaging channels represent a foundational building block of modern secure communication systems. While end-to-end encrypted group chats capture user attention, the underlying infrastructure that makes these systems possible relies (at least somewhat) on secure one-to-one communication primitives. Just as higher-level network protocols are built upon reliable transport primitives like TCP, sophisticated communication systems depend on robust pairwise channels to function correctly and securely.
These channels serve purposes beyond simple content delivery. They transmit not only user-visible messages but also critical metadata, coordination signals, and state synchronization information between clients. This signaling capability makes pairwise channels essential infrastructure for distributed systems: key material distribution, membership updates, administrative actions, and protocol coordination all flow through these channels. While more sophisticated group communication strategies can achieve better efficiency at scale—particularly for broadcast-style communication patterns — they struggle to match the privacy and security properties that pairwise channels provide inherently. The fundamental asymmetry of two-party communication enables stronger guarantees: minimal metadata exposure, simpler key management, clearer authentication boundaries, and more straightforward security analysis.
However, being encrypted is merely the starting point, not the complete solution. Production-quality one-to-one channels must function reliably in the messy reality of modern networks. Real-world deployment demands resilience to unreliable networks where messages may be lost, delayed, duplicated, or arrive out of order. Channels must efficiently handle arbitrarily large payloads—from short text messages to multi-megabyte file transfers—while respecting the maximum transmission unit constraints imposed by various transport layers. Perhaps most critically, the protocol must remain fully operational even when one or more participants are offline or intermittently connected.
Private V1
PRIVATE1 is a conversation type specification that establishes a full-duplex secure communication channel between two participants. It combines the Double Ratchet algorithm for encryption with Scalable Data Sync (SDS) for reliable delivery and an efficient segmentation strategy to handle transport constraints.
PRIVATE1 provides the following properties:
- Payload Confidentiality: Only the two participants can read the contents of any message sent. Observers, transport providers, and other third parties cannot decrypt message contents.
- Content Integrity: Recipients can detect if message contents were modified by a third party. Any tampering with encrypted payloads will cause decryption to fail, preventing corrupted messages from being accepted as authentic.
- Sender Privacy: Only the recipient can determine who the sender was. Observers cannot identify the sender from encrypted payloads, though both participants can authenticate each other's messages.
- Forward Secrecy: A compromise in the future does not allow previous messages to be decrypted by a third party. Message keys are deleted immediately after use and cannot be reconstructed from current state, even if long-term keys are later compromised.
- Post-Compromise Security: Conversations eventually recover from a key compromise. After an attacker loses access to a device, the security properties are eventually restored.
- Dropped Message Observability: Messages lost in transit are eventually observable to both sender and recipient.
Definitions
This document makes use of the shared terminology defined in the CHAT-DEFINITIONS specification.
The terms include:
- Application
- Content
- Participant
- Payload
- Recipient
- Sender
Architecture
This conversation type assumes there is some service or application which wishes to generate and receive end-to-end encrypted content. It also assumes that some other component is responsible for delivering the generated payloads. At its core this protocol takes the content provided and creates a series of payloads to be sent to the recipient.
flowchart LR
Content:::plain--> PrivateV1 --> Payload:::plain
classDef plain fill:none,stroke:transparent;
Content
Applications provide content as encoded bytes, which is then packaged into payloads for transmission.
Size Limit
Content MUST be smaller than 255 * max_seg_size
due to segmentation protocol limitations.
Structure
The protocol treats the contents as an arbitrary sequence of bytes and is agnostic to its contents.
Payload Delivery
How payloads are sent and received by clients is deliberately not specified by this protocol. Transport choice is an client/application decision that should be made based on deployment requirements.
The choice of transport mechanism has no impact on PRIVATE1's security properties. Confidentiality, integrity, and forward secrecy are provided regardless of how payloads are delivered. However, transport choice may affect other properties and characteristics.
Recipient Privacy: The routing/addressing layer may leak sensitive metadata including the recipient's identity. The payloads generated by this protocol do not reveal the participants of a conversation, however the overall privacy properties are determined by the delivery mechanism used to transport payloads.
Reliability Performance While PRIVATE1 handles message losses, more reliable transports reduce retransmission overhead.
Initialization
The channel is initialized by both sender and recipient agreeing on the following values for each conversation:
sk- initial secret key [32 bytes]ssk- sender DH seed keyrsk- recipient DH seed keyconversation_id- globally unique identifier
To maintain the security properties:
skMUST be known only by the participants.skMUST be derived in a way that ensures mutual authentication of the participantsskSHOULD have forward secrecy by incorporating ephemeral key materialrskandsskSHOULD incorporate ephemeral key material
PRIVATE1 requires a unique identifier, however the exact derivation is left to implementations to determine.
conversation_idMUST be unique across all instances of chat conversationsconversation_idSHOULD be consistent across applications to maintain interoperability
Additionally implementations MUST determine the following constants:
max_seg_size- maximum segmentation size to be used.max_skip- number of keys which can be skipped per session.
Value Derivations
These values are derived during protocol operation and are deterministically computed from protocol data.
Frame Identifier
For reliability tracking, every payload MUST have a unique deterministic identifier.
The frame identifier is computed as:
frame_id = rhex(blake2b(encoded_frame_bytes))
Where:
rhexis lowercase hexadecimal encoding without the0xprefixblake2bis BLAKE2b hash function with 128-bit outputencoded_frame_bytesis the protobuf-encodedPrivateV1Frameframe_idis a 32 character string
Protobuf Encoding Considerations
Protobuf does not guarantee byte-identical outputs for multiple serializations of the same logical message.
Because of this, the frame_id represents the hash of specific encoded bytes rather than an abstract frame structure.
Implementations MUST compute frame_id from the actual bytes being transmitted to ensure sender and receiver derive identical identifiers.
Protocol Operation
PRIVATE1 processes messages through a three-stage pipeline where each stage's output becomes the next stage's input. The specific ordering of these stages is critical for maintaining security properties while enabling efficient operation.
flowchart TD
C("Content"):::plain
S(Segmentation)
R(Reliability)
E(Encryption)
D(Delivery):::plain
C --> S --> R --> E --> D
classDef plain fill:none,stroke:transparent;
Pipeline Stages:
- Segmentation: Divides content into transport-appropriate fragments
- Reliability (SDS): Adds tracking metadata for delivery detection and ordering
- Encryption (Double Ratchet): Provides confidentiality, authentication, and forward secrecy
Segmentation
While PRIVATE1 itself has no inherent message size limitation, practical transport mechanisms typically impose maximum payload sizes.
Why Segment Before Encryption
Segmenting after encryption would force the transport layer to handle fragmentation of ciphertext blobs, creating several problems.
- Transport-layer segmentation would require buffering all segments before any can be authenticated, increasing the DOS attack surface.
- Unauthenticated segment reassembly opens the door to malicious segment injection and substitution attacks.
- Unencrypted segmentation metadata reveals size and other metadata about the content in transit.
Why Segment Before Reliability
Placing segmentation after reliability tracking would mean retransmission of a dropped segment would require re-broadcasting the entire frame. By segmenting first, the reliability layer can track individual segments and request retransmission of only the missing fragments.
Implementation
The segmentation strategy used is defined by the Segmentation specification
Implementation specifics:
- Error correction is not used, as reliable delivery is already provided by lower layers.
segmentSize=max_seg_size- All payloads regardless of size are wrapped in a segmentation message.
Message Reliability
Scalable Data Sync (SDS) is used to detect missing messages, provide delivery confirmation, and handle retransmission of payloads. SDS is implemented according to the specification.
SDS Field Mappings
The following mappings connect PRIVATE1 concepts to SDS fields:
sender_id: !TODO: This requires PRIVATE1 to be identity awaremessage_id: uses theframe_iddefinition.channel_id: uses theconversation_idparameter.
Sender Validation
SDS uses a sender_id payload field to determine whether a message was sent by the remote party. This value is sender reported and not validated which can have unknown implications if trusted in other contexts. For security hygiene Clients SHOULD drop SDS messages if sender_id != the sender derived from the encryption layer. !TODO: PRIVATE1 is not sender aware currently
Bloom Filter Configuration
PRIVATE1 uses bloom filter parameters of n=2000 (expected elements) and p=0.001 (false positive probability).
This configuration produces bloom filters of approximately 3.5 KiB per message.
!TODO: Can the bloom filter be dropped in 1:1 communication?
Encryption
Payloads are encrypted using the Double Ratchet algorithm with the following cryptographic primitive choices:
Double Ratchet Configuration
DH: X25519 for Diffie-Hellman operationsKDF_RK: HKDF with Blake2b,info = "PrivateV1RootKey"KDF_CK: Blake2b as KDF truncated to 32 bytes, 'key'= previous_ck 'salt'=@[], usingpersonal=mkfor message keys andpersonal=ckfor chain keysKDF_MK: HKDF with SHA256,info = "PrivateV1MessageKey"ENCRYPT:AEAD_CHACHA20_POLY1305
AEAD Implementation
ChaCha20-Poly1305 is used with randomly generated 96-bit (12-byte) nonces.
The nonce MUST be generated using a cryptographically secure random number generator for each message.
The complete ciphertext format for transport is:
encrypted_payload = nonce || ciphertext || tag
Where nonce is 12 bytes, ciphertext is variable length, and tag is 16 bytes.
Frame Handling
This protocol uses explicit frame type tagging to remove ambiguity when parsing and handling frames. This creates a clear distinction between protocol-generated frames and application content.
Type Discrimination
All frames carry an explicit type field that identifies their purpose.
The content frame type is reserved exclusively for application-level data.
All other frame types are protocol-owned and intended for client processing, not application consumption.
This establishes a critical invariant: any frame that is not content is meant for the protocol layer.
When a client encounters an unknown frame type, it can definitively conclude this represents a version compatibility issue.
Processing Rules
- All application-level content MUST use the
contentframe type - Clients SHALL only pass
contentframes to applications - Clients MAY drop unrecognized frame types
Future Extensibility
This explicit tagging mechanism allows the protocol to evolve without breaking existing implementations.
Future versions may define additional frame types for protocol-level functionality while legacy clients continue processing content frames normally.
Wire Format Specification / Syntax
Payload Parse Tree
A deterministic parse tree is used to avoid ambiguity when receiving payloads.
flowchart TD
D[DoubleRatchet]
S[SDS Message]
Segment1[ Segment]
Segment2[ Segment]
Segment3[ Segment]
P[PrivateV1Frame]
start@{ shape: start }
start --> D
D -->|Payload| S
S -->|Payload| Segment1
Segment1 --> P
Segment2:::plain --> P
Segment3:::plain --> P
P --> T{frame_type}
T --content--> Bytes
classDef plain fill:none,stroke:transparent;
Payloads
!TODO: Don't duplicate payload definitions from other specs. Though its helpful for now.
Encrypted Payload
message DoubleRatchet {
bytes dh = 1; // 32 byte publickey
uint32 msgNum = 2;
uint32 prevChainLen = 3;
bytes ciphertext = 4; // arbitrary length bytes
}
dh: the x component of the dh_pair.publickey encoded as raw bytes. ciphertext: A protobuf encoded SDS Message
SDS Message
This payload is used without modification from the SDS Spec.
message HistoryEntry {
string message_id = 1; // Unique identifier of the SDS message, as defined in `Message`
optional bytes retrieval_hint = 2; // Optional information to help remote parties retrieve this SDS message; For example, A Waku deterministic message hash or routing payload hash
}
message Message {
string sender_id = 1; // Participant ID of the message sender
string message_id = 2; // Unique identifier of the message
string channel_id = 3; // Identifier of the channel to which the message belongs
optional int32 lamport_timestamp = 10; // Logical timestamp for causal ordering in channel
repeated HistoryEntry causal_history = 11; // List of preceding message IDs that this message causally depends on. Generally 2 or 3 message IDs are included.
optional bytes bloom_filter = 12; // Bloom filter representing received message IDs in channel
optional bytes content = 20; // Actual content of the message
}
content: This field is a protobuf encoded Segment
Segmentation
This payload is used without modification from the Segmentation specification
message SegmentMessageProto {
bytes entire_message_hash = 1; // 32 Bytes
uint32 index = 2;
uint32 segments_count = 3;
bytes payload = 4;
uint32 parity_segment_index = 5;
uint32 parity_segments_count = 6;
}
payload: This field is an protobuf encoded PrivateV1Frame
!TODO: This should be encoded as a FrameType so it can be optional.
PrivateV1Frame
message PrivateV1Frame {
uint64 timestamp = 1; // Sender reported timestamp
oneof frame_type {
bytes content = 10;
Placeholder placeholder = 11;
// ....
}
}
content: is encoded as bytes in order to allow implementations to define the type at runtime.
Implementation Suggestions
Content Types
Implementers need to be mindful of maintaining interoperability between clients, when deciding how content is encoded prior to transmission. In a decentralized context, clients cannot be assumed to be using the same version let alone application. It is recommended that implementers use a self-describing content payload such as CONTENTFRAME specification. This provides the ability for clients to determine support for incoming frames, regardless of the software used to receive them.
Initialization
Mutual authentication is provided by the sk, so there is no requirement of using authenticated keys for ssk and rsk.
Implementations SHOULD use the most ephemeral key available in order incorporate as much key material as possible.
This means that senders SHOULD generate a new ephemeral key for ssk for every conversation assuming channels are asynchronously initialized.
Excessive Skipped Message
Handling of skipped message keys is not strictly defined in double ratchet. Implementations need to choose a strategy which works best for their environment, and delivery mechanism. Halting operation of the channel is the safest, as it bounds resource utilization in the event of a DOS attack but is not always possible.
If eventual delivery of messages is not guaranteed, implementers should regularly delete keys that are older than a given time window. Unreliable delivery mechanisms will result in increased key storage over time, as more messages are lost with no hope of delivery.
Security/Privacy Considerations
Sender Deniability and Authentication
Encrypted messages do not have a cryptographically provable sender to third parties due to the deniability property of the Double Ratchet algorithm. However, participants in a conversation can authenticate each other through the shared cryptographic state. When receiving a message, the recipient knows it must have come from the other participant because only they possess the necessary key material to produce valid ciphertexts.
Because sender identity is implicitly authenticated through shared secrets rather than explicit signatures, it is critical that the initial shared secret sk be derived from an authenticated key exchange process.
Without proper authentication during initialization, an adversary could perform a man-in-the-middle attack and establish separate sessions with each participant, allowing them to read and modify all messages.
Copyright
Copyright and related rights waived via CC0.
References
- DOUBLERATCHET "The Double Ratchet Algorithm", Signal, 2016.
- SDS "Scalable Data Sync Specification", vac, 2024.
- SEGMENTATION "Message Segmentation Specification", Waku, 2024.
- CONTENTFRAME "ContentFrame Specification", Waku, 2024.
- CHAT-DEFINITIONS "Chat Definitions Specification", Waku, 2024.
RELIABLE-CHANNEL-API
| Field | Value |
|---|---|
| Name | Reliable Channel API definition |
| Slug | 173 |
| Status | raw |
| Category | application |
| Tags | reliability, application, api, sds, segmentation |
| Editor | Ivan Folgueira Bande [email protected] |
| Contributors | Jazz Turner-Baggs [email protected], Igor Sirotin [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-13 —
bb48a0d— Improvement : MessageId must be unique per segment (#356) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
d3ee034— docs: add Reliable Channel API spec (#325)
Table of contents
- Table of contents
- Abstract
- Motivation
- Syntax
- API design
- Components
- Procedures
- The Reliable Channel API
- Security/Privacy Considerations
- Copyright
Abstract
This document specifies the Reliable Channel API,
an application-level interface that sits between the application layer and the MESSAGING-API plus P2P-RELIABILITY, i.e., application <-> reliable-channel-api <-> messaging-api/p2p-reliability.
It bundles segmentation, end-to-end reliability via Scalable Data Sync (SDS), rate limit management, and a pluggable encryption hook into a single interface for sending and receiving messages reliably.
Motivation
The MESSAGING-API provides peer-to-peer reliability via P2P-RELIABILITY, but does not provide high end-to-end delivery guarantees from sender to recipient.
This API addresses that gap by introducing:
- SEGMENTATION to handle large messages exceeding network size limits.
- SDS to provide causal-history-based end-to-end acknowledgement and retransmission.
- Rate Limit Manager to comply with RLN constraints when sending segmented messages.
- Encryption Hook to allow upper layers to provide a pluggable encryption mechanism. This enables applications to provide Confidentiality and Integrity if desired.
The separation between Reliable Channels and encryption ensures the API remains agnostic to identity and key management concerns, which are handled by higher layers.
Syntax
The keywords "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC2119.
API design
Architectural position
The Reliable Channel API sits between the application layer and the Messaging API, as follows:
┌────────────────────────────────────────────────────────────┐
│ Application Layer │
└───────────────────────────┬────────────────────────────────┘
│
┌───────────────────────────▼────────────────────────────────┐
│ Reliable Channel API │
│ ┌──────────────┐ ┌─────┐ ┌───────────────┐ ┌──────────┐ │
│ │ Segmentation │ │ SDS │ │ Rate Limit Mgr│ │Encryption│ │
│ │ │ │ │ │ │ │ Hook │ │
│ └──────────────┘ └─────┘ └───────────────┘ └──────────┘ │
└───────────────────────────┬────────────────────────────────┘
│
┌───────────────────────────▼────────────────────────────────┐
│ Messaging API │
│ (P2P Reliability, Relay, Filter, Lightpush, Store) │
└────────────────────────────────────────────────────────────┘
IDL
A custom Interface Definition Language (IDL) in YAML is used, consistent with MESSAGING-API.
Components
Segmentation
A protocol that splits message payloads into smaller units during transmission and reassembles them upon reception. The component is instantiated by supplying the appropriate value to SegmentationConfig.
See SEGMENTATION.
Scalable Data Sync (SDS)
SDS provides end-to-end delivery guarantees using causal history tracking.
-
Each new segment to be sent, requires the following data:
MessageId: a keccak-256(senderId+ timestamp + message's content) hex string (e.g.4e03657aea45a94fc7d47ba826c8d667c0d1e6e33a64a036ec44f58fa12d6c45), generated by the Reliable Channel API.- MUST be unique for every segment, including segments with identical content, since SDS deduplicates received messages by their
MessageId. - The timestamp is the sender's local Unix time in nanoseconds, read when the segment is wrapped. It acts only as a uniqueness salt; ordering is provided by the SDS Lamport timestamp.
- MUST be unique for every segment, including segments with identical content, since SDS deduplicates received messages by their
ChannelId: thechannelIdpassed tocreateReliableChannel.Retrieval hint: the transportMessageHashof previous segments, mentioned asmessage_hashin MESSAGING-API, upon ``MessageSendPropagatedEventreception. The hint provider registered during [Node initialization](#node-initialization) performs thisMessageId → MessageHashlookup. In turn, that mapping MUST be persisted by SDS using thepersistencebackend configured inSdsConfig`.
-
Each sent segment is added to an outgoing buffer.
-
The recipient sends acknowledgements back to the sender upon receiving segments.
-
The sender removes acknowledged segments from the outgoing buffer.
-
Unacknowledged segments are retransmitted after
acknowledgementTimeoutMs. -
SDS state MUST be persisted using the
persistencebackend configured inSdsConfig.
Rate Limit Manager
The Rate Limit Manager ensures compliance with RLN rate constraints.
- It tracks how many messages have been sent in the current epoch.
- When the limit is approached, segment dispatch MUST be delayed to the next epoch.
- The epoch size MUST match the
[epochPeriodSec](https://lip.logos.co/messaging/draft/17/rln-relay.html#epoch-length)configured inRateLimitConfig.
Encryption Hook
The Encryption Hook provides a pluggable interface for upper layers to inject encryption.
- The hook is optional; when not provided, messages are sent unencrypted.
- Encryption is applied per segment, after segmentation and SDS.
- Decryption is applied per segment before being processed by SDS.
- The
Encryptioninterface MUST be implemented by the caller when the hook is provided. - The Reliable Channel API MUST NOT impose any specific encryption scheme.
Procedures
Node initialization
When a node is created via createNode (defined in MESSAGING-API),
the implementation MUST perform the following setup before the node is used:
- Configure SDS persistence: Supply the
Persistencebackend fromSdsConfigto the SDS module so that causal history and outgoing buffers survive restarts. - Configure SDS hint provider: Register a hint provider with the SDS module.
The hint provider converts an SDS
MessageIdinto its correspondingMessageHash. - Configure Segmentation persistence: Supply the
Persistencebackend fromSegmentationConfigto the Segmentation module so that partially reassembled messages survive restarts. - Fetch missed messages: Retrieve messages missed while offline as described in MESSAGING-API — Fetching missed messages on startup.
Outgoing message processing
When send is called, the implementation MUST process message in the following order:
- Segment: Split the payload into segments as defined in SEGMENTATION.
- Apply SDS: add each sds message to the SDS outgoing buffer (see SDS for parameter bindings).
- Encrypt: If an
Encryptionimplementation is provided, encrypt each segment before transmission. - Rate Limit: If
RateLimitConfig.enabledistrue, delay dispatch as needed to comply with RLN epoch constraints. - Dispatch: Send each segment via the underlying MESSAGING-API.
Incoming message processing
When a segment is received from the network, the implementation MUST process it in the following order:
- Decrypt: If an
Encryptionimplementation is provided, decrypt the segment. - Apply SDS: Deliver the segment to the SDS layer, which emits acknowledgements and detects gaps.
- Detect missing dependencies: If SDS detects a gap in the causal history, it MUST make a best-effort attempt to retrieve the missing message. The
Retrieval hint(see Scalable Data Sync (SDS)) carried in each SDS message provides the transportMessageHashneeded to query the store; without it, store retrieval is not possible. If the message cannot be retrieved, SDS MAY mark it as lost.
- Detect missing dependencies: If SDS detects a gap in the causal history, it MUST make a best-effort attempt to retrieve the missing message. The
- Reassemble: Once all segments for a message have been received, reassemble and emit a
reliable:message:receivedevent.
Rate limiting
When RateLimitConfig.enabled is true, the implementation MUST space segment transmissions
to comply with the RLN epoch constraints defined in [epochPeriodSec](https://lip.logos.co/messaging/draft/17/rln-relay.html#epoch-length).
Segments MUST NOT be sent at a rate that would violate the RLN message rate limit for the active epoch.
Encryption
The encryption parameter in createReliableChannel is intentionally optional.
The Reliable Channel API is agnostic to encryption mechanisms.
When an Encryption implementation is provided, it MUST be applied as described in Outgoing message processing and Incoming message processing.
The Reliable Channel API
This API considers the types defined by MESSAGING-API plus the following.
Channel lifecycle
This point assumes that a WakuNode instance is created beforehand. See createNode function
in MESSAGING-API.
functions:
createReliableChannel:
description: "Creates a reliable channel over the given content topic. Sets up the required SDS state,
segmentation, and encryption, and subscribes to `contentTopic`."
parameters:
- name: node
type: WakuNode
description: "The underlying messaging node, as defined in [MESSAGING-API](messaging-api.md).
Used to send segments and to subscribe/unsubscribe to the content topics."
- name: channelId
type: string
description: "Unique identifier for this channel. Represents the reliable (SDS), segmented, and optionally-encrypted session."
- name: contentTopic
type: string
description: "The topic this channel listens and sends on. This has routing and filtering connotations."
- name: senderId
type: string
description: "An identifier for this sender. SHOULD be unique and persisted between sessions."
- name: encryption
type: optional<Encryption>
default: none
description: "Optional pluggable encryption implementation. If none, messages are sent unencrypted."
returns:
type: result<ReliableChannel, error>
closeChannel:
description: "Closes a reliable channel, releases all associated resources and internal state,
and unsubscribes from its content topic via the underlying [MESSAGING-API](messaging-api.md)."
parameters:
- name: channel
type: ReliableChannel
description: "The channel handle returned by `createReliableChannel`."
returns:
type: result<void, error>
Channel usage
functions:
send:
description: "Send a message through a reliable channel. The message is always segmented,
SDS-tracked, rate-limited (optional), and encrypted (optional)."
parameters:
- name: channel
type: ReliableChannel
description: "The channel handle returned by `createReliableChannel`."
- name: message
type: array<byte>
description: "The raw message payload to send."
returns:
type: result<RequestId, error>
description: "Returns a `RequestId` that callers can use to correlate subsequent `MessageSentEvent` or `MessageSendErrorEvent` events."
Node configuration
This spec extends NodeConfig, needed to create a node, which is
defined in MESSAGING-API,
with sds_config and rate_limit_config fields.
NodeConfig: # Extends NodeConfig defined in MESSAGING-API
fields:
sds_config:
type: SdsConfig
description: "SDS configuration. See SdsConfig defined in this spec."
rate_limit_config:
type: RateLimitConfig
description: "See RateLimitConfig defined in this spec."
segmentation_config:
type: SegmentationConfig
description: "See SegmentationConfig defined in this spec."
Type definitions
types:
ReliableChannel:
type: object
description: "A handle representing an open reliable channel.
Returned by `createReliableChannel` and used to send messages and receive events.
Internal state (SDS, segmentation, encryption) is managed by the implementation."
events:
"reliable:message:received":
type: MessageReceivedEvent
"reliable:message:sent":
type: MessageSentEvent
"reliable:message:delivered":
type: MessageDeliveredEvent
"reliable:message:send-error":
type: MessageSendErrorEvent
"reliable:message:delivery-error":
type: MessageDeliveryErrorEvent
MessageReceivedEvent:
type: object
description: "Event emitted when a complete message has been received and reassembled."
fields:
message:
type: array<byte>
description: "The reassembled message payload."
MessageSentEvent:
type: object
description: "Event emitted when all segments of a message have been transmitted to the network.
This confirms network-level dispatch only; it does not guarantee the recipient has processed the message.
For end-to-end confirmation, listen for `MessageDeliveredEvent`."
fields:
requestId:
type: RequestId
description: "The identifier of the `send` operation whose segments have all been dispatched to the network."
MessageDeliveredEvent:
type: object
description: "Event emitted when the recipient has confirmed end-to-end receipt of a message via SDS acknowledgements.
This event is fired asynchronously after `MessageSentEvent`, once the SDS layer receives explicit acknowledgements from the recipient."
fields:
requestId:
type: RequestId
description: "The identifier of the `send` operation confirmed as delivered by the recipient."
MessageSendErrorEvent:
type: object
description: "Event emitted when one or more segments of a message could not be dispatched to the network.
This indicates a network-level failure; the message was never fully transmitted."
fields:
requestId:
type: RequestId
description: "The identifier of the `send` operation that failed to dispatch."
error:
type: string
description: "Human-readable description of the dispatch failure."
MessageDeliveryErrorEvent:
type: object
description: "Event emitted when end-to-end delivery could not be confirmed.
The message reached the network and there's no need to explicit re-send.
Fired after `maxRetransmissions` attempts have been exhausted without receiving an SDS acknowledgement from the recipient."
fields:
requestId:
type: RequestId
description: "The identifier of the `send` operation that was not acknowledged by the recipient."
error:
type: string
description: "Human-readable description of the delivery failure."
RequestId:
type: string
description: "Unique identifier for a single `send` operation on a reliable channel.
It groups all segments produced by segmenting one message, so callers can correlate
acknowledgement and error events back to the original send call.
Internally, each segment is dispatched as an independent [MESSAGING-API](messaging-api.md) call,
producing one `RequestId` (as defined in [MESSAGING-API](messaging-api.md)) per segment.
A single `RequestId` therefore maps to one or more underlying [MESSAGING-API](messaging-api.md)'s `RequestId` values,
one per segment sent.
For example, the `RequestId` `Req_a` yields these MESSAGING-API requests:
`Req_a:1`, `Req_a:2`, ..., `Req_a:N`, where `Req_a:k` represents the k-th
MESSAGING-API segment `RequestId`.
That is, `Req_a` is the `RequestId` from the RELIABLE-CHANNEL-API spec PoV,
whereas `Req_a:k` is the `RequestId` from the MESSAGING-API spec PoV.
"
SegmentationConfig:
type: object
fields:
enableReedSolomon:
type: bool
default: false
description: When enabled, the message sender adds parity (redundant) segments to allow recovery in case of data segment loss. See [SEGMENTATION](segmentation.md).
segmentSizeBytes:
type: uint
default: 102400 # 100 KiB
description: "Maximum segment size in bytes.
Messages larger than this value are split before SDS processing."
persistence:
type: Persistence
description: "Backend for persisting partial reassembly state across restarts.
Implementations MUST use this backend to store received segments until all segments of a message have arrived and can be reassembled.
Refer to [SEGMENTATION](segmentation.md) for the full definition of what state must be persisted."
SdsConfig:
type: object
description: Scalable Data Sync config items.
fields:
persistence:
type: Persistence
description: "Backend for persisting the SDS local history. Implementations MAY support custom backends."
acknowledgementTimeoutMs:
type: uint
default: 5000
description: "Time in milliseconds to wait for acknowledgement before retransmitting."
maxRetransmissions:
type: uint
default: 5
description: "Maximum number of retransmission attempts before considering delivery failed."
causalHistorySize:
type: uint
default: 2
description: "Number of message IDs to consider in the causal history. With longer value, a stronger correctness is guaranteed but it requires higher bandwidth and memory."
RateLimitConfig:
type: object
description: Rate limiting configuration, containing RLN-specific attributes.
fields:
enabled:
type: bool
default: false
description: "Whether rate limiting is enforced. SHOULD be true when RLN is active."
epochPeriodSec:
type: uint
default: 600 # 10 minutes
description: "The epoch size used by the RLN relay, in seconds."
Encryption:
type: object
description: "Interface for a pluggable encryption mechanism.
When provided as a parameter to `createReliableChannel`, the API consumer MUST implement both encrypt and decrypt operations.
Implementations MAY use different signatures than those described below, as long as each operation accepts a byte array and returns a byte array."
fields:
encrypt:
type: function
description: "Encrypts a byte payload. Returns the encrypted payload."
parameters:
- name: content
type: array<byte>
returns:
type: result<array<byte>, error>
decrypt:
type: function
description: "Decrypts a byte payload. Returns the decrypted payload."
parameters:
- name: payload
type: array<byte>
returns:
type: result<array<byte>, error>
Persistence:
type: object
description: "Interface for a pluggable SDS persistence backend.
Implementations MUST provide all functions required to save and retrieve SDS state per channel. Implementations MUST also provide the persistence method of interest, e.g., SQLite, custom encrypted storage, etc.
Refer to the [SDS spec](https://lip.logos.co/anoncomms/raw/sds.html) for the full definition of what state must be persisted."
Security/Privacy Considerations
- This API does not provide confidentiality by default. An
Encryptionimplementation MUST be supplied when confidentiality is required. - Segment metadata (message ID, segment index, total segments) is visible to network observers unless encrypted by the hook.
- SDS acknowledgement messages are sent over the same content topic and are subject to the same confidentiality concerns.
- Rate limiting compliance is required to avoid exclusion from the network by RLN-enforcing relays.
Copyright
Copyright and related rights waived via CC0.
WAKU-P2P-RELIABILITY
| Field | Value |
|---|---|
| Name | Waku P2P Reliability |
| Slug | 172 |
| Status | raw |
| Type | RFC |
| Category | application |
| Editor | Hanno Cornelius [email protected] |
| Contributors | Danish Arora [email protected], Kaichao Sun [email protected], Oleksandr Kozlov [email protected], Prem Chaitanya Prathi [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
48600b5— Migrate logos-messaging/specs into docs/messaging/ (#315)
Abstract
This specification defines peer-to-peer (p2p) reliability within 10/WAKU2 networks, addressing dependability of message propagation between Waku node hops. It situates the problem of p2p reliability between the lower layer transport reliability and the higher layer end-to-end reliability. We also propose strategies to enhance message propagation reliability and mechanisms to detect and mitigate message loss between Waku nodes, taking into account the trade-offs between reliability, bandwidth usage, latency, and resource consumption.
Reliability in a Waku context
Reliability can be considered on three layers within a 10/WAKU2 context:
- Transport layer reliability: Reliability within the networking layer of an individual node. This includes reliability of the underlying libp2p layer, constituent transports, peer management, and peer discovery.
- Peer-to-peer (p2p) reliability: Reliability between nodes within a 10/WAKU2 p2p network, including message routing and discovery between peers. Note that reliability at this layer is agnostic of the application. At this layer, 10/WAKU2 nodes have no knowledge of the origin or intended destination of messages being routed.
- End-to-end (e2e) reliability: Reliability within the application layer on top of the Waku p2p routing layer. This layer is concerned with message delivery between intended participants from the application's perspective regardless of the underlying Waku network. As such, e2e reliability mechanisms are usually implemented within the encrypted application payload.
Scope
This specification focuses on p2p reliability. It does not cover:
- Transport-level reliability mechanisms, such as fine-tuning libp2p parameters, improving peer discovery and management, etc.
- End-to-end message reliability protocols, covered by higher-layer application logic.
We focus on p2p reliability within the context of the following 10/WAKU2 protocols:
- 17/WAKU2-RLN-RELAY: used by nodes to publish and receive messages on a pub/sub topic by participating in libp2p gossipsub routing
- 12/WAKU2-FILTER: used by nodes to receive messages from a pub/sub topic without participating in gossipsub routing
- WAKU2-LIGHTPUSH: used by nodes to publish messages to a pub/sub topic without participating in gossipsub routing
- 13/WAKU2-STORE: used by any node to query and retrieve historical messages
Problem statement
The primary challenge at the p2p layer is ensuring that messages sent from one Waku node propagate to peers with a high probability of success while minimising redundant transmissions and excessive bandwidth use.
Factors affecting reliability include:
- Network instability: detected and undetected network connectivity drops can lead to message loss or duplication.
- Network churn: frequent changes in the network topology as peers connect and disconnect can lead to potential message loss.
- Node resource constraints: nodes with limited bandwidth or processing power may struggle to handle high message volumes, leading to potential drops.
- Adversarial behaviour: adversarial nodes may deliberately drop, delay, or selectively forward messages.
Reliability Strategies
General
In this section, we first summarise strategies to improve p2p reliability based on their functional effect before specifying the detailed strategies for each Waku protocol. P2p reliability consists of either configuring individual Waku protocols or composing several Waku protocols to achieve one or both of the following two objectives:
1. Improve redundancy
Redundancy improves the probability that a message reaches its intended recipients. Redundancy strategies can focus on:
- Redundant publishing:
Publishers MAY improve the probability of their messages propagating through the network by publishing it simultaneously to several peers as first hop. Several peers would then continue routing the message. 17/WAKU2-RLN-RELAY already implements redundant publishing by forwarding a message at least to all mesh peers or, as is RECOMMENDED for Waku, publishing the message to all peers using flood publishing. Configuring 17/WAKU2-RLN-RELAY is part of the transport layer and a detailed description falls outside the scope of this spec. WAKU2-LIGHTPUSH MAY similarly be configured to publish to more than one lightpush service node at the same time. See the lightpush section for a specification of the strategy.
- Redundant receiving:
Nodes MAY improve the probability for receiving all messages by increasing the number of sources from which they receive messages. 17/WAKU2-RLN-RELAY already implements redundant receiving as messages are eagerly pushed from all mesh peers with added gossip mechanisms to allow lazy pulling from all peers as described in the GossipSub v1.1 specification. Configuring 17/WAKU2-RLN-RELAY is part of the transport layer and a detailed description falls outside the scope of this spec. 12/WAKU2-FILTER MAY similarly be configured to subscribe to receive messages from more than one filter service node at the same time. See the filter section for a specification of the strategy.
2. Detect and remedy losses
Nodes MAY combine different Waku protocols to detect and remedy possible losses. Losses can occur either from the publisher's or the recipient's perspective.
- Failure to publish:
Nodes using either 17/WAKU2-RLN-RELAY or WAKU2-LIGHTPUSH to publish MAY determine that a message has probably failed to publish by combining these protocols with 12/WAKU2-FILTER or 13/WAKU2-STORE to attempt to retrieve the published message from other peers in the network. Failure to detect the message could indicate a publishing failure. The usual remedial action is to retransmit the message. See Store-based reliability for a specification of the strategy to combine 17/WAKU2-RLN-RELAY or WAKU2-LIGHTPUSH with 13/WAKU2-STORE. See Lightpush for a specification of the strategy to combine WAKU2-LIGHTPUSH with 12/WAKU2-FILTER. Combining 17/WAKU2-RLN-RELAY with 12/WAKU2-FILTER is conceptually possible, but underspecified.
- Failure to receive:
Nodes using either 17/WAKU2-RLN-RELAY or 12/WAKU2-FILTER to receive messages MAY determine message losses by combining these protocols with 13/WAKU2-STORE to compare their local message history with the historical messages cached in the 13/WAKU2-STORE. The usual remedial action is to retrieve the missing messages from the 13/WAKU2-STORE. See Store-based reliability for a specification of this strategy.
Store-based reliability
13/WAKU2-STORE provides a way for nodes to query the existence of or fetch specific historical messages. Nodes using any combination of 17/WAKU2-RLN-RELAY, 12/WAKU2-FILTER and WAKU2-LIGHTPUSH to publish/receive messages MAY combine these protocols with 13/WAKU2-STORE to improve p2p reliability. Depending on the use case, such a node MAY use any of the strategies below:
1. Store-based reliability for publishing
- A publishing node using this strategy MUST consider a published message as "unacknowledged" at first.
- The publisher MUST keep a copy of this message against its deterministic message hash in a local outgoing message buffer. It MAY keep the last several published messages in this buffer.
- The publisher MUST periodically perform a presence query to the 13/WAKU2-STORE service
against the message hashes of all published messages in the outgoing buffer
to verify their existence in the store.
- If a message hash exists in the 13/WAKU2-STORE service, the publisher SHOULD consider the corresponding message as "acknowledged" and remove it from the outgoing buffer.
- If a message hash does not exist in the 13/WAKU2-STORE service, the publisher MUST consider the corresponding message as still "unacknowledged".
- The publisher SHOULD retransmit all unacknowledged messages either periodically or upon reception of the presence query response until a positive presence query response is received for the corresponding message hash. A publisher MAY consider a message publication as having failed irremediably after a set number of failed presence query attempts.
2. Store-based reliability for receiving
- A receiving node using this strategy MUST have a local cache of the deterministic message hashes of all received messages spanning at least the time period for which reliability is required.
- The node MUST periodically perform a content filtered query to the 13/WAKU2-STORE service,
spanning the time period for which reliability is required ("reliability window")
and including all content topics over which it is interested to receive messages.
The
include_datafield SHOULD be set tofalseto retrieve only the matching message hashes from the 13/WAKU2-STORE service. If a connection loss is detected (e.g. if a query fails due to disconnection), the next query MAY span at least the time period since the last successful query if this is longer than the reliability window. - The node MUST compare the received message hashes to those in the local cache. Any message hashes in the response that are not in the local cache MUST be considered "missing".
- The node SHOULD perform a message hash lookup query for all missing message hashes to retrieve the full contents of the corresponding messages. It MAY do so either periodically (in batches) or upon reception of the content filtered query response.
- The node MUST add to the local cache all message hashes corresponding to the retrieved messages, in order to prevent them from being considered missing in future.
3. Combined store-based reliability for publishing and receiving messages
- A node using this strategy MUST have a local cache of the deterministic message hashes of all received messages spanning at least the time period for which reliability is required.
- In addition, the node MUST consider a published message as "unacknowledged" at first. The node MUST keep a copy of this message against its deterministic message hash in a local outgoing message buffer. It MAY keep the last several published messages in this buffer.
- The node MUST periodically perform a content filtered query to the 13/WAKU2-STORE service,
spanning the time period for which reliability is required
and including all content topics over which it is interested to both publish and receive messages.
The
include_datafield SHOULD be set tofalseto retrieve only the matching message hashes from the 13/WAKU2-STORE service. - The node MUST compare the message hashes in the content filtered query response to the message hashes of all published messages in the outgoing buffer
to verify their existence in the store.
- If a message hash is included in the query response, the publisher SHOULD consider the corresponding message as "acknowledged" and remove it from the outgoing buffer.
- If a message hash is not included in the query response, the publisher MUST consider the corresponding messages as still "unacknowledged".
- In addition, the node MUST compare the message hashes in the content filtered query response to the message hashes in the local cache. Any message hashes in the response that are not in the local cache MUST be considered "missing".
- The node SHOULD retransmit all unacknowledged messages in the outgoing buffer, either periodically or upon reception of the query response, until a positive inclusion in a follow-up query response for the corresponding message hashes. The node MAY consider a message publication as having failed irremediably after a set number of query attempts without inclusion.
- In addition, the node SHOULD perform a message hash lookup query for all missing message hashes to retrieve the full contents of the corresponding messages. It MAY do so either periodically (in batches) or upon reception of the content filtered query response.
- The node MUST add to the local cache all message hashes corresponding to the retrieved messages, in order to prevent them from being considered missing in future.
Lightpush
WAKU2-LIGHTPUSH provides a way for client nodes to publish messages to a pub/sub topic via a lightpush service node without participating in gossipsub routing. Lightpush clients MAY use any of the following strategies to improve reliability of the service:
1. Maintain a pool of reliable lightpush service nodes
A lightpush client using this strategy MUST maintain a pool of reliable lightpush service nodes. Discovery of these service nodes falls outside the scope of this specification. As a simple heuristic, a lightpush client MAY consider all discovered lightpush service nodes as reliable until it detects a service failure. In case the lightpush service fails due to service node behaviour, the client MAY disconnect from the service node and replace it with another service node from the pool. Such a client SHOULD also remove the failing service node from the pool of reliable service nodes.
We RECOMMEND replacing a lightpush service node after a single failure in the following categories:
- the connection to the service node is lost or a lightpush request times out
- the lightpush request fails due to a service-side error, for example if the response contains one of the following error codes:
UNSUPPORTED_PUBSUB_TOPICINTERNAL_SERVER_ERRORNO_PEERS_TO_RELAY
- the request failed without an error response
2. Redundant lightpush publishing
A lightpush client using this strategy MUST publish each message simultaneously to two or more lightpush service nodes. Note that bandwidth usage increases proportionally to the amount of service nodes used. For this reason, we RECOMMEND using only two lightpush service nodes at a time.
3. Retransmit on failure
- A lightpush client using this strategy MUST wait for a WAKU2-LIGHTPUSH response after publishing a message.
- If the response times out or contains a recoverable error code (e.g.
TOO_MANY_REQUESTS) the lightpush client SHOULD attempt to retransmit the message after some interval. - The client MAY choose to continue retransmitting the message until an
OKresponse is received from the service node. The interval between each retransmission attempt is up to the implementation, but we RECOMMEND starting with1 secondand increasing it after each failure. - The client MAY consider a message publication as having failed irremediably after a set number of failed lightpush requests.
4. Retransmit on possible message loss detection
Note: Lightpush clients participating in Store-based reliability already performs this strategy and can ignore this section.
- A lightpush client using this strategy MUST use either Store-based reliability or install one or more 12/WAKU2-FILTER subscriptions matching the content topic(s) used for publishing. In this way, the client can confirm that a published message did indeed reach the targeted store or filter service node(s).
- The store queries or filter subscription SHOULD be requested at service nodes different from those used for the lightpush service.
- If the client determines that a published message has not been received by the filter or store service node, it SHOULD retransmit the message after some interval.
- The client MAY choose to continue retransmitting the message until it is confirmed by one more service nodes.
The interval between each retransmission attempt is up to the implementation,
but we RECOMMEND starting with
1 secondand increasing it after each attempt. - The client MAY consider a message publication as having failed irremediably after a set number of failed lightpush requests.
Filter
12/WAKU2-FILTER provides a way for client nodes to receive messages from a pub/sub topic via a filter service node without participating in gossipsub routing. Filter clients MAY use any of the following strategies to improve reliability of the service:
1. Maintain a pool of reliable filter service nodes
A filter client using this strategy MUST maintain a pool of reliable filter service nodes. Discovery of these service nodes falls outside the scope of this specification. As a simple heuristic, a filter client MAY consider all discovered filter service nodes as reliable until it detects a service failure. In case the filter service fails due to service node behaviour, the client MAY disconnect from the service node and replace it with another service node from the pool. Such a client SHOULD also remove the failing service node from the pool of reliable service nodes.
We RECOMMEND replacing a filter service node under the following conditions:
- a
SUBSCRIBErequest fails due to a service-side error - a
SUBSCRIBER_PINGrequest fails twice in a row
2. Redundant filter subscriptions
A filter client using this strategy MUST subscribe to two or more filter service nodes. Such clients SHOULD filter out duplicate messages by comparing deterministic message hashes. Note that both bandwidth usage and computational complexity increases proportionally to the amount of service nodes used. For this reason, we RECOMMEND using only two filter service nodes at a time.
3. Maintaining healthy subscriptions
- A filter client using this strategy MUST regularly send a
SUBSCRIBER_PINGto each of its filter service nodes, to ensure that the service node is online and maintaining an active subscription for the client. The interval between eachSUBSCRIBER_PINGis up to the implementation, but we RECOMMEND1 minute. - If the
SUBSCRIBER_PINGrequest times out or returns an error code, the client SHOULD attempt to reinstall its filter subscription with aSUBSCRIBErequest. - If a [
SUBSCRIBER_PING] or [SUBSCRIBE] request fails more than once to the same filter service node, the client MAY choose to replace this service node with another from the service node pool. We RECOMMEND a strict policy of replacing filter service nodes after only twoSUBSCRIBER_PINGfailures or after a singleSUBSCRIBEfailure. - A filter client MAY also choose to refresh its existing subscriptions periodically,
by submitting the same filter criteria as before in a new
SUBSCRIBErequest to the same service node. This helps ensure that local and remote views of filter criteria remains synchronised.
4. Store query on possible message loss detection
Note: Filter clients participating in Store-based reliability already performs this strategy and can ignore this section.
- A filter client using this strategy MUST use 13/WAKU2-STORE queries to retrieve lost messages.
- Such clients MAY use Store-based reliability to periodically detect and remedy message losses.
- If Store-based reliability is unsuitable (e.g. due to the high resource usage of repeated store queries), the client MAY perform opportunistic store queries covering periods over which it detected a disconnection. For example, a client MAY consider itself offline over a period of repeated failed regular pings and perform a store query once the connection has been restored. The store query SHOULD cover the period from the last successfully received message to the reestablishment of connectivity.
Tradeoffs
All p2p reliability strategies set out in this document increases resource usage, most prominently bandwidth usage but also processing power and storage in some circumstances. As such, each strategy SHOULD be carefully considered and configured based on the intended use case. Increasing redundancy 20-fold may significantly improve reliability, but the accompanying bump in resource usage will be unacceptable for the average Waku user. At the same time, none of the reliability strategies described here can guarantee end-to-end reliability from an application's perspective. This is due to the inherent probabilistic nature of p2p message propagation on the routing layer. For example, certain sections of the network may become temporarily unreachable due to a network split, without this being visible on a hop-to-hop basis. Only the application has the end-to-end view to ensure reliability spanning all routing layer hops between that application's publishers and intended recipients. For applications with an integrated end-to-end reliability protocol, most p2p reliability strategies can be minimally configured (or even disabled) to save resources.
References
- 10/WAKU2
- 12/WAKU2-FILTER
- 13/WAKU2-STORE
- 17/WAKU2-RLN-RELAY
- 14/WAKU2-MESSAGE
- GossipSub v1.1
- WAKU2-LIGHTPUSH
Copyright
Copyright and related rights waived via CC0.
WAKU-RLN-KEYSTORE
| Field | Value |
|---|---|
| Name | Waku RLN Keystore |
| Slug | 174 |
| Status | raw |
| Type | RFC |
| Category | application |
| Editor | Jimmy Debe [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
48600b5— Migrate logos-messaging/specs into docs/messaging/ (#315)
Abstract
This specification describes how the RLN, Rate Limit Nullifier, credentials are securely stored in a JSON schema.
Background
A keystore is a construct to store a user’s cryptographic keys. The keys are encrypted and decrypted based on the methods specified in this specification. A 17/WAKU2-RLN-RELAY keystore stores a node's credentials locally and 32/RLN-V1 is used as a spam-prevention mechanism with the help of zero-knowledge proofs.
The secure storage of keys is important in peer-to-peer messaging applications. Zero-knowledge proofs are used to have anonymous rate-limiting for messaging frameworks. Node's Credentials are encrypted and stored in the keystore to be retrieved at any time over the Waku network. With 32/RLN-V1, sending and receiving messages will ensure a message rate for the network is being followed while preserving the anonymity of the message owner.
Specification
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “NOT RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in RFC 2119.
Waku RLN Keystore Format:
A format example of a keystore used by a 17/WAKU2-RLN-Relay.
const Keystore {
application: "waku-rln-relay" ,
appIdentifier: "string",
version: "string",
credentials: {
"membershipHash": {
crypto: {
cipher: "string",
cipherparams: {
iv: "string",
},
ciphertext: "string",
kdf: "string",
kdfparams: {
dklen: integer,
c: integer,
prf: "string",
salt: "string",
},
mac: "string",
}
}
}
}
The keystore MUST be generated using a cryptographic construction that supports password verification and decryption. Keystore modules MUST include metadata, a key derivation function, a checksum, a cipher, and a membership hash.
Metadata:
Information about the keystore SHOULD be stored in the metadata.
The declaration of application, version, and appIdentifier MAY occur in the metadata.
application: current application, MUST be a stringversion: application version, MUST be a string, SHOULD follow semantic versioningappIdentifier: application identifier, MUST be a string
Credentials:
After the RLN credentials are generated, it MUST be stored in a JSON schema.
The credentials MUST consist of a membershipHash and WakuCredential.
The membershipHash will be an identity hash of the user.
The WakuCredential will store the encryption portion of the keystore.
There MAY be multiple credentials stored in a keystore,
categorized by the membershipHash.
Each contruct MUST include the keypair:
key: [
membershipHash]: pair: [WakuCredential]
membershipHash
The membershipHash SHOULD be generated by nodes participating in a membership group,
as decribed in 32/RLN-V1.
Each node SHOULD register to the group using an identity_commitment stored in a Merkle tree.
The RECOMMENDED cryptographic hash function used to generate the membershipHash is SHA256,
other hash functions MAY be used.
The hash function SHOULD be defined in the verison attribute.
A membershipHash MUST NOT already exist in the keystore.
To generate the membershipHash the following attributes SHOULD be used to create a hexadecimal string:
treeIndex:membershipContractchainId,identityCredentialrateLimit
treeIndex
After a node registers to a group,
a treeIndex value of the position in the Merkle tree SHOULD be returned.
- it MUST be a Merkle tree data structure filled with the
identity_commitmentfrom node registrations. - it SHOULD be a hexadecimal string
membershipContract
For decentralized membership registrations,
the membershipContract value SHOULD be a contractAddress of a smart contract deployed on a blockchain.
- it SHOULD be a string.
chainId
It uniquely defines the chain upon which the registration has occurred.
The chainId value SHOULD be the blockchain identifier used for membershipContract,
as described in EIP155.
- it MUST be a string
identityCredential
The identityCredential MUST be derived after a succussful decryption of the keystore.
The identityCredential MUST be constructed with the identity_secret, identity_secret_hash, identity_commitment values.
- it MUST be a hash of
identity_commitmentstored in a Merkle tree. - it MUST be a string.
identity_secret
The identity_secret MUST be constructed with identity_nullifier + identity_trapdoor values.
identity_nullifier: Random 32 byte valueidentity_trapdoor: Random 32 byte value
identity_secret_hash
Used to derive the identity_commitment of the node, and
as a private input for zero-knowledge proof generation.
- it MUST be created with
identity_secretas a parameter for the hash function. - This secret hash SHOULD be kept private by the node.
identity_commitment
- it SHOULD be created with
identity_secret_hashby using the hash function Poseidon, as described in Poseidon Paper. - it MUST be used by a node for group registering.
rateLimit
- it SHOULD be the node's membership rate limit
WakuCredential
The WakuCredential will store values used for encrypting and decrypting a node's keystore.
- it MUST be used for password verification.
- it MUST follow EIP-2335
- it SHOULD use SHA256 as the hash function
KDF
The password-based encryption used SHOULD be KDF, key derivation function, to produce a derived key from a password and other parameters. The keystore MAY use PBKDF2 password-based encryption, as described in RFC 2898.
A WakuCredential object MUST include:
| Name | Description |
|---|---|
| password | used to encrypt keystore and decryption key |
| secret | key to be encrypted |
| pubKey | public key |
| path | HD, hardened derivation, path used to generate the secret |
| checksum | hash function |
| cipher | cipher function |
crypto: {
cipher: "string" // The cipher function
cipherparams: {
iv: "string" // The cipher parameters
},
ciphertext: "string" // The cipher message,
kdf: "string" // KDF Function,
kdfparams: {
param: integer // Salt value and iteration count,
dklen: integer // Length in octets of derived key, MUST be positive integer,
c: "string" // Iteration count, MUST be positive integer,
prf: "string" // Underlying pseudorandom function,
salt: "string" // Produces a large set of keys based on the password
},
mac: "string" // Checksum
}
Decryption
The keystore SHOULD decrypt a node's credentials using a password and the membershipHash,
using PBKDF2 that returns the decryptionKey key.
The decryptionKey is used to verify that the keystore has the correct credentials.
- To generate the
decryptionKey, it MUST be constructed from a password and KDF, as desrcibed in ERC-2335: BLS12-381 Keystore. - The
decryptionKey, is derived from the cipher function and cipher parameters described in the KDF used in the keystore.
Test Vectors
RLN uses Poseidon hash algorithm to generate the identityCredential,
as described in Poseidon Paper.
The keystore hash algorithm used is SHA256.
Input:
application: "waku-rln-relay"appIdentifier: "01234567890abcdef"version: "0.2"hashFunction: "poseidonHash"password: "sup3rsecure"
identityCredential = {
IDTrapdoor: [
211, 23, 66, 42, 179, 130, 131, 111, 201, 205, 244, 34, 27, 238, 244,
216, 131, 240, 188, 45, 193, 172, 4, 168, 225, 225, 43, 197, 114, 176,
126, 9,
],
IDNullifier: [
238, 168, 239, 65, 73, 63, 105, 19, 132, 62, 213, 205, 191, 255, 209, 9,
178, 155, 239, 201, 131, 125, 233, 136, 246, 217, 9, 237, 55, 89, 81,
42,
],
IDSecretHash: [
150, 54, 194, 28, 18, 216, 138, 253, 95, 139, 120, 109, 98, 129, 146,
101, 41, 194, 36, 36, 96, 152, 152, 89, 151, 160, 118, 15, 222, 124,
187, 4,
],
IDCommitment: [
112, 216, 27, 89, 188, 135, 203, 19, 168, 211, 117, 13, 231, 135, 229,
58, 94, 20, 246, 8, 33, 65, 238, 37, 112, 97, 65, 241, 255, 93, 171, 15,
],
}
membership = {
chainId: "0xAA36A7",
treeIndex: 8,
address: "0x8e1F3742B987d8BA376c0CBbD7357fE1F003ED71",
}
Output:
application: "waku-rln-relay",
appIdentifier: "01234567890abcdef",
version: "0.2",
credentials: {
"9DB2B4718A97485B9F70F68D1CC19F4E10F0B4CE943418838E94956CB8E57548": {
crypto: {
cipher: "aes-128-ctr",
cipherparams: {
iv: "fd6b39eb71d44c59f6bf5ff3d8945c80",
},
ciphertext: "9c72f47ce95de03ed34502d0288e7576b66b51b9e7d5ae882c27bd89f94e6a03c2c44c2ddf0c982e72003d67212105f1b64614f57cabb0ceadab7e07be165eee1121ad6b81951368a9f3be2dd99ea294515f6013d5f2bd4702a40e36cfde2ea298b23b31e5ce719d8040c3331f73d6bf44f88bca39bac0e917d8bf545500e4f40d321c235426a80f315ac70666acbd3bdf803fbc1e7e7103fed466525ed332b25d72b2dbedf6fa383b2305987c1fe276b029570519b3e79930edf08c1029868d05c2c08ab61d7c64f63c054b4f6a5a12d43cdc79751b6fe58d3ed26b69443eb7c9f7efce27912340129c91b6b813ac94efd5776a40b1dda896d61357de208c7c47a14af911cc231355c8093ee6626e89c07e1037f9e0b22c690e3e049014399ca0212c509cb04c71c7860d1b17a0c47711c490c27bad2825926148a1f15a507f36ba2cdaa04897fce2914e53caed0beaf1bebd2a83af76511cc15bff2165ff0860ad6eca1f30022d7739b2a6b6a72f2feeef0f5941183cda015b4631469e1f4cf27003cab9a90920301cb30d95e4554686922dc5a05c13dfb575cdf113c700d607896011970e6ee7d6edb61210ab28ac8f0c84c606c097e3e300f0a5f5341edfd15432bef6225a498726b62a98283829ad51023b2987f30686cfb4ea3951f3957654035ec291f9b0964a3a8665d81b16cec20fb40f944d5f9bf03ac1e444ad45bae3fa85e7465ce620c0966d8148d6e2856f676c4fbbe3ebe470453efb4bbda1866680037917e37765f680e3da96ef3991f3fe5cda80c523996c2234758bf5f7b6d052dc6942f5a92c8b8eec5d2d8940203bbb6b1cba7b7ebc1334334ca69cdb509a5ea58ec6b2ebaea52307589eaae9430eb15ad234c0c39c83accdf3b77e52a616e345209c5bc9b442f9f0fa96836d9342f983a7",
kdf: "pbkdf2",
kdfparams: {
dklen: 32,
c: 1000000,
prf: "hmac-sha256",
salt: "60f0aa92fbf63a8356dfdbed2ab18058",
},
mac: "51a227ac6db7f2797c63925880b3db664e034231a4c68daa919ab42d8df38bc6",
},
}
Security Considerations
1.) Add a Password
An attacker can identify which credential belongs to a node with a combination of chainId and
contractAddress pair by brute forcing the treeIndex iteratively to find a hash match.
The RECOMMENDED solution is to add a password to the construction of membershipHash to prevent this attack.
The RECOMMENDED membershipHash Construction:
- The
membershipHashRECOMMENDED to be constructed withtreeIndex,membershipContract,identityCredential,rateLimit, andmembershipPasswordmembershipPassword: a new password created to private attacks compromising keystore credentials.
- The user MUST store the
membershipPasswordprivately.
Copyright
Copyright and related rights waived via CC0.
References
- 32/RLN-V1
- 17/WAKU2-RLN-RELAY
- SHA256
- EIP155
- Poseidon Paper
- EIP-2335
- RFC 2898
- ERC-2335: BLS12-381 Keystore
WAKU2-DEVICE-PAIRING
| Field | Value |
|---|---|
| Name | Device pairing and secure transfers with Noise |
| Slug | 167 |
| Status | raw |
| Type | RFC |
| Category | application |
| Tags | waku/core-protocol |
| Editor | Giuseppe [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
48600b5— Migrate logos-messaging/specs into docs/messaging/ (#315)
Abstract
In this document we describe a compound protocol for enabling two devices to mutually authenticate and securely exchange (arbitrary) information over the Waku network.
Background / Rationale / Motivation
In order to implement multi-device communications using one of the Noise session management mechanisms proposed in WAKU2-NOISE-SESSIONS, we require a protocol to securely exchange (cryptographic) information between 2 or more devices possessed by a user.
Since, in this scenario, the devices would be close to each other, authentication can be initialized by exchanging a QR code out-of-band and then securely completed over the Waku network.
The protocol we propose consists of two main subprotocols or phases:
- Device Pairing: two physically close devices initialize the pairing by exchanging a QR code out-of-band. The devices then exchange and authenticate their respective long-term device ID static key by exchanging handshake messages over the Waku network;
- Secure Transfer: the devices securely exchange information in encrypted form using key material obtained during a successful pairing phase. The communication will happen over the Waku network, hence the devices do not need to be phisically close in this phase.
Theory / Semantics
Device Pairing
In the pairing phase, device B requests to be paired to a device A.
Once the two devices are paired, the devices will be mutually authenticated
and will share a Noise session within which they can securely exchange information.
The request is made by exposing a QR code that, by default, has to be scanned by device A.
If device A doesn't have a camera while device B does,
it is possible to execute a slightly different pairing (with same security guarantees),
where A is exposing a QR code instead.
This protocol is designed in order to achieve two main security objectives:
- resistance to Man-in-the-Middle attacks;
- provide network anonymity on devices' static keys, i.e. only paired devices will learn each other static key.
Employed Cryptographic Primitives
H: the underlying cryptographically-secure hash function, e.g. SHA-256;HKDF: the key derivation function (based onH);Curve25519: the underlying elliptic curve for Diffie-Hellman (DH) operations.
The WakuPairing Noise Handshake
The devices execute a custom handshake derived from XX,
where they mutually exchange and authenticate their respective device static key
by exchanging messages over the content topic with the following format
contentTopic = /{application-name}/{application-version}/wakunoise/1/sessions_shard-{shard-id}/proto
The handshake, detailed in next section, can be summarized as:
WakuPairing:
a. <- eB {H(sB||r), contentTopicParams, messageNametag}
...
b. -> eA, eAeB {H(sA||s)} [authcode]
c. <- sB, eAsB {r}
d. -> sA, sAeB, sAsB {s}
{}: payload, []: user interaction
Protocol Flow
-
The device
Bexposes through a QR code a base64 (url safe) serialization of:- An ephemeral public key
eB; - The content topic parameters
contentTopicParams = {application-name}, {application-version}, {shard-id}. - A (randomly generated) 16-bytes long
messageNametag. - A commitment
H(sB||r)for its static keysBwhereris a random fixed-lenght value.
- An ephemeral public key
-
The device
A:- scans the QR code;
- obtains
eB,contentTopicParams,messageNametag,Hash(sB||r); - checks if
{application-name}and{application-version}fromcontentTopicParamsmatch the local application name and version: if not, aborts the pairing. SetscontentTopic = /{application-name}/{application-version}/wakunoise/1/sessions_shard-{shard-id}/proto; - initializes the Noise handshake by passing
contentTopicParams,messageNametagandHash(sB||r)to the handshake prologue; - performs the pre-handshake process, i.e. processes the key
eB; - executes the first handshake message over
contentTopic, i.e.- processes and sends a 14/WAKU2-MESSAGE containing an ephemeral key
eA; - performs
DH(eA,eB)(which computes a symmetric encryption key); - attaches, as payload to the handshake message,
the (encrypted) commitment
H(sA||s)forA's static keysA, wheresis a random fixed-length value;
- processes and sends a 14/WAKU2-MESSAGE containing an ephemeral key
- an 8-digits authorization code
authcodeobtained asHKDF(h) mod 10^8is displayed on the device, wherehis the handshake hash value obtained once the first handshake message is processed.
-
The device
B:- sets
contentTopic = /{application-name}/{application-version}/wakunoise/1/sessions_shard-{shard-id}/proto; - listens to messages sent to
contentTopicand locally filters only those with Waku payload starting withmessageNametag. If any, continues. - initializes the Noise handshake by passing
contentTopicParams,messageNametagandHash(sB||r)to the handshake prologue; - performs the pre-handshake process, i.e. processes its ephemeral key
eB; - processes the received first handshake message, i.e.
- obtains from the received message a public key
eA. IfeAis not a valid public key, the protocol is aborted. - performs
DH(eA,eB)(which computes a symmetric encryption key); - decrypts the commitment
H(sA||s)forA's static keysA.
- obtains from the received message a public key
- an 8 decimal digits authorization code
authcodeobtained asHKDF(h) mod 10^8is displayed on the device, wherehis the handshake hash value obtained once the first handshake message is processed.
- sets
-
Device
AandBwait for user confirmations, through a user interface, that the authorization code displayed on both devices are the same. If not, the protocol is aborted. -
The device
B:- executes the second handshake message, i.e.
- processes and sends his (encrypted) device static key
sBovercontentTopic; - performs
DH(eA,sB)(which updates the symmetric encryption key); - attaches as payload the (encrypted) commitment randomness
rused to computeH(sB||r).
- processes and sends his (encrypted) device static key
- executes the second handshake message, i.e.
-
The device
A:- listens to messages sent to
contentTopicand locally filters only those with 26/WAKU2-PAYLOAD starting withmessageNametag. If any, continues. - decrypts the received message and obtains the public key
sB. IfsBis not a valid public key, the protocol is aborted. - performs
DH(eA,sB)(which updates a symmetric encryption key); - decrypts the payload to obtain the randomness
r. - computes
H(sB||r)and checks if this value corresponds to the commitment obtained in step 2. If not, the protocol is aborted. - executes the third handshake message, i.e.
- processes and sends his (encrypted) device static key
sAovercontentTopic; - performs
DH(sA,eB)(which updates the symmetric encryption key); - performs
DH(sA,sB)(which updates the symmetric encryption key); - attaches as payload the (encrypted) commitment randomness
sused to computeH(sA||s).
- processes and sends his (encrypted) device static key
- calls Split() and obtains two cipher states to encrypt inbound and outbound messages.
- listens to messages sent to
-
The device
B:- listens to messages sent to
contentTopicand locally filters only those with 26/WAKU2-PAYLOAD starting withmessageNametag. If any, continues. - processess the third handshake message, i.e.
- obtains from decrypting the received message a public key
sA. IfsAis not a valid public key, the protocol is aborted. - performs
DH(sA,eB)(which updates a symmetric encryption key); - performs
DH(sA,sB)(which updates a symmetric encryption key); - decrypts the payload to obtain the randomness
s. - Computes
H(sA||s)and checks if this value corresponds to the commitment obtained in step 3. If not, the protocol is aborted.
- obtains from decrypting the received message a public key
- Calls Split() and obtains two cipher states to encrypt inbound and outbound messages.
- listens to messages sent to
The WakuPairing for Devices without a Camera
In the above pairing handshake, the QR is by default exposed by device B and not by A
because in most use-cases we foresee, the secure transfer phase would consist in
exchanging a single message (e.g., Noise sessions, cryptographic keys, signatures, etc.) from device A to B.
However, since the user(s) confirm(s) at the end of message b. that the authorization code is the same on both devices,
the role of the handhsake initiator and responder can be safely swapped in message a. and b..
Indeed, if the pairing phase successfully completes on both devices, the authentication code, the committed static keys and the Noise processing rules will ensure that no Man-in-the-Middle attack took place. Messages can then be securely exchanged bi-directionally in the transfer phase.
This allows pairing in case device A does not have a camera to scan a QR (e.g. a desktop client) while device B has.
The resulting handshake would then be:
WakuPairing2:
a. -> eA {H(sB||r), contentTopicParams, messageNametag}
...
b. <- eB, eAeB {H(sB||r)} [authcode]
c. <- sB, eAsB {r}
d. -> sA, sAeB, sAsB {s}
{}: payload, []: user interaction
Secure Transfer
The pairing phase is designed to be application-agnostic and should be flexible enough to mutually authenticate and allow exchange of cryptographic key material between two devices over a distributed network of Waku2 nodes.
Once the handshake is concluded, (privacy-sensitive) information can be exchanged using the encryption keys agreed upon the pairing phase. If stronger security guarantees are required, some additional tweaks are possible.
Implementation Suggestions
Timebox QR exposure
We suggest to timebox the exposure of each pairing QR code to few seconds, e.g. 30. After this time limit, a QR code containing a new ephemeral key, random static key commitment and message nametag (content topic parameters could remain the same) should replace the previously exposed QR, which can then be discarded.
The reason for such suggestion is due to the fact that if an attacker is able to compromise one of the ephemeral keys,
he might successfully realize an undetected MitM attack up to the authcode confirmation
(we note that compromising ephemeral keys is outside our and Noise security assumptions).
The attacker could indeed proceed as follows:
- intercepts the QR;
- blocks/delays the delivery of the pairing message
b.; - compromises
AorBephemeral key; - recovers the genuine
authcodethat would have been generated byAandB; - generates ~
10^8randomtvalues until the Noise processing of the messageb'. -> eC, eCeB {H(sC||t)}, whereeCandsCare the attacker ephemeral and static key, respectively, results in computing the sameauthcodeas the one betweenAandB; - delivers the message
b'. -> eC, eCeB {H(sC||t)}toB(beforeAis able to deliver its messageb.).
At this point A and B will observe the same authcode (and would then confirm it),
but B will process the attacker's ephemeral key eC instead of eA.
However, the attacker would not be able to open to device A the static key commitment H(sB||s) sent by device B out-of-band,
and the pairing will abort on A side before it reveals its static key.
Device B, instead, will successfully complete the pairing with the attacker.
Hence, timeboxing the QR exposure,
also in combination with increasing the number of decimal digits of the authcode,
will strongly limit the probability that an attacker can successfully impersonate device A to B.
We stress once more, that such attack requires the compromise of an ephemeral key (outside our security model)
and that device A will in any case detect a mismatch and abort the pairing,
regardless of the fact that the QR timeboxing mitigation is implemented or not.
Randomized Rekey
The Noise Protocol framework supports Rekey()
in order to update encryption keys "so that a compromise of cipherstate keys will not decrypt older [exchanged] messages".
However, if a certain cipherstate key is compromised,
it will be possible for the attacker not only to decrypt messages encrypted under that key,
but also all those messages encrypted under any successive new key obtained through a call to Rekey().
This could be mitigated by attaching an ephemeral key to messages sent after a Split() so that a new random symmetric key can be derived, in a similar fashion to Double-Ratchet.
This can be practically achieved by:
- keeping the full Handhshake State even after the handshake is complete (by Noise specification a call to
Split()should delete the Handshake State) - continuing updating the Handshake State by processing every after-handshake exchanged message (i.e. the
payload) according to the Noise processing rules (i.e. by callingEncryptAndHash(payload)andDecryptAndHash(payload)); - adding to each (or every few) message exchanged in the transfer phase a random ephemeral key
eand perform Diffie-Hellman operations with the other party's ephemeral/static keys in order to update the underlying CipherState and recover new random inbound/outbound encryption keys by callingSplit().
In short, the transfer phase would look like (but not necessarily the same as):
TransferPhase:
-> eA, eAeB, eAsB {payload}
<- eB, eAeB, sAeB {payload}
...
{}: payload
Messages Nametag Derivation
To reduce metadata leakages and increase devices's anonymity over the p2p network,
WAKU2-NOISE suggests to use some common secrets mntsInbound, mntsOutbound (e.g. mntsInbound, mntsOutbound = HKDF(h)
where h is the handshake hash value of the Handshake State at some point of the pairing phase)
in order to frequently and deterministically change the messageNametag of messages exchanged during the pairing and transfer phase -
ideally, at each message exchanged.
Given the proposed construction,
the mntsInbound and mntsOutbound secrets can be used to iteratively generate the messageNametag field of 26/WAKU2-PAYLOADs
for inbound and outbound messages, respectively.
The derivation of messageNametag should be deterministic only for communicating devices
and independent from message content,
otherwise lost messages will prevent computing the next message nametag.
A possible approach consists in computing the n-th messageNametag as H( mntsInbound || n),
where n is serialized as uint64.
In this way, sender's and recipient's devices
can keep updated a buffer of messageNametag to sieve
while listening to messages sent over /{application-name}/{application-version}/wakunoise/1/sessions-{shard-id}/ (i.e., the next 50 not yet seen).
They will then be able to further identify if one or more messages were eventually lost
or not-yet-delivered during the communication.
This approach brings also the advantage that
communicating devices can efficiently identify encrypted messages addressed to them.
We note that since the ChaChaPoly cipher used to encrypt messages supports additional data,
an encrypted payload can be further authenticated by passing the messageNametag as additional data to the encryption/decryption routine.
In this way, an attacker would be unable to craft an authenticated Waku message
even in case the currently used symmetric encryption key is compromised,
unless mntsInbound, mntsOutbound or the messageNametag buffer lists were compromised too.
Security/Privacy Considerations
Assumptions
-
The attacker is active, i.e. can interact with both devices
AandBby sending messages overcontentTopic. -
The attacker has access to the QR code, that is knows the ephemeral key
eB, the commitmentH(sB||r)and thecontentTopicexposed by the deviceB. -
Devices
AandBare considered trusted (otherwise the attacker will simply exfiltrate the relevant information from the attacked device). -
As common for Noise, we assume that ephemeral keys cannot be compromised, while static keys might be later compromised. However, we enforce in the pairing phase extra security mechanisms (i.e. use of commitments for static keys) that will prevent some attacks possible when ephemeral keys are weak or get compromised.
Rationale
-
The device
Bexposes a commitment to its static keysBbecause:- it can commit to its static key before the authentication code is confirmed without revealing it.
- If the private key of
eBis weak or gets compromised, an attacker can impersonateBby sending in messagec.to deviceAhis own static key and successfully complete the pairing phase. Note that being able to compromiseeBis not contemplated by our security assumptions. Bcannot adaptively choose a static key based on the state of the Noise handshake at the end of messageb., i.e. after the authentication code is confirmed. Note that deviceBis trusted in our security assumptions.- Confirming the authentication code after processing message
b.will ensure that no Man-in-the-Middle (MitM) can later send a static key different thansB.
-
The device
Asends a commitment to its static keysAbecause:- it can commit to its static key before the authentication code is confirmed without revealing it.
Acannot adaptively choose a static key based on the state of the Noise handshake at the end of messageb., i.e. after the authentication code is confirmed. Note that deviceAis trusted in our security assumptions.- Confirming the authentication code after processing message
b.will ensure that no MitM can later send a static key different thansA.
-
The authorization code is shown and has to be confirmed at the end of message
b.because:- an attacker that frontruns device
Aby sending faster his own ephemeral key would be detected before he's able to know deviceBstatic keysB; - it ensures that no MitM attacks will happen during the whole pairing handshake, since commitments to the (later exchanged) device static keys will be implicitly acknowledged by the authorization code confirmation;
- it enables to safely swap the role of handshake initiator and responder (see above);
- an attacker that frontruns device
-
Device
Bsends his static key first because:- by being the pairing requester, it cannot probe device
Aidentity without revealing its own (static key) first. Note that deviceBstatic key and its commitment can be bound to other cryptographic material (e.g., seed phrase).
- by being the pairing requester, it cannot probe device
-
Device
Bopens a commitment to its static key at messagec.because:- if device
Areplies concluding the handshake according to the protocol, deviceBacknowledges that deviceAcorrectly received his static keysB, sincerwas encrypted under an encryption key derived from the static keysBand the genuine (due to the previousauthcodeverification) ephemeral keyseAandeB.
- if device
-
Device
Aopens a commitment to its static key at messaged.because:- if device
Bdoesn't abort the pairing, deviceAacknowledges that deviceBcorrectly received his static keysA, sinceswas encrypted under an encryption key derived from the static keyssAandsBand the genuine (due to the previousauthcodeverification) ephemeral keyseAandeB.
- if device
Application to Noise Sessions
The N11M session management mechanism
In the N11M session management mechanism,
one of Alice's devices is already communicating with one of Bob's devices within an active Noise session,
e.g. after a successful execution of a Noise handshake.
Alice and Bob would then share some cryptographic key material, used to encrypt their communications. According to WAKU2-NOISE-SESSIONS this information consists of:
- A
session-id(32 bytes) - Two cipher state
CSOutbound,CSInbound, where each of them contains:- an encryption key
k(2x32bytes) - a nonce
n(2x8bytes) - (optionally) an internal state hash
h(2x32bytes)
- an encryption key
for a total of 176 bytes of information.
In a N11M session mechanism scenario,
all (synced) Alice's devices that are communicating with Bob
share the same Noise session cryptographic material.
Hence, if Alice wishes to add a new device,
she must securely transfer a copy of such data from one of her device A to a new device B in her possession.
In order to do so she can:
- pair device
AwithBin order to have a Noise session between them; - securely transfer within such session the 176 bytes serializing the active session with Bob;
- manually instantiate in
Ba Noise session with Bob from the received session serialization.
Copyright
Copyright and related rights waived via CC0.
References
Normative
Informative
- 26/WAKU2-PAYLOAD
- format
- The Double-Ratchet Algorithm
- The Noise Protocol Framework specifications
- IETF RFC 4648 - The Base16, Base32, and Base64 Data Encodings
- 14/WAKU2-MESSAGE
WAKU2-NOISE
| Field | Value |
|---|---|
| Name | Noise Protocols for Waku Payload Encryption |
| Slug | 170 |
| Status | raw |
| Type | RFC |
| Category | application |
| Tags | waku-core-protocol |
| Editor | Giuseppe [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
48600b5— Migrate logos-messaging/specs into docs/messaging/ (#315)
This specification describes how payloads of Waku messages with version 2 can be encrypted in order to achieve confidentiality, authenticity, and integrity as well as some form of identity-hiding on communicating parties.
This specification extends the functionalities provided by 26/WAKU-PAYLOAD, adding support to modern symmetric encryption primitives and asymmetric key-exchange protocols.
Specifically, it adds support to the ChaChaPoly cipher for symmetric authenticated encryption.
It further describes how the Noise Protocol Framework can be used to exchange cryptographic keys and encrypt/decrypt messages
in a way that the latter are authenticated and protected by strong forward secrecy.
This ultimately allows Waku applications to instantiate end-to-end encrypted communication channels with strong conversational security guarantees, as similarly done by 5/SECURE-TRANSPORT but in a more modular way, adapting key-exchange protocols to the knowledge communicating parties have of each other.
Design requirements
- Confidentiality: the adversary should not be able to learn what data is being sent from one Waku endpoint to one or several other Waku endpoints. - Strong forward secrecy: an active adversary cannot decrypt messages nor infer any information on the employed encryption key, even in the case he has access to communicating parties' long-term private keys (during or after their communication).
- Authenticity: the adversary should not be able to cause a Waku endpoint to accept messages coming from an endpoint different than their original senders.
- Integrity: the adversary should not be able to cause a Waku endpoint to accept data that has been tampered with.
- Identity-hiding: once a secure communication channel is established, a passive adversary should not be able to link exchanged encrypted messages to their corresponding sender and recipient.
Supported Cryptographic Protocols
Noise Protocols
Two parties executing a Noise protocol exchange one or more handshake messages and/or transport messages. A Noise protocol consists of one or more Noise handshakes. During a Noise handshake, two parties exchange multiple handshake messages. A handshake message contains ephemeral keys and/or static keys from one of the parties and an encrypted or unencrypted payload that can be used to transmit optional data. These public keys are used to perform a protocol-dependent sequence of Diffie-Hellman operations, whose results are all hashed into a shared secret key. After a handshake is complete, each party will then use the derived shared secret key to send and receive authenticated encrypted transport messages. We refer to Noise protocol framework specifications for the full details on how parties shared secret key is derived from each exchanged message.
Four Noise handshakes are currently supported: K1K1, XK1, XX, XXpsk0. Their description can be found in Appendix: Supported Handshakes Description.
These are instantiated combining the following cryptographic primitives:
Curve25519for Diffie-Hellman key-exchanges (32 bytes curve coordinates);ChaChaPolyfor symmetric authenticated encryption (16 bytes authentication tag);SHA256hash function used inHMACandHKDFkeys derivation chains (32 bytes output size);
Content Topics and Message Nametags of Noise Handshake Messages
We note that all design requirements on exchanged messages would be satisfied only after a supported Noise handshake is completed, corresponding to a total of 1 Round Trip Time communication (1-RTT). In particular, identity-hiding properties can be guaranteed only if the recommendation described in After-handshake are implemented.
In the following, we assume that communicating parties reciprocally know an initial contentTopic
where they can send/receive the first handshake message(s).
We further assume that messages sent over a certain contentTopic can be efficiently identified by their intended recipients
thanks to an arbitrary 16 bytes long message-nametag field embedded in the message payload
which is known in advance before messages reception.
The second handshake message MAY be sent/received with a message-nametag deterministically derived from the handshake state obtained after processing the first handshake message
(using, for example, HKDF over the handshake hash value h).
This allows
- the recipient to efficiently continue the handshakes started by each initiator;
- the initiators to efficiently associate the recipient's second handshake message to their first handshake message, However, this does not provide any identity-hiding guarantee to the recipient.
After the second handshake message is correctly received by initiators, the recommendation described in After-handshake SHOULD be implemented to provide full identity-hiding guarantees for both initiator and recipient against passive attackers.
Encryption Primitives
The symmetric primitives supported are:
ChaChaPolyfor authenticated encryption (16 bytes authentication tag).
Specification
When 14/WAKU-MESSAGE version is set to 2,
the corresponding WakuMessage's payload will encapsulate the two fields handshake-message and transport-message.
The handshake-message field MAY contain
- a Noise handhshake message (only encrypted/unencrypted public keys).
The transport-message field MAY contain
- a Noise handshake message payload (encrypted/unencrypted);
- a Noise transport message;
- a
ChaChaPolyciphertext.
When a transport-message encodes a ChaChaPoly ciphertext, the corresponding handshake-message field MUST be empty.
The following fields are concatenated to form the payload field:
message-nametag: an arbitrary identifier for the Waku message (16 byte). If the underlying encryption primitive supports it, the contents of this field SHOULD be passed as additional data to the encryption and decryption routines.protocol-id: identifies the protocol or primitive in use (1 byte). Supported values are: -0: protocol specification omitted (set for after-handshake messages); -10: Noise protocolNoise_K1K1_25519_ChaChaPoly_SHA256; -11: Noise protocolNoise_XK1_25519_ChaChaPoly_SHA256; -12: Noise protocolNoise_XX_25519_ChaChaPoly_SHA256; -13: Noise protocolNoise_XXpsk0_25519_ChaChaPoly_SHA256; -30:ChaChaPolysymmetric encryption.handshake-message-len: the length in bytes of the Noise handshake message (1 byte). Ifprotocol-idis not equal to0,10,11,12,13, this field MUST be set to0;handshake-message: the Noise handshake message (handshake-message-lenbytes). Ifhandshake-message-lenis not0, it contains the concatenation of one or more Noise Diffie-Hellman ephemeral or static keys encoded as in Public Keys Encoding;transport-message-len: the length in bytes oftransport-message(8 bytes, stored in Little-Endian);transport-message: the transport message (transport-message-lenbytes); Only during a Noise handshake, this field would contain the Noise handshake message payload. The symmetric encryption authentication data fortransport-message, when present, is appended at the end oftransport-message(16 bytes).
ABNF
Using Augmented Backus-Naur form (ABNF) we have the following format:
; message nametag
message-nametag = 16OCTET
; protocol ID
protocol-id = 1OCTET
; contains the size of handshake-message
handshake-message-len = 1OCTET
; contains one or more Diffie-Hellman public keys
handshake-message = *OCTET
; contains the size of transport-message
transport-message-len = *OCTET
; contains the transport message, eventually encrypted.
; If encrypted, authentication data is appended
transport-message = *OCTET
; the Waku WakuMessage payload field
payload = message-nametag protocol-id handshake-message-len handshake-message transport-message-len transport-message
Protocol Payload Format
Based on the specified protocol-id,
the Waku message payload field will encode different types of protocol-dependent messages.
In particular, if protocol-id is
0: payload encodes an after-handshake message.handshake-message-lenMAY be 0;transport-messagecontains the Noise transport message;
10,11,12,13: payload encodes a supported Noise handshake message.transport-messagecontains the Noise transport message;
30: payload encapsulate aChaChaPolyciphertextct.handshake-message-lenis set to0;transport-messagecontains the concatenation of the encryption nonce (12 bytes) followed by the ciphertextctand the authentication data forct(16 bytes);transport-message-lenis set accordingly totransport-messagelength;
Public Keys Serialization
Diffie-Hellman public keys can be trasmitted in clear
or in encrypted form (cf. WriteMessage) with authentication data attached.
To distinguish between these two cases, public keys are serialized as the concatenation of the following three fields:
flag: is equal to1if the public key is encrypted;0otherwise (1 byte);pk: ifflag = 0, it contains an encoding of the X coordinate of the public key. Ifflag = 1, it contains a symmetric encryption of an encoding of the X coordinate of the public key, followed by encryption's authentication data;
The corresponding serialization is obtained as flag pk.
As regards the underlying supported cryptographic primitives:
Curve25519public keys X coordinates are encoded in little-endian as 32 bytes arrays;ChaChaPolyauthentication data consists of 16 bytes (nonces are implicitely defined by Noise processing rules).
In all supported Noise protocols,
parties' static public keys are transmitted encrypted (cf. EncryptAndHash),
while ephemeral keys MAY be encrypted after a handshake is complete.
Padding
To prevent some metadata leakage, encrypted transport messages SHOULD be padded before encryption.
It is therefore recommended to right pad transport messages using RFC2630 so that their final length is a multiple of 248 bytes.
After-handshake
During the initial 1-RTT communication,
handshake messages might be linked,
depending on the message-nametag derivation rule implemented,
to the respective parties through the contentTopic and message-nametag fields employed for such communication.
After a handshake is completed,
parties MAY derive from their shared secret key (preferably using HKDF)
two random nametag-secret-outbound and nametag-secret-inbound values used to deterministically derive
two arbitrary-long ordered lists of message-nametag
used to indentify outbound and inbound messages, respectively
(e.g. the n-th inbound message-nametag MAY be computed as HKDF(nametag-secret-inbound || n)).
This allows communicating parties to efficiently identify messages addressed to them sent over a certain contentTopic
and thus minimize the number of trial decryptions.
When communicating,
parties SHOULD set protocol-id to 0
to reduce metadata leakages and indicate that the message is an after-handshake message.
Each party SHOULD attach an (unencrypted) ephemeral key in handshake-message to every message sent.
According to Noise processing rules,
this allows updates to the shared secret key
by hashing the result of an ephemeral-ephemeral Diffie-Hellman exchange every 1-RTT communication.
Backward Support for Symmetric/Asymmetric Encryption
It is possible to have backward compatibility to symmetric/asymmetric encryption primitives from 26/WAKU-PAYLOAD, effectively encapsulating payload encryption 14/WAKU-MESSAGE version 1 in version 2.
It suffices to extend the list of supported protocol-id to:
254: AES-256-GCM symmetric encryption;255: ECIES asymmetric encryption.
and set the transport-message field to the 26/WAKU-PAYLOAD data field, whenever these protocol-id values are set.
Namely, if protocol-id = 254, 255 then:
message-nametag: is empty;handshake-message-len: is set to0;handshake-message: is empty;transport-message: contains the 26/WAKU-PAYLOADdatafield (AES-256-GCM or ECIES, depending onprotocol-id);transport-message-lenis set accordingly totransport-messagelength;
When a transport-message corresponding to protocol-id = 254, 255 is retrieved,
it SHOULD be decoded as the data field in 26/WAKU-PAYLOAD specification.
Appendix: Supported Handshakes Description
Supported Noise handshakes address four typical scenarios occurring when an encrypted communication channel between Alice and Bob is going to be created:
- Alice and Bob know each others' static key.
- Alice knows Bob's static key;
- Alice and Bob share no key material and they don't know each others' static key.
- Alice and Bob share some key material, but they don't know each others' static key.
Adversarial Model: an active attacker who compromised one party's static key may lower the identity-hiding security guarantees provided by some handshakes. In our security model we exclude such adversary, but for completeness we report a summary of possible de-anonymization attacks that can be performed by an active attacker.
The K1K1 Handshake
If Alice and Bob know each others' static key (e.g., these are public or were already exchanged in a previous handshake) , they MAY execute a K1K1 handshake. Using Noise notation (Alice is on the left) this can be sketched as:
K1K1:
-> s
<- s
...
-> e
<- e, ee, es
-> se
We note that here only ephemeral keys are exchanged. This handshake is useful in case Alice needs to instantiate a new separate encrypted communication channel with Bob, e.g. opening multiple parallel connections, file transfers, etc.
Security considerations on identity-hiding (active attacker): no static key is transmitted, but an active attacker impersonating Alice can check candidates for Bob's static key.
The XK1 Handshake
Here, Alice knows how to initiate a communication with Bob and she knows his public static key: such discovery can be achieved, for example, through a publicly accessible register of users' static keys, smart contracts, or through a previous public/private advertisement of Bob's static key.
A Noise handshake pattern that suits this scenario is XK1:
XK1:
<- s
...
-> e
<- e, ee, es
-> s, se
Within this handshake, Alice and Bob reciprocally authenticate their static keys s using ephemeral keys e. We note that while Bob's static key is assumed to be known to Alice (and hence is not transmitted), Alice's static key is sent to Bob encrypted with a key derived from both parties ephemeral keys and Bob's static key.
Security considerations on identity-hiding (active attacker): Alice's static key is encrypted with forward secrecy to an authenticated party. An active attacker initiating the handshake can check candidates for Bob's static key against recorded/accepted exchanged handshake messages.
The XX and XXpsk0 Handshakes
If Alice is not aware of any static key belonging to Bob (and neither Bob knows anything about Alice), she can execute an XX handshake, where each party tranXmits to the other its own static key.
The handshake goes as follows:
XX:
-> e
<- e, ee, s, es
-> s, se
We note that the main difference with XK1 is that in second step Bob sends to Alice his own static key encrypted with a key obtained from an ephemeral-ephemeral Diffie-Hellman exchange.
This handshake can be slightly changed in case both Alice and Bob pre-shares some secret psk which can be used to strengthen their mutual authentication during the handshake execution. One of the resulting protocol, called XXpsk0, goes as follow:
XXpsk0:
-> psk, e
<- e, ee, s, es
-> s, se
The main difference with XX is that Alice's and Bob's static keys, when transmitted, would be encrypted with a key derived from psk as well.
Security considerations on identity-hiding (active attacker): Alice's static key is encrypted with forward secrecy to an authenticated party for both XX and XXpsk0 handshakes. In XX, Bob's static key is encrypted with forward secrecy but is transmitted to a non-authenticated user which can then be an active attacker. In XXpsk0, instead, Bob's secret key is protected by forward secrecy to a partially authenticated party (through the pre-shared secret psk but not through any static key), provided that psk was not previously compromised (in such case identity-hiding properties provided by the XX handshake applies).
References
- 5/SECURE-TRANSPORT
- 10/WAKU2
- 26/WAKU-PAYLOAD
- 14/WAKU-MESSAGE
- Noise protocol
- Noise handshakes as key-exchange mechanism for Waku2
- Augmented Backus-Naur form (ABNF)
- RFC2630 - Content-encryption Process and padding
Copyright
Copyright and related rights waived via CC0.
WAKU2-NOISE-SESSIONS
| Field | Value |
|---|---|
| Name | Session Management for Waku Noise |
| Slug | 169 |
| Status | raw |
| Type | RFC |
| Category | application |
| Tags | waku-core-protocol |
| Editor | Giuseppe [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
48600b5— Migrate logos-messaging/specs into docs/messaging/ (#315)
Introduction
In WAKU2-NOISE we defined how Waku messages' payloads can be encrypted using key material derived from key agreements based on the Noise Protocol Framework.
Once two users complete a Noise handshake, an encryption/decryption session - or a Noise session - would be instantiated.
This post provides an overview on how we can possibly implement and manage one or multiple Noise sessions in Waku.
Preliminaries
We assume that two users, e.g. Alice and Bob, successfully completed a Noise handshake.
Using Noise terminology, at the end of the handshake they will share:
- two Cipher States
CSOutboundandCSInbound, to encrypt and decrypt outbound and inbound messages, respectively; - a handshake hash value
h.
As suggested in Noise specifications in regards to Channel Binding,
we can identify a Noise session with a session-id derived from the handshake hash value h shared on completion of a Noise handshake.
More specifically, when Alice and Bob call Split() in order to derive the two final encryption and decryption Cipher States,
they further compute session-id = HKDF(h) using the supported key derivation function HKDF.
Such session-id will uniquely identify the Noise cryptographic session instantiated on completion of a Noise handshake,
which would then consist of the tuple (session-id, CSOutbound, CSInbound).
For each instantiated Noise session we assume this tuple to be properly persisted,
since it is required to either retrieve and encrypt/decrypt any further exchanged message.
Once a Noise session is instantiated,
any further encrypted message between Alice and Bob within this session is exchanged on a contentTopic with name /{application-name}/{application-version}/wakunoise/1/sessions/{ct-id}/proto,
where ct-id = Hash(Hash(session-id))
and /{application-name}/{application-version}/ identifies the application currently employing WAKU2-NOISE.
Session states
A Noise session corresponding to a certain session-id:
- is always active as long as it is not marked as stale.
For an active
session-id, new messages are published on the content topic/{application-name}/{application-version}/wakunoise/1/sessions/{ct-id}/proto; - is marked as stale if a session termination message containing
Hash(session-id)is published on the content topic/{application-name}/{application-version}/wakunoise/1/sessions/{ct-id}/proto. Session information relative to stale sessions MAY be deleted from users' device, unless required for later channel binding purposes.
When a Noise session is marked as stale, it means that one party requested its termination while being online,
since publication of a hash pre-image for ct-id is required (i.e. Hash(session-id)).
Currently, it is not possible to mark a Noise session as stale when session-id is lost or gets corrupted in users' devices.
However, since session-id is shared between Alice and Bob,
one party MAY decide to mark a Noise session as stale if no message from the other end was received within a certain fixed time window.
The above mechanism allows a Noise session to be marked as stale either privately or publicly,
depending if Hash(session-id) is sent on /{application-name}/{application-version}/wakunoise/1/sessions/{ct-id}/proto to the other party in encrypted form or not, respectively.
When a Noise session is publicly marked as stale,
network peers MAY discard all stored messages addressed to the content topic /{application-name}/{application-version}/wakunoise/1/sessions/{ct-id}/proto.
In this the case and in order for parties to retrieve any eventually delayed message,
peers SHOULD wait a fixed amount of time before discarding stored messages corresponding to a stale Noise session.
A stale Noise session cannot be directly marked as active and parties are required to instantiate a new Noise session if they wish to communicate again.
However, parties can optionally persist and include the session-id corresponding to a stale Noise session in the prologue information employed in the Noise handshake they execute to instantiate their new Noise session.
This effectively emulates a mechanism to "re-activate" a stale Noise session by binding it to a newly created active Noise session.
In order to reduce users' metadata leakage, it is desirable (as suggested in WAKU2-NOISE) that content topics used for communications change every time a new message is exchanged.
This can be easily realized by employing a key derivation function to compute a new session-id from the previously employed one (e.g. session-id = HKDF(prev-session-id)),
while keeping the Inbound/outbound Cipher States, the content topic derivation mechanism and the stale mechanism the same as above.
In this case, when one party sends and receives at least one message,
he SHALL publicly mark as stale all Noise sessions relative to messages exchanged before the earlier of these two send/receive events.
Multi-Device support
Alice and Bob might possess one or more devices (e.g. laptops, smartphones, etc.) they wish to use to communicate. In the following, we assume Alice and Bob to possess and devices, respectively.
Since a Noise session contains cryptographic material required to encrypt and decrypt messages exchanged on a pre-defined content topic derived from a session-id,
messages should be encrypted and decrypted within the Noise session instantiated between the currently-in-use sender's and receiver's device.
This is achieved through two main supported session management mechanisms that we called N11M and NM, respectively.
The N11M session management mechanism
In an N11M setting, each party's device shares the same Noise session information used to encrypt and decrypt messages exchanged with the other party.
More precisely, once the first Noise session between any of Alice's and Bob's device is instantiated, its session information is securely propagated to all other devices, which then become able to send and receive new messages on the content topic associated to such session. We note, however, that two devices belonging to one party cannot simultaneously send different messages to the other, since only the first message received will be correctly decrypted using the next nonce.
The most updated session information between Alice and Bob is propagated in encrypted form to other devices, using previously instantiated Noise sessions. In particular, all Alice's (resp., Bob's) devices that want to receive such updated session information, are required to have an already instantiated Noise session between them in order to receive it in encrypted form. The propagated session information corresponds to the latest session information stored on the device currently communicating with (any of the devices of) the other party.
We note that sessions information is propagated only among devices belonging to the same party and not with other party's devices. Hence, Alice has no knowledge on the number of devices Bob is using and vice versa.
When any device marks a Noise session between Alice and Bob as stale,
all other (updated) devices will consider such session as stale
without publishing the Hash(session-id) on the corresponding session content topic.
In case a Noise session between two devices belonging to the same party is marked as stale, such two devices stop to reciprocally propagate any information regarding Noise sessions instantiated with other parties.
As regards security, an attacker that compromises an encrypted message propagating session information, might be able to compromise one or multiple messages exchanged within the session such information refers to. This can be mitigated by adopting techniques similar to the the ones proposed in WAKU2-NOISE, where encryption keys are changed every time a new message is exchanged.
This session management mechanism is loosely based on the paper "Multi-Device for Signal".
The NM session management mechanism
In an NM setting, we require all of Alice's devices to have an active Noise session with each of Bob's devices,
for a total of concurrently active Noise sessions between Alice and Bob.
A message is sent from the currently-in-use sender's device to all recipent's devices, by properly encrypting and sending it to the content topics of each corresponding active Noise session.
We note that this allows the recipient to receive a message on all his devices simultaneously. However, on the sender side, only the device which effectively sent the message will know its full content.
If it is required for sent messages to be available on all sender's devices, each pair of sender's devices SHOULD have an active Noise session used for syncing purposes: this sums up to a total of and extra Noise sessions instantiated on each Alice's and Bob's device, respectively.
Thus, if Alice wants to send a message to Bob from one of her devices, she encrypts and sends her message to each of Bob's devices (and, eventually, to each of her other devices), using the appropriate Noise session information.
If one device marks a Noise session as stale, all active sessions instantiated with such device SHOULD be marked as stale as soon as possible. If the device declaring a stale session does not send a session termination message to all the other party's devices with which has an active session, the other party SHOULD send a termination message to mark all such Noise sessions as stale.
This session management mechanism is loosely based on Signal's Sesame Algorithm.
References
- 13/WAKU2-STORE
- WAKU2-NOISE
- The Noise Protocol Framework
- The Sesame Algorithm: Session Management for Asynchronous Message Encryption
- "Multi-Device for Signal"
Application
Application-level messaging draft specifications.
3/REMOTE-LOG
| Field | Value |
|---|---|
| Name | Remote log specification |
| Slug | 3 |
| Status | draft |
| Type | RFC |
| Category | application |
| Editor | Oskar Thorén [email protected] |
| Contributors | Dean Eigenmann [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-02-01 —
3fd8b5a— Update and rename README.md to remote-log.md - 2024-01-30 —
dce61fe— Create README.md
A remote log is a replication of a local log. This means a node can read data that originally came from a node that is offline.
This specification is complemented by a proof of concept implementation1.
Definitions
| Term | Definition |
|---|---|
| CAS | Content-addressed storage. Stores data that can be addressed by its hash. |
| NS | Name system. Associates mutable data to a name. |
| Remote log | Replication of a local log at a different location. |
Wire Protocol
Secure Transport, storage, and name system
This specification does not define anything related to: secure transport, content addressed storage, or the name system. It is assumed these capabilities are abstracted away in such a way that any such protocol can easily be implemented.
Payloads
Payloads are implemented using protocol buffers v3.
CAS service:
syntax = "proto3";
package vac.cas;
service CAS {
rpc Add(Content) returns (Address) {}
rpc Get(Address) returns (Content) {}
}
message Address {
bytes id = 1;
}
message Content {
bytes data = 1;
}
NS service:
syntax = "proto3";
package vac.cas;
service NS {
rpc Update(NameUpdate) returns (Response) {}
rpc Fetch(Query) returns (Content) {}
}
message NameUpdate {
string name = 1;
bytes content = 2;
}
message Query {
string name = 1;
}
message Content {
bytes data = 1;
}
message Response {
bytes data = 1;
}
Remote log:
syntax = "proto3";
package vac.cas;
message RemoteLog {
repeated Pair pair = 1;
bytes tail = 2;
message Pair {
bytes remoteHash = 1;
bytes localHash = 2;
bytes data = 3;
}
}
Synchronization
Roles
There are four fundamental roles:
- Alice
- Bob
- Name system (NS)
- Content-addressed storage (CAS)
The remote log protobuf is what is stored in the name system.
"Bob" can represent anything from 0 to N participants. Unlike Alice, Bob only needs read-only access to NS and CAS.
Flow
Remote log
The remote log lets receiving nodes know what data they are missing. Depending on the specific requirements and capabilities of the nodes and name system, the information can be referred to differently. We distinguish between three rough modes:
- Fully replicated log
- Normal sized page with CAS mapping
- "Linked list" mode - minimally sized page with CAS mapping
Data format:
| H1_3 | H2_3 |
| H1_2 | H2_2 |
| H1_1 | H2_1 |
| ------------|
| next_page |
Here the upper section indicates a list of ordered pairs, and the lower section
contains the address for the next page chunk. H1 is the native hash function,
and H2 is the one used by the CAS. The numbers corresponds to the messages.
To indicate which CAS is used, a remote log SHOULD use a multiaddr.
Embedded data:
A remote log MAY also choose to embed the wire payloads that corresponds to the native hash. This bypasses the need for a dedicated CAS and additional round-trips, with a trade-off in bandwidth usage.
| H1_3 | | C_3 |
| H1_2 | | C_2 |
| H1_1 | | C_1 |
| -------------|
| next_page |
Here C stands for the content that would be stored at the CAS.
Both patterns can be used in parallel, e,g. by storing the last k messages
directly and use CAS pointers for the rest. Together with the next_page page
semantics, this gives users flexibility in terms of bandwidth and
latency/indirection, all the way from a simple linked list to a fully replicated
log. The latter is useful for things like backups on durable storage.
Next page semantics
The pointer to the 'next page' is another remote log entry, at a previous point in time.
Interaction with MVDS
vac.mvds.Message payloads are the only payloads that MUST be uploaded. Other messages types MAY be uploaded, depending on the implementation.
Acknowledgments
TBD.
Copyright
Copyright and related rights waived via CC0.
Footnotes
4/MVDS-META
| Field | Value |
|---|---|
| Name | MVDS Metadata Field |
| Slug | 4 |
| Status | draft |
| Type | RFC |
| Category | application |
| Editor | Sanaz Taheri [email protected] |
| Contributors | Dean Eigenmann [email protected], Andrea Maria Piana [email protected], Oskar Thorén [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-02-01 —
3a396b5— Update and rename README.md to mvds-meta.md - 2024-01-30 —
2e80c3b— Create README.md
In this specification, we describe a method to construct message history that will aid the consistency guarantees of 2/MVDS. Additionally, we explain how data sync can be used for more lightweight messages that do not require full synchronization.
Motivation
In order for more efficient synchronization of conversational messages, information should be provided allowing a node to more effectively synchronize the dependencies for any given message.
Format
We introduce the metadata message which is used to convey information about a message and how it SHOULD be handled.
package vac.mvds;
message Metadata {
repeated bytes parents = 1;
bool ephemeral = 2;
}
Nodes MAY transmit a Metadata message by extending the MVDS message
with a metadata field.
message Message {
bytes group_id = 6001;
int64 timestamp = 6002;
bytes body = 6003;
+ Metadata metadata = 6004;
}
Fields
| Name | Description |
|---|---|
parents | list of parent message identifiers for the specific message. |
ephemeral | indicates whether a message is ephemeral or not. |
Usage
parents
This field contains a list of parent message identifiers
for the specific message.
It MUST NOT contain any messages as parent whose ack flag was set to false.
This establishes a directed acyclic graph (DAG)[^2] of persistent messages.
Nodes MAY buffer messages until dependencies are satisfied for causal consistency[^3], they MAY also pass the messages straight away for eventual consistency[^4].
A parent is any message before a new message that a node is aware of that has no children.
The number of parents for a given message is bound by [0, N],
where N is the number of nodes participating in the conversation,
therefore the space requirements for the parents field is O(N).
If a message has no parents it is considered a root. There can be multiple roots, which might be disconnected, giving rise to multiple DAGs.
ephemeral
When the ephemeral flag is set to false,
a node MUST send an acknowledgment when they have received and processed a message.
If it is set to true, it SHOULD NOT send any acknowledgment.
The flag is false by default.
Nodes MAY decide to not persist ephemeral messages, however they MUST NOT be shared as part of the message history.
Nodes SHOULD send ephemeral messages in batch mode. As their delivery is not needed to be guaranteed.
Copyright
Copyright and related rights waived via CC0.
Footnotes
1: 2/MVDS 2: directed_acyclic_graph 3: Jepsen. Causal Consistency Jepsen, LLC. 4: https://en.wikipedia.org/wiki/Eventual_consistency
20/TOY-ETH-PM
| Field | Value |
|---|---|
| Name | Toy Ethereum Private Message |
| Slug | 20 |
| Status | draft |
| Type | RFC |
| Category | application |
| Editor | Franck Royer [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-30 —
d5a9240— chore: removed archived (#283) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-04-09 —
3b152e4— 20/TOY-ETH-PM: Update (#141) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-01-31 —
89a94a5— Update toy-eth-pm.md - 2024-01-30 —
c4ff509— Create toy-eth-pm.md - 2024-01-30 —
8841f49— Update toy-eth-pm.md - 2024-01-29 —
a16a2b4— Create toy-eth-pm.md
Content Topics:
- Public Key Broadcast:
/eth-pm/1/public-key/proto - Private Message:
/eth-pm/1/private-message/proto
Abstract
This specification explains the Toy Ethereum Private Message protocol which enables a peer to send an encrypted message to another peer over the Waku network using the peer's Ethereum address.
Goal
Alice wants to send an encrypted message to Bob, where only Bob can decrypt the message. Alice only knows Bob's Ethereum Address.
The goal of this specification is to demonstrate how Waku can be used for encrypted messaging purposes, using Ethereum accounts for identity. This protocol caters to Web3 wallet restrictions, allowing it to be implemented using standard Web3 API. In the current state, Toy Ethereum Private Message, ETH-PM, has privacy and features limitations, has not been audited and hence is not fit for production usage. We hope this can be an inspiration for developers wishing to build on top of Waku.
Design Requirements
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in 2119.
Variables
Here are the variables used in the protocol and their definition:
Bis Bob's Ethereum address (or account),bis the private key ofB, and is only known by Bob.B'is Bob's Encryption Public Key, for whichb'is the private key.Mis the private message that Alice sends to Bob.
The proposed protocol MUST adhere to the following design requirements:
- Alice knows Bob's Ethereum address
- Bob is willing to participate to Eth-PM, and publishes
B' - Bob's ownership of
B'MUST be verifiable - Alice wants to send message
Mto Bob - Bob SHOULD be able to get
Musing 10/WAKU2 - Participants only have access to their Ethereum Wallet via the Web3 API
- Carole MUST NOT be able to read
M's content, even if she is storing it or relaying it - Waku Message Version 1 Asymmetric Encryption is used for encryption purposes.
Limitations
Alice's details are not included in the message's structure, meaning that there is no programmatic way for Bob to reply to Alice or verify her identity.
Private messages are sent on the same content topic for all users. As the recipient data is encrypted, all participants must decrypt all messages which can lead to scalability issues.
This protocol does not guarantee Perfect Forward Secrecy nor Future Secrecy: If Bob's private key is compromised, past and future messages could be decrypted. A solution combining regular X3DH bundle broadcast with Double Ratchet encryption would remove these limitations; See the Status secure transport specification for an example of a protocol that achieves this in a peer-to-peer setting.
Bob MUST decide to participate in the protocol before Alice can send him a message. This is discussed in more detail in Consideration for a non-interactive/uncoordinated protocol
The Protocol
Generate Encryption KeyPair
First, Bob needs to generate a keypair for Encryption purposes.
Bob SHOULD get 32 bytes from a secure random source as Encryption Private Key, b'.
Then Bob can compute the corresponding SECP-256k1 Public Key, B'.
Broadcast Encryption Public Key
For Alice to encrypt messages for Bob,
Bob SHOULD broadcast his Encryption Public Key B'.
To prove that the Encryption Public Key B'
is indeed owned by the owner of Bob's Ethereum Account B,
Bob MUST sign B' using B.
Sign Encryption Public Key
To prove ownership of the Encryption Public Key,
Bob must sign it using EIP-712 v3,
meaning calling eth_signTypedData_v3 on his wallet's API.
Note: While v4 also exists, it is not available on all wallets and the features brought by v4 is not needed for the current use case.
The TypedData to be passed to eth_signTypedData_v3 MUST be as follows, where:
encryptionPublicKeyis Bob's Encryption Public Key,B', in hex format, without0xprefix.bobAddressis Bob's Ethereum address, corresponding toB, in hex format, with0xprefix.
const typedData = {
domain: {
chainId: 1,
name: 'Ethereum Private Message over Waku',
version: '1',
},
message: {
encryptionPublicKey: encryptionPublicKey,
ownerAddress: bobAddress,
},
primaryType: 'PublishEncryptionPublicKey',
types: {
EIP712Domain: [
{ name: 'name', type: 'string' },
{ name: 'version', type: 'string' },
{ name: 'chainId', type: 'uint256' },
],
PublishEncryptionPublicKey: [
{ name: 'encryptionPublicKey', type: 'string' },
{ name: 'ownerAddress', type: 'string' },
],
},
}
Public Key Message
The resulting signature is then included in a PublicKeyMessage, where
encryption_public_keyis Bob's Encryption Public KeyB', not compressed,eth_addressis Bob's Ethereum AddressB,signatureis the EIP-712 as described above.
syntax = "proto3";
message PublicKeyMessage {
bytes encryption_public_key = 1;
bytes eth_address = 2;
bytes signature = 3;
}
This MUST be wrapped in a 14/WAKU-MESSAGE version 0, with the Public Key Broadcast content topic. Finally, Bob SHOULD publish the message on Waku.
Consideration for a non-interactive/uncoordinated protocol
Alice has to get Bob's public Key to send a message to Bob. Because an Ethereum Address is part of the hash of the public key's account, it is not enough in itself to deduce Bob's Public Key.
This is why the protocol dictates that Bob MUST send his Public Key first, and Alice MUST receive it before she can send him a message.
Moreover, nwaku, the reference implementation of 13/WAKU2-STORE, stores messages for a maximum period of 30 days. This means that Bob would need to broadcast his public key at least every 30 days to be reachable.
Below we are reviewing possible solutions to mitigate this "sign up" step.
Retrieve the public key from the blockchain
If Bob has signed at least one transaction with his account then his Public Key can be extracted from the transaction's ECDSA signature. The challenge with this method is that standard Web3 Wallet API does not allow Alice to specifically retrieve all/any transaction sent by Bob.
Alice would instead need to use the eth.getBlock API
to retrieve Ethereum blocks one by one.
For each block, she would need to check the from value of each transaction
until she finds a transaction sent by Bob.
This process is resource intensive and can be slow when using services such as Infura due to rate limits in place, which makes it inappropriate for a browser or mobile phone environment.
An alternative would be to either run a backend that can connect directly to an Ethereum node, use a centralized blockchain explorer or use a decentralized indexing service such as The Graph.
Note that these would resolve a UX issue only if a sender wants to proceed with air drops.
Indeed, if Bob does not publish his Public Key in the first place then it MAY be an indication that he does not participate in this protocol and hence will not receive messages.
However, these solutions would be helpful if the sender wants to proceed with an air drop of messages: Send messages over Waku for users to retrieve later, once they decide to participate in this protocol. Bob may not want to participate first but may decide to participate at a later stage and would like to access previous messages. This could make sense in an NFT offer scenario: Users send offers to any NFT owner, NFT owner may decide at some point to participate in the protocol and retrieve previous offers.
Publishing the public in long term storage
Another improvement would be for Bob not having to re-publish his public key every 30 days or less. Similarly to above, if Bob stops publishing his public key then it MAY be an indication that he does not participate in the protocol anymore.
In any case, the protocol could be modified to store the Public Key in a more permanent storage, such as a dedicated smart contract on the blockchain.
Send Private Message
Alice MAY monitor the Waku network to collect Ethereum Address and
Encryption Public Key tuples.
Alice SHOULD verify that the signatures of PublicKeyMessages she receives
are valid as per EIP-712.
She SHOULD drop any message without a signature or with an invalid signature.
Using Bob's Encryption Public Key, retrieved via 10/WAKU2, Alice MAY now send an encrypted message to Bob.
If she wishes to do so,
Alice MUST encrypt her message M using Bob's Encryption Public Key B',
as per 26/WAKU-PAYLOAD Asymmetric Encryption specs.
Alice SHOULD now publish this message on the Private Message content topic.
Copyright
Copyright and related rights waived via CC0.
References
- 10/WAKU2
- Waku Message Version 1
- X3DH
- Double Ratchet
- Status secure transport specification
- EIP-712
- 13/WAKU2-STORE
- The Graph
26/WAKU2-PAYLOAD
| Field | Value |
|---|---|
| Name | Waku Message Payload Encryption |
| Slug | 26 |
| Status | draft |
| Type | RFC |
| Category | application |
| Editor | Oskar Thoren [email protected] |
| Contributors | Oskar Thoren [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-30 —
d5a9240— chore: removed archived (#283) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-03-31 —
f08de10— 26/WAKU2-PAYLOADS: Update (#136) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-01-31 —
33cf551— Update payload.md - 2024-01-31 —
29acb80— Rename README.md to payload.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-25 —
7bd0712— Create README.md
Abstract
This specification describes how Waku provides confidentiality, authenticity, and integrity, as well as some form of unlinkability. Specifically, it describes how encryption, decryption and signing works in 6/WAKU1 and in 10/WAKU2 with 14/WAKU-MESSAGE.
This specification effectively replaces 7/WAKU-DATA as well as 6/WAKU1 Payload encryption but written in a way that is agnostic and self-contained for 6/WAKU1 and 10/WAKU2.
Large sections of the specification originate from EIP-627: Whisper spec as well from RLPx Transport Protocol spec (ECIES encryption) with some modifications.
Specification
The keywords “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in 2119.
For 6/WAKU1,
the data field is used in the waku envelope
and the field MAY contain the encrypted payload.
For 10/WAKU2,
the payload field is used in WakuMessage
and MAY contain the encrypted payload.
The fields that are concatenated and
encrypted as part of the data (Waku legacy) or
payload (Waku) field are:
flagspayload-lengthpayloadpaddingsignature
Design requirements
- Confidentiality: The adversary SHOULD NOT be able to learn what data is being sent from one Waku node to one or several other Waku nodes.
- Authenticity: The adversary SHOULD NOT be able to cause Waku endpoint to accept data from any third party as though it came from the other endpoint.
- Integrity: The adversary SHOULD NOT be able to cause a Waku endpoint to accept data that has been tampered with.
Notable, forward secrecy is not provided for at this layer. If this property is desired, a more fully featured secure communication protocol can be used on top.
It also provides some form of unlinkability since:
- only participants who are able to decrypt a message can see its signature
- payload are padded to a fixed length
Cryptographic primitives
- AES-256-GCM (for symmetric encryption)
- ECIES
- ECDSA
- KECCAK-256
ECIES is using the following cryptosystem:
- Curve: secp256k1
- KDF: NIST SP 800-56 Concatenation Key Derivation Function, with SHA-256 option
- MAC: HMAC with SHA-256
- AES: AES-128-CTR
ABNF
Using Augmented Backus-Naur form (ABNF) we have the following format:
; 1 byte; first two bits contain the size of payload-length field,
; third bit indicates whether the signature is present.
flags = 1OCTET
; contains the size of payload.
payload-length = 4*OCTET
; byte array of arbitrary size (may be zero).
payload = *OCTET
; byte array of arbitrary size (may be zero).
padding = *OCTET
; 65 bytes, if present.
signature = 65OCTET
data = flags payload-length payload padding [signature]
; This field is called payload in Waku
payload = data
Signature
Those unable to decrypt the payload/data are also unable to access the signature.
The signature, if provided,
SHOULD be the ECDSA signature of the Keccak-256 hash of the unencrypted data
using the secret key of the originator identity.
The signature is serialized as the concatenation of the r, s and v parameters
of the SECP-256k1 ECDSA signature, in that order.
r and s MUST be big-endian encoded, fixed-width 256-bit unsigned.
v MUST be an 8-bit big-endian encoded,
non-normalized and should be either 27 or 28.
See Ethereum "Yellow paper": Appendix F Signing transactions for more information on signature generation, parameters and public key recovery.
Encryption
Symmetric
Symmetric encryption uses AES-256-GCM for
authenticated encryption.
The output of encryption is of the form (ciphertext, tag, iv)
where ciphertext is the encrypted message,
tag is a 16 byte message authentication tag and
iv is a 12 byte initialization vector (nonce).
The message authentication tag and
initialization vector iv field MUST be appended to the resulting ciphertext,
in that order.
Note that previous specifications and
some implementations might refer to iv as nonce or salt.
Asymmetric
Asymmetric encryption uses the standard Elliptic Curve Integrated Encryption Scheme (ECIES) with SECP-256k1 public key.
ECIES
This section originates from the RLPx Transport Protocol spec specification with minor modifications.
The cryptosystem used is:
- The elliptic curve secp256k1 with generator
G. KDF(k, len): the NIST SP 800-56 Concatenation Key Derivation Function.MAC(k, m): HMAC using the SHA-256 hash function.AES(k, iv, m): the AES-128 encryption function in CTR mode.
Special notation used: X || Y denotes concatenation of X and Y.
Alice wants to send an encrypted message that can be decrypted by
Bob's static private key kB.
Alice knows about Bobs static public key KB.
To encrypt the message m, Alice generates a random number r and
corresponding elliptic curve public key R = r * G and
computes the shared secret S = Px where (Px, Py) = r * KB.
She derives key material for encryption and
authentication as kE || kM = KDF(S, 32)
as well as a random initialization vector iv.
Alice sends the encrypted message R || iv || c || d where c = AES(kE, iv , m)
and d = MAC(sha256(kM), iv || c) to Bob.
For Bob to decrypt the message R || iv || c || d,
he derives the shared secret S = Px where (Px, Py) = kB * R
as well as the encryption and authentication keys kE || kM = KDF(S, 32).
Bob verifies the authenticity of the message
by checking whether d == MAC(sha256(kM), iv || c)
then obtains the plaintext as m = AES(kE, iv || c).
Padding
The padding field is used to align data size,
since data size alone might reveal important metainformation.
Padding can be arbitrary size.
However, it is recommended that the size of data field
(excluding the iv and tag) before encryption (i.e. plain text)
SHOULD be a multiple of 256 bytes.
Decoding a message
In order to decode a message, a node SHOULD try to apply both symmetric and asymmetric decryption operations. This is because the type of encryption is not included in the message.
Copyright
Copyright and related rights waived via CC0.
References
- 6/WAKU1
- 10/WAKU2 spec
- 14/WAKU-MESSAGE version 1
- 7/WAKU-DATA
- EIP-627: Whisper spec
- RLPx Transport Protocol spec (ECIES encryption)
- Status 5/SECURE-TRANSPORT
- Augmented Backus-Naur form (ABNF)
- Ethereum "Yellow paper": Appendix F Signing transactions
- authenticated encryption
53/WAKU2-X3DH
| Field | Value |
|---|---|
| Name | X3DH usage for Waku payload encryption |
| Slug | 53 |
| Status | draft |
| Type | RFC |
| Category | application |
| Editor | Aaryamann Challani [email protected] |
| Contributors | Andrea Piana [email protected], Pedro Pombeiro [email protected], Corey Petty [email protected], Oskar Thorén [email protected], Dean Eigenmann [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-07-01 —
b60abdb— update waku/standards/application/53/x3dh.md (#150) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-08-05 —
eb25cd0— chore: replace email addresses (#86) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-02-01 —
51567b1— Rename X3DH.md to x3dh.md - 2024-01-31 —
9fd3266— Update and rename README.md to X3DH.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-25 —
5e95a1a— Rename README.md to README.md - 2024-01-25 —
555eb20— Create README.md
Abstract
This document describes a method that can be used to provide a secure channel between two peers, and thus provide confidentiality, integrity, authenticity and forward secrecy. It is transport-agnostic and works over asynchronous networks.
It builds on the X3DH and Double Ratchet specifications, with some adaptations to operate in a decentralized environment.
Motivation
Nodes on a network may want to communicate with each other in a secure manner, without other nodes network being able to read their messages.
Specification
Definitions
-
Perfect Forward Secrecy is a feature of specific key-agreement protocols which provide assurances that session keys will not be compromised even if the private keys of the participants are compromised. Specifically, past messages cannot be decrypted by a third-party who manages to obtain those private key.
-
Secret channel describes a communication channel where a Double Ratchet algorithm is in use.
Design Requirements
- Confidentiality: The adversary should not be able to learn what data is being exchanged between two Status clients.
- Authenticity: The adversary should not be able to cause either endpoint to accept data from any third party as though it came from the other endpoint.
- Forward Secrecy: The adversary should not be able to learn what data was exchanged between two clients if, at some later time, the adversary compromises one or both of the endpoints.
- Integrity: The adversary should not be able to cause either endpoint to accept data that has been tampered with.
All of these properties are ensured by the use of Signal's Double Ratchet
Conventions
Types used in this specification are defined using the Protobuf wire format.
End-to-End Encryption
End-to-end encryption (E2EE) takes place between two clients. The main cryptographic protocol is a Double Ratchet protocol, which is derived from the Off-the-Record protocol, using a different ratchet. The Waku v2 protocol subsequently encrypts the message payload, using symmetric key encryption. Furthermore, the concept of prekeys (through the use of X3DH) is used to allow the protocol to operate in an asynchronous environment. It is not necessary for two parties to be online at the same time to initiate an encrypted conversation.
Cryptographic Protocols
This protocol uses the following cryptographic primitives:
- X3DH
- Elliptic curve Diffie-Hellman key exchange (secp256k1)
- KECCAK-256
- ECDSA
- ECIES
- Double Ratchet
-
HMAC-SHA-256 as MAC
-
Elliptic curve Diffie-Hellman key exchange (Curve25519)
-
AES-256-CTR with HMAC-SHA-256 and IV derived alongside an encryption key
The node achieves key derivation using HKDF.
-
Pre-keys
Every client SHOULD initially generate some key material which is stored locally:
- Identity keypair based on secp256k1 -
IK - A signed prekey based on secp256k1 -
SPK - A prekey signature -
Sig(IK, Encode(SPK))
More details can be found in the X3DH Prekey bundle creation section of 2/ACCOUNT.
Prekey bundles MAY be extracted from any peer's messages,
or found via searching for their specific topic, {IK}-contact-code.
The following methods can be used to retrieve prekey bundles from a peer's messages:
- contact codes;
- public and one-to-one chats;
- QR codes;
- ENS record;
- Decentralized permanent storage (e.g. Swarm, IPFS).
- Waku
Waku SHOULD be used for retrieving prekey bundles.
Since bundles stored in QR codes or ENS records cannot be updated to delete already used keys, the bundle MAY be rotated every 24 hours, and distributed via Waku.
Flow
The key exchange can be summarized as follows:
-
Initial key exchange: Two parties, Alice and Bob, exchange their prekey bundles, and derive a shared secret.
-
Double Ratchet: The two parties use the shared secret to derive a new encryption key for each message they send.
-
Chain key update: The two parties update their chain keys. The chain key is used to derive new encryption keys for future messages.
-
Message key derivation: The two parties derive a new message key from their chain key, and use it to encrypt a message.
1. Initial key exchange flow (X3DH)
Section 3 of the X3DH protocol describes the initial key exchange flow, with some additional context:
- The peers' identity keys
IK_AandIK_Bcorrespond to their public keys; - Since it is not possible to guarantee that a prekey will be used only once
in a decentralized world, the one-time prekey
OPK_Bis not used in this scenario; - Nodes SHOULD not send Bundles to a centralized server, but instead provide them in a decentralized way as described in the Pre-keys section.
Alice retrieves Bob's prekey bundle, however it is not specific to Alice. It contains:
Wire format:
// X3DH prekey bundle
message Bundle {
// Identity key 'IK_B'
bytes identity = 1;
// Signed prekey 'SPK_B' for each device, indexed by 'installation-id'
map<string,SignedPreKey> signed_pre_keys = 2;
// Prekey signature 'Sig(IK_B, Encode(SPK_B))'
bytes signature = 4;
// When the bundle was created locally
int64 timestamp = 5;
}
message SignedPreKey {
bytes signed_pre_key = 1;
uint32 version = 2;
}
The signature is generated by sorting installation-id in lexicographical order,
and concatenating the signed-pre-key and version:
installation-id-1signed-pre-key1version1installation-id2signed-pre-key2-version-2
2. Double Ratchet
Having established the initial shared secret SK through X3DH,
it SHOULD be used to seed a Double Ratchet exchange between Alice and Bob.
Refer to the Double Ratchet spec for more details.
The initial message sent by Alice to Bob is sent as a top-level ProtocolMessage
(reference wire format)
containing a map of DirectMessageProtocol indexed by installation-id
(reference wire format):
message ProtocolMessage {
// The installation id of the sender
string installation_id = 2;
// A sequence of bundles
repeated Bundle bundles = 3;
// One to one message, encrypted, indexed by installation_id
map<string,DirectMessageProtocol> direct_message = 101;
// Public message, not encrypted
bytes public_message = 102;
}
message EncryptedMessageProtocol {
X3DHHeader X3DH_header = 1;
DRHeader DR_header = 2;
DHHeader DH_header = 101;
// Encrypted payload
// if a bundle is available, contains payload encrypted with the Double Ratchet algorithm;
// otherwise, payload encrypted with output key of DH exchange (no Perfect Forward Secrecy).
bytes payload = 3;
}
Where:
-
X3DH_header: theX3DHHeaderfield inDirectMessageProtocolcontains:
message X3DHHeader {
// Alice's ephemeral key `EK_A`
bytes key = 1;
// Bob's bundle signed prekey
bytes id = 4;
}
DR_header: Double ratchet header (reference wire format). Used when Bob's public bundle is available:
message DRHeader {
// Alice's current ratchet public key
bytes key = 1;
// number of the message in the sending chain
uint32 n = 2;
// length of the previous sending chain
uint32 pn = 3;
// Bob's bundle ID
bytes id = 4;
}
Alice's current ratchet public key (above) is mentioned in DR spec section 2.2
DH_header: Diffie-Hellman header (used when Bob's bundle is not available): (reference wire format)
message DHHeader {
// Alice's compressed ephemeral public key.
bytes key = 1;
}
3. Chain key update
The chain key MUST be updated according to the DR_Header
received in the EncryptedMessageProtocol message,
described in 2.Double Ratchet.
4. Message key derivation
The message key MUST be derived from a single ratchet step in the symmetric-key ratchet as described in Symmetric key ratchet
The message key MUST be used to encrypt the next message to be sent.
Security Considerations
-
Inherits the security considerations of X3DH and Double Ratchet.
-
Inherits the security considerations of the Waku v2 protocol.
-
The protocol is designed to be used in a decentralized manner, however, it is possible to use a centralized server to serve prekey bundles. In this case, the server is trusted.
Privacy Considerations
- This protocol does not provide message unlinkability. It is possible to link messages signed by the same keypair.
Copyright
Copyright and related rights waived via CC0.
References
- X3DH
- Double Ratchet
- Signal's Double Ratchet
- Protobuf
- Off-the-Record protocol
- The Waku v2 protocol
- HKDF
- 2/ACCOUNT
- reference wire format
- Symmetric key ratchet
54/WAKU2-X3DH-SESSIONS
| Field | Value |
|---|---|
| Name | Session management for Waku X3DH |
| Slug | 54 |
| Status | draft |
| Type | RFC |
| Category | application |
| Editor | Aaryamann Challani [email protected] |
| Contributors | Andrea Piana [email protected], Pedro Pombeiro [email protected], Corey Petty [email protected], Oskar Thorén [email protected], Dean Eigenmann [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-04-24 —
db365cb— update waku/standards/application/54/x3dh-sessions.md (#151) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-08-05 —
eb25cd0— chore: replace email addresses (#86) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-02-01 —
0e490d4— Rename X3DH-sessions.md to x3dh-sessions.md - 2024-01-31 —
7f8b187— Update and rename README.md to X3DH-sessions.md - 2024-01-27 —
a22c2a0— Rename README.md to README.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-25 —
484df92— Create README.md
Abstract
This document specifies how to manage sessions based on an X3DH key exchange. This includes how to establish new sessions, how to re-establish them, how to maintain them, and how to close them.
53/WAKU2-X3DH specifies the Waku X3DH protocol
for end-to-end encryption.
Once two peers complete an X3DH handshake, they SHOULD establish an X3DH session.
Session Establishment
A node identifies a peer by their installation-id
which MAY be interpreted as a device identifier.
Discovery of pre-key bundles
The node's pre-key bundle MUST be broadcast on a content topic derived from the node's public key, so that the first message may be PFS-encrypted. Each peer MUST publish their pre-key bundle periodically to this topic, otherwise they risk not being able to perform key-exchanges with other peers. Each peer MAY publish to this topic when their metadata changes, so that the other peer can update their local record.
If peer A wants to send a message to peer B, it MUST derive the topic from peer B's public key, which has been shared out of band. Partitioned topics have been used to balance privacy and efficiency of broadcasting pre-key bundles.
The number of partitions that MUST be used is 5000.
The topic MUST be derived as follows:
var partitionsNum *big.Int = big.NewInt(5000)
var partition *big.Int = big.NewInt(0).Mod(peerBPublicKey, partitionsNum)
partitionTopic := "contact-discovery-" + strconv.FormatInt(partition.Int64(), 10)
var hash []byte = keccak256(partitionTopic)
var topicLen int = 4
if len(hash) < topicLen {
topicLen = len(hash)
}
var contactCodeTopic [4]byte
for i = 0; i < topicLen; i++ {
contactCodeTopic[i] = hash[i]
}
Initialization
A node initializes a new session once a successful X3DH exchange has taken place. Subsequent messages will use the established session until re-keying is necessary.
Negotiated topic to be used for the session
After the peers have performed the initial key exchange, they MUST derive a topic from their shared secret to send messages on. To obtain this value, take the first four bytes of the keccak256 hash of the shared secret encoded in hexadecimal format.
sharedKey, err := ecies.ImportECDSA(myPrivateKey).GenerateShared(
ecies.ImportECDSAPublic(theirPublicKey),
16,
16,
)
hexEncodedKey := hex.EncodeToString(sharedKey)
var hash []byte = keccak256(hexEncodedKey)
var topicLen int = 4
if len(hash) < topicLen {
topicLen = len(hash)
}
var topic [4]byte
for i = 0; i < topicLen; i++ {
topic[i] = hash[i]
}
To summarize, following is the process for peer B to establish a session with peer A:
- Listen to peer B's Contact Code Topic to retrieve their bundle information, including a list of active devices
- Peer A sends their pre-key bundle on peer B's partitioned topic
- Peer A and peer B perform the key-exchange using the shared pre-key bundles
- The negotiated topic is derived from the shared secret
- Peers A & B exchange messages on the negotiated topic
Concurrent sessions
If a node creates two sessions concurrently between two peers, the one with the symmetric key first in byte order SHOULD be used, this marks that the other has expired.
Re-keying
On receiving a bundle from a given peer with a higher version, the old bundle SHOULD be marked as expired and a new session SHOULD be established on the next message sent.
Multi-device support
Multi-device support is quite challenging
as there is not a central place where information on which and how many devices
(identified by their respective installation-id) a peer has, is stored.
Furthermore, account recovery always needs to be taken into consideration, where a user wipes clean the whole device and the node loses all the information about any previous sessions. Taking these considerations into account, the way the network propagates multi-device information using X3DH bundles, which will contain information about paired devices as well as information about the sending device. This means that every time a new device is paired, the bundle needs to be updated and propagated with the new information, the user has the responsibility to make sure the pairing is successful.
The method is loosely based on Signal's Sesame Algorithm.
Pairing
A new installation-id MUST be generated on a per-device basis.
The device should be paired as soon as possible if other devices are present.
If a bundle is received, which has the same IK as the keypair present on the device,
the devices MAY be paired.
Once a user enables a new device,
a new bundle MUST be generated which includes pairing information.
The bundle MUST be propagated to contacts through the usual channels.
Removal of paired devices is a manual step that needs to be applied on each device, and consist simply in disabling the device, at which point pairing information will not be propagated anymore.
Sending messages to a paired group
When sending a message,
the peer SHOULD send a message to other installation-id that they have seen.
The node caps the number of devices to n, ordered by last activity.
The node sends messages using pairwise encryption, including their own devices.
Where n is the maximum number of devices that can be paired.
Account recovery
Account recovery is the same as adding a new device, and it MUST be handled the same way.
Partitioned devices
In some cases
(i.e. account recovery when no other pairing device is available, device not paired),
it is possible that a device will receive a message
that is not targeted to its own installation-id.
In this case an empty message containing bundle information MUST be sent back,
which will notify the receiving end not to include the device in any further communication.
Security Considerations
- Inherits all security considerations from 53/WAKU2-X3DH.
Recommendations
- The value of
nSHOULD be configured by the app-protocol.- The default value SHOULD be 3, since a larger number of devices will result in a larger bundle size, which may not be desirable in a peer-to-peer network.
Copyright
Copyright and related rights waived via CC0.
References
Application
Application-level messaging stable specifications.
7/WAKU-DATA
| Field | Value |
|---|---|
| Name | Waku Envelope data field |
| Slug | 7 |
| Status | stable |
| Type | RFC |
| Category | application |
| Editor | Oskar Thorén [email protected] |
| Contributors | Dean Eigenmann [email protected], Kim De Mey [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-02-12 —
a57d7b4— Rename data.md to data.md - 2024-01-31 —
900a3e9— Update and rename DATA.md to data.md - 2024-01-27 —
662eb12— Rename README.md to DATA.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-25 —
93c3896— Create README.md
This specification describes the encryption, decryption and signing of the content in the data field used in Waku.
Specification
The data field is used within the waku envelope,
the field MUST contain the encrypted payload of the envelope.
The fields that are concatenated and encrypted as part of the data field are:
- flags
- auxiliary field
- payload
- padding
- signature
In case of symmetric encryption, a salt
(a.k.a. AES Nonce, 12 bytes) field MUST be appended.
ABNF
Using Augmented Backus-Naur form (ABNF) we have the following format:
; 1 byte; first two bits contain the size of auxiliary field,
; third bit indicates whether the signature is present.
flags = 1OCTET
; contains the size of payload.
auxiliary-field = 4*OCTET
; byte array of arbitrary size (may be zero)
payload = *OCTET
; byte array of arbitrary size (may be zero).
padding = *OCTET
; 65 bytes, if present.
signature = 65OCTET
; 2 bytes, if present (in case of symmetric encryption).
salt = 2OCTET
data = flags auxiliary-field payload padding [signature] [salt]
Signature
Those unable to decrypt the envelope data are also unable to access the signature.
The signature, if provided,
is the ECDSA signature of the Keccak-256 hash of the unencrypted data
using the secret key of the originator identity.
The signature is serialized as the concatenation of the R, S and
V parameters of the SECP-256k1 ECDSA signature, in that order.
R and S MUST be big-endian encoded, fixed-width 256-bit unsigned.
V MUST be an 8-bit big-endian encoded,
non-normalized and should be either 27 or 28.
Padding
The padding field is used to align data size, since data size alone might reveal important metainformation. Padding can be arbitrary size. However, it is recommended that the size of Data Field (excluding the Salt) before encryption (i.e. plain text) SHOULD be factor of 256 bytes.
Copyright
Copyright and related rights waived via CC0.
8/WAKU-MAIL
| Field | Value |
|---|---|
| Name | Waku Mailserver |
| Slug | 8 |
| Status | stable |
| Type | RFC |
| Category | application |
| Editor | Andrea Maria Piana [email protected] |
| Contributors | Adam Babik [email protected], Dean Eigenmann [email protected], Oskar Thorén [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-02-12 —
fa77279— Rename mail.md to mail.md - 2024-01-31 —
0c8e39b— Rename MAIL.md to mail.md - 2024-01-27 —
de5cfa2— Rename README.md to MAIL.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-25 —
28e7862— Create README.md
Abstract
In this specification, we describe Mailservers. These are nodes responsible for archiving envelopes and delivering them to peers on-demand.
Specification
A node which wants to provide mailserver functionality MUST store envelopes
from incoming Messages packets (Waku packet-code 0x01).
The envelopes can be stored in any format,
however they MUST be serialized and deserialized to the Waku envelope format.
A mailserver SHOULD store envelopes for all topics to be generally useful for any peer, however for specific use cases it MAY store envelopes for a subset of topics.
Requesting Historic Envelopes
In order to request historic envelopes,
a node MUST send a packet P2P Request (0x7e)
to a peer providing mailserver functionality.
This packet requires one argument which MUST be a Waku envelope.
In the Waku envelope's payload section, there MUST be RLP-encoded information about the details of the request:
; UNIX time in seconds; oldest requested envelope's creation time
lower = 4OCTET
; UNIX time in seconds; newest requested envelope's creation time
upper = 4OCTET
; array of Waku topics encoded in a bloom filter to filter envelopes
bloom = 64OCTET
; unsigned integer limiting the number of returned envelopes
limit = 4OCTET
; array of a cursor returned from the previous request (optional)
cursor = *OCTET
; List of topics interested in
topics = "[" *1000topic "]"
; 4 bytes of arbitrary data
topic = 4OCTET
payload-without-topic = "[" lower upper bloom limit [ cursor ] "]"
payload-with-topic = "[" lower upper bloom limit cursor [ topics ] "]"
payload = payload-with-topic | payload-without-topic
The Cursor field SHOULD be filled in if a number of envelopes between Lower and
Upper is greater than Limit so that the requester can send another request
using the obtained Cursor value.
What exactly is in the Cursor is up to the implementation.
The requester SHOULD NOT use a Cursor obtained from one mailserver in a request
to another mailserver because the format or the result MAY be different.
The envelope MUST be encrypted with a symmetric key agreed between the requester and Mailserver.
If Topics is used the Cursor field MUST be specified
for the argument order to be unambiguous.
However, it MAY be set to null.
Topics is used to specify which topics a node is interested in.
If Topics is not empty,
a mailserver MUST only send envelopes that belong to a topic from Topics list and
Bloom value MUST be ignored.
Receiving Historic Envelopes
Historic envelopes MUST be sent to a peer as a packet with a P2P Message code (0x7f)
followed by an array of Waku envelopes.
A Mailserver MUST limit the amount of messages sent,
either by the Limit specified in the request or
limited to the maximum RLPx packet size,
whichever limit comes first.
In order to receive historic envelopes from a mailserver, a node MUST trust the selected mailserver, that is allow to receive expired packets with the P2P Message code. By default, such packets are discarded.
Received envelopes MUST be passed through the Whisper envelope pipelines so that they are picked up by registered filters and passed to subscribers.
For a requester, to know that all envelopes have been sent by mailserver,
it SHOULD handle P2P Request Complete code (0x7d).
This code is followed by a list with:
; array with a Keccak-256 hash of the envelope containing the original request.
request-id = 32OCTET
; array with a Keccak-256 hash of the last sent envelope for the request.
last-envelope-hash = 32OCTET
; array of a cursor returned from the previous request (optional)
cursor = *OCTET
payload = "[" request-id last-envelope-hash [ cursor ] "]"
If Cursor is not empty,
it means that not all envelopes were sent due to the set Limit in the request.
One or more consecutive requests MAY be sent with Cursor field filled
in order to receive the rest of the envelopes.
Security considerations
There are several security considerations to take into account when running or interacting with Mailservers. Chief among them are: scalability, DDoS-resistance and privacy.
Mailserver High Availability requirement:
A mailserver has to be online to receive envelopes for other nodes, this puts a high availability requirement on it.
Mailserver client privacy:
A mailserver client fetches archival envelopes from a mailserver through a direct connection. In this direct connection, the client discloses its IP/ID as well as the topics/ bloom filter it is interested in to the mailserver. The collection of such information allows the mailserver to link clients' IP/IDs to their topic interests and build a profile for each client over time. As such, the mailserver client has to trust the mailserver with this level of information. A similar concern exists for the light nodes and their direct peers which is discussed in the security considerations of 6/WAKU1.
Mailserver trusted connection:
A mailserver has a direct TCP connection, which means they are trusted to send traffic. This means a malicious or malfunctioning mailserver can overwhelm an individual node.
Changelog
| Version | Comment |
|---|---|
| 1.0.0 | marked stable as it is in use. |
| 0.2.0 | Add topic interest to reduce bandwidth usage |
| 0.1.0 | Initial Release |
Difference between wms 0.1 and wms 0.2
topicsoption
Copyright
Copyright and related rights waived via CC0.
Application
Application-level messaging deprecated specifications.
18/WAKU2-SWAP
| Field | Value |
|---|---|
| Name | Waku SWAP Accounting |
| Slug | 18 |
| Status | deprecated |
| Type | RFC |
| Category | application |
| Editor | Oskar Thorén [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-04-18 —
8f94e97— docs: deprecate swap protocol (#31) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-01-31 —
0d8ad08— Update and rename SWAP.md to swap.md - 2024-01-31 —
3c8410c— Create SWAP.md
Abstract
This specification outlines how we do accounting and settlement based on the provision and usage of resources, most immediately bandwidth usage and/or storing and retrieving of Waku message. This enables nodes to cooperate and efficiently share resources, and in the case of unequal nodes to settle the difference through a relaxed payment mechanism in the form of sending cheques.
Protocol identifier*: /vac/waku/swap/2.0.0-beta1
Motivation
The Waku network makes up a service network, and some nodes provide a useful service to other nodes. We want to account for that, and when imbalances arise, settle this. The core of this approach has some theoretical backing in game theory, and variants of it have practically been proven to work in systems such as Bittorrent. The specific model use was developed by the Swarm project (previously part of Ethereum), and we re-use contracts that were written for this purpose.
By using a delayed payment mechanism in the form of cheques, a barter-like mechanism can arise, and nodes can decide on their own policy as opposed to be strictly tied to a specific payment scheme. Additionally, this delayed settlement eases requirements on the underlying network in terms of transaction speed or costs.
Theoretically, nodes providing and using resources over a long, indefinite, period of time can be seen as an iterated form of Prisoner's Dilemma (PD). Specifically, and more intuitively, since we have a cost and benefit profile for each provision/usage (of Waku Message's, e.g.), and the pricing can be set such that mutual cooperation is incentivized, this can be analyzed as a form of donations game.
Game Theory - Iterated prisoner's dilemma / donation game
What follows is a sketch of what the game looks like between two nodes.
We can look at it as a special case of iterated prisoner's dilemma called a
Donation game
where each node can cooperate with some benefit b at a personal cost c,
where b>c.
From A's point of view:
| A/B | Cooperate | Defect |
|---|---|---|
| Cooperate | b-c | -c |
| Defect | b | 0 |
What this means is that if A and B cooperates,
A gets some benefit b minus a cost c.
If A cooperates and B defects she only gets the cost,
and if she defects and B cooperates A only gets the benefit.
If both defect they get neither benefit nor cost.
The generalized form of PD is:
| A/B | Cooperate | Defect |
|---|---|---|
| Cooperate | R | S |
| Defect | T | P |
With R=reward, S=Sucker's payoff, T=temptation, P=punishment
And the following holds:
T>R>P>S2R>T+S
In our case, this means b>b-c>0>-c and 2(b-c)> b-c which is trivially true.
As this is an iterated game with no clear finishing point in most circumstances, a tit-for-tat strategy is simple, elegant and functional. To be more theoretically precise, this also requires reasonable assumptions on error rate and discount parameter. This captures notions such as "does the perceived action reflect the intended action" and "how much do you value future (uncertain) actions compared to previous actions". See Axelrod - Evolution of Cooperation (book) for more details. In specific circumstances, nodes can choose slightly different policies if there's a strong need for it. A policy is simply how a node chooses to act given a set of circumstances.
A tit-for-tat strategy basically means:
- cooperate first (perform service/beneficial action to other node)
- defect when node stops cooperating (disconnect and similar actions), i.e. when it stops performing according to set parameters re settlement
- resume cooperation if other node does so
This can be complemented with node selection mechanisms.
SWAP protocol overview
We use SWAP for accounting and settlement in conjunction with other request/reply protocols in Waku v2, where accounting is done in a pairwise manner. It is an acronym with several possible meanings (as defined in the Book of Swarm), for example:
- service wanted and provided
- settle with automated payments
- send waiver as payment
- start without a penny
This approach is based on communicating payment thresholds and sending cheques as indications of later payments. Communicating payment thresholds MAY be done out-of-band or as part of the handshake. Sending cheques is done once payment threshold is hit.
See Book of Swarm section 3.2. on Peer-to-peer accounting etc., for more context and details.
Accounting
Nodes perform their own accounting for each relevant peer
based on some "volume"/bandwidth metric.
For now we take this to mean the number of WakuMessages exchanged.
Additionally, a price is attached to each unit. Currently, this is simply a "karma counter" and equal to 1 per message.
Each accounting balance SHOULD be w.r.t. to a given protocol it is accounting for.
NOTE: This may later be complemented with other metrics, either as part of SWAP or more likely outside of it. For example, online time can be communicated and attested to as a form of enhanced quality of service to inform peer selection.
Flow
Assuming we have two store nodes, one operating mostly as a client (A) and another as server (B).
- Node A performs a handshake with B node. B node responds and both nodes communicate their payment threshold.
- Node A and B creates an accounting entry for the other peer, keep track of peer and current balance.
- Node A issues a
HistoryRequest, and B responds with aHistoryResponse. Based on the number of WakuMessages in the response, both nodes update their accounting records. - When payment threshold is reached, Node A sends over a cheque to reach a neutral balance. Settlement of this is currently out of scope, but would occur through a SWAP contract (to be specified). (mock and hard phase).
- If disconnect threshold is reached, Node B disconnects Node A (mock and hard phase).
Note that not all of these steps are mandatory in initial stages, see below for more details. For example, the payment threshold MAY initially be set out of bounds, and policy is only activated in the mock and hard phase.
Protobufs
We use protobuf to specify the handshake and signature. This current protobuf is a work in progress. This is needed for mock and hard phase.
A handshake gives initial information about payment thresholds and possibly other information. A cheque is best thought of as a promise to pay at a later date.
message Handshake {
bytes payment_threshold = 1;
}
// TODO Signature?
// Should probably be over the whole Cheque type
message Cheque {
bytes beneficiary = 1;
// TODO epoch time or block time?
uint32 date = 2;
// TODO ERC20 extension?
// For now karma counter
uint32 amount = 3;
}
Incremental integration and roll-out
To incrementally integrate this into Waku v2, we have divided up the roll-out into three phases:
- Soft - accounting only
- Mock - send mock cheques and take word for it
- Hard Test - blockchain integration and deployed to public testnet (Goerli, Optimism testnet or similar)
- Hard Main - deployed to a public mainnet
An implementation MAY support any of these phases.
Soft phase
In the soft phase only accounting is performed, without consequence for the peers. No disconnect or sending of cheques is performed at this tage.
SWAP protocol is performed in conjunction with another request-reply protocol to account for its usage. It SHOULD be done for 13/WAKU2-STORE and it MAY be done for other request/reply protocols.
A client SHOULD log accounting state per peer and SHOULD indicate when a peer is out of bounds (either of its thresholds met).
Mock phase
In the mock phase, we send mock cheques and send cheques/disconnect peers as appropriate.
- If a node reaches a disconnect threshold, which MUST be outside the payment threshold, it SHOULD disconnect the other peer.
- If a node is within payment balance, the other node SHOULD stay connected to it.
- If a node receives a valid Cheque it SHOULD update its internal accounting records.
- If any node behaves badly, the other node is free to disconnect and
pick another node.
- Peer rating is out of scope of this specification.
Hard phase
In the hard phase, in addition to sending cheques and activating policy, this is done with blockchain integration on a public testnet. More details TBD.
This also includes settlements where cheques can be redeemed.
Copyright
Copyright and related rights waived via CC0.
References
Application
Application-level messaging deleted specifications.
21/WAKU2-FAULT-TOLERANT-STORE
| Field | Value |
|---|---|
| Name | Waku v2 Fault-Tolerant Store |
| Slug | 21 |
| Status | deleted |
| Type | RFC |
| Category | application |
| Editor | Sanaz Taheri [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-11-04 —
cb4d0de— Update 21/WAKU2-FAULT-TOLERANT-STORE: Deleted (#181) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-01-31 —
5da8a11— Update and rename FAULT-TOLERANT-STORE.md to fault-tolerant-store.md - 2024-01-27 —
206133e— Create FAULT-TOLERANT-STORE.md
The reliability of 13/WAKU2-STORE protocol heavily relies on the fact that full nodes i.e., those who persist messages have high availability and uptime and do not miss any messages. If a node goes offline, then it will risk missing all the messages transmitted in the network during that time. In this specification, we provide a method that makes the store protocol resilient in presence of faulty nodes. Relying on this method, nodes that have been offline for a time window will be able to fix the gap in their message history when getting back online. Moreover, nodes with lower availability and uptime can leverage this method to reliably provide the store protocol services as a full node.
Method description
As the first step towards making the 13/WAKU2-STORE protocol fault-tolerant, we introduce a new type of time-based query through which nodes fetch message history from each other based on their desired time window. This method operates based on the assumption that the querying node knows some other nodes in the store protocol which have been online for that targeted time window.
Security Consideration
The main security consideration to take into account while using this method is that a querying node has to reveal its offline time to the queried node. This will gradually result in the extraction of the node's activity pattern which can lead to inference attacks.
Wire Specification
We extend the HistoryQuery protobuf message
with two fields of start_time and end_time to signify the time range to be queried.
Payloads
syntax = "proto3";
message HistoryQuery {
// the first field is reserved for future use
string pubsubtopic = 2;
repeated ContentFilter contentFilters = 3;
PagingInfo pagingInfo = 4;
+ sint64 start_time = 5;
+ sint64 end_time = 6;
}
HistoryQuery
RPC call to query historical messages.
start_time: this field MAY be filled out to signify the starting point of the queried time window. This field holds the Unix epoch time in nanoseconds.
Themessagesfield of the correspondingHistoryResponseMUST contain historical waku messages whosetimestampis larger than or equal to thestart_time.end_time: this field MAY be filled out to signify the ending point of the queried time window. This field holds the Unix epoch time in nanoseconds. Themessagesfield of the correspondingHistoryResponseMUST contain historical waku messages whosetimestampis less than or equal to theend_time.
A time-based query is considered valid if
its end_time is larger than or equal to the start_time.
Queries that do not adhere to this condition will not get through e.g.
an open-end time query in which the start_time is given but
no end_time is supplied is not valid.
If both start_time and
end_time are omitted then no time-window filter takes place.
In order to account for nodes asynchrony, and
assuming that nodes may be out of sync for at most 20 seconds
(i.e., 20000000000 nanoseconds),
the querying nodes SHOULD add an offset of 20 seconds to their offline time window.
That is if the original window is [l,r]
then the history query SHOULD be made for [start_time: l - 20s, end_time: r + 20s].
Note that HistoryQuery preserves AND operation among the queried attributes.
As such, the messages field of the corresponding
HistoryResponse
MUST contain historical waku messages that satisfy the indicated pubsubtopic AND
contentFilters AND the time range [start_time, end_time].
Copyright
Copyright and related rights waived via CC0.
References
Informational
Supporting informational messaging specifications.
Informational
Supporting information, terminology, registries, and threat models for messaging raw specifications.
ADVERSARIAL-MODELS
| Field | Value |
|---|---|
| Name | Waku v2 Adversarial Models and Attack-based Threat List |
| Slug | 162 |
| Status | raw |
| Type | RFC |
| Category | informational |
| Editor | Daniel Kaiser [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
48600b5— Migrate logos-messaging/specs into docs/messaging/ (#315)
Abstract
This document lists adversarial models and attack-based threats relevant in the context of Waku v2.
Motivation and Background
Future versions of this document will serve as a comprehensive list of adversarial models and attack based threats relevant for Waku v2. The main purpose of this document is being a linkable resource for specifications that address protection as well as mitigation mechanisms within the listed models.
Discussing and introducing countermeasures to specific attacks in specific models is out of scope for this document. Analyses and further information about Waku's properties within these models may be found in our Waku v2 Anonymity Analysis series of research log posts:
Note: This document adds to the adversarial models and threat list discussed in our research log post. It does not cover analysis of Waku, as the research log post does. Future versions of this document will extend the adversarial models and threat list.
Informal Definitions: Security, Privacy, and Anonymity
The concepts of security, privacy, and anonymity are linked and have quite a bit of overlap.
Security
Of the three, Security has the clearest agreed upon definition, at least regarding its key concepts: confidentiality, integrity, and availability.
- confidentiality: data is not disclosed to unauthorized entities.
- integrity: data is not modified by unauthorized entities.
- availability: data is available, i.e. accessible by authorized entities.
While these are the key concepts, the definition of information security has been extended over time including further concepts, e.g. authentication and non-repudiation.
Privacy
Privacy allows users to choose which data and information
- they want to share
- and with whom they want to share it.
This includes data and information that is associated with and/or generated by users. Protected data also comprises metadata that might be generated without users being aware of it. This means, no further information about the sender or the message is leaked. Metadata that is protected as part of the privacy-preserving property does not cover protecting the identities of sender and receiver. Identities are protected by the anonymity property.
Often privacy is realized by the confidentiality property of security. This neither makes privacy and security the same, nor the one a sub category of the other. While security is abstract itself (its properties can be realized in various ways), privacy lives on a more abstract level using security properties. Privacy typically does not use integrity and availability. An adversary who has no access to the private data, because the message has been encrypted, could still alter the message.
Anonymity
Privacy and anonymity are closely linked. Both the identity of a user and data that allows inferring a user's identity should be part of the privacy policy. For the purpose of analysis, we want to have a clearer separation between these concepts.
We define anonymity as unlinkablity of users' identities and their shared data and/or actions.
We subdivide anonymity into receiver anonymity and sender anonymity.
Receiver Anonymity
We define receiver anonymity as unlinkability of users' identities and the data they receive and/or related actions. Because each Waku message is associated with a content topic, and each receiver is interested in messages with specific content topics, receiver anonymity in the context of Waku corresponds to subscriber-topic unlinkability. An example for the "action" part of our receiver anonymity definition is subscribing to a specific topic.
Sender Anonymity
We define sender anonymity as unlinkability of users' identities and the data they send and/or related actions. Because the data in the context of Waku is Waku messages, sender anonymity corresponds to sender-message unlinkability.
Anonymity Trilemma
The Anonymity trilemma states that only two out of strong anonymity, low bandwidth, and low latency can be guaranteed in the global attacker model. Waku's goal, being a modular set of protocols, is to offer any combination of two out of these three properties, as well as blends.
A fourth factor that influences the anonymity trilemma is frequency and patterns of messages. The more messages there are, and the more randomly distributed they are, the better the anonymity protection offered by a given anonymous communication protocol. So, incentivising users to use the protocol, for instance by lowering entry barriers, helps protecting the anonymity of all users. The frequency/patterns factor is also related to k-anonymity.
Censorship Resistance
Another security related property that Waku aims to offer is censorship resistance. Censorship resistance guarantees that users can participate even if an attacker tries to deny them access. So, censorship resistance ties into the availability aspect of security. In the context of Waku that means users should be able to send messages as well as receive all messages they are interested in, even if an attacker tries to prevent them from disseminating messages or tries to deny them access to messages.
An example for a censorship resistance technique is Tor's Pluggable Transports.
Adversarial Models
The following lists various attacker types with varying degrees of power. The more power an attacker has, the more difficult it is to gain the respective attacker position.
Each attacker type comes in a passive and an active variant. While a passive attacker can stay hidden and is not suspicious, the respective active attacker has more (or at least the same) deanonymization power.
We also distinguish between internal and external attackers. Since in permissionless protocols it is easy to obtain an internal position, in practice attackers are expected to mount combined attacks that leverage both internal and external attacks.
Internal
In the passive variant, an internal attacker behaves like an honest node towards peers. The passive internal attacker has the same access rights as any honest node. In the active variant, an internal attacker can additionally drop, inject, and alter messages. With respect to Waku relay, for example, an internal attacker participates in the same pubsub topic as its victims, and can read messages related to that topic.
Single Node
This attacker controls a single node.
Multi Node
This attacker controls a fixed number of nodes (not scaling with the total number of nodes in the network). The multi node position can be achieved by setting up multiple nodes. Botnets might be leveraged to increase the number of available hosts. Multi node attackers could use Sybil attacks to increase the number of controlled nodes. A countermeasure is for nodes to only accept libp2p gossipsub graft requests from peers with different IP addresses, or even different subnets.
Nodes controlled by the attacker can efficiently communicate out-of-band to coordinate.
Scaling Multi Node
This attacker controls a number of nodes that scales linearly with the number of nodes in the network. The attacker controls of all nodes in the network.
Nodes controlled by the attacker can efficiently communicate out-of-band to coordinate.
External
An external attacker can only see encrypted traffic. Waku protocols are protected by a secure channel set up with Noise.
Local
A local attacker has access to communication links in a local network segment. This could be a rogue access point (with routing capability).
AS
An AS attacker controls a single AS (autonomous system). A passive AS attacker can listen to traffic on arbitrary links within the AS. An active AS attacker can drop, delay, inject, and alter traffic on arbitrary links within the AS.
In practice, a malicious ISP would be considered as an AS attacker. A malicious ISP could also easily setup a set of nodes at specific points in the network, gaining internal attack power similar to a strong multi node or even scaling multi node attacker.
Global (On-Net)
A global (on-net) attacker has complete overview over the whole network. A passive global attacker can listen to traffic on all links, while the active global attacker basically carries the traffic: it can freely drop, delay, inject, and alter traffic at all positions in the network. This basically corresponds to the Dolev-Yao model.
An entity with this power would, in practice, also have the power of the internal scaling multi node attacker.
Attack-based Threats
The following lists various attacks against Waku v2 protocols. If not specifically mentioned, the attacks refer to Waku relay and the underlying libp2p GossipSub. We also list the weakest attacker model in which the attack can be successfully performed against.
An attack is considered more powerful if it can be successfully performed in a weaker attacker model.
Note: This list is work in progress. We will either expand this list adding more attacks in future versions of this document, or remove it and point to the "Security Considerations" sections of respective RFCs.
Prerequisite: Get a Specific Position in the Network
Some attacks require the attacker node(s) to be in a specific position in the network. In most cases, this corresponds to trying to get into the mesh peer list for the desired pubsub topic of the victim node.
In libp2p gossipsub, and by extension Waku v2 relay, nodes can simply send a graft message for the desired topic to the victim node. If the victim node still has open slots, the attacker gets the desired position. This only requires the attacker to know the gossipsub multiaddress of the victim node.
A scaling multi node attacker can leverage DHT based discovery systems to boost the probability of malicious nodes being returned, which in turn significantly increases the probability of attacker nodes ending up in the peer lists of victim nodes.
Sender Deanonymization
This section lists attacks that aim at deanonymizing a message sender.
We assume that protocol messages are transmitted within a secure channel set up using the Noise Protocol Framework.
For Waku Relay this means we only consider messages with version field 2,
which indicates that the payload has to be encoded using Noise.
Note: The currently listed attacks are against libp2p in general. The data field of Waku v2 relay must be a Waku v2 message. The attacks listed in the following do not leverage that fact.
Replay Attack
In a replay attack, the attacker replays a valid message it received.
Waku relay is inherently safe against replay attack,
because GossipSub nodes, and by extension Waku relay nodes,
feature a seen cache, and only relay messages they have not seen before.
Further, replay attacks will be punished by RLN Relay.
Observing Messages
If Waku relay was not protected with Noise, the AS attacker could simply check for messages leaving which have not been relayed to . These are the messages sent by . Waku relay protects against this attack by employing secure channels setup using Noise.
Neighbourhood Surveillance
This attack can be performed by a single node attacker that is connected to all peers of the victim node with respect to a specific topic mesh. The attacker also has to be connected to . In this position, the attacker will receive messages sent by both on the direct path from , and on indirect paths relayed by peers of . It will also receive messages that are not sent by . These messages are relayed by both and the peers of . Messages that are received (significantly) faster from than from any other of 's peers are very likely messages that sent, because for these messages the attacker is one hop closer to the source.
The attacker can (periodically) measure latency between itself and , and between itself and the peers of to get more accurate estimates for the expected timings. An AS attacker (and if the topology allows, even a local attacker) could also learn the latency between and its well-behaving peers. An active AS attacker could also increase the latency between and its peers to make the timing differences more prominent. This, however, might lead to switching to other peers.
This attack cannot (reliably) distinguish messages sent by from messages relayed by peers of the attacker is not connected to. Still, there are hop-count variations that can be leveraged. Messages always have a hop-count of 1 on the path from to the attacker, while all other paths are longer. Messages might have the same hop-count on the path from as well as on other paths. Further techniques that are part of the mass deanonymization category, such as bayesian analysis, can be used here as well.
Controlled Neighbourhood
If a multi node attacker manages to control all peers of the victim node, it can trivially tell which messages originated from .
Correlation
Monitoring all traffic (in an AS or globally), allows the attacker to identify traffic correlated with messages originating from . This (alone) does not allow an external attacker to learn which message sent, but it allows identifying the respective traffic propagating through the network. The more traffic in the network, the lower the success rate of this attack.
Combined with just a few nodes controlled by the attacker, the actual message associated with the correlated traffic can eventually be identified.
Mass Deanonymization
While attacks in the sender deanonymization category target a set of either specific or arbitrary users, attacks in the mass deanonymization category aim at deanonymizing (parts of) the whole network. Mass deanonymization attacks do not necessarily link messages to senders. They might only reduce the anonymity set in which senders hide, or infer information about the network topology.
Graph Learning
Graph learning attacks are a prerequisite for some mass deanonymization attacks, in which the attacker learns the overlay network topology. Graph learning attacks require a scaling multinode attacker
For gossipsub this means an attacker learns the topic mesh for specific pubsub topics. Dandelion++ describes ways to perform this attack.
Bayesian Analysis
Bayesian analysis allows attackers to assign each node in the network a likelihood of having sent (originated) a specific message. Bayesian analysis for mass deanonymization is detailed in On the Anonymity of Peer-To-Peer Network Anonymity Schemes Used by Cryptocurrencies. It requires a scaling node attacker as well as knowledge of the network topology, which can be learned via graph learning attacks.
Denial of Service (DoS)
Flooding
In a flooding attack, attackers flood the network with bogus messages.
Waku employs RLN Relay as the main countermeasure to flooding. SWAP also helps mitigating DoS attacks.
Black Hole (internal)
In a black hole attack, the attacker does not relay messages it is supposed to relay. Analogous to a black hole, attacker nodes do not allow messages to leave once they entered.
While single node and smaller multi node attackers can have a negative effect on availability, the impact is not significant. A scaling multi node attacker, however, can significantly disrupt the network with such an attack.
The effects of this attack are especially severe in conjunction with deanonymization mitigation techniques that reduce the out-degree of the overlay, such as Waku Dandelion. Waku Dandelion) also discusses mitigation techniques compensating the amplified black hole potential.)
Traffic Filtering (external)
A local attacker can filter and drop all Waku traffic within its controlled network segment. An AS attacker can filter and drop all Waku traffic within its authority, while a global attacker can censor the whole network. A countermeasure are censorship resistance techniques like Pluggable Transports.
An entity trying to censor Waku can employ both the black hole attack and traffic filtering; the former is internal while the latter is external.
Copyright
Copyright and related rights waived via CC0.
References
- 10/WAKU2
- 11/WAKU2-RELAY
- libp2p GossipSub
- Security
- Authentication
- Anonymity Trilemma
- Waku v2 message
- Pluggable Transports
- Sybil attack
- Dolev-Yao model
- Noise Protocol Framework
- Noise
- 17/WAKU-RLN-RELAY
- 18/WAKU2-SWAP
- Dandelion++
- On the Anonymity of Peer-To-Peer Network Anonymity Schemes Used by Cryptocurrencies
- Waku Dandelion)
CHAT-CAST
| Field | Value |
|---|---|
| Name | Roles and Entities Used in Chat Protocol Documentation |
| Slug | 163 |
| Status | raw |
| Type | RFC |
| Category | informational |
| Tags | chat/informational |
| Editor | Jazzz [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
48600b5— Migrate logos-messaging/specs into docs/messaging/ (#315)
Abstract
This document defines a reusable cast of characters to be used in chat protocol documentation and related supporting materials. The goal is to improve clarity and consistency when describing protocol roles, actors, and message flows.
Background
When documenting applications and protocols, it is often beneficial to define a consistent set of characters representing common roles. A shared cast allows authors to convey meaning and intent quickly to readers. Readers are not required to understand these meanings, however consistent usage can make comprehension faster to achieve.
This approach is well established in cryptographic literature, where Alice and Bob are commonly used to describe participants in key exchange protocols.
Within that context, Alice typically initiates the exchange and Bob responds.
Readers familiar with this convention can quickly understand protocol flows without additional explanation.
In messaging and communication protocols, a similar approach can be helpful, particularly when describing multiple actors and roles required for correct protocol operation.
However, reusing Alice and Bob in these contexts can introduce ambiguity:
- In cryptography, Alice is the initiator of a key exchange, but in a communication protocol the initiator role may vary by sub-protocol or phase.
- Complex, multi-step systems may embed multiple cryptographic and application-level processes, each with their own initiator and responder.
- The use of Alice and Bob implicitly frames the discussion as cryptographic, which may be misleading when describing application-level behavior such as message encoding, routing, or reliability.
For these reasons, when documenting communication protocols that integrate multiple roles and procedures, it is preferable to use a context-specific cast of characters designed for that domain.
Guidelines
Use of Alice and Bob
Alice and Bob SHOULD be used when describing novel cryptographic constructions or key exchange mechanisms that are not embedded within higher-layer communication protocols.
These names are widely understood in cryptographic contexts, and introducing alternatives would reduce clarity.
Communication protocols may incorporate cryptographic components, but they are not themselves cryptographic key exchanges. When documenting application-centric or protocol-level processes, the cast defined in this document SHOULD be used instead. This separation establishes clear contextual boundaries and prepares the reader to reason about different layers independently.
Standalone Documents
Knowledge of this cast MUST NOT be a requirement to understand a given document. Documents MUST be fully standalone and understandable to first-time readers.
Consistency
Use of the cast is optional. Characters SHOULD only be used when their presence improves understanding. Using characters in the wrong context can negatively impact comprehension by implying incorrect information. It is always acceptable to use other identifiers.
Character List
The following characters are defined for use throughout the documentation of chat protocols. Documentation and examples focus on a portion of a real clients operation for simplicity. Using the character who corresponds to the role or perspective being highlighted, can help convey this information to readers.
Saro
Sender ::
Saro is the participant who sends the first message within a given time window or protocol context.
Saro MAY be the party who initiates a conversation, or simply the first participant to act relative to a defined starting reference.
Raya
Recipient ::
Raya is the participant who receives the first message sent by Saro.
After the initial exchange, Raya MAY send messages and behave as a regular participant in the conversation.
When documenting message receipt or processing, Raya’s perspective SHOULD be used.
Pax
Participant ::
Pax represents an additional member of a conversation, typically in a group context.
Pax is often used when the specific identity or perspective of the participant is not relevant to the discussion.
Decision Criteria
The following criteria SHOULD be applied when considering the introduction of new character names or roles.
Clarity
Names without strong pre-existing associations or implied behavior SHOULD be preferred where possible.
Brevity
Short, easily distinguishable names SHOULD be preferred, provided they do not reduce clarity.
Inclusivity
The cast of characters SHOULD be diverse, culturally neutral, and avoid reinforcing stereotypes.
Mnemonic Naming
Where possible the characters name should hint at their role in order to make them easier to remember.
Copyright
Copyright and related rights waived via CC0.
References
A global cast of characters for cryptography
CHAT-DEFINITIONS
| Field | Value |
|---|---|
| Name | Shared definitions for Chat Protocols |
| Slug | 164 |
| Status | raw |
| Type | RFC |
| Category | informational |
| Tags | definitions, terminology, reference |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
48600b5— Migrate logos-messaging/specs into docs/messaging/ (#315)
Abstract
This specification establishes a common vocabulary and standardized definitions for terms used across chat protocol specifications. It serves as a normative reference to ensure consistent interpretation of terminology across application level specifications.
Background / Rationale / Motivation
Chat protocol specifications often employ similar terminology with subtle but important semantic differences. The absence of standardized definitions leads to ambiguity in specification interpretation and implementation inconsistencies across different protocol variants.
Establishing a shared definitions document provides several benefits:
- Semantic Consistency: Ensures uniform interpretation of common terms across multiple specifications
- Implementation Clarity: Reduces ambiguity for protocol implementers
- Specification Quality: Enables more precise and concise specification language through reference to established definitions
- Ecosystem Coherence: Promotes consistent understanding within the chat protocol ecosystem.
This specification provides normative definitions that other chat protocol specifications MAY reference to establish precise semantic meaning for common terminology.
Theory / Semantics
Definition Categories
Terms are organized into the following categories for clarity and ease of reference:
- Roles: Defined entity types that determine how a participant behaves within a communication protocol.
- Message Types: Classifications and categories of protocol messages
- Transports: Abstract methods of transmitting payloads -Software Entities: Distinct software-defined actors or components that participate in the operation of chat protocols.
Definitions
Roles
Sender: A client which is pushing a payload on to the network, to one or more recipients.
Recipient: A client which is the intended receiver of a payload. In a group context there maybe multiple recipients
Participant: A generic term for the rightful members of a conversation. Senders and Recipients are roles that participants can hold.
Message Types
The term "message" often has multiple meanings depending on context. The following definitions are used to disambiguate between different abstraction levels.
Content: An opaque byte sequence whose meaning is defined solely by the Application. The chat protocol layer neither interprets nor validates Content structure.
Frame: A structured protocol message exchanged between Clients. Frames are typed data structures that carry protocol meaning — they are how clients coordinate state and exchange information. Some Frames may carry Content as an opaque field. Once serialized for transport they become Payloads.
Payload: The serialized binary representation of a Frame, treated by the transport layer as an opaque byte sequence with no chat-layer semantics.
Other specific message types include:
Content Type: A definition of the structure and encoding of a Content instance, interpreted solely by the Application.
Delivery Acknowledgement: A notification from a receiving client to sender that their message was successfully received. While similar to a read-receipt, delivery acknowledgements differ in that the acknowledgement originates based on the client, where read-receipts are fired when they are displayed to a user.
Invite: A frame used to initialize a new conversation. Invites notify a client that someone wants to communicate with them, and provides the required information to do so.
Transports
Out-of-Band: The transfer of information using a channel separate from the defined chat protocol. Data sent Out-of-Band is transmitted using an undefined mechanism. This is used when protocols requires information to be shared with another entity, but it does not describe how that should occur. The responsibility to define how this occurs is the implementer or other protocols in the suite.
Software Entities
Client: A software component that manages Conversations and exposes messaging capabilities to Applications. The Client acts as the interface between the Application and the underlying protocol.
Application: Software that integrates with a Client in order to send and receive content. Applications are responsible for displaying content and controlling what content gets sent.
Conversation: An instance of a chat protocol between a set of participants. Conversations are responsible for protocol operations including encryption, key management, and frame generation.
Wire Format Specification / Syntax
This specification does not define wire format elements. All definitions are semantic and apply to the interpretation of terms used in other specifications that do define wire formats.
Security/Privacy Considerations
This specification defines terminology only and does not introduce security or privacy considerations beyond those present in specifications that reference these definitions.
The definitions provided in this specification do not alter the security or privacy properties of implementations that adopt the defined terminology.
Copyright
Copyright and related rights waived via CC0.
References
[RFC2119] Bradner, S., "Key words for use in RFCs to Indicate Requirement Levels", BCP 14, RFC 2119, March 1997.
RELAY-STATIC-SHARD-ALLOC
| Field | Value |
|---|---|
| Name | Waku v2 Relay Static Shard Allocation |
| Slug | 165 |
| Status | raw |
| Type | RFC |
| Category | informational |
| Tags | waku/informational |
| Editor | Daniel Kaiser [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
48600b5— Migrate logos-messaging/specs into docs/messaging/ (#315)
Abstract
This document lists static shard flag index assignments (see WAKU2-RELAY-SHARDING).
Background
Similar to the IANA port allocation, this document lists static shard index assignments (see WAKU2-RELAY-SHARDING.
Assingment Process
Note: Future versions of this document will specify the assignment process.
List of Cluster Ids
| index | Protocol/App | Description |
|---|---|---|
| 0 | global | global use |
| 1 | reserved | The Waku Network |
| 2 | reserved | |
| 3 | reserved | |
| 4 | reserved | |
| 5 | reserved | |
| 6 | reserved | |
| 7 | reserved | |
| 8 | reserved | |
| 9 | reserved | |
| 10 | reserved | |
| 11 | reserved | |
| 12 | reserved | |
| 13 | reserved | |
| 14 | reserved | |
| 15 | reserved | |
| 16 | Status | Status main net |
| 17 | Status | |
| 18 | Status |
Copyright
Copyright and related rights waived via CC0.
References
Informational
Supporting informational messaging draft specifications.
22/TOY-CHAT
| Field | Value |
|---|---|
| Name | Waku v2 Toy Chat |
| Slug | 22 |
| Status | draft |
| Type | RFC |
| Category | informational |
| Editor | Franck Royer [email protected] |
| Contributors | Hanno Cornelius [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-01-31 —
722c3d2— Rename TOY-CHAT.md to toy-chat.md - 2024-01-29 —
5c5ea36— Update TOY-CHAT.md - 2024-01-27 —
411e135— Create TOY-CHAT.md
Content Topic: /toy-chat/2/huilong/proto.
This specification explains a toy chat example using Waku v2. This protocol is mainly used to:
- Dogfood Waku v2,
- Show an example of how to use Waku v2.
Currently, all main Waku v2 implementations support the toy chat protocol: nim-waku, js-waku (NodeJS and web) and go-waku.
Note that this is completely separate from the protocol the Status app is using for its chat functionality.
Design
The chat protocol enables sending and receiving messages in a chat room. There is currently only one chat room, which is tied to the content topic. The messages SHOULD NOT be encrypted.
The contentTopic MUST be set to /toy-chat/2/huilong/proto.
Payloads
syntax = "proto3";
message Chat2Message {
uint64 timestamp = 1;
string nick = 2;
bytes payload = 3;
}
timestamp: The time at which the message was sent, in Unix Epoch seconds,nick: The nickname of the user sending the message,payload: The text of the messages, UTF-8 encoded.
Copyright
Copyright and related rights waived via CC0.
23/WAKU2-TOPICS
| Field | Value |
|---|---|
| Name | Waku v2 Topic Usage Recommendations |
| Slug | 23 |
| Status | draft |
| Type | RFC |
| Category | informational |
| Editor | Oskar Thoren [email protected] |
| Contributors | Hanno Cornelius [email protected], Daniel Kaiser [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-08 —
c0ef3b9— Cleanup: rewrite specs-repo links in pre-existing messaging specs (#316) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-04-22 —
4df2d5f— update waku/informational/23/topics.md (#144) - 2025-01-02 —
dc7497a— add usage guidelines for waku content topics (#117) - 2024-11-20 —
ff87c84— Update Waku Links (#104) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-02-07 —
e63d8a0— Update topics.md - 2024-01-31 —
b8f088c— Update and rename README.md to topics.md - 2024-01-31 —
2b693e8— Update README.md - 2024-01-29 —
055c525— Update README.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-25 —
a11dfed— Create README.md
This document outlines recommended usage of topic names in Waku v2. In 10/WAKU2 spec there are two types of topics:
- Pubsub topics, used for routing
- Content topics, used for content-based filtering
Pubsub Topics
Pubsub topics are used for routing of messages (see 11/WAKU2-RELAY), and can be named implicitly by Waku sharding (see RELAY-SHARDING). This document comprises recommendations for explicitly naming pubsub topics (e.g. when choosing named sharding as specified in RELAY-SHARDING).
Pubsub Topic Format
Pubsub topics SHOULD follow the following structure:
/waku/2/{topic-name}
This namespaced structure makes compatibility, discoverability, and automatic handling of new topics easier.
The first two parts indicate:
- it relates to the Waku protocol domain, and
- the version is 2.
If applicable, it is RECOMMENDED to structure {topic-name}
in a hierarchical way as well.
Note: In previous versions of this document, the structure was
/waku/2/{topic-name}/{encoding}. The now deprecated/{encoding}was always set to/proto, which indicated that the data field in pubsub is serialized/encoded as protobuf. The inspiration for this format was taken from Ethereum 2 P2P spec. However, because the payload of messages transmitted over 11/WAKU2-RELAY must be a 14/WAKU2-MESSAGE, which specifies the wire format as protobuf,/protois the only valid encoding. This makes the/protoindication obsolete. The encoding of thepayloadfield of a WakuMessage is indicated by the/{encoding}part of the content topic name. Specifying an encoding is only significant for the actual payload/data field. Waku preserves this option by allowing to specify an encoding for the WakuMessage payload field as part of the content topic name.
Default PubSub Topic
The Waku v2 default pubsub topic is:
/waku/2/default-waku/proto
The {topic name} part is default-waku/proto,
which indicates it is default topic for exchanging WakuMessages;
/proto remains for backwards compatibility.
Application Specific Names
Larger apps can segregate their pubsub meshes using topics named like:
/waku/2/status/
/waku/2/walletconnect/
This indicates that these networks carry WakuMessages, but for different domains completely.
Named Topic Sharding Example
The following is an example of named sharding, as specified in RELAY-SHARDING.
waku/2/waku-9_shard-0/
...
waku/2/waku-9_shard-9/
This indicates explicitly that the network traffic has been partitioned into 10 buckets.
Content Topics
The other type of topic that exists in Waku v2 is a content topic. This is used for content based filtering. See 14/WAKU2-MESSAGE spec for where this is specified. Note that this doesn't impact routing of messages between relaying nodes, but it does impact using request/reply protocols such as 12/WAKU2-FILTER and 13/WAKU2-STORE.
This is especially useful for nodes that have limited bandwidth, and only want to pull down messages that match this given content topic.
Since all messages are relayed using the relay protocol regardless of content topic, you MAY use any content topic you wish without impacting how messages are relayed.
Content Topic Format
The format for content topics is as follows:
/{application-name}/{version-of-the-application}/{content-topic-name}/{encoding}
The name of a content topic is application-specific. As an example, here's the content topic used for an upcoming testnet:
/toychat/2/huilong/proto
Content Topic Naming Recommendations
Application names SHOULD be unique to avoid conflicting issues with other protocols.
Application version (if applicable) SHOULD be specified in the version field.
The {content-topic-name} portion of the content topic is up to the application,
and depends on the problem domain.
It can be hierarchical, for instance to separate content, or
to indicate different bandwidth and privacy guarantees.
The encoding field indicates the serialization/encoding scheme
for the WakuMessage payload field.
Content Topic usage guidelines
Applications SHOULD be mindful while designing/using content topics so that a bloat of content-topics does not happen. A content-topic bloat causes performance degradation in Store and Filter protocols while trying to retrieve messages.
Store queries have been noticed to be considerably slow (e.g doubling of response-time when content-topic count is increased from 10 to 100) when a lot of content-topics are involved in a single query. Similarly, a number of filter subscriptions increase, which increases complexity on client side to maintain and manage these subscriptions.
Applications SHOULD analyze the query/filter criteria for fetching messages from the network and select/design content topics to match such filter criteria. e.g: even though applications may want to segregate messages into different sets based on some application logic, if those sets of messages are always fetched/queried together from the network, then all those messages SHOULD use a single content-topic.
Differences with Waku v1
In 5/WAKU1 there is no actual routing. All messages are sent to all other nodes. This means that we are implicitly using the same pubsub topic that would be something like:
/waku/1/default-waku/rlp
Topics in Waku v1 correspond to Content Topics in Waku v2.
Bridging Waku v1 and Waku v2
To bridge Waku v1 and Waku v2 we have a 15/WAKU-BRIDGE. For mapping Waku v1 topics to Waku v2 content topics, the following structure for the content topic SHOULD be used:
/waku/1/<4bytes-waku-v1-topic>/rfc26
The <4bytes-waku-v1-topic> SHOULD be the lowercase hex representation
of the 4-byte Waku v1 topic.
A 0x prefix SHOULD be used.
/rfc26 indicates that the bridged content is encoded according to RFC 26/WAKU2-PAYLOAD.
See 15/WAKU-BRIDGE
for a description of the bridged fields.
This creates a direct mapping between the two protocols. For example:
/waku/1/0x007f80ff/rfc26
Copyright
Copyright and related rights waived via CC0.
References
- 10/WAKU2 spec
- 11/WAKU2-RELAY
- RELAY-SHARDING
- Ethereum 2 P2P spec
- 14/WAKU2-MESSAGE
- 12/WAKU2-FILTER
- 13/WAKU2-STORE
- 6/WAKU1
- 15/WAKU-BRIDGE
- 26/WAKU-PAYLOAD
27/WAKU2-PEERS
| Field | Value |
|---|---|
| Name | Waku v2 Client Peer Management Recommendations |
| Slug | 27 |
| Status | draft |
| Type | RFC |
| Category | informational |
| Editor | Hanno Cornelius [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-04-22 —
af7c413— update waku/informational/27/peers.md (#145) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-01-31 —
4b77d10— Update and rename README.md to peers.md - 2024-01-31 —
e65c359— Update README.md - 2024-01-31 —
4a78cac— Update README.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-25 —
7daec2f— Create README.md
27/WAKU2-PEERS describes a recommended minimal set of peer storage and
peer management features to be implemented by Waku v2 clients.
In this context, peer storage refers to a client's ability to keep track of discovered or statically-configured peers and their metadata. It also deals with matters of peer persistence, or the ability to store peer data on disk to resume state after a client restart.
Peer management is a closely related concept and refers to the set of actions a client MAY choose to perform based on its knowledge of its connected peers, e.g. triggering reconnects/disconnects, keeping certain connections alive, etc.
Peer store
The peer store SHOULD be an in-memory data structure where information about discovered or configured peers are stored. It SHOULD be considered the main source of truth for peer-related information in a Waku v2 client. Clients MAY choose to persist this store on-disk.
Tracked peer metadata
It is RECOMMENDED that a Waku v2 client tracks at least the following information about each of its peers in a peer store:
| Metadata | Description |
|---|---|
| Public key | The public key for this peer. This is related to the libp2p Peer ID. |
| Addresses | Known transport layer multiaddrs for this peer. |
| Protocols | The libp2p protocol IDs supported by this peer. This can be used to track the client's connectivity to peers supporting different Waku v2 protocols, e.g. 11/WAKU2-RELAY or 13/WAKU2-STORE. |
| Connectivity | Tracks the peer's current connectedness state. See Peer connectivity below. |
| Disconnect time | The timestamp at which this peer last disconnected. This becomes important when managing peer reconnections |
Peer connectivity
A Waku v2 client SHOULD track at least the following connectivity states for each of its peers:
NotConnected: The peer has been discovered or configured on this client, but no attempt has yet been made to connect to this peer. This is the default state for a new peer.CannotConnect: The client attempted to connect to this peer, but failed.CanConnect: The client was recently connected to this peer and disconnected gracefully.Connected: The client is actively connected to this peer.
This list does not preclude clients from tracking more advanced connectivity metadata,
such as a peer's blacklist status (see 18/WAKU2-SWAP).
Persistence
A Waku v2 client MAY choose to persist peers across restarts, using any offline storage technology, such as an on-disk database. Peer persistence MAY be used to resume peer connections after a client restart.
Peer management
Waku v2 clients will have different requirements when it comes to managing the peers tracked in the peer store. It is RECOMMENDED that clients support:
- automatic reconnection to peers under certain conditions
- connection keep-alive
Reconnecting peers
A Waku v2 client MAY choose to reconnect to previously connected, managed peers under certain conditions. Such conditions include, but are not limited to:
- Reconnecting to all
relay-capable peers after a client restart. This will require persistent peer storage.
If a client chooses to automatically reconnect to previous peers, it MUST respect the backing off period specified for GossipSub v1.1 before attempting to reconnect. This requires keeping track of the last time each peer was disconnected.
Connection keep-alive
A Waku v2 client MAY choose to implement a keep-alive mechanism to certain peers.
If a client chooses to implement keep-alive on a connection,
it SHOULD do so by sending periodic libp2p pings
as per 10/WAKU2 client recommendations.
The recommended period between pings SHOULD be at most 50%
of the shortest idle connection timeout for the specific client and transport.
For example, idle TCP connections often times out after 10 to 15 minutes.
Implementation note: the
nim-wakuclient currently implements a keep-alive mechanism every5 minutes, in response to a TCP connection timeout of10 minutes.
Copyright
Copyright and related rights waived via CC0.
References
Peer IDmultiaddrsprotocol IDs11/WAKU2-RELAY13/WAKU2-STORE18/WAKU2-SWAP- backing off period
- libp2p pings
10/WAKU2client recommendations
29/WAKU2-CONFIG
| Field | Value |
|---|---|
| Name | Waku v2 Client Parameter Configuration Recommendations |
| Slug | 29 |
| Status | draft |
| Type | RFC |
| Category | informational |
| Editor | Hanno Cornelius [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-04-22 —
7408956— update waku/informational/29/config.md (#146) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-01-31 —
c506eac— Update and rename CONFIG.md to config.md - 2024-01-31 —
930f84d— Update and rename README.md to CONFIG.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-25 —
e6396b9— Create README.md
29/WAKU2-CONFIG describes the RECOMMENDED values
to assign to configurable parameters for Waku v2 clients.
Since Waku v2 is built on libp2p,
most of the parameters and reasonable defaults are derived from there.
Waku v2 relay messaging is specified in 11/WAKU2-RELAY,
a minor extension of the libp2p GossipSub protocol.
GossipSub behaviour is controlled by a series of adjustable parameters.
Waku v2 clients SHOULD configure these parameters to the recommended values below.
GossipSub v1.0 parameters
GossipSub v1.0 parameters are defined in the corresponding libp2p specification.
We repeat them here with RECOMMMENDED values for 11/WAKU2-RELAY implementations.
| Parameter | Purpose | RECOMMENDED value |
|---|---|---|
D | The desired outbound degree of the network | 6 |
D_low | Lower bound for outbound degree | 4 |
D_high | Upper bound for outbound degree | 8 |
D_lazy | (Optional) the outbound degree for gossip emission | D |
heartbeat_interval | Time between heartbeats | 1 second |
fanout_ttl | Time-to-live for each topic's fanout state | 60 seconds |
mcache_len | Number of history windows in message cache | 5 |
mcache_gossip | Number of history windows to use when emitting gossip | 3 |
seen_ttl | Expiry time for cache of seen message ids | 2 minutes |
GossipSub v1.1 parameters
GossipSub v1.1 extended GossipSub v1.0 and
introduced several new parameters.
We repeat the global parameters here
with RECOMMMENDED values for 11/WAKU2-RELAY implementations.
| Parameter | Description | RECOMMENDED value |
|---|---|---|
PruneBackoff | Time after pruning a mesh peer before we consider grafting them again. | 1 minute |
FloodPublish | Whether to enable flood publishing | true |
GossipFactor | % of peers to send gossip to, if we have more than D_lazy available | 0.25 |
D_score | Number of peers to retain by score when pruning from oversubscription | D_low |
D_out | Number of outbound connections to keep in the mesh. | D_low - 1 |
11/WAKU2-RELAY clients SHOULD implement a peer scoring mechanism
with the parameter constraints as
specified by libp2p.
Other configuration
The following behavioural parameters are not specified by libp2p,
but nevertheless describes constraints that 11/WAKU2-RELAY clients
MAY choose to implement.
| Parameter | Description | RECOMMENDED value |
|---|---|---|
BackoffSlackTime | Slack time to add to prune backoff before attempting to graft again | 2 seconds |
IWantPeerBudget | Maximum number of IWANT messages to accept from a peer within a heartbeat | 25 |
IHavePeerBudget | Maximum number of IHAVE messages to accept from a peer within a heartbeat | 10 |
IHaveMaxLength | Maximum number of messages to include in an IHAVE message | 5000 |
Copyright
Copyright and related rights waived via CC0.
References
- libp2p
- 11/WAKU2-RELAY
- libp2p GossipSub protocol
- corresponding libp2p specification
- several new parameters
30/ADAPTIVE-NODES
| Field | Value |
|---|---|
| Name | Adaptive nodes |
| Slug | 30 |
| Status | draft |
| Type | RFC |
| Category | informational |
| Editor | Oskar Thorén [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-04-29 —
91c9679— update waku/informational/30/adaptive-nodes.md (#147) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-01-31 —
b35846a— Update and rename README.md to adaptive-nodes.md - 2024-01-27 —
eef961b— remove rfs folder - 2024-01-25 —
04036ad— Create README.md
This is an informational spec that show cases the concept of adaptive nodes.
Node types - a continuum
We can look at node types as a continuum, from more restricted to less restricted, fewer resources to more resources.

Possible limitations
- Connectivity: Not publicly connectable vs static IP and DNS
- Connectivity: Mostly offline to mostly online to always online
- Resources: Storage, CPU, Memory, Bandwidth
Accessibility and motivation
Some examples:
- Opening browser window: costs nothing, but contribute nothing
- Desktop: download, leave in background, contribute somewhat
- Cluster: expensive, upkeep, but can contribute a lot
These are also illustrative, so a node in a browser in certain environment might contribute similarly to Desktop.
Adaptive nodes
We call these nodes adaptive nodes to highlights different modes of contributing, such as:
- Only leeching from the network
- Relaying messages for one or more topics
- Providing services for lighter nodes such as lightpush and filter
- Storing historical messages to various degrees
- Ensuring relay network can't be spammed with RLN
Planned incentives
Incentives to run a node is currently planned around:
- SWAP for accounting and settlement of services provided
- RLN RELAY for spam protection
- Other incentivization schemes are likely to follow and is an area of active research
Node protocol selection
Each node can choose which protocols to support, depending on its resources and goals.
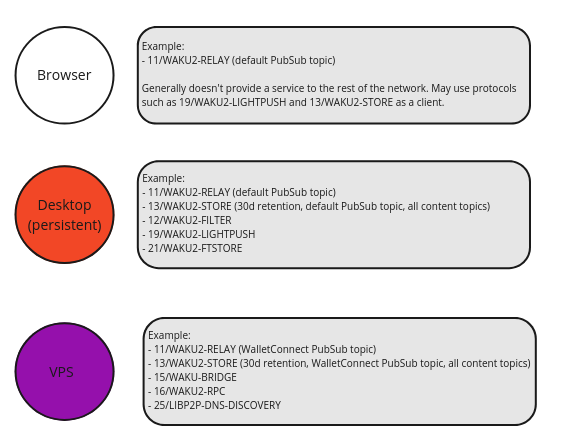
Protocols like 11/WAKU2-RELAY, as well as [12], [13], [19], and [21], correspond to libp2p protocols.
However, other protocols like 16/WAKU2-RPC (local HTTP JSON-RPC), 25/LIBP2P-DNS-DISCOVERY, Discovery v5 (DevP2P) or interfacing with distributed storage, are running on different network stacks.
This is in addition to protocols that specify payloads, such as 14/WAKU2-MESSAGE, 26/WAKU2-PAYLOAD, or application specific ones. As well as specs that act more as recommendations, such as 23/WAKU2-TOPICS or 27/WAKU2-PEERS.
Waku network visualization
We can better visualize the network with some illustrative examples.
Topology and topics
This illustration shows an example topology with different PubSub topics for the relay protocol.
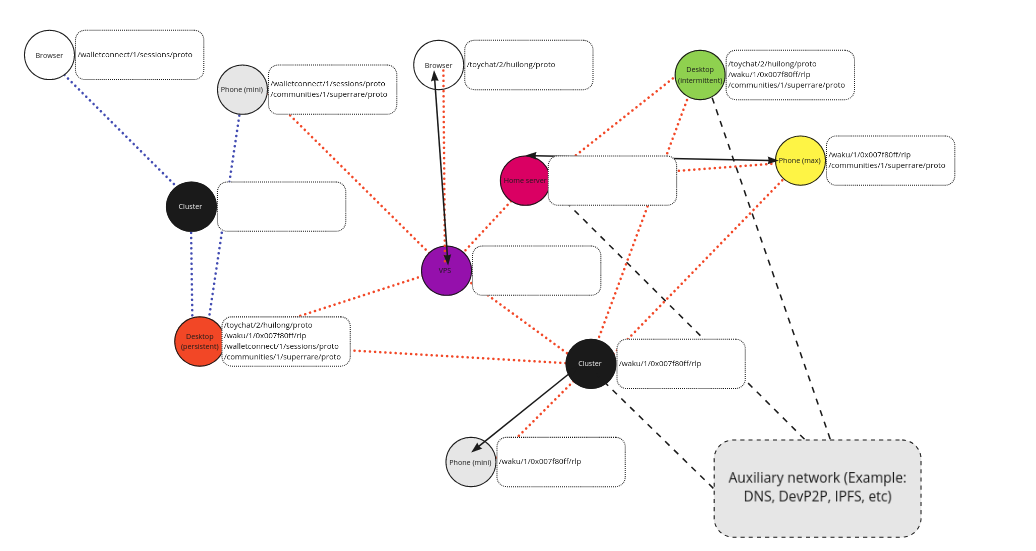
Legend
This illustration shows an example of content topics a node is interested in.
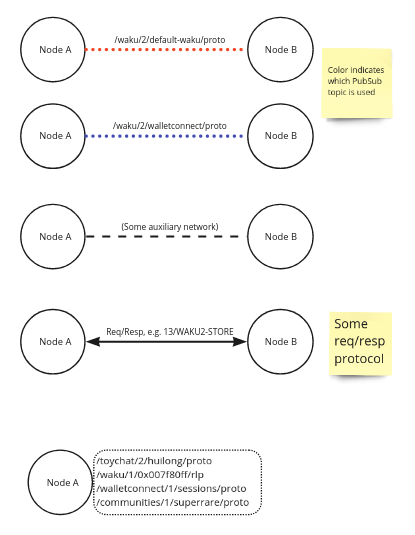
The dotted box shows what content topics (application-specific) a node is interested in.
A node that is purely providing a service to the network might not care.
In this example, we see support for toy chat, a topic in Waku v1 (Status chat), WalletConnect, and SuperRare community.
Auxiliary network
This is a separate component with its own topology.
Behavior and interaction with other protocols specified in Logos LIPs, e.g. 25/LIBP2P-DNS-DISCOVERY and 15/WAKU-BRIDGE.
Node Cross Section
This one shows a cross-section of nodes in different dimensions and shows how the connections look different for different protocols.
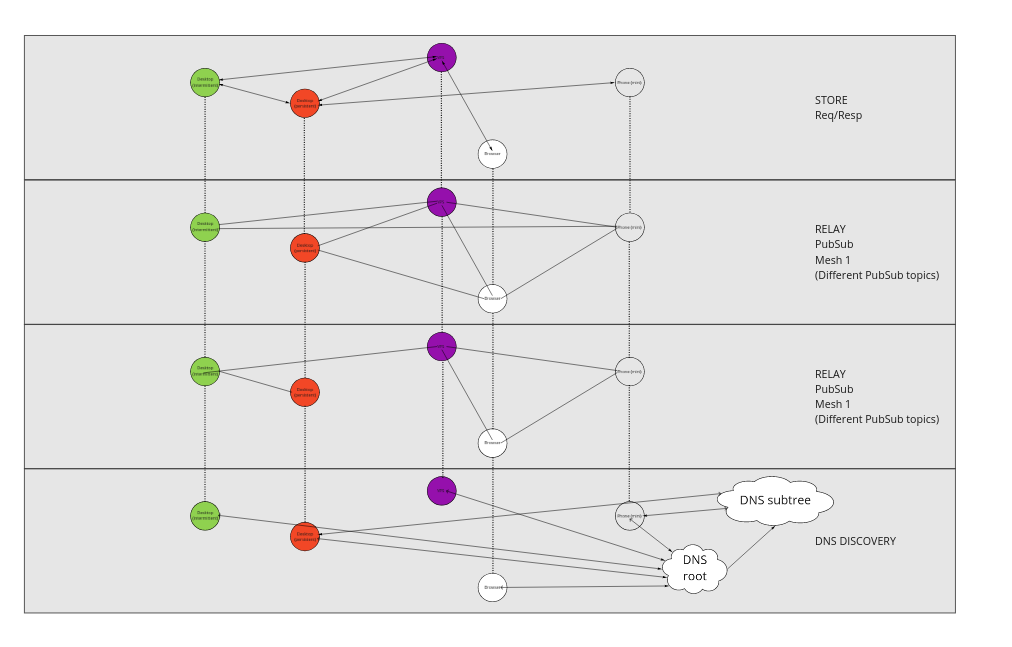
Copyright
Copyright and related rights waived via CC0.
References
Blockchain LIPs
Logos Blockchain is building a secure, flexible, and scalable infrastructure for developers creating applications for the network state. Published specifications are available in the topic tree below.
Loading topic tree…
NETWORK-WIRE-FORMAT
| Field | Value |
|---|---|
| Name | Network Wire Format |
| Slug | 203 |
| Status | raw |
| Category | Standards Track |
| Editor | Daniel Sanchez Quiros [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-08-20 |
| 1.0.1 | Renamed Nomos to Logos Blockchain | 2026-04-17 |
Introduction
The Logos Blockchain consists of multiple networks. Peers within these networks need a common language to exchange information effectively. This document defines the standardized language used for this communication.
This document outlines a clear strategy for writing and reading messages transmitted across various Logos Blockchain networks.
The key objectives of this wire format are to have message structures that are sharable across different implementations and languages, and to use a stable encoding and decoding processes that do not depend on interpretation.
Overview
The Logos Blockchain relies on established message structures and standard encoding/decoding formats rather than creating new ones. All messages follow familiar patterns and utilize widely-adopted industry standards for encoding and decoding.
All data transmitted across Logos Blockchain networks adheres to a single consistent format and serialization structure. The schemas are designed to be compatible with or easily implementable in various programming languages.
Construction
Format
Logos Blockchain messages use C layout representation. This means that regardless of the programming language, the order, size, and alignment of fields follow the standardized C/C++ layout.
When you see a message in the specification (typically in Python format), you can easily translate it to its equivalent C-based structure.
For example:
Python
@dataclass
class Foo:
data: bytes
size: int
Rust
#![allow(unused)] fn main() { #[repr(c)] struct Foo { data: Vec<u8>, size: usize } }
C
struct Foo
{
data: *uint8_t
size: size_t
}
Encoding and Decoding
Logos Blockchain messages are encoded using bincode - a compact binary serialization format with zero overhead. The format is defined as "a compact encoder/decoder pair that uses a binary zero-fluff encoding scheme." Bincode has been battle-tested in other blockchain protocol implementations, making it production-ready.
The complete specification can be found in the official documentation.
Reference
P2P-NAT-SOLUTION
| Field | Value |
|---|---|
| Name | P2P Nat Solution |
| Slug | 138 |
| Status | raw |
| Category | networking |
| Editor | Antonio Antonino [email protected] |
| Contributors | Álvaro Castro-Castilla [email protected], Daniel Sanchez-Quiros [email protected], Petar Radovic [email protected], Gusto Bacvinka [email protected], Youngjoon Lee [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-18 —
58b5698— chore(blockchain): migrate contributor emails to @logos.co (#338) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-09-25 —
cfb3b78— Created nomos/raw/p2p-nat-solution.md draft (#174)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-08-22 |
| 1.0.1 | Renamed Nomos to Logos Blockchain | 2026-04-17 |
Introduction
Network Address Translation (NAT) is a critical challenge that Logos Blockchain participants must address to the largest extent possible. Logos Blockchain is designed to operate on modern laptops for a significant subset of users, many of whom may lack the technical expertise to troubleshoot NAT-related issues. Therefore, the Logos Blockchain aims to resolve these challenges automatically.
The Logos Blockchain NAT traversal strategy is the process by which a node:
- Determines its NAT status, i.e., whether it is publicly reachable (via a public IP address or valid port mapping on a router), or hidden behind a NAT/firewall without a valid port mapping.
- Must be able to both establish outbound connections and accept inbound connections from other nodes regardless of their NAT status.
In this document, Public denotes a publicly reachable node, as described above. A node that does not have those properties is considered Private. Dialing refers to the process of establishing an outbound connection using the libp2p stack, where the dialing peer is the initiator of the connection.
This document defines a phased strategy for enabling and maintaining public reachability in libp2p nodes. By combining AutoNAT, dynamic port mapping, and continuous verification, the protocol aims to maximize the likelihood that a node can be contacted from the public Internet - even in the presence of different types of NATs and firewalls.
Overview
Key design principles
Optional Configuration
The NAT traversal strategy must work out-of-the-box whenever possible. On one hand, users who do not want to engage in any configuration should not be required to do more than install the node software package. On the other hand, users that want to be in full control of the node must be able to configure every aspect of the strategy.
Decentralized
Leverage the existing Logos Blockchain P2P network for coordination rather than relying on centralized third-party services.
Progressive Fallback
Begin with lightweight checks, escalating through more complex and resource-hungry protocols. A failure at any step moves the protocol to the next stage in the strategy.
Changing Network Environment
It is assumed that unless explicitly specified (which is the case for non-consumer grade hardware and specialized node operators with statically configured addresses), each node’s private or public status is prone to change (i.e., a once publicly-reachable node can become unreachable and vice versa).
Node discovery considerations
Unlike other networks, the Logos Blockchain public network encourages a large number of participants, many of whom are expected to be deployed with a simple installation procedure (i.e., a package manager on a laptop). Some of these nodes will not achieve Public node status. Nevertheless, the discovery protocol must also track these peers and allow other nodes to discover them. Otherwise, the network would effectively become quasi-partitioned, with Private nodes being unavailable to the rest of the participants.
Protocol
Each node must
- Run an AutoNAT client, except for nodes statically configured as Public.
- Use the Identify protocol to advertise support for the following protocols:
/libp2p/autonat/2/dial-requestfor client requests/libp2p/autonat/2/dial-backfor server responses
In the future the NAT traversal protocol will most likely be using its own stream protocol.
NAT State Machine
graph TD
Start@{shape: circle, label: "Start"} -->|Preconfigured public IP or port mapping| StaticPublic[Statically configured as<br/>**Public**]
subgraph Phase 0
Start -->|Default configuration| Boot
end
subgraph Phase 1
Boot[Bootstrap and discover AutoNAT servers]--> Inspect
Inspect[Inspect own IP addresses]-->|At least 1 IP address in the public range| ConfirmPublic[AutoNAT]
end
subgraph Phase 2
Inspect -->|No IP addresses in the public range| MapPorts[Port Mapping Client<br/>UPnP/NAT-PMP/PCP]
MapPorts -->|Successful port map| ConfirmMapPorts[AutoNAT]
end
ConfirmPublic -->|Node's IP address reachable by AutoNAT server| Public[**Public** Node]
ConfirmPublic -->|Node's IP address not reachable by AutoNAT server or Timeout| MapPorts
ConfirmMapPorts -->|Mapped IP address and port reachable by AutoNAT server| Public
ConfirmMapPorts -->|Mapped IP address and port not reachable by AutoNAT server or Timeout| Private
MapPorts -->|Failure or Timeout| Private[**Private** Node]
subgraph Phase 3
Public -->Monitor
Private --> Monitor
end
Monitor[Network Monitoring] -->|Restart| Inspect
Phases
Phase 0: Bootstrapping and identifying Public nodes
If the node is statically configured by the operator to be Public, the procedure is stopped.
The node utilizes bootstrapping (see P2P Network Bootstrapping) and discovery (see P2P Network) to find other Public nodes. The Identify protocol is used to confirm which of the detected Public nodes support AutoNAT v2.
The node then moves to the next phase.
Phase 1: NAT Detection
The node starts an AutoNAT client and inspects its own addresses. Using the AutoNAT client, for each of its own addresses, the node checks that the address is indeed publicly reachable. If any of the IP addresses are confirmed to be public via AutoNAT, the node assumes Public status and the procedure moves to Phase 3: Network Monitoring. Otherwise, the node continues to the next phase.
Phase 2: Automated Port Mapping
The node attempts to secure a port mapping on the default gateway using one of the following protocols: PCP, NAT-PMP, or UPnP-IGD. PCP is the successor of NAT-PMP and is the most reliable protocol of the three. UPnP-IGD is the most widely deployed protocol, but the least reliable. The port mapping procedure takes this into account and proceeds as follows:
def try_port_mapping():
# Step 1: Get the local IPv4 address
local_ip = get_local_ipv4_address()
# Step 2: Get the default gateway IPv4 address
gateway_ip = get_default_gateway_address()
# Step 3: Abort if local or gateway IP could not be determined
if not local_ip or not gateway_ip:
return "Mapping failed: Unable to get local or gateway IPv4"
# Step 4: Try mapping with PCP first, because it's the most reliable
mapping = try_pcp_mapping(local_ip, gateway_ip)
if mapping:
return mapping
# Step 5: Try NAT-PMP if PCP failed, because it's the second most reliable
mapping = try_nat_pmp_mapping(local_ip, gateway_ip)
if mapping:
return mapping
# Step 6: Try UPnP as the last resort
mapping = try_upnp_mapping(local_ip, gateway_ip)
if mapping:
return mapping
# Step 7: All mapping attempts failed
return "Mapping failed: No protocol succeeded"
If the mapping is successful, the node uses an AutoNAT client to confirm that Public nodes can reach it. Upon successful confirmation the node assumes Public status. If the confirmation fails or the mapping is unsuccessful, the node assumes Private status.
A Public node must ensure that the port mapping is periodically renewed according to the policy recommended by the port mapping protocol in use.
Finally, the node continues to the next phase.
sequenceDiagram
box Node
participant AutoNAT Client
participant NAT State Machine
participant Port Mapping Client
end
participant Router
alt Mapping is successful
Note left of AutoNAT Client: Phase 2
Port Mapping Client ->> +Router: Requests new mapping
Router ->> Port Mapping Client: Confirms new mapping
Port Mapping Client ->> NAT State Machine: Mapping secured
NAT State Machine ->> AutoNAT Client: Requests confirmation<br/>that mapped address<br/>is publicly reachable
alt Node asserts Public status
AutoNAT Client ->> NAT State Machine: Mapped address<br/>is publicly reachable
Note left of AutoNAT Client: Phase 3<br/>Network Monitoring
else Node asserts Private status
AutoNAT Client ->> NAT State Machine: Mapped address<br/>is not publicly reachable
Note left of AutoNAT Client: Phase 3<br/>Network Monitoring
end
else Mapping fails, node asserts Private status
Note left of AutoNAT Client: Phase 2
Port Mapping Client ->> Router: Requests new mapping
Router ->> Port Mapping Client: Refuses new mapping or Timeout
Port Mapping Client ->> NAT State Machine: Mapping failed
Note left of AutoNAT Client: Phase 3<br/>Network Monitoring
end
Phase 3: Network Monitoring
Unless explicitly configured by the operator, it is assumed the node can leave and rejoin the network at any time. The node must monitor its network status, and restart the procedure from Phase 1 if any change is detected.
A Public node must do this when:
- AutoNAT client no longer confirms that at least one of the node’s addresses is publicly reachable.
- A previously successful port mapping has been lost or refreshing of the mapping failed.
sequenceDiagram
participant AutoNAT Server
box Node
participant AutoNAT Client
participant NAT State Machine
participant Port Mapping Client
end
participant Router
Note left of AutoNAT Server: Phase 3<br/>Network Monitoring
par Refresh mapping and monitor changes
loop periodically refreshes mapping
Port Mapping Client ->> Router: Requests refresh
Router ->> Port Mapping Client: Confirms mapping refresh
end
break Mapping is lost, the node loses Public status
Router ->> Port Mapping Client: Refresh failed or mapping dropped
Port Mapping Client ->> NAT State Machine: Mapping lost
NAT State Machine ->> NAT State Machine: Restart
end
and Monitor public reachability of mapped addresses
loop periodically checks public reachability
AutoNAT Client ->> AutoNAT Server: Requests dialback
AutoNAT Server ->> AutoNAT Client: Dialback successful
end
break
AutoNAT Server ->> AutoNAT Client: Dialback failed or Timeout
AutoNAT Client ->> NAT State Machine: Public reachability lost
NAT State Machine ->> NAT State Machine: Restart
end
end
Note left of AutoNAT Server: Phase 1
A Private node must do this when:
- It has gained a new, public IP address.
- A port mapping attempt is likely to succeed (e.g. default gateway has changed, sufficient time has passed after mapping was refused or dropped).
Node duties once Public status is assumed
A Public node must
- Run an AutoNAT server.
- Listen on and advertise via the Identify protocol its publicly reachable multiaddresses in the form:
/{public_peer_ip}/udp/{port}/quic-v1/p2p/{peer_id}
Annex
References
- Multiaddress spec
- Identify v1 protocol spec
- AutoNAT v2 protocol spec
- RFC 6887 – PCP
- RFC 6886 – NAT-PMP
- RFC 6970 – UPnP IGD
P2P-NETWORK
| Field | Value |
|---|---|
| Name | P2P Network |
| Slug | 135 |
| Status | draft |
| Type | RFC |
| Category | networking |
| Editor | Daniel Sanchez-Quiros [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-29 —
67e498e— chore: fix math issues (#350) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-18 —
58b5698— chore(blockchain): migrate contributor emails to @logos.co (#338) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-09-25 —
a3a5b91— Created nomos/raw/p2p-network.md file (#169)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-01-20 |
| 1.0.1 | Rename Nomos to Logos Blockchain | 2026-04-17 |
Introduction
The Logos Blockchain peer-to-peer (P2P) network serves as the comprehensive communication layer connecting Logos Blockchain nodes. Its primary functions include facilitating the mempool for transaction dissemination and enabling block propagation. This specification leverages established, publicly available protocols to ensure robust performance. The Logos Blockchain P2P network is designed to scale according to the project's requirements, supporting efficient communication with low bandwidth and minimal latency.
Participants, or peers, operating Logos Blockchain nodes encompass a diverse array of machine specifications, ranging from laptops to dedicated servers, as well as various operating systems and geographic locations. A key priority is to streamline communication for non-technical users, ensuring accessibility. This entails enabling peers to remain reachable—ideally even with limited connectivity or when situated behind a router—thereby enhancing inclusivity and usability across the network.
Overview
The Logos Blockchain network constitutes a foundational element of the communication infrastructure, addressing several critical challenges:
- Peer Connectivity: Establishing mechanisms for peers to join and connect to the network.
- Peer Discovery: Enabling peers to locate and identify other participants within the network.
- Message Transmission: Facilitating the efficient exchange of messages among peers across the network.
The Logos Blockchain network uses production-tested protocols to ensure all of the above is achieved.
Network Protocols Details
Transport
The Logos Blockchain network extensively leverages the libp2p suite of plug-and-play protocols, which forms a foundational component for delivering the essential functionalities outlined previously.
At its core, the Logos Blockchain network employs the QUIC transport protocol. QUIC provides rapid connection establishment and offers several advantages, including enhanced NAT traversal capabilities stemming from its UDP foundation. Additionally, its default multiplexing feature simplifies configuration processes.
Peer Discovery
Following an evaluation of existing protocols and network requirements, the optimal approach for the Logos Blockchain is to leverage the established libp2p stack, incorporating libp2p-kad for peer discovery. This provides a robust, modular, and scalable solution that seamlessly integrates with other libp2p protocols (e.g., gossipsub, identify, ping), enabling support for large-scale, dynamic networks with eventual consistency and resilience.
The Logos Blockchain P2P network integrates a combination of libp2p's Kademlia and Identify protocols to facilitate peer discovery. Kademlia enables the identification and connection to new peers by employing proximity-based heuristics, optimizing the discovery process. Complementing this, the Identify protocol supports the exchange of peer information, including details about the protocols each peer supports, thereby enhancing interoperability and network coordination.
The specific protocols to be negotiated are:
- Kademlia:
/logos-blockchain/kad/{version}for main network and/logos-blockchain-testnet/kad/{version}for public testnet. - Identify:
/logos-blockchain/identify/{version}and/logos-blockchain-testnet/identify/{version}for public testnet.
Current versions are 1.0.0.
The Logos Blockchain team acknowledges that the current Kademlia DHT implementation is only optimal for the V1 solution, as it is a heavier protocol for the limited utility the Logos Blockchain actually requires. However, it remains a viable interim approach. An ideal protocol would feature:
- A lightweight design, excluding the DHT which is of no use for the Logos Blockchain network.
- Lightweight and highly-scalable eventual consistency for network membership, supporting +10k nodes (ideally unbounded in practice).
This will be worked on in the future.
NAT Traversal
Network Address Translation (NAT) poses a common challenge in peer-to-peer networks. The Logos Blockchain network prioritizes seamless, configuration-free connections among peers to accommodate participants with varying levels of technical expertise, ranging from none to advanced. Simplicity is a critical objective, given the goal of enabling nodes to operate on standard hardware, such as laptops.
To achieve this, the Logos Blockchain employs a tailored set of solutions adapted to the user's specific configuration. Comprehensive details are provided in the NAT Solution Specification.
Gossiping
The Logos Blockchain leverages gossipsub for its messaging capabilities. This works in combination with the above exposed peer discovery protocol and NAT traversal solution as they are members of the same libp2p stack. It automatically leverages kademlia connections to keep an updated list of available peers in the network.
Logos Blockchain gossiping uses two major topics. One dedicated to mempool and one for block dissemination:
-
Mempool:
/logos-blockchain/mempool/{version}for mainnet./logos-blockchain-testnet/mempool/{version}for testnet. Current version is1.0.0. -
Blocks:
/logos-blockchain/cryptarchia/{version}for mainnet./logos-blockchain-testnet/cryptarchia/{version}for testnet. Current version is1.0.0.gossipsub is openly customizable but it is encouraged to have a peering degree of at least 8 peers.
Bootstrapping
The Logos Blockchain P2P network is engineered for simplicity and ease of use. Upon initial connection, nodes in the network connect to publicly designated nodes to acquire the essential information required to become fully operational. Further details regarding this process are elaborated in the bootstrapping specification.
Message Encoding
Messages that goes through wire follow a specific encoding scheme defined in the following specification.
P2P-NETWORK-BOOTSTRAPPING
| Field | Value |
|---|---|
| Name | P2P Network Bootstrapping |
| Slug | 134 |
| Status | raw |
| Category | networking |
| Editor | Daniel Sanchez-Quiros [email protected] |
| Contributors | Álvaro Castro-Castilla [email protected], Petar Radovic [email protected], Gusto Bacvinka [email protected], Antonio Antonino [email protected], Youngjoon Lee [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-18 —
58b5698— chore(blockchain): migrate contributor emails to @logos.co (#338) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-09-25 —
aa8a3b0— Created nomos/raw/p2p-network-bootstrapping.md draft (#175)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-08-25 |
| 1.0.1 | Renamed Nomos to Logos Blockchain | 2026-04-17 |
Introduction
Logos Blockchain network bootstrapping is the process by which a new node discovers peers and synchronizes with the existing decentralized network. It ensures that a node can:
- Discover Peers – Find other active nodes in the network.
- Establish Connections – Securely connect to trusted peers.
- Negotiate (libp2p) Protocols - Ensure that other peers operate in the same protocols as the node needs.
Overview
The Logos Blockchain P2P network bootstrapping strategy relies on a designated subset of bootstrap nodes to facilitate secure and efficient node onboarding. These nodes serve as the initial entry points for new network participants.
Key Design Principles
Trusted Bootstrap Nodes
A curated set of publicly announced and highly available nodes ensures reliability during initial peer discovery. These nodes are configured with elevated connection limits to handle a high volume of incoming bootstrapping requests from new participants.
Node Configuration & Onboarding
New node operators must explicitly configure their instances with the addresses of bootstrap nodes. This configuration may be preloaded or dynamically fetched from a trusted source to minimize manual setup.
Network Integration
Upon initialization, the node establishes connections with the bootstrap nodes and begins participating in Logos Blockchain networking protocols. Through these connections, the node discovers additional peers, synchronizes with the network state, and engages in protocol-specific communication (e.g., consensus, block propagation).
Security & Decentralization Considerations
Trust Minimization: While bootstrap nodes provide initial connectivity, the network rapidly transitions to decentralized peer discovery to prevent over-reliance on any single entity.
Authenticated Announcements: The identities and addresses of bootstrap nodes are publicly verifiable to mitigate impersonation attacks. From the libp2p documentation:
To authenticate each others’ peer IDs, peers encode their peer ID into a self-signed certificate, which they sign using their host’s private key.
Dynamic Peer Management: After bootstrapping, nodes continuously refine their peer lists to maintain a resilient and distributed network topology.
This approach ensures rapid, secure, and scalable network participation while preserving the decentralized ethos of the Logos Blockchain.
Protocol
Step-by-Step bootstrapping process
- Node Initial Configuration: New nodes load pre-configured bootstrap node addresses. Addresses may be
IPorDNSembedded in a compatible libp2p PeerId multiaddress. Node operators may chose to advertise more than one address. This is out of the scope of this protocol. For example:/ip4/198.51.100.0/udp/4242/p2p/QmYyQSo1c1Ym7orWxLYvCrM2EmxFTANf8wXmmE7DWjhx5Nor
/dns/foo.bar.net/udp/4242/p2p/QmYyQSo1c1Ym7orWxLYvCrM2EmxFTANf8wXmmE7DWjhx5N
- Secure Connection: Nodes establish connections to bootstrap nodes announced addresses and verify network identity and protocol compatibility.
- Peer Discovery: Requests and receive validated peer lists from bootstrap nodes. Each entry includes connectivity details as per the Peer Discovery protocol engaging after the initial connection.
- Network Integration: Iteratively connects to discovered peers. Gradually build peer connections.
- Protocol Engagement: Establishes required protocol channels (gossip/consensus/sync). Begins participating in network operations.
- Ongoing Maintenance: Continuously evaluates and refreshes peer connections. Ideally removes the connection to the bootstrap node itself. Bootstrap nodes may chose to remove the connection on their side to keep high availability for other nodes.
sequenceDiagram
participant Logos Blockchain Network
participant Node
participant Bootstrap Node
Node->>Node: Fetches bootstrapping addresses
loop Interacts with bootstrap node
Node->>+Bootstrap Node: Connects
Bootstrap Node->>-Node: Sends discovered peers' information
end
loop Connects to Network participants
Node->>Logos Blockchain Network: Engages in connections
Node->>Logos Blockchain Network: Negotiates protocols
end
loop Ongoing maintenance
Node-->>Logos Blockchain Network: Evaluates peer connections
alt Bootstrap connection no longer needed
Node-->>Bootstrap Node: Disconnects
else Bootstrap enforces disconnection
Bootstrap Node-->>Node: Disconnects
end
end
Details
The bootstrapping process for the Logos Blockchain p2p network uses the QUIC transport as specified in the Transport.
Bootstrapping is separated from the network’s peer discovery protocol. It assumes that there is one protocol that would engage as soon as the connection with the bootstrapping node triggers. Currently, the Logos Blockchain network uses kademlia as the current first approach for the Logos Blockchain p2p network (see Peer Discovery), which comes built-in.
Annex
P2P-HARDWARE-REQUIREMENTS
| Field | Value |
|---|---|
| Name | Logos Blockchain p2p Network Hardware Requirements Specification |
| Slug | 137 |
| Type | RFC |
| Status | deprecated |
| Category | infrastructure |
| Editor | Daniel Sanchez-Quiros [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-18 —
58b5698— chore(blockchain): migrate contributor emails to @logos.co (#338) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-09-25 —
34bbd7a— Created nomos/raw/hardware-requirements.md file (#172)
Abstract
This specification defines the hardware requirements for running various types of Logos Blockchain nodes. Hardware needs vary significantly based on the node's role, from lightweight verification nodes to high-performance Zone Executors. The requirements are designed to support diverse participation levels while ensuring network security and performance.
Motivation
The Logos Blockchain network is designed to be inclusive and accessible across a wide range of hardware configurations. By defining clear hardware requirements for different node types, we enable:
- Inclusive Participation: Allow users with limited resources to participate as Light Nodes
- Scalable Infrastructure: Support varying levels of network participation based on available resources
- Performance Optimization: Ensure adequate resources for computationally intensive operations
- Network Security: Maintain network integrity through properly resourced validator nodes
- Service Quality: Define requirements for optional services that enhance network functionality
Important Notice: These hardware requirements are preliminary and subject to revision based on implementation testing and real-world network performance data.
Specification
Node Types Overview
Hardware requirements vary based on the node's role and services:
- Light Node: Minimal verification with minimal resources
- Basic Bedrock Node: Standard validation participation
- Service Nodes: Enhanced capabilities for optional network services
Light Node
Light Nodes provide network verification with minimal resource requirements, suitable for resource-constrained environments.
Target Use Cases:
- Mobile devices and smartphones
- Single-board computers (Raspberry Pi, etc.)
- IoT devices with network connectivity
- Users with limited hardware resources
Hardware Requirements:
| Component | Specification |
|---|---|
| CPU | Low-power processor (smartphone/SBC capable) |
| Memory (RAM) | 512 MB |
| Storage | Minimal (few GB) |
| Network | Reliable connection, 1 Mbps free bandwidth |
Basic Bedrock Node (Validator)
Basic validators participate in Bedrock consensus using typical consumer hardware.
Target Use Cases:
- Individual validators on consumer hardware
- Small-scale validation operations
- Entry-level network participation
Hardware Requirements:
| Component | Specification |
|---|---|
| CPU | 2 cores, 2 GHz modern multi-core processor |
| Memory (RAM) | 1 GB minimum |
| Storage | SSD with 100+ GB free space, expandable |
| Network | Reliable connection, 1 Mbps free bandwidth |
Service-Specific Requirements
Nodes can optionally run additional Bedrock Services that require enhanced resources beyond basic validation.
Data Availability (DA) Service
DA Service nodes store and serve data shares for the network's data availability layer.
Service Role:
- Store blockchain data and blob data long-term
- Serve data shares to requesting nodes
- Maintain high availability for data retrieval
Additional Requirements:
| Component | Specification | Rationale |
|---|---|---|
| CPU | Same as Basic Bedrock Node | Standard processing needs |
| Memory (RAM) | Same as Basic Bedrock Node | Standard memory needs |
| Storage | Fast SSD, 500+ GB free | Long-term chain and blob storage |
| Network | High bandwidth (10+ Mbps) | Concurrent data serving |
| Connectivity | Stable, accessible external IP | Direct peer connections |
Network Requirements:
- Capacity to handle multiple concurrent connections
- Stable external IP address for direct peer access
- Low latency for efficient data serving
Blend Protocol Service
Blend Protocol nodes provide anonymous message routing capabilities.
Service Role:
- Route messages anonymously through the network
- Provide timing obfuscation for privacy
- Maintain multiple concurrent connections
Additional Requirements:
| Component | Specification | Rationale |
|---|---|---|
| CPU | Same as Basic Bedrock Node | Standard processing needs |
| Memory (RAM) | Same as Basic Bedrock Node | Standard memory needs |
| Storage | Same as Basic Bedrock Node | Standard storage needs |
| Network | Stable connection (10+ Mbps) | Multiple concurrent connections |
| Connectivity | Stable, accessible external IP | Direct peer connections |
Network Requirements:
- Low-latency connection for effective message blending
- Stable connection for timing obfuscation
- Capability to handle multiple simultaneous connections
Executor Network Service
Zone Executors perform the most computationally intensive work in the network.
Service Role:
- Execute Zone state transitions
- Generate zero-knowledge proofs
- Process complex computational workloads
Critical Performance Note: Zone Executors perform the heaviest computational work in the network. High-performance hardware is crucial for effective participation and may provide competitive advantages in execution markets.
Hardware Requirements:
| Component | Specification | Rationale |
|---|---|---|
| CPU | Very high-performance multi-core processor | Zone logic execution and ZK proving |
| Memory (RAM) | 32+ GB strongly recommended | Complex Zone execution requirements |
| Storage | Same as Basic Bedrock Node | Standard storage needs |
| GPU | Highly recommended/often necessary | Efficient ZK proof generation |
| Network | High bandwidth (10+ Mbps) | Data dispersal and high connection load |
GPU Requirements:
- NVIDIA: CUDA-enabled GPU (RTX 3090 or equivalent recommended)
- Apple: Metal-compatible Apple Silicon
- Performance Impact: Strong GPU significantly reduces proving time
Network Requirements:
- Support for 2048+ direct UDP connections to DA Nodes (for blob publishing)
- High bandwidth for data dispersal operations
- Stable connection for continuous operation
Note: DA Nodes utilizing libp2p connections need sufficient capacity to receive and serve data shares over many connections.
Implementation Requirements
Minimum Requirements
All Logos Blockchain nodes MUST meet:
- Basic connectivity to the Logos Blockchain network via libp2p
- Adequate storage for their designated role
- Sufficient processing power for their service level
- Reliable network connection with appropriate bandwidth for QUIC transport
Optional Enhancements
Node operators MAY implement:
- Hardware redundancy for critical services
- Enhanced cooling for high-performance configurations
- Dedicated network connections for service nodes utilizing libp2p protocols
- Backup power systems for continuous operation
Resource Scaling
Requirements may vary based on:
- Network Load: Higher network activity increases resource demands
- Zone Complexity: More complex Zones require additional computational resources
- Service Combinations: Running multiple services simultaneously increases requirements
- Geographic Location: Network latency affects optimal performance requirements
Security Considerations
Hardware Security
- Secure Storage: Use encrypted storage for sensitive node data
- Network Security: Implement proper firewall configurations
- Physical Security: Secure physical access to node hardware
- Backup Strategies: Maintain secure backups of critical data
Performance Security
- Resource Monitoring: Monitor resource usage to detect anomalies
- Redundancy: Plan for hardware failures in critical services
- Isolation: Consider containerization or virtualization for service isolation
- Update Management: Maintain secure update procedures for hardware drivers
Performance Characteristics
Scalability
- Light Nodes: Minimal resource footprint, high scalability
- Validators: Moderate resource usage, network-dependent scaling
- Service Nodes: High resource usage, specialized scaling requirements
Resource Efficiency
- CPU Usage: Optimized algorithms for different hardware tiers
- Memory Usage: Efficient data structures for constrained environments
- Storage Usage: Configurable retention policies and compression
- Network Usage: Adaptive bandwidth utilization based on libp2p capacity and QUIC connection efficiency
References
Copyright
Copyright and related rights waived via CC0.
ANALYSIS-BLOCK-TIMES-BLEND-NETWORK
| Field | Value |
|---|---|
| Name | [Analysis] Block Times & Blend Network |
| Slug | 186 |
| Status | raw |
| Category | Informational |
| Editor | David Rusu [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-08-20 |
Introduction
We are interested in finalizing the Cryptarchia and Blend Network parameters. There are some competing requirements here: the Blend Network would like to have longer block times in order to provide better privacy, while Cryptarchia wants shorter block times in order to provide faster finality.
We need to find the right balance that would give us good enough privacy while not sacrificing finality times too much.
Overview
Adversary Model
The analysis centres on the block-witholding attack where an adversary does not participate in the main chain, instead building a secret side-chain and releasing it on the network in an attempt to trigger the honest chain to reorg.
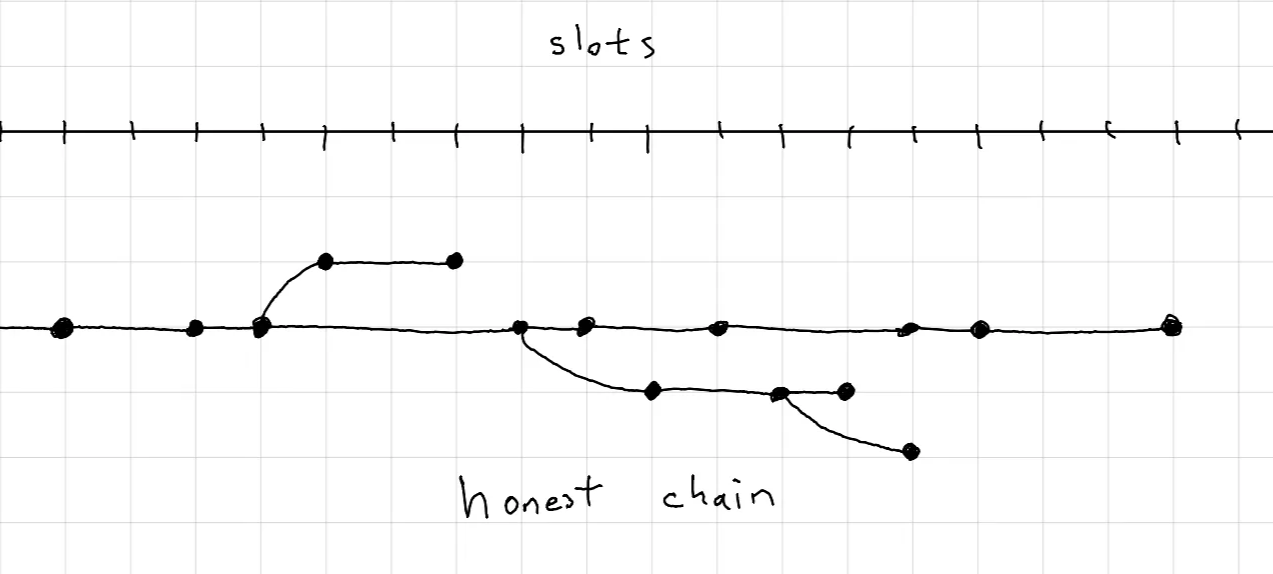
We first simulate the honest network to build out a block tree.

We then simulate the adversary slot wins.
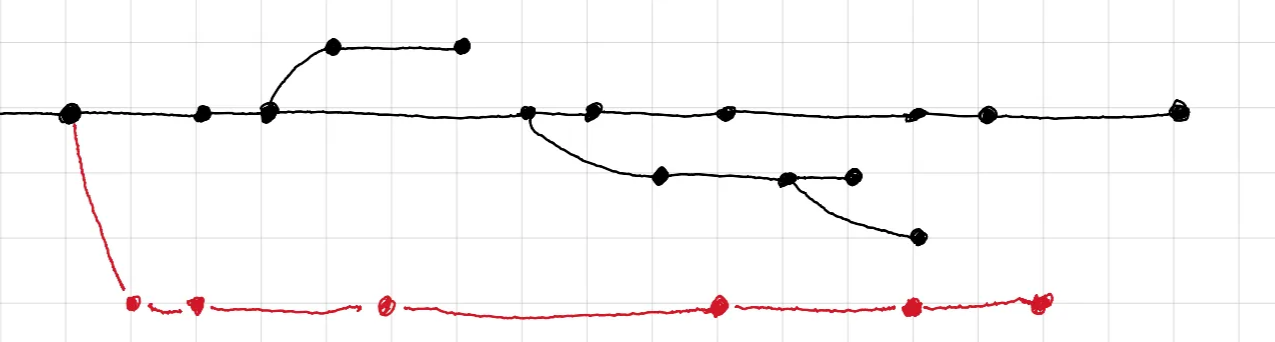
We also consider the effect of extending from the honest block tree at each block to see how many reorgs the adversary can induce.
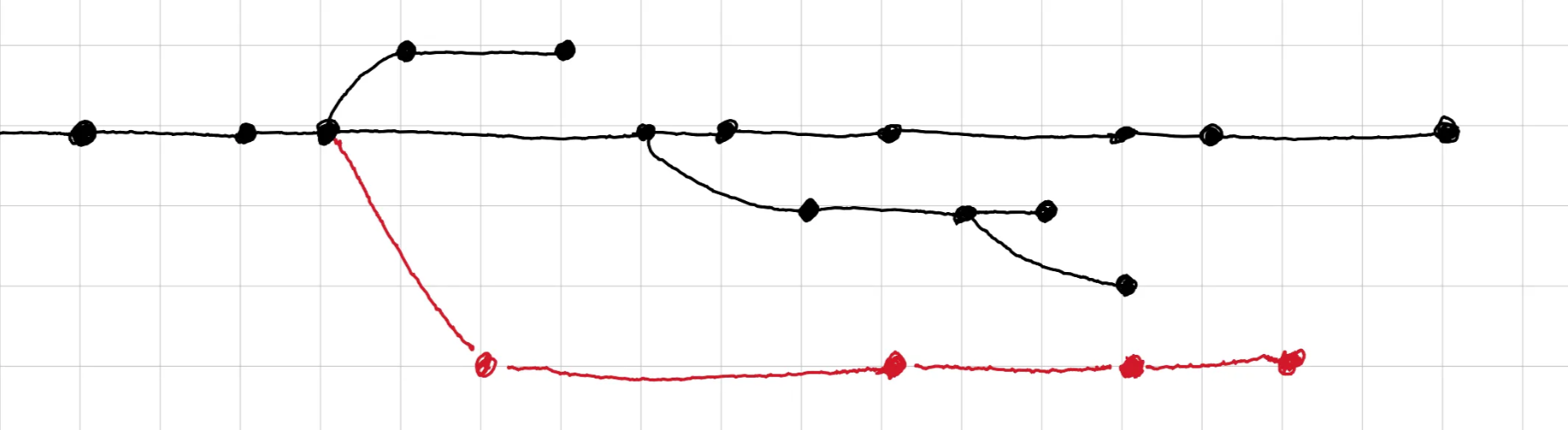
This is repeated, with the adversary branch forking off of each block.
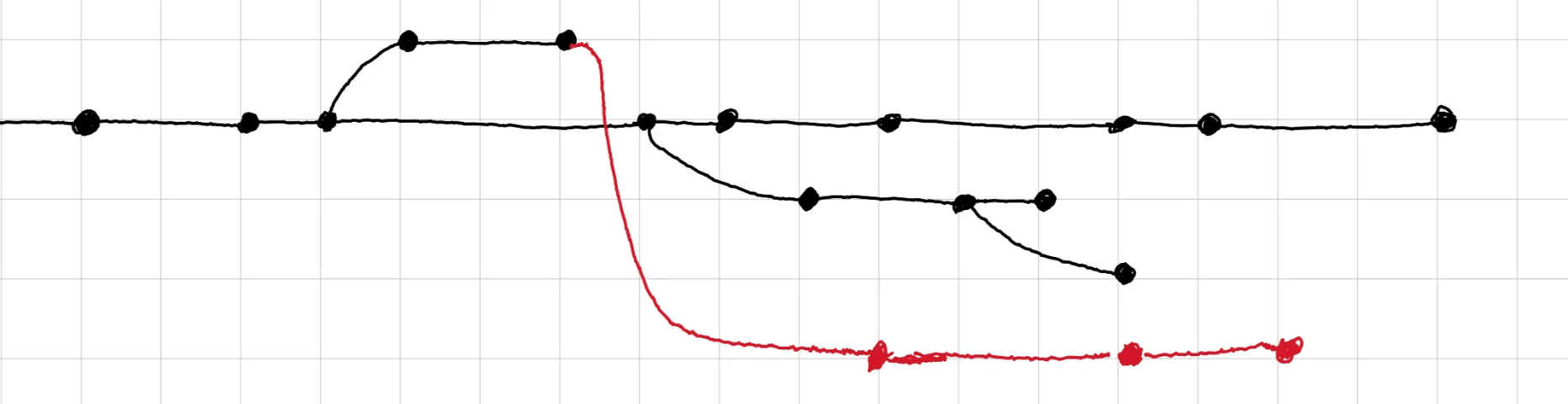
The adversary can even boost his attack by continuing abandoned branches.
Network Model
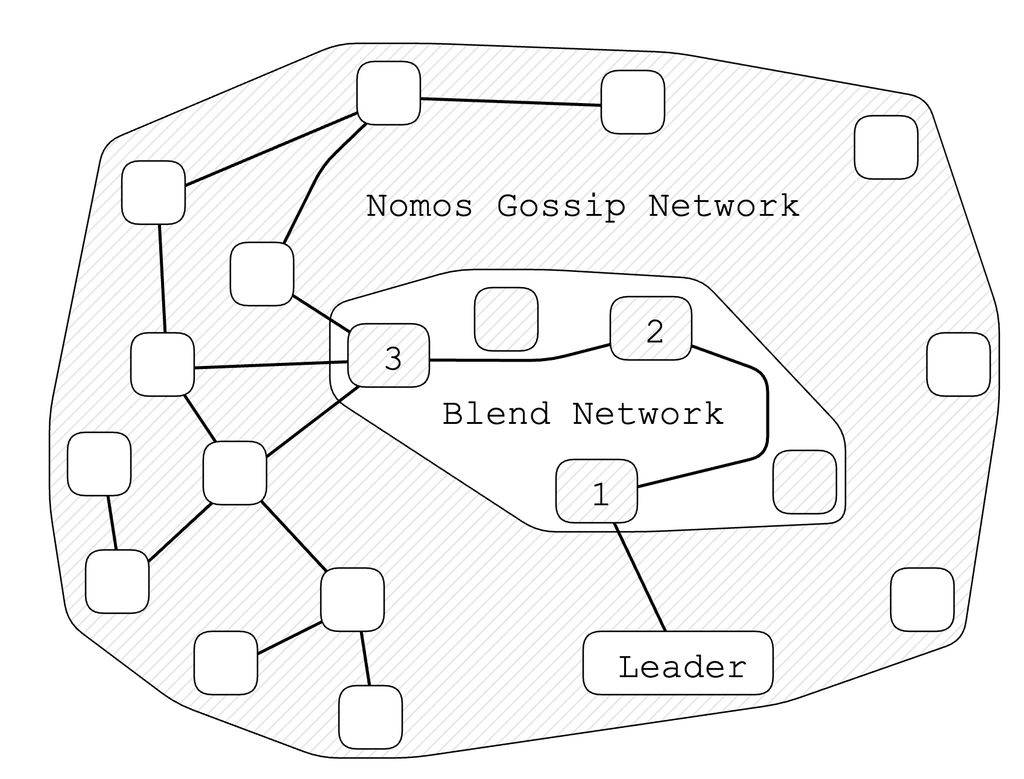
Leader proposing a block through the Blend Network.
blend_network = NetworkParams(
broadcast_delay_mean=0.5, # seconds
pol_proof_time=1, # 1 second PoL delay
blending_delay=3, # seconds spent in each Blend node
desimenation_delay_mean=0.5, # seconds to disseminate message within Blend
blend_hops=3, # hops within Blend
)
no_blend_net = replace(blend_net, blend_hops=0)
The block delay distribution from the network model looks like this:
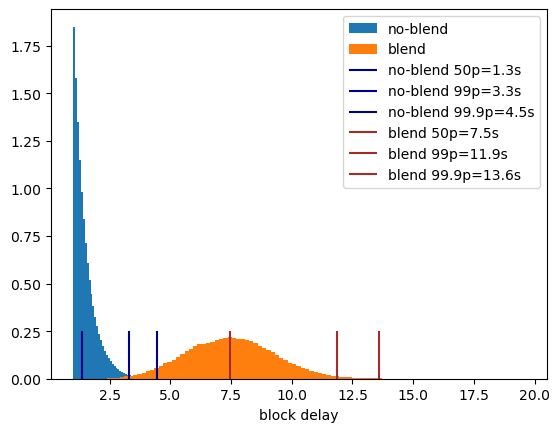
Choosing a Block Time
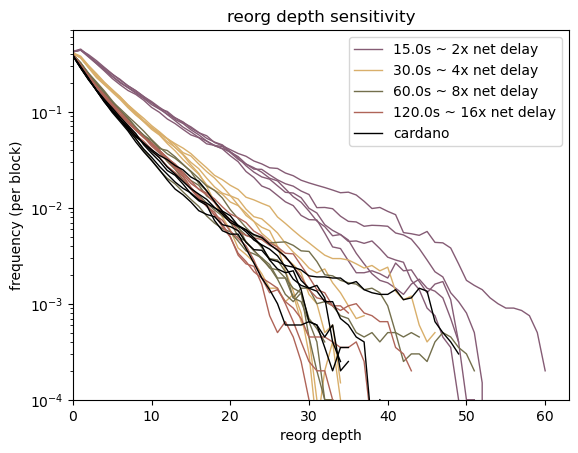
30% Adversary
PATHS = 5
target_block_num = 20000
np.random.seed(0)
stake = np.random.pareto(10, 1000)
network = blend_net
sim_params = Params(
SLOTS=0,
f=0.05,
adversary_control = 0.30,
honest_stake = stake
)
np.random.seed(1)
sims = [Sim(
params=replace(
sim_params,
SLOTS=int(target_block_num * block_time),
f=1/block_time
),
network=network
) for block_time in np.array([15, 30, 60, 120]).repeat(PATHS)]
Choosing Blend Parameters
There are two parameters that are of concern here: Number of Hops and the Blending Delay.
The number of hops tells us how many times the block proposal needs to be processed by the network before the proposal is broadcast to the wider network.
The Blending delay tells us the maximum time each message is processed at each hop.
Number of Hops
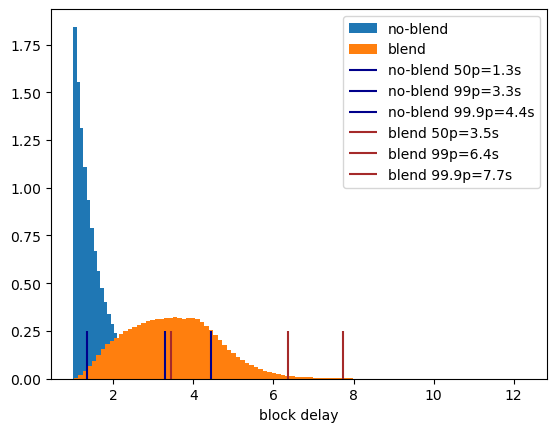
1 hop
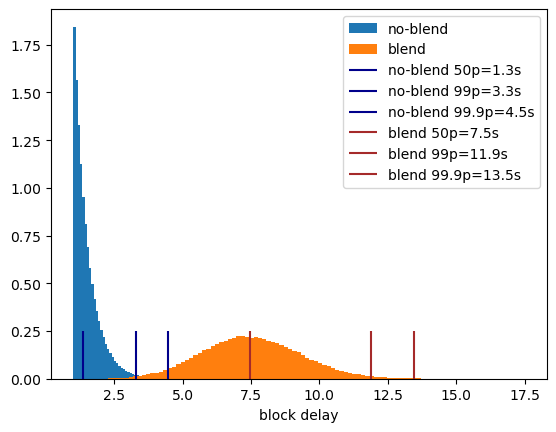
3 hops
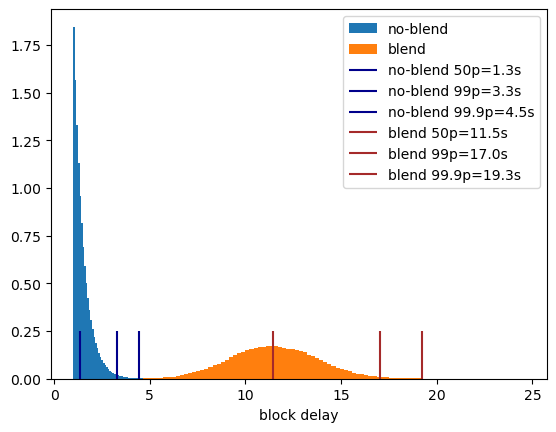
5 hops
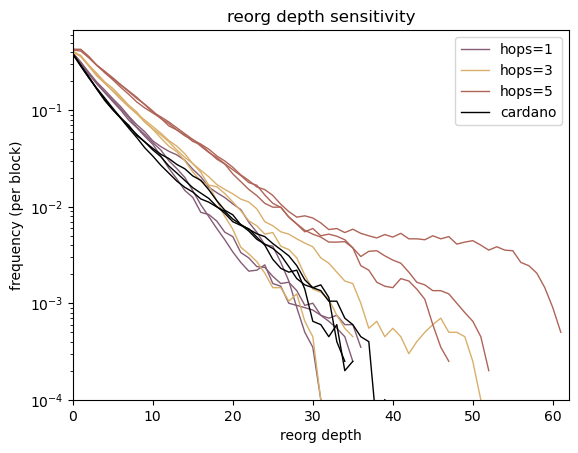
PATHS = 3
target_block_num = 20000
np.random.seed(0)
stake = np.random.pareto(10, 1000)
block_time = 30
sim_params = Params(
SLOTS=int(target_block_num * block_time),
f=1/block_time,
adversary_control = 0.30,
honest_stake = stake
)
np.random.seed(1)
sims = [Sim(
params=sim_params,
network=replace(blend_net, blend_hops=hops)
) for hops in np.array([1, 2, 3]).repeat(PATHS)]
From these plots we can see that going above 3 hops begins to induce too many reorgs.
Blending Delay
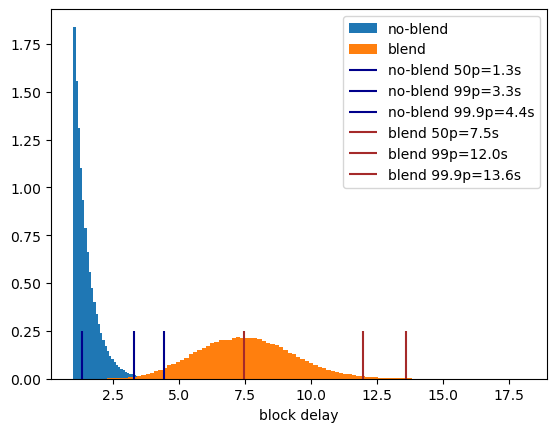
3 second Blend delay
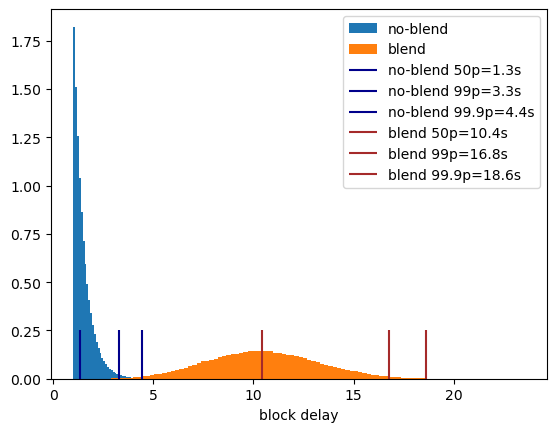
5 second Blend delay
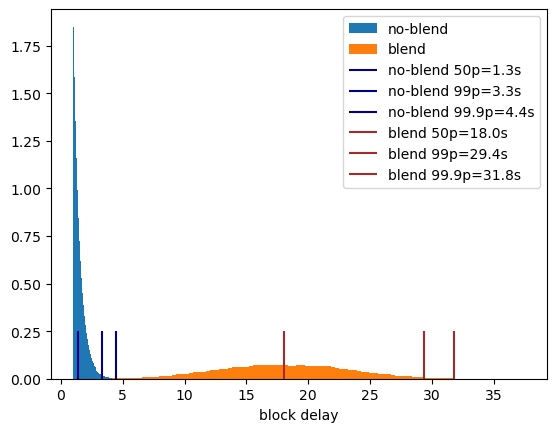
10 second Blend delay
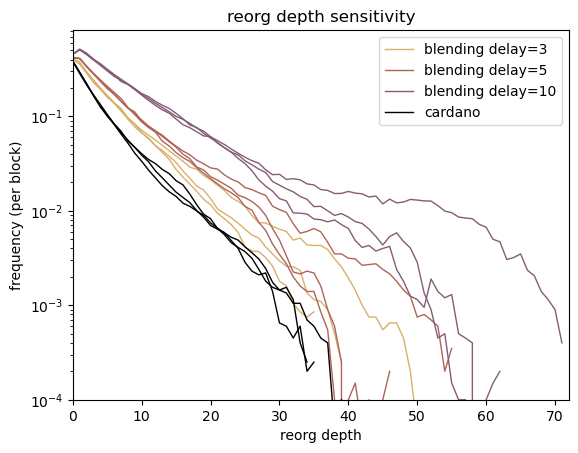
PATHS = 3
target_block_num = 20000
np.random.seed(0)
stake = np.random.pareto(10, 1000)
block_time = 30
sim_params = Params(
SLOTS=int(target_block_num * block_time),
f=1/block_time,
adversary_control = 0.30,
honest_stake = stake
)
np.random.seed(1)
sims = [Sim(
params=sim_params,
network=replace(blend_net, blending_delay=delay)
) for delay in np.array([3, 5, 10]).repeat(PATHS)]
A blending delay above 3 seconds induces too many reorgs.
Impact of Combinations of Hops and Delays
Checking parameters in combinations shows that again, going above 3 hops or above a 3 second delay leads to divergence from the Cardano baseline.
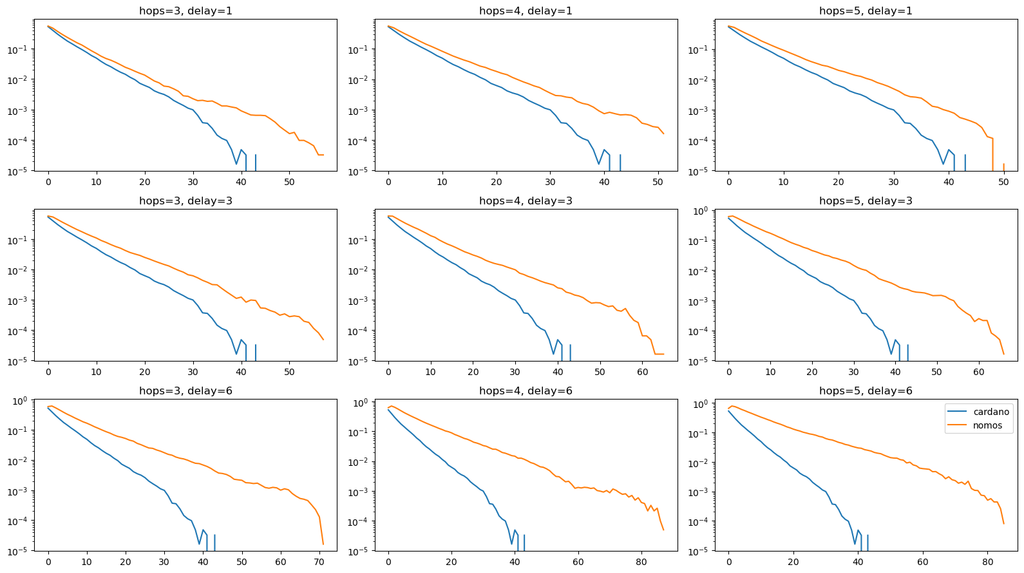
25 second block times
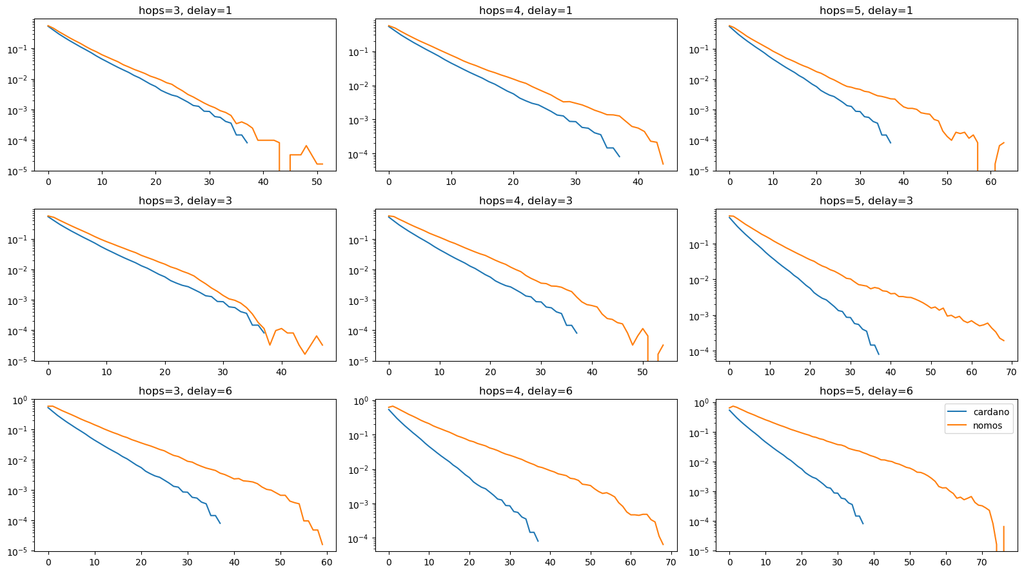
30 second block times
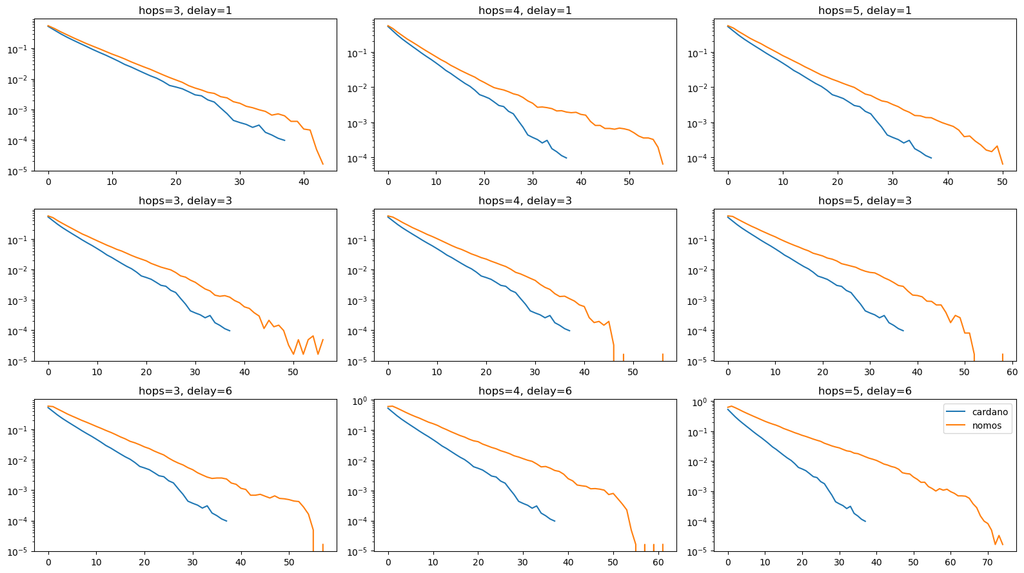
35 second block times
Powerful Adversaries
With 3 hops and 3 second delays, it’s interesting too look at how the network would behave under different strength adversaries.
10% Adversary
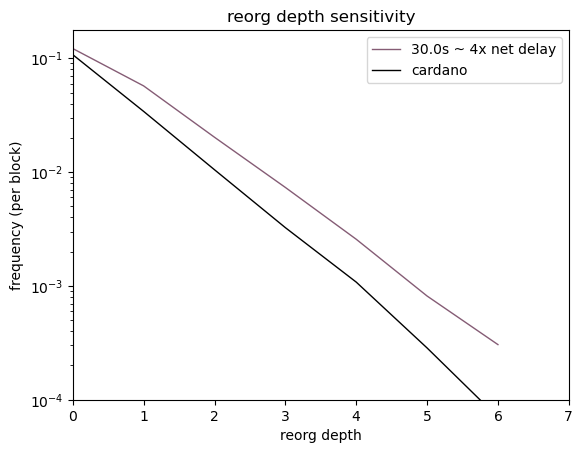
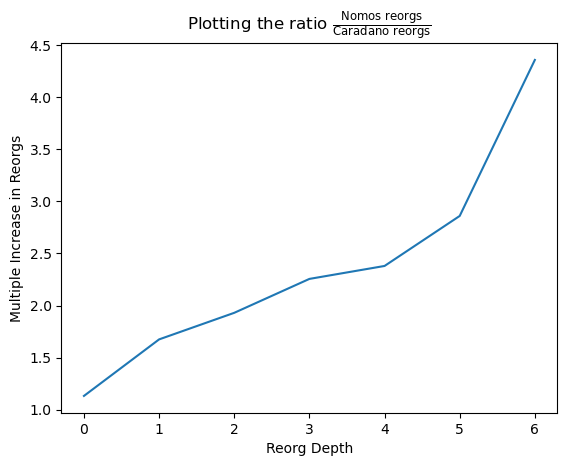
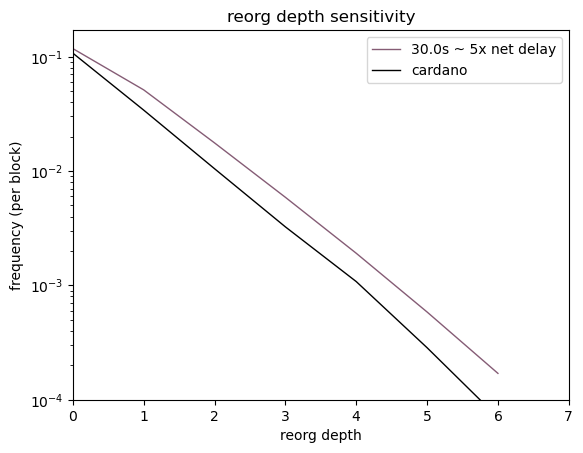
2s blending delay
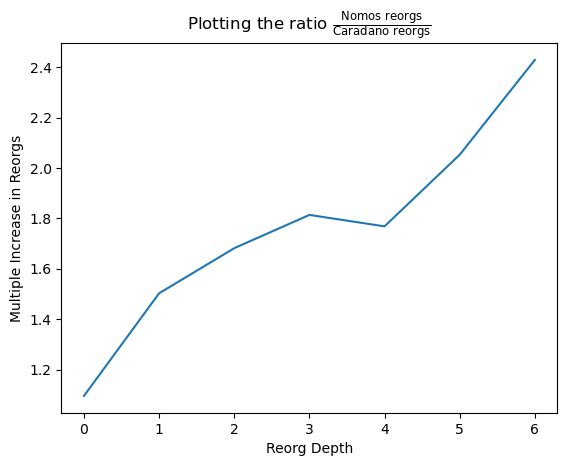
2s blending delay
Params
PATHS = 3
target_block_num = 20000
np.random.seed(0)
stake = np.random.pareto(10, 1000)
network = blend_net
sim_params = Params(
SLOTS=0,
f=0.05,
adversary_control = 0.10,
honest_stake = stake
)
np.random.seed(1)
sims = [Sim(
params=replace(
sim_params,
SLOTS=int(target_block_num * block_time),
f=1/block_time
),
network=network
) for block_time in np.array([30]).repeat(PATHS)]
30% Adversary
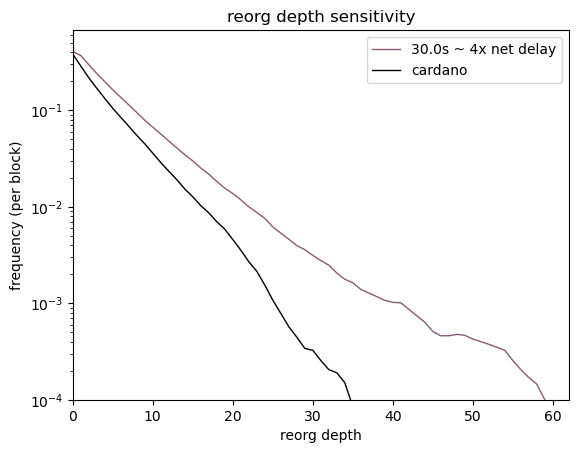
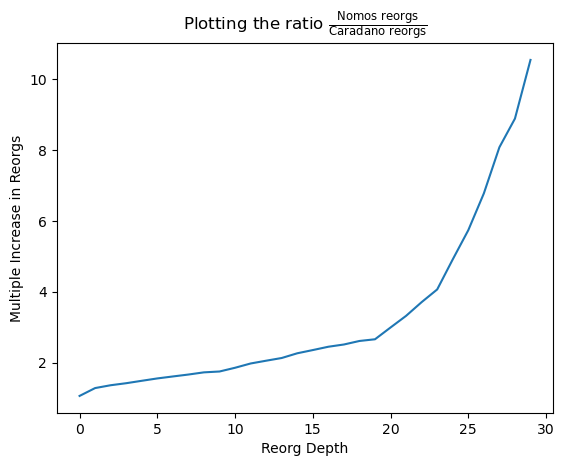
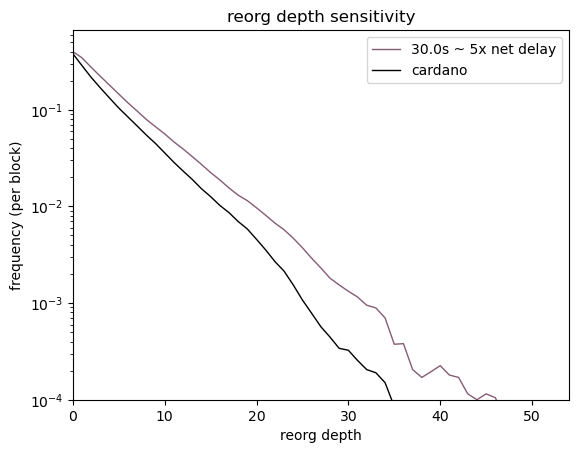
2s blending delay
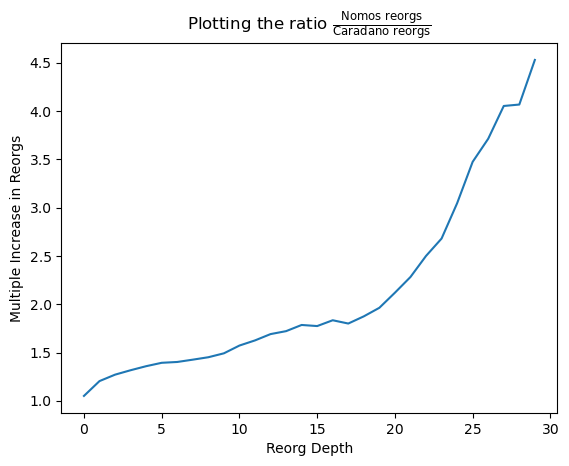
2s blending delay
35s block times, 3s blending delay
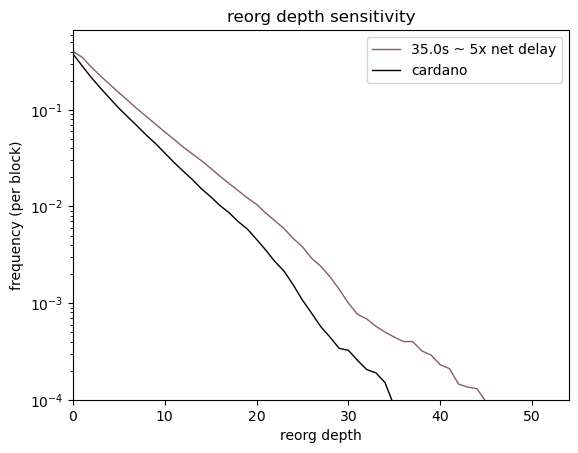
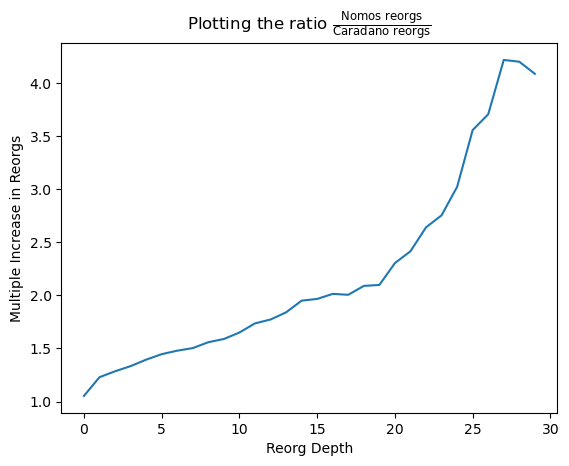
Params
PATHS = 1
target_block_num = 200000
np.random.seed(0)
stake = np.random.pareto(10, 100)
network = blend_net
sim_params = Params(
SLOTS=0,
f=0.05,
adversary_control = 0.3,
honest_stake = stake
)
np.random.seed(1)
sims = [Sim(
params=replace(
sim_params,
SLOTS=int(target_block_num * block_time),
f=1/block_time
),
network=network
) for block_time in np.array([30]).repeat(PATHS)]
for i, sim in enumerate(sims):
print(f"simulating {i+1}/{len(sims)}")
sim.run(seed=i)
print("finished simulation, starting analysis")
advs = [sim.adverserial_analysis() for sim in sims]
print("cardano parameters")
cardano_block_time = 20
cardano_sims = [Sim(
params=replace(
sim_params,
SLOTS=int(target_block_num * cardano_block_time),
f=1/cardano_block_time,
),
network=replace(network, blend_hops=0)
) for _ in range(PATHS)]
for i, sim in enumerate(cardano_sims):
print(f"simulating {i+1}/{len(cardano_sims)}")
sim.run(seed=i)
cardano_advs = [sim.adverserial_analysis() for sim in cardano_sims]
# -------
PATHS = 3
target_block_num = 20000
np.random.seed(0)
stake = np.random.pareto(10, 1000)
network = blend_net
sim_params = Params(
SLOTS=0,
f=0.05,
adversary_control = 0.30,
honest_stake = stake
)
np.random.seed(1)
sims = [Sim(
params=replace(
sim_params,
SLOTS=int(target_block_num * block_time),
f=1/block_time
),
network=network
) for block_time in np.array([30]).repeat(PATHS)]
40% Adversary
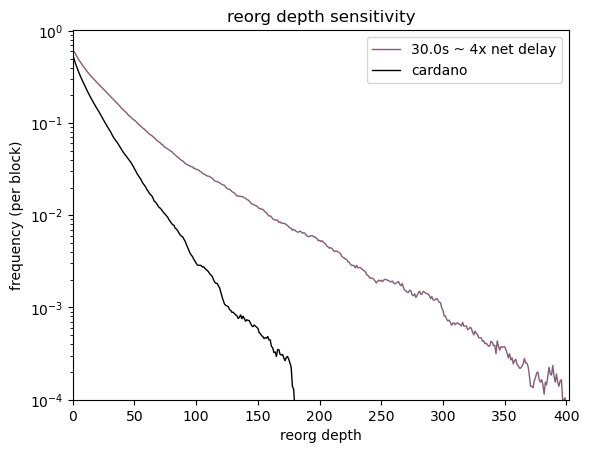
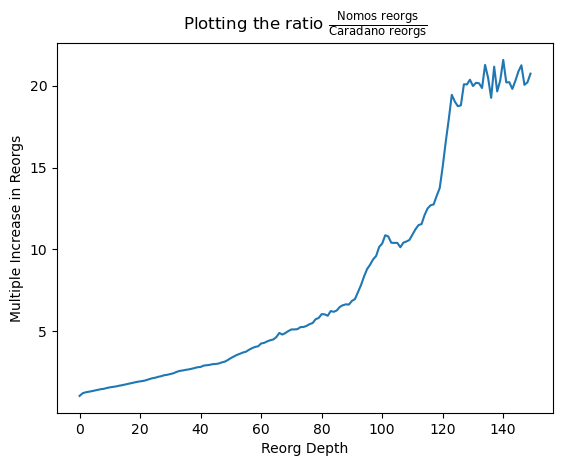
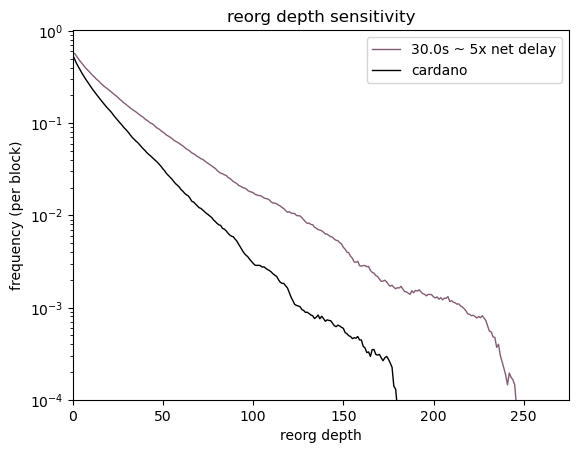
2s blending delay
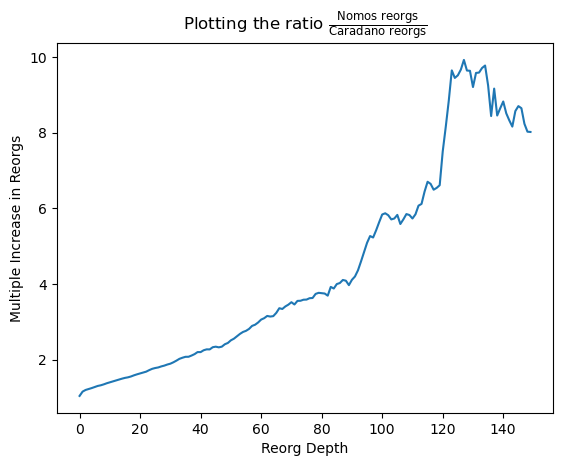
2s blend delay
Params
PATHS = 5
target_block_num = 40000
np.random.seed(0)
stake = np.random.pareto(10, 1000)
network = blend_net
sim_params = Params(
SLOTS=0,
f=0.05,
adversary_control = 0.40,
honest_stake = stake
)
np.random.seed(1)
sims = [Sim(
params=replace(
sim_params,
SLOTS=int(target_block_num * block_time),
f=1/block_time
),
network=network
) for block_time in np.array([30]).repeat(PATHS)]
45% Adversary
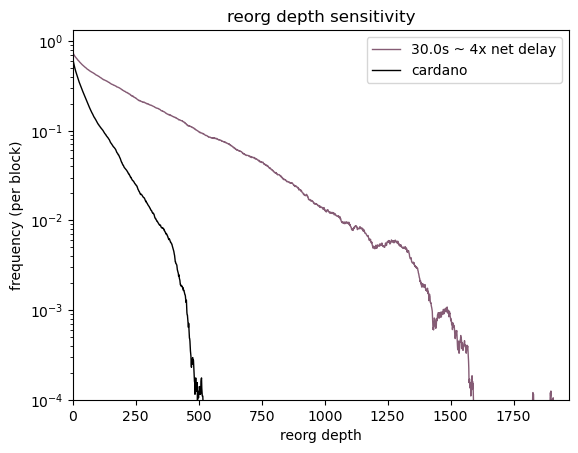
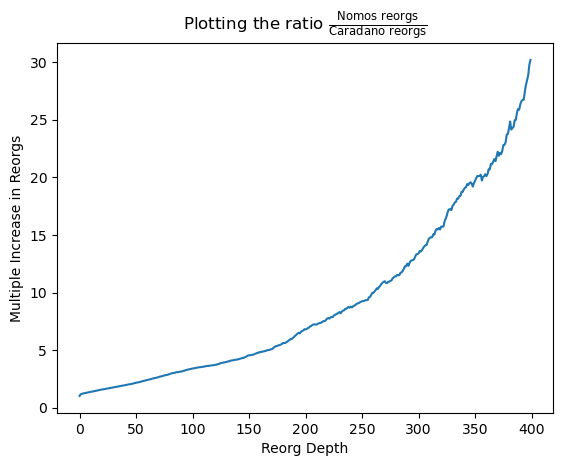
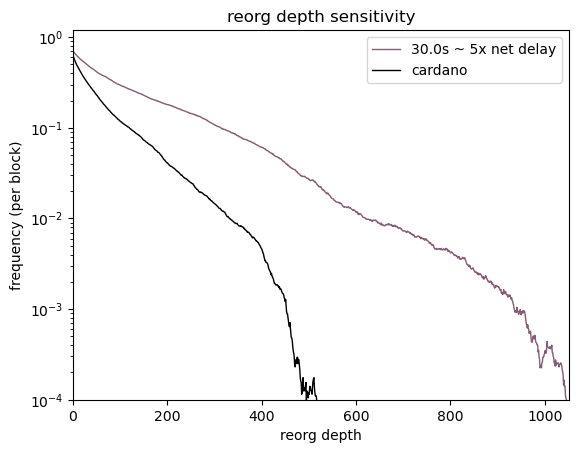
2s blending delay
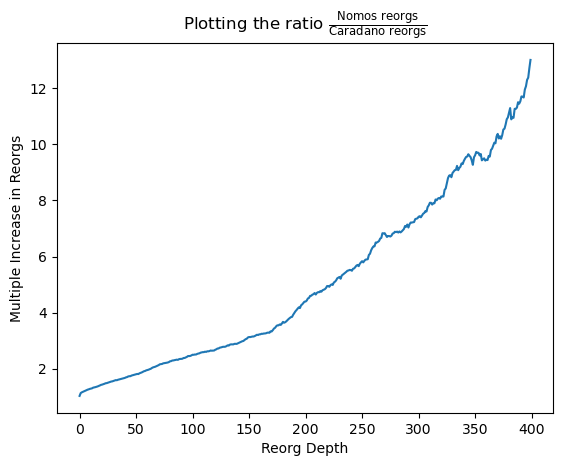
2s blending delay
Params
PATHS = 5
target_block_num = 40000
np.random.seed(0)
stake = np.random.pareto(10, 1000)
network = blend_net
sim_params = Params(
SLOTS=0,
f=0.05,
adversary_control = 0.45,
honest_stake = stake
)
np.random.seed(1)
sims = [Sim(
params=replace(
sim_params,
SLOTS=int(target_block_num * block_time),
f=1/block_time
),
network=network
) for block_time in np.array([30]).repeat(PATHS)]
49% Adversary
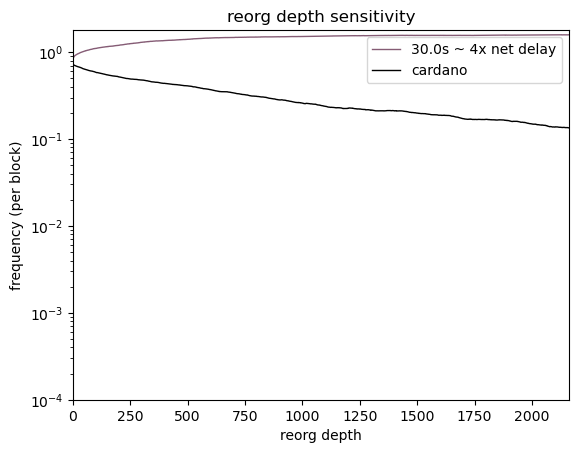
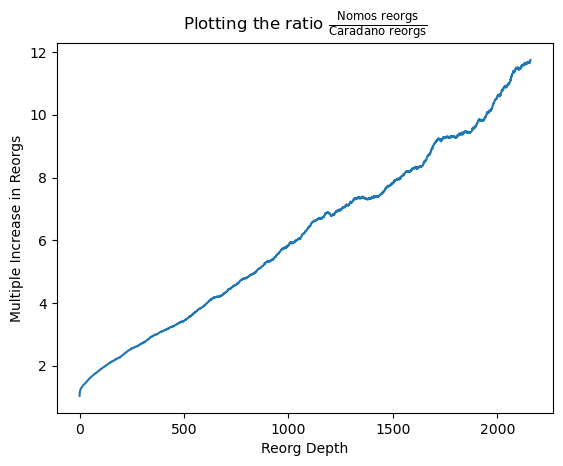
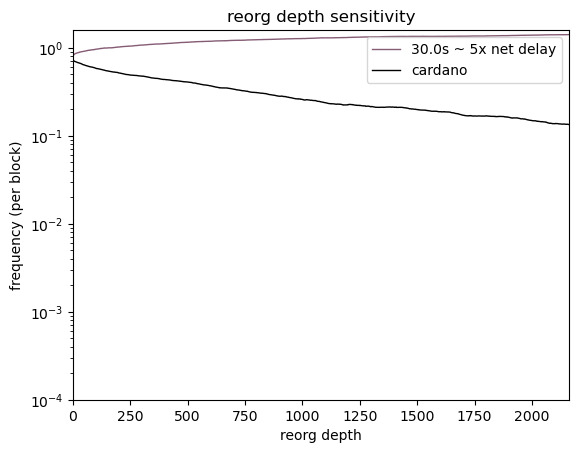
2s blending delay
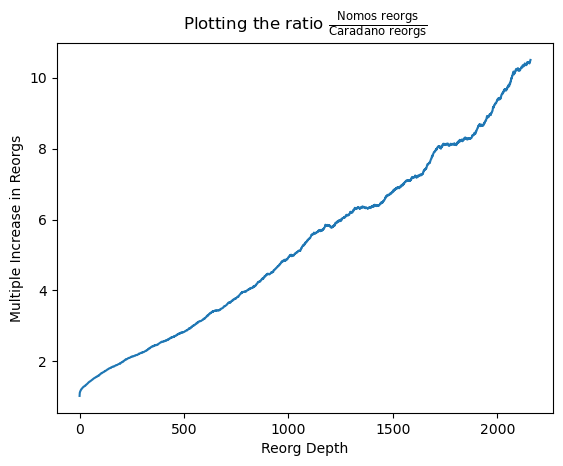
2s blending delay
Params
PATHS = 5
target_block_num = 30000
np.random.seed(0)
stake = np.random.pareto(10, 1000)
network = blend_net
sim_params = Params(
SLOTS=0,
f=0.05,
adversary_control = 0.49,
honest_stake = stake
)
np.random.seed(1)
sims = [Sim(
params=replace(
sim_params,
SLOTS=int(target_block_num * block_time),
f=1/block_time
),
network=network
) for block_time in np.array([30]).repeat(PATHS)]
Conclusion
Our conclusion is that 30s block times, 3 blend hops, 2s blending delay are safe and we propose we use this parameter set for Nomos.
Annex
Exploring Analytical Results from Praos
Praos provides the following theorem about the probability of violating the common prefix property:

In addition to simulations, we could try to use this analytical results to determine the impact of changing block times and network assumptions.
Theorem Condition
First we must satisfy the condition where
- is the stake held by honest parties
- is the active slot coefficient
- is the max network delay
- is the advantage of the honest network over the adversarial network
We want to understand for a given parameter set, what is the required honest stake to satisfy the safety condition:
We can then look at the minimum that satisfies this condition for Cardano and Nomos.
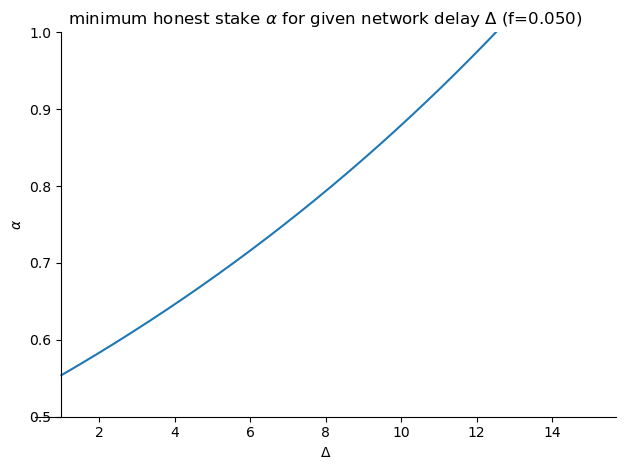
Cardano’s parameter set
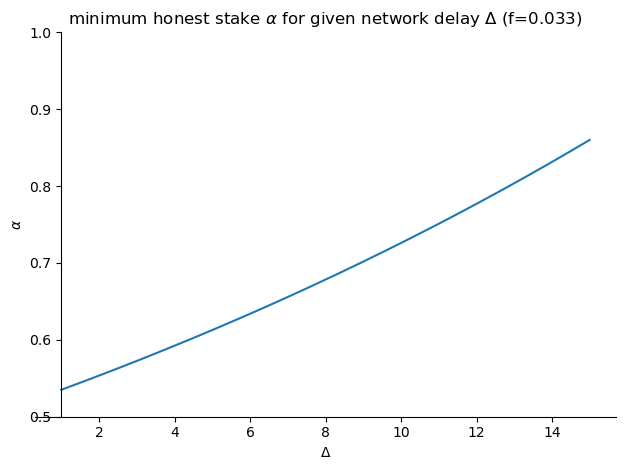
Nomos’ parameter set
Surprisingly, at at 5s max network delay, we are already requiring ~70% of stake to be honest in Cardano.
On Nomos, based on the network modelling we had done, we had a ~14s max delay. This would require 83% of the network to be honest in order to satisfy this condition.
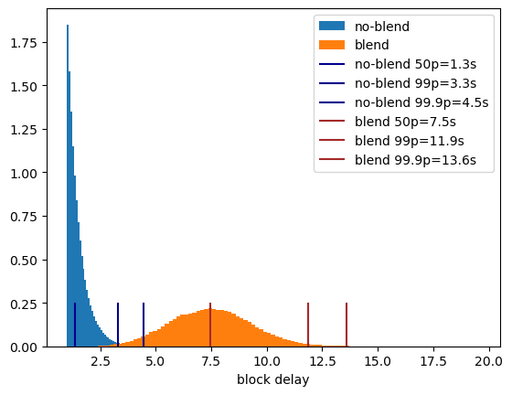
If we change our blending delay to 2s, then we have a ~11s max delay. This would require 75% of the network to be honest in order to satisfy this condition.
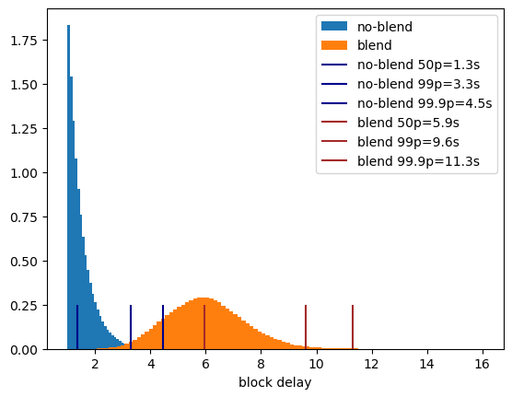
Probability of Violating Common Prefix
The main result of the theorem states that the probability of violating common prefix is bounded above by , where is asymptotic notation reflecting a term that grows at least as fast as .
We can ask the question “how does the probability change if we change our parameters from Cardano’s to Nomos’?”
We don’t know the term, but we can get the relative change by dividing the Cardano probability by the Nomos probability, and cancel out the term:
So, we have the ratio . Plotting this for against different network delays in Nomos gives this plot:
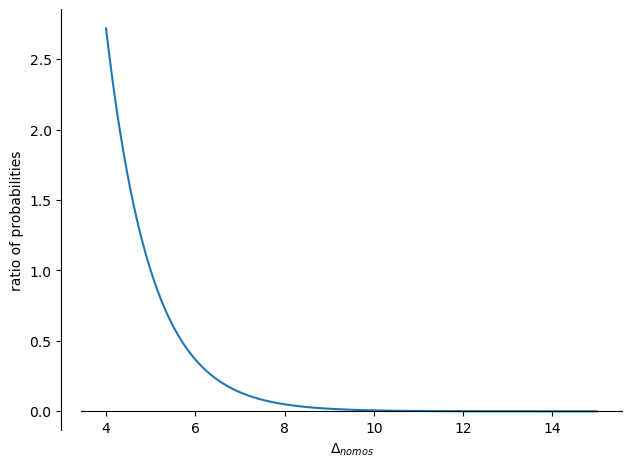
My interpretation of this result is that this probability is a very loose upper bound. e.g. reducing network delay by 1s leads to a ~2.7x lower probability, and adding 1 second of delay leads again to a 2.7x higher probability, it’s too sensitive to make useful interpretations.
ANALYSIS-CRYPTARCHIA-DE-ANONYMISATION-OF-RELATIVE-STAKE
| Field | Value |
|---|---|
| Name | [Analysis] Cryptarchia De-anonymisation of Relative Stake |
| Slug | 189 |
| Status | raw |
| Category | Informational |
| Editor | David Rusu [email protected] |
| Contributors | Alexander Mozeika [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-08-26 |
Details of derivations are in the documents Statistical inference of relative stake and Analysis of leader election process in PoS.
Stake Distribution Strategies Based on Adversarial Inference Which Uses a Naive Estimator
- The adversary observes the leader election process of a node with the relative stake .
- In time slots, he/she is able to observe wins in observations.
- For he/she uses the naive estimator of the true relative stake .
- Here , known to adversary, is the fraction of time-slots with at least one winner.
- For “accuracy” , the probability that for large is given by where is the lottery function, and . Here is the fraction of observed time-slots such that slots are observed on average.
- An example of above probability is given below.
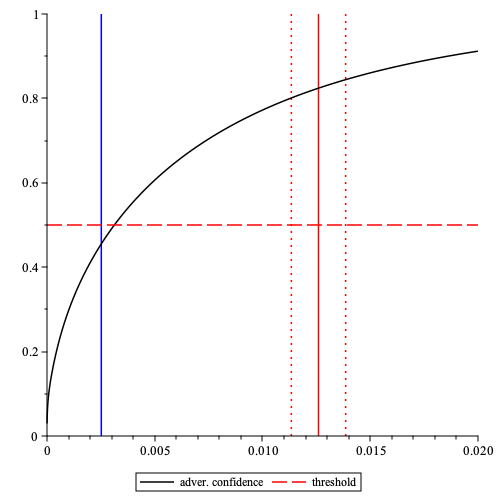
The probability that inferred relative stake , i.e. adversarial “confidence”, as a function of the true relative stake obtained in time-slots (the number used in Cardano) when fraction of slots is observed. Here the probability that the stake of a node with the true stake (the max. stake in the Bitcoin network), represented by a red vertical line, is inferred with an “accuracy” within the fraction of relative stake , represented by red vertical dotted lines, is approx. . The red dashed horizontal line corresponds to the threshold . The blue vertical line at is the result of dividing the stake into nodes.
- Having estimated the fraction of observed time-slots and accuracy a node can use its stake , to compute the probability , i.e. the “confidence” obtained by an adversary in time-slots. For a node, it is beneficial to reduce the latter, which can be done by distributing its stake among a number of nodes. To this end, the probability is compared with some threshold and if then the stake is divided, i.e. , , etc., until .
- The main functions of the algorithm which uses to distribute the stake are as follows:
from math import erf, sqrt, log
def phi(alpha):
global f
return 1 - (1 - f)**alpha
def dphi(alpha):
global f
return -((1 - f)**alpha) * log(1 - f)
def Prob2(alpha, epsilon, T, q):
sqrt2 = sqrt(2.0)
numerator = -2.0 * erf(sqrt2 * epsilon / (2 * sqrt(phi(alpha) * (1 - phi(alpha)) / (T * q))))
denominator = (-erf(phi(alpha) * sqrt2 / (2 * sqrt(phi(alpha) * (1 - phi(alpha)) / (T * q)))) + erf(sqrt2 * (phi(alpha) - 1) / (2 * sqrt(phi(alpha) * (1 - phi(alpha)) / (T * q)))))
return numerator / denominator
- The above functions are then used to find minimum number of nodes such that distributing the stake into these nodes reduces the probability to as follows
import math
# Define parameters
T = 432000 # number of time-slots in one epoch
theta = 0.5 # adversarial confidence threshold
gamma0 = 0.1 # adversarial accuracy
a = 0.3 # fraction of compromised paths in the mixnet
r = 3 # redundancy in messages sent through the mixnet
q0 = 1 - (1 - a)**r # fraction of compromised messages
f = 0.05
n_max = 10 # maximum number of iterations
alpha0 = 0.0126 #initial stake
# Initialize relative stake alpha and delta
alpha = alpha0
epsilon = dphi(alpha) * alpha * gamma0
delta = Prob2(alpha, epsilon, T, q0)
# Loop until delta <= theta or n reaches n_max
n = 2
while delta > theta and n <= n_max:
alpha = alpha0 / n
epsilon = dphi(alpha) * alpha * gamma0
delta = Prob2(alpha, epsilon, T, q0)
n += 1
# Update alpha and Prob
alpha = alpha0 / (n - 1)
epsilon = dphi(alpha) * alpha * gamma0
delta = Prob2(alpha, epsilon, T, q0)
print("Final num. of nodes:", n-1)
print("Final alpha:", alpha)
print("Final Prob:", delta)
- The above program suggests that the stake has to be divided among 5 nodes for the adversarial confidence when of paths in the mixnet are compromised (this is , where is the number of layers, with a mixnet sampled from nodes with adversarial nodes) and each message is sent times giving for the fraction of messages being compromised.
Analysis of Naive Estimator
- The naive estimator of relative stake is obtained from the maximum likelihood (ML) estimator by setting .
- The probability that , where is true relative stake and is “accuracy”, is given by , where is the binomial distribution of number of observations , with the parameter such that is the average number of observations, and is the binomial distribution of the number of observed wins n, with the parameter such that is the average number of observed wins.
- The probability of can be interpreted as “confidence”. The probability that , given by , is also of interest. However, for , which can happen for short observation times , the estimator (and hence the probability of ) can be considered only for long observation times where the probability of the event is small.
- The bounds and (large time T) asymptotic estimates on the probability , as well as on the probability , can be obtained by adopting the results in Analysis of leader election process in proof of stake consensus model.
Numerical Results
The maximum likelihood (ML) estimator performance is dependent on the fraction of observed nodes (or the mixnet failure probability) and the number of slots . The [erformance of the estimator improves as increases, as can be seen in this plot:
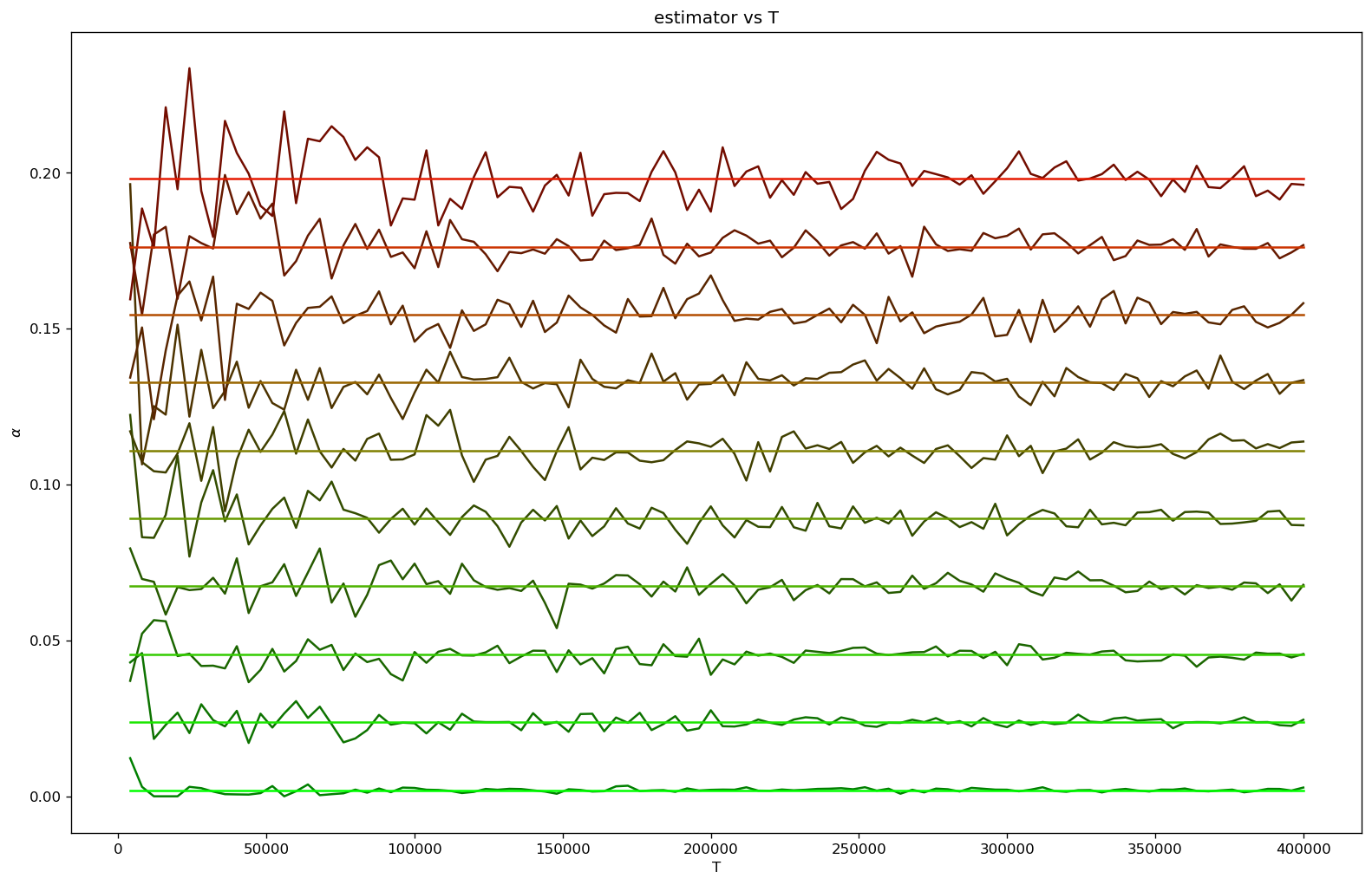
The (naive) ML estimator, given by the frequency of elections won, as a function of the number of slots plotted for a number of nodes with relative stakes . Here on average the fraction of slots was observed.
The performance of ML estimators was also evaluated using the Jaccard Index. The index evaluates the estimators’ ability to correctly classify nodes as “high” or “low” stake. The simulation was done across multiple mixnet failure probabilities .
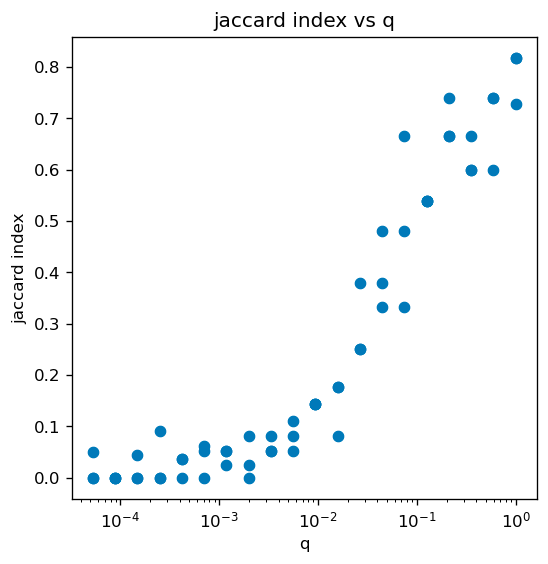
The performance of the (non-naive) ML estimator in classifying validators, measured by the Jaccard index, in the top 1pct of stakers as a function of the fraction of observed nodes, q. Here the N=2000 stake values were drawn from the distribution and T=432000. For q close 1, i.e. all nodes are observed, most high stake nodes are inferred correctly (Jaccard index is close to 1). As q (i.e. fraction of observed nodes) decreases, the accuracy decreases and for is significantly reduced (Jaccard index is close to 0).
Analysis was also done using Cardano’s real world stake values. Clearly, Cardano’s stake distribution incentives somehow seem to protect against inferring top 1pct of stakers. More analysis is needed:
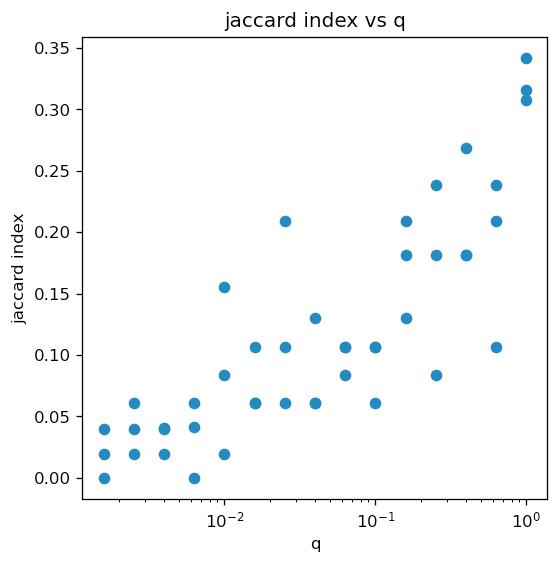
The performance of (non-naive) ML estimator in classifying validators, measured by the Jaccard index, in the top 1pct of stakers as a function of the fraction of observed nodes, q. Here T=432000 and N=2500 stake values were obtained from Cardano.
Analysis of ML Estimator: Inference of Lagrange Multiplier
The naive estimator above assumed the Lagrange multiplier, which ensures that inferred relative stake is normalized , . A more sophisticated estimator can be derived from the ML framework by inferring for a given sample.
The Lagrange multiplier is inferred by minimizing the distance between the LHS and RHS of equation (18) :
In the above, the “distance” used is the relative entropy. Computing the partial derivative w.r.t. gives us a gradient which we can then follow using gradient descent, or any other algorithm which uses a gradient, to discover the choice of which minimizes the above distance.
Inferred Distributions of Relative Stake
Relative stake obtained in 1000 inferences for stake distribution drawn from
Here is the fraction of observed time-slots (or the “mixnet failure probability”) out of the total time-slots. The small, grad and naive above refer to the approximation, the inferred , and the estimators respectively. The inferred estimator produces a smoother distribution for small . The small and naive estimators produce near identical inferred distributions.
The Total of Inferred Relative Stake
The sum of all relative stake (by definition) must sum to 1. Here we plot the error in inferred total stake for the different estimators:
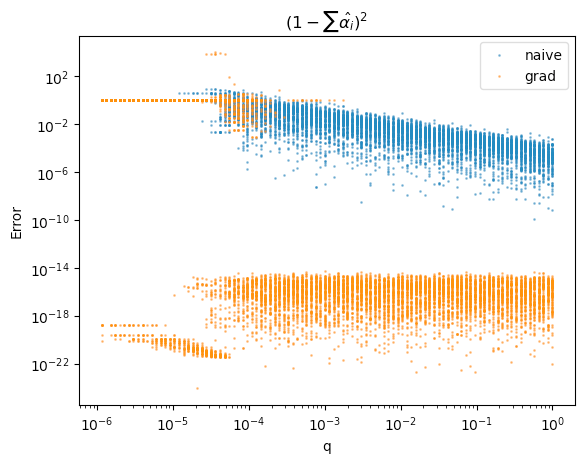
Plotting the squared distance to 1 of the sum of inferred relative stakes. The inferred estimator produces a much lower and constant error across values on this metric.
Classification Performance
Despite the reduced error in total relative stake inference, and the smoother histogram, the naive estimator performed identically to the inferred estimator when tasked to identify the top stakers of the distribution.
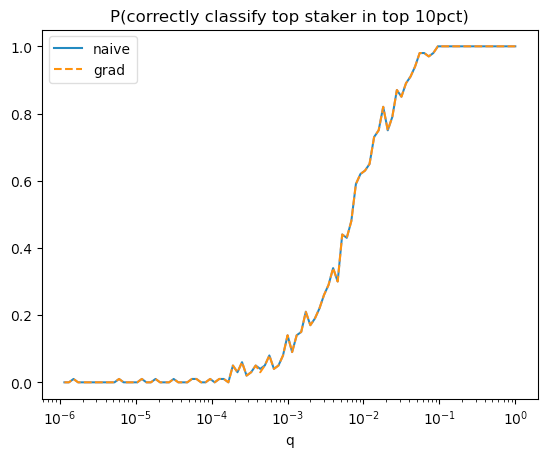
We ask the question: given the top 10% of inferred stakers, is the true top staker among those inferred top 10%.
Naive and grad estimators performed identically at this task.
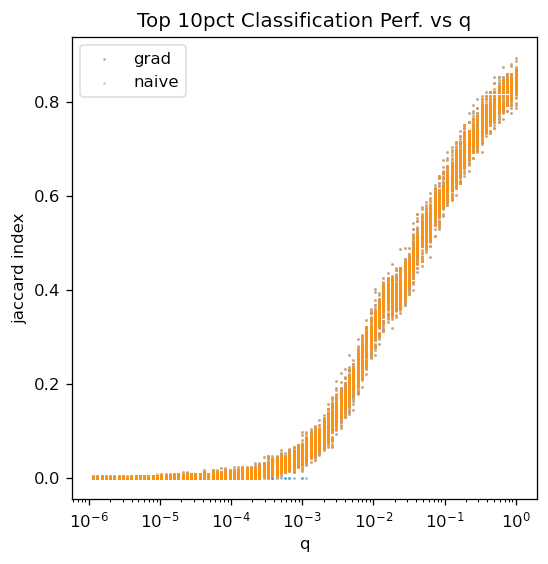
Plot of the Jaccard Index: J(inferred 90th pct, true 90th pct). High Jaccard index tells us there is a high degree of overlap between the two sets, low index tells us that the sets are nearly disjoint.
Estimator Accuracy
Here we measure the accuracy of estimators. The left plot shows inferred vs true relative stake for one simulation, right plot shows mean squared error between inferred and true relative stakes. We find that both naive and inferred estimators produce similar results.
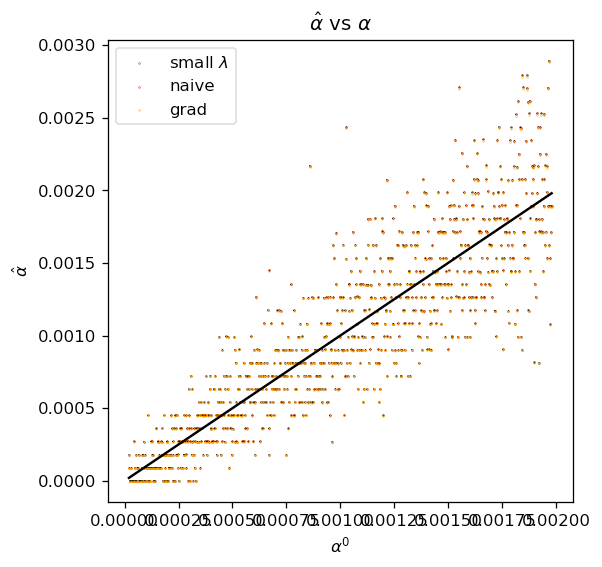
X-axis is the true relative stake, Y-axis is the inferred relative stake. Perfect inference would produce the solid black line. All estimators perform nearly identically.
Simulation parameters:
, ,
stake distribution=np.linspace(1, 100, 1000)
Simulation parameters: , ,
Simulation parameters:
, ,
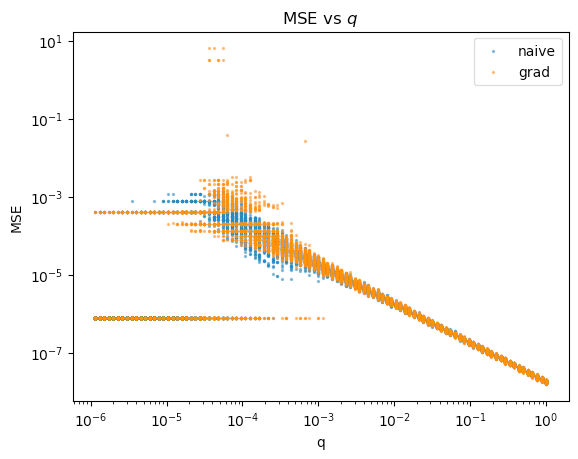
Plotting the Mean Squared Error (i.e. average squared distance between true and inferred relative stake pairs) against .
Simulation Parameters:
stake distribution = Cardano
Simulation Parameters:
Simulation Parameters:
Statistical Inference of Relative Stake
- Leader election process: at time-slot the probability of a node winning the election is given by the “lottery” function , where is the relative stake of node .
- Observation process: the outcome of the election for node is observed with the probability .
- Statistical inference: we define the log-likelihood $\mathcal{L} =\sum_{t=1}^T\sum_{i=1}^N \eta_i(t)\log P_i(s_i(t))s_i(t)=1/0iP_i(1)=\phi(\alpha_i)\eta_i(t)=1/0s_i(t)$.
- Maximisation of , subject to constraint , gives the ML estimator of relative stake which is a solution of the equation for .
- Here , i.e. the number of 1’s observed divided by the total number of observations, and is a parameter which ensures that .

The leader election and observation processes. Node participates in the leader election (or ``lottery'') at times . The (binary) outcome of this lottery, where 0/1 corresponds to lost/won, is either observed (numbers in square brackets) or unobserved.
Appendix
Analysis of leader election process in proof of stake consensus model
File attachment: Analysis_of_leader_election_process_in_PoS.pdf
Statistical inference of relative stake
File attachment: Statistical_inference_of_relative_stake.pdf
Cardano Stake Distribution
Data was pulled from Cexplorer to determine the stake value of every pool in Cardano
File attachment: pools.csv
The histogram seems to shows it seems to follow a classic power law
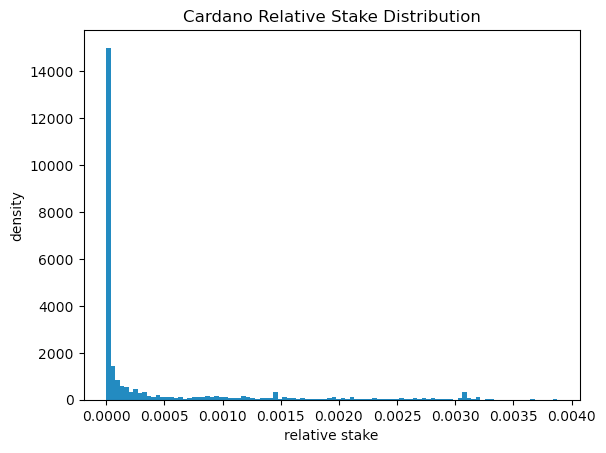
Anomalies in the Distribution
Removing the low stakers from the distribution reveals a few peaks and a sharp decline after 70MM ADA:
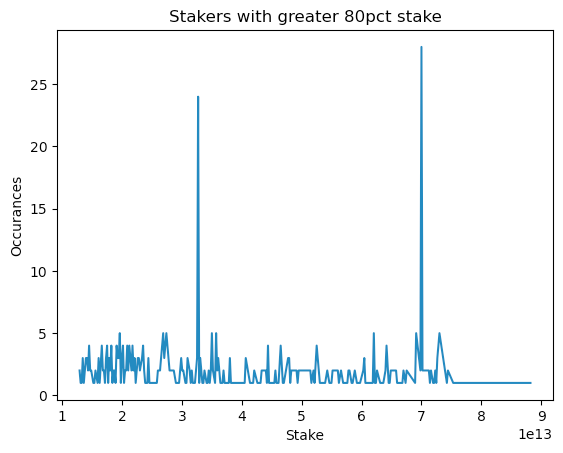
These two peaks occur at 32.7MM ADA and 69.9MM ADA respectively.
Doing some research shows that Cardano has a concept of “Pool Saturation”, that is controlled by a global “Saturation Parameter ()”. This parameter sets the target number of pools in the network. The target is enforced through a soft “stake cap”, i.e. a pool with 200 ADA when the stake cap is 100 ADA will earn the same rewards as a pool with 100 ADA.
Currently , this sets the stake cap at 64MM ADA. The IOHK blog posts suggest that there is a plan to move to in the future, which would correspond to a stake cap of 32.7MM ADA.
We suspect the peak at ~70MM ADA we see in the data is the result of pool operators who are slightly over their target of 64MM but don’t yet feel the incentive to split into smaller pools.
The other peak at 32MM ADA likely corresponds to pools who are anticipating the switch to and hoping to avoid any lost revenue due to the stake cap.
The sharp decline after 70MM ADA is likely explained by this Saturation Parameter incentivizing smaller pools.
- The IOHK blog post announcing the change to and a plan to increase to 1000 in 2021 (didn’t seem to happen) https://iohk.io/en/blog/posts/2020/11/05/parameters-and-decentralization-the-way-ahead/
- Reddit discussion anticipating the change to https://www.reddit.com/r/cardano/comments/nfor5t/when_is_a_pools_saturation_too_high/
ANALYSIS-TOTAL-STAKE-INFERENCE
| Field | Value |
|---|---|
| Name | [Analysis] Total Stake Inference |
| Slug | 198 |
| Status | raw |
| Category | Informational |
| Editor | David Rusu [email protected] |
| Contributors | Alexander Mozeika [email protected], Daniel Kashepava [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-29 —
67e498e— chore: fix math issues (#350) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-04-09 |
Introduction
Cryptarchia consensus leadership is determined by a lottery in which the chances of winning are higher for eligible nodes with a greater stake relative to the total active stake. At the same time, the true total active stake cannot be known by participants due to the privacy properties of Logos Blockchain notes. This tension is resolved in Cryptarchia by having the network estimate the total active stake based on the observed activity of the network.
Goals
The Cryptarchia total stake inference algorithm must satisfy the following criteria:
- The inference process converges quickly, yielding a mean estimate that closely matches the true total stake. However, mean accuracy alone is not sufficient—if the estimator’s variance remains high at steady state, block production rates may fluctuate significantly. Thus, effective total stake inference requires both rapid, accurate mean convergence and low variance to ensure stable, predictable block production throughout the protocol.
- The process can be approximated well enough with the information we have in Cryptarchia.
Overview
This document provides an analysis of the Cryptarchia total stake inference algorithm based on the following criteria:
- Accuracy: The closeness of the mean inferred total stake to the true total stake; it measures systematic bias in the estimator.
- Precision: The degree to which repeated inferences yield similar results at equilibrium; it is quantified by the variance of the estimator and reflects how tightly values cluster around the mean, independent of accuracy.
- Stability Conditions: The range of possible values for the learning rate that result in the stake inference values converging to the true total stake under stable conditions.
- Convergence Speed: The bounds under which the total stake inference values converge exponentially to the true total stake under stable conditions. This analysis also includes an optimal value for .
Total Stake Inference Process
The inference algorithm is described in Total Stake Inference - Algorithm. In order to analyze the properties of this algorithm, we model it analytically as the following sequence . We then verify that this model aligns with the algorithm to ensure that the analysis accurately reflects the actual process.
where,
- is the inferred total stake at epoch ;
- is the learning rate which governs how quickly we adjust our estimate to new information;
- is the target slot occupancy rate;
- is the observation period in which we observe the slot occupancy rate;
- is the indicator function resolving to if is true, otherwise;
- is the number of nodes in the system;
- is the lottery result of node at slot , in epoch ; here, 1 signals a win, and 0 signals a loss;
- is the number of slots in epoch that could have extended the honest chain but instead were wasted on orphaned blocks.
We note that the form above captures how the protocol updates its estimate of the total active stake based on observed network activity, and the actual inference process is described at: Total Stake Inference - Algorithm. Specifically, at each epoch , the estimate is adjusted according to the difference between the target slot occupancy rate and the observed average fraction of slots with at least one block extending the honest chain (after accounting for wasted slots, ). The learning rate and normalization by control how aggressively the estimate is updated.
Analysis
Accuracy
The process converges to the following value:
where,
- is the mean fixed point of the inference process;
- is the true total stake active during the consensus protocol execution;
- is the honest slot utilization rate representing the rate of occupied slots contributing to the honest chain growth.
We note that for , we have that . This suggests that increased network delay, which reduces the honest slot utilization rate through wasted blocks results in a systematic underestimate of true total stake.
For a derivation of this result, please see Accuracy Derivation.
Measuring from simulations
In simulation, we can derive the value by measuring how many of the active slots contributed towards the honest chain with this formula:
Since varies by epoch and is impacted by the total stake inference process, measurements should be taken after the system converges to a steady state. From simulations, this tends to be after 5 epochs.
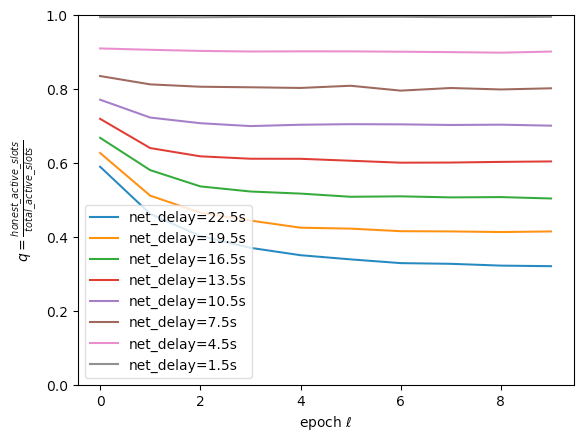
Measured value for each epoch under different network delays. typically converges after a few epochs for reasonable networks.
Simulation Results
This result predicts that we consistently underestimate true stake by a factor of . We verified this prediction in simulations and saw a strong correlation between this prediction and the stake we inferred in simulation:
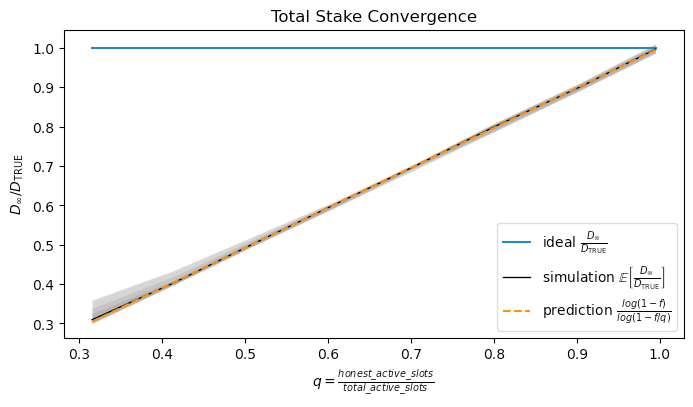
The percent of total stake that we converged to under varying honest slot utilization rates . The model provides a very accurate prediction of the behaviour in simulation. Here, .
Connecting Simulation to Logos Blockchain
With our choice of Blend Network parameters, we measured a value of 0.85 in simulation, plugging that into our model gives . That is, if the Blend Network behaves like our simulation, we expect to infer a total stake that is ~84.7% of the true total stake, or ~15% below true total stake. This loss in accuracy is due to not being able to count blocks off the honest branch.
Precision
The variance at equilibrium is given by
Furthermore, because of and , the variance is bounded above by:
The implication is that wasted blocks caused by network delays have a stabilizing effect on the inference process. As the network delay grows, the variance in our estimate decreases.
For a derivation of this result, see Precision Derivation.
Simulation Results
Checking these predictions in simulations shows very good agreement with analysis:
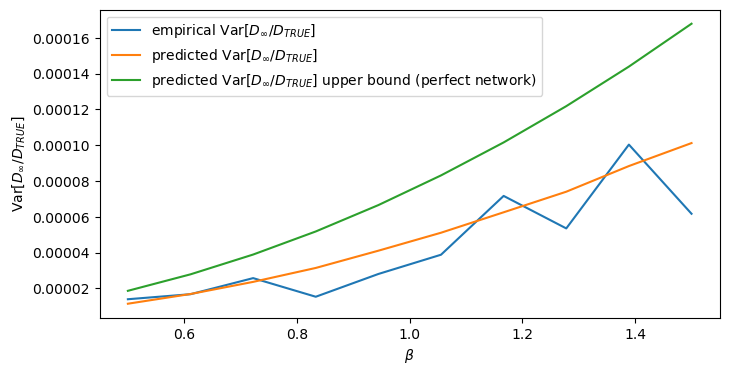
Here we measure the variance of the inferred total stake after the process has converged. We observe low variance across a wide spectrum of values suggesting that our epoch lengths are long enough to give us a sufficiently precise measurement of total stake for any reasonable learning rate. We see strong agreement with predictions from analysis.
We note that and is measured as described in Measuring from simulations.
Stability Condition
The inference process is stable for values that satisfy the following condition
where is the honest slot utilization rate as mentioned above.
Note that for (perfect network, all active slots are used by the honest chain), we have a lower bound on the stability condition, meaning we can tolerate a higher learning rate and converge faster when the network is inefficient:
For a derivation of this result, see Stability Condition Derivation.
Simulation Results
In simulations, we see that when we exceed the condition, the spread in values explodes for .
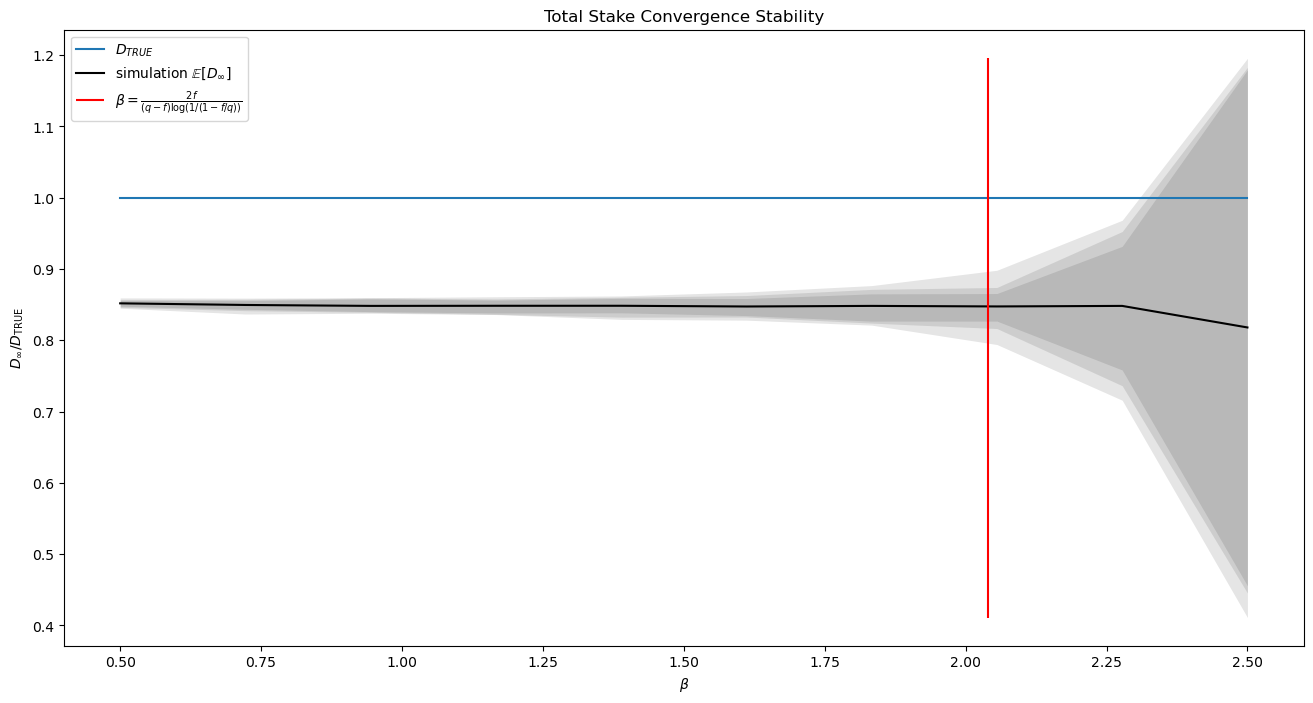
The plot shows the spread of values observed over 45 epochs after the process has been given sufficient time to converge. We observe that we have high precision when is comfortably within the stability condition range and grows rapidly outside of the range. Red line signals the boundary of the convergence condition ().
Here, and is measured as described in Measuring from simulations.
Convergence Speed and Optimal Learning Rate
The process converges exponentially with the following bound:
That is, for some constant , at epoch , the distance between the value for the total stake and the equilibrium estimate falls exponentially. Moreover, this result predicts an optimal convergence rate
For reasonable values, this gives us a slightly higher than 1. Choosing a smaller can only improve the stability of the inference algorithm. This fact, combined with the uncertainty in selecting a value suggests that we should just select as our learning rate.
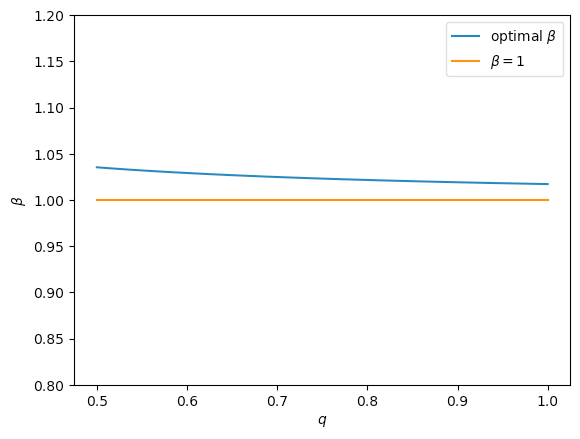
Plotting optimal under varying values shows that is a close enough approximation to the optimal learning rate. Here .
For a derivation of this result, see Convergence Speed and Optimal Learning Rate Derivation.
Simulation Results
We verified these results in simulations, showing that the bound holds for varying ’s.
The plots show the measured normalized error decreasing as epoch increases. Cryptarchia parameters for all plots were .
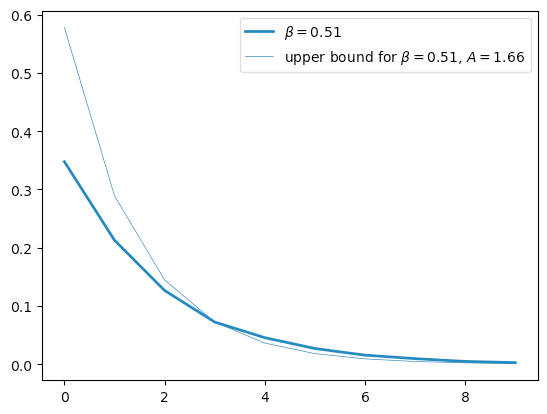
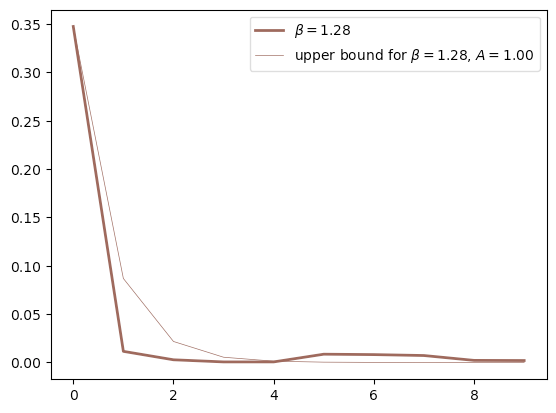
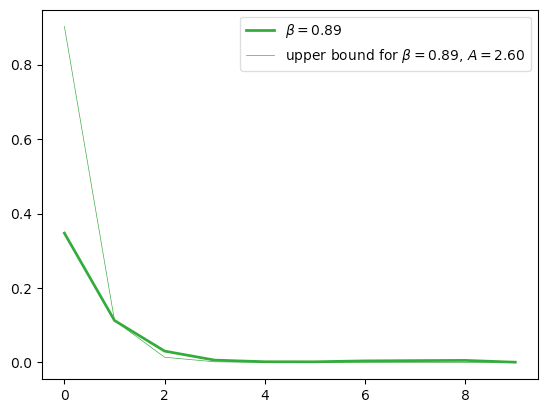
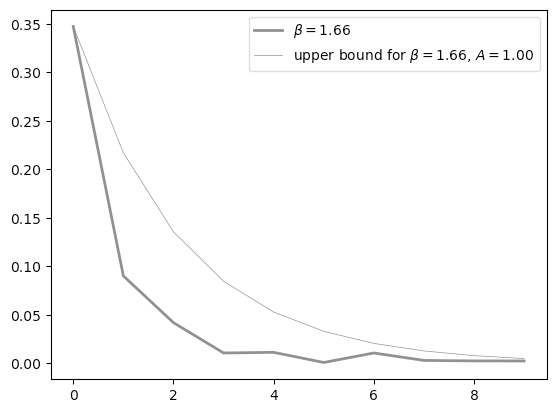
Optimal convergence was checked as well showing that with optimal[#convergence-speed-and-optimal-learning-rate), even with massive shocks to total stake, we can converge within 2 epochs.
Plots show the distribution of normalized error at each epoch for the optimal parameter under different initial conditions. Cryptarchia parameters for all plots were .
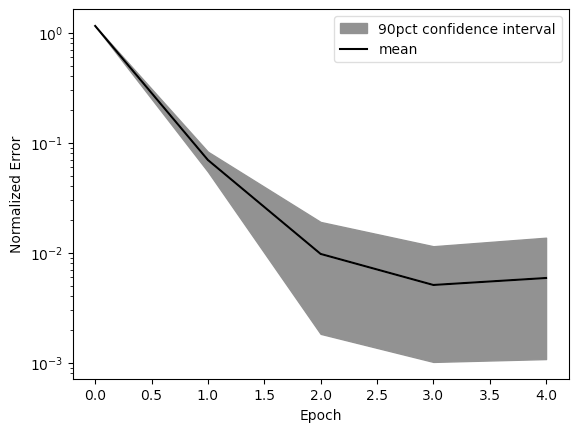
Converging to new equilibrium after losing half active stake.
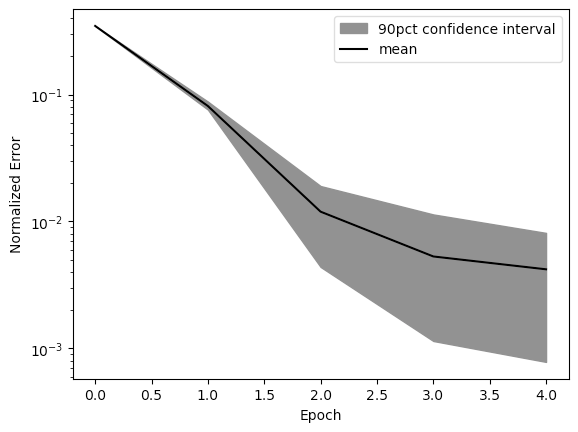
Converging to new equilibrium after doubling active stake.
Details
Accuracy Derivation
The following is the derivation for the property described in Accuracy.
- The total stake inference equation is given by
where is the learning rate. In the above, we write to emphasise that the random variable is conditional on .
- In the equation used in inference of total stake, we take but the starting point of our analysis uses a more general learning rate .
- We note that is the number of active slots, i.e. slots with at least one winner, in the -th epoch.
- For the outcome of leader election process at the time-slot , the probability of outcomes at times is given by
where
is the probability of winning and is the stake of node .
- We note that is a random variable.
- Node uses its (local) copy of the blockchain in the inference of the total stake and the latter can give a different count for the number of active slots because of a number of slots being “wasted”.
- To model this scenario, we introduce variable , i.e. is conditional on , such that
is the number of blocks on the chain of an honest node, i.e. the number of “honest” slots. The latter will be used for inference by an honest node as follows
where in above .
- We note that
i.e. for the same , the of the honest node’s equation is bounded above by the of the idealised equation.
- Let us assume that is a random variable from the binomial distribution with the parameters and .
- Here is the probability that a slot is “wasted” in epoch and hence there are (on average) number of slots wasted in epoch .
- We note that the above assumption about is mathematically convenient but not necessary true. However it is the simplest non-trivial assumption, and its validity can be tested in simulations.
- We first consider the equation
- Averaging above over the random variable gives us the equation
- Now, let us assume that is deterministic and consider the average of , , with respect to the distribution as follows
- Thus using in above the definition we obtain the following equation
where in above is the true total stake.
- We note that for we recover the following equation
- Next, we define the normalised inferred stake , and the average , and postulate that the latter satisfies the equation
where , i.e. the probability that a slot is not wasted in epoch .
- We note that is the average number of slots not wasted in epoch .
- Let us assume that , i.e. the probability is the same in all epochs, and consider the equation
- Then such that is the fixed point of the above equation. Solving the latter gives us
- We note that above solution exists for . The function is monotonic increasing function of on the interval and hence
Precision Derivation
The following is a derivation for the property described in Precision.
- We consider the equation
where is random variable from the binomial distribution with the parameters and .
- The variance of is given by
- We note that
by the identity.
- First, we consider
- Second, we consider
- Hence
- Third, we consider the variance
- Hence
- To obtain above, we used identities described in the Annex and the following results
- Finally, combining all of the above we obtain the following result
where .
- Thus we obtain
- Based on the above, the variance of the normalised total stake is given by
- Now, for , where , we obtain
- Furthermore, if we assume that above is true for all , i.e.
where . For and we have and hence
- We note that for we have and from the latter follows
- Thus assuming that the equation is correct, we have shown that
i.e. the variance for is bounded from above by the variance for .
Stability Condition Derivation
The following is a derivation for the property described in Stability Condition.
- Let us assume that and consider the equation for , where , as follows
- The above suggests that the solution is stable when
- We note that above is equivalent to
- Thus the solution is stable for
- Furthermore, is a monotonic decreasing function of and hence
i.e. the equation is stable for larger values of the learning rate when .
Convergence Speed and Optimal Learning Rate Derivation
The following is a derivation for the properties described in Convergence Speed and Optimal Learning Rate.
- Applying Corollary 2.1 to the equation with we obtain
where , for some constant .
- We note that for the learning rate , where
the base function is exactly zero suggesting that for any at . The latter is not possible and hence the bound, which assumes that the first order derivative of the map exists, can not be applied when .
- However, for any and learning rate the bound can be used and the speed of convergence is .
- What happens when ? Considering the equation for , the latter gives us
- Ignoring the higher order terms in above and solving $\epsilon(\ell+1) =A(q,f)\epsilon^2(\ell)A(q,f)=\frac{\log \left(1-\frac{f}{q}\right)^{2}}{2 \log \left(1-f \right)}\epsilon(0)$ gives us the equation
- We note that for the is doubly-exponential as .
- Thus locally, i.e. for with , the speed of convergence to is doubly-exponential. The latter suggests that for the learning rate
is optimal.
- The double exponential form dominates convergence to the fixed point for small as can be seen in the figures below
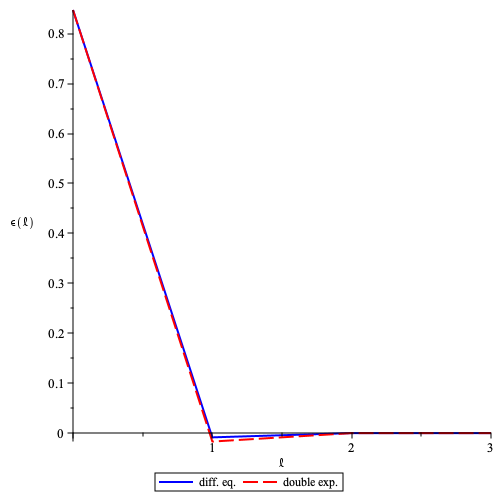
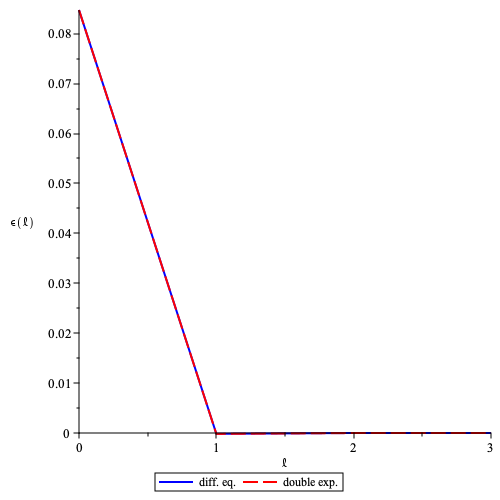
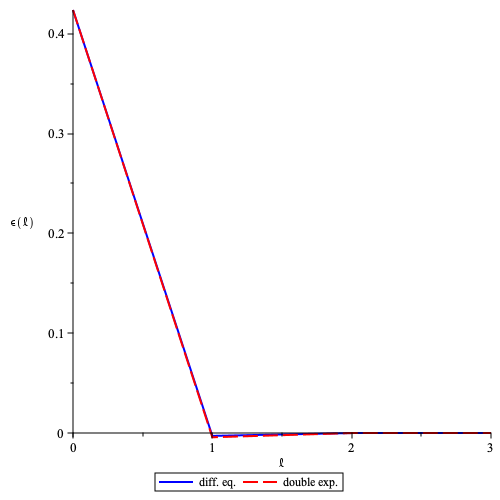
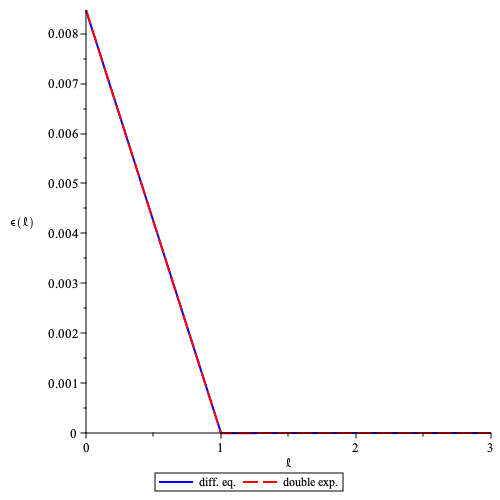
The difference between average (normalised) stake at epoch and its equilibrium value plotted as a function of for and . The solid (red) line is the solution of the difference equation using optimal learning rate and the dashed (blue) line is the double exponential. Here for and (top left, top right, bottom left, bottom right) the is, respectively, of order .
Annex
Why Use Total Active Stake instead of Total Supply
Rather than inferring total stake participating in consensus, we could conceivably relativize stake values for the leadership election by dividing by total supply. A good way to analyze this possibility is by using metrics from Cardano. As of January 23, 2023, there are 22.81B ADA staked vs. a total supply of 36.56B, meaning that ~62% of ADA is staked.
For a sense of how using total supply would affect block proposal rates in Cardano, consider the simple case where one validator controls all the stake. In this scenario, the ratio of the probability of producing a block when relativized with total supply compared to with total stake is
In other words, roughly a 40% suppression in occupied slots. This goes against Cryptarchia’s target of maintaining an average of occupied slots (i.e. roughly seconds between blocks).
Additionally, since we do not adjust our block production rate to compensate for variable participation, we can expect to see fluctuations in block production rates as the percentage of participation changes. This can lead to uncertain finality times, making it difficult to maintain the epoch schedule.
Prior Work
DarkFi
An earlier version of DarkFi also implemented Crypsinous and ran into the same problem. Their solution was to use a Proportional-Integral-Derivative (PID) controller to control the block rate:
A discrete PID controller has been implemented to stabilize the leader selection frequency. In simple terms, the controller is auto-tuning to produce a single leader per slot as often as possible. DarkFi Testnet v0.1 alpha
This has several problems:
-
Ouroboros Praos and its successors, including Crypsinous and Cryptarchia, deliberately select a small active slot coefficient to ensure there is sufficient time for blocks to propagate across the network before the next slot is activated. If were set higher—such that nearly every slot was expected to be filled—there would be insufficient time for block dissemination, leading to a significant increase in blockchain forks. This design choice is fundamental to maintaining network stability and minimizing chain splits in these protocols.
-
The PID controller in the earlier DarkFi implementation was used to dynamically adjust the active slot coefficient in an attempt to regulate block production rates. However, in protocols like Praos, Genesis, and Crypsinous, is a critical security parameter that must remain fixed for the underlying security proofs to hold. Dynamically changing undermines these proofs and could compromise protocol guarantees. Therefore, should be held constant rather than tuned by a PID controller during protocol execution.
-
PID is a heavy tool for the job. It requires careful tuning to system dynamics in order for the PID to behave optimally and modelling the system well enough is difficult.
Bibliography
-
Ortega JM. Stability of difference equations and convergence of iterative processes. SIAM Journal on Numerical Analysis. 1973 Apr; 10(2): 268-82.
-
DarkFi: anonymous, uncensored, sovereign. 2021 [cited 2025 Aug 9]. Available from: https://dark.fi/
-
David B, Gaži P, Kiayias A, Russell A. Ouroboros Praos: An adaptively-secure, semi-synchronous proof-of-stake protocol. EUROCRYPT 2018.
-
Kerber T, Kohlweiss M, Kiayias A, Zikas V. Ouroboros Crypsinous: Privacy-preserving proof-of-stake. IEEE Symposium on Security and Privacy 2019 .
Covariance Identities
- Let us consider , where is a random variable and is a random variable conditional on , as follows
- Hence
- The covariance can be computed as follows
and hence
- The variance can be computed as follows
and hence
Cryptarchia Metrics
The following plot shows various metrics from Cryptarchia as we run the total stake inference protocol. We can see that the total stake inference protocol is able to control the honest chain growth to maintain a growth rate of blocks/slot, the side-effect of this is an increased block production rate, more active slots and an underestimation of total stake.
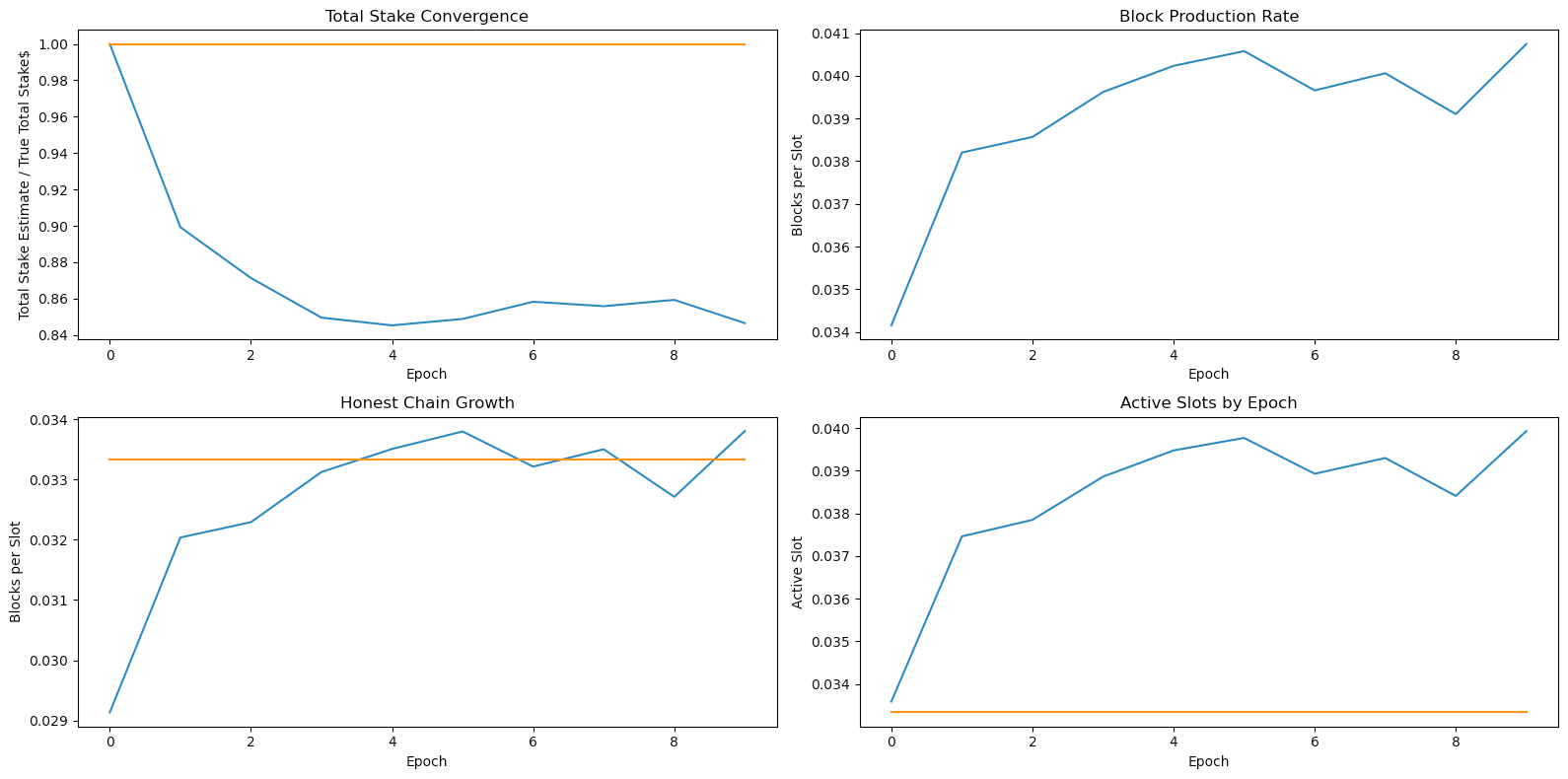
Parameters: , and ; Logos Blockchain blend network: 3 hops, 2-second per‑hop delay, 6-second mean end‑to‑end network delay. The yellow horizontal lines show the ideal values for each metric given a perfect network (no block delay).
Simulation Code
cryptarchia-with-total-stake-inference.ipynb
CRYPTARCHIA-BOOTSTRAPPING-SYNCHRONIZATION
| Field | Value |
|---|---|
| Name | Cryptarchia Bootstrapping & Synchronization |
| Slug | 96 |
| Status | raw |
| Category | Standards Track |
| Editor | Youngjoon Lee [email protected] |
| Contributors | David Rusu [email protected], Giacomo Pasini [email protected], Álvaro Castro-Castilla [email protected], Daniel Sanchez Quiros [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-18 —
58b5698— chore(blockchain): migrate contributor emails to @logos.co (#338) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-02-17 |
Introduction
When a new node joins the network or a previously-bootstrapped node has been offline for a while, it cannot follow the most recent honest chain solely by receiving only new blocks because those new blocks cannot be added to the block tree that does not have their parent block. These nodes must first catch up with the most recent honest chain by fetching missing blocks from their peers before they start listening for new blocks.
This document specifies a protocol for nodes to bootstrap with the honest chain efficiently while mitigating long range attacks. It also defines how to handle the case which the node falls behind after the bootstrapping is complete.
This protocol adheres to the key invariant: We never roll back blocks that are deeper than the latest immutable block in the local chain , as defined in Cryptarchia Protocol .
Overview
This protocol defines the bootstrapping mechanism that covers all of the following cases:
- From the Genesis block
- From the checkpoint block obtained from a trusted checkpoint provider
- From the local block tree (with newer than the Genesis and the checkpoint)
Additionally, the protocol defines the synchronization mechanism that handles orphan blocks while listening for new blocks after the bootstrapping is completed.
The protocol consists of the following key components:
- Determining the fork choice rule (Bootstrap Fork Choice Rule or Online Fork Choice Rule) at startup
- Switching the fork choice rule from Bootstrap to Online
- Downloading blocks from peers
The details are described in the Protocol. This section provides only a high-level overview.
flowchart TD
Start@{shape: circle, label: "Start"} --> SettingForkChoice
subgraph SettingForkChoice[Setting Fork Choice]
subgraph CheckBoostrap[Any condition true?]
direction TB
Cond1{{LIB is set to Genesis or Checkpoint?}}
Cond2{{Restarting after long offline?}}
Cond3{{Bootstrap flag enabled?}}
end
CheckBoostrap -->|Yes| SetBootstrap[ForkChoice=BOOTSTRAP]
CheckBoostrap -->|No| SetOnline[ForkChoice=ONLINE]
end
SetBootstrap --> IBD
SetOnline --> IBD
subgraph IBD[Initial Block Download]
IBDPeersConfigured{{IBD peers configured?}} --> |Yes|DownloadUpToTips
DownloadUpToTips[Download all blocks up to peers' tip] --> |"Failed (e.g. No peers available)"| Terminate@{shape: circle, label: "Terminate"}
end
IBDPeersConfigured --> |No|IsBootstrapRule
DownloadUpToTips -->|Completed|IsBootstrapRule
IsBootstrapRule{{ForkChoice==BOOTSTRAP?}}
IsBootstrapRule -->|Yes|StartBootstrapPeriod
IsBootstrapRule -->|Anyway|NewBlocks
subgraph Prolonged Bootstrap Period
StartBootstrapPeriod[Start ProlongedBootstrapPeriod timer: 24h] --> |Expired|SetOnlineAfterBootstrap[ForkChoice=ONLINE]
end
SetOnlineAfterBootstrap --> ProposeBlocks[Propose Blocks]
subgraph ListenNewBlocks[Listen for New Blocks]
NewBlocks[Listen/Process a new block] --> CheckOrphan{{Is orphan?}}
CheckOrphan -->|Yes| HandleOrphan[Download ancestors]
CheckOrphan -->|No| NewBlocks
HandleOrphan --> |Completed|NewBlocks
end
Upon startup, a node determines the fork choice rule, as defined in Setting the Fork Choice Rule. If the Bootstrap rule is selected, it is maintained for the Prolonged Bootstrap Period, after which the node switches to the Online rule.
Using the fork choice rule chosen, the node downloads blocks to catch up with the tip of the local chain of each peer.
After downloading is done, the node starts listening for new blocks. Upon receiving a new block, the node validates and adds it to its local block tree. If the ancestors of the block are missing from the local block tree, the node downloads missing ancestors using the same mechanism as above.
The node can propose blocks after switching to the Online fork choice rule.
Protocol
Constants
| Constant | Name | Description | Value |
|---|---|---|---|
| Offline Grace Period | A period during which a node can be restarted without switching to the Bootstrap rule. | 20 minutes | |
| Prolonged Bootstrap Period | A period during which Bootstrap fork choice rule must be continuously used after Initial Block Download is completed. This gives nodes additional time to compare their synced chain with a broader set of peers. | 24 hours | |
| Density Check Slot Window | A number of slots used by density check of Bootstrap rule. This constant is defined in Definitions. | (=4h30m) |
Setting the Fork Choice Rule
Upon startup, a node sets the fork choice rule to the Bootstrap rule in one of the following cases. Otherwise, the node uses the Online fork choice rule.
-
A node is starting with set to the Genesis block or from a checkpoint block. The node is setting its latest immutable block to the Genesis or a checkpoint, which clearly indicates that the node intends to catch up with the subsequent blocks. Regardless of how many subsequent blocks remain, the node should use the Bootstrap rule to mitigate long range attacks.
-
A node is restarting after being offline longer than (20 minutes). Unlike starting from Genesis or checkpoint, in the case where a node is restarted while preserving its existing block tree, the node must choose a fork choice rule depending on how long it has been offline.
If it is certain that a node has been offline longer than the offline grace period since it last used the Online rule, the node uses the Bootstrap rule upon startup. Otherwise, it starts with the Online rule.
Details of are described in Offline Grace Period. A recommended way how to measure the offline duration is introduced in Offline Duration Measurement.
-
A node operator set the Bootstrap rule explicitly (e.g., by
--bootstrapflag). In any case where the node operator is clearly aware that the node has fallen behind by more than blocks, they should be able to start the node with the Bootstrap rule. For example, the operator may obtain the latest block height from another trusted operator and realize that their node has fallen significantly behind due to some issue.
Initial Block Download
If peers for Initial Block Download (IBD) are configured, a node performs IBD by downloading blocks to catch up with the tip of the local chain of each peer using the fork choice rule chosen in Setting the Fork Choice Rule. If no peer is configured, the node skips IBD. For example, genesis nodes will configure no IBD peer because they have to build a chain from scratch.
Blocks are downloaded in parent-to-child order, as defined in the Downloading Blocks mechanism. This mechanism applies not only when a node starts from the Genesis block, but also when it already has the local block tree (or a checkpoint block)
def initial_block_download(peers, local_tree):
# Skip IBD if no peer is set.
# For example, genesis nodes should be able to skip IBD.
if len(peers) == 0:
return
# In real implementation, these downloadings can be run in parallel.
# Also, any optimization can be applied to minimize downloadings, such as grouping peers by tip.
num_success = 0
for peer in peers:
is_success = download_blocks(local_tree, peer, target_block=None)
num_success += 1 if is_success else 0
# If none of download succeeds (e.g. network errors or invalid blocks),
# IBD is considered failed.
if num_success == 0:
raise IBDFailure
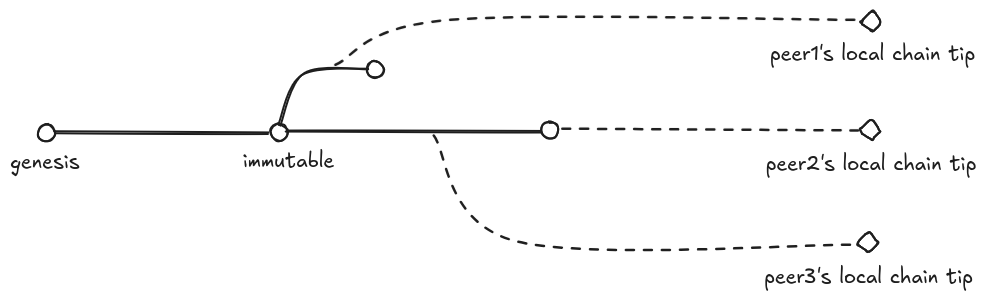
The downloaded blocks are validated and added to the local block tree using the fork choice rule determined above. Both block headers and block bodies must be validated. The header validation rules are defined in Block Header Validation.
If the node fails to catch up with at least one IBD peer (e.g., network error or invalid blocks), the node is terminated with an error, allowing the operator to restart the node with other IBD peers.
If downloading is done successfully, the node starts listening for new blocks as described in Listening for New Blocks.
Prolonged Bootstrap Period
After Initial Block Download is completed, a node must maintain the Bootstrap fork choice rule during the Bootstrap Period , if the node chose the Bootstrap rule at Setting the Fork Choice Rule.
The purpose of the Prolonged Bootstrap Period is giving a syncing node additional time to compare its synced chain with a broader set of peers. In other words, it provides the node with an opportunity to connect to different peers and verify whether they are on the same chain. If the syncing node has downloaded blocks only from peers within an isolated network, the result of Initial Block Download may not reflect the honest chain followed by the majority of the entire network. To resolve such situations, the node should continue using the Bootstrap rule while discovering additional peers, allowing it to switch to a better chain if one is found.
Theoretically, the Bootstrap rule should be prolonged until the node has seen a sufficient number of blocks beyond the slot window, which is required for the density check of the Bootstrap rule to be meaningful. However, if the node has seen a fork longer than blocks from its divergence block during Initial Block Download, it means that the node has already seen more slots than with very high probability, considering the small size of ). If the node has never seen any fork longer than blocks, it means that all forks could have been handled by the longest chain rule, which is part of the Bootstrap rule. Therefore, this protocol does not explicitly wait slots after Initial Block Download. In other words, the protocol does not use to configure the Prolonged Bootstrap Period.
This protocol configures the Bootstrap Period to 24 hours.
A timer must be started when Listening for New Blocks is started after Initial Block Download is completed. Once the time is completed, the fork choice rule is switched to the Online rule.
Listening for New Blocks
Once Initial Block Download is complete and Prolonged Bootstrap Period is started, a node starts listening for new blocks relayed by its peers.
Upon receiving a new block, the node tries to validate and add it to its local block tree, as defined in Chain Maintenance.
If the parent of the block is missing from the local block tree, the block cannot be fully validated and added. These blocks are called orphan blocks. To handle an orphan block, the node downloads missing blocks from a randomly selected peer, as described in Downloading Blocks. If the request fails, the node may retry with different peers before abandoning the orphan block. The retry policy can be configured by implementers.
Note that downloading missing blocks does not need to be triggered if it is clear that the orphan block is in a fork diverged before the latest immutable (committed) block, as the node should never revert immutable blocks.
def listen_and_process_new_blocks(fork_choice: ForkChoice, local_tree: Tree, peers: List[Node]):
for block in listen_for_new_blocks():
try:
# Run the chain maintenance defined in the Cryptarchia spec.
local_tree.on_block(block, fork_choice)
except InvalidBlock:
continue
except ParentNotFound:
# Ignore the orphan block proactively,
# if it's clear that the orphan block is in a fork behind the latest immutable block
# because immutable blocks should never be revereted.
# This check doesn't cover all cases, but the uncovered cases will be handled by
# the Cryptarchia block validation during the `download_blocks` below.
if block.height ≤ local_tree.latest_immutable_block().height:
continue
# In real implemention, downloading can be run in background with the retry policy.
download_blocks(local_tree, random.choice(peers), target_block=block.id)
Downloading Blocks
For performing Initial Block Download and handling orphan blocks while Listening for New Blocks, a node sends a DownloadBlocksRequest to a peer, which must respond with blocks in parent-to-child order. This communication should be implemented based on the Libp2p streaming.
Libp2p Protocol ID
- Mainnet:
/logos-blockchain/cryptarchia/sync/1.0.0 - Testnet:
/logos-blockchain-testnet/cryptarchia/sync/1.0.0
class DownloadBlocksRequest:
# Ask blocks up to the target block.
# The response may not contain the target block if the responder limits the number of blocks returned.
# In that case, the requester must repeat the request.
target_block: BlockId
# To allow the peer to determine the starting block to return.
known_blocks: KnownBlocks
class KnownBlocks:
local_tip: BlockId
latest_immutable_block: BlockId
# Additional known blocks.
# A responder will reject a request if this list contains more than 5.
additional_blocks: list[BlockId]
class DownloadBlocksResponse:
# A stream of blocks in parent-to-child order.
# The max number of blocks to be returned can be limited by implementers.
# A requester can read the stream until the stream returns "NoMoreBlock".
blocks: Stream[Block | "NoMoreBlock"]
The responding peer uses KnownBlocks to determine the optimal starting block for the response stream, aiming to minimize the number of blocks to be returned. The requesting node can include any block it believes could assist in this process to the KnownBlocks.additional_blocks. To avoid spamming responders, the size of KnownBlocks.additional_blocks is limited to 5.
The responding peer finds the latest common ancestor (i.e. LCA) between the target_block and each of the known blocks. Then, it returns a stream of blocks, starting from the highest LCA. To mitigate malicious downloading requests, the peer limits the number of blocks to be returned. The detailed implementation is up to implementers, depending on their internal architecture (e.g. storage design).
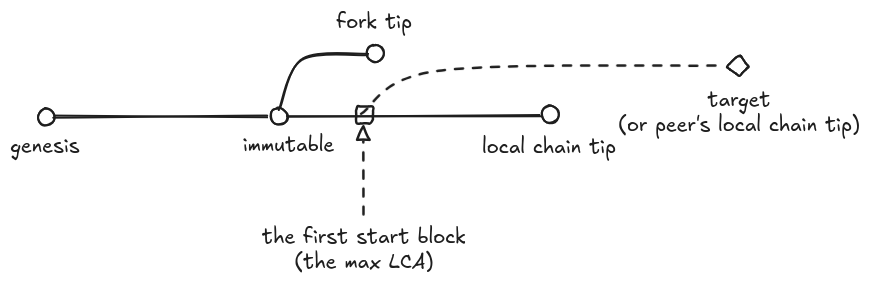
The requesting node should repeat DownloadBlocksRequests by updating the KnownBlocks in order to download the next batches of blocks. The following code shows how the requesting node can be implemented.
def download_blocks(local_tree: Tree, peer: Node, target_block: Optional[BlockId]):
latest_downloaded: Optional[Block] = None
while True:
# Fetch the peer's tip if target is not specified.
target_block = target_block if target_block is not None else peer.tip()
# Don't start downloading if target is already in local.
if local_tree.has(target_block):
return
req = DownloadBlocksRequest(
# If target_block is None, specify the current peer's tip each time when we build DownloadBlocksRequest,
# so that we can catch up with the most recent peer's tip.
target_block=target_block,
known_blocks=KnownBlocks(
local_tip=local_tree.tip().id,
latest_immutable_block=local_tree.latest_immutable_block().id,
# Provide the latest downloaded block as well
# to avoid downloading duplicate blocks
additional_blocks=[latest_downloaded.id] if latest_downloaded is not None else [],
)
)
resp = send_request(peer, req)
for block in resp.blocks():
latest_downloaded = block
try:
# Run the chain maintenance defined in the Cryptarchia spec.
local_tree.on_block(block)
# Early stop if the target has been reached.
if block == req.target_block:
break
except:
return
If the node is continuing from a previous DownloadBlocksRequest, it is important to include the latest downloaded block to the KnownBlocks.additional_blocks to avoid downloading duplicate blocks.
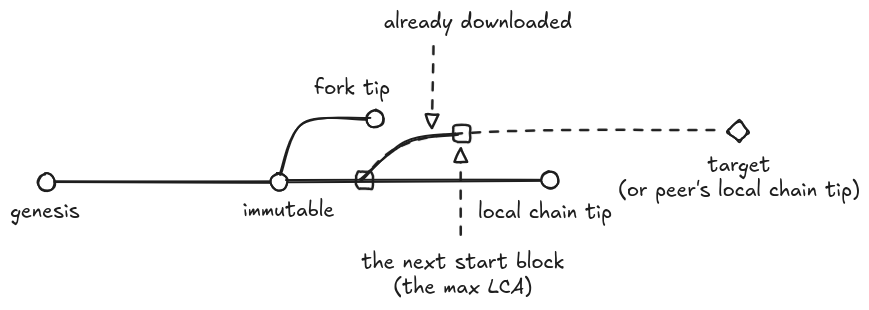
If the requesting node is downloading blocks up to the peer’s tip (e.g. Initial Block Download) by repeating DownloadBlocksRequests, the may switch between requests. The algorithm described above also handles this case by specifying the most recent peer’s tip each time when a DownloadBlocksRequest is constructed.
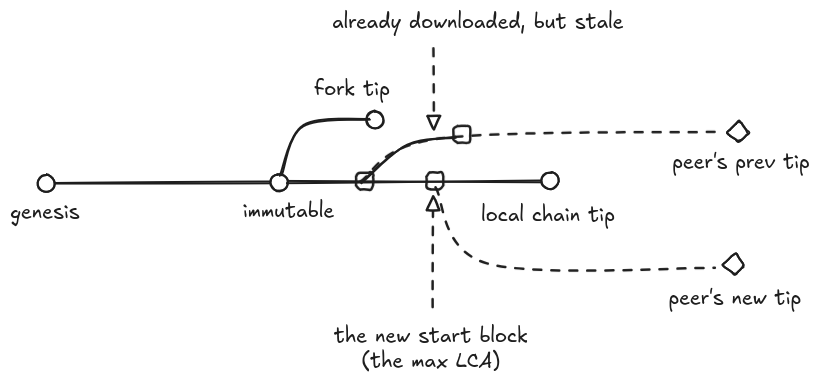
Proposing New Blocks
Unlike Listening for New Blocks, a node can start proposing blocks after Prolonged Bootstrap Period is complete. In other words, the node should not propose blocks before switching to the Online fork choice rule.
Bootstrapping from Checkpoint
Instead of bootstrapping from the Genesis block or from the local block tree, a node can choose to bootstrap the honest chain starting from a checkpoint block obtained from a trusted checkpoint provider. In this case, the node fully trusts the checkpoint provider and considers blocks deeper than the checkpoint block as immutable (including the checkpoint block itself).
A trusted checkpoint provider exposes a HTTP endpoint, allowing nodes to download the checkpoint block and the corresponding ledger state. The details are defined in Checkpoint Provider HTTP API.
The bootstrapping node imports the downloaded checkpoint block and ledger state before starting bootstrapping. The imported checkpoint block is used as the latest immutable block and the local chain tip . Starting from the checkpoint block, the same Initial Block Download is used to downloads blocks up to the tip of the local chain of each peer. As defined in Setting the Fork Choice Rule, the Bootstrap fork choice rule must be used upon startup.
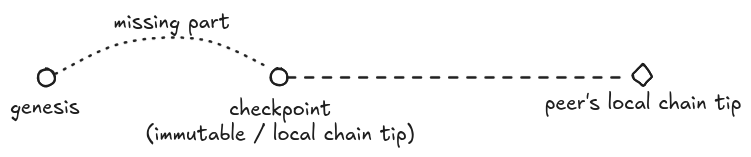
If it turns out that none of the peers’ local chains are connected to the checkpoint block, the node is terminated with an error, allowing the node operator to select a new checkpoint.
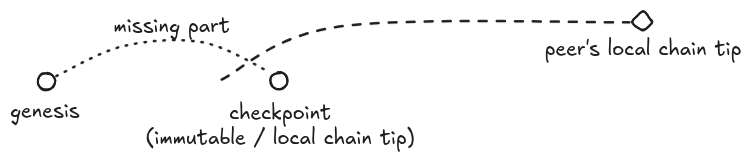
Details
Offline Grace Period
The offline grace period is a period during which a node can be restarted without switching to the Bootstrap rule.
This protocol configures to 20 minutes. Here are the advantages and disadvantages of a short period:
-
Advantages
- Limits chances for malicious peers to build long alternative chains beyond the scope of the Online rule.
- Conservatively enables the Bootstrap rule to handle long forks.
-
Disadvantages
- Even a short offline duration can too sensitively trigger the Bootstrap rule, which then lasts for the long Prolonged Bootstrap Period.
The following example explains why should not be set too long.
-
A local node stopped in the following situation. A malicious peer is building a fork which is now a little shorter () than the honest chain.
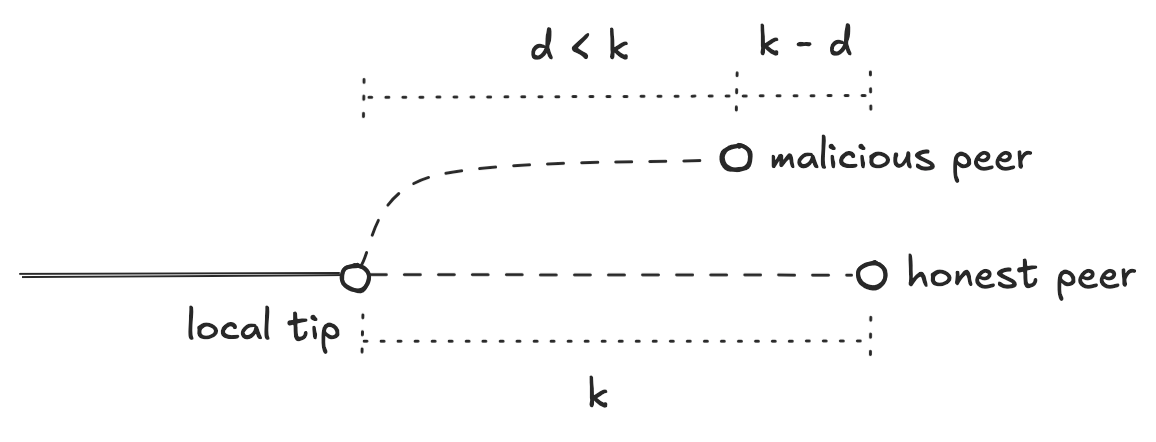
-
The local node has been offline shorter than and just restarted. As defined in this protocol, the Online fork choice rule is used because the offline duration is short.
-
During the offline duration, the malicious peer made its fork longer by adding blocks. Now the fork is in the same length as the honest chain.
-
If the malicious peer sends the fork to the restarted node faster than the honest peer, the restarted node will commit to the fork because it has new blocks. Even if the node later receives the honest chain from the honest peer, it cannot revert blocks that are already immutable.
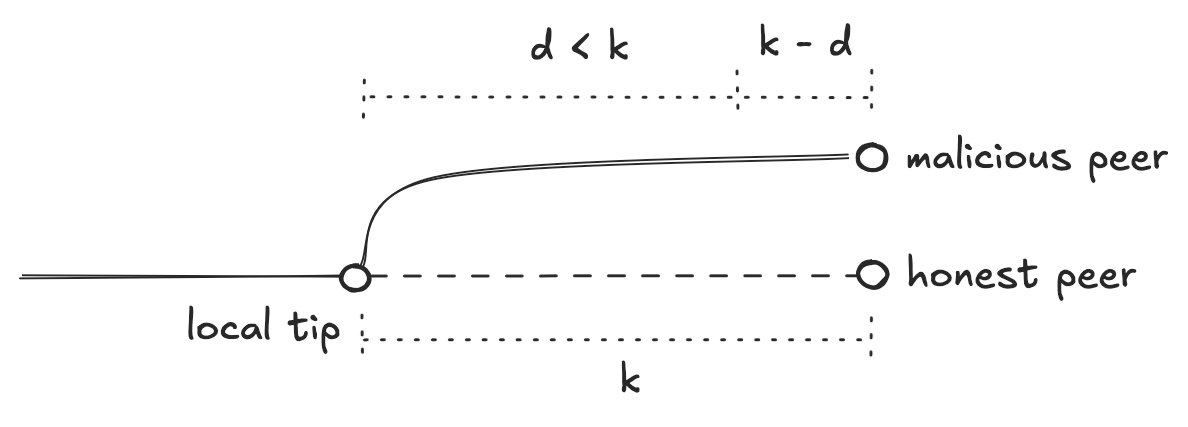
-
If is short, the malicious peer would not have enough time to make its fork acceptable by the Online rule. Even if the malicious peer made its fork long enough after , the fork will be rejected by the syncing node because it will use the Bootstrap rule if it has been offline longer after .
A disadvantage is that a syncing node, which has been offline longer than , should maintain the Bootstrap rule during the Prolonged Bootstrap Period, which is 24 hours in the current setting. In the future, the team will consider designing a better mechanism to replace the long Bootstrap Period.
Offline Duration Measurement
As defined in Setting the Fork Choice Rule, when a node is restarted, it should be able to choose a proper fork choice rule depending on how long it has been offline since it last used the Online rule.
It is considered unsafe to rely on any external information (e.g. the slot or height of peer’s tip) to check how long the node has been offline, since such information could be manipulated as an attack vector. Instead, it is recommended to employ a local method to measure the offline duration.
While the specific implementation is left to the discretion of implementers, one approach is for the node to periodically record the current time to a local file while it is running with the Online fork choice rule. Upon restart, it can use this timestamp to calculate how long it has been offline.
Checkpoint Provider HTTP API
A trusted checkpoint provider serves the GET /checkpoint API, allowing users (which are not connected via p2p) to download the latest checkpoint block and its corresponding ledger state.
openapi: 3.0
paths:
/checkpoint
get:
responses:
'200':
description: OK
content:
multipart/mixed:
schema:
type: object
properties:
checkpoint_block:
type: string
format: binary
checkpoint_ledger_state:
type: string
format: binary
CRYPTARCHIA-FORK-CHOICE-RULE
| Field | Value |
|---|---|
| Name | Cryptarchia Fork Choice Rule |
| Slug | 147 |
| Status | raw |
| Category | Standards Track |
| Editor | David Rusu [email protected] |
| Contributors | Jimmy Debe [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-29 —
67e498e— chore: fix math issues (#350) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-18 —
58b5698— chore(blockchain): migrate contributor emails to @logos.co (#338) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-01-30 —
0ef87b1— New RFC: CODEX-MANIFEST (#191) - 2026-01-29 —
a428c03— New RFC: NOMOS-FORK-CHOICE (#247)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-02-17 |
Introduction
Cryptarchia makes use of two fork choice rules, one during bootstrapping and a second once a node completes bootstrapping and comes online.
During bootstrapping, we must be resilient to malicious peers feeding us false chains. This calls for a more expensive fork choice rule that can differentiate between malicious long-range attacks and the honest chain.
Once bootstrapping completes, the node commits to the best chain it has seen so far and switches to a different fork choice rule that rejects forks that diverge too much.
Overview
During bootstrapping, we use the Ouroboros Genesis fork choice rule, after bootstrapping, we switch to the Ouroboros Praos fork choice rule.
To understand why we use the Genesis rule during bootstrapping, it’s useful to consider the long range attack.
The Long Range Attack
The leadership lottery difficulty adjusts dynamically based on how much stake is participating in consensus.
The scenario we are worried about is where an attacker forks the chain and generates a very sparse branch where he is the only winner for an epoch. This fork would be very sparse since the attacker does not control a large amount of stake initially.
Each epoch, the lottery difficulty is adjusted based on participation in the previous epoch to maintain a target block rate. When this happens on the adversary’s chain, the lottery difficulty will plummet and he will be able to produce a chain that has similar growth rate to the main chain with the advantage that his chain is very efficient. Unlike the honest chain, which needs to deal with unintentional forks caused by network delays, the attacker’s branch has no wasted blocks.
With this advantage, the adversary can eventually make up for that sparse initial period and extend his fork until it’s longer than the honest chain. He can then convince bootstrapping nodes to join his fork where he has had a monopoly on block rewards.
How This Attack is Mitigated by the Genesis Fork Choice Rule
If we look at the honest branch and the adversary branch in the period immediately following the fork, we can see that the honest chain is dense and the adversary’s fork will be quite sparse.
If an honest node had seen the adversary’s fork in that period, it would not have followed this fork since the honest chain would be longer, so selecting the fork using the longest chain rule is fine for a short range fork.
If an honest node sees the adversary’s fork after he’s completed the attack, the longest chain rule is no longer enough to protect them. Instead, the node can look at the density of both chains in that short period after they diverge and select the chain with the higher density of blocks.
How This Attack is Mitigated by the Praos Fork Choice Rule
Under two assumptions:
- A node has successfully bootstrapped and found the honest chain.
- Nodes see honest blocks reasonably quickly.
Nodes will remain on the honest chain if they reject forks that diverge further back than blocks without further inspection. In order for an adversary to succeed, they would need to build a -deep chain faster than the time it takes the honest nodes to grow the honest chain by blocks. The adversary must build this chain live, alongside the honest chain. They cannot build this chain after-the-fact since online nodes will be rejecting any fork that diverges before their -deep block.
Protocol
Definitions
-
: safety parameter, i.e. the depth at which a block is considered immutable
-
: sufficient time measured in slots to measure the density of block production with enough statistical significance. In practice, we say , where is the active slot coefficient from the leader lottery. (see Theorem 2 of Badertscher et al., 2018 “Ouroboros Genesis”)
-
Returns the minimum block depth at which the two branches converge to a common chain.
Examples:
- implies that is ahead of by 4 blocks i.e.
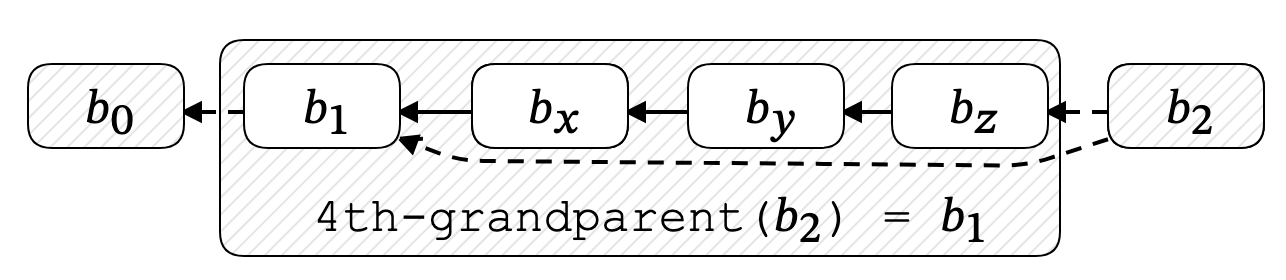
- would represent a forking tree like the one illustrated below
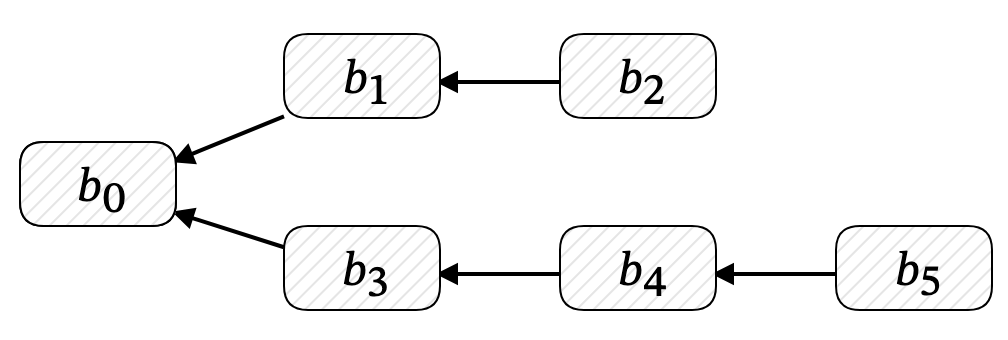
-
Returns the number of blocks produced in the slots following block .
For example, in the following diagram, count the number of blocks produced in the slots of the highlighted area.

We look backwards starting from , looking at the grandparent of . We denote this block and note that it was created in slot . The density calculation considers the number of blocks created in the next slots. The last block in this interval is , that is, its the last block who’s slot number is less than or equal to slots after .
Bootstrap Fork Choice Rule
During bootstrapping, we use the Ouroboros Genesis fork choice rule (maxvalid-bg)
def bootstrap_fork_choice(c_local, forks, k, s_gen):
c_max = c_local
for c_fork in forks:
depth_max, depth_fork = common_prefix_depth(c_max, c_fork):
if depth_max <= k:
# the fork depth is less than our safety parameter `k`. It's safe
# to use longest chain to decide the fork choice.
if depth_max < depth_fork
# strict inequality to ensure we choose first-seen chain as our tie break
c_max = c_fork
else:
# here the fork depth is larger than our safety parameter `k`.
# It's unsafe to use longest chain here, instead we check the density
# of blocks immediately after the divergence.
if density(c_max, depth_max, s_gen) < density(c_fork, depth_fork, s_gen):
# The denser chain immediately after the divergence wins.
c_max = c_fork
Online Fork Choice Rule
During normal operations, we use the Ouroboros Praos fork choice rule (maxvalid-mc). Here we reject any forks that diverge further back than blocks.
def online_fork_choice(c_local, forks, k):
c_max = c_local
for c_fork in forks:
depth_max, depth_fork = common_prefix_depth(c_max, c_fork):
if depth_max <= k:
# the fork depth is less than our safety parameter `k`. It's safe
# to use longest chain to decide the fork choice.
if depth_max < depth_fork
# strict inequality to ensure we choose first-seen chain as our tie break
c_max = c_fork
else:
# The fork depth is larger than our safety parameter `k`.
# Ignore this fork.
continue
References
- Ouroboros Genesis: Composable Proof-of-Stake Blockchains with Dynamic Availability eprint.iacr.org
- Ouroboros Praos: An adaptively-secure, semi-synchronous proof-of-stake blockchain eprint.iacr.org
CRYPTARCHIA-PROTOCOL
| Field | Value |
|---|---|
| Name | Cryptarchia Protocol |
| Slug | 92 |
| Status | raw |
| Category | Standards Track |
| Editor | David Rusu [email protected] |
| Contributors | Álvaro Castro-Castilla [email protected], Giacomo Pasini [email protected], Thomas Lavaur [email protected], Mehmet [email protected], Marcin Pawlowski [email protected], Daniel Sanchez Quiros [email protected], Youngjoon Lee [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-20 —
5b20a2d— docs(blockchain) Channel Participation in PoS (#364) - 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-29 —
67e498e— chore: fix math issues (#350) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-01-20 |
| 1.0.1 | Replaced Logos Blockchain name with Logos Blockchain | 2026-04-17 |
| 1.0.2 | Added details for block root computation | 2026-05-26 |
Introduction
Cryptarchia is the consensus protocol of the Logos Blockchain’s Bedrock layer. This document specifies how Bedrock comes to agreement to a single history of blocks.
The values that Cryptarchia optimizes for are resilience and privacy. These come at the cost of block times and finality. These values have significant implications on user experience and we should understand them well.
Resilience
In consensus, we are presented with a choice of prioritizing either safety or liveness in the presence of catastrophic failure (this is a re-formalization of the CAP theorem). Choosing safety means the chain never forks, instead the chain halts until the network heals. On the other hand, choosing liveness (a la Bitcoin/Ethereum) means that block production continues but finality will stall, leading to confusion around which blocks are on the honest chain.
On the surface both options seem to provide similar guarantees. If finality is delayed indefinitely, is this not equivalent to a halted chain? The differences come down to how safety or liveness is implemented.
Prioritizing Safety
Chains that provide a safety guarantee do so using quorum-based consensus. This requires a known set of participants (i.e. a permissioned network) and extensive communication between them to reach agreement. This restricts the number of participants in the network. Furthermore, quorum based consensus can only tolerate up to 1/3rd of the participants becoming faulty.
A small participant set and low threshold for faults generally pushes these networks to put large barriers to entry, either through large staking requirements or politics.
Prioritizing Liveness
Chains that prioritize liveness generally do so by relying on fork choice rules such as the longest chain rule from Nakamoto consensus. These protocols allow each participant to make a local choice about which fork to follow, and therefore do not require quorums and thus can be permissionless.
Additionally, due to a lack of quorums, these protocols can be quite message efficient. Thus, participation does not need to be artificially reduced to remain within bandwidth restrictions.
These protocols tolerate up to 1/2 of participants becoming faulty. The large fault tolerance threshold and the large number of participants provides for much higher resilience to corruption.
Privacy
The motivation behind the design of Cryptarchia can be boiled down to this statement:
A block proposer should not feel the need to self-censor when proposing a block.
Working to give leaders confidence in this statement has had ripple effects throughout the protocol, including that:
- The block proposals should not be linkable to a leader. An adversary should not be able to connect together the block proposals of a leader in order to build a profile. In particular, one should not be able to infer a proposer's stake from their past on-chain activity.
- Cryptarchia must not reveal the stake of the leader - that is, it must be a Private Proof of Stake (PPoS) protocol. If the activity of the leader reveals their stake values (e.g. through weighted voting), then this value can be used to reduce the anonymity set for the leader by bucketing the leader as high/low stake and can open him up to targeting.
- Leaders should be protected against network triangulation attacks. This is outside of the scope of this document, but it suffices to say that in-protocol cryptographic privacy is not sufficient to guarantee a leader's privacy. This topic is dealt with directly in Blend Protocol.
Limitations of Cryptarchia V1
Despite our best efforts, we cannot provide perfect privacy and censorship resistance to all parties. In particular:
- We are unable to protect leaders from leaking information about themselves based on the contents of blocks they propose. The tagging attack is an example of this, where an adversary may distribute a transaction to only a small subset of the network. If the block proposal includes this transaction, the adversary learns that the leader was one of those nodes in that subset.
- The leader is a single point of failure (SPOF). Despite all the efforts we go through to protect the leader, the network can be easily censored by the leader. The leader may choose to exclude certain types of transactions from blocks, leading to a worse UX for targeted parties.
As far as we can tell, these limitations are not insurmountable and we have sketches towards solutions that we will develop in following iterations of the protocol.
Overview
Cryptarchia is a probabilistic consensus protocol with properties similar to Bitcoin’s Nakamoto Consensus.
At a high level, Cryptarchia divides time into slots and at each slot, a leadership lottery is run. To participate in the lottery, a node must have held stake in the chain in the form of a note for a minimum time period. Given a sufficiently aged note, you can check if it has won a slot lottery by cryptographically flipping a weighted coin. The weight of the coin is proportional to the value of your note, thus higher valued notes lead to increased chances of winning. To ensure privacy and avoid revealing the note value, this lottery result is proven within a ZK proof system.
Our design starts from the solid foundation provided by Ouroboros Crypsinous: Privacy-Preserving Proof-of-Stake eprint.iacr.org and builds upon it, incorporating the latest research at the intersection of cryptography, consensus and network engineering.
Protocol
Constants
| Symbol | Name | Description | Value |
|---|---|---|---|
| slot activation coefficient | The target rate of occupied slots. Not all slots contain blocks, many are empty. (see ANALYSIS-BLOCK-TIMES-BLEND-NETWORK for analysis leading to the choice of value) | 1/30 | |
| security parameter | Block depth finality. Blocks deeper than on any given chain are considered immutable. | 2160 blocks | |
| none | slot length | The duration of a single slot. | 1 second |
| MAX_BLOCK_SIZE | max block size | The maximum size of the block body (not including the header) | 1 MB |
| MAX_BLOCK_TXS | max block transactions | The maximum number of transactions in a block | 1024 |
Notation
| Symbol | Name | Description | Value |
|---|---|---|---|
| slot security parameter | Sufficient slots such that blocks have been produced with high probability. | ||
| the block tree | This is the block tree observed by a node. | ||
| tips of block tree | The set of concurrent forks of some block tree . | ||
| tip of local chain | The chain that a node considers to be the honest chain. | ||
| the latest immutable block | The latest block which was committed (finalized) by the chain maintenance. | ||
| slot number | Index of slot. denotes the genesis slot. | ||
| epoch number | Index of epoch. denotes the genesis epoch. |
Latest Immutable Block
The latest immutable block is the most recent block considered permanently finalized. The blocks deeper than in the local chain are never to be reorganized.
This is maintained locally by the Chain Maintenance procedure. When the Online fork choice rule is in use, corresponds to the -deep block. However, it may be deeper than the -deep block if the fork choice rule has been switched from Online to Bootstrap. Unlike the -deep block, does not advance as new blocks are added unless the Online fork choice rule is used.
The details of fork choice rule transitions are defined in the bootstrap spec: Cryptarchia Bootstrapping & Synchronization
Slot
Time is divided up into slots of equal length, where one instance of the leadership lottery is held in each slot. A slot is said to be occupied if some validator has won the leadership lottery and proposed a block for that slot, otherwise the slot is said to be unoccupied.
Epoch
Cryptarchia has a few global variables that are adjusted periodically in order for consensus to function. Namely, we need:
- Dynamic participation, thus the eligible notes must be refreshed regularly.
- An unpredictable source of randomness for the leadership lottery. This source of randomness is derived from in-protocol activity and thus must be selected carefully to avoid giving adversaries an advantage.
- Approximately constant block production rate achieved by dynamically adjusting the lottery difficulty based on observed participation levels.
The order in which these variables are calculated is important and is done w.r.t. the epoch schedule.
Epoch Schedule
An epoch is divided into 3 phases, as outlined below.
| Epoch Phase | Phase Length | Description |
|---|---|---|
| Stake Distribution Snapshot | slots | A snapshot of note commitments are taken at the beginning of the epoch. We wait for this value to finalize before entering the next phase. |
| Buffer phase | slots | After the stake distribution is finalized, we wait another slot finality period before entering the next phase. This is to further ensure that there is at least one honest leader contributing to the epoch nonce randomness. If an adversary can predict the nonce, they can grind their coin secret keys to gain an advantage. |
| Lottery Constants Finalization | slots | On the slot into the epoch, the epoch nonce and the inferred total stake can be computed. We wait another slots for these values to finalize. |
The epoch length is the sum of the individual phases: slots.
Epoch State
The epoch state holds the variables derived over the course of the epoch schedule. It is the 3-tuple described below.
| Symbol | Name | Description | Value |
|---|---|---|---|
| Eligible Leader Notes Commitment | A commitment to the set of notes eligible for leadership. | See Eligible Leader Notes | |
| Epoch Nonce | Randomness used in the leadership lottery (selected once per epoch) | See Epoch Nonce | |
| Inferred Total Stake (Lottery Difficulty) | Total stake inferred from watching the results of the lottery during the course of the epoch. is used as the stake relativization constant for the following epoch. | See Total Stake Inference |
Eligible Leader Notes
A note is eligible to participate in the leadership lottery if it has not been spent and was a member of the note set at the beginning of the previous epoch, i.e. they are members of .
Note Ageing
If an adversary knows the epoch nonce , they may grind a note that wins the lottery more frequently than should be statistically expected. Thus, it’s critical that notes participating in the lottery are sufficiently old to ensure that they have no predictive power over .
Epoch Nonce
The epoch nonce is evolved after each block.
Given block where
- is the parent of block
- is the slot that is occupying.
- is the epoch nonce entropy contribution from the block’s leadership proof
Then, is derived as
where is the domain separator EPOCH_NONCE_V1, maps the slot number to the corresponding scalser in Poseidon’s scalar field and is Poseidon2 as specified in Common Cryptographic Components .
The epoch nonce used in the next epoch is where is the last block before the start of the “Lottery Constants Finalization” phase in the epoch schedule.
Total Stake Inference
Given that stake is private in Cryptarchia, and that we want to maintain an approximately constant block rate, we must therefore adjust the difficulty of the slot lottery somehow based on the level of participation. The details can be found in the following document:
Epoch State Pseudocode
At the start of each epoch, each validator must derive the new epoch state variables. This is done through the following protocol:
:
The genesis epoch state is hardcoded upon chain initialization.
The epoch state is derived w.r.t. observations in the previous epoch. Here we compute the slot at the start of the previous epoch. We will query observations relative to this slot.
Notes eligible for leadership lottery are those present in the commitment root at the start of the previous epoch.
The epoch nonce for epoch is the value of at the beginning of the lottery constants finalization phase in the epoch schedule
Total active stake is inferred from the number of blocks produced in the previous epoch during the stake freezing phase. It is also derived from the previous estimate of total stake, thus we recurse here to retrieve the previous epochs estimate
The number of blocks produced during the first slots of the previous epoch
Leadership Lottery
A lottery is run for every slot to decide who is eligible to propose a block. For each slot, we can have 0 or more winners. In fact, it’s desirable to have short slots and many empty slots to allow for the network to propagate blocks and to reduce the chances of two leaders winning the same slot which are guaranteed forks.
Proof of Leadership
The specifications of how a leader can prove that they have won the lottery are specified in the following document:
Leader Rewards
As an incentive for producing blocks, leaders are rewarded with every block proposal. The rewarding protocol is specified in Anonymous Leaders Reward Protocol.
Block Chain
Fork Choice Rule
We use two fork choice rules, one during bootstrapping and a second once a node completes bootstrapping.
During bootstrapping, we must be resilient to malicious peers feeding us false chains, this calls for a more expensive fork choice rule that can differentiate between malicious long-range attacks and honest chains.
After bootstrapping we commit to the most honest looking chain we found and switch to a fork choice rule that rejects chains that diverge by more than blocks
Block ID
Block ID is defined by the hash of the block header Block Header, where hash is Blake2b as specified in Common Cryptographic Components
def block_id(header: Header) -> hash
return hash(
b"BLOCK_ID_V1",
header.bedrock_version,
header.parent_block,
header.slot.to_bytes(8, byteorder='little'),
header.block_root,
# PoL fields
header.proof_of_leadership.leader_voucher,
header.proof_of_leadership.entropy_contribution,
header.proof_of_leadership.proof.serialize(),
header.proof_of_leadership.leader_key.compressed(),
)
Block Header
class Header: # 297 bytes
bedrock_version: byte # 1 bytes
parent_block: hash # 32 bytes
slot: int # 8 bytes
block_root: hash # 32 bytes
proof_of_leadership: ProofOfLeadership # 224 bytes
class ProofOfLeadership: # 224 bytes
leader_voucher: zkhash # 32 bytes
entropy_contribution: zkhash # 32 bytes
proof: Groth16Proof # 128 bytes
leader_key: Ed25519PublicKey # 32 bytes
Block
Block Construction, Validation and Execution
Block Header Validation
Given block and the block tree where:
- is the header defined in Header
- is the sequence of transactions in the block
We say returns True if all of the following constraints hold, otherwise it returns False.
-
Ensure bedrock version number.
-
Ensure block size is smaller than the maximum allowed block size
-
Ensure the number of transactions in the block is below the limit
-
Ensure block root is over the transaction list. Compute the block root by using transaction hashes (see Mantle - Mantle Transaction Hash) as leaves, and
0to represent the hash of an empty transaction, padding leaves to the closest power of two. -
Ensure the block’s slot comes after the parent block’s slot.
-
Ensure this block’s slot time has elapsed. Local time is used in this validation. See Clocks for discussion around clock synchronization.
-
Ensure we have already accepted the block’s parent into the block tree.
-
Ensure the block comes after the latest immutable block. Assuming that prunes all forks diverged deeper than , this step, along with step 5, ensures that is descendant from . If all forks cannot be pruned completely in the implementation, this step must be replaced with , which checks whether is an ancestor of .
-
Verify the leader’s right to propose and ensure it is the one proposing this block: Given leadership proof , where
- is the slot lottery win proof as defined in Proof of Leadership
- is the public key committed to in .
- is a signature.
A leaders proposal is valid if
- Ensure that the leader who won the lottery is actually proposing this block since PoL’s are not bound to blocks directly.
Chain Maintenance
We define the chain maintenance procedure that governs how the block tree is updated.
Note: It’s assumed that block contents have already been validated by the execution layer w.r.t. the parent block’s execution state.
:
if :
Either we’ve already seen or it’s invalid, in both cases we ignore this block
Explicitly commit to the -deep block if the Online Fork Choice Rule is being used.
Commit
We define the procedure that commits to the block, which is deep from . This procedure computes the new latest immutable block .
Compute the latest immutable block, which is deep from .
Prune all forks diverged deeper than , so that future blocks on those forks can be rejected by Block Header Validation.
Fork Pruning
We define the fork pruning procedure that removes all blocks which are part of forks diverged deeper than a certain block.
If is a fork diverged deeper than , prune the fork.
Remove all blocks in the chain within range from .
Versioning and Protocol Upgrades
Protocol versions are signalled through the bedrock_version field of the block header. Protocol upgrades need to be co-ordinated well in advance to ensure that node operators have enough time to update their node. We will use block height to schedule the activation of protocol updates. E.g. bedrock version 35 will be active after block height 32000.
Annexes
Proof of Stake vs. Proof of Work
From a privacy and resiliency point of view, Proof of Work is highly attractive. The amount of hashing power of a node is private, they can provide a new public key for each block he mines ensuring that his blocks cannot be connected by this identity, and PoW is not susceptible to long range attacks as is PoS. Unfortunately, it is wasteful and demands that leaders have powerful machines. We want to ensure strong decentralization by having a low barrier to entry and we believe we can achieve a good enough level of security given by having participants have an economic stake in the protocol.
Clocks
Cryptarchia depends on honest nodes having relatively in-sync clocks. We are currently rely on NTP to synchronize clocks, this may be improved upon in the future, borrowing ideas from Ouroboros Chronos: Permissionless Clock Synchronization via Proof-of-Stake eprint.iacr.org
References
- Ouroboros Crypsinous: Privacy-Preserving Proof-of-Stake eprint.iacr.org
- Ouroboros Chronos: Permissionless Clock Synchronization via Proof-of-Stake eprint.iacr.org
Test Vectors
The operations used to derive the block_root are the same as those defined in Test Vectors.
| Input | Output |
|---|---|
| empty block (no transaction) | block_root: 0x0000000000000000000000000000000000000000000000000000000000000000 |
| one transaction per operation kind: - leaf[0]: 0x6ab0046084f3ce8dad90eb28afe5692ad92d5d0588a4e868ad38d0d841d7a60e (Transfer)- leaf[1]: 0xd3a1aa9d2df8383e389dba072b1397f5e7fc290f884e04147c787619f60493cf (ChannelConfig) - leaf[2]: 0x50e5674eea7fa17f531a51159ea7c3cab843fb1c8e8bf9bd5518a8aad08865d3 (ChannelInscribe)- leaf[3]: 0xd52da59d9db42391363d6c4f96447536e5dfff747b91b88320310b07581a8dee (ChannelDeposit)- leaf[4]: 0x6f57c77dc872cc3f01380fbd57a97e9f7998a1cd8b24e84594ceba796cfa0822 (ChannelWithdraw)- leaf[5]: 0x2c04be946507e2b8c239b85b03cf476a8be5af8e4de853660d0447a46ea460fc (ChannelTransfer)- leaf[6]: 0x9ce9fa694b4c801eca6c9a1d3dca6401952404bda8c144fb16e03e3872fd475e (SDPDeclare)- leaf[7]: 0x3555b3d8f5d05ea5d69efb17aab7639474738bcb4bfee8d354107433d781ef9c (SDPWithdraw)- leaf[8]: 0x0a91ab8271016f212061e6b45ea35c95cfa0f9a70c5225508f284b2657f4d931 (SDPActive)- leaf[9]: 0xc992f1a63a7ea665a3766fae6b032df3db12ef386caf0ef1f3654afedbc51c6c (LeaderClaim) | block_root: 0xcfbf83500e534669d039d09ec9ada459970610bb03b2ce06f944df72833c7de3 |
Header:- bedrock_version: 0x01- parent_block: 0x1111111111111111111111111111111111111111111111111111111111111111- slot: 0x42- block_root: 0xcfbf83500e534669d039d09ec9ada459970610bb03b2ce06f944df72833c7de3 - leader_voucher: 0x4444000000000000000000000000000000000000000000000000000000000000- entropy_contribution: 0x5555000000000000000000000000000000000000000000000000000000000000- proof: 0x2222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222- leader_key: 0x17cb79fb2b4120f2b1ec65e4198d6e08b28e813feb01e4a400839b85e18080ce | block_id: 0x ec351be5585023f3e96140b8903baba40028f222037b1dd12e1dbc1884788071 |
PROOF-OF-LEADERSHIP
| Field | Value |
|---|---|
| Name | Proof of Leadership |
| Slug | 83 |
| Status | raw |
| Category | Standards Track |
| Editor | Thomas Lavaur [email protected] |
| Contributors | Mehmet [email protected], Giacomo Pasini [email protected], Daniel Sanchez Quiros [email protected], Álvaro Castro-Castilla [email protected], David Rusu [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-06-25 —
27ae01b— docs(blockchain): precise pol specific case where v >> total stake (#362) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-18 —
58b5698— chore(blockchain): migrate contributor emails to @logos.co (#338) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-12-09 |
| 1.1.0 | Remove the protection against adaptive adversary from PoL removing a non-enforced feature, simplifying work for engineers, improving UX and performances of PoL and PoQ. Update the performance according to the new circuit. Remove the notion of NOMOS in DSTs | 2026-01-29 |
| 1.1.1 | Introduced a discussion for when the value of a participating note is way higher than the total estimated stake | 2026-06-24 |
Introduction
The Proof of Leadership enables a leader to produce a zero-knowledge proof attesting to the fact that they have an eligible note that has won the leadership lottery. This proof must be as lightweight as possible to generate and verify, due to the following reasons:
- Impose minimal restrictions on access to the role of leader and thus maximize the decentralization of that role.
- Similarly, the proof and its context must be efficiently verifiable for validators
This document extends the work presented in the Ouroboros Crypsinous paper with recent cryptographic developments.
References
Overview
Overview of the Protocol
The PoL mechanism ensures that a note has legitimately won the leadership election while protecting the leader’s privacy. The protocol is:
- Setup: The note becomes eligible for PoS when it has aged sufficiently.
- PoL generation:
- First, check if the note is winning by simulating the lottery
- Prove the membership of the note identifier in an old snapshot of the Mantle Ledger, proving its age and its existence.
- Prove the membership of the note identifier in the most recent Mantle ledger, proving it’s unspent.
- Prove that the note won the PoS lottery.
- The proof is bound to a cryptographic public key used for signing the leader’s proposed blocks.
Comparison with Original Crypsinous PoL
Our description differs from the original paper proposition, proving that a note is unspent directly instead of delegating the verification to validators. Moreover, we don't include the protection against adaptive adversaries that cannot be enforced by the chain or incentivized. This design choice brings the following tradeoffs:
Advantages
-
The ledger isn’t required to be private using shielded notes.
- Validators don’t need to maintain a nullifier list.
- Leaders keep their privacy unlinking their stake, block and PoL.
-
There is no leader note evolution mechanism anymore (see the paper for details)
- There are no orphan proofs anymore, removing the need to include valid PoL proofs from abandoned forks.
- Crypsinous forced us to maintain a parallel note commitment set integrating evolving notes over time. This requirement is removed now
Disadvantages
- We cannot compute the PoL far in advance because the leader must know the latest ledger state of Mantle.
Protocol
Ledger Root
In order to prove that the winning note exists in the ledger and existed at the start of the previous epoch, every node must compute two ledger commitments. These commitments and are Merkle roots constructed over the Note IDs. The trees have a depth of (32 layers without counting the root) and are populated with note IDs, that is, the tree has a maximal capacity of note IDs. The value represents an empty leaf. When the set is updated, during insertion, the first empty leaf is replaced with the new note ID, and during deletion, the leaf containing the deleted note ID is replaced with . The following pseudo-code shows how the tree is managed:
def insert_new_note(note_set: list[NoteId], new_note: NoteId):
i = 0
while i < len(note_set) and note_set[i] != 0:
i += 1
if i < len(note_set):
note_set[i] = new_note
else:
note_set.append(new_note)
return note_set
def delete_note(note_set: list[NodeId], note: NoteId):
i = 0
while i < len(note_set) and note_set[i] != note:
i += 1
if i == len(note_set):
# note not in the set
return note_set
note_set[i] = 0
return note_set
def empty_tree_root(depth: int):
root = 0
for i in range(depth):
h = hasher() # zk hash
h.update(root)
h.update(root)
root = h.digest()
return root
def get_ledger_root(note_set: list[NoteId]):
assert(len(note_set) < 2**32)
ledger_root = get_merkle_root(note_set) # return the Merkle root of the set
# padded with 0 to next power of 2
ledger_root_height = len(note_set).bit_length()
for height in range(ledger_root_height, 32):
h= Hasher() # zk hash
h.update(ledger_root)
h.update(empty_tree_root(height))
ledger_root = h.digest()
return ledger_root
The ledger root may not be unique because the note Ids set can cycle. Indeed, even if it’s not possible to insert the same note Id twice, it’s possible to cycle on a previous set state by removing notes. However, note Ids uniqueness guarantees protection against attacks on note aging.
Zero-knowledge Proof Statement
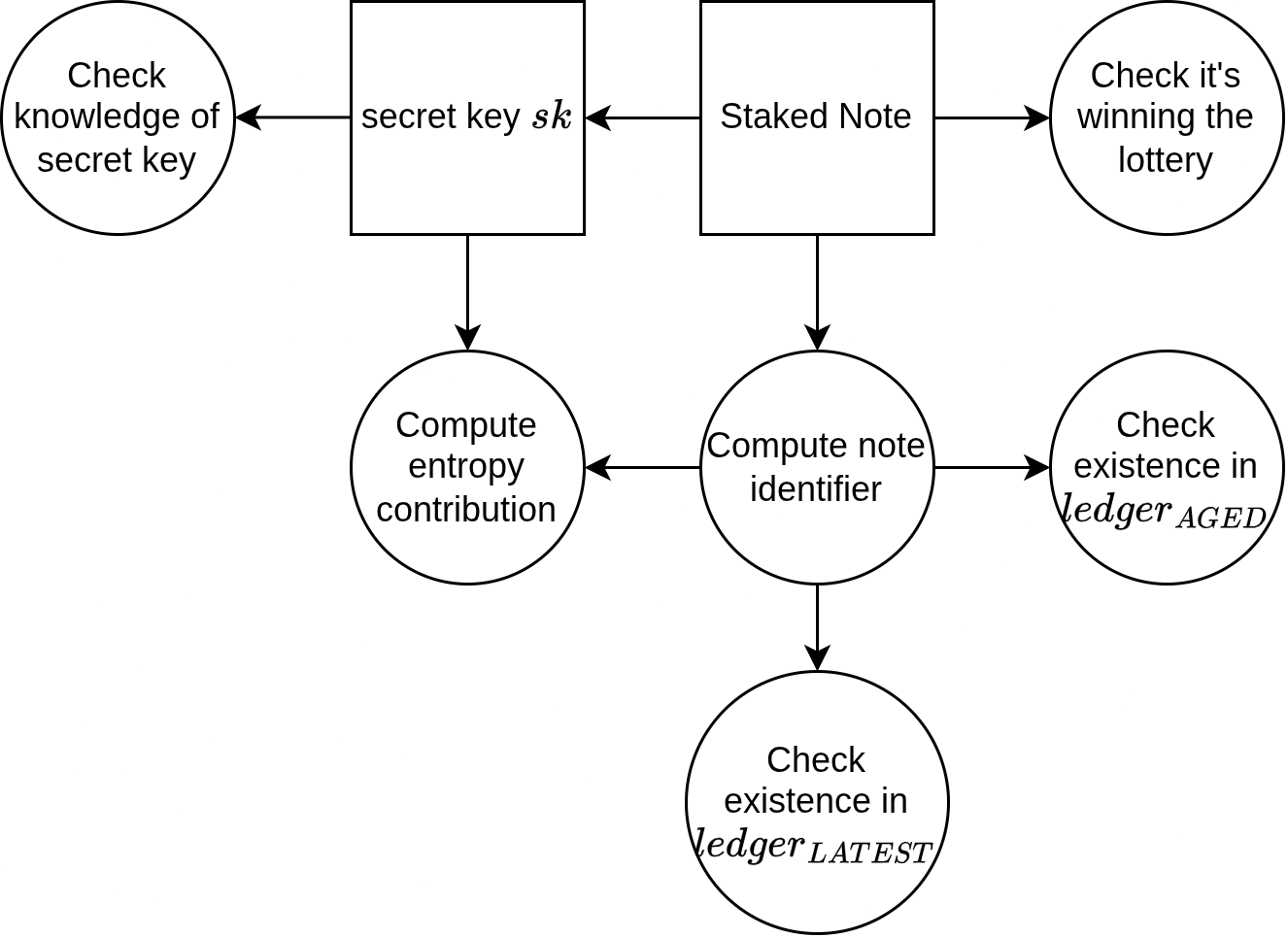
Circuit Public Inputs
The prover (the leader) and the verifiers (nodes of the chain) must agree on these values:
-
The slot number: .
-
The epoch nonce: .
- For details see Epoch Nonce.
-
The lottery function constants: and .
- For details see Lottery Approximation.
- These numbers must be computed with high precision outside the proof.
-
The root of the note Merkle tree when the stake distribution was frozen .
- For details see Epoch State Pseudocode.
-
The latest root of the note Merkle tree: .
- Used to ensure the leadership note has not been spent.
-
The leader's one-time public key represented by 2 public inputs, each of 16 bytes in little endian. This key is needed to sign the proposed block.
- For details see Linking the Proof of Leadership to a Block.
-
The entropy contribution verified to be correctly derived.
- This is the epoch nonce entropy contribution. See Epoch Nonce.
Circuit Private Inputs
The prover has to provide these values, but they remain secret:
-
The eligible note and its related information used to derive the Note Id:
- The note secret key: .
- The note value: .
- The note transaction zk hash: .
- The note outputs number: .
-
The proof of membership of the note identifier in the zone ledgers and . This is done by providing the complementary Merkle nodes and indicating whether they are left (0) or right (1) through boolean selectors:
- The aged ledger complementary nodes: .
- The aged ledger complementary node selectors: .
- The latest ledger complementary nodes: .
- The latest ledger complementary node selectors: .
Circuit Constraints
The proof confirms the following relations:
-
The derivation of the public key.
-
The computation of the note identifier.
-
The note identifier is in and .
-
The computation of the lottery ticket: using Poseidon2.
-
The computation of the threshold: . The ticket must be lower than this threshold to win the lottery.
-
The check that indeed .
-
Compute and output the entropy contribution
Linking the Proof of Leadership to a Block
The PoL is bound to a public key from an asymmetric signature scheme. This public key is given as two public inputs during the PoL proof generation, binding the proof to the key.
- The public key is represented by two public inputs of 16 bytes to guarantee the support of every possible Eddsa25519 public key.
- This public key is later used to verify the signature of a block when it is dispersed. This ensures that the PoL is tied to a specific block, and only the entity creating the proof can perform this binding.
- The key is single-use, as reusing the same one could allow multiple PoLs to be linked to the same identity. An observer could then infer the stake of that identity by observing the frequency at which it emits a PoL.
Appendix
Lottery Approximation
- The function of Ouroboros Crypsinous cannot be computed in a hand-written circuit as it can only operates on elements of for a certain prime number .
- Managing floating point numbers and mathematical functions involving floating points like exponentiations or logarithms in circuits is very inefficient.
- We compared the Taylor expansion of order 1 and 2 and used the Taylor expansion of order 2 method to approximate the Ouroboros Genesis (and Crypsinous) function by the following linear function
- means nearly equal in the neighborhood of 0
- is the probability that at least one leader wins the lottery on each slot
- is the stake of the proven note
Then the threshold is with and
. Since everything is known by every node except the value of the staked note, we pre-compute and outside of the circuit.
- The Hash functions used to derive the lottery ticket is Poseidon2 so the is the order of the scalar field of the BN254 elliptic curve.
- To compute and , we precomputed the constant parts using sagemath and real number of 512 bits precision. In the implementation, and should then be derived using 256-bit precision integers following:
| Variable | Formula |
|---|---|
| 0x30644e72e131a029b85045b68181585d2833e84879b9709143e1f593f0000001 | |
| 0x1a3fb997fd5838f2a1585ee090a95c88129ab25cc4d2e2d28f1a95f81d85465 | |
| 0x71e790b4199113a9a00298d823c5716ddac764a110a45fe3b770bbb3e8a57 | |
**Python code to derive constants**
from sage.all import RealField
FIELD_ORDER = 0x30644E72E131A029B85045B68181585D2833E84879B9709143E1F593F0000001
R = RealField(512)
F = R(1) / R(30)
t_0_constant = int(-R(FIELD_ORDER) * (R(1) - F).log())
t_1_constant = int(R(FIELD_ORDER) * (R(1) - F).log() ** 2 / R(2))
def lottery_constants(inferred_total_stake: int) -> tuple[int, int]:
t_0 = t_0_constant // inferred_total_stake
t_1 = FIELD_ORDER - (t_1_constant // inferred_total_stake**2)
return t_0, t_1
print(f"p = {FIELD_ORDER:#x}")
print(f"t_0_constant = {t_0_constant:#x}")
print(f"t_1_constant = {t_1_constant:#x}")
Error Analysis
- For . The error percentage is computed with
- We will consider that is 23.5B as in Cardano
- Original function:
- Taylor expansion of order 1:
- Taylor expansion of order 2:
| stake (%) | order 1 error | order 2 error |
|---|---|---|
| 5% | 0.13% | -0.0001% |
| 10% | 0.26% | -0.0004% |
| 15% | 0.39% | -0.0010% |
| 20% | 0.51% | -0.0018% |
| 25% | 0.64% | -0.0027% |
| 30% | 0.77% | -0.0040% |
| 35% | 0.90% | -0.0054% |
| 40% | 1.03% | -0.0071% |
| 45% | 1.16% | -0.0089% |
| 50% | 1.29% | -0.0110% |
| 55% | 1.42% | -0.0134% |
| 60% | 1.55% | -0.0159% |
| 65% | 1.68% | -0.0187% |
| 70% | 1.81% | -0.0217% |
| 75% | 1.94% | -0.0249% |
| 80% | 2.07% | -0.0284% |
| 85% | 2.20% | -0.0320% |
| 90% | 2.33% | -0.0359% |
| 95% | 2.46% | -0.0406% |
| 100% | 2.59% | -0.0444% |
Corner Case: Note Value Exceeding Inferred Total Stake
The lottery threshold approximation relies on a second-order Taylor expansion of , which is only accurate when . Under normal operation this holds trivially, since no single note can hold a significant fraction of the total stake. However, a pathological regime exists where this assumption breaks down.
Scenario
Suppose the chain halts and only a small fraction of the original stakers come back online to restart it.
The inferred_total_stake parameter, which is derived from recent epoch snapshots, may lag far behind the actual participating stake.
A note with value could then satisfy , placing it well outside the valid domain of the approximation.
What happens
The threshold is a downward-opening parabola in the reals. It peaks near and crosses zero again near . Past the peak, the real-valued threshold becomes negative. In this wraps to a large value close to , meaning the lottery ticket is almost certain to be below the threshold. The note wins nearly every slot. Past the second zero crossing, the threshold wraps back toward zero and the behavior becomes an oscillation between near-certain win and near-certain loss depending on the exact ratio
Severity
This cannot be triggered by a rational adversary under normal conditions, since it requires inferred_total_stake to be severely underestimated relative to individual note values.
Several scenarios can produce this regime:
- Chain halt and partial restart: only a fraction of original stakers come back online, so
inferred_total_stakelags the actual participating stake by a large factor. - Mass unstaking: a large coordinated withdrawal in a short period (confidence crisis, protocol migration) deflates
inferred_total_stakewhile large notes remain in circulation. - Early bootstrap: at genesis or in the first epochs, total stake has not built up yet but individual notes may already carry significant value.
- Estimation failure: a bug or manipulation in the
inferred_total_stakederivation mechanism produces a value far below reality.
In all these cases the effect on liveness is arguably beneficial: large-stake notes winning aggressively helps the chain find leaders and recover from the depressed-stake regime.
Once epochs progress and inferred_total_stake converges back toward reality, the lottery returns to its normal operating range.
No circuit-level mitigation is strictly necessary given the above.
Benchmarks
The material used for the benchmarks is the following:
- CPU : 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM : 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS : Ubuntu 22.04.5 LTS
- Kernel : 6.8.0-59-generic
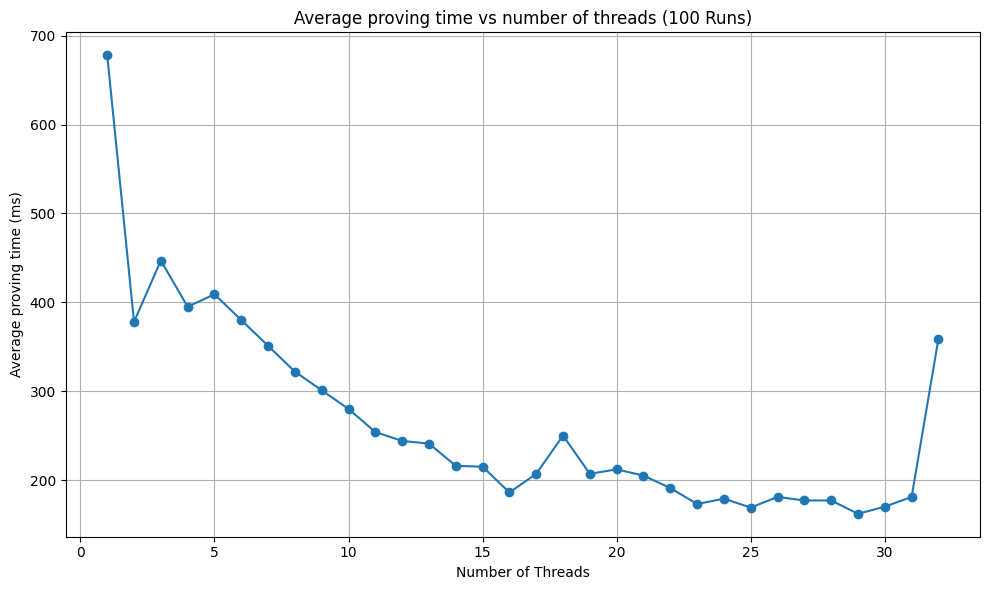
TOTAL-STAKE-INFERENCE
| Field | Value |
|---|---|
| Name | Total Stake Inference |
| Slug | 94 |
| Status | raw |
| Category | Standards Track |
| Editor | David Rusu [email protected] |
| Contributors | Alexander Mozeika [email protected], Daniel Kashepava [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-18 —
58b5698— chore(blockchain): migrate contributor emails to @logos.co (#338) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-01-20 |
Introduction
As with any Proof of Stake (PoS) consensus protocol, the probability that an eligible Cryptarchia participant wins the right to propose a block depends on that participant’s stake relative to the total active stake. Because leader selection in Cryptarchia is private, the total active stake is not directly observable. Instead, nodes must infer it from observable chain growth.
Overview
The total active stake can be inferred by observing the slot occupancy rate: a higher fraction of occupied slots implies more stake participating in consensus. By observing the rate of occupied slots from the previous epoch and knowing the total stake estimate used during that period, we can infer a correction to the total stake estimate to compensate for any changes in consensus participation. This inference process is done by each node following the chain. Leaders will use this total stake estimate to calculate their relative stake as part of the leadership lottery without revealing their stake to others.
The stake inference algorithm adjusts the previous total stake estimate based on the difference between the empirical slot activation rate (measured as the growth rate of the honest chain) and the expected slot activation rate. A large difference serves as an indicator that the total stake estimate is not accurate and must be adjusted.
This algorithm has been analyzed and shown to have good accuracy, precision and convergence speed. A caveat to note is that accuracy decreases with increased network delays. The analysis can be found in [Analysis] Total Stake Inference.
Construction
Definitions
Parameters and variables
| Symbol | Value | Name | Description |
|---|---|---|---|
beta | 1.0 | learning rate | Controls how quickly we adjust to new participation levels. Lower values for beta give a more stable / gradual adjustment, while higher values give faster convergence but at the cost of less stability. |
PERIOD | observation period | The length of the observation period in slots. | |
f | inherited from Constants | slot activation coefficient | The target rate of occupied slots. Not all slots contain blocks, many are empty. |
k | inherited from Constants | security parameter | Block depth finality. Blocks deeper than k on any given chain are considered immutable. |
Functions
- Returns the number of blocks produced in the slots following slot in the honest chain.
Algorithm
For a current epoch’s estimate total_stake_estimate and the epoch’s first slot epoch_slot, the next epoch’s estimate is calculated as shown below:
#![allow(unused)] fn main() { const PRECISION: u64 = 1e3 fn total_stake_inference(total_stake_estimate: u64, epoch_slot: u64) -> u64 { // f: f64 // PERIOD: u64 // density_over_slots(u64, u64) -> u64 let beta_p: u64 = truncate(beta * PRECISION) let f_p: u64 = truncate(f * PRECISION) let tse_p: u64 = total_stake_estimate * PRECISION let measured_density_p: u64 = density_over_slots(epoch_slot, PERIOD) * PRECISION let expected_density_p: u64 = PERIOD * f_p let density_diff_p: i128 = (expected_density_p as i128) - (measured_density_p as i128) let slot_activation_error_p: i128 = (tse_p * density_diff_p) / (expected_density_p as i128) let correction_p: i128 = (beta_p * slot_activation_error_p) / PRECISION; let new_total_stake_estimate = (tse_p - correction_p) / PRECISION; max(new_total_stake_estimate, 1) as u64 } }
Annex
[Analysis] Total Stake Inference
V1.0.0-CRYPTARCHIA-PROOF-OF-LEADERSHIP
| Field | Value |
|---|---|
| Name | Proof of Leadership |
| Slug | 214 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Thomas Lavaur [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-12-09 |
Introduction
The Proof of Leadership enables a leader to produce a zero-knowledge proof attesting to the fact that they have an eligible note that has won the leadership lottery. This proof must be as lightweight as possible to generate and verify, due to the following reasons:
- Impose minimal restrictions on access to the role of leader and thus maximize the decentralization of that role.
- Similarly, the proof and its context must be efficiently verifiable for validators
This document extends the work presented in the Ouroboros Crypsinous paper with recent cryptographic developments.
References
Overview
Overview of the Protocol
The PoL mechanism ensures that a note has legitimately won the leadership election while protecting the leaders privacy. The protocol is comprised of two parts: setup and PoL generation.
- Setup:
- Draw uniformly a random seed.
- Construct a Merkle tree composed of slot secrets derived from the seed.
- Use the root of the tree and the starting slot to get the leaders secret key. The starting slot is when the note can start to be used for PoL.
- The leader receives their stake in a note that uses this generated secret key. The leader either transfers this stake to themselves or obtains it from a different user.
- The note becomes eligible for PoS when it has aged sufficiently, and the actual slot number is greater than or equal to the starting slot of the note.
- PoL generation:
- First, check if the note is winning by simulating the lottery
- Prove the membership of the note identifier in an old snapshot of the Mantle Ledger, proving its age and its existence.
- Prove the membership of the note identifier in the most recent Mantle ledger, proving its unspent.
- Prove that the note won the PoS lottery.
- Prove the knowledge of the slot secret for the winning slot.
- The proof is bound to a cryptographic public key used for signing the leaders proposed blocks.
Comparison with Original Crypsinous PoL
Our description differs from the original paper proposition, proving that a note is unspent directly instead of delegating the verification to validators. This design choice brings the following tradeoffs:
Advantages
- The ledger isnt required to be private using shielded notes.
- Validators dont need to maintain a nullifier list.
- Leaders keep their privacy unlinking their stake, block and PoL.
- There is no leader note evolution mechanism anymore (see the paper for details)
- There are no orphan proofs anymore, removing the need to include valid PoL proofs from abandoned forks.
- Crypsinous forced us to maintain a parallel note commitment set integrating evolving notes over time. This requirement is removed now.
- The derivation of the slot secret and its Merkle proof can be done locally without connection to the Logos Blockchain.
Disadvantages
- We cannot compute the PoL far in advance because the leader must know the latest ledger state of Mantle.
Protocol
Protection Against Adaptive Adversaries
Introduction
The Ouroboros Crypsinous paper integrates protection against adaptive adversaries:
The design has several subtleties since a critical consideration in the PoS setting is tolerating adaptive corruptions: this ensures that even if the adversary can corrupt parties in the course of the protocol execution in an adaptive manner, it does not gain any non-negligible advantage by e.g., re-issuing past PoS blocks. (p. 2)
To avoid a leaked note being reused to maliciously regenerate past PoLs, we will adopt the solution proposed in the paper using slightly different parameters.
Overview
We recall here the solution proposed in the paper:
We solve the former issue, by adding a cheap key-erasure scheme into the NIZK for leadership proofs. Specifically, parties have a Merkle tree of secret keys, the root of which is hashed to create the corresponding public key. The Merkle tree roots acts like a Zerocash coin secret key, and can be used to spend coins. For leadership however, parties also must prove knowledge of a path in the Merkle tree to a leaf at the index of the slot they are claiming to lead. After a slot passes, honest parties erase their preimages of this part of that path in the tree. As the size of this tree is linear with the number of slots, we allow parties to keep it small, by restricting its size. (p. 5)
The paper proposed a tree of depth 24.
- This implies that the note is usable for PoS for only 194 days approximately (because 1 slot is 1 second).
- After this period, the note must be refreshed to include new randomness. We will keep it simple and design the refresh mechanism as a classical transaction modifying the nullifier secret key.
- This solution has good performance:
For a reasonable value of , this is of little practical concern. Public keys are valid for slots and employing standard space/time trade-offs, key updates take under 10,000 hashes, with less than 500kB storage requirement. The most expensive part of the process, key generation, still takes less than a minute on a modern CPU. (p. 29)
The disadvantages of this solution are that:
- The public key of the note will change periodically (each time all slot secrets are consumed) for the ones participating in PoL.
- The note will not be reusable directly after refresh as only old enough notes are usable for PoS.
We will propose a tree with a depth of , extending the note's eligibility to around 388 days, with a maximum of two epochs remaining ineligible not counted in these days. Note that this requirement applies specifically to proving leadership in PoS and is not needed for every note. While any note can be used for PoL, the knowledge of the secret slots behind the public key is only necessary to demonstrate that you are a leader.
Protocol
- Setup: When refreshing their notes, potential leaders will:
- Uniformly randomly draw a seed .
- Construct a Merkle Tree of root containing slot secrets (that are random numbers). One way to efficiently construct the tree is to:
- Derive the slot secrets using a zkhash chain: .
- More concretely, each leaf is the zkhash of the previous leaf (slot secret).
- This reduces storage requirements compared to directly randomly drawn independently slot secrets.
- The first generation of the Merkle tree should be fast enough as it only requires hashing data. A correct implementation that erases data over time could maintain an upper bound in memory usage during the generation of the tree to only zk hashes which is bytes.
- Leaders are only required to maintain the MMR up to the current slot. This means at minimum, leaders hold only 25 hashes in memory at any point in time.
- After the first generation, the wallets optimize their storage by holding only the necessary information to maintain a correct Merkle path, deriving the next one over time using the fact that slot secrets were derived from the previous ones.
- It guarantees protection against adaptive adversaries.
- Thanks to the pseudo-random properties of the hash function, slot secrets are indistinguishable from true randomness.
- The one-way property of the hash function guarantees that an adaptative adversary cannot retrieve past slot secrets using a fresher one.
- Derive the slot secrets using a zkhash chain: .
- The user chooses a starting slot from which their note will be eligible for PoS. The note must be on-chain by the start of epoch to be eligible for PoL in epoch because of the age requirement. Based on this, we suggest to not be earlier than the start of the epoch following the one after the transaction is emitted. This prevents the inclusion of unusable slot secrets in the tree (because the note would not be aged enough), optimizing the PoL lifetime of the note.
- Finally, they derive their secret key , binding the starting slot and the Merkle tree of slot secret to the note secret key. This is verified in Circuit Constraints. These four steps are summarized in the following pseudo-code:
def pol_sk_gen(sl_start, seed): frontier_nodes = MMR() path = MerkleProof() # Generate 2^25 slot secrets using a hash chain initialized with `seed`. r = zkhash(seed) for i in range(2**25): frontier_nodes.append(r) # Append the slot secret to the MMR path.update(frontier_nodes) # Update Merkle path of this slot secret r = zkhash(r) # Derive the next slot secret # Derive the root of the MMR root = frontier_nodes.get_root() # Finally, derive the final PoL secret key. # Return the secret key and the Merkle proof of seed. return (zkhash(b"LOGOS_POL_SK_V1" + sl_start + root), path) def update_secret_and_path(r, path): r = zkhash(r) # Derive next slot secret path.update(r) # Update the path for the Merkle proof of the new slot secret return (r, path)Note that the generation of the slot secret tree is not constrained by proofs or at consensus level and can be adapted by the node as long as they are enable to derive the merkle proof of their slot secret.
- PoL: When proving the leadership election, note owners will prove knowledge of the slot secret corresponding to the slot .
- To do that, they will give a Merkle path from the leaf at index
- The root of the tree hashed with must be the secret key , which will be used for public key derivation.
- Protection against adaptive adversaries: Since each slot has its own slot secret, requiring wallets to delete slot secrets used for previous slots avoids the risk of corruption that leads to the creation of PoL for previous blocks.
- The slot secret is derived from the previous one but the opposite is impossible.
- An adaptive adversary corrupting the node would not have access to previous slot secrets if correctly deleted. Therefore, an adversary would not be able to generate the PoL for previous slots.
Ledger Root
In order to prove that the winning note exists in the ledger and existed at the start of the previous epoch, every node must compute two ledger commitments. These commitments and are Merkle roots constructed over the Note IDs. The trees have a depth of and are populated with note IDs. The value represents an empty leaf. When the set is updated, during insertion, the first empty leaf is replaced with the new note ID, and during deletion, the leaf containing the deleted note ID is replaced with . The following pseudo-code shows how the tree is managed:
def insert_new_note(note_set: list[NoteId], new_note: NoteId):
i = 0
while i < len(note_set) and note_set[i] != 0:
i += 1
if i < len(note_set):
note_set[i] = new_note
else:
note_set.append(new_note)
return note_set
def delete_note(note_set: list[NodeId], note: NoteId):
i = 0
while i < len(note_set) and note_set[i] != note:
i += 1
if i == len(note_set):
# note not in the set
return note_set
note_set[i] = 0
return note_set
def empty_tree_root(depth: int):
root = 0
for i in range(depth):
h = hasher() # zk hash
h.update(root)
h.update(root)
root = h.digest()
return root
def get_ledger_root(note_set: list[NoteId]):
assert(len(note_set) < 2**32)
ledger_root = get_merkle_root(note_set) # return the Merkle root of the set
# padded with 0 to next power of 2
ledger_root_height = len(note_set).bit_length()
for height in range(ledger_root_height, 32):
h= Hasher() # zk hash
h.update(ledger_root)
h.update(empty_tree_root(height))
ledger_root = h.digest()
return ledger_root
The ledger root may not be unique because the note Ids set can cycle. Indeed, even if its not possible to insert the same note Id twice, its possible to cycle on a previous set state by removing notes. However, note Ids uniqueness guarantees protection against attacks on note aging.
Zero-knowledge Proof Statement
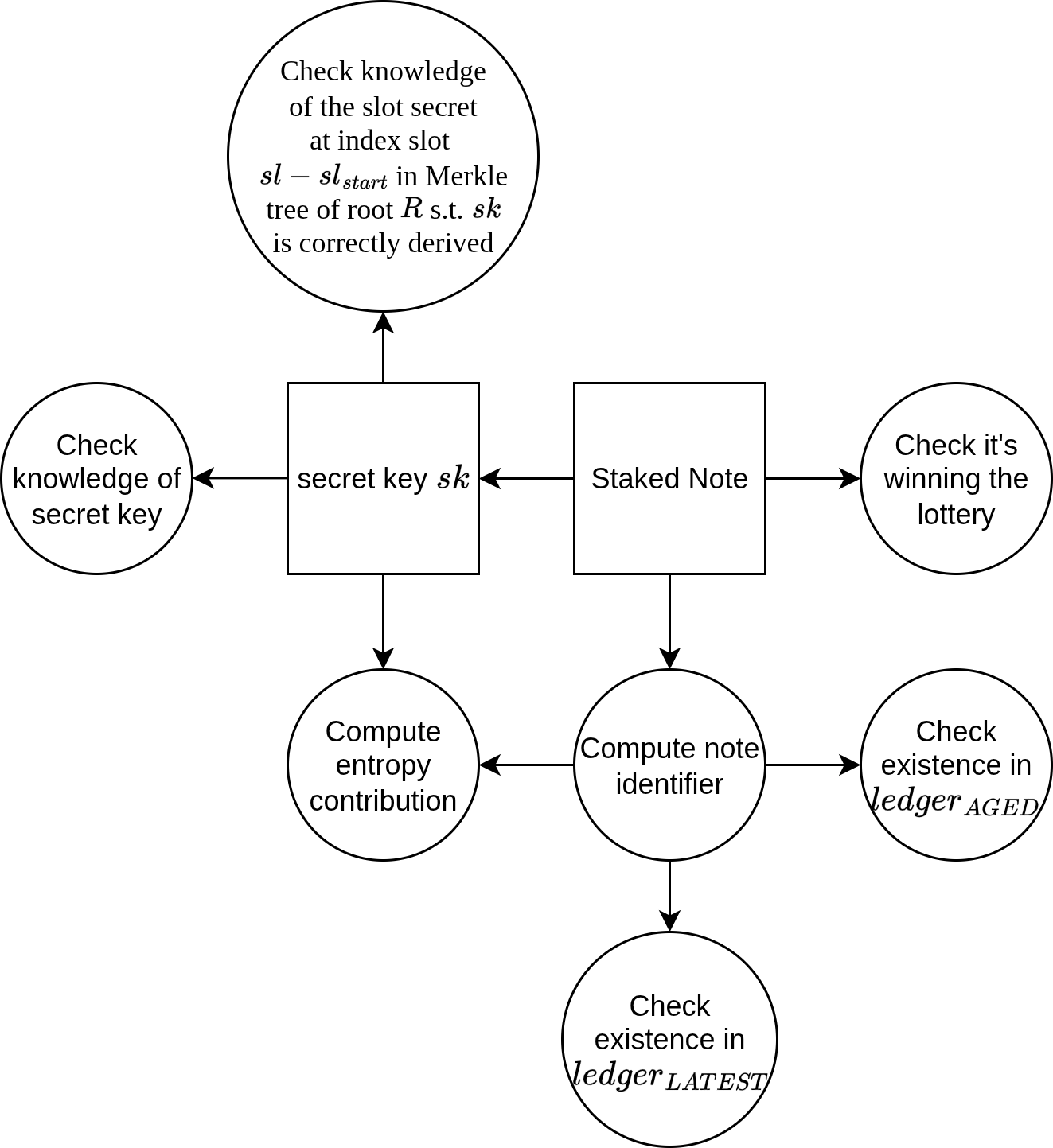
Circuit Public Inputs
The prover (the leader) and the verifiers (nodes of the chain) must agree on these values:
- The slot number: .
- The epoch nonce: .
- For details see Cryptarchia Protocol - Epoch Nonce.
- The lottery function constants: and .
- For details see Lottery Approximation.
- These numbers must be computed with high precision outside the proof.
- The root of the note Merkle tree when the stake distribution was frozen .
- For details see Cryptarchia Protocol - Epoch State Pseudocode.
- The latest root of the note Merkle tree: .
- Used to ensure the leadership note has not been spent.
- The leader's one-time public key represented by 2 public inputs, each of 16 bytes in little endian. This key is needed to sign the proposed block.
- For details see Linking the Proof of Leadership to a Block.
- The entropy contribution verified to be correctly derived.
- This is the epoch nonce entropy contribution. See Cryptarchia Protocol - Epoch Nonce.
Circuit Private Inputs
The prover has to provide these values, but they remain secret:
- The slot secret and the related information used for the slot as described in Protection Against Adaptive Adversaries:
- The slot secret .
- The Merkle path of leading to the root .
- The starting secret slot .
- The eligible note and its related information used to derive the noteID (the secret key is derived for the previous step):
- The note value: .
- The note transaction zk hash: .
- The note outputs number: .
- The proof of membership of the note identifier in the zone ledgers and . This is done by providing the complementary Merkle nodes and indicating whether they are left (0) or right (1) through boolean selectors:
- The aged ledger complementary nodes: .
- The aged ledger complementary node selectors: .
- The latest ledger complementary nodes: .
- The latest ledger complementary node selectors: .
Circuit Constraints
The proof confirms the following relations:
- The derivation of the Merkle tree root using the slot secret as the s leaf of the Merkle tree using the Merkle path. This is a proof of knowledge of the secret slot guaranteeing protection against adaptive adversaries.
- The derivation of , as documented in Protection Against Adaptive Adversaries.
- The computation of the note identifier.
- The note identifier is in and .
- The computation of the lottery ticket: using Poseidon2.
- The computation of the threshold: . The ticket must be lower than this threshold to win the lottery.
- The check that indeed .
- Compute and output the entropy contribution
Linking the Proof of Leadership to a Block
The PoL is bound to a public key from an asymmetric signature scheme. This public key is given as two public inputs during the PoL proof generation, binding the proof to the key.
- The public key is represented by two public inputs of 16 bytes to guarantee the support of every possible Eddsa25519 public key.
- This public key is later used to verify the signature of a block when it is dispersed. This ensures that the PoL is tied to a specific block, and only the entity creating the proof can perform this binding.
- The key is single-use, as reusing the same one could allow multiple PoLs to be linked to the same identity. An observer could then infer the stake of that identity by observing the frequency at which it emits a PoL.
Appendix
Lottery Approximation
- The function of Ouroboros Crypsinous cannot be computed in a hand-written circuit as it can only operates on elements of for a certain prime number .
- Managing floating point numbers and mathematical functions involving floating points like exponentiations or logarithms in circuits is very inefficient.
- We compared the Taylor expansion of order 1 and 2 and used the Taylor expansion of order 2 method to approximate the Ouroboros Genesis (and Crypsinous) function by the following linear function
- means nearly equal in the neighborhood of 0
- is the probability that at least one leader wins the lottery on each slot
- is the stake of the proven note
Then the threshold is with and
. Since everything is known by every node except the value of the staked note, we pre-compute and outside of the circuit.
- The Hash functions used to derive the lottery ticket is Poseidon2 so the is the order of the scalar field of the BN254 elliptic curve.
- To compute and , we precomputed the constant parts using sagemath and real number of 512 bits precision. In the implementation, and should then be derived using 256-bit precision integers following:
Variable Formula 0x30644e72e131a029b85045b68181585d2833e84879b9709143e1f593f0000001 0x1a3fb997fd58374772808c13d1c2ddacb5ab3ea77413f86fd6e0d3d978e5438 0x71e790b41991052e30c93934b5612412e7958837bac8b1c524c24d84cc7d0
Error Analysis
- For . The error percentage is computed with
- We will consider that is 23.5B as in Cardano
- Original function:
- Taylor expansion of order 1:
- Taylor expansion of order 2:
| stake (%) | order 1 error | order 2 error |
|---|---|---|
| 5% | 0.13% | -0.0001% |
| 10% | 0.26% | -0.0004% |
| 15% | 0.39% | -0.0010% |
| 20% | 0.51% | -0.0018% |
| 25% | 0.64% | -0.0027% |
| 30% | 0.77% | -0.0040% |
| 35% | 0.90% | -0.0054% |
| 40% | 1.03% | -0.0071% |
| 45% | 1.16% | -0.0089% |
| 50% | 1.29% | -0.0110% |
| 55% | 1.42% | -0.0134% |
| 60% | 1.55% | -0.0159% |
| 65% | 1.68% | -0.0187% |
| 70% | 1.81% | -0.0217% |
| 75% | 1.94% | -0.0249% |
| 80% | 2.07% | -0.0284% |
| 85% | 2.20% | -0.0320% |
| 90% | 2.33% | -0.0359% |
| 95% | 2.46% | -0.0406% |
| 100% | 2.59% | -0.0444% |
Benchmarks
The material used for the benchmarks is the following:
- CPU : 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM : 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS : Ubuntu 22.04.5 LTS
- Kernel : 6.8.0-59-generic
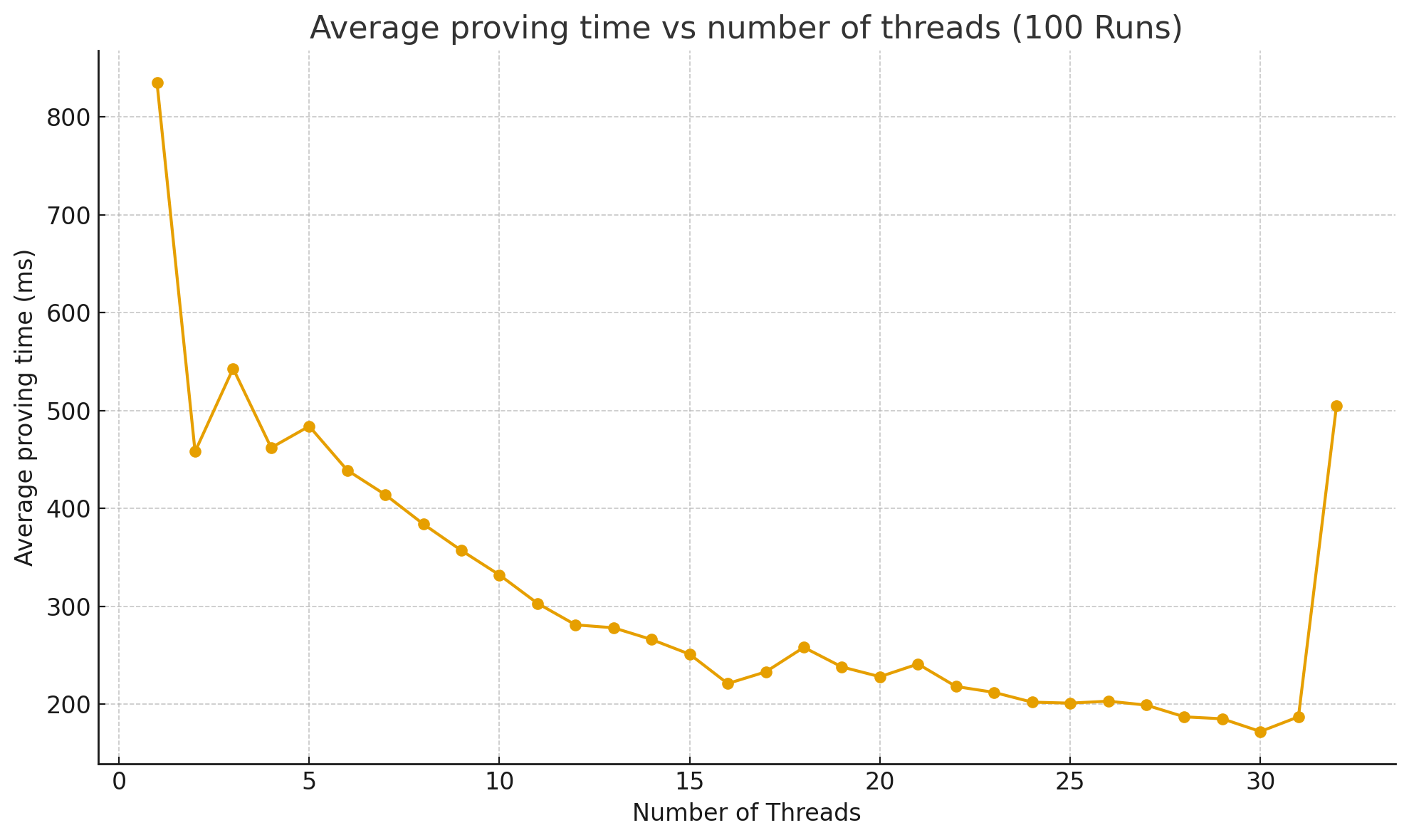
CONSENSUS-CLARO
| Field | Value |
|---|---|
| Name | Claro Consensus Protocol |
| Slug | 140 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Corey Petty [email protected] |
| Contributors | Álvaro Castro-Castilla, Mark Evenson |
Timeline
- 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-18 —
58b5698— chore(blockchain): migrate contributor emails to @logos.co (#338) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-02-15 —
1ddddc7— update to tree structure (#128) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-02-02 —
f52c54f— Update and rename CLARO.md to claro.md - 2024-01-27 —
01e2781— Create CLARO.md
Abstract
This document specifies Claro: a Byzantine, fault-tolerant, binary decision agreement algorithm that utilizes bounded memory for its execution. Claro is a novel variant of the Snow family providing a probabilistic leaderless BFT consensus algorithm that achieves metastablity via network sub-sampling. We present an application context of the use of Claro in an efficient, leaderless, probabilistic permission-less consensus mechanism. We outline a simple taxonomy of Byzantine adversaries, leaving explicit explorations of to subsequent publication.
NOTE: We have renamed this variant to Claro from Glacier
in order to disambiguate from a previously released research endeavor by
Amores-Sesar, Cachin, and Tedeschi.
Their naming was coincidentally named the same as our work but
is sufficiently differentiated from how ours works.
Motivation
This work is a part of a larger research endeavor to explore highly scalable Byzantine Fault Tolerant (BFT) consensus protocols. Consensus lies at the heart of many decentralized protocols, and thus its characteristics and properties are inherited by applications built on top. Thus, we seek to improve upon the current state of the art in two main directions: base-layer scalability and censorship resistance.
Avalanche has shown to exibit the former in a production environment in a way that is differentiated from Nakamoto consensus and other Proof of Stake (PoS) protocols based in practical Byzantine Fault Tolerant (pBFT) methodologies. We aim to understand its limitations and improve upon them.
Background
Our starting point is Avalanche’s Binary Byzantine Agreement algorithm, called Snowball. As long as modifications allow a DAG to be constructed later on, this simplifies the design significantly. The DAG stays the same in principle: it supports confidence, but the core algorithm can be modeled without.
The concept of the Snowball algorithm is relatively simple. Following is a simplified description (lacking some details, but giving an overview). For further details, please refer to the Avalanche paper.
- The objective is to vote yes/no on a decision (this decision could be a single bit or, in our DAG use case, whether a vertex should be included or not).
- Every node has an eventually-consistent complete view of the network. It will select at random k nodes, and will ask their opinion on the decision (yes/no).
- After this sampling is finished,
if there is a vote that has more than an
alphathreshold, it accumulates one count for this opinion, as well as changes its opinion to this one. But, if a different opinion is received, the counter is reset to 1. If no thresholdalphais reached, the counter is reset to 0 instead. - After several iterations of this algorithm,
we will reach a threshold
beta, and decide on that as final.
Next, we will proceed to describe our new algorithm, based on Snowball.
We have identified a shortcoming of the Snowball algorithm that was a perfect starting point for devising improvements. The scenario is as follows:
- There is a powerful adversary in the network, that controls a large percentage of the node population: 10% to ~50%.
- This adversary follows a strategy that allows them to rapidly change the decision bit (possibly even in a coordinated way) so as to maximally confuse the honest nodes.
- Under normal conditions,
honest nodes will accumulate supermajorities soon enough, and
reach the
betathreshold. However, when an honest node performs a query and does not reach the thresholdalphaof responses, the counter will be set to 0. - The highest threat to Snowball is an adversary
that keeps it from reaching the
betathreshold, managing to continuously reset the counter, and steering Snowball away from making a decision.
This document only outlines the specification to Claro. Subsequent analysis work on Claro (both on its performance and how it differentiates with Snowball) will be published shortly and this document will be updated.
Claro Algorithm Specification
The Claro consensus algorithm computes a boolean decision on a proposition via a set of distributed computational nodes. Claro is a leaderless, probabilistic, binary consensus algorithm with fast finality that provides good reliability for network and Byzantine fault tolerance.
Algorithmic concept
Claro is an evolution of the Snowball Byzantine Binary Agreement (BBA) algorithm, in which we tackle specifically the perceived weakness described above. The main focus is going to be the counter and the triggering of the reset. Following, we elaborate the different modifications and features that have been added to the reference algorithm:
- Instead of allowing the latest evidence to change the opinion completely, we take into account all accumulated evidence, to reduce the impact of high variability when there is already a large amount of evidence collected.
- Eliminate the counter and threshold scheme,
and introduce instead two regimes of operation:
- One focused on grabbing opinions and reacting as soon as possible. This part is somewhat closer conceptually to the reference algorithm.
- Another one focused on interpreting the accumulated data instead of reacting to the latest information gathered.
- Finally, combine those two phases via a transition function. This avoids the creation of a step function, or a sudden change in behavior that could complicate analysis and understanding of the dynamics. Instead, we can have a single algorithm that transfers weight from one operation to the other as more evidence is gathered.
- Additionally, we introduce a function for weighted sampling.
This will allow the combination of different forms of weighting:
- Staking
- Heuristic reputation
- Manual reputation.
It’s worth delving a bit into the way the data is interpreted in order to reach a decision. Our approach is based conceptually on the paper Confidence as Higher-Order Uncertainty, which describes a frequentist approach to decision certainty. The first-order certainty, measured by frequency, is caused by known positive evidence, and the higher-order certainty is caused by potential positive evidence. Because confidence is a relative measurement defined on evidence, it naturally follows comparing the amount of evidence the system knows with the amount that it will know in the near future (defining “near” as a constant).
Intuitively, we are looking for a function of evidence, w,
call it c for confidence, that satisfies the following conditions:
- Confidence
cis a continuous and monotonically increasing function ofw. (More evidence, higher confidence.) - When
w = 0,c = 0. (Without any evidence, confidence is minimum.) - When
wgoes to infinity,cconverges to 1. (With infinite evidence, confidence is maximum.)
The paper describes also a set of operations for the evidence/confidence pairs, so that different sources of knowledge could be combined. However, we leave here the suggestion of a possible research line in the future combining an algebra of evidence/confidence pairs with swarm-propagation algorithm like the one described in this paper.
Initial opinion
A proposal is formulated to which consensus of truth or falsity is
desired. Each node that participates starts the protocol with an
opinion on the proposal, represented in the sequel as NO, NONE,
and YES.
A new proposition is discovered either by local creation or in
response to a query, a node checks its local opinion. If the node can
compute a justification of the proposal, it sets its opinion to one of
YES or NO. If it cannot form an opinion, it leaves its opinion as
NONE.
For now, we will ignore the proposal dissemination process and assume all nodes participating have an initial opinion to respond to within a given request. Further research will relax this assumption and analyze timing attacks on proposal propagation through the network.
The node then participates in a number of query rounds in which it
solicits other node's opinion in query rounds. Given a set of N
leaderless computational nodes, a gossip-based protocol is presumed to
exist which allows members to discover, join, and leave a weakly
transitory maximally connected graph. Joining this graph allows each
node to view a possibly incomplete node membership list of all other
nodes. This view may change as the protocol advances, as nodes join
and leave. Under generalized Internet conditions, the membership of
the graph would experience a churn rate varying across different
time-scales, as the protocol rounds progress. As such, a given node
may not have a view on the complete members participating in the
consensus on a proposal in a given round.
The algorithm is divided into 4 phases:
- Querying
- Computing
confidence,evidence, andaccumulated evidence - Transition function
- Opinion and Decision
Setup Parameters
The node initializes the following integer ratios as constants:
# The following values are constants chosen with justification from experiments
# performed with the adversarial models
#
confidence_threshold
<-- 1
# constant look ahead for number of rounds we expect to finalize a
# decision. Could be set dependent on number of nodes
# visible in the current gossip graph.
look_ahead
<-- 19
# the confidence weighting parameter (aka alpha_1)
certainty
<-- 4 / 5
doubt ;; the lack of confidence weighting parameter (aka alpha_2)
<-- 2 / 5
k_multiplier ;; neighbor threshold multiplier
<-- 2
;;; maximal threshold multiplier, i.e. we will never exceed
;;; questioning k_initial * k_multiplier ^ max_k_multiplier_power peers
max_k_multiplier_power
<-- 4
;;; Initial number of nodes queried in a round
k_initial
<-- 7
;;; maximum query rounds before termination
max_rounds ;; placeholder for simulation work, no justification yet
<-- 100
The following variables are needed to keep the state of Claro:
;; current number of nodes to attempt to query in a round
k
<-- k_original
;; total number of votes examined over all rounds
total_votes
<-- 0
;; total number of YES (i.e. positive) votes for the truth of the proposal
total_positive
<-- 0
;; the current query round, an integer starting from zero
round
<-- 0
Phase One: Query
A node selects k nodes randomly from the complete pool of peers in the
network. This query is can optionally be weighted, so the probability
of selecting nodes is proportional to their
Node Weighting
where w is evidence.
The list of nodes is maintained by a separate protocol (the network layer),
and eventual consistency of this knowledge in the network
suffices. Even if there are slight divergences in the network view
from different nodes, the algorithm is resilient to those.
A query is sent to each neighbor with the node's current opinion of
the proposal.
Each node replies with their current opinion on the proposal.
See the wire protocol Interoperability section for details on the semantics and syntax of the "on the wire" representation of this query.
Adaptive querying. An additional optimization in the query
consists of adaptively growing the k constant in the event of
high confusion. We define high confusion as the situation in
which neither opinion is strongly held in a query (i.e. a
threshold is not reached for either yes or no). For this, we will
use the alpha threshold defined below. This adaptive growth of
the query size is done as follows:
Every time the threshold is not reached, we multiply k by a
constant. In our experiments, we found that a constant of 2 works
well, but what really matters is that it stays within that order of
magnitude.
The growth is capped at 4 times the initial k value. Again, this
is an experimental value, and could potentially be increased. This
depends mainly on complex factors such as the size of the query
messages, which could saturate the node bandwidth if the number of
nodes queried is too high.
When the query finishes, the node now initializes the following two values:
new_votes
<-- |total vote replies received in this round to the current query|
positive_votes
<-- |YES votes received from the query|
Phase Two: Computation
When the query returns, three ratios are used later on to compute the
transition function and the opinion forming. Confidence encapsulates
the notion of how much we know (as a node) in relation to how much we
will know in the near future (this being encoded in the look-ahead
parameter l.) Evidence accumulated keeps the ratio of total positive
votes vs the total votes received (positive and negative), whereas the
evidence per round stores the ratio of the current round only.
Parameters
Computation
The node runs the new_votes and positive_votes parameters received
in the query round through the following algorithm:
total_votes
+== new_votes
total_positive
+== positive_votes
confidence
<-- total_votes / (total_votes + look_ahead)
total_evidence
<-- total_positive / total_votes
new_evidence
<-- positive_votes / new_votes
evidence
<-- new_evidence * ( 1 - confidence ) + total_evidence * confidence
alpha
<-- doubt * ( 1 - confidence ) + certainty * confidence
Phase Three: Computation
In order to eliminate the need for a step function (a conditional in the code), we introduce a transition function from one regime to the other. Our interest in removing the step function is twofold:
-
Simplify the algorithm. With this change the number of branches is reduced, and everything is expressed as a set of equations.
-
The transition function makes the regime switch smooth, making it harder to potentially exploit the sudden regime change in some unforeseen manner. Such a swift change in operation mode could potentially result in a more complex behavior than initially understood, opening the door to elaborated attacks. The transition function proposed is linear with respect to the confidence.
Transition Function
Since the confidence is modeled as a ratio that depends on the
constant l, we can visualize the transition function at
different values of l. Recall that this constant encapsulates
the idea of “near future” in the frequentist certainty model: the
higher it is, the more distant in time we consider the next
valuable input of evidence to happen.
We have observed via experiment that for a transition function to be useful, we need establish two requirements:
-
The change has to be balanced and smooth, giving an opportunity to the first regime to operate and not jump directly to the second regime.
-
The convergence to 1.0 (fully operating in the second regime) should happen within a reasonable time-frame. We’ve set this time-frame experimentally at 1000 votes, which is in the order of ~100 queries given a
kof 9.
[[ Note: Avalanche uses k = 20, as an experimental result from their deployment. Due to the fundamental similarities between the algorithms, it’s a good start for us. ]]
The node updates its local opinion on the consensus proposal by
examining the relationship between the evidence accumulated for a
proposal with the confidence encoded in the alpha parameter:
IF
evidence > alpha
THEN
opinion <-- YES
ELSE IF
evidence < 1 - alpha
THEN
opinion <-- NO
If the opinion of the node is NONE after evaluating the relation
between evidence and alpha, adjust the number of uniform randomly
queried nodes by multiplying the neighbors k by the k_multiplier
up to the limit of k_max_multiplier_power query size increases.
;; possibly increase number nodes to uniformly randomly query in next round
WHEN
opinion is NONE
AND
k < k_original * k_multiplier ^ max_k_multiplier_power
THEN
k <-- k * k_multiplier
Decision
The next step is a simple one: change our opinion if the threshold
alpha is reached. This needs to be done separately for the YES/NO
decision, checking both boundaries. The last step is then to decide
on the current opinion. For that, a confidence threshold is
employed. This threshold is derived from the network size, and is
directly related to the number of total votes received.
Decision
After the OPINION phase is executed, the current value of confidence
is considered: if confidence exceeds a threshold derived from the
network size and directly related to the total votes received, an
honest node marks the decision as final, and always returns this
opinion is response to further queries from other nodes on the
network.
IF
confidence > confidence_threshold
OR
round > max_rounds
THEN
finalized <-- T
QUERY LOOP TERMINATES
ELSE
round +== 1
QUERY LOOP CONTINUES
Thus, after the decision phase, either a decision has been finalized and the local node becomes quiescent never initiating a new query, or it initiates a new query.
Termination
A local round of Claro terminates in one of the following execution model considerations:
-
No queries are received for any newly initiated round for temporal periods observed via a locally computed passage of time. See the following point on local time.
-
The
confidenceon the proposal exceeds our threshold for finalization. -
The number of
roundsexecuted would be greater thanmax_rounds.
Quiescence
After a local node has finalized an opinion into a decision, it enters a quiescent
state whereby it never solicits new votes on the proposal. The local
node MUST reply with the currently finalized decision.
Clock
The algorithm only requires that nodes have computed the drift of observation of the passage of local time, not that that they have coordinated an absolute time with their peers. For an implementation of a phase locked-loop feedback to measure local clock drift see NTP.
Further points
Node receives information during round
In the query step, the node is envisioned as packing information into
the query to cut down on the communication overhead a query to each of
this k nodes containing the node's own current opinion on the
proposal (YES, NO, or NONE). The algorithm does not currently
specify how a given node utilizes this incoming information. A
possible use may be to count unsolicited votes towards a currently
active round, and discard the information if the node is in a
quiescent state.
Problems with Weighting Node Value of Opinions
If the view of other nodes is incomplete, then the sum of the optional weighting will not be a probability distribution normalized to 1.
The current algorithm doesn't describe how the initial opinions are formed.
Implementation status
The following implementations have been created for various testing and simulation purposes:
- Rust
- Python - FILL THIS IN WITH NEWLY CREATED REPO
- Common Lisp - FILL THIS IN WITH NEWLY CREATED REPO
Wire Protocol
For interoperability we present a wire protocol semantics by requiring
the validity of the following statements expressed in Notation3 (aka
n3) about any query performed by a query node:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix Claro <https://rdf.logos.co/protocol/Claro#> .
Claro:query
:holds (
:_0 [ rdfs:label "round";
a xsd:postitiveInteger; ],
rdfs:comment """
The current round of this query
A value of zero corresponds to the initial round.
""" ;
:_1 [ rdfs:label "uri";
rdfs:comment """
A unique URI for the proposal.
It MAY be possible to examine the proposal by resolving this resource,
and its associated URIs.
""" ;
a xsd:anyURI ],
:_2 [ rdfs:label "opinion";
rdfs:comment """
The opinion on the proposal
One of the strings "YES" "NO" or "NONE".
""" ;
# TODO constrain as an enumeration on three values efficiently
a xsd:string ]
) .
Nodes are advised to use Waku messages to include their own metadata in serializations as needed.
Syntax
The semantic description presented above can be reliably round-tripped through a suitable serialization mechanism. JSON-LD provides a canonical mapping to UTF-8 JSON.
At their core, the query messages are a simple enumeration of the three possible values of the opinion:
{ NO, NONE, YES }
When represented via integers, such as choosing
{ -1, 0, +1 }
the parity summations across network invariants often become easier to manipulate.
Security Considerations
Privacy
In practice, each honest node gossips its current opinion which reduces the number of messages that need to be gossiped for a given proposal. The resulting impact on the privacy of the node's opinion is not currently analyzed.
Security with respect to various Adversarial Models
Adversarial models have been tested for which the values for current parameters of Claro have been tuned. Exposition of the justification of this tuning need to be completed.
Local Strategies
Random Adversaries
A random adversary optionally chooses to respond to all queries with a random decision. Note that this adversary may be in some sense Byzantine but not malicious. The random adversary also models some software defects involved in not "understanding" how to derive a truth value for a given proposition.
Infantile Adversary
Like a petulant child, an infantile adversary responds with the opposite vote of the honest majority on an opinion.
Omniscient Adversaries
Omniscient adversaries have somehow gained an "unfair" participation in
consensus by being able to control f of N nodes with a out-of-band
"supra-liminal" coordination mechanism. Such adversaries use this
coordinated behavior to delay or sway honest majority consensus.
Passive Gossip Adversary
The passive network omniscient adversary is fully aware at all times of the network state. Such an adversary can always chose to vote in the most efficient way to block the distributed consensus from finalizing.
Active Gossip Adversary
An omniscient gossip adversary somehow not only controls f of N
nodes, but has also has corrupted communications between nodes such
that she may inspect, delay, and drop arbitrary messages. Such an
adversary uses capability to corrupt consensus away from honest
decisions to ones favorable to itself. This adversary will, of
course, choose to participate in an honest manner until defecting is
most advantageous.
Future Directions
Although we have proposed a normative description of the implementation of the underlying binary consensus algorithm (Claro), we believe we have prepared for analysis its adversarial performance in a manner that is amenable to replacement by another member of the snow* family.
We have presumed the existence of a general family of algorithms that can be counted on to vote on nodes in the DAG in a fair manner. Avalanche provides an example of the construction of votes on UTXO transactions. One can express all state machine, i.e. account-based models as checkpoints anchored in UTXO trust, so we believe that this presupposition has some justification. We can envision a need for tooling abstraction that allow one to just program the DAG itself, as they should be of stable interest no matter if Claro isn't.
Informative References
Normative References
Copyright
Copyright and related rights waived via CC0
ANALYSIS-GAS-COST-DETERMINATION
| Field | Value |
|---|---|
| Name | [Analysis] Gas Cost Determination |
| Slug | 191 |
| Status | raw |
| Category | Informational |
| Editor | Thomas Lavaur [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-20 —
5b20a2d— docs(blockchain) Channel Participation in PoS (#364) - 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revisions History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | N/A |
| 1.2.0 | Removed DA, included Execution Gas determination for channel deposits and withdraws. Updated the Execution Gas of the Channel config. | N/A |
| 1.3.0 | [RFC] Make Ledger Transaction an Operation. Updated project references to Logos Blockchain | N/A |
| 1.4.0 | [RFC] Enforce NoteId uniqueness | N/A |
| 1.4.1 | [RFC] Simplify Mantle Transaction and Refactor Ledger Operations | N/A |
| 1.5.0 | Introduce the new Operation CHANNEL_STAKE_ASSIGNATION and update of the channel operations to reflect changes in Mantle | 2026-06-24 |
Introduction
In Mantle, each Mantle Transaction contains one or more Operations. These components consume gas, measured through fixed gas units that reflect their execution or storage impact. Logos Blockchain introduces two independent gas markets:
- Execution Gas: measuring computational workload.
- Permanent Storage Gas: measuring cost of fully replicated storage.
Gas constants are carefully calibrated to reflect the computational and storage requirements of different operations on Logos Blockchain. By standardizing gas measurements, the system can accurately charge fees proportional to resource usage, preventing network abuse and incentivizing efficient transaction design.
Overview
We conducted a comprehensive analysis of execution requirements for each Operation type in Mantle Transactions. This detailed examination allowed us to determine precise gas amounts for each Operation based on the actual computational resources consumed.
The gas constants we established are strategically divided between permanent storage and execution components, directly proportional to their respective resource utilization within Mantle Transactions. This separation ensures that gas costs accurately reflect the true computational burden of different operations. Moreover, gas can also be adjusted arbitrarily to incentivize or disincentivize the usage of certain Operations compared to others.
Our methodology involved measuring execution complexity and defining how gas is determined for each Gas Market. This is critical for proper network operation as it directly impacts transaction prioritization and network economics.
Permanent Storage Gas
Permanent Storage is paid directly for the entire signed Mantle Transaction. The Permanent Storage Gas price is derived from Storage Markets and is used to determine the Permanent Storage fee. 1 Permanent Storage Gas corresponds to 1 byte.
permanent_storage_fee = len(encode(tx_signed)) * permanent_storage_gas_price
Execution Gas
Execution is a second general market that represents how costly an Operation is to execute. This cost can be fixed or variable based on the content of the Operation. The Execution Gas base price is derived from Execution Market and each Operation defines its execution gas amount. 1 Execution Gas corresponds to 1,000 CPU cycles.
execution_base_fee = tx.ops.get_summed_gas() * execution_gas_base_price
The gas derivation of each Operation are:
TRANSFER_GAS = 590
CHANNEL_INSCRIBE_GAS = 56
CHANNEL_CONFIG_GAS = 56 * configuration_threshold
CHANNEL_DEPOSIT_GAS = 590
CHANNEL_TRANSFER_GAS = 56 * stake_manipulation_threshold
CHANNEL_WITHDRAW_GAS = 56 * stake_manipulation_threshold
SDP_DECLARE_GAS = 646
SDP_WITHDRAW_GAS = 590
SDP_ACTIVE_GAS = 590
LEADER_CLAIM_GAS = 580
and come from our implementation observations as described in Gas determination from measures. To get these numbers, we based our calculations on the following measures:
| Operation | Number of CPU cycles |
|---|---|
| ZkSignature batch verification | 3,900,000 + number_of_proof x 590,000 |
| Proof of Claim batch verification | 2,640,000 + number_of_proof x 580,000 |
| Eddsa25519 signature verification | 56,000 |
Comparison, list searching, hashes and operation in small fields are neglected. We also supposed that the initialization cost for batch verification is paid by everyone and deduced from the block directly. The user then pay only for the part that is proportional to the number of proofs.
Transfer
The Execution Gas of the Transfer Operation compensates for the verification of the ZkSignature proof.
Execution: ~590k CPU cycles.
- Verification of the ZK signature: 590,000 cycles.
Input Gas
Input gas covers the computational cost of verifying that one Note Id exists in the Ledger and is not locked. Additionally, it compensates for the removal of one Note Id from the Ledger.
Execution: negligible.
- Verification that the note is in the ledger: negligible.
- Verification that the note is unlocked: negligible.
- Removing of the note from the ledger: negligible.
Output Gas
Output gas accounts for the computational resources required to verify that one output is well-formed and for its inclusion in the Ledger.
Execution: negligible.
- Verification of the output validity: negligible.
- Insertion of the note in the ledger: negligible.
- Derivation of the note identifiers: negligible
Channel Inscription
The validation process includes verifying an Eddsa25519 signature, confirming that the signer is authorized for the specified channel, and checking the chaining sequence of the channel. The execution encompasses creating channel records (if not previously used) and updating the tip of the channel.
Execution: ~56k CPU cycles.
- Verification of the Ed25519 signature: 56,000 cycles.
- Verification of the signer authorization: negligible.
- Verification of channel sequencing: negligible
- Update the channel state: negligible
Channel Deposit
The Execution Gas of the Channel Deposit Operation compensates for the verification of the ZkSignature proof and for the check of the inputs.
Execution: ~590k CPU cycles.
- Verification of the ZK signature: 590,000 cycles.
- Verification that the notes are in the ledger: negligible.
- Verification that the notes are unlocked: negligible.
- Marking of the notes as channel notes: negligible.
Channel Withdraw
The validation process requires verifying multiple Eddsa25519 signatures. The execution require consuming the channel notes, deriving note Id and adding notes to the ledger.
Execution: ~56k CPU cycles * transfer_threshold.
- Verification of
transfer_thresholdEd25519Signatures: 56,000 cycles per signature. - Verification that the notes are in the ledger: negligible.
- Verification that the notes are in the channel: negligible.
- Removing the notes from channel notes: negligible.
Channel Stake Assignation
The validation process requires verifying multiple Eddsa25519 signatures, and managing the channel notes. The execution require deriving note Id and adding notes to the ledger.
Execution: ~56k CPU cycles * transfer_threshold.
- Verification of
transfer_thresholdEd25519Signatures: 56,000 cycles per signature. - Verification that the notes are in the ledger: negligible.
- Verification that the notes are in the channel: negligible.
- Removing of the note from the ledger: negligible.
- Verification of the output validity: negligible.
- Insertion of the note in the ledger: negligible.
- Derivation of the note identifiers: negligible
Channel Config
This gas amount covers the verification of multiple Eddsa25519 signatures and ensures the operation is well-formed. This represents the computational cost associated with processing channel configuration operations.
- Execution: ~56k CPU cycles * configuration_threshold.
- Verification of the configuration_threshold Ed25519 signatures: 56,000 cycles per signature.
- Modification of the state of the channel: negligible.
SDP Declaration
This gas covers multiple verification processes: confirming ownership of the locked note through ZkSignature verification, validating the zk_id via a second ZkSignature, and establishing ownership of the provider_id through an Eddsa25519 signature. It also includes verification of the declaration format, confirmation of note existence, validation that the note is not already locked, and verification of its amount. Additionally, it accounts for the computational costs associated with the note locking mechanism and declaration management.
Execution: ~ 646k CPU cycles.
- Verification of the Ed25519 signature: 56,000 cycles.
- Verification of the ZK signature: 590,000 cycles.
- Verification that the declaration doesn’t already exist: negligible.
- Verification of locator length: negligible.
- Verification of locked note existence: negligible.
- Verification of locked note value: negligible.
- Verification that the note isn’t already locked for the service: negligible.
- Locking the note: negligible.
SDP Withdraw
This gas covers a verification process that includes: confirming ownership of the zk_id through ZkSignature verification, validating the existence of the locked note, verifying that the note has exceeded its lock period, and confirming that the declaration exists and has not been previously withdrawn. The validation process also ensures that the withdrawal message's nonce is greater than any previous nonce, preventing replay attacks. During execution, the system updates the declaration's status to withdrawn, removes the declaration from the locked note's associated declarations, and—if the note has no remaining declarations—removes it from the locked notes dictionary.
Execution: ~ 590k CPU cycles.
- Verification that the note exists, is locked and bound to the declaration: negligible.
- Verification that the note can be unlocked: negligible.
- Verification that the declaration exist: negligible.
- Verification of the ZK signature: 590,000 cycles.
- Verification that the declaration wasn’t already withdrawn: negligible.
- Verification of nonce incrementation: negligible.
- Update declaration: negligible.
- Remove declaration from locked note: negligible.
- Unlock the note if not linked to any declaration: negligible.
SDP Activation
This gas funds the verification of the zk_id signature through the ZkSignature verification process, validates the existence of the declaration in the system, and ensures that the activation message's nonce is greater than any previous nonce to prevent replay attacks. The validation includes confirming that the declaration ID is present in the declarations dictionary and that the signature corresponds to the declaration's registered zk_id public key.
- Execution: ~590k CPU cycles.
- Verification that the declaration exist: negligible.
- Verification of nonce incrementation: negligible.
- Verification of the ZK signature: 590,000 cycles.
- Evaluation of the activity depends on the service and is neglected here
Leader Claims
This gas covers the verification of reward voucher ownership through a Proof of Claim, confirmation that the voucher nullifier is not already present in the nullifier set, and validation that the rewards root exists in the list of recent voucher Merkle tree roots. The execution process involves adding the voucher nullifier to the nullifier set and increasing the Mantle Transaction balance by the designated leader reward amount.
Execution: ~580k CPU cycles.
- Verification that the voucher nullifier isn’t already in the set: negligible.
- Verification that the rewards root is one of the root of the reward tree of the last blocks: negligible.
- Verification of the proof of claim: 580,000 cycles.
- Insertion of the nullifier in the voucher nullifier set: negligible.
- Insertion of the note in the ledger: negligible.
- Derivation of the note identifiers: negligible
Annex
Gas determination from measures
The material used for the benchmarks is the following:
- CPU : 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM : 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS : Ubuntu 22.04.5 LTS
- Kernel : 6.8.0-59-generic
Eddsa Signature Verification
To get the numbers, we executed the test included in the official Rust implementation of the node.
Over 100 iterations, verifying an Eddsa25519 signature requires an average of 56,000 CPU cycles.
Proof of Claim
To get the numbers, we executed the test included in the official Rust implementation of the node.
We found the best linear curve approximating these measures (over 100 iterations):
| Number of Batches | Number of CPU cycles |
|---|---|
| 1 | 2,502,356 |
| 2 | 3,662,746 |
| 3 | 4,216,022 |
| 4 | 4,800,445 |
| 5 | 5,324,304 |
| 6 | 6,091,442 |
| 7 | 6,618,446 |
| 8 | 7,165,629 |
| 9 | 7,692,432 |
| 10 | 8,421,783 |
| 20 | 14,257,450 |
| 30 | 20,131,137 |
| 40 | 25,782,519 |
| 50 | 31,595,523 |
| 60 | 37,286,419 |
| Number of Batches | Number of CPU cycles |
|---|---|
| 70 | 42,901,298 |
| 80 | 48,309,912 |
| 90 | 54,191,072 |
| 100 | 61,082,050 |
| 110 | 66,927,817 |
| 120 | 73,758,494 |
| 130 | 78,816,789 |
| 140 | 84,801,250 |
| 150 | 91,693,824 |
| 160 | 94,248,613 |
| 170 | 99,430,138 |
| 180 | 105,607,812 |
| 190 | 112,379,089 |
| 200 | 116,599,001 |
We got the curve that we decided to approximate to :
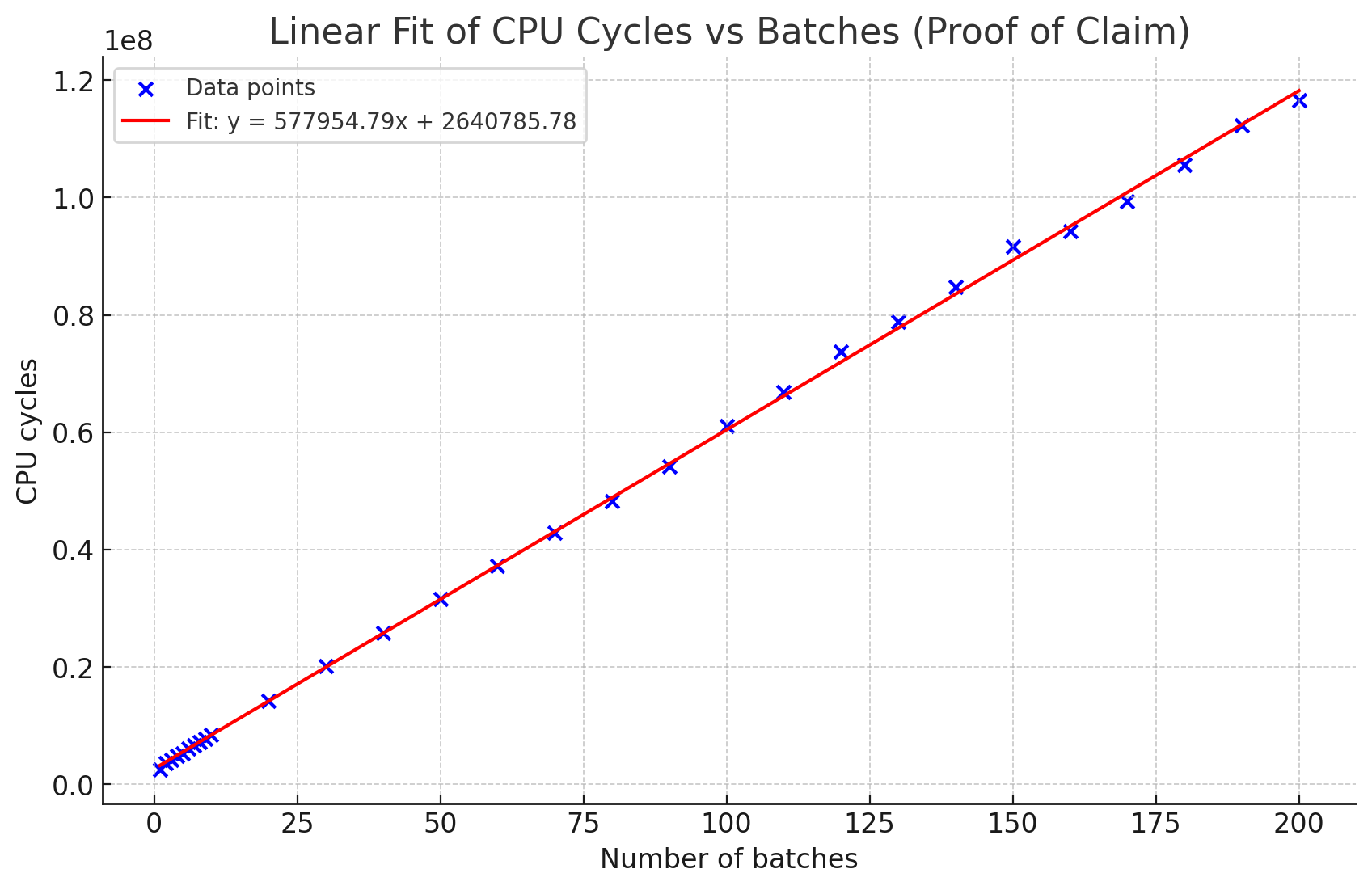
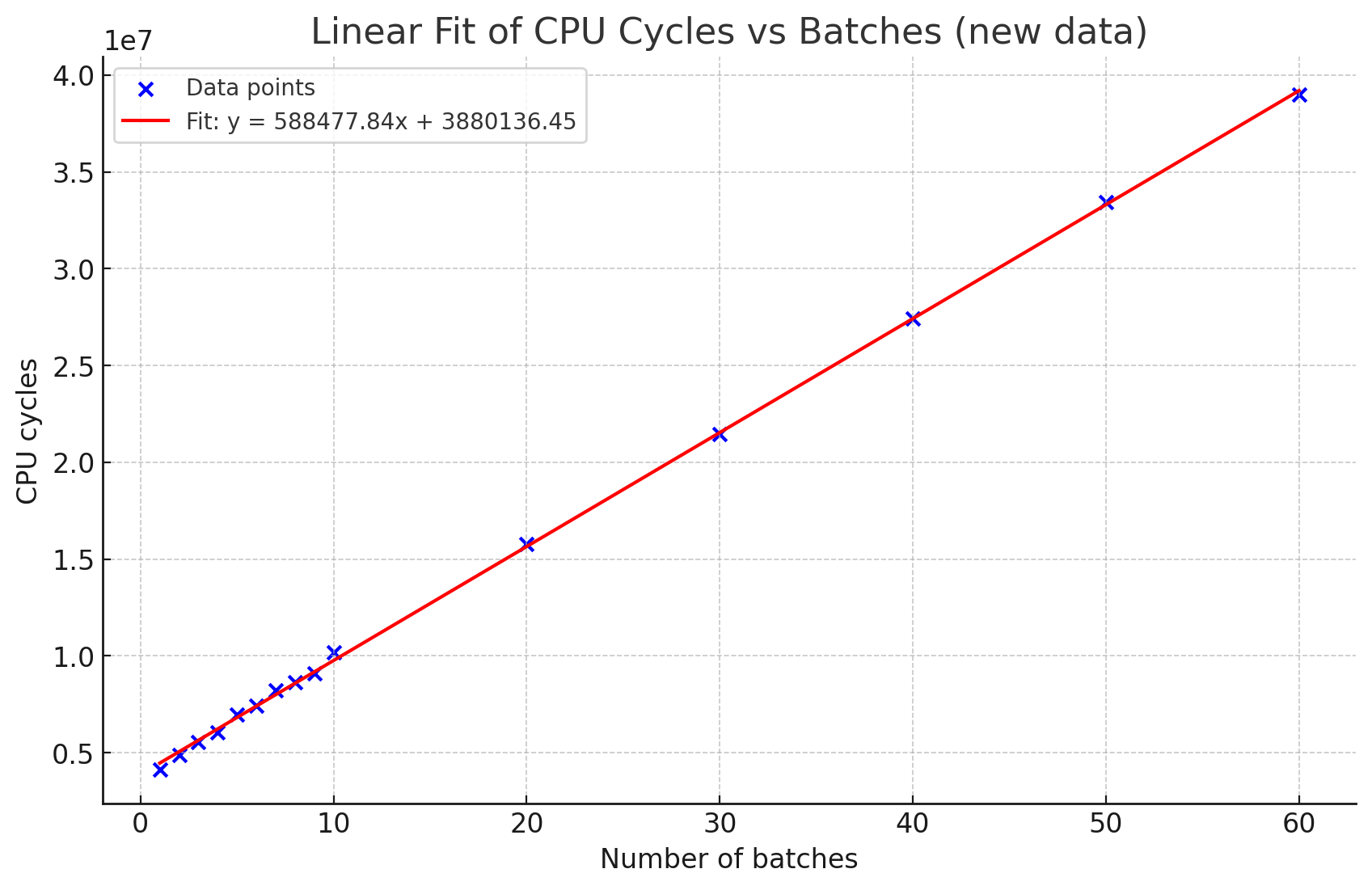
ZkSignature
To get the numbers, we executed the test included in the official Rust implementation of the node.
We found the best linear curve approximating these measures (over 1000 iterations):
| Number of Batches | Number of CPU cycles |
|---|---|
| 1 | 4,126,177 |
| 2 | 4,904,084 |
| 3 | 5,538,085 |
| 4 | 6,061,800 |
| 5 | 6,957,754 |
| 6 | 7,421,851 |
| 7 | 8,237,485 |
| 8 | 8,621,986 |
| 9 | 9,115,091 |
| 10 | 10,186,171 |
| 20 | 15,777,800 |
| 30 | 21,456,771 |
| 40 | 27,441,722 |
| 50 | 33,430,729 |
| 60 | 38,986,389 |
| Number of Batches | Number of CPU cycles |
|---|---|
| 70 | 44,708,450 |
| 80 | 50,894,373 |
| 90 | 56,534,430 |
| 100 | 63,606,624 |
| 110 | 70,036,347 |
| 120 | 75,612,096 |
| 130 | 82,048,010 |
| 140 | 87,080,407 |
| 150 | 91,473,391 |
| 160 | 97,862,623 |
| 170 | 104,019,852 |
| 180 | 111,498,103 |
| 190 | 114,814,226 |
| 200 | 119,739,702 |
OVERVIEW-BEDROCK-ARCHITECTURE
| Field | Value |
|---|---|
| Name | [Overview] Bedrock Architecture |
| Slug | 146 |
| Status | raw |
| Category | Informational |
| Editor | David Rusu [email protected] |
| Contributors | Álvaro Castro-Castilla [email protected], Daniel Kashepava [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-18 —
58b5698— chore(blockchain): migrate contributor emails to @logos.co (#338) - 2026-01-30 —
0ef87b1— New RFC: CODEX-MANIFEST (#191) - 2026-01-30 —
5c123d6— Nomos/raw/bedrock architecture overview raw (#257)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-08-22 |
| 1.1.0 | Remove references to DA Replace Nomos with Logos Blockchain | 2026-01-14 |
Introduction
Bedrock enables high-performance Sovereign Zones to leverage the security guarantees of Logos. Sovereign Zones build on the Logos Blockchain through Mantle, Bedrock’s minimal execution layer which in turn runs on Cryptarchia, Logos' consensus protocol. Taken together, Bedrock provides a private, highly scalable and resilient substrate for high-performance decentralized applications.
Overview
Bedrock is composed of Cryptarchia and Bedrock Mantle. Bedrock is in turn supported by the Bedrock Services such as the Blend Network. Together, they provide an interface for building high performance Sovereign Zones that leverage the security and resilience of Logos.
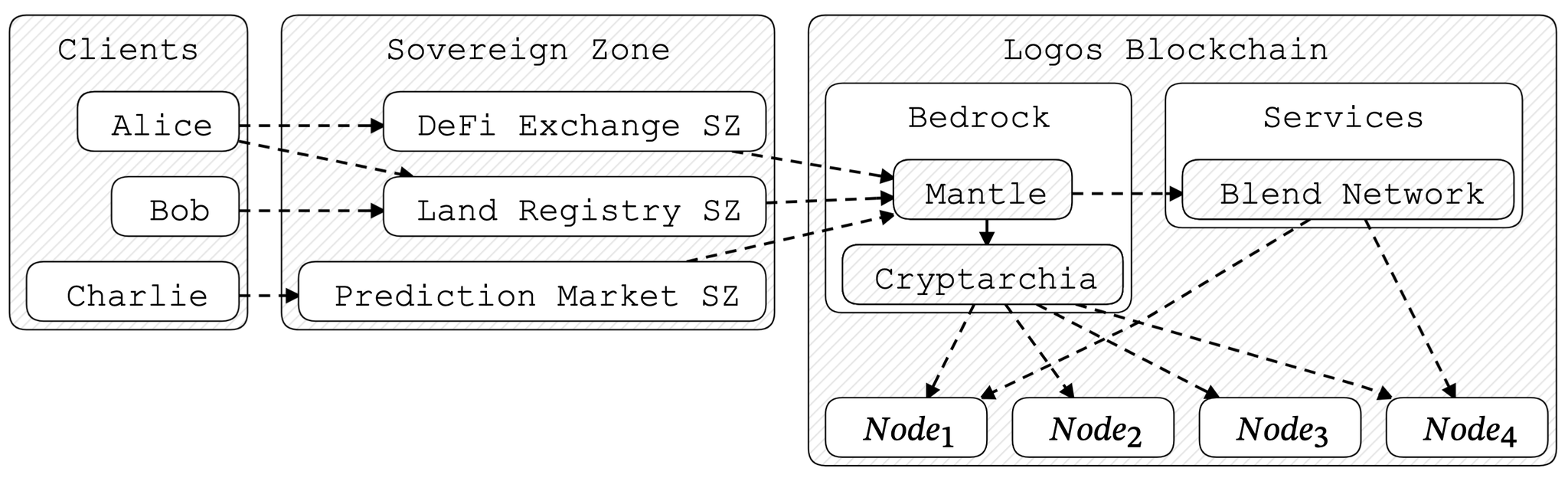
Bedrock Mantle
Mantle forms the minimal execution layer of the Logos Blockchain. Mantle Transactions consist of a sequence of Operations together with a Ledger Transaction used for paying fees and transferring funds.
Sovereign Zones make use of Mantle Transactions when posting their updates to Bedrock. This is done through the use of Mantle channels and channel Operations.
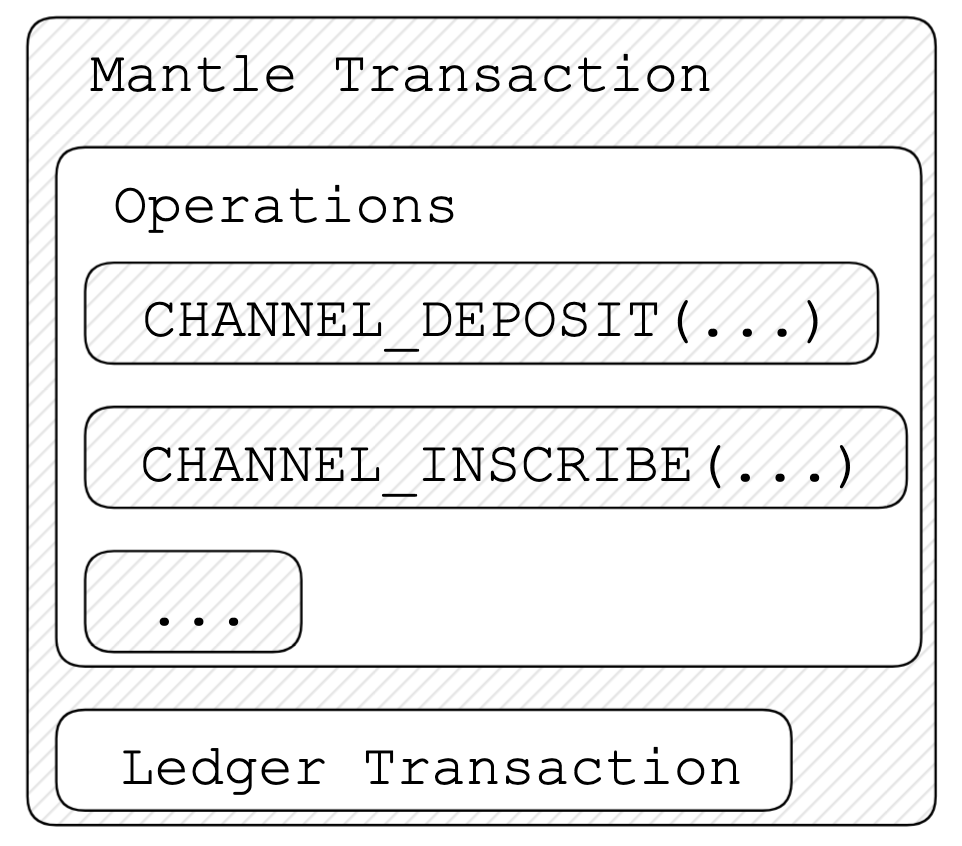
Mantle Channels
Mantle channels are lightweight virtual chains overlaid on top of the Logos Blockchain. Sovereign Zones are built on top of these channels, allowing them to outsource the hard parts of running a decentralized application to Logos, namely ordering and replicating state updates.
Channels are permissioned, ordered logs of messages. These messages, known as Inscriptions, are signed by an authorized party known as the sequencer, storing the message data permanently in-ledger. A Mantle channel can support several authorized sequencers, who share the right to post messages to that channel. In this case, the parties take turns acting as sequencers in a round-robin fashion.
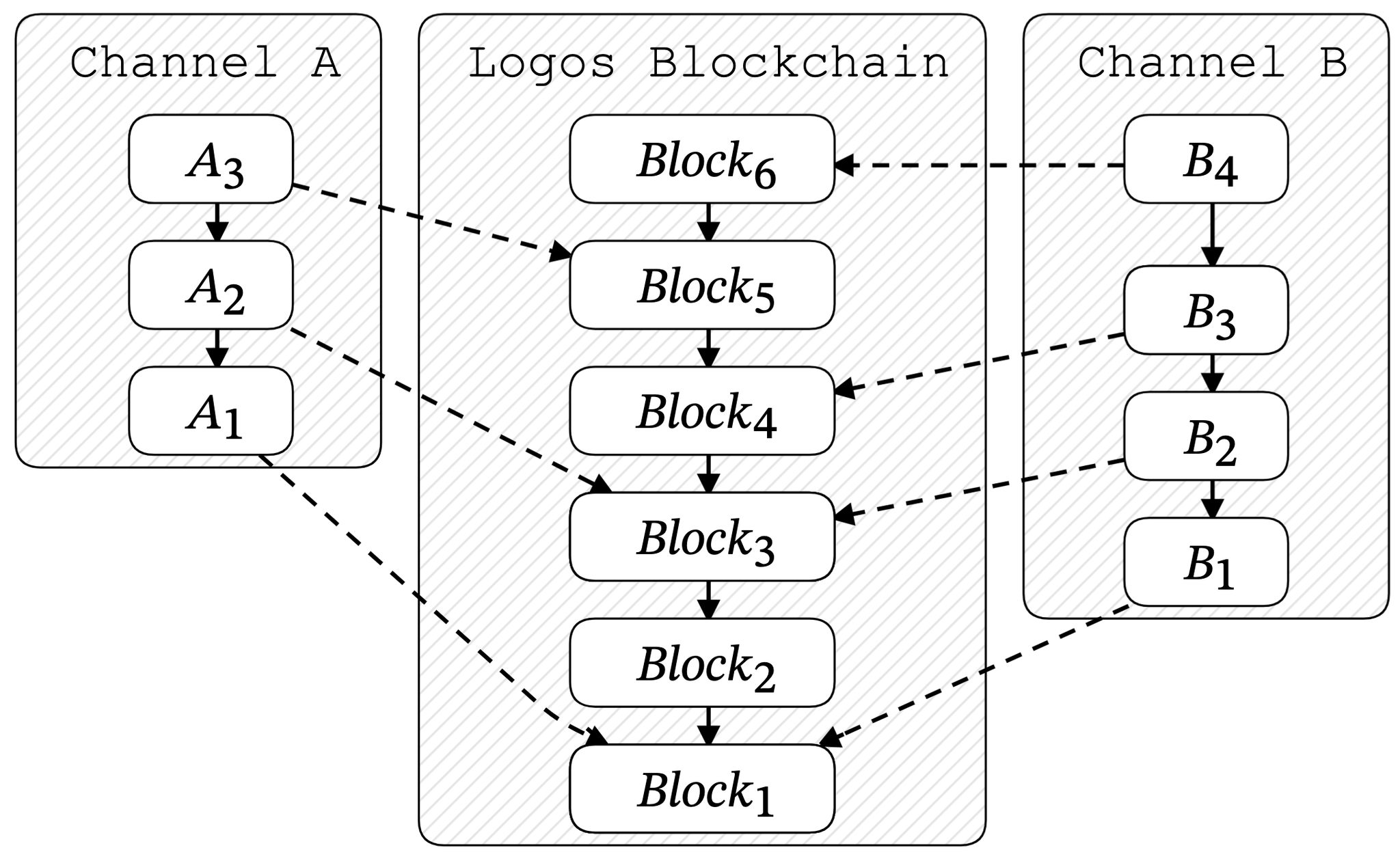
Channels A and B form virtual chains on top of the Logos Blockchain. Channel messages are included in blocks on the Logos Blockchain in such a way that they respect the ordering of channel messages e.g. must come after in the Logos Blockchain.
Channel messages can be used by Sovereign Zone sequencers to asynchronously communicate and coordinate actions amongst themselves. This could include planning cross-Zone transactions that affect the state of several Zones, or agreeing to modify a channel's properties.
Every Mantle channel also has an associated token balance. This balance allows users to bridge tokens from Bedrock to Sovereign Zones and vice versa. Channel balances also facilitate atomic token transfers between several Sovereign Zones.
Cryptarchia
Bedrock Mantle is powered by the Cryptarchia Protocol, a highly scalable, permisionless consensus protocol optimized for privacy and resilience. Cryptarchia is a Private Proof of Stake (PPoS) consensus protocol with properties very similar to Bitcoin. Just like in Bitcoin, where a miner’s hashing power is not revealed when they win a block, we ensure privacy for block proposers by breaking the link between a proposal and its proposer. Unlike Bitcoin, the Logos Blockchain extends block proposer confidentiality to the network layer by routing proposals through the Blend Network, making network analysis attacks prohibitively expensive.
Sovereign Zones
Sovereign Zones bridge the gap between traditional server-based applications and decentralized, permissionless applications.
Sovereign Zones alleviate the contention caused by decentralized applications competing for the limited resources of a single threaded VM (e.g. EVM in Ethereum) while still remaining auditable and fault tolerant. This is achieved through shifting transaction ordering and execution off of the main chain into SZ sequencer nodes, with SZ sequencers posting only a state diff or batch of transactions to Bedrock as an Inscription.
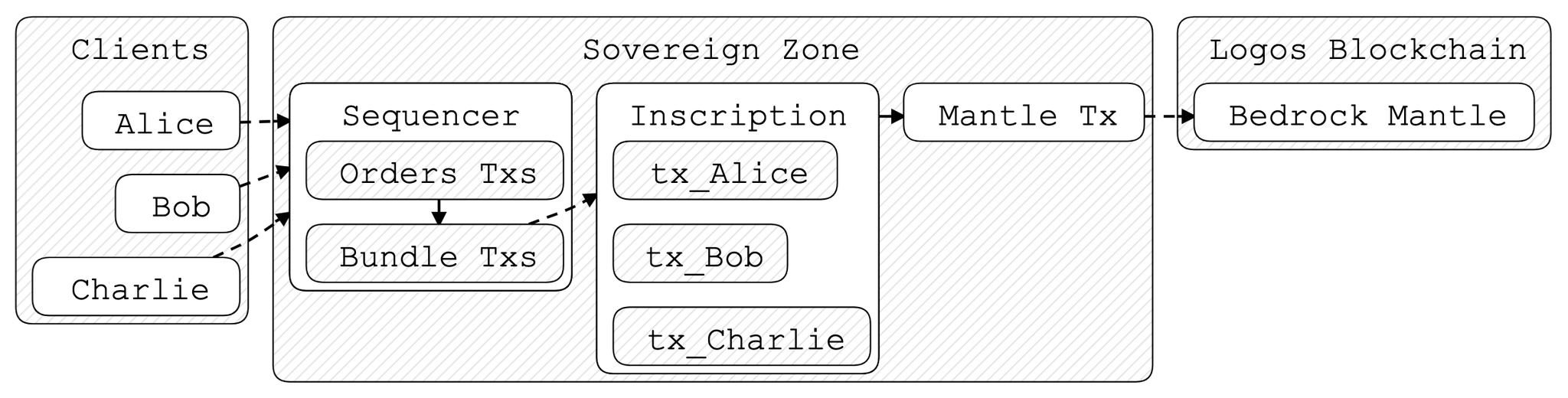
sequenceDiagram
participant C as Clients
participant SZ as Sovereign Zone
box rgba(255,255,255,0.3) Logos Blockchain
participant Mempool as Logos Mempool
participant Cryptarchia
end
C->>SZ: Alice's Tx
C->>SZ: Bob's Tx
C->>SZ: Charlie's Tx
SZ-->>SZ: Order, Execute and Bundle Tx's into an Inscription
SZ ->> Mempool: Inscription Mantle Transaction
Mempool ->> Cryptarchia: Leader includes transaction in next block
Cryptarchia -->> Cryptarchia: Block finalizes after being buried by 2160 blocks
Cryptarchia ->> C: Client observes the SR Inscription finalized (finality)
Sovereign Zones form a virtual chain overlaid on top of the Logos Blockchain. This architecture allows application developers to easily spin up high performance applications while taking advantage of the security of Logos to distribute the application state widely for auditing and resilience purposes.
TEMPLATE-CROSS-CHANNEL-MESSAGING
| Field | Value |
|---|---|
| Name | [Template] Cross-Channel Messaging |
| Slug | 206 |
| Status | raw |
| Category | Informational |
| Editor | Thomas Lavaur [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revisions History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial version. | 2026-03-31 |
| 1.1.0 | [RFC] Enforce NoteId uniqueness. | 2026-04-24 |
| 1.1.1 | [RFC] Simplify Mantle Transaction and Refactor Ledger Operations | 2026-05-06 |
Introduction
This document outlines the cross-channel messaging framework. A channel is a reserved identifier where only authorized keys can post messages on-chain, while anyone can read them. Cross-channel messaging allows different channels (including channels representing a Zone) to communicate and coordinate actions (such as Zone state transitions), enabling interoperability while maintaining security and decentralization.
Reference: Mantle.
Objectives
The primary objectives of this framework are to:
- Enable secure communication between different channels without compromising decentralization.
- Support both synchronous and asynchronous messaging patterns to accommodate different use cases and trust assumptions.
- Provide a standard message format while allowing flexibility for custom implementations.
- Provide atomicity guarantees for cross-channel operations when required.
Requirements
The cross-channel messaging framework must satisfy the following requirements:
- Synchronous operations must provide atomicity guarantees (all-or-nothing execution).
- Asynchronous operations must handle finality periods correctly.
- The framework should be flexible enough to support various channel implementations.
Overview
Cross-channel messaging allows different channels to interact and coordinate. The framework supports two distinct messaging modes.
- Asynchronous Messaging: Channels send messages to each other without requiring real-time and/or off-chain coordination. The receiving channel waits for the sending channels message to achieve finality on the chain before processing it. This approach minimizes coordination overhead but introduces latency due to finality requirements.
- Synchronous Messaging: Multiple channels coordinate to include their messages in a single Mantle Transaction. All messages in the transaction either succeed or fail together, providing strong consistency guarantees. This requires off-chain coordination between sequencers but enables use cases like atomic Zone state transitions. Since each Inscription Operation proof is a signature of the entire Mantle Transaction hash, the signature cannot be reused in a different context, for example, posting an Inscription alone after signing it as part of a coordinated transaction.
| Pros | Cons | |
|---|---|---|
| Asynchronous messaging | - Simple coordination model. - Channels operate independently. - Higher decentralization (no trusted coordinator). | - Higher latency due to waiting for finality. - No atomicity across channels (possible partial failures). |
| Synchronous messaging | - Strong atomicity guarantees across channels (all-or-nothing). - Lower end-to-end latency vs waiting for async finality. - Better suited for cross-channel financial operations (atomic swaps, cross-channel transfers). | - Requires off-chain coordination between sequencers. - Depends on availability of all participating sequencers. - More complex orchestration and implementation. |
The coordinator typically pays fees and must be trusted for timing of submission. Channel designers should implement mechanisms if they want to share these fees, either by:
- Requesting to cover a part of the coordinator's fee costs as part of the operation (e.g., including fee reimbursement in a Zone's state transition logic).
- Establishing external fee recovery protocols where the coordinator is compensated through off-chain agreements or separate on-chain transactions.
- Using a shared note to pay using a threshold Eddsa25519 public key.
Use Cases
Channels should choose between synchronous and asynchronous messaging based on their requirements:
Use Synchronous Messaging when:
- Atomicity is required (operations must all succeed or all fail).
- Low latency is important (faster than waiting for asynchronous finality).
- Coordinating sequencers have established trust and communication pathways.
- The use case justifies the additional coordination complexity.
Use Asynchronous Messaging when:
- Operations can be processed independently.
- Simplicity and decentralization are prioritized over latency.
- Sequencer coordination is difficult or undesirable.
- The application can handle eventual consistency.
Message Flow
Cross-channel messaging follows this general flow:
- The source channel's sequencer generates a message for one or more destination channels.
- The message is included in a Mantle Transaction (through an InscriptionOperation):
- For asynchronous messaging: the channel's sequencer includes it in a separate transaction.
- For synchronous messaging: a coordinator gathers Operations from different channel sequencers and includes them in a common transaction.
- Once the Mantle Transaction is built, each channel sequencer signs their Operation using the Mantle Transaction hash as input.
- The transaction is submitted to the chain:
- For asynchronous messaging: by the channel's sequencer.
- For synchronous messaging: by the coordinator.
Protocol
Asynchronous Messaging
Asynchronous messaging allows channels to send messages to each other without requiring real-time and off-chain coordination between sequencers. This mode prioritizes simplicity and independent operation over low latency and atomicity.
Message Format
We provide a recommended data structure for formatting messages in Inscriptions. This structure uses compact binary encoding to minimize on-chain storage costs while clearly indicating the message recipient:
Inscription = MessageCount *Messages
MessageCount = Byte
Messages = Destination MessageLength *Message
Destination = ChannelId
MessageLength = UINT64
Message = UINT32 *Byte
ChannelId = 4 *Byte
The structure consists of:
- MessageCount: A single byte indicating the number of messages in this Inscription (supports up to 255 messages).
- Destination: A 32-byte number identifying the target channel.
- MessageLength: An 4-byte unsigned integer specifying the total length of all messages for this destination in bytes.
- Message: The actual message payload, prefixed by a 3-byte length field indicating the size of each individual message in bytes.
Note on Format Flexibility: This structure is not enforced by the blockchain. It serves as a recommended standard for interoperability. Channels can choose to:
- Parse messages themselves according to this format.
- Implement their own custom message formats based on specific requirements. However, following the recommended format ensures better interoperability with other channels in the ecosystem.
Processing Flow
The asynchronous messaging process follows these steps:
- Message Creation: The source channels sequencer creates a message according to the recommended format (or their custom format) and includes it in an Inscription within a Mantle Transaction.
- Transaction Submission: The sequencer signs the Operation and submits the Mantle Transaction to the chain independently.
- Finality Wait: The transaction propagates through the network and eventually achieves finality on-chain. This guarantee that this transaction wont be reverted due to a reorganization.
- Message Observation: Destination channels sequencers monitor the chain for messages addressed to their ChannelId. When a relevant message is detected and has achieved finality, the channel can safely process it.
- State Transition: The destination channel checks that the message is valid and publishes a corresponding state transition in its own Inscription.

Security Considerations
Asynchronous messaging relies on the finality guarantees of the underlying chain. Destination channels must:
- Wait for sufficient confirmation before processing messages to avoid issues with chain reorganizations. Channels can choose a specific probability threshold or wait for finality to achieve a 100% guarantee.
- Since the chain does not verify channels' Inscriptions, the destination channel must understand the source channel's logic to determine whether the message is valid.
Synchronous Messaging
Synchronous messaging enables atomic cross-channel operations by including multiple messages in a single Mantle Transaction. All messages either succeed or fail together, providing strong consistency guarantees across multiple channels.
Atomicity Guarantees
The atomicity property is crucial for use cases that require coordinated changes across multiple channels. Examples include:
- Atomic swaps: Trading assets between two zones where both transfers must succeed or both must fail. It involves executing a CHANNEL_WITHDRAW, a CHANNEL_DEPOSIT and two state transitions encoded as CHANNEL_INSCRIPTION.
- Cross-channel funds transfers: Moving assets from one channel to another with guarantees that the asset is directly deposited to the other channel.
Without atomicity, these operations would be vulnerable to partial failures, leading to inconsistent global state.
Example of an atomic transfer
# Build the inscription that sends a transfer from Zone A to Zone B
sending = Inscription(
channel=CHANNEL_ZONE_A,
inscription=b"Alice burns 5 tokens to send to Bob in Zone B",
parent=hash(PREVIOUS_ZONE_A_INSCRIPTION)
signer=sequencer_of_zone_a
)
# Build the inscription that receives the transfer from Zone A to Zone B
receiving = Inscription(
channel=CHANNEL_ZONE_B,
inscription=b"Bob mints 5 tokens, received from Alice in Zone A",
parent=hash(PREVIOUS_ZONE_B_INSCRIPTION)
signer=sequencer_of_zone_b
)
# Sequencer of Zone A encodes the withdrawal from Zone A
withdrawal = ChannelWithdraw(
channel=CHANNEL_ZONE_A,
outputs=[temporary_transfer_note]
)
# Sequencer of zone B encodes the deposit to Zone B
deposit = ChannelDeposit(
channel=CHANNEL_ZONE_B,
inputs=[temporary_transfer_note],
)
# Transfer
Trasfer = Transfer(
inputs=[<sequencer_zone_a_note_id>],
outputs=[<change_note>]
)
# Wrap it in a transaction
tx = MantleTx(
ops=[Op(opcode=CHANNEL_INSCRIBE, payload=encode(sending)),
Op(opcode=CHANNEL_INSCRIBE, payload=encode(receiving)),
Op(opcode=CHANNEL_WITHDRAW, payload=encode(withdrawal)),
Op(opcode=CHANNEL_DEPOSIT, payload=encode(deposit)),
Op(opcode=TRANSFER, payload=encode(transfer))],
)
# Sign the transaction
signed_tx = SignedMantleTx(
tx=tx,
# Sequencer A is responsible for Zone A so it signs the
# Inscription and Withdraw of Zone A while Sequencer B, who signs the
# Inscription and the Deposit, doesn't require a proof
# Note that the withdraw OpProof has a ChannelWitdrawOpProof structure
op_proofs=[Ed25519_sign(mantle_txhash(tx), sequencer_of_zone_a_sk),
Ed25519_sign(mantle_txhash(tx), sequencer_of_zone_b_sk),
[[Ed25519_sign(mantle_txhash(tx), sequencer_of_zone_a_sk)],[0]],
None,
transfer.prove(sequencer_of_zone_a_sk)]
)
# Send the transaction to the mempool
mempool.push(signed_tx)
Signature Coordination
Synchronous messaging requires coordination between sequencers from different channels. The process works as follows:
- Transaction Construction: One sequencer (the coordinator) constructs a Mantle Transaction containing multiple channel operations for different channels. Each Operation represents an Inscription, withdraw or deposit for a specific channel or a transfer. In order to construct this transaction, the coordinator must gather the different intentions of the affected channels sequencers. For example, a Zone sequencer needs to inform another Zone sequencer that a user is transferring tokens so the receiving Zone can mint the token in its state.
- Signature Collection: Each participating sequencer receives the complete Mantle Transaction and verifies it. If all checks pass, the sequencer builds a proof for the Operations of its channel which includes the signature of the Mantle Transaction hash. The signature covers the entire transaction, ensuring that all sequencers approve the atomic Operations as a whole and preventing signature replay attacks.
- Coordination and Submission: The coordinator collects Operation proofs from all participating sequencers. Once all required proofs are gathered, the coordinator assembles the fully signed transaction and submits it to Bedrock.
- Atomic Execution: The chain validates the Mantle Transaction. If any validation check fails, the entire transaction is rejected and no state changes are applied. If all checks pass, all Operations are executed atomically.
Coordination Failure Handling: If coordination fails (e.g., a sequencer goes offline or refuses to sign), the atomic operation cannot proceed. The sequencers must either:
- Wait for the unavailable sequencer to return and complete the protocol.
- Abort the operation and potentially fall back to asynchronous messaging.
- Initiate a new coordination round with modified parameters. This coordination requirement is the main trade-off of synchronous messaging: it provides stronger guarantees but requires more complex orchestration and is susceptible to availability issues of the involved sequencers.

Security Considerations
Synchronous messaging introduces additional security considerations:
- While the coordinator cannot forge signatures, they control transaction submission timing. Sequencers should implement timeouts and designate backup coordinators in the case where the coordinator aborts or delays the posting of the transaction.
- The protocol's liveness depends on all participating sequencers being available and responsive.
- Sequencers must agree on fee payment as the coordinator is the only one paying for submitting the transaction. The fee construction is internal to the Channel sequencers and is out of the scope of this document.
And trust assumptions:
- Each participating sequencer is assumed to verify the entire Mantle Transaction and only sign transactions that are valid with respect to its own channel rules.
- The protocol does not enforce or verify this behavior on-chain.
- Bedrock does not validate channel-specific Inscription semantics. As a result, correctness of cross-channel operations depends on off-chain verification by sequencers.
ANONYMOUS-LEADERS-REWARD-PROTOCOL
| Field | Value |
|---|---|
| Name | Anonymous Leaders Reward Protocol |
| Slug | 85 |
| Status | raw |
| Category | Standards Track |
| Editor | Thomas Lavaur [email protected] |
| Contributors | David Rusu [email protected], Mehmet Gonen [email protected], Álvaro Castro-Castilla [email protected], Frederico Teixeira [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-18 —
58b5698— chore(blockchain): migrate contributor emails to @logos.co (#338) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-03-30 |
Introduction
In many blockchain designs, leaders receive rewards for producing valid blocks. Traditionally, this reward is linked directly to the block or its producer, potentially opening the door to manipulation or self-censorship, where leaders may avoid including certain transactions or messages out of fear of retaliation or reputational harm. As the Logos Blockchain must protect its nodes and ensure that they do not need to engage in self-censorship, we must design a reward mechanism that preserves the anonymity of block leaders while maintaining correctness and preventing double rewards.
This document specifies the mechanism for anonymous reward distribution based on voucher commitments, nullifiers, and zero-knowledge (ZK) proofs. The goal is to ensure that block leaders can claim their rewards without linking them to specific blocks and without revealing their identities.
Overview
The protocol introduces a concept of vouchers to unlink the block reward claim from the block itself. Instead of directly crediting themselves in the block, leaders include a commitment (a zkhash in this protocol) to a secret voucher. These commitments are gathered into a Merkle tree. In the first block of an epoch, we add all vouchers from the previous epoch to the voucher Merkle tree, accumulating the vouchers together in a set and guaranteeing a minimal anonymity set. Leaders may anonymously claim their reward using a ZK proof later, proving the ownership of their voucher. This is summarized in the following diagram:
graph LR
A[Leader block] --> B[reward voucher]
B --> F[wait until next epoch] --> C[Merkle tree]
C --> D[Claim with ZK proof]
D --> E[Reward]
By anonymizing the identity of block leaders at the time of reward claiming, the protocol removes any direct link between block production and the recipient of the reward. This is essential to prevent self-censorship behaviors. With anonymous claiming, leaders are free to act honestly according to protocol rules without concern for external consequences, thus improving the overall neutrality and robustness of the network.
Key properties of the protocol:
- Anonymity: Block rewards are unlinkable to the blocks they originate from (avoiding deanonymization).
- Soundness: No reward can be claimed twice.
In parallel, the blockchain maintains the value leaders_rewards accumulating the rewards for leaders over time. Each voucher included in the Merkle tree represents the same share of leaders_rewards. Just like for voucher inclusion, more rewards are added to this variable on an epoch-by-epoch basis, which guarantees a stable and equal claimable reward for leaders over an epoch.
Protocol
Voucher creation and inclusion
When producing a block, a leader performs the following:
- Generate a one-time random secret .
- Compute the commitment:
voucher_cm := zkHash(b"LEAD_VOUCHER_CM_V1, voucher). - Include the
voucher_cmin the block header.
Each voucher_cm is added to a Merkle tree of voucher commitments by validators during the execution of the first block of the following epoch, maintained throughout the entire blockchain history by everyone.
Claiming the reward
Protocol
Each leader may submit a LEADER_CLAIM Operation to claim their reward. This Operation includes:
- The Merkle root of the global voucher set when the Mantle Transaction containing the claim is submitted.
- A Proof of Claim.
This Operation increases the balance of a Mantle Transaction by the leader reward amount, letting the leader move the funds as desired through the Ledger transaction or another Operation.
This means that a leader may use their funds directly, getting their reward and using them atomically.
Note that every leader will receive a reward that is independent of the block content to avoid de-anonymization. This means that the fees of the block cannot be collected by the leader directly, or need to be pooled for all the leaders.
Leaders Reward
At the start of epoch N+1, validators aggregate the leaders rewards of epoch N into the leader rewards variable. The amount of the reward claimable with a voucher corresponds to a share of the leaders_rewards. This share is exactly equal to the total value of rewards divided by the size of the anonymity set of leaders, that is:
This amount is stable through an epoch because when a leader withdraws, both the pool value and the number of unclaimed vouchers decrease proportionally, so the price per share remains unchanged. However, the share value will vary across epochs if the leader rewards are variable.
Validation
Nodes validate a LEADER_CLAIM Operation by:
- Verifying the ZK proof.
- Checking that
voucher_nfis not already in the voucher nullifier set. - Executing the reward logic:
- Add the
voucher_nfto the voucher nullifier set to prevent claiming the same reward more than once. - Increase the balance of the Mantle Transaction by the share amount.
- Decrease the value of the
leaders_rewardsby the same amount.
Details
Unlinking Block Rewards from Proposals
Each reward voucher is a cryptographic commitment derived from a voucher secret. This commitment, when included in the block header, reveals no information about the block producer's identity or the actual secret voucher. It is computationally infeasible to reverse the commitment to retrieve the voucher secret.
Crucially, when the leader reward is claimed and the voucher nullifier revealed, a third party cannot link this nullifier to the initial voucher commitment. A reward is claimable if its reward voucher is in the reward voucher set and its voucher nullifier is not in the voucher nullifier set.
The reward voucher set will be maintained as a Merkle tree of depth 32, and validators will be required to hold the frontier of the MMR in memory to continue appending to the set. The voucher nullifier set will be maintained as a searchable database.
ZK Proof of Membership
When claiming a reward, the leader provides a ZK proof that they know a leaf in the global Merkle tree of reward vouchers and the preimage of that leaf. Crucially, the ZK proof does not reveal which leaf is being proven. The verifier only learns that some valid leaf exists in the tree for which the prover knows the secret voucher. This property ensures that the claim cannot be linked to any specific block header or reward voucher commitment.
Preventing Double Claims Without Breaking Privacy
To prevent double claiming, the leader derives a voucher nullifier. This nullifier is unique to the voucher but reveals nothing about the original reward voucher or block. It acts as a one-way identifier that allows nodes to track whether a voucher has already been claimed, without compromising the anonymity of the claim.
BEDROCK-GENESIS-BLOCK
| Field | Value |
|---|---|
| Name | Bedrock Genesis Block |
| Slug | 90 |
| Status | raw |
| Category | Standards Track |
| Editor | David Rusu [email protected] |
| Contributors | Hong-Sheng Zhou, Thomas Lavaur [email protected], Marcin Pawlowski [email protected], Mehmet Gonen [email protected], Álvaro Castro-Castilla [email protected], Daniel Sanchez Quiros [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-18 —
58b5698— chore(blockchain): migrate contributor emails to @logos.co (#338) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258)
Revisions History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-02-12 |
| 1.1.0 | [RFC] Make Ledger Transaction an Operation Renamed Nomos to Logos Blockchain Remove notions of DA Minor fix in gas price | 2026-03-27 |
| 1.1.1 | [RFC] Simplify Mantle Transaction and Refactor Ledger Operations | 2026-05-06 |
Introduction
The Genesis Block defines the starting state for the Bedrock chain, including the initial bedrock service providers, LGO token distribution and protocol parameters. Its design draws from best practices in the Ouroboros family of protocols (notably Praos and Genesis), as well as privacy and resilience advances from Cryptarchia and related research. The Genesis Block is the root of trust for all subsequent protocol operations and must be constructed in a way that is deterministic, verifiable, and robust against long-range or bootstrap attacks.
Overview
The Genesis Block establishes the initializing values for the various protocols and services. This includes the initial token distribution, initial nodes participating in Blend Network and the result of running the epoch nonce ceremony.
The block body is a single Mantle Transaction (see Mantle) containing a Transfer Operation distributing the notes to initial token holders. The bedrock services are initialized through SDP_DECLARE Operations embedded in the Mantle Transaction’s Operations list and protocol initializing constants are encoded through a CHANNEL_INSCRIBE Operation also embedded in the Operations list.
Not all protocol constants are encoded in the Genesis block. The principle we use to decide whether a value should be in the Genesis block or not is whether it is a value that is derived from blockchain activity or whether it is updated through a protocol update (hard / soft fork). For example, the epoch nonce is updated through normal blockchain Operations and therefore it should be specified in the Genesis block. Gas constants are only changed through protocol updates and hard forks and therefore they will be hardcoded in the node implementation.
Genesis Block Data Structure
The Genesis Block is composed of the Genesis Block Header and the Genesis Mantle Transaction (there is a single transaction in the genesis block). The Mantle Transaction contains all information necessary for initializing Bedrock Services and Cryptarchia state, as well as distributing the initial tokens to stakeholders.
Initial Token Distribution
Initial tokens will be distributed through a Transfer Operation containing zero inputs and one output note for each initial stakeholder. Note that since the Ledger is transparent, the initial stake allocation is visible to everyone. Those wishing to hide their initial stake may opt to subdivide their note into a few different notes of equal value.
In order to participate in the Cryptarchia lottery, stakeholders must generate their note keys in accordance with the Proof of Leadership protocol specified at Protocol.
The initial state of the Ledger will be derived through normal execution of this Transfer Operation, that is, each output’s note ID will be added to the unspent notes set.
Example
STAKE_DISTRIBUTION = Transfer(
inputs=[],
outputs=[
Note(value=1000, public_key=STAKE_HOLDER_0_PK),
Note(value=2000, public_key=STAKE_HOLDER_1_PK),
Note(value=1500, public_key=STAKE_HOLDER_2_PK),
# ...
]
)
Initial Service Declarations
Blend Network MUST initialize its set of providers. This is done through a set of SDP_DECLARE Operations in the Genesis Mantle Transaction.
Blend enforces a minimal network size for the service to be active. Thus, in order to have an active Blend service at Genesis, we MUST have at least as many declarations in the Genesis block to meet Blend service’s minimal network size Minimal Network Size.
Example
BLEND_DECLARATIONS = [
Declaration(
msg=DeclarationMessage(
ServiceType.BLEND, ["ip://1.1.1.1:3000"], PROVIDER_ID_0, ZK_ID_0
),
locked_note_id=STAKE_DISTRIBUTION_TX.output_note_id(0)
),
# ... 32 total declarations
]
SERVICE_DECLARATIONS = BLEND_DECLARATIONS
Cryptarchia Parameters
Cryptarchia is initialized with the following parameters:
-
genesis_time: ISO 8601 encoded timestamp. Cryptarchia uses slots as a measure of time offset from some start time. This timestamp must be agreed upon by all nodes in order to have a common clock. -
chain_id: string. It is useful to differentiate testnets from mainnet. To avoid confusion, we place the chain ID in the Genesis block to guarantee that the networks are disjoint. -
genesis_epoch_nonce: 32 bytes, hex encoded. The initial source of randomness for the Cryptarchia lottery. The process for selecting this value is described in detail at Epoch Nonce Ceremony.
These parameters are encoded in the Genesis block as an inscription sent to the null channel.
Example
from datetime import datetime
CHAIN_ID = "logos-blockchain-mainnet"
GENESIS_TIME = "2026-01-05T19:20:35+00:00"
GENESIS_EPOCH_NONCE = "abcdef1234567890abcdef1234567890abcdef1234567890abcdef1234567890"
chain_id_enc = CHAIN_ID.encode("utf-8")
chain_id_len = len(chain_id_enc).to_bytes(8, "little")
genesis_time = int(datetime.fromisoformat(GENESIS_TIME).timestamp()).to_bytes(8, "little")
genesis_epoch_nonce = bytes.fromhex(GENESIS_EPOCH_NONCE)
inscription = chain_id_len + chain_id_enc + genesis_time + genesis_epoch_nonce
# >>> inscription.hex()
# '0d000000000000006e6f6d6f732d6d61696e6e6574030f5c6900000000abcdef1234567890abcdef1234567890abcdef1234567890abcdef1234567890'
CRYPTARCHIA_INSCRIPTION = Inscribe(
channel=bytes(32),
inscription=inscription
parent=bytes(32),
signer=Ed25519PublicKey_ZERO,
)
Epoch Nonce Ceremony
The initial epoch nonce value governs the Cryptarchia lottery randomness for the first epoch. It must be revealed AFTER the initial stake distribution has been frozen. This is done to prevent any stakeholders from gaining an unfair advantage from prior knowledge of the lottery randomness.
The protocol for generating the initial randomness nonce can be found below.
- Schedule Epoch Nonce Ceremony Event:
We must fix well in advance when this epoch nonce ceremony will take place, let
tdenote the time of the Epoch Nonce Ceremony, broadcasttwidely.
The STAKE_DISTRIBUTION must be finalized before t to ensure a fair Cryptarchia slot lottery.
- Randomness Collection: We collect the entropy from multiple randomness sources:
| Entropy Source | Details |
|---|---|
Bitcoin block hash immediately after time t, denoted as . | Block hash can be found on blockchain.com ’s bitcoin block explorer, e.g. https://www.blockchain.com/explorer/blocks/btc/905030 |
Ethereum block hash immediately after time t, denoted as . | Block hash can be found in the more details section of when viewing a block on etherscan, e.g. https://etherscan.io/block/22894116 |
DRAND beacon value for the round immediately after t, denoted as . | Use the default beacon, and find the round number corresponding to t. https://api.drand.sh/v2/beacons/default/rounds/1234 |
- Randomness Derivation: Once all above entropy contributions, i.e., are collected, then we can compute the initial epoch randomness as:
where is a collision-resistant zkhash function.
Genesis Mantle Transaction
The initial stake distribution, service declarations and Cryptarchia inscription are components of the Genesis Mantle Transaction. This is the single transaction that forms the body of the Genesis block.
GENESIS_MANTLE_TX = MantleTx(
ops=[STAKE_DISTRIBUTION, CRYPTARCHIA_INSCRIPTION] + SERVICE_DECLARATIONS,
)
Block Header Fields
The Genesis Block header fields are set to the following values:
bedrock_version: Protocol version (e.g., 1).parent_block: 0 (as this is the first block).slot: 0 (the Genesis slot).block_root: Block Merkle root over the (single) initial transaction.proof_of_leadership: Stubbed leadership proof.leader_voucher: 0 (as there is no leader block reward for the initial block).entropy_contribution: 0 (no entropy is provided through the initial PoL).proof: Null Groth16Proof, all values are set to zero.leader_key: Null PublicKey.
Example
GENESIS_HEADER = Header(
bedrock_version=1,
parent_block=0,
slot=0,
block_root=block_merkle_root([GENESIS_MANTLE_TX]),
proof_of_leadership=ProofOfLeadership(
leader_voucher=bytes(32),
entropy_contribution=bytes(32),
proof=Groth16Proof(G1_ZERO, G2_ZERO, G1_ZERO),
leader_key=Ed25519PublicKey_ZERO,
)
)
# distribute NMO to all stakeholders
STAKE_DISTRIBUTION = Transfer(
inputs=[],
outputs=[
Note(value=1000, public_key=STAKE_HOLDER_0_PK),
Note(value=2000, public_key=STAKE_HOLDER_1_PK),
Note(value=1500, public_key=STAKE_HOLDER_2_PK),
# ...
]
)
# set Cryptarchia parameters
CRYPTARCHIA_PARAMS = {
"chain_id": "logos-mainnet",
"genesis_time": "2026-01-05T19:20:35Z",
"genesis_epoch_nonce": "abcdef1234567890abcdef1234567890abcdef1234567890abcdef1234567890",
}
CRYPTARCHIA_INSCRIPTION = Inscribe(
channel=bytes(32),
inscription=json.dumps(CRYPTARCHIA_PARAMS).encode("utf-8"),
parent=bytes(32),
signer=Ed25519PublicKey_ZERO,
)
# service declarations
BLEND_DECLARATIONS = [
Declaration(
msg=DeclarationMessage(ServiceType.BLEND, ["ip://1.1.1.1:3000"], PROVIDER_ID_0, ZK_ID_0),
locked_note_id=STAKE_DISTRIBUTION.output_note_id(0)
),
# ... more declarations
]
SERVICE_DECLARATIONS = BLEND_DECLARATIONS
# build the genesis Mantle Transaction
GENESIS_MANTLE_TX = MantleTx(
ops=[STAKE_DISTRIBUTION, CRYPTARCHIA_INSCRIPTION] + SERVICE_DECLARATIONS,
)
GENESIS_HEADER = Header(
bedrock_version=1,
parent_block=bytes(32),
slot=0,
block_root=block_merkle_root([GENESIS_MANTLE_TX]),
proof_of_leadership=ProofOfLeadership(
leader_voucher=bytes(32),
entropy_contribution=bytes(32),
proof=Groth16Proof(G1.ZERO, G2.ZERO, G1.ZERO),
leader_key=Ed25519PublicKey_ZERO,
)
)
GENESIS_BLOCK = (GENESIS_HEADER, [GENESIS_MANTLE_TX])
Sample Genesis Block
Initializing Bedrock
Bedrock is initialized by executing the Mantle Transaction without validating the Mantle Operations. No validation or execution is done for the Genesis block header; in particular, processing of proof_of_leadership is skipped.
Mantle Ledger Initialization
The Transfer Operation should be executed without checking that the transaction is balanced. However, other validations are checked, e.g. that output note values are positive and smaller than the maximum allowed value. The result of normal transfer execution adds all outputs to the Ledger.
Cryptarchia Initialization
The Mantle Transaction contains an inscription sent to the null channel containing the parameters for initializing Cryptarchia.
The Cryptarchia slot clock is initialized to genesis_time, LIB is set to the Genesis block and the epoch state is then initialized:
Initial Epoch State
Cryptarchia progresses in epochs where the variables governing the lottery are fixed for the duration of an epoch and the activity during that epoch is used to derive the values of those variables for the next epoch. These variables taken together are called the Epoch State. (see Epoch State).
To initialize the Epoch State, we derive the epoch variables from the genesis block.
- : the epoch nonce is taken directly from the
genesis_epoch_nonce. - : Eligible leader commitment is set to the the Ledger Root over all notes from the initial token distribution. The derivation of this root is specified in Ledger Root.
- : The initial estimate of total stake will be the total tokens distributed at genesis.
Bedrock Services Initialization
Blend network is initialized through normal Mantle Transaction execution. The SDP_DECLARE Operations in the Genesis Mantle Transaction will create the initial set of providers in each service.
During normal operations, Blend services would wait until a block is deep enough to be finalized, but for the Genesis block, we consider it finalized by definition and so Blend will immediately use the provider set without the usual finalization delay.
References
- Ouroboros Praos: https://eprint.iacr.org/2017/573.pdf
- Ouroboros Genesis: https://eprint.iacr.org/2018/378.pdf
- Ouroboros Crypsinous: https://eprint.iacr.org/2018/1132.pdf
- Cardano Shelley Genesis File Format: https://cardano-course.gitbook.io/cardano-course/handbook/protocol-parameters-and-configuration-files/shelley-genesis-file
- Cardano CIP-16 Key Serialisation: https://cips.cardano.org/cip/CIP-16
BLOCK-CONSTRUCTION-VALIDATION-AND-EXECUTION
| Field | Value |
|---|---|
| Name | Block Construction, Validation and Execution |
| Slug | 93 |
| Status | raw |
| Category | Standards Track |
| Editor | Marcin Pawlowski [email protected] |
| Contributors | Thomas Lavaur [email protected], Daniel Sanchez Quiros [email protected], David Rusu [email protected], Álvaro Castro-Castilla [email protected], Mehmet Gonen [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-18 —
58b5698— chore(blockchain): migrate contributor emails to @logos.co (#338) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258)
Revisions History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-12-03 |
| 1.1.0 | Removed service_rewards due to updated SERVICE-REWARD-DISTRIBUTION-PROTOCOL. Extended the Block Execution logic with rewards distribution due to updated SERVICE-REWARD-DISTRIBUTION-PROTOCOL. Removed Block Samples subsection of the Batch verification of ZK proofs from the Annex. Reordered the Block Execution steps to enable immediate use of reward notes as inputs for transactions included in the proposal. | 2026-03-27 |
| 1.1.1 | [RFC] Simplify Mantle Transaction and Refactor Ledger Operations | 2026-05-06 |
Introduction
In this document, we present the specification defining the construction of the block proposal, its validation, and execution. We define the block proposal construction that contains references to transactions (from the mempool) instead of a complete transaction to limit its length. The raw block size increases with the size of transactions it contains up to 1 MB, and the proposal compresses its size down to 33 kB, which saves the bandwidth necessary to broadcast new blocks.
Overview
For the consensus protocol to make progress, a new leader is elected through the leader lottery. The new leader is in possession of a proof of leadership (PoL) that confirms that it is indeed the leader. The main objective of the leader is to construct a new block, hence becoming a block builder, and share it with other members of the network as a block proposer. The block must be correctly constructed; otherwise, it will be rejected by the consensus nodes who are validating every block. Only validated blocks are executed, which means that the transactions included in the block are interpreted by all nodes, and the state of the chain is modified according to the instructions embedded in the transactions.
High-level Flow
Below, we present a high-level description of the block lifecycle. The main focus of this section is to build an intuition on the block construction, validation, and execution.
-
A leader is selected. The leader becomes a block builder.
-
The block builder constructs a block proposal.
-
The block builder selects the latest block (parent) as the reference point for the chain state update.
-
The block builder selects valid Mantle Transactions (as defined in Mantle) from its mempool and includes references to them in the proposal.
-
The block builder populates the block header of the block proposal.
-
The block proposer sends the block proposal to the Blend network.
-
The validators receive the block proposal.
-
The validators validate the block proposal.
-
They validate the block header.
-
They retrieve complete transactions from their mempool that are referred in the block.
-
They validate each transaction included in the block.
-
The validators execute the block proposal.
-
They derive the new blockchain state from the previous one by executing transactions as defined in Mantle.
-
They update the different variables that need to be maintained over time.
-
They execute the Service Reward Distribution Protocol to generate reward notes locally.
Constructions
Hash
We are using two hashing algorithms that have the same output length of 256 bits (32 bytes) that are Poseidon2 and Blake2b.
Block Proposal
A block proposal, instead of containing complete Mantle Transactions of an unlimited size, contains references of fixed size to the transactions. Therefore, the size of the proposal is constant and it is 33129 bytes.
We define the following message structure:
class Proposal: # 33129 bytes
header: Header # 297 bytes
references: References # 32768 bytes
signature: Ed25519Signature # 64 bytes
Where:
-
headeris the header of the proposal; defined below: Header. -
referencesis a set of 1024 references to transactions of ahashtype; the size of thehashtype is 32 bytes and is the transaction hash as defined in Mantle Transaction. -
signatureis the signature of the completeheaderusing theleader_keyfrom theProofOfLeadership; the size of theEd25519Signaturetype is 64 bytes.The length of the
referenceslist must be preserved to maintain the message’s indistinguishability in the Blend protocol. Therefore, the list must be padded with zeros when necessary.
Header
class Header: # 297 bytes
bedrock_version: byte # 1 byte
parent_block: hash # 32 bytes
slot: SlotNumber # 8 bytes
block_root: hash # 32 bytes
proof_of_leadership: ProofOfLeadership # 224 bytes
Where:
bedrock_versionis the version of the proposal message structure that supports other protocols defined in linked reference; its size is 1 byte and is fixed to0x01.parent_blockis the block ID (Cryptarchia Protocol) of the parent block, validated and accepted by the block builder. It is used for the derivation of theAgedLedgerandLatestLedgervalues necessary for validating the PoL; the size of thehashis 32 bytes.slotis the consensus slot number; the size of theSlotNumbertype is 8 bytes.block_rootis the root of the Merkle tree constructed from transaction hashes (defined in Mantle Transaction) used for constructing thereferenceslist in themempool_ransactions; the size of thehashis 32 bytes.proof_of_leadershipis the proof confirming that the sender is the leader; defined below: Proof of Leadership.
References
class References: # 32768 bytes
mempool_transactions: list[hash] # 1024 * 32 bytes
Where mempool_transactions is a set of up to 1024 references to transactions of a hash type; the size of the hash type is 32 bytes and is the transaction hash as defined in Mantle Transaction.
Proof of Leadership
class ProofOfLeadership: # 224 bytes
leader_voucher: RewardVoucher # 32 bytes
entropy_contribution: zkhash # 32 bytes
proof: ProofOfLeadership # 128 bytes
leader_key: Ed25519PublicKey # 32 bytes
Where:
leader_voucheris the voucher value used for retrieving the reward by the leader for proposal; the size of theRewardVoucheris 32 bytes.entropy_contributionis the output of the PoL contribution for Cryptarchia entropy; the size of thezkhashtype is 32 bytes.proofis the proof confirming that the proposal is constructed by the leader; the size of theProofOfLeadershiptype is 128 bytes (2 compressed and 1 compressed BN256 elements).leader_keyis the one-timeEd25519PublicKeyused for signing theProposal. This binds the content of the proposal with theProofOfLeadership; the size of theEd25519PublicKeytype is 32 bytes.
Proposal Construction
In this section, we explain how the block proposal structure presented above is populated by the consensus leader.
The block proposal is constructed by the leader of the current slot. The node becomes a leader only after successfully generating a valid PoL for a given (Epoch, Slot).
Prerequisites
Before constructing the proposal, the block builder must:
- Select a valid parent block referenced by
ParentBlockon which they will extend the chain. - Derive the required Ledger state snapshots
AgedLedgerandLatestLedgerfrom the state of the chain including the last block. - Select a valid unspent note winning the PoL.
- Generate a valid PoL proving leadership eligibility for
(Epoch, Slot)based on the selected note. Attach the PoL to a one-time Ed25519 public key used to sign the block proposal.
Only after the PoL is generated can the block proposal be constructed (see Proof of Leadership).
Construction Procedure
- Initialize proposal metadata with the last known state of the blockchain. Set the:
header:bedrock_versionparent_blockslotblock_rootproof_of_leadership:leader_voucherentropy_contributionproofleader_key
-
Construct the
mempool_transactionsobject: -
Select Mantle transactions:
- Choose up to
1024validSignedMantleTxfrom the local mempool. - Ensure each transaction:
- Is valid according to Mantle.
- Has no conflicts with others (e.g., two transactions trying to spend the same note).
- Choose up to
-
Derive references values:
references: list[hash] = [mantle_txhash(tx) for tx in mempool_transactions]
- Compute the
header.block_rootas the root of the Merkle tree constructed from themempool_transactionstransactions used to buildreferences. - Sign the block proposal header.
signature = Ed25519.sign(leader_secret_key, header)
- Assemble the block proposal.
proposal = Proposal(
header,
references,
signature
)
The PoL must have been generated beforehand and bound to the same Ledger view as mentioned in the Prerequisites.
The constructed proposal can now be broadcast to the network for validation.
Block Proposal Reconstruction
Given a block proposal, we assume transaction maturity. This means that the block proposal must include transactions from the mempool that have had enough time to spread across the network to reach all nodes. This ensures that transactions are widely known and recognized before block reconstruction.
This transaction maturity assumption holds true because the block proposal must be sent through the Blend Network before it reaches validators and can be reconstructed. The Blend Network introduces significant delay, ensuring that transactions referenced in the proposal have reached all network participants. This approach is crucial for maintaining smooth network operation and reducing the risk that proposals get rejected due to transactions being unavailable to some validators. Moreover, by increasing the number of nodes that have seen the transaction, anonymity is also enhanced as the set of nodes with the same view is larger. This may result in increased difficulty—or even practical prevention—of executing deanonymization attacks such as tagging attacks.
Upon receipt of a block proposal, validators must confirm the presence of all referenced transactions within their local mempool. This verification is an absolute requirement—if even a single referenced transaction is missing from the validator's mempool, the entire proposal must be rejected. This stringent validation protocol ensures only widely-distributed transactions are included in the blockchain, safeguarding against potential network state fragmentation.
The process works as follows:
- Transaction is added to the node mempool.
- Node sends the transaction to all its neighbors.
- Neighbors add the transaction to their own mempools and propagate it to their neighbors—transaction is gossiped throughout the network.
- Block builder selects a transaction from its local mempool, which is guaranteed to be propagated through the network due to steps 1-3.
- Block builder constructs a block proposal with references to selected transactions.
- Block proposal is sent through the Blend Network, which requires multiple rounds of gossiping. This introduces a delay that ensures the transaction has reached most of the network participants' mempools.
- Block proposal is received by validators.
- Validators check their local mempools for all referenced transactions from the proposal.
- If any transaction is missing, the entire proposal is rejected.
- If all transactions are present, the block proposal is reconstructed and proceeds to further validation steps.
Block Proposal Validation
This section defines the procedure followed by a Logos Blockchain node to validate a received block proposal.
Given a proposal, a proposed block consisting of a header and references. This block proposal is considered valid if the following conditions are met:
-
Block Validation The
proposalmust satisfy the rules defined in Block Header Validation. -
Block Proposal Reconstruction The
referencesmust refer to existingmempool_transactionentries that are retrievable from the node's local mempool. -
Mempool Transactions Validation
mempool_transactionsmust refer to a valid sequence of Mantle Transactions from the mempool. Each transaction must be valid according to the rules defined in the Mantle. In order to verify ZK proofs, they are batched for verification as explained in Batch verification of ZK proofs to get better performance.
If any of the above checks fail, the block proposal must be rejected.
Block Execution
This section specifies how a Logos Blockchain node executes a valid block proposal to update its local state.
Given a ValidBlock that has successfully passed proposal validation, the node must:
- Append the
leader_vouchercontained in the block to the set of reward vouchers when the following epoch starts. - Execute the reward distribution protocol defined in Service Reward Distribution Protocol to generate reward notes locally and include them in the ledger.
- Execute the Mantle Transactions included in the block sequentially, using the execution rules defined in the Mantle.
Annex
Batch verification of ZK proofs
Proofs of Claim
-
For each proof of Claim, the verifier collects the classic Groth16 elements required for verification. It includes the proof , and the public values for each proof of claim.
-
The verifier draws one random value for each proof .
-
The verifier computes:
-
for .
-
-
-
They test if .
Note that this batch verification of Groth16 proofs is the same as what is described in the Zcash paper, Appendix B.2.
ZkSignatures
The verifier follows the same procedure as in Proofs of Claim but with the Groth16 proofs of ZkSignatures.
MANTLE
| Field | Value |
|---|---|
| Name | Mantle |
| Slug | 98 |
| Status | raw |
| Category | Informational |
| Editor | Thomas Lavaur [email protected] |
| Contributors | David Rusu [email protected], Filip Dimitrijevic [email protected], Marcin Pawlowski [email protected] |
Timeline
- 2026-07-20 —
5b20a2d— docs(blockchain) Channel Participation in PoS (#364) - 2026-07-09 —
18c373b— docs(blockchain): Factor out multiple Ed25519 threshold verification and validate configuration threshold (#367) - 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-18 —
58b5698— chore(blockchain): migrate contributor emails to @logos.co (#338) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258)
Revisions History
| Version | Changes | Date |
|---|---|---|
| 1.1.0 | Initial revision. | 2026-12-01 |
| 1.2.0 | Removed DA references. Removed notions of Sovereignty and Rollups and used Zones for simplicity. Removed Nomos from specifications and DSTs. Added bridging and decentralized sequencing for channels. | 2026-01-01 |
| 1.2.1 | [RFC] Improve Mantle Transaction hash. | 2026-03-25 |
| 1.3.0 | [RFC] Make Ledger Transaction an Operation. | 2026-04-02 |
| 1.4.0 | [RFC] Enforce NoteId uniqueness. | 2026-04-24 |
| 1.5.0 | [RFC] Simplify Mantle Transaction and Refactor Ledger Operations. | 2026-05-06 |
| 1.6.0 | [RFC] Remove Concept of a Session | 2026-06-22 |
| 1.7.0 | Factor out the multi eddsa threshold verification and added a validation step in channel config to check the new config threshold is lower or equal than the number of accredited keys | 2026-06-25 |
| 1.8.0 | [RFC] Update channels to support proof of stake participation and test vectors for OpId and Mantle Transaction Hash | 2026-07-06 |
Introduction
Mantle is a foundational element of Bedrock, designed to provide a minimal and efficient execution layer that connects together Bedrock Services in order to provide the necessary functionality for Zones. It can be viewed as the system call interface of Bedrock, exposing a safe and constrained set of Operations to interact with lower-level Bedrock services, similar to syscalls in an operating system.
Mantle Transactions provide Operations for Zones and blockchain Services to interact with Bedrock. For example, a Zone sequencer posting an update to Bedrock, or a node operator declaring its participation in the Blend Network, would be done through the corresponding Operations within a Mantle Transaction.
Mantle manages assets using a note-based ledger that follows an UTXO model. Each Mantle Transaction can include Transfer Operation, and any excess balance serves as the fee payment.
Overview
Mantle Transaction
The features of the Logos Blockchain are exposed through Mantle Transactions. Each transaction can contain zero or more Operations. Mantle Transactions enable users to execute multiple Operations atomically.
Mantle Operations
Logos Blockchain features are exposed through Mantle Operations, which can be combined and executed together in a single Mantle Transaction atomically. These Operations enable transfers and functions such as on-chain data posting, Cross-Zone interactions, SDP interaction, and leader reward claims.
Mantle Ledger
The Mantle Ledger enables asset transfers using a transparent UTXO model. While a Transfer Operation can consume more tokens than it creates, the Mantle Transaction excess balance must exactly pay for the fees. The ledger tracks three kinds of notes: regular notes, locked notes (collateral for service declarations) and channel notes (channel bridge funds eligible for PoS participation only).
Transaction Fees
Mantle Transaction fees are derived from a gas model. The Logos Blockchain has two different gas markets, accounting for permanent data storage, and execution costs. Each Operation has an associated Execution Gas cost. Users can build unbalanced Mantle Transactions to tip the leaders and incentivize the network to include their transaction.
| Gas Market | Charged On | Pricing Basis |
|---|---|---|
| Execution Gas | Operations | Fixed per Operation |
| Permanent Storage Gas | Signed Mantle Transaction | Proportional to encoded size |
Mantle Transaction
Mantle Transactions form the core of Mantle, enabling users to combine multiple Operations to access different functions. Each transaction contains zero or more Operations. The system executes all Operations atomically, while using the Mantle Transaction's excess balance—calculated as the difference between the consumed and created value— as the fee payment.
class MantleTx:
ops: list[Op]
class Op:
opcode: byte
payload: bytes
def mantle_txhash(tx: MantleTx) -> Hash:
tx_bytes = encode(tx)
h = Hasher()
h.update(b"MANTLE_TXHASH_V1")
h.update(tx_bytes)
return h.digest()
The hash function used, as well as other cryptographic primitives like ZK proofs and signature schemes, are described in Common Cryptographic Components.
Mantle Transaction Hash
A Mantle Transaction must include all relevant signatures and proofs for each Operation.
class SignedMantleTx:
tx: MantleTx
op_proofs: list[OpProof | None] # each Op has at most 1 associated proof
Each proof (op proof and signature) must be cryptographically bound to the MantleTx through the mantle_txhash to prevent replay attacks. This binding is achieved by including the MantleTx hash reduced modulo as a public input in every ZK proof.
mantle_txhash_fr = FiniteField(mantle_txhash, byte_order="little", modulus = p)
mantle_txhash is a classical 256-bit hash digest and must be reduced to a field element before being passed to any ZkHasher or used as a ZK public input. We apply a direct modular reduction mod (via FiniteField(..., modulus=p)). Since , the reduction is slightly non-uniform. This is inconsequential in practice as the collision probability remains around , and proof binding is derived from the collision-resistance of the classic hash, not from uniformity over .
Mantle Transaction Fee
The transaction mandatory fee is a sum of two components: the multiplication of the total Execution Gas by the execution_base_fee, and the total size of the encoded signed Mantle Transaction multiplied by the permanent_storage_gas_price. The execution base fee and the permanent storage gas price are protocol-determined values that are the same for every Mantle Transaction in a block. They are derived following [Execution Market and Storage Markets.
def mandatory_fees(signed_tx: SignedMantleTx,
permanent_storage_gas_price: TokenValue, # Given by Storage Market
execution_gas_base_price: TokenValue) -> int: # Given by Execution Market
mantle_tx = signed_tx.tx
permanent_storage_fees = len(encode(signed_mantle_tx)) * permanent_storage_gas_price
tx_execution_gas = 0
for op in mantle_tx.ops:
# Compute how much execution gas of this operation as defined
# in the gas determination Appendix
tx_execution_gas += execution_gas(op)
execution_base_fees = tx_execution_gas * execution_gas_base_price
return execution_base_fees + permanent_storage_fees
If the Mantle Transaction is unbalanced (meaning that the Transaction consume more value than it creates) and that the leftover balance cover more than the mandatory fees, the remaining is treated as execution tip fees.
Validation
Given
signed_tx = SignedMantleTx(
tx=MantleTx(ops),
op_proofs
)
Mantle validators will ensure the following:
-
We have a proof or a
Nonevalue for each operation.assert len(op_proofs) == len(ops) -
Each Operation is valid.
for op, op_proof in zip(ops, op_proofs): assert op.opcode in MANTLE_OPCODES validate_mantle_op(mantle_txhash(tx), op.opcode, op.payload, op_proof) def validate_mantle_op(txhash, opcode, payload, op_proof): if opcode == CHANNEL_INSCRIBE: validate_channel_inscribe(txhash, payload, op_proof) # elif opcode == ... # ... -
The Mantle Transaction excess balance pays least the mandatory fees.
tx_mandatory_fee = mandatory_gas_fees(signed_tx) # Not an unsigned int tx_balance = get_transaction_balance(signed_tx) assert tx_mandatory_fee <= tx_balance tx_execution_tip = tx_balance - tx_mandatory_fee def get_transaction_balance(signed_tx: SignedMantleTx) -> int: balance = 0 # It's important to not use unsigned int here to avoid # overflow vulnerabilities for op in signed_tx.tx.ops: if op.opcode == TRANSFER: for inp in op.inputs: balance += get_value_from_note_id(inp) for out in op.outputs: balance -= out.value return balance
Execution
Given
SignedMantleTx(
tx=MantleTx(ops),
op_proofs
)
Mantle Validators execute sequentially each Operation in ops according to its opcode.
Operations
Opcodes
| Operation | Opcode | Description |
|---|---|---|
| TRANSFER | 0x00 | Consume and create notes. |
| RESERVED | 0x01 - 0x0F | |
| CHANNEL_CONFIG | 0x10 | Configure a channel |
| CHANNEL_INSCRIBE | 0x11 | Write a message permanently onto Mantle. |
| CHANNEL_DEPOSIT | 0x12 | Deposit assets into a channel |
| CHANNEL_WITHDRAW | 0x13 | Withdraw assets from a channel |
| CHANNEL_TRANSFER | 0x14 | Consume and create notes belonging to a channel |
| RESERVED | 0x15 - 0x1F | |
| SDP_DECLARE | 0x20 | Declare intention to participate as a node in a Bedrock Service, locking funds as collateral. |
| SDP_WITHDRAW | 0x21 | Withdraw participation from a Bedrock Service, unlocking your funds in the process. |
| SDP_ACTIVE | 0x22 | Signal that you are still an active participant of a Bedrock Service. |
| RESERVED | 0x23 - 0xFF | |
| LEADER_CLAIM | 0x30 | Claim leader reward anonymously. |
| RESERVED | 0x31 - 0xFF |
Channel Operations
Channels allow Zones to post their updates on chain. Channels form virtual chains that overlay on top of the Cryptarchia blockchain. Clients and Followers of a Zone can watch its channel to learn the state of that Zone. Each channel has an associated balance, enabling bridging between Zones and Bedrock.
Message Ordering
Channels form virtual chains by having each message reference its parent message. The order of messages in these channels is enforced by the sequencer by building a hash chain of messages, i.e. new messages reference the previous messages through a parent hash. Given that Cryptarchia has long finality times, these message parent references allow Zone sequencers to continue to post new updates to channels without having to wait for finality. No matter how Cryptarchia forks and reorgs, the channel messages from honest sequencers will eventually be re-included in a way that satisfies the virtual chain order.
The first time a message is sent to an unclaimed channel, the key that signs the initial message becomes the only accredited key in the list (Note that this key may correspond to a threshold signature key). Accredited keys of a channel forms a committee that can configure the channel, withdraw funds and take turns to write messages to that channel following a round-robin algorithm. Configuring a channel includes modifying the list of accredited keys, the round-robin parameters and the required number of signatures to withdraw funds or establish a new configuration.
Validators must maintain the following state to process channel Operations:
channels: dict[ChannelId, ChannelState] # ChannelId is 32 bytes
class ChannelState:
# Channel Configuration
accredited_keys: list[Ed25519PublicKey] # limited to 65 535 keys
configuration_threshold: u16 # indicating how many keys are
# required to update the configuration
# Message Ordering
tip_hash: hash
# Decentralized Sequencing
tip_slot: Slot
tip_sequencer: u16 # indicating the actual
# sequencer position in the list of accredited keys
tip_sequencer_starting_slot: Slot
posting_timeframe: u32 # number of slots (0 = infinity)
posting_timeout: u32 # number of slots (0 = no timeout)
# Bridging
transfer_threshold: u16 # indicating how many keys are
# required to transfer or withdraw funds from the channel
def default_channel(block_slot: Slot, keys: list[Ed25519PublicKey]) -> ChannelState:
return ChannelState(
tip_hash = ZERO,
tip_slot = block_slot,
accredited_keys = keys,
tip_sequencer = 0,
tip_sequencer_starting_slot = block_slot,
posting_timeframe = 0,
posting_timeout = 0,
configuration_threshold = 1,
transfer_threshold = 1)
Note that the user chooses the ChannelId mapping to the ChannelState (but it’s restricted to 32 bytes). We don't currently impose restrictions on it, but we may do so in the future to prevent undesirable behaviors.
Decentralized Sequencing
To determine which sequencer is currently authorized to send messages, we use a round-robin algorithm. When a message is posted to a channel, the following algorithm is used to determine who the sequencer is:
# Round Robin algorithm determining the new sequencer index and the
# new sequencer starting slot
def round_robin(block_slot: Slot, channel: ChannelState) -> (u16, u64):
elapsed_slots = block_slot - channel.tip_slot
if elapsed_slots >= channel.posting_timeout and channel.posting_timeout != 0:
# Get the number of sequencers that get timed out
sequencers_timed_out = elapsed_slots // channel.posting_timeout
index = (
(channel.tip_sequencer + sequencers_timed_out)
% len(channel.accredited_keys)
)
starting_slot = (
channel.tip_slot
+ sequencers_timed_out * channel.posting_timeout
)
else:
# Get the number of timeframes elapsed to get who is the sequencer
tip_sequencer_duration = block_slot - channel.tip_sequencer_starting_slot
index = (
(channel.tip_sequencer + (tip_sequencer_duration // channel.posting_timeframe))
% len(channel.accredited_keys)
)
starting_slot = (
channel.tip_sequencer_starting_slot
+ (tip_sequencer_duration // channel.posting_timeframe) * channel.posting_timeframe
)
return (index, starting_slot)
Bridging
Channels let their bridged funds keep participating in Proof of Stake. When a user deposits funds into a channel, the deposited notes are not removed from the ledger and are not turned into inert collateral. They become channel notes that continue to count toward Proof of Stake and can still be used to create PoLs (see Channel Notes). Two goals motivate this design:
- More PoS participation, stronger security. Funds deposited into a channel would otherwise leave the staking set. Keeping them as channel notes means the capital backing the application layer also backs consensus security, so bridging does not shrink the stake that secures the chain.
- No split between security and application. A user no longer has to choose between staking funds or using them in a channel. The same funds do both at once. They stay usable inside the channel while still earning Proof of Leadership rewards, so capital is never fragmented between the two.
Ownership vs. staking power. A CHANNEL_DEPOSIT separates the two rights that a normal note bundles together:
- Ownership moves to the channel. The note is registered in the ledger's
channel_notesset with the channel as its owner, and the channel keeps full control over it. The deposited notes are neither consumed nor re-created. They keep theirNoteId, value andZkPublicKey, and are simply re-registered as channel-owned. The channel is now the party responsible for the note. - Staking power stays with the
ZkPublicKeycarried by the note. That key does not confer ownership. It only delegates the note's value for PoL creation. Whoever controls the key is the one allowed to turn the note into a PoL and collect the resulting rewards. On deposit this key is still the depositor's, so the user keeps the PoS participation power they had before bridging.
Because the channel owns the note but does not hold the delegated key, the note earns rewards for the key holder, never for the channel itself.
What each party can do.
| Party | Can | Cannot |
|---|---|---|
Holder of the note's ZkPublicKey (by default, the depositor) | Use the note to create a PoL and earn its leader rewards | Spend the note, withdraw it, reassign it, or use it as service stake |
| Channel sequencers (owner of the note) | Reassign the note to a different ZkPublicKey (CHANNEL_TRANSFER) and spend it to fund withdrawals (CHANNEL_WITHDRAW), both without ZkSignature verification | Use the note as service stake, or earn PoL rewards without first assigning the note to their own key |
This makes delegated staking explicit. Sequencers can assign a channel note to their own ZkPublicKey and earn the Proof of Leadership rewards it produces, but those rewards always follow the assigned key, so the channel earns nothing merely by owning the note. Conversely, ownership never leaving the channel is exactly what lets sequencers redelegate value or cover withdrawals at any time without a user signature.
Warning: a deposit is a transfer of custody. Depositors must understand that channel note handling is fully defined by the channel. Once a CHANNEL_DEPOSIT is executed the note belongs to the channel, and its sequencers can reassign it to any ZkPublicKey with CHANNEL_TRANSFER or release it to whoever they choose with CHANNEL_WITHDRAW, at any time and without any signature from the depositor. The ledger enforces no return path to the original depositor. Holding the note's ZkPublicKey grants PoS participation power only and never a claim on the value, so it confers no ability to recover the funds. A user who deposits into a dishonest or faulty channel has no on-chain recourse. Deposit only into channels you trust to honour their own withdrawal policy.
CHANNEL_INSCRIBE
Write a message to a channel with the message data being permanently stored on the Logos Blockchain.
Payload
class Inscribe:
channel: ChannelId # 32 bytes Channel being written to
inscription : bytes # Message to be written on the blockchain
parent: hash # Previous message in the channel
signer: Ed25519PublicKey # Identity of message sender
Proof
Ed25519Signature
Execution Gas
Channel Inscribe Operations have a fixed Execution Gas cost of EXECUTION_CHANNEL_INSCRIBE_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: hash
msg: Inscribe
sig: Ed25519Signature
channels: dict[ChannelId, ChannelState]
block_slot: Slot
Validate
if msg.channel in channels:
chan = channels[msg.channel]
current_sequencer_index = round_robin(block_slot, chan)[0]
# Ensure the signer is the one authorized to write to the channel
assert msg.signer == chan.accredited_keys[current_sequencer_index]
# Ensure message is continuing the channel sequence
assert msg.parent == chan.tip_hash
else:
# Channel will be created automatically upon execution
# Ensure that this message is the genesis message (parent == ZERO)
assert msg.parent == ZERO
# Ensure the msg signer signature
assert Ed25519_verify(txhash, msg.signer, sig)
Execution
Given
msg: Inscribe
sig: Ed25519Signature
channels: dict[ChannelId, ChannelState]
block_slot: Slot
Execute
-
If the channel does not exist, create it just-in-time.
if msg.channel not in channels: channels[msg.channel] = default_channel(block_slot, [msg.signer]) -
Update the channel sequencer.
chan = channels[msg.channel] (new_sequencer_index, new_sequencer_starting_slot) = round_robin(block_slot, chan) chan.tip_sequencer_starting_slot = new_sequencer_starting_slot chan.tip_sequencer = new_sequencer_index -
Update the channel tip.
chan = channels[msg.channel] chan.tip_hash = hash(encode(msg)) chan.tip_slot = block_slot
Example
# Build the inscription
greeting = Inscription(
channel=CHANNEL_EARTH,
inscription=b"Live long and prosper",
parent=ZERO
signer=spock_pk
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[<spocks_note_id>], outputs=[<change_note>])
# Wrap it in a transaction
tx = MantleTx(
ops=[Op(opcode=CHANNEL_INSCRIBE, payload=encode(greeting)),
Op(opcode=TRANSFER, payload=encode(transfer))],
)
# Sign the transaction
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[Ed25519_sign(mantle_txhash(tx), spock_sk),
transfer.prove(spock_sk)]
)
# Send the transaction to the mempool
mempool.push(signed_tx)
CHANNEL_CONFIG
Overwrite the configuration of a channel.
Payload
class ChannelConfig:
channel: ChannelId
keys: list[Ed25519PublicKey]
posting_timeframe: u32
posting_timeout: u32
configuration_threshold: u16
transfer_threshold: u16
Proof
A Channel Config is authorized by a threshold of the channel's accredited keys using Multiple Ed25519 Signatures Verification.
class ChannelConfigOpProof:
signatures: list[Ed25519Signature] # signatures from configuration_threshold
indexes: list[u16] # signatures of accredited keys with their index.
# indexes must be ordered from smallest to
# biggest without duplication
Execution Gas
Channel Config Operations have a linear Execution Gas cost equal to EXECUTION_CHANNEL_CONFIG_GAS * configuration_threshold. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash
config: ChannelConfig
proof: ChannelConfigOpProof
channels: dict[ChannelId, ChannelState]
Validate
assert config.configuration_threshold > 0
assert config.transfer_threshold > 0
assert len(config.keys) > 0
assert len(config.keys) < 2^16
# The configuration threshold must be reachable with the accredited keys,
# otherwise the channel would be locked out of any future reconfiguration
assert config.configuration_threshold <= len(config.keys)
if config.channel in channels:
chan = channels[config.channel]
# Verify the configuration_threshold signatures (see Appendix)
MultiEd25519_verify(txhash,
proof.signatures,
proof.indexes,
chan.accredited_keys,
chan.configuration_threshold)
Execution
Given
config: ChannelConfig
channels: dict[ChannelId, ChannelState]
block_slot: Slot
Execute
-
If the channel does not exist, create it just-in-time.
if config.channel not in channels: channels[config.channel] = default_channel(block_slot, config.keys) -
Update the configuration.
chan = channels[config.channel] # Update Channel Configuration Parameters chan.accredited_keys = config.keys chan.configuration_threshold = config.configuration_threshold # Update Decentralized Sequencing Parameters chan.tip_sequencer = 0 chan.tip_sequencer_starting_slot = block_slot chan.posting_timeframe = config.posting_timeframe chan.posting_timeout = config.posting_timeout # Update Bridging Parameters chan.transfer_threshold = config.transfer_threshold -
Update the channel tip.
chan = channels[config.channel] chan.tip_slot = block_slot chan.tip_hash = hash(encode(config))
Example
Suppose the unique sequencer of Zone A wants to add a key to the list of accredited keys:
# Given a key to add
new_sequencer_pk: Ed25519PublicKey
# The unique sequencer encodes the update and builds the payload
config = ChannelConfig(
channel=ZONE_A,
keys=[old_sequencer_pk, new_sequencer_pk],
posting_timeframe = 5000,
posting_timeout = 500,
configuration_threshold = 2,
transfer_threshold = 1
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[old_sequencer_funds], outputs=[<change_note>])
tx = MantleTx(
ops=[Op(opcode=CHANNEL_CONFIG, payload=encode(config)),
Op(opcode=TRANSFER, payload=encode(transfer))],
)
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[[Ed25519_sign(mantle_txhash(tx), old_sequencer_sk)], [0]],
transfer.prove(old_sequencer_sk)]
)
CHANNEL_DEPOSIT
Deposit notes to a channel.
Payload
class ChannelDeposit:
channel: ChannelId
inputs: list[NoteId] # the notes to be marked as channel notes
metadata: bytes
Proof
A Channel Deposit proves the ownership of the notes being marked as channel notes using a Zero Knowledge Signature Scheme (ZkSignature).
ZkSignature
Execution Gas
Channel Deposit Operations have a fixed Execution Gas cost of EXECUTION_CHANNEL_DEPOSIT_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
mantle_txhash: zkhash # zkhash of mantle tx containing this ledger tx
deposit: ChannelDeposit
deposit_proof: ZkSignature
channels: dict[ChannelId, ChannelState]
ledger: Ledger
Validate
-
Verify that the channel exist
assert deposit.channel in channels -
Ensure all inputs are spendable and not already channel notes.
ledger.assert_spendable(deposit.inputs) -
Validate ownership over deposited notes.
input_notes = [ledger[input_note_id] for input_note_id in deposit.inputs] input_pks = [note.public_key for note in input_notes] assert ZkSignature_verify(mantle_txhash, deposit_proof, input_pks)
Execution
Given
deposit: ChannelDeposit
channels: dict[ChannelId, ChannelState]
ledger: Ledger
Execute
Mark the inputs as channel notes owned by the channel. The notes are neither consumed nor re-created: they keep their NoteId, value and ZkPublicKey, and are simply registered in the channel_notes set.
for note_id in deposit.inputs:
ledger.channel_notes[note_id] = deposit.channel
Example
Suppose Alice wants to make a deposit of 50 tokens on Zone A.
# Alice encodes her deposit
deposit = ChannelDeposit(
channel=ZONE_A,
inputs=[alice_deposit_note_id] # This is a note of 50 tokens
metadata=b"deposit to address: 0x..."
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[Alice_funds], outputs=[<change_note>])
tx = MantleTx(
ops=[Op(opcode=CHANNEL_DEPOSIT, payload=encode(deposit)),
Op(opcode=TRANSFER, payload=encode(transfer))],
)
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[deposit.prove(Alice_sk), transfer.prove(Alice_sk)],
)
A Zone that credits a deposit in its own state must be sure the deposit really lands on-chain. If the Zone reflects the deposit through a CHANNEL_INSCRIBE posted in a separate Mantle Transaction, a reorganization can reorder the two so that the inscription is included while the deposit is not, leaving the Zone crediting funds it never received. Two options avoid this:
- Wait for the deposit to be finalized before interpreting it, at the cost of the finalization delay.
- Make the inscription conditional on the deposit, by including a
CHANNEL_TRANSFERthat consumes the deposited note in the same Mantle Transaction as the inscription. Mantle Transactions execute atomically, so the inscription is included only if the deposited note exists and is consumed. This removes the waiting period entirely.
The second option resets the ageing of the value. A CHANNEL_TRANSFER consumes its inputs and creates new notes, so the resulting note starts the ageing process again and must age before it can create a PoL. CHANNEL_DEPOSIT and CHANNEL_WITHDRAW keep the NoteId of the notes they touch and therefore never reset ageing.
CHANNEL_WITHDRAW
Withdraw notes from a channel.
Payload
class ChannelWithdraw:
channel: ChannelId
inputs: list[NoteId]
Proof
A Channel Withdraw is authorized by a threshold of the channel's accredited keys using Multiple Ed25519 Signatures Verification.
class ChannelWithdrawOpProof:
signatures: list[Ed25519Signature] # exactly transfer_threshold signatures
indexes: list[int] # signatures of accredited keys with their index
# indexes must be ordered from smallest to
# biggest without duplication
Execution Gas
Channel Withdraw Operations have a linear Execution Gas cost equal to EXECUTION_CHANNEL_WITHDRAW_GAS * transfer_threshold. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash
withdrawal: ChannelWithdraw
proof: ChannelWithdrawOpProof
channels: dict[ChannelId, ChannelState]
ledger: Ledger
Validate
-
Check that the channel exists
assert withdrawal.channel in channels -
Check that the inputs are valid and belongs to the channel
ledger.assert_spendable(withdrawal.inputs, withdrawal.channel) -
Check the signatures (see Multiple Ed25519 Signatures Verification)
MultiEd25519_verify(txhash, proof.signatures, proof.indexes, channels[withdrawal.channel].accredited_keys, channels[withdrawal.channel].transfer_treshold)
Execution
Given
withdrawal: ChannelWithdraw
channels: dict[ChannelId, ChannelState]
ledger: Ledger
Execute
Remove the inputs from channel notes owned by the channel. The notes are neither consumed nor re-created: they keep their NoteId, value and ZkPublicKey, and are simply unregistered in the channel_notes set.
for note_id in withdrawal.inputs:
ledger.channel_notes.pop(note_id)
Example
Suppose the unique sequencer of Zone A wants to withdraw 50 tokens.
# Sequencer encodes his withdrawal
withdrawal = ChannelWithdraw(
channel=ZONE_A,
inputs = [Channel_note_id]
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[Sequencer_funds], outputs=[<change_note>])
tx = MantleTx(
ops=[Op(opcode=CHANNEL_WITHDRAW, payload=encode(withdrawal)),
Op(opcode=TRANSFER, payload=encode(transfer))],
)
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[[[Ed25519_sign(mantle_txhash(tx), sequencer_sk)],[0]],
transfer.prove(Sequencer_node_sk)],
)
CHANNEL_TRANSFER
Assign funds from a channel to new ZkPublicKey. This funds are only usable to participate in PoS and to withdraw from the channel.
Payload
class ChannelTransfer:
channel: ChannelId
inputs: list[NoteId]
outputs: list[Note]
Proof
class ChannelTransferOpProof:
signatures: list[Ed25519Signature] # signature from transfer_threshold keys
indexes: list[int] # signatures of accredited keys with their index.
# indexes must be ordered from smallest to biggest without duplication
Execution Gas
CHANNEL_TRANSFER Operations have a linear Execution Gas cost equal to EXECUTION_CHANNEL_TRANSFER_GAS * transfer_threshold. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash
chan_transfer: ChannelTransfer
proof: ChannelTransferOpProof
channels: dict[ChannelId, ChannelState]
ledger: Ledger
Validate
- Check that the outputs are valid
ledger.assert_valid_output(chan_transfer.outputs)
- Check that the channel exists
assert chan_transfer.channel in channels
- Check that the inputs are valid and belongs to the channel
ledger.assert_spendable(chan_transfer.inputs, chan_transfer.channel)
- Check the balance
input_amount = sum(ledger.get_note(input).value for input in chan_transfer.inputs)
output_amount = sum(output.value for output in chan_transfer.outputs)
assert input_amount == output_amount
- Check the signatures (see Multiple Ed25519 Signatures Verification)
MultiEd25519_verify(txhash,
proof.signatures,
proof.indexes,
channels[chan_transfer.channel].accredited_keys,
channels[chan_transfer.channel].transfer_treshold)
Execution
Given
chan_transfer: ChannelTransfer
channels: dict[ChannelId, ChannelState]
ledger: Ledger
Execute
- Remove inputs from the ledger
ledger.execute_spending(chan_transfer.inputs, chan_transfer.channel)
- Add outputs to the ledger.
chan_transfer_id = derive_op_id(chan_transfer)
ledger.execute_adding(chan_transfer_id, chan_transfer.outputs, chan_transfer.channel)
Example
Suppose the unique sequencer of Zone A wants to attribute 50 tokens to themself.
# Sequencer encodes their assignation
chan_transfer = ChannelTransfer(
channel=ZONE_A,
inputs = [Channel_note_id]
outputs = [Note(pk=alice, value=50)]
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[Sequencer_funds], outputs=[<change_note>])
tx = MantleTx(
ops=[Op(opcode=CHANNEL_TRANSFER, payload=encode(chan_transfer)),
Op(opcode=TRANSFER, payload=encode(transfer))],
)
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[[[Ed25519_sign(mantle_txhash(tx), sequencer_sk)],[0]],
transfer.prove(Sequencer_node_sk)],
)
Service Declaration Protocol (SDP) Operations
These Operations implement the Service Declaration Protocol.
Validators must keep the following state when implementing SDP Operations:
locked_notes: dict[NoteID, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
class LockedNote:
declarations: set[DeclarationID]
Common SDP Structures
class ServiceType(Enum):
BN="BN" # Blend Network
class Locator(str):
def validate(self):
assert len(self) <= 329
assert validate_multiaddr(self)
class MinStake:
stake_threshold: int # stake value
epoch: EpochNumber # epoch number
class ServiceParameters:
inactivity_period: NumberOfEpochs # number of epochs
epoch: EpochNumber # epoch number at which the Service Parameters were set
class DeclarationInfo:
service: ServiceType
locators: list[Locator]
provider_id: Ed25519PublicKey
zk_id: ZkPublicKey
locked_note_id: NoteId
created: EpochNumber
active: EpochNumber | None
withdraw_at: EpochNumber | None
# SDP ops updating a declaration must use monotonically increasing nonces
nonce: int
SDP_DECLARE
The service registration follows the definition given in Declaration Message:
Payload
class DeclarationMessage:
service_type: ServiceType
locators: list[Locator]
provider_id: Ed25519PublicKey
zk_id: ZkPublicKey
locked_note_id: NoteId
Locked notes are introduced in Locked notes and serve as Service collaterals. They cannot be spent before the owner withdraw its participation from the declared service(s).
Proof
class DeclarationProof:
zk_sig: ZkSignature # signature proving ownership over
# locked note and zk_id
provider_sig: Ed25519Signature # signature proving ownership of provider key
see: Zero Knowledge Signature Scheme (ZkSignature).
Execution Gas
SDP Declare Operations have a fixed Execution Gas cost of EXECUTION_SDP_DECLARE_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash # the txhash of the transaction we are validating
declaration: DeclarationMessage # the declaration we are validating
proof: DeclarationProof
min_stake: MinStake # the (global) minimum stake setting
ledger: Ledger # the set of unspent notes
locked_notes: dict[NoteId, LockedNote]
declarations: dict[NoteId, DeclarationInfo]
Validate
The declaration is verified according to Declare.
-
Ensure ownership over the locked note,
zk_idandprovider_id.assert ZkSignature_verify( txhash, proof.zk_sig, [note.public_key, declaration.zk_id] ) assert Ed25519_verify(txhash, proof.provider_sig, provider_id) -
Ensure declaration does not already exist.
assert declaration_id(declaration) not in declarations -
Ensure the locators list is non-empty and has no more than 8 entries.
assert len(declaration.locators) >= 1 assert len(declaration.locators) <= 8 -
Ensure the locked note exists and its value is sufficient for joining the service.
assert ledger.is_unspent(declaration.locked_note_id) note = ledger.get_note(declaration.locked_note_id) assert note.value >= min_stake.stake_threshold -
Ensure the note has not already been locked for this service.
if declaration.locked_note in locked_notes: locked_note = locked_notes[declaration.locked_note] services = [declarations[declare_id] for declare_id in locked_note.declarations] assert declaration.service_type not in services
Execution
Given
declaration: DeclarationMessage # the declaration we are executing
current_epoch: EpochNumber
locked_notes : dict[NoteId, LockedNote]
Execute
-
Create the locked note state if it doesn't already exist.
if declaration.locked_note not in locked_notes: locked_notes[declaration.locked_note_id] = LockedNote(declarations=set()) locked_note = locked_notes[declaration.locked_note_id] -
Add this declaration to the locked note.
declare_id = declaration_id(declaration) locked_note.declarations.add(declare_id) -
Store the declaration as explained in Declaration Storage.
declarations[declare_id] = DeclarationInfo( service: declaration.service locators: declaration.locators provider_id: declaration.provider_id zk_id: declaration.zk_id locked_note_id: declaration.locked_note_id declaration, created=current_epoch, active=None, withdraw_at=None nonce=0 )
Example
# Assume `alice_note` is in the ledger:
alice_note = Utxo(
txhash=0x2948904F2F0F479B8F8197694B30184B0D2ED1C1CD2A1EC0FB85D299A192A447,
output_number=3,
note=Note(value=500, public_key=alice_pk_1),
)
# Alice wishes to lock it to join the Blend network
declaration=DeclarationMessage(
service_type=ServiceType.BN,
locators=["/ip4/203.0.113.10/tcp/4001/p2p"],
provider_id=alice_provider_pk,
zk_id=alice_pk_2,
locked_note_id=alice_note.id()
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[fee_note_id], outputs=[])
tx = MantleTx(
ops=[Op(opcode=SDP_DECLARE, payload=encode(declaration)),
Op(opcode=TRANSFER, payload=encode(transfer))],
)
txhash = mantle_txhash(tx)
declaration_proof = DeclarationProof(
# proof of ownership of the staked note and zk_id
zk_sig=ZkSignature([alice_sk_1, alice_sk_2], txhash),
# proof of ownership of the provider id
provider_sig=Ed25519Signature(alice_provider_sk, txhash),
)
SignedMantleTx(
tx=tx,
op_proofs=[declaration_proof, transfer.prove(alice_sk_1)],
)
SDP_WITHDRAW
The service withdrawal follows the definition given in Withdraw Message.
Payload
class WithdrawMessage:
declaration: DeclarationID
locked_note_id: NoteId
nonce: int
Proof
A signature from the zk_id and the locked note pk attached to the declaration is required for withdrawing from a service, (see Zero Knowledge Signature Scheme (ZkSignature)).
ZkSignature
Execution Gas
SDP Withdraw Operations have a fixed Execution Gas cost of EXECUTION_SDP_WITHDRAW_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash # Mantle transaction hash of the tx containing this operation
withdraw: WithdrawMessage
signature: ZkSignature
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
Validate
-
Ensure that the locked note exists, is locked and bound to this declaration.
assert ledger.is_unspent(withdraw.locked_note_id) assert withdraw.locked_note_id in locked_notes locked_note = locked_notes[withdraw.locked_note_id] assert withdraw.declaration in locked_note.declarations -
Validate SDP withdrawal according to Withdraw.
- Ensure declaration exists.
assert withdraw.declaration in declarations declare_info = declarations[withdraw.declaration] - Ensure the declaration is not already scheduled for withdrawal.
assert declare_info.withdraw_at is None - Ensure locked note
pkandzk_idattached to this declaration authorized this Operation.locked_note = ledger[withdraw.locked_note_id] assert ZkSignature_verify(txhash, signature, [locked_note.pk, declare_info.zk_id]) - Ensure that the nonce is greater than the previous one.
assert withdraw.nonce > declare_info.nonce
- Ensure declaration exists.
Execution
Given
withdraw: WithdrawMessage
signature: ZkSignature
current_epoch: EpochNumber # current epoch
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
Execute
Executes the withdrawal protocol Withdraw.
Withdrawal only records the intent: withdraw_at is set to the current
(withdrawal) epoch e, the node's last rewardable epoch. The declaration is
removed and its stake unlocked at epoch e+2 by the
SDP Epoch Finalization step, right after the final
reward is paid out.
- Update the declaration info with the nonce and the withdrawal epoch.
declare_info = declarations[withdraw.declaration] declare_info.nonce = withdraw.nonce declare_info.withdraw_at = current_epoch
Example
withdraw=Withdraw(
declaration=alice_declaration_id,
locked_note_id=alices_locked_note_id
nonce=1579532
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[alices_locked_note_id],
outputs=[Note(100, alice_note_pk)])
tx = MantleTx(
ops=[Op(opcode=SDP_WITHDRAW, payload=encode(withdraw)),
Op(opcode=TRANSFER, payload=encode(transfer))],
)
SignedMantleTx(
tx=tx,
# proof ownership of the withdrawn note and zk id
op_proofs=[ZkSignature_sign([alice_note_sk, alice_sk], mantle_txhash(tx)),
transfer.prove(alice_sk)]
)
SDP Epoch Finalization
Withdrawn declarations are removed by Mantle as part of the epoch transition,
not when the WithdrawMessage is processed. A node that withdrew in epoch e
has withdraw_at == e, and its last rewardable epoch is e; the epoch-e
rewards are distributed in the first block of epoch e+2 (see
Service Reward Distribution Protocol).
In that same first block, after the rewards have been distributed, every
declaration whose final reward has been paid out (withdraw_at <= current_epoch - 2)
is removed and its stake unlocked. Performing the removal after the reward
distribution guarantees a declaration is never removed before its final reward
is paid. Declarations that withdrew without earning a final reward are removed
by the same step, so their stake is always released.
Given
current_epoch: EpochNumber
locked_notes: dict[NoteId, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
Execute
For every declare_id, declare_info in declarations where
declare_info.withdraw_at is not None and declare_info.withdraw_at <= current_epoch - 2:
-
Remove the declaration from its locked note.
locked_note = locked_notes[declare_info.locked_note_id] locked_note.declarations.remove(declare_id) -
Remove the declaration.
del declarations[declare_id] -
Unlock the note once it is no longer bound to any declaration.
if len(locked_note.declarations) == 0: del locked_notes[declare_info.locked_note_id]
SDP_ACTIVE
The service active action follows the definition given in Active Message.
Payload
class Active:
declaration: DeclarationID
nonce: int
metadata: bytes # a service-specific node activeness metadata
Proof
ZkSignature
Execution Gas
SDP Active Operations have a fixed Execution Gas cost of EXECUTION_SDP_ACTIVE_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash # Mantle transaction hash of the tx containing this operation
active: Active
signature: ZkSignature
declarations: dict[DeclarationID, DeclarationInfo]
Validate
assert active.declaration in declarations
declaration_info = declarations[active.declaration]
assert active.nonce > declaration_info.nonce
assert ZkSignature_verify(txhash, signature, declaration_info.zk_id)
Execution
Executes the active protocol Active. The activation, i.e. setting the declaration.active, is handled by the service-specific logic.
Example
active=Active(
declaration=alice_declaration_id,
nonce=1579532,
metadata=b"Look, I am still doing my job"
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[fee_note_id], outputs=[])
tx = MantleTx(
ops=[Op(opcode=SDP_ACTIVE, payload=encode(active))],
)
txhash = mantle_txhash(tx)
SignedMantleTx(
tx=tx,
op_proofs=[Ed25519_sign(txhash, validator_sk), transfer.prove(fee_note_sk)]
)
Leader Operations
LEADER_CLAIM
This Operation claims the leader's block reward anonymously.
Payload
class ClaimRequest:
rewards_root: zkhash # Merkle root used in the proof for voucher membership
voucher_nf: zkhash
public_key: ZkPublicKey
Proof
The provider proves that they have won a proof of Leadership before the start of the current epoch, i.e., their reward voucher is indeed in the voucher set: Proof of Claim.
Execution gas
Leader Claim Operations have a fixed Execution Gas cost of EXECUTION_LEADER_CLAIM_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
mantle_txhash: zkhash
claim : ClaimRequest
last_voucher_root: zkhash # The last root of the voucher Merkle tree
# at the start of the epoch
voucher_nullifier_set: set[zkhash]
proof: ProofOfClaim
Validate
assert claim.voucher_nf not in voucher_nullifier_set
assert claim.rewards_root == last_voucher_root
validate_proof(claim, proof, mantle_txhash)
Execution
Given
claim: ClaimRequest
ledger: Ledger
voucher_nullifier_set: set[zkhash]
leaders_rewards: TokenValue # The pool of tokens to be claim by leaders
leader_reward: TokenValue # The amount one leader can claim
Execution
-
Add
claim.voucher_nfto thevoucher_nullifier_set. -
Denoting by
leader_rewardthe amount defined for leader rewards in Leaders Reward, construct a single output note with value leader_reward under the public key defined in the payload, and insert it into the Ledger:output_note=Note( value = leader_reward public_key = claim.public_key, ) claim_id = derive_op_id(claim) ledger.execute_adding(claim_id, [output_note]) -
Reduce the leader’s reward
leaders_rewardsvalue by the same amount (without ZK proof).
Example
secret_voucher = 0xDEADBEAF;
reward_voucher = leader_claim_voucher(secret_voucher)
voucher_nullifier = leader_claim_nullifier(secret_voucher)
claim=ClaimRequest(
rewards_root=REWARDS_MERKLE_TREE.root(),
voucher_nf=voucher_nullifier,
public_key=leader_one_time_key
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[<fee_note>], outputs=[<change_note>])
tx = MantleTx(
ops=[Op(opcode=LEADER_CLAIM, payload=encode(claim)),
Op(opcode=TRANSFER, payload=encode(transfer))],
)
claim_proof = claim.prove(
secret_voucher,
REWARDS_MERKLE_TREE.path(leaf=reward_voucher),
mantle_txhash(tx)
)
SignedMantleTx(
tx=tx,
op_proofs=[claim_proof, transfer.prove(fee_note_sk)]
)
TRANSFER
Transactions must prove the ownership of spent notes. In classical blockchains, this is done through a signature. To stay compatible with our architecture, the signature is done by a ZK proof (see Zero Knowledge Signature Scheme (ZkSignature)), proving the knowledge of the secret key associated with the public key.
Transactions allow complete transaction linkability and the public key spending the note is not hidden.
Payload
class Transfer:
inputs: list[NoteId] # the list of consumed note identifiers
# must be non-empty
outputs: list[Note]
Proof
A Transfer proves the ownership of the consumed notes using a Zero Knowledge Signature Scheme (ZkSignature).
ZkSignature
Execution Gas
Transfer have a fixed Execution Gas cost of EXECUTION_TRANSFER_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
mantle_txhash: zkhash # zkhash of mantle tx containing this ledger tx
transfer: Transfer
transfer_proof: ZkSignature
ledger: Ledger
Validate
-
Ensure the Transfer in non-empty
assert len(transfer.inputs) > 0 -
Ensure all inputs are spendable and not in a channel.
ledger.assert_spendable(transfer.inputs) -
Validate transfer proof to show ownership over input notes.
input_notes = [ledger[input_note_id] for input_note_id in transfer.inputs] input_pks = [note.public_key for note in input_notes] assert ZkSignature_verify(mantle_txhash, transfer_proof, input_pks) -
Ensure outputs are valid.
ledger.assert_valid_output(transfer.output)
Execution
Given
transfer: Transfer
transfer_proof: ZkSignature
ledger: Ledger
Execution
-
Remove inputs from the ledger.
ledger.execute_spending(transfer.inputs) -
Add outputs to the ledger.
transfer_id = derive_operation_id(transfer) ledger.execute_adding(transfer_id, transfer.outputs)
Example
alice_note_id = ... # assume Alice holds a note worth 501 tokens
bob_note=Note(
value=500
public_key=bob_pk,
)
transfer = Transfer(
inputs=[alice_note_id],
outputs=[bob_note],
)
Mantle Ledger
Notes
Notes are composed of two fields representing their value and their owner:
class Note:
value: TokenValue # u64
public_key: ZkPublicKey # 32 bytes
Note Id
A note can be uniquely identified by the Operation that created it and its output number: (op_id, output_number) if each Operation are uniquely identifiable. For this reason, every Operation that output notes have a unique payload that is used to derive the Operation identifier. Because it is often useful to have a commitment to the note fields for use in ZK proofs (e.g., for PoL), we included the note in the note identifier derivation.
def derive_op_id(operation: Op) -> Hash:
op_bytes = encode(op)
h = Hasher() # /!\ This is a classic hash not a zkhash /!\
h.update(b"OPERATION_ID_V1")
h.update(op_bytes)
return h.digest()
def derive_note_id(op_id: Hash, output_number: int, note: Note) -> NoteId:
return zkhash(
FiniteField(b"NOTE_ID_V1", byte_order="little", modulus= p),
FiniteField(op_id, byte_order="little", modulus= p),
FiniteField(output_number, byte_order="little", modulus= p),
FiniteField(note.value, byte_order="little", modulus= p),
note.public_key
)
op_id is a classical 256-bit hash digest and must be reduced to a field element before being passed to the ZkHasher. We apply a direct modular reduction mod p (via FiniteField(..., modulus=p)). Since , the reduction is slightly non-uniform, values in appear one extra time, but this is inconsequential in practice: the collision probability remains around , and NoteId uniqueness is not derived from uniformity of op_id over but from the collision-resistance of the underlying hash and per-operation payload uniqueness.
These note identifiers uniquely define notes in the system and cannot be chosen by the user. Nodes maintain the set of notes through a dictionary mapping the NoteId to the note.
Locked notes
Locked notes are special notes in Mantle that serve as collateral for Service Declarations. A note can become locked after executing a Declare Operation, preventing it from being spent until explicitly released through a Withdraw Operation. The system maintains a mapping of locked note IDs to their supporting declarations. Though locked, these notes remain in the Ledger and can still participate in Proof of Stake. When service providers withdraw all their declarations, the associated note(s) become unlocked and available for spending again.
Channel Notes
Channel notes are on-ledger notes minted to represent channel funds. They are distinct from Locked Notes as they can’t be used to declare a service. However, they follow the same ageing rule as ordinary notes since they are part of the ledger and can be used for PoL creation once aged enough.
The system maintains a channel_notes set in the Ledger tracking all active channel NoteId and their respective ChannelId.
Ledger
class Ledger:
notes: list[Note]
locked_notes: dict[NoteId, LockedNote]
channel_notes: dict[NoteId, ChannelId]
Input Notes Spendability Validation
A note is spendable if and only if it exists, it is not spent or locked. The following function validates that an input of notes can be consumed:
class Ledger:
def assert_spendable(inputs: list[NoteId], channel_id: ChannelId | None):
## Check there is no duplicate
assert len(inputs) == len(set(inputs))
# Check that each note is individualy not locked, for the correct channel and unspent
for note_id in inputs:
assert ledger.is_unspent(note_id)
assert note_id not in locked_notes
if channel_id is None:
assert note_id not in ledger.channel_notes
else:
assert note_id in ledger.channel_notes
assert ledger.channel_notes[note_id] == channel_id
Output Notes Validation
Before an output of notes can be inserted into the Ledger, every note field must satisfy the following constraints:
class Ledger:
def assert_valid_output(outputs: list[Note]):
for note in outputs:
assert note.value > 0
assert note.value <= 2**64-1
Consuming Input Notes Execution
Consuming a set of notes removes them from the Ledger’s Merkle tree and recycles their leaf indices:
class Ledger:
def execute_spending(inputs: list[NoteId], channel_id: ChannelId | None):
for note_id in inputs:
# updates the merkle tree to zero out the leaf for this entry
# and adds that leaf index to the list of unused leaves
ledger.remove(note_id)
if channel_id is not None:
ledger.channel_notes.pop(note_id)
Creating Output Notes Execution
Creating notes derives their NoteId from the Operation’s OpId and insert them in the Ledger:
class Ledger:
def execute_adding(op_id: Hash, outputs: list[Note], channel_id: ChannelId | None):
for (output_index, output_note) in enumerate(outputs):
output_note_id = derive_note_id(op_id, output_index, output_note)
ledger.add(output_note_id)
if channel_id is not None:
ledger.channel_notes[output_note_id] = channel_id
Appendix
Gas Determination
From the [Analysis] Gas Cost Determination, we get the table below:
| Constants | Value |
|---|---|
| EXECUTION_TRANSFER_GAS | 590 |
| EXECUTION_CHANNEL_INSCRIBE_GAS | 56 |
| EXECUTION_CHANNEL_CONFIG_GAS | 56 |
| EXECUTION_CHANNEL_DEPOSIT_GAS | 590 |
| EXECUTION_CHANNEL_WITHDRAW_GAS | 56 |
| EXECUTION_CHANNEL_TRANSFER_GAS | 56 |
| EXECUTION_SDP_DECLARE_GAS | 646 |
| EXECUTION_SDP_WITHDRAW_GAS | 590 |
| EXECUTION_SDP_ACTIVE_GAS | 590 |
| EXECUTION_LEADER_CLAIM_GAS | 580 |
Zero Knowledge Signature Scheme (ZkSignature)
A proof attesting that for the following public values:
class ZkSignaturePublic:
public_keys: list[ZkPublicKey] # public keys signing the message (len = 32)
msg: zkhash # a finite field element uniquely representing the message
The prover knows a witness:
class ZkSignatureWitness:
# The list of secret keys used to signed the message
secret_keys: list[ZkSecretKey] # (len = 32)
Such that the following constraints hold:
-
The number of secret keys is equal to the number of public keys.
assert len(secret_keys) == len(public_keys) -
Each public key is derived from the corresponding secret key.
assert all( notes[i].public_key == zkhash(FiniteField(b"KDF", byte_order="little", modulus= p), secret_keys[i]) for i in range(len(public_keys)) ) -
The proof is bound to
msg(it’s themantle_tx_hashreduced modulo in case of transactions).For implementation, the ZkSignature circuit will take a maximum of 32 public keys as inputs. To prove ownership of fewer keys, the remaining inputs will be padded with the public key corresponding to the secret key
0and ignored during execution. The outputs have no size limit since they are included in the hashed message.
Benchmark
The material used for the benchmarks is the following:
- CPU : 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM : 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS : Ubuntu 22.04.5 LTS
- Kernel : 6.8.0-59-generic
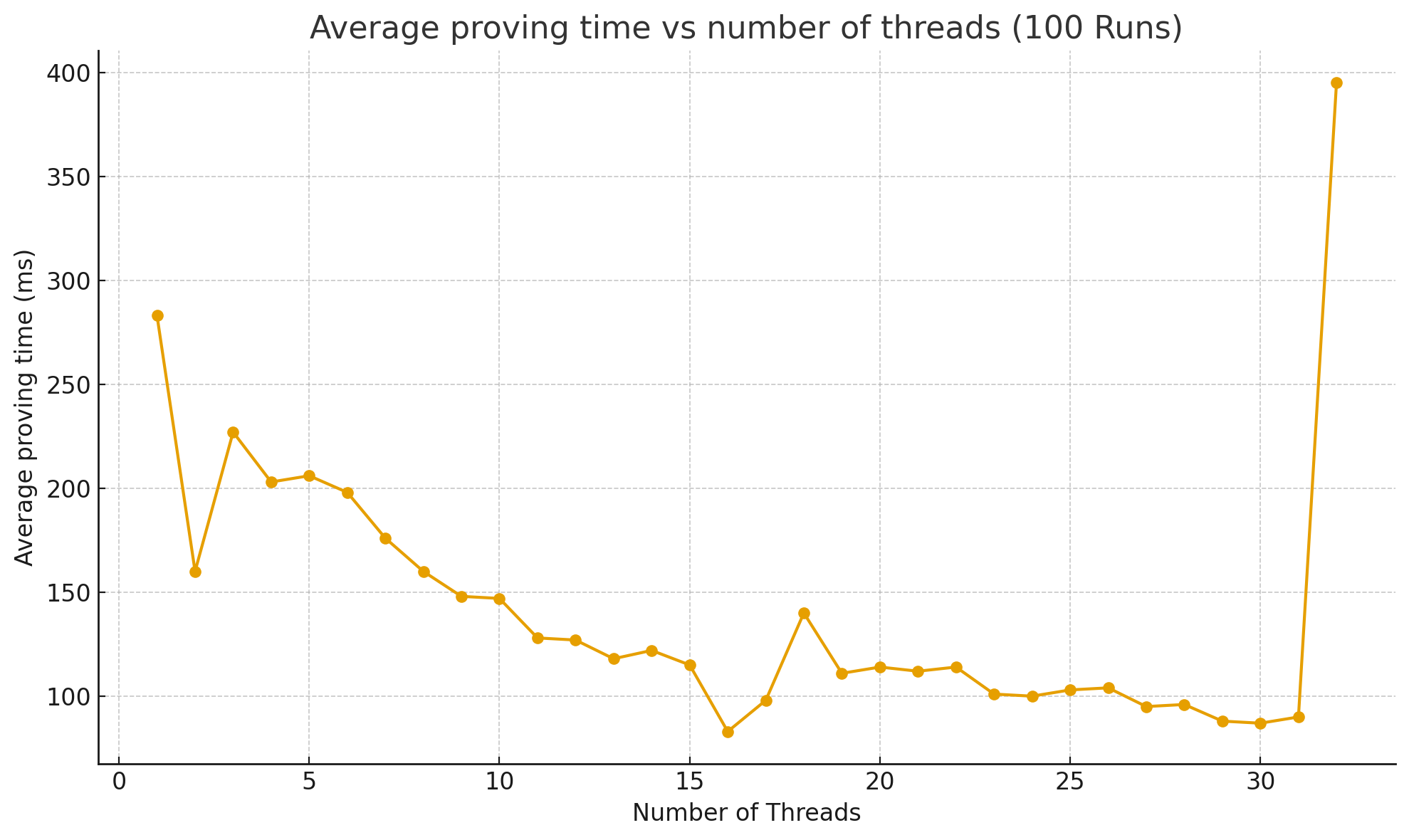
Multiple Ed25519 Signatures Verification
Several operations (e.g. Channel Configuration and Channel Withdraw) authorize an action with a threshold of Ed25519 signatures produced by a list of accredited keys. Each signature comes with the index, in the accredited keys list, of the key that produced it. The verification is factored out in the following routine:
Given
msg: zkhash # the message being signed (the mantle txhash)
signatures: list[Ed25519Signature]
indexes: list[u16] # for each signature, the index in `keys` of
# the signing key
keys: list[Ed25519PublicKey] # the accredited keys
threshold: u16 # the number of required signatures
Verify
def MultiEd25519_verify(msg, signatures, indexes, keys, threshold):
# There must be exactly one index per signature
assert len(signatures) == len(indexes)
# There must be exactly `threshold` signatures
assert len(signatures) == threshold
# Indexes must be ordered from smallest to biggest without duplication.
# Being strictly increasing rejects duplicates and, since `idx` is used to
# index `keys`, guarantees every index stays within bounds.
for i in range(len(indexes) - 1):
assert indexes[i] < indexes[i + 1]
# Each signature must be valid for the accredited key at its index
for sig, idx in zip(signatures, indexes):
assert Ed25519_verify(msg, keys[idx], sig)
Proof of Claim
A proof attesting that given these public values:
class ProofOfClaimPublic:
voucher_root: zkhash # Merkle root of the reward_voucher maintained by everyone
voucher_nullifier: zkhash
mantle_tx_hash_fr: zkhash # attached hash reduced modulo p
The prover knows the following witness:
class ProofOfClaimWitness:
secret_voucher: zkhash
voucher_merkle_path: list[zkhash]
voucher_merkle_path_selectors: list[bool]
such that the following constraints hold:
- The reward voucher is derived from the secret voucher.
assert reward_voucher == zkhash(
FiniteField(b"REWARD_VOUCHER", byte_order="little", modulus= p),
secret_voucher)
- There exists a valid Merkle path from the reward voucher as a leaf to the Merkle root.
assert voucher_root == path_root(leaf=reward_voucher,
path=voucher_merkle_path,
selectors=voucher_merkle_path_selectors)
- The voucher nullifier is derived from the secret voucher correctly.
assert voucher_nullifier == zkhash(
FiniteField(b"VOUCHER_NF", byte_order="little", modulus= p),
secret_voucher)
- The proof is bound to the
mantle_tx_hashreduced modulo .
Benchmark
The material used for the benchmarks is the following:
- CPU : 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM : 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS : Ubuntu 22.04.5 LTS
- Kernel : 6.8.0-59-generic
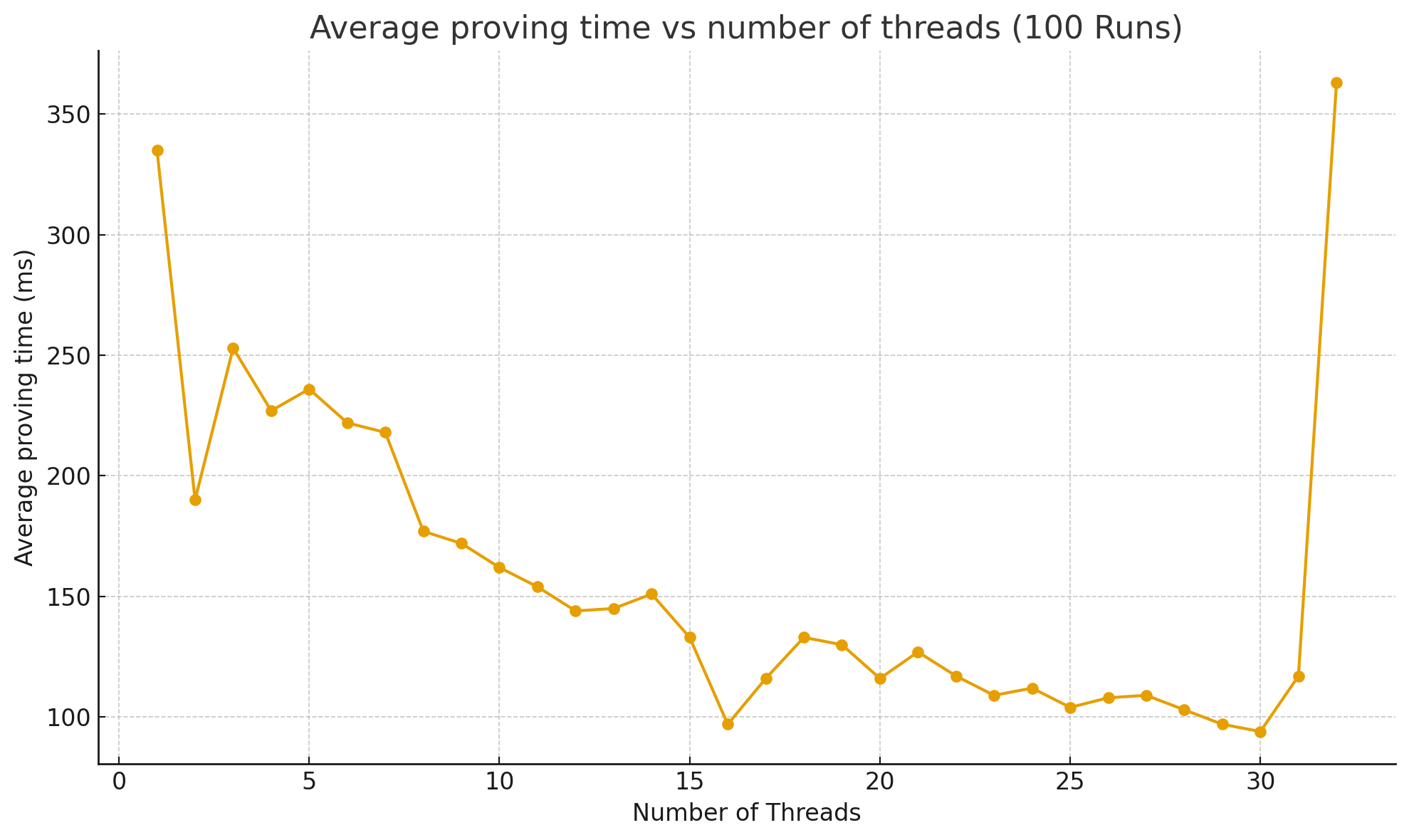
Test Vectors
To see what the payloads represent, refer to Mantle Transaction Encoding.
Operation Id
| Operation | Payload | op_id |
|---|---|---|
TRANSFER | 0x0201000000000000000000000000000000000000000000000000000000000000000200000000000000000000000000000000000000000000000000000000000000020300000000000000040000000000000000000000000000000000000000000000000000000000000005000000000000000600000000000000000000000000000000000000000000000000000000000000 | 0x5e5e1b318aa0c2aec93fbb327e6af5f705e5684269a34e0c1319539d00d06cdb |
CHANNEL_CONFIG | 0x070707070707070707070707070707070707070707070707070707070707070702001398f62c6d1a457c51ba6a4b5f3dbd2f69fca93216218dc8997e416bd17d93cafd1724385aa0c75b64fb78cd602fa1d991fdebf76b13c58ed702eac835e9f6180a0000000b0000000c000d00 | 0x0cf0dd115eadfc303eeb4c103a7d2faba3cf3a25b549da79c30857fb9eebc0cb |
CHANNEL_INSCRIBE | 0x0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0b00000068656c6c6f206c6f676f730000000000000000000000000000000000000000000000000000000000000000d9bf2148748a85c89da5aad8ee0b0fc2d105fd39d41a4c796536354f0ae2900c | 0xfb9af7fb1384fff51780ec8c5afbcba76449ab7603484f797df3a472e48826c1 |
CHANNEL_DEPOSIT | 0x1010101010101010101010101010101010101010101010101010101010101010011100000000000000000000000000000000000000000000000000000000000000100000006465706f7369742d6d65746164617461 | 0xf14ff0aad9bc5e8e30c5d1aa3710aaa1c1cc1f47c2c256e7d9e73104cb17ccaf |
CHANNEL_WITHDRAW | 0x1212121212121212121212121212121212121212121212121212121212121212011300000000000000000000000000000000000000000000000000000000000000 | 0x503d0d08f9faef971864943103965d13be7159fe6e0361c8ea614c6d0431e59c |
CHANNEL_TRANSFER | 0x14141414141414141414141414141414141414141414141414141414141414140115000000000000000000000000000000000000000000000000000000000000000116000000000000001700000000000000000000000000000000000000000000000000000000000000 | 0xfb24c17731954e8bbe1b0dedd69e4857c8083d1689aff331ba16f3ed5883f0ce |
SDP_DECLARE | 0x00010b00047f00000191020bb8cd0353470962558a6e0839022ae65c6b2723b32772e5c0c5f4776cb8e6a3e10ba2f319000000000000000000000000000000000000000000000000000000000000001a00000000000000000000000000000000000000000000000000000000000000 | 0x42e93fdce121a5ab4da3201a6fd2da1d42ca8b7d8c1a8c9e2a657a6cdc7aa468 |
SDP_WITHDRAW | 0x1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1d000000000000001c00000000000000000000000000000000000000000000000000000000000000 | 0xc95aea0e46f60c12a8b29b259ca1b39947093c0d88a1ea8400c49e392ca491a0 |
SDP_ACTIVE | 0x1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1f0000000000000001010a0000008a88e3dd7409f195fd52db2d3cba5d72ca6709bf1d94121bf3748801b40f6f5c020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020303030303030303030303030303030303030303030303030303030303030303 | 0x76afa55f5733db75a982dc5ccabb5c6a7dab992eda78cdfd5f657f314e388354 |
LEADER_CLAIM | 0x200000000000000000000000000000000000000000000000000000000000000021000000000000000000000000000000000000000000000000000000000000002200000000000000000000000000000000000000000000000000000000000000 | 0x0dc1a007fdd184b4553a83d166b749a621f5be2de4b3b0429ebf0520d1dd9a51 |
Mantle Transaction Hash
| Transaction | Payload | Transaction Hash |
|---|---|---|
| Empty transaction | 0x00 | 0x2eba3f667b80a508f3d44d149a1c27a90ea365a51e4fc8209289088142b364e5 |
| Transaction with one of each operation | 0x0a00020100000000000000000000000000000000000000000000000000000000000000020000000000000000000000000000000000000000000000000000000000000002030000000000000004000000000000000000000000000000000000000000000000000000000000000500000000000000060000000000000000000000000000000000000000000000000000000000000010070707070707070707070707070707070707070707070707070707070707070702001398f62c6d1a457c51ba6a4b5f3dbd2f69fca93216218dc8997e416bd17d93cafd1724385aa0c75b64fb78cd602fa1d991fdebf76b13c58ed702eac835e9f6180a0000000b0000000c000d00110e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0e0b00000068656c6c6f206c6f676f730000000000000000000000000000000000000000000000000000000000000000d9bf2148748a85c89da5aad8ee0b0fc2d105fd39d41a4c796536354f0ae2900c121010101010101010101010101010101010101010101010101010101010101010011100000000000000000000000000000000000000000000000000000000000000100000006465706f7369742d6d6574616461746113121212121212121212121212121212121212121212121212121212121212121201130000000000000000000000000000000000000000000000000000000000000014141414141414141414141414141414141414141414141414141414141414141401150000000000000000000000000000000000000000000000000000000000000001160000000000000017000000000000000000000000000000000000000000000000000000000000002000010b00047f00000191020bb8cd0353470962558a6e0839022ae65c6b2723b32772e5c0c5f4776cb8e6a3e10ba2f319000000000000000000000000000000000000000000000000000000000000001a00000000000000000000000000000000000000000000000000000000000000211b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1b1d000000000000001c00000000000000000000000000000000000000000000000000000000000000221e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1e1f0000000000000001010a0000008a88e3dd7409f195fd52db2d3cba5d72ca6709bf1d94121bf3748801b40f6f5c02020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202020202030303030303030303030303030303030303030303030303030303030303030330200000000000000000000000000000000000000000000000000000000000000021000000000000000000000000000000000000000000000000000000000000002200000000000000000000000000000000000000000000000000000000000000 | 0x5d3ff950e0752dc4ebf8c8d73a8cc7b22445b9245ea317f7ebdaa8d6fd881589 |
MANTLE-TRANSACTION-ENCODING
| Field | Value |
|---|---|
| Name | Mantle Transaction Encoding |
| Slug | 202 |
| Status | raw |
| Category | Standards Track |
| Editor | David Rusu [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-20 —
5b20a2d— docs(blockchain) Channel Participation in PoS (#364) - 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-29 —
67e498e— chore: fix math issues (#350) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revisions History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-12-01 |
| 1.1.0 | [RFC] Make Ledger Transaction an Operation | 2026-03-25 |
| 1.2.0 | [RFC] Add Deposit/Withdraw to Tx Encoding | 2026-04-02 |
| 1.3.0 | [RFC] Enforce NoteId uniqueness | 2026-04-24 |
| 1.4.0 | [RFC] Simplify Mantle Transaction and Refactor Ledger Operations | 2026-05-06 |
| 1.4.1 | Removed mention of DA. Updated KeyCount from Byte to UINT16 to follow Mantle. | 2026-05-21 |
| 1.5.0 | Introduce the new Operation CHANNEL_STAKE_ASSIGNATION and update of the channel operations to reflect changes in Mantle | 2026-06-24 |
Introduction
This document specifies the canonical encoding of Mantle transactions (see Mantle - Mantle Transaction) and its sub-components. Transactions sent through the mempool and included in blocks use this encoding.
Overview
The transaction encoding is specified in ABNF form to remove any ambiguity and guarantee a canonical encoding. The high level encoding choices which were not immediately derivable from the Mantle specification are listed here:
- All multi-byte integers use little-endian encoding
- Any lists are length-prefixed with fixed width uints
- We derive number of proofs and type of proof from the Ops list parsed earlier
Specification
Signed Mantle Tx
SignedMantleTx = MantleTx OpsProofs
Mantle Tx
MantleTx = OpCount *Op
OpCount = Byte
Operations
Op = Opcode OpPayload
Opcode = Byte
OpPayload = Transfer /
ChannelInscribe /
ChannelConfig /
ChannelDeposit /
ChannelWithdraw /
ChannelTransfer /
SDPDeclare /
SDPWithdraw /
SDPActive /
LeaderClaim
Channel Operations
ChannelInscribe = ChannelId Inscription Parent Signer
Inscription = UINT32 *BYTE
ChannelConfig = ChannelId KeyCount *Signer PostingTimeframe PostingTimeout ConfigThreshold TransferThreshold
KeyCount = UINT16
PostingTimeframe = UINT32
PostingTimeout = UINT32
ConfigThreshold = UINT16
TransferThreshold = UINT16
ChannelDeposit = ChannelId Inputs Metadata
Inputs = InputCount *NoteId
InputCount = Byte
Metadata = UINT32 *BYTE
ChannelTransfer = ChannelId Inputs Outputs
ChannelWithdraw = ChannelId Inputs
ChannelId = Hash32
Parent = Hash32
Signer = Ed25519PublicKey
Outputs = OutputCount *Note
OutputCount = Byte
Inputs = InputCount *NoteId
SDP Operations
SDPDeclare = ServiceType LocatorCount *Locator ProviderId ZkId LockedNoteId
ServiceType = Byte ; 0 = BN
LocatorCount = Byte ; Max 8
Locator = 2Byte *BYTE ; Max 329 bytes, multiaddr format
ProviderId = Ed25519PublicKey
ZkId = ZkPublicKey
LockedNoteId = NoteId
SDPWithdraw = DeclarationId Nonce LockedNoteId
DeclarationId = Hash32
Nonce = UINT64
SDPActive = DeclarationId Nonce Metadata
Metadata = UINT32 *BYTE ; Service-specific node activeness metadata
Leader operations
LeaderClaim = RewardsRoot VoucherNullifier PublicKey
RewardsRoot = FieldElement ; Merkle root for voucher membership proof
VoucherNullifier = FieldElement
PublicKey = ZkPublicKey
Transfer Operations
Transfer = Inputs Outputs
Inputs = InputCount *NoteId
InputCount = Byte
Outputs = OutputCount *Note
OutputCount = Byte
Ledger
Note = Value ZkPublicKey
Value = UINT64
NoteId = FieldElement
Op Proofs
OpsProofs = *OpProof ; 1. Lenth must equal OpCount
; 2. OpProof variant is derived from the corresponding Op.
; That is, type(OpProofs[i]) == ProofFor(Op[i])
OpProof = Ed25519SigProof /
ZkSigProof /
ZkAndEd25519SigsProof /
ChannelWithdrawOpProof /
ProofOfClaimProof
Ed25519SigProof = Ed25519Signature
ZkSigProof = ZkSignature
ZkAndEd25519SigsProof = ZkSignature Ed25519Signature
ChannelWithdrawOpProof = SignatureCount *Ed25519Signature
ProofOfClaimProof = Groth16
SignatureCount = UINT16
Common Structures
; Zero-knowledge signature
ZkSignature = Groth16
; Cryptographic primitives
Groth16 = 128BYTE ; pi_a (32) + pi_b (64) + pi_c (32)
ZkPublicKey = FieldElement
Ed25519PublicKey = 32BYTE
Ed25519Signature = 64BYTE
FieldElement = 32BYTE ; BN254 field element (little-endian)
Hash32 = 32BYTE
; Primitive types
UINT64 = 8BYTE ; 64-bit unsigned integer, little-endian
UINT32 = 4BYTE ; 32-bit unsigned integer, little-endian
UINT16 = 2BYTE ; 16-bit unsigned integer, little-endian
Byte = OCTET
[RFC] Add Deposit/Withdraw to Tx Encoding
Authors: Youngjoon Lee Approvals (research): Marcin Pawlowski, Thomas Lavaur Approvals (engineering): Daniel Sanchez Quiros, Alex Cabeza Romero
Motivation
Mantle Transaction Encoding does not cover channel deposit and withdraw operations, even though they have been already added to the Mantle. This RFC proposes adding the encoding format of channel deposit and withdraw operations and their proofs to the Mantle Transaction Encoding.
Proposal
We adapt the Mantle Transaction Encoding to include the Channel Deposit and Channel Withdraw operations as defined below:
- CHANNEL_DEPOSIT
- CHANNEL_WITHDRAW
We add
ChannelDepositandChannelWithdrawto Operations:
OpPayload = Transfer /
ChannelInscribe /
ChannelBlob /
ChannelSetKeys /
+ ChannelDeposit /
+ ChannelWithdraw /
SDPDeclare /
SDPWithdraw /
SDPActive /
LeaderClaim
Then define the structures in Channel Operations:
ChannelSetKeys = ChannelId KeyCount *Signer
KeyCount = Byte
+ ChannelDeposit = ChannelId Amount Metadata
+ Amount = UINT64
+ Metadata = UINT32 *BYTE
+ ChannelWithdraw = ChannelId Amount
ChannelId = Hash32
Parent = Hash32
Signer = Ed25519PublicKey
Next we add ChannelWithdrawOpProof to Op Proofs:
OpsProofs = *OpProof ; 1. Lenth must equal OpCount
; 2. OpProof variant is derived from the corresponding Op.
; That is, type(OpProofs[i]) == ProofFor(Op[i])
OpProof = Ed25519SigProof /
ZkSigProof /
ZkAndEd25519SigsProof /
+ ChannelWithdrawOpProof /
ProofOfClaimProof
Ed25519SigProof = Ed25519Signature
ZkSigProof = ZkSignature
ZkAndEd25519SigsProof = ZkSignature Ed25519Signature
+ ChannelWithdrawOpProof = SignatureCount *IndexedEd25519Signature
ProofOfClaimProof = Groth16
+ SignatureCount = UINT16
+ ChannelKeyIndex = UINT16
+ IndexedEd25519Signature = Ed25519Signature ChannelKeyIndex
Finally we extend the Common Structures with definition of UINT16:
; Zero-knowledge signature
ZkSignature = Groth16
; Cryptographic primitives
Groth16 = 128BYTE ; pi_a (32) + pi_b (64) + pi_c (32)
ZkPublicKey = FieldElement
Ed25519PublicKey = 32BYTE
Ed25519Signature = 64BYTE
FieldElement = 32BYTE ; BN254 field element (little-endian)
Hash32 = 32BYTE
; Primitive types
UINT64 = 8BYTE ; 64-bit unsigned integer, little-endian
UINT32 = 4BYTE ; 32-bit unsigned integer, little-endian
+ UINT16 = 2 BYTE ; 16-bit unsigned integer, little-endian
Byte = OCTET
Justification
Mantle Transaction Encoding does not cover channel deposit and withdraw operations, even though they have been already added to the Mantle.
Specifications Update
- [v1.2] Mantle Transaction Encoding
[RFC] Enforce NoteId uniqueness
Authors: Thomas Lavaur
Motivation
In Mantle, the NoteId is derived from the Transfer Operation that mints it:
The introduction of LEADER_CLAIM and CHANNEL_WITHDRAW operations creates a collision risk in NoteId derivation. Both operations allow a Mantle transaction to be balanced without consuming any note as input, breaking the hash chain that previously guaranteed NoteId uniqueness. As a result, two distinct Mantle transactions can produce notes with identical NoteIds whenever their TRANSFER operations share the same output value and public key and carry no inputs.
Proposal
We propose three complementary changes:
Generalize NoteId derivation to use a per-operation identifier OpId
Rather than deriving NoteId from a transfer_hash specific to TRANSFER, we introduce a generic Op``Id that each Operation creating new notes computes independently.
The NoteId derivation ZK circuit is left entirely unchanged, each Operation that outputs notes simply supplies its own op_id as the first input. Uniqueness is guaranteed as long as each op_id is itself unique.
So instead of using
# v 1.3
def derive_note_id(transfer_hash: zkhash, output_number: int, note: Note) -> NoteId:
return zkhash(
FiniteField(b"NOTE_ID_V1", byte_order="little", modulus= p)
transfer_hash,
FiniteField(output_number, byte_order="little", modulus= p)
FiniteField(note.value, byte_order="little", modulus= p)
note.public_key
)
we would be using:
# new version
def derive_note_id(op_id: OpId, output_index: int, note: Note) -> NoteId:
return ZkHash(
FiniteField(b"NOTE_ID_V1", byte_order="little", modulus=p),
op_id, # transfer_id, leader_claim_id, etc.
FiniteField(output_index, byte_order="little", modulus=p),
FiniteField(note.value, byte_order="little", modulus=p),
note.public_key,
)
Restrict TRANSFER to require at least one input note
TRANSFER is amended to require at least one input note. This re-establishes a hash chain: transfer_id (previously transfer_hash) is derived from at least one existing NoteId, making each new NoteId depend on a prior unpredictable value and eliminating the collision vector. This is achieved because each TRANSFER payload is now unique because they include a unique NoteId.
The transfer_id is not derived using a specific transfer_hashfunction anymore but using a common derive_op_id function that output a unique OpId as long as the inputted Operation as a unique payload. So instead of
# v1.3
def transfer_hash(tx: LedgerTx) -> ZkHash:
tx_bytes = encode(tx)
h = Hasher() # /!\ This is a classic hash not a ZkHash /!\
h.update(b"TRANSFER_HASH_V1")
h.update(tx_bytes)
classic_digest = h.digest()
zkh = ZkHasher() # /!\ This is a ZkHash not a classic hash /!\
zkh.update(FiniteField(classic_digest[0:16], bytes_order="little", modulus = p))
zkh.update(FiniteField(classic_digest[16:32], bytes_order="little", modulus = p))
return zkh.digest()
We would use:
# new version
def derive_op_id(operation: Op) -> Hash:
op_bytes = encode(op)
h = Hasher() # /!\ This is a classic hash not a ZkHash /!\
h.update(b"OPERATION_ID_V1")
h.update(op_bytes)
return h.digest()
Decouple CHANNEL_WITHDRAW, CHANNEL_DEPOSIT, and LEADER_CLAIM from the Mantle transaction balance
Rather than adjusting the transaction balance, which would require a compensating TRANSFER and force the consumption of an otherwise unneeded note, these operations directly consume or create notes using their own OpId as input to the shared derive_note_id function.
Now the Operations changed from
# v 1.3
class ChannelDeposit:
channel: ChannelId
amount: TokenValue
metadata: bytes
class ChannelWithdraw:
channel: ChannelId
amount: TokenValue
class ClaimRequest:
rewards_root: zkhash # Merkle root used in the proof for voucher membership
voucher_nf: zkhash
to
# new version
class ChannelDeposit:
channel: ChannelId
inputs: list[NoteId] # the list of consumed note identifiers
metadata: bytes
class ChannelWithdraw:
channel: ChannelId
outputs: list[Note]
withdrawal_nonce: u32
class ClaimRequest:
rewards_root: zkhash # Merkle root used in the proof for voucher membership
voucher_nf: zkhash
public_key: ZkPublicKey
And the balance is now computed using only transfers, while CHANNEL_DEPOSIT, CHANNEL_WITHDRAW and LEADER_CLAIM directly create or consume the note they need.
Discussion
Security
A NoteId collision results in fund loss. The UTXO model marks notes as consumed upon spending; once a NoteId is spent, it cannot be spent again. If two distinct notes share the same NoteId, only one can ever be consumed, the other becomes permanently unspendable.
Beyond accidental collisions, the vulnerability is actively exploitable. An adversary who learns a target's public key and the value of a pending note can front-run it by submitting an input-free TRANSFER with identical parameters, forcing a collision with an already-spent NoteId. Requiring an input makes this attack computationally infeasible, as the attacker would also need to control the input NoteId.
ZK Circuit Simplicity
Crucially, the derive_note_id template circuit requires no modification. By parameterising it on a generic op_id, each operation type, TRANSFER, LEADER_CLAIM, CHANNEL_WITHDRAW feeds its own unique Identifier while reusing the same constraint system. This keeps the proving infrastructure stable and avoids per-operation circuit variants.
Semantic Correctness
TRANSFER is semantically a movement of value: it consumes existing notes and produces new ones, and is the right tool for splitting, merging, or redirecting value already held in the Mantle ledger. LEADER_CLAIM, CHANNEL_WITHDRAW, and CHANNEL_DEPOSIT are boundary operations: they interface with external systems (the PoS reward pool, payment channels) and directly issue or redeem notes without routing through TRANSFER's balance accounting. This proposal enforces that boundary by requiring TRANSFER to have at least one input, and by having each boundary operation own its note issuance or consumption directly. The result is clean separation: value movement and value creation/destruction are handled by distinct operations, which simplifies protocol reasoning.
Details
Mantle Specification
Mantle Transaction Balance
We change the Mantle Transaction Balance computation to calculate the balance of Transfer Operations only:
tx_fee = gas_fees(signed_tx) # Not an unsigned int
assert tx_fee == get_transaction_balance(signed_tx)
def get_transaction_balance(signed_tx: SignedMantleTx) -> int:
balance = 0 # It's important to not use unsigned int here to avoid
# overflow vulnerabilities
for op in signed_tx.tx.ops:
- if op.opcode == LEADER_CLAIM:
- balance += get_leader_reward()
- if op.opcode == CHANNEL_DEPOSIT:
- balance -= get_channel_deposit_amount(op)
- if op.opcode == CHANNEL_WITHDRAW:
- balance += get_channel_withdrawal_amount(op)
if op.opcode == TRANSFER:
for inp in op.inputs:
balance += get_value_from_note_id(inp)
for out in op.outputs:
balance -= out.value
return balance
Channel Operations
Channel State
We add a channel identifier nonce in the Channel State. It is initialized at 0, and each time a CHANNEL_WITHDRAW creates a note as output, it is used to derive a unique OpId:
channels: dict[ChannelId, ChannelState] # ChannelId is 32 bytes
class ChannelState:
# Channel Configuration
accredited_keys: list[Ed25519PublicKey] # limited to 65 535 keys
configuration_threshold: u16 # indicating how many keys are
# required to update the configuration
# Message Ordering
tip_hash: hash
# Decentralized Sequencing
tip_slot: Slot
tip_sequencer: u16 # indicating the actual
# sequencer position in the list of accredited keys
tip_sequencer_starting_slot: Slot
posting_timeframe: u32 # number of slots (0 = infinity)
posting_timeout: u32 # number of slots (0 = no timeout)
# Bridging
balance: TokenValue # See the Note section for its precision
+ withdrawal_nonce: u32 # Nonce used to derive a withdraw OpId
withdraw_threshold: u16 # indicating how many keys are
# required to withdraw funds from the channel
def default_channel(block_slot: Slot, keys: list[Ed25519PublicKey])
-> ChannelState:
return ChannelState(
tip_hash = ZERO,
tip_slot = block_slot,
accredited_keys = keys,
tip_sequencer = 0,
tip_sequencer_starting_slot = block_slot,
posting_timeframe = 0,
posting_timeout = 0,
configuration_threshold = 1,
balance = 0,
+ withdrawal_nonce = 0,
withdraw_threshold = 1)
The withdraw nonce is incremented by one during CHANNEL_WITHDRAW execution: Increase the channel withdrawal_nonce.
Channel Deposit
Payload
The CHANNEL_DEPOSIT Operation now takes a list of inputs to consume. The consume notes replace the amount because it’s directly derived from the consume notes.
class ChannelDeposit:
channel: ChannelId
- amount: TokenValue
+ inputs: list[NoteId] # the list of consumed note identifiers
metadata: bytes
Proof
The Channel Deposit now consumes notes as input. For this reason the Operation needs to prove the ownership of the note. This is done through a ZkSignature.
A Channel Deposit proves the ownership of the consumed notes using a Zero Knowledge Signature Scheme (ZkSignature).
None # Indirectly signed through the Transfer signature
ZkSignature
Validation
We now need to check the proof and the validity of the consumed NoteId. This is done in the exact same way as transfer is validated and executed.
Given
mantle_txhash: ZkHash # ZkHash of mantle tx containing this ledger tx
deposit: ChannelDeposit
deposit_proof: ZkSignature
channels: dict[ChannelId, ChannelState]
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
Validate
- Verify that the channel exist
assert deposit.channel in channels
- Ensure all inputs are unspent.
assert all(ledger.is_unspent(note_id) for note_id in deposit.inputs)
- Validate ownership over deposited notes.
input_notes = [ledger[input_note_id] for input_note_id in deposit.inputs]
input_pks = [note.public_key for note in input_notes]
assert ZkSignature_verify(mantle_txhash, deposit_proof, input_pks)
- Ensure inputs are not locked.
# Ensure inputs are not locked
for note_id in deposit.inputs:
assert note_id not in locked_notes
Execution
We now need to remove the note from the Ledger:
Given
deposit: ChannelDeposit
channels: dict[ChannelId, ChannelState]
ledger: Ledger
Execute
- Remove inputs from the ledger.
for note_id in deposit.inputs:
# updates the merkle tree to zero out the leaf for this entry
# and adds that leaf index to the list of unused leaves
ledger.remove(note_id)
- Increase the balance of the channel
for inp in deposit.inputs:
channels[deposit.channel].balance += inp.value
channels[deposit.channel].balance += deposit.amount
Example
We need to update the example because the payload was modified:
deposit = ChannelDeposit(
channel=ZONE_A,
- amount=50,
+ inputs=[alice_deposit_note_id] # This is a note of 50 tokens
metadata=b"deposit to address: 0x..."
)
Channel Withdraw
Payload
We redefine the Payload to take notes as output instead of an amount:
class ChannelWithdraw:
channel: ChannelId
- amount: TokenValue
+ outputs: list[Note]
+ withdrawal_nonce: u32
Validation
We update the validation to check the format of outputted Notes and to fit the new payload
+ # Check that the outputs are valid
+ for output in withdrawal.outputs:
+ assert output.value > 0
+ assert output.value < 2**64
# Check that the channel exists
assert withdrawal.channel in channels
chan = channels[withdrawal.channel]
+ # Check that the withdraw nonce is correct
+ assert channels[withdrawal.channel].withdrawal_nonce == withdrawal.withdrawal_nonce
# Check that the channel has enough funds
+ withdrawal_amount = sum(output.value for output in withdrawal.outputs)
+ assert chan.balance >= withdrawal_amount
- assert chan.balance >= withdrawal.amount
# Check that there are enough signatures
assert len(proof.signatures) == len(proof.indexes)
assert len(proof.signatures) == chan.withdraw_threshold
# Check that every index is unique
assert len(proof.indexes) == len(set(proof.indexes))
# Check the signatures
for sig, idx in zip(proof.signatures, proof.indexes):
assert Ed25519_verify(txhash, chan.accredited_keys[idx], sig)
Execution
We update the execution to remove notes from the ledger and updated the way the balance is decreased:
- Decrease the balance of the Channel
for output in withdrawal.outputs:
channels[withdrawal.channel].balance -= output.value
channels[withdrawal.channel].balance -= withdrawal.amount
- Add outputs to the ledger.
withdrawal_id = derive_op_id(withdrawal)
for (output_number, output_note) in enumerate(withdrawal.outputs):
output_note_id = derive_note_id(withdrawal_id, output_number, output_note)
ledger.add(output_note_id)
- Increase the channel
withdrawal_nonce
channels[withdrawal.channel].withdrawal_nonce += 1
Example
The example needs an update to match the new payload
# Sequencer encodes his withdrawal
withdrawal = ChannelWithdraw(
channel=ZONE_A,
+ outputs=[Note(pk=alice, value=50)]
- amount=50
)
Leader Claim
Payload
Because the note is created directly through this Operation, the leader need to indicate its Public key to receive the funds. This needs an update in the Payload:
class ClaimRequest:
rewards_root: zkhash # Merkle root used in the proof for voucher membership
voucher_nf: zkhash
+ public_key: ZkPublicKey
Execution
The execution now derives the note id and directly introduces it in the ledger:
Execution Given
claim: ClaimRequest
ledger: Ledger
voucher_nullifier_set: set[zkhash]
leaders_rewards: TokenValue # The pool of tokens to be claim by leaders
leader_reward: TokenValue # The amount one leader can claim
Execution
- Add
claim.voucher_nfto thevoucher_nullifier_set. - ~~Increase the balance of the Mantle Transaction by the leader reward amount according to Leaders Reward. ~~
- Denoting by
leader_rewardthe amount defined for leader rewards in Leaders Reward, construct a single output note with value leader_reward under the public key defined in the payload, and insert it into the Ledger:
output_note = Note(
value = leader_reward
public_key = claim.public_key,
)
claim_id = derive_op_id(claim)
output_note_id = derive_note_id(claim_id, 0, output_note)
ledger.add(output_note_id)
- Reduce the leader’s reward
leaders_rewardsvalue by the same amount (without ZK proof).
Example
The example needed an update to match the new payload
claim=ClaimRequest(
rewards_root=REWARDS_MERKLE_TREE.root(),
voucher_nf=voucher_nullifier,
+ public_key=leader_one_time_key
)
Transfer
Payload
We added an enforcement in the comment to say that the list of inputs must be at least 1
class Transfer:
inputs: list[NoteId] # the non-empty list of consumed note identifiers
outputs: list[Note]
Transfer Hash
We removed this section to match the new derive_operation_id function.
Validation
We need to verify that the transfer is non-empty. So we added this as a first step of the verification:
- Ensure the Transfer in non-empty
assert len(transfer.inputs) > 0
Execution
In the execution we update how the N``oteId is computed to match the new functions names
- transfer_hash = transfer_hash(transfer)
+ transfer_id = derive_operation_id(transfer)
for (output_number, output_note) in enumerate(transfer.outputs):
- output_note_id = derive_note_id(transfer_hash, output_number, output_note)
+ output_note_id = derive_note_id(transfer_id, output_number, output_note)
ledger.add(output_note_id)
Note Id
The NoteId Section also needs an update to include the new OpId derivation. We need to define a common way to derive the OpId and to update the function that derives the NoteId:
Any note can be uniquely identified by the Transfer Operation that created it and its output number:
A note can be uniquely identified by the Operation that created it and its output number: (transfer_hash, output_number). However, it is often useful to have a commitment to the note fields for use in ZK proofs (e.g., for PoL), so we include the note in the note identifier derivation.(op_id, output_number) if each Operation is uniquely identifiable. For this reason, every Operation that output notes have a unique payload that is used to derive the Operation identifier. It is useful to have a commitment to the note fields for use in ZK proofs (e.g., for PoL), we include the note in the note identifier derivation.
+ def derive_op_id(operation: Op) -> Hash:
+ op_bytes = encode(op)
+ h = Hasher() # /!\ This is a classic hash not a ZkHash /!\
+ h.update(b"OPERATION_ID_V1")
+ h.update(op_bytes)
+ return h.digest()
- def derive_note_id(transfer_hash: zkhash, output_number: int, note: Note) -> NoteId:
+ def derive_note_id(op_id: Hash, output_number: int, note: Note) -> NoteId:
return zkhash(
FiniteField(b"NOTE_ID_V1", byte_order="little", modulus= p),
- transfer_hash,
+ FiniteField(op_id, byte_order="little", modulus= p),
FiniteField(output_number, byte_order="little", modulus= p),
FiniteField(note.value, byte_order="little", modulus= p),
note.public_key
)
op_idis a classical 256-bit hash digest and must be reduced to a field element before being passed to the ZkHasher. We apply a direct modular reduction modp(viaFiniteField(..., modulus=p)). Since , the reduction is slightly non-uniform, values in appear one extra time, but this is inconsequential in practice: the collision probability remains around , andNoteIduniqueness is not derived from uniformity ofop_idover but from the collision-resistance of the underlying hash and per-operation payload uniqueness.
Gas Determination
The Gas Cost table was also updated to reflect the new CHANNEL_DEPOSIT cost:
| Constants | Value |
|---|---|
| EXECUTION_TRANSFER_GAS | 590 |
| EXECUTION_CHANNEL_INSCRIBE_GAS | 56 |
| EXECUTION_CHANNEL_CONFIG_GAS | 56 |
| EXECUTION_CHANNEL_DEPOSIT_GAS | 590 |
| EXECUTION_CHANNEL_WITHDRAW_GAS | 56 |
| EXECUTION_SDP_DECLARE_GAS | 646 |
| EXECUTION_SDP_WITHDRAW_GAS | 590 |
| EXECUTION_SDP_ACTIVE_GAS | 590 |
| EXECUTION_LEADER_CLAIM_GAS | 580 |
Gas Cost Determination
Overview
The table containing the summary of Gas Costs needs an update because the CHANNEL_DEPOSIT gas cost increases (see Channel Deposit):
TRANSFER_GAS = 590
CHANNEL_INSCRIBE_GAS = 56
CHANNEL_CONFIG_GAS = 56 * configuration_threshold
- CHANNEL_DEPOSIT_GAS = 0
+ CHANNEL_DEPOSIT_GAS = 590
CHANNEL_WITHDRAW_GAS = 56 * withdraw_threshold
SDP_DECLARE_GAS = 646
SDP_WITHDRAW_GAS = 590
SDP_ACTIVE_GAS = 590
LEADER_CLAIM_GAS = 580
Transfer
We add the derivation of the outputs NoteId in the cost of a TRANSFER
Execution: negligible.
- Verification of the output validity: negligible.
- Insertion of the note in the ledger: negligible.
+ - Derivation of the note identifiers: negligible
Channel Deposit
This needs a full update that changes its price from 0 to 590 Execution Gas.
The validation process is free as it doesn't require any verification and its execution only requires modifying the balance of the channel.
The Execution Gas of the Channel Deposit Operation compensates for the verification of the ZkSignature proof and for the check of the inputs.
Execution: negligible. ~590k CPU cycles.
- Verification of the ZK signature: 590,000 cycles.
- Verification that the notes are in the ledger: negligible.
- Verification that the notes are unlocked: negligible.
- Increase of the channel balance: negligible
Channel Withdraw
We update what covers a channel withdraw. This doesn’t affect its Execution Gas cost:
The validation process requires verifying multiple Eddsa25519 signatures, and updating the balance of the channel. The execution require deriving note Id and adding notes to the ledger. Execution: ~56k CPU cycles * withdraw_threshold.
- Verification of
withdraw_thresholdEd25519Signatures: 56,000 cycles per signature. - Decrease of the channel balance: negligible.
- Verification of the output validity: negligible.
- Insertion of the note in the ledger: negligible.
- Derivation of the note identifiers: negligible
Leader Claim
We updated what covers a leader claim to include the new output note.
Execution: ~580k CPU cycles. - Verification that the voucher nullifier isn’t already in the set: negligible. - Verification that the rewards root is one of the root of the reward tree of the last blocks: negligible. - Verification of the proof of claim: 580,000 cycles. - Insertion of the nullifier in the voucher nullifier set: negligible. - Insertion of the note in the ledger: negligible. - Derivation of the note identifiers: negligible
Mantle Transaction Encoding
We update the encoding to match the new payloads
Ledger
We move the definition of notes and noteIds that was previously in the Transfer Section into a dedicated Ledger section:
Ledger
Note = Value ZkPublicKey
Value = UINT64
NoteId = FieldElement
Channel Deposit
- ChannelDeposit = ChannelId Amount Metadata
- Amount = UINT64
+ ChannelDeposit = ChannelId Inputs Metadata
+ Inputs = InputCount *NoteId
+ InputCount = Byte
Metadata = UINT32 *BYTE
Channel Withdraw
- ChannelWithdraw = ChannelId Amount
+ ChannelWithdraw = ChannelId Outputs WithdrawalNonce
+ Outputs = OutputCount *Note
+ OutputCount = Byte
+ WithdrawalNonce = UINT32
Leader Claim
- LeaderClaim = RewardsRoot VoucherNullifier
+ LeaderClaim = RewardsRoot VoucherNullifier PublicKey
RewardsRoot = FieldElement ; Merkle root for voucher membership proof
VoucherNullifier = FieldElement
+ PublicKey = ZkPublicKey
Cross-Channel Messaging
This document needs only a small fix in the Atomic transfer between two zones example:
# Sequencer of Zone A encodes the withdrawal from Zone A
withdrawal = ChannelWithdraw(
channel=CHANNEL_ZONE_A,
+ outputs=[temporary_transfer_note]
- amount=5
)
# Sequencer of zone B encodes the deposit to Zone B
deposit = ChannelDeposit(
channel=CHANNEL_ZONE_B,
+ inputs=[temporary_transfer_note],
- amount=5
)
Service Reward Distribution Protocol
The SRDP protocol also needs an update: the rewards are directly inserted in the ledger without coming from an Operation. For this reason, the way the NoteId of these rewards are derived need to be updated:
from
The note Id is computed using the result of
zkhash(FiniteField(ServiceType, byte_order="little", modulus= p) || session_number)as the transaction hash. The output number corresponds to the position of thezk_idwhen sorted in ascending order.
to
The
NoteIdis computed using the result ofhash(ServiceType|| session_number)as theop_id. The output number corresponds to the position of thezk_idwhen sorted in ascending order.
Affected Specifications
Created
Updated
-
[v1.4] Mantle Specification
-
[v1.4][Analysis] Gas Cost Determination
-
[v1.3] Mantle Transaction Encoding
-
[v1.1][Template] Cross-Channel Messaging
-
[v1.2.1] Service Reward Distribution Protocol
Deprecated
Mantle [Analysis] Gas Cost Determination Mantle Transaction Encoding [Template] Cross-Channel Messaging Service Reward Distribution Protocol
Retired
[RFC] Improve Mantle Transaction hash
This RFC follows an older schema and will be updated when time allows.
Authors: Thomas Lavaur Approvals (research): Marcin Pawlowski Approvals (engineering): Daniel Sanchez Quiros, Youngjoon Lee
Motivation
As Mantle Transactions grow (notably with large CHANNEL_INSCRIBE Operations), computing ZkHash over the whole transaction becomes a noticeable cost during transaction construction and verification. This RFC proposes a small change that preserves the use of ZkHash while reducing the amount of data hashed inside the circuit.
Proposal
In version Mantle, the Mantle Transaction hash is defined as the ZkHash of the entire Mantle Transaction, excluding the Ledger Transaction proof and the Operation proofs.
Currently we perform a zero-knowledge hashing on a Mantle Transaction (without proofs):
tx_hash = ZkHash(mantle_tx_without_proofs).
However, execution of this hashing algorithm is time consuming and grows with the size of the input. Therefore, we propose instead hashing the Mantle Transaction using the classic hash defined in Common Cryptographic Components, then hashing the result with ZkHash:
tx_hash = ZkHash(classic_hash(mantle_tx_without_proofs)),
where classic_hash() is the classic hash defined in Common Cryptographic Components.
Justification
The proposed change speeds up computation of the Mantle Transaction hash by moving most of the work out of ZkHash and into a classic hash, while still committing to the result inside ZkHash. This becomes an issue as Mantle Transactions grow, since hashing can take a substantial amount of time (for example, if the transaction contains a large CHANNEL_INSCRIBE Operation).
Here we show the difference of computation speed for Mantle Transactions encoding and hashing containing a single Ledger Transaction and a single Inscription varying the size of the inscription to make the transaction longer.
+--------------+-----------------------+------------------+-------------------------------+---------------------------+
| payload_size | blake2b_poseidon2_avg | poseidon2_avg | poseidon2 / blake2b_poseidon2 | blake2b+poseidon2 faster |
+--------------+-----------------------+------------------+-------------------------------+---------------------------+
| 64 | 10.84 us | 65.89 us | 6.08x | 83.55% |
| 256 | 10.40 us | 62.14 us | 5.98x | 83.26% |
| 1,024 | 10.89 us | 142.30 us | 13.07x | 92.35% |
| 4,096 | 13.02 us | 561.00 us | 43.09x | 97.68% |
| 65,536 | 71.34 us | 8.851 ms | 124.07x | 99.19% |
| 524,288 | 657.20 us | 70.69 ms | 107.56x | 99.07% |
| 1,048,576 | 1.315 ms | 143.30 ms | 108.97x | 99.08% |
| 2,097,152 | 2.652 ms | 283.90 ms | 107.05x | 99.07% |
| 4,194,304 | 5.981 ms | 563.70 ms | 94.25x | 98.94% |
+--------------+-----------------------+------------------+-------------------------------+---------------------------+
We can clearly see that combining the classic and zk hashes yields a significant improvement. The material used for the benchmarks is the following:
- CPU : 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM : 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS : Ubuntu 22.04.5 LTS
- Kernel : 6.8.0-59-generic
The code of the benchmarks can be found here.
Specifications Update
- [v1.2.1] Mantle Specification
[RFC] Make Ledger Transaction an Operation
This RFC follows an older schema and will be updated when time allows.
Authors: Thomas Lavaur Approvals (research): Marcin Pawlowski Approvals (engineering): Daniel Sanchez Quiros, Youngjoon Lee
Motivation
In Mantle, the Ledger Transaction is modeled as a special, mandatory component of every Mantle Transaction. Each Mantle Transaction must include exactly one Ledger Transaction, which is validated and executed separately from the rest of the transaction:
# v1.2
class MantleTx:
ledger_tx: LedgerTx
ops: list[Op]
permanent_storage_gas_price: TokenValue
execution_gas_price: TokenValue
class SignedMantleTx:
tx: MantleTx
op_proofs: list[OpProof | None]
ledger_tx_proof: ZkSignature # separate from op proofs
This structure introduces unnecessary complexity by treating the Ledger Transaction asymmetrically: it is validated and executed in a dedicated step, outside the normal Operation pipeline. It also prevents multiple users from issuing independent transfers within a single atomic Mantle Transaction. This RFC proposes removing that constraint. Instead, the Ledger Transaction becomes a regular transfer Operation, subject to the same validation and execution rules as any other Operation.
Proposal
We introduce a TRANSFER Operation (opcode 0x00) that is semantically equivalent to the former LedgerTx. The Mantle Transaction structure is simplified to a flat list of Operations:
# v1.3 — proposed
class MantleTx:
ops: list[Op]
permanent_storage_gas_price: TokenValue
execution_gas_price: TokenValue
class SignedMantleTx:
tx: MantleTx
op_proofs: list[OpProof | None] # Transfer proof now included here
A transfer that previously lived in ledger_tx is now represented as a TRANSFER Operation inside ops. A Mantle Transaction becomes a homogeneous bundle of Operations that are either all valid or all invalid together.
Justification
Simplicity and consistency
The distinction between LedgerTx and Op was an artificial split. Treating transfers as first-class Operations removes a special case from every layer of the stack (validation, execution, encoding, gas).
Multiple transfers per transaction
Several actors can issue independent transfers within one atomic Mantle Transaction, with no off-chain compensation required.
Atomic cross-zone deposits
A representative use case requires two transfers in a single transaction (user burn + sequencer fee), which was not possible in v1.2 without out-of-band coordination.
Details
Chores
We updated project references to Logos Blockchain and removed all references to DA throughout the documents.
The Mantle Specification
Mantle Transaction
class MantleTx:
ops: list[Op]
- ledger_tx: LedgerTx
permanent_storage_gas_price: TokenValue
execution_gas_price: TokenValue
We removed the ledger_tx field because the transfers will be part of the ops.
Signed Mantle Transaction
We removed the Ledger Transaction from the structure
class SignedMantleTx:
tx: MantleTx
op_proofs: list[OpProof | None]
- ledger_tx_proof: ZkSignature
The proof for the Transfer Operation is now included in op_proofs at the index corresponding to the Transfer Op's position in ops.
We redefined how the gas fees are calculated
def gas_fees(signed_tx: SignedMantleTx) -> int:
mantle_tx = signed_tx.tx
permanent_storage_fees = len(encode(signed_mantle_tx)) * mantle_tx.permanent_storage_gas_price
- execution_fees = execution_gas(mantle_tx.ledger_tx)
- * mantle_tx.execution_gas_price
+ execution_fees = 0
for op in mantle_tx.ops:
# Compute the execution gas of this operation as defined
# in the gas cost determination specification.
execution_fees += execution_gas(op) * mantle_tx.execution_gas_price
return execution_fees + permanent_storage_fees
The gas fees are computed over every operation and doesn’t need to be initialized with the ledger transaction price first.
We redefined the validation
The validation of the signed Mantle Transaction now doesn’t need a specific first step validating the ledger transaction so the first block of this part is removed:
Mantle validators will ensure the following:
The ledger transaction is valid according to .
validate_ledger_tx(ledger_tx, ledger_tx_proof, mantle_txhash(tx))
- We have a proof or a
Nonevalue for each operation.
assert len(op_proofs) == len(ops)
We redefined the execution
The same thing happens for the execution: we removed the special execution of the ledger transaction since everything will be embedded in the operations.
Mantle Validators execute sequentially each Operation in ops according to its opcode. ~~ the following:~~
Execute the Ledger Transaction as described in .Execute sequentially each Operation inopsaccording to its opcode.
We updated the balance computation
The computation of the balance of the Mantle Transaction also needs an update because the entire Mantle transaction must be balanced not the transfers individually.
def get_transaction_balance(signed_tx: SignedMantleTx) -> int:
balance = 0 # It's important to not use unsigned int here to avoid
# overflow vulnerabilities
for op in signed_tx.tx.ops:
if op.opcode == LEADER_CLAIM:
balance += get_leader_reward()
if op.opcode == CHANNEL_DEPOSIT:
balance -= get_channel_deposit_amount(op)
if op.opcode == CHANNEL_WITHDRAW:
balance += get_channel_withdrawal_amount(op)
+ if op.opcode == TRANSFER:
for inp in op.inputs:
balance += get_value_from_note_id(inp)
for out in op.outputs:
balance -= out.value
return balance
Opcode table
Add TRANSFER as opcode 0x00 and rearrange the different opcodes:
| Operation | Opcode | Description |
|---|---|---|
| TRANSFER | 0x00 | Consume and create notes. |
| RESERVED | 0x01 - 0x0F | |
| CHANNEL_CONFIG | 0x10 | Configure a channel |
| CHANNEL_INSCRIBE | 0x11 | Write a message permanently onto Mantle. |
| CHANNEL_DEPOSIT | 0x12 | Deposit assets into a channel |
| CHANNEL_WITHDRAW | 0x13 | Withdraw assets from a channel |
| RESERVED | 0x14 - 0x1F | |
| SDP_DECLARE | 0x20 | Declare intention to participate as a node in a Bedrock Service, locking funds as collateral. |
| SDP_WITHDRAW | 0x21 | Withdraw participation from a Bedrock Service, unlocking your funds in the process. |
| SDP_ACTIVE | 0x22 | Signal that you are still an active participant of a Bedrock Service. |
| RESERVED | 0x23 - 0xFF | |
| LEADER_CLAIM | 0x30 | Claim leader reward anonymously. |
| RESERVED | 0x31 - 0xFF |
Operation Examples
All operation examples that are embedded in a Mantle Transaction during the example needed an update like SDP_ACTIVE for example:
active=Active(
declaration=alice_declaration_id,
nonce=1579532,
metadata=b"Look, I am still doing my job"
)
+ # Build the transfer operation to pay the fees
+ transfer = Transfer(inputs=[fee_note_id], outputs=[])
tx = MantleTx(
ops=[Op(opcode=SDP_ACTIVE, payload=encode(active))],
permanent_storage_gas_price=150,
execution_gas_price=70,
- ledger_tx=LedgerTx(inputs=[fee_note_id], outputs=[]),
)
txhash = mantle_txhash(tx)
SignedMantleTx(
tx=tx,
- ledger_tx_proof=tx.ledger_tx.prove(fee_note_sk),
op_proofs=[Ed25519_sign(txhash, validator_sk),
+ transfer.prove(fee_note_sk)]
)
The Transfer Operation specification
This section replace previous Ledger Transaction section. Mostly by renaming the Ledger Transaction by Transfer Operation.
The EXECUTION_LEDGER_TX_GAS was renamed forEXECUTION_TRANSFER_GAS.
transfer_op_hash replaces the former ledger_tx_hash. The domain separator changes:
- h.update(b"LEDGER_TX_HASH_V1")
+ h.update(b"TRANSFER_HASH_V1")
Note that the noteId derivation still uses the transfer hash of the transfer that outputs the note.
The Gas Cost Determination Analysis
Execution Gas Formula Calculation We updated the execution gas computation formula:
- execution_fee = (tx.ops.get_summed_gas() + tx.ledger_tx.get_gas())
- * execution_gas_price
+ execution_fee = tx.ops.get_summed_gas() * execution_gas_price
Gas computation of Ledger Transaction We updated names and the paragraph on the Ledger Transaction Gas determination. We removed the inclusion of the Mantle Transaction cost (balance and computation of the hash that was negligeable):
The Execution Gas of the~~ Ledger Transaction~~Transfer Operation compensates for the verification of the ZkSignature proof and the validation of the overall Mantle Transaction balance. This fundamental gas cost ensures proper cryptographic verification and data integrity of both the Ledger Transaction and the Mantle Transaction. It covers the cost of computing the Mantle Transaction hash.
Execution: ~590k CPU cycles.
- Verification of the ZK signature: 590,000 cycles.
- Verification of the balance: negligible.
- Computation of the Mantle Transaction hash: negligible.
Bedrock Genesis Block
The previous version of genesis block was formed with a ledger transaction, an inscription as the very first operation and a list of SDP declaration. With the new Transfer Operation, the genesis block must now be constructed with exactly one Transfer Operation, exactly one Inscription and a potential list of SDP Declare Operations:
# build the genesis Mantle Transaction
GENESIS_MANTLE_TX = MantleTx(
- ops=[CRYPTARCHIA_INSCRIPTION] + SERVICE_DECLARATIONS,
- ledger_tx=STAKE_DISTRIBUTION,
+ ops=[STAKE_DISTRIBUTION, CRYPTARCHIA_INSCRIPTION] + SERVICE_DECLARATIONS,
permanent_storage_gas_price=0,
execution_gas_price=0
)
Mantle Transaction Encoding
Signed Mantle Transaction
The encoding of the Signed Mantle Transaction doesn’t require the Ledger Transaction Proof field anymore as it is part of the Operation proofs.
- SignedMantleTx = MantleTx OpsProofs LedgerTxProof
+ SignedMantleTx = MantleTx OpsProofs
Mantle Transaction
- MantleTx = Ops LedgerTx ExecutionGasPrice StorageGasPrice
+ MantleTx = Ops ExecutionGasPrice StorageGasPrice
We once again updated the name from Ledger Transaction for Transfer Operation and removed the redundant part of the Ledger Transaction proof:
- LedgerTx = Inputs Outputs
+ Transfer = Inputs Outputs
Inputs = InputCount *NoteId
InputCount = Byte
Outputs = OutputCount *Note
OutputCount = Byte
Note = Value ZkPublicKey
Value = UINT64
NoteId = FieldElement
Specification Updates
-
[v1.3] Mantle Specification
-
[v1.3] Gas Cost Determination
-
[v1.1] Bedrock Genesis Block
-
[v1.1] Mantle Transaction Encoding
[RFC] Simplify Mantle Transaction and Refactor Ledger Operations
Authors: Thomas Lavaur
Motivation
The current Mantle Specification (v1.4) has accumulated several areas of unnecessary complexity and inconsistency that hinder readability, maintainability and implementation correctness:
- Duplicated Ledger logic: every Operation that consumes or creates notes (actually
TRANSFER,CHANNEL_DEPOSIT,CHANNEL_WITHDRAWandLEADER_CLAIM) independently re-implement the same validation and execution steps to check that inputs are unspent and unlocked, validating output note format, removing consumed notes from the Ledger and inserting new notes. This duplication increases the possibility of implementation and comprehension error. - Unnecessary
ZkHashin the Mantle Transaction hash: themantle_tx_hashfunction currently computes a classical Blake2bHashdigest and then wraps it in a Poseidon2ZkHash. This second hashing step is unnecessary and increase complexity, attack surface and reduce the efficiency of deriving the hash. The Mantle Transaction hash is not only consumed inside ZK circuits as a public input but it’s also used to build theblock_rootin headers. ZK circuits use the Mantle Transaction hash as a signature scheme and a simple modular reduction of theHashto a field element suffices to achieve the same (exactly as is already done forop_idin thederive_note_idfunction). Removing theZkHashstep simplifies implementation, increase the efficiency which makes bootstrapping faster and removes an extra Poseidon2 evaluation that may be cryptographically more vulnerable than Blake2b. - Embedded gas prices in Mantle Transaction: the current design embeds
permanent_storage_gas_priceandexecution_gas_priceinside each Mantle Transaction. In practice thepermanent_storage_gas_priceis fixed per epoch and is the same for every transaction. Theexecution_gas_priceis composed of a protocol-determined base fee (identical for every transaction in a block) plus a priority tip. Encoding these prices inside the transaction is redundant, inflates transaction size which increase its price. This offers better UX where users don’t have to correctly guess the storage price during epoch transitions.
Proposal
We propose four complementary changes:
- Refactor the Ledger code into a dedicated Section. We introduce common helper functions for note consumption and creation that are reused by every Operation. This eliminates code duplication and guarantees uniform validation across
TRANSFER,CHANNEL_DEPOSIT,CHANNEL_WITHDRAWandLEADER_CLAIM. - Simplify
mantle_tx_hashto only a classical Blake2bHashinstead of returning aZkHash. ZK circuits that consumes transaction hash as a public input will instead consume the modular reduction modulo , identical to the treatment ofop_idinderive_note_id. - Remove gas prices from Mantle Transaction. The
permanent_storage_gas_pricebecomes a protocol parameter fixed per epoch. The execution gas is split into a base fee (protocol-determined, same for all transactions in a block) and a tip (the leftover balance after mandatory fees). The balance validation of a Mantle Transaction checks that the balance covers at least the mandatory fees. Any excess is treated as the execution tip.
Discussion
Ledger Refactoring
The duplicated note validation and ledger manipulation across four Operations is the primary source of specification drift risk. By extracting these into shared functions, reviewers need only audit one code path for correctness. Future Operations that consume or creates notes automatically inherit the same checks.
Transaction Hash Simplification
The current two-stage hash (Blake2b and then Poseidon2) was introduced to fasten the transaction hash derivation (that was previously slowing down bootstrapping). Before it was only Poseidon2 because the transaction hash is also used as a public input of Operations’ zero-knowledge proofs to achieve binding to the transaction and avoid replay attacks. With the derive_op_id and derive_note_id refactoring from [RFC] Enforce NoteId uniqueness, we already have a well-understood pattern for reducing classical digests to field elements via a modulo operation. Applying the same pattern to the transaction hash removes Poseidon2 evaluation for transactions and unifies the hash-to-field approach across the Mantle Specification. The modular reduction is slightly non-uniform but since , the bias is negligible and does not affect security.
Fee Model Simplification
Embedding gas prices in the transaction couples the encoding format to the fee market mechanism. By deriving prices from protocol state instead, transaction become smaller and the fee market can evolve independently of the transaction encoding. The new model is closer to EIP-1559-style designs where the base fee is protocol-determined and users only express willingness to pay through the balance of their Mantle Transaction.
Details
Refactored Ledger Functions
Introducing New Helpers
We introduce a new Ledger Helpers subsection in the already existing Mantle Ledger. This Section defines reusable helper functions for note validation and ledger manipulation. All Operations that consume or create notes must use these helpers. At the same time we add inputs uniqueness check to prevent double spending. The double spending bug was introduced in the previous specification therefore we need to fix this vulnerability.
Ledger
class Ledger:
notes: list[Note]
locked_notes: dict[NoteId, LockedNote]
Input Notes Spendability Validation
A note is spendable if and only if it exists, it is not spent or locked. The following function validates that an input of notes can be consumed:
class Ledger:
def assert_spendable(inputs: list[NoteId]):
## Check there is no duplicate
assert len(inputs) == len(set(inputs))
# Check that each note is individually not locked and unspent
for note_id in inputs:
assert ledger.is_unspent(note_id)
assert note_id not in locked_notes
Output Notes Validation
Before an output of notes can be inserted into the Ledger, every note field must satisfy the following constraints:
class Ledger:
def assert_valid_output(outputs: list[Note]):
for note in outputs:
assert note.value > 0
assert note.value <= 2**64-1
Consuming Input Notes Execution
Consuming a set of notes removes them from the Ledger’s Merkle tree and recycles their leaf indices:
class Ledger:
def execute_spending(inputs: list[NoteId]):
for note_id in inputs:
# updates the merkle tree to zero out the leaf for this entry
# and adds that leaf index to the list of unused leaves
ledger.remove(note_id)
Creating Output Notes Execution
Creating notes derives their NoteId from the Operation’s OpId and insert them in the Ledger:
class Ledger:
def execute_adding(op_id: Hash,
outputs: list[Note]):
for (output_index, output_note) in enumerate(outputs):
output_note_id = derive_note_id(op_id, output_index, output_note)
ledger.add(output_note_id)
Updating Operations
Channel Deposit Validation
- Ensure all inputs are
unspentspendable.
assert all(ledger.is_unspent(note_id) for note_id in deposit.inputs)
ledger.assert_spendable(note_id)
Ensure inputs are not locked.
# Ensure inputs are not locked
for note_id in deposit.inputs:
assert note_id not in locked_notes
Channel Deposit Execution
- for note_id in deposit.inputs:
- # updates the merkle tree to zero out the leaf for this entry
- # and adds that leaf index to the list of unused leaves
- ledger.remove(note_id)
+ ledger.execute_spending(deposit.inputs)
Channel Withdraw Validation
We took the opportunity to also refactor the presentation of the validation steps to match the other Operations’ style. Validate
- Check that the outputs are valid
ledger.assert_valid_output(withdrawal.outputs)
- Check that the channel exists
assert withdrawal.channel in channels
- Check that the withdraw nonce is correct
assert channels[withdrawal.channel].withdraw_nonce == withdrawal.withdraw_nonce
- Check that the channel has enough funds
withdrawal_amount = sum(output.value for output in withdrawal.outputs)
assert channels[withdrawal.channel].balance >= withdrawal_amount
- Check that there are enough signatures
assert len(proof.signatures) == len(proof.indexes)
assert len(proof.signatures) == channels[withdrawal.channel]
.withdraw_threshold
- Check that every proof index is unique
assert len(proof.indexes) == len(set(proof.indexes))
- Check the signatures
for sig, idx in zip(proof.signatures, proof.indexes):
assert Ed25519_verify(txhash,
channels[withdrawal.channel].accredited_keys[idx],
sig)
# Check that the outputs are valid
for output in withdrawal.outputs:
assert output.value > 0
assert output.value < 2**64
# Check that the withdraw nonce is correct
assert channels[withdrawal.channel].withdraw_nonce == withdrawal.withdraw_nonce
# Check that the channel exists
assert withdrawal.channel in channels
chan = channels[withdrawal.channel]
# Check that the channel has enough funds
withdrawal_amount = sum(output.value for output in withdrawal.outputs)
assert chan.balance >= withdrawal_amount
# Check that there are enough signatures
assert len(proof.signatures) == len(proof.indexes)
assert len(proof.signatures) == chan.withdraw_threshold
# Check that every index is unique
assert len(proof.indexes) == len(set(proof.indexes))
# Check the signatures
for sig, idx in zip(proof.signatures, proof.indexes):
assert Ed25519_verify(txhash, chan.accredited_keys[idx], sig)
Channel Withdraw Execution
withdrawal_id = derive_op_id(withdrawal)
+ ledger.execute_adding(withdrawal_id, withdrawal.outputs)
- for (output_number, output_note) in enumerate(withdrawal.outputs):
- output_note_id = derive_note_id(withdrawal_id, output_number, output_note)
- ledger.add(output_note_id)
Leader Claim Execution
output_note=Note(
value = leader_reward
public_key = claim.public_key,
)
claim_id = derive_op_id(claim)
+ ledger.execute_adding(claim_id, [output_note])
- output_note_id = derive_note_id(claim_id, 0, output_note)
- ledger.add(output_note_id)
Transfer Validation
- Ensure all inputs are
unspentspendable
ledger.assert_spendable(transfer.inputs)
assert all(ledger.is_unspent(note_id) for note_id in transfer.inputs)
Ensure inputs are not locked.
# Ensure inputs are not locked
for note_id in transfer.inputs:
assert note_id not in locked_notes
- Ensure outputs are valid.
ledger.assert_valid_output(transfer.output)
for output in transfer.outputs:
assert output.value > 0
assert output.value < 2**64
Transfer Execution
+ ledger.execute_spending(transfer.inputs)
- for note_id in transfer.inputs:
- # updates the merkle tree to zero out the leaf for this entry
- # and adds that leaf index to the list of unused leaves
- ledger.remove(note_id)
transfer_id = derive_operation_id(transfer)
+ ledger.execute_adding(transfer_id, transfer.outputs)
- for (output_number, output_note) in enumerate(transfer.outputs):
- output_note_id = derive_note_id(transfer_id, output_number, output_note)
- ledger.add(output_note_id)
Simplify mantle_tx_hash
Updating Mantle Transaction Hash Computation
- def mantle_txhash(tx: MantleTx) -> ZkHash:
+ def mantle_txhash(tx: MantleTx) -> Hash:
tx_bytes = encode(tx)
- h = Hasher() # /!\ This is a classic hash not a ZkHash /!\
+ h = Hasher()
h.update(b"MANTLE_TXHASH_V1")
h.update(tx_bytes)
+ return h.digest()
- classic_digest = h.digest()
- zkh = ZkHasher() # /!\ This is a ZkHash not a classic hash /!\
- zkh.update(FiniteField(classic_digest[0:16], bytes_order="little", modulus = p))
- zkh.update(FiniteField(classic_digest[16:32], bytes_order="little", modulus = p))
- return zkh.digest()
In the Mantle Transaction section explaining that ZK proofs are linked to Mantle Transaction Hash:
Each proof (op proof and signature) must be cryptographically bound to the MantleTx through the mantle_txhash to prevent replay attacks. This binding is achieved by including the MantleTx hash reduced modulo as a public input in every ZK proof.
mantle_txhash_fr = FiniteField(mantle_txhash, byte_order="little", modulus = p)
mantle_txhash is a classical 256-bit hash digest and must be reduced to a field element before being passed to any ZkHasher or used as a ZK public input. We apply a direct modular reduction mod (via FiniteField(..., modulus=p)). Since , the reduction is slightly non-uniform. This is inconsequential in practice as the collision probability remains around , and proof binding is derived from the collision-resistance of the classic hash, not from uniformity over .
Updating ZK Proofs Inputs
Zk Signature
In the public values definition:
class ZkSignaturePublic:
public_keys: list[ZkPublicKey] # public keys signing the message (len = 32)
- msg: zkhash # zkhash of the message
+ msg: zkhash # a finite field element uniquely representing the message
and in the last bullet point of the proof constraints:
- The proof is bound to msg (it’s the mantle_tx_hash in case of transactions).
+ The proof is bound to msg (it’s the mantle_tx_hash reduced modulo p in case of transactions).
Proof of Claim
In the public values:
class ProofOfClaimPublic:
voucher_root: zkhash # Merkle root of the reward_voucher maintained by everyone
voucher_nullifier: zkhash
- mantle_tx_hash: zkhash # attached hash
+ mantle_tx_hash_fr: zkhash # attached hash reduced modulo p
and in the last bullet point of the proof constraint:
- The proof is bound to the mantle_tx_hash.
+ The proof is bound to the mantle_tx_hash reduced modulo p.
Mantle Transaction Encoding
We removed the callout:
~~In future iterations, we will use this encoding to derive the `mantle_txhash`~~
Remove Gas Price From MantleTx
Overview
Users can build unbalanced
specify their gas prices in theirMantle Transactions to tip the leaders and incentivize the network to include their transaction.
Mantle Transaction
Definition
class MantleTx:
ops: list[Op]
- permanent_storage_gas_price: TokenValue # See the note section
- execution_gas_price: TokenValue
Fee
Mantle Transaction Fee
The transaction mandatory fee is a sum of two components: the multiplication of the total Execution Gas by the execution_``base_feegas_pricepermanent_storage_gas_price. The execution base fee and the permanent storage gas price are protocol-determined values that are the same for every Mantle Transaction in a block. They are derived following Execution Market and Storage Markets.
We replaced this old code:
def gas_fees(signed_tx: SignedMantleTx) -> int:
mantle_tx = signed_tx.tx
permanent_storage_fees = len(encode(signed_mantle_tx)) * mantle_tx.permanent_storage_gas_price
execution_fees = 0
for op in mantle_tx.ops:
# Compute the execution gas of this operation as defined
# in the gas cost determination specification.
execution_fees += execution_gas(op) * mantle_tx.execution_gas_price
return execution_fees + permanent_storage_fees
by this new code:
def mandatory_fees(signed_tx: SignedMantleTx,
permanent_storage_gas_price: TokenValue, # Given by Storage Market
execution_gas_base_price: TokenValue) -> int: # Given by Execution Market
mantle_tx = signed_tx.tx
permanent_storage_fees = len(encode(signed_mantle_tx)) * permanent_storage_gas_price
tx_execution_gas = 0
for op in mantle_tx.ops:
# Compute how much execution gas of this operation as defined
# in the gas determination Appendix
tx_execution_gas += execution_gas(op)
execution_base_fees = tx_execution_gas * execution_gas_base_price
return execution_base_fees + permanent_storage_fees
If the Mantle Transaction is unbalanced (meaning that the Transaction consume more value than it creates) and that the leftover balance cover more than the mandatory fees, the remaining is treated as execution tip fees.
Validation
signed_tx = SignedMantleTx(
tx=MantleTx(ops, permanent_storage_gas_price, execution_gas_price),
op_proofs
)
We also changed the third validation point:
The Mantle Transaction excess balance pays
for theat least the mandatory ~~transaction ~~fees.
- tx_fee = gas_fees(signed_tx) # Not an unsigned int
+ tx_mandatory_fee = mandatory_gas_fees(signed_tx) # Not an unsigned int
+ tx_balance = get_transaction_balance(signed_tx)
- assert tx_fee == get_transaction_balance(signed_tx)
+ assert tx_mandatory_fee <= tx_balance
+ tx_execution_tip = tx_balance - tx_mandatory_fee
Execution
SignedMantleTx(
tx=MantleTx(ops, permanent_storage_gas_price, execution_gas_price),
op_proofs
)
Gas Determination Storage Definition
Permanent Storage is paid directly for the entire signed Mantle Transaction. The Permanent Storage Gas price is derived from Storage Markets
included in the Mantle Transaction structureand is used to determine the Permanent Storage fee. 1 Permanent Storage Gas corresponds to 1 byte.
Gas Determination Execution Definition
Execution is a second general market that represents how costly an Operation is to execute. This cost can be fixed or variable based on the content of the Operation. The Execution Gas base price is derived from Execution Market ~~contained in the Mantle Transaction structure ~~and each Operation defines its execution gas amount. 1 Execution Gas corresponds to 1,000 CPU cycles.
execution_base_fee = tx.ops.get_summed_gas() * execution_gas_base_price
Mantle Transaction Encoding
Mantle Transaction
- MantleTx = Ops ExecutionGasPrice StorageGasPrice
+ MantleTx = OpCount *Op
+ OpCount = Byte
- ExecutionGasPrice = UINT64
- StorageGasPrice = UINT64
Operation
- Ops = OpCount *Op
- OpCount = Byte
Chores
Simplify Transaction Hash
Mantle Transaction Type
We changed the zkhash type of the Mantle Transaction hash to a simple hash like in
mempool_transactions: list[zkhash] # 1024 * 32 bytes
Exemples
Every examples including a Mantle Transaction need an update to remove the prices. Here is an example:
tx = MantleTx(
ops=[Op(opcode=CHANNEL_INSCRIBE, payload=encode(greeting)),
Op(opcode=TRANSFER, payload=encode(transfer)],
- permanent_storage_gas_price=150,
- execution_gas_price=70,
)
Spendable Note Validation
In the validation of notes we were verifying the zero-knowledge proof before verifying that the note isn’t locked. Even if the Specification doesn’t enforce an order, we swapped this order to provide the most efficient order for implementation pushing ZK verification for the end in TRANSFER and CHANNEL_DEPOSIT (the only two Operations consuming notes).
Clean Mantle Transaction Encoding
Mantle Transaction Encoding document still refers to deprecated blobs from DA and ChannelSetKey Operation that was deprecated. We remove the blobs reference and update the ChannelSetKey to ChannelConfig as in Mantle:
ChannelConfig = ChannelId KeyCount *Signer PostingTimeframe PostingTimeout ConfigThreshold WithdrawThreshold
KeyCount = Byte
PostingTimeframe = UINT32
PostingTimeout = UINT32
ConfigThreshold = UINT16
WithdrawThreshold = UINT16
Specification updates
New
Update
-
Mantle
-
[Analysis] Gas Cost Determination
-
Mantle Transaction Encoding
-
[Template] Cross-Channel Messaging
-
Block Construction, Validation and Execution
-
Bedrock Genesis Block
Deprecate
Mantle [Analysis] Gas Cost Determination Mantle Transaction Encoding [Template] Cross-Channel Messaging Block Construction, Validation and Execution Bedrock Genesis Block
Retire
SERVICE-DECLARATION-PROTOCOL
| Field | Value |
|---|---|
| Name | Service Declaration Protocol |
| Slug | 87 |
| Status | raw |
| Category | Standards Track |
| Editor | Marcin Pawlowski [email protected] |
| Contributors | Mehmet Gonen [email protected], Daniel Sanchez Quiros [email protected], Álvaro Castro-Castilla [email protected], Thomas Lavaur [email protected], Gusto Bacvinka [email protected], David Rusu [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-13 —
d064449— RFC-Bedrock-SDP: Per-Service Uniqueness ofprovider_idandzk_id(#371) - 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-18 —
58b5698— chore(blockchain): migrate contributor emails to @logos.co (#338) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-04-09 |
| 1.1.0 | [RFC] Remove Concept of a Session | 2026-06-22 |
| 1.2.0 | [RFC] Per-service uniqueness of provider_id and zk_id | 2026-07-08 |
Introduction
This document defines a mechanism enabling validators to declare their participation in specific protocols that require a known and agreed-upon list of participants. One example of this is the Blend Network. We create a single repository of identifiers which is used to establish secure communication between validators and provide services. Before being admitted to the repository, the validator proves that it locked at least a minimum stake.
Requirements
The requirements for the protocol are defined as follows:
- A declaration must be backed by a confirmation that the sender of the declaration owns a certain value of the stake.
- A declaration is valid until it is withdrawn or is not actively used for a service-specific amount of time.
Overview
The SDP enables nodes to declare their eligibility to provide a specific service in the system, and withdraw their declarations.
Protocol
The protocol defines the following actions:
- Declare: A node sends a declaration that confirms its willingness to provide a specific service, which is confirmed by locking a stake above a certain threshold.
- Active: A node marks that its participation in the protocol is active according to the service-specific activity logic. This action enables the protocol to monitor the node’s activity. We utilize this as a non-intrusive differentiator of node activity. It is crucial to exclude inactive nodes from the set of active nodes, as it enhances the stability of services.
- Withdraw: A node withdraws its declaration and stops providing a service.
The logic of the protocol is straightforward.
- A node sends a declaration message for a specific service and proves it has a minimum stake.
- The declaration is registered on the Ledger, and the node can commence its service according to the service-specific service logic.
- After a service-specific service-providing time, the node confirms its activity.
- The node must confirm its activity with a service-specific minimum frequency; otherwise, its declaration is inactive.
- After the service-specific locking period, the node can send a withdrawal message, and its declaration is removed from the Ledger, which means that the node will no longer provide the service.
The protocol messages are subject to a finality that means messages become part of the immutable ledger after a delay. The delay at which it happens is defined by the consensus. Therefore, the protocol’s progress must be tracked from the perspective of the latest finalized block, not the tip of the chain. Otherwise, the protocol and services using it would need to handle chain reorganizations, which we must avoid due to their potential to break services. Hence, the services must use a snapshot from a fully finalized epoch:
finalized_epoch = current_epoch - 2. For more details about finalization, refer to Cryptarchia Protocol.
Construction
In this section, we present the main constructions of the protocol. First, we start with data definitions. Second, we describe the protocol actions. Finally, we present part of the Bedrock Mantle design responsible for storing and processing SDP-related messages and data.
Data
In this section, we discuss and define data types, messages, and their storage.
Service Types
We define the following service type:
BN: for Blend Network service.
class ServiceType(Enum):
BN="BN" # Blend Network
A declaration can be generated for any of the services above. Any declaration that is not one of the above must be rejected. The number of services might grow in the future.
Minimum Stake
The minimum stake is a global value that defines the minimum stake a node must have to perform any service.
The MinStake is a structure that holds the value of the stake stake_threshold and the epoch, which is an epoch number at which the threshold was set; it is uint64.
class MinStake:
stake_threshold: StakeThreshold
epoch: EpochNumber
The stake_thresholds is a structure aggregating all defined MinStake values.
stake_thresholds: list[MinStake]
For more information on how the minimum stake is calculated, please refer to the [Analysis] Static Minimum Stake Estimation for Service Declaration Protocol.
Service Parameters
The service parameters structure defines the parameters set necessary for correctly handling interaction between the protocol and services. Each of the service types defined above must be mapped to a set of the following parameters:
inactivity_perioddefines the maximum time (as a number of epochs) during which an activation message must be sent; otherwise, the declaration is considered inactive. It must be at least 2 epochs long due to finalization reasons.epochdefines the epoch number at which the parameter was set; it isuint64.
class ServiceParameters:
inactivity_period: NumberOfEpochs
epoch: EpochNumber
The parameters is a structure aggregating all defined ServiceParameters values.
parameters: list[ServiceParameters]
Snapshots
At the start of epoch , each node takes a snapshot of the SDP registry at the last block from the finalized epoch.
Each snapshot updates the common view of the registry. Changes to the declaration registry take effect with up to a two-epoch delay: messages sent during epoch n are included in the next snapshot (for epoch n+2).
Epochs 0 and 1 read the snapshot at the genesis block, because the chain has not yet progressed far enough to provide a later finalized block. While at epoch 2, the last block of epoch 0 is read, and so forth according to the above logic.
Identifiers
We define the following set of identifiers which are used for service-specific cryptographic operations:
provider_id: used to sign the SDP messages and to establish secure links between validators; it isEd25519PublicKey.zk_id: used for zero-knowledge operations by the validator that includes rewarding (Zero Knowledge Signature Scheme (ZkSignature)).
Locators
A Locator is the address of a validator which is used to establish secure communication between validators. It follows the multiaddr addressing scheme from libp2p, but it must contain only the location part and must not contain the node identity (peer_id).
The provider_id must be used as the node identity. Therefore, the Locator must be completed by adding the provider_id at the end of it, which makes the Locator usable in the context of libp2p.
The length of the Locator is restricted to 329 characters.
The common formatting of every Locator must be applied to maintain its unambiguity, to make deterministic ID generation work consistently. The Locator must at least contain only lowercase letters and every part of the address must be explicit (no implicit defaults).
Declaration Message
The construction of the declaration message is as follows.
class DeclarationMessage:
service_type: ServiceType
locators: list[Locator]
provider_id: Ed25519PublicKey
locked_note_id: NoteId
zk_id: ZkPublicKey
The locators list must be non-empty and its length must be limited to reduce the potential for abuse. Therefore, the length of the list cannot be longer than 8.
The message must be signed by the provider_id key to prove ownership of the key that is used for network-level authentication of the validator.
The locked_note_id points to a locked note used for minimum stake threshold verification purposes.
The message is also signed by the zk_id key.
Declaration Storage
Only valid declaration messages can be stored on the ledger. We define the DeclarationInfo as follows:
class DeclarationInfo:
service: ServiceType
provider_id: Ed25519PublicKey
locked_note_id: NoteId
zk_id: ZkPublicKey
locators: list[Locator]
created: EpochNumber
active: EpochNumber | None
withdraw_at: EpochNumber | None
nonce: Nonce
Where:
servicedefines the service type of the declaration;provider_idis anEd25519PublicKeyused to sign the message by the validator;locked_note_idis aNoteIdused for minimum stake threshold verification purposes;zk_idis used for zero-knowledge operations by the validator that includes rewarding;locatorsis a copy of thelocatorsfrom theDeclarationMessage;createdrefers to the epoch number of the block that contained the declaration;activerefers to the latest epoch number for which the active message was sent (it is set toNoneby default);withdraw_atrefers to the epoch number for which the service declaration will be withdrawn (it is set toNoneby default);- The
noncemust be set to 0 for the declaration message and must increase monotonically by every message sent for thedeclaration_id.
We also define the declaration_id (of a DeclarationId type) that is the unique identifier of DeclarationInfo calculated as a hash of the concatenation of service, provider_id, zk_id and locators. The implementation of the hash function is blake2b using 256 bits of the output.
declaration_id = Hash(service||provider_id||zk_id||locators)
The declaration_id is not stored as part of the DeclarationInfo but it is used to index it.
All DeclarationInfo references are stored in the declarations and are indexed by declaration_id.
declarations: list[declaration_id]
Identifier Uniqueness
The SDP is responsible for enforcing the uniqueness of the provider_id and the zk_id in the context of a service. This means that, for a given service, each provider_id and each zk_id must appear in at most one active DeclarationInfo at a time.
The declaration_id uniqueness alone is insufficient to guarantee this property. Because declaration_id = Hash(service||provider_id||zk_id||locators), two declarations for the same service that reuse the same provider_id (or the same zk_id) but differ in any other component would produce distinct declaration_ids and would therefore not collide. The SDP must reject such declarations regardless.
Consequently, within a single service:
- A
provider_idmust not be bound to more than oneDeclarationInfo. - A
zk_idmust not be bound to more than oneDeclarationInfo.
The uniqueness is scoped per-service: the same provider_id or zk_id may be reused across different services, but never more than once within the same service. A provider_id or zk_id becomes available for reuse in a service only once its previous DeclarationInfo for that service has been withdrawn and removed (see Withdraw).
Active Message
The construction of the active message is as follows:
class ActiveMessage:
declaration_id: DeclarationId
nonce: Nonce
metadata: Metadata
where metadata is service-specific node activeness metadata.
The message must be signed by the zk_id key associated with the declaration_id.
The nonce must increase monotonically by every message sent for the declaration_id.
Withdraw Message
The construction of the withdraw message is as follows:
class WithdrawMessage:
declaration_id: DeclarationId
locked_note_id: NoteId
nonce: Nonce
The message must be signed by the zk_id key from the declaration_id.
The locked_note_id is a NoteId that was used for minimum stake threshold verification purposes and will be unlocked after withdrawal.
The nonce must increase monotonically by every message sent for the declaration_id.
Indexing
Every event must be correctly indexed to enable lighter synchronization of the changes. Therefore, we index every declaration_id according to EventType, ServiceType, and Epoch. Where EventType = { "created", "active", "withdrawn" } follows the type of the message.
events = {
event_type: {
service_type: {
epoch: {
declarations: list[declaration_id]
}
}
}
}
Protocol
Declare
The Declare action associates a validator with a service it wants to provide. It requires sending a valid DeclarationMessage (as defined in Declaration Message), which is then processed (as defined below) and stored (as defined in Declaration Storage).
The declaration message is considered valid when all of the following are met:
- The sender meets the stake requirements and its
locked_note_idis valid. - The
declaration_idis unique. - The
provider_idand thezk_idare each unique in the context of theservice(as defined in Identifier Uniqueness). - The sender knows the secret behind the
provider_ididentifier. - The length of the
locatorslist must not be longer than 8. - The
nonceincreases monotonically.
If all of the above conditions are fulfilled, then the message is stored on the ledger; otherwise, the message is discarded.
Active
The Active action enables marking the provider as actively providing a service. It requires sending a valid ActiveMessage (as defined in Active Message), which is relayed to the service-specific node activity logic (as indicated by the service type in Common SDP Structures).
The Active action updates the active value of the DeclarationInfo, which means that it also activates inactive (but not expired) providers.
The SDP active action logic is:
- A node sends an
ActiveMessagetransaction. - The
ActiveMessageis verified by the SDP logic:- The
declaration_idreturns an existingDeclarationInfo. - The transaction containing
ActiveMessageis signed by thezk_id. - The
nonceincreases monotonically.
- The
- If any of these conditions fail, discard the message and stop processing.
- The message is processed by the service-specific activity logic alongside the
activevalue indicating the period since the last active message was sent. Theactivevalue comes from theDeclarationInfo. - If the service-specific activity logic approves the node active message, then the
activefield of theDeclarationInfois set to the epoch number indicated by metadata.
Withdraw
The withdraw action enables a withdrawal of a service declaration. It requires sending a valid WithdrawMessage (as defined in Withdraw Message). The withdrawal marks the intent to stop providing the service: the node provides the service through the withdrawal epoch e and stops afterwards. The withdraw_at field records this withdrawal epoch e, which is the node's last rewardable epoch. The declaration is removed and the stake unlocked at epoch e+2, right after the epoch-e reward is paid out, by the Mantle epoch finalization step (see SDP Epoch Finalization). Removing the declaration only after its final reward is paid guarantees it is never removed before the payout.
The logic of the withdraw action is:
- A node sends a
WithdrawMessagetransaction. - The
WithdrawMessageis verified by the SDP logic.- The
declaration_idreturns an existingDeclarationInfo. - The transaction containing
WithdrawMessageis signed by thezk_id. - The
withdraw_atfromDeclarationInfois set toNone. - The
nonceincreases monotonically.
- The
- If any of the above is not correct, then discard the message and stop.
- Set the
withdraw_atfrom theDeclarationInfoto the current epoch number (the withdrawal epoche). - The
DeclarationInfois removed and the stake unlocked (releasing thelocked_note_id) at epoche+2by the Mantle epoch finalization step, right after the final reward is paid out.
Query
The protocol must enable querying the ledger in at least the following manner:
GetAllProviderId(epoch), returns allprovider_ids associated with theepoch.GetAllProviderIdSince(epoch), returns allprovider_ids since theepoch.GetAllDeclarationInfo(epoch), returns allDeclarationInfoentries associated with theepoch.GetAllDeclarationInfoSince(epoch), returns allDeclarationInfoentries since theepoch.GetDeclarationInfo(provider_id), returns theDeclarationInfoentry identified by theprovider_id.GetDeclarationInfo(declaration_id), returns theDeclarationInfoentry identified by thedeclaration_id.GetAllServiceParameters(epoch), returns all entries of theServiceParametersstore for the requestedepoch.GetAllServiceParametersSince(epoch), returns all entries of theServiceParametersstore since the requestedepoch.GetServiceParameters(service_type, epoch), returns the service parameter entry from theServiceParametersstore of aservice_typefor a specifiedepoch.GetMinStake(epoch), returns theMinStakestructure at the requestedepoch.GetMinStakeSince(epoch), returns a set ofMinStakestructures since the requestedepoch.
The query must return an error if the requested information is not available.
The list of queries may be extended.
Every query must return information for a finalized state only.
Mantle and ZK Proofs
For more information about Mantle and ZK proofs, please refer to Mantle.
Default Service Parameters
Blend Network
class BlendNetworkServiceParameters:
inactivity_period: 2
epoch: 0
SERVICE-REWARD-DISTRIBUTION-PROTOCOL
| Field | Value |
|---|---|
| Name | Service Reward Distribution Protocol |
| Slug | 86 |
| Status | raw |
| Category | Standards Track |
| Editor | Thomas Lavaur [email protected] |
| Contributors | David Rusu [email protected], Mehmet Gonen [email protected], Marcin Pawlowski [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-18 —
58b5698— chore(blockchain): migrate contributor emails to @logos.co (#338) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258)
Revisions History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial version. | 2025-11-03 |
| 1.1.0 | Removed references to DA Replaced references to Nomos with Logos Blockchain | 2026-04-17 |
| 1.2.1 | [RFC] Enforce NoteId uniqueness. | 2026-04-24 |
| 1.3.0 | [RFC] Remove Concept of a Session | 2026-06-22 |
Introduction
Logos Blockchain relies on the Blend Network service to operate. The service requires an independent set of known nodes. For sustainability and fairness, these services must compensate service validators based on their participation. Validators first declare their participation through Service Declaration Protocol. The Service Reward Distribution Protocol enables deterministic, efficient, and verifiable reward distribution to validators based on their activity within each service.
Each service defines:
- The validator activity rule that distinguishes between active and inactive validators.
- The reward formula for distributing the epoch’s rewards at the end of the epoch.
This document describes the protocol's logic for deterministically distributing rewards through Mantle Transactions for services.
Overview
The protocol unfolds over three key phases, aligned with validator epochs:
- Service Activity Tracking (epoch N+1): Service validators submit signed activity messages to attest to their participation of epoch N through a Mantle Transaction, including an activity message (see SDP_ACTIVE).
- Service Reward Derivation (End of epoch N+1): Nodes compute each validator’s reward based on validated activity messages and the different service reward policies.
- Service Reward Distribution (First block of epoch N+2): Rewards are distributed to validators marked as active for the service. This is done by inserting new notes in the ledger corresponding to the reward amount for each active validator.
Core Properties:
- Service rewards are distributed to the
zk_idfrom validator SDP declarations. - Minimal Block Overhead: rewards are directly added to the ledger without involving Mantle Transactions.
Protocol
Activity tracking
Throughout epoch N+1, the block proposers integrate Mantle Transactions containing SDP_ACTIVE Operations. These transactions originate from service validators and are used to derive their activity according to the service provided policy. The protocol does not prescribe a unique activity rule: each service defines what qualifies as valid participation, enabling flexibility across different services.
Service validators are economically incentivized to participate actively since only active validators will be rewarded. Moreover, by decoupling activity submission from reward calculation, the system remains robust to network latency.
This generalized mechanism accommodates a wide range of services without requiring specialized infrastructure. It enables services to evolve their own activity rules independently while preserving a shared framework for reward distribution.
Service Reward Calculation
At the end of epoch N+1, service rewards for the validator n for the epoch N are computed by the different services taking as input the rewards of the epoch:
Where are the total rewards of epoch N. The is determined by the linked reference, which calculates how much each service receives based on fees burnt during epoch N and the blockchain's state. is stored as an array that maps each validator's zk_id to their allocated reward.
Service Reward Distribution
Starting immediately after epoch N+1, service rewards are distributed in the first block of epoch N+2. The rewards are inserted directly in the ledger without triggering any Mantle validation. The NoteId is computed using the result of hash(ServiceType|| epoch_number) as the op_id. The output number corresponds to the position of the zk_id when sorted in ascending order.
The reward must:
- Transfer the correct reward amount according to Service Reward Calculation.2
- Be sent to the public key
zk_idof the validator registered during declaration of the service. - Be distributed into a single note if several rewards share the same
zk_id. - Be executed identically by every node processing the first block of epoch N+2. This happens by inserting notes in the ledger in ascending order of
zk_id.
Nodes indirectly verify the correct inclusion of rewards because all consensus-validating nodes must maintain the same ledger view to derive the latest ledger root, which serves as input for verifying the Proof of Leadership.
After the epoch-N rewards are distributed, withdrawn declarations whose last rewardable epoch was N are removed by Mantle as part of the same epoch transition (see SDP Epoch Finalization).
WALLET-TECHNICAL-STANDARD
| Field | Value |
|---|---|
| Name | Wallet Technical Standard |
| Slug | 154 |
| Status | raw |
| Category | Standards Track |
| Tags | wallet, key derivation, HD wallet, mnemonic, BIP-32, BIP-39, Poseidon2 |
| Editor | Giacomo Pasini [email protected] |
| Contributors | Thomas Lavaur [email protected], Mehmet Gonen [email protected], Daniel Sanchez Quiros [email protected], Alvaro Castro-Castilla [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-02-05 |
| 1.0.1 | Updated project references to Logos Blockchain | 2026-04-17 |
Introduction
The main motivation behind this spec is avoiding being locked into a wallet software. By specifying the algorithms used to derive keys, we allow users to easily migrate from one implementation to the other.
Overview
This document mostly follows pre-existing standards in Bitcoin and adapts it to Logos’ needs when necessary. This is also the choice of other Bitcoin-inspired projects like Cardano or Zcash. For this reason, this document will not go over the entire spec itself, and just highlight differences with existing standards.
Mnemonic codes for key generation
Mnemonic codes are far easier to interact with as humans than raw binary or hex strings and are the standard for wallets. In this regard we can reuse BIP-39 entirely, as it’s just operations on strings and bytes.
Hierarchical Deterministic wallet
Hierarchical Deterministic (HD) wallets are nowadays the standard. Using a single source of entropy (usually obtained through the process above), it’s possible to generate many different addresses and share all or part of it.
The industry standard is BIP32. However, we can’t use it as it is, as we use different keys and cryptographic components. In addition, some of the BIP32 features are only possible thanks to homomorphic properties of ECC, which we don’t have in the Logos Blockchain since we use hash-based sk/pk.
BIP-32 specifies two kinds of child keys:
- Normal: you can derive a child public key from the parent public key
- Hardened: you need the parent private key to derive a child private and public key
Unfortunately, ‘normal’ children are possible thanks to specific properties of the keys used in Bitcoin that we don’t have in the Logos Blockchain (namely, homomorphism).
To maintain compatibility, we will still use the same structure but non-hardened children will not be available.
Extended Keys (from BIP32)
In what follows, we will define a function that derives a number of child keys from a parent key. In order to prevent these from depending solely on the key itself, we extend both private and public keys first with an extra 256 bits of entropy. This extension, called the chain code, is identical for corresponding private and public keys, and consists of 32 bytes.
We represent an extended private key as (k, c), with k the normal private key, and c the chain code. An extended public key is represented as , with the public key and the chain code.
Each extended key has hardened children keys. Each of these child key has an index. The hardened child keys use indices from through .
Details
The main novelty with respect to the aforementioned protocols is one last additional step before obtaining a secret key that can be used in the Logos Blockchain network, described in ZK-Compatible Secret Key Derivation in the Logos Blockchain.
For the remaining procedures, we only highlight the differences instead of going over all the details again as they’re already covered extensively elsewhere.
Notation:
- : the parent extended key, composed of the private key and the chain code .
- : serialize a 32-bit unsigned integer i as a 4-byte sequence, most significant byte first.
- : refers to unkeyed BLAKE2b-512 in sequential mode, with an output digest length of 64 bytes, 16-byte personalization string p, and input x.
- , a pseudo-random function.
Child Key Derivation
-
Check whether (whether the child is a hardened key).
- If so (hardened child): let .
- If not (normal child): failure.
-
Split into two 32-byte sequences, .
-
The returned child key is .
-
The returned chain code is .
Master Key Generation
- Generate a seed byte sequence of a chosen length (e.g. with BIP0039)
- Calculate
- Split into two 32-byte sequences, and .
- Use as master secret key, and as master chain code.
ZK-Compatible Secret Key Derivation in the Logos Blockchain
Since we make extensive use of ZK proofs, we need our secret → public derivation to be efficient. For this purpose, we use a ZK-optimized hash function: Poseidon2.
However, Poseidon2 operates on field elements rather than raw bytes, so we cannot simply input as specified above. Instead, we must encode these bytes into field elements. Using the parameters described in Use in the Logos Blockchain:, we need two field elements to encode 32 bytes (the size of ). This creates inefficiency because although a single field element provides adequate security, we must use twice as many, increasing computation costs to accommodate the entire key.
To reduce this additional cost inside the proof, we apply one final hash function that compresses these two field elements into a single one, which becomes the actual key used in the Logos Blockchain network:
Let be 16-byte sequences such that and be their values when interpreted as little-endian unsigned integers. Let be scalar field elements in BN254 such that . The Logos key can be obtained as , where outputs a single field element.
Why not use Poseidon2 for the full derivation? While Poseidon2 is optimized for ZK circuits, its long-term stability and parameterization are still evolving. General-purpose hash functions like Blake2b offer a more stable and audited base layer. By introducing Poseidon2 only at the last compression step we isolate ZK-dependencies from the rest of the key derivation path. This ensures the wallet hierarchy remains valid even if Poseidon2 parameters are updated.
References
ZIP 32: Shielded Hierarchical Deterministic Wallets
V1.0.0-ANALYSIS-GAS-COST-DETERMINATION
| Field | Value |
|---|---|
| Name | [Analysis] Gas Cost Determination |
| Slug | 209 |
| Status | deprecated |
| Type | RFC |
| Category | Informational |
| Editor | Thomas Lavaur [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Owner: @Thomas Lavaur
Reviewers: @Mehmet @Daniel Sanchez Quiros @lvaro Castro-Castilla @David Rusu
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-09-25 |
Introduction
In Mantle, each Mantle Transaction contains one Ledger Transaction and one or more Operations. These components consume gas, measured through fixed gas units that reflect their execution or storage impact. Logos Blockchain introduces three independent gas markets:
- Execution Gas: measuring computational workload.
- Permanent Storage Gas: measuring cost of fully replicated storage.
- Ephemeral DA Storage Gas: measuring sharded storage in the DA layer.
Gas constants are carefully calibrated to reflect the computational and storage requirements of different operations on the Logos Blockchain. By standardizing gas measurements, the system can accurately charge fees proportional to resource usage, preventing network abuse and incentivizing efficient transaction design.
Overview
We conducted a comprehensive analysis of execution requirements for each Operation type in Mantle Transactions and of Ledger Transaction. This detailed examination allowed us to determine precise gas amounts for each Operation based on the actual computational resources consumed.
The gas constants we established are strategically divided between permanent storage, ephemeral data store on the DA layer and execution components, directly proportional to their respective resource utilization within Mantle Transactions. This separation ensures that gas costs accurately reflect the true computational burden of different operations. Moreover, gas can also be adjusted arbitrarily to incentivize or disincentivize the usage of certain Operations compared to others.
Our methodology involved measuring execution complexity and defining how gas is determined for each Gas Market. This is critical for proper network operation as it directly impacts transaction prioritization and network economics.
Permanent Storage Gas
Permanent Storage is paid directly for the entire signed Mantle Transaction. The Permanent Storage Gas price is included in the Mantle Transaction structure and is used to determine the Permanent Storage fee. 1 Permanent Storage Gas corresponds to 1 byte.
permanent_storage_fee = len(encode(tx_signed)) * permanent_storage_gas_price
Ephemeral Storage Gas
Ephemeral storage is a unique market exclusive to Blobs. For this reason, the DA Storage Gas price is included in the Blob Operation structure and is used to determine the DA Storage fee. 1 DA Storage Gas corresponds to 1 byte.
da_storage_fee = blob_size * DA_storage_gas_price
Execution Gas
Execution is a third general market that represent how costly an operation or a Ledger Transaction is to execute. This cost can be fixed or variable based on the content of the Operation / Transaction. The Execution Gas price is contained in the Mantle Transaction structure and each Operation or Ledger Transaction define its execution gas amount. 1 Execution Gas corresponds to 1,000 CPU cycles.
execution_fee = (tx.ops.get_summed_gas() + tx.ledger_tx.get_gas())
* execution_gas_price
The gas derivation of each Operation and of a Ledger Transaction are:
LEDGER_TRANSACTION_GAS = 9331
CHANNEL_INSCRIBE_GAS = 85
CHANNEL_BLOB_GAS = 111800 + 7400 * blob_size/(1024*31)
CHANNEL_SET_KEYS = 85
SDP_DECLARE_GAS = 9417
SDP_WITHDRAW_GAS = 9331
SDP_ACTIVE_GAS = 9331
LEADER_CLAIM_GAS = 3291
and come from our implementation observations. To get this numbers, we based our calculations on the following measures:
| Operation | Number of CPU cycles |
|---|---|
| ZkSignature | 9,331,367 |
| Proof of Claim | 3,291,100 |
| Blob sampling | 5,586,527 + 369,701 x blob_size/(1024 x 31) |
| Eddsa25519 signature verification | 85,201 |
Comparison, list searching, hashes and operation in small fields are neglected.
Ledger Transaction
The Execution Gas of the Ledger Transaction compensates for the verification of the ZkSignature proof and the validation of the overall Mantle Transaction balance. This fundamental gas cost ensures proper cryptographic verification and data integrity of both the Ledger Transaction and the Mantle Transaction. It covers the cost of computing the Mantle Transaction hash.
Execution: ~9.3M CPU cycles.
- Verification of the ZK signature: 9,331,367 cycles.
- Verification of the balance: negligible.
- Computation of the Mantle Transaction hash: negligible.
Input Gas
Input gas covers the computational cost of verifying that one Note Id exists in the Ledger and is not locked. Additionally, it compensates for the removal of one Note Id from the Ledger.
Execution: negligible.
- Verification that the note is in the ledger: negligible.
- Verification that the note is unlocked: negligible.
- Removing of the note from the ledger: negligible.
Output Gas
Output gas accounts for the computational resources required to verify that one output is well-formed and for its inclusion in the Ledger.
Execution: negligible.
- Verification of the output validity: negligible.
- Insertion of the note in the ledger: negligible.
Operations
Channel Inscription
The validation process includes verifying an Eddsa25519 signature, confirming that the signer is authorized for the specified channel, and checking the chaining sequence of the channel. The execution encompasses creating channel records (if not previously used) and updating the tip of the channel.
Execution: ~85k CPU cycles.
- Verification of the Ed25519 signature: 85,201 cycles.
- Verification of the signer authorization (signer in the list): negligible.
- Verification of channel sequencing (equality check): negligible
- Update the tip of the channel: negligible
Channel Blobs
The validation encompasses several critical security checks: verifying an Eddsa25519 signature, confirming the signer's authorization for the specified channel, and validating the chaining sequence of the channel. The execution process involves creating channel records (if not previously established), updating the channel tip, and executing the sampling operations necessary to verify data availability.
Execution: ~111.8M + blob_size/(1024 x 31) * 7.4M CPU cycles
- Verification of the Ed25519 Signature: 85,201cycles.
- Verification of the signer authorization (signer in the list): negligible.
- Verification of channel sequencing (equality check): negligible.
- Update the tip of the channel: negligible.
- Verification of twenty samples of size blob_size/(1024 x 31) : 5,586,527 cycles + 369,701 * blob_size/(1024 x 31) for each sample.
Channel Set Keys
This gas amount covers the verification of the Eddsa25519 signature and ensures the operation is well-formed. This represents the computational cost associated with processing key management operations.
- Execution: ~85k CPU cycles.
- Verification of the Ed25519 signature: 85,201 cycles.
- Modification of the key list of the channel: negligible.
SDP Declaration
This gas covers multiple verification processes: confirming ownership of the locked note through ZkSignature verification, validating the zk_id via a second ZkSignature, and establishing ownership of the provider_id through an Eddsa25519 signature. It also includes verification of the declaration format, confirmation of note existence, validation that the note is not already locked, and verification of its amount. Additionally, it accounts for the computational costs associated with the note locking mechanism and declaration management.
Execution: ~ 9.4M CPU cycles.
- Verification of the Ed25519 signature: 85,201 cycles.
- Verification of the ZK signature: 9,331,367 cycles.
- Verification that the declaration doesnt already exist: negligible.
- Verification of locator length: negligible.
- Verification of locked note existence: negligible.
- Verification of locked note value: negligible.
- Verification that the note isnt already locked for the service: negligible.
- Locking the note: negligible.
SDP Withdraw
This gas covers a verification process that includes: confirming ownership of the zk_id through ZkSignature verification, validating the existence of the locked note, verifying that the note has exceeded its lock period, and confirming that the declaration exists and has not been previously withdrawn. The validation process also ensures that the withdrawal message's nonce is greater than any previous nonce, preventing replay attacks. During execution, the system updates the declaration's status to withdrawn, removes the declaration from the locked note's associated declarations, andif the note has no remaining declarationsremoves it from the locked notes dictionary.
Execution: ~ 9.3M CPU cycles.
- Verification that the note exists, is locked and bound to the declaration: negligible.
- Verification that the note can be unlocked: negligible.
- Verification that the declaration exist: negligible.
- Verification of the ZK signature: 9,331,367 cycles.
- Verification that the declaration wasnt already withdrawn: negligible.
- Verification of nonce incrementation: negligible.
- Update declaration: negligible.
- Remove declaration from locked note: negligible.
- Unlock the note if not linked to any declaration: negligible.
SDP Activation
This gas funds the verification of the zk_id signature through the ZkSignature verification process, validates the existence of the declaration in the system, and ensures that the activation message's nonce is greater than any previous nonce to prevent replay attacks. The validation includes confirming that the declaration ID is present in the declarations dictionary and that the signature corresponds to the declaration's registered zk_id public key.
- Execution: ~9.3M CPU cycles.
- Verification that the declaration exist: negligible.
- Verification of nonce incrementation: negligible.
- Verification of the ZK signature: 9,331,367 cycles.
- Evaluation of the activity depends on the service and is neglected here
Leader Claims
This gas covers the verification of reward voucher ownership through a Proof of Claim, confirmation that the voucher nullifier is not already present in the nullifier set, and validation that the rewards root exists in the list of recent voucher Merkle tree roots. The execution process involves adding the voucher nullifier to the nullifier set and increasing the Ledger Transaction balance by the designated leader reward amount.
Execution: ~3.3M CPU cycles.
- Verification that the voucher nullifier isnt already in the set: negligible.
- Verification that the rewards root is one of the root of the reward tree of the last blocks: negligible.
- Verification of the proof of claim: 3,291,100 cycles.
- Insertion of the nullifier in the voucher nullifier set: negligible.
V1.0.0-BEDROCK-ARCHITECTURE-OVERVIEW
| Field | Value |
|---|---|
| Name | [Overview] Bedrock Architecture |
| Slug | 210 |
| Status | deprecated |
| Type | RFC |
| Category | Informational |
| Editor | David Rusu [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Owners: @David Rusu
Reviewers: @lvaro Castro-Castilla @Daniel Kashepava
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-08-22 |
Introduction
Bedrock enables high-performance Sovereign Rollups to leverage the security guarantees of Logos Blockchain. Sovereign Rollups build on Logos Blockchain through Bedrock Mantle, Bedrocks minimal execution layer which in turn runs on Cryptarchia, the Logos Blockchain consensus protocol. Taken together, Bedrock provides a private, highly scalable and resilient substrate for high-performance decentralized applications.
Overview
Bedrock is composed of Cryptarchia and Bedrock Mantle. Bedrock is in turn supported by the Bedrock Services: Blend Network and DA Network. Together they provide an interface for building high performance Sovereign Rollups that leverage the security and resilience of Logos Blockchain.
Bedrock Mantle
Mantle forms the minimal execution layer of Logos Blockchain. Mantle Transactions consist of a sequence of Operations together with a Ledger Transaction used for paying fees and transferring funds.
Sovereign Rollups make use of Mantle Transactions when posting their updates to Logos Blockchain. This is done through the use of Mantle Channels and Channel Operations.
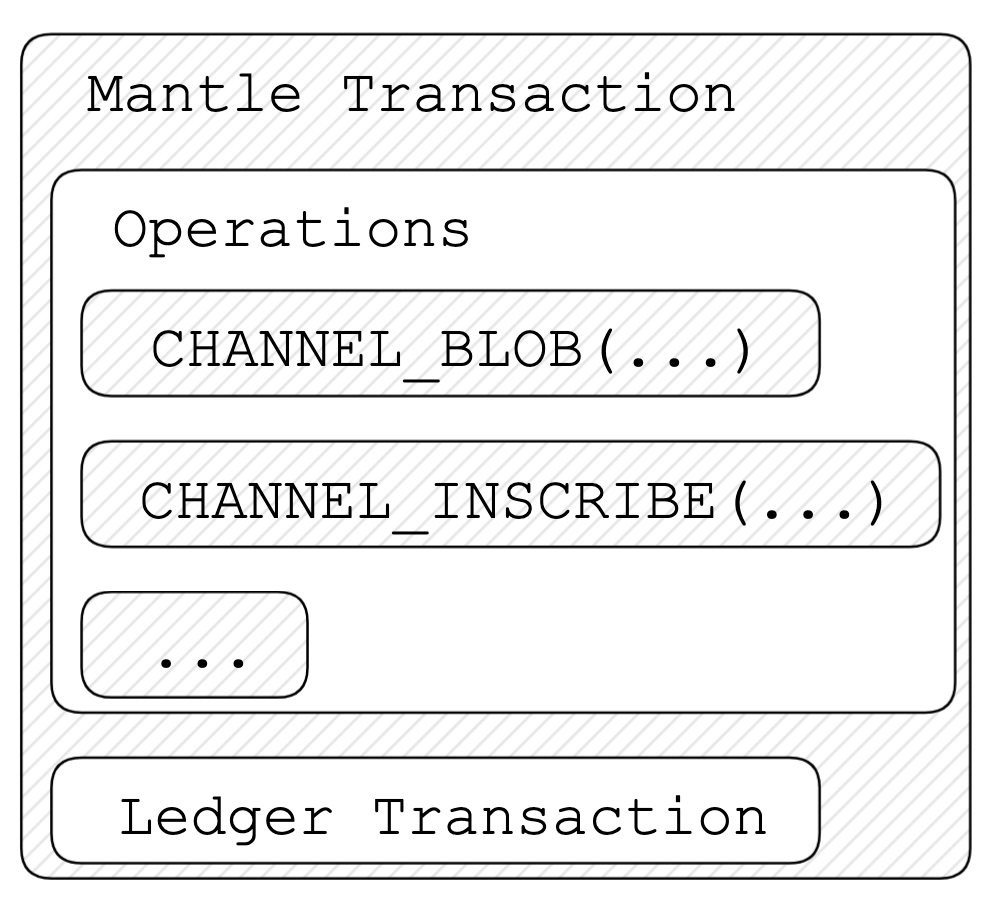
Mantle Channels
Mantle Channels are lightweight virtual chains overlaid on top of the Logos Blockchain. Sovereign Rollups are built on top of these channels, allowing them to outsource the hard parts of running a decentralized service to Logos Blockchain, namely ordering and replicating state updates.
Channels are permissioned, ordered logs of messages. These messages are signed by the Channel owner and come in two types: Inscriptions or Blobs. Inscriptions store the message data permanently in-ledger, while Blobs store only a commitment to the message data permanently. The actual message data is stored temporarily in DA Network, just long enough for interested parties to fetch a copy for themselves.
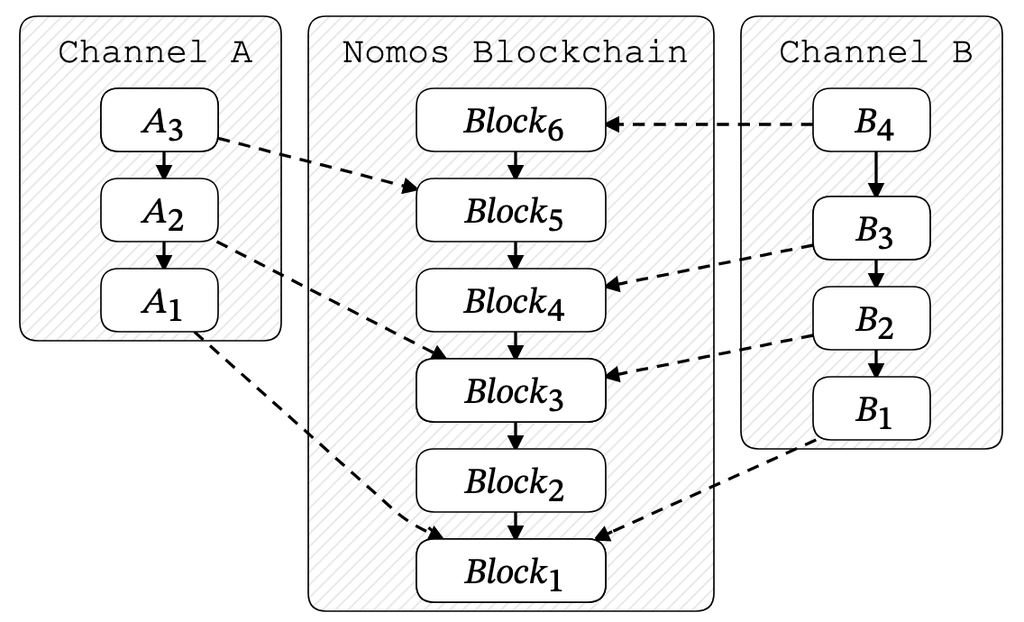
Channels A and B form virtual chains on top of the Logos Blockchain. Channel messages are included in blocks on the Logos Blockchain in such a way that they respect the ordering of channel messages e.g. must come after in the Logos Blockchain.
A Note on Transient Blobs
The fact that Blobs are stored only temporarily in DA Network allows Logos Blockchain to provide cheap, temporary storage for Sovereign Rollups without incurring long-term scalability concerns. The network can serve a large amount of data without the risk of bloating with obsolete data after years of operations.
At the same time, the transient nature of Blobs shifts the burden of long-term replication from the Logos Blockchain network to the parties interested in that Blob data - that is, the Sovereign Rollup operators, their clients, and other interested parties (archival nodes, block explorers, etc.). So long as at least one party holds a copy of a Blob and is willing to provide it to the network, the SR can continue to be verified by checking provided Blobs against their corresponding on-chain Blob commitments, which are stored permanently on the Logos Blockchain.
Cryptarchia
Bedrock Mantle is powered by Cryptarchia, a highly scalable, permisionless consensus protocol optimized for privacy and resilience. Cryptarchia is a Private Proof of Stake (PPoS) consensus protocol with properties very similar to Bitcoin. Just like in Bitcoin, where a miners hashing power is not revealed when they win a block, we ensure privacy for block proposers by breaking the link between a proposal and its proposer. Unlike Bitcoin, Logos Blockchain extends block proposer confidentiality to the network layer by routing proposals through the Blend Network, making network analysis attacks prohibitively expensive.
Sovereign Rollups
Sovereign Rollups bridge the gap between traditional server-based applications and decentralized, permissionless applications.
Sovereign Rollups alleviate the contention caused by decentralized applications competing for the limited resources of a single threaded VM (e.g. EVM in Ethereum) while still remaining auditable and fault tolerant. This is achieved through shifting transaction ordering and execution off of the main chain into SR nodes, with SR nodes posting only a state diff or batch of transactions to Logos Blockchain as an opaque data Blob.
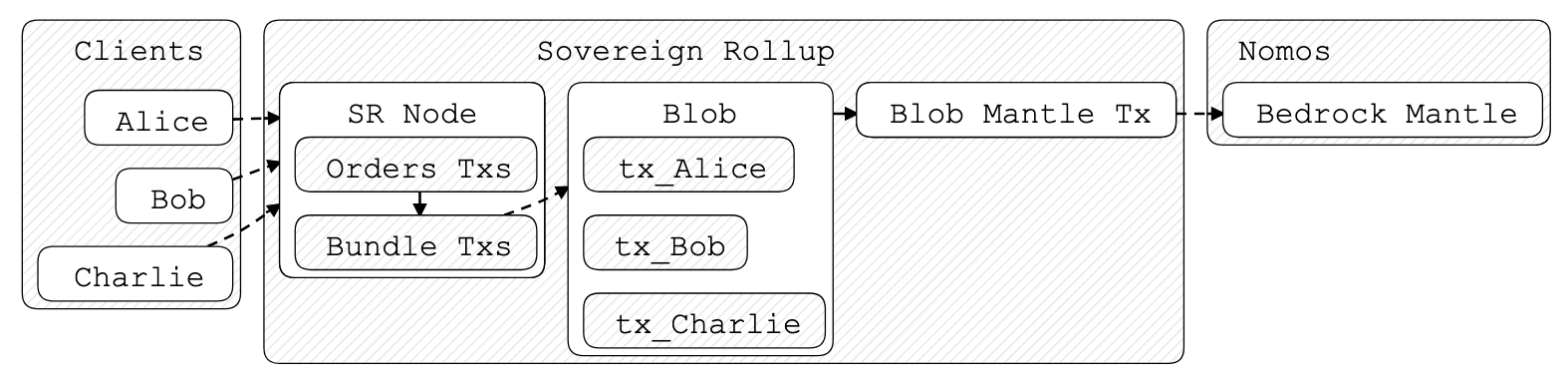
Typical end-to-end flow for clients interacting with a Sovereign Rollup, which in turn interacts with Bedrock. Clients send transactions to Sovereign Rollups who order and bundle them into Blobs, which are stored on Logos Blockchain. Clients can get finality guarantees by observing the Logos Blockchain and watching for the inclusion of their transactions.
Sovereign Rollups form a virtual chain overlaid on top of the Logos Blockchain. This architecture allows application developers to easily spin up high performance applications while taking advantage of the security of Logos Blockchain to distribute the application state widely for auditing and resilience purposes.
V1.0.0-TEMPLATE-CROSS-CHANNEL-MESSAGING
| Field | Value |
|---|---|
| Name | [Template] Cross-Channel Messaging |
| Slug | 218 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Thomas Lavaur [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial version. | 2026-03-31 |
Introduction
This document outlines the cross-channel messaging framework. A channel is a reserved identifier where only authorized keys can post messages on-chain, while anyone can read them. Cross-channel messaging allows different channels (including channels representing a Zone) to communicate and coordinate actions (such as Zone state transitions), enabling interoperability while maintaining security and decentralization.
Reference: Mantle.
Objectives
The primary objectives of this framework are to:
- Enable secure communication between different channels without compromising decentralization.
- Support both synchronous and asynchronous messaging patterns to accommodate different use cases and trust assumptions.
- Provide a standard message format while allowing flexibility for custom implementations.
- Provide atomicity guarantees for cross-channel operations when required.
Requirements
The cross-channel messaging framework must satisfy the following requirements:
- Synchronous operations must provide atomicity guarantees (all-or-nothing execution).
- Asynchronous operations must handle finality periods correctly.
- The framework should be flexible enough to support various channel implementations.
Overview
Cross-channel messaging allows different channels to interact and coordinate. The framework supports two distinct messaging modes.
- Asynchronous Messaging: Channels send messages to each other without requiring real-time and/or off-chain coordination. The receiving channel waits for the sending channels message to achieve finality on the chain before processing it. This approach minimizes coordination overhead but introduces latency due to finality requirements.
- Synchronous Messaging: Multiple channels coordinate to include their messages in a single Mantle Transaction. All messages in the transaction either succeed or fail together, providing strong consistency guarantees. This requires off-chain coordination between sequencers but enables use cases like atomic Zone state transitions. Since each Inscription Operation proof is a signature of the entire Mantle Transaction hash, the signature cannot be reused in a different context, for example, posting an Inscription alone after signing it as part of a coordinated transaction.
| Pros | Cons | |
|---|---|---|
| Asynchronous messaging | - Simple coordination model. - Channels operate independently. - Higher decentralization (no trusted coordinator). | - Higher latency due to waiting for finality. - No atomicity across channels (possible partial failures). |
| Synchronous messaging | - Strong atomicity guarantees across channels (all-or-nothing). - Lower end-to-end latency vs waiting for async finality. - Better suited for cross-channel financial operations (atomic swaps, cross-channel transfers). | - Requires off-chain coordination between sequencers. - Depends on availability of all participating sequencers. - More complex orchestration and implementation. |
The coordinator typically pays fees and must be trusted for timing of submission. Channel designers should implement mechanisms if they want to share these fees, either by:
- Requesting to cover a part of the coordinator's fee costs as part of the operation (e.g., including fee reimbursement in a Zone's state transition logic).
- Establishing external fee recovery protocols where the coordinator is compensated through off-chain agreements or separate on-chain transactions.
- Using a shared note to pay using a threshold Eddsa25519 public key.
Use Cases
Channels should choose between synchronous and asynchronous messaging based on their requirements:
Use Synchronous Messaging when:
- Atomicity is required (operations must all succeed or all fail).
- Low latency is important (faster than waiting for asynchronous finality).
- Coordinating sequencers have established trust and communication pathways.
- The use case justifies the additional coordination complexity.
Use Asynchronous Messaging when:
- Operations can be processed independently.
- Simplicity and decentralization are prioritized over latency.
- Sequencer coordination is difficult or undesirable.
- The application can handle eventual consistency.
Message Flow
Cross-channel messaging follows this general flow:
- The source channel's sequencer generates a message for one or more destination channels.
- The message is included in a Mantle Transaction (through an InscriptionOperation):
- For asynchronous messaging: the channel's sequencer includes it in a separate transaction.
- For synchronous messaging: a coordinator gathers Operations from different channel sequencers and includes them in a common transaction.
- Once the Mantle Transaction is built, each channel sequencer signs their Operation using the Mantle Transaction hash as input.
- The transaction is submitted to the chain:
- For asynchronous messaging: by the channel's sequencer.
- For synchronous messaging: by the coordinator.
Protocol
Asynchronous Messaging
Asynchronous messaging allows channels to send messages to each other without requiring real-time and off-chain coordination between sequencers. This mode prioritizes simplicity and independent operation over low latency and atomicity.
Message Format
We provide a recommended data structure for formatting messages in Inscriptions. This structure uses compact binary encoding to minimize on-chain storage costs while clearly indicating the message recipient:
Inscription = MessageCount *Messages
MessageCount = Byte
Messages = Destination MessageLength *Message
Destination = ChannelId
MessageLength = UINT64
Message = UINT32 *Byte
ChannelId = 4 *Byte
The structure consists of:
- MessageCount: A single byte indicating the number of messages in this Inscription (supports up to 255 messages).
- Destination: A 32-byte number identifying the target channel.
- MessageLength: An 4-byte unsigned integer specifying the total length of all messages for this destination in bytes.
- Message: The actual message payload, prefixed by a 3-byte length field indicating the size of each individual message in bytes.
Note on Format Flexibility: This structure is not enforced by the blockchain. It serves as a recommended standard for interoperability. Channels can choose to:
- Parse messages themselves according to this format.
- Implement their own custom message formats based on specific requirements. However, following the recommended format ensures better interoperability with other channels in the ecosystem.
Processing Flow
The asynchronous messaging process follows these steps:
- Message Creation: The source channels sequencer creates a message according to the recommended format (or their custom format) and includes it in an Inscription within a Mantle Transaction.
- Transaction Submission: The sequencer signs the Operation and submits the Mantle Transaction to the chain independently.
- Finality Wait: The transaction propagates through the network and eventually achieves finality on-chain. This guarantee that this transaction wont be reverted due to a reorganization.
- Message Observation: Destination channels sequencers monitor the chain for messages addressed to their ChannelId. When a relevant message is detected and has achieved finality, the channel can safely process it.
- State Transition: The destination channel checks that the message is valid and publishes a corresponding state transition in its own Inscription.
Destination SequencerBedrockSource SequencerDestination SequencerBedrockSource SequencerTransaction is propagatedand eventually finalized1. Generate cross-channel message(for one or more destination channels)12. Include message in Mantle Tx(Inscription Operation)24. Submit Mantle Transaction to chain3Destination channel sequencer observesfinalized inscription(s) to its ChannelId4Validate message, applycorresponding state change5
Security Considerations
Asynchronous messaging relies on the finality guarantees of the underlying chain. Destination channels must:
- Wait for sufficient confirmation before processing messages to avoid issues with chain reorganizations. Channels can choose a specific probability threshold or wait for finality to achieve a 100% guarantee.
- Since the chain does not verify channels' Inscriptions, the destination channel must understand the source channel's logic to determine whether the message is valid.
Synchronous Messaging
Synchronous messaging enables atomic cross-channel operations by including multiple messages in a single Mantle Transaction. All messages either succeed or fail together, providing strong consistency guarantees across multiple channels.
Atomicity Guarantees
The atomicity property is crucial for use cases that require coordinated changes across multiple channels. Examples include:
- Atomic swaps: Trading assets between two zones where both transfers must succeed or both must fail. It involves executing a CHANNEL_WITHDRAW, a CHANNEL_DEPOSIT and two state transitions encoded as CHANNEL_INSCRIPTION.
- Cross-channel funds transfers: Moving assets from one channel to another with guarantees that the asset is directly deposited to the other channel.
Without atomicity, these operations would be vulnerable to partial failures, leading to inconsistent global state.
Example of an atomic transfer
# Build the inscription that sends a transfer from Zone A to Zone B
sending = Inscription(
channel=CHANNEL_ZONE_A,
inscription=b"Alice burns 5 tokens to send to Bob in Zone B",
parent=hash(PREVIOUS_ZONE_A_INSCRIPTION)
signer=sequencer_of_zone_a
)
# Build the inscription that receives the transfer from Zone A to Zone B
receiving = Inscription(
channel=CHANNEL_ZONE_B,
inscription=b"Bob mints 5 tokens, received from Alice in Zone A",
parent=hash(PREVIOUS_ZONE_B_INSCRIPTION)
signer=sequencer_of_zone_b
)
# Sequencer of Zone A encodes the withdrawal from Zone A
withdrawal = ChannelWithdraw(
channel=CHANNEL_ZONE_A,
amount=5
)
# Sequencer of zone B encodes the deposit to Zone B
deposit = ChannelDeposit(
channel=CHANNEL_ZONE_B,
amount=5
)
# Transfer
Trasfer = Transfer(
inputs=[<sequencer_zone_a_note_id>],
outputs=[<change_note>]
)
# Wrap it in a transaction
tx = MantleTx(
ops=[Op(opcode=CHANNEL_INSCRIBE, payload=encode(sending)),
Op(opcode=CHANNEL_INSCRIBE, payload=encode(receiving)),
Op(opcode=CHANNEL_WITHDRAW, payload=encode(withdrawal)),
Op(opcode=CHANNEL_DEPOSIT, payload=encode(deposit)),
Op(opcode=TRANSFER, payload=encode(transfer))],
permanent_storage_gas_price=150,
execution_gas_price=70,
)
# Sign the transaction
signed_tx = SignedMantleTx(
tx=tx,
# Sequencer A is responsible for Zone A so it signs the
# Inscription and Withdraw of Zone A while Sequencer B, who signs the
# Inscription and the Deposit, doesn't require a proof
# Note that the withdraw OpProof has a ChannelWitdrawOpProof structure
op_proofs=[Ed25519_sign(mantle_txhash(tx), sequencer_of_zone_a_sk),
Ed25519_sign(mantle_txhash(tx), sequencer_of_zone_b_sk),
[[Ed25519_sign(mantle_txhash(tx), sequencer_of_zone_a_sk)],[0]],
None,
transfer.prove(sequencer_of_zone_a_sk)]
)
# Send the transaction to the mempool
mempool.push(signed_tx)
Signature Coordination
Synchronous messaging requires coordination between sequencers from different channels. The process works as follows:
- Transaction Construction: One sequencer (the coordinator) constructs a Mantle Transaction containing multiple channel operations for different channels. Each Operation represents an Inscription, withdraw or deposit for a specific channel or a transfer. In order to construct this transaction, the coordinator must gather the different intentions of the affected channels sequencers. For example, a Zone sequencer needs to inform another Zone sequencer that a user is transferring tokens so the receiving Zone can mint the token in its state.
- Signature Collection: Each participating sequencer receives the complete Mantle Transaction and verifies it. If all checks pass, the sequencer builds a proof for the Operations of its channel which includes the signature of the Mantle Transaction hash. The signature covers the entire transaction, ensuring that all sequencers approve the atomic Operations as a whole and preventing signature replay attacks.
- Coordination and Submission: The coordinator collects Operation proofs from all participating sequencers. Once all required proofs are gathered, the coordinator assembles the fully signed transaction and submits it to Bedrock.
- Atomic Execution: The chain validates the Mantle Transaction. If any validation check fails, the entire transaction is rejected and no state changes are applied. If all checks pass, all Operations are executed atomically.
Coordination Failure Handling: If coordination fails (e.g., a sequencer goes offline or refuses to sign), the atomic operation cannot proceed. The sequencers must either:
- Wait for the unavailable sequencer to return and complete the protocol.
- Abort the operation and potentially fall back to asynchronous messaging.
- Initiate a new coordination round with modified parameters. This coordination requirement is the main trade-off of synchronous messaging: it provides stronger guarantees but requires more complex orchestration and is susceptible to availability issues of the involved sequencers.
BedrockCoordinator(one of the sequencers)Sequencer B(Channel B)Sequencer A(Channel A)BedrockCoordinator(one of the sequencers)Sequencer B(Channel B)Sequencer A(Channel A)1. Intention gathering2. Transaction construction3. Signature collectionRepeat for all sequencers4. Submission and atomic executionalt[All checks pass][Any check fails]Propose cross-channel operation(e.g., atomic cross-zone transfer burning tokens in A state)1Propose cross-channel operation(e.g., the same atomic cross-zone transfer minting tokens in B state)2Build MantleTx with ops forall involved channels(CHANNEL_INSCRIBE / WITHDRAW / DEPOSIT, etc.)3Send full MantleTx4Verify MantleTx(channel A logic, fees, etc.)5Proofs for A's Operations(sign mantle_txhash(MantleTx))6Send full MantleTx7Verify MantleTx(channel B logic, fees, etc.)8Proofs for B's Operations(sign mantle_txhash(MantleTx))9Submit fully proved MantleTx10Validate tx + all op proofs11Apply all channel ops atomically(all succeed together)12Reject MantleTx(no state changes applied)13
Security Considerations
Synchronous messaging introduces additional security considerations:
- While the coordinator cannot forge signatures, they control transaction submission timing. Sequencers should implement timeouts and designate backup coordinators in the case where the coordinator aborts or delays the posting of the transaction.
- The protocol's liveness depends on all participating sequencers being available and responsive.
- Sequencers must agree on fee payment as the coordinator is the only one paying for submitting the transaction. The fee construction is internal to the Channel sequencers and is out of the scope of this document.
And trust assumptions:
- Each participating sequencer is assumed to verify the entire Mantle Transaction and only sign transactions that are valid with respect to its own channel rules.
- The protocol does not enforce or verify this behavior on-chain.
- Bedrock does not validate channel-specific Inscription semantics. As a result, correctness of cross-channel operations depends on off-chain verification by sequencers.
V1.0.0-BEDROCK-GENESIS-BLOCK
| Field | Value |
|---|---|
| Name | Bedrock Genesis Block |
| Slug | 212 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | David Rusu [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Owners: @David Rusu @Hong-Sheng Zhou
Reviewers: @Thomas Lavaur @Giacomo Pasini @Marcin Pawlowski @Mehmet @lvaro Castro-Castilla @Daniel Sanchez Quiros
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-02-12 |
Introduction
The Genesis Block defines the starting state for the Bedrock chain, including the initial bedrock service providers, NMO token distribution and protocol parameters. Its design draws from best practices in the Ouroboros family of protocols (notably Praos and Genesis), as well as privacy and resilience advances from Cryptarchia and related research. The Genesis Block is the root of trust for all subsequent protocol operations and must be constructed in a way that is deterministic, verifiable, and robust against long-range or bootstrap attacks.
Overview
The Genesis Block establishes the initializing values for the various protocols and services. This includes the initial token distribution, initial nodes participating in Blend Network and the DA network and the result of running the epoch nonce ceremony.
The block body is a single Mantle Transaction containing a Ledger Transaction distributing the notes to initial token holders. The bedrock services are initialized through SDP_DECLARE Operations embedded in the Mantle Transactions Operations list and protocol initializing constants are encoded through a CHANNEL_INSCRIBE Operation also embedded in the Operations list.
Not all protocol constants are encoded in the Genesis block. The principle we use to decide whether a value should be in the Genesis block or not is whether it is a value that is derived from blockchain activity or whether it is updated through a protocol update (hard / soft fork). For example, the epoch nonce is updated through normal blockchain Operations and therefore it should be specified in the Genesis block. Gas constants are only changed through protocol updates and hard forks and therefore they will be hardcoded in the node implementation.
Genesis Block Data Structure
The Genesis Block is composed of the Genesis Block Header and the Genesis Mantle Transaction (there is a single transaction in the genesis block). The Mantle Transaction contains all information necessary for initializing Bedrock Services and Cryptarchia state, as well as distributing the initial tokens to stakeholders.
Initial Token Distribution
Initial tokens will be distributed through a Ledger Transaction containing zero inputs and one output note for each initial stakeholder. Note that since the Ledger is transparent, the initial stake allocation is visible to everyone. Those wishing to hide their initial stake may opt to subdivide their note into a few different notes of equal value.
In order to participate in the Cryptarchia lottery, stakeholders must generate their note keys in accordance with the Proof of Leadership protocol specified at Proof of Leadership - Protocol.
The initial state of the Ledger will be derived through normal execution of this Ledger Transaction, that is, each outputs note ID will be added to the unspent notes set.
Example
STAKE_DISTRIBUTION_TX = LedgerTx(
inputs=[],
outputs=[
Note(value=1000, public_key=STAKE_HOLDER_0_PK),
Note(value=2000, public_key=STAKE_HOLDER_1_PK),
Note(value=1500, public_key=STAKE_HOLDER_2_PK),
# ...
]
)
Initial Service Declarations
Data Availability (DA) and Blend Network MUST initialize their set of providers. This is done through a set of SDP_DECLARE Operations in the Genesis Mantle Transaction.
Both Blend and DA enforce a minimal network size for the service to be active. Thus, in order to have active Blend and DA services at Genesis, we MUST have at least as many declarations for each service in the Genesis block to meet each services minimal network size:
Example
DA_DECLARATIONS = [
Declaration(
msg=DeclarationMessage(
ServiceType.DA, ["ip://1.1.1.1:3000"], PROVIDER_ID_0, ZK_ID_0
),
locked_note_id=STAKE_DISTRIBUTION_TX.output_note_id(0)
),
# ... 40 total declarations
]
BLEND_DECLARATIONS = [
Declaration(
msg=DeclarationMessage(
ServiceType.BLEND, ["ip://1.1.1.1:3000"], PROVIDER_ID_0, ZK_ID_0
),
locked_note_id=STAKE_DISTRIBUTION_TX.output_note_id(0)
),
# ... 32 total declarations
]
SERVICE_DECLARATIONS = DA_DECLARATIONS + BLEND_DECLARATIONS
Cryptarchia Parameters
Cryptarchia is initialized with the following parameters:
- genesis_time: ISO 8601 encoded timestamp. Cryptarchia uses slots as a measure of time offset from some start time. This timestamp must be agreed upon by all nodes in order to have a common clock.
- chain_id: string. It is useful to differentiate testnets from mainnet. To avoid confusion, we place the chain ID in the Genesis block to guarantee that the networks are disjoint.
- genesis_epoch_nonce: 32 bytes, hex encoded. The initial source of randomness for the Cryptarchia lottery. The process for selecting this value is described in detail at Epoch Nonce Ceremony.
These parameters are encoded in the Genesis block as an inscription sent to the null channel.
Example
from datetime import datetime
CHAIN_ID = "logos-blockchain-mainnet"
GENESIS_TIME = "2026-01-05T19:20:35+00:00"
GENESIS_EPOCH_NONCE = "abcdef1234567890abcdef1234567890abcdef1234567890abcdef1234567890"
chain_id_enc = CHAIN_ID.encode("utf-8")
chain_id_len = len(chain_id_enc).to_bytes(8, "little")
genesis_time = int(datetime.fromisoformat(GENESIS_TIME).timestamp()).to_bytes(8, "little")
genesis_epoch_nonce = bytes.fromhex(GENESIS_EPOCH_NONCE)
inscription = chain_id_len + chain_id_enc + genesis_time + genesis_epoch_nonce
# >>> inscription.hex()
# '0d000000000000006e6f6d6f732d6d61696e6e6574030f5c6900000000abcdef1234567890abcdef1234567890abcdef1234567890abcdef1234567890'
CRYPTARCHIA_INSCRIPTION = Inscribe(
channel=bytes(32),
inscription=inscription
parent=bytes(32),
signer=Ed25519PublicKey_ZERO,
)
Epoch Nonce Ceremony
The initial epoch nonce value governs the Cryptarchia lottery randomness for the first epoch. It must be revealed AFTER the initial stake distribution has been frozen. This is done to prevent any stakeholders from gaining an unfair advantage from prior knowledge of the lottery randomness.
The protocol for generating the initial randomness nonce can be found below.
- Schedule Epoch Nonce Ceremony Event: We must fix well in advance when this epoch nonce ceremony will take place, let t denote the time of the Epoch Nonce Ceremony, broadcast t widely. The STAKE_DISTRIBUTION_TX must be finalized before t to ensure a fair Cryptarchia slot lottery.
- Randomness Collection:
We collect the entropy from multiple randomness sources:
Entropy Source Details Bitcoin block hash immediately after time t, denoted as . Block hash can be found on blockchain.com s bitcoin block explorer, e.g. https://www.blockchain.com/explorer/blocks/btc/905030 Ethereum block hash immediately after time t, denoted as . Block hash can be found in the more details section of when viewing a block on etherscan, e.g. https://etherscan.io/block/22894116 DRAND beacon value for the round immediately after t, denoted as . Use the default beacon, and find the round number corresponding to t. https://api.drand.sh/v2/beacons/default/rounds/1234 - Randomness Derivation: Once all above entropy contributions, i.e., are collected, then we can compute the initial epoch randomness as: where is a collision-resistant zkhash function.
Genesis Mantle Transaction
The initial stake distribution, service declarations and Cryptarchia inscription are components of the Genesis Mantle Transaction. This is the single transaction that forms the body of the Genesis block.
GENESIS_MANTLE_TX = MantleTx(
ops=[CRYPTARCHIA_INSCRIPTION] + SERVICE_DECLARATIONS,
ledger_tx=STAKE_DISTRIBUTION_TX,
permanent_storage_gas_price=0,
execution_gas_price=0
)
Block Header Fields
The Genesis Block header fields are set to the following values:
- bedrock_version: Protocol version (e.g., 1).
- parent_block: 0 (as this is the first block).
- slot: 0 (the Genesis slot).
- block_root: Block Merkle root over the (single) initial transaction.
- proof_of_leadership: Stubbed leadership proof.
- leader_voucher: 0 (as there is no leader block reward for the initial block).
- entropy_contribution: 0 (no entropy is provided through the initial PoL).
- proof: Null Groth16Proof, all values are set to zero.
- leader_key: Null PublicKey.
Example
GENESIS_HEADER = Header(
bedrock_version=1,
parent_block=0,
slot=0,
block_root=block_merkle_root([GENESIS_MANTLE_TX]),
proof_of_leadership=ProofOfLeadership(
leader_voucher=bytes(32),
entropy_contribution=bytes(32),
proof=Groth16Proof(G1_ZERO, G2_ZERO, G1_ZERO),
leader_key=Ed25519PublicKey_ZERO,
)
)
Sample Genesis Block
# distribute NMO to all stakeholders
STAKE_DISTRIBUTION_TX = LedgerTx(
inputs=[],
outputs=[
Note(value=1000, public_key=STAKE_HOLDER_0_PK),
Note(value=2000, public_key=STAKE_HOLDER_1_PK),
Note(value=1500, public_key=STAKE_HOLDER_2_PK),
# ...
]
)
# set Cryptarchia parameters
CRYPTARCHIA_PARAMS = {
"chain_id": "logos-mainnet",
"genesis_time": "2026-01-05T19:20:35Z",
"genesis_epoch_nonce": "abcdef1234567890abcdef1234567890abcdef1234567890abcdef1234567890",
}
CRYPTARCHIA_INSCRIPTION = Inscribe(
channel=bytes(32),
inscription=json.dumps(CRYPTARCHIA_PARAMS).encode("utf-8"),
parent=bytes(32),
signer=Ed25519PublicKey_ZERO,
)
# service declarations
DA_DECLARATIONS = [
Declaration(
msg=DeclarationMessage(ServiceType.DA, ["ip://1.1.1.1:3000"], PROVIDER_ID_0, ZK_ID_0),
locked_note_id=STAKE_DISTRIBUTION_TX.output_note_id(0)
),
# ... more declarations
]
BLEND_DECLARATIONS = [
Declaration(
msg=DeclarationMessage(ServiceType.BLEND, ["ip://1.1.1.1:3000"], PROVIDER_ID_0, ZK_ID_0),
locked_note_id=STAKE_DISTRIBUTION_TX.output_note_id(0)
),
# ... more declarations
]
SERVICE_DECLARATIONS = DA_DECLARATIONS + BLEND_DECLARATIONS
# build the genesis Mantle Transaction
GENESIS_MANTLE_TX = MantleTx(
ops=[CRYPTARCHIA_INSCRIPTION] + SERVICE_DECLARATIONS,
ledger_tx=STAKE_DISTRIBUTION_TX,
gas_price=0,
)
GENESIS_HEADER = Header(
bedrock_version=1,
parent_block=bytes(32),
slot=0,
block_root=block_merkle_root([GENESIS_MANTLE_TX]),
proof_of_leadership=ProofOfLeadership(
leader_voucher=bytes(32),
entropy_contribution=bytes(32),
proof=Groth16Proof(G1.ZERO, G2.ZERO, G1.ZERO),
leader_key=Ed25519PublicKey_ZERO,
)
)
GENESIS_BLOCK = (GENESIS_HEADER, [GENESIS_MANTLE_TX])
Initializing Bedrock
Bedrock is initialized by executing the Mantle Transaction without validating the Ledger Transaction and Mantle Operations. No validation or execution is done for the Genesis block header; in particular, processing of proof_of_leadership is skipped.
Mantle Ledger Initialization
The Ledger Transaction should be executed without checking that the transaction is balanced. However, other validations are checked, e.g. that output note values are positive and smaller than the maximum allowed value. The result of normal transaction execution adds all transaction outputs to the Ledger.
Cryptarchia Initialization
The Mantle Transaction contains an inscription sent to the null channel containing the parameters for initializing Cryptarchia.
The Cryptarchia slot clock is initialized to genesis_time, LIB is set to the Genesis block and the epoch state is then initialized:
Initial Epoch State
Cryptarchia progresses in epochs where the variables governing the lottery are fixed for the duration of an epoch and the activity during that epoch is used to derive the values of those variables for the next epoch. These variables taken together are called the Epoch State. (see Cryptarchia Protocol - Epoch State).
To initialize the Epoch State, we derive the epoch variables from the genesis block.
- : the epoch nonce is taken directly from the genesis_epoch_nonce.
- : Eligible leader commitment is set to the the Ledger Root over all notes from the initial token distribution. The derivation of this root is specified in Proof of Leadership - Ledger Root.
- : The initial estimate of total stake will be the total tokens distributed at genesis.
Bedrock Services Initialization
DA and Blend network are initialized through normal Mantle Transaction execution. The SDP_DECLARE Operations in the Genesis Mantle Transaction will create the initial set of providers in each service.
During normal operations, DA/Blend services would wait until a block is deep enough to be finalized, but for the Genesis block, we consider it finalized by definition and so DA/Blend will immediately use the provider set without the usual finalization delay.
References
- Ouroboros Praos: https://eprint.iacr.org/2017/573.pdf
- Ouroboros Genesis: https://eprint.iacr.org/2018/378.pdf
- Ouroboros Crypsinous: https://eprint.iacr.org/2018/1132.pdf
- Cardano Shelley Genesis File Format: https://cardano-course.gitbook.io/cardano-course/handbook/protocol-parameters-and-configuration-files/shelley-genesis-file
- Cardano CIP-16 Key Serialisation: https://cips.cardano.org/cip/CIP-16
what should the inscription proof (sig) look like? all zeros?
V1.0.0-BEDROCK-BLOCK-CONSTRUCTION
| Field | Value |
|---|---|
| Name | Block Construction, Validation and Execution |
| Slug | 211 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Marcin Pawlowski [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Owner: @Marcin Pawlowski @Thomas Lavaur
Reviewers: @Daniel Sanchez Quiros @David Rusu @lvaro Castro-Castilla
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-12-03 |
Introduction
In this document, we present the specification defining the construction of the block proposal, its validation, and execution. We define the block proposal construction that contains references to transactions (from the mempool) instead of a complete transaction to limit its length. The raw block size increases with the size of transactions it contains up to 1 MB, and the proposal compresses its size down to 33 kB, which saves the bandwidth necessary to broadcast new blocks.
Overview
For the consensus protocol to make progress, a new leader is elected through the leader lottery. The new leader is in possession of a proof of leadership (PoL) that confirms that it is indeed the leader. The main objective of the leader is to construct a new block, hence becoming a block builder, and share it with other members of the network as a block proposer. The block must be correctly constructed; otherwise, it will be rejected by the consensus nodes who are validating every block. Only validated blocks are executed, which means that the transactions included in the block are interpreted by all nodes, and the state of the chain is modified according to the instructions embedded in the transactions.
High-level Flow
Below, we present a high-level description of the block lifecycle. The main focus of this section is to build an intuition on the block construction, validation, and execution.
- A leader is selected. The leader becomes a block builder.
- The block builder constructs a block proposal.
- The block builder selects the latest block (parent) as the reference point for the chain state update.
- The block builder constructs references to the deterministically generated Mantle Transactions that execute the Service Reward Distribution Protocol, if such transactions can be constructed. For example, there is no need to distribute rewards when all rewards have already been distributed.
- The block builder selects valid Mantle Transactions (as defined in Mantle) from its mempool and includes references to them in the proposal.
- The block builder populates the block header of the block proposal.
- The block proposer sends the block proposal to the Blend network.
- The validators receive the block proposal.
- The validators validate the block proposal.
- They validate the block header.
- They verify distribution of service rewards through Mantle Transactions as specified in Service Reward Distribution Protocol. This is done by independently deriving the distribution transaction and confirming that it matches the first reference, if there is rewards to be distributed.
- They retrieve complete transactions from their mempool that are referred in the block.
- They validate each transaction included in the block.
- The validators execute the block proposal.
- They derive the new blockchain state from the previous one by executing transactions as defined in Mantle.
- They update the different variables that need to be maintained over time.
Constructions
Hash
We are using two hashing algorithms that have the same output length of 256 bits (32 bytes) that are Poseidon2 and Blake2b.
Block Proposal
A block proposal, instead of containing complete Mantle Transactions of an unlimited size, contains references of fixed size to the transactions. Therefore, the size of the proposal is constant and it is 33129 bytes.
We define the following message structure:
class Proposal: # 33129 bytes
header: Header # 297 bytes
references: References # 32768 bytes
signature: Ed25519Signature # 64 bytes
Where:
- header is the header of the proposal; defined below: Header.
- references is a set of 1024 references to transactions of a hash type; the size of the hash type is 32 bytes and is the transaction hash as defined in Mantle - Mantle Transaction.
- signature is the signature of the complete header using the leader_key from the ProofOfLeadership; the size of the Ed25519Signature type is 64 bytes.
The length of the references list must be preserved to maintain the messages indistinguishability in the Blend protocol. Therefore, the list must be padded with zeros when necessary.
Header
class Header: # 297 bytes
bedrock_version: byte # 1 bytes
parent_block: hash # 32 bytes
slot: SlotNumber # 8 bytes
block_root: hash # 32 bytes
proof_of_leadership: ProofOfLeadership # 224 bytes
Where:
- bedrock_version is the version of the proposal message structure that supports other protocols defined in Bedrock Specification; the size of it is 1 byte and is fixed to 0x01.
- parent_block is the block ID (Cryptarchia Protocol) of the parent block, validated and accepted by the block builder. It is used for the derivation of the AgedLedger and LatestLedger values necessary for validating the PoL; the size of the hash is 32 bytes.
- slot is the consensus slot number; the size of the SlotNumber type is 8 bytes.
- block_root is the root of the Merkle tree constructed from transaction hashes (defined in Mantle - Mantle Transaction) used for constructing the references list in the transactions; the size of the hash is 32 bytes.
- proof_of_leadership is the proof confirming that the sender is the leader; defined below: Proof of Leadership.
References
class References: # 32768 bytes
service_reward: list[zkhash] # 1*32 bytes
mempool_transactions: list[zkhash] # 1024-len(service_reward)*32 bytes
Where:
- service_reward is a set of up to 1 reference to a reward transaction of a zkhash type; the size of the zkhash type is 32 bytes and is the transaction hash as defined in Mantle - Mantle Transaction.
- mempool_transactions is a set of up to 1024 references to transactions of a zkhash type; the size of the zkhash type is 32 bytes and is the transaction hash as defined in Mantle - Mantle Transaction.
The service_reward transaction is created deterministically by the leader and is not obtained from the mempool. If this transaction were obtained from the mempool, it could expose the leader's identity as the transaction creator. To protect the leader's identity, only the service_reward reference is included in the proposal, and it is derived again by the nodes verifying the block.
The service_reward transaction is a Service Rewards Distribution Transaction that distributes service rewards. It is a Mantle Transaction with no input and up to service_count x 4 outputs, service_count being the number of services (global parameter). The outputs represent the validators rewarded (up to 4 per service).
If the service_reward transaction cannot be created, then nothing is added to the list. Therefore, we allow the service_reward list to have a length of 0.
Proof of Leadership
class ProofOfLeadership: # 224 bytes
leader_voucher: RewardVoucher # 32 bytes
entropy_contribution: zkhash # 32 bytes
proof: ProofOfLeadership # 128 bytes
leader_key: Ed25519PublicKey # 32 bytes
Where:
- leader_voucher is the voucher value used for retrieving the reward by the leader for proposal; the size of the RewardVoucher is 32 bytes.
- entropy_contribution is the output of the PoL contribution for Cryptarchia entropy; the size of the zkhash type is 32 bytes.
- proof is the proof confirming that the proposal is constructed by the leader; the size of the ProofOfLeadership type is 128 bytes (2 compressed and 1 compressed BN256 elements).
- leader_key is the one-time Ed25519PublicKey used for signing the Proposal. This binds the content of the proposal with the ProofOfLeadership; the size of the Ed25519PublicKey type is 32 bytes.
Proposal Construction
In this section, we explain how the block proposal structure presented above is populated by the consensus leader.
The block proposal is constructed by the leader of the current slot. The node becomes a leader only after successfully generating a valid PoL for a given (Epoch, Slot).
Prerequisites
Before constructing the proposal, the block builder must:
- Select a valid parent block referenced by ParentBlock on which they will extend the chain.
- Derive the required Ledger state snapshots AgedLedger and LatestLedger from the state of the chain including the last block.
- Select a valid unspent note winning the PoL.
- Generate a valid PoL proving leadership eligibility for (Epoch, Slot) based on the selected note. Attach the PoL to a one-time Ed25519 public key used to sign the block proposal.
Only after the PoL is generated can the block proposal be constructed (see Proof of Leadership).
Construction Procedure
- Initialize proposal metadata with the last known state of the blockchain. Set the:
- header:
- bedrock_version
- parent_block
- slot
- block_root
- proof_of_leadership:
- leader_voucher
- entropy_contribution
- proof
- leader_key
- header:
- Construct the service_reward object:
- If there are service rewards to be distributed construct the transaction that distributes the service rewards from previous session and add its reference to the service_reward list. This transaction must be computed locally, do not disseminate this transaction.
- Construct the mempool_transactions object:
- Select Mantle transactions:
- Choose up to 1024-len(service_reward) valid SignedMantleTx from the local mempool.
- Ensure each transaction:
- Is valid according to Mantle.
- Has no conflicts with others (e.g., two transactions trying to spend the same note).
- Select Mantle transactions:
- Derive references values:
references: list[zkhash] = [mantle_txhash(tx) for tx in service_reward + mempool_transactions] - Compute the header.block_root as the root of the Merkle tree using Blake2b (of arbitrary depth) constructed from the list(service_reward) + mempool_transactions transactions used to build references.
- Sign the block proposal header.
signature = Ed25519.sign(leader_secret_key, header) - Assemble the block proposal.
The PoL must have been generated beforehand and bound to the same Ledger view as mentioned in the Prerequisites.proposal = Proposal( header, references, signature )
The constructed proposal can now be broadcast to the network for validation.
Block Proposal Reconstruction
Given a block proposal, we assume transaction maturity. This means that the block proposal must include transactions from the mempool that have had enough time to spread across the network to reach all nodes. This ensures that transactions are widely known and recognized before block reconstruction.
This transaction maturity assumption holds true because the block proposal must be sent through the Blend Network before it reaches validators and can be reconstructed. The Blend Network introduces significant delay, ensuring that transactions referenced in the proposal have reached all network participants. This approach is crucial for maintaining smooth network operation and reducing the risk that proposals get rejected due to transactions being unavailable to some validators. Moreover, by increasing the number of nodes that have seen the transaction, anonymity is also enhanced as the set of nodes with the same view is larger. This may result in increased difficultyor even practical preventionof executing deanonymization attacks such as tagging attacks.
Upon receipt of a block proposal, validators must confirm the presence of all referenced transactions within their local mempool. This verification is an absolute requirementif even a single referenced transaction is missing from the validator's mempool, the entire proposal must be rejected. This stringent validation protocol ensures only widely-distributed transactions are included in the blockchain, safeguarding against potential network state fragmentation.
The process works as follows:
- Transaction is added to the node mempool.
- Node sends the transaction to all its neighbors.
- Neighbors add the transaction to their own mempools and propagate it to their neighborstransaction is gossiped throughout the network.
- Block builder selects a transaction from its local mempool, which is guaranteed to be propagated through the network due to steps 1-3.
- Block builder constructs a block proposal with references to selected transactions.
- Block proposal is sent through the Blend Network, which requires multiple rounds of gossiping. This introduces a delay that ensures the transaction has reached most of the network participants' mempools.
- Block proposal is received by validators.
- Validators check their local mempools for all referenced transactions from the proposal.
- If any transaction is missing, the entire proposal is rejected.
- If all transactions are present, the block proposal is reconstructed and proceeds to further validation steps.
Block Proposal Validation
This section defines the procedure followed by a Logos Blockchain node to validate a received block proposal.
Given a Proposal, a proposed block consisting of a header and references. This block proposal is considered valid if the following conditions are met:
- Block Validation The Proposal must satisfy the rules defined in Cryptarchia Protocol - Block Header Validation.
- Block Proposal Reconstruction The references must refer to either a service_reward transaction that is locally derivable or to existing mempool_transaction entries that are retrievable from the node's local mempool.
- Mempool Transactions Validation mempool_transactions must refer to a valid sequence of Mantle Transactions from the mempool. Each transaction must be valid according to the rules defined in the Mantle.
- Rewards Validation
- Check if the first reference matches a deterministically derived Service Rewards Distribution Transaction that distributes previous session service fees as defined in Service Reward Distribution Protocol. It should take no input and output up to service_count * 4 reward notes distributed to the correct validators.
- If the above rewarding transactions cannot be derived, then the first reference must refer to a mempool_transaction.
If any of the above checks fail, the block proposal must be rejected.
Block Execution
This section specifies how a Logos Blockchain node executes a valid block proposal to update its local state.
Given a ValidBlock that has successfully passed proposal validation, the node must:
- Append the leader_voucher contained in the block to the set of reward vouchers when the following epoch starts.
- Execute the Mantle Transactions included in the block sequentially, using the execution rules defined in the Mantle.
this can be removed after rewards distribution v2
V1.0.0-MANTLE
| Field | Value |
|---|---|
| Name | Mantle |
| Slug | 216 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Thomas Lavaur [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Owner: @Thomas Lavaur @David Rusu
Reviewers: @Giacomo Pasini @Mehmet @lvaro Castro-Castilla @Marcin Pawlowski @Daniel Sanchez Quiros @Gusto Bacvinka @Youngjoon Lee
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-11-17 |
Introduction
Mantle is a foundational element of Bedrock, designed to provide a minimal and efficient execution layer that connects together Logos Blockchain Services in order to provide the necessary functionality for Sovereign Rollups. It can be viewed as the system call interface of Bedrock, exposing a safe and constrained set of Operations to interact with lower-level Bedrock services, similar to syscalls in an operating system.
Mantle Transactions provide Operations for interacting with Logos Blockchain Services. For example, a Sovereign Rollup node posting an update to Bedrock, or a node operator declaring its participation in the Blend Network, would be done through the corresponding Operations within a Mantle Transaction.
Mantle manages assets using a Note-based ledger that follows an UTXO model. Each Mantle Transaction includes a Ledger Transaction, and any excess balance serves as the fee payment.
Overview
Mantle Transaction
The features of Logos Blockchain are exposed through Mantle Transactions. Each transaction can contain zero or more Operations and one Ledger Transaction. Mantle Transactions enable users to execute multiple Operations atomically. The Ledger Transaction serves two purposes: it can pays the transaction fee and allows users to issue transfers.
Mantle Operations
Logos Blockchain features are exposed through Mantle Operations, which can be combined and executed together in a single Mantle Transaction. These Operations enable functions such as on-chain data posting, SDP interaction, and leader reward claims.
Mantle Ledger
The Mantle Ledger enables asset transfers using a transparent UTXO model. While a Ledger Transactions can consume more NMO than it creates, the Mantle Transaction excess balance must exactly pay for the fees.
Transaction Fees
Mantle Transaction fees are derived from a gas model. Logos Blockchain has three different Gas markets, accounting for permanent data storage, ephemeral data storage through DA, and execution costs. Permanent data storage is paid at the Mantle Transaction level, while ephemeral data storage is paid at the Blob Operation level. Each Operation and Ledger Transaction has an associated Execution Gas cost. Users can specify their Gas prices in their Mantle Transactions or in the Blob Operation to incentivize the network to include their transaction.
| Gas Market | Charged On | Pricing Basis |
|---|---|---|
| Execution Gas | Ledger Transaction and Operations | Fixed per Operation |
| Permanent Storage Gas | Signed Mantle Transaction | Proportional to encoded size |
| DA Storage Gas | Blob Operation | Proportional to blob size |
Mantle Transaction
Mantle Transactions form the core of Mantle, enabling users to combine multiple Operations to access different Logos Blockchain functions. Each transaction contains zero or more Operations plus a Ledger Transaction. The system executes all Operations atomically, while using the Mantle Transaction's excess balancecalculated as the difference between consumed and created value as the fee payment.
class MantleTx:
ops: list[Op]
ledger_tx: LedgerTx # excess balance is used for fee payment
permanent_storage_gas_price: int # 8 bytes
execution_gas_price: int # 8 bytes
class Op:
opcode: byte
payload: bytes
def mantle_txhash(tx: MantleTx) -> zkhash:
h = Hasher() # zk hash
h.update(FiniteField(b"LOGOS_MANTLE_TXHASH_V1", byte_order="little", modulus= p))
for op in tx.ops:
h.update(FiniteField(op.opcode, byte_order="little", modulus= p))
# The payload is interpreted as a slice of 31-byte elements individually
# converted into Fp elements before hashing.
for i in range((len(op.payload)+30)//31):
h.update(FiniteField(op.payload[i*31:(i+1)*31],
byte_order="little",
modulus=p))
h.update(FiniteField(b"END_OPS", byte_order="little", modulus= p))
h.update(FiniteField(tx.permanent_storage_gas_price, byte_order="little", modulus= p))
h.update(FiniteField(tx.execution_gas_price, byte_order="little", modulus= p))
h.update(ledger_txhash(ledger_tx))
return h.digest()
The hash function used, as well as other cryptographic primitives like ZK proofs and signature schemes, are described in Common Cryptographic Components.
A Mantle Transaction must include all relevant signatures and proofs for each Operation, as well as for the Ledger Transaction.
class SignedMantleTx:
tx: MantleTx
op_proofs: list[OpProof | None] # each Op has at most 1 associated proof
ledger_tx_proof: ZkSignature # ZK proof of ownership of the spent notes
Each proof (op proof and signature) must be cryptographically bound to the MantleTx through the mantle_txhash to prevent replay attacks. This binding is achieved by including the MantleTx hash as a public input in every ZK proof.
The transaction fee is a sum of two components: the multiplication of the total Execution Gas by the execution_gas_price, and the total size of the encoded signed Mantle Transaction multiplied by the permanent_storage_gas_price. If the Mantle Transaction contains a Blob Operations, the fee also accounts for ephemeral data storage. In this case, the blob_size of each blob is multiplied by the DA_storage_gas_price stored in the Blob Operation and added to the previous amounts to determine the final fee.
def gas_fees(signed_tx: SignedMantleTx) -> int:
permanent_storage_fees = len(encode(signed_tx)) * signed_tx.tx.permanent_storage_gas_price
execution_fees = execution_gas(signed_tx.tx.ledger_tx) * signed_tx.tx.execution_gas_price
da_storage_fees = 0
for op in signed_tx.tx.ops:
if op.opcode == CHANNEL_BLOB:
blob = decode_blob(op.payload)
da_storage_fees += blob.da_storage_gas_price * blob.blob_size
# Compute the execution gas of this operation as defined
# in the gas cost determination specification.
execution_fees += execution_gas(op) * signed_tx.tx.execution_gas_price
return execution_fees + da_storage_fees + permanent_storage_fees
Validation
Given
signed_tx = SignedMantleTx(
tx=MantleTx(ops, permanent_storage_gas_price, execution_gas_price, ledger_tx),
op_proofs,
ledger_tx_proof
)
Mantle validators will ensure the following:
- The ledger transaction is valid according to Ledger Validation.
validate_ledger_tx(ledger_tx, ledger_tx_proof, mantle_txhash(tx)) - We have a proof or a None value for each operation.
assert len(op_proofs) == len(ops) - Each Operation is valid.
for op, op_proof in zip(ops, op_proofs): assert op.opcode in MANTLE_OPCODES validate_mantle_op(mantle_txhash(tx), op.opcode, op.payload, op_proof) def validate_mantle_op(txhash, opcode, payload, op_proof): if opcode == INSCRIBE: validate_inscribe(txhash, payload, op_proof) # elif opcode == ... # ... - The Mantle Transaction excess balance pays for the transaction fees.
tx_fee = get_fees(signed_tx) assert tx_fee == get_transaction_balance(signed_tx) def get_transaction_balance(signed_tx): balance = 0 for op in signed_tx.tx.ops: if op.opcode == LEADER_CLAIM: balance += get_leader_reward() for inp in signed_tx.tx.ledger_tx.inputs: balance += get_value_from_note_id(inp) for out in signed_tx.tx.ledger_tx.outputs: balance -= out.value
Execution
Given
SignedMantleTx(
tx=MantleTx(ops, permanent_storage_gas_price, execution_gas_price, ledger_tx),
op_proofs,
ledger_tx_proof
)
Mantle Validators execute the following:
- Execute the Ledger Transaction as described in Ledger Execution.
- Execute sequentially each Operation in ops according to its opcode.
Operations
Opcodes
| Operation | Opcode | Description |
|---|---|---|
| CHANNEL_INSCRIBE | 0x00 | Write a message permanently onto Mantle. |
| CHANNEL_BLOB | 0x01 | Store a blob in DA. |
| CHANNEL_SET_KEYS | 0x02 | Manage the list of keys accredited to post to a channel. |
| SDP_DECLARE | 0x03 | Declare intention to participate as a node in a Logos Blockchain Service, locking funds as collateral. |
| SDP_WITHDRAW | 0x04 | Withdraw participation from a Logos Blockchain Service, unlocking your funds in the process. |
| SDP_ACTIVE | 0x05 | Signal that you are still an active participant of a Logos Blockchain Service. |
| LEADER_CLAIM | 0x06 | Claim leader reward anonymously. |
Full nodes will track and process every Operation. In contrast, nodes focused on a specific rollup will also track all Operations but will only fully process blobs that target their own rollup referenced by a channel ID.
Channel Operations
Channels allow Rollups to post their updates on chain. Channels form virtual chains that overlay on top of the Cryptarchia blockchain. Clients and dependents of Rollups can watch the Rollups channels to learn the state of that Rollup.
Channel Sequencing
These channels form virtual chains by having each message reference its parent message. The order of messages in these channels is enforced by the sequencer by building a hash chain of messages, i.e. new messages reference the previous messages through a parent hash. Given that Cryptarchia has long finality times, these message parent references allow the Rollup sequencers to continue to post new updates to channels without having to wait for finality. No matter how Cryptarchia forks and reorgs, the channel messages will eventually be re-included in a way that satisfies the virtual chain order.
The first time a message is sent to an unclaimed channel, the message signing key that signs the initial message becomes both the administrator and an accredited key. The administrator can update the list of accredited keys who are authorized to write messages to that channel.
Validators must keep the following state for processing channel Operations:
channels: dict[ChannelId, ChannelState]
class ChannelState:
tip: hash
accredited_keys: list[Ed25519PublicKey]
CHANNEL_INSCRIBE
Write a message to a channel with the message data being permanently stored on the Logos Blockchain.
Payload
class Inscribe:
channel: ChannelID # Channel being written to
inscription : bytes # Message to be written on the blockchain
parent: hash # Previous message in the channel
signer: Ed25519PublicKey # Identity of message sender
Proof
Ed25519Signature
Execution Gas
Channel Inscribe Operations have a fixed Execution Gas cost of EXECUTION_CHANNEL_INSCRIBE_GAS. See [Analysis] Gas Cost Determination for the Execution Gas values.
Validation
Given
txhash: zkhash
msg: Inscribe
sig: Ed25519Signature
channels: dict[ChannelID, ChannelState]
Validate
# Ensure the msg signer signature
assert Ed25519_verify(msg.signer, txhash, sig)
if msg.channel in channels:
chan = channels[msg.channel]
# Ensure signer is authorized to write to the channel
assert msg.signer is in chan.accredited_keys
# Ensure message is continuing the channel sequence
assert msg.parent == chan.tip
else:
# Channel will be created automatically upon execution
# Ensure that this message is the genesis message (parent==ZERO)
assert msg.parent == ZERO
Execution
Given
msg: Inscribe
sig: Ed25519Signature
channels: dict[ChannelId, ChannelState]
Execute
- If the channel does not exist, create it just-in-time.
if msg.channel not in channels: channels[msg.channel] = ChannelState( tip=ZERO accredited_keys=[msg.signer] ) - Update the channel tip.
chan = channels[msg.channel] chan.tip = hash(encode(msg))
Example
# Build the inscription
greeting = Inscription(
channel=CHANNEL_EARTH,
inscription=b"Live long and prosper",
parent=ZERO
signer=spock_pk
)
# Wrap it in a transaction
tx = MantleTx(
ops=[Op(opcode=INSCRIBE, payload=encode(greeting))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[<spocks_note_id>], outputs=[<change_note>]),
)
# Sign the transaction
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[Ed25519_sign(mantle_txhash(tx), spock_sk)]
ledger_tx_proof=tx.ledger_tx.prove(spock_sk)
)
# Send the transaction to the mempool
mempool.push(signed_tx)
CHANNEL_BLOB
Write a message to a channel where the message data is stored temporarily in DA Network. Data stored in DA Network will eventually expire but its commitment (BlobID) remains permanently on chain. Anyone with access to the original data can confirm that it matches this commitment.
Payload
class Blob:
channel: ChannelID # Channel we are writing this message to
current_session: SessionNumber # Session during which dispersal happened
blob: BlobID # Blob commitment
blob_size: int # Size of blob before encoding in bytes
da_storage_gas_price: int # 8 bytes
parent: hash # Previous message written to the channel
signer: Ed25519PublicKey # Identity of the message sender
Proof
Ed25519Signature
Execution Gas
The Execution Gas consumed by a Blob Operation is proportional to the size of the samples verified by the nodes. The bigger the sample,s the harder it is to verify it. The size of one sample is:
NUMBER_OF_DA_COLUMNS = 1024 # before RS encoding
ELEMENT_SIZE = 31 # in bytes
SAMPLE_SIZE = blob_size/(NUMBER_OF_DA_COLUMNS * ELEMENT_SIZE)
Channel Blob Operations have an Execution Gas cost proportional to the blob size:
EXECUTION_CHANNEL_BLOB_BASE_GAS
+ EXECUTION_CHANNEL_BLOB_SIZED_GAS * SAMPLE_SIZE
See [Analysis] Gas Cost Determination for the Execution Gas values.
DA Storage Gas
Channel Blob Operations have a DA Storage Gas consumption proportional to Blob size:
CHANNEL_BLOB_DA_STORAGE_GAS = blob_size * da_storage_gas_price
Validation
Validators will perform DA sampling to ensure availability. From these samples, we can determine the Blob size and check that it matches what is written in the Blob payload.
Given
txhash: zkhash
msg: Blob
sig: Ed25519Signature
block_slot: int
channels: dict[ChannelID, ChannelState]
Validate
# Verify the msg signature
assert Ed25519_verify(msg.signer, txhash, sig)
if msg.channel in channels:
chan = channels[msg.channel]
# Ensure signer is authorized to write to the channel
assert msg.signer is in chan.accredited_keys
# Ensure message is continuing the channel sequence
assert msg.parent == chan.tip
else:
# Channel will be created automatically upon execution
# Ensure that this message is the Genesis message
assert msg.parent == ZERO
if DA Network.should_validate_block_availability(block_slot):
# Validate Blobs that are still held in DA
assert DA Network.validate_availability(msg.blob)
# Derive Blob size from DA sample
actual_blob_size = DA Network.derive_blob_size(msg.blob)
assert msg.blob_size == actual_blob_size
Execution
Given
msg: Blob
sig: Ed25519Signature
channels: dict[ChannelId, ChannelState]
Execute
# If the channel does not exist, create it JIT
if msg.channel not in channels:
channels[msg.channel] = ChannelState(
tip=ZERO
accredited_keys=[msg.signer]
)
chan = channels[msg.channel]
chan.tip = hash(encode(msg))
Example
Suppose a sequencer for Rollup A wants to post a Rollup update. They would first build the Blob payload:
# Given a rollup update and the previous txhash
rollup_update: bytes = encode([tx1, tx2, tx3])
last_channel_msg_hash: hash
# The sequencer encodes the rollup update and builds the blob payload
blob_id, blob_size = DA Network.upload_blob(rollup_update)
msg = Blob(
channel=ROLLUP_A,
current_session=current_session,
blob=blob_id,
blob_size=blob_size,
da_storage_gas_price=10,
parent=last_channel_msg_hash,
signer=sequencer_pk,
)
tx = MantleTx(
ops=[Op(opcode=BLOB, payload=encode(msg))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[sequencer_funds], outputs=[<change_note>])
)
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[sequencer_sk.sign(mantle_txhash(tx))]
ledger_tx_proof=[tx.ledger_tx.prove(sequencer_sk)]
)
The Signed Mantle Transaction is then sent to DA nodes for dispersal and added to the mempool for inclusion in a block (see DA Network Dispersal ).
CHANNEL_SET_KEYS
Overwrite the list of accredited keys to post Blobs to a channel
Payload
class ChannelSetKeys:
channel: ChannelID
keys: list[Ed25519PublicKey]
Proof
Ed25519Signature # signature from `administrator` over the Mantle tx hash.
Execution Gas
Channel Set Keys Operations have a fixed Execution Gas cost of EXECUTION_CHANNEL_SET_KEYS. See [Analysis] Gas Cost Determination for the Execution Gas values.
Validation
Given
txhash: zkhash
setkeys: ChannelSetKeys
sig: Ed25519Signature
channels: dict[ChannelID, ChannelState]
Validate
# Ensure at least one key
assert len(setkeys.keys) > 0
if setkeys.channel in channels:
chan = channels[setkeys.channel]
admin_pk = chan.accredited_keys[0]
assert Ed25519_verify(txhash, admin_pk, sig)
Execution
Given
setkeys: ChannelSetKeys
channels: dict[ChannelID, ChannelState]
Execute
# Create the channel if it does not exist
if setkeys.channel not in channels:
channels[setkeys.channel] = ChannelState(
tip=CHANNEL_GENESIS,
accredited_keys=[],
)
# Update the set of accredited keys
channels[setkeys.channel].accredited_keys = setkeys.keys
Example
Suppose the administrator of Rollup A wants to add a key to the list of accredited keys:
# Given a key to add
sequencer_pk: Ed25519PublicKey
# The administrator encodes the update and builds the payload
setkeys = ChannelSetKeys(
channel=ROLLUP_A,
keys=[admin_pk, sequencer_pk],
)
tx = MantleTx(
ops=[Op(opcode=CHANNEL_SET_KEYS, payload=encode(setkeys))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[admin_funds], outputs=[<change note>])
)
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[Ed25519_sign(mantle_txhash(tx), admin_sk)]
ledger_tx_proof=tx.ledger_tx.prove(admin_sk),
)
Service Declaration Protocol (SDP) Operations
These Operations implement the Service Declaration Protocol.
Validators must keep the following state when implementing SDP Operations:
locked_notes: dict[NoteID, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
class LockedNote:
declarations: set[DeclarationID]
locked_until: BlockNumber
Common SDP Structures
class ServiceType(Enum):
BN="BN" # Blend Network
DA="DA" # Data Availability
class Locator(str):
def validate(self):
assert len(self) <= 329
assert validate_multiaddr(self)
class MinStake:
stake_threshold: int # stake value
timestamp: int # block number
class ServiceParameters:
lock_period: int # number of blocks
inactivity_period: int # number of blocks
retention_period: int # number of blocks
timestamp: int # block number
class DeclarationInfo:
service: ServiceType
provider_id: Ed25519PublicKey
zk_id: ZkPublicKey
locators: list[Locator]
created: BlockNumber
active: BlockNumber
withdrawn: BlockNumber
# SDP ops updating a declaration must use monotonically increasing nonces
nonce: int
SDP_DECLARE
The service registration follows the definition given in Service Declaration Protocol - Declaration Message:
Payload
class DeclarationMessage:
service_type: ServiceType
locators: list[Locator]
provider_id: Ed25519PublicKey
zk_id: ZkPublicKey
class Declaration
msg: DeclarationMessage
locked_note_id: NoteId
Locked notes are introduced in Locked notes and serve as Service collaterals. They cannot be spent before the owner withdraw its participation from the declared service(s).
Proof
class DeclarationProof:
zk_sig: ZkSignature # signature proving ownership over
# locked note and zk_id
provider_sig: Ed25519Signature # signature proving ownership of provider key
see: Zero Knowledge Signature Scheme (ZkSignature).
Execution Gas
SDP Declare Operations have a fixed Execution Gas cost of EXECUTION_SDP_DECLARE_GAS. See [Analysis] Gas Cost Determination for the Execution Gas values.
Validation
Given
txhash: zkhash # the txhash of the transaction we are validating
declaration: Declaration # the declaration we are validating
proof: DeclarationProof
min_stake: MinStake # the (global) minimum stake setting
ledger: Ledger # the set of unspent notes
locked_notes: dict[NoteId, LockedNote]
declarations: dict[NoteId, DeclarationInfo]
Validate
The declaration is verified according to Service Declaration Protocol - Declare.
- Ensure ownership over the locked note, zk_id and provider_id.
assert ZkSignature_verify( txhash, proof.zk_sig, [note.public_key, declaration.zk_id] ) assert Ed25519_verify(txhash, proof.provider_sig, provider_id) - Ensure declaration does not already exist.
assert declaration_id(declaration.msg) not in declarations - Ensure it has no more than 8 locators.
assert len(declaration.msg.locators) <= 8 - Ensure locked note exists and value of locked note is sufficient for joining the service.
assert ledger.is_unspent(declaration.locked_note_id) note = ledger.get_note(declaration.locked_note_id) assert note.value >= min_stake.stake_threshold - Ensure the note has not already been locked for this service.
if declaration.locked_note in locked_notes: locked_note = locked_notes[declaration.locked_note] services = [declarations[declare_id] for declare_id in locked_note.declarations] assert declaration.msg.service_type not in services
Execution
Given
declaration: Declaration # the declaration we are executing
service_parameters: dict[ServiceType, ServiceParameters]
current_block_height: int
locked_notes : dict[NoteId, LockedNote]
Execute
- Create the locked note state if it doesn't already exist.
if declaration.locked_note not in locked_notes: locked_notes[declaration.locked_note_id] = \ LockedNote(declarations=set(), locked_until=0) locked_note = locked_notes[declaration.locked_note_id] - Update the locked notes timeout using this services lock period.
lock_period = service_parameters[declaration.msg.service_type].lock_period service_lock = current_block_height + lock_period locked_note.locked_until = max(service_lock, locked_note.locked_until) - Add this declaration to the locked note.
declare_id = declaration_id(declaration.msg) locked_note.declarations.add(declare_id) - Store the declaration as explained in Service Declaration Protocol - Declaration Storage.
declarations[declare_id] = DeclarationInfo( declaration.msg, created=current_block_height, active=current_block_height, withdrawn=0 )
Notice that locked notes cannot refresh their keys to update their slot secrets required for Proof of Leadership participation (see Proof of Leadership - Protection Against Adaptive Adversaries). It's recommended to refresh the note before locking it, which guarantees a key life of more than a year. After this period, the note cannot be used in PoL until its private key is refreshed (see leader key setup).
Example
# Assume there exists `note_to_lock` in the ledger:
note_to_lock=Note(
value=500,
public_key=alice_zk_pk_1
)
# Alice wishes to lock it to join the DA network
declaration=Declaration(
service_type=ServiceType.DA,
locators=["/ip4/203.0.113.10/tcp/4001/p2p"],
provider_id=alice_pk
zk_id=alice_zk_pk_2
locked_note_id=note_to_lock.id()
)
tx = MantleTx(
ops=[Op(opcode=SDP_DECLARE, payload=encode(declaration))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[fee_note_id], outputs=[]),
)
txhash = mantle_txhash(tx)
declaration_proof = DeclarationProof(
# proof of ownership of the staked note and zk_id
zk_sig=ZkSignature([alice_zk_sk_1, alice_zk_sk_2], txhash),
# proof of ownership of the provider id
provider_sig=Ed25519Signature(alice_sk, txhash),
)
SignedMantleTx(
tx=tx,
ledger_tx_proof=LedgerTxProof,
op_proofs=[declaration_proof],
ledger_proof=prove_ledger_tx(tx.ledger_tx, alice_zk_sk_1),
)
SDP_WITHDRAW
The service withdrawal follows the definition given in Service Declaration Protocol - Withdraw Message.
Payload
class WithdrawMsg:
declaration: DeclarationID
nonce: int
class Withdraw:
msg: WithdrawMsg
locked_note_id: NoteId
Proof
A signature from the zk_id attached to the declaration is required for withdrawing from a service, (see Zero Knowledge Signature Scheme (ZkSignature)).
ZkSignature
Execution Gas
SDP Withdraw Operations have a fixed Execution Gas cost of EXECUTION_SDP_WITHDRAW_GAS. See [Analysis] Gas Cost Determination for the Execution Gas values.
Validation
Given
txhash: zkhash # Mantle transaction hash of the tx containing this operation
withdraw: Withdraw
signature: ZkSignature
block_height: int # block height of the current block
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
Validate
- Ensure that the locked note exists, is locked and bound to this declaration.
assert ledger.is_unspent(withdraw.locked_note_id) assert withdraw.locked_note_id in locked_notes locked_note = locked_notes[withdraw.locked_note_id] assert withdraw.msg.declaration in locked_note.declarations - Ensure that the locked note has expired.
assert locked_note.locked_until <= block_height - Validate SDP withdrawal according to Service Declaration Protocol - Withdraw.
- Ensure declaration exists.
assert withdraw.msg.declaration in declarations declare_info = declarations[withdraw.msg.declaration] - Ensure zk_id attached to this declaration authorized this Operation.
assert ZkSignature_verify(txhash, signature, [declare_info.zk_id]) - Ensure the declaration has not already been withdrawn.
assert declare_info.withdrawn == 0 - Ensure that the nonce is greater than the previous one.
assert withdraw.msg.nonce > declare_info.nonce
- Ensure declaration exists.
Execution
Given
withdraw: Withdraw
signature: ZkSignature
block_height: int # block height of the current block
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
Execute
Executes the withdrawal protocol Service Declaration Protocol - Withdraw.
- Update declaration info with nonce and withdrawn timestamp.
declare_info = declarations[withdraw.msg.declaration] declare_info.nonce = withdraw.msg.nonce declare_info.withdrawn = block_height - Remove this declaration from the locked note.
locked_note = locked_notes[withdraw.locked_note_id] locked_note.declarations.remove(withdraw.msg.declaration) - Remove the locked note if it is no longer bound to any declarations.
if len(locked_note.declarations) == 0: del locked_notes[withdraw.locked_note_id)
Example
withdraw=Withdraw(
declaration=alice_declaration_id,
nonce=1579532
)
note=Note(
value=500,
public_key=alice_pk,
)
tx = MantleTx(
ops=[Op(opcode=SDP_WITHDRAW, payload=encode(withdraw))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[<fee_note>], outputs=[]),
)
SignedMantleTx(
tx=tx,
ledger_tx_proof= tx.ledger_tx.prove(alice_sk),
# proof ownership of the withdrawn note
op_proofs=[ZkSignature_sign([alice_sk], mantle_txhash(tx))]
)
SDP_ACTIVE
The service active action follows the definition given in Service Declaration Protocol - Active Message.
Payload
class Active:
declaration: DeclarationID
nonce: int
metadata: bytes # a service-specific node activeness metadata
Proof
ZkSignature
Execution Gas
SDP Active Operations have a fixed Execution Gas cost of EXECUTION_SDP_ACTIVE_GAS. See [Analysis] Gas Cost Determination for the Execution Gas values.
Validation
Given
txhash: zkhash # Mantle transaction hash of the tx containing this operation
active: Active
signature: ZkSignature
declarations: dict[DeclarationId, DeclarationInfo]
Validate
assert active.declaration in declarations
declaration_info = declarations[active.declaration]
assert active.nonce > declaration_info.nonce
assert ZkSignature_verify(txhash, signature, declaration_info.zk_id)
Execution
Executes the active protocol Service Declaration Protocol - Active. The activation, i.e. setting the declaration.active, is handled by the service-specific logic.
Example
alice_decl = Declaration(
zk_id=alice_zk_pk,
...
)
active=Active(
declaration=alice_decl.id(),
nonce=1579532,
metadata=b"Look, I am still doing my job"
)
tx = MantleTx(
ops=[Op(opcode=SDP_ACTIVE, payload=encode(active))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[fee_note_id], outputs=[]),
)
txhash = mantle_txhash(tx)
SignedMantleTx(
tx=tx,
ledger_tx_proof=tx.ledger_tx.prove(fee_note_sk),
op_proofs=[ZkSignature_sign(txhash, alice_zk_sk)]
)
Reward Operations
LEADER_CLAIM
This Operation claims the leader's block reward anonymously.
Payload
class ClaimRequest:
rewards_root: zkhash # Merkle root used in the proof for voucher membership
voucher_nf: zkhash
Proof
The provider proves that they have won a proof of Leadership before the start of the current epoch, i.e., their reward voucher is indeed in the voucher set: Proof of Claim.
Execution gas
Leader Claim Operations have a fixed Execution Gas cost of EXECUTION_LEADER_CLAIM_GAS. See [Analysis] Gas Cost Determination for the Execution Gas values.
Validation
# Given
mantle_txhash: zkhash
claim : ClaimRequest
last_voucher_root: zkhash # The last root of the voucher Merkle tree
# at the start of the epoch
voucher_nullifier_set: set[zkhash]
proof: ProofOfClaim
# Validate
assert claim.voucher_nf not in voucher_nullifier_set
assert claim.rewards_root == last_voucher_root
validate_proof(claim, proof, mantle_txhash)
Execution
- Add claim.voucher_nf to the voucher_nullifier_set .
- Increase the balance of the Mantle Transaction by the leader reward amount according to Anonymous Leaders Reward Protocol - Leaders Reward.
- Reduce the leaders reward leaders_rewards value by the same amount (without ZK proof). Example
secret_voucher = 0xDEADBEAF;
reward_voucher = leader_claim_voucher(secret_voucher)
voucher_nullifier = leader_claim_nullifier(secret_voucher)
claim=ClaimRequest(
rewards_root=REWARDS_MERKLE_TREE.root(),
voucher_nf=voucher_nullifier,
)
tx = MantleTx(
ops=[Op(opcode=LEADER_CLAIM, payload=encode(claim))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[<fee_note>], outputs=[<change_note>]),
)
claim_proof = claim.prove(
secret_voucher,
REWARDS_MERKLE_TREE.path(leaf=reward_voucher),
mantle_txhash(tx)
)
SignedMantleTx(
tx=tx,
ledger_tx_proof=tx.ledger_tx.prove(fee_note_sk),
op_proofs=[claim_proof]
)
Mantle Ledger
Notes
Notes are composed of two fields representing their value and their owner:
class Note:
value: int # 8 bytes
public_key: ZkPublicKey # 32 bytes
Note Id
Any note can be uniquely identified by the Ledger Transaction that created it and its output number: (txhash, output_number). However, it is often useful to have a commitment to the note fields for use in ZK proofs (e.g., for PoL), so we include the note in the note identifier derivation.
def derive_note_id(txhash: zkhash, output_number: int, note: Note) -> NoteId:
return zkhash(
FiniteField(b"LOGOS_NOTE_ID_V1", byte_order="little", modulus= p)
txhash,
FiniteField(output_number, byte_order="little", modulus= p)
FiniteField(note.value, byte_order="little", modulus= p)
note.public_key
)
These note identifiers uniquely define notes in the system and cannot be chosen by the user. Nodes maintain the set of notes through a dictionary mapping the NoteId to the note.
Locked notes
Locked notes are special notes in Mantle that serve as collateral for Service Declarations. A note can become locked after executing a Declare Operation, preventing it from being spent until explicitly released through a Withdraw Operation. The system maintains a mapping of locked note IDs to their supporting declarations. Though locked, these notes remain in the Ledger and can still participate in Proof of Stake. When service providers withdraw all their declarations, the associated note(s) become unlocked and available for spending again.
Ledger Transactions
Transactions must prove the ownership of spent notes. In classical blockchains, this is done through a signature. To stay compatible with our architecture, the signature is done by a ZK proof (see Zero Knowledge Signature Scheme (ZkSignature)), proving the knowledge of the secret key associated with the public key.
Transactions allow complete transaction linkability and the public key spending the note is not hidden.
Structure
class LedgerTx:
inputs: list[NoteId] # the list of consumed note identifiers
outputs: list[Note]
Proof
A transaction proves the ownership of the consumed notes using a Zero Knowledge Signature Scheme (ZkSignature)
ZkSignature
Execution Gas
Ledger Transactions have a fixed Execution Gas cost of EXECUTION_LEDGER_TX_GAS. See [Analysis] Gas Cost Determination for the Execution Gas values.
Ledger Transaction Hash
def ledger_txhash(tx: LedgerTx) -> zkhash:
h = Hasher() # zk hash
h.update(FiniteField(b"LOGOS_LEDGER_TXHASH_V1",
byte_order="little", modulus= p))
for in_note_id in tx.inputs:
h.update(note_id)
h.update(FiniteField(b"INOUT_SEP", byte_order="little", modulus= p))
for out_note in tx.outputs:
h.update(FiniteField(out_note.value, byte_order="little", modulus= p))
h.update(out_note.public_key)
return h.digest()
Ledger Validation
Given
mantle_txhash: zkhash # zkhash of mantle tx containing this ledger tx
ledger_tx: LedgerTx
ledger_tx_proof: ZkSignature
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
Validate
- Ensure all inputs are unspent.
assert all(ledger.is_unspent(note_id) for note_id in ledger_tx.inputs) - Validate ledger proof to show ownership over input notes.
input_notes = [ledger[input_note_id] for input_note_id in ledger_tx.inputs] input_pks = [note.public_key for note in input_notes] assert ZkSignature_verify(mantle_txhash, ledger_tx_proof, input_pks) - Ensure inputs are not locked.
# Ensure inputs are not locked for note_id in ledger_tx.inputs: assert note_id not in locked_notes - Ensure outputs are valid.
for output in ledger_tx.outputs: assert output.value > 0 assert output.value < 2**64
Ledger Execution
Given
ledger_tx: LedgerTx
ledger_tx_proof: ZkSignature
ledger: Ledger
Execution
- Remove inputs from the ledger.
for note_id in ledger_tx.inputs: # updates the merkle tree to zero out the leaf for this entry # and adds that leaf index to the list of unused leaves ledger.remove(note_id) - Add outputs to the ledger.
txhash = ledger_txhash(ledger_tx) for (output_number, output_note) in enumerate(tx.outputs): output_note_id = derive_note_id(txhash, output_number, output_note) ledger.add(output_note_id)
Ledger Example
alice_note_id = ... # assume Alice holds a note worth 501 NMO
bob_note=Note(
value=500
public_key=bob_pk,
)
ledger_tx = LedgerTx(
inputs=[alice_note_id],
outputs=[bob_note],
)
Appendix
Gas Determination
From the [Analysis] Gas Cost Determination, we get the table below:
| Variable | Value |
|---|---|
| EXECUTION_LEDGER_TX_GAS | 9331 |
| EXECUTION_CHANNEL_INSCRIBE_GAS | 85 |
| EXECUTION_CHANNEL_BLOB_BASE_GAS | 111800 |
| EXECUTION_CHANNEL_BLOB_SIZED_GAS | 7400 |
| EXECUTION_CHANNEL_SET_KEYS | 85 |
| EXECUTION_SDP_DECLARE_GAS | 9417 |
| EXECUTION_SDP_WITHDRAW_GAS | 9331 |
| EXECUTION_SDP_ACTIVE_GAS | 9331 |
| EXECUTION_LEADER_CLAIM_GAS | 3291 |
Zero Knowledge Signature Scheme (ZkSignature)
A proof attesting that for the following public values:
class ZkSignaturePublic:
public_keys: list[ZkPublicKey] # public keys signing the message (len = 32)
msg: zkhash # zkhash of the message
The prover knows a witness:
class ZkSignatureWitness:
# The list of secret keys used to signed the message
secret_keys: list[ZkSecretKey] # (len = 32)
Such that the following constraints hold:
- The number of secret keys is equal to the number of public keys.
assert len(secret_keys) == len(public_keys) - Each public key is derived from the corresponding secret key.
assert all( notes[i].public_key == zkhash( FiniteField(b"LOGOS_KDF", byte_order="little", modulus= p), secret_keys[i]) for i in range(len(public_keys)) ) - The proof is bound to msg (its the mantle_tx_hash in case of transactions).
For implementation, the ZkSignature circuit will take a maximum of 32 public keys as inputs. To prove ownership of fewer keys, the remaining inputs will be padded with the public key corresponding to the secret key 0 and ignored during execution. The outputs have no size limit since they are included in the hashed message.
Proof of Claim
A proof attesting that given these public values:
class ProofOfClaimPublic:
voucher_root: zkhash # Merkle root of the reward_voucher maintained by everyone
voucher_nullifier: zkhash
mantle_tx_hash: zkhash # attached hash
The prover knows the following witness:
class ProofOfClaimWitness:
secret_voucher: zkhash
voucher_merkle_path: list[zkhash]
voucher_merkle_path_selectors: list[bool]
such that the following constraints hold:
- The reward voucher is derived from the secret voucher.
assert reward_voucher == zkhash( FiniteField(b"REWARD_VOUCHER", byte_order="little", modulus= p), secret_voucher) - There exists a valid Merkle path from the reward voucher as a leaf to the Merkle root.
assert voucher_root == path_root(leaf=reward_voucher, path=voucher_merkle_path, selectors=voucher_merkle_path_selectors) - The voucher nullifier is derived from the secret voucher correctly.
assert voucher_nullifier == zkhash( FiniteField(b"VOUCHER_NF", byte_order="little", modulus= p), secret_voucher) - The proof is bound to the mantle_tx_hash.
V1.0.0-MANTLE-TRANSACTION-ENCODING
| Field | Value |
|---|---|
| Name | Mantle Transaction Encoding |
| Slug | 215 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | David Rusu [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Owner: @David Rusu
Reviewers: @Thomas Lavaur @Giacomo Pasini @Gusto Bacvinka @Daniel Sanchez Quiros @lvaro Castro-Castilla
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-01-20 |
Introduction
This document specifies the canonical encoding of Mantle transactions and its sub-components. Transactions sent through the mempool and included in blocks use this encoding.
Overview
The transaction encoding is specified in ABNF form to remove any ambiguity and guarantee a canonical encoding. The high level encoding choices which were not immediately derivable from the Mantle specification are listed here:
- All multi-byte integers use little-endian encoding
- Any lists are length-prefixed with fixed width uints
- We derive number of proofs and type of proof from the Ops list parsed earlier
Specification
Signed Mantle Tx
SignedMantleTx = MantleTx OpsProofs LedgerTxProof
Mantle Tx
MantleTx = Ops LedgerTx ExecutionGasPrice StorageGasPrice
ExecutionGasPrice = UINT64
StorageGasPrice = UINT64
In future iterations, we will use this encoding to derive the mantle_txhash
Operations
Ops = OpCount *Op
OpCount = Byte
Op = Opcode OpPayload
Opcode = Byte
OpPayload = ChannelInscribe /
ChannelBlob /
ChannelSetKeys /
SDPDeclare /
SDPWithdraw /
SDPActive /
LeaderClaim
Channel Operations
ChannelInscribe = ChannelId Inscription Parent Signer
Inscription = UINT32 *BYTE
ChannelBlob = ChannelId Session BlobId BlobSize DaStorageGasPrice Parent Signer
Sesssion = UINT64
BlobId = Hash32
BlobSize = UINT64
DaStorageGasPrice = UINT64
ChannelSetKeys = ChannelId KeyCount *Signer
KeyCount = Byte
ChannelId = Hash32
Parent = Hash32
Signer = Ed25519PublicKey
SDP Operations
SDPDeclare = ServiceType LocatorCount *Locator ProviderId ZkId LockedNoteId
ServiceType = Byte ; 0 = BN, 1 = DA
LocatorCount = Byte ; Max 8
Locator = 2Byte *BYTE ; Max 329 bytes, multiaddr format
ProviderId = Ed25519PublicKey
ZkId = ZkPublicKey
LockedNoteId = NoteId
SDPWithdraw = DeclarationId Nonce LockedNoteId
DeclarationId = Hash32
Nonce = UINT64
SDPActive = DeclarationId Nonce Metadata
Metadata = UINT32 *BYTE ; Service-specific node activeness metadata
Leader operations
LeaderClaim = RewardsRoot VoucherNullifier
RewardsRoot = FieldElement ; Merkle root for voucher membership proof
VoucherNullifier = FieldElement
Ledger Transaction
LedgerTx = Inputs Outputs
Inputs = InputCount *NoteId
InputCount = Byte
Outputs = OutputCount *Note
OutputCount = Byte
Note = Value ZkPublicKey
Value = UINT64
NoteId = FieldElement
Proofs
Op Proofs
OpsProofs = *OpProof ; 1. Lenth must equal OpCount
; 2. OpProof variant is derived from the corresponding Op.
; That is, type(OpProofs[i]) == ProofFor(Op[i])
OpProof = Ed25519SigProof /
ZkSigProof /
ZkAndEd25519SigsProof /
ProofOfClaimProof
Ed25519SigProof = Ed25519Signature
ZkSigProof = ZkSignature
ZkAndEd25519SigsProof = ZkSignature Ed25519Signature
ProofOfClaimProof = Groth16
Ledger Transaction Proof
LedgerTxProof = ZkSignature
Common Structures
; Zero-knowledge signature
ZkSignature = Groth16
; Cryptographic primitives
Groth16 = 128BYTE ; pi_a (32) + pi_b (64) + pi_c (32)
ZkPublicKey = FieldElement
Ed25519PublicKey = 32BYTE
Ed25519Signature = 64BYTE
FieldElement = 32BYTE ; BN254 field element (little-endian)
Hash32 = 32BYTE
; Primitive types
UINT64 = 8BYTE ; 64-bit unsigned integer, little-endian
UINT32 = 4BYTE ; 32-bit unsigned integer, little-endian
Byte = OCTET
V1.0.0-BEDROCK-SERVICE-REWARD-DISTRIBUTION
| Field | Value |
|---|---|
| Name | Service Reward Distribution Protocol |
| Slug | 213 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Thomas Lavaur [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Owner: @Thomas Lavaur
Reviewers: @David Rusu @Mehmet @lvaro Castro-Castilla @Marcin Pawlowski @Frederico Teixeira
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-11-03 |
Introduction
Logos Blockchain relies on multiple services, including the Data Availability and Blend Network - each operated by independent validator sets. For sustainability and fairness, these services must compensate service validators based on their participation. Validators first declare their participation through Service Declaration Protocol. The Service Reward Distribution Protocol enables deterministic, efficient, and verifiable reward distribution to validators based on their activity within each service.
Each service defines a session, a fixed number of blocks during which its validator set remains unchanged. For every session, the service specifies:
- A validator activity rule that distinguishes between active and inactive validators.
- A reward formula for distributing the sessions rewards at the end of the session.
This document describes the protocol's logic for deterministically distributing rewards through Mantle Transactions for services.
Overview
The protocol unfolds over three key phases, aligned with validator sessions:
- Service Activity Tracking (Session N+1): Service validators submit signed activity messages to attest to their participation of session N through a Mantle Transaction, including an activity message (see Mantle - SDP_ACTIVE).
- Service Reward Derivation (End of Session N+1): Nodes compute each validators reward based on validated activity messages and the different service reward policies.
- Service Reward Distribution (Post-Session N+1): Rewards are distributed to validators marked as active for the service over several blocks. This is done through a single Mantle Transaction per block, potentially distributing for all services if the sessions coincide.
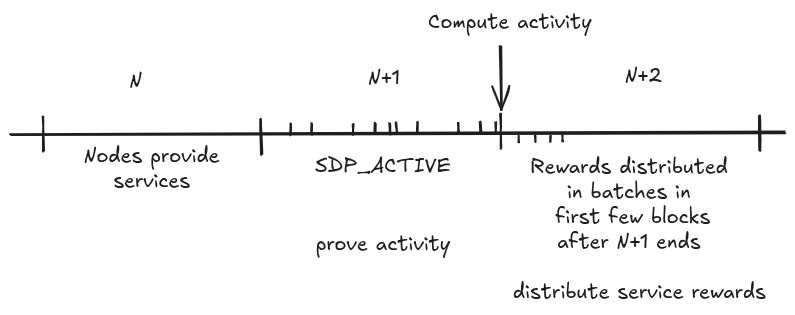
Core Properties:
- Service rewards are distributed to the zk_id from validator SDP declarations.
- Deterministic Validator Reward Schedule: A verifiable pseudo-random process ensures fair order of distribution and prevents manipulation.
- Minimal Block Overhead: Each block accommodates 1 reward transaction.
- Transparent Transfers: Service rewards are distributed using standard Mantle Transactions (but with a negative balance).
Protocol
Sessions
Each service defines its own session length (e.g., 10000 blocks), during which:
- The service validator set remains static.
- Activity criteria and reward policy are fixed.
Activity tracking
Throughout session N+1, the block proposers integrate Mantle Transactions containing SDP_ACTIVE Operations. These transactions originate from service validators and are used to derive their activity according to the service provided policy. The protocol does not prescribe a unique activity rule: each service defines what qualifies as valid participation, enabling flexibility across different services.
Each node maintains the activity state of service validators for the sessions. These activity records can be discarded after the reward distribution process ends. The distribution process is considered complete when:
- All active validators entitled to rewards for this session have received them.
- The last distributed reward is in a finalized block, ensuring rewards can always be computed in case of forks.
class ServiceActivities:
service: ServiceType
session: int
activities: dict[DeclarationId, float] # activity of each validator
funds: int # rewards for this service during the session
Service validators are economically incentivized to participate actively since only active validators will be rewarded. Moreover, by decoupling activity submission from reward calculation, the system remains robust to network latency.
This generalized mechanism accommodates a wide range of services without requiring specialized infrastructure. It enables services to evolve their own activity rules independently while preserving a shared framework for reward distribution.
Service Reward Calculation
At the end of session N+1, service rewards for the validator n for the session N are computed by the different services taking as input the rewards of the session:
Where are the total rewards of session N. The is determined by the service, which calculates how much each service receives based on fees burnt during session N and the blockchain's state. is stored as an array that maps each validator's zk_id to their allocated reward.
Service Reward Distribution
Starting immediately after session N+1, service rewards are distributed gradually. Each block includes one Mantle Transaction distributing the rewards of every service up to 4 validators per service. The Mantle Transaction only contains one Ledger Transaction without Operations, creating new notes with their value representing the correct amount of rewards. The Ledger Transaction of this Mantle Transaction should be executed without checking that the transaction is balanced, other validations are checked, e.g. output note values are positive and smaller than the maximum allowed value.
- The reward transaction must be the first Mantle Transaction included by the leader in the block. This enables nodes to verify service rewards distribution easily.
- The validators receiving the rewards must be chosen deterministically and uniformly randomly according to Deterministic Validator Reward Schedule among the validators marked as active by the related service (with a pending reward greater than 0).
- The reward transaction must:
- Transfer the correct reward amount according to Service Reward Calculation.
- Be sent to the public key zk_id of the validator registered during declaration of the service.
To ensure that all active validators of a service can be rewarded within a single session, a maximum threshold is imposed on the number of validators per service. For example, if a session lasts only 10,000 blocks, the number of active validators must not exceed 40,000 per service. This constraint guarantees that no reward distribution needs to span multiple sessions. Consequently, the number of reward transactions per block remains capped at one reward transaction distributing the funds for all Logos Blockchain services.
Details
Deterministic Validator Reward Schedule
The validator reward schedule is derived deterministically. The validator set of the session being rewarded is ordered by the declaration IDs. The selection takes as input the service being rewarded, the remaining number of validators to be rewarded and Cryptarchia randomness of the epoch taken at the start of the session.
def select_validators_to_rewards(service, session, cryptarchia_epoch_nonce, remaining_validators):
"""
service: ServiceType # the service that is being rewarded
session: int # the session that is being rewarded
cryptarchia_epoch_nonce: bytes # the epoch nonce at the start of the session
"""
rewarded_this_block = []
for i in range(4):
n = len(remaining_validators)
validator_idx = hash(b"SERVICE_REWARD_V1", service, session, cryptarchia_epoch_nonce, n) % n
rewarded_this_block += remaining_validators[validator_idx]
del remaining_validators[validator_idx]
return rewarded_this_block
This approach ensures fairness and prevents favoritism.
- nit: this is now a special field in the block structure
V1.1.0-ANALYSIS-GAS-COST-DETERMINATION
| Field | Value |
|---|---|
| Name | [Analysis] Gas Cost Determination |
| Slug | 219 |
| Status | deprecated |
| Type | RFC |
| Category | Informational |
| Editor | Thomas Lavaur [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Owner: @Thomas Lavaur
Reviewers: @Mehmet @Daniel Sanchez Quiros @lvaro Castro-Castilla @David Rusu
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-09-25 |
| 1.1.0 | ? | 2025-10-07 |
Introduction
In Mantle, each Mantle Transaction contains one Ledger Transaction and one or more Operations. These components consume gas, measured through fixed gas units that reflect their execution or storage impact. Logos Blockchain introduces three independent gas markets:
- Execution Gas: measuring computational workload.
- Permanent Storage Gas: measuring cost of fully replicated storage.
- Ephemeral DA Storage Gas: measuring sharded storage in the DA layer.
Gas constants are carefully calibrated to reflect the computational and storage requirements of different operations on the Logos Blockchain. By standardizing gas measurements, the system can accurately charge fees proportional to resource usage, preventing network abuse and incentivizing efficient transaction design.
Overview
We conducted a comprehensive analysis of execution requirements for each Operation type in Mantle Transactions and of Ledger Transaction. This detailed examination allowed us to determine precise gas amounts for each Operation based on the actual computational resources consumed.
The gas constants we established are strategically divided between permanent storage, ephemeral data store on the DA layer and execution components, directly proportional to their respective resource utilization within Mantle Transactions. This separation ensures that gas costs accurately reflect the true computational burden of different operations. Moreover, gas can also be adjusted arbitrarily to incentivize or disincentivize the usage of certain Operations compared to others.
Our methodology involved measuring execution complexity and defining how gas is determined for each Gas Market. This is critical for proper network operation as it directly impacts transaction prioritization and network economics.
Permanent Storage Gas
Permanent Storage is paid directly for the entire signed Mantle Transaction. The Permanent Storage Gas price is included in the Mantle Transaction structure and is used to determine the Permanent Storage fee. 1 Permanent Storage Gas corresponds to 1 byte.
permanent_storage_fee = len(encode(tx_signed)) * permanent_storage_gas_price
Ephemeral Storage Gas
Ephemeral storage is a unique market exclusive to Blobs. For this reason, the DA Storage Gas price is included in the Blob Operation structure and is used to determine the DA Storage fee. 1 DA Storage Gas corresponds to 1 byte.
da_storage_fee = blob_size * DA_storage_gas_price
Execution Gas
Execution is a third general market that represents how costly an operation or a Ledger Transaction is to execute. This cost can be fixed or variable based on the content of the Operation / Transaction. The Execution Gas price is contained in the Mantle Transaction structure and each Operation or Ledger Transaction define its execution gas amount. 1 Execution Gas corresponds to 1,000 CPU cycles.
execution_fee = (tx.ops.get_summed_gas() + tx.ledger_tx.get_gas())
* execution_gas_price
The gas derivation of each Operation and of a Ledger Transaction are:
LEDGER_TRANSACTION_GAS = 590
CHANNEL_INSCRIBE_GAS = 56
CHANNEL_BLOB_GAS = 6356 + 1600 * sample_size
CHANNEL_SET_KEYS = 56
SDP_DECLARE_GAS = 646
SDP_WITHDRAW_GAS = 590
SDP_ACTIVE_GAS = 590
LEADER_CLAIM_GAS = 580
and come from our implementation observations as described in Gas determination from measures. As a reminder, sample_size = blob_size / (1024x31).To get these numbers, we based our calculations on the following measures:
| Operation | Number of CPU cycles |
|---|---|
| ZkSignature batch verification | 3,900,000 + number_of_proof x 590,000 |
| Proof of Claim batch verification | 2,640,000 + number_of_proof x 580,000 |
| Blob sampling batch verification | 5,000,000 + number_of_sample x (315,000 + 80,000 x sample_size ) |
| Eddsa25519 signature verification | 56,000 |
Comparison, list searching, hashes and operation in small fields are neglected. We also supposed that the initialization cost for batch verification is paid by everyone and deduced from the block directly. The user then pay only for the part that is proportional to the number of proofs.
Ledger Transaction
The Execution Gas of the Ledger Transaction compensates for the verification of the ZkSignature proof and the validation of the overall Mantle Transaction balance. This fundamental gas cost ensures proper cryptographic verification and data integrity of both the Ledger Transaction and the Mantle Transaction. It covers the cost of computing the Mantle Transaction hash.
Execution: ~590k CPU cycles.
- Verification of the ZK signature: 590,000 cycles.
- Verification of the balance: negligible.
- Computation of the Mantle Transaction hash: negligible.
Input Gas
Input gas covers the computational cost of verifying that one Note Id exists in the Ledger and is not locked. Additionally, it compensates for the removal of one Note Id from the Ledger.
Execution: negligible.
- Verification that the note is in the ledger: negligible.
- Verification that the note is unlocked: negligible.
- Removing of the note from the ledger: negligible.
Output Gas
Output gas accounts for the computational resources required to verify that one output is well-formed and for its inclusion in the Ledger.
Execution: negligible.
- Verification of the output validity: negligible.
- Insertion of the note in the ledger: negligible.
Operations
Channel Inscription
The validation process includes verifying an Eddsa25519 signature, confirming that the signer is authorized for the specified channel, and checking the chaining sequence of the channel. The execution encompasses creating channel records (if not previously used) and updating the tip of the channel.
Execution: ~56k CPU cycles.
- Verification of the Ed25519 signature: 56,000 cycles.
- Verification of the signer authorization (signer in the list): negligible.
- Verification of channel sequencing (equality check): negligible
- Update the tip of the channel: negligible
Channel Blobs
The validation encompasses several critical security checks: verifying an Eddsa25519 signature, confirming the signer's authorization for the specified channel, and validating the chaining sequence of the channel. The execution process involves creating channel records (if not previously established), updating the channel tip, and executing the sampling operations necessary to verify data availability.
Execution: ~6.356M + sample_size x 1.6M CPU cycles
- Verification of the Ed25519 Signature: 56,000 cycles.
- Verification of the signer authorization (signer in the list): negligible.
- Verification of channel sequencing (equality check): negligible.
- Update the tip of the channel: negligible.
- Verification of twenty sample : 20 x (315,000 + 80,000 x sample_size ) cycles.
Channel Set Keys
This gas amount covers the verification of the Eddsa25519 signature and ensures the operation is well-formed. This represents the computational cost associated with processing key management operations.
- Execution: ~56k CPU cycles.
- Verification of the Ed25519 signature: 56,000 cycles.
- Modification of the key list of the channel: negligible.
SDP Declaration
This gas covers multiple verification processes: confirming ownership of the locked note through ZkSignature verification, validating the zk_id via a second ZkSignature, and establishing ownership of the provider_id through an Eddsa25519 signature. It also includes verification of the declaration format, confirmation of note existence, validation that the note is not already locked, and verification of its amount. Additionally, it accounts for the computational costs associated with the note locking mechanism and declaration management.
Execution: ~ 646k CPU cycles.
- Verification of the Ed25519 signature: 56,000 cycles.
- Verification of the ZK signature: 590,000 cycles.
- Verification that the declaration doesnt already exist: negligible.
- Verification of locator length: negligible.
- Verification of locked note existence: negligible.
- Verification of locked note value: negligible.
- Verification that the note isnt already locked for the service: negligible.
- Locking the note: negligible.
SDP Withdraw
This gas covers a verification process that includes: confirming ownership of the zk_id through ZkSignature verification, validating the existence of the locked note, verifying that the note has exceeded its lock period, and confirming that the declaration exists and has not been previously withdrawn. The validation process also ensures that the withdrawal message's nonce is greater than any previous nonce, preventing replay attacks. During execution, the system updates the declaration's status to withdrawn, removes the declaration from the locked note's associated declarations, andif the note has no remaining declarationsremoves it from the locked notes dictionary.
Execution: ~ 590k CPU cycles.
- Verification that the note exists, is locked and bound to the declaration: negligible.
- Verification that the note can be unlocked: negligible.
- Verification that the declaration exist: negligible.
- Verification of the ZK signature: 590,000 cycles.
- Verification that the declaration wasnt already withdrawn: negligible.
- Verification of nonce incrementation: negligible.
- Update declaration: negligible.
- Remove declaration from locked note: negligible.
- Unlock the note if not linked to any declaration: negligible.
SDP Activation
This gas funds the verification of the zk_id signature through the ZkSignature verification process, validates the existence of the declaration in the system, and ensures that the activation message's nonce is greater than any previous nonce to prevent replay attacks. The validation includes confirming that the declaration ID is present in the declarations dictionary and that the signature corresponds to the declaration's registered zk_id public key.
- Execution: ~590k CPU cycles.
- Verification that the declaration exist: negligible.
- Verification of nonce incrementation: negligible.
- Verification of the ZK signature: 590,000 cycles.
- Evaluation of the activity depends on the service and is neglected here
Leader Claims
This gas covers the verification of reward voucher ownership through a Proof of Claim, confirmation that the voucher nullifier is not already present in the nullifier set, and validation that the rewards root exists in the list of recent voucher Merkle tree roots. The execution process involves adding the voucher nullifier to the nullifier set and increasing the Ledger Transaction balance by the designated leader reward amount.
Execution: ~580k CPU cycles.
- Verification that the voucher nullifier isnt already in the set: negligible.
- Verification that the rewards root is one of the root of the reward tree of the last blocks: negligible.
- Verification of the proof of claim: 580,000 cycles.
- Insertion of the nullifier in the voucher nullifier set: negligible.
Annex
Gas determination from measures
The material used for the benchmarks is the following:
- CPU : 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM : 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS : Ubuntu 22.04.5 LTS
- Kernel : 6.8.0-59-generic
Proof of Claim
We found the best linear curve approximating these measures (over 100 iterations):
| Number of Batches | Number of CPU cycles |
|---|---|
| 1 | 2,502,356 |
| 2 | 3,662,746 |
| 3 | 4,216,022 |
| 4 | 4,800,445 |
| 5 | 5,324,304 |
| 6 | 6,091,442 |
| 7 | 6,618,446 |
| 8 | 7,165,629 |
| 9 | 7,692,432 |
| 10 | 8,421,783 |
| 20 | 14,257,450 |
| 30 | 20,131,137 |
| 40 | 25,782,519 |
| 50 | 31,595,523 |
| 60 | 37,286,419 |
| Number of Batches | Number of CPU cycles |
|---|---|
| 70 | 42,901,298 |
| 80 | 48,309,912 |
| 90 | 54,191,072 |
| 100 | 61,082,050 |
| 110 | 66,927,817 |
| 120 | 73,758,494 |
| 130 | 78,816,789 |
| 140 | 84,801,250 |
| 150 | 91,693,824 |
| 160 | 94,248,613 |
| 170 | 99,430,138 |
| 180 | 105,607,812 |
| 190 | 112,379,089 |
| 200 | 116,599,001 |
We got the curve that we decided to approximate to :
ZkSignature
We found the best linear curve approximating these measures (over 1000 iterations):
| Number of Batches | Number of CPU cycles |
|---|---|
| 1 | 4,126,177 |
| 2 | 4,904,084 |
| 3 | 5,538,085 |
| 4 | 6,061,800 |
| 5 | 6,957,754 |
| 6 | 7,421,851 |
| 7 | 8,237,485 |
| 8 | 8,621,986 |
| 9 | 9,115,091 |
| 10 | 10,186,171 |
| 20 | 15,777,800 |
| 30 | 21,456,771 |
| 40 | 27,441,722 |
| 50 | 33,430,729 |
| 60 | 38,986,389 |
| Number of Batches | Number of CPU cycles |
|---|---|
| 70 | 44,708,450 |
| 80 | 50,894,373 |
| 90 | 56,534,430 |
| 100 | 63,606,624 |
| 110 | 70,036,347 |
| 120 | 75,612,096 |
| 130 | 82,048,010 |
| 140 | 87,080,407 |
| 150 | 91,473,391 |
| 160 | 97,862,623 |
| 170 | 104,019,852 |
| 180 | 111,498,103 |
| 190 | 114,814,226 |
| 200 | 119,739,702 |
We got the curve that we decided to approximate to :
Blob Sampling
We measure different scenarios. For each size of sample, we derived a linear equation of the form with the number of samples to verify.
32 KiB blobs (2 sample elements):
| Batch Size | CPU Cycles |
|---|---|
| 10 | 8,529,507 |
| 20 | 13,818,649 |
| 30 | 18,985,695 |
| 40 | 25,089,415 |
| 50 | 30,648,329 |
| 60 | 35,502,866 |
| 70 | 38,892,864 |
| 80 | 43,399,433 |
| 90 | 47,671,839 |
| 100 | 52,314,907 |
| Batch Size | CPU Cycles |
|---|---|
| 110 | 58,208,545 |
| 120 | 62,786,791 |
| 130 | 67,786,161 |
| 140 | 72,179,484 |
| 150 | 76,278,407 |
| 160 | 80,940,080 |
| 170 | 86,766,298 |
| 180 | 90,567,870 |
| 190 | 93,692,283 |
| 200 | 98,343,499 |
The best fitting curve is that we approximated by :
64 KiB blobs (3 sample elements)
| Batch Size | CPU Cycles |
|---|---|
| 10 | 9,239,126 |
| 20 | 15,131,351 |
| 30 | 20,961,330 |
| 40 | 27,594,193 |
| 50 | 32,845,900 |
| 60 | 37,949,973 |
| 70 | 43,022,847 |
| 80 | 48,129,313 |
| 90 | 53,190,914 |
| 100 | 58,218,004 |
| Batch Size | CPU Cycles |
|---|---|
| 110 | 63,390,371 |
| 120 | 68,451,282 |
| 130 | 75,767,779 |
| 140 | 80,669,658 |
| 150 | 85,627,442 |
| 160 | 90,819,416 |
| 170 | 95,532,120 |
| 180 | 100,443,619 |
| 190 | 105,375,207 |
| 200 | 110,394,398 |
The best fitting curve is that we approximated by :
128 KiB blobs (5 sample elements)
| Batch Size | CPU Cycles |
|---|---|
| 10 | 10,964,607 |
| 20 | 20,686,848 |
| 30 | 28,941,578 |
| 40 | 38,295,293 |
| 50 | 45,960,757 |
| 60 | 53,745,474 |
| 70 | 61,650,124 |
| 80 | 69,167,994 |
| 90 | 76,875,286 |
| 100 | 84,404,885 |
| Batch Size | CPU Cycles |
|---|---|
| 110 | 92,380,948 |
| 120 | 99,812,683 |
| 130 | 109,947,874 |
| 140 | 117,477,348 |
| 150 | 124,924,958 |
| 160 | 132,430,262 |
| 170 | 141,098,267 |
| 180 | 148,117,833 |
| 190 | 157,570,978 |
| 200 | 166,188,496 |
The best fitting curve is that we approximated by :
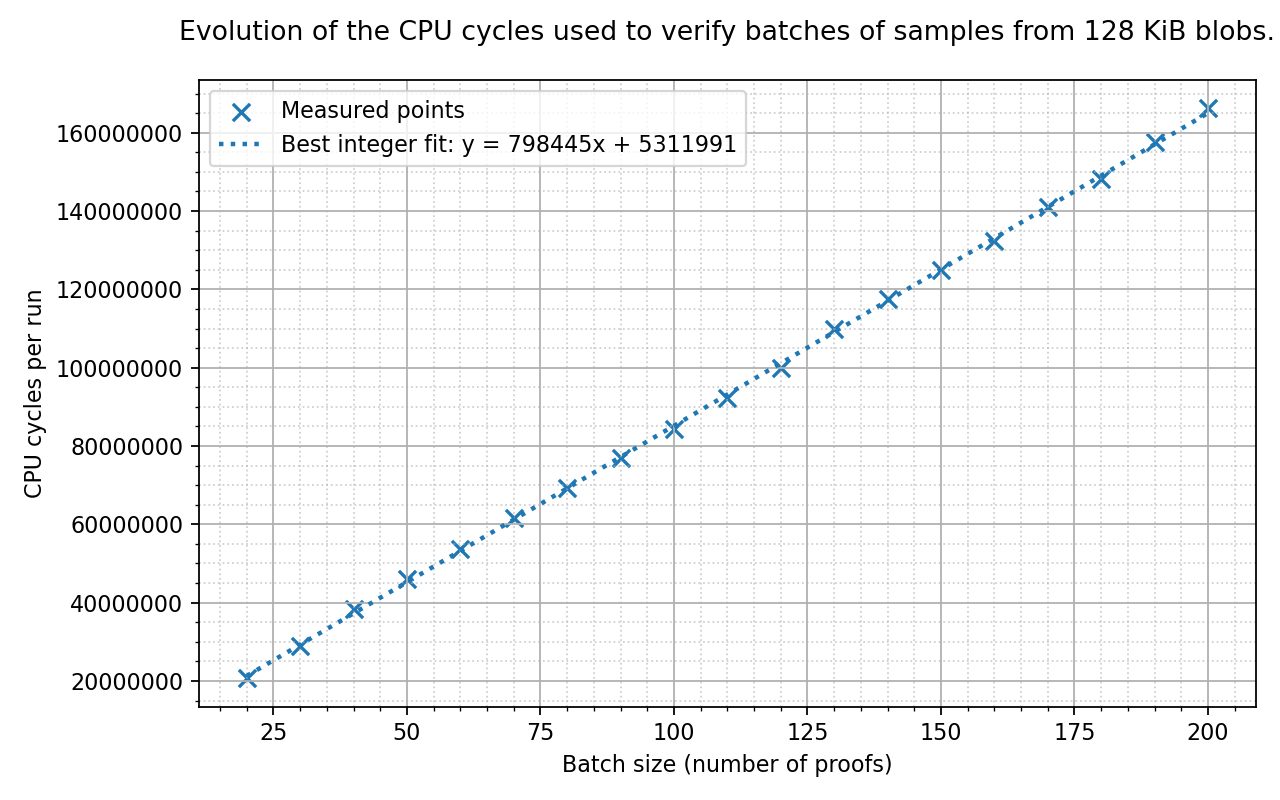
256 KiB blobs (10 sample elements)
| Batch Size | CPU Cycles |
|---|---|
| 10 | 14,785,938 |
| 20 | 26,318,392 |
| 30 | 38,260,143 |
| 40 | 50,502,225 |
| 50 | 61,301,092 |
| 60 | 72,028,954 |
| 70 | 82,362,773 |
| 80 | 93,485,923 |
| 90 | 104,042,321 |
| 100 | 114,602,636 |
| Batch Size | CPU Cycles |
|---|---|
| 110 | 125,615,987 |
| 120 | 136,706,128 |
| 130 | 148,619,389 |
| 140 | 158,348,399 |
| 150 | 168,918,545 |
| 160 | 179,787,233 |
| 170 | 192,484,193 |
| 180 | 203,995,906 |
| 190 | 212,814,837 |
| 200 | 223,817,125 |
The best fitting curve is that we approximated by :
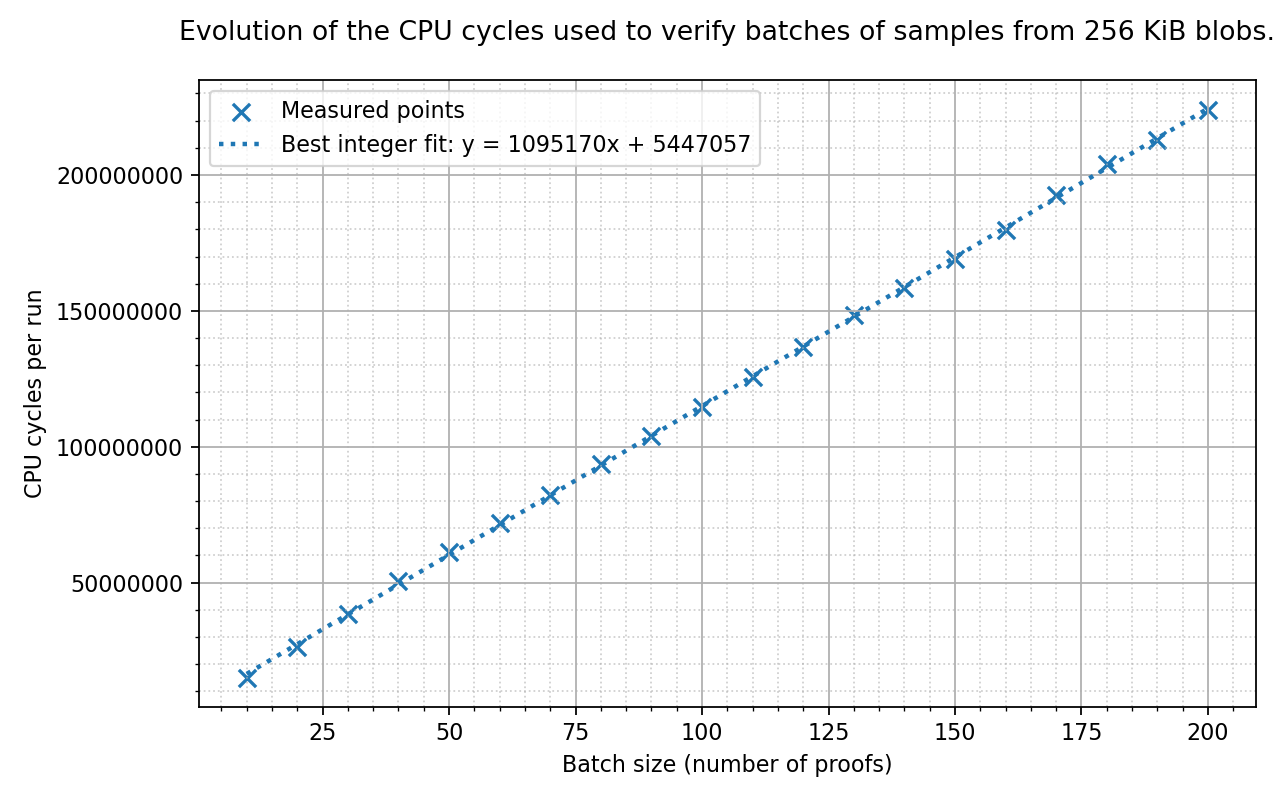
512 KiB blobs (17 sample elements)
| Batch Size | CPU Cycles |
|---|---|
| 10 | 19,822,834 |
| 20 | 36,328,022 |
| 30 | 52,876,723 |
| 40 | 70,217,070 |
| 50 | 86,017,119 |
| 60 | 101,724,856 |
| 70 | 117,470,096 |
| 80 | 133,111,662 |
| 90 | 149,254,798 |
| 100 | 164,761,143 |
| Batch Size | CPU Cycles |
|---|---|
| 110 | 180,287,296 |
| 120 | 195,906,310 |
| 130 | 213,611,965 |
| 140 | 229,460,354 |
| 150 | 245,987,045 |
| 160 | 261,140,370 |
| 170 | 276,891,655 |
| 180 | 293,255,638 |
| 190 | 309,324,730 |
| 200 | 324,752,182 |
The best fitting curve is that we approximated by :
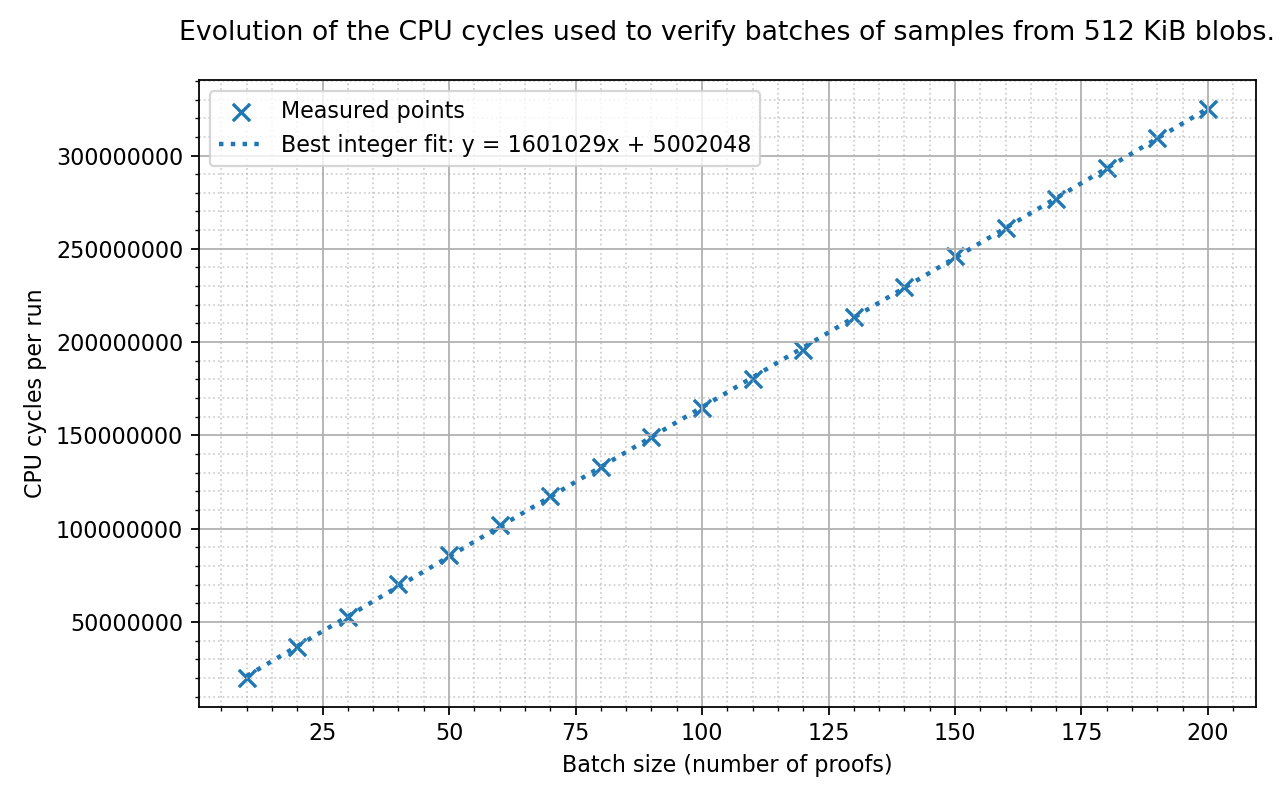
768 KiB blobs (25 sample elements)
| Batch Size | CPU Cycles |
|---|---|
| 10 | 24,802,125 |
| 20 | 46,362,059 |
| 30 | 67,781,105 |
| 40 | 90,334,595 |
| 50 | 111,300,953 |
| 60 | 131,842,378 |
| 70 | 152,872,933 |
| 80 | 173,311,447 |
| 90 | 194,630,157 |
| 100 | 215,504,778 |
| Batch Size | CPU Cycles |
|---|---|
| 110 | 235,840,678 |
| 120 | 257,025,208 |
| 130 | 279,135,548 |
| 140 | 299,488,712 |
| 150 | 319,182,136 |
| 160 | 340,687,653 |
| 170 | 361,057,665 |
| 180 | 379,539,673 |
| 190 | 402,246,965 |
| 200 | 419,518,033 |
The best fitting curve is that we approximated by :
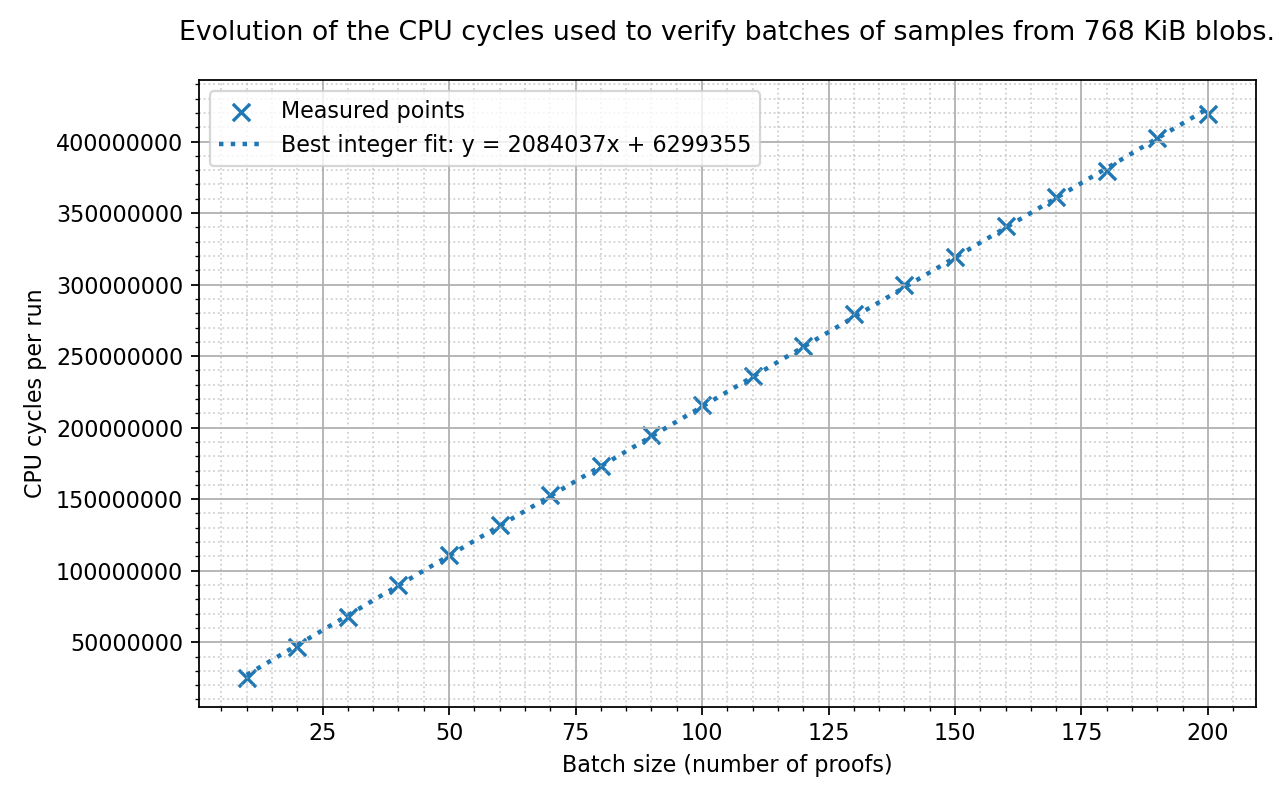
1024 KiB blobs (34 sample elements)
| Batch Size | CPU Cycles |
|---|---|
| 10 | 34,936,346 |
| 20 | 66,539,633 |
| 30 | 97,890,996 |
| 40 | 130,256,521 |
| 50 | 160,952,882 |
| 60 | 191,807,748 |
| 70 | 222,242,226 |
| 80 | 253,226,954 |
| 90 | 283,563,420 |
| 100 | 315,080,511 |
| Batch Size | CPU Cycles |
|---|---|
| 110 | 344,833,795 |
| 120 | 376,006,265 |
| 130 | 409,130,375 |
| 140 | 439,438,063 |
| 150 | 471,270,848 |
| 160 | 501,121,144 |
| 170 | 532,336,865 |
| 180 | 563,566,629 |
| 190 | 592,486,314 |
| 200 | 622,146,228 |
The best fitting curve is that we approximated by :
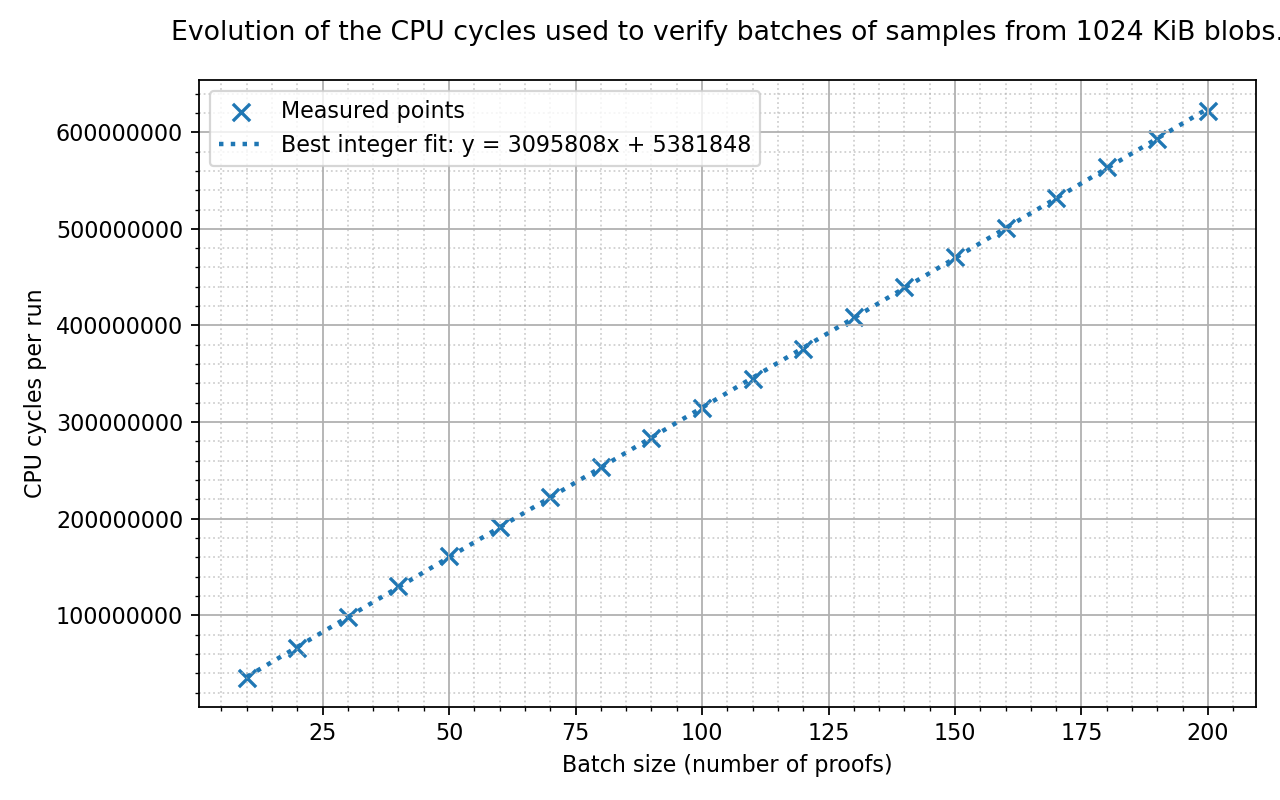
From all these curves and for simplification, we assumed that the initialization cost is the same for every sample size and equals 5M CPU cycles. Then, we simply linearized again the linear factor of each curve giving us:
| Sample size | Linear factor |
|---|---|
| 2 | 470,000 |
| 3 | 530,000 |
| 5 | 800,000 |
| 10 | 1,100,000 |
| 17 | 1,600,000 |
| 25 | 2,100,000 |
| 34 | 3,100,000 |
Which gives use the linear equation that we approximated by .
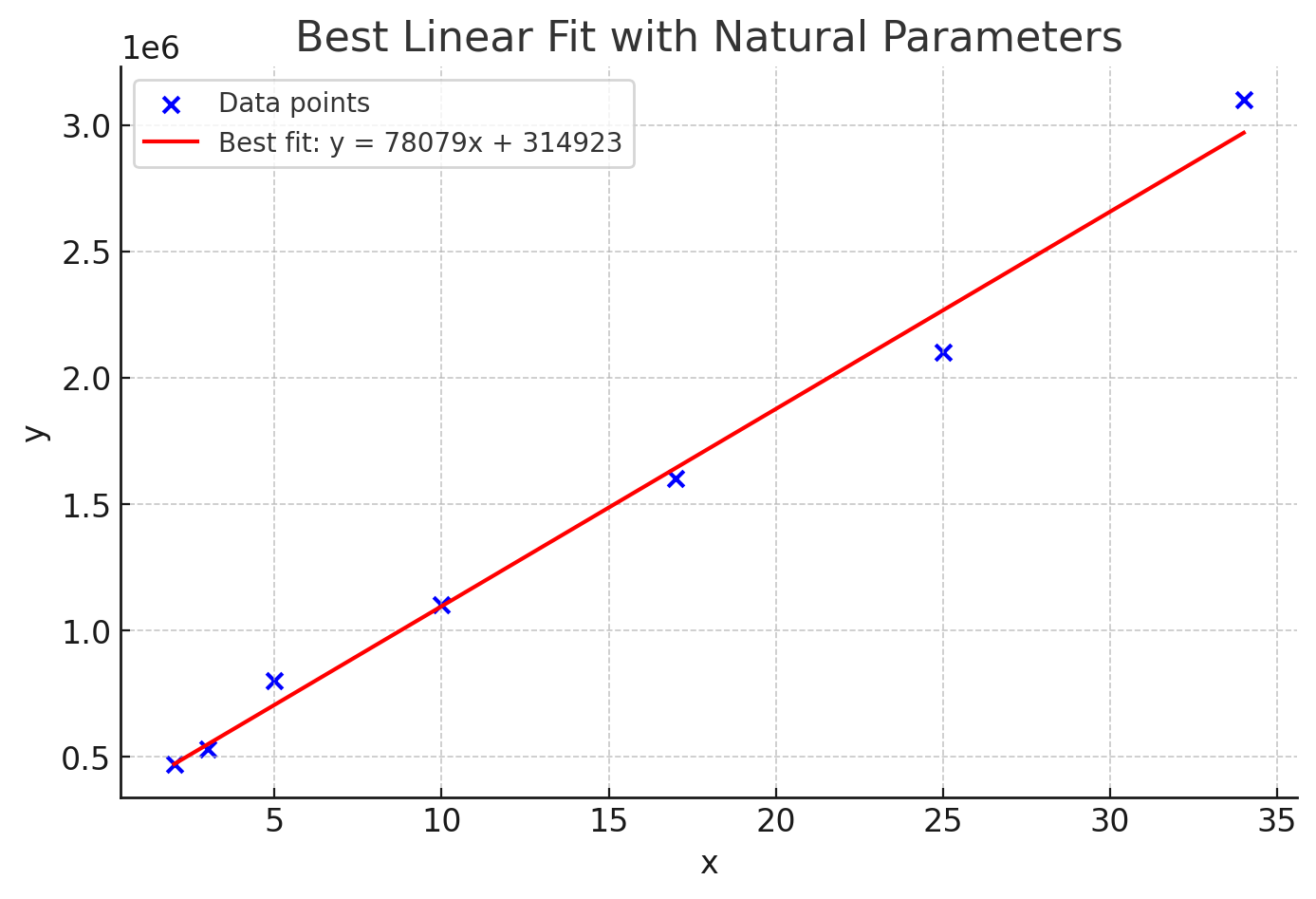
This gives us a final sample verification cost (in Execution Gas) of:
The 5000 Execution Gas cost is removed from the Execution Gas limit directly and the rest is applied per Blob Operation individually.
V1.1.0-BEDROCK-GENESIS-BLOCK
| Field | Value |
|---|---|
| Name | Bedrock Genesis Block |
| Slug | 222 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | David Rusu [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-02-12 |
| 1.1.0 | added [RFC] Make Ledger Transaction an Operation renamed Nomos to Logos Blockchain remove notions of DA minor fix in gas price | 2026-03-27 |
Introduction
The Genesis Block defines the starting state for the Bedrock chain, including the initial bedrock service providers, LGO token distribution and protocol parameters. Its design draws from best practices in the Ouroboros family of protocols (notably Praos and Genesis), as well as privacy and resilience advances from Cryptarchia and related research. The Genesis Block is the root of trust for all subsequent protocol operations and must be constructed in a way that is deterministic, verifiable, and robust against long-range or bootstrap attacks.
Overview
The Genesis Block establishes the initializing values for the various protocols and services. This includes the initial token distribution, initial nodes participating in Blend Network and the result of running the epoch nonce ceremony.
The block body is a single Mantle Transaction (see Mantle) containing a Transfer Operation distributing the notes to initial token holders. The bedrock services are initialized through SDP_DECLARE Operations embedded in the Mantle Transactions Operations list and protocol initializing constants are encoded through a CHANNEL_INSCRIBE Operation also embedded in the Operations list.
Not all protocol constants are encoded in the Genesis block. The principle we use to decide whether a value should be in the Genesis block or not is whether it is a value that is derived from blockchain activity or whether it is updated through a protocol update (hard / soft fork). For example, the epoch nonce is updated through normal blockchain Operations and therefore it should be specified in the Genesis block. Gas constants are only changed through protocol updates and hard forks and therefore they will be hardcoded in the node implementation.
Genesis Block Data Structure
The Genesis Block is composed of the Genesis Block Header and the Genesis Mantle Transaction (there is a single transaction in the genesis block). The Mantle Transaction contains all information necessary for initializing Bedrock Services and Cryptarchia state, as well as distributing the initial tokens to stakeholders.
Initial Token Distribution
Initial tokens will be distributed through a Transfer Operation containing zero inputs and one output note for each initial stakeholder. Note that since the Ledger is transparent, the initial stake allocation is visible to everyone. Those wishing to hide their initial stake may opt to subdivide their note into a few different notes of equal value.
In order to participate in the Cryptarchia lottery, stakeholders must generate their note keys in accordance with the Proof of Leadership protocol specified at Proof of Leadership - Protocol.
The initial state of the Ledger will be derived through normal execution of this Transfer Operation, that is, each outputs note ID will be added to the unspent notes set.
Example
STAKE_DISTRIBUTION = Transfer(
inputs=[],
outputs=[
Note(value=1000, public_key=STAKE_HOLDER_0_PK),
Note(value=2000, public_key=STAKE_HOLDER_1_PK),
Note(value=1500, public_key=STAKE_HOLDER_2_PK),
# ...
]
)
Initial Service Declarations
Blend Network MUST initialize its set of providers. This is done through a set of SDP_DECLARE Operations in the Genesis Mantle Transaction.
Blend enforces a minimal network size for the service to be active. Thus, in order to have an active Blend service at Genesis, we MUST have at least as many declarations in the Genesis block to meet Blend services minimal network size Blend Protocol - Minimal Network Size.
Example
BLEND_DECLARATIONS = [
Declaration(
msg=DeclarationMessage(
ServiceType.BLEND, ["ip://1.1.1.1:3000"], PROVIDER_ID_0, ZK_ID_0
),
locked_note_id=STAKE_DISTRIBUTION_TX.output_note_id(0)
),
# ... 32 total declarations
]
SERVICE_DECLARATIONS = BLEND_DECLARATIONS
Cryptarchia Parameters
Cryptarchia is initialized with the following parameters:
- genesis_time: ISO 8601 encoded timestamp. Cryptarchia uses slots as a measure of time offset from some start time. This timestamp must be agreed upon by all nodes in order to have a common clock.
- chain_id: string. It is useful to differentiate testnets from mainnet. To avoid confusion, we place the chain ID in the Genesis block to guarantee that the networks are disjoint.
- genesis_epoch_nonce: 32 bytes, hex encoded. The initial source of randomness for the Cryptarchia lottery. The process for selecting this value is described in detail at Epoch Nonce Ceremony.
These parameters are encoded in the Genesis block as an inscription sent to the null channel.
Example
from datetime import datetime
CHAIN_ID = "logos-blockchain-mainnet"
GENESIS_TIME = "2026-01-05T19:20:35+00:00"
GENESIS_EPOCH_NONCE = "abcdef1234567890abcdef1234567890abcdef1234567890abcdef1234567890"
chain_id_enc = CHAIN_ID.encode("utf-8")
chain_id_len = len(chain_id_enc).to_bytes(8, "little")
genesis_time = int(datetime.fromisoformat(GENESIS_TIME).timestamp()).to_bytes(8, "little")
genesis_epoch_nonce = bytes.fromhex(GENESIS_EPOCH_NONCE)
inscription = chain_id_len + chain_id_enc + genesis_time + genesis_epoch_nonce
# >>> inscription.hex()
# '0d000000000000006e6f6d6f732d6d61696e6e6574030f5c6900000000abcdef1234567890abcdef1234567890abcdef1234567890abcdef1234567890'
CRYPTARCHIA_INSCRIPTION = Inscribe(
channel=bytes(32),
inscription=inscription
parent=bytes(32),
signer=Ed25519PublicKey_ZERO,
)
Epoch Nonce Ceremony
The initial epoch nonce value governs the Cryptarchia lottery randomness for the first epoch. It must be revealed AFTER the initial stake distribution has been frozen. This is done to prevent any stakeholders from gaining an unfair advantage from prior knowledge of the lottery randomness.
The protocol for generating the initial randomness nonce can be found below.
- Schedule Epoch Nonce Ceremony Event: We must fix well in advance when this epoch nonce ceremony will take place, let t denote the time of the Epoch Nonce Ceremony, broadcast t widely. The STAKE_DISTRIBUTION must be finalized before t to ensure a fair Cryptarchia slot lottery.
- Randomness Collection:
We collect the entropy from multiple randomness sources:
Entropy Source Details Bitcoin block hash immediately after time t, denoted as . Block hash can be found on blockchain.com s bitcoin block explorer, e.g. https://www.blockchain.com/explorer/blocks/btc/905030 Ethereum block hash immediately after time t, denoted as . Block hash can be found in the more details section of when viewing a block on etherscan, e.g. https://etherscan.io/block/22894116 DRAND beacon value for the round immediately after t, denoted as . Use the default beacon, and find the round number corresponding to t. https://api.drand.sh/v2/beacons/default/rounds/1234 - Randomness Derivation: Once all above entropy contributions, i.e., are collected, then we can compute the initial epoch randomness as: where is a collision-resistant zkhash function.
Genesis Mantle Transaction
The initial stake distribution, service declarations and Cryptarchia inscription are components of the Genesis Mantle Transaction. This is the single transaction that forms the body of the Genesis block.
GENESIS_MANTLE_TX = MantleTx(
ops=[STAKE_DISTRIBUTION, CRYPTARCHIA_INSCRIPTION] + SERVICE_DECLARATIONS,
permanent_storage_gas_price=0,
execution_gas_price=0
)
Block Header Fields
The Genesis Block header fields are set to the following values:
- bedrock_version: Protocol version (e.g., 1).
- parent_block: 0 (as this is the first block).
- slot: 0 (the Genesis slot).
- block_root: Block Merkle root over the (single) initial transaction.
- proof_of_leadership: Stubbed leadership proof.
- leader_voucher: 0 (as there is no leader block reward for the initial block).
- entropy_contribution: 0 (no entropy is provided through the initial PoL).
- proof: Null Groth16Proof, all values are set to zero.
- leader_key: Null PublicKey.
Example
GENESIS_HEADER = Header(
bedrock_version=1,
parent_block=0,
slot=0,
block_root=block_merkle_root([GENESIS_MANTLE_TX]),
proof_of_leadership=ProofOfLeadership(
leader_voucher=bytes(32),
entropy_contribution=bytes(32),
proof=Groth16Proof(G1_ZERO, G2_ZERO, G1_ZERO),
leader_key=Ed25519PublicKey_ZERO,
)
)
# distribute NMO to all stakeholders
STAKE_DISTRIBUTION = Transfer(
inputs=[],
outputs=[
Note(value=1000, public_key=STAKE_HOLDER_0_PK),
Note(value=2000, public_key=STAKE_HOLDER_1_PK),
Note(value=1500, public_key=STAKE_HOLDER_2_PK),
# ...
]
)
# set Cryptarchia parameters
CRYPTARCHIA_PARAMS = {
"chain_id": "logos-mainnet",
"genesis_time": "2026-01-05T19:20:35Z",
"genesis_epoch_nonce": "abcdef1234567890abcdef1234567890abcdef1234567890abcdef1234567890",
}
CRYPTARCHIA_INSCRIPTION = Inscribe(
channel=bytes(32),
inscription=json.dumps(CRYPTARCHIA_PARAMS).encode("utf-8"),
parent=bytes(32),
signer=Ed25519PublicKey_ZERO,
)
# service declarations
BLEND_DECLARATIONS = [
Declaration(
msg=DeclarationMessage(ServiceType.BLEND, ["ip://1.1.1.1:3000"], PROVIDER_ID_0, ZK_ID_0),
locked_note_id=STAKE_DISTRIBUTION.output_note_id(0)
),
# ... more declarations
]
SERVICE_DECLARATIONS = BLEND_DECLARATIONS
# build the genesis Mantle Transaction
GENESIS_MANTLE_TX = MantleTx(
ops=[STAKE_DISTRIBUTION, CRYPTARCHIA_INSCRIPTION] + SERVICE_DECLARATIONS,
permanent_storage_gas_price=0,
execution_gas_price=0
)
GENESIS_HEADER = Header(
bedrock_version=1,
parent_block=bytes(32),
slot=0,
block_root=block_merkle_root([GENESIS_MANTLE_TX]),
proof_of_leadership=ProofOfLeadership(
leader_voucher=bytes(32),
entropy_contribution=bytes(32),
proof=Groth16Proof(G1.ZERO, G2.ZERO, G1.ZERO),
leader_key=Ed25519PublicKey_ZERO,
)
)
GENESIS_BLOCK = (GENESIS_HEADER, [GENESIS_MANTLE_TX])
Sample Genesis Block
Initializing Bedrock
Bedrock is initialized by executing the Mantle Transaction without validating the Mantle Operations. No validation or execution is done for the Genesis block header; in particular, processing of proof_of_leadership is skipped.
Mantle Ledger Initialization
The Transfer Operation should be executed without checking that the transaction is balanced. However, other validations are checked, e.g. that output note values are positive and smaller than the maximum allowed value. The result of normal transfer execution adds all outputs to the Ledger.
Cryptarchia Initialization
The Mantle Transaction contains an inscription sent to the null channel containing the parameters for initializing Cryptarchia.
The Cryptarchia slot clock is initialized to genesis_time, LIB is set to the Genesis block and the epoch state is then initialized:
Initial Epoch State
Cryptarchia progresses in epochs where the variables governing the lottery are fixed for the duration of an epoch and the activity during that epoch is used to derive the values of those variables for the next epoch. These variables taken together are called the Epoch State. (see Cryptarchia Protocol - Epoch State).
To initialize the Epoch State, we derive the epoch variables from the genesis block.
- : the epoch nonce is taken directly from the genesis_epoch_nonce.
- : Eligible leader commitment is set to the the Ledger Root over all notes from the initial token distribution. The derivation of this root is specified in Proof of Leadership - Ledger Root.
- : The initial estimate of total stake will be the total tokens distributed at genesis.
Bedrock Services Initialization
Blend network is initialized through normal Mantle Transaction execution. The SDP_DECLARE Operations in the Genesis Mantle Transaction will create the initial set of providers in each service.
During normal operations, Blend services would wait until a block is deep enough to be finalized, but for the Genesis block, we consider it finalized by definition and so Blend will immediately use the provider set without the usual finalization delay.
References
- Ouroboros Praos: https://eprint.iacr.org/2017/573.pdf
- Ouroboros Genesis: https://eprint.iacr.org/2018/378.pdf
- Ouroboros Crypsinous: https://eprint.iacr.org/2018/1132.pdf
- Cardano Shelley Genesis File Format: https://cardano-course.gitbook.io/cardano-course/handbook/protocol-parameters-and-configuration-files/shelley-genesis-file
- Cardano CIP-16 Key Serialisation: https://cips.cardano.org/cip/CIP-16
V1.1.0-BEDROCK-BLOCK-CONSTRUCTION
| Field | Value |
|---|---|
| Name | Block Construction, Validation and Execution |
| Slug | 221 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Marcin Pawlowski [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Owner: @Marcin Pawlowski @Thomas Lavaur
Reviewers: @Daniel Sanchez Quiros @David Rusu @lvaro Castro-Castilla @Mehmet
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-12-03 |
| 1.1.0 | ? | 2026-01-20 |
Introduction
In this document, we present the specification defining the construction of the block proposal, its validation, and execution. We define the block proposal construction that contains references to transactions (from the mempool) instead of a complete transaction to limit its length. The raw block size increases with the size of transactions it contains up to 1 MB, and the proposal compresses its size down to 33 kB, which saves the bandwidth necessary to broadcast new blocks.
Overview
For the consensus protocol to make progress, a new leader is elected through the leader lottery. The new leader is in possession of a proof of leadership (PoL) that confirms that it is indeed the leader. The main objective of the leader is to construct a new block, hence becoming a block builder, and share it with other members of the network as a block proposer. The block must be correctly constructed; otherwise, it will be rejected by the consensus nodes who are validating every block. Only validated blocks are executed, which means that the transactions included in the block are interpreted by all nodes, and the state of the chain is modified according to the instructions embedded in the transactions.
High-level Flow
Below, we present a high-level description of the block lifecycle. The main focus of this section is to build an intuition on the block construction, validation, and execution.
- A leader is selected. The leader becomes a block builder.
- The block builder constructs a block proposal.
- The block builder selects the latest block (parent) as the reference point for the chain state update.
- The block builder constructs references to the deterministically generated Mantle Transactions that execute the Service Reward Distribution Protocol, if such transactions can be constructed. For example, there is no need to distribute rewards when all rewards have already been distributed.
- The block builder selects valid Mantle Transactions (as defined in Mantle) from its mempool and includes references to them in the proposal.
- The block builder populates the block header of the block proposal.
- The block proposer sends the block proposal to the Blend network.
- The validators receive the block proposal.
- The validators validate the block proposal.
- They validate the block header.
- They verify distribution of service rewards through Mantle Transactions as specified in Service Reward Distribution Protocol. This is done by independently deriving the distribution transaction and confirming that it matches the first reference, if there is rewards to be distributed.
- They retrieve complete transactions from their mempool that are referred in the block.
- They validate each transaction included in the block.
- The validators execute the block proposal.
- They derive the new blockchain state from the previous one by executing transactions as defined in Mantle.
- They update the different variables that need to be maintained over time.
Constructions
Hash
We are using two hashing algorithms that have the same output length of 256 bits (32 bytes) that are Poseidon2 and Blake2b.
Block Proposal
A block proposal, instead of containing complete Mantle Transactions of an unlimited size, contains references of fixed size to the transactions. Therefore, the size of the proposal is constant and it is 33129 bytes.
We define the following message structure:
class Proposal: # 33129 bytes
header: Header # 297 bytes
references: References # 32768 bytes
signature: Ed25519Signature # 64 bytes
Where:
- header is the header of the proposal; defined below: Header.
- references is a set of 1024 references to transactions of a hash type; the size of the hash type is 32 bytes and is the transaction hash as defined in Mantle - Mantle Transaction.
- signature is the signature of the complete header using the leader_key from the ProofOfLeadership; the size of the Ed25519Signature type is 64 bytes.
The length of the references list must be preserved to maintain the messages indistinguishability in the Blend protocol. Therefore, the list must be padded with zeros when necessary.
Header
class Header: # 297 bytes
bedrock_version: byte # 1 bytes
parent_block: hash # 32 bytes
slot: SlotNumber # 8 bytes
block_root: hash # 32 bytes
proof_of_leadership: ProofOfLeadership # 224 bytes
Where:
- bedrock_version is the version of the proposal message structure that supports other protocols defined in Bedrock Specification; the size of it is 1 byte and is fixed to 0x01.
- parent_block is the block ID (Cryptarchia Protocol) of the parent block, validated and accepted by the block builder. It is used for the derivation of the AgedLedger and LatestLedger values necessary for validating the PoL; the size of the hash is 32 bytes.
- slot is the consensus slot number; the size of the SlotNumber type is 8 bytes.
- block_root is the root of the Merkle tree constructed from transaction hashes (defined in Mantle - Mantle Transaction) used for constructing the references list in the transactions; the size of the hash is 32 bytes.
- proof_of_leadership is the proof confirming that the sender is the leader; defined below: Proof of Leadership.
References
class References: # 32768 bytes
service_reward: list[zkhash] # 1*32 bytes
mempool_transactions: list[zkhash] # 1024-len(service_reward)*32 bytes
Where:
- service_reward is a set of up to 1 reference to a reward transaction of a zkhash type; the size of the zkhash type is 32 bytes and is the transaction hash as defined in Mantle - Mantle Transaction.
- mempool_transactions is a set of up to 1024 references to transactions of a zkhash type; the size of the zkhash type is 32 bytes and is the transaction hash as defined in Mantle - Mantle Transaction.
The service_reward transaction is created deterministically by the leader and is not obtained from the mempool. If this transaction were obtained from the mempool, it could expose the leader's identity as the transaction creator. To protect the leader's identity, only the service_reward reference is included in the proposal, and it is derived again by the nodes verifying the block.
The service_reward transaction is a Service Rewards Distribution Transaction that distributes service rewards. It is a Mantle Transaction with no input and up to service_count x 4 outputs, service_count being the number of services (global parameter). The outputs represent the validators rewarded (up to 4 per service).
If the service_reward transaction cannot be created, then nothing is added to the list. Therefore, we allow the service_reward list to have a length of 0.
Proof of Leadership
class ProofOfLeadership: # 224 bytes
leader_voucher: RewardVoucher # 32 bytes
entropy_contribution: zkhash # 32 bytes
proof: ProofOfLeadership # 128 bytes
leader_key: Ed25519PublicKey # 32 bytes
Where:
- leader_voucher is the voucher value used for retrieving the reward by the leader for proposal; the size of the RewardVoucher is 32 bytes.
- entropy_contribution is the output of the PoL contribution for Cryptarchia entropy; the size of the zkhash type is 32 bytes.
- proof is the proof confirming that the proposal is constructed by the leader; the size of the ProofOfLeadership type is 128 bytes (2 compressed and 1 compressed BN256 elements).
- leader_key is the one-time Ed25519PublicKey used for signing the Proposal. This binds the content of the proposal with the ProofOfLeadership; the size of the Ed25519PublicKey type is 32 bytes.
Proposal Construction
In this section, we explain how the block proposal structure presented above is populated by the consensus leader.
The block proposal is constructed by the leader of the current slot. The node becomes a leader only after successfully generating a valid PoL for a given (Epoch, Slot).
Prerequisites
Before constructing the proposal, the block builder must:
- Select a valid parent block referenced by ParentBlock on which they will extend the chain.
- Derive the required Ledger state snapshots AgedLedger and LatestLedger from the state of the chain including the last block.
- Select a valid unspent note winning the PoL.
- Generate a valid PoL proving leadership eligibility for (Epoch, Slot) based on the selected note. Attach the PoL to a one-time Ed25519 public key used to sign the block proposal.
Only after the PoL is generated can the block proposal be constructed (see Proof of Leadership).
Construction Procedure
- Initialize proposal metadata with the last known state of the blockchain. Set the:
- header:
- bedrock_version
- parent_block
- slot
- block_root
- proof_of_leadership:
- leader_voucher
- entropy_contribution
- proof
- leader_key
- header:
- Construct the service_reward object:
- If there are service rewards to be distributed construct the transaction that distributes the service rewards from previous session and add its reference to the service_reward list. This transaction must be computed locally, do not disseminate this transaction.
- Construct the mempool_transactions object:
- Select Mantle transactions:
- Choose up to 1024-len(service_reward) valid SignedMantleTx from the local mempool.
- Ensure each transaction:
- Is valid according to Mantle.
- Has no conflicts with others (e.g., two transactions trying to spend the same note).
- Select Mantle transactions:
- Derive references values:
references: list[zkhash] = [mantle_txhash(tx) for tx in service_reward + mempool_transactions] - Compute the header.block_root as the root of the Merkle tree constructed from the list(service_reward) + mempool_transactions transactions used to build references.
- Sign the block proposal header.
signature = Ed25519.sign(leader_secret_key, header) - Assemble the block proposal.
The PoL must have been generated beforehand and bound to the same Ledger view as mentioned in the Prerequisites.proposal = Proposal( header, references, signature )
The constructed proposal can now be broadcast to the network for validation.
Block Proposal Reconstruction
Given a block proposal, we assume transaction maturity. This means that the block proposal must include transactions from the mempool that have had enough time to spread across the network to reach all nodes. This ensures that transactions are widely known and recognized before block reconstruction.
This transaction maturity assumption holds true because the block proposal must be sent through the Blend Network before it reaches validators and can be reconstructed. The Blend Network introduces significant delay, ensuring that transactions referenced in the proposal have reached all network participants. This approach is crucial for maintaining smooth network operation and reducing the risk that proposals get rejected due to transactions being unavailable to some validators. Moreover, by increasing the number of nodes that have seen the transaction, anonymity is also enhanced as the set of nodes with the same view is larger. This may result in increased difficultyor even practical preventionof executing deanonymization attacks such as tagging attacks.
Upon receipt of a block proposal, validators must confirm the presence of all referenced transactions within their local mempool. This verification is an absolute requirementif even a single referenced transaction is missing from the validator's mempool, the entire proposal must be rejected. This stringent validation protocol ensures only widely-distributed transactions are included in the blockchain, safeguarding against potential network state fragmentation.
The process works as follows:
- Transaction is added to the node mempool.
- Node sends the transaction to all its neighbors.
- Neighbors add the transaction to their own mempools and propagate it to their neighborstransaction is gossiped throughout the network.
- Block builder selects a transaction from its local mempool, which is guaranteed to be propagated through the network due to steps 1-3.
- Block builder constructs a block proposal with references to selected transactions.
- Block proposal is sent through the Blend Network, which requires multiple rounds of gossiping. This introduces a delay that ensures the transaction has reached most of the network participants' mempools.
- Block proposal is received by validators.
- Validators check their local mempools for all referenced transactions from the proposal.
- If any transaction is missing, the entire proposal is rejected.
- If all transactions are present, the block proposal is reconstructed and proceeds to further validation steps.
Block Proposal Validation
This section defines the procedure followed by a Logos Blockchain node to validate a received block proposal.
Given a Proposal, a proposed block consisting of a header and references. This block proposal is considered valid if the following conditions are met:
- Block Validation The Proposal must satisfy the rules defined in Cryptarchia Protocol - Block Header Validation.
- Block Proposal Reconstruction The references must refer to either a service_reward transaction that is locally derivable or to existing mempool_transaction entries that are retrievable from the node's local mempool.
- Mempool Transactions Validation mempool_transactions must refer to a valid sequence of Mantle Transactions from the mempool. Each transaction must be valid according to the rules defined in the Mantle. In order to verify ZK proofs, they are batched for verification as explained in Batch verification of ZK proofs to get better performances.
- Rewards Validation
- Check if the first reference matches a deterministically derived Service Rewards Distribution Transaction that distributes previous session service fees as defined in Service Reward Distribution Protocol. It should take no input and output up to service_count * 4 reward notes distributed to the correct validators.
- If the above rewarding transactions cannot be derived, then the first reference must refer to a mempool_transaction.
If any of the above checks fail, the block proposal must be rejected.
Block Execution
This section specifies how a Logos Blockchain node executes a valid block proposal to update its local state.
Given a ValidBlock that has successfully passed proposal validation, the node must:
- Append the leader_voucher contained in the block to the set of reward vouchers when the following epoch starts.
- Execute the Mantle Transactions included in the block sequentially, using the execution rules defined in the Mantle.
Annex
Batch verification of ZK proofs
Blob Samples
- For each sample the verifier follow the classic cryptographic verification procedure as described in DA Cryptographic Protocol - Verification except the last step, once the verifier has a single commitment , an aggregated element at position and one proof for each sample.
- The verifier draws a random value for each sample .
- The verifier computes:
- They test if .
Proofs of Claim
- For each proof of Claim the verifier collect the classic Groth16 elements required for verification. It includes the proof , and the public values for each proof of claim.
- The verifier draws one random value for each proof .
- The verifier computes:
- for .
- $IC := r' \cdot \Psi_0 + \sum_{j=1}^l\left( \sum_{i=1}^k r_i \cdot x_j^{(i)} \right) \cdot \Psi_j$
- They test if .
Note that this batch verification of Groth16 proofs is the same as what is described in the Zcash paper, Appendix B.2.
ZkSignatures
The verifier follows the same procedure as in Proofs of Claim but with the Groth16 proofs of ZkSignatures.
V1.1.0-BEDROCK-BLOCK-CONSTRUCTION-ALT
| Field | Value |
|---|---|
| Name | Block Construction, Validation and Execution (alt) |
| Slug | 220 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Marcin Pawlowski [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-12-03 |
| 1.1.0 | Removed service_rewards due to updated Service Reward Distribution Protocol. Extended the Block Execution logic with rewards distribution due to updated Service Reward Distribution Protocol. Removed Block Samples subsection of the Batch verification of ZK proofs from the Annex. Reordered the Block Execution steps to enable immediate use of reward notes as inputs for transactions included in the proposal. | 2026-03-27 |
Introduction
In this document, we present the specification defining the construction of the block proposal, its validation, and execution. We define the block proposal construction that contains references to transactions (from the mempool) instead of a complete transaction to limit its length. The raw block size increases with the size of transactions it contains up to 1 MB, and the proposal compresses its size down to 33 kB, which saves the bandwidth necessary to broadcast new blocks.
Overview
For the consensus protocol to make progress, a new leader is elected through the leader lottery. The new leader is in possession of a proof of leadership (PoL) that confirms that it is indeed the leader. The main objective of the leader is to construct a new block, hence becoming a block builder, and share it with other members of the network as a block proposer. The block must be correctly constructed; otherwise, it will be rejected by the consensus nodes who are validating every block. Only validated blocks are executed, which means that the transactions included in the block are interpreted by all nodes, and the state of the chain is modified according to the instructions embedded in the transactions.
High-level Flow
Below, we present a high-level description of the block lifecycle. The main focus of this section is to build an intuition on the block construction, validation, and execution.
- A leader is selected. The leader becomes a block builder.
- The block builder constructs a block proposal.
- The block builder selects the latest block (parent) as the reference point for the chain state update.
- The block builder selects valid Mantle Transactions (as defined in Mantle) from its mempool and includes references to them in the proposal.
- The block builder populates the block header of the block proposal.
- The block proposer sends the block proposal to the Blend network.
- The validators receive the block proposal.
- The validators validate the block proposal.
- They validate the block header.
- They retrieve complete transactions from their mempool that are referred in the block.
- They validate each transaction included in the block.
- The validators execute the block proposal.
- They derive the new blockchain state from the previous one by executing transactions as defined in Mantle.
- They update the different variables that need to be maintained over time.
- They execute the Service Reward Distribution Protocol to generate reward notes locally.
Constructions
Hash
We are using two hashing algorithms that have the same output length of 256 bits (32 bytes) that are Common Cryptographic Components - Poseidon2 (ZK Friendly Hash Function) and Common Cryptographic Components - BLAKE2b (General-Purpose Hashing).
Block Proposal
A block proposal, instead of containing complete Mantle Transactions of an unlimited size, contains references of fixed size to the transactions. Therefore, the size of the proposal is constant and it is 33129 bytes.
We define the following message structure:
class Proposal: # 33129 bytes
header: Header # 297 bytes
references: References # 32768 bytes
signature: Ed25519Signature # 64 bytes
Where:
- header is the header of the proposal; defined below: Header.
- references is a set of 1024 references to transactions of a hash type; the size of the hash type is 32 bytes and is the transaction hash as defined in Mantle - Mantle Transaction.
- signature is the signature of the complete header using the leader_key from the ProofOfLeadership; the size of the Ed25519Signature type is 64 bytes.
The length of the references list must be preserved to maintain the messages indistinguishability in the Blend protocol. Therefore, the list must be padded with zeros when necessary.
Header
class Header: # 297 bytes
bedrock_version: byte # 1 byte
parent_block: hash # 32 bytes
slot: SlotNumber # 8 bytes
block_root: hash # 32 bytes
proof_of_leadership: ProofOfLeadership # 224 bytes
Where:
- bedrock_version is the version of the proposal message structure that supports other protocols defined in [Overview] Bedrock Architecture; its size is 1 byte and is fixed to 0x01.
- parent_block is the block ID (Cryptarchia Protocol) of the parent block, validated and accepted by the block builder. It is used for the derivation of the AgedLedger and LatestLedger values necessary for validating the PoL; the size of the hash is 32 bytes.
- slot is the consensus slot number; the size of the SlotNumber type is 8 bytes.
- block_root is the root of the Merkle tree constructed from transaction hashes (defined in Mantle - Mantle Transaction) used for constructing the references list in the mempool_ransactions; the size of the hash is 32 bytes.
- proof_of_leadership is the proof confirming that the sender is the leader; defined below: Proof of Leadership.
References
class References: # 32768 bytes
mempool_transactions: list[zkhash] # 1024 * 32 bytes
Where mempool_transactions is a set of up to 1024 references to transactions of a zkhash type; the size of the zkhash type is 32 bytes and is the transaction hash as defined in Mantle - Mantle Transaction.
Proof of Leadership
class ProofOfLeadership: # 224 bytes
leader_voucher: RewardVoucher # 32 bytes
entropy_contribution: zkhash # 32 bytes
proof: ProofOfLeadership # 128 bytes
leader_key: Ed25519PublicKey # 32 bytes
Where:
- leader_voucher is the voucher value used for retrieving the reward by the leader for proposal; the size of the RewardVoucher is 32 bytes.
- entropy_contribution is the output of the PoL contribution for Cryptarchia entropy; the size of the zkhash type is 32 bytes.
- proof is the proof confirming that the proposal is constructed by the leader; the size of the ProofOfLeadership type is 128 bytes (2 compressed and 1 compressed BN256 elements).
- leader_key is the one-time Ed25519PublicKey used for signing the Proposal. This binds the content of the proposal with the ProofOfLeadership; the size of the Ed25519PublicKey type is 32 bytes.
Proposal Construction
In this section, we explain how the block proposal structure presented above is populated by the consensus leader.
The block proposal is constructed by the leader of the current slot. The node becomes a leader only after successfully generating a valid PoL for a given (Epoch, Slot).
Prerequisites
Before constructing the proposal, the block builder must:
- Select a valid parent block referenced by ParentBlock on which they will extend the chain.
- Derive the required Ledger state snapshots AgedLedger and LatestLedger from the state of the chain including the last block.
- Select a valid unspent note winning the PoL.
- Generate a valid PoL proving leadership eligibility for (Epoch, Slot) based on the selected note. Attach the PoL to a one-time Ed25519 public key used to sign the block proposal.
Only after the PoL is generated can the block proposal be constructed (see Proof of Leadership).
Construction Procedure
- Initialize proposal metadata with the last known state of the blockchain. Set the:
- header:
- bedrock_version
- parent_block
- slot
- block_root
- proof_of_leadership:
- leader_voucher
- entropy_contribution
- proof
- leader_key
- header:
- Construct the mempool_transactions object:
- Select Mantle transactions:
- Choose up to 1024 valid SignedMantleTx from the local mempool.
- Ensure each transaction:
- Is valid according to Mantle.
- Has no conflicts with others (e.g., two transactions trying to spend the same note).
- Select Mantle transactions:
- Derive references values:
references: list[zkhash] = [mantle_txhash(tx) for tx in mempool_transactions] - Compute the header.block_root as the root of the Merkle tree constructed from the mempool_transactions transactions used to build references.
- Sign the block proposal header.
signature = Ed25519.sign(leader_secret_key, header) - Assemble the block proposal.
The PoL must have been generated beforehand and bound to the same Ledger view as mentioned in the Prerequisites.proposal = Proposal( header, references, signature )
The constructed proposal can now be broadcast to the network for validation.
Block Proposal Reconstruction
Given a block proposal, we assume transaction maturity. This means that the block proposal must include transactions from the mempool that have had enough time to spread across the network to reach all nodes. This ensures that transactions are widely known and recognized before block reconstruction.
This transaction maturity assumption holds true because the block proposal must be sent through the Blend Network before it reaches validators and can be reconstructed. The Blend Network introduces significant delay, ensuring that transactions referenced in the proposal have reached all network participants. This approach is crucial for maintaining smooth network operation and reducing the risk that proposals get rejected due to transactions being unavailable to some validators. Moreover, by increasing the number of nodes that have seen the transaction, anonymity is also enhanced as the set of nodes with the same view is larger. This may result in increased difficultyor even practical preventionof executing deanonymization attacks such as tagging attacks.
Upon receipt of a block proposal, validators must confirm the presence of all referenced transactions within their local mempool. This verification is an absolute requirementif even a single referenced transaction is missing from the validator's mempool, the entire proposal must be rejected. This stringent validation protocol ensures only widely-distributed transactions are included in the blockchain, safeguarding against potential network state fragmentation.
The process works as follows:
- Transaction is added to the node mempool.
- Node sends the transaction to all its neighbors.
- Neighbors add the transaction to their own mempools and propagate it to their neighborstransaction is gossiped throughout the network.
- Block builder selects a transaction from its local mempool, which is guaranteed to be propagated through the network due to steps 1-3.
- Block builder constructs a block proposal with references to selected transactions.
- Block proposal is sent through the Blend Network, which requires multiple rounds of gossiping. This introduces a delay that ensures the transaction has reached most of the network participants' mempools.
- Block proposal is received by validators.
- Validators check their local mempools for all referenced transactions from the proposal.
- If any transaction is missing, the entire proposal is rejected.
- If all transactions are present, the block proposal is reconstructed and proceeds to further validation steps.
Block Proposal Validation
This section defines the procedure followed by a Logos Blockchain node to validate a received block proposal.
Given a proposal, a proposed block consisting of a header and references. This block proposal is considered valid if the following conditions are met:
- Block Validation The proposal must satisfy the rules defined in Cryptarchia Protocol - Block Header Validation.
- Block Proposal Reconstruction The references must refer to existing mempool_transaction entries that are retrievable from the node's local mempool.
- Mempool Transactions Validation mempool_transactions must refer to a valid sequence of Mantle Transactions from the mempool. Each transaction must be valid according to the rules defined in the Mantle. In order to verify ZK proofs, they are batched for verification as explained in Batch verification of ZK proofs to get better performance.
If any of the above checks fail, the block proposal must be rejected.
Block Execution
This section specifies how a Logos Blockchain node executes a valid block proposal to update its local state.
Given a ValidBlock that has successfully passed proposal validation, the node must:
- Append the leader_voucher contained in the block to the set of reward vouchers when the following epoch starts.
- Execute the reward distribution protocol defined in Service Reward Distribution Protocol to generate reward notes locally and include them in the ledger.
- Execute the Mantle Transactions included in the block sequentially, using the execution rules defined in the Mantle.
Annex
Batch verification of ZK proofs
Proofs of Claim
- For each proof of Claim, the verifier collects the classic Groth16 elements required for verification. It includes the proof , and the public values for each proof of claim.
- The verifier draws one random value for each proof .
- The verifier computes:
- for .
- $IC := r' \cdot \Psi_0 + \sum_{j=1}^l\left( \sum_{i=1}^k r_i \cdot x_j^{(i)} \right) \cdot \Psi_j$
- They test if .
Note that this batch verification of Groth16 proofs is the same as what is described in the Zcash paper, Appendix B.2.
ZkSignatures
The verifier follows the same procedure as in Proofs of Claim but with the Groth16 proofs of ZkSignatures.
V1.1.0-MANTLE
| Field | Value |
|---|---|
| Name | Mantle |
| Slug | 225 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Thomas Lavaur [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Owner: @Thomas Lavaur @David Rusu
Reviewers: @Giacomo Pasini @Mehmet @lvaro Castro-Castilla @Marcin Pawlowski @Daniel Sanchez Quiros @Gusto Bacvinka @Youngjoon Lee
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-11-17 |
| 1.1.0 | ? | 2026-02-06 |
Introduction
Mantle is a foundational element of Bedrock, designed to provide a minimal and efficient execution layer that connects together Logos Blockchain Services in order to provide the necessary functionality for Sovereign Rollups. It can be viewed as the system call interface of Bedrock, exposing a safe and constrained set of Operations to interact with lower-level Bedrock services, similar to syscalls in an operating system.
Mantle Transactions provide Operations for interacting with Logos Blockchain Services. For example, a Sovereign Rollup node posting an update to Bedrock, or a node operator declaring its participation in the Blend Network, would be done through the corresponding Operations within a Mantle Transaction.
Mantle manages assets using a Note-based ledger that follows an UTXO model. Each Mantle Transaction includes a Ledger Transaction, and any excess balance serves as the fee payment.
Overview
Mantle Transaction
The features of Logos Blockchain are exposed through Mantle Transactions. Each transaction can contain zero or more Operations and one Ledger Transaction. Mantle Transactions enable users to execute multiple Operations atomically. The Ledger Transaction serves two purposes: it can pays the transaction fee and allows users to issue transfers.
Mantle Operations
Logos Blockchain features are exposed through Mantle Operations, which can be combined and executed together in a single Mantle Transaction. These Operations enable functions such as on-chain data posting, SDP interaction, and leader reward claims.
Mantle Ledger
The Mantle Ledger enables asset transfers using a transparent UTXO model. While a Ledger Transactions can consume more NMO than it creates, the Mantle Transaction excess balance must exactly pay for the fees.
Transaction Fees
Mantle Transaction fees are derived from a gas model. Logos Blockchain has three different Gas markets, accounting for permanent data storage, ephemeral data storage through DA, and execution costs. Permanent data storage is paid at the Mantle Transaction level, while ephemeral data storage is paid at the Blob Operation level. Each Operation and Ledger Transaction has an associated Execution Gas cost. Users can specify their Gas prices in their Mantle Transactions or in the Blob Operation to incentivize the network to include their transaction.
| Gas Market | Charged On | Pricing Basis |
|---|---|---|
| Execution Gas | Ledger Transaction and Operations | Fixed per Operation |
| Permanent Storage Gas | Signed Mantle Transaction | Proportional to encoded size |
| DA Storage Gas | Blob Operation | Proportional to blob size |
Mantle Transaction
Mantle Transactions form the core of Mantle, enabling users to combine multiple Operations to access different Logos Blockchain functions. Each transaction contains zero or more Operations plus a Ledger Transaction. The system executes all Operations atomically, while using the Mantle Transaction's excess balancecalculated as the difference between consumed and created value as the fee payment.
class MantleTx:
ops: list[Op]
ledger_tx: LedgerTx # excess balance is used for fee payment
permanent_storage_gas_price: int # 8 bytes
execution_gas_price: int # 8 bytes
class Op:
opcode: byte
payload: bytes
def mantle_txhash(tx: MantleTx) -> ZkHash:
tx_bytes = encode(tx)
h = Hasher()
h.update(FiniteField(b"LOGOS_MANTLE_TXHASH_V1", byte_order="little", modulus=p))
for i in range((len(tx_bytes)+30)//31):
chunk = tx_bytes[i*31:(i+1)*31]
fr = FiniteField(chunk, byte_order="little", modulus=p)
h.update(fr)
return h.digest()
The hash function used, as well as other cryptographic primitives like ZK proofs and signature schemes, are described in Common Cryptographic Components.
A Mantle Transaction must include all relevant signatures and proofs for each Operation, as well as for the Ledger Transaction.
class SignedMantleTx:
tx: MantleTx
op_proofs: list[OpProof | None] # each Op has at most 1 associated proof
ledger_tx_proof: ZkSignature # ZK proof of ownership of the spent notes
Each proof (op proof and signature) must be cryptographically bound to the MantleTx through the mantle_txhash to prevent replay attacks. This binding is achieved by including the MantleTx hash as a public input in every ZK proof.
The transaction fee is a sum of two components: the multiplication of the total Execution Gas by the execution_gas_price, and the total size of the encoded signed Mantle Transaction multiplied by the permanent_storage_gas_price. If the Mantle Transaction contains a Blob Operations, the fee also accounts for ephemeral data storage. In this case, the blob_size of each blob is multiplied by the DA_storage_gas_price stored in the Blob Operation and added to the previous amounts to determine the final fee.
def gas_fees(signed_tx: SignedMantleTx) -> int:
mantle_tx = signed_tx.tx
permanent_storage_fees = len(encode(signed_mantle_tx)) * mantle_tx.permanent_storage_gas_price
execution_fees = execution_gas(mantle_tx.ledger_tx) * mantle_tx.execution_gas_price
da_storage_fees = 0
for op in mantle_tx.ops:
if op.opcode == CHANNEL_BLOB:
blob = decode_blob(op.payload)
da_storage_fees += blob.da_storage_gas_price * blob.blob_size
# Compute the execution gas of this operation as defined
# in the gas cost determination specification.
execution_fees += execution_gas(op) * mantle_tx.execution_gas_price
return execution_fees + da_storage_fees + permanent_storage_fees
Validation
Given
signed_tx = SignedMantleTx(
tx=MantleTx(ops, permanent_storage_gas_price, execution_gas_price, ledger_tx),
op_proofs,
ledger_tx_proof
)
Mantle validators will ensure the following:
- The ledger transaction is valid according to Ledger Validation.
validate_ledger_tx(ledger_tx, ledger_tx_proof, mantle_txhash(tx)) - We have a proof or a None value for each operation.
assert len(op_proofs) == len(ops) - Each Operation is valid.
for op, op_proof in zip(ops, op_proofs): assert op.opcode in MANTLE_OPCODES validate_mantle_op(mantle_txhash(tx), op.opcode, op.payload, op_proof) def validate_mantle_op(txhash, opcode, payload, op_proof): if opcode == INSCRIBE: validate_inscribe(txhash, payload, op_proof) # elif opcode == ... # ... - The Mantle Transaction excess balance pays for the transaction fees.
tx_fee = get_fees(signed_tx) assert tx_fee == get_transaction_balance(signed_tx) def get_transaction_balance(signed_tx): balance = 0 for op in signed_tx.tx.ops: if op.opcode == LEADER_CLAIM: balance += get_leader_reward() for inp in signed_tx.tx.ledger_tx.inputs: balance += get_value_from_note_id(inp) for out in signed_tx.tx.ledger_tx.outputs: balance -= out.value
Execution
Given
SignedMantleTx(
tx=MantleTx(ops, permanent_storage_gas_price, execution_gas_price, ledger_tx),
op_proofs,
ledger_tx_proof
)
Mantle Validators execute the following:
- Execute the Ledger Transaction as described in Ledger Execution.
- Execute sequentially each Operation in ops according to its opcode.
Operations
Opcodes
| Operation | Opcode | Description |
|---|---|---|
| CHANNEL_INSCRIBE | 0x00 | Write a message permanently onto Mantle. |
| CHANNEL_BLOB | 0x01 | Store a blob in DA. |
| CHANNEL_SET_KEYS | 0x02 | Manage the list of keys accredited to post to a channel. |
| RESERVED | 0x03 - 0x1F | |
| SDP_DECLARE | 0x20 | Declare intention to participate as a node in a Logos Blockchain Service, locking funds as collateral. |
| SDP_WITHDRAW | 0x21 | Withdraw participation from a Logos Blockchain Service, unlocking your funds in the process. |
| SDP_ACTIVE | 0x22 | Signal that you are still an active participant of a Logos Blockchain Service. |
| RESERVED | 0x23 - 0x2F | |
| LEADER_CLAIM | 0x30 | Claim leader reward anonymously. |
| RESERVED | 0x31 - 0xFF |
Full nodes will track and process every Operation. In contrast, nodes focused on a specific rollup will also track all Operations but will only fully process blobs that target their own rollup referenced by a channel ID.
Channel Operations
Channels allow Rollups to post their updates on chain. Channels form virtual chains that overlay on top of the Cryptarchia blockchain. Clients and dependents of Rollups can watch the Rollups channels to learn the state of that Rollup.
Channel Sequencing
These channels form virtual chains by having each message reference its parent message. The order of messages in these channels is enforced by the sequencer by building a hash chain of messages, i.e. new messages reference the previous messages through a parent hash. Given that Cryptarchia has long finality times, these message parent references allow the Rollup sequencers to continue to post new updates to channels without having to wait for finality. No matter how Cryptarchia forks and reorgs, the channel messages will eventually be re-included in a way that satisfies the virtual chain order.
The first time a message is sent to an unclaimed channel, the message signing key that signs the initial message becomes both the administrator and an accredited key. The administrator can update the list of accredited keys who are authorized to write messages to that channel.
Validators must keep the following state for processing channel Operations:
channels: dict[ChannelId, ChannelState]
class ChannelState:
tip: hash
accredited_keys: list[Ed25519PublicKey]
CHANNEL_INSCRIBE
Write a message to a channel with the message data being permanently stored on the Logos Blockchain.
Payload
class Inscribe:
channel: ChannelID # Channel being written to
inscription: bytes # Message to be written on the blockchain
parent: hash # Previous message in the channel
signer: Ed25519PublicKey # Identity of message sender
Proof
Ed25519Signature
Execution Gas
Channel Inscribe Operations have a fixed Execution Gas cost of EXECUTION_CHANNEL_INSCRIBE_GAS. See [Analysis] Gas Cost Determination for the Execution Gas values.
Validation
Given
txhash: zkhash
msg: Inscribe
sig: Ed25519Signature
channels: dict[ChannelID, ChannelState]
Validate
# Ensure the msg signer signature
assert Ed25519_verify(msg.signer, txhash, sig)
if msg.channel in channels:
chan = channels[msg.channel]
# Ensure signer is authorized to write to the channel
assert msg.signer is in chan.accredited_keys
# Ensure message is continuing the channel sequence
assert msg.parent == chan.tip
else:
# Channel will be created automatically upon execution
# Ensure that this message is the genesis message (parent==ZERO)
assert msg.parent == ZERO
Execution
Given
msg: Inscribe
sig: Ed25519Signature
channels: dict[ChannelId, ChannelState]
Execute
- If the channel does not exist, create it just-in-time.
if msg.channel not in channels: channels[msg.channel] = ChannelState( tip=ZERO accredited_keys=[msg.signer] ) - Update the channel tip.
chan = channels[msg.channel] chan.tip = hash(encode(msg))
Example
# Build the inscription
greeting = Inscription(
channel=CHANNEL_EARTH,
inscription=b"Live long and prosper",
parent=ZERO
signer=spock_pk
)
# Wrap it in a transaction
tx = MantleTx(
ops=[Op(opcode=INSCRIBE, payload=encode(greeting))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[<spocks_note_id>], outputs=[<change_note>]),
)
# Sign the transaction
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[Ed25519_sign(mantle_txhash(tx), spock_sk)]
ledger_tx_proof=tx.ledger_tx.prove(spock_sk)
)
# Send the transaction to the mempool
mempool.push(signed_tx)
CHANNEL_BLOB
Write a message to a channel where the message data is stored temporarily in DA Network. Data stored in DA Network will eventually expire but its commitment (BlobID) remains permanently on chain. Anyone with access to the original data can confirm that it matches this commitment.
Payload
class Blob:
channel: ChannelID # Channel we are writing this message to
session: SessionNumber # Session during which dispersal happened
blob: BlobID # Blob commitment
blob_size: int # Size of blob before encoding in bytes
da_storage_gas_price: int # 8 bytes
parent: hash # Previous message written to the channel
signer: Ed25519PublicKey # Identity of the message sender
Proof
Ed25519Signature
Execution Gas
The Execution Gas consumed by a Blob Operation is proportional to the size of the sample verified by the nodes. The bigger the sample, the harder it is to verify it. The size of this sample is:
NUMBER_OF_DA_COLUMNS = 1024 # before RS encoding
ELEMENT_SIZE = 31 # in bytes
SAMPLE_SIZE = blob_size/(NUMBER_OF_DA_COLUMNS * ELEMENT_SIZE)
Channel Blob Operations have an Execution Gas cost proportional to the blob size:
EXECUTION_CHANNEL_BLOB_BASE_GAS
+ EXECUTION_CHANNEL_BLOB_SIZED_GAS * SAMPLE_SIZE
See [Analysis] Gas Cost Determination for the Execution Gas values.
DA Storage Gas
Channel Blob Operations have a DA Storage Gas consumption proportional to Blob size:
CHANNEL_BLOB_DA_STORAGE_GAS = blob_size * da_storage_gas_price
Validation
Validators will perform DA sampling to ensure availability. From these samples, we can determine the Blob size and check that it matches what is written in the Blob payload.
Given
txhash: zkhash
msg: Blob
sig: Ed25519Signature
block_slot: int
channels: dict[ChannelID, ChannelState]
Validate
# Verify the msg signature
assert Ed25519_verify(msg.signer, txhash, sig)
if msg.channel in channels:
chan = channels[msg.channel]
# Ensure signer is authorized to write to the channel
assert msg.signer is in chan.accredited_keys
# Ensure message is continuing the channel sequence
assert msg.parent == chan.tip
else:
# Channel will be created automatically upon execution
# Ensure that this message is the Genesis message
assert msg.parent == ZERO
if DA Network.should_validate_block_availability(block_slot):
# Validate Blobs that are still held in DA
assert DA Network.validate_availability(msg.session, msg.blob)
# Derive Blob size from DA sample
actual_blob_size = DA Network.derive_blob_size(msg.blob)
assert msg.blob_size == actual_blob_size
Execution
Given
msg: Blob
sig: Ed25519Signature
channels: dict[ChannelId, ChannelState]
Execute
# If the channel does not exist, create it JIT
if msg.channel not in channels:
channels[msg.channel] = ChannelState(
tip=ZERO
accredited_keys=[msg.signer]
)
chan = channels[msg.channel]
chan.tip = hash(encode(msg))
Example
Suppose a sequencer for Rollup A wants to post a Rollup update. They would first build the Blob payload:
# Given a rollup update and the previous txhash
rollup_update: bytes = encode([tx1, tx2, tx3])
last_channel_msg_hash: hash
# The sequencer encodes the rollup update and builds the blob payload
blob_id, blob_size = DA Network.upload_blob(rollup_update)
msg = Blob(
channel=ROLLUP_A,
current_session=current_session,
blob=blob_id,
blob_size=blob_size,
da_storage_gas_price=10,
parent=last_channel_msg_hash,
signer=sequencer_pk,
)
tx = MantleTx(
ops=[Op(opcode=BLOB, payload=encode(msg))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[sequencer_funds], outputs=[<change_note>])
)
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[sequencer_sk.sign(mantle_txhash(tx))]
ledger_tx_proof=[tx.ledger_tx.prove(sequencer_sk)]
)
The Signed Mantle Transaction is then sent to DA nodes for dispersal and added to the mempool for inclusion in a block (see DA Network Dispersal ).
CHANNEL_SET_KEYS
Overwrite the list of accredited keys to post Blobs to a channel
Payload
class ChannelSetKeys:
channel: ChannelID
keys: list[Ed25519PublicKey]
Proof
Ed25519Signature # signature from `administrator` over the Mantle tx hash.
Execution Gas
Channel Set Keys Operations have a fixed Execution Gas cost of EXECUTION_CHANNEL_SET_KEYS. See [Analysis] Gas Cost Determination for the Execution Gas values.
Validation
Given
txhash: zkhash
setkeys: ChannelSetKeys
sig: Ed25519Signature
channels: dict[ChannelID, ChannelState]
Validate
# Ensure at least one key
assert len(setkeys.keys) > 0
if setkeys.channel in channels:
chan = channels[setkeys.channel]
admin_pk = chan.accredited_keys[0]
assert Ed25519_verify(txhash, admin_pk, sig)
Execution
Given
setkeys: ChannelSetKeys
channels: dict[ChannelID, ChannelState]
Execute
# Create the channel if it does not exist
if setkeys.channel not in channels:
channels[setkeys.channel] = ChannelState(
tip=CHANNEL_GENESIS,
accredited_keys=[],
)
# Update the set of accredited keys
channels[setkeys.channel].accredited_keys = setkeys.keys
Example
Suppose the administrator of Rollup A wants to add a key to the list of accredited keys:
# Given a key to add
sequencer_pk: Ed25519PublicKey
# The adminsitrator encodes the update and builds the payload
setkeys = ChannelSetKeys(
channel=ROLLUP_A,
keys=[admin_pk, sequencer_pk],
)
tx = MantleTx(
ops=[Op(opcode=CHANNEL_SET_KEYS, payload=encode(setkeys))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[admin_funds], outputs=[<change note>])
)
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[Ed25519_sign(mantle_txhash(tx), admin_sk)]
ledger_tx_proof=tx.ledger_tx.prove(admin_sk),
)
Service Declaration Protocol (SDP) Operations
These Operations implement the Service Declaration Protocol.
Validators must keep the following state when implementing SDP Operations:
locked_notes: dict[NoteID, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
class LockedNote:
declarations: set[DeclarationID]
locked_until: BlockNumber
Common SDP Structures
class ServiceType(Enum):
BN="BN" # Blend Network
DA="DA" # Data Availability
class Locator(str):
def validate(self):
assert len(self) <= 329
assert validate_multiaddr(self)
class MinStake:
stake_threshold: int # stake value
timestamp: int # block number
class ServiceParameters:
lock_period: int # number of blocks
inactivity_period: int # number of blocks
retention_period: int # number of blocks
timestamp: int # block number
class DeclarationInfo:
service: ServiceType
locators: list[Locator]
provider_id: Ed25519PublicKey
zk_id: ZkPublicKey
locked_note_id: NoteId
created: BlockNumber
active: BlockNumber
withdrawn: BlockNumber
# SDP ops updating a declaration must use monotonically increasing nonces
nonce: int
SDP_DECLARE
The service registration follows the definition given in Service Declaration Protocol - Declaration Message:
Payload
class DeclarationMessage:
service_type: ServiceType
locators: list[Locator]
provider_id: Ed25519PublicKey
zk_id: ZkPublicKey
locked_note_id: NoteId
Locked notes are introduced in Locked notes and serve as Service collaterals. They cannot be spent before the owner withdraw its participation from the declared service(s).
Proof
class DeclarationProof:
zk_sig: ZkSignature # signature proving ownership over
# locked note and zk_id
provider_sig: Ed25519Signature # signature proving ownership of provider key
see: Zero Knowledge Signature Scheme (ZkSignature).
Execution Gas
SDP Declare Operations have a fixed Execution Gas cost of EXECUTION_SDP_DECLARE_GAS. See [Analysis] Gas Cost Determination for the Execution Gas values.
Validation
Given
txhash: zkhash # the txhash of the transaction we are validating
declaration: DeclarationMessage # the declaration we are validating
proof: DeclarationProof
min_stake: MinStake # the (global) minimum stake setting
ledger: Ledger # the set of unspent notes
locked_notes: dict[NoteId, LockedNote]
declarations: dict[NoteId, DeclarationInfo]
Validate
The declaration is verified according to Service Declaration Protocol - Declare.
- Ensure ownership over the locked note, zk_id and provider_id.
assert ZkSignature_verify( txhash, proof.zk_sig, [note.public_key, declaration.zk_id] ) assert Ed25519_verify(txhash, proof.provider_sig, provider_id) - Ensure declaration does not already exist.
assert declaration_id(declaration) not in declarations - Ensure it has no more than 8 locators.
assert len(declaration.locators) <= 8 - Ensure locked note exists and value of locked note is sufficient for joining the service.
assert ledger.is_unspent(declaration.locked_note_id) note = ledger.get_note(declaration.locked_note_id) assert note.value >= min_stake.stake_threshold - Ensure the note has not already been locked for this service.
if declaration.locked_note in locked_notes: locked_note = locked_notes[declaration.locked_note] services = [declarations[declare_id] for declare_id in locked_note.declarations] assert declaration.service_type not in services
Execution
Given
declaration: DeclarationMessage # the declaration we are executing
service_parameters: dict[ServiceType, ServiceParameters]
current_block_height: int
locked_notes : dict[NoteId, LockedNote]
Execute
- Create the locked note state if it doesn't already exist.
if declaration.locked_note not in locked_notes: locked_notes[declaration.locked_note_id] = \ LockedNote(declarations=set(), locked_until=0) locked_note = locked_notes[declaration.locked_note_id] - Update the locked notes timeout using this services lock period.
lock_period = service_parameters[declaration.service_type].lock_period service_lock = current_block_height + lock_period locked_note.locked_until = max(service_lock, locked_note.locked_until) - Add this declaration to the locked note.
declare_id = declaration_id(declaration) locked_note.declarations.add(declare_id) - Store the declaration as explained in Service Declaration Protocol - Declaration Storage.
declarations[declare_id] = DeclarationInfo( service: declaration.service locators: declaration.locators provider_id: declaration.provider_id zk_id: declaration.zk_id locked_note_id: declaration.locked_note_id declaration, created=current_block_height, active=current_block_height, withdrawn=0 nonce=0 )
Notice that locked notes cannot refresh their keys to update their slot secrets required for Proof of Leadership participation (see Proof of Leadership - Protection Against Adaptive Adversaries). It's recommended to refresh the note before locking it, which guarantees a key life of more than a year. After this period, the note cannot be used in PoL until its private key is refreshed (see leader key setup).
Example
# Assume `alice_note` is in the ledger:
alice_note = Utxo(
txhash=0x2948904F2F0F479B8F8197694B30184B0D2ED1C1CD2A1EC0FB85D299A192A447,
output_number=3,
note=Note(value=500, public_key=alice_pk_1),
)
# Alice wishes to lock it to join the DA network
declaration=DeclarationMessage(
service_type=ServiceType.DA,
locators=["/ip4/203.0.113.10/tcp/4001/p2p"],
provider_id=alice_provider_pk,
zk_id=alice_pk_2,
locked_note_id=alice_note.id()
)
tx = MantleTx(
ops=[Op(opcode=SDP_DECLARE, payload=encode(declaration))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[fee_note_id], outputs=[]),
)
txhash = mantle_txhash(tx)
declaration_proof = DeclarationProof(
# proof of ownership of the staked note and zk_id
zk_sig=ZkSignature([alice_sk_1, alice_sk_2], txhash),
# proof of ownership of the provider id
provider_sig=Ed25519Signature(alice_provider_sk, txhash),
)
SignedMantleTx(
tx=tx,
ledger_tx_proof=LedgerTxProof,
op_proofs=[declaration_proof],
ledger_proof=prove_ledger_tx(tx.ledger_tx, [alice_sk_1]),
)
SDP_WITHDRAW
The service withdrawal follows the definition given in Service Declaration Protocol - Withdraw Message.
Payload
class WithdrawMessage:
declaration: DeclarationID
locked_note_id: NoteId
nonce: int
Proof
A signature from the zk_id and the locked note pk attached to the declaration is required for withdrawing from a service, (see Zero Knowledge Signature Scheme (ZkSignature)).
ZkSignature
Execution Gas
SDP Withdraw Operations have a fixed Execution Gas cost of EXECUTION_SDP_WITHDRAW_GAS. See [Analysis] Gas Cost Determination for the Execution Gas values.
Validation
Given
txhash: zkhash # Mantle transaction hash of the tx containing this operation
withdraw: WithdrawMessage
signature: ZkSignature
block_height: int # block height of the current block
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
Validate
- Ensure that the locked note exists, is locked and bound to this declaration.
assert ledger.is_unspent(withdraw.locked_note_id) assert withdraw.locked_note_id in locked_notes locked_note = locked_notes[withdraw.locked_note_id] assert withdraw.declaration in locked_note.declarations - Ensure that the locked note has expired.
assert locked_note.locked_until <= block_height - Validate SDP withdrawal according to Service Declaration Protocol - Withdraw.
- Ensure declaration exists.
assert withdraw.declaration in declarations declare_info = declarations[withdraw.declaration] - Ensure locked note pk and zk_id attached to this declaration authorized this Operation.
locked_note = ledger[withdraw.locked_note_id] assert ZkSignature_verify(txhash, signature, [locked_note.pk, declare_info.zk_id]) - Ensure the declaration has not already been withdrawn.
assert declare_info.withdrawn == 0 - Ensure that the nonce is greater than the previous one.
assert withdraw.nonce > declare_info.nonce
- Ensure declaration exists.
Execution
Given
withdraw: WithdrawMessage
signature: ZkSignature
block_height: int # block height of the current block
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
Execute
Executes the withdrawal protocol Service Declaration Protocol - Withdraw.
- Update declaration info with nonce and withdrawn timestamp.
declare_info = declarations[withdraw.declaration] declare_info.nonce = withdraw.nonce declare_info.withdrawn = block_height - Remove this declaration from the locked note.
locked_note = locked_notes[withdraw.locked_note_id] locked_note.declarations.remove(withdraw.declaration) - Remove the locked note if it is no longer bound to any declarations.
if len(locked_note.declarations) == 0: del locked_notes[withdraw.locked_note_id)
Example
withdraw=Withdraw(
declaration=alice_declaration_id,
locked_note_id=alices_locked_note_id
nonce=1579532
)
tx = MantleTx(
ops=[Op(opcode=SDP_WITHDRAW, payload=encode(withdraw))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(
inputs=[alices_locked_note_id],
outputs=[Note(100, alice_note_pk)]
),
)
SignedMantleTx(
tx=tx,
ledger_tx_proof= tx.ledger_tx.prove(alice_sk),
# proof ownership of the withdrawn note and zk id
op_proofs=[ZkSignature_sign([alice_note_sk, alice_sk], mantle_txhash(tx))]
)
SDP_ACTIVE
The service active action follows the definition given in Service Declaration Protocol - Active Message.
Payload
class Active:
declaration: DeclarationID
nonce: int
metadata: bytes # a service-specific node activeness metadata
Proof
ZkSignature
Execution Gas
SDP Active Operations have a fixed Execution Gas cost of EXECUTION_SDP_ACTIVE_GAS. See [Analysis] Gas Cost Determination for the Execution Gas values.
Validation
Given
txhash: zkhash # Mantle transaction hash of the tx containing this operation
active: Active
signature: ZkSignature
declarations: dict[DeclarationId, DeclarationInfo]
Validate
assert active.declaration in declarations
declaration_info = declarations[active.declaration]
assert active.nonce > declaration_info.nonce
assert ZkSignature_verify(txhash, signature, declaration_info.zk_id)
Execution
Executes the active protocol Service Declaration Protocol - Active. The activation, i.e. setting the declaration.active, is handled by the service-specific logic.
Example
active=Active(
declaration=alice_declaration_id,
nonce=1579532,
metadata=b"Look, I am still doing my job"
)
tx = MantleTx(
ops=[Op(opcode=SDP_ACTIVE, payload=encode(active))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[fee_note_id], outputs=[]),
)
txhash = mantle_txhash(tx)
SignedMantleTx(
tx=tx,
ledger_tx_proof=tx.ledger_tx.prove(fee_note_sk),
op_proofs=[Ed25519_sign(txhash, validator_sk)]
)
Leader Operations
LEADER_CLAIM
This Operation claims the leader's block reward anonymously.
Payload
class ClaimRequest:
rewards_root: zkhash # Merkle root used in the proof for voucher membership
voucher_nf: zkhash
Proof
The provider proves that they have won a proof of Leadership before the start of the current epoch, i.e., their reward voucher is indeed in the voucher set: Proof of Claim.
Execution gas
Leader Claim Operations have a fixed Execution Gas cost of EXECUTION_LEADER_CLAIM_GAS. See [Analysis] Gas Cost Determination for the Execution Gas values.
Validation
# Given
mantle_txhash: zkhash
claim : ClaimRequest
last_voucher_root: zkhash # The last root of the voucher Merkle tree
# at the start of the epoch
voucher_nullifier_set: set[zkhash]
proof: ProofOfClaim
# Validate
assert claim.voucher_nf not in voucher_nullifier_set
assert claim.rewards_root == last_voucher_root
validate_proof(claim, proof, mantle_txhash)
Execution
- Add claim.voucher_nf to the voucher_nullifier_set .
- Increase the balance of the Mantle Transaction by the leader reward amount according to Anonymous Leaders Reward Protocol - Leaders Reward.
- Reduce the leaders reward leaders_rewards value by the same amount (without ZK proof). Example
secret_voucher = 0xDEADBEAF;
reward_voucher = leader_claim_voucher(secret_voucher)
voucher_nullifier = leader_claim_nullifier(secret_voucher)
claim=ClaimRequest(
rewards_root=REWARDS_MERKLE_TREE.root(),
voucher_nf=voucher_nullifier,
)
tx = MantleTx(
ops=[Op(opcode=LEADER_CLAIM, payload=encode(claim))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[<fee_note>], outputs=[<change_note>]),
)
claim_proof = claim.prove(
secret_voucher,
REWARDS_MERKLE_TREE.path(leaf=reward_voucher),
mantle_txhash(tx)
)
SignedMantleTx(
tx=tx,
ledger_tx_proof=tx.ledger_tx.prove(fee_note_sk),
op_proofs=[claim_proof]
)
Mantle Ledger
Notes
Notes are composed of two fields representing their value and their owner:
class Note:
value: int # 8 bytes
public_key: ZkPublicKey # 32 bytes
Note Id
Any note can be uniquely identified by the Ledger Transaction that created it and its output number: (txhash, output_number). However, it is often useful to have a commitment to the note fields for use in ZK proofs (e.g., for PoL), so we include the note in the note identifier derivation.
def derive_note_id(txhash: zkhash, output_number: int, note: Note) -> NoteId:
return zkhash(
FiniteField(b"LOGOS_NOTE_ID_V1", byte_order="little", modulus= p)
txhash,
FiniteField(output_number, byte_order="little", modulus= p)
FiniteField(note.value, byte_order="little", modulus= p)
note.public_key
)
These note identifiers uniquely define notes in the system and cannot be chosen by the user. Nodes maintain the set of notes through a dictionary mapping the NoteId to the note.
Locked notes
Locked notes are special notes in Mantle that serve as collateral for Service Declarations. A note can become locked after executing a Declare Operation, preventing it from being spent until explicitly released through a Withdraw Operation. The system maintains a mapping of locked note IDs to their supporting declarations. Though locked, these notes remain in the Ledger and can still participate in Proof of Stake. When service providers withdraw all their declarations, the associated note(s) become unlocked and available for spending again.
Ledger Transactions
Transactions must prove the ownership of spent notes. In classical blockchains, this is done through a signature. To stay compatible with our architecture, the signature is done by a ZK proof (see Zero Knowledge Signature Scheme (ZkSignature)), proving the knowledge of the secret key associated with the public key.
Transactions allow complete transaction linkability and the public key spending the note is not hidden.
Structure
class LedgerTx:
inputs: list[NoteId] # the list of consumed note identifiers
outputs: list[Note]
Proof
A transaction proves the ownership of the consumed notes using a Zero Knowledge Signature Scheme (ZkSignature)
ZkSignature
Execution Gas
Ledger Transactions have a fixed Execution Gas cost of EXECUTION_LEDGER_TX_GAS. See [Analysis] Gas Cost Determination for the Execution Gas values.
Ledger Transaction Hash
def ledger_txhash(tx: LedgerTx) -> ZkHash:
tx_bytes = encode(tx)
h = Hasher()
h.update(FiniteField(b"LOGOS_LEDGER_TXHASH_V1", byte_order="little", modulus=p))
for i in range((len(tx_bytes)+30)//31):
chunk = tx_bytes[i*31:(i+1)*31]
fr = FiniteField(chunk, byte_order="little", modulus=p)
h.update(fr)
return h.digest()
Ledger Validation
Given
mantle_txhash: ZkHash # ZkHash of mantle tx containing this ledger tx
ledger_tx: LedgerTx
ledger_tx_proof: ZkSignature
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
Validate
- Ensure all inputs are unspent.
assert all(ledger.is_unspent(note_id) for note_id in ledger_tx.inputs) - Validate ledger proof to show ownership over input notes.
input_notes = [ledger[input_note_id] for input_note_id in ledger_tx.inputs] input_pks = [note.public_key for note in input_notes] assert ZkSignature_verify(mantle_txhash, ledger_tx_proof, input_pks) - Ensure inputs are not locked.
# Ensure inputs are not locked for note_id in ledger_tx.inputs: assert note_id not in locked_notes - Ensure outputs are valid.
for output in ledger_tx.outputs: assert output.value > 0 assert output.value < 2**64
Ledger Execution
Given
ledger_tx: LedgerTx
ledger_tx_proof: ZkSignature
ledger: Ledger
Execution
- Remove inputs from the ledger.
for note_id in ledger_tx.inputs: # updates the merkle tree to zero out the leaf for this entry # and adds that leaf index to the list of unused leaves ledger.remove(note_id) - Add outputs to the ledger.
txhash = ledger_txhash(ledger_tx) for (output_number, output_note) in enumerate(tx.outputs): output_note_id = derive_note_id(txhash, output_number, output_note) ledger.add(output_note_id)
Ledger Example
alice_note_id = ... # assume Alice holds a note worth 501 NMO
bob_note=Note(
value=500
public_key=bob_pk,
)
ledger_tx = LedgerTx(
inputs=[alice_note_id],
outputs=[bob_note],
)
Appendix
Gas Determination
From the [Analysis] Gas Cost Determination, we get the table below:
| Variable | Value |
|---|---|
| EXECUTION_LEDGER_TX_GAS | 590 |
| EXECUTION_CHANNEL_INSCRIBE_GAS | 56 |
| EXECUTION_CHANNEL_BLOB_BASE_GAS | 6356 |
| EXECUTION_CHANNEL_BLOB_SIZED_GAS | 1600 |
| EXECUTION_CHANNEL_SET_KEYS | 56 |
| EXECUTION_SDP_DECLARE_GAS | 646 |
| EXECUTION_SDP_WITHDRAW_GAS | 590 |
| EXECUTION_SDP_ACTIVE_GAS | 590 |
| EXECUTION_LEADER_CLAIM_GAS | 580 |
Zero Knowledge Signature Scheme (ZkSignature)
A proof attesting that for the following public values:
class ZkSignaturePublic:
public_keys: list[ZkPublicKey] # public keys signing the message (len = 32)
msg: zkhash # zkhash of the message
The prover knows a witness:
class ZkSignatureWitness:
# The list of secret keys used to signed the message
secret_keys: list[ZkSecretKey] # (len = 32)
Such that the following constraints hold:
- The number of secret keys is equal to the number of public keys.
assert len(secret_keys) == len(public_keys) - Each public key is derived from the corresponding secret key.
assert all( notes[i].public_key == zkhash( FiniteField(b"LOGOS_KDF", byte_order="little", modulus= p), secret_keys[i]) for i in range(len(public_keys)) ) - The proof is bound to msg (its the mantle_tx_hash in case of transactions).
For implementation, the ZkSignature circuit will take a maximum of 32 public keys as inputs. To prove ownership of fewer keys, the remaining inputs will be padded with the public key corresponding to the secret key 0 and ignored during execution. The outputs have no size limit since they are included in the hashed message.
Benchmark
The material used for the benchmarks is the following:
- CPU : 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM : 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS : Ubuntu 22.04.5 LTS
- Kernel : 6.8.0-59-generic
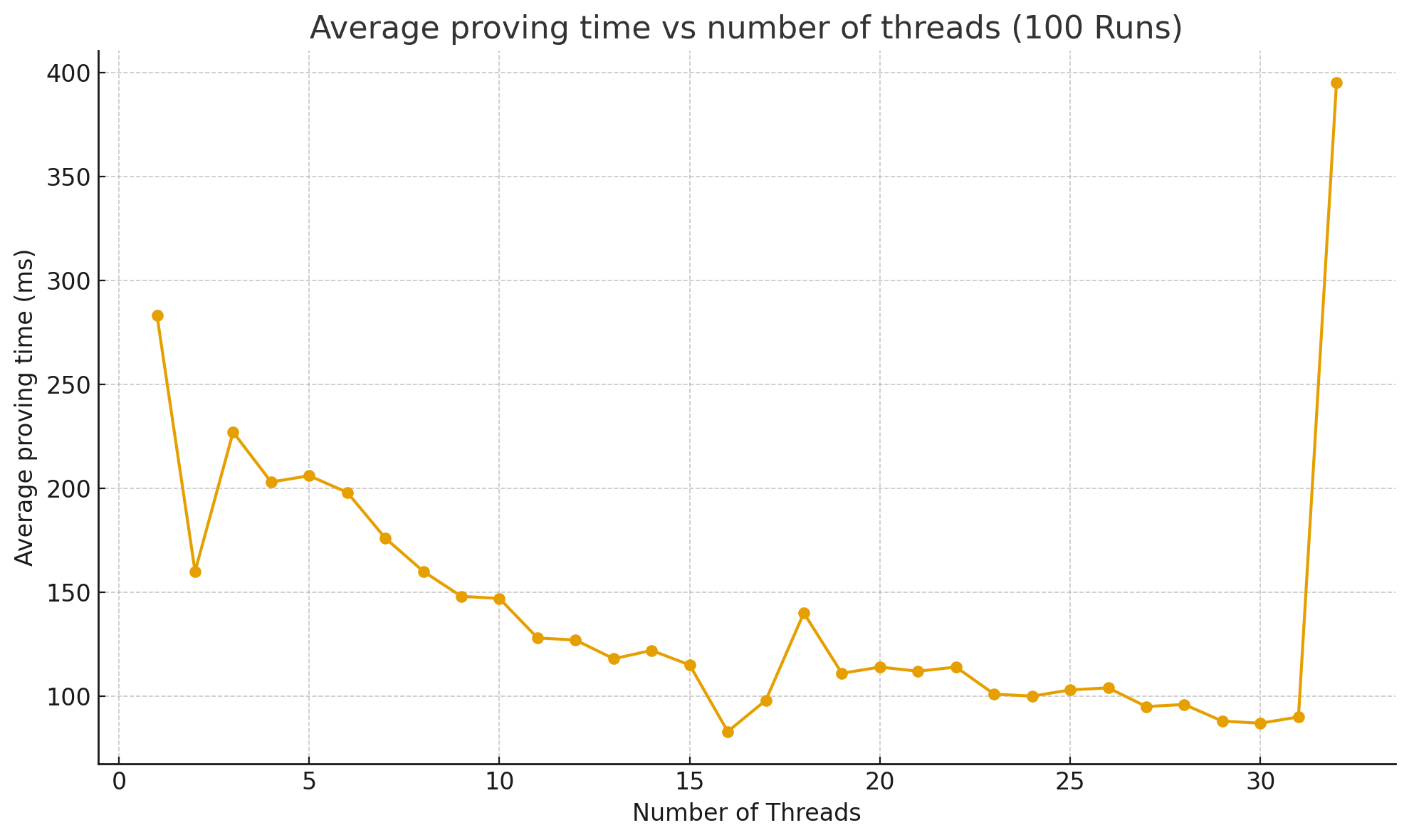
Proof of Claim
A proof attesting that given these public values:
class ProofOfClaimPublic:
voucher_root: zkhash # Merkle root of the reward_voucher maintained by everyone
voucher_nullifier: zkhash
mantle_tx_hash: zkhash # attached hash
The prover knows the following witness:
class ProofOfClaimWitness:
secret_voucher: zkhash
voucher_merkle_path: list[zkhash]
voucher_merkle_path_selectors: list[bool]
such that the following constraints hold:
- The reward voucher is derived from the secret voucher.
assert reward_voucher == zkhash( FiniteField(b"REWARD_VOUCHER", byte_order="little", modulus= p), secret_voucher) - There exists a valid Merkle path from the reward voucher as a leaf to the Merkle root.
assert voucher_root == path_root(leaf=reward_voucher, path=voucher_merkle_path, selectors=voucher_merkle_path_selectors) - The voucher nullifier is derived from the secret voucher correctly.
assert voucher_nullifier == zkhash( FiniteField(b"VOUCHER_NF", byte_order="little", modulus= p), secret_voucher) - The proof is bound to the mantle_tx_hash.
Benchmark
The material used for the benchmarks is the following:
- CPU : 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM : 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS : Ubuntu 22.04.5 LTS
- Kernel : 6.8.0-59-generic
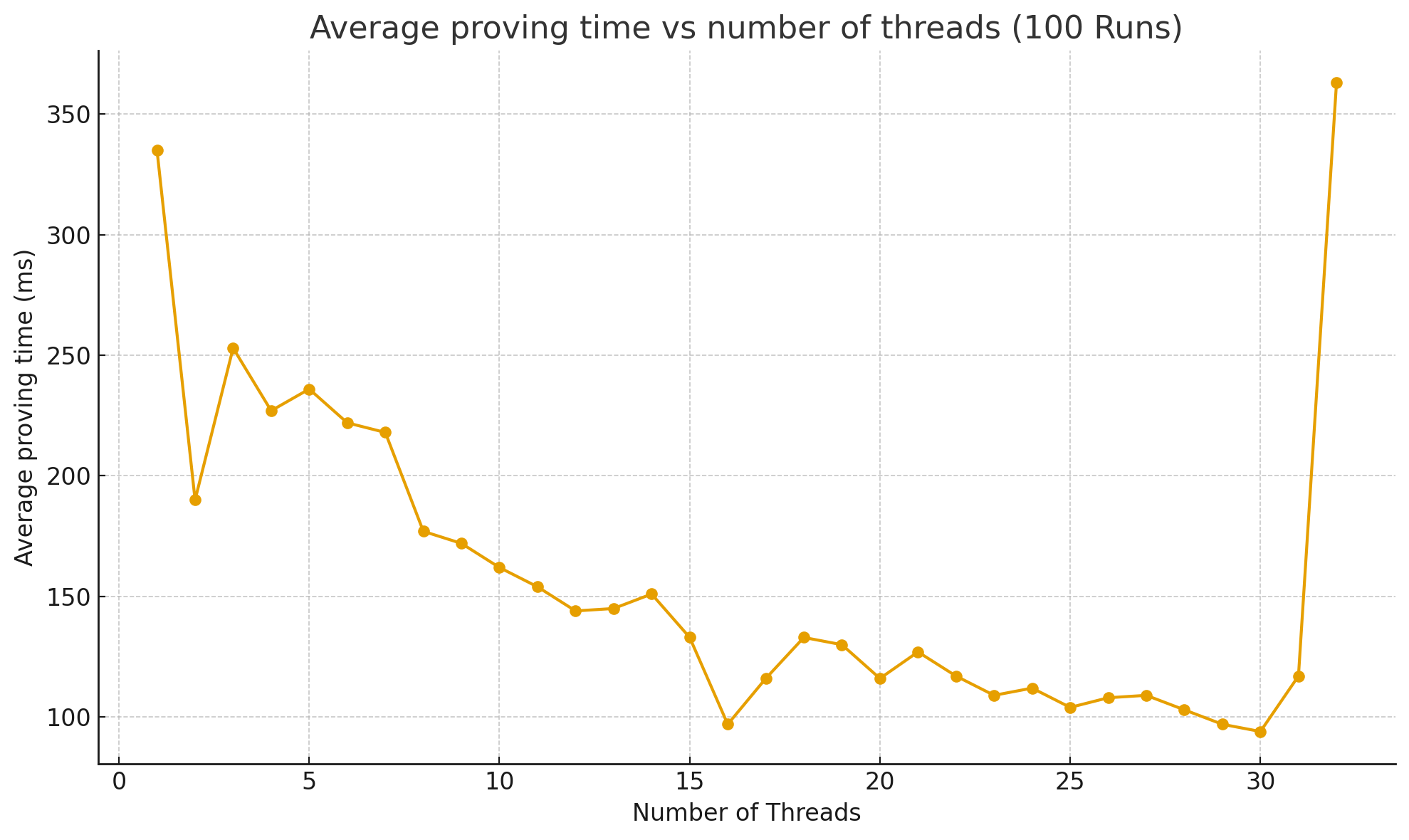
V1.1.0-MANTLE-TRANSACTION-ENCODING
| Field | Value |
|---|---|
| Name | Mantle Transaction Encoding |
| Slug | 224 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | David Rusu [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Owner: @David Rusu
Reviewers: @Thomas Lavaur @Giacomo Pasini @Gusto Bacvinka @Daniel Sanchez Quiros @lvaro Castro-Castilla
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-01-20 |
| 1.1.0 | Added [RFC] Make Ledger Transaction an Operation | 2026-04-02 |
Introduction
This document specifies the canonical encoding of Mantle transactions (see Mantle - Mantle Transaction) and its sub-components. Transactions sent through the mempool and included in blocks use this encoding.
Overview
The transaction encoding is specified in ABNF form to remove any ambiguity and guarantee a canonical encoding. The high level encoding choices which were not immediately derivable from the Mantle specification are listed here:
- All multi-byte integers use little-endian encoding
- Any lists are length-prefixed with fixed width uints
- We derive number of proofs and type of proof from the Ops list parsed earlier
Specification
Signed Mantle Tx
SignedMantleTx = MantleTx OpsProofs
Mantle Tx
MantleTx = Ops ExecutionGasPrice StorageGasPrice
ExecutionGasPrice = UINT64
StorageGasPrice = UINT64
In future iterations, we will use this encoding to derive the mantle_txhash
Operations
Ops = OpCount *Op
OpCount = Byte
Op = Opcode OpPayload
Opcode = Byte
OpPayload = Transfer /
ChannelInscribe /
ChannelBlob /
ChannelSetKeys /
SDPDeclare /
SDPWithdraw /
SDPActive /
LeaderClaim
Channel Operations
ChannelInscribe = ChannelId Inscription Parent Signer
Inscription = UINT32 *BYTE
ChannelBlob = ChannelId Session BlobId BlobSize DaStorageGasPrice Parent Signer
Sesssion = UINT64
BlobId = Hash32
BlobSize = UINT64
DaStorageGasPrice = UINT64
ChannelSetKeys = ChannelId KeyCount *Signer
KeyCount = Byte
ChannelId = Hash32
Parent = Hash32
Signer = Ed25519PublicKey
SDP Operations
SDPDeclare = ServiceType LocatorCount *Locator ProviderId ZkId LockedNoteId
ServiceType = Byte ; 0 = BN, 1 = DA
LocatorCount = Byte ; Max 8
Locator = 2Byte *BYTE ; Max 329 bytes, multiaddr format
ProviderId = Ed25519PublicKey
ZkId = ZkPublicKey
LockedNoteId = NoteId
SDPWithdraw = DeclarationId Nonce LockedNoteId
DeclarationId = Hash32
Nonce = UINT64
SDPActive = DeclarationId Nonce Metadata
Metadata = UINT32 *BYTE ; Service-specific node activeness metadata
Leader operations
LeaderClaim = RewardsRoot VoucherNullifier
RewardsRoot = FieldElement ; Merkle root for voucher membership proof
VoucherNullifier = FieldElement
Transfer Operations
Transfer = Inputs Outputs
Inputs = InputCount *NoteId
InputCount = Byte
Outputs = OutputCount *Note
OutputCount = Byte
Note = Value ZkPublicKey
Value = UINT64
NoteId = FieldElement
Op Proofs
OpsProofs = *OpProof ; 1. Lenth must equal OpCount
; 2. OpProof variant is derived from the corresponding Op.
; That is, type(OpProofs[i]) == ProofFor(Op[i])
OpProof = Ed25519SigProof /
ZkSigProof /
ZkAndEd25519SigsProof /
ProofOfClaimProof
Ed25519SigProof = Ed25519Signature
ZkSigProof = ZkSignature
ZkAndEd25519SigsProof = ZkSignature Ed25519Signature
ProofOfClaimProof = Groth16
Common Structures
; Zero-knowledge signature
ZkSignature = Groth16
; Cryptographic primitives
Groth16 = 128BYTE ; pi_a (32) + pi_b (64) + pi_c (32)
ZkPublicKey = FieldElement
Ed25519PublicKey = 32BYTE
Ed25519Signature = 64BYTE
FieldElement = 32BYTE ; BN254 field element (little-endian)
Hash32 = 32BYTE
; Primitive types
UINT64 = 8BYTE ; 64-bit unsigned integer, little-endian
UINT32 = 4BYTE ; 32-bit unsigned integer, little-endian
Byte = OCTET
V1.1.0-BEDROCK-SERVICE-REWARD-DISTRIBUTION
| Field | Value |
|---|---|
| Name | Service Reward Distribution Protocol |
| Slug | 223 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Thomas Lavaur [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-11-03 |
| 1.1.0 | Removed references to DA Replaced references to Nomos with Logos Blockchain | 2026-04-17 |
Introduction
The Logos Blockchain relies on multiple services, including the Blend Network - each operated by independent validator sets. For sustainability and fairness, these services must compensate service validators based on their participation. Validators first declare their participation through Service Declaration Protocol. The Service Reward Distribution Protocol enables deterministic, efficient, and verifiable reward distribution to validators based on their activity within each service.
Each service defines:
- The session length, a fixed number of blocks during which its validator set remains unchanged.
- The validator activity rule that distinguishes between active and inactive validators.
- The reward formula for distributing the sessions rewards at the end of the session.
This document describes the protocol's logic for deterministically distributing rewards through Mantle Transactions for services.
Overview
The protocol unfolds over three key phases, aligned with validator sessions:
- Service Activity Tracking (Session N+1): Service validators submit signed activity messages to attest to their participation of session N through a Mantle Transaction, including an activity message (see Mantle - SDP_ACTIVE).
- Service Reward Derivation (End of Session N+1): Nodes compute each validators reward based on validated activity messages and the different service reward policies.
- Service Reward Distribution (First block of session N+2): Rewards are distributed to validators marked as active for the service. This is done by inserting new notes in the ledger corresponding to the reward amount for each active validator.
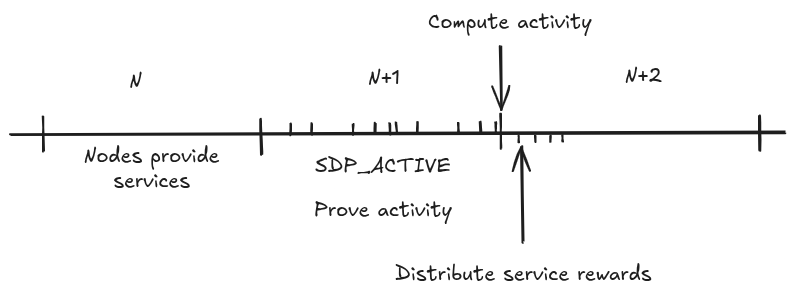
Core Properties:
- Service rewards are distributed to the zk_id from validator Service Declaration Protocol - Declaration Messages.
- Minimal Block Overhead: rewards are directly added to the ledger without involving Mantle Transactions.
Protocol
Sessions
Each service defines its own session length (e.g., 10000 blocks), during which:
- The service validator set remains static.
- Activity criteria and reward policy are fixed.
Activity tracking
Throughout session N+1, the block proposers integrate Mantle Transactions containing Mantle - SDP_ACTIVE Operations. These transactions originate from service validators and are used to derive their activity according to the service provided policy (see Service Declaration Protocol - Active). The protocol does not prescribe a unique activity rule: each service defines what qualifies as valid participation, enabling flexibility across different services.
Service validators are economically incentivized to participate actively since only active validators will be rewarded. Moreover, by decoupling activity submission from reward calculation, the system remains robust to network latency.
This generalized mechanism accommodates a wide range of services without requiring specialized infrastructure. It enables services to evolve their own activity rules independently while preserving a shared framework for reward distribution.
Service Reward Calculation
At the end of session N+1, service rewards for the validator n for the session N are computed by the different services taking as input the rewards of the session:
Where are the total rewards of session N. The is determined by the service, which calculates how much each service receives based on fees burnt during session N and the blockchain's state. is stored as an array that maps each validator's zk_id to their allocated reward.
Service Reward Distribution
Starting immediately after session N+1, service rewards are distributed in the first block of session N+2. The rewards are inserted directly in the ledger without triggering any Mantle validation. The note Id is computed using the result of zkhash(FiniteField(ServiceType, byte_order="little", modulus= p) || session_number) as the transaction hash. The output number corresponds to the position of the zk_id when sorted in ascending order.
The reward must:
- Transfer the correct reward amount according to Service Reward Calculation.2
- Be sent to the public key zk_id of the validator registered during declaration of the service (see Service Declaration Protocol - Declaration Message).
- Be distributed into a single note if several rewards share the same zk_id.
- Be executed identically by every node processing the first block of session N+2. This happens by inserting notes in the ledger in ascending order of zk_id. Nodes indirectly verify the correct inclusion of rewards because all consensus-validating nodes must maintain the same ledger view to derive the latest ledger root, which serves as input for verifying the Proof of Leadership.
V1.1.0-TEMPLATE-CROSS-CHANNEL-MESSAGING
| Field | Value |
|---|---|
| Name | [Template] Cross-Channel Messaging |
| Slug | 226 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Thomas Lavaur [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Owner: @Thomas Lavaur
Reviewers: @Daniel Kashepava @Youngjoon Lee @Mehmet @Marcin Pawlowski @David Rusu
Revisions History
| Version | Changes |
|---|---|
| v1 | Initial version. |
| v1.1 | Added [RFC] Enforce NoteId uniqueness. |
Introduction
This document outlines the cross-channel messaging framework. A channel is a reserved identifier where only authorized keys can post messages on-chain, while anyone can read them. Cross-channel messaging allows different channels (including channels representing a Zone) to communicate and coordinate actions (such as Zone state transitions), enabling interoperability while maintaining security and decentralization.
Reference: Mantle.
Objectives
The primary objectives of this framework are to:
- Enable secure communication between different channels without compromising decentralization.
- Support both synchronous and asynchronous messaging patterns to accommodate different use cases and trust assumptions.
- Provide a standard message format while allowing flexibility for custom implementations.
- Provide atomicity guarantees for cross-channel operations when required.
Requirements
The cross-channel messaging framework must satisfy the following requirements:
- Synchronous operations must provide atomicity guarantees (all-or-nothing execution).
- Asynchronous operations must handle finality periods correctly.
- The framework should be flexible enough to support various channel implementations.
Overview
Cross-channel messaging allows different channels to interact and coordinate. The framework supports two distinct messaging modes.
- Asynchronous Messaging: Channels send messages to each other without requiring real-time and/or off-chain coordination. The receiving channel waits for the sending channels message to achieve finality on the chain before processing it. This approach minimizes coordination overhead but introduces latency due to finality requirements.
- Synchronous Messaging: Multiple channels coordinate to include their messages in a single Mantle Transaction. All messages in the transaction either succeed or fail together, providing strong consistency guarantees. This requires off-chain coordination between sequencers but enables use cases like atomic Zone state transitions. Since each Inscription Operation proof is a signature of the entire Mantle Transaction hash, the signature cannot be reused in a different context, for example, posting an Inscription alone after signing it as part of a coordinated transaction.
| Pros | Cons | |
|---|---|---|
| Asynchronous messaging | - Simple coordination model. - Channels operate independently. - Higher decentralization (no trusted coordinator). | - Higher latency due to waiting for finality. - No atomicity across channels (possible partial failures). |
| Synchronous messaging | - Strong atomicity guarantees across channels (all-or-nothing). - Lower end-to-end latency vs waiting for async finality. - Better suited for cross-channel financial operations (atomic swaps, cross-channel transfers). | - Requires off-chain coordination between sequencers. - Depends on availability of all participating sequencers. - More complex orchestration and implementation. |
The coordinator typically pays fees and must be trusted for timing of submission. Channel designers should implement mechanisms if they want to share these fees, either by:
- Requesting to cover a part of the coordinator's fee costs as part of the operation (e.g., including fee reimbursement in a Zone's state transition logic).
- Establishing external fee recovery protocols where the coordinator is compensated through off-chain agreements or separate on-chain transactions.
- Using a shared note to pay using a threshold Eddsa25519 public key.
Use Cases
Channels should choose between synchronous and asynchronous messaging based on their requirements:
Use Synchronous Messaging when:
- Atomicity is required (operations must all succeed or all fail).
- Low latency is important (faster than waiting for asynchronous finality).
- Coordinating sequencers have established trust and communication pathways.
- The use case justifies the additional coordination complexity.
Use Asynchronous Messaging when:
- Operations can be processed independently.
- Simplicity and decentralization are prioritized over latency.
- Sequencer coordination is difficult or undesirable.
- The application can handle eventual consistency.
Message Flow
Cross-channel messaging follows this general flow:
- The source channel's sequencer generates a message for one or more destination channels.
- The message is included in a Mantle Transaction (through an InscriptionOperation):
- For asynchronous messaging: the channel's sequencer includes it in a separate transaction.
- For synchronous messaging: a coordinator gathers Operations from different channel sequencers and includes them in a common transaction.
- Once the Mantle Transaction is built, each channel sequencer signs their Operation using the Mantle Transaction hash as input.
- The transaction is submitted to the chain:
- For asynchronous messaging: by the channel's sequencer.
- For synchronous messaging: by the coordinator.
Protocol
Asynchronous Messaging
Asynchronous messaging allows channels to send messages to each other without requiring real-time and off-chain coordination between sequencers. This mode prioritizes simplicity and independent operation over low latency and atomicity.
Message Format
We provide a recommended data structure for formatting messages in Inscriptions. This structure uses compact binary encoding to minimize on-chain storage costs while clearly indicating the message recipient:
Inscription = MessageCount *Messages
MessageCount = Byte
Messages = Destination MessageLength *Message
Destination = ChannelId
MessageLength = UINT64
Message = UINT32 *Byte
ChannelId = 4 *Byte
The structure consists of:
- MessageCount: A single byte indicating the number of messages in this Inscription (supports up to 255 messages).
- Destination: A 32-byte number identifying the target channel.
- MessageLength: An 4-byte unsigned integer specifying the total length of all messages for this destination in bytes.
- Message: The actual message payload, prefixed by a 3-byte length field indicating the size of each individual message in bytes.
Note on Format Flexibility: This structure is not enforced by the blockchain. It serves as a recommended standard for interoperability. Channels can choose to:
- Parse messages themselves according to this format.
- Implement their own custom message formats based on specific requirements. However, following the recommended format ensures better interoperability with other channels in the ecosystem.
Processing Flow
The asynchronous messaging process follows these steps:
- Message Creation: The source channels sequencer creates a message according to the recommended format (or their custom format) and includes it in an Inscription within a Mantle Transaction.
- Transaction Submission: The sequencer signs the Operation and submits the Mantle Transaction to the chain independently.
- Finality Wait: The transaction propagates through the network and eventually achieves finality on-chain. This guarantee that this transaction wont be reverted due to a reorganization.
- Message Observation: Destination channels sequencers monitor the chain for messages addressed to their ChannelId. When a relevant message is detected and has achieved finality, the channel can safely process it.
- State Transition: The destination channel checks that the message is valid and publishes a corresponding state transition in its own Inscription.
Destination SequencerBedrockSource SequencerDestination SequencerBedrockSource SequencerTransaction is propagatedand eventually finalized1. Generate cross-channel message(for one or more destination channels)12. Include message in Mantle Tx(Inscription Operation)24. Submit Mantle Transaction to chain3Destination channel sequencer observesfinalized inscription(s) to its ChannelId4Validate message, applycorresponding state change5
Security Considerations
Asynchronous messaging relies on the finality guarantees of the underlying chain. Destination channels must:
- Wait for sufficient confirmation before processing messages to avoid issues with chain reorganizations. Channels can choose a specific probability threshold or wait for finality to achieve a 100% guarantee.
- Since the chain does not verify channels' Inscriptions, the destination channel must understand the source channel's logic to determine whether the message is valid.
Synchronous Messaging
Synchronous messaging enables atomic cross-channel operations by including multiple messages in a single Mantle Transaction. All messages either succeed or fail together, providing strong consistency guarantees across multiple channels.
Atomicity Guarantees
The atomicity property is crucial for use cases that require coordinated changes across multiple channels. Examples include:
- Atomic swaps: Trading assets between two zones where both transfers must succeed or both must fail. It involves executing a CHANNEL_WITHDRAW, a CHANNEL_DEPOSIT and two state transitions encoded as CHANNEL_INSCRIPTION.
- Cross-channel funds transfers: Moving assets from one channel to another with guarantees that the asset is directly deposited to the other channel.
Without atomicity, these operations would be vulnerable to partial failures, leading to inconsistent global state.
Example of an atomic transfer
# Build the inscription that sends a transfer from Zone A to Zone B
sending = Inscription(
channel=CHANNEL_ZONE_A,
inscription=b"Alice burns 5 tokens to send to Bob in Zone B",
parent=hash(PREVIOUS_ZONE_A_INSCRIPTION)
signer=sequencer_of_zone_a
)
# Build the inscription that receives the transfer from Zone A to Zone B
receiving = Inscription(
channel=CHANNEL_ZONE_B,
inscription=b"Bob mints 5 tokens, received from Alice in Zone A",
parent=hash(PREVIOUS_ZONE_B_INSCRIPTION)
signer=sequencer_of_zone_b
)
# Sequencer of Zone A encodes the withdrawal from Zone A
withdrawal = ChannelWithdraw(
channel=CHANNEL_ZONE_A,
outputs=[temporary_transfer_note]
)
# Sequencer of zone B encodes the deposit to Zone B
deposit = ChannelDeposit(
channel=CHANNEL_ZONE_B,
inputs=[temporary_transfer_note],
)
# Transfer
Trasfer = Transfer(
inputs=[<sequencer_zone_a_note_id>],
outputs=[<change_note>]
)
# Wrap it in a transaction
tx = MantleTx(
ops=[Op(opcode=CHANNEL_INSCRIBE, payload=encode(sending)),
Op(opcode=CHANNEL_INSCRIBE, payload=encode(receiving)),
Op(opcode=CHANNEL_WITHDRAW, payload=encode(withdrawal)),
Op(opcode=CHANNEL_DEPOSIT, payload=encode(deposit)),
Op(opcode=TRANSFER, payload=encode(transfer))],
permanent_storage_gas_price=150,
execution_gas_price=70,
)
# Sign the transaction
signed_tx = SignedMantleTx(
tx=tx,
# Sequencer A is responsible for Zone A so it signs the
# Inscription and Withdraw of Zone A while Sequencer B, who signs the
# Inscription and the Deposit, doesn't require a proof
# Note that the withdraw OpProof has a ChannelWitdrawOpProof structure
op_proofs=[Ed25519_sign(mantle_txhash(tx), sequencer_of_zone_a_sk),
Ed25519_sign(mantle_txhash(tx), sequencer_of_zone_b_sk),
[[Ed25519_sign(mantle_txhash(tx), sequencer_of_zone_a_sk)],[0]],
None,
transfer.prove(sequencer_of_zone_a_sk)]
)
# Send the transaction to the mempool
mempool.push(signed_tx)
Signature Coordination
Synchronous messaging requires coordination between sequencers from different channels. The process works as follows:
- Transaction Construction: One sequencer (the coordinator) constructs a Mantle Transaction containing multiple channel operations for different channels. Each Operation represents an Inscription, withdraw or deposit for a specific channel or a transfer. In order to construct this transaction, the coordinator must gather the different intentions of the affected channels sequencers. For example, a Zone sequencer needs to inform another Zone sequencer that a user is transferring tokens so the receiving Zone can mint the token in its state.
- Signature Collection: Each participating sequencer receives the complete Mantle Transaction and verifies it. If all checks pass, the sequencer builds a proof for the Operations of its channel which includes the signature of the Mantle Transaction hash. The signature covers the entire transaction, ensuring that all sequencers approve the atomic Operations as a whole and preventing signature replay attacks.
- Coordination and Submission: The coordinator collects Operation proofs from all participating sequencers. Once all required proofs are gathered, the coordinator assembles the fully signed transaction and submits it to Bedrock.
- Atomic Execution: The chain validates the Mantle Transaction. If any validation check fails, the entire transaction is rejected and no state changes are applied. If all checks pass, all Operations are executed atomically.
Coordination Failure Handling: If coordination fails (e.g., a sequencer goes offline or refuses to sign), the atomic operation cannot proceed. The sequencers must either:
- Wait for the unavailable sequencer to return and complete the protocol.
- Abort the operation and potentially fall back to asynchronous messaging.
- Initiate a new coordination round with modified parameters. This coordination requirement is the main trade-off of synchronous messaging: it provides stronger guarantees but requires more complex orchestration and is susceptible to availability issues of the involved sequencers.
BedrockCoordinator(one of the sequencers)Sequencer B(Channel B)Sequencer A(Channel A)BedrockCoordinator(one of the sequencers)Sequencer B(Channel B)Sequencer A(Channel A)1. Intention gathering2. Transaction construction3. Signature collectionRepeat for all sequencers4. Submission and atomic executionalt[All checks pass][Any check fails]Propose cross-channel operation(e.g., atomic cross-zone transfer burning tokens in A state)1Propose cross-channel operation(e.g., the same atomic cross-zone transfer minting tokens in B state)2Build MantleTx with ops forall involved channels(CHANNEL_INSCRIBE / WITHDRAW / DEPOSIT, etc.)3Send full MantleTx4Verify MantleTx(channel A logic, fees, etc.)5Proofs for A's Operations(sign mantle_txhash(MantleTx))6Send full MantleTx7Verify MantleTx(channel B logic, fees, etc.)8Proofs for B's Operations(sign mantle_txhash(MantleTx))9Submit fully proved MantleTx10Validate tx + all op proofs11Apply all channel ops atomically(all succeed together)12Reject MantleTx(no state changes applied)13
Security Considerations
Synchronous messaging introduces additional security considerations:
- While the coordinator cannot forge signatures, they control transaction submission timing. Sequencers should implement timeouts and designate backup coordinators in the case where the coordinator aborts or delays the posting of the transaction.
- The protocol's liveness depends on all participating sequencers being available and responsive.
- Sequencers must agree on fee payment as the coordinator is the only one paying for submitting the transaction. The fee construction is internal to the Channel sequencers and is out of the scope of this document.
And trust assumptions:
- Each participating sequencer is assumed to verify the entire Mantle Transaction and only sign transactions that are valid with respect to its own channel rules.
- The protocol does not enforce or verify this behavior on-chain.
- Bedrock does not validate channel-specific Inscription semantics. As a result, correctness of cross-channel operations depends on off-chain verification by sequencers.
V1.2.0-ANALYSIS-GAS-COST-DETERMINATION
| Field | Value |
|---|---|
| Name | [Analysis] Gas Cost Determination |
| Slug | 227 |
| Status | deprecated |
| Type | RFC |
| Category | Informational |
| Editor | Thomas Lavaur [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Owner: @Thomas Lavaur
Reviewers: @Mehmet @Daniel Sanchez Quiros @David Rusu @Daniel Kashepava
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-09-25 |
| 1.1.0 | ? | 2025-10-07 |
| v1.2 | Removed DA, included Execution Gas determination for channel deposits and withdraws. Updated the Exeuction Gas of the Channel config. | 2026-01-14 |
Introduction
In Mantle, each Mantle Transaction contains one Ledger Transaction and one or more Operations. These components consume gas, measured through fixed gas units that reflect their execution or storage impact. Logos Blockchain introduces two independent gas markets:
- Execution Gas: measuring computational workload.
- Permanent Storage Gas: measuring cost of fully replicated storage.
Gas constants are carefully calibrated to reflect the computational and storage requirements of different operations on the Logos Blockchain. By standardizing gas measurements, the system can accurately charge fees proportional to resource usage, preventing network abuse and incentivizing efficient transaction design.
Overview
We conducted a comprehensive analysis of execution requirements for each Operation type in Mantle Transactions and of Ledger Transaction. This detailed examination allowed us to determine precise gas amounts for each Operation based on the actual computational resources consumed.
The gas constants we established are strategically divided between permanent storage and execution components, directly proportional to their respective resource utilization within Mantle Transactions. This separation ensures that gas costs accurately reflect the true computational burden of different operations. Moreover, gas can also be adjusted arbitrarily to incentivize or disincentivize the usage of certain Operations compared to others.
Our methodology involved measuring execution complexity and defining how gas is determined for each Gas Market. This is critical for proper network operation as it directly impacts transaction prioritization and network economics.
Permanent Storage Gas
Permanent Storage is paid directly for the entire signed Mantle Transaction. The Permanent Storage Gas price is included in the Mantle Transaction structure and is used to determine the Permanent Storage fee. 1 Permanent Storage Gas corresponds to 1 byte.
permanent_storage_fee = len(encode(tx_signed)) * permanent_storage_gas_price
Execution Gas
Execution is a second general market that represents how costly an operation or a Ledger Transaction is to execute. This cost can be fixed or variable based on the content of the Operation / Transaction. The Execution Gas price is contained in the Mantle Transaction structure and each Operation or Ledger Transaction define its execution gas amount. 1 Execution Gas corresponds to 1,000 CPU cycles.
execution_fee = (tx.ops.get_summed_gas() + tx.ledger_tx.get_gas())
* execution_gas_price
The gas derivation of each Operation and of a Ledger Transaction are:
LEDGER_TRANSACTION_GAS = 590
CHANNEL_INSCRIBE_GAS = 56
CHANNEL_CONFIG_GAS = 56 * configuration_threshold
CHANNEL_DEPOSIT_GAS = 0
CHANNEL_WITHDRAW_GAS = 56 * withdraw_threshold
SDP_DECLARE_GAS = 646
SDP_WITHDRAW_GAS = 590
SDP_ACTIVE_GAS = 590
LEADER_CLAIM_GAS = 580
and come from our implementation observations as described in Gas determination from measures. To get these numbers, we based our calculations on the following measures:
| Operation | Number of CPU cycles |
|---|---|
| ZkSignature batch verification | 3,900,000 + number_of_proof x 590,000 |
| Proof of Claim batch verification | 2,640,000 + number_of_proof x 580,000 |
| Eddsa25519 signature verification | 56,000 |
Comparison, list searching, hashes and operation in small fields are neglected. We also supposed that the initialization cost for batch verification is paid by everyone and deduced from the block directly. The user then pay only for the part that is proportional to the number of proofs.
Ledger Transaction
The Execution Gas of the Ledger Transaction compensates for the verification of the ZkSignature proof and the validation of the overall Mantle Transaction balance. This fundamental gas cost ensures proper cryptographic verification and data integrity of both the Ledger Transaction and the Mantle Transaction. It covers the cost of computing the Mantle Transaction hash.
Execution: ~590k CPU cycles.
- Verification of the ZK signature: 590,000 cycles.
- Verification of the balance: negligible.
- Computation of the Mantle Transaction hash: negligible.
Input Gas
Input gas covers the computational cost of verifying that one Note Id exists in the Ledger and is not locked. Additionally, it compensates for the removal of one Note Id from the Ledger.
Execution: negligible.
- Verification that the note is in the ledger: negligible.
- Verification that the note is unlocked: negligible.
- Removing of the note from the ledger: negligible.
Output Gas
Output gas accounts for the computational resources required to verify that one output is well-formed and for its inclusion in the Ledger.
Execution: negligible.
- Verification of the output validity: negligible.
- Insertion of the note in the ledger: negligible.
Operations
Channel Inscription
The validation process includes verifying an Eddsa25519 signature, confirming that the signer is authorized for the specified channel, and checking the chaining sequence of the channel. The execution encompasses creating channel records (if not previously used) and updating the tip of the channel.
Execution: ~56k CPU cycles.
- Verification of the Ed25519 signature: 56,000 cycles.
- Verification of the signer authorization: negligible.
- Verification of channel sequencing: negligible
- Update the channel state: negligible
Channel Deposit
The validation process is free as it doesn't require any verification and its execution only requires modifying the balance of the channel.
Execution: negligible.
- Increase of the channel balance: negligible
Channel Withdraw
The validation process requires verifying multiple Eddsa25519 signatures, and updating the balance of the channel.
Execution: ~56k CPU cycles * withdraw_threshold.
- Verification of
withdraw_thresholdEd25519Signatures: 56,000 cycles per signature. - Decrease of the channel balance: negligible.
Channel Config
This gas amount covers the verification of multiple Eddsa25519 signatures and ensures the operation is well-formed. This represents the computational cost associated with processing channel configuration operations.
- Execution: ~56k CPU cycles * configuration_threshold.
- Verification of the configuration_threshold Ed25519 signatures: 56,000 cycles per signature.
- Modification of the state of the channel: negligible.
SDP Declaration
This gas covers multiple verification processes: confirming ownership of the locked note through ZkSignature verification, validating the zk_id via a second ZkSignature, and establishing ownership of the provider_id through an Eddsa25519 signature. It also includes verification of the declaration format, confirmation of note existence, validation that the note is not already locked, and verification of its amount. Additionally, it accounts for the computational costs associated with the note locking mechanism and declaration management.
Execution: ~ 646k CPU cycles.
- Verification of the Ed25519 signature: 56,000 cycles.
- Verification of the ZK signature: 590,000 cycles.
- Verification that the declaration doesnt already exist: negligible.
- Verification of locator length: negligible.
- Verification of locked note existence: negligible.
- Verification of locked note value: negligible.
- Verification that the note isnt already locked for the service: negligible.
- Locking the note: negligible.
SDP Withdraw
This gas covers a verification process that includes: confirming ownership of the zk_id through ZkSignature verification, validating the existence of the locked note, verifying that the note has exceeded its lock period, and confirming that the declaration exists and has not been previously withdrawn. The validation process also ensures that the withdrawal message's nonce is greater than any previous nonce, preventing replay attacks. During execution, the system updates the declaration's status to withdrawn, removes the declaration from the locked note's associated declarations, andif the note has no remaining declarationsremoves it from the locked notes dictionary.
Execution: ~ 590k CPU cycles.
- Verification that the note exists, is locked and bound to the declaration: negligible.
- Verification that the note can be unlocked: negligible.
- Verification that the declaration exist: negligible.
- Verification of the ZK signature: 590,000 cycles.
- Verification that the declaration wasnt already withdrawn: negligible.
- Verification of nonce incrementation: negligible.
- Update declaration: negligible.
- Remove declaration from locked note: negligible.
- Unlock the note if not linked to any declaration: negligible.
SDP Activation
This gas funds the verification of the zk_id signature through the ZkSignature verification process, validates the existence of the declaration in the system, and ensures that the activation message's nonce is greater than any previous nonce to prevent replay attacks. The validation includes confirming that the declaration ID is present in the declarations dictionary and that the signature corresponds to the declaration's registered zk_id public key.
- Execution: ~590k CPU cycles.
- Verification that the declaration exist: negligible.
- Verification of nonce incrementation: negligible.
- Verification of the ZK signature: 590,000 cycles.
- Evaluation of the activity depends on the service and is neglected here
Leader Claims
This gas covers the verification of reward voucher ownership through a Proof of Claim, confirmation that the voucher nullifier is not already present in the nullifier set, and validation that the rewards root exists in the list of recent voucher Merkle tree roots. The execution process involves adding the voucher nullifier to the nullifier set and increasing the Ledger Transaction balance by the designated leader reward amount.
Execution: ~580k CPU cycles.
- Verification that the voucher nullifier isnt already in the set: negligible.
- Verification that the rewards root is one of the root of the reward tree of the last blocks: negligible.
- Verification of the proof of claim: 580,000 cycles.
- Insertion of the nullifier in the voucher nullifier set: negligible.
Annex
Gas determination from measures
The material used for the benchmarks is the following:
- CPU : 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM : 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS : Ubuntu 22.04.5 LTS
- Kernel : 6.8.0-59-generic
Eddsa Signature Verification
To get the numbers, we executed the test included in the official Rust implementation of the node.
Over 100 iterations, verifying an Eddsa25519 signature requires an average of 56,000 CPU cycles.
Proof of Claim
To get the numbers, we executed the test included in the official Rust implementation of the node.
We found the best linear curve approximating these measures (over 100 iterations):
| Number of Batches | Number of CPU cycles |
|---|---|
| 1 | 2,502,356 |
| 2 | 3,662,746 |
| 3 | 4,216,022 |
| 4 | 4,800,445 |
| 5 | 5,324,304 |
| 6 | 6,091,442 |
| 7 | 6,618,446 |
| 8 | 7,165,629 |
| 9 | 7,692,432 |
| 10 | 8,421,783 |
| 20 | 14,257,450 |
| 30 | 20,131,137 |
| 40 | 25,782,519 |
| 50 | 31,595,523 |
| 60 | 37,286,419 |
| Number of Batches | Number of CPU cycles |
|---|---|
| 70 | 42,901,298 |
| 80 | 48,309,912 |
| 90 | 54,191,072 |
| 100 | 61,082,050 |
| 110 | 66,927,817 |
| 120 | 73,758,494 |
| 130 | 78,816,789 |
| 140 | 84,801,250 |
| 150 | 91,693,824 |
| 160 | 94,248,613 |
| 170 | 99,430,138 |
| 180 | 105,607,812 |
| 190 | 112,379,089 |
| 200 | 116,599,001 |
We got the curve that we decided to approximate to :
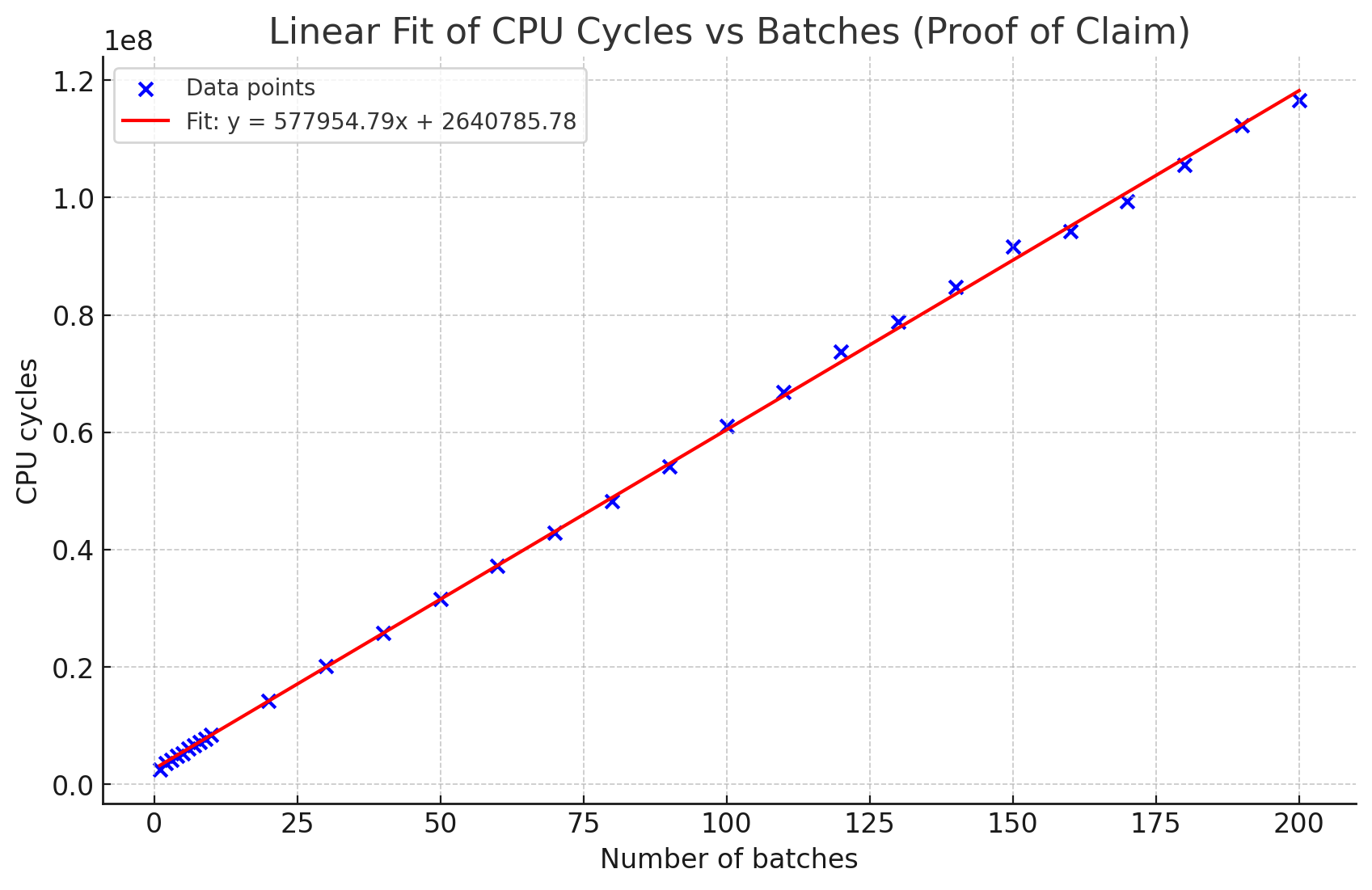
ZkSignature
To get the numbers, we executed the test included in the official Rust implementation of the node.
We found the best linear curve approximating these measures (over 1000 iterations):
| Number of Batches | Number of CPU cycles |
|---|---|
| 1 | 4,126,177 |
| 2 | 4,904,084 |
| 3 | 5,538,085 |
| 4 | 6,061,800 |
| 5 | 6,957,754 |
| 6 | 7,421,851 |
| 7 | 8,237,485 |
| 8 | 8,621,986 |
| 9 | 9,115,091 |
| 10 | 10,186,171 |
| 20 | 15,777,800 |
| 30 | 21,456,771 |
| 40 | 27,441,722 |
| 50 | 33,430,729 |
| 60 | 38,986,389 |
| Number of Batches | Number of CPU cycles |
|---|---|
| 70 | 44,708,450 |
| 80 | 50,894,373 |
| 90 | 56,534,430 |
| 100 | 63,606,624 |
| 110 | 70,036,347 |
| 120 | 75,612,096 |
| 130 | 82,048,010 |
| 140 | 87,080,407 |
| 150 | 91,473,391 |
| 160 | 97,862,623 |
| 170 | 104,019,852 |
| 180 | 111,498,103 |
| 190 | 114,814,226 |
| 200 | 119,739,702 |
We got the curve that we decided to approximate to :
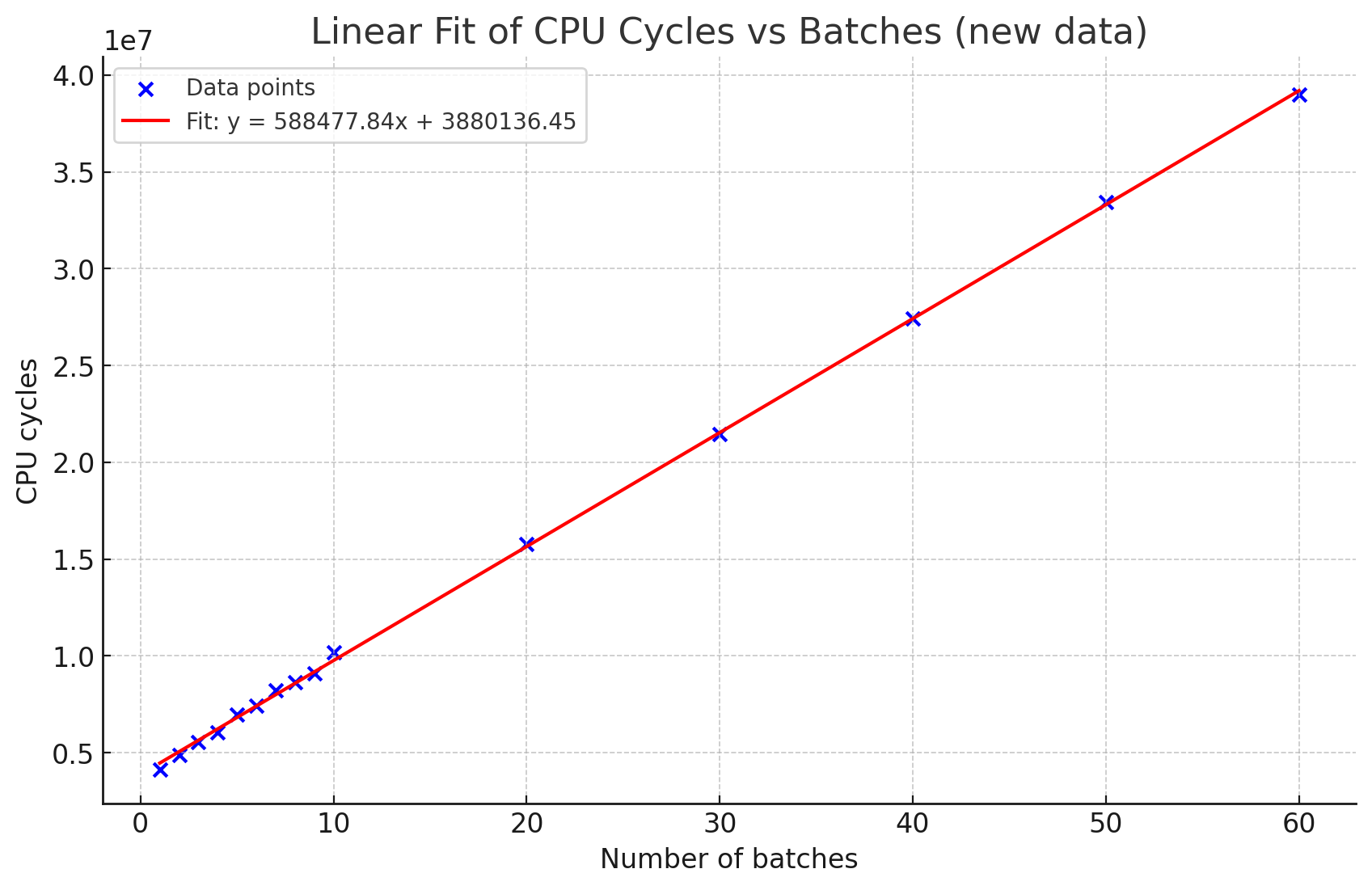
V1.2.0-MANTLE
| Field | Value |
|---|---|
| Name | Mantle |
| Slug | 229 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Thomas Lavaur [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Owner: @Thomas Lavaur
Reviewers: @Mehmet @Marcin Pawlowski @Daniel Sanchez Quiros @Gusto Bacvinka @Youngjoon Lee @Daniel Kashepava @David Rusu
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-11-17 |
| 1.1.0 | ? | 2026-02-06 |
| 1.2.0 | Removed DA references. Removed notions of Sovereignty and Rollups and used Zones for simplicity. Removed Nomos from specifications and DSTs. Added bridging and decentralized sequencing for channels. | 2026-03-20 |
Introduction
Mantle is a foundational element of Bedrock, designed to provide a minimal and efficient execution layer that connects together Bedrock Services in order to provide the necessary functionality for Zones. It can be viewed as the system call interface of Bedrock, exposing a safe and constrained set of Operations to interact with lower-level Bedrock services, similar to syscalls in an operating system.
Mantle Transactions provide Operations for Zones and blockchain Services to interact with Bedrock. For example, a Zone sequencer posting an update to Bedrock, or a node operator declaring its participation in the Blend Network, would be done through the corresponding Operations within a Mantle Transaction.
Mantle manages assets using a note-based ledger that follows an UTXO model. Each Mantle Transaction includes a Ledger Transaction, and any excess balance serves as the fee payment.
Overview
Mantle Transaction
The features of the Logos Blockchain are exposed through Mantle Transactions. Each transaction can contain zero or more Operations and one Ledger Transaction. Mantle Transactions enable users to execute multiple Operations atomically. The Ledger Transaction serves two purposes: it pays the transaction fee and allows users to issue transfers.
Mantle Operations
Logos Blockchain features are exposed through Mantle Operations, which can be combined and executed together in a single Mantle Transaction atomically. These Operations enable functions such as on-chain data posting, Cross-Zone interactions, SDP interaction, and leader reward claims.
Mantle Ledger
The Mantle Ledger enables asset transfers using a transparent UTXO model. While a Ledger Transaction can consume more tokens than it creates, the Mantle Transaction excess balance must exactly pay for the fees.
Transaction Fees
Mantle Transaction fees are derived from a gas model. The Logos Blockchain has two different gas markets, accounting for permanent data storage, and execution costs. Each Operation and Ledger Transaction has an associated Execution Gas cost. Users can specify their gas prices in their Mantle Transactions to incentivize the network to include their transaction.
| Gas Market | Charged On | Pricing Basis |
|---|---|---|
| Execution Gas | Ledger Transaction and Operations | Fixed per Operation |
| Permanent Storage Gas | Signed Mantle Transaction | Proportional to encoded size |
Mantle Transaction
Mantle Transactions form the core of Mantle, enabling users to combine multiple Operations to access different functions. Each transaction contains zero or more Operations plus a Ledger Transaction. The system executes all Operations atomically, while using the Mantle Transaction's excess balancecalculated as the difference between the consumed and created value as the fee payment.
class MantleTx:
ops: list[Op]
ledger_tx: LedgerTx # excess balance is used for fee payment
permanent_storage_gas_price: TokenValue # See the note section
execution_gas_price: TokenValue
class Op:
opcode: byte
payload: bytes
def mantle_txhash(tx: MantleTx) -> ZkHash:
tx_bytes = encode(tx)
h = Hasher()
h.update(FiniteField(b"MANTLE_TXHASH_V1", byte_order="little", modulus=p))
for i in range((len(tx_bytes)+30)//31):
chunk = tx_bytes[i*31:(i+1)*31]
fr = FiniteField(chunk, byte_order="little", modulus=p)
h.update(fr)
return h.digest()
The hash function used, as well as other cryptographic primitives like ZK proofs and signature schemes, are described in Common Cryptographic Components.
A Mantle Transaction must include all relevant signatures and proofs for each Operation, as well as for the Ledger Transaction.
class SignedMantleTx:
tx: MantleTx
op_proofs: list[OpProof | None] # each Op has at most 1 associated proof
ledger_tx_proof: ZkSignature # ZK proof of ownership of the spent notes
Each proof (op proof and signature) must be cryptographically bound to the MantleTx through the mantle_txhash to prevent replay attacks. This binding is achieved by including the MantleTx hash as a public input in every ZK proof.
The transaction fee is a sum of two components: the multiplication of the total Execution Gas by the execution_gas_price, and the total size of the encoded signed Mantle Transaction multiplied by the permanent_storage_gas_price.
def gas_fees(signed_tx: SignedMantleTx) -> int:
mantle_tx = signed_tx.tx
permanent_storage_fees = len(encode(signed_mantle_tx)) * mantle_tx.permanent_storage_gas_price
execution_fees = execution_gas(mantle_tx.ledger_tx) * mantle_tx.execution_gas_price
for op in mantle_tx.ops:
# Compute the execution gas of this operation as defined
# in the gas cost determination specification.
execution_fees += execution_gas(op) * mantle_tx.execution_gas_price
return execution_fees + permanent_storage_fees
Validation
Given
signed_tx = SignedMantleTx(
tx=MantleTx(ops, permanent_storage_gas_price, execution_gas_price, ledger_tx),
op_proofs,
ledger_tx_proof
)
Mantle validators will ensure the following:
- The ledger transaction is valid according to Ledger Validation.
validate_ledger_tx(ledger_tx, ledger_tx_proof, mantle_txhash(tx)) - We have a proof or a None value for each operation.
assert len(op_proofs) == len(ops) - Each Operation is valid.
for op, op_proof in zip(ops, op_proofs): assert op.opcode in MANTLE_OPCODES validate_mantle_op(mantle_txhash(tx), op.opcode, op.payload, op_proof) def validate_mantle_op(txhash, opcode, payload, op_proof): if opcode == CHANNEL_INSCRIBE: validate_channel_inscribe(txhash, payload, op_proof) # elif opcode == ... # ... - The Mantle Transaction excess balance pays for the transaction fees.
tx_fee = gas_fees(signed_tx) # Not an unsigned int assert tx_fee == get_transaction_balance(signed_tx) def get_transaction_balance(signed_tx: SignedMantleTx) -> int: balance = 0 # It's important to not use unsigned int here to avoid # overflow vulnerabilities for op in signed_tx.tx.ops: if op.opcode == LEADER_CLAIM: balance += get_leader_reward() if op.opcode == CHANNEL_DEPOSIT: balance -= get_channel_deposit_amount(op) if op.opcode == CHANNEL_WITHDRAW: balance += get_channel_withdrawal_amount(op) for inp in signed_tx.tx.ledger_tx.inputs: balance += get_value_from_note_id(inp) for out in signed_tx.tx.ledger_tx.outputs: balance -= out.value return balance
Execution
Given
SignedMantleTx(
tx=MantleTx(ops, permanent_storage_gas_price, execution_gas_price, ledger_tx),
op_proofs,
ledger_tx_proof
)
Mantle Validators execute the following:
- Execute the Ledger Transaction as described in Ledger Execution.
- Execute sequentially each Operation in ops according to its opcode.
Operations
Opcodes
| Operation | Opcode | Description |
|---|---|---|
| CHANNEL_INSCRIBE | 0x00 | Write a message permanently onto Mantle. |
| RESERVED | 0x01 | |
| CHANNEL_CONFIG | 0x02 | Configure a channel |
| CHANNEL_DEPOSIT | 0x03 | Deposit assets into a channel |
| CHANNEL_WITHDRAW | 0x04 | Withdraw assets from a channel |
| RESERVED | 0x05 - 0x1F | |
| SDP_DECLARE | 0x20 | Declare intention to participate as a node in a Bedrock Service, locking funds as collateral. |
| SDP_WITHDRAW | 0x21 | Withdraw participation from a Bedrock Service, unlocking your funds in the process. |
| SDP_ACTIVE | 0x22 | Signal that you are still an active participant of a Bedrock Service. |
| RESERVED | 0x23 - 0x2F | |
| LEADER_CLAIM | 0x30 | Claim leader reward anonymously. |
| RESERVED | 0x31 - 0xFF |
Channel Operations
Channels allow Zones to post their updates on chain. Channels form virtual chains that overlay on top of the Cryptarchia blockchain. Clients and Followers of a Zone can watch its channel to learn the state of that Zone. Each channel has an associated balance, enabling bridging between Zones and Bedrock.
Message Ordering
Channels form virtual chains by having each message reference its parent message. The order of messages in these channels is enforced by the sequencer by building a hash chain of messages, i.e. new messages reference the previous messages through a parent hash. Given that Cryptarchia has long finality times, these message parent references allow Zone sequencers to continue to post new updates to channels without having to wait for finality. No matter how Cryptarchia forks and reorgs, the channel messages from honest sequencers will eventually be re-included in a way that satisfies the virtual chain order.
The first time a message is sent to an unclaimed channel, the key that signs the initial message becomes the only accredited key in the list (Note that this key may correspond to a threshold signature key). Accredited keys of a channel forms a committee that can configure the channel, withdraw funds and take turns to write messages to that channel following a round-robin algorithm. Configuring a channel includes modifying the list of accredited keys, the round-robin parameters and the required number of signatures to withdraw funds or establish a new configuration.
Validators must maintain the following state to process channel Operations:
channels: dict[ChannelId, ChannelState] # ChannelId is 32 bytes
class ChannelState:
# Channel Configuration
accredited_keys: list[Ed25519PublicKey] # limited to 65 535 keys
configuration_threshold: u16 # indicating how many keys are
# required to update the configuration
# Message Ordering
tip_hash: hash
# Decentralized Sequencing
tip_slot: Slot
tip_sequencer: u16 # indicating the actual
# sequencer position in the list of accredited keys
tip_sequencer_starting_slot: Slot
posting_timeframe: u32 # number of slots (0 = infinity)
posting_timeout: u32 # number of slots (0 = no timeout)
# Bridging
balance: TokenValue # See the Note section for its precision
withdraw_threshold: u16 # indicating how many keys are
# required to withdraw funds from the channel
def default_channel(block_slot: Slot, keys: list[Ed25519PublicKey])
-> ChannelState:
return ChannelState(
tip_hash = ZERO,
tip_slot = block_slot,
accredited_keys = keys,
tip_sequencer = 0,
tip_sequencer_starting_slot = block_slot,
posting_timeframe = 0,
posting_timeout = 0,
configuration_threshold = 1,
withdraw_threshold = 1)
Note that the user chooses the ChannelId mapping to the ChannelState (but its restricted to 32 bytes). We don't currently impose restrictions on it, but we may do so in the future to prevent undesirable behaviors.
Decentralized Sequencing
To determine which sequencer is currently authorized to send messages, we use a round-robin algorithm. When a message is posted to a channel, the following algorithm is used to determine who the sequencer is:
# Round Robin algorithm determining the new sequencer index and the
# new sequencer starting slot
def round_robin(block_slot: Slot, channel: ChannelState) -> (u16,u64):
elapsed_slots = block_slot - channel.tip_slot
if elapsed_slots >= channel.posting_timeout && channel.posting_timeout != 0:
# Get the number of sequencers that get timed out
sequencers_timed_out = elapsed_slots // channel.posting_timeout
index = (channel.tip_sequencer + sequencers_timed_out)
% len(channel.accredited_keys)
starting_slot = channel.tip_slot
+ sequencers_timed_out * channel.posting_timeout
else:
# Get the number of timeframes elapsed to get who is the sequencer
tip_sequencer_duration = block_slot - channel.tip_sequencer_starting_slot
index = (channel.tip_sequencer
+ (tip_sequencer_duration // channel.posting_timeframe))
% len(channel.accredited_keys)
starting_slot = channel.tip_sequencer_starting_slot
+ (tip_sequencer_duration // channel.posting_timeframe)
* channel.posting_timeframe
return (index, starting_slot)
CHANNEL_INSCRIBE
Write a message to a channel with the message data being permanently stored on the Logos Blockchain.
Payload
class Inscribe:
channel: ChannelId # 32 bytes Channel being written to
inscription : bytes # Message to be written on the blockchain
parent: hash # Previous message in the channel
signer: Ed25519PublicKey # Identity of message sender
Proof
Ed25519Signature
Execution Gas
Channel Inscribe Operations have a fixed Execution Gas cost of EXECUTION_CHANNEL_INSCRIBE_GAS. See [Analysis] Gas Cost Determination for the Execution Gas values.
Validation
Given
txhash: zkhash
msg: Inscribe
sig: Ed25519Signature
channels: dict[ChannelId, ChannelState]
block_slot: Slot
Validate
if msg.channel in channels:
chan = channels[msg.channel]
current_sequencer_index = round_robin(block_slot, chan)[0]
# Ensure the signer is the one authorized to write to the channel
assert msg.signer == chan.accredited_keys[current_sequencer_index]
# Ensure message is continuing the channel sequence
assert msg.parent == chan.tip_hash
else:
# Channel will be created automatically upon execution
# Ensure that this message is the genesis message (parent == ZERO)
assert msg.parent == ZERO
# Ensure the msg signer signature
assert Ed25519_verify(txhash, msg.signer, sig)
Execution
Given
msg: Inscribe
sig: Ed25519Signature
channels: dict[ChannelId, ChannelState]
block_slot: Slot
Execute
- If the channel does not exist, create it just-in-time.
if msg.channel not in channels: channels[msg.channel] = default_channel(block_slot, [msg.signer]) - Update the channel sequencer.
chan = channels[msg.channel] (new_sequencer_index, new_sequencer_starting_slot) = round_robin( block_slot, chan) chan.tip_sequencer_starting_slot = new_sequencer_starting_slot chan.tip_sequencer = new_sequencer_index - Update the channel tip.
chan = channels[msg.channel] chan.tip_hash = hash(encode(msg)) chan.tip_slot = block_slot
Example
# Build the inscription
greeting = Inscription(
channel=CHANNEL_EARTH,
inscription=b"Live long and prosper",
parent=ZERO
signer=spock_pk
)
# Wrap it in a transaction
tx = MantleTx(
ops=[Op(opcode=CHANNEL_INSCRIBE, payload=encode(greeting))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[<spocks_note_id>], outputs=[<change_note>]),
)
# Sign the transaction
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[Ed25519_sign(mantle_txhash(tx), spock_sk)]
ledger_tx_proof=tx.ledger_tx.prove(spock_sk)
)
# Send the transaction to the mempool
mempool.push(signed_tx)
CHANNEL_CONFIG
Overwrite the configuration of a channel.
Payload
class ChannelConfig:
channel: ChannelId
keys: list[Ed25519PublicKey]
posting_timeframe: u32
posting_timeout: u32
configuration_threshold: u16
withdraw_threshold: u16
Proof
class ChannelConfigOpProof:
signatures: list[Ed25519Signature] # signatures from configuration_threshold
indexes: list[u16] # signatures of accredited keys with their index.
# indexes must be ordered from smallest to
# biggest without duplication
Execution Gas
Channel Config Operations have a linear Execution Gas cost equal to EXECUTION_CHANNEL_CONFIG_GAS * configuration_threshold. See [Analysis] Gas Cost Determination for the Execution Gas values.
Validation
Given
txhash: zkhash
config: ChannelConfig
proof: ChannelConfigOpProof
channels: dict[ChannelId, ChannelState]
Validate
assert len(proof.signatures) == len(proof.indexes)
assert config.configuration_threshold > 0
assert config.withdraw_threshold > 0
assert len(config.keys) > 0
assert len(config.keys) < 2^16
if config.channel in channels:
chan = channels[config.channel]
# Check there are enough signatures
assert len(proof.signatures) == chan.configuration_threshold
# Check that indexes are ordered to avoid duplication
for i in range(len(proof.indexes)-1):
assert proof.indexes[i] < proof.indexes[i+1]
for sig, idx in zip(proof.signatures, proof.indexes):
# and at the same time that chan.accredited_keys[idx] isn't out of bound
assert Ed25519_verify(txhash, chan.accredited_keys[idx], sig)
Execution
Given
config: ChannelConfig
channels: dict[ChannelId, ChannelState]
block_slot: Slot
Execute
- If the channel does not exist, create it just-in-time.
if config.channel not in channels:
channels[config.channel] = default_channel(block_slot, config.keys)
- Update the configuration.
chan = channels[config.channel]
# Update Channel Configuration Parameters
chan.accredited_keys = config.keys
chan.configuration_threshold = config.configuration_threshold
# Update Decentralized Sequencing Parameters
chan.tip_sequencer = 0
chan.tip_sequencer_starting_slot = block_slot
chan.posting_timeframe = config.posting_timeframe
chan.posting_timeout = config.posting_timeout
# Update Bridging Parameters
chan.withdraw_threshold = config.withdraw_threshold
- Update the channel tip.
chan = channels[config.channel]
chan.tip_slot = block_slot
chan.tip_hash = hash(encode(config))
Example
Suppose the unique sequencer of Zone A wants to add a key to the list of accredited keys:
# Given a key to add
new_sequencer_pk: Ed25519PublicKey
# The unique sequencer encodes the update and builds the payload
config = ChannelConfig(
channel=ZONE_A,
keys=[old_sequencer_pk, new_sequencer_pk],
posting_timeframe = 5000,
posting_timeout = 500,
configuration_threshold = 2,
withdraw_threshold = 1
)
tx = MantleTx(
ops=[Op(opcode=CHANNEL_CONFIG, payload=encode(config))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[old_sequencer_funds], outputs=[<change note>])
)
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[[Ed25519_sign(mantle_txhash(tx), old_sequencer_sk)], [0]]]
ledger_tx_proof=tx.ledger_tx.prove(old_sequencer_sk),
)
CHANNEL_DEPOSIT
Deposit funds to a channel, reducing the Mantle Transaction balance.
Payload
class ChannelDeposit:
channel: ChannelId
amount: TokenValue
metadata: bytes
Proof
None # Indirectly signed through the Ledger Transaction signature
Execution Gas
Channel Deposit Operations have a fixed Execution Gas cost of EXECUTION_CHANNEL_DEPOSIT_GAS. See [Analysis] Gas Cost Determination for the Execution Gas values.
Validation
Given
deposit: ChannelDeposit
channels: dict[ChannelId, ChannelState]
Validate
assert deposit.channel in channels
Execution
Given
deposit: ChannelDeposit
channels: dict[ChannelId, ChannelState]
Execute
channels[deposit.channel].balance += deposit.amount
Example
Suppose Alice wants to make a deposit of 50 tokens on Zone A.
# Alice encodes her deposit
deposit = ChannelDeposit(
channel=ZONE_A,
amount=50,
metadata=b"deposit to address: 0x..."
)
tx = MantleTx(
ops=[Op(opcode=CHANNEL_DEPOSIT, payload=encode(deposit))],
permanent_storage_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[Alice_funds], outputs=[<change note>])
)
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=None,
ledger_tx_proof=tx.ledger_tx.prove(Alice_sk)
)
Note that the Zone may wait for the deposit to be finalized before interpreting the deposit in order to guarantee that the deposit will occur on-chain and won't be removed due to reorganization of the chain.
CHANNEL_WITHDRAW
Withdraw funds from a channel, increasing the Mantle Transaction balance.
Payload
class ChannelWithdraw:
channel: ChannelId
amount: TokenValue
Proof
class ChannelWithdrawOpProof:
signatures: list[Ed25519Signature] # signature from withdraw_threshold keys
indexes: list[int] # signatures of accredited keys with their index.
# indexes must be ordered from smallest to
# biggest without duplication
Execution Gas
Channel Withdraw Operations have a linear Execution Gas cost equal to EXECUTION_CHANNEL_WITHDRAW_GAS * withdraw_threshold. See [Analysis] Gas Cost Determination for the Execution Gas values.
Validation
Given
txhash: zkhash
withdrawal: ChannelWithdraw
proof: ChannelWithdrawOpProof
channels: dict[ChannelId, ChannelState]
Validate
# Check that the channel exists
assert withdrawal.channel in channels
chan = channels[withdrawal.channel]
# Check that the channel has enough funds
assert chan.balance >= withdrawal.amount
# Check that there are enough signatures
assert len(proof.signatures) == len(proof.indexes)
assert len(proof.signatures) == chan.withdraw_threshold
# Check that every index is unique
assert len(proof.indexes) == len(set(proof.indexes))
# Check the signatures
for sig, idx in zip(proof.signatures, proof.indexes):
assert Ed25519_verify(txhash, chan.accredited_keys[idx], sig)
Execution
Given
withdrawal: ChannelWithdraw
channels: dict[ChannelId, ChannelState]
Execute
channels[withdrawal.channel].balance -= withdrawal.amount
Example
Suppose the unique sequencer of Zone A wants to withdraw 50 tokens.
# Sequencer encodes his withdrawal
withdrawal = ChannelWithdraw(
channel=ZONE_A,
amount=50
)
tx = MantleTx(
ops=[Op(opcode=CHANNEL_WITHDRAW, payload=encode(withdrawal))],
permanent_storage_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[Sequencer_funds], outputs=
[<withdraw_funds>, <change note>])
)
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[[[Ed25519_sign(mantle_txhash(tx), sequencer_sk)],[0]]],
ledger_tx_proof=tx.ledger_tx.prove(Sequencer_note_sk)
)
Service Declaration Protocol (SDP) Operations
These Operations implement the Service Declaration Protocol.
Validators must keep the following state when implementing SDP Operations:
locked_notes: dict[NoteID, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
class LockedNote:
declarations: set[DeclarationID]
locked_until: BlockNumber
Common SDP Structures
class ServiceType(Enum):
BN="BN" # Blend Network
class Locator(str):
def validate(self):
assert len(self) <= 329
assert validate_multiaddr(self)
class MinStake:
stake_threshold: int # stake value
timestamp: int # block number
class ServiceParameters:
lock_period: int # number of blocks
inactivity_period: int # number of blocks
retention_period: int # number of blocks
timestamp: int # block number
class DeclarationInfo:
service: ServiceType
locators: list[Locator]
provider_id: Ed25519PublicKey
zk_id: ZkPublicKey
locked_note_id: NoteId
created: BlockNumber
active: BlockNumber
withdrawn: BlockNumber
# SDP ops updating a declaration must use monotonically increasing nonces
nonce: int
SDP_DECLARE
The service registration follows the definition given in Service Declaration Protocol - Declaration Message:
Payload
class DeclarationMessage:
service_type: ServiceType
locators: list[Locator]
provider_id: Ed25519PublicKey
zk_id: ZkPublicKey
locked_note_id: NoteId
Locked notes are introduced in Locked notes and serve as Service collaterals. They cannot be spent before the owner withdraw its participation from the declared service(s).
Proof
class DeclarationProof:
zk_sig: ZkSignature # signature proving ownership over
# locked note and zk_id
provider_sig: Ed25519Signature # signature proving ownership of provider key
see: Zero Knowledge Signature Scheme (ZkSignature).
Execution Gas
SDP Declare Operations have a fixed Execution Gas cost of EXECUTION_SDP_DECLARE_GAS. See [Analysis] Gas Cost Determination for the Execution Gas values.
Validation
Given
txhash: zkhash # the txhash of the transaction we are validating
declaration: DeclarationMessage # the declaration we are validating
proof: DeclarationProof
min_stake: MinStake # the (global) minimum stake setting
ledger: Ledger # the set of unspent notes
locked_notes: dict[NoteId, LockedNote]
declarations: dict[NoteId, DeclarationInfo]
Validate
The declaration is verified according to Service Declaration Protocol - Declare.
- Ensure ownership over the locked note, zk_id and provider_id.
assert ZkSignature_verify( txhash, proof.zk_sig, [note.public_key, declaration.zk_id] ) assert Ed25519_verify(txhash, proof.provider_sig, provider_id) - Ensure declaration does not already exist.
assert declaration_id(declaration) not in declarations - Ensure it has no more than 8 locators.
assert len(declaration.locators) <= 8 - Ensure locked note exists and value of locked note is sufficient for joining the service.
assert ledger.is_unspent(declaration.locked_note_id) note = ledger.get_note(declaration.locked_note_id) assert note.value >= min_stake.stake_threshold - Ensure the note has not already been locked for this service.
if declaration.locked_note in locked_notes: locked_note = locked_notes[declaration.locked_note] services = [declarations[declare_id] for declare_id in locked_note.declarations] assert declaration.service_type not in services
Execution
Given
declaration: DeclarationMessage # the declaration we are executing
service_parameters: dict[ServiceType, ServiceParameters]
current_block_height: int
locked_notes : dict[NoteId, LockedNote]
Execute
- Create the locked note state if it doesn't already exist.
if declaration.locked_note not in locked_notes: locked_notes[declaration.locked_note_id] = \ LockedNote(declarations=set(), locked_until=0) locked_note = locked_notes[declaration.locked_note_id] - Update the locked notes timeout using this services lock period.
lock_period = service_parameters[declaration.service_type].lock_period service_lock = current_block_height + lock_period locked_note.locked_until = max(service_lock, locked_note.locked_until) - Add this declaration to the locked note.
declare_id = declaration_id(declaration) locked_note.declarations.add(declare_id) - Store the declaration as explained in Service Declaration Protocol - Declaration Storage.
declarations[declare_id] = DeclarationInfo( service: declaration.service locators: declaration.locators provider_id: declaration.provider_id zk_id: declaration.zk_id locked_note_id: declaration.locked_note_id declaration, created=current_block_height, active=current_block_height, withdrawn=0 nonce=0 )
Example
# Assume `alice_note` is in the ledger:
alice_note = Utxo(
txhash=0x2948904F2F0F479B8F8197694B30184B0D2ED1C1CD2A1EC0FB85D299A192A447,
output_number=3,
note=Note(value=500, public_key=alice_pk_1),
)
# Alice wishes to lock it to join the Blend network
declaration=DeclarationMessage(
service_type=ServiceType.BN,
locators=["/ip4/203.0.113.10/tcp/4001/p2p"],
provider_id=alice_provider_pk,
zk_id=alice_pk_2,
locked_note_id=alice_note.id()
)
tx = MantleTx(
ops=[Op(opcode=SDP_DECLARE, payload=encode(declaration))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[fee_note_id], outputs=[]),
)
txhash = mantle_txhash(tx)
declaration_proof = DeclarationProof(
# proof of ownership of the staked note and zk_id
zk_sig=ZkSignature([alice_sk_1, alice_sk_2], txhash),
# proof of ownership of the provider id
provider_sig=Ed25519Signature(alice_provider_sk, txhash),
)
SignedMantleTx(
tx=tx,
ledger_tx_proof=LedgerTxProof,
op_proofs=[declaration_proof],
ledger_proof=prove_ledger_tx(tx.ledger_tx, [alice_sk_1]),
)
SDP_WITHDRAW
The service withdrawal follows the definition given in Service Declaration Protocol - Withdraw Message.
Payload
class WithdrawMessage:
declaration: DeclarationID
locked_note_id: NoteId
nonce: int
Proof
A signature from the zk_id and the locked note pk attached to the declaration is required for withdrawing from a service, (see Zero Knowledge Signature Scheme (ZkSignature)).
ZkSignature
Execution Gas
SDP Withdraw Operations have a fixed Execution Gas cost of EXECUTION_SDP_WITHDRAW_GAS. See [Analysis] Gas Cost Determination for the Execution Gas values.
Validation
Given
txhash: zkhash # Mantle transaction hash of the tx containing this operation
withdraw: WithdrawMessage
signature: ZkSignature
block_height: int # block height of the current block
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
Validate
- Ensure that the locked note exists, is locked and bound to this declaration.
assert ledger.is_unspent(withdraw.locked_note_id) assert withdraw.locked_note_id in locked_notes locked_note = locked_notes[withdraw.locked_note_id] assert withdraw.declaration in locked_note.declarations - Ensure that the locked note has expired.
assert locked_note.locked_until <= block_height - Validate SDP withdrawal according to Service Declaration Protocol - Withdraw.
- Ensure declaration exists.
assert withdraw.declaration in declarations declare_info = declarations[withdraw.declaration] - Ensure locked note pk and zk_id attached to this declaration authorized this Operation.
locked_note = ledger[withdraw.locked_note_id] assert ZkSignature_verify(txhash, signature, [locked_note.pk, declare_info.zk_id]) - Ensure the declaration has not already been withdrawn.
assert declare_info.withdrawn == 0 - Ensure that the nonce is greater than the previous one.
assert withdraw.nonce > declare_info.nonce
- Ensure declaration exists.
Execution
Given
withdraw: WithdrawMessage
signature: ZkSignature
block_height: int # block height of the current block
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
Execute
Executes the withdrawal protocol Service Declaration Protocol - Withdraw.
- Update declaration info with nonce and withdrawn timestamp.
declare_info = declarations[withdraw.declaration] declare_info.nonce = withdraw.nonce declare_info.withdrawn = block_height - Remove this declaration from the locked note.
locked_note = locked_notes[withdraw.locked_note_id] locked_note.declarations.remove(withdraw.declaration) - Remove the locked note if it is no longer bound to any declarations.
if len(locked_note.declarations) == 0: del locked_notes[withdraw.locked_note_id)
Example
withdraw=Withdraw(
declaration=alice_declaration_id,
locked_note_id=alices_locked_note_id
nonce=1579532
)
tx = MantleTx(
ops=[Op(opcode=SDP_WITHDRAW, payload=encode(withdraw))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(
inputs=[alices_locked_note_id],
outputs=[Note(100, alice_note_pk)]
),
)
SignedMantleTx(
tx=tx,
ledger_tx_proof= tx.ledger_tx.prove(alice_sk),
# proof ownership of the withdrawn note and zk id
op_proofs=[ZkSignature_sign([alice_note_sk, alice_sk], mantle_txhash(tx))]
)
SDP_ACTIVE
The service active action follows the definition given in Service Declaration Protocol - Active Message.
Payload
class Active:
declaration: DeclarationID
nonce: int
metadata: bytes # a service-specific node activeness metadata
Proof
ZkSignature
Execution Gas
SDP Active Operations have a fixed Execution Gas cost of EXECUTION_SDP_ACTIVE_GAS. See [Analysis] Gas Cost Determination for the Execution Gas values.
Validation
Given
txhash: zkhash # Mantle transaction hash of the tx containing this operation
active: Active
signature: ZkSignature
declarations: dict[DeclarationID, DeclarationInfo]
Validate
assert active.declaration in declarations
declaration_info = declarations[active.declaration]
assert active.nonce > declaration_info.nonce
assert ZkSignature_verify(txhash, signature, declaration_info.zk_id)
Execution
Executes the active protocol Service Declaration Protocol - Active. The activation, i.e. setting the declaration.active, is handled by the service-specific logic.
Example
active=Active(
declaration=alice_declaration_id,
nonce=1579532,
metadata=b"Look, I am still doing my job"
)
tx = MantleTx(
ops=[Op(opcode=SDP_ACTIVE, payload=encode(active))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[fee_note_id], outputs=[]),
)
txhash = mantle_txhash(tx)
SignedMantleTx(
tx=tx,
ledger_tx_proof=tx.ledger_tx.prove(fee_note_sk),
op_proofs=[Ed25519_sign(txhash, validator_sk)]
)
Leader Operations
LEADER_CLAIM
This Operation claims the leader's block reward anonymously.
Payload
class ClaimRequest:
rewards_root: zkhash # Merkle root used in the proof for voucher membership
voucher_nf: zkhash
Proof
The provider proves that they have won a proof of Leadership before the start of the current epoch, i.e., their reward voucher is indeed in the voucher set: Proof of Claim.
Execution gas
Leader Claim Operations have a fixed Execution Gas cost of EXECUTION_LEADER_CLAIM_GAS. See [Analysis] Gas Cost Determination for the Execution Gas values.
Validation
# Given
mantle_txhash: zkhash
claim : ClaimRequest
last_voucher_root: zkhash # The last root of the voucher Merkle tree
# at the start of the epoch
voucher_nullifier_set: set[zkhash]
proof: ProofOfClaim
# Validate
assert claim.voucher_nf not in voucher_nullifier_set
assert claim.rewards_root == last_voucher_root
validate_proof(claim, proof, mantle_txhash)
Execution
- Add claim.voucher_nf to the voucher_nullifier_set .
- Increase the balance of the Mantle Transaction by the leader reward amount according to Anonymous Leaders Reward Protocol - Leaders Reward.
- Reduce the leaders reward leaders_rewards value by the same amount (without ZK proof). Example
secret_voucher = 0xDEADBEAF;
reward_voucher = leader_claim_voucher(secret_voucher)
voucher_nullifier = leader_claim_nullifier(secret_voucher)
claim=ClaimRequest(
rewards_root=REWARDS_MERKLE_TREE.root(),
voucher_nf=voucher_nullifier,
)
tx = MantleTx(
ops=[Op(opcode=LEADER_CLAIM, payload=encode(claim))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[<fee_note>], outputs=[<change_note>]),
)
claim_proof = claim.prove(
secret_voucher,
REWARDS_MERKLE_TREE.path(leaf=reward_voucher),
mantle_txhash(tx)
)
SignedMantleTx(
tx=tx,
ledger_tx_proof=tx.ledger_tx.prove(fee_note_sk),
op_proofs=[claim_proof]
)
Mantle Ledger
Notes
Notes are composed of two fields representing their value and their owner:
class Note:
value: TokenValue # u64
public_key: ZkPublicKey # 32 bytes
Note Id
Any note can be uniquely identified by the Ledger Transaction that created it and its output number: (txhash, output_number). However, it is often useful to have a commitment to the note fields for use in ZK proofs (e.g., for PoL), so we include the note in the note identifier derivation.
def derive_note_id(txhash: zkhash, output_number: int, note: Note) -> NoteId:
return zkhash(
FiniteField(b"NOTE_ID_V1", byte_order="little", modulus= p)
txhash,
FiniteField(output_number, byte_order="little", modulus= p)
FiniteField(note.value, byte_order="little", modulus= p)
note.public_key
)
These note identifiers uniquely define notes in the system and cannot be chosen by the user. Nodes maintain the set of notes through a dictionary mapping the NoteId to the note.
Locked notes
Locked notes are special notes in Mantle that serve as collateral for Service Declarations. A note can become locked after executing a Declare Operation, preventing it from being spent until explicitly released through a Withdraw Operation. The system maintains a mapping of locked note IDs to their supporting declarations. Though locked, these notes remain in the Ledger and can still participate in Proof of Stake. When service providers withdraw all their declarations, the associated note(s) become unlocked and available for spending again.
Ledger Transactions
Transactions must prove the ownership of spent notes. In classical blockchains, this is done through a signature. To stay compatible with our architecture, the signature is done by a ZK proof (see Zero Knowledge Signature Scheme (ZkSignature)), proving the knowledge of the secret key associated with the public key.
Transactions allow complete transaction linkability and the public key spending the note is not hidden.
Structure
class LedgerTx:
inputs: list[NoteId] # the list of consumed note identifiers
outputs: list[Note]
Proof
A transaction proves the ownership of the consumed notes using a Zero Knowledge Signature Scheme (ZkSignature)
ZkSignature
Execution Gas
Ledger Transactions have a fixed Execution Gas cost of EXECUTION_LEDGER_TX_GAS. See [Analysis] Gas Cost Determination for the Execution Gas values.
Ledger Transaction Hash
def ledger_txhash(tx: LedgerTx) -> ZkHash:
tx_bytes = encode(tx)
h = Hasher()
h.update(FiniteField(b"LEDGER_TXHASH_V1", byte_order="little", modulus=p))
for i in range((len(tx_bytes)+30)//31):
chunk = tx_bytes[i*31:(i+1)*31]
fr = FiniteField(chunk, byte_order="little", modulus=p)
h.update(fr)
return h.digest()
Ledger Validation
Given
mantle_txhash: ZkHash # ZkHash of mantle tx containing this ledger tx
ledger_tx: LedgerTx
ledger_tx_proof: ZkSignature
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
Validate
- Ensure all inputs are unspent.
assert all(ledger.is_unspent(note_id) for note_id in ledger_tx.inputs) - Validate ledger proof to show ownership over input notes.
input_notes = [ledger[input_note_id] for input_note_id in ledger_tx.inputs] input_pks = [note.public_key for note in input_notes] assert ZkSignature_verify(mantle_txhash, ledger_tx_proof, input_pks) - Ensure inputs are not locked.
# Ensure inputs are not locked for note_id in ledger_tx.inputs: assert note_id not in locked_notes - Ensure outputs are valid.
for output in ledger_tx.outputs: assert output.value > 0 assert output.value < 2**64
Ledger Execution
Given
ledger_tx: LedgerTx
ledger_tx_proof: ZkSignature
ledger: Ledger
Execution
- Remove inputs from the ledger.
for note_id in ledger_tx.inputs: # updates the merkle tree to zero out the leaf for this entry # and adds that leaf index to the list of unused leaves ledger.remove(note_id) - Add outputs to the ledger.
txhash = ledger_txhash(ledger_tx) for (output_number, output_note) in enumerate(tx.outputs): output_note_id = derive_note_id(txhash, output_number, output_note) ledger.add(output_note_id)
Ledger Example
alice_note_id = ... # assume Alice holds a note worth 501 tokens
bob_note=Note(
value=500
public_key=bob_pk,
)
ledger_tx = LedgerTx(
inputs=[alice_note_id],
outputs=[bob_note],
)
Appendix
Gas Determination
From the [Analysis] Gas Cost Determination, we get the table below:
| Constants | Value |
|---|---|
| EXECUTION_LEDGER_TX_GAS | 590 |
| EXECUTION_CHANNEL_INSCRIBE_GAS | 56 |
| EXECUTION_CHANNEL_CONFIG_GAS | 56 |
| EXECUTION_CHANNEL_DEPOSIT_GAS | 0 |
| EXECUTION_CHANNEL_WITHDRAW_GAS | 56 |
| EXECUTION_SDP_DECLARE_GAS | 646 |
| EXECUTION_SDP_WITHDRAW_GAS | 590 |
| EXECUTION_SDP_ACTIVE_GAS | 590 |
| EXECUTION_LEADER_CLAIM_GAS | 580 |
Zero Knowledge Signature Scheme (ZkSignature)
A proof attesting that for the following public values:
class ZkSignaturePublic:
public_keys: list[ZkPublicKey] # public keys signing the message (len = 32)
msg: zkhash # zkhash of the message
The prover knows a witness:
class ZkSignatureWitness:
# The list of secret keys used to signed the message
secret_keys: list[ZkSecretKey] # (len = 32)
Such that the following constraints hold:
- The number of secret keys is equal to the number of public keys.
assert len(secret_keys) == len(public_keys) - Each public key is derived from the corresponding secret key.
assert all( notes[i].public_key == zkhash( FiniteField(b"KDF", byte_order="little", modulus= p), secret_keys[i]) for i in range(len(public_keys)) ) - The proof is bound to msg (its the mantle_tx_hash in case of transactions).
For implementation, the ZkSignature circuit will take a maximum of 32 public keys as inputs. To prove ownership of fewer keys, the remaining inputs will be padded with the public key corresponding to the secret key 0 and ignored during execution. The outputs have no size limit since they are included in the hashed message.
Benchmark
The material used for the benchmarks is the following:
- CPU : 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM : 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS : Ubuntu 22.04.5 LTS
- Kernel : 6.8.0-59-generic
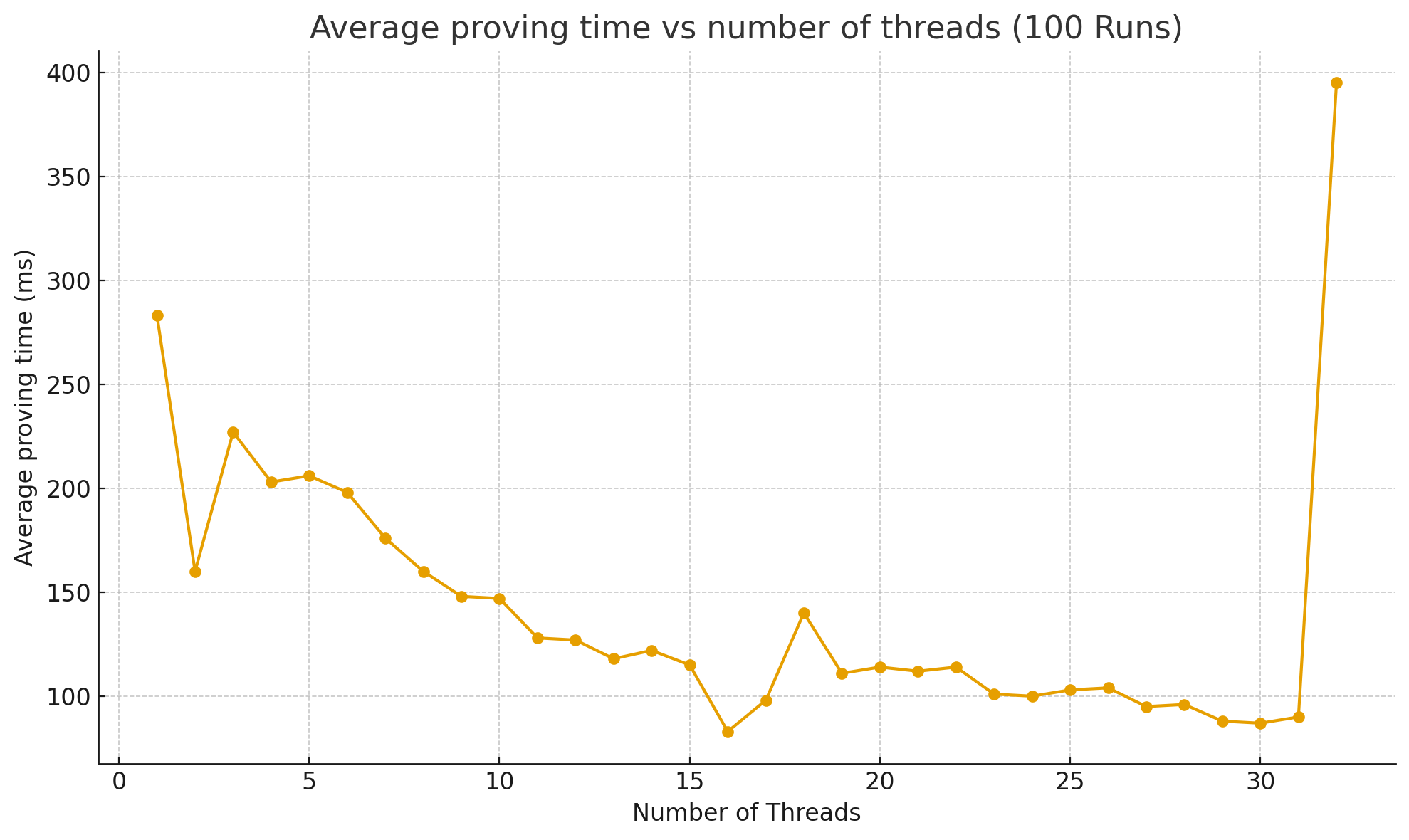
Proof of Claim
A proof attesting that given these public values:
class ProofOfClaimPublic:
voucher_root: zkhash # Merkle root of the reward_voucher maintained by everyone
voucher_nullifier: zkhash
mantle_tx_hash: zkhash # attached hash
The prover knows the following witness:
class ProofOfClaimWitness:
secret_voucher: zkhash
voucher_merkle_path: list[zkhash]
voucher_merkle_path_selectors: list[bool]
such that the following constraints hold:
- The reward voucher is derived from the secret voucher.
assert reward_voucher == zkhash( FiniteField(b"REWARD_VOUCHER", byte_order="little", modulus= p), secret_voucher) - There exists a valid Merkle path from the reward voucher as a leaf to the Merkle root.
assert voucher_root == path_root(leaf=reward_voucher, path=voucher_merkle_path, selectors=voucher_merkle_path_selectors) - The voucher nullifier is derived from the secret voucher correctly.
assert voucher_nullifier == zkhash( FiniteField(b"VOUCHER_NF", byte_order="little", modulus= p), secret_voucher) - The proof is bound to the mantle_tx_hash.
Benchmark
The material used for the benchmarks is the following:
- CPU : 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM : 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS : Ubuntu 22.04.5 LTS
- Kernel : 6.8.0-59-generic

V1.2.0-MANTLE-TRANSACTION-ENCODING
| Field | Value |
|---|---|
| Name | Mantle Transaction Encoding |
| Slug | 228 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | David Rusu [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-01-20 |
| 1.1.0 | Added [RFC] Make Ledger Transaction an Operation | 2026-04-02 |
| 1.2.0 | Added [RFC] Add Deposit/Withdraw to Tx Encoding | 2026-04-13 |
Introduction
This document specifies the canonical encoding of Mantle transactions (see Mantle - Mantle Transaction) and its sub-components. Transactions sent through the mempool and included in blocks use this encoding.
Overview
The transaction encoding is specified in ABNF form to remove any ambiguity and guarantee a canonical encoding. The high level encoding choices which were not immediately derivable from the Mantle specification are listed here:
- All multi-byte integers use little-endian encoding
- Any lists are length-prefixed with fixed width uints
- We derive number of proofs and type of proof from the Ops list parsed earlier
Specification
Signed Mantle Tx
SignedMantleTx = MantleTx OpsProofs
Mantle Tx
MantleTx = Ops ExecutionGasPrice StorageGasPrice
ExecutionGasPrice = UINT64
StorageGasPrice = UINT64
In future iterations, we will use this encoding to derive the mantle_txhash
Operations
Ops = OpCount *Op
OpCount = Byte
Op = Opcode OpPayload
Opcode = Byte
OpPayload = Transfer /
ChannelInscribe /
ChannelBlob /
ChannelSetKeys /
ChannelDeposit /
ChannelWithdraw /
SDPDeclare /
SDPWithdraw /
SDPActive /
LeaderClaim
Channel Operations
ChannelInscribe = ChannelId Inscription Parent Signer
Inscription = UINT32 *BYTE
ChannelBlob = ChannelId Session BlobId BlobSize DaStorageGasPrice Parent Signer
Sesssion = UINT64
BlobId = Hash32
BlobSize = UINT64
DaStorageGasPrice = UINT64
ChannelSetKeys = ChannelId KeyCount *Signer
KeyCount = Byte
ChannelDeposit = ChannelId Amount Metadata
Amount = UINT64
Metadata = UINT32 *BYTE
ChannelWithdraw = ChannelId Amount
ChannelId = Hash32
Parent = Hash32
Signer = Ed25519PublicKey
SDP Operations
SDPDeclare = ServiceType LocatorCount *Locator ProviderId ZkId LockedNoteId
ServiceType = Byte ; 0 = BN, 1 = DA
LocatorCount = Byte ; Max 8
Locator = 2Byte *BYTE ; Max 329 bytes, multiaddr format
ProviderId = Ed25519PublicKey
ZkId = ZkPublicKey
LockedNoteId = NoteId
SDPWithdraw = DeclarationId Nonce LockedNoteId
DeclarationId = Hash32
Nonce = UINT64
SDPActive = DeclarationId Nonce Metadata
Metadata = UINT32 *BYTE ; Service-specific node activeness metadata
Leader operations
LeaderClaim = RewardsRoot VoucherNullifier
RewardsRoot = FieldElement ; Merkle root for voucher membership proof
VoucherNullifier = FieldElement
Transfer Operations
Transfer = Inputs Outputs
Inputs = InputCount *NoteId
InputCount = Byte
Outputs = OutputCount *Note
OutputCount = Byte
Note = Value ZkPublicKey
Value = UINT64
NoteId = FieldElement
Op Proofs
OpsProofs = *OpProof ; 1. Lenth must equal OpCount
; 2. OpProof variant is derived from the corresponding Op.
; That is, type(OpProofs[i]) == ProofFor(Op[i])
OpProof = Ed25519SigProof /
ZkSigProof /
ZkAndEd25519SigsProof /
ChannelWithdrawOpProof /
ProofOfClaimProof
Ed25519SigProof = Ed25519Signature
ZkSigProof = ZkSignature
ZkAndEd25519SigsProof = ZkSignature Ed25519Signature
ChannelWithdrawOpProof = SignatureCount *IndexedEd25519Signature
ProofOfClaimProof = Groth16
SignatureCount = UINT16
ChannelKeyIndex = UINT16
IndexedEd25519Signature = Ed25519Signature ChannelKeyIndex
Common Structures
; Zero-knowledge signature
ZkSignature = Groth16
; Cryptographic primitives
Groth16 = 128BYTE ; pi_a (32) + pi_b (64) + pi_c (32)
ZkPublicKey = FieldElement
Ed25519PublicKey = 32BYTE
Ed25519Signature = 64BYTE
FieldElement = 32BYTE ; BN254 field element (little-endian)
Hash32 = 32BYTE
; Primitive types
UINT64 = 8BYTE ; 64-bit unsigned integer, little-endian
UINT32 = 4BYTE ; 32-bit unsigned integer, little-endian
UINT16 = 2BYTE ; 16-bit unsigned integer, little-endian
Byte = OCTET
V1.2.1-MANTLE
| Field | Value |
|---|---|
| Name | Mantle |
| Slug | 230 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Thomas Lavaur [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Owner: @Thomas Lavaur
Reviewers: @Mehmet @Marcin Pawlowski @Daniel Sanchez Quiros @Gusto Bacvinka @Youngjoon Lee @Daniel Kashepava @David Rusu
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-11-17 |
| 1.1.0 | ? | 2026-02-06 |
| 1.2.0 | Removed DA references. Removed notions of Sovereignty and Rollups and used Zones for simplicity. Removed Nomos from specifications and DSTs. Added bridging and decentralized sequencing for channels. | 2026-03-20 |
| 1.2.1 | Added [RFC] Improve Mantle Transaction hash. | 2026-03-24 |
Introduction
Mantle is a foundational element of Bedrock, designed to provide a minimal and efficient execution layer that connects together Bedrock Services in order to provide the necessary functionality for Zones. It can be viewed as the system call interface of Bedrock, exposing a safe and constrained set of Operations to interact with lower-level Bedrock services, similar to syscalls in an operating system.
Mantle Transactions provide Operations for Zones and blockchain Services to interact with Bedrock. For example, a Zone sequencer posting an update to Bedrock, or a node operator declaring its participation in the Blend Network, would be done through the corresponding Operations within a Mantle Transaction.
Mantle manages assets using a note-based ledger that follows an UTXO model. Each Mantle Transaction includes a Ledger Transaction, and any excess balance serves as the fee payment.
Overview
Mantle Transaction
The features of the Logos Blockchain are exposed through Mantle Transactions. Each transaction can contain zero or more Operations and one Ledger Transaction. Mantle Transactions enable users to execute multiple Operations atomically. The Ledger Transaction serves two purposes: it pays the transaction fee and allows users to issue transfers.
Mantle Operations
Logos Blockchain features are exposed through Mantle Operations, which can be combined and executed together in a single Mantle Transaction atomically. These Operations enable functions such as on-chain data posting, Cross-Zone interactions, SDP interaction, and leader reward claims.
Mantle Ledger
The Mantle Ledger enables asset transfers using a transparent UTXO model. While a Ledger Transaction can consume more tokens than it creates, the Mantle Transaction excess balance must exactly pay for the fees.
Transaction Fees
Mantle Transaction fees are derived from a gas model. The Logos Blockchain has two different gas markets, accounting for permanent data storage, and execution costs. Each Operation and Ledger Transaction has an associated Execution Gas cost. Users can specify their gas prices in their Mantle Transactions to incentivize the network to include their transaction.
| Gas Market | Charged On | Pricing Basis |
|---|---|---|
| Execution Gas | Ledger Transaction and Operations | Fixed per Operation |
| Permanent Storage Gas | Signed Mantle Transaction | Proportional to encoded size |
Mantle Transaction
Mantle Transactions form the core of Mantle, enabling users to combine multiple Operations to access different functions. Each transaction contains zero or more Operations plus a Ledger Transaction. The system executes all Operations atomically, while using the Mantle Transaction's excess balancecalculated as the difference between the consumed and created value as the fee payment.
class MantleTx:
ops: list[Op]
ledger_tx: LedgerTx # excess balance is used for fee payment
permanent_storage_gas_price: TokenValue # See the note section
execution_gas_price: TokenValue
class Op:
opcode: byte
payload: bytes
def mantle_txhash(tx: MantleTx) -> ZkHash:
tx_bytes = encode(tx)
h = Hasher() # /!\ This is a classic hash not a ZkHash /!\
h.update(b"MANTLE_TXHASH_V1")
h.update(tx_bytes)
classic_digest = h.digest()
zkh = ZkHasher() # /!\ This is a ZkHash not a classic hash /!\
zkh.update(FiniteField(classic_digest[0:16], bytes_order="little", modulus = p))
zkh.update(FiniteField(classic_digest[16:32], bytes_order="little", modulus = p))
return zkh.digest()
The hash function used, as well as other cryptographic primitives like ZK proofs and signature schemes, are described in Common Cryptographic Components.
A Mantle Transaction must include all relevant signatures and proofs for each Operation, as well as for the Ledger Transaction.
class SignedMantleTx:
tx: MantleTx
op_proofs: list[OpProof | None] # each Op has at most 1 associated proof
ledger_tx_proof: ZkSignature # ZK proof of ownership of the spent notes
Each proof (op proof and signature) must be cryptographically bound to the MantleTx through the mantle_txhash to prevent replay attacks. This binding is achieved by including the MantleTx hash as a public input in every ZK proof.
The transaction fee is a sum of two components: the multiplication of the total Execution Gas by the execution_gas_price, and the total size of the encoded signed Mantle Transaction multiplied by the permanent_storage_gas_price.
def gas_fees(signed_tx: SignedMantleTx) -> int:
mantle_tx = signed_tx.tx
permanent_storage_fees = len(encode(signed_mantle_tx)) * mantle_tx.permanent_storage_gas_price
execution_fees = execution_gas(mantle_tx.ledger_tx) * mantle_tx.execution_gas_price
for op in mantle_tx.ops:
# Compute the execution gas of this operation as defined
# in the gas cost determination specification.
execution_fees += execution_gas(op) * mantle_tx.execution_gas_price
return execution_fees + permanent_storage_fees
Validation
Given
signed_tx = SignedMantleTx(
tx=MantleTx(ops, permanent_storage_gas_price, execution_gas_price, ledger_tx),
op_proofs,
ledger_tx_proof
)
Mantle validators will ensure the following:
- The ledger transaction is valid according to Ledger Validation.
validate_ledger_tx(ledger_tx, ledger_tx_proof, mantle_txhash(tx)) - We have a proof or a None value for each operation.
assert len(op_proofs) == len(ops) - Each Operation is valid.
for op, op_proof in zip(ops, op_proofs): assert op.opcode in MANTLE_OPCODES validate_mantle_op(mantle_txhash(tx), op.opcode, op.payload, op_proof) def validate_mantle_op(txhash, opcode, payload, op_proof): if opcode == CHANNEL_INSCRIBE: validate_channel_inscribe(txhash, payload, op_proof) # elif opcode == ... # ... - The Mantle Transaction excess balance pays for the transaction fees.
tx_fee = gas_fees(signed_tx) # Not an unsigned int assert tx_fee == get_transaction_balance(signed_tx) def get_transaction_balance(signed_tx: SignedMantleTx) -> int: balance = 0 # It's important to not use unsigned int here to avoid # overflow vulnerabilities for op in signed_tx.tx.ops: if op.opcode == LEADER_CLAIM: balance += get_leader_reward() if op.opcode == CHANNEL_DEPOSIT: balance -= get_channel_deposit_amount(op) if op.opcode == CHANNEL_WITHDRAW: balance += get_channel_withdrawal_amount(op) for inp in signed_tx.tx.ledger_tx.inputs: balance += get_value_from_note_id(inp) for out in signed_tx.tx.ledger_tx.outputs: balance -= out.value return balance
Execution
Given
SignedMantleTx(
tx=MantleTx(ops, permanent_storage_gas_price, execution_gas_price, ledger_tx),
op_proofs,
ledger_tx_proof
)
Mantle Validators execute the following:
- Execute the Ledger Transaction as described in Ledger Execution.
- Execute sequentially each Operation in ops according to its opcode.
Operations
Opcodes
| Operation | Opcode | Description |
|---|---|---|
| CHANNEL_INSCRIBE | 0x00 | Write a message permanently onto Mantle. |
| RESERVED | 0x01 | |
| CHANNEL_CONFIG | 0x02 | Configure a channel |
| CHANNEL_DEPOSIT | 0x03 | Deposit assets into a channel |
| CHANNEL_WITHDRAW | 0x04 | Withdraw assets from a channel |
| RESERVED | 0x05 - 0x1F | |
| SDP_DECLARE | 0x20 | Declare intention to participate as a node in a Bedrock Service, locking funds as collateral. |
| SDP_WITHDRAW | 0x21 | Withdraw participation from a Bedrock Service, unlocking your funds in the process. |
| SDP_ACTIVE | 0x22 | Signal that you are still an active participant of a Bedrock Service. |
| RESERVED | 0x23 - 0x2F | |
| LEADER_CLAIM | 0x30 | Claim leader reward anonymously. |
| RESERVED | 0x31 - 0xFF |
Channel Operations
Channels allow Zones to post their updates on chain. Channels form virtual chains that overlay on top of the Cryptarchia blockchain. Clients and Followers of a Zone can watch its channel to learn the state of that Zone. Each channel has an associated balance, enabling bridging between Zones and Bedrock.
Message Ordering
Channels form virtual chains by having each message reference its parent message. The order of messages in these channels is enforced by the sequencer by building a hash chain of messages, i.e. new messages reference the previous messages through a parent hash. Given that Cryptarchia has long finality times, these message parent references allow Zone sequencers to continue to post new updates to channels without having to wait for finality. No matter how Cryptarchia forks and reorgs, the channel messages from honest sequencers will eventually be re-included in a way that satisfies the virtual chain order.
The first time a message is sent to an unclaimed channel, the key that signs the initial message becomes the only accredited key in the list (Note that this key may correspond to a threshold signature key). Accredited keys of a channel forms a committee that can configure the channel, withdraw funds and take turns to write messages to that channel following a round-robin algorithm. Configuring a channel includes modifying the list of accredited keys, the round-robin parameters and the required number of signatures to withdraw funds or establish a new configuration.
Validators must maintain the following state to process channel Operations:
channels: dict[ChannelId, ChannelState] # ChannelId is 32 bytes
class ChannelState:
# Channel Configuration
accredited_keys: list[Ed25519PublicKey] # limited to 65 535 keys
configuration_threshold: u16 # indicating how many keys are
# required to update the configuration
# Message Ordering
tip_hash: hash
# Decentralized Sequencing
tip_slot: Slot
tip_sequencer: u16 # indicating the actual
# sequencer position in the list of accredited keys
tip_sequencer_starting_slot: Slot
posting_timeframe: u32 # number of slots (0 = infinity)
posting_timeout: u32 # number of slots (0 = no timeout)
# Bridging
balance: TokenValue # See the Note section for its precision
withdraw_threshold: u16 # indicating how many keys are
# required to withdraw funds from the channel
def default_channel(block_slot: Slot, keys: list[Ed25519PublicKey])
-> ChannelState:
return ChannelState(
tip_hash = ZERO,
tip_slot = block_slot,
accredited_keys = keys,
tip_sequencer = 0,
tip_sequencer_starting_slot = block_slot,
posting_timeframe = 0,
posting_timeout = 0,
configuration_threshold = 1,
withdraw_threshold = 1)
Note that the user chooses the ChannelId mapping to the ChannelState (but its restricted to 32 bytes). We don't currently impose restrictions on it, but we may do so in the future to prevent undesirable behaviors.
Decentralized Sequencing
To determine which sequencer is currently authorized to send messages, we use a round-robin algorithm. When a message is posted to a channel, the following algorithm is used to determine who the sequencer is:
# Round Robin algorithm determining the new sequencer index and the
# new sequencer starting slot
def round_robin(block_slot: Slot, channel: ChannelState) -> (u16,u64):
elapsed_slots = block_slot - channel.tip_slot
if elapsed_slots >= channel.posting_timeout && channel.posting_timeout != 0:
# Get the number of sequencers that get timed out
sequencers_timed_out = elapsed_slots // channel.posting_timeout
index = (channel.tip_sequencer + sequencers_timed_out)
% len(channel.accredited_keys)
starting_slot = channel.tip_slot
+ sequencers_timed_out * channel.posting_timeout
else:
# Get the number of timeframes elapsed to get who is the sequencer
tip_sequencer_duration = block_slot - channel.tip_sequencer_starting_slot
index = (channel.tip_sequencer
+ (tip_sequencer_duration // channel.posting_timeframe))
% len(channel.accredited_keys)
starting_slot = channel.tip_sequencer_starting_slot
+ (tip_sequencer_duration // channel.posting_timeframe)
* channel.posting_timeframe
return (index, starting_slot)
CHANNEL_INSCRIBE
Write a message to a channel with the message data being permanently stored on the Logos Blockchain.
Payload
class Inscribe:
channel: ChannelId # 32 bytes Channel being written to
inscription : bytes # Message to be written on the blockchain
parent: hash # Previous message in the channel
signer: Ed25519PublicKey # Identity of message sender
Proof
Ed25519Signature
Execution Gas
Channel Inscribe Operations have a fixed Execution Gas cost of EXECUTION_CHANNEL_INSCRIBE_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash
msg: Inscribe
sig: Ed25519Signature
channels: dict[ChannelId, ChannelState]
block_slot: Slot
Validate
if msg.channel in channels:
chan = channels[msg.channel]
current_sequencer_index = round_robin(block_slot, chan)[0]
# Ensure the signer is the one authorized to write to the channel
assert msg.signer == chan.accredited_keys[current_sequencer_index]
# Ensure message is continuing the channel sequence
assert msg.parent == chan.tip_hash
else:
# Channel will be created automatically upon execution
# Ensure that this message is the genesis message (parent == ZERO)
assert msg.parent == ZERO
# Ensure the msg signer signature
assert Ed25519_verify(txhash, msg.signer, sig)
Execution
Given
msg: Inscribe
sig: Ed25519Signature
channels: dict[ChannelId, ChannelState]
block_slot: Slot
Execute
- If the channel does not exist, create it just-in-time.
if msg.channel not in channels: channels[msg.channel] = default_channel(block_slot, [msg.signer]) - Update the channel sequencer.
chan = channels[msg.channel] (new_sequencer_index, new_sequencer_starting_slot) = round_robin( block_slot, chan) chan.tip_sequencer_starting_slot = new_sequencer_starting_slot chan.tip_sequencer = new_sequencer_index - Update the channel tip.
chan = channels[msg.channel] chan.tip_hash = hash(encode(msg)) chan.tip_slot = block_slot
Example
# Build the inscription
greeting = Inscription(
channel=CHANNEL_EARTH,
inscription=b"Live long and prosper",
parent=ZERO
signer=spock_pk
)
# Wrap it in a transaction
tx = MantleTx(
ops=[Op(opcode=CHANNEL_INSCRIBE, payload=encode(greeting))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[<spocks_note_id>], outputs=[<change_note>]),
)
# Sign the transaction
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[Ed25519_sign(mantle_txhash(tx), spock_sk)]
ledger_tx_proof=tx.ledger_tx.prove(spock_sk)
)
# Send the transaction to the mempool
mempool.push(signed_tx)
CHANNEL_CONFIG
Overwrite the configuration of a channel.
Payload
class ChannelConfig:
channel: ChannelId
keys: list[Ed25519PublicKey]
posting_timeframe: u32
posting_timeout: u32
configuration_threshold: u16
withdraw_threshold: u16
Proof
class ChannelConfigOpProof:
signatures: list[Ed25519Signature] # signatures from configuration_threshold
indexes: list[u16] # signatures of accredited keys with their index.
# indexes must be ordered from smallest to
# biggest without duplication
Execution Gas
Channel Config Operations have a linear Execution Gas cost equal to EXECUTION_CHANNEL_CONFIG_GAS * configuration_threshold. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash
config: ChannelConfig
proof: ChannelConfigOpProof
channels: dict[ChannelId, ChannelState]
Validate
assert len(proof.signatures) == len(proof.indexes)
assert config.configuration_threshold > 0
assert config.withdraw_threshold > 0
assert len(config.keys) > 0
assert len(config.keys) < 2^16
if config.channel in channels:
chan = channels[config.channel]
# Check there are enough signatures
assert len(proof.signatures) == chan.configuration_threshold
# Check that indexes are ordered to avoid duplication
for i in range(len(proof.indexes)-1):
assert proof.indexes[i] < proof.indexes[i+1]
for sig, idx in zip(proof.signatures, proof.indexes):
# and at the same time that chan.accredited_keys[idx] isn't out of bound
assert Ed25519_verify(txhash, chan.accredited_keys[idx], sig)
Execution
Given
config: ChannelConfig
channels: dict[ChannelId, ChannelState]
block_slot: Slot
Execute
- If the channel does not exist, create it just-in-time.
if config.channel not in channels:
channels[config.channel] = default_channel(block_slot, config.keys)
- Update the configuration.
chan = channels[config.channel]
# Update Channel Configuration Parameters
chan.accredited_keys = config.keys
chan.configuration_threshold = config.configuration_threshold
# Update Decentralized Sequencing Parameters
chan.tip_sequencer = 0
chan.tip_sequencer_starting_slot = block_slot
chan.posting_timeframe = config.posting_timeframe
chan.posting_timeout = config.posting_timeout
# Update Bridging Parameters
chan.withdraw_threshold = config.withdraw_threshold
- Update the channel tip.
chan = channels[config.channel]
chan.tip_slot = block_slot
chan.tip_hash = hash(encode(config))
Example
Suppose the unique sequencer of Zone A wants to add a key to the list of accredited keys:
# Given a key to add
new_sequencer_pk: Ed25519PublicKey
# The unique sequencer encodes the update and builds the payload
config = ChannelConfig(
channel=ZONE_A,
keys=[old_sequencer_pk, new_sequencer_pk],
posting_timeframe = 5000,
posting_timeout = 500,
configuration_threshold = 2,
withdraw_threshold = 1
)
tx = MantleTx(
ops=[Op(opcode=CHANNEL_CONFIG, payload=encode(config))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[old_sequencer_funds], outputs=[<change note>])
)
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[[Ed25519_sign(mantle_txhash(tx), old_sequencer_sk)], [0]]]
ledger_tx_proof=tx.ledger_tx.prove(old_sequencer_sk),
)
CHANNEL_DEPOSIT
Deposit funds to a channel, reducing the Mantle Transaction balance.
Payload
class ChannelDeposit:
channel: ChannelId
amount: TokenValue
metadata: bytes
Proof
None # Indirectly signed through the Ledger Transaction signature
Execution Gas
Channel Deposit Operations have a fixed Execution Gas cost of EXECUTION_CHANNEL_DEPOSIT_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
deposit: ChannelDeposit
channels: dict[ChannelId, ChannelState]
Validate
assert deposit.channel in channels
Execution
Given
deposit: ChannelDeposit
channels: dict[ChannelId, ChannelState]
Execute
channels[deposit.channel].balance += deposit.amount
Example
Suppose Alice wants to make a deposit of 50 tokens on Zone A.
# Alice encodes her deposit
deposit = ChannelDeposit(
channel=ZONE_A,
amount=50,
metadata=b"deposit to address: 0x..."
)
tx = MantleTx(
ops=[Op(opcode=CHANNEL_DEPOSIT, payload=encode(deposit))],
permanent_storage_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[Alice_funds], outputs=[<change note>])
)
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=None,
ledger_tx_proof=tx.ledger_tx.prove(Alice_sk)
)
Note that the Zone may wait for the deposit to be finalized before interpreting the deposit in order to guarantee that the deposit will occur on-chain and won't be removed due to reorganization of the chain.
CHANNEL_WITHDRAW
Withdraw funds from a channel, increasing the Mantle Transaction balance.
Payload
class ChannelWithdraw:
channel: ChannelId
amount: TokenValue
Proof
class ChannelWithdrawOpProof:
signatures: list[Ed25519Signature] # signature from withdraw_threshold keys
indexes: list[int] # signatures of accredited keys with their index.
# indexes must be ordered from smallest to
# biggest without duplication
Execution Gas
Channel Withdraw Operations have a linear Execution Gas cost equal to EXECUTION_CHANNEL_WITHDRAW_GAS * withdraw_threshold. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash
withdrawal: ChannelWithdraw
proof: ChannelWithdrawOpProof
channels: dict[ChannelId, ChannelState]
Validate
# Check that the channel exists
assert withdrawal.channel in channels
chan = channels[withdrawal.channel]
# Check that the channel has enough funds
assert chan.balance >= withdrawal.amount
# Check that there are enough signatures
assert len(proof.signatures) == len(proof.indexes)
assert len(proof.signatures) == chan.withdraw_threshold
# Check that every index is unique
assert len(proof.indexes) == len(set(proof.indexes))
# Check the signatures
for sig, idx in zip(proof.signatures, proof.indexes):
assert Ed25519_verify(txhash, chan.accredited_keys[idx], sig)
Execution
Given
withdrawal: ChannelWithdraw
channels: dict[ChannelId, ChannelState]
Execute
channels[withdrawal.channel].balance -= withdrawal.amount
Example
Suppose the unique sequencer of Zone A wants to withdraw 50 tokens.
# Sequencer encodes his withdrawal
withdrawal = ChannelWithdraw(
channel=ZONE_A,
amount=50
)
tx = MantleTx(
ops=[Op(opcode=CHANNEL_WITHDRAW, payload=encode(withdrawal))],
permanent_storage_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[Sequencer_funds], outputs=
[<withdraw_funds>, <change note>])
)
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[[[Ed25519_sign(mantle_txhash(tx), sequencer_sk)],[0]]],
ledger_tx_proof=tx.ledger_tx.prove(Sequencer_note_sk)
)
Service Declaration Protocol (SDP) Operations
These Operations implement the Service Declaration Protocol.
Validators must keep the following state when implementing SDP Operations:
locked_notes: dict[NoteID, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
class LockedNote:
declarations: set[DeclarationID]
locked_until: BlockNumber
Common SDP Structures
class ServiceType(Enum):
BN="BN" # Blend Network
class Locator(str):
def validate(self):
assert len(self) <= 329
assert validate_multiaddr(self)
class MinStake:
stake_threshold: int # stake value
timestamp: int # block number
class ServiceParameters:
lock_period: int # number of blocks
inactivity_period: int # number of blocks
retention_period: int # number of blocks
timestamp: int # block number
class DeclarationInfo:
service: ServiceType
locators: list[Locator]
provider_id: Ed25519PublicKey
zk_id: ZkPublicKey
locked_note_id: NoteId
created: BlockNumber
active: BlockNumber
withdrawn: BlockNumber
# SDP ops updating a declaration must use monotonically increasing nonces
nonce: int
SDP_DECLARE
The service registration follows the definition given in Service Declaration Protocol - Declaration Message:
Payload
class DeclarationMessage:
service_type: ServiceType
locators: list[Locator]
provider_id: Ed25519PublicKey
zk_id: ZkPublicKey
locked_note_id: NoteId
Locked notes are introduced in Locked notes and serve as Service collaterals. They cannot be spent before the owner withdraw its participation from the declared service(s).
Proof
class DeclarationProof:
zk_sig: ZkSignature # signature proving ownership over
# locked note and zk_id
provider_sig: Ed25519Signature # signature proving ownership of provider key
see: Zero Knowledge Signature Scheme (ZkSignature).
Execution Gas
SDP Declare Operations have a fixed Execution Gas cost of EXECUTION_SDP_DECLARE_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash # the txhash of the transaction we are validating
declaration: DeclarationMessage # the declaration we are validating
proof: DeclarationProof
min_stake: MinStake # the (global) minimum stake setting
ledger: Ledger # the set of unspent notes
locked_notes: dict[NoteId, LockedNote]
declarations: dict[NoteId, DeclarationInfo]
Validate
The declaration is verified according to Service Declaration Protocol - Declare.
- Ensure ownership over the locked note, zk_id and provider_id.
assert ZkSignature_verify( txhash, proof.zk_sig, [note.public_key, declaration.zk_id] ) assert Ed25519_verify(txhash, proof.provider_sig, provider_id) - Ensure declaration does not already exist.
assert declaration_id(declaration) not in declarations - Ensure it has no more than 8 locators.
assert len(declaration.locators) <= 8 - Ensure locked note exists and value of locked note is sufficient for joining the service.
assert ledger.is_unspent(declaration.locked_note_id) note = ledger.get_note(declaration.locked_note_id) assert note.value >= min_stake.stake_threshold - Ensure the note has not already been locked for this service.
if declaration.locked_note in locked_notes: locked_note = locked_notes[declaration.locked_note] services = [declarations[declare_id] for declare_id in locked_note.declarations] assert declaration.service_type not in services
Execution
Given
declaration: DeclarationMessage # the declaration we are executing
service_parameters: dict[ServiceType, ServiceParameters]
current_block_height: int
locked_notes : dict[NoteId, LockedNote]
Execute
- Create the locked note state if it doesn't already exist.
if declaration.locked_note not in locked_notes: locked_notes[declaration.locked_note_id] = \ LockedNote(declarations=set(), locked_until=0) locked_note = locked_notes[declaration.locked_note_id] - Update the locked notes timeout using this services lock period.
lock_period = service_parameters[declaration.service_type].lock_period service_lock = current_block_height + lock_period locked_note.locked_until = max(service_lock, locked_note.locked_until) - Add this declaration to the locked note.
declare_id = declaration_id(declaration) locked_note.declarations.add(declare_id) - Store the declaration as explained in Service Declaration Protocol - Declaration Storage.
declarations[declare_id] = DeclarationInfo( service: declaration.service locators: declaration.locators provider_id: declaration.provider_id zk_id: declaration.zk_id locked_note_id: declaration.locked_note_id declaration, created=current_block_height, active=current_block_height, withdrawn=0 nonce=0 )
Example
# Assume `alice_note` is in the ledger:
alice_note = Utxo(
txhash=0x2948904F2F0F479B8F8197694B30184B0D2ED1C1CD2A1EC0FB85D299A192A447,
output_number=3,
note=Note(value=500, public_key=alice_pk_1),
)
# Alice wishes to lock it to join the Blend network
declaration=DeclarationMessage(
service_type=ServiceType.BN,
locators=["/ip4/203.0.113.10/tcp/4001/p2p"],
provider_id=alice_provider_pk,
zk_id=alice_pk_2,
locked_note_id=alice_note.id()
)
tx = MantleTx(
ops=[Op(opcode=SDP_DECLARE, payload=encode(declaration))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[fee_note_id], outputs=[]),
)
txhash = mantle_txhash(tx)
declaration_proof = DeclarationProof(
# proof of ownership of the staked note and zk_id
zk_sig=ZkSignature([alice_sk_1, alice_sk_2], txhash),
# proof of ownership of the provider id
provider_sig=Ed25519Signature(alice_provider_sk, txhash),
)
SignedMantleTx(
tx=tx,
ledger_tx_proof=LedgerTxProof,
op_proofs=[declaration_proof],
ledger_proof=prove_ledger_tx(tx.ledger_tx, [alice_sk_1]),
)
SDP_WITHDRAW
The service withdrawal follows the definition given in Service Declaration Protocol - Withdraw Message.
Payload
class WithdrawMessage:
declaration: DeclarationID
locked_note_id: NoteId
nonce: int
Proof
A signature from the zk_id and the locked note pk attached to the declaration is required for withdrawing from a service, (see Zero Knowledge Signature Scheme (ZkSignature)).
ZkSignature
Execution Gas
SDP Withdraw Operations have a fixed Execution Gas cost of EXECUTION_SDP_WITHDRAW_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash # Mantle transaction hash of the tx containing this operation
withdraw: WithdrawMessage
signature: ZkSignature
block_height: int # block height of the current block
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
Validate
- Ensure that the locked note exists, is locked and bound to this declaration.
assert ledger.is_unspent(withdraw.locked_note_id) assert withdraw.locked_note_id in locked_notes locked_note = locked_notes[withdraw.locked_note_id] assert withdraw.declaration in locked_note.declarations - Ensure that the locked note has expired.
assert locked_note.locked_until <= block_height - Validate SDP withdrawal according to Service Declaration Protocol - Withdraw.
- Ensure declaration exists.
assert withdraw.declaration in declarations declare_info = declarations[withdraw.declaration] - Ensure locked note pk and zk_id attached to this declaration authorized this Operation.
locked_note = ledger[withdraw.locked_note_id] assert ZkSignature_verify(txhash, signature, [locked_note.pk, declare_info.zk_id]) - Ensure the declaration has not already been withdrawn.
assert declare_info.withdrawn == 0 - Ensure that the nonce is greater than the previous one.
assert withdraw.nonce > declare_info.nonce
- Ensure declaration exists.
Execution
Given
withdraw: WithdrawMessage
signature: ZkSignature
block_height: int # block height of the current block
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
Execute
Executes the withdrawal protocol Service Declaration Protocol - Withdraw.
- Update declaration info with nonce and withdrawn timestamp.
declare_info = declarations[withdraw.declaration] declare_info.nonce = withdraw.nonce declare_info.withdrawn = block_height - Remove this declaration from the locked note.
locked_note = locked_notes[withdraw.locked_note_id] locked_note.declarations.remove(withdraw.declaration) - Remove the locked note if it is no longer bound to any declarations.
if len(locked_note.declarations) == 0: del locked_notes[withdraw.locked_note_id)
Example
withdraw=Withdraw(
declaration=alice_declaration_id,
locked_note_id=alices_locked_note_id
nonce=1579532
)
tx = MantleTx(
ops=[Op(opcode=SDP_WITHDRAW, payload=encode(withdraw))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(
inputs=[alices_locked_note_id],
outputs=[Note(100, alice_note_pk)]
),
)
SignedMantleTx(
tx=tx,
ledger_tx_proof= tx.ledger_tx.prove(alice_sk),
# proof ownership of the withdrawn note and zk id
op_proofs=[ZkSignature_sign([alice_note_sk, alice_sk], mantle_txhash(tx))]
)
SDP_ACTIVE
The service active action follows the definition given in Service Declaration Protocol - Active Message.
Payload
class Active:
declaration: DeclarationID
nonce: int
metadata: bytes # a service-specific node activeness metadata
Proof
ZkSignature
Execution Gas
SDP Active Operations have a fixed Execution Gas cost of EXECUTION_SDP_ACTIVE_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash # Mantle transaction hash of the tx containing this operation
active: Active
signature: ZkSignature
declarations: dict[DeclarationID, DeclarationInfo]
Validate
assert active.declaration in declarations
declaration_info = declarations[active.declaration]
assert active.nonce > declaration_info.nonce
assert ZkSignature_verify(txhash, signature, declaration_info.zk_id)
Execution
Executes the active protocol Service Declaration Protocol - Active. The activation, i.e. setting the declaration.active, is handled by the service-specific logic.
Example
active=Active(
declaration=alice_declaration_id,
nonce=1579532,
metadata=b"Look, I am still doing my job"
)
tx = MantleTx(
ops=[Op(opcode=SDP_ACTIVE, payload=encode(active))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[fee_note_id], outputs=[]),
)
txhash = mantle_txhash(tx)
SignedMantleTx(
tx=tx,
ledger_tx_proof=tx.ledger_tx.prove(fee_note_sk),
op_proofs=[Ed25519_sign(txhash, validator_sk)]
)
Leader Operations
LEADER_CLAIM
This Operation claims the leader's block reward anonymously.
Payload
class ClaimRequest:
rewards_root: zkhash # Merkle root used in the proof for voucher membership
voucher_nf: zkhash
Proof
The provider proves that they have won a proof of Leadership before the start of the current epoch, i.e., their reward voucher is indeed in the voucher set: Proof of Claim.
Execution gas
Leader Claim Operations have a fixed Execution Gas cost of EXECUTION_LEADER_CLAIM_GAS. See Gas Determination for the Execution Gas values.
Validation
# Given
mantle_txhash: zkhash
claim : ClaimRequest
last_voucher_root: zkhash # The last root of the voucher Merkle tree
# at the start of the epoch
voucher_nullifier_set: set[zkhash]
proof: ProofOfClaim
# Validate
assert claim.voucher_nf not in voucher_nullifier_set
assert claim.rewards_root == last_voucher_root
validate_proof(claim, proof, mantle_txhash)
Execution
- Add claim.voucher_nf to the voucher_nullifier_set .
- Increase the balance of the Mantle Transaction by the leader reward amount according to Anonymous Leaders Reward Protocol - Leaders Reward.
- Reduce the leaders reward leaders_rewards value by the same amount (without ZK proof). Example
secret_voucher = 0xDEADBEAF;
reward_voucher = leader_claim_voucher(secret_voucher)
voucher_nullifier = leader_claim_nullifier(secret_voucher)
claim=ClaimRequest(
rewards_root=REWARDS_MERKLE_TREE.root(),
voucher_nf=voucher_nullifier,
)
tx = MantleTx(
ops=[Op(opcode=LEADER_CLAIM, payload=encode(claim))],
permanent_storage_gas_price=150,
execution_gas_price=70,
ledger_tx=LedgerTx(inputs=[<fee_note>], outputs=[<change_note>]),
)
claim_proof = claim.prove(
secret_voucher,
REWARDS_MERKLE_TREE.path(leaf=reward_voucher),
mantle_txhash(tx)
)
SignedMantleTx(
tx=tx,
ledger_tx_proof=tx.ledger_tx.prove(fee_note_sk),
op_proofs=[claim_proof]
)
Mantle Ledger
Notes
Notes are composed of two fields representing their value and their owner:
class Note:
value: TokenValue # u64
public_key: ZkPublicKey # 32 bytes
Note Id
Any note can be uniquely identified by the Ledger Transaction that created it and its output number: (txhash, output_number). However, it is often useful to have a commitment to the note fields for use in ZK proofs (e.g., for PoL), so we include the note in the note identifier derivation.
def derive_note_id(txhash: zkhash, output_number: int, note: Note) -> NoteId:
return zkhash(
FiniteField(b"NOTE_ID_V1", byte_order="little", modulus= p)
txhash,
FiniteField(output_number, byte_order="little", modulus= p)
FiniteField(note.value, byte_order="little", modulus= p)
note.public_key
)
These note identifiers uniquely define notes in the system and cannot be chosen by the user. Nodes maintain the set of notes through a dictionary mapping the NoteId to the note.
Locked notes
Locked notes are special notes in Mantle that serve as collateral for Service Declarations. A note can become locked after executing a Declare Operation, preventing it from being spent until explicitly released through a Withdraw Operation. The system maintains a mapping of locked note IDs to their supporting declarations. Though locked, these notes remain in the Ledger and can still participate in Proof of Stake. When service providers withdraw all their declarations, the associated note(s) become unlocked and available for spending again.
Ledger Transactions
Transactions must prove the ownership of spent notes. In classical blockchains, this is done through a signature. To stay compatible with our architecture, the signature is done by a ZK proof (see Zero Knowledge Signature Scheme (ZkSignature)), proving the knowledge of the secret key associated with the public key.
Transactions allow complete transaction linkability and the public key spending the note is not hidden.
Structure
class LedgerTx:
inputs: list[NoteId] # the list of consumed note identifiers
outputs: list[Note]
Proof
A transaction proves the ownership of the consumed notes using a Zero Knowledge Signature Scheme (ZkSignature)
ZkSignature
Execution Gas
Ledger Transactions have a fixed Execution Gas cost of EXECUTION_LEDGER_TX_GAS. See Gas Determination for the Execution Gas values.
Ledger Transaction Hash
def ledger_txhash(tx: LedgerTx) -> ZkHash:
tx_bytes = encode(tx)
h = Hasher() # /!\ This is a classic hash not a ZkHash /!\
h.update(b"LEDGER_TXHASH_V1")
h.update(tx_bytes)
classic_digest = h.digest()
zkh = ZkHasher() # /!\ This is a ZkHash not a classic hash /!\
zkh.update(FiniteField(classic_digest[0:16], bytes_order="little", modulus = p))
zkh.update(FiniteField(classic_digest[16:32], bytes_order="little", modulus = p))
return zkh.digest()
Ledger Validation
Given
mantle_txhash: ZkHash # ZkHash of mantle tx containing this ledger tx
ledger_tx: LedgerTx
ledger_tx_proof: ZkSignature
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
Validate
- Ensure all inputs are unspent.
assert all(ledger.is_unspent(note_id) for note_id in ledger_tx.inputs) - Validate ledger proof to show ownership over input notes.
input_notes = [ledger[input_note_id] for input_note_id in ledger_tx.inputs] input_pks = [note.public_key for note in input_notes] assert ZkSignature_verify(mantle_txhash, ledger_tx_proof, input_pks) - Ensure inputs are not locked.
# Ensure inputs are not locked for note_id in ledger_tx.inputs: assert note_id not in locked_notes - Ensure outputs are valid.
for output in ledger_tx.outputs: assert output.value > 0 assert output.value < 2**64
Ledger Execution
Given
ledger_tx: LedgerTx
ledger_tx_proof: ZkSignature
ledger: Ledger
Execution
- Remove inputs from the ledger.
for note_id in ledger_tx.inputs: # updates the merkle tree to zero out the leaf for this entry # and adds that leaf index to the list of unused leaves ledger.remove(note_id) - Add outputs to the ledger.
txhash = ledger_txhash(ledger_tx) for (output_number, output_note) in enumerate(tx.outputs): output_note_id = derive_note_id(txhash, output_number, output_note) ledger.add(output_note_id)
Ledger Example
alice_note_id = ... # assume Alice holds a note worth 501 tokens
bob_note=Note(
value=500
public_key=bob_pk,
)
ledger_tx = LedgerTx(
inputs=[alice_note_id],
outputs=[bob_note],
)
Appendix
Gas Determination
From the [Analysis] Gas Cost Determination, we get the table below:
| Constants | Value |
|---|---|
| EXECUTION_LEDGER_TX_GAS | 590 |
| EXECUTION_CHANNEL_INSCRIBE_GAS | 56 |
| EXECUTION_CHANNEL_CONFIG_GAS | 56 |
| EXECUTION_CHANNEL_DEPOSIT_GAS | 0 |
| EXECUTION_CHANNEL_WITHDRAW_GAS | 56 |
| EXECUTION_SDP_DECLARE_GAS | 646 |
| EXECUTION_SDP_WITHDRAW_GAS | 590 |
| EXECUTION_SDP_ACTIVE_GAS | 590 |
| EXECUTION_LEADER_CLAIM_GAS | 580 |
Zero Knowledge Signature Scheme (ZkSignature)
A proof attesting that for the following public values:
class ZkSignaturePublic:
public_keys: list[ZkPublicKey] # public keys signing the message (len = 32)
msg: zkhash # zkhash of the message
The prover knows a witness:
class ZkSignatureWitness:
# The list of secret keys used to signed the message
secret_keys: list[ZkSecretKey] # (len = 32)
Such that the following constraints hold:
- The number of secret keys is equal to the number of public keys.
assert len(secret_keys) == len(public_keys) - Each public key is derived from the corresponding secret key.
assert all( notes[i].public_key == zkhash( FiniteField(b"KDF", byte_order="little", modulus= p), secret_keys[i]) for i in range(len(public_keys)) ) - The proof is bound to msg (its the mantle_tx_hash in case of transactions).
For implementation, the ZkSignature circuit will take a maximum of 32 public keys as inputs. To prove ownership of fewer keys, the remaining inputs will be padded with the public key corresponding to the secret key 0 and ignored during execution. The outputs have no size limit since they are included in the hashed message.
Benchmark
The material used for the benchmarks is the following:
- CPU : 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM : 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS : Ubuntu 22.04.5 LTS
- Kernel : 6.8.0-59-generic
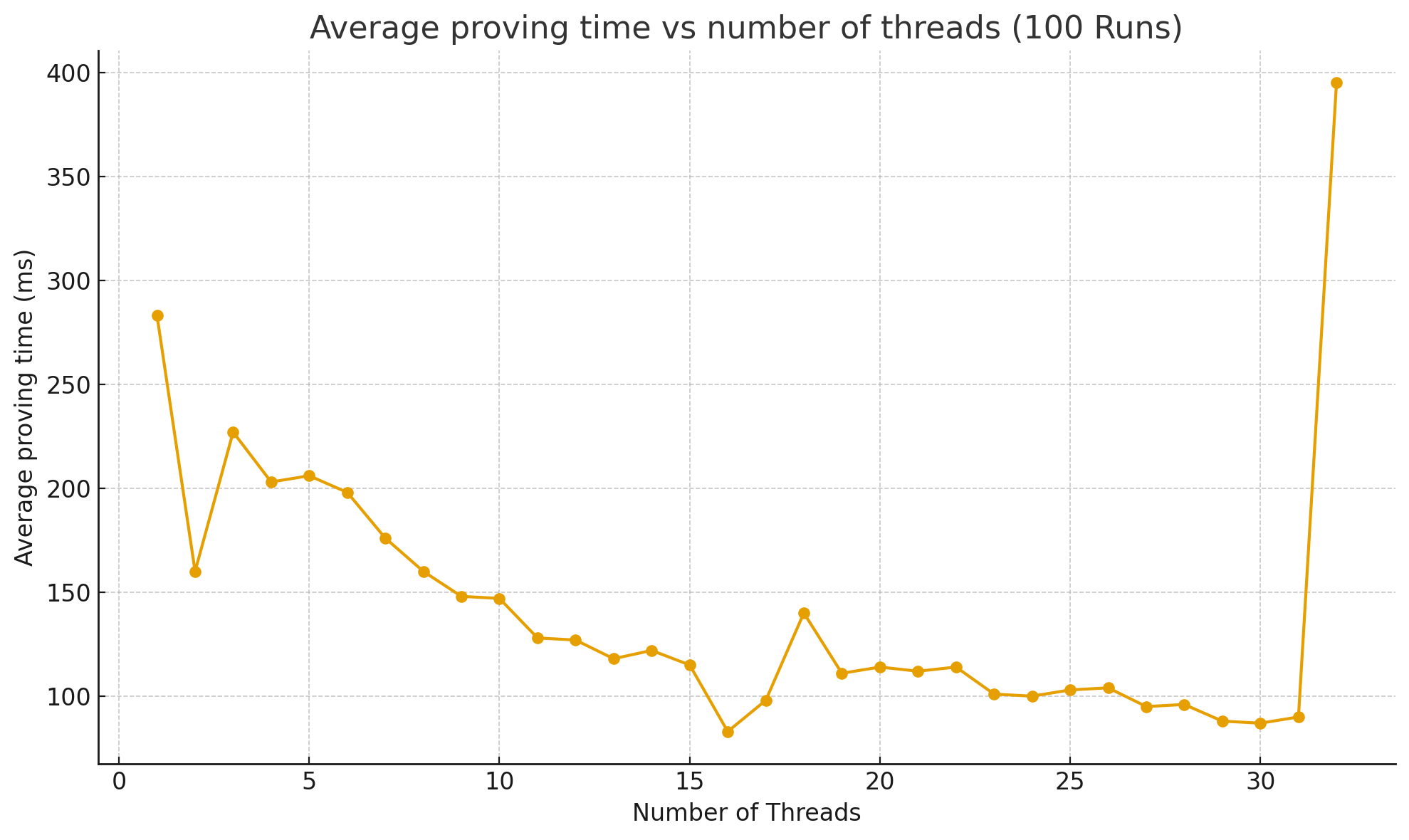
Proof of Claim
A proof attesting that given these public values:
class ProofOfClaimPublic:
voucher_root: zkhash # Merkle root of the reward_voucher maintained by everyone
voucher_nullifier: zkhash
mantle_tx_hash: zkhash # attached hash
The prover knows the following witness:
class ProofOfClaimWitness:
secret_voucher: zkhash
voucher_merkle_path: list[zkhash]
voucher_merkle_path_selectors: list[bool]
such that the following constraints hold:
- The reward voucher is derived from the secret voucher.
assert reward_voucher == zkhash( FiniteField(b"REWARD_VOUCHER", byte_order="little", modulus= p), secret_voucher) - There exists a valid Merkle path from the reward voucher as a leaf to the Merkle root.
assert voucher_root == path_root(leaf=reward_voucher, path=voucher_merkle_path, selectors=voucher_merkle_path_selectors) - The voucher nullifier is derived from the secret voucher correctly.
assert voucher_nullifier == zkhash( FiniteField(b"VOUCHER_NF", byte_order="little", modulus= p), secret_voucher) - The proof is bound to the mantle_tx_hash.
Benchmark
The material used for the benchmarks is the following:
- CPU : 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM : 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS : Ubuntu 22.04.5 LTS
- Kernel : 6.8.0-59-generic
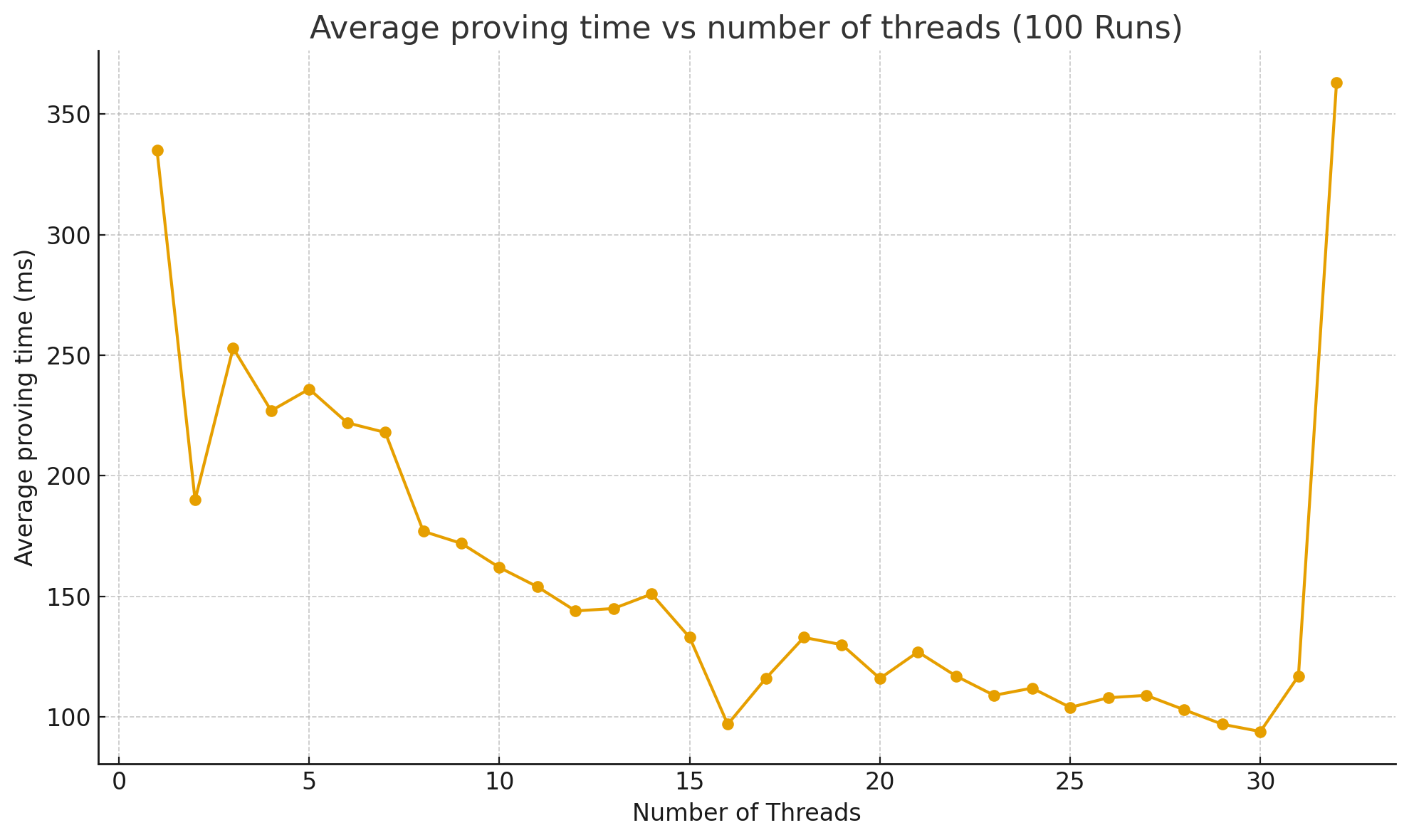
V1.3.0-ANALYSIS-GAS-COST-DETERMINATION
| Field | Value |
|---|---|
| Name | [Analysis] Gas Cost Determination |
| Slug | 231 |
| Status | deprecated |
| Type | RFC |
| Category | Informational |
| Editor | Thomas Lavaur [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-09-25 |
| 1.1.0 | ? | 2025-10-07 |
| 1.2.0 | Removed DA, included Execution Gas determination for channel deposits and withdraws. Updated the Execution Gas of the Channel config. | 2026-01-14 |
| 1.3.0 | Added [RFC] Make Ledger Transaction an Operation. Renamed Nomos to Logos Blockchain | 2026-04-02 |
Introduction
In Mantle, each Mantle Transaction contains one or more Operations. These components consume gas, measured through fixed gas units that reflect their execution or storage impact. Logos Blockchain introduces two independent gas markets:
- Execution Gas: measuring computational workload.
- Permanent Storage Gas: measuring cost of fully replicated storage.
Gas constants are carefully calibrated to reflect the computational and storage requirements of different operations on Logos Blockchain. By standardizing gas measurements, the system can accurately charge fees proportional to resource usage, preventing network abuse and incentivizing efficient transaction design.
Overview
We conducted a comprehensive analysis of execution requirements for each Operation type in Mantle Transactions. This detailed examination allowed us to determine precise gas amounts for each Operation based on the actual computational resources consumed.
The gas constants we established are strategically divided between permanent storage and execution components, directly proportional to their respective resource utilization within Mantle Transactions. This separation ensures that gas costs accurately reflect the true computational burden of different operations. Moreover, gas can also be adjusted arbitrarily to incentivize or disincentivize the usage of certain Operations compared to others.
Our methodology involved measuring execution complexity and defining how gas is determined for each Gas Market. This is critical for proper network operation as it directly impacts transaction prioritization and network economics.
Permanent Storage Gas
Permanent Storage is paid directly for the entire signed Mantle Transaction. The Permanent Storage Gas price is included in the Mantle Transaction structure and is used to determine the Permanent Storage fee. 1 Permanent Storage Gas corresponds to 1 byte.
permanent_storage_fee = len(encode(tx_signed)) * permanent_storage_gas_price
Execution Gas
Execution is a second general market that represents how costly an Operation is to execute. This cost can be fixed or variable based on the content of the Operation. The Execution Gas price is contained in the Mantle Transaction structure and each Operation defines its execution gas amount. 1 Execution Gas corresponds to 1,000 CPU cycles.
execution_fee = tx.ops.get_summed_gas() * execution_gas_price
The gas derivation of each Operation are:
TRANSFER_GAS = 590
CHANNEL_INSCRIBE_GAS = 56
CHANNEL_CONFIG_GAS = 56 * configuration_threshold
CHANNEL_DEPOSIT_GAS = 0
CHANNEL_WITHDRAW_GAS = 56 * withdraw_threshold
SDP_DECLARE_GAS = 646
SDP_WITHDRAW_GAS = 590
SDP_ACTIVE_GAS = 590
LEADER_CLAIM_GAS = 580
and come from our implementation observations as described in Gas determination from measures. To get these numbers, we based our calculations on the following measures:
| Operation | Number of CPU cycles |
|---|---|
| ZkSignature batch verification | 3,900,000 + number_of_proof x 590,000 |
| Proof of Claim batch verification | 2,640,000 + number_of_proof x 580,000 |
| Eddsa25519 signature verification | 56,000 |
Comparison, list searching, hashes and operation in small fields are neglected. We also supposed that the initialization cost for batch verification is paid by everyone and deduced from the block directly. The user then pay only for the part that is proportional to the number of proofs.
Transfer
The Execution Gas of the Transfer Operation compensates for the verification of the Mantle - Zero Knowledge Signature Scheme (ZkSignature) proof.
Execution: ~590k CPU cycles.
- Verification of the ZK signature: 590,000 cycles.
Input Gas
Input gas covers the computational cost of verifying that one Note Id exists in the Ledger and is not locked. Additionally, it compensates for the removal of one Note Id from the Ledger.
Execution: negligible.
- Verification that the note is in the ledger: negligible.
- Verification that the note is unlocked: negligible.
- Removing of the note from the ledger: negligible.
Output Gas
Output gas accounts for the computational resources required to verify that one output is well-formed and for its inclusion in the Ledger.
Execution: negligible.
- Verification of the output validity: negligible.
- Insertion of the note in the ledger: negligible.
Operations
Channel Inscription
The validation process includes verifying an Eddsa25519 signature, confirming that the signer is authorized for the specified channel, and checking the chaining sequence of the channel. The execution encompasses creating channel records (if not previously used) and updating the tip of the channel.
Execution: ~56k CPU cycles.
- Verification of the Ed25519 signature: 56,000 cycles.
- Verification of the signer authorization: negligible.
- Verification of channel sequencing: negligible
- Update the channel state: negligible
Channel Deposit
The validation process is free as it doesn't require any verification and its execution only requires modifying the balance of the channel.
Execution: negligible.
- Increase of the channel balance: negligible
Channel Withdraw
The validation process requires verifying multiple Eddsa25519 signatures, and updating the balance of the channel.
Execution: ~56k CPU cycles * withdraw_threshold.
- Verification of
withdraw_thresholdEd25519Signatures: 56,000 cycles per signature. - Decrease of the channel balance: negligible.
Channel Config
This gas amount covers the verification of multiple Eddsa25519 signatures and ensures the operation is well-formed. This represents the computational cost associated with processing channel configuration operations.
- Execution: ~56k CPU cycles * configuration_threshold.
- Verification of the configuration_threshold Ed25519 signatures: 56,000 cycles per signature.
- Modification of the state of the channel: negligible.
SDP Declaration
This gas covers multiple verification processes: confirming ownership of the locked note through ZkSignature verification, validating the zk_id via a second ZkSignature, and establishing ownership of the provider_id through an Eddsa25519 signature. It also includes verification of the declaration format, confirmation of note existence, validation that the note is not already locked, and verification of its amount. Additionally, it accounts for the computational costs associated with the note locking mechanism and declaration management.
Execution: ~ 646k CPU cycles.
- Verification of the Ed25519 signature: 56,000 cycles.
- Verification of the ZK signature: 590,000 cycles.
- Verification that the declaration doesnt already exist: negligible.
- Verification of locator length: negligible.
- Verification of locked note existence: negligible.
- Verification of locked note value: negligible.
- Verification that the note isnt already locked for the service: negligible.
- Locking the note: negligible.
SDP Withdraw
This gas covers a verification process that includes: confirming ownership of the zk_id through ZkSignature verification, validating the existence of the locked note, verifying that the note has exceeded its lock period, and confirming that the declaration exists and has not been previously withdrawn. The validation process also ensures that the withdrawal message's nonce is greater than any previous nonce, preventing replay attacks. During execution, the system updates the declaration's status to withdrawn, removes the declaration from the locked note's associated declarations, andif the note has no remaining declarationsremoves it from the locked notes dictionary.
Execution: ~ 590k CPU cycles.
- Verification that the note exists, is locked and bound to the declaration: negligible.
- Verification that the note can be unlocked: negligible.
- Verification that the declaration exist: negligible.
- Verification of the ZK signature: 590,000 cycles.
- Verification that the declaration wasnt already withdrawn: negligible.
- Verification of nonce incrementation: negligible.
- Update declaration: negligible.
- Remove declaration from locked note: negligible.
- Unlock the note if not linked to any declaration: negligible.
SDP Activation
This gas funds the verification of the zk_id signature through the ZkSignature verification process, validates the existence of the declaration in the system, and ensures that the activation message's nonce is greater than any previous nonce to prevent replay attacks. The validation includes confirming that the declaration ID is present in the declarations dictionary and that the signature corresponds to the declaration's registered zk_id public key.
- Execution: ~590k CPU cycles.
- Verification that the declaration exist: negligible.
- Verification of nonce incrementation: negligible.
- Verification of the ZK signature: 590,000 cycles.
- Evaluation of the activity depends on the service and is neglected here
Leader Claims
This gas covers the verification of reward voucher ownership through a Proof of Claim, confirmation that the voucher nullifier is not already present in the nullifier set, and validation that the rewards root exists in the list of recent voucher Merkle tree roots. The execution process involves adding the voucher nullifier to the nullifier set and increasing the Mantle Transaction balance by the designated leader reward amount.
Execution: ~580k CPU cycles.
- Verification that the voucher nullifier isnt already in the set: negligible.
- Verification that the rewards root is one of the root of the reward tree of the last blocks: negligible.
- Verification of the proof of claim: 580,000 cycles.
- Insertion of the nullifier in the voucher nullifier set: negligible.
Annex
Gas determination from measures
The material used for the benchmarks is the following:
- CPU : 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM : 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS : Ubuntu 22.04.5 LTS
- Kernel : 6.8.0-59-generic
Eddsa Signature Verification
To get the numbers, we executed the test included in the official Rust implementation of the node.
Over 100 iterations, verifying an Eddsa25519 signature requires an average of 56,000 CPU cycles.
Proof of Claim
To get the numbers, we executed the test included in the official Rust implementation of the node.
We found the best linear curve approximating these measures (over 100 iterations):
| Number of Batches | Number of CPU cycles |
|---|---|
| 1 | 2,502,356 |
| 2 | 3,662,746 |
| 3 | 4,216,022 |
| 4 | 4,800,445 |
| 5 | 5,324,304 |
| 6 | 6,091,442 |
| 7 | 6,618,446 |
| 8 | 7,165,629 |
| 9 | 7,692,432 |
| 10 | 8,421,783 |
| 20 | 14,257,450 |
| 30 | 20,131,137 |
| 40 | 25,782,519 |
| 50 | 31,595,523 |
| 60 | 37,286,419 |
| Number of Batches | Number of CPU cycles |
|---|---|
| 70 | 42,901,298 |
| 80 | 48,309,912 |
| 90 | 54,191,072 |
| 100 | 61,082,050 |
| 110 | 66,927,817 |
| 120 | 73,758,494 |
| 130 | 78,816,789 |
| 140 | 84,801,250 |
| 150 | 91,693,824 |
| 160 | 94,248,613 |
| 170 | 99,430,138 |
| 180 | 105,607,812 |
| 190 | 112,379,089 |
| 200 | 116,599,001 |
We got the curve that we decided to approximate to :
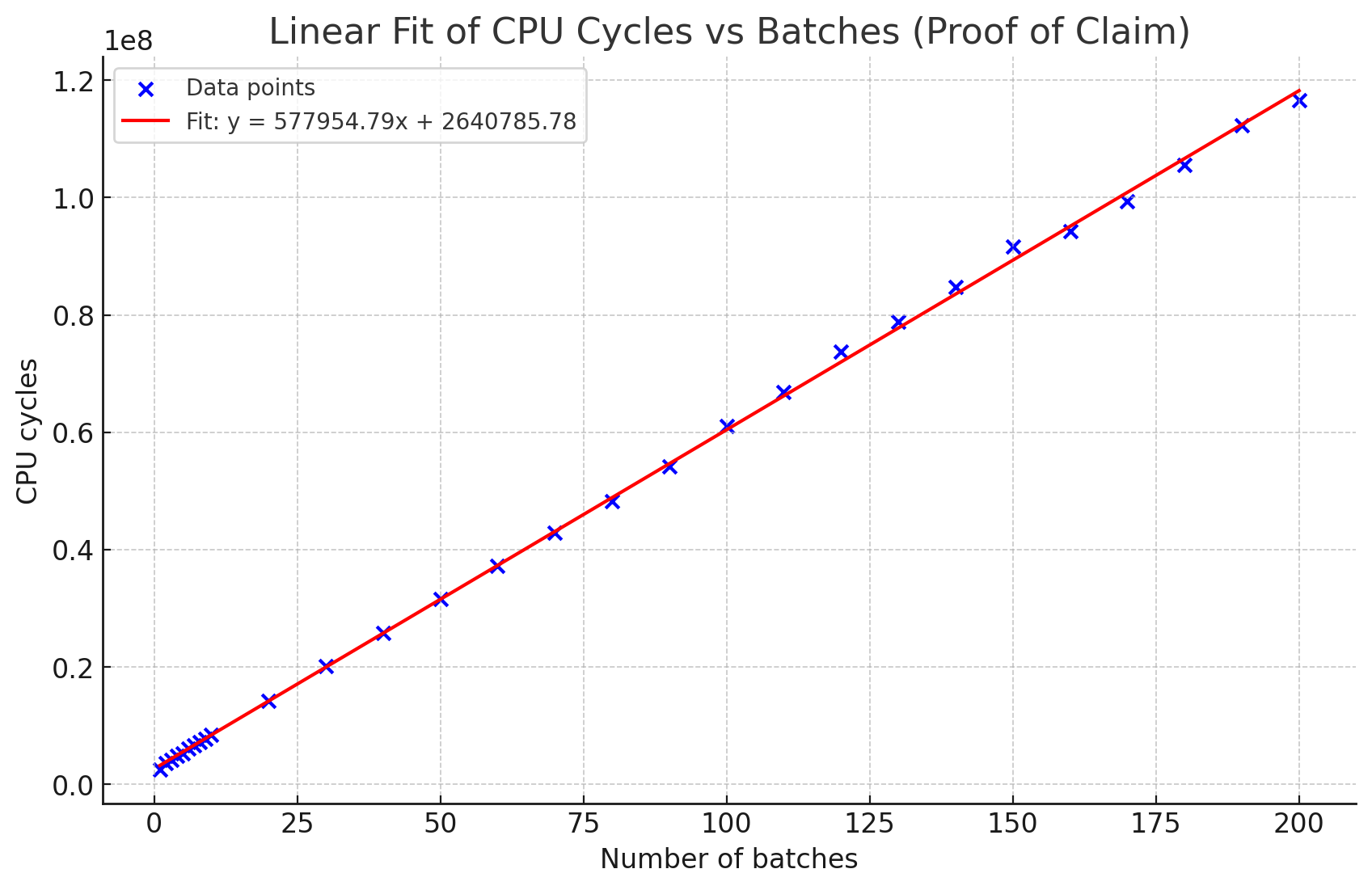
ZkSignature
To get the numbers, we executed the test included in the official Rust implementation of the node.
We found the best linear curve approximating these measures (over 1000 iterations):
| Number of Batches | Number of CPU cycles |
|---|---|
| 1 | 4,126,177 |
| 2 | 4,904,084 |
| 3 | 5,538,085 |
| 4 | 6,061,800 |
| 5 | 6,957,754 |
| 6 | 7,421,851 |
| 7 | 8,237,485 |
| 8 | 8,621,986 |
| 9 | 9,115,091 |
| 10 | 10,186,171 |
| 20 | 15,777,800 |
| 30 | 21,456,771 |
| 40 | 27,441,722 |
| 50 | 33,430,729 |
| 60 | 38,986,389 |
| Number of Batches | Number of CPU cycles |
|---|---|
| 70 | 44,708,450 |
| 80 | 50,894,373 |
| 90 | 56,534,430 |
| 100 | 63,606,624 |
| 110 | 70,036,347 |
| 120 | 75,612,096 |
| 130 | 82,048,010 |
| 140 | 87,080,407 |
| 150 | 91,473,391 |
| 160 | 97,862,623 |
| 170 | 104,019,852 |
| 180 | 111,498,103 |
| 190 | 114,814,226 |
| 200 | 119,739,702 |
We got the curve that we decided to approximate to :
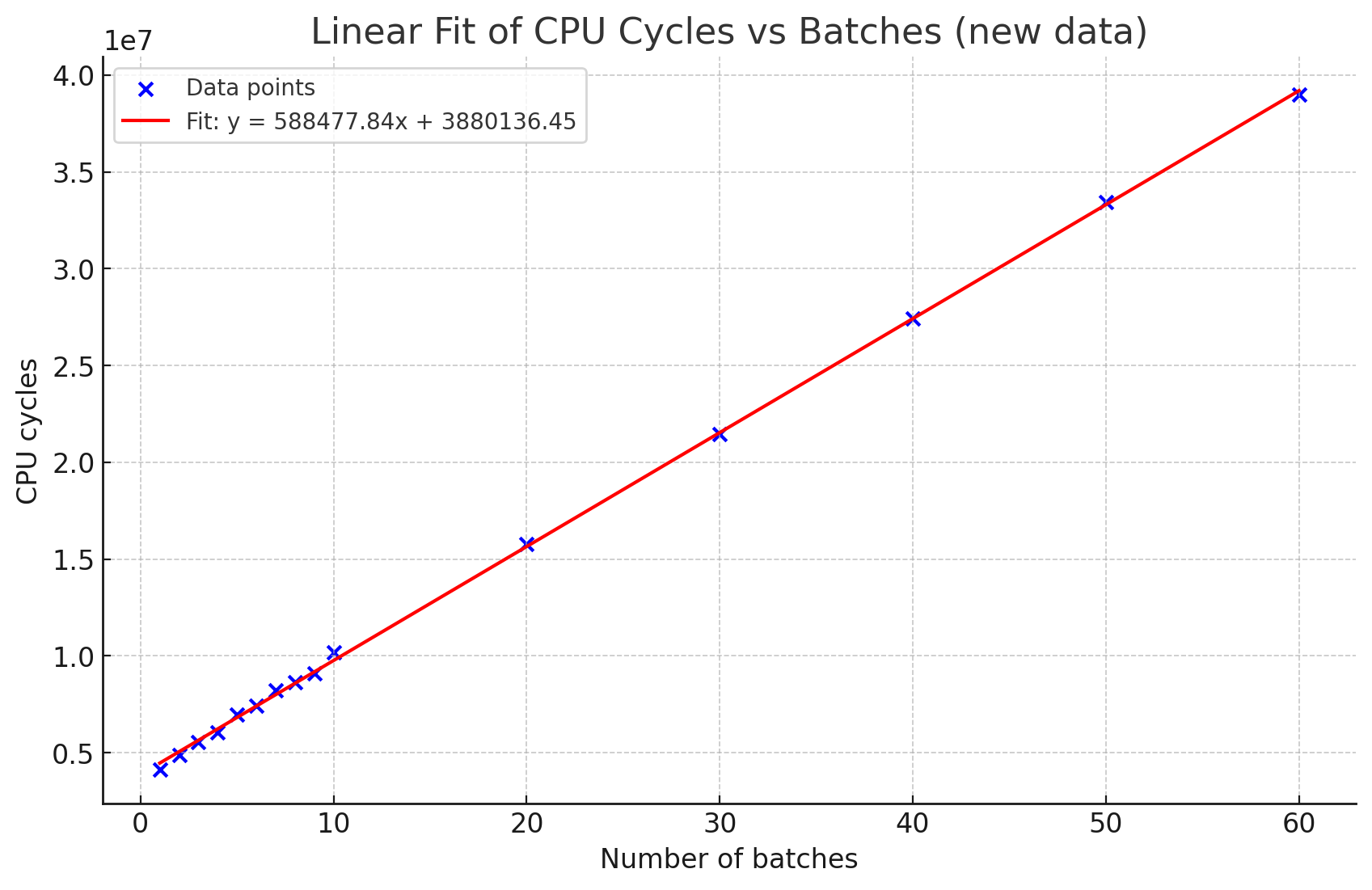
V1.3.0-MANTLE
| Field | Value |
|---|---|
| Name | Mantle |
| Slug | 233 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Thomas Lavaur [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-11-17 |
| 1.1.0 | ? | 2026-02-06 |
| 1.2.0 | Removed DA references. Removed notions of Sovereignty and Rollups and used Zones for simplicity. Removed Nomos from specifications and DSTs. Added bridging and decentralized sequencing for channels. | 2026-03-20 |
| 1.2.1 | Added [RFC] Improve Mantle Transaction hash. | 2026-03-24 |
| 1.3.0 | added [RFC] Make Ledger Transaction an Operation | 2026-04-02 |
Introduction
Mantle is a foundational element of Bedrock, designed to provide a minimal and efficient execution layer that connects together Bedrock Services in order to provide the necessary functionality for Zones. It can be viewed as the system call interface of Bedrock, exposing a safe and constrained set of Operations to interact with lower-level Bedrock services, similar to syscalls in an operating system.
Mantle Transactions provide Operations for Zones and blockchain Services to interact with Bedrock. For example, a Zone sequencer posting an update to Bedrock, or a node operator declaring its participation in the Blend Network, would be done through the corresponding Operations within a Mantle Transaction.
Mantle manages assets using a note-based ledger that follows an UTXO model. Each Mantle Transaction can include Transfer Operation, and any excess balance serves as the fee payment.
Overview
Mantle Transaction
The features of the Logos Blockchain are exposed through Mantle Transactions. Each transaction can contain zero or more Operations. Mantle Transactions enable users to execute multiple Operations atomically.
Mantle Operations
Logos Blockchain features are exposed through Mantle Operations, which can be combined and executed together in a single Mantle Transaction atomically. These Operations enable transfers and functions such as on-chain data posting, Cross-Zone interactions, SDP interaction, and leader reward claims.
Mantle Ledger
The Mantle Ledger enables asset transfers using a transparent UTXO model. While a Transfer Operation can consume more tokens than it creates, the Mantle Transaction excess balance must exactly pay for the fees.
Transaction Fees
Mantle Transaction fees are derived from a gas model. The Logos Blockchain has two different gas markets, accounting for permanent data storage, and execution costs. Each Operation has an associated Execution Gas cost. Users can specify their gas prices in their Mantle Transactions to incentivize the network to include their transaction.
| Gas Market | Charged On | Pricing Basis |
|---|---|---|
| Execution Gas | Operations | Fixed per Operation |
| Permanent Storage Gas | Signed Mantle Transaction | Proportional to encoded size |
Mantle Transaction
Mantle Transactions form the core of Mantle, enabling users to combine multiple Operations to access different functions. Each transaction contains zero or more Operations. The system executes all Operations atomically, while using the Mantle Transaction's excess balancecalculated as the difference between the consumed and created value as the fee payment.
class MantleTx:
ops: list[Op]
permanent_storage_gas_price: TokenValue # See the note section
execution_gas_price: TokenValue
class Op:
opcode: byte
payload: bytes
def mantle_txhash(tx: MantleTx) -> ZkHash:
tx_bytes = encode(tx)
h = Hasher() # /!\ This is a classic hash not a ZkHash /!\
h.update(b"MANTLE_TXHASH_V1")
h.update(tx_bytes)
classic_digest = h.digest()
zkh = ZkHasher() # /!\ This is a ZkHash not a classic hash /!\
zkh.update(FiniteField(classic_digest[0:16], bytes_order="little", modulus = p))
zkh.update(FiniteField(classic_digest[16:32], bytes_order="little", modulus = p))
return zkh.digest()
The hash function used, as well as other cryptographic primitives like ZK proofs and signature schemes, are described in Common Cryptographic Components.
A Mantle Transaction must include all relevant signatures and proofs for each Operation.
class SignedMantleTx:
tx: MantleTx
op_proofs: list[OpProof | None] # each Op has at most 1 associated proof
Each proof (op proof and signature) must be cryptographically bound to the MantleTx through the mantle_txhash to prevent replay attacks. This binding is achieved by including the MantleTx hash as a public input in every ZK proof.
The transaction fee is a sum of two components: the multiplication of the total Execution Gas by the execution_gas_price, and the total size of the encoded signed Mantle Transaction multiplied by the permanent_storage_gas_price.
def gas_fees(signed_tx: SignedMantleTx) -> int:
mantle_tx = signed_tx.tx
permanent_storage_fees = len(encode(signed_mantle_tx)) * mantle_tx.permanent_storage_gas_price
execution_fees = 0
for op in mantle_tx.ops:
# Compute the execution gas of this operation as defined
# in the gas cost determination specification.
execution_fees += execution_gas(op) * mantle_tx.execution_gas_price
return execution_fees + permanent_storage_fees
Validation
Given
signed_tx = SignedMantleTx(
tx=MantleTx(ops, permanent_storage_gas_price, execution_gas_price),
op_proofs
)
Mantle validators will ensure the following:
- We have a proof or a None value for each operation.
assert len(op_proofs) == len(ops) - Each Operation is valid.
for op, op_proof in zip(ops, op_proofs): assert op.opcode in MANTLE_OPCODES validate_mantle_op(mantle_txhash(tx), op.opcode, op.payload, op_proof) def validate_mantle_op(txhash, opcode, payload, op_proof): if opcode == CHANNEL_INSCRIBE: validate_channel_inscribe(txhash, payload, op_proof) # elif opcode == ... # ... - The Mantle Transaction excess balance pays for the transaction fees.
tx_fee = gas_fees(signed_tx) # Not an unsigned int assert tx_fee == get_transaction_balance(signed_tx) def get_transaction_balance(signed_tx: SignedMantleTx) -> int: balance = 0 # It's important to not use unsigned int here to avoid # overflow vulnerabilities for op in signed_tx.tx.ops: if op.opcode == LEADER_CLAIM: balance += get_leader_reward() if op.opcode == CHANNEL_DEPOSIT: balance -= get_channel_deposit_amount(op) if op.opcode == CHANNEL_WITHDRAW: balance += get_channel_withdrawal_amount(op) if op.opcode == TRANSFER: for inp in op.inputs: balance += get_value_from_note_id(inp) for out in op.outputs: balance -= out.value return balance
Execution
Given
SignedMantleTx(
tx=MantleTx(ops, permanent_storage_gas_price, execution_gas_price),
op_proofs
)
Mantle Validators execute sequentially each Operation in ops according to its opcode.
Operations
Opcodes
| Operation | Opcode | Description |
|---|---|---|
| TRANSFER | 0x00 | Consume and create notes. |
| RESERVED | 0x01 - 0x0F | |
| CHANNEL_CONFIG | 0x10 | Configure a channel |
| CHANNEL_INSCRIBE | 0x11 | Write a message permanently onto Mantle. |
| CHANNEL_DEPOSIT | 0x12 | Deposit assets into a channel |
| CHANNEL_WITHDRAW | 0x13 | Withdraw assets from a channel |
| RESERVED | 0x14 - 0x1F | |
| SDP_DECLARE | 0x20 | Declare intention to participate as a node in a Bedrock Service, locking funds as collateral. |
| SDP_WITHDRAW | 0x21 | Withdraw participation from a Bedrock Service, unlocking your funds in the process. |
| SDP_ACTIVE | 0x22 | Signal that you are still an active participant of a Bedrock Service. |
| RESERVED | 0x23 - 0xFF | |
| LEADER_CLAIM | 0x30 | Claim leader reward anonymously. |
| RESERVED | 0x31 - 0xFF |
Channel Operations
Channels allow Zones to post their updates on chain. Channels form virtual chains that overlay on top of the Cryptarchia blockchain. Clients and Followers of a Zone can watch its channel to learn the state of that Zone. Each channel has an associated balance, enabling bridging between Zones and Bedrock.
Message Ordering
Channels form virtual chains by having each message reference its parent message. The order of messages in these channels is enforced by the sequencer by building a hash chain of messages, i.e. new messages reference the previous messages through a parent hash. Given that Cryptarchia has long finality times, these message parent references allow Zone sequencers to continue to post new updates to channels without having to wait for finality. No matter how Cryptarchia forks and reorgs, the channel messages from honest sequencers will eventually be re-included in a way that satisfies the virtual chain order.
The first time a message is sent to an unclaimed channel, the key that signs the initial message becomes the only accredited key in the list (Note that this key may correspond to a threshold signature key). Accredited keys of a channel forms a committee that can configure the channel, withdraw funds and take turns to write messages to that channel following a round-robin algorithm. Configuring a channel includes modifying the list of accredited keys, the round-robin parameters and the required number of signatures to withdraw funds or establish a new configuration.
Validators must maintain the following state to process channel Operations:
channels: dict[ChannelId, ChannelState] # ChannelId is 32 bytes
class ChannelState:
# Channel Configuration
accredited_keys: list[Ed25519PublicKey] # limited to 65 535 keys
configuration_threshold: u16 # indicating how many keys are
# required to update the configuration
# Message Ordering
tip_hash: hash
# Decentralized Sequencing
tip_slot: Slot
tip_sequencer: u16 # indicating the actual
# sequencer position in the list of accredited keys
tip_sequencer_starting_slot: Slot
posting_timeframe: u32 # number of slots (0 = infinity)
posting_timeout: u32 # number of slots (0 = no timeout)
# Bridging
balance: TokenValue # See the Note section for its precision
withdraw_threshold: u16 # indicating how many keys are
# required to withdraw funds from the channel
def default_channel(block_slot: Slot, keys: list[Ed25519PublicKey])
-> ChannelState:
return ChannelState(
tip_hash = ZERO,
tip_slot = block_slot,
accredited_keys = keys,
tip_sequencer = 0,
tip_sequencer_starting_slot = block_slot,
posting_timeframe = 0,
posting_timeout = 0,
configuration_threshold = 1,
balance = 0,
withdraw_threshold = 1)
Note that the user chooses the ChannelId mapping to the ChannelState (but its restricted to 32 bytes). We don't currently impose restrictions on it, but we may do so in the future to prevent undesirable behaviors.
Decentralized Sequencing
To determine which sequencer is currently authorized to send messages, we use a round-robin algorithm. When a message is posted to a channel, the following algorithm is used to determine who the sequencer is:
# Round Robin algorithm determining the new sequencer index and the
# new sequencer starting slot
def round_robin(block_slot: Slot, channel: ChannelState) -> (u16,u64):
elapsed_slots = block_slot - channel.tip_slot
if elapsed_slots >= channel.posting_timeout && channel.posting_timeout != 0:
# Get the number of sequencers that get timed out
sequencers_timed_out = elapsed_slots // channel.posting_timeout
index = (channel.tip_sequencer + sequencers_timed_out)
% len(channel.accredited_keys)
starting_slot = channel.tip_slot
+ sequencers_timed_out * channel.posting_timeout
else:
# Get the number of timeframes elapsed to get who is the sequencer
tip_sequencer_duration = block_slot - channel.tip_sequencer_starting_slot
index = (channel.tip_sequencer
+ (tip_sequencer_duration // channel.posting_timeframe))
% len(channel.accredited_keys)
starting_slot = channel.tip_sequencer_starting_slot
+ (tip_sequencer_duration // channel.posting_timeframe)
* channel.posting_timeframe
return (index, starting_slot)
CHANNEL_INSCRIBE
Write a message to a channel with the message data being permanently stored on the Logos Blockchain.
Payload
class Inscribe:
channel: ChannelId # 32 bytes Channel being written to
inscription : bytes # Message to be written on the blockchain
parent: hash # Previous message in the channel
signer: Ed25519PublicKey # Identity of message sender
Proof
Ed25519Signature
Execution Gas
Channel Inscribe Operations have a fixed Execution Gas cost of EXECUTION_CHANNEL_INSCRIBE_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: hash
msg: Inscribe
sig: Ed25519Signature
channels: dict[ChannelId, ChannelState]
block_slot: Slot
Validate
if msg.channel in channels:
chan = channels[msg.channel]
current_sequencer_index = round_robin(block_slot, chan)[0]
# Ensure the signer is the one authorized to write to the channel
assert msg.signer == chan.accredited_keys[current_sequencer_index]
# Ensure message is continuing the channel sequence
assert msg.parent == chan.tip_hash
else:
# Channel will be created automatically upon execution
# Ensure that this message is the genesis message (parent == ZERO)
assert msg.parent == ZERO
# Ensure the msg signer signature
assert Ed25519_verify(txhash, msg.signer, sig)
Execution
Given
msg: Inscribe
sig: Ed25519Signature
channels: dict[ChannelId, ChannelState]
block_slot: Slot
Execute
- If the channel does not exist, create it just-in-time.
if msg.channel not in channels: channels[msg.channel] = default_channel(block_slot, [msg.signer]) - Update the channel sequencer.
chan = channels[msg.channel] (new_sequencer_index, new_sequencer_starting_slot) = round_robin( block_slot, chan) chan.tip_sequencer_starting_slot = new_sequencer_starting_slot chan.tip_sequencer = new_sequencer_index - Update the channel tip.
chan = channels[msg.channel] chan.tip_hash = hash(encode(msg)) chan.tip_slot = block_slot
Example
# Build the inscription
greeting = Inscription(
channel=CHANNEL_EARTH,
inscription=b"Live long and prosper",
parent=ZERO
signer=spock_pk
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[<spocks_note_id>], outputs=[<change_note>])
# Wrap it in a transaction
tx = MantleTx(
ops=[Op(opcode=CHANNEL_INSCRIBE, payload=encode(greeting)),
Op(opcode=TRANSFER, payload=encode(transfer)],
permanent_storage_gas_price=150,
execution_gas_price=70,
)
# Sign the transaction
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[Ed25519_sign(mantle_txhash(tx), spock_sk),
transfer.prove(spock_sk)]
)
# Send the transaction to the mempool
mempool.push(signed_tx)
CHANNEL_CONFIG
Overwrite the configuration of a channel.
Payload
class ChannelConfig:
channel: ChannelId
keys: list[Ed25519PublicKey]
posting_timeframe: u32
posting_timeout: u32
configuration_threshold: u16
withdraw_threshold: u16
Proof
class ChannelConfigOpProof:
signatures: list[Ed25519Signature] # signatures from configuration_threshold
indexes: list[u16] # signatures of accredited keys with their index.
# indexes must be ordered from smallest to
# biggest without duplication
Execution Gas
Channel Config Operations have a linear Execution Gas cost equal to EXECUTION_CHANNEL_CONFIG_GAS * configuration_threshold. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash
config: ChannelConfig
proof: ChannelConfigOpProof
channels: dict[ChannelId, ChannelState]
Validate
assert len(proof.signatures) == len(proof.indexes)
assert config.configuration_threshold > 0
assert config.withdraw_threshold > 0
assert len(config.keys) > 0
assert len(config.keys) < 2^16
if config.channel in channels:
chan = channels[config.channel]
# Check there are enough signatures
assert len(proof.signatures) == chan.configuration_threshold
# Check that indexes are ordered to avoid duplication
for i in range(len(proof.indexes)-1):
assert proof.indexes[i] < proof.indexes[i+1]
for sig, idx in zip(proof.signatures, proof.indexes):
# and at the same time that chan.accredited_keys[idx] isn't out of bound
assert Ed25519_verify(txhash, chan.accredited_keys[idx], sig)
Execution
Given
config: ChannelConfig
channels: dict[ChannelId, ChannelState]
block_slot: Slot
Execute
- If the channel does not exist, create it just-in-time.
if config.channel not in channels:
channels[config.channel] = default_channel(block_slot, config.keys)
- Update the configuration.
chan = channels[config.channel]
# Update Channel Configuration Parameters
chan.accredited_keys = config.keys
chan.configuration_threshold = config.configuration_threshold
# Update Decentralized Sequencing Parameters
chan.tip_sequencer = 0
chan.tip_sequencer_starting_slot = block_slot
chan.posting_timeframe = config.posting_timeframe
chan.posting_timeout = config.posting_timeout
# Update Bridging Parameters
chan.withdraw_threshold = config.withdraw_threshold
- Update the channel tip.
chan = channels[config.channel]
chan.tip_slot = block_slot
chan.tip_hash = hash(encode(config))
Example
Suppose the unique sequencer of Zone A wants to add a key to the list of accredited keys:
# Given a key to add
new_sequencer_pk: Ed25519PublicKey
# The unique sequencer encodes the update and builds the payload
config = ChannelConfig(
channel=ZONE_A,
keys=[old_sequencer_pk, new_sequencer_pk],
posting_timeframe = 5000,
posting_timeout = 500,
configuration_threshold = 2,
withdraw_threshold = 1
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[old_sequencer_funds], outputs=[<change_note>])
tx = MantleTx(
ops=[Op(opcode=CHANNEL_CONFIG, payload=encode(config)),
Op(opcode=TRANSFER, payload=encode(transfer)],
permanent_storage_gas_price=150,
execution_gas_price=70,
)
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[[Ed25519_sign(mantle_txhash(tx), old_sequencer_sk)], [0]],
transfer.prove(old_sequencer_sk)]
)
CHANNEL_DEPOSIT
Deposit funds to a channel, reducing the Mantle Transaction balance.
Payload
class ChannelDeposit:
channel: ChannelId
amount: TokenValue
metadata: bytes
Proof
None # Indirectly signed through the Transfer signature
Execution Gas
Channel Deposit Operations have a fixed Execution Gas cost of EXECUTION_CHANNEL_DEPOSIT_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
deposit: ChannelDeposit
channels: dict[ChannelId, ChannelState]
Validate
assert deposit.channel in channels
Execution
Given
deposit: ChannelDeposit
channels: dict[ChannelId, ChannelState]
Execute
channels[deposit.channel].balance += deposit.amount
Example
Suppose Alice wants to make a deposit of 50 tokens on Zone A.
# Alice encodes her deposit
deposit = ChannelDeposit(
channel=ZONE_A,
amount=50,
metadata=b"deposit to address: 0x..."
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[Alice_funds], outputs=[<change_note>])
tx = MantleTx(
ops=[Op(opcode=CHANNEL_DEPOSIT, payload=encode(deposit)),
Op(opcode=TRANSFER, payload=encode(transfer)],
permanent_storage_price=150,
execution_gas_price=70,
)
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[transfer.prove(Alice_sk)],
)
Note that the Zone may wait for the deposit to be finalized before interpreting the deposit in order to guarantee that the deposit will occur on-chain and won't be removed due to reorganization of the chain.
CHANNEL_WITHDRAW
Withdraw funds from a channel, increasing the Mantle Transaction balance.
Payload
class ChannelWithdraw:
channel: ChannelId
amount: TokenValue
Proof
class ChannelWithdrawOpProof:
signatures: list[Ed25519Signature] # signature from withdraw_threshold keys
indexes: list[int] # signatures of accredited keys with their index.
# indexes must be ordered from smallest to
# biggest without duplication
Execution Gas
Channel Withdraw Operations have a linear Execution Gas cost equal to EXECUTION_CHANNEL_WITHDRAW_GAS * withdraw_threshold. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash
withdrawal: ChannelWithdraw
proof: ChannelWithdrawOpProof
channels: dict[ChannelId, ChannelState]
Validate
# Check that the channel exists
assert withdrawal.channel in channels
chan = channels[withdrawal.channel]
# Check that the channel has enough funds
assert chan.balance >= withdrawal.amount
# Check that there are enough signatures
assert len(proof.signatures) == len(proof.indexes)
assert len(proof.signatures) == chan.withdraw_threshold
# Check that every index is unique
assert len(proof.indexes) == len(set(proof.indexes))
# Check the signatures
for sig, idx in zip(proof.signatures, proof.indexes):
assert Ed25519_verify(txhash, chan.accredited_keys[idx], sig)
Execution
Given
withdrawal: ChannelWithdraw
channels: dict[ChannelId, ChannelState]
Execute
channels[withdrawal.channel].balance -= withdrawal.amount
Example
Suppose the unique sequencer of Zone A wants to withdraw 50 tokens.
# Sequencer encodes his withdrawal
withdrawal = ChannelWithdraw(
channel=ZONE_A,
amount=50
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[Sequencer_funds], outputs=[<change_note>])
tx = MantleTx(
ops=[Op(opcode=CHANNEL_WITHDRAW, payload=encode(withdrawal)),
Op(opcode=TRANSFER, payload=encode(transfer)],
permanent_storage_price=150,
execution_gas_price=70
)
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[[[Ed25519_sign(mantle_txhash(tx), sequencer_sk)],[0]],
transfer.prove(Sequencer_node_sk)],
)
Service Declaration Protocol (SDP) Operations
These Operations implement the Service Declaration Protocol.
Validators must keep the following state when implementing SDP Operations:
locked_notes: dict[NoteID, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
class LockedNote:
declarations: set[DeclarationID]
locked_until: BlockNumber
Common SDP Structures
class ServiceType(Enum):
BN="BN" # Blend Network
class Locator(str):
def validate(self):
assert len(self) <= 329
assert validate_multiaddr(self)
class MinStake:
stake_threshold: int # stake value
timestamp: int # block number
class ServiceParameters:
lock_period: int # number of blocks
inactivity_period: int # number of blocks
retention_period: int # number of blocks
timestamp: int # block number
class DeclarationInfo:
service: ServiceType
locators: list[Locator]
provider_id: Ed25519PublicKey
zk_id: ZkPublicKey
locked_note_id: NoteId
created: BlockNumber
active: BlockNumber
withdrawn: BlockNumber
# SDP ops updating a declaration must use monotonically increasing nonces
nonce: int
SDP_DECLARE
The service registration follows the definition given in Service Declaration Protocol - Declaration Message:
Payload
class DeclarationMessage:
service_type: ServiceType
locators: list[Locator]
provider_id: Ed25519PublicKey
zk_id: ZkPublicKey
locked_note_id: NoteId
Locked notes are introduced in Locked notes and serve as Service collaterals. They cannot be spent before the owner withdraw its participation from the declared service(s).
Proof
class DeclarationProof:
zk_sig: ZkSignature # signature proving ownership over
# locked note and zk_id
provider_sig: Ed25519Signature # signature proving ownership of provider key
see: Zero Knowledge Signature Scheme (ZkSignature).
Execution Gas
SDP Declare Operations have a fixed Execution Gas cost of EXECUTION_SDP_DECLARE_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash # the txhash of the transaction we are validating
declaration: DeclarationMessage # the declaration we are validating
proof: DeclarationProof
min_stake: MinStake # the (global) minimum stake setting
ledger: Ledger # the set of unspent notes
locked_notes: dict[NoteId, LockedNote]
declarations: dict[NoteId, DeclarationInfo]
Validate
The declaration is verified according to Service Declaration Protocol - Declare.
- Ensure ownership over the locked note, zk_id and provider_id.
assert ZkSignature_verify( txhash, proof.zk_sig, [note.public_key, declaration.zk_id] ) assert Ed25519_verify(txhash, proof.provider_sig, provider_id) - Ensure declaration does not already exist.
assert declaration_id(declaration) not in declarations - Ensure it has no more than 8 locators.
assert len(declaration.locators) <= 8 - Ensure locked note exists and value of locked note is sufficient for joining the service.
assert ledger.is_unspent(declaration.locked_note_id) note = ledger.get_note(declaration.locked_note_id) assert note.value >= min_stake.stake_threshold - Ensure the note has not already been locked for this service.
if declaration.locked_note in locked_notes: locked_note = locked_notes[declaration.locked_note] services = [declarations[declare_id] for declare_id in locked_note.declarations] assert declaration.service_type not in services
Execution
Given
declaration: DeclarationMessage # the declaration we are executing
service_parameters: dict[ServiceType, ServiceParameters]
current_block_height: int
locked_notes : dict[NoteId, LockedNote]
Execute
- Create the locked note state if it doesn't already exist.
if declaration.locked_note not in locked_notes: locked_notes[declaration.locked_note_id] = \ LockedNote(declarations=set(), locked_until=0) locked_note = locked_notes[declaration.locked_note_id] - Update the locked notes timeout using this services lock period.
lock_period = service_parameters[declaration.service_type].lock_period service_lock = current_block_height + lock_period locked_note.locked_until = max(service_lock, locked_note.locked_until) - Add this declaration to the locked note.
declare_id = declaration_id(declaration) locked_note.declarations.add(declare_id) - Store the declaration as explained in Service Declaration Protocol - Declaration Storage.
declarations[declare_id] = DeclarationInfo( service: declaration.service locators: declaration.locators provider_id: declaration.provider_id zk_id: declaration.zk_id locked_note_id: declaration.locked_note_id declaration, created=current_block_height, active=current_block_height, withdrawn=0 nonce=0 )
Example
# Assume `alice_note` is in the ledger:
alice_note = Utxo(
txhash=0x2948904F2F0F479B8F8197694B30184B0D2ED1C1CD2A1EC0FB85D299A192A447,
output_number=3,
note=Note(value=500, public_key=alice_pk_1),
)
# Alice wishes to lock it to join the Blend network
declaration=DeclarationMessage(
service_type=ServiceType.BN,
locators=["/ip4/203.0.113.10/tcp/4001/p2p"],
provider_id=alice_provider_pk,
zk_id=alice_pk_2,
locked_note_id=alice_note.id()
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[fee_note_id], outputs=[])
tx = MantleTx(
ops=[Op(opcode=SDP_DECLARE, payload=encode(declaration)),
Op(opcode=TRANSFER, payload=encode(transfer)],
permanent_storage_gas_price=150,
execution_gas_price=70,
)
txhash = mantle_txhash(tx)
declaration_proof = DeclarationProof(
# proof of ownership of the staked note and zk_id
zk_sig=ZkSignature([alice_sk_1, alice_sk_2], txhash),
# proof of ownership of the provider id
provider_sig=Ed25519Signature(alice_provider_sk, txhash),
)
SignedMantleTx(
tx=tx,
op_proofs=[declaration_proof, transfer.prove(alice_sk_1)],
)
SDP_WITHDRAW
The service withdrawal follows the definition given in Service Declaration Protocol - Withdraw Message.
Payload
class WithdrawMessage:
declaration: DeclarationID
locked_note_id: NoteId
nonce: int
Proof
A signature from the zk_id and the locked note pk attached to the declaration is required for withdrawing from a service, (see Zero Knowledge Signature Scheme (ZkSignature)).
ZkSignature
Execution Gas
SDP Withdraw Operations have a fixed Execution Gas cost of EXECUTION_SDP_WITHDRAW_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash # Mantle transaction hash of the tx containing this operation
withdraw: WithdrawMessage
signature: ZkSignature
block_height: int # block height of the current block
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
Validate
- Ensure that the locked note exists, is locked and bound to this declaration.
assert ledger.is_unspent(withdraw.locked_note_id) assert withdraw.locked_note_id in locked_notes locked_note = locked_notes[withdraw.locked_note_id] assert withdraw.declaration in locked_note.declarations - Ensure that the locked note has expired.
assert locked_note.locked_until <= block_height - Validate SDP withdrawal according to Service Declaration Protocol - Withdraw.
- Ensure declaration exists.
assert withdraw.declaration in declarations declare_info = declarations[withdraw.declaration] - Ensure locked note pk and zk_id attached to this declaration authorized this Operation.
locked_note = ledger[withdraw.locked_note_id] assert ZkSignature_verify(txhash, signature, [locked_note.pk, declare_info.zk_id]) - Ensure the declaration has not already been withdrawn.
assert declare_info.withdrawn == 0 - Ensure that the nonce is greater than the previous one.
assert withdraw.nonce > declare_info.nonce
- Ensure declaration exists.
Execution
Given
withdraw: WithdrawMessage
signature: ZkSignature
block_height: int # block height of the current block
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
Execute
Executes the withdrawal protocol Service Declaration Protocol - Withdraw.
- Update declaration info with nonce and withdrawn timestamp.
declare_info = declarations[withdraw.declaration] declare_info.nonce = withdraw.nonce declare_info.withdrawn = block_height - Remove this declaration from the locked note.
locked_note = locked_notes[withdraw.locked_note_id] locked_note.declarations.remove(withdraw.declaration) - Remove the locked note if it is no longer bound to any declarations.
if len(locked_note.declarations) == 0: del locked_notes[withdraw.locked_note_id)
Example
withdraw=Withdraw(
declaration=alice_declaration_id,
locked_note_id=alices_locked_note_id
nonce=1579532
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[alices_locked_note_id],
outputs=[Note(100, alice_note_pk)])
tx = MantleTx(
ops=[Op(opcode=SDP_WITHDRAW, payload=encode(withdraw)),
Op(opcode=TRANSFER, payload=encode(transfer)],
permanent_storage_gas_price=150,
execution_gas_price=70,
)
SignedMantleTx(
tx=tx,
# proof ownership of the withdrawn note and zk id
op_proofs=[ZkSignature_sign([alice_note_sk, alice_sk], mantle_txhash(tx)),
transfer.prove(alice_sk)]
)
SDP_ACTIVE
The service active action follows the definition given in Service Declaration Protocol - Active Message.
Payload
class Active:
declaration: DeclarationID
nonce: int
metadata: bytes # a service-specific node activeness metadata
Proof
ZkSignature
Execution Gas
SDP Active Operations have a fixed Execution Gas cost of EXECUTION_SDP_ACTIVE_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash # Mantle transaction hash of the tx containing this operation
active: Active
signature: ZkSignature
declarations: dict[DeclarationID, DeclarationInfo]
Validate
assert active.declaration in declarations
declaration_info = declarations[active.declaration]
assert active.nonce > declaration_info.nonce
assert ZkSignature_verify(txhash, signature, declaration_info.zk_id)
Execution
Executes the active protocol Service Declaration Protocol - Active. The activation, i.e. setting the declaration.active, is handled by the service-specific logic.
Example
active=Active(
declaration=alice_declaration_id,
nonce=1579532,
metadata=b"Look, I am still doing my job"
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[fee_note_id], outputs=[])
tx = MantleTx(
ops=[Op(opcode=SDP_ACTIVE, payload=encode(active))],
permanent_storage_gas_price=150,
execution_gas_price=70,
)
txhash = mantle_txhash(tx)
SignedMantleTx(
tx=tx,
op_proofs=[Ed25519_sign(txhash, validator_sk), transfer.prove(fee_note_sk)]
)
Leader Operations
LEADER_CLAIM
This Operation claims the leader's block reward anonymously.
Payload
class ClaimRequest:
rewards_root: zkhash # Merkle root used in the proof for voucher membership
voucher_nf: zkhash
Proof
The provider proves that they have won a proof of Leadership before the start of the current epoch, i.e., their reward voucher is indeed in the voucher set: Proof of Claim.
Execution gas
Leader Claim Operations have a fixed Execution Gas cost of EXECUTION_LEADER_CLAIM_GAS. See Gas Determination for the Execution Gas values.
Validation
# Given
mantle_txhash: zkhash
claim : ClaimRequest
last_voucher_root: zkhash # The last root of the voucher Merkle tree
# at the start of the epoch
voucher_nullifier_set: set[zkhash]
proof: ProofOfClaim
# Validate
assert claim.voucher_nf not in voucher_nullifier_set
assert claim.rewards_root == last_voucher_root
validate_proof(claim, proof, mantle_txhash)
Execution
- Add claim.voucher_nf to the voucher_nullifier_set .
- Increase the balance of the Mantle Transaction by the leader reward amount according to Anonymous Leaders Reward Protocol - Leaders Reward.
- Reduce the leaders reward leaders_rewards value by the same amount (without ZK proof). Example
secret_voucher = 0xDEADBEAF;
reward_voucher = leader_claim_voucher(secret_voucher)
voucher_nullifier = leader_claim_nullifier(secret_voucher)
claim=ClaimRequest(
rewards_root=REWARDS_MERKLE_TREE.root(),
voucher_nf=voucher_nullifier,
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[<fee_note>], outputs=[<change_note>])
tx = MantleTx(
ops=[Op(opcode=LEADER_CLAIM, payload=encode(claim)),
Op(opcode=TRANSFER, payload=encode(transfer)],
permanent_storage_gas_price=150,
execution_gas_price=70,
)
claim_proof = claim.prove(
secret_voucher,
REWARDS_MERKLE_TREE.path(leaf=reward_voucher),
mantle_txhash(tx)
)
SignedMantleTx(
tx=tx,
op_proofs=[claim_proof, transfer.prove(fee_note_sk)]
)
TRANSFER
Transactions must prove the ownership of spent notes. In classical blockchains, this is done through a signature. To stay compatible with our architecture, the signature is done by a ZK proof (see Zero Knowledge Signature Scheme (ZkSignature)), proving the knowledge of the secret key associated with the public key.
Transactions allow complete transaction linkability and the public key spending the note is not hidden.
Payload
class Transfer:
inputs: list[NoteId] # the list of consumed note identifiers
outputs: list[Note]
Proof
A Transfer proves the ownership of the consumed notes using a Zero Knowledge Signature Scheme (ZkSignature).
ZkSignature
Execution Gas
Transfer have a fixed Execution Gas cost of EXECUTION_TRANSFER_GAS. See Gas Determination for the Execution Gas values.
Transfer Operation Hash
def transfer_hash(transfer: Transfer) -> ZkHash:
transfer_bytes = encode(transfer)
h = Hasher() # /!\ This is a classic hash not a ZkHash /!\
h.update(b"TRANSFER_HASH_V1")
h.update(transfer_bytes)
classic_digest = h.digest()
zkh = ZkHasher() # /!\ This is a ZkHash not a classic hash /!\
zkh.update(FiniteField(classic_digest[0:16], bytes_order="little", modulus = p))
zkh.update(FiniteField(classic_digest[16:32], bytes_order="little", modulus = p))
return zkh.digest()
Validation
Given
mantle_txhash: ZkHash # ZkHash of mantle tx containing this ledger tx
transfer: Transfer
transfer_proof: ZkSignature
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
Validate
- Ensure all inputs are unspent.
assert all(ledger.is_unspent(note_id) for note_id in transfer.inputs) - Validate transfer proof to show ownership over input notes.
input_notes = [ledger[input_note_id] for input_note_id in transfer.inputs] input_pks = [note.public_key for note in input_notes] assert ZkSignature_verify(mantle_txhash, transfer_proof, input_pks) - Ensure inputs are not locked.
# Ensure inputs are not locked for note_id in transfer.inputs: assert note_id not in locked_notes - Ensure outputs are valid.
for output in transfer.outputs: assert output.value > 0 assert output.value < 2**64
Execution
Given
transfer: Transfer
transfer_proof: ZkSignature
ledger: Ledger
Execution
- Remove inputs from the ledger.
for note_id in transfer.inputs: # updates the merkle tree to zero out the leaf for this entry # and adds that leaf index to the list of unused leaves ledger.remove(note_id) - Add outputs to the ledger.
transfer_hash = transfer_hash(transfer) for (output_number, output_note) in enumerate(transfer.outputs): output_note_id = derive_note_id(transfer_hash, output_number, output_note) ledger.add(output_note_id)
Example
alice_note_id = ... # assume Alice holds a note worth 501 tokens
bob_note=Note(
value=500
public_key=bob_pk,
)
transfer = Transfer(
inputs=[alice_note_id],
outputs=[bob_note],
)
Mantle Ledger
Notes
Notes are composed of two fields representing their value and their owner:
class Note:
value: TokenValue # u64
public_key: ZkPublicKey # 32 bytes
Note Id
Any note can be uniquely identified by the Transfer Operation that created it and its output number: (transfer_hash, output_number). However, it is often useful to have a commitment to the note fields for use in ZK proofs (e.g., for PoL), so we include the note in the note identifier derivation.
def derive_note_id(transfer_hash: zkhash, output_number: int, note: Note) -> NoteId:
return zkhash(
FiniteField(b"NOTE_ID_V1", byte_order="little", modulus= p)
transfer_hash,
FiniteField(output_number, byte_order="little", modulus= p)
FiniteField(note.value, byte_order="little", modulus= p)
note.public_key
)
These note identifiers uniquely define notes in the system and cannot be chosen by the user. Nodes maintain the set of notes through a dictionary mapping the NoteId to the note.
Locked notes
Locked notes are special notes in Mantle that serve as collateral for Service Declarations. A note can become locked after executing a Declare Operation, preventing it from being spent until explicitly released through a Withdraw Operation. The system maintains a mapping of locked note IDs to their supporting declarations. Though locked, these notes remain in the Ledger and can still participate in Proof of Stake. When service providers withdraw all their declarations, the associated note(s) become unlocked and available for spending again.
Appendix
Gas Determination
From the [Analysis] Gas Cost Determination, we get the table below:
| Constants | Value |
|---|---|
| EXECUTION_TRANSFER_GAS | 590 |
| EXECUTION_CHANNEL_INSCRIBE_GAS | 56 |
| EXECUTION_CHANNEL_CONFIG_GAS | 56 |
| EXECUTION_CHANNEL_DEPOSIT_GAS | 0 |
| EXECUTION_CHANNEL_WITHDRAW_GAS | 56 |
| EXECUTION_SDP_DECLARE_GAS | 646 |
| EXECUTION_SDP_WITHDRAW_GAS | 590 |
| EXECUTION_SDP_ACTIVE_GAS | 590 |
| EXECUTION_LEADER_CLAIM_GAS | 580 |
Zero Knowledge Signature Scheme (ZkSignature)
A proof attesting that for the following public values:
class ZkSignaturePublic:
public_keys: list[ZkPublicKey] # public keys signing the message (len = 32)
msg: zkhash # zkhash of the message
The prover knows a witness:
class ZkSignatureWitness:
# The list of secret keys used to signed the message
secret_keys: list[ZkSecretKey] # (len = 32)
Such that the following constraints hold:
- The number of secret keys is equal to the number of public keys.
assert len(secret_keys) == len(public_keys) - Each public key is derived from the corresponding secret key.
assert all( notes[i].public_key == zkhash( FiniteField(b"KDF", byte_order="little", modulus= p), secret_keys[i]) for i in range(len(public_keys)) ) - The proof is bound to msg (its the mantle_tx_hash in case of transactions).
For implementation, the ZkSignature circuit will take a maximum of 32 public keys as inputs. To prove ownership of fewer keys, the remaining inputs will be padded with the public key corresponding to the secret key 0 and ignored during execution. The outputs have no size limit since they are included in the hashed message.
Benchmark
The material used for the benchmarks is the following:
- CPU : 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM : 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS : Ubuntu 22.04.5 LTS
- Kernel : 6.8.0-59-generic
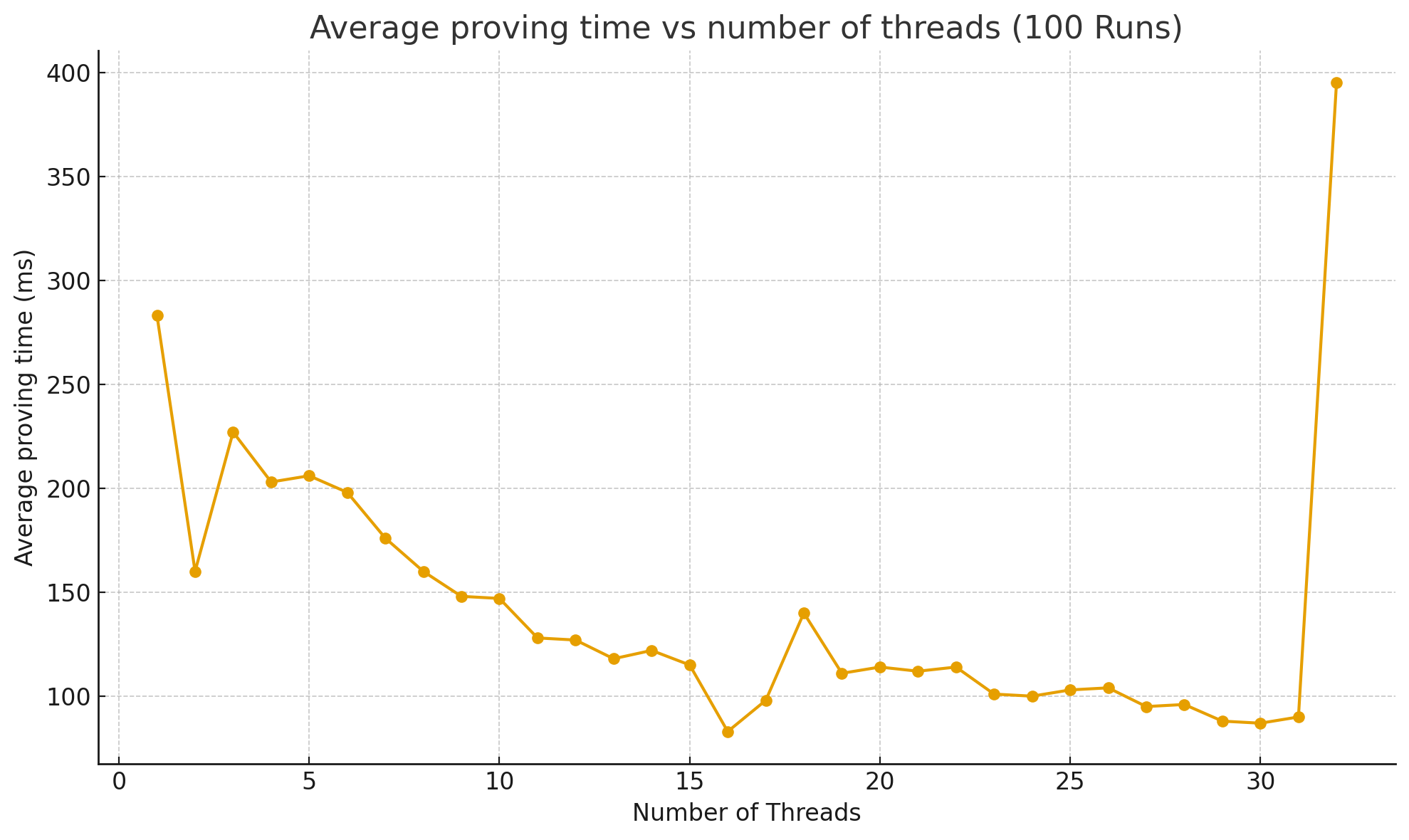
Proof of Claim
A proof attesting that given these public values:
class ProofOfClaimPublic:
voucher_root: zkhash # Merkle root of the reward_voucher maintained by everyone
voucher_nullifier: zkhash
mantle_tx_hash: zkhash # attached hash
The prover knows the following witness:
class ProofOfClaimWitness:
secret_voucher: zkhash
voucher_merkle_path: list[zkhash]
voucher_merkle_path_selectors: list[bool]
such that the following constraints hold:
- The reward voucher is derived from the secret voucher.
assert reward_voucher == zkhash( FiniteField(b"REWARD_VOUCHER", byte_order="little", modulus= p), secret_voucher) - There exists a valid Merkle path from the reward voucher as a leaf to the Merkle root.
assert voucher_root == path_root(leaf=reward_voucher, path=voucher_merkle_path, selectors=voucher_merkle_path_selectors) - The voucher nullifier is derived from the secret voucher correctly.
assert voucher_nullifier == zkhash( FiniteField(b"VOUCHER_NF", byte_order="little", modulus= p), secret_voucher) - The proof is bound to the mantle_tx_hash.
Benchmark
The material used for the benchmarks is the following:
- CPU : 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM : 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS : Ubuntu 22.04.5 LTS
- Kernel : 6.8.0-59-generic
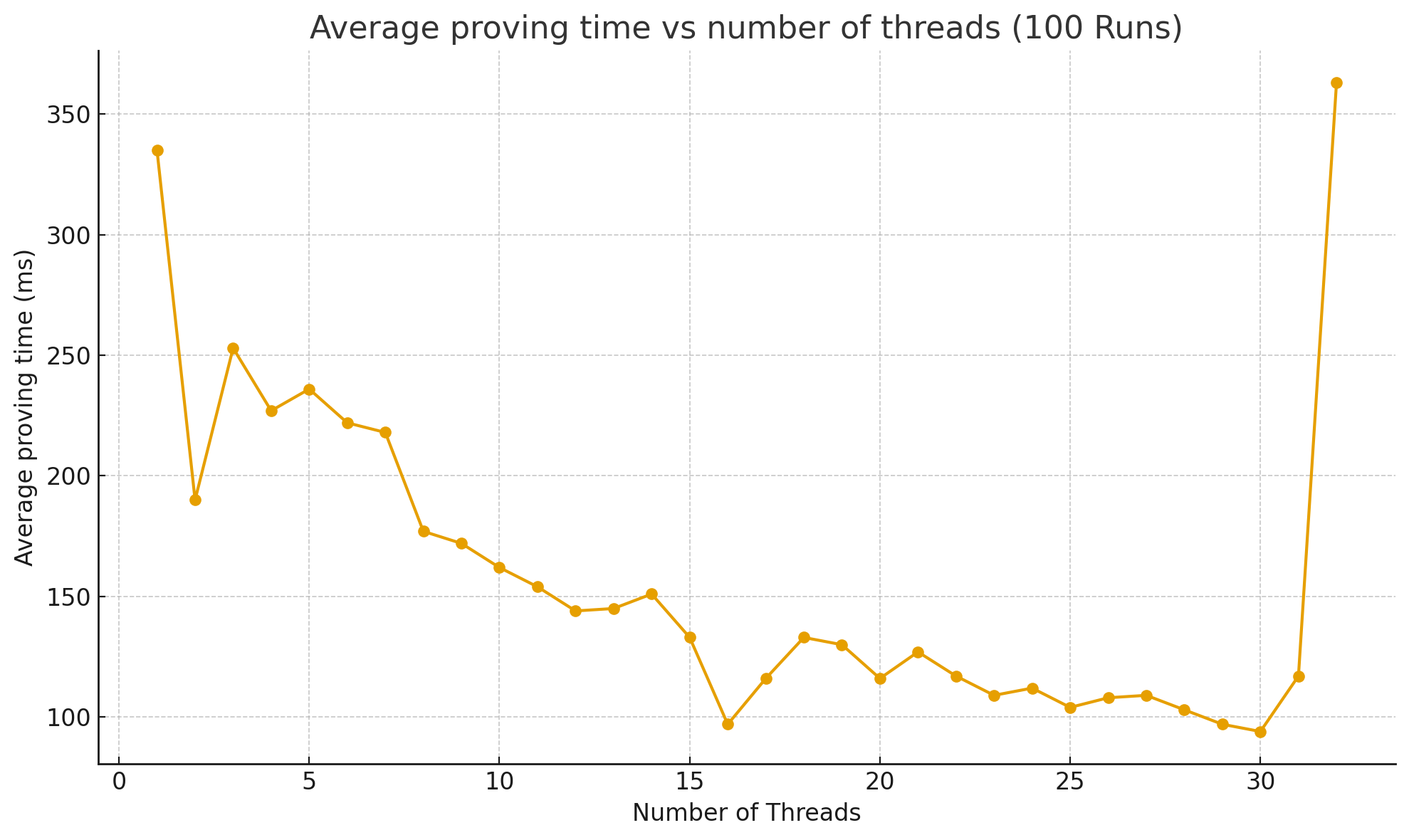
V1.3.0-MANTLE-TRANSACTION-ENCODING
| Field | Value |
|---|---|
| Name | Mantle Transaction Encoding |
| Slug | 232 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | David Rusu [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revisions History
| Version | Changes |
|---|---|
| 1.0.0 | Initial revision. |
| 1.1.0 | Added [RFC] Make Ledger Transaction an Operation |
| 1.2.0 | Added [RFC] Add Deposit/Withdraw to Tx Encoding |
| 1.3.0 | Added [RFC] Enforce NoteId uniqueness |
Introduction
This document specifies the canonical encoding of Mantle transactions (see Mantle - Mantle Transaction) and its sub-components. Transactions sent through the mempool and included in blocks use this encoding.
Overview
The transaction encoding is specified in ABNF form to remove any ambiguity and guarantee a canonical encoding. The high level encoding choices which were not immediately derivable from the Mantle specification are listed here:
- All multi-byte integers use little-endian encoding
- Any lists are length-prefixed with fixed width uints
- We derive number of proofs and type of proof from the Ops list parsed earlier
Specification
Signed Mantle Tx
SignedMantleTx = MantleTx OpsProofs
Mantle Tx
MantleTx = Ops ExecutionGasPrice StorageGasPrice
ExecutionGasPrice = UINT64
StorageGasPrice = UINT64
In future iterations, we will use this encoding to derive the mantle_txhash
Operations
Ops = OpCount *Op
OpCount = Byte
Op = Opcode OpPayload
Opcode = Byte
OpPayload = Transfer /
ChannelInscribe /
ChannelBlob /
ChannelSetKeys /
ChannelDeposit /
ChannelWithdraw /
SDPDeclare /
SDPWithdraw /
SDPActive /
LeaderClaim
Channel Operations
ChannelInscribe = ChannelId Inscription Parent Signer
Inscription = UINT32 *BYTE
ChannelBlob = ChannelId Session BlobId BlobSize DaStorageGasPrice Parent Signer
Sesssion = UINT64
BlobId = Hash32
BlobSize = UINT64
DaStorageGasPrice = UINT64
ChannelSetKeys = ChannelId KeyCount *Signer
KeyCount = Byte
ChannelDeposit = ChannelId Inputs Metadata
Inputs = InputCount *NoteId
InputCount = Byte
Metadata = UINT32 *BYTE
ChannelWithdraw = ChannelId Outputs WithdrawalNonce
Outputs = OutputCount *Note
OutputCount = Byte
WithdrawalNonce = UINT32
ChannelId = Hash32
Parent = Hash32
Signer = Ed25519PublicKey
SDP Operations
SDPDeclare = ServiceType LocatorCount *Locator ProviderId ZkId LockedNoteId
ServiceType = Byte ; 0 = BN, 1 = DA
LocatorCount = Byte ; Max 8
Locator = 2Byte *BYTE ; Max 329 bytes, multiaddr format
ProviderId = Ed25519PublicKey
ZkId = ZkPublicKey
LockedNoteId = NoteId
SDPWithdraw = DeclarationId Nonce LockedNoteId
DeclarationId = Hash32
Nonce = UINT64
SDPActive = DeclarationId Nonce Metadata
Metadata = UINT32 *BYTE ; Service-specific node activeness metadata
Leader operations
LeaderClaim = RewardsRoot VoucherNullifier PublicKey
RewardsRoot = FieldElement ; Merkle root for voucher membership proof
VoucherNullifier = FieldElement
PublicKey = ZkPublicKey
Transfer Operations
Transfer = Inputs Outputs
Inputs = InputCount *NoteId
InputCount = Byte
Outputs = OutputCount *Note
OutputCount = Byte
Ledger
Note = Value ZkPublicKey
Value = UINT64
NoteId = FieldElement
Op Proofs
OpsProofs = *OpProof ; 1. Lenth must equal OpCount
; 2. OpProof variant is derived from the corresponding Op.
; That is, type(OpProofs[i]) == ProofFor(Op[i])
OpProof = Ed25519SigProof /
ZkSigProof /
ZkAndEd25519SigsProof /
ChannelWithdrawOpProof /
ProofOfClaimProof
Ed25519SigProof = Ed25519Signature
ZkSigProof = ZkSignature
ZkAndEd25519SigsProof = ZkSignature Ed25519Signature
ChannelWithdrawOpProof = SignatureCount *Ed25519Signature
ProofOfClaimProof = Groth16
SignatureCount = UINT16
Common Structures
; Zero-knowledge signature
ZkSignature = Groth16
; Cryptographic primitives
Groth16 = 128BYTE ; pi_a (32) + pi_b (64) + pi_c (32)
ZkPublicKey = FieldElement
Ed25519PublicKey = 32BYTE
Ed25519Signature = 64BYTE
FieldElement = 32BYTE ; BN254 field element (little-endian)
Hash32 = 32BYTE
; Primitive types
UINT64 = 8BYTE ; 64-bit unsigned integer, little-endian
UINT32 = 4BYTE ; 32-bit unsigned integer, little-endian
UINT16 = 2BYTE ; 16-bit unsigned integer, little-endian
Byte = OCTET
V1.4.0-MANTLE
| Field | Value |
|---|---|
| Name | Mantle |
| Slug | 235 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Thomas Lavaur [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revisions History
| Version | Changes |
|---|---|
| 1.1.0 | Initial revision. |
| 1.2.0 | Removed DA references. Removed notions of Sovereignty and Rollups and used Zones for simplicity. Removed Nomos from specifications and DSTs. Added bridging and decentralized sequencing for channels. |
| 1.2.1 | Added [RFC] Improve Mantle Transaction hash. |
| 1.3.0 | Added [RFC] Make Ledger Transaction an Operation. |
| 1.4.0 | Added [RFC] Enforce NoteId uniqueness. |
Introduction
Mantle is a foundational element of Bedrock, designed to provide a minimal and efficient execution layer that connects together Bedrock Services in order to provide the necessary functionality for Zones. It can be viewed as the system call interface of Bedrock, exposing a safe and constrained set of Operations to interact with lower-level Bedrock services, similar to syscalls in an operating system.
Mantle Transactions provide Operations for Zones and blockchain Services to interact with Bedrock. For example, a Zone sequencer posting an update to Bedrock, or a node operator declaring its participation in the Blend Network, would be done through the corresponding Operations within a Mantle Transaction.
Mantle manages assets using a note-based ledger that follows an UTXO model. Each Mantle Transaction can include Transfer Operation, and any excess balance serves as the fee payment.
Overview
Mantle Transaction
The features of the Logos Blockchain are exposed through Mantle Transactions. Each transaction can contain zero or more Operations. Mantle Transactions enable users to execute multiple Operations atomically.
Mantle Operations
Logos Blockchain features are exposed through Mantle Operations, which can be combined and executed together in a single Mantle Transaction atomically. These Operations enable transfers and functions such as on-chain data posting, Cross-Zone interactions, SDP interaction, and leader reward claims.
Mantle Ledger
The Mantle Ledger enables asset transfers using a transparent UTXO model. While a Transfer Operation can consume more tokens than it creates, the Mantle Transaction excess balance must exactly pay for the fees.
Transaction Fees
Mantle Transaction fees are derived from a gas model. The Logos Blockchain has two different gas markets, accounting for permanent data storage, and execution costs. Each Operation has an associated Execution Gas cost. Users can specify their gas prices in their Mantle Transactions to incentivize the network to include their transaction.
| Gas Market | Charged On | Pricing Basis |
|---|---|---|
| Execution Gas | Operations | Fixed per Operation |
| Permanent Storage Gas | Signed Mantle Transaction | Proportional to encoded size |
Mantle Transaction
Mantle Transactions form the core of Mantle, enabling users to combine multiple Operations to access different functions. Each transaction contains zero or more Operations. The system executes all Operations atomically, while using the Mantle Transaction's excess balancecalculated as the difference between the consumed and created value as the fee payment.
class MantleTx:
ops: list[Op]
permanent_storage_gas_price: TokenValue # See the note section
execution_gas_price: TokenValue
class Op:
opcode: byte
payload: bytes
def mantle_txhash(tx: MantleTx) -> ZkHash:
tx_bytes = encode(tx)
h = Hasher() # /!\ This is a classic hash not a ZkHash /!\
h.update(b"MANTLE_TXHASH_V1")
h.update(tx_bytes)
classic_digest = h.digest()
zkh = ZkHasher() # /!\ This is a ZkHash not a classic hash /!\
zkh.update(FiniteField(classic_digest[0:16], bytes_order="little", modulus = p))
zkh.update(FiniteField(classic_digest[16:32], bytes_order="little", modulus = p))
return zkh.digest()
The hash function used, as well as other cryptographic primitives like ZK proofs and signature schemes, are described in Common Cryptographic Components.
A Mantle Transaction must include all relevant signatures and proofs for each Operation.
class SignedMantleTx:
tx: MantleTx
op_proofs: list[OpProof | None] # each Op has at most 1 associated proof
Each proof (op proof and signature) must be cryptographically bound to the MantleTx through the mantle_txhash to prevent replay attacks. This binding is achieved by including the MantleTx hash as a public input in every ZK proof.
The transaction fee is a sum of two components: the multiplication of the total Execution Gas by the execution_gas_price, and the total size of the encoded signed Mantle Transaction multiplied by the permanent_storage_gas_price.
def gas_fees(signed_tx: SignedMantleTx) -> int:
mantle_tx = signed_tx.tx
permanent_storage_fees = len(encode(signed_mantle_tx)) * mantle_tx.permanent_storage_gas_price
execution_fees = 0
for op in mantle_tx.ops:
# Compute the execution gas of this operation as defined
# in the gas cost determination specification.
execution_fees += execution_gas(op) * mantle_tx.execution_gas_price
return execution_fees + permanent_storage_fees
Validation
Given
signed_tx = SignedMantleTx(
tx=MantleTx(ops, permanent_storage_gas_price, execution_gas_price),
op_proofs
)
Mantle validators will ensure the following:
- We have a proof or a None value for each operation.
assert len(op_proofs) == len(ops) - Each Operation is valid.
for op, op_proof in zip(ops, op_proofs): assert op.opcode in MANTLE_OPCODES validate_mantle_op(mantle_txhash(tx), op.opcode, op.payload, op_proof) def validate_mantle_op(txhash, opcode, payload, op_proof): if opcode == CHANNEL_INSCRIBE: validate_channel_inscribe(txhash, payload, op_proof) # elif opcode == ... # ... - The Mantle Transaction excess balance pays for the transaction fees.
tx_fee = gas_fees(signed_tx) # Not an unsigned int assert tx_fee == get_transaction_balance(signed_tx) def get_transaction_balance(signed_tx: SignedMantleTx) -> int: balance = 0 # It's important to not use unsigned int here to avoid # overflow vulnerabilities for op in signed_tx.tx.ops: if op.opcode == TRANSFER: for inp in op.inputs: balance += get_value_from_note_id(inp) for out in op.outputs: balance -= out.value return balance
Execution
Given
SignedMantleTx(
tx=MantleTx(ops, permanent_storage_gas_price, execution_gas_price),
op_proofs
)
Mantle Validators execute sequentially each Operation in ops according to its opcode.
Operations
Opcodes
| Operation | Opcode | Description |
|---|---|---|
| TRANSFER | 0x00 | Consume and create notes. |
| RESERVED | 0x01 - 0x0F | |
| CHANNEL_CONFIG | 0x10 | Configure a channel |
| CHANNEL_INSCRIBE | 0x11 | Write a message permanently onto Mantle. |
| CHANNEL_DEPOSIT | 0x12 | Deposit assets into a channel |
| CHANNEL_WITHDRAW | 0x13 | Withdraw assets from a channel |
| RESERVED | 0x14 - 0x1F | |
| SDP_DECLARE | 0x20 | Declare intention to participate as a node in a Bedrock Service, locking funds as collateral. |
| SDP_WITHDRAW | 0x21 | Withdraw participation from a Bedrock Service, unlocking your funds in the process. |
| SDP_ACTIVE | 0x22 | Signal that you are still an active participant of a Bedrock Service. |
| RESERVED | 0x23 - 0xFF | |
| LEADER_CLAIM | 0x30 | Claim leader reward anonymously. |
| RESERVED | 0x31 - 0xFF |
Channel Operations
Channels allow Zones to post their updates on chain. Channels form virtual chains that overlay on top of the Cryptarchia blockchain. Clients and Followers of a Zone can watch its channel to learn the state of that Zone. Each channel has an associated balance, enabling bridging between Zones and Bedrock.
Message Ordering
Channels form virtual chains by having each message reference its parent message. The order of messages in these channels is enforced by the sequencer by building a hash chain of messages, i.e. new messages reference the previous messages through a parent hash. Given that Cryptarchia has long finality times, these message parent references allow Zone sequencers to continue to post new updates to channels without having to wait for finality. No matter how Cryptarchia forks and reorgs, the channel messages from honest sequencers will eventually be re-included in a way that satisfies the virtual chain order.
The first time a message is sent to an unclaimed channel, the key that signs the initial message becomes the only accredited key in the list (Note that this key may correspond to a threshold signature key). Accredited keys of a channel forms a committee that can configure the channel, withdraw funds and take turns to write messages to that channel following a round-robin algorithm. Configuring a channel includes modifying the list of accredited keys, the round-robin parameters and the required number of signatures to withdraw funds or establish a new configuration.
Validators must maintain the following state to process channel Operations:
channels: dict[ChannelId, ChannelState] # ChannelId is 32 bytes
class ChannelState:
# Channel Configuration
accredited_keys: list[Ed25519PublicKey] # limited to 65 535 keys
configuration_threshold: u16 # indicating how many keys are
# required to update the configuration
# Message Ordering
tip_hash: hash
# Decentralized Sequencing
tip_slot: Slot
tip_sequencer: u16 # indicating the actual
# sequencer position in the list of accredited keys
tip_sequencer_starting_slot: Slot
posting_timeframe: u32 # number of slots (0 = infinity)
posting_timeout: u32 # number of slots (0 = no timeout)
# Bridging
balance: TokenValue # See the Note section for its precision
withdrawal_nonce: u32 # Nonce used to derive a channel OpId
withdraw_threshold: u16 # indicating how many keys are
# required to withdraw funds from the channel
def default_channel(block_slot: Slot, keys: list[Ed25519PublicKey])
-> ChannelState:
return ChannelState(
tip_hash = ZERO,
tip_slot = block_slot,
accredited_keys = keys,
tip_sequencer = 0,
tip_sequencer_starting_slot = block_slot,
posting_timeframe = 0,
posting_timeout = 0,
configuration_threshold = 1,
balance = 0,
withdrawal_nonce = 0,
withdraw_threshold = 1)
Note that the user chooses the ChannelId mapping to the ChannelState (but its restricted to 32 bytes). We don't currently impose restrictions on it, but we may do so in the future to prevent undesirable behaviors.
Decentralized Sequencing
To determine which sequencer is currently authorized to send messages, we use a round-robin algorithm. When a message is posted to a channel, the following algorithm is used to determine who the sequencer is:
# Round Robin algorithm determining the new sequencer index and the
# new sequencer starting slot
def round_robin(block_slot: Slot, channel: ChannelState) -> (u16,u64):
elapsed_slots = block_slot - channel.tip_slot
if elapsed_slots >= channel.posting_timeout && channel.posting_timeout != 0:
# Get the number of sequencers that get timed out
sequencers_timed_out = elapsed_slots // channel.posting_timeout
index = (channel.tip_sequencer + sequencers_timed_out)
% len(channel.accredited_keys)
starting_slot = channel.tip_slot
+ sequencers_timed_out * channel.posting_timeout
else:
# Get the number of timeframes elapsed to get who is the sequencer
tip_sequencer_duration = block_slot - channel.tip_sequencer_starting_slot
index = (channel.tip_sequencer
+ (tip_sequencer_duration // channel.posting_timeframe))
% len(channel.accredited_keys)
starting_slot = channel.tip_sequencer_starting_slot
+ (tip_sequencer_duration // channel.posting_timeframe)
* channel.posting_timeframe
return (index, starting_slot)
CHANNEL_INSCRIBE
Write a message to a channel with the message data being permanently stored on the Logos Blockchain.
Payload
class Inscribe:
channel: ChannelId # 32 bytes Channel being written to
inscription : bytes # Message to be written on the blockchain
parent: hash # Previous message in the channel
signer: Ed25519PublicKey # Identity of message sender
Proof
Ed25519Signature
Execution Gas
Channel Inscribe Operations have a fixed Execution Gas cost of EXECUTION_CHANNEL_INSCRIBE_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: hash
msg: Inscribe
sig: Ed25519Signature
channels: dict[ChannelId, ChannelState]
block_slot: Slot
Validate
if msg.channel in channels:
chan = channels[msg.channel]
current_sequencer_index = round_robin(block_slot, chan)[0]
# Ensure the signer is the one authorized to write to the channel
assert msg.signer == chan.accredited_keys[current_sequencer_index]
# Ensure message is continuing the channel sequence
assert msg.parent == chan.tip_hash
else:
# Channel will be created automatically upon execution
# Ensure that this message is the genesis message (parent == ZERO)
assert msg.parent == ZERO
# Ensure the msg signer signature
assert Ed25519_verify(txhash, msg.signer, sig)
Execution
Given
msg: Inscribe
sig: Ed25519Signature
channels: dict[ChannelId, ChannelState]
block_slot: Slot
Execute
- If the channel does not exist, create it just-in-time.
if msg.channel not in channels: channels[msg.channel] = default_channel(block_slot, [msg.signer]) - Update the channel sequencer.
chan = channels[msg.channel] (new_sequencer_index, new_sequencer_starting_slot) = round_robin( block_slot, chan) chan.tip_sequencer_starting_slot = new_sequencer_starting_slot chan.tip_sequencer = new_sequencer_index - Update the channel tip.
chan = channels[msg.channel] chan.tip_hash = hash(encode(msg)) chan.tip_slot = block_slot
Example
# Build the inscription
greeting = Inscription(
channel=CHANNEL_EARTH,
inscription=b"Live long and prosper",
parent=ZERO
signer=spock_pk
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[<spocks_note_id>], outputs=[<change_note>])
# Wrap it in a transaction
tx = MantleTx(
ops=[Op(opcode=CHANNEL_INSCRIBE, payload=encode(greeting)),
Op(opcode=TRANSFER, payload=encode(transfer)],
permanent_storage_gas_price=150,
execution_gas_price=70,
)
# Sign the transaction
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[Ed25519_sign(mantle_txhash(tx), spock_sk),
transfer.prove(spock_sk)]
)
# Send the transaction to the mempool
mempool.push(signed_tx)
CHANNEL_CONFIG
Overwrite the configuration of a channel.
Payload
class ChannelConfig:
channel: ChannelId
keys: list[Ed25519PublicKey]
posting_timeframe: u32
posting_timeout: u32
configuration_threshold: u16
withdraw_threshold: u16
Proof
class ChannelConfigOpProof:
signatures: list[Ed25519Signature] # signatures from configuration_threshold
indexes: list[u16] # signatures of accredited keys with their index.
# indexes must be ordered from smallest to
# biggest without duplication
Execution Gas
Channel Config Operations have a linear Execution Gas cost equal to EXECUTION_CHANNEL_CONFIG_GAS * configuration_threshold. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash
config: ChannelConfig
proof: ChannelConfigOpProof
channels: dict[ChannelId, ChannelState]
Validate
assert len(proof.signatures) == len(proof.indexes)
assert config.configuration_threshold > 0
assert config.withdraw_threshold > 0
assert len(config.keys) > 0
assert len(config.keys) < 2^16
if config.channel in channels:
chan = channels[config.channel]
# Check there are enough signatures
assert len(proof.signatures) == chan.configuration_threshold
# Check that indexes are ordered to avoid duplication
for i in range(len(proof.indexes)-1):
assert proof.indexes[i] < proof.indexes[i+1]
for sig, idx in zip(proof.signatures, proof.indexes):
# and at the same time that chan.accredited_keys[idx] isn't out of bound
assert Ed25519_verify(txhash, chan.accredited_keys[idx], sig)
Execution
Given
config: ChannelConfig
channels: dict[ChannelId, ChannelState]
block_slot: Slot
Execute
- If the channel does not exist, create it just-in-time.
if config.channel not in channels:
channels[config.channel] = default_channel(block_slot, config.keys)
- Update the configuration.
chan = channels[config.channel]
# Update Channel Configuration Parameters
chan.accredited_keys = config.keys
chan.configuration_threshold = config.configuration_threshold
# Update Decentralized Sequencing Parameters
chan.tip_sequencer = 0
chan.tip_sequencer_starting_slot = block_slot
chan.posting_timeframe = config.posting_timeframe
chan.posting_timeout = config.posting_timeout
# Update Bridging Parameters
chan.withdraw_threshold = config.withdraw_threshold
- Update the channel tip.
chan = channels[config.channel]
chan.tip_slot = block_slot
chan.tip_hash = hash(encode(config))
Example
Suppose the unique sequencer of Zone A wants to add a key to the list of accredited keys:
# Given a key to add
new_sequencer_pk: Ed25519PublicKey
# The unique sequencer encodes the update and builds the payload
config = ChannelConfig(
channel=ZONE_A,
keys=[old_sequencer_pk, new_sequencer_pk],
posting_timeframe = 5000,
posting_timeout = 500,
configuration_threshold = 2,
withdraw_threshold = 1
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[old_sequencer_funds], outputs=[<change_note>])
tx = MantleTx(
ops=[Op(opcode=CHANNEL_CONFIG, payload=encode(config)),
Op(opcode=TRANSFER, payload=encode(transfer)],
permanent_storage_gas_price=150,
execution_gas_price=70,
)
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[[Ed25519_sign(mantle_txhash(tx), old_sequencer_sk)], [0]],
transfer.prove(old_sequencer_sk)]
)
CHANNEL_DEPOSIT
Deposit funds to a channel, reducing the Mantle Transaction balance.
Payload
class ChannelDeposit:
channel: ChannelId
inputs: list[NoteId] # the list of consumed note identifiers
metadata: bytes
Proof
A Channel Deposit proves the ownership of the consumed notes using a Zero Knowledge Signature Scheme (ZkSignature).
ZkSignature
Execution Gas
Channel Deposit Operations have a fixed Execution Gas cost of EXECUTION_CHANNEL_DEPOSIT_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
mantle_txhash: ZkHash # ZkHash of mantle tx containing this ledger tx
deposit: ChannelDeposit
deposit_proof: ZkSignature
channels: dict[ChannelId, ChannelState]
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
Validate
- Verify that the channel exist
assert deposit.channel in channels - Ensure all inputs are unspent.
assert all(ledger.is_unspent(note_id) for note_id in deposit.inputs) - Ensure inputs are not locked.
# Ensure inputs are not locked for note_id in deposit.inputs: assert note_id not in locked_notes - Validate ownership over deposited notes.
input_notes = [ledger[input_note_id] for input_note_id in deposit.inputs] input_pks = [note.public_key for note in input_notes] assert ZkSignature_verify(mantle_txhash, deposit_proof, input_pks)
Execution
Given
deposit: ChannelDeposit
channels: dict[ChannelId, ChannelState]
ledger: Ledger
Execute
- Remove inputs from the ledger.
for note_id in deposit.inputs: # updates the merkle tree to zero out the leaf for this entry # and adds that leaf index to the list of unused leaves ledger.remove(note_id) - Increase the balance of the channel
for inp in deposit.inputs: channels[deposit.channel].balance += inp.value
Example
Suppose Alice wants to make a deposit of 50 tokens on Zone A.
# Alice encodes her deposit
deposit = ChannelDeposit(
channel=ZONE_A,
inputs=[alice_deposit_note_id] # This is a note of 50 tokens
metadata=b"deposit to address: 0x..."
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[Alice_funds], outputs=[<change_note>])
tx = MantleTx(
ops=[Op(opcode=CHANNEL_DEPOSIT, payload=encode(deposit)),
Op(opcode=TRANSFER, payload=encode(transfer)],
permanent_storage_price=150,
execution_gas_price=70,
)
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[transfer.prove(Alice_sk)],
)
Note that the Zone may wait for the deposit to be finalized before interpreting the deposit in order to guarantee that the deposit will occur on-chain and won't be removed due to reorganization of the chain.
CHANNEL_WITHDRAW
Withdraw funds from a channel, increasing the Mantle Transaction balance.
Payload
class ChannelWithdraw:
channel: ChannelId
outputs: list[Note]
op_id_nonce: u32
Proof
class ChannelWithdrawOpProof:
signatures: list[Ed25519Signature] # signature from withdraw_threshold keys
indexes: list[int] # signatures of accredited keys with their index.
# indexes must be ordered from smallest to
# biggest without duplication
Execution Gas
Channel Withdraw Operations have a linear Execution Gas cost equal to EXECUTION_CHANNEL_WITHDRAW_GAS * withdraw_threshold. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash
withdrawal: ChannelWithdraw
proof: ChannelWithdrawOpProof
channels: dict[ChannelId, ChannelState]
Validate
# Check that the outputs are valid
for output in withdrawal.outputs:
assert output.value > 0
assert output.value < 2**64
# Check that the channel exists
assert withdrawal.channel in channels
chan = channels[withdrawal.channel]
# Check that the withdraw nonce is correct
assert channels[withdrawal.channel].withdrawal_nonce == withdrawal.withdrawal_nonce
# Check that the channel has enough funds
withdrawal_amount = sum(output.value for output in withdrawal.outputs)
assert chan.balance >= withdrawal_amount
# Check that there are enough signatures
assert len(proof.signatures) == len(proof.indexes)
assert len(proof.signatures) == chan.withdraw_threshold
# Check that every index is unique
assert len(proof.indexes) == len(set(proof.indexes))
# Check the signatures
for sig, idx in zip(proof.signatures, proof.indexes):
assert Ed25519_verify(txhash, chan.accredited_keys[idx], si
Execution
Given
withdrawal: ChannelWithdraw
channels: dict[ChannelId, ChannelState]
ledger: Ledger
Execute
- Decrease the balance of the Channel
for output in withdrawal.outputs: channels[withdrawal.channel].balance -= output.value - Add outputs to the ledger.
withdrawal_id = derive_op_id(withdrawal) for (output_number, output_note) in enumerate(withdrawal.outputs): output_note_id = derive_note_id(withdrawal_id, output_number, output_note) ledger.add(output_note_id) - Increase the channel withdrawal_nonce
channels[withdrawal.channel].withdrawal_nonce += 1
Example
Suppose the unique sequencer of Zone A wants to withdraw 50 tokens.
# Sequencer encodes his withdrawal
withdrawal = ChannelWithdraw(
channel=ZONE_A,
outputs=[Note(pk=alice, value=50)]
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[Sequencer_funds], outputs=[<change_note>])
tx = MantleTx(
ops=[Op(opcode=CHANNEL_WITHDRAW, payload=encode(withdrawal)),
Op(opcode=TRANSFER, payload=encode(transfer)],
permanent_storage_price=150,
execution_gas_price=70
)
signed_tx = SignedMantleTx(
tx=tx,
op_proofs=[[[Ed25519_sign(mantle_txhash(tx), sequencer_sk)],[0]],
transfer.prove(Sequencer_node_sk)],
)
Service Declaration Protocol (SDP) Operations
These Operations implement the Service Declaration Protocol.
Validators must keep the following state when implementing SDP Operations:
locked_notes: dict[NoteID, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
class LockedNote:
declarations: set[DeclarationID]
locked_until: BlockNumber
Common SDP Structures
class ServiceType(Enum):
BN="BN" # Blend Network
class Locator(str):
def validate(self):
assert len(self) <= 329
assert validate_multiaddr(self)
class MinStake:
stake_threshold: int # stake value
timestamp: int # block number
class ServiceParameters:
lock_period: int # number of blocks
inactivity_period: int # number of blocks
retention_period: int # number of blocks
timestamp: int # block number
class DeclarationInfo:
service: ServiceType
locators: list[Locator]
provider_id: Ed25519PublicKey
zk_id: ZkPublicKey
locked_note_id: NoteId
created: BlockNumber
active: BlockNumber
withdrawn: BlockNumber
# SDP ops updating a declaration must use monotonically increasing nonces
nonce: int
SDP_DECLARE
The service registration follows the definition given in Service Declaration Protocol - Declaration Message:
Payload
class DeclarationMessage:
service_type: ServiceType
locators: list[Locator]
provider_id: Ed25519PublicKey
zk_id: ZkPublicKey
locked_note_id: NoteId
Locked notes are introduced in Locked notes and serve as Service collaterals. They cannot be spent before the owner withdraw its participation from the declared service(s).
Proof
class DeclarationProof:
zk_sig: ZkSignature # signature proving ownership over
# locked note and zk_id
provider_sig: Ed25519Signature # signature proving ownership of provider key
see: Zero Knowledge Signature Scheme (ZkSignature).
Execution Gas
SDP Declare Operations have a fixed Execution Gas cost of EXECUTION_SDP_DECLARE_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash # the txhash of the transaction we are validating
declaration: DeclarationMessage # the declaration we are validating
proof: DeclarationProof
min_stake: MinStake # the (global) minimum stake setting
ledger: Ledger # the set of unspent notes
locked_notes: dict[NoteId, LockedNote]
declarations: dict[NoteId, DeclarationInfo]
Validate
The declaration is verified according to Service Declaration Protocol - Declare.
- Ensure ownership over the locked note, zk_id and provider_id.
assert ZkSignature_verify( txhash, proof.zk_sig, [note.public_key, declaration.zk_id] ) assert Ed25519_verify(txhash, proof.provider_sig, provider_id) - Ensure declaration does not already exist.
assert declaration_id(declaration) not in declarations - Ensure it has no more than 8 locators.
assert len(declaration.locators) <= 8 - Ensure locked note exists and value of locked note is sufficient for joining the service.
assert ledger.is_unspent(declaration.locked_note_id) note = ledger.get_note(declaration.locked_note_id) assert note.value >= min_stake.stake_threshold - Ensure the note has not already been locked for this service.
if declaration.locked_note in locked_notes: locked_note = locked_notes[declaration.locked_note] services = [declarations[declare_id] for declare_id in locked_note.declarations] assert declaration.service_type not in services
Execution
Given
declaration: DeclarationMessage # the declaration we are executing
service_parameters: dict[ServiceType, ServiceParameters]
current_block_height: int
locked_notes : dict[NoteId, LockedNote]
Execute
- Create the locked note state if it doesn't already exist.
if declaration.locked_note not in locked_notes: locked_notes[declaration.locked_note_id] = \ LockedNote(declarations=set(), locked_until=0) locked_note = locked_notes[declaration.locked_note_id] - Update the locked notes timeout using this services lock period.
lock_period = service_parameters[declaration.service_type].lock_period service_lock = current_block_height + lock_period locked_note.locked_until = max(service_lock, locked_note.locked_until) - Add this declaration to the locked note.
declare_id = declaration_id(declaration) locked_note.declarations.add(declare_id) - Store the declaration as explained in Service Declaration Protocol - Declaration Storage.
declarations[declare_id] = DeclarationInfo( service: declaration.service locators: declaration.locators provider_id: declaration.provider_id zk_id: declaration.zk_id locked_note_id: declaration.locked_note_id declaration, created=current_block_height, active=current_block_height, withdrawn=0 nonce=0 )
Example
# Assume `alice_note` is in the ledger:
alice_note = Utxo(
txhash=0x2948904F2F0F479B8F8197694B30184B0D2ED1C1CD2A1EC0FB85D299A192A447,
output_number=3,
note=Note(value=500, public_key=alice_pk_1),
)
# Alice wishes to lock it to join the Blend network
declaration=DeclarationMessage(
service_type=ServiceType.BN,
locators=["/ip4/203.0.113.10/tcp/4001/p2p"],
provider_id=alice_provider_pk,
zk_id=alice_pk_2,
locked_note_id=alice_note.id()
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[fee_note_id], outputs=[])
tx = MantleTx(
ops=[Op(opcode=SDP_DECLARE, payload=encode(declaration)),
Op(opcode=TRANSFER, payload=encode(transfer)],
permanent_storage_gas_price=150,
execution_gas_price=70,
)
txhash = mantle_txhash(tx)
declaration_proof = DeclarationProof(
# proof of ownership of the staked note and zk_id
zk_sig=ZkSignature([alice_sk_1, alice_sk_2], txhash),
# proof of ownership of the provider id
provider_sig=Ed25519Signature(alice_provider_sk, txhash),
)
SignedMantleTx(
tx=tx,
op_proofs=[declaration_proof, transfer.prove(alice_sk_1)],
)
SDP_WITHDRAW
The service withdrawal follows the definition given in Service Declaration Protocol - Withdraw Message.
Payload
class WithdrawMessage:
declaration: DeclarationID
locked_note_id: NoteId
nonce: int
Proof
A signature from the zk_id and the locked note pk attached to the declaration is required for withdrawing from a service, (see Zero Knowledge Signature Scheme (ZkSignature)).
ZkSignature
Execution Gas
SDP Withdraw Operations have a fixed Execution Gas cost of EXECUTION_SDP_WITHDRAW_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash # Mantle transaction hash of the tx containing this operation
withdraw: WithdrawMessage
signature: ZkSignature
block_height: int # block height of the current block
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
Validate
- Ensure that the locked note exists, is locked and bound to this declaration.
assert ledger.is_unspent(withdraw.locked_note_id) assert withdraw.locked_note_id in locked_notes locked_note = locked_notes[withdraw.locked_note_id] assert withdraw.declaration in locked_note.declarations - Ensure that the locked note has expired.
assert locked_note.locked_until <= block_height - Validate SDP withdrawal according to Service Declaration Protocol - Withdraw.
- Ensure declaration exists.
assert withdraw.declaration in declarations declare_info = declarations[withdraw.declaration] - Ensure locked note pk and zk_id attached to this declaration authorized this Operation.
locked_note = ledger[withdraw.locked_note_id] assert ZkSignature_verify(txhash, signature, [locked_note.pk, declare_info.zk_id]) - Ensure the declaration has not already been withdrawn.
assert declare_info.withdrawn == 0 - Ensure that the nonce is greater than the previous one.
assert withdraw.nonce > declare_info.nonce
- Ensure declaration exists.
Execution
Given
withdraw: WithdrawMessage
signature: ZkSignature
block_height: int # block height of the current block
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
declarations: dict[DeclarationID, DeclarationInfo]
Execute
Executes the withdrawal protocol Service Declaration Protocol - Withdraw.
- Update declaration info with nonce and withdrawn timestamp.
declare_info = declarations[withdraw.declaration] declare_info.nonce = withdraw.nonce declare_info.withdrawn = block_height - Remove this declaration from the locked note.
locked_note = locked_notes[withdraw.locked_note_id] locked_note.declarations.remove(withdraw.declaration) - Remove the locked note if it is no longer bound to any declarations.
if len(locked_note.declarations) == 0: del locked_notes[withdraw.locked_note_id)
Example
withdraw=Withdraw(
declaration=alice_declaration_id,
locked_note_id=alices_locked_note_id
nonce=1579532
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[alices_locked_note_id],
outputs=[Note(100, alice_note_pk)])
tx = MantleTx(
ops=[Op(opcode=SDP_WITHDRAW, payload=encode(withdraw)),
Op(opcode=TRANSFER, payload=encode(transfer)],
permanent_storage_gas_price=150,
execution_gas_price=70,
)
SignedMantleTx(
tx=tx,
# proof ownership of the withdrawn note and zk id
op_proofs=[ZkSignature_sign([alice_note_sk, alice_sk], mantle_txhash(tx)),
transfer.prove(alice_sk)]
)
SDP_ACTIVE
The service active action follows the definition given in Service Declaration Protocol - Active Message.
Payload
class Active:
declaration: DeclarationID
nonce: int
metadata: bytes # a service-specific node activeness metadata
Proof
ZkSignature
Execution Gas
SDP Active Operations have a fixed Execution Gas cost of EXECUTION_SDP_ACTIVE_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
txhash: zkhash # Mantle transaction hash of the tx containing this operation
active: Active
signature: ZkSignature
declarations: dict[DeclarationID, DeclarationInfo]
Validate
assert active.declaration in declarations
declaration_info = declarations[active.declaration]
assert active.nonce > declaration_info.nonce
assert ZkSignature_verify(txhash, signature, declaration_info.zk_id)
Execution
Executes the active protocol Service Declaration Protocol - Active. The activation, i.e. setting the declaration.active, is handled by the service-specific logic.
Example
active=Active(
declaration=alice_declaration_id,
nonce=1579532,
metadata=b"Look, I am still doing my job"
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[fee_note_id], outputs=[])
tx = MantleTx(
ops=[Op(opcode=SDP_ACTIVE, payload=encode(active))],
permanent_storage_gas_price=150,
execution_gas_price=70,
)
txhash = mantle_txhash(tx)
SignedMantleTx(
tx=tx,
op_proofs=[Ed25519_sign(txhash, validator_sk), transfer.prove(fee_note_sk)]
)
Leader Operations
LEADER_CLAIM
This Operation claims the leader's block reward anonymously.
Payload
class ClaimRequest:
rewards_root: zkhash # Merkle root used in the proof for voucher membership
voucher_nf: zkhash
public_key: ZkPublicKey
Proof
The provider proves that they have won a proof of Leadership before the start of the current epoch, i.e., their reward voucher is indeed in the voucher set: Proof of Claim.
Execution gas
Leader Claim Operations have a fixed Execution Gas cost of EXECUTION_LEADER_CLAIM_GAS. See Gas Determination for the Execution Gas values.
Validation
# Given
mantle_txhash: zkhash
claim : ClaimRequest
last_voucher_root: zkhash # The last root of the voucher Merkle tree
# at the start of the epoch
voucher_nullifier_set: set[zkhash]
proof: ProofOfClaim
# Validate
assert claim.voucher_nf not in voucher_nullifier_set
assert claim.rewards_root == last_voucher_root
validate_proof(claim, proof, mantle_txhash)
Execution
Given
claim: ClaimRequest
ledger: Ledger
voucher_nullifier_set: set[zkhash]
leaders_rewards: TokenValue # The pool of tokens to be claim by leaders
leader_reward: TokenValue # The amount one leader can claim
Execution
- Add claim.voucher_nf to the voucher_nullifier_set.
- Denoting by leader_reward the amount defined for leader rewards in Anonymous Leaders Reward Protocol - Leaders Reward, construct a single output note with value leader_reward under the public key defined in the payload, and insert it into the Ledger:
output_note=Note( value = leader_reward public_key = claim.public_key, ) claim_id = derive_op_id(claim) output_note_id = derive_note_id(claim_id, 0, output_note) ledger.add(output_note_id) - Reduce the leaders reward leaders_rewards value by the same amount (without ZK proof).
Example
secret_voucher = 0xDEADBEAF;
reward_voucher = leader_claim_voucher(secret_voucher)
voucher_nullifier = leader_claim_nullifier(secret_voucher)
claim=ClaimRequest(
rewards_root=REWARDS_MERKLE_TREE.root(),
voucher_nf=voucher_nullifier,
public_key=leader_one_time_key
)
# Build the transfer operation to pay the fees
transfer = Transfer(inputs=[<fee_note>], outputs=[<change_note>])
tx = MantleTx(
ops=[Op(opcode=LEADER_CLAIM, payload=encode(claim)),
Op(opcode=TRANSFER, payload=encode(transfer)],
permanent_storage_gas_price=150,
execution_gas_price=70,
)
claim_proof = claim.prove(
secret_voucher,
REWARDS_MERKLE_TREE.path(leaf=reward_voucher),
mantle_txhash(tx)
)
SignedMantleTx(
tx=tx,
op_proofs=[claim_proof, transfer.prove(fee_note_sk)]
)
TRANSFER
Transactions must prove the ownership of spent notes. In classical blockchains, this is done through a signature. To stay compatible with our architecture, the signature is done by a ZK proof (see Zero Knowledge Signature Scheme (ZkSignature)), proving the knowledge of the secret key associated with the public key.
Transactions allow complete transaction linkability and the public key spending the note is not hidden.
Payload
class Transfer:
inputs: list[NoteId] # the non-empty list of consumed note identifiers
outputs: list[Note]
Proof
A Transfer proves the ownership of the consumed notes using a Zero Knowledge Signature Scheme (ZkSignature).
ZkSignature
Execution Gas
Transfer have a fixed Execution Gas cost of EXECUTION_TRANSFER_GAS. See Gas Determination for the Execution Gas values.
Validation
Given
mantle_txhash: ZkHash # ZkHash of mantle tx containing this ledger tx
transfer: Transfer
transfer_proof: ZkSignature
ledger: Ledger
locked_notes: dict[NoteId, LockedNote]
Validate
- Ensure the Transfer in non-empty
assert len(transfer.inputs) > 0 - Ensure all inputs are unspent.
assert all(ledger.is_unspent(note_id) for note_id in transfer.inputs) - Ensure inputs are not locked.
# Ensure inputs are not locked for note_id in transfer.inputs: assert note_id not in locked_notes - Ensure outputs are valid.
for output in transfer.outputs: assert output.value > 0 assert output.value < 2**64 - Validate transfer proof to show ownership over input notes.
input_notes = [ledger[input_note_id] for input_note_id in transfer.inputs] input_pks = [note.public_key for note in input_notes] assert ZkSignature_verify(mantle_txhash, transfer_proof, input_pks)
Execution
Given
transfer: Transfer
transfer_proof: ZkSignature
ledger: Ledger
Execution
- Remove inputs from the ledger.
for note_id in transfer.inputs: # updates the merkle tree to zero out the leaf for this entry # and adds that leaf index to the list of unused leaves ledger.remove(note_id) - Add outputs to the ledger.
transfer_id = derive_operation_id(transfer) for (output_number, output_note) in enumerate(transfer.outputs): output_note_id = derive_note_id(transfer_id, output_number, output_note) ledger.add(output_note_id)
Example
alice_note_id = ... # assume Alice holds a note worth 501 tokens
bob_note=Note(
value=500
public_key=bob_pk,
)
transfer = Transfer(
inputs=[alice_note_id],
outputs=[bob_note],
)
Mantle Ledger
Notes
Notes are composed of two fields representing their value and their owner:
class Note:
value: TokenValue # u64
public_key: ZkPublicKey # 32 bytes
Note Id
A note can be uniquely identified by the Operation that created it and its output number: (op_id, output_number) if each Operation are uniquely identifiable. For this reason, every Operation that output notes have a unique payload that is used to derive the Operation identifier. Because it is often useful to have a commitment to the note fields for use in ZK proofs (e.g., for PoL), we included the note in the note identifier derivation.
def derive_op_id(operation: Op) -> Hash:
op_bytes = encode(op)
h = Hasher() # /!\ This is a classic hash not a ZkHash /!\
h.update(b"OPERATION_ID_V1")
h.update(op_bytes)
return h.digest()
def derive_note_id(op_id: Hash, output_number: int, note: Note) -> NoteId:
return zkhash(
FiniteField(b"NOTE_ID_V1", byte_order="little", modulus= p),
FiniteField(op_id, byte_order="little", modulus= p),
FiniteField(output_number, byte_order="little", modulus= p),
FiniteField(note.value, byte_order="little", modulus= p),
note.public_key
)
op_id is a classical 256-bit hash digest and must be reduced to a field element before being passed to the ZkHasher. We apply a direct modular reduction mod p (via FiniteField(..., modulus=p)). Since , the reduction is slightly non-uniform, values in appear one extra time, but this is inconsequential in practice: the collision probability remains around , and NoteId uniqueness is not derived from uniformity of op_id over but from the collision-resistance of the underlying hash and per-operation payload uniqueness.
These note identifiers uniquely define notes in the system and cannot be chosen by the user. Nodes maintain the set of notes through a dictionary mapping the NoteId to the note.
Locked notes
Locked notes are special notes in Mantle that serve as collateral for Service Declarations. A note can become locked after executing a Declare Operation, preventing it from being spent until explicitly released through a Withdraw Operation. The system maintains a mapping of locked note IDs to their supporting declarations. Though locked, these notes remain in the Ledger and can still participate in Proof of Stake. When service providers withdraw all their declarations, the associated note(s) become unlocked and available for spending again.
Appendix
Gas Determination
From the [Analysis] Gas Cost Determination, we get the table below:
| Constants | Value |
|---|---|
| EXECUTION_TRANSFER_GAS | 590 |
| EXECUTION_CHANNEL_INSCRIBE_GAS | 56 |
| EXECUTION_CHANNEL_CONFIG_GAS | 56 |
| EXECUTION_CHANNEL_DEPOSIT_GAS | 590 |
| EXECUTION_CHANNEL_WITHDRAW_GAS | 56 |
| EXECUTION_SDP_DECLARE_GAS | 646 |
| EXECUTION_SDP_WITHDRAW_GAS | 590 |
| EXECUTION_SDP_ACTIVE_GAS | 590 |
| EXECUTION_LEADER_CLAIM_GAS | 580 |
Zero Knowledge Signature Scheme (ZkSignature)
A proof attesting that for the following public values:
class ZkSignaturePublic:
public_keys: list[ZkPublicKey] # public keys signing the message (len = 32)
msg: zkhash # zkhash of the message
The prover knows a witness:
class ZkSignatureWitness:
# The list of secret keys used to signed the message
secret_keys: list[ZkSecretKey] # (len = 32)
Such that the following constraints hold:
- The number of secret keys is equal to the number of public keys.
assert len(secret_keys) == len(public_keys) - Each public key is derived from the corresponding secret key.
assert all( notes[i].public_key == zkhash( FiniteField(b"KDF", byte_order="little", modulus= p), secret_keys[i]) for i in range(len(public_keys)) ) - The proof is bound to msg (its the mantle_tx_hash in case of transactions).
For implementation, the ZkSignature circuit will take a maximum of 32 public keys as inputs. To prove ownership of fewer keys, the remaining inputs will be padded with the public key corresponding to the secret key 0 and ignored during execution. The outputs have no size limit since they are included in the hashed message.
Benchmark
The material used for the benchmarks is the following:
- CPU : 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM : 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS : Ubuntu 22.04.5 LTS
- Kernel : 6.8.0-59-generic
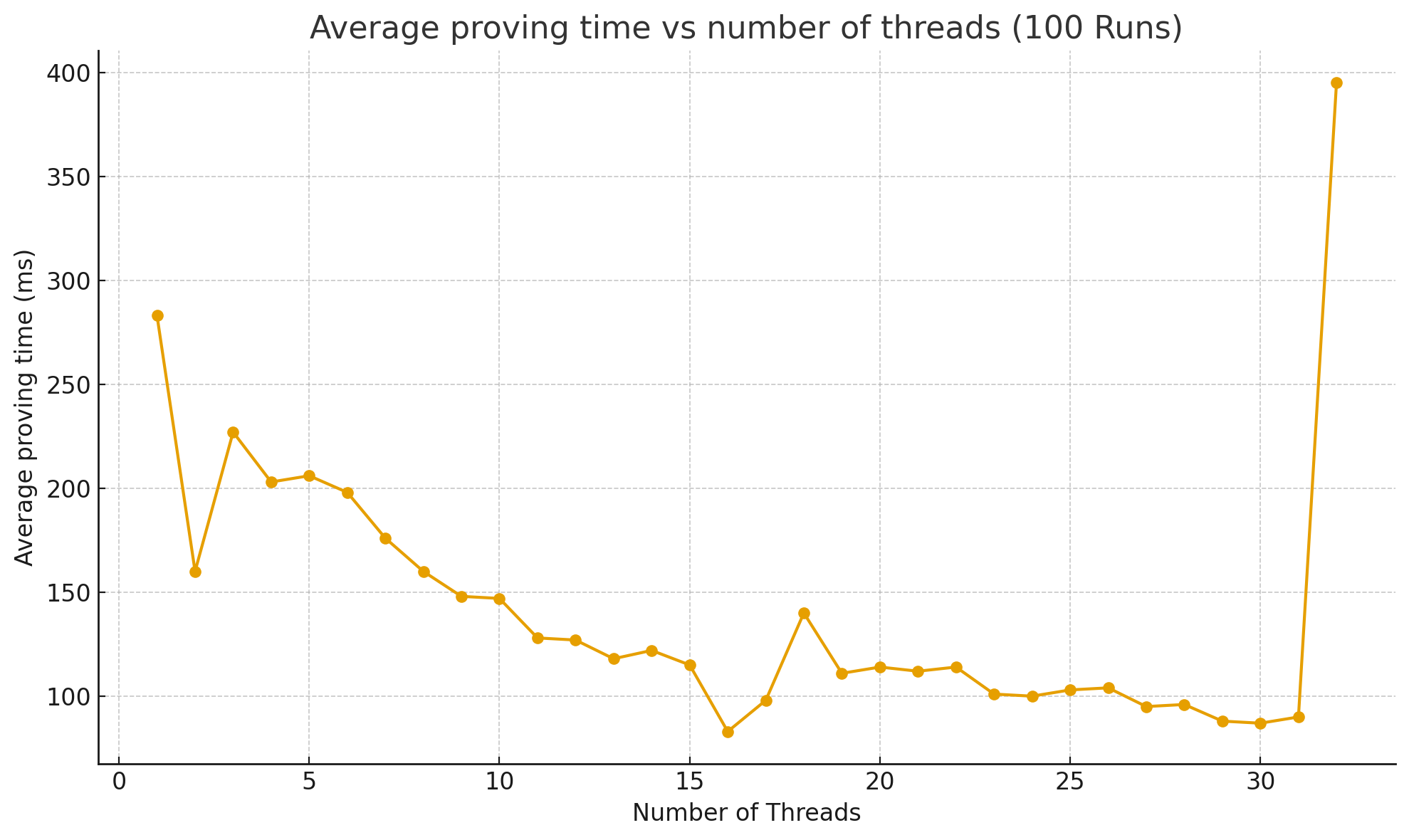
Proof of Claim
A proof attesting that given these public values:
class ProofOfClaimPublic:
voucher_root: zkhash # Merkle root of the reward_voucher maintained by everyone
voucher_nullifier: zkhash
mantle_tx_hash: zkhash # attached hash
The prover knows the following witness:
class ProofOfClaimWitness:
secret_voucher: zkhash
voucher_merkle_path: list[zkhash]
voucher_merkle_path_selectors: list[bool]
such that the following constraints hold:
- The reward voucher is derived from the secret voucher.
assert reward_voucher == zkhash( FiniteField(b"REWARD_VOUCHER", byte_order="little", modulus= p), secret_voucher) - There exists a valid Merkle path from the reward voucher as a leaf to the Merkle root.
assert voucher_root == path_root(leaf=reward_voucher, path=voucher_merkle_path, selectors=voucher_merkle_path_selectors) - The voucher nullifier is derived from the secret voucher correctly.
assert voucher_nullifier == zkhash( FiniteField(b"VOUCHER_NF", byte_order="little", modulus= p), secret_voucher) - The proof is bound to the mantle_tx_hash.
Benchmark
The material used for the benchmarks is the following:
- CPU : 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM : 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS : Ubuntu 22.04.5 LTS
- Kernel : 6.8.0-59-generic
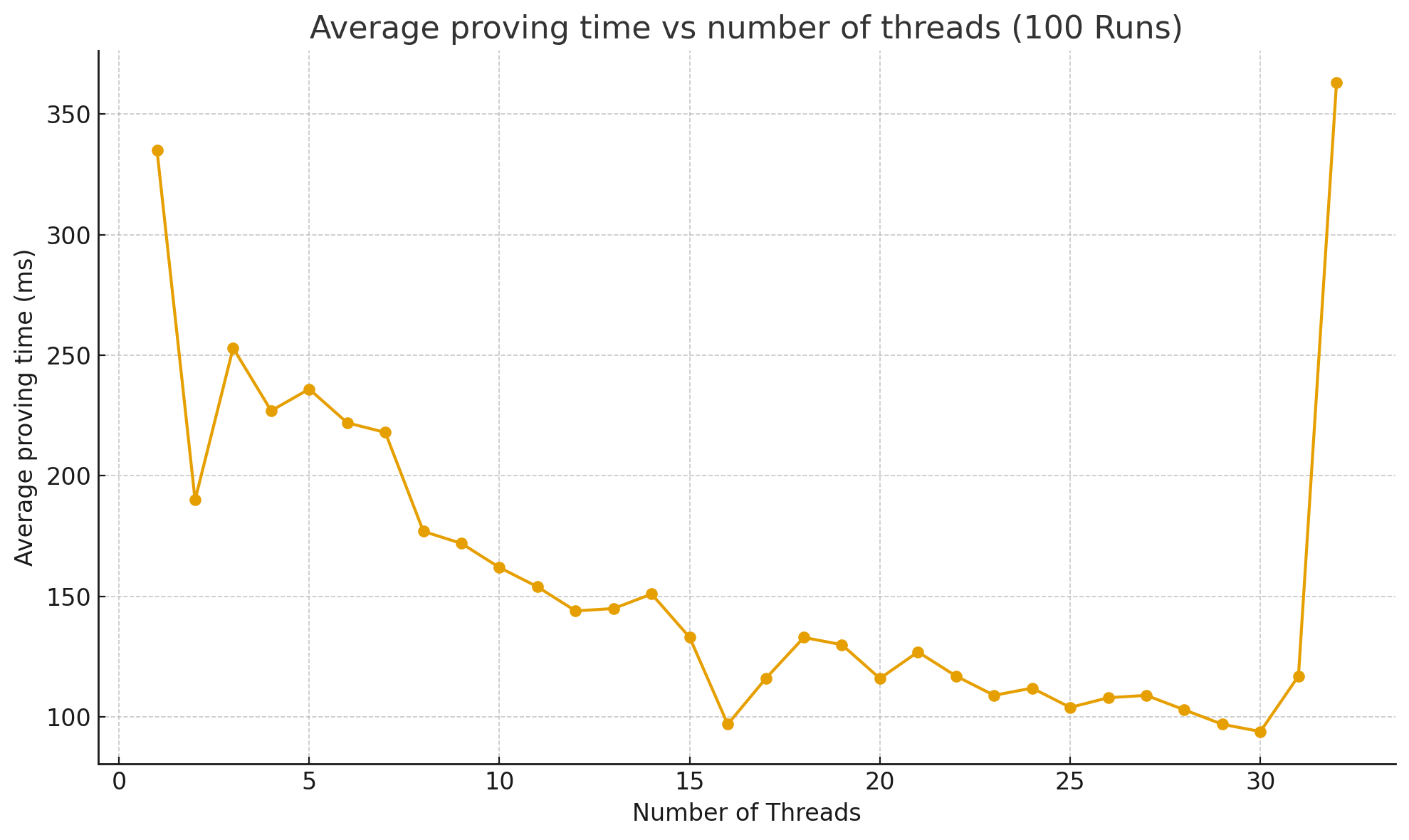
@Thomas Lavaur I think we should rename this to op_id_nonce probably? I missed this when doing review.
V1.4.0-ANALYSIS-GAS-COST-DETERMINATION
| Field | Value |
|---|---|
| Name | [Analysis] Gas Cost Determination |
| Slug | 234 |
| Status | deprecated |
| Type | RFC |
| Category | Informational |
| Editor | Thomas Lavaur [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Owner: @Thomas Lavaur
Reviewers: @Mehmet @Daniel Sanchez Quiros @David Rusu @Daniel Kashepava
Revisions History
| Version | Changes |
|---|---|
| v1 | Initial revision. |
| v1.2 | Removed DA, included Execution Gas determination for channel deposits and withdraws. Updated the Execution Gas of the Channel config. |
| v.1.3 | Added [RFC] Make Ledger Transaction an Operation. Renamed Nomos to Logos Blockchain |
| v1.4 | added [RFC] Enforce NoteId uniqueness |
Introduction
In Mantle, each Mantle Transaction contains one or more Operations. These components consume gas, measured through fixed gas units that reflect their execution or storage impact. Logos Blockchain introduces two independent gas markets:
- Execution Gas: measuring computational workload.
- Permanent Storage Gas: measuring cost of fully replicated storage.
Gas constants are carefully calibrated to reflect the computational and storage requirements of different operations on Logos Blockchain. By standardizing gas measurements, the system can accurately charge fees proportional to resource usage, preventing network abuse and incentivizing efficient transaction design.
Overview
We conducted a comprehensive analysis of execution requirements for each Operation type in Mantle Transactions. This detailed examination allowed us to determine precise gas amounts for each Operation based on the actual computational resources consumed.
The gas constants we established are strategically divided between permanent storage and execution components, directly proportional to their respective resource utilization within Mantle Transactions. This separation ensures that gas costs accurately reflect the true computational burden of different operations. Moreover, gas can also be adjusted arbitrarily to incentivize or disincentivize the usage of certain Operations compared to others.
Our methodology involved measuring execution complexity and defining how gas is determined for each Gas Market. This is critical for proper network operation as it directly impacts transaction prioritization and network economics.
Permanent Storage Gas
Permanent Storage is paid directly for the entire signed Mantle Transaction. The Permanent Storage Gas price is included in the Mantle Transaction structure and is used to determine the Permanent Storage fee. 1 Permanent Storage Gas corresponds to 1 byte.
permanent_storage_fee = len(encode(tx_signed)) * permanent_storage_gas_price
Execution Gas
Execution is a second general market that represents how costly an Operation is to execute. This cost can be fixed or variable based on the content of the Operation. The Execution Gas price is contained in the Mantle Transaction structure and each Operation defines its execution gas amount. 1 Execution Gas corresponds to 1,000 CPU cycles.
execution_fee = tx.ops.get_summed_gas() * execution_gas_price
The gas derivation of each Operation are:
TRANSFER_GAS = 590
CHANNEL_INSCRIBE_GAS = 56
CHANNEL_CONFIG_GAS = 56 * configuration_threshold
CHANNEL_DEPOSIT_GAS = 590
CHANNEL_WITHDRAW_GAS = 56 * withdraw_threshold
SDP_DECLARE_GAS = 646
SDP_WITHDRAW_GAS = 590
SDP_ACTIVE_GAS = 590
LEADER_CLAIM_GAS = 580
and come from our implementation observations as described in Gas determination from measures. To get these numbers, we based our calculations on the following measures:
| Operation | Number of CPU cycles |
|---|---|
| ZkSignature batch verification | 3,900,000 + number_of_proof x 590,000 |
| Proof of Claim batch verification | 2,640,000 + number_of_proof x 580,000 |
| Eddsa25519 signature verification | 56,000 |
Comparison, list searching, hashes and operation in small fields are neglected. We also supposed that the initialization cost for batch verification is paid by everyone and deduced from the block directly. The user then pay only for the part that is proportional to the number of proofs.
Transfer
The Execution Gas of the Transfer Operation compensates for the verification of the ZkSignature proof.
Execution: ~590k CPU cycles.
- Verification of the ZK signature: 590,000 cycles.
Input Gas
Input gas covers the computational cost of verifying that one Note Id exists in the Ledger and is not locked. Additionally, it compensates for the removal of one Note Id from the Ledger.
Execution: negligible.
- Verification that the note is in the ledger: negligible.
- Verification that the note is unlocked: negligible.
- Removing of the note from the ledger: negligible.
Output Gas
Output gas accounts for the computational resources required to verify that one output is well-formed and for its inclusion in the Ledger.
Execution: negligible.
- Verification of the output validity: negligible.
- Insertion of the note in the ledger: negligible.
- Derivation of the note identifiers: negligible
Operations
Channel Inscription
The validation process includes verifying an Eddsa25519 signature, confirming that the signer is authorized for the specified channel, and checking the chaining sequence of the channel. The execution encompasses creating channel records (if not previously used) and updating the tip of the channel.
Execution: ~56k CPU cycles.
- Verification of the Ed25519 signature: 56,000 cycles.
- Verification of the signer authorization: negligible.
- Verification of channel sequencing: negligible
- Update the channel state: negligible
Channel Deposit
The Execution Gas of the Channel Deposit Operation compensates for the verification of the ZkSignature proof and for the check of the inputs.
Execution: ~590k CPU cycles.
- Verification of the ZK signature: 590,000 cycles.
- Verification that the notes are in the ledger: negligible.
- Verification that the notes are unlocked: negligible.
- Increase of the channel balance: negligible
Channel Withdraw
The validation process requires verifying multiple Eddsa25519 signatures, and updating the balance of the channel. The execution require deriving note Id and adding notes to the ledger.
Execution: ~56k CPU cycles * withdraw_threshold.
- Verification of
withdraw_thresholdEd25519Signatures: 56,000 cycles per signature. - Decrease of the channel balance: negligible.
- Verification of the output validity: negligible.
- Insertion of the note in the ledger: negligible.
- Derivation of the note identifiers: negligible
Channel Config
This gas amount covers the verification of multiple Eddsa25519 signatures and ensures the operation is well-formed. This represents the computational cost associated with processing channel configuration operations.
- Execution: ~56k CPU cycles * configuration_threshold.
- Verification of the configuration_threshold Ed25519 signatures: 56,000 cycles per signature.
- Modification of the state of the channel: negligible.
SDP Declaration
This gas covers multiple verification processes: confirming ownership of the locked note through ZkSignature verification, validating the zk_id via a second ZkSignature, and establishing ownership of the provider_id through an Eddsa25519 signature. It also includes verification of the declaration format, confirmation of note existence, validation that the note is not already locked, and verification of its amount. Additionally, it accounts for the computational costs associated with the note locking mechanism and declaration management.
Execution: ~ 646k CPU cycles.
- Verification of the Ed25519 signature: 56,000 cycles.
- Verification of the ZK signature: 590,000 cycles.
- Verification that the declaration doesnt already exist: negligible.
- Verification of locator length: negligible.
- Verification of locked note existence: negligible.
- Verification of locked note value: negligible.
- Verification that the note isnt already locked for the service: negligible.
- Locking the note: negligible.
SDP Withdraw
This gas covers a verification process that includes: confirming ownership of the zk_id through ZkSignature verification, validating the existence of the locked note, verifying that the note has exceeded its lock period, and confirming that the declaration exists and has not been previously withdrawn. The validation process also ensures that the withdrawal message's nonce is greater than any previous nonce, preventing replay attacks. During execution, the system updates the declaration's status to withdrawn, removes the declaration from the locked note's associated declarations, andif the note has no remaining declarationsremoves it from the locked notes dictionary.
Execution: ~ 590k CPU cycles.
- Verification that the note exists, is locked and bound to the declaration: negligible.
- Verification that the note can be unlocked: negligible.
- Verification that the declaration exist: negligible.
- Verification of the ZK signature: 590,000 cycles.
- Verification that the declaration wasnt already withdrawn: negligible.
- Verification of nonce incrementation: negligible.
- Update declaration: negligible.
- Remove declaration from locked note: negligible.
- Unlock the note if not linked to any declaration: negligible.
SDP Activation
This gas funds the verification of the zk_id signature through the ZkSignature verification process, validates the existence of the declaration in the system, and ensures that the activation message's nonce is greater than any previous nonce to prevent replay attacks. The validation includes confirming that the declaration ID is present in the declarations dictionary and that the signature corresponds to the declaration's registered zk_id public key.
- Execution: ~590k CPU cycles.
- Verification that the declaration exist: negligible.
- Verification of nonce incrementation: negligible.
- Verification of the ZK signature: 590,000 cycles.
- Evaluation of the activity depends on the service and is neglected here
Leader Claims
This gas covers the verification of reward voucher ownership through a Proof of Claim, confirmation that the voucher nullifier is not already present in the nullifier set, and validation that the rewards root exists in the list of recent voucher Merkle tree roots. The execution process involves adding the voucher nullifier to the nullifier set and increasing the Mantle Transaction balance by the designated leader reward amount.
Execution: ~580k CPU cycles.
- Verification that the voucher nullifier isnt already in the set: negligible.
- Verification that the rewards root is one of the root of the reward tree of the last blocks: negligible.
- Verification of the proof of claim: 580,000 cycles.
- Insertion of the nullifier in the voucher nullifier set: negligible.
- Insertion of the note in the ledger: negligible.
- Derivation of the note identifiers: negligible
Annex
Gas determination from measures
The material used for the benchmarks is the following:
- CPU : 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM : 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS : Ubuntu 22.04.5 LTS
- Kernel : 6.8.0-59-generic
Eddsa Signature Verification
To get the numbers, we executed the test included in the official Rust implementation of the node.
Over 100 iterations, verifying an Eddsa25519 signature requires an average of 56,000 CPU cycles.
Proof of Claim
To get the numbers, we executed the test included in the official Rust implementation of the node.
We found the best linear curve approximating these measures (over 100 iterations):
| Number of Batches | Number of CPU cycles |
|---|---|
| 1 | 2,502,356 |
| 2 | 3,662,746 |
| 3 | 4,216,022 |
| 4 | 4,800,445 |
| 5 | 5,324,304 |
| 6 | 6,091,442 |
| 7 | 6,618,446 |
| 8 | 7,165,629 |
| 9 | 7,692,432 |
| 10 | 8,421,783 |
| 20 | 14,257,450 |
| 30 | 20,131,137 |
| 40 | 25,782,519 |
| 50 | 31,595,523 |
| 60 | 37,286,419 |
| Number of Batches | Number of CPU cycles |
|---|---|
| 70 | 42,901,298 |
| 80 | 48,309,912 |
| 90 | 54,191,072 |
| 100 | 61,082,050 |
| 110 | 66,927,817 |
| 120 | 73,758,494 |
| 130 | 78,816,789 |
| 140 | 84,801,250 |
| 150 | 91,693,824 |
| 160 | 94,248,613 |
| 170 | 99,430,138 |
| 180 | 105,607,812 |
| 190 | 112,379,089 |
| 200 | 116,599,001 |
We got the curve that we decided to approximate to :
ZkSignature
To get the numbers, we executed the test included in the official Rust implementation of the node.
We found the best linear curve approximating these measures (over 1000 iterations):
| Number of Batches | Number of CPU cycles |
|---|---|
| 1 | 4,126,177 |
| 2 | 4,904,084 |
| 3 | 5,538,085 |
| 4 | 6,061,800 |
| 5 | 6,957,754 |
| 6 | 7,421,851 |
| 7 | 8,237,485 |
| 8 | 8,621,986 |
| 9 | 9,115,091 |
| 10 | 10,186,171 |
| 20 | 15,777,800 |
| 30 | 21,456,771 |
| 40 | 27,441,722 |
| 50 | 33,430,729 |
| 60 | 38,986,389 |
| Number of Batches | Number of CPU cycles |
|---|---|
| 70 | 44,708,450 |
| 80 | 50,894,373 |
| 90 | 56,534,430 |
| 100 | 63,606,624 |
| 110 | 70,036,347 |
| 120 | 75,612,096 |
| 130 | 82,048,010 |
| 140 | 87,080,407 |
| 150 | 91,473,391 |
| 160 | 97,862,623 |
| 170 | 104,019,852 |
| 180 | 111,498,103 |
| 190 | 114,814,226 |
| 200 | 119,739,702 |
We got the curve that we decided to approximate to :
ANALYSIS-BLOCK-REWARD-PARAMETER-CALIBRATION
| Field | Value |
|---|---|
| Name | [Analysis] Block Reward Parameter Calibration |
| Slug | 184 |
| Status | raw |
| Category | Informational |
| Editor | Frederico Teixeira [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revisions History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-04-24 |
Disclaimer: This material, including any linked pages or documents, is provided for informational purposes only. It does not constitute investment advice, a solicitation, or an offer to buy or sell any securities, tokens, or other financial instruments, nor should it be construed as legal, financial, or tax advice.
All information regarding project details, token design, distribution mechanisms, technical parameters, and any forward-looking statements is preliminary and subject to change without notice. No representations or warranties are made as to the completeness or accuracy of the information herein.
Nothing in this material should be relied upon for investment or business decisions. Recipients of this information assume all risks associated with its use and are responsible for seeking independent professional advice regarding any actions based on it.
Introduction
This document explains the rationale behind the parameter values proposed in Block Rewards.
The block reward mechanism adjusts the protocol’s token emission rate based on on-chain signals such as the deviation of the inferred total stake from its target and the moving average of the fee-burning rate. The parameters calibrated here control how strongly the emission rate reacts to those signals, how quickly it transitions between regimes, and the bounds it must respect.
The goal of this calibration is to make incentives predictable and robust: provide sufficient security while the chain is below its target staking level, and converge toward a more stable long-run regime in which issuance is primarily constrained by fee burns rather than persistent inflation.
The Parameter
The normalized deviation from target, namely , is measured in percentage units.
The parameter , defined here, can be described as the “unit of emission rate per unit of target deviation”. This parameter should be defined based on the expected variance of the KPI with respect to the target.
For the sake of an example, let's set , , , and .
The figure below shows a KPI whose deviation around the target has a standard deviation .
Figure 2
As a consequence, the emission rate frequently reaches the maximum value.
Figure 3
Let's now consider a scenario where the volatility of the KPI deviation decreases to . The figure below shows an example (the difference in the signal oscillation with respect to Figure 2 is very subtle).

Figure 4
As a consequence, all else equal, the annualized token emission rate becomes considerably less volatile.
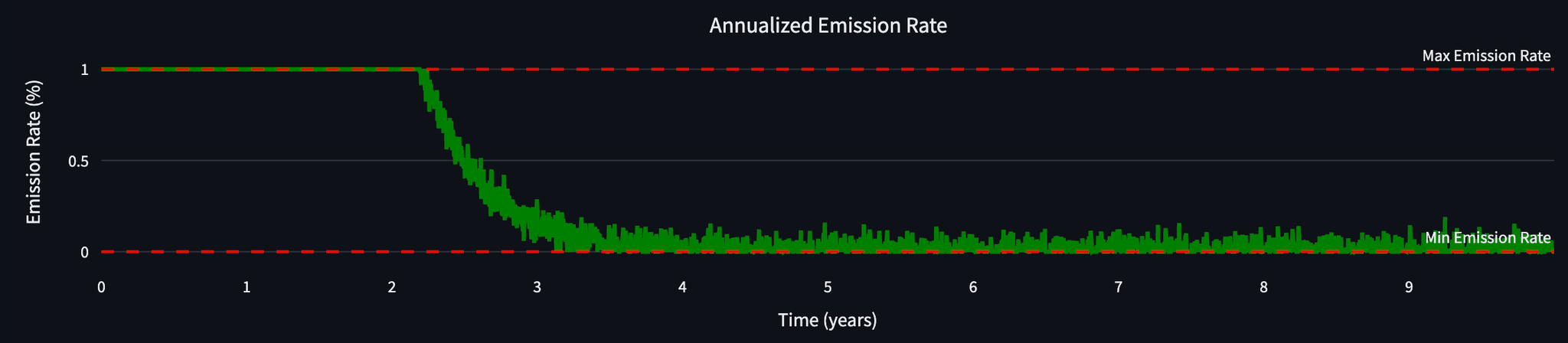
Figure 5
The parameter also controls the sensitivity of the normalized deviation from target () in the emission rate factor function ():
- If is too high, for example , a small value of turns to 1, so that the system stays in the maximum inflationary regime driven by , see equation (1).
- If is too low, for example , the system needs to be too much off-target to stay in the maximum inflationary regime driven by .
The parameter therefore allows for a smooth transition from the maximum inflationary regime (driven by ) to the stable regime (driven by the averaged burned fees).
The value is chosen so that when the total inferred stake is off target by (i.e. ), the system starts moving from the maximum inflationary regime to the regime driven by the burned fees. If , this means that this happens when the security level reaches .
The Parameter
The weighted average metric, namely , is measured in percentage units.
The parameter , defined here, can be described as the "unit of emission rate per unit of averaged KPI." This parameter should be defined based on the expected magnitude of the KPI.
For the sake of an example, let's set , , , and .
The figure below shows a KPI whose deviation around the target has a standard deviation of
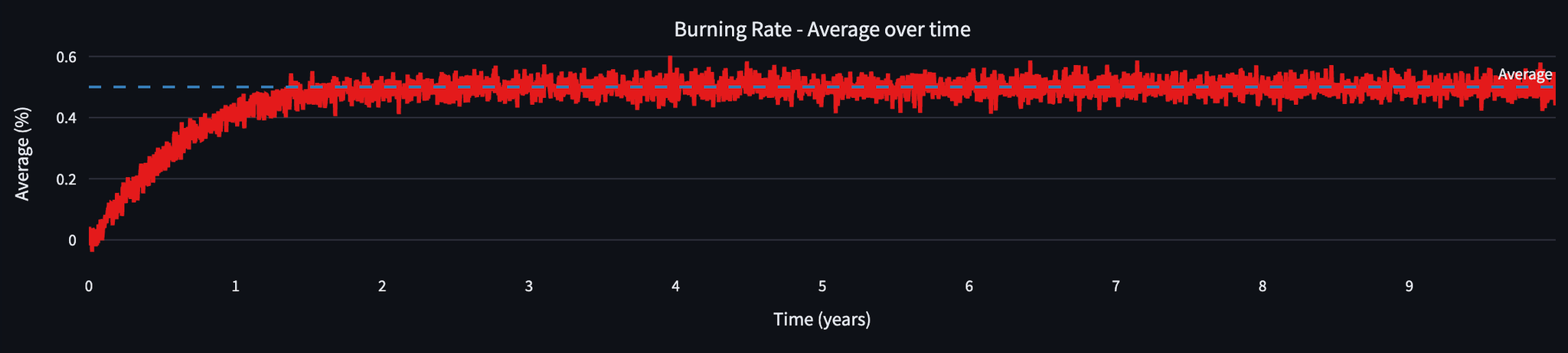
Figure 6
As a consequence of the parametrization, specifically , the emission rate never reaches the maximum value.
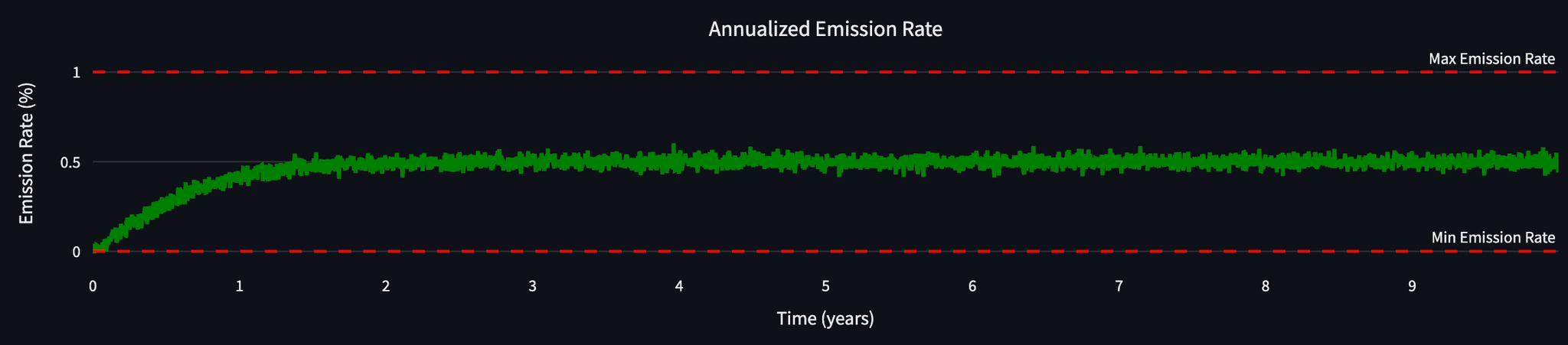
Figure 7
If we set , then the emission rate reaches the maximum value, but never surpasses it.
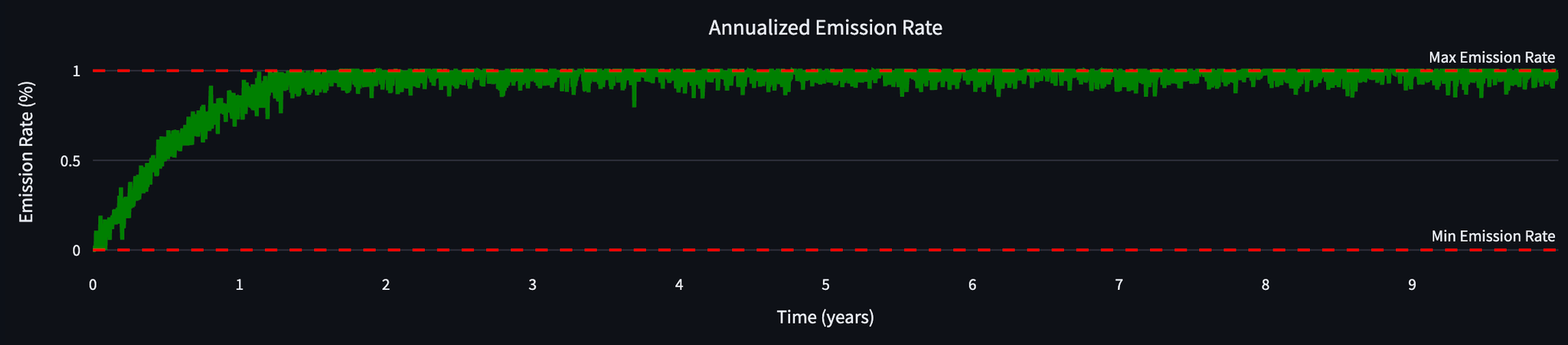
Figure 8
The Inferred Total Stake ()
This section explains the rationale for defining the target as of the TGE supply.
The TGE supply of the LGO token has to account for:
- The tokens disbursed as rewards to team, investors, ecosystem, etc. (subject to different vesting schemes),
- The security of the blockchain.
- Access to the blockchain utility.
The first allocation is fixed. The second and third should be balanced to ensure sufficient security while facilitating access to the blockchain utility.
Assuming a constant growth rate of the inferred total stake:
- if is too high, the inferred total stake will take longer to achieve the predefined target → resulting in more token inflation before the regime stabilizes around the burning rate.
- if is too low, the inferred total stake will take less time to achieve the predefined target → resulting in less token inflation before the regime stabilizes around the burning rate.
There is no closed formula for defining the appropriate . Our rationale was guided by observations from existing blockchains.
This website shows the PoS participation ratio of several blockchains. When examining chains that haven't defined a upfront, we observe a negative correlation between utility in the chain and staked amount (at the time of writing). This means that for Logos Blockchain, which aims to become a chain with utility, data suggests that a very high (e.g., ) is not recommended.
On the other hand, data also shows that many blockchains have their in the range of . Given that the proposed token emission mechanism is pegged to the deviation from the target, the decision to peg the system behavior to the lower end of this range is meant to stop token inflation sooner.
The Burning Rate Average Factor ()
As already described above, is taken to be equal to so that evaluates the annualized average burning rate with respect to the TGE supply. This makes the equation above consistent.
Maximum Emission Rate ()
The maximum emission rate caps only the number of tokens that will be minted per year by the block reward protocol. It is unrelated to the tokens that will be burned over the same period. The following information is available:
- The net inflation/deflation rate is the difference between the actual emission rate and the actual burning rate. By thinking in terms of , we consider the worst-case minting scenario.
- Various sources indicate that gold's inflation rate, defined as the total increase in supply compared to existing stock, ranges from per year.
- is the main variable that impacts the nodes' APY, while the inferred total stake is below the target security level.
- Analysis of other blockchain networks indicates that an emission rate is excessively high.
- A burning rate between is feasible for chains with very high demand.
If Logos Blockchain features similar issuance behavior as gold, when operating under an (net) inflationary regime, then the following conclusions can be reached:
- is too conservative. There is insufficient evidence to support such a recommendation.
- per year is moderate. Although spikes in the burn rate may make the system too deflationary and unpredictable, these are not expected to be common.
- per year is moderate, but risks overpaying for security. Logos Blockchain would need an average burning rate to achieve a reasonable net inflation rate (similar to gold). However, given the target security level of , this range would distribute to APY to nodes (see Table 1 below), which would currently place Logos Blockchain in the top (see Real Reward Rate here).
- per year is aggressive. Values above should be justified by very high expected usage of the blockchain, which would cause high burning rates. Given the cyclical behavior of economic activity, this may trigger hyperinflation.
Constraining to the range , the decision for is taken so that the rewards APY stabilizes around (see Table 1) as the inferred total stake approaches the target security level.
Minimum Emission Rate ()
The recommendation is . While has a slight inflationary bias and a slight deflationary bias, both need a strong argument to be defined. There is currently no evidence for .
ANALYSIS-BLOCK-REWARDS
| Field | Value |
|---|---|
| Name | [Analysis] Block Rewards |
| Slug | 185 |
| Status | raw |
| Category | Informational |
| Editor | Frederico Teixeira [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-29 —
67e498e— chore: fix math issues (#350) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revisions History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-04-24 |
Disclaimer: This material, including any linked pages or documents, is provided for informational purposes only. It does not constitute investment advice, a solicitation, or an offer to buy or sell any securities, tokens, or other financial instruments, nor should it be construed as legal, financial, or tax advice.
All information regarding project details, token design, distribution mechanisms, technical parameters, and any forward-looking statements is preliminary and subject to change without notice. No representations or warranties are made as to the completeness or accuracy of the information herein.
Nothing in this material should be relied upon for investment or business decisions. Recipients of this information assume all risks associated with its use and are responsible for seeking independent professional advice regarding any actions based on it.
Introduction
This document presents an analysis of Logos Blockchain's block rewards mechanism, with the goal of evaluating its sustainability, security guarantees, and long-term economic effects. Block rewards are a cornerstone of the protocols incentive model, ensuring that validators and service providers are compensated while the token supply remains predictable and stable.
Objectives
The analysis seeks to:
- Model how a KPI-based emission system behaves under different assumptions.
- Quantify the long-term supply curve and inflation path for LGO.
- Assess how quickly the system converges to equilibrium once network participation and fee burning stabilize.
- Identify risks related to delayed convergence, volatility, or adversarial manipulation of inputs.
Requirements & Rationale
The Logos Blockchain architecture introduces specific requirements that shape this analysis:
- All transaction fees are burned rather than distributed directly to block proposers.
- Rewards are based on global KPIs (inferred total stake, average burning rate) rather than local signals like per-block transactions, which are subject to manipulation.
- Privacy-preserving unlinkability between block proposers and reward recipients requires careful separation of reward timing and allocation.
By anchoring rewards to KPIs that reflect both security (stake) and demand (burning), the mechanism is designed to self-regulate issuance while preserving decentralization and censorship resistance.
Key Findings
Our simulations under baseline parameters indicate:
- The system begins with a maximum issuance of 1% annually, incentivizing early staking participation.
- As participation and burn rates converge to targets, issuance declines naturally, stabilizing the supply.
- Under baseline assumptions, total long-term inflation is ~1.33% over 10 years, a level broadly comparable to hard money benchmarks like gold.
- The design is robust to short-term volatility due to moving averages and bounded control functions, though delayed convergence of KPIs can temporarily maximize issuance.
Analysis
Supply Evolution
The token supply evolves according to:
where:
- denotes the token supply at Token Generation Event (TGE).
- denotes the maximum allowable token supply (hard cap), if any.
- is the emission rate factor on a per year basis.
- is the maximum emission rate per year.
- denotes the fraction of year in one time step per e.g., epoch, block, or day
It is assumed here that already accounts for the burned tokens. This equation implies that the supply evolution does not compound over time, meaning the amount of tokens minted at time is not proportional to .
Token Supply Curve (Baseline Simulation)
Assume the following parameters for the model:
- LGO (this allows us to understand the system behavior in terms)
- (1 day)
- (the number of 30 seconds intervals in 1 day)
- days (moving average is ignored)
In addition, we assume the following behavior of the system:
- The simulation runs for years.
- The volatility of the inferred total stake deviation is .
- The deviation between the inferred total stake and the target takes years to stabilize within . Note that this differs from the intrinsic convergence property of the inferred total stake algorithm that needs only one epoch to approximate the true value of the stake (see [Analysis] Total Stake Inference for further details).
- The burn rate converges to after years, with volatility .
The figure below shows the evolution of the inferred total stake deviation and the burn rate, given the parametrization above.
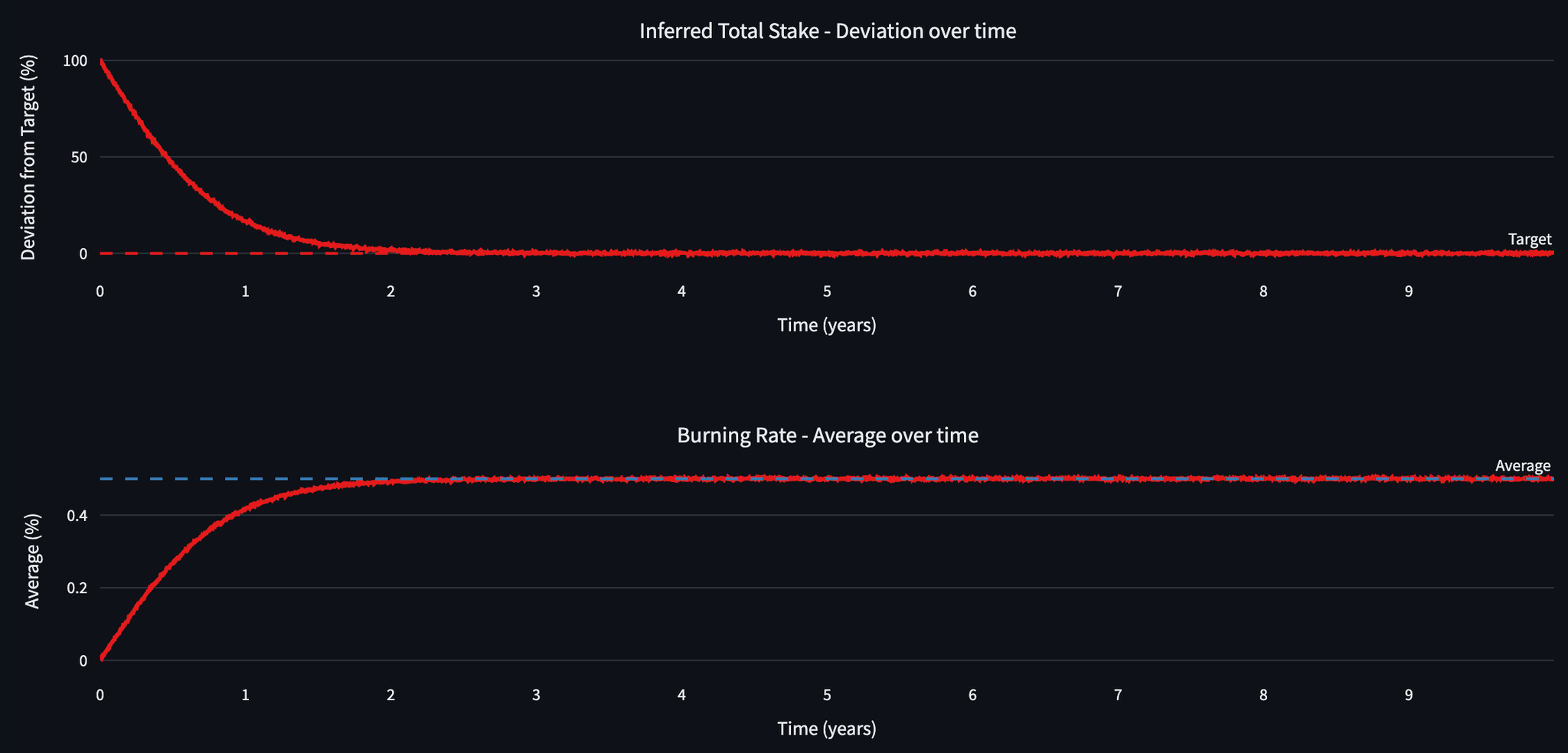
Figure 9: The convergence of the inferred total stake shown in this Figure regards the true value reaching the predefined target. This only happens when stakers increase their stake or more stakers join. This is a behavioral assumption.
The following figure shows the evolution of the annualized issuance rate:
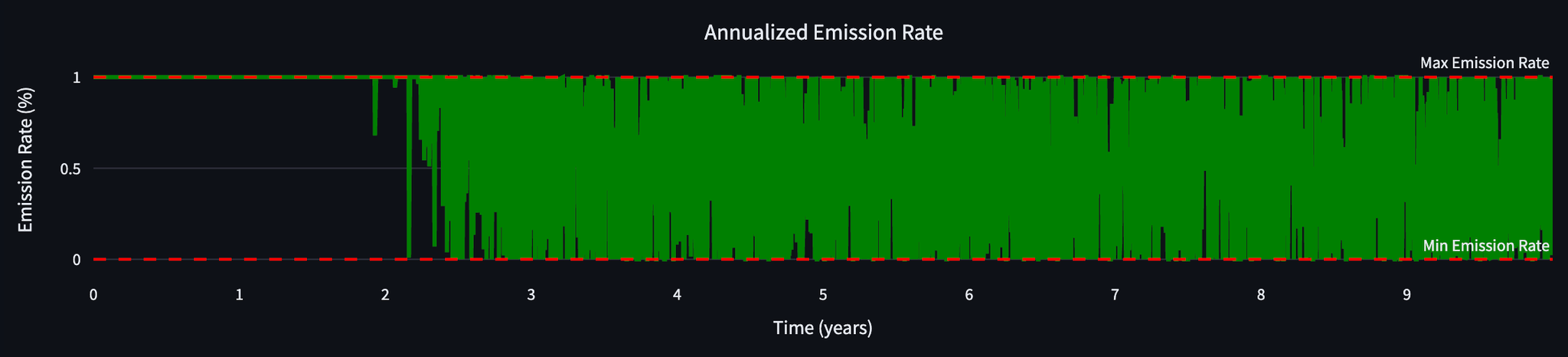
Figure 10
Finally, the figure below displays the token supply evolution.
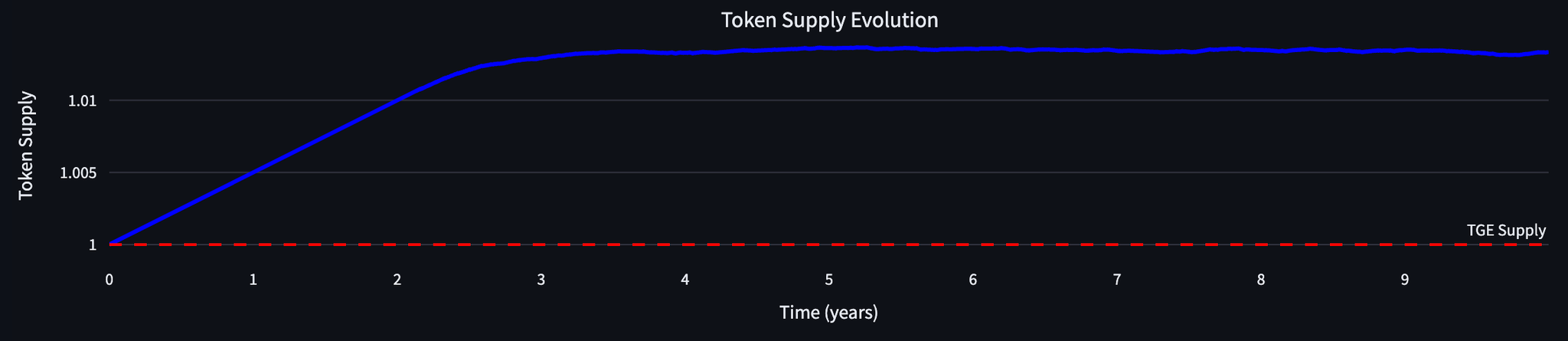
Figure 11
The final normalized token supply yielded by this specific parametrization is , which implies a total inflation of after years.
There are two strong assumptions in these results:
- It is assumed that both inferred total stake and average burn rate take years to converge to their respective target and expected values. The longer the time to convergence, the longer the emission rate is maximized, and the more tokens are minted.
- No shocks happen after the system enters the stable regime. Sudden changes in both of the KPIs might trigger token issuances near the boundaries of the interval .
Rewards APY Curve
Block rewards incentivize block production and Blend service. Nodes participation in PoS (leaders) set aside some form of stake and expect compensation for giving up the opportunity cost of participating. The block reward APY, compared against the size of the stake, is in theory the decisive factor in starting or continuing to provide the block proposal service.
In Logos Blockchain, the APY depends on the deviation from the inferred total stake if the target was not reached yet, and on the burning rate if the target was reached. Only the former can be calculated, as the latter depends on the utilization of the blockchain. Therefore, this section only evaluates the APY within the range .
The table below shows the average APY per level of total stake for each choice of and (expressed in terms of the ). The proposed parametrization is highlighted in orange.
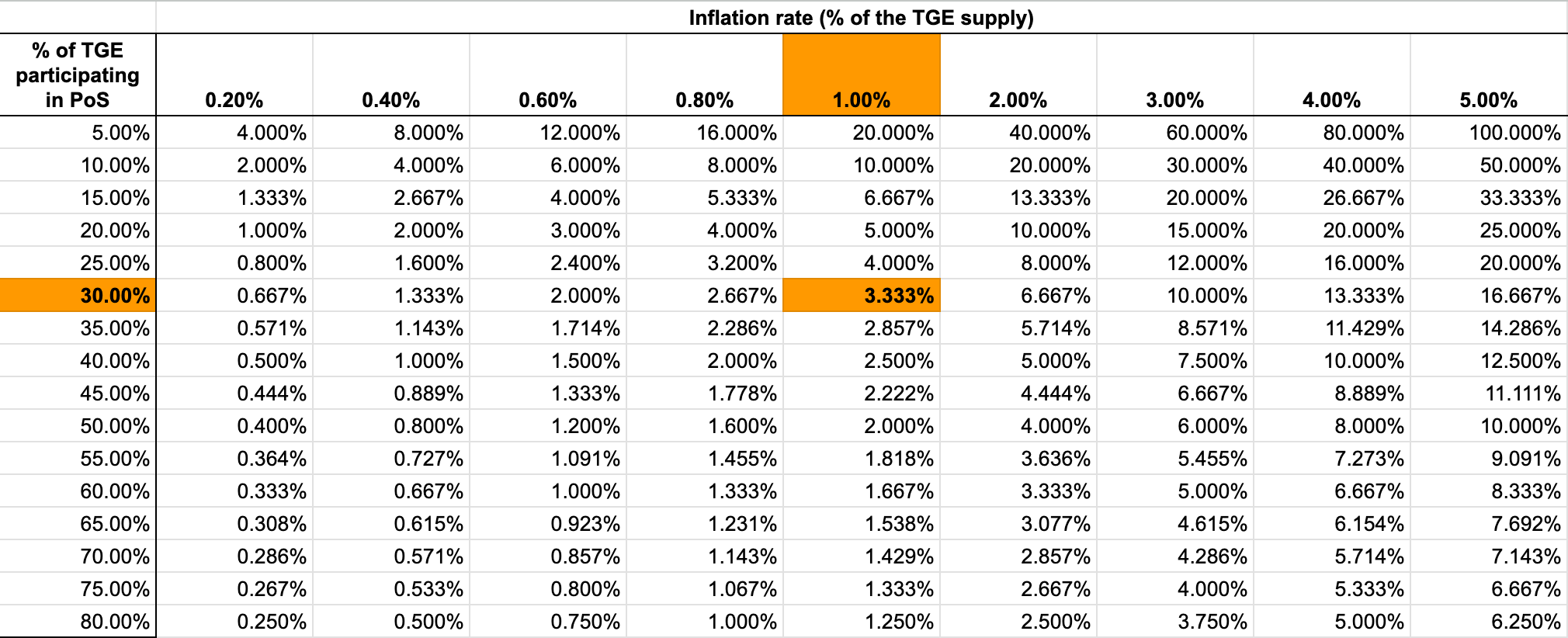
Table 1: Assuming and , the average APY decreases from to as the % of TGE supply participating in PoS increases from to .
Each entry of the table above is computed by:
The figure below zooms in on APY evolution of the proposed parametrization, as the inferred total stake approaches the target.
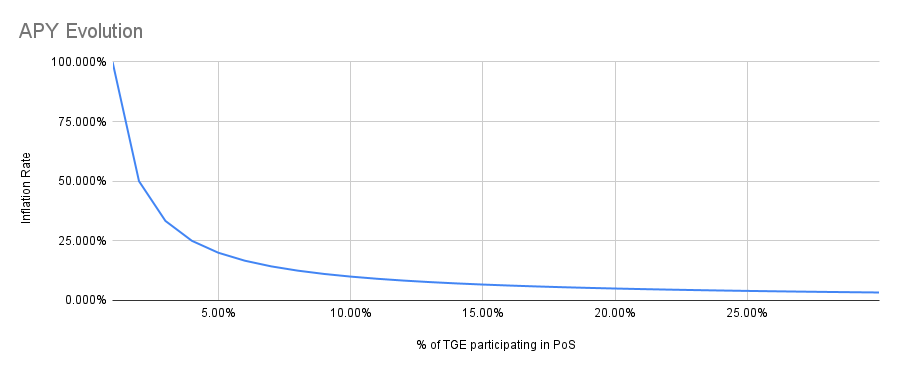
Figure 12:
The block reward APY starts at when only of the TGE supply participates in PoS. As more validators participate in PoS, the inferred total stake increases and the average APY decreases.
This APY dynamics achieves the following: the APY is high enough in the beginning to attract new validators, but quickly decreases to a sustainable level that can be maintained in the long term. If only of the TGE participates in PoS (half of the proposed target), the average is well within the value observed in other blockchains (source: Staking Rewards).
The issuance pegged to the inferred total stake incentivizes validators to participate until the rewards APY is small enough to become unattractive for newcomers. This dynamic creates a natural discovery processes, in which the APY is just enough for most validators. Logos Blockchain doesnt overpay or underpay.
This token issuance design should not impact stake variability, given that the token issuance rate is inversely proportional to the total stake. The reward per validator is proportional to the size of the validator's stake with respect to the total stake. The aggregation of validators into pools should more likely be a consequence of infrastructure requirements to run the blockchain rather than a consequence of the token issuance design.
Risk Considerations
The KPI-based emission rate depends on the KPI not being manipulated. Two actions can mitigate risks:
- Using a moving average value of the KPI, instead of its spot value this mitigates both true shocks and intentional gamification in the short term.
- Bounding all functions to prevent runaway inflation/deflation is capped, so that the worst case scenario () is controllable.
The Expected Outcome of Combining KPIs
According to the Equation (1) and KPIs definitions, controls the responsiveness of the emission rate to the deviation with respect to a target inferred total stake, while converts from annualized burn rate to annualized token emission rates.
For the sake of the following analysis, assume that . This allows to directly convert from KPIs to token emission rates.
The beginning of the blockchain has the following features:
- The burning rate, expressed by expected utilization of the blockchain, is expected to be well below .
- The deviation from the target inferred total stake is expected to be far above .
These two aspects imply that, at the beginning of the system, tokens are expected to be minted as block rewards at a rate of per year. The actual rate will be slightly below because some tokens will still be burned.
Given that:
- The burning rate can only approach from below (that is, it increases from to ).
- The current inferred total stake can only approach from above (that is, it decreases from to ),
The expected token issuance of per year should last at least until the inferred total stake deviates less than from the target.
As the inferred total stake deviation from the target approaches , the token issuance rate becomes driven by the annualized burning rate of Execution base fees and Permanent Storage fees.
At this stage, by the definition of the burning rate KPI, the total token supply is expected to stabilize, as the amount of burned tokens is expected to be minted again at a similar rate.
After certain level of usage, service providers are being overloaded but do not receive payment at the 1:1 ratio. This is done for a few reasons:
- This is equivalent to being paid in two different methods: actual LGO tokens (until is fulfilled) plus larger stake of the supply (which is decreased more than it is increased).
- In the beginning, when the network usage is very small and not many nodes participate in PoS, nodes are also paid at the maximum rate of .
If adoption grows and the burning rate exceeds , then the token supply becomes deflationary because the burning rate will be greater than the maximum allowed minting rate.
References
HackMDMinimum Viable Issuance - HackMD
Titania ResearchExploring Minimum Viable Issuance (MVI)
HackMDProperties of issuance level (part 1) - HackMD
Ethereum ResearchProperties of issuance level: consensus incentives and varia
Ethereum ResearchPractical endgame on issuance policy
Staking RewardsTop Proof of Stake Tokens | Staking Rewards
ANALYSIS-EXECUTION-MARKET
| Field | Value |
|---|---|
| Name | [Analysis] Execution Market |
| Slug | 190 |
| Status | raw |
| Category | Informational |
| Editor | Juan Pablo Madrigal-Cianci [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-29 —
67e498e— chore: fix math issues (#350) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revisions History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision | 2026-04-24 |
Disclaimer: This material, including any linked pages or documents, is provided for informational purposes only. It does not constitute investment advice, a solicitation, or an offer to buy or sell any securities, tokens, or other financial instruments, nor should it be construed as legal, financial, or tax advice.
All information regarding project details, token design, distribution mechanisms, technical parameters, and any forward-looking statements is preliminary and subject to change without notice. No representations or warranties are made as to the completeness or accuracy of the information herein.
Nothing in this material should be relied upon for investment or business decisions. Recipients of this information assume all risks associated with its use and are responsible for seeking independent professional advice regarding any actions based on it.
Introduction
We provide here a formal mathematical analysis of the execution market's fee mechanism. We model the system's dynamics to evaluate its equilibrium state, stability, and the economic impact of its unique features, particularly the block builder subsidy. We also refer the interested reader to Base Fee Manipulation In Ethereums EIP-1559 Transaction Fee Mechanism.
System Dynamics and Equilibrium
The state of the system evolves block-by-block, defined by two key variables: the base fee, , and the EMA of execution gas usage, . Their evolution is described by the following system of equations:
Here, we model the total Execution Gas used in a block, , as a function of the base fee, , where we assume a standard demand curve with (demand for Execution Gas decreases as the price increases).
The system is in equilibrium when its state variables no longer change. Let the equilibrium state be . From the base fee update rule (2), for , the adjustment factor must be zero. This implies:
From the EMA update rule (1), for , we must have:
Conclusion: Combining these results, the system reaches equilibrium when the execution gas demanded by the market at price is exactly equal to the protocol's target: . The equilibrium base fee, , is the market-clearing price that induces a level of network activity precisely equal to the desired target.
Base Fee Stability Analysis
Stability analysis determines if the system will naturally converge to the equilibrium state after a market shock. Due to the two-variable, cross-dependent nature of the system, we analyze the Jacobian matrix of the linearized system around the equilibrium point.
The system can be written as a function . The Jacobian matrix is:
Evaluating the partial derivatives at the equilibrium point yields:
The system is stable if and only if the eigenvalues of this matrix have a magnitude less than 1. While the full characteristic equation is complex, the analysis shows that stability is primarily dependent on the parameters , , and the price elasticity of demand, .
The introduction of the EMA smoothing factor significantly enhances stability compared to the classic EIP-1559 model (which is equivalent to setting ). The term acts as a damper, reducing the magnitude of the eigenvalues and making the system resilient to oscillations and divergence, even with highly elastic demand. This mathematical property is the foundation of the mechanism's resistance to base fee manipulation attacks.
User and block builder Incentive Analysis
User Strategy: A rational user has a private valuation for their transaction's inclusion, Their utility is . For the transaction to be valid, they must set their Execution Gas price . The user's problem is to choose to maximize their expected utility.
- Setting much higher than does not guarantee faster inclusion than setting it slightly higher; inclusion speed is determined by the priority fee relative to other users.
- The optimal strategy is to set such that it reflects their true marginal valuation per unit of execution gas, . They then pay (base fee) plus a competitive tip that they believe is sufficient for inclusion.
block builder Strategy: A rational block builder seeks to maximize their total block reward, (cf Block Rewards). Maximizing this sum is achieved by a greedy algorithm: sort all valid transactions by their revenue and include them in descending order until the block is full.
Conclusion: The subsidy mechanism, while critical for block builder revenue, does not distort the transaction selection incentive. The dominant strategy remains to prioritize transactions with the highest total tips, which aligns the block builder's interest with that of users who value inclusion the most.
References
- Blend Protocol - Rewarding
- StableFee https://pubsonline.informs.org/doi/abs/10.1287/mnsc.2023.4735
- Base Fee Manipulation In Ethereums EIP-1559 Transaction Fee Mechanism
- Transaction fees on a honeymoon
- Anonymous Leaders Reward Protocol
- [Overview] Cryptoeconomics
- EIP 1559: A transaction fee market proposal
ANALYSIS-STATIC-MINIMUM-STAKE-ESTIMATION-FOR-SERVICE-DECLARATION-PROTOCOL
| Field | Value |
|---|---|
| Name | [Analysis] Static Minimum Stake Estimation for Service Declaration Protocol |
| Slug | 196 |
| Status | raw |
| Category | Informational |
| Editor | Frederico Teixeira [email protected] |
| Contributors | Juan Pablo Madrigal-Cianci [email protected], Filip Dimitrijevic [email protected]. Marcin Pawlowski [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revisions History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-04-24 |
| 1.0.1 | [RFC] Remove Concept of a Session | 2026-06-22 |
Disclaimer: This material, including any linked pages or documents, is provided for informational purposes only. It does not constitute investment advice, a solicitation, or an offer to buy or sell any securities, tokens, or other financial instruments, nor should it be construed as legal, financial, or tax advice.
All information regarding project details, token design, distribution mechanisms, technical parameters, and any forward-looking statements is preliminary and subject to change without notice. No representations or warranties are made as to the completeness or accuracy of the information herein.
Nothing in this material should be relied upon for investment or business decisions. Recipients of this information assume all risks associated with its use and are responsible for seeking independent professional advice regarding any actions based on it.
Introduction
The Service Declaration Protocol enables nodes to register for specific services in decentralized public registries by committing a predefined stake. Registered nodes may then provide the declared service in exchange for rewards. The protocol uses staking as a mechanism to ensure Sybil resistance and incentivize honest participation.
This document aims to define an optimal minimum stake value per node in the context of the SDP. The optimal minimum stake value must strike a careful balance: it should be high enough to discourage sybil attacks while remaining low enough to ensure broad participation, especially in early network stages. Importantly, the protocol mandates a uniform, constant stake value across services and epochs, adding constraints to its determination. We focus on static stake estimation method due to its simplicity.
Given that Logos Blockchain is a pre-launch L1 blockchain with no on-chain economic data, we include an analysis that builds on comparative valuation research of privacy related chains (Monero, Zcash, Dash, Mina Protocol, Oasis Network, and Secret Network). The methodology includes:
- Estimating Logos Blockchain's Fully Diluted Valuation (FDV) using internal valuation models and comparable projects.
- Defining key variables influencing staking mechanics, such as token supply at TGE, staking ratio, and target number of service providers.
- Deriving a simple and transparent formula to calculate the required stake per service provider, both in LGO and stablecoins or fiat terms.
Overview
The SDP is a staking-based registration mechanism designed for decentralized services in the Logos Blockchain ecosystem. Its primary purpose is to assign nodes to public service registries by requiring them to lock a predefined amount of LGO tokens as stake. Only nodes who stake the required amount are allowed to offer the service they declare, thereby creating a natural filter that promotes honest behavior and sybil resistance.
This protocol is parameterized by a single stake value that is:
- Constant across all services and epochs, to ensure predictability and fairness.
- Calibrated to balance security and accessibility, based on Logos Blockchains economic assumptions.
Using the model specified below, the protocol ensures that the stake requirement scales proportionally with Logos Blockchains market valuation and design goals, while remaining robust to economic fluctuations.
Under the assumptions explained below, we define the minimum stake value in LGO as
Assuming a fully diluted valuation of million FIAT, and , then the minimum stake would be valued at
Construction
Generic Model
Let
- denote the maximum supply of LGO (e.g., 10 million LGO).
- denote the expected fully diluted valuation in FIAT (e.g., $100 million).
- denote the supply at token generation event (e.g., 1 million LGO).
- denote the market cap at TGE in FIAT:
- denote the Price per LGO in FIAT:
- denote the fraction of TGE supply expected to be staked by a service (e.g., 15%).
- denote the expected initial number of stakers (e.g., 1,000).
The following quantities are derived from the definitions above:
-
Total LGO to be staked:
-
Amount of stake per staker in LGO:
-
Amount of stake per staker in FIAT:
Staking Ratio ()
The Block Rewards proposes a 30% of TGE tokens as a target for the security of the PoS participation of Cryptarchia. This implies that it should not be possible for a single entity to acquire of TGE supply. Therefore, we set .
Number of Service Providers ()
A network size that is considered small has 1000 nodes. Therefore, .
Minimum Stake ()
The stake value for the Service Declaration Protocol (SDP) must satisfy the following requirements:
- The stake value for all services should be the same and remain constant across epochs.
- It should be high enough to prevent Sybil attacks, and low enough to ensure maximum participation.
Under the following conditions:
- While rewards are desirable, there is no guarantee that all services provide rewards.
- There is no cap to the amount of validators that can register to a specific service.
Therefore, the size of the stake should facilitate at least nodes to acquire at least of TGE supply. This implies the following cap to the stake value (per staker):
In order to lower even further any barriers to enter and promote decentralization, we set the minimum stake as:
Analysis
In what follows, this document defines Logos Blockchain valuation based on comparable projects, and then applies it to derive the minimal stake size in FIAT terms using the equation (1) above. FIAT, in this particular section, is USD.
Logos Blockchain Valuation ()
For a yet-to-be-released L1 blockchain, fundamental valuation is more challenging because there is no on-chain data (users, fees, transactions). Therefore, we will adopt a simple framework that compares Logos Blockchain with similar projects and assumes a valuation based on the mean or median of these comparable valuations.
| Project | Valuation | Last update | Remark |
|---|---|---|---|
| Monero (XMR) | $4.19B | Feb 2025 | Ring signatures, stealth addresses, confidential transactions Fully private transactions by default; resistance to ASIC mining. |
| Zcash (ZEC) | $534M | Feb 2025 | zk-SNARKs Optional transparency ("shielded" vs. "transparent" addresses). |
| Dash (DASH) | $309M | Feb 2025 | CoinJoin mixing (PrivateSend) Instant transactions (InstantSend); hybrid consensus (masternodes) |
| Mina Protocol | $356M | July 2024 | Recursive zk-SNARKs Constant-sized blockchain (22 KB); lightweight node participation. |
| Oasis Network | $246M | July 2024 | Trusted Execution Environments (TEEs) Privacy-preserving smart contracts; data tokenization for DeFi. |
| Secret Network | $62M | July 2024 | Encrypted contract states, secure MPC Private NFTs; encrypted data governance for decentralized apps. |
Given that the mean and median of the above valuations of already established projects are $949.5 million and $332.5 million, respectively, we establish Logos Blockchain valuation with a starting point of million.
Minimum Stake in FIAT Terms ()
For the sake of this analysis, suppose that
- million.
- LGO.
- LGO.
- .
From the Construction section,
(In the second row, and cancel each other because they are assumed to be equal.)
By plugging the numbers, and considering the above-mentioned assumptions, the single stake value for the SDP would be
which would be valued at
ANALYSIS-STORAGE-MARKET
| Field | Value |
|---|---|
| Name | [Analysis] Storage Market |
| Slug | 197 |
| Status | raw |
| Category | Informational |
| Editor | Juan Pablo Madrigal-Cianci [email protected] |
| Contributors | Frederico Teixeira [email protected], Filip Dimitrijevic [email protected], Marcin Pawlowski [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-29 —
67e498e— chore: fix math issues (#350) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision | 2026-04-24 |
| 1.0.1 | [RFC] Remove Concept of a Session | 2026-06-22 |
Disclaimer: This material, including any linked pages or documents, is provided for informational purposes only. It does not constitute investment advice, a solicitation, or an offer to buy or sell any securities, tokens, or other financial instruments, nor should it be construed as legal, financial, or tax advice.
All information regarding project details, token design, distribution mechanisms, technical parameters, and any forward-looking statements is preliminary and subject to change without notice. No representations or warranties are made as to the completeness or accuracy of the information herein.
Nothing in this material should be relied upon for investment or business decisions. Recipients of this information assume all risks associated with its use and are responsible for seeking independent professional advice regarding any actions based on it.
Introduction
This document provides a formal mathematical analysis of the proposed fee mechanism. We model the price update rule as a discrete-time dynamical system to evaluate its stability, long-term behaviour, and incentive properties rigorously.
System Dynamics and Equilibrium
Let's define the state of the system at the end of timeframe by the price and the usage EMA, . The core of the mechanism is the price update rule:
Where the adjustment is a function of the timeframe's usage, . For this analysis, let's assume usage is a function of the price, , where (demand decreases as price increases).
The system is in equilibrium when the price no longer changes between timeframes, i.e., . This occurs if and only if the clamped_adjustment term is zero. This condition implies:
where is the equilibrium price. The effective target itself depends on the usage EMA, which at equilibrium will have stabilized such that . Substituting this into the effective target equation:
Therefore, the equilibrium condition simplifies to:
Conclusion: The system is designed to reach equilibrium when the long-term average usage, dictated by the market's demand curve , equals the static, governance-set baseline target (note that by governance we refer to clients and protocol design, not on-chain governance). The equilibrium price is therefore the price that induces exactly Gas of usage from the market. This proves that the parameter acts as the effective long-term controller of network usage.
Price Stability Analysis
Stability determines whether the system will naturally converge to the equilibrium price after a shock. We can analyze this by examining how a small deviation from equilibrium evolves.
Let's consider the un-clamped adjustment for simplicity, as the clamping factor only serves to dampen the dynamics and enhance stability. The price update function is:
To analyze the stability around the equilibrium , we can linearize this system. Let's find the derivative of with respect to and evaluate it at . A system is stable if the absolute value of this derivative is less than 1.
At equilibrium, . The expression simplifies to:
The derivative of the effective target is . Substituting this in:
For stability, we require , which means:
Since (demand falls with price) and for reasonable parameter choices, the right-hand inequality is always satisfied. The left-hand inequality defines the stability condition:
The term on the left is the price elasticity of demand at equilibrium.
Conclusion: The system is guaranteed to be stable if the elasticity of demand is not excessively high (see the stability condition above), i.e., if the market is so sensitive that a small price increase to curb overuse causes a demand crash so severe that the system begins to oscillate uncontrollably. The parameters and directly contribute to stability; higher values (stronger anchor, faster EMA) relax the stability condition, making the system robust against a wider range of market behaviors. The clamping factor provides an additional, powerful guarantee of stability by bounding the adjustment step, ensuring that even under extreme demand shocks, the price cannot diverge uncontrollably.
If the stability condition wouldn’t hold, this just cause price to become more unpredictable. That said, we have the levers of , and to adjust should this be the case. Specifically, privdes a hard limit in the amount that these storage fees can increase and decrease by, hence reducing this unpredictability.
Long-Term Price Behavior Under Demand Shifts
Consider a permanent upward shift in demand, where a new demand curve replaces such that for all .
Immediately after the shift, usage will be consistently above the effective target. The price update rule will cause to increase in each timeframe. At the end of this first high-usage epoch, the protocol observes the overuse. This single event triggers two parallel responses:
- Usage will begin to decrease due to the higher price.
- The usage EMA, , will rise, pulling the effective target upwards.
This begins a "chasing" dynamic across subsequent epochs. As long as the new, higher demand persists, usage will likely remain above the (now rising) effective target. Each epoch's high usage continues to send the same two signals to the protocol: "increase the price" and "increase the EMA." The system will seek a new equilibrium price where . Since is constant, it must be that
The anchor weight is critical here. If (no anchor), the equilibrium condition becomes , which means the target would simply follow the demand, and the price would not effectively respond to the new normal. The non-zero anchor weight ensures the system always feels a "pull" back towards the governance-set target , forcing the price to adjust until usage realigns with this long-term policy goal.
Conclusion: The mechanism is proven to autonomously guide the market to a new, stable equilibrium price that respects the long-term usage target, even in the face of permanent shifts in market demand. It avoids the failure modes of purely static models (which would see chronic overuse) and purely adaptive models (which would normalize the new, higher usage level instead of controlling it).
OVERVIEW-CRYPTOECONOMICS
| Field | Value |
|---|---|
| Name | [Overview] Cryptoeconomics |
| Slug | 204 |
| Status | raw |
| Category | Informational |
| Editor | Thomas Lavaur [email protected] |
| Contributors | Marcin Pawlowski [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revisions History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-04-25 |
| 1.0.1 | [RFC] Remove Concept of a Session | 2026-06-22 |
Disclaimer: This material, including any linked pages or documents, is provided for informational purposes only. It does not constitute investment advice, a solicitation, or an offer to buy or sell any securities, tokens, or other financial instruments, nor should it be construed as legal, financial, or tax advice.
All information regarding project details, token design, distribution mechanisms, technical parameters, and any forward-looking statements is preliminary and subject to change without notice. No representations or warranties are made as to the completeness or accuracy of the information herein.
Nothing in this material should be relied upon for investment or business decisions. Recipients of this information assume all risks associated with its use and are responsible for seeking independent professional advice regarding any actions based on it.
Introduction
This document outlines the cryptoeconomic model for the Logos Blockchain protocol. The network features a balanced set of economic incentives designed to ensure security, optimize resources, and support sustainable growth.
The Logos Blockchain framework rests on three core mechanisms: a cryptoeconomic model that manages supply and distribution across actors, a fee market system that efficiently allocates network resources and regulates demand, and a rewards structure that incentivizes participation from various network contributors.
Logos Blockchain implements a three-part fee structure covering execution and permanent storage, each addressing specific aspects of network resource consumption. The reward system distinguishes between block-proposing leaders and service providers (like Blend), with mechanisms that preserve leaders privacy while maintaining economic efficiency.
In this document, we detail the mathematical models underlying these systems, explain the rationale for key parameter choices, and describe the participant behaviors these mechanisms are designed to encourage.
Overview
In this section we present an overview of the cryptoeconomical aspects of the Logos Blockchain protocol.
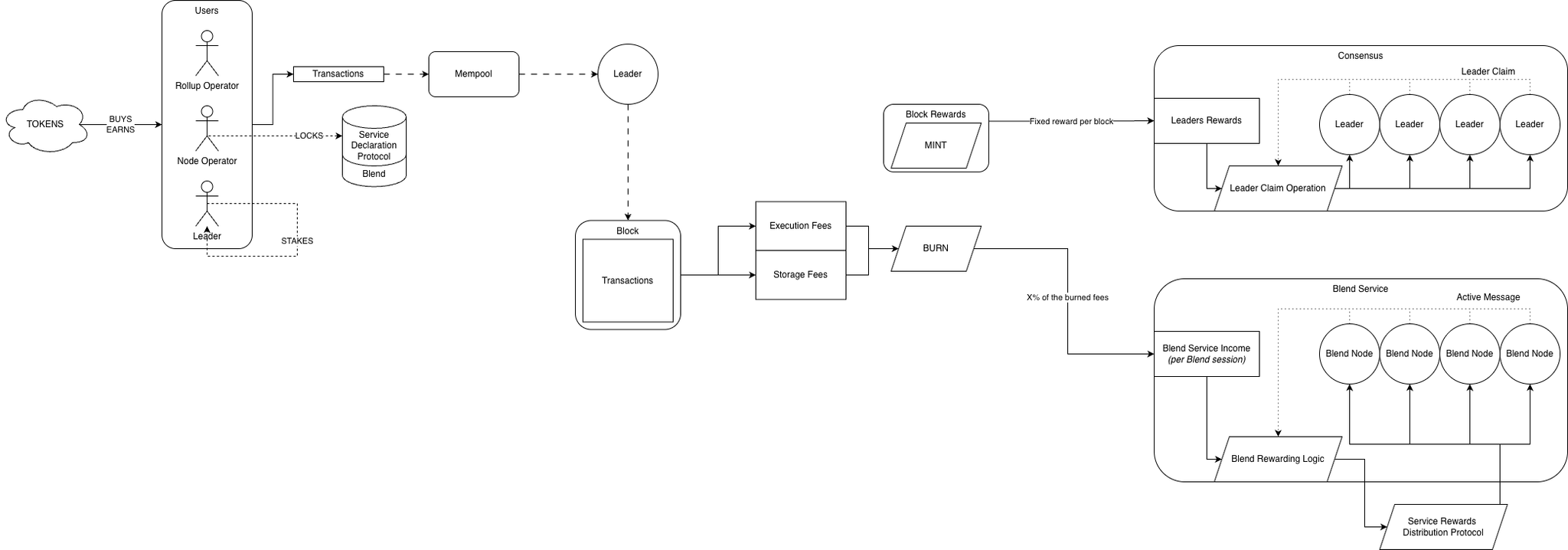
- Users (rollup sequencers, node operators, or leaders) acquire tokens through purchase or by earning them as rewards.
- Tokens serve three main purposes:
- Paying for transaction processing resources used: Fee Markets.
- Declaring service participation: node operators lock a Minimum Stake through the Service Declaration Protocol to become Blend Service providers.
- PoS Participation: leaders can propose (build) blocks by participating in a lottery where their chances of winning are proportional to their number of owned and unmoved tokens (aged tokens).
- Transactions may incur up to two types of fees:
- Execution fee: covers the computational resources consumed by the transaction.
- Permanent Storage fee: covers the permanent Ledger storage resources consumed by the transaction.
- All fees are burned for each block.
- Rewards are distributed on an epoch basis:
- Leaders (block proposers) include Mantle Transactions in every block. Each transaction pays Permanent Storage and Execution fees, which are burnt. For each block, a reward is calculated following the Block Rewards. Additionally, a portion of the Execution fees is minted back for leaders according to the Execution Market. These two sources determine the total rewards allocated to leaders, as explained in Blend Service and Consensus Leaders, which correspond to tips from the Execution market and 40% of block rewards. For anonymity reasons, block proposers don't receive rewards directly. Instead, leader rewards accumulate in a single pool that increases on an epoch basis rather than per block (see Anonymous Leaders Reward Protocol). When a new epoch begins, the pool increases by the total leader rewards from all blocks in the previous epoch. Simultaneously, leaders from the previous epoch can start claiming their rewards, with each unclaimed reward (since genesis) representing one equal share of the pool.
- Blend nodes provide Blend service to the network for at least one epoch. Using the same Block Rewards, the protocol determines the total rewards allocated to the Blend network, as explained in Blend Service and Consensus Leaders which correspond to 60% of the block rewards. When an epoch e ends, Blend validators have one additional epoch to send an active message used by the Reward Distribution Protocols to determine reward distribution among validators. During the first block of epoch , Blend validators from epoch receive their portion of Blend Service and Consensus Leaders rewards, with proportions determined by the Reward Distribution Protocols. These rewards are distributed at the start of the next epoch.
- The Service Rewards Distribution Protocol handles payments of rewards for Blend Services to individual nodes.
- Individual leaders claim their rewards through a Leader Claim Operation (on-chain transaction) that preserves privacy by separating the leader reward from the proposed block.
Constructions
Minimum Stake
To provide a service, a node must lock a minimum number of tokens to be considered valid. This stake is locked through the Service Declaration Protocol and can be withdrawn after the node stops providing the service. The minimum stake enhances economic security by increasing the cost of connecting to the network, which makes Sybil attacks more expensive. While the stake value must be sufficiently high for security, it also raises the barrier to network participation, potentially reducing decentralization. We therefore aim to balance security needs with decentralization goals. The [Analysis] Static Minimum Stake Estimation for Service Declaration Protocol defines the methodology on how to calculate the minimum stake value.
Gas
Mantle Transactions (see Mantle - Mantle Transaction) consume different types of Gas related to the various fee markets. Gas serves as a unit of measurement to quantify the computational or storage effort required to process a Ledger Transaction or an Operation. Gas is a unit of account that was introduced to normalize and facilitate the pricing of resources. Through the gas, the protocol is defining a way to measure computational demand for Operations and Ledge Transactions. The costs for these computational resources are defined by the leaders/nodes.
The two types of Gas are:
- Execution Gas (corresponding to 1,000 CPU cycles).
- Permanent Storage Gas (corresponding to 1 permanently stored byte).
In Logos Blockchain, Permanent Storage Gas is determined for an entire encoded Mantle Transaction. Execution Gas, however, is determined differently for each Operation and Ledger Transaction. For more details on how the Gas amounts were determined for each Operation, we invite the reader to read [Analysis] Gas Cost Determination.
Fee Markets
Users (rollup sequencers, node operators, or leaders) pay fees in Logos Blockchain for their Mantle Transactions to compensate for service usage. Logos Blockchain operates with two distinct fee markets. The goal of each market is to ensure fair compensation, sustainability, and proper incentives. However each market has its own unique characteristics:
- The Execution fee market covers the validation and execution of Mantle Transactions. The consensus does not directly limit the number of CPU cycles or Execution Gas per block but a fee regulating mechanism is necessary to be compliant with minimum hardware requirements of a node. The fees must regulate the use of CPU cycles for validation and execution of the blockchain.
- The Permanent Storage fee market covers the permanent storage of encoded Mantle Transactions. Blocks are limited to 1MiB with a maximum of 1024 Mantle Transactions per block. However, the fees must reduce the maximum amount of Storage to meet the minimum hardware requirements.
All fee markets aim to ensure fair compensation, sustainability, proper incentives, and to address specific market needs. Because every Operation (except the Channel Inscribe and the Channel Config Operations), whether it involves computation, or permanent storage, requires some execution to be validated and processed, reaching the execution limit effectively constrains the Permanent Storage market (except for Channel Inscribe and Channel Config). In practice, this means that the Permanent Storage market is limited in the number of transactions it can process per block except for Channel Inscribe and Channel Config Operations.
Execution Fee Market
Execution fees cover the validation and execution of Mantle Transactions. The protocol does not directly cap the number of CPU cycles per block, but fees must enforce an Execution Gas limit to ensure compliance with the minimum hardware requirements of a node. The execution limit () represents the maximum acceptable number of Execution Gas per block that a node with the minimum-specification CPU can process to validate and execute the block in a reasonable time.
We define "reasonable" as limiting the Execution Gas such that a potential leader can verify and execute it in 1 second using 80% (arbitrary) of its CPU (based on minimum CPU specifications in Hardware Requirements - Basic Bedrock Node (Validator)). This corresponds to a maximum of 3,200,000,000 CPU cycles for a leader, which converts to 3,200,000 Execution Gas. We require this 1-second verification for leaders to ensure they can quickly identify the correct chain and extend it with their own produced block in time when they are close to proposing a new block.
Consensus nodes must validate and execute a block using a small percentage of their CPU but during a longer period than the 1 second period for leaders, as they don't have the strict timing constraints that affect consensus and would increase forking. Using only 20% of their CPU, consensus nodes can validate and execute such blocks in approximately 4 seconds.
We will also assume that block verification requires an initial and fixed amount of Execution Gas for different ZK proofs. According to Block Construction, Validation and Execution, we will reduce the Execution Gas limit by 6,540 which is dedicated to initializing batch verification for ZkSignature and Proof of Claim.
Therefore, Execution Gas. This limit is also important to guarantee a rapid syncing of the chain.
Node CPU consumption is managed by the per-block Execution Gas limit. The Execution fee market dynamically adjusts fees based on usage relative to this limit: as consumption approaches the limit, fees rise to dampen demand; when consumption drops, fees decrease to encourage additional throughput. Since execution is the bottleneck, these adjustments indirectly bound the Permanent Storage market.
More details on the execution fee calculations can be found in Execution Market.
Permanent Storage Fee Market
Permanent Storage fees cover the permanent storage of Mantle Transactions. This market is subject to a strict maximum block size limit of 1MiB with a maximum of 1024 Mantle Transactions per block. While stored transactions consume execution resources, certain operations, such as Channel Inscribe or Channel Config, can consume only a limited amount of Execution Gas with no restriction on Permanent Storage consumption. This creates a corner case where a block could, in principle, be filled entirely with such Operations until the limit is reached. To prevent extensive usage of block space and to maintain predictability, Cryptarchia imposes a maximum block size limit of 1 MiB. This cap is a protocol parameter and is chosen such that it remains compatible with the storage limit defined below.
In the storage context, the minimum hardware requirement is expressed as the amount of data to be stored per year. Assuming ideal operation the network generates roughly 1 Terabyte of data per year, which can be seen as a technical limit.
The Permanent Storage fee market manages node storage resource consumption through the maximum block size limit. Fees are adjusted based on block space usage: when Permanent Storage Gas consumption rises, fees increase to discourage excessive usage; when Permanent Storage Gas usage drops, fees decrease to encourage more transactions. This dynamic pricing mechanism ensures efficient use of available block space.
More details on the Permanent Storage fee calculations can be found in Storage Markets.
Rewards Determination
The Logos Blockchain rewards structure is built on key principles that create a balanced and sustainable economic framework while ensuring network security and encouraging participation.
Our rewards system is guided by three core principles:
- Alignment of incentives: Rewards align all network participants' interests with the protocol's long-term health and success.
- Proportional compensation: Contributors earn rewards proportional to their resource contributions and risks.
- Sustainable economics: The model maintains economic sustainability without excessive inflation or security compromises.
The following sections explain how these principles apply to different roles in the Logos Blockchain ecosystem.
Blend Service and Consensus Leaders
The Blend service and the leaders proposing the blocks share a same block reward that is calculated for each block based on a KPI function. This KPI function takes as input the inferred total stake and the amount of Execution and Permanent Storage fees of the block. How the KPI function calculates each block reward is explained in Block Rewards.
- Blend rewards are distributed among all active Blend Nodes. Blend rewards are composed of a fraction of the block rewards. These rewards of epoch are defined when a new Blend epoch starts (a defined number of blocks) and are allocated to nodes based on their reported Active Messages and the Reward Distribution Protocols during epoch . The Service Reward Distribution Protocol manages the direct payment to nodes.
- Leaders get a voucher for each included block in epoch e. Vouchers represent an equal share of the leader reward pool. At the start of epoch e+1, the leaders rewards of epoch e are added to the pool (represented by a variable) and the voucher of epoch e can start being used. The amount added to the pool is composed of a fraction of the block rewards and a portion of the Execution fees minted back according to the Execution Market from all blocks of epoch e. Vouchers can be exchanged with a reward through a Leader Claim Operation (on-chain transaction) that preserves privacy by decoupling the leader reward from the proposed block. The reward amount, represented by a share of the pool, is computed when the claim Operation is executed (c.f. Anonymous Leaders Reward Protocol).
Each block reward of each block is split as follows between the Blend service and the leader:
- 40% for the leader.
- 60% for the Blend service.
The reasons for this split ratio are:
- Blend nodes must stake a minimum amount while leaders have no such requirement, making Blend nodes more exposed to risks.
- Blend nodes, having met the minimum stake requirement, are incentivized to run the validator protocol to earn greater rewards.
- Leaders who can afford the minimum stake are incentivized to lock it and run a Blend node to earn more rewards.
- Leaders who cannot afford the minimum stake can still earn enough to eventually reach it.
At the start of each Blend epoch, a Blend reward variable is computed. Its amount equals 60% of the total block rewards of the previous epoch:
def get_blend_reward(e: epoch): # rewards for the epoch e
blend_rewards = 0
for b in e.blocks: # for each block of the previous epoch
blend_rewards += 0.6 * get_block_rewards(b) # get 60% of the rewards
return blend_rewards
At the start of each epoch, the rewards are added to the leader rewards. Its amount is increased by 40% of the total block rewards of the previous epoch. The blocks from the previous epoch are denoted by B in the pseudocode below:
def update_leader_rewards(e: epoch, # rewards for the epoch e
leader_rewards: int): # added to the leader reward pool
for b in e.blocks: # for each block of the previous epoch
leader_rewards += 0.4 * get_block_rewards(b) # get 40% of the rewards
leader_rewards += get_execution_market_tips(b) # get Execution market tips
return leader_rewards
Reward Distribution Protocols
Anonymous Leaders Reward Protocol
To protect leaders' privacy, we must not link leaders to their blocks and rewards. Therefore, we designed a mechanism for anonymous reward claiming. A key design decision in this mechanism is that the amount of rewards a leader receives cannot be associated with or calculated based on the block they proposed. Without this approach, leaders could be linked back to their proposed blocks based on the value of their claimed rewards. This mechanism creates an anonymity pool where all leaders contribute, turning the leader-to-block assignment into a guessing game.
The Anonymous Leaders Reward Protocol defines how leader rewards are maintained in the ledger and how leaders can claim them. Leader rewards follow a two-step procedure:
- When a new epoch e starts, the unique reward pool variable for leaders is updated, increasing by the reward amount for the previous epoch e-1. This reward amount is calculated as the sum of leader block rewards from epoch e-1. Simultaneously, consensus nodes update the voucher set, adding vouchers of leaders from epoch e-1 to the global voucher set.
- From epoch e onward, leaders can exchange their vouchers for shares of the rewards pool, as their vouchers are now in the set. Each unclaimed voucher represents an equal share of the leader rewards pool.
Claimable rewards remain stable during an epoch because the reward pool decreases proportionally to the number of unclaimed vouchers, and the pool is neither increased nor are new vouchers added to the set during an epoch.
Blend Service
The Blend Protocol - Rewarding mechanism determines how Blend nodes receive compensation. Only active nodes qualify for rewards, with activity verification conducted through a probabilistic system that works as follows:
- During an epoch , nodes collect blending tokens embedded in processed messages.
- When epoch begins, the system generates a random target token. Nodes must submit their single blending token closest to this target as proof of activity.
- In epoch , rewards are distributed to all nodes whose tokens fall sufficiently close to the target, with additional bonuses for those achieving the closest matches.
The rewards for Blend are given to nodes on the basis of a lottery system where the winning chances are proportional to the work performed by the node. The Blend node receives a base reward for providing the basic service and a bonus reward for an extra work. Both are identical for all qualifying nodes in an epoch and are calculated by the Blend rewarding logic on the basis of the block rewards. For more details on block reward calculations, see Blend Service and Consensus Leaders.
Service Rewards Distribution Protocol
The Service Reward Distribution Protocol defines how service rewards are minted and inserted in the Ledger and how active service nodes receive their rewards. When a new service epoch starts, rewards for the previous epoch are calculated and directly inserted in the ledger. The reward amount is calculated as the sum of service block rewards from the previous epoch .
Further Details
In this section we provide references to the core specifications that define the mechanisms introduced throughout this document. Together, these specifications form the foundation of the Logos Blockchain cryptoeconomic model by detailing how fees are collected, how rewards are determined, and how incentives align across different roles in the network. Below is a short overview of each:
- Block Rewards. Outlines the KPI-based reward emission model that governs leader and Blend rewards. It details how token issuance adapts to network conditions using inferred stake and burn rates, ensuring sustainability, security, and deflationary pressure when demand is high.
- Execution Market. Describes the fee mechanism for execution resources, including the use of a dynamic base fee and priority tips. It explains how execution demand is smoothed over time, how fees are burned and later reminted as rewards, and how the system mitigates manipulation risks while maintaining predictable costs.
- Storage Markets. Defines the transaction fee mechanism for the Permanent Storage market. It introduces a timeframe-based model where prices are fixed during an epoch and adjusted smoothly between them, ensuring predictability for users while allowing the market to adapt to long-term trends.
These documents serve as complementary technical references, offering the deeper mathematical and procedural foundations that support the economic model described here.
On Execution vs Storage Markets
As a general overview, and to prepare the reader before embarking in the study of these documents, we will highlight here the conceptual differences between the Execution Market and the Storage Market, since they operate under distinct economic logics even though both rely on fee mechanisms:
- Execution Market Pricing is more reactive and adaptive, with the base fee updated every block using a smoothed demand signal. The system uses a dual-component fee structure: a protocol-defined base_fee and a priority_fee (tip) defined by the user setting the transaction's gas price. It is explicitly anchored to a target utilization (50% of gas limit, similar to EIP-1559) and a hard maximum gas per block, ensuring the network remains operable on minimal hardware. Both base and priority fees are initially burned, but the priority fee is later reminted back as part of leader rewardsproviding a clear, strategy-aligned mechanism for transaction inclusion and incentivization.
- Storage Markets Pricing is designed to be predictable and stable over a timeframe. Fees remain fixed within an epoch and are updated only at the transition to the next timeframe. This creates a single-component fee that is straightforward for users. While the mechanism has an anchoring point , it is not built around strict capacity limitsunlike execution. Instead, it prioritizes robustness and predictability, with parameters (such as the clipping factor) chosen to filter out volatility and keep pricing agnostic to short-term demand spikes.
Taken together, these distinctions show how the storage market emphasizes stability and medium-term predictability, while the execution market emphasizes responsiveness and short-term allocation efficiency, each addressing the unique constraints of their underlying resources.
BLOCK-REWARDS
| Field | Value |
|---|---|
| Name | Block Rewards |
| Slug | 199 |
| Status | raw |
| Category | Standards Track |
| Editor | Frederico Teixeira [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-29 —
67e498e— chore: fix math issues (#350) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revisions History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-04-24 |
Disclaimer: This material, including any linked pages or documents, is provided for informational purposes only. It does not constitute investment advice, a solicitation, or an offer to buy or sell any securities, tokens, or other financial instruments, nor should it be construed as legal, financial, or tax advice.
All information regarding project details, token design, distribution mechanisms, technical parameters, and any forward-looking statements is preliminary and subject to change without notice. No representations or warranties are made as to the completeness or accuracy of the information herein.
Nothing in this material should be relied upon for investment or business decisions. Recipients of this information assume all risks associated with its use and are responsible for seeking independent professional advice regarding any actions based on it.
Introduction
This document outlines the specifications for Logos Blockchain's block rewards mechanism, a critical component of the network's economic model. The mechanism is designed to create a sustainable economic framework that incentivizes network participation while maintaining long-term stability.
The objective is to develop a block rewards system that addresses key challenges specific to Logos Blockchain's architecture, including the unlinkability between block proposal and reward collection, and the inability to directly allocate transaction fees to specific block proposers. These constraints necessitate a carefully designed economic incentive structure.
Building on previous work in blockchain economics, this specification proposes a dynamic token emission system that calibrates LGO issuance according to network Key Performance Indicators (KPIs). The system uses two primary metrics: inferred total stake (as a security indicator) and average burning rate (to maintain supply equilibrium).
The document references internal mathematical models and simulations that demonstrate how the proposed mechanism would behave under various conditions. Key parameters include maximum annual emission rate (), control responsiveness factors, and target metrics for network security.
The conclusion of our analysis indicates that this KPI-based emission model should achieve several important outcomes:
- Initially higher emission rates (capped at annually) to bootstrap network participation.
- Gradual stabilization of token supply as the system matures, with our baseline simulation showing just total inflation after years.
- Self-regulating mechanism where token issuance naturally adjusts to compensate for burned transaction fees.
- Built-in safeguards against manipulation through moving averages and bounded functions.
This specification represents a comprehensive approach to creating a robust economic foundation for the Logos Blockchain network that balances security requirements with long-term economic sustainability.
Overview
The Logos Blockchain block rewards mechanism is a KPI-based dynamic token emission system designed to create a sustainable economic framework that incentivizes network participation while maintaining long-term stability. This section provides a high-level understanding of how the system works and its key components.
Key Principles
The design of the rewards system reflects three architectural constraints unique to Logos Blockchain:
- Unlinkability: Block proposal and reward collection are intentionally decoupled for privacy, meaning rewards cannot be assigned to a single proposer.
- Fee burning: All transaction fees (execution base fees and permanent storage fees) are burned, rather than directly given to block proposers.
- Global metrics over local signals: Rewards are computed from network-wide KPIs at block production time, rather than from easily manipulated per-block data.
These principles ensure that the system is censorship-resistant, manipulation-resistant, and aligned with long-term network incentives.
Requirements
Building upon the requirements for Logos Blockchain's block rewards system, the implementation will establish that all transaction fees are burned while block rewards are tied to measurable global metrics that reflect network health and security. This mechanism ensures that if network activity surges substantially, the accelerated burning of tokens will be balanced by compensatory emissions over time.
For optimal functionality, block rewards should be anchored to specific observable metrics rather than arbitrary values. Block numbers simply track time passage without indicating chain state. Transaction counts per block are vulnerable to manipulation. On the other hand, tracking the number of Blend nodes or inferring total stake provide more robust information about the chain state, specially when they can be compared with targets that are considered “healthy”.
Crucially, any metric-pegged reward system should aim toward a target value or equilibrium point, creating predictability and stability in the token economics.
High-level System Design
The system dynamically adjusts token emission based on two primary KPIs:
- Inferred Total Stake: Measures network security by tracking the total amount staked against a target threshold (e.g., of TGE supply).
- Average Burning Rate: Tracks transaction fees (both Execution base fees and Permanent Storage) burned to maintain supply equilibrium.
A control function combines these KPIs to determine the emission rate factor, bounded between a minimum and maximum annual issuance. This ensures that:
- When security participation is below target, higher issuance attracts more validators.
- As usage increases and fees are burned, emissions adjust downward to stabilize supply.

The equation that defines the amount of block rewards is given by:
where:
- is the emission rate factor on a per year basis.
- is the maximum emission rate per year.
- denotes the token supply at Token Generation Event (TGE).
- denotes the fraction of year in one time step per e.g., epoch, block, or day.
- be the average number of block proposal within units.
- denotes the total amount of Execution base fees and Permanent Storage fees that are burned when the block is proposed.
Lifecycle Phases
The system is designed to evolve through different phases:
- Bootstrap Phase: Initially higher emission rates (up to annually) to incentivize network participation when stake is below target. As it is explained below, this is viable even when Logos Blockchain experiences low activity because the level of activity only plays a role when the network participation gets close to the predefined target.
- Stabilization Phase: As Proof-of-Stake (PoS) participation approaches target levels, emission becomes primarily driven by burning rate.
- Equilibrium Phase: Supply stabilizes with issuance matching burned fees.
- High-Adoption Phase: If burning exceeds maximum emission, supply becomes deflationary.
Benefits
This KPI-based approach delivers several advantages:
- Self-regulating mechanism that automatically adjusts to network conditions.
- Long-term sustainability with projected total inflation of just after years (assuming constant burning rate of per year).
- Built-in safeguards against manipulation through moving averages and bounded functions.
- Predictable economic model that balances security incentives with controlled supply.
The overall design creates a robust economic foundation for the Logos Blockchain blockchain that effectively balances the need for strong security incentives with long-term token supply stability.
Construction
The proposed mechanism implements a dynamic token emission system that precisely calibrates LGO issuance according to network performance metrics (KPIs). This adaptive model adjusts emission rates based on how KPIs perform relative to their predetermined targets, while maintaining strict adherence to supply parameters and economic boundaries.
Core Variables
The following variables are input to the model:
- denotes the token supply at Token Generation Event (TGE).
- denotes the maximum allowable token supply (hard cap), if any.
- denotes the fraction of year in one time step per e.g., epoch, block, or day:
- if the time step is 1 day, then .
- if the time step is 1 block every seconds, then .
- if the time step is 1 epoch, which lasts 7.5 days, then .
- be the average number of block proposal within units:
- if the time step is 1 day and blocks are proposed every 30 seconds, then (the number of 30 seconds intervals in 1 day).
- if the time step is 1 epoch, which lasts 7.5 days, and blocks are processed every 30 seconds, then (the number of 30 seconds intervals in 7.5 day).
- is the minimum emission rate per year (default: ).
- is the maximum emission rate per year (default: ).
- denotes the target value for the -th KPI.
- denotes the weight of the -th KPI in the normalized deviation from target or in the normalized average; it satisfies .
- denotes the control responsiveness to KPI deviation metrics.
- denotes the control responsiveness to KPI average metrics.
- be the number of periods in the look-back window for the moving average.
Let us define the following variables:
- denotes the token circulating supply at time .
- denotes the emission rate factor on a per year basis.
- This implies that denotes the emission within the time-step.
- denotes the -th key performance indicator at time (e.g., TVL, staked amount, active users).
- denotes the total amount of Execution Gas and Permanent Storage fees burnt in a block. Refer to Execution Market and Storage Markets for how to compute .
Parametrization
| Symbol | Definition | Default Value | Explanation |
|---|---|---|---|
| | Token supply at TGE | 10 billion LGO | N.A. |
| | The number of periods in the look-back window for the moving average. | | As the system is expected to mint 1 block every 30 seconds, this look-back window defines that the minting averages the fees burned in the last hour. |
| | Denotes the control responsiveness to KPI average metrics. | | This parameter drives the token emission from the burn rate. It must be one-to-one. |
| | Denotes the control responsiveness to KPI deviation metrics. | | See [Analysis] Block Reward Parameter Calibration, for details. |
| | Denotes the weight of the -th KPI in the normalized deviation from target | | There's only one KPI of this type in our system. |
| | Denotes the target value for the first KPI based on stake. | 3 billion LOGOS | of the token supply. |
| | Denotes the target value for the second KPI based on fees. | billon LOGOS | In the context of this KPI, this value behaves as a normalizer |
| | The maximum emission rate per year | | This value guarantees that, when the total inferred stake reaches , then the APY for validation is ~3.33%. |
| | The minimum emission rate per year | | This avoids inflationary token emissions. |
| | The average number of block proposal within units | | The time step was chosen so that equals to . |
| | Time step, the fraction of year in one time step (per e.g., epoch, block, or day) | | The time step is 1 block every seconds; there are 2880 blocks of 30 seconds in a day. |
The calibration of these parameters can be found in [Analysis] Block Reward Parameter Calibration.
Block Rewards
The amount of tokens to be rewarded in a block depends on the emission rate factor . This controls how much is minted from inflation and how much is diverted from transaction fees. The following behavior is expected:
- When the aggregate KPI is far from the target, , then the emission of new tokens (inflation) is maximized, and most of the transaction fees aren't minted back. The amount of tokens burned does not impact the block rewards in this situation. This means that the system can burn more tokens than it mints.
- When the aggregate KPI is close to the target, , then the emission from inflation is minimized, and most of is minted back for leaders and Blend nodes.
That is, what drives the source of minting is the KPI: if far from the target, the system mints new tokens; if close to the target, the system mints exactly what was burned (up to of TGE).
The emission from inflation within the time step is given by
The actual amount of tokens minted per block (because of inflation) also depends on how many blocks are expected to be proposed between and . This is expressed by the factor , as defined above.
The equation that implements the behavior above in terms of is given by:
where:
- is the emission rate factor on a per year basis.
- is the maximum emission rate per year.
- denotes the token supply at Token Generation Event (TGE).
- denotes the fraction of year in one time step per e.g., epoch, block, or day.
- be the average number of block proposal within units.
- denotes the total amount of Execution base fees and Storage fees that are burned when the block is proposed.
def block_rewards(
S_tge:float,
emission_rate_factor:float,
I_max:float,
Delta_t:float,
f:float,
D_1_t: float
) -> float:
"""
Calculate the rewards per block.
It implements equation (1).
"""
emission_from_inflation = emission_rate_factor * I_max * S_tge * Delta_t / f
emission_from_rewards = (1. - emission_rate_factor) * R_block_cur
return emission_from_inflation + emission_from_rewards
Emission Rate Factor Function
The emission rate factor determines the portion of that should be emitted based on current values of and :
where
- controls the responsiveness to KPI deviation metrics.
- is measuring the KPI deviation from targets.
- controls the responsiveness to KPI average metrics.
- is measuring the KPI average values of over the last steps.
- is the minimum emission rate per year.
- is the maximum emission rate per year.
All terms are displayed in annualized form to ease comparison.
def calculate_emission_rate_factor(
alpha_dev:float,
weighted_target_deviation: float,
alpha_avg:float,
weighted_avg: float,
i_min: float = 0.0,
i_max: float = 0.01
) -> float:
"""It calculates the current emission rate factor"""
emission_rate:float = alpha_dev * weighted_target_deviation + alpha_avg * weighted_avg + i_min
emission_rate_factor:float = emission_rate / i_max
emission_rate_factor = min(1.0, max(emission_rate_factor, 0.0))
return emission_rate_factor
KPI Deviation from Target
The weighted deviation from target
def weighted_deviation_from_target(
kpi_weights: List[float],
kpi_deviations: List[float]
) -> float:
"""
Calculate the normalized deviation (delta_t).
Inputs:
* kpi_weights: constant list of floats
* kpi_deviations: for each KPI, it contains the results of "deviation_from_target"
Returns:
* a normalized annualized KPI in units of %.
"""
assert len(kpi_weights) == len(kpi_deviations)
weighted_target_deviation:float = 0.0
for deviation, weight in zip(kpi_deviations, kpi_weights):
weighted_target_deviation += weight * deviation value
return weighted_target_deviation
It implies that:
- → KPI below target → should increase the token emission by a factor of .
- → KPI at target → should not change the token emission.
- → KPI above target → should reduce the token emission by a factor of .
To measure the deviation, only the total estimated stake KPI is used in this part of the computation
KPI Average
The weighted average metric is defined as
where:
- The value can be any number with the same units of .
- The factor turns into an annualized quantity. This depends on the specific KPI.
def weighted_average(
kpi_weights: List[float],
kpi_average: List[float]
) -> float:
"""
Calculate the weighted average metric (gamma_t)
* kpi_weights: constant list of floats
* kpi_average: for each KPI, it contains the results of "average_kpi"
"""
assert len(kpi_weights) == len(kpi_deviations)
weighted_avg:float = 0.0
for avg, weight in zip(kpi_average, kpi_weights):
weighted_avg += weight * avg
return weighted_avg
The weighted average metric features:
- → should increase the token emission by a factor of .
- → should not change the token emission.
- → should reduce the token emission by a factor of .
To measure the average, only the average burning rate KPI is used in this part of the computation
Key Performance Indicator(s)
KPI 1 - The Inferred Total Stake
Given the privacy features of Logos Blockchain and the fact that the token TGE supply is known, the inferred total stake is the most appropriate indicator of the system's security.
Let:
- denotes the evolution of the inferred total stake.
- denotes the total stake that is considered secure. For the blockchain to be secure, we aim for of the TGE supply.
The inferred total stake affects the emission rate through the "normalized deviation from target." The deviation implied by this KPI is characterized by the plot below.
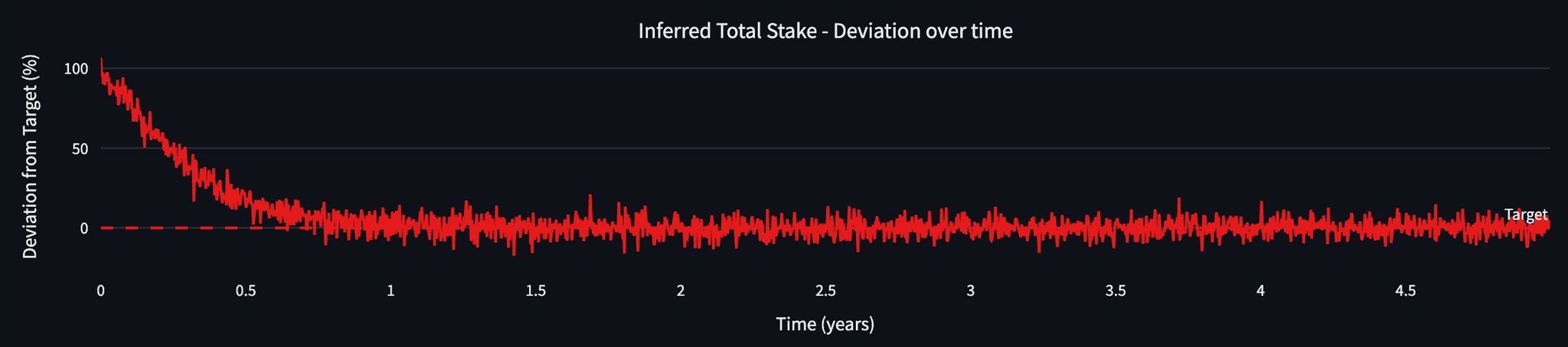
Figure 1
This happens because, when the blockchain starts, is very likely a small number compared to the target. Therefore, the equation above tilts towards (or ) at that moment. As time passes and more stake participates in the PoS, the difference between the current total stake and the target diminishes. The equation above oscillates around 0 (or ) when oscillates around .
Let the Logos Blockchain’s security level be defined by:
KPI 2 - The Average Burning Rate
In the long run, Logos Blockchain should mint only enough tokens to compensate for the burned transaction fees.
Let
- denote the amount of Storage fees and Execution base fees burned since .
- denote the "normalizing factor" (it is the TGE supply, in this case).
This choice of "target" implies that evaluates the annualized average burning rate with respect to the TGE supply. This makes the equation above consistent.
Float Precision for Implementation
Because block rewards affect consensus state, the implementation must be fully deterministic across all nodes. For that reason, the normative implementation of the reward function should not rely on floating-point arithmetic, machine-dependent rounding behavior, or comparisons against machine epsilon. Earlier sections use real-valued formulas to explain the mechanism and its economic meaning, but the consensus rule itself should be defined only in terms of integer arithmetic. This is especially important because the current document already notes floating-point concerns in the KPI helper functions and then introduces a final integer rewrite for the reward computation. The issue is therefore not whether integers should be used, but how to present that integer formulation in a way that remains auditable and clearly derived from the protocol parameters.
The goal of this section is not to change the reward mechanism. It is only to restate the already-specified mechanism in a canonical deterministic form with explicit named constants. In particular, the reward logic remains driven by the same two KPI components described previously: the inferred total stake relative to its target, and the moving average of burned fees over the look-back window. Likewise, the reward still interpolates between inflationary issuance and burned-fee compensation through the emission factor .
Because we have
and denotes the weight of the -th KPI in the normalized deviation from target or in the normalized average; it satisfies .
Therefore,
and
So we rewrite by
And by denoting
We can compute the block reward using only integers:
and
So:
So we propose a reference implementation that uses integers:
A_SCALE = 120_000_000 # denominator of 1/(I_max * D1_target * Delta_t * T)
INFLATION_NUMERATOR = 62_500 # numerator of I_max * S_TGE * DELTA_t / f
INFLATION_DENOMINATOR = 657 # denominator of I_max * S_TGE * DELTA_t / f
FEE_AVG_NUMERATOR = 10_512 # numerator of 1/(I_max * D1_target * Delta_t * T)
STAKE_TARGET = int(3e9)
def block_reward(total_stake: int, burned_fees_window: list[int]) -> tuple[int, int]:
sum_fees = sum(burned_fees_window)
last_burned_fee = burned_fees_window[-1]
a_numerator = min(
max(STAKE_TARGET + FEE_AVG_NUMERATOR * sum_fees - total_stake, 0),
A_SCALE
)
reward_numerator = INFLATION_NUMERATOR * a_numerator
+ INFLATION_DENOMINATOR * (A_SCALE - a_num) * last_burned_fee
reward_denominator = INFLATION_DENOMINATOR * A_SCALE
blend_reward = reward_numerator * 6 // (reward_denominator * 10)
leader_reward = reward_numerator * 4 // (reward_denominator * 10)
return blend_reward, leader_reward
EXECUTION-MARKET
| Field | Value |
|---|---|
| Name | Execution Market |
| Slug | 201 |
| Status | raw |
| Category | Standards Track |
| Editor | Juan Pablo Madrigal-Cianci [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-29 —
67e498e— chore: fix math issues (#350) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revisions History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision | 2026-04-24 |
Disclaimer: This material, including any linked pages or documents, is provided for informational purposes only. It does not constitute investment advice, a solicitation, or an offer to buy or sell any securities, tokens, or other financial instruments, nor should it be construed as legal, financial, or tax advice.
All information regarding project details, token design, distribution mechanisms, technical parameters, and any forward-looking statements is preliminary and subject to change without notice. No representations or warranties are made as to the completeness or accuracy of the information herein.
Nothing in this material should be relied upon for investment or business decisions. Recipients of this information assume all risks associated with its use and are responsible for seeking independent professional advice regarding any actions based on it.
Introduction
Objectives
This specification details the transaction fee mechanism (TFM) for the Logos Blockchain Execution Market, which encompasses the finite resources of on-chain computation. The design is engineered to achieve four primary, interconnected objectives:
- To implement a market that allocates execution resources to transactions that derive the highest economic value from it, ensuring the network's limited capacity is used to maximize total utility.
- To create an environment where the process of bidding for execution is intuitive and the transaction costs are predictable. This is paramount for fostering a healthy developer ecosystem and serving the professional entities that are the intended primary users of the Logos Blockchain network.
- To design a system of rules where the dominant, profit-maximizing strategy for all participants (users and block builders) is to behave honestly and in accordance with the protocol's intended function. This minimizes the potential for manipulative behaviors like transaction censorship or mempool gaming.
- To ensure that network usage contributes directly to the economic value of the native Logos Blockchain token, creating a positive feedback loop between network adoption and the health of its underlying asset.
Design Rationale
The design is founded on a target-based mechanism, philosophically aligned with Ethereum's EIP-1559. This model is crucial for long-term network health and security, as it actively steers execution utilization around a predefined target. This ensures the network remains performant and accessible for nodes with minimal hardware specifications, thereby promoting decentralization.
To further enhance security, this specification addresses a known vulnerability in the classic EIP-1559 design. As demonstrated by recent research (Cachin et al., 2023), EIP-1559 is susceptible to base fee manipulation by rational, non-myopic block builders. Our design incorporates a direct mitigation for this threat, as proposed in Cachin et al., 2023: an Exponential Moving Average (EMA) based update rule for the base fee. Given the EMA nature of this update, these enhancements smooth fluctuations in execution gas consumption, making the protocol significantly more resilient to strategic manipulation without compromising its core benefits of responsiveness and predictability
Furthermore, as opposed to the standard EIP-1559 mechanism, where base fee is burned and tips are immediately given to miners, in our setting we burn fees, and later, we mint rewards to which we add tips which are given to the block builders at a later block through the Anonymous Leaders Reward Protocol, for privacy preservation.
Overview
Our fee mechanism adapts Ethereum's EIP-1559 to the specific economic and security goals of the Logos Blockchain network. It provides predictable execution gas costs for users while creating a robust incentive structure for block builders and Blend nodes that minimizes harmful emergent strategies.
The mechanism operates on four core principles:
- Dynamic Base Fee: A protocol-defined base_fee for Execution Gas must be paid for a transaction to be included in a block. This fee adjusts automatically based on a smoothed average of recent network demand relative to a predefined capacity target, ensuring sustainable network load. This base_fee is the minimal threshold to be paid for the transaction to be accepted by the block builder.
- Priority Fee (Tip): To incentivize faster inclusion by block builders, users add a priority_fee on top of the base fee. This creates a simple and transparent auction for block space during periods of high demand. The proceeds of this goes to the block builder.
- Fee Splitting and Deflation: The two fee components are treated differently. The entire base_fee is burned, permanently removing it from the supply. This creates a direct link between network activity and the economic value of the native token, applying deflationary pressure as usage grows. The priority_fee is not immediately distributed to the block builder (to preserve privacy), but instead it is directed into the block builders reward stream. 40% of the rewards will be allocated to block builders and the remaining 60% to Blend nodes. Rewards are privacy-preserving via Anonymous Leaders Reward Protocol.
The entire lifecycle can be visualized in the following flow:

Incentive Analysis
- User Strategy: The mechanism promotes a straightforward bidding strategy. A rational user should set their execution_gas_price () to their true maximum willingness to pay. Setting it higher provides no advantage and risks overpayment, while setting it lower risks the transaction being delayed if the base_fee rises. The priority_fee acts as a simple tip to gauge the market rate for priority inclusion during congestion.
- Block Builder Strategy: The dominant strategy for a rational, profit-maximizing block builder is to follow the prescribed block construction algorithm honestly. The block builder's revenue is derived from (a) priority fees and (b) block rewards in accordance with network Key Performance Indicators (KPIs) as described in Block Rewards, which incentivize them to include the transactions that maximize their revenue. Because the base_fee is determined algorithmically based on historical data, a block builder cannot manipulate it for their own immediate gain.
Economic Properties
- Sustainable Resource Management: The TFM automatically steers network usage toward the target (). By increasing the cost of Execution Gas during high demand, the protocol prevents network overload. This protects the ability of nodes with modest hardware to participate, safeguarding decentralization.
- Deflationary Pressure: Burning the base_fee (and minting later a proportion of it back as rewards, cf Block Rewards) establishes a direct link between network activity and the intrinsic economic utility of the Logos Blockchain token. As usage grows, the rate of token burn increases, applying deflationary pressure on the total supply and creating a sustainable economic flywheel.
Security Properties: Mitigation of Base Fee Manipulation
A critical feature of this design is its resilience to the base fee manipulation attack identified in classic EIP-1559. Our EMA-based update rule directly mitigates this vulnerability in two ways:
- Impact Dampening: The influence of any single block's Execution Gas consumption (e.g., an empty block) on the fee update is dampened by a factor of (), preventing sharp, manipulative drops in the base_fee.
- Exponential Decay: The effect of a manipulative block on subsequent base_fee calculations decays exponentially, making it economically infeasible for an attacker to sustain the attack.
Construction
Notation
| Symbol | Name | Value | Description |
|---|---|---|---|
| Block Number | - | The index of a block in the chain. | |
| Transaction | - | A single transaction submitted by a user. | |
| Execution Gas Consumed | - | The actual amount of Execution Gas consumed by transaction upon execution. | |
| Execution Gas Price | - | The user-specified price per unit of execution gas they will pay. | |
| Base Fee | - | The protocol-defined Execution Gas price for inclusion in block . This is initialized at 1 for the first block. | |
| Priority Fee | - | The portion of the Execution Gas price that serves as a tip to the block builder (). | |
| Total Execution Gas Used | - | The sum of Execution Gas consumed by all transactions in block . | |
| Smoothed Average Execution Gas | - | The Exponential Moving Average (EMA) of Execution Gas used up to block . | |
| Max Execution Gas Per Block | 3,193,460 | A protocol constant defining the hard limit on . | |
| Target Execution Gas Per Block | 1,596,730 | A protocol constant for the ideal Execution Gas usage. The TFM steers usage towards this target. This is set to half of execution gas units. | |
| Fee Adjustment Rate | 1/8 | A protocol constant controlling how quickly the base fee adjusts to demand. | |
| EMA Smoothing Factor | 9/10 | A protocol constant defining the weight of historical average in the EMA update rule. | |
| Total fee | - | ||
| Amount of base fees burnt | - | This is used as an input to compute the block rewards |
Parameter Justification
We set , which results in up to a 12.5% increase or decrease in the fee at every block. This choice of parameter is made following empirical evidence on other protocols where it has worked sufficiently well, such as Ethereum (cf. EIP 1559: A transaction fee market proposal).
We set a value of as it robustly achieves the primary security goal of mitigating base fee manipulation while retaining sufficient market responsiveness. This setting heavily dampens the influence of any single block's gas usage on the new smoothed average to a mere 10%, making manipulation attacks prohibitively expensive for their limited impact. This is economically equivalent to a lookback period of approximately 19 blocks.
Furthermore, we set Execution Gas units (cf as explained in [Overview] Cryptoeconomics), and Execution Gas units. The 50% target creates a perfectly symmetrical buffer, giving the network equal capacity to elastically expand block sizes to absorb demand spikes or contract them during lulls. Any other value would create an asymmetric system, making it either too volatile and over-reactive to demand increases (e.g., a 75% target) or too sluggish to respond to periods of low activity. This rationale is also borrowed from Ethereums EIP-1559 (cf EIP 1559: A transaction fee market proposal) and is also used in (Base Fee Manipulation In Ethereums EIP-1559 Transaction Fee Mechanism).
Block Builder Mechanism: Block Construction
A rational, profit-maximizing block builder must follow this algorithm to construct a valid and optimal block .
Algorithm Steps:
- Fetch State: Retrieve the current base fee for the block to be built, .
- Filter Mempool: From the set of all available transactions , create a candidate set containing only valid transactions where the user's Execution Gas price cap is sufficient to pay the base fee.
- Sort Candidates: Sort the valid transactions in in descending order of revenue
- Greedy Inclusion: Initialize an empty block and a running total for Execution Gas used, current_block_gas = 0. Iterate through the sorted transactions and add them to the block one by one, as long as the block's total Execution Gas does not exceed the limit.
Pseudocode for Block Construction:
def construct_block(mempool, base_fee, gt, G_max):
# Step 2: Filter Mempool
valid_txs = [tx for tx in mempool if tx.execution_gas_price >= base_fee]
# Step 3: Sort Candidates by priority fee (descending)
valid_txs.sort(key=lambda tx: tx.revenue, reverse=True)
# Step 4: Greedy Inclusion
block_txs = []
current_block_gas = 0
for tx in valid_txs:
if current_block_gas + tx.gas_limit <= G_max:
block_txs.append(tx)
current_block_gas += tx.gas_limit # Using gas_limit for packing
return block_txs
On-Chain Rules: Fee Update and Revenue
After a block is executed and its total Execution Gas usage is known, the protocol deterministically applies the following rules.
Base Fee Update Rule
The base fee for the next block, , is calculated based on the state of block .
- Total Execution Gas Used: First, sum the actual Execution Gas consumed, , for all transactions in the block : .
- Smoothed Average Update: Update the EMA of Execution Gas usage: .
- Next Base Fee Calculation: Update the base fee for block : .
Pseudocode for Base Fee Update:
Because base fee computation affects consensus state, the implementation must be fully deterministic across all nodes. For that reason, the normative implementation of the reward function should not rely on floating-point arithmetic, machine-dependent rounding behavior, or comparisons against machine epsilon. Earlier sections use real-valued formulas to explain the mechanism and its economic meaning, but the consensus rule itself should be defined only in terms of integer arithmetic.
The goal of this section is not to change the execution mechanism. It is only to restate the already-specified mechanism in a canonical deterministic form with explicit named constants. Therefore we provide here a reference implementation that uses unsigned integers to have a common reference.
First we rewrite
And so we propose the following code reference:
EMA_DENOMINATOR = 10 # from q = 9/10
EMA_PREV_WEIGHT = 9 # from q = 9/10
BASE_FEE_NUMERATOR = 11_176_760 # = 7 * G_target
BASE_FEE_DENOMINATOR = 12_773_440 # = 8 * G_target
def update_g_avg_num(prev_g_avg_num: int, block_gas_used: int) -> int:
numerator = block_gas_used + EMA_PREV_WEIGHT * prev_g_avg_num
return numerator // EMA_DENOMINATOR
def update_base_fee(base_fee: int, g_avg: int) -> int:
numerator = base_fee * (BASE_FEE_NUMERATOR + g_avg)
return numerator // BASE_FEE_DENOMINATOR
Fee Distribution
For every transaction t, the effective priority fee is
The final fee paid by the transaction is:
Let the amount of Execution fee burnt in a block be:
This burned quantity is then used as a input for the computation of the block rewards, as described in Block Rewards.
STORAGE-MARKETS
| Field | Value |
|---|---|
| Name | Storage Markets |
| Slug | 205 |
| Status | raw |
| Category | Standards Track |
| Editor | Juan Pablo Madrigal-Cianci [email protected] |
| Contributors | Frederico Teixeira [email protected], Filip Dimitrijevic [email protected], Marcin Pawlowski [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-29 —
67e498e— chore: fix math issues (#350) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revisions History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-04-24 |
| 1.0.1 | [RFC] Remove Concept of a Session | 2026-06-22 |
Disclaimer: This material, including any linked pages or documents, is provided for informational purposes only. It does not constitute investment advice, a solicitation, or an offer to buy or sell any securities, tokens, or other financial instruments, nor should it be construed as legal, financial, or tax advice.
All information regarding project details, token design, distribution mechanisms, technical parameters, and any forward-looking statements is preliminary and subject to change without notice. No representations or warranties are made as to the completeness or accuracy of the information herein.
Nothing in this material should be relied upon for investment or business decisions. Recipients of this information assume all risks associated with its use and are responsible for seeking independent professional advice regarding any actions based on it.
Introduction
This document provides the formal specification for the fee collection mechanism of the Permanent Storage market. The primary objective is to define a system that is robust, predictable, and economically sustainable. This mechanism is a critical component of the overall Permanent Storage Market Transaction Fee Mechanism (TFM), which is designed as a self-contained, usage-driven market, economically decoupled from the protocol's core consensus and privacy services.
In what follows, Logos Blockchain Storage refers to the Permanent Storage markets and Logos Blockchain Storage Gas refers to the Permanent Storage Gas respectively.
Requirements and Rationale
The mechanism is designed with the following core requirements, derived from the project's goals:
- Predictability: Consumers of the Logos Blockchain Storage require a high degree of cost predictability for their own operational planning.
- Robustness: The mechanism must be able to adapt to significant, medium-term shifts in demand without requiring constant, emergency governance intervention.
- Fairness: The fee paid by a user must be directly and transparently proportional to the resources they consume.
- Simplicity: The on-chain implementation should be as simple as possible to minimize attack surface and ensure auditability.
Justification. As will be discussed later, the tradeoff between adaptability and predictability of the mechanism is determined by its parameters. In scenarios of high volatility, its core design principle is to act as a shock absorber, deliberately filtering out high-frequency, transient volatility by operating over longer timeframes and using a smoothed moving average (EMA). For the primary consumer, reacting to every momentary spike in demand would create untenable price chaos. This model, therefore, intentionally forgoes instantaneous adaptation in favor of providing crucial timeframe-level price certainty, ensuring that fees reflect meaningful, medium-term trends rather than reacting to volatile, short-term market noise.
Overview
The proposed fee mechanism operates on a simple but powerful principle: the price for Logos Blockchain Storage is fixed and predictable within a given timeframe (epoch for Permanent Storage), but it adjusts smoothly between timeframes based on observed network usage.
When a user submits data, a fee is calculated based on the Logos Blockchain Storage Gas consumption. This fee is determined by a price per Gas, , which is known in advance for the entire timeframe.
At the end of each timeframe, the protocol tallies the total amount of Logos Blockchain Storage Gas that was stored. It compares this actual usage to an adaptive targeta "healthy" usage level that is itself a dynamic blend of a long-term policy goal and recent historical usage. Based on whether the actual usage was above or below this target, the price for the next timeframe is adjusted slightly up or down.
This flow can be visualized as follows:

This model provides the best of both worlds: users have perfect price clarity for the duration of a timeframe, while the system as a whole can gracefully adapt to evolving market conditions over time.
Construction
This section defines the precise algorithm, constants, and state variables for the Logos Blockchain Storage TFM.
Core Fee Equation
The fee for a Logos Blockchain Storage transaction, , is a linear function of Logos Blockchain Storage Gas' size, , and the price-per-gas for the current timeframe, .
As a remark, the equation above assumes a linear increase of with respect to . For completeness, a more general version can be
with a monotonically increasing function. Making f sublinear can be understood as accounting for economies of scale, while making superlinear can be understood as a penalization for using larger data sizes. We decided to go with the linear form of as it was the least opinionated. Examples of this could be
Protocol Constants
To ensure on-chain efficiency, the protocol shall use an Exponential Moving Average (EMA) for its adaptive target calculation. The behavior of the TFM is governed by the following on-chain constants, which are set at genesis.
| Symbol | Name | Description | Initial Value | Justification |
|---|---|---|---|---|
| Baseline Target | A static, policy-driven usage target in Logos Blockchain Storage Gas per timeframe. Acts as a long-term gravitational anchor for the dynamic target. | 0 Permanent Storage Gas per block. | It should represent a conservative initial timeframe capacity. providing a healthy buffer and a clear policy goal. | |
| Anchor Weight | A coefficient in determining the influence of . It's the "gravity knob" for the system. | for Permanent Storage: 0 | Allows the target to be primarily driven by recent demand, ensuring adaptability, while the % pull from prevents long-term drift. | |
| Max Adjustment Factor | The maximum fractional amount the price can change per timeframe. Acts as "safety brakes" to bound price volatility. | 0.125 for Permanent Storage | A % cap provides strong predictability for users planning across timeframes while allowing the price to respond effectively to sustained demand changes. | |
| EMA Smoothing Factor | A coefficient in controlling the responsiveness of the usage EMA. It governs the speed of adaptation. | 0.5 for Permanent Storage | A value of gives significant weight to the most recent timeframe's usage while incorporating the "memory" of the system with a half-life of 1 timeframe, balancing responsiveness and stability. | |
| Initial Usage EMA | First value for EMA | 0 (=) | Given , this is the least opinionated choice: with no prior usage data at genesis, a neutral prior of zero makes no assumption about initial market activity and anchors the EMA to the long-term policy goal from the outset. | |
| Initial Price | The price on the first epoch | 1 LGO/gas | The initial price is set conservatively low at the beginning and let to discover the true market price | |
| timeframe | How often things adjust | 1 epoch | Primary users of the Storage market plan operational costs over days or weeks, not block-by-block. |
Parameter Justification
-
For simplicity, we set as an anchor and as blocks are already constrained by execution. This is to avoid imposing an opinionated choice of parameters, specially at the beginning of the protocol.
-
The EMA factor () makes the adaptive target highly sensitive to recent network activity by giving 50% weight to the latest epoch's usage, creating an effective "memory" of approximately 3 epochs.
-
The maximum adjustment factor () provides a crucial layer of predictability, guaranteeing users that the price cannot change by more than 12.5% between any two epochs, thus fulfilling a core design requirement for stable operational planning.
-
The seed value for the EMA is set to . Given , this is the least opinionated choice: with no prior usage data at genesis, a neutral prior of zero makes no assumption about initial market activity and anchors the EMA to the long-term policy goal from the outset.
Why is the index , not ? The price update algorithm runs at the end of timeframe and requires as its prior EMA value. When , the algorithm therefore requires as its seed. The value is already a well-defined computed quantity the EMA produced after the first epoch's observed usage: . Using index for the seed avoids a naming collision with this computed value. Implementation note. With and , the effective target will be zero during the first epoch unless . The reference implementation handles this correctly via the if effective_target == 0: return self.price guard, which holds the price at until the first non-zero usage epoch provides a meaningful signal. This is the intended behavior at genesis.
-
The precise value of is not critical to the long-term behavior of the mechanism. As established in the equilibrium analysis, the price update rule converges autonomously to the market-clearing price regardless of the starting point, provided the stability condition holds (see [Analysis] Storage Market - Price Stability Analysis). The only hard requirement is for to be sufficiently low so as not to suppress early adoption before the mechanism has observed enough demand to self-correct.
More precisely, since the price can increase by at most per epoch, the number of epochs required to reach a target price from an initial price is bounded above by .
For example, if is set to one tenth of the true equilibrium price, the mechanism reaches within at most epochs. Starting one hundredth below requires at most epochs. Both are negligible relative to the expected lifetime of the network. We therefore set .
This corresponds to a cost of 1 LGO per permanently stored byte. Genesis governance may adjust this value based on the LGO price at TGE, but the adjustment has no long-term consequence: the mechanism will converge to the true market price within epochs regardless.
-
The timeframe corresponds to one epoch. The core reason is that the primary users of the Storage market plan operational costs over days or weeks, not block-by-block. An epoch-length timeframe provides price certainty over hundreds of blocks, directly fulfilling the predictability requirement. It also ensures the EMA aggregates a meaningful volume of usage data before influencing the price, rather than reacting to per-block noise.
State Variables
The protocol must maintain the following state variables, updated at the end of each timeframe:
| Symbol | Name | Description |
|---|---|---|
| Price Per Logos Blockchain Storage Gas | The price per Gas of storage for the current timeframe . | |
| Usage EMA | The Exponential Moving Average of storage usage, updated with the usage from timeframe . |
Price Update Algorithm
At the conclusion of each timeframe , the protocol shall execute the following algorithm to determine the price for the next timeframe, . This is done as follows.
-
Tally Usage: Aggregate the total Logos Blockchain Storage Gas consumed during timeframe into a final value, , where corresponds to one block in timeframe and corresponds to the Logos Blockchain Storage Gas used by transaction .
-
Update Usage EMA: Update the Exponential Moving Average of usage:
-
Calculate Effective Target: Calculate the blended, effective target,
-
Calculate Adjustment Factor: Determine the fractional deviation of usage from the target and clamp the result to the range :
- Update Price: Calculate the price for the next timeframe, :
Implementation
Because computation affect consensus state, the implementation must be fully deterministic across all nodes. For that reason, the normative implementation of the reward function should not rely on floating-point arithmetic, machine-dependent rounding behavior, or comparisons against machine epsilon. Earlier sections use real-valued formulas to explain the mechanism and its economic meaning, but the consensus rule itself should be defined only in terms of integer arithmetic.
The goal of this section is not to change the execution mechanism. It is only to restate the already-specified mechanism in a canonical deterministic form with explicit named constants. To we provide here a reference implementation that uses unsigned integers to have a common reference.
First because we have , . Then because
Secondly, we can rewrite equation:
and so:
and so we can derive the following reference code:
EMA_DENOMINATOR = 2 # 1/beta
CLAMP_DENOMINATOR = 8 # denominator of 1+ alpha and 1-alpha
CLAMP_DOWN_NUMERATOR = 7 # numerator of 1-alpha
CLAMP_UP_NUMERATOR = 9 # numerator of 1+alpha
def update_usage(total_gas_consumed: int, previous_usage: int) -> int:
return (total_gas_consumed + previous_usage) // EMA_DENOMINATOR
def update_storage_price(prev_price: int, total_gas_consumed: int, usage: int) -> int:
if CLAMP_DENOMINATOR * total_gas_consumed <= CLAMP_DOWN_NUMERATOR * usage:
return prev_price * CLAMP_DOWN_NUMERATOR // CLAMP_DENOMINATOR
elif CLAMP_DENOMINATOR * total_gas_consumed >= CLAMP_UP_NUMERATOR * usage:
return prev_price * CLAMP_UP_NUMERATOR // CLAMP_DENOMINATOR
else:
return prev_price * total_gas_consumed // usage
def update_storage_fee(total_gas_consumed: int, prev_price: int, prev_usage: int) -> tuple[int, int]:
usage = update_usage(total_gas_consumed, prev_usage)
price = update_storage_price(prev_price, total_gas_consumed, usage)
return price, usage
Genesis State
The initial state of the TFM at network launch shall be configured as follows:
- Initial Price P_STR(0): Set to a pre-determined value established by genesis governance.
- Initial Usage EMA T_RA(-1): Set to the value of the baseline target, . This anchors the mechanism to its long-term policy goal from the outset.
ANALYSIS-ANONYMITY
| Field | Value |
|---|---|
| Name | [Analysis] Anonymity |
| Slug | 208 |
| Status | raw |
| Category | Informational |
| Editor | |
| Contributors | Alexander Mozeika [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-09-08 |
Introduction
In this document we consider anonymity properties of a network constructed from mix nodes. We assume that queueing systems of nodes in the network delay messages. This delay is a random variable from the Geometric distribution. Furthermore, we assume that an adversary is able to observe communication links, but can not distinguish between message. Also a fraction of nodes can be corrupted by adversary but in a static and passive manner.
First, we consider a single (uncorrupted) node observed by an adversary. For this scenario we show that the temporal order of two messages which arrived at the node is preserved, with some probability, when they leave the node. We show that the probability is achieved for a large (average) delay per message and a small difference between the arrival times of messages. For prob. the temporal order of outgoing messages is unbiased and random, and hence adversary does not have advantage over the random guessing.
Second, we consider two (uncorrupted) nodes sending messages, through the path of (uncorrupted) mix nodes, to the receiver node which is corrupted by adversary. We also assume that the adversary is able to observe only communication links connecting sender nodes to the first mix node. Here in this more complicated set up, we show that the probability of preserving temporal order of messages can be , i.e adversary does not have advantage over random guessing.
Analysis
Single node
-
Let us assume that messages and arrived, respectively, at a node at the time and , where . Assuming that the message was delayed by , where is random variable from the Geometric distribution , we have message leaving the node at time .
-
We are interested in the probability , i.e. the probability that the order of two messages arrived at the node is preserved. The latter, for the (rescaled) time-difference , is given by
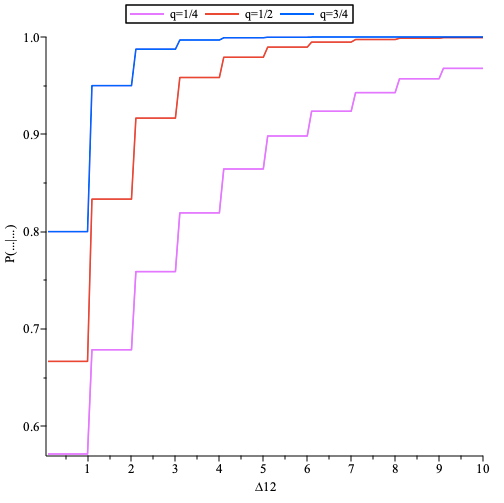
The probability as function of the (rescaled) time-difference , where , plotted for .
Two senders and a single path of mixes scenario: analysis of the FIFO attack
-
A detailed description of the FIFO attack is provided in the Appendix. Here we develop analysis of the FIFO attack for mix nodes with a queuing system.
-
We assume that messages are removed from the out-queue with probability .
-
We assume that nodes and send messages via the same path going through nodes.
-
We assume that each node sends a message to the node at time . A message in the node is delayed by (at most) , where is random variable from the Geometric distribution with parameter , and it is delayed in the link to the node 3 by . Hence a message from node arrives to node 3 at the time .
-
A message from node is delayed by , where is random variable from the Geometric distribution with parameter , while travelling through the nodes. Thus a message from node exits the last node at the time
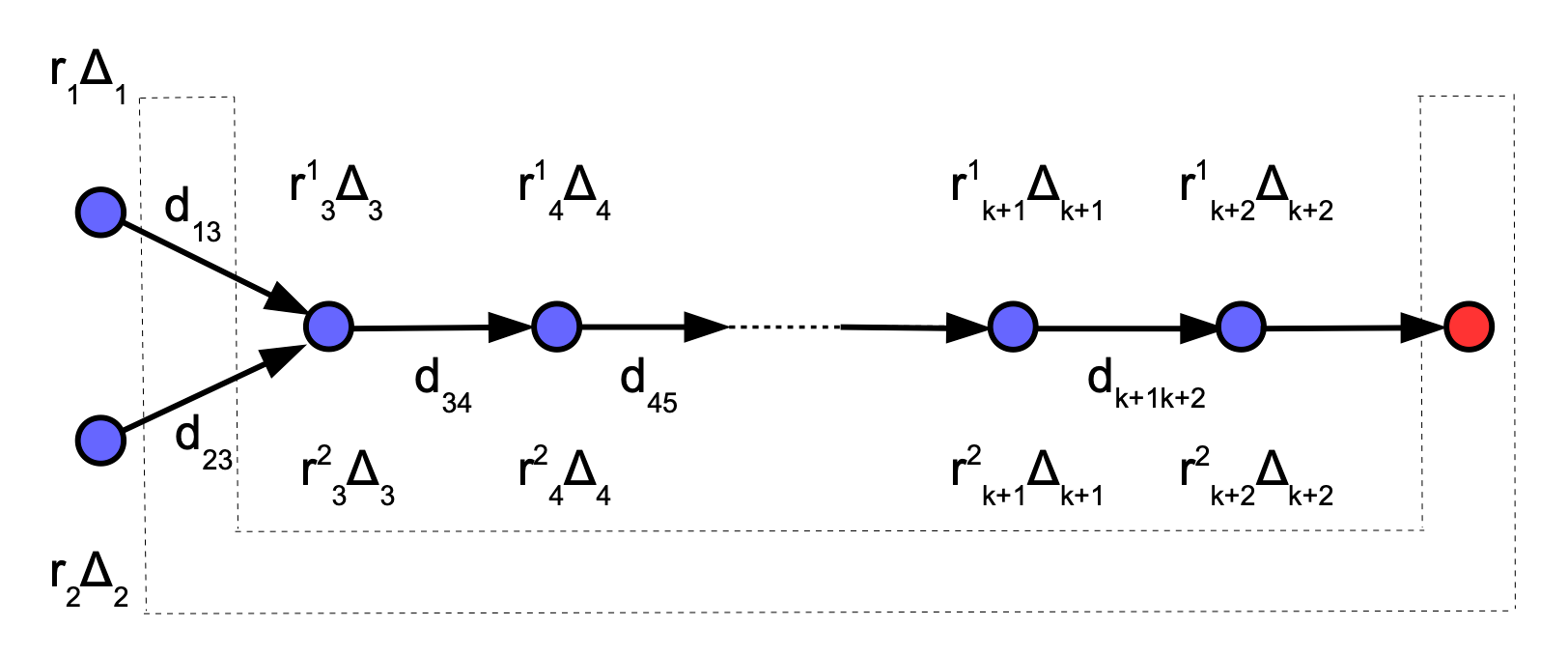
At time the nodes and send messages, via nodes, to the receiver node (red filled circle). The latter is controlled by an adversary which is also observing sender nodes.
-
The events and , i.e. the temporal order of two messages is preserved. These events are mutually exclusive, and hence the probability the at least one of these event will happen is equal to .
-
The probability , i.e. the probability that temporal order of incoming and ougoing messages is preserved, is the probability of success of the FIFO attack.
-
Assuming we have , where is random variable from the negative binomial distribution with parameters and . Furthermore, for and the probability
-
We note that in above the random variables and , where is a random variable from the prob. distr. , models the arrival times of two messages to the first mix node and the first indicator function ensures that only the event contributes to the probability . Furthermore, the random variables and , where is a random variable from the prob. distr. , model arrival times of two messages to the last (receiver) node and the second indicator function ensures that only the event contributes to the probability .
-
In a similar manner, we obtain the probability
- The probability can be approximated by generating a large population of independent random variables sampled from the prob. distributions and , and computing the (empirical) probability
-
In a similar manner we define .
-
We expect that by the law of large numbers.
-
The (empirical) prob. allows us to estimate the probability of success of FIFO attack .
The probability , i.e. the probability of success of FIFO attack, as a function of plotted for (black, magenta, red, blue) and . The population size is equal to .
- We note that the above result, i.e. the probability of success of FIFO attack is a monotonic decreasing function of , is very similar to the result for continuous mixes when , i.e. the connections 1-3 and 2-3 have the same latency. However, when the latter is not true the prob. can be much higher as can be seen in the plot below.
The probability as a function of plotted for and (black, magenta, red, blue). The population size is equal to .
- Let us assume that in our setup the random variables and are sampled from the Geometric distribution with parameter , and for the random variable is sampled from the Geometric distribution with parameter . Thus parameters of delays of the sender and mix nodes are different. The latter can be used to reduce the probability of success, , of the FIFO attack as can be seen in the plot below.
The probability as a function of plotted for , and . The population size is equal to .
-
We note that a message is delayed by the sender node by (on average) and by the mix node by (on average). We note that a similar setup is used in continuous mixes where the ratio plays important role.
-
The probability of success of FIFO attack , , is decreasing with increasing as can be seen in the plots below.
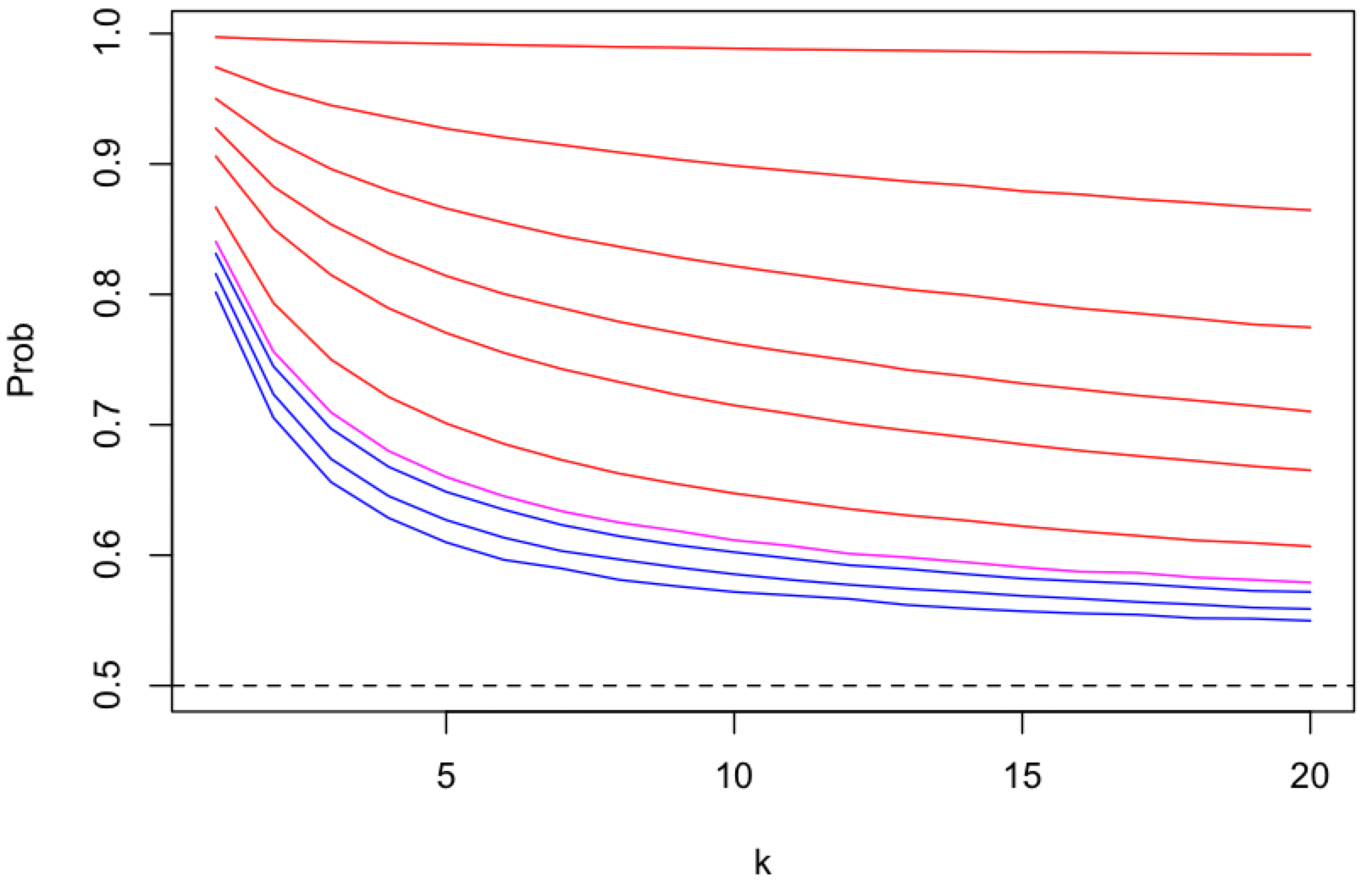
The probability as a function of plotted for , (top to bottom), i.e. , and . The case is plotted in magenta colour, and () and () cases are, respectively, plotted in red and blue colours. The population size is equal to .
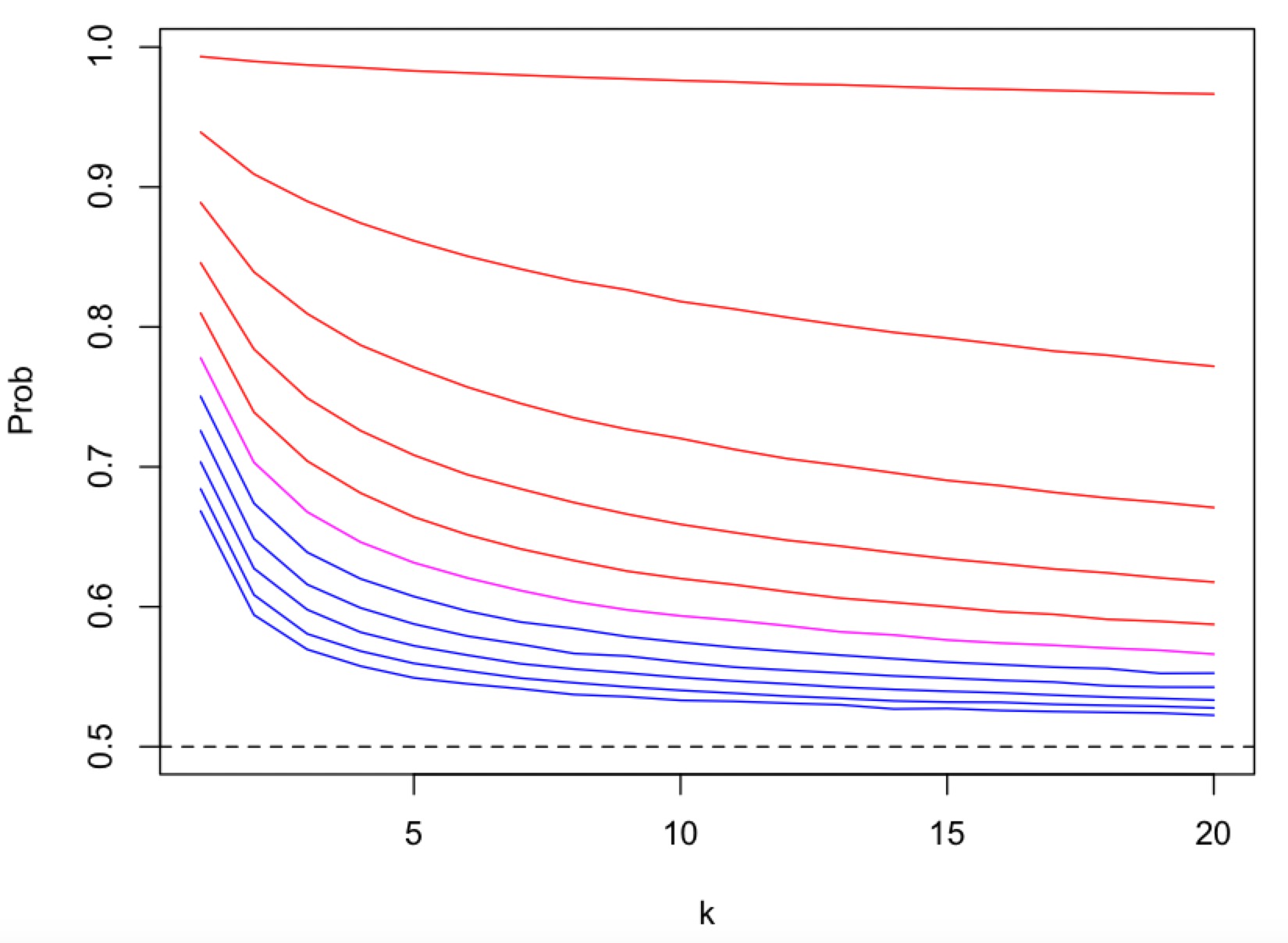
The probability as a function of plotted for , (top to bottom), i.e. , and . The case is plotted in magenta colour, and () and () cases are, respectively, plotted in red and blue colours. The population size is equal to .
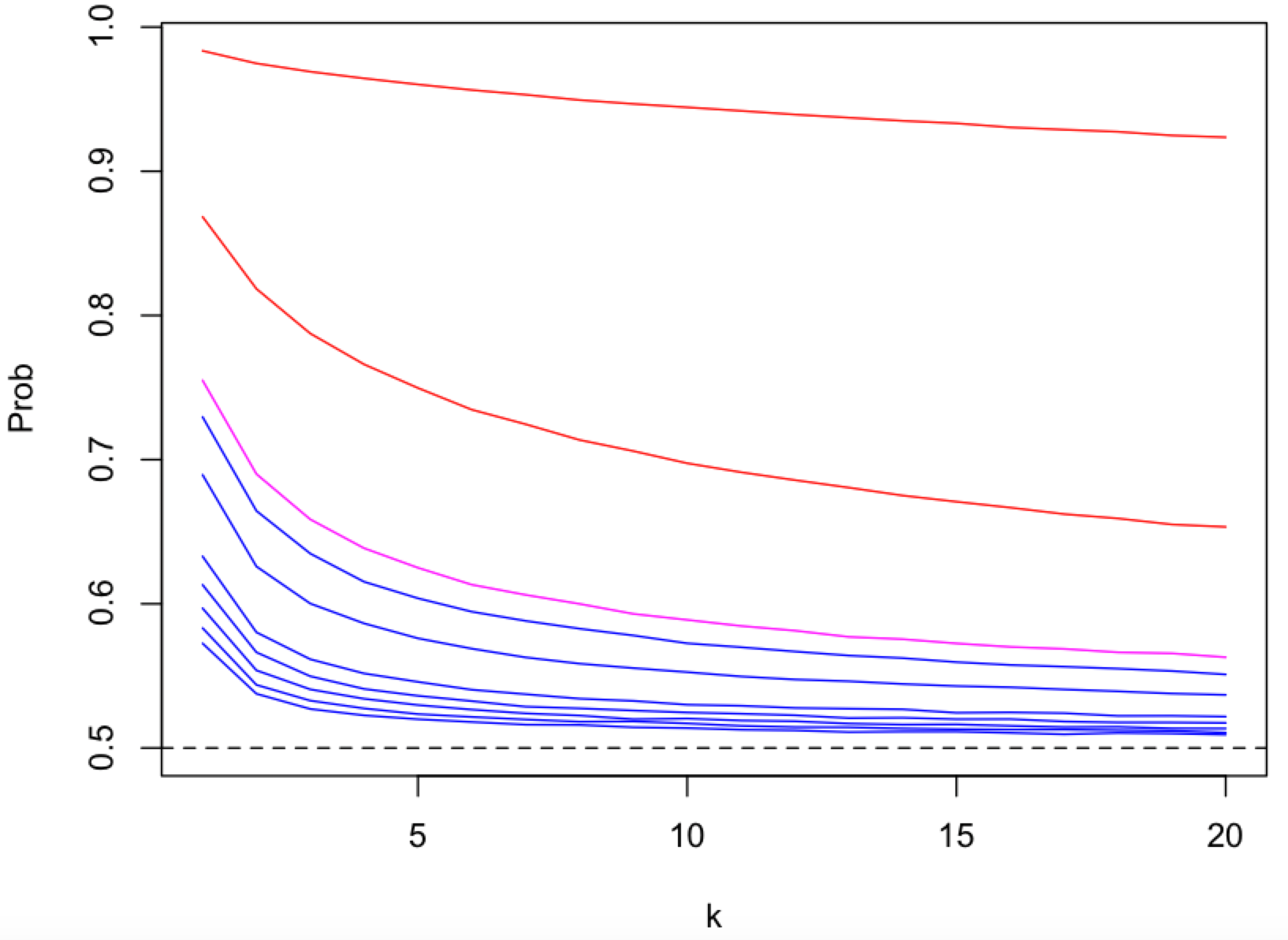
The probability as a function of plotted for , (top to bottom), i.e. , and . The case is plotted in magenta colour, and () and () cases are, respectively, plotted in red and blue colours. The population size is equal to .
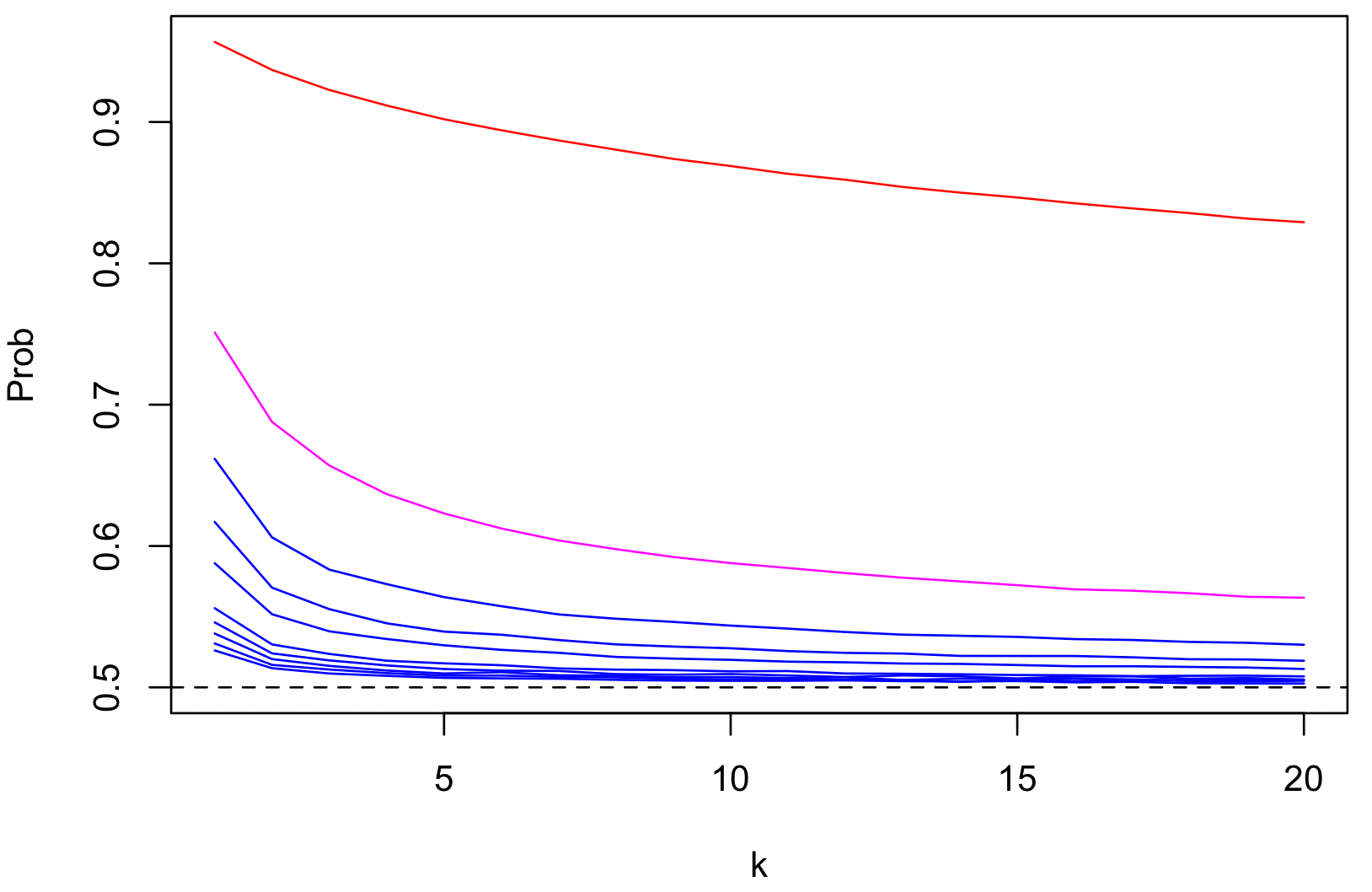
The probability as a function of plotted for , (top to bottom), i.e. , and . The case is plotted in magenta colour, and () and () cases are, respectively, plotted in red and blue colours. The population size is equal to .
-
Above plots suggest that the probability of success of FIFO attack, , approaches , i.e. an adversary has no advantage over the case of random guessing, as . Furthermore, the speed of convergence (in ) to is monotonic increasing function of the ratio .
-
The probability of success of FIFO attack , , is increasing with increasing , i.e. the sender connections 1-3 and 2-3 have different latency, as can be seen by comparing the figure with the plots below.
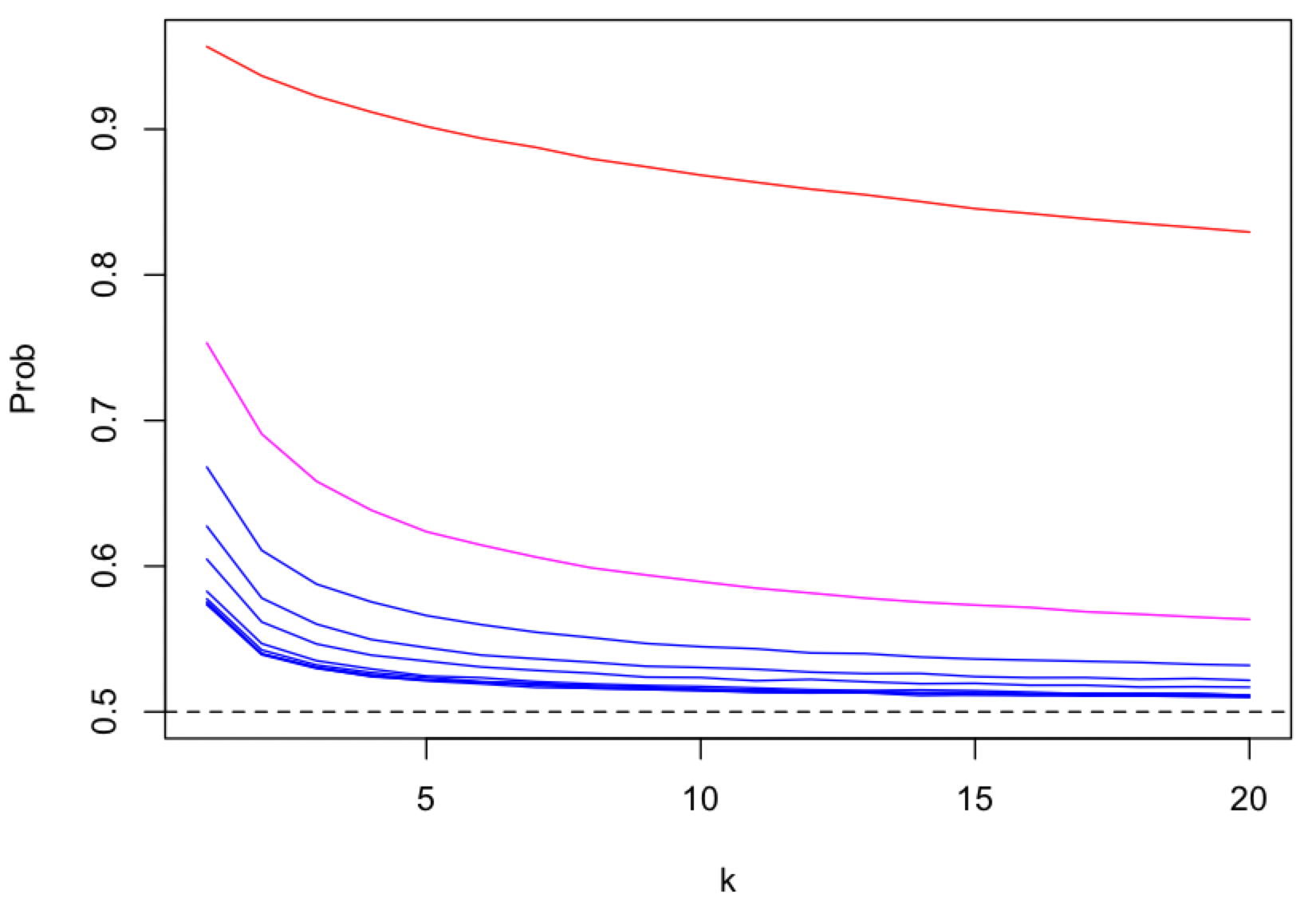
The probability as a function of plotted for , (top to bottom), i.e. , and . The case is plotted in magenta colour, and () and () cases are, respectively, plotted in red and blue colours. The population size is equal to .
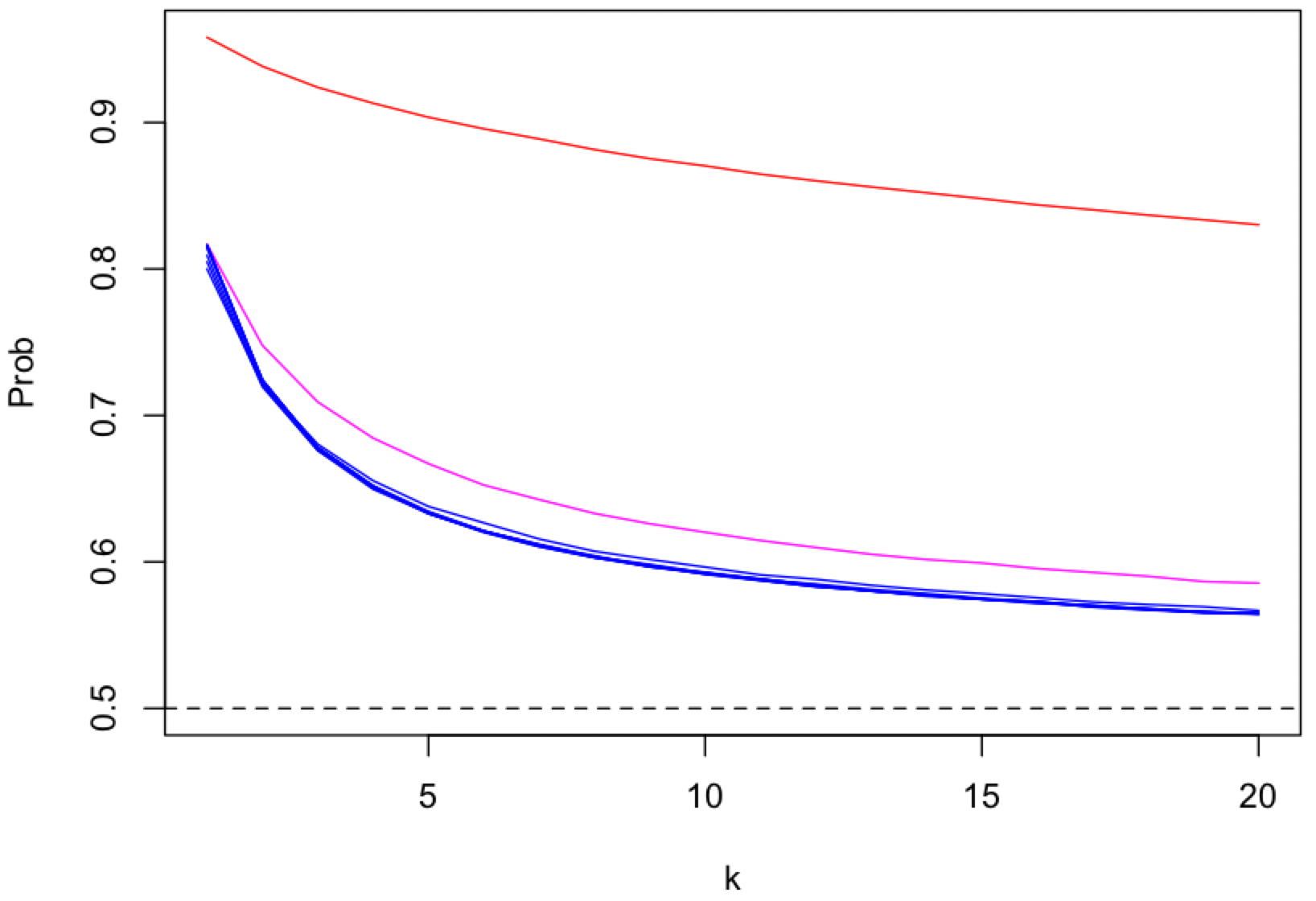
The probability as a function of plotted for , (top to bottom), i.e. , and . The case is plotted in magenta colour, and () and () cases are, respectively, plotted in red and blue colours. The population size is equal to .
- Furthermore, the probability of success of FIFO attack , , is not dependent on the (rescaled) difference of latencies when and is increasing with increasing when as can be seen in the figure below.
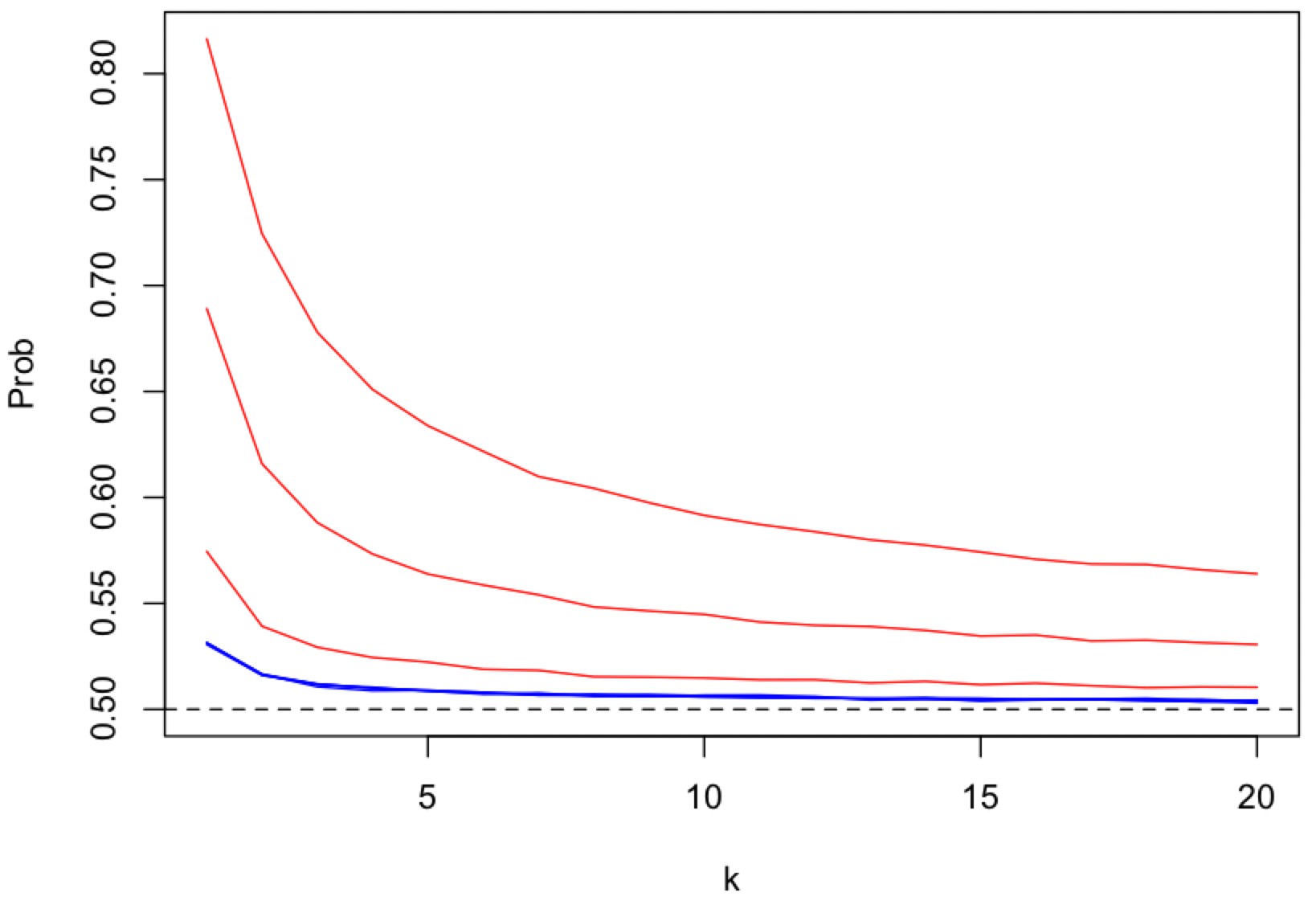
The probability as a function of plotted for , , i.e. , and (bottom to top). The cases are plotted in blue colour and cases are plotted in red colour. The population size is equal to .
- For the probability behaves in a similar way as when as can be seen by comparing above figure with the figure below.
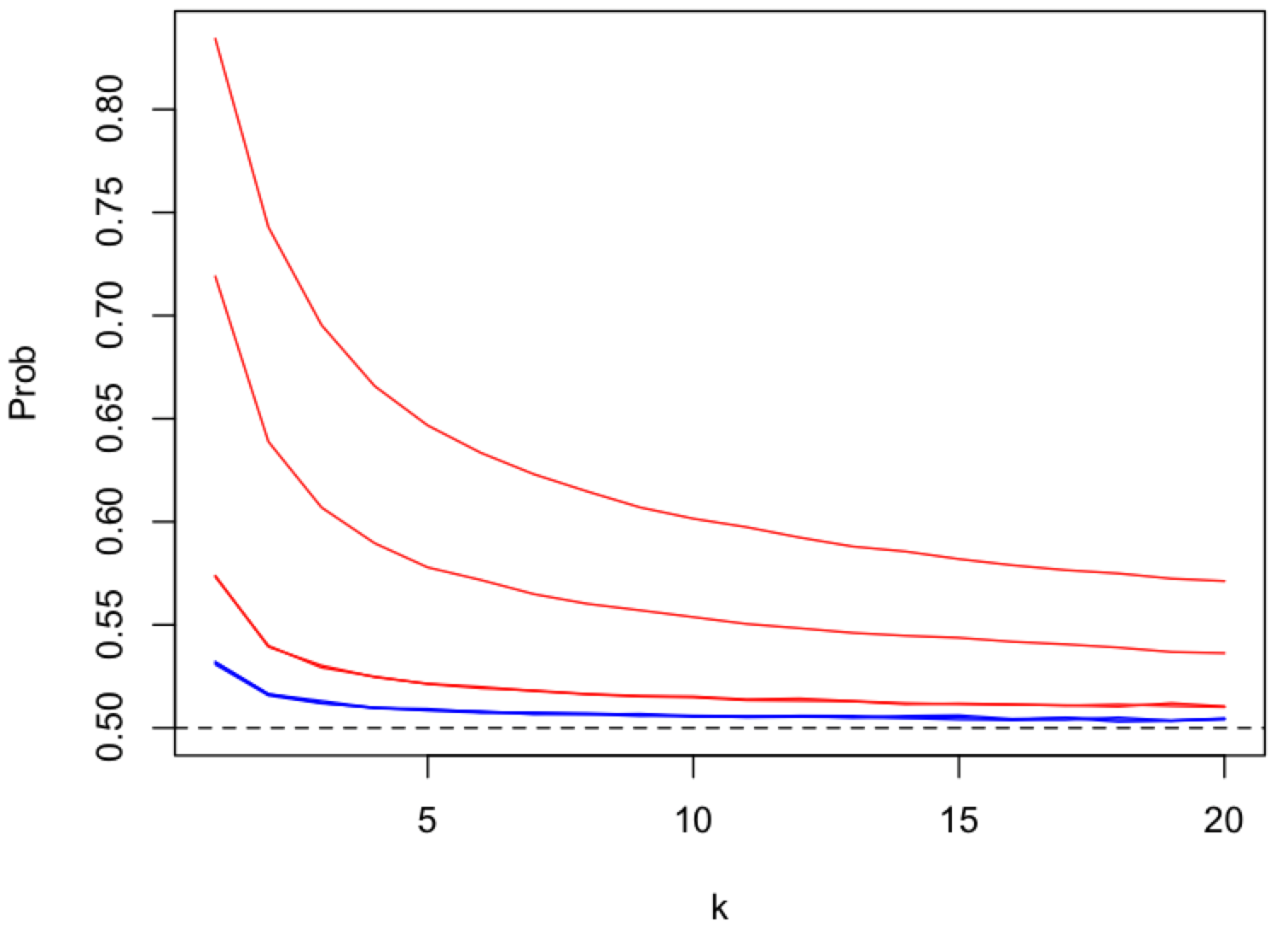
The probability as a function of plotted for , , i.e. , and (top to bottom). The cases are plotted in blue colour and cases are plotted in red colour. The population size is equal to .
- However, the and cases are different as can be seen in the figure below.
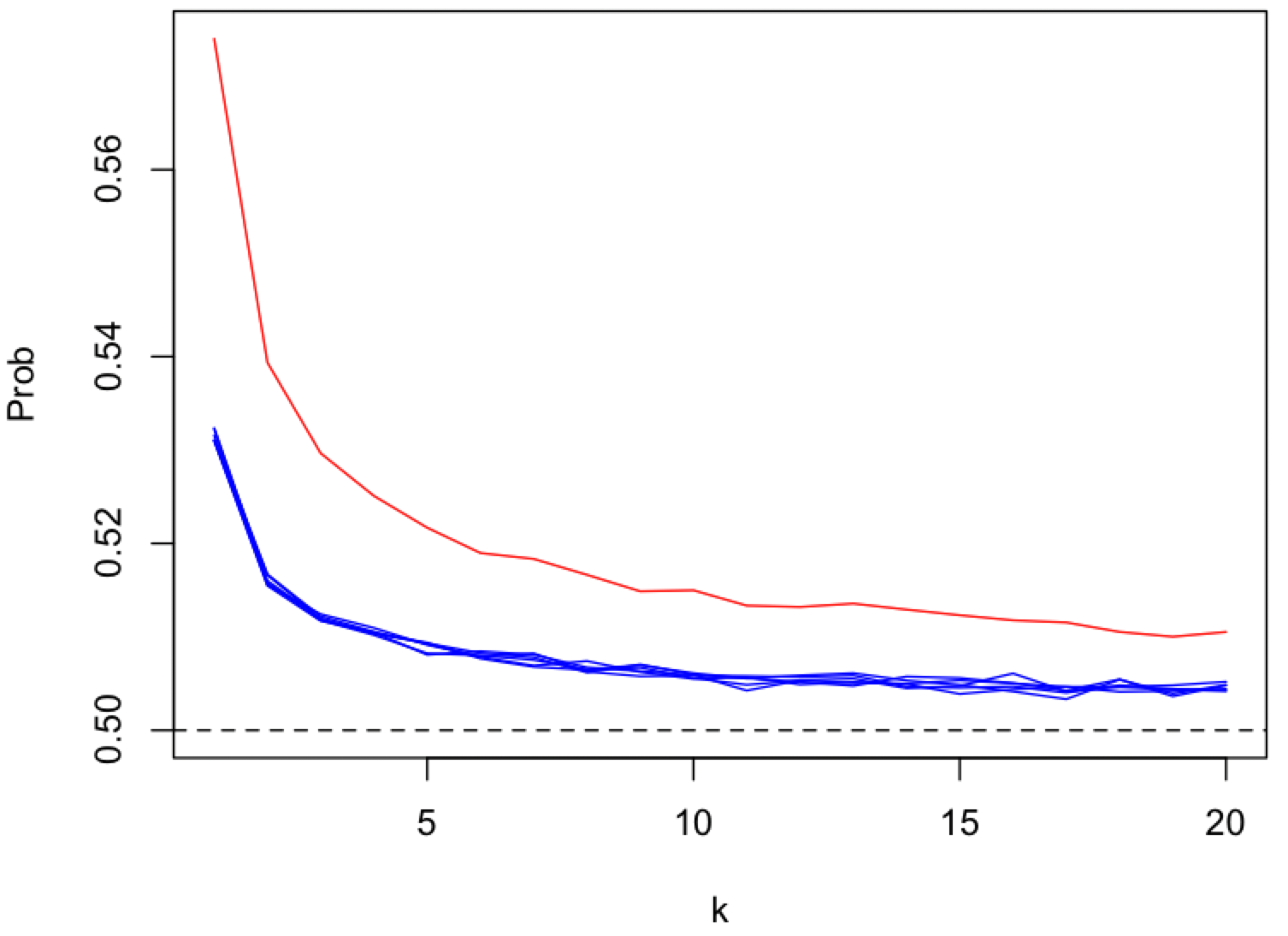
The probability as a function of plotted for , , i.e. , and (top to bottom). The case is plotted in red colour. The population size is equal to .
Summary of FIFO attack analysis
From above analysis, it follows that the probability of success of FIFO attack is reduced by:
-
Increasing the number of mix nodes .
-
Increasing the ratio , where a message is delayed by the sender node by (on average) and by the mix node by (on average).
-
Decreasing differences between latencies of communication links.
Bibliography
Das, D., Diaz, C., Kiayias, A., & Zacharias, T. (2024). Are continuous stop-and-go mixnets provably secure?. Proceedings on Privacy Enhancing Technologies. https://doi.org/10.56553/popets-2024-0136
Appendix
Literature review
Summary of “Are continuous stop-and-go mixnets provably secure?” article.
- Adversary: We consider a probabilistic polynomial time (PPT) adversary that can observe (but not alter) all network traffic. The adversary can also perform passive and static corruptions of senders, the recipient R, and a subset of mixnodes. Passive and static corruption means that the adversary chooses the subset of corrupted parties before the protocol starts; the adversary then has access to the internal states of these c mixnodes, including all of their keys and random choices; however, the compromised parties still follow the protocol specifications.
- User Unlinkability: In our first definition, the adversary does not control the time when the challenge messages are released, and the content of any other messages from the honest users. This more closely captures the surveil- lance scenario where the adversary observes an interesting/disturbing message received by the recipient and then tries to figure out who among Alice and Bob could have sent that message. Informally, the protocol achieves anonymity according to this definition as long as a target message from Alice is ‘mixed’ with at least one message from Bob.
- Pairwise Unlinkability: Our second definition is stronger; here, we consider that the adversary controls the time when the challenge messages are released to the challenge users, the content of all other messages from the honest users, and then tries to distinguish who among them have sent which of the challenge messages after they are received by the recipient. Such a definition is useful to capture a strong adversarial scenario in the context of whistleblowing where the adversary might release fake/tagged documents and observe the time of its release to identify the whistleblower.
- In one of our main results, we prove that in continuous mixnets, by controlling the time of release, the adversary can exploit the fact that whichever message goes into the AC network first, comes out first with good probability - which we formally denote as the FIFO attack.
- The cascade continuous mixing (CCM) protocol: i) Each message travels through a fixed cascade of k hops before getting delivered to the recipient; ii) The sender then onion encrypts the message (using Sphinx packet structure) for the cascade (including the recipient), and sends it to the first of the mixnode in the cascade after some delay sampled from exponential distribution; iii) Each mixnode delays the messages also following an exponential distribution.
- The multi-path continuous mixing (MCM) protocol: i) We consider a stratified topology where mixnodes are arranged in a number of layers, such that mixnodes in layer i receives messages from mixnodes in layer i - 1 and sends messages to mixnodes in layer i+1. The path length of message routes is determined by the number of layers, and is denoted by k. Further, we consider that each layer has exactly K mixnodes; ii) The sender of the message picks a path of length k by picking one mixnode uniformly at random from each layer, independent of the choices of other users or other messages; iii) The sender samples k independent delay values from exp. distribution. They then onion-encrypt the message for the path (including the recipient), and embed the values in the onions header such that only i-th mixnode can see its delay value. Then they send it to the first of the mixnodes in the path after a delay sampled from the exp. distr.
- A trusted third party (TTP) anonymizer receives messages and shuffles them. If there are a sufficient number of messages received by the TTP regularly, then each message will mix with enough number of other messages. However, if a set messages are received by the TTP exactly at the same moment, their output order will not reveal anything to the adversary; and we could say that those messages are “shuffled” with each other.
- TTP interacts with the senders in U and the recipient R, and is parameterized by latency k and delay λ. The senders provide TTP with their messages over a secure channel, so that no information about the message content is leaked to the adversary.
- TTP acts as a central mixing node that delivers the messages to R after adding a delay (sampled from some prob. distribution related to the protocol).
- Assuming that the central mixing node is honest, the power of the adversary is limited to an observer that monitors incoming and outgoing traffic.
- As this sets the minimum power for a global passive adversary, the security of TTP serves as an optimistic bound of the security expected by a typical mixing construction.
- TTP interacts with the senders in U and the recipient R, and is parameterized by latency k and delay λ. The senders provide TTP with their messages over a secure channel, so that no information about the message content is leaked to the adversary.
- FIFO attack
- We consider a simplified setting with (i) two senders u0, u1; (ii) a single recipient R; and (iii) TTP. The system state is as follows: each sender has a single message in her buffer and the queue is empty, i.e. there are no prior pending messages. The senders u0 and u1 send their messages to the recipient R that receives the messages m0 and m1.
- The goal of the mix is to provide sender anonymity against an adversary that controls R and is a global observer, i.e. to hide whether communication occurs in 1) a “direct” manner: i.e. the users u0 and u1 sent, respectively, the messages m0 and m1 to R or 2) a “cross” manner: i.e. the users u0 and u1 sent, respectively, the messages m1 and m0 to R.
- The adversary begins observation at some given time when the messages m0 , m1 are in the sender’s queues and are about to be delivered. By the memoryless property (?) and the description of the system state, we may assume that observation begins at time 0. Then adversary executes the following steps:

- In a nutshell, adversary guesses based on the prediction that messages input earlier to the mixing node are more likely to be delivered earlier to the intended recipient.
- We consider a simplified setting with (i) two senders u0, u1; (ii) a single recipient R; and (iii) TTP. The system state is as follows: each sender has a single message in her buffer and the queue is empty, i.e. there are no prior pending messages. The senders u0 and u1 send their messages to the recipient R that receives the messages m0 and m1.
- Analysis of the FIFO attack
- Without loss of generality, assume that the users and provide the messages and , respectively, in a “direct” manner to (due to symmetry and independence, the “cross” case can be analysed similarly?).
- We denote the following random variables:
- The delay until is sent to TTP by .
- The delay until is sent to TTP by .
- The delay of TTP until is forwarded to , i.e. the time stays in the TTP.
- The delay of the TTP until is forwarded to , i.e. the time stays in the TTP
- We have that ,, and are the time values of , , +, , that adversary observes, in the direct case.
- Thus adversary wins when either one of the following events happen:
- and ;
- or and ;
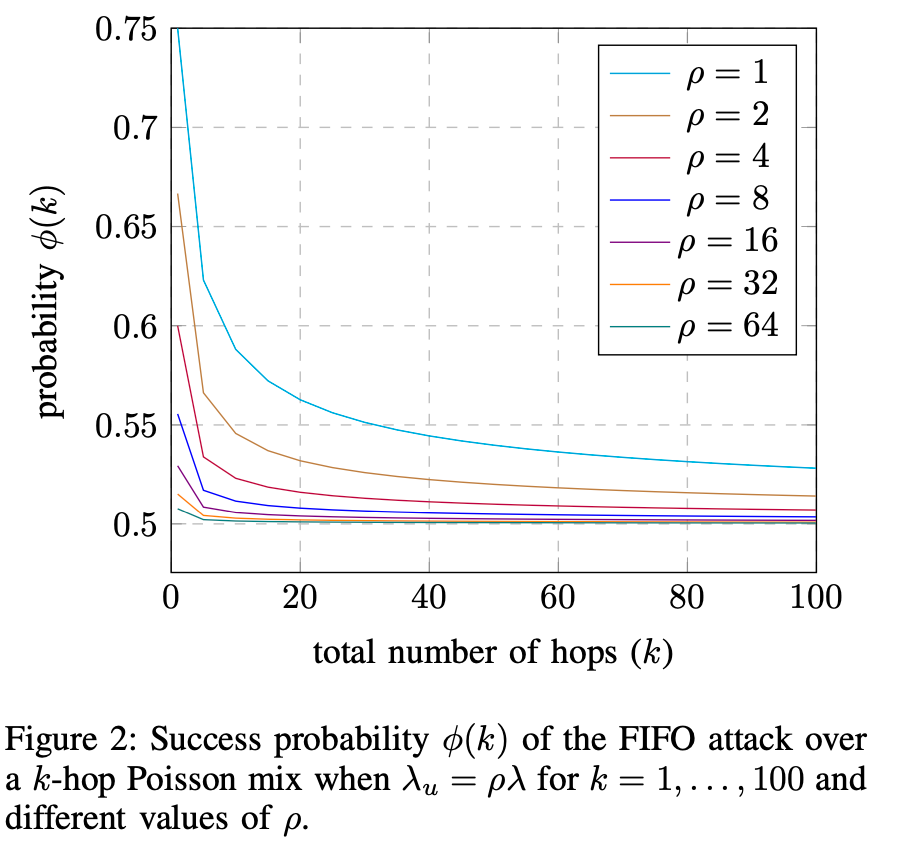
- User unlinkability definition


- Analysis for User Unlinkability



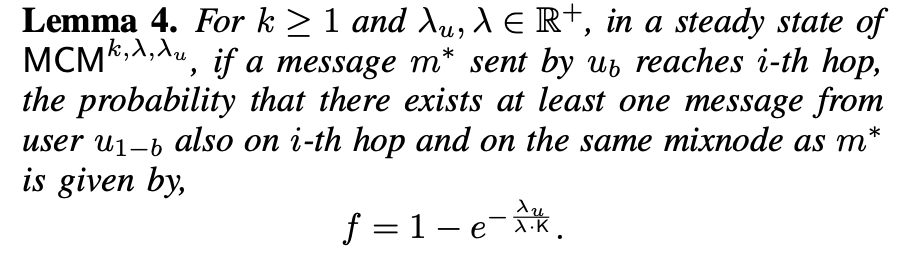


- Pairwise Unlinkability definition


- Analysis for Pairwise Unlinkability


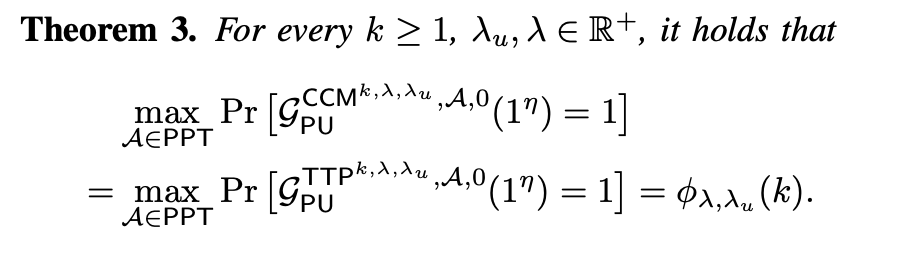




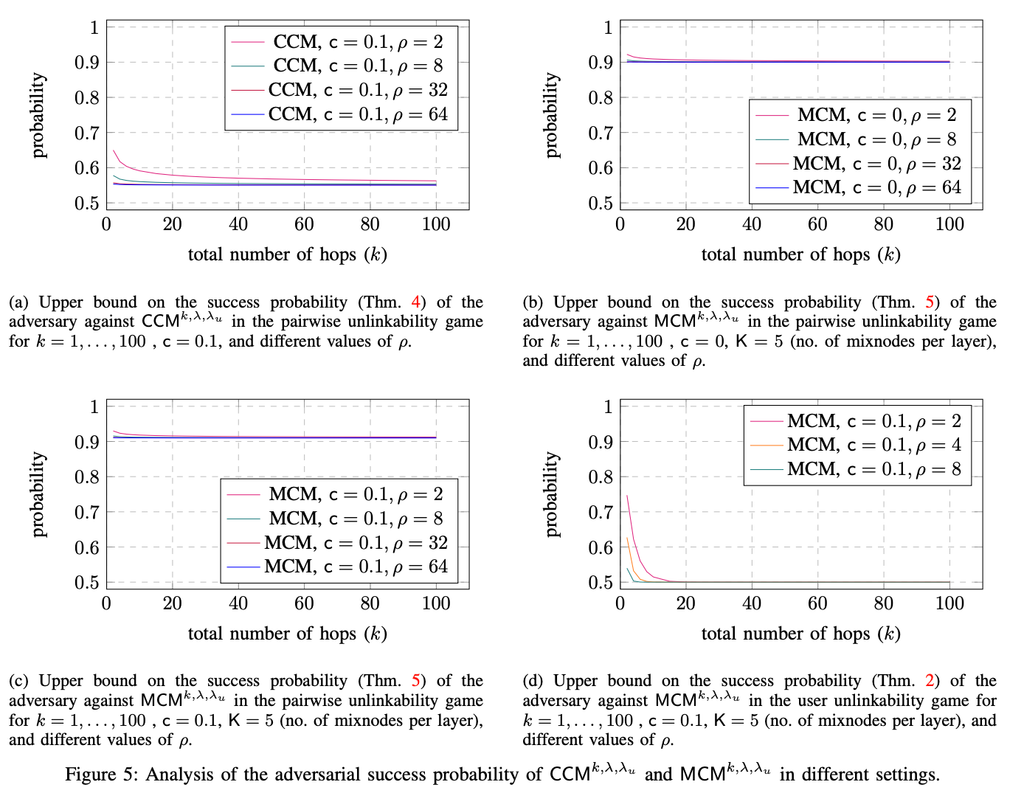
- In above we plot the prob. bound from the inequality |prob. -1/2| \leq \delta . For example using Theorem 2 (plot (d) in the above) we obtain the following
Summary of “The Generals' Scuttlebutt: Byzantine-Resilient Gossip Protocols”
- Abstract



ANALYSIS-COMMUNICATION-ON-TREES
| Field | Value |
|---|---|
| Name | [Analysis] Communication on Trees |
| Slug | 187 |
| Status | raw |
| Category | Informational |
| Editor | Alexander Mozeika [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-08-25 |
Introduction
We would like to understand how to reduce probability of a communication failure, i.e. when a message sent by a node is “lost” somewhere in the network and not broadcasted. The latter is a main concern as a naive approach of retransmission increases the delay and bandwidth, and reduces anonymity. We have identified two approaches with a potential to reduce communication failure. In the first approach, the sender node uses multiple independent linear paths, i.e. linear trees, to send a message. However, initial analysis suggests that to reduce communication failure in the latter, one must increase the number of communication paths significantly which would have detrimental effect on the bandwidth of a sending node. In the second approach, where the sender node is root of a branching tree, bandwidth of a sending node is only weakly affected by the number communication paths.
First, we assume that a fraction of nodes in the network is adversarial and compute the probability of broadcast and anonymity failures for broadcasting on linear trees. We note that if each communication path has at least one adversarial node then this is considered to be a broadcasting failure and if there is at least one path where all nodes are adversarial then this considered to be anonymity failure. Probabilities are parametrised by the fraction of adversarial nodes, number of paths and number of nodes per path. Second, we compute failure probabilities for broadcasting on branching trees. Assuming the same number of paths, we compare results for linear and branching trees and we find that the linear tree design has better broadcast failure properties than the branching tree design, but worse anonymity failure properties. Finally, we assume that, in addition to adversarial nodes, we also have “faulty” nodes in the network. The latter are unable to relay a messages and their faultiness is a result of some “natural” process. Here we find only quantitative differences with the scenario when only adversarial nodes are considered, but we expect that the model which accounts for “natural” failures to be more realistic.
Details of mathematical derivations, with references to literature, and additional numerical results are provided in the Appendix.
Overview
This document investigates methods to reduce communication failures in network messaging by comparing two primary designs: linear trees and branching trees. The study focuses on minimizing broadcast failures (lost messages) and anonymity failures (privacy breaches) while considering bandwidth constraints.
The analysis uses probabilistic models and recursive equations to compute failure probabilities under adversarial and faulty node conditions. For linear trees, broadcast and anonymity failures are derived based on path length and the number of independent paths. For branching trees, recursive methods determine critical thresholds where failures become inevitable.
A two-variable model is introduced to separate natural faults from adversarial behavior, improving realism. Simulations validate theoretical results, showing trade-offs:
- Linear trees offer better broadcast reliability but worse anonymity and higher bandwidth costs.
- Branching trees reduce anonymity risks and bandwidth usage but are more vulnerable to shared-node failures.
The findings guide design choices based on network priorities (e.g., reliability vs. privacy) and constraints (e.g., node bandwidth). The appendix includes detailed derivations and simulation results.
Analysis
Communication on Linear Trees
Communication on Linear Trees. The node sends a message through communication paths where each path is a linear tree constructed from exactly nodes.
We assume that a node sends a message through communication paths where each path is a linear tree constructed from exactly nodes (see figure above). We assumed that nodes were sampled (with replacement) from the population of nodes where nodes are “faulty”. If a path contains at least one faulty node then communication failure occurred. If all paths have communication failure then broadcast failure occurred.
If nodes in communication paths are sampled with replacement from the network nodes with faulty nodes then the probability that a node is faulty is . The probability of broadcast failure is given by
We note that in the limit , such that , the probability of broadcast failure and in the limit , such that , the probability .
Let us now assume that is the probability that a node is “curious”. Then the event "there is at least one path where all nodes are curious" is the anonymity failure. The probability of anonymity failure is given by
We note that in the limit , such that , the probability of anonymity failure and in the limit , such that , the probability .
Above analytic expressions, derived for infinite number of random samples, for failure probabilities are in good agreement with probabilities computed from a finite number of samples obtained in simulations as can be seen in figures below
Analysis of failures in linear trees with layers. Left: The probability of broadcast failure plotted as a function of number of layers for the fraction of faulty nodes. Right: The probability of anonymity failure plotted as a function of the number of layers for the fraction of “curious” nodes. In simulation probabilities were computed from samples.
Analysis of failures in linear trees with layers. Left: The probability of broadcast failure plotted as a function of number of layers for the fraction of faulty nodes. Right: The probability of anonymity
failure plotted as a function of the number of layers for the fraction of “curious” nodes. In simulation probabilities were computed from samples.
We note that the number of samples in above figures is equivalent to the number of messages sent by a sender node.
Communication on Branching Trees
Assumptions
We consider broadcasting on a tree with layers labeled, from leaf nodes to the root node, by the set (see figure below). All nodes in a tree at the same distance from its root constitute a layer. We assume that the root node of is sending a message to leaf nodes. A node inside is relaying a message to nodes, i.e. is -ary tree. The set of all leaf node is the “boundary” of the tree . -ary tree is balanced and complete if all distances from the root node to a leaf node are the same.
In this document we consider only balanced and complete -ary trees. The number of leaf nodes is also the number of paths from the root node to leaf nodes. If all leaf nodes didn't receive a message sent from the root node then broadcast failure occurred. Let us now assume that is the probability that a node is “curious”. Then the event "there is at least one path where all nodes are curious" is the anonymity failure.
Communication on a (balanced and complete) tree . The layers in the tree are labeled by the set (bottom to top). A message is sent from the root node (layer ) to the leaf nodes (layer ). All leaf nodes of the tree constitute its boundary . Each node in the tree, but the root, has associated with it binary random variable.
Analysis of communication failures
The prob. of broadcast failure in the tree with layers and branching parameter can be computed recursively (see the Details of derivations section) via the following set of equations
Solving above equations gives the following results
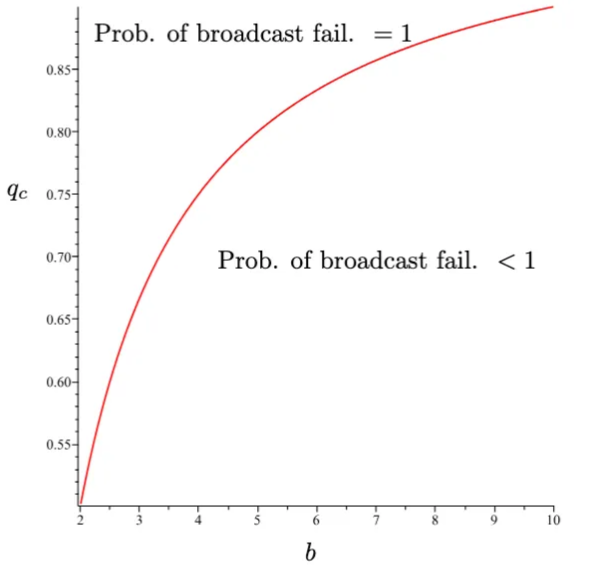
The (critical) probability that a node is faulty, , as a function of tree branching factor . For broadcast on a tree is only possible for a small number of layers. For broadcast is possible for infinite number of layers.
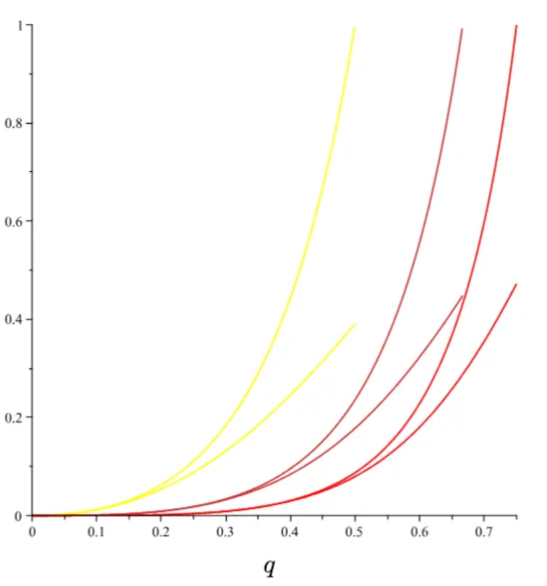
The probability of broadcast failure (lower and upper bound) plotted as a function of probability that a node is faulty, , for the values of tree branching factor (yellow, orange, red). Here and the lower bound corresponds to a branching tree with layers. The upper bound corresponds to a branching tree with an infinite number of layers.
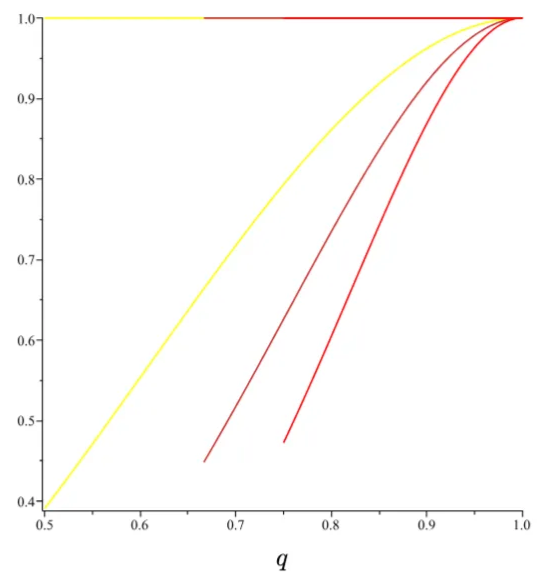
The probability of broadcast failure (lower and upper bound) plotted as a function of probability that a node is faulty, , for the values of tree branching factor (yellow, orange, red). Here and the lower bound corresponds to a branching tree with layers. The upper bound corresponds to a branching tree with an infinite number of layers.
Analysis of anonymity failure
The prob. of anonymity failure in the tree with layers and branching parameter can be computed recursively (see the Details of derivations section) via the following set of equations
Solving above equations gives the following results
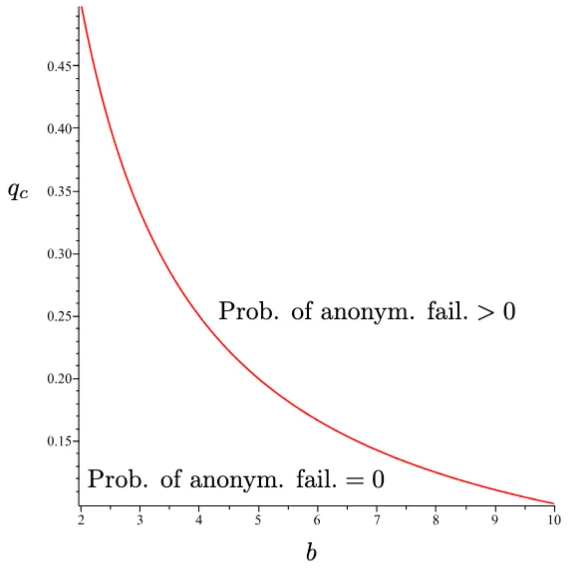
The (critical) probability that a node is “curious”, , as a function of tree branching factor . For the probability of anonymity failure is bounded away from and for infinite number of layers, i.e. the probability of anonymity failure is approaching a non-zero value with increasing number of layers in a tree. For the probability of anonymity failure is exactly for infinite number of layers.
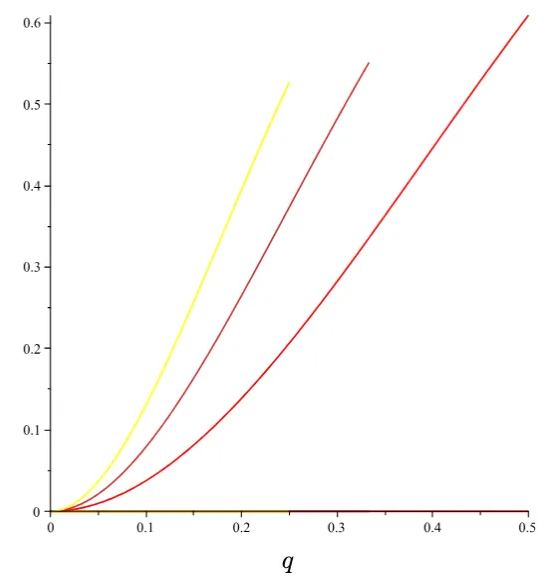
The probability of anonymity failure (lower and upper bound) plotted as a function of probability that a node is “curious”, , for the values of tree branching factor (red, orange, yellow). Here and the lower bound, given by , corresponds to a branching tree with an infinite number of layers. The upper bound corresponds to a branching tree with layers.
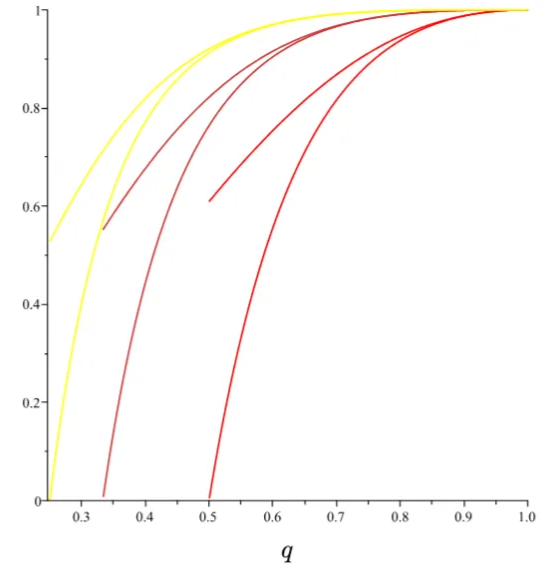
The probability of anonymity failure (lower and upper bound) plotted as a function of probability that a node is “curious”, , for the values of tree branching factor (red, orange, yellow). Here and the lower bound corresponds to a branching tree with an infinite number of layers. The upper bound corresponds to a branching tree with layers.
Results of simulations
Above analytic results, derived for infinite number of random samples, for failure probabilities are in good agreement with probabilities computed from a finite number of samples obtained in simulations as can be seen in figures below
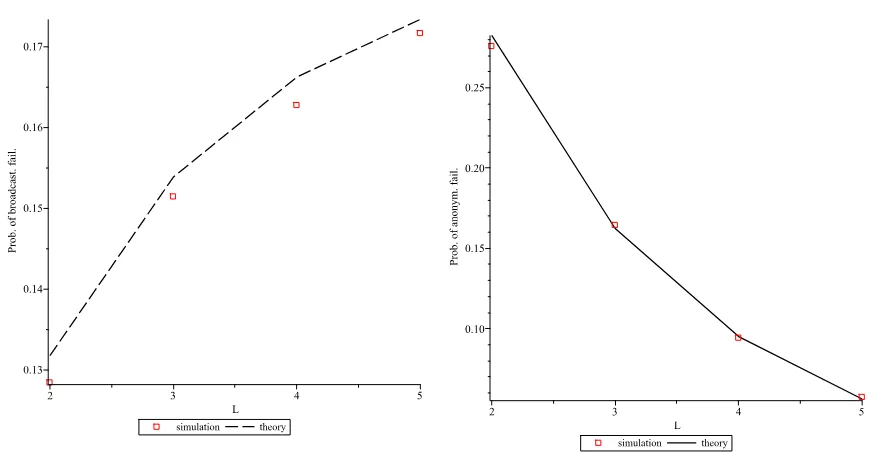
Analysis of failures in branching trees with branching factor . Left: The probability of broadcast failure plotted as a function of number of layers for the fraction of faulty nodes. Right: The probability of anonymity failure plotted as a function of the number of layers for the fraction of “curious” nodes. In simulation probabilities were computed from samples.
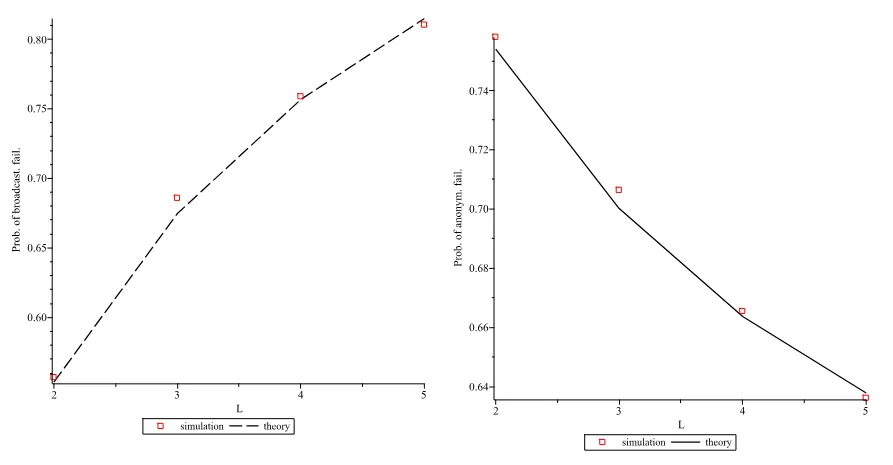
Analysis of failures in branching trees with branching factor . Left: The probability of broadcast failure plotted as a function of number of layers for the fraction of faulty nodes. Right: The probability of anonymity failure plotted as a function of the number of layers for the fraction of “curious” nodes. In simulation probabilities were computed from samples.
- We note that the number of samples in above figures is equivalent to the number of messages sent by a sender node.
Discussion of results for linear and branching tree designs
Discussion of difference between designs
The number of leaf nodes in the branching tree is , where is the branching parameter and is the number of layers, which is also the number of communication paths. To compare the two designs we assume that both of them have the same number of communication paths. The latter implies that the total number of nodes used in linear tree design is (the number of nodes in linear tree design is , where is the number of paths and is the number of nodes in a path without the sender node) and in branching tree design is . We note that the number of paths grows exponentially with the number of layers (and branching parameter ) as can be seen in the figure below
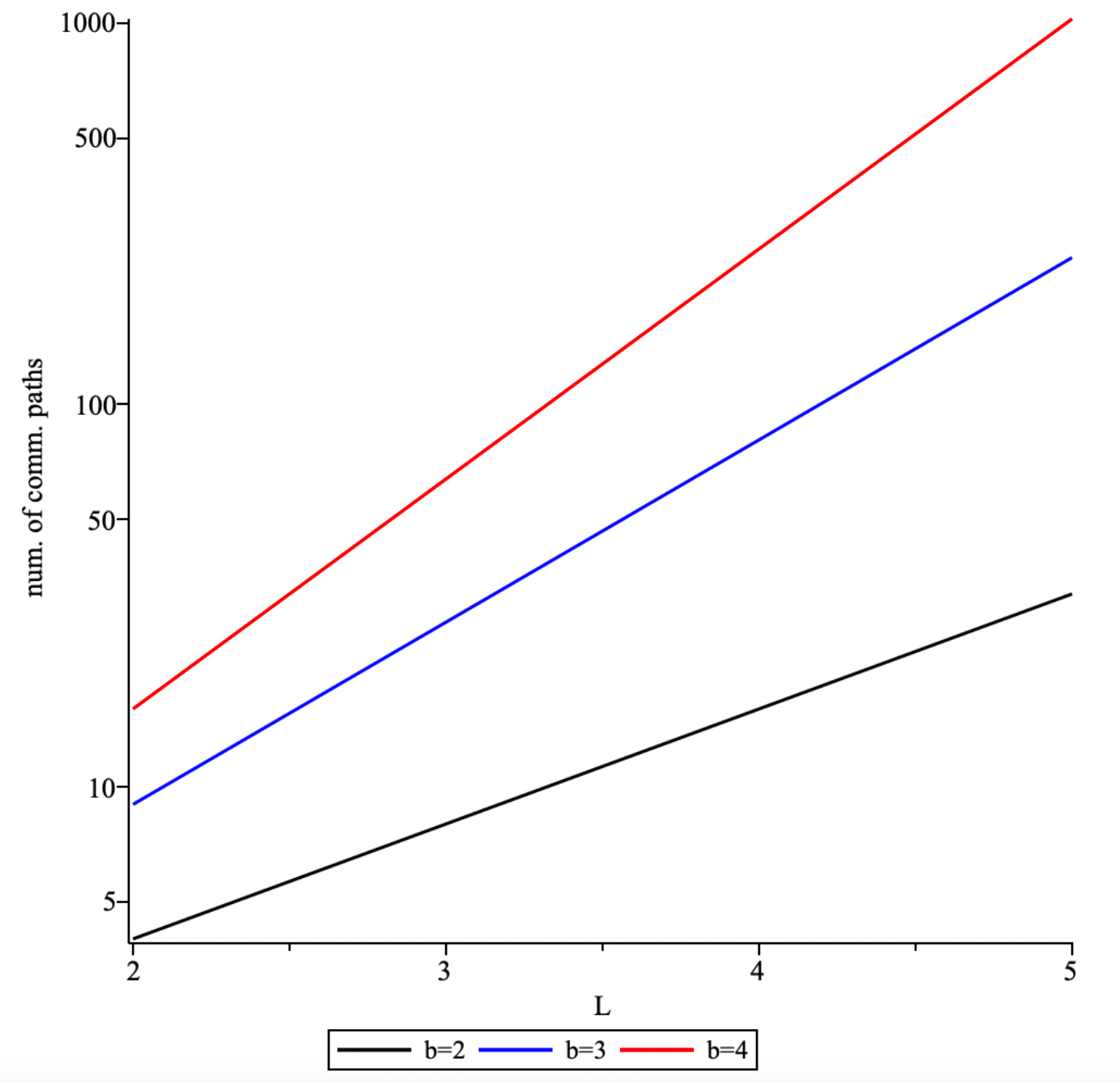
The consequences of having comm. paths in both designs is that the out-degree of a sender node in linear design is and in branching design is . However, the out-degree is the number of messages sent by a node and hence the number of messages which have to be sent by a sender node grows exponentially in the linear design, but in the branching design it is a constant, i.e. . This suggests that the out-degree of a sender node (in linear and branching designs) is constrained by bandwidth of a node.
The ratio in the linear design and in the branching design the , i.e. the ratio is growing linearly with in the linear design and it is at most , i.e. a constant, in the branching design.
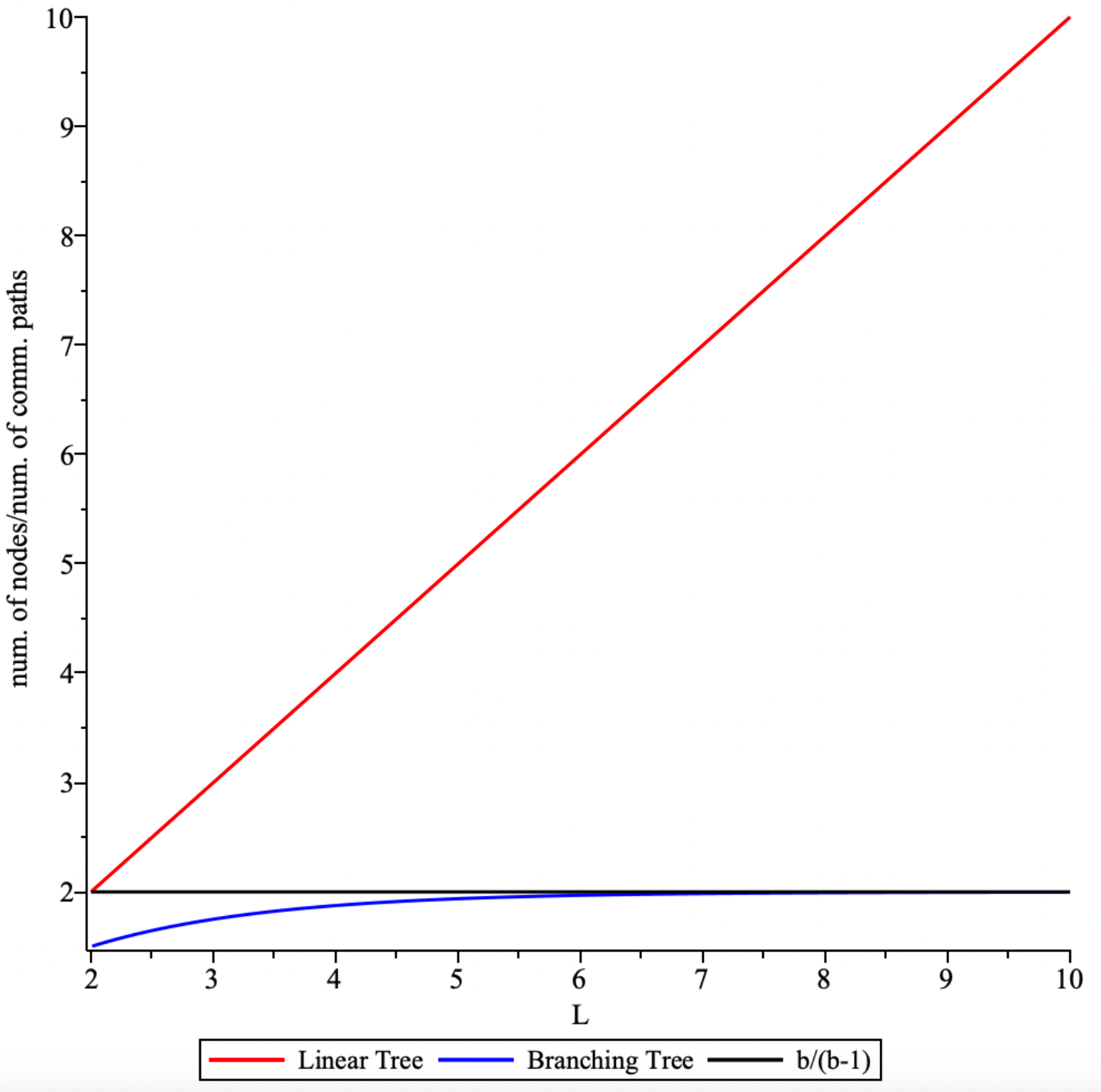
Given that the number of communication paths is the same in both designs, the bandwidth consumption "pattern" is very different between these two designs. In linear tree design the root node has to send messages to other nodes and other nodes, but leaf nodes, receive a single message and send a single message. In branching tree design the root node sends number of messages to other nodes and other nodes, but leaf nodes, receive a single message and send messages. For the branching tree design a node might need to send the same number of messages as in the linear tree design as we might not be able to encode messages in a way that it will be able to use topology efficiently.
For now bandwidth optimisation is not a priority as it depends on possibility of efficient implementation of a communication design which is not investigated at the moment. Assuming that branching tree design can be implemented efficiently, the root node in the linear case is more "chatty", where the number of messages sent is equal to the number of comm. paths, than in the branching case, where the number of messages sent is equal to the branching parameter and is independent from the number of comm. paths, which would make "anonymity" properties of the sender (root node) in these designs very different which has to be taken in to consideration when making decision on which design to choose.
Discussion of results for failures
We assume that the number of comm. paths in both designs is and consider communication and anonymity failures. For anonymity failure we will use the same statistical model as for communication failure, with "faulty" replaced by "curious", and the same probability that node is faulty or curious. The linear tree design has better communication failure properties than the branching tree design but worse anonymity failure properties as can be seen in two figures below
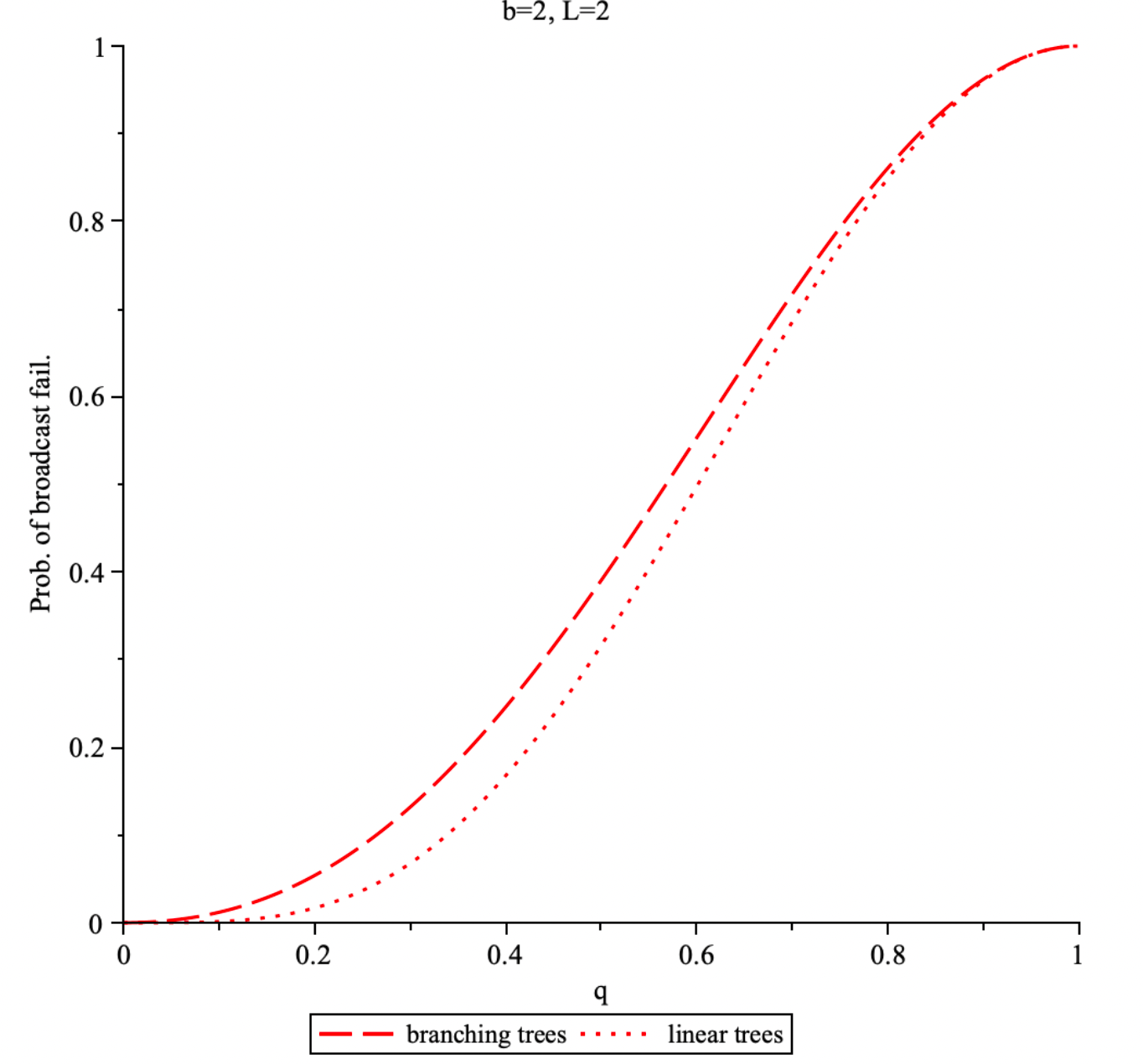
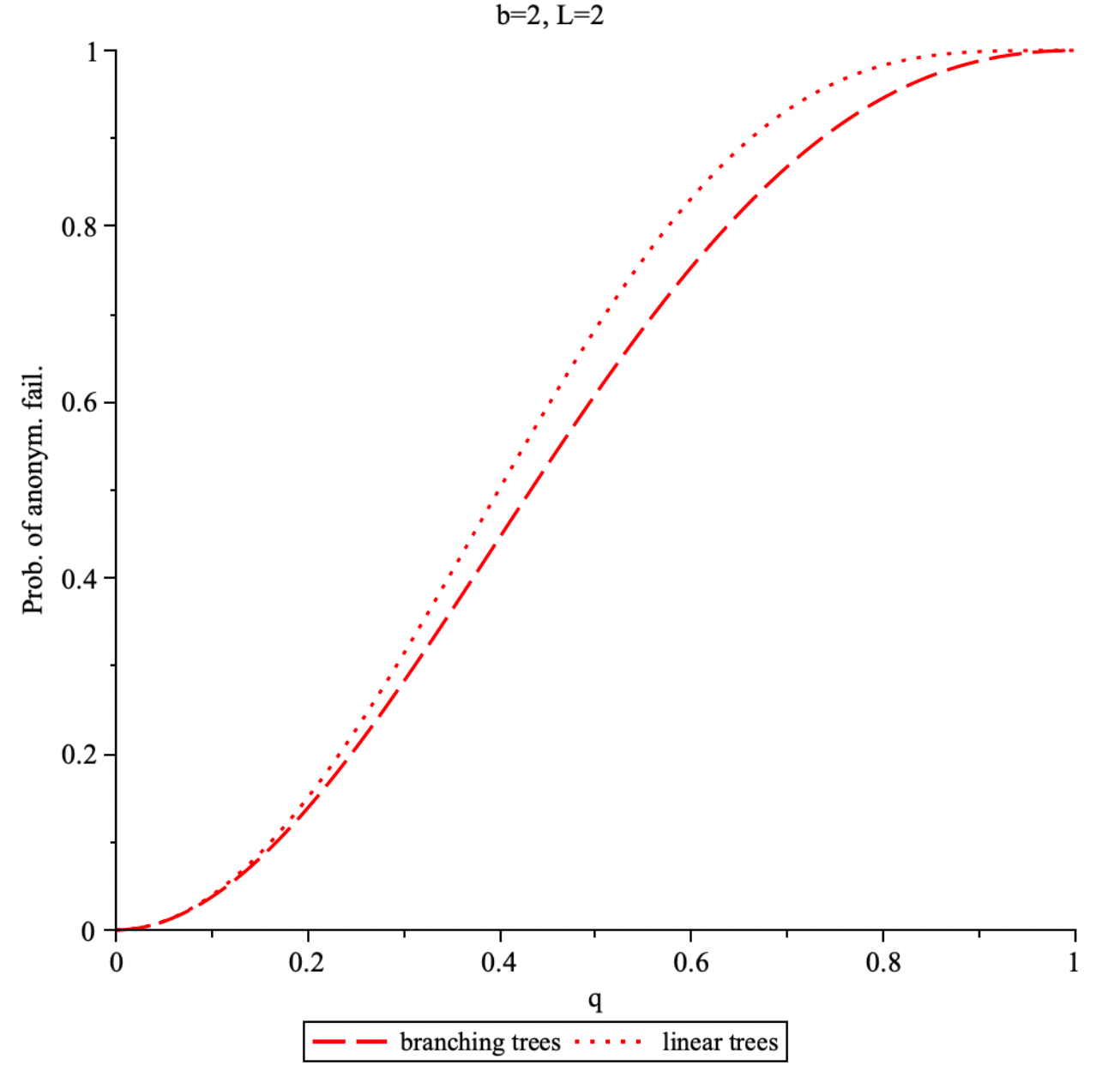
We want to find a solution that minimises both failure probabilities. Plotting one prob. against another gives us
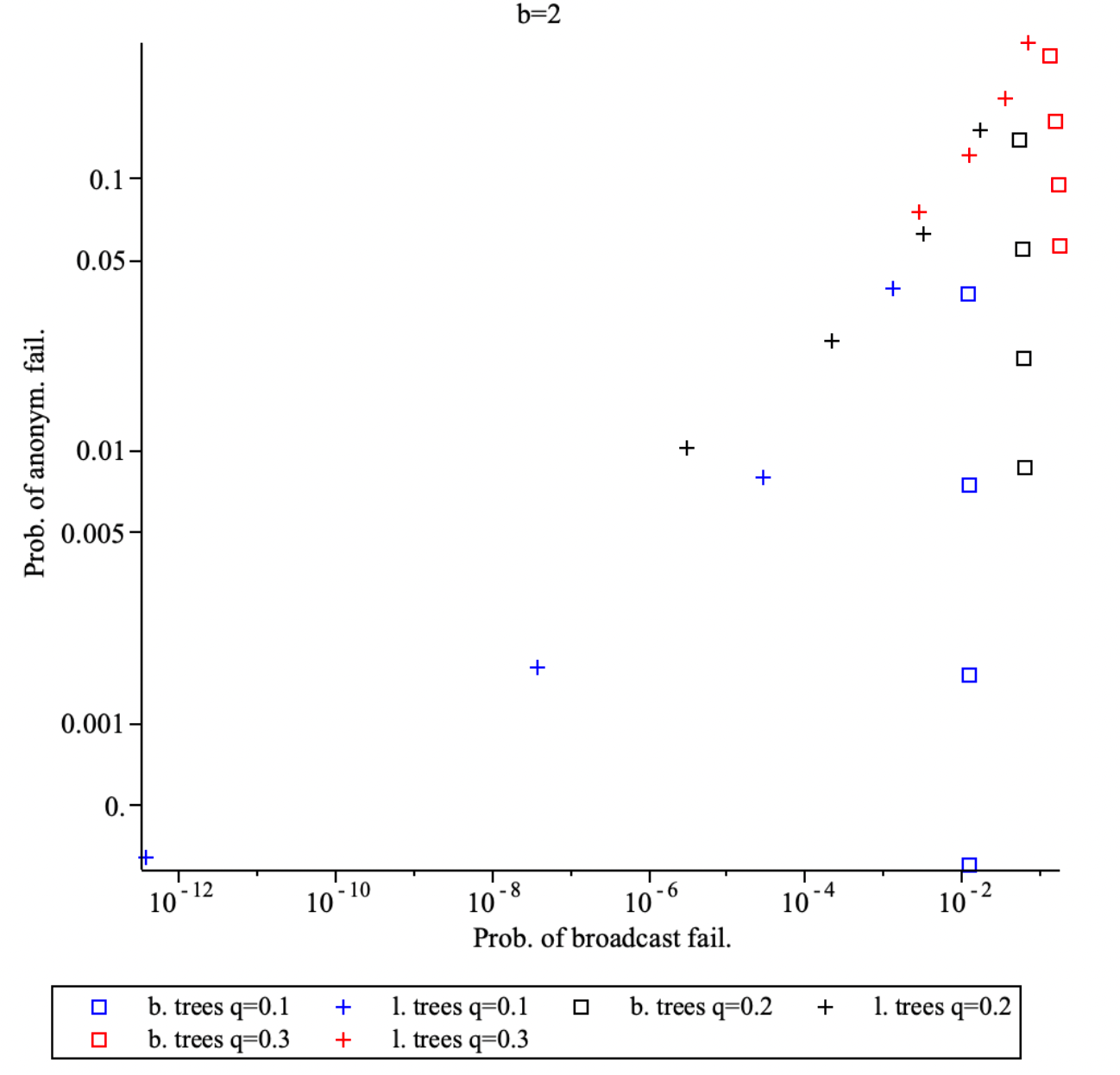
We note that in above is increasing from top to bottom. For linear tree design both probabilities are minimal for , i.e. maximum number of layers. For branching tree design we can not minimise both probabilities , but the probability of anonymity failure is always less than in the linear tree design for any . Also, we note that linear trees design has better communication failure properties since it consists of independent paths. Paths in branching trees design share nodes which increases the ramifications of communication failure at an interior node. On the other hand, linear trees has worse anonymity properties since it consists of more nodes to form the paths.
Discussion of failure model
The current approach, where we label a node by a single binary (random) variable, can be used to model only communication failures or anonymity failures but not both. When both communication and anonymity failures are modelled with a single binary variable then this can be interpreted as a scenario where an adversary controls some number of nodes in a tree. Then it uses these nodes to cause broadcast failure or anonymity failure. Hence here a probability of failure can interpreted as frequency of adversarial opportunities to cause failures.
We note that in above single-variable approach adversary is cause of both communication and anonymity failures, when both of these failures are considered together. However, in real world scenario communication failures can occur “naturally” and independently from adversarial behaviour. The latter can also cause communication failures, but natural failures can for e.g. interfere with adversary’s ability to cause anonymity failure which is not accounted for in the current single-variable model.
We note that an adversary can use communication failures to provoke node operators to increase number of communication paths, but the latter could increase chances of anonymity failure. Such adversarial strategy can be used in the linear design for example.
In order to separate “natural” communication failures from adversarial, we need to introduce two (random) binary variables which will be associated with a node. One variable to model natural communication failures of nodes and the other variable is an adversarial “label”, i.e. second variable labels a node as "adversarial" or "honest". The adversary will choose on how to use nodes it controls. It can use these nodes to cause communication failure, anonymity failure, etc. From analysis perspective a two-variable model is not much more complex than single-variable model, but will allow us to separate better adversarial failures from non-adversarial.
Communication on Linear Trees: two-variable failure model
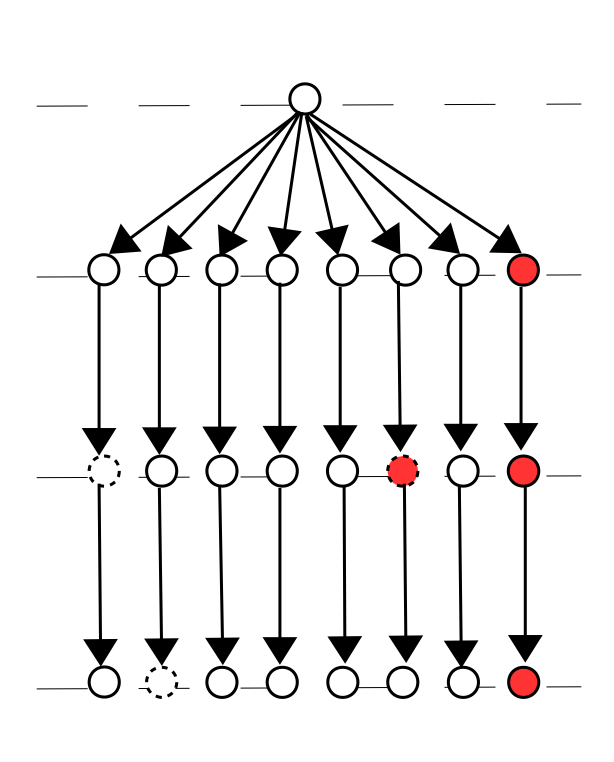
Communication on Linear Trees. A message is sent from a node through communication paths where each path has nodes. A node could be faulty (circle with dashed boundary), or adversarial (red circle). Presence of faulty node leads to communication failures. Presence of adversarial nodes could lead to communication and anonymity failures.
We assume that a node sends a message through communication paths where each path contains exactly nodes. We assumed that nodes were sampled with replacement from the population of nodes.
Analysis of broadcast failure
We assume that nodes in the population are “faulty” (faulty node is unable to relay a message). The probability that a node is faulty is . If a path contains at least one faulty node then communication failure occurred. If all nodes in a communication path are non-faulty then this is a functioning communication path. If all paths have communication failure then broadcast failure occurred. The probability of broadcast failure is given by
We note that is (monotonic) decreasing function of and (monotonic) increasing function of . Above result is intuitive as increasing number of communications paths (of fixed length) increases chances that at least one of these paths is functional. Also increasing length of paths (for a fixed number of paths) increases chances that in each path at least one node is faulty. For , with fixed, the prob. and for , with fixed, the prob. .
We note that anonymity properties are improved for larger (see Analysis of anonymity failure) and we would like to find a relation between and such that we have both good communication and anonymity properties. Let us assume that , where , and consider the prob. . For the latter we have the following inequality
where in above we used to obtain inequality. Hence for we can have when as .
We note that and hence for any the following condition
ensures that when . Above suggests
where , i.e. the number of paths has to grow exponentially with to ensure that when .
Analysis of anonymity failure
We assume that nodes in the population are “adversarial”; adversarial nodes are controlled by an adversary which can make nodes faulty, use them for traffic analysis, etc. The probability that a node is adversarial is . If there is at least one functioning communication paths where all nodes are adversarial, then adversary has opportunity to cause anonymity failure. The probability of anonymity failure is given by
We note that is (monotonic) increasing function of and (monotonic) decreasing function of . Also is monotonic increasing function of and hence monotonic decreasing function of . For , with fixed, the prob. and for , with fixed, the prob. .
Let us assume that , where , and consider the prob. . For the latter we have the following inequality
Hence for we can have when as . We note that when and hence is the dominant term in . Thus when as .
Let us assume and consider
From above follows that as when . Hence, if is such that then the number of comm. paths ensures that and as .
Analysis of adversarial broadcast-failure
If there is at least one adversarial node in each functioning communication paths then adversary has opportunity to cause broadcast failure. The probability of adversarial broadcast failure is given by
We note that and hence is bounded from above by (monotonic) decreasing function of and (monotonic) increasing function of . For , with fixed, the prob. and for , with fixed, the prob. .
Let us assume and consider
Hence when as . Furthermore, we can obtain the lower bound on as follows
We note that and hence for such that , as , but we have .
For we have
From above, it follows that if , which is equivalent to , then when . Thus to have , , and as we have to choose
for the number of paths with
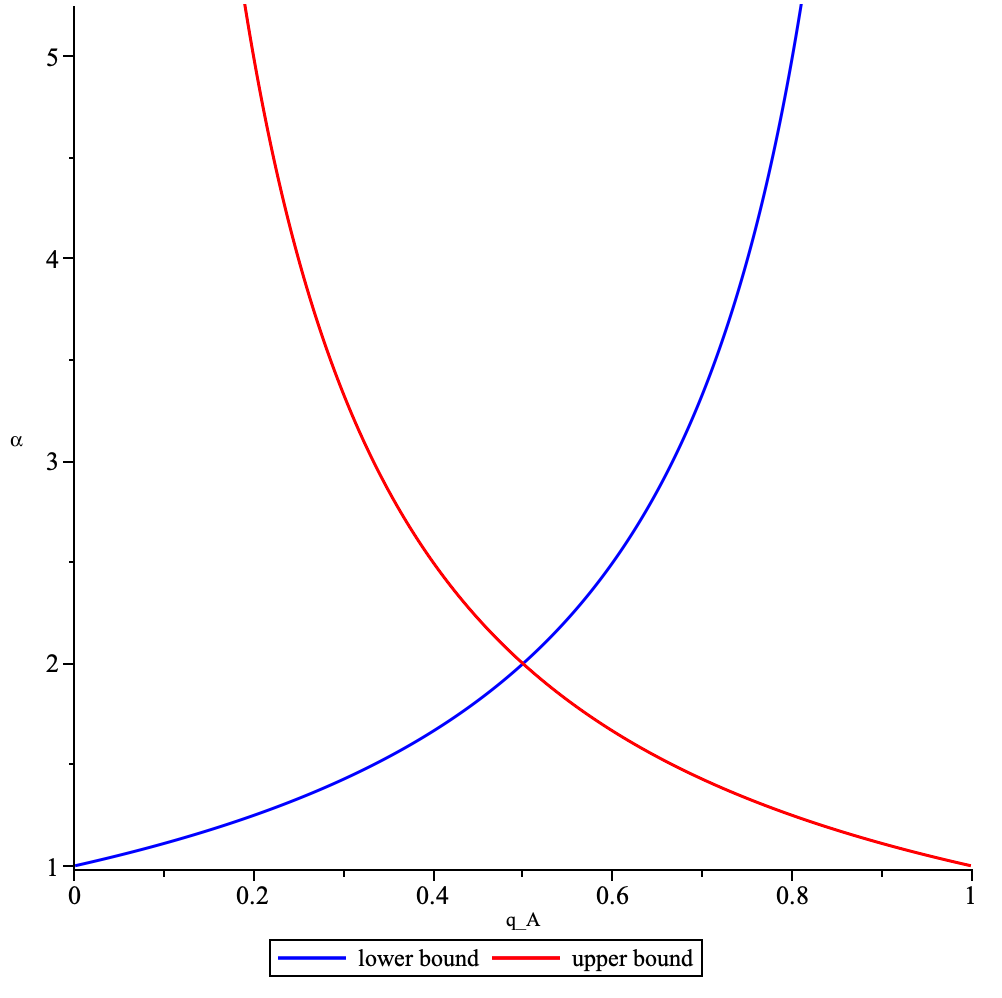
The lower bound and upper bound on parameter plotted as a function of .
Analysis of failures
Using the expression , where is the number of nodes in a path and parameter such that , for the number of paths in the upper bounds on failure probabilities , , and we obtain the following inequalities
and for any all of the above are vanishing as . From above follows that broadcast failure probabilities and are tending to with increasing at a much higher rate for a larger values of , but the anonymity failure prob. is tending to at a much higher rate for a smaller values of .
We note that the number of comm. paths and the number of nodes involved in communication , which is bounded by the number of nodes in the network , is growing slowly (with ) when is small and very fast when is large when we increase the number of nodes per path . For values of close to probabilities of broadcast failures are tending to with increasing at a much lower rate than the prob. of anonymity failure as can be seen in the figures below
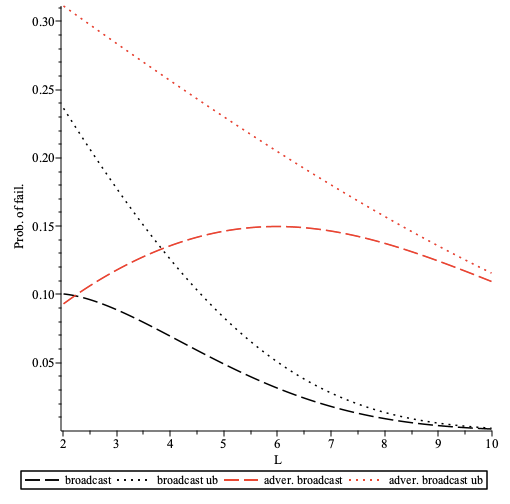
Probability of comm. failure as a function of plotted for and . The number of communication paths is given by , where . Here .
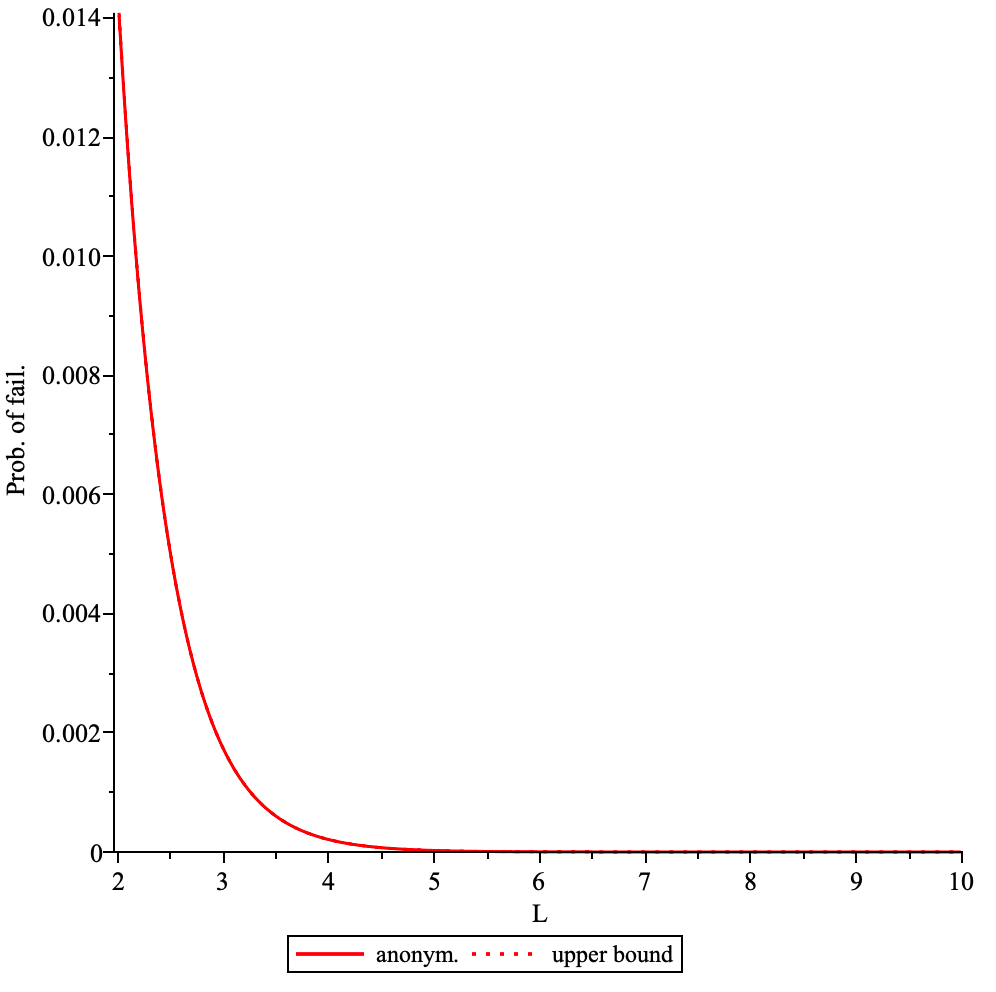
Probability of anonymity failure as a function of plotted for and . The number of communication paths is given by , where . Here .
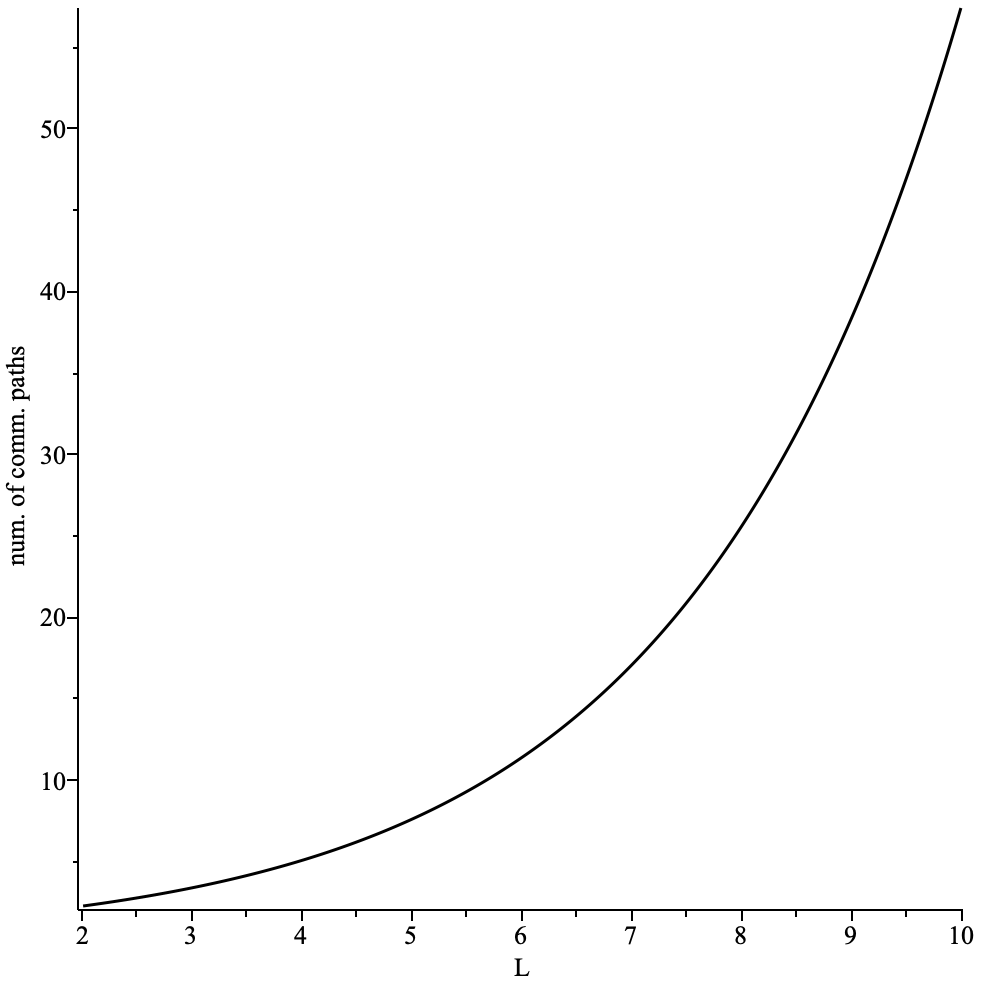
The number of communication paths as a function of plotted for and .
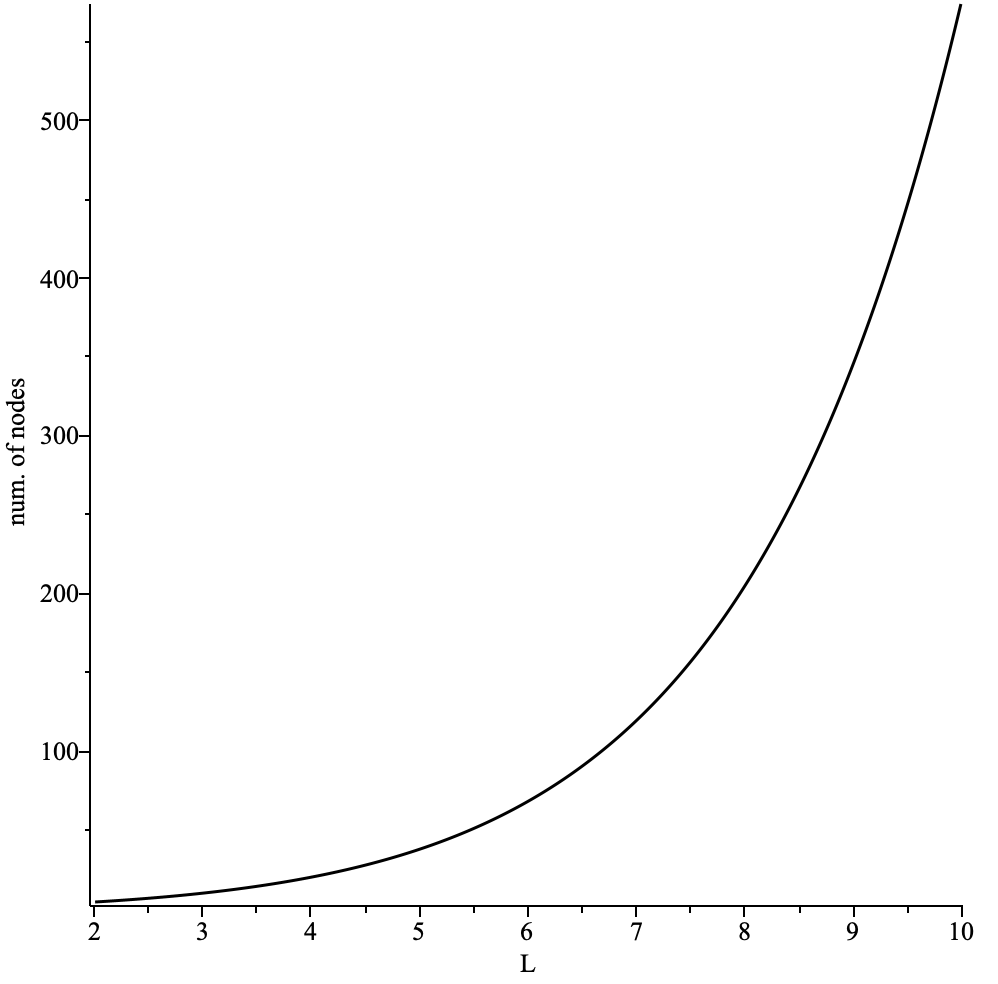
The number of nodes in communication paths as a function of plotted for and .
For values closer to probabilities of broadcast failures are tending to with increasing at a much higher rate than the prob. of anonymity failure as can be seen in the figures below
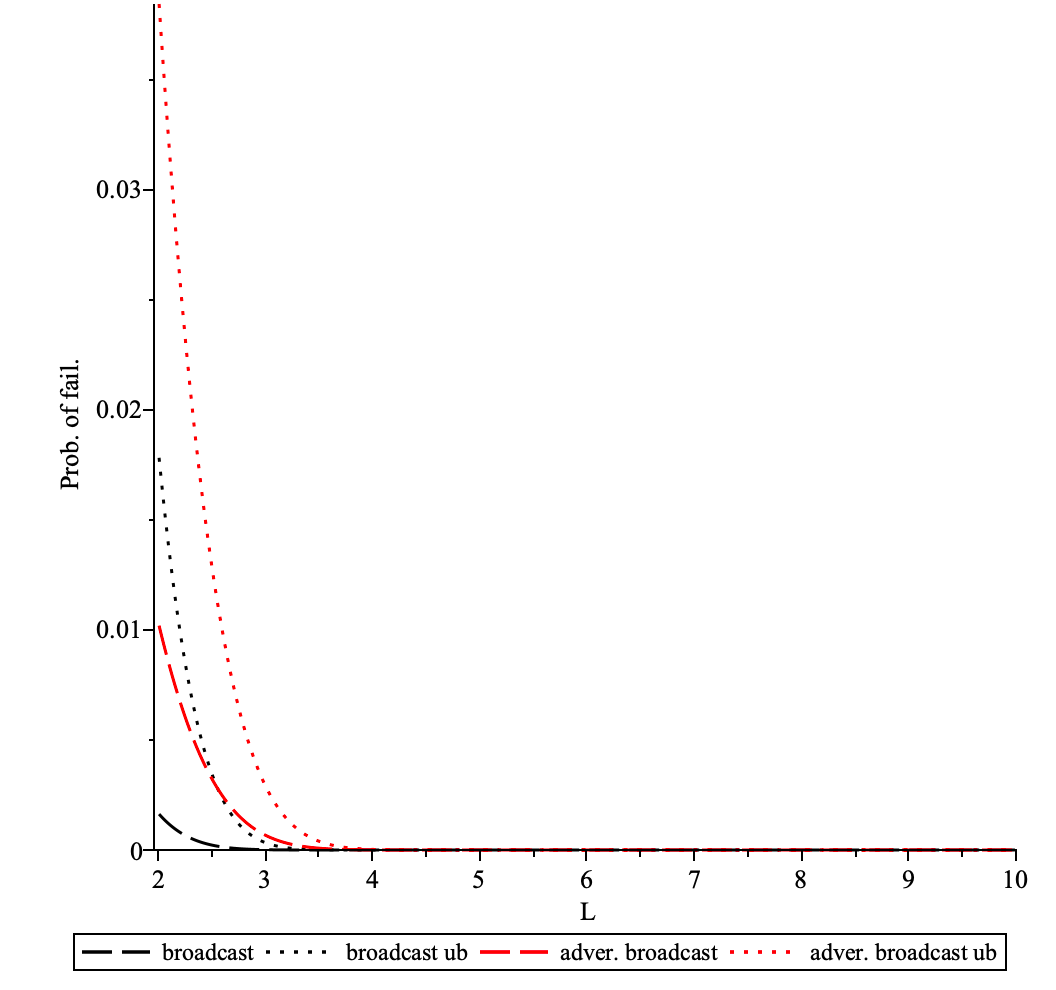
Probability of comm. failure as a function of plotted for and . The number of communication paths is given by , where . Here .
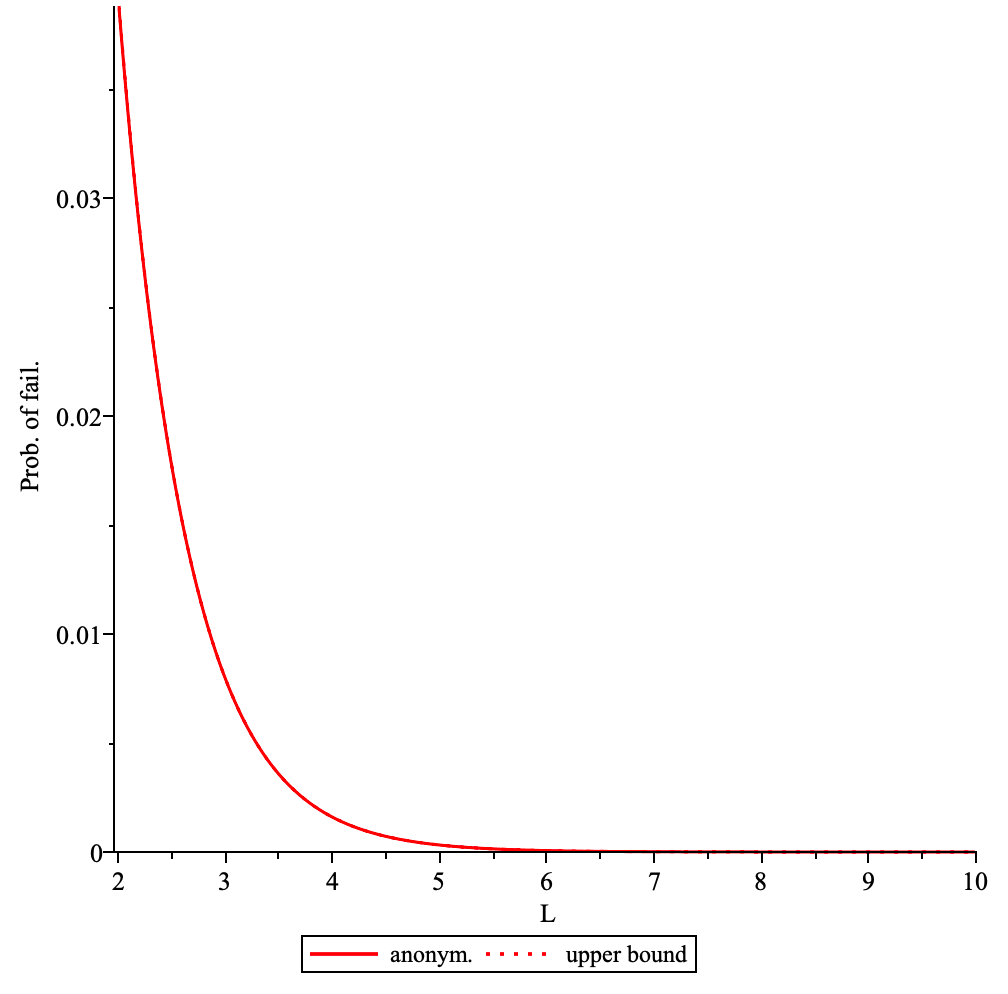
Probability of anonymity failure as a function of plotted for and . The number of communication paths is given by , where . Here .
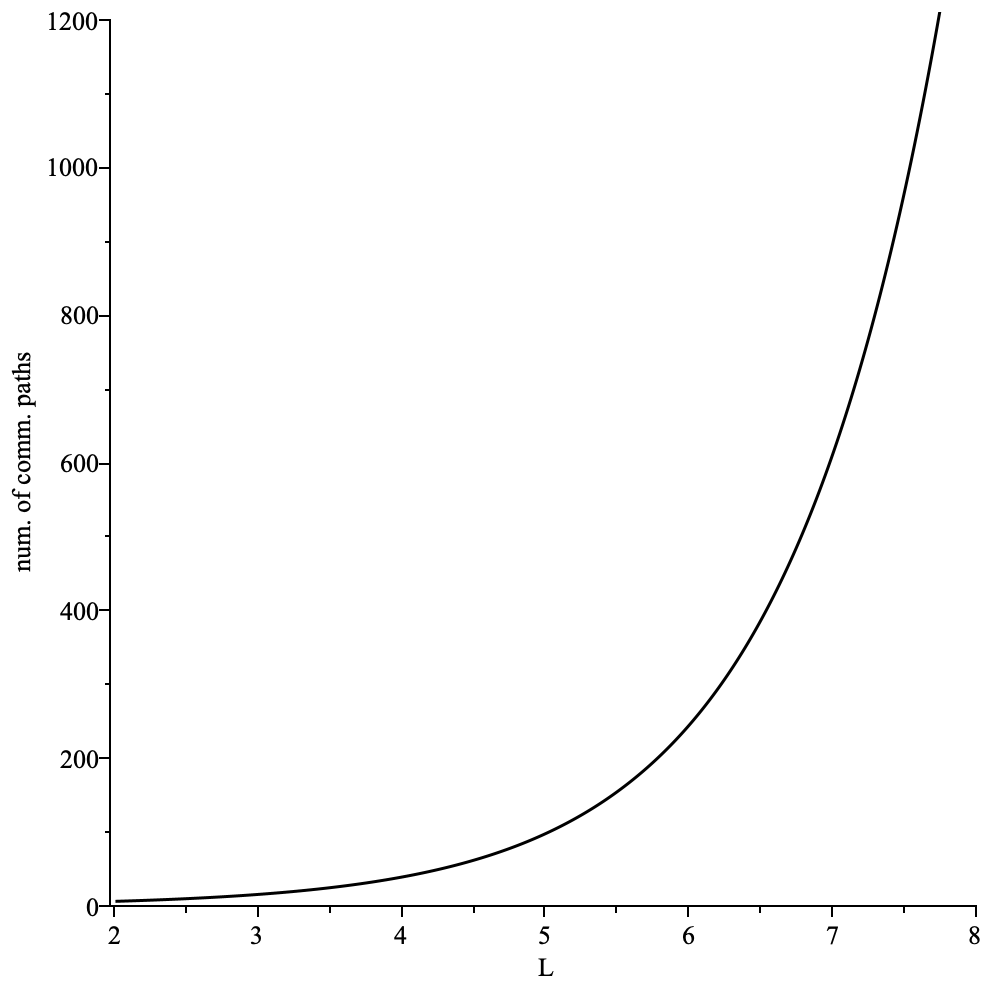
The number of communication paths as a function of plotted for and .
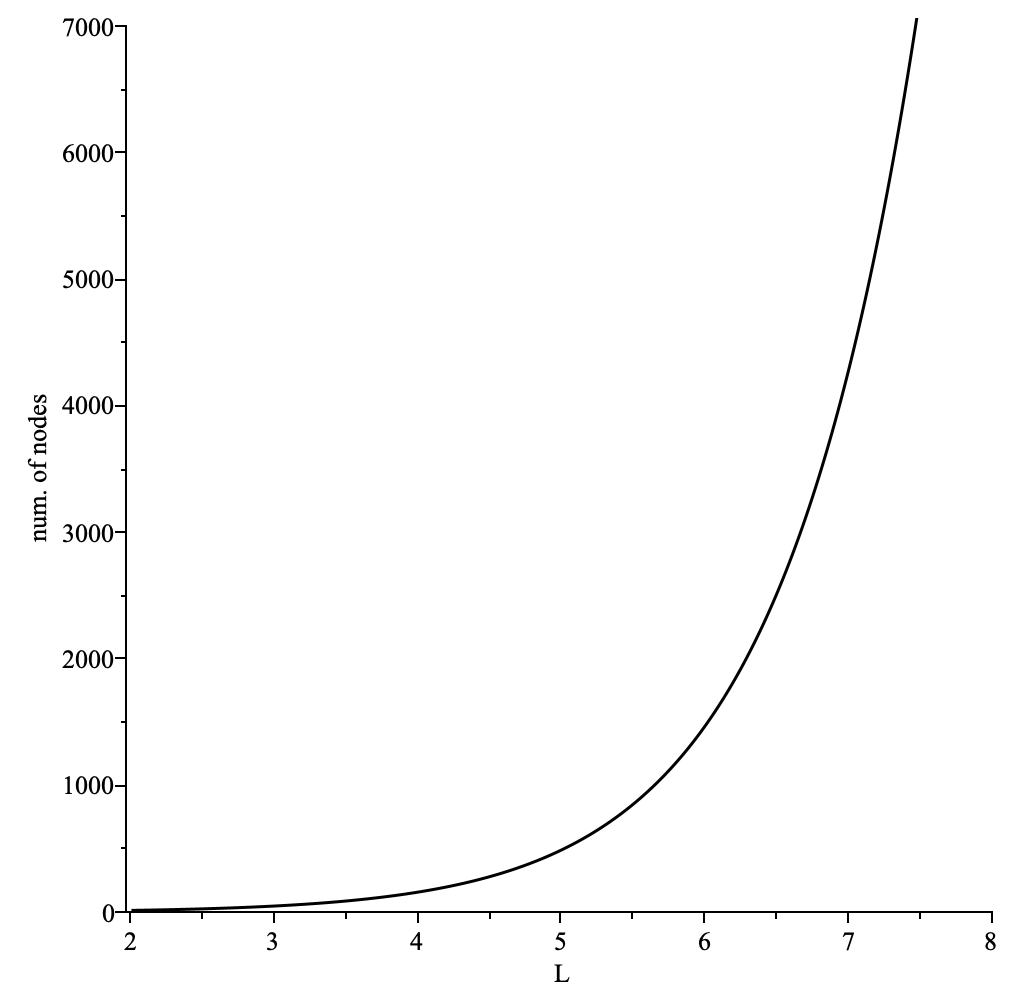
The number of nodes in communication paths as a function of plotted for and .
For outside of the interval we have that either the broadcast failure probabilities are increasing and anonymity failure prob. is decreasing with increasing when or the broadcast failure probabilities are decreasing and anonymity failure prob. is increasing with increasing when .
We note that , §11, and . The latter implies that for finite the broadcast failure probabilities are reduced when we increase , i.e. when the number of communication paths is increased. However, for finite the probability of anonymity failure is reduced when we decrease , i.e. when the number of communication paths is decreased. This behaviour of failure probabilities for finite can be seen in the plots below.
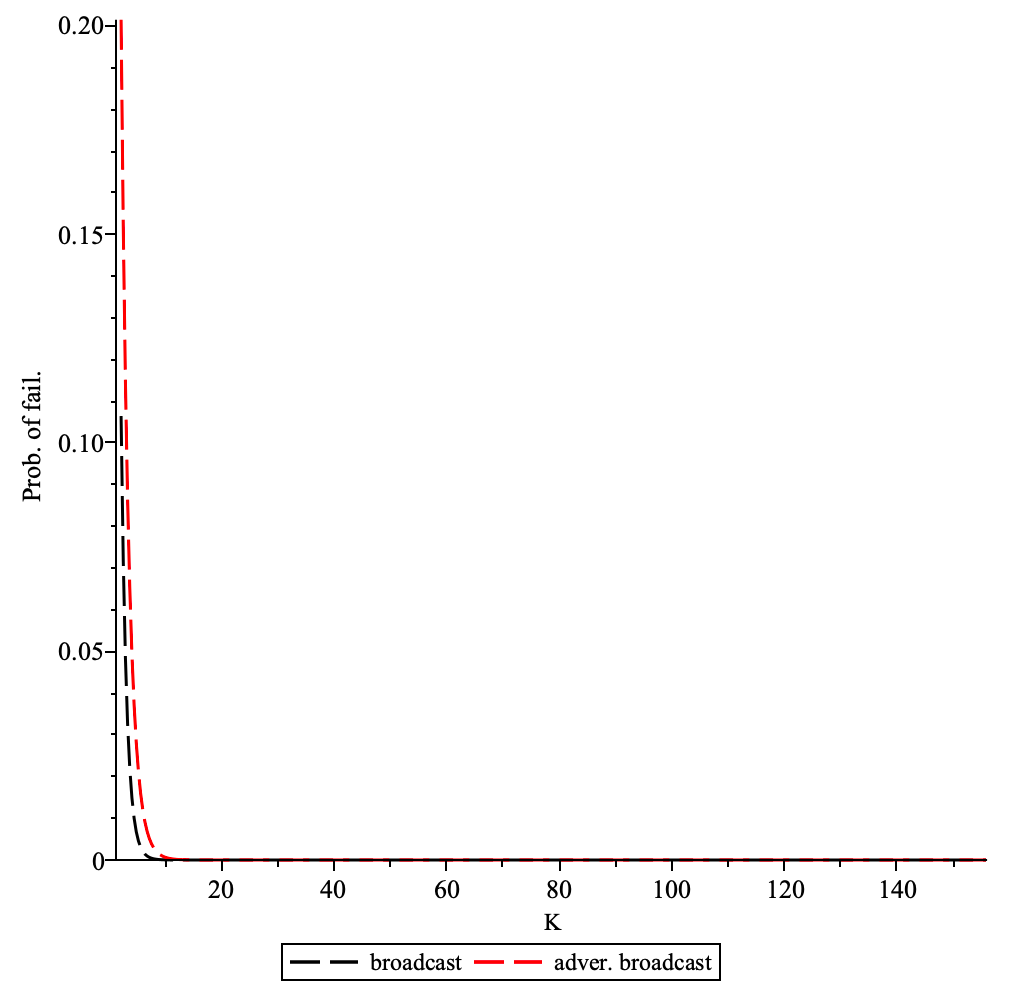
Probability of comm. failure as a function of the number of communication paths plotted for , and . Here is for .
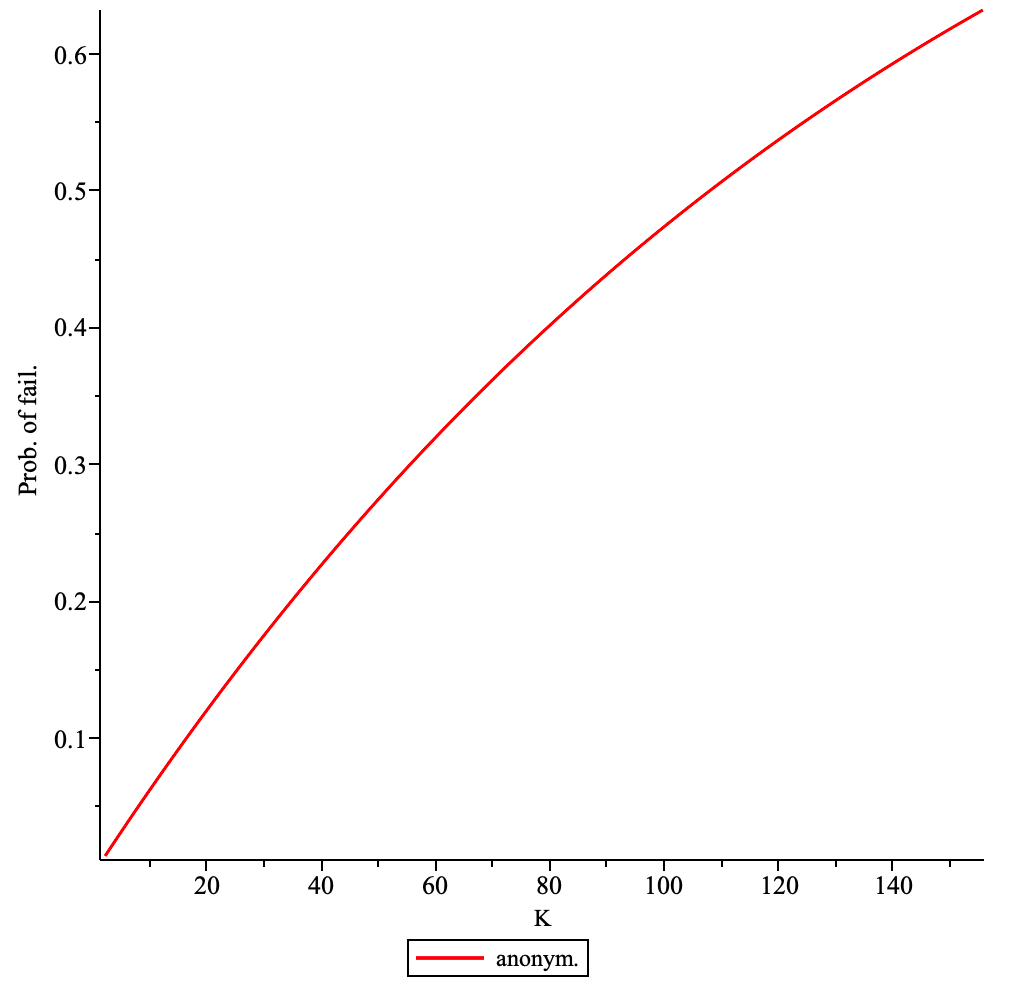
Probability of anonymity failure as a function of the number of communication paths plotted for , and . Here is for .
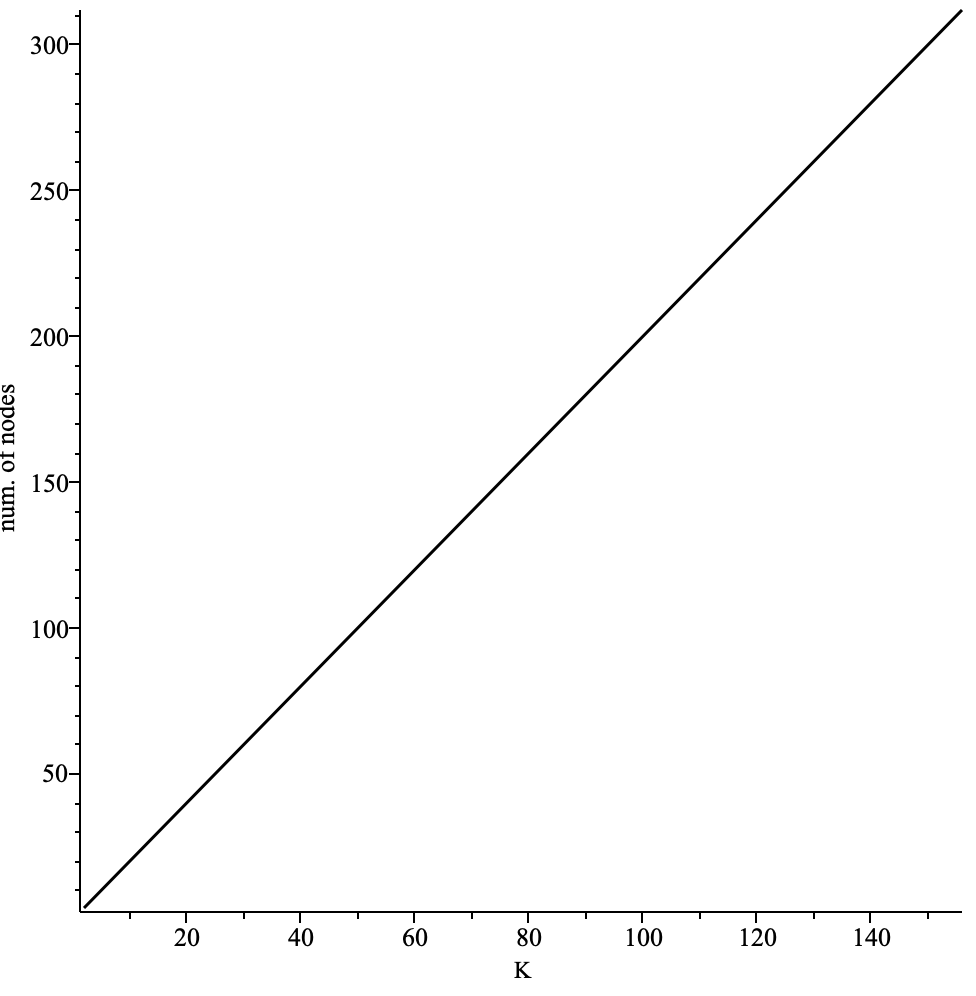
The number of nodes involved in communication as a function of the number of comm. paths plotted for .
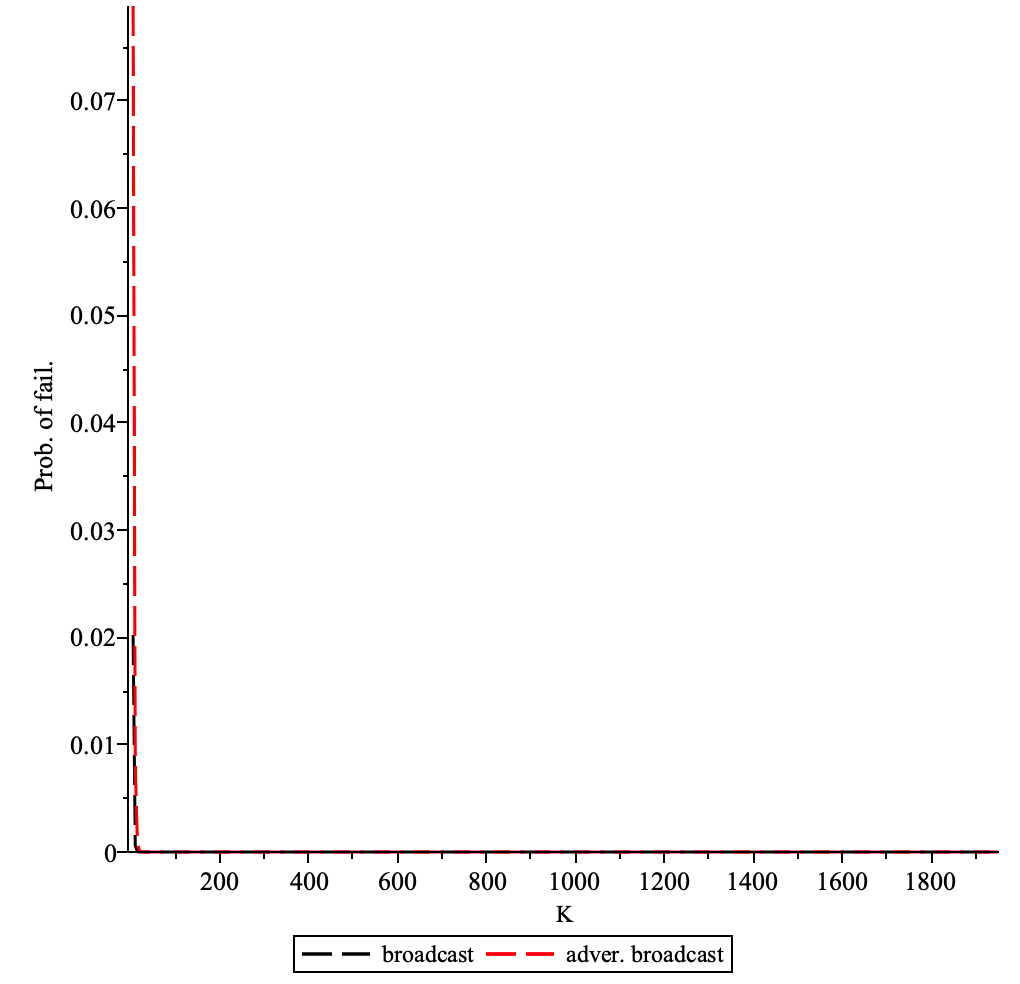
Probability of comm. failure as a function of the number of communication paths plotted for , and . Here is for .
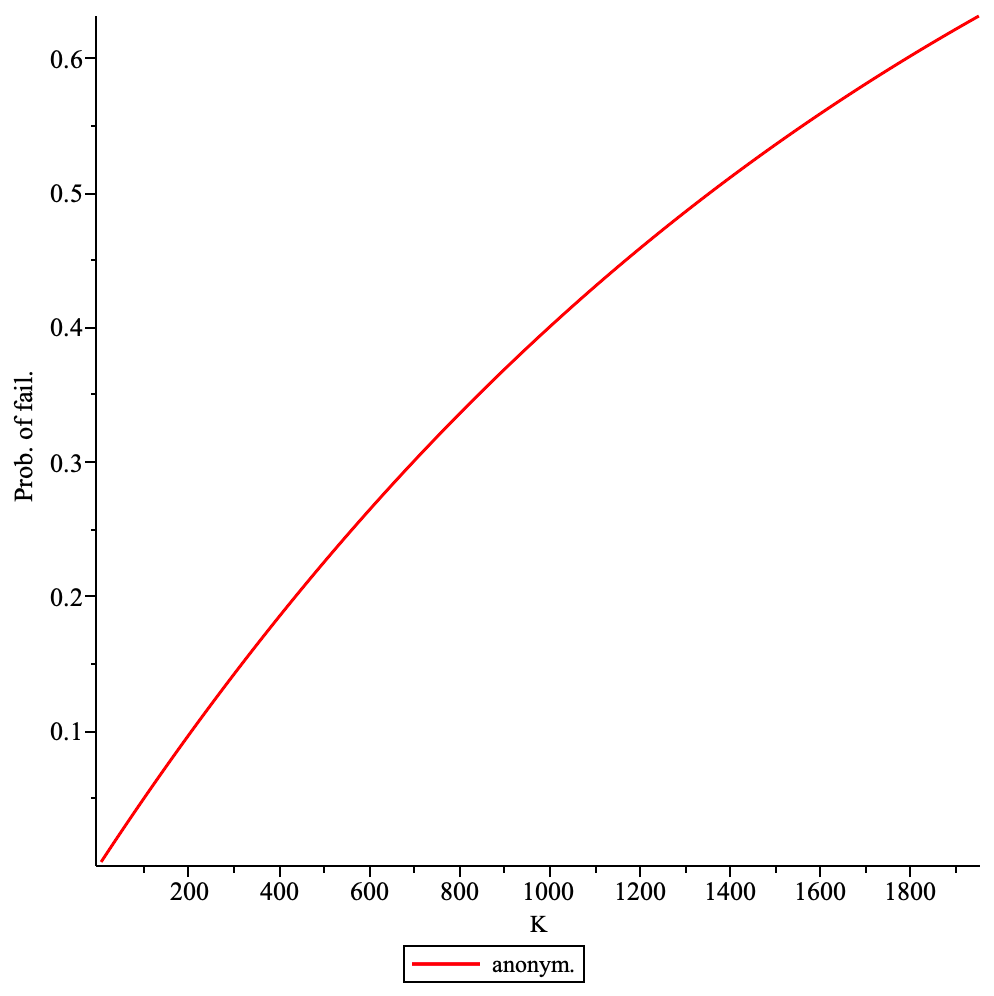
Probability of anonymity failure as a function of the number of communication paths plotted for , and . Here is for .
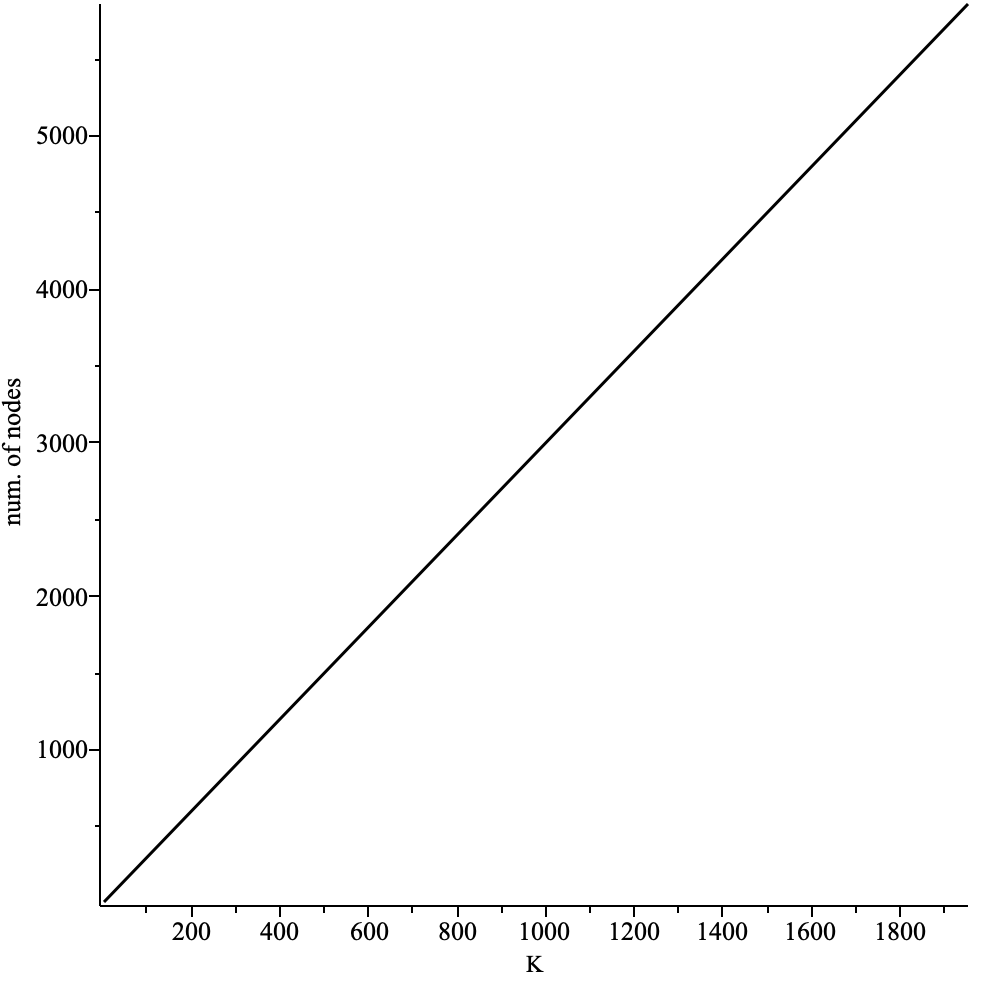
The number of nodes involved in communication as a function of the number of comm. paths plotted for .
Simulation results
Above analytic expressions, derived for infinite number of random samples, for failure probabilities are in good agreement with probabilities computed from a finite number of samples obtained in simulations as can be seen in figures below
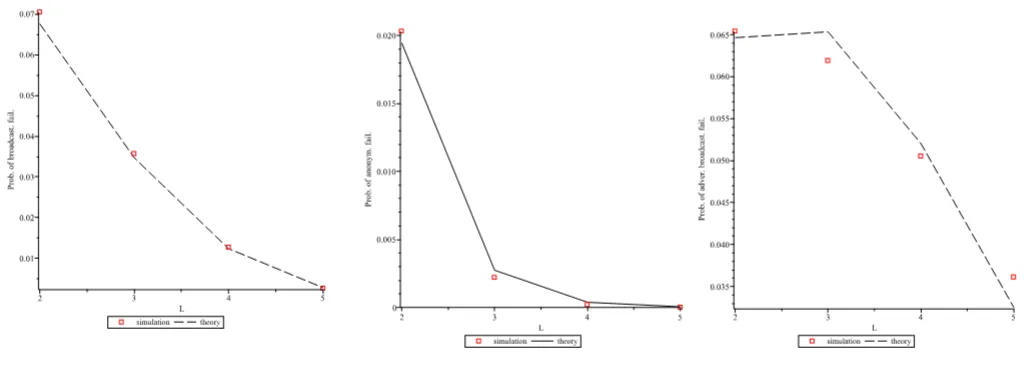
Analysis of failures in linear trees with layers. Left: The probability of broadcast failure plotted as a function of number of layers for the (average) fraction of faulty nodes. Center: The probability of anonymity failure plotted as a function of the number of layers for the (average) fraction of adversarial nodes and . Right: The probability of adversarial broadcast failure plotted as a function of the number of layers for and . In simulation probabilities were computed from samples.
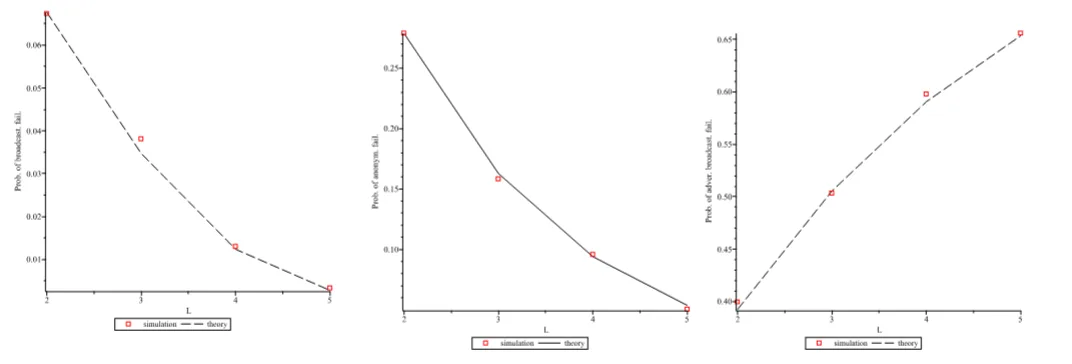
Analysis of failures in linear trees with layers. Left: The probability of broadcast failure plotted as a function of number of layers for the (average) fraction of faulty nodes. Center: The probability of anonymity failure plotted as a function of the number of layers for the (average) fraction of adversarial nodes and . Right: The probability of adversarial broadcast failure plotted as a function of the number of layers for and . In simulation probabilities were computed from samples.
We note that the number of samples in above figures is equivalent to the number of messages sent by a sender node.
Communication on Branching Trees: two-variable failure model
Assumptions
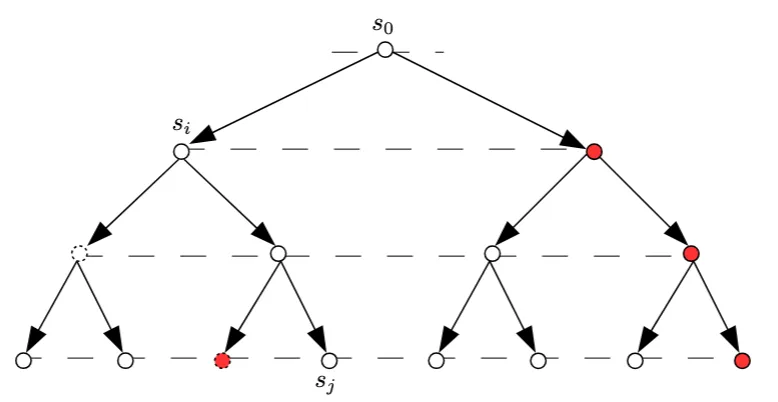
Communication on a (balanced and complete) tree . The layers in the tree are labeled by the set (bottom to top). A message is sent from the root node (layer ) to the leaf nodes (layer ). All leaf nodes of the tree constitute its boundary . Each node in the tree, but the root, has associated with it binary random variable. A node could be faulty (circle with dashed boundary), or adversarial (red circle). Presence of faulty node leads to communication failures. Presence of adversarial nodes could lead to communication and anonymity failures.
We consider broadcast on a tree (see figure above) constructed from nodes sampled (with replacement) from the nodes of the network. We assume that nodes in the network are “faulty” (faulty node is unable to relay a message) and the probability that a sampled node is faulty is . We assume that nodes in the network are “adversarial” (Adversarial nodes are controlled by an adversary which can make nodes faulty, use them for traffic analysis, etc.) and the probability that a sampled node is adversarial is .
We assume that the root node of sends a message to all leaf nodes. The root node is labeled by and all leaf nodes constitute the set . We assume that each node can fail to relay the message with probability independently from other nodes. We assume that a node can be adversarial with probability independently from other nodes.
Let us define the binary variable for a node in some communication path. A node is faulty/not-faulty when with probability . If the sum of all variables of nodes on the path from the root to some leaf node , , is less than , i.e. then there is at least one faulty node in this path. Hence, node did not receive the message, i.e. communication failure occurred. If all nodes in a communication path are non-faulty then this is a functioning communication path. If , i.e. each comm. path contains at least one faulty node, then all leaf nodes didn't receive the message, i.e. broadcast failure occurred.
Also we define the binary variable . A node is “honest/adversarial” when with probability . If and , i.e. all functioning communication paths have at least one adversarial node, then adversary has opportunity to cause broadcast failure. If , i.e. there is at least one functioning communication paths where all nodes are adversarial, then adversary has opportunity to cause anonymity failure. We note that above definition of anonymity failure is equivalent to the event . Here the counts number of adversarial nodes on the path .
Analysis of broadcast failure
The probability of broadcast failure is give by , where the prob. can be computed recursively (see the Details of derivations section) as follows
The above equation has only one solution , which corresponds to prob. of broadcast failure being , when . However, the fixed point becomes unstable when and a second (stable) solution , which corresponds to prob. of broadcast failure being less than , emerges.
Analysis of anonymity failure
The probability of anonymity failure is give by , where can be computed recursively (see the Details of derivations section) as follows
The above equation has only one solution , which corresponds to prob. of anonymity failure being , when . However, the fixed point becomes unstable when and a second (stable) solution , which corresponds to prob. of anonymity failure being greater than , emerges.
From above follows that we would like to have and as it allows us to make failure prob. arbitrarily small by increasing the number of layers . The latter gives us conditions for this in the inequalities and . The threshold is increasing with the branching ratio , i.e. when for higher values of , but the threshold is decreasing with , i.e. when for lower values of . Also is increasing function of .
Analysis of adversarial broadcast-failure
We have exploited a recursive property of on trees (see equation (48) in the Details of derivations) to derive expressions for the prob. of broadcast and anonymity failures, however if such recursive approach is possible in analysis of adversarial broadcast-failure is not clear. In particular we don’t know how to estimate probability of the event
analytically. However for , i.e. there are no faulty nodes, we know from ourearlier analysis that the probability of adversarial broadcast failure is strictly less than as when .
Simulation results
Above analytic expressions, derived for infinite number of random samples, for failure probabilities are in good agreement with probabilities computed from a finite number of samples obtained in simulations as can be seen in figures below
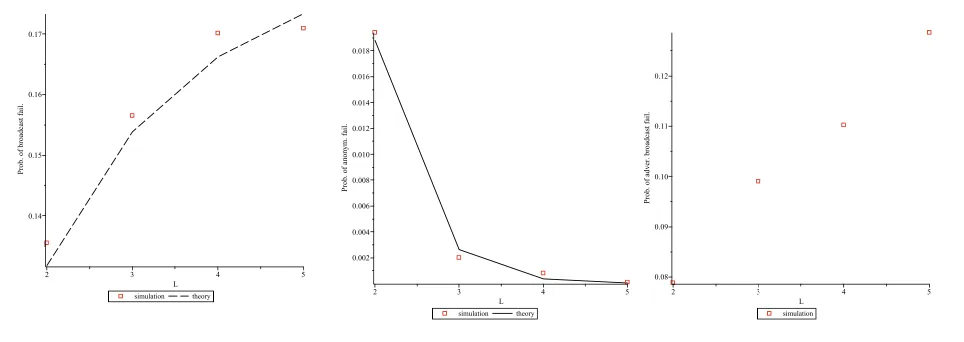
Analysis of failures in branching trees with branching factor . Left: The probability of broadcast failure plotted as a function of number of layers for the (average) fraction of faulty nodes. Center: The probability of anonymity failure plotted as a function of the number of layers for the (average) fraction of adversarial nodes and . Right: The probability of adversarial broadcast failure plotted as a function of the number of layers for and . In simulation probabilities were computed from samples.
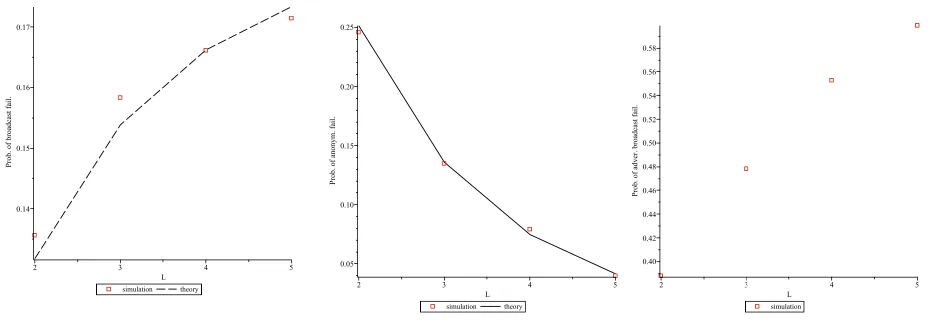
Analysis of failures in branching trees with branching factor . Left: The probability of broadcast failure plotted as a function of number of layers for the (average) fraction of faulty nodes. Center: The probability of anonymity failure plotted as a function of the number of layers for the (average) fraction of adversarial nodes and . Right: The probability of adversarial broadcast failure plotted as a function of the number of layers for and . In simulation probabilities were computed from samples.
Discussion of results for linear and branching tree designs: two-variable failure model
To compare linear and branching tree designs we assume that both have the same number of paths , where is branching parameter and is the number of layers (see diagram of linear trees and diagram of branching tree). The differences between designs when above assumption is used were discussed above.
First, we consider the prob. of broadcast failure for values of below and above the threshold plotted in the figure below.
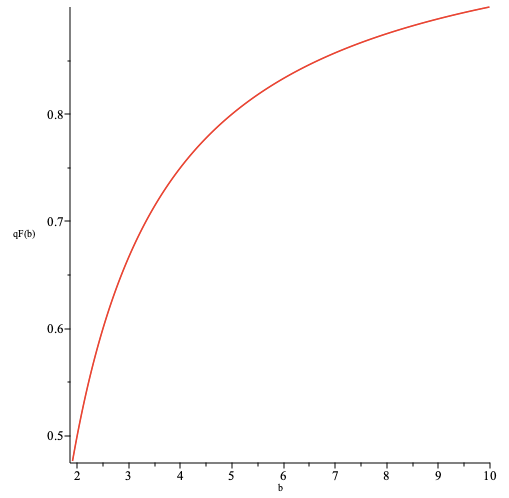
The threshold plotted as a function of branching ratio . For the prob. of broadcast failure in branching trees is strictly less than even for infinite number of layers . For the prob. of broadcast failure in branching trees is tending to with increasing number of layers .
For the branching parameter the prob. of broadcast failure, , in linear trees is smaller than in the branching trees as can be seen in the figure below. We note that in linear trees the prob. as when and when . The threshold follows from the condition , which ensures , in the linear trees analysis.
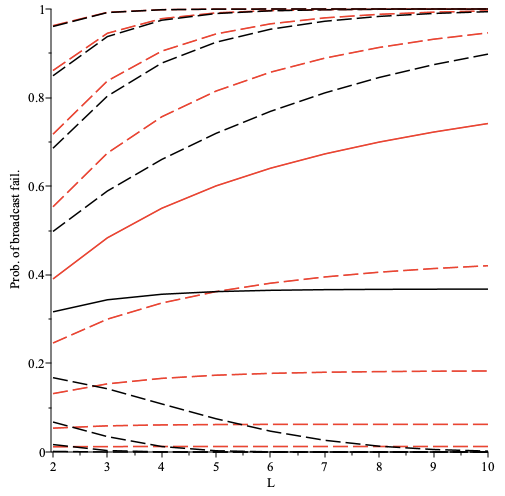
The prob. of broadcast failure in linear (black lines) and branching (red lines) trees as a function of the number of layers plotted for fraction of faulty nodes (bottom to top) and branching parameter . Solid lines correspond to .
However, the number of nodes involved in communication grows much faster in linear trees as can be seen in the figure below.
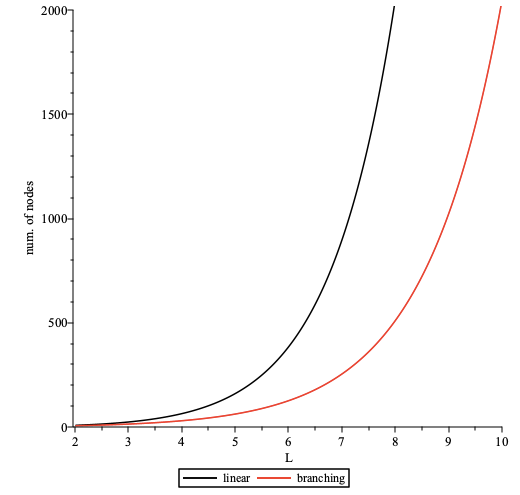
The number of nodes involved in communication as function of number of layers plotted for the branching parameter .
As we increase the branching parameter the probability of broadcast failure is reduced for each number of layers as can be seen in the figure below
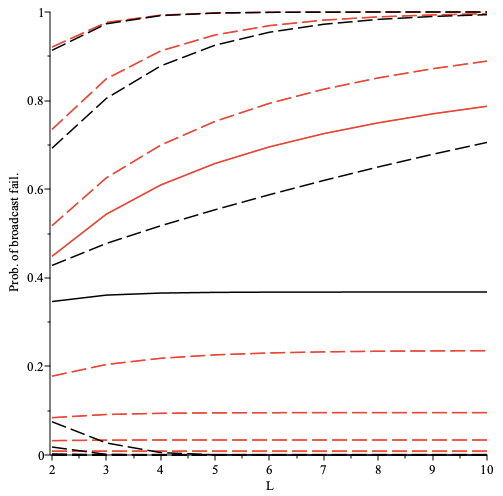
The prob. of broadcast failure in linear (black lines) and branching (red lines) trees as a function of the number of layers plotted for fraction of faulty nodes (bottom to top) and branching parameter . Solid lines correspond to .
However, the number of nodes involved in communication is growing much faster with the number of layers for higher values of the branching parameter (cf. figure below and figure above)
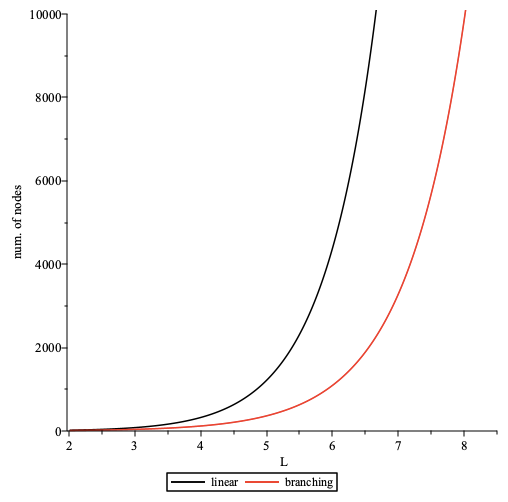
The number of nodes involved in communication as function of number of layers plotted for the branching ratio .
Second, we consider the prob. of anonymity failure for values of below and above the threshold plotted in the figure below.
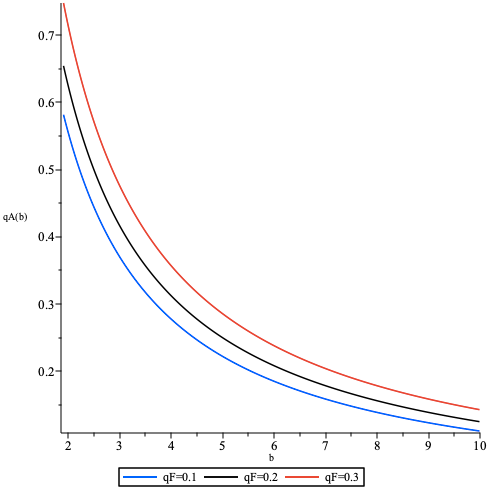
The threshold as a function of branching parameter . For the prob. of anonymity failure in branching trees as the number of layers . For the prob. of anonymity failure in branching trees is tending to some value as the number of layers .
For the branching parameter the prob. of anonymity failure, , in linear trees is higher than in the branching trees as can be seen in the figure below. We note that in linear trees the prob. as when and when . The threshold follows from the condition , which ensures , in the linear trees analysis. For branching trees we have as when but when .
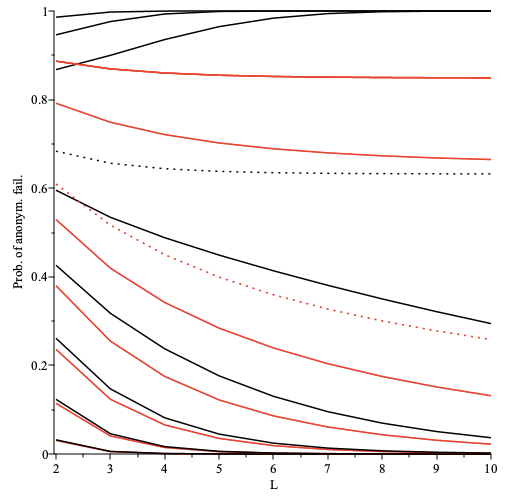
The prob. of anonymity failure in linear (black lines) and branching (red lines) trees as a function of the number of layers plotted for fraction of adversarial nodes (bottom to top), fraction of faulty nodes and branching parameter . Dotted lines correspond to .
As we increase the probability of anonymity failure is reduced for each number of layers as can be seen in figures below
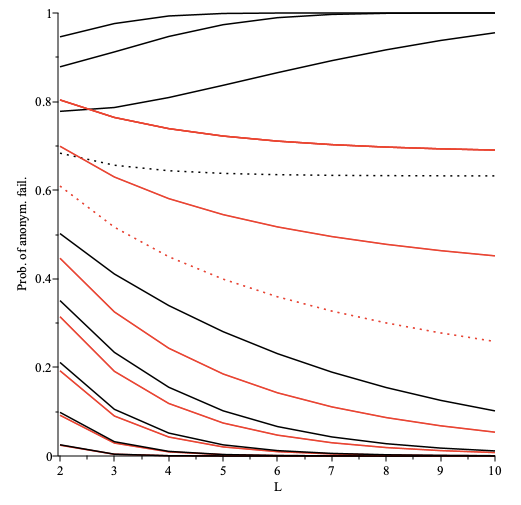
The prob. of anonymity failure in linear (black lines) and branching (red lines) trees as a function of the number of layers plotted for fraction of adversarial nodes (bottom to top), fraction of faulty nodes and branching parameter . Dotted lines correspond to .
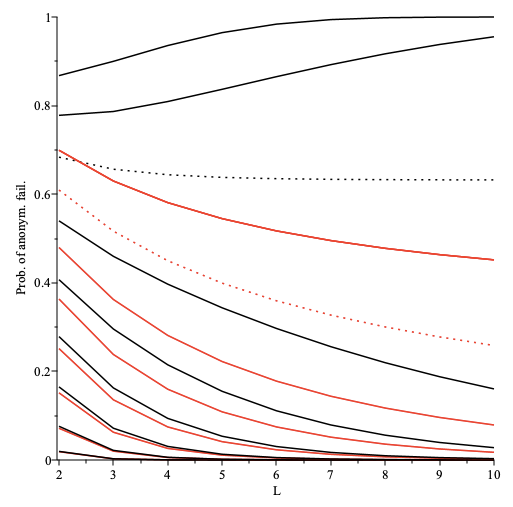
The prob. of anonymity failure in linear (black lines) and branching (red lines) trees as a function of the number of layers plotted for fraction of adversarial nodes (bottom to top), fraction of faulty nodes and branching parameter . Dotted lines correspond to .
As we increase the branching parameter the probability of anonymity failure is increased for each number of layers as can be seen in figures below
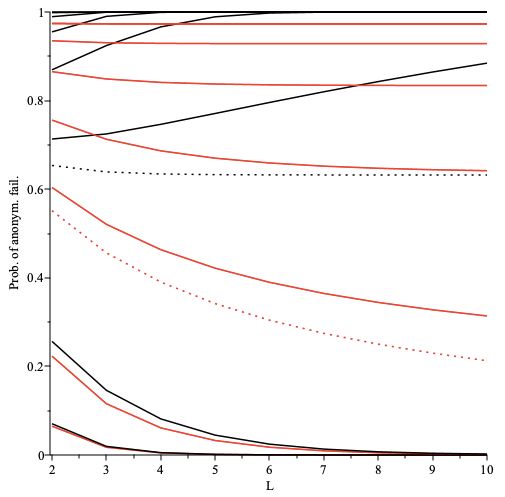
The prob. of anonymity failure in linear (black lines) and branching (red lines) trees as a function of the number of layers plotted for fraction of adversarial nodes (bottom to top), fraction of faulty nodes and branching parameter . Dotted lines correspond to .
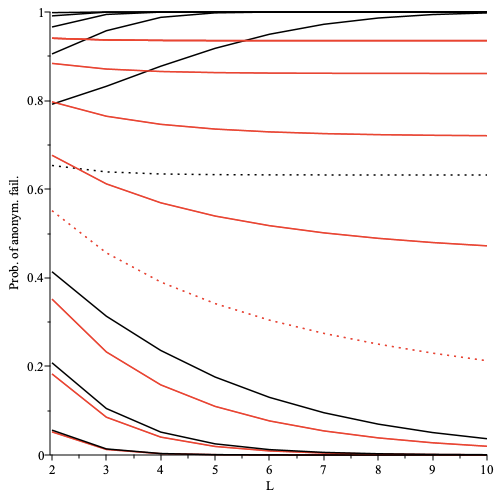
The prob. of anonymity failure in linear (black lines) and branching (red lines) trees as a function of the number of layers plotted for fraction of adversarial nodes (bottom to top), fraction of faulty nodes and branching parameter . Dotted lines correspond to .
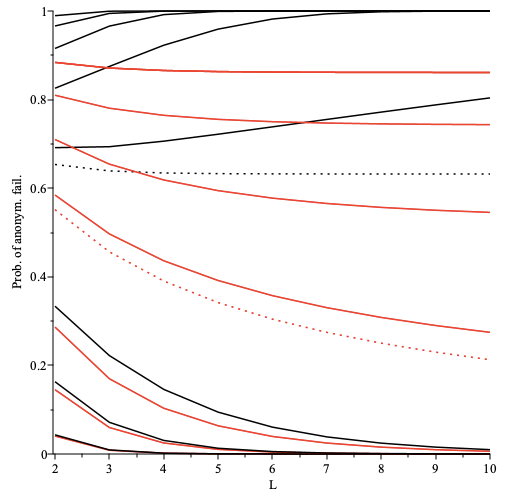
The prob. of anonymity failure in linear (black lines) and branching (red lines) trees as a function of the number of layers plotted for fraction of adversarial nodes (bottom to top), fraction of faulty nodes and branching parameter . Dotted lines correspond to .
Finally, we consider the prob. of adversarial broadcast failure . Here for branching trees we have only simulation results and we compare the latter with analytic results for linear trees. We note that in linear trees the prob. as when and when and (see the linear trees analysis). The latter gives us , i.e. the condition for the prob. of broadcast failure in linear and branching trees. For the branching parameter the prob. of adversarial broadcast failure, , in linear trees is higher than in the branching trees as can be seen in the figure below.
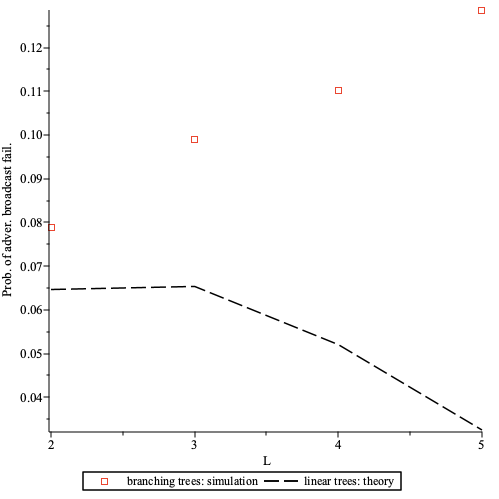
The probability of adversarial broadcast failure as a function of plotted for , and . In simulation probabilities were computed from samples.
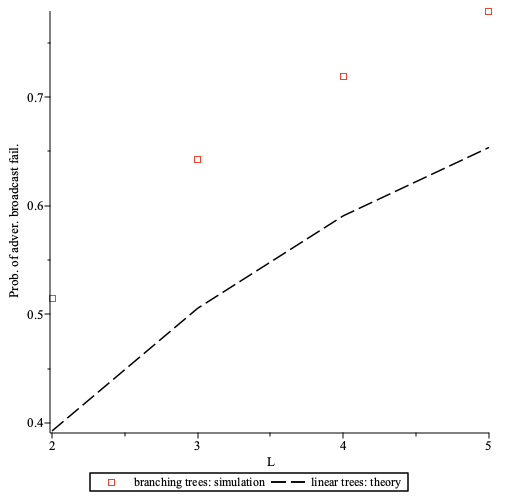
The probability of adversarial broadcast failure as a function of plotted for , and . In simulation probabilities were computed from samples.
Appendix
Details of derivations
PDF attachment: Broadcasting_on_Trees.pdf
ANALYSIS-CORRELATION-FUNCTIONS
| Field | Value |
|---|---|
| Name | [Analysis] Correlation Functions |
| Slug | 188 |
| Status | raw |
| Category | Informational |
| Editor | Alexander Mozeika [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-05-29 —
67e498e— chore: fix math issues (#350) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-09-08 |
Introduction
One of possible approaches to design a reliable anonymous communication (AC) system is to reduce statistical correlations between communicating nodes. Here we model a network of communicating nodes as a probabilistic discrete-state cellular automata (CA). We consider a node-centred approach where a node has associated with it variable representing its discrete state, such as sending, receiving, etc. Also we suggest a more granular connection-centred approach where discrete states of communication links of a node are considered. We note that message-centred approach is also possible but not pursued here. Finally, we discuss functions which can be used to quantify correlations in empirical analysis of AC systems.
The “cellular automata” (CA) model
- The system we consider is a network of communicating nodes where nodes are labelled by the set .
- We assume that nodes receive and send messages and these messages are indistinguishable, i.e. it is either impossible to observe bitstreams of messages, or incoming and outgoing messages are bitwise uncorrelated.
- The node at time can be in the state of either sending (message) or receiving (message) or inactive, i.e. neither sending or receiving. The latter is modelled by the variable as follows
| | Node at time is |
|---|---|
| -1 | sending a message |
| 0 | inactive |
| 1 | receiving a message |
- We note that a node can be in more states, for example in addition to sending, receiving, and inactive it could have an additional state of simultaneous sending and receiving, i.e. “send-receive” state. Additional states c can be modelled by extending the alphabet from which takes its values, i.e. for the most general case.
- The vector is the state of the network at time and for , where , the (ordered by time) set of vectors is the path, through the state-space , taken by the system from the time to the time . The latter can be represented by a table (or matrix) as in the example below obtained from simulations.
The state of the network as a function of time. The node at time , represented by dot, is either sending (red dot) or receiving (blue dots) or inactive (white dot). All nodes are sending messages through nodes with .
- Here we expect that dynamics of the network state is Markovian, i.e. depends only on , and can be described by the probability . We note if the latter is factorises, i.e. , for all then nodes are uncorrelated and “observing” any given node doesn’t reveal any information about the other node/nodes.
- To take this research route further would require to derive master equation for , to derive and analyse equations for correlation functions, etc.
Empirical analysis of correlations in CA model
- If node at time is in the state then the Kronecker delta function is defined as follows
- The sum counts how many times node i was in state on the (ordered) set of times , where . Additionally, the latter can be used to define the (empirical) frequency .
- The sum counts number of nodes in the network which are in state at time and can be used to define the (empirical) frequency .
- The sum counts how many nodes in the network were in state at time and in state at time , where , can be used to define the joint (empirical) frequency (or correlation function) .
- In a similar manner we can define the (spatial) correlation function
- In above the sum counts how many pairs of distinct nodes in the network (there are such pairs in total ) were in state and at, respectively, the time and
Node-centred approach
- We adopt the CA model where state of AC system at time is described by the vector , where the variable is the state of node , such as receiving a message, sending a message, etc., at time . For example , where corresponds to sending, corresponds to inactive and corresponds to receiving.
- We note that a node connected to more than two nodes can be receiving and/or sending multiple messages at the same time. However, to simplify analysis we will assume that at any time a node can receive (or send) at most one message.
- We assume that we have observed such vectors at times collected in the (ordered) set , where .
| | | | | | |
|---|---|---|---|---|---|
| | -1 | 0 | 1 | | -1 |
| | 0 | 1 | 0 | | 1 |
| | | | | | |
| | -1 | 0 | -1 | | 1 |
| | 1 | 0 | -1 | | 1 |
| | | | | | |
| | 0 | 0 | 0 | | 1 |
- We define the indicator function: when and otherwise, i.e. this is the Kronecker delta function. The latter allows us to define various “correlation functions” such as the (empirical) frequency , the joint frequency , etc.
- In general the product could be used to construct any correlation function.
Connection-centred approach
- The state of node , with respect to its connection to the node , at time is described by the variable , where corresponds to node sending message to node , corresponds to “no-communication” state between nodes and corresponds to node receiving a message from node .
- We could use an extended alphabet as additional states may exist. For example, it is possible that node is both simultaneously sending a message to node and receiving a message from , i.e. node is in “send-receive” state. This situation can be modelled by the variable , where corresponds to “no-communication” state between nodes, corresponds to node sending message to node , corresponds to node i in “send-receive” state and corresponds to node receiving a message from node .
- Let us define the set of nodes connected to the node as the (ordered) set ( notation here means “neighbourhood” of node ) then the state of node , with respect to all of its connections, at time is the (ordered by ) set (or vector) , i.e. the state of its connections at time . We note that “no-communication” and not being a member of are different concepts.
- Using above definition the state of all nodes at time can be described by the “vector”
- We note that , i.e. can be any ternary string of length . Hence can be represented by a single number from the set once the mapping between the sets and is fixed.
- For we can define the frequency for node as follows
where , which “counts” how many times connections of node , with respect to , were in some specific communication “pattern” .
- In a similar manner for and we can define the joint frequency
for nodes and .
Mutual information
- For the joint frequency the (empirical) mutual information can be used as a measure of dependence between states of node and . The latter can be used in both node-centric and connection-centric approaches.
Hamming distance
- The (normalised) Hamming distance between the vectors and is the sum , i.e. the number of disagreements between the and is counted and divided by .
- We note when is set (or vector) as in the section on connection-centric approach then , i.e. the latter is if and only if states of all connections of node in and are the same.
- We note that with when and 1 when for all .
- Assuming that we observe the states and of two systems on the same time-set , where , the (average) Hamming distance measures how these two systems are different. We note that with when for all and when for all and all .
- Let us assume we observed at times the states and of two copies of exactly the same AC system. That is the graph is the same in both copies, with exactly the same LEVEL 0 noise, i.e. if node in copy , described by , is sending a (LEVEL 0) message then node in copy , described by , is also sending the same message, etc. We note that the latter can be achieved in simulation which usually uses pseudo-randomness and hence evolution of AC system in time is deterministic. The latter implies that for all and hence in this case .
- Let us now, without loss of generality, assume that node in the copy , described by , sent a LEVEL 2 message, through the nodes , to the node at time and node received this message at time .
- We note that for we have because states of copies 1 and 2, described by and , are exactly the same before this event. For times we can have , i.e. the states of copies and , described by and , are different after the event at .
ANALYSIS-IMPACT-OF-THE-SERVICE-DECLARATION-PROTOCOL-ON-THE-STATISTICAL-INFERENCE-OF-RELATIVE-STAKE
| Field | Value |
|---|---|
| Name | [Analysis] Impact of the Service Declaration Protocol on the Statistical Inference of Relative Stake |
| Slug | 192 |
| Status | raw |
| Category | Informational |
| Editor | Alexander Mozeika [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-05-29 —
67e498e— chore: fix math issues (#350) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-08-22 |
Introduction
The Service Declaration Protocol (SDP) introduces a piece of a priori information: the knowledge that a node's relative stake cannot be less than a known threshold, . Our research investigates the significance of the impact of this information on the statistical inference of relative stake. We propose a new estimator which explicitly utilises by setting any estimated stake below this threshold to .
Our new estimator works better because it fixes estimation errors at the lower end. When a node's true stake value () is close to the minimum threshold (), the standard maximum likelihood (ML) estimator often produces values that are too low. By automatically adjusting these too-low estimates up to the minimum threshold (), our new approach reduces errors. This improvement can be measured as a lower mean squared error (MSE) compared to the true stake value (). Thus any party, including potential adversaries, performing stake inference gains in accuracy by using the new estimator.
Numerical experiments demonstrate reduction in MSE of the new estimator compared to the ML estimator, particularly for stakes near . For example, for used in experiments, a reduction of MSE by a (approx.) factor of at most was observed. Furthermore, the probability, measured in the same experiment, that the inferred stake falls within a desired accuracy interval is higher (by factor of (approx.) at least) when the new estimator is used. While the advantage diminishes for much higher stake values where both estimators converge, the heightened accuracy near the critical threshold presents a meaningful enhancement for any party performing stake inference, including potential adversaries.
Key Findings
- Introduction of a priori information: The Service Declaration Protocol (SDP) introduces the knowledge that a node's relative stake cannot be less than a threshold (), which impacts statistical inference of relative stake.
- New estimator proposed: The research introduces a new estimator that explicitly uses α₀ by setting any estimated stake below this threshold to .
- Improved accuracy: The new estimator performs better because it corrects estimation errors at the lower end, particularly when a node's true stake value is close to the minimum threshold.
- Measurable improvements: Numerical experiments show:
- Reduction in Mean Squared Error (MSE) of the new estimator compared to the ML estimator, particularly for stakes near .
- For , MSE reduction by a factor of approximately was observed.
- Higher probability (by a factor of approximately 3) that inferred stake falls within desired accuracy intervals.
- Statistical significance: The advantage diminishes for much higher stake values where both estimators converge, but the enhanced accuracy near the critical α₀ threshold presents a meaningful improvement for any party performing stake inference.
- Security implications: This improvement benefits anyone performing stake inference, including potential adversaries.
The research provides mathematical proof and numerical simulations to validate these findings, showing that the proposed estimator is both unbiased and consistent in the limit of large number of observations.
Overview
This document examines the impact of minimum stake threshold, introduced in the SDP, on the statistical inference of relative stake along the following points:
In particular:
- We consider the Leader Election Process where nodes allowed to participate only if their relative stake is no less than some prescribed by SDP threshold.
- We assume that the Adversary observes wins (and losses) of nodes and uses statistical inference to infer relative stake of nodes.
- The Adversary knows the SDP stake threshold, and using this information, the Adversary constructs a statistical estimator.
- This New estimator improves inference of stake when compared with an estimator which doesn’t use the SDP threshold. The simulation of adversarial inference shows that those most affected by this improvement are the nodes with values of relative stake close to the threshold.
Analysis
The Model
The relative stake of node , , is computed via the formula , where is the stake of node . We assume that the total stake can be inferred (with high accuracy) by using the total stake inference algorithm. We note that for the set , i.e. relative stakes of all nodes, it is possible that . It is known, through the declaration of the Service Declaration Protocol (SDP), that the relative stake of a node is at least . For , the relative stake of a node can be written as , where is unknown. Intuitively, this suggests that if, relative to the , the minimum stake is large, then then there is less “uncertainty” about the relative stake .
Node participates in the leader election and its probability of winning is given by the “lottery” function
where is the parameter of the consensus. Since the lottery function is a monotonically increasing function of relative stake, for the relative stake we have , i.e. the prob. of winning for nodes with relative stake greater than is higher.
Inference of relative stake
For the fractionof wins in the observations of the leader election process of a node the (naive) statistical estimator of , , is the solution of the equation given by
We note that for we have that . The estimator is biased because
where the average is defined in the Appendix. However, the average and the variance . If when then in this (”large number of observations”) limit we have
i.e. is consistent estimator of the relative stake .
Similarly to the estimator of, we construct new estimator of relative stake
The above can be written as follows
We note that from which follows that
but we showed that for a large number of observations, and hence in this limit.
Let us consider the (squared) distance
From the above follows the difference
Now, because , we have the following inequality
and hence
i.e. the mean squared error (MSE) of the estimator is greater than the MSE of the estimator . Furthermore, for the MSE of we have
Now is a consistent estimator of the relative stake and hence in the large number of observations limit, but , so is also a consistent estimator of the relative stake .
Simulations confirm that MSE of the estimator is greater than the MSE of the new estimator , as can be seen in the figures below.
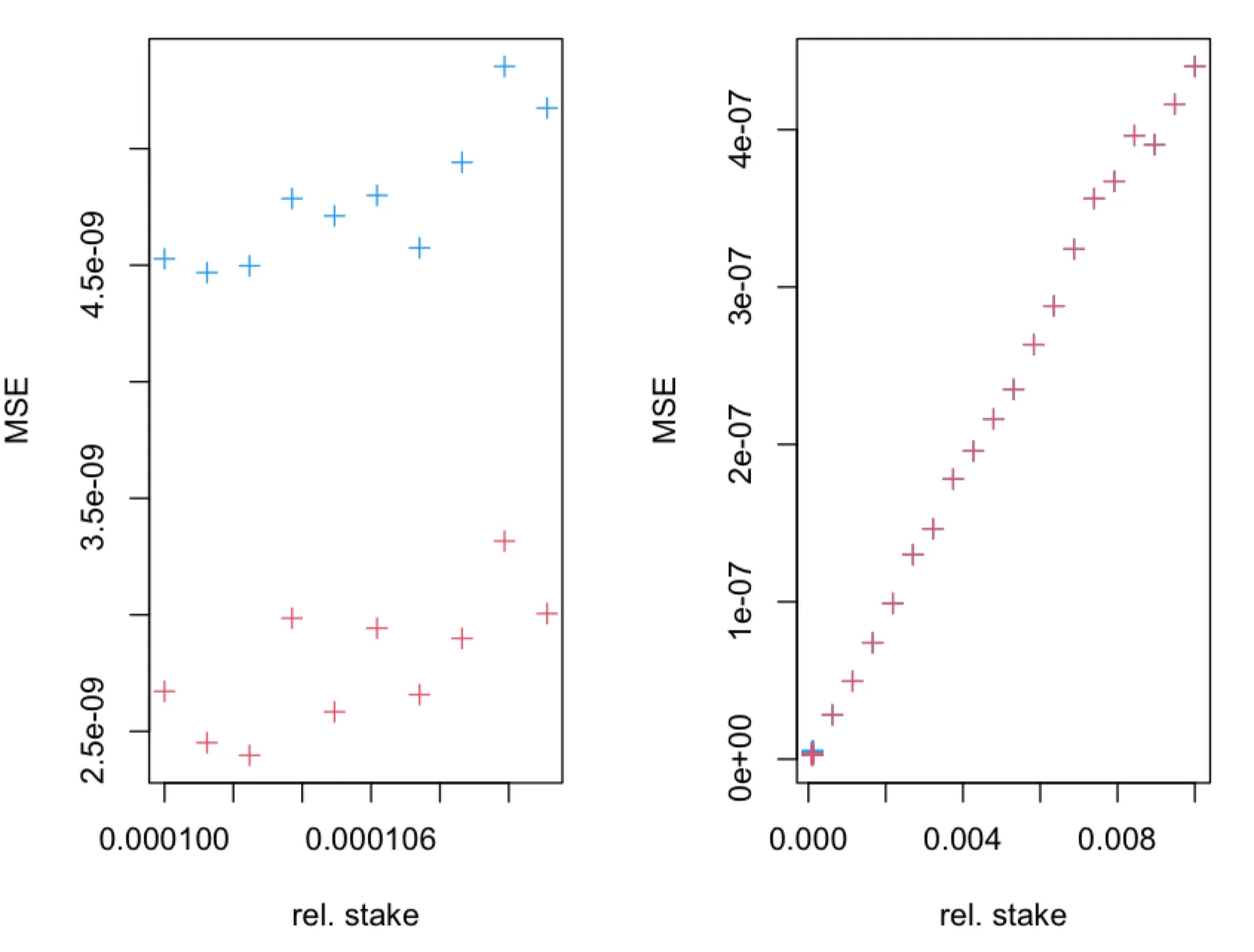
The MSE of the estimator (blue + symbols) and (red + symbols), obtained in simulations of leader election process, as a function of true relative stake , where . The leader election process, with parameter, was simulated for time-slots. The fraction of observed slots is .
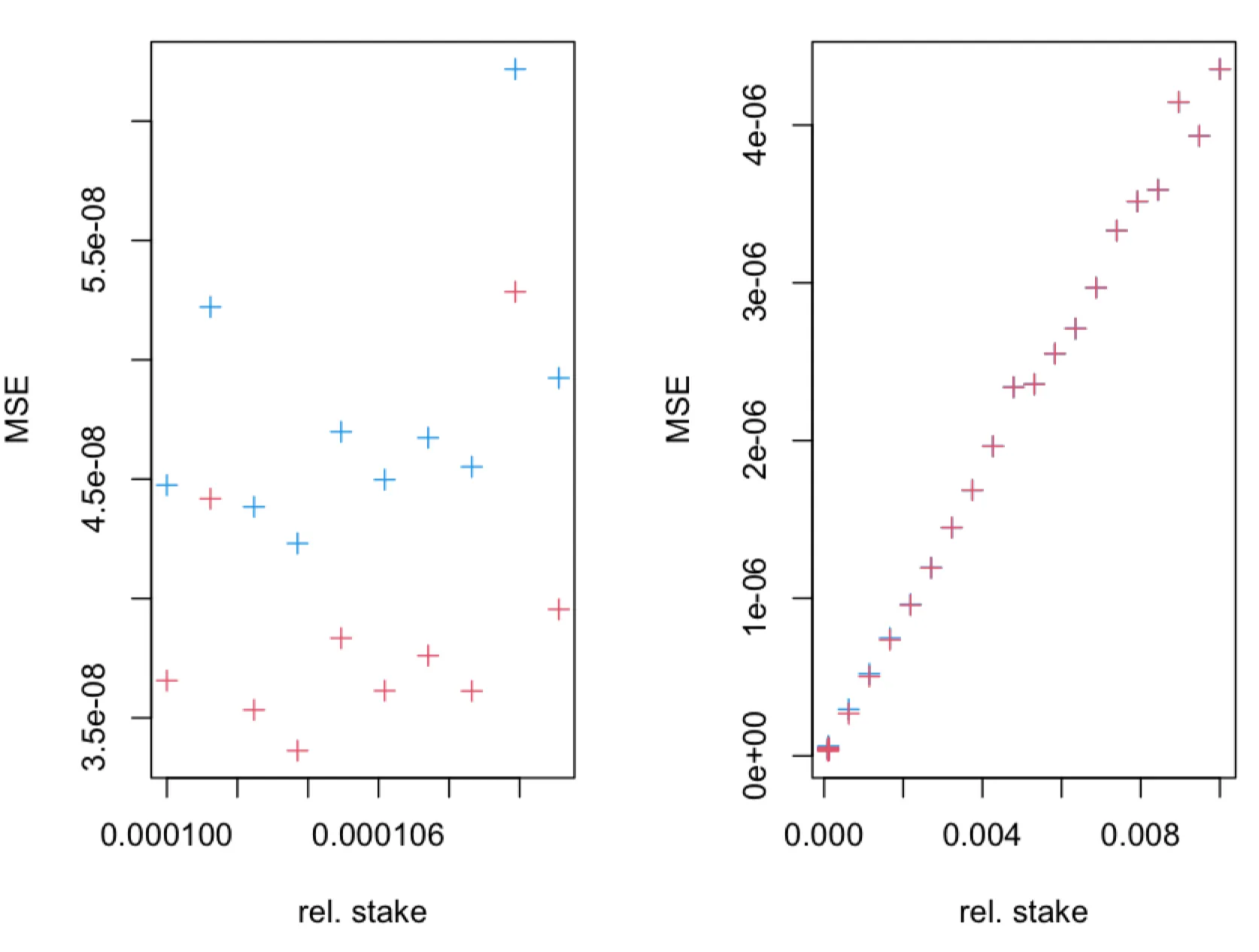
The MSE of the estimator (blue + symbols) and (red + symbols), obtained in simulations of leader election process, as a function of true relative stake , where . The leader election process, with parameter, was simulated for time-slots. The fraction of observed slots is .
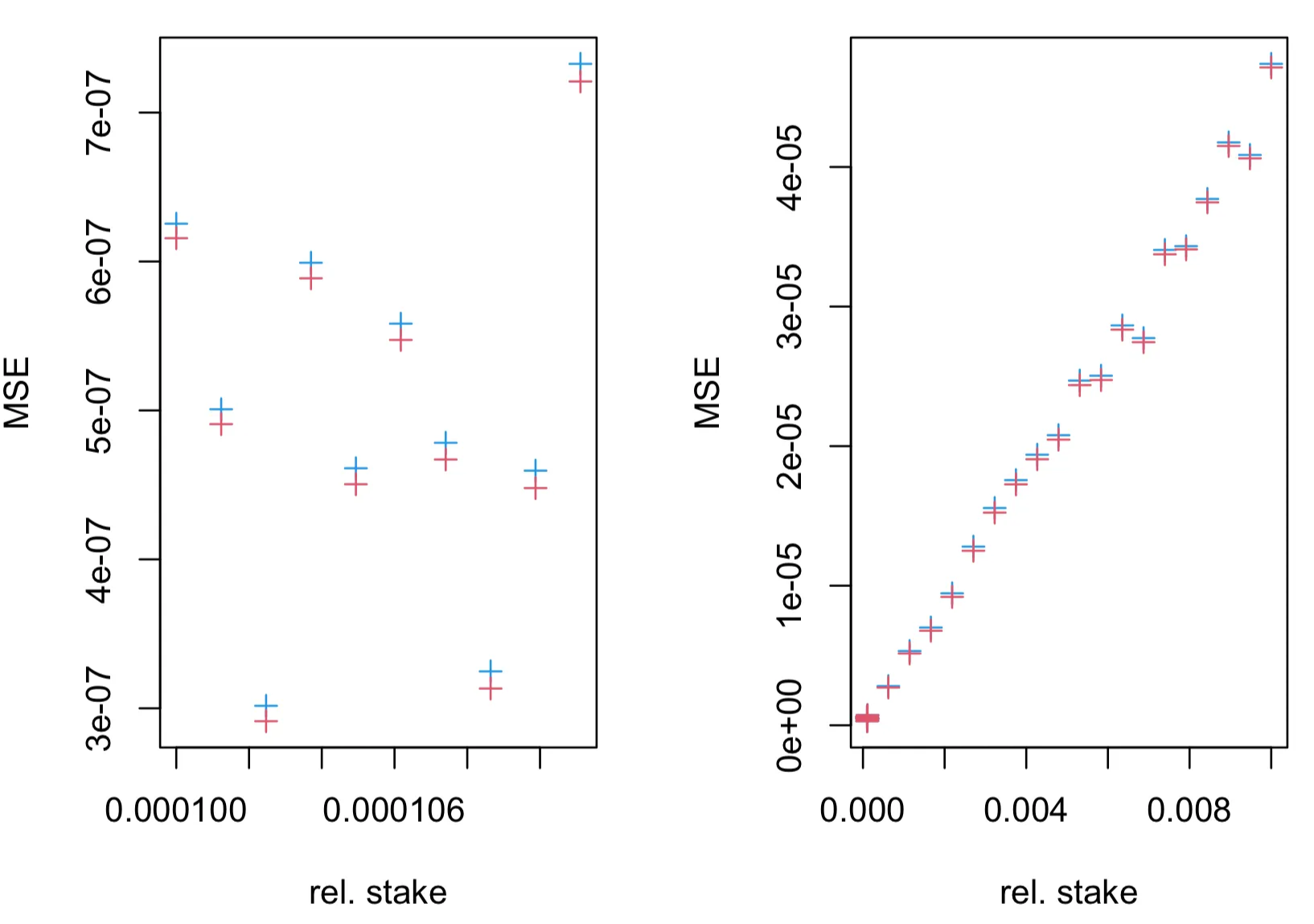
The MSE of the estimator (blue + symbols) and (red + symbols), obtained in simulations of leader election process, as a function of true relative stake , where . The leader election process, with parameter, was simulated for time-slots. The fraction of observed slots is .
We are interested in the probability which can be seen as adversarial "confidence". Here prescribes desired “accuracy” of the inference. We note that the probability can be estimated analytically for large . If for a given (accuracy) parameter we have that then the adversary has an advantage by using the new estimator, i.e. an adversary which knows that has a higher confidence than the adversary which doesn’t know the latter.
Recall that . We note that , provided . Let us assume (without loss of generality) that for some . Then, from follows that . Hence, if this inequality is satisfied, an adversary may have advantage. We compute the probabilities and using simulation and find that the adversary has advantage for the relative stake , as can be seen in figures below.
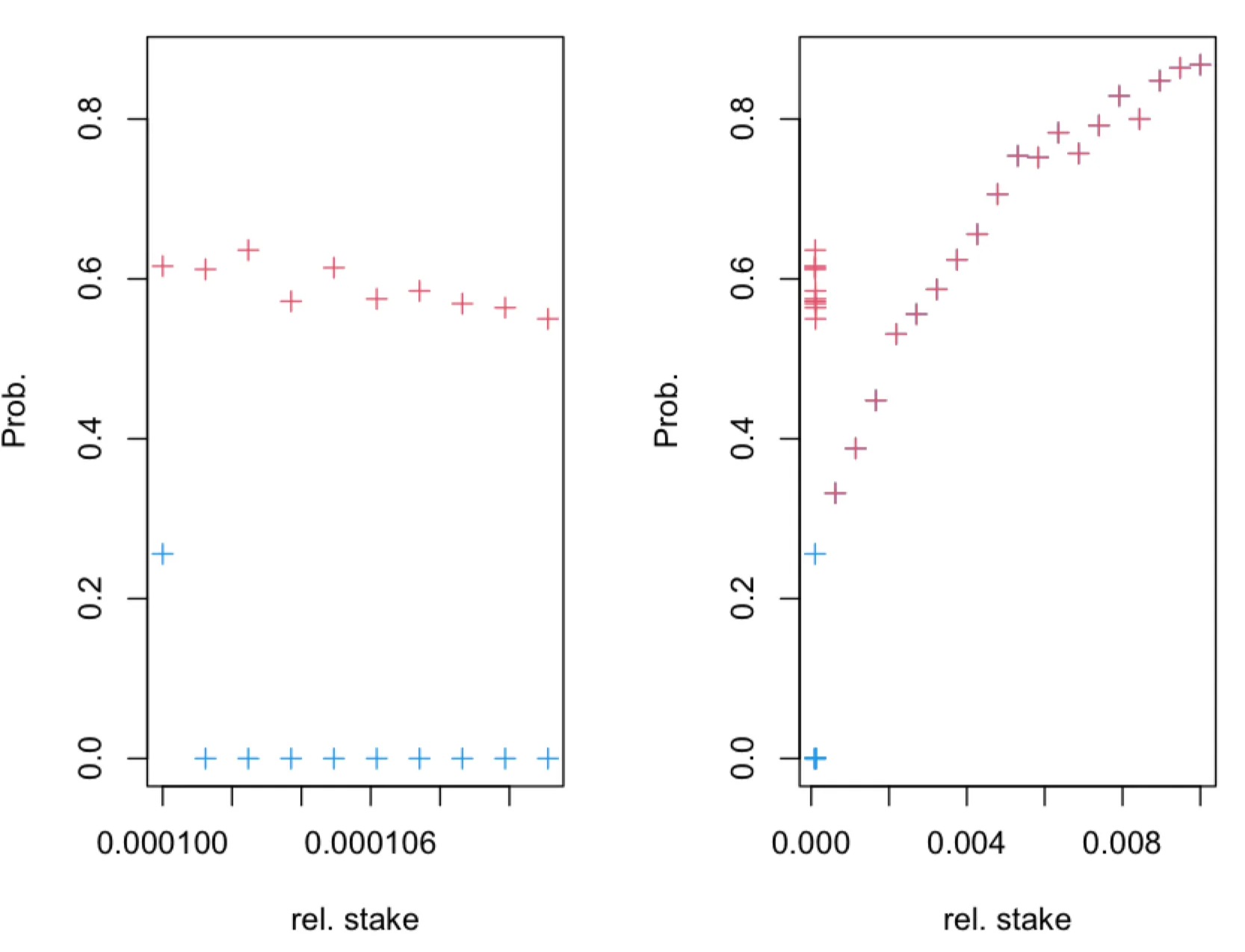
The probability (blue + symbols) and (red + symbols), obtained in simulations of leader election process for , as a function of true relative stake , where . The leader election process, with parameter, was simulated for time-slots. The fraction of observed slots is .
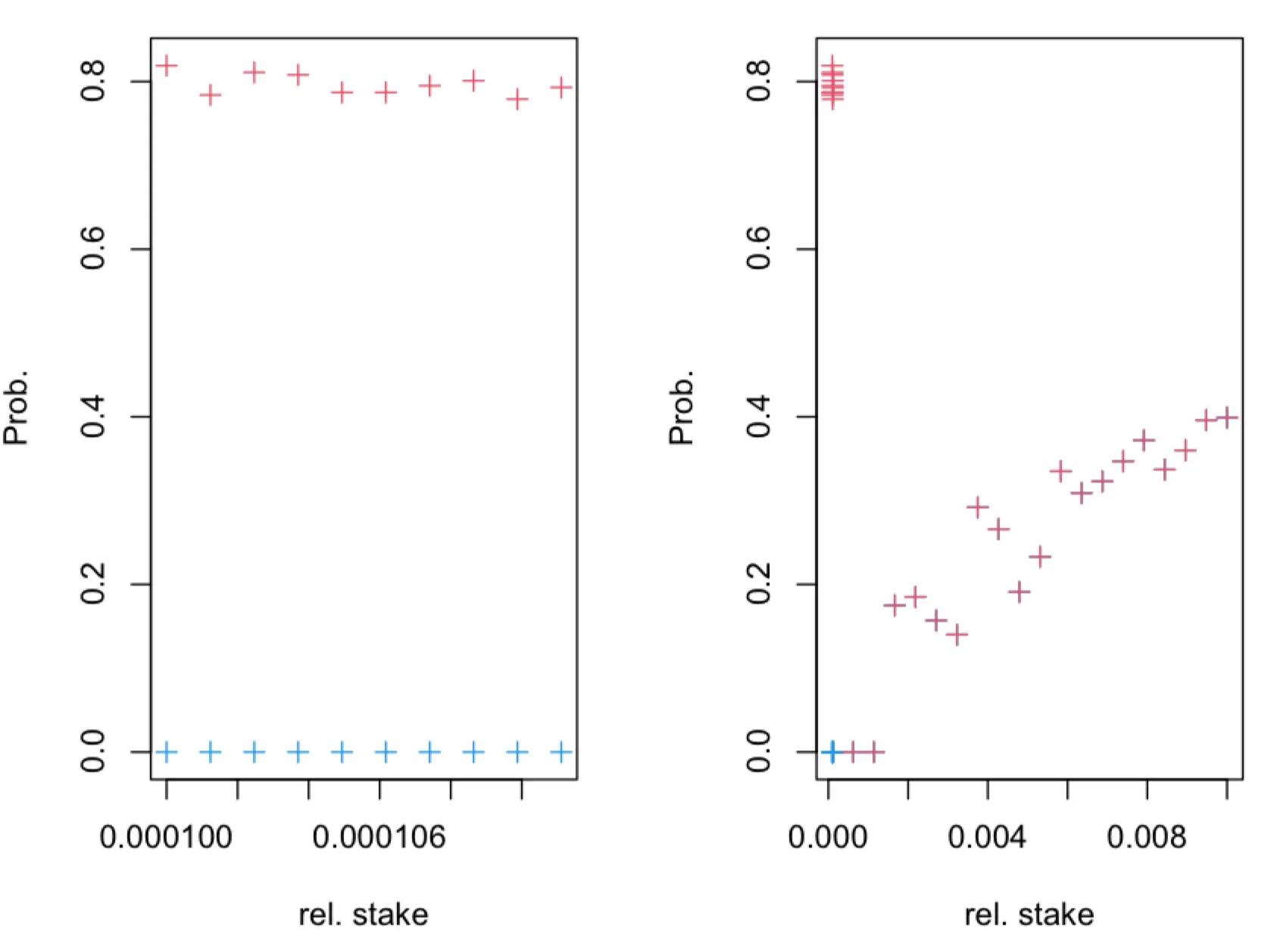
The probability (blue + symbols) and (red + symbols), obtained in simulations of leader election process for , as a function of true relative stake , where . The leader election process, with parameter, was simulated for time-slots. The fraction of observed slots is .
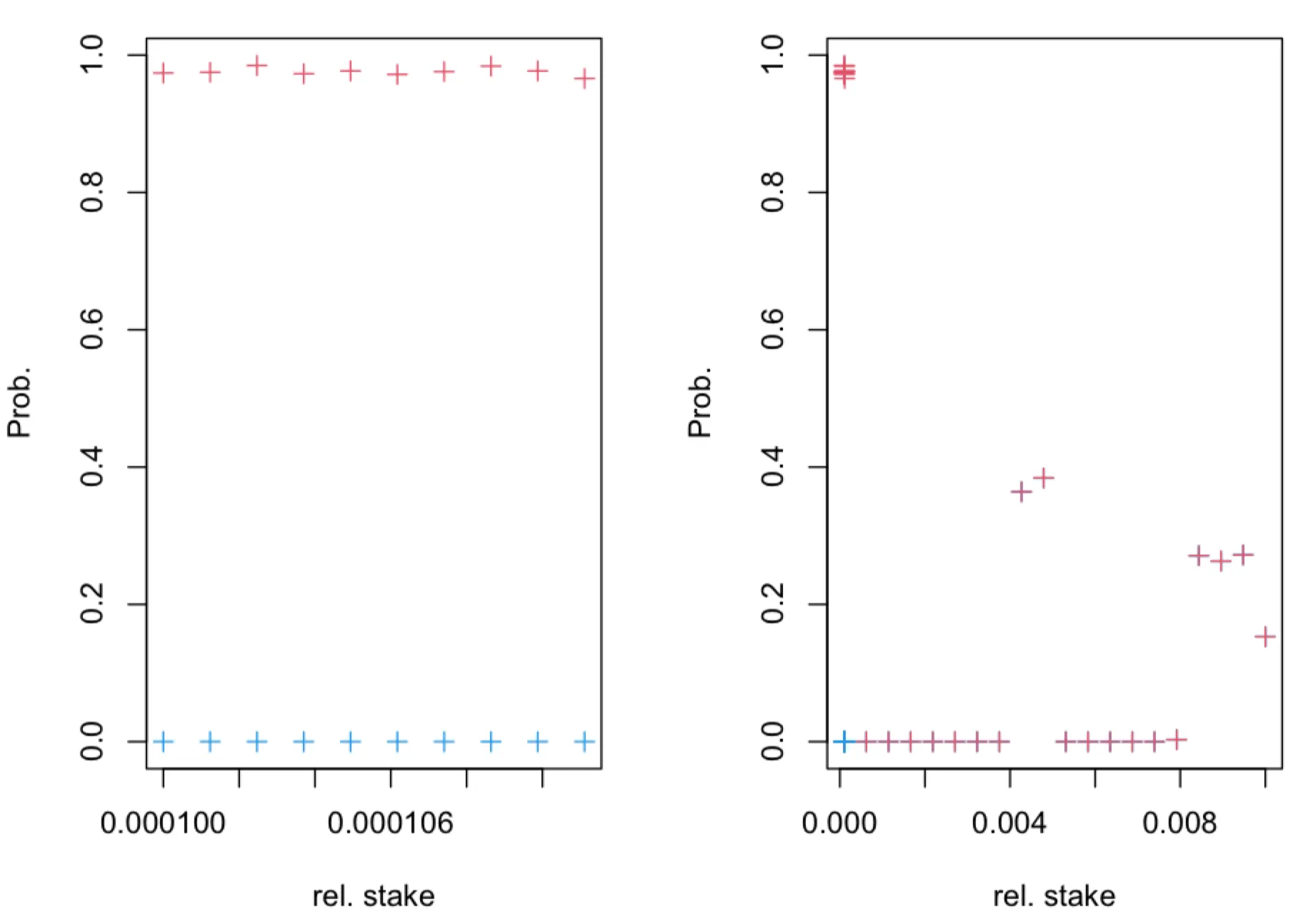
The probability (blue + symbols) and (red + symbols), obtained in simulations of leader election process for , as a function of true relative stake , where . The leader election process, with parameter, was simulated for time-slots. The fraction of observed slots is .
Numerical Experiments
In this section, we compare performance of the statistical estimators and in a single run of a simulation. This can be seen as a scenario where two adversaries collect the same data from the leader election process, but one of the adversaries knows and uses this in the statistical inference. To simulate the statistical inference of relative stake in one epoch ( time-slots) of the leader election process with parameter , we sampled random (stake) values from the Pareto distribution with shape parameter and scale parameter . The histogram of (relative) stake values is given below
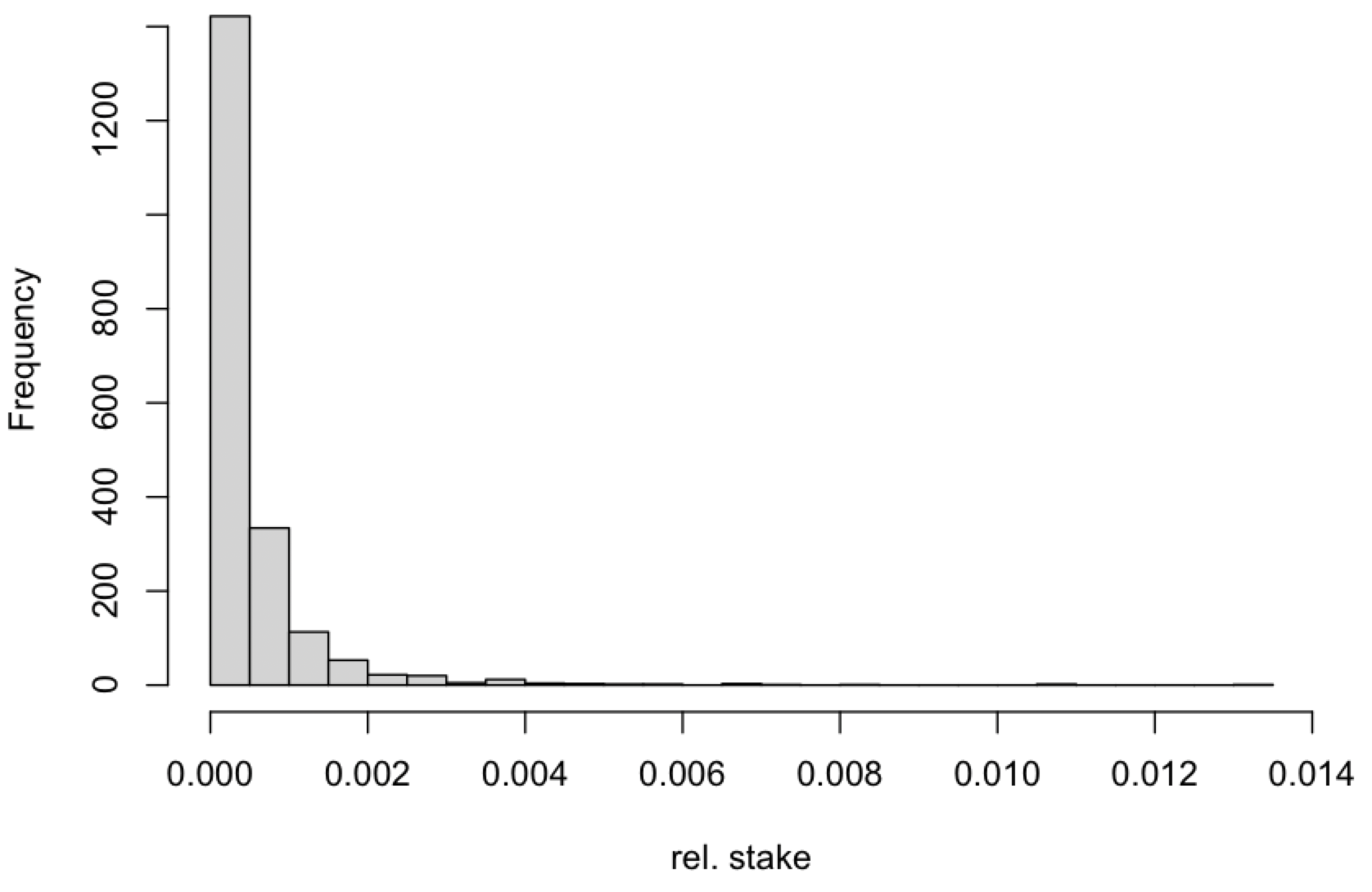
We consider inference only for nodes with the highest relative stake and for nodes with relative stake just above the threshold . We consider a scenario where fraction of time-slots of the leader election process are observed by adversary. Here we find differences between estimators only for nodes with relative stake close to as can be seen in the figures below.
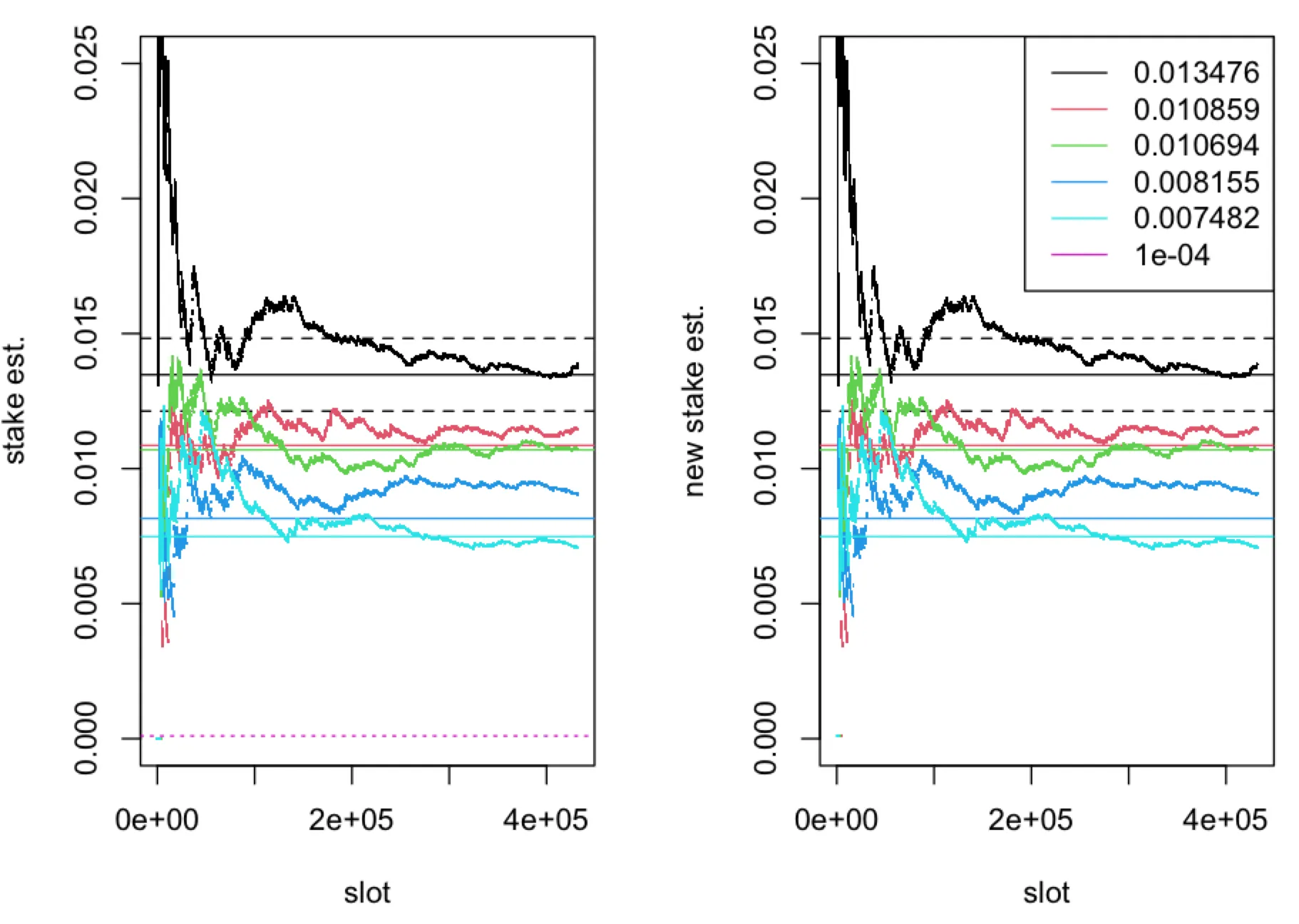
The (relative) stake estimator (left panel) and (right panel), computed in one epoch ( time-slots) of the leader election process with parameter , plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. The boundaries of the interval for and are represented by dashed horizontal lines. The dotted horizontal line corresponds to . The fraction of observed slots is .
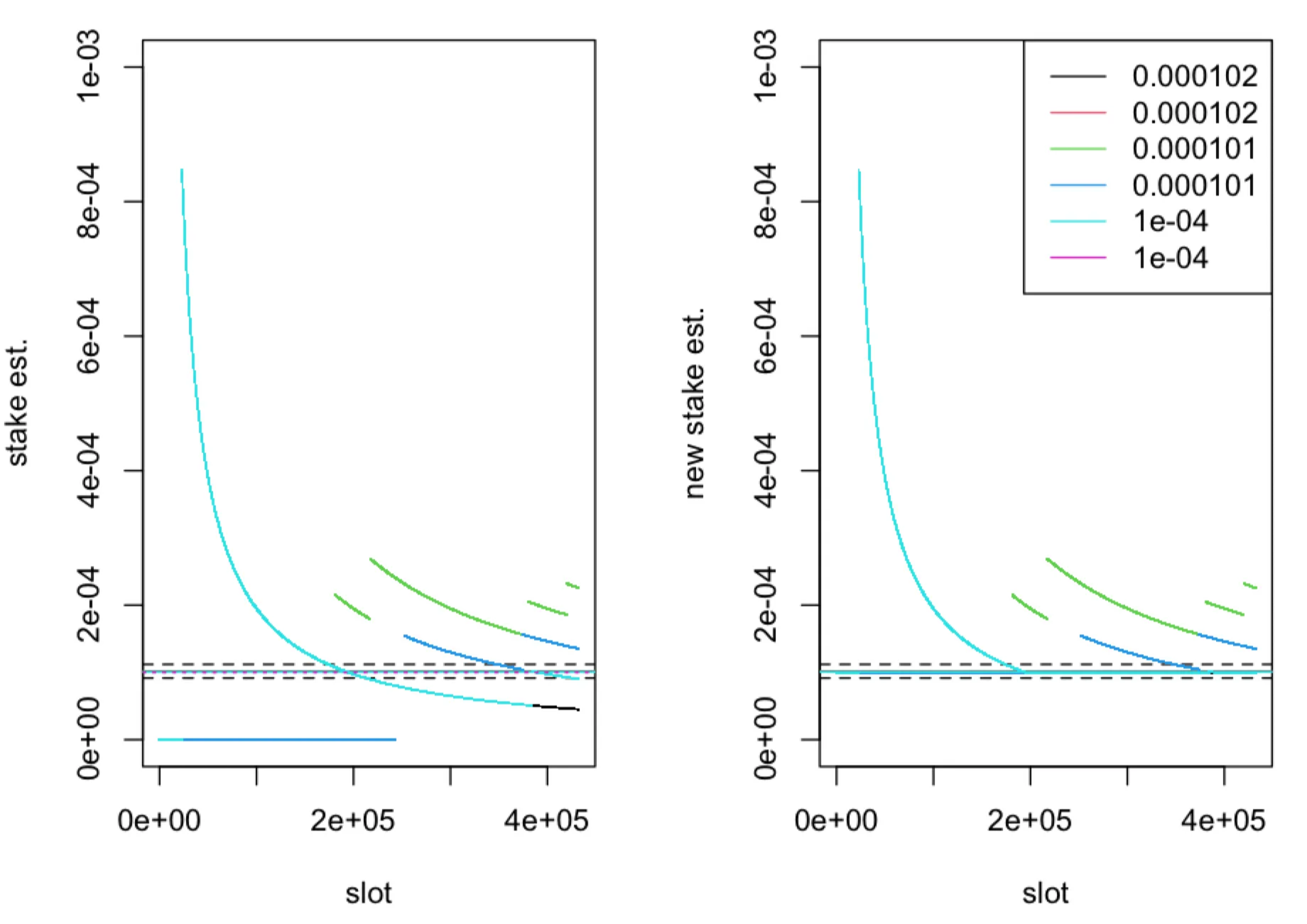
The (relative) stake estimator (left panel) and (right panel), computed in one epoch ( time-slots) of the leader election process with parameter , plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. The boundaries of the interval for and are represented by dashed horizontal lines. The dotted horizontal line corresponds to . The fraction of observed slots is .
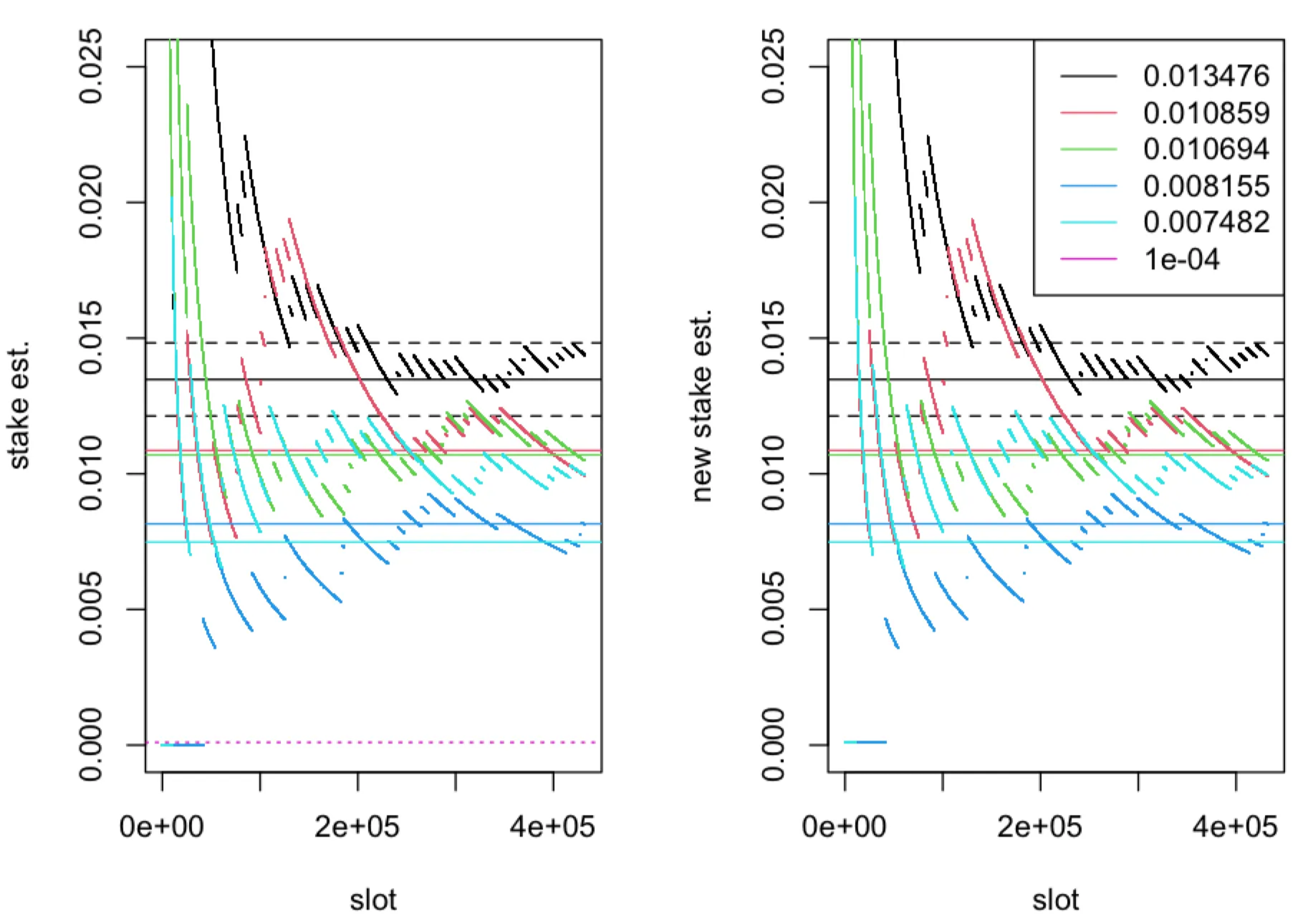
The (relative) stake estimator (left panel) and (right panel), computed in one epoch ( time-slots) of the leader election process with parameter , plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. The boundaries of the interval for and are represented by dashed horizontal lines. The dotted horizontal line corresponds to . The fraction of observed slots is .
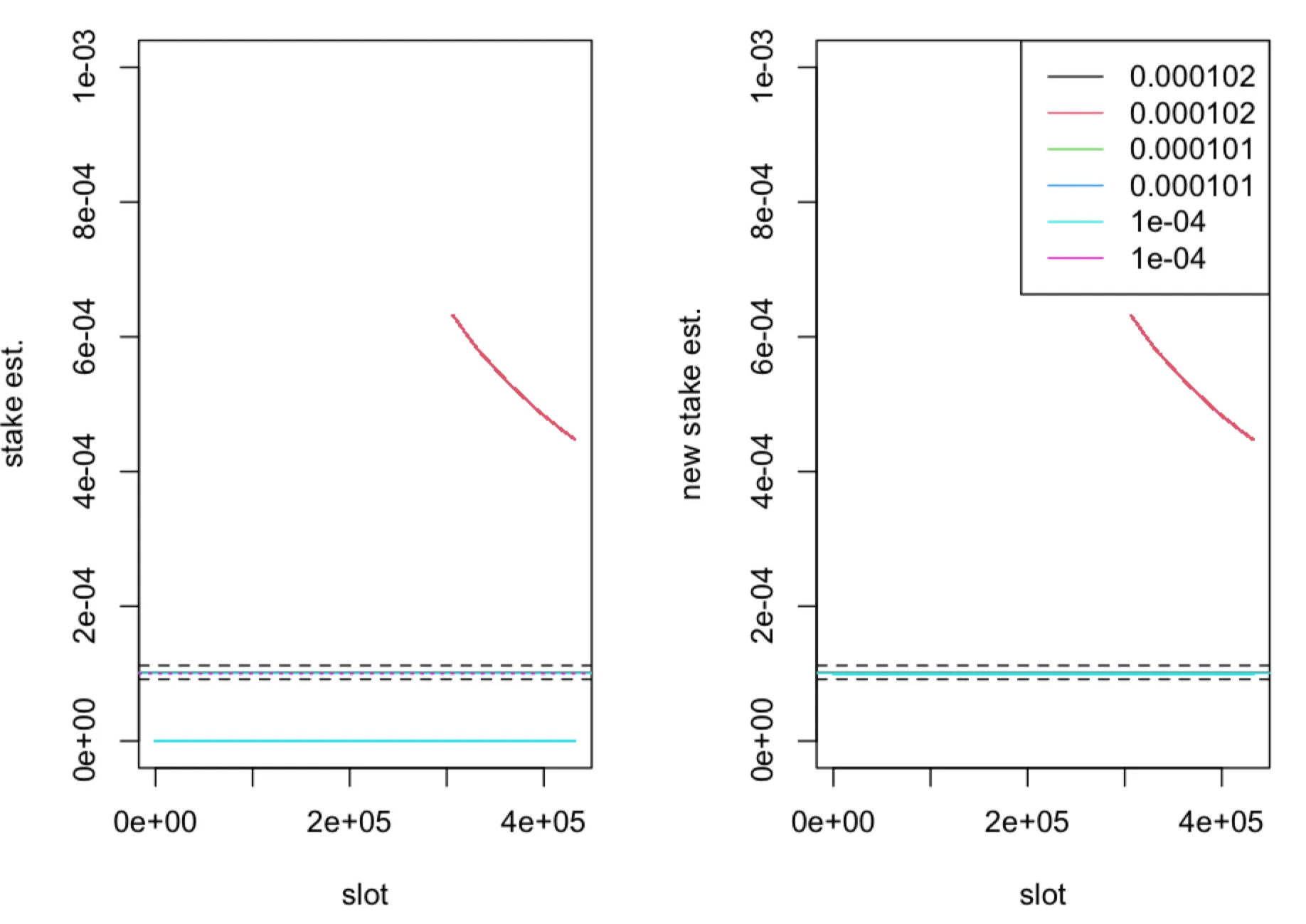
The (relative) stake estimator (left panel) and (right panel), computed in one epoch ( time-slots) of the leader election process with parameter , plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. The boundaries of the interval for and are represented by dashed horizontal lines. The dotted horizontal line corresponds to . The fraction of observed slots is .
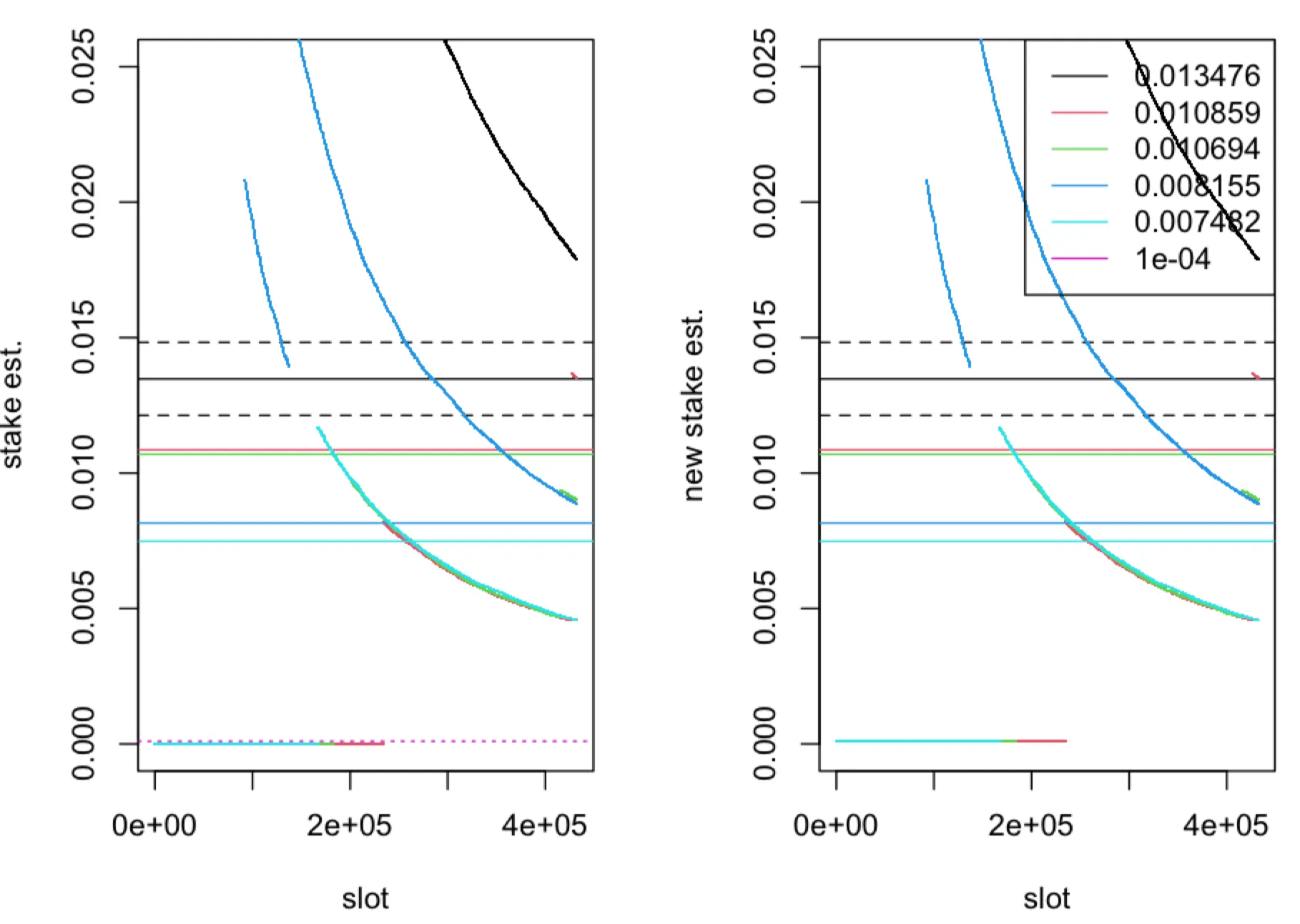
The (relative) stake estimator (left panel) and (right panel), computed in one epoch ( time-slots) of the leader election process with parameter , plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. The boundaries of the interval for and are represented by dashed horizontal lines. The dotted horizontal line corresponds to . The fraction of observed slots is .
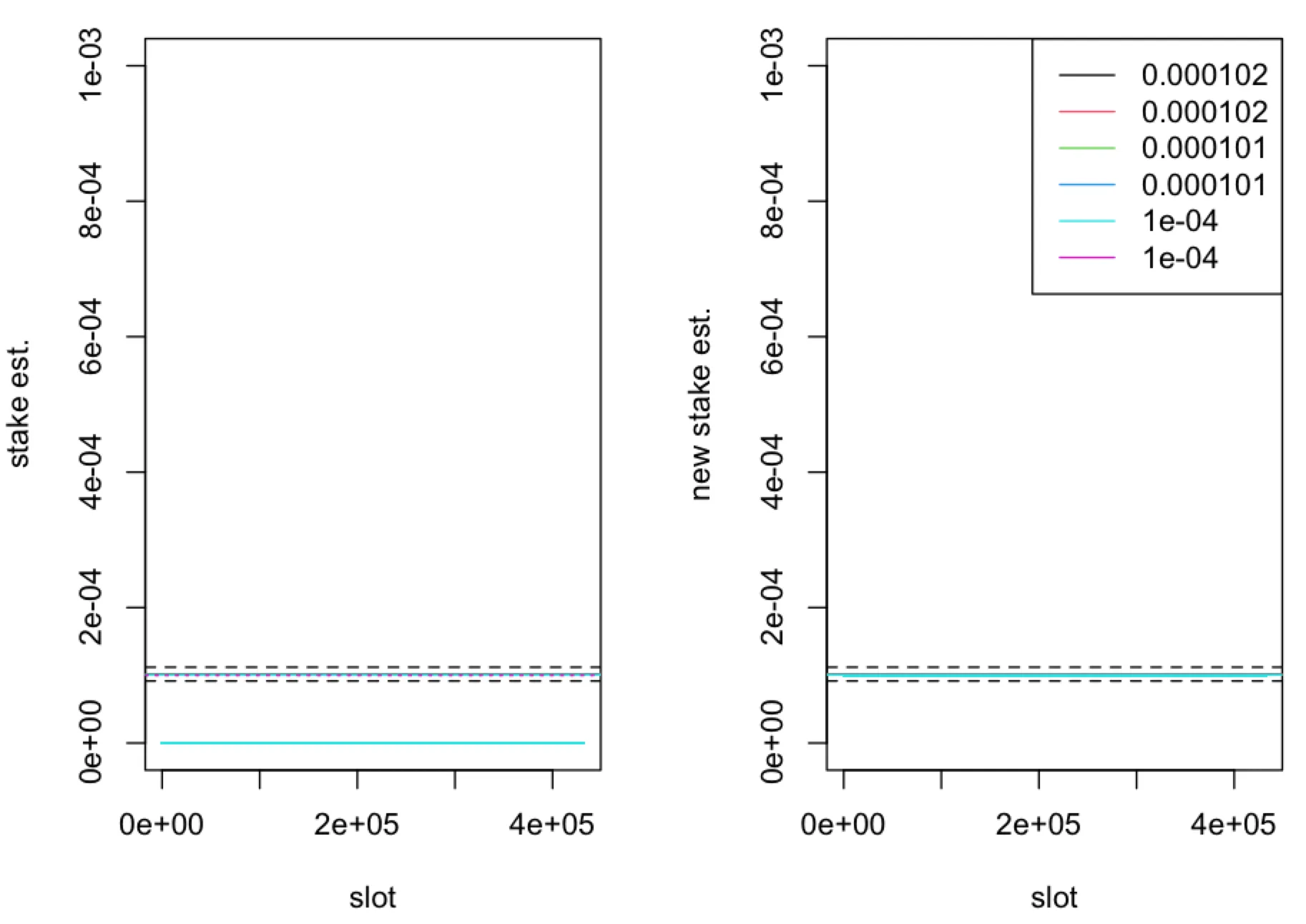
The (relative) stake estimator (left panel) and (right panel), computed in one epoch ( time-slots) of the leader election process with parameter , plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. The boundaries of the interval for and are represented by dashed horizontal lines. The dotted horizontal line corresponds to . The fraction of observed slots is .
Appendix
Inference of probability
The leader election process is governed by the probability distribution
of the outcome of election , where models outcome ( loss/win) for node in time-slot . The fraction of observed wins of node in one epoch is
where , with , is the total number of observations.
The average with respect to the leader election process gives us
i.e. is unbiased statistical estimator of prob. of winning . In the above is the averaging “operator” defines as
where . Since and , from above follows that .
The variance of is given by
If as , i.e. for a large number of observations, then , i.e. is a consistent estimator of the prob. .
Let us define the new estimator of as follows
The average with respect to leader election process gives us
i.e. the estimator has (positive) bias. We expect that in the limit as , i.e. for a large number of observations, the average . We note that since , we have that
and
Now, for by the Markov’s inequality we have
where . Using the definition, the average on the RHS of the above can be computed as follows
Using above result in the inequality we obtain
Furthermore, optimising the RHS in above with respect to we obtain the inequality
We note that is monotonic decreasing function of which is exactly zero when and hence this function is negative for . Hence we have the following inequality
where when .
From above follows that in the limit as , i.e. for a large number of observations. Using the latter in the upper bound gives us that in this limit. If in the limit of large number of observations we also have that the then is a consistent estimator of the prob. .
For , where we defined , the is given by
In the Variance section we show that
Hence in the limit of large number of observations .
Thus from above follows that
is unbiased and consistent estimator of the prob. in the limit of large number of observations as .
For the mean squared error (MSE) of the estimator is given by
Assuming that the variables are exactly the same as in the above, the MSE of the estimator is given by
Consider the difference as follows
Now the last line in the above can be bounded as follows
Hence
Thus, the MSE of the unbiased estimator is greater that the MSE of the biased, but consistent, estimator .
Variance of
For , where , we consider the variance
First, we consider the covariance
Because of , from the above it follows that .
Second, we consider the variance
Thus, from the above it follows that . The latter with implies which using the variance equation gives us that
ANALYSIS-LATENCY
| Field | Value |
|---|---|
| Name | [Analysis] Latency |
| Slug | 193 |
| Status | raw |
| Category | Informational |
| Editor | Alexander Mozeika [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-05-29 —
67e498e— chore: fix math issues (#350) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-03-20 |
Introduction
We consider latency of a broadcast on the network constructed from mix nodes which use queues to store in-coming and out-going messages. A message is removed from the queue with probability which delays messages by a random amount of time governed by the Geometric distribution with parameter . The other source of message delays are due to the latency in communication links which we assume to be “frozen”, i.e. not changing with time. We show that for a single path constructed from mix nodes the average message latency is proportional to and we estimate the probability of latency being greater than the average. Furthermore, we consider latency of a broadcast on the network with the topology of a random regular graph with connectivity . Here we find that the latency of broadcast, divided by , is approaching for a small probability of message removal as the number of nodes in the network is growing. However, for finite the distribution of latency can have long tails. We note that the latter result is established semi-analytically and only for trees we managed to develop a complete analytical framework which can be used to compute the latency of a broadcast. Finally, in this document we propose a simple model of communication latency in consensus.
Analysis
Single Node
- Assuming that a message is removed from the queue of a node with probability (see the document), a message in node is delayed by (at most) , where is a random variable from the Geometric distribution with parameter and is a “cost” of one attempt of removing a message.
- Assuming that node has connections and it puts a message into all out-queues associated with these connections, i.e. the node is sending a message. The message will be delayed by (at most) in the queue , by in the queue , etc., where is sample from the Geometric distr. with parameter .
- Assuming that node has connections and it puts a message into all out-queues but not the queue associated with the connection labelled by , i.e. the node is relaying a message, the message will be delayed by (at most) in the queue , by in the queue , etc., where is sample from the Geometric distr. with parameter .
Single Path
- Without loss of generality, we consider a message traveling from node to node . A message is delayed at the node by , at the node by , etc. For node we assume that is a random variable from the Geometric distribution with parameter and that . The latter is prop. to a max. time elapsed between attempts to “flip a coin”. Furthermore, a message traveling between the nodes and is delayed by .
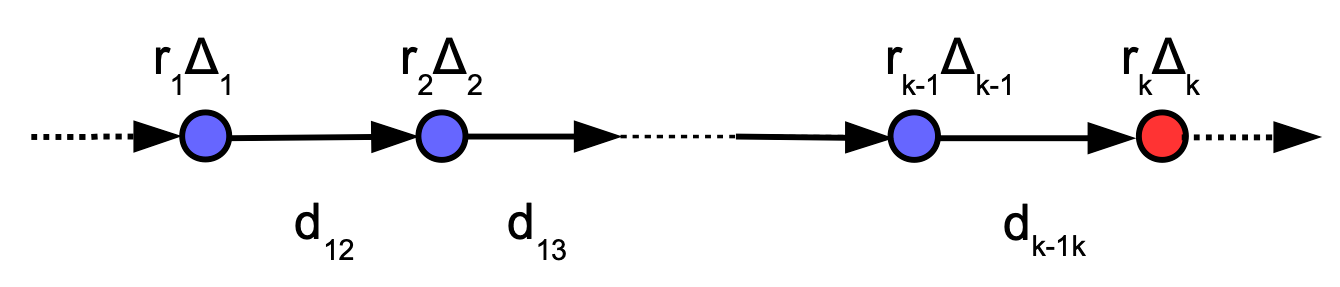
- Using above the total delay is given by . We note that for and we have
- The sum is random variable from the negative binomial distribution
- Using that is a random variable from the Geometric distribution with parameter the average and variance of the total delay is given, respectively, by and . The latter, for and , is simplifies to and .
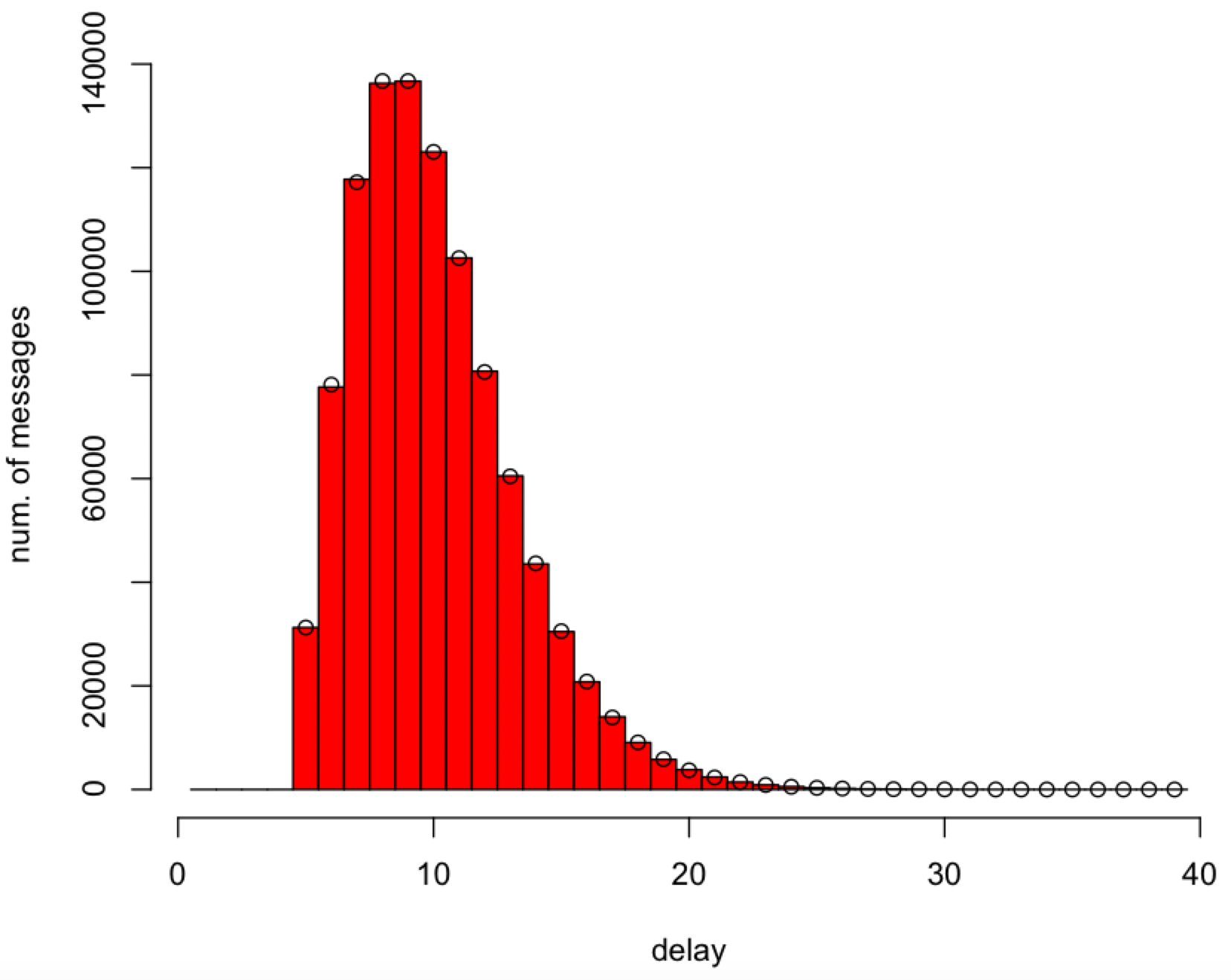
The histogram of delays of messages traveling through nodes (red histogram bars) is compared with negative binomial (o symbols) with parameters and . Here we assumed that and .
- The mean of sum is equals to . For the probability can bounded from above as follows
- To show the above we used for any and Markov’s inequality.
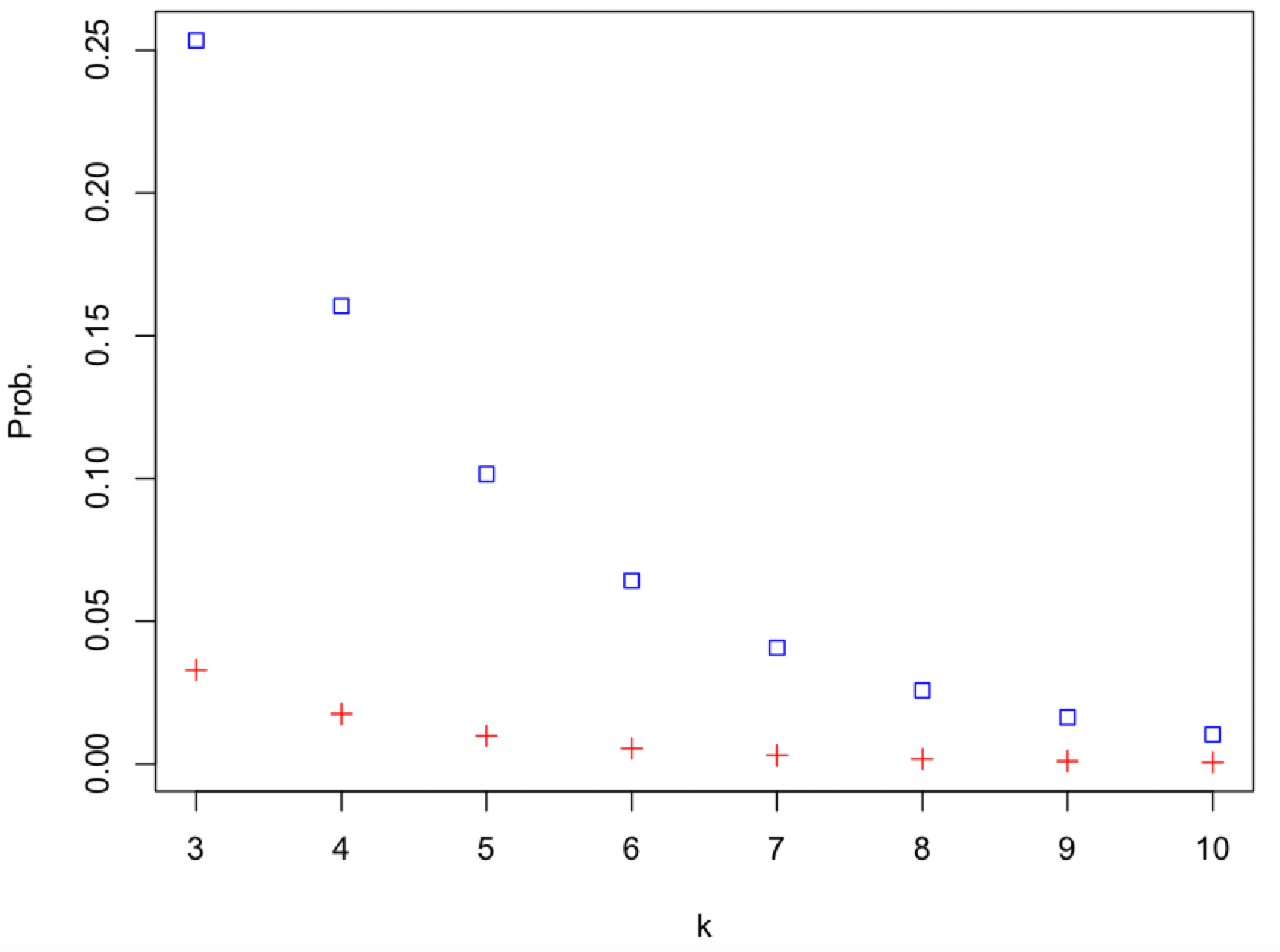
The prob. as a function of plotted for and . Here the simulation (red + symbols) is compared with the upper bound (blue square symbols). In simulation the prob. distr. of was represented by samples of random variables generated from the Geometric distribution with parameter .
- The probability is increasing with decreasing for
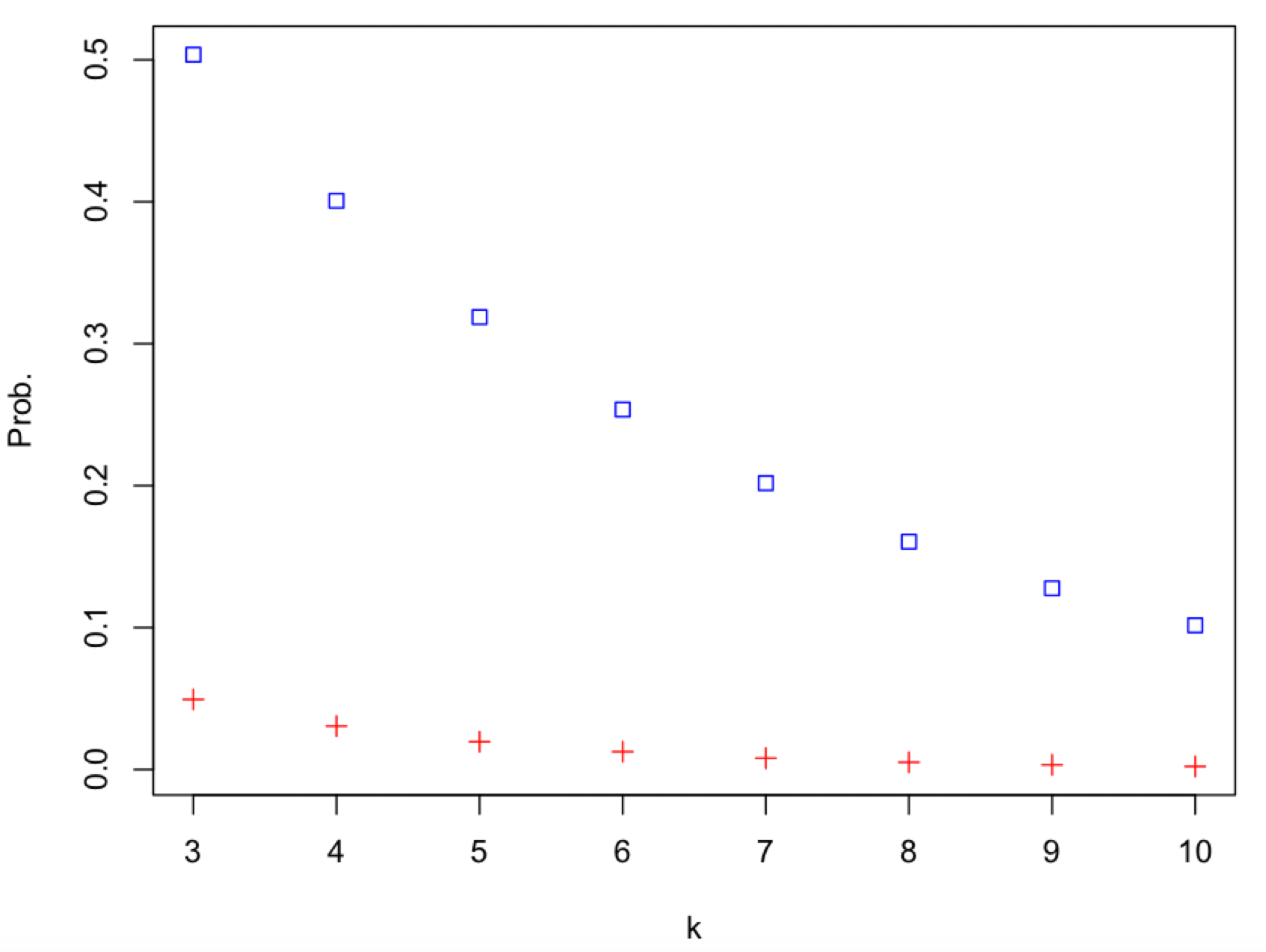
The prob. as a function of plotted for and . Here the simulation (red + symbols) is compared with the upper bound (blue square symbols). In simulation the prob. distr. of was represented by samples of random variables generated from the Geometric distribution with parameter .
- and decreasing with increasing for
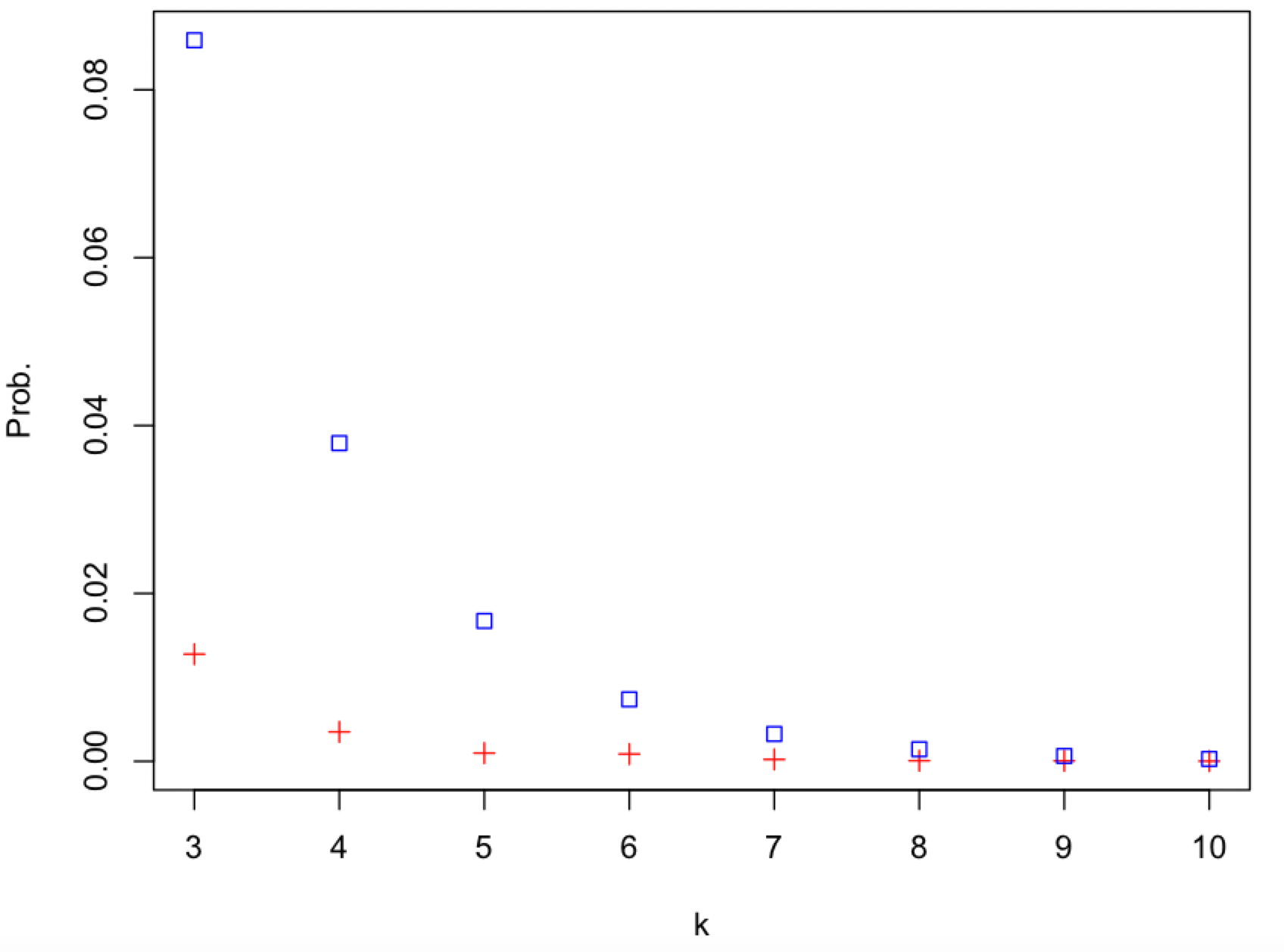
The prob. as a function of plotted for and . Here the simulation (red + symbols) is compared with the upper bound (blue square symbols). In simulation the prob. distr. of was represented by samples of random variables generated from the Geometric distribution with parameter .
- We note that the upper bound can be represented as
as a function of and .
- Plotting suggests that the upper bound is monotonic decreasing function of , and .
Random Networks
Configuration Model
- Let us consider the probability distribution over the non-negative integers such that and define the probability distribution
- We consider the random rooted tree generated as follows. First, we sample from the distr. and connect the root node to offspring nodes. Second, for each offspring node we sample from the distr. and connect to nodes. The latter is repeated until the tree of height is generated.
- We consider the random graph , where is the set of nodes and is the set of edges, generated by connecting nodes with connectivities sampled from the probability distribution , i.e. the “configuration model”.
- For we have that , where is the subgraph of induced by nodes at a distance (length of shortest path between two nodes) at most from the node , with high probability.
- A special case is a random regular graph (RRG) of connectivity , i.e. each node in is connected to exactly nodes.
Distance on a graph and latency of a broadcast
- Let us assume, without loss of generality, that node in this network wants to send a message to the all nodes of network.
- A node puts a message in to all of its out-queues. Assuming that coin-flipping algorithm is used to remove a message from the queue, we have that a message is delayed by (at most) (see previous section), where random variable from the Geometric distribution with parameter . A message is delayed further in a communication link and hence, for example, a message sent from the node to the node is delayed (at most) by . We note that copies of the same message, sent to other neighbours of node , are delayed in a similar manner.
- For node sending a message to its neighbour the delay is .
- The total delay of a message sent from the node to the node is the sum of delays
along the (directed) path from node to node , .
- Let us define the distance between node 1 and node as the
i.e. the minimum total delay over all (directed) paths from node 1 to node i.
- Now the maximum distance
i.e. the maximum over distances between node and all other nodes, is the time that elapsed from the event “node sent a message” to the event “the message was delivered to all nodes”.
- Thus is the latency of broadcast from node . Let us define the latter as
- We note that maximum distance can be computed using Dijkstra's algorithm.
- Finally, for all pairs of distinct nodes we define the diameter of as follows
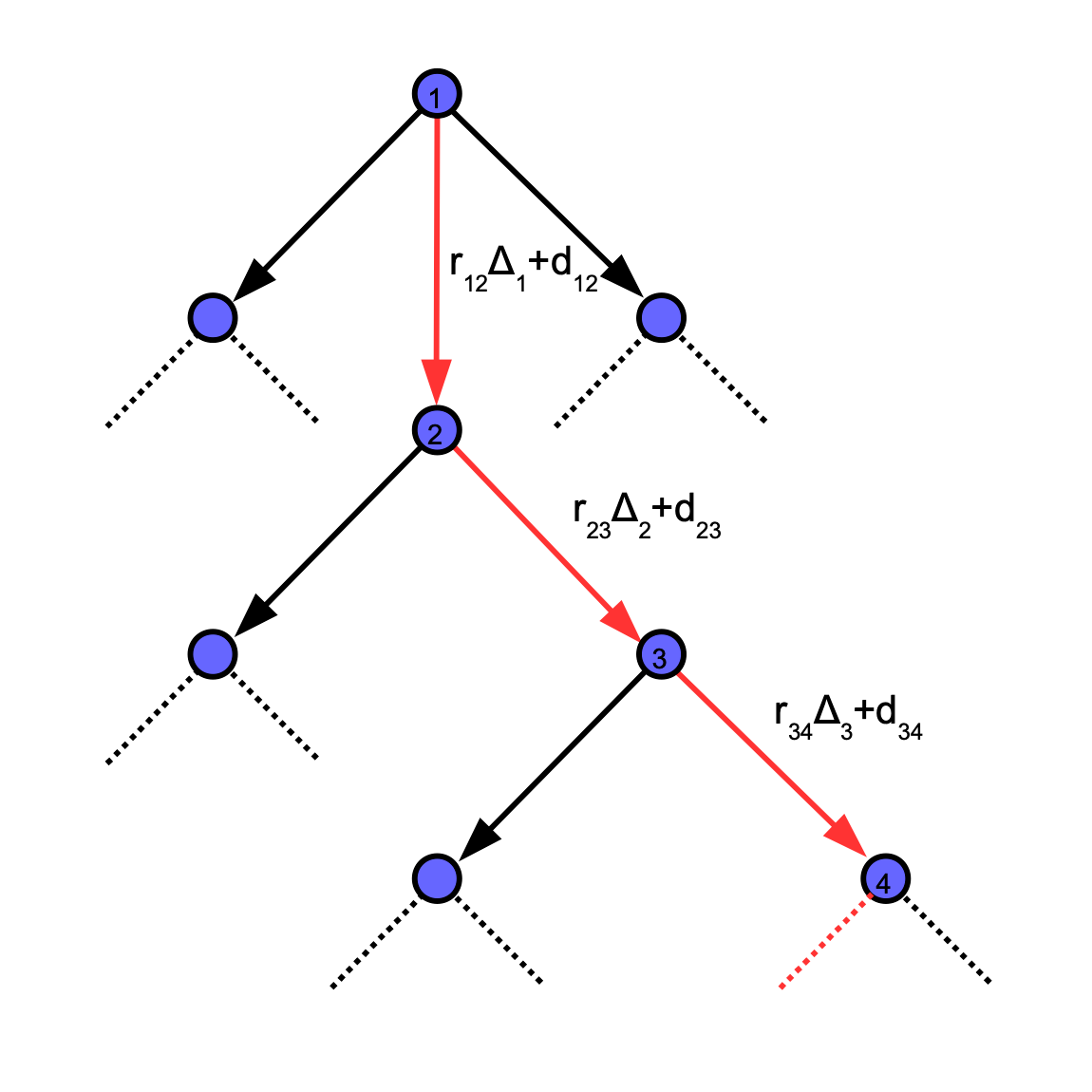
A single message is sent from node to all nodes of the network. The latter has topology of a random regular graph of connectivity which is locally tree-like for large . The total delay of a message sent from node to node , via the nodes and , is given by the sum .
Results for a High Connectivity Regime
- We consider networks with topology of a random regular graph in the high connectivity regime of , where , with and .
- First we consider the case of , i.e. the network is a complete graph, where the least latency is expected. Measuring the latency of broadcast for , we see that it is increasing as and decreasing as as can be seen in the figure below.
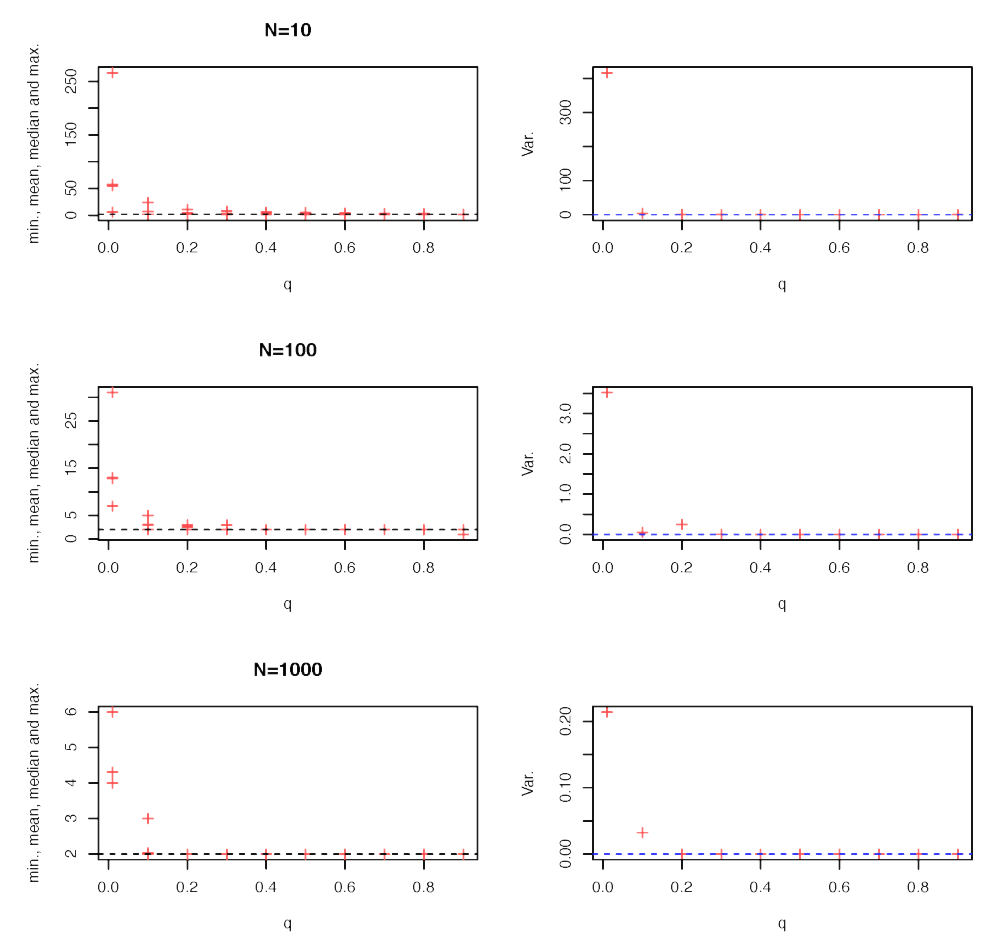
Statistics of message latencies computed for the number of messages (bottom, top and middle) broadcasted on the network of nodes. The latter has the topology of a complete graph. The delay model, for a message sent from node to its neighbours , used is , where , and is random variable from the Geometric distribution with parameter . The black dashed horizontal line corresponds to . The blue dashed horizontal line corresponds to .
- Furthermore, as is increased from to the latency of broadcast becomes more concentrated on the value of 2 as can be seen in figures below.
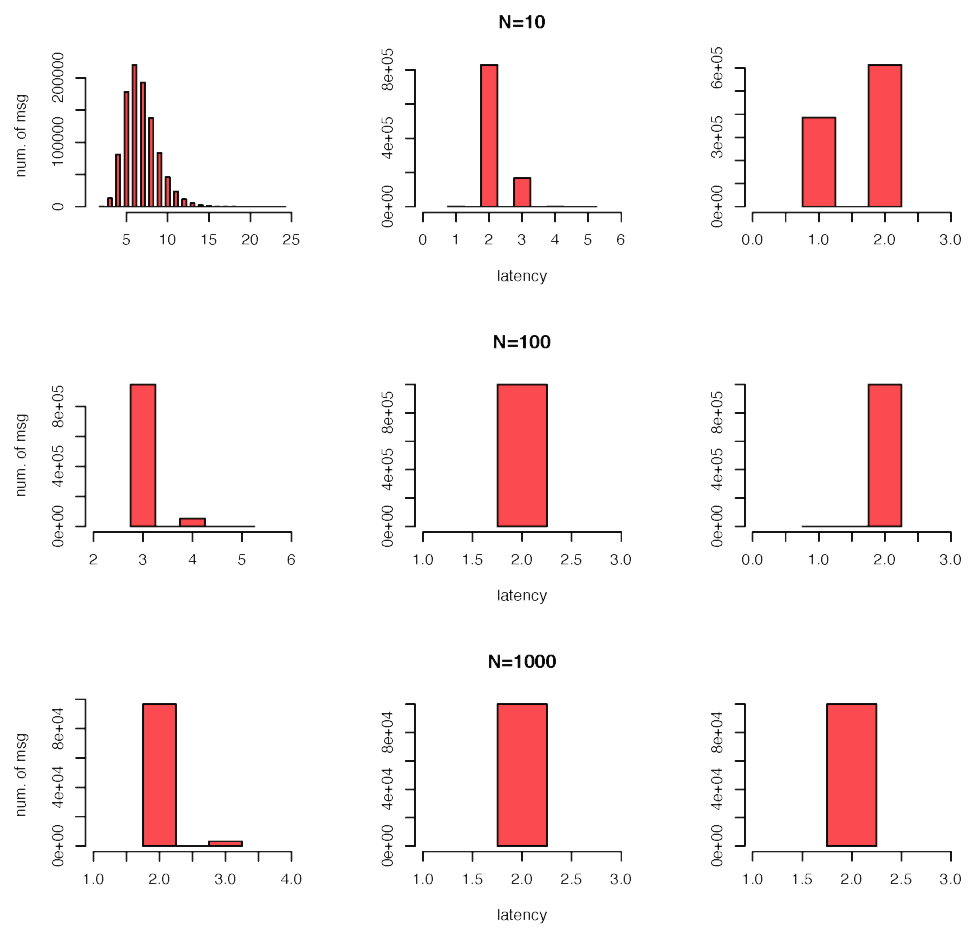
The histogram of message latencies computed for the (top and middle, bottom) messages broadcasted for the network of nodes. The latter has topology of a complete graph. The delay model, for a message sent from node to its neighbours , used is , where , and is random variable from the Geometric distribution with the parameter (left, middle, right).
- Finally, we consider random regular graph in the high connectivity regime of , where .
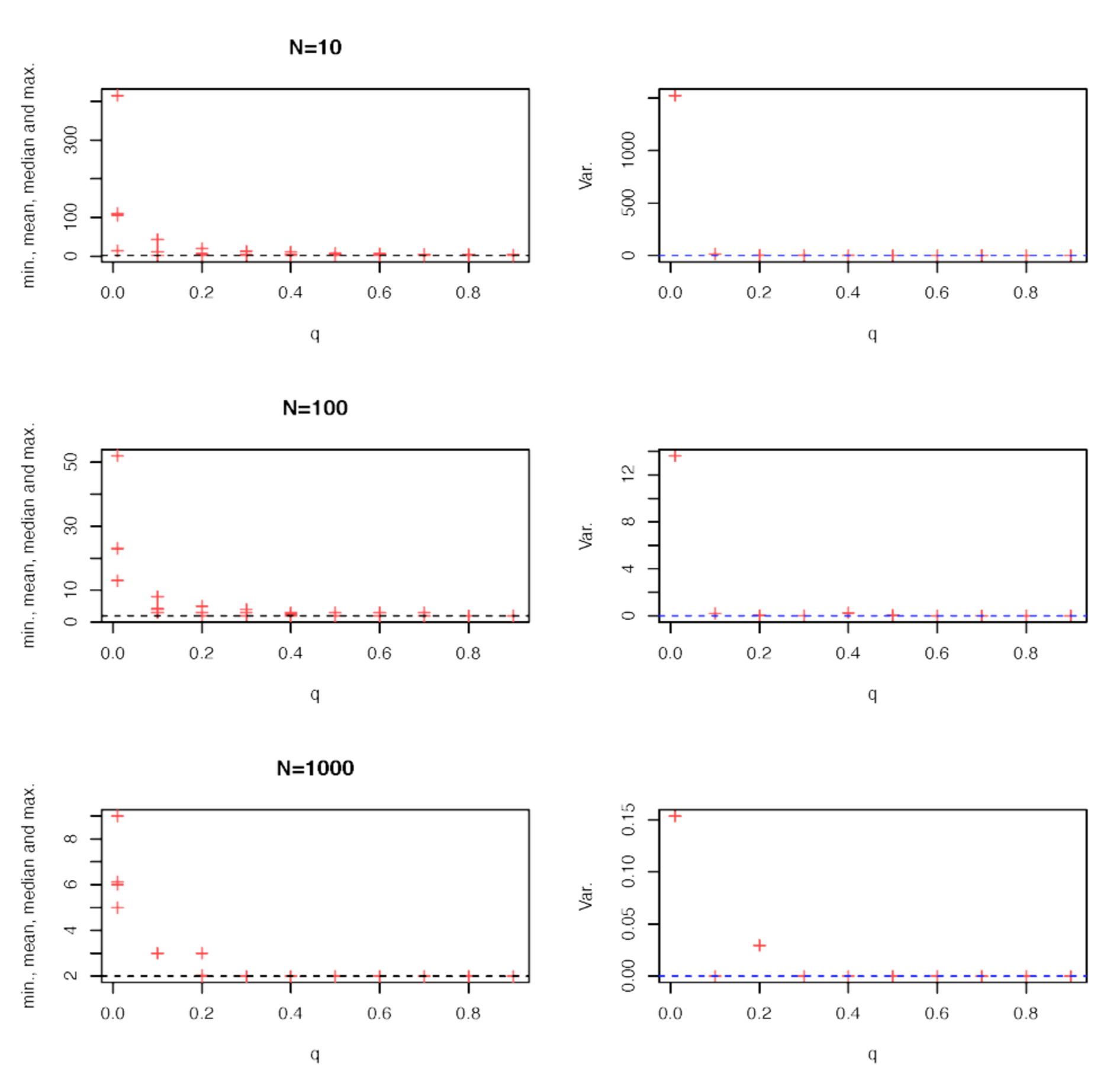
Statistics of message latencies computed for (bottom, top and middle) messages broadcasted on the network of nodes. The latter has topology of a random regular graph with connectivity . The delay model, for a message sent from node to its neighbours , used is , where , and is random variable from the Geometric distribution with parameter . The black dashed horizontal line corresponds to . The blue dashed horizontal line corresponds to .
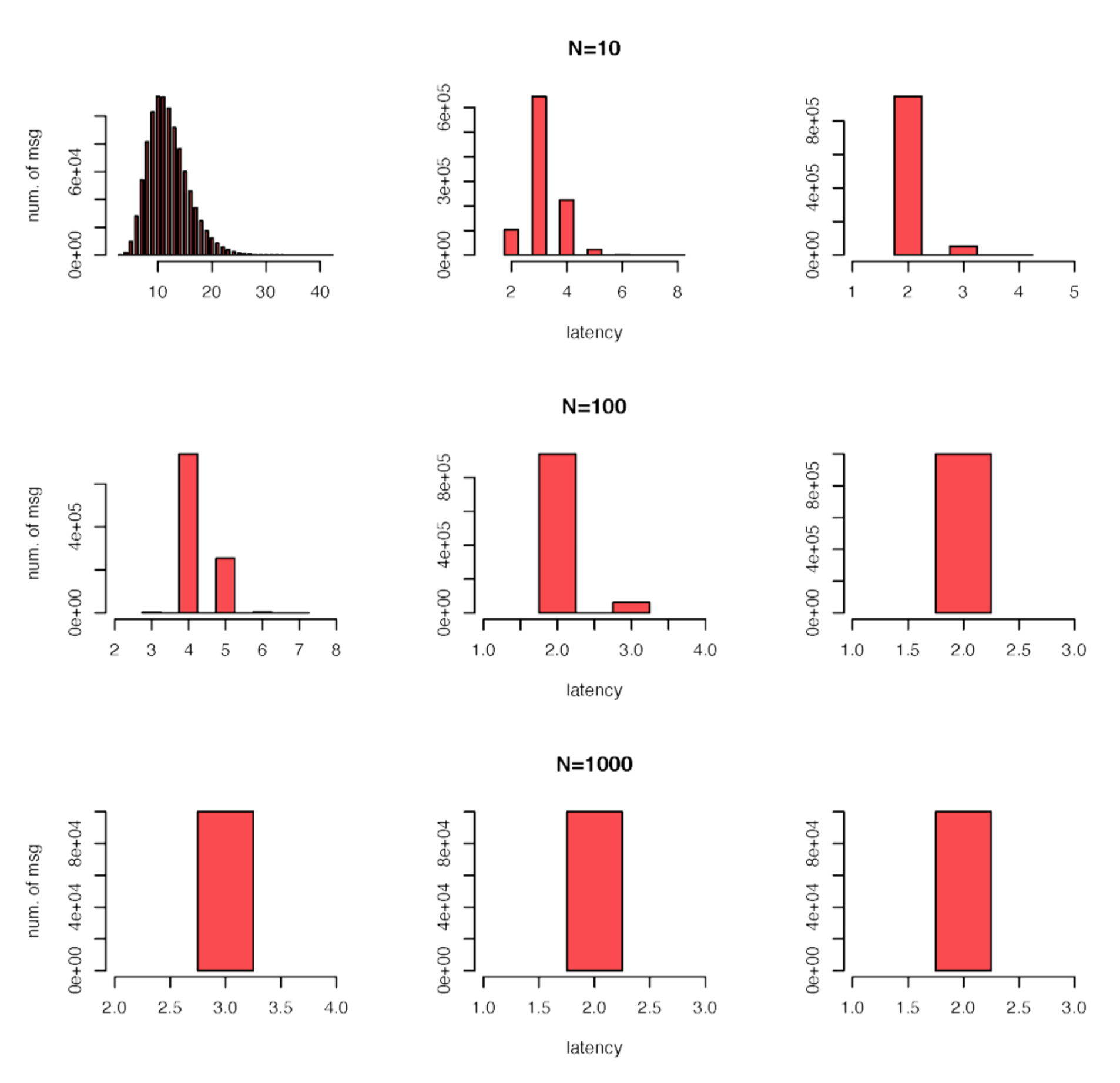
The histogram of message latencies computed for the (top and middle, bottom) messages broadcasted for the network of nodes. The latter has topology of a random regular graph of connectivity . The delay model, for a message sent from node to its neighbours , used is , where , and is random variable from the Geometric distribution with the parameter (left, middle, right).
Results for a Finite Connectivity Regime
- We consider broadcast on networks with topology of a random regular graph in the finite connectivity regime of with and .
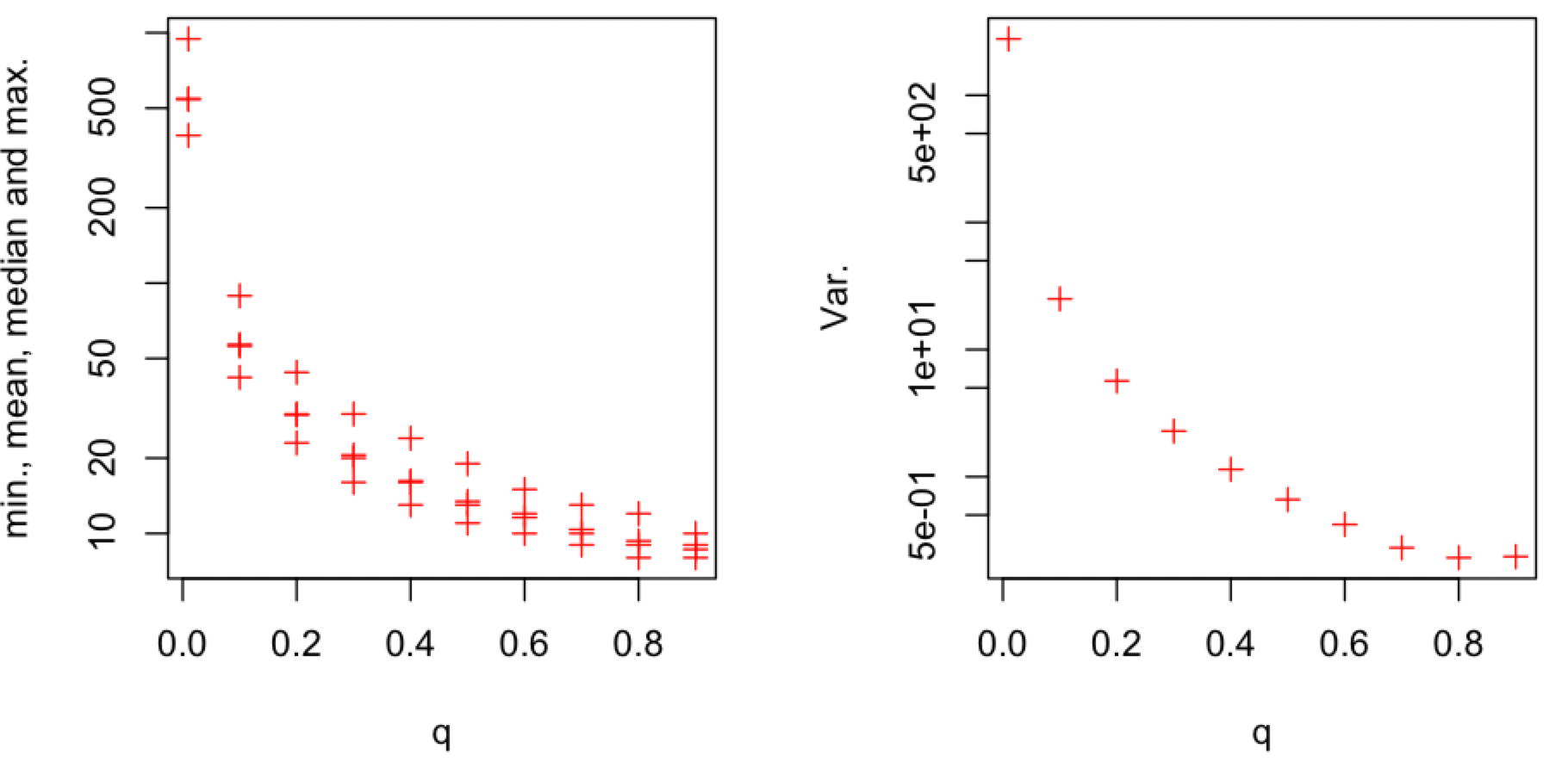
Top: Statistics of message latencies computed for the number of messages broadcasted on the network of nodes. The latter has topology of a random regular graph with connectivity . The delay model, for a message sent from node to its neighbours , used is , where , and is random variable from the Geometric distribution with parameter . Bottom: The histogram of message latencies computed for (left, middle, right).
- Dividing the latency of broadcast by suggests that the latter is converging to some value, dependent on and connectivity , as as can be seen in the figure below.
The average latency of broadcast standard deviation (divided by ) plotted as a function of network size for (left, middle, right). The number of messages broadcasted is . The network has topology of a random regular graph with connectivity . The delay model, for a message sent from node to its neighbours , used is , where , and is random variable from the Geometric distribution with parameter .
- For distribution of the random variable , where is sampled from the geometric distribution with parameter , is exponential distribution with parameter . The latter follows from the properties of the Geometric distribution.
- Furthermore, the latency of broadcast, , for delays sampled from the exponential distribution with parameter and is
i.e. the latency of broadcast is withhigh probability when is large.
- The above two points suggest that for small , the latency of broadcast is approximately when are sampled from the geometric distribution with parameter , i.e. the latency of broadcast is diverging as . The latter is consistent with latency measured in simulations.
Statistics of message latencies computed for the number of messages broadcasted on the network of nodes. The latter has the topology of a random regular graph with connectivity . The delay model, for a message sent from node to its neighbours , used is , where , and is random variable from the Geometric distribution with parameter . The dashed black line is the function .
- For larger values of q, the average latency of broadcast computed numerically deviates from the asymptotic as can be seen in the figure above.
- We note that the (asymptotic) latency of broadcast is a special case of for some (unknown) function .
- Assuming that the latency of broadcast , with high prob. as , and inverting this expression gives us . Using the data to plot the latter suggests the form for some parameter as can be seen in the figure below.
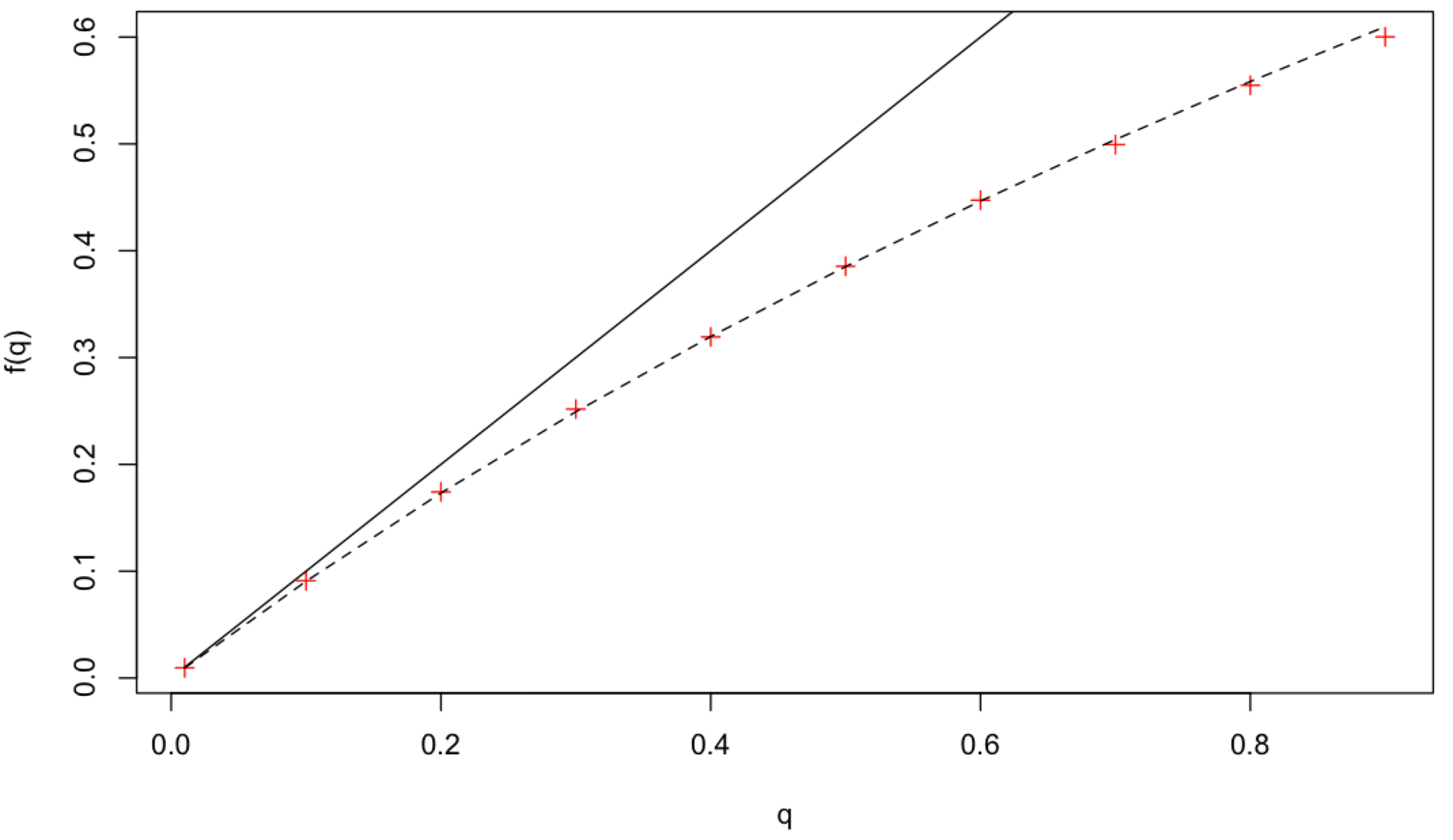
The function as function of . Solid line is and dashed line is with . Here for the broadcast latency the (empirical) mean from the figure was used.
- We note that for we have as .
- Furthermore, fitting to the mean of data gives us
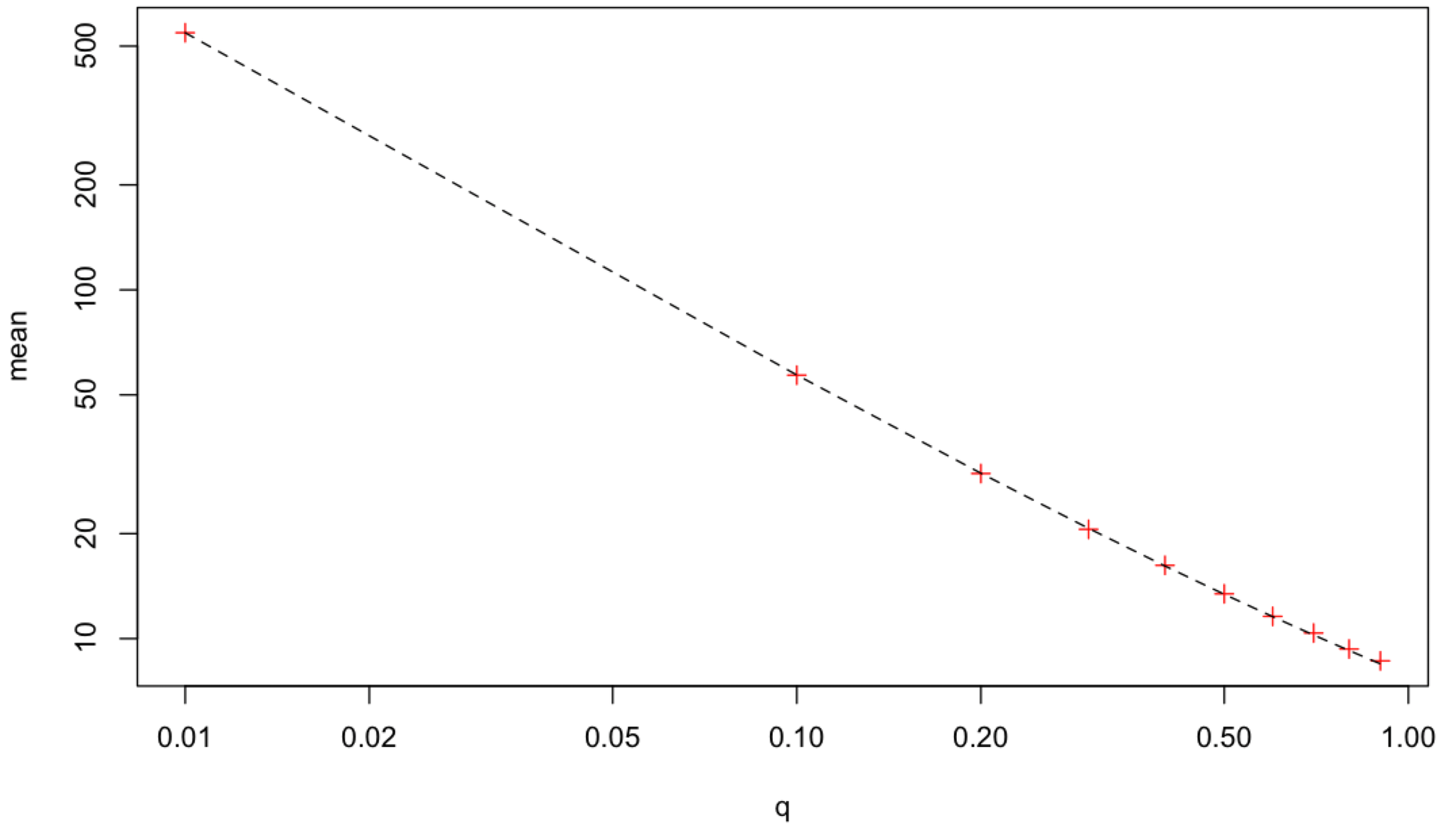
The mean latency of broadcast (+ symbols), computed from the data, is explained by (dashed line). Here the value of , obtained by fitting, is .
- Testing the expression for the mean value of broadcast obtained numerically suggests that the latter is accurate when the connectivity and q are small but significantly diverges from the data when and are large as can be seen in the figure below.
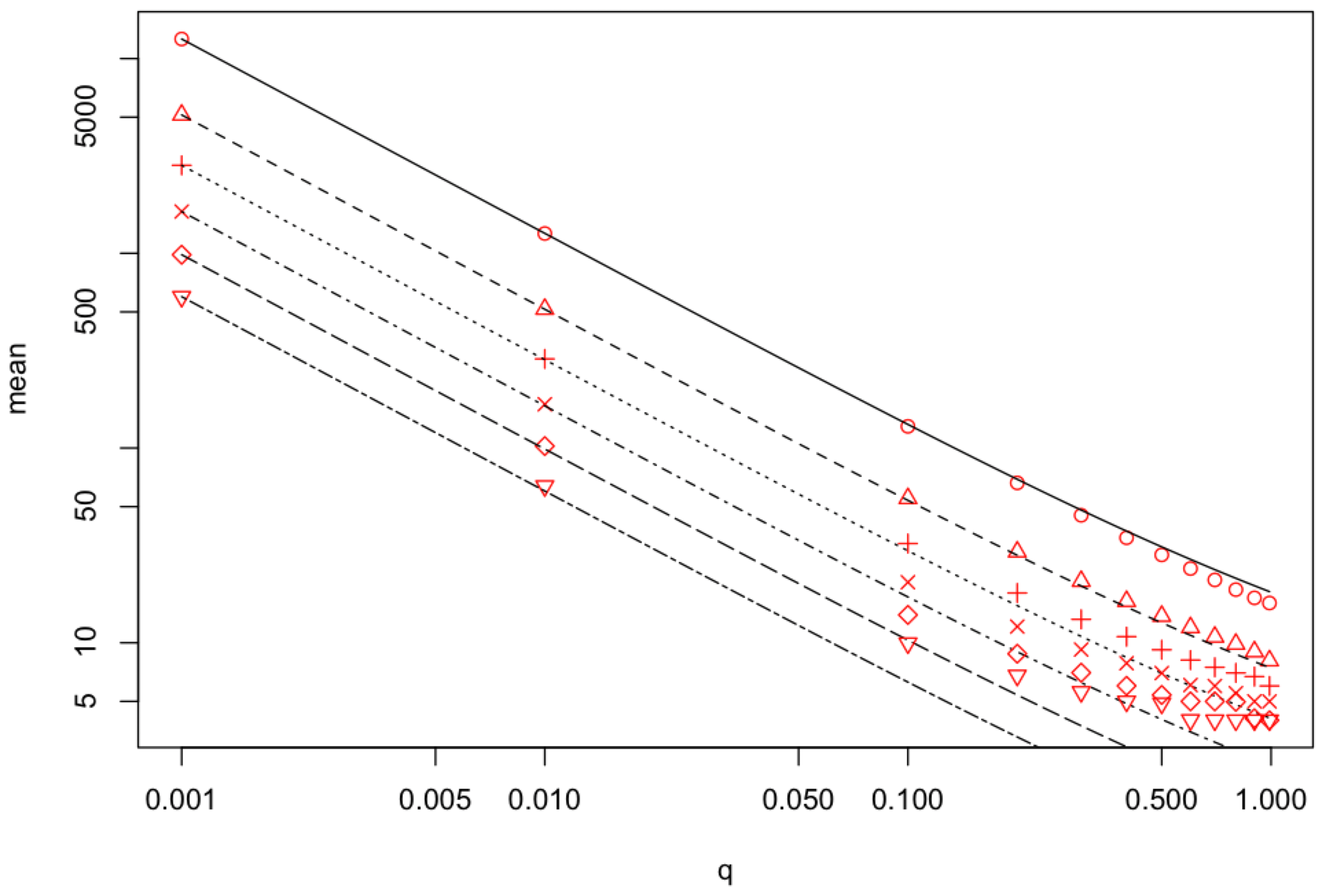
The mean latency of broadcast, represented by symbols, as a function of computed for the number of messages broadcasted on the network of nodes. The latter has topology of a random regular graph with connectivity (top to bottom). The lines were obtained by fitting the parameter in the expression . The delay model, for a message sent from node to its neighbours , used is , where , and is random variable from the Geometric distribution with parameter .
- The probability that the latency of broadcast is greater than some threshold decreases with the connectivity as can be seen in the figure below.
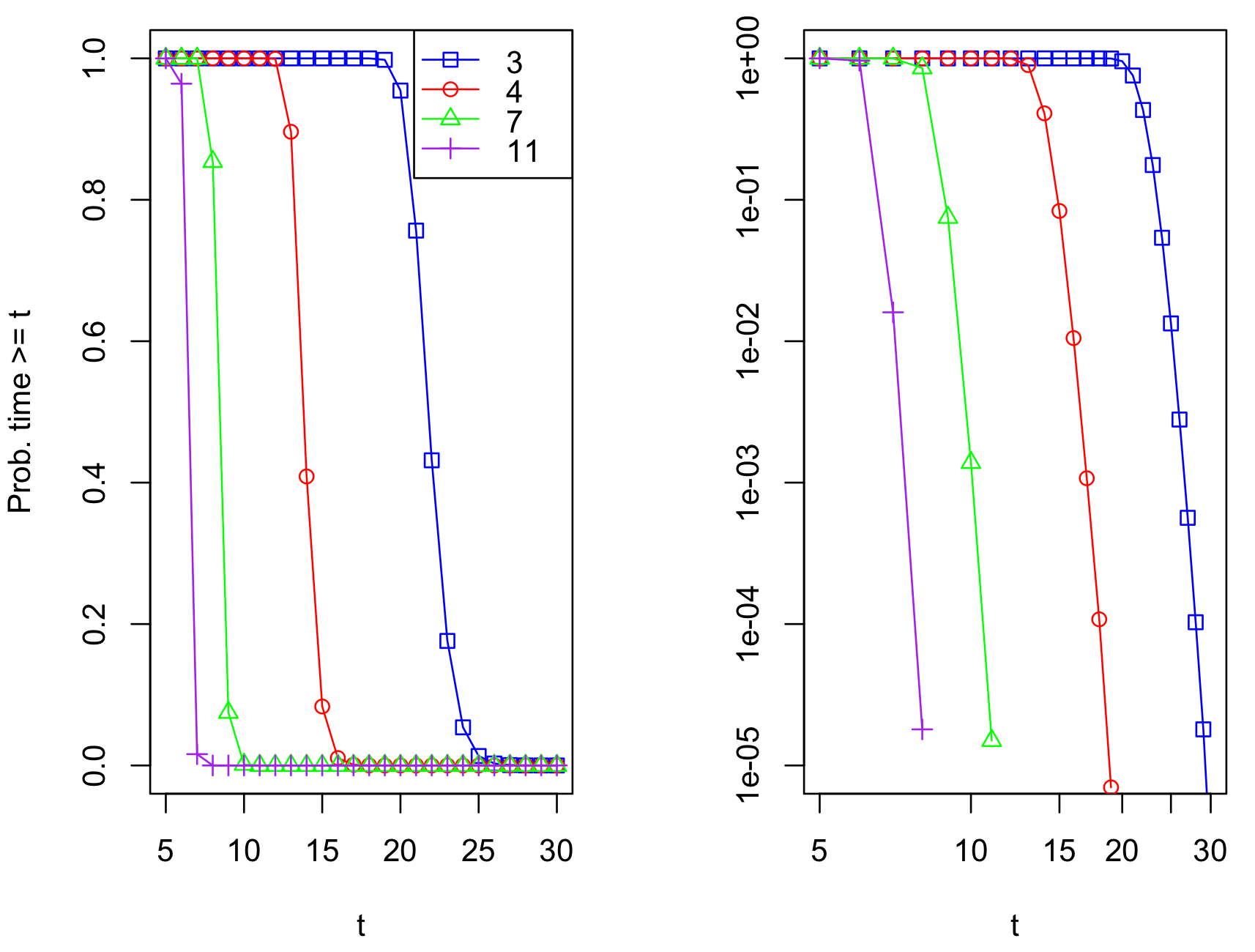
The probability that the latency of broadcast is greater than as a function of computed for the number of messages broadcasted on the network of nodes. The latter has the topology of a random regular graph with connectivity (top to bottom). The delay model, for a message sent from node to its neighbours , used is , where , and is random variable from the Geometric distribution with parameter .
- We note that random regular graph is locally tree-like, i.e. when is large any node is a root of a tree of some height with high probability.
- For the node connectivity the number of nodes in the tree of height , rooted at node , is given by
- In above we assumed that root node has children and every internal node has children (see figure).
- For nodes, the minimum such that is given by
- The latency of broadcast on a tree of nodes is expected to be higher than on random regular with the same and the same connectivity . This is due to the presence of loops in the latter.
- The numerical results for (average) latency of broadcast on a tree of nodes suggest that this average is an upper bound on the average latency of broadcast on on random regular with the same and the same connectivity as can be seen in the figure below.
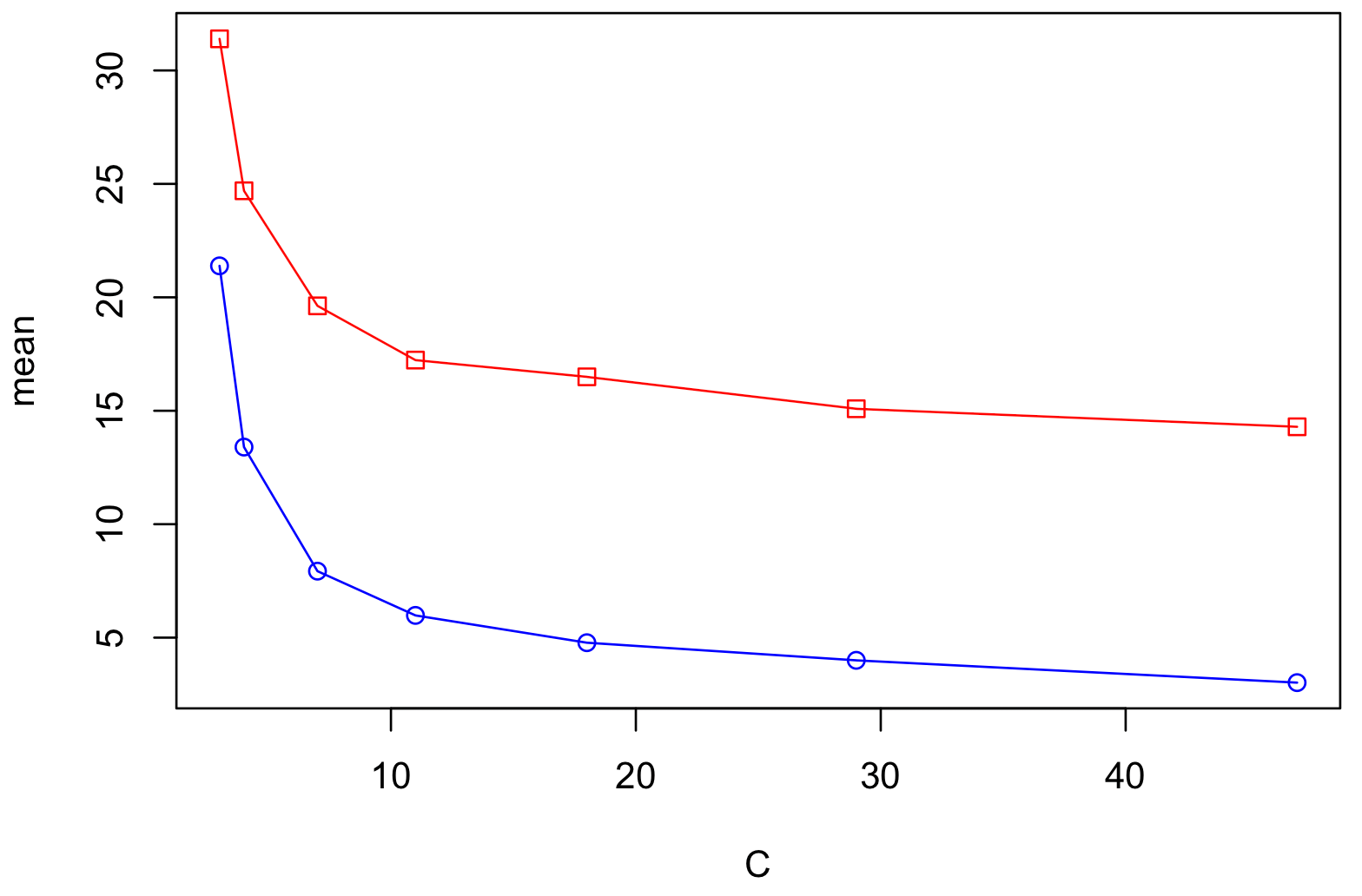
The average latency of broadcast as a function of connectivity computed for the number of messages broadcasted on the network of nodes. The latter has the topology of a random regular graph with connectivity or of a balanced complete tree, rooted at node 1, with the same and . The delay model, for a message sent from node to its neighbours , used is , where , and is random variable from the Geometric distribution with parameter .
- Furthermore, numerical results for latency of broadcast on trees suggest that the latter also can be used to obtain an upper bound on probability as can be seen in the figure below.
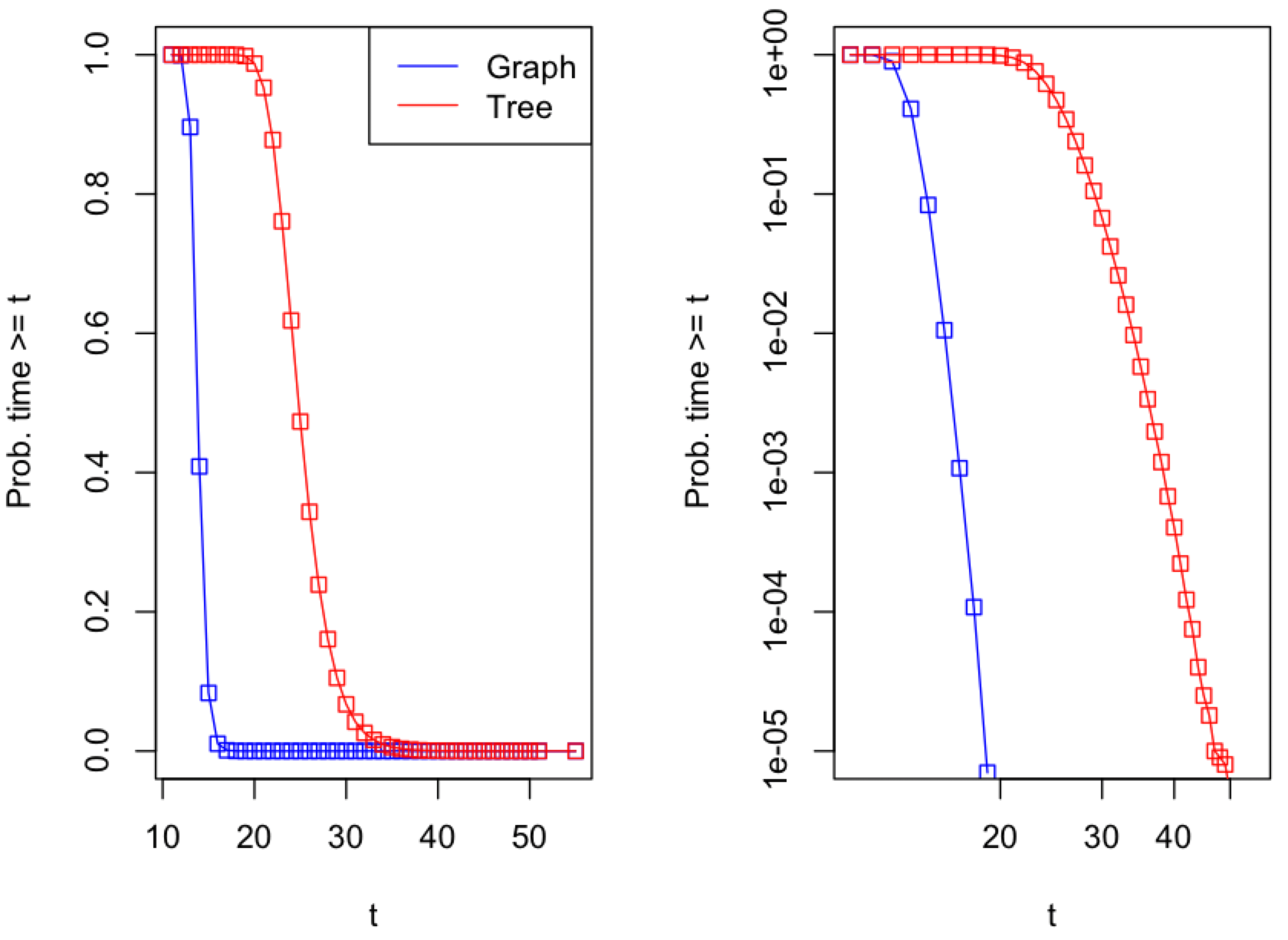
The probability that the latency of broadcast is greater than as a function of computed for the number of messages broadcasted on the network of nodes. The latter has the topology of a random regular graph with connectivity or of a balanced complete tree rooted at node 1. The delay model, for a message sent from node to its neighbours , used is , where , and is random variable from the Geometric distribution with parameter .
- We note that the latency of broadcast on a tree of finite size is equivalent to the latency of broadcast in finite neighbourhood of a sender node in large random regular graph. In the latter, as the finite neighbourhood of a node is (with high prob.) a Cayley tree (see figure below) up to some distance, measured in by number edges between the node and any other node.
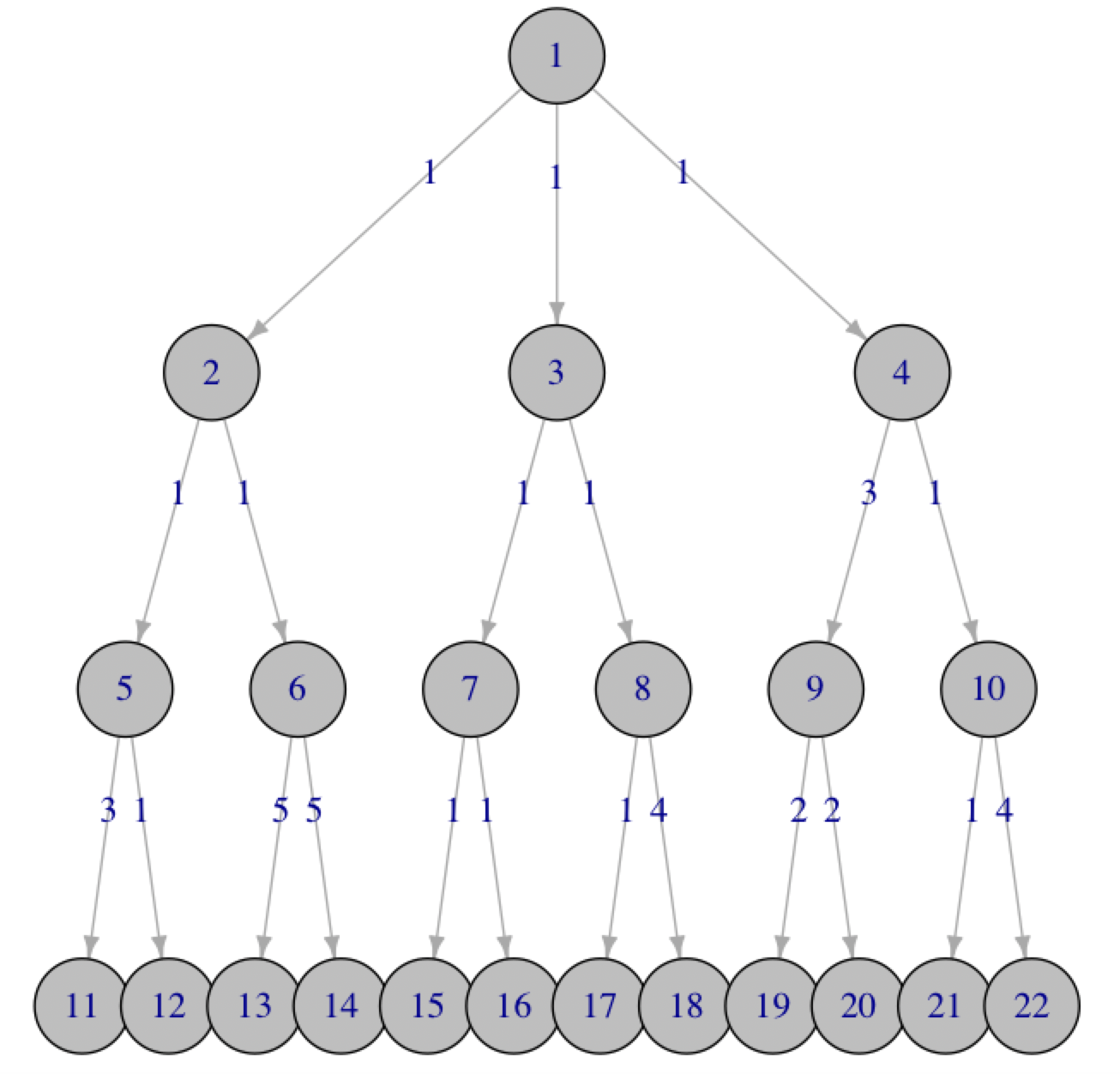
The neighbourhood of node in a very large random regular graph of connectivity . The weights in the latter are independent random variables from geometric distribution with parameter .
- The numerical results for latency of broadcast on Cayley trees suggest that the latter also can be used to obtain an upper bound on probability as can be seen in the figure below.
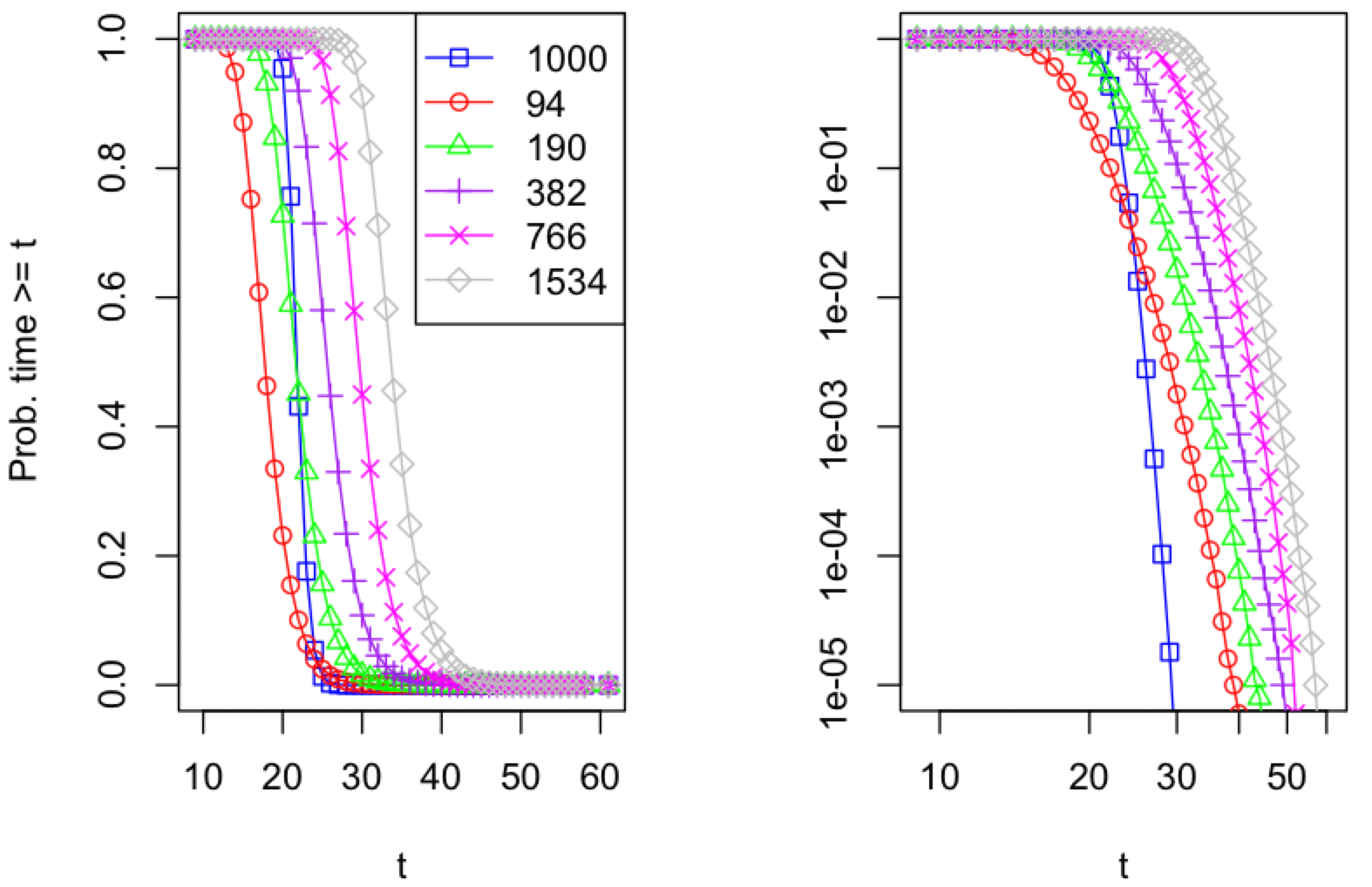
The probability that the latency of broadcast is greater than as a function of computed for the number of messages broadcasted on the network of nodes. The latter for has the topology of a random regular graph with connectivity and for is a Cayley tree rooted at node 1. The delay model, for a message sent from node to its neighbours , used is , where , and is random variable from the Geometric distribution with parameter .
- The latency of broadcast on a tree can be computed iteratively. The latter uses the property
- To show this we consider the latency of broadcast on a tree of nodes rooted at node (see figure) as follows.
- First, we define the latency of communication a message, sent from node to all nodes in, when it is relayed from the node to as then the latency of broadcast
- Second, we consider the latency of broadcast
- Now the maximum distance from node to a leaf node , , can be computed as follows
- Furthermore, if node is adjacent only to leaf nodes but one then
- For node not adjacent to leaf nodes the can be computed via equation similar to the equation. The latter suggests that the latency of broadcast can be computed recursively using above equations and numerical complexity of this computation is . This is better than when Dijkstra's algorithm is used to compute .
- The distribution of the latency of broadcast on a Cayley tree of height can computed by the population dynamics algorithmas follows.
- First, for each compute boundary conditions as follows
- Second, for each do the following for each
- Finally, for each compute
- The prob. distribution of for a Cayley tree of height can be estimated by the density
- The above dynamics can be described by the equation
- The boundary condition corresponding to the Cayley tree is given by
- The prob. distribution of for a Cayley tree of height is given by
- Using that the prob. distribution is geometric with parameter , one could try to solve above equations analytically. Also one could consider a single loop and see how this will change the equation.
- For we have with prob. and hence the latency of broadcast is dominated by the diameter of a random regular graph, i.e. the largest distance between any two nodes. The bounds (using the Theorems 1 and 3) for the latter for (very small) are given by
A Simple Model of Communication Latency in Consensus
- To model the communication latency of a node participating in consensus, we assume that latency has two dominant components which are due to delays in “mixing“ and “broadcast” (cf. the formula “Mixnet delay (gamma distribution) sampled once per block + PoL (constant) + final broadcast from exit mixnode (exponential distribution) sampled per node” used in consensus simulations).
- We assume that given a network of nodes, a gossiping-like mode of communication is used.
- Let us assume that the network topology used is a random regular graph , where is the set of nodes and is the set of edges, with connectivity . The latter is sampled only once and remains fixed for the duration of a consensus protocol.
- Furthermore, to each edge we assign a random variable , sampled from some probability distribution, to model delays in communication links. This gives rise to the weighted graph . The probability distribution could be exponential, with parameter such that is the average and is the variance, or for all (cf. the “300ms” constant delay used in current estimates of latency).
- To model the mixing delay we assume, without loss of generality, that node sends (via mix nodes) a message to node , and adopt the single-path model as follows
- In above we assume that mix nodes, and the sender node , introduce delays modeled by random variables sampled from the Geometric distribution with the parameter . The latter models a queue which uses coin-flipping to remove a message. Here is a cost of attempt to remove a message, measured in units of time, from the queue.
- The second part of above equation models the contribution of gossiping to the delay. Here is the “distance”, measured in units of time, between the nodes and on the graph which is defined as follows
- Furthermore, the distance , i.e. samples of random variables are different for different to model the gossiping aspect of communication.
- The distance can be interpreted as the latency of (communication) path between the sender node and the receiver node when the gossiping mode of communication is used.
- We note that in a weighted graph the distance can computed by using the Dijkstra's algorithm.
- To model the broadcast delay we assume, without loss of generality, that the node broadcasts the message, received from node , to all nodes in the network. Assuming that gossiping is used the delay is for each node .
- To simulate the mixing and broadcast delays in a consensus simulation the following algorithm can be used
- Generate a random regular graph with connectivity .
- For the sender node , sending a message to the receiver node , sample (without replacement) the mix nodes and from the set of all available nodes .
- Sample the random delays , from the geometric distribution with parameter .
- Given the random regular graph , generate the sequence of weighted graphs associated with each directed edge in the path and compute the distances on these graphs.
- Compute the mixing delay
- Given the same random regular graph , generate the graph with random weights and for the node compute the distance for all . The latter are broadcast delays.
- Repeat the steps 2 to 6 for each sender node.
- We note that when , i.e. all communication links have the same latency, then all distances on the weighted graph can be precomputed which simplifies the steps 4 and 6 in the above algorithm.
- Also the algorithm can be easily adopted to use other models of random graphs, and other models of mixing and communication delays.
Bibliography
Amir Dembo. Andrea Montanari. "Ising models on locally tree-like graphs." Ann. Appl. Probab. 20 (2) 565 - 592, April 2010. https://doi.org/10.1214/09-AAP627
Hamed Amini. Marc Lelarge. "The diameter of weighted random graphs." Ann. Appl. Probab. 25 (3) 1686 - 1727, June 2015. https://doi.org/10.1214/14-AAP1034
Mézard, M., Parisi, G. “The Bethe lattice spin glass revisited.” Eur. Phys. J. B 20, 217–233 (2001). https://doi.org/10.1007/PL00011099
Bollobás, B., Fernandez de la Vega, W. “The diameter of random regular graphs.” Combinatorica 2, 125–134 (1982). https://doi.org/10.1007/BF02579310
ANALYSIS-QUEUING-SYSTEM-IN-THE-MIX-NODE
| Field | Value |
|---|---|
| Name | [Analysis] Queuing System in the Mix Node |
| Slug | 194 |
| Status | raw |
| Category | Informational |
| Editor | Alexander Mozeika [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-09-08 |
Introduction
We consider queuing system of a mix node where coin-flipping algorithm is used to remove messages. We show that the amount of time message spends in a queue is governed by the Geometric distribution. The consequence of the latter is memorylessness property, i.e. the amount of time a message will spend in the queue is independent on how long it is already been in the queue, which is important for anonymity of communication.
Overview
This document analyses how a mix node—a privacy tool that hides message origins—manages delays using randomised queues. Key points:
- Queue Design:
- Each connection has an in-queue (FIFO order) and out-queue with randomised removal.
- A "Relayer" forwards real messages to all out-queues except the sender’s, dropping dummies.
- Randomised Delays:
- Messages in the out-queue are shuffled, then each has probability (e.g., 50%) of being sent per round.
- This follows a Geometric distribution: ~50% sent in Round 1, ~25% in Round 2, etc.
- Anonymity Guarantee:
- The system’s memorylessness ensures delays are independent of past wait times, preventing timing attacks.
Methods used:
- Geometric distribution models rounds until a message is sent.
- Simulations (e.g., sending 10,000 messages) validate the theory.
- Binomial distribution tracks messages removed per round.
Why It Matters:
- Balances privacy (unpredictable delays) with efficiency (tunable via ).
- Foundations for Tor-like systems and anonymous networks.
Analysis
Assumptions
We assume that node has connections to other nodes, labelled by the set , and two queues (”in-queue” and “out-queue”), associated with each connection. Messages which arrive via the connection are stored in the in-queue . Messages which are sent via the connection are stored in the out-queue . Messages are added to the back and removed from the front of , i.e. the latter is the FIFO queue
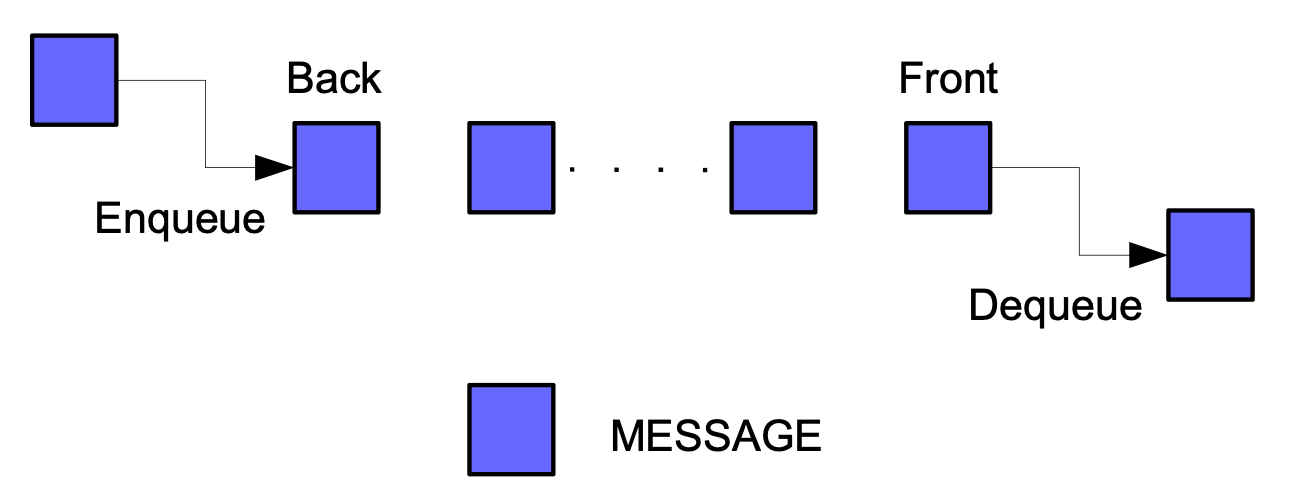
Representation of a FIFO (first in, first out) queue.
We note that FIFO queue preserves temporal order of arriving messages.
The Relayer removes a message from the front of and i) drops it if the message is a dummy or ii) adds the message to the back of all , where , queues (i.e. all out-queues but ) if message is “real”.
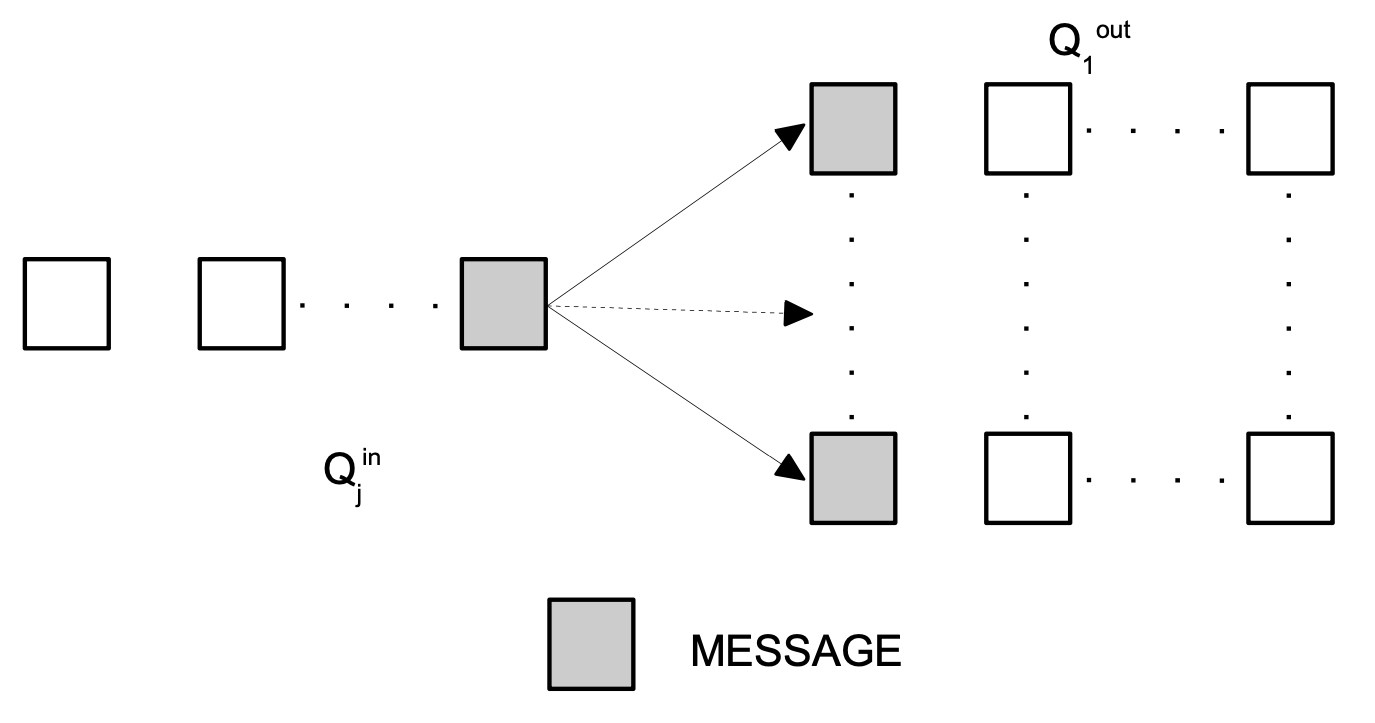
Above operation is repeated by Relayer for all
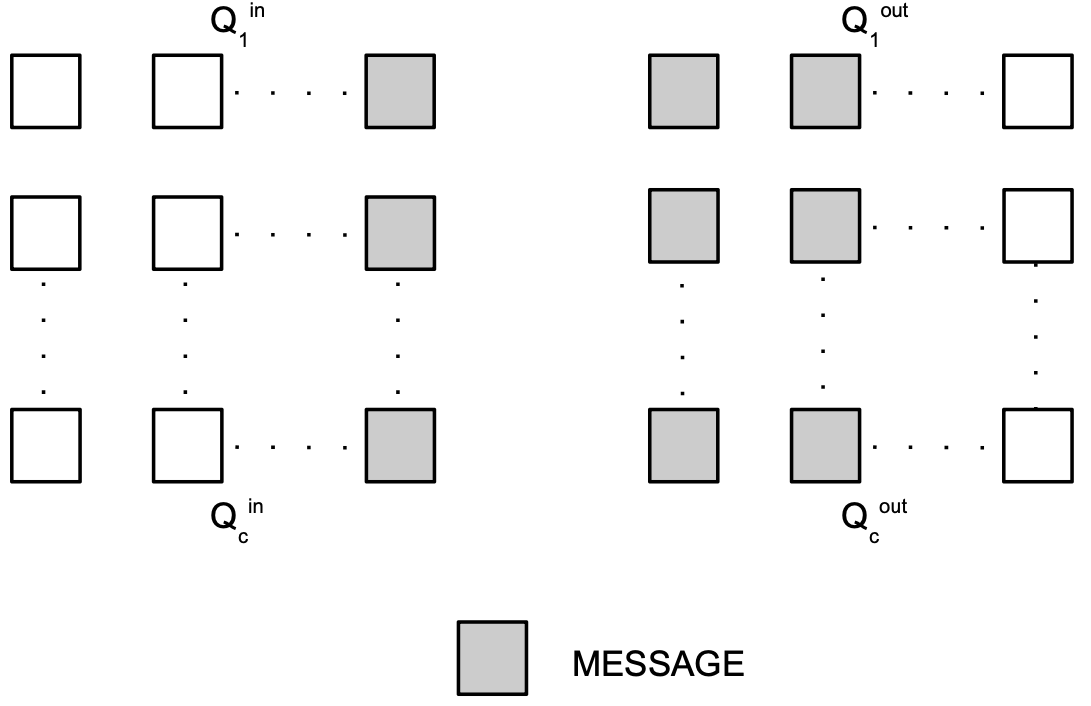
Analysis of a single out-queue
Let us consider, without loss of generality, the out-queue and assume that the front of holds messages which arrived at times . Furthermore, we assume that messages which arrive at times after time , , are labelled by , i.e. we assume that messages are labelled by the set .
The above messages are shuffled, which is equivalent to random permutation, then each message is removed from the queue with probability and sent. In above removal of a message which arrived at time can be modeled by the binary variable , where corresponds to not-removed/removed. We note that number of removed messages in this process is the random variable from binomial distribution with parameters and . Hence above process on average (and (approx.) typically) removes messages from the queue . The above algorithm can be seen as a variant of the pool mix (see the article)
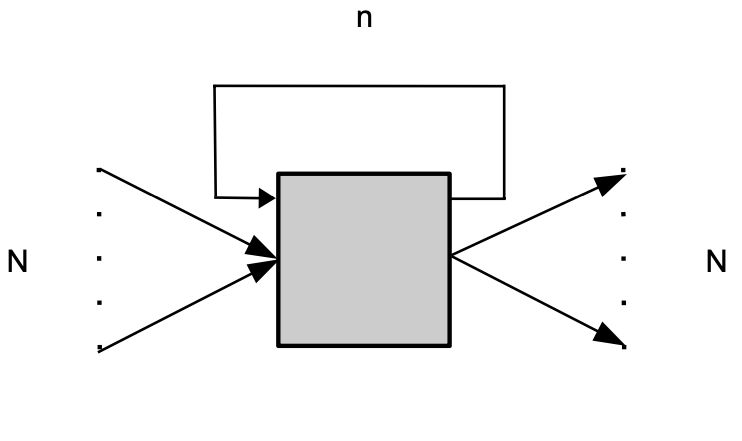
A pool mix.
However, in the pool mix model a fixed number (of randomly selected messages) is removed and sent, but in the algorithm this number is random.
Let us assume that messages are removed from the front of the out-queue in rounds (or epochs) and if a message which arrived at time , where , was removed at round then and for . We assume that after each round of removal the removed messages are replaced with new messages and the front messages in the queue are shuffled before the next round of removal. We assume that round follows the Geometric distribution
To test above hypothesis we consider the following random process.

The message removal process in the out-queue . At round the front of the queue contained messages. Here messages are labelled by the set (top row). In round , and in subsequent rounds, each message is removed, with the prob. , and replaced with a next message from the queue .
Computing the histogram of “the number of rounds a messages stays in the queue” random variable confirms that the latter follows the Geometric distribution.
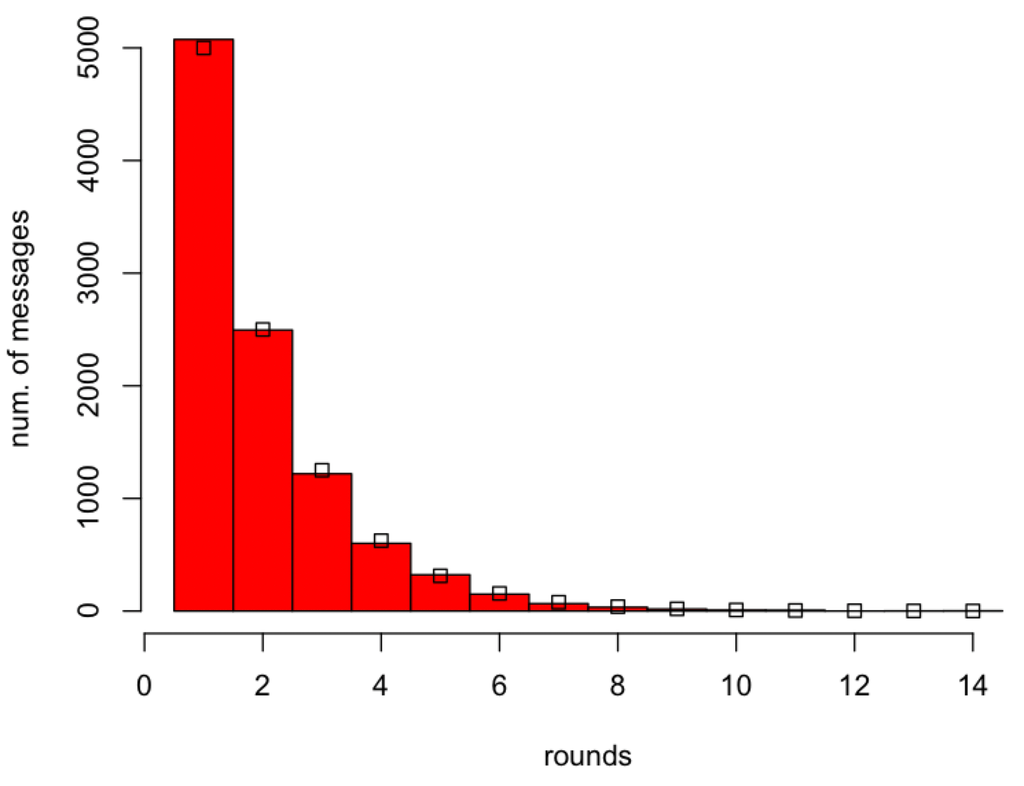
Histogram of the number of messages removed from the front of the queue at round , , etc. of the random message removal process with . At round the front of the queue contained messages. Here the simulation (red histogram bars) is compared with the prediction of Geometric distribution (square boxes). We note that for on average messages were removed at round , messages were removed at round , etc.
Decreasing reduces number of messages removed per round as can be seen below.
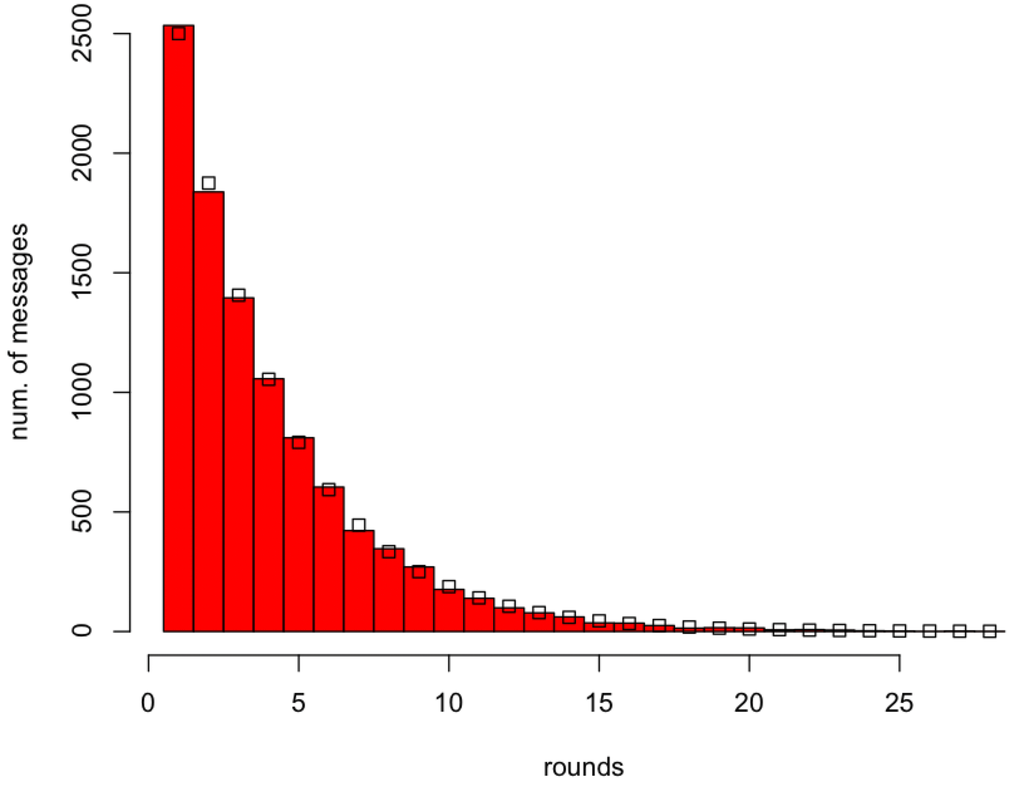
Histogram of the number of messages removed from the front of the queue at round , , etc. of the random message removal process with . At round the front of queue contained messages. Here the simulation (red histogram bars) is compared with the prediction of Geometric distribution (square boxes). We note that for on average messages were removed at round , messages were removed at round , etc.
Increasing increases number of messages removed per round as can be seen below.
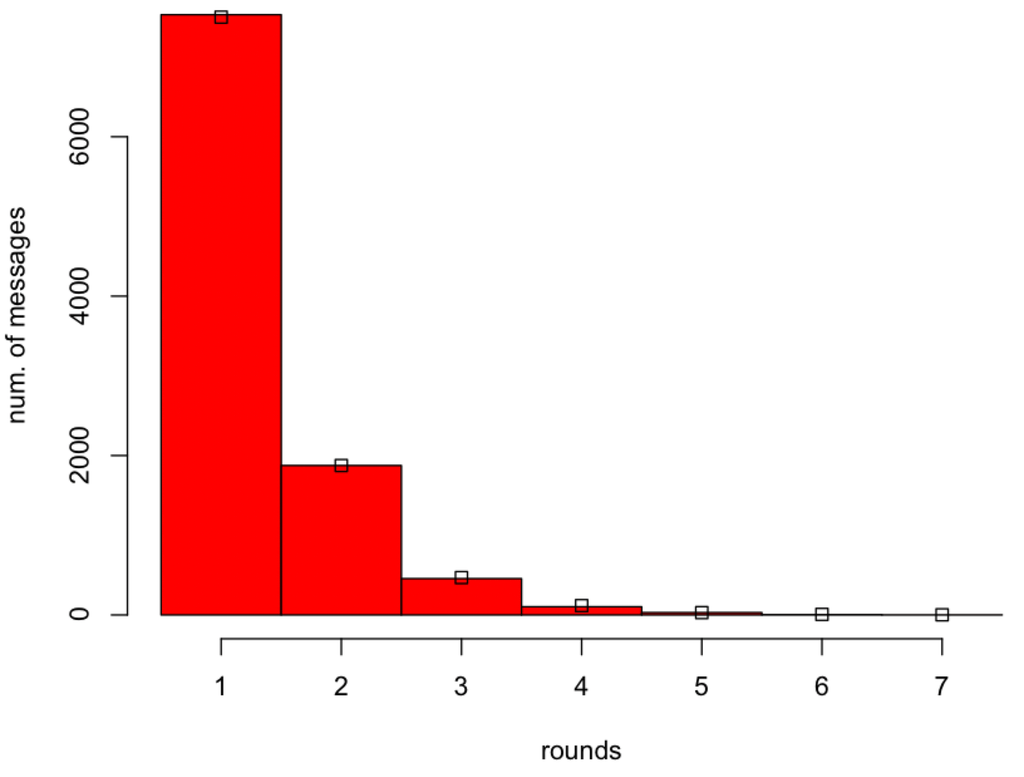
Histogram of the number of messages removed from the front of the queue at round , , etc. of the random message removal process with . At round the front of queue contained messages. Here the simulation (red histogram bars) is compared with the prediction of Geometric distribution (square boxes). We note that for on average messages were removed at round , messages were removed at round , etc.
The Geometric distribution is increasing function of for and decreasing function of for .
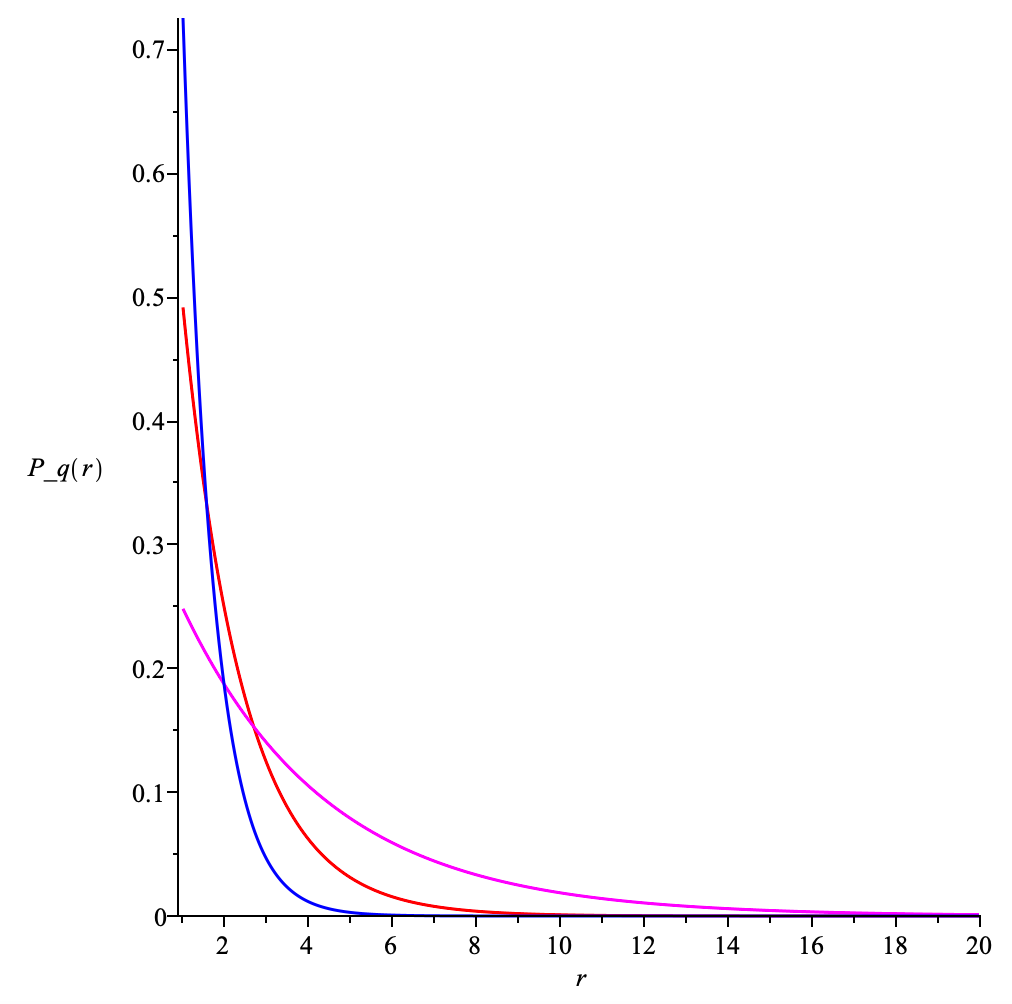
The Geometric distribution plotted as the function of for (magenta, red, blue).
Assuming that the duration of round is the message which arrived at time will be removed from the queue at time , where is random variable from the Geometric distribution . We expect that is a function of the number of messages removed at round , i.e. . Here is random number from the binomial distribution with parameters ( size of queue) and (prob. of dequeuing a message). We note that at most messages can be removed and . The latter implies that , where we defined . Thus a message is delayed in the out-queue by at most , where is the random variable from the distribution .
Furthermore, the probability for the random variable from the Geometric distribution . Hence
Thus a message is delayed by with the probability . We note that for the random variable from the Geometric distribution we can show that . The latter is memorylessness property of Geometric distribution and the consequence of the latter is that the amount of time a message will spend in the queue is independent on how long it is already been in the queue.
Bibliography
Das D., Diaz C., Kiayias A., Zacharias T. (2024). Are continuous stop-and-go mixnets provably secure? Proceedings on Privacy Enhancing Technologies. https://eprint.iacr.org/2023/1311
Serjantov, A., Danezis, G. (2003). Towards an Information Theoretic Metric for Anonymity. In: Dingledine, R., Syverson, P. (eds) Privacy Enhancing Technologies. PET 2002. Lecture Notes in Computer Science, vol 2482. Springer, Berlin, Heidelberg. https://doi.org/10.1007/3-540-36467-6_4
ANALYSIS-RESILIENCE-AND-ANONYMITY
| Field | Value |
|---|---|
| Name | [Analysis] Resilience and Anonymity |
| Slug | 195 |
| Status | raw |
| Category | Informational |
| Editor | Alexander Mozeika [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-08-25 |
Introduction
In order to guide a design of the Blend Network, this document summarises parameters (and results of analysis) of the leader election process, communication on trees and inference of relative stake. In addition to this, we considered sampling of linear trees and derived conditions under which results for communication on trees can be used. Also, we analysed the probability of linking a sender node to its message which allows us to quantify the “unlinkability of block proposer.” All these parameters (and results) were used to design (and implement) the “calculator” which can be used to quantify resilience and anonymity of communication in the Blend Network.
Finally, in this document we also analysed strategies which can be used to reduce anonymity failure and statistical properties of number of time-slots between two consecutive blocks in Cryptarchia.
Analysis
Leader election process
The leader election process is organised into epochs and each epoch is divided into time-slots.

One epoch of the leader election process. Node participates in the leader election at time-slots . The (binary) outcome of this lottery, where 0/1 corresponds to lost/won, is either observed (numbers in square brackets) or unobserved.
The leader election process has the following parameters
| Parameter | Description | Value/Range |
|---|---|---|
| Number of nodes | | |
| | Number of time-slots per epoch | |
| | Fraction of time-slots with at least one winner | |
| | The duration of a single time-slot | s |
Sampling of Linear Trees
Communication on Linear Trees. A message is sent from a root node through communication paths where each path has nodes.
The number of nodes in linear tree design is , where is the number of paths and is the number of nodes in each path excluding the sender node. In the linear tree design, one node is the sender node and the other nodes are mix nodes.
We assume that in each epoch of the protocol there are sender nodes, labelled by the set . Each of the sender nodes sample nodes from the population of nodes (labeled by the set ). The total number of nodes involved in communication is .
We assume that each sender node samples nodes, independently from other nodes, using sampling without replacement. A node among the nodes sampled from just by chance can also appear in other random subsets of nodes.
The result of the sampling process described above can be represented by the following random factor-graph:
The random factor-graph generated by sampling of subsets of nodes, represented by factors (squares), from the set of all nodes represented by (filled) circles. If a node is a member of a subset then this is represented by an edge on this graph. Each node in the subset of , , is a member of at least of these subsets. Here .
Structure of a factor in the random factor graph associated with sampling of linear trees. Here . Node , associated with , is a sending a message to nodes and via the mix nodes and .
Connectivity of a node is the number of random edges connecting this nodes to factors labelled by the set . The connectivity of a node is the number of linear trees that appears in. The connectivity is a random number from the binomial distribution
with parameters and .
The probability that a node has more than one random connection , i.e. the prob. that a mix node participates in more than one subset of mix nodes used in linear trees, for is given by the sum
where with .
We note that and for , i.e. the probability is monotonic increasing function of for . Furthermore, the probability is monotonic increasing function of , i.e. increasing the number of nodes , , in the linear tree sampled by each sender node in increases probability that a node in has more than one random connection.
The probability is computed using the following parameters
| Parameter | Description | Value/Range |
|---|---|---|
| | Number of nodes | |
| | Number of sender nodes | |
| | Number of nodes in a linear tree | |
Communication on Linear Trees
We consider the following communication system
Communication on Linear Trees. A message is sent from a node through communication paths where each path has nodes. A node could be faulty (circle with dashed boundary), or adversarial (red circle). The presence of faulty node leads to communication failures. The presence of adversarial nodes could lead to communication and anonymity failures.
We assume that nodes in the population are “faulty” (faulty node is unable to relay a message) and the probability that a node is faulty is .
We assume that nodes in the population are “adversarial” (adversarial nodes are controlled by an adversary which can make nodes faulty, use them for traffic analysis, etc.) and the probability that a node is adversarial is .
If a path contains at least one faulty node then communication failure occurred.
If a path does not have any faulty nodes then this path is functioning.
If all paths have a communication failure then broadcast failure occurred.
The probability of broadcast failure is given by
We note that is the site percolation threshold of random regular graph (RRG) with connectivity C, i.e. for the RRG becomes disconnected with high probability as . The latter suggests if our model of the network is RRG then for the fraction of faulty nodes the communication is not possible with high probability in .
If all nodes in a communication path are non-faulty then this is a functioning communication path.
If there is at least one functioning communication paths where all nodes are adversarial, then adversary has opportunity to cause anonymity failure.
The probability of anonymity failure is given by
If there is at least one adversarial node in each functioning communication paths then the adversary has an opportunity to cause broadcast failure. The probability of adversarial broadcast failure is given by
The probabilities , and are computed the following parameters
| Parameter | Description | Value/Range | |
|---|---|---|---|
| | Fraction of faulty nodes | | |
| | Fraction of adversarial nodes | | |
| | Number of communication paths | | |
| | Number of nodes in a communication path | |
The code which computes above probabilities is given below
def Prob_b(K, L, qF):
"""
Compute the probability of broadcast failure.
Formula: (1 - (1 - qF)^L)^K
"""
return (1 - (1 - qF) ** L) ** K
def Prob_ab(K, L, qF, qA):
"""
Compute the probability of adversarial broadcast failure.
Formula: (1 - ((1 - qF)^L * (1 - qA)^L))^K - (1 - (1 - qF)^L)^K
"""
term1 = (1 - qF) ** L
term2 = (1 - qA) ** L
return (1 - (term1 * term2)) ** K - (1 - term1) ** K
def Prob_a(K, L, qF, qA):
"""
Compute the probability of anonymity failure.
Formula: 1 - (1 - ((1 - qF)^L * qA^L))^K
"""
term1 = (1 - qF) ** L
term2 = qA ** L
return 1 - (1 - (term1 * term2)) ** K
Inference of relative stake
The adversary observes the leader election process of a node with the relative stake .
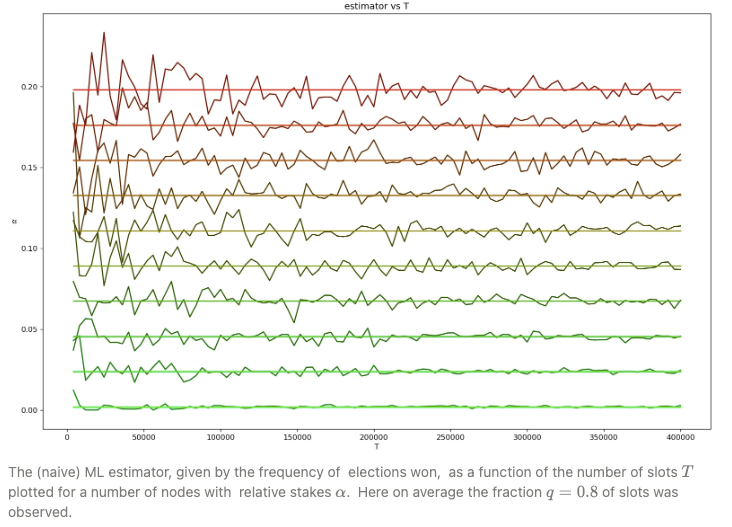
In time-slots, the adversary is able to observe fraction of wins in observations. The probability of observing the election outcome of a node is . For adversary uses the “naive” estimator of the true relative stake . For large , the probability that is given by
In the above, is the lottery function with parameter , and , where is the fraction of observed time-slots such that slots are observed on average.
The probability can be interpreted as adversarial “confidence” and the parameter as “accuracy”. An example of the above probability is given below
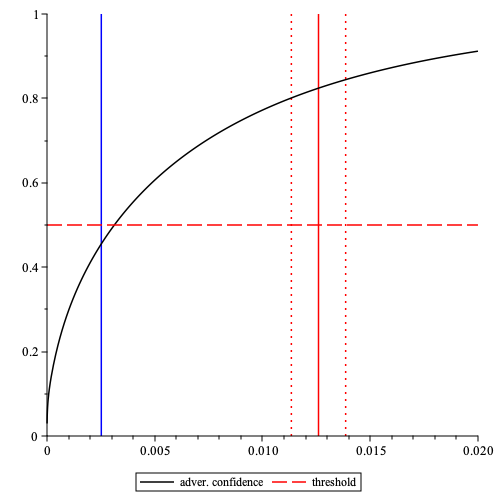
The probability that inferred relative stake , i.e. adversarial “confidence”, as a function of true relative stake obtained in time-slots (this value is used in Cardano) when the fraction of slots is observed. Here the probability that stake of a node with the true stake (the max. stake in the Bitcoin network), represented by a red vertical line, is inferred with an “accuracy” within the fraction of relative stake , represented by red vertical dotted lines, is approx. . The red dashed horizontal line corresponds to the threshold . The blue vertical line at is the result of dividing the stake among the nodes.
The probability , i.e. adversarial “confidence,” is computed using the following parameters:
| Parameter | Description | Value/Range |
|---|---|---|
| | Number of slots per epoch | |
| | Fraction of non-empty slots | |
| | Relative stake of a node | |
| | “Accuracy” parameter | |
| | Fraction of observed time-slots | |
The code which computes adversarial “confidence” is given below
def phi(alpha, f):
return 1 - (1 - f) ** alpha
def dphi(alpha, f):
return -((1 - f) ** alpha) * log(1 - f)
def Prob2(alpha, epsilon, T, q):
sqrt2 = sqrt(2.0)
phi_alpha = phi(alpha, f)
# Denominator term
denominator = (
erf((phi_alpha - 1) * sqrt2 / (2 * sqrt(phi_alpha * (1 - phi_alpha) / (T * q))))
- erf(phi_alpha * sqrt2 / (2 * sqrt(phi_alpha * (1 - phi_alpha) / (T * q))))
)
# Numerator term
numerator = -2.0 * erf(
sqrt2 * epsilon / (2 * sqrt(phi_alpha * (1 - phi_alpha) / (T * q)))
)
# Final result
return numerator / denominator
# Compute epsilon = dphi(alpha) * alpha * gamma
epsilon = dphi(alpha, f) * alpha * gamma
# Compute Prob2
Prob2_result = Prob2(alpha, epsilon, T, q)
The probability can also compute the (minimum) number of time-slots, , such that , for some . Here is the time needed by an adversary to achieve “confidence” greater than . The code which computes is given below
T0 = T # One epoch
T1 = 730 * T # 10 years
dT = 10**3 # Step size
if Prob2_t < delta:
# Increase T until Prob2_result >= delta
t = T0
while t <= T1 and Prob2_t < delta:
Prob2_t = Prob2(alpha, epsilon, t, result3)
t += dT
else:
# Decrease T until Prob2_result <= delta
t = T
while t >= 100 and Prob2_t > delta:
Prob2_t = Prob2(alpha, epsilon, t, result3)
t -= dT
Adversarial Confidence as a Measure of Statistical “Noise”
The probability , where is the (average) number of time-slots observed by adversary in one epoch, can be seen as a measure of the magnitude of “noise” which prevents accurate measurements of the relative stake . One source of this noise is the actual (stochastic) leader election process and the other is the sampling (or “observation”), controlled by parameter , of the latter by an adversary. For , i.e. all time-slots are observed, and leader election process is the only source of noise. In this regime, for a given accuracy (), the relative stake can be inferred with high confidence as can be seen in the figure below
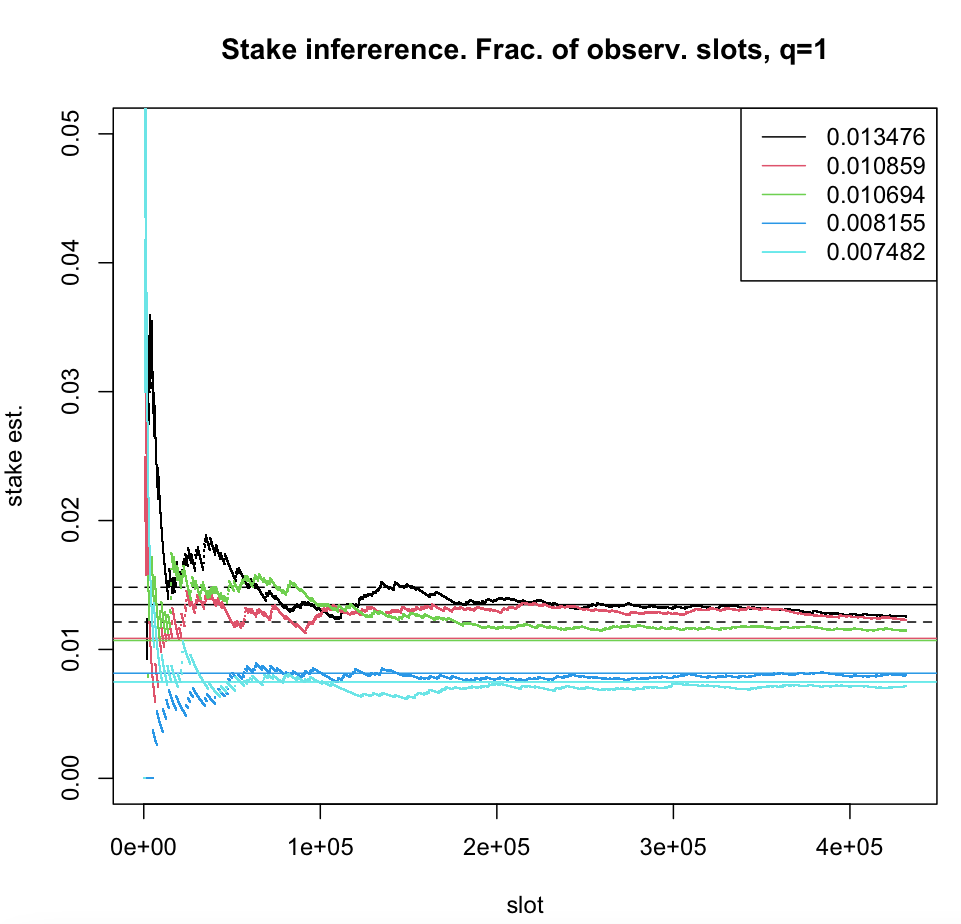
The (relative) stake estimator , computed in one epoch of leader election process, plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. For a node with the stake the prob. , where , (fraction of observed time-slots) and (number of time-slots in one epoch). The boundaries of the interval for are represented by dashed horizontal lines.
For , sampling becomes an additional source of noise interfering with measurements done by adversary. Here, for a given accuracy, the confidence deteriorates as (see figures below).
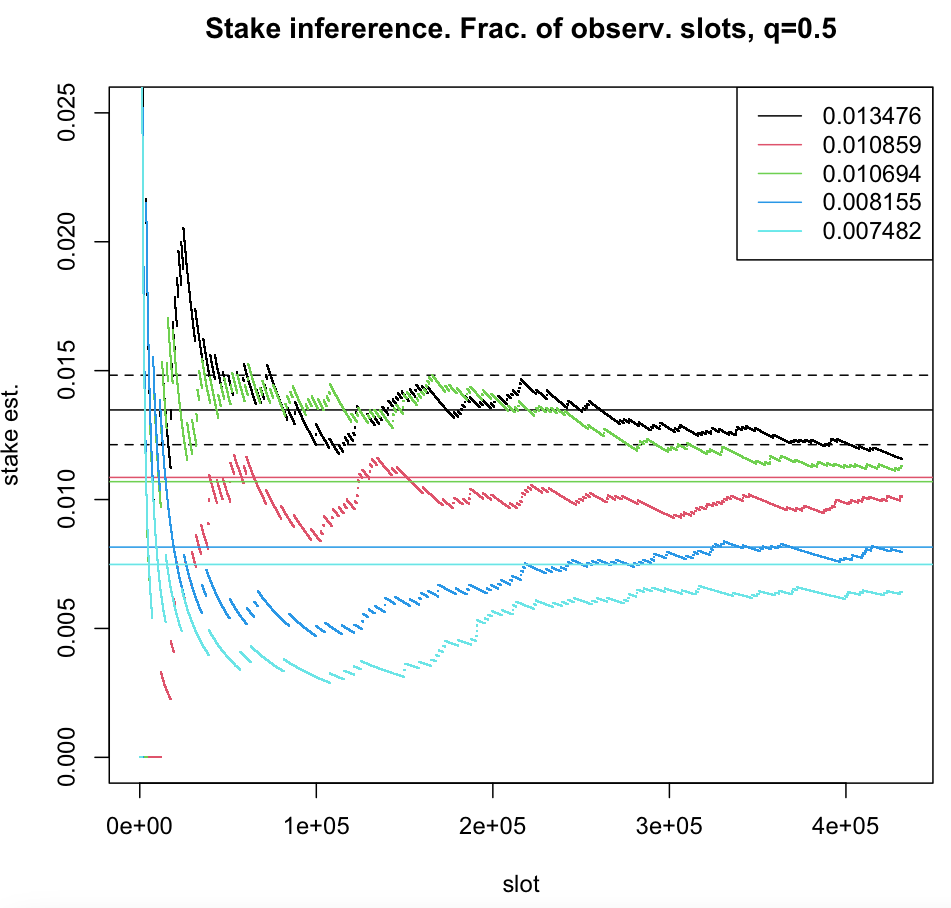
The (relative) stake estimator , computed in one epoch of the leader election process, plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. For a node with the stake the prob. , where , (fraction of observed time-slots) and (number of time-slots in one epoch). The boundaries of the interval for are represented by dashed horizontal lines.
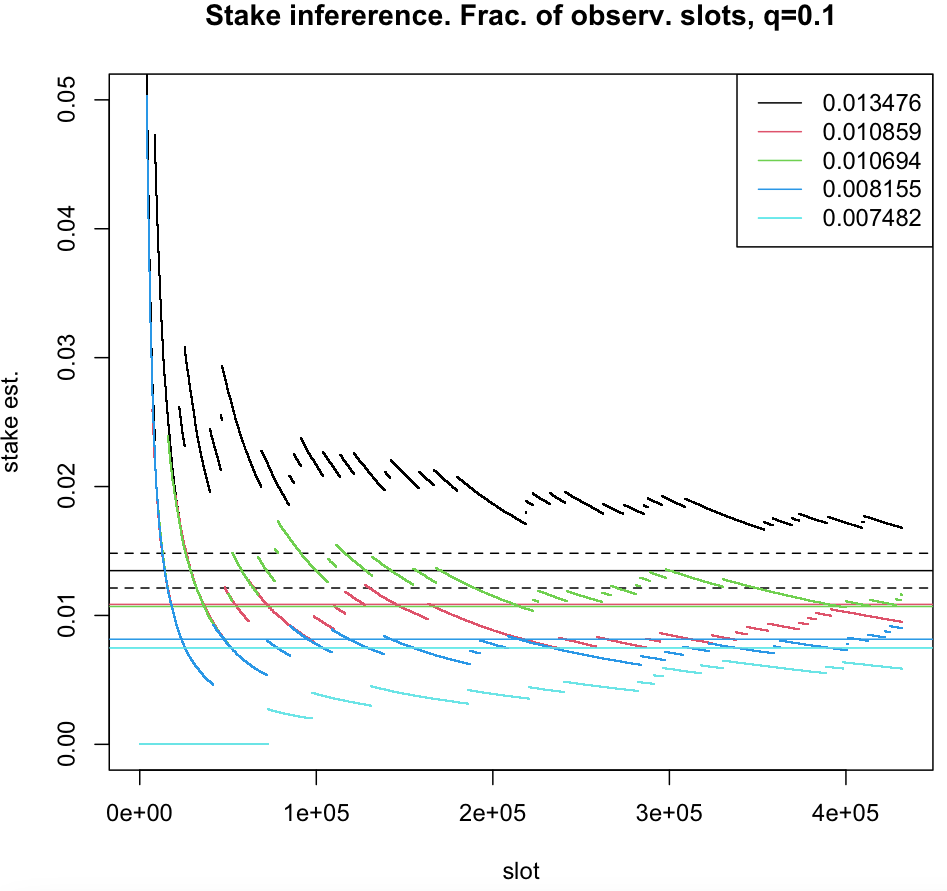
The (relative) stake estimator , computed in one epoch of leader election process, plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. For a node with the stake the prob. , where , (fraction of observed time-slots) and (number of time-slots in one epoch). The boundaries of the interval for are represented by dashed horizontal lines.
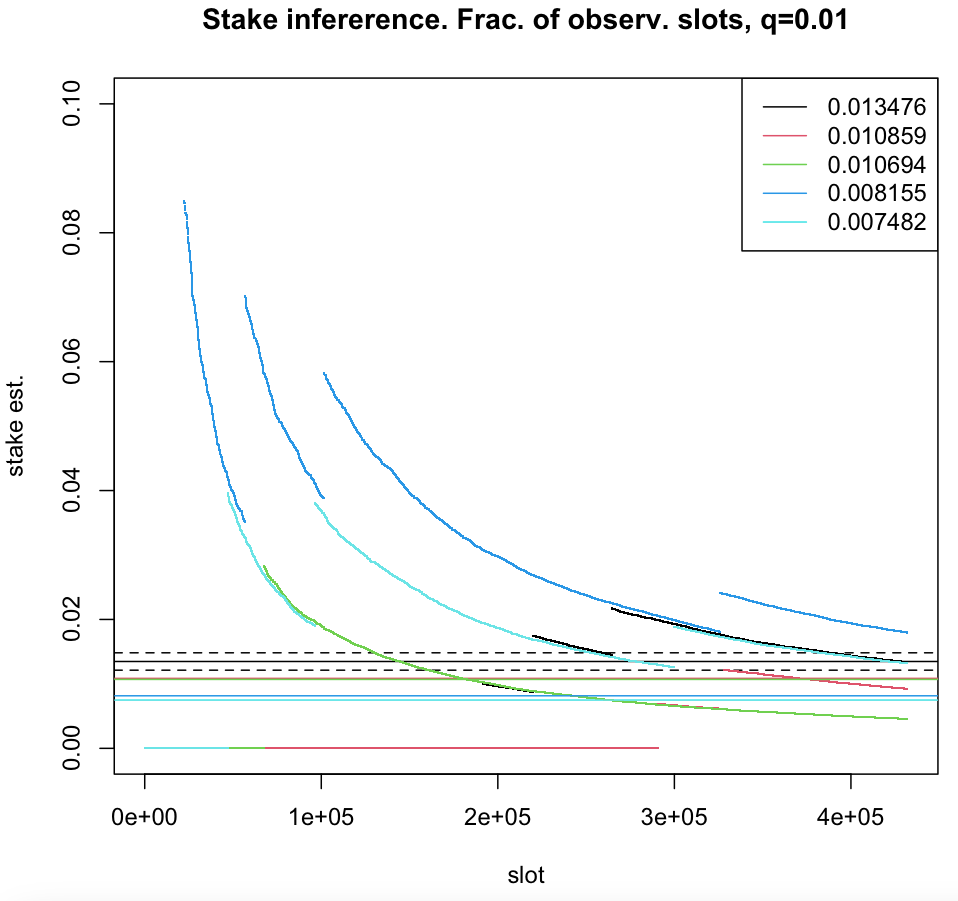
The (relative) stake estimator , computed in one epoch of leader election process, plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. For a node with the stake the prob. , where , (fraction of observed time-slots) and (number of time-slots in one epoch). The boundaries of the interval for are represented by dashed horizontal lines.
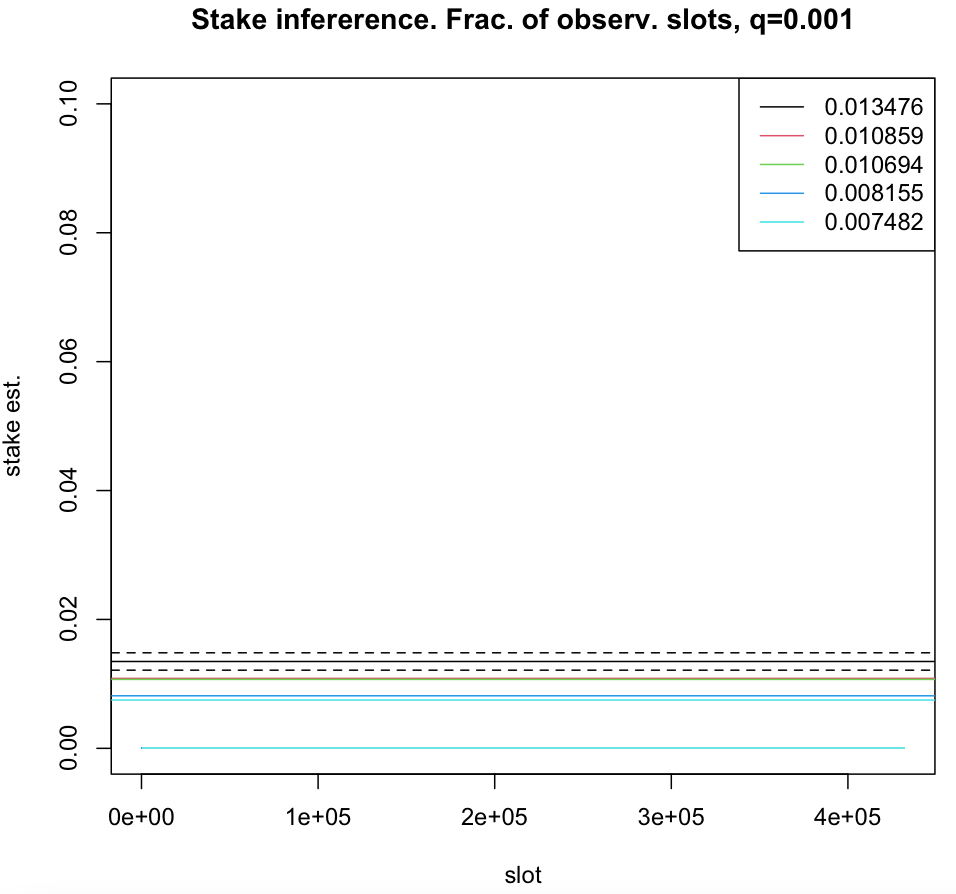
The (relative) stake estimator , computed in one epoch of leader election process, plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. For a node with the stake the prob. , where , (fraction of observed time-slots) and (number of time-slots in one epoch). The boundaries of the interval for are represented by dashed horizontal lines.
Let us define a function which compares properties of inference for and as follows
We note that above is when , i.e. no sampling noise, and is growing when (see figure below). Hence, above can be seen as “amplitude” of the sampling noise.
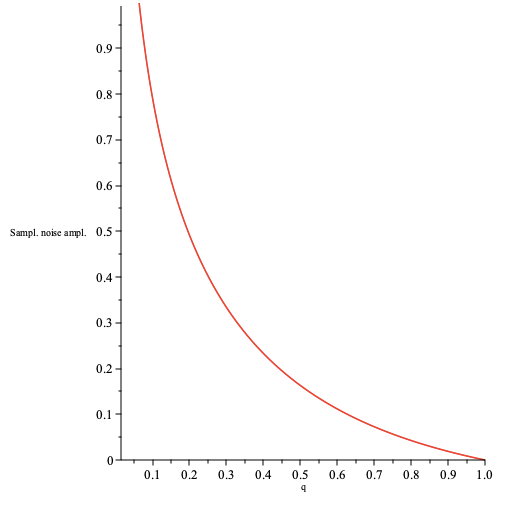
plotted as function of for and .
The Unlinkability of Block Proposers
We assume that node wins the election and broadcasts message to the network using linear trees. We assume that in the network the sender node has neighbouring nodes. Message is first sent to the neighbouring nodes then, via the latter, to the rest of the network. A node in the neighbourhood , where , is adversarial with the prob. . The prob. that at least one node in is adversarial is .
If has at least one adversarial neighbour and anonymity failure occurred then the message can linked to the sender node . We note that just occurrence of the anonymity failure alone is not sufficient to link to and at least one compromised node is also needed in . Furthermore, an adversary may need not one but at least compromised nodes in . The probability of the latter is given by the binomial
We note that the case one adversarial node in is recovered by setting in the above. The probability of above event, given that won the election, is the product of two probabilities
We note that in above we assumed that , i.e. there are no faulty nodes in the network. The probability above is an upper bound for a scenario with faulty nodes. Since for , the prob. of anonymity failure is an upper bound on the above prob. If node has (relative) stake then the prob. of node winning is , where is thelottery function. Hence, the prob. that the message , sent by the winning node , can be linked to is given by
The prob. that message can not be linked to the sender is
Hence the prob. that any message sent by node can be linked to in elections is given by
For the above prob. to be greater than some threshold (for example ) the number of elections has to satisfy the following inequality
The minimum for which above inequality holds , which is the RHS of the above, is computed using the following parameters
| Parameter | Description | Value/Range |
|---|---|---|
| | Prob. threshold | |
| | Fraction of non-empty slots | |
| | Relative stake of a node | |
| | Node neighbourhood size | |
| | Number of adver. nodes threshold | |
| | Fraction of adversarial nodes | |
| | Number of communication paths | |
| | Number of nodes per communication path | |
The code which computes is given below
def phi(alpha, f):
return 1 - (1 - f) ** alpha
def calculate_t(qA, L, K, alpha, f, C, nA, theta):
#compute prob. Pa
x = 1 - pow(qA, L)
Pa = (1 - pow(x, K))
#compute prob. Pan
p = 1 - qA
Pan = 0
for n in range(nA, C + 1):
Pan += comb(C, n) * (p ** (C - n)) * (qA ** n)
#compute prod. of prob.
Prob = Pan * Pa
#compute t
numerator = log(1 - theta)
denominator = log(1 - phi(alpha, f) * Prob)
t = ceil(numerator / denominator)
return t
Design of the “Calculator”
Here we combine the results for leader election process, sampling of linear trees, broadcasting on linear trees and inference of relative stake to design a calculator which takes parameters of the latter and computes properties of a node related to the resilience and anonymity of communication. The calculator has the following modules:
PDF attachment: Modules.pdf
The dependencies between modules can be represented as the following diagram
PDF attachment: Flowchart.pdf
Using above diagram of dependencies a first and later versions of the calculator were implemented as an online app. The input and output of the most recent version is presented below. The app is available in the repository.
Strategies to Reduce Anonymity Failure
Let us assume that a node won at time of the election process and it broadcasts a message to the network using linear trees. Furthermore, assume that the neighbourhood of this node has at least one adversarial node. Conditioned that these two assumptions are true, the probability of anonymity failure is given by
Above corresponds to a scenario when a node at time sends a message through paths of length (see figure) constructed from nodes sampled (with replacement) from the set of network nodes . Here and is, respectively, the fraction of faulty and adversarial nodes in the network.
For , i.e. a message is sent through one path, the probability of anonymity failure is given by
We note that in above is the prob. that path is functional and is the prob. that every single node on this path is adversarial. Hence is the prob. that either the path is not functional or at least one node in the path is not adversarial.
Now let us assume that node sends the same message (or different messages) through different paths of length at times (see figure below)
Communication on Linear Trees. Node sends a message at times . Each time a different, sampled randomly (with replacement) from , communication path of nodes is used.
After sending the first message at time the prob. of anonymity failure is , after sending the second message at time the prob. of anonymity failure is , etc. Thus after sending the last message at time the prob. anonymity failure is , i.e. the same as sending a message through paths simultaneously. We note that for fixed the prob. is monotonic increasing function of and hence is monotonic increasing function of the number of sent messages as can be seen in the figure below.
The prob. of anonymity failure as a function of the number of sent messages plotted for the number of nodes per path (top to bottom). Here the fraction of faulty nodes is and the fraction of adversarial nodes is .
Furthermore, the probability that no anonymity failure occurred after sending messages is given by
From above, it follows that for we have
Hence the probability that no anonymity failure occurred is much larger if the number of messages sent is much less than . Equivalently, the probability of anonymity failure is much smaller if the number of messages sent is much less than .
We now consider the prob. of broadcast failure
which is a monotonic decreasing function of when is fixed. Hence is monotonic decreasing function of the number of sent messages as can be seen in the figure below.
The prob. of broadcast failure as a function of the number of sent messages plotted for the number of nodes per path (bottom to top). Here the fraction of faulty nodes is .
We note that the probability of adversarial broadcast-failure behaves in a similar way as can be seen in the figure below
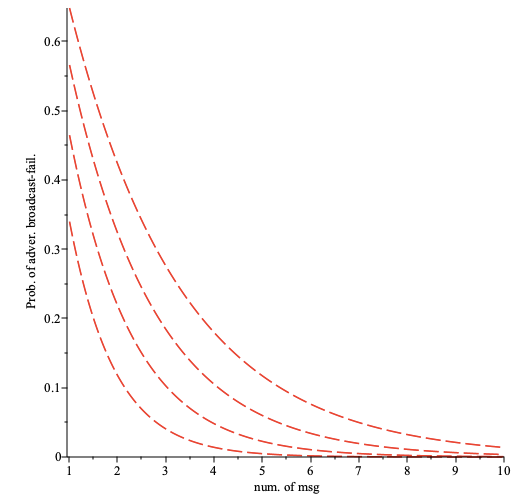
The prob. of adversarial broadcast-failure as a function of the number of sent messages plotted for the number of nodes per path (bottom to top). Here the fraction of faulty nodes is and the fraction of adversarial nodes is .
The number of nodes used for broadcasting of messages is , i.e. grows linearly with the number of messages .
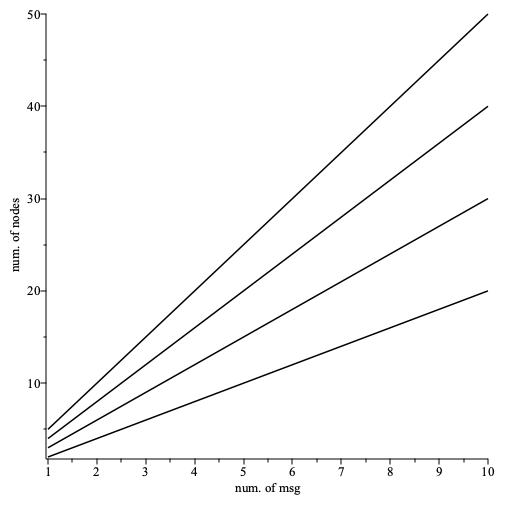
The number of nodes used in broadcasting as a function of the number of sent messages plotted for the number of nodes per path (bottom to top).
We note that
is the probability that the first occurrence of a successful broadcast requires sending messages. We note that above is generalisation of the Geometric prob. distribution.
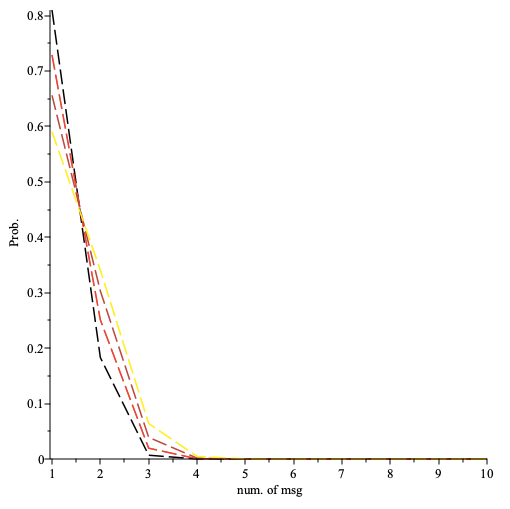
The probability that the first occurrence of a successful broadcast requires sending number of messages () plotted for the number of nodes per path (black, red, orange,yellow). Here the fraction of faulty nodes is .
From the above, it follows that
is the prob. that the first occurrence of a successful broadcast requires sending more than messages.
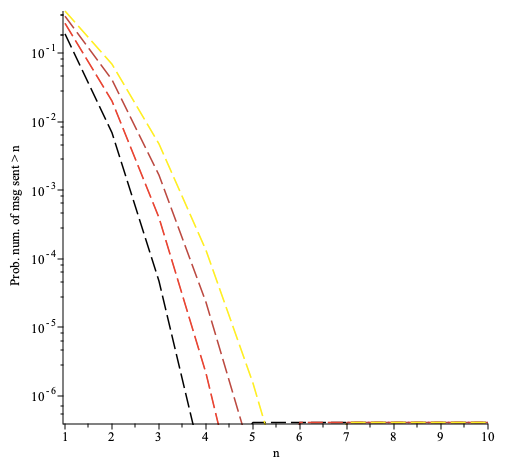
The prob. that the first occurrence of broadcast requires sending more than messages as a function of plotted for the number of nodes per path (bottom to top). Here the fraction of faulty nodes is .
In a similar manner, we obtain the probability
that the first occurrence of anonymity failure requires sending messages.
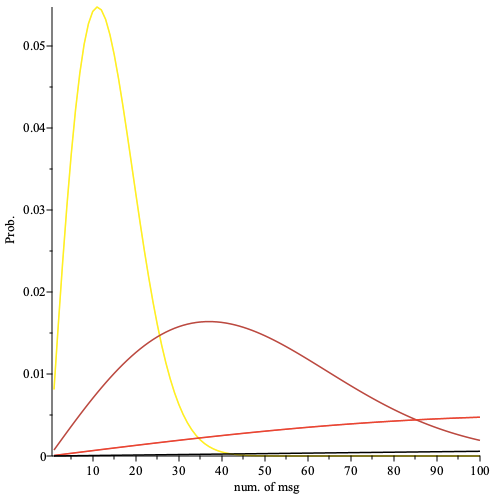
The prob. that the first occurrence of anonymity failure requires sending number of messages () plotted for the number of nodes per path (yellow, orange, red, black). Here the fraction of faulty nodes is and the fraction of adversarial nodes is .
From the above, it follows that
is the prob. that the first occurrence of anonymity failure requires sending less than messages.
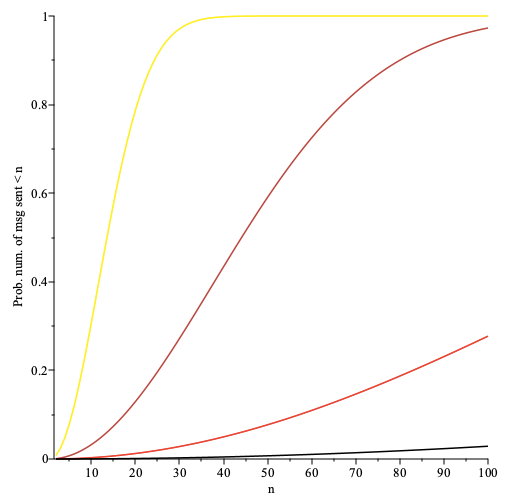
The prob. that the first occurrence of anonymity failure requires sending less than messages as a function of plotted for the number of nodes per path (top to bottom). Here the fraction of faulty nodes is and the fraction of adversarial nodes is .
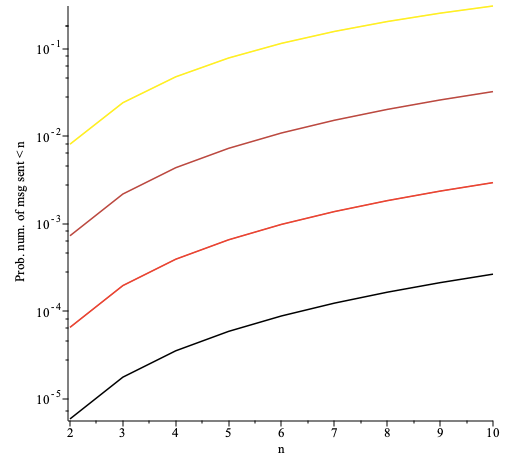
The prob. that the first occurrence of anonymity failure requires sending less than messages as a function of plotted for the number of nodes per path (top to bottom). Here the fraction of faulty nodes is and the fraction of adversarial nodes is .
Analysis of Latency
We consider a network constructed from nodes. We assume that a message sent from node , via nodes of , to the network using the broadcast method of communication. The message is delayed at the node by the amount of time, at the node by the amount of time, etc. Furthermore, a message traveling between the nodes and is delayed by due to the latency of broadcast on used for communication.
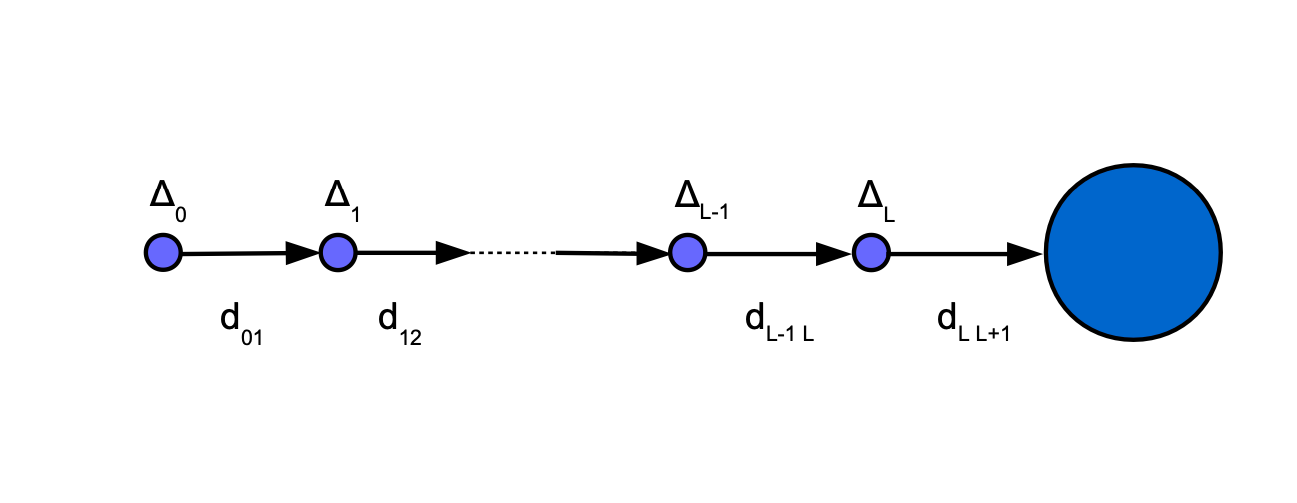
A message is sent by node to the network via nodes using the broadcast mode of communication. Here nodes are represented by blue circles and is represented by large blue circle.
Assuming that the message was successfully broadcasted by the last node to the network , the total delay is given by . We note that for and we have a simple upper bound
We note that we have equality in the above when and , i.e. all delays are the same.
Assuming that sender node monitors, via observation of broadcasts on , how a message is propagated along the path, the sender node sends first messages and if this message is not broadcasted to after some time, for example after time , it will send a second message and if this message is not broadcasted it send a third message, etc. We note that a worst case scenario of above strategy is when the 1st message “travels” to the last node , but is not broadcasted to the network . Then nodes send a 2nd message and again this message is not broadcasted by the last node, etc. Assuming that the -th message is broadcasted by the last node to , gives us that the total delay in the sequential scenario is at most
if the delay on each -th path, i.e. the value of , is known exactly.
Furthermore, we have the following inequality
where and . We can assume that and .
We note that when messages are sent simultaneously and if at least one of them is successfully broadcasted by a last node to the network , then the total delay is at most
if the delay on each -th path, i.e. the value of , is known exactly. Furthermore, for and we have the following inequality
From the above, it follows that in the worst case the latency of sequential communication is times the latency of synchronous communication.
Let us assume that , and sender node is not delaying messages. The latter gives us the upper bound on latency in synchronous communication and for the upper bound on latency of sequential communication.
The Number of Time-Slots Between Two Consecutive Blocks
In the leader election process the probability of winning a slot is and the number of time-slots per epoch is . Assuming that winning a slots results in generation of a valid block, the number of time-slots between two consecutive blocks, , follow the geometric distribution
where . Follows from above that the average of is , i.e. on average we expected to see a next block after time-slots. The probability that is greater than the average is given by
For , the above gives us . Furthermore, the maximum of observed in time-slots (approximately) follows the distribution
where .
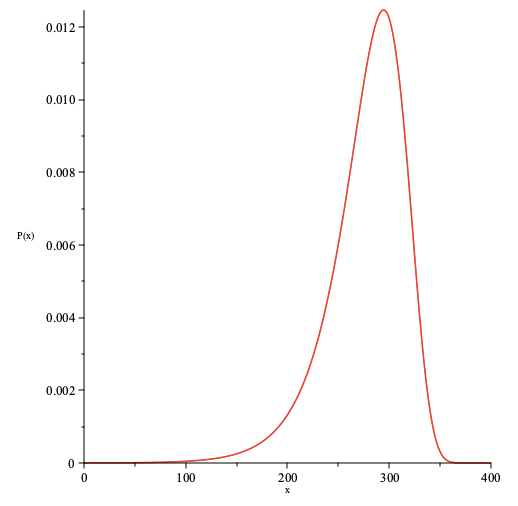
The probability distribution as a function of plotted for and .
We note that the mode of is at and hence the typical value of the maximum of observed in time-slots for is . The prob. that the maximum of observed in time-slots for is greater than can be computed with high accuracy from simulations and is as suggested by the simulation data tabulated below.
| Num. of samples | Prob. |
|---|---|
| | |
| | |
| | |
| | |
The histogram of the maximum of obtained in one such simulation is presented below
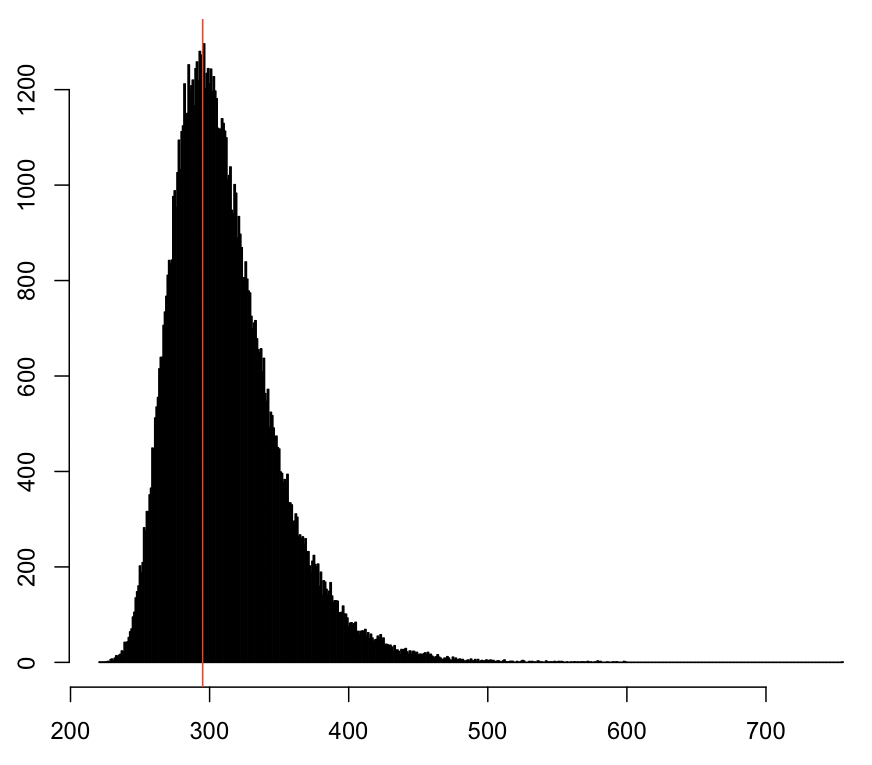
This histogram of the maximum number of time-slots between two consecutive blocks, , obtained in simulations of one epoch with and . The red vertical line corresponds to the typical value of . Here estimating the prob. that gives us the value of .
Bibliography
Svante Janson. (2009). On percolation in random graphs with given vertex degrees. Electron. J. Probab. 14: 86 - 118. https://doi.org/10.1214/EJP.v14-603
Gordon, L., Schilling, M. F. and Waterman, M. S. (1986). An extreme value theory for long head runs. Probability Theory and Related Fields 72: 279-287. https://doi.org/10.1007/BF00699107
Analysis of Rewarding in DA Network
Owner: Alexander Mozeika Reviewers: Marcin Pawlowski, Marvin Jones, Mehmet, Alvaro Castro-Castilla
Introduction
This document examines the conditions required for fair and reliable distribution of rewards in a decentralised data availability (DA) network, where nodes independently sample peers to judge their performance. Our focus is on three core properties:
- Ensuring coverage. We show that even when each node samples only a small number of peers per round, across rounds, the probability that every node gets observed is very high when .
- Stability of peer sampling. By treating the collection of all peer samples as a random graph, we demonstrate that each node's number of observations remains tightly clustered around the average. This ensures the mechanism stays predictable and robust.
- Robust opinion aggregation. We consider a simple majority-vote rule for combining all (binary) reports of nodes into a single consensus judgment and prove that this rule tolerates the maximum number of inconsistent or malicious reports without breaking. Throughout, we support our theoretical claims with simulations and numerical experiments, showing that the proposed sampling rates, observation windows, and voting thresholds create an efficient, scalable reward system that is both reliable and resilient against failures or adversarial behaviour.
Key Findings
- Small sampling rates achieve network coverage exponentially fast when the block count exceeds some fraction of the network size as can be seen in the figure below:
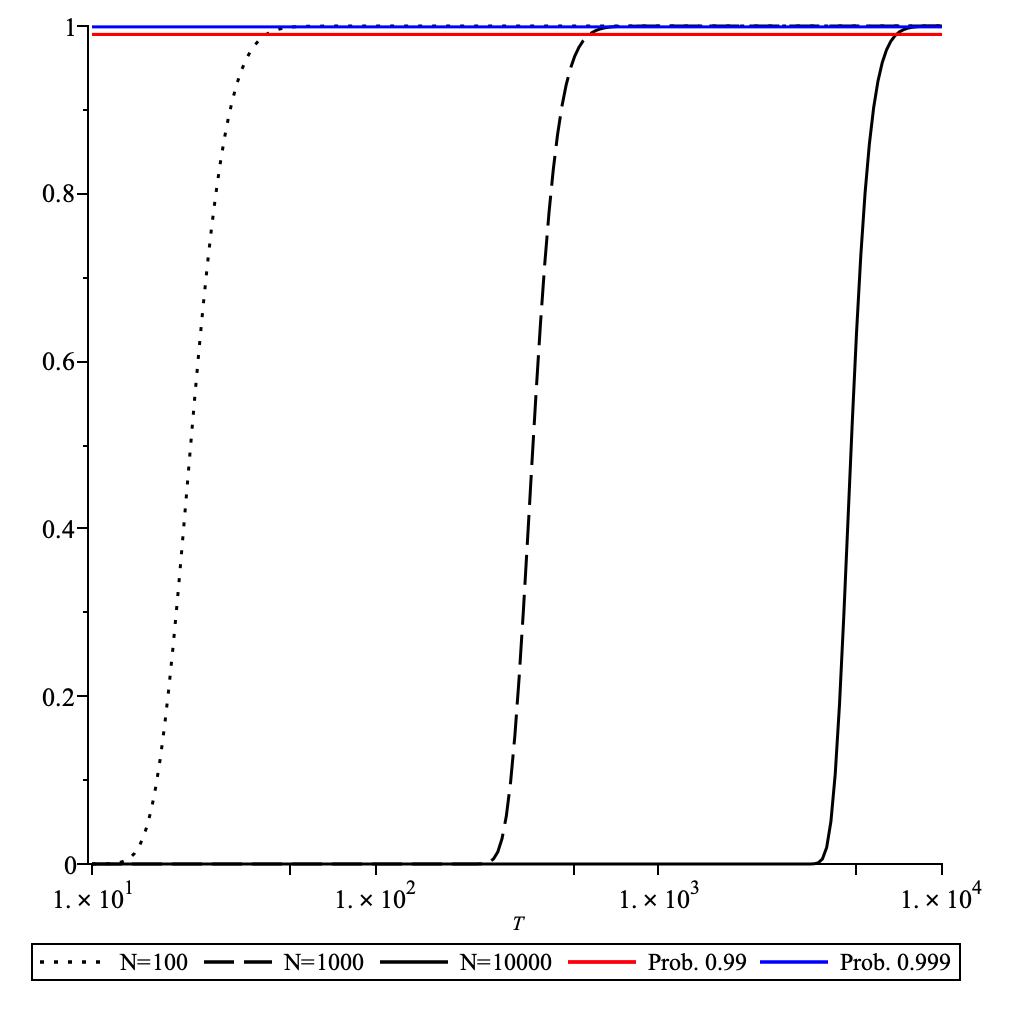
The probability to achieve full coverage plotted as function of the number of blocks for the network size . Here it assumed that a node samples nodes per block.
- The number of blocks needed to achieve full coverage (with high prob. ) is less than the network size as can be seen in the figure below:
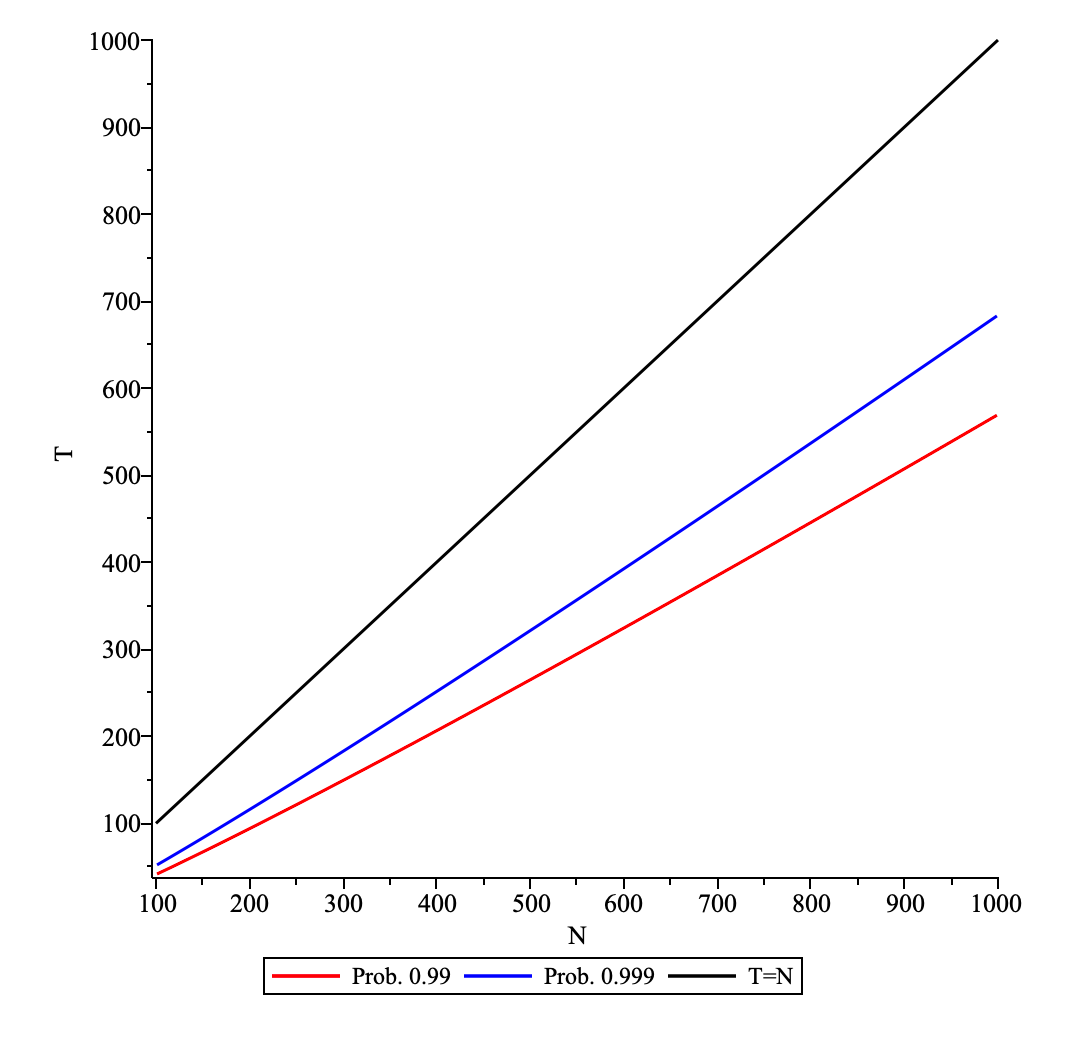
The number of blocks , which is needed to achieve full coverage (with prob. and ), is plotted as function of the network size . Here it assumed that a node samples nodes per block.
- Node connectivity follows a predictable binomial distribution.
- The threshold maximises disagreement tolerance while recovering true opinions.
- The system tolerates up to disagreements in odd-sized networks and disagreements in even-sized networks. This analysis provides theoretical foundations for a robust decentralised reward system resistant to failures and adversarial behaviour.
Overview
This document examines conditions for fair and reliable reward distribution in a decentralized data availability network with independent peer sampling. We present a comprehensive mathematical model and theoretical framework supporting the reward distribution system. The framework consists of:
- Assumptions: Exploration of network structure, participant interaction patterns, and underlying sampling mechanisms.
- Efficiency of Sampling: Probability analysis backed by simulations and statistical validation.
- Analysis of DA Sampling: Protocol specifications, implementation considerations, and network connectivity assessment.
- Fault Tolerant Properties: System resilience against failure modes and mathematical approach to threshold optimization.
Analysis
Assumptions
We consider nodes participating in the data availability (DA) network. Each node provides his opinion about all nodes. This opinion is about the performance of a node and is modelled by a binary variable (don’t know/good performance). Node submits a vector of opinions , where is the opinion of a node about the node . Each node samples nodes per block in DA, so a node could have opinions per block. DA works in sessions and the length of the latter is measured in the number of blocks .
Efficiency of Sampling
The set of nodes sampled by node in one session of DA is , where is the set of nodes sampled randomly (without replacement) by node from the set of all nodes for block . We note that with . The probability that an element of is not in any of the subsets is . From the latter follows that the probability that an element of is in at least one subset is given by . Hence the probability that , i.e. a node sampled all elements of , is given by
Note that while measures “observability” of a specific node, the expression ensures that all nodes are observed at least once. To achieve, e.g. , probability of full observability, it suffices to sample nodes per block for the number of blocks dependent on . Furthermore, the prob. since . The latter is given by
Hence for the prob. . The latter happens exponentially fast with as can be seen in the plot below:
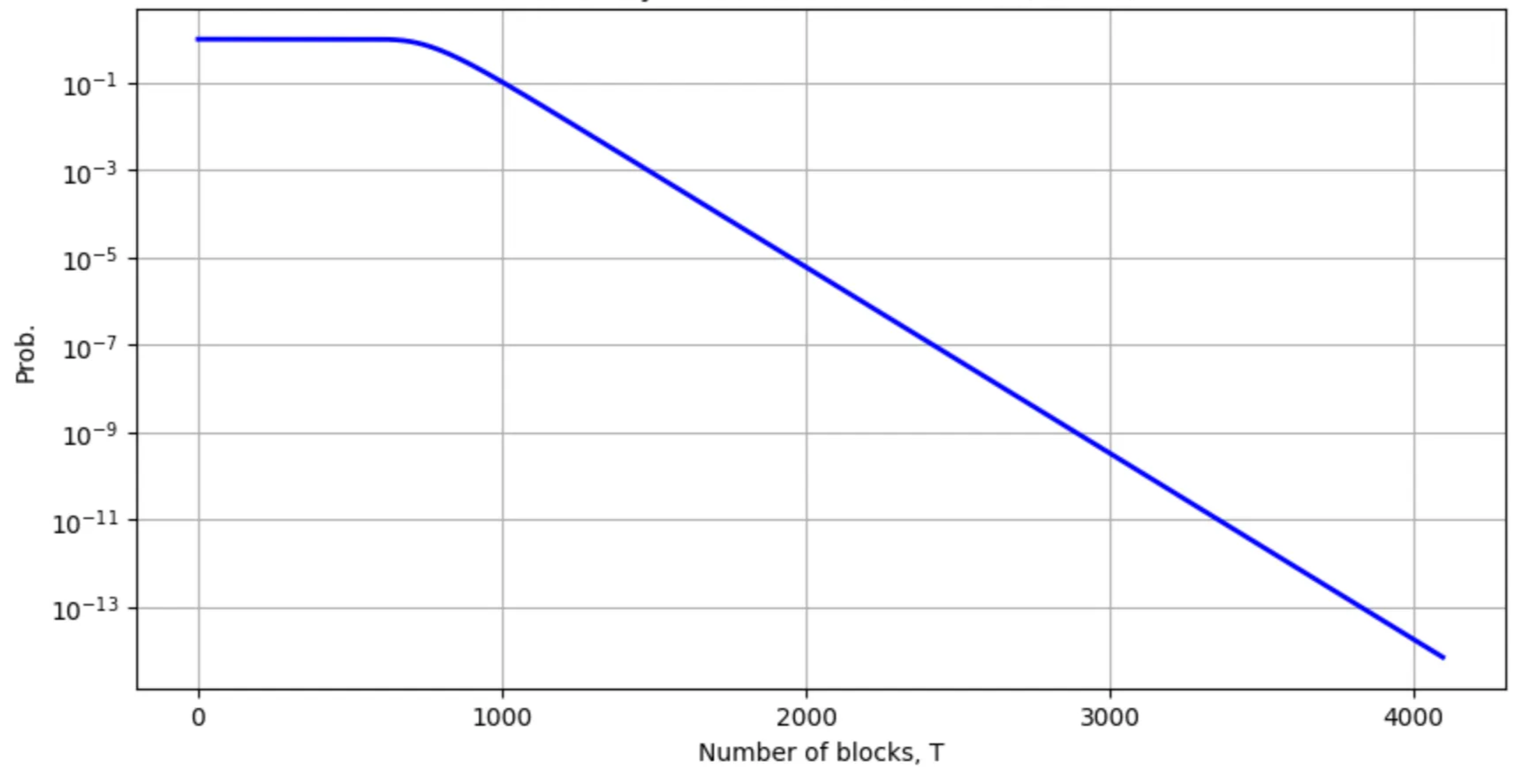
The probability as a function of the number of blocks plotted for and .
The speed of approach to in above is controlled by and for larger the same probability can be attained with a smaller number of blocks. The probability matches simulations to a high degree of accuracy as can be seen in the figure below:
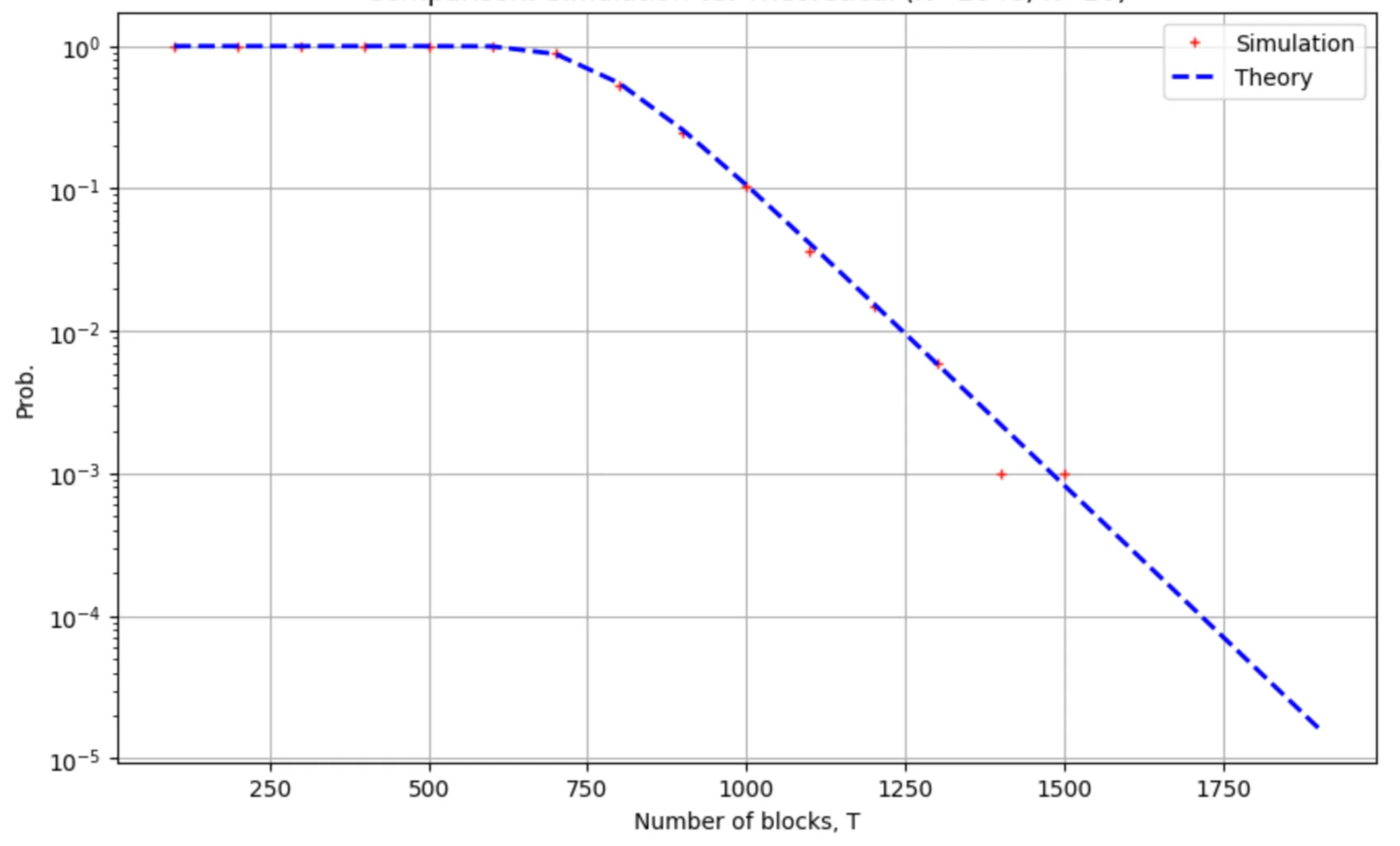
Comparing the empirical version of the probability , obtained from samples of simulation, with the analytic expression. The probability is plotted as a function of the number of blocks for and .
Furthermore, the probability is a monotonically increasing function of , as can be seen in the figure below:
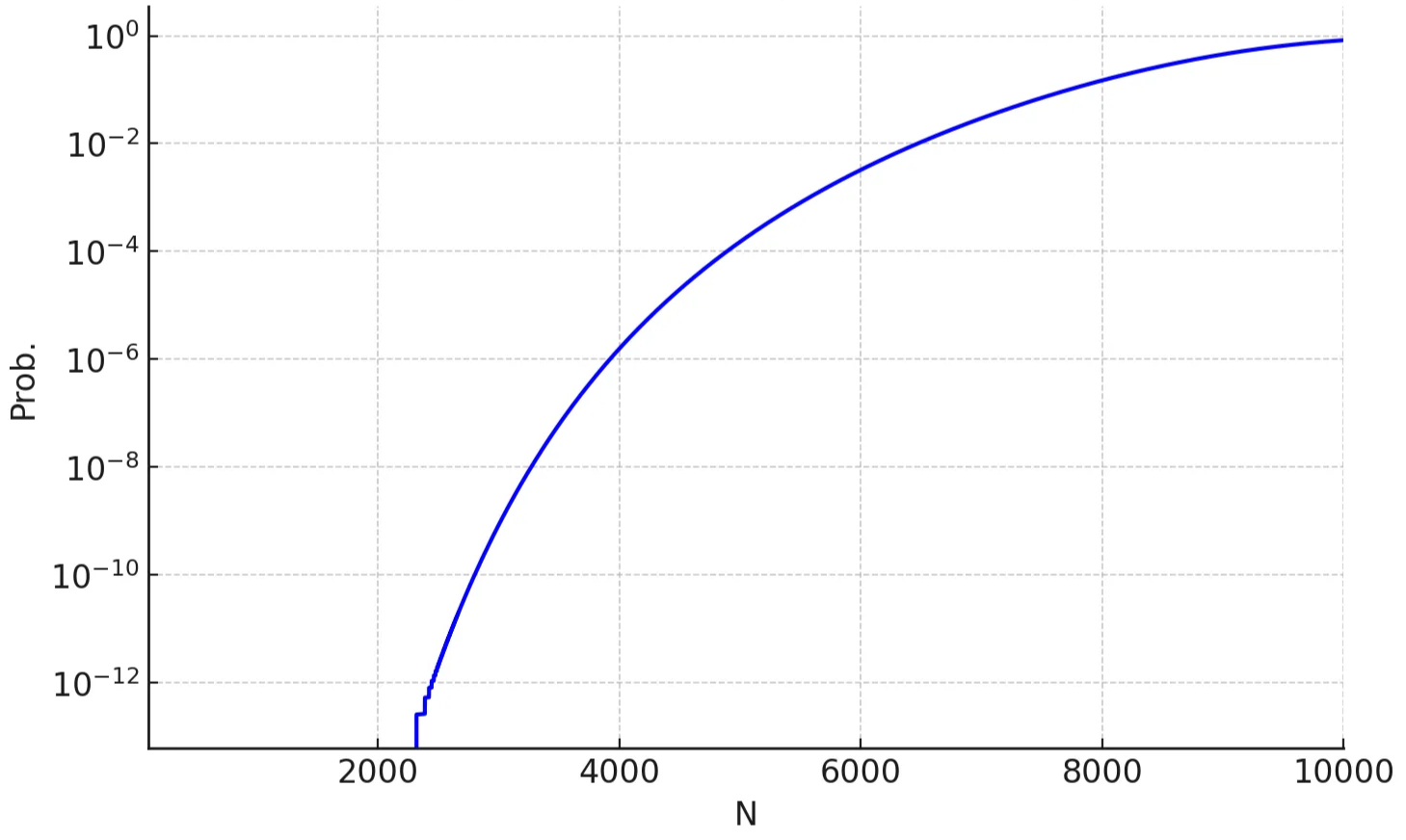
The probability as plotted a function of the number of nodes for blocks and . For the prob. is (approx.) and for the prob. is (approx.) .
Analysis of DA Sampling
Details of DA Sampling
The set of nodes participating in the DA network is divided (almost) equally into subnetworks. In each subnetwork there is at least one node from . Each node in first samples randomly (without replacement) subnetworks from the subnetworks. Then, in each of the sampled subnetworks, a single node is sampled. If , then the above is equivalent to random sampling (without replacement) of nodes from .
Analysis of Connectivity
We consider the case of . We assume that each node samples randomly nodes from exactly times, where . The result of sampling is that we have subsets of nodes (-subsets). We would like to know in how many subsets of nodes node is a member, i.e. how many times node was sampled by other nodes. We note that the result of sampling can be represented as a random factor-graph:
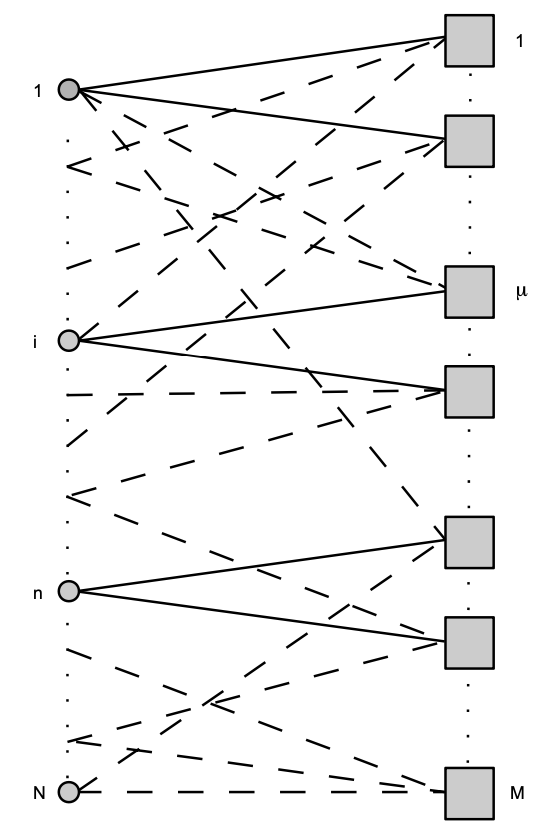
The random factor-graph generated by sampling of subsets of nodes (-subsets), represented by factors (squares), from the set of all nodes represented by (filled) circles. If node is member of a subset then this is represented by an edge on this graph; for .
The connectivity of a node in this factor graph counts the number of -subsets in which this node is a member. The connectivity of a node is a random variable from the binomial distribution with the parameters and . Thus using , the average connectivity of a node is . We note that the typical, i.e. most probable, connectivity is also approx. . The probability that connectivity of node is is given by , i.e the probability is small when the average connectivity is large. We note that for the prob. is bounded above by . For the probability that node connectivity is less than average, , is bounded from above by . The latter follows from
where the first line in above is the binomial (Chernoff) tail bound and the second line is obtained by application of Pinsker’s inequality. The latter is also upper bound on the prob. of the event . Let for some . From the above, the probability of has an upper bound of . We note that for we have that if in this limit, but for we have the upper bound independent on the number of nodes . For , we have:
For the probability that or for , i.e. 10% deviation from the average, is bounded from above by ( for ) and for , i.e. 20% deviation from the average, the upper bound is ( for ). A much tighter upper bound is given by
where and . In a similar manner, we have
where . From the above, it follows that
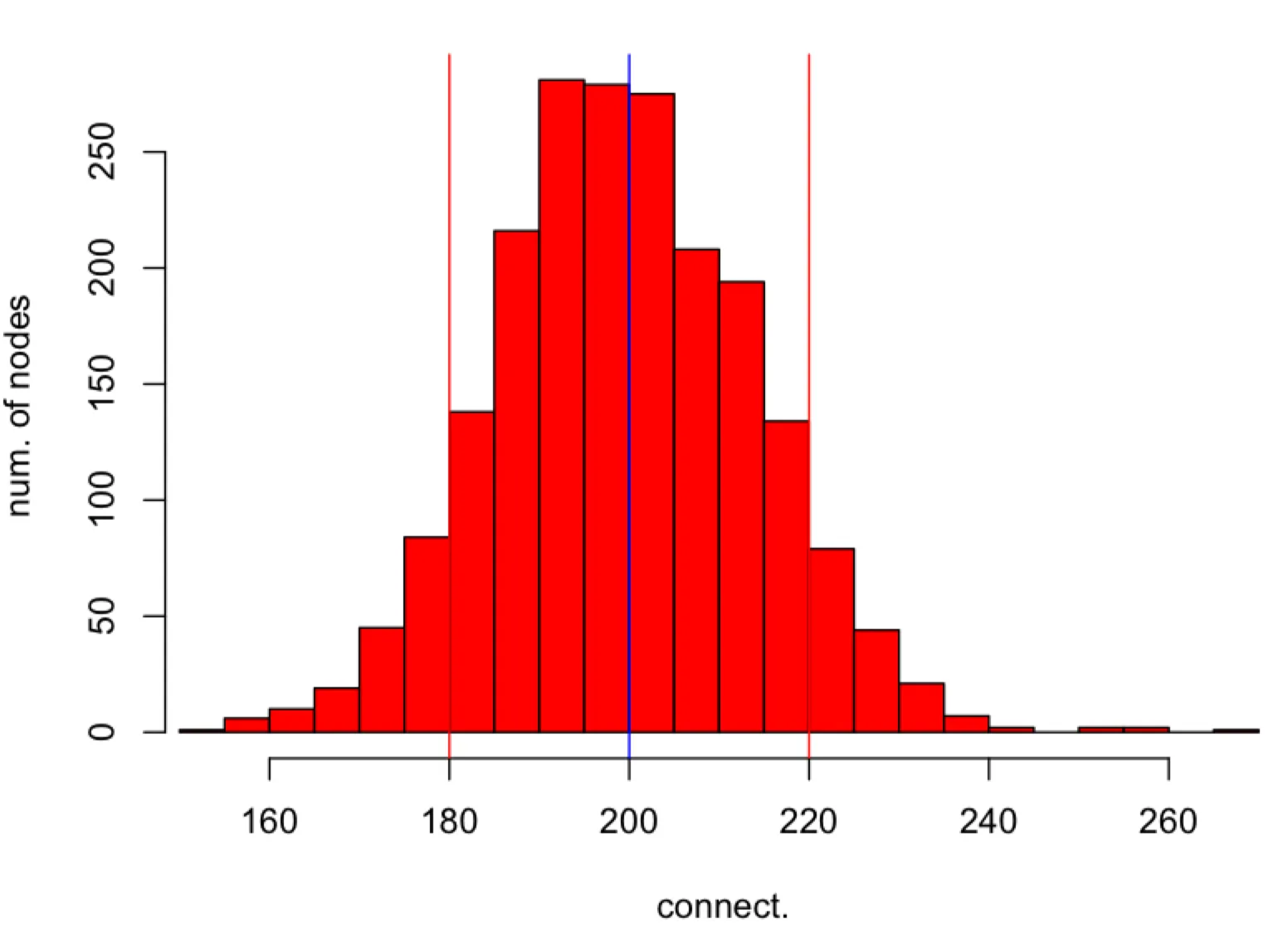
The histogram of connectivities of nodes in obtained in simulation (red colour). Each node in is sampling subsets of nodes from . The average connectivity is represented by the (blue) vertical line in the middle and deviations from the average are represented by two (red) vertical lines. The parameters of simulation are , , and . The probability that the connectivity is outside the interval is at most follows from the upper bound.
The histogram of connectivities of nodes in obtained in simulation (red colour). Each node in is sampling subsets of nodes from . The average connectivity is represented by the (blue) vertical line in the middle and deviations from the average are represented by two (red) vertical lines. The parameters of simulation are , , and . The probability that the connectivity is outside the interval is at most follows from the upper bound.
The histogram of connectivities of nodes in obtained in simulation (red colour). Each node in is sampling subsets of nodes from . The average connectivity is represented by the (blue) vertical line in the middle and deviations from the average are represented by two (red) vertical lines. The parameters of simulation are , , and . The probability that the connectivity is outside the interval is at most follows from the upper bound.
Fault Tolerant Properties of Rewarding and Optimal Threshold
The true opinion is the opinion about node based on some objective criteria independent from other nodes. We assume that there exists a vector of “true” opinions , where , about all nodes in . Node submits the vector of opinions about other nodes in DA. Here is the opinion of node about the node . The sum is the sum of opinions about node . Performance of node is considered to be “good” if , where is some threshold, e.g. . We assume that , where . Here for we use for . We note that for we have and for we have , i.e. the opinion of a node about the node is either the true opinion or the opposite of true opinion . We note that gives rise to the following “opinion” matrix
where the -th row is the vector of opinions submitted by node about all nodes and the -th column is the vector of opinions of all N nodes about the node . Let us consider the sum of opinions about the node as follows
In the above expression, if , then the first term evaluates to zero; and if , then the second term evaluates to zero. Thus, only the correct specific to term remains active in each scenario. Hence from above follows that
where is the number of nodes disagreeing with the true opinion . We note that
where is the indicator function, is the opinion about the node computed from the “opinion” matrix . If for all then all true and inferred opinions are in agreement, i.e. true opinions are recovered from opinion vectors submitted by nodes. Let us assume that and . For to agree with and for to agree with the following two inequalities
have to be satisfied. Let us assume that the threshold then this gives us and . If is even then the upper bound on and are, respectively, and . The minimum from the latter two, i.e. , satisfies both inequalities. Hence is the maximum number of disagreements which allow us to recover the true opinions and from the computed opinions and . For and odd, a similar argument gives us for the maximum number of disagreements under which the true opinions and can be recovered. We note that for any vector of true opinions the condition to recover these true opinions from the opinion matrix is given by the system of inequalities
where and . For the above system is satisfied by
which is the maximum number of disagreements under which the true opinions vector can be recovered exactly. We note that above is true for any distribution of .
Image representation of the opinion matrix for . The vector of true opinions is represented by the black and white pixels corresponding, respectively, to s and s. The red pixels indicate disagreements with true opinions in the opinion (row) vectors submitted by nodes. Here less than of pixels in column vectors, used to compute opinions about nodes, are red and hence true opinion about each node can be recovered exactly.
The threshold is optimal as it allows the maximum number of disagreements with the true opinion about a node but still allows to recover the true opinion about each node exactly.
Proof that the Threshold is Optimal
- It is sufficient to consider only two inequalities from the system. In particular we consider
- We want to find such that is maximised.**The latter is given by the solution of (see figure below) which is .
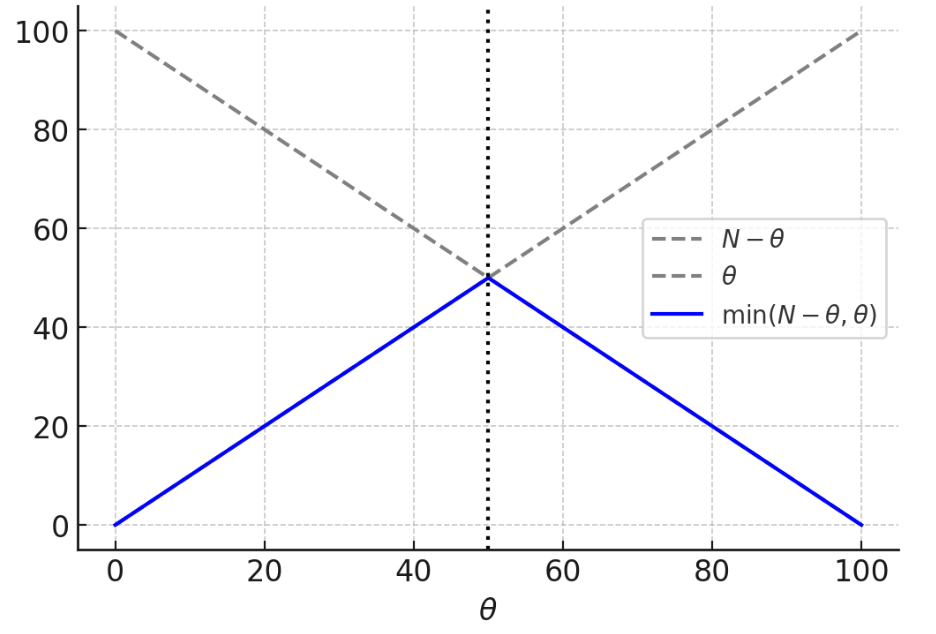
and plotted as a function of for .
- If is even, then
to satisfy the system of inequalities and hence is the maximum which saturates above.
- If is odd, then
then is the maximum.
Conclusion
This document provides a comprehensive theoretical and empirical evaluation of the reward distribution mechanism in the DA network based on independent peer sampling. Through probabilistic modelling and simulations, we demonstrate that:
- High coverage of peer observations is achieved exponentially fast with respect to the number of blocks, even with modest per-block sampling rates.
- Connectivity across the network remains tightly concentrated around the average number of observations per node, enabling predictable and equitable participation.
- A majority voting rule with a threshold of is proven to be optimal, allowing the maximum possible number of disagreements while still correctly recovering the true underlying performance vector. These findings validate the soundness and scalability of the DA Network rewarding protocol. The analysis guarantees both robustness to adversarial behavior and fairness across the participant set, laying a strong foundation for deploying this mechanism in a decentralized setting. Future work may consider adaptive sampling strategies or reputation-weighted voting to further enhance the system’s resilience under dynamic network conditions.
Appendix
Statistical Properties of Node Connectivities
Let us define the random (”connectivity”) variable , where and , which is with prob. when node is in the -subset and with prob. otherwise. Given that variables are sampled randomly, but subject to the constraint for all , the joint prob. distribution of all ’s, i.e. the set , is given by
where is the normalisation constant. We are interested in the random variable , i.e. the “connectivity” of node . In particular we consider the distribution . We note that, without loss of generality, we have and for some the moment generating function (MGF) of the latter is given by and hence , i.e. is the binomial distribution with parameters and .
Bibliography
Ferrante, Guido Carlo. "Bounds on binomial tails with applications." IEEE Transactions on Information Theory 67, no. 12 (2021): 8273-8279.
BLEND-PROTOCOL
| Field | Value |
|---|---|
| Name | Blend Protocol |
| Slug | 95 |
| Status | raw |
| Category | Standards Track |
| Editor | Marcin Pawlowski [email protected] |
| Contributors | Alexander Mozeika [email protected], Youngjoon Lee [email protected], Frederico Teixeira [email protected], Mehmet Gonen [email protected], Daniel Sanchez Quiros [email protected], Álvaro Castro-Castilla [email protected], Daniel Kashepava [email protected], Thomas Lavaur [email protected], Antonio Antonino [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-29 —
67e498e— chore: fix math issues (#350) - 2026-05-28 —
15f410b— chore: fix math issue (#349) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-04-09 |
| 1.1.0 | [RFC] Remove Concept of a Session | 2026-06-22 |
Introduction
The privacy of a Proof-of-Stake (PoS) system is defined by the inability of an adversary to learn:
- Which node proposed a given block. This property is known as unlinkability.
- How much stake a node has. This property is known as stake privacy.
While a node can be de-anonymized based on the content of its block proposals, this angle of attack is mitigated by Private Proof of Stake systems. However, a node can also be de-anonymized based on its network activity. An adversary can observe the node’s network behavior and link the node to the proposal it sends. Because a node’s relative stake correlates with its network activity in all PoS systems, observing a node’s behavior for some time enables the adversary to estimate the node’s stake. It is this network-based de-anonymization that is addressed by the Blend Protocol, allowing Logos Blockchain to achieve a truly Private PoS system.
The Blend Protocol is designed as a way to allow nodes to send block proposals that cannot be linked back to them. The idea is to make it very difficult and costly for someone trying to figure out who sent a proposal and what stake they hold. Because the protocol spreads messages out over many nodes, it becomes even harder to attack, which enhances network privacy. The Blend Protocol increases the time to link the sender to the proposal by at least times, which makes the stake inference highly impractical (Impact of the Blend Protocol on the Time to Link and Time to Infer the Stake).
The Blend Protocol targets a specific set of requirements that differentiate it from mixnets and other general-purpose anonymous communication systems. It achieves probabilistic unlinkability in a highly decentralized environment with low bandwidth cost but high latency. It hides the sender of a block proposal, making it costly for an adversary to learn its origin with high confidence. The cost of attacking the network is high due to decentralization and the economic value of stake needed to add a single node. The protocol works well even when many nodes are involved and not much data is being sent, but it may take longer for proposals to be delivered.
In this document, we present a succinct description of the Blend protocol, which is responsible for providing censorship resistance and network-level privacy for the block producers of the Logos Blockchain Bedrock ([Overview] Bedrock Architecture), the foundational layer of Logos Blockchain.
Privacy of Proof of Stake Systems
All Proof of Stake (PoS) systems have an inherent privacy problem — the stake of the node determines the node’s behavior. That is, by observing the node’s behavior (or impact of the node on the system), one can infer the node’s stake. More precisely, the stake that is discovered is relative to the stake involved in the PoS — stake that is used for the PoS purposes by the adversary. There are two things that can be observed:
- The content of the blocks.
- The network activity of the node.
Observing the content of the blocks makes it possible to execute a tagging attack. The consequence of a successful attack is that the stake of a node can be learned by controlling which transactions are included in the proposals built by the node. This is achieved by submitting a transaction only to the mempool of a targeted node — thus creating a difference in the transactions seen by this node compared to the other nodes — and observing the time when this transaction is included in the block.
The tagging attack can be addressed by designing a mempool in such a way that the node has an attestation that the transaction was seen by the majority of the network, which makes the adversary’s ability to manipulate the view of the node severely limited.
Observing the network activity of the node leads to an easier but still powerful attack that can also disclose the node stake even after the tagging attack is mitigated. That is, a node’s stake can be inferred by observing the frequency of the messages node emits during a particular portion of time — this attack is addressed by the Blend protocol.
The Blend protocol achieves network-level leader-proposal unlinkability with statistical indistinguishability. That is, a leader cannot be linked back to its proposal and cannot be distinguished from its peers based on its network behavior. This property translates into an increased difficulty of learning the node’s stake through the node’s network behavior.
To have a truly privacy-preserving system, we need to apply both techniques simultaneously. Solving one without the other will not suffice.
Terminology
Message Types
- Data message is a message generated by a node (consensus leader), whose payload contains a block proposal. Any data message is indistinguishable from any other message until it is fully processed by the network. The privacy of the sender of a data message is what the protocol aims to protect.
- Cover message is a message that contains meaningless content, and its goal is to create noise (anonymity pool) in which data messages can hide. The cover message is indistinguishable, from the network perspective, from a data message.
Protocol Actors
- Logos Blockchain node is a node that is part of the Logos Blockchain network.
- Core node is a Logos Blockchain node that declared its willingness to participate in the Blend Network Service through the Service Declaration Protocol (SDP — Service Declaration Protocol). The core node is responsible for core protocol functions such as cover message generation, message relaying, message processing, and message broadcasting. Additionally, the core node generates data messages that are blended with the rest of the messages generated by the network.
- Edge node is a Logos Blockchain node that is not a core node. Edge nodes connect to core nodes through which they send messages (block proposals).
- Block proposer node is a core or edge node that is generating a new data message.
- Blend node is a core node that processes a data or cover message.
Node Types
- Honest node is a node that follows the protocol fully.
- Lazy node is a node that does not follow the protocol due to a lack of incentives and only takes part in the protocol when it is directly beneficial to the node.
- Spammy node is a node that does not follow the protocol and emits more messages than the protocol expects. In other words, it is a spamming node.
- Unhealthy node is a node that emits fewer messages than the protocol expects. We cannot assume that this node is misbehaving deliberately, as it can be under an attack.
- Malicious node is a node that does not follow the protocol regardless of incentives.
- Unresponsive node is a node that does not follow the protocol due to technical reasons, such as a lack of connectivity or malfunction.
Adversary Types
- Passive adversary is an adversary that cannot modify the behavior of a node, but can only observe.
- Active adversary is an adversary that can modify the behavior of a node in addition to observing the network.
- Local observer is an passive adversary with a limited view of the network and with the ability to observe the internals of a limited number of nodes.
Networking
- Blending is an operation of cryptographically transforming and randomly delaying messages. This shuffles the temporal order of incoming and outgoing messages so that they cannot be linked back to the sender based on the network statistical analysis or message content inspection. The key difference between blending and mixing (as defined in mixnets) is in the source of the anonymity. In mixing, the anonymity comes from processing multiple messages by the same node, while in blending the anonymity comes from processing the same message by multiple nodes.
- Broadcasting is the process of sending a data message payload (block proposal) to all Logos Blockchain nodes.
- Disseminating is the process of relaying messages by core nodes through the network to edge and core nodes.
- Communication failure is an event when a message that is disseminated through the network is not finally broadcast. The communication failure might be due to lazy, malicious, or unresponsive nodes.
- Anonymity failure is an event when an adversary can link the sender to the broadcast message.
Time
- Epoch is a period that is defined by the consensus. It lasts for slots, each slot lasting 1 second. A new block is proposed for each slot with a probability of , which translates to blocks, as on average, every slots a single block is proposed.
- Round is the primitive measure of time in the protocol. It defines a period during which a node can emit a new message. The definition of a round is also important for defining the message releasing logic, which handles the randomized emission delay for processed messages. In this version of the protocol, the length of the round is 1 second (an equivalent of a single slot).
Overview
The Blend Protocol is a peer-to-peer anonymous broadcasting protocol with cryptographic and timing obfuscation capabilities. The main purpose of the Blend protocol is to increase the difficulty of linking any block proposal to the node that proposed it, maintaining privacy before and after the election, which increases the censorship resistance and privacy of the Logos Blockchain Bedrock. More precisely, the Blend protocol attempts to hide that the consensus leader is sending a leader message (a block proposal) by unlinking the sender from the message through cryptographic and timing patterns obfuscation mechanisms.
The Blend Protocol is one of the Logos Blockchain Bedrock Services. It consists of nodes that declare their intention to serve as core nodes through the Service Declaration Protocol (SDP, Service Declaration Protocol).
The protocol works as follows:
- Core nodes form a network by establishing encrypted connections with other core nodes at random.
- A block proposer node selects several core nodes and creates a data message (containing a block proposal) that can be processed only by the set of selected core nodes (according to the order given by the block proposer node).
- The block proposer node sends the data message to its neighbors (core nodes). If the block proposer is an edge node, it connects to randomly selected core nodes to send the data message.
- Core nodes disseminate (relay) the message to the rest of the network.
- Core nodes generate new cover messages every round, which are blended with other messages.
- When the data message reaches a blend node (designated core node), then it is processed by the node, that is:
- It is cryptographically transformed, so the incoming and outgoing messages cannot be linked together based on the content of the message.
- It is randomly delayed, so the outgoing message cannot be linked to the incoming message based on the timing observation of the message.
- The blend node disseminates the processed message to the network so that the next selected blend node can process the message.
- When the message reaches the last blend node, then:
- The blend node processes the message.
- Decrypts the message.
- Delays the message.
- It extracts the message payload (the block proposal).
- It broadcasts the block proposal to the Logos Blockchain network.
- The blend node processes the message.
Below we present a simplified diagram of the protocol, which depicts how the protocol is evolving in time.
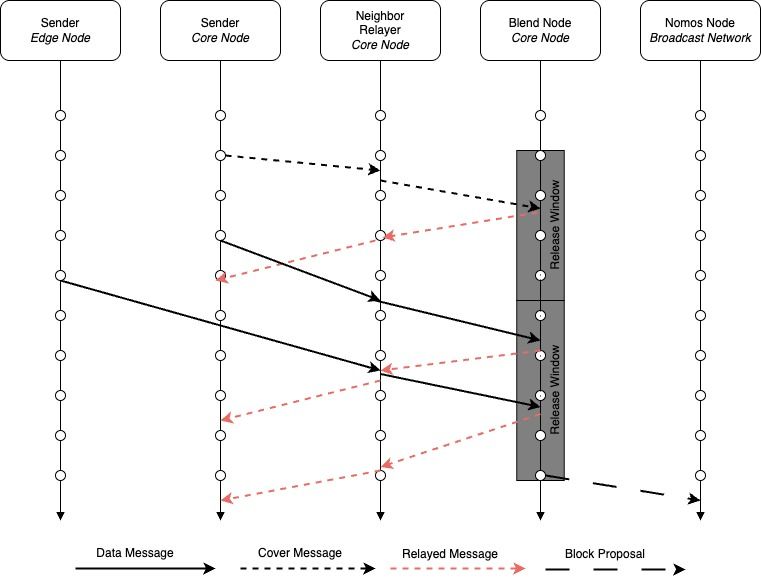
The sender is an edge node or a core node. The sender sends a data message to its neighbor (a core node). In addition to data message, core nodes send cover messages. The neighbor/relayer relays messages to other core nodes. The blend node relays all received messages immediately, but it also relays messages that it processed once every release window. There is no delay when disseminating/relaying a message due to the processing of messages.
The current version of the protocol is optimized for the privacy of core nodes. The level of privacy that edge nodes gain is not as high as core nodes. The problem with maintaining a high level of privacy for edge nodes is that it would require increasing the delay of the network significantly (which is bad for the resilience of the consensus) or increasing the number of messages that an edge node emits (which is bad for the core nodes’ bandwidth). This is acceptable as we assume that edge nodes are mobile and do not have any static long-term network identifier. Therefore, they cannot be tracked easily. Moreover, edge nodes should have lower stake than the core nodes so they will connect to the network sporadically, which makes identifying them even harder.
Network
In this section, we briefly discuss the way the network is created and maintained.
Bootstrapping
The process of creating a network is called bootstrapping.
At the beginning of an epoch, all core nodes retrieve a fresh set of core nodes’ connectivity information from the SDP protocol. Then each core node selects at random a set of other core nodes and connects to them through fully encrypted connections. After some time, when all core nodes connect to other core nodes, a new network is formed.
Minimal Network Size
The minimal network size is . This is the minimum number of nodes (unique ProviderIds from declarations) that must be retrieved from the SDP to consider the Blend protocol safe to use.
This minimal size of nodes allows the network to release, on average, a single message per round under the assumption of unresponsive nodes. With fewer nodes, the network would need to either release more messages per round or queue them. This would increase the time messages take to traverse the network, potentially compromising the safety of the consensus.
The calculations supporting this requirement are provided in the Releasing section, where the number of nodes has been estimated without assuming any unresponsive nodes. Therefore, we have doubled that value to accommodate the potential unresponsive nodes.
Fallback
If the minimal network size is not reached, nodes must not use the Blend protocol. In such cases, nodes must broadcast data messages directly, bypassing the Blend network.
Maintenance
To maintain an adequate quality of the network, all connections must be monitored by the nodes.
Nodes monitor connections with their neighbors by verifying the correctness of messages and the number of messages they receive.
-
If the messages are badly constructed or the number of messages is above a certain acceptable level, then:
-
The connection with that neighbor must be closed.
-
Then a new connection with a randomly selected core node must be established.
-
If the number of messages is below a certain acceptable level, then a new connection with a random core node must be established.
The above logic enables a node to maintain the quality of the network by closing connections with abusive, malicious, lazy, and unresponsive nodes. All honest nodes, by following this mechanism in the long run, will isolate themselves from other nodes, which will increase the overall performance of the network.
Messages
The protocol defines two types of messages: data, and cover.
-
Data messages contain a meaningful payload, which is used by the Logos Blockchain network to advance the Bedrock consensus. The mechanism that triggers data message generation is external to the Blend Protocol and is defined by the leader election process of the Bedrock consensus.
-
Cover messages do not contain any meaningful payload and are generated by nodes to increase network noise and to blend with data messages. Cover messages mimic the behavior of data messages, meaning that they are disseminated and processed by core nodes in the same manner as data messages. Data and cover messages are indistinguishable, which means that a local observer cannot tell the difference between the data and cover message by looking at it.
Cover messages make learning the communication patterns of core nodes harder, even from the perspective of a local observer.
Generation
A message is generated according to the following logic:
- The node generates a message payload :
- The payload is a block proposal, then a data message is generated.
- The payload is a random number, then a cover message is generated.
Both types of messages are created at random by independent processes.
-
The payload is cryptographically processed as follows:
-
core nodes are selected at random from the set retrieved by SDP,
-
The message is generated, which encapsulates the payload in layers of encryption. Each ’th layer can be decrypted by the ’th node from the selected set.
-
The message is relayed.
Relaying
A message is relayed according to the following logic.
-
If the message is the outcome of the generation logic, then the message is sent to all neighbors (core nodes) of the node.
-
If the message is the outcome of the processing logic, then:
- If the message is not unique, then the message is dropped;
- The message is randomly delayed;
- Then the message is sent to all neighbors (core nodes) of the node.
-
If the message is received from the neighbor:
- If the message is not unique, then the message is dropped;
- Else, the message is sent out to the rest of the node's neighbors (core nodes) and concurrently is processed by the node.
Processing
-
A message is received by a node.
-
If the node is the ’th node, then:
-
The message is decapsulated from the message;
-
The message is relayed.
-
Else, the message is discarded as the node cannot process the message. Note that the message was previously relayed according to the Relaying logic.
-
After decryptions, the last node can determine the type of the message by examining the payload :
-
If the payload contains a block proposal, then it is broadcast to the entire Logos Blockchain network;
-
Otherwise, the message is discarded.
Broadcasting
Broadcasting is a process of delivering a block proposal extracted from a data message to the entire Logos Blockchain network by the core node that received it. Only block proposals that are constructed correctly can be broadcast. Any badly constructed block proposal must be rejected. The logic behind the verification of the block proposal is out of the scope of the Blend protocol. It is defined by the Logos Blockchain Bedrock ([Overview] Bedrock Architecture).
Rewarding
A node must be encouraged to follow the protocol, which means that it must be rewarded for the contribution it is making. Otherwise, honest nodes might become lazy nodes, nodes that are not motivated to follow the protocol due to a lack of incentives. In simple terms, a lazy node will not work until it gets paid. Therefore, we motivate the following set of protocol actions:
- Message generation: a node must be motivated to generate messages according to the protocol, where generation means that a new message is created that is not the outcome of the processing. This is especially important for cover messages. Data messages already incentivize the node that is generating them, since they include a block proposal, and it rewards the sender of the message directly through the consensus-defined rewarding mechanism (Anonymous Leaders Reward Protocol).
- Message relaying: a node must be motivated to relay every received message, where relaying means that a node forwards all messages it received to its neighbors to deliver messages to their next destinations (blend nodes).
- Message processing: a node must be motivated to process every received message, where processing means that a node has decapsulated and delayed the message.
- Message broadcasting: a node must be motivated to broadcast any data message it processed, where broadcasting means that a node sends the processed message to the Logos Blockchain network broadcasting channel.
Motivations
We address the above motivations in the following manner:
- Cover message generation is motivated by the node’s individual need for privacy.
- The node must generate and emit cover messages to keep itself private. Otherwise, it will lose the protection given by the protocol.
- The node must also limit the number of cover messages to generate to be indistinguishable from all other nodes. That is, for every data message a node generates it must generate one less cover message; otherwise the node could be distinguished from other nodes based on the number of emitted messages.
- Message relaying is motivated by monitoring the connection quality with the node by its neighbors.
- The node must relay messages according to a network-defined limit. Otherwise, the neighbors will close the connection with the node. This will lead to a network-level isolation of that node, and if the node is isolated, it will not receive any messages to process, so it will earn no rewards.
- The node must relay processed messages. If it does not, the node that generated the message will learn this fact and might stop addressing messages to the relaying node. This is possible because a node can select the recipients of the messages freely but from a random subset of all nodes.
- Message processing is motivated by calculating a reward as a node’s activity function.
- The node collects message-unique information (blending tokens); the number of tokens collected increases the chances for a reward. The node receives a base reward after showing that it performed a minimal amount of work, which is verified by the step 3 of the Rewarding Mechanics.
- The node that collects more tokens increases its chances of winning a premium reward through a lottery mechanism. The node receives a premium reward after showing that it performed extra work, which is verified by the step 4 of the Rewarding Mechanics.
- The distinction between the base and premium reward is necessary to reward nodes for the work they perform and to continue to motivate them. The base reward provides a level of fairness, meaning every node should receive it if they were active enough. However, a lazy node might stop providing service after collecting just enough tokens to get the reward, which might be less than what an honest node collects. Therefore, the premium reward continues to motivate the lazy node to work more and collect more tokens. The premium reward is paid on a randomized competition basis, which cannot be biased by the node.
- Message broadcasting is motivated by increasing the base reward.
- The node is motivated to broadcast the block proposal message as each block proposal that extends the chain directly increases the Blend Network Service income pool. That is, the block rewards and/or fees for each block are summed up and form the service income pool, which is then shared with active core nodes.
There is a subtle distinction between the broadcasting and relaying motivation logic:
- The broadcasting action is motivated by the fact that each broadcast block is contributing to the service income pool .
- The relaying action is motivated by a fear of losing a reward, which impacts the chances for winning a reward (node’s activity ).
- The reward is calculated as a multiplication of both .
Therefore, the nuance between such a distinction is with the “direction” of the motivation. For broadcasting, it is positive (earning), and for relaying, it is negative (losing).
- Messaging abuse is limited by a quota construction.
- The quota limits message generation, which helps maintain network health and enables fair reward calculation.
- This is achieved by limiting the number of unique encryption keys that can be used for message generation. That is, processing a single message consumes a number of keys, which effectively limits the number of messages that can be processed by the network.
Mechanics
- Every node during the epoch of the protocol collects some bits of information, which are called blending tokens, from processed messages.
- After the epoch, every node selects a single blending token that has a certain property: it is most similar to the next Epoch Randomness. This token is registered on the ledger.
- Every node that submitted a token receives a base reward if the token’s similarity to the next epoch randomness is above a certain (predefined) threshold (called the activity threshold).
- Every node that submitted a token receives a premium reward if the token is in the set of the most similar tokens (as defined below) to the next epoch randomness.
Protocol
Network Maintenance
In this section, we present the part of the protocol responsible for maintaining the network connectivity.
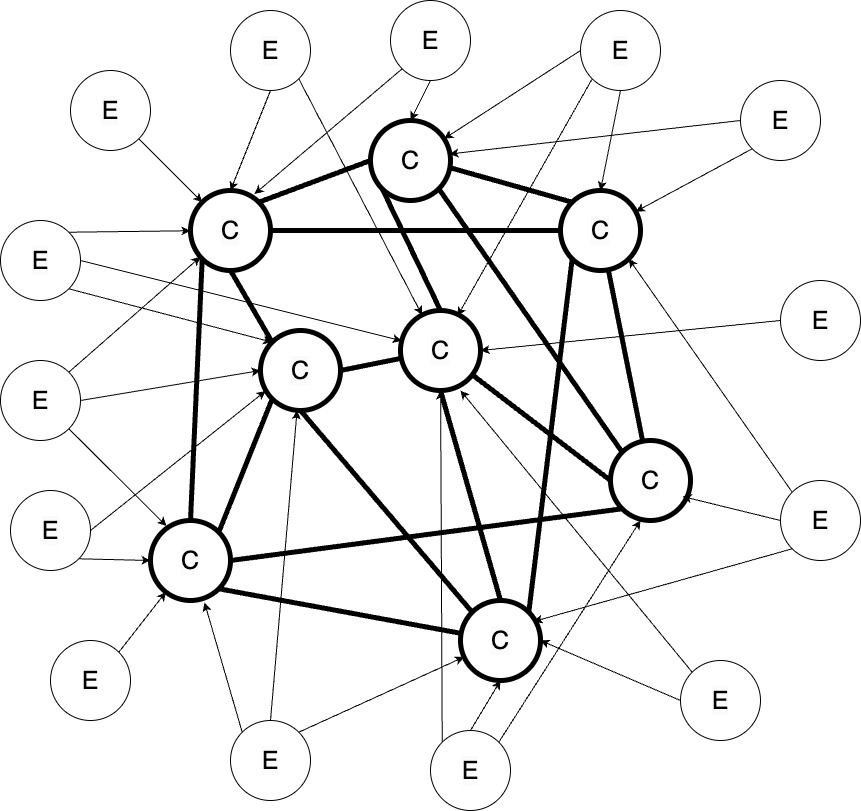
A simple diagram representing the Blend Network, where core nodes (denoted as C) form a Core Network (bold connections) and edge nodes (denoted as E) form an Edge Network (thin connections).
Since the network is built based on two types of nodes, we define two network types. The Core Network is built with core nodes, while the Edge Network is built with edge nodes that connect to the core nodes. This distinction is necessary as the process of bootstrapping and maintaining each network is different.
Core Network
Bootstrapping
The bootstrapping defines the process of creating the network, which happens at the beginning of each epoch.
- A core node at the beginning of an epoch retrieves a set of core nodes’ information from the SDP protocol (Service Declaration Protocol).
- If the number of core nodes is below the minimum number of nodes (Minimal Network Size), then stop and use regular broadcasting.
- It starts opening new connections.
-
It selects at random (without replacement) a node from the set of core nodes.
-
It establishes a secure connection with the selected node, that is:
- It opens a TLS connection using ephemeral keys to the node according to the Connection Details.
- It identifies its neighbor using the Neighbor Distinction Process (NDP).
- The node learns that the neighbor is a core or an edge node.
- The neighbor learns that the node is a core node.
- The node stops connecting to selected peer after reaching the maximum number of tries ( parameter: Core Node Parameters). Then a new random peer is selected.
-
It repeats the above steps until it connects to the minimal core peering degree of nodes. That is, 4 according to the parameter: Core Node Parameters. Both incoming and outgoing connections count toward this minimal degree.
-
- It starts accepting incoming connections and maintaining all connections as defined in Maintenance.
- It can maintain up to the maximum number of connections with core nodes ( parameter: Core Node Parameters). For example, a node initiates connections and , then it can still accept connections from core nodes.
- It can receive up to the maximum number of connections with edge nodes. For example, 300 or according to the parameter: Core Node Parameters.
- If two nodes open two connections with each other, so that both have incoming and outgoing connections to the same neighbor (core node), then:
- The node with the lower public key value (
provider_idfrom SDP) must close the outgoing connection to the node with the higher public key value. - The node with the higher public key value (
provider_idfrom SDP) must close the incoming connection from the node with the lower public key value.
- The node with the lower public key value (
Public key values are compared lexicographically. Specifically, we use the libp2p peer_id format of the provider_id and apply standard Base58 encoding (to_base58() libp2p function) for the comparison.
Maintenance
This process defines the way the network connections are maintained during the epoch.
A core node monitors the connection quality of each connection with its neighbors, according to the Connectivity Maintenance:
- It monitors the transmission rate of each neighbor’s connection.
- If the transmission rate drops below a certain threshold, then the neighbor is marked unhealthy.
- If the transmission rate goes above a threshold, then the neighbor is marked spammy.
- A connection with a spammy neighbor is dropped, and a new one (with another randomly selected core node) must be established to maintain the minimum peering degree.
- A connection with an unhealthy core node neighbor is maintained, but an additional connection is established.
- The number of open connections must be below the maximum core connections.
- If the maximum core connections is exceeded, then:
- A message is added to the logs informing about this situation;
- Possibility to establish new connections is paused until the maximum number of established connections goes down.
- A connection with an unhealthy edge node is closed.
Edge Network
Bootstrapping
The edge network is maintained by core nodes because edge nodes can only establish connections with core nodes.
Each core node defines individually the maximum number of edge connections allowed. Therefore, every core node is a potential entry point to the network, but not every node is connectable.
The bootstrapping logic of an edge node:
- At the beginning of an epoch, the edge node retrieves a set of core nodes’ information from the SDP protocol.
- If the number of core nodes is below the minimum number of nodes (Minimal Network Size), then stop and use regular broadcasting.
- Whenever an edge node needs to send a message, it selects at random (without replacement) a node from that set.
- It establishes a secure connection with the selected node.
- It opens a TLS connection using ephemeral keys to the node according to the Connection Details.
- It identifies itself and authenticates using the Neighbor Distinction Process.
- A core node learns that the neighbor is an edge node.
- An edge node confirms that the neighbor is a core node.
- A core node might drop the connection if the maximum number of edge connections, defined by the core node, is reached.
- An edge node must drop the connection if the neighbor is not the intended core node. Please note that technically it is done during TLS handshake, where the handshake will fail if the core node is using a different key than provided in the SDP declaration.
- When the connection is established, it sends the message and closes the connection.
- Concurrently to the above, it repeats steps 4 and 5 until it is sends the message to a number of nodes equal to the communication redundancy number defined by the edge node. It stops connecting to each node after a certain number of tries, which is defined by the edge node.
Message Lifecycle
Generation
Generation of a message is triggered by any of the following events:
- A core or edge node won a consensus lottery and has a proof of leadership, which entitles the node to emit a data message. The payload of the message is a block proposal.
- A cover message is released at random by the core node, as described in Cover Message Schedule section. The payload of the message contains random data.
When this happens, a number of messages (limited by the Quota) are generated as follows:
- A number of keys are generated according to the Key Types and Generation.
- Each key uses a message-type-specific allowance as described in the Quota.
- The correct usage of the allowance is proven by Proof of Quota.
- The payload of the message is formatted according to the Payload Formatting.
- The above set of keys is used to encapsulate the payload of a message according to the Message Encapsulation Mechanism.
- Each key is used for a single encapsulation of a message, which can be processed (decapsulated) by a single node.
- The node selection is random and deterministic, and is provable by Proof of Selection. This restricts the possibility of targeting a specific node by an adversary. The adversary is limited only to a subset of keys that can be used to generate a message to a particular node.
- The message is formatted according to the Message Formatting.
- The message is released by the node to the Blend network according to the Releasing logic.
- Core nodes send the message to their neighbors.
- Edge nodes send the message to randomly selected core nodes.
For a complete description of the generation logic, refer to Generation.
Relaying
When a node receives a message from one of its neighbors, it does the following:
- Checks the public header of the message, that is:
- The version of the message must be equal to
0x01; if not, then discard the message. - The proof of quota nullifier must be unique; if not, then discard the message.
- The signature must be valid; if not, then discard the message.
- The version of the message must be equal to
- The message is released to the network as defined in the Releasing section.
- Concurrently to the above, the message is handled by the processing logic as defined in the Processing section.
For a complete description of the relaying logic, refer to Relaying.
Processing
Every message that passes Relaying verification is processed as follows:
- The message is decapsulated as defined in the decapsulation section of the Message Encapsulation Mechanism. This means the node successfully decrypted the blending header and can now read and process it.
- If decapsulation succeeds, the decrypted blending header is processed:
- If the proof of selection is invalid, discard the message.
- Information is extracted from the message and saved as proof of processing a blending token and is used to claim rewards.
- If the last flag of the decrypted blending header is turned on, the message is completely decapsulated. The payload can then be processed according to the Payload Formatting:
- If the type is a data message, add the payload to the broadcasting queue.
- If the type is a cover message, discard the payload.
- Otherwise, examine the decapsulated header:
- Verify the proof of quota is valid; if not, discard the message.
- Verify the signature is valid; if not, discard the message.
- Verify the public key is unique; if not, discard the message.
- Format the message according to the Message Formatting.
- Attempt a subsequent decapsulation to validate whether the node is the recipient (return to step 1). This must be done recursively to remove all consecutive encapsulation layers where the node is the intended recipient.
- If the decapsulation fails (meaning no more layers remain), randomly delay the message and release it to all neighbors.
- If decapsulation fails, return the appropriate decapsulation failure message.
For a complete description of the processing logic, refer to Processing.
Broadcasting
Every payload that is added to the broadcasting queue is processed as follows:
- The correctness of the payload content is verified; that is, the payload must contain a valid block proposal structure — the block proposal is not validated; otherwise, it is discarded.
- The block proposal is extracted from the payload and is broadcasted to the Logos Blockchain broadcasting channel after a random delay.
For a complete description of the processing logic, refer to Broadcasting.
Rewarding
Every active core node receives a reward. The activity of a node is verified in a probabilistic manner, where a more active node has higher chances of getting a reward and a premium reward. To claim a reward, the node must do the following:
- Generate a proof of its activity for a specific epoch as defined in Activity Proof. The proof confirms that the node was processing messages during the epoch. The node activity confirmation is probabilistic, and the odds increase with the number of collected blending tokens.
- Use SDP active functionality (Active) to request a reward as described in Rewarding Distribution Logic, that is:
- Create an Active Message.
- Send it as a part of the reward message (Active Message).
- The reward is calculated as defined in Reward Calculation, that is:
- The number of correct activity messages is calculated.
- The number of correct and winning messages is calculated, where a winning message is defined by a lottery mechanism.
- Every node that sends a correct activity message receives a base reward.
- Every node that sends a correct and winning message receives a premium reward.
- The rewards are distributed by the mechanisms provided by the Service Reward Distribution Protocol.
Details
Notation
- denotes the actual number of established connections of the core node with other core nodes;
- denotes the actual number of connections of the core node with edge nodes;
- denotes the actual number of connections of the edge node with core nodes;
- denotes a function that returns the number of healthy connections of a given type, where type is: ;
- denotes a maximal delay time between two release rounds;
- denotes a maximum number of processing rounds for a single message;
- denotes the upper bound on the number of messages to be released during a single release round;
- denotes a number of rounds in an epoch;
- denote the observation window expressed in the number of rounds;
- denote a frequency at which messages are observed during an observation window ;
- denote the maximal frequency at which messages can be generated during an observation window ;
- denote the minimal frequency at which messages must be generated during an observation window ;
- denote a frequency at which cover messages are generated per round;
- denote a frequency at which data messages are generated per round;
- denote the expected number of cover messages that are generated during an epoch by the core nodes;
- denote the expected number of blending operations for each cover message;
- denote the expected number of blending operations for each data message;
- denote a redundancy parameter for cover messages, defining the number of “replications” of the same message;
- denote a redundancy parameter for data messages, defining the number of “replications” of the same message;
- denote a set of core nodes providing the Blend service for the epoch returned by the SDP protocol (Service Declaration Protocol);
- denote a number of core nodes providing the Blend service;
- is a cryptographically secure pseudo-random number generator, implemented as a BLAKE2b-Based PRNG Construction;
Global Parameters
- , as defined in the Delaying section below.
- , the number of rounds per epoch.
- , the maximum number of blending operations of a single message.
- , the expected number of blending operations for each cover message;
- , the expected number of blending operations for each data message;
- , the observation window is rounds.
- , the maximum number of messages per-connection during the observation window is a function of the , which is defined in the Releasing section.
- , the minimum number of messages per-connection during observation is a function of the , which is defined in the Releasing section.
Core Node Parameters
A core node maintains the following set of parameters:
- denotes the maximal peering degree a core node can maintain with other core nodes. It is set by a core node individually.
- denotes the minimal peering degree a core node must maintain with other core nodes. It is set by a core node individually.
- denotes the maximum number of connections with edge nodes. It is set by the core node individually.
- denotes the maximum number of retries a core node will do to connect with another core node.
Implementations should choose a default based on the deployment they operate in, and users can override these defaults before joining.
Edge Node Parameters
An edge node maintains the following parameters:
- denotes the connection redundancy number for the edge node. A node must send a single message that needs to be blended to this number of core nodes.
- denotes the maximum number of retries an edge node will do to establish a connection with a core node.
Implementations should choose a default based on the deployment they operate in, and users can override these defaults before joining.
Network Maintenance
Connection Details
The connections are established using libp2p with TLS version 1.3 (not older). The cryptographic scheme is Ed25519 with ephemeral keys**.** The libp2p protocol name is /logos-blockchain/blend/1.0.0 for mainnet and /logos-blockchain-testnet/blend/1.0.0 for testnet.
Neighbor Distinction Process
The Neighbor Distinction Process (NDP) enables the core node to distinguish between node types (core, edge) of its neighbors in the Blend Network. The process is straightforward:
- A node extracts
peer_idfrom the TLS metadata of the accepted connection. - If the
peer_idis found in the set ofprovider_ids, then the neighbor is a core node; otherwise, the peer is an edge node.
Connectivity Maintenance
The core node is responsible for maintaining the level of connectivity and monitoring the state of connection with its neighbors. The neighbors must comply with the maximum and minimum frequencies of emitting messages. Otherwise, the connection with that node may be dropped.
The monitoring logic is defined as follows:
- The messages are counted after successful connection-level decryption of the message for each neighbor.
- The node counts the number of messages during a window of observation . The frequency of observed messages is calculated as the number of messages recorded during the observation time divided by the length of the observation window (denoted in rounds).
- If the measured message frequency is higher than maximal (), then the node marks the neighbor as spammy, and the connection with that node must be closed.
- The node can mark the neighbor as spammy with high confidence, as the neighbor is the true source of messages due to the usage of the TLS protocol, which eliminates the possibility of executing replay attacks by the adversary.
- To maintain the minimal number of connections, a new one must be established when a connection with an abusive node is closed.
- The neighbor is added to a black list, and its selection must be avoided.
- If the measured frequency is lower than the minimum (), then the connection is marked unhealthy.
- If the number of healthy connections is below the minimum number of connections ( for core-to-core connections), then another connection must be opened with a new randomly selected core node. We cannot assume that the neighbor is spammy, as it might be under a denial-of-service attack or other censoring attack.
- An unhealthy connection is monitored continuously. If the message frequency goes above the minimal value during the next observation window, then the connection must be treated as healthy, and the node must remove the unhealthy marking for that connection.
- If the number of open connections is above the maximum () then:
- Add an entry to the log that the maximum number of connections has been reached*.*
- Pause the ability to establish new connections until the number of open connections drops below the maximum.
- If the neighbor is an edge node, then the edge node must send a message immediately after establishing the connection with the core node and then close the connection. Otherwise, the connection must be closed by the core node.
- If the node receives a message that has been discarded during the relaying process due to invalidity of the signature (Relaying), then:
- If the sender is a core node, then it must be marked as malicious, and the connection with that node must be closed.
- If the sender is an edge node, then do nothing as the connection must already be closed with that node.
- If a node receives a second message from its neighbor (core node) that is using an already seen message identifier, then the connection with that neighbor must be closed.
The message identifier is the message proof of quota nullifier embedded in the public header of the message. It is used for signing the message and must be unique; otherwise, the message must be discarded.
We do not force any action when the measured transmission rate is below the thresholds defined above, which means that the sender is not emitting enough messages. The primary reason is security; a node might be under an attack, and an adversary is trying to exploit the node and force the node to connect to a different peer (who might be malicious). The severity of that attack is high, as it is not attributable to the adversary. That is, the adversary can execute this attack without disclosing its identity even if it is not controlling the other end of the connection. Therefore, it is better not to close the connection immediately but to establish another one with a randomly selected node from the list.
However, this must also be carefully engineered as the number of connections must not rise above the maximal connection values. The reaction of the node operator to the situation when the number of connections reached maximum is a complex matter, which needs to be handled according to the privacy requirements of the operator. For example, it might be a sign that the node is under attack. Therefore, we have decided to define a privacy-first strategy that is to inform the operator about the potential problem (through logs) and pause the ability to establish new connections until the number of open connections goes below the maximum.
Transition Period
When a new epoch begins, the set of public information checked against proofs embedded in messages changes, which renders some messages invalid. However, these messages may still contain valid payloads that must reach their destination. Therefore, we implement a Transition Period (TP, ) during which the network can gracefully react to the change and allow these messages to safely exit the network.
The duration of the TP is calculated as follows:
where:
- defines the maximal blending delay;
- defines the network dissemination delay;
- defines maximum number of blending operations of a single message.
We assume that is an average message dissemination delay, then:
That means that after rounds, all messages for the past epoch should have been processed and disseminated.
However, to provide an additional safety buffer, we round up the transition period to rounds. After this period, all old connections can be safely terminated, and messages for the past epoch must not be processed anymore.
When a new epoch begins:
- The node validates message proofs against both new and past epoch-related public input for the duration of TP. This allows past-epoch messages to safely transit through the network, as their validity is bound to the epoch in which they were generated.
- The node must open new connections to process new messages for the new epoch.
- The node needs to maintain old connections and process all messages received from these connections for the duration of TP.
Quota
The quota limits the number of messages that can be generated during an epoch. This bound is necessary for the health of the network as it decreases the bandwidth usage and enables us to calculate rewards fairly.
Core Quota
The core quota () defines the messaging allowance that can be used by a core node during a single epoch. The purpose of is to limit the number of cover messages and the number of blending operations that can be used for a single message. We assume that the core quota is used for generating cover messages, but the core node is not limited by this assumption. We define it as follows:
Where:
- denotes an expected number of cover messages that are generated during an epoch by the core nodes;
- denotes the expected number of blending operations for each cover message;
- denotes a redundancy parameter for cover messages, increasing the number of core node messages a node can send;
- denote a number of core nodes providing the Blend service for the epoch returned by the SDP protocol (Service Declaration Protocol).
Additionally, we introduce the total core quota, which defines the total number of generated cover messages that the whole network can emit (independently of the number of nodes):
Leadership Quota
The leadership quota () defines the number of blending operations a block proposer (consensus leader) node can perform within the network. A single quota is used per single proof of leadership. Therefore, a single node can use multiple leadership quotas during a single epoch. We assume that the leader is interested in using most of its quota to generate data messages; however, the leader is not limited by this assumption. We define the leadership quota as follows:
where:
- denotes the expected number of blending operations for each data message;
- denotes a redundancy parameter for data messages, defining the number of “replications” of the same message.
We can calculate an average data message number () which informs us about the average number of data messages generated per epoch:
where is the average number of leaders per epoch.
The depends on the consensus leader election algorithm, which at the time of writing can be estimated as follows:
where and are taken from the Cryptarchia Protocol. This is equivalent to the average rate of a slot having an elected leader.
Finally, let us define the leadership quota for node (), which can only be calculated by the node :
where is the exact number of leader elections won by the node in an epoch. The value of is known only to the node because its value is a function of the stake of a node , which is kept private.
Quota Application
We define a mechanism that applies the quota to the protocol and makes the messaging restriction effective. We start by modifying the mechanism that governs message generation, processing, and relaying. That is:
- We require every message introduced to the network to be identified by a unique (ephemeral) key.
- We restrict the number of messages a node can generate to the value of the quota.
For this to happen, a node creates a pool of keys that can be used for message generation and processing (the pool is epoch-specific):
which describes a collection of key pairs for a node with proofs of quota for the epoch , where is the -th public key, is its corresponding private key, and is its proof of quota. Additionally:
- is the sum of core quota and leadership quota for the node .
- is a proof of quota which confirms that for every key from the key pool of a node, without disclosing the identity of the node .
Keys Generation
This protocol uses multiple types of keys that are described in the following specification: Key Types and Generation
Proof of Quota
One of the key ideas behind the Proof of Quota (PoQ — [Proof of Quota) is to guarantee that honestly generated messages are relayed and will be disseminated to the entire network. This is because an honestly generated message uses a unique identifier; otherwise, the network will eventually flag the message as duplicated and halt its dissemination.
If two messages use the same identifier, then the network does not guarantee that the message will be relayed. In such a case, any node that observes the second message with the same identifier will drop it.
This might lead to a situation where part of the network will see the first message and another part of the network will see the second. In this scenario, both messages are not disseminated to the whole network, as expected, due to spam limits in the network. However, this does not mean that either message has not reached its destination and was not processed.
The PoQ is constructed from two parts.
The first part of the PoQ is dedicated to the core quota. We define the proof of core quota () as true when all of the following conditions are met:
- : there exists a node that is part of the set of registered nodes , which is retrieved from the SDP protocol for the epoch . The value identifying the node must be hidden.
- : the public key is generated by the node for the epoch .
- : the number (index) of proof nullifiers that limits the number of proof of quotas a core node can generate in one epoch.
The proof of the core quota assumes:
- Public input: , , .
- Private input: , .
- Public output: .
Where is a PoQ nullifier and uniquely identifies the PoQ.
The second part of the PoQ is dedicated to the leadership quota. The proof of the leadership quota () is true when all of the following conditions are met:
- : there exists a valid proof of leadership for node valid for epoch .
- : the key is generated by the node for the epoch .
- : the number of key nullifiers that limits the number of proof of quotas a leader can generate per won slot.
The proof of the leadership quota assumes:
- Public input: , , .
- Private input: , , .
- Public output: .
Where is a PoQ nullifier and uniquely identifies the PoQ.
Finally, we use both constrains and create a single proof of quota (). That is, the proof is true when any of the following conditions are met:
- constraints are true.
- constraints are true.
This means that the proof of quota is a logical sum of the proof of core quota and the proof of leadership quota, .
Please refer to the document below for more details.
The set of PoQ for leaders must be precomputed for each epoch to minimize the impact of proof generation on the proposal broadcast delay.
For more details see Proof of Quota.
Message Lifecycle
Proof of Selection
The proof of selection (PoSel, ) is a construction that makes the selection of nodes for message processing a random and verifiable process. The reasons behind such restrictions are:
- Due to random (unbiased) sampling of blend nodes, messages are distributed uniformly across the whole set of nodes. Therefore, we avoid creating communication hotspots, and through this, we make the rewarding process fair.
- The restriction on the selection of the blend node limits the possibility of targeting a specific node by an adversary. The adversary is limited only to a subset of keys that can be used to generate a message to a particular node.
- It limits the possibility of selfish behavior where a node “consumes” all of its keys and “sends” all messages to itself to increase its reward.
Note that the Proof of Selection alongside the Proof of Quota restricts the set of nodes that can be used for blending path construction. However, the selection of blend nodes from the set and the particular order they are used for path construction is not restricted. Therefore, a node can freely select nodes from the set of blending nodes defined by the PoSel and PoQ mechanisms to construct blending paths for any of the messages it wants to send.
The PoSel assumes:
- Public input: .
- Shared secret: .
- Public output: .
Where is the secret selection randomness generated by the and shared only with the recipient (node ), and is an index of the node on the list of core nodes.
The PoSel () is true when all of the following conditions are met:
-
, where:
- is secret selection randomness that is encoded using little-endian,
- is the index of the recipient node (from the SDP list of core nodes) encoded as little-endian,
- is a cryptographically secure pseudo-random bytes generator whose output is restricted to bytes which is encoded using little-endian,
- is a domain separated
blake2bhash function, - and is the number of core nodes.
This operation is statistically secure for relatively small that we assume to have in our system as analyzed in Statistical Analysis of Selection Bias of Modulo Operation.
-
, where is the PoQ nullifier of the and is the PoQ nullifier derived from the secret and is the Posiedon2 hash function.
The PoSel must be used alongside the PoQ, as the PoSel is tightly coupled with the PoQ.
When performing modulo operation on the hash we do the following:
def modular_bytes(data: bytes, modulus: int) -> int:
# Convert data into an unsigned big integer using little-endian.
return int.from_bytes(data, byteorder='little') % modulus
Cover Message Schedule
Generation of cover messages is handled by each core node individually. The only protocol-enforced limitation is through the Core Quota (), which limits the number of messages a node can generate.
To protect its own privacy, a core node should emit cover messages in a fully random manner to ensure that the cover messages are evenly distributed across the duration of an epoch.
Message Structure
For this document, we present a definition of the message structure as defined in the Message Encapsulation Mechanism. For simplicity, we omit the versioning of the message as defined in Message Formatting.
A node constructs a message according to the format presented below.
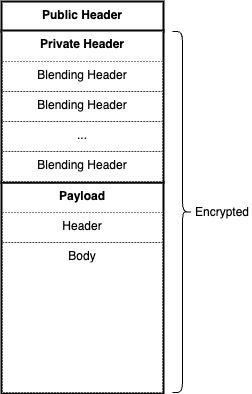
-
is a public header:
- , a public key from the set .
- , a corresponding proof of quota for the key from the and contains its PoQ nullifier .
- , a signature of the -th encapsulation of the payload , that can be verified by the public key .
-
is an encrypted private header , which contains:
- , a public key from the set .
- , a corresponding proof of quota for the key from the and contains its PoQ nullifier .
- , a signature of the -th encapsulation of the payload , that can be verified by the public key .
- , a proof of selection of the node index assuming a public key .
- , a flag that indicates that this is the last blending header.
-
is a payload.
Encapsulation Overhead Calculation: Assuming that we use Groth16 SNARKs as a proving system, we need bytes per PoQ ( for proof and for nullifier) quota. Which gives us bytes per hop (proof of quota bytes + proof of selection bytes + public key bytes + signature bytes + last flag byte) plus bytes for the public header. Which for hops gives us bytes in total. That increases the block proposal message defined in Block Construction, Validation and Execution, of bytes by .
Formatting
The payload of the message must be formatted according to the following document: Message Formatting
The payload must be encapsulated according to the following document: Payload Formatting
Every encapsulated message must be formatted according to the following document: Message Encapsulation Mechanism
Generation
Generation of a message is triggered by any of the following events:
- A core or edge node won a consensus lottery and has a proof of leadership, which entails a node to emit a data message. The payload of the message is a block proposal.
- A Cover Message Schedule. The payload of the message contains random data.
When this happens, a number of messages (limited by the Quota) are generated as follows:
- A number of keys are generated according to the Key Types and Generation.
- Each key uses a message-type-specific allowance as described in the Quota.
- The correct usage of the allowance is proven by Proof of Quota.
- The payload of the message is formatted according to the Payload Formatting.
- The above set of keys is used to encapsulate the payload of a message according to the Message Encapsulation Mechanism.
- Each key is used for a single encapsulation of a message, which can be processed (decapsulated) by a single node.
- The node selection is random and deterministic, and is provable by Proof of Selection.
- The message is formatted according to the Message Formatting.
- The message is released according to the Releasing logic.
Relaying
The relaying logic is defined as follows:
- The node checks the header of the message that was received from its neighbor, according to the Message Formatting.
- If the neighbor is a core node, then update the message counter for the neighbor.
- If the neighbor is an edge node, then close the connection with the neighbor.
- If the header of the message is incorrect, then discard the message and mark the neighbor as malicious and close the connection. We assume that an adversary cannot inject any spoofed message to the connection.
- If the PoQ nullifier from the public header of the message was already seen, then the message is a duplicate and must be discarded. The PoQ nullifiers are valid during a single epoch, therefore, they need to be stored for the duration of the current epoch and during the Transition Period.
- If the signature from the public header of the message is invalid, then the message must be discarded, and the neighbor must be marked malicious.
- Release the message according to the Releasing logic.
- Concurrently to the above step, add the message to the processing queue, where it is handled by the Processing logic.
The node must cache the PoQ nullifiers () for every message it relays for a duration of a single epoch plus the Transition Period (TP). Then the node can clear the cache. That means that the size of the cache must be at least:
Processing
When a message is received by the node, then it is processed by this logic:
-
If the proof from the public header of the message is not correct, then the message must be discarded.
-
Decapsulate the message as defined in the decapsulation section of the Message Encapsulation Mechanism.
-
If the decapsulation is successful, then:
- If the proof of selection () is invalid, then the message is discarded. A valid proof of selection points to the index of the node in the list of nodes returned from the SDP.
- Store the blending token which is the collection of the proof of quota from the header (), and the proof of selection from the private header ():
-
If the last flag is set () then examine the header type of the payload as defined in the Payload Formatting, then:
- If the payload is a block proposal, then the payload structure is verified and broadcast, as defined in the Broadcasting section.
- If the payload is a cover message, then the payload is discarded.
-
Else:
- Examine the decapsulated public header:
- If the PoQ nullifier from the public header of the message was already seen, then the node was not allowed to use the same PoQ nullifier and the message must be discarded. The PoQ nullifiers are valid during a single epoch, so they do not need to be stored for more than a single epoch.
- If the signature from the public header of the message is invalid, then the message must be discarded.
- If the proof of quota from the public header of the message is not correct, then the message must be discarded.
- Format the message according to the Message Formatting.
- Attempt a subsequent decapsulation to validate whether the node is the recipient (return to step 1). This must be done recursively to remove all consecutive encapsulation layers where the node is the intended recipient.
- If the decapsulation fails (meaning no more layers remain), randomly delay the message and release the formatted message according to the Releasing logic.
- Examine the decapsulated public header:
-
If decapsulation fails, return the appropriate decapsulation failure message.
Blending tokens are stored by the node for rewarding purposes, as they prove that the node processed the message. The blending tokens are stored alongside context information such as the epoch number. We denote the set of blending tokens from an epoch stored by a node as .
Delaying
The purpose of message delaying is to hide timing correlations between incoming and outgoing messages from a node. That is, a message is delayed in a random manner, which makes it harder to link the incoming and outgoing messages based on the network timing observation.
The message anonymity pool is the total number of messages that have been seen by the node between two subsequent message release events. The set of seen messages does not necessarily include a message that the node is the recipient of.
The key design objective is to release messages with an upper bound on the delay. Therefore, the design assumes that there is a maximum delay between two subsequent message release attempts that define the longest waiting time for message release. This also defines the maximal message anonymity pool (assuming a single message is released in a round by the network).
Now we can define the delaying logic:
- Select at random a delay: .
- Start counting rounds: is the starting round.
- Every round check if the current round () is the delayed one , then:
- Release messages from the queue according to the Releasing logic.
- Select at random a delay: .
- Start counting rounds: is the starting round.
If the queue is empty, then we do not release any message.
However, the release round selection must work independently of the queue state. Otherwise, the maximal anonymity set is going to be , which must be scaled by the number of messages that are released in a single round.
Releasing
The process of releasing messages involves the following steps:
- Upon receiving a message, it is immediately released to all neighboring.
- All processed messages are queued and released at the next release round determined by the Delaying logic.
- Every generated message is released at the beginning of the next round after its generation.
- As soon as a data message is generated, one random unreleased (future) cover message must be removed from the release schedule to maintain the node’s statistical indistinguishability.
- If more than one message needs to be released for the same round, they must be randomly shuffled before release.
The cover and data message generation processes are independent, and there is a non-zero probability that more than one message will be scheduled for the same round. Therefore, the number of messages that can be released during a single round is not restricted.
However, a node can calculate the expected number of messages to be released per release round. This depends on the value of , the network size (number of core nodes), and the generation quota. This number can be used to detect spammy nodes as part of the Connectivity Maintenance logic.
For sufficiently large networks, the number of processed messages queued in a node will be smaller than on average.
However, in smaller networks, the number of messages queued in a node will be larger than . We must avoid this property because the additional delay negatively impacts the consensus protocol's safety. Therefore, we need to determine the network size threshold where the number of messages to be released exceeds .
The expected number of messages to be released during a single release round for a single node is:
Where:
- is the maximal delay time between two release rounds;
- denotes an expected number of blending operations for each cover message;
- is a message number normalization constant;
- is the number of core nodes in the network.
Let us assume:
- is our target value, as defined in the Delaying section above;
- , which means that every round, nodes are going to be processing messages generated by the network, which is a reasonable assumption as it defines the maximum number that the protocol can tolerate due to the quota limitations;
- , corrects the number of new messages emitted by the network per round to include data messages, where is the number of cover messages, and is the number of data messages per round.
This gives us:
- For core nodes; message per release round on average.
- For core nodes; messages per release round on average.
- For core nodes; messages per release round on average.
We use the estimator for calculating the maximum and minimum number of messages that can be received by a node, as listed in the Global Parameters section.
Broadcasting
Every payload that is added to the broadcasting queue is processed as follows:
- The block proposal is extracted from the payload.
- The block proposal is sent to a Logos Blockchain broadcasting channel after a random delay, as defined in the Releasing section.
The broadcasting happens through an independent protocol. All Logos Blockchain nodes form the broadcasting network, which means that it is larger than the blend network.
Rewarding
To better understand the context of the constructions defined in this section refer to the overview of the Mechanics, and for the motivation of the processing of messages in Motivations.
Epoch Randomness
The rewarding protocol requires a common and unbiased randomness. We assume that it is provided by the consensus once per epoch.
Activity Proof
The node activity proof () is a construction that attests in a probabilistic manner that a node was active during the epoch , by presenting a blending token .
In other words, the activity proof is when:
-
A node has a blending token collected during epoch , and that:
- Proof of Quota is true assuming epoch .
- Proof of Selection is true assuming epoch .
- , a public key from the set , that is used to verify the above proofs.
-
The Hamming distance ( — returns the number of different bits between and binary strings) between the blending token and the next epoch randomness is smaller than the node activity threshold . That is:
Where:
- is a hash function (the implementation of the hash function is
blake2breturning bits). - is a number of bits that can represent an expected number of blending tokens generated during an epoch. The number is rounded up to full bytes as required by the
blake2bhash algorithm:
The Hamming distance verification prevents nodes from the grinding or pre-computation attacks due to the unpredictability of the randomness of the next epoch. Even if a node knows the value of the randomness in advance, it will not increase its chance for getting a reward as the node does not control the process of generating blending tokens. However, a dishonest node could use that knowledge to refrain from sending a message with a token that has a potential (probabilistic, not deterministic) of granting a premium reward for the recipient blend node.
The node activity proof construction is:
class ActivityProof:
epoch_number: EpochNumber
signing_key: SigningKey
proof_of_quota: ProofOfQuota
proof_of_selection: ProofOfSelection
Where:
EpochNumberis the number of the epoch for which the activity proof is generated.ProofOfQuotais defined as in Proof of Quota.ProofOfSelectionis defined in Proof of Selection.SigningKeyis the key used to sign theProofOfQuota.
Activity Threshold
The activity threshold defines the expected maximal Hamming distance from the epoch randomness to the blending token expressed as an integer smaller or equal .
We define the activity threshold as follows:
Where:
- represents the number of bits that are needed to express the number of nodes in the network , it makes the lottery difficulty a function of the network size;
- represents the number of bits needed to express all blending tokens generated during an epoch, where is the total number of cover messages generated by the network during an epoch (as defined here);
- represents a sensitivity parameter that controls the winning conditions of the lottery.
We assume that setting is enough to eliminate nodes that have not been active enough without too aggressively eliminating nodes that worked but had less luck with the lottery. However, we are going to revise this parameter in the future version of the protocol.
Active Message
A node for every epoch must construct an active message , which must follow the Active Message.
The active message metadata field must start with a header that contains a one byte version field which is fixed to 0x01 value, the rest of the metadata is populated by the Activity Proof.
The active message is stored on the ledger.
The active message is used for calculating the node reward.
The active message is constructed after the current epoch, when the next epoch randomness is known.
The active message for epoch must only be sent during epoch ; otherwise, it must be rejected.
The node selects the activity proof to include in the active message such that the Hamming distance between the proof and the new randomness is minimal.
The ledger must only accept a single active message per-node per-epoch. Any duplicate must be rejected.
Reward Calculation
The node rewards for epoch are calculated according to the following schema:
-
Rewards are not calculated if the number of nodes (unique
ProviderIds from declarations) retrieved from the SDP protocol is lower than the Minimal Network Size. -
Count the number of true activity proofs registered on the ledger:
This value is used for calculating the base reward paid for all active nodes. -
Count the number of true activity proofs registered on the ledger with the smallest Hamming distance—that is, calculate the number of nodes with the minimal distance among all submitted active messages:
This value is used for calculating the premium reward, which is paid for all active nodes that have their activity proofs closest to the epoch randomness. -
Calculate the base reward:
where is the value of income for the Blend Network service for the epoch . For more details about the income calculation, refer to linked reference. -
Calculate the reward of the node :
That is, a base reward () is paid out to all nodes who have submitted a true activity proof, and the reward is doubled for nodes that submitted a true proof with a minimal Hamming distance.
Rewarding Distribution Logic
The reward is paid out to the node based on the node's activity declaration and the above reward calculation.
The rewards are distributed according to Service Reward Distribution Protocol. Here we are briefly sketching the main idea of the reward distribution protocol. For more details refer to the above document.
- To receive a reward, a node must send an Active Message as described in the Active Message, where the
Metadatafield consists of a node activity proof. The node must point to a single declaration (declaration_id) and use a single provider identity (provider_id) for constructing the Active Message. Any reuse of theprovider_idmust make the Active Message invalid. - The Active Message must be sent after the end of an epoch (), that is, during the next epoch (), and after the epoch transition period as defined in the Transition Period section. The delay allows nodes to include blending tokens collected during the epoch transition period for rewarding purposes.
- When the following epoch begins () Mantle distributes rewards (Service Reward Distribution Protocol). This delay is required to calculate the partition of rewards as defined in the above section.
- If a node does not send the Active Message on time, then it will not receive a reward.
Analysis
Impact of the Blend Protocol on the Time to Link and Time to Infer the Stake
The main objective of the Blend protocol is to reduce the probability of linking a sender with the proposal, which also translates to increasing the time of learning the node’s (relative) stake.
The average latency penalty does not include the network delay.
The Blend Protocol increases the Time to Infer (TTI — Inference of relative stake) the stake times (assuming a network of a peering degree 4) in comparison to not using the Blend Protocol. This TTI increases times for every additional Blend node used, reaching more than years ( epochs) to infer a node stake.
When the peering degree is increased to 6 the time to infer the stake increases times that means that higher peering degree decreases the time as an adversary has more chances to observe traffic.
(*) Our TTI calculations are capped at more than epochs, which can be interpreted as more than years — a relatively safe threshold.
The time to infer the node stake depends on the confidence of the adversary. The confidence increases as the network observation time increases. Assuming node adversaries in the network and stake inference confidence of (which tells us about the confidence of the adversary when learning the node stake), we obtain the following values.
TTI — peering degree 4:
| 1% node stake | 0.1% node stake | 0.01% node stake | Average latency increase | |
|---|---|---|---|---|
| No Blend | 0.32 epochs | 3.2 epochs | 32.2 epochs | 0 |
| 1-hop Blend | 94 epochs | more than 487 epochs (*) | more than 487 epochs (*) | 1.5s |
| 2-hop Blend | more than 487 epochs (*) | more than 487 epochs (*) | more than 487 epochs (*) | 3s |
| 3-hop Blend | more than 487 epochs (*) | more than 487 epochs (*) | more than 487 epochs (*) | 4.5s |
TTI — peering degree 6:
| 1% node stake | 0.1% node stake | 0.01% node stake | Average latency increase | |
|---|---|---|---|---|
| No Blend | 0.32 epochs | 3.2 epochs | 32.2 epochs | 0 |
| 1-hop Blend | 68 epochs | more than 487 epochs (*) | more than 487 epochs (*) | 1.5s |
| 2-hop Blend | more than 487 epochs (*) | more than 487 epochs (*) | more than 487 epochs (*) | 3s |
| 3-hop Blend | more than 487 epochs (*) | more than 487 epochs (*) | more than 487 epochs (*) | 4.5s |
When the Blend protocol is applied, then the the Time to Link (TTL — The Unlinkability of Block Proposers) is non-instant, and it increases with the number of blend nodes used. For each additional blend used, the time increases times and the cost is of additional seconds of average latency.
Without the Blend protocol, the TTL is instant as the proposal is directly broadcast by the sender. Below we present a table where we show how long it takes to link a node to a single message with more than probability.
TTL — peering degree 4:
| 1% node stake | 0.1% node stake | 0.01% node stake | Average latency increase | |
|---|---|---|---|---|
| No Blend | instant | instant | instant | 0 |
| 1-hop Blend | 0.9 epochs | 9 epochs | 91 epochs | 1.5s |
| 2-hop Blend | 9 epochs | 91 epochs | 917 epochs | 3s |
| 3-hop Blend | 91 epochs | 917 epochs | 9175 epochs | 4.5s |
TTL — peering degree 6:
| 1% node stake | 0.1% node stake | 0.01% node stake | Average latency increase | |
|---|---|---|---|---|
| No Blend | instant | instant | instant | 0 |
| 1-hop Blend | 0.7 epochs | 6.7 epochs | 67.3 epochs | 1.5s |
| 2-hop Blend | 6.7 epochs | 67.3 epochs | 673.4 epochs | 3s |
| 3-hop Blend | 67.4 epochs | 673.4 epochs | 6734 epochs | 4.5s |
Statistical Analysis of Selection Bias of Modulo Operation
Applying a modulo operation to the output of a pseudorandom number generator (here the Blake2b hash function) with a large range (here from to ), introduces a statistical bias when mapping to the smaller domain . This bias arises because is typically not divisible by , meaning that some residues modulo will occur slightly more often than others. Specifically, let , then with . The first values modulo will appear times, while the remaining values will appear times. Thus, the maximum bias between two values and in is:
Where is the probability that is the result of the modulo operation and the probability that is the result of the modulo operation.
The maximum per-value bias is exactly , regardless of , as long as . That means no single output differs from uniform by more than .
But now we consider total variation distance, a better global metric of distinguishability between the true distribution and uniform. This is:
We know then:
Reinjecting in the formula of :
So the distribution deviation is less than which is cryptographically negligible when . Since . Since the number of nodes participating in Blend is expected to be less than 10 million (less than ) we can safely skip the rejection process necessary to draw random numbers uniformly in .
KEY-TYPES-AND-GENERATION
| Field | Value |
|---|---|
| Name | Key Types and Generation |
| Slug | 84 |
| Status | raw |
| Category | Standards Track |
| Editor | Mehmet Gonen [email protected] |
| Contributors | Marcin Pawlowski [email protected], Youngjoon Lee [email protected], Alexander Mozeika [email protected], Thomas Lavaur [email protected], Álvaro Castro-Castilla [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-04-09 |
| 1.0.1 | [RFC] Remove Concept of a Session | 2026-06-22 |
Introduction
This document defines the key types used in the Blend protocol and describes the process of generating them.
Overview
This document ensures that the keys are used and generated in a common manner, which is necessary for making the Blend protocol work. The keys include:
- Non-ephemeral Quota Key (NQK) — used for proving that a node is a core node.
- Non-ephemeral Signing Key (NSK) — used to authenticate the node on the network level and derive the Non-ephemeral Encryption Key.
- Ephemeral Signing Key (ESK) — used for signing Blend messages, one per encapsulation.
- Non-ephemeral Encryption Key (NEK) — used for deriving shared secrets for message encryption.
- Ephemeral Encryption Key (EEK) — used for encrypting Blend messages, one per encapsulation.
Construction
Non-ephemeral Quota Key
A node generates a Non-ephemeral Quota Key (NQK) that is a ZkSignature (Zero Knowledge Signature Scheme (ZkSignature)). The NQK is stored on the ledger as the zk_id field in the DeclarationInfo of the node’s outcome of the participation in the Service Declaration Protocol (SDP — Service Declaration Protocol).
The NQK is used to prove that the node is part of the set of core nodes as indicated through the SDP.
Non-ephemeral Signing Key
A node generates a Non-ephemeral Signing Key (NSK) that is a Ed25519 key. The NSK is stored on the ledger as the provider_id field in the DeclarationInfo of the node’s outcome of the participation in the Service Declaration Protocol (SDP — Service Declaration Protocol).
The NSK is used to authenticate the node on the network level and to derive Non-ephemeral Encryption Key.
Ephemeral Signing Key
A node generates Ephemeral Signing Keys (ESK) that are proved to be limited in number by the Proof of Quota (PoQ — Proof of Quota). The PoQ for core nodes requires a valid NQK for the epoch for which the PoQ is generated.
A unique signing key must be generated for every encapsulation as required by the Message Encapsulation Mechanism.
The key must not be reused. Otherwise, the messages that reuse the same key can be linked together. The node is responsible for not reusing the key.
Non-ephemeral Encryption Key
A node generates a Non-ephemeral Encryption Key (NEK). It is an X25519 curve key derived from the NSK (Ed25519) public key retrieved from the provider_id, which is stored on the ledger when the node executes the SDP protocol.
The NEK key is used for deriving a shared secret (alongside EEK defined below) for the Blend message encapsulation purposes.
Ephemeral Encryption Key
A node derives an Ephemeral Encryption Key (EEK) pair using the X25519 curve from the ESK.
A unique encryption key must be generated for every encapsulation as required by the Message Encapsulation Mechanism.
The derivation of a shared secret for the encryption of an encapsulated message requires using the EEK of the sender and the derived X25519 key from the NEK of the recipient.
The key must not be reused. Otherwise, the messages that reuse the same key can be linked together. The node is responsible for not reusing the key.
MESSAGE-ENCAPSULATION-MECHANISM
| Field | Value |
|---|---|
| Name | Message Encapsulation Mechanism |
| Slug | 91 |
| Status | raw |
| Category | Standards Track |
| Editor | Marcin Pawlowski [email protected] |
| Contributors | Youngjoon Lee [email protected], Alexander Mozeika [email protected], Mehmet Gonen [email protected], Álvaro Castro-Castilla [email protected], Daniel Kashepava [email protected], Daniel Sanchez Quiros [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-29 —
67e498e— chore: fix math issues (#350) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-04-09 |
| 1.0.1 | [RFC] Remove Concept of a Session | 2026-06-22 |
Introduction
The message encapsulation mechanism is part of the Blend Protocol and it describes the cryptographic operations necessary for building and processing messages by a Blend node.
This document is part of the Formatting section. Please read through that document to better understand the context of the encapsulation mechanism and constructions used here.
Overview
The Message Encapsulation Mechanism is a core component of the Blend Protocol that ensures privacy and security during node-to-node message transmission. By implementing multiple encryption layers and cryptographic operations, this mechanism keeps messages confidential while concealing their origins.
The encapsulation process includes:
- Building a multi-layered structure with public headers, private headers, and encrypted payloads
- Using cryptographic keys and proofs for layer security and authentication
- Applying verifiable random node selection for message routing
- Using shared key derivation for secure inter-node communication
This document outlines the cryptographic notation, data structures, and algorithms essential to the encapsulation process, providing a complete specification for implementing this mechanism within the Blend Protocol.
Notation
-
is a collection of key pairs for a node with proofs of quota, where is the -th public key and is its corresponding private key, and is its proof of quota.
Ed25519PublicKey = bytes Ed25519PrivateKey = bytes KEY_SIZE = 32 ProofOfQuota = bytes PROOF_OF_QUOTA_SIZE = 160 KeyCollection = List[KeyPair] class KeyPair: signing_public_key: Ed25519PublicKey signing_private_key: Ed25519PrivateKey proof_of_quota: ProofOfQuota class ProofOfQuota: key_nullifier: zkhash # 32 bytes proof: bytes # 128 bytesFor more information about key generation mechanism please refer to Key Types and Generation.
For more information about proof of quota please refer to Proof of Quota.
-
is a public key of the node , which is globally accessible using the Service Declaration Protocol (SDP). We are using this notation to distinguish the origin of the key, hence the following simplified notation. For more information about Service Declaration Protocol please refer to Service Declaration Protocol.
-
is the set of nodes globally accessible using the SDP.
Nodes = set[Ed25519PublicKey] # set of signing public keys -
is the number of nodes globally accessible using the SDP.
-
, is a shared key calculated between node and node using the -th key of the node , is the public key of the node retrieved from the SDP protocol and is its corresponding private key.
SharedKey = bytes # KEY_SIZE -
is the proof of selection of the public key to the node index from a set of all nodes .
ProofOfSelection = bytes PROOF_OF_SELECTION_SIZE = 32For more information about the proof of selection, please refer to Proof of Selection.
-
is a domain-separated hash function dedicated to the node index selection (the implementation of the hash function is
blake2b).def hashds(domain=b"BlendNode", data: bytes) -> bytes: return Blake2B.hash512(domain + data) -
is a domain-separated hash function dedicated to the initialization of the blend header (the implementation of the hash function is
blake2b).def hashds(domain=b"BlendInitialization", data: bytes) -> bytes: return Blake2b.hash512(domain + data) -
is a domain-separated hash function dedicated to the blend header encryption operations (the implementation of the hash function is
blake2b).def hashds(domain=b"BlendHeader", data: bytes) -> bytes: return Blake2b.hash512(domain + data) -
is a domain-separated hash function dedicated to the payload encryption operations (the implementation of the hash function is
blake2b).def hashds(domain=b"BlendPayload", data: bytes) -> bytes: return Blake2b.hash512(domain + data) -
is the maximal number of blending headers in the private header.
ENCAPSULATION_COUNT: int -
is a generalized cryptographically secure pseudo-random bytes generator, it is implemented as BLAKE2b-Based PRNG Construction.
-
is a cryptographically secure pseudo-random bytes generator whose output is restricted to bytes, it is implemented as BLAKE2b-Based PRNG Construction.
def pseudo_random(domain: bytes, key: bytes, size: int) -> bytes: rand = BlakeRng.from_seed(hashds(domain, key)).generate(size) assert len(rand) == size return rand -
returns the length of the expressed in bytes.
-
is a XOR operation.
def xor(a: bytes, b: bytes) -> bytes: assert len(a) == len(b) return bytes(x ^ y for x, y in zip(a, b)) -
is an encryption that uses a cryptographically secure pseudo-random bytes generator with a secret and payload .
def encrypt(data: bytes, key: bytes -> bytes: return xor(data, pseudo_random(b"BlendEncapsulation", key, len(data)))) -
is a decryption that uses using cryptographically secure pseudo-random bytes generator with a secret and payload .
def decrypt(data: bytes, key: bytes) -> bytes: return xor(data, pseudo_random(b"BlendEncapsulation", key, len(data))))
Construction
Message Structure
We start with a definition of the message structure that must be used to provide the protocol with the envisioned capabilities.
A node constructs a message according to the format presented below.
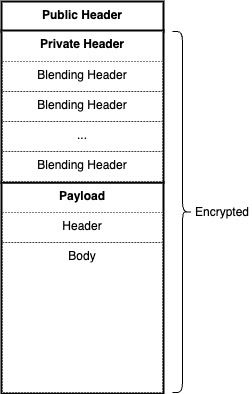
class Message:
public_header: PublicHeader
private_header: PrivateHeader
payload: EncryptedPayload
-
is a public header:
- , version of the header, it is set to .
- , a public key from the set .
- , a corresponding proof of quota for the key from the set and contains its proof nullifier.
- , a signature of the concatenation of the -th encapsulation of the payload and the private header , that can be verified by the public key .
Signature = bytes SIGNATURE_SIZE = 64 class PublicHeader: version: int = 1 # u8 signing_public_key: Ed25519PublicKey proof_of_quota: ProofOfQuota signature: Signature -
is an encrypted private blending header :
- , a public key from the set .
- , a corresponding proof of quota for the key from the and contains its proof nullifier.
- , a signature of the concatenation of the -th encapsulation of the payload and the private header , that can be verified by public key .
- , a proof of selection of the node index assuming public key .
- , a flag that indicates that this is the last blending header.
PrivateHeader = List[EncryptedBlendingHeader] # length: ENCAPSULATION_COUNT EncryptedBlendingHeader = bytes class BlendingHeader: signing_public_key: Ed25519PublicKey proof_of_quota: ProofOfQuota signature: Signature proof_of_selection: ProofOfSelection is_last: bool # 1 byte -
is a payload.
EncryptedPayload = bytes PAYLOAD_BODY_SIZE = 34 * 1024 class Payload: header: PayloadHeader body: bytes # PAYLOAD_BODY_SIZE class PayloadHeader: payload_type: PayloadType # 1 byte body_len: int # u16 class PayloadType(Enum): COVER = 0x00 DATA = 0x01
Keys and Proof Generation
For simplicity of the presentation, we do not distinguish between signing and encryption keys. However, in practice, such a distinction is necessary, that is:
- The contains Ephemeral Signing Keys (ESK) that are part of the PoQ generation and are used for message signing; these are included in the public and private headers.
- Shared secret keys used for encryption of messages are generated from an Ephemeral Encryption Key (sender), which is derived from the ESK, and from a Non-ephemeral Encryption Key (NEK) (receiver), which is derived from a Non-ephemeral Signing Key (NSK) retrieved from the SDP protocol.
For more information, look at Key Types and Generation.
The first step is to generate a set of keys alongside all necessary proofs that will be used in the next steps of the algorithm.
-
Generate the collection , where defines the number of encapsulation layers such that .
def generate_key_collection(num_layers: int) -> List[KeyPair]: assert num_layers <= ENCAPSULATION_COUNT # Generate `num_layers` random KeyPairs non-deterministically. return [KeyPair.random() for _ in range(num_layers)]The key collection generation requires generation of Proof of Quota (Proof of Quota) for each key, as defined in the following steps.
- The
ProofOfQuotaPublic(Public values) structure must be filled with public information:core_quota,leader_quota,core_root,pol_epoch_nonce,pol_t0,pol_t1,pol_ledger_agedare retrieved from the blockchain.K_part_oneandK_part_twoare first and second part of the signature key (KeyPair) generated by the abovegenerate_key_collection.
- The
ProofOfQuotaWitness(Witness) structure must be filled as follows:- If the message contains cover traffic then:
- We assume that the core quota is used and the
selector=0value must be specified. - The
indexcounts the number of cover messages and must be belowcore_quota. - The
core_sk,core_path,core_path_selectorare filled by the node to prove that the node is the core node. - The rest of the
ProofOfQuotaWitness, is filled with arbitrary data.
- We assume that the core quota is used and the
- If the message contains data then:
- We assume that the leader quota is used and the
selector=1value must be specified. - The
indexcounts the number of data messages and must be belowleader_quota. - The
core_sk,core_path,core_path_selectorare filled with arbitrary data. - The rest is filled with Proof of Leadership (PoL — Proof of Leadership) related data.
- We assume that the leader quota is used and the
- The
ProofOfQuotaPublicandProofOfQuotaWitnessare passed to the zero-knowledge circuits that generate the proof which derives thekey_nullifier() frompol_epoch_nonce, privateindex, private secret key during proof generation.
- If the message contains cover traffic then:
- The
-
Select nodes from the set of nodes in a random and verifiable manner. For , select , where is a selection randomness (using little-endian encoding), a shared secret derived during Proof of Quota generation, the output of the is returns 8 bytes (little-endian).
def select_nodes(key_collection: List[KeyPair], nodes: List[Node]) -> List[Node]: selected_nodes = [] for keypair in key_collection: rand = pseudo_random( b"BlendNode", selection_randomness, 8 ) index = modular_bytes(rand, NUM_NODES) selected_nodes.append(nodes[index]) return selected_nodes def modular_bytes(data: bytes, modulus: int) -> int: # Convert data into an unsigned big integer using little-endian. return int.from_bytes(data, byteorder='little') % modulus -
Generate proofs of selection for , which proves that the public key correctly maps to the index from the set of nodes .
-
For , retrieve public keys for all selected nodes using the SDP protocol (defined as
provider_idin Identifiers).def blend_node_signing_public_keys(selected_nodes: List[Node]) -> List[Ed25519PublicKey]: return [node.signing_public_key for node in selected_nodes] -
For , calculate shared keys from a set of public keys of selected nodes .
def derive_shared_keys(key_collection: List[KeyPair], blend_node_signing_public_keys: List[Ed25519PublicKey]) -> List[SharedKey]: assert len(key_collection) == len(blend_node_signing_public_keys) assert len(key_collection) <= ENCAPSULATION_COUNT shared_keys = [] for (keypair, blend_node_signing_public_key) in zip(key_collection, blend_node_signing_public_keys): encryption_private_key = signing_private_key.derive_x25519() blend_node_encryption_public_key = blend_node_signing_public_key shared_key = diffie_hellman(encryption_private_key, blend_node_encryption_public_key) shared_keys.append(shared_key) return shared_keys
In step 2 of the algorithm above, the sender constructs a blending path from nodes sampled at random but in a verifiable manner. The nodes are selected deterministically (and randomly) by the key value. The key to node mapping is proven in step 3.
The node selection proof is constructed in such a way that it proves only the fact that the key used for the encryption maps correctly to the node index from the stable set of nodes . This proof should be considered a private proof intended only for the recipient blend node.
This mechanism intends to limit the possibility of “double spending” the emission token. This restricts the sender's ability to use the same emission token twice, first for constructing and emitting a message and then for claiming a reward for it.
For more information about proof of selection please refer to Proof of Selection.
Message Initialization
The second step is to create an empty message and fill the private header with random values.
-
Create an empty message (filled with zeros).
-
Randomize the private header: For , set , where is some random value.
def randomize_private_header() -> PrivateHeader: blending_headers = [] for _ in range(ENCAPSULATION_COUNT): blending_header = pseudo_random(b"BlendRandom", entropy(), BlendingHeader.SIZE) blending_headers.append(blending_header) return blending_headers -
Fill the last blend headers with reconstructable payloads: For , do the following:
- .
def fill_last_blending_headers(private_header: PrivateHeader, shared_keys: List[SharedKeys]) -> PrivateHeader: assert len(private_header) == ENCAPSULATION_COUNT assert len(shared_keys) <= ENCAPSULATION_COUNT pseudo_random_blending_headers = [] for shared_key in shared_keys: r1 = pseudo_random(b"BlendInitialization", shared_key + b"\x01", KEY_SIZE) r2 = pseudo_random(b"BlendInitialization", shared_key + b"\x02", PROOF_OF_QUOTA_SIZE) r3 = pseudo_random(b"BlendInitialization", shared_key + b"\x03", SIGNATURE_SIZE) r4 = pseudo_random(b"BlendInitialization", shared_key + b"\x04", PROOF_OF_SELECTION_SIZE) is_last = False pseudo_random_blending_headers.append(r1 + r2 + r3 + r4 + is_last) # Replace the last `len(shared_keys)` blending headers. private_header[-num_layers:] = pseudo_random_blending_headers return private_header -
Encrypt the last blend headers in a reconstructable manner:
For , for , encrypt blend header .
def encrypt_last_blending_headers(private_header: PrivateHeader, shared_keys: List[SharedKeys]) -> PrivateHeader: assert len(private_header) == ENCAPSULATION_COUNT assert len(shared_keys) <= ENCAPSULATION_COUNT for i, _ in enumerate(shared_keys): index = len(private_header) - i - 1 for shared_key in shared_keys[:i + 1]: private_header[index] = encrypt(private_header[index], shared_key) return private_headerThis prevents leakage of the encryption sequence when a message is encapsulated less than times, and enables us to encode the header in a way that it can be reconstructed during the decapsulation.
Message Encapsulation
The final part of the algorithm is the true encapsulation of the payload. That is, given the payload and number of encapsulations we do the following.
For do the following:
-
If then generate a new ephemeral key pair:
.
-
Calculate the signature of the concatenation of the current header and payload:
.
-
Using the shared key , encrypt the payload:
Note that the uniqueness of the key stream is preserved as the encryption is done on a domain separated checksum of the shared key, which renders a different key stream than the encryption of the header.
-
Shift blending headers by one downward:
for .
The first blending header is now empty, and the last blending header is truncated.
-
Fill the blending header , where refers to the top position:
-
If then:
-
Fill the proof of quota with random data:
-
Set the last flag to 1:
-
-
Else set the last flag to 0:
-
.
-
-
Using shared key , encrypt the private header :
For each using a shared key , encrypt the blending header:
.
Fill in the public header: .
The message is encapsulated.
def encapsulate(
private_header: PrivateHeader,
payload: Payload,
shared_keys: List[SharedKeys],
key_collection: List[KeyPair],
list_of_pos: List[ProofOfSelection]
) -> bytes:
# Step 1 ~ 6: Encapsulate private header and payload
prev_keypair = KeyPair.random()
is_first_selected = True
for shared_key, keypair, proof_of_selection) in zip(shared_keys, key_collection, list_of_pos):
private_header, payload = encapsulate_private_part(
private_header,
payload.bytes(),
shared_key,
prev_keypair.signing_private_key,
prev_keypair.proof_of_quota,
proof_of_selection,
# The first encapsulation is for the last decapsulation.
is_last=is_first_selected,
)
prev_keypair = keypair
is_first = False
# Fill in the public header
public_header = PublicHeader(
prev_keypair.signing_public_key,
prev_keypair.proof_of_quota,
signature=sign(private_part, prev_keypair.signing_private_key),
version=1,
)
return public_header.bytes() + b"".join(private_headers) + payload
def encapsulate_private_part(
private_header: PrivateHeader,
payload: EncryptedPayload,
shared_key: SharedKey,
signing_private_key: Ed25519PrivateKey,
proof_of_quota: ProofOfQuota,
proof_of_selection: ProofOfSelection,
is_last: bool
) -> bytes:
# Step 2: Calculate a signature on `private_header + payload`.
signature = sign(
signing_body(private_header, payload),
signing_private_key
)
# Step 3: Encrypt the payload
payload = encrypt(payload, shared_key)
# Step 4: Shift blending headers by one rightward.
private_header.pop() # Remove the last blending header
# Step 5: Add the new blending header to the front.
blending_header = BlendingHeader(
signing_private_key.public(),
proof_of_quota,
signature,
proof_of_selection,
is_last
)
private_header.insert(0, blending_header.bytes())
# Step 6: Encrypt the private header
for i, _ in enumerate(private_header):
private_header[i] = encrypt(private_header[i], shared_key)
return private_header, payload
def signing_body(private_header: PrivateHeader, payload: EncryptedPayload) -> bytes:
return b"".join(private_headers) + payload
Message Decapsulation
If a message is received by the node and its public header is correct - that is, it was verified according to the relay logic defined here: Relaying - then the node executes the following logic:
-
Calculate the shared secret. Using the key from the public header of the message and the private key of the node calculate:
.
-
Decrypt the private header using the shared key .
For each using a shared key decrypt the blending header:
.
-
Verify the header:
- If the proof is not correct, discard the message. That is, if the node index does not correspond to the , then the message must be rejected.
- If the key was already seen, discard the message.
- If the proof is incorrect, discard the message.
- If equals , then stop processing the message and process the payload.
-
Using the blending header , set the public header:
.
-
Decrypt the payload, using the shared key :
.
-
Reconstruct the blend header:
- .
-
Encrypt the blending header:
-
Shift blending headers by one upward:
for . The first blending header is truncated, and the last blending header is empty.
-
Reconstruct the private header:
, .
-
If the signature from the public header does not match the signature of the reconstructed header and the decrypted payload, discard the message:
.
-
The message is decapsulated.
-
Follow the message processing logic: Processing.
def decapsulate(
message: bytes,
signing_private_key: Ed25519PrivateKey
) -> bytes:
# Step 1: Derive the shared key.
encryption_private_key = signing_private_key.derive_x25519()
public_header = PublicHeader.from_bytes(
message[Header.SIZE : Header.SIZE + PublicHeader.SIZE]
)
shared_key = diffie_hellman(
encryption_private_key,
public_header.signing_public_key.derive_x25519()
)
# Step 2: Decrypt the private header
private_header = message[
Header.SIZE + PublicHeader.SIZE:
Header.SIZE + PublicHeader.SIZE + (BlendingHeader.SIZE * ENCAPSULATION_COUNT)
]
for i, _ in enumerate(private_header):
private_header[i] = decrypt(private_header[i], shared_key)
# Step 3: Verify the first blending header
first_blending_header = BlendingHeader.from_bytes(private_header[0])
first_blending_header.validate()
# Step 4: Construct the new public header
public_header = PublicHeader(
first_blending_header.signing_public_key,
first_blending_header.proof_of_quota,
first_blending_header.signature,
version= 1,
)
# Step 5: Decrypt the payload
payload_offset = (
Header.SIZE + PublicHeader.SIZE + (BlendingHeader.SIZE * ENCAPSULATION_COUNT)
)
payload = message[payload_offset:]
payload = decrypt(payload, shared_key)
# Step 6: Reconstruct the new blending header
r1 = pseudo_random(b"BlendInitialization", shared_key + b"\x01", KEY_SIZE)
r2 = pseudo_random(b"BlendInitialization", shared_key + b"\x02", PROOF_OF_QUOTA_SIZE)
r3 = pseudo_random(b"BlendInitialization", shared_key + b"\x03", SIGNATURE_SIZE)
r4 = pseudo_random(b"BlendInitialization", shared_key + b"\x04", PROOF_OF_SELECTION_SIZE)
is_last = False
# Step 7: Encrypt the new blending header
encrypted_new_blending_header = encrypt(r1 + r2 + r3 + r4 + is_last, shared_key)
# Step 8: Shift blending headers by one leftward.
private_header.pop(0) # Remove the first blending header.
# Step 9: Add the new blending header to the end.
private_header.append(encrypted_new_blending_header)
# Step 10: Verify the signature
verify_signature(
first_blending_header.signature,
signing_body(private_header, payload)
first_blending_header.signing_public_key,
)
header = message[0:Header.SIZE]
return header + public_header.bytes() + b"".join(private_header) + payload
Appendix
Example
Let us look at an example of the above mechanism. Let us assume that . We are omitting protocol version in the header for simplicity.
Initialization
-
Create an empty message:
-
Randomize the private header:
,
,
,
,
.
-
Fill the last blend headers with reconstructable payloads:
,
,
,
,
.
-
Encrypt the last blend headers in a reconstructable manner:
,
,
,
,
.
Encapsulation
:
-
Generate a new ephemeral key pair:
.
-
Calculate the signature of the header and the payload:
.
-
Using shared key encrypt the payload: .
-
Shift blending headers by one down:
,
,
,
,
.
-
Fill the first blending header (the in this case):
,
,
,
,
.
-
Using shared key encrypt the private header:
,
,
,
,
.
:
-
.
-
Calculate the signature of the header and the payload:
.
-
Using shared key encrypt the payload:
.
-
Shift blending headers by one down:
,
,
,
,
.
-
Fill the first blending header:
,
,
,
,
.
-
Using shared key encrypt the private header:
,
,
,
,
.
:
-
.
-
Calculate the signature of the header and the payload:
.
-
Using shared key encrypt the payload:
.
-
Shift blending headers by one down:
,
,
,
,
.
-
Fill the first blending header:
,
,
,
,
.
-
Using shared key encrypt the private header:
,
,
,
,
.
The above calculations give us the final message where:
,
,
,
,
,
,
.
Decapsulation
Now let us take the above message and decapsulate it. We verify that the node doing the processing is the rightful recipient of the message and that the public header is correct.
:
-
Calculate shared secret:
, where and is the private part of the public key of the node .
-
Decrypt the header:
,
,
,
,
-
Verify the header:
- If the proof of selection fails then stop.
- If the key was already seen, discard the message.
- If the proof is incorrect, discard the message.
-
Reconstruct the public header:
-
Decrypt the payload:
.
-
Reconstruct the blend header:
,
,
,
,
,
-
Encrypt the blend header:
.
-
Shift blending headers by one upward, the first blending header is discarded:
.
-
Reconstruct the private header:
,
,
,
,
-
If the signature from the public header does not match the signature of the reconstructed header and the decrypted payload then discard the message:
-
The message is decapsulated.
-
Follow the processing logic: Processing.
:
-
Calculate shared secret:
, where and is the private part of the public key of the node .
-
Decrypt the header:
,
,
,
,
-
Verify the header:
- If the proof of selection fails then stop.
- If the key was already seen, discard the message.
- If the proof is incorrect, discard the message.
-
Reconstruct the public header:
-
Decrypt the payload:
.
-
Reconstruct the blend header:
,
,
,
,
,
-
Encrypt the reconstructed blend header:
.
-
Shift blending headers by one upward, the first blending header is discarded:
.
-
Reconstruct the private header:
,
,
,
,
-
Check the signature:
-
The message is decapsulated.
-
Follow the message processing logic: Processing.
:
-
Calculate shared secret:
, where and is the private part of the public key of the node .
-
Decrypt the private header:
,
,
,
,
-
Verify the header:
- If the proof of selection fails then stop.
- If the key was already seen, discard the message.
- If the proof is incorrect, discard the message.
-
Reconstruct the public header:
-
Decrypt the payload:
.
-
Reconstruct the blend header:
,
,
,
,
,
-
Encrypt the reconstructed blend header:
.
-
Shift blending headers by one upward, the first blending header is discarded:
.
-
Reconstruct the private header:
,
,
,
,
-
If the signature from the public header does not match the signature of the reconstructed header and the decrypted payload then discard the message: .
-
The message is decapsulated.
-
Follow the message processing logic: Processing.
MESSAGE-FORMATTING
| Field | Value |
|---|---|
| Name | Message Formatting |
| Slug | 89 |
| Status | raw |
| Category | Standards Track |
| Editor | Marcin Pawlowski |
| Contributors | Youngjoon Lee [email protected], Alexander Mozeika [email protected], Álvaro Castro-Castilla [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-04-09 |
Introduction
This document defines an implementation-friendly specification of the Message Formatting, which is introduced in the Formatting section.
In this document we are reusing notation from Notation.
Overview
The message contains a header and a payload. The header informs the protocol about the version of the protocol and the payload type. The message contains a drop or a non-drop payload. The length of a payload is fixed to prevent adversaries from distinguishing types of messages based on their length.
Construction
Message
The Message is a structure that contains a public_header, private_header and a payload.
class Message:
public_header: PublicHeader,
private_header: Private_Header,
payload: bytes
Public Header
The public_header must be generated as the outcome of the Message Encapsulation Mechanism.
The public_header is defined as follows:
class PublicHeader:
version: byte,
public_key: PublicKey,
proof_of_quota: ProofOfQuota,
signature: Signature
Where:
version=0x01is version of the protocol.public_keyis , a public key from the set as defined in the Message Encapsulation spec.proof_of_quotais , a corresponding proof of quota for the key from the it also contains the key nullifier.signatureis , a signature of the concatenation of the -th encapsulation of the payload and the private header , that can be verified by the public key .
Private Header
The private_header must be generated as the outcome of the Message Encapsulation Mechanism.
The private header contains a set of encrypted blending headers .
private_header: list[BlendingHeader]
The size of the set is limited to BlendingHeader entries, as defined in the Global Parameters.
The BlendingHeader () is defined as follows:
class BlendingHeader:
public_key: PublicKey,
proof_of_quota: ProofOfQuota,
signature: Signature,
proof_of_selection: ProofOfSelection
is_last: byte
Where:
public_keyis , a public key from the set .proof_of_quotais , a corresponding proof of quota for the key from the it also contains the key nullifier.signatureis , a signature of the concatenation of -th encapsulation of the payload and the private header , that can be verified by public key .proof_of_selectionis , a proof of selection of the node index assuming valid proof of quota .is_lastis , a flag that indicates that this is the last encapsulation.
Payload
The payload must be formatted according to the Payload Formatting. The formatted payload must be generated as the outcome of the Message Encapsulation Mechanism.
Maximum Payload Length
The Max_Payload_Length parameter defines the maximum length of the payload, which for version 1 of the Blend Protocol is fixed as Max_Payload_Length=34003. That is, 34kB for the payload body (Max_Body_Length) and 3 bytes for the payload header. More information about payload formatting can be found in Payload Formatting.
PAYLOAD-FORMATTING
| Field | Value |
|---|---|
| Name | Payload Formatting |
| Slug | 97 |
| Status | raw |
| Category | Standards Track |
| Editor | Marcin Pawlowski [email protected] |
| Contributors | Youngjoon Lee [email protected], Alexander Mozeika [email protected], Álvaro Castro-Castilla [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-04-09 |
Introduction
This document defines an implementation-friendly specification of the Payload Formatting, which is introduced in the Formatting section.
Overview
The payload contains a header and a body. The header informs the protocol about the way the body must be handled. The body contains a raw message (data/proposal or cover message). The payload must be of a fixed length to prevent adversaries from distinguishing types of messages based on their length. Therefore, shorter messages must be padded with random data.
Construction
Payload
The Payload is a structure that contains a header and a body.
class Payload:
header: Header,
body: bytes
Header
The header is a structure that contains a body_type and a body_length.
class Header:
body_type: byte,
body_length: uint16
Type
We define the following values of the body_type:
body_type=0x00, informs that thebodycontains a cover message.body_type=0x01, informs that thebodycontains a data message.
Any other value of type means that the message was not decapsulated correctly and must be discarded.
Length
We define the body_length as uint16 (encoded as little-endian). Therefore, the theoretical limit of the length of the body is 65535 bytes. The body_length must be set to the length of the body of the payload message (body_length=len(raw_message)).
Body
The Max_Body_Length parameter defines the maximum length of the body. Currently, we assume that the maximal length of a raw data message is 33129 (Block Proposal), so the Max_Body_Length=33129.
The body length is fixed to Max_Body_Length bytes. Therefore, if the length of the raw message is shorter than the Max_Body_Length, then it must be padded with random data.
If the body length is less than the Max_Body_Length, then the last Max_Body_Length - len(Raw_Message) bytes must be filled with random data.
PROOF-OF-QUOTA
| Field | Value |
|---|---|
| Name | Proof of Quota |
| Slug | 88 |
| Status | raw |
| Category | Standards Track |
| Editor | Mehmet Gonen [email protected] |
| Contributors | Marcin Pawlowski [email protected], Thomas Lavaur [email protected], Youngjoon Lee [email protected], David Rusu [email protected], Álvaro Castro-Castilla [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revisions History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-04-09 |
| 1.0.1 | Remove the protection against adaptive adversary from PoL. It impacts the PoL section of PoQ. Update the performance according to the new circuit. Remove old project name from DSTs | 2026-04-09 |
| 1.1.0 | [RFC] Remove Concept of a Session | 2026-06-22 |
Introduction
This document defines an implementation-friendly specification of the Proof of Quota (PoQ), which is introduced in Proof of Quota.
Overview
The PoQ ensures that there is a limited number of message encapsulations that a node can perform. This constrains the number of messages a node can introduce to the Blend network. The mechanism regulating these messages is similar to rate-limiting nullifiers.
Construction
The Proof of Quota (PoQ) verifies that a node's public key is within a limit for either a core node or a leader node. It consists of two parts:
- Proof of Core Quota (
PoQ_C): Ensures that the core node is declared and hasn’t already produced more keys than the core quotaQ_C. - Proof of Leadership Quota (
PoQ_L): Ensures that the leader node would win the proof of stake for current Cryptarchia epoch and hasn’t already produced more keys than the leadership quotaQ_L. That doesn’t guarantee that the node is indeed winning because the PoQ doesn’t check if the note is unspent enabling generation of the proof ahead of time preventing extreme delays.
The final proof PoQ is valid if either PoQ_C or PoQ_L holds.
Zero-Knowledge Proof Statement
Public values
A proof attesting that for the following public values derived from blockchain parameters:
class ProofOfQuotaPublic:
core_quota: int # Allowed messages per epoch for core nodes (20 bits)
leader_quota: int # Allowed messages per epoch for potential leaders (20 bits)
core_root: zkhash # Merkle root of zk_id of the core nodes
K_part_one: int # First part of the signature public key (16 bytes)
K_part_two: int # Second part of the signature public key (16 bytes)
pol_epoch_nonce: int # PoL Epoch nonce
pol_t0: int # PoL constant t0
pol_t1: int # PoL constant t1
pol_ledger_aged: zkhash # Merkle root of the PoL eligible notes
# Outputs:
key_nullifier: zkhash # derived from epoch, private index and private sk
Witness
The prover knows a witness:
class ProofOfQuotaWitness:
index: int # This is the index of the generated key. Limiting this index limits the maximum number of key generated. (20 bits)
selector: bool # Indicates if it's a leader (=1) or a core node (=0)
# This part is filled randomly by potential leaders
core_sk: zkhash # sk corresponding to the zk_id of the core node
core_path: list[zkhash] # Merkle path proving zk_id membership (len = 20)
core_path_selectors: list[bool] # Indicates how to read the core_path (if Merkle nodes are left or right in the path)
# This part is filled randomly by core nodes
pol_sl: int # PoL slot
pol_secret_key: int # PoL note secret key
pol_note_value: int # PoL note value
pol_note_tx_hash: zkhash # PoL note transaction
pol_note_output_number: int # PoL note transaction output number
pol_noteid_path: list[zkhash] # PoL Merkle path proving noteID membership in ledger aged (len = 32)
pol_noteid_path_selectors: list[bool] # Indicates how to read the note_path (if Merkle nodes are left or right in the path)
Note that every inputs and outputs of zero-knowledge proofs are all scalar field elements.
Constraints
Such that the following constraints hold:
Step 1: The prover selects an index for the chosen key. This index must be lower than the allowed quota and not already used. This index is used to derive the key nullifier in step 4. Limiting the possible values of this index also limit the possible nullifier created which produce the desired effect: limiting the generation of keys to a certain quota. index will be on 20 bits enabling up to messages per node per epoch.
Step 2: If the prover indicated that the node is a core node for the proof, the proof checks that:
- The core node is registered in the set
N = SDP(epoch). This is proven by demonstrating knowledge of acore_skthat corresponds to a declaredzk_id, which is a valid SDP registry for the currentepoch. Thezk_idvalues are stored in a Merkle tree with a fixed depth of 20, with the root provided as a public input. To build the Merkle tree,zk_idare ordered from the smallest to the biggest (when seen as natural numbers between 0 and ) and remaining empty leaves are represented by the0after the sorting (appended at the end of the vector). This structure supports up to 1M validators. - The index is valid:
index < core_quota.
Step 3: If the prover indicated that the node is a potential leader node for the proof, the proof checks that:
- The leader node possesses a note that would win a slot in the consensus lottery. Unlike leadership conditions, the proof of quota doesn't verify that the note is unspent. This enables potential provers to generate the PoQ well in advance. All other lottery constraints are the same as in Circuit Constraints.
- The index is valid:
index < leader_quota.
Step 4: The prover derives a key_nullifier maintained by blend nodes during the epoch for message deduplication purpose.
selection_randomness = zkhash(b"SELECTION_RANDOMNESS_V1", sk, index, period_nonce)
key_nullifier = zkhash(b"KEY_NULLIFIER_V1", selection_randomness)
Where sk is:
- The
core_skas defined in the Mantle specification if the node is a core node. - The secret key of the PoL note if it’s a leader node.
and period_nonce is:
- The
pol_epoch_nonceif the node is a core node. - The winning slot of the PoL if it’s a leader node.
Here we use two hashes because the selection randomness is used in the Proof of Selection in order to prove the ownership of a valid PoQ (see Proof of Selection).
Step 5: The prover attaches a one-time signature key used in the blend protocol. This public key is split into two 16-byte parts: K_part_one and K_part_two. When written in little-endian byte order, the complete public key equals the concatenation K_part_one||K_part_two.
Pseudocode
# Verify selector is a boolean
# selector = 1 if it's a potential leader and 0 if it's a core node
selector * (1 - selector) == 0 # to check that selector is indeed a bit.
# Verify index is lower than quota. It's exactly like saying index < leader_quota
# if selector == 1 or index < core_quota if selector == 0
index < selector * (leader_quota - core_quota) + core_quota
# Check if it's a registered core node
zk_id = zkhash(b"KDF", core_sk)
is_registered = merkle_verify(core_root, core_path, core_path_selectors, zk_id)
# Check if it's a potential leader
is_leader = would_win_leadership(pol_epoch_nonce,
pol_t0,
pol_t1,
pol_ledger_aged,
pol_sl,
pol_secret_key,
pol_sk_secrets_root,
pol_note_value,
pol_note_tx_hash,
pol_note_output_number,
pol_noteid_path,
pol_noteid_path_selectors)
# Verify that it's a core node or a leader
assert( selector * (is_leader - is_registered) + is_registered == 1)
# Derive nullifier
selection_randomness = zkhash(
b"SELECTION_RANDOMNESS_V1",
selector * (pol_secret_key - core_sk) + core_sk,
index,
selector * (pol_sl - pol_epoch_nonce) + pol_epoch_nonce)
key_nullifier = zkhash(b"KEY_NULLIFIER_V1", selection_randomness)
Proof Compression
The proof confirming that the PoQ is correct must be compressed to a size of 128 bytes, where the UncompressedProof is comprising of 2 and 1 BN256 elements as presented below.
class UncompressedProof:
pi_a: G1 # BN256 element
pi_b: G2 # BN256 element
pi_c: G1 # BN256 element
Proof Serialization
The ProofOfQuota structure contains key_nullifier and the compressed proof transformed in bytes according Use in the Logos Blockchain:. The key_nullifier must be transformed into bytes. The bytes of the compressed proof are then concatenated together with the bytes representing the key_nullifier, with the encoded key_nullifier preceding the encoded compressed proof. Reconstruction of a serialized ProofOfQuota interpreting the bytes as the concatenation of the key_nullifier and of the compressed proof following the same rule of conversion.
class ProofOfQuota:
key_nullifier: zkhash # 32 bytes
proof: bytes # 128 bytes
Appendix
Benchmarks
The material used for the benchmarks is the following:
- CPU: 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM: 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS: Ubuntu 22.04.5 LTS
- Kernel: 6.8.0-59-generic
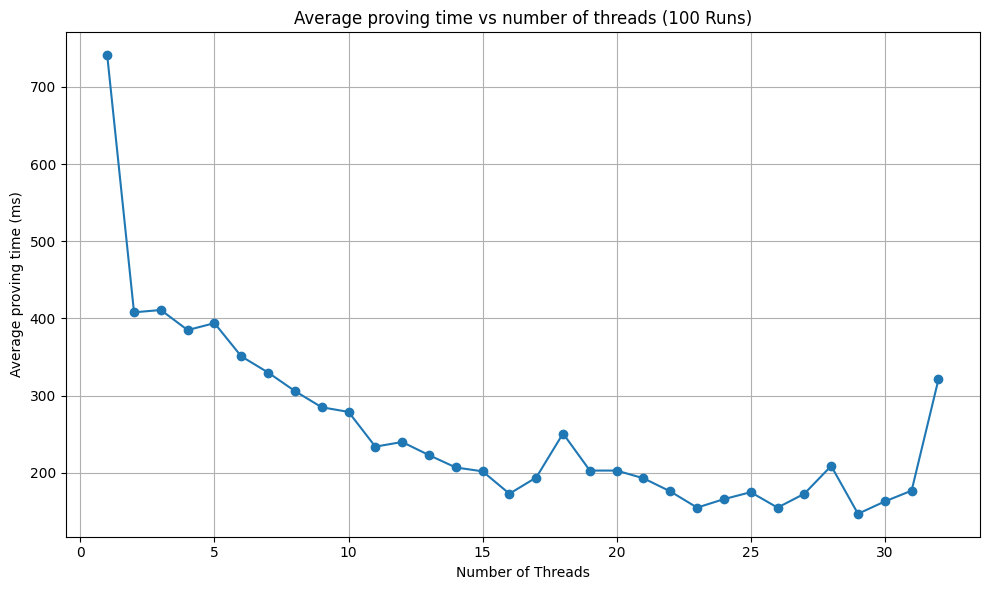
V1.0.0-LOGOS-PROOF-OF-QUOTA
| Field | Value |
|---|---|
| Name | Proof of Quota |
| Slug | 217 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Mehmet Gonen [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Owner: @Mehmet @Marcin Pawlowski @Thomas Lavaur
Reviewers: @Youngjoon Lee @David Rusu @lvaro Castro-Castilla
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2026-04-09 |
Introduction
This document defines an implementation-friendly specification of the Proof of Quota (PoQ), which is introduced in Blend Protocol - Proof of Quota.
Overview
The PoQ ensures that there is a limited number of message encapsulations that a node can perform. This constrains the number of messages a node can introduce to the Blend network. The mechanism regulating these messages is similar to rate-limiting nullifiers.
Construction
The Proof of Quota (PoQ) verifies that a node's public key is within a limit for either a core node or a leader node. It consists of two parts:
- Proof of Core Quota (PoQ_C): Ensures that the core node is declared and hasnt already produced more keys than the core quota Q_C.
- Proof of Leadership Quota (PoQ_L): Ensures that the leader node would win the proof of stake for current Cryptarchia epoch and hasnt already produced more keys than the leadership quota Q_L. That doesnt guarantee that the node is indeed winning because the PoQ doesnt check if the note is unspent enabling generation of the proof ahead of time preventing extreme delays.
The final proof PoQ is valid if either PoQ_C or PoQ_L holds.
Zero-Knowledge Proof Statement
Public values
A proof attesting that for the following public values derived from blockchain parameters:
class ProofOfQuotaPublic:
session: int # Session number (uint64)
core_quota: int # Allowed messages per session for core nodes (20 bits)
leader_quota: int # Allowed messages per session for potential leaders (20 bits)
core_root: zkhash # Merkle root of zk_id of the core nodes
K_part_one: int # First part of the signature public key (16 bytes)
K_part_two: int # Second part of the signature public key (16 bytes)
pol_epoch_nonce: int # PoL Epoch nonce
pol_t0: int # PoL constant t0
pol_t1: int # PoL constant t1
pol_ledger_aged: zkhash # Merkle root of the PoL eligible notes
# Outputs:
key_nullifier: zkhash # derived from session, private index and private sk
Witness
The prover knows a witness:
class ProofOfQuotaWitness:
index: int # This is the index of the generated key. Limiting this index limits the maximum number of key generated. (20 bits)
selector: bool # Indicates if it's a leader (=1) or a core node (=0)
# This part is filled randomly by potential leaders
core_sk: zkhash # sk corresponding to the zk_id of the core node
core_path: list[zkhash] # Merkle path proving zk_id membership (len = 20)
core_path_selectors: list[bool] # Indicates how to read the core_path (if Merkle nodes are left or right in the path)
# This part is filled randomly by core nodes
pol_sl: int # PoL slot
pol_sk_starting_slot: int # PoL starting slot of the slot secrets
pol_note_value: int # PoL note value
pol_note_tx_hash: zkhash # PoL note transaction
pol_note_output_number: int # PoL note transaction output number
pol_noteid_path: list[zkhash] # PoL Merkle path proving noteID membership in ledger aged (len = 32)
pol_noteid_path_selectors: list[bool] # Indicates how to read the note_path (if Merkle nodes are left or right in the path)
pol_slot_secret: int # PoL slot secret corresponding to sl
pol_slot_secret_path: list[zkhash] # PoL slot secret Merkle path to sk_secrets_root (len = 25)
Note that every inputs and outputs of zero-knowledge proofs are all scalar field elements.
Constraints
Such that the following constraints hold:
Step 1: The prover selects an index for the chosen key. This index must be lower than the allowed quota and not already used. This index is used to derive the key nullifier in step 4. Limiting the possible values of this index also limit the possible nullifier created which produce the desired effect: limiting the generation of keys to a certain quota. index will be on 20 bits enabling up to messages per node per session.
Step 2: If the prover indicated that the node is a core node for the proof, the proof checks that:
-
The core node is registered in the set N = SDP(session). This is proven by demonstrating knowledge of a core_sk that corresponds to a declared zk_id, which is a valid SDP registry for the current session. The zk_id values are stored in a Merkle tree with a fixed depth of 20, with the root provided as a public input. To build the Merkle tree, zk_id are ordered from the smallest to the biggest (when seen as natural numbers between 0 and ) and remaining empty leaves are represented by the 0 after the sorting (appended at the end of the vector). This structure supports up to 1M validators.
-
The index is valid: index < core_quota. Step 3: If the prover indicated that the node is a potential leader node for the proof, the proof checks that:
-
The leader node possesses a note that would win a slot in the consensus lottery. Unlike leadership conditions, the proof of quota doesn't verify that the note is unspent. This enables potential provers to generate the PoQ well in advance. All other lottery constraints are the same as in Proof of Leadership - Circuit Constraints.
-
The index is valid: index < leader_quota. Step 4: The prover derives a key_nullifier maintained by blend nodes during the session for message deduplication purpose.
selection_randomness = zkhash(b"SELECTION_RANDOMNESS_V1", sk, index, session)
key_nullifier = zkhash(b"KEY_NULLIFIER_V1", selection_randomness)
Where sk is:
- The core_sk as defined in the Mantle specification if the node is a core node.
- The secret key of the PoL note if its a leader node derived from inputs. Here we use two hashes because the selection randomness is used in the Proof of Selection in order to prove the ownership of a valid PoQ (see Blend Protocol - Proof of Selection).
Step 5: The prover attaches a one-time signature key used in the blend protocol. This public key is split into two 16-byte parts: K_part_one and K_part_two. When written in little-endian byte order, the complete public key equals the concatenation K_part_one||K_part_two.
Pseudocode
# Verify selector is a boolean
# selector = 1 if it's a potential leader and 0 if it's a core node
selector * (1 - selector) == 0 # to check that selector is indeed a bit.
# Verify index is lower than quota. It's exactly like saying index < leader_quota
# if selector == 1 or index < core_quota if selector == 0
index < selector * (leader_quota - core_quota) + core_quota
# Check if it's a registered core node
zk_id = zkhash(b"LOGOS_KDF", core_sk)
is_registered = merkle_verify(core_root, core_path, core_path_selectors, zk_id)
# Check if it's a potential leader
is_leader = would_win_leadership(pol_epoch_nonce,
pol_t0,
pol_t1,
pol_ledger_aged,
pol_sl,
pol_sk_starting_slot,
pol_sk_secrets_root,
pol_note_value,
pol_note_tx_hash,
pol_note_output_number,
pol_noteid_path,
pol_noteid_path_selectors,
pol_slot_secret,
pol_slot_secret_path)
# Verify that it's a core node or a leader
assert( selector * (is_leader - is_registered) + is_registered == 1)
# get leader note secret key
pol_sk_secrets_root = get_merkle_root(pol_sk_starting_slot, sl, pol_slot_secret_path)
pol_note_sk = zkhash(b"LOGOS_POL_SK_V1",pol_sk_starting_slot,pol_sk_secrets_root)
# Derive nullifier
selection_randomness = zkhash(
b"SELECTION_RANDOMNESS_V1",
selector * (pol_note_sk - core_sk) + core_sk,
index,
session)
key_nullifier = zkhash(b"KEY_NULLIFIER_V1", selection_randomness)
Proof Compression
The proof confirming that the PoQ is correct must be compressed to a size of 128 bytes, where the UncompressedProof is comprising of 2 and 1 BN256 elements as presented below.
class UncompressedProof:
pi_a: G1 # BN256 element
pi_b: G2 # BN256 element
pi_c: G1 # BN256 element
Proof Serialization
The ProofOfQuota structure contains key_nullifier and the compressed proof transformed in bytes according Common Cryptographic Components - Use in the Logos Blockchain:. The key_nullifier must be transformed into bytes. The bytes of the compressed proof are then concatenated together with the bytes representing the key_nullifier, with the encoded key_nullifier preceding the encoded compressed proof. Reconstruction of a serialized ProofOfQuota interpreting the bytes as the concatenation of the key_nullifier and of the compressed proof following the same rule of conversion.
class ProofOfQuota:
key_nullifier: zkhash # 32 bytes
proof: bytes # 128 bytes
Appendix
Benchmarks
The material used for the benchmarks is the following:
- CPU: 13th Gen Intel(R) Core(TM) i9-13980HX (24 cores / 32 threads)
- RAM: 32GB - Speed: 5600 MT/s
- Motherboard: Micro-Star International Co., Ltd. MS-17S1
- OS: Ubuntu 22.04.5 LTS
- Kernel: 6.8.0-59-generic
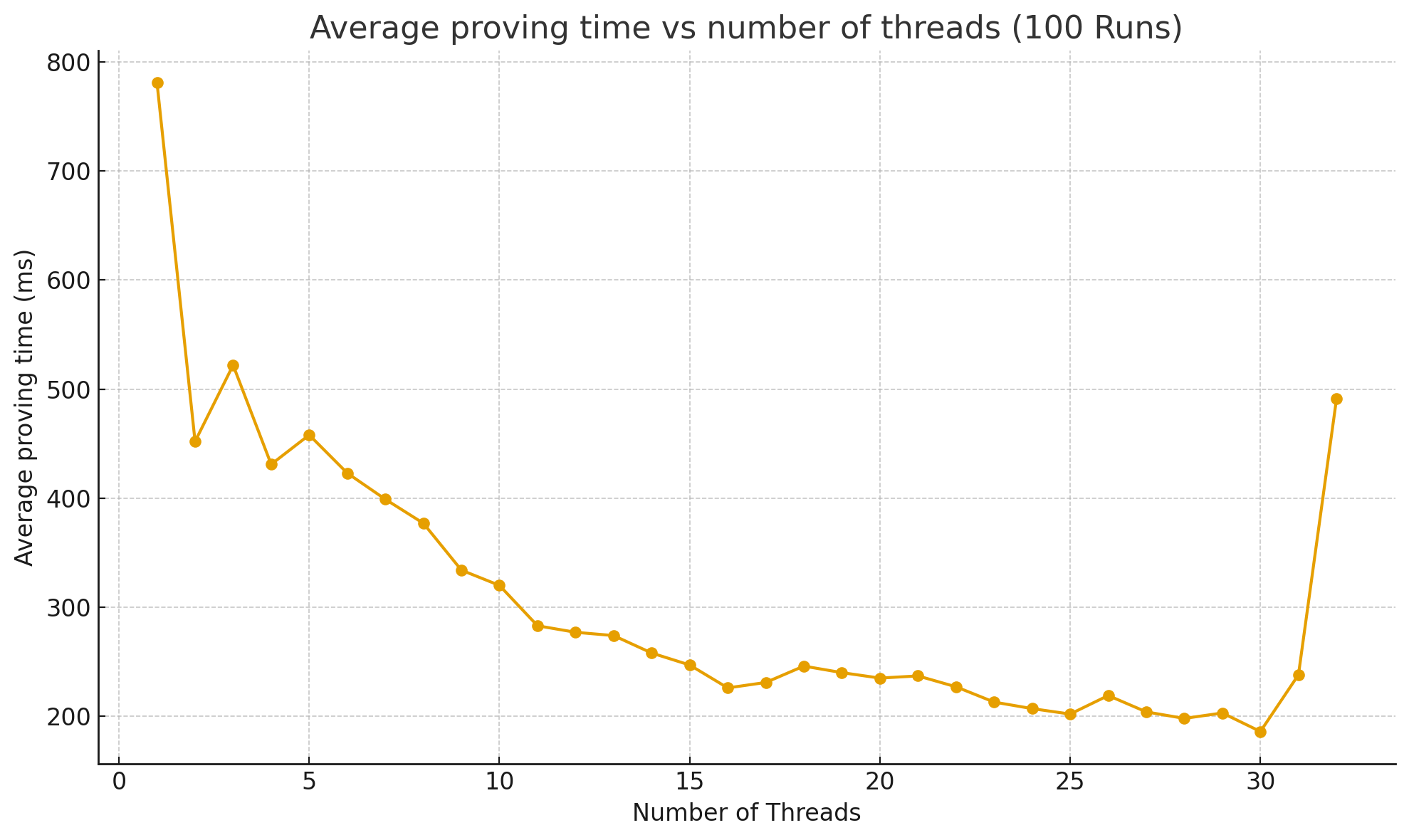
COMMON-CRYPTOGRAPHIC-COMPONENTS
| Field | Value |
|---|---|
| Name | Common Cryptographic Components |
| Slug | 200 |
| Status | raw |
| Category | Standards Track |
| Editor | Mehmet Gonen [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-11-18 |
| 1.0.1 | Renamed Nomos to Logos Blockchain | 2026-04-23 |
| 1.0.2 | Clarification of the Poseidon2 function Add test values | 2026-05-07 |
Introduction
The Logos Blockchain relies on a variety of cryptographic primitives to ensure security, privacy, and verifiability across its components. This document defines the common cryptographic building blocks used throughout the Logos Blockchain design.
Its primary purpose is to standardize the selection and usage of these primitives, provide rationale for each choice, and establish consistency across implementations. It also offers guidance for developers and researchers working on different parts of the system so that all components rely on a coherent and interoperable cryptographic foundation.
Overview
This document specifies the cryptographic primitives selected for the Logos Blockchain and explains how they interconnect across different layers of the protocol stack. It outlines their technical foundations, rationale, and security considerations to ensure consistent usage across Logos Blockchain components.
The primitives span multiple domains:
- Hash functions (Poseidon2, BLAKE2b) serve as the base layer for commitments, nullifier derivation, Merkle trees, signature key derivation, pseudorandom number generator and general purpose hashing.
- Signature schemes (EdDSA, ZkSignature) authenticate messages and participants, with ZkSignature designed specifically for ownership verification within zero-knowledge circuits.
- Proof systems (Groth16) enable succinct and verifiable computation. Groth16 is used in hand-written circuits.
Each primitive is chosen for its suitability in a particular context, balancing efficiency, cryptographic strength, and developer usability.
The table below summarizes the recommended component for each context:
| Context | Recommended Component |
|---|---|
| ZK Hashing | Poseidon2 |
| General Hashing & PRNG | BLAKE2b |
| General Signatures | EdDSA |
| ZK Signatures | ZkSignature (see Mantle - Zero Knowledge Signature Scheme (ZkSignature)) |
| Proof System (SNARK) | Groth16 |
1. Hash Functions
The Logos Blockchain utilizes different hash functions depending on the use case context—primarily distinguishing between zero-knowledge circuit contexts and general usage scenarios. The Logos Blockchain selects hash functions based on their performance characteristics: Poseidon2 for arithmetic-oriented handwritten circuits, and Blake2 for bit-oriented operations in ZkVM and general computations. In specifications, we refer to these arithmetic hash function as zkhash and the general purpose hash function as Hash.
BLAKE2b(General-Purpose Hashing)
Description:
BLAKE2b is a cryptographic hash function providing strong security and high performance. It supports variable-length outputs through parameterization, making it flexible for different cryptographic contexts.
Technical Details:
- Construction: ARX-based (Addition, Rotation, XOR) design.
- Output Size: Configurable, typically 256-bit or 512-bit.
- Internal State: 64-bit words, utilizing ChaCha-inspired quarter-round operations.
- Performance: Faster than SHA-2/SHA-3 in software implementations.
Use in the Logos Blockchain:
BLAKE2b is used for cryptographic hashing outside of zk-circuits in the Logos Blockchain, such as in data integrity checks, identifier generation, and other non-zk cryptographic operations.
Throughout the Logos Blockchain specifications, BLAKE2b is referred to simply as Hash.
Domain separation tags (DSTs) are included by treating the DST as a byte string (by convention ASCII-compatible) and prefixing it to the input before hashing.
Rationale for Use:
- Proven cryptographic strength as a well-studied and mature construction, with BLAKE2b being a finalist in the NIST SHA-3 competition.
- It was selected because of its high software performance and efficiency compared to SHA-2/SHA-3, while providing comparable security guarantees.
- Its adjustable output length and ARX-based design offer flexibility and practical deployment advantages over the SHA family.
Security Considerations:
- Considered secure under standard cryptanalytic models.
- Resistant to collision, preimage, and second-preimage attacks at intended security levels.
BLAKE2b-Based PRNG Construction
The Logos Blockchain also uses BLAKE2b as the basis for a deterministic pseudorandom byte generator, suitable for different purposes.
Construction:
Given a 64-byte seed and an integer index i, the PRNG output is derived by:
PRNG(seed, i) = BLAKE2b(seed || encode_u64(i), out_len=64)
- seed: 64-bytes seed (domain-separated if needed).
- encode_u64(i): 8-byte little-endian encoding of the index i.
- out_len: fixed to 64 bytes (maximum output size of BLAKE2b).
Output:
- For generating n bytes (bigger than 64 bytes), concatenate outputs of PRNG(seed, i) for i = 0, 1, ... until the desired length is reached.
- For generating k bits, compute enough full 64-byte outputs to cover at least k bits, then truncate the last byte to the required bit-length.
- This minimizes the number of BLAKE2b invocations by using the full 64-byte output capacity.
Notes:
- Seed choice and domain separation must be handled at the protocol level.
Poseidon2 (ZK Friendly Hash Function)
Description:
Poseidon2 is a cryptographic sponge permutation that can be used in different modes. It’s often used as a hash function or compression function designed specifically for arithmetic circuits, frequently used in zero-knowledge proofs. It follows the HADES permutation construction, consisting of multiple rounds of full and partial substitution-box (S-box) applications separated by linear layers.
Technical Details:
- Structure: HADES permutation (substitution-permutation network).
- Rounds: Clearly defined full and partial round structure, typically around 8 full rounds and ~60 partial rounds, depending on the security parameter.
- S-box: Nonlinear exponentiation-based S-box, typically of the form over a finite field (often or ).
- Field: Operates over prime fields (), usually matching the field used in zk-SNARK circuits.
Use in the Logos Blockchain:
Used as the hash function and compression function for all hand-written zero-knowledge circuits (e.g., note IDs, membership proofs) in the Logos Blockchain. For these protocols, the Logos Blockchain relies on the BN254 elliptic curve, so the elements are taken from the prime field corresponding to BN254. The parameters of the Poseidon2 permutation are the following in the Logos Blockchain:
- The rate = 1.
- The capacity = 3.
- 8 external rounds and 56 internal rounds.
- The rounds constants are derived following the original Poseidon paper following their implementation referenced in the paper.
- The state of the sponge is initialized with three 0s.
We provide test values in Poseidon2 Test Values.
We use the 10* padding rule for the hash mode of Poseidon2. Since our rate is 1, this means a single field element with value 1 is appended to the input before absorption.
We modified the compression mode compared to the Poseidon2 paper: to compress two elements (with rate=1), we compute zkhash(a,b) instead of zkhash(a,b) + a.
Throughout the Logos Blockchain specifications, Poseidon2 is referred to as zkhash.
In the Logos Blockchain, bytes and elements are frequently converted between formats (such as when interpreting DST byte strings as Poseidon2 inputs). To convert from an element to bytes, we interpret the little-endian unsigned representation of the number as 32 bytes. Conversely, we can interpret 32 bytes as an element provided the resulting number is smaller than .
We use Poseidon2 in hash function mode everywhere except in: Merkle proofs, public key derivation, nullifier derivation and reward voucher derivation where we use the modified compression mode.
Rationale for Use:
- Optimized for SNARK systems (minimizes constraint amount for hand-written circuit).
- Allows significantly fewer constraints compared to SHA or BLAKE, drastically reducing proving time. Reduces the number of constraints by a factor of approximately 100 compared to SHA256 or BLAKE2b, drastically lowering proving time and computational effort in zero-knowledge circuits.
Security Considerations:
- Subjected to ongoing cryptanalysis, including differential and algebraic attacks.
- Current research demonstrates security at 100-bit+ levels when using recommended round parameters.
- Resistant to collision, preimage, and second-preimage attacks at intended security levels.
References
- Poseidon2: https://eprint.iacr.org/2023/323
- Poseidon Cryptanalysis Initiative: https://www.poseidon-initiative.info/
- Algebraic Cryptanalysis of Poseidon: https://eprint.iacr.org/2023/537
- BLAKE2b Specification: https://eprint.iacr.org/2013/322
2. Digital Signature Schemes
EdDSA
Description:
EdDSA is a digital-signature scheme built on twisted Edwards curves. Ed25519 is a widely used instantiation of EdDSA over the Edwards25519 curve that provides approximately 128 bits of security.
Technical Details:
- Curve: Twisted Edwards curve Edwards25519 (it is birationally equivalent to Curve25519): such that .
- Signature Size: 64 bytes.
- Public Key Size: 32 bytes.
- Security Level: Approximately 128 bits.
- Operations: Efficient scalar multiplications with Montgomery ladder for constant-time execution.
Use in the Logos Blockchain:
- General-purpose digital signatures: EdDSA is used for authenticating operations in the Logos Blockchain that require standard digital signatures outside of hand-written ZK circuits.
Rationale for Use:
- High-performance, constant-time implementations available.
- Well-studied cryptographic primitives, broadly adopted (e.g., TLS, SSH, blockchain ecosystems).
Security Considerations:
- Standard security assumptions: discrete logarithm hardness on Curve25519.
- Resistant to timing and side-channel attacks due to uniform implementation characteristics.
ZkSignature (Zero-Knowledge Signature)
Description:
The ZkSignature scheme enables a prover to demonstrate cryptographic knowledge of a secret key corresponding to a publicly available key, without revealing the secret key itself. Specifically designed for efficient verification within zero-knowledge circuits, it provides both authentication and privacy, binding proofs securely to particular messages.
Technical Details:
Public Parameters:
- Public Key: A cryptographic commitment derived from the secret key using a secure collision-resistant hash function. This public key acts as a verifier’s reference to authenticate the prover without disclosing secrets.
- Message Hash: A cryptographic hash of the specific message intended to be signed. Binding the proof directly to this hash ensures that the signature is valid only for this exact message, providing protection against replay attacks and unauthorized reuse.
Private Parameters (Witness):
- Secret Key: A securely generated secret scalar value that must remain confidential. The secret key serves as the prover’s private witness input within the zero-knowledge circuit.
Security Level:
The security level of a ZKSignature depends on the concrete instantiations of its underlying primitives—namely the hash function, the zero-knowledge proof system, and the elliptic curve used. Since different instantiations may offer varying security guarantees and may be evaluated under different metrics (e.g., soundness, knowledge extraction, or cryptanalytic resistance), we do not commit to a fixed bit-level security.
The zk-circuit enforcing the validity of ZkSignature imposes the following conditions through arithmetic constraints:
- Key Ownership Constraint: The prover must demonstrate that they possess the secret key corresponding precisely to the provided public key. Within the circuit, this is validated by recomputing the public key using the secret key and the specified cryptographic hash function, then checking equivalence with the given public key.
- Message Binding Constraint: The signature is explicitly tied to a particular message by embedding its cryptographic hash into the circuit constraints. As a result, the zk-proof validity inherently ensures the prover’s knowledge of the secret key specifically with respect to this message.
Use in the Logos Blockchain:
ZkSignature is used to sign every object that are linked at some point to a hand-written circuit and if the signature is included in a bigger circuit.
Rationale for Use:
- Critically, the proof generation is fast, allowing rapid transaction processing and state updates in the Logos Blockchain without bottlenecks, which is essential for scalable systems.
- Allows anonymous and secure verification of message ownership within zero-knowledge circuits.
- Efficiently verifiable with minimal constraints in zk-SNARK circuits, ensuring performance in cryptographic operations.
Security Considerations:
- Dependent on the security properties (collision resistance and preimage resistance) of the default hash function for zk-circuits utilized for key derivation and verification.
- Robust against signature forgery, replay attacks, and impersonation, assuming the correct implementation of constraints and binding to the specific message hash.
References
- IETF RFC for EdDSA: https://datatracker.ietf.org/doc/html/rfc8032
- EdDSA original paper: High-speed high-security signatures. Daniel J. Bernstein, Niels Duif, Tanja Lange, Peter Schwabe, Bo-Yin Yang. https://eprint.iacr.org/2011/368
- Curve25519: https://iacr.org/archive/pkc2006/39580209/39580209.pdf
- ZkSignature: Mantle - Zero Knowledge Signature Scheme (ZkSignature)
3. Proof Systems
Groth16 (zk-SNARK)
Description: Groth16 is a succinct zero-knowledge proof system that allows proving arbitrary statements about computations with very short proofs and fast verification.
Technical Details:
- Proof Size: Approximately 192 bytes per proof (128 bytes if compressed).
- Verification Complexity: Efficient pairing checks (typically ~3 pairing operations).
- Trusted Setup: Required.
- Curve Family: Pairing-friendly elliptic curves (e.g., BN254 or BLS12-381).
Use in the Logos Blockchain:
- Groth16 is the primary zk-SNARK proving system used in Bedrock.
Rationale for Use:
- Produces the shortest possible zk-SNARK proofs, a provably optimal size among practical zk-SNARK constructions.
- Minimal verifier cost makes it highly suitable for on-chain verification in resource-constrained environments.
- Extensive adoption and availability of well-supported libraries.
Security Considerations:
- Groth16 is a zk-SNARK in the Common Reference String (CRS) model. Its knowledge soundness is proved in the generic bilinear group model, under the assumption that the structured CRS was generated honestly and that the trapdoor was destroyed. In practice, producing such a CRS via a one-time multi-party trusted setup ceremony (see Trusted Setup Ceremony) relies on standard hardness assumptions for the chosen pairing groups and on the at-least-one-honest-participant with secure erasure.
- Groth16’s security has been thoroughly analyzed in the literature, and the protocol is widely used in production zk-blockchain stacks.
References
- Groth16: https://eprint.iacr.org/2016/260.pdf
Annex
Poseidon2 Test Values
Hash Mode
| Input | Output |
|---|---|
| [0] | 0x1fed118d9f4466859761f22cad078722b8c4a743b5ebe90443b2dce6bbeb7b23 |
| [1] | 0x1eda5b2807bb78c5d061263409295d5115b7793a68c5220e37ea8ab2e94068f8 |
| [0,0] | 0x20579a2bf857cd36947250ec60f374c1faf02a40130b5fc867c2bde4da940fd2 |
| [1,2] | 0x1f36d032e4a519d0fbe1502fd8e4ad5fad61868c72c03f4294589f506bb52b6b |
| [2,1] | 0x26418d3cada2e7ad9e17b50731f6de916c80fc0ef88ea3ea6520dafbd37f4d7b |
| [1,0,0] | 0x129e88e8d9ae077e2e750222bc131da8b2268ad957cbf83d2b9beed6b9eed7c2 |
| [0,0,1] | 0x2a29cf254d2376ef660166c0647bcbed3decee8b3903eadeebecf304cd404dd0 |
| [0,1,0,1] | 0x793b1db3204a1bbb8cd7d06dac0b8ef98ae2664aa1ed57fccd37baf01682d3d |
Compression Mode
| Input | Output |
|---|---|
| [0,0] | 0x2ed1da00b14d635bd35b88ab49390d5c13c90da7e9e3a5f1ea69cd87a0aa3e82 |
| [1,0] | 0x63c4e8cac9a858304f0035b069255b069288c2af698ececf362cd8ec8c96665 |
| [0,1] | 0x222816f2669279d4c256ed2f196e8b0d54df83d35d61811bac36ea4e858483fc |
| [1,1] | 0x277530b5f2b87dfe4535f43bb1998eda77736b4b05d15d983503566743c88031 |
TRUSTED-SETUP-CEREMONY
| Field | Value |
|---|---|
| Name | Trusted Setup Ceremony |
| Slug | 207 |
| Status | raw |
| Category | Standards Track |
| Editor | Mehmet Gonen [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-07-03 —
709cf7f— Bedrock-RFC: Remove Concept of a Session (#365) - 2026-05-29 —
67e498e— chore: fix math issues (#350) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-09-04 |
| 1.0.1 | Renamed Nomos to Logos Blockchain. Removed mentions of DA. | 2026-04-23 |
Introduction
The Logos Blockchain utilizes zero-knowledge proof systems not only to ensure strong privacy and security guarantees across its decentralized architecture, but also to reduce the computational burden on validators by compressing execution into succinct proofs. Some of the Logos Blockchain's cryptographic applications specifically use Groth16 (see Common Cryptographic Components - Groth16 (zk-SNARK)), a proof system renowned for its succinctness and efficient verification.
A critical requirement of Groth16 is the secure generation of a Common Reference String (CRS) through a one-time cryptographic ceremony, commonly known as a Trusted Setup Ceremony. This ceremony ensures that cryptographic parameters are generated in a decentralized manner, such that no individual participant can later compromise the security or privacy guarantees of the system.
The Logos Blockchain adopts a secure, publicly verifiable, and auditable Multi-Party Computation (MPC) protocol known as Powers-of-Tau, performed over the BN254 elliptic curve as a first step for Groth16-based zero-knowledge proofs, to generate and extend these trusted setup parameters.
This document defines the cryptographic foundations and provides detailed instructions for securely performing or extending a trusted setup ceremony, including:
- Essential cryptographic definitions and parameters.
- Step-by-step guidance for participant contributions.
- Procedures for extending an existing Powers-of-Tau ceremony.
Overview
At a high level, the Powers-of-Tau ceremony generates a structured set of elliptic curve points corresponding to powers of a secret scalar . These elements form the Phase 1 CRS that underpins the Groth16 protocol in the Logos Blockchain. For Groth16, the CRS can be extended in a short Phase 2 MPC to derive circuit-specific proving and verification keys, ensuring the underlying secret remains hidden as long as at least one participant discards their randomness. The Logos Blockchain adopts an MPC setup ceremony: the Powers-of-Tau protocol.
Powers-of-Tau Ceremony Overview
- Each participant securely contributes randomness sequentially.
- Each participant iterates over the existing CRS parameters to update it.
- At least one participant must be honest and destroy their secret input to guarantee the security of ZK schemes using the CRS.
- All transformations are accompanied by publicly verifiable proofs, ensuring full auditability of the ceremony.
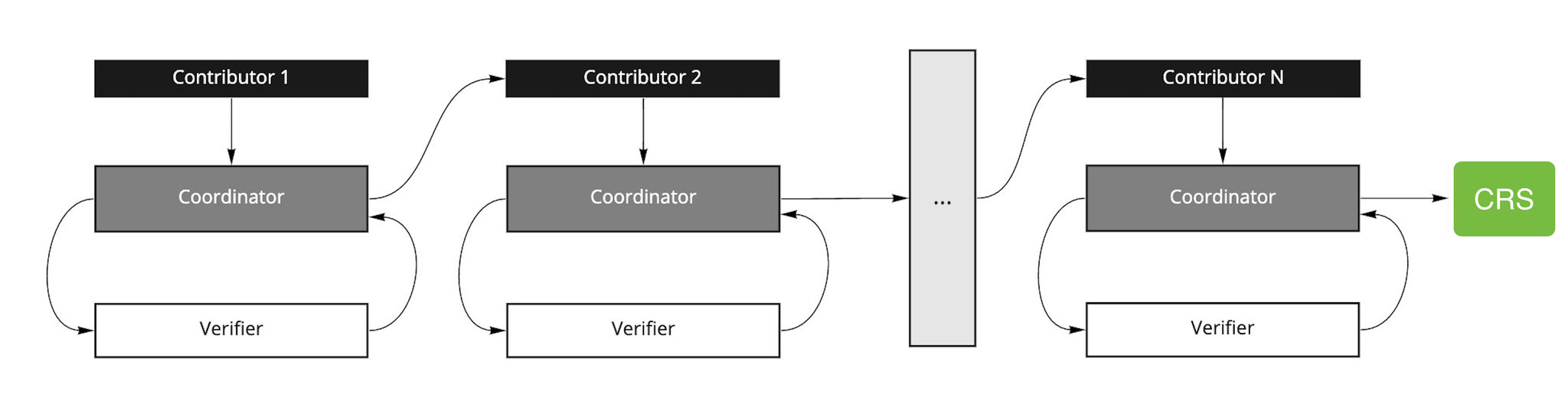
In the ceremony, a coordinator manages the sequential flow of contributions. Each contributor downloads the current CRS, applies their secret randomness, and sends the updated CRS back through the coordinator, who relays it to the next participant. At each step, an independent verifier can check that the update was performed correctly. Once all contributions are complete, the final CRS is published.
Security of Powers-of-Tau
Let N denote the total number of contributors participating in the ceremony. The Powers-of-Tau ceremony achieves computational soundness against adversaries that corrupt up to (N-1) participants, under certain number-theoretic assumptions (e.g., the q-Strong Diffie-Hellman (q-SDH) assumption in the underlying elliptic curve groups), provided that at least one honest participant successfully erases their secret randomness.
- Honest Participation: The core trust assumption is that at least one participant in the multi-party computation securely deletes their secret contribution (i.e., the toxic waste). If this holds, then the final CRS remains sound and cannot be used to forge proofs.
- Computational Assumptions: The protocol relies on several number-theoretic assumptions, most notably the q-SDH assumption over the elliptic curve. These assumptions are fundamental to pairing-based cryptography and are not specific to the ceremony.
- Erasure Assumption: Powers-of-Tau is typically analyzed in the secure erasure model, where each participant is assumed to be capable of permanently deleting their internal secret randomness after applying it. This ensures that even if an adversary later compromises a participant, they cannot recover the toxic waste. While not a computational assumption, secure erasure is essential for the soundness of the protocol in this model.
The security of Groth16-based zero-knowledge proofs in the Logos Blockchain critically depends on a sound and verifiable trusted setup. Each participant contributes to the CRS without revealing their secret randomness, and public proofs guarantee the correctness of every transformation. The procedure applies to all required secret scalars, , ensuring that all toxic waste is handled consistently and securely. Furthermore, the Logos Blockchain builds its Powers-of-Tau ceremony on top of an existing, already-audited CRS instead of starting from scratch, providing greater confidence in its security. This trusted setup process forms a foundational cryptographic pillar for ensuring privacy, integrity, and long-term resilience in the Logos architecture.
We have two phases for the ceremony. Phase 1 is circuit-independent and involves generating elliptic curve encodings of powers of a toxic waste scalar . This enables polynomial commitments up to a certain degree and can be reused across any circuit of bounded size. Phase 2 is circuit-specific and requires knowledge of the exact constraint system. It introduces four additional toxic waste scalars , which are used to encode the circuit's polynomials and, crucially, compute the elements in the verification key. These terms represent compressed combinations of public input polynomials and must be computed for each unique circuit. As a result, while Phase 1 can be performed once and reused broadly, Phase 2 must be securely executed for every new circuit.
Curve Selection and Parameter Structure
The Logos Blockchain uses the BN254 elliptic curve for Groth16-based zero-knowledge proofs because proving time and proof size are critical in these applications. BN254 offers smaller proofs and faster proving times compared to alternatives like BLS12-381, and is backed by mature, highly optimized libraries such as Circom, SnarkJS, and libsnark.
Groth16 Parameters
Groth16 proving systems derive two key components from a structured CRS:
- Proving Key (): This is a set of cryptographic parameters enabling the prover to generate proofs. Includes group elements from the prime-order cyclic subgroups and on elliptic curve, where is defined over a degree-2 extension field.
- Verification Key (): This is a smaller set of parameters allowing efficient verification of proofs. The verification key contains a much smaller set of elliptic curve elements from groups and .
Protocol
Technical and Cryptographic Steps
This section describes the trusted setup procedure in detail, outlining both the cryptographic computations and the interactive flow of the multi-party Powers-of-Tau protocol. The process begins with a coordinator initializing elliptic curve parameters and generating the initial set of structured CRS elements. Each participant builds on the previous one’s output by applying a secret random transformation and publishing a proof of correctness — so the process is sequential. As long as at least one participant discards their secret input, the entire setup remains secure. These contributions are chained together, and the ceremony concludes with a publicly verifiable aggregation of the final CRS.
The Groth16 protocol requires a CRS with a suite of powers of one random scalar . To ensure soundness and zero-knowledge for a given arithmetic circuit, four additional toxic-waste elements must also be sampled independently and uniformly at random. While their values are circuit-independent, the way they are applied in constructing the proving and verification keys depends on the specific circuit.
In addition to , the Groth16 proving system requires, for each circuit, four additional secret scalars, and all sampled independently and uniformly at random from the field . These values are essential for securely encoding different components of the constraint system and for ensuring zero-knowledge in the final proof. Specifically, and are used to randomize the circuit polynomials and , is used to compress linear combinations of public inputs, and provides blinding for the quotient polynomial that ensures witness-hiding. Like , each of these values must be treated as toxic waste and securely discarded after use. All five values: must be generated using the same secure procedure and structure. In Groth16 Phase 2, these scalars are used immediately to derive circuit-specific CRS elements, in particular the terms in the verification key, before all toxic waste is securely destroyed.
Step 1: Initialization (Coordinator)
The coordinator publicly specifies the foundational cryptographic parameters:
- Elliptic Curve: BN254: such that Here denotes distinct prime fields of size .
- Cryptographic Groups:
- : prime-order subgroups of elliptic curve points over and its extensions.
- : a bilinear, non-degenerate pairing function.
- Generators:
- are fixed public generators.
- Element Notation:
- Elements of the group are written additively by using the following notation: .
These values are fixed and published to all ceremony participants.
- An initialized CRS:
- The initialized CRS contains elements in and elements in . For the secret in Groth16, the value of defines the maximum degree of polynomials that will be committed and the maximum size of circuits (the number of R1CS constraints must be ≤ ) and . In contrast, the parameters of the Groth16 protocol each require only . But, Phase 2 also includes the computation of the elements in , whose number depends on the circuit’s public inputs. These must be generated at the same time, while the toxic waste scalars are still in memory.
- The CRS is of the form when initializing from scratch.
For performance reasons, especially to leverage Number Theoretic Transforms (NTT) for fast polynomial arithmetic, it is common to choose as a power of two. For example, setting allows working with polynomials of degree up to , and proving circuits with up to constraints.
Step 2: Participant Contribution
Each participant in the sequence performs the following:
- Downloads the current CRS: ( at the initialization phase).
- Generates a random secret scalar .
- Updates the CRS by contributing its secret into the CRS.
- .
- .
- Creates a proof showing they know , and that the CRS is a correct transformation of the old one.
- This proof consists of three checks (detailed in Step 4):
- Knowledge of exponent for the first element.
- Non-zero: ensuring previous contributions are not erased.
- Well-formedness of the updated CRS via random linear combination pairing check.
- This proof consists of three checks (detailed in Step 4):
- Submits:
- Updated parameters .
- Proof of correct transformation.
In Phase 2 for Groth16, participants also update all circuit-specific elements derived from the toxic waste scalars (including the terms), ensuring they are transformed consistently with the rest of the CRS.
Step 3: Public Verification
- Knowledge of Exponent
This is proven using a Fiat–Shamir transform of a Schnorr-like protocol:
- Let: .
- Prover samples random values uniformly .
- Computes: .
- Computes challenge: .
- Computes response: .
- Publishes proof .
- Verifier checks: . This protocol confirms that the first element of the CRS was exponentiated with a known secret .
- Well-Formedness of CRS
- Verifier samples .
- The verifier computes the following pairing equation on the new CRS:
This pairing check confirms that the CRS has been updated via exponentiation by the same secret scalar , preserving the structure of the powers of .
- Non-Erasing Contribution
- Checks that : .
- ’s verification (Phase2 only)
For each public , check the pairing equation:
- Left side encodes the division by (respectively for private inputs).
- Right side encodes the linear combination .
- If it holds for all , the are correct and consistent with the same for public inputs (respectively for private inputs).
Step 4: Toxic Waste Destruction
While each participant is expected to delete their secret scalar immediately after contribution, security is guaranteed as long as at least one participant successfully deletes their randomness.
Finalized CRS
Once all participants have contributed:
- The final CRS is published ( being the number of participants).
- This CRS is used to derive:
- Circuit-specific proving keys .
- Circuit-specific verification keys .
Extending an Existing Trusted Setup Ceremony
Logos may choose to leverage an existing, publicly verified Powers-of-Tau ceremony to inherit trust and security. To do this, Logos simply adds additional participants following the above participant contribution steps (Step 2):
- Logos participants securely download existing Powers-of-Tau parameters.
- Each Logos participant sequentially adds their randomness and generates proofs-of-knowledge, updating the parameters.
- After all Logos contributions, a new final set of parameters is derived.
- A Logos coordinator aggregates the auditable contributions to compute the new CRS parameters and publish them for Logos.
By following this protocol, Logos ensures robust security guarantees without repeating the entire ceremony from scratch. Most importantly, this process allows Logos to onboard previous contributions from external parties, inheriting their randomness and strengthening the trust assumption. It also preserves the transparency, integrity, and auditability of the original ceremony while enhancing its security by contributing additional entropy from Logos’ own participants, effectively extending a trusted foundation with new safeguards.
References
- [Groth16] IACR Cryptology ePrint ArchiveOn the Size of Pairing-based Non-interactive Arguments, Jens Groth, Eurocrypt 2016
- [WCB25] IACR Cryptology ePrint ArchiveSoK: Trusted setups for powers-of-tau strings, Faxing Wang, Shaanan Cohney, Joseph Bonneau, FC 2025
Annex
# Pseudocode for Multi-Party Powers-of-Tau Ceremony
# Input:
# - n: Max degree of polynomials to support (e.g., #constraints in Groth16)
# - m: Usually 1
# - G1, G2: Elliptic curve generators for groups G1 and G2
# - p: Prime order of the field F_p
# Output:
# - crs: Common Reference String with structured powers of tau
# - transcript: List of contributions and public proofs
# Assume Point is a placeholder for an elliptic curve point class
Point = object
Scalar = int
@dataclass
class ContributionProof:
z_point: Point
s: Scalar
def initialize_crs(n: int, m: int, G1: Point, G2: Point):
crs_G1 = [(1 ** j) * G1 for j in range(n)] # [1]_1, [1]_1, ..., [1]_1
crs_G2 = [(1 ** k) * G2 for k in range(m)] # [1]_2, [1]_2
return crs_G1, crs_G2
def contribute(
crs_G1: list[Point],
crs_G2: list[Point],
G1: Point,
G2: Point,
p: int):
r: Scalar = random_non_zero_scalar(p) # secret toxic waste scalar. 254-bit for BN254 and 255-bit for BLS12-381
# Apply exponentiation to CRS
crs_G1_prime = [(r ** j) * crs_G1[j] for j in range(len(crs_G1))]
crs_G2_prime = [(r ** k) * crs_G2[k] for k in range(len(crs_G2))]
# Generate proof of correct exponentiation
proof = generate_proof_of_knowledge(crs_G1[1], crs_G1_prime[1], r, G1, p)
# Destroy r securely
del r
return crs_G1_prime, crs_G2_prime, proof
def generate_proof_of_knowledge(
old_point: Point,
new_point: Point,
r: Scalar,
G: Point,
p: int):
z: Scalar = random_non_zero_scalar(p)
z_point = z * G
# Schnorr-style proof with Fiat–Shamir challenge
h: Scalar = hash_to_scalar(old_point, new_point, z_point)
s: Scalar = (z + h * r) % p
return ContributionProof(z_point, s)
def verify_contribution(
old_crs_G1: list[Point],
old_crs_G2: list[Point],
new_crs_G1: list[Point],
new_crs_G2: list[Point],
proof: ContributionProof,
G1: Point,
G2: Point,
p: int):
z_point, s = proof.z_point, proof.s
h = hash_to_scalar(old_crs_G1[1], new_crs_G1[1], z_point)
lhs = s * G1
rhs = z_point + h * new_crs_G1[1]
if lhs != rhs:
return False
rho_one = random_non_zero_scalar(p)
rho_two = random_non_zero_scalar(p)
lhs = pairing(
sum([(rho_one ** j) * new_crs_G1[j] for j in range(len(new_crs_G1))]),
(1 * old_crs_G2[0]) + sum([(rho_two ** k) * old_crs_G2[k] for k in range(len(old_crs_G2))])
)
rhs = pairing(
(1 * old_crs_G1[0]) + sum([(rho_one ** j) * old_crs_G1[j] for j in range(len(old_crs_G1))]),
sum([(rho_two ** k) * new_crs_G2[k] for k in range(len(new_crs_G2))])
)
return lhs == rhs
def powers_of_tau_ceremony(
participants: list[object], # Should ideally be a class/interface with contribute()
n: int,
m: int,
G1: Point,
G2: Point,
p: int):
crs_G1, crs_G2 = initialize_crs(n, m, G1, G2)
transcript: list[ContributionProof] = []
for participant in participants:
crs_G1_new, crs_G2_new, proof = participant.contribute(crs_G1, crs_G2, G1, G2, p)
if not verify_contribution(crs_G1, crs_G2, crs_G1_new, crs_G2_new, proof, G1, G2, p):
raise ValueError("Invalid contribution by participant")
transcript.append(proof)
crs_G1, crs_G2 = crs_G1_new, crs_G2_new
return crs_G1, crs_G2, transcript
LOGOS-DIGITAL-SIGNATURE
| Field | Value |
|---|---|
| Name | Logos Blockchain Digital Signature |
| Slug | 150 |
| Type | RFC |
| Status | deprecated |
| Category | Standards Track |
| Editor | Jimmy Debe [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-18 —
58b5698— chore(blockchain): migrate contributor emails to @logos.co (#338) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-30 —
99ca13a— New RFC: Nomos Digital Signature (#167)
Abstract
This specification describes the digital signature schemes used across different components in the Logos Blockchain system design. Throughout the system, each Logos Blockchain layer shares the same signature scheme, ensuring consistent security and interoperability. The specification covers EdDSA for general-purpose signing and ZKSignature for zero-knowledge proof of key ownership.
Keywords: digital signature, EdDSA, Ed25519, zero-knowledge proof, ZKSignature, cryptography, elliptic curve, Curve25519
Semantics
The keywords "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119.
Definitions
| Term | Description |
|---|---|
| EdDSA | Edwards-curve Digital Signature Algorithm, a signature scheme based on twisted Edwards curves. |
| Ed25519 | An instance of EdDSA using Curve25519, providing 128-bit security. |
| ZKSignature | A zero-knowledge signature scheme that proves knowledge of a secret key without revealing it. |
| Prover | An entity that generates a cryptographic proof or signature. |
| Verifier | An entity that validates a cryptographic proof or signature. |
| Public Key | The publicly shareable component of a key pair, used for verification. |
| Secret Key | The private component of a key pair, used for signing and proof generation. |
Background
The Logos Blockchain Bedrock consists of a few key components that Logos Blockchain network is built on. See the Logos Blockchain whitepaper for more information. The Bedrock Mantle component serves as the operating system of Logos Blockchain. This includes facilitating operations like writing data to the blockchain or a restricted ledger of notes to support payments and staking. This component also defines how Logos Blockchain Zones update their state and the coordination between the Logos Blockchain zone executor nodes. It is like a system call interface designed to provide a minimal set of operations to interact with lower-level Bedrock services. It is an execution layer that connects Logos Blockchain services to provide the necessary functionality for sovereign rollups and zones. See Common Ledger specification for more on Logos Blockchain Zones.
In order for the Bedrock layer to remain lightweight, it focuses on data availability and verification rather than execution. Native zones on the other hand will be able to define their state transition function and prove to the Bedrock layer their correct execution. The Bedrock layer components share the same digital signature mechanism to ensure security and privacy. This document describes the validation tools that are used with Bedrock services in the Logos Blockchain network.
Protocol Specification
The signature schemes used by the provers and verifiers include:
- EdDSA Digital Signature Algorithm
- ZKSignature (Zero-Knowledge Signature)
EdDSA
EdDSA is a signature scheme based on elliptic-curve cryptography, defined over twisted Edwards curves. Logos Blockchain uses the Ed25519 instance with Curve25519, providing 128-bit security for general-purpose signing. EdDSA SHOULD NOT be used for ZK circuit construction.
The prover computes the following EdDSA signature using twisted Edwards curve Curve25519:
- The public key size MUST be 32 bytes.
- The signature size MUST be 64 bytes.
- The public key MUST NOT already exist in the system.
ZKSignature
The ZKSignature scheme enables a prover to demonstrate cryptographic knowledge of a secret key, corresponding to a publicly available key, without revealing the secret key itself. The following is the structure for a proof attesting public key ownership:
class ZkSignaturePublic:
public_keys: list[ZkPublicKey] # The public keys signing the message
msg: hash # The hash of the message
The prover knows a witness:
class ZkSignatureWitness:
# The list of secret keys used to sign the message
secret_keys: list[ZkSecretKey]
Such that the following constraints hold:
- The number of secret keys is equal to the number of public keys:
assert len(secret_keys) == len(public_keys)
- Each public key is derived from the corresponding secret key:
assert all(
notes[i].public_key == hash("LOGOS_KDF", secret_keys[i])
for i in range(len(public_keys))
)
- The proof MUST be embedded in the hashed
msg.
The ZKSignature circuit MUST take a maximum of 32 public keys as inputs.
To prove ownership when using fewer than 32 keys,
the remaining inputs MUST be padded with the public key corresponding
to the secret key 0.
These padding entries are ignored during execution.
The outputs of the circuit have no size limit,
as they MUST be included in the hashed msg.
Security Considerations
Key Management
Secret keys MUST be stored securely and never transmitted in plaintext. Implementations MUST use secure random number generators for key generation.
EdDSA Security
EdDSA provides 128-bit security when used with Ed25519. Implementations MUST validate public keys before use to prevent small subgroup attacks. Signature verification MUST reject malformed signatures.
ZKSignature Security
The ZKSignature scheme relies on the security of the underlying hash function
and the zero-knowledge proof system.
The hash function used for key derivation (LOGOS_KDF) MUST be collision-resistant.
Implementations MUST verify that proofs are well-formed before accepting them.
Replay Protection
Signatures SHOULD include context-specific data (such as timestamps or nonces) to prevent replay attacks across different contexts or time periods.
References
Normative
- RFC 2119 - Key words for use in RFCs to Indicate Requirement Levels
Informative
- Logos Blockchain whitepaper - The Logos Blockchain Whitepaper
- Common Ledger specification - Common Ledger Specification
- Edwards curves - Twisted Edwards Curves
Copyright
Copyright and related rights waived via CC0.
Common Ledger Specification
Owners: Thomas Lavaur David Rusu Reviewers: Giacomo Pasini Mehmet Álvaro Castro-Castilla
Introduction
Unlike a typical blockchain, where a single ledger would track all notes, Logos Blockchain partitions the ledger across zones. The partitioned ledgers will be maintained locally by Native zones, but enforced globally as a common format to enable certain properties and functionalities otherwise not possible (such as PACTs, see ). Each Native zone manages its own ledger partition and defines its own application. Despite this separation, global ledger rules ensure zones can confidently process notes originating from other ledger partitions. The common ledger is also directly used by the Mantle through the Mantle ledger. The Mantle ledger enforces additional constraints and restrains interactions on its partition of the ledger, favoring efficiency while keeping the model described in this document.
References
The following documents provide the necessary background for related topics:
-
What a note is. Notes
-
How the update requests of the ledger are built. Transactions
-
How we chose the representation of the ledger.
-
Preliminary Research: Ledger Representation
-
Preliminary Research: Mutator Sets and their Application to Scalable Privacy
- How Ledger updates are verified and coordinated by Logos Blockchain Bedrock. Preliminary Research: Bedrock Mantle Specification (Native Zones)
Overview
The Zone Ledger is composed of two sets, the commitment set and the nullifier set. The commitment set holds every note that has been created in a zone, and the nullifier set maintains a record of every note that has been spent in a zone. Bundles are used to update the Zone Ledger and the rules governing these updates are enforced in The Ledger proof. The Commitment Set is represented as an MMR (see Merkle Mountain Ranges (MMR)). This representation is used to achieve state compression.
- Wallets must track changes to the MMR to maintain proofs of membership as new notes are added.
- Executors are only required to store the Frontier Nodes (see Frontier Nodes) of the MMR. The Nullifier Set is represented as an Indexed Merkle Tree (IMT, see Preliminary Research: Sparse Merkle Tree vs Indexed Merkle Tree).
- Wallets reveal nullifiers to prove a note is consumed. This nullifier on its own cannot be linked to the note commitments.
- Executors must retain the full nullifier list in order to update the IMT. The Ledger proof governs the evolution of these two sets by applying bundles to the ledger state. The newly created commitments from each bundle are added to the commitment set and the spent nullifiers are inserted into the nullifier set after verifying their non-membership.
Commitment Set
The set of commitments is stored in the zone ledger and represents the entire history of notes that have been created and included within the zone ledger. By proving a note’s membership in a commitment set, a note owner can show that a note is not counterfeit.
For more information on notes and transactions, the reader is referred to Execution Model Specification.
Commitments coming from Bundles will be continuously added to an ever-growing list. To avoid linear state growth here, the list is compressed using an MMR so that at any moment, no entity is required to store the entire list of commitments to carry out zone operations. A new note commitment follows a lifecycle of 3 phases:
- Wallets
- Executors
- Bedrock Mantle
1. Wallets
A wallet must maintain the Merkle paths to the notes it holds. These Merkle paths are used to build proofs of membership when a note is spent in a transaction. These membership proofs do not disclose the commitment, therefore making it impossible to link together the old transaction that created the note and this new transaction consuming this note. These Merkle paths can become outdated as the commitment set evolves, since each new commitment modifies the set’s Merkle root. Therefore, a wallet must follow the activity of all zones in which it holds notes in and update the Merkle paths of those notes accordingly. An additional complication is that, transactions must prove the membership of input notes w.r.t. the latest commitment root. This raises the issue that since the commitment root is changing frequently, membership proofs will become outdated rapidly if they are not immediately included on chain. To resolve this, we divide commitment membership proofing into two stages:
- The wallet proves commitment membership w.r.t. the frontier nodes of the most recent MMR it had seen.
- The executor then extends this proof by proving that these frontier nodes are nodes in the latest commitment Merkle tree.
The intuition behind why this works is that since the commitment set MMR is append-only, an old state of an MMR will always be a subset of the latest MMR:
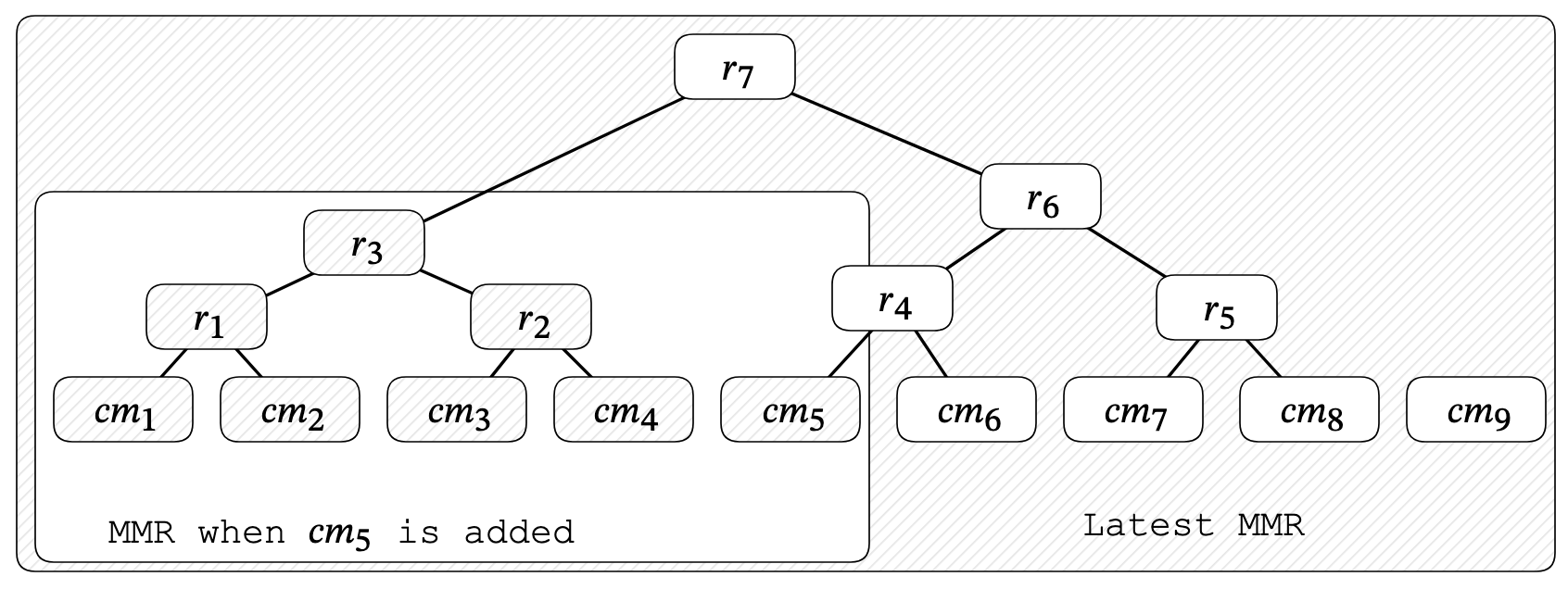
The MMR when was added is a subset of the latest MMR, we can prove that the frontier nodes of the old MMR are members of the latest MMR by providing paths up to
This works insofar as executors maintain a far enough history of MMR states. If a wallet membership proof is too old, an executor may not have kept MMR states so far back and so he won’t be able to extend the membership proof to the latest root. In this case, the wallet must sync with the zone to update its membership proof to proceed (see Membership Proof Updates).
Compression of the Commitment Set
The commitment set is compressed using an MMR. This state compression means that it is enough for executors to hold only the frontier nodes of the MMR to continue processing new commitments. The Frontier Root (Frontier Root) of the MMR is the commitment set root and its evolution is proved through the Ledger proof. Wallets are only required to follow the updates of the MMR to prevent excessive work.
- To emit transactions, wallets can retrieve one valid list of frontier nodes which includes their commitment.
- Provide a proof of membership according to the frontier nodes.
- The executor would complete the proof, proving that the frontier nodes are in the latest commitment set according to the Merkle root.
Proof of Membership
The first generation of the commitment Merkle proof When a wallet wants to store a new note, because it's waiting to receive a note or because it scanned the network and detected a new note under its ownership, the wallet must construct an initial Merkle proof, proving the membership of the note commitment in the zone ledger. In order to construct this first proof of membership, the receiver doesn’t need help from the issuer.
For the detection of new notes by wallets, see
- Wallet scanning the network for the notes
The wallet can build this proof of membership w.r.t. some frontier nodes by providing the witness where
- is the commitment we are proving membership for.
- is the Merkle path provided by the note owner. The membership proof attests to the statement:
- . By proving membership against the frontier nodes, we do not leak temporal information about which mountain a commitment is part of in the MMR. Membership Proof Updates To ensure transaction unlinkability, it is essential that an observer cannot determine which commitment is used in the proof of membership.
- Ideally, when there are commitments in the set, the probability that an observer can identify whether a particular commitment is being used should satisfy for 128 bits of security.
- This means that a wallet cannot simply use the frontier nodes of the commitment set from when it was initially created. Doing so would allow an observer to infer that the proven commitment is more likely to be one of the recently added ones Therefore, it is essential for wallets to update this list of frontier nodes representing the commitment set regularly.
- The wallets main maintenance task is centred around maintaining the one frontier node in which his note is a member of.
-
The moments when the Merkle path of this frontier node needs to be updated by wallets are easily predictable because they occur when the frontier node is merged with another one.
- When two frontier nodes have the same height, they are merged according to Merkle Mountain Ranges (MMR).
-
The merging process of two frontier nodes can be anticipated.
- If a commitment is the commitment added to the set (starting from 0), the folding happens every time a new commitment added is the commitment and has a binary representation that changes a 0 to a 1 in ’s binary representation from right to left.
- For example, if a commitment is the n°54 (counting the first commitment as commitment 0), 54 in binary is 110110.
- Its tree will be merged after the inclusion of the 110111, 111111, 1111111, etc. commitment, or whenever another leading 1 is added to the binary representation.
- In other words, the Merkle path should be updated when commitments 55, 63, 127, 255, and so on are added.
- As time passes, this situation occurs less frequently (logarithmically)
-
This update process is efficient because it only requires adding the root of the other merged node to the end of the current Merkle proof.
- The remaining frontier nodes represent the rest of the commitment set for a maximal transaction unlinkability. This part does not need to be maintained over time if communicated by the executor. When the wallet generates a transaction, it recovers the remaining frontier nodes that don’t contain the note commitment from the executor and updates its Merkle path according to what was described before. Recommendation To maximize unlinkability between transactions and minimize the storage required by executors, we recommend that wallets update the following as frequently as possible:
- Merkle paths for each note they hold as frontier node folds are observed
- Maintain their list of frontier nodes, as described in Merkle Mountain Ranges (MMR).
2. Executors
Executors must provide all the necessary information for wallets to update their membership proofs. This includes newly added commitments. Executors could optionally share the list of frontier nodes to reduce how often wallets need to update their membership proofs. They are also responsible for maintaining the state of the commitment set and proving the correct insertion of new commitments from bundles in the ledger proof. When the executor processes bundles, the executor must recursively prove that the bundles are valid according to the requirements shared by all native zones. The ledger proof will demonstrate:
- The bundle is valid using the bundle proof.
- For each frontier node used for membership proofs in the bundle, we have a Merkle path up to the latest frontier (the executor being the one providing the remaining Merkle path).
- The new commitments have been appended to the commitment MMR.
- The new commitment root is derived as the Frontier Root of the MMR. (Frontier Root). To make all necessary information available to other executors, the executor must provably make available all commitments added in the latest ledger update. To facilitate wallet’s proof of membership update, they could optionally communicate off-chain to wallets the merged MMR roots and the frontier nodes after each update, see:
- Executor dispersal to wallets
Nullifier Set
The set of nullifiers in a zone represents the entire history of all notes that have been consumed within the zone. This set allows someone who knows the nullifier to prove that the note was never consumed. Nullifiers will be continuously added to an ever-growing list maintained by Executors:
- New nullifiers are added from bundles being applied to the ledger.
- Before a nullifier is added to the list, the ledger proof first verifies its non-membership to protect against double spends
- This is done using an Indexed Merkle tree compression scheme that enables proof of non-membership (presented in Indexed Merkle Tree (IMT) ). Just like commitments, nullifiers also experience different representations depending on which phase of their lifecycle they are on:
- Wallets
- Executors
- Bedrock Mantle
1. Wallets
Note owners must derive nullifiers for any notes they wish to spend. The difficult work of proving non-membership against the nullifier set is delegated to executors.
2. Executors
Executors are responsible for processing nullifiers derived from valid bundles. To do that, the Ledger proof must show that nullifiers aren’t already included in the set, preventing notes from being used twice. They must also publish the necessary information to allow other executors to rebuild the ledger of the native zone and take over the executor's role. This includes:
- All nullifiers added in the latest ledger update.
- All commitments added in the latest ledger update. As already presented in 2. Executors, zones are responsible for the verification of bundles. For this, bundles must only consume notes that aren’t already consumed as described in .
Ledger Updates
In this section, there are some components that are described in detail in Execution Model Specification and Preliminary Research: Bedrock Mantle Specification (Native Zones). Here we will just provide a brief intuition of what they do, and kindly refer the reader to the original documents for further detail:
- Bundle: A bundle is an aggregation of one or several valid transactions that are balancing each other.
- Zone Sync Logs: This is a list of the form used to verify the correct coordination between zones.
- Zone Update is what will land on the Bedrock Mantle for posting about a zone update, which includes the update of its ledger. This update processes several valid bundles and updates the ledger of a zone accordingly.
Proof overview
In order to prove the correct update of the ledger to the Bedrock, zones will produce ledger proofs to:
- Validate bundle proofs according to Bundles.
- Prove nullifiers are not already in the nullifier set of the ledger.
- Prove the inclusion of the nullifiers in the nullifier set.
- Verify the commitment proof of membership against the commitment set.
- Output updated ledger state.
- Output the hash of the ledger diff to check its availability on-chain.
- Output cross-zone zone sync logs to communicate to Bedrock and guarantee validity of bundles even for those involving several zones according to Consistency between zones.
Proof design
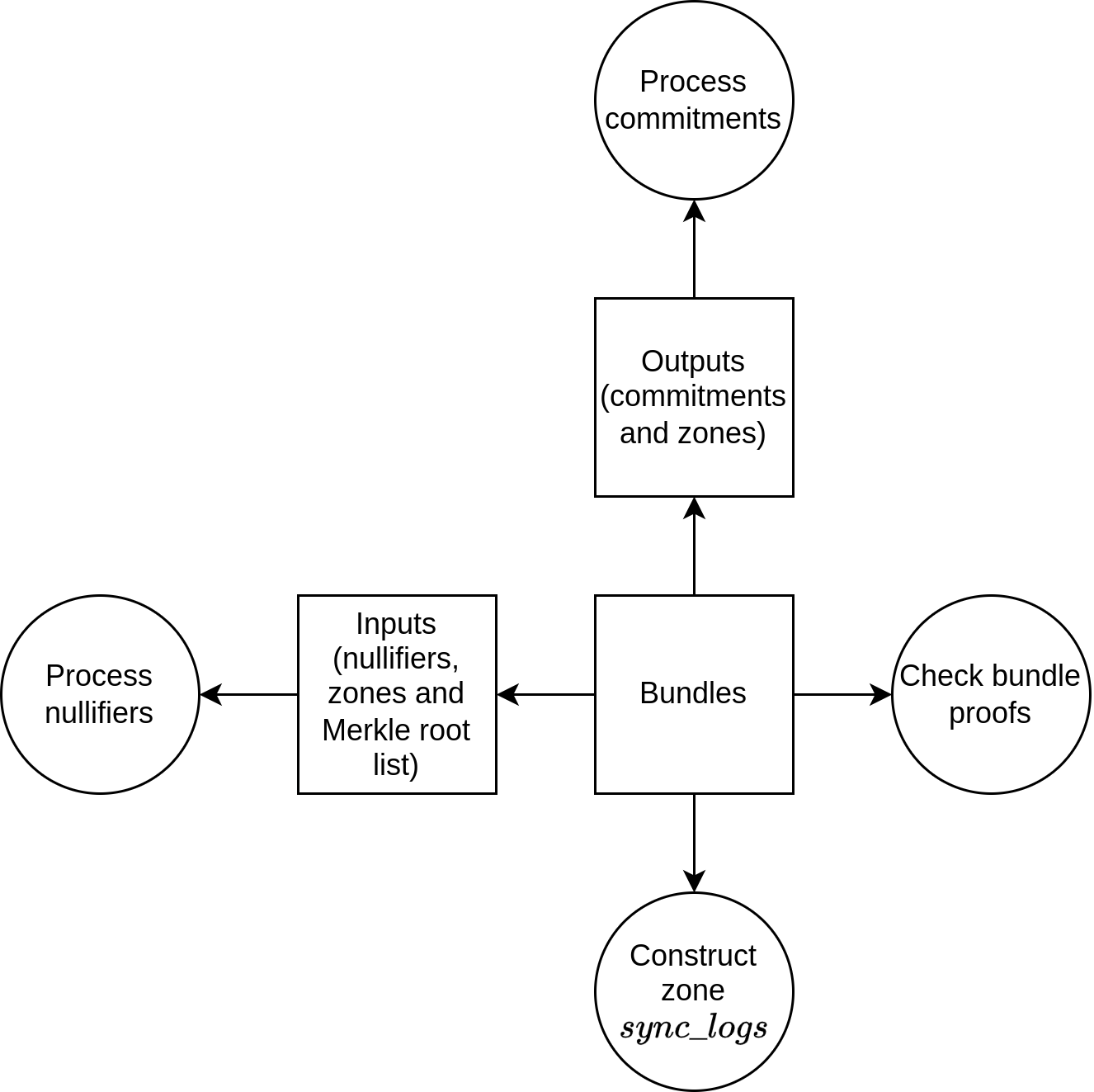
- The executor will bring bundles, of input , and of root , to apply an update on the ledger of its zone. The ledger proof checks that each bundle has a valid bundle proof:
- Proving that each of them is balanced.
- Proving that inputs and outputs are valid notes that can be included in the zone ledger on the condition that the frontier nodes used for proof of membership are nodes included in the ledger state of the zone.
-
For each different bundle , , If is the executor’s zone, the ledger proof guarantees that nullifiers are not already in the set and include them afterward.
-
To finalize the proof of membership, the executor must prove that there exists a Merkle path from each node in to one of the latest frontier nodes.
-
The nullifier is checked to be indeed not present in the last known nullifier set of the zone.
- For that, the executor is providing a Merkle path demonstrating that there is a different nullifier in the nullifier set Merkle tree.
- That is strictly lower than
- That the leaf of is pointing to another nullifier .
- That is strictly greater than .
-
Integrate in the nullifier set of the zone:
- Integrate a new leaf which includes the new nullifier pointing to the greater nullifier .
- Change the pointer of to using the Merkle path of .
- This ensures that each leaf is still pointing to the next nullifier, conserving the ordered property of the list.
-
For each different bundle , , if is the executor’s zone, the ledger proof appends the commitment in the commitment set MMR of the zone.
-
The ledger proof then constructs the Merkle root of the bundle , representing uniquely the bundle. This is achieved by constructing a Merkle tree over the transaction roots.
-
The ledger proof constructs the zone that is used by validators to ensure correct coordination between zones for cross-zone bundles. This takes the form of one tuple per cross-zone bundle (with the followed by every zone involved in the bundle).
-
Output updated ledger state , the hash of cross-zone and the hash of the nullifiers and commitments included in the ledger in correct order. The following diagram summarizes the executor’s ledger proof:
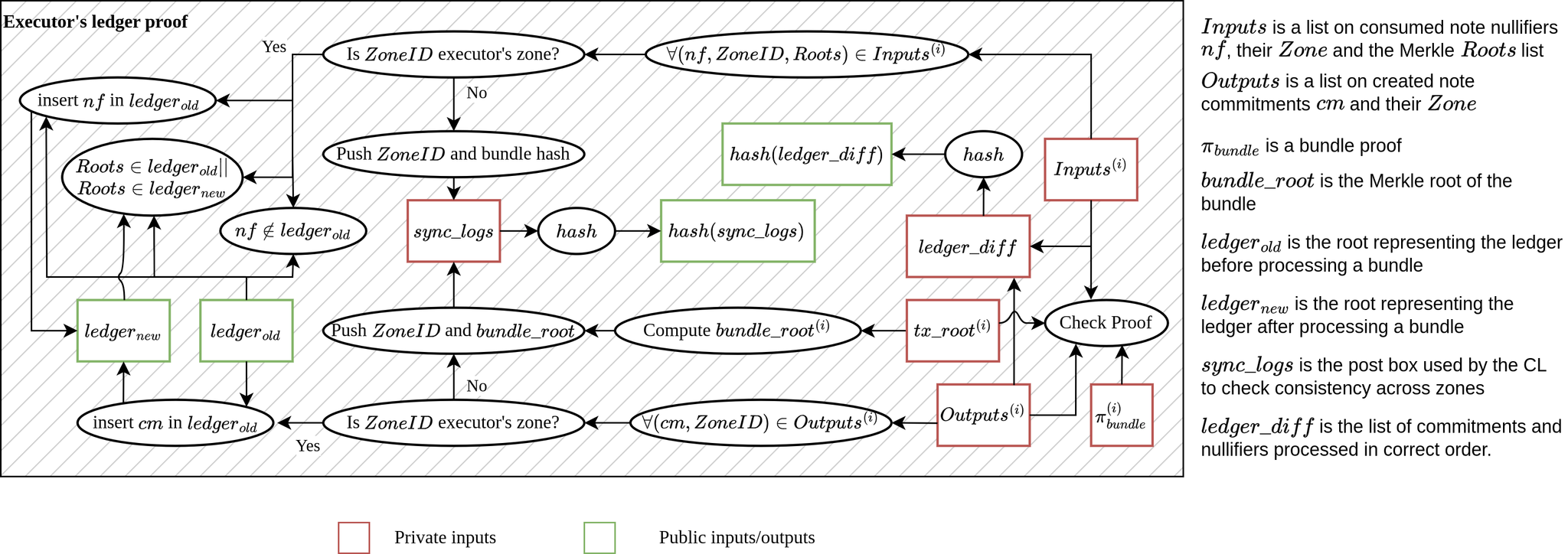
Annexes
Merkle Mountain Ranges (MMR)
From the original presentation of MMR on github: As digests are accumulated we hash them into trees, building up the largest perfect binary trees possible as we go. At least one tree will always exist, with digests at the base, and total elements. If the total number of digests doesn't divide up into one perfect tree, more than one tree will exist. This data structure we call a Merkle Mountain Range, for obvious reasons:
graph BT
%% Leaves (elements)
%% Internal Nodes
node0[N0] --> Hash01[N0-1]
node1[N1] --> Hash01
node2[N2] --> Hash23[N2-3]
node3[N3] --> Hash23
node4[N4] --> Hash45[N4-5]
node5[N5] --> Hash45
node6[N6]
%% Next level of parents
Hash01 --> Hash0-3[N0-3]
Hash23 --> Hash0-3
Since the trees are strictly append only, we can easily build, and store them, on disk in the standard breadth first tree storage. In this array we can define a height for each digest, and that height is equal to where n is the number of digests in the base of the tree. The following shows the contents of that array as it is progressively extended with new digests:
0
00
001 <- indexes 0 and 1 are hashed to form index 2
0010
0010012 <- another tree, which leads to the two subtrees being merged (height 2)
00100120
0010012001 <- now we have two trees, one of height 2, one of height 1
Now we have two trees, or mountains, and the result looks like the following:
graph BT
%% Leaves (elements)
%% Internal Nodes
node0[N0] --> Hash01[N0-1]
node1[N1] --> Hash01
node2[N2] --> Hash23[N2-3]
node3[N3] --> Hash23
node4[N4] --> Hash45[N4-5]
node5[N5] --> Hash45
%% Next level of parents
Hash01 --> Hash0-3[N0-3]
Hash23 --> Hash0-3
This range has six digests at the base. Another four digests, or ten in total, would result in the first mountain range, shown above. Next we need to create a single digest linked to every mountain in the range, and in turn every digest submitted. For that, we pad the the tree with empty nodes at the base until it reach a power of two in order to have a full Merkle tree:
graph BT
%% Leaves (elements)
%% Internal Nodes
node0[N0] --> Hash01[N0-1]
node1[N1] --> Hash01
node2[N2] --> Hash23[N2-3]
node3[N3] --> Hash23
node4[N4] --> Hash45[N4-5]
node5[N5] --> Hash45
node6[empty] --> Hash67[N6-7]
node7[empty] --> Hash67
%% Next level of parents
Hash01 --> Hash0-3[N0-3]
Hash23 --> Hash0-3
Hash45 --> N4-7
Hash67 --> N4-7
Hash0-3 --> root
N4-7 --> root
The process can be completely deterministic, producing the exact same digest every time provided you have every base digest and their order. By knowing the number of digests in a given mountain range you can always efficiently reproduce the peak enclosing the mountain whole range at that point in time. The storage cost for all the intermediate hashes is . Moreover, knowing Merkle roots of different depth Merkle tree filled with empty leaves able the computation of the Merkle root logarithmically without needing to really pad the tree.
The Logos Blockchain Whitepaper
Owner: Álvaro Castro-Castilla Daniel Kashepava
The information here is up-to-date, but note that the whitepaper is still in active development.
Introduction
Once again, the world stands at a crossroads. For as long as humanity has lived together, there have been individuals seeking to control others, and individuals seeking freedom from that control. As history marched onward, technologies emerged that shifted this struggle toward one side or the other. From writing, to gunpowder, to the printing press, to the revolver – inventions would periodically arise and upset the balance of forces in unpredictable ways. In recent times, the internet – initially hailed as a bastion for free speech and free association – has become a tool for mass surveillance and control. The ideological experiments of the 19th and 20th centuries have made it clear that political action alone will not bring lasting freedoms to the human race. Recognising this, the cypherpunk movement sought to proactively create technologies to ensure that civil liberties become inviolable by design. Among their most influential creations was Bitcoin which, along with the blockchain protocols it inspired, built the foundation for a financial system independent from state power and elite control. However, as the public nature of these blockchains exposed their participants to government scrutiny and regulation, that original vision was gradually replaced with arcane financial instruments and predatory speculation. The Logos movement was founded as a revival of the cypherpunk ideal that has been all but forgotten over the past several decades. Logos has dedicated itself to the creation of decentralised technologies that would enable people to engage in social collaboration on their own terms – without being worried about censorship or coercion. These voluntary associations and institutions that function with an emergent order and are resistant to corruption are referred to as network states, in contrast to traditional states that rely on threats of violence to maintain control. Only with a technology stack that facilitates private and permissionless consensus, data storage, and communication can this vision be made a reality. Logos Blockchain was created by Logos to be the infrastructure facilitating the creation of network states and enabling people to easily interact with them. Using Logos Blockchain, network states are implemented as lightweight blockchains known as Zones, with an underlying chain providing consensus, security, and interoperability. Importantly, network states implemented on Logos Blockchain allow for social order to emerge and govern their operations, all while preserving critical properties that guarantee individual freedoms for all participants. These include privacy for users and infrastructure providers, censorship resistance, resilience against attacks, and credible neutrality. In essence, Logos Blockchain is the platform that will produce the conditions for true improvements over millennia-old cooperation techniques based on trust and control. The world stands at a crossroads. The greatest minds of this generation are working tirelessly to build the technology that will determine the future of civil rights for centuries to come – both on the side of coercion, and on the side of freedom. Your decisions now will determine which side emerges victorious.
Overview
Logos Blockchain is a blockchain infrastructure designed for network states and other decentralised applications that require high levels of privacy, decentralisation, and resilience. It facilitates the creation and operation of these applications, provides a common context for their interaction, and gives users the ability to freely use any application they desire. Despite the diverse variety of apps that can be built on Logos Blockchain, it provides guarantees that they will operate correctly, securely, and without corruption. To accomplish this, Logos Blockchain is implemented as two blockchain layers. Applications can be implemented as lightweight, permissionless blockchains known as Zones, which are built on top of a solid Layer 1 foundation known as Bedrock. Logos Blockchain’s Bedrock together with its Zones is known as the Logos Blockchain network. The entire Logos Blockchain architecture can be visualised as in the diagram in Figure 1.
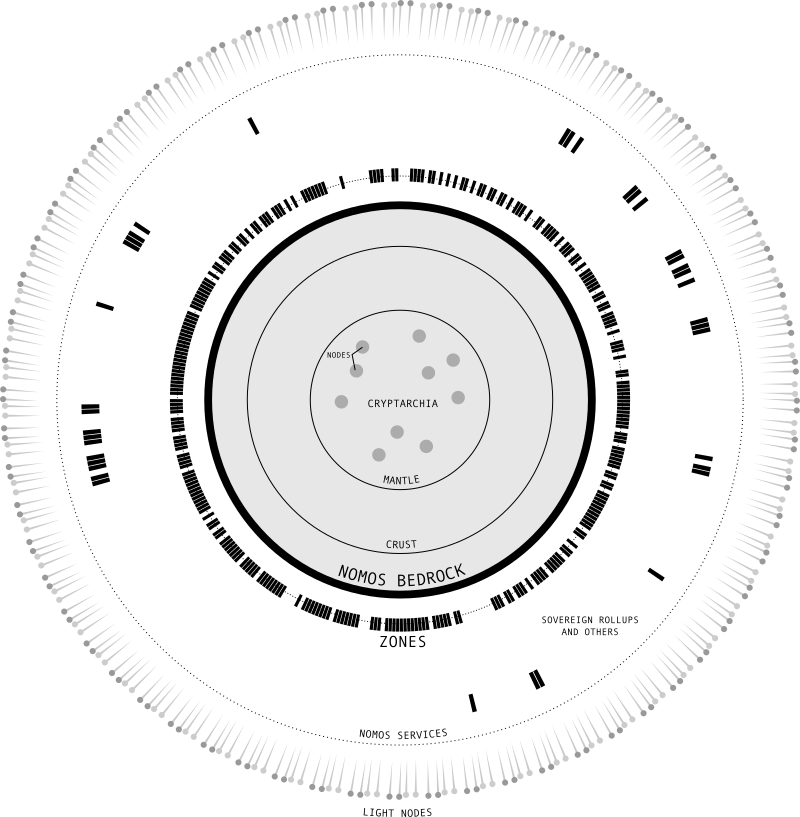
Figure 1. The Logos Blockchain architecture diagram.
Bedrock is the foundational layer of Logos Blockchain, which provides consensus and lightweight verification to Logos Blockchain Zones. This consensus mechanism provides privacy for block proposers and is highly scalable, resilient, and supports dynamic participation by Logos Blockchain nodes. It also verifies proofs sent to it by Zones to ensure their correct operation. Bedrock is a decentralised network in which anyone can easily participate, where serving as a validator should ideally be as simple as running the Logos Blockchain Node application on a laptop. Validators contribute to the security, consensus, and interoperability of the Logos Blockchain network. The basic functionality of Bedrock is expanded and improved by a variety of Logos Blockchain Bedrock Services. Bedrock uses these Services to provide data scalability, network-level privacy for consensus, and executors that maintain Zone liveness by updating their ledger and state. While these Services are important for ensuring that Logos Blockchain can operate under the most adversarial conditions, Logos Blockchain' Bedrock can still operate without them. This may occur under adversarial conditions, or if a Service fails for some other reason. Validators who choose to participate in providing any number of Bedrock Services are expected to have increased hardware requirements compared to the minimal ones necessary for Bedrock validation. Bedrock and Bedrock Services are used to create very lightweight and interoperable blockchains for applications known as Logos Blockchain Zones. Users have two options for interacting with these applications:
- A user could run a simpleclient, which relies solely on a direct connection to the relevant Zone, with Bedrock abstracted from view. The Zone, in turn, interacts with Bedrock in order to interact with other Zones and to obtain guarantees of security and data availability.
- Additionally, a user may choose to run a light node, which would connect to Bedrock for lightweight verification. Running a light node allows the user to fully verify the state of the Zone they care about, without relying on any trusted entity. Logos Blockchain is primarily designed for applications on Zones, which together form the Native Execution Space. Zones rely on Bedrock to the fullest extent, thereby benefiting from the collective security of the entire Logos Blockchain network. From a user’s perspective, Zones are deeply interconnected environments that require minimal setup and maintenance, as a result of their common structure and strong interoperability. They are also totally permissionless, with any Logos Blockchain validator - or user, if no validators are available - having the ability to keep a Zone live by serving as its executor. Despite this, Zones are resistant to censorship due to specific mechanisms guaranteeing transaction inclusion. This also means that users of a Zone will always have the option to exit that Zone if they so desire. Despite the advantages of Zones, they are not suitable for all applications and remain a work in progress. Therefore, Logos Blockchain also provides support and unique features for Sovereign Rollups. These rollups are fully independent, without any constraints on their state imposed by Bedrock. This sovereign model provides greater freedom and customisability in creating a chain, allowing creators to maximise properties like performance. To achieve this, Sovereign Rollups must sacrifice native features such as the interoperability available between Zones as well as their censorship resistance guarantees.
The Three Lines of Defence
The Logos Blockchain network described above is designed to be resilient against a variety of adversaries while remaining decentralised and permissionless. In order to mount a defense against threats, Logos Blockchain relies on a three-tiered strategy to ensure the longevity and resilience of its applications. Given that an application on Logos Blockchain is implemented as a Zone or a set of Zones, each layer of the Logos Blockchain architecture will contribute to safeguarding its survival and correct operation. Whenever one layer fails and the defence strategy proceeds to the next stage, there is greater decentralisation and less concentrated trust assumptions to prevent further failure. At the same time, these secondary layers come with tradeoffs on properties such as latency and user experience, which is why they are only used as a last resort. The three lines of defence are:
-
As a first line of defence, we have the Zone(s). Zones are executed in a permissionless fashion by executors, with the Executor Network providing incentives for doing so correctly. An executor may choose to provide preconfirmations to users, giving various degrees of confidence that a transaction will be included. Once an executor has made Zone data available and generated ZK proofs for the correctness of its transitions, Bedrock provides assurances of correct execution.
-
In case an executor acts maliciously, Bedrockprovides broad cryptoeconomic security and emergency recovery. At this stage, the user relies on the Logos Blockchain validator set to protect against two types of attacks by a Zone:
-
If the Zone is deleting or withholding data from its users, any party can use Bedrock to reconstruct the entire Zone data up to a certain time window. This time window is sufficient for third-party protocols to take over in assuring the long-term availability of the data. For long-term storage, the only guarantee that we need for correct data recovery is that a single honest entity in the entire world has the original data - and is willing to share it. Additionally, Zone data can be both stored and recovered independently of all the other Zones, which makes it easy for any interested party to store the history of specific Zones.
-
If the Zone is attempting to include incorrect ZK proofs, they will be rejected. Zones submit proofs to ensure the correctness of their state transitions. Bedrock also enables synchronous composability by enforcing cross-Zone transaction correctness, discarding the entire operation if any part of it cannot be verified.
-
Finally, a user can rely on light nodes or better yet, run one themselves to collectively detect Logos Blockchain Bedrock misbehaviour. This misbehaviour can manifest itself in the realms of data availability, consensus, or by wrongfully accepting incorrect ZK proofs from the Zones. In these situations, light nodes have two options:
-
Light nodes can choose to follow a valid minority fork of Bedrock, if it exists. This is possible because Logos Blockchain uses a consensus protocol that favors liveness over finality, which allows an honest minority to keep building a minority fork while the majority is misbehaving. Following a minority fork can occur without an explicit removal of the dishonest majority.
-
In the event where there is no valid minority fork, light nodes can initiate a collaborative protocol for data reconstruction and/or a mass exit from the Logos Blockchain network. Their goal, at the very least, will be to ensure that the last valid state can be recovered and reactivated by a new, healthy network. This type of process can be bootstrapped with less strict constraints than a full consensus protocol.
Logos Blockchain Bedrock
Logos Blockchain' Bedrock is the basis on top of which the broader Logos Blockchain network is built, operating as a large and decentralised peer-to-peer blockchain network. Its purpose is to provide consensus and a common context for Zone correctness and interoperability, while safeguarding participants’ privacy and remaining neutral and permissionless. Bedrock simultaneously preserves the autonomy of Logos Blockchain Zones and the applications that run on them, as well as every user’s rights and access to their digital property and identity. While the average user will rarely interact with Bedrock directly (only doing so to forcibly include Zone user transactions due to censorship, or if they have to act as an executor under extraordinary circumstances), its presence in the background ensures that decentralised applications “just work” the way they should, without falling to corruption or malicious behaviour.
Design Principles
Logos Blockchain' Bedrock was designed with several guiding principles that are critical to the Logos Blockchain vision. Chief among these is privacy, Logos Blockchain’s most important feature. This privacy must protect information associated with all participants, regardless of their role in the protocol. On the infrastructure level, validators participating in Bedrock must be confident that their block proposals have a sufficiently low probability of being traced. From an outsider’s perspective, the network looks like a large mass of indistinguishable nodes, producing noise to avoid any detectable patterns. This privacy guarantee allows validators to support all Zones autonomously and neutrally, with the confidence that their contribution to the progress of the chain appears no different to that of any other node. This mitigates the risk of self-censorship, ensuring that no Zone update is actively excluded due to concerns about its content or source. For Logos Blockchain developers, Bedrock makes private applications not just easy to build, but ensures that privacy is available by default. Ensuring that Bedrock remains operational and protects privacy in spite of attacks requires a high level of resilience. Due to Logos Blockchain’s decentralised nature, more validators participating in Bedrock results in fewer individual points of failure and thus a better resistance to attacks. To enable this, it was necessary to create a network characterised by low entry barriers to attract as many validators as possible. A basic Bedrock node must therefore be easy to run - with a simple interface and requiring only typical consumer hardware. As a result of these requirements, validator nodes only participate in consensus, with more advanced functionality available on an opt-in basis. Validators can participate with any amount of stake, reducing economic barriers to participation. Accommodating this large network of nodes is accomplished by using a very scalable consensus protocol that prioritises liveness. This results in a network that continues operating even in unstable or extremely adversarial conditions, with any fork producing a simultaneously-operating chain. In the latter scenario, a fork can be resolved in favour of one chain in case the recovery process can be completed within the finality period. However, if two chains operate independently for longer than this period, both forks are considered valid and independent, and further decisions are subject to social consensus. While Logos Blockchain Zones have considerable autonomy, this autonomy cannot come at the user’s expense. Bedrock therefore provides protection to users by guaranteeing censorship resistance - that is, an assurance that every correct transaction on Zones will eventually be added to the blockchain. In the optimistic default scenario where Zone executors act honestly, users’ transactions get processed by Zone executors quickly and inexpensively. However, in the event that a Zone attempts to censor a user by excluding their transactions, Bedrock provides a fallback path for the transaction to be included. This path is slower and more expensive, but is only expected to be used in a small minority of cases. The mere existence of the fallback path serves as deterrent to prevent executors from engaging in censorship. Finally, Bedrock block proposers provide an assurance of credible neutrality to users**.** This means that block proposers operate neutrally and include transactions in their blocks based only on simple criteria. At the time of writing, the Logos Blockchain Team is considering implementing different methods, such as distributed block building, that would reduce the impact proposers have on blocks.
Bedrock Components Overview
Bedrock is organised into several key components, which can be visualised as a series of concentric circles (see Figure 2). The most basic of these is the peer-to-peer network that allows Logos Blockchain nodes to communicate with each other in a decentralised way. On top of this network sits Cryptarchia, the consensus protocol used to reach an agreement about the state of the blockchain. As a Private Proof of Stake (PPoS) protocol, Cryptarchia gives all participants a proportional chance to propose a block, while ensuring that blocks cannot be linked to their proposers both before and after the proposal.
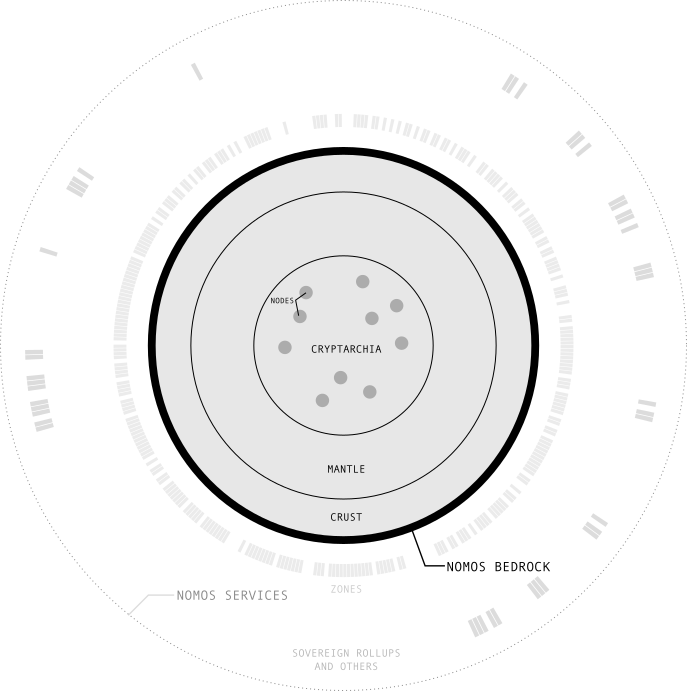
Figure 2. The components of Logos Blockchain' Bedrock.
Mantle, a Bedrock component that serves as the operating system of Logos Blockchain, provides a minimal shared execution environment for Logos Blockchain Zones that allows them to interact with Bedrock and Bedrock Services. This includes operations like writing data to the blockchain, as well as a restricted ledger of notes to support payments and staking. Mantle also defines Zone updates and coordination between Zone executors. Finally, BedrockCrust defines the high-level functionality shared primarily by Zones. This includes common standards such as a Common Ledger and execution model that enable Zones to have strong interoperability while facilitating private transactions. Crust also includes support for the delegation of execution rights for Zones in the form of execution tickets, giving ticket owners the exclusive privilege to act as Zone executors for a defined range of blocks. It is important to note that Crust remains in a state of active research at the time of writing. All these components work together to create a resilient, functional Bedrock that the rest of the Logos Blockchain network can safely rely on.
Consensus: Cryptarchia
Cryptarchia, Logos Blockchain' Bedrock’s consensus protocol, ensures that the Logos Blockchain network reaches an agreement on the correct state of the blockchain. Cryptarchia’s use of a Private Proof of Stake (PPoS) mechanism ensures that validators cannot be linked to blocks they propose, thereby ensuring that the proposer’s relative stake cannot be deduced based on their activity. This separation reinforces the neutrality of the network, since validators cannot be linked to any specific activity on the network. At the same time, Cryptarchia has no stake barrier for participating in consensus, fostering further decentralisation.
Cryptarchia provides PPoS consensus with privacy guarantees that are stronger than merely using a secret leadership election. Such an election mechanism only hides the identity of the leader before they propose a block. After the leader does so, it is trivial to link them to their proposed block without additional privacy measures in place. Cryptarchia, by contrast, hides the identity of the leader both before and after a proposal. This property creates a much more powerful layer of privacy, resilience and neutrality.
Safety vs Liveness
In designing a resilient consensus protocol to use for Logos Blockchain, it was deemed necessary to choose between the properties of safety or liveness, in terms of which is prioritised by the protocol during a catastrophic failure. If safety is deemed a priority, the chain can never fork in order to ensure that the blockchain is always agreed-upon - even if activity has to halt while the network recovers. Protocols that provide such safety guarantees generally rely on quorum-based consensus, which requires a permissioned set of participants with extensive communication and a low fault tolerance. These requirements introduce high barriers to entry that are antithetical to Logos Blockchain’s vision. Prioritising liveness means that block production will continue during a failure, but competing forks will be created before the network settles on one honest chain. These protocols involve participants systematically making local choices about which fork to follow, with no need for a permissioned network or for extensive communication. Accordingly, Cryptarchia was designed with this principle in mind.
Overview of Cryptarchia
Following the Ouroboros model, Cryptarchia divides time into basic units called slots that are grouped into larger units called epochs. Each slot allows for the addition of at most one block to a given chain, while each new epoch refreshes the leadership election parameters and eligibility set. The fork choice rule involves selecting the longest chain when a node is already online and the densest chain when bootstrapping a node to ensure that honest parties can join or rejoin the protocol without trust assumptions. Cryptarchia uses Logos Blockchain notes - fungible assets with data attached - to select block proposers. Each note that is sufficiently old is eligible to win the Cryptarchia slot lottery. The owner of a winning note can then propose a block. Notes from anywhere, including Mantle and Zones, can be used for consensus - potentially allowing for powerful forms of restaking. Notes are discussed in more detail in the Crust section. Each slot presents an opportunity for a block proposer to add a block to the chain, so long as they win the leadership election for that slot. The leadership election is run locally for each individual eligible note using information obtained from the previous epoch. Whether a particular note wins the leadership election for a given slot is determined by comparing a threshold derived from the note’s relative stake to a random value cryptographically derived from Cryptarchia’s lottery randomness and the note data. Due to the privacy properties of Cryptarchia, this relative stake relies on an estimate of the total participating stake derived from the block production rate. The owner of a note that won an election can submit a block proposal, which will contain a Proof of Leadership (PoL). Most slots will have no leader to allow parties to synchronise, while some will have one or even several leaders. A key deletion protocol used in the maintenance of the note’s secret key ensures that an adaptive adversary who corrupts an honest participant will not be able to generate proofs of leadership for past slots.
Bedrock Mantle
Mantle is a Bedrock component that serves as the operating system of Logos Blockchain. It provides essential functionality that allows nodes to participate in Bedrock Services, as well as providing minimal operations to enable anybody to interact with Bedrock. Mantle maintains a restricted ledger that provides a very limited execution environment and operations to support Logos Blockchain Bedrock Services, and is primarily concerned with fee payment for Mantle operations (see below). This ledger keeps track of fungible assets known as notes, which are bound to their owners. Note transfer transactions are based on the UTXO model where a sender spends their note and creates an equivalent new note belonging to the recipient. A spent note can never be spent again. Mantle notes keep their information public, and are stored in a Merkle tree of unique note identifiers. Mantle notes are necessary for the Mantle Ledger’s slashing mechanism, and each Zone provides operations to convert Zone notes (that is, notes in their respective Zone state partition) to Mantle notes (notes in the global Mantle ledger). Unlike ledger transitions in Zones, the Mantle Ledger does not use ZK proofs to compress the ledger state - instead, validators execute all ledger transitions, functioning like validators in a traditional blockchain. Mantle also serves as a censorship resistant message delivery mechanism for Zones, allowing Zone executors to send information either to be recorded on the blockchain permanently, or only for temporary storage in the form of a blob. Bedrock can therefore be seen as a resilient and decentralized message passing infrastructure for Zones, either on-ledger (inscriptions) or through a cheap DA protocol (blobs) for large amounts of data. Blobs are discussed in more detail in the Data Availability section.
Mantle Operations
Mantle operations are the way Logos Blockchain nodes and Zone executors interact with Mantle. These are submitted to Mantle in the form of a transaction, paid for by notes stored in Mantle. Zone executors use operations to post blob data from their Zone to DA Network, and to inscribe data permanently onto a Bedrock block. Zones submit their own state transition proofs to Bedrock via similar Mantle operations. Logos Blockchain nodes use Mantle operations to indicate their participation in Bedrock Services, with Mantle providing a locking mechanism used to incentivise correct behaviour by Service participants. The operations supported by Mantle include staking notes for participation in Bedrock Services, paying rewards to compensate participants, and unstaking notes. Mantle operations also allow for Zones to be created and updated. An update to the Zone state must be accompanied by a proof that the ledger was updated according to the Common Ledger rules, and another proof that the Zone data was updated in accordance with that Zone’s state transition function. The availability of the Zone data must also be verified so it can be recovered in case an executor or rollup operator attempts to withhold it.
Bedrock Crust
Bedrock Crust is a Bedrock component built on top of Mantle that provides specific functionality for Zones. This functionality includes providing the necessary common structures and coordination mechanisms to ensure privacy and advanced interoperability between Zones. Importantly, it provides a mechanism to keep track of a Zone’s executors in the form of execution tickets.
Common Ledger & Execution Model
Logos Blockchain Zones each have a ledger that adheres to a common set of rules to facilitate interoperability between Zones. As a result, they can be thought of as partitions of a single Common Ledger spanning all Zones. This ledger keeps track of shielded notes, where the information is private by default. Notes are bound to their owners and the Zone they are in, and only the owner can spend a note. Like notes on Mantle, note transfer transactions are based on the UTXO model, where notes belonging to the sender are spent and new notes belonging to the recipient are created with the same total value. These notes each have their own secret key for spending, and a corresponding public key for receiving new notes. Zone Notes may also have associated rules, known as covenants, that govern spending notes and creating or destroying note value. The Common Ledger represents unspent notes in the form of commitments, and spent notes in the form of nullifiers. It keeps track of spent and unspent notes by maintaining Merkle trees over commitments and nullifiers in each Zone. When a transaction to spend a note is submitted by its owner, the transaction must be processed by the Zone executor and validators on Bedrock before it can be accepted as valid. This process involves generating and verifying proofs to ensure that the transaction is correct and that the resulting state transition follows the rules of the Zone and the Common Ledger. A valid transaction results in the updated Zone state and ledger being published to DA Network.
Zone Representation and Updates
Bedrock Crust defines a common framework for Logos Blockchain Zones and allows for the coordination of communications between them. Every such Zone has a unique ID and state, which are maintained by Crust in the form of a map between IDs and Zone states for every existing Zone. For Zones, the Zone state consists of the following three fields:
- Ledger: A partition of the Common Ledger that is controlled by this Zone.
- Data: A commitment to internal Zone data not governed by the Common Ledger rules.
- State Transition Function (STF): The custom rules a Zone enforces on its data.
Executor Coordination and Execution Tickets
Crust provides a protocol for coordination between Zone executors to coordinate activities executed across Zones. When a transaction spans multiple zones, the note owner must submit it in every affected Zone. The executors of these Zones must coordinate to build compatible transaction bundles and execute them to produce the resulting ledger update. Special sync logs, produced by executors, are used by validators to verify the bundle is valid and that every part of the bundle was executed in every Zone. Cross-Zone transactions proceed optimistically, with the coordinated effort going to waste if even one Zone executor does not cooperate. There are several ways to mitigate this risk, including separating cross-Zone transactions from local ones and splitting cross-Zone transactions into chunks based on a “risk score” determined by each executor’s known history of successful collaboration. The executor coordination protocol remains a work in progress at the time of writing. Execution tickets were designed to resolve the tension between the fact that a Zone can only be sequenced by one party at any given time, and the desire to make this valuable role available to a large variety of participants. By defining a common timeline for Zones in the form of discrete block ranges, execution tickets are used to give exclusive execution rights for a Zone during the specified block range. As a result, the benefits of Zone execution are distributed between different executors who obtain these tickets in advance. Additionally, execution tickets provide advance knowledge of who will execute a given Zone, facilitating executor coordination for cross-Zone transactions and improving user experience. Zones can distribute execution tickets in any way they see fit, with Logos Blockchain providing optional templates for how this can be done. Some possibilities include selling execution tickets in an auction, random assignation, or distributing them round robin to a permissioned set of executors. Crust only specifies the minimum interface required for validators to be able to reject Zone updates submitted by an executor without a ticket to the relevant block range. It is ultimately the role of Logos Blockchain validators to enforce the ticketing mechanism on Zone executors. Crust also provides the fallback mechanism used to trigger the “anarchy” state, where anyone (including users) can execute a Zone. This state is invoked when an executor has missed their submission window, or if no executor has obtained an execution ticket for some timeslot.
Logos Blockchain Bedrock Services
While Logos Blockchain' Bedrock relies on a broad base of participants to provide the most essential functionality to the Logos Blockchain network, this functionality is extended by a variety of specialised Logos Blockchain Bedrock Services. These Services give Logos Blockchain more privacy and scalability, and allow it to be more resilient and serve its Zones more efficiently. Participation in a Logos Blockchain Service requires more resources than participating in Bedrock alone, and therefore is not incumbent upon a node unless it opts in. Opt-ins are used for tracking Service participation - important information due to Cryptarchia’s permissionless nature, under which nodes are not required to maintain a list of Bedrock validators. For the more complex Services, there is a need to maintain full agreement on Service participation sets, without dynamic membership like in consensus.
Common Functionality
Despite the differences between the various Services extending Bedrock, they all make use of some common protocols. For example, Logos Blockchain nodes that choose to participate in a Logos Blockchain Service explicitly declare their intent by using the Service Declaration Protocol (SDP). The goal of the SDP is to create a single repository of identifiers to determine which nodes have opted into which Services at a given time. To submit a Service declaration, a node must prove that it owns a note with a certain minimum stake value, which depends on the Service they choose to participate in. This stake requirement makes Service declarations sufficiently expensive to avoid spamming or Sybil attacks. Nodes participating in Services are assigned addresses (known as locators) based on some addressing scheme, allowing them to communicate securely while engaging in a Service. A locator consists of a public key and the network identifier of the validator. Bedrock Services rely on a common framework to enable staking and reward distribution. The basic token mechanics are defined by the Mantle, but each Service defines its own parameters for these operations - including a lock period for staking after which a node participating in a Service can request rewards for its contributions. The reward mechanism that handles the logic of reward distribution and slashing is also defined by each Service. Nodes participating in Bedrock Services send activity messages, which are used by the SDP to determine whether a node is active, how much to reward nodes for their activity, and to remove inactive nodes from a Service.
Current Services Overview
Logos Blockchain currently supports three Bedrock Services that extend and enhance the basic functionality of Bedrock. They may also overlap with each other, since validators can choose to participate in several Services at a time. Much of the functionality for these Services is used by components found in Bedrock. The Data Availability Service provides additional scalability by sharding Zone data to reduce the data processed by each node. At the same time, the service ensures that the data remain publicly available for enough time to allow it to be replicated by any interested party, and can be downloaded if desired by any participant in the network. This is accomplished by encoding Zone data with error-correcting codes and distributing shares of that data between groups of DA nodes. Parties who wish to verify the data’s availability can do so very quickly using sampling and cryptographic techniques and with minimal hardware requirements. The Blend Protocol Service enhances Logos Blockchain’s privacy guarantees by virtually eliminating the likelihood of linking the proposer of a block to the block they propose. It does this by encrypting the proposal message several times and selecting a random path of Blend nodes that can decrypt it at each stage. The final node in the path will then broadcast the transaction to the network, obscuring its origin. As a result, the Blend Protocol Service improves the Private Proof of Stake of Cryptarchia by making it harder to learn a node’s relative stake from its proposal frequency by analysing network patterns. The Executor Network Service allows any participating validator to serve as a state transition executor for any Zone. Using execution tickets to create a schedule of validators with exclusive execution rights for predetermined timeslots makes Zone execution simpler and allows for smoother executor handover in the optimistic case. The permissionless execution facilitated by the Executor Network effectively makes Zones into virtual blockchains run by a decentralized network of readily-available executors. Knowing in advance who will execute a given zone within a particular block range allows for the executor coordination required for cross-Zone transactions. The Executor Network Service remains a work in progress at the time of writing.
Data Availability: DA Network
The data availability (DA) Service used by Logos Blockchain' Bedrock is also known as DA Network. DA Network is a scalability protocol that ensures that data from Zones and other architectures built on Logos Blockchain - known as blobs - are public and can be downloaded if desired by any participant in the network. While data availability can be easily achieved by having each node keep copies of entire blobs, this naive solution introduces serious limitations on scaling and data throughput. The primary motivation for using DA Network, therefore, is to allow for the network to scale while ensuring that blob data remains available. DA Network achieves scalability by minimising the amount of data sent to each node and the bandwidth that the node must support, while maximising the data throughput supported by the network at large. Additionally, Logos Blockchain’s decentralised ethos requires that data availability guarantees be achieved without reliance on trust assumptions and centralised actors - including “supernodes” and special DA roles. DA Network therefore involves splitting up blob data and distributing it among network participants, with cryptographic properties used to verify the data’s integrity. A major feature of this design is that parties who wish to receive an assurance of data availability can do so very quickly and with minimal bandwidth requirements. This lightweight process is known as Data Availability Sampling (DAS). However, lightweight DAS requires participants to be more stable and devote more bandwidth than Bedrock nodes. These participants, known as DA nodes, are required to temporarily store portions of blob data and maintain open connections with several other DA nodes to maximise connection efficiency. In exchange for their efforts, DA nodes are compensated via a rewarding mechanism.
Protocol Overview
The DA Network protocol typically involves three distinct stages: encoding, dispersal, and sampling. Additionally, reconstruction can be invoked as a fourth stage in the scenario where some of the data cannot be directly obtained through other means.
In the encoding stage, the encoder takes the padded blob data and creates an initial matrix of data chunks. They proceed to expand the blob data using Reed-Solomon erasure coding, doubling the size of the rows in the blob matrix. In this expanded matrix, the original data remains intact alongside the new data added via expansion. The executor will also calculate various cryptographic commitments and proofs to enable DA nodes to verify the data’s integrity. The expanded blob is shown in Figure 3.
Figure 3. A blob expanded with DA Network.
DA Network then proceeds with the dispersal phase, in which the encoder splits up their encoded blob and sends each column to a node in a group of DA nodes known as a subnet. This node replicates the column data it received to the other nodes in its subnet, and all the nodes use the published commitments and proofs to verify that their column was correctly encoded. This dispersal process is depicted in Figure 4.
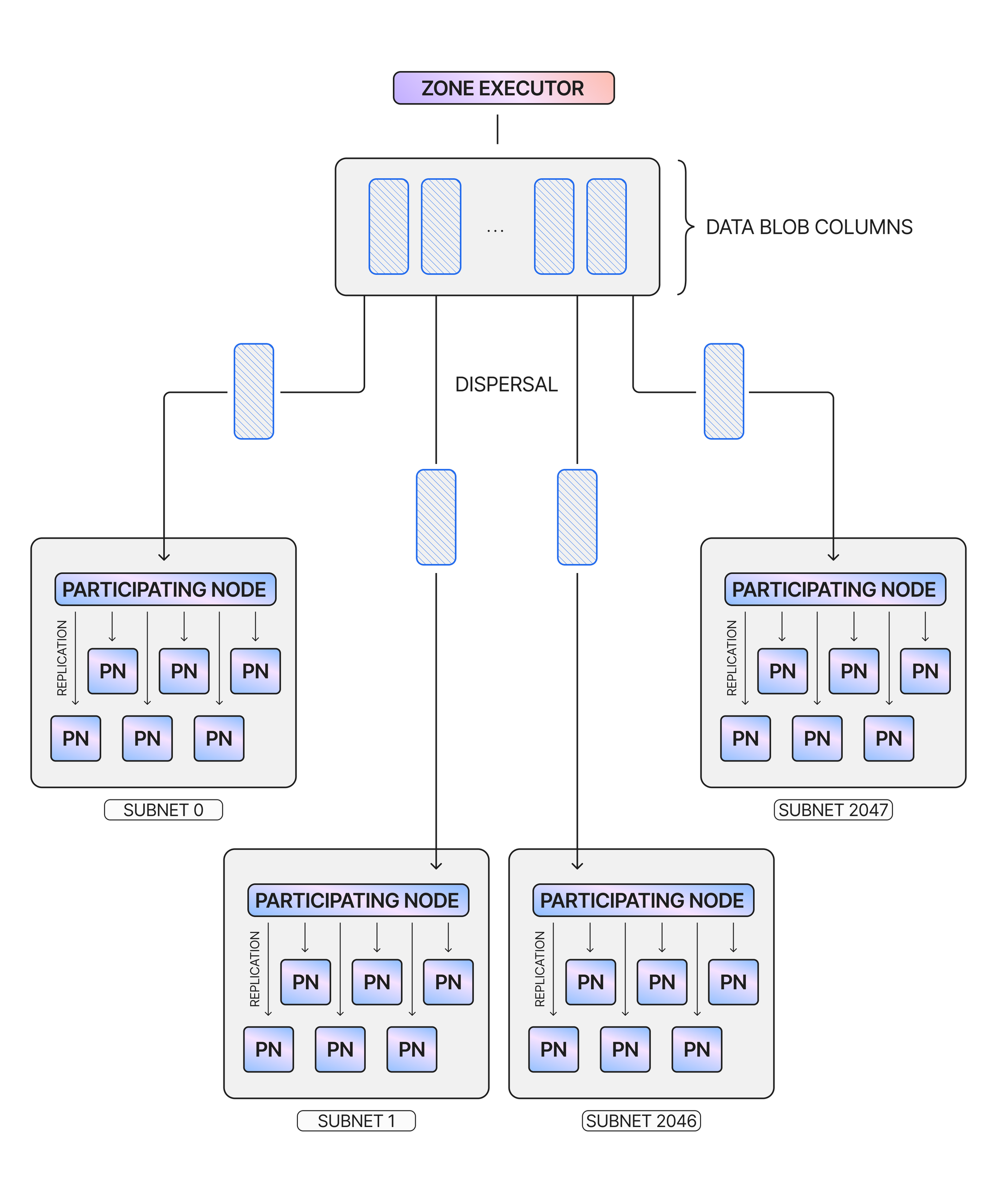
Figure 4. The process of dispersing blob columns to nodes in different subnets.
Once dispersed, the data can be sampled by anybody with Data Availability Sampling (DAS). Choosing a random set of columns, a sampling client sends requests to the corresponding nodes hosting those columns. These samples, combined with the relevant commitments and proofs pulled from the chain, are used to obtain a local opinion on whether the data is available or not. Reconstruction is an option available to clients that choose to download an entire blob. Such a client can use the error-correcting properties of Reed-Solomon codes to reconstruct the blob data, so long as at least 50% of every row is intact.
Blend Protocol
The Logos Blockchain Blend Protocol is a peer-to-peer anonymous broadcasting protocol with cryptographic and timing obfuscation capabilities. Its main objective is to reduce the probability of linking a block proposal with its proposer, which also translates to increasing the difficulty of learning the proposer’s relative stake. At the same time, the Blend Protocol was designed to minimise bandwidth usage on the network compared to general-use mixnets, and to maximise decentralisation by involving all nodes in the obfuscation process. By doing so, the Blend Network increases the cost of attacking the network to deanonymise a block proposal without straining the network with high bandwidth usage. The Blend Network supports the privacy of the Logos Blockchain network as a whole, by providing additional anonymity to block proposers, protecting against adversaries with both a complete (global) and partial (local) view of the Logos Blockchain network. The anonymity provided by the Blend Network also substantially improves the privacy guarantees of Cryptarchia by making it even harder to learn a proposer’s relative stake - which would allow an attacker to estimate the likelihood of that node winning the leadership election. Like other Logos Blockchain Bedrock Services, participation in the Blend Network requires staking and declaration using the SDP. Participating nodes must maintain a minimum number of connections with other nodes, and must ensure that these connections remain compliant with the protocol. There is also a limit to the frequency of messages sent from any given node, putting an upper bound on bandwidth usage.
Protocol Overview
The Blend Protocol underlying the Blend Network makes it difficult to link a proposer to their proposal by having the message travel between several nodes before being revealed. A proposer selects the Blend nodes that will form this path, encrypts their data message several times, and disseminates the encrypted message across the Blend Network. Once the first node in the intended path receives the message, it decrypts one layer and disseminates the result for the second node to decrypt, and so on. Timing delays and artificial traffic are added to make it even more difficult to link a received message with the decrypted message. When the message reaches the last node in the path which finally decodes the message, this Blend node broadcasts the unlinked block proposal to the whole Logos Blockchain network of validators, including nodes not participating in the Blend Protocol. The Blend Protocol consists of four components, all of which work together to enhance the anonymity of block proposers. These are:
- Message Blending: Cryptographically decrypts messages and randomly delays their propagation to reduce the likelihood of linking incoming and outgoing messages based on their content or sending time. This addresses the problem of anonymity failure with a local observer, where we take into account corrupted nodes that are part of the protocol.
- Cover Traffic: Introduces artificial “cover messages” that are encrypted and transmitted along a path in the same way as true data messages, mimicking real traffic. This makes identifying a data message a probabilistic game for local observers.
- Economic Incentives: Provides a privacy-preserving participation measurement mechanism in order to reward nodes based on their contribution to the Blend Protocol. It addresses the problem of node incentivisation, providing motivation for the generation of cover traffic and active participation in the network through economic means.
- Reliable Communication: Introduces a level of redundancy of communication through message replication and erasure coding. This module is meant to decrease the probability of a communication failure by adding resilience to the Blend Network. As a result of these four modules, the Blend Network provides strong anonymity guarantees to block proposers and ensures incentives are aligned. To learn the identity of a proposer under this model, the adversary must control all the nodes on a transmission path in order to trace the message to its origin. In addition, because all messages are broadcast to the network, this adversary must also control a portion of the proposer node’s neighbourhood to be able to break its anonymity.
Executor Network
The Executor Network Service supports Zone liveness by allowing Logos Blockchain validators to act as Zone executors. Executors service all Zones on an equal footing, ordering transactions and executing their state and ledger transitions. They also produce ZK proofs for Zone updates and send Zone data as blobs using DA Network. Due to the heavy workload undertaken by executors, they are required to have powerful machines with GPUs that are capable of quick ZK proving. The Executor Network Service remains a work in progress at the time of writing.
Description
Once a Logos Blockchain node decides to participate in the Executor Network and is registered with the SDP, it can begin to acquire execution tickets. The execution ticket mechanism, described in the Bedrock Crust section, defines a common timeline for Zones and allows executors to obtain exclusive execution rights for a Zone during a specified block range. Each Zone can distribute execution tickets in any way it sees fit. In the case where nobody owns an execution ticket for a given time period, any party can serve as a Zone executor in what is known as the “anarchy” scenario. This scenario, intended only as a fallback option, could involve any executor - or even users acting as executors not registered with the SDP - maintaining Zone liveness. These unregistered executors provide somewhat limited functionality since they are not able to submit Zone data to DA Network, and would need to inscribe it instead. An executor produces a ledger update for the Zone it is executing by processing transactions sent by Zone users. Each Zone receives transactions from users of that Zone, which are processed by the Zone executor. This processing includes verifying transaction correctness, determining the resulting ledger state, and ensuring that the Zone ledger adheres to global rules after effecting the update. The Zone ledger update process is described in the Common Ledger section. In addition, the Zone executor is responsible for updating the Zone’s internal state by running its state transition function.
Light Nodes
In decentralised networks, full nodes engage in consensus, but light nodes’ limited resources only allow for much more intermittent participation, suitable for browsers and small devices. To foster true decentralisation, light nodes require mechanisms enabling them to directly assess the network's integrity, without relying on third parties. By letting light nodes independently and affordably audit the system state, Logos Blockchain gives them an equal seat in validating the network. The collective of light nodes is what allows Logos Blockchain to be verified by large numbers of actors. This in turn helps realise the decentralization vision of open access and peer-to-peer cooperative dynamics between participants, regardless of their resources. The idea of using a Light Node Network is integral for ensuring network scalability and user accessibility. Logos Blockchain's Light Nodes are designed to be run by the users of the network and capable of functioning on minimal-resource hardware. Light nodes perform the following tasks:
- Consensus verification. Light nodes verify the consensus process engaged in by full nodes. This is accomplished by downloading block headers and minimal block data, without actually participating in the mempool as a full node would. Following the network allows light nodes to make independent choices about the correct fork to follow.
- Data Availability Sampling (DAS). An important function of these light nodes is independently verifying Zone data availability via DA Network. Leveraging probabilistic methods, they can asses whether this data is available without needing to access the full data, a method that significantly reduces the workload for light nodes while maintaining network integrity.
- Selective ZK proof verification. Light nodes in Logos Blockchain can selectively verify Zone proofs on Bedrock relevant to their interests, such as from one or several Zones. This verification allows light nodes to engage in state verification in a selective manner, by verifying only the Zones they care about. In addition to the above, Logos Blockchain light nodes aim to provide strong security with minimal hardware requirements. Both Data Availability Sampling and ZK proof verification processes are lightweight and are intended to be run from a phone, a browser wallet and potentially even more limited devices. Making verification so cheap strengthens the security of the network by the sheer number of entities collaboratively verifying the work of the Logos Blockchain validators.
Light Node Coordination
The network of light nodes ultimately helps protect the most important actors in the system: the users of Logos Blockchain Zones. It is important to note that all these light node mechanisms are opt-in, altruistic and are not enforced by any cryptoeconomic incentives. Every light node, as a client of the network, is free to participate (or not) in altruistic data replication, and/or collaborating in collective action in the face of a massive disruption or misbehaviour on the Logos Blockchain network.
Last Resort Data Reconstruction via Altruistic Replication
Bedrock provides a probabilistic guarantee of availability for Zone data. However, strictly speaking this guarantee can only be proven in an instant in time - when a client engages in DAS and obtains an assurance of the data’s integrity. After this point, there is no way to guarantee the continued availability of this data without engaging in DAS again. This is because data loss cannot be punished by slashing (since lack of data availability is unattributable), and because nodes can stop participating in DA Network or exhibit any kind of Byzantine behaviour. Even beyond this limitation, DA nodes are only expected to host their shares of blob data for a short period of time. After this point, it is expected that at least one entity among the network participants - such as an archival node, Zone executor, or an interested user or collective - will have copied the data and will make it available. To aid in this process, light nodes can contribute with an altruistic, decentralized replication protocol of sharing data they have sampled among themselves. With enough participation, this replication allow them to not rely on any third party to make the data available. Hence, this mechanism exists solely as a last-resort system to reconstruct the blockchain and potentially fork it following a mass-exit and/or user-activated fork protocol.
Mass-Exiting the Logos Blockchain network
Exiting the Logos Blockchain network may occur as the last stage of protection for users, when the Zone and Bedrock fail to act correctly. Exiting is based on the premise of light nodes being capable of verifying the entire network. This requires both verifying Zone state and verifying data availability. The former is done via ZK proofs, and the latter via Data Availability Sampling. When misbehaviour is detected, a light node operator can choose to follow an honest minority fork of the chain, if it exists. However, the scenario where all available forks are dishonest remains an open problem. At the time of writing, the Logos Blockchain Team is exploring protocols to coordinate light node-activated forks and similar processes via the Waku P2P messaging network - a component of the Logos stack.
Building on Logos Blockchain
Logos Blockchain is built to support lightweight, interconnected blockchains - known as Zones - that rely on Bedrock and Bedrock Services to run private, secure applications. Zones adhere completely to the Common Ledger specifications, enabling cross-Zone interoperability and censorship resistance guarantees. These totally permissionless Zones inherit their security properties from Bedrock, but are constrained by ZK performance limitations. Decentralization for Zone execution is achieved as a result of the permissionless and censorship-resistant properties of Zones. Users of applications on Logos Blockchain almost always interact directly with these Zones, with Bedrock and Services supporting the Zone in the background. In some rare cases, such as when a Zone misbehaves or there are no executors for that Zone, a user will fall back to using Bedrock to enable them to execute transactions. The primary motivation for Zones is to allow scaling by partitioning their global state, compressing updates, and drastically reducing the effort to verify - all while maintaining a good level of interoperability, privacy, and coordination.
Native Execution Space: Zones
Zones are turnkey application environments that make dApp deployment simple, while fully embracing Logos Blockchain’s core values of privacy, censorship resistance, and decentralisation. Their adherence to the Common Ledger specifications gives Zones strong interoperability with each other, enabling atomic cross-Zone transactions and allowing them to work as one coherent Native Execution Space. Transactions and state updates on Zones are private by default, with Bedrock ensuring their security by validating ZK proofs. Due to these restrictions, Zones allow for less freedom in their implementation, and are constrained by ZK performance limitations. Zones adhere to a set of standards that regulate their state and ensure security and compatibility with other Zones. This state can be divided into two parts: the Zone’s partition of the Common Ledger, and an internal Zone state. The ledger partition allows Zones to keep track of notes in their Zone and facilitates note spending within and across Zones. The data fields and owner of a Zone note are hidden from observers, with the Common Ledger providing a mechanism for transferring note value in a private way. This system is described in detail in the Common Ledger section. Zones maintain an internal state together with the aforementioned ledger partition. This state is only governed by the Zone’s state transition function (STF), which is set when the Zone is created. While the internal state may contain any assortment of assets and data without regard for their compatibility with those on other Zones, the Zone must ensure that any state update adheres to its STF. Just like ledger updates, state updates are verified by Logos Blockchain validators via ZK proofs posted on Bedrock, ensuring the security and correctness of the Zone state. A key advantage of Zones is their permissionless nature, allowing anyone to participate in ensuring that a Zone remains live. Transactions on Zones are processed by executors, who update the Zone state and generate proofs that are verified by Bedrock validators. Executors are not linked to a particular Zone - rather, they are assigned by the Executor Network Service for fixed block ranges based on a ticketing system. In the event that no executors are available to service some Zone, any Logos Blockchain node can step in and process Zone updates.
Zone Interoperability
The Native Execution Space allows users to engage in cross-Zone activities that are executed simultaneously across all affected Zones, as if all Zones share one execution space. Zone executors coordinate to create transaction bundles spanning their Zones for verification by Logos Blockchain validators. This functionality is referred to as synchronous composability, which means that functions in one Zone can call functions in another and use their output as input. Together with privacy guarantees for notes and transactions, synchronous composability opens up a realm of possibilities for private, seamless operations throughout the Native Execution Space. These may include the following, all executed within one block:
- Transferring a note of unit A to another Zone, performing a swap to obtain a note of unit B, and transferring it back to the first Zone.
- Taking out a flash loan, performing swaps in several Zones with optimal swapping routes, and paying back the loan.
- Creating transactions with cross-Zone intents included in the notes’ spending covenants. The first full implementation of limited synchronous composability on Logos Blockchain is known as a PACT - Private Atomic Cross-Zone Transaction. PACTs are used to “teleport” note value between Zones with full privacy and atomic inclusion guarantees - either the state is updated correctly across all affected Zones within the same block, or no update occurs. This protocol operates on an optimistic basis, assuming good faith cooperation among executors but including fallback options in case of misbehaviour. In such a scenario, the transaction and all its associated updates are deemed invalid immediately and will not be included in the block. At the time of writing, the full array of possibilities introduced by synchronous composability remains complex, to be a focus of research in later stages of the project.
Use Cases
Zones are ideal for developers who want to launch a private, decentralised application that inherits the security of Bedrock with minimal setup required. A Zone only needs to define its state and STF, and the problem of bootstrapping sequencers is solved since Logos Blockchain executors permissionlessly maintain the Zone. The default toolkit is built with Risc0, allowing developers to write Zone applications directly in Rust and any other Risc0-compatible language. Bridging and cross-Zone communication are built-in to Zones, making them great for applications that accept assets from different Zones. Zones’ private notes and permissionless execution are well-suited for applications where user privacy, infrastructure resilience, and neutrality are paramount.
Other Ways to Build on Logos Blockchain
Zones represent only the most common and well-supported way to make use of the Logos Blockchain network. Logos Blockchain also supports other kinds of application platforms with some favourable properties. As one such solution, Sovereign Rollups have complete freedom to define their own state, only using Logos Blockchain to ensure consensus and the availability of rollup data. This design allows applications built on Sovereign Rollups to have low fees and maximise scalability, but with reduced interoperability and no censorship resistance enforced by Bedrock. Sovereign Rollups can implement almost anything, ranging from applications to virtual machines that are home to many different applications. They are best suited for applications that require high performance and do not need strong interoperability. This could include gaming applications whose state changes quickly but is largely isolated from other blockchain applications, DeFi platforms focusing on high-frequency transactions of internally-issued assets, and a great variety of web applications not often implemented on-chain due to performance requirements. Although Logos Blockchain provides support for Sovereign Rollups, almost any combination of Logos Blockchain’s modular components and independent architectures is technically possible. One possibility is to create validiums - independent blockchains that use their own Data Availability Committee (DAC) instead of DA Network, while still posting ZK proofs to Bedrock for validation by Logos Blockchain full and light nodes. Another option could be to use Zone infrastructure to prove state transitions with SNARKs in custom ways, without regard to the methods employed by Logos Blockchain Zones. Ultimately, Logos Blockchain provides a robust infrastructure for decentralised applications, complete with preferred solutions, while giving developers the freedom to use this infrastructure however they wish.
Interoperability
Despite lacking the interoperability of Zones, other application environments built on Logos Blockchain still have the ability to communicate with each other. This form of trustless communication only happens asynchronously via message-passing, unlike the atomic cross-Zone transactions available between Zones. DA Network is used as the message buffer for communication between rollups. Communication is crucial for enabling dependency relationships between applications located in different Logos Blockchain-based environments. One application may choose to define a function based on the state of another application hosted elsewhere, but cannot force the second application to depend on its own state. Mantle has a specific mechanism to encode these dependencies to provide a faster communication channel between environments that read the state of others.
Sovereign Rollups
Sovereign Rollups represent the most customisable, performant solutions for applications built on Logos Blockchain. They function as independent modular blockchains, only relying on Bedrock and its Services for consensus and data availability. State validity and execution, by contrast, are solely determined by the Sovereign Rollup.
The idea behind Sovereign Rollups is to make performant applications with the freedom to define an execution environment to suit their needs, with the Logos Blockchain network providing economic security and data availability guarantees that the rollup alone could not provide, helping to bootstrap rollups’ economic security. To ensure the correctness of the rollup state, Sovereign Rollups are left to their own devices instead of relying on a smart contract on the L1 as with Ethereum L2s. This could be done in any number of ways - including publishing ZK validity proofs to be verified by its validators, providing a challenge window for fraud proofs, or by requiring rollup nodes to re-execute the state transition function.
Bedrock does not attempt to interpret rollup data, only providing operations via Mantle to allow rollups to temporarily post data in the form of a DA Network blob. This blob is distributed among DA nodes, allowing all Logos Blockchain light clients to verify its availability. The blob commitments are written on-chain, ensuring that the rollup state enjoys the benefits of Cryptarchia consensus.
One possible implementation of a Sovereign Rollup that uses validity proofs is illustrated in Figure 5.
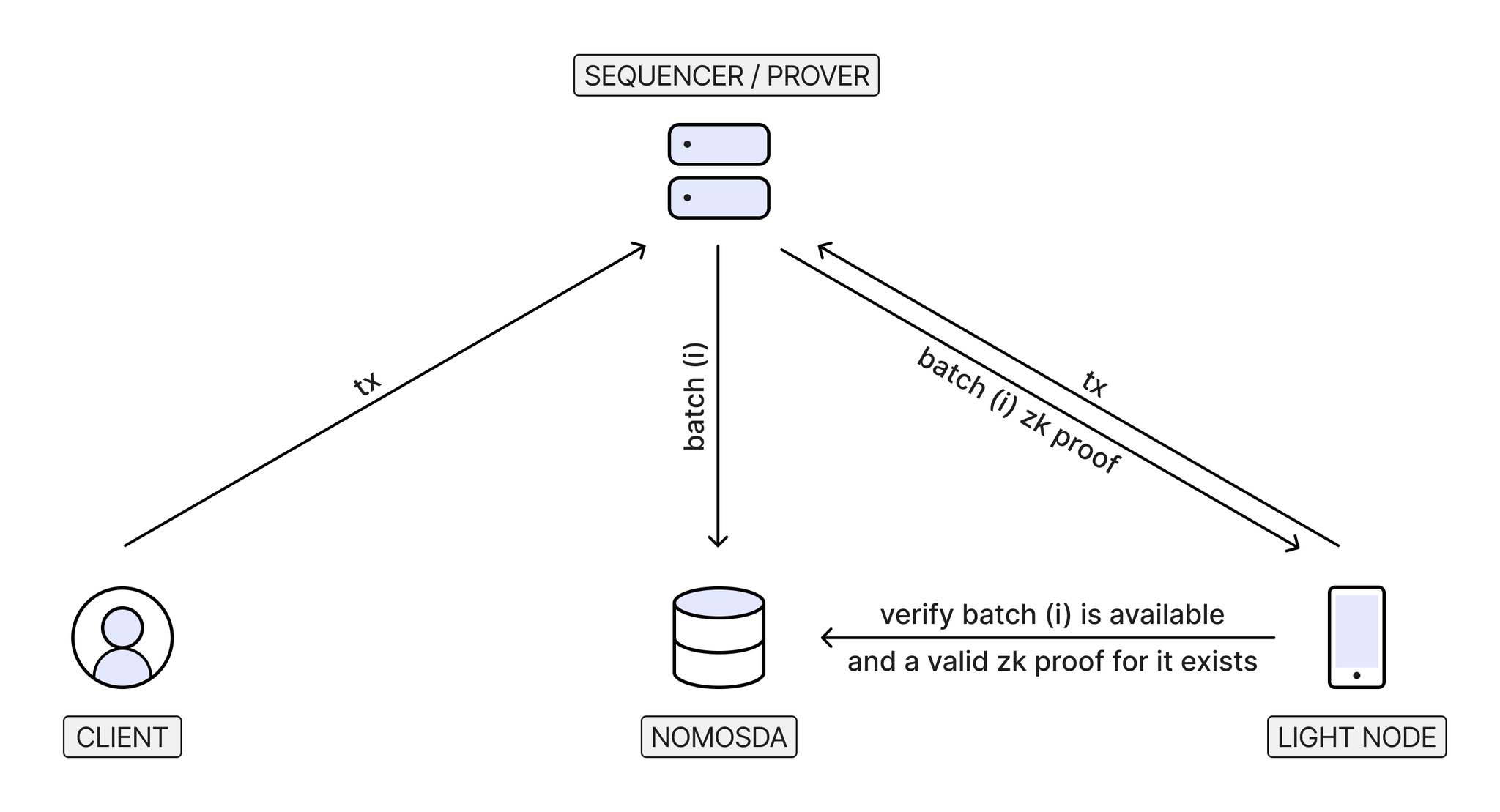
Figure 5. One example of a Sovereign Rollup that uses validity proofs to verify its state.
This example rollup’s sequencer processes transactions from clients and sends the batched state data to DA Network, while simultaneously creating ZK proofs for its state updates and distributing them off-chain. Rollup light nodes can then verify the proofs received from the sequencer and check the availability of the data via data availability sampling.
Annex
References
Agarwal, R. (2024). Preconfirmations: Credible Promise of Future Execution. [online] Longhash.vc. Available at: https://www.longhash.vc/post/preconfirmations-credible-promise-of-future-execution [Accessed 21 May 2025]. Al-Bassam, M. (2019). LazyLedger: A Distributed Data Availability Ledger With Client-Side Smart Contracts. arXiv (Cornell University). doi:https://doi.org/10.48550/arxiv.1905.09274. Al-Bassam, M., Sonnino, A. and Buterin, V. (2018). Fraud and Data Availability Proofs: Maximising Light Client Security and Scaling Blockchains with Dishonest Majorities. arXiv (Cornell University). doi:https://doi.org/10.48550/arXiv.1809.09044. Al-Bassam, M., Tas, E.N. and Nima Vaziri (2022). Rollups as Sovereign Chains. [online] Celestia Blog. Available at: https://blog.celestia.org/sovereign-rollup-chains/ [Accessed 21 May 2025]. Buterin, V. (2021). An Incomplete Guide to Rollups. [online] vitalik.eth.limo. Available at: https://vitalik.eth.limo/general/2021/01/05/rollup.html. Ethereum Foundation (2019). Home | Ethereum. [online] ethereum.org. Available at: https://ethereum.org/. Kerber, T., Kiayias, A., Kohlweiss, M. and Zikas, V. (2019). Ouroboros Crypsinous: Privacy-Preserving Proof-of-Stake. [online] IEEE Xplore. doi:https://doi.org/10.1109/SP.2019.00063. Kiayias, A., Russell, A., David, B. and Oliynykov, R. (2016). Ouroboros: A Provably Secure Proof-of-Stake Blockchain Protocol. [online] Cryptology ePrint Archive. Available at: https://eprint.iacr.org/2016/889 [Accessed 21 May 2025]. Kohlweiss, M., Madathil, V., Nayak, K. and Scafuro, A. (2021). On the Anonymity Guarantees of Anonymous Proof-of-Stake Protocols. Edinburgh Research Explorer (University of Edinburgh). doi:https://doi.org/10.1109/sp40001.2021.00107. Logos.co. (2025). Logos - A Declaration of Independence in Cyberspace | Logos Network. [online] Available at: https://logos.co/ [Accessed 21 May 2025]. Neuder, M. and Drake, J. (2023). Execution Tickets. [online] Ethereum Research. Available at: https://ethresear.ch/t/execution-tickets/17944 [Accessed 21 May 2025]. RISC Zero. (2025). RISC Zero. [online] Available at: https://www.risc0.com/ [Accessed 21 May 2025]. Sun Yin, A. (2023). An Introduction to Intents and Intent-centric Architectures | Research - Anoma. [online] Anoma.net. Available at: https://anoma.net/blog/an-introduction-to-intents-and-intent-centric-architectures [Accessed 21 May 2025]. Syverson, P. (2009). Why I’m Not an Entropist. [online] https://gwern.net/doc/cs/security/2009-syverson.pdf. Available at: https://gwern.net/doc/cs/security/2009-syverson.pdf [Accessed 20 May 2025]. Waku.org. (2024). Waku is Uncompromising Web3 Communication at Scale | Waku. [online] Available at: https://waku.org/ [Accessed 21 May 2025].
DA-CRYPTOGRAPHIC-PROTOCOL
| Field | Value |
|---|---|
| Name | DA Cryptographic Protocol |
| Slug | 148 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Mehmet Gonen [email protected] |
| Contributors | Álvaro Castro-Castilla [email protected], Thomas Lavaur [email protected], Daniel Kashepava [email protected], Marcin Pawlowski [email protected], Daniel Sanchez Quiros [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-18 —
58b5698— chore(blockchain): migrate contributor emails to @logos.co (#338) - 2026-01-30 —
0ef87b1— New RFC: CODEX-MANIFEST (#191) - 2026-01-30 —
25ebb3a— Replace nomosda-encoding with da-cryptographic-protocol (#264)
Abstract
This document describes the cryptographic protocol underlying DA Network, the data availability (DA) layer for the Logos Blockchain. DA Network ensures that all blob data submitted is made available and verifiable by all network participants, including sampling clients and validators. The protocol uses Reed–Solomon erasure coding for data redundancy and KZG polynomial commitments for cryptographic verification, enabling efficient and scalable data availability sampling.
Keywords: DA Network, data availability, KZG, polynomial commitment, erasure coding, Reed-Solomon, sampling, BLS12-381
Semantics
The keywords "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119.
Definitions
| Terminology | Description |
|---|---|
| Blob | A unit of data submitted to DA Network for availability guarantees. |
| Chunk | A 31-byte field element in the BLS12-381 scalar field. |
| DA Node | A node responsible for storing and serving column data. |
| Encoder | The entity that transforms blob data into encoded form with proofs. |
| Sampling Client | A client (e.g., light node) that verifies availability by sampling columns. |
| KZG Commitment | A polynomial commitment using the Kate-Zaverucha-Goldberg scheme. |
| Reed-Solomon Coding | An erasure coding scheme used for data redundancy. |
| Row Polynomial | A polynomial interpolated from chunks in a single row. |
| Combined Polynomial | A random linear combination of all row polynomials. |
Notations
| Symbol | Description |
|---|---|
| Polynomial interpolated from the chunks in row . | |
| KZG commitment of the row polynomial . | |
| Combined polynomial formed as a random linear combination of all row polynomials. | |
| KZG commitment of the combined polynomial . | |
| Primitive -th root of unity in the finite field. In this protocol, . | |
| Random scalar generated using the Fiat–Shamir heuristic from row commitments. | |
| KZG evaluation proof for column of the combined polynomial. | |
| Combined evaluation of column (i.e., ). | |
| Number of columns in the original data matrix. | |
| Number of rows in the data matrix. |
Background
To achieve data availability, the blob data is first encoded using Reed–Solomon erasure coding and arranged in a matrix format. Each row of the matrix is interpreted as a polynomial and then committed using a KZG polynomial commitment. The columns of this matrix are then distributed across a set of decentralized DA nodes.
Rather than requiring individual proofs for each chunk, DA Network uses a random linear combination of all row polynomials to construct a single combined polynomial. This allows for generating one proof per column, which enables efficient and scalable verification without sacrificing soundness. Sampling clients verify availability by selecting random columns and checking that the data and proof they receive are consistent with the committed structure. Because each column intersects all rows, even a small number of sampled columns provides strong confidence that the entire blob is available.
Protocol Stages
The protocol is structured around three key stages:
- Encoding: Transform blob data into a matrix with commitments and proofs.
- Dispersal: Distribute columns to DA nodes for storage.
- Sampling: Verify data availability by sampling random columns.
Design Principles
The reason for expanding the original data row-wise is to ensure data availability by sending a column to each DA node and obtaining a sufficient number of responses from different DA nodes for sampling. Three core commitment types are used, and verification is done via column sampling:
-
Row commitment: Ensures the integrity of the original and RS-encoded data and binds the order of chunks within each row.
-
Combined commitment: Constructed by the verifier using a random linear combination of the row commitments. Used to verify the encoder's single proof per column and ensures that the column data is consistent with the committed row structure. Even if a single chunk is invalid, the combined evaluation will likely fail due to the unpredictability of the random coefficients.
-
Column sampling: Allows sampling clients to verify data availability efficiently by checking a small number of columns. With the combined commitment and a single proof, the sampling client can validate that an entire column is consistent with the committed data.
Protocol Specification
Encoding
In the DA Network protocol, encoders perform the encoding process by dividing the blob data into chunks. Each chunk represents a 31-byte element in the scalar finite field used for the BLS12-381 elliptic curve. 31 bytes are chosen instead of 32 bytes because some 32-byte elements will exceed the BLS12-381 modulus, making it impossible to recover the data later.
The matrix representation has columns which include chunks each. The row and column numbers used in the representation are decided based on the size of the block data and the number of DA nodes.
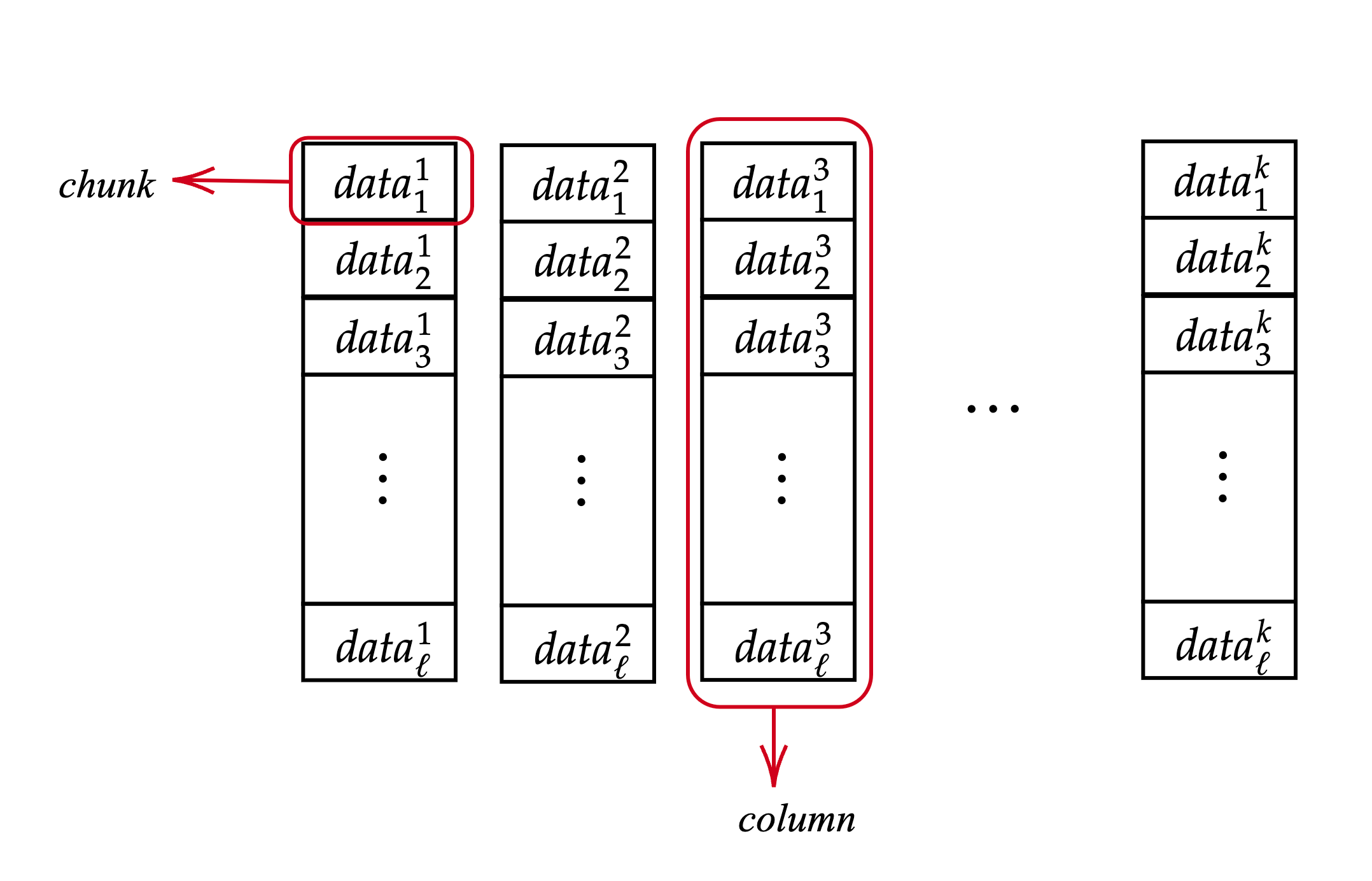
Figure 1: Data matrix structure showing chunks and columns. Each chunk is a 31-byte element, and each column contains chunks.
The encoding process consists of three steps:
- Calculating row commitments.
- Expanding the original data using RS coding.
- Computing the combined row polynomial and the combined column proofs.
Row Commitments
The original data chunks are considered in the evaluation form, and unique polynomials are interpolated for each row. For every row , the encoder interpolates a unique degree polynomial such that for row indices and column indices. Recall that is a primitive element of the field.
Subsequently, 48-byte row commitment values for these polynomials are computed by the encoder. These commitments ensure the correct ordering of chunks within each row.
Note: In this protocol, elliptic curves are used as a group, thus the entries of 's are also elliptic curve points. Let the -coordinate of be represented as and the -coordinate of as . If you have just and one bit of , then you can construct . Therefore, there is no need to use both coordinates of . However, for the sake of simplicity in this document, the value is used.
Reed-Solomon Expansion
Using RS coding, the encoder extends the original data row-wise to obtain the expanded data matrix. The expansion is calculated by evaluating the row polynomials at the new points where . The current design of DA Network uses an expansion factor of 2, but it can also work with different factors. This expanded data matrix has rows of length .
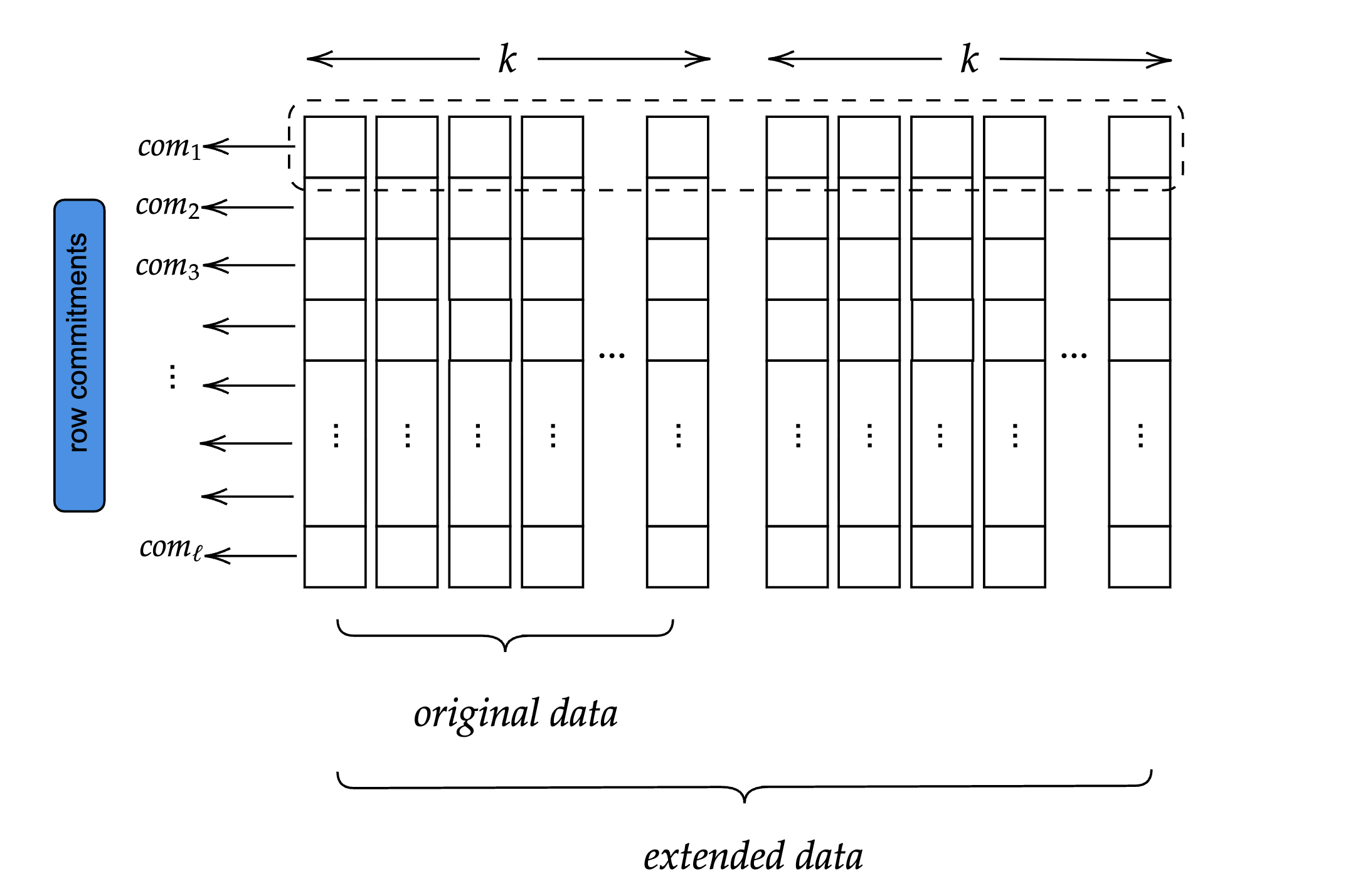
Figure 2: Extended data matrix showing original data ( columns) and extended data ( columns total) after Reed-Solomon expansion.
Due to the homomorphic property of KZG, the row commitment values calculated in the previous step are also valid for the row polynomials of the extended data.
Combined Row Commitment and Column Proofs
To eliminate the need for generating one proof per chunk, a more efficient technique using random linear combinations of row polynomials is used, allowing only one proof to be generated per column while still ensuring the validity of all underlying row data.
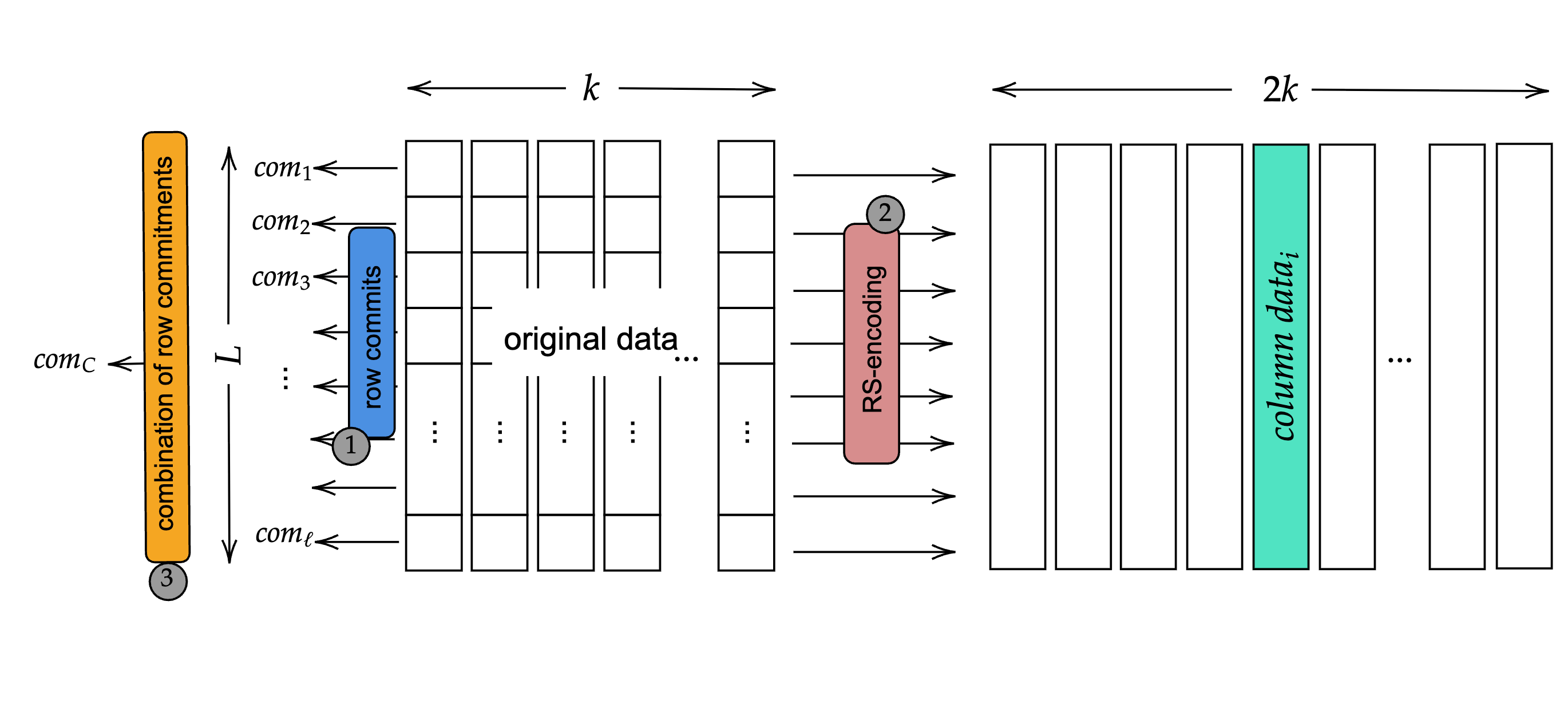
Figure 3: Complete encoding pipeline showing row commitments (step 1), RS-encoding (step 2), and combined row commitment with column data (step 3).
This process consists of the following steps:
Compute the Random Linear Combination Polynomial
Let each row have an associated polynomial and commitment .
The encoder computes random scalar using the Fiat–Shamir heuristic,
applying the BLAKE2b hash function with a 31-byte output,
over the row commitments with a domain separation tag DA_V1
to ensure uniqueness and prevent cross-protocol collisions:
The resulting digest is interpreted as a field element in the scalar field of BLS12-381.
Then, the encoder computes the combined polynomial , defined as:
The corresponding commitment to this polynomial is . This value does not need to be computed by the encoder, since the verifier can derive it directly from the row commitments using the same random scalar .
Compute Combined Evaluation Points per Column
For each column , the encoder has the set of column values , where each value corresponds to .
The encoder computes the combined evaluation value at column position directly:
Generate One Proof per Column
For each column index , the encoder computes a single KZG evaluation proof for the combined polynomial at the evaluation point :
The result is a set of evaluation proofs, one for each column, derived from the combined row structure.
Dispersal
The encoder sends the following information to a DA node in the subnet corresponding to the expanded column number :
- The row commitments .
- The column chunks .
- The combined proof of the column chunks .
This information is also replicated by the receiving node to every other node in the subnet.
Verification
A DA node that receives the column information described above performs the following checks:
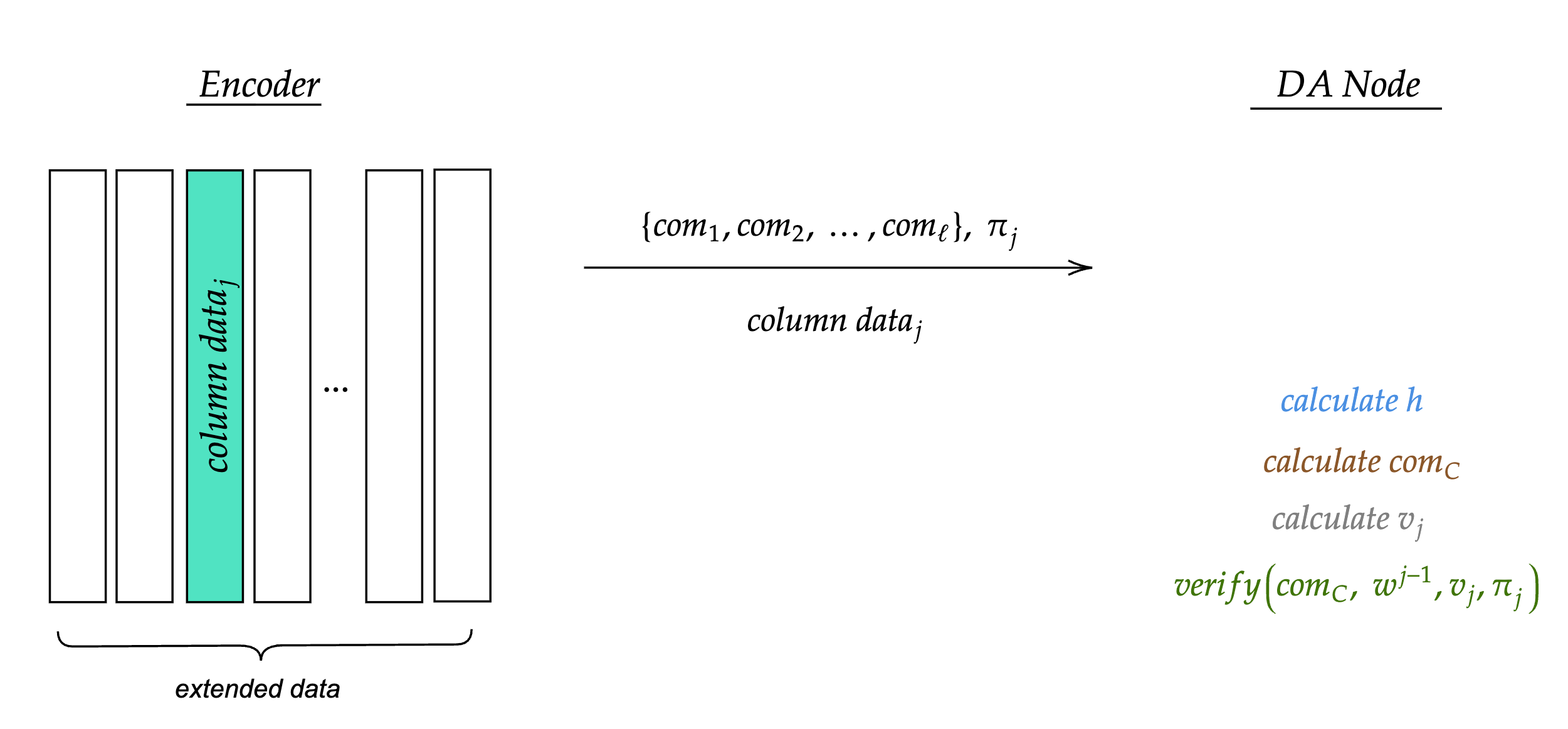
Figure 4: Dispersal and verification flow from Encoder to DA Node. The DA Node receives row commitments, column data, and combined proof, then verifies by calculating , , and .
-
The DA node computes the scalar challenge using a Fiat–Shamir hash over the row commitments with a domain separation tag:
-
The DA node computes the combined commitment :
This is the commitment of the following polynomial:
-
The DA node computes:
This represents , the evaluation of the combined polynomial at the corresponding column index.
-
The DA node verifies that is a valid proof:
Sampling
A sampling client, such as a light node, selects a random column index . It sends a request for column to a DA node hosting that column's data. The DA node sends the client the column data and the combined proof .
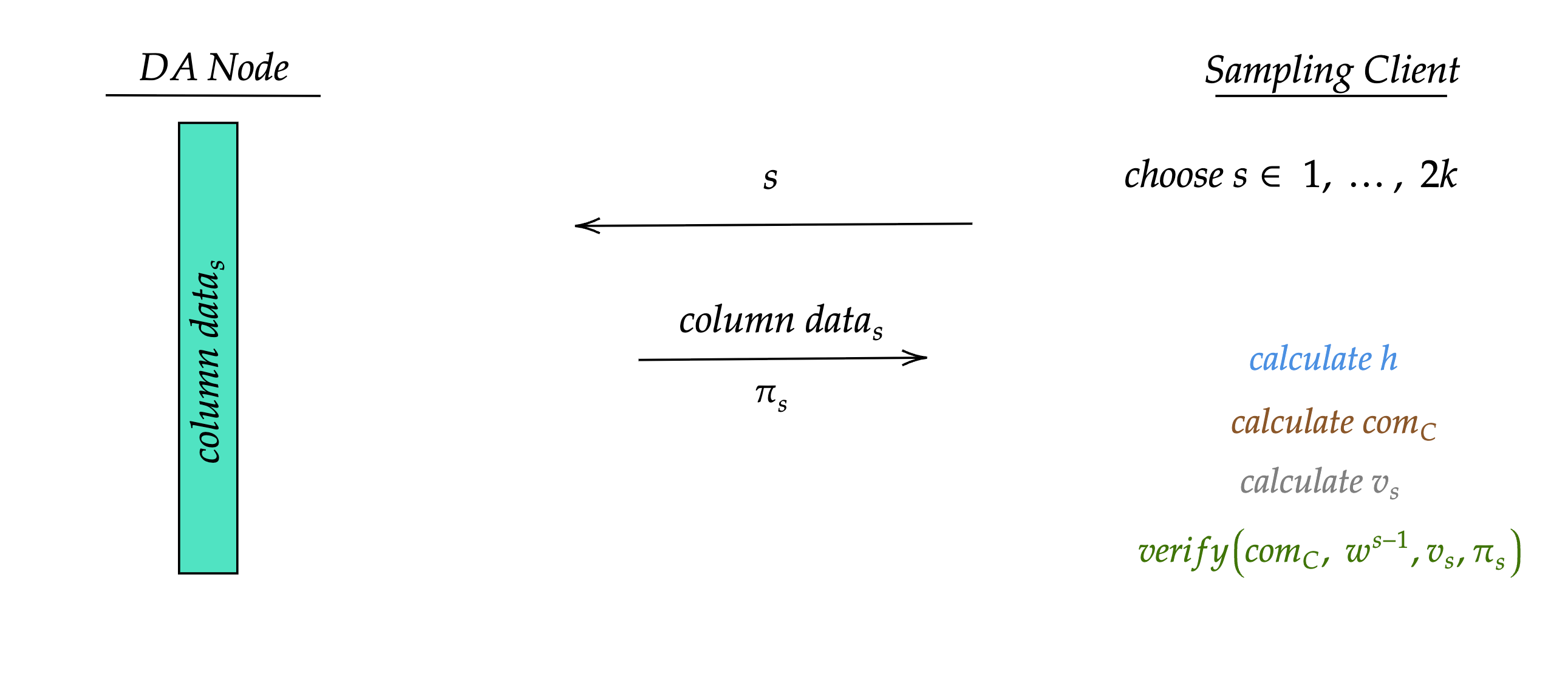
Figure 5: Sampling flow between DA Node and Sampling Client. The client requests a random column index , receives the column data and proof, then verifies by calculating , , and .
Note: The row commitments for a given blob are public and remain unchanged across multiple queries to that blob. If a sampling client has already obtained them, it does not need to request them again.
The verification process run by the sampling client proceeds as follows:
-
Compute the scalar using the domain-separated Fiat–Shamir hash:
-
Compute the combined commitment :
-
Compute the combined evaluation value using the received column data:
-
Verify the evaluation proof:
If these checks succeed, then this proves to the sampling client that the column is correctly encoded and matches the committed data. The sampling client can query several columns to reach a local opinion on the availability of the entire data.
Security Considerations
Fiat–Shamir Security
The random scalar MUST be computed using the Fiat–Shamir heuristic
with the domain separation tag DA_V1 to prevent cross-protocol attacks.
The hash function MUST be BLAKE2b with a 31-byte output.
Chunk Size
Chunks MUST be 31 bytes to ensure they fit within the BLS12-381 scalar field modulus. Using 32-byte chunks would cause some values to exceed the modulus, making data recovery impossible.
Column Sampling Confidence
The more columns a sampling client verifies, the higher confidence it has in the availability of the entire blob. Implementations SHOULD sample a sufficient number of columns to achieve the desired confidence level.
Proof Validity
If a single chunk is invalid, the combined evaluation will likely fail verification due to the unpredictability of the random coefficients. This provides strong guarantees against malicious encoders attempting to hide invalid data.
Part II: Implementation Considerations
IMPORTANT: The sections above define the normative protocol requirements. All implementations MUST comply with those requirements.
The sections below are non-normative. They provide mathematical background for implementers unfamiliar with the underlying cryptographic concepts.
Mathematical Background
Polynomial Interpolation
Polynomial interpolation is the process of creating a unique polynomial from a set of data. In DA Network, univariate interpolation is used, where each polynomial is defined over a single variable. There are two main ways to represent polynomials:
Coefficient form: Given a set of coefficients , a unique polynomial of degree at most in coefficient form is:
If , then the degree of is exactly .
Evaluation form: Let be a primitive -th root of unity in the field, i.e., and for all . Given a dataset , there exists a unique polynomial in of degree less than such that:
This representation of a polynomial using its values at distinct points is called the evaluation form.
KZG Polynomial Commitment
The KZG polynomial commitment scheme provides a way to commit to a polynomial and provide a proof for an evaluation of this polynomial. This scheme has 4 steps: setup, polynomial commitment, proof evaluation, and proof verification.
The setup phase generates a structured reference string (SRS) and is required only once for all future uses of the scheme. The prover performs the polynomial commitment and proof generation steps, while the verifier checks the validity of the proof against the commitment and the evaluation point.
Setup:
- Choose a generator of a pairing-friendly elliptic curve group .
- Select the maximum degree of the polynomials to be committed to.
- Choose a secret parameter and compute global parameters . Delete and release the parameters publicly.
Note: The expression refers to elliptic curve point addition, i.e., where is the generator point of the group . This is known as multiplicative notation.
Polynomial Commitment: Given a polynomial , compute the commitment of as follows:
Proof Evaluation: Given an evaluation , compute the proof , where is called the quotient polynomial and it is a polynomial if and only if .
Proof Verification: Given commitment , the evaluation point , the evaluation , and proof , verify that:
where is a non-trivial bilinear pairing.
Note: The evaluation of the polynomial commitment to the function at the point , yielding the result and evaluation proof , is represented as: . The verification function is defined as: .
Random Linear Combination of Commitments and Evaluations
When multiple committed polynomials are evaluated at the same point, it's possible to verify all evaluations using a single combined proof, thanks to the homomorphic properties of KZG commitments. This technique improves efficiency by reducing multiple evaluation proofs to just one.
Suppose there are polynomials with corresponding commitments , and the goal is to verify that each .
Instead of generating separate proofs and performing pairing checks:
-
Use the Fiat–Shamir heuristic to derive deterministic random scalars from the commitments :
-
Form the combined polynomial:
-
Compute the combined evaluation:
-
Compute the proof for using the standard KZG method:
Verification: Given commitments , evaluation point and value , and proof :
The verifier calculates the combined commitment using random scalars :
and checks:
This ensures that all original evaluations are correct with a single proof and a single pairing check. Since the random scalars are generated via Fiat–Shamir, any incorrect will almost certainly cause the combined evaluation to fail verification.
Reed-Solomon Erasure Coding
Reed-Solomon coding, also known as RS coding, is an error-correcting code based on the fact that any -degree polynomial can be uniquely determined by points satisfying the polynomial equation. It uses the interpreted polynomial over the data set to produce more points in a process called expansion or encoding. Once the data is expanded, any elements of the total set of points can be used to reconstruct the original data.
Pairing Details
Let , , and be three cyclic groups of large prime order. A map is a pairing map such that:
Given and , a pairing can check that some element without knowing and .
For the KZG commitment scheme to work, a so-called trusted setup is needed, consisting of a structured reference string (SRS). This is a set of curve points in and . For a field element , define . The SRS consists of two sequences of group elements:
where is a secret field element, not known by either participant. is the generator point of and is the generator point of . is the upper bound for the degree of the polynomials that can be committed to, and is the maximum number of evaluations to be proven using a batched proof.
Verify Operation: To verify an evaluation proof, the verifier checks the following equation:
As the verifier does not have access to the actual polynomials and , the next best thing would be to check that:
Expanding the definition of :
For elliptic curve additive notation this is equivalent to:
Now there is a problem, namely, the multiplication on the left-hand side. Pairings allow us to get away with one multiplication. So the verifier actually checks:
i.e.,
This works because of the bilinearity property of elliptic curve pairings:
References
Normative
- BLS12-381 - BLS12-381 elliptic curve specification
Informative
- DA Cryptographic Protocol - Original specification document
- Elliptic Curve Pairings - Background on elliptic curve pairings
Copyright
Copyright and related rights waived via CC0.
DA-NETWORK
| Field | Value |
|---|---|
| Name | DA Network |
| Slug | 136 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Daniel Sanchez Quiros [email protected] |
| Contributors | Álvaro Castro-Castilla [email protected], Daniel Kashepava [email protected], Gusto Bacvinka [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-18 —
58b5698— chore(blockchain): migrate contributor emails to @logos.co (#338) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-09-25 —
51ef4cd— added nomos/raw/nomosda-network.md (#160)
Introduction
DA Network is the scalability solution protocol for data availability within the Logos Blockchain network.
This document delineates the protocol's structure at the network level,
identifies participants,
and describes the interactions among its components.
Please note that this document does not delve into the cryptographic aspects of the design.
For comprehensive details on the cryptographic operations,
a detailed specification is a work in progress.
Objectives
DA Network was created to ensure that data from Logos Blockchain Zones is distributed, verifiable, immutable, and accessible. At the same time, it is optimised for the following properties:
-
Decentralization: DA Network’s data availability guarantees must be achieved with minimal trust assumptions and centralised actors. Therefore, permissioned DA schemes involving a Data Availability Committee (DAC) had to be avoided in the design. Schemes that require some nodes to download the entire blob data were also off the list due to the disproportionate role played by these “supernodes”.
-
Scalability: DA Network is intended to be a bandwidth-scalable protocol, ensuring that its functions are maintained as the Logos Blockchain network grows. Therefore, DA Network was designed to minimise the amount of data sent to participants, reducing the communication bottleneck and allowing more parties to participate in the DA process.
To achieve the above properties, DA Network splits up zone data and distributes it among network participants, with cryptographic properties used to verify the data’s integrity. A major feature of this design is that parties who wish to receive an assurance of data availability can do so very quickly and with minimal hardware requirements. However, this comes at the cost of additional complexity and resources required by more integral participants.
Requirements
In order to ensure that the above objectives are met, the DA network requires a group of participants that undertake a greater burden in terms of active involvement in the protocol. Recognising that not all node operators can do so, DA Network assigns different roles to different kinds of participants, depending on their ability and willingness to contribute more computing power and bandwidth to the protocol. It was therefore necessary for DA Network to be implemented as an opt-in Service Network.
Because the DA network has an arbitrary amount of participants, and the data is split into a fixed number of portions (see the Encoding & Verification Specification), it was necessary to define exactly how each portion is assigned to a participant who will receive and verify it. This assignment algorithm must also be flexible enough to ensure smooth operation in a variety of scenarios, including where there are more or fewer participants than the number of portions.
Overview
Network Participants
The DA network includes three categories of participants:
- Executors: Tasked with the encoding and dispersal of data blobs.
- DA Nodes: Receive and verify the encoded data, subsequently temporarily storing it for further network validation through sampling.
- Light Nodes: Employ sampling to ascertain data availability.
Network Distribution
The DA network is segmented into num_subnets subnetworks.
These subnetworks represent subsets of peers from the overarching network,
each responsible for a distinct portion of the distributed encoded data.
Peers in the network may engage in one or multiple subnetworks,
contingent upon network size and participant count.
Sub-protocols
The DA Network protocol consists of the following sub-protocols:
- Dispersal: Describes how executors distribute encoded data blobs to subnetworks. DA Network Dispersal
- Replication: Defines how DA nodes distribute encoded data blobs within subnetworks. DA Network Subnetwork Replication
- Sampling: Used by sampling clients (e.g., light clients) to verify the availability of previously dispersed and replicated data. DA Network Sampling
- Reconstruction: Describes gathering and decoding dispersed data back into its original form. DA Network Reconstruction
- Indexing: Tracks and exposes blob metadata on-chain. DA Network Indexing
Construction
DA Network Registration
Entities wishing to participate in DA Network must declare their role via SDP (Service Declaration Protocol). Once declared, they're accounted for in the subnetwork construction.
This enables participation in:
- Dispersal (as executor)
- Replication & sampling (as DA node)
- Sampling (as light node)
Subnetwork Assignment
The DA network comprises num_subnets subnetworks,
which are virtual in nature.
A subnetwork is a subset of peers grouped together so nodes know who they should connect with,
serving as groupings of peers tasked with executing the dispersal and replication sub-protocols.
In each subnetwork, participants establish a fully connected overlay,
ensuring all nodes maintain permanent connections for the lifetime of the SDP set
with peers within the same subnetwork.
Nodes refer to nodes in the Data Availability SDP set to ascertain their connectivity requirements across subnetworks.
Assignment Algorithm
The concrete distribution algorithm is described in the following specification: DA Subnetwork Assignation
Executor Connections
Each executor maintains a connection with one peer per subnetwork, necessitating at least num_subnets stable and healthy connections. Executors are expected to allocate adequate resources to sustain these connections. An example algorithm for peer selection would be:
def select_peers(
subnetworks: Sequence[Set[PeerId]],
filtered_subnetworks: Set[int],
filtered_peers: Set[PeerId]
) -> Set[PeerId]:
result = set()
for i, subnetwork in enumerate(subnetworks):
available_peers = subnetwork - filtered_peers
if i not in filtered_subnetworks and available_peers:
result.add(next(iter(available_peers)))
return result
DA Network Protocol Steps
Dispersal
- The DA Network protocol is initiated by executors who perform data encoding as outlined in the Encoding Specification.
- Executors prepare and distribute each encoded data portion
to its designated subnetwork (from
0tonum_subnets - 1). - Executors might opt to perform sampling to confirm successful dispersal.
- Post-dispersal, executors publish the dispersed
blob_idand metadata to the mempool.
Replication
DA nodes receive columns from dispersal or replication and validate the data encoding. Upon successful validation, they replicate the validated column to connected peers within their subnetwork. Replication occurs once per blob; subsequent validations of the same blob are discarded.
Sampling
- Sampling is invoked based on the node's current role.
- The node selects
sample_sizerandom subnetworks and queries each for the availability of the corresponding column for the sampled blob. Sampling is deemed successful only if all queried subnetworks respond affirmatively.
- If
num_subnetsis 2048,sample_sizeis 20 as per the sampling research
sequenceDiagram
SamplingClient ->> DANode_1: Request
DANode_1 -->> SamplingClient: Response
SamplingClient ->>DANode_2: Request
DANode_2 -->> SamplingClient: Response
SamplingClient ->> DANode_n: Request
DANode_n -->> SamplingClient: Response
Network Schematics
The overall network and protocol interactions is represented by the following diagram
flowchart TD
subgraph Replication
subgraph Subnetwork_N
N10 -->|Replicate| N20
N20 -->|Replicate| N30
N30 -->|Replicate| N10
end
subgraph ...
end
subgraph Subnetwork_0
N1 -->|Replicate| N2
N2 -->|Replicate| N3
N3 -->|Replicate| N1
end
end
subgraph Sampling
N9 -->|Sample 0| N2
N9 -->|Sample S| N20
end
subgraph Dispersal
Executor -->|Disperse| N1
Executor -->|Disperse| N10
end
Details
Network specifics
The DA network is engineered for connection efficiency. Executors manage numerous open connections, utilizing their resource capabilities. DA nodes, with their resource constraints, are designed to maximize connection reuse.
DA Network uses multiplexed streams over QUIC connections. For each sub-protocol, a stream protocol ID is defined to negotiate the protocol, triggering the specific protocol once established:
- Dispersal: /blockchain/da/{version}/dispersal
- Replication: /blockchain/da/{version}/replication
- Sampling: /blockchain/da/{version}/sampling
Through these multiplexed streams, DA nodes can utilize the same connection for all sub-protocols. This, combined with virtual subnetworks (membership sets), ensures the overlay node distribution is scalable for networks of any size.
References
- Encoding Specification
- Encoding & Verification Specification
- DA Network Dispersal
- DA Network Subnetwork Replication
- DA Subnetwork Assignation
- DA Network Sampling
- DA Network Reconstruction
- DA Network Indexing
- SDP
- invoked based on the node's current role
- 20 as per the sampling research
- multiplexed
- QUIC
Copyright
Copyright and related rights waived via CC0.
DA-REWARDING
| Field | Value |
|---|---|
| Name | DA Rewarding |
| Slug | 149 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Marcin Pawlowski [email protected] |
| Contributors | Alexander Mozeika [email protected], Mehmet Gonen [email protected], Daniel Sanchez Quiros [email protected], Álvaro Castro-Castilla [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-18 —
58b5698— chore(blockchain): migrate contributor emails to @logos.co (#338) - 2026-01-30 —
0ef87b1— New RFC: CODEX-MANIFEST (#191) - 2026-01-30 —
3f76dd8— Add NomosDA Rewarding specification (#269)
Abstract
This document specifies the opinion-based rewarding mechanism for the DA Network (Logos Blockchain Data Availability) service. The mechanism incentivizes DA nodes to maintain consistent and high-quality service through peer evaluation using a binary opinion system. Nodes assess the service quality of their counterparts across different subnetworks, and rewards are distributed based on accumulated positive opinions exceeding a defined activity threshold.
Keywords: DA Network, data availability, rewarding, incentives, peer evaluation, activity proof, quality of service, sampling
Semantics
The keywords "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119.
Definitions
| Terminology | Description |
|---|---|
| Block Finality | A period expressed in number of blocks (2160) after which a block is considered finalized, as defined by parameter in Cryptarchia. |
| Session | A time period during which the same set of nodes executes the protocol. Session length is two block finalization periods (4320 blocks). |
| Activity Proof | A data structure containing binary opinion vectors about other nodes' service quality. |
| Active Message | A message registered on the ledger that contains a node's activity proof for a session. |
| Opinion Threshold | The ratio of positive to negative opinions required for a node to be positively opinionated (default: 10). |
| Activity Threshold | The number of positive opinions () a node must collect to be considered active. |
| DA Node | A node providing data availability service, identified by a unique ProviderId. |
| SDP | Service Declaration Protocol, used to retrieve the list of active DA nodes. |
Notations
| Symbol | Description |
|---|---|
| Current session number. | |
Set of DA nodes (unique ProviderIds) active during session . | |
| Session length in blocks (4320). | |
| Block number. | |
| Activity threshold (). | |
| Base reward for session . | |
| Total income for DA service during session . | |
| Reward for node . |
Background
The DA Network service is a crucial component of the Logos Blockchain architecture, responsible for ensuring accessibility and retrievability of blockchain data. This specification defines an opinion-based rewarding mechanism that incentivizes DA nodes to maintain consistent and high-quality service.
The approach uses peer evaluation through a binary opinion system, where nodes assess the service quality of their counterparts across different subnetworks of DA. This mechanism balances simplicity and effectiveness by integrating with the existing Logos Blockchain architecture while promoting decentralized quality control.
The strength of this approach comes from its economic design, which reduces possibilities for dishonest behaviour and collusion. The reward calculation method divides rewards based on the total number of nodes rather than just active ones, further discouraging manipulation of the opinion system.
Three-Session Operation
The mechanism operates across three consecutive sessions:
-
Session : DA Network nodes perform sampling of data blobs referenced in blocks. While sampling, nodes interact with and evaluate the service quality of other randomly selected nodes from different subnetworks. Nodes sample both new blocks and old blocks.
-
Session : Nodes formalize their evaluations by submitting Activity Proofs— binary vectors where each bit represents their opinion (positive or negative) about other nodes' service quality. These opinions are tracked separately for new and old blocks. The proofs are recorded on the ledger through Active Messages.
-
Session : Rewards are distributed. Nodes that accumulate positive opinions above the activity threshold receive a fixed reward calculated as a portion of the session's DA service income.
Protocol Specification
Session : Sampling Phase
-
If the number of DA nodes (unique
ProviderIds from declarations) retrieved from the SDP is below the minimum, then do not perform sampling for new blocks. -
If the number of DA nodes retrieved from the SDP for session was below the minimum, then do not perform sampling for old blocks.
-
If the number of DA nodes retrieved from the SDP is below the minimum for both session and , then stop and do not execute this protocol.
-
The DA node performs sampling for every new block it receives, and for an old block for every new block received (where is the session length).
-
The node selects at random (without replacement) 20 out of 2048 subnetworks.
Note: The set of nodes selected does not have to be the same for old and new blocks.
-
The node connects to a random node in each of the selected subnetworks. If a node does not respond to a sampling request, another node is selected from the same subnetwork and the sampling request is repeated until success is achieved or a specified limit is reached.
-
-
During sampling, the node measures the quality of service provided by selected nodes as defined in Quality of Service Measurement.
Session : Opinion Submission Phase
-
The DA node generates an Activity Proof that contains opinion vectors, where all DA nodes are rated for positive or negative quality of service for new and old blocks.
-
The DA node sends an Active Message that is registered on the ledger and contains the node's Activity Proof.
Session : Reward Distribution Phase
-
Every node that collected above positive opinions receives a fixed reward as defined in Reward Calculation.
-
The rewards are distributed by the Service Reward Distribution Protocol.
Constructions
Quality of Service Measurement
A node MUST measure the quality of service for each sampling it performs to gather opinions about the quality of service of the entire DA network. These opinions are used to construct the Activity Proof.
The global parameter opinion_threshold is set to 10,
meaning a node must receive 10 positive opinions for each negative opinion
to be positively opinionated (at least 90% positive opinions).
To build an opinions vector describing the quality of data availability sampling, a node MUST:
-
Retrieve , a list of active DA nodes (unique
ProviderIds) for session , from the SDP. -
Retrieve , a list of active DA nodes for session , from the SDP (can be retained from the previous session).
-
Order and in ascending lexicographical order by
ProviderIdof each node from both lists. -
Create for each session and independently for old () and new () blocks:
-
positive_opinionsvector of size where the -th element (integer) represents positive opinions about the -th node from list . -
negative_opinionsvector of size where the -th element (integer) represents negative opinions about the -th node from list . -
blacklistvector of size where the -th element (bool) marks whether the -th node is blacklisted due to providing an invalid response.
-
-
Send a sampling request to a node such that
blacklist[n]==0:-
If the node responds:
- If the response is valid, then
positive_opinions[n]++ - If the response is not valid, then:
- Clear positive opinions about the node:
positive_opinions[n]=0 - Mark the node as blacklisted:
blacklist[n]=1
- Clear positive opinions about the node:
- If the response is valid, then
-
If the node does not respond, then
negative_opinions[n]++
-
-
When the next session starts, create an opinions binary for every node :
previous_session_opinions[i] = opinion(i, old.positive_opinions, old.negative_opinions, old.opinions_threshold) current_session_opinions[i] = opinion(i, new.positive_opinions, new.negative_opinions, new.opinions_threshold) def opinion(i, positive_opinions, negative_opinions, opinion_threshold): return (positive_opinions[i] > (negative_opinions[i] * opinion_threshold)) -
A node sets a positive opinion about itself in the
current_session_opinionsvector. -
A node sets a positive opinion about itself in the
previous_session_opinionsif the node was taking part in the protocol during the previous session.
Activity Proof
The Activity Proof structure is:
class ActivityProof:
current_session: SessionNumber
previous_session_opinions_length: int
previous_session_opinions: Opinions
current_session_opinions_length: int
current_session_opinions: Opinions
Opinions is a binary vector of length
(total number of nodes identified by unique ProviderIds from declarations)
where each bit represents a node providing DA service for the session.
A bit is set to 1 only when the node considers the sampling service
provided by the DA node to meet quality standards.
Field Descriptions
-
current_session: The session number of the assignations used for forming opinions. -
previous_session_opinions_length: The number of bytes used byprevious_session_opinions. -
previous_session_opinions: Opinions gathered from sampling old blocks. When there are no old blocks (first session after genesis or after a non-operational DA period), these opinions SHOULD NOT be collected nor validated. -
current_session_opinions_length: The number of bytes used bycurrent_session_opinions. -
current_session_opinions: Opinions gathered from sampling new blocks.
Validity Rules
The Activity Proof is valid when:
-
The
current_session_opinionsvector is not provided (andcurrent_session_opinions_length==0) when the DA service was not operational during that session. -
The byte-length of the
previous_session_opinionsvector is: -
The
previous_session_opinionsvector is not provided (andprevious_session_opinions_length==0) when the DA service was not operational during that session. -
The byte-length of the
current_session_opinionsvector is: -
The -th node (note that ) is represented by the -th bit of the vector (counting nodes from 0), with the vector encoded as little-endian. The rightmost byte of the vector MAY contain bits not mapped to any node; these bits are disregarded.
Activity Threshold
The activity threshold defines the number of positive opinions a node must collect from peers to be considered active for session .
Where controls the number of positive opinions a node must collect to be considered active.
Active Message
Each node for every session constructs an active_message
that MUST follow the specified format.
A node MAY stop sending active_message
when the DA service is non-operational for more than a single session.
The active_message metadata field MUST be populated with:
- A
headercontaining a one-byteversionfield fixed to0x01value. - The
activity_proofas defined above.
Active Message Rules
- An Active Message is stored on the ledger.
- An Active Message is used for calculating the node reward.
- An Active Message for session MUST only be sent during session ; otherwise, it MUST be rejected.
- The ledger MUST only accept a single Active Message per node per session; any duplicate MUST be rejected.
Reward Calculation
The reward calculation follows these steps:
Step 1: Calculate Base Reward
Calculate the base reward for session :
Where is the income for DA service during session , and is the number of nodes providing DA service during session .
Note: The base reward is fixed to the total number of nodes providing the service instead of the number of active nodes. This disincentivizes nodes from providing dishonest opinions about other nodes to increase their own reward.
The income leftovers MUST be burned or consumed in such a way that will not benefit the nodes.
Step 2: Count Positive Opinions
Count the number of positive opinions for node in session :
Where returns true only when the activity_proof for node is valid
and the opinion about node is positive for session .
Step 3: Calculate Node Reward
Calculate the reward for node based on node activity:
Where returns true only when and the number of positive opinions on node for session is greater than or equal to :
The reward is a function of the node's capacity (quality) to respond to sampling requests for both new and old blocks. Therefore, the reward draws from half of the income from session (for new blocks) and half of the income from session (for old blocks).
The base reward is distributed to nodes that both:
- Submitted a valid Activity Proof
- Received positive opinions exceeding the activity threshold for at least one of the sessions
Note: Inactive nodes are not rewarded. Nodes that have not participated in the previous session are not rewarded for the past session.
Security Considerations
Subjective Opinions
The mechanism intentionally uses subjective node opinions rather than strict performance metrics. While this introduces some arbitrariness, it provides a simple and flexible approach that aligns with Logos Blockchain' architectural goals.
Dishonest Evaluation
The system has potential for dishonest evaluation. However, the economic design reduces possibilities for dishonest behaviour and collusion:
- The reward calculation divides rewards based on total number of nodes rather than just active ones, discouraging manipulation of the opinion system.
- Income leftovers are burned to prevent benefit from underreporting.
Collusion Resistance
The activity threshold of requires a node to receive positive opinions from at least half of all nodes. This makes collusion attacks expensive, as an attacker would need to control a majority of nodes to guarantee rewards for malicious nodes.
References
Normative
- Service Declaration Protocol - Protocol for declaring DA node participation
Informative
- DA Rewarding - Original specification document
- Analysis of Sampling Strategy - Motivation for sampling 20 subnetworks
Copyright
Copyright and related rights waived via CC0.
LEE v0.3 Specifications
| Field | Value |
|---|---|
| Name | LEE v0.3 Specifications |
| Slug | 237 |
| Status | raw |
| Category | Standards Track |
| Tags | LEZ, LEE, execution zone, private accounts |
| Source | logos-blockchain/logos-execution-zone docs/specs.md |
Timeline
- 2026-06-08 —
9b6919f— Chore/move lez to lips (#353)
LEE v0.3 basic types and constants
#![allow(unused)] fn main() { type AccountId = [u8; 32]; type NativeToken = u128; type ProgramId = [u32; 8]; struct PdaSeed([u8; 32]); type Data = List<u8>; type Nonce = u128; type ByteString = List<u8>; type InstructionData = List<u32>; /// Sequencer-supplied block height and timestamp. type BlockId = u64; /// Unix timestamp in milliseconds. type Timestamp = u64; /// Diversifies private accounts for a given NPK. /// A single (nsk, vpk) keypair controls up to 2^128 distinct private accounts, /// one per identifier value. type Identifier = u128; type Commitment = [u8; 32]; struct CommitmentSet { merkle_tree: MerkleTree, commitments: HashMap<Commitment, usize>, root_history: HashSet<CommitmentSetDigest>, } type CommitmentSetDigest = [u8; 32]; type MembershipProof = (usize, List<[u8; 32]>); type Nullifier = [u8; 32]; type NullifierSecretKey = [u8; 32]; type NullifierPublicKey = [u8; 32]; type NullifierSet = BTreeSet<Nullifier>; /// A secp256k1 scalar (32 bytes). type EphemeralSecretKey = [u8; 32]; /// A SEC1-compressed secp256k1 point (33 bytes). type EphemeralPublicKey = [u8; 33]; /// A SEC1-compressed secp256k1 point (33 bytes). type ViewingPublicKey = [u8; 33]; /// The x-coordinate of the ECDH shared point (32 bytes). type SharedSecretKey = [u8; 32]; struct EncryptedAccountData { ciphertext: Ciphertext, epk: EphemeralPublicKey, view_tag: u8, // 1-byte view tag } /// BIP-340 Schnorr on secp256k1 (x-only pubkeys) type Signature = [u8; 64]; type PublicKey = [u8; 32]; // 32-byte x-only secp256k1 public key /// The borsh serialization of a `risc0_zkvm::InnerReceipt`. type Proof = ByteString; const DATA_MAX_LENGTH_IN_BYTES = 100 * 1024; const MAX_NUMBER_CHAINED_CALLS: usize = 10; const DEFAULT_PROGRAM_ID: ProgramId = [0; 8]; }
Byte order: LEE uses little-endian encoding throughout for integers, with the exception of the key protocol which follows BIP-32 (big-endian).
Accounts
All accounts (public and private) share a common schema with standard fields:
#![allow(unused)] fn main() { struct Account { program_owner: ProgramId, balance: NativeToken, data: Data, nonce: Nonce, } /// Account default value /// (The notation `[]` means the unique array of length zero) impl Default for Account { fn default() -> Self { Self { program_owner: [0; 8], balance: 0, data: [], nonce: 0, } } } }
Program owner field
The identification number of the program that can operate on this account's data. It's represented as a [u32; 8] identifier (ProgramId). This field ties the account to a specific program (often called the account's owner program program_owner) which defines the rules for how the account's data can be manipulated.
Balance field
The number of native tokens held by the account. It's represented as a 128-bit number. That means, the total supply of the system should never exceed . As long as that is guaranteed, transfer operations on the balance will not overflow. This is because under normal transfer operations, no account can end up with a balance greater than the total supply of the system. LEE prevents overflow exploits on the balance field by upcasting each term to u256 when computing the total balances before and after an execution.
Data field
An arbitrary byte string field to be managed by the program_owner program. The content and interpretation of this field are defined by the program logic. The maximum size of it is defined by the constant DATA_MAX_LENGTH_IN_BYTES.
Nonce field
The nonce is a 128-bit integer value. It has different uses depending on the visibility of the account:
- Public accounts: The nonce counts the number of transactions in which the associated public key of the account appears as a signer. This serves as a sequence number to prevent replay of transactions involving this account.
- Private accounts: A pseudorandom value used to provide entropy for the account's commitment, making it unconditionally hiding. The initial nonce is derived from the account ID, and subsequent nonces are iteratively derived from the nullifier secret key (
nsk) and the previous nonce. (account_idandnskare formally defined in the Nullifier public key derivation and Account ID subsections below.)
In both cases the nonce is iteratively produced: each accepted transaction increments a public account's nonce by one, and each private state update derives a fresh nonce from the previous one.
Private account nonce initialization:
where the result is the first 16 bytes of the hash, interpreted as a u128 little-endian integer. The full preimage is 64 bytes: the 32-byte account ID followed by 32 zero bytes.
Private account nonce update:
where nonce_i is the 16-byte little-endian encoding of the current nonce, and the result is the first 16 bytes of the hash interpreted as a u128 little-endian integer. The full preimage is 64 bytes: 32-byte nsk + 16-byte nonce + 16 zero bytes.
#![allow(unused)] fn main() { impl Nonce { fn private_account_nonce_init(account_id: &AccountId) -> Self { let mut bytes = [0_u8; 64]; bytes[..32].copy_from_slice(account_id.value()); // bytes[32..64] are zero let hash: [u8; 32] = sha256(bytes); Self(u128::from_le_bytes(*hash.first_chunk::<16>().unwrap())) } fn private_account_nonce_increment(self, nsk: &NullifierSecretKey) -> Self { let mut bytes = [0_u8; 64]; bytes[..32].copy_from_slice(nsk); bytes[32..48].copy_from_slice(&self.0.to_le_bytes()); // bytes[48..64] are zero let hash: [u8; 32] = sha256(bytes); Self(u128::from_le_bytes(*hash.first_chunk::<16>().unwrap())) } } }
Private accounts use a nullifier public key (Npk) as a core identifier. The next two subsections derive Npk and define the account ID formats — both are prerequisites for the commitment and nullifier fields that follow.
Nullifier public key derivation
The nullifier public key is derived from the nullifier secret key via a pure hash function:
The total input is 64 bytes: 8 bytes prefix + 32 bytes nsk + 1 byte [7] + 23 bytes zero padding.
#![allow(unused)] fn main() { impl NullifierPublicKey { fn from(nsk: &NullifierSecretKey) -> Self { const PREFIX: &[u8; 8] = b"LEE/keys"; const SUFFIX_1: &[u8; 1] = &[7]; const SUFFIX_2: &[u8; 23] = &[0; 23]; let mut bytes = Vec::new(); bytes.extend_from_slice(PREFIX); bytes.extend_from_slice(nsk); bytes.extend_from_slice(SUFFIX_1); bytes.extend_from_slice(SUFFIX_2); Self(sha256(bytes)) } } }
Account ID
Public account ID:
#![allow(unused)] fn main() { /// ASCII "/LEE/v0.3/AccountId/Public/" zero-padded to 32 bytes PUBLIC_ACCOUNT_ID_PREFIX: [u8; 32] = b"/LEE/v0.3/AccountId/Public/\x00\x00\x00\x00\x00" }
Private account ID:
The hash input is 80 bytes: 32-byte prefix + 32-byte Npk + 16-byte little-endian identifier. Each (Npk, identifier) pair yields a distinct account ID, so the same set of private account keys can be reused across up to independent private accounts. One per identifier value.
#![allow(unused)] fn main() { /// ASCII "/LEE/v0.3/AccountId/Private/" zero-padded to 32 bytes PRIVATE_ACCOUNT_ID_PREFIX: [u8; 32] = b"/LEE/v0.3/AccountId/Private/\x00\x00\x00\x00" }
#![allow(unused)] fn main() { impl AccountId { fn from_private(npk: &NullifierPublicKey, identifier: Identifier) -> Self { let mut bytes = [0_u8; 80]; bytes[0..32].copy_from_slice(PRIVATE_ACCOUNT_ID_PREFIX); bytes[32..64].copy_from_slice(&npk.0); bytes[64..80].copy_from_slice(&identifier.to_le_bytes()); sha256(bytes) } } }
Public program-derived account ID (public PDA):
The hash input is 96 bytes: 32-byte prefix + 32-byte program_id (as 8 LE u32 words) + 32-byte seed.
#![allow(unused)] fn main() { /// ASCII "/LEE/v0.3/AccountId/PDA/" zero-padded to 32 bytes PUBLIC_PDA_PREFIX: [u8; 32] = b"/LEE/v0.3/AccountId/PDA/\x00\x00\x00\x00\x00\x00\x00\x00" }
Private program-derived account ID (private PDA):
The hash input is 144 bytes: 32 + 32 + 32 + 32 + 16. Unlike public PDAs, the private PDA derivation includes Npk and identifier. This ensures two different users at the same (program_id, seed) get different addresses, and a single user at (program_id, seed, Npk) controls a family of private PDA addresses (one per identifier value).
#![allow(unused)] fn main() { /// ASCII "/LEE/v0.3/AccountId/PrivatePDA/" zero-padded to 32 bytes PRIVATE_PDA_PREFIX: [u8; 32] = b"/LEE/v0.3/AccountId/PrivatePDA/\x00" }
#![allow(unused)] fn main() { impl AccountId { fn for_private_pda( program_id: &ProgramId, seed: &PdaSeed, npk: &NullifierPublicKey, identifier: Identifier, ) -> Self { let mut bytes = [0_u8; 144]; bytes[0..32].copy_from_slice(PRIVATE_PDA_PREFIX); let program_id_bytes: &[u8] = bytemuck::cast_slice(program_id); bytes[32..64].copy_from_slice(program_id_bytes); bytes[64..96].copy_from_slice(&seed.0); bytes[96..128].copy_from_slice(&npk.to_byte_array()); bytes[128..144].copy_from_slice(&identifier.to_le_bytes()); sha256(bytes) } } }
Commitment
The commitment of an account is computed as:
where
COMMITMENT_PREFIXis the domain separator:#![allow(unused)] fn main() { /// ASCII "/LEE/v0.3/Commitment/" zero-padded to 32 bytes COMMITMENT_PREFIX: [u8; 32] = b"/LEE/v0.3/Commitment/\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00" }account_idis the 32-byte account ID of the private account (which encodes both the owner'sNpkand theIdentifier; see the Account ID section above).ProgramOwneris the 32 bytes of the program owner field encoded as 8 little-endianu32words.BalanceBytesare the 16 bytes of the little-endian representation of the balance.NonceBytesare the 16 bytes of the little-endian representation of the nonce.DataDigestare the 32 bytes of the SHA256 digest of the data field.
The total preimage is 160 bytes.
#![allow(unused)] fn main() { impl Commitment { fn new(account_id: &AccountId, account: &Account) -> Self { const COMMITMENT_PREFIX: &[u8; 32] = b"/LEE/v0.3/Commitment/\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00"; let mut bytes = Vec::new(); bytes.extend_from_slice(COMMITMENT_PREFIX); bytes.extend_from_slice(account_id.value()); for word in &account.program_owner { bytes.extend_from_slice(&word.to_le_bytes()); } bytes.extend_from_slice(&account.balance.to_le_bytes()); bytes.extend_from_slice(&account.nonce.to_le_bytes()); let data_digest: [u8; 32] = sha256(&account.data); bytes.extend_from_slice(&data_digest); sha256(bytes) } } }
Nullifier
A private account's commitment is nullified each time the account's state is updated. There are two methods for computing a nullifier:
- Initialization nullifier (used when the private account is created for the first time):
#![allow(unused)] fn main() { /// ASCII "/LEE/v0.3/Nullifier/Initialize/" zero-padded to 32 bytes INIT_PREFIX: [u8; 32] = b"/LEE/v0.3/Nullifier/Initialize/\x00" }
- Update nullifier (used when an existing private account's state is updated):
#![allow(unused)] fn main() { /// ASCII "/LEE/v0.3/Nullifier/Update/" zero-padded to 32 bytes UPDATE_PREFIX: [u8; 32] = b"/LEE/v0.3/Nullifier/Update/\x00\x00\x00\x00\x00" }
#![allow(unused)] fn main() { impl Nullifier { fn for_account_initialization(account_id: &AccountId) -> Self { let mut bytes = INIT_PREFIX.to_vec(); bytes.extend_from_slice(account_id.value()); sha256(bytes) } fn for_account_update(commitment: &Commitment, nsk: &NullifierSecretKey) -> Self { let mut bytes = UPDATE_PREFIX.to_vec(); bytes.extend_from_slice(&commitment.to_byte_array()); bytes.extend_from_slice(nsk); sha256(bytes) } } }
Private account kind and encryption scheme
PrivateAccountKind
Every private account output is tagged with a PrivateAccountKind that allows the receiver to reconstruct the account ID after decryption, without storing the ID on chain:
#![allow(unused)] fn main() { pub enum PrivateAccountKind { Regular(Identifier), Pda { program_id: ProgramId, seed: PdaSeed, identifier: Identifier, }, } }
The kind is serialized as a fixed 81-byte header prepended to the encrypted account data:
Regular(ident): 0x00 || ident (16 bytes LE) || [0u8; 64]
Pda { program_id, seed, ident }: 0x01 || program_id (8 × u32 LE) || seed (32 bytes) || ident (16 bytes LE)
Both variants produce 81 header bytes, so ciphertext lengths are uniform across account types.
After decryption the receiver reconstructs the account ID from the kind:
Regular(ident)→AccountId::from_private(npk, ident)Pda { program_id, seed, ident }→AccountId::for_private_pda(program_id, seed, npk, ident)
Key agreement and shared secret
When creating a private account output, the sender generates an ephemeral secret key esk and the corresponding ephemeral public key Epk = esk * G. The shared secret is the x-coordinate of the ECDH result (32 bytes, not a SEC1-compressed point):
- Sender:
- Receiver:
where vpk is the receiver's ViewingPublicKey (a 33-byte SEC1-compressed secp256k1 point) and vsk is the corresponding viewing secret key (a secp256k1 scalar).
KDF
#![allow(unused)] fn main() { fn kdf( shared_secret: &SharedSecretKey, // 32-byte x-coordinate commitment: &Commitment, // 32-byte output commitment output_index: u32, // index of this output within the tx (LE) ) -> [u8; 32] { let mut bytes = Vec::new(); bytes.extend_from_slice(b"LEE/v0.3/KDF-SHA256/"); bytes.extend_from_slice(&shared_secret.0); bytes.extend_from_slice(&commitment.to_byte_array()); bytes.extend_from_slice(&output_index.to_le_bytes()); sha256(bytes) } }
Encryption
#![allow(unused)] fn main() { fn encrypt( account: &Account, kind: &PrivateAccountKind, shared_secret: &SharedSecretKey, commitment: &Commitment, output_index: u32, ) -> Ciphertext { // Plaintext: 81-byte kind header || account serialization let mut buffer = kind.to_header_bytes().to_vec(); buffer.extend_from_slice(&account.to_bytes()); // Apply ChaCha20 keystream with a [0; 12] nonce let key = kdf(shared_secret, commitment, output_index); chacha20_xor(&key, &[0u8; 12], &mut buffer); Ciphertext(buffer) } }
account.to_bytes() serializes the account as:
program_owner (8 × u32 LE) || balance (16 bytes LE) || nonce (16 bytes LE) || data_len (u32 LE) || data
Decryption
#![allow(unused)] fn main() { fn decrypt( ciphertext: &Ciphertext, shared_secret: &SharedSecretKey, commitment: &Commitment, output_index: u32, ) -> Option<(PrivateAccountKind, Account)> { let mut buffer = ciphertext.0.clone(); let key = kdf(shared_secret, commitment, output_index); chacha20_xor(&key, &[0u8; 12], &mut buffer); if buffer.len() < PrivateAccountKind::HEADER_LEN { return None; } let header: &[u8; 81] = buffer[..81].try_into().unwrap(); let kind = PrivateAccountKind::from_header_bytes(header)?; let account = Account::from_bytes(&buffer[81..]).ok()?; Some((kind, account)) } }
Programs
Programs define the logic for operating on accounts. They are stateless and can only execute instructions and modify the state of accounts passed to them. All changes to public or private accounts must be performed through program execution. There's no way to alter account state directly without invoking a program.
A program can only directly modify the state of accounts that are owned by the program. A program can queue other program executions to modify accounts owned by those programs. These queued executions are called chained calls.
All programs share the same function signature. They take as input:
- The executing program's own ID.
- The caller program's ID, or
Noneif this is a top-level call. - A list of accounts, each annotated with metadata.
- An instruction-specific data word list.
Programs are treated as blackboxes: given some inputs, they produce a ProgramOutput that represents their claimed state transition. All validation is performed on the output, never on the raw inputs. In privacy-preserving transactions the program runs inside an off-chain ZK circuit; the sequencer receives only a proof that the circuit was executed correctly, without seeing the program's inputs. In public transactions the program is executed directly, but the same output-based validation applies — this uniformity is intentional, so that the constraint rules do not differ between the two execution paths.
ProgramOutput is the program's complete claimed state transition and contains:
pre_states— the accounts the program claims to have operated on, including their pre-execution state.post_states— the resulting account states after execution.chained_calls— queued executions of other programs.self_program_idandcaller_program_id— used by the verifier to check that the output was produced by the expected program and invoked through the correct call chain.instruction_data— used to verify that each chained call was executed with the instruction the calling program requested.block_validity_windowandtimestamp_validity_window— range constraints on which blocks/timestamps this output is valid for.
Formally:
#![allow(unused)] fn main() { struct AccountWithMetadata { account: Account, is_authorized: bool, account_id: AccountId, } pub struct AccountPostState { account: Account, claim: Option<Claim>, } pub struct ProgramOutput { self_program_id: ProgramId, caller_program_id: Option<ProgramId>, instruction_data: InstructionData, pre_states: Vec<AccountWithMetadata>, post_states: Vec<AccountPostState>, chained_calls: Vec<ChainedCall>, block_validity_window: BlockValidityWindow, timestamp_validity_window: TimestampValidityWindow, } /// A claim request indicating the executing program intends to take ownership of an account. pub enum Claim { /// Standard claim path, used for all account kinds that are not self-owned PDAs. Succeeds /// when the account's `is_authorized` flag is true (public accounts, public PDAs, private /// PDAs), or unconditionally for standalone private accounts. Authorized, /// Ownership via a PDA seed. Only valid for PDAs owned by the executing program itself: /// the AccountId must match the derivation from (self_program_id, seed) for public PDAs, /// or from (self_program_id, seed, npk, identifier) for private PDAs. Pda(PdaSeed), } pub struct ChainedCall { pub program_id: ProgramId, pub pre_states: Vec<AccountWithMetadata>, pub instruction_data: InstructionData, /// PDA seeds authorized for the callee. For each seed, the callee is authorized to /// mutate the AccountId derived from (caller_program_id, seed) — whether public or private. pub pda_seeds: Vec<PdaSeed>, } type Program = fn( ProgramId, Option<ProgramId>, List<AccountWithMetadata>, InstructionData ) -> ProgramOutput; }
The verifier validates that a ProgramOutput satisfies the following constraints:
- The output's
pre_statescontain unique account IDs. EachAccountIdin the list is unique. - The output's
pre_statesandpost_stateshave the same lengthN. - Program cannot update an account's nonce. For all
i in 0..N,pre_states[i].account.nonce == post_states[i].account.nonce. - Program cannot change the program owner of an account. For all
i in 0..N,pre_states[i].account.program_owner == post_states[i].account.program_owner. - Program can only decrease the native token balance for accounts that the program owns. For all
i in 0..N, ifpost_states[i].account.balance < pre_states[i].account.balance, thenpre_states[i].account.program_owner == executing_program_id. - Program can only change an account's data for accounts that the program owns (or if the account is default). For all
i in 0..N, ifpre_states[i].account.data != post_states[i].account.datathen eitherpre_states[i].account == Account::default()orpre_states[i].account.program_owner == executing_program_id. - Any account that has default program owner after execution must have been a default account before execution. For all
i in 0..N, ifpost_states[i].account.program_owner == DEFAULT_PROGRAM_IDthenpre_states[i].account == Account::default(). - The sum of balances across all
pre_statesequals the sum across allpost_states.
In pseudocode:
#![allow(unused)] fn main() { pub fn validate_execution( pre_states: &[AccountWithMetadata], post_states: &[AccountPostState], executing_program_id: ProgramId, ) -> Result<(), ExecutionValidationError> { // 1. Check account ids are all different if !validate_uniqueness_of_account_ids(pre_states) { return Err(ExecutionValidationError::PreStateAccountIdsNotUnique); } // 2. Lengths must match if pre_states.len() != post_states.len() { return Err(ExecutionValidationError::MismatchedPreStatePostStateLength { .. }); } for (pre, post) in pre_states.iter().zip(post_states) { // 3. Nonce must remain unchanged if pre.account.nonce != post.account.nonce { return Err(ExecutionValidationError::ModifiedNonce { .. }); } // 4. Program ownership changes are not allowed if pre.account.program_owner != post.account.program_owner { return Err(ExecutionValidationError::ModifiedProgramOwner { .. }); } let account_program_owner = pre.account.program_owner; // 5. Decreasing balance only allowed if owned by executing program if post.account.balance < pre.account.balance && account_program_owner != executing_program_id { return Err(ExecutionValidationError::UnauthorizedBalanceDecrease { .. }); } // 6. Data changes only allowed if owned by executing program or if account is default if pre.account.data != post.account.data && pre.account != Account::default() && account_program_owner != executing_program_id { return Err(ExecutionValidationError::UnauthorizedDataModification { .. }); } // 7. If post state has default program owner, pre state must have been default if post.account.program_owner == DEFAULT_PROGRAM_ID && pre.account != Account::default() { return Err(ExecutionValidationError::NonDefaultAccountWithDefaultOwner { .. }); } } // 8. Total balance is preserved let total_pre = WrappedBalanceSum::from_balances(pre_states.iter().map(|p| p.account.balance)); let total_post = WrappedBalanceSum::from_balances(post_states.iter().map(|p| p.account.balance)); if total_pre != total_post { return Err(ExecutionValidationError::MismatchedTotalBalance { .. }); } Ok(()) } }
The is_authorized flag in AccountWithMetadata indicates whether the account owner has provided authorization. It is the program's responsibility to check it where needed. Authorization is granted via different mechanisms depending on the account type:
- For public accounts: through digital signatures.
- For private accounts: through knowledge proofs of the corresponding nullifier secret key.
- For PDAs: through the
pda_seedsmechanism in chained calls (and, for self-owned PDAs, viaClaim::Pdawhich proves ownership by address derivation).
Account authority vs program ownership
is_authorized and program_owner serve distinct purposes:
is_authorizedindicates whether the account owner has authorized the account to be used in this transaction. For public accounts this comes from a signature; for private accounts from a valid nullifier secret key proof. For PDAs it is established through thepda_seedsmechanism.program_ownerindicates which program can mutate the account's state. It is set once via the claiming mechanism and cannot be changed by programs directly.
Account claiming mechanism
Programs output a list of AccountPostState, each optionally carrying a Claim:
#![allow(unused)] fn main() { impl AccountPostState { /// No claim — executing program does not request ownership. pub fn new(account: Account) -> Self { Self { account, claim: None } } /// Always claims ownership with the given claim type. pub fn new_claimed(account: Account, claim: Claim) -> Self { Self { account, claim: Some(claim) } } /// Claims ownership only if account.program_owner == DEFAULT_PROGRAM_ID. pub fn new_claimed_if_default(account: Account, claim: Claim) -> Self { let is_default = account.program_owner == DEFAULT_PROGRAM_ID; Self { account, claim: is_default.then_some(claim) } } } }
After execution, the runtime processes each post-state's optional claim:
Claim::Authorized— the standard claim path: setsprogram_owner = executing_program_id(when currently default) for all account kinds except self-owned PDAs. Whetheris_authorizedis required depends on the account kind:- Public accounts:
is_authorizedmust betrue, set when the transaction signer included the account in the authorized set. - Public PDAs:
is_authorizedmust betrue, set when the caller included the matching seed inChainedCall.pda_seeds. - Private accounts (regular and PDA): there's no enforcement for claiming. For regular accounts the circuit ensures the right authorization posture via the
PrivateAuthorizedInit/PrivateAuthorizedUpdate/PrivateUnauthorizedvariant selection.
- Public accounts:
Claim::Pda(seed)— setsprogram_owner = executing_program_id(when currently default) by proving the account's ID is structurally derived from the executing program's own ID and the given seed, with no user authorization required. UnlikeClaim::Authorized, the claim is not backed by a signature or nullifier key proof; instead, the program demonstrates ownership by construction: if the address was computed from(self_program_id, seed), then no other program could have produced that same address. The derivation formula depends on the account kind: for public accounts it isAccountId::for_public_pda(executing_program_id, seed); for private PDAs it isAccountId::for_private_pda(executing_program_id, seed, npk, identifier)using the npk supplied for that pre-state, making the claim user-specific.Claim::Pdais not applicable to standalone private accounts.
Program-derived account IDs (PDAs)
Public PDA: derived from (program_id, seed) — see the Account ID section above.
Private PDA: derived from (program_id, seed, npk, identifier). Unlike public PDAs, private PDAs are per-user: two users at the same (program_id, seed) get different addresses. Within a single user's namespace the identifier diversifies further.
Authorization for private PDAs in chained calls is established by the caller including the PDA seed in pda_seeds, or via Claim::Pda(seed) for the owning program itself. When neither mechanism is available the seed can be externally supplied. For external seed the circuit verifies AccountId::for_private_pda(authority_program_id, seed, npk, identifier) == pre_state.account_id directly. In such case the pre-state must have is_authorized == false..
Validity windows
Programs can constrain when their outputs are accepted by the sequencer:
#![allow(unused)] fn main() { /// A half-open interval [from, to) with optional bounds. /// None means unbounded on that side. pub struct ValidityWindow<T> { from: Option<T>, to: Option<T>, } pub type BlockValidityWindow = ValidityWindow<BlockId>; pub type TimestampValidityWindow = ValidityWindow<Timestamp>; }
An output outside its window is rejected at the sequencer level before any state transition is applied.
LEE v0.3 state
#![allow(unused)] fn main() { struct LeeState { public_state: Map<AccountId, Account>, private_state: (CommitmentSet, NullifierSet), programs: Map<ProgramId, Program>, } }
public_state: A map from each account ID to its correspondingAccountfor all public accounts. The entireAccountIdspace is conceptually populated; account IDs not explicitly stored are treated as having default values (sparse representation).private_state: A combination of two structures tracking private account state:CommitmentSet: An authenticated Merkle tree of all existing private account commitments.NullifierSet: ABTreeSetof all revealed nullifiers.
programs: A map fromProgramIdto program bytecode for each deployed program.
The CommitmentSet exposes:
insert(element)— add a commitment.get_authentication_path_for(element)— Merkle inclusion path.compute_digest_for_path(element, proof)— verify inclusion against a root.is_current_or_previous_digest(digest)— check against the root history.
The NullifierSet is a plain ordered set.
Dummy commitment and dummy commitment hash
Two special constants are derived from the default account and the null account ID [0; 32]:
#![allow(unused)] fn main() { /// DUMMY_COMMITMENT = Commitment::new(&AccountId([0; 32]), &Account::default()) /// Concretely: SHA256(COMMITMENT_PREFIX || [0]*32 || [0]*32 || [0]*16 || [0]*16 || SHA256([])) pub const DUMMY_COMMITMENT: Commitment = Commitment([ 55, 228, 215, 207, 112, 221, 239, 49, 238, 79, 71, 135, 155, 15, 184, 45, 104, 74, 51, 211, 238, 42, 160, 243, 15, 124, 253, 62, 3, 229, 90, 27, ]); pub const DUMMY_COMMITMENT_HASH: [u8; 32] = [ 250, 237, 192, 113, 155, 101, 119, 30, 235, 183, 20, 84, 26, 32, 196, 229, 154, 74, 254, 249, 129, 241, 118, 39, 41, 253, 141, 171, 184, 71, 8, 41, ]; }
DUMMY_COMMITMENT is the commitment of the default account (Account::default()) under the null account ID ([0; 32]). It is not a real user account: no keys exist that could spend it, so it can never be nullified.
At genesis, the CommitmentSet is initialized by inserting DUMMY_COMMITMENT as its first entry. This bootstraps the Merkle tree before any real private accounts exist and gives the set a well-defined root from the very first state. Because the Merkle tree hashes each leaf as SHA256(value), the root of a tree containing only DUMMY_COMMITMENT is SHA256(DUMMY_COMMITMENT) — which is exactly DUMMY_COMMITMENT_HASH. As a result, DUMMY_COMMITMENT_HASH is permanently present in the CommitmentSet's root_history from genesis onward.
Role in initialization nullifiers. Every nullifier submitted in a PrivacyPreservingTransaction must be paired with a CommitmentSetDigest. For update nullifiers this is the Merkle root that was current when the sender computed their membership proof. For init nullifiers — emitted when a private account is created for the first time (PrivateAuthorizedInit, PrivateUnauthorized, PrivatePdaInit) — no prior commitment exists to be spent, so there is no natural Merkle root to cite. Rather than special-casing this in the sequencer's acceptance logic, init nullifiers uniformly use DUMMY_COMMITMENT_HASH as their digest. Since DUMMY_COMMITMENT_HASH is always in root_history, the standard root_history.contains(digest) check accepts them without any extra branching — the same validation path covers both init and update nullifiers.
Built-in programs
See Built-in Programs. Additional user-defined programs may also be deployed via ProgramDeploymentTransaction (see "State transition from program deployment transactions").
Structure of a public transaction
#![allow(unused)] fn main() { struct Message { program_id: ProgramId, account_ids: List<AccountId>, nonces: List<Nonce>, instruction_data: InstructionData, } type WitnessSet = List<(Signature, PublicKey)>; struct PublicTransaction { message: Message, witness_set: WitnessSet, } }
The message hash prefix is:
#![allow(unused)] fn main() { /// ASCII "/LEE/v0.3/Message/Public/" zero-padded to 32 bytes PREFIX: [u8; 32] = b"/LEE/v0.3/Message/Public/\x00\x00\x00\x00\x00\x00\x00" }
The message hash is SHA256(PREFIX || borsh_serialize(message)).
Message
program_id: TheProgramIdof the program to invoke.account_ids: The list of relevant account IDs that the program will operate on.nonces: One nonce per signer (public account). Each must match the current nonce of the corresponding account in state.instruction_data: Parameters encoded as a list ofu32words.
Witness set
A list of (signature, public_key) pairs. Each pair must produce a valid BIP-340 Schnorr signature over the message hash. The accounts derived from each public_key (via AccountId::from(&public_key)) form the authorized signer set. The program receives is_authorized = true for any pre-state account in this set (programs use the flag to decide whether to permit user-driven actions like transfers). Programs may also gain authorization for additional accounts via the PDA mechanism in chained calls. Authorization propagates down the call chain monotonically: the authorized set passed to each child call is the union of the parent's own authorized set and the parent's verified authorized pre-states, so an account authorized at any hop remains authorized for all subsequent calls even if an intermediate hop does not include it in its pre-states. This monotonicity applies equally to PDA-authorized accounts. Upon acceptance, each signing account's nonce is incremented by 1.
Structure of a privacy-preserving transaction
#![allow(unused)] fn main() { struct Message { public_account_ids: List<AccountId>, nonces: List<Nonce>, public_post_states: List<Account>, encrypted_private_post_states: List<EncryptedAccountData>, new_commitments: List<Commitment>, new_nullifiers: List<(Nullifier, CommitmentSetDigest)>, block_validity_window: BlockValidityWindow, timestamp_validity_window: TimestampValidityWindow, } struct WitnessSet { signatures_and_public_keys: List<(Signature, PublicKey)>, proof: Proof, } struct PrivacyPreservingTransaction { message: Message, witness_set: WitnessSet, } }
The message hash prefix is:
#![allow(unused)] fn main() { /// ASCII "/LEE/v0.3/Message/Privacy/" zero-padded to 32 bytes PREFIX: [u8; 32] = b"/LEE/v0.3/Message/Privacy/\x00\x00\x00\x00\x00\x00" }
The hash is SHA256(PREFIX || borsh_serialize(message)).
Message
public_account_ids: Account IDs of all public accounts involved.nonces: One nonce per signing public account.public_post_states: New states of any public accounts modified by this transaction.encrypted_private_post_states: Encrypted details of each new private account output, decryptable by the respective recipient.new_commitments: New commitment values added to theCommitmentSet.new_nullifiers: Nullifiers revealed by this transaction, each paired with theCommitmentSetDigestof the commitment being spent.block_validity_window/timestamp_validity_window: Time-bound constraints propagated from theProgramOutput. Outputs outside their window are rejected.
Witness set
signatures_and_public_keys: BIP-340 Schnorr signature pairs for any public accounts requiring authorization.proof: A borsh-serializedrisc0_zkvm::InnerReceiptproving correct execution of the privacy-preserving circuit.
The privacy-preserving execution circuit
The circuit is a RISC-V program proven with the risc0 zkVM. It is executed entirely off-chain by the transaction sender; the sequencer only verifies the proof. It is not a built-in program in the LEE sense. It wraps the execution of built-in programs inside a ZK proof.
Workflow:
The circuit takes as private inputs a PrivacyPreservingCircuitInput: the sequence of ProgramOutputs for each call in the execution chain, one InputAccountIdentity per pre-state (carrying nullifier secret keys, shared secret keys, membership proofs, and identifiers as required by each account variant), and the top-level program ID.
- Verify that each
ProgramOutputin the chain has a valid proof of execution for the corresponding program. - Verify that
validate_executionpasses for each program call. - Check that chained-call instruction data, accounts, and
is_authorizedflags are consistent across caller/callee boundaries, using the sameCallerData-based authorization propagation as the public execution path: the initialauthorized_accountsis the set of public accounts whoseis_authorizedflag istruein the top-levelpublic_pre_states(i.e. the signers), and each hop propagates its authorized pre-states to child calls. The total number of calls must not exceedMAX_NUMBER_CHAINED_CALLS + 1(same bound enforced in the public acceptance criteria). - For each account:
- Public: collect pre/post state; increment nonce if authorized.
- Private init: verify pre-state is default; derive account_id; compute init nullifier; set nonce via
nonce_init; encrypt post-state. - Private update: verify membership proof; compute update nullifier; increment nonce via
nonce_increment; encrypt post-state.
- Emit
PrivacyPreservingCircuitOutput.
Transaction-wide private PDA family binding. The same (program_id, seed) pair can produce different program-derived account IDs for different npk and identifier. This creates a subtle authorization hazard: a caller that places seed S in pda_seeds intends to authorize exactly one account to the callee. Without an additional constraint, however, a callee could present two private PDA pre-states that both derive from (caller_program_id, S) and the single seed entry would authorize both.
To close this, the circuit enforces the following rule across an entire transaction:
Each
(program_id, seed)pair may resolve to at most one account ID for the duration of the transaction.
The rule applies to both the Claim::Pda(seed) path and the pda_seeds authorization path. Every time either path resolves an account under a given (program_id, seed), the resolved account ID is recorded. A later resolution of the same pair must agree with the recorded account ID, or the transaction is rejected.
In pseudocode:
#![allow(unused)] fn main() { // Checked at every Claim::Pda(seed) and at every pda_seeds match, for both public and private PDAs. fn record_or_assert_pda_binding( bindings: &mut Map<(ProgramId, Seed), AccountId>, program_id: ProgramId, seed: Seed, resolved_account_id: AccountId, ) { match bindings.get((program_id, seed)) { None => bindings.insert((program_id, seed), resolved_account_id), Some(existing) => assert_eq!( existing, resolved_account_id, "two different accounts resolved under (program_id, seed) in one transaction", ), } } }
Circuit input
#![allow(unused)] fn main() { pub struct PrivacyPreservingCircuitInput { /// Outputs of the program execution chain. pub program_outputs: Vec<ProgramOutput>, /// One entry per pre-state, in the same order as they appear across program_outputs. pub account_identities: Vec<InputAccountIdentity>, /// Top-level program ID. pub program_id: ProgramId, } pub enum InputAccountIdentity { /// Public account. The guest reads pre/post state from program_outputs and emits no /// commitment, ciphertext, or nullifier. Public, /// Initialization of a standalone private account the caller owns. /// Pre-state must be Account::default(). /// AccountId = AccountId::from_private(npk(nsk), identifier). PrivateAuthorizedInit { ssk: SharedSecretKey, nsk: NullifierSecretKey, identifier: Identifier, }, /// Update of an existing standalone private account the caller owns. /// Membership proof for the current on-chain commitment is required. PrivateAuthorizedUpdate { ssk: SharedSecretKey, nsk: NullifierSecretKey, membership_proof: MembershipProof, identifier: Identifier, }, /// Initialization of a standalone private account the caller does not own /// (e.g. a recipient who does not yet exist on chain). No nsk, no membership proof. PrivateUnauthorized { npk: NullifierPublicKey, ssk: SharedSecretKey, identifier: Identifier, }, /// Initialization of a private PDA. /// Authorization comes via Claim::Pda(seed) or the caller's pda_seeds. /// The identifier diversifies the PDA within the (program_id, seed, npk) family. PrivatePdaInit { npk: NullifierPublicKey, ssk: SharedSecretKey, identifier: Identifier, /// When `Some((seed, authority_program_id))`, the circuit verifies /// `AccountId::for_private_pda(authority_program_id, seed, npk, identifier) == /// pre_state.account_id` directly, binding the position without requiring a /// `Claim::Pda` or caller `pda_seeds`. The `pre_state` must have /// `is_authorized == false`; a seed in this field does not provide authorization. seed: Option<(PdaSeed, ProgramId)>, }, /// Update of an existing private PDA. npk is derived from nsk. /// Membership proof is required. PrivatePdaUpdate { ssk: SharedSecretKey, nsk: NullifierSecretKey, membership_proof: MembershipProof, identifier: Identifier, /// When `Some((seed, authority_program_id))`, the circuit verifies /// `AccountId::for_private_pda(authority_program_id, seed, npk(nsk), identifier) == /// pre_state.account_id` directly, binding the position without requiring a /// caller `pda_seeds`. The `pre_state` must have `is_authorized == false`. A seed in /// this field does not provide authorization. seed: Option<(PdaSeed, ProgramId)>, }, } }
The ssk field carries the shared secret key — the 32-byte x-coordinate of the ECDH shared point used to encrypt the post-state. Note that the key protocol uses ssk for "spending secret key" (the master key that derives nsk and vsk); here ssk means the per-output ECDH shared secret. It is computed in two equivalent ways:
- Sender:
ssk = x-coordinate of (esk · vpk_recipient) - Receiver:
ssk = x-coordinate of (vsk · Epk_sender)
where esk/Epk are the ephemeral key pair, vpk is the recipient's viewing public key, and vsk is the corresponding viewing secret key.
Circuit output
#![allow(unused)] fn main() { pub struct PrivacyPreservingCircuitOutput { pub public_pre_states: Vec<AccountWithMetadata>, pub public_post_states: Vec<Account>, pub ciphertexts: Vec<Ciphertext>, pub new_commitments: Vec<Commitment>, pub new_nullifiers: Vec<(Nullifier, CommitmentSetDigest)>, pub block_validity_window: BlockValidityWindow, pub timestamp_validity_window: TimestampValidityWindow, } }
Circuit logic summary
For each InputAccountIdentity the circuit performs the following:
| Variant | AccountId derivation | Nonce init | Nullifier emitted | Auth requires | Claim::Authorized precondition |
|---|---|---|---|---|---|
Public | from pre-state | +1 if authorized | none | signature | is_authorized must be true |
PrivateAuthorizedInit | from_private(npk(nsk), ident) | nonce_init(account_id) | init nullifier | nsk | not enforced (skipped) |
PrivateAuthorizedUpdate | from_private(npk(nsk), ident) | nonce_increment(nsk) | update nullifier | nsk + membership proof | not enforced (skipped) |
PrivateUnauthorized | from_private(npk, ident) | nonce_init(account_id) | init nullifier | none | not enforced (skipped) |
PrivatePdaInit | for_private_pda(prog, seed, npk, ident) | nonce_init(account_id) | init nullifier | chained call pda_seed or Claim::Pda | not enforced (skipped) |
PrivatePdaUpdate | for_private_pda(prog, seed, npk(nsk), ident) | nonce_increment(nsk) | update nullifier | chained call pda_seed + nsk + membership proof | not enforced (skipped) |
For each private account the post-state commitment is Commitment::new(account_id, post_account) (with the new nonce applied). The ciphertext is EncryptionScheme::encrypt(post_account, kind, ssk, commitment, output_index).
The chain-of-calls logic and validate_execution rules are identical to the public execution path. The claiming rules diverge for all private accounts: Claim::Authorized on any private kind (regular or PDA) is allowed unconditionally. No is_authorized check is performed for claiming. For public accounts, Claim::Authorized still requires is_authorized == true.
Encrypted private account discovery and tagging
Ephemeral view tags
Each private account output includes a 1-byte view tag to allow wallets to quickly filter outputs before attempting decryption:
where Npk is the 32-byte nullifier public key and vpk is the 33-byte SEC1-compressed ViewingPublicKey of the recipient. On average only 1 in 256 outputs will pass this filter for a given account, avoiding expensive ECDH on irrelevant outputs.
Private account discovery with viewing keys
- For each encrypted output, compute the expected view tag from
(Npk, vpk). Skip if it does not match. - Perform ECDH:
ss = x-coordinate of (vsk * Epk). - Run
kdf(ss, commitment, output_index)to derive the symmetric key. - Decrypt the ciphertext with ChaCha20.
- Parse the 81-byte header to recover
PrivateAccountKind. - Parse the remaining bytes to recover the
Account. - Recompute the account ID from the kind and verify that
Commitment::new(account_id, account)equals the on-chain commitment. Discard on mismatch (false positive).
#![allow(unused)] fn main() { fn private_account_discovery( tx: &PrivacyPreservingTransaction, vsk: &ViewingSecretKey, npk: &NullifierPublicKey, vpk: &ViewingPublicKey, ) -> Vec<(PrivateAccountKind, Account)> { let expected_tag = EncryptedAccountData::compute_view_tag(npk, vpk); let mut discovered = Vec::new(); for (output_index, (encrypted_account, commitment)) in tx.message.encrypted_private_post_states .iter() .zip(&tx.message.new_commitments) .enumerate() { if encrypted_account.view_tag != expected_tag { continue; } let ss = SharedSecretKey::new(vsk, &encrypted_account.epk); if let Some((kind, account)) = EncryptionScheme::decrypt( &encrypted_account.ciphertext, &ss, commitment, output_index as u32 ) { let account_id = AccountId::for_private_account(npk, &kind); if Commitment::new(&account_id, &account) == *commitment { discovered.push((kind, account)); } } } discovered } }
Domain separator summary
| Purpose | Domain separator |
|---|---|
| Commitment | b"/LEE/v0.3/Commitment/\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00" |
| Nullifier — initialization | b"/LEE/v0.3/Nullifier/Initialize/\x00" |
| Nullifier — update | b"/LEE/v0.3/Nullifier/Update/\x00\x00\x00\x00\x00" |
| Account ID — public | b"/LEE/v0.3/AccountId/Public/\x00\x00\x00\x00\x00" |
| Account ID — private | b"/LEE/v0.3/AccountId/Private/\x00\x00\x00\x00" |
| Account ID — public PDA | b"/LEE/v0.3/AccountId/PDA/\x00\x00\x00\x00\x00\x00\x00\x00" |
| Account ID — private PDA | b"/LEE/v0.3/AccountId/PrivatePDA/\x00" |
| Nullifier public key (from NSK) | b"LEE/keys" + nsk + [7] + [0; 23] |
| KDF | b"LEE/v0.3/KDF-SHA256/" |
| View tag | b"/LEE/v0.3/ViewTag/" |
| Public transaction message hash | b"/LEE/v0.3/Message/Public/\x00\x00\x00\x00\x00\x00\x00" |
| Privacy transaction message hash | b"/LEE/v0.3/Message/Privacy/\x00\x00\x00\x00\x00\x00" |
Public transaction acceptance criteria
For a public transaction to be accepted and applied to the state:
- No duplicate account IDs: The
account_idslist must not contain repeated entries. - Signature/nonce count match: The number of nonces in the message must equal the number of
(signature, public_key)pairs in the witness set. - Valid signatures: All BIP-340 Schnorr signatures must verify against the message hash.
- Nonce checks: For each signing account, the nonce in the transaction must match the account's current nonce in state.
- Program existence: The
program_idmust correspond to a deployed program. - Valid execution: The program is invoked with the provided accounts and instruction data.
validate_executionmust pass. At each call in the chain, an account inpre_statesreceivesis_authorized = trueif it is either a top-level signer (derived from a public key in the witness set), a PDA explicitly seeded by the immediate caller viapda_seeds, or an account that wasis_authorizedin the parent program's verified pre-states (authorization propagates down the call chain). - Pre-state consistency: Each
program_output.pre_states[i]must equal the current state ofpre_states[i].account_id(or the diffed value from earlier chained calls). Theis_authorizedflag in each pre-state must match the actual authorization status. - Program identity consistency: Each program output's
self_program_idmust equal the program ID it was invoked under, and itscaller_program_idmust equal the caller (orNonefor the top-level call). - Validity window enforcement: For each
ProgramOutputin the chain (top-level and chained calls), the currentblock_idmust fall withinprogram_output.block_validity_windowand the currenttimestampmust fall withinprogram_output.timestamp_validity_window. Out-of-window outputs are rejected. - Maximum chained-call depth: The total number of chained call executions (not including the top-level call) must not exceed
MAX_NUMBER_CHAINED_CALLS. - Claiming: Any
AccountPostStatewith aClaimcauses the runtime to setprogram_owner = executing_program_idfor that account, but only if the account's currentprogram_owner == DEFAULT_PROGRAM_ID. In the public path all accounts are public, soClaim::Authorizedalways requiresis_authorized == true(signature, or PDA via caller'spda_seeds), andClaim::Pda(seed)requires the account ID to matchAccountId::for_public_pda(executing_program_id, seed). (The privacy path relaxes theClaim::Authorizedprecondition for standalone private accounts — see the Programs section.) - No silent default-account modifications: Any account whose pre-state has
program_owner == DEFAULT_PROGRAM_IDand whose post-state differs from the pre-state must have been claimed (i.e. its post-stateprogram_owneris no longer the default).
In pseudocode:
#![allow(unused)] fn main() { fn validate_and_produce_public_state_diff( tx: PublicTransaction, lee_state: LeeState, block_id: BlockId, timestamp: Timestamp, ) -> Map<AccountId, Account> { let message = tx.message; let witness_set = tx.witness_set; // No duplicate account ids assert_no_duplicates(message.account_ids); // One nonce per signature assert_eq!(message.nonces.len(), witness_set.signatures_and_public_keys.len()); // Verify signatures and nonces let mut signer_account_ids = []; for ((signature, public_key), nonce) in witness_set.signatures_and_public_keys.zip(message.nonces) { assert!(signature.is_valid_for(message.hash(), public_key)); let account_id = AccountId::from(public_key); assert_eq!(lee_state.public_state.get(account_id).nonce, nonce); signer_account_ids.push(account_id); } let input_pre_states = message.account_ids.map(|id| AccountWithMetadata { account: lee_state.public_state.get(id), is_authorized: signer_account_ids.contains(id), account_id: id, }); let mut state_diff = {}; // The chained-call queue. Each entry carries the call to execute and the program ID // of its caller (None for the top-level call). let initial_call = ChainedCall { program_id: message.program_id, instruction_data: message.instruction_data, pre_states: input_pre_states, pda_seeds: [], }; struct CallerData { program_id: Option<ProgramId>, /// Accounts that were `is_authorized` in the parent program's verified pre-states. /// For the top-level call this is the signer set; for chained calls it propagates /// from the parent's authorized pre-states, enabling multi-hop authorization. authorized_accounts: Set<AccountId>, } let initial_caller_data = CallerData { program_id: None, authorized_accounts: signer_account_ids, }; let mut queue = [(initial_call, initial_caller_data)]; let mut counter = 0; while let Some((call, caller_data)) = queue.pop_front() { assert!(counter <= MAX_NUMBER_CHAINED_CALLS); let program = lee_state.programs.get(call.program_id); let program_output = program.execute( call.program_id, caller_data.program_id, call.pre_states, call.instruction_data, ); // Compute the set of public PDAs the callee is authorized to mutate via the // caller's pda_seeds. For the top-level call (caller_data.program_id == None) this is // always the empty set. let authorized_pdas = compute_public_authorized_pdas(caller_data.program_id, call.pda_seeds); // An account is authorized if it was in the parent's authorized set (propagated from // its verified pre-states) or if it is a PDA the caller explicitly seeded. let is_authorized = |account_id| { caller_data.authorized_accounts.contains(account_id) || authorized_pdas.contains(account_id) }; // Verify pre-state and authorization consistency: programs cannot fabricate inputs. for pre in program_output.pre_states { let expected_pre = state_diff.get(pre.account_id) .unwrap_or(lee_state.public_state.get(pre.account_id)); assert_eq!(pre.account, expected_pre); // The is_authorized flag must exactly match the actual authorization status: // programs cannot forge it (flag true on an unauthorized account) nor // under-report it (flag false on a truly-authorized account). assert_eq!(pre.is_authorized, is_authorized(pre.account_id)); } // Verify the output identifies its own program ID and caller correctly. assert_eq!(program_output.self_program_id, call.program_id); assert_eq!(program_output.caller_program_id, caller_data.program_id); validate_execution( program_output.pre_states, program_output.post_states, call.program_id, ); // Validity window: this output is valid only within its declared block / timestamp range. assert!(program_output.block_validity_window.is_valid_for(block_id)); assert!(program_output.timestamp_validity_window.is_valid_for(timestamp)); // Apply claims and update the state diff. for (pre, post) in program_output.pre_states.zip(program_output.post_states) { if let Some(claim) = post.claim { // Claims only fire when the account currently has the default program owner. assert_eq!(post.account.program_owner, DEFAULT_PROGRAM_ID); match claim { Claim::Authorized => assert!(pre.is_authorized), Claim::Pda(seed) => { assert_eq!(pre.account_id, AccountId::for_public_pda(call.program_id, seed)); } } post.account.program_owner = call.program_id; } state_diff.insert(pre.account_id, post.account); } // Build the authorized set for child calls: the union of the caller's authorized set // and the verified authorized pre-states of this call. Using program_output.pre_states // (not call.pre_states) ensures the new entries are derived from already-validated data // and cannot be forged by a caller-supplied input. Authorization is monotonically // growing — once an account is authorized at any point in the chain it remains // authorized for all subsequent calls, even if an intermediate hop does not include // it in its own pre-states. let authorized_accounts = caller_data.authorized_accounts .union( program_output.pre_states .filter(|pre| pre.is_authorized) .map(|pre| pre.account_id) ); // Push chained calls (in declared order). Pushing them to the front of the queue // produces a depth-first traversal. for new_call in program_output.chained_calls.reversed() { queue.push_front((new_call, CallerData { program_id: Some(call.program_id), authorized_accounts: authorized_accounts, })); } counter += 1; } // Default-owner accounts that were modified must have been claimed. for (account_id, post) in state_diff { let pre = lee_state.public_state.get(account_id); if pre.program_owner == DEFAULT_PROGRAM_ID && pre != post { assert_ne!(post.program_owner, DEFAULT_PROGRAM_ID); } } state_diff } }
Note on replay attacks
The nonce mechanism ensures authorized public transactions cannot be replayed. Once accepted, nonces for all signing accounts are incremented — the same transaction can never be valid again. Purely unauthorized transactions (no signatures required) could theoretically be replayed.
Privacy-preserving transaction acceptance criteria
For a privacy transaction to be accepted:
- Non-empty commitments or nullifiers: At least one new commitment or nullifier must be present.
- No duplicate public account IDs: The
public_account_idslist must not contain repeated entries. - Commitment uniqueness: No two entries within the transaction's
new_commitmentslist may be equal. - Commitment freshness: No new commitment may already exist in the
CommitmentSet. - Nullifier uniqueness: No new nullifier may already exist in the
NullifierSet. No duplicates within the transaction'snew_nullifierslist either. - Valid commitment set digests: Each nullifier's associated
CommitmentSetDigestmust match a current or previous digest of theCommitmentSet. - Signature/nonce count match: The number of nonces in the message must equal the number of
(signature, public_key)pairs in the witness set. - Nonce checks and valid signatures: Same rules as for public transactions, applied to any public accounts present.
- Validity window enforcement: The current
block_idmust fall withinmessage.block_validity_windowand the currenttimestampmust fall withinmessage.timestamp_validity_window. These windows are the intersection of all per-ProgramOutputwindows in the chain, computed and committed by the circuit. - Proof verification: The ZK proof must verify against the circuit output values in the message and the current public pre-states. Public accounts in
public_pre_statesreceiveis_authorized = trueif they are top-level signers; the circuit then applies the sameCallerData-based authorization propagation as the public execution path, so authorized accounts (including PDAs) flow through chained calls as described there.
In pseudocode:
#![allow(unused)] fn main() { fn verify_privacy_preserving_transaction( tx: PrivacyPreservingTransaction, lee_state: LeeState, block_id: BlockId, timestamp: Timestamp, ) { let message = tx.message; let witness_set = tx.witness_set; // 1. Non-empty assert!(!message.new_commitments.is_empty() || !message.new_nullifiers.is_empty()); // 2. No duplicate public account ids assert_no_duplicates(message.public_account_ids); // 3. Commitment uniqueness within the transaction assert_no_duplicates(message.new_commitments); // 4. Nullifier uniqueness within the transaction assert_no_duplicates(message.new_nullifiers.map(|(n, _)| n)); // 5. Nonce checks and valid signatures assert_eq!(witness_set.signatures_and_public_keys.len(), message.nonces.len()); let mut authorized_ids = []; for ((sig, pk), nonce) in witness_set.signatures_and_public_keys.zip(message.nonces) { assert!(sig.is_valid_for(message.hash(), pk)); let account_id = AccountId::from(pk); assert_eq!(lee_state.public_state.get(account_id).nonce, nonce); authorized_ids.push(account_id); } // 6. Validity window enforcement assert!(message.block_validity_window.is_valid_for(block_id)); assert!(message.timestamp_validity_window.is_valid_for(timestamp)); // 7. Build public pre-states for proof verification let public_pre_states = message.public_account_ids.map(|id| AccountWithMetadata { account: lee_state.public_state.get(id), is_authorized: authorized_ids.contains(id), account_id: id, }); // 8. Proof verification assert_privacy_circuit_proof_is_valid( witness_set.proof, public_pre_states, message.public_post_states, message.encrypted_private_post_states.map(|e| e.ciphertext), message.new_commitments, message.new_nullifiers, message.block_validity_window, message.timestamp_validity_window, ); // 9. Commitment freshness and valid digests are checked against the current CommitmentSet // and NullifierSet. for commitment in message.new_commitments { assert!(!lee_state.private_state.0.contains(commitment)); } for (nullifier, digest) in message.new_nullifiers { assert!(!lee_state.private_state.1.contains(nullifier)); assert!(lee_state.private_state.0.is_current_or_previous_digest(digest)); } } }
Note on replay attacks
Replay attacks are not possible for privacy transactions. Any accepted transaction either adds commitments or nullifiers to the state. A replay attempt is rejected by commitment freshness or nullifier uniqueness checks.
State transitions
State transition from public transactions
- Verify acceptance criteria — including the per-
ProgramOutputvalidity windows — and produce a state diff. - Apply the state diff: update (or insert) each account in
public_state. - Increment nonces for all signing accounts.
#![allow(unused)] fn main() { fn transition_from_public_transaction( tx: PublicTransaction, lee_state: LeeState, block_id: BlockId, timestamp: Timestamp, ) { let state_diff = validate_and_produce_public_state_diff(tx, lee_state, block_id, timestamp); for (account_id, post) in state_diff { lee_state.public_state[account_id] = post; } for account_id in tx.signer_account_ids() { lee_state.public_state[account_id].nonce += 1; } } }
State transition from privacy-preserving transactions
- Verify acceptance criteria — including the message's validity windows.
- Add new commitments to the
CommitmentSet. - Add new nullifiers to the
NullifierSet. - Apply public account changes from
public_post_states. - Increment nonces for all signing public accounts.
#![allow(unused)] fn main() { fn transition_from_privacy_preserving_transaction( tx: PrivacyPreservingTransaction, lee_state: LeeState, block_id: BlockId, timestamp: Timestamp, ) { verify_privacy_preserving_transaction(tx, lee_state, block_id, timestamp); for commitment in tx.message.new_commitments { lee_state.private_state.0.insert(commitment); } for (nullifier, _) in tx.message.new_nullifiers { lee_state.private_state.1.insert(nullifier); } for (account_id, post) in tx.message.public_account_ids.zip(tx.message.public_post_states) { lee_state.public_state[account_id] = post; } for account_id in tx.signer_account_ids() { lee_state.public_state[account_id].nonce += 1; } } }
For both transaction types, the validity-window check is part of the acceptance criteria — outputs outside their declared windows are rejected before any state mutation occurs.
State transition from program deployment transactions
A program deployment transaction contains only the program bytecode. The program ID is derived from the bytecode image.
#![allow(unused)] fn main() { struct ProgramDeploymentMessage { bytecode: ByteString, } struct ProgramDeploymentTransaction { message: ProgramDeploymentMessage, } }
- Verify the derived
ProgramIddoes not already exist inprograms. - Insert the new program.
#![allow(unused)] fn main() { fn transition_from_program_deployment_transaction( tx: &ProgramDeploymentTransaction, lee_state: &mut LeeState, ) { let program = Program::new(tx.message.bytecode.clone()).expect("Valid program bytecode"); assert!(!lee_state.programs.contains_key(&program.id()), "Program already deployed"); lee_state.programs.insert(program.id(), program); } }
Built-in Programs
Source: logos-blockchain/logos-execution-zone docs/builtin_programs.md
LEZ v0.3 supports the following built-in programs, loaded at genesis. They are immutable and identified by unique ProgramId values.
- Authenticated transfer (
AUTHENTICATED_TRANSFER_ID) - Token (
TOKEN_ID) - AMM (
AMM_ID) - Associated Token Account (
ASSOCIATED_TOKEN_ACCOUNT_ID) - Clock (
CLOCK_ID) - Vault (
VAULT_ID) - Faucet (
FAUCET_ID) - Piñata (
PINATA_ID) — testnet only
Authenticated transfer program
Moves native tokens from a source account to a destination account, requiring the source account to be authorized. Has two instruction variants:
Initializewith a single pre-state: claims the pre-state account (which must beAccount::default()) on behalf of the caller. Authorization is enforced by the runtime when processingClaim::Authorized.Transfer { amount }with two pre-states[sender, recipient]: standard transfer. Sender must be authorized. The recipient is claimed only if itsprogram_owneris currently the default — pre-existing accounts owned by other programs keep their owner.
#![allow(unused)] fn main() { pub enum Instruction { /// Initialize a new account under the ownership of this program. /// Required accounts: `[account_to_initialize]`. Initialize, /// Transfer `amount` of native balance from sender to recipient. /// Required accounts: `[sender, recipient]`. Transfer { amount: NativeToken }, } fn transfer_authorized( self_program_id: ProgramId, caller_program_id: Option<ProgramId>, pre_states: Vec<AccountWithMetadata>, instruction: Instruction, ) -> (Vec<AccountWithMetadata>, Vec<AccountPostState>, Vec<ChainedCall>) { let post_states = match instruction { Instruction::Initialize => { let [account_to_claim] = <[_; 1]>::try_from(pre_states.clone()).unwrap(); assert_eq!(account_to_claim.account, Account::default()); vec![AccountPostState::new_claimed( account_to_claim.account.clone(), Claim::Authorized, )] } Instruction::Transfer { amount } => { let [sender, recipient] = <[_; 2]>::try_from(pre_states.clone()).unwrap(); assert!(sender.is_authorized, "Sender must be authorized"); let mut sender_post = sender.account.clone(); sender_post.balance = sender_post.balance.checked_sub(amount).unwrap(); let mut recipient_post = recipient.account.clone(); recipient_post.balance = recipient_post.balance.checked_add(amount).unwrap(); vec![ AccountPostState::new(sender_post), AccountPostState::new_claimed_if_default(recipient_post, Claim::Authorized), ] } }; (pre_states, post_states, vec![]) } }
Piñata program
Distributes a fixed prize of native tokens to the account that provides the correct solution to a proof-of-work–style challenge stored in the pinata account's data. Used for native token distribution during testing.
The pinata account's data is a 33-byte buffer: [difficulty (1 byte), seed (32 bytes)]. A solution s: u128 is valid iff the leftmost difficulty bytes of SHA256(seed || s_le_bytes) are all zero. After a winning solution the seed is rotated to SHA256(seed).
#![allow(unused)] fn main() { const PRIZE: NativeToken = 150; /// Instruction data: u128 solution. fn pinata( self_program_id: ProgramId, caller_program_id: Option<ProgramId>, pre_states: Vec<AccountWithMetadata>, solution: u128, ) -> (Vec<AccountWithMetadata>, Vec<AccountPostState>, Vec<ChainedCall>) { let [pinata, winner] = <[_; 2]>::try_from(pre_states.clone()).unwrap(); let challenge = Challenge::parse(&pinata.account.data); if !challenge.validate_solution(solution) { // No valid solution: the program exits without writing any output, // causing the sequencer to reject the transaction entirely. return; } let mut pinata_post = pinata.account.clone(); let mut winner_post = winner.account.clone(); pinata_post.balance = pinata_post.balance.checked_sub(PRIZE).unwrap(); pinata_post.data = challenge.next_data().to_vec().try_into().unwrap(); winner_post.balance = winner_post.balance.checked_add(PRIZE).unwrap(); let post_states = vec![ // Pinata is claimed if its program_owner is currently default // (so the very first invocation locks it under the pinata program). AccountPostState::new_claimed_if_default(pinata_post, Claim::Authorized), AccountPostState::new(winner_post), ]; (pre_states, post_states, vec![]) } }
Token program
Manages user-defined fungible and non-fungible tokens. Each token consists of a definition account (immutable rules) and one or more holding accounts (per-owner balances). Optional metadata is stored in a separate metadata account.
#![allow(unused)] fn main() { pub enum TokenDefinition { Fungible { name: String, total_supply: u128, metadata_id: Option<AccountId>, }, NonFungible { name: String, printable_supply: u128, metadata_id: AccountId, }, } pub enum TokenHolding { /// Balance of a fungible token. Fungible { definition_id: AccountId, balance: u128 }, /// Master holding of an NFT collection. `print_balance` is the number of printable copies left. NftMaster { definition_id: AccountId, print_balance: u128 }, /// A printed instance of an NFT. NftPrintedCopy { definition_id: AccountId, owned: bool }, } pub struct TokenMetadata { pub definition_id: AccountId, pub standard: MetadataStandard, pub uri: String, pub creators: Vec<...>, pub primary_sale_date: u64, } }
Instructions:
Transfer { amount_to_transfer: u128 }— accounts:[sender_holding, recipient_holding]. Sender must be authorized. Recipient is auto-initialized whenAccount::default(). NFT master copies and printed copies are also transferred via this instruction (withamount_to_transfer == print_balancefor masters and1for printed copies). The recipient holding is claimed only if itsprogram_owneris currently default (new_claimed_if_default).NewFungibleDefinition { name: String, total_supply: u128 }— accounts:[definition_target, holding_target]. Both must beAccount::default(). The definition holds the supply; the holding is initialized tototal_supply. Both are claimed (new_claimed).NewDefinitionWithMetadata { new_definition, metadata }— accounts:[definition_target, holding_target, metadata_target]. Same as above plus a metadata account; supports both fungible and non-fungible variants. All three are claimed.InitializeAccount— accounts:[definition, account_to_initialize]. Creates a zero-balance holding bound todefinition.account_id. Only the holding is claimed.Burn { amount_to_burn: u128 }— accounts:[definition, user_holding]. Holding must be authorized. Decreases bothholding.balanceanddefinition.total_supply. Neither account is claimed.Mint { amount_to_mint: u128 }— accounts:[definition, holding_target]. Definition must be authorized. Increases bothholding.balanceanddefinition.total_supply. Holding is claimed if currently default.PrintNft— accounts:[nft_master_holding, nft_printed_copy_target]. Decrementsprint_balanceon the master and produces a new printed copy holding.
All Token Program operations check that the definition_id referenced by each holding matches the supplied definition account.
AMM program
Manages liquidity pools for token pairs; supports pool initialization, add/remove liquidity, and swaps. Pools are primarily intended to be public, in which case each (token_a, token_b) pair yields a unique pool. In private state a pool is scoped to the user's (Npk, identifier) namespace, so each pair produces one pool per namespace.
Pool Definition Account:
#![allow(unused)] fn main() { struct PoolDefinition { definition_token_a_id: AccountId, definition_token_b_id: AccountId, vault_a_id: AccountId, vault_b_id: AccountId, liquidity_pool_id: AccountId, liquidity_pool_supply: u128, reserve_a: u128, reserve_b: u128, fees: u128, active: bool, } }
Initialize pool:
Creates the pool definition, two vaults (one per token), and an LP token definition. Deposits the initial liquidity through chained Token Program calls.
Add liquidity:
Deposits tokens into the vaults in proportion to the current reserves. Mints LP tokens to the depositor through chained Token Program calls. The LP amount is calculated as:
#![allow(unused)] fn main() { let delta_lp = min( pool_supply * actual_amount_a / reserve_a, pool_supply * actual_amount_b / reserve_b, ); }
Remove liquidity:
Burns LP tokens and withdraws proportional amounts of each token from the vaults:
#![allow(unused)] fn main() { let withdraw_a = (reserve_a * amount_lp) / pool_supply; let withdraw_b = (reserve_b * amount_lp) / pool_supply; }
Swap:
Executes a constant-product AMM swap. For a deposit of amount_in of one token:
#![allow(unused)] fn main() { let amount_out = (reserve_out * amount_in) / (reserve_in + amount_in); }
All AMM operations use chained calls to the Token Program for the actual token movements between user holding accounts and vault accounts. PDAs are used to authorize vault transfers.
Associated Token Account (ATA) program
Provides a deterministic, per-(owner, token_definition) holding-account address derived as a public PDA of the ATA program. Removes the need for users to manage explicit token-holding account IDs; given an owner account and a token definition, anyone can compute the corresponding ATA address.
#![allow(unused)] fn main() { pub fn compute_ata_seed(owner_id: AccountId, definition_id: AccountId) -> PdaSeed { PdaSeed::new(SHA256(owner_id || definition_id)) } pub fn get_associated_token_account_id(ata_program_id: &ProgramId, seed: &PdaSeed) -> AccountId { AccountId::for_public_pda(ata_program_id, seed) } }
Instructions:
Create { ata_program_id }— accounts:[owner, token_definition, ata_account]. Creates the ATA for(owner, definition)if it does not already exist (idempotent). Chains to the Token Program'sInitializeAccountto populate the holding data.Transfer { ata_program_id, amount }— accounts:[owner, sender_ata, recipient_holding]. Owner must be authorized. The ATA program verifiessender_ata.account_id == for_public_pda(ata_program_id, compute_ata_seed(owner.id, definition_id)), then chains to the Token Program'sTransfer, passing the ATA seed inpda_seedsto authorize the ATA inside the Token Program.Burn { ata_program_id, amount }— accounts:[owner, holder_ata, token_definition]. Same PDA-seed authorization mechanism asTransfer; chains to the Token Program'sBurn.
The ata_program_id is passed as part of the instruction (rather than read from self_program_id) so it can be precomputed by callers without invoking the program.
Clock program
Records the current block ID and timestamp into three dedicated clock accounts, updated at different cadences (every 1, 10, and 50 blocks). Programs that need recent timestamps can read whichever granularity matches their needs.
#![allow(unused)] fn main() { pub const CLOCK_01_PROGRAM_ACCOUNT_ID: AccountId = AccountId::new(*b"/LEZ/ClockProgramAccount/0000001"); pub const CLOCK_10_PROGRAM_ACCOUNT_ID: AccountId = AccountId::new(*b"/LEZ/ClockProgramAccount/0000010"); pub const CLOCK_50_PROGRAM_ACCOUNT_ID: AccountId = AccountId::new(*b"/LEZ/ClockProgramAccount/0000050"); pub struct ClockAccountData { pub block_id: BlockId, pub timestamp: Timestamp, } }
The clock accounts are created at genesis and assigned program_owner = clock_program_id, so no claiming is required at runtime. The Clock Program is invoked exclusively by the sequencer as the last transaction in every block: users cannot invoke it directly. Its single instruction is the new block's Timestamp.
On execution, the program reads block_id from the 01 account, increments it, and updates each of the three clock accounts only when new_block_id is a multiple of the corresponding cadence.
Vault program
Provides a native-token escrow via per-user vault PDAs. Each user's vault is a PDA of the Vault program keyed by the user's account ID. Two instructions:
Transfer { recipient_id, amount }— accounts:[sender, recipient, recipient_vault_pda]. Sender must be authorized. Transfersamountnative tokens fromsenderto the vault PDA ofrecipient_id. The vault PDA is claimed on first use.Claim { amount }— accounts:[owner, owner_vault_pda]. Owner must be authorized. Withdrawsamountnative tokens from the owner's vault PDA back to the owner's account.
Vault PDA seed derivation:
#![allow(unused)] fn main() { const VAULT_SEED_DOMAIN_SEPARATOR: &[u8; 32] = b"/LEZ/v0.3/VaultSeed/00000000000/"; pub fn compute_vault_seed(owner_id: AccountId) -> PdaSeed { let mut bytes = [0_u8; 64]; bytes[..32].copy_from_slice(VAULT_SEED_DOMAIN_SEPARATOR); bytes[32..64].copy_from_slice(&owner_id.to_bytes()); PdaSeed::new(sha256(bytes)) } pub fn compute_vault_account_id(vault_program_id: ProgramId, owner_id: AccountId) -> AccountId { AccountId::for_public_pda(&vault_program_id, &compute_vault_seed(owner_id)) } }
Faucet program
Manages the system faucet, a pre-funded account used to distribute native tokens. The faucet account is a public PDA of the Faucet program, created at genesis. One instruction:
Transfer { vault_program_id, recipient_id, amount }— accounts:[faucet_pda, recipient_vault_pda]. Transfersamountnative tokens from the system faucet to the vault PDA ofrecipient_id. User-submitted transactions cannot invoke the Faucet program directly; only sequencer-originated transactions may do so.
Faucet PDA seed and account derivation:
#![allow(unused)] fn main() { const FAUCET_SEED_DOMAIN_SEPARATOR: [u8; 32] = *b"/LEZ/v0.3/FaucetSeed/0000000000/"; pub fn compute_faucet_seed() -> PdaSeed { PdaSeed::new(FAUCET_SEED_DOMAIN_SEPARATOR) } pub fn compute_faucet_account_id(faucet_program_id: ProgramId) -> AccountId { AccountId::for_public_pda(&faucet_program_id, &compute_faucet_seed()) } }
Storage LIPs
Specifications related the Logos Storage decentralised data platform. Visit Storage specs to view the new Storage specifications currently under discussion.
Storage Raw Specifications
Early-stage Storage specifications collected before reaching draft status.
CODEX-BLOCK-EXCHANGE
| Field | Value |
|---|---|
| Name | Codex Block Exchange Protocol |
| Slug | 111 |
| Status | raw |
| Category | Standards Track |
| Editor | Codex Team |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-12-12 —
b2f3564— Improved codex/raw/codex-block-exchange.md file (#215) - 2025-11-19 —
63107d3— Created new codex/raw/codex-block-exchange.md file (#211)
Specification Status
This specification contains a mix of:
- Verified protocol elements: Core message formats, protobuf structures, and addressing modes confirmed from implementation
- Design specifications: Payment flows, state machines, and negotiation strategies representing intended behavior
- Recommended values: Protocol limits and timeouts that serve as guidelines (actual implementations may vary)
- Pending verification: Some technical details (e.g., multicodec 0xCD02) require further validation
Sections marked with notes indicate areas where implementation details may differ from this specification.
Abstract
The Block Exchange (BE) is a core Codex component responsible for peer-to-peer content distribution across the network. It manages the sending and receiving of data blocks between nodes, enabling efficient data sharing and retrieval. This specification defines both an internal service interface and a network protocol for referring to and providing data blocks. Blocks are uniquely identifiable by means of an address and represent fixed-length chunks of arbitrary data.
Semantics
The keywords "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119.
Definitions
| Term | Description |
|---|---|
| Block | Fixed-length chunk of arbitrary data, uniquely identifiable |
| Standalone Block | Self-contained block addressed by SHA256 hash (CID) |
| Dataset Block | Block in ordered set, addressed by dataset CID + index |
| Block Address | Unique identifier for standalone/dataset addressing |
| WantList | List of block requests sent by a peer |
| Block Delivery | Transmission of block data from one peer to another |
| Block Presence | Indicator of whether peer has requested block |
| Merkle Proof | Proof verifying dataset block position correctness |
| CodexProof | Codex-specific Merkle proof format verifying a block's position within a dataset tree |
| Stream | Bidirectional libp2p communication channel between two peers for exchanging messages |
| Peer Context Store | Internal data structure tracking active peer connections, their WantLists, and exchange state |
| CID | Content Identifier - hash-based identifier for content |
| Multicodec | Self-describing format identifier for data encoding |
| Multihash | Self-describing hash format |
Motivation
The Block Exchange module serves as the fundamental layer for content distribution in the Codex network. It provides primitives for requesting and delivering blocks of data between peers, supporting both standalone blocks and blocks that are part of larger datasets. The protocol is designed to work over libp2p streams and integrates with Codex's discovery, storage, and payment systems.
When a peer wishes to obtain a block, it registers its unique address with the Block Exchange, and the Block Exchange will then be in charge of procuring it by finding a peer that has the block, if any, and then downloading it. The Block Exchange will also accept requests from peers which might want blocks that the node has, and provide them.
Discovery Separation: Throughout this specification we assume that if a peer wants a block, then the peer has the means to locate and connect to peers which either: (1) have the block; or (2) are reasonably expected to obtain the block in the future. In practical implementations, the Block Exchange will typically require the support of an underlying discovery service, e.g., the Codex DHT, to look up such peers, but this is beyond the scope of this document.
The protocol supports two distinct block types to accommodate different use cases: standalone blocks for independent data chunks and dataset blocks for ordered collections of data that form larger structures.
Block Format
The Block Exchange protocol supports two types of blocks:
Standalone Blocks
Standalone blocks are self-contained pieces of data addressed by their SHA256 content identifier (CID). These blocks are independent and do not reference any larger structure.
Properties:
- Addressed by content hash (SHA256)
- Default size: 64 KiB
- Self-contained and independently verifiable
Dataset Blocks
Dataset blocks are part of ordered sets and are addressed by a
(datasetCID, index) tuple.
The datasetCID refers to the Merkle tree root of the entire dataset,
and the index indicates the block's position within that dataset.
Formally, we can define a block as a tuple consisting of raw data and
its content identifier: (data: seq[byte], cid: Cid), where standalone
blocks are addressed by cid, and dataset blocks can be addressed
either by cid or a (datasetCID, index) tuple.
Properties:
- Addressed by
(treeCID, index)tuple - Part of a Merkle tree structure
- Require Merkle proof for verification
- Must be uniformly sized within a dataset
- Final blocks MUST be zero-padded if incomplete
Block Specifications
All blocks in the Codex Block Exchange protocol adhere to the following specifications:
| Property | Value | Description |
|---|---|---|
| Default Block Size | 64 KiB | Standard size for data blocks |
| Maximum Block Size | 100 MiB | Upper limit for block data field |
| Multicodec | codex-block (0xCD02)* | Format identifier |
| Multihash | sha2-256 (0x12) | Hash algorithm for addressing |
| Padding Requirement | Zero-padding | Incomplete final blocks padded |
Note: *The multicodec value 0xCD02 is not currently registered in the official multiformats multicodec table. This may be a reserved/private code pending official registration.
Protocol Limits
To ensure network stability and prevent resource exhaustion, implementations SHOULD enforce reasonable limits. The following are recommended values (actual implementation limits may vary):
| Limit | Recommended Value | Description |
|---|---|---|
| Maximum Block Size | 100 MiB | Maximum size of block data in BlockDelivery |
| Maximum WantList Size | 1000 entries | Maximum entries per WantList message |
| Maximum Concurrent Requests | 256 per peer | Maximum simultaneous block requests per peer |
| Stream Timeout | 60 seconds | Idle stream closure timeout |
| Request Timeout | 300 seconds | Maximum time to fulfill a block request |
| Maximum Message Size | 105 MiB | Maximum total message size (protobuf) |
| Maximum Pending Bytes | 10 GiB | Maximum pending data per peer connection |
Note: These values are not verified from implementation and serve as reasonable guidelines. Actual implementations MAY use different limits based on their resource constraints and deployment requirements.
Enforcement:
- Implementations MUST reject messages exceeding their configured size limits
- Implementations SHOULD track per-peer request counts
- Implementations SHOULD close streams exceeding configured timeout limits
- Implementations MAY implement stricter or more lenient limits based on local resources
Service Interface
The Block Exchange module exposes two core primitives for block management:
requestBlock
async def requestBlock(address: BlockAddress) -> Block
Registers a block address for retrieval and returns the block data when available. This function can be awaited by the caller until the block is retrieved from the network or local storage.
Parameters:
address: BlockAddress - The unique address identifying the block to retrieve
Returns:
Block- The retrieved block data
cancelRequest
async def cancelRequest(address: BlockAddress) -> bool
Cancels a previously registered block request.
Parameters:
address: BlockAddress - The address of the block request to cancel
Returns:
bool- True if the cancellation was successful, False otherwise
Dependencies
The Block Exchange module depends on and interacts with several other Codex components:
| Component | Purpose |
|---|---|
| Discovery Module | DHT-based peer discovery for locating nodes |
| Local Store (Repo) | Persistent block storage for local blocks |
| Advertiser | Announces block availability to the network |
| Network Layer | libp2p connections and stream management |
Protocol Specification
Protocol Identifier
The Block Exchange protocol uses the following libp2p protocol identifier:
/codex/blockexc/1.0.0
Version Negotiation
The protocol version is negotiated through libp2p's multistream-select protocol during connection establishment. The following describes standard libp2p version negotiation behavior; actual Codex implementation details may vary.
Protocol Versioning
Version Format: /codex/blockexc/<major>.<minor>.<patch>
- Major version: Incompatible protocol changes
- Minor version: Backward-compatible feature additions
- Patch version: Backward-compatible bug fixes
Current Version: 1.0.0
Version Negotiation Process
1. Initiator opens stream
2. Initiator proposes: "/codex/blockexc/1.0.0"
3. Responder checks supported versions
4. If supported:
Responder accepts: "/codex/blockexc/1.0.0"
→ Connection established
5. If not supported:
Responder rejects with: "na" (not available)
→ Try fallback version or close connection
Compatibility Rules
Major Version Compatibility:
- Major version
1.x.xis incompatible with2.x.x - Nodes MUST support only their major version
- Cross-major-version communication requires protocol upgrade
Minor Version Compatibility:
- Version
1.1.0MUST be backward compatible with1.0.0 - Newer minors MAY include optional features
- Older nodes ignore unknown message fields (protobuf semantics)
Patch Version Compatibility:
- All patches within same minor version are fully compatible
- Patches fix bugs without changing protocol behavior
Multi-Version Support
Implementations MAY support multiple protocol versions simultaneously:
Supported protocols (in preference order):
1. /codex/blockexc/1.2.0 (preferred, latest features)
2. /codex/blockexc/1.1.0 (fallback, stable)
3. /codex/blockexc/1.0.0 (legacy support)
Negotiation Strategy:
- Propose highest supported version first
- If rejected, try next lower version
- If all rejected, connection fails
- Track peer's supported version for future connections
Feature Detection
For optional features within same major.minor version:
Method 1: Message field presence
- Send message with optional field
- Peer ignores if not supported (protobuf default)
Method 2: Capability exchange (future extension)
- Exchange capability bitmask in initial message
- Enable features only if both peers support
Version Upgrade Path
Backward Compatibility:
- New versions MUST handle messages from older versions
- Unknown message fields silently ignored
- Unknown WantList flags ignored
- Unknown BlockPresence types treated as DontHave
Forward Compatibility:
- Older versions MAY ignore new message types
- Critical features require major version bump
- Optional features use minor version bump
Connection Model
The protocol operates over libp2p streams. When a node wants to communicate with a peer:
- The initiating node dials the peer using the protocol identifier
- A bidirectional stream is established
- Both sides can send and receive messages on this stream
- Messages are encoded using Protocol Buffers
- The stream remains open for the duration of the exchange session
- Peers track active connections in a peer context store
The protocol handles peer lifecycle events:
- Peer Joined: When a peer connects, it is added to the active peer set
- Peer Departed: When a peer disconnects gracefully, its context is cleaned up
- Peer Dropped: When a peer connection fails, it is removed from the active set
Message Flow Examples
This section illustrates typical message exchange sequences for common block exchange scenarios.
Example 1: Standalone Block Request
Scenario: Node A requests a standalone block from Node B
Node A Node B
| |
|--- Message(wantlist) ------------------>|
| wantlist.entries[0]: |
| address.cid = QmABC123 |
| wantType = wantBlock |
| priority = 0 |
| |
|<-- Message(blockPresences, payload) ----|
| blockPresences[0]: |
| address.cid = QmABC123 |
| type = presenceHave |
| payload[0]: |
| cid = QmABC123 |
| data = <64 KiB block data> |
| address.cid = QmABC123 |
| |
Steps:
- Node A sends WantList requesting block with
wantType = wantBlock - Node B checks local storage, finds block
- Node B responds with BlockPresence confirming availability
- Node B includes BlockDelivery with actual block data
- Node A verifies CID matches SHA256(data)
- Node A stores block locally
Example 2: Dataset Block Request with Merkle Proof
Scenario: Node A requests a dataset block from Node B
Node A Node B
| |
|--- Message(wantlist) ------------------>|
| wantlist.entries[0]: |
| address.leaf = true |
| address.treeCid = QmTree456 |
| address.index = 42 |
| wantType = wantBlock |
| |
|<-- Message(payload) ---------------------|
| payload[0]: |
| cid = QmBlock789 |
| data = <64 KiB zero-padded data> |
| address.leaf = true |
| address.treeCid = QmTree456 |
| address.index = 42 |
| proof = <CodexProof bytes> |
| |
Steps:
- Node A sends WantList for dataset block at specific index
- Node B locates block in dataset
- Node B generates CodexProof for block position in Merkle tree
- Node B delivers block with proof
- Node A verifies proof against treeCid
- Node A verifies block data integrity
- Node A stores block with dataset association
Example 3: Block Presence Check (wantHave)
Scenario: Node A checks if Node B has a block without requesting full data
Node A Node B
| |
|--- Message(wantlist) ------------------>|
| wantlist.entries[0]: |
| address.cid = QmCheck999 |
| wantType = wantHave |
| sendDontHave = true |
| |
|<-- Message(blockPresences) -------------|
| blockPresences[0]: |
| address.cid = QmCheck999 |
| type = presenceHave |
| price = 0x00 (free) |
| |
Steps:
- Node A sends WantList with
wantType = wantHave - Node B checks local storage without loading block data
- Node B responds with BlockPresence only (no payload)
- Node A updates peer availability map
- If Node A decides to request, sends new WantList with
wantType = wantBlock
Example 4: Block Not Available
Scenario: Node A requests block Node B doesn't have
Node A Node B
| |
|--- Message(wantlist) ------------------>|
| wantlist.entries[0]: |
| address.cid = QmMissing111 |
| wantType = wantBlock |
| sendDontHave = true |
| |
|<-- Message(blockPresences) -------------|
| blockPresences[0]: |
| address.cid = QmMissing111 |
| type = presenceDontHave |
| |
Steps:
- Node A requests block with
sendDontHave = true - Node B checks storage, block not found
- Node B sends BlockPresence with
presenceDontHave - Node A removes Node B from candidates for this block
- Node A queries discovery service for alternative peers
Example 5: WantList Cancellation
Scenario: Node A cancels a previous block request
Node A Node B
| |
|--- Message(wantlist) ------------------>|
| wantlist.entries[0]: |
| address.cid = QmCancel222 |
| cancel = true |
| |
Steps:
- Node A sends WantList entry with
cancel = true - Node B removes block request from peer's want queue
- Node B stops any pending block transfer for this address
- No response message required for cancellation
Example 6: Delta WantList Update
Scenario: Node A adds requests to existing WantList
Node A Node B
| |
|--- Message(wantlist) ------------------>|
| wantlist.full = false |
| wantlist.entries[0]: |
| address.cid = QmNew1 |
| wantType = wantBlock |
| wantlist.entries[1]: |
| address.cid = QmNew2 |
| wantType = wantBlock |
| |
Steps:
- Node A sends WantList with
full = false(delta update) - Node B merges entries with existing WantList for Node A
- Node B begins processing new requests
- Previous WantList entries remain active
Sequence Diagrams
These diagrams illustrate the complete flow of block exchange operations including service interface, peer discovery, and network protocol interactions.
Complete Block Request Flow
The protocol supports two strategies for WantBlock requests, each with different trade-offs. Implementations may choose the strategy based on network conditions, peer availability, and resource constraints.
Strategy 1: Parallel Request (Low Latency)
In this strategy, the requester sends wantType = wantBlock to all
discovered peers simultaneously.
This minimizes latency as the first peer to respond with the block
data wins, but it wastes bandwidth since multiple peers may send
the same block data.
Trade-offs:
- Pro: Lowest latency - block arrives as soon as any peer can deliver it
- Pro: More resilient to slow or unresponsive peers
- Con: Bandwidth-wasteful - multiple peers may send duplicate data
- Con: Higher network overhead for the requester
- Best for: Time-critical data retrieval, unreliable networks
sequenceDiagram
participant Client
participant BlockExchange
participant LocalStore
participant Discovery
participant PeerA
participant PeerB
participant PeerC
Client->>BlockExchange: requestBlock(address)
BlockExchange->>LocalStore: checkBlock(address)
LocalStore-->>BlockExchange: Not found
BlockExchange->>Discovery: findPeers(address)
Discovery-->>BlockExchange: [PeerA, PeerB, PeerC]
par Send wantBlock to all peers
BlockExchange->>PeerA: Message(wantlist: wantBlock)
BlockExchange->>PeerB: Message(wantlist: wantBlock)
BlockExchange->>PeerC: Message(wantlist: wantBlock)
end
Note over PeerA,PeerC: All peers start preparing block data
PeerB-->>BlockExchange: Message(payload: BlockDelivery)
Note over BlockExchange: First response wins
BlockExchange->>BlockExchange: Verify block
BlockExchange->>LocalStore: Store block
par Cancel requests to other peers
BlockExchange->>PeerA: Message(wantlist: cancel)
BlockExchange->>PeerC: Message(wantlist: cancel)
end
Note over PeerA,PeerC: May have already sent data (wasted bandwidth)
BlockExchange-->>Client: Return block
Strategy 2: Two-Phase Discovery (Bandwidth Efficient)
In this strategy, the requester first sends wantType = wantHave to
discover which peers have the block, then sends wantType = wantBlock
only to a single selected peer.
This conserves bandwidth but adds an extra round-trip of latency.
Trade-offs:
- Pro: Bandwidth-efficient - only one peer sends block data
- Pro: Enables price comparison before committing to a peer
- Pro: Allows selection based on peer reputation or proximity
- Con: Higher latency due to extra round-trip for presence check
- Con: Selected peer may become unavailable between phases
- Best for: Large blocks, paid content, bandwidth-constrained networks
sequenceDiagram
participant Client
participant BlockExchange
participant LocalStore
participant Discovery
participant PeerA
participant PeerB
participant PeerC
Client->>BlockExchange: requestBlock(address)
BlockExchange->>LocalStore: checkBlock(address)
LocalStore-->>BlockExchange: Not found
BlockExchange->>Discovery: findPeers(address)
Discovery-->>BlockExchange: [PeerA, PeerB, PeerC]
Note over BlockExchange: Phase 1: Discovery
par Send wantHave to all peers
BlockExchange->>PeerA: Message(wantlist: wantHave)
BlockExchange->>PeerB: Message(wantlist: wantHave)
BlockExchange->>PeerC: Message(wantlist: wantHave)
end
PeerA-->>BlockExchange: BlockPresence(presenceDontHave)
PeerB-->>BlockExchange: BlockPresence(presenceHave, price=X)
PeerC-->>BlockExchange: BlockPresence(presenceHave, price=Y)
BlockExchange->>BlockExchange: Select best peer (PeerB: lower price)
Note over BlockExchange: Phase 2: Retrieval
BlockExchange->>PeerB: Message(wantlist: wantBlock)
PeerB-->>BlockExchange: Message(payload: BlockDelivery)
BlockExchange->>BlockExchange: Verify block
BlockExchange->>LocalStore: Store block
BlockExchange-->>Client: Return block
Hybrid Approach
Implementations MAY combine both strategies:
- Use two-phase discovery for large blocks or paid content
- Use parallel requests for small blocks or time-critical data
- Adaptively switch strategies based on network conditions
flowchart TD
A[Block Request] --> B{Block Size?}
B -->|Small < 64 KiB| C[Parallel Strategy]
B -->|Large >= 64 KiB| D{Paid Content?}
D -->|Yes| E[Two-Phase Discovery]
D -->|No| F{Network Condition?}
F -->|Reliable| E
F -->|Unreliable| C
C --> G[Return Block]
E --> G
Dataset Block Verification Flow
sequenceDiagram
participant Requester
participant Provider
participant Verifier
Requester->>Provider: WantList(leaf=true, treeCid, index)
Provider->>Provider: Load block at index
Provider->>Provider: Generate CodexProof
Provider->>Requester: BlockDelivery(data, proof)
Requester->>Verifier: Verify proof
alt Proof valid
Verifier-->>Requester: Valid
Requester->>Requester: Verify CID
alt CID matches
Requester->>Requester: Store block
Requester-->>Requester: Success
else CID mismatch
Requester->>Requester: Reject block
Requester->>Provider: Disconnect
end
else Proof invalid
Verifier-->>Requester: Invalid
Requester->>Requester: Reject block
Requester->>Provider: Disconnect
end
Payment Flow with State Channels
sequenceDiagram
participant Buyer
participant Seller
participant StateChannel
Buyer->>Seller: Message(wantlist)
Seller->>Seller: Check block availability
Seller->>Buyer: BlockPresence(price)
alt Buyer accepts price
Buyer->>StateChannel: Create update
StateChannel-->>Buyer: Signed state
Buyer->>Seller: Message(payment: StateChannelUpdate)
Seller->>StateChannel: Verify update
alt Payment valid
StateChannel-->>Seller: Valid
Seller->>Buyer: BlockDelivery(data)
Buyer->>Buyer: Verify block
Buyer->>StateChannel: Finalize
else Payment invalid
StateChannel-->>Seller: Invalid
Seller->>Buyer: BlockPresence(price)
end
else Buyer rejects price
Buyer->>Seller: Message(wantlist.cancel)
end
Peer Lifecycle Management
sequenceDiagram
participant Network
participant BlockExchange
participant PeerStore
participant Peer
Network->>BlockExchange: PeerJoined(Peer)
BlockExchange->>PeerStore: AddPeer(Peer)
BlockExchange->>Peer: Open stream
loop Active exchange
BlockExchange->>Peer: Message(wantlist/payload)
Peer->>BlockExchange: Message(payload/presence)
end
alt Graceful disconnect
Peer->>BlockExchange: Close stream
BlockExchange->>PeerStore: RemovePeer(Peer)
else Connection failure
Network->>BlockExchange: PeerDropped(Peer)
BlockExchange->>PeerStore: RemovePeer(Peer)
BlockExchange->>BlockExchange: Requeue pending requests
end
Message Format
All messages use Protocol Buffers encoding for serialization. The main message structure supports multiple operation types in a single message.
Main Message Structure
message Message {
Wantlist wantlist = 1;
// Field 2 reserved for future use
repeated BlockDelivery payload = 3;
repeated BlockPresence blockPresences = 4;
int32 pendingBytes = 5;
AccountMessage account = 6;
StateChannelUpdate payment = 7;
}
Fields:
wantlist: Block requests from the sender- Field 2: Reserved (unused, see note below)
payload: Block deliveries (actual block data)blockPresences: Availability indicators for requested blockspendingBytes: Number of bytes pending deliveryaccount: Account information for micropaymentspayment: State channel update for payment processing
Note on Missing Field 2:
Field number 2 is intentionally skipped in the Message protobuf definition. This is a common protobuf practice for several reasons:
- Protocol Evolution: Field 2 may have been used in earlier versions and removed, with the field number reserved to prevent reuse
- Forward Compatibility: Reserving field numbers ensures old clients can safely ignore new fields
- Implementation History: May have been used during development and removed before final release
The gap does not affect protocol operation. Protobuf field numbers need not be sequential, and skipping numbers is standard practice for protocol evolution.
Block Address
The BlockAddress structure supports both standalone and dataset block addressing:
message BlockAddress {
bool leaf = 1;
bytes treeCid = 2; // Present when leaf = true
uint64 index = 3; // Present when leaf = true
bytes cid = 4; // Present when leaf = false
}
Fields:
leaf: Indicates if this is dataset block (true) or standalone (false)treeCid: Merkle tree root CID (present whenleaf = true)index: Position of block within dataset (present whenleaf = true)cid: Content identifier of the block (present whenleaf = false)
Addressing Modes:
- Standalone Block (
leaf = false): Direct CID reference to a standalone content block - Dataset Block (
leaf = true): Reference to a block within an ordered set, identified by a Merkle tree root and an index. The Merkle root may refer to either a regular dataset, or a dataset that has undergone erasure-coding
WantList
The WantList communicates which blocks a peer desires to receive:
message Wantlist {
enum WantType {
wantBlock = 0;
wantHave = 1;
}
message Entry {
BlockAddress address = 1;
int32 priority = 2;
bool cancel = 3;
WantType wantType = 4;
bool sendDontHave = 5;
}
repeated Entry entries = 1;
bool full = 2;
}
WantType Values:
wantBlock (0): Request full block deliverywantHave (1): Request availability information only (presence check)
Entry Fields:
address: The block being requestedpriority: Request priority (currently always 0, reserved for future use)cancel: If true, cancels a previous want for this blockwantType: Specifies whether full block or presence is desiredwantHave (1): Only check if peer has the blockwantBlock (0): Request full block data
sendDontHave: If true, peer should respond even if it doesn't have the block
Priority Field Clarification:
The priority field is currently fixed at 0 in all implementations and is
reserved for future protocol extensions. Originally intended for request
prioritization, this feature is not yet implemented.
Current Behavior:
- All WantList entries use
priority = 0 - Implementations MUST accept priority values but MAY ignore them
- Blocks are processed in order received, not by priority
Future Extensions:
The priority field is reserved for:
- Bandwidth Management: Higher priority blocks served first during congestion
- Time-Critical Data: Urgent blocks (e.g., recent dataset indices) prioritized
- Fair Queueing: Priority-based scheduling across multiple peers
- QoS Tiers: Different service levels based on payment/reputation
Implementation Notes:
- Senders SHOULD set
priority = 0for compatibility - Receivers MUST NOT reject messages with non-zero priority
- Future protocol versions may activate priority-based scheduling
- When activated, higher priority values = higher priority (0 = lowest)
WantList Fields:
entries: List of block requestsfull: If true, replaces all previous entries; if false, delta update
Delta Updates:
WantLists support delta updates for efficiency.
When full = false, entries represent additions or modifications to
the existing WantList rather than a complete replacement.
Block Delivery
Block deliveries contain the actual block data along with verification information:
message BlockDelivery {
bytes cid = 1;
bytes data = 2;
BlockAddress address = 3;
bytes proof = 4;
}
Fields:
cid: Content identifier of the blockdata: Raw block data (up to 100 MiB)address: The BlockAddress identifying this blockproof: Merkle proof (CodexProof) verifying block correctness (required for dataset blocks)
Merkle Proof Verification:
When delivering dataset blocks (address.leaf = true):
- The delivery MUST include a Merkle proof (CodexProof)
- The proof verifies that the block at the given index is correctly part of the Merkle tree identified by the tree CID
- This applies to all datasets, irrespective of whether they have been erasure-coded or not
- Recipients MUST verify the proof before accepting the block
- Invalid proofs result in block rejection
Block Presence
Block presence messages indicate whether a peer has or does not have a requested block:
enum BlockPresenceType {
presenceHave = 0;
presenceDontHave = 1;
}
message BlockPresence {
BlockAddress address = 1;
BlockPresenceType type = 2;
bytes price = 3;
}
Fields:
address: The block address being referencedtype: Whether the peer has the block or notprice: Price in wei (UInt256 format, see below)
UInt256 Price Format:
The price field encodes a 256-bit unsigned integer representing the cost in
wei (the smallest Ethereum denomination, where 1 ETH = 10^18 wei).
Encoding Specification:
- Format: 32 bytes, big-endian byte order
- Type: Unsigned 256-bit integer
- Range: 0 to 2^256 - 1
- Zero Price:
0x0000000000000000000000000000000000000000000000000000000000000000(block is free)
Examples:
Free (0 wei):
0x0000000000000000000000000000000000000000000000000000000000000000
1 wei:
0x0000000000000000000000000000000000000000000000000000000000000001
1 gwei (10^9 wei):
0x000000000000000000000000000000000000000000000000000000003b9aca00
0.001 ETH (10^15 wei):
0x00000000000000000000000000000000000000000000000000038d7ea4c68000
1 ETH (10^18 wei):
0x0000000000000000000000000000000000000000000000000de0b6b3a7640000
Maximum (2^256 - 1):
0xffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff
Conversion Logic:
# Wei to bytes (big-endian)
def wei_to_bytes(amount_wei: int) -> bytes:
return amount_wei.to_bytes(32, byteorder='big')
# Bytes to wei
def bytes_to_wei(price_bytes: bytes) -> int:
return int.from_bytes(price_bytes, byteorder='big')
# ETH to wei to bytes
def eth_to_price_bytes(amount_eth: float) -> bytes:
amount_wei = int(amount_eth * 10**18)
return wei_to_bytes(amount_wei)
Payment Messages
Payment-related messages for micropayments using Nitro state channels.
Account Message:
message AccountMessage {
bytes address = 1; // Ethereum address to which payments should be made
}
Fields:
address: Ethereum address for receiving payments
Concrete Message Examples
This section provides real-world examples of protobuf messages for different block exchange scenarios.
Example 1: Simple Standalone Block Request
Scenario: Request a single standalone block
Protobuf (wire format representation):
Message {
wantlist: Wantlist {
entries: [
Entry {
address: BlockAddress {
leaf: false
cid: 0x0155a0e40220b94d27b9934d3e08a52e52d7da7dabfac484efe37a5380ee9088f7ace2efcde9 // CID bytes
}
priority: 0
cancel: false
wantType: wantBlock // 0
sendDontHave: true
}
]
full: true
}
}
Hex representation (sample):
0a2e 0a2c 0a24 0001 5512 2012 20b9 4d27
b993 4d3e 08a5 2e52 d7da 7dab fac4 84ef
e37a 5380 ee90 88f7 ace2 efcd e910 0018
0020 0028 011201 01
Example 2: Dataset Block Request
Scenario: Request block at index 100 from dataset
Protobuf:
Message {
wantlist: Wantlist {
entries: [
Entry {
address: BlockAddress {
leaf: true
treeCid: 0x0155a0e40220c5d2460186f7233c927e7db2dcc703c0e500b653ca82273b7bfad8045d85a470 // Tree CID
index: 100
}
priority: 0
cancel: false
wantType: wantBlock
sendDontHave: true
}
]
full: false // Delta update
}
}
Example 3: Block Delivery with Proof
Scenario: Provider sends dataset block with Merkle proof
Protobuf:
Message {
payload: [
BlockDelivery {
cid: 0x0155a0e40220a1b2c3d4e5f6071829... // Block CID
data: <65536 bytes of block data> // 64 KiB
address: BlockAddress {
leaf: true
treeCid: 0x0155a0e40220c5d2460186f7233c927e7db2dcc703c0e500b653ca82273b7bfad8045d85a470
index: 100
}
proof: <CodexProof bytes> // Merkle proof data
// Contains: path indices, sibling hashes, tree height
// Format: Implementation-specific (e.g., [height][index][hash1][hash2]...[hashN])
// Size varies by tree depth (illustrative: ~1KB for depth-10 tree)
}
]
}
Example 4: Block Presence Response
Scenario: Provider indicates block availability with price
Protobuf:
Message {
blockPresences: [
BlockPresence {
address: BlockAddress {
leaf: false
cid: 0x0155a0e40220b94d27b9934d3e08a52e52d7da7dabfac484efe37a5380ee9088f7ace2efcde9
}
type: presenceHave // 0
price: 0x00000000000000000000000000000000000000000000000000038d7ea4c68000 // 0.001 ETH in wei
}
]
}
Example 5: Payment Message
Scenario: Send payment via state channel update
Protobuf:
Message {
account: AccountMessage {
address: 0x742d35Cc6634C0532925a3b844200a717C48D6d9 // 20 bytes Ethereum address
}
payment: StateChannelUpdate {
update: <JSON bytes>
// Contains signed Nitro state as UTF-8 JSON string
// Example: {"channelId":"0x1234...","nonce":42,...}
}
}
Example 6: Multiple Operations in One Message
Scenario: Combined WantList, BlockPresence, and Delivery
Protobuf:
Message {
wantlist: Wantlist {
entries: [
Entry {
address: BlockAddress {
leaf: false
cid: 0x0155a0e40220... // Requesting new block
}
wantType: wantBlock
priority: 0
cancel: false
sendDontHave: true
}
]
full: false
}
blockPresences: [
BlockPresence {
address: BlockAddress {
leaf: false
cid: 0x0155a0e40220... // Response to previous request
}
type: presenceHave
price: 0x00 // Free
}
]
payload: [
BlockDelivery {
cid: 0x0155a0e40220... // Delivering another block
data: <65536 bytes>
address: BlockAddress {
leaf: false
cid: 0x0155a0e40220...
}
}
]
pendingBytes: 131072 // 128 KiB more data pending
}
Example 7: WantList Cancellation
Scenario: Cancel multiple pending requests
Protobuf:
Message {
wantlist: Wantlist {
entries: [
Entry {
address: BlockAddress {
leaf: false
cid: 0x0155a0e40220abc123...
}
cancel: true // Cancellation flag
},
Entry {
address: BlockAddress {
leaf: true
treeCid: 0x0155a0e40220def456...
index: 50
}
cancel: true
}
]
full: false
}
}
CID Format Details
CID Structure:
CID v1 format (multibase + multicodec + multihash):
[0x01] [0x55] [0xa0] [0xe4] [0x02] [0x20] [<32 bytes SHA256 hash>]
│ │ │ │ │ │ │
│ │ │ │ │ │ └─ Hash digest
│ │ │ │ │ └───────── Hash length (32)
│ │ │ │ └──────────────── Hash algorithm (SHA2-256)
│ │ │ └─────────────────────── Codec size
│ │ └────────────────────────────── Codec (raw = 0x55)
│ └───────────────────────────────────── Multicodec prefix
└──────────────────────────────────────────── CID version (1)
Actual: 0x01 55 a0 e4 02 20 <hash bytes>
Example Block CID Breakdown:
Full CID: 0x0155a0e40220b94d27b9934d3e08a52e52d7da7dabfac484efe37a5380ee9088f7ace2efcde9
Parts:
Version: 0x01 (CID v1)
Multicodec: 0x55 (raw)
Codec Size: 0xa0e402 (codex-block = 0xCD02, varint encoded)*
Hash Type: 0x20 (SHA2-256)
Hash Len: 0x12 (20) (32 bytes)
Hash: b94d27b993... (32 bytes SHA256)
State Channel Update:
message StateChannelUpdate {
bytes update = 1; // Signed Nitro state, serialized as JSON
}
Fields:
update: Nitro state channel update containing payment information
Payment Flow and Price Negotiation
The Block Exchange protocol integrates with Nitro state channels to enable micropayments for block delivery.
Payment Requirements
When Payment is Required:
- Blocks marked as paid content by the provider
- Provider's local policy requires payment for specific blocks
- Block size exceeds free tier threshold (implementation-defined)
- Requester has insufficient credit with provider
Free Blocks:
- Blocks explicitly marked as free (
price = 0x00) - Blocks exchanged between trusted peers
- Small metadata blocks (implementation-defined)
Price Discovery
Initial Price Advertisement:
- Requester sends WantList with
wantType = wantHave - Provider responds with BlockPresence including
pricefield - Price encoded as UInt256 in wei (smallest Ethereum unit)
- Requester evaluates price against local policy
Price Format:
price: bytes (32 bytes, big-endian UInt256)
Example: 0x0000000000000000000000000000000000000000000000000de0b6b3a7640000
represents 1 ETH = 10^18 wei
Payment Negotiation Process
Step 1: Price Quote
Requester → Provider: Message(wantlist: wantHave)
Provider → Requester: BlockPresence(type=presenceHave, price=<amount>)
Step 2: Payment Decision
Requester evaluates price:
- Accept: Proceed to payment
- Reject: Send cancellation
- Counter: Not supported in current protocol (future extension)
Step 3: State Channel Update
If accepted:
Requester:
1. Load existing state channel with Provider
2. Create new state with updated balance
3. Sign state update
4. Encode as JSON
Requester → Provider: Message(payment: StateChannelUpdate(update=<signed JSON>))
Step 4: Payment Verification
Provider:
1. Decode state channel update
2. Verify signatures
3. Check balance increase matches price
4. Verify state channel validity
5. Check nonce/sequence number
If valid:
Provider → Requester: BlockDelivery(data, proof)
Else:
Provider → Requester: BlockPresence(price) // Retry with correct payment
Step 5: Delivery and Finalization
Requester:
1. Receive and verify block
2. Store block locally
3. Finalize state channel update
4. Update peer credit balance
Payment State Machine
Note: The following state machine represents a design specification for payment flow logic. Actual implementation may differ.
State: INIT
→ Send wantHave
→ Transition to PRICE_DISCOVERY
State: PRICE_DISCOVERY
← Receive BlockPresence(price)
→ If price acceptable: Transition to PAYMENT_CREATION
→ If price rejected: Transition to CANCELLED
State: PAYMENT_CREATION
→ Create state channel update
→ Send payment message
→ Transition to PAYMENT_PENDING
State: PAYMENT_PENDING
← Receive BlockDelivery: Transition to DELIVERY_VERIFICATION
← Receive BlockPresence(price): Transition to PAYMENT_FAILED
State: PAYMENT_FAILED
→ Retry with corrected payment: Transition to PAYMENT_CREATION
→ Abort: Transition to CANCELLED
State: DELIVERY_VERIFICATION
→ Verify block
→ If valid: Transition to COMPLETED
→ If invalid: Transition to DISPUTE
State: COMPLETED
→ Finalize state channel
→ End
State: CANCELLED
→ Send cancellation
→ End
State: DISPUTE
→ Reject block
→ Dispute state channel update
→ End
State Channel Integration
Account Message Usage:
Sent early in connection to establish payment address:
Message {
account: AccountMessage {
address: 0x742d35Cc6634C0532925a3b8... // Ethereum address
}
}
State Channel Update Format:
{
"channelId": "0x1234...",
"nonce": 42,
"balances": {
"0x742d35Cc...": "1000000000000000000", // Seller balance
"0x8ab5d2F3...": "500000000000000000" // Buyer balance
},
"signatures": [
"0x789abc...", // Buyer signature
"0x456def..." // Seller signature
]
}
Error Scenarios
Insufficient Funds:
- State channel balance < block price
- Response: BlockPresence with price (retry after funding)
Invalid Signature:
- State update signature verification fails
- Response: Reject payment, close stream if repeated
Nonce Mismatch:
- State update nonce doesn't match expected sequence
- Response: Request state sync, retry with correct nonce
Channel Expired:
- State channel past expiration time
- Response: Refuse payment, request new channel creation
Error Handling
The Block Exchange protocol defines error handling for common failure scenarios:
Verification Failures
Merkle Proof Verification Failure:
- Condition: CodexProof validation fails for dataset block
- Action: Reject block delivery, do NOT store block
- Response: Send BlockPresence with
presenceDontHavefor the address - Logging: Log verification failure with peer ID and block address
- Peer Management: Track repeated failures; disconnect after threshold
CID Mismatch:
- Condition: SHA256 hash of block data doesn't match provided CID
- Action: Reject block delivery immediately
- Response: Close stream and mark peer as potentially malicious
- Logging: Log CID mismatch with peer ID and expected/actual CIDs
Network Failures
Stream Disconnection:
- Condition: libp2p stream closes unexpectedly during transfer
- Action: Cancel pending block requests for that peer
- Recovery: Attempt to request blocks from alternative peers
- Timeout: Wait for stream timeout (60s) before peer cleanup
Missing Blocks:
- Condition: Peer responds with
presenceDontHavefor requested block - Action: Remove peer from candidates for this block
- Recovery: Query discovery service for alternative peers
- Fallback: If no peers have block, return error to
requestBlockcaller
Request Timeout:
- Condition: Block not received within request timeout (300s)
- Action: Cancel request with that peer
- Recovery: Retry with different peer if available
- User Notification: If all retry attempts exhausted,
requestBlockreturns timeout error
Protocol Violations
Oversized Messages:
- Condition: Message exceeds maximum size limits
- Action: Close stream immediately
- Peer Management: Mark peer as non-compliant
- No Response: Do not send error message (message may be malicious)
Invalid WantList:
- Condition: WantList exceeds entry limit or contains malformed addresses
- Action: Ignore malformed entries, process valid ones
- Response: Continue processing stream
- Logging: Log validation errors for debugging
Payment Failures:
- Condition: State channel update invalid or payment insufficient
- Action: Do not deliver blocks requiring payment
- Response: Send BlockPresence with price indicating payment needed
- Stream: Keep stream open for payment retry
Recovery Strategies
Retry Responsibility Model
The protocol defines a clear separation between system-level and caller-level retry responsibilities:
System-Level Retry (Automatic):
The Block Exchange module automatically retries in these scenarios:
- Peer failure: If a peer disconnects or times out, the system transparently tries alternative peers from the discovery set
- Transient errors: Network glitches, temporary unavailability
- Peer rotation: Automatic failover to next available peer
The caller's requestBlock call remains pending during system-level retries.
This is transparent to the caller.
Caller-Level Retry (Manual):
The caller is responsible for retry decisions when:
- All peers exhausted: No more peers available from discovery
- Permanent failures: Block doesn't exist in the network
- Timeout exceeded: Request timeout (300s) expired
- Verification failures: All peers provided invalid data
In these cases, requestBlock returns an error and the caller decides
whether to retry, perhaps after waiting or refreshing the peer list
via discovery.
Retry Flow:
requestBlock(address)
│
├─► System tries Peer A ──► Fails
│ │
│ └─► System tries Peer B ──► Fails (automatic, transparent)
│ │
│ └─► System tries Peer C ──► Success ──► Return block
│
└─► All peers failed ──► Return error to caller
│
└─► Caller decides: retry? wait? abort?
Peer Rotation:
When a peer fails to deliver blocks:
- Mark peer as temporarily unavailable for this block
- Query discovery service for alternative peers
- Send WantList to new peers
- Implement exponential backoff before retrying failed peer
Graceful Degradation:
- If verification fails, request block from alternative peer
- If all peers fail, propagate error to caller
- Clean up resources (memory, pending requests) on unrecoverable failures
Error Propagation:
- Service interface functions (
requestBlock,cancelRequest) return errors to callers only after system-level retries are exhausted - Internal errors logged for debugging
- Network errors trigger automatic peer rotation before surfacing to caller
- Verification errors result in block rejection and peer reputation impact
Security Considerations
Block Verification
- All dataset blocks MUST include and verify Merkle proofs before acceptance
- Standalone blocks MUST verify CID matches the SHA256 hash of the data
- Peers SHOULD reject blocks that fail verification immediately
DoS Protection
- Implementations SHOULD limit the number of concurrent block requests per peer
- Implementations SHOULD implement rate limiting for WantList updates
- Large WantLists MAY be rejected to prevent resource exhaustion
Data Integrity
- All blocks MUST be validated before being stored or forwarded
- Zero-padding in dataset blocks MUST be verified to prevent data corruption
- Block sizes MUST be validated against protocol limits
Privacy Considerations
- Block requests reveal information about what data a peer is seeking
- Implementations MAY implement request obfuscation strategies
- Presence information can leak storage capacity details
Rationale
Design Decisions
Two-Tier Block Addressing: The protocol supports both standalone and dataset blocks to accommodate different use cases. Standalone blocks are simpler and don't require Merkle proofs, while dataset blocks enable efficient verification of large datasets without requiring the entire dataset.
WantList Delta Updates: Supporting delta updates reduces bandwidth consumption when peers only need to modify a small portion of their wants, which is common in long-lived connections.
Separate Presence Messages: Decoupling presence information from block delivery allows peers to quickly assess availability without waiting for full block transfers.
Fixed Block Size: The 64 KiB default block size balances efficient network transmission with manageable memory overhead.
Zero-Padding Requirement: Requiring zero-padding for incomplete dataset blocks ensures uniform block sizes within datasets, simplifying Merkle tree construction and verification.
Protocol Buffers: Using Protocol Buffers provides efficient serialization, forward compatibility, and wide language support.
Copyright
Copyright and related rights waived via CC0.
References
Normative
- RFC 2119 - Key words for use in LIPs to Indicate Requirement Levels
- libp2p: https://libp2p.io
- Protocol Buffers: https://protobuf.dev
- Multihash: https://multiformats.io/multihash/
- Multicodec: https://github.com/multiformats/multicodec
Informative
- Codex Documentation: https://docs.codex.storage
- Codex Block Exchange Module Spec: https://github.com/codex-storage/codex-docs-obsidian/blob/main/10%20Notes/Specs/Block%20Exchange%20Module%20Spec.md
- Merkle Trees: https://en.wikipedia.org/wiki/Merkle_tree
- Content Addressing: https://en.wikipedia.org/wiki/Content-addressable_storage
CODEX-COMMUNITY-HISTORY
| Field | Value |
|---|---|
| Name | Codex Community History |
| Slug | 76 |
| Status | raw |
| Category | Standards Track |
| Editor | Jimmy Debe [email protected] |
| Contributors | Jimmy Debe [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-30 —
d5a9240— chore: removed archived (#283) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258)
Abstract
This document describes how nodes in Status Communities archive historical message data of their communities. Not requiring to follow the time range limit provided by 13/WAKU2-STORE nodes using the BitTorrent protocol. It also describes how the archives are distributed to community members via the Status network, so they can fetch them and gain access to a complete message history.
Background
Messages are stored permanently by 13/WAKU2-STORE nodes for a configurable time range, which is limited by the overall storage provided by a 13/WAKU2-STORE nodes. Messages older than that period are no longer provided by 13/WAKU2-STORE nodes, making it impossible for other nodes to request historical messages that go beyond that time range. This raises issues in the case of Status communities, where recently joined members of a community are not able to request complete message histories of the community channels.
Terminology
| Name | Description |
|---|---|
| Waku node | A 10/WAKU2 node that implements 11/WAKU2-RELAY |
| Store node | A 10/WAKU2 node that implements 13/WAKU2-STORE |
| Waku network | A group of 10/WAKU2 nodes forming a graph, connected via 11/WAKU2-RELAY |
| Status user | A Status account that is used in a Status consumer product, such as Status Mobile or Status Desktop |
| Status node | A Status client run by a Status application |
| Control node | A Status node that owns the private key for a Status community |
| Community member | A Status user that is part of a Status community, not owning the private key of the community |
| Community member node | A Status node with message archive capabilities enabled, run by a community member |
| Live messages | 14/WAKU2-MESSAGE received through the Waku network |
| BitTorrent client | A program implementing the BitTorrent protocol |
| Torrent/Torrent file | A file containing metadata about data to be downloaded by BitTorrent clients |
| Magnet link | A link encoding the metadata provided by a torrent file (Magnet URI scheme) |
Specification
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in 2119.
Message History Archive
Message history archives are represented as WakuMessageArchive and
created from a 14/WAKU2-MESSAGE exported from the local database.
The following describes the protocol buffer for WakuMessageArchive :
syntax = "proto3";
message WakuMessageArchiveMetadata {
uint8 version = 1;
uint64 from = 2;
uint64 to = 3;
repeated string content_Topic = 4;
}
message WakuMessageArchive {
uint8 version = 1;
WakuMessageArchiveMetadata metadata = 2;
repeated WakuMessage messages = 3; // `WakuMessage` is provided by 14/WAKU2-MESSAGE
bytes padding = 4;
}
The from field SHOULD contain a timestamp of the time range's lower bound.
This type parallels to the timestamp of a WakuMessage.
The to field SHOULD contain a timestamp of the time range's the higher bound.
The contentTopic field MUST contain a list of all community channel contentTopics.
The messages field MUST contain all messages that belong in the archive, given its from,
to, and contentTopic fields.
The padding field MUST contain the amount of zero bytes needed for the protobuf encoded WakuMessageArchive.
The overall byte size MUST be a multiple of the pieceLength used to divide the data into pieces.
This is needed for seamless encoding and
decoding of archival data when interacting with BitTorrent,
as explained in creating message archive torrents.
Message History Archive Index
Control nodes MUST provide message archives for the entire community history.
The entire history consists of a set of WakuMessageArchive,
where each archive contains a subset of historical WakuMessage for a time range of seven days.
All the WakuMessageArchive are concatenated into a single file as a byte string, see Ensuring reproducible data pieces.
Control nodes MUST create a message history archive index,
WakuMessageArchiveIndex with metadata,
that allows receiving nodes to only fetch the message history archives they are interested in.
WakuMessageArchiveIndex
syntax = "proto3"
message WakuMessageArchiveIndexMetadata {
uint8 version = 1
WakuMessageArchiveMetadata metadata = 2
uint64 offset = 3
uint64 num_pieces = 4
}
message WakuMessageArchiveIndex {
map<string, WakuMessageArchiveIndexMetadata> archives = 1
}
A WakuMessageArchiveIndex is a map where the key is the KECCAK-256 hash of the WakuMessageArchiveIndexMetadata,
is derived from a 7-day archive
and the value is an instance of that WakuMessageArchiveIndexMetadata corresponding to that archive.
The offset field MUST contain the position at which the message history archive starts in the byte string
of the total message archive data.
This MUST be the sum of the length of all previously created message archives in bytes, see creating message archive torrents.
The control node MUST update the WakuMessageArchiveIndex every time it creates one or
more WakuMessageArchives and bundle it into a new torrent.
For every created WakuMessageArchive,
there MUST be a WakuMessageArchiveIndexMetadata entry in the archives field WakuMessageArchiveIndex.
Creating Message Archive Torrents
Control nodes MUST create a .torrent file containing metadata for all message history archives. To create a .torrent file, and later serve the message archive data on the BitTorrent network, control nodes MUST store the necessary data in dedicated files on the file system.
A torrent's source folder MUST contain the following two files:
data: Contains all protobuf encodedWakuMessageArchive's (as bit strings) concatenated in ascending order based on their timeindex: Contains the protobuf encodedWakuMessageArchiveIndex
Control nodes SHOULD store these files in a dedicated folder that is identifiable via a community identifier.
Ensuring Reproducible Data Pieces
The control node MUST ensure that the byte string from the protobuf encoded data
is equal to the byte string data from the previously generated message archive torrent.
Including the data of the latest seven days worth of messages encoded as WakuMessageArchive.
Therefore, the size of data grows every seven days as it's append-only.
Control nodes MUST ensure that the byte size,
for every individual WakuMessageArchive encoded protobuf,
is a multiple of pieceLength using the padding field.
If the WakuMessageArchive is not a multiple of pieceLength,
its padding field MUST be filled with zero bytes and
the WakuMessageArchive MUST be re-encoded until its size becomes a multiple of pieceLength.
This is necessary because the content of the data file will be split into pieces of pieceLength when the torrent file is created,
and the SHA1 hash of every piece is then stored in the torrent file and
later used by other nodes to request the data for each individual data piece.
By fitting message archives into a multiple of pieceLength and
ensuring they fill the possible remaining space with zero bytes,
control nodes prevent the next message archive from occupying that remaining space of the last piece,
which will result in a different SHA1 hash for that piece.
Example: Without padding
Let WakuMessageArchive "A1" be of size 20 bytes:
0 11 22 33 44 55 66 77 88 99
10 11 12 13 14 15 16 17 18 19
With a pieceLength of 10 bytes, A1 will fit into 20 / 10 = 2 pieces:
0 11 22 33 44 55 66 77 88 99 // piece[0] SHA1: 0x123
10 11 12 13 14 15 16 17 18 19 // piece[1] SHA1: 0x456
Example: With padding
Let WakuMessageArchive "A2" be of size 21 bytes:
0 11 22 33 44 55 66 77 88 99
10 11 12 13 14 15 16 17 18 19
20
With a pieceLength of 10 bytes,
A2 will fit into 21 / 10 = 2 pieces.
The remainder will introduce a third piece:
0 11 22 33 44 55 66 77 88 99 // piece[0] SHA1: 0x123
10 11 12 13 14 15 16 17 18 19 // piece[1] SHA1: 0x456
20 // piece[2] SHA1: 0x789
The next WakuMessageArchive "A3" will be appended ("#3") to the existing data and
occupy the remaining space of the third data piece.
The piece at index 2 will now produce a different SHA1 hash:
0 11 22 33 44 55 66 77 88 99 // piece[0] SHA1: 0x123
10 11 12 13 14 15 16 17 18 19 // piece[1] SHA1: 0x456
20 #3 #3 #3 #3 #3 #3 #3 #3 #3 // piece[2] SHA1: 0xeef
#3 #3 #3 #3 #3 #3 #3 #3 #3 #3 // piece[3]
By filling up the remaining space of the third piece with A2 using its padding field, it is guaranteed that its SHA1 will stay the same:
0 11 22 33 44 55 66 77 88 99 // piece[0] SHA1: 0x123
10 11 12 13 14 15 16 17 18 19 // piece[1] SHA1: 0x456
20 0 0 0 0 0 0 0 0 0 // piece[2] SHA1: 0x999
#3 #3 #3 #3 #3 #3 #3 #3 #3 #3 // piece[3]
#3 #3 #3 #3 #3 #3 #3 #3 #3 #3 // piece[4]
Seeding Message History Archives
The control node MUST seed the generated torrent until a new WakuMessageArchive is created.
The control node SHOULD NOT seed torrents for older message history archives. Only one torrent at a time SHOULD be seeded.
Creating Magnet Links
Once a torrent file for all message archives is created, the control node MUST derive a magnet link, following the Magnet URI scheme using the underlying BitTorrent protocol client.
Message Archive Distribution
Message archives are available via the BitTorrent network as they are being seeded by the control node. Other community member nodes will download the message archives, from the BitTorrent network, after receiving a magnet link that contains a message archive index.
The control node MUST send magnet links containing message archives and
the message archive index to a special community channel.
The content_Topic of that special channel follows the following format:
/{application-name}/{version-of-the-application}/{content-topic-name}/{encoding}
All messages sent with this special channel's content_Topic MUST be instances of ApplicationMetadataMessage,
with a 62/STATUS-PAYLOADS of CommunityMessageArchiveIndex.
Only the control node MAY post to the special channel. Other messages on this specified channel MUST be ignored by clients. Community members MUST NOT have permission to send messages to the special channel. However, community member nodes MUST subscribe to a special channel, to receive a 14/WAKU2-MESSAGE containing magnet links for message archives.
Canonical Message Histories
Only control nodes are allowed to distribute messages with magnet links, via the special channel for magnet link exchange. Status nodes MUST ignore all messages in the special channel that aren't signed by a control node. Since the magnet links are created from the control node's database (and previously distributed archives), the message history provided by the control node becomes the canonical message history and single source of truth for the community.
Community member nodes MUST replace messages in their local database with the messages extracted from archives within the same time range. Messages that the control node didn't receive MUST be removed and are no longer part of the message history of interest, even if it already existed in a community member node's database.
Fetching Message History Archives
The process of fetching message history:
- Receive message archive index magnet link as described in Message archive distribution,
- Download the index file from the torrent, then determine which message archives to download
- Download individual archives
Community member nodes subscribe to the special channel of the control nodes that publish magnet links for message history archives. Two RECOMMENDED scenarios in which community member nodes can receive such a magnet link message from the special channel:
- The member node receives it via live messages, by listening to the special channel.
- The member node requests messages for a time range of up to 30 days from store nodes (this is the case when a new community member joins a community.)
- Downloading message archives
When community member nodes receive a message with a CommunityMessageHistoryArchive 62/STATUS-PAYLOADS,
they MUST extract the magnet_uri.
Then SHOULD pass it to their underlying BitTorrent client to fetch the latest message history archive index,
which is the index file of the torrent, see [Creating message archive torrents].
Due to the nature of distributed systems,
there's no guarantee that a received message is the "last" message.
This is especially true when community member nodes request historical messages from store nodes.
Therefore, community member nodes MUST wait for 20 seconds after receiving the last CommunityMessageArchive,
before they start extracting the magnet link to fetch the latest archive index.
Once a message history archive index is downloaded and
parsed back into WakuMessageArchiveIndex,
community member nodes use a local lookup table to determine which of the listed archives are missing,
using the KECCAK-256 hashes stored in the index.
For this lookup to work,
member nodes MUST store the KECCAK-256 hashes,
of the WakuMessageArchiveIndexMetadata provided by the index file,
for all of the message history archives that have been downloaded into their local database.
Given a WakuMessageArchiveIndex, member nodes can access individual WakuMessageArchiveIndexMetadata to download individual archives.
Community member nodes MUST choose one of the following options:
- Download all archives: Request and download all data pieces for the data provided by the torrent (this is the case for new community member nodes that haven't downloaded any archives yet.)
- Download only the latest archive: Request and
download all pieces starting at the offset of the latest
WakuMessageArchiveIndexMetadata(this is the case for any member node that already has downloaded all previous history and is now interested in only the latest archive). - Download specific archives: Look into from and
to fields of every
WakuMessageArchiveIndexMetadataand determine the pieces for archives of a specific time range (can be the case for member nodes that have recently joined the network and are only interested in a subset of the complete history).
Storing Historical Messages
When message archives are fetched,
community member nodes MUST unwrap the resulting WakuMessage instances into ApplicationMetadataMessage instances
and store them in their local database.
Community member nodes SHOULD NOT store the wrapped WakuMessage messages.
All messages within the same time range MUST be replaced with the messages provided by the message history archive.
Community members' nodes MUST ignore the expiration state of each archive message.
Security Considerations
Multiple Community Owners
It is possible for control nodes to export the private key of their owned community and pass it to other users so they become control nodes as well. This means it's possible for multiple control nodes to exist for one community.
This might conflict with the assumption that the control node serves as a single source of truth. Multiple control nodes can have different message histories. Not only will multiple control nodes multiply the amount of archive index messages being distributed to the network, but they might also contain different sets of magnet links and their corresponding hashes. Even if just a single message is missing in one of the histories, the hashes presented in the archive indices will look completely different, resulting in the community member node downloading the corresponding archive. This might be identical to an archive that was already downloaded, except for that one message.
Copyright
Copyright and related rights waived via CC0.
References
- 13/WAKU2-STORE
- BitTorrent protocol
- Status network
- 10/WAKU2
- 11/WAKU2-RELAY
- 14/WAKU2-MESSAGE
- 62/STATUS-PAYLOADS
CODEX-DHT
| Field | Value |
|---|---|
| Name | Codex Discovery |
| Slug | 75 |
| Status | raw |
| Category | Standards Track |
| Editor | Jimmy Debe [email protected] |
| Contributors | Jimmy Debe [email protected], Giuliano Mega [email protected] |
Timeline
- 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258)
Abstract
This document explains the Codex DHT (Distributed Hash Table) component. The DHT maps content IDs (CIDs) into providers of that content.
Background and Overview
Codex is a network of nodes, identified as providers, participating in a decentralized peer-to-peer storage protocol. The decentralized storage solution offers data durability guarantees, incentive mechanisms and data persistence guarantees.
The Codex DHT is the service responsible for helping providers find other peers hosting both dataset and standalone blocks1 in the Codex network. It maps content IDs -- which identify blocks and datasets -- into lists of providers -- which identify and provide the information required to connect to those providers.
The Codex DHT is a modified version of discv5, with the following differences:
- it uses libp2p SPRs instead of Ethereum's ENRs to identify peers and convey connection information;
- it extends the DHT message interface with
GET_PROVIDERS/ADD_PROVIDERrequests for managing provider lists; - it replaces discv5 packet encoding with protobuf.
The Codex DHT is, indeed, closer to the libp2p DHT than to discv5 in terms of what it provides. Historically, this is because the Nim version of libp2p did not implement the Kad DHT spec at the time, so project builders opted to adapt the nim-eth Kademlia-based discv5 DHT instead.
A Codex provider will support this protocol at no extra cost other than the use of resources to store node records, and the bandwidth to serve queries and process data advertisements. As it is usually the case with DHTs, any publicly reachable node running the DHT protocol can be used as a bootstrap node into the Codex network.
Service Interface
The two core primitives provided by the Codex DHT on top of discv5 are:
def addProvider(cid: NodeId, provider: SignedPeerRecord)
def getProviders(cid: NodeId): List[SignedPeerRecord]
where NodeId is a 256-bit string, obtained from the keccak256 hash function of the node's public key, the same used to sign peer records.
By convention, we convert from libp2p CIDs to NodeId by taking the keccak256 hash of the CID's contents. For reference, the Nim implementation of this conversion looks like:
proc toNodeId*(cid: Cid): NodeId =
## Cid to discovery id
##
readUintBE[256](keccak256.digest(cid.data.buffer).data)
Wire Format
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “NOT RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in RFC 2119.
As in discv5, all messages in the Codex DHT MUST be encoded with a request_id, which SHALL be serialized before the actual message data, as per the message envelope below:
message MessageEnvelope {
bytes request_id = 1; // RequestId (max 8 bytes)
bytes message_data = 2; // Encoded specific message
}
Signed peer records are simply libp2p peer records wrapped in a signed envelope and MUST be serialized according to the libp2p protobuf wire formats.
Providers MUST2 support the standard discv5 messages, with the following additions:
ADD_PROVIDER request (0x0B)
message AddProviderMessage {
bytes content_id = 1; // NodeId - 32 bytes, big-endian
Envelope signed_peer_record = 2;
}
Registers the peer in signed_peer_record as a provider of the content identified by content_id.
GET_PROVIDERS request (0x0C)
message GetProvidersMessage {
bytes content_id = 1; // NodeId - 32 bytes, big-endian
}
Requests the list of providers of the content identified by content_id.
PROVIDERS response (0x0D)
message ProvidersMessage {
uint32 total = 1;
repeated Envelope signed_peer_records = 2;
}
Returns the list of known providers of the content identified by content_id. total is currently always set to .
Copyright
Copyright and related rights waived via CC0.
References
This is actually stronger than necessary, but we'll refine it over time.
This should link to the block exchange spec once it's done.
CODEX-MANIFEST
| Field | Value |
|---|---|
| Name | Codex Manifest |
| Slug | 145 |
| Status | raw |
| Category | Standards Track |
| Tags | codex, manifest, metadata, cid |
| Editor | Jimmy Debe [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-01-30 —
0ef87b1— New RFC: CODEX-MANIFEST (#191)
Abstract
This specification defines the Codex Manifest, a metadata structure that describes datasets stored on the Codex network. The manifest contains essential information such as the Merkle tree root CID, block size, dataset size, and optional attributes like filename and MIME type. Similar to BitTorrent's metainfo files, the Codex Manifest enables content identification and retrieval but is itself content-addressed and announced on the Codex DHT.
Keywords: manifest, metadata, CID, Merkle tree, content addressing, BitTorrent, DHT, protobuf
Semantics
The keywords "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119.
Definitions
| Term | Description |
|---|---|
| Manifest | A metadata structure describing a dataset stored on the Codex network. |
| CID | Content Identifier, a self-describing content-addressed identifier used in IPFS and Codex. |
| Codex Tree | A Merkle tree structure computed over the blocks in a dataset. See CODEX-MERKLE-TREE. |
| treeCid | The CID of the root of the Codex Tree corresponding to a dataset. |
| Block | A fixed-size chunk of data in the dataset. |
| Multicodec | A self-describing protocol identifier from the Multicodec table. |
Background
The Codex Manifest provides the description of the metadata uploaded to the Codex network. It is in many ways similar to the BitTorrent metainfo file, also known as .torrent files. For more information, see BEP3 from BitTorrent Enhancement Proposals (BEPs). While the BitTorrent metainfo files are generally distributed out-of-band, the Codex Manifest receives its own content identifier (CIDv1) that is announced on the Codex DHT. See the CODEX-DHT specification for more details.
In version 1 of the BitTorrent protocol,
when a user wants to upload (seed) some content to the BitTorrent network,
the client chunks the content into pieces.
For each piece, a hash is computed and
included in the pieces attribute of the info dictionary in the BitTorrent metainfo file.
In Codex,
instead of hashes of individual pieces,
a Merkle tree is computed over the blocks in the dataset.
The CID of the root of this Merkle tree is included as the treeCid attribute in the Codex Manifest.
See CODEX-MERKLE-TREE for more information.
Version 2 of the BitTorrent protocol also uses Merkle trees and
includes the root of the tree in the info dictionary for each .torrent file.
The Codex Manifest CID has the ability to uniquely identify the content and enables retrieval of that content from any Codex client.
Protocol Specification
Manifest Encoding
The manifest is encoded using Protocol Buffers (proto3) and serialized with multibase base58btc encoding. Each manifest has a corresponding CID (the manifest CID).
Manifest Attributes
syntax = "proto3";
message Manifest {
optional bytes treeCid = 1; // CID (root) of the tree
optional uint32 blockSize = 2; // Size of a single block
optional uint64 datasetSize = 3; // Size of the dataset
optional uint32 codec = 4; // Dataset codec
optional uint32 hcodec = 5; // Multihash codec
optional uint32 version = 6; // CID version
optional string filename = 7; // Original filename
optional string mimetype = 8; // Original mimetype
}
| Attribute | Type | Description |
|---|---|---|
treeCid | bytes | A hash based on CIDv1 of the root of the Codex Tree, which is a form of a Merkle tree corresponding to the dataset described by the manifest. Its multicodec is codex-root (0xCD03). |
blockSize | uint32 | The size of each block for the given dataset. The default block size used in Codex is 64 KiB. |
datasetSize | uint64 | The total size of all blocks for the original dataset. |
codec | uint32 | The Multicodec used for the CIDs of the dataset blocks. Codex uses codex-block (0xCD02). |
hcodec | uint32 | The Multicodec used for computing the multihash used in block CIDs. Codex uses sha2-256 (0x12). |
version | uint32 | The version of CID used for the dataset blocks. |
filename | string | When provided, it MAY be used by the client as a file name while downloading the content. |
mimetype | string | When provided, it MAY be used by the client to set a content type of the downloaded content. |
DHT Announcement
The manifest CID SHOULD be announced on the CODEX-DHT, so that nodes storing the corresponding manifest block can be found by other clients requesting to download the corresponding dataset.
From the manifest,
providers storing relevant blocks SHOULD be identified using the treeCid attribute.
The manifest CID in Codex is similar to the info_hash from BitTorrent.
Security Considerations
Content Integrity
The treeCid attribute provides cryptographic binding between the manifest and the dataset content.
Implementations MUST verify that retrieved blocks match the expected hashes
derived from the Merkle tree root.
Manifest Authenticity
The manifest CID provides content addressing, ensuring that any modification to the manifest will result in a different CID. Implementations SHOULD verify manifest integrity by recomputing the CID from the received manifest data.
References
Normative
- CODEX-MERKLE-TREE - Codex Merkle tree specification
- CODEX-DHT - Codex DHT specification
Informative
- BEP3 - The BitTorrent Protocol Specification
- CIDv1 - Content Identifier version 1 specification
- Multicodec - Self-describing protocol identifiers
- Codex Manifest Spec - Original specification
Copyright
Copyright and related rights waived via CC0.
CODEX-STORE
| Field | Value |
|---|---|
| Name | Codex Store Module |
| Slug | 80 |
| Status | raw |
| Category | Standards Track |
| Editor | Codex Team |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258)
Abstract
This specification describes the Store Module, the core storage abstraction in Codex, providing a unified interface for storing and retrieving content-addressed blocks and associated metadata.
The Store Module decouples storage operations from underlying datastore semantics
by introducing the BlockStore interface,
which standardizes methods for storing and retrieving both ephemeral
and persistent blocks across different storage backends.
The module integrates a maintenance engine responsible for cleaning up
expired ephemeral data according to configured policies.
The Store Module is built on top of the generic DataStore (DS) interface, which is implemented by multiple backends such as SQLite, LevelDB, and the filesystem.
Background / Rationale / Motivation
The primary design goal is to decouple storage operations from the underlying
datastore semantics by introducing the BlockStore interface.
This interface standardizes methods for storing and retrieving both ephemeral
and persistent blocks,
ensuring a consistent API across different storage backends.
The DataStore provides a KV-store abstraction with Get, Put, Delete,
and Query operations, with backend-dependent guarantees.
At a minimum, row-level consistency and basic batching are expected.
The DataStore supports:
- Namespace mounting for isolating backend usage
- Layering backends (e.g., caching in front of persistent stores)
- Flexible stacking and composition of storage proxies
The current implementation has several limitations:
- No dataset-level operations or advanced batching support
- Lack of consistent locking and concurrency control, which may lead to inconsistencies during crashes or long-running operations on block groups (e.g., reference count updates, expiration updates)
Theory / Semantics
BlockStore Interface
The BlockStore interface provides the following methods:
| Method | Description | Input | Output |
|---|---|---|---|
getBlock(cid: Cid) | Retrieve block by CID | CID | Future[?!Block] |
getBlock(treeCid: Cid, index: Natural) | Retrieve block from a Merkle tree by leaf index | Tree CID, index | Future[?!Block] |
getBlock(address: BlockAddress) | Retrieve block via unified address | BlockAddress | Future[?!Block] |
getBlockAndProof(treeCid: Cid, index: Natural) | Retrieve block with Merkle proof | Tree CID, index | Future[?!(Block, CodexProof)] |
getCid(treeCid: Cid, index: Natural) | Retrieve leaf CID from tree metadata | Tree CID, index | Future[?!Cid] |
getCidAndProof(treeCid: Cid, index: Natural) | Retrieve leaf CID with inclusion proof | Tree CID, index | Future[?!(Cid, CodexProof)] |
putBlock(blk: Block, ttl: Duration) | Store block with quota enforcement | Block, optional TTL | Future[?!void] |
putCidAndProof(treeCid: Cid, index: Natural, blkCid: Cid, proof: CodexProof) | Store leaf metadata with ref counting | Tree CID, index, block CID, proof | Future[?!void] |
hasBlock(...) | Check block existence (CID or tree leaf) | CID / Tree CID + index | Future[?!bool] |
delBlock(...) | Delete block/tree leaf (with ref count checks) | CID / Tree CID + index | Future[?!void] |
ensureExpiry(...) | Update expiry for block/tree leaf | CID / Tree CID + index, expiry timestamp | Future[?!void] |
listBlocks(blockType: BlockType) | Iterate over stored blocks | Block type | Future[?!SafeAsyncIter[Cid]] |
getBlockExpirations(maxNumber, offset) | Retrieve block expiry metadata | Pagination params | Future[?!SafeAsyncIter[BlockExpiration]] |
blockRefCount(cid: Cid) | Get block reference count | CID | Future[?!Natural] |
reserve(bytes: NBytes) | Reserve storage quota | Bytes | Future[?!void] |
release(bytes: NBytes) | Release reserved quota | Bytes | Future[?!void] |
start() | Initialize store | — | Future[void] |
stop() | Gracefully shut down store | — | Future[void] |
close() | Close underlying datastores | — | Future[void] |
Store Implementations
The Store module provides three concrete implementations of the BlockStore
interface,
each optimized for a specific role in the Codex architecture:
RepoStore, NetworkStore, and CacheStore.
RepoStore
The RepoStore is a persistent BlockStore implementation
that interfaces directly with low-level storage backends,
such as hard drives and databases.
It uses two distinct DataStore backends:
- FileSystem — for storing raw block data
- LevelDB — for storing associated metadata
This separation ensures optimal performance, allowing block data operations to run efficiently while metadata updates benefit from a fast key-value database.
Characteristics:
- Persistent storage via datastore backends
- Quota management with precise usage tracking
- TTL (time-to-live) support with automated expiration
- Metadata storage for block size, reference count, and expiry
- Transaction-like operations implemented through reference counting
Configuration:
quotaMaxBytes: Maximum storage quotablockTtl: Default TTL for stored blockspostFixLen: CID key postfix length for sharding
┌─────────────────────────────────────────────────────────────┐
│ RepoStore │
├─────────────────────────────────────────────────────────────┤
│ ┌─────────────┐ ┌──────────────────────────┐ │
│ │ repoDs │ │ metaDs │ │
│ │ (Datastore) │ │ (TypedDatastore) │ │
│ │ │ │ │ │
│ │ Block Data: │ │ Metadata: │ │
│ │ - Raw bytes │ │ - BlockMetadata │ │
│ │ - CID-keyed │ │ - LeafMetadata │ │
│ │ │ │ - QuotaUsage │ │
│ │ │ │ - Block counts │ │
│ └─────────────┘ └──────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
NetworkStore
The NetworkStore is a composite BlockStore that combines local persistence
with network-based retrieval for distributed content access.
It follows a local-first strategy — attempting to retrieve or store blocks locally first, and falling back to network retrieval via the Block Exchange Engine if the block is not available locally.
Characteristics:
- Integrates local storage with network retrieval
- Works seamlessly with the block exchange engine for peer-to-peer access
- Transparent block fetching from remote sources
- Local caching of blocks retrieved from the network for future access
┌────────────────────────────────────────────────────────────┐
│ NetworkStore │
├────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────────┐ ┌──────────────────────┐ │
│ │ LocalStore - RS │ │ BlockExcEngine │ │
│ │ • Store blocks │ │ • Request blocks │ │
│ │ • Get blocks │ │ • Resolve blocks │ │
│ └─────────────────┘ └──────────────────────┘ │
│ │ │ │
│ └──────────────┬───────────────┘ │
│ │ │
│ ┌─────────────┐ │
│ │BS Interface │ │
│ │ │ │
│ │ • getBlock │ │
│ │ • putBlock │ │
│ │ • hasBlock │ │
│ │ • delBlock │ │
│ └─────────────┘ │
└────────────────────────────────────────────────────────────┘
CacheStore
The CacheStore is an in-memory BlockStore implementation
designed for fast access to frequently used blocks.
This store maintains two separate LRU caches:
- Block Cache —
LruCache[Cid, Block]- Stores actual block data indexed by CID
- Acts as the primary cache for block content
- CID/Proof Cache —
LruCache[(Cid, Natural), (Cid, CodexProof)]- Maps
(treeCid, index)to(blockCid, proof) - Supports direct access to block proofs keyed by
treeCidand index
- Maps
Characteristics:
- O(1) access times for cached data
- LRU eviction policy for memory management
- Configurable maximum cache size
- No persistence — cache contents are lost on restart
- No TTL — blocks remain in cache until evicted
Configuration:
cacheSize: Maximum total cache size (bytes)chunkSize: Minimum block size unit
Storage Layout
| Key Pattern | Data Type | Description | Example |
|---|---|---|---|
repo/manifests/{XX}/{full-cid} | Raw bytes | Manifest block data | repo/manifests/Cd/bafy...Cd → [data] |
repo/blocks/{XX}/{full-cid} | Raw bytes | Block data | repo/blocks/Ab/bafy...Ab → [data] |
meta/ttl/{cid} | BlockMetadata | Expiry, size, refCount | meta/ttl/bafy... → {...} |
meta/proof/{treeCid}/{index} | LeafMetadata | Merkle proof for leaf | meta/proof/bafy.../42 → {...} |
meta/total | Natural | Total stored blocks | meta/total → 12039 |
meta/quota/used | NBytes | Used quota | meta/quota/used → 52428800 |
meta/quota/reserved | NBytes | Reserved quota | meta/quota/reserved → 104857600 |
Workflows
The following flow charts summarize how put, get, and delete operations interact with the shared block storage, metadata store, and quota management systems.
PutBlock
The following flow chart shows how a block is stored with metadata and quota management:
putBlock: blk, ttl
│
├─> Calculate expiry = now + ttl
│
├─> storeBlock: blk, expiry
│
├─> Block empty?
│ ├─> Yes: Return AlreadyInStore
│ └─> No: Create metadata & block keys
│
├─> Block metadata exists?
│ ├─> Yes: Size matches?
│ │ ├─> Yes: Return AlreadyInStore
│ │ └─> No: Return Error
│ └─> No: Create new metadata
│
├─> Store block data
│
├─> Store successful?
│ ├─> No: Return Error
│ └─> Yes: Update quota usage
│
├─> Quota update OK?
│ ├─> No: Rollback: Delete block → Return Error
│ └─> Yes: Update total blocks count
│
├─> Trigger onBlockStored callback
│
└─> Return Success
GetBlock
The following flow chart explains how a block is retrieved by CID or tree reference, resolving metadata if necessary, and returning the block or an error:
getBlock: cid/address
│
├─> Input type?
│ ├─> BlockAddress with leaf
│ │ └─> getLeafMetadata: treeCid, index
│ │ ├─> Leaf metadata found?
│ │ │ ├─> No: Return BlockNotFoundError
│ │ │ └─> Yes: Extract block CID from metadata
│ └─> CID: Direct CID access
│
├─> CID empty?
│ ├─> Yes: Return empty block
│ └─> No: Create prefix key
│
├─> Query datastore: repoDs.get
│
├─> Block found?
│ ├─> No: Error type?
│ │ ├─> DatastoreKeyNotFound: Return BlockNotFoundError
│ │ └─> Other: Return Error
│ └─> Yes: Create Block with verification
│
└─> Return Block
DelBlock
The following flow chart shows how a block is deleted when it is unused or expired, including metadata cleanup and quota/counter updates:
delBlock: cid
│
├─> delBlockInternal: cid
│
├─> CID empty?
│ ├─> Yes: Return Deleted
│ └─> No: tryDeleteBlock: cid, now
│
├─> Metadata exists?
│ ├─> No: Check if block exists in repo
│ │ ├─> Block exists?
│ │ │ ├─> Yes: Warn & remove orphaned block
│ │ │ └─> No: Return NotFound
│ │ └─> Return NotFound
│ └─> Yes: refCount = 0 OR expired?
│ ├─> No: Return InUse
│ └─> Yes: Delete block & metadata → Return Deleted
│
├─> Handle result
│
├─> Result type?
│ ├─> InUse: Return Error: Cannot delete dataset block
│ ├─> NotFound: Return Success: Ignore
│ └─> Deleted: Update total blocks count
│ └─> Update quota usage
│ └─> Return Success
│
└─> Return Success
Data Models
Stores
RepoStore* = ref object of BlockStore
postFixLen*: int
repoDs*: Datastore
metaDs*: TypedDatastore
clock*: Clock
quotaMaxBytes*: NBytes
quotaUsage*: QuotaUsage
totalBlocks*: Natural
blockTtl*: Duration
started*: bool
NetworkStore* = ref object of BlockStore
engine*: BlockExcEngine
localStore*: BlockStore
CacheStore* = ref object of BlockStore
currentSize*: NBytes
size*: NBytes
cache: LruCache[Cid, Block]
cidAndProofCache: LruCache[(Cid, Natural), (Cid, CodexProof)]
Metadata Types
BlockMetadata* {.serialize.} = object
expiry*: SecondsSince1970
size*: NBytes
refCount*: Natural
LeafMetadata* {.serialize.} = object
blkCid*: Cid
proof*: CodexProof
BlockExpiration* {.serialize.} = object
cid*: Cid
expiry*: SecondsSince1970
QuotaUsage* {.serialize.} = object
used*: NBytes
reserved*: NBytes
Functional Requirements
Available Today
-
Atomic Block Operations
- Store, retrieve, and delete operations must be atomic.
- Support retrieval via:
- Direct CID
- Tree-based addressing (
treeCid + index) - Unified block address
-
Metadata Management
- Store protocol-level metadata (e.g., storage proofs, quota usage).
- Store block-level metadata (e.g., reference counts, total block count).
-
Multi-Datastore Support
- Pluggable datastore interface supporting various backends.
- Typed datastore operations for metadata type safety.
-
Lifecycle & Maintenance
- BlockMaintainer service for removing expired data.
- Configurable maintenance intervals (default: 10 min).
- Batch processing (default: 1000 blocks/cycle).
Future Requirements
-
Transaction Rollback & Error Recovery
- Rollback support for failed multi-step operations.
- Consistent state restoration after failures.
-
Dataset-Level Operations
- Handle Dataset level meta data.
- Batch operations for dataset block groups.
-
Concurrency Control
- Consistent locking and coordination mechanisms to prevent inconsistencies during crashes or long-running operations.
-
Lifecycle & Maintenance
- Cooperative scheduling to avoid blocking.
- State tracking for large datasets.
Non-Functional Requirements
Currently Implemented
-
Security
- Verify block content integrity upon retrieval.
- Enforce quotas to prevent disk exhaustion.
- Safe orphaned data cleanup.
-
Scalability
- Configurable storage quotas (default: 20 GiB).
- Pagination for metadata queries.
- Reference counting–based garbage collection.
-
Reliability
- Metrics collection (
codex_repostore_*). - Graceful shutdown with resource cleanup.
- Metrics collection (
Planned Enhancements
-
Performance
- Batch metadata updates.
- Efficient key lookups with configurable prefix lengths.
- Support for both fast and slower storage tiers.
- Streaming APIs optimized for extremely large datasets.
-
Security
- Finer-grained quota enforcement across tenants/namespaces.
-
Reliability
- Stronger rollback semantics for multi-node consistency.
- Auto-recovery from inconsistent states.
Wire Format Specification / Syntax
The Store Module does not define a wire format specification. It provides an internal storage abstraction for Codex and relies on underlying datastore implementations for serialization and persistence.
Security/Privacy Considerations
-
Block Integrity: The Store Module verifies block content integrity upon retrieval to ensure data has not been corrupted or tampered with.
-
Quota Enforcement: Storage quotas are enforced to prevent disk exhaustion attacks. The default quota is 20 GiB, but this is configurable.
-
Safe Data Cleanup: The maintenance engine safely removes expired ephemeral data and orphaned blocks without compromising data integrity.
-
Reference Counting: Reference counting–based garbage collection ensures that blocks are not deleted while they are still in use by other components.
Future security enhancements include finer-grained quota enforcement across tenants/namespaces and stronger rollback semantics for multi-node consistency.
Rationale
The Store Module design prioritizes:
-
Decoupling: By introducing the
BlockStoreinterface, the Store Module decouples storage operations from underlying datastore semantics, allowing for flexible backend implementations. -
Performance: The separation of block data (filesystem) and metadata (LevelDB) in RepoStore ensures optimal performance for both types of operations.
-
Flexibility: The three store implementations (RepoStore, NetworkStore, CacheStore) provide different trade-offs between persistence, network access, and performance, allowing Codex to optimize for different use cases.
-
Scalability: Reference counting, quota management, and pagination enable the Store Module to scale to large datasets while preventing resource exhaustion.
The current limitations (lack of dataset-level operations, inconsistent locking) are acknowledged and will be addressed in future versions.
Copyright
Copyright and related rights waived via CC0.
References
normative
informative
- nim-datastore
- DataStore Interface
- chronos - Async runtime
- libp2p - P2P networking and CID types
- questionable - Error handling
- lrucache - LRU cache implementation
DATASET-STORE
| Field | Value |
|---|---|
| Name | Dataset Store |
| Slug | 151 |
| Status | raw |
| Category | Standards Track |
| Editor | Giuliano Mega [email protected] |
Timeline
- 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-02-05 —
4d0ee49— feat: Logos Storage dataset store (#278)
Abstract
This specification contains the interface for a simple local storage component, named the Dataset Store, which supports Logos Storage nodes in storing and keeping track of partial and complete datasets along with their metadata on-disk, and provides basic support for dataset caching.
Keywords. dataset, block, dataset storage, caching, local storage, Logos Storage
Specification
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in RFC 2119.
Interface
The interface is specified as pseudo-Python. The focus here is on primitive semantics, not code realism. In particular, we will ignore:
- whether the operations are run synchronously or asynchronously, in a single thread or in multiple threads;
- error conditions which are not domain specific; e.g.
IOErrordoes not belong here, whereasQuotaExceededErrorperhaps does. Errors are presented as exceptions, but these can be mapped into result types in languages that support or have a preference for them; - methods which could be present for efficiency reasons. Those can be added at the discretion of the implementor.
A DatasetStore is typically mounted on a local folder. Implementations will therefore typically provide, at its simplest:
def new_dataset_store(path: Path, quota: uint): DatasetStore
"""Creates a new `DatasetStore`, which can hold up to `quota`
bytes worth of `Datasets`."""
...
Listing 1. Creating a new DatasetStore.
High-level Dataset creation/deletion operations, as well as quota management and caching operations, are provided at the DatasetStore interface, shown in Listing 2. Block-level operations are provided in the Dataset interface, shown in Listing 3.
The DatasetStore/Dataset interfaces rely on a few external pseudotypes:
BytesIOrepresents a generic read or write byte stream;Bitsetis a fixed-size set - typically represented as a bit array - which encodes an integer set. Bit in this array is set to if is in the set, or otherwise;CIDrepresents a libp2p Content Identifier;Manifestrepresents a Logos Storage Manifest;Blockrepresents an arbitrary chunk of data;MerkleProofrepresents a Merkle inclusion proof for aBlock.
We omit the self parameter from all method signatures for brevity.
class DatasetStore:
def remaining() -> uint:
"""Returns the free available space in this DatasetStore, in bytes.
This MUST be equal to the quota minus the size of all Datasets
in this store. Partially completed Datasets MUST count with their
full size, even if not all of the Dataset blocks are available locally.
"""
...
def create_dataset(
stream: BytesIO,
block_size: uint,
file_name: Optional[string] = None,
mime_type: Optional[MimeType] = None,
) -> Dataset:
"""Creates a new Dataset from a byte stream and stores
it on disk. Store quota SHOULD be deducted as the stream gets
processed. Errors in this method SHOULD cause the
`DatasetStore` to clean up the partially created `Dataset`,
and return the quota back to the pool.
:raises QuotaExceededError: if quota is exceeded.
"""
...
def create_empty(manifest: Manifest) -> Dataset:
"""Creates a `Dataset` with the size described in the
`Manifest`, but no completed blocks; i.e., an empty
`Dataset`.
:raises DatasetExistsError: if the dataset already exists.
:raises QuotaExceededError: if quota would be exceeded by creating this dataset.
"""
...
def get_dataset(cid: CID) -> Optional[Dataset]:
"""Returns a `Dataset` previously stored on-disk, or
None if the `Dataset` is not present.
:param cid: The Manifest's CID.
"""
...
def delete_dataset(cid: CID) -> bool:
"""Removes a `Dataset` from disk, along with all of its
associated metadata.
:return: `false` if no `Dataset` corresponding to the
provided CID is found on-disk; `true` otherwise.
"""
...
def lru() -> Iterator[Dataset]:
"""Returns datasets in Least-Recently Used order.
Nodes can use this to implement cache eviction; e.g.,
when the quota is about to run out.
LRU order is defined by the last time a dataset was accessed
(read or written, both at the dataset or block level).
"""
...
Listing 2. DatasetStore interface.
class Dataset:
def manifest() -> Manifest:
"""Returns the `Manifest` for this dataset.
"""
...
def blockmap() -> Bitset:
"""Returns a `Bitset` in which the indexes of
all completed blocks are set. Unset bits correspond
instead to missing blocks.
"""
...
def completion() -> Tuple[uint, uint]:
"""Returns a tuple (a, b) where:
* a = blockmap.cardinality(), and;
* b = manifest.block_count
If a == b, then we have all the blocks on disk;
i.e., the dataset is complete.
"""
...
def put_block(
block: Block,
index: uint,
proof: MerkleProof,
) -> None:
"""Stores the given `Block` as the index-th block
of this `Dataset`, verifying and storing its Merkle
inclusion as part of that process. Calling this method
for a block that is already present is a no-op.
:raises InvalidProofError: if the Merkle proof provided
in `proof` fails to verify.
"""
...
def get_block(
index: uint,
) -> Optional[Tuple[Block, MerkleProof]]:
"""Retrieves and returns the block at index `index`, together
with its Merkle proof, if present. Otherwise returns None.
"""
...
def data() -> BytesIO:
"""Allows one to stream the contents of a dataset.
The stream MUST block if it bumps into an incomplete
block, until the block is again available.
"""
...
Listing 3. Dataset interface.
Copyright
Copyright and related rights waived via CC0.
References
DATASETS
| Field | Value |
|---|---|
| Name | Logos Storage Datasets |
| Slug | 152 |
| Category | Standards Track |
| Status | raw |
| Editor | Giuliano Mega [email protected] |
Timeline
- 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-02-05 —
e008949— feat: Logos Storage datasets spec (#277)
Abstract
This spec defines the basic structure, constraints, and representation for Logos Storage Datasets and their metadata. Datasets are the unit of data which Logos Storage manipulates: those can be published, downloaded, or deleted. They could be compared to objects in S3 or, somewhat more loosely, to blocks in IPFS.
Specification
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in 2119.
Dataset
A dataset is an ordered set of fixed-sized blocks, . Different datasets MAY have different block sizes, but all blocks within a single dataset MUST have the same size. A valid dataset MUST have at least one block.
A dataset is comparable to a regular filesystem (e.g. ext4) file, in that blocks are totally ordered within the file. This allows us to identify a block within a file by an integer-valued index . This is in direct contrast with systems like, say, IPFS, in which blocks might not be ordered and block-dataset membership is much more fluid, requiring the use of unique block content identifiers (CID) per block instead.
Manifest
Every dataset MUST have an associated manifest, which contains metadata describing and is required to correctly store, decode, and validate its blocks individually. It MAY also contain optional metadata such as a content type, and a file name. In CDDL:
manifest = {
version: uint,
codec: bstr,
block_size: uint,
block_count: uint,
merkle_root: bytes .size 32,
? content_type: tstr,
? file_name: tstr,
}
The content type, when present, MUST be a valid RFC6838 media type string.
Identifying Datasets and Blocks
A dataset MUST be identified by the hash of its serialized manifest, . The encoding of this serialization is specified in its codec attribute, which MUST contain a libp2p multicodec type. This means a block within a file MUST be uniquely addressable within the network by the tuple , where is an integer .
It is important to note that different values for file_name and content_type will produce different datasets, even if the set of blocks contained in remains the same. If this turns out to be undesirable, future versions of this spec might adopt an approach in which a subset of the attributes of the manifest gets hashed instead; akin to how Bittorrent does with its info dictionaries.
Copyright
Copyright and related rights waived via CC0.
References
Normative
Informative
Storage Draft Specifications
Storage specifications that have reached draft status live here.
MERKLE-TREE
| Field | Value |
|---|---|
| Name | Merkle Tree |
| Slug | 153 |
| Status | draft |
| Type | RFC |
| Category | Standards Track |
| Editor | Balázs Kőműves [email protected] |
| Contributors | Giuliano Mega [email protected], Mohammed Alghazwi [email protected] |
Timeline
- 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-28 —
7c47307— chore: metadata validator improvements (#320) - 2026-04-20 —
5cb91fc— improved Merkle tree spec (#293) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-02-06 —
af4cd78— feat: revamped Merkle tree spec (#281)
Abstract
This specification describes the Merkle tree construction adopted in Logos Storage. The principal consideration driving the design described below is to avoid security issues resulting from API abuse. Incorrectly using both low- and high-level cryptography APIs is a known source of never-ending security vulnerabilities (see eg. arXiv:2306.08869).
This construction relies on keyed compression, domain separation, injective encodings, and standard padding conventions to prevent a variety of possible collision attacks; and is designed to operate with a wide variety of hash functions, including both conventional ones like SHA-2, and arithmetic (ZK-friendly) hashes like the Poseidon family. In the Appendix, we specify some concrete hash function instances covering our use cases.
So while this construction may seem unnecessarily convoluted at first, it exists to avoid possibilities for one to shoot themselves in the foot.
Merkle tree specification
A Merkle tree is a tree data structure (most often a binary tree), where nodes store the hash of their children. When working as intended, the root node behaves like a normal collision-resistant hash; in particular, the root is a commitment for the sequence of the leaves.
The primary advantage of Merkle trees is that there are short cryptographic proofs (called "Merkle inclusion proofs" or "Merkle paths") for a given leaf being present in the tree; and similarly, one can also update a leaf. These operations have O(log(N)) cost.
Merkle trees are usually fixed depth (each leaf is at the same level). In the simplest possible version they are also complete binary trees (2^n leaves). In such a situation, where everything is fixed in advance, one can get away with much simpler constructions than the below one. However, unseen future changes in an application could then easily break any guarantees.
The cryptographic guarantees we expect from the Merkle root are the same as for normal hash functions:
- collision resistance
- preimage resistance
- second preimage resistance
In our setting, allowing arithmetic (finite field based) hash functions allow for further extra complications (eg. domain confusion, and padding problems).
Overview
Merkle trees can be implemented in a variety of ways, and if done naively, can be also attacked in a variety of ways (e.g BitCoinOps25). For this reason, this document focuses on a concrete implementation of a family of Merkle trees which helps to avoid common pitfalls.
We start by laying out some basic definitions in the Definitions section, followed by our keyed hash construction, which guards the Merkle against certain padding and layer abuse attacks. We then discuss injective encodings and their role in the construction of secure Merkle trees that deal with finite field elements in the Encoding section. Next, we provide some brief guidance on serialization in the Serialization/Deserialization section. Finally, we present an abstract interface for a Merkle tree module in the Interfaces section.
Definitions
A Merkle tree, built on a hash function H : S -> T, produces a Merkle root; this root has essentially always the same type T (for "Target type") as the output of the hash function H (we will assume this from now on).
Some examples of hash functions used in the wild are:
- SHA1:
Tis 160 bits - SHA256:
Tis 256 bits - Keccak / SHA3:
Tcan be one of 224, 256, 384 or 512 bits - the Poseidon(2) family:
Tis one or more finite field element(s), depending on the field size - Monolith-64:
Tis a 4-tuple of Goldilocks field elements - Monolith-31:
Tis an 8-tuple of Mersenne-31 field elements
The hash function H : S -> T can also have different types S ("Source type") of inputs. For example:
- SHA1 / SHA2 / SHA3:
Sis an arbitrary sequence of bits1 - binary compression function:
S = T x Tis a pair ofT-s - Poseidon2 sponge:
Sis a sequence of finite field elements - Poseidon2 compression function:
Sis at mostt-kfield elements, wheret>1is the state size, andkfield elements (the "capacity") should be approximately 256 bits (in our caset=3,k=1for BN254 field; ort=12,k=4for the Goldilocks field; ort=24,k=8for a ~32 bit field) - as an alternative, the "Jive strategy" for binary compression (see [Bouvier22]) can eliminate the "minus
k" requirement (you can compresstintot/2) - A naive Merkle tree implementation could for example accept only a power-of-two sized sequence of
T-s
As an interesting example from the wild, the ZK proof library Plonky3 (because of performance considerations) uses a binary compression function T x T -> T which is neither collision nor preimage resistant (!), to construct a Merkle tree, which at the end of the day is still safe to use in the particular situation they use it. However, such constructions can be pretty fragile (it would be safer to use the Jive strategy mentioned above, with negligible extra cost).
Notation: Let's denote the type of a sequence of T-s by [T].
A Merkle tree is built on an ordered sequence of leaves. The leaves contain some kind of data, whose type we will denote by D (for data). In classical implementations, D is just a bytestring (a finite sequence of bytes); however, in the ZK setting, sometimes D can also be a field element F, or a sequence of field elements [F].
So the input of a Merkle tree is of type [D], a sequence of things with type D; and using a hash function H : S -> T, we output a Merkle root of type T. We can immediately see that we will also need a transformation from D to S; more about this below.
Keyed Hash Construction
One of the main goals of a secure Merkle tree construction is to avoid collision attacks; i.e., situations in which an attacker is able to obtain a tree with the same Merkle root as a legitimate tree, but using data that is different from the data used to construct the tree originally. In that sense, we are interested in two different types of attacks here.
A (binary) Merkle tree requires, at its minimum, two pieces of building blocks:
- A leaf hashing function
H' : D -> T; - and a binary compression function
C : T x T -> T.
In the classical situation, like for example SHA2 or SHA3, the leaves are just bytestrings, and the leaf hashing is just normal hashing: D = S and H = H'. However, in the arithmetic hash (eg. the Poseidon family) context, this is more involved: There D can be a bytestring, but S a sequence of field elements, and T a fixed length array of field elements.
1. Layer abuse attacks
Using traditional functions like SHA256, one could express the compression C(a,b) as H(f(a,b)), where f is just concatenation: f(a,b) = a || b (Fig. 1(a)). This creates a type of symmetry one can then exploit - since a naive Merkle tree root does not encode its depth, one could pretend that f(a,b) is actually data, and construct a shorter (that is, less deep) Merkle tree which evaluates to the same root as before (Fig. 1(b)); i.e., in the second tree is the same as in the original tree.
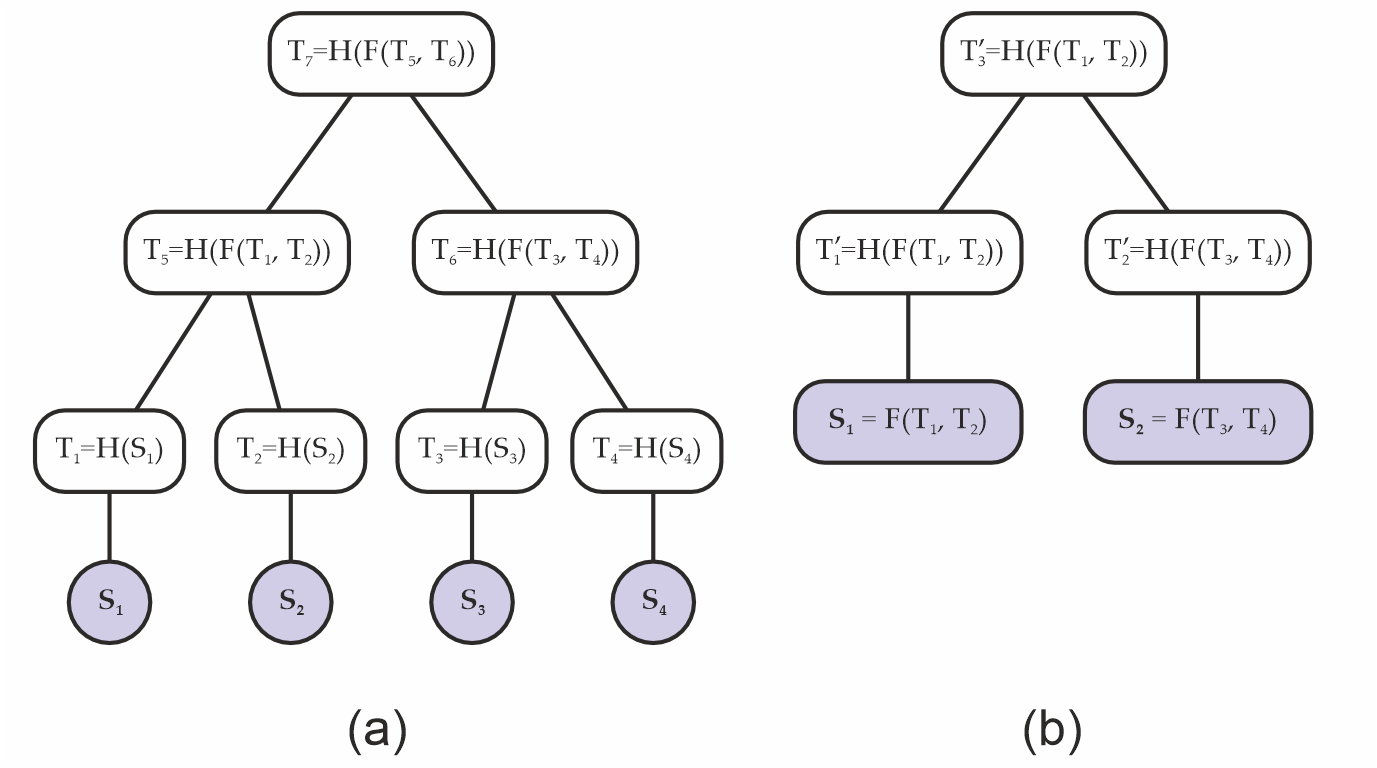
Figure 1. (a) original Merkle tree; (b) a different Merkle tree with the same Merkle root as the original; i.e., , constructed from a layer abuse attack.
2. Padding attacks
A layer of a (binary) Merkle trees can be incomplete, when the number of leaves is odd. A common technique is then to "pad" the odd layers by adding a "synthetic" missing children, so that each layer becomes even (Fig. 2(b)).
If done carelessly, this can potentially allow an attacker to replace the padding with some fake data below that is equivalent to such padding (Fig. 2(b)), and again generate the same Merkle root from data that is different from what had been intended.
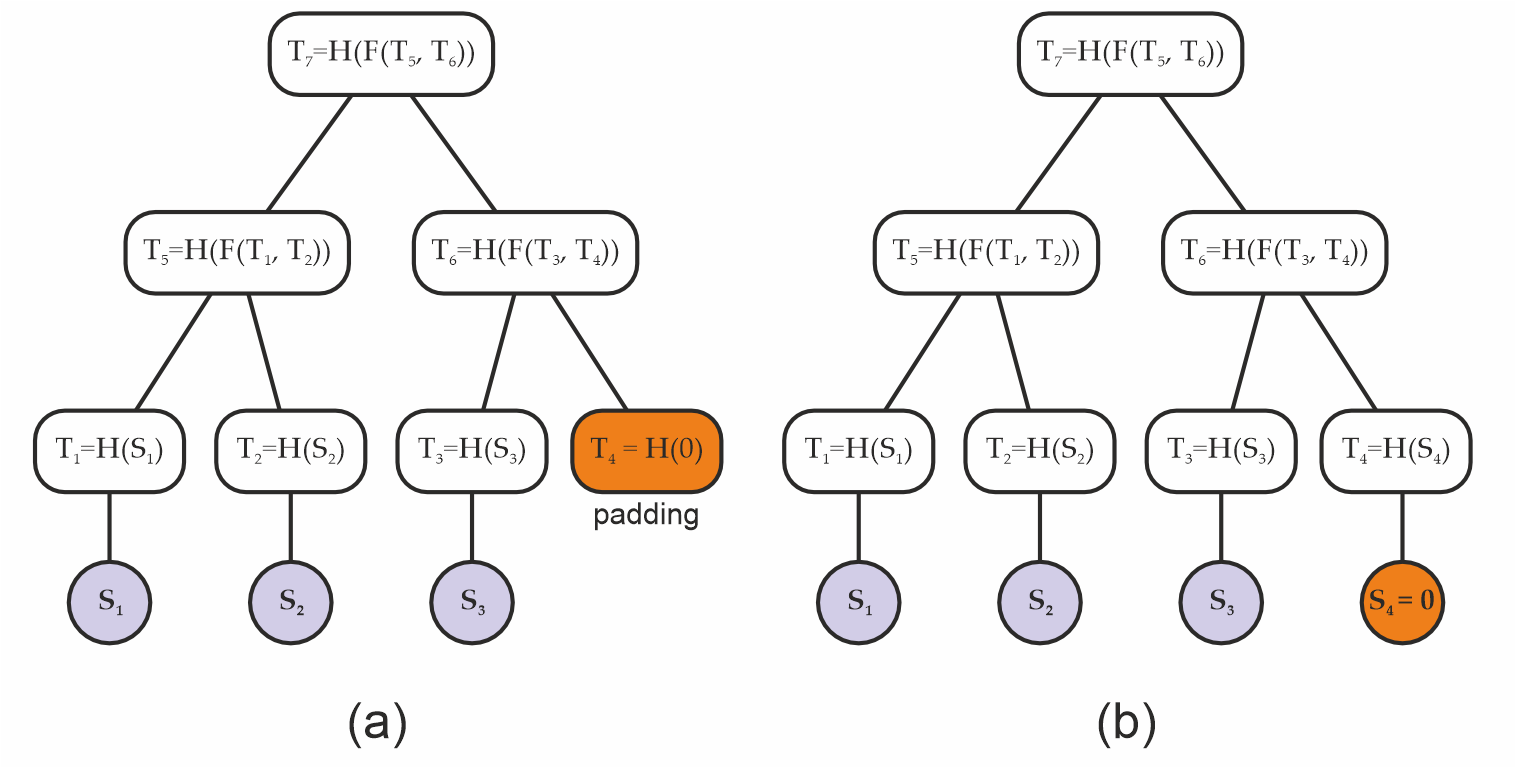
Figure 2. (a) Original padded Merkle tree, and (b) a Merkle tree with the same root as the original built from a padding attack.
If this sounds hypothetical, early versions of Bitcoin padded their Merkle trees by using the existing child of a node as padding, and this led to security issues that had to be later addressed (e.g. see [CVE-2012-2459]).
Remark: At the core, this is again an API abuse attack. Leaf data and node hashes are supposed to be two different types, so that they can be never confused. And if you add a dummy hash value as the dummy leaf (unlike in the above Bitcoin example), well, ideally the hash functions are preimage-resistant, so nobody will find neither a leaf data nor artificial children nodes which hash to a randomly chosen dummy value (for example the constant zero hash. This is more-or-less the same concept as burn addresses in blockchain).
But if you are not careful, problems can still arise! Here is a simple example of a possible issue:
- We want to use the Merkle tree as a normal hash function; taking a sequence of field elements
[F]as the input, and producing a field elementFas the output. - Note that this is a perfectly normal use case: For example the well known BLAKE3 hash function is in fact secretly a Merkle tree!
- We push an odd-length sequence as the input;
- the Merkle tree implementation pads that with a zero;
- but what if we ourselves appended the zero, before calling the Merkle tree?
- That results in a trivial collision!
Again, this is not really an attack on the cryptography itself, but an API abuse. We just shouldn't allow the user to be in the above situation!
A simple solution would be to disallow the Merkle tree routine taking a sequence of field elements as an input (as opposed to the more usual sequence of bytestrings). Unfortunately, the real world has a say too: In the process of implementing Codex, we wanted to first hash fixed-sized network blocks (with whatever custom construction required), and then build a Merkle tree on the top of these hashes.
In code, these are two separate functions. So internally, we need to use a more abuse-prone functionality, which if naively implemented, can at the end result in very subtle security bugs with potentially serious consequences...
Another simple solution would be to always hash the leaves first (and use a dummy padding value with no known hash preimage), even when they already look like hashes themselves. This however doubles the amount of hashing required, in turn doubling the time required to construct the tree. With the below construction, we can avoid this extra cost.
Construction
To prevent the problems described above, we adopt a keyed compression function C : K x (T x T) -> T which also takes a key of type K as an input, in addition to the two hash target elements it needs to compress. Our key is composed of two bits, which encode:
- whether a parent node is an even or an odd node; that is, whether it has 2 or 1 children, respectively;
- and whether the node belongs to the bottom layer; that is, is it the first layer of internal nodes above the leaves or not.
This information is converted to an integer 0 <= key < 4 by setting the first bit based on being the bottom layer, and the second bit based on the parity:
data LayerFlag
= BottomLayer -- it's the bottom (initial, widest) layer
| OtherLayer -- it's not the bottom layer
data NodeParity
= EvenNode -- it has 2 children
| OddNode -- it has 1 child
-- Key based on the node type:
--
-- > bit0 := 1 if bottom layer, 0 otherwise
-- > bit1 := 1 if odd, 0 if even
--
nodeKey :: LayerFlag -> NodeParity -> Int
nodeKey OtherLayer EvenNode = 0x00
nodeKey BottomLayer EvenNode = 0x01
nodeKey OtherLayer OddNode = 0x02
nodeKey BottomLayer OddNode = 0x03
The number is then used to "key" the compression function, as follows:
- for hash functions like SHA256, we can simply append the key; i.e., we take
SHA256(x|y|key)wherekeyis encoded as a single byte (but see the Appendix below for a more efficient solution!). - for finite field, permutation-based hash functions, like Poseidon2 or Monolith, we apply the permutation function to
(x,y,key) in T^3, where the key (interpreted as a field element) is embedded in the hash target spaceT = F^(t/3)at the beginning:(key,0,...,0). Then as usual, we take the first component (typeT) of the result of the permutation.
For example, in case of BN254 and t=3, the input of the permutation will be (x,y,key); while in case of Goldilocks and t=12, the input will be (x0,x1,x2,x3, y0,y1,y2,y3, key,0,0,0).
This is in practice equivalent to having 4 different compression functions C_key(x,y) := C(key; x,y).
Remark: Since standard SHA256 already includes mandatory padding (to a multiple of 64 bytes), appending key byte at the end doesn't result in extra computation (it's always two internal hash calls). However, a faster (twice as fast!) alternative would be to choose 4 different random-looking initialization vectors, and not do padding at all. This would be a non-standard SHA256 invocation; but the speed advantage can be critical when proving SHA256 hashes in ZK! See the Appendix below for more details.
Merkle tree algorithm
Thus a Merkle tree computation is a function merkleRoot : [D] -> T taking a sequence of leaf data [D], and producing a Merkle root T. In practice, we also need a version which produces the whole tree Tree<T> (eg. to be able to produce inclusion proofs), but that's just keeping the intermediate results.
Normally, this is done in two or three steps:
- hash the leaf data:
hash : D -> T - then build the tree:
tree : [T] -> Tree<T> - finally extract the root:
root : Tree<T> -> T
The tree building proceeds in layers: Take the previous sequence, apply the keyed compression function for each consecutive pairs (x,y) : (T,T) with the correct key based on whether this was the initial (bottom) layer, and whether it's a singleton "pair" x : T, in which case it's also padded with a zero to (x,0).
Note that if the input was a singleton list [x], we still apply one layer, so in that case the root will be compress[key=3](x,0).
Remark: The singleton input is another subtle corner case which can be potentially abused! While in practice it's unlikely to happen, such a bug in fact happened in the history of Codex development (happily, it was just a pathological failure case, not an actual vulnerability).
Encoding
Our Merkle trees are created from arbitrary data, and arbitrary data can mean, depending on the usage:
- a raw bytestring (sequence of bytes), when the Merkle tree is used as a normal hash function;
- or a sequence of raw bytestrings, when the Merkle tree is used as an actual tree. So in this case the leaves are bytestrings themselves.
The first case can be for example implemented by splitting the input into equally-sized blocks2 of length b, and passing those to the second version.
In that context, each such data block3 (of size b) then undergoes hashing under H' : D -> T, and the resulting hashes become the tree's leaves (Fig. 3(a)). When D = S (eg. with SHA256), this is very straightforward; but maybe it's a better mental model to consider the finite field situation.
For hashing functions which do not take bytestrings as input - like Poseidon2, which operates on sequences of finite field elements - we must encode our data blocks into the proper type first (Figure 3(b)).
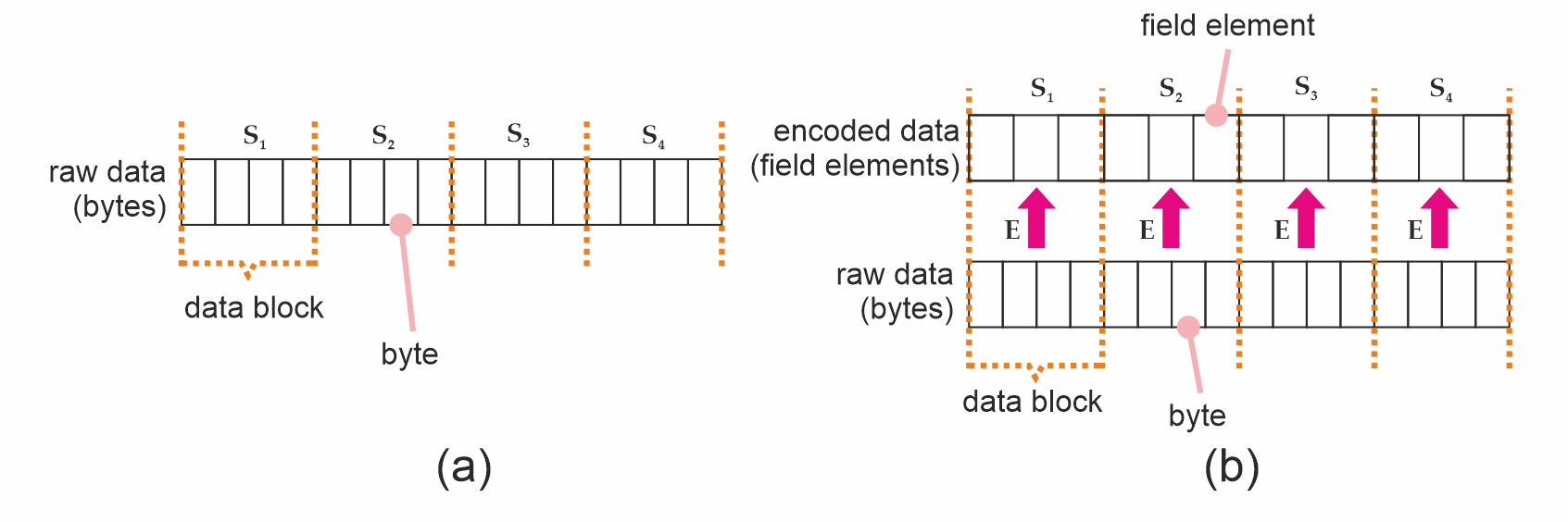
Figure 3. (a) A byte string (raw data), split into data blocks which are also bytestrings. (b) Data blocks after undergoing encoding.
We define an encoding function E to be a function which can do that for us. Formally speaking, E can encode an arbitrary-valued byte string of length b into a value of the required type S; that is, E : byte[b] -> S. Such an encoding function MUST always be injective; i.e., distinct bytestrings MUST map into distinct values of the type S. To see why, suppose E were not injective. This means there are two bytestrings D_1 and D_2 such that E(D_1) = E(D_2) = S_1 = S_2. We could then take the raw data used to build a Merkle tree A, replace all occurrences of D_1 with D_2, and build an identical Merkle tree from distinct data - which is what we want to avoid.
The next section deals with injective encodings for the major types we use - including SHA256, BN254, Goldilocks. We then discuss padding in Sec. Padding.
Injective Encodings
Encoding for classical hash functions like SHA256 is trivial in that they already operates on bytestrings, so there is no extra work to be done. On the other hand, for arithmetic hash functions like Poseidon(2), S is a sequence of finite field elements, and we therefore need to perform encoding.
In such situations, it is convenient to construct our injective encoding function E by chunking the input sequence of size b into smaller pieces of size M, and then applying an element encoding function E_s function to each chunk. This function can output either a single or multiple field elements per M-sized chunk (Listing 1).
def E( raw: List[byte],
E_s: List[byte] -> List[FieldElement],
M: uint,
) -> List[FieldElement]:
# requires len(raw) to be multiple of M
chunks = len(raw) / M
assert chunks * M == len(raw)
encoded = []
for i in range(0, chunks):
encoded.extend(E_s(raw[i*M:(i+1)*M-1]))
return encoded
Listing 1. Constructing E from E_s.
For the BN254 field, we can construct E_s by taking M = 31, and having the 31 bytes interpreted as a little-endian integer modulo p (remember that 31 x 8 < log2(p) < 32 x 8). This outputs a single field element per 31 bytes.
On the other hand, over the Goldilocks field, Poseidon2 or Monolith take multiples of four Goldilocks field elements at a time. We have some choices: We could have M = 4*7 = 28, as a single field element can encode 7 bytes but not 8. Or, if we want to be more efficient, we can still achieve M = 31 by storing 62 bits in each field element. For this to work, some convention needs to be chosen; our implementation is the following:
#define MASK 0x3fffffffffffffffULL
// NOTE: we assume a little-endian architecture here
void goldilocks_convert_31_bytes_to_4_field_elements(const uint8_t *ptr, uint64_t *felts) {
const uint64_t *q0 = (const uint64_t*)(ptr );
const uint64_t *q7 = (const uint64_t*)(ptr+ 7);
const uint64_t *q15 = (const uint64_t*)(ptr+15);
const uint64_t *q23 = (const uint64_t*)(ptr+23);
felts[0] = (q0 [0]) & MASK;
felts[1] = ((q7 [0]) >> 6) | ((uint64_t)(ptr[15] & 0x0f) << 58);
felts[2] = ((q15[0]) >> 4) | ((uint64_t)(ptr[23] & 0x03) << 60);
felts[3] = ((q23[0]) >> 2);
}
This simply chunks the 31 bytes = 248 bits into 62 bits chunks, and interprets them as little endian 62 bit integers.
Padding
The element encoding function E_s requires bytestrings of length M, but the input's length; i.e., the size b our data blocks, might not be a multiple of M. We might therefore need to pad the blocks, and we need to do it in a way that avoids the usual trap: different input data resulting in the same padded representation.
We adopt a 10* padding strategy to pad raw data blocks to a multiple of M bytes; i.e., we always add a 0x01 byte, and then as many 0x00 bytes as required for the length to be divisible by M. Assuming again a data block of length b bytes, then the padded sequence will have M*(floor(b/M)+1) bytes.
Note: The 10* padding strategy is an invertible operation, which will ensure that there is no collision between sequences of different lengths; i.e., to unpad scan from the end, drop 0x00 bytes until the first 0x01, drop that too; reject if no 0x01 found
Once the data is padded, it can be chunked to pieces of M bytes (so there will be floor(b/M)+1 chunks) and encoded by calling the element encoding function for each chunk.
Remark: We don't pad the sequence of leaf hashes (T-s) when constructing the Merkle tree, as the tree construction ensures that different lengths will result in different root hashes. However, when using the sponge construction, we need to further pad the sequence of encoded field elements to be a multiple of the sponge rate; there again we apply the 10* strategy, but there the 1 and 0 are finite field elements.
Serializing / Deserializing
When using SHA256 or similar, this is trivial (use the standard, big-endian encoding).
When T consists of prime field elements, simply take the smallest number of bytes the field fits in (usually 256, 64 or 32 bits, that is 32, 8 or 4 bytes), and encode as a little-endian integer (modulo the prime). This is trivial to invert.
To serialize the actual tree, just add enough metadata that the size of each layer is known, then you can simply concatenate the layers, and serialize like as above. This metadata can be as small as the size of the initial layer, that is, a single integer.
Remark: we could (de)serialize in the so-called Montgomery representation instead. That would be more efficient, however, the minor efficiency gains are probably not worth the confusion and incompatibility with standard implementations.
Reference Implementations
- in Haskell: https://github.com/logos-storage/logos-storage-proofs-circuits/blob/master/reference/haskell/src/Poseidon2/Merkle.hs
- in Nim: https://github.com/codex-storage/codex-storage-proofs-circuits/blob/master/reference/nim/proof_input/src/merkle.nim
Interfaces
The interface for a Merkle tree typically require the following API:
- the Merkle tree construction function takes a sequence
D-s (typically bytestrings) of lengthnas input, and produces a Merkle tree of typeT; that is,mkTree: [D] -> Tree<T> - if we also want to use the Merkle tree as a normal hash function, then
merkleHashTree : [byte] -> Tree<T> - further standard functionality are:
- extract the tree root
root : Tree<T> -> T - extract a Merkle inclusion proof
- check a Merkle inclusion proof against a root
- update a leaf of the tree
- extract the tree root
In practice, we split the tree construction into two parts:
- leaf encoding:
D -> S - tree construction:
[S] -> Tree<T>
This split makes the API inherently less safe, but in practice is required. However, our construction is hopefully robust enough that this loss of safety cannot be easily exploited (especially accidentally).
Interface pseudo-code
We also typically want to be able to obtain proofs for existing data blocks, and check blocks along with their proofs against a root. The interface is described in Listing 2. We avoid going into actual algorithms here as those are already specified in the reference implementations.
class Encoder[S]:
"""
Encodes sequences of bytes to S. The encoding
produced by `Encoder` MUST be injective.
"""
def encodeBytes(data: List[byte]) -> S:
...
class MerkleProof[T]:
"""
A `MerkleProof` contains enough information to check
a leaf against a tree root.
The verifier MUST reconstruct node parity and
layer keys deterministically from index and
the `leaf_count`; these values MUST NOT be supplied
externally.
"""
index: uint
leaf_count: uint
path: List[T]
def create(data: List[S]) -> MerkleTree[T]:
"""Creates a `MerkleTree` from a sequence
of data, encoded to be compatible with the hash."""
...
def create(
data: List[byte],
block_size: uint,
encoder: Encoder[S],
) -> MerkleTree[T]:
"""Creates a `MerkleTree` from raw data by
splitting into blocks of `block_size` size and
encoding them.
"""
return create(
encoder.encodeBytes(data_block)
for split_chunks(data_block, block_size)
)
def get_proof(
self: MerkleTree[T],
i: uint,
) -> MerkleProof[T]:
"""Obtains a `MerkleProof` for the i-th leaf
in the tree."""
...
def verify_proof(
root: T,
proof: MerkleProof[T],
) -> bool:
"""Verifies an existing `MerkleProof` against
a tree's root.
:return: `True` if the proof verifies, or `False`
otherwise.
"""
...
Listing 2. Abstract interface for a Merkle tree.
Copyright
Copyright and related rights waived via CC0.
References
[Bouvier22]: Bouvier et al. "New Design Techniques for Efficient Arithmetization-Oriented Hash Functions: Anemoi Permutations and Jive Compression Mode", Cryptology ePrint Archive, 2022.
[BitCoinOps25]: Merkle tree vulnerabilities. https://bitcoinops.org/en/topics/merkle-tree-vulnerabilities/
[CVE-2012-2459]: Block Merkle Calculation Exploit. https://bitcointalk.org/?topic=102395
[arXiv:2306.08869]: "Detecting Misuse of Security APIs: A Systematic Review"
[eprint:2026/089]: "The Billion Dollar Merkle Tree"
Some less-conforming implementation of these could take a sequence of bytes instead.
Data blocks might also need to be padded to a multiple of b, but raw data padding is beyond the scope of this document.
The standard block size for Logos storage is (currently) 2^16 = 65536 bytes for SHA256 trees. In the "old Codex" design, we used 2^10 = 2048 bytes sized "cells" for probabilistic storage proofs, using a secondary, Poseidon2-based Merkle tree.
Appendix
In this Appendix we propose some concrete hash function instances to be used with the above Merkle tree specification.
These are:
- "standard" SHA256
- "optimized" SHA256
- Poseidon2 over the BN254 curve's scalar field
- Poseidon2 over the Goldilocks field
- Monolith over the Goldilocks field
These all come with some advantages and disadvantages, and are useful in different situations; hence the variety.
Standard SHA256
A hash is 256 bits (32 bytes). The keys 0,1,2,3 are encoded as a single byte, 0x00, ..., 0x03. The keyed compression function is defined as
compress(x,y,key) := SHA256( x || y || key )
(so the input of the SHA256 call is 32+32+1 = 65 bytes).
Remark: This is the version currently (January 2026) used in Logos Storage.
Hashing leaf data (that is, sequences of bytes) is normally just a standard SHA256 call.
However, in the Logos Storage context, the leaves are often fixed size (eg. 64kb) blocks. To facilitate lightweight storage proofs, we may want to use a small (eg. depth 10) Merkle tree with say 64 byte leaves to hash these blocks.
Test vectors
TODO: add test vectors
Optimized SHA256
This is a non-standard SHA256 instance, but in exchange it's twice as fast. This optimization is most important in the case where we want to use SHA256-based lightweight storage proofs, as SHA256 is very expensive to compute inside ZK proofs.
The problem: The way SHA256 hashing works is to take the input, pad it to the next multiple of 64 bytes, and consume in 64 byte (512 bit) chunks. So in the above "standard" instance, the keyed compression function invokes the internal SHA256 compression function twice. In fact even the un-keyed version would do that, as padding is mandatory (and always appends a nonempty bitstring)!
We can avoid this by encoding the key into the initialization vector (from a birds-eye point of view, this is in fact quite similar to the permutation-based keyed compression functions below: Namely, the key is encoded in the internal state), skip padding, and use the internal SHA256 compression function. This is safe to do as the input of the compression is constant length (2x32 = 64 bytes).
Standard SHA256 derives its initial state (which is 256 bits) from the square roots of the first 8 primes. This is known as a "nothing-up-to-my-sleeve" construction. But really it could be just about anything. Here we need 4 different random-looking initial states corresponding to the 4 different keys. We propose
IV_0 := SHA3-256("LOGOS_STORAGE|MERKLE_SHA256_INITIAL_STATE|KEY=0x00")
IV_1 := SHA3-256("LOGOS_STORAGE|MERKLE_SHA256_INITIAL_STATE|KEY=0x01")
IV_2 := SHA3-256("LOGOS_STORAGE|MERKLE_SHA256_INITIAL_STATE|KEY=0x02")
IV_3 := SHA3-256("LOGOS_STORAGE|MERKLE_SHA256_INITIAL_STATE|KEY=0x03")
(note: we intentially use a different hash function - namely, SHA3 - to generate these IVs here, to avoid any possible collusion with the internal structure of SHA256).
In concrete (big-endian) values, these are:
IV_0 = 0xc616dedc2fd8bba1e2c31efeb8555bfa37efe48c7e84c7d67cc9afa0b008b2b7
IV_1 = 0x08e555becbc79204178a3e20f689eb74552523e5d75d42e8be555a9ee671bd86
IV_2 = 0x53eabf5ee9bff4c87515e738558093128797f2015d5994443787a215875a9a27
IV_3 = 0x17c13498c9884a64005dda79b147b9a9c88588c62fb7138fb72d528c01eb8287
However, SHA256 initial state is represented as a length 8 array of 32-bit words. As customary, the encoding for these words is big-endian, so for example IV_0 will become
IV_0 = { 0xc616dedc, 0x2fd8bba1, 0xe2c31efe, 0xb8555bfa, 0x37efe48c, 0x7e84c7d6, 0x7cc9afa0, 0xb008b2b7 }
Our keyed compression function then would be:
compress(x,y,key) := SHA256_COMPRESS( init = IV_key, chunk = x||y )
See eg. Wikipedia for the description of the SHA256 internal compression algorithm.
Hashing leaf data (bytes) is exactly the same as above (either standard SHA256, or a small Merkle tree for fixed-sized data blocks).
Test vectors and implementation
TODO: implement this, add test vectors, and a link to the implementation.
Poseidon2 over BN254
Poseidon2 hash function is parametrized by a prime field, and the other parameters are usually derived from this (except the round constants, which are just kind of random, but deterministically derived from some seed).
In this case, the field is the BN254 (aka. alt-bn128 or sometimes BN256 - though the latter name is also used for a different curve!) elliptic curve's scalar field:
p = 21888242871839275222246405745257275088548364400416034343698204186575808495617
We use a state consisting of t = 3 field elements (approx. 762 bits). A hash in this case consists of a single field element (approx. 254 bits).
We use the parameters from the zkfriendlyhashzoo implementation.
This defines the so called "Poseidon2 permutation function":
permute : F^3 -> F^3
From this, our keyed compression function is derived as:
compress(x,y,key) := permute([x,y,key])[0]
That is, take the three field elements (x,y,key) in F^3 (the keys 0,1,2,3 interpreted as field elements), permute the triple, and output the first element of the resulting triple.
Linear hashing of leaf data
Linear hashing of a sequence of field elements is implemented using the sponge construction, with rate=2 and capacity=1. As traditional, the first 2 elements of the state corresponds to the input chunk, and the last element to the internal capacity. The 10* padding strategy is used (always add a single 1 field element, then as many zeros as required for the length to be divisible by r=2). A domain separation value is used, so the initial state is (0,0,domSep).
Linear hashing of bytes. First we need to pad the byte sequence to a multiple of 2 x 31 = 62 bytes (again we use the 10* padding strategy, with bytes here), then encode each 31 byte chunk into a field element, interpreting it as a little-endian integer. The resulting field element sequence (of even length) is now hashed with the sponge (rate=2), without padding (the byte sequence padding is enough for it to be injective). NOTE: a different domain separator value MUST be used in this case than for the public API hashing field elements!
Test vectors
Permutation of (0,1,2):
x' = 0x30610a447b7dec194697fb50786aa7421494bd64c221ba4d3b1af25fb07bd103
y' = 0x13f731d6ffbad391be22d2ac364151849e19fa38eced4e761bcd21dbdc600288
z' = 0x1433e2c8f68382c447c5c14b8b3df7cbfd9273dd655fe52f1357c27150da786f
Keyed compression:
compress(x=1234, y=5678, key=0) = 0x152ef46ec26a9afb6748e7fff3f75081af33f84b77d2afa05207509fb63ec4a6
compress(x=6666, y=7777, key=1) = 0x04f222443879d40e17174f08adfd76c23d515d370e351f5d5da69a41d84dc48a
compress(x=9876, y=5432, key=2) = 0x1ddd85a82b30a09cded68735a8fb9a353e6448f64f28f96a6f0e495b4e50f372
compress(x=1133, y=5577, key=3) = 0x222eda4baf17bf55f2167e6c9cd8828b8cb1762cfc61ec3195892ebc38d5d478
Implementations
- https://github.com/logos-storage/nim-poseidon2 (includes the full Merkle tree construction)
- https://github.com/logos-storage/rust-poseidon-bn254-pure (permutation only)
- https://github.com/logos-storage/rust-bn254-hash (permutation only)
- https://github.com/faulhornlabs/hash-circuits
Poseidon2 over Goldilocks
The Goldilocks prime field is defined by
p = 2^64 - 2^32 + 1 = 18446744069414584321
As a Goldilocks field element contains approx. 64 bits, we use a state of t = 12 field elements to have a comparable setting as before. A hash value consists of 4 field elements.
The parameters we use are the same as the HorizenLabs implementation. Note: At some point, HorizenLabs generated new constants (this can be seen in their github history). While all our other implementations use the old constants (which are the same as the zkfriendlyhashzoo ones), because of a historical accident, here we use the new ones. This doesn't matter at all apart from being consistent. It could be changed but let's not do that now...
The keyed compression function is then defined as:
compress( [x0,x1,x2,x3], [y0,y1,y2,y3], key) :=
let newState = permute( [x0,x1,x2,x3, y0,y1,y2,y3, key,0,0,0] )
in newState[0..3]
that is, the resulting hash is the first four elements of the permuted state.
For the sponge construction, we use rate=8 and capacity=4 (with the first 8 field elements corresponding to the chunk we consume). For hashing bytes, we first convert the bytes into field elements very similarly to the BN254 case, except that we encode 31 bytes into 4 field elements (10% more efficient than 7 bytes into 1 field element, while also being a drop-in replacement for the BN254 version).
In Nim:
func decodeBytesToDigestFrom(bytes: openarray[byte], ofs: int): Digest =
const mask : uint64 = 0x3fffffffffffffff'u64
let p = bytesToUint64FromLE( bytes , ofs + 0 )
let q = bytesToUint64FromLE( bytes , ofs + 7 )
let r = bytesToUint64FromLE( bytes , ofs + 15 )
let s = bytesToUint64FromLE( bytes , ofs + 23 )
let a = bitand( p , mask )
let b = bitor( q shr 6 , bitand(r , 0x0f) shl 58 )
let c = bitor( r shr 4 , bitand(s , 0x03) shl 60 )
let d = s shr 2
return mkDigestU64(a,b,c,d)
and in C:
#define MASK 0x3fffffffffffffffULL
// NOTE: we assume a little-endian architecture here
void goldilocks_convert_31_bytes_to_4_field_elements(const uint8_t *ptr, uint64_t *felts) {
const uint64_t *q0 = (const uint64_t*)(ptr );
const uint64_t *q7 = (const uint64_t*)(ptr+ 7);
const uint64_t *q15 = (const uint64_t*)(ptr+15);
const uint64_t *q23 = (const uint64_t*)(ptr+23);
felts[0] = (q0 [0]) & MASK;
felts[1] = ((q7 [0]) >> 6) | ((uint64_t)(ptr[15] & 0x0f) << 58);
felts[2] = ((q15[0]) >> 4) | ((uint64_t)(ptr[23] & 0x03) << 60);
felts[3] = ((q23[0]) >> 2);
}
Again care should we taken with the padding and domain separation! By convention, the domain separation value is put in the 8th field element of the initial state:
initial_state = [0,0,0,0, 0,0,0,0, domSep,0,0,0]
Test vectors
Permutation of [0,1,2,..9,10,11]:
[ 0x01eaef96bdf1c0c1
, 0x1f0d2cc525b2540c
, 0x6282c1dfe1e0358d
, 0xe780d721f698e1e6
, 0x280c0b6f753d833b
, 0x1b942dd5023156ab
, 0x43f0df3fcccb8398
, 0xe8e8190585489025
, 0x56bdbf72f77ada22
, 0x7911c32bf9dcd705
, 0xec467926508fbe67
, 0x6a50450ddf85a6ed
]
Implementation
- https://github.com/logos-storage/nim-goldilocks-hash (includes the Merkle tree construction)
Monolith over Goldilocks
The is exactly the same as Poseidon2 over Goldilocks, but using the Monolith permutation instead of the Poseidon2 permutation.
Monolith is significantly faster than Poseidon2 in a CPU implementation; but less widely used, and requires lookup tables in a ZK proof implementation.
We use the parameters from the zkfriendlyhashzoo implementation.
Test vectors
Permutation of [0,1,2,..9,10,11]:
[ 0x516dd661e959f541
, 0x082c137169707901
, 0x53dff3fd9f0a5beb
, 0x0b2ebaa261590650
, 0x89aadb57e2969cb6
, 0x5d3d6905970259bd
, 0x6e5ac1a4c0cfa0fe
, 0xd674b7736abfc5ce
, 0x0d8697e1cd9a235f
, 0x85fc4017c247136e
, 0x572bafd76e511424
, 0xbec1638e28eae57f
]
Implementation
- https://github.com/logos-storage/nim-goldilocks-hash (includes the Merkle tree construction)
Storage Deprecated Specifications
Deprecated Storage specifications kept for archival and reference purposes.
CODEX-ERASUE-CODING
| Field | Value |
|---|---|
| Name | Codex Erasue Coding |
| Slug | 79 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Giuliano Mega [email protected] |
Timeline
- 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-22 —
e356a07— Chore/add makefile (#271) - 2026-01-22 —
af45aae— chore: deprecate Marketplace-related specs (#268) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258)
Abstract
This specification describes the erasure coding technique used by Codex clients. A Codex client will encode a dataset before it is stored on the network.
Background
The Codex protocol uses storage proofs to verify whether a storage provider (SP) is storing a certain dataset. Before a dataset is retrieved on the network, SPs must agree to store the dataset for a certain period of time. When a storage request is active, erasure coding helps ensure the dataset is retrievable from the network. This is achieved by the dataset that is chunked, which is restored in retrieval by erasure coding. When data blocks are abandoned by storage providers, the requester can be assured of data retrievability.
Specification
The keywords “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in 2119.
A client SHOULD perform the erasure encoding locally before providing a dataset to the network. During validation, nodes will conduct error correction and decoding based on the erasure coding technique known to the network. Datasets using encodings not recognized by the network MAY be ignored during decoding and validation by other nodes in the network.
The dataset SHOULD be split into data chunks represented by k, e.g. .
Each chunk k MUST be encoded into n blocks, using an erasure encoding technique like the Reed Solomon algorithm.
Including a set of parity blocks that MUST be generated,
represented by m.
All node roles on the Codex network use the Leopard Codec.
Below is the encoding process:
- Prepare the dataset for the marketplace using erasure encoding.
- Derive a manifest CID from the root encoded blocks
- Error correction by validator nodes once the storage contract begins
- Decode data back to the original data.
Encoding
A client MAY prepare a dataset locally before making the request to the network.
The data chunks, k, MUST be the same size, if not,
the smaller chunk MAY be padded with empty data.
The data blocks are encoded based on the following parameters:
struct encodingParms {
ecK: int, // Number of data blocks (K)
ecM: int, // Number of parity blocks (M)
rounded: int, // Dataset rounded to multiple of (K)
steps: int, // Number of encoding iterations (steps)
blocksCount: int, // Total blocks after encoding
strategy: enum, // Indexing strategy used
}
After the erasure coding process, a protected manifest SHOULD be generated for the dataset, which would store the CID of the root Merkle tree. The content of the protected manifest below, see CODEX-MANIFEST for more information:
syntax = "proto3";
message verifiable {
string verifyRoot = 1 // Root of verification tree with CID
repeated string slot_roots = 2 // List Individual slot roots with CID
uint32 cellSize = 3 // Size of verification cells
string verifiableStrategy = 4 // Strategy for verification
}
message ErasureInfo {
optional uint32 ecK = 1; // number of encoded blocks
optional uint32 ecM = 2; // number of parity blocks
optional bytes originalTreeCid = 3; // cid of the original dataset
optional uint32 originalDatasetSize = 4; // size of the original dataset
optional VerificationInformation verification = 5; // verification information
}
message Manifest {
optional bytes treeCid = 1; // cid (root) of the tree
optional uint32 blockSize = 2; // size of a single block
optional uint64 datasetSize = 3; // size of the dataset
optional codec: MultiCodec = 4; // Dataset codec
optional hcodec: MultiCodec = 5 // Multihash codec
optional version: CidVersion = 6; // Cid version
optional ErasureInfo erasure = 7; // erasure coding info
}
After the encoding process, is ready to be stored on the network via the CODEX-MARKETPLACE. The Merkle tree root SHOULD be included in the manifest so other nodes are able to locate and reconstruct a dataset from the erasure encoded blocks.
Data Repair
Storage providers may have periods during a storage contract where they are not storing the data.
A validator node MAY store the treeCid from the Manifest to locate all the data blocks and
reconstruct the merkle tree.
When a missing branch of the tree is not retrievable from an SP, data repair will be REQUIRED.
The validator will open a request for a new SP to reconstruct the Merkle tree and
store the missing data blocks.
The validator role is described in the CODEX-MARKETPLACE specification.
Decode Data
During dataset retrieval, a node will use the treeCid to locate the data blocks.
The number of retrieved blocks by the node MUST be greater than k.
If less than k, the node MAY not be able to reconstruct the dataset.
The node SHOULD request missing data chunks from the network and
wait until the threshold is reached.
Security Considerations
Adversarial Attack
An adversarial storage provider can remove only the first element from more than half of the block, and the slot data can no longer be recovered from the data that the host stores. For example, with data blocks of size 1TB, erasure coded into 256 data and parity shards. An adversary could strategically remove 129 bytes, and the data can no longer be fully recovered with the erasure-coded data that is present on the host.
The RECOMMENDED solution should perform checks on entire shards to protect against adversarial erasure. In the Merkle storage proofs, the entire shard SHOULD be hashed, then that hash is checked against the Merkle proof. Effectively, the block size for Merkle proofs should equal the shard size of the erasure coding interleaving. Hashing large amounts of data will be expensive to perform in an SNARK, which is used to compress proofs in size in Codex.
Data Encryption
If data is not encrypted before entering the encoding process, nodes, including storage providers, MAY be able to access the data. This may lead to privacy concerns and the misuse of data.
Copyright
Copyright and related rights waived via CC0.
References
- Leapard Codec
- CODEX-MANIFEST
- CODEX-MARKETPLACE
CODEX-MARKETPLACE
| Field | Value |
|---|---|
| Name | Codex Storage Marketplace |
| Slug | 77 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Codex Team and Dmitriy Ryajov [email protected] |
| Contributors | Mark Spanbroek [email protected], Adam Uhlíř [email protected], Eric Mastro [email protected], Jimmy Debe [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-01-22 —
e356a07— Chore/add makefile (#271) - 2026-01-22 —
af45aae— chore: deprecate Marketplace-related specs (#268) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-11-19 —
d2df7e0— Created codex/raw/codex-marketplace.md file, without integration of Sales a… (#208)
Abstract
Codex Marketplace and its interactions are defined by a smart contract deployed on an EVM-compatible blockchain. This specification describes these interactions for the various roles within the network.
The document is intended for implementors of Codex nodes.
Semantics
The keywords "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in 2119.
Definitions
| Terminology | Description |
|---|---|
| Storage Provider (SP) | A node in the Codex network that provides storage services to the marketplace. |
| Validator | A node that assists in identifying missing storage proofs. |
| Client | A node that interacts with other nodes in the Codex network to store, locate, and retrieve data. |
| Storage Request or Request | A request created by a client node to persist data on the Codex network. |
| Slot or Storage Slot | A space allocated by the storage request to store a piece of the request's dataset. |
| Smart Contract | A smart contract implementing the marketplace functionality. |
| Token | The ERC20-based token used within the Codex network. |
Motivation
The Codex network aims to create a peer-to-peer storage engine with robust data durability, data persistence guarantees, and a comprehensive incentive structure.
The marketplace is a critical component of the Codex network, serving as a platform where all involved parties interact to ensure data persistence. It provides mechanisms to enforce agreements and facilitate data repair when SPs fail to fulfill their duties.
Implemented as a smart contract on an EVM-compatible blockchain, the marketplace enables various scenarios where nodes assume one or more roles to maintain a reliable persistence layer for users. This specification details these interactions.
The marketplace contract manages storage requests, maintains the state of allocated storage slots, and orchestrates SP rewards, collaterals, and storage proofs.
A node that wishes to participate in the Codex persistence layer MUST implement one or more roles described in this document.
Roles
A node can assume one of the three main roles in the network: the client, SP, and validator.
A client is a potentially short-lived node in the network with the purpose of persisting its data in the Codex persistence layer.
An SP is a long-lived node providing storage for clients in exchange for profit. To ensure a reliable, robust service for clients, SPs are required to periodically provide proofs that they are persisting the data.
A validator ensures that SPs have submitted valid proofs each period where the smart contract required a proof to be submitted for slots filled by the SP.
Part I: Protocol Specification
This part defines the normative requirements for the Codex Marketplace protocol. All implementations MUST comply with these requirements to participate in the Codex network. The protocol is defined by smart contract interactions on an EVM-compatible blockchain.
Storage Request Lifecycle
The diagram below depicts the lifecycle of a storage request:
┌───────────┐
│ Cancelled │
└───────────┘
▲
│ Not all
│ Slots filled
│
┌───────────┐ ┌──────┴─────────────┐ ┌─────────┐
│ Submitted ├───►│ Slots Being Filled ├──────────►│ Started │
└───────────┘ └────────────────────┘ All Slots └────┬────┘
Filled │
│
┌───────────────────────┘
Proving ▼
┌────────────────────────────────────────────────────────────┐
│ │
│ Proof submitted │
│ ┌─────────────────────────► All good │
│ │ │
│ Proof required │
│ │ │
│ │ Proof missed │
│ └─────────────────────────► After some time slashed │
│ eventually Slot freed │
│ │
└────────┬─┬─────────────────────────────────────────────────┘
│ │ ▲
│ │ │
│ │ SP kicked out and Slot freed ┌───────┴────────┐
All good │ ├─────────────────────────────►│ Repair process │
Time ran out │ │ └────────────────┘
│ │
│ │ Too many Slots freed ┌────────┐
│ └─────────────────────────────►│ Failed │
▼ └────────┘
┌──────────┐
│ Finished │
└──────────┘
Client Role
A node implementing the client role mediates the persistence of data within the Codex network.
A client has two primary responsibilities:
- Requesting storage from the network by sending a storage request to the smart contract.
- Withdrawing funds from the storage requests previously created by the client.
Creating Storage Requests
When a user prompts the client node to create a storage request, the client node SHOULD receive the input parameters for the storage request from the user.
To create a request to persist a dataset on the Codex network, client nodes MUST split the dataset into data chunks, . Using the erasure coding method and the provided input parameters, the data chunks are encoded and distributed over a number of slots. The applied erasure coding method MUST use the Reed-Solomon algorithm. The final slot roots and other metadata MUST be placed into a Manifest (TODO: Manifest RFC). The CID for the Manifest MUST then be used as the cid for the stored dataset.
After the dataset is prepared, a client node MUST call the smart contract function requestStorage(request), providing the desired request parameters in the request parameter. The request parameter is of type Request:
struct Request {
address client;
Ask ask;
Content content;
uint64 expiry;
bytes32 nonce;
}
struct Ask {
uint256 proofProbability;
uint256 pricePerBytePerSecond;
uint256 collateralPerByte;
uint64 slots;
uint64 slotSize;
uint64 duration;
uint64 maxSlotLoss;
}
struct Content {
bytes cid;
bytes32 merkleRoot;
}
The table below provides the description of the Request and the associated types attributes:
| attribute | type | description |
|---|---|---|
client | address | The Codex node requesting storage. |
ask | Ask | Parameters of Request. |
content | Content | The dataset that will be hosted with the storage request. |
expiry | uint64 | Timeout in seconds during which all the slots have to be filled, otherwise Request will get cancelled. The final deadline timestamp is calculated at the moment the transaction is mined. |
nonce | bytes32 | Random value to differentiate from other requests of same parameters. It SHOULD be a random byte array. |
pricePerBytePerSecond | uint256 | Amount of tokens that will be awarded to SPs for finishing the storage request. It MUST be an amount of tokens offered per slot per second per byte. The Ethereum address that submits the requestStorage() transaction MUST have approval for the transfer of at least an equivalent amount of full reward (pricePerBytePerSecond * duration * slots * slotSize) in tokens. |
collateralPerByte | uint256 | The amount of tokens per byte of slot's size that SPs submit when they fill slots. Collateral is then slashed or forfeited if SPs fail to provide the service requested by the storage request (more information in the [Slashing](#### Slashing) section). |
proofProbability | uint256 | Determines the average frequency that a proof is required within a period: . SPs are required to provide proofs of storage to the marketplace contract when challenged. To prevent hosts from only coming online when proofs are required, the frequency at which proofs are requested from SPs is stochastic and is influenced by the proofProbability parameter. |
duration | uint64 | Total duration of the storage request in seconds. It MUST NOT exceed the limit specified in the configuration config.requestDurationLimit. |
slots | uint64 | The number of requested slots. The slots will all have the same size. |
slotSize | uint64 | Amount of storage per slot in bytes. |
maxSlotLoss | uint64 | Max slots that can be lost without data considered to be lost. |
cid | bytes | An identifier used to locate the Manifest representing the dataset. It MUST be a CIDv1, SHA-256 multihash and the data it represents SHOULD be discoverable in the network, otherwise the request will be eventually canceled. |
merkleRoot | bytes32 | Merkle root of the dataset, used to verify storage proofs |
Renewal of Storage Requests
It should be noted that the marketplace does not support extending requests. It is REQUIRED that if the user wants to extend the duration of a request, a new request with the same CID must be [created](### Creating Storage Requests) before the original request completes.
This ensures that the data will continue to persist in the network at the time when the new (or existing) SPs need to retrieve the complete dataset to fill the slots of the new request.
Monitoring and State Management
Client nodes MUST implement the following smart contract interactions for monitoring and state management:
-
getRequest(requestId): Retrieve the full
StorageRequestdata from the marketplace. This function is used for recovery and state verification after restarts or failures. -
requestState(requestId): Query the current state of a storage request. Used for monitoring request progress and determining the appropriate client actions.
-
requestExpiresAt(requestId): Query when the request will expire if not fulfilled.
-
getRequestEnd(requestId): Query when a fulfilled request will end (used to determine when to call
freeSlotorwithdrawFunds).
Client nodes MUST subscribe to the following marketplace events:
-
RequestFulfilled(requestId): Emitted when a storage request has enough filled slots to start. Clients monitor this event to determine when their request becomes active and transitions from the submission phase to the active phase.
-
RequestFailed(requestId): Emitted when a storage request fails due to proof failures or other reasons. Clients observe this event to detect failed requests and initiate fund withdrawal.
Withdrawing Funds
The client node MUST monitor the status of the requests it created. When a storage request enters the Cancelled, Failed, or Finished state, the client node MUST initiate the withdrawal of the remaining or refunded funds from the smart contract using the withdrawFunds(requestId) function.
Request states are determined as follows:
- The request is considered
Cancelledif noRequestFulfilled(requestId)event is observed during the timeout specified by the value returned from therequestExpiresAt(requestId)function. - The request is considered
Failedwhen theRequestFailed(requestId)event is observed. - The request is considered
Finishedafter the interval specified by the value returned from thegetRequestEnd(requestId)function has elapsed.
Storage Provider Role
A Codex node acting as an SP persists data across the network by hosting slots requested by clients in their storage requests.
The following tasks need to be considered when hosting a slot:
- Filling a slot
- Proving
- Repairing a slot
- Collecting request reward and collateral
Filling Slots
When a new request is created, the StorageRequested(requestId, ask, expiry) event is emitted with the following properties:
requestId- the ID of the request.ask- the specification of the request parameters. For details, see the definition of theRequesttype in the [Creating Storage Requests](### Creating Storage Requests) section above.expiry- a Unix timestamp specifying when the request will be canceled if all slots are not filled by then.
It is then up to the SP node to decide, based on the emitted parameters and node's operator configuration, whether it wants to participate in the request and attempt to fill its slot(s) (note that one SP can fill more than one slot). If the SP node decides to ignore the request, no further action is required. However, if the SP decides to fill a slot, it MUST follow the remaining steps described below.
The node acting as an SP MUST decide which slot, specified by the slot index, it wants to fill. The SP MAY attempt to fill more than one slot. To fill a slot, the SP MUST first reserve the slot in the smart contract using reserveSlot(requestId, slotIndex). If reservations for this slot are full, or if the SP has already reserved the slot, the transaction will revert. If the reservation was unsuccessful, then the SP is not allowed to fill the slot. If the reservation was successful, the node MUST then download the slot data using the CID of the manifest (TODO: Manifest RFC) and the slot index. The CID is specified in request.content.cid, which can be retrieved from the smart contract using getRequest(requestId). Then, the node MUST generate a proof over the downloaded data (TODO: Proving RFC).
When the proof is ready, the SP MUST call fillSlot() on the smart contract with the following REQUIRED parameters:
requestId- the ID of the request.slotIndex- the slot index that the node wants to fill.proof- theGroth16Proofproof structure, generated over the slot data.
The Ethereum address of the SP node from which the transaction originates MUST have approval for the transfer of at least the amount of tokens required as collateral for the slot (collateralPerByte * slotSize).
If the proof delivered by the SP is invalid or the slot was already filled by another SP, then the transaction will revert. Otherwise, a SlotFilled(requestId, slotIndex) event is emitted. If the transaction is successful, the SP SHOULD transition into the proving state, where it will need to submit proof of data possession when challenged by the smart contract.
It should be noted that if the SP node observes a SlotFilled event for the slot it is currently downloading the dataset for or generating the proof for, it means that the slot has been filled by another node in the meantime. In response, the SP SHOULD stop its current operation and attempt to fill a different, unfilled slot.
Proving
Once an SP fills a slot, it MUST submit proofs to the marketplace contract when a challenge is issued by the contract. SPs SHOULD detect that a proof is required for the current period using the isProofRequired(slotId) function, or that it will be required using the willProofBeRequired(slotId) function in the case that the proving clock pointer is in downtime.
Once an SP knows it has to provide a proof it MUST get the proof challenge using getChallenge(slotId), which then
MUST be incorporated into the proof generation as described in Proving RFC (TODO: Proving RFC).
When the proof is generated, it MUST be submitted by calling the submitProof(slotId, proof) smart contract function.
Slashing
There is a slashing scheme orchestrated by the smart contract to incentivize correct behavior and proper proof submissions by SPs. This scheme is configured at the smart contract level and applies uniformly to all participants in the network. The configuration of the slashing scheme can be obtained via the configuration() contract call.
The slashing works as follows:
- When SP misses a proof and a validator trigger detection of this event using the
markProofAsMissing()call, the SP is slashed byconfig.collateral.slashPercentageof the originally required collateral (hence the slashing amount is always the same for a given request). - If the number of slashes exceeds
config.collateral.maxNumberOfSlashes, the slot is freed, the remaining collateral is burned, and the slot is offered to other nodes for repair. The smart contract also emits theSlotFreed(requestId, slotIndex)event.
If, at any time, the number of freed slots exceeds the value specified by the request.ask.maxSlotLoss parameter, the dataset is considered lost, and the request is deemed failed. The collateral of all SPs that hosted the slots associated with the storage request is burned, and the RequestFailed(requestId) event is emitted.
Repair
When a slot is freed due to too many missed proofs, which SHOULD be detected by listening to the SlotFreed(requestId, slotIndex) event, an SP node can decide whether to participate in repairing the slot. Similar to filling a slot, the node SHOULD consider the operator's configuration when making this decision. The SP that originally hosted the slot but failed to comply with proving requirements MAY also participate in the repair. However, by refilling the slot, the SP will not recover its original collateral and must submit new collateral using the fillSlot() call.
The repair process is similar to filling slots. If the original slot dataset is no longer present in the network, the SP MAY use erasure coding to reconstruct the dataset. Reconstructing the original slot dataset requires retrieving other pieces of the dataset stored in other slots belonging to the request. For this reason, the node that successfully repairs a slot is entitled to an additional reward. (TODO: Implementation)
The repair process proceeds as follows:
- The SP observes the
SlotFreedevent and decides to repair the slot. - The SP MUST reserve the slot with the
reserveSlot(requestId, slotIndex)call. For more information see the [Filling Slots](###filling slots) section. - The SP MUST download the chunks of data required to reconstruct the freed slot's data. The node MUST use the Reed-Solomon algorithm to reconstruct the missing data.
- The SP MUST generate proof over the reconstructed data.
- The SP MUST call the
fillSlot()smart contract function with the same parameters and collateral allowance as described in the [Filling Slots](###filling slots) section.
Collecting Funds
An SP node SHOULD monitor the requests and the associated slots it hosts.
When a storage request enters the Cancelled, Finished, or Failed state, the SP node SHOULD call the freeSlot(slotId) smart contract function.
The aforementioned storage request states (Cancelled, Finished, and Failed) can be detected as follows:
- A storage request is considered
Cancelledif noRequestFulfilled(requestId)event is observed within the time indicated by theexpiryrequest parameter. Note that aRequestCancelledevent may also be emitted, but the node SHOULD NOT rely on this event to assert the request expiration, as theRequestCancelledevent is not guaranteed to be emitted at the time of expiry. - A storage request is considered
Finishedwhen the time indicated by the value returned from thegetRequestEnd(requestId)function has elapsed. - A node concludes that a storage request has
Failedupon observing theRequestFailed(requestId)event.
For each of the states listed above, different funds are handled as follows:
- In the
Cancelledstate, the collateral is returned along with a proportional payout based on the time the node actually hosted the dataset before the expiry was reached. - In the
Finishedstate, the full reward for hosting the slot, along with the collateral, is collected. - In the
Failedstate, no funds are collected. The reward is returned to the client, and the collateral is burned. The slot is removed from the list of slots and is no longer included in the list of slots returned by themySlots()function.
Validator Role
In a blockchain, a contract cannot change its state without a transaction and gas initiating the state change. Therefore, our smart contract requires an external trigger to periodically check and confirm that a storage proof has been delivered by the SP. This is where the validator role is essential.
The validator role is fulfilled by nodes that help to verify that SPs have submitted the required storage proofs.
It is the smart contract that checks if the proof requested from an SP has been delivered. The validator only triggers the decision-making function in the smart contract. To incentivize validators, they receive a reward each time they correctly mark a proof as missing corresponding to the percentage of the slashed collateral defined by config.collateral.validatorRewardPercentage.
Each time a validator observes the SlotFilled event, it SHOULD add the slot reported in the SlotFilled event to the validator's list of watched slots. Then, after the end of each period, a validator has up to config.proofs.timeout seconds (a configuration parameter retrievable with configuration()) to validate all the slots. If a slot lacks the required proof, the validator SHOULD call the markProofAsMissing(slotId, period) function on the smart contract. This function validates the correctness of the claim, and if right, will send a reward to the validator.
If validating all the slots observed by the validator is not feasible within the specified timeout, the validator MAY choose to validate only a subset of the observed slots.
Part II: Implementation Suggestions
IMPORTANT: The sections above (Abstract through Validator Role) define the normative Codex Marketplace protocol requirements. All implementations MUST comply with those protocol requirements to participate in the Codex network.
The sections below are non-normative. They document implementation approaches used in the nim-codex reference implementation. These are suggestions to guide implementors but are NOT required by the protocol. Alternative implementations MAY use different approaches as long as they satisfy the protocol requirements defined in Part I.
Implementation Suggestions
This section describes implementation approaches used in reference implementations. These are suggestions and not normative requirements. Implementations are free to use different internal architectures, state machines, and data structures as long as they correctly implement the protocol requirements defined above.
Storage Provider Implementation
The nim-codex reference implementation provides a complete Storage Provider implementation with state machine management, slot queueing, and resource management. This section documents the nim-codex approach.
State Machine
The Sales module implements a deterministic state machine for each slot, progressing through the following states:
- SalePreparing - Find a matching availability and create a reservation
- SaleSlotReserving - Reserve the slot on the marketplace
- SaleDownloading - Stream and persist the slot's data
- SaleInitialProving - Wait for stable challenge and generate initial proof
- SaleFilling - Compute collateral and fill the slot
- SaleFilled - Post-filling operations and expiry updates
- SaleProving - Generate and submit proofs periodically
- SalePayout - Free slot and calculate collateral
- SaleFinished - Terminal success state
- SaleFailed - Free slot on market and transition to error
- SaleCancelled - Cancellation path
- SaleIgnored - Sale ignored (no matching availability or other conditions)
- SaleErrored - Terminal error state
- SaleUnknown - Recovery state for crash recovery
- SaleProvingSimulated - Proving with injected failures for testing
All states move to SaleErrored if an error is raised.
SalePreparing
- Find a matching availability based on the following criteria:
freeSize,duration,collateralPerByte,minPricePerBytePerSecondanduntil - Create a reservation
- Move to
SaleSlotReservingif successful - Move to
SaleIgnoredif no availability is found or ifBytesOutOfBoundsErroris raised because of no space available. - Move to
SaleFailedonRequestFailedevent from themarketplace - Move to
SaleCancelledon cancelled timer elapsed, set to storage contract expiry
SaleSlotReserving
- Check if the slot can be reserved
- Move to
SaleDownloadingif successful - Move to
SaleIgnoredifSlotReservationNotAllowedErroris raised or the slot cannot be reserved. The collateral is returned. - Move to
SaleFailedonRequestFailedevent from themarketplace - Move to
SaleCancelledon cancelled timer elapsed, set to storage contract expiry
SaleDownloading
- Select the correct data expiry:
- When the request is started, the request end date is used
- Otherwise the expiry date is used
- Stream and persist data via
onStore - For each written batch, release bytes from the reservation
- Move to
SaleInitialProvingif successful - Move to
SaleFailedonRequestFailedevent from themarketplace - Move to
SaleCancelledon cancelled timer elapsed, set to storage contract expiry - Move to
SaleFilledonSlotFilledevent from themarketplace
SaleInitialProving
- Wait for a stable initial challenge
- Produce the initial proof via
onProve - Move to
SaleFillingif successful - Move to
SaleFailedonRequestFailedevent from themarketplace - Move to
SaleCancelledon cancelled timer elapsed, set to storage contract expiry
SaleFilling
- Get the slot collateral
- Fill the slot
- Move to
SaleFilledif successful - Move to
SaleIgnoredonSlotStateMismatchError. The collateral is returned. - Move to
SaleFailedonRequestFailedevent from themarketplace - Move to
SaleCancelledon cancelled timer elapsed, set to storage contract expiry
SaleFilled
- Ensure that the current host has filled the slot by checking the signer address
- Notify by calling
onFilledhook - Call
onExpiryUpdateto change the data expiry from expiry date to request end date - Move to
SaleProving(orSaleProvingSimulatedfor simulated mode) - Move to
SaleFailedonRequestFailedevent from themarketplace - Move to
SaleCancelledon cancelled timer elapsed, set to storage contract expiry
SaleProving
- For each period: fetch challenge, call
onProve, and submit proof - Move to
SalePayoutwhen the slot request ends - Re-raise
SlotFreedErrorwhen the slot is freed - Raise
SlotNotFilledErrorwhen the slot is not filled - Move to
SaleFailedonRequestFailedevent from themarketplace - Move to
SaleCancelledon cancelled timer elapsed, set to storage contract expiry
SaleProvingSimulated
- Submit invalid proofs every
Nperiods (failEveryNProofsin configuration) to test failure scenarios
SalePayout
- Get the current collateral and try to free the slot to ensure that the slot is freed after payout.
- Forward the returned collateral to cleanup
- Move to
SaleFinishedif successful - Move to
SaleFailedonRequestFailedevent from themarketplace - Move to
SaleCancelledon cancelled timer elapsed, set to storage contract expiry
SaleFinished
- Call
onClearhook - Call
onCleanUphook
SaleFailed
- Free the slot
- Move to
SaleErroredwith the failure message
SaleCancelled
- Ensure that the node hosting the slot frees the slot
- Call
onClearhook - Call
onCleanUphook with the current collateral
SaleIgnored
- Call
onCleanUphook with the current collateral
SaleErrored
- Call
onClearhook - Call
onCleanUphook
SaleUnknown
- Recovery entry: get the
on-chainstate and jump to the appropriate state
Slot Queue
Slot queue schedules slot work and instantiates one SalesAgent per item with bounded concurrency.
- Accepts
(requestId, slotIndex, …)items and orders them by priority - Spawns one
SalesAgentfor each dequeued item, in other words, one item for one agent - Caps concurrent agents to
maxWorkers - Supports pause/resume
- Allows controlled requeue when an agent finishes with
reprocessSlot
Slot Ordering
The criteria are in the following order:
- Unseen before seen - Items that have not been seen are dequeued first.
- More profitable first - Higher
profitabilitywins.profitabilityisduration * pricePerSlotPerSecond. - Less collateral first - The item with the smaller
collateralwins. - Later expiry first - If both items carry an
expiry, the one with the greater timestamp wins.
Within a single request, per-slot items are shuffled before enqueuing so the default slot-index order does not influence priority.
Pause / Resume
When the Slot queue processes an item with seen = true, it means that the item was already evaluated against the current availabilities and did not match.
To avoid draining the queue with untenable requests (due to insufficient availability), the queue pauses itself.
The queue resumes when:
OnAvailabilitySavedfires after an availability update that increases one of:freeSize,duration,minPricePerBytePerSecond, ortotalRemainingCollateral.- A new unseen item (
seen = false) is pushed. unpause()is called explicitly.
Reprocess
Availability matching occurs in SalePreparing.
If no availability fits at that time, the sale is ignored with reprocessSlot to true, meaning that the slot is added back to the queue with the flag seen to true.
Startup
On SlotQueue.start(), the sales module first deletes reservations associated with inactive storage requests, then starts a new SalesAgent for each active storage request:
- Fetch the active
on-chainactive slots. - Delete the local reservations for slots that are not in the active list.
- Create a new agent for each slot and assign the
onCleanUpcallback. - Start the agent in the
SaleUnknownstate.
Main Behaviour
When a new slot request is received, the sales module extracts the pair (requestId, slotIndex, …) from the request.
A SlotQueueItem is then created with metadata such as profitability, collateral, expiry, and the seen flag set to false.
This item is pushed into the SlotQueue, where it will be prioritised according to the ordering rules.
SalesAgent
SalesAgent is the instance that executes the state machine for a single slot.
- Executes the sale state machine across the slot lifecycle
- Holds a
SalesContextwith dependencies and host hooks - Supports crash recovery via the
SaleUnknownstate - Handles errors by entering
SaleErrored, which runs cleanup routines
SalesContext
SalesContext is a container for dependencies used by all sales.
- Provides external interfaces:
Market(marketplace) andClock - Provides access to
Reservations - Provides host hooks:
onStore,onProve,onExpiryUpdate,onClear,onSale - Shares the
SlotQueuehandle for scheduling work - Provides configuration such as
simulateProofFailures - Passed to each
SalesAgent
Marketplace Subscriptions
The sales module subscribes to on-chain events to keep the queue and agents consistent.
StorageRequested
When the marketplace signals a new request, the sales module:
- Computes collateral for free slots.
- Creates per-slot
SlotQueueItementries (one perslotIndex) withseen = false. - Pushes the items into the
SlotQueue.
SlotFreed
When the marketplace signals a freed slot (needs repair), the sales module:
- Retrieves the request data for the
requestId. - Computes collateral for repair.
- Creates a
SlotQueueItem. - Pushes the item into the
SlotQueue.
RequestCancelled
When a request is cancelled, the sales module removes all queue items for that requestId.
RequestFulfilled
When a request is fulfilled, the sales module removes all queue items for that requestId and notifies active agents bound to the request.
RequestFailed
When a request fails, the sales module removes all queue items for that requestId and notifies active agents bound to the request.
SlotFilled
When a slot is filled, the sales module removes the queue item for that specific (requestId, slotIndex) and notifies the active agent for that slot.
SlotReservationsFull
When the marketplace signals that reservations are full, the sales module removes the queue item for that specific (requestId, slotIndex).
Reservations
The Reservations module manages both Availabilities and Reservations. When an Availability is created, it reserves bytes in the storage module so no other modules can use those bytes. Before a dataset for a slot is downloaded, a Reservation is created, and the freeSize of the Availability is reduced. When bytes are downloaded, the reservation of those bytes in the storage module is released. Accounting of both reserved bytes in the storage module and freeSize in the Availability are cleaned up upon completion of the state machine.
graph TD
A[Availability] -->|creates| R[Reservation]
A -->|reserves bytes in| SM[Storage Module]
R -->|reduces| AF[Availability.freeSize]
R -->|downloads data| D[Dataset]
D -->|releases bytes to| SM
TC[Terminal State] -->|triggers cleanup| C[Cleanup]
C -->|returns bytes to| AF
C -->|deletes| R
C -->|returns collateral to| A
Hooks
- onStore: streams data into the node's storage
- onProve: produces proofs for initial and periodic proving
- onExpiryUpdate: notifies the client node of a change in the expiry data
- onSale: notifies that the host is now responsible for the slot
- onClear: notification emitted once the state machine has concluded; used to reconcile Availability bytes and reserved bytes in the storage module
- onCleanUp: cleanup hook called in terminal states to release resources, delete reservations, and return collateral to availabilities
Error Handling
- Always catch
CancelledErrorfromnim-chronosand log a trace, exiting gracefully - Catch
CatchableError, log it, and route toSaleErrored
Cleanup
Cleanup releases resources held by a sales agent and optionally requeues the slot.
- Return reserved bytes to the availability if a reservation exists
- Delete the reservation and return any remaining collateral
- If
reprocessSlotis true, push the slot back into the queue marked as seen - Remove the agent from the sales set and track the removal future
Resource Management Approach
The nim-codex implementation uses Availabilities and Reservations to manage local storage resources:
Reservation Management
- Maintain
AvailabilityandReservationrecords locally - Match incoming slot requests to available capacity using prioritisation rules
- Lock capacity and collateral when creating a reservation
- Release reserved bytes progressively during download and free all remaining resources in terminal states
Note: Availabilities and Reservations are completely local to the Storage Provider implementation and are not visible at the protocol level. They provide one approach to managing storage capacity, but other implementations may use different resource management strategies.
Protocol Compliance Note: The Storage Provider implementation described above is specific to nim-codex. The only normative requirements for Storage Providers are defined in the Storage Provider Role section of Part I. Implementations must satisfy those protocol requirements but may use completely different internal designs.
Client Implementation
The nim-codex reference implementation provides a complete Client implementation with state machine management for storage request lifecycles. This section documents the nim-codex approach.
The nim-codex implementation uses a state machine pattern to manage purchase lifecycles, providing deterministic state transitions, explicit terminal states, and recovery support. The state machine definitions (state identifiers, transitions, state descriptions, requirements, data models, and interfaces) are documented in the subsections below.
Note: The Purchase module terminology and state machine design are specific to the nim-codex implementation. The protocol only requires that clients interact with the marketplace smart contract as specified in the Client Role section.
State Identifiers
- PurchasePending:
pending - PurchaseSubmitted:
submitted - PurchaseStarted:
started - PurchaseFinished:
finished - PurchaseErrored:
errored - PurchaseCancelled:
cancelled - PurchaseFailed:
failed - PurchaseUnknown:
unknown
General Rules for All States
- If a
CancelledErroris raised, the state machine logs the cancellation message and takes no further action. - If a
CatchableErroris raised, the state machine moves toerroredwith the error message.
State Transitions
|
v
------------------------- unknown
| / /
v v /
pending ----> submitted ----> started ---------> finished <----/
\ \ /
\ ------------> failed <----/
\ /
--> cancelled <-----------------------
Note:
Any state can transition to errored upon a CatchableError.
failed is an intermediate state before errored.
finished, cancelled, and errored are terminal states.
State Descriptions
Pending State (pending)
A storage request is being created by making a call on-chain. If the storage request creation fails, the state machine moves to the errored state with the corresponding error.
Submitted State (submitted)
The storage request has been created and the purchase waits for the request to start. When it starts, an on-chain event RequestFulfilled is emitted, triggering the subscription callback, and the state machine moves to the started state. If the expiry is reached before the callback is called, the state machine moves to the cancelled state.
Started State (started)
The purchase is active and waits until the end of the request, defined by the storage request parameters, before moving to the finished state. A subscription is made to the marketplace to be notified about request failure. If a request failure is notified, the state machine moves to failed.
Marketplace subscription signature:
method subscribeRequestFailed*(market: Market, requestId: RequestId, callback: OnRequestFailed): Future[Subscription] {.base, async.}
Finished State (finished)
The purchase is considered successful and cleanup routines are called. The purchase module calls marketplace.withdrawFunds to release the funds locked by the marketplace:
method withdrawFunds*(market: Market, requestId: RequestId) {.base, async: (raises: [CancelledError, MarketError]).}
After that, the purchase is done; no more states are called and the state machine stops successfully.
Failed State (failed)
If the marketplace emits a RequestFailed event, the state machine moves to the failed state and the purchase module calls marketplace.withdrawFunds (same signature as above) to release the funds locked by the marketplace. After that, the state machine moves to errored.
Cancelled State (cancelled)
The purchase is cancelled and the purchase module calls marketplace.withdrawFunds to release the funds locked by the marketplace (same signature as above). After that, the purchase is terminated; no more states are called and the state machine stops with the reason of failure as error.
Errored State (errored)
The purchase is terminated; no more states are called and the state machine stops with the reason of failure as error.
Unknown State (unknown)
The purchase is in recovery mode, meaning that the state has to be determined. The purchase module calls the marketplace to get the request data (getRequest) and the request state (requestState):
method getRequest*(market: Market, id: RequestId): Future[?StorageRequest] {.base, async: (raises: [CancelledError]).}
method requestState*(market: Market, requestId: RequestId): Future[?RequestState] {.base, async.}
Based on this information, it moves to the corresponding next state.
Note: Functional and non-functional requirements for the client role are summarized in the Codex Marketplace Specification. The requirements listed below are specific to the nim-codex Purchase module implementation.
Functional Requirements
Purchase Definition
- Every purchase MUST represent exactly one
StorageRequest - The purchase MUST have a unique, deterministic identifier
PurchaseIdderived fromrequestId - It MUST be possible to restore any purchase from its
requestIdafter a restart - A purchase is considered expired when the expiry timestamp in its
StorageRequestis reached before the request start, i.e, an eventRequestFulfilledis emitted by themarketplace
State Machine Progression
- New purchases MUST start in the
pendingstate (submission flow) - Recovered purchases MUST start in the
unknownstate (recovery flow) - The state machine MUST progress step-by-step until a deterministic terminal state is reached
- The choice of terminal state MUST be based on the
RequestStatereturned by themarketplace
Failure Handling
- On marketplace failure events, the purchase MUST immediately transition to
erroredwithout retries - If a
CancelledErroris raised, the state machine MUST log the cancellation and stop further processing - If a
CatchableErroris raised, the state machine MUST transition toerroredand record the error
Non-Functional Requirements
Execution Model
A purchase MUST be handled by a single thread; only one worker SHOULD process a given purchase instance at a time.
Reliability
load supports recovery after process restarts.
Performance
State transitions should be non-blocking; all I/O is async.
Logging
All state transitions and errors should be clearly logged for traceability.
Safety
- Avoid side effects during
newother than initialising internal fields;on-chaininteractions are delegated to states usingmarketplacedependency. - Retry policy for external calls.
Testing
- Unit tests check that each state handles success and error properly.
- Integration tests check that a full purchase flows correctly through states.
Protocol Compliance Note: The Client implementation described above is specific to nim-codex. The only normative requirements for Clients are defined in the Client Role section of Part I. Implementations must satisfy those protocol requirements but may use completely different internal designs.
Copyright
Copyright and related rights waived via CC0.
References
Normative
- RFC 2119 - Key words for use in LIPs to Indicate Requirement Levels
- Reed-Solomon algorithm - Erasure coding algorithm used for data encoding
- CIDv1 - Content Identifier specification
- multihash - Self-describing hashes
- Proof-of-Data-Possession - Zero-knowledge proof system for storage verification
- Original Codex Marketplace Spec - Source specification for this document
Informative
- Codex Implementation - Reference implementation in Nim
- Codex market implementation - Marketplace module implementation
- Codex Sales Component Spec - Storage Provider implementation details
- Codex Purchase Component Spec - Client implementation details
- Nim Chronos - Async/await framework for Nim
- Storage proof timing design - Proof timing mechanism
CODEX-MERKLE-TREE
| Field | Value |
|---|---|
| Name | Codex Merkle Tree |
| Slug | 82 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Codex Team |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-02-06 —
af4cd78— feat: revamped Merkle tree spec (#281) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258)
Abstract
This specification defines the Merkle tree implementation for Codex. The purpose of this component is to deal with Merkle trees (and Merkle trees only; except that certain arithmetic hashes constructed via the sponge construction use the same encoding standards).
Background / Rationale / Motivation
Merkle trees and Merkle tree roots are used for:
- content addressing (via the Merkle root hash)
- data authenticity (via a Merkle path from a block to the root)
- remote auditing (via Merkle proofs of pieces)
Merkle trees can be implemented in quite a few different ways, and if naively implemented, can be also attacked in several ways.
Some possible attacks:
- Data encoding attacks: occur when different byte sequences can be encoded to the same target type, potentially creating collisions
- Padding attacks: occur when different data can be padded to produce identical hashes
- Layer abusing attacks: occur when nodes from different layers can be substituted or confused with each other
These all can create root hash collisions for example.
Hence, a concrete implementation is specified which should be safe from these attacks through:
- Injective encoding: The
10*padding strategy ensures that different byte sequences always encode to different target types - Keyed compression: Using distinct keys for different node types (even/odd, bottom/other layers) prevents node substitution attacks
- Deterministic construction: The layer-by-layer construction with explicit handling of singleton nodes ensures consistent tree building
The specification supports multiple hash function types (SHA256, Poseidon2, Goldilocks) while maintaining these security properties across all implementations.
Storing Merkle trees on disc is out of scope here (but should be straightforward, as serialization of trees should be included in the component).
Theory / Semantics
Vocabulary
A Merkle tree, built on a hash function H,
produces a Merkle root of type T ("Target type").
This is usually the same type as the output of the hash function
(this is assumed below).
Some examples:
- SHA1:
Tis 160 bits - SHA256:
Tis 256 bits - Keccak (SHA3):
Tcan be one of 224, 256, 384 or 512 bits - Poseidon:
Tis one or more finite field element(s) (based on the field size) - Monolith:
Tis 4 Goldilocks field elements
The hash function H can also have different types S ("Source type") of inputs.
For example:
- SHA1 / SHA256 / SHA3:
Sis an arbitrary sequence of bits - some less-conforming implementation of these could take a sequence of bytes instead (but that's often enough in practice)
- binary compression function:
Sis a pair ofT-s - Poseidon:
Sis a sequence of finite field elements - Poseidon2 compression function:
Sis at mostt-kfield elements, wherekfield elements should be approximately 256 bits (in our caset=3,k=1for BN254 field; ort=12,k=4for the Goldilocks field; ort=24,k=8for a ~32 bit field) - as an alternative,
the "Jive compression mode" for binary compression
can eliminate the "minus
k" requirement (you can compresstintot/2) - A naive Merkle tree implementation could for example
accept only a power-of-two sized sequence of
T
Notation: Let's denote a sequence of T-s by [T];
and an array of T-s of length l by T[l].
Data Models
H, the set of supported hash functions, is an enumerationS := Source[H]andT := Target[H]MerklePath[H]is a record, consisting ofpath: a sequence ofT-sindex: a linear index (int)leaf: the leaf being proved (aT)size: the number of elements from which the tree was created
MerkleTree[H]: a binary tree ofT-s; alternatively a sequence of sequences ofT-s
Tree Construction
We want to avoid the following kind of attacks:
- padding attacks
- layer abusing attacks
Hence, instead of using a single compression functions, a keyed compression function is used, which is keyed by two bits:
- whether the new parent node is an even or odd node (that is, has 2 or 1 children; alternatively, whether compressing 2 or 1 nodes)
- whether it's the bottom (the widest, initial) layer or not
This information is converted to a number 0 <= key < 4
by the following algorithm:
data LayerFlag
= BottomLayer -- ^ it's the bottom (initial, widest) layer
| OtherLayer -- ^ it's not the bottom layer
data NodeParity
= EvenNode -- ^ it has 2 children
| OddNode -- ^ it has 1 child
-- | Key based on the node type:
--
-- > bit0 := 1 if bottom layer, 0 otherwise
-- > bit1 := 1 if odd, 0 if even
--
nodeKey :: LayerFlag -> NodeParity -> Int
nodeKey OtherLayer EvenNode = 0x00
nodeKey BottomLayer EvenNode = 0x01
nodeKey OtherLayer OddNode = 0x02
nodeKey BottomLayer OddNode = 0x03
This number is used to key the compression function (essentially, 4 completely different compression functions).
When the hash function is a finite field sponge based,
like Poseidon2 or Monolith,
the following construction is used:
The permutation function is applied to (x,y,key),
and the first component of the result is taken.
When the hash function is something like SHA256,
the following is done: SHA256(key|x|y) (here key is encoded as a byte).
SHA256 implementation uses bearssl.
Remark: Since standard SHA256 includes padding, adding a key at the beginning doesn't result in extra computation (it's always two internal hash calls). However, a faster (twice as fast) alternative would be to choose 4 different random-looking initialization vectors, and not do padding. This would be a non-standard SHA256 invocation.
Finally, the process proceeds from the initial sequence in layers:
Take the previous sequence,
apply the keyed compression function for each consecutive pairs (x,y) : (T,T)
with the correct key:
based on whether this was the initial (bottom) layer,
and whether it's a singleton "pair" x : T,
in which case it's also padded with a zero to (x,0).
Note: If the input was a singleton list [x],
one layer is still applied,
so in that case the root will be compress[key=3](x,0).
Encoding and (De)serialization from/to Bytes
This has to be done very carefully to avoid potential attacks.
Note: This is a rather special situation,
in that encoding and serialization are NOT THE INVERSE OF EACH OTHER.
The reason for this is that they have different purposes:
In case of encoding from bytes to T-s,
it MUST BE injective to avoid trivial collision attacks;
while when serializing from T-s to bytes,
it needs to be invertible
(so that what is stored on disk can be loaded back;
in this sense this is really 1+2 = 3 algorithms).
The two can coincide when T is just a byte sequence like in SHA256,
but not when T consists of prime field elements.
Remark: The same encoding of sequence of bytes to sequence of T-s
is used for the sponge hash construction, when applicable.
Encoding into a Single T
For any T = Target[H],
fix a size M and an injective encoding byte[M] -> T.
For SHA256 etc, this will be standard encoding (big-endian; M=32).
For the BN254 field (T is 1 field element),
M=31, and the 31 bytes interpreted as a little-endian integer modulo p.
For the Goldilocks field,
there are some choices:
M=4*7=28 can be used, as a single field element can encode 7 bytes but not 8.
Or, for more efficiency,
M=31 can still be achieved by storing 62 bits in each field element.
For this some convention needs to be chosen;
the implementation is the following:
#define MASK 0x3fffffffffffffffULL
// NOTE: we assume a little-endian architecture here
void goldilocks_convert_31_bytes_to_4_field_elements(const uint8_t *ptr, uint64_t *felts) {
const uint64_t *q0 = (const uint64_t*)(ptr );
const uint64_t *q7 = (const uint64_t*)(ptr+ 7);
const uint64_t *q15 = (const uint64_t*)(ptr+15);
const uint64_t *q23 = (const uint64_t*)(ptr+23);
felts[0] = (q0 [0]) & MASK;
felts[1] = ((q7 [0]) >> 6) | ((uint64_t)(ptr[15] & 0x0f) << 58);
felts[2] = ((q15[0]) >> 4) | ((uint64_t)(ptr[23] & 0x03) << 60);
felts[3] = ((q23[0]) >> 2);
}
This simply chunks the 31 bytes = 248 bits into 62 bits chunks, and interprets them as little endian 62 bit integers.
Encoding from a Sequence of Bytes
First, the byte sequence is padded with the 10* padding strategy
to a multiple of M bytes.
This means that a 0x01 byte is always added,
and then as many 0x00 bytes as required for the length to be divisible by M.
If the input was l bytes,
then the padded sequence will have M*(floor(l/M)+1) bytes.
Note: the 10* padding strategy is an invertible operation,
which will ensure that there is no collision
between sequences of different length.
This padded byte sequence is then chunked to pieces of M bytes
(so there will be floor(l/M)+1 chunks),
and the above fixed byte[M] -> T is applied for each chunk,
resulting in the same number of T-s.
Remark: The sequence of T-s is not padded
when constructing the Merkle tree
(as the tree construction ensures
that different lengths will result in different root hashes).
However, when using the sponge construction,
the sequence of T-s needs to be further padded
to be a multiple of the sponge rate;
there again the 10* strategy is applied,
but there the 1 and 0 are finite field elements.
Serializing / Deserializing
When using SHA256 or similar, this is trivial (use the standard, big-endian encoding).
When T consists of prime field elements,
simply take the smallest number of bytes the field fits in
(usually 256, 64 or 32 bits, that is 32, 8 or 4 bytes),
and encode as a little-endian integer (mod the prime).
This is obvious to invert.
Tree Serialization
Just add enough metadata that the size of each layer is known, then the layers can simply be concatenated, and serialized as above. This metadata can be as small as the size of the initial layer, that is, a single integer.
Wire Format Specification / Syntax
Interfaces
At least two types of Merkle tree APIs are usually needed:
- one which takes a sequence
S = [T]of lengthnas input, and produces an output (Merkle root) of typeT - and one which takes a sequence of bytes
(or even bits, but in practice only bytes are probably needed):
S = [byte]
The latter can be decomposed into the composition
of an encodeBytes function and the former
(it's safer this way, because there are a lot of subtle details here).
| Interface | Description | Input | Output |
|---|---|---|---|
| computeTree() | computes the full Merkle tree | sequence of T-s | a MerkleTree[T] data structure (a binary tree) |
| computeRoot() | computes the Merkle root of a sequence of T-s | sequence of T-s | a single T |
| extractPath() | computes a Merkle path | MerkleTree[T] and a leaf index | MerklePath[T] |
| checkMerkleProof() | checks the validity of a Merkle path proof | root hash (a T) and MerklePath[T] | a bool (ok or not) |
| encodeBytesInjective() | converts a sequence of bytes into a sequence of T-s, injectively | seqences of bytes | sequence of T-s |
| serializeToBytes() | serializes a sequence of T-s into bytes | sequence of T-s | sequence of bytes |
| deserializeFromBytes() | deserializes a sequence of T-s from bytes | sequence of bytes | sequence of T-s, or error |
| serializeTree() | serializes the Merkle tree data structure (to be stored on disk) | MerkleTree[T] | sequence of bytes |
| deserializeTree() | deserializes the Merkle tree data structure (to be load from disk) | sequence of bytes | error or MerkleTree[T] |
Dependencies
Hash function implementations, for example:
- bearssl (for SHA256)
- nim-poseidon2 (which should be renamed to
nim-poseidon2-bn254) - nim-goldilocks-hash
Security/Privacy Considerations
Attack Mitigation
The specification addresses three major attack vectors:
-
Data encoding attacks: Prevented by using injective encoding from bytes to target types with the
10*padding strategy. The strategy always adds a0x01byte followed by0x00bytes to reach a multiple ofMbytes, ensuring that different byte sequences of different lengths cannot encode to the same target type. -
Padding attacks: Prevented by the keyed compression function that distinguishes between even and odd nodes. When a node has only one child (odd node), it is padded with zero to form a pair
(x,0), but the compression function uses a different key (0x02 or 0x03) than for even nodes (0x00 or 0x01), preventing confusion between padded and non-padded nodes. -
Layer abusing attacks: Prevented by the keyed compression function that distinguishes between bottom layer and other layers. The bottom layer uses keys with bit0 set to 1 (0x01 or 0x03), while other layers use keys with bit0 set to 0 (0x00 or 0x02), preventing nodes from different layers from producing identical hashes.
Keyed Compression Function
The keyed compression function uses four distinct keys (0x00, 0x01, 0x02, 0x03) based on two bits:
- bit0: Set to 1 if bottom layer, 0 otherwise
- bit1: Set to 1 if odd node (1 child), 0 if even node (2 children)
This ensures that different structural positions in the tree cannot produce hash collisions, as:
- For finite field sponge hash functions (Poseidon2, Monolith):
The permutation is applied to
(x,y,key)and the first component is extracted - For standard hash functions (SHA256):
The hash is computed as
SHA256(key|x|y)wherekeyis encoded as a byte
Hash Function Flexibility
The specification is parametrized by the hash function, allowing different implementations to use appropriate hash functions for their context while maintaining consistent security properties. All supported hash functions must maintain the injective encoding property and support the keyed compression function pattern.
Rationale
Keyed Compression Design
The use of a keyed compression function with four distinct keys is the primary defense mechanism against theoretical attacks. By encoding both the layer position (bottom vs. other) and node parity (even vs. odd) into the compression function, the design ensures that:
- Nodes at different layers cannot be confused
- Even and odd nodes produce different hashes even with the same input data
- Padding attacks are prevented by distinguishing singleton nodes from pair nodes
Encoding vs. Serialization Separation
The specification explicitly separates encoding and serialization as distinct operations:
- Encoding (bytes to
T-s) must be injective to prevent collision attacks - Serialization (
T-s to bytes) must be invertible to enable storage and retrieval
This separation is necessary because they serve different purposes.
The two operations only coincide when T is a byte sequence (as in SHA256),
but differ when T consists of prime field elements.
10* Padding Strategy
The 10* padding strategy
(always adding 0x01 followed by 0x00 bytes)
is an invertible operation
that ensures no collision between sequences of different lengths.
This is applied at the byte level before chunking into M-byte pieces.
Parametrized Hash Function Design
The design is parametrized by the hash function, supporting:
- Standard hash functions (SHA256, SHA3)
- Finite field-based sponge constructions (Poseidon2, Monolith)
- Binary compression functions
This flexibility allows easy addition of new hash functions while maintaining security guarantees.
Copyright
Copyright and related rights waived via CC0.
References
normative
- Codex Merkle Tree Implementation: GitHub - codex-storage/nim-codex
informative
- Merkle Tree Conventions: GitHub - codex-storage-proofs-circuits - Merkle tree specification in codex-storage-proofs-circuits
- nim-poseidon2: GitHub - codex-storage/nim-poseidon2 - Poseidon2 hash function for BN254
- nim-goldilocks-hash: GitHub - codex-storage/nim-goldilocks-hash - Goldilocks field hash functions
- BearSSL: bearssl.org - BearSSL cryptographic library
- Jive Compression Mode: Anemoi Permutations and Jive Compression Mode - Efficient arithmetization-oriented hash functions
CODEX-PROVER
| Field | Value |
|---|---|
| Name | Codex Prover Module |
| Slug | 81 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Codex Team |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-01-22 —
e356a07— Chore/add makefile (#271) - 2026-01-22 —
af45aae— chore: deprecate Marketplace-related specs (#268) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258)
Abstract
This specification defines the Proving module for Codex, which provides a succinct, publicly verifiable way to check that storage providers still hold the data they committed to. The proving module samples cells from stored slots, and generates zero-knowledge proofs that tie those samples and Merkle paths back to the published dataset root commitment. The marketplace contract verifies these proofs on-chain and uses the result to manage incentives such as payments and slashing.
Background / Rationale / Motivation
In decentralized storage networks such as Codex, one of the main challenges is ensuring durability and availability of data stored by storage providers. To achieve durability, random sampling combined with erasure coding is used to provide probabilistic guarantees while touching only a tiny fraction of the stored data per challenge.
The proving module addresses this challenge by:
- Checking for storage proof requests from the marketplace
- Sampling cells from slots in the stored dataset and constructing Merkle proofs
- Generating zero-knowledge proofs for randomly selected cells in stored slots
- Submitting proofs to the on-chain marketplace smart contract for verification
The proving module consists of three main sub-components:
- Sampler: Derives random sample indices from public entropy and slot commitments, then generates the proof input
- Prover: Produces succinct ZK proofs for valid proof inputs and verifies such proofs
- ZK Circuit: Defines the logic for sampling, cell hashing, and Merkle tree membership checks
The proving module relies on BlockStore for block-level storage access
and SlotsBuilder to build initial commitments to the stored data.
BlockStore is Codex's local storage abstraction that provides
block retrieval by CID.
SlotsBuilder constructs the Merkle tree commitments for slots and datasets
(see CODEX-SLOT-BUILDER for details).
The incentives involved, including collateral and slashing,
are handled by the marketplace logic.
Theory / Semantics
Terminology
| Term | Description |
|---|---|
| Storage Client (SC) | A node that participates in Codex to buy storage. |
| Storage Provider (SP) | A node that participates in Codex by selling disk space to other nodes. |
| Dataset | A set of fixed-size slots provided by possibly different storage clients. |
| Cell | Smallest circuit sampling unit (e.g., 2 KiB), its bytes are packed into field elements and hashed. |
| Block | Network transfer unit (e.g., 64 KiB) consists of multiple cells, used for transport. |
| Slot | The erasure-coded fragment of a dataset stored by a single storage provider. Proof requests are related to slots. |
| Commitment | Cryptographic binding (and hiding if needed) to specific data. In Codex this is a Poseidon2 Merkle root (e.g., Dataset Root or Slot Root). It allows anyone to verify proofs against the committed content. |
| Dataset Root / Slot Root | Poseidon2 Merkle roots used as public commitments in the circuit. Not the SHA-256 content tree used for CIDs. |
| Entropy | Public randomness (e.g., blockhash) used to derive random sample indices. |
| Witness | Private zk circuit inputs. |
| Public Inputs | Values known to or shared with the verifier. |
| Groth16 | Succinct zk-SNARK proof system used by Codex. |
| Proof Window | The time/deadline within which the storage provider must submit a valid proof. |
Data Commitment
In Codex, a dataset is split into numSlots slots which are the ones sampled. Each slot is split into nCells fixed-size cells. Since networking operates on blocks, cells are combined to form blocks where each block contains BLOCKSIZE/CELLSIZE cells. The following describes how raw bytes become commitments in Codex (cells -> blocks -> slots -> dataset):
Cell hashing:
- Split each cell's bytes into chunks (31-byte for BN254), map to field elements (little-endian). Pad the last chunk with
10*. - Hash the resulting field-element stream with a Poseidon2 sponge.
Block tree (cell -> block):
- A network block in Codex is 64 KiB and contains 32 cells of 2 KiB each.
- Build a Merkle tree of depth 5 over the 32 cell hashes. The root is the block hash.
Slot tree (block -> slot):
- For all blocks in a slot, build a Merkle tree over their block hashes
(root of block trees).
The number of leaves is expected to be a power of two
(in Codex, the
SlotsBuilderpads the slots). The Slot tree root is the public commitment that is sampled. See CODEX-SLOT-BUILDER for the detailed slot building process.
Dataset tree (slot -> dataset):
- Build a Merkle tree over the slot trees roots to obtain the dataset root (this is different from SHA-256 CID used for content addressing). The dataset root is the public commitment to all slots hosted by a single storage provider.
Codex Merkle Tree Conventions
Codex extends the standard Merkle tree with a keyed compression that depends on
(a) whether a node is on the bottom (i.e. leaf layer) and
(b) whether a node is odd (has a single child) or even (two children).
These two bits are encoded as {0,1,2,3} and fed into the hash so tree shape
cannot be manipulated.
Steps in building the Merkle tree (bytes/leaves -> root):
Cell bytes are split into 31-byte chunks to fit in BN254,
each mapped little-endian into a BN254 field element.
10* padding is used.
Leaves (cells) are hashed with a Poseidon2 sponge with state size t=3
and rate r=2.
The sponge is initialized with IV (0,0, domSep) where:
domSep := 2^64 + 256*t + rate
This is a domain-separation constant.
When combining two child nodes x and y, Codex uses the keyed compression:
compress(x, y, key) = Poseidon2_permutation(x, y, key)[0]
where key encodes the two bits:
- bit 0: 1 if we're at the bottom layer, else 0
- bit 1: 1 if this is an odd node (only one child present), else 0
Special cases:
- Odd node with single child
x:compress(x, 0, key)(i.e., the missing sibling is zero). - Singleton tree (only one element in the tree): still apply one compression round.
- Merkle Paths need only sibling hashes: left/right direction is inferred from the binary decomposition of the leaf index, so you don't transmit direction flags.
Sampling
Sampling request:
Sampling begins when a proof is requested containing the entropy
(also called ProofChallenge).
A DataSampler instance is created for a specific slot and then used to
produce Sample records.
The sampler needs:
slotIndex: the index of the slot being proven. This is fixed when theDataSampleris constructed.entropy: public randomness (e.g., blockhash).nSamples: the number of cells to sample.
Derive indices:
The sampler derives deterministic cell indices from the challenge entropy and the slot commitment:
idx = H(entropy || slotRoot || counter) mod nCells
where counter = 1..nSamples and H is the Poseidon2 sponge (rate = 2)
with 10* padding.
The result is a sequence of indices in [0, nCells),
identical for any honest party given the same (entropy, slotRoot, nSamples).
Note that there is a chance however small that you would have multiple of
the same cell index samples purely by chance.
The chance of that depends on the slot and cell sizes;
the larger the slot and smaller the cell,
the lower the chance of landing on the same cell index.
Generate per-sample data:
- Fetch the
cellDatavia theBlockStoreandbuilder, and fetch the storedcell -> block,block -> slot,slot -> datasetMerkle paths. Note thatcell -> blockcan be built on the fly andslot -> datasetcan be reused for all samples in that slot.
Collect Proof Inputs:
The DataSampler collects the ProofInputs required for the zk proof system
which contains the following:
entropy: the challenge randomness.datasetRoot: the root of the dataset Merkle tree.slotIndex: the index of the proven slot.slotRoot: the Merkle root of the slot tree.nCellsPerSlot: total number of cells in the slot.nSlotsPerDataSet: total number of slots in the dataset.slotProof: theslot -> datasetMerkle path.samples: a list where each element is:cellData: the sampled cell encoded as field elements.merklePaths: the concatenation(cell -> block) || (block -> slot).
These ProofInputs are then passed to the prover to generate the succinct
ZK proof.
Proof Generation
To produce a zk storage proof, Codex uses a pluggable proving backend.
In practice, Groth16 over BN254 (altbn128) is used with circuits written
in Circom.
The Prover with ProofInputs calls the backend to create a succinct proof,
and optionally verifies it locally before submission.
ZK Circuit Specification
Circuit parameters (compile-time constants):
MAXDEPTH # max depth of slot tree (block -> slot)
MAXSLOTS # max number of slots in dataset (slot -> dataset)
CELLSIZE # cell size in bytes (e.g., 2048)
BLOCKSIZE # block size in bytes (e.g., 65536)
NSAMPLES # number of sampled cells per challenge (e.g. 100)
Public inputs:
datasetRoot # root of the dataset (slot -> dataset)
slotIndex # index of the slot being proven
entropy # public randomness used to derive sample indices
Witness (private inputs):
slotRoot # root of the slot (block -> slot) tree
slotProof # Merkle path for slot -> dataset
samples[]: # one entry per sampled cell:
cellData # the sampled cell encoded as field elements
merklePaths # (cell -> block) || (block -> slot) Merkle path
Constraints (informal):
For each sampled cell, the circuit enforces:
- Cell hashing: recompute the cell digest from
cellDatausing the Poseidon2 sponge (rate=2,10*padding). - Cell -> Block: verify inclusion of the cell digest in the block tree using the provided
cell -> blockpath. - Block -> Slot: verify inclusion of the block digest in the slot tree using the
block -> slotpath. - Slot -> Dataset: verify inclusion of
slotRootin dataset tree usingslotProof. - Sampling indices: recompute the required sample indices from
(entropy, slotRoot, NSAMPLES)and check that the supplied samples correspond exactly to those indices.
Output (proof):
- Groth16 proof over BN254: the tuple (A ∈ G₁, B ∈ G₂, C ∈ G₁), referred to in code as
CircomProof.
Verification:
- The verifier (on-chain or off-chain) checks the
proofagainst thepublic inputsusing the circuit'sverifying key(derived from theCRSgenerated at setup). - On EVM chains, verification leverages BN254 precompiles.
Functional Requirements
Data Commitment:
- Fetch existing slot commitments using
BlockStoreandSlotsBuilder:cell -> block -> slotMerkle trees for each slot in the locally stored dataset. - Fetch dataset commitment:
slot -> datasetverification tree root. - Proof material: retrieve cell data (as field elements).
Sampling:
- Checks for marketplace challenges per slot.
- Random sampling: Derive
nSamplescell indices for theslotIndexfrom(entropy, slotRoot). - For each sampled cell, fetch:
cellData(as field elements) and Merkle paths (allcell -> block -> slot -> dataset) - Generate
ProofInputscontaining the public inputs (datasetRoot,slotIndex,entropy) and private witness (cellData,slotRoot,MerklePaths).
Proof Generation:
- Given
ProofInputs, use the configured backend (Groth16 over BN254) to create a succinct Groth16 proof. - The circuit enforces the same Merkle layout and Poseidon2 hashing used for commitments.
Non-Functional Requirements
Performance / Latency:
- End-to-end (sample -> prove -> submit) completes within the on-chain proof window with some safety margin.
- Small Proof size, e.g. Groth16/BN254 plus public inputs.
- On-chain verification cost is minimal.
- Support concurrent proving for multiple slots.
Security & Correctness:
- Soundness and completeness: only accept valid proofs, invalid inputs must not yield accepted proofs.
- Commitment integrity: proofs are checked against the publicly available Merkle commitments to the stored data.
- Entropy binding: sample indices must be derived from the on-chain entropy and the slot commitment. This binds the proofs to specific cell indices and time period, and makes the challenge unpredictable until the period begins. This prevents storage providers from precomputing the proofs or selectively retaining a set of cells.
Wire Format Specification / Syntax
Data Models
SlotsBuilder
SlotsBuilder*[T, H] = ref object of RootObj
store: BlockStore
manifest: Manifest # current manifest
strategy: IndexingStrategy # indexing strategy
cellSize: NBytes # cell size
numSlotBlocks: Natural
# number of blocks per slot (should yield a power of two number of cells)
slotRoots: seq[H] # roots of the slots
emptyBlock: seq[byte] # empty block
verifiableTree: ?T # verification tree (dataset tree)
emptyDigestTree: T # empty digest tree for empty blocks
Contains references to the BlockStore, current Manifest, indexing strategy, cell size, number of blocks per slot, slot roots, empty block data, the verification tree (dataset tree), and empty digest tree for empty blocks.
DataSampler
DataSampler*[T, H] = ref object of RootObj
index: Natural
blockStore: BlockStore
builder: SlotsBuilder[T, H]
Contains the slot index, reference to BlockStore, and reference to SlotsBuilder.
Prover
Prover* = ref object of RootObj
backend: AnyBackend
store: BlockStore
nSamples: int
Contains the proving backend, reference to BlockStore, and number of samples.
Sample
Sample*[H] = object
cellData*: seq[H]
merklePaths*: seq[H]
Contains the sampled cell data as a sequence of hash elements and the Merkle paths as a sequence of hash elements.
PublicInputs
PublicInputs*[H] = object
slotIndex*: int
datasetRoot*: H
entropy*: H
Contains the slot index, dataset root hash, and entropy hash.
ProofInputs
ProofInputs*[H] = object
entropy*: H
datasetRoot*: H
slotIndex*: Natural
slotRoot*: H
nCellsPerSlot*: Natural
nSlotsPerDataSet*: Natural
slotProof*: seq[H]
samples*: seq[Sample[H]]
Contains entropy, dataset root, slot index, slot root, number of cells per slot, number of slots per dataset, slot proof as a sequence of hashes, and samples as a sequence of Sample objects.
CircomCompat
CircomCompat* = object
slotDepth: int # max depth of the slot tree
datasetDepth: int # max depth of dataset tree
blkDepth: int # depth of the block merkle tree (pow2 for now)
cellElms: int # number of field elements per cell
numSamples: int # number of samples per slot
r1csPath: string # path to the r1cs file
wasmPath: string # path to the wasm file
zkeyPath: string # path to the zkey file
backendCfg: ptr CircomBn254Cfg
vkp*: ptr CircomKey
Contains configuration for Circom compatibility including tree depths, paths to circuit artifacts (r1cs, wasm, zkey), backend configuration pointer, and verifying key pointer.
Proof
#![allow(unused)] fn main() { pub struct Proof { pub a: G1, pub b: G2, pub c: G1, } }
Groth16 proof structure containing three elements: a and c in G₁, and b in G₂.
G1
#![allow(unused)] fn main() { pub struct G1 { pub x: [u8; 32], pub y: [u8; 32], } }
Elliptic curve point in G₁ with x and y coordinates as 32-byte arrays.
G2
#![allow(unused)] fn main() { pub struct G2 { pub x: [[u8; 32]; 2], pub y: [[u8; 32]; 2], } }
Elliptic curve point in G₂ with x and y coordinates, each consisting of two 32-byte arrays.
VerifyingKey
#![allow(unused)] fn main() { pub struct VerifyingKey { pub alpha1: G1, pub beta2: G2, pub gamma2: G2, pub delta2: G2, pub ic: *const G1, pub ic_len: usize, } }
Groth16 verifying key structure containing alpha1 in G₁, beta2, gamma2, and delta2 in G₂, and an array of G₁ points (ic) with its length.
Interfaces
Sampler Interfaces
| Interface | Description | Input | Output |
|---|---|---|---|
new[T,H] | Construct a DataSampler for a specific slot index. | index: Natural, blockStore: BlockStore, builder: SlotsBuilder[T,H] | DataSampler[T,H] |
getSample | Retrieve one sampled cell and its Merkle path(s) for a given slot. | cellIdx: int, slotTreeCid: Cid, slotRoot: H | Sample[H] |
getProofInput | Generate the full proof inputs for the proving circuit (calls getSample internally). | entropy: ProofChallenge, nSamples: Natural | ProofInputs[H] |
Prover Interfaces
| Interface | Description | Input | Output |
|---|---|---|---|
new | Construct a Prover with a block store and the backend proof system. | blockStore: BlockStore, backend: AnyBackend, nSamples: int | Prover |
prove | Produce a succinct proof for the given slot and entropy. | slotIdx: int, manifest: Manifest, entropy: ProofChallenge | (proofInputs, proof) |
verify | Verify a proof against its public inputs. | proof: AnyProof, proofInputs: AnyProofInputs | bool |
Circuit Interfaces
| Template | Description | Parameters | Inputs (signals) | Outputs (signals) |
|---|---|---|---|---|
SampleAndProve | Main component in the circuit. Verifies nSamples cells (cell->block->slot) and the slot->dataset path, binding the proof to dataSetRoot, slotIndex, and entropy. | maxDepth, maxLog2NSlots, blockTreeDepth, nFieldElemsPerCell, nSamples | entropy, dataSetRoot, slotIndex, slotRoot, nCellsPerSlot, nSlotsPerDataSet, slotProof[maxLog2NSlots], cellData[nSamples][nFieldElemsPerCell], merklePaths[nSamples][maxDepth] | - |
ProveSingleCell | Verifies one sampled cell: hashes cellData with Poseidon2 and checks the concatenated Merkle path up to slotRoot. | nFieldElemsPerCell, botDepth, maxDepth | slotRoot, data[nFieldElemsPerCell], lastBits[maxDepth], indexBits[maxDepth], maskBits[maxDepth+1], merklePath[maxDepth] | - |
RootFromMerklePath | Reconstructs a Merkle root from a leaf and path using KeyedCompression. | maxDepth | leaf, pathBits[maxDepth], lastBits[maxDepth], maskBits[maxDepth+1], merklePath[maxDepth] | recRoot |
CalculateCellIndexBits | Derives the index bits for a sampled cell from (entropy, slotRoot, counter), masked by cellIndexBitMask. | maxLog2N | entropy, slotRoot, counter, cellIndexBitMask[maxLog2N] | indexBits[maxLog2N] |
All parameters are compile-time constants that are defined when building the circuit.
Circuit Utility Templates
| Template | Description | Parameters | Inputs (signals) | Outputs (signals) |
|---|---|---|---|---|
Poseidon2_hash_rate2 | Poseidon2 fixed-length hash (rate = 2). Used for hashing cell field-elements. | n: number of field elements to hash. | inp[n]: array of field elements to hash. | out: Poseidon2 hash digest. |
PoseidonSponge | Generic Poseidon2 sponge (absorb/squeeze). | t: sponge state width, capacity: capacity part of the state, input_len: number of elements to absorb, output_len: number of elements to squeeze | inp[input_len]: field elements to absorb. | out[output_len]: field elements squeezed. |
KeyedCompression | Keyed 2->1 compression where key ∈ {0,1,2,3}. | - | key, inp[2]: left and right child node digests. | out: parent node digest |
ExtractLowerBits | Extracts the lower n bits of inp (LSB-first). | n: number of low bits to extract | inp: field elements to extract. | out[n]: extracted bits. |
Log2 | Checks inp == 2^out with 0 < out <= n. Also emits a mask vector with ones for indices < out. | n: max allowed bit width. | inp: field element. | out: exponent, mask[n+1]: prefix mask. |
CeilingLog2 | Computes ceil(log2(inp)) and returns the bit-decomposition and a mask. | n: bit width of input and output. | inp: field element. | out: ceil(log2(inp)), bits[n]: bit decomposition, mask[n+1]: prefix mask |
BinaryCompare | Compares two n-bit numbers A and B (LSB-first); outputs -1 if A<B, 0 if equal, +1 if A>B. | n: bit width of A and B | A[n], B[n] | out: comparison result. |
Security/Privacy Considerations
Entropy Binding
Sample indices must be derived from the on-chain entropy and the slot commitment. This binds the proofs to specific cell indices and time period, and makes the challenge unpredictable until the period begins. This prevents storage providers from precomputing the proofs or selectively retaining a set of cells.
Commitment Integrity
Proofs are checked against the publicly available Merkle commitments to the stored data. The proving module uses Poseidon2 Merkle roots as public commitments which allow anyone to verify proofs against the committed content.
Soundness and Completeness
The zero-knowledge proof system must only accept valid proofs. Invalid inputs must not yield accepted proofs. The circuit enforces:
- Cell hashing using Poseidon2 sponge
- Merkle tree membership checks at all levels (cell -> block, block -> slot, slot -> dataset)
- Correct sampling index derivation from entropy and slot root
Keyed Merkle Tree Compression
Codex extends the standard Merkle tree with a keyed compression that encodes whether a node is on the bottom layer and whether a node is odd or even. These bits are fed into the hash so tree shape cannot be manipulated.
Proof Window
Storage providers must submit valid proofs within the proof window deadline. This time constraint ensures timely verification and allows the marketplace to manage incentives appropriately.
Rationale
This specification is based on the Proving module component specification from the Codex project.
Probabilistic Verification
The proving module uses random sampling combined with erasure coding to provide probabilistic guarantees of data availability while touching only a tiny fraction of the stored data per challenge. This approach balances security with efficiency, as verifying the entire dataset for every challenge would be prohibitively expensive.
Groth16 over BN254
The specification uses Groth16 zero-knowledge proofs over the BN254 elliptic curve. This choice provides:
- Succinct proofs: Small proof size enables efficient on-chain verification
- EVM compatibility: BN254 precompiles on EVM chains minimize verification costs
- Strong security: Groth16 provides computational zero-knowledge and soundness
Poseidon2 Hash Function
Poseidon2 is used for all cryptographic commitments (cell hashing, Merkle tree construction). Poseidon2 is optimized for zero-knowledge circuits, resulting in significantly fewer constraints compared to traditional hash functions like SHA-256.
Keyed Compression Design
The keyed compression scheme that depends on node position (bottom layer vs. internal) and child count (odd vs. even) prevents tree shape manipulation attacks. By feeding these bits into the hash function, the commitment binds to the exact tree structure.
Pluggable Backend Architecture
The proving module uses a pluggable proving backend abstraction. While the current implementation uses Groth16 over BN254 with Circom circuits, this architecture allows for future flexibility to adopt different proof systems or curves without changing the core proving module logic.
Entropy-Based Sampling
Deriving sample indices deterministically from public entropy (e.g., blockhash) and the slot commitment ensures that:
- Challenges are unpredictable until the period begins
- Storage providers cannot precompute proofs
- Storage providers cannot selectively retain only a subset of cells
- Any honest party can verify the sampling was done correctly
Copyright
Copyright and related rights waived via CC0.
References
Normative
- Codex: GitHub - codex-storage/nim-codex
- Codex Prover Specification: Codex Docs - Component Specification - Prover
- CODEX-SLOT-BUILDER: Codex Slot Builder specification (defines
SlotsBuilderand slot commitment construction)
Informative
- Codex Storage Proofs Circuits: GitHub - codex-storage/codex-storage-proofs-circuits - Circom implementations of Codex's proof circuits targeting Groth16 over BN254
- Nim Circom Compat: GitHub - codex-storage/nim-circom-compat - Nim bindings that load compiled Circom artifacts
- Circom Compat FFI: GitHub - codex-storage/circom-compat-ffi - Rust library with C ABI for running Arkworks Groth16 proving and verification on BN254
- Groth16: Jens Groth. "On the Size of Pairing-based Non-interactive Arguments." EUROCRYPT 2016
- Poseidon2: Lorenzo Grassi, Dmitry Khovratovich, Markus Schofnegger. "Poseidon2: A Faster Version of the Poseidon Hash Function." IACR ePrint 2023/323
CODEX-SLOT-BUILDER
| Field | Value |
|---|---|
| Name | Codex Slot Builder |
| Slug | 78 |
| Status | deprecated |
| Type | RFC |
| Category | Standards Track |
| Editor | Jimmy Debe [email protected] |
| Contributors | Jimmy Debe [email protected] |
Timeline
- 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-22 —
e356a07— Chore/add makefile (#271) - 2026-01-22 —
af45aae— chore: deprecate Marketplace-related specs (#268) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258)
Abstract
This document describes the Codex slot builder mechanism. Slots used in the Codex protocol are an important component of node collaboration in the network.
Background
The Codex protocol places a dataset into blocks before sending a storage request to the network. Slots control and facilitate the distribution of the data blocks to participating storage providers. The mechanism builds individual Merkle trees for each slot, enabling cell-level proof generation, and constructs a root verification tree over all slot roots.
Specification
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “NOT RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in RFC 2119.
A Codex client wanting to present a dataset to the network will present a set of erasure encoded data blocks, as described in the CODEX-ERASURE-CODING specification. These data blocks will be placed into slots for storage providers to access. The slot building process MUST construct a block digest Merkle tree from the data blocks. The root hashes from this tree are used as the leaves in a slot merkle tree.
The prepared dataset is presented to storage providers in the form of slots. A slot represents the location of a data block cell with an open storage contract. Storage providers SHOULD be able to locate a specific data block and all the details of the storage contract. See, the CODEX-MARKETPLACE specification.
Construct a Slot Tree
Block Digest Tree
A slot stores a list of root hashes that help with the retrieval of a dataset. The block digest tree SHOULD be constructed before building any slots. A data block is divided into cells that are hashed. The block size MUST be divisible by the cell size for the block digest tree construction.
A block digest tree SHOULD contain the unique root hashes of blocks of the entire dataset, which MAY be based on the Poseidon2 algorithm. The result of one digest tree will be represented by the root hash of the tree.
Slot Tree
A slot tree represents one slot, which includes the list of digest root hashes. If a block is empty, the slot branch SHOULD be a hash of an empty block. Some slots MAY be empty, depending on the size of the dataset.
The cells per slot tree branch MUST be padded to a power of two. This will ensure a balanced slot Merkle tree.
Below are the REQUIRED values to build a slot.
type SlotsBuilder*[T, H] = ref object of RootObj
store: BlockStore # Storage backend for blocks
manifest: Manifest # Current dataset manifest
strategy: IndexingStrategy # Block indexing strategy
cellSize: NBytes # Size of each cell in bytes
numSlotBlocks: Natural # Blocks per slot (including padding)
slotRoots: seq[H] # Computed slot root hashes
emptyBlock: seq[byte] # Pre-allocated empty block data
verifiableTree: ?T # Optional verification tree
emptyDigestTree: T # Pre-computed empty block tree
Verification Tree
Nodes within the network are REQUIRED to verify a dataset before retrieving it.
A verification tree is a Merkle proof derived from the slotRoot.
The entire dataset is not REQUIRED to construct the tree.
The following are the inputs to verify a proof:
type
H = array[32, byte]
Natural = uint64
type ProofInputs*[H] = object
entropy*: H # Randomness value
datasetRoot*: H # Dataset root hash
slotIndex*: Natural # Slot identifier
slotRoot*: H # Root hash of slot
nCellsPerSlot*: Natural # Cell count per slot
nSlotsPerDataSet*: Natural # Total slot count
slotProof*: seq[H] # Inclusion proof for slot in dataset
samples*: seq[Sample[H]] # Cell inclusion proofs
To verify, a node MUST recompute the root hash,
based on slotProof and the hash of the slotIndex,
to confirm that the slotIndex is a member of the dataset represented by datasetRoot.
Copyright
Copyright and related rights waived via CC0.
References
AnonComms LIPs
AnonComms cover protocols and cryptographic mechanisms for anonymous, private, and censorship-resistant communication. This includes mixnets, rate-limiting nullifiers, private membership systems, secure discovery, encrypted messaging, and related primitives that let users communicate without unnecessary metadata exposure.
AnonComms Raw Specifications
All AnonComms specifications that have not reached draft status will live in this repository. To learn more about raw specifications, take a look at 1/COSS.
DECENTRALIZED-MLS-OFFCHAIN-CONSENSUS
| Field | Value |
|---|---|
| Name | Secure channel setup using decentralized MLS |
| Slug | 104 |
| Status | raw |
| Category | Standards Track |
| Editor | Ugur Sen [email protected] |
| Contributors | seemenkina [email protected] |
Timeline
- 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
a4ef18f— de-MLS clarifying edge cases (#318) - 2026-04-15 —
5a3e844— Chore/move repo into logos co (#312) - 2026-04-02 —
155c310— de-MLS RFC name change (#303) - 2026-03-29 —
ff05dbd— ETH-MLS-OFFCHAIN RFC multi-steward follow up (#298) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-11-26 —
e39d288— VAC/RAW/ ETH-MLS-OFFCHAIN RFC multi-steward support (#193) - 2025-08-21 —
3b968cc— VAC/RAW/ ETH-MLS-OFFCHAIN RFC (#166)
Abstract
The following document specifies scalable and decentralized secure group messaging application by integrating Message Layer Security (MLS) backend. Decentralization refers each user is a node in P2P network and each user has voice for any changes in group. This is achieved by integrating a consensus mechanism. Lastly, this RFC can also be referred to as de-MLS, decentralized MLS, to emphasize its deviation from the centralized trust assumptions of traditional MLS deployments.
Motivation
Group messaging is a fundamental part of digital communication, yet most existing systems depend on centralized servers, which introduce risks around privacy, censorship, and unilateral control. In restrictive settings, servers can be blocked or surveilled; in more open environments, users still face opaque moderation policies, data collection, and exclusion from decision-making processes. To address this, a decentralized, scalable peer-to-peer group messaging system is proposed, where each participant runs a node, contributes to message propagation, and takes part in governance autonomously. Group membership changes are decided collectively through a lightweight partially synchronous, fault-tolerant consensus protocol without a centralized identity. This design enables truly democratic group communication and is well-suited for use cases like activist collectives, research collaborations, DAOs, support groups, and decentralized social platforms.
Format Specification
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in 2119.
Assumptions
- At least of the members are honest and follow the de-MLS protocol as specified.
- The nodes in the P2P network can discover other nodes or will connect to other nodes when subscribing to same topic in a gossipsub.
- The presence of non-reliable (silent) nodes MAY be assumed.
- A lightweight, scalable consensus mechanism with deterministic finality within a specific time MUST be employed.
- The network MUST enforce a rate-limiting mechanism for all entities in order to mitigate spam.
- (Delta) is a protocol parameter denoting a bounded time interval (in seconds) that defines the maximum synchronization window of the system.
- At least of the members MUST become synchronized within time, where is the group size.
Roles
The three roles used in de-MLS is as follows:
node: Nodes are participants in the network that are not currently members of any secure group messaging session but remain available as potential candidates for group membership.member: Members are special nodes in the secure group messaging who obtains current group key of secure group messaging. Each node is assigned a unique identity represented as a 20-byte value namedmember id.steward: Stewards are special and transparent members in the secure group messaging who organize the changes by releasing commit messages upon the voted proposals. There are two special subsets of steward as epoch and backup steward, which are defined in the section de-MLS Objects.
MLS Background
The de-MLS consists of MLS backend, so the MLS services and other MLS components are taken from the original MLS specification, with or without modifications.
MLS Services
MLS is operated in two services authentication service (AS) and delivery service (DS).
Authentication service enables group members to authenticate the credentials presented by other group members.
The delivery service routes MLS messages among the nodes or
members in the protocol in the correct order and
manage the keyPackage of the users where the keyPackage is the objects
that provide some public information about a user as specified in MLS specification.
MLS Objects
Following section presents the MLS objects and components that used in this RFC:
Epoch: Time intervals that changes the state that is defined by members,
section 3.4 in MLS RFC 9420.
An epoch is represented as a monotonically increasing integer.
It does not correspond to a fixed wall-clock time interval.
Instead, the epoch is incremented upon each valid commit message that results in a state transition.
MLS proposal message: Members MUST receive the proposal message prior to the
corresponding commit message that initiates a new epoch with key changes,
in order to ensure the intended security properties, section 12.1 in MLS RFC 9420.
Here, the add and remove proposals are used.
Application message: This message type used in arbitrary encrypted communication between group members.
This is restricted by MLS RFC 9420 as if there is pending proposal,
the application message should be cut.
Note that: Since the MLS is based on servers, this delay between proposal and commit messages are very small.
Commit message: After members receive the proposals regarding group changes,
the committer, who may be any member of the group, as specified in MLS RFC 9420,
generates the necessary key material for the next epoch, including the appropriate welcome messages
for new joiners and new entropy for removed members. In this RFC, the committers only MUST be stewards.
de-MLS Objects
This section presents the de-MLS objects:
Voting Proposal: Similar to MLS proposals, but processed only if approved through a voting process.
They function as application messages in the MLS group,
allowing the steward to collect them without halting the protocol.
There are three types of Voting Proposal according to the type of consensus as in shown Consensus Types section,
these are, Commit Proposal, Steward Election Proposal and Emergency Criteria Proposal.
Epoch steward: The steward assigned to commit in epoch E according to the steward list.
Holds the primary responsibility for creating commit in that epoch.
Backup steward: The steward next in line after the epoch steward on the steward list in epoch E.
Only becomes active if the epoch steward is malicious or fails,
in which case it completes the commitment phase.
If unused in epoch E, it automatically becomes the epoch steward in epoch E+1.
Steward list: It is an ordered list that contains the member ids of authorized stewards.
Each steward in the list becomes main responsible for creating the commit message when its turn arrives,
according to this order for each epoch.
For example, suppose there are two stewards in the list steward A first and steward B last in the list.
steward A is responsible for creating the commit message for first epoch.
Similarly, steward B is for the last epoch.
Since the epoch steward is the primary committer for an epoch,
it holds the main responsibility for producing the commit.
However, other stewards MAY also generate a commit within the same epoch to preserve liveness
in case the epoch steward is inactive or slow.
Duplicate commits are not re-applied and only the single valid commit for the epoch is accepted by the group,
as in described in commit validation service against the multiple comitting.
Therefore, if a malicious steward occurred, the backup steward will be charged with committing.
Lastly, the size of the list named as sn, which also shows the epoch interval for steward list determination.
Flow
General flow is as follows:
- Each
nodecreates and sends theircredentialincludeskeyPackage. - Each
membercreatesvoting proposalssends them to from MLS group duringepoch E. - Proposals are voted on during the time window. During this period, the system enters a freezing phase (no new proposals are accepted) to ensure that at least 2n/3 members become synchronized, thereby preserving the health and correctness of the commit validation service.
- Meanwhile, the
stewardcollects finalizedvoting proposalsfrom MLS group and converts them intoMLS proposalsthen sends them with correspondingcommit messages - Eventually, upon receiving
commit messages, each member applies the commit validation service locally. After successful validation, the member transitions to the nextepoch E+1.
Creating Voting Proposal
A member MAY initializes the voting with the proposal payload
which is implemented using protocol buffers v3 as follows:
syntax = "proto3";
message Proposal {
string name = 10; // Proposal name
string payload = 11; // Describes the what is voting fore
int32 proposal_id = 12; // Unique identifier of the proposal
bytes proposal_owner = 13; // Public key of the creator
repeated Vote votes = 14; // Vote list in the proposal
int32 expected_voters_count = 15; // Maximum number of distinct voters
int32 round = 16; // Number of Votes
int64 timestamp = 17; // Creation time of proposal
int64 expiration_time = 18; // Time interval that the proposal is active
bool liveness_criteria_yes = 19; // Shows how managing the silent peers vote
}
message Vote {
int32 vote_id = 20; // Unique identifier of the vote
bytes vote_owner = 21; // Voter's public key
int64 timestamp = 22; // Time when the vote was cast
bool vote = 23; // Vote bool value (true/false)
bytes parent_hash = 24; // Hash of previous owner's Vote
bytes received_hash = 25; // Hash of previous received Vote
bytes vote_hash = 26; // Hash of all previously defined fields in Vote
bytes signature = 27; // Signature of vote_hash
}
The voting proposal MAY include adding a node or removing a member.
After the member creates the voting proposal,
it is emitted to the network via the MLS Application message with a lightweight,
epoch based voting such as hashgraphlike consensus.
This consensus result MUST be finalized within the epoch as YES or NO.
If the voting result is YES, this points out the voting proposal will be converted into
the MLS proposal by the steward and following commit message that starts the new epoch.
All members including stewards MUST maintain a local store of finalized voting proposals
for at least the duration threshold_duration mentioned in Steward Violation List,
required to validate incoming commits and perform Commit validation service.
Creating welcome message
When a MLS MLS proposal message is created by the steward,
a commit message SHOULD follow,
as in section 12.04 MLS RFC 9420 to the members.
In order for the new member joining the group to synchronize with the current members
who received the commit message,
the steward sends a welcome message to the node as the new member,
as in section 12.4.3.1. MLS RFC 9420.
Single steward
To naive way to create a decentralized secure group messaging is having a single transparent steward
who only applies the changes regarding the result of the voting.
This is mostly similar with the general flow and specified in voting proposal and welcome message creation sections.
- Each time a single
stewardinitializes a group with group parameters with parameters as in section 8.1. Group Context in MLS RFC 9420. - The each
nodewho wants to be amemberneeds to obtain this anouncement and createcredentialincludeskeyPackagethat is specified in MLS RFC 9420 section 10. - The
nodeMUST send the plaintextKeyPackage, as defined in MLS RFC 9420, accompanied by its signature, and publish it to the Welcome topic. This ensures that all current group members are aware that a new participant intends to join. Upon receipt, thestewardMUST initiate a voting proposal to decide on admitting the new member. It also provides flexibility for liveness in multi-steward settings, allowing more than one steward to obtainKeyPackagesto commit. - The
stewardaggregates allKeyPackagesutilizes them to provision group additions for new members, based on the outcome of the voting process. - Any
memberstart to createvoting proposalsfor adding or removing users, and present them to the voting in the MLS group as an application message. However, unlimited use ofvoting proposalswithin the group may be misused by malicious or overly active members. Therefore, an application-level constraint MAY be introduced to limit the number or frequency of proposals initiated by each member in order to prevent spam or abuse. - After waiting for the synchronization window, the
stewardcollects finalizedvoting proposalswithin epochEthat have received affirmative votes from members via application messages. Thestewardincludes only those proposals that have obtained a majority of "YES" votes. Since voting proposals are transmitted as application messages, omitting non-finalized proposals does not affect the protocol’s correctness or consistency. - The
stewardconverts all approvedvoting proposalsinto correspondingMLS proposalsandcommit message, and transmits both in a single operation as in MLS RFC 9420 section 12.4, including welcome messages for the new members. Therefore, thecommit messageends the previous epoch and create new ones. - Upon receiving a
commit message, themembersfirst execute the commit validation service, including verification of signatures and associatedvoting proposals. If the commit is deemed valid, themembersapply the commit and synchronize to the upcoming epoch.
Multi stewards
Decentralization has already been achieved in the previous section. However, to improve availability and ensure censorship resistance, the single steward protocol is extended to a multi steward architecture. In this design, each epoch is coordinated by a designated steward, operating under a similar protocol as the single steward model. Thus, the multi steward approach primarily defines how steward roles rotate across epochs while preserving the underlying structure and logic of the original protocol. Two variants of the multi steward design are introduced to address different system requirements.
In the multi steward setting, multiple stewards MAY issue commit messages within the same epoch.
As a result, members may receive different numbers of commit messages with potentially differing contents.
For all received commits, the commit validation service is executed locally and
MUST deterministically output at most one valid commit to be applied for the epoch transition.
Buffering KeyPackages
In the multi-steward setting, to preserve liveness in the presence of a silent or inactive epoch steward,
all members MUST locally buffer KeyPackages received for 3 epochs after the KeyPackage was received,
or until a commit referencing that KeyPackages has been successfully validated and applied, whichever comes first.
Consensus Types
Consensus is agnostic with its payload; therefore, it can be used for various purposes.
Note that each message for the consensus of proposals is an application message in the MLS object section.
It is used in three ways as follows:
Commit Proposal: It is the proposal instance that is specified in Creating Voting Proposal section withProposal.payloadMUST show the commit request frommembers. Any member MAY create this proposal in any epoch andepoch stewardMUST collect and commit YES voted proposals. This is the only proposal type common to both single steward and multi steward designs.Steward Election Proposal: This is the process that finalizes thesteward list, which sets and orders stewards responsible for creating commits over a predefined number of range in (sn_min,sn_max). The validity of the choosensteward listends when the last steward in the list (the one at the final index) completes its commit. At that point, a newSteward Election ProposalMUST be initiated again by any member during the corresponding epoch. TheProposal.payloadfield MUST represent the ordered identities of the proposed stewards. Each steward election proposal MUST be verified and finalized through the consensus process so that members can identify which steward will be responsible in each epoch and detect any unauthorized steward commits.Emergency criteria proposal (ECP): A consensus action carrying aviolation_typefield that discriminates between (a) member removal, whereProposal.payloadMUST include the target identifier and supporting evidence per the Steward Violation List; (b) protocol deadlock, where no specific target exists and recovery is handled per Layer 3. Any member MAY create anEmergency criteria proposal (ECP)in any epoch. On YES, members MUST enter the freezing phase immediately, bypassing the inactivity timer, so the consequent commit lands without waiting a full cycle and a peer-score reward MUST be granted to the creator of the proposal; on NO, a peer-score penalty MUST be applied to the creator to deter abuse.
The order of consensus proposal messages is important to achieving a consistent result. Therefore, messages MUST be prioritized by type in the following order, from highest to lowest priority:
-
Emergency Criteria Proposal -
Steward Election Proposal -
Commit Proposal
This means that if a higher-priority consensus proposal is present in the network, lower-priority messages MUST be withheld from transmission until the higher-priority proposals have been finalized.
Partial Freeze Semantics
This prioritization is realized through a partial freeze of lower-priority governance traffic.
When an active Emergency Criteria Proposal is observed and has not yet been finalized,
honest nodes MUST temporarily suspend the propagation and creation of lower-priority consensus proposal messages,
including Steward election proposals and Commit proposals.
Such messages MUST be dropped and MUST NOT be forwarded over the network until the emergency proposal is finalized.
This partial freeze applies only to governance-related messages, MLS application messages MAY continue to be transmitted normally.
If a malicious member attempts to generate or propagate lower-priority proposals during an active emergency, these messages will not be observed by the majority of honest nodes due to deterministic message filtering. Implementations MAY additionally penalize such behavior using peer scoring mechanisms.
To enforce this behavior, members MUST be able to identify the type of incoming consensus messages and apply priority-based filtering accordingly.
Steward list creation
The steward list consists of steward nominees who will become actual stewards
if the Steward Election Proposal is finalized with YES,
is arbitrarily chosen from member and OPTIONALLY adjusted depending on the needs of the implementation.
The steward list size, defined by the minimum sn_min and maximum sn_max bounds,
is determined at the time of group creation.
The sn_min requirement is applied only when the total number of members exceeds sn_min;
if the number of available members falls below this threshold,
the list size automatically adjusts to include all existing members.
The actual size of the list MAY vary within this range as sn, with the minimum value being at least 1.
The index of the slots shows epoch info and value of index shows member ids.
The next in line steward for the epoch E is named as epoch steward, which has index E.
And the subsequent steward in the epoch E is named as the backup steward.
For example, let's assume steward list is (S3, S2, S1) if in the previous epoch the roles were
(backup steward: S2, epoch steward: S1), then in the next epoch they become
(backup steward: S3, epoch steward: S2) by shifting.
If the epoch steward is honest, the backup steward does not involve the process in epoch,
and the backup steward will be the epoch steward within the epoch E+1.
If the epoch steward is malicious, the backup steward is involved in the commitment phase in epoch E
and the former steward becomes the backup steward in epoch E.
Liveness criteria:
Once the active steward list has completed its assigned epochs,
members MUST proceed to elect the next set of stewards
(which MAY include some or all of the previous members).
This election is conducted through a type 2 consensus procedure, Steward Election Proposal.
A Steward Election Proposal is considered valid only if the resulting steward list
is produced through a deterministic process that ensures an unbiased distribution of steward assignments,
since allowing bias could enable a malicious participant to manipulate the list
and retain control within a favored group for multiple epochs.
The list MUST consist of at least sn_min members, including retained previous stewards,
sorted according to the ascending value of SHA256(epoch E || retry_round || member id || group id),
where epoch E is the epoch in which the election proposal is initiated,
retry_round is a counter for having different shuffling in the same epoch for recovering situation,
and group id for shuffling the list across the different groups.
Any proposal with a list that does not adhere to this generation method MUST be rejected by all members.
It is assumed that that there are no recurring entries in SHA256(epoch E || member id || group id),
since the SHA256 outputs are unique when there is no repetition in the member id values,
against the conflicts on sorting issues.
Three-Layer Steward Protection Mechanism
de-MLS employs a three-layer protection mechanism to preserve liveness while maintaining security guarantees. Mitigation of malicious behavior proceeds progressively across layers. Layer 1 applies local prevention and recovery strategies; if the issue cannot be resolved at this level, Layer 2 introduces coordinated fallback mechanisms; finally, Layer 3 enforces network-wide corrective actions. Each layer is activated only if the previous layer fails to restore normal operation, ensuring minimal intervention while maintaining system continuity.
Layer 1 - Local steward rotation
Layer 1 ensures that a finalized voting proposal is committed by locally rotating over the active steward list in deterministic order.
A steward is eligible to act as the epoch steward if it is a current group member and not pending removal.
Misbehavior per the Steward Violation List does not affect eligibility directly;
it decrements peer score per the Peer Scoring section,
and a steward becomes ineligible only once an Emergency Criteria Proposal (ECP) finalizes the removal.
When the nominal epoch steward is ineligible,
members MUST walk the steward list in deterministic order and accept the commit produced by the first eligible steward.
The backup steward or any subsequent eligible steward MAY commit without an Emergency Criteria Proposal.
Even when individual stewards are silent or have been removed,
Layer 1 preserves liveness by walking the steward list until an eligible steward produces the commit.
Misbehaving stewards continue to participate in rotation until accumulated scoring triggers an Emergency Criteria Proposal (ECP),
at which point removal makes them ineligible and Layer 1 walks past them on subsequent rounds.
If no eligible steward exists across the entire list, the protocol escalates to Layer 2.
Layer 2 - Re-election
Layer 2 enables re-election when Layer 1 fails to produce an eligible steward from the active steward list.
In this layer, the members MAY initiate a new Steward Election Proposal within the same MLS epoch.
Since the MLS epoch does not advance in this case,
the proposer MUST increment the local retry_round value and generate a new deterministic steward ordering using:
SHA256(epoch E || retry_round || member id || group id).
Members that are pending removal, self-removal, or otherwise ineligible MUST be excluded from the proposed steward list.
If the re-election proposal is finalized with YES, the new steward list is installed and Layer 1 is applied again.
Otherwise, if the proposal is finalized with NO, retry_round MUST be incremented
and the re-election process MAY be repeated until max_reelection_attempts is reached.
Note that max_reelection_attempts is the parameter that is set during group creation.
If no new steward list can be established after exhausting max_reelection_attempts,
the system enters a steward deadlock condition, and Layer 3 MUST be activated.
Layer 3 — Anti-deadlock ECP
Layer 3 is the final layer of the liveness mechanism and is triggered only
when Layer 2 fails after max_reelection_attempts many re-elections.
At this point, any member MAY submit an Emergency Criteria Proposal with deadlock violation_type.
This proposal does not target a specific member for removal.
Instead, it signals that the protocol cannot produce a valid commit
through the active steward list or through bounded re-election.
If the deadlock Emergency Criteria Proposal is finalized with YES,
the protocol enters a temporary recovery mode.
During recovery mode, the steward gate is relaxed and any remaining member MAY produce the next valid commit.
The first valid commit that is accepted by the commit validation service ends
recovery mode and returns the protocol to the normal working state.
Finally, under the assumption that at least 2n/3 honest members follow the de-MLS protocol,
the deadlock Emergency Criteria Proposal cannot be finalized with NO.
Multi steward with big consensuses
In this model, all group modifications, such as adding or removing members,
must be approved through consensus by all participants,
including the steward assigned for epoch E.
A configuration with multiple stewards operating under a shared consensus protocol offers
increased decentralization and stronger protection against censorship.
However, this benefit comes with reduced operational efficiency.
The model is therefore best suited for small groups that value
decentralization and censorship resistance more than performance.
To create a multi steward with a big consensus, the group is initialized with a single steward as specified as follows:
- The steward initialized the group with the config file.
This config file MUST contain (
sn_min,sn_max) as thesteward listsize range. - The steward adds the members as a centralized way till the number of members reaches the
sn_min. Then, members propose lists by voting proposal with sizesnas a consensus among all members, as mentioned in the consensus section 2, according to the checks: the size of the proposed listsnis in the interval (sn_min,sn_max). Note that if the total number of members is belowsn_min, then the steward list size MUST be equal to the total member count. - After the voting proposal ends up with a
steward list, and group changes are ready to be committed as specified in single steward section with a difference which is members also check the committed steward isepoch stewardorbackup steward, otherwise anyone can createEmergency Criteria Proposal.
A large consensus group provides better decentralization, but it requires significant coordination, which MAY not be suitable for groups with more than 1000 members.
Multi steward with small consensuses
The small consensus model offers improved efficiency with a trade-off in decentralization.
In this design, group changes require consensus only among the stewards, rather than all members.
Regular members participate by periodically selecting the stewards by Steward Election Proposal
but do not take part in commit decision by Commit Proposal.
This structure enables faster coordination since consensus is achieved within a smaller group of stewards.
It is particularly suitable for large user groups, where involving every member in each decision would be impractical.
The flow is similar to the big consensus including the steward list finalization with all members consensus
only the difference here, the commit messages requires Commit Proposal only among the stewards.
Commit validation service
Since stewards are allowed to produce a commit even when they are not the designated epoch steward,
multiple commits may appear within the same commit context, often reflecting recurring versions of the same proposals.
To ensure a consistent and deterministic outcome, all members MUST locally perform
commit validation over the set of candidate commits.
This validation process takes as input the set of finalized voting proposals locally stored by the member,
as remarked in Creating Voting Proposal, and multiple candidate commit messages
with different lengths and contents, each containing voting proposals.
The process deterministically selects at most a single valid commit as output.
In cases where protocol violations are detected, the process MAY additionally trigger peer scoring penalties.
For all candidate commits entering validation, the creator ID MUST be identified
and verified against the local epoch context to ensure that the commit is eligible for the current epoch.
Commits originating from unauthorized or context-inconsistent creators MUST be rejected.
The creator ID MAY additionally be used for peer scoring purposes, including optional slashing or rewarding mechanisms,
depending on whether the commit is determined to be valid or invalid.
A commit is considered valid only if it references governance proposals that have been finalized through voting and are known to the member. Commits that reference non-finalized voting proposals MUST be rejected and MUST trigger a peer score penalty for the commit author, as this behavior constitutes a protocol violation.
Among the valid candidate commits, the commit derived from the longest
deterministic proposal sequence SHOULD be selected as the single valid commit.
Any other competing commits that do not match the selected commit MUST be
classified as misbehaviour and penalized with a lower reputation score
according to the misbehaviour scoring rules defined in this specification.
The proposal sequence is ordered by the ascending value of each proposal as SHA256(proposal).
Therefore, commit messages that contain the same set of voting proposals
are identical in content and can be easily deduplicated.
Since MLS derives new group secrets from the committer’s contribution,
two commit_messages containing the exact same ordered set of voting_proposals
but produced by different stewards will generate different group keys.
Therefore, proposal equivalence alone does not guarantee state equivalence.
If multiple valid commits contain the identical deterministic proposal sequence,
the commit validation service MUST select the epoch_steward's commit when present;
otherwise (e.g., during Layer 3 recovery mode, where any member MAY commit),
the commit with the lexicographically smallest committer_id (according to canonical ordering)
MUST be selected, thereby avoiding state divergence.
Competing commits that contain the same deterministic proposal sequence but differ only due to steward-generated MLS commit entropy MUST NOT be classified as misbehaviour and MAY instead be treated as honest participation for peer scoring purposes.
Self-Removal
A steward MUST NOT produce a commit that includes its own removal.
This is not a protocol violation but an inherent constraint of MLS RFC 9420:
a member cannot apply a commit that removes itself from the group;
otherwise, the resulting group key would be accessible to the removed member again,
which is a contradiction of removal.
A member's request to leave the group is not subject to voting. A removal voting proposal is auto-finalized YES only if its sender, proposal_owner, and RemoveMember.target all reference the same identity; members MUST reject any proposal claiming auto-YES status that fails this check and MAY apply a peer-score penalty against the sender. Qualifying proposals MUST be processed by the epoch steward in the subsequent commit.
The offload mechanism is implementation-defined, examples include queuing the removal for the next eligible steward to commit on their next turn, or triggering an epoch transition (e.g. via a key rotation) so that role rotation hands off naturally. The originating steward MUST NOT be penalized for omitting its own removal from its commits, this is a recognized exception to the rule that finalized voting proposals MUST be committed.
Implementations MAY choose either approach. Both are compliant with this specification.
Steward violation list
A steward’s activity is called a violation if the action is one or more of the following:
- Broken commit: The steward releases a different commit message from the voted
Commit Proposal. This activity is identified by thememberssince the MLS RFC 9420 provides the methods that members can use to identify the broken commit messages that are possible in a few situations, such as commit and proposal incompatibility. Specifically, the broken commit can arise as follows:- The commit belongs to the earlier epoch.
- The commit message should equal the latest epoch
- The commit needs to be compatible with the previous epoch’s
MLS Proposal.
- Broken MLS proposal: The steward prepares a different
MLS Proposalfor the correspondingVoting Proposal. This activity is identified by thememberssince bothMLS ProposalandVoting Proposalare visible and can be identified by checking the hash ofProposal.payloadandMLSProposal.payloadis the same as RFC9240 section 12.1. Proposals. - Censorship and inactivity: The situation where there is a voting proposal that is visible for every member,
and the Steward does not provide an MLS proposal and commit within the configured
threshold_duration, after which the voting process is considered finalized by the majority timer. This activity is again identified by thememberssinceVoting Proposalsare visible to every member in the group, therefore each member can verify that there is noMLS Proposalcorresponding toVoting Proposal, or commit was produced for a voting proposal that has already been finalized due to timer expiration.
All three violation types are detected locally by members;
each detection contributes a peer-score decrement per the Peer Scoring section.
Removal occurs only after the steward's accumulated score drops below threshold_peer_score,
triggering an Emergency Criteria Proposal (ECP).
Peer Scoring
To improve fairness in member and steward management, de-MLS SHOULD incorporate a lightweight peer scoring mechanism. Unfairness is not an intrinsic property of a member. Instead, it arises as a consequence of punitive actions such as removal following an observed malicious behavior. However, behaviors that appear malicious are not always the result of intent. Network faults, temporary partitions, message delays, or client-side failures may lead to unintended protocol deviations. A peer scoring mechanism allows de-MLS to account for such transient and non-adversarial conditions by accumulating evidence over time. This enables the system to distinguish persistent and intentional misbehavior from accidental faults. Member removal should be triggered only in cases of sustained and intentional malicious activity, thereby preserving fairness while maintaining security and liveness.
In this approach, each node maintains a local peer score table mapping member_id to a score,
with new members starting from a configurable default value default_peer_score.
Peer score updates MUST be performed only for stewards that are active in the current epoch context.
Peer scores may decrease due to violations and increase due to honest behavior;
such score adjustments are derived from observable protocol events, such as
successful commits or emergency criteria proposals, and each peer updates its local table accordingly.
In particular, peer score updates MAY be triggered either by direct local observation of protocol violations.
Regardless of the trigger, score updates are applied locally by each peer to its own peer score table.
Members MUST periodically evaluate peer scores against the predefined threshold threshold_peer_score.
A removal operation based on the threshold_peer_score MUST be initiated as an Emergency Criteria Proposal
by at least one member and, only after being finalized with a YES outcome, MUST be included in the subsequent commit.
To prevent abuse, if such a removal emergency criteria proposal is finalized with a NO outcome,
a low score MAY be applied to the proposal owner.
This mechanism allows accidental or transient failures to be tolerated while still enabling
decisive action against repeated or harmful behavior.
The exact scoring rules, recovery mechanisms, and escalation criteria are left for future discussion.
Inactivity Timer
Each member MUST maintain local timers to detect when expected protocol events fail to occur within a bounded time. The protocol relies on inactivity detection in three contexts:
- Commit inactivity: The epoch steward does not produce a commit referencing a finalized voting proposal. On expiry, the member treats the epoch steward as inactive and proceeds with Layer 1 rotation.
- Recovery inactivity: During an active recovery window in Layer 2, or Layer 3, a separate, typically shorter inactivity duration SHOULD apply so retries do not burn a full epoch.
- Voting inactivity: A submitted update request (e.g. an add or remove) does not progress to an open consensus session within the expected window. Members MAY initiate or re-submit the corresponding voting proposal directly.
Each timer's duration and any tolerance buffer for P2P timing variance are configured per group. Escalation beyond Layer 1 follows the Three-Layer Steward Protection Mechanism.
Security Considerations
In this section, the security considerations are shown as de-MLS assurance.
- Malicious Steward: A Malicious steward can act maliciously, as in the Steward violation list section. Therefore, de-MLS enforces that any steward only follows the protocol under the consensus order and commits without emergency criteria application.
- Malicious Member: A member is only marked as malicious when the member acts by releasing a commit message.
- Steward list election bias: Although SHA256 is used together with two global variables to shuffle stewards in a deterministic and verifiable manner, this approach only minimizes election bias; it does not completely eliminate it. This design choice is intentional, in order to preserve the efficiency advantages provided by the MLS mechanism.
Copyright
Copyright and related rights waived via CC0
References
ETH-DCGKA
| Field | Value |
|---|---|
| Name | Decentralized Key and Session Setup for Secure Messaging over Ethereum |
| Slug | 103 |
| Status | raw |
| Category | informational |
| Editor | Ramses Fernandez-Valencia [email protected] |
Timeline
- 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-04-04 —
517b639— Update the RFCs: Vac Raw RFC (#143) - 2024-10-03 —
c655980— Eth secpm splitted (#91) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-05-27 —
7e3a625— ETH-SECPM-DEC (#28)
Abstract
This document introduces a decentralized group messaging protocol using Ethereum adresses as identifiers. It is based in the proposal DCGKA by Weidner et al. It includes also approximations to overcome limitations related to using PKI and the multi-device setting.
Motivation
The need for secure communications has become paramount. Traditional centralized messaging protocols are susceptible to various security threats, including unauthorized access, data breaches, and single points of failure. Therefore a decentralized approach to secure communication becomes increasingly relevant, offering a robust solution to address these challenges.
Secure messaging protocols used should have the following key features:
-
Asynchronous Messaging: Users can send messages even if the recipients are not online at the moment.
-
Resilience to Compromise: If a user's security is compromised, the protocol ensures that previous messages remain secure through forward secrecy (FS). This means that messages sent before the compromise cannot be decrypted by adversaries. Additionally, the protocol maintains post-compromise security (PCS) by regularly updating keys, making it difficult for adversaries to decrypt future communication.
-
Dynamic Group Management: Users can easily add or remove group members at any time, reflecting the flexible nature of communication within the app.
In this field, there exists a trilemma, similar to what one observes in blockchain, involving three key aspects:
- security,
- scalability, and
- decentralization.
For instance, protocols like the MLS perform well in terms of scalability and security. However, they falls short in decentralization.
Newer studies such as CoCoa improve features related to security and scalability, but they still rely on servers, which may not be fully trusted though they are necessary.
On the other hand, older studies like Causal TreeKEM exhibit decent scalability (logarithmic) but lack forward secrecy and have weak post-compromise security (PCS).
The creators of DCGKA introduce a decentralized, asynchronous secure group messaging protocol that supports dynamic groups. This protocol operates effectively on various underlying networks without strict requirements on message ordering or latency. It can be implemented in peer-to-peer or anonymity networks, accommodating network partitions, high latency links, and disconnected operation seamlessly. Notably, the protocol doesn't rely on servers or a consensus protocol for its functionality.
This proposal provides end-to-end encryption with forward secrecy and post-compromise security, even when multiple users concurrently modify the group state.
Theory
Protocol overview
This protocol makes use of ratchets to provide FS by encrypting each message with a different key.
In the figure one can see the ratchet for encrypting a sequence of messages.
The sender requires an initial update secret I_1, which is introduced in a PRG.
The PRG will produce two outputs, namely a symmetric key for AEAD encryption, and
a seed for the next ratchet state.
The associated data needed in the AEAD encryption includes the message index i.
The ciphertext c_i associated to message m_i
is then broadcasted to all group members.
The next step requires deleting I_1, k_i and any old ratchet state.
After a period of time the sender may replace the ratchet state with new update secrets
I_2, I_3, and so on.
To start a post-compromise security update,
a user creates a new random value known as a seed secret and
shares it with every other group member through a secure two-party channel.
Upon receiving the seed secret,
each group member uses it to calculate an update secret for both the sender's ratchet
and their own.
Additionally, the recipient sends an unencrypted acknowledgment to the group
confirming the update.
Every member who receives the acknowledgment updates
not only the ratchet for the original sender but
also the ratchet for the sender of the acknowledgment.
Consequently, after sharing the seed secret through n - 1 two-party messages and
confirming it with n - 1 broadcast acknowledgments,
every group member has derived an update secret and updated their ratchet accordingly.
When removing a group member, the user who initiates the removal conducts a post-compromise security update by sending the update secret to all group members except the one being removed. To add a new group member, each existing group member shares the necessary state with the new user, enabling them to derive their future update secrets.
Since group members may receive messages in various orders, it's important to ensure that each sender's ratchet is updated consistently with the same sequence of update secrets at each group member.
The network protocol used in this scheme ensures that messages from the same sender are processed in the order they were sent.
Components of the protocol
This protocol relies in 3 components: authenticated causal broadcast (ACB), decentralized group membership (DGM) and 2-party secure messaging (2SM).
Authenticated causal broadcast
A causal order is a partial order relation < on messages.
Two messages m_1 and m_2 are causally ordered, or
m_1 causally precedes m_2
(denoted by m_1 < m_2), if one of the following contiditions hold:
m_1andm_2were sent by the same group member, andm_1was sent beforem_2.m_2was sent by a group member U, andm_1was received and processed byUbefore sendingm_2.- There exists
m_3such thatm_1 < m_3andm_3 < m_2.
Causal broadcast requires that before processing m, a group member must
process all preceding messages {m' | m' < m}.
The causal broadcast module used in this protocol authenticates the sender of each message, as well as its causal ordering metadata, using a digital signature under the sender’s identity key. This prevents a passive adversary from impersonating users or affecting causally ordered delivery.
Decentralized group membership
This protocol assumes the existence of a decentralized group membership function (denoted as DGM) that takes a set of membership change messages and their causal order relantionships, and returns the current set of group members’ IDs. It needs to be deterministic and depend only on causal order, and not exact order.
2-party secure messaging (2SM)
This protocol makes use of bidirectional 2-party secure messaging schemes,
which consist of 3 algorithms: 2SM-Init, 2SM-Send and 2SM-Receive.
Function 2SM-Init
This function takes two IDs as inputs:
ID1 representing the local user and ID2 representing the other party.
It returns an initial protocol state sigma.
The 2SM protocol relies on a Public Key Infrastructure (PKI) or
a key server to map these IDs to their corresponding public keys.
In practice, the PKI should incorporate ephemeral prekeys.
This allows users to send messages to a new group member,
even if that member is currently offline.
Function 2SM-Send
This function takes a state sigma and a plaintext m as inputs, and returns
a new state sigma’ and a ciphertext c.
Function 2SM-Receive
This function takes a state sigma and a ciphertext c, and
returns a new state sigma’ and a plaintext m.
This function takes a state sigma and a ciphertext c, and returns a new
state sigma’ and a plaintext m.
Function 2SM Syntax
The variable sigma denotes the state consisting in the variables below:
sigma.mySks[0] = sk
sigma.nextIndex = 1
sigma.receivedSk = empty_string
sigma.otherPk = pk`<br>
sigma.otherPksender = “other”
sigma.otherPkIndex = 0
2SM-Init
On input a key pair (sk, pk), this functions otuputs a state sigma.
2SM-Send
This function encrypts the message m using sigma.otherPk, which represents
the other party’s current public key.
This key is determined based on the last public key generated for the other
party or the last public key received from the other party,
whichever is more recent. sigma.otherPkSender is set to me in the former
case and other in the latter case.
Metadata including otherPkSender and otherPkIndex are included in the
message to indicate which of the recipient’s public keys is being utilized.
Additionally, this function generates a new key pair for the local user,
storing the secret key in sigma.mySks and sending the public key.
Similarly, it generates a new key pair for the other party,
sending the secret key (encrypted) and storing the public key in
sigma.otherPk.
sigma.mySks[sigma.nextIndex], myNewPk) = PKE-Gen()
(otherNewSk, otherNewPk) = PKE-Gen()
plaintext = (m, otherNewSk, sigma`.nextIndex, myNewPk)
msg = (PKE-Enc(sigma.otherPk, plaintext), sigma.otherPkSender, sigma.otherPkIndex)
sigma.nextIndex++
(sigma.otherPk, sigma.otherPkSender, sigma.otherPkIndex) = (otherNewPk, "me", empty_string)
return (sigma`, msg)
2SM-Receive
This function utilizes the metadata of the message c to determine which
secret key to utilize for decryption, assigning it to sk.
If the secret key corresponds to one generated by ourselves,
that secret key along with all keys with lower index are deleted.
This deletion is indicated by sigma.mySks[≤ keyIndex] = empty_string.
Subsequently, the new public and secret keys contained in the message are
stored.
(ciphertext, keySender, keyIndex) = c
if keySender = "other" then
sk = sigma.mySks[keyIndex]
sigma.mySks[≤ keyIndex] = empty_string
else sk = sigma.receivedSk
(m, sigma.receivedSk, sigma.otherPkIndex, sigma.otherPk) = PKE-Dec(sk, ciphertext)
sigma.otherPkSender = "other"
return (sigma, m)
PKE Syntax
The required PKE that MUST be used is ElGamal with a 2048-bit modulus p.
Parameters
The following parameters must be used:
p = 308920927247127345254346920820166145569
g = 2
PKE-KGen
Each user u MUST do the following:
PKE-KGen():
a = randint(2, p-2)
pk = (p, g, g^a)
sk = a
return (pk, sk)
PKE-Enc
A user v encrypting a message m for u MUST follow these steps:
PKE-Enc(pk):
k = randint(2, p-2)
eta = g^k % p
delta = m * (g^a)^k % p
return ((eta, delta))
PKE-Dec
The user u recovers a message m from a ciphertext c
by performing the following operations:
PKE-Dec(sk):
mu = eta^(p-1-sk) % p
return ((mu * delta) % p)
DCGKA Syntax
Auxiliary functions
There exist 6 functions that are auxiliary for the rest of components of the protocol, namely:
init
This function takes an ID as input and returns its associated initial state,
denoted by gamma:
gamma.myId = ID
gamma.mySeq = 0
gamma.history = empty
gamma.nextSeed = empty_string
gamma.2sm[·] = empty_string
gamma.memberSecret[·, ·, ·] = empty_string
gamma.ratchet[·] = empty_string
return (gamma)
encrypt-to
Upon reception of the recipient’s ID and a plaintext, it encrypts a direct
message for another group member.
Should it be the first message for a particular ID,
then the 2SM protocol state is initialized and stored in
gamma.2sm[recipient.ID].
One then uses 2SM_Send to encrypt the message and store the updated protocol
in gamma.
if gamma.2sm[recipient_ID] = empty_string then
gamma.2sm[recipient_ID] = 2SM_Init(gamma.myID, recipient_ID)
(gamma.2sm[recipient_ID], ciphertext) = 2SM_Send(gamma.2sm[recipient_ID], plaintext)
return (gamma, ciphertext)
decrypt-from
After receiving the sender’s ID and a ciphertext, it behaves as the reverse
function of encrypt-to and has a similar initialization:
if gamma.2sm[sender_ID] = empty_string then
gamma.2sm[sender_ID] = 2SM_Init(gamma.myID, sender_ID)
(gamma.2sm[sender_ID], plaintext) = 2SM_Receive(gamma.2sm[sender_ID], ciphertext)
return (gamma, plaintext)
update-ratchet
This function generates the next update secret I_update for the group member
ID.
The ratchet state is stored in gamma.ratchet[ID].
It is required to use a HMAC-based key derivation function HKDF to combine the
ratchet state with an input, returning an update secret and a new ratchet
state.
(updateSecret, gamma.ratchet[ID]) = HKDF(gamma.ratchet[ID], input)
return (gamma, updateSecret)
member-view
This function calculates the set of group members
based on the most recent control message sent by the specified user ID.
It filters the group membership operations
to include only those observed by the specified ID, and
then invokes the DGM function to generate the group membership.
ops = {m in gamma.history st. m was sent or acknowledged by ID}
return DGM(ops)
generate-seed
This functions generates a random bit string and
sends it encrypted to each member of the group using the 2SM mechanism.
It returns the updated protocol state and
the set of direct messages (denoted as dmsgs) to send.
gamma.nextSeed = random.randbytes()
dmsgs = empty
for each ID in recipients:
(gamma, msg) = encrypt-to(gamma, ID, gamma.nextSeed)
dmsgs = dmsgs + (ID, msg)
return (gamma, dmsgs)
Creation of a group
A group is generated in a 3 steps procedure:
- A user calls the
createfunction and broadcasts a control message of type create. - Each receiver of the message processes the message and broadcasts an ack control message.
- Each member processes the ack message received.
create
This function generates a create control message and calls generate-seed to
define the set of direct messages that need to be sent.
Then it calls process-create to process the control message for this user.
The function process-create returns a tuple including an updated state gamma
and an update secret I.
control = (“create”, gamma.mySeq, IDs)
(gamma, dmsgs) = generate-seed(gamma, IDs)
(gamma, _, _, I, _) = process-create(gamma, gamma.myId, gamma.mySeq, IDs, empty_string)
return (gamma, control, dmsgs, I)
process-seed
This function initially employs member-view to identify the users who were
part of the group when the control message was dispatched.
Then, it attempts to acquire the seed secret through the following steps:
- If the control message was dispatched by the local user, it uses the most
recent invocation of
generate-seedstored the seed secret ingamma.nextSeed. - If the
controlmessage was dispatched by another user, and the local user is among its recipients, the function utilizesdecrypt-fromto decrypt the direct message that includes the seed secret. - Otherwise, it returns an
ackmessage without deriving an update secret.
Afterwards, process-seed generates separate member secrets for each group
member from the seed secret by combining the seed secret and
each user ID using HKDF.
The secret for the sender of the message is stored in senderSecret, while
those for the other group members are stored in gamma.memberSecret.
The sender's member secret is immediately utilized to update their KDF ratchet
and compute their update secret I_sender using update-ratchet.
If the local user is the sender of the control message, the process is
completed, and the update secret is returned.
However, if the seed secret is received from another user, an ack control
message is constructed for broadcast, including the sender ID and sequence
number of the message being acknowledged.
The final step computes an update secret I_me for the local user invoking the
process-ack function.
recipients = member-view(gamma, sender) - {sender}
if sender = gamma.myId then seed = gamma.nextSeed; gamma.nextSeed =
empty_string
else if gamma.myId in recipients then (gamma, seed) = decrypt-from(gamma,
sender, dmsg)
else
return (gamma, (ack, ++gamma.mySeq, (sender, seq)), empty_string ,
empty_string , empty_string)
for ID in recipients do gamma.memberSecret[sender, seq, ID] = HKDF(seed, ID)
senderSecret = HKDF(seed, sender)
(gamma, I_sender) = update-ratchet(gamma, sender, senderSecret)
if sender = gamma.myId then return (gamma, empty_string , empty_string ,
I_sender, empty_string)
control = (ack, ++gamma.mySeq, (sender, seq))
members = member-view(gamma, gamma.myId)
forward = empty
for ID in {members - (recipients + {sender})}
s = gamma.memberSecret[sender, seq, gamma.myId]
(gamma, msg) = encrypt-to(gamma, ID, s)
forward = forward + {(ID, msg)}
(gamma, _, _, I_me, _) = process-ack(gamma, gamma.myId, gamma.mySeq,
(sender, seq), empty_string)
return (gamma, control, forward, I_sender, I_me)
process-create
This function is called by the sender and each of the receivers of the create
control message.
First, it records the information from the create message in the
gamma.history+ {op}, which is used to track group membership changes. Then,
it proceeds to call process-seed.
op = (”create”, sender, seq, IDs)
gamma.history = gamma.history + {op}
return (process-seed(gamma, sender, seq, dmsg))
process-ack
This function is called by those group members once they receive an ack
message.
In process-ack, ackID and ackSeq are the sender and sequence number of
the acknowledged message.
Firstly, if the acknowledged message is a group membership operation, it
records the acknowledgement in gamma.history.
Following this, the function retrieves the relevant member secret from
gamma.memberSecret, which was previously obtained from the seed secret
contained in the acknowledged message.
Finally, it updates the ratchet for the sender of the ack and returns the
resulting update secret.
if (ackID, ackSeq) was a create / add / remove then
op = ("ack", sender, seq, ackID, ackSeq)
gamma.history = gamma.history + {op}`
s = gamma.memberSecret[ackID, ackSeq, sender]
gamma.memberSecret[ackID, ackSeq, sender] = empty_string
if (s = empty_string) & (dmsg = empty_string) then return (gamma, empty_string,
empty_string, empty_string, empty_string)
if (s = empty_string) then (gamma, s) = decrypt-from(gamma, sender, dmsg)
(gamma, I) = update-ratchet(gamma, sender, s)
return (gamma, empty_string, empty_string, I, empty_string)
The HKDF function MUST follow RFC 5869 using the hash function SHA256.
Post-compromise security updates and group member removal
The functions update and remove share similarities with create:
they both call the function generate-seed to encrypt a new seed secret for
each group member.
The distinction lies in the determination of the group members using member view.
In the case of remove, the user being removed is excluded from the recipients
of the seed secret.
Additionally, the control message they construct is designated with type
update or remove respectively.
Likewise, process-update and process-remove are akin to process-create.
The function process-update skips the update of gamma.history,
whereas process-remove includes a removal operation in the history.
update
control = ("update", ++gamma.mySeq, empty_string)
recipients = member-view(gamma, gamma.myId) - {gamma.myId}
(gamma, dmsgs) = generate-seed(gamma, recipients)
(gamma, _, _, I , _) = process-update(gamma, gamma.myId, gamma.mySeq,
empty_string, empty_string)
return (gamma, control, dmsgs, I)
remove
control = ("remove", ++gamma.mySeq, empty)
recipients = member-view(gamma, gamma.myId) - {ID, gamma.myId}
(gamma, dmsgs) = generate-seed(gamma, recipients)
(gamma, _, _, I , _) = process-update(gamma, gamma.myId, gamma.mySeq, ID,
empty_string)
return (gamma, control, dmsgs, I)
process-update
return process-seed(gamma, sender, seq, dmsg)
process-remove
op = ("remove", sender, seq, removed)
gamma.history = gamma.history + {op}
return process-seed(gamma, sender, seq, dmsg)
Group member addition
add
When adding a new group member, an existing member initiates the process by
invoking the add function and providing the ID of the user to be added.
This function prepares a control message marked as add for broadcast to the
group. Simultaneously, it creates a welcome message intended for the new member
as a direct message.
This welcome message includes the current state of the sender's KDF ratchet,
encrypted using 2SM, along with the history of group membership operations
conducted so far.
control = ("add", ++gamma.mySeq, ID)
(gamma, c) = encrypt-to(gamma, ID, gamma.ratchet[gamma.myId])
op = ("add", gamma.myId, gamma.mySeq, ID)
welcome = (gamma.history + {op}, c)
(gamma, _, _, I, _) = process-add(gamma, gamma.myId, gamma.mySeq, ID, empty_string)
return (gamma, control, (ID, welcome), I)
process-add
This function is invoked by both the sender and each recipient of an add
message, which includes the new group member. If the local user is the newly
added member, the function proceeds to call process-welcome and then exits.
Otherwise, it extends gamma.history with the add operation.
Line 5 determines whether the local user was already a group member at the time
the add message was sent; this condition is typically true but may be false
if multiple users were added concurrently.
On lines 6 to 8, the ratchet for the sender of the add message is updated
twice. In both calls to update-ratchet, a constant string is used as the
ratchet input instead of a random seed secret.
The value returned by the first ratchet update is stored in
gamma.memberSecret as the added user’s initial member secret. The result of
the second ratchet update becomes I_sender, the update secret for the sender
of the add message. On line 10, if the local user is the sender, the update
secret is returned.
If the local user is not the sender, an acknowledgment for the add message is
required.
Therefore, on line 11, a control message of type add-ack is constructed for
broadcast.
Subsequently, in line 12 the current ratchet state is encrypted using 2SM to
generate a direct message intended for the added user, allowing them to decrypt
subsequent messages sent by the sender.
Finally, in lines 13 to 15, process-add-ack is called to calculate the local
user’s update secret (I_me), which is then returned along with I_sender.
if added = gamma.myId then return process-welcome(gamma, sender, seq, dmsg)
op = ("add", sender, seq, added)
gamma.history = gamma.history + {op}
if gamma.myId in member-view(gamma, sender) then
(gamma, s) = update-ratchet(gamma, sender, "welcome")
gamma.memberSecret[sender, seq, added] = s
(gamma, I_sender) = update-ratchet(gamma, sender, "add")
else I_sender = empty_string
if sender = gamma.myId then return (gamma, empty_string, empty_string,
I_sender, empty_string)
control = ("add-ack", ++gamma.mySeq, (sender, seq))
(gamma, c) = encrypt-to(gamma, added, ratchet[gamma.myId])
(gamma, _, _, I_me, _) = process-add-ack(gamma, gamma.myId, gamma.mySeq,
(sender, seq), empty_string)
return (gamma, control, {(added, c)}, I_sender, I_me)
process-add-ack
This function is invoked by both the sender and each recipient of an add-ack
message, including the new group member. Upon lines 1–2, the acknowledgment is
added to gamma.history, mirroring the process in process-ack.
If the current user is the new group member, the add-ack message includes the
direct message constructed in process-add; this direct message contains the
encrypted ratchet state of the sender of the add-ack, then it is decrypted on
lines 3–5.
Upon line 6, a check is performed to check if the local user was already a
group member at the time the add-ack was sent. If affirmative, a new update
secret I for the sender of the add-ack is computed on line 7 by invoking
update-ratchet with the constant string add.
In the scenario involving the new member, the ratchet state was recently initialized on line 5. This ratchet update facilitates all group members, including the new addition, to derive each member’s update by obtaining any update secret from before their inclusion.
op = ("ack", sender, seq, ackID, ackSeq)
gamma$.history = gamma.history + {op}
if dmsg != empty_string then
(gamma, s) = decrypt-from(gamma, sender, dmsg)
gamma.ratchet[sender] = s
if gamma.myId in member-view(gamma, sender) then
(gamma, I) = update-ratchet(gamma, sender, "add")
return (gamma, empty_string, empty_string, I, empty_string)
else return (gamma, empty_string, empty_string, empty_string, empty_string)
process-welcome
This function serves as the second step called by a newly added group member.
In this context, adderHistory represents the adding user’s copy of
gamma.history sent in their welcome message, which is utilized to initialize
the added user’s history.
Here, c denotes the ciphertext of the adding user’s ratchet state, which is
decrypted on line 2 using decrypt-from.
Once gamma.ratchet[sender] is initialized, update-ratchet is invoked twice
on lines 3 to 5 with the constant strings welcome and add respectively.
These operations mirror the ratchet operations performed by every other group
member in process-add.
The outcome of the first update-ratchet call becomes the first member secret
for the added user,
while the second call returns I_sender, the update secret for the sender of
the add operation.
Subsequently, the new group member constructs an ack control message to
broadcast on line 6 and calls process-ack to compute their initial update
secret I_me. The function process-ack reads from gamma.memberSecret and
passes it to update-ratchet. The previous ratchet state for the new member is
the empty string empty, as established by init, thereby initializing the
new member’s ratchet.
Upon receiving the new member’s ack, every other group member initializes
their copy of the new member’s ratchet in a similar manner.
By the conclusion of process-welcome, the new group member has acquired
update secrets for themselves and the user who added them.
The ratchets for other group members are initialized by process-add-ack.
gamma.history = adderHistory
(gamma, gamma.ratchet[sender]) = decrypt-from(gamma, sender, c)
(gamma, s) = update-ratchet(gamma, sender, "welcome")
gamma.memberSecret[sender, seq, gamma.myId] = s
(gamma, I_sender) = update-ratchet(gamma, sender, "add")
control = ("ack", ++gamma.mySeq, (sender, seq))
(gamma, _, _, I_me, _) = process-ack(gamma, gamma.myId, gamma.mySeq, (sender,
seq), empty_string)
return (gamma, control, empty_string , I_sender, I_me)
Privacy Considerations
Dependency on PKI
The DCGKA proposal presents some limitations highlighted by the authors. Among these limitations one finds the requirement of a PKI (or a key server) mapping IDs to public keys.
One method to overcome this limitation is adapting the protocol SIWE (Sign in
with Ethereum) so a user u_1 who wants to start a communication with a user
u_2 can interact with latter’s wallet to request a public key using an
Ethereum address as ID.
SIWE
The SIWE (Sign In With Ethereum) proposal was a suggested standard for leveraging Ethereum to authenticate and authorize users on web3 applications. Its goal is to establish a standardized method for users to sign in to web3 applications using their Ethereum address and private key, mirroring the process by which users currently sign in to web2 applications using their email and password. Below follows the required steps:
- A server generates a unique Nonce for each user intending to sign in.
- A user initiates a request to connect to a website using their wallet.
- The user is presented with a distinctive message that includes the Nonce and details about the website.
- The user authenticates their identity by signing in with their wallet.
- Upon successful authentication, the user's identity is confirmed or approved.
- The website grants access to data specific to the authenticated user.
Our approach
The idea in the DCGKA setting closely resembles the procedure outlined in SIWE. Here:
- The server corresponds to user D1,who initiates a request (instead of generating a nonce) to obtain the public key of user D2.
- Upon receiving the request, the wallet of D2 send the request to the user,
- User D2 receives the request from the wallet, and decides whether accepts or rejects.
- The wallet and responds with a message containing the requested public key in case of acceptance by D2.
This message may be signed, allowing D1 to verify that the owner of the received public key is indeed D2.
Multi-device setting
One may see the set of devices as a group and create a group key for internal
communications.
One may use treeKEM for instance, since it provides interesting properties like
forward secrecy and post-compromise security.
All devices share the same ID, which is held by one of them, and from other
user’s point of view, they would look as a single user.
Using servers, like in the paper Multi-Device for Signal, should be avoided; but this would imply using a particular device as receiver and broadcaster within the group. There is an obvious drawback which is having a single device working as a “server”. Should this device be attacked or without connection, there should be a mechanism for its revocation and replacement.
Another approach for communications between devices could be using the keypair of each device. This could open the door to use UPKE, since keypairs should be regenerated frequently.
Each time a device sends a message, either an internal message or an external message, it needs to replicate and broadcast it to all devices in the group.
The mechanism for the substitution of misbehaving leader devices follows:
- Each device within a group knows the details of other leader devices. This information may come from metadata in received messages, and is replicated by the leader device.
- To replace a leader, the user should select any other device within its group and use it to send a signed message to all other users.
- To get the ability to sign messages, this new leader should request the keypair associated to the ID to the wallet.
- Once the leader has been changed, it revocates access from DCGKA to the former leader using the DCGKA protocol.
- The new leader starts a key update in DCGKA.
Not all devices in a group should be able to send messages to other users. Only
the leader device should be in charge of sending and receiving messages.
To prevent other devices from sending messages outside their group, a
requirement should be signing each message. The keys associated to the ID
should only be in control of the leader device.
The leader device is in charge of setting the keys involved in the DCGKA. This information must be replicated within the group to make sure it is updated.
To detect missing messages or potential misbehavior, messages must include a counter.
Using UPKE
Managing the group of devices of a user can be done either using a group key protocol such as treeKEM or using the keypair of each device. Setting a common key for a group of devices under the control of the same actor might be excessive, furthermore it may imply some of the problems one can find in the usual setting of a group of different users; for example: one of the devices may not participate in the required updating processes, representing a threat for the group.
The other approach to managing the group of devices is using each device’s keypair, but it would require each device updating these materia frequently, something that may not happens.
UPKE is a form of asymetric cryptography where any user can update any other user’s key pair by running an update algorithm with (high-entropy) private coins. Any sender can initiate a key update by sending a special update ciphertext. This ciphertext updates the receiver’s public key and also, once processed by the receiver, will update their secret key.
To the best of my knowledge, there exists several efficient constructions both UPKE from ElGamal (based in the DH assumption) and UPKE from Lattices (based in lattices). None of them have been implemented in a secure messaging protocol, and this opens the door to some novel research.
Copyright
Copyright and related rights waived via CC0.
References
- DCGKA
- MLS
- CoCoa
- Causal TreeKEM
- SIWE
- Multi-device for Signal
- UPKE
- UPKE from ElGamal
- UPKE from Lattices
ETH-MLS-ONCHAIN
| Field | Value |
|---|---|
| Name | Secure channel setup using decentralized MLS and Ethereum accounts |
| Slug | 101 |
| Status | raw |
| Category | Standards Track |
| Editor | Ramses Fernandez [email protected] |
| Contributors | Aaryamann Challani [email protected], Ekaterina Broslavskaya [email protected], Ugur Sen [email protected], Ksr [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-15 —
5a3e844— Chore/move repo into logos co (#312) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-04-04 —
517b639— Update the RFCs: Vac Raw RFC (#143) - 2024-10-03 —
c655980— Eth secpm splitted (#91) - 2024-08-29 —
13aaae3— Update eth-secpm.md (#84) - 2024-05-21 —
e234e9d— Update eth-secpm.md (#35) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-02-28 —
b842725— Update eth-secpm.md - 2024-02-01 —
f2e1b4c— Rename ETH-SECPM.md to eth-secpm.md - 2024-02-01 —
22bb331— Update ETH-SECPM.md - 2024-01-27 —
5b8ce46— Create ETH-SECPM.md
Motivation
The need for secure communications has become paramount.
Traditional centralized messaging protocols are susceptible to various security threats,
including unauthorized access, data breaches, and single points of failure.
Therefore a decentralized approach to secure communication becomes increasingly relevant,
offering a robust solution to address these challenges.
This document specifies a private messaging service using the Ethereum blockchain as authentication service. Rooted in the existing model, this proposal addresses the deficiencies related to forward privacy and authentication inherent in the current framework. The specification is divided into the following sections:
- Private group messaging protocol, based on the MLS protocol.
- Specification of an Ethereum-based authentication protocol, based on SIWE.
Protocol flow
The following steps outline the flow of the protocol.
Account Registration and Key Generation
Each user starts by registering their Ethereum account.
It is used as the authentication service.
Upon registration, the user generates a KeyPackage
that contains a public key
and supporting metadata required for the MLS group.
Group Initialization and Member Management
When a new group is created, the initiating client generates a new GroupContext.
It contains a unique group ID and an initial epoch.
To add members, the initiator sends an Add request,
which includes the new member’s KeyPackage.
Existing members can update their identity in the group using the Update proposal,
which replaces the sender’s LeafNode in the group’s ratchet tree.
Members can be removed from the group via a Remove proposal,
which specifies the index of the member to be removed from the tree.
Upon processing this proposal,
the group generates a new group key to ensure that removed members
no longer have access to future communications.
Commit and Authentication
After receiving a valid list of proposals (Add, Update, Remove),
a client initiates a Commit message,
processing the pending proposals and updates the group’s state.
The Commit message includes the updated GroupContext
and a FramedContentAuthData,
which ensures that all group members are aware of the changes.
Each member verifies the FramedContentAuthData to ensure the changes are consistent
with the current epoch of the GroupContext.
Message Exchange
Once the group is established and all members have processed the latest Commit,
messages can be securely exchanged using
the session keyderived from the group's ratchet tree.
Each message is encapsulated within a FramedContent structure
and authenticated using the FramedContentAuthData,
ensuring message integrity.
Group members use the current GroupContext to validate incoming messages
and ensure they are consistent with the current group state.
Use of smart contracts
This protocol accomplishes decentralization through the use of smart contracts for managing groups. They are used to register users in a group and keep the state of the group updated. Smart contracts MUST include an ACL to keep the state of the group.
Private group messaging protocol
Background
The Messaging Layer Security (MLS) protocol aims at providing a group of users with end-to-end encryption in an authenticated and asynchronous way. The main security characteristics of the protocol are: Message confidentiality and authentication, sender authentication, membership agreement, post-remove and post-update security, and forward secrecy and post-compromise security. The MLS protocol achieves: low-complexity, group integrity, synchronization and extensibility.
This document describes how the structure and methods of the MLS protocol are extended for their application in decentralized environments. The approach described in this document makes use of smart contracts. It makes use of a smart contract to manage each group chat. Furthermore, this document describes how to use the Sign-in With Ethereum protocol as authentication method.
Structure
Each MLS session uses a single cipher suite that specifies the primitives to be used in group key computations. The cipher suite MUST use:
X488as Diffie-Hellman function.SHA256as KDF.AES256-GCMas AEAD algorithm.SHA512as hash function.XEd448for digital signatures.
Formats for public keys, signatures and public-key encryption MUST follow Section 5.1 of RFC9420.
Hash-based identifiers
Some MLS messages refer to other MLS objects by hash. These identifiers MUST be computed according to Section 5.2 of RFC9420.
Credentials
Each member of a group presents a credential that provides one or more identities for the member and associates them with the member's signing key. The identities and signing key are verified by the Authentication Service in use for a group.
Credentials MUST follow the specifications of section 5.3 of RFC9420.
Below follows the flow diagram for the generation of credentials.
Users MUST generate key pairs by themselves.
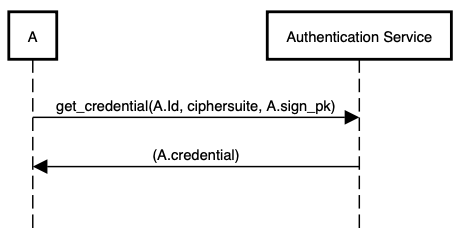
Message framing
Handshake and application messages use a common framing structure providing encryption to ensure confidentiality within the group, and signing to authenticate the sender.
The structure is:
PublicMessage: represents a message that is only signed, and not encrypted. The definition and the encoding/decoding of aPublicMessageMUST follow the specification in section 6.2 of RFC9420.PrivateMessage: represents a signed and encrypted message, with protections for both the content of the message and related metadata.
The definition, and the encoding/decoding of a PrivateMessage
MUST follow the specification in section 6.3 of
RFC9420.
Applications MUST use PrivateMessage to encrypt application messages.
Applications SHOULD use PrivateMessage to encode handshake messages.
Each encrypted MLS message carries a "generation" number which is a per-sender incrementing counter. If a group member observes a gap in the generation sequence for a sender, then they know that they have missed a message from that sender.
Nodes contents
This section makes use of sections 4 and 7 of RFC9420.
The nodes of a ratchet tree (Section 4 in RFC9420) contain several types of data:
- Leaf nodes describe individual members.
- Parent nodes describe subgroups.
Contents of each kind of node, and its structure MUST follow the indications described in sections 7.1 and 7.2 of RFC9420.
Leaf node validation
KeyPackage objects describe the client's capabilities and
provides keys that can be used to add the client to a group.
The validity of a leaf node needs to be verified at the following stages:
- When a leaf node is downloaded in a
KeyPackage, before it is used to add the client to the group. - When a leaf node is received by a group member in an Add, Update, or Commit message.
- When a client validates a ratchet tree.
A client MUST verify the validity of a leaf node following the instructions of section 7.3 in RFC9420.
Ratchet tree evolution
Whenever a member initiates an epoch change, they MAY need to refresh the key pairs of their leaf and of the nodes on their direct path. This is done to keep forward secrecy and post-compromise security. The member initiating the epoch change MUST follow this procedure. A member updates the nodes along its direct path as follows:
- Blank all the nodes on the direct path from the leaf to the root.
- Generate a fresh HPKE key pair for the leaf.
- Generate a sequence of path secrets, one for each node on the leaf's filtered direct path.
It MUST follow the procedure described in section 7.4 of RFC9420.
- Compute the sequence of HPKE key pairs
(node_priv,node_pub), one for each node on the leaf's direct path.
It MUST follow the procedure described in section 7.4 of RFC9420.
Views of the tree synchronization
After generating fresh key material and applying it to update their local tree state, the generator broadcasts this update to other members of the group. This operation MUST be done according to section 7.5 of RFC9420.
Leaf synchronization
Changes to group memberships MUST be represented by adding and removing leaves of the tree. This corresponds to increasing or decreasing the depth of the tree, resulting in the number of leaves being doubled or halved. These operations MUST be done as described in section 7.7 of RFC9420.
Tree and parent hashing
Group members can agree on the cryptographic state of the group by
generating a hash value that represents the contents of the group
ratchet tree and the member’s credentials.
The hash of the tree is the hash of its root node,
defined recursively from the leaves.
Tree hashes summarize the state of a tree at point in time.
The hash of a leaf is the hash of the LeafNodeHashInput object.
At the same time the hash of a parent node, including the root,
is the hash of a ParentNodeHashInput object.
Parent hashes capture information about
how keys in the tree were populated.
Tree and parent hashing MUST follow the directions in Sections 7.8 and 7.9 of RFC9420.
Key schedule
Group keys are derived using the Extract and Expand functions from
the KDF for the group's cipher suite,
as well as the functions defined below:
ExpandWithLabel(Secret, Label, Context, Length) = KDF.Expand(Secret, KDFLabel, Length)
DeriveSecret(Secret, Label) = ExpandWithLabel(Secret, Label, "", KDF.Nh)
KDFLabel MUST be specified as:
struct {
uint16 length;
opaque label<V>;
opaque context<V>;
} KDFLabel;
The fields of KDFLabel MUST be:
length = Length;
label = "MLS 1.0 " + Label;
context = Context;
Each member of the group MUST maintaint a GroupContext object
summarizing the state of the group.
The sturcture of such object MUST be:
struct {
ProtocolVersion version = mls10;
CipherSuite cipher_suite;
opaque group_id<V>;
uint64 epoch;
opaque tree_hash<V>;
opaque confirmed_trasncript_hash<V>;
Extension extension<V>;
} GroupContext;
The use of key scheduling MUST follow the indications in sections 8.1 - 8.7 in RFC9420.
Secret trees
For the generation of encryption keys and nonces, the key schedule
begins with the encryption_secret at the root and derives a tree of
secrets with the same structure as the group's ratchet tree.
Each leaf in the secret tree is associated with the same group member
as the corresponding leaf in the ratchet tree.
If N is a parent node in the secret tree, the secrets of the children
of N MUST be defined following section 9 of
RFC9420.
Encryption keys
MLS encrypts three different types of information:
- Metadata (sender information).
- Handshake messages (Proposal and Commit).
- Application messages.
For handshake and application messages, a sequence of keys is derived via a sender ratchet. Each sender has their own sender ratchet, and each step along the ratchet is called a generation. These procedures MUST follow section 9.1 of RFC9420.
Deletion schedule
All security-sensitive values MUST be deleted as soon as they are consumed.
A sensitive value S is consumed if:
- S was used to encrypt or (successfully) decrypt a message.
- A key, nonce, or secret derived from S has been consumed.
The deletion procedure MUST follow the instruction described in section 9.2 of RFC9420.
Key packages
KeyPackage objects are used to ease the addition of clients to a group asynchronously.
A KeyPackage object specifies:
- Protocol version and cipher suite supported by the client.
- Public keys that can be used to encrypt Welcome messages. Welcome messages provide new members with the information to initialize their state for the epoch in which they were added or in which they want to add themselves to the group
- The content of the leaf node that should be added to the tree to represent this client.
KeyPackages are intended to be used only once and SHOULD NOT be reused.
Clients MAY generate and publish multiple KeyPackages to support multiple cipher suites.
The structure of the object MUST be:
struct {
ProtocolVersion version;
CipherSuite cipher_suite;
HPKEPublicKey init_key;
LeafNode leaf_node;
Extension extensions<V>;
/* SignWithLabel(., "KeyPackageTBS", KeyPackageTBS) */
opaque signature<V>;
}
struct {
ProtocolVersion version;
CipheSuite cipher_suite;
HPKEPublicKey init_key;
LeafNode leaf_node;
Extension extensions<V>;
}
KeyPackage object MUST be verified when:
- A
KeyPackageis downloaded by a group member, before it is used to add the client to the group. - When a
KeyPackageis received by a group member in anAddmessage.
Verification MUST be done as follows:
- Verify that the cipher suite and protocol version of the
KeyPackagematch those in theGroupContext. - Verify that the
leaf_nodeof theKeyPackageis valid for aKeyPackage. - Verify that the signature on the
KeyPackageis valid. - Verify that the value of
leaf_node.encryption_keyis different from the value of theinit_key field.
HPKE public keys are opaque values in a format defined by Section 4 of RFC9180.
Signature public keys are represented as opaque values in a format defined by the cipher suite's signature scheme.
Group creation
A group is always created with a single member. Other members are then added to the group using the usual Add/Commit mechanism. The creator of a group MUST set:
- the group ID.
- cipher suite.
- initial extensions for the group.
If the creator intends to add other members at the time of creation,
then it SHOULD fetch KeyPackages for those members, and select a
cipher suite and extensions according to their capabilities.
The creator MUST use the capabilities information in these
KeyPackages to verify that the chosen version and cipher suite is the
best option supported by all members.
Group IDs SHOULD be constructed so they are unique with high probability.
To initialize a group, the creator of the group MUST initialize a one member group with the following initial values:
- Ratchet tree: A tree with a single node, a leaf node containing an HPKE public key and credential for the creator.
- Group ID: A value set by the creator.
- Epoch:
0. - Tree hash: The root hash of the above ratchet tree.
- Confirmed transcript hash: The zero-length octet string.
- Epoch secret: A fresh random value of size
KDF.Nh. - Extensions: Any values of the creator's choosing.
The creator MUST also calculate the interim transcript hash:
- Derive the
confirmation_keyfor the epoch according to Section 8 of RFC9420. - Compute a
confirmation_tagover the emptyconfirmed_transcript_hashusing theconfirmation_keyas described in Section 8.1 of RFC9420. - Compute the updated
interim_transcript_hashfrom theconfirmed_transcript_hashand theconfirmation_tagas described in Section 8.2 RFC9420.
All members of a group MUST support the cipher suite and protocol
version in use. Additional requirements MAY be imposed by including a
required_capabilities extension in the GroupContext.
struct {
ExtensionType extension_types<V>;
ProposalType proposal_types<V>;
CredentialType credential_types<V>;
}
The flow diagram shows the procedure to fetch key material from other users:
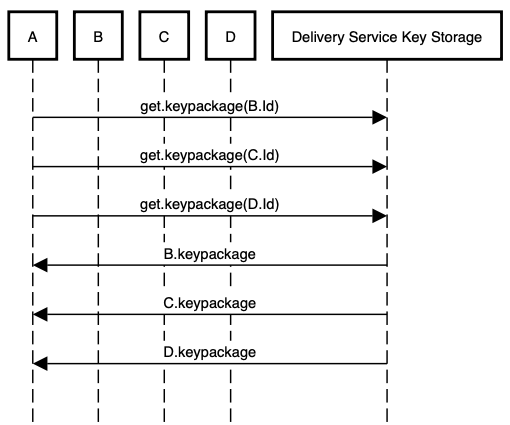
Below follows the flow diagram for the creation of a group:
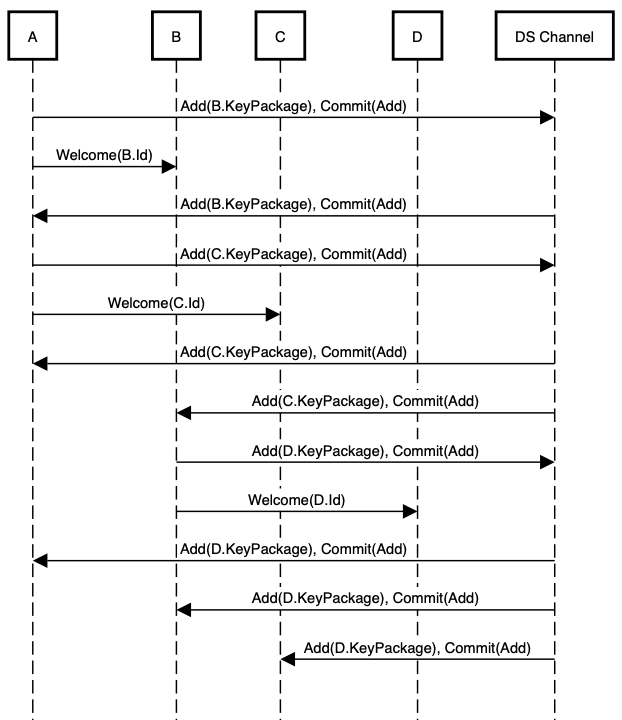
Group evolution
Group membership can change, and existing members can change their keys in order to achieve post-compromise security. In MLS, each such change is accomplished by a two-step process:
- A proposal to make the change is broadcast to the group in a Proposal message.
- A member of the group or a new member broadcasts a Commit message that causes one or more proposed changes to enter into effect.
The group evolves from one cryptographic state to another each time a Commit message is sent and processed. These states are called epochs and are uniquely identified among states of the group by eight-octet epoch values.
Proposals are included in a FramedContent by way of a Proposal
structure that indicates their type:
struct {
ProposalType proposal_type;
select (Proposal.proposal_type) {
case add: Add:
case update: Update;
case remove: Remove;
case psk: PreSharedKey;
case reinit: ReInit;
case external_init: ExternalInit;
case group_context_extensions: GroupContextExtensions;
}
}
On receiving a FramedContent containing a Proposal, a client MUST
verify the signature inside FramedContentAuthData and that the epoch
field of the enclosing FramedContent is equal to the epoch field of the
current GroupContext object.
If the verification is successful, then the Proposal SHOULD be cached
in such a way that it can be retrieved by hash in a later Commit
message.
Proposals are organized as follows:
Add: requests that a client with a specified KeyPackage be added to the group.Update: similar to Add, it replaces the sender's LeafNode in the tree instead of adding a new leaf to the tree.Remove: requests that the member with the leaf index removed be removed from the group.ReInit: requests to reinitialize the group with different parameters.ExternalInit: used by new members that want to join a group by using an external commit.GroupContentExtensions: it is used to update the list of extensions in the GroupContext for the group.
Proposals structure and semantics MUST follow sections 12.1.1 - 12.1.7 of RFC9420.
Any list of commited proposals MUST be validated either by a the group member who created the commit, or any group member processing such commit. The validation MUST be done according to one of the procedures described in Section 12.2 of RFC9420.
When creating or processing a Commit, a client applies a list of
proposals to the ratchet tree and GroupContext.
The client MUST apply the proposals in the list in the order described
in Section 12.3 of RFC9420.
Below follows the flow diagram for the addition of a member to a group:
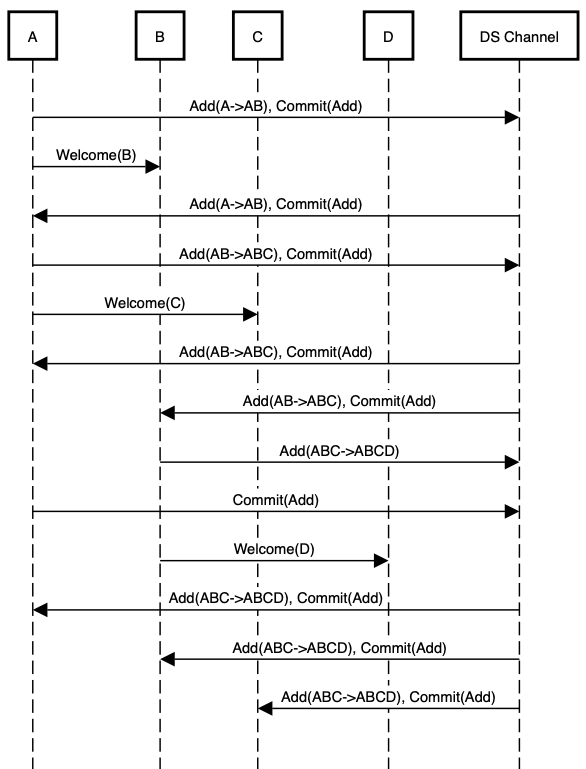
The diagram below shows the procedure to remove a group member:
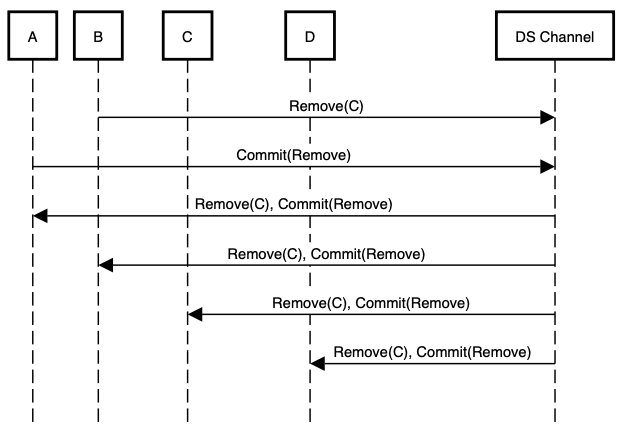
The flow diagram below shows an update procedure:
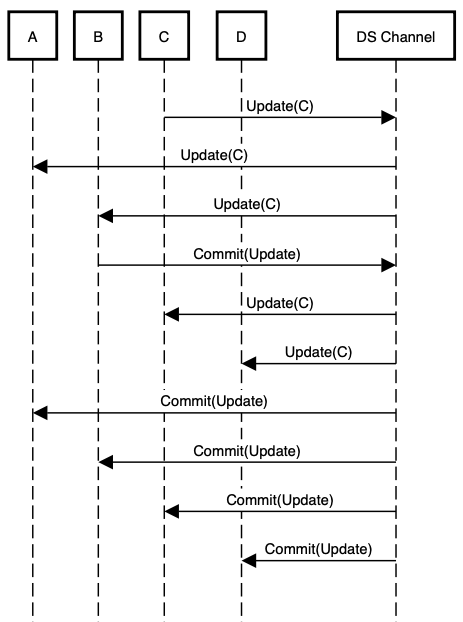
Commit messages
Commit messages initiate new group epochs. It informs group members to update their representation of the state of the group by applying the proposals and advancing the key schedule.
Each proposal covered by the Commit is included by a
ProposalOrRef value.
ProposalOrRef identify the proposal to be applied by value
or by reference.
Commits that refer to new Proposals from the committer
can be included by value.
Commits for previously sent proposals from anyone can be sent
by reference.
Proposals sent by reference are specified by including the hash of the
AuthenticatedContent.
Group members that have observed one or more valid proposals within an epoch MUST send a Commit message before sending application data. A sender and a receiver of a Commit MUST verify that the committed list of proposals is valid. The sender of a Commit SHOULD include all valid proposals received during the current epoch.
Functioning of commits MUST follow the instructions of Section 12.4 of RFC9420.
Application messages
Handshake messages provide an authenticated group key exchange
to clients.
To protect application messages sent among the members of a group, the
encryption_secret provided by the key schedule is used to derive a
sequence of nonces and keys for message encryption.
Each client MUST maintain their local copy of the key schedule for each epoch during which they are a group member. They derive new keys, nonces, and secrets as needed. This data MUST be deleted as soon as they have been used.
Group members MUST use the AEAD algorithm associated with the negotiated MLS ciphersuite to encrypt and decrypt Application messages according to the Message Framing section. The group identifier and epoch allow a device to know which group secrets should be used and from which Epoch secret to start computing other secrets and keys. Application messages SHOULD be padded to provide resistance against traffic analysis techniques. This avoids additional information to be provided to an attacker in order to guess the length of the encrypted message. Padding SHOULD be used on messages with zero-valued bytes before AEAD encryption.
Functioning of application messages MUST follow the instructions of Section 15 of RFC9420.
Implementation of the onchain component of the protocol
Assumptions
- Users have set a secure 1-1 communication channel.
- Each group is managed by a separate smart contract.
Addition of members to a group
- On-chain: Alice creates a Smart Contract with ACL.
- Off-chain: Alice sends the contract address and an invitation message to Bob over the secure channel.
- Off-chain: Bob sends a signed response confirming his Ethereum address and agreement to join.
- Off-chain: Alice verifies the signature using the public key of Bob.
- On-chain: Alice adds Bob’s address to the ACL.
- Off-chain: Alice sends a welcome message to Bob.
- Off-chain: Alice sends a broadcast message to all group members, notifying them the addition of Bob.
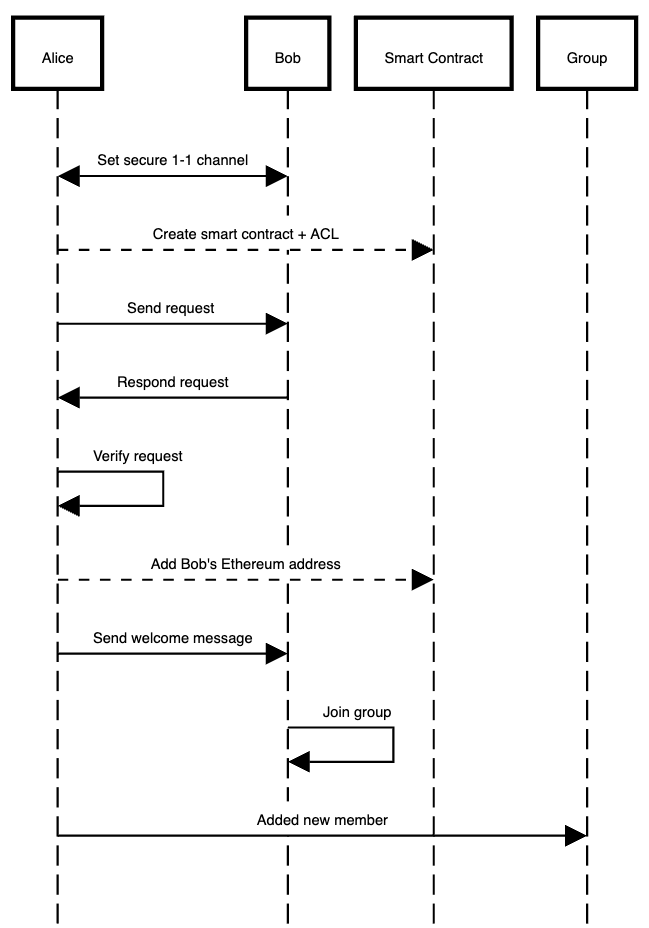
Updates in groups
Removal requests and update requests are considered the same operation. One assumes Alice is the creator of the contract. They MUST be processed as follows:
- Off-chain: Bob creates a new update request.
- Off-chain: Bob sends the update request to Alice.
- Off-chain: Alice verifies the request.
- On-chain: If the verification is successfull, Alice sends it to the smart contract for registration.
- Off-chain: Alice sends a broadcast message communicating the update to all users.
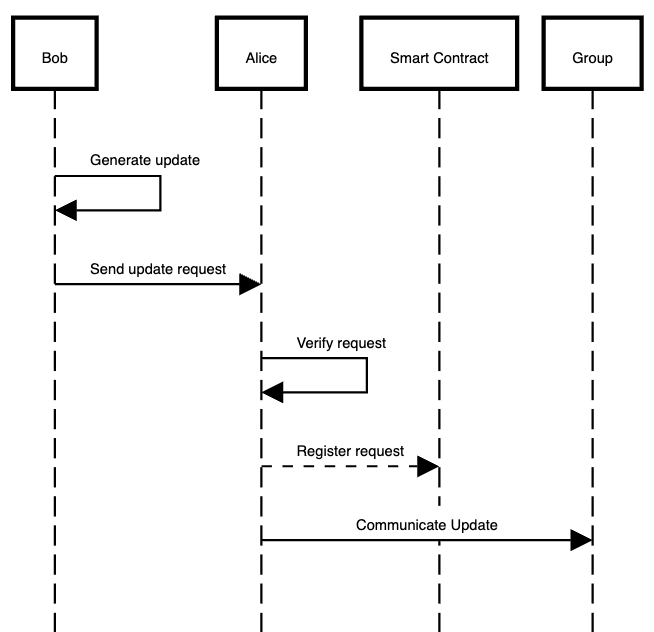
Ethereum-based authentication protocol
Introduction
Sign-in with Ethereum describes how Ethereum accounts authenticate with off-chain services by signing a standard message format parameterized by scope, session details, and security mechanisms. Sign-in with Ethereum (SIWE), which is described in the EIP 4361, MUST be the authentication method required.
Pattern
Message format (ABNF)
A SIWE Message MUST conform with the following Augmented Backus–Naur Form (RFC 5234) expression.
sign-in-with-ethereum =
[ scheme "://" ] domain %s" wants you to sign in with your
Ethereum account:" LF address LF
LF
[ statement LF ]
LF
%s"URI: " uri LF
%s"Version: " version LF
%s"Chain ID: " chain-id LF
%s"Nonce: " nonce LF
%s"Issued At: " issued-at
[ LF %s"Expiration Time: " expiration-time ]
[ LF %s"Not Before: " not-before ]
[ LF %s"Request ID: " request-id ]
[ LF %s"Resources:"
resources ]
scheme = ALPHA *( ALPHA / DIGIT / "+" / "-" / "." )
; See RFC 3986 for the fully contextualized
; definition of "scheme".
domain = authority
; From RFC 3986:
; authority = [ userinfo "@" ] host [ ":" port ]
; See RFC 3986 for the fully contextualized
; definition of "authority".
address = "0x" 40*40HEXDIG
; Must also conform to captilization
; checksum encoding specified in EIP-55
; where applicable (EOAs).
statement = *( reserved / unreserved / " " )
; See RFC 3986 for the definition
; of "reserved" and "unreserved".
; The purpose is to exclude LF (line break).
uri = URI
; See RFC 3986 for the definition of "URI".
version = "1"
chain-id = 1*DIGIT
; See EIP-155 for valid CHAIN_IDs.
nonce = 8*( ALPHA / DIGIT )
; See RFC 5234 for the definition
; of "ALPHA" and "DIGIT".
issued-at = date-time
expiration-time = date-time
not-before = date-time
; See RFC 3339 (ISO 8601) for the
; definition of "date-time".
request-id = *pchar
; See RFC 3986 for the definition of "pchar".
resources = *( LF resource )
resource = "- " URI
This specification defines the following SIWE Message fields that can be parsed from a SIWE Message by following the rules in ABNF Message Format. This section follows the section ABNF message format in EIP 4361.
-
schemeOPTIONAL. The URI scheme of the origin of the request. Its value MUST be a RFC 3986 URI scheme. -
domainREQUIRED. The domain that is requesting the signing. Its value MUST be a RFC 3986 authority. The authority includes an OPTIONAL port. If the port is not specified, the default port for the provided scheme is assumed.
If scheme is not specified, HTTPS is assumed by default.
-
addressREQUIRED. The Ethereum address performing the signing. Its value SHOULD be conformant to mixed-case checksum address encoding specified in ERC-55 where applicable. -
statementOPTIONAL. A human-readable ASCII assertion that the user will sign which MUST NOT include '\n' (the byte 0x0a). -
uriREQUIRED. An RFC 3986 URI referring to the resource that is the subject of the signing. -
versionREQUIRED. The current version of the SIWE Message, which MUST be 1 for this specification. -
chain-idREQUIRED. The EIP-155 Chain ID to which the session is bound, and the network where Contract Accounts MUST be resolved. -
nonceREQUIRED. A random string (minimum 8 alphanumeric characters) chosen by the relying party and used to prevent replay attacks. -
issued-atREQUIRED. The time when the message was generated, typically the current time.
Its value MUST be an ISO 8601 datetime string.
expiration-timeOPTIONAL. The time when the signed authentication message is no longer valid.
Its value MUST be an ISO 8601 datetime string.
not-beforeOPTIONAL. The time when the signed authentication message will become valid.
Its value MUST be an ISO 8601 datetime string.
-
request-idOPTIONAL. An system-specific identifier that MAY be used to uniquely refer to the sign-in request. -
resourcesOPTIONAL. A list of information or references to information the user wishes to have resolved as part of authentication by the relying party.
Every resource MUST be a RFC 3986 URI separated by "\n- " where \n is the byte 0x0a.
Signing and Verifying Messages with Ethereum Accounts
-
For Externally Owned Accounts, the verification method specified in ERC-191 MUST be used.
-
For Contract Accounts,
-
The verification method specified in ERC-1271 SHOULD be used. Otherwise, the implementer MUST clearly define the verification method to attain security and interoperability for both wallets and relying parties.
-
When performing ERC-1271 signature verification, the contract performing the verification MUST be resolved from the specified
chain-id. -
Implementers SHOULD take into consideration that ERC-1271 implementations are not required to be pure functions. They can return different results for the same inputs depending on blockchain state. This can affect the security model and session validation rules.
-
Resolving Ethereum Name Service (ENS) Data
-
The relying party or wallet MAY additionally perform resolution of ENS data, as this can improve the user experience by displaying human friendly information that is related to the
address. Resolvable ENS data include:- The primary ENS name.
- The ENS avatar.
- Any other resolvable resources specified in the ENS documentation.
-
If resolution of ENS data is performed, implementers SHOULD take precautions to preserve user privacy and consent. Their
addresscould be forwarded to third party services as part of the resolution process.
Implementer steps: specifying the request origin
The domain and, if present, the scheme, in the SIWE Message MUST
correspond to the origin from where the signing request was made.
Implementer steps: verifying a signed message
The SIWE Message MUST be checked for conformance to the ABNF Message Format and its signature MUST be checked as defined in Signing and Verifying Messages with Ethereum Accounts.
Implementer steps: creating sessions
Sessions MUST be bound to the address and not to further resolved resources that can change.
Implementer steps: interpreting and resolving resources
Implementers SHOULD ensure that that URIs in the listed resources are human-friendly when expressed in plaintext form.
Wallet implementer steps: verifying the message format
The full SIWE message MUST be checked for conformance to the ABNF defined in ABNF Message Format.
Wallet implementers SHOULD warn users if the substring "wants you to sign in with your Ethereum account" appears anywhere in an
ERC-191
message signing request unless the message fully conforms to the format
defined ABNF Message Format.
Wallet implementer steps: verifying the request origin
Wallet implementers MUST prevent phishing attacks by verifying the
origin of the request against the scheme and domain fields in the
SIWE Message.
The origin SHOULD be read from a trusted data source such as the browser window or over WalletConnect ERC-1328 sessions for comparison against the signing message contents.
Wallet implementers MAY warn instead of rejecting the verification if the origin is pointing to localhost.
The following is a RECOMMENDED algorithm for Wallets to conform with the requirements on request origin verification defined by this specification.
The algorithm takes the following input variables:
- fields from the SIWE message.
originof the signing request: the origin of the page which requested the signin via the provider.allowedSchemes: a list of schemes allowed by the Wallet.defaultScheme: a scheme to assume when none was provided. Wallet implementers in the browser SHOULD use https.- developer mode indication: a setting deciding if certain risks should
be a warning instead of rejection. Can be manually configured or
derived from
originbeing localhost.
The algorithm is described as follows:
- If
schemewas not provided, then assigndefaultSchemeas scheme. - If
schemeis not contained inallowedSchemes, then theschemeis not expected and the Wallet MUST reject the request. Wallet implementers in the browser SHOULD limit the list of allowedSchemes to just 'https' unless a developer mode is activated. - If
schemedoes not match the scheme of origin, the Wallet SHOULD reject the request. Wallet implementers MAY show a warning instead of rejecting the request if a developer mode is activated. In that case the Wallet continues processing the request. - If the
hostpart of thedomainandorigindo not match, the Wallet MUST reject the request unless the Wallet is in developer mode. In developer mode the Wallet MAY show a warning instead and continues procesing the request. - If
domainandoriginhave mismatching subdomains, the Wallet SHOULD reject the request unless the Wallet is in developer mode. In developer mode the Wallet MAY show a warning instead and continues procesing the request. - Let
portbe the port component ofdomain, and if no port is contained in domain, assign port the default port specified for the scheme. - If
portis not empty, then the Wallet SHOULD show a warning if theportdoes not match the port oforigin. - If
portis empty, then the Wallet MAY show a warning iforigincontains a specific port. - Return request origin verification completed.
Wallet implementer steps: creating SIWE interfaces
Wallet implementers MUST display to the user the following fields from
the SIWE Message request by default and prior to signing, if they are
present: scheme, domain, address, statement, and resources.
Other present fields MUST also be made available to the user prior to
signing either by default or through an extended interface.
Wallet implementers displaying a plaintext SIWE Message to the user SHOULD require the user to scroll to the bottom of the text area prior to signing.
Wallet implementers MAY construct a custom SIWE user interface by parsing the ABNF terms into data elements for use in the interface. The display rules above still apply to custom interfaces.
Wallet implementer steps: supporting internationalization (i18n)
After successfully parsing the message into ABNF terms, translation MAY happen at the UX level per human language.
Consideration to secure 1-to-1 channels
There are situations where users need to set one-to-one communication channels in a secure way. One of these situations is when a user A wants to add a new user B to an existing group. In such situations communications between users MUST be done following the instructions in this specification describing the use of X3DH in combination with the double ratchet mechanism.
Considerations with respect to decentralization
The MLS protocol assumes the existence of a (central, untrusted) delivery service, whose responsabilites include:
- Acting as a directory service providing the initial keying material for clients to use.
- Routing MLS messages among clients.
The central delivery service can be avoided in protocols using the publish/gossip approach, such as gossipsub.
Concerning keys, each node can generate and disseminate their encryption key among the other nodes, so they can create a local version of the tree that allows for the generation of the group key.
Another important component is the authentication service, which is replaced with SIWE in this specification.
Privacy and Security Considerations
- For the information retrieval, the algorithm MUST include a access control mechanisms to restrict who can call the set and get functions.
- One SHOULD include event logs to track changes in public keys.
- The curve vurve448 MUST be chosen due to its higher security level: 224-bit security instead of the 128-bit security provided by X25519.
- It is important that Bob MUST NOT reuse
SPK.
Copyright
Copyright and related rights waived via CC0.
References
- Augmented BNF for Syntax Specifications
- Gossipsub
- HMAC-based Extract-and-Expand Key Derivation Function
- Hybrid Public Key Encryption
- Security Analysis and Improvements for the IETF MLS Standard for Group Messaging
- Signed Data Standard
- Sign-In with Ethereum
- Standard Signature Validation Method for Contracts
- The Messaging Layer Security Protocol
- Toy Ethereum Private Messaging Protocol
- Uniform Resource Identifier
- WalletConnect URI Format
EXTENDED-KADEMLIA-DISCOVERY
| Field | Value |
|---|---|
| Name | Extended Kademlia Discovery with capability filtering |
| Slug | 143 |
| Status | raw |
| Category | Standards Track |
| Editor | Simon-Pierre Vivier [email protected] |
| Contributors | Hanno Cornelius [email protected] |
Timeline
- 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-17 —
9c6ba99— removal of the API section of extended kad disco spec (#310) - 2026-04-15 —
5a3e844— Chore/move repo into logos co (#312) - 2026-01-26 —
8bba444— chore: fix lint (#275) - 2026-01-23 —
8164992— chore: fix lint
Abstract
This specification defines a lightweight peer discovery mechanism
built on top of the libp2p Kademlia DHT.
It allows nodes to advertise themselves by storing a new type of peer record under
their own peer ID and enables other nodes to discover peers in the network via
random walks through the DHT.
The mechanism supports capability-based filtering of services entries,
making it suitable for overlay networks that
require connectivity to peers offering specific protocols or features.
Motivation
The standard libp2p Kademlia DHT provides content routing and peer routing toward specific keys or peer IDs, but offers limited support for general-purpose random peer discovery — i.e. finding any well-connected peer in the network.
Existing alternatives such as mDNS, Rendezvous, or bootstrap lists do not always satisfy the needs of large-scale decentralized overlay networks that require:
- Organic growth of connectivity without strong trust in bootstrap nodes
- Discovery of peers offering specific capabilities (e.g. protocols, bandwidth classes, service availability)
- Resilience against eclipse attacks and network partitioning
- Low overhead compared to gossip-based or pubsub-based discovery
By leveraging the already-deployed Kademlia routing table and random-walk behavior, this document define a simple, low-cost discovery primitive that reuses existing infrastructure while adding capability advertisement and filtering via a new record type.
Semantic
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in 2119.
Please refer to libp2p Kademlia DHT specification (Kad-DHT)
and extensible peer records specification (XPR) for terminology used in this document.
Protocol
Record Propagation
A node that wants to make itself discoverable,
also known as an advertiser,
MUST encode its discoverable information in an XPR.
The encoded information MUST be sufficient for discoverers to connect to this advertiser.
It MAY choose to encode some or all of its capabilities (and related information)
as services in the XPR.
This will allow future discoverers to filter discovered records based on desired capabilities.
In order to advertise this record,
the advertiser SHOULD first retrieve the k closest peers to its own peer ID
in its own Kad-DHT routing table.
This assumes that the routing table has been previously initialised
and follows the regular bootstrap process as per the Kad-DHT specification.
The advertiser SHOULD then send a PUT_VALUE message to these k peers
to store the XPR against its own peer ID.
This process SHOULD be repeated periodically to maintain the advertised record.
We RECOMMEND an interval of once every 30 minutes.
Use of XPR in identify
Advertisers SHOULD include their XPRs as the signedPeerRecord
in libp2p Identify messages.
Note: For more information, see the
identifyprotocol implementations, such as go-libp2p, as at the time of writing (Jan 2026) thesignedPeerRecordfield extension is not yet part of any official specification.
Record Discovery
A node that wants to discover peers to connect to,
also known as a discoverer,
SHOULD perform the following random walk discovery procedure (FIND_RANDOM):
-
Choose a random value in the
Kad-DHTkey space. (R_KEY). -
Follow the
Kad-DHTpeer routing algorithm, withR_KEYas the target. This procedure loops theKad-DHTFIND_NODEprocedure to the target key, each time receiving closer peers (closerPeers) to the target key in response, until no new closer peers can be found. Since the target is random, the discoverer SHOULD consider each previously unseen peer in each response'scloserPeersfield, as a randomly discovered node of potential interest. The discoverer MUST keep track of such peers asdiscoveredPeers. -
For each
discoveredPeer, attempt to retrieve a correspondingXPR. This can be done in one of two ways:3.1 If the
discoveredPeerin the response contains at least one multiaddress in theaddrsfield, attempt a connection to that peer and wait to receive theXPRas part of theidentifyprocedure.3.2 If the
discoveredPeerdoes not includeaddrsinformation, or the connection attempt to includedaddrsfails, or more service information is required before a connection can be attempted, MAY perform a value retrieval procedure to thediscoveredPeerID. -
For each retrieved
XPR, validate the signature against the peer ID. In addition, the discoverer MAY filter discovered peers based on the capabilities encoded within theservicesfield of theXPR. The discoverer SHOULD ignore (and disconnect, if already connected) discovered peers with invalidXPRs or that do not advertise theservicesof interest to the discoverer.
Privacy Enhancements
To prevent network topology mapping and eclipse attacks,
Kad-DHT nodes MUST NOT disclose connection type in response messages.
The connection field of every Peer MUST always be set to NOT_CONNECTED.
Copyright
Copyright and related rights waived via CC0.
References
- extended peer records specification
- libp2p Kademlia DHT specification
- RFC002 Signed Envelope
- RFC003 Routing Records
- capability discovery
EXTENSIBLE-PEER-RECORDS
| Field | Value |
|---|---|
| Name | Extensible Peer Records |
| Slug | 74 |
| Status | raw |
| Category | Standards Track |
| Editor | Hanno Cornelius [email protected] |
| Contributors | Simon-Pierre Vivier [email protected] |
Timeline
- 2026-06-03 —
7a43c29— fix: extended peer record domain & payload type (#343) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-24 —
ffca40a— Mix spam and sybil protection protocol using RLN (#252) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258)
Abstract
This RFC proposes Extensible Peer Records, an extension of libp2p's routing records, that enables peers to encode an arbitrary list of supported services and essential service-related information in distributable records. This version of routing records allows peers to communicate capabilities such as protocol support, and essential information related to such capabilities. This is especially useful when (signed) records are used in peer discovery, allowing discoverers to filter for peers matching a desired set of capability criteria. Extensible Peer Records maintain backwards compatibility with standard libp2p routing records, while adding an extensible service information field that supports finer-grained capability communication.
A note on terminology: We opt to call this structure a "peer record", even though the corresponding libp2p specification refers to a "routing record". This is because the libp2p specification itself defines an internal
PeerRecordtype, and, when serialised into a signed envelope, this is most often called a "signed peer record" (see, for example, go-libp2p identify protocol).
The keywords “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in 2119.
Motivation
We propose a new peer record as an extension of libp2p's RFC003 Routing Records that allows encoding an arbitrary list of services, and essential information pertaining to those services, supported by the peer.
There are at least two reasons why a peer might want to encode service information in its peer records:
- To augment
identifywith peer capabilities: The libp2pidentifyprotocol allows peers to exchange critical information, such as supported protocols, on first connection. The peer record (in a signed envelope) can also be exchanged duringidentify. However, peers may want to exchange finer-grained information related to supported protocols/services, that would otherwise require an application-level negotiation protocol, or that is critical to connect to the service in the first place. An example would be nodes supporting libp2pmixprotocol also needing to exchange the mix key before the service can be used. - To advertise supported services: If the peer record is used as the discoverable record for a peer (as we propose for various discovery methods) that peer may want to encode a list of supported services in its advertised record. These services may be (but is not limited to) a list of supported libp2p protocols and critical information pertaining to that service (such as the mix key, explained above). Discoverers can then filter discovered records for desired capabilities based on the encoded service information or use it to initiate the service.
Wire protocol
Extensible Peer Records
Extensible Peer Records MUST adhere to the following structure:
syntax = "proto3";
package peer.pb;
// ExtensiblePeerRecord messages contain information that is useful to share with other peers.
// Currently, an ExtensiblePeerRecord contains the public listen addresses for a peer
// and an extensible list of supported services as key-value pairs.
//
// ExtensiblePeerRecords are designed to be serialised to bytes and placed inside of
// SignedEnvelopes before sharing with other peers.
message ExtensiblePeerRecord {
// AddressInfo is a wrapper around a binary multiaddr. It is defined as a
// separate message to allow us to add per-address metadata in the future.
message AddressInfo {
bytes multiaddr = 1;
}
// peer_id contains a libp2p peer id in its binary representation.
bytes peer_id = 1;
// seq contains a monotonically-increasing sequence counter to order ExtensiblePeerRecords in time.
uint64 seq = 2;
// addresses is a list of public listen addresses for the peer.
repeated AddressInfo addresses = 3;
message ServiceInfo{
string id = 1;
optional bytes data = 2;
}
// Extensible list of advertised services
repeated ServiceInfo services = 4;
}
A peer MAY include a list of supported services in the services field.
These services could be libp2p protocols,
in which case it is RECOMMENDED that the ServiceInfo id field
be derived from the libp2p protocol identifier.
In any case, for each supported service,
the id field MUST be populated with a string identifier for that service.
In addition, the data field MAY be populated with additional information about the service.
It is RECOMMENDED that each data field be no more than 33 bytes.
(We choose 33 here to allow for the encoding of 256 bit keys with parity.
Also see Size constraints for recommendations on limiting the overall record size.)
The rest of the ExtensiblePeerRecord
MUST be populated as per the libp2p PeerRecord specification.
Due to the natural extensibility of protocol buffers,
serialised ExtensiblePeerRecords are backwards compatible with libp2p PeerRecords,
only adding the functionality related to service info exchange.
Size constraints
To limit the impact on resources,
ExtensiblePeerRecords SHOULD NOT be used to encode information
that is not essential for discovery or service initiation.
Since these records are likely to be exchanged frequently,
they should be kept as small as possible while still providing all necessary functionality.
Although specific applications MAY choose to enforce a smaller size,
it is RECOMMENDED that an absolute maximum size of 1024 bytes is enforced for valid records.
Extensible Peer Records may be included in size-constrained protocols
that further limit the size (such as DNS).
Wrapping in Signed Peer Envelopes
Extensible Peer Records MUST be wrapped in libp2p signed envelopes
before distributing them to peers.
The corresponding ExtensiblePeerRecord message is serialised into the signed envelope's payload field.
Both domain, payload type and protobuf serialization are compatible with libp2p peer record so that both records can be used interchangeably.
Signed Envelope Domain
Extensible Peer Records MUST use libp2p-peer-record as domain separator string
for the envelope signature.
Signed Envelope Payload Type
Extensible Peer Records MUST use the hexadecimal 0x0301
as the payload_type value.
The payload type is the multicodec
libp2p-peer-recordtype
Copyright
Copyright and related rights waived via CC0.
References
GOSSIPSUB-TOR-PUSH
| Field | Value |
|---|---|
| Name | Gossipsub Tor Push |
| Slug | 105 |
| Status | raw |
| Category | Standards Track |
| Editor | Daniel Kaiser [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-05-27 —
99be3b9— Move Raw Specs (#37) - 2024-02-01 —
cd8c9f4— Update and rename GOSSIPSUB-TOR-PUSH.md to gossipsub-tor-push.md - 2024-01-27 —
0db60c1— Create GOSSIPSUB-TOR-PUSH.md
Abstract
This document extends the libp2p gossipsub specification specifying gossipsub Tor Push, a gossipsub-internal way of pushing messages into a gossipsub network via Tor. Tor Push adds sender identity protection to gossipsub.
Protocol identifier: /meshsub/1.1.0
Note: Gossipsub Tor Push does not have a dedicated protocol identifier. It uses the same identifier as gossipsub and works with all pubsub based protocols. This allows nodes that are oblivious to Tor Push to process messages received via Tor Push.
Background
Without extensions, libp2p gossipsub does not protect sender identities.
A possible design of an anonymity extension to gossipsub is pushing messages through an anonymization network before they enter the gossipsub network. Tor is currently the largest anonymization network. It is well researched and works reliably. Basing our solution on Tor both inherits existing security research, as well as allows for a quick deployment.
Using the anonymization network approach, even the first gossipsub node that relays a given message cannot link the message to its sender (within a relatively strong adversarial model). Taking the low bandwidth overhead and the low latency overhead into consideration, Tor offers very good anonymity properties.
Functional Operation
Tor Push allows nodes to push messages over Tor into the gossipsub network. The approach specified in this document is fully backwards compatible. Gossipsub nodes that do not support Tor Push can receive and relay Tor Push messages, because Tor Push uses the same Protocol ID as gossipsub.
Messages are sent over Tor via SOCKS5. Tor Push uses a dedicated libp2p context to prevent information leakage. To significantly increase resilience and mitigate circuit failures, Tor Push establishes several connections, each to a different randomly selected gossipsub node.
Specification
This section specifies the format of Tor Push messages, as well as how Tor Push messages are received and sent, respectively.
Wire Format
The wire format of a Tor Push message corresponds verbatim to a typical libp2p pubsub message.
message Message {
optional string from = 1;
optional bytes data = 2;
optional bytes seqno = 3;
required string topic = 4;
optional bytes signature = 5;
optional bytes key = 6;
}
Receiving Tor Push Messages
Any node supporting a protocol with ID /meshsub/1.1.0 (e.g. gossipsub),
can receive Tor Push messages.
Receiving nodes are oblivious to Tor Push and
will process incoming messages according to the respective meshsub/1.1.0 specification.
Sending Tor Push Messages
In the following, we refer to nodes sending Tor Push messages as Tp-nodes (Tor Push nodes).
Tp-nodes MUST setup a separate libp2p context, i.e. libp2p switch, which MUST NOT be used for any purpose other than Tor Push. We refer to this context as Tp-context. The Tp-context MUST NOT share any data, e.g. peer lists, with the default context.
Tp-peers are peers a Tp-node plans to send Tp-messages to.
Tp-peers MUST support /meshsub/1.1.0.
For retrieving Tp-peers,
Tp-nodes SHOULD use an ambient peer discovery method
that retrieves a random peer sample (from the set of all peers),
e.g. 33/WAKU2-DISCV5.
Tp-nodes MUST establish a connection as described in sub-section
Tor Push Connection Establishment to at least one Tp-peer.
To significantly increase resilience,
Tp-nodes SHOULD establish Tp-connections to D peers,
where D is the desired gossipsub out-degree,
with a default value of 8.
Each Tp-message MUST be sent via the Tp-context over at least one Tp-connection. To increase resilience, Tp-messages SHOULD be sent via the Tp-context over all available Tp-connections.
Control messages of any kind, e.g. gossipsub graft, MUST NOT be sent via Tor Push.
Connection Establishment
Tp-nodes establish a /meshsub/1.1.0 connection to tp-peers via
SOCKS5 over Tor.
Establishing connections, which in turn establishes the respective Tor circuits, can be done ahead of time.
Epochs
Tor Push introduces epochs. The default epoch duration is 10 minutes. (We might adjust this default value based on experiments and evaluation in future versions of this document. It seems a good trade-off between traceablity and circuit building overhead.)
For each epoch, the Tp-context SHOULD be refreshed, which includes
- libp2p peer-ID
- Tp-peer list
- connections to Tp-peers
Both Tp-peer selection for the next epoch and establishing connections to the newly selected peers SHOULD be done during the current epoch and be completed before the new epoch starts. This avoids adding latency to message transmission.
Security/Privacy Considerations
Fingerprinting Attacks
Protocols that feature distinct patterns are prone to fingerprinting attacks when using them over Tor Push. Both malicious guards and exit nodes could detect these patterns and link the sender and receiver, respectively, to transmitted traffic. As a mitigation, such protocols can introduce dummy messages and/or padding to hide patterns.
DoS
General DoS against Tor
Using untargeted DoS to prevent Tor Push messages from entering the gossipsub network would cost vast resources, because Tor Push transmits messages over several circuits and the Tor network is well established.
Targeting the Guard
Denying the service of a specific guard node blocks Tp-nodes using the respective guard. Tor guard selection will replace this guard [TODO elaborate]. Still, messages might be delayed during this window which might be critical to certain applications.
Targeting the Gossipsub Network
Without sophisticated rate limiting (for example using 17/WAKU2-RLN-RELAY), attackers can spam the gossipsub network. It is not enough to just block peers that send too many messages, because these messages might actually come from a Tor exit node that many honest Tp-nodes use. Without Tor Push, protocols on top of gossipsub could block peers if they exceed a certain message rate. With Tor Push, this would allow the reputation-based DoS attack described in Bitcoin over Tor isn't a Good Idea.
Peer Discovery
The discovery mechanism could be abused to link requesting nodes to their Tor connections to discovered nodes. An attacker that controls both the node that responds to a discovery query, and the node who’s ENR the response contains, can link the requester to a Tor connection that is expected to be opened to the node represented by the returned ENR soon after.
Further, the discovery mechanism (e.g. discv5) could be abused to distribute disproportionately many malicious nodes. For instance if p% of the nodes in the network are malicious, an attacker could manipulate the discovery to return malicious nodes with 2p% probability. The discovery mechanism needs to be resilient against this attack.
Roll-out Phase
During the roll-out phase of Tor Push, during which only a few nodes use Tor Push, attackers can narrow down the senders of Tor messages to the set of gossipsub nodes that do not originate messages. Nodes who want anonymity guarantees even during the roll-out phase can use separate network interfaces for their default context and Tp-context, respectively. For the best protection, these contexts should run on separate physical machines.
Copyright
Copyright and related rights waived via CC0.
References
- libp2p gossipsub
- libp2p pubsub
- libp2p pubsub message
- libp2p switch
- SOCKS5
- Tor
- 33/WAKU2-DISCV5
- Bitcoin over Tor isn't a Good Idea
- 17/WAKU2-RLN-RELAY
HASHGRAPHLIKE CONSENSUS
| Field | Value |
|---|---|
| Name | Hashgraphlike Consensus Protocol |
| Slug | 73 |
| Status | raw |
| Category | Standards Track |
| Editor | Ugur Sen [email protected] |
| Contributors | seemenkina [email protected] |
Timeline
- 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-09-15 —
f051117— VAC-RAW/Consensus-hashgraphlike RFC (#142)
Abstract
This document specifies a scalable, decentralized, and Byzantine Fault Tolerant (BFT) consensus mechanism inspired by Hashgraph, designed for binary decision-making in P2P networks.
Motivation
Consensus is one of the essential components of decentralization. In particular, in the decentralized group messaging application is used for binary decision-making to govern the group. Therefore, each user contributes to the decision-making process. Besides achieving decentralization, the consensus mechanism MUST be strong:
-
Under the assumption of at least
2/3honest users in the network. -
Each user MUST conclude the same decision and scalability: message propagation in the network MUST occur within
O(log n)rounds, wherenis the total number of peers, in order to preserve the scalability of the messaging application.
Format Specification
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in 2119.
Flow
Any user in the group initializes the consensus by creating a proposal.
Next, the user broadcasts the proposal to the whole network.
Upon each user receives the proposal, validates the proposal,
adds its vote as yes or no and with its signature and timestamp.
The user then sends the proposal and vote to a random peer in a P2P setup,
or to a subscribed gossipsub channel if gossip-based messaging is used.
Therefore, each user first validates the signature and then adds its new vote.
Each sending message counts as a round.
After log(n) rounds all users in the network have the others vote
if at least 2/3 number of users are honest where honesty follows the protocol.
In general, the voting-based consensus consists of the following phases:
- Initialization of voting
- Exchanging votes across the rounds
- Counting the votes
Assumptions
- The users in the P2P network can discover the nodes or they are subscribing same channel in a gossipsub.
- We MAY have non-reliable (silent) nodes.
- Proposal owners MUST know the number of voters.
1. Initialization of voting
A user initializes the voting with the proposal payload which is implemented using protocol buffers v3 as follows:
syntax = "proto3";
package vac.voting;
message Proposal {
string name = 10; // Proposal name
string payload = 11; // Proposal description
uint32 proposal_id = 12; // Unique identifier of the proposal
bytes proposal_owner = 13; // Public key of the creator
repeated Vote votes = 14; // Vote list in the proposal
uint32 expected_voters_count = 15; // Maximum number of distinct voters
uint32 round = 16; // Number of rounds
uint64 timestamp = 17; // Creation time of proposal
uint64 expiration_timestamp = 18; // The timestamp at which the proposal becomes outdated
bool liveness_criteria_yes = 19; // Shows how managing the silent peers vote
}
message Vote {
uint32 vote_id = 20; // Unique identifier of the vote
bytes vote_owner = 21; // Voter's public key
uint32 proposal_id = 22; // Linking votes and proposals
uint64 timestamp = 23; // Time when the vote was cast
bool vote = 24; // Vote bool value (true/false)
bytes parent_hash = 25; // Hash of previous owner's Vote
bytes received_hash = 26; // Hash of previous received Vote
bytes vote_hash = 27; // Hash of all previously defined fields in Vote
bytes signature = 28; // Signature of vote_hash
}
To initiate a consensus for a proposal,
a user MUST complete all the fields in the proposal, including attaching its vote
and the payload that shows the purpose of the proposal.
Notably, parent_hash and received_hash are empty strings because there is no previous or received hash.
Then the initialization section ends when the user who creates the proposal sends it
to the random peer from the network or sends it to the proposal to the specific channel.
2. Exchanging votes across the peers
Once the peer receives the proposal message P_1 from a 1-1 or a gossipsub channel does the following checks:
-
Check the signatures of the each votes in proposal, in particular for proposal
P_1, verify the signature ofV_1whereV_1 = P_1.votes[0]withV_1.signatureandV_1.vote_owner -
Do
parent_hashcheck: If there are repeated votes from the same sender, check that the hash of the former vote is equal to theparent_hashof the later vote. -
Do
received_hashcheck: If there are multiple votes in a proposal, check that the hash of a vote is equal to thereceived_hashof the next one. -
After successful verification of the signature and hashes, the receiving peer proceeds to generate
P_2containing a new voteV_2as following:4.1. Add its public key as
P_2.vote_owner.4.2. Set
timestamp.4.3. Set boolean
vote.4.4. Define
V_2.parent_hash = 0if there is no previous peer's vote, otherwise hash of previous owner's vote.4.5. Set
V_2.received_hash = hash(P_1.votes[0]).4.6. Set
proposal_idfor thevote.4.7. Calculate
vote_hashby hash of all previously defined fields in Vote:V_2.vote_hash = hash(vote_id, owner, proposal_id, timestamp, vote, parent_hash, received_hash)4.8. Sign
vote_hashwith its private key corresponding the public key asvote_ownercomponent then addsV_2.vote_hash. -
Create
P_2with by addingV_2as follows:5.1. Assign
P_2.name,P_2.proposal_id, andP_2.proposal_ownerto be identical to those inP_1.5.2. Add the
V_2to theP_2.Voteslist.5.3. Increase the round by one, namely
P_2.round = P_1.round + 1.5.4. Verify that the proposal has not expired by checking that:
current_time in [P_timestamp, P_expiration_timestamp]. If this does not hold, other peers ignore the message.
After the peer creates the proposal P_2 with its vote V_2,
sends it to the random peer from the network or
sends it to the proposal to the specific channel.
3. Determining the result
Because consensus depends on meeting a quorum threshold,
each peer MUST verify the accumulated votes to determine whether the necessary conditions have been satisfied.
The voting result is set YES if the majority of the 2n/3 from the distinct peers vote YES.
To verify, the findDistinctVoter method processes the proposal by traversing its Votes list to determine the number of unique voters.
If this method returns true, the peer proceeds with strong validation, which ensures that if any honest peer reaches a decision, no other honest peer can arrive at a conflicting result.
-
Check each
signaturein the vote as shown in the Section 2. -
Check the
parent_hashchain if there are multiple votes from the same owner namelyvote_iandvote_i+1respectively, the parent hash ofvote_i+1should be the hash ofvote_i -
Check the
previous_hashchain, each received hash ofvote_i+1should be equal to the hash ofvote_i. -
Check the
timestampagainst the replay attack. In particular, thetimestampcannot be the old in the determined threshold. -
Check that the liveness criteria defined in the Liveness section are satisfied.
If a proposal is verified by all the checks,
the countVote method counts each YES vote from the list of Votes.
4. Properties
The consensus mechanism satisfies liveness and security properties as follows:
Liveness
Liveness refers to the ability of the protocol to eventually reach a decision when sufficient honest participation is present.
In this protocol, if n > 2 and more than n/2 of the votes among at least 2n/3 distinct peers are YES,
then the consensus result is defined as YES; otherwise, when n ≤ 2, unanimous agreement (100% YES votes) is required.
The peer calculates the result locally as shown in the Section 3. From the hashgraph property, if a node could calculate the result of a proposal, it implies that no peer can calculate the opposite of the result. Still, reliability issues can cause some situations where peers cannot receive enough messages, so they cannot calculate the consensus result.
Rounds are incremented when a peer adds and sends the new proposal.
Calculating the required number of rounds, 2n/3 from the distinct peers' votes is achieved in two ways:
2n/3rounds in pure P2P networks2rounds in gossipsub
Since the message complexity is O(1) in the gossipsub channel,
in case the network has reliability issues,
the second round is used for the peers cannot receive all the messages from the first round.
If an honest and online peer has received at least one vote but not enough to reach consensus, it MAY continue to propagate its own vote — and any votes it has received — to support message dissemination. This process can continue beyond the expected round count, as long as it remains within the expiration time defined in the proposal. The expiration time acts as a soft upper bound to ensure that consensus is either reached or aborted within a bounded timeframe.
Equality of votes
An equality of votes occurs when verifying at least 2n/3 distinct voters and
applying liveness_criteria_yes the number of YES and NO votes is equal.
Handling ties is an application-level decision. The application MUST define a deterministic tie policy:
RETRY: re-run the vote with a new proposal_id, optionally adjusting parameters.
REJECT: abort the proposal and return voting result as NO.
The chosen policy SHOULD be consistent for all peers via proposal's payload to ensure convergence on the same outcome.
Silent Node Management
Silent nodes are the nodes that not participate the voting as YES or NO. There are two possible counting votes for the silent peers.
- Silent peers means YES: Silent peers counted as YES vote, if the application prefer the strong rejection for NO votes.
- Silent peers means NO: Silent peers counted as NO vote, if the application prefer the strong acception for NO votes.
The proposal is set to default true, which means silent peers' votes are counted as YES namely liveness_criteria_yes is set true by default.
Security
This RFC uses cryptographic primitives to prevent the malicious behaviours as follows:
- Vote forgery attempt: creating unsigned invalid votes
- Inconsistent voting: a malicious peer submits conflicting votes (e.g., YES to some peers and NO to others) in different stages of the protocol, violating vote consistency and attempting to undermine consensus.
- Integrity breaking attempt: tampering history by changing previous votes.
- Replay attack: storing the old votes to maliciously use in fresh voting.
5. Copyright
Copyright and related rights waived via CC0
6. References
LIONESS-PAYLOAD-ENCRYPTION-FOR-MIX
| Field | Value |
|---|---|
| Name | LIONESS encryption scheme for LIBP2P-MIX payload encryption |
| Slug | 183 |
| Status | raw |
| Category | Standards Track |
| Editor | Mohammed Alghazwi [email protected] |
| Contributors | Balázs Kőműves [email protected] |
Timeline
- 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-28 —
15f410b— chore: fix math issue (#349) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-25 —
f1017b9— Add LIONESS specification for Mix payload encryption (#329)
Abstract
This specification defines the LIONESS wide-block encryption scheme for the Sphinx payload encryption. The purpose of this is to perform layered-encryption and preserve payload integrity in the Sphinx construction used by the Mix Protocol while keeping the payload fixed-size. The routing header integrity mechanism defined in the Mix Protocol remains unchanged. Only the payload field is affected by this specification.
Scope
This specification defines:
- the LIONESS construction to use for payload encryption and decryption,
- the concrete primitives used to instantiate LIONESS for the Mix Protocol.
- the required Sphinx payload format and construction.
- the hop payload processing and integrity verification.
1. Introduction
The Mix Protocol uses a Sphinx packet format with four fields (). The header fields () provide per-hop layered-encrypted routing information which includes header integrity. The payload field carries only the application message in layered-encrypted form.
In the current Mix Protocol, AES-CTR is used to encrypt the routing header . This is sufficient for because header integrity is separately protected by the per-hop MAC field . However, the integrity of is not covered by , since the Sphinx design intentionally separates header integrity from payload integrity.
This separation is necessary because SURB replies require the sender of the SURB to construct the return header before the reply payload is known. As a result, payload integrity MUST be provided independently of header integrity.
A malleable encryption scheme such as AES-CTR does not satisfy this requirement. Bit modifications to the ciphertext result in modifications to the decrypted plaintext. This violates the integrity of the Sphinx payload. Therefore, the payload-encryption scheme MUST satisfy the following:
- It MUST preserve the fixed payload size .
- It MUST support layered encryption and per-hop layer removal.
- It MUST be compatible with SURBs and therefore MUST NOT require payload-dependent header authentication.
- It MUST allow the final hop to detect payload tampering.
- It MUST avoid adding external authentication material/tags that change the packet or payload size.
To achieve this, this specification uses LIONESS as described in anderson et al. LIONESS is a wide-block cipher built from a stream cipher and a keyed hash function. LIONESS acts as a pseudo-random permutation (PRP) over the entire payload block, allowing us to add the payload integrity prefix into the plaintext and verify it after decryption.
2. Terminology
The following terms are used throughout this specification. Other terms are as defined in the Mix Protocol.
- Sphinx packet: The packet format as defined in the Mix Protocol, consisting of ().
- Sphinx payload () The fixed-size encrypted field of a Sphinx packet. It carries the padded application message and any payload extensions such as SURBs.
- Payload integrity prefix A fixed all-zero byte string prepended to the plaintext payload before applying the payload encryption. The final hop verifies this prefix after payload decryption to detect payload tampering.
- Payload encryption key () A per-hop key used to encrypt or decrypt one layer of the Sphinx payload field . For LIONESS payload encryption, this key is used as the seed for deriving the internal LIONESS round keys.
- Round keys: The four keys used by the LIONESS Feistel network.
- Wide-block cipher: A block cipher with a large block size compared to conventional fixed-size block ciphers such as AES. LIONESS is a wide-block cipher that supports variable-length input blocks above a lower bound.
- Pseudo-random permutation (PRP): A keyed permutation over a fixed-size message block that is computationally indistinguishable from a uniformly random permutation. Changing even one bit of the input is expected to produce unpredictable changes to a large number of output bits.
3. Cryptographic Primitives
This section defines the primitives used by this specification. In this specification, we will assume the following constants:
- The security parameter bytes (-bits) as defined in the Mix Protocol.
- The LIONESS internal parameter bytes, which defines the size of multiple LIONESS components.
3.1 Stream Cipher
The stream cipher used in LIONESS can be abstracted as the following keyed function that produces an arbitrary-length keystream:
where:
- is a -byte key
- is the output arbitrary-length keystream.
Encryption and decryption can then be done by first generating a key stream and then XORing the key stream with the message/ciphertext. Encryption and decryption work in the same way:
where is the plaintext and is the ciphertext.
- is the arbitrary-length message
- is the arbitrary-length ciphertext of the same size as , i.e.,
3.2 Keyed Hash Function
In this specification, the keyed hash function used in LIONESS is denoted as:
where:
- is a -byte key
- is an arbitrary-length input message.
- is the -byte digest output
3.3 Key Derivation Function (KDF)
The key derivation function is used to derive fixed-size keys from a domain-separation string and a seed:
where
- : is an arbitrary-length domain-separation string.
- : is an arbitrary-length seed at least bytes in size.
- is a -byte output key.
4. Concrete Primitive Instantiation
This section defines the concrete primitive choices used by this specification.
4.1 Stream Cipher Instantiation
The LIONESS stream cipher is instantiated using AES-CTR.
Each LIONESS stream-cipher round key is bytes. For AES-CTR, this -byte value is split as follows:
where:
- is the first bytes of .
- is the last bytes of .
4.2 Keyed Hash Instantiation
The LIONESS keyed hash function is instantiated as SHA-256 with the key prepended to the input message:
where:
- is a -byte key.
- is the input message.
- the output is a -byte digest.
This construction is used only as the keyed hash function inside the LIONESS Feistel construction. It is not (and must not be used as) a general-purpose MAC.
4.3 KDF Instantiation
The KDF is instantiated using SHA-256 with domain-separation:
where:
- is a domain-separation string.
- is an arbitrary-length seed at least bytes in size.
- the output is a -byte key.
The following domain-separation strings are used by this specification:
| Purpose | Domain-separator |
|---|---|
| Payload encryption key | payload_enc_key |
| LIONESS round key | lioness_key1 |
| LIONESS round key | lioness_key2 |
| LIONESS round key | lioness_key3 |
| LIONESS round key | lioness_key4 |
5. LIONESS Construction
5.1 High-level API
In general, the LIONESS wide-block cipher provides the following:
where:
- is the arbitrary-length LIONESS seed from which the internal round keys are derived, with size at least bytes
- is the plaintext message with size bytes.
- is the corresponding ciphertext with size
5.2 Block Structure
LIONESS is a wide-block cipher, meaning that its block size is large compared to conventional fixed-size block ciphers such as AES. In this specification, LIONESS is applied once to the entire Sphinx payload . The whole payload is treated as a single message block, and LIONESS acts as a PRP over that full payload block. For both LIONESS encryption and decryption, the input block is split into two chunks:
where:
- is the plaintext message block of any size
- is the left chunk with size bytes
- is the right chunk with size bytes.
In this specification, we require the size of the message to be at least , i.e., . This requirement ensures that and . The Mix protocol payload size satisfies this requirement since the expected payload is much larger than .
In summary, we set bytes. Therefore:
- bytes
- bytes,
- bytes.
The choice bytes must match:
- the stream cipher () key size, and
- the keyed hash () key size and digest () size.
As a result, we can observe that for large messages, the right chunk is expected to be much larger than the left chunk.
+----------------+----------------------------------+
| L | R |
| mu bytes | (|B| - mu) bytes |
+----------------+----------------------------------+
5.3 Key Derivation
LIONESS requires four internal round keys, one for each round: :
- and are the keys used for the stream cipher.
- and are the keys used for the keyed hash function.
All internal round keys are bytes in size. Given a LIONESS seed , we require four calls to the , each with a different domain-separation string:
The LIONESS seed is arbitrary-length and MUST be at least bytes. The derivation of the seed depends on whether the packet is a forward packet or a reply packet. Further details are specified in Section 6 and section 7.
5.4 Encryption
Let:
- plaintext message
- round keys
- is the stream cipher as defined in section 3.1
- is the keyed hash function as defined in section 3.2
LIONESS encryption proceeds with applying a small Feistel network of four rounds:
round 1: R1 = R0 ^ S(L0 ^ K1)
+-----------+ +-----------+
| L0 | | R0 |
+-----------+ +-----------+
| K1 |
| │ | xor
| │ v
| v +-------------+
+----------------xor------------>| S |
+-------------+
|
v
+-----------+ +-----------+
| L0 | | R1 |
+-----------+ +-----------+
round 2: L1 = L0 ^ H_K2(R1)
+-----------+ +-----------+
| L0 | | R1 |
+-----------+ +-----------+
| |
| xor |
v |
+-------------+<------------------------------+
| H |<----- K2
+-------------+
|
v
+-----------+ +-----------+
| L1 | | R1 |
+-----------+ +-----------+
round 3: R2 = R1 ^ S(L1 ^ K3)
+-----------+ +-----------+
| L1 | | R1 |
+-----------+ +-----------+
| K3 |
| │ | xor
| │ v
| v +-------------+
+---------------xor------------->| S |
+-------------+
|
v
+-----------+ +-----------+
| L1 | | R2 |
+-----------+ +-----------+
round 4: L2 = L1 ^ H_K4(R2)
+-----------+ +-----------+
| L1 | | R2 |
+-----------+ +-----------+
| |
| xor |
v |
+-------------+<------------------------------+
| H |<----- K4
+-------------+
|
v
+-----------+ +-----------+
| L2 | | R2 |
+-----------+ +-----------+
5.5 Decryption
LIONESS decryption is the inverse of the four internal rounds defined in the previous section:
6. Payload Construction
This section specifies how the Sphinx payload is constructed using the LIONESS wide-block encryption. Some parts of this section restates the Mix specification for clarity. For full specification of how the Sphinx packet is constructed, refer to the mix protocol specification.
6.1 Payload Plaintext Format
Before layered encryption, the sender MUST construct the payload plaintext as the following concatenation:
where:
- is the payload integrity prefix, consisting of zero bytes.
- is the application message padded to fill the remaining payload space.
Thus:
- bytes
The size of the payload is specified in the Mix protocol, and if the application message is small payload padding is added as specified in the mix protocol.
6.2 Sphinx Payload Construction
6.2.1 Forward Payload
Once the plaintext is formatted as specified in section 6.1, it needs to be encrypted in layers such that each hop in the mix path removes exactly one layer using the per-hop session key. This ensures that only the final hop (i.e., the exit node) can fully recover the plaintext message , validate its integrity, and forward it to the destination. To compute the encrypted payload, perform the following steps for each hop down to , recursively:
-
Derive the payload encryption key:
where is the per-hop shared secret for hop
ias defined in the Mix protocol specification. -
Using , compute the encrypted payload :
- If (i.e., exit node):
- Otherwise (i.e., intermediary node):
The resulting is placed into the final Sphinx packet.
6.2.2 Reply payload (SURB payload)
For a SURB reply, the reply sender (i.e., the SURB user not the SURB creator) does not know the return-path shared secrets . Instead, it only has the first node in the return path (), a pre-computed Sphinx header (), and a reply key ().
Therefore, the reply sender encrypts the reply payload only once using as the LIONESS seed:
Note that the reply key is bytes in size as defined in the Mix Protocol, so it satisfies the LIONESS seed requirement. The resulting is placed into the SURB reply packet. Then each hop on the return path subsequently applies the normal payload-processing rule, namely one LIONESS decryption under its per-hop payload encryption key, resulting in one layer of LIONESS encryption and layers of LIONESS decryptions. These return path layers are later removed during reply recovery as described in section 7.3.
7. Sphinx Payload Processing
Once the Sphinx packet is deserialized into () and the header is preprocessed as specified in the Mix protocol, the mix node performs the following steps depending on its role (as defined in the Mix Protocol, Section 8.6.2):
7.1 Intermediary Processing
If the node is an intermediary, it MUST:
-
Derive the payload encryption key using the shared secret :
-
Decrypt one layer of the payload using the payload encryption key :
-
use as the outgoing payload,
-
forward the updated packet as defined by the Mix Protocol.
7.2 Exit Processing - Forward packet
If the node is the exit, and the packet is not a reply (using SURBs), it MUST:
- Derive the payload encryption key using the shared secret in the same way as defined in section 7.1 step 1.
- Decrypt one layer of the payload using the payload encryption key in the same way as defined in section 7.1 step 2.
- perform the payload integrity prefix check as follows:
- parse the decrypted payload as , where bytes.
- verify that
- discard the packet if this payload integrity prefix check fails.
- otherwise remove (i.e., the bytes of payload integrity prefix) and return .
- pass to the Mix Exit Layer.
7.3 Exit Processing - Reply packet
If the node is the exit, and the packet is a reply, it MUST:
-
reverse the return-path transformations, i.e., since the hops apply LIONESS decryption, the exit must apply LIONESS encryption. Therefore, the node must perform the same LIONESS layered encryption pattern as defined in Section 6.2.1, with the reply payload used as the initial input instead of the plaintext payload block .
-
Decrypt the final layer i.e., reversing the effect of the initial encryption in section 6.2.2:
-
perform the payload integrity prefix check as defined in section 7.2 step 3 and then pass to the Mix Exit Layer.
Note: We assume here that the exit is the SURB creator, if not then the exit will simply forward to the destination which will process the reply payload as specified above.
8. Security Considerations
8.1 LIONESS Blocks/Messages
This specification requires the LIONESS input block to be at least bytes, i.e., 64 bytes since we assume .
LIONESS splits the input block into two parts
where:
- bytes,
- bytes.
Therefore, the 64-byte minimum ensures that both and contain at least bytes. The Mix Protocol payload size is expected to be much larger than this minimum, so this requirement is satisfied by normal Mix payloads.
8.2 LIONESS Integrity
This specification does not use an explicit payload authentication tag. Instead, integrity is obtained by:
- embedding a fixed payload integrity prefix, specified as bytes of zeros, into the plaintext,
- encrypting the whole payload as a single block with LIONESS.
Because the payload is encrypted as a single block, LIONESS acts as a pseudo-random permutation (PRP) over the entire payload, a modification to the ciphertext will, except with negligible probability, produce a decrypted plaintext whose first bytes are not all zero. Replacing LIONESS with a malleable stream construction invalidates this property.
8.3 Primitive Choices
The security of LIONESS depends on the security of the primitives used to instantiate it:
- the stream cipher ,
- the keyed hash function ,
- the key derivation function .
For detailed analysis on the security of LIONESS, refer to the paper.
9. Reference Implementations
These reference implementations are generic and can support any compatible , , and .
10. Future Work
The following are under research/consideration:
- support for faster alternative wide-block ciphers:
References
LOGOS-SERVICE-DISCOVERY
| Field | Value |
|---|---|
| Name | Logos Service Discovery Protocol |
| Slug | 107 |
| Status | raw |
| Category | Standards Track |
| Editor | Arunima Chaudhuri [email protected] |
| Contributors | Ugur Sen [email protected], Hanno Cornelius [email protected] |
Timeline
- 2026-07-18 —
6d7d58e— Clarify lower bound enforcement and update logic for waiting time (#322) - 2026-07-17 —
15f7006— docs(service-discovery): fix bucket index formula in Distance section (#374) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-06-03 —
7a43c29— fix: extended peer record domain & payload type (#343) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-15 —
5a3e844— Chore/move repo into logos co (#312) - 2026-03-24 —
513d8ea— feat: renaming capability to service discovery (#300) - 2026-02-27 —
2ec272e— docs: refactor and add algo explanation before pseudocode (#280) - 2026-01-27 —
ab9337e— Add recipe for algorithms (#232) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-12-09 —
aaf158a— VAC/RAW/LOGOS-DISCOVERY-CAPABILITY RFC (#212)
Note: This specification is currently a WIP and undergoing a high rate of changes.
Abstract
This RFC defines the Logos Service Discovery protocol, a discovery mechanism inspired by DISC-NG service discovery built on top of Kad-dht.
The protocol enables nodes to:
- Advertise their participation in specific services
- Efficiently discover other peers participating in those services
In this RFC, the terms "capability" and "service" are used interchangeably. Within Logos, a node’s “capabilities” map directly to the “services” it participates in. Similarly, "peer" and "node" refer to the same entity: a participant in the Logos Discovery network.
Logos discovery extends Kad-dht toward a multi-service, resilient discovery layer, enhancing reliability while maintaining compatibility with existing Kad-dht behavior. For everything else that isn't explicitly stated herein, it is safe to assume behaviour similar to Kad-dht.
Motivation
In decentralized networks supporting multiple services, efficient peer discovery for specific services is critical. Traditional approaches face several challenges:
- Inefficiency: Random-walk–based discovery is inefficient for unpopular services.
- Load imbalance: A naive approach where nodes advertise their service at DHT peers whose IDs are closest to the service ID leads to hotspots and overload at popular services.
- Scalability: Discovery must scale logarithmically across many distinct services.
Logos discovery addresses these through:
- Service-specific routing tables
- Adaptive advertisement placement with admission control
- Improved lookup operations balancing efficiency and resilience
Format Specification
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in 2119.
Protocol Roles
The Logos service discovery protocol defines three roles that nodes can perform:
Advertiser
Advertisers are nodes that participate in a service and want to be discovered by other peers.
Discoverer
Discoverers are nodes attempting to find peers that provide a specific service.
Registrar
Registrars are nodes that store and serve advertisements.
Responsibilities:
- Registrars MUST use a waiting time based admission control mechanism to decide whether to store an advertisement coming from an advertiser or not.
- Registrars SHOULD respond to query requests for advertisements coming from discoverers.
Definitions
DHT Routing Table
Every participant in the kad-dht peer discovery layer
maintains the peer routing table KadDHT(peerID).
It is a distributed key-value store with
peer IDs
as key against their matching
signed peer records values.
It is centered on the node's own peerID.
“Centered on” means the table is organized using that ID as the reference point for computing distances with other peers and assigning peers to buckets.
Bucket
Each routing table is organized into buckets. A bucket is a logical container that stores information about peers at a particular distance range from a reference ID.
Conceptually:
- Each bucket corresponds to a specific range in the XOR distance metric
- Peers are assigned to buckets based on their XOR distance from the table's center ID
- Buckets enable logarithmic routing by organizing the keyspace into manageable segments
The number of buckets and their organization is described in the Distance section. Implementation considerations for bucket management are detailed in Bucket Management section.
Service
A service is a logical sub-network within the larger peer-to-peer network.
It represents a specific capability a node supports
— for example, a particular protocol or functionality it offers.
A service MUST be identified by a libp2p protocol ID via the
identify protocol.
This service protocol ID (e.g., /waku/store/1.0.0)
identifies the capability being discovered.
Service ID
The service ID service_id_hash MUST be the SHA-256 hash of the protocol ID.
For example:
| Service Identifier | Service ID |
|---|---|
/waku/store/1.0.0 | 313a14f48b3617b0ac87daabd61c1f1f1bf6a59126da455909b7b11155e0eb8e |
/libp2p/mix/1.2.0 | 9c55878d86e575916b267195b34125336c83056dffc9a184069bcb126a78115d |
Advertisement Cache
An advertisement cache ad_cache is a bounded storage structure
maintained by registrars to store accepted advertisements.
Advertise Table
For every service it participates in, an advertiser node MUST maintain an
advertise table AdvT(service_id_hash) centered on service_id_hash.
The table MAY be initialized using
peers from the advertiser’s KadDHT(peerID) routing table.
It SHOULD be updated opportunistically through interactions with
registrars during the advertisement process.
Each bucket in the advertise table contains a list of registrar peers at a
particular XOR distance range from service_id_hash, which are candidates for placing
advertisements.
Search Table
For every service it attempts to discover, a discoverer node MUST maintain a
search table DiscT(service_id_hash) centered on service_id_hash.
The table MAY be initialized using
peers from the discoverer’sKadDHT(peerID) routing table.
It SHOULD be updated through interactions with
registrars during lookup operations.
Each bucket in the search table contains a list of registrar peers at a
particular XOR distance range from service_id_hash, which discoverers can query to
retrieve advertisements for that service.
Registrar Table
For every service for which it stores and serves advertisements,
a registrar node SHOULD maintain a registrar table RegT(service_id_hash)
centered on service_id_hash.
The table MAY be initialized using peers from the
registrar’s KadDHT(peerID) routing table.
It SHOULD be updated opportunistically
through interactions with advertisers and discoverers.
Each bucket in the registrar table contains a list of peer nodes
at a particular XOR distance range from service_id_hash.
Registrars use this table to return
closerPeers in REGISTER and GET_ADS responses,
enabling advertisers and discoverers to
refine their service-specific routing tables.
Address
A multiaddress is a standardized way used in libp2p to represent network addresses. Implementations SHOULD use multiaddresses for peer connectivity. However, implementations MAY use alternative address representations if they:
- Remain interoperable
- Convey sufficient information (IP + port) to establish connections
Signature
Refer to Peer Ids and Keys
to know about supported signatures.
In the base Kad DHT specification, signatures are optional,
typically implemented as a PKI signature over the tuple (key || value || author).
In this RFC digital signatures MUST be used to
authenticate advertisements and tickets.
Expiry Time E
E is advertisement expiry time in seconds.
The expiry time E is a system wide parameter,
not an individual advertisement field or parameter of an individual registrar.
Data Structures
Advertisement
An advertisement indicates that a specific node participates in a service.
In this RFC we refer to advertisement objects as ads.
For a single advertisement object we use ad.
An advertisement logically represents:
- Service identification: Which service the node participates in (via
service_id_hash) - Peer identification: The advertiser's unique peer ID
- Network addresses: How to reach the advertiser (multiaddrs)
- Authentication: Cryptographic proof that the advertiser controls the peer ID
Implementations are RECOMMENDED to use ExtensiblePeerRecord (XPR) encoding for advertisements. See the Advertisement Encoding section in the wire protocol specification for transmission format details.
Ticket
Tickets are digitally signed objects issued by registrars to advertisers to track accumulated waiting time for admission into the advertisement cache.
A ticket logically represents:
- Advertisement reference: The advertisement this ticket is associated with
- Time tracking: When the ticket was created (
t_init) and last modified (t_mod) - Waiting time: How long the advertiser must wait before retrying (
t_wait_for) - Authentication: Cryptographic proof that the registrar issued this ticket
Tickets enable stateless admission control at registrars. Advertisers accumulate waiting time across registration attempts by presenting tickets from previous attempts.
See the RPC Messages section for the wire format specification of tickets.
Protocol Specifications
System Parameters
The system parameters are derived directly from the DISC-NG paper. Implementations SHOULD modify them as needed based on specific requirements.
| Parameter | Default Value | Description |
|---|---|---|
K_register | 3 | Max number of active (i.e. unexpired) registrations + ongoing registration attempts per bucket. |
K_lookup | 5 | For each bucket in the search table, number of random registrar nodes queried by discoverers |
F_lookup | 30 | number of advertisers to find in the lookup process. We stop lookup process when we have found these many advertisers |
F_return | 10 | max number of service-specific peers returned from a single registrar |
E | 900 seconds | Advertisement expiry time (15 minutes) |
C | 1,000 | Advertisement cache capacity |
P_occ | 10 | Occupancy exponent for waiting time calculation |
G | 10⁻⁷ | Safety parameter for waiting time calculation |
δ | 1 second | Registration window time |
m | 16 | Number of buckets for service-specific tables |
Distance
The distance d between any two keys in Logos Service Discovery
MUST be calculated using the bitwise XOR applied to their 256-bit SHA-256 representations.
This provides a deterministic, uniform, and symmetric way to measure proximity in the keyspace.
The keyspace is the entire numerical range of possible peerID and service_id_hash
— the 256-bit space in which all SHA-256–derived IDs exist.
XOR MUST be used to measure distances between them in the keyspace.
For every node in the network, the peerID is unique.
In this system, both peerID and the service_id_hash are 256-bit SHA-256 hashes.
Thus both belong to the same keyspace.
KadDHT(peerID) table is centered on peerID.
AdvT(service_id_hash), DiscT(service_id_hash)
and RegT(service_id_hash) are service-specific tables
and MUST be centered on service_id_hash.
Bootstrapping of service-specific tables
MAY be done from the KadDHT(peerID) table.
When inserting a peer into the service-specific tables, the bucket index into which the peer will be inserted MUST be determined by:
- x = reference ID which is the
service_id_hash - y = target peer ID
peerID - L = 256 = bit length of IDs
m= 16 = number of buckets in the advertise/search tabled = x ⊕ y = service_id_hash ⊕ peerID= bitwise XOR distance (interpreted as an unsigned integer)
The bucket index i where y is placed in x's table is calculated as:
- Let
lz = CLZ(d)= number of leading zeros in the 256-bit representation ofd i = min( lz , m − 1 )- Special case: For
d = 0(same ID),i = m - 1
Lower-index buckets represent peers far away from service_id_hash in the keyspace,
while higher-index buckets contain peers closer to service_id_hash.
This property allows efficient logarithmic routing:
each hop moves to a peer that shares a longer prefix of bits
with the target service_id_hash.
Service-specific tables may initially have low peer density,
especially when service_id_hash and peerID are distant in the keyspace.
Buckets SHOULD be filled opportunistically through response.closerPeers
during interactions (see Peer Table Updates)
using the same formula.
RPC Messages
All RPC messages use the libp2p Kad-DHT message format with extensions for Logos discovery operations.
Base Message Structure
syntax = "proto2";
message Register {
// Used in response to indicate the status of the registration
enum RegistrationStatus {
CONFIRMED = 0;
WAIT = 1;
REJECTED = 2;
}
// Ticket protobuf definition
message Ticket {
// Copy of the original advertisement
bytes advertisement = 1;
// Ticket creation timestamp (Unix time in seconds)
uint64 t_init = 2;
// Last modification timestamp (Unix time in seconds)
uint64 t_mod = 3;
// Remaining wait time in seconds
uint32 t_wait_for = 4;
// Ed25519 signature over (ad || t_init || t_mod || t_wait_for)
bytes signature = 5;
}
// Used to indicate the encoded advertisement against the key (service ID)
bytes advertisement = 1;
// Used in response to indicate the status of the registration
RegistrationStatus status = 2;
// Used in response to provide a ticket if status is WAIT
// Used in request to provide a ticket if previously received
optional Ticket ticket = 3;
}
message GetAds {
// Used in response to provide a list of encoded advertisements
repeated bytes advertisements = 1;
}
// Record represents a dht record that contains a value
// for a key value pair
message Record {
// The key that references this record
bytes key = 1;
// The actual value this record is storing
bytes value = 2;
// Note: These fields were removed from the Record message
//
// Hash of the authors public key
// optional string author = 3;
// A PKI signature for the key+value+author
// optional bytes signature = 4;
// Time the record was received, set by receiver
// Formatted according to https://datatracker.ietf.org/doc/html/rfc3339
string timeReceived = 5;
};
message Message {
enum MessageType {
PUT_VALUE = 0;
GET_VALUE = 1;
ADD_PROVIDER = 2;
GET_PROVIDERS = 3;
FIND_NODE = 4;
PING = 5;
REGISTER = 6; // New DISC-NG capability discovery type
GET_ADS = 7; // New DISC-NG capability discovery type
}
enum ConnectionType {
// sender does not have a connection to peer, and no extra information (default)
NOT_CONNECTED = 0;
// sender has a live connection to peer
CONNECTED = 1;
// sender recently connected to peer
CAN_CONNECT = 2;
// sender recently tried to connect to peer repeatedly but failed to connect
// ("try" here is loose, but this should signal "made strong effort, failed")
CANNOT_CONNECT = 3;
}
message Peer {
// ID of a given peer.
bytes id = 1;
// multiaddrs for a given peer
repeated bytes addrs = 2;
// used to signal the sender's connection capabilities to the peer
ConnectionType connection = 3;
}
// defines what type of message it is.
MessageType type = 1;
// defines what coral cluster level this query/response belongs to.
// in case we want to implement coral's cluster rings in the future.
int32 clusterLevelRaw = 10; // NOT USED
// Used to specify the key associated with this message.
// PUT_VALUE, GET_VALUE, ADD_PROVIDER, GET_PROVIDERS
// New DISC-NG capability discovery contains service ID hash for types REGISTER, GET_ADS
bytes key = 2;
// Used to return a value
// PUT_VALUE, GET_VALUE
Record record = 3;
// Used to return peers closer to a key in a query
// GET_VALUE, GET_PROVIDERS, FIND_NODE
repeated Peer closerPeers = 8;
// Used to return Providers
// GET_VALUE, ADD_PROVIDER, GET_PROVIDERS
repeated Peer providerPeers = 9;
// Used in REGISTER request and response
Register register = 21;
// Used in GET_ADS response
GetAds getAds = 22;
}
Key Design Principles:
- Standard Kad-DHT message types (
PUT_VALUE,GET_VALUE,ADD_PROVIDER,GET_PROVIDERS,FIND_NODE,PING) remain completely unchanged - The
Recordmessage is preserved as-is for Kad-DHT routing table operations - Logos adds two new message types (
REGISTER,GET_ADS) without modifying existing types - Advertisements are encoded as generic
bytes(RECOMMENDED: ExtensiblePeerRecord/XPR) to avoid coupling the protocol to specific formats - The existing
keyfield is reused forservice_id_hashin Logos operations - Nodes without Logos Service Discovery support will ignore
REGISTERandGET_ADSmessages
Advertisement Encoding
Advertisements in the Register.advertisement and GetAds.advertisements fields are encoded as bytes. Implementations are RECOMMENDED to use ExtensiblePeerRecord (XPR) encoding.
Alternative encodings MAY be used if they provide equivalent functionality and can be verified by discoverers.
REGISTER Message
Used by advertisers to register their advertisements with registrars.
REGISTER Request
| Field | Usage | Value |
|---|---|---|
type | REQUIRED | REGISTER (6) |
key | REQUIRED | service_id_hash (32 bytes) |
register.advertisement | REQUIRED | Encoded advertisement as bytes (RECOMMENDED: XPR) |
register.ticket | OPTIONAL | Ticket from previous registration attempt |
| All other fields | UNUSED | Empty/not set |
Example (First attempt):
Message {
type: REGISTER
key: <service_id_hash>
register: {
advertisement: <encoded_xpr_bytes>
}
}
Example (Retry with ticket):
Message {
type: REGISTER
key: <service_id_hash>
register: {
advertisement: <encoded_xpr_bytes>
ticket: {
ad: <encoded_xpr_bytes>
t_init: 1234567890
t_mod: 1234567900
t_wait_for: 300
signature: <registrar_signature>
}
}
}
REGISTER Response
| Field | Usage | Value |
|---|---|---|
type | REQUIRED | REGISTER (6) |
register.status | REQUIRED | CONFIRMED, WAIT, or REJECTED |
closerPeers | REQUIRED | List of peers for advertise table |
register.ticket | CONDITIONAL | Present if status = WAIT |
| All other fields | UNUSED | Empty/not set |
Status values:
CONFIRMED: Advertisement stored in cacheWAIT: Not yet accepted, wait and retry with ticketREJECTED: Invalid signature, duplicate, or error
Example (WAIT):
Message {
type: REGISTER
register: {
status: WAIT
ticket: {
ad: <encoded_xpr_bytes>
t_init: 1234567890
t_mod: 1234567905
t_wait_for: 295
signature: <registrar_signature>
}
}
closerPeers: [
{id: <peer1_id>, addrs: [<addr1>]},
{id: <peer2_id>, addrs: [<addr2>]}
]
}
Example (CONFIRMED):
Message {
type: REGISTER
register: {
status: CONFIRMED
}
closerPeers: [
{id: <peer1_id>, addrs: [<addr1>]},
{id: <peer2_id>, addrs: [<addr2>]}
]
}
Example (REJECTED):
Message {
type: REGISTER
register: {
status: REJECTED
}
}
GET_ADS Message
Used by discoverers to retrieve advertisements from registrars.
GET_ADS Request
| Field | Usage | Value |
|---|---|---|
type | REQUIRED | GET_ADS (7) |
key | REQUIRED | service_id_hash (32 bytes) |
| All other fields | UNUSED | Empty/not set |
Example:
Message {
type: GET_ADS
key: <service_id_hash>
}
GET_ADS Response
| Field | Usage | Value |
|---|---|---|
type | REQUIRED | GET_ADS (7) |
getAds.advertisements | REQUIRED | List of encoded advertisements (up to F_return = 10) |
closerPeers | REQUIRED | List of peers for search table |
| All other fields | UNUSED | Empty/not set |
Each advertisement in getAds.advertisements is encoded as bytes (RECOMMENDED: XPR).
Discoverers MUST verify signatures before accepting.
Example:
Message {
type: GET_ADS
getAds: {
advertisements: [
<encoded_xpr_bytes_1>,
<encoded_xpr_bytes_2>,
... // up to F_return
]
}
closerPeers: [
{id: <peer1_id>, addrs: [<addr1>]},
{id: <peer2_id>, addrs: [<addr2>]}
]
}
Message Validation
REGISTER Request Validation
Registrars MUST validate:
type=REGISTER(6)key= 32 bytes (valid SHA-256)register.advertisementis present and non-empty- If
register.ticketpresent:- Valid signature issued by this registrar
ticket.admatchesregister.advertisement- Retry within window:
ticket.t_mod + ticket.t_wait_for ≤ NOW() ≤ ticket.t_mod + ticket.t_wait_for + δ
- Advertisement signature is valid (see Advertisement Signature Verification)
- Advertisement not already in
ad_cache
Respond with register.status = REJECTED if validation fails.
GET_ADS Request Validation
Registrars MUST validate:
type=GET_ADS(7)key= 32 bytes (valid SHA-256)
Return empty getAds.advertisements list or close stream if validation fails.
Advertisement Signature Verification
Both registrars (on REGISTER) and discoverers (on GET_ADS response) MUST verify advertisement signatures. For XPR-encoded advertisements:
VERIFY_ADVERTISEMENT(encoded_ad_bytes, service_id_hash):
envelope = DECODE_SIGNED_ENVELOPE(encoded_ad_bytes)
assert(envelope.domain == "libp2p-routing-state")
assert(envelope.payload_type == "/libp2p/extensible-peer-record/")
xpr = DECODE_XPR(envelope.payload)
public_key = DERIVE_PUBLIC_KEY(xpr.peer_id)
assert(VERIFY_ENVELOPE_SIGNATURE(envelope, public_key))
// Verify service advertised
service_found = false
for service in xpr.services:
if SHA256(service.id) == service_id_hash:
service_found = true
assert(service_found)
Discard advertisements with invalid signatures or that don't advertise the requested service.
Note: ExtensiblePeerRecord uses protocol strings (e.g.,
/waku/store/1.0.0) inServiceInfo.id. Logos discovery usesservice_id_hash = SHA256(ServiceInfo.id)for routing. When verifying, implementations MUST hash the protocol string and compare with thekeyfield (service_id_hash).
Stream Management
Following standard Kad-DHT behavior:
- Implementations MAY reuse streams for sequential requests
- Implementations MUST handle multiple requests per stream
- Reset stream on protocol errors or validation failures
- Prefix messages with length as unsigned varint per multiformats spec
Error Handling
| Error | Handling |
|---|---|
| Invalid message format | Close stream |
| Signature verification failure | REJECTED for REGISTER; discard invalid ads for GET_ADS |
| Timeout | Close stream, retry with exponential backoff |
| Cache full (registrar) | Issue ticket with waiting time |
| Unknown service_id_hash | Empty advertisements list but include closerPeers |
| Missing required fields | Close stream |
Sequence Diagram
Advertisers
Advertisers distribute advertisements for their service across registrars.
Distributing ads across registrars
For each service, identified by service_id_hash,
that an advertiser wants to advertise,
the advertiser MUST instantiate a
new advertise table, AdvT(service_id_hash),
centered on that service_id_hash.
The advertiser MAY bootstrap AdvT(service_id_hash)
from the KadDHT(peerID) routing table using the formula
described in the Distance section.
The advertiser SHOULD try to maintain up to K_register
active registrations per bucket.
It does so by selecting random registrars
from each bucket of AdvT(service_id_hash).
These ongoing registrations MAY be tracked in a separate data structure.
Ongoing registrations include those registrars
at which the advertiser has an active registration or
for which there is an ongoing registration attempt.
To maintain each registration, the advertiser:
- MUST send a REGISTER message to the registrar.
If there is already a cached
ticketfrom a previous registration attempt for the sameadin the same registrar, theticketMUST also be included in the REGISTER message. - on receipt of the
REGISTERresponse: SHOULD add the closer peers indicated in the response toAdvT(service_id_hash)using the formula described in the Distance section. - MUST interpret the response
statusfield and schedule actions accordingly:- If the
statusisConfirmed, the registration is maintained in the registrar'sad_cacheforEseconds. AfterEseconds the advertiser MUST remove the registration from the ongoing registrations for that bucket. - If the
statusisWait, the advertiser MUST schedule a next registration attempt to the same registrar based on theticket.t_wait_forvalue included in the response. The Response contains aticket, which MUST be included in the next registration attempt to this registrar. - If the
statusisRejected, the advertiser MUST remove the registrar from the ongoing registrations for that bucket and SHOULD NOT attempt further registrations with this registrar for this advertisement.
- If the
Example ADVERTISE algorithm
The following pseudocode block shows one way of implementing the Advertising algorithm. Advertisers MAY follow this example.
procedure ADVERTISE(service_id_hash):
ongoing ← MAP<bucketIndex; LIST<registrars>>
AdvT(service_id_hash) ← KadDHT(peerID)
for i in 0, 1, ..., m-1:
while ongoing[i].size < K_register:
registrar ← AdvT(service_id_hash).getBucket(i).getRandomNode()
if registrar = None:
break
end if
ongoing[i].add(registrar)
ad.service_id_hash ← service_id_hash
ad.peerID ← peerID
ad.addrs ← node.addrs
SIGN(ad)
async(ADVERTISE_SINGLE(registrar, ad, i, service_id_hash))
end while
end for
end procedure
procedure ADVERTISE_SINGLE(registrar, ad, i, service_id_hash):
ticket ← None
while True:
response ← registrar.Register(ad, ticket)
AdvT(service_id_hash).add(response.closerPeers)
if response.status = Confirmed:
SLEEP(E)
break
else if response.status = Wait:
SLEEP(min(E, response.ticket.t_wait_for))
ticket ← response.ticket
else:
break
end if
end while
ongoing[i].remove(registrar)
end procedure
Refer to the Advertiser Algorithms Explanation section for a detailed explanation.
Discoverers
Discoverers look up advertisers for services by querying registrars.
Looking up services
For each service, identified by service_id_hash,
that a discoverer wants to find advertisers for,
the discoverer MUST instantiate a
new search table, DiscT(service_id_hash),
centered on that service_id_hash.
The discoverer MAY bootstrap DiscT(service_id_hash)
from the KadDHT(peerID) routing table using the formula
described in the Distance section.
The discoverer MUST attempt to find up to F_lookup advertisers
for this service_id_hash
by following the lookup procedure below.
It SHOULD perform the lookup procedure periodically,
or whenever more peers are requested by the encapsulating application.
To perform a lookup,
the discoverer MUST iterate through every bucket of DiscT(service_id_hash).
It MUST start from the farthest bucket (b_0),
which has the registrar nodes with the fewest shared bits to the service_id_hash,
gradually moving through buckets (b_(m-1)),
containing registrar nodes with ever increasing number of shared bits to the service_id_hash.
During the lookup procedure,
the discoverer SHOULD keep track of unique foundPeers.
terminating the procedure once F_lookup advertisers have been found,
or if all buckets have been traversed.
- For each bucket, the discoverer MUST select
up to
K_lookuprandom registrar peers to query. - For each selected registrar, the discoverer
- MUST send a
GET_ADSmessage to the registrar - on receipt of a
GET_ADSresponse, SHOULD add the closer peers indicated in the response toDiscT(service_id_hash)using the formula described in the Distance section. - SHOULD validate each
advertisementincluded in the response, and add valid advertisers tofoundPeers. Note that a valid response could also contain0advertisements.
This iterative procedure continues until F_lookup advertisers have been found,
or all buckets have been traversed.
Example LOOKUP algorithm
The following pseudocode block shows one way of implementing the Lookup algorithm. Discoverers MAY follow this example.
procedure LOOKUP(service_id_hash):
DiscT(service_id_hash) ← KadDHT(peerID)
foundPeers ← SET<Peers>
for i in 0, 1, ..., m-1:
for j in 0, ..., K_lookup - 1:
peer ← DiscT(service_id_hash).getBucket(i).getRandomNode()
if peer = None:
break
end if
response ← peer.GetAds(service_id_hash)
for ad in response.ads:
assert(ad.hasValidSignature())
foundPeers.add(ad.peerID)
if foundPeers.size ≥ F_lookup:
break
end if
end for
DiscT(service_id_hash).add(response.closerPeers)
if foundPeers.size ≥ F_lookup:
return foundPeers
end if
end for
end for
return foundPeers
end procedure
Refer to the Lookup Algorithm Explanation section for the detailed explanation.
Registrars
Registrars are nodes that store advertisements,
by handling REGISTER requests,
and serve cached advertisements,
by handling GET_ADS requests.
Registrars MUST maintain a cache of advertisements, ad_cache,
that associates each advertisement
to its service_id,
and an expiry timestamp based on admission time plus configured expiry time, E.
Once an ad has expired, it SHOULD be removed from the ad_cache
Handling REGISTER requests
When a registrar node receives a REGISTER request from an advertiser node
to admit its ad for a service into the ad_cache,
the registrar SHOULD process the request
and respond with a REGISTER response according to the steps below.
The registrar SHOULD include a list of closer peers (response.closerPeers) in the response
using the algorithm described in Peer Table Updates section.
To populate the rest of the response, the registrar MUST:
-
If an identical
adalready exists in thead_cache, reject the request and respond with statusRejected. -
Calculate (or recalculate, if this is a resubmission) a waiting time for the
ad,t_wait, using the formula in Waiting Time Calculation. -
If no
ticketis provided in theREGISTERrequest this is the advertiser's first registration attempt for thead. Create a new signedticketbased ont_wait, and return the signedticketin a response with statusWait. -
If a
ticketis provided in theREGISTERrequest, validate the ticket and respond with the statusRejectedif any of the following fails:ticket.signaturecontains a valid signature, issued by this registrarticket.admatches the currentad- calculate the expected time of ticket submission,
t_scheduled, ast_scheduled = ticket.t_mod + ticket.t_waitand verify that the actual submission time,current_time, falls within a valid registration window,δ, wheret_scheduled <= current_time <= t_scheduled + δ. The duration ofδis up to the application, but SHOULD be just enough to accommodate for the maximum delay between the advertiser and the registrar.
-
Calculate remaining wait time
t_remaining = t_wait - (current_time - ticket.t_init). This ensures advertisers accumulate waiting time across retries -
If
t_remaining ≤ 0, add theadto thead_cache, with an expiry timestamp set tocurrent_time + E. The registrar SHOULD return a response with statusConfirmed. -
If
t_remaining > 0, issue a new signedticketwithticket.t_modset tocurrent_timeandticket.t_wait_for = min(E, t_remaining). The registrar SHOULD return the signedticketin a response with statusWait.
Example REGISTER algorithm
The following pseudocode block shows one way of implementing the algorithm to handle register requests. Registrars MAY follow this example.
procedure REGISTER(ad, ticket):
assert(ad not in ad_cache)
response.ticket.ad ← ad
t_wait ← CALCULATE_WAITING_TIME(ad)
if ticket.empty():
t_remaining ← t_wait
response.ticket.t_init ← NOW()
response.ticket.t_mod ← NOW()
else:
assert(ticket.hasValidSignature())
assert(ticket.ad = ad)
assert(ad.notInAdCache())
t_scheduled ← ticket.t_mod + ticket.t_wait_for
assert(t_scheduled ≤ NOW() ≤ t_scheduled + δ)
t_remaining ← t_wait - (NOW() - ticket.t_init)
end if
if t_remaining ≤ 0:
ad_cache.add(ad)
response.status ← Confirmed
else:
response.status ← Wait
response.ticket.t_wait_for ← MIN(E, t_remaining)
response.ticket.t_mod ← NOW()
SIGN(response.ticket)
end if
response.closerPeers ← GETPEERS(ad.service_id_hash)
return response
end procedure
Refer to the Register Algorithm Explanation section for detailed explanation.
Handling GET_ADS requests
Registrars SHOULD respond to GET_ADS requests from discoverers
with a GET_ADS response:
- Include up to
F_returnadvertisements from thead_cachefor the requestedservice_id_hash. - Include a list of closer peers to help discoverers populate their search table using the algorithm described in Peer Table Updates section.
Example LOOKUP_RESPONSE algorithm
The following pseudocode block shows one way of implementing the algorithm to handle GET_ADS requests.
Registrars MAY follow this example.
procedure LOOKUP_RESPONSE(service_id_hash):
response.ads ← ad_cache.getAdvertisements(service_id_hash)[:F_return]
response.closerPeers ← GETPEERS(service_id_hash)
return response
end procedure
Peer Table Updates
Overview
While responding to both REGISTER requests by advertisers
and GET_ADS request by discoverers,
registrars play an important role in helping nodes discover the network topology.
The registrar table RegT(service_id_hash) is a routing structure
that SHOULD be maintained by registrars
to provide better peer suggestions to advertisers and discoverers.
Registrars SHOULD use the formula specified in the Distance section
to add peers to RegT(service_id_hash).
Peers are added under the following circumstances:
- Registrars MAY initialize their registrar table
RegT(service_id_hash)from theirKadDHT(peerID)using the formula described in the Distance Section. - When an advertiser sends a
REGISTERrequest, the registrar SHOULD add the advertiser'speerIDtoRegT(service_id_hash). - When a discoverer sends a
GET_ADSrequest, the registrar SHOULD add the discoverer'speerIDtoRegT(service_id_hash). - When registrars receive responses from other registrars
(if acting as advertiser or discoverer themselves),
they SHOULD add peers from
closerPeersfields to relevantRegT(service_id_hash)tables.
Note: The
ad_cacheandRegT(service_id_hash)are completely different data structures that serve different purposes and are independent of each other.
When responding to requests, registrars:
- SHOULD return a list of peers to help advertisers
populate their
AdvT(service_id_hash)tables and discoverers populate theirDiscT(service_id_hash)tables. - SHOULD return peers that are diverse and distributed across different buckets to prevent malicious registrars from polluting routing tables.
Recommended Peer Selection Algorithm
We RECOMMEND that the following algorithm be used to select peers to return in responses.
procedure GETPEERS(service_id_hash):
peers ← SET<peers>
RegT(service_id_hash) ← KadDHT(peerID)
for i in 0, 1, ..., m-1:
peer ← b_i(service_id_hash).getRandomNode()
if peer ≠ None:
peers.add(peer)
end if
end for
return peers
end procedure
peersis initialized as an empty setRegT(service_id_hash)is initialized from the node’sKadDHT(peerID).- Go through all
mbuckets in the registrar’s table —- Pick one random peer from bucket
i.getRandomNode()function remembers already returned nodes and never returns the same one twice. - If
peerreturned is not null then we move on to next bucket. Else we try to get another peer in the same bucket
- Pick one random peer from bucket
- Return
peerswhich contains one peer from every bucket ofRegT(service_id_hash).
The algorithm returns one random peer per bucket to provide diverse suggestions
and prevent malicious registrars from polluting routing tables.
Contacting registrars in consecutive buckets divides the search space by a constant factor,
and allows learning new peers from more densely-populated routing tables towards the destination.
The procedure mitigates the risk of having malicious peers polluting the table
while still learning rare peers in buckets close to service_id_hash.
Waiting Time Calculation
Formula
The waiting time is the time advertisers have to
wait before their ad is admitted to the ad_cache.
The waiting time is given based on the ad itself
and the current state of the registrar’s ad_cache.
The waiting time for an advertisement MUST be calculated using:
w(ad) = E × (1/(1 - c/C)^P_occ) × (c(ad.service_id_hash)/C + score(getIP(ad.addrs)) + G)
c: Current cache occupancyc(ad.service_id_hash): Number of advertisements forservice_id_hashin cachegetIP(ad.addrs)is a function to get the IP address from the multiaddress of the advertisement.score(getIP(ad.addrs)): IP similarity score (0 to 1). Refer to the IP Similarity Score section
Section System Parameters can be referred for the definitions of the remaining parameters in the formula.
Issuing waiting times promote diversity in the ad_cache.
It results in high waiting times and slower admission for malicious advertisers
using Sybil identities from a limited number of IP addresses.
It also promotes less popular services with fast admission
ensuring fairness and robustness against failures of single registrars.
Scaling
The waiting time is normalized by the ad’s expiry time E.
It binds waiting time to E and allows us to reason about the number of incoming requests
regardless of the time each ad spends in the ad_cache.
Occupancy Score
occupancy_score = 1 / (1 - c/C)^P_occ
The occupancy score increases progressively as the cache fills:
- When
c << C: Score ≈ 1 (minimal impact) - As the
ad_cachefills up, the score will be amplified by the divisor of the equation. The higher the value ofP_occ, the faster the increase. Implementations should consider this while setting the value forP_occ - As
c → C: Score → ∞ (prevents overflow)
Service Similarity
service_similarity = c(ad.service_id_hash) / C
The service similarity score promotes diversity:
- Low when
service_id_hashhas few advertisements in cache. Thus lower waiting time. - High when
service_id_hashdominates the cache. Thus higher waiting time.
IP Similarity Score
The IP similarity score is used to detect and limit Sybil attacks where malicious actors create multiple advertisements from the same network or IP prefix.
Registrars MUST use an IP similarity score to
limit the number of ads coming from the same subnetwork
by increasing their waiting time.
The IP similarity mechanism MUST:
- Calculate a score (0-1): higher scores indicate similar IP prefixes (potential Sybil attacks)
- Track IP addresses of
adscurrently in thead_cache. - MUST update its tracking structure when:
- A new
adis admitted to thead_cache: MUST add the IP - An
adexpires after timeE: MUST remove IP if there are no other activeadsfrom the same IP
- A new
- Recalculate score for each registration attempt
Tree Structure
We RECOMMEND using an IP tree data structure
to efficiently track and calculate IP similarity scores.
An IP tree is a binary tree that stores
IPs used by ads currently present in the ad_cache.
This data structure provides logarithmic time complexity
for insertion, deletion, and score calculation.
Implementations MAY use alternative data structures
as long as they satisfy the requirements specified above.
Apart from root, the IP tree is a 32-level binary tree where:
- Each vertex stores
IP_counter(number of IPs passing through). It is initially set to 0. - Edges represent bits (0/1) in IPv4 binary representation
- When an
adis admitted to thead_cache, its IPv4 address is added to the IP tracking structure using theADD_IP_TO_TREE()algorithm. - Every time a waiting time is calculated for a registration attempt,
the registrar calculates the IP similarity score for the advertiser's IP address.
using
CALCULATE_IP_SCORE()algorithm. - When an
adis removed from thead_cacheafterE, The registrar also removes the IP from IP tracking structure using theREMOVE_FROM_IP_TREE()algorithm if there are no other activeadinad_cachefrom the same IP. - All the algorithms work efficiently with O(32) time complexity.
- The root
IP_countertracks total IPs currently inad_cache
ADD_IP_TO_TREE() algorithm
The algorithm traverses the tree following the IP's binary representation, incrementing counters at each visited node.
procedure ADD_IP_TO_TREE(tree, IP):
v ← tree.root
bits ← IP.toBinary()
for i in 0, 1, ..., 31:
v.IP_counter ← v.IP_counter + 1
if bits[i] = 0:
v ← v.left
else:
v ← v.right
end if
end for
end procedure
CALCULATE_IP_SCORE() algorithm
The algorithm traverses the tree following the IP's binary representation
to detect how many IPs share common prefixes, providing a Sybil attack measure.
At each node, if the IP_counter is larger than expected in a perfectly balanced tree,
it indicates too many IPs share that prefix, incrementing the similarity score.
procedure CALCULATE_IP_SCORE(tree, IP):
v ← tree.root
score ← 0
bits ← IP.toBinary()
for i in 0, 1, ..., 31:
if bits[i] = 0:
v ← v.left
else:
v ← v.right
end if
if v.IP_counter > tree.root.IP_counter / 2^i:
score ← score + 1
end if
end for
return score / 32
end procedure
REMOVE_FROM_IP_TREE() algorithm
This algorithm traverses the tree following the IP's binary representation, decrementing counters at each visited node.
procedure REMOVE_FROM_IP_TREE(tree, IP):
v ← tree.root
bits ← IP.toBinary()
for i in 0, 1, ..., 31:
v.IP_counter ← v.IP_counter - 1
if bits[i] = 0:
v ← v.left
else:
v ← v.right
end if
end for
end procedure
Implementations can extend the IP tree algorithms to IPv6 by using a 128-level binary tree, corresponding to the 128-bit length of IPv6 addresses.
Safety Parameter
The safety parameter G ensures waiting times never reach zero even when:
- Service similarity is zero (new service).
- IP similarity is zero (completely distinct IP)
It prevents ad_cache overflow in cases when attackers try to
send ads for random services or from diverse IPs.
Lower Bound Enforcement
To prevent "ticket grinding" attacks where advertisers repeatedly request new tickets hoping for better waiting times, registrars MUST enforce lower bounds.
Invariant: a newly issued waiting time at time t_current
MUST NOT be smaller than a previously issued waiting time
by more than the elapsed time since that waiting time was issued.
Formally:
w_new ≥ w_previous - (t_current - t_previous)
For each service_id_hash, the registrar MUST maintain:
bound(service_id_hash): the last issued waiting timetimestamp(service_id_hash): the time at which the waiting time was issued
For each IP in the IP tree, the registrar MUST maintain:
bound(IP): the last issued waiting timetimestamp(IP): the time at which the waiting time was issued
The final waiting time respects the lower bound only if both service-level and IP-level bounds are enforced.
Service-level entries are bounded by the number of distinct
service_id_hash values currently tracked in the registrar state.
IP-level entries are bounded by the number of distinct IPs
present in advertisements currently tracked in the registrar state.
Lower bounds SHOULD be calculated as follows:
When a service_id_hash first enters the registrar state,
the registrar sets:
bound(service_id_hash) = 0
timestamp(service_id_hash) = current_time
When an IP first enters the registrar state, the registrar sets:
bound(IP) = 0
timestamp(IP) = current_time
When a new ticket request arrives at time t_current,
the registrar first calculates the base waiting time w_base
using the waiting time formula.
For the corresponding service_id_hash,
the registrar calculates the elapsed time since the bound
was last updated:
elapsed_service_time =
t_current - timestamp(service_id_hash)
It then calculates the remaining service-level lower bound:
remaining_service_bound =
bound(service_id_hash) - elapsed_service_time
remaining_service_bound MAY be negative if the elapsed time
exceeds the previous bound. This is expected and MUST NOT
be clamped to zero.
The service-level waiting time is then calculated as:
w_service =
max(w_base, remaining_service_bound)
After the ticket is issued, the registrar updates the service-level lower-bound state only if the base waiting time exceeds the remaining service-level bound:
if w_base > remaining_service_bound:
bound(service_id_hash) = w_service
timestamp(service_id_hash) = t_current
The same logic is applied for each IP associated with the advertisement:
elapsed_ip_time =
t_current - timestamp(IP)
remaining_ip_bound =
bound(IP) - elapsed_ip_time
w_ip =
max(w_base, remaining_ip_bound)
if w_base > remaining_ip_bound:
bound(IP) = w_ip
timestamp(IP) = t_current
The final waiting time issued in the ticket is the maximum of the service-level and IP-level waiting times:
w_final = max(w_service, w_ip_1, w_ip_2, ...)
The lower-bound state is removed when the corresponding entry expires.
This ensures that the final issued waiting time respects both the service-level and IP-level lower-bound rules.
Implementation Notes
Client and Server Mode
Logos discovery respects the client/server mode distinction from the base Kad-dht specification:
- Server mode nodes: MAY be Discoverer, Advertiser or Registrar
- Client mode nodes: MUST be only Discoverer
Implementations MAY include incentivization mechanisms to encourage peers to participate as advertisers or registrars, rather than operating solely in client mode. This helps prevent free-riding behavior, ensures a fair distribution of network load, and maintains the overall resilience and availability of the discovery layer. Incentivization mechanisms are beyond the scope of this RFC.
Bucket Management
Bucket Representation
For simplicity in this RFC, we represent each bucket as a list of peer IDs. However, in a full implementation, each entry in the bucket MUST store complete peer information necessary to enable communication.
Bucket Size
The number of entries a bucket can hold is implementation-dependent:
- Smaller buckets → lower memory usage but reduced resilience to churn
- Larger buckets → better redundancy but increased maintenance overhead
Implementations SHOULD ensure that each bucket contains only unique peers. If the peer to be added is already present in the bucket, the implementation SHOULD NOT create a duplicate entry and SHOULD instead update the existing entry.
Bucket Overflow Handling
When a bucket reaches its maximum capacity and a new peer needs to be added, implementations SHOULD decide how to handle the overflow. The specific strategy is implementation-dependent, but implementations MAY consider one of the following approaches:
-
Least Recently Used (LRU) Eviction: Replace the peer that was least recently contacted or updated. This keeps more active and responsive peers in the routing table.
-
Least Recently Seen (LRS) Eviction: Replace the peer that was seen (added to the bucket) earliest. This provides a time-based rotation of peers.
-
Ping-based Eviction: When the bucket is full, ping the least recently contacted peer. If the ping fails, replace it with the new peer. If the ping succeeds, keep the existing peer and discard the new one. This prioritizes responsive, reachable peers.
-
Reject New Peer: Keep existing peers and reject the new peer. This strategy assumes existing peers are more stable or valuable.
-
Bucket Extension: Dynamically increase bucket capacity (within reasonable limits) when overflow occurs, especially for buckets closer to the center ID.
Implementations MAY combine these strategies or use alternative approaches based on their specific requirements for performance, security, and resilience.
References
[0] Kademlia: A Peer-to-Peer Information System Based on the XOR Metric
[1] DISC-NG: Robust Service Discovery in the Ethereum Global Network
[2] libp2p Kademlia DHT specification
Appendix
This appendix provides detailed explanations of some algorithms and helper procedures referenced throughout this RFC. To maintain clarity and readability in the main specification, the body contains only the concise pseudocode and high-level descriptions.
Advertiser Algorithms Explanation
Refer to the Advertisement Algorithm section for the pseudocode.
ADVERTISE() algorithm explanation
- Initialize a map
ongoingfor tracking which registrars are currently being advertised to. - Initialize
AdvT(service_id_hash)by bootstrapping peers from the advertiser’sKadDHT(peerID)using the formula described in the Distance section. - Iterate over all buckets (i = 0 through
m-1), wheremis the number of buckets inAdvT(service_id_hash)andongoingmap. Each bucket corresponds to a particular distance from theservice_id_hash.ongoing[i]contains list of registrars with active (unexpired) registrations or ongoing registration attempts at a distanceifrom theservice_id_hashof the service that the advertiser is advertising for.- Advertisers continuously maintain up to
K_registeractive (unexpired) registrations or ongoing registration attempts in every bucket of theongoingmap for its service. IncreasingK_registermakes the advertiser easier to find at the cost of increased communication and storage costs. - Pick a random registrar from bucket
iofAdvT(service_id_hash)to advertise to.AdvT(service_id_hash).getBucket(i)→ returns a list of registrars in bucketifromAdvT(service_id_hash).getRandomNode()→ function returns a random registrar node. The advertiser tries to place its advertisement into that registrar. The function remembers already returned nodes and never returns the same one twice during the sameadplacement process. If there are no peers, it returnsNone.
- if we get a peer then we add that to that bucket
ongoing[i] - Build the advertisement object
adcontainingservice_id_hash,peerID, andaddrs(Refer to the Advertisement section). Then it is signed by the advertiser using the node’s private key (Ed25519 signature) - Then send this
adasynchronously to the selected registrar. The helperADVERTISE_SINGLE()will handle registration to a single registrar. Asynchronous execution allows multipleads(to multiple registrars) to proceed in parallel.
ADVERTISE_SINGLE() algorithm explanation
ADVERTISE_SINGLE() algorithm handles registration to one registrar at a time
- Initialize
tickettoNoneas we have not yet got any ticket from registrar - Keep trying until the registrar confirms or rejects the
ad.- Send the
adto the registrar usingRegisterrequest. Request structure is described in section Register Message Structure. If we already have a ticket, include it in the request. - The registrar replies with a
response. Refer to the Register Message Structure section for the response structure - Add the list of peers returned by the registrar
response.closerPeerstoAdvT(service_id_hash). Refer to the [Distance](#distance section) on how to add. - If the registrar accepted the advertisement successfully,
wait for
Eseconds, then stop retrying because theadis already registered. - If the registrar says “wait” (its cache is full or overloaded),
sleep for the time written in the ticket
ticket.t_wait_for(but not more thanE). Then updateticketwith the new one from the registrar, and try again. - If the registrar rejects the ad, stop trying with this registrar.
- Send the
- Remove this registrar from the
ongoingmap in bucket i (ongoing[i]), since we’ve finished trying with it.
Discoverer Algorithms
LOOKUP(service_id_hash) algorithm explanation
Refer to the Lookup Algorithm section for the pseudocode.
DiscT(service_id_hash)is initialized by bootstrapping peers from the discoverer’sKadDHT(peerID)using the formula described in the Distance section.- Create an empty set
foundPeersto store unique advertisers peer IDs discovered during the lookup. - Go through each bucket of
DiscT(service_id_hash)— from farthest (b₀) to closest (bₘ₋₁) to the service IDservice_id_hash. For each bucket, query up toK_lookuprandom peers.- Pick a random registrar node from bucket
iofDiscT(service_id_hash)to queryDiscT(service_id_hash).getBucket(i)→ returns a list of registrars in bucketifromDiscT(service_id_hash).getRandomNode()→ function returns a random registrar node. The discover queries this node to getadsfor a particular service IDservice_id_hash. The function remembers already returned nodes and never returns the same one twice. If there are no peers, it returnsNone.
- A
GET_ADSrequest is sent to the selected registrar peer. Refer to the GET_ADS Message section to see the request and response structure forGET_ADS. The response returned by the registrar node is stored inresponse - The
responsecontains a list of advertisementsresponse.ads. A queried registrar returns at mostF_returnadvertisements. If it returns more we can just randomly keepF_returnof them. For each advertisement returned:- Verify its digital signature for authenticity.
- Add the advertiser’s peer ID
ad.peerIDto the listfoundPeers.
- The
responsealso contains a list of peersresponse.closerPeersthat is inserted intoDiscT(service_id_hash)using the formula described in the Distance section. - Stop early if enough advertiser peers (
F_lookup) have been found. For popular servicesF_lookupadvertisers are generally found in the initial phase from the farther buckets and the search terminates. But for unpopular ones it might take longer but not more thanO(log N)where N is number of nodes participating in the network as registrars. - If early stop doesn’t happen then the search stops when no unqueried registrars remain in any of the buckets.
- Pick a random registrar node from bucket
- Return
foundPeerswhich is the final list of discovered advertisers that provide serviceservice_id_hash
Making the advertisers and discoverers walk towards service_id_hash in a similar fashion
guarantees that the two processes overlap and contact a similar set of registrars that relay the ads.
At the same time, contacting random registrars in each encountered bucket using getRandomNode()
makes it difficult for an attacker to strategically place malicious registrars in the network.
The first bucket b_0(service_id_hash) covers the largest fraction of the key space
as it corresponds to peers with no common prefix to service_id_hash (i.e. 50% of all the registrars).
Placing malicious registrars in this fraction of the key space
to impact service discovery process would require considerable resources.
Subsequent buckets cover smaller fractions of the key space,
making it easier for the attacker to place Sybils
but also increasing the chance of advertisers already gathering enough ads in previous buckets.
Parameters F_return and F_lookup play an important role
in setting a compromise between security and efficiency.
A small value of F_return << F_lookup increases the diversity of the source of ads
received by the discoverer but increases search time,
and requires reaching buckets covering smaller key ranges where eclipse risks are higher.
On the other hand, similar values for F_lookup and F_return reduce overheads
but increase the danger of a discoverer receiving ads uniquely from malicious nodes.
Finally, low values of F_lookup stop the search operation early,
before reaching registrars close to the service hash,
contributing to a more balanced load distribution.
Implementations should consider these trade-offs carefully when selecting appropriate values.
Registrar Algorithms
REGISTER() algorithm explanation
Refer to the Register Algorithm section for the pseudocode
- Make sure this advertisement
adis not already in the registrar’s advertisement cachead_cache. - Prepare a response ticket
response.ticketlinked to thisad. - Then calculate how long the advertiser should wait
t_waitbefore being admitted. Refer to the Waiting Time Calculation section for details. - Check if this is the first registration attempt (no ticket yet):
- If yes then it’s the first try. The advertiser must wait for the full waiting time
t_wait. The ticket’s creation timet_initand last-modified timet_modare both set toNOW(). - If no, then this is a retry, so a previous ticket exists.
- Validate that the ticket is properly signed by the registrar,
belongs to this same advertisement and that the
adis still not already in thead_cache. - Ensure the retry is happening within the allowed time window
δafter the scheduled time. If the advertiser waits too long or too short, the ticket is invalid. - Calculate how much waiting time is left
t_remainingby subtracting how long the advertiser has already waited (NOW() - ticket.t_init) fromt_wait.
- Validate that the ticket is properly signed by the registrar,
belongs to this same advertisement and that the
- If yes then it’s the first try. The advertiser must wait for the full waiting time
- Check if the remaining waiting time
t_remainingis less than or equal to 0. This means the waiting time is over.t_remainingcan be 0 also when the registrar decides that the advertiser doesn’t have to wait for admission to thead_cache(waiting timet_waitis 0).- If yes, add the
adtoad_cacheand confirm registration. The advertisement is now officially registered. - If no, then there is still time to wait.
In this case registrar does not store
adbut instead issues a ticket.- set
reponse.statustowait - Update the ticket with the new remaining waiting time
t_wait_for - Update the ticket last modification time
t_mod - Sign the ticket again. The advertiser will retry later using this new ticket.
- set
- If yes, add the
- Add a list of peers closer to the
ad.service_id_hashusing theGETPEERS()function to the response (the advertiser uses this to updateAdvT(service_id_hash)). - Send the full response back to the advertiser
Upon receiving a ticket, the advertiser waits for the specified t_wait time
before trying to register again with the same registrar.
Tickets can only be used within registration window δ,
preventing attackers from accumulating and batch-submitting tickets.
Clock synchronization is not required as advertisers only use t_wait_for values.
Waiting times are recalculated on each retry based on current cache state, ensuring advertisers accumulate waiting time and are eventually admitted. This stateless design protects registrars from memory exhaustion and DoS attacks.
The waiting time t_wait is not fixed.
Each time an advertiser tries to register,
the registrar recalculates a new waiting time.
The remaining time t_remaining is then computed as the difference between
the new waiting time and the time the advertiser has already waited,
as recorded in the ticket.
With every retry, the advertiser accumulates waiting time
and will eventually be admitted.
However, if the advertiser misses its registration window
or fails to include the last ticket,
it loses all accumulated waiting time and
must restart the registration process from the beginning.
Implementations must consider these factors
while deciding the registration window δ time.
This design lets registrars prioritize advertisers that have waited longer
without keeping any per-request state before the ad is admitted to the cache.
Because waiting times are recalculated
and tickets are stored only on the advertiser’s side,
the registrar is protected from memory exhaustion
and DoS attacks caused by inactive or malicious advertisers.
LON-ORACLE-ZONE
| Field | Value |
|---|---|
| Name | Logos Oracle Network (LON) Oracle Zone |
| Slug | 244 |
| Status | raw |
| Category | Standards Track |
| Editor | Ugur Sen [email protected] |
| Contributors |
Timeline
- 2026-07-21 —
0ab1783— docs(anoncomms): commit the initial Logos Oracle Zone RFC (#366)
Abstract
The following document specifies the Logos Oracle Network (LON), a dedicated Logos Blockchain zone that aggregates and attests external price data and delivers it to consumers in the Logos ecosystem, in particular the Logos Execution Zone (LEZ). A set of oracle nodes fetch prices from external sources, sign their observations, and publish them as inscriptions on the Logos Blockchain. Bedrock totally orders and finalizes these inscriptions, which makes the input data immutable and identical for every reader. Because the input is immutable and the aggregation code is fixed and deterministic, every honest indexer that reads the same finalized inscriptions computes the same attested price.
The oracle nodes double as indexers that read the finalized inscriptions and compute the attested price. Aggregation follows an optimistic model, since an indexer can be malicious and cannot be trusted. In each round, one indexer acts as the proposer. It computes the attested price as the median of the valid observations and writes it to LEZ, which opens a dispute window. If no dispute is raised before the window closes, the proposed price is accepted as final. If a dispute is raised, LEZ verifies the signatures and membership of the observations, recomputes the median itself, and compares it with the proposed value. The faulty proposer is slashed by LEZ contracts.
The Oracle Zone deliberately holds no general-purpose execution environment. Therefore, economic security with oracle node registration by staking and slashing is anchored in LEZ contracts. This RFC specifies the price-fetching format, the aggregation and attestation logic, the round and timing model, the optimistic delivery and dispute model, the incentivization bridge, and the parameters.
Motivation
A decentralized price oracle must verify multiple independent signed observations per update while sustaining a reasonable update frequency. Two categorical design approaches are significant:
LEZ-native design:
- All oracle nodes and logic live in the LEZ environment. Research shows that ECDSA signature verification exhausts the LEZ cycle budget at a relatively small committee size which is too small for a decentralized oracle. It is still doable, but the verification must be split across several transactions and blocks, which breaks atomicity. Aggregate-signature schemes relax the per-signature cost but still couple the price-update load to the general-purpose execution layer.
Separate Oracle Zone:
- This approach removes the signature verification load from LEZ. Prices are published as inscriptions on the Logos Blockchain, and the heavy work of checking them runs off the LEZ execution path. LEZ consumes only the final attested price on the optimistic path, and performs signature verification only when a dispute is raised. This raises the achievable signer count and the update frequency, which improves both liveness, since more oracle nodes and faster rounds are possible, and price accuracy, since more independent sources feed a robust median.
The rationale for a separate zone is therefore performance. Feeding price data does not load the LEZ execution layer, and the zone can be tuned for fast aggregation and high verification throughput independently of LEZ.
The trade-off introduced by this separation is that the Oracle Zone has no execution environment in which to custody stake or run slashing logic. This RFC resolves that by keeping all economic security in LEZ contracts for stake and slash operations.
Format Specification
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119.
Assumptions
- At least more than half of the oracle nodes (indexers) are honest, who fetch-then-forward price data by following this protocol.
- No indexer can manipulate observation ordering. Ordering authority is delegated entirely to Bedrock's immutable inscription order.
- Indexers have no immutable execution logic beyond aggregation. Stake custody and slashing enforcement are delegated entirely to LEZ contracts.
- At least one honest indexer disputes a wrong proposal before the dispute window closes, by sending the observations to LEZ. LEZ resolves the dispute by recomputing the median. Correctness of the attested price rests on this one honest indexer existing.
- The active oracle set is large enough that the quorum
Nis reached every round. Liveness of attestation depends on this oversizing.
Roles
The roles used in the Oracle Zone are as follows:
Bedrock: The Logos Blockchain ordering layer, acting as the L1. It totally orders and finalizes the inscriptions, giving every indexer the same immutable input to aggregate over.oracle node: An off-chain agent run by an oracle operator. It fetches prices from external sources, computes a local price observation, signs and publishes it as an inscription onBedrock. Eachoracle nodeis identified by its public key asoracle id. The same key is its channel key on Bedrock and its staking identity in LEZ.indexer: Anoracle nodein its second role. It reads the finalized inscription stream fromBedrockand computes the attested price as the median of the valid observations. Because the input is immutable and the aggregation code is fixed and deterministic, every honest indexer MUST derive the same value.proposer: The one indexer that, in a given round, writes the attested price to LEZ and opens the dispute window. Only one proposer acts per round.challenger: Any indexer that reads the proposed price from LEZ, recomputes it from the same finalized inscriptions, if the proposed value is wrong, disputes it before the window closes.
Flow
Before a round begins, each oracle node must be a member of the active oracle set.
A node joins by bonding stake in the LEZ contract and registering its oracle id in the membership tree held in LEZ.
Only observations from registered nodes are aggregated.
The general flow of a round is as follows:
- Each
oracle nodefetches prices from external sources for the feed, computes a local price observation, signs and publishes it as an inscription onBedrock. Bedrock totally orders and finalizes the inscriptions. - Every
indexerreads the finalized inscriptions of the current round and computes the attested price as the median of the valid observations. Because the input is immutable and the code is deterministic, all honest indexers MUST reach the same value. - One
indexeracts as theproposerfor the round. On the optimistic path it writes to the LEZ contract its attested price together with the observations and their membership proofs, and this opens a dispute window. During the window, the contract waits for a dispute from any otherindexer. - Every other
indexeracts as achallenger. It reads the proposed value from the LEZ contract and compares it with the value it computed itself. - If the proposed value differs, a
challengerdisputes it before the window closes. To dispute, it sends the observations to the LEZ contract. The contract verifies their signatures and membership, recomputes the median itself, and compares it with the proposed value. If they differ, the proposed value is rejected and the faultyproposeris slashed. - If no dispute is raised before the window closes, this is the optimistic path, and the LEZ contract finalizes the proposed value as the attested price.
Price Fetching
Each oracle node fetches the price of the feed from external sources.
The protocol is agnostic to the specific sources and to the local pre-aggregation method.
It is RECOMMENDED that a node query at least three independent sources and submit a local median,
to reduce the chance of its observation being discarded as an outlier.
A node builds its observation deterministically,
so that two honest nodes reading the same prices produce the same value. First, it reads its sources.
How it connects to each source, which endpoints or APIs it uses, is left to the operator, and the protocol does not constrain the source side.
A node MUST validate each source value before using it.
A value that is not a positive number, or that deviates grossly from the others,
MUST be dropped, so a broken or malicious source cannot enter the local median.
Second, it reduces the remaining source values to one local value by taking their median.
Sources report prices at different decimal precisions,
so the node normalizes each to the fixed decimals of the feed, rounding half up.
If the number of values is even, it takes the lower of the two middle values,
so the result is always one of the observed prices and never an average.
Third, it encodes that value as an integer at the fixed decimals.
As an example, a node reads four sources for BTC/USDT and gets 67123.1, 67124.2071, 67125.40215, and 67126.0.
Each is a valid positive number, and none is a gross outlier, so all are kept.
The feed fixes decimals = 6, so the node normalizes each to six decimals rounding half up,
giving 67123.100000, 67124.207100, 67125.402150, and 67126.000000.
Since the count is even, it takes the lower of the two middle values, 67124.207100.
It scales that to an integer at six decimals, 67124.207100 * 10^6 = 67124207100,
and sets price = 67124207100 and decimals = 6.
The indexer applies the same normalization and even-count rule when it takes the median over observations.
Each observation is encoded as a PriceObservation.
The price is carried as an integer price together with a decimals field,
so that no floating-point value crosses the protocol boundary.
The real value is price * 10^(-decimals).
Authentication of an observation on the optimistic path comes from Bedrock.
An oracle node publishes to its own channel,
so Bedrock verifies the writer signature at the inscription level and records who wrote each observation.
The signature field carries a BIP-340 Schnorr signature
over the SHA-256 hash of the canonical serialization of fields 1 to 6.
The indexer verifies this signature off-chain during aggregation.
On the optimistic path LEZ does not verify it.
LEZ verifies it only when a dispute is raised, without depending on Bedrock,
which is what lets the dispute be resolved inside LEZ.
The membership_proof is a separate witness and is not covered by the signature.
The PriceObservation is specified using protocol buffers v3:
syntax = "proto3";
message PriceObservation {
string feed_id = 1; // asset pair identifier, e.g. "BTC/USDT"
int64 price = 2; // integer-encoded price, real value = price * 10^(-decimals)
int32 decimals = 3; // number of decimal places in `price` which is 6
int64 round = 4; // round identifier, in Bedrock block-height terms
int64 timestamp = 5; // observation time (unix milliseconds), advisory only
bytes oracle_id = 6; // the node's 32-byte BIP-340 x-only public key, also its channel key and staking identity
bytes signature = 7; // BIP-340 Schnorr signature over SHA-256 of fields 1 to 6, verified off-chain by the indexer and on-chain by LEZ only on dispute
bytes membership_proof = 8; // Merkle inclusion proof of oracle_id under the LEZ membership root (outside signature scope)
}
Aggregation
The indexer is the core logic of the Oracle Zone.
Within each round it performs the following steps deterministically over the ordered inscription stream.
- Deserialize. Decode each finalized inscription from
Bedrockinto aPriceObservation. - Verify signature. Verify the
signaturefield againstoracle_idas in BIP-340. Observations with an invalid signature are discarded. This runs off-chain in the indexer. - Check membership. Confirm
oracle_idis a member of the active oracle set by verifying itsmembership_proofagainst the membership root. Observations from non-members are discarded. - Compute median. Once the number of observations in the round reaches the quorum threshold
N, compute theattested priceas the median of all observations in the round, not only the firstN. The median structurally tolerates up to half the observations being adversarial without moving outside the honest range.
LEZ does not verify signatures on the optimistic path. The indexer checks them off-chain during aggregation, and LEZ verifies them only when a dispute is raised, over the observations behind the disputed value. This keeps the heavy per-signature cost off LEZ.
Every honest indexer runs these steps over the same finalized inscriptions and,
because the input is immutable and the code is deterministic, derives the same attested price.
The attested price is specified as follows:
syntax = "proto3";
message AttestedPrice {
string feed_id = 1; // asset pair identifier, e.g. "BTC/USDT"
int64 price = 2; // attested median, real value = price * 10^(-decimals)
int32 decimals = 3; // number of decimal places in `price`
uint32 valid_count = 4; // number of observations aggregated in this round
int64 round = 5; // round identifier, in Bedrock block-height terms
int64 confidence = 6; // OPTIONAL: dispersion of observations, scaled like `price`
}
The indexer MAY also compute an optional confidence value
that reports how tightly the observations cluster around the median.
It is the median absolute deviation scaled to standard-deviation units, 1.4826 * median(|xᵢ - median|).
The constant 1.4826 is the standard factor that rescales the median absolute deviation so that,
for normally distributed data, it matches the ordinary standard deviation,
which makes the value easier to read against familiar volatility figures.
A small value means the observations agree closely,
a large value means they are dispersed.
LEZ MAY use it to widen margins or pause when dispersion is high.
Rounds and Timing
The Logos Oracle Zone has no separate zone-level blocks,
since it runs no independent consensus.
Ordering and finality come entirely from the Bedrock.
Every reference to block height or block time in this document is to the Bedrock.
The Oracle Zone operates in rounds of length R_round.
Two rules govern the timing:
- Deterministic windowing. Round boundaries MUST be defined by block height, not by wall-clock time. A wall-clock window is non-deterministic across indexer replicas. Defining the window as a fixed block range lets every replica derive the identical attested price.
- Delivery cadence. Once per round the proposer writes the attested price to LEZ,
which opens the dispute window
W_dispute. An on-chain write cannot occur faster than the Logos Blockchain produces blocks, soR_round >= T_block. With the defaultT_block = 30 s, the default round is one block, about30 s.
The price is not final the moment it is written.
It becomes final only after W_dispute passes with no dispute in LEZ contract.
The effective freshness of a price is therefore the round cadence plus W_dispute.
This design targets applications that tolerate this latency.
It does not offer sub-second or high-frequency updates
and that is a deliberate limitation of the current version.
If fewer than N observations are finalized within a round,
no new price is attested for that round, and the last attested price remains the current value
until a round again reaches quorum.
Handling of a proposer that attests incorrectly,
or before quorum, is covered in Incentivization.
Oracle Set Membership
Membership of the active oracle set determines which oracle ids submit observations that indexers will accept.
Membership is also the basis of incentivization.
To join, an oracle node MUST bond stake in a LEZ contract and register its oracle id in the membership tree held in LEZ.Registration is a LEZ-only operation and does not require a cross-zone write into the Oracle Zone.
An indexer does not query LEZ state live, which would make aggregation non-deterministic across replicas.
Instead, each observation carries a membership_proof,
a Merkle inclusion proof of its oracle id against the LEZ membership root,
and the indexer verifies the proof against the membership root it holds.
The indexer is assumed to hold the latest membership root.
Each oracle id is the node's BIP-340 x-only public key,
and the membership tree stores these public keys directly.
During aggregation, every indexer discards observations whose membership_proof does not verify,
so observations from non-members never enter the median.
On the dispute path the LEZ contract checks the same proofs against its own membership root,
so only registered nodes count toward the disputed value.
Incentivization
The Oracle Zone has no execution environment of its own,
so it custodies no stake and runs no slashing logic.
All economic security lives in LEZ contracts.
Setting membership by staking, reward settlement, and slashing all happen in LEZ contracts.
The Oracle Zone only produces the data that these contracts act on.
Rewards and Revenue
oracle nodes earn from serving the feed, and this reward stream is not just compensation but a security primitive.
An oracle node's admission right (see Oracle Set Membership) is a scarce,
income-producing, transferable seat whose market value approximates the net present value of its future reward stream.
This franchise value raises the cost of acquiring a median-controlling set and
makes misbehavior economically self-defeating, since a fault forfeits that future income.
For this to hold, rewards SHOULD be fee-backed (funded by consumers of the feed) rather than pure emissions,
so that the seat's value reflects real, sustainable income rather than speculation.
Reward accounting is computed in the Oracle Zone,
since only the indexer knows which oracle nodes submitted valid,
within-bound observations in the epoch.
At each epoch boundary the indexer commits a reward table, for example a Merkle root of oracle node amounts,
to a LEZ settlement contract in a single cross-zone transaction.
This keeps reward traffic off the per-round path.
The settlement contract does not run a scheduler.
Each oracle node claims against the committed root,
so payout is pull-based and per-epoch rather than a per-round push,
and the claimant pays its own settlement cost.
Reward eligibility is assessed against a soft deviation band around the round's attested median.
The indexer marks each observation as reward-eligible if it lies
within a small deviation D_reward of the attested median, and reward-ineligible otherwise.
An eligible observation earns a full, equal share regardless of its exact distance from the median (validity, not proximity),
so oracle nodes are not pushed to herd toward the median,
while an ineligible observation earns nothing for that round but is not slashed.
This soft band is distinct from, and much tighter than, the hard validity bound whose breach is a slashable out-of-bound fault.
The band affects reward accounting only.
The attested median is always the plain median of all valid observations, unaffected by D_reward.
Slashing
Slashing MUST fire only on strict and provable conditions. A slash is triggered by submitting fault evidence to the LEZ contract, which verifies it and applies the penalty. Four slashable faults are defined:
-
Equivocation. An
oracle idproduces two conflicting signed observations for the same feed and round. The two BIP-340 signatures are a self-contained fraud proof, verified in LEZ, and non-malleable signatures make this unambiguous. Because the proof is cryptographic and false positives are effectively impossible, this fault SHOULD carry the highest penalty. -
Out-of-bound value. A signed observation lies outside the hard validity bound
D_slashfor the round. The signed value plus the round context is itself the proof.D_slashis an absolute sanity bound checked during slashing, and it is much wider than the tightD_rewardband used for reward eligibility (D_reward < D_slash), so that an honest node stays well inside it and a value outside it indicates malice or gross malfunction. Because bound-checking can still have edge cases, a stale reference or a genuine market dislocation may make an honest value appear out of bound, this fault SHOULD carry a capped fraction rather than the full stake, and MAY be paired with a challenge window. -
Premature attestation. A proposer attests a price before the round reaches the quorum
N. The number of observations finalized in a round is fixed and provable from the immutable Bedrock inscriptions, so a challenger proves that fewer thanNobservations existed when the proposer attested. The fault is objective and cheaply proven. The proposed price is rejected and the proposer is slashed. -
Wrong median. A proposer attests a value that is not the median of the valid observations of the round, where valid means correctly signed and from a registered member. On a dispute, the LEZ contract discards observations that fail signature or membership, recomputes the median over the rest, and compares. If the proposed value does not match, the proposer is slashed and LEZ takes its own recomputed median as the correct value. Including a non-member or badly signed observation is therefore only a fault when it changes the median. If it does not change the result, the attestation is still correct and nothing is slashed. A failed round is not re-proposed. The feed continues from the next round, so a proposer that forces a failed round pays a slash for each attempt, which makes stalling the feed economically unsustainable.
Slashed stake MAY be burnt or split between a bounty to the party that submitted the fault evidence,
which funds a permissionless watchdog economy, and burn or treasury for the remainder.
Liveness and non-participation are NOT slashed.
Missing oracle nodes are tolerated by a sufficiently large active set
and are handled through reward eligibility rather than penalties.
Falling outside the D_reward band is likewise NOT a slashable fault.
It only forfeits that round's reward.
Subjective incorrect price and within-bound majority bias are also deliberately excluded,
since no trust-minimized programmatic predicate for them exists.
These are addressed economically rather than by slashing,
through the franchise value of the reward stream above,
the unbonding period below, and randomized selection,
as discussed in Security Considerations.
Parameters
The parameters below are drawn from values used by comparable oracle systems and adjusted for this design. Block-time and finality parameters are properties of the LEZ and are listed for reference.
| Parameter | Symbol | Default | Notes |
|---|---|---|---|
| Feed | BTC/USDT | Single feed, more added later. | |
| Feed decimals | 6 | Fixed integer scale for the feed. Every observation uses it, so the indexer needs no rescaling. | |
| Quorum threshold | N | 50 | Minimum observations required to attest a price for a round. |
| Honest-majority assumption | majority of the aggregated observations | Over the observations aggregated per attestation, not the total pool. | |
| Heartbeat / round cadence | R_round | 1 block (~30 s) | Defined in block-height terms; must be >= T_block. |
| Dispute window | W_dispute | 3 Bedrock blocks (~90 s) | Time a proposed price waits for a dispute before it finalizes. |
| LEZ block time | ~1 s | Consumer zone block time, faster than the host chain block. | |
| Aggregation function | median | Plain median of all signature and membership-observations. | |
| Reward band | D_reward | 0.5%* | Tight band around the median for reward eligibility; D_reward < D_slash. |
| Hard validity bound | D_slash | 2.5%* | Wide sanity bound; a signed value outside it is a slashable out-of-bound fault. |
| Signature scheme | BIP-340 Schnorr | oracle_id is the node's 32-byte x-only public key. | |
| Active oracle set size | AOS | 500* | Scarce, transferable seats (~10x N) so a random per-round subset resists majority capture |
| Stake requirement | fixed floor, greater of token amount or USD value* | Hybrid floor to resist token-price drawdown; magnitude set with tokenomics. | |
| Slash fraction (equivocation) | up to 100%* | Cryptographic proof, effectively zero false positives, so the highest tier is justified. | |
| Slash fraction (out-of-bound) | 5% cap* | Capped due to edge-case risk; MAY use a challenge window. | |
| Slash fraction (premature attestation) | up to 100%* | Provable from immutable inscriptions, effectively zero false positives. | |
| Slash fraction (wrong median) | capped* | Proposer attested a value a successful dispute proved wrong. | |
| Unbonding / cooldown period | 21 days* | Cosmos/Band anchor; must exceed fault-proving window plus deep-finality horizon. | |
| Reward settlement | per epoch, pull-based | Claim against a committed Merkle root | |
| Epoch length | 7 days* | Weekly settlement. | |
| Reward backing | fee-backed preferred* | Fees over pure emissions for sustainable franchise value. | |
| Host chain block time | T_block | 30 s | Logos default assumed here; verify against spec. |
| Host chain finality depth | k | immutable bound (reference) | Worst-case bound; practical confirmation depth is much shallower. |
Security Considerations
Two properties matter most for a price oracle network.
One is liveness, meaning a fresh price is attested every round.
The other is accuracy, meaning the attested price tracks the real market.
Running as a separate zone serves both.
It lifts the per-round signature-verification load off LEZ,
so the zone can aggregate many more observations per round than an LEZ-native design.
More observations per round improves liveness,
since the quorum N is easily reached even when many oracle nodes are absent,
and improves accuracy, since more independent observations feed the median.
Accuracy is further backed by the median itself
and by the slashing conditions in Incentivization.
The points below expand on the assumptions this relies on.
-
Quorum and honest majority. The quorum
Nis the minimum number of valid observations needed before a price is attested. It is a floor, so every valid observation in the round is aggregated. The security assumption is that a majority of the aggregated observations are honest, which keeps the median within the honest range. A large active set makes it unlikely that a whole round is majority-malicious, since an attacker would need to control more than half of many independent observations. -
Indexer liveness is not oracle node liveness. Replicating the indexer keeps the indexer layer live. It does not ensure that enough
oracle nodessubmit each round.Oracle nodeliveness is handled by keeping the active set large and by rewards, not by replication or by slashing non-participation. -
The optimistic path rests on honest indexers. On the optimistic path LEZ accepts the proposer's value without checking it. A wrong value is caught only if at least one honest indexer, having recomputed the median offchain from the same finalized inscriptions, sees the mismatch and raises a dispute. To dispute, the indexer only sends the observations to LEZ. LEZ then resolves it, by verifying signatures and membership and recomputing the median over the immutable observations, so the resolution is trust-minimized and does not rely on any indexer's word. Safety therefore rests on a one-of-many honest assumption to raise the dispute, and on LEZ to resolve it correctly.
-
Cross-zone boundary. The attested price and the slashing evidence both cross into LEZ over a cross-zone transaction. Bedrock guarantees that an inscription is validly ordered and finalized, but not that the sending side computed correctly, so the correctness of what LEZ consumes is re-established inside LEZ. On a dispute LEZ verifies the BIP-340 signatures and membership of the observations itself and recomputes the median, so a slash rests on evidence LEZ checks directly, not on trusting the party that delivered it.
-
Completeness of the observation set. A proposer could omit valid observations to shift the median. Because the same observations are finalized on Bedrock and carry their own signatures, an honest indexer can present an omitted observation, with its
roundfield and signature, to LEZ during the dispute window. LEZ contract verifies it and sees it should have been included. Theroundfield prevents a proposer from claiming a valid observation arrived too late. Completeness therefore reduces to the same one-of-many honest assumption as the optimistic path.
Future Work
This section records design directions deferred beyond this version.
-
Randomized selection. This version fixes neither which nodes attest in a round nor which node proposes, and both are currently predictable. Two selections are left to future work, and both need a shared randomness source with a specified construction. First, the attesting set. Accepting observations in inscription order until quorum is adequate while the set is small and curated, but as it grows an attacker holding many seats could place a majority into a round and bias the median. Selecting each round's attesting set at random from the larger registered set forces an attacker to control a large fraction of the whole set rather than a bare majority. Second, the proposer. A simple round-robin is the starting point, but a proposer that is unpredictable in advance stops an attacker from targeting the known next writer.
-
Cooldown and unbonding period. The unbonding period must be long enough that stake stays locked until any fault can be detected, proven, and settled in LEZ, plus the Logos Blockchain deep-finality margin. The exact duration is left to tokenomics and should be set well above the deep-finality bound. The LEZ contracts that hold stake and enforce the cooldown and unbonding are also left to be specified, since this version covers only the Oracle Zone side.
-
Volatility handling. In fast markets, honest prices spread out. A fixed
D_rewardband can then mark many honest observations ineligible for reward exactly when fresh prices matter most. A mechanism to widen the band or grow the attesting set during high volatility is left to future work. -
Slash proof submission. The slashing flow is not yet specified formally. Who submits the fault evidence is one, and this is an open watcher role paid by the bounty. What the evidence holds is another. For equivocation it is the two conflicting signed observations. For an out-of-bound value it is the signed observation and the round context. For premature attestation it is the finalized inscriptions showing fewer than
Nobservations. For a wrong median it is the observations behind the disputed value. How the LEZ contract checks each kind of evidence, and the challenge window for the faults that need one, are open. Slashing is never automatic. An oracle node or watcher always starts it by sending evidence to the LEZ contract. -
Reward and slash amount analysis. This version fixes the reward and slashing mechanisms but not their exact economic parameters. Several values are left to future work. These are the concrete stake requirement, the four slash fractions, the reward rate and its fee backing, the epoch length, and the unbonding duration. Each must be sized against the value the feed secures. The goal is to keep the cost of corruption above the profit from corruption. This work also covers how the reward table is committed. It covers whether that commitment needs the same optimistic-proposer-and-dispute protection as the attested price.
-
LEZ contract specification. This version defines what the LEZ contracts must achieve but not their implementation. On the optimistic path a contract only stores the proposed price, opens the dispute window, and finalizes if the window closes clean, so this path does no computation and must be cheap. On the dispute path the contract does real work. It verifies signatures, checks membership, recomputes the median, and applies the slash. This is the heavy path that a separate zone was meant to keep rare. Left to future work are the concrete contracts for registration and staking, price finalization, dispute resolution, and reward settlement, and a check that the dispute-path computation fits within the LEZ cycle budget.
-
Confidence threshold. The
confidencevalue reports how tightly observations cluster around the median, but this version does not fix what counts as an acceptable value. A normal spread in a fast market can look too wide in a calm one. Defining this threshold, or a rule that adapts it, is left to future work together with the volatility handling above.
Copyright
Copyright and related rights waived via CC0
References
- Logos Improvement Proposals (LIPs) index: https://lip.logos.co/
- Cryptarchia and Bedrock (Logos): https://lip.logos.co/blockchain/raw/bedrock-architecture-overview.html?highlight=Cryptarchia#cryptarchia
- BIP-340: Schnorr Signatures for secp256k1
- RFC 2119: Key words for use in RFCs
- protocol buffers v3
- Flare Time Series Oracle (FTSO): https://docs.flare.network/tech/ftso/
- Supra DORA (Distributed Oracle Agreement): https://docs.supra.com/oracles/dora-price-feeds
- LON proof-of-concept 1: https://github.com/sydhds/lon_poc
- LON proof-of-concept 2: https://github.com/seugu/lon_oracle_zone_bench
- LON proof-of-concept 3, mocked zone: https://github.com/seugu/lon_oracle_zone_bench/tree/mocked-zone
MIX
| Field | Value |
|---|---|
| Name | LIBP2P-MIX |
| Slug | 99 |
| Status | raw |
| Category | Standards Track |
| Editor | Akshaya Mani [email protected] |
| Contributors | Prem Prathi [email protected], Daniel Kaiser [email protected], Hanno Cornelius [email protected], Mohammed Alghazwi [email protected] |
Timeline
- 2026-05-25 —
f1017b9— Add LIONESS specification for Mix payload encryption (#329) - 2026-05-20 —
1383661— Add SURB specification (§8.7) (#335) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-11 —
2aa2bcd— feat: Mix Cover Traffic specification (#311) - 2026-04-30 —
474c7e5— Extract Mix DoS protection to a standalone spec (#302) - 2026-04-30 —
ccd5bf4— Restructure spam protection: Split into Exit Abuse Prevention and DoS Protection sections (#297) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-29 —
925aeac— chore: changes to how per-hop proof is added to sphinx packet which makes it simpler (#263) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-12-15 —
dabc317— fixing format errors in mix rfc (#229) - 2025-12-12 —
4f54254— fix format errors in math sections for mix rfc (#225) - 2025-12-11 —
7f1df32— chore: use sembreaks for easy review and edits (#223) - 2025-12-10 —
e742cd5— RFC Addition: Section 9 Security Considerations (#194) - 2025-12-10 —
9d11a22— docs: finalize Section 8 Sphinx Packet Construction and Handling (#202) - 2025-10-05 —
36be428— RFC Refactor: Sphinx Packet Format (#173) - 2025-06-27 —
5e3b478— RFC Refactor PR: Modular Rewrite of Mix Protocol Specification (#158) - 2025-06-02 —
db90adc— Fix LaTeX errors (#163) - 2024-11-08 —
38fce27— typo fix - 2024-09-16 —
7f5276e— libp2p Mix Protocol Spec Draft (#97)
Abstract
The Mix Protocol defines a decentralized anonymous message routing layer for libp2p networks. It enables sender anonymity by routing each message through a decentralized mix overlay network composed of participating libp2p nodes, known as mix nodes. Each message is routed independently in a stateless manner, allowing other libp2p protocols to selectively anonymize messages without modifying their core protocol behavior.
1. Introduction
The Mix Protocol is a custom libp2p protocol that defines a message-layer routing abstraction designed to provide sender anonymity in peer-to-peer systems built on the libp2p stack. It addresses the absence of native anonymity primitives in libp2p by offering a modular, content-agnostic protocol that other libp2p protocols can invoke when anonymity is required.
This document describes the design, behavior, and integration of the Mix Protocol within the libp2p architecture. Rather than replacing or modifying existing libp2p protocols, the Mix Protocol complements them by operating independently of connection state and protocol negotiation. It is intended to be used as an optional anonymity layer that can be selectively applied on a per-message basis.
Integration with other libp2p protocols is handled through external interface components—the Mix Entry and Exit layers—which mediate between these protocols and the Mix Protocol instances. These components allow applications to defer anonymity concerns to the Mix layer without altering their native semantics or transport assumptions.
The rest of this document describes the motivation for the protocol, defines relevant terminology, presents the protocol architecture, and explains how the Mix Protocol interoperates with the broader libp2p protocol ecosystem.
2. Terminology
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119.
The following terms are used throughout this specification:
-
Origin Protocol A libp2p protocol (e.g., Ping, GossipSub) that generates and receives the actual message payload. The origin protocol MUST decide on a per-message basis whether to route the message through the Mix Protocol or not.
-
Sender The application-level entity that originates the origin protocol message.
-
Mix Node A libp2p node that supports the Mix Protocol and participates in the mix network. A mix node initiates anonymous routing when invoked with a message. It also receives and processes Sphinx packets when selected as a hop in a mix path.
-
Initiating Node The mix node that constructs and transmits Sphinx packet(s) on behalf of the sender. Handles all mix-layer responsibilities, such as path selection, forwarding delay encoding, and preparation of any configured packet components.
-
Mix Path A non-repeating sequence of mix nodes through which a Sphinx packet is routed across the mix network.
-
Mixify A per-message flag set by the origin protocol to indicate that a message should be routed using the Mix Protocol or not. Only messages with mixify set are forwarded to the Mix Entry Layer. Other messages SHOULD be routed using the origin protocol's default behavior. The phrases 'messages to be mixified', 'to mixify a message' and related variants are used informally throughout this document to refer to messages that either have the
mixifyflag set or are selected to have it set. -
Mix Entry Layer A component that receives messages to be mixified from an origin protocol and forwards them to the local Mix Protocol instance. The Entry Layer is external to the Mix Protocol.
-
Mix Exit Layer A component that receives decrypted messages from a Mix Protocol instance and delivers them to the appropriate origin protocol instance at the destination. Like the Entry Layer, it is external to the Mix Protocol.
-
Mixnet or Mix Network A decentralized overlay network formed by all nodes that support the Mix Protocol. It operates independently of libp2p's protocol-level routing and origin protocol behavior.
-
Sphinx Packet A cryptographic packet format used by the Mix Protocol to encapsulate messages. It uses layered encryption to hide routing information and protect message contents as packets are forwarded hop-by-hop. Sphinx packets are fixed-size and indistinguishable from one another, providing unlinkability and metadata protection.
-
Initialization Vector (IV) A fixed-length input used to initialize block ciphers to add randomness to the encryption process. It ensures that encrypting the same plaintext with the same key produces different ciphertexts. The IV is not secret but must be unique for each encryption.
-
Single-Use Reply Block (SURB) A pre-computed Sphinx header that encodes a return path back to the sender. SURBs are generated by the initiating node and included in the Sphinx packet sent to the recipient. It enables the recipient to send anonymous replies, without learning the sender's identity, the return path, or the forwarding delays.
-
Sphinx payload () The fixed-size encrypted field of a Sphinx packet. It carries the padded application message and any payload extensions such as SURBs.
-
Payload encryption key () A per-hop key used to encrypt or decrypt one layer of the Sphinx payload field .
-
Payload integrity prefix A fixed all-zero byte string prepended to the plaintext payload before applying the payload encryption. The final hop verifies this prefix after payload decryption to detect payload tampering. The length and construction of this prefix are defined in the LIONESS specification.
3. Motivation and Background
libp2p enables modular peer-to-peer applications, but it lacks built-in support for sender anonymity. Most protocols expose persistent peer identifiers, transport metadata, or traffic patterns that can be exploited to deanonymize users through passive observation or correlation.
While libp2p supports NAT traversal mechanisms such as Circuit Relay, these focus on connectivity rather than anonymity. Relays may learn peer identities during stream setup and can observe traffic timing and volume, offering no protection against metadata analysis.
libp2p also supports a Tor transport for network-level anonymity, tunneling traffic through long-lived, encrypted circuits. However, Tor relies on session persistence and is ill-suited for protocols requiring per-message unlinkability.
The Mix Protocol addresses this gap with a decentralized message routing layer based on classical mix network principles. It applies layered encryption and per-hop delays to obscure both routing paths and timing correlations. Each message is routed independently, providing resistance to traffic analysis and protection against metadata leakage.
By decoupling anonymity from connection state and transport negotiation, the Mix Protocol offers a modular privacy abstraction that existing libp2p protocols can adopt without altering their core behavior.
To better illustrate the differences in design goals and threat models, the following subsection contrasts the Mix Protocol with Tor, a widely known anonymity system.
3.1 Comparison with Tor
The Mix Protocol differs fundamentally from Tor in several ways:
-
Unlinkability: In the Mix Protocol, there is no direct connection between source and destination. Each message is routed independently, eliminating correlation through persistent circuits.
-
Delay-based mixing: Mix nodes introduce randomized delays (e.g., from an exponential distribution) before forwarding messages, making timing correlation significantly harder.
-
High-latency focus: Tor prioritizes low-latency communication for interactive web traffic, whereas the Mix Protocol is designed for scenarios where higher latency is acceptable in exchange for stronger anonymity.
-
Message-based design: Each message in the Mix Protocol is self-contained and independently routed. No sessions or state are maintained between messages.
-
Resistance to endpoint attacks: The Mix Protocol is less susceptible to certain endpoint-level attacks, such as traffic volume correlation or targeted probing, since messages are delayed, reordered, and unlinkable at each hop.
To understand the underlying anonymity properties of the Mix Protocol, we next describe the core components of a mix network.
4. Mixing Strategy and Packet Format
The Mix Protocol relies on two core design elements to achieve sender unlinkability and metadata protection: a mixing strategy and a cryptographically secure mix packet format.
4.1 Mixing Strategy
A mixing strategy defines how mix nodes delay and reorder incoming packets to resist timing correlation and input-output linkage. Two commonly used approaches are batch-based mixing and continuous-time mixing.
In batching-based mixing, each mix node collects incoming packets over a fixed or adaptive interval, shuffles them, and forwards them in a batch. While this provides some unlinkability, it introduces high latency, requires synchronized flushing rounds, and may result in bursty output traffic. Anonymity is bounded by the batch size, and performance may degrade under variable message rates.
The Mix Protocol instead uses continuous-time mixing, where each mix node applies a randomized delay to every incoming packet, typically drawn from an exponential distribution. This enables theoretically unbounded anonymity sets, since any packet may, with non-zero probability, be delayed arbitrarily long. In practice, the distribution is truncated once the probability of delay falls below a negligible threshold. Continuous-time mixing also offers improved bandwidth utilization and smoother output traffic compared to batching-based approaches.
To make continuous-time mixing tunable and predictable, the sender MUST select the mean delay for each hop and encode it into the Sphinx packet header. This allows top-level applications to balance latency and anonymity according to their requirements.
4.2 Mix Packet Format
A mix packet format defines how messages are encapsulated and routed through a mix network. It must ensure unlinkability between incoming and outgoing packets, prevent metadata leakage (e.g., path length, hop position, or payload size), and support uniform processing by mix nodes regardless of direction or content.
The Mix Protocol uses Sphinx packets to meet these goals. Each message is encrypted in layers corresponding to the selected mix path. As a packet traverses the network, each mix node removes one encryption layer to obtain the next hop and delay, while the remaining payload remains encrypted and indistinguishable.
Sphinx packets are fixed in size and bit-wise unlinkable. This ensures that they appear identical on the wire regardless of payload, direction, or route length, reducing opportunities for correlation based on packet size or format. Even mix nodes learn only the immediate routing information and the delay to be applied. They do not learn their position in the path or the total number of hops.
The packet format is resistant to tagging and replay attacks and is compact and efficient to process. Sphinx packets also include per-hop integrity checks and enforce a maximum path length. Together with a constant-size header and payload, this provides bounded protection against endless routing and malformed packet propagation.
It also supports anonymous and indistinguishable reply messages through Single-Use Reply Blocks (SURBs).
A complete specification of the Sphinx packet structure and fields is provided in Section 8.
5. Protocol Overview
The Mix Protocol defines a decentralized, message-based routing layer that provides sender anonymity within the libp2p framework. It is agnostic to message content and semantics. Each message is treated as an opaque payload, wrapped into a Sphinx packet and routed independently through a randomly selected mix path. Along the path, each mix node removes one layer of encryption, adds a randomized delay, and forwards the packet to the next hop. This combination of layered encryption and per-hop delay provides resistance to traffic analysis and enables message-level unlinkability.
Unlike typical custom libp2p protocols, the Mix Protocol is stateless—it does not establish persistent streams, negotiate protocols, or maintain sessions. Each message is self-contained and routed independently.
The Mix Protocol sits above the transport layer and below the protocol layer in the libp2p stack. It provides a modular anonymity layer that other libp2p protocols MAY invoke selectively on a per-message basis.
Integration with other libp2p protocols is handled through external components that mediate between the origin protocol and the Mix Protocol instances. This enables selective anonymous routing without modifying protocol semantics or internal behavior.
The following subsections describe how the Mix Protocol integrates with origin protocols via the Mix Entry and Exit layers, how per-message anonymity is controlled through the mixify flag, the rationale for defining Mix as a protocol rather than a transport, and the end-to-end message interaction flow.
5.1 Integration with Origin Protocols
libp2p protocols that wish to anonymize messages MUST do so by integrating with the Mix Protocol via the Mix Entry and Exit layers.
-
The Mix Entry Layer receives messages to be mixified from an origin protocol and forwards them to the local Mix Protocol instance.
-
The Mix Exit Layer receives the final decrypted message from a Mix Protocol instance and forwards it to the appropriate origin protocol instance at the destination over a client-only connection.
This integration is external to the Mix Protocol and is not handled by mix nodes themselves.
5.2 Mixify Option
Some origin protocols may require selective anonymity, choosing to anonymize only certain messages based on their content, context, or destination. For example, a protocol may only anonymize messages containing sensitive metadata while delivering others directly to optimize performance.
To support this, origin protocols MAY implement a per-message mixify flag that indicates whether a message should be routed using the Mix Protocol.
- If the flag is set, the message MUST be handed off to the Mix Entry Layer for anonymous routing.
- If the flag is not set, the message SHOULD be routed using the origin protocol's default mechanism.
This design enables protocols to invoke the Mix Protocol only for selected messages, providing fine-grained control over privacy and performance trade-offs.
5.3 Why a Protocol, Not a Transport
The Mix Protocol is specified as a custom libp2p protocol rather than a transport to support selective anonymity while remaining compatible with libp2p's architecture.
As noted in Section 5.2, origin protocols may anonymize only specific messages based on content or context. Supporting such selective behavior requires invoking Mix on a per-message basis.
libp2p transports, however, are negotiated per peer connection and apply globally to all messages exchanged between two peers. Enabling selective anonymity at the transport layer would therefore require changes to libp2p's core transport semantics.
Defining Mix as a protocol avoids these constraints and offers several benefits:
- Supports selective invocation on a per-message basis.
- Works atop existing secure transports (e.g., QUIC, TLS) without requiring changes to the transport stack.
- Preserves a stateless, content-agnostic model focused on anonymous message routing.
- Integrates seamlessly with origin protocols via the Mix Entry and Exit layers.
This design preserves the modularity of the libp2p stack and allows Mix to be adopted without altering existing transport or protocol behavior.
5.4 Protocol Interaction Flow
A typical end-to-end Mix Protocol flow consists of the following three conceptual phases. Only the second phase—the anonymous routing performed by mix nodes—is part of the core Mix Protocol. The entry-side and exit-side integration steps are handled externally by the Mix Entry and Exit layers.
-
Entry-side Integration (Mix Entry Layer):
- The origin protocol generates a message and sets the
mixifyflag. - The message is passed to the Mix Entry Layer, which invokes the local Mix Protocol instance with the message, destination, and origin protocol codec as input.
- The origin protocol generates a message and sets the
-
Anonymous Routing (Core Mix Protocol):
- The Mix Protocol instance wraps the message in a Sphinx packet and selects a random mix path.
- Each mix node along the path:
- Processes the Sphinx packet by removing one encryption layer.
- Applies a delay and forwards the packet to the next hop.
- The final node in the path (exit node) decrypts the final layer, extracting the original plaintext message, destination, and origin protocol codec.
-
Exit-side Integration (Mix Exit Layer):
- The Mix Exit Layer receives the plaintext message, destination, and origin protocol codec.
- It routes the message to the destination origin protocol instance using a client-only connection.
The destination node does not need to support the Mix Protocol to receive or respond to anonymous messages.
The behavior described above represents the core Mix Protocol. In addition, the protocol supports a set of pluggable components that extend its functionality. These components cover areas such as node discovery, delay strategy, exit abuse prevention, cover traffic generation, incentivization, and DoS protection. Some are REQUIRED for interoperability; others are OPTIONAL or deployment-specific. The next section describes each component.
5.5 Stream Management and Multiplexing
Each Mix Protocol message is routed independently, and forwarding it to the next hop requires opening a new libp2p stream using the Mix Protocol. This applies to both the initial Sphinx packet transmission and each hop along the mix path.
In high-throughput environments (e.g., messaging systems with continuous anonymous traffic), mix nodes may frequently communicate with a subset of mix nodes. Opening a new stream for each Sphinx packet in such scenarios can incur performance costs, as each stream setup requires a multistream handshake for protocol negotiation.
While libp2p supports multiplexing multiple streams over a single transport connection using stream muxers such as mplex and yamux, it does not natively support reusing the same stream over multiple message transmissions. However, stream reuse may be desirable in the mixnet setting to reduce overhead and avoid hitting per protocol stream limits between peers.
The lifecycle of streams, including their reuse, eviction, or pooling strategy, is outside the scope of this specification. It SHOULD be handled by the libp2p host, connection manager, or transport stack.
Mix Protocol implementations MUST NOT assume persistent stream availability and SHOULD gracefully fall back to opening a new stream when reuse is not possible.
6. Pluggable Components
Pluggable components define functionality that extends or configures the behavior of the Mix Protocol beyond its core message routing logic. Each component in this section falls into one of two categories:
- Required for interoperability and path construction (e.g., discovery, delay strategy, DoS protection).
- Optional or deployment-specific (e.g., exit abuse prevention, cover traffic, incentivization).
The following subsections describe the role and expected behavior of each.
6.1 Discovery
The Mix Protocol does not mandate a specific peer discovery mechanism. However, nodes participating in the mixnet MUST be discoverable so that other nodes can construct routing paths that include them.
To enable this, regardless of the discovery mechanism used, each mix node MUST make the following information available to peers:
- Indicate Mix Protocol support (e.g., using a
mixfield or bit). - Its X25519 public key for Sphinx encryption.
- One or more routable libp2p multiaddresses that identify the mix node's own network endpoints.
To support sender anonymity at scale, the discovery mechanism SHOULD support unbiased random sampling from the set of live mix nodes. This enables diverse path construction and reduces exposure to adversarial routing bias.
While no existing mechanism provides unbiased sampling by default, Waku's ambient discovery—an extension over Discv5—demonstrates an approximate solution. It combines topic-based capability advertisement with periodic peer sampling. A similar strategy could potentially be adapted for the Mix Protocol.
A more robust solution would involve integrating capability-aware discovery directly into the libp2p stack, such as through extensions to libp2p-kaddht.
This would enable direct lookup of mix nodes based on protocol support and eliminate reliance on external mechanisms such as Discv5.
Such an enhancement remains exploratory and is outside the scope of this specification.
Regardless of the mechanism, the goal is to ensure mix nodes are discoverable and that path selection is resistant to bias and node churn.
6.2 Delay Strategy
The Mix Protocol uses per-hop delay as a core mechanism for achieving timing unlinkability. For each hop in the mix path, the sender MUST specify a mean delay value, which is embedded in the Sphinx packet header. The mix node at each hop uses this value to sample a randomized delay before forwarding the packet.
By default, delays are sampled from an exponential distribution. This supports continuous-time mixing, produces smooth output traffic, and enables tunable trade-offs between latency and anonymity. Importantly, it allows for unbounded anonymity sets: each packet may, with non-zero probability, be delayed arbitrarily long.
The delay strategy is considered pluggable, and other distributions MAY be used to match application-specific anonymity or performance requirements. However, any delay strategy MUST ensure that:
- Delays are sampled independently at each hop.
- Delay sampling introduces sufficient variability to obscure timing correlation between packet arrival and forwarding across multiple hops.
Strategies that produce deterministic or tightly clustered output delays are NOT RECOMMENDED, as they increase the risk of timing correlation. Delay strategies SHOULD introduce enough uncertainty to prevent adversaries from linking packet arrival and departure times, even when monitoring multiple hops concurrently.
6.3 Exit Abuse Prevention
The Mix Protocol supports optional exit abuse prevention mechanisms to defend exits against flooding attacks routed through them. These mechanisms are validated at the exit node, which is the final node in the mix path before the message is delivered to its destination via the respective libp2p protocol.
Exit nodes that enforce exit abuse prevention MUST validate the attached proof before forwarding the message. If validation fails, the message MUST be discarded.
Common strategies include Proof of Work (PoW), Verifiable Delay Functions (VDFs), and Rate-limiting Nullifiers (RLNs).
The initiating node is responsible for appending the appropriate exit abuse prevention data (e.g., nonce, timestamp) to the message payload. The format and verification logic depend on the selected method.
Note: The exit abuse prevention mechanisms described above are intended to protect the exit from flooding attacks routed through them. They do not provide protection against denial-of-service (DoS) or resource exhaustion attacks targeting the mixnet itself (e.g., flooding mix nodes with traffic, inducing processing overhead, or targeting bandwidth).
Protections against attacks targeting the mixnet itself are addressed in Section 6.6.
6.4 Cover Traffic
Cover traffic is an optional mechanism used to improve privacy by making the presence or absence of actual messages indistinguishable to observers. It helps achieve unobservability where a passive adversary cannot determine whether a node is sending real messages or not.
In the Mix Protocol, cover traffic is limited to loop messages—dummy Sphinx packets that follow a valid mix path and return to the originating node. These messages carry no application payload but are indistinguishable from real messages in structure, size, and routing behavior.
Cover traffic MAY be generated by either mix nodes or senders. The strategy for generating such traffic—such as timing and frequency—is pluggable and not specified in this document.
Implementations that support cover traffic SHOULD generate loop messages at randomized intervals. This helps mask actual sending behavior and increases the effective anonymity set. Timing strategies such as Poisson processes or exponential delays are commonly used, but the choice is left to the implementation.
In addition to enhancing privacy, loop messages can be used to assess network liveness or path reliability without requiring explicit acknowledgments.
6.5 Incentivization
The Mix Protocol supports a simple tit-for-tat model to discourage free-riding and promote mix node participation. In this model, nodes that wish to send anonymous messages using the Mix Protocol MUST also operate a mix node. This requirement ensures that participants contribute to the anonymity set they benefit from, fostering a minimal form of fairness and reciprocity.
This tit-for-tat model is intentionally lightweight and decentralized. It deters passive use of the mixnet by requiring each user to contribute bandwidth and processing capacity. However, it does not guarantee the quality of service provided by participating nodes. For example, it does not prevent nodes from running low-quality or misbehaving mix instances, nor does it deter participation by compromised or transient peers.
The Mix Protocol does not mandate any form of payment, token exchange, or accounting. More sophisticated economic models—such as stake-based participation, credentialed relay networks, or zero-knowledge proof-of-contribution systems—MAY be layered on top of the protocol or enforced via external coordination.
Additionally, network operators or application-layer policies MAY require nodes to maintain minimum uptime, prove their participation, or adhere to service-level guarantees.
While the Mix Protocol defines a minimum participation requirement, additional incentivization extensions are considered pluggable and experimental in this version of the specification. No specific mechanism is standardized.
6.6 DoS Protection
The Mix Protocol supports a pluggable DoS protection mechanism to defend the mixnet against denial-of-service (DoS) or resource exhaustion attacks. Without DoS protection, malicious actors could flood mix nodes with valid Sphinx packets, exhausting computational resources or bandwidth of the mix nodes, eventually making them unusable. Deployments MUST implement a DoS protection mechanism to make the mixnet robust under adversarial conditions.
The DoS protection mechanism is pluggable because different deployments may require different trade-offs between computational overhead, attack resistance, and Sybil resistance. For a specific mix deployment, the same DoS protection mechanism MUST be followed by all participating mix nodes to ensure interoperability.
Detailed design requirements, architectural approaches, packet structure considerations, node responsibilities, and recommendations are specified in Mix DoS Protection.
7. Core Mix Protocol Responsibilities
This section defines the core routing behavior of the Mix Protocol, which all conforming implementations MUST support.
The Mix Protocol defines the logic for anonymously routing messages through the decentralized mix network formed by participating libp2p nodes. Each mix node MUST implement support for:
- initiating anonymous routing when invoked with a message.
- receiving and processing Sphinx packets when selected as a hop in a mix path.
These roles and their required behaviors are defined in the following subsections.
7.1 Protocol Identifier
The Mix Protocol is identified by the protocol string "/mix/1.0.0".
All Mix Protocol interactions occur over libp2p streams negotiated using this identifier. Each Sphinx packet transmission—whether initiated locally or forwarded as part of a mix path—involves opening a new libp2p stream to the next hop. Implementations MAY optimize performance by reusing streams where appropriate; see Section 5.5 for more details on stream management.
7.2 Initiation
A mix node initiates anonymous routing only when it is explicitly invoked with a message to be routed. As specified in Section 5.2, the decision to anonymize a message is made by the origin protocol. When anonymization is required, the origin protocol instance forwards the message to the Mix Entry Layer, which then passes the message to the local Mix Protocol instance for routing.
To perform message initiation, a mix node MUST:
- Select a random mix path.
- Assign a delay value for each hop and encode it into the Sphinx packet header.
- Wrap the message in a Sphinx packet by applying layered encryption in reverse order of nodes in the selected mix path.
- Forward the resulting packet to the first mix node in the mix path using the Mix Protocol.
The Mix Protocol does not interpret message content or origin protocol context. Each invocation is stateless, and the implementation MUST NOT retain routing metadata or per-message state after the packet is forwarded.
7.3 Sphinx Packet Receiving and Processing
A mix node that receives a Sphinx packet is oblivious to its position in the path. The first hop is indistinguishable from other intermediary hops in terms of processing and behavior.
After decrypting one layer of the Sphinx packet, the node MUST inspect the routing information. If this layer indicates that the next hop is the final destination, the packet MUST be processed as an exit. Otherwise, it MUST be processed as an intermediary.
7.3.1 Intermediary Processing
To process a Sphinx packet as an intermediary, a mix node MUST:
- Extract the next hop address and associated delay from the decrypted packet.
- Wait for the specified delay.
- Forward the updated packet to the next hop using the Mix Protocol.
A mix node performing intermediary processing MUST treat each packet as stateless and self-contained.
7.3.2 Exit Processing
To process a Sphinx packet as an exit, a mix node MUST:
- Extract the plaintext message from the final decrypted packet.
- Validate any attached exit abuse prevention proof.
- Discard the message if validation fails.
- Forward the valid message to the Mix Exit Layer for delivery to the destination origin protocol instance.
The node MUST NOT retain decrypted content after forwarding.
The routing behavior described in this section relies on the use of Sphinx packets to preserve unlinkability and confidentiality across hops. The next section specifies their structure, cryptographic components, and construction.
8. Sphinx Packet Format
The Mix Protocol uses the Sphinx packet format to enable unlinkable, multi-hop message routing with per-hop confidentiality and integrity. Each message transmitted through the mix network is encapsulated in a Sphinx packet constructed by the initiating mix node. The packet is encrypted in layers such that each hop in the mix path can decrypt exactly one layer and obtain the next-hop routing information and forwarding delay, without learning the complete path or the message origin. Only the final hop learns the destination, which is encoded in the innermost routing layer.
Sphinx packets are self-contained and indistinguishable on the wire, providing strong metadata protection. Mix nodes forward packets without retaining state or requiring knowledge of the source or destination beyond their immediate routing target.
To ensure uniformity, each Sphinx packet consists of a fixed-length header and a payload that is padded to a fixed maximum size. Although the original message payload may vary in length, padding ensures that all packets are identical in size on the wire. This ensures unlinkability and protects against correlation attacks based on message size.
If a message exceeds the maximum supported payload size, it MUST be fragmented before being passed to the Mix Protocol. Fragmentation and reassembly are the responsibility of the origin protocol or the top-level application. The Mix Protocol handles only messages that do not require fragmentation.
The structure, encoding, and size constraints of the Sphinx packet are detailed in the following subsections.
8.1 Packet Structure Overview
Each Sphinx packet consists of three fixed-length header fields— , , and —followed by a fixed-length encrypted payload . Together, these components enable per-hop message processing with strong confidentiality and integrity guarantees in a stateless and unlinkable manner.
- (Alpha): An ephemeral public value. Each mix node uses its private key and to derive a shared session key for that hop. This session key is used to decrypt and process one layer of the packet.
- (Beta): The nested encrypted routing information. It encodes the next hop address, the forwarding delay, integrity check for the next hop, and the for subsequent hops. At the final hop, encodes the destination address and fixed-length zero padding to preserve uniform size.
- (Gamma): A message authentication code computed over using the session key derived from . It ensures header integrity at each hop.
- (Delta): The encrypted payload. It consists of the message padded to a fixed maximum length and encrypted in layers corresponding to each hop in the mix path.
At each hop, the mix node derives the session key from , verifies the header integrity using , decrypts one layer of to extract the next hop and delay, and decrypts one layer of . It then constructs a new packet with updated values of , , , and , and forwards it to the next hop. At the final hop, the mix node decrypts the innermost layer of and , which yields the destination address and the original application message respectively.
All Sphinx packets are fixed in size and indistinguishable on the wire. This uniform format, combined with layered encryption and per-hop integrity protection, ensures unlinkability, tamper resistance, and robustness against correlation attacks.
The structure and semantics of these fields, the cryptographic primitives used, and the construction and processing steps are defined in the following subsections.
8.2 Cryptographic Primitives
This section defines the cryptographic primitives used in Sphinx packet construction and processing.
-
Security Parameter: All cryptographic operations target a minimum of bits of security, balancing performance with resistance to modern attacks.
-
Elliptic Curve Group :
- Curve: Curve25519
- Notation: Let denote the canonical base point (generator) of .
- Purpose: Used for deriving a Diffie–Hellman-style shared key at each hop using .
- Representation: Small 32-byte group elements, efficient for both encryption and key exchange.
- Scalar Field: The curve is defined over the finite field , where . Ephemeral exponents used in Sphinx packet construction are selected uniformly at random from , the multiplicative subgroup of .
-
Hash Function:
- Construction: SHA-256
- Notation: The hash function is denoted by in subsequent sections.
-
Key Derivation Function (KDF):
- Purpose: To derive encryption keys, IVs, and MAC keys from seed material such as the shared session key at each hop or a SURB reply key.
- Construction: SHA-256 hash with output of the size bits.
- Key Derivation: The KDF takes two inputs: an arbitrary-length seed at least bytes in size and a domain-separation string. The domain-separation strings (e.g.,
"aes_key","mac_key") are fixed and MUST be agreed upon across implementations.
-
Header Encryption: AES-128 in Counter Mode (AES-CTR)
- Purpose: To encrypt the Sphinx routing header for each hop.
- Keys and IVs: Each derived from the session key for the hop using the KDF output truncated to bits.
-
Payload Encryption: LIONESS wide-block encryption
- Purpose: To encrypt the fixed-size payload for each hop and enable end-to-end payload-integrity.
- Construction: Defined by the LIONESS specification.
- Keys and IVs: LIONESS internal round keys and IVs are derived using the KDF output according to the LIONESS specification.
-
Message Authentication Code (MAC):
- Construction: HMAC-SHA-256 with output truncated to bits.
- Purpose: To compute for each hop.
- Key: Derived using KDF from the session key for the hop.
These primitives are used consistently throughout packet construction and decryption, as described in the following sections.
8.3 Packet Component Sizes
This section defines the size of each component in a Sphinx packet, deriving them from the security parameter and protocol parameters introduced earlier. All Sphinx packets MUST be fixed in length to ensure uniformity and indistinguishability on the wire. The serialized packet is structured as follows:
+--------+----------+--------+----------+
| α | β | γ | δ |
| 32 B | variable | 16 B | variable |
+--------+----------+--------+----------+
8.3.1 Header Field Sizes
The header consists of the fields , , and , totaling a fixed size per maximum path length:
-
(Alpha): 32 bytes The size of is determined by the elliptic curve group representation used (Curve25519), which encodes group elements as 32-byte values.
-
(Beta): bytes The size of depends on:
-
Maximum path length (): The recommended value of balances bandwidth versus anonymity tradeoffs.
-
Combined address and delay width (): The recommended accommodates standard libp2p relay multiaddress representations plus a 2-byte delay field. While the actual multiaddress and delay fields may be shorter, they are padded to bytes to maintain fixed field size. The structure and rationale for the block and its encoding are specified in Section 8.4.
Note: This expands on the original Sphinx packet format, which embeds a fixed -byte mix node identifier per hop in . The Mix Protocol generalizes this to bytes to accommodate libp2p multiaddresses and forwarding delays while preserving the cryptographic properties of the original design.
-
Per-hop size () (defined below): Accounts for the integrity tag included with each hop's routing information.
Using the recommended value of and , the resulting size is bytes. At the final hop, encodes the destination address in the first bytes and the remaining bytes are zero-padded.
-
-
(Gamma): bytes The size of equals the security parameter , providing a -bit integrity tag at each hop.
Thus, the total header length is:
Notation: denotes the size (in bytes) of field .
Using the recommended value of and , the header size is:
8.3.2 Payload Size
This subsection defines the size of the encrypted payload in a Sphinx packet.
contains the application message, padded to a fixed maximum length to ensure all packets are indistinguishable on the wire. The size of is calculated as:
The recommended total packet size is bytes, chosen to:
- Accommodate larger libp2p application messages, such as those commonly observed in Status chat using Waku (typically ~4KB payloads),
- Allow inclusion of additional data such as SURBs without requiring fragmentation,
- Maintain reasonable per-hop processing and bandwidth overhead.
Note: When DoS protection is enabled, the maximum packet size MUST be increased to accommodate the proof size of the chosen DoS protection mechanism.
This recommended total packet size of bytes yields:
Implementations MUST account for payload integrity prefix size (defined in the LIONESS specification) and payload extensions, such as SURBs, when determining the maximum message size that can be encapsulated in a single Sphinx packet.
Note: In this specification, the payload size MUST be at least 64 bytes, including the payload integrity prefix. This is due to the use of LIONESS which requires the input block (payload in this case) to be at least 64 bytes. For more details see the LIONESS specification.
The following subsection defines the padding and fragmentation requirements for ensuring this fixed-size constraint.
8.3.3 Padding and Fragmentation
Implementations MUST ensure that all messages shorter than the maximum payload size are padded before Sphinx encapsulation to ensure that all packets are indistinguishable on the wire. Messages larger than the maximum payload size MUST be fragmented by the origin protocol or top-level application before being passed to the Mix Protocol. Reassembly is the responsibility of the consuming application, not the Mix Protocol.
8.3.4 Anonymity Set Considerations
The fixed maximum packet size is a configurable parameter. Protocols or applications that choose to configure a different packet size (either larger or smaller than the default) MUST be aware that using unique or uncommon packet sizes can reduce their effective anonymity set to only other users of the same size. Implementers SHOULD align with widely used defaults to maximize anonymity set size.
Similarly, parameters such as and are configurable. Changes to these parameters affect header size and therefore impact payload size if the total packet size remains fixed. However, if such changes alter the total packet size on the wire, the same anonymity set considerations apply.
The following subsection defines how the next-hop or destination address and forwarding delay are encoded within to enable correct routing and mixing behavior.
8.4 Address and Delay Encoding
Each hop's includes a fixed-size block containing the next-hop address and the forwarding delay, except for the final hop, which encodes the destination address and a delay-sized zero padding. This section defines the structure and encoding of that block.
The combined address and delay block MUST be exactly bytes in length, as defined in Section 8.3.1, regardless of the actual address or delay values. The first bytes MUST encode the address, and the final bytes MUST encode the forwarding delay. This fixed-length encoding ensures that packets remain indistinguishable on the wire and prevents correlation attacks based on routing metadata structure.
Implementations MAY use any address and delay encoding format agreed upon by all participating mix nodes, as long as the combined length is exactly bytes. The encoding format MUST be interpreted consistently by all nodes within a deployment.
For interoperability, a recommended default encoding format involves:
-
Encoding the next-hop or destination address as a libp2p multi-address:
- To keep the address block compact while allowing relay connectivity, each mix node is limited to one IPv4 circuit relay multiaddress. This ensures that most nodes can act as mix nodes, including those behind NATs or firewalls.
- In libp2p terms, this combines transport addresses with multiple peer identities to form an address that describes a relay circuit:
/ip4/<ipv4>/tcp/<port>/p2p/<relayPeerID>/p2p-circuit/p2p/<relayedPeerID>Variants may include directly reachable peers and transports such as/quic-v1, depending on the mix node's supported stack. - IPv6 support is deferred, as it adds bytes just for the IP field.
- Future revisions may extend this format to support IPv6 or DNS-based multiaddresses.
With these constraints, the recommended encoding layout is:
- IPv4 address (4 bytes)
- Protocol identifier e.g., TCP or QUIC (1 byte)
- Port number (2 bytes)
- Peer IDs (39 bytes, post-Base58 decoding)
-
Encoding the forwarding delay as an unsigned 16-bit integer (2 bytes), representing the mean delay in milliseconds for the configured delay distribution, using big endian network byte order. The delay distribution is pluggable, as defined in Section 6.2.
If the encoded address or delay is shorter than its respective allocated field, it MUST be padded with zeros. If it exceeds the allocated size, it MUST be rejected or truncated according to the implementation policy.
Note: Future versions of the Mix Protocol may support address compression by encoding only the peer identifier and relying on external peer discovery mechanisms to retrieve full multiaddresses at runtime. This would allow for more compact headers and greater address flexibility, but requires fast and reliable lookup support across deployments. This design is out of scope for the current version.
With the field sizes and encoding conventions established, the next section describes how a mix node constructs a complete Sphinx packet when initiating the Mix Protocol.
8.5 Packet Construction
This section defines how a mix node constructs a Sphinx packet when initiating the Mix Protocol on behalf of a local origin protocol instance. The construction process wraps the message in a sequence of encryption layers—one for each hop—such that only the corresponding mix node can decrypt its layer and retrieve the routing instructions for that hop.
8.5.1 Inputs
To initiate the Mix Protocol, the origin protocol instance submits a message to the Mix Entry Layer on the same node. This layer forwards it to the local Mix Protocol instance, which constructs a Sphinx packet using the following REQUIRED inputs:
- Application message: The serialized message provided by the origin protocol instance. The Mix Protocol instance applies any configured exit abuse prevention mechanism and attaches one or two SURBs prior to encapsulating the message in the Sphinx packet. The initiating node MUST ensure that the resulting payload size does not exceed the maximum supported size defined in Section 8.3.2.
- Origin protocol codec: The libp2p protocol string corresponding to the origin protocol instance. This is included in the payload so that the exit node can route the message to the intended destination protocol after decryption.
- Mix Path length : The number of mix nodes to include in the path. The mix path MUST consist of at least three hops, each representing a distinct mix node.
- Destination address : The routing address of the intended recipient of the message. This address is encoded in bytes as defined in Section 8.4 and revealed only at the last hop.
8.5.2 Construction Steps
This subsection defines how the initiating mix node constructs a complete Sphinx packet using the inputs defined in Section 8.5.1. The construction MUST follow the cryptographic structure defined in Section 8.1, use the primitives specified in Section 8.2, and adhere to the component sizes and encoding formats from Section 8.3 and Section 8.4.
The construction MUST proceed as follows:
-
Prepare Application Message
- Apply any configured exit abuse prevention mechanism (e.g., PoW, VDF, RLN) to the serialized message. Exit abuse prevention mechanisms are pluggable as defined in Section 6.3.
- Attach one or more SURBs, if required, following the steps in Section 8.7.2.
- Append the origin protocol codec in a format that enables the exit node to reliably extract it during parsing. A recommended encoding approach is to prefix the codec string with its length, encoded as a compact varint field limited to two bytes. Regardless of the scheme used, implementations MUST agree on the format within a deployment to ensure deterministic decoding.
- Pad the result to the maximum application message length of bytes using a deterministic padding scheme. This value is derived from the fixed payload size in Section 8.3.2 ( bytes) minus the payload integrity prefix, which is set to bytes to match the security parameter defined in Section 8.2. The chosen padding scheme MUST yield a fixed-size padded output and MUST be consistent across all mix nodes to ensure correct interpretation during unpadding. For example, schemes that explicitly encode the padding length and prepend zero-valued padding bytes MAY be used.
- Let the resulting message be .
-
Select A Mix Path
- First obtain an unbiased random sample of live, routable mix nodes using some discovery mechanism. The choice of discovery mechanism is deployment-specific as defined in Section 6.1. The discovery mechanism MUST be unbiased and provide, at a minimum, the multiaddress and X25519 public key of each mix node.
- From this sample, choose a random mix path of length . As defined in Section 2, a mix path is a non-repeating sequence of mix nodes.
- For each hop :
- Retrieve the multiaddress and corresponding X25519 public key of the -th mix node.
- Encode the multiaddress in bytes as defined in Section 8.4. Let the resulting encoded multiaddress be .
-
Wrap Plaintext Payload In Sphinx Packet
a. Compute Ephemeral Secrets
-
Choose a random private exponent .
-
Initialize:
-
For each hop (from to ), compute:
Note that the length of is bytes, as defined in Section 8.3.1.
b. Compute Per-Hop Filler Strings
Filler strings are encrypted strings that are appended to the header during encryption. They ensure that the header length remains constant across hops, regardless of the position of a node in the mix path.
To compute the sequence of filler strings, perform the following steps:
-
Initialize (empty string).
-
For each (from to ):
-
Derive per-hop AES key and IV:
-
Compute the filler string using , which is AES-CTR encryption with the keystream starting from index :
where defines the string of bits of length .
-
Note that the length of is , .
c. Construct Routing Header The routing header as defined in Section 8.1 is the encrypted structure that carries the forwarding instructions for each hop. It ensures that a mix node can learn only its immediate next hop and forwarding delay without inferring the full path.
Filler strings computed in the previous step are appended during encryption to ensure that the header length remains constant across hops. This prevents a node from distinguishing its position in the path based on header size.
To construct the routing header, perform the following steps for each hop down to , recursively:
-
Derive per-hop AES key, MAC key, and IV:
-
Set the per hop two-byte encoded delay as defined in Section 8.4:
- If final hop (i.e., ), encode two-byte zero padding.
- For all other hop , , select the mean forwarding delay for the delay strategy configured by the application, and encode it as a two-byte value. The delay strategy is pluggable, as defined in Section 6.2.
-
Using the derived keys and encoded forwarding delay, compute the nested encrypted routing information :
-
If (i.e., exit node):
-
Otherwise (i.e., intermediary node):
where denotes the substring of from byte offset to , inclusive, using zero-based indexing.
Note that the length of is , as defined in Section 8.3.1.
-
Compute the message authentication code :
Note that the length of is , as defined in Section 8.3.1.
-
d. Encrypt Payload The encrypted payload contains the message defined in step 1, prepended with the payload integrity prefix of size . It is encrypted in layers using the LIONESS wide-block encryption (defined in the LIONESS specification) such that each hop in the mix path removes exactly one layer using the per-hop session key. This ensures that only the final hop (i.e., the exit node) can fully recover , validate its integrity, and forward it to the destination. To compute the encrypted payload, perform the following steps for each hop down to , recursively:
-
Derive per-hop payload encryption key:
-
Using the derived keys, compute the encrypted payload using LIONESS encryption (see LIONESS specification):
-
If (i.e., exit node):
-
Otherwise (i.e., intermediary node):
Note that the length of , is bytes.
Given that the derived size of is bytes as defined in Section 8.3.2, this allows to be of length bytes as defined in step 1.
-
e. Assemble Final Packet The final Sphinx packet is structured as defined in Section 8.3:
α = α_0 // 32 bytes β = β_0 // 576 bytes γ = γ_0 // 16 bytes δ = δ_0 // 3984 bytesSerialize the final packet using a consistent format and prepare it for transmission.
f. Transmit Packet
- Sample a randomized delay from the same distribution family used for per-hop delays (in step 3.c.) with an independently chosen mean.
This delay prevents timing correlation when multiple Sphinx packets are sent in quick succession. Such bursts may occur when an upstream protocol fragments a large message, or when several messages are sent close together.
- After the randomized delay elapses, transmit the serialized packet to the first hop via a libp2p stream negotiated under the
"/mix/1.0.0"protocol identifier.
Implementations MAY reuse an existing stream to the first hop as described in Section 5.5, if doing so does not introduce any observable linkability between the packets.
-
Once a Sphinx packet is constructed and transmitted by the initiating node, it is processed hop-by-hop by the remaining mix nodes in the path.
Each node receives the packet over a libp2p stream negotiated under the "/mix/1.0.0" protocol.
The following subsection defines the per-hop packet handling logic expected of each mix node, depending on whether it acts as an intermediary or an exit.
8.6 Sphinx Packet Handling
Each mix node MUST implement a handler for incoming data received over libp2p streams negotiated under the "/mix/1.0.0" protocol identifier.
The incoming stream may have been reused by the previous hop, as described in Section 5.5.
Implementations MUST ensure that packet handling remains stateless and unlinkable, regardless of stream reuse.
Upon receiving the stream payload, the node MUST interpret it as a Sphinx packet and process it in one of two roles—intermediary or exit— as defined in Section 7.3. This section defines the exact behavior for both roles.
8.6.1 Shared Preprocessing
Upon receiving a stream payload over a libp2p stream, the mix node MUST first deserialize it into a Sphinx packet (α, β, γ, δ).
The deserialized fields MUST match the sizes defined in Section 8.5.2 Step 3.e., and the total packet length MUST match the fixed packet size defined in Section 8.3.2.
If the stream payload does not match the expected length, it MUST be discarded and the processing MUST terminate.
After successful deserialization, the mix node performs the following steps:
-
Derive Session Key
Let denote the node's X25519 private key. Compute the shared secret .
-
Check for Replays
- Compute the tag .
- If the tag exists in the node's table of previously seen tags, discard the packet and terminate processing.
- Otherwise, store the tag in the table.
The table MAY be flushed when the node rotates its private key. Implementations SHOULD perform this cleanup securely and automatically.
Note: This check also enforces SURB single-use defined in Section 8.7. A reused SURB produces a duplicate tag at the first return-path node and is discarded.
-
Check Header Integrity
-
Derive the MAC key from the session secret :
-
Verify the integrity of the routing header:
If the check fails, discard the packet and terminate processing.
-
-
Decrypt One Layer of the Routing Header
-
Derive the routing header AES key and IV from the session secret :
-
Decrypt the suitably padded to obtain the routing block for this hop:
This step removes the filler string appended during header encryption in Section 8.5.2 Step 3.c. and yields the plaintext routing information for this hop.
The routing block MUST be parsed according to the rules and field layout defined in Section 8.6.2 to determine whether the current node is an intermediary or the exit.
-
-
Decrypt One Layer of the Payload
-
Derive the payload encryption key from the session secret :
-
Decrypt one layer of the encrypted payload :
The resulting is the decrypted payload for this hop and MUST be interpreted depending on the parsed node's role, determined by , as described in Section 8.6.2.
-
8.6.2 Node Role Determination
As described in Section 8.6.1, the mix node obtains the routing block by decrypting one layer of the encrypted header .
At this stage, the node MUST determine whether it is an intermediary or the exit based on the prefix of , in accordance with the construction of defined in Section 8.5.2 Step 3.c.:
- If contains a two-byte zero delay, process the packet as an exit.
- Otherwise, process the packet as an intermediary.
The following subsections define the precise behavior for each case.
8.6.3 Intermediary Processing
Once the node determines its role as an intermediary following the steps in Section 8.6.2, it MUST perform the following steps to interpret routing block and decrypted payload obtained in Section 8.6.1:
-
Parse Routing Block
Parse the routing block according to the , construction defined in Section 8.5.2 Step 3.c.:
-
Extract the first bytes of as the next hop address
-
Extract the next two bytes as the mean delay
-
Extract the next bytes as the next hop MAC
-
Extract the next bytes as the next hop routing information
If parsing fails, discard the packet and terminate processing.
-
-
Update Header Fields
Update the header fields according to the construction steps defined in Section 8.5.2:
-
Compute the next hop ephemeral public value , deriving the blinding factor from the shared secret computed in Section 8.6.1 Step 1.
-
Use the and extracted in step 1. as the routing information and MAC respectively in the outgoing packet.
-
-
Update Payload
Use the decrypted payload computed in Section 8.6.1 Step 5. as the payload in the outgoing packet.
-
Assemble Final Packet The final Sphinx packet is structured as defined in Section 8.3:
α = α' // 32 bytes β = β' // 576 bytes γ = γ' // 16 bytes δ = δ' // 3984 bytesSerialize using the same format used in Section 8.5.2. The remaining fields are already fixed-length buffers and do not require further transformation.
-
Transmit Packet
-
Interpret the and extracted in step 1. according to the encoding format used during construction in Section 8.5.2 Step 3.c.
-
Sample the actual forwarding delay from the configured delay distribution, using the decoded mean delay value as the distribution parameter.
-
After the forwarding delay elapses, transmit the serialized packet to the next hop address via a libp2p stream negotiated under the
"/mix/1.0.0"protocol identifier.
Implementations MAY reuse an existing stream to the next hop as described in Section 5.5, if doing so does not introduce any observable linkability between the packets.
-
-
Erase State
-
After transmission, erase all temporary values securely from memory, including session keys, decrypted content, and routing metadata.
-
If any error occurs—such as malformed header, invalid delay, or failed stream transmission—silently discard the packet and do not send any error response.
-
8.6.4 Exit Processing
Once the node determines its role as an exit following the steps in Section 8.6.2, it MUST determine the exit message type from the routing block obtained in Section 8.6.1:
-
If encodes zero address and is nonzero (i.e., contains a SURB identifier), the packet is a SURB reply. Process per Section 8.7.4.
-
Otherwise, the packet is a forward message. The node MUST perform the following steps to interpret routing block and decrypted payload obtained in Section 8.6.1:
-
Parse Routing Block
Parse the routing block according to the , construction defined in Section 8.5.2 Step 3.c.:
-
Extract the first bytes of as the destination address
-
-
Recover Padded Application Message
-
Verify the decrypted payload computed in Section 8.6.1 Step 5.:
If the payload integrity prefix check fails, discard and terminate processing.
-
Extract rest of the bytes of as the padded application message :
where denotes the substring of from byte offset to the end of the string, using zero-based indexing.
-
-
Extract Application Message
Interpret recovered according to the construction steps defined in Section 8.5.2 Step 1.:
-
First, unpad using the deterministic padding scheme defined during construction.
-
Next, parse the unpadded message deterministically to extract:
- optional exit abuse prevention proof
- zero or more SURBs
- the origin protocol codec
- the serialized application message
-
Parse and deserialize the metadata fields required for exit abuse prevention validation, SURB extraction, and protocol codec identification, consistent with the format and extensions applied by the initiating node. The application message itself MUST remain serialized.
-
If parsing fails at any stage, discard and terminate processing.
-
-
Internal Protocol Codec Check
-
If the origin protocol codec extracted in step 3 matches a reserved internal protocol codec, the Mix Protocol MUST handle the message internally without handing off to the Mix Exit Layer. Internal protocol codecs are used by pluggable components (e.g., cover traffic) that route packets through the mix network for protocol-internal purposes. The specific handling is defined by the component that registered the codec.
-
If the codec does not match any reserved internal protocol codec, proceed to step 5.
-
-
Handoff to Exit Layer
-
Hand off the serialized application message, the origin protocol codec, destination address (extracted in step 1.), and any SURBs extracted in step 3. to the local Exit Layer for further processing and delivery.
-
The Exit Layer is responsible for establishing a client-only connection and forwarding the message to the destination. Implementations MAY reuse an existing stream to the destination, if doing so does not introduce any observable linkability between forwarded messages. It is also responsible for storing any received SURBs and routing responses from the destination using them (see Section 8.7.3).
-
8.7 Single-Use Reply Blocks
A Single-Use Reply Block (SURB) allows the recipient of a Sphinx packet to send a reply without learning the sender's identity, the return mix path, or any forwarding delays.
The recipient MUST NOT use the same SURB more than once. Reusing a SURB would allow nodes on the return path to link multiple replies back to the original sender. The single-use requirement is enforced by the replay protection of Section 8.6.1 Step 2.
A SURB encodes a complete Sphinx header for a return path, a symmetric reply key, and a unique reply identifier. The initiating node constructs one or more SURBs and embeds them in the outgoing Sphinx packet payload. The recipient uses a SURB to reply — only the original sender can decrypt the reply.
This section defines SURB component sizes and total size (Section 8.7.1), how SURBs are created (Section 8.7.2), used by the recipient (Section 8.7.3), processed by the exit node (Section 8.7.4), and recovered by the Exit Layer (Section 8.7.5).
8.7.1 SURB Component Sizes
A SURB consists of the following components:
-
: bytes. The address of the first mix node on the return path. Uses the same address block encoding defined in Section 8.4, minus the 2-byte delay field, since no delay is encoded here.
-
: A complete Sphinx header for the return path, with component sizes as defined in Section 8.3.1:
- : bytes. The ephemeral public value for the first hop.
- : bytes. The nested encrypted routing information for the return path.
- : bytes. The message authentication code computed over using the session key derived from .
-
: bytes. The reply key, sampled uniformly at random by the initiating node.
The total SURB size is:
Using the recommended parameters (, , bytes):
Each SURB embedded in the message payload reduces the available application message space by bytes. With the allowable message size of bytes derived in Section 8.5.2 Step 3.d, attaching SURBs leaves bytes for the application message, protocol codec, and any exit abuse prevention proof.
8.7.2 SURB Creation
Depending on whether an application message requires a reply, the initiating node may create and attach one or more SURBs during its preparation (Section 8.5.2 Step 1) for Sphinx packet construction. To construct each SURB, the initiating node MUST perform the following steps:
-
Select Return Path and Compute Ephemeral Secrets
Select a return mix path of length with the initiating node as the final hop. Compute the ephemeral public value and per-hop shared secrets following the same procedure as Section 8.5.2 Steps 2 and 3.a.
-
Sample SURB Identifier and Reply Key
Sample a unique SURB identifier and a reply key of length bytes uniformly at random.
-
Construct Return Path Header
Compute per-hop filler strings and construct the routing header following the same procedure in Section 8.5.2 Steps 3.b and 3.c, with just computed as follows:
That is, encode zero address and delay followed by the SURB identifier in . The SURB identifier is embedded so that the initiating node can match an incoming reply to the stored decryption keys in step 4 below.
Use the same construction for the remaining routing blocks , , and all per-hop MACs , .
Note: A SURB construction follows the same steps for Sphinx packet construction in Section 8.5.2 Steps 2 and 3, with a modified exit routing block that signals a SURB reply.
-
Assemble SURB
Assemble the SURB tuple as defined in Section 8.7.1. Here is the address of the first hop on the return path. Embed the SURB in the message payload.
The initiating node MUST store the tuple in a local table indexed by , for reply recovery defined in Section 8.7.5.
Note: A SURB becomes unusable once any return-path mix node rotates its X25519 key. Implementations SHOULD discard these tuples after a configurable timeout, or at most by the key rotation interval.
8.7.3 Using a SURB
When the Exit Layer receives any SURBs as part of the handoff defined in Section 8.6.4 Step 4, it MUST retain them for routing the destination's responses back to the sender.
If no response arrives within a configurable timeout, the Exit Layer SHOULD drop the SURBs.
Note: Each retained SURB consists of the hop address of the first node in the return path, a pre-computed Sphinx header, and a reply key, as defined in Section 8.7.1.
Once the destination responds with a reply message, the Exit Layer MUST perform the following steps to use a SURB :
-
Prepare Reply Message
Pad the reply message to bytes using a deterministic padding scheme, consistent with Section 8.5.2 Step 1. Let the resulting message be .
-
Encrypt Reply Payload
For a SURB reply, the Exit Layer does not know the return-path shared secrets . Instead, it only has the first node in the return path (), a pre-computed Sphinx header (), and a reply key ().
Therefore, the Exit Layer encrypts the reply payload only once using as the LIONESS seed.
Note that the reply key is bytes in size, which satisfies the LIONESS seed requirement. The resulting is placed into the SURB reply packet. Then each hop on the return path subsequently applies the normal payload-processing rule, namely one LIONESS decryption under its per-hop payload encryption key (Section 8.6.1 Step 5), resulting in one layer of LIONESS encryption and layers of LIONESS decryptions. These return path layers are later removed during reply recovery as described in Section 8.7.5.
-
Assemble and Transmit Reply Packet
Assemble the Sphinx packet using the SURB header and encrypted payload from step 2, following the packet format defined in Section 8.5.2 Step 3.e. Serialize and transmit packet to (retrieved from the SURB) via a libp2p stream negotiated under the
"/mix/1.0.0"protocol identifier. Discard the SURB.
8.7.4 SURB Reply Processing
During Sphinx packet handling, once a node determines its role as an exit following the steps in Section 8.6.2 and the message type as SURB reply from Section 8.6.4, it MUST perform the following steps to interpret the routing block and decrypted payload obtained in Section 8.6.1:
-
Extract SURB Identifier
Extract the SURB identifier from , at the position defined in Section 8.7.2 Step 3:
-
Handoff to Exit Layer
Hand off the decrypted payload and the extracted SURB identifier to the local Exit Layer for reply recovery, as defined in Section 8.7.5.
8.7.5 Reply Recovery
When the Exit Layer receives decrypted payload and the SURB identifier , as part of the handoff defined in Section 8.7.4 Step 2, it MUST perform the following steps to recover the reply message:
-
Retrieve Decryption Keys
Retrieve the decryption keys tuple indexed by stored as defined in Section 8.7.2 Step 4.
If no tuple is found, discard the reply and terminate processing.
-
Recover Padded Reply Message
The encrypted payload contains the padded reply message defined in Section 8.7.3 Step 1, prepended with the payload integrity prefix of size -byte. It is encrypted in a total of layers: A first layer of LIONESS encryption using the reply key as the seed, and layers of LIONESS decryption using per-hop session keys . To recover the padded reply message, we must first remove all the decryption layers with a LIONESS encryption, and then remove the initial reply encryption (using ) with a decryption. Therefore, we must perform the following steps:
-
reverse the return-path layers by performing the same LIONESS layered encryption pattern as defined in Section 8.5.2, with the reply payload used as the initial input instead of the plaintext payload (). This process removes layers, resulting in .
-
Decrypt the final layer i.e., reversing the effect of the initial encryption in step 2 of section 8.7.3:
-
Verify the decrypted payload :
If the check fails, discard and terminate processing.
-
-
Recover Reply Message
-
Extract rest of the bytes of as the padded reply message :
-
Unpad using the deterministic padding scheme defined during construction in Section 8.7.3 Step 1.
-
Erase all temporary values and the stored decryption keys from memory.
-
9. Security Considerations
This section describes the security guarantees and limitations of the Mix Protocol. It begins by outlining the anonymity properties provided by the core protocol when routing messages through the mix network. It then discusses the trust assumptions required at the edges of the network, particularly at the final hop. Finally, it presents an alternative trust model for destinations that support Mix Protocol directly, followed by a summary of broader limitations and areas that may be addressed in future iterations.
9.1 Security Guarantees of the Core Mix Protocol
The core Mix Protocol—comprising anonymous routing through a sequence of mix nodes using Sphinx packets—provides the following security guarantees:
- Sender anonymity: Each message is wrapped in layered encryption and routed independently, making it unlinkable to the sender even if multiple mix nodes are colluding.
- Metadata protection: All messages are fixed in size and indistinguishable on the wire. Sphinx packets reveal only the immediate next hop and delay to each mix node. No intermediate node learns its position in the path or the total path length.
- Traffic analysis resistance: Continuous-time mixing with randomized per-hop delays reduces the risk of timing correlation and input-output linkage.
- Per-hop header confidentiality and integrity: Each hop decrypts only its assigned layer of the Sphinx packet and verifies header integrity via a per-hop MAC.
- Per-hop payload confidentiality: Each hop removes only one layer of encryption, so intermediate hops cannot recover the plaintext.
- End-to-end payload integrity: The exit node verifies the payload integrity prefix after fully decrypting the payload. For more details see the LIONESS specification.
- No long-term state: All routing is stateless. Mix nodes do not maintain per-message metadata, reducing the surface for correlation attacks.
These guarantees hold only within the boundaries of the Mix Protocol. Additional trust assumptions are introduced at the edges, particularly at the final hop, where the decrypted message is handed off to the Mix Exit Layer for delivery to the destination outside the mixnet. The next subsection discusses these trust assumptions in detail.
9.2 Exit Node Trust Model
The Mix Protocol ensures strong sender anonymity and metadata protection between the Mix Entry and Exit layers. However, once a Sphinx packet is decrypted at the final hop, additional trust assumptions are introduced. The node processing the final layer of encryption is trusted to forward the correct message to the destination and return any reply using the provided reply key. This section outlines the resulting trust boundaries.
9.2.1 Message Delivery and Origin Trust
At the final hop, the decrypted Sphinx packet reveals the plaintext message and destination address. The exit node is then trusted to deliver this message to the destination application, and—if a reply is expected—to return the response using the embedded reply key.
In this model, the exit node becomes a privileged middleman. It has full visibility into the decrypted payload. Specifically, the exit node could tamper with either direction of communication without detection:
- It may alter or drop the forwarded message.
- It may fabricate a reply instead of forwarding the actual response from the destination.
This limitation is consistent with the broader mixnet trust model. While intermediate nodes are constrained by layered encryption, edge nodes—specifically the initiating and the exit nodes in the path—are inherently more privileged and operate outside the cryptographic protections of the mixnet.
In systems like Tor, such exit-level tampering is mitigated by long-lived circuits that allow endpoints to negotiate shared session keys (e.g., via TLS). A malicious exit cannot forge a valid forward message or response without access to these session secrets.
The Mix Protocol, by contrast, is stateless and message-based. Each message is routed independently, with no persistent circuit or session context. As a result, endpoints cannot correlate messages, establish session keys, or validate message origin. That is, the exit remains a necessary point of trust for message delivery and response handling.
The next subsection describes a related limitation: the exit's ability to pose as a legitimate client to the destination's origin protocol, and how that can be abused to bypass application-layer expectations.
9.2.2 Origin Protocol Trust and Client Role Abuse
In addition to the message delivery and origin trust assumption, the exit node also initiates a client-side connection to the origin protocol instance at the destination. From the destination's perspective, this appears indistinguishable from a conventional peer connection, and the exit is accepted as a legitimate peer.
As a result, any protocol-level safeguards and integrity checks are applied to the exit node as well. However, since the exit node is not a verifiable peer and may open fresh connections at will, such protections are limited in their effectiveness. A malicious exit may repeatedly initiate new connections, send well-formed fabricated messages and circumvent any peer scoring mechanisms by reconnecting. These messages are indistinguishable from legitimate peer messages from the destination's point of view.
This class of attack is distinct from basic message tampering. Even if the message content is well-formed and semantically valid, the exit's role as an unaccountable client allows it to bypass application-level assumptions about peer behavior. This results in protocol misuse, targeted disruption, or spoofed message injection that the destination cannot attribute.
Despite these limitations, this model is compatible with legacy protocols and destinations that do not support the Mix Protocol. It allows applications to preserve sender anonymity without requiring any participation from the recipient.
However, in scenarios that demand stronger end-to-end guarantees—such as verifiable message delivery, origin authentication, or control over client access—it may be beneficial for the destination itself to operate a Mix instance. This alternative model is described in the next subsection.
9.3 Destination as Final Hop
In some deployments, it may be desirable for the destination node to participate in the Mix Protocol directly. In this model, the destination operates its own Mix instance and is selected as the final node in the mix path. The decrypted message is then delivered by the Mix Exit Layer directly to the destination's local origin protocol instance, without relying on a separate exit node.
From a security standpoint, this model provides end-to-end integrity guarantees. It removes the trust assumption on an external exit. The message is decrypted and delivered entirely within the destination node, eliminating the risk of tampering during the final delivery step. The response, if used, is also encrypted and returned by the destination itself, avoiding reliance on a third-party node to apply the reply key.
This model also avoids client role abuse. Since the Mix Exit Layer delivers the message locally, the destination need not accept arbitrary inbound connections from external clients. This removes the risk of an adversarial exit posing as a peer and injecting protocol-compliant but unauthorized messages.
This approach does require the destination to support the Mix Protocol. However, this requirement can be minimized by supporting a lightweight mode in which the destination only sends and receives messages via Mix, without participating in message routing for other nodes. This is similar to the model adopted by Waku, where edge nodes are not required to relay traffic but still interact with the network. In practice, this tradeoff is often acceptable.
The core Mix Protocol does not mandate destination participation. However, implementations MAY support this model as an optional mode for use in deployments that require stronger end-to-end security guarantees. The discovery mechanism MAY include a flag to advertise support for routing versus receive-only participation. Additional details on discovery configurations are out of scope for this specification.
This trust model is not required for interoperability, but is recommended when assessing deployment-specific threat models, especially in protocols that require message integrity or authenticated replies.
9.4 Known Protocol Limitations
The Mix Protocol provides strong sender anonymity and metadata protection guarantees within the mix network. However, it does not address all classes of network-level disruption or application-layer abuse. This section outlines known limitations that deployments MUST consider when evaluating system resilience and reliability.
9.4.1 Undetectable Node Misbehavior
The Mix Protocol in its current version does not include mechanisms to detect or attribute misbehavior by mix nodes. Since Sphinx packets are unlinkable and routing is stateless, malicious or faulty nodes may delay, drop, or selectively forward packets without detection.
This behavior is indistinguishable from benign network failure. There is no native support for feedback, acknowledgment, or proof-of-relay. As a result, unreliable nodes cannot be penalized or excluded based on observed reliability.
Future versions may explore accountability mechanisms. For now, deployments MAY improve robustness by sending each packet along multiple paths as defined in [Section X.X], but MUST treat message loss as a possibility.
9.4.2 No Built-in Retry or Acknowledgment
The Mix Protocol does not support retransmission, delivery acknowledgments, or automated fallback logic. Each message is sent once and routed independently through the mixnet. If a message is lost or a node becomes unavailable, recovery is the responsibility of the top-level application.
Single-Use Reply Blocks (SURBs) (defined in Section 8.7) enable destinations to send responses back to the sender via a fresh mix path. However, SURBs are optional, and their usage for acknowledgments or retries must be coordinated by the application.
Applications using the Mix Protocol MUST treat delivery as probabilistic. To improve reliability, the sender MAY:
- Use parallel transmission across
Ddisjoint paths. - Estimate end-to-end delay bounds based on chosen per-hop delays (defined in Section 6.2), and retry using different paths if a response is not received within the expected window.
These strategies MUST be implemented at the origin protocol layer or through Mix integration logic and are not enforced by the Mix Protocol itself.
9.4.3 No Sybil Resistance
The Mix Protocol does not include any built-in defenses against Sybil attacks. All nodes that support the protocol and are discoverable via peer discovery are equally eligible for path selection. An adversary that operates a large number of Sybil nodes may be selected into mix paths more often than expected, increasing the likelihood of partial or full path compromise.
In the worst case, if an adversary controls a significant fraction of nodes (e.g., one-third of the network), the probability that a given path includes only adversarial nodes increases sharply. This raises the risk of deanonymization through end-to-end traffic correlation or timing analysis.
Deployments concerned with Sybil resistance MAY implement passive defenses such as minimum path length constraints. More advanced mitigations such as stake-based participation or resource proofs typically require some form of trusted setup or blockchain-based coordination.
Such defenses are not built into the current version of the Mix Protocol, but are critical to ensuring anonymity at scale. Deployments that enable DoS protection (see Section 6.6) may gain Sybil resistance as a side effect, depending on the approach chosen.
9.4.4 Vulnerability to Denial-of-Service Attacks
The Mix Protocol does not provide built-in defenses against denial-of-service (DoS) attacks targeting mix nodes. A malicious mix node may generate a high volume of valid Sphinx packets to exhaust computational, memory, or bandwidth resources along random paths through the network.
This risk stems from the protocol's stateless and sender-anonymous design. Mix nodes process each packet independently and cannot distinguish honest users from attackers. There is no mechanism to attribute packets, limit per-sender usage, or apply network-wide fairness constraints.
While the Mix Protocol includes safeguards such as layered encryption, per-hop integrity checks, and fixed-size headers, these primarily defend against tagging attacks and structurally invalid or malformed traffic. The Sphinx packet format also enforces a maximum path length , which prevents infinite loops or excessively long paths being embedded. However, these protections do not prevent adversaries from injecting large volumes of short, well-formed messages to exhaust mix node resources.
DoS protection—such as admission control, rate-limiting, or resource-bound access—can be plugged in as explained in Section 6.6. Any such mechanism MUST preserve sender unlinkability and SHOULD be evaluated carefully to avoid introducing correlation risks.
Mix Cover Traffic
| Field | Value |
|---|---|
| Name | Mix Cover Traffic |
| Slug | 161 |
| Status | raw |
| Category | Standards Track |
| Editor | Prem Prathi [email protected] |
| Contributors |
Timeline
- 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-11 —
2aa2bcd— feat: Mix Cover Traffic specification (#311)
Abstract
This document specifies the cover traffic architecture for the libp2p Mix Protocol. The architecture ensures that an observer cannot distinguish cover traffic from locally originated messages by observing a node's emission pattern. It defines how cover packets are generated and emitted, how the rate-limit budget is shared across cover and non-cover traffic, and specifies the Constant-Rate cover traffic strategy, with Poisson-Rate as a future consideration in §11.5.
1. Introduction
The Mix Protocol provides sender anonymity through layered encryption and per-hop delays. However, without cover traffic, an adversary observing a mix node's emission rate can mount several attacks:
- Traffic analysis: by correlating emission bursts with known events, an adversary can link a node's activity periods to specific senders or recipients.
- Intersection attack: by observing which nodes are active each time a message reaches its destination, an adversary can progressively narrow down the set of possible senders across multiple messages.
- Timing correlation: by matching idle and active periods across mix nodes, an adversary can correlate ingress and egress packets.
All three attacks rely on the same weakness: a node's emission pattern leaks information about whether it is carrying non-cover traffic.
Cover traffic addresses this by ensuring a node's emission pattern does not depend on non-cover traffic volume, making it indistinguishable to an observer whether the node is sending locally originated messages or none at all.
The Mix Protocol defines cover traffic as a pluggable component (see Mix Protocol §6.4). This specification provides a concrete instantiation of that component, defining the cover traffic architecture, the rate-limit budget model, and two concrete scheduling strategies. The architecture is designed to be compatible with the DoS protection mechanism defined in Mix DoS Protection and specifically with the Mix RLN DoS Protection mechanism.
2. Terminology
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119.
Other terms used in this document are as defined in the libp2p Mix Protocol and Mix DoS Protection.
The following additional terms are used throughout this specification:
-
Cover Packet A dummy Sphinx packet that carries no application payload and is indistinguishable from non-cover Sphinx packets in structure, size, and routing behavior.
-
Slot A single rate-limit token within an epoch's budget of
Rtokens, as defined by the DoS protection mechanism. Each outgoing packet — whether cover or non-cover — consumes exactly one slot. -
Slot Pool The collection of rate-limit slots available for a given epoch.
-
Epoch A fixed time window of duration
Pseconds during which each mix node is permitted to emit at mostRpackets, as enforced by the DoS protection mechanism.
3. Design Principles
The cover traffic architecture is guided by the following principles:
- Sender unobservability: A node's emission pattern must not depend on non-cover traffic volume, making it indistinguishable to an observer whether the node is carrying non-cover traffic or not.
- Indistinguishability: Cover packets are structurally identical to non-cover Sphinx packets in size and routing behavior, preventing packet-level classification. (Mix Protocol §6.4)
- Self-exit: Cover packets SHOULD use loop paths where the originating node is also the exit node. This ensures the dummy payload is never decrypted by an external party, eliminating the risk of cover classification at the exit.
- DoS protection compliance: All cover traffic operates within the rate-limit budget
Renforced per epoch. Proofs are epoch-bound and unused slots are discarded at epoch boundaries. (Mix DoS Protection) - Slot integrity: Each rate-limit slot is consumed at most once on the wire per epoch. When a non-cover claim reclaims a slot held by a queued cover packet, that packet's pre-computed proof is discarded before the slot is reused.
- Mix node only: Cover traffic is generated only for mix nodes that act as intermediate nodes forwarding mix traffic and participate continuously in the network. Initiating-only nodes are mostly short-lived with dynamic identifiers and do not forward traffic, making cover traffic neither practical nor beneficial for them.
- Pre-computation: As an optimization, cover packets and their proofs MAY be generated during epoch
N-1, so they are ready to emit at the start of epochNwithout any cryptographic work at emission time.
Overview
A mix node plays multiple roles at once: it sends its own messages, relays messages for other nodes, and ideally hides which of these it is doing. Without protection, an observer watching the node's outgoing packets can tell when it is active, how busy it is, and when it is idle — enough to link users to their messages through traffic patterns.
Cover traffic addresses this by emitting additional dummy packets that look identical to real mix traffic from the outside. An observer still sees packets leaving the node, but can no longer tell from the pattern alone whether those packets are real or dummy.
The node operates under a rate limit that bounds total packets emitted per epoch (§4). Every packet — cover, locally originated, or forwarded — consumes one slot from this shared budget. Forwarding typically takes a large share of the budget because each originated packet traverses multiple hops, so the maximum cover rate is naturally bounded below the total.
Cover is emitted at a steady configurable rate, up to this bound (§7.1).
A cover_rate_fraction parameter scales cover down from the maximum,
leaving headroom in the budget for spikes in real traffic.
Real traffic (locally originated and forwarded) claims slots from the same pool as it arrives;
cover yields whatever slots remain.
Cover packets follow round-trip paths — the sender is also the final destination, so the dummy payload is never decrypted by another party (§5.1). For efficiency, cover packets and their rate-limit proofs MAY be pre-built during the previous epoch (§6.1) and revalidated at send time in case the underlying state has changed (§6.5).
Each epoch begins by discarding previous state and initializing a fresh slot budget, loading any pre-built cover packets prepared during the prior epoch. Throughout the epoch, cover, locally originated, and forwarded packets independently claim slots. Near the midpoint, the node starts pre-computing cover packets for the next epoch. At epoch end, unused slots are discarded and the cycle repeats.
The specification focuses on the Constant-Rate strategy. An alternative Poisson-Rate strategy, where cover emission times are randomized, is kept for future consideration in §11.5.
4. Rate Limit Budget Model
Each mix node receives a budget of R slots per epoch from the DoS protection mechanism.
Cover emission, locally originated message sending, and packet forwarding all draw from the same pool.
Since each originated packet traverses L forwarding hops — where L is the mix path length
as defined in Mix Protocol §6 —
forwarding traffic naturally consumes a significant portion of the budget.
If every node originates at rate C packets per epoch (cover plus locally originated combined),
each node forwards approximately C * L packets per epoch.
Since origination and forwarding share the same budget R:
C + C * L ≤ R
C ≤ R / (1 + L)
R / (1 + L) is therefore the upper bound on total origination,
not a target for cover emission alone.
Cover rate does not need to be explicitly reduced by a node's locally originated rate,
because the slot pool is self-balancing (see below).
This means the actual cover traffic emitted by a node is always less than R and depends on:
- Path length
L: longer paths consume more forwarding slots, leaving fewer for cover. ForL=3, approximately 25% of slots are available for cover and locally originated message sending. - Network size
Nand forwarding variance: with random path selection, forwarding load is not uniform. Some nodes receive more forwarding traffic than the equilibrium average, leaving even fewer slots for cover. The actual cover output per node therefore varies with network conditions.
The slot pool is self-balancing — no explicit origination rate constraint is needed. Heavier forwarding load automatically leaves fewer slots for cover; lighter load leaves more.
Note on DoS protection architecture:
The self-balancing pool model assumes per-hop generated proofs
(Mix DoS Protection §4.2),
where forwarding consumes slots from the node's own R budget.
With sender-generated proofs (Mix DoS Protection §4.1),
forwarding nodes only verify proofs and do not consume their own R,
but cover emission must still account for forwarding load to maintain constant total output.
The budget model and slot pool semantics for sender-generated proofs require separate analysis
and are deferred to §11.4.
5. Integration with the Mix Protocol
The cover traffic mechanism integrates with the Mix Protocol at four points in packet processing.
Cover packets are identified by the reserved protocol codec "/mix/cover/1.0.0".
This codec is used as the origin protocol codec during Sphinx packet construction
and is checked during exit processing to distinguish cover packets from application traffic.
All mix nodes in a deployment SHOULD use the same strategy type and parameters
to ensure uniform emission patterns across the anonymity set.
The configured path length L for cover packets
MUST match the path length used for locally originated messages
as defined in Mix Protocol §6.
5.1 Cover Packet Transmission
Trigger: The configured strategy schedules a cover emission.
During Sphinx packet construction: The mechanism constructs a cover Sphinx packet following the same construction procedure as a locally originated message, with the following differences:
- The mix path is a loop path — the final hop routes the packet back to the originating node.
- The origin protocol codec MUST be set to the cover traffic codec defined in §5. This codec is recognized by the Mix Protocol during exit processing to identify returning cover packets (see §5.4).
- The application message content SHOULD be filled with cryptographically random bytes. Random payloads provide defense-in-depth against partial path compromise and ensure that cover packets remain indistinguishable from non-cover traffic if the design evolves to support non-loop cover paths in the future.
- If pre-computation is enabled, the pre-built cover packet is used directly without re-construction.
Wire format: Cover packets use the exact Sphinx packet format defined in Mix Protocol §8. No additional fields or framing are introduced. A cover packet on the wire is indistinguishable from a non-cover traffic packet, ensuring that intermediary nodes and external observers cannot classify packets as cover or non-cover.
The cover packet is then transmitted to the first hop following the standard Mix Protocol transmission procedure.
5.2 Non-Cover Slot Claim
Procedure: ClaimSlot() -> success
Trigger: The Mix Protocol needs to send a message or forward a packet and requires a slot from the budget.
The mechanism atomically claims a slot from the pool using the following procedure:
- If
slots_remaining == 0, the claim fails. - If
slots_remaining == len(cover_queue), the only way to free a slot is to reclaim one held by a queued cover packet: dequeue the head ofcover_queueand discard it. Its pre-computed proof MUST NOT be sent on the wire. - Decrement
slots_remainingand return success.
Free (unreserved) slots are taken first; a queued cover packet is reclaimed only when no free slots remain (i.e., when every remaining slot is committed to either non-cover claims already on the wire or pre-built cover in the queue).
On success, the caller then generates a DoS protection proof
via GenerateProof(binding_data) (Mix DoS Protection §8.2.1),
where binding_data is the packet-specific data as defined by the DoS protection mechanism.
If the claim fails, the packet SHOULD be handled as follows to avoid hitting DoS protection limits:
- Locally originated messages: queued for the next epoch.
- Forwarded packets: dropped.
5.3 Epoch Boundary
Procedure: ResetEpoch(epoch) -> void
Trigger: The DoS protection mechanism signals the start of a new epoch
via OnEpochChange (Mix DoS Protection §8.2.3).
The Mix Protocol MUST call ResetEpoch before processing any packets in the new epoch.
The mechanism refreshes the slot pool for the new epoch:
all remaining slots from the previous epoch are discarded,
and a new pool of R slots is initialized.
If pre-computation is enabled, the pre-built cover packets prepared during the previous epoch
are loaded into the new pool.
Cover packets emitted near epoch end may arrive at later hops in a subsequent epoch.
The DoS protection mechanism is responsible for accepting proofs within a configurable epoch window
(e.g., the max_epoch_gap parameter in Mix RLN DoS Protection).
5.4 Cover Packet Reception
Trigger: The Mix Protocol completes exit processing on a received Sphinx packet and extracts the origin protocol codec from the decrypted payload.
If the codec matches the cover traffic codec (see §5), the Mix Protocol MUST handle the packet internally without handing off to the Mix Exit Layer. The packet SHOULD be silently discarded. Implementations MAY use this reception event for diagnostics such as path health monitoring (see §11.2).
This is handled by the cover traffic codec check in Mix Protocol §8.6.4 step 4, which intercepts cover packets before handing off to the Mix Exit Layer.
Since cover packets use loop paths (see the self-exit principle in §3), the exit node is always the originating node itself. The cover traffic codec is therefore never visible to any external party. If a cover packet were routed to a different exit node, that node would detect the cover traffic codec during exit processing and classify the packet as cover traffic. Although the Sphinx construction prevents the exit from identifying the sender, a malicious exit could accumulate cover-to-non-cover traffic ratios over time, leaking information about network-wide cover strategy and volume.
5.5 Data Structures
PrebuiltCoverPacket {
slot_id: bytes // Slot identifier within the epoch
packet: bytes // Pre-built wire-format packet (Sphinx packet + DoS protection proof), ready to transmit
path: []bytes // Ordered list of mix node identifiers on the cover path
created_at: uint64 // Unix timestamp (seconds) when this packet was constructed
}
SlotPool {
epoch: uint64 // The epoch this pool belongs to
cover_queue: []PrebuiltCoverPacket // Pre-built cover packets, dequeued on emission or reclaimed by non-cover claims
slots_remaining: uint32 // Slots still spendable in this epoch (R minus what's already on the wire);
// invariant: slots_remaining >= len(cover_queue)
}
CoverTrafficConfig {
strategy_type: enum { CONSTANT_RATE, POISSON, NONE }
cover_rate_fraction: float64 // f ∈ (0.0, 1.0], scales cover rate relative to the maximum safe rate (see §7); RECOMMENDED default 0.7
// Strategy-specific parameters (see §7):
// For CONSTANT_RATE: emission_rate (float64, packets per second)
// For POISSON: lambda_cover (float64, packets per second)
}
6. Node Responsibilities
This section defines what each mix node MUST do at each integration point.
The slot pool (SlotPool) is a token bucket of R slots per epoch.
Each outgoing packet — cover or non-cover — atomically claims one slot.
Slot claim operations MUST be atomic.
6.1 At Epoch Boundary
When the DoS protection mechanism signals the start of a new epoch,
the Mix Protocol instance MUST invoke ResetEpoch (§5.3) on the cover traffic mechanism
to discard previous epoch state and initialize a new slot pool.
If pre-computation is enabled (RECOMMENDED):
The cover traffic mechanism pre-builds cover packets during epoch N-1 for use in epoch N.
For each slot to be pre-computed (at most R; see §9.1 for sizing guidance),
construct a cover Sphinx packet following the procedure in §5.1
and generate a DoS protection proof for the next epoch
via GenerateProof(binding_data) (Mix DoS Protection §8.2.1).
Store the result as a PrebuiltCoverPacket.
Slots without a pre-built packet will require on-demand generation if selected for cover emission.
Pre-computed proofs are bound to a specific epoch and MUST NOT be reused in subsequent epochs.
Proof validity over time:
Pre-computed proofs may be invalidated within their target epoch, not just across epochs.
For example, in Mix RLN DoS Protection,
accumulating membership updates can push the root used at generation time
out of the current acceptable_root_window_size before the epoch ends.
Implementations MUST therefore validate pre-computed proofs at send time
(see §6.5).
Fallback caveat: On-demand generation when pre-computation falls behind introduces timing jitter, which shifts emissions off-grid for deterministic strategies (e.g., §7.1) and weakens timing unobservability. Implementations SHOULD size the pre-computation pipeline (§9.1) to avoid the fallback path in steady state.
6.2 Cover Emission
The cover emission loop runs continuously as a background process.
Emission timing is governed by the configured strategy (CoverTrafficConfig).
Cover emission consumes from cover_queue.
Slots are deducted from slots_remaining at claim time, not at wire transmission:
forwarded packets within their mixing delay (see §6.4)
have already been deducted, so their slots are unavailable to any later claim.
Algorithm: Cover Emission
The following steps repeat continuously throughout each epoch:
- Wait for the next emission event as determined by the configured strategy.
- If the strategy schedules an emission and
cover_queueis non-empty:
- a. Dequeue the head of
cover_queueand decrementslots_remaining.- b. Validate the proof per §6.5.
- c. Transmit the
packetfield ofPrebuiltCoverPacketto the first hop (other fields are internal and MUST NOT be sent).- If
cover_queueis empty for the remainder of the epoch (because pre-built packets were exhausted by emission or reclaimed under heavy non-cover load), cover emission is suppressed until the next epoch boundary.
6.3 Locally Originated Message Sending
During Sphinx packet construction:
When the Mix Entry Layer submits a locally originated message for mixification,
the Mix Protocol instance MUST first call ClaimSlot() (§5.2).
If no slot can be claimed, the message is queued for the next epoch.
Otherwise, the Mix Protocol instance proceeds with
Sphinx packet construction.
6.4 Packet Forwarding
During Sphinx packet handling:
When the Mix Protocol instance acts as an intermediary and receives a Sphinx packet to forward,
it MUST first call ClaimSlot() (§5.2) before applying the mixing delay.
This ensures no two forwarded packets consume the same slot regardless of how their mixing delays overlap.
If no slot can be claimed, the packet is dropped.
Otherwise, the Mix Protocol instance proceeds with
intermediary processing.
Slot consumption:
The slot is consumed on successful ClaimSlot(), not on transmission (see §6.2).
Send timing: The packet is dispatched when its mixing delay elapses, independently of the cover emission schedule.
6.5 Pre-Computed Proof Validation at Send Time
Before transmitting a pre-built cover packet,
the mechanism MUST validate the carried DoS protection proof against the current state
(see §6.1 for rationale).
For Mix RLN DoS Protection,
this means verifying the merkle_root bound into the proof
is still within the node's acceptable_root_window_size.
If validation fails, implementations MUST either:
- Regenerate the proof against the current anchor, keeping the Sphinx packet body unchanged; or
- Skip the emission if regeneration is infeasible.
A pre-built packet with a stale proof MUST NOT be sent. When regenerating, implementations MAY reuse the message identifier bound to the cover packet where the DoS protection mechanism permits (see Mix RLN DoS Protection).
7. Recommended Strategy
This section defines the Constant-Rate cover emission strategy, which is the normative strategy for this specification.
An alternative Poisson-Rate strategy is documented as a future consideration in §11.5.
Cover emission operates over the R-slot pool and produces irregular total output
because forwarding traffic claims slots at unpredictable times.
Cover is emitted at up to R / (1 + L) packets per epoch —
a maximum, not a target;
the self-balancing pool (§4)
accommodates locally originated messages without explicit adjustment.
Cover rate fraction f:
The strategy takes a configurable cover_rate_fraction f ∈ (0.0, 1.0] (§5.5)
that scales the configured cover rate relative to the maximum safe rate R / ((1 + L) × P).
A value of f = 1.0 emits cover at the maximum; lower values reduce cover output
and leave more headroom in the slot budget for locally originated messages and forwarded traffic.
The RECOMMENDED default is f = 0.7,
which reserves roughly 30% of the per-node slot budget as headroom against forwarding variance.
All mix nodes in a deployment SHOULD use the same f to preserve a uniform anonymity set across the network.
7.1 Constant-Rate Cover Traffic
The cover traffic mechanism emits cover packets at a fixed interval of 1 / emission_rate seconds,
where emission_rate = f × R / ((1 + L) × P) packets per second.
f is the configured cover_rate_fraction (§5.5),
and R / ((1 + L) × P) is the maximum safe cover rate (achieved at f = 1.0).
Non-cover traffic claims slots via ClaimSlot() (§5.2) as it arrives,
making total output inherently irregular even though the cover emission rate is constant.
At the configured rate, up to f × R / (1 + L) cover packets are emitted per epoch;
the actual count is lower when locally originated messages or forwarding variance claim slots first.
The originated cover emission rate is perfectly constant,
so an adversary cannot distinguish epochs with heavy locally originated traffic from idle epochs
by observing cover timing alone.
Tradeoff — timing separability: Cover packets fire on a fixed grid, while forwarded packets fire at arrival time plus mixing delay — always off-grid relative to the cover schedule. Over enough observations, an adversary can separate cover from non-cover by timing alone, regardless of forwarding load. Constant-Rate therefore provides volume unobservability (the node's emission count does not leak non-cover activity) but not timing unobservability (individual packets remain classifiable by timing).
Full timing unobservability requires the pre-scheduled emission timing enhancement (§11.3), where all traffic types share the same timing grid. Constant-Rate is the only strategy compatible with this upgrade path, as it requires deterministic emission times known at epoch start.
Characteristics:
Constant-Rate emits up to N = f × R / (1 + L) cover packets per epoch.
The count is exact when forwarding does not exhaust the pool —
the design intent behind the RECOMMENDED cover_rate_fraction = 0.7 (§7),
which reserves roughly 30% of the per-node slot budget as headroom against forwarding spikes.
Pre-computation sizing matches N; no further safety margin beyond f is needed.
Under exhaustion, cover emission is suppressed for the remainder of the epoch
(§6.2, §10.5),
and per-epoch cover output drops below N.
An observer who knows f can upper-bound the per-epoch forwarding count as total_emissions - N,
so volume unobservability holds only against observers unaware of f or watching aggregate rates.
8. Initiating-Only Node Considerations
Initiating-only nodes are short-lived with dynamic identifiers and do not forward traffic. They SHOULD NOT generate cover traffic, as cover traffic is only meaningful for nodes that participate continuously in the network with a stable identity — a briefly connected node has no sustained emission pattern to protect or contribute.
Residual privacy for initiating-only nodes: Without cover traffic, initiating-only nodes still retain:
- Path anonymity: Sphinx layered encryption prevents any single intermediary or exit from learning both sender and recipient.
- Identity unlinkability: dynamic identifiers prevent cross-session linking.
However, an adversary on the link to the first hop — or a malicious first hop itself — can directly observe session volume and timing, since no cover or forwarded packets are blended with originated traffic.
Deployments where this matters SHOULD route initiating-only traffic through trusted first hops.
If an initiating-only node is promoted to a mix node and becomes long-lived, it SHOULD activate cover traffic using the Constant-Rate strategy. During the first epoch after promotion, pre-computed cover packets are unavailable; the node SHOULD fall back to on-demand cover packet generation for that epoch and begin pre-computation immediately upon promotion.
9. Implementation Recommendations
This section provides non-normative guidance for implementers.
9.1 Pre-computation Scheduling
The pre-computation pipeline SHOULD be initiated at the midpoint of the current epoch to allow sufficient time for slots to be processed before the next epoch begins. Implementations SHOULD interleave pre-computation with normal packet processing (e.g., yielding to non-cover traffic between slot generations) to avoid contention with ongoing packet handling.
Rather than pre-computing all cover packets in the previous epoch,
implementations MAY batch pre-computation across epochs:
an initial batch during epoch N-1 to ensure cover packets are available at the start of epoch N,
with subsequent batches computed incrementally during epoch N itself, staying ahead of the emission schedule.
This reduces peak computational load and memory usage.
9.2 Pool Status Tracking
Implementations SHOULD maintain runtime counters for available slots, cover emissions, and non-cover consumptions. These aid in diagnostics, monitoring, and tuning the emission strategy.
Exposure restrictions: The non-cover consumption counter reveals the exact per-epoch count of real traffic, which is what traffic analysis aims to recover.
Implementations MUST keep this counter (and any derived per-epoch breakdowns) in-memory only and MUST NOT export it via metrics endpoints, structured logs, or any monitoring interface.
9.3 Slot Exhaustion Logging
When a forwarded packet is dropped due to slot exhaustion, implementations SHOULD log a warning.
Persistent slot exhaustion may indicate that R is too low for the network's forwarding load,
or that the node is under a traffic flooding attack.
9.4 Synchronization
Slot claim operations MUST be atomic. Implementations may enforce this using mutexes, lock-free atomic operations, or single-threaded event loops, depending on the concurrency model.
10. Security Considerations
The design principles motivating slot integrity and DoS protection compliance are described in §3. This section discusses the threat context behind those principles.
10.1 Proof Reuse via Proof Leakage
If a pre-computed cover proof and a freshly generated non-cover proof for the same slot are both sent on the wire, the DoS protection mechanism detects a reuse. Depending on the mechanism, this may result in slashing or reputation loss for the node. The slot integrity principle (§3) prevents this by ensuring the cover proof is discarded before the slot is reused.
10.2 Slot Exhaustion Under Heavy Non-Cover Traffic
If non-cover traffic consumes all R slots before the epoch ends,
the node cannot emit further cover traffic.
This is a natural consequence of DoS protection compliance (§3).
Locally originated messages that arrive after slot exhaustion MUST be queued for the next epoch.
Cover emission ceases when no slots remain.
10.3 Network-Wide Cover-Rate Correlation
When a message traverses multiple mix nodes, each node on the path claims one slot for forwarding, slightly reducing its available cover capacity for the remainder of the epoch. A global passive adversary observing all nodes simultaneously could in principle detect correlated cover-rate perturbations across nodes and use them to trace message paths.
In practice, each forwarded message consumes only one slot out of R,
making the perturbation negligible for sufficiently large R.
The pre-scheduled emission timing enhancement (§11.3)
would eliminate this concern entirely by fixing all emission times at epoch start,
making individual slot consumption events unobservable.
10.4 Timing Separability of Cover and Non-Cover Packets
The default Constant-Rate strategy (§7.1) emits cover packets on a fixed grid while forwarded packets are dispatched at arrival time plus mixing delay. With enough observations, a passive adversary can classify individual packets by timing alone, regardless of forwarding load.
Constant-Rate therefore provides volume unobservability but not timing unobservability. Under Constant-Rate, the pre-scheduled emission timing enhancement (§11.3) is the only design that closes this gap, by assigning all outgoing packets — cover, locally originated, and forwarded — to a shared fixed-time grid determined at epoch start.
10.5 Cover Priority and Forwarded Packet Drops
Cover emissions occur on a schedule independent of forwarding load,
so slots consumed by cover early in an epoch are unavailable to forwarded packets arriving later.
Under uneven forwarding load, this can cause honest forwards to be dropped (§6.4)
even when total traffic stays within the R budget.
The cover_rate_fraction f (§7) reduces this risk
by holding back a fraction of the per-node slot budget from cover emission,
leaving headroom for forwarding spikes.
With the RECOMMENDED f = 0.7, approximately 30% of the budget is reserved as headroom.
Deployments SHOULD adjust f based on observed network behavior;
see §11.1 for adaptive tuning as a future enhancement.
11. Future Work
11.1 Adaptive Cover Rate Fraction
The cover_rate_fraction f (§7) is currently a static deployment-wide configuration.
A future enhancement MAY define a method for nodes to adapt f based on observed forwarding load,
network size N, and path length L,
allowing cover rate to be tuned closer to the node's actual available budget
and reducing unnecessary cryptographic work.
Any adaptive scheme MUST preserve uniformity of f across the anonymity set
to avoid leaking per-node load through emission rate differences.
11.2 Path Health Monitoring
When cover packets are implemented as loop packets — dummy Sphinx packets that follow a valid mix path and return to the originating node — their return confirms path liveness. Failures to return indicate potential node failures or active attacks along the path. A future revision of this specification MAY define an interface for exposing loop return status to enable path health monitoring.
11.3 Pre-Scheduled Emission Timing
Inspired by the Blend Protocol, a future enhancement MAY define pre-scheduled emission slots where all outgoing packets — cover, locally originated, and forwarded — are assigned to fixed time slots determined at epoch start. All traffic types would share the same timing grid, producing a perfectly periodic total output regardless of traffic mix. This would eliminate the periodic emission pattern tradeoff noted in §7.1, as an observer would see uniform intervals with no way to classify individual packets. When using Constant-Rate, this is the only design path to full timing unobservability (see §10.4).
This approach is only compatible with the Constant-Rate strategy, which provides deterministic emission times known at epoch start. Poisson-Rate, where emission times are sampled at runtime, cannot support pre-scheduled slots. Note that pre-scheduled slots would require changes to the mixing delay strategy in the Mix Protocol, as forwarded packets would need to be held until their assigned slot time rather than forwarded after the sampled delay elapses.
11.4 Budget Model for Sender-Generated Proofs
The rate-limit budget model in §4 assumes per-hop generated proofs,
where forwarding consumes from the node's own R budget and the slot pool self-balances.
With sender-generated proofs, the initiating node generates L proofs per originated packet from its own R,
while forwarding nodes only verify and do not consume their own budget.
A future revision MAY define an adapted budget model for this architecture,
including revised slot pool semantics, an explicit emission rate target that accounts for observed forwarding load,
and updated pre-computation sizing.
11.5 Poisson-Rate Cover Traffic
Poisson-Rate is a candidate alternative strategy retained here for future consideration.
The node emits cover packets according to a Poisson process with rate λ_cover packets per second,
producing random memoryless inter-emission gaps.
λ_cover would be set to f × R / ((1 + L) × P) packets per second,
where f is the configured cover_rate_fraction (§5.5).
Emissions are suppressed when no slots are available.
Potential strengths:
- Timing unobservability: both cover and forwarded emissions are exp-distributed, making it statistically hard for an observer to classify individual packets by timing (addressing the separability concern in §10.4).
- Short-window volume unobservability: per-epoch cover count is
Poisson(N)rather than deterministic, so forwarding-count estimates from total emissions carry at least±√Nuncertainty per epoch.
Costs:
- Per-epoch variance: cover emissions per epoch are
Poisson(N)— some epochs are thin and weaken in-epoch mixing. - Front-loading: random clustering can consume cover budget early, starving late-arriving non-cover traffic.
- Pre-computation margin: pipelines need a safety margin (e.g.,
N + 3√N) to avoid running dry. - Budget coupling: cover rate drops with non-cover load as the pool nears exhaustion.
Interaction with R:
Poisson-Rate's per-epoch variance shrinks relative to its mean as R grows (√N / N → 0).
At small R, front-loading and thin-cover epochs are pronounced.
At large R, these effects become negligible.
Simulation of real traffic distributions is required before adopting Poisson-Rate as a normative option.
Copyright
Copyright and related rights waived via CC0.
References
- libp2p Mix Protocol
- Mix DoS Protection
- Mix RLN DoS Protection
- Loopix: Providing Anonymity in a Message Passing System
- Nym: Mixnet for Network-Level Privacy
- Blend Protocol
Mix DoS Protection
| Field | Value |
|---|---|
| Name | Mix DoS Protection |
| Slug | 157 |
| Status | raw |
| Category | Standards Track |
| Editor | Prem Prathi [email protected] |
| Contributors | Akshaya Mani [email protected] |
Timeline
- 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-11 —
2aa2bcd— feat: Mix Cover Traffic specification (#311) - 2026-05-04 —
0e5882e— Chore/auto assign slugs (#328) - 2026-04-30 —
474c7e5— Extract Mix DoS protection to a standalone spec (#302)
Abstract
This document defines the DoS protection architecture for the libp2p Mix Protocol. It specifies the requirements, integration architectures, node responsibilities, and standardized interfaces that any DoS protection mechanism must satisfy to integrate with the Mix Protocol. Two primary architectural approaches are defined: sender-generated proofs and per-hop generated proofs. Concrete instantiation of this architecture, using Rate Limiting Nullifier (RLN), is defined in a separate specification (see Mix RLN DoS Protection).
1. Introduction
The Mix Protocol is a stateless, sender-anonymous message routing protocol. Without DoS protection, malicious actors can flood mix nodes with valid Sphinx packets, exhausting computational resources or bandwidth, eventually making the mixnet unusable.
This specification expands on the pluggable DoS protection framework introduced in the Mix Protocol.
2. Terminology
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119.
Other terms used in this document are as defined in the libp2p Mix Protocol.
3. Requirements
Any DoS protection mechanism integrated with the Mix Protocol MUST satisfy the following requirements:
-
Each mix node in the path MUST verify proofs before applying delay and forwarding, or, in the case of exit nodes, taking further action.
-
DoS protection data and verification MUST NOT enable linking or correlating packets across hops. Therefore, DoS protection proofs MUST be unique per hop.
-
DoS protection proofs MUST NOT be reusable across different packets or hops. Each hop SHOULD be able to detect replayed or forged proofs (e.g., via cryptographic binding to packet-specific or hop-specific data).
-
Proofs SHOULD be bound to unique signals per message that cannot be known in advance, preventing adversaries from pre-computing large batches of proofs offline for DoS attacks.
-
Verification overhead MUST be low to minimise per-hop delays. Otherwise, under load, substantial delay at each hop can cause congestion at mix nodes, making the DoS protection mechanism itself a resource exhaustion vector.
-
Proof generation and verification methods MUST preserve unlinkability of the sender and MUST NOT leak any additional metadata about the sender or node.
-
The mechanism SHOULD provide a way to punish offenders or detect misuse.
4. Integration Architecture
Two primary architectural approaches exist for integrating DoS protection with the Mix Protocol, each with distinct trade-offs. This section describes each approach in detail, including trade-offs and deployment considerations.
4.1 Sender-Generated Proofs
In this approach, the initiating node (on behalf of the sender) generates DoS protection proofs for all hops in the mix path during Sphinx packet construction. These proofs are then independently verified at each hop during Sphinx packet processing.
4.1.1 Details
The proof generation and verification proceed as follows:
-
Sender Proof Generation and Embedding: During Sphinx packet construction of the Mix Protocol, the initiating node first computes the ephemeral secrets (step 3.a) and encrypted payload (step 3.d). Note that this deviates from the standard Sphinx construction order. Next, it computes the filler strings (step 3.b), where the zero-padding length depends on the size of the DoS protection proof embedded in each hop's routing block (see Section 4.1.4). Then, during step 3.c, for each hop in the path, the initiating node:
a. Computes the DoS protection proof cryptographically bound to the decrypted payload that hop obtains after decrypting one layer. This binding ensures proofs are path-specific and tied to specific encrypted message content, preventing proof extraction and reuse.
b. Embeds the DoS protection proof and related metadata required for verification in hop 's routing block, .
-
Per-Hop Proof Verification: During Sphinx processing, each hop decrypts and to obtain the routing block (Step 4) and (Step 5) respectively, then:
a. Extracts the DoS protection proof and metadata from . b. Verifies the proof is bound to .
4.1.2 Advantages
- Only the initiating node performs the expensive proof generation. All nodes in the path only verify proofs, which is less expensive and also reduces latency per hop.
- Each hop's proof is encrypted in a separate layer of , making proofs unique per hop and cryptographically isolated.
- Aligns with Sphinx design philosophy, where the initiating node bears the computational complexity while all nodes in the path only perform lightweight operations.
4.1.3 Disadvantages
- The initiating node must generate proofs, which can be expensive.
- Each hop's routing block must include DoS protection data, increasing overall header and packet size (see impact analysis below).
- When packets are sent along multiple paths for reliability, the initiating node must generate fresh proofs for each path.
- Proofs can only be verified after expensive Sphinx processing operations (session key derivation, replay checking, header integrity verification, and decryption), since they are encrypted within the field and bound to the decrypted payload state . Deployments using this approach SHOULD augment with additional network-level protections (connection rate limiting, localized peer reputation) to defend against attacks that can lead to draining nodes' resources.
- This approach does not inherently provide Sybil resistance since nodes in the path do not generate any proof using their credentials.
4.1.4 Impact on Header Size
Each hop's routing block includes , consisting of the DoS protection proof and all verification metadata. MUST be exactly bytes for some positive integer , where bits is the security parameter defined in cryptographic primitives of the Mix Protocol. This format is required for the Sphinx construction to hold.
Including increases the per-hop routing block size from to bytes. Consequently, the zero-padding in the filler string computation (see Section 4.1.1) increases from to , giving a filler string length of , .
As a result, the total size becomes bytes (see header field sizes) — an increase of bytes over the baseline. To offset this increase and maintain the same payload size, the total packet size MUST be increased to bytes (see payload size).
4.2 Per-Hop Generated Proofs
In this approach, the initiating node generates a DoS protection proof for the first hop, and each mix node in the path generates a fresh proof for the subsequent hop after verifying the proof attached to the incoming packet.
4.2.1 Details
The proof generation, verification, and forwarding proceed as follows:
- During Sphinx packet construction of the Mix Protocol, after step 3.e, the initiating node generates an initial DoS protection proof for the first hop and appends it after the Sphinx packet, forming the wire format:
SphinxPacket || σ. The proof SHOULD be cryptographically bound to the complete outgoing Sphinx packet and include any verification metadata required by the DoS protection proof. - The first hop extracts and verifies before processing the Sphinx packet.
- After successful verification and Sphinx processing, the hop generates a new proof for the next hop bound to the transformed packet.
- The updated packet is forwarded to the next hop.
- This process repeats at each intermediate hop until the packet reaches the final hop. The exit just verifies the proof in the incoming packet without generating a new one.
4.2.2 Advantages
- The initiating node only generates one initial proof instead of proofs.
- DoS protection data has less overhead on packet header size.
- Proofs can be verified before Sphinx processing operations (session key derivation, header integrity verification, and decryption). Given that verification is cheaper (see Section 3), this allows nodes to reject invalid packets without performing expensive Sphinx processing.
- If a membership-based DoS protection mechanism is used (e.g., Rate Limiting Nullifiers), the same mechanism can provide Sybil resistance as a side effect (see Section 9.4.3 of the Mix Protocol). Nodes must prove membership at each hop, making it infeasible to operate large numbers of Sybil nodes; provided membership carries a cost and offenders can be penalized (see Section 7).
4.2.3 Disadvantages
- Each intermediary node must generate fresh proofs, adding additional latency and processing cost at each hop. Pre-computing proofs offline is not an option, as proofs SHOULD be bound to message contents or an alternative unique signal that cannot be known in advance (see Section 3).
- When using rate-limiting mechanisms (such as RLN), a node may exhaust its rate limit solely by being selected on multiple independent senders' paths. This causes legitimate packets to be dropped, resulting in unpredictable message delivery, even when no individual sender misbehaves. The Mix Protocol's unlinkability guarantees make it impossible to distinguish a node forwarding messages from one originating them. This makes mitigations such as assigning differential or reputation-based rate limits infeasible.
4.2.4 Impact on Packet Size
As mentioned in Section 4.2.1, consists of the DoS protection proof and all verification metadata. Unlike sender-generated proofs, appending after the Sphinx packet does not affect the internal Sphinx packet structure.
Consequently, only the total packet size MUST be configured to bytes (see payload size).
MUST be fixed for a chosen DoS protection mechanism. If the mechanism produces variable-length proofs, they MUST be padded to a fixed size, ensuring all packets remain indistinguishable on the wire.
4.3 Comparison
The following table provides a brief comparison between both integration approaches.
| Aspect | Sender-Generated Proofs | Per-Hop Generated Proofs |
|---|---|---|
| DoS protection | Weaker (verify after Sphinx decryption) | Stronger (verify before Sphinx decryption) |
| Sender burden | High (generates proofs) | Low (generates 1 proof) |
| Per-hop computational overhead | Low (verify only) | High (verify + generate) |
| Per-hop latency | Minimal (fast verification) | Higher |
| Total end-to-end latency | Lower | Higher |
| Sybil resistance | Requires separate mechanism | Can be integrated |
| Packet size increase |
Separate specifications defining concrete DoS protection mechanisms SHOULD specify recommended approaches and provide detailed integration instructions.
5. Node Responsibilities
In addition to the core Mix Protocol responsibilities defined in Section 7, all mix nodes MUST implement the following DoS protection responsibilities for the chosen architectural approach.
5.1 For Sender-Generated Proofs
During Sphinx packet construction: Generate and embed DoS protection proofs for all hops as described in Section 4.1.1. The proofs MUST NOT contain any identifying information.
During Sphinx packet preprocessing: Verify the DoS protection proof in its routing block as described in Section 4.1.1. If verification fails, discard the packet and apply any penalties or rate-limiting measures.
5.2 For Per-Hop Generated Proofs
During Sphinx packet construction: Generate the initial proof and append it after the Sphinx packet as described in Section 4.2.1. The proof MUST NOT contain any identifying information.
During Sphinx packet preprocessing: Extract and verify the incoming proof before any Sphinx processing as described in Section 4.2.1. If verification fails, discard the packet and apply any penalties or rate-limiting measures.
After node role determination:
- If intermediary, during intermediary processing, generate a fresh unlinkable proof and append it to the assembled packet before Step 5.
- If exit, perform exit processing without generating a new proof.
6. Anonymity and Security Considerations
DoS protection mechanisms MUST be carefully designed to avoid introducing correlation risks:
-
Timing side channels: Proof verification and generation SHOULD use constant-time implementations to avoid timing-based side channel attacks that could enable packet fingerprinting.
-
Proof unlinkability: Linking incoming and outgoing proofs at intermediary hops MUST be cryptographically hard, to preserve the bitwise unlinkability guaranteed by the Mix Protocol.
-
Verification failure handling: Nodes MUST silently discard packets that fail proof verification, without revealing the reason for failure, to prevent probing attacks.
-
Global state and coordination: Mechanisms that maintain global state (e.g., nullifier sets, membership trees) MUST ensure that state reads and writes do not reveal packet processing patterns or enable correlation across hops, in accordance with the DoS vulnerability considerations of the Mix Protocol.
-
Sybil attacks: The Mix Protocol provides no built-in Sybil resistance. Sender-generated proofs do not address this limitation. Per-hop generated proofs with membership-based mechanisms MAY provide Sybil resistance as a side effect (see Section 4.2.2).
7. Recommended Methods
Specific DoS protection methods fall outside this specification's scope. Common strategies that MAY be adapted include:
-
PoW-style approaches: Approaches like EquiHash or VDF Client puzzles that satisfy DoS protection requirements can be used. These, however, do not provide Sybil resistance, which requires a separate mechanism.
-
Privacy-preserving rate-limiting: Rate-limiting approaches with zero-knowledge cryptography, such as RLN, that preserve users' privacy can be used (see Mix RLN DoS Protection). This approach requires careful design of state access patterns. Deployments requiring Sybil resistance SHOULD augment this mechanism with staking and slashing.
Deployments MUST evaluate each method's computational overhead, latency impact, anonymity implications, infrastructure requirements, attack resistance, Sybil resistance, pre-computation resistance, economic cost, and architectural fit.
8. DoS Protection Interface
This section defines the standardized interface that DoS protection mechanisms MUST implement to integrate with the Mix Protocol. The interface is designed to be architecture-agnostic, supporting both sender-generated proofs and per-hop generated proofs approaches described in Section 4.
Initialization and configuration of DoS protection mechanisms are out of scope for this interface specification. Implementations MUST handle their own initialization, configuration management, and runtime state independently before being integrated with the Mix Protocol.
Any DoS protection mechanism integrated with the Mix Protocol MUST implement the procedures defined in this section. The specific cryptographic constructions, proof systems, and verification logic are left to the mechanism's specification, but implementations MUST adhere to the interface signatures and behavior defined here for interoperability.
8.1 Deployment Configuration
The following parameters MUST be agreed upon and configured consistently across all nodes in a deployment:
-
Proof Size: The fixed size in bytes of
encoded_proof_dataproduced byGenerateProof. This value is used by Mix Protocol implementations to calculate header sizes and payload capacity. -
Integration Architecture: The DoS protection integration architecture used by the deployment. MUST be one of:
SENDER_GENERATED: Initiating node generates proofs for each hop (see Section 8.3.1)PER_HOP_GENERATED: Each node generates a fresh proof for the next hop (see Section 8.3.2)
All nodes in a deployment MUST use the same integration architecture. Nodes MUST refuse to process packets that do not conform to the deployment's configured architecture.
8.2 Interface Procedures
All DoS protection mechanisms MUST implement the following procedures.
8.2.1 Proof Generation
GenerateProof(binding_data) -> encoded_proof_data
Generate a DoS protection proof bound to specific packet data.
Parameters:
binding_data: The packet-specific data to which the proof MAY be cryptographically bound. For sender-generated proofs, this is (the decrypted payload that hop will see). For per-hop generated proofs, this is the complete outgoing Sphinx packet state .
Returns:
encoded_proof_data: Serialized bytes containing the DoS protection proof and any required verification metadata. This is treated as opaque data by the Mix Protocol layer.
Requirements:
- The DoS protection mechanism is responsible for managing its own runtime state (e.g., current epochs, difficulty levels, merkle tree states). The Mix Protocol layer does not provide or track mechanism-specific runtime context.
- The encoding MUST produce a fixed-length output.
8.2.2 Proof Verification
VerifyProof(encoded_proof_data, binding_data) -> valid
Verify that a DoS protection proof is valid and correctly bound to the provided packet data.
Parameters:
encoded_proof_data: Serialized bytes containing the DoS protection proof and verification metadata, extracted from the routing block (for sender-generated proofs) or from the appended field (for per-hop generated proofs).binding_data: The packet-specific data against which the proof MUST be verified. For nodes verifying sender-generated proofs, this is (the decrypted payload). For per-hop verification, this is the received Sphinx packet state .
Returns:
valid: Boolean indicating whether the proof is valid.
Requirements:
- Implementations MUST handle malformed or truncated
encoded_proof_datagracefully and returnfalse. - For mechanisms that maintain global state (e.g., nullifier sets, rate-limit counters, membership trees), this procedure MUST update the internal state atomically when verification succeeds. State updates (e.g., recording nullifiers, updating rate-limit counters) and state cleanup (e.g., removing expired epochs, old nullifiers) are managed internally by the DoS protection mechanism.
8.2.3 Epoch Change Notification
OnEpochChange(callback) -> void
Register a callback to be invoked when the DoS protection mechanism detects an epoch transition.
Parameters:
callback: A function invoked with the newepochwhen an epoch boundary is detected. The DoS protection mechanism MUST invoke this callback before accepting proofs for the new epoch.
Requirements:
- The DoS protection mechanism MUST notify registered callbacks at every epoch boundary.
- Callbacks MUST be invoked before any packets are processed in the new epoch.
- This enables pluggable components (e.g., cover traffic) to synchronize their internal state with epoch transitions.
8.3 Integration Points in Sphinx Processing
The Mix Protocol invokes DoS protection procedures at specific points in Sphinx packet construction and processing:
8.3.1 For Sender-Generated Proofs
During Sphinx packet construction:
After computing encrypted payloads for each hop (step 3.d), the initiating node MUST:
- For each hop in the path (from to ):
- Call
GenerateProof(binding_data = δ_{i+1})to generateencoded_proof_datafor hop - Embed the
encoded_proof_datain hop 's routing block within during header construction (step 3.c)
- Call
During Sphinx packet preprocessing:
After decrypting the routing block and payload (Steps 4-5), the node MUST:
- Extract
encoded_proof_datafrom the routing block at the appropriate offset - Call
VerifyProof(encoded_proof_data, binding_data = δ') - If
valid = false, discard the packet and terminate processing - If
valid = true, continue with node role determination and role-specific processing
8.3.2 For Per-Hop Generated Proofs
During Sphinx packet construction:
After assembling the final Sphinx packet (step 3.e), the initiating node MUST:
- Call
GenerateProof(binding_data)wherebinding_datais the complete Sphinx packet bytes - Append
encoded_proof_dataafter the Sphinx packet and send to the first hop
During Sphinx packet preprocessing:
Before any Sphinx decryption operations, nodes MUST:
- Extract
encoded_proof_datafrom the lastproofSizebytes of the received packet - Call
VerifyProof(encoded_proof_data, binding_data)wherebinding_datais the Sphinx packet bytes - If
valid = false, discard the packet and terminate processing - If
valid = true, continue with node role determination and role-specific processing
Role-specific processing:
- Intermediary processing
- Perform standard Sphinx processing, then call
GenerateProof(binding_data)with the transformed packet asbinding_data - Append the new
encoded_proof_datato the transformed Sphinx packet and forward
- Perform standard Sphinx processing, then call
- Exit processing Perform standard Sphinx processing without generating a new proof.
Copyright
Copyright and related rights waived via CC0.
References
- libp2p Mix Protocol
- Mix RLN DoS Protection
- EquiHash
- VDF Client Puzzles
- Rate Limiting Nullifiers (RLN)
Multi-message_id Burn RLN
| Field | Value |
|---|---|
| Name | Multi-message_id burn feature RLN |
| Slug | 141 |
| Status | raw |
| Category | Standards Track |
| Editor | Ugur Sen [email protected] |
Timeline
- 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-01-21 —
70f3cfb— chore: mdbook font fix (#266)
Abstract
This document specifies multi-message_id burn RLN which the users
can use their multiple message rights at once unlike previous versions of RLN
that require a separate execution per message_id.
Motivation
RLN is a decentralized rate-limiting mechanism designed for anonymous networks.
In RLNv2, the latest version of the protocol, users can apply arbitrary rate limits
by defining a specific limit over the message_id.
However, this version does not support the simultaneous exercise
of multiple messaging rights under a single message_id.
In other words, if a user needs to consume multiple message_id units,
they must compute separate proofs for each one.
This lack of flexibility creates an imbalance: users sending signals
of significantly different sizes still consume only one message_id per proof.
While computing multiple proofs is a trivial workaround,
it is neither computationally efficient nor manageable for high-throughput applications.
Multiple burning refers to the mechanism where a fixed number of message_id units are processed
within the circuit to generate multiple corresponding nullifiers inside a single cryptographic proof.
This multiple burning feature may unlock the usage of RLN for big signals
such as large messages or complex transactions, by validating their resource consumption in a single proof.
Alternatively, multiple burning could be realized by defining a separate circuit
for each possible number of message_id units to be consumed.
While such an approach would allow precise specialization, it would significantly increase
operational complexity by requiring the management, deployment, and verification
of multiple circuit variants.
To avoid this complexity, this document adopts a single, fixed-size but flexible
circuit design, where a bounded number of message_id units can be selectively
burned using selector bits.
This approach preserves the simplicity of a single
circuit while enabling efficient multi-burn proofs within a single execution.
This document specifies the mechanism that allows users to burn multiple message_id units
at once by slightly modifying the existing RLNv2 circuit.
Format Specification
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in 2119.
Recap of RLNv2
Since the multi-message_id RLN is achieved by modifying the existing RLNv2 protocol, it is helpful to first recap RLNv2. Note that this modification only affects the signaling section; the remaining sections—registration, verification, and slashing—remain identical to RLNv2.
RLNv2 Registration
RLN-Diff introduces per-user rate limits. Therefore, id_commitment must depend on
user_message_limit, where
0 ≤ user_message_limit ≤ message_limit.
The user submits the same identity_secret_hash as in
32/RLN-V1, i.e.
poseidonHash(identity_secret), together with user_message_limit to a server or
smart contract.
The verifier computes
rate_commitment = poseidonHash(identity_secret_hash, user_message_limit),
which is inserted as a leaf in the membership Merkle tree.
RLNv2 Signalling
For proof generation, the user need to submit the following fields to the circuit:
{
identity_secret: identity_secret_hash,
path_elements: Merkle_proof.path_elements,
identity_path_index: Merkle_proof.indices,
x: signal_hash,
message_id: message_id,
external_nullifier: external_nullifier,
user_message_limit: message_limit
}
Calculating output
The output [y, internal_nullifier] is calculated in the following way:
a_0 = identity_secret_hash;
a_1 = poseidonHash([a0, external_nullifier, message_id]);
y = a_0 + x * a_1;
internal_nullifier = poseidonHash([a_1]);
RLNv2 Verification/slashing
Verification and slashing in both subprotocols remain the same as in 32/RLN-V1.
The only difference that may arise is the message_limit check in RLN-Same,
since it is now a public input of the Circuit.
Multi-message_id Burn RLN (Multi-burn RLN)
The multi-burn protocol follows previous versions by comprising registration, signaling, and verification/slashing sections.
Since the registration and verification/slashing mechanisms remain unchanged, this section focuses exclusively on the modifications to the signaling process.
Multi-burn RLN Signalling
The multi-burn RLN signalling section consists of the proving of the circuit as follows:
Circuit parameters
Public Inputs
xexternal_nullifierselector_used []
Private Inputs
identity_secret_hashpath_elementsidentity_path_indexmessage_id []user_message_limit
Outputs
y []rootinternal_nullifiers []
The output (root, y [], internal_nullifiers []) is calculated in the following way:
a_0 = identity_secret_hash;
a_1i = poseidonHash([a0, external_nullifier, message_id [i]]);
y_i = a_0 + x * a_1i;
internal_nullifiers_i = poseidonHash([a_1i]);
where 0 < i ≤ max_out, max_out is a new parameter that is fixed for a application.
max_out is arranged the requirements of the application.
To define this fixed number makes the circuit is flexiable with a single circuit that is maintable.
Since the user is free to burn arbitrary number of message_id at once up to max_out.
Note that within a given epoch, the external_nullifier MUST be identical for all messages
as shown in NULL (unused) output section,
as it is computed deterministically from the epoch value and the rln_identifier as follows:
external_nullifier = poseidonHash([epoch, rln_identifier]);
NULL (unused) outputs
Since the number of used message_id values MAY be less than max_out, the difference
j = max_out - i, where 0 ≤ j ≤ max_out − 1, denotes the number of unused output slots.
These j outputs are referred to as NULL outputs. NULL outputs carry no semantic meaning and
MUST be identical to one another in order to unambiguously indicate that they correspond to
unused message_id slots and do not represent valid proofs.
To compute NULL outputs, the circuit makes use of a selector bit array selector_used [],
where selector_used[i] = 1 denotes a used message_id slot and selector_used[i] = 0 denotes
an unused slot.
The message_id values MUST NOT be checked in the circuit incrementally (e.g., 1, 2, 3, ...),
independently of whether a slot is used or unused.
For the best practice the application MAY pass the message_id values incrementally and
tracks unused message_id values across executions to ensure that subsequent executions
continue from the last assigned message_id without reuse or skipping.
The circuit computes the corresponding intermediate values for all slots according to the RLNv2 equations.
For each slot k, the final outputs are masked using the selector bits as
follows:
a_0 = identity_secret_hash;
a_1i = poseidonHash([a0, external_nullifier, message_id [i]]);
y_i = selector_used[i] * (a_0 + x * a_1i);
internal_nullifiers_i = selector_used[i] * poseidonHash([a_1i]);
Since multiplication by zero yields the additive identity in the field,
all unused slots (selector_used[k] = 0) result in
y[k] = 0 and internal_nullifiers[k] = 0, which are interpreted as
NULL outputs and carry no semantic meaning.
As a consequence, the presence of valid-looking message_id values in unused
slots does not result in additional burns, as their corresponding outputs are
fully masked and ignored during verification.
Moreover, message_id values that are provided to the circuit but correspond to unused slots (selector_used[k] = 0)
are not considered consumed and MAY be reused in subsequent proofs in which the corresponding selector bit is set to 1.
Copyright
Copyright and related rights waived via CC0
References
NOISE-X3DH-DOUBLE-RATCHET
| Field | Value |
|---|---|
| Name | Secure 1-to-1 channel setup using X3DH and the double ratchet |
| Slug | 108 |
| Status | raw |
| Category | Standards Track |
| Editor | Ramses Fernandez [email protected] |
Timeline
- 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-04-04 —
517b639— Update the RFCs: Vac Raw RFC (#143) - 2024-10-03 —
c655980— Eth secpm splitted (#91)
Motivation
The need for secure communications has become paramount. This specification outlines a protocol describing a secure 1-to-1 comunication channel between 2 users. The main components are the X3DH key establishment mechanism, combined with the double ratchet. The aim of this combination of schemes is providing a protocol with both forward secrecy and post-compromise security.
Theory
The specification is based on the noise protocol framework. It corresponds to the double ratchet scheme combined with the X3DH algorithm, which will be used to initialize the former. We chose to express the protocol in noise to be be able to use the noise streamlined implementation and proving features. The X3DH algorithm provides both authentication and forward secrecy, as stated in the X3DH specification.
This protocol will consist of several stages:
- Key setting for X3DH: this step will produce prekey bundles for Bob which will be fed into X3DH. It will also allow Alice to generate the keys required to run the X3DH algorithm correctly.
- Execution of X3DH: This step will output
a common secret key
SKtogether with an additional data vectorAD. Both will be used in the double ratchet algorithm initialization. - Execution of the double ratchet algorithm
for forward secure, authenticated communications,
using the common secret key
SK, obtained from X3DH, as a root key.
The protocol assumes the following requirements:
- Alice knows Bob’s Ethereum address.
- Bob is willing to participate in the protocol, and publishes his public key.
- Bob’s ownership of his public key is verifiable,
- Alice wants to send message M to Bob.
- An eavesdropper cannot read M’s content even if she is storing it or relaying it.
Syntax
Cryptographic suite
The following cryptographic functions MUST be used:
X488as Diffie-Hellman functionDH.SHA256as KDF.AES256-GCMas AEAD algorithm.SHA512as hash function.XEd448for digital signatures.
X3DH initialization
This scheme MUST work on the curve curve448. The X3DH algorithm corresponds to the IX pattern in Noise.
Bob and Alice MUST define personal key pairs
(ik_B, IK_B) and (ik_A, IK_A) respectively where:
- The key
ikmust be kept secret, - and the key
IKis public.
Bob MUST generate new keys using
(ik_B, IK_B) = GENERATE_KEYPAIR(curve = curve448).
Bob MUST also generate a public key pair
(spk_B, SPK_B) = GENERATE_KEYPAIR(curve = curve448).
SPK is a public key generated and stored at medium-term.
Both signed prekey and the certificate MUST
undergo periodic replacement.
After replacing the key,
Bob keeps the old private key of SPK
for some interval, dependant on the implementation.
This allows Bob to decrypt delayed messages.
Bob MUST sign SPK for authentication:
SigSPK = XEd448(ik, Encode(SPK))
A final step requires the definition of
prekey_bundle = (IK, SPK, SigSPK, OPK_i)
One-time keys OPK MUST be generated as
(opk_B, OPK_B) = GENERATE_KEYPAIR(curve = curve448).
Before sending an initial message to Bob,
Alice MUST generate an AD: AD = Encode(IK_A) || Encode(IK_B).
Alice MUST generate ephemeral key pairs
(ek, EK) = GENERATE_KEYPAIR(curve = curve448).
The function Encode() transforms a
curve448 public key into a byte sequence.
This is specified in the RFC 7748
on elliptic curves for security.
One MUST consider q = 2^446 - 13818066809895115352007386748515426880336692474882178609894547503885
for digital signatures with (XEd448_sign, XEd448_verify):
XEd448_sign((ik, IK), message):
Z = randbytes(64)
r = SHA512(2^456 - 2 || ik || message || Z )
R = (r * convert_mont(5)) % q
h = SHA512(R || IK || M)
s = (r + h * ik) % q
return (R || s)
XEd448_verify(u, message, (R || s)):
if (R.y >= 2^448) or (s >= 2^446): return FALSE
h = (SHA512(R || 156326 || message)) % q
R_check = s * convert_mont(5) - h * 156326
if R == R_check: return TRUE
return FALSE
convert_mont(u):
u_masked = u % mod 2^448
inv = ((1 - u_masked)^(2^448 - 2^224 - 3)) % (2^448 - 2^224 - 1)
P.y = ((1 + u_masked) * inv)) % (2^448 - 2^224 - 1)
P.s = 0
return P
Use of X3DH
This specification combines the double ratchet with X3DH using the following data as initialization for the former:
- The
SKoutput from X3DH becomes theSKinput of the double ratchet. See section 3.3 of Signal Specification for a detailed description. - The
ADoutput from X3DH becomes theADinput of the double ratchet. See sections 3.4 and 3.5 of Signal Specification for a detailed description. - Bob’s signed prekey
SigSPKBfrom X3DH is used as Bob’s initial ratchet public key of the double ratchet.
X3DH has three phases:
- Bob publishes his identity key and prekeys to a server, a network, or dedicated smart contract.
- Alice fetches a prekey bundle from the server, and uses it to send an initial message to Bob.
- Bob receives and processes Alice's initial message.
Alice MUST perform the following computations:
dh1 = DH(IK_A, SPK_B, curve = curve448)
dh2 = DH(EK_A, IK_B, curve = curve448)
dh3 = DH(EK_A, SPK_B)
SK = KDF(dh1 || dh2 || dh3)
Alice MUST send to Bob a message containing:
IK_A, EK_A.- An identifier to Bob's prekeys used.
- A message encrypted with AES256-GCM using
ADandSK.
Upon reception of the initial message, Bob MUST:
- Perform the same computations above with the
DH()function. - Derive
SKand constructAD. - Decrypt the initial message encrypted with
AES256-GCM. - If decryption fails, abort the protocol.
Initialization of the double datchet
In this stage Bob and Alice have generated key pairs
and agreed a shared secret SK using X3DH.
Alice calls RatchetInitAlice() defined below:
RatchetInitAlice(SK, IK_B):
state.DHs = GENERATE_KEYPAIR(curve = curve448)
state.DHr = IK_B
state.RK, state.CKs = HKDF(SK, DH(state.DHs, state.DHr))
state.CKr = None
state.Ns, state.Nr, state.PN = 0
state.MKSKIPPED = {}
The HKDF function MUST be the proposal by
Krawczyk and Eronen.
In this proposal chaining_key and input_key_material
MUST be replaced with SK and the output of DH respectively.
Similarly, Bob calls the function RatchetInitBob() defined below:
RatchetInitBob(SK, (ik_B,IK_B)):
state.DHs = (ik_B, IK_B)
state.Dhr = None
state.RK = SK
state.CKs, state.CKr = None
state.Ns, state.Nr, state.PN = 0
state.MKSKIPPED = {}
Encryption
This function performs the symmetric key ratchet.
RatchetEncrypt(state, plaintext, AD):
state.CKs, mk = HMAC-SHA256(state.CKs)
header = HEADER(state.DHs, state.PN, state.Ns)
state.Ns = state.Ns + 1
return header, AES256-GCM_Enc(mk, plaintext, AD || header)
The HEADER function creates a new message header
containing the public key from the key pair output of the DHfunction.
It outputs the previous chain length pn,
and the message number n.
The returned header object contains ratchet public key
dh and integers pn and n.
Decryption
The function RatchetDecrypt() decrypts incoming messages:
RatchetDecrypt(state, header, ciphertext, AD):
plaintext = TrySkippedMessageKeys(state, header, ciphertext, AD)
if plaintext != None:
return plaintext
if header.dh != state.DHr:
SkipMessageKeys(state, header.pn)
DHRatchet(state, header)
SkipMessageKeys(state, header.n)
state.CKr, mk = HMAC-SHA256(state.CKr)
state.Nr = state.Nr + 1
return AES256-GCM_Dec(mk, ciphertext, AD || header)
Auxiliary functions follow:
DHRatchet(state, header):
state.PN = state.Ns
state.Ns = state.Nr = 0
state.DHr = header.dh
state.RK, state.CKr = HKDF(state.RK, DH(state.DHs, state.DHr))
state.DHs = GENERATE_KEYPAIR(curve = curve448)
state.RK, state.CKs = HKDF(state.RK, DH(state.DHs, state.DHr))
SkipMessageKeys(state, until):
if state.NR + MAX_SKIP < until:
raise Error
if state.CKr != none:
while state.Nr < until:
state.CKr, mk = HMAC-SHA256(state.CKr)
state.MKSKIPPED[state.DHr, state.Nr] = mk
state.Nr = state.Nr + 1
TrySkippedMessageKey(state, header, ciphertext, AD):
if (header.dh, header.n) in state.MKSKIPPED:
mk = state.MKSKIPPED[header.dh, header.n]
delete state.MKSKIPPED[header.dh, header.n]
return AES256-GCM_Dec(mk, ciphertext, AD || header)
else: return None
Information retrieval
Static data
Some data, such as the key pairs (ik, IK) for Alice and Bob,
MAY NOT be regenerated after a period of time.
Therefore the prekey bundle MAY be stored in long-term
storage solutions, such as a dedicated smart contract
which outputs such a key pair when receiving an Ethereum wallet
address.
Storing static data is done using a dedicated
smart contract PublicKeyStorage which associates
the Ethereum wallet address of a user with his public key.
This mapping is done by PublicKeyStorage
using a publicKeys function, or a setPublicKey function.
This mapping is done if the user passed an authorization process.
A user who wants to retrieve a public key associated
with a specific wallet address calls a function getPublicKey.
The user provides the wallet address as the only
input parameter for getPublicKey.
The function outputs the associated public key
from the smart contract.
Ephemeral data
Storing ephemeral data on Ethereum MAY be done using a combination of on-chain and off-chain solutions. This approach provides an efficient solution to the problem of storing updatable data in Ethereum.
- Ethereum stores a reference or a hash that points to the off-chain data.
- Off-chain solutions can include systems like IPFS, traditional cloud storage solutions, or decentralized storage networks such as a Swarm.
In any case, the user stores the associated IPFS hash, URL or reference in Ethereum.
The fact of a user not updating the ephemeral information can be understood as Bob not willing to participate in any communication.
Copyright
Copyright and related rights waived via CC0.
References
Payment Streams
| Field | Value |
|---|---|
| Name | Payment Streams Protocol for Logos Services |
| Slug | 155 |
| Status | raw |
| Category | Standards Track |
| Editor | Sergei Tikhomirov [email protected] |
| Contributors | Akhil Peddireddy [email protected] |
Timeline
- 2026-07-08 —
b9b4160— Add on-chain part of payment streams spec (#299) - 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-03-18 —
e07c655— Chore: move and fix header for payment streams spec (#295) - 2026-02-24 —
14fd5c0— docs: add payment streams raw spec (#224)
Abstract
This specification defines payment streams for incentivized Logos request-response services.
Users pay providers over time from vault deposits instead of settling each request on chain,
while allocation caps how much funds may accrue to a provider.
On chain, users deposit funds into vaults and allocate streams from which funds accrue to providers at a configured rate. The chain enforces allocation accounting and lazy accrual on each stream-touching operation using a monotonic timestamp. Stream lifecycle covers create, pause, resume, top-up, close, and claim.
Off chain, the protocol extends the incentivization request-response envelope with
VaultProof, StreamProposal, and StreamProof.
Providers advertise a policy, verify proofs against vault and stream state,
and grant service when a signed proposal satisfies that policy
and an on-chain stream matching the accepted StreamParams backs the session.
The document specifies generic on-chain and off-chain requirements, a reference integration with the Logos Execution Zone and Logos Delivery Store queries, security and privacy considerations, and optional protocol extensions.
Language
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119.
Protobuf uint64 timestamp fields use the chain integration time unit
defined for on-chain accrual, unless stated otherwise.
Change Process
This document is governed by the 1/COSS (COSS).
Motivation
Logos is a privacy-focused tech stack that includes Logos Messaging, Logos Blockchain, and Logos Storage.
Logos Messaging comprises a suite of communication protocols with both P2P and request-response structures. The backbone P2P protocols use tit-for-tat mechanisms. Incentivization is introduced for auxiliary request-response protocols with well-defined user and provider roles. One such protocol is Store, which allows users to query historical messages from Logos Messaging relay nodes.
Logos Blockchain includes the Logos Execution Zone (LEZ), which enables both transparent and shielded execution.
We target the following design goals:
- Performance: Low latency and fees without settling each service request on chain.
- Security: Limited loss exposure when service stops or the user is offline.
- Privacy: On-chain deposit activity unlinkable from off-chain service use.
- Extendability: A simple base protocol with room for optional extensions.
Payment streams enable unidirectional time-based fund flows. Streams map well to this use case. Unlike alternatives (payment channels, e-cash), payment streams avoid storing old states or initiating disputes, and do not rely on a centralized mint.
The document proceeds from on-chain streams, to stream-backed request-response eligibility, to the LEZ and Logos Delivery reference integration, and then security and privacy considerations.
On-Chain Payment Streams Protocol
This specification refers to payment streams as streams.
Roles
The protocol has two roles:
- User: the party paying for services.
- Provider: the party delivering services and receiving payment.
On chain, the user authorized to operate a vault is the vault owner
(for example VaultConfig.owner on LEZ).
Vaults and streams
The protocol uses a two-level architecture of vaults and streams.
A vault holds a user's deposit in the vault token. The user is designated as the vault's owner. A user MAY own multiple vaults. One vault MAY back multiple streams, possibly to different providers.
A stream represents an individual flow of funds from a vault to one provider. Each stream MUST belong to exactly one vault.
Each stream MUST record provider_id,
a byte string designating the party authorized to claim accrued funds.
Each chain integration MUST define that encoding
and its mapping to the on-chain account authorized to claim those funds.
In the base protocol, vault funds are denominated in the chain native token. Each stream MUST specify a positive accrual rate in tokens per time unit. This specification does not fix the time unit; each chain integration MUST define the time unit used by rates and accrual.
To start using the protocol,
the user MUST deposit funds into a vault.
The funds deposited into a vault are initially unallocated.
When creating a stream,
the user MUST allocate a portion of unallocated vault funds to that stream.
For each stream, funds within its allocation accrue from the user to the provider.
Thus each allocation is divided into accrued and unaccrued.
A stream is depleted when unaccrued = 0.
Let balance be the vault balance.
Let total_allocated be the sum of all allocation values for streams in a vault.
The following identities MUST hold:
balance = total_allocated + unallocated
allocation = accrued + unaccrued
Vault operations include:
- Initialize: create an empty vault. Chain integrations MAY attach privacy or metadata fields at initialization (see Security and privacy considerations).
- Deposit: increase
balanceandunallocated. - Withdraw: decrease
balanceby at mostunallocated.
The user MAY withdraw unallocated funds at any time. Vault operations MUST NOT modify allocated funds.
Any change to a stream's allocation MUST be funded only from that vault's
unallocated balance.
An increase to allocation MUST decrease unallocated by the same amount,
increase total_allocated by the same amount,
and MUST NOT change vault balance.
An operation that increases allocation MUST fail when unallocated is
insufficient.
Stream lifecycle
At any point in time, a stream MUST be in one of the following states:
ACTIVE, PAUSED, CLOSED.
State transition diagram:
graph LR
ACTIVE -->|pause / deplete| PAUSED
PAUSED -->|resume / top-up| ACTIVE
ACTIVE -->|close| CLOSED
PAUSED -->|close| CLOSED
Stream operations include:
- Create: assign a provider, set rate and initial
allocation. - Pause: stop fund accrual on an
ACTIVEstream. - Resume: resume fund accrual on a non-depleted
PAUSEDstream. - Top-up: increase the stream's
allocation. - Close: release remaining
unaccruedto vaultunallocatedand mark the streamCLOSED. - Claim: transfer all
accruedfunds to the provider; setaccruedto zero and decreaseallocationand the vault'stotal_allocatedby the claimed amount.
The user MAY create a stream if the vault has unallocated funds.
Stream creation MUST assign a stable stream_id in chain-specific encoding.
A newly created stream MUST be ACTIVE.
Funds MUST accrue only on ACTIVE streams.
Each stream MUST store accrued_as_of, the fold timestamp through which stored accrued has been computed
(see Lazy accrual and folding).
The user MAY pause an ACTIVE stream.
An ACTIVE stream MUST also transition to PAUSED automatically upon depletion.
The user MAY resume a PAUSED stream.
Resume of a depleted stream MUST fail.
The user MAY top-up a stream.
Top-up MUST increase the stream's allocation under the allocation increase rules above.
Top-up MUST transition the stream to ACTIVE.
To add funds and keep the stream PAUSED,
the user MUST pause the stream after top-up.
Either user or provider MAY close the stream from any non-CLOSED state.
Unaccrued funds of a CLOSED stream MUST be immediately transferred to the vault's unallocated balance.
A CLOSED stream MUST NOT transition to any other state.
Accrued funds of a CLOSED stream remain available for the provider to claim.
The provider MAY claim accrued funds from a stream in any state. A claim MUST transfer all accrued funds from this stream to the provider.
Lazy accrual and folding
To fold a stream means to apply accrual and lifecycle updates through a fold timestamp t.
A fold timestamp is monotonic chain time up to which the fold applies accrual.
Each stream MUST record accrued_as_of, the latest fold timestamp.
Let Δt be t minus accrued_as_of.
Folding a non-ACTIVE stream MUST leave accrued and accrued_as_of unchanged.
Otherwise the fold MUST set:
accrued := min(allocation, accrued + rate × Δt)
When folding results in a depleted stream,
accrued_as_of MUST be set to the fold timestamp at which depletion occurred
(MAY be earlier than t).
Otherwise accrued_as_of MUST be set to t.
Any stream operation MUST fold the stream before executing its logic.
A chain integration MUST expose a monotonic system timestamp. The integration MUST define which accounts supply the system timestamp. Accrual MUST be computed relative to the system timestamp. Stored on-chain fields MAY lag behind effective state at the current system timestamp until a transaction folds the stream.
On-chain protocol extensions
This section describes optional modifications to the streams protocol. The user MAY enable an extension when creating a vault or stream, as specified in that extension.
Auto-Pause
In the base streams protocol,
the user SHOULD pause or close a stream when the provider stops delivering service.
If the user is offline,
funds on an ACTIVE stream MAY keep accruing until depletion,
which increases loss exposure while service is unavailable.
The auto-pause extension limits offline exposure by time,
in addition to the funds cap from allocation.
The stream records an auto-pause duration in the chain integration time unit.
When that duration has elapsed in chain time since stream creation
or since the last resume,
an ACTIVE stream MUST automatically transition to PAUSED at fold time.
For an already-PAUSED stream, that transition has no further effect.
The user MAY resume the stream.
Each resume MUST restart the auto-pause duration from the time of that resume.
Automatic Claim on Closure
In the base streams protocol,
close does not pay the provider.
Accrued funds remain on a CLOSED stream until the provider claims them.
The automatic claim on closure extension merges close and claim. Close MUST transfer all accrued funds to the provider in the same operation, so that the closed stream holds no funds afterward.
This removes the need for the provider to track or claim balances on closed streams. Trade-offs include:
- The provider can no longer batch claims across streams.
- Close and payout happen in one transaction, which can increase timing correlation for observers.
- When the user initiates close on a fee-charging chain, the same transaction runs the provider payout logic, so the user pays transaction fees for that logic, instead of the provider paying via a separate claim.
- If the payout fails,
close fails atomically and the stream does not transition to the
CLOSEDstate.
Activation Fee
In the base streams protocol,
funds accrue only on ACTIVE streams.
The user MAY pause at any time and MAY resume a non-depleted PAUSED stream.
A user can leave a stream PAUSED for long periods,
resume briefly to obtain service,
and pay only during brief ACTIVE intervals.
The activation fee extension charges a fixed fee when fund accrual starts.
Only the operation that transitions the stream to ACTIVE MUST charge the activation fee.
The fee SHOULD reflect the provider's minimum acceptable payment for a service session.
If unaccrued is less than the activation fee,
the activation MUST fail.
Providers MAY also mitigate pause-and-resume attacks through off-chain policy.
Multi-Token Vaults
In the base streams protocol, the vault token is the chain native token and needs no on-chain identity field.
The multi-token vaults extension allows support for other tokens.
Each vault MUST record exactly one token identity in chain-specific form.
Every stream in that vault MUST denominate
rate, allocation, accrued, and claims in that vault's token.
A vault MUST NOT mix multiple token types.
If a provider accepts multiple tokens,
its stream policy advertisements MUST list accepted tokens.
Delivery Receipts
In the base streams protocol, funds accrue based purely on on-chain stream state. The provider does not submit off-chain proof that service was delivered.
The delivery receipts extension ties claim to user acknowledgment. Claim MUST include valid receipts.
A delivery receipt is an off-chain message signed by the user. It MUST include the on-chain stream identifier (as assigned at stream creation, in chain-specific encoding), the service delivery details covered by the claim, and a signature over those fields.
Integrations choose how many deliveries each receipt covers: per-message receipts increase signing and coordination overhead, while batched receipts reduce overhead but bundle user approval.
Deferred first stream proof
In the base streams protocol paired with stream-backed eligibility,
the user MUST send the first stream-proof-backed ServiceRequest
by create_stream_deadline.
That request proves a matching on-chain stream was open by naming it in
StreamProof and supplying a valid session signature.
With this extension,
the user MUST still create an on-chain stream that matches the accepted
StreamParams before create_stream_deadline,
but MAY send the first stream-proof-backed request later.
The provider MAY scan on-chain streams for the vault to verify that a matching
stream existed by create_stream_deadline.
The provider SHOULD advertise support for this extension via discovery.
Stream-Backed Eligibility for Request-Response Services
This section specifies how stream-backed eligibility
is integrated into a request-response protocol.
It extends the ServiceRequest, ServiceResponse,
EligibilityProof, and EligibilityStatus envelopes
from the incentivization specification
with stream-specific proposal, proof, and termination messages.
Off-chain messages coordinate proposal, ongoing proof, and termination.
On-chain state remains authoritative for funds accrual and stream lifecycle.
Protocol overview
The protocol consists of the following stages:
- Discovery.
Providers advertise a policy (
StreamProviderPolicy) that proposals MUST satisfy before acceptance. Discovery mechanics are out of scope for this specification. - Initial request-response exchange.
The user sends a
StreamProposalin the firstServiceRequest; the provider MAY accept and serve the first unit. - Stream-proof-backed request-response.
Each further
ServiceRequestcarries aStreamProof. - Termination.
The provider ends service with
ServiceTermination(standalone or insideServiceResponse.eligibility_status).
sequenceDiagram
participant User
participant Provider
participant Chain as On-chain streams
Note over User,Provider: Discovery (mechanics out of scope)
User->>Provider: ServiceRequest (EligibilityProof.stream_proposal)
Provider->>User: ServiceResponse (OK, first service unit)
User->>Chain: Create stream on-chain (before create_stream_deadline)
loop Stream-proof-backed request-response
User->>Provider: ServiceRequest (EligibilityProof.stream_proof)
Provider->>User: ServiceResponse
end
Provider->>User: ServiceTermination (optional standalone or in ServiceResponse)
User->>Chain: Close stream on-chain
Message structure
ServiceRequest
A ServiceRequest has the following fields:
ServiceRequest
├── request_data
└── eligibility_proof: EligibilityProof
└── exactly one of:
├── stream_proposal: StreamProposal
│ ├── vault_proof: VaultProof
│ ├── stream_params: StreamParams
│ └── public_key
└── stream_proof: StreamProof
├── stream_id
└── signature
Protobuf excerpts below are normative wire shapes. The ASCII tree is illustrative.
ServiceResponse
A ServiceResponse MUST include:
eligibility_status: anEligibilityStatuswith:status_code: indicating acceptance, parameter rejection, proof invalidity, etc.status_desc: human-readable description (RECOMMENDED to include actionable guidance on parameter rejection)
response_data: service-specific payload (included if and only if the request is served)
Stream-backed eligibility uses the following EligibilityStatus.status_code values:
status_code | Name | Meaning |
|---|---|---|
| 0 | OK | Request served. |
| 1 | PARAMS_REJECTED | Proposal does not satisfy a policy, the on-chain stream does not match accepted StreamParams, or create_stream_deadline obligations were missed. User MAY retry with adjusted parameters. |
| 2 | PROOF_INVALID | Malformed proof, failed signature, or failed cryptographic verification. |
| 3 | STREAM_NOT_ACTIVE | No on-chain stream for stream_id, or stream lifecycle state is not ACTIVE. |
EligibilityProof
message EligibilityProof {
optional bytes proof_of_payment = 1;
optional bytes stream_proposal = 2;
optional bytes stream_proof = 3;
}
The user MUST NOT set proof_of_payment or other non-stream incentivization fields.
Exactly one of stream_proposal or stream_proof MUST be present.
StreamProposal
message StreamProposal {
VaultProof vault_proof = 1;
StreamParams stream_params = 2;
bytes public_key = 3;
}
public_key is the session key for StreamProof signatures.
The session key is the key pair committed in public_key.
The user signs each StreamProof with the session key private key.
StreamProof
A StreamProof links a request to an active stream.
message StreamProof {
bytes stream_id = 1;
bytes signature = 2;
}
stream_id is the on-chain identifier of the stream.
signature proves eligibility for this request.
It MUST be over request_data using the committed session key.
It MUST use the same signature scheme and encoding
as VaultProof.owner_signature for the integration,
with a domain prefix and canonical_body_bytes defined for the service request
(for example Store eligibility signature on LEZ).
request_data is the service-specific payload in the enclosing ServiceRequest,
as defined by the service integration building on the
incentivization specification.
VaultProof
A VaultProof proves that the user controls a vault
with sufficient unallocated funds
to back the proposed stream.
For a StreamProposal, the vault account for vault_id MUST exist on-chain.
Proposed allocation MUST be at most that vault's unallocated balance.
owner_public_key MUST match the on-chain vault owner for that vault.
message VaultProof {
bytes vault_id = 1;
bytes provider_id = 2;
bytes owner_public_key = 3;
bytes owner_signature = 4;
}
vault_id is the on-chain identifier of the vault.
provider_id is the provider identity for this protocol.
It pins the proposal to one provider and prevents replay across providers.
Chain integrations MUST define how provider_id maps to on-chain claim authorization
(for example octet equality with StreamConfig.provider on LEZ).
A chain integration MAY map provider_id to a long-lived service identity
and separately map that identity to the chain account that receives stream claims.
owner_public_key is the key used to verify owner_signature.
Chain integrations MUST define how owner_public_key
cryptographically binds to the vault owner stored on-chain.
owner_signature authorizes the proposed stream session.
It MUST cover at least the other VaultProof fields,
the accompanying StreamParams,
and StreamProposal.public_key.
This prevents a valid vault proof from being recombined
with different stream parameters or a different session key.
Chain integrations MUST document the canonical signed payload.
LEZ defines vault-owner authorization in Vault owner authorization.
StreamParams
message StreamParams {
bytes service_id = 1;
uint64 stream_rate = 2;
uint64 allocation = 3;
uint64 create_stream_deadline = 4;
}
create_stream_deadline is the latest chain time by which the stream MUST exist on-chain.
StreamParams holds the proposed stream fields for one StreamProposal.
service_id is an opaque byte string that identifies the request-response service for the stream session.
The provider assigns or advertises acceptable service_id values via discovery.
The user MUST set service_id to a value the provider accepts for that session.
For a service session, an on-chain stream matches accepted StreamParams
when the chain integration reports exact equality on every comparable field.
StreamProviderPolicy
The provider advertises a policy as the following message:
message StreamProviderPolicy {
uint64 min_rate = 1;
uint64 min_allocation = 2;
uint64 max_create_stream_deadline_delay = 3;
uint64 vault_proof_max_response_bytes = 4;
}
Allocation caps on-chain payment exposure but does not attest to service quality; providers MAY adjust serving policy when users abuse pause, resume, or request patterns.
A StreamProposal satisfies a policy at verification time t
when the policy is a StreamProviderPolicy and:
stream_params.stream_rateMUST be greater than or equal tomin_ratestream_params.allocationMUST be greater than or equal tomin_allocationstream_params.create_stream_deadlineMUST be greater than or equal totand MUST be less than or equal totplusmax_create_stream_deadline_delay
RECOMMENDED default for max_create_stream_deadline_delay: 300 seconds.
vault_proof_max_response_bytes sets the per-response byte limit for response_data
when the provider serves the initial vault-proof-backed request.
ServiceTermination
message ServiceTermination {
enum TerminationType {
TEMPORARY = 0;
PERMANENT = 1;
}
TerminationType termination_type = 1;
uint64 resume_after = 2;
}
For PERMANENT termination, resume_after MUST be zero.
For TEMPORARY termination, resume_after MUST be a chain timestamp
after which service MAY resume.
Cryptographic commitments
Off-chain proofs use vault-owner authorization on StreamProposal
and per-request eligibility on StreamProof.
Each signature role MUST use a chain-specific canonical form
and its own domain separation prefix.
A chain integration MUST define signed payload coverage for each role,
document the canonical bytes,
and publish deterministic test vectors.
Protocol Flow
Discovery
A discovery protocol (out of scope for this specification)
SHOULD enable providers to announce which eligibility proof types they accept.
Advertisements for stream-backed eligibility MUST include StreamProviderPolicy.
Updated policy advertisements apply only to new proposals.
Initial request-response exchange
The first ServiceRequest MUST carry a StreamProposal.
The StreamProposal MUST satisfy the provider's policy at verification time t.
owner_signature MUST verify under owner_public_key over the canonical proposal payload.
The user MUST NOT send another StreamProposal for the same vault-provider pair
while a proposal is pending.
Before serving the request,
the provider MUST confirm that the proposal satisfies the policy,
the VaultProof requirements,
and owner_signature validity.
On success it MUST return EligibilityStatus.status_code OK with response_data.
The provider SHOULD keep response_data within
vault_proof_max_response_bytes from policy
(RECOMMENDED default: 65536 bytes).
The provider SHOULD cap parameter-adjustment attempts at 5 per vault
within 600 seconds (RECOMMENDED).
A service session is the provider's off-chain state for one accepted proposal.
On acceptance the provider MUST record accepted StreamParams,
the policy pinned at acceptance,
StreamProposal.public_key as the session key,
and vault_id, provider_id, and owner_public_key from the vault proof.
Later stream-proof verification MUST use that pinned policy and session record.
After acceptance the user MUST create an on-chain stream that matches the
accepted StreamParams before create_stream_deadline.
Until an on-chain stream matching those params exists or the deadline passes,
vault unallocated MUST remain at least the accepted allocation,
and the user MUST NOT send another StreamProposal to the same provider.
If unallocated falls below the accepted allocation after acceptance,
the provider SHOULD send PERMANENT ServiceTermination.
Stream-proof-backed request-response
Stream-proof-backed ServiceRequest messages apply only after an on-chain stream
matching the accepted StreamParams exists for the service session.
Each such request MUST carry EligibilityProof.stream_proof only.
The first stream-proof-backed ServiceRequest MUST arrive by create_stream_deadline.
That request proves a matching on-chain stream was open by the deadline.
The provider learns stream_id from each StreamProof.
For verification it MUST read that stream's on-chain account state
for the session vault_id under the chain integration,
and then fold that state to the current chain time.
Each StreamProof MUST name the on-chain stream that matches the accepted
StreamParams for the service session,
and MUST carry a valid signature over request_data with the session key.
The referenced stream MUST be ACTIVE.
On the first valid stream-proof request,
the provider MUST record stream_id in session state if not already set.
The provider MAY retain session state across on-chain pause and resume. After resume, the user MAY continue stream-proof-backed requests under the same session.
Termination
The session ends when the provider sends ServiceTermination
with PERMANENT termination_type,
or when create_stream_deadline passes
without the first stream-proof-backed ServiceRequest
corresponding to an on-chain stream that matches the accepted StreamParams.
The provider MUST send ServiceTermination before stopping service
for an accepted service session.
The provider MUST NOT cease serving under that session without ServiceTermination,
except when the session ends due to a missed create_stream_deadline.
ServiceTermination MAY be sent standalone or inside ServiceResponse,
including before any on-chain stream exists.
When service ends, the user MAY pause or close the on-chain stream and MAY stop sending stream proofs.
For TEMPORARY termination, the user MAY pause the stream until resume_after.
The provider MAY resume the same service session after resume_after.
For PERMANENT termination, the user SHOULD close the on-chain stream promptly.
Further service requires a newly accepted StreamProposal.
Request-response protocol extensions
This section describes optional extensions to the request-response protocol with stream-backed eligibility.
Load Cap
The base protocol bounds one vault-proof-backed response through
vault_proof_max_response_bytes in policy.
The load cap extension adds a cumulative limit per stream per time window
(for example, total bytes or requests per minute).
When this extension is used,
the provider MUST advertise a load cap via discovery.
The provider MAY refuse to serve requests that would exceed the cap.
When sustained load requires a higher cap, the user SHOULD open multiple streams to the same provider. Note that the user MAY request work without knowing the response size in advance (such as message history over a time range).
Multi-round Stream Parameter Negotiation
In the base request-response protocol,
PARAMS_REJECTED does not carry provider counter-proposals.
A future extension MAY allow counter-proposed parameters in a
PARAMS_REJECTED response,
enabling iterative negotiation before the first request is served.
LEZ and Logos Delivery Integration
This section maps the On-Chain Payment Streams Protocol and Stream-Backed Eligibility for Request-Response Services onto LEZ account layout, guest instructions, and reference off-chain bytes.
Scope and normative boundary
Clock account ids, domain prefixes, and other demo fixtures are pinned in the reference integration and MAY change when the network is redeployed. Instruction wire layout and error codes are defined only there. Implementations MUST follow the deployed network and published test vectors from the reference integration when they differ from this section on demo-only fields. Account layout, authorization, and privacy-tier rules here are normative and are not overridden by the reference integration.
On-chain mapping
The payment-streams guest program maps vault and stream state to
VaultConfig, VaultHolding, and StreamConfig accounts.
Account types
VaultConfig holds total_allocated, owner, and an immutable privacy tier
(Public or PseudonymousFunder) set at initialization.
For PseudonymousFunder vaults,
owner MUST be an identifier derived from a nullifier public key.
VaultHolding holds vault token balance and a version byte in application data.
The guest MUST reject instructions when version bytes across
VaultConfig, VaultHolding, and StreamConfig for a vault do not match.
The reference guest uses version 1 on the demo network.
Per-stream state is stored in StreamConfig.
PDA derivation
VaultConfig is a PDA from the owner account identifier
and a user-chosen vault identifier.
VaultHolding is derived from the VaultConfig address.
StreamConfig is a PDA from the VaultConfig address
and the stream identifier assigned sequentially on stream creation.
StreamConfig.provider is stored in account data, not in the stream PDA seeds.
Off-chain vault resolution derives the same VaultConfig PDA from
VaultProof.vault_id and the LEZ account identifier for
VaultProof.owner_public_key (see Vault owner authorization).
Deposit path
On deposit, the guest validates vault ownership and amount,
then invokes the platform authenticated-transfer program
to move native balance into VaultHolding.
Guest instructions
Reference instruction names and signers:
| On-chain operation | Reference instruction | Authorizer |
|---|---|---|
| Initialize vault | InitializeVault | Vault owner |
| Deposit | Deposit | Vault owner |
| Withdraw unallocated | Withdraw | Vault owner |
| Create stream | CreateStream | Vault owner |
| Pause stream | PauseStream | Vault owner |
| Resume stream | ResumeStream | Vault owner |
| Top-up stream | TopUpStream | Vault owner |
| Close stream | CloseStream | Vault owner or stream provider |
| Claim accrued | Claim | Stream provider |
CloseStream and Claim MUST pass VaultConfig.owner as an explicit
non-signing account equal to the vault owner.
System clock accounts
Guest instructions that fold streams read time from a caller-supplied
clock account.
The guest accepts exactly three clock program account identifiers.
Each id is a UTF-8 string of seven decimal digits, zero-padded
(for example 0000010 is decimal ten, not octal):
| Clock account id (UTF-8 prefix string) | Typical update cadence |
|---|---|
/LEZ/ClockProgramAccount/0000001 | Highest frequency (finest folding granularity) |
/LEZ/ClockProgramAccount/0000010 | Medium frequency |
/LEZ/ClockProgramAccount/0000050 | Coarsest frequency |
Each account stores Borsh ClockAccountData { timestamp }.
The guest rejects unknown clock account ids and malformed payloads.
The caller passes one clock account per instruction;
any id in the table is valid when its timestamp is monotonic for the
transaction.
Off-chain bytes
Identifier encodings
| Field | Encoding |
|---|---|
VaultProof.vault_id | Exactly 8 octets, little-endian VaultId (u64). |
StreamProof.stream_id | Exactly 8 octets, little-endian StreamId (u64). |
VaultProof.provider_id | Exactly 32 octets, LEZ AccountId of the stream provider. |
VaultProof.owner_public_key | Exactly 32 octets, x-only secp256k1 public key. |
VaultProof.owner_signature | Exactly 64 octets, Schnorr signature over the vault-owner digest. |
StreamProposal.public_key | Exactly 32 octets, session key for StreamProof.signature. |
StreamProof.signature | Exactly 64 octets, Schnorr signature over the Store eligibility digest. |
StreamParams.service_id | UTF-8, no NUL terminator. Max length 128. |
Decoders MUST reject wrong lengths for fixed-width fields.
On-chain stream allocation and the vault-owner Borsh body use u128,
zero-extending StreamParams.allocation from protobuf uint64.
Canonical signing bytes
LEZ satisfies Cryptographic commitments
with Schnorr signatures over
SHA-256(domain_prefix || canonical_body_bytes).
Each role below defines a 32-byte ASCII domain_prefix (NUL-padded)
and canonical_body_bytes.
Implementations MUST match published reference test vectors
(including cross-language Store parity).
Vault owner authorization (VaultProof.owner_signature)
Domain prefix (32 bytes):
/LEZ/v0.1/VaultOwnerAuth/ followed by seven NUL bytes (32 bytes total)
canonical_body_bytes is Borsh serialization of the following fields in order:
| Field | Borsh type |
|---|---|
vault_id | u64 LE |
provider_id | 32 raw bytes (LEZ AccountId) |
owner_public_key | 32 raw bytes (x-only secp256k1 public key) |
service_id | Borsh string (4-byte LE length + UTF-8) |
rate | u64 LE |
allocation | u128 LE |
create_stream_deadline | u64 LE |
session_public_key (StreamProposal.public_key) | 32 raw bytes |
VaultProof.owner_public_key MUST bind to VaultConfig.owner
via the LEZ account-identifier derivation in the reference implementation.
Store eligibility signature
Domain prefix (32 bytes):
/LEZ/v0.1/StoreEligibility/ followed by five NUL bytes (32 bytes total)
canonical_body_bytes is Borsh serialization of CanonicalStoreRequest
with field order and optional-field encoding matching Logos Delivery
StoreQueryRequest without eligibility fields
(presence-byte optional encoding, Borsh strings,
message hash array, pagination fields).
Providers derive digest by decoding the Store query from request_data
and applying the encoding rules above.
Logos Delivery Store query integration
The reference Store integration sets StreamParams.service_id to
/vac/waku/store-query/3.0.0 and signs request_data with
Store eligibility signature.
Security and privacy considerations
Privacy goals
The primary goal is funder unlinkability: separating the user's primary public key from on-chain vault and stream activity carried out under the vault owner identity.
The secondary goal is provider receiving privacy: limiting linkage between on-chain claims and the provider's real receiving addresses.
LEZ visibility and execution
Vault and stream accounts are public. Observers can read each stream's terms and accrual state from on-chain data and reconstruct the vault-to-stream graph from account identifiers.
Transparent and shielded transactions run the same guest logic. They differ in which signing identities and transfer endpoints appear on chain. Shielded execution hides the vault owner and claim destinations, but it does not hide the vault-to-stream relationship or how funds accrue on streams. A transparent stream creation permanently links the vault owner on chain. Each transparent claim links that stream to the visible receiving address. Later shielded operations cannot remove linkage from an earlier transparent operation.
Coarser system clock accounts reduce how often folding updates visible timestamps on stream accounts.
Funder unlinkability
Privacy tiers (see Account types) express intent at vault creation.
The guest records Public or PseudonymousFunder on LEZ and does not enforce execution mode.
Any submitter can still post transparent transactions against public accounts.
To obtain funder unlinkability on a PseudonymousFunder vault,
the vault owner MUST run all vault and stream operations through shielded transactions,
and the user MUST pre-shield funds before deposit so no transparent path
links the primary public key to the vault.
Wallets MUST NOT transfer directly into a VaultHolding for PseudonymousFunder vaults.
Wallets SHOULD avoid other transparent paths that link the user's primary public key
to vault activity when funder unlinkability is intended.
Receiver privacy
To obtain receiving-address unlinkability, the provider SHOULD claim through shielded transactions to receiving addresses not tied to its primary identity.
References
Normative
Informative
Related Work
Payment Streaming Protocols
Existing payment streaming protocols target EVM-like architectures. Protocols vary in duration (fixed-duration in Sablier Lockup or open-ended in Sablier Flow) and in deposit architectures (stream-level deposits in Sablier or multi-stream vaults in LlamaPay V2).
Appendix A: Illustrative EVM Implementation
This appendix provides an illustrative EVM-based implementation outline. The actual implementation will target LEZ. The sketch uses one vault per contract and omits multi-vault support from the main protocol.
A.1 Contract Structure
contract PaymentVault {
enum StreamState { ACTIVE, PAUSED, CLOSED }
struct Stream {
address token;
address provider;
uint128 ratePerSecond;
uint128 allocation;
uint64 lastUpdatedAt;
uint128 accruedBalance;
StreamState state;
}
address public user;
mapping(address token => uint256) public vaultBalance;
uint256 public nextStreamId;
mapping(uint256 => Stream) public streams;
}
A.2 Vault Operations
event Deposited(address indexed token, uint256 amount);
event Withdrawn(address indexed token, uint256 amount, address indexed to);
function deposit(address token, uint256 amount) external;
function withdraw(address token, uint256 amount, address to) external;
A.3 Stream Lifecycle
event StreamCreated(
uint256 indexed streamId,
address indexed provider,
address indexed token,
uint128 ratePerSecond,
uint128 allocation
);
event StreamPaused(uint256 indexed streamId);
event StreamResumed(uint256 indexed streamId);
event StreamToppedUp(uint256 indexed streamId, uint128 additionalAllocation);
event StreamClosed(uint256 indexed streamId, uint128 refundedToVault);
event Claimed(uint256 indexed streamId, address indexed provider, uint128 amount);
/// @notice Create a new stream in ACTIVE state (user only)
/// @dev MUST revert if allocation exceeds available vault balance
function createStream(
address provider,
address token,
uint128 ratePerSecond,
uint128 allocation
) external returns (uint256 streamId);
/// @notice Pause an ACTIVE stream (user only)
function pauseStream(uint256 streamId) external;
/// @notice Resume a PAUSED stream (user only)
/// @dev MUST revert if remaining allocation (allocation - accruedBalance) is zero
function resumeStream(uint256 streamId) external;
/// @notice Add funds to stream allocation; transitions to ACTIVE (user only)
/// @dev MUST revert if additionalAllocation exceeds available vault balance
function topUpStream(uint256 streamId, uint128 additionalAllocation) external;
/// @notice Close stream permanently
/// @dev Callable by user or provider. Unaccrued funds (allocation - accruedBalance)
/// MUST be returned to vaultBalance. Accrued funds remain claimable by provider.
function closeStream(uint256 streamId) external;
/// @notice Provider claims accrued funds from a stream
/// @dev Callable in any state (ACTIVE, PAUSED, or CLOSED).
/// Transfers full accruedBalance to provider and resets it to zero.
function claim(uint256 streamId) external;
A.4 Internal Accrual
/// @notice Update accruedBalance based on elapsed time since lastUpdatedAt
/// @dev Called by createStream, pauseStream, resumeStream, topUpStream, closeStream, and claim
/// before modifying stream state. Caps accrual at allocation and
/// transitions to PAUSED when depleted (lazy evaluation:
/// state updates on next interaction, not at exact depletion time).
function _accrue(uint256 streamId) internal;
Copyright
Copyright and related rights waived via CC0.
RLN DoS Protection for Mixnet
| Field | Value |
|---|---|
| Name | RLN DoS Protection for Mixnet |
| Slug | 144 |
| Status | raw |
| Category | Standards Track |
| Editor | Prem Prathi [email protected] |
| Contributors |
Timeline
- 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-15 —
5a3e844— Chore/move repo into logos co (#312) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-29 —
3cd2d09— fix title of doc (#282) - 2026-01-29 —
0e53ebb— change header to new format (#279) - 2026-01-24 —
ffca40a— Mix spam and sybil protection protocol using RLN (#252)
Abstract
This document defines a spam and sybil protection protocol for libp2p mix based mixnets. The protocol specifies how Rate Limiting Nullifiers (RLN) can be integrated into libp2p mix. RLN allows mix nodes to detect and drop spam without identifying legitimate users, addressing spam attacks. RLN requires membership for mix nodes to send or forward messages, addressing the sybil attack vector. RLN satisfies the spam protection requirements defined in the libp2p mix protocol.
Background / Rationale / Motivation
Mixnets provide strong privacy guarantees by routing messages through multiple mix nodes using layered encryption and per-hop delays to obscure both routing paths and timing correlations. In order to have a production-ready mixnet using the libp2p mix, two critical vulnerabilities must be addressed:
- Spam attacks: An attacker can generate well-formed sphinx packets targeting mix nodes and can exhaust their resources. In case of mixnets, it is easy to attack a later hop in the mix path by choosing different first hop nodes. An attacker with minimal resources can launch spam/DoS attacks against individual mix nodes. By targeting all mix nodes in this manner, the attacker can render the entire mixnet unusable.
- Sybil attacks: Adversaries operating multiple node identities can increase the probability of path compromise, enabling deanonymization through traffic correlation or timing analysis.
The libp2p mix protocol provides an extension for integrating spam protection mechanisms. This specification proposes to use Rate Limiting Nullifiers (RLN) as the spam prevention and sybil protection mechanism. This approach introduces some trade-offs such as additional per-hop latency for proof generation which are discussed in the Tradeoffs section.
Terminology
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “NOT RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in RFC 2119.
Node Roles
Mix protocol defines 3 roles for the nodes in the mix network - sender, exit, intermediary.
- A sender node is the originator node of a message, i.e a node that wishes to originate/send messages using the mix network.
- An exit node is responsible for delivering messages to the destination protocol.
- An intermediary node is responsible for forwarding a mix packet to the next mix node in the path.
Message
Message is the actual sphinx packet including headers and encrypted payload that is either originated or forwarded by a mix node.
Messaging Rate
The messaging rate is defined as the number of messages that can be sent/forwarded per fixed unit of time, termed an epoch.
Since we're using this as shorthand for the maximum allowable rate, this is also known as the rate limit.
The length of each epoch is constant and defined as the period.
We define an epoch as unix_time / period .
For example, if unix_time is 1644810116 and we set period to 30, then epoch is (unix_time/period) = 54827004.
NOTE: The
epochrefers to the epoch in RLN and not Unix epoch. This means that no more messages than the registered rate limit can be sent per epoch, where the epoch length (period) is up to the application.
See section System Parameters for details on the period parameter.
Approach
Overview
The protocol implements RLN using a per-hop generated proof approach, where each node in the mix path generates and verifies proofs. This enables network-wide spam protection while preserving user privacy.
Each mix node MUST have an RLN group membership in order to send or forward messages in the mixnet. Each mix node in the path (except the sender) verifies the incoming RLN proof before processing the message. After verification, each node generates and attaches a new RLN proof before forwarding the message to the next hop.
To effectively detect spam, mix nodes SHOULD identify when a node exceeds its messaging rate by reusing the same nullifier across multiple messages within an epoch (known as "double signalling"). Since a message does not traverse all the mix nodes in the network, a spammer could exploit different paths to avoid detection by any single mix node. To address this, intermediary and exit nodes SHOULD participate in a coordination layer that indicates already seen messaging metadata across the mix nodes. This enables all participating mix nodes to detect double signalling across different paths, derive the spammer's private key, and initiate slashing.
Rationale
RLN is well-suited for spam and sybil protection in libp2p mix based mixnets due to the following properties:
-
Sybil Resistance:
- Requiring membership for each mix node creates friction to participate in the mixnet to send or forward messages
- Operating multiple identities becomes costly, mitigating sybil attacks that could compromise mix path selection
-
Privacy-Preserving Spam Protection:
- Uses zero-knowledge proofs to enforce rate limits without revealing sender identities
- Ties spam protection proof to the message content, making proofs non-reusable across messages
- Enables economic deterrence through slashing without compromising anonymity
-
Network-Level Benefits:
- RLN enables setting a deterministic messaging rate for the mixnet, which translates to predictable bandwidth requirements (messages per epoch × sphinx packet size).
- This makes it easier to provision and estimate resource usage for nodes participating in the mixnet.
- The rate limit creates a baseline traffic level that, when combined with cover traffic, helps maintain k-anonymity even during periods of low organic traffic.
Setup
Each mix node has an RLN key pair consisting of a secret key sk and public key pk as defined in RLN.
The secret key sk MUST be persisted securely by the mix node.
A mixnet that is spam-protected requires all mix nodes in it to form an RLN group.
- Mix nodes MUST be registered to the RLN group to be able to send or forward messages.
- Registration MAY be moderated through a smart contract deployed on a blockchain.
Note: The criteria for membership is out of scope of the spec and should be implementation-specific (e.g requiring stake)
The group membership data MUST be synchronized initially so that the mix node has the latest Merkle root in order to generate or verify RLN proofs. See Group Synchronization for details on maintaining synchronization.
Intermediary and exit mix nodes SHOULD subscribe to the coordination layer (defined below) in order to detect rate limit violations collaboratively. This ensures that mix nodes can detect spam and trigger slashing.
Sending and forwarding messages
In order to send/forward messages via mixnet, a mix node MUST include the RateLimitProof in the sphinx packet as .
Proof Generation
When generating an RLN proof, the node MUST:
- Use its secret key
skand the currentepoch - Obtain the current Merkle root and
path_elementsfrom the synchronized membership tree - Generate a keccak256 hash of all components of the outgoing sphinx packet (α', β', γ', δ') and set it as the proof signal. This prevents proof reuse across different messages.
Sender nodes:
- generate an RLN proof for the initial sphinx packet
- attach the proof to the packet before sending to the next hop
Intermediary and Exit nodes:
MUST do the following for every incoming mix packet:
- verify the incoming packet's RLN proof (see Message validation)
- process the sphinx packet according to the mix protocol
- generate a NEW RLN proof for the outgoing packet
- attach the new proof before forwarding to the next hop
Group Synchronization
Proof generation relies on the knowledge of Merkle tree root merkle_root and path_elements (the authentication path in the Merkle proof as defined in RLN) which both require access to the membership Merkle tree.
Proof verification also requires knowledge of the merkle_root to validate that the proof was generated against a valid membership tree state.
The RLN membership group MUST be synchronized across all mix nodes to ensure the latest Merkle root is used for RLN proof generation and verification.
Stale roots may cause legitimate proofs to be rejected.
Using an old root can allow inference about the index of the user's pk in the membership tree hence compromising user privacy and breaking message unlinkability.
In order to accommodate network delays, nodes MUST maintain a window of recent valid roots (see acceptable_root_window_size in System Parameters).
We recommend 5 for acceptable_root_window_size.
Coordination Layer
The coordination layer enables network-wide spam detection by preventing rate limit violations through nullifier reuse detection. The coordination layer SHOULD be used to broadcast messaging metadata. When a node detects spam, it can reconstruct the spammer's secret key using the shared key shares and initiate slashing.
Intermediary and exit nodes that participate in the coordination layer MUST both subscribe to receive metadata and broadcast metadata from messages they process. Sender-only nodes need not participate in this coordination layer as they only originate messages and do not forward or validate messages from others.
The coordination layer MUST have its own spam and sybil protection mechanism in order to prevent from these attacks. We recommend using WAKU-RLN-RELAY In this case, the Messaging Metadata MUST be encoded as the Waku Message payload. We recommend using the public Waku Network with a content topic agreed by all mix nodes.
Message validation
A mix node MUST validate a received message using the below checks, discard the message and stop further checks or processing on failure.
- If the
epochin the received message differs from the mix node's currentepochby more thanmax_epoch_gap. - If the
merkle_rootis NOT in theacceptable_root_window_sizepast roots of the mix node. - If the zero-knowledge proof
proofis valid. It does so by running the zk verification algorithm as explained in RLN.
If all checks pass, the node proceeds to spam detection before processing the message.
Spam detection and Slashing
To enable local spam detection and slashing, mix nodes MUST store the messaging metadata in a local cache. This includes metadata from:
- messages processed locally by the mix layer
- messages received via the coordination layer
The cache SHOULD be cleared for epoch data older than max_epoch_gap.
To identify spam messages, the node checks whether a message with an identical nullifier is present in the epoch's cache.
- If no entry exists for this
nullifier, the node stores the messaging metadata in the cache and proceeds to process the message normally. - If an entry exists and its
share_xandshare_ycomponents are different from the incoming message, then proceed with slashing. The mix node uses theshare_xandshare_yof the new message and the shares from the local cache to reconstruct theskof the message owner. Theskthen MUST be used to delete the spammer from the group and withdraw its staked funds. The node MUST discard the message and MUST NOT forward it. - If the
share_xandshare_yfields in the local cache are identical to the incoming message, then the message is a duplicate and MUST be discarded.
After successfully validating a message, intermediary and exit nodes SHOULD broadcast the message's metadata using the coordination layer to enable network-wide spam detection. The broadcast on the coordination layer MAY be batched atleast once per epoch to reduce constant traffic on coordination layer.
Wire Format Specification / Syntax
Spam protection proof
The following RateLimitProof MUST be added to the sphinx packet as as explained in sending.
syntax = "proto3";
message RateLimitProof {
bytes proof = 1;
bytes merkle_root = 2;
bytes epoch = 3;
bytes share_x = 4;
bytes share_y = 5;
bytes nullifier = 6;
}
RateLimitProof
Below is the description of the fields of RateLimitProof and their types.
| Parameter | Type | Description |
|---|---|---|
proof | array of 128 bytes compressed | the zkSNARK proof as explained in the Sending process |
merkle_root | array of 32 bytes in little-endian order | the root of membership group Merkle tree at the time of sending the message |
epoch | array of 32 bytes | the current epoch at time of sending the message |
share_x and share_y | array of 32 bytes each | Shamir secret shares of the user's secret identity key sk . share_x is the hash of the message. share_y is calculated using Shamir secret sharing scheme |
nullifier | array of 32 bytes | internal nullifier derived from epoch and node's sk as explained in RLN construct |
Messaging Metadata
Messaging metadata is metadata which is broadcasted via coordination layer and cached by mix nodes locally. This helps identify duplicate signalling in order to detect spam.
syntax = "proto3";
message ExternalNullifier {
bytes internal_nullifier = 1;
repeated bytes x_shares = 2;
repeated bytes y_shares = 3;
}
message MessagingMetadata {
repeated ExternalNullifier nullifiers = 1;
}
System Parameters
The system parameters are summarized in the following table.
| Parameter | Description |
|---|---|
period | the length of epoch in seconds |
staked_fund | the amount of funds to be staked by mix nodes at the registration |
max_epoch_gap | the maximum allowed gap between the epoch of a mix node and the incoming message |
acceptable_root_window_size | the maximum number of past Merkle roots to store |
Security/Privacy Considerations
Known Attack Vectors and Mitigations
Sybil Attacks
- Attack: Adversary operates multiple node identities to increase path compromise probability
- Limitation: Well-funded adversary can still acquire multiple memberships
- Mitigation: Membership registration can consider other criteria along with stake to reduce chance of sybil identities.
Coordination Layer Attacks
- Attack: Flood coordination layer with spam metadata to create DoS
- Mitigation: Coordination layer MUST implement its own spam protection (line 156)
Timing Attacks
- Attack: Correlate message timing across hops to deanonymize users
- Mitigation: Mix protocol's per-hop delays provide timing obfuscation
- Note: RLN metadata broadcast may create additional timing side-channels requiring analysis
Privacy Considerations
Nullifier Linkability
- Concern: Nullifiers are broadcast via coordination layer, potentially enabling traffic analysis
- Analysis: Nullifiers are derived from epoch and secret key, changing per epoch
- Limitation: Within an epoch, multiple messages from same node share nullifier metadata structure
Out of Scope
The following are explicitly out of scope for this specification and left to implementations:
- Specific membership criteria and stake amounts
- Coordination layer protocol selection and configuration
- Blockchain selection for RLN group management
Tradeoffs
Additional Latency due to proof generation in every hop
Per-hop RLN proof generation introduces additional latency at each mix node in the path:
- Proof generation time: Typically
100-500msper hop depending on hardware capabilities - End-to-end impact: For a
3-hoppath, this adds300-1500msto total message delivery time - Comparison: This is significant compared to the mix protocol's per-hop delay
- Mitigation: See Future Work for potential optimizations using pre-computed proofs
This latency needs to be considered while deciding the approach to be used.
Membership registration friction
Requiring RLN group membership for all mix nodes creates barriers to network participation:
- Stake requirement: Nodes MUST stake funds to join, limiting casual participation
- Registration overhead: On-chain registration adds complexity and potential costs (gas fees)
- Benefit: This friction is intentional and necessary for sybil resistance
The appropriate stake amount MUST balance accessibility against attack economics (see System Parameters).
Cost of ZK Proof Generation
Zero-knowledge proof generation imposes computational costs on mix nodes. Proof generation is CPU-intensive, requiring modern processors. May be prohibitive for mobile or embedded devices.
Mitigation: See Future Work for potential research into using alternative proving systems.
These costs must be factored into operational expenses and node requirements.
Future Work
In order to reduce latency introduced at each hop:
- RLN can be used with pre-computed proofs as explained here. This approach can be explored further and could potentially replace the current proposed RLN implementation.
- Research other proving systems that would generate faster ZK proofs.
Additional sybil resistance mechanisms could augment RLN by incorporating reputation-based lists similar to Tor's "directory authorities".
These help clients build circuits that are less likely to be entirely controlled by sybils through a range of techniques that limit nodes' possible influence based on trustworthiness metrics.
Copyright
Copyright and related rights waived via CC0.
References
- libp2p mix protocol
- Rate Limiting Nullifiers (RLN)
- Rate Limiting Nullifiers v2
- RLN v1
- Waku-Relay
- RLN with precomputed proofs
- Poseidon hash implementation
RLN-INTEREP-SPEC
| Field | Value |
|---|---|
| Name | Interep as group management for RLN |
| Slug | 100 |
| Status | raw |
| Category | Standards Track |
| Editor | Aaryamann Challani [email protected] |
Timeline
- 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-08-05 —
eb25cd0— chore: replace email addresses (#86) - 2024-05-27 —
99be3b9— Move Raw Specs (#37) - 2024-02-01 —
860bae2— Update rln-interep-spec.md - 2024-02-01 —
3f722d9— Update and rename README.md to rln-interep-spec.md - 2024-01-30 —
ea62398— Create README.md
Abstract
This spec integrates Interep into the RLN spec. Interep is a group management protocol that allows for the creation of groups of users and the management of their membership. It is used to manage the membership of the RLN group.
Interep ties in web2 identities with reputation, and sorts the users into groups based on their reputation score. For example, a GitHub user with over 100 followers is considered to have "gold" reputation.
Interep uses Semaphore under the hood to allow anonymous signaling of membership in a group. Therefore, a user with a "gold" reputation can prove the existence of their membership without revealing their identity.
RLN is used for spam prevention, and Interep is used for group management.
By using Interep with RLN, we allow users to join RLN membership groups without the need for on-chain financial stake.
Motivation
To have Sybil-Resistant group management, there are implementations of RLN which make use of financial stake on-chain. However, this is not ideal because it reduces the barrier of entry for honest participants.
In this case, honest participants will most likely have a web2 identity accessible to them, which can be used for joining an Interep reputation group. By modifying the RLN spec to use Interep, we can have Sybil-Resistant group management without the need for on-chain financial stake.
Since RLN and Interep both use Semaphore-style credentials, it is possible to use the same set of credentials for both.
Functional Operation
Using Interep with RLN involves the following steps -
- Generate Semaphore credentials
- Verify reputation and join Interep group
- Join RLN membership group via interaction with Smart Contract, by passing a proof of membership to the Interep group
1. Generate Semaphore credentials
Semaphore credentials are generated in a standard way, depicted in the Semaphore documentation.
2. Verify reputation and join Interep group
Using the Interep app deployed on Goerli, the user can check their reputation tier and join the corresponding group. This results in a transaction to the Interep contract, which adds them to the group.
3. Join RLN membership group
Instead of sending funds to the RLN contract to join the membership group, the user can send a proof of membership to the Interep group. This proof is generated by the user, and is verified by the contract. The contract ensures that the user is a member of the Interep group, and then adds them to the RLN membership group.
Following is the modified signature of the register function in the RLN contract -
/// @param groupId: Id of the group.
/// @param signal: Semaphore signal.
/// @param nullifierHash: Nullifier hash.
/// @param externalNullifier: External nullifier.
/// @param proof: Zero-knowledge proof.
/// @param idCommitment: ID Commitment of the member.
function register(
uint256 groupId,
bytes32 signal,
uint256 nullifierHash,
uint256 externalNullifier,
uint256[8] calldata proof,
uint256 idCommitment
)
Verification of messages
Messages are verified the same way as in the RLN spec.
Slashing
The slashing mechanism is the same as in the RLN spec. It is important to note that the slashing may not have the intended effect on the user, since the only consequence is that they cannot send messages. This is due to the fact that the user can send a identity commitment in the registration to the RLN contract, which is different than the one used in the Interep group.
Proof of Concept
A proof of concept is available at vacp2p/rln-interp-contract which integrates Interep with RLN.
Security Considerations
- As mentioned in Slashing, the slashing mechanism may not have the intended effect on the user.
- This spec inherits the security considerations of the RLN spec.
- This spec inherits the security considerations of Interep.
- A user may make multiple registrations using the same Interep proofs but different identity commitments. The way to mitigate this is to check if the nullifier hash has been detected previously in proof verification.
References
- RLN spec
- Interep
- Semaphore
- Decentralized cloudflare using Interep
- Interep contracts
- RLN contract
- RLNP2P
RLN-MEMBERSHIP-SERVICE
| Field | Value |
|---|---|
| Name | RLN Membership Allocation |
| Slug | 158 |
| Status | raw |
| Category | Standards Track |
| Tags | rln |
| Editor | Arseniy Klempner [email protected] |
| Contributors |
Timeline
- 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-04 —
0e5882e— Chore/auto assign slugs (#328) - 2026-04-27 —
2107152— Fix Frontmatter - Update RLN Membership Allocation to RLN Membership … (#319) - 2026-04-27 —
8301bba— docs: spec for rln membership allocation protocol (#254)
Protocol identifier: /logos/rln/membership/1.0.0
Abstract
This specification defines the RLN Membership Allocation Protocol, which registers RLN identity commitments on behalf of clients. The protocol enables membership providers to allocate RLN memberships to eligible clients without requiring those clients to interact directly with the on-chain membership contract. It aims to do so while minimising linkability between the client's network identity and their RLN identity. The specification includes a pluggable authentication mechanism to determine client eligibility for membership allocation.
Motivation
The Rate Limiting Nullifier (RLN) protocol, as specified in 32/RLN-V1, requires users to register their identity commitments in a membership Merkle tree before participating in rate-limited anonymous signaling. In the standard registration flow, clients submit a transaction to a smart contract on a blockchain to register their identity commitments.
There are two main concerns with the standard registration flow:
- This typically requires clients to have a wallet with sufficient funds to pay for gas fees, and access to a node for the blockchain network.
- Access to a node is typically done using an RPC provider, which risks creating a correlation between the client's IP address and their RLN identity.
The RLN Membership Allocation Protocol addresses the first concern by defining an interaction in which a membership provider registers identity commitments on behalf of clients. Each membership provider can implement their own authentication mechanism to determine client eligibility for membership allocation.
The second concern is out of scope for this specification and is considered future work. It can be addressed by using a privacy-preserving identity mechanism like RLN Stealth Commitments, which would allow the provider to register identity commitments on behalf of clients without gaining knowledge of the client's network identity.
Membership Provider Eligibility
A membership provider SHOULD have sufficient funds to register memberships on behalf of clients at the expected rate for the desired application. A membership provider MAY track registered memberships and processed requests through local accounting, depending on deployment requirements.
Wire Format Specification
Membership Allocation Request
message MembershipAllocationRequest {
// Unique identifier used to correlate requests and responses
string request_id = 1;
// Indicates which authentication mechanism is used
bytes authentication_type = 2;
// Generic payload, further defined by the authentication mechanism
bytes authentication_payload = 3;
// The identity commitment to register
bytes identity_commitment = 4;
// Rate limit for the membership
optional uint64 rate_limit = 5;
}
A client who wants to obtain an RLN membership using this protocol
MUST send a MembershipAllocationRequest to a relevant membership provider.
A client MUST include a unique request_id to correlate the request with
the response.
A client MUST specify the authentication method to use in the
authentication_type field.
A client MUST include a payload in the authentication_payload field,
further defined by the authentication method.
A client MUST include the
identity commitment to register in the
identity_commitment field.
A client MAY include a rate_limit value specifying the requested
per-epoch message rate limit for the membership; if omitted, the
membership provider applies its default rate limit. Supported values
are determined by the membership provider and the underlying RLN
membership contract.
Authentication is pluggable: membership providers MAY support any authentication mechanism, including token-based authentication, cryptographic signatures over eligibility claims, or demo/testnet memberships with minimal authentication.
A client MAY retry a MembershipAllocationRequest after a suitable
timeout if no response is received. When retrying, the client SHOULD
reuse the same request_id so the membership provider can detect
duplicates.
Membership Allocation Response
message MembershipAllocationResponse {
string request_id = 1;
// Result of the authentication attempt
bool auth_success = 2;
optional string error = 3;
oneof result {
MembershipAllocationSuccess success = 4;
MembershipAllocationFailure failure = 5;
}
}
message MembershipAllocationSuccess {
// Leaf index in the membership tree
uint64 leaf_index = 1;
// Current Merkle root after registration
bytes merkle_root = 2;
// Block number at which registration was confirmed
uint64 block_number = 3;
// Transaction hash of the registration
bytes transaction_hash = 4;
}
message MembershipAllocationFailure {
string error_message = 1;
}
A membership provider SHOULD respond to the client's request with a
MembershipAllocationResponse message.
A membership provider SHOULD perform basic validation on the identity
commitment, such as total bit length.
A membership provider SHOULD check if the identity commitment has already
been registered in the RLN membership contract.
A membership provider SHOULD check if the hash of the request has already
been processed.
A membership provider MUST deserialize the authentication payload based
on the authentication method specified in the authentication_type field.
A membership provider MUST authenticate the client's request using the
authentication payload.
Upon successful authentication, a membership provider SHOULD send a
transaction to the RLN membership contract with the identity_commitment
as an argument.
A membership provider's response MUST include the auth_success field
indicating whether the authentication for the request was accepted.
If the transaction to register was successful, the response MUST include
a MembershipAllocationSuccess message in the result field.
If the transaction to register was unsuccessful, the response MUST include
a MembershipAllocationFailure message in the result field.
A membership provider SHOULD include a descriptive error message in the
error_message field of MembershipAllocationFailure to help clients
diagnose the cause of failure.
Registration Flow
A membership provider MAY construct a hash of the
MembershipAllocationRequest message and use it for local accounting
of processed requests, or include it when calling a provider-specific
smart contract that tracks processed request hashes.
Example Authentication Mechanism
A simple authentication mechanism would require the client to sign a message using a private key for which the associated public address passes some criteria, e.g. held a certain amount of a specific token before a specific block number.
message BasicAuthenticationPayload {
bytes message = 1;
bytes signature = 2;
}
Depending on the claims being verified, the authentication payload may require additional fields:
message OnchainAuthenticationPayload {
bytes message = 1;
bytes signature = 2;
bytes transaction_hash = 3;
uint64 chain_id = 4;
}
Appendix A: Discovery
A membership provider MAY advertise that it offers membership allocation
services by participating in the
Logos Capability Discovery protocol.
A membership provider SHOULD include a list of supported authentication
methods in the metadata field of the Advertisement message.
A membership provider MUST use the protocol ID /rln/membership/<version>
when generating the service_id_hash.
A membership provider MAY also advertise support for a specific
authentication method by using the protocol ID
/rln/membership/<version>/<authentication_method>.
A client MAY send a GET_ADS request for the /rln/membership/<version>
service to registrars to discover membership providers that offer
membership allocation.
Copyright
Copyright and related rights waived via CC0.
References
RLN-STEALTH-COMMITMENTS
| Field | Value |
|---|---|
| Name | RLN Stealth Commitment Usage |
| Slug | 102 |
| Status | raw |
| Category | Standards Track |
| Editor | Aaryamann Challani [email protected] |
| Contributors | Jimmy Debe [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-08-05 —
eb25cd0— chore: replace email addresses (#86) - 2024-04-15 —
0b0e00f— feat(rln-stealth-commitments): add initial tech writeup (#23)
Abstract
This specification describes the usage of stealth commitments to add prospective users to a network-governed 32/RLN-V1 membership set.
Motivation
When 32/RLN-V1 is enforced in 10/Waku2, all users are required to register to a membership set. The membership set will store user identities allowing the secure interaction within an application. Forcing a user to do an on-chain transaction to join a membership set is an onboarding friction, and some projects may be opposed to this method. To improve the user experience, stealth commitments can be used by a counterparty to register identities on the user's behalf, while maintaining the user's anonymity.
This document specifies a privacy-preserving mechanism,
allowing a counterparty to utilize 32/RLN-V1
to register an identityCommitment on-chain.
Counterparties will be able to register members
to a RLN membership set without exposing the user's private keys.
Background
The 32/RLN-V1 protocol,
consists of a smart contract that stores a idenitityCommitment
in a membership set.
In order for a user to join the membership set,
the user is required to make a transaction on the blockchain.
A set of public keys is used to compute a stealth commitment for a user,
as described in ERC-5564.
This specification is an implementation of the
ERC-5564 scheme,
tailored to the curve that is used in the 32/RLN-V1 protocol.
This can be used in a couple of ways in applications:
- Applications can add users to the 32/RLN-V1 membership set in a batch.
- Users of the application can register other users to the 32/RLN-V1 membership set.
This is useful when the prospective user does not have access to funds on the network that 32/RLN-V1 is deployed on.
Wire Format Specification
The two parties, the requester and the receiver, MUST exchange the following information:
message Request {
// The spending public key of the requester
bytes spending_public_key = 1;
// The viewing public key of the requester
bytes viewing_public_key = 2;
}
Generate Stealth Commitment
The application or user SHOULD generate a stealth_commitment
after a request to do so is received.
This commitment MAY be inserted into the corresponding application membership set.
Once the membership set is updated, the receiver SHOULD exchange the following as a response to the request:
message Response {
// The used to check if the stealth_commitment belongs to the requester
bytes view_tag = 2;
// The stealth commitment for the requester
bytes stealth_commitment = 3;
// The ephemeral public key used to generate the commitment
bytes ephemeral_public_key = 4;
}
The receiver MUST generate an ephemeral_public_key,
view_tag and stealth_commitment.
This will be used to check the stealth commitment
used to register to the membership set,
and the user MUST be able to check ownership with their viewing_public_key.
Implementation Suggestions
An implementation of the Stealth Address scheme is available in the erc-5564-bn254 repository, which also includes a test to generate a stealth commitment for a given user.
Security/Privacy Considerations
This specification inherits the security and privacy considerations of the Stealth Address scheme.
Copyright
Copyright and related rights waived via CC0.
References
RLN-V2
| Field | Value |
|---|---|
| Name | Rate Limit Nullifier V2 |
| Slug | 106 |
| Status | raw |
| Category | Standards Track |
| Editor | Rasul Ibragimov [email protected] |
| Contributors | Lev Soukhanov [email protected] |
Timeline
- 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-05-27 —
99be3b9— Move Raw Specs (#37) - 2024-02-01 —
8342636— Update and rename RLN-V2.md to rln-v2.md - 2024-01-27 —
d7e84b4— Create RLN-V2.md
Abstract
The protocol specified in this document is an improvement of 32/RLN-V1, being more general construct, that allows to set various limits for an epoch (it's 1 message per epoch in 32/RLN-V1) while remaining almost as simple as it predecessor. Moreover, it allows to set different rate-limits for different RLN app users based on some public data, e.g. stake or reputation.
Motivation
The main goal of this RFC is to generalize 32/RLN-V1 and expand its applications. There are two different subprotocols based on this protocol:
- RLN-Same - RLN with the same rate-limit for all users;
- RLN-Diff - RLN that allows to set different rate-limits for different users.
It is important to note that by using a large epoch limit value,
users will be able to remain anonymous,
because their internal_nullifiers will not be repeated until they exceed the limit.
Flow
As in 32/RLN-V1, the general flow can be described by three steps:
- Registration
- Signaling
- Verification and slashing
The two sub-protocols have different flows, and hence are defined separately.
Important note
All terms and parameters used remain the same as in 32/RLN-V1, more details here
RLN-Same flow
Registration
The registration process in the RLN-Same subprotocol does not differ from 32/RLN-V1.
Signalling
For proof generation, the user needs to submit the following fields to the circuit:
{
identity_secret: identity_secret_hash,
path_elements: Merkle_proof.path_elements,
identity_path_index: Merkle_proof.indices,
x: signal_hash,
message_id: message_id,
external_nullifier: external_nullifier,
message_limit: message_limit
}
Calculating output
The following fields are needed for proof output calculation:
{
identity_secret_hash: bigint,
external_nullifier: bigint,
message_id: bigint,
x: bigint,
}
The output [y, internal_nullifier] is calculated in the following way:
a_0 = identity_secret_hash
a_1 = poseidonHash([a0, external_nullifier, message_id])
y = a_0 + x * a_1
internal_nullifier = poseidonHash([a_1])
RLN-Diff flow
Registration
id_commitment in 32/RLN-V1 is equal to poseidonHash(identity_secret).
The goal of RLN-Diff is to set different rate-limits for different users.
It follows that id_commitment must somehow depend
on the user_message_limit parameter,
where 0 <= user_message_limit <= message_limit.
There are few ways to do that:
- Sending
identity_secret_hash=poseidonHash(identity_secret, userMessageLimit)and zk proof thatuser_message_limitis valid (is in the right range). This approach requires zkSNARK verification, which is an expensive operation on the blockchain. - Sending the same
identity_secret_hashas in 32/RLN-V1 (poseidonHash(identity_secret)) and a user_message_limit publicly to a server or smart-contract whererate_commitment=poseidonHash(identity_secret_hash, userMessageLimit)is calculated. The leaves in the membership Merkle tree would be the rate_commitments of the users. This approach requires additional hashing in the Circuit, but it eliminates the need for zk proof verification for the registration.
Both methods are correct, and the choice of the method is left to the implementer. It is recommended to use second method for the reasons already described. The following flow description will also be based on the second method.
Signalling
For proof generation, the user need to submit the following fields to the circuit:
{
identity_secret: identity_secret_hash,
path_elements: Merkle_proof.path_elements,
identity_path_index: Merkle_proof.indices,
x: signal_hash,
message_id: message_id,
external_nullifier: external_nullifier,
user_message_limit: message_limit
}
Calculating output
The Output is calculated in the same way as the RLN-Same sub-protocol.
Verification and slashing
Verification and slashing in both subprotocols remain the same as in 32/RLN-V1.
The only difference that may arise is the message_limit check in RLN-Same,
since it is now a public input of the Circuit.
ZK Circuits specification
The design of the 32/RLN-V1 circuits is different from the circuits of this protocol. RLN-v2 requires additional algebraic constraints. The membership proof and Shamir's Secret Sharing constraints remain unchanged.
The ZK Circuit is implemented using a Groth-16 ZK-SNARK, using the circomlib library. Both schemes contain compile-time constants/system parameters:
- DEPTH - depth of membership Merkle tree
- LIMIT_BIT_SIZE - bit size of
limitnumbers, e.g. for the 16 - maximumlimitnumber is 65535.
The main difference of the protocol is that instead of a new polynomial
(a new value a_1) for a new epoch, a new polynomial is generated for each message.
The user assigns an identifier to each message;
the main requirement is that this identifier be in the range from 1 to limit.
This is proven using range constraints.
RLN-Same circuit
Circuit parameters
Public Inputs
xexternal_nullifiermessage_limit- limit per epoch
Private Inputs
identity_secret_hashpath_elementsidentity_path_indexmessage_id
Outputs
yrootinternal_nullifier
RLN-Diff circuit
In the RLN-Diff scheme, instead of the public parameter message_limit,
a parameter is used that is set for each user during registration (user_message_limit);
the message_id value is compared to it in the same way
as it is compared to message_limit in the case of RLN-Same.
Circuit parameters
Public Inputs
xexternal_nullifier
Private Inputs
identity_secret_hashpath_elementsidentity_path_indexmessage_iduser_message_limit
Outputs
yrootinternal_nullifier
Appendix A: Security considerations
Although there are changes in the circuits, this spec inherits all the security considerations of 32/RLN-V1.
Copyright
Copyright and related rights waived via CC0.
References
SDS
| Field | Value |
|---|---|
| Name | Scalable Data Sync protocol for distributed logs |
| Slug | 109 |
| Status | raw |
| Category | Standards Track |
| Editor | Hanno Cornelius [email protected] |
| Contributors | Akhil Peddireddy [email protected] |
Timeline
- 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-10-24 —
6980237— Fix Linting Errors (#204) - 2025-10-13 —
171e934— docs: add SDS-Repair extension (#176) - 2025-10-02 —
6672c5b— docs: update lamport timestamps to uint64, pegged to current time (#196) - 2025-09-15 —
b1da703— fix: use milliseconds for Lamport timestamp initialization (#179) - 2025-08-22 —
3505da6— sds lint fix (#177) - 2025-08-19 —
536d31b— docs: re-add sender ID to messages (#170) - 2025-03-07 —
8ee2a6d— docs: add optional retrieval hint to causal history in sds (#130) - 2025-02-20 —
235c1d5— docs: clarify receiving sync messages (#131) - 2025-02-18 —
7182459— docs: update sds sync message requirements (#129) - 2025-01-28 —
7a01711— fix(sds): remove optional from causal history field in Message protobuf (#123) - 2024-12-17 —
08b363d— Update SDS.md: Remove Errors (#115) - 2024-11-28 —
bee78c4— docs: add SDS protocol for scalable e2e reliability (#108)
Abstract
This specification introduces the Scalable Data Sync (SDS) protocol to achieve end-to-end reliability when consolidating distributed logs in a decentralized manner. The protocol is designed for a peer-to-peer (p2p) topology where an append-only log is maintained by each member of a group of nodes who may individually append new entries to their local log at any time and is interested in merging new entries from other nodes in real-time or close to real-time while maintaining a consistent order. The outcome of the log consolidation procedure is that all nodes in the group eventually reflect in their own logs the same entries in the same order. The protocol aims to scale to very large groups.
Motivation
A common application that fits this model is a p2p group chat (or group communication), where the participants act as log nodes and the group conversation is modelled as the consolidated logs maintained on each node. The problem of end-to-end reliability can then be stated as ensuring that all participants eventually see the same sequence of messages in the same causal order, despite the challenges of network latency, message loss, and scalability present in any communications transport layer. The rest of this document will assume the terminology of a group communication: log nodes being the participants in the group chat and the logged entries being the messages exchanged between participants.
Design Assumptions
We make the following simplifying assumptions for a proposed reliability protocol:
- Broadcast routing: Messages are broadcast disseminated by the underlying transport. The selected transport takes care of routing messages to all participants of the communication.
- Store nodes: There are high-availability caches (a.k.a. Store nodes) from which missed messages can be retrieved. These caches maintain the full history of all messages that have been broadcast. This is an optional element in the protocol design, but improves scalability by reducing direct interactions between participants.
- Message ID: Each message has a globally unique, immutable ID (or hash). Messages can be requested from the high-availability caches or other participants using the corresponding message ID.
- Participant ID: Each participant has a globally unique, immutable ID visible to other participants in the communication.
- Sender ID: The Participant ID of the original sender of a message, often coupled with a Message ID.
Wire protocol
The keywords “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in 2119.
Message
Messages MUST adhere to the following meta structure:
syntax = "proto3";
message HistoryEntry {
string message_id = 1; // Unique identifier of the SDS message, as defined in `Message`
optional bytes retrieval_hint = 2; // Optional information to help remote parties retrieve this SDS message; For example, A Waku deterministic message hash or routing payload hash
optional string sender_id = 3; // Participant ID of original message sender. Only populated if using optional SDS Repair extension
}
message Message {
string sender_id = 1; // Participant ID of the message sender
string message_id = 2; // Unique identifier of the message
string channel_id = 3; // Identifier of the channel to which the message belongs
optional uint64 lamport_timestamp = 10; // Logical timestamp for causal ordering in channel
repeated HistoryEntry causal_history = 11; // List of preceding message IDs that this message causally depends on. Generally 2 or 3 message IDs are included.
optional bytes bloom_filter = 12; // Bloom filter representing received message IDs in channel
repeated HistoryEntry repair_request = 13; // Capped list of history entries missing from sender's causal history. Only populated if using the optional SDS Repair extension.
optional bytes content = 20; // Actual content of the message
}
The sending participant MUST include its own globally unique identifier in the sender_id field.
In addition, it MUST include a globally unique identifier for the message in the message_id field,
likely based on a message hash.
The channel_id field MUST be set to the identifier of the channel of group communication
that is being synchronized.
For simple group communications without individual channels,
the channel_id SHOULD be set to 0.
The lamport_timestamp, causal_history and
bloom_filter fields MUST be set according to the protocol steps
set out below.
These fields MAY be left unset in the case of ephemeral messages.
The message content MAY be left empty for periodic sync messages,
otherwise it MUST contain the application-level content
Note: Close readers may notice that, outside of filtering messages originating from the sender itself, the
sender_idfield is not used for much. Its importance is expected to increase once a p2p retrieval mechanism is added to SDS, as is planned for the protocol.
Participant state
Each participant MUST maintain:
- A Lamport timestamp for each channel of communication, initialized to current epoch time in millisecond resolution. The Lamport timestamp is increased as described in the protocol steps to maintain a logical ordering of events while staying close to the current epoch time. This allows the messages from new joiners to be correctly ordered with other recent messages, without these new participants first having to synchronize past messages to discover the current Lamport timestamp.
- A bloom filter for received message IDs per channel. The bloom filter SHOULD be rolled over and recomputed once it reaches a predefined capacity of message IDs. Furthermore, it SHOULD be designed to minimize false positives through an optimal selection of size and hash functions.
- A buffer for unacknowledged outgoing messages
- A buffer for incoming messages with unmet causal dependencies
- A local log (or history) for each channel, containing all message IDs in the communication channel, ordered by Lamport timestamp.
Messages in the unacknowledged outgoing buffer can be in one of three states:
- Unacknowledged - there has been no acknowledgement of message receipt by any participant in the channel
- Possibly acknowledged - there has been ambiguous indication that the message has been possibly received by at least one participant in the channel
- Acknowledged - there has been sufficient indication that the message has been received by at least some of the participants in the channel. This state will also remove the message from the outgoing buffer.
Protocol Steps
For each channel of communication,
participants MUST follow these protocol steps to populate and interpret
the lamport_timestamp, causal_history and bloom_filter fields.
Send Message
Before broadcasting a message:
- the participant MUST set its local Lamport timestamp
to the maximum between the current value +
1and the current epoch time in milliseconds. In other words the local Lamport timestamp is set tomax(timeNowInMs, current_lamport_timestamp + 1). - the participant MUST include the increased Lamport timestamp in the message's
lamport_timestampfield. - the participant MUST determine the preceding few message IDs in the local history
and include these in an ordered list in the
causal_historyfield. The number of message IDs to include in thecausal_historydepends on the application. We recommend a causal history of two message IDs. - the participant MAY include a
retrieval_hintin theHistoryEntryfor each message ID in thecausal_historyfield. This is an application-specific field to facilitate retrieval of messages, e.g. from high-availability caches. - the participant MUST include the current
bloom_filterstate in the broadcast message.
After broadcasting a message, the message MUST be added to the participant’s buffer of unacknowledged outgoing messages.
Receive Message
Upon receiving a message,
- the participant SHOULD ignore the message if it has a
sender_idmatching its own. - the participant MAY deduplicate the message by comparing its
message_idto previously received message IDs. - the participant MUST review the ACK status of messages in its unacknowledged outgoing buffer using the received message's causal history and bloom filter.
- if the message has a populated
contentfield, the participant MUST include the received message ID in its local bloom filter. - the participant MUST verify that all causal dependencies are met
for the received message.
Dependencies are met if the message IDs in the
causal_historyof the received message appear in the local history of the receiving participant.
If all dependencies are met and the message has a populated content field,
the participant MUST deliver the message.
If dependencies are unmet,
the participant MUST add the message to the incoming buffer of messages
with unmet causal dependencies.
Deliver Message
Triggered by the Receive Message procedure.
If the received message’s Lamport timestamp is greater than the participant's local Lamport timestamp, the participant MUST update its local Lamport timestamp to match the received message. The participant MUST insert the message ID into its local log, based on Lamport timestamp. If one or more message IDs with the same Lamport timestamp already exists, the participant MUST follow the Resolve Conflicts procedure.
Resolve Conflicts
Triggered by the Deliver Message procedure.
The participant MUST order messages with the same Lamport timestamp in ascending order of message ID. If the message ID is implemented as a hash of the message, this means the message with the lowest hash would precede other messages with the same Lamport timestamp in the local log.
Review ACK Status
Triggered by the Receive Message procedure.
For each message in the unacknowledged outgoing buffer,
based on the received bloom_filter and causal_history:
- the participant MUST mark all messages in the received
causal_historyas acknowledged. - the participant MUST mark all messages included in the
bloom_filteras possibly acknowledged. If a message appears as possibly acknowledged in multiple received bloom filters, the participant MAY mark it as acknowledged based on probabilistic grounds, taking into account the bloom filter size and hash number.
Periodic Incoming Buffer Sweep
The participant MUST periodically check causal dependencies for each message in the incoming buffer. For each message in the incoming buffer:
- the participant MAY attempt to retrieve missing dependencies from the Store node
(high-availability cache) or other peers.
It MAY use the application-specific
retrieval_hintin theHistoryEntryto facilitate retrieval. - if all dependencies of a message are met, the participant MUST proceed to deliver the message.
If a message's causal dependencies have failed to be met after a predetermined amount of time, the participant MAY mark them as irretrievably lost.
Periodic Outgoing Buffer Sweep
The participant MUST rebroadcast unacknowledged outgoing messages after a set period. The participant SHOULD use distinct resend periods for unacknowledged and possibly acknowledged messages, prioritizing unacknowledged messages.
Periodic Sync Message
For each channel of communication, participants SHOULD periodically send sync messages to maintain state. These sync messages:
- MUST be sent with empty content
- MUST include a Lamport timestamp increased to
max(timeNowInMs, current_lamport_timestamp + 1), wheretimeNowInMsis the current epoch time in milliseconds. - MUST include causal history and bloom filter according to regular message rules
- MUST NOT be added to the unacknowledged outgoing buffer
- MUST NOT be included in causal histories of subsequent messages
- MUST NOT be included in bloom filters
- MUST NOT be added to the local log
Since sync messages are not persisted, they MAY have non-unique message IDs without impacting the protocol. To avoid network activity bursts in large groups, a participant MAY choose to only send periodic sync messages if no other messages have been broadcast in the channel after a random backoff period.
Participants MUST process the causal history and bloom filter of these sync messages following the same steps as regular messages, but MUST NOT persist the sync messages themselves.
Ephemeral Messages
Participants MAY choose to send short-lived messages for which no synchronization or reliability is required. These messages are termed ephemeral.
Ephemeral messages SHOULD be sent with lamport_timestamp, causal_history, and
bloom_filter unset.
Ephemeral messages SHOULD NOT be added to the unacknowledged outgoing buffer
after broadcast.
Upon reception,
ephemeral messages SHOULD be delivered immediately without buffering for causal dependencies
or including in the local log.
SDS Repair (SDS-R)
SDS Repair (SDS-R) is an optional extension module for SDS, allowing participants in a communication to collectively repair any gaps in causal history (missing messages) preferably over a limited time window. Since SDS-R acts as coordinated rebroadcasting of missing messages, which involves all participants of the communication, it is most appropriate in a limited use case for repairing relatively recent missed dependencies. It is not meant to replace mechanisms for long-term consistency, such as peer-to-peer syncing or the use of a high-availability centralised cache (Store node).
SDS-R message fields
SDS-R adds the following fields to SDS messages:
sender_idinHistoryEntry: the original message sender's participant ID. This is used to determine the group of participants who will respond to a repair request.repair_requestinMessage: a capped list of history entries missing for the message sender and for which it's requesting a repair.
SDS-R participant state
SDS-R adds the following to each participant state:
-
Outgoing repair request buffer: a list of locally missing
HistoryEntrys each mapped to a future request timestamp,T_req, after which this participant will request a repair if at that point the missing dependency has not been repaired yet.T_reqis computed as a pseudorandom backoff from the timestamp when the dependency was detected missing. DeterminingT_reqis described below. We RECOMMEND that the outgoing repair request buffer be chronologically ordered in ascending order ofT_req. -
Incoming repair request buffer: a list of locally available
HistoryEntrys that were requested for repair by a remote participant AND for which this participant might be an eligible responder, each mapped to a future response timestamp,T_resp, after which this participant will rebroadcast the corresponding requestedMessageif at that point no other participant had rebroadcast theMessage.T_respis computed as a pseudorandom backoff from the timestamp when the repair was first requested. DeterminingT_respis described below. We describe below how a participant can determine if they're an eligible responder for a specific repair request. -
Augmented local history log: for each message ID kept in the local log for which the participant could be a repair responder, the full SDS
Messagemust be cached rather than just the message ID, in case this participant is called upon to rebroadcast the message. We describe below how a participant can determine if they're an eligible responder for a specific message.
Note: The required state can likely be significantly reduced in future by simply requiring that a responding participant should reconstruct the original Message when rebroadcasting, rather than the simpler, but heavier,
requirement of caching the entire received Message content in local history.
SDS-R global state
For a specific channel (that is, within a specific SDS-controlled communication) the following SDS-R configuration state SHOULD be common for all participants in the conversation:
T_min: the minimum time period to wait before a missing causal entry can be repaired. We RECOMMEND a value of at least 30 seconds.T_max: the maximum time period over which missing causal entries can be repaired. We RECOMMEND a value of between 120 and 600 seconds.
Furthermore, to avoid a broadcast storm with multiple participants responding to a repair request,
participants in a single channel MAY be divided into discrete response groups.
Participants will only respond to a repair request if they are in the response group for that request.
The global num_response_groups variable configures the number of response groups for this communication.
Its use is described below.
A reasonable default value for num_response_groups is one response group for every 128 participants.
In other words, if the (roughly) expected number of participants is expressed as num_participants, then
num_response_groups = num_participants div 128 + 1.
In other words, if there are fewer than 128 participants in a communication,
they will all belong to the same response group.
We RECOMMEND that the global state variables T_min, T_max and num_response_groups
be set statically for a specific SDS-R application,
based on expected number of group participants and volume of traffic.
Note: Future versions of this protocol will recommend dynamic global SDS-R variables, based on the current number of participants.
SDS-R send message
SDS-R adds the following steps when sending a message:
Before broadcasting a message,
- the participant SHOULD populate the
repair_requestfield in the message with eligible entries from the outgoing repair request buffer. An entry is eligible to be included in arepair_requestif its corresponding request timestamp,T_req, has expired (in other words,T_req <= current_time). The maximum number of repair request entries to include is up to the application. We RECOMMEND that this quota be filled by the eligible entries from the outgoing repair request buffer with the lowestT_req. We RECOMMEND a maximum of 3 entries. If there are no eligible entries in the buffer, this optional field MUST be left unset.
SDS-R receive message
On receiving a message,
- the participant MUST remove entries matching the received message ID from its outgoing repair request buffer. This ensures that the participant does not request repairs for dependencies that have now been met.
- the participant MUST remove entries matching the received message ID from its incoming repair request buffer. This ensures that the participant does not respond to repair requests that another participant has already responded to.
- the participant SHOULD add any unmet causal dependencies to its outgoing repair request buffer against a unique
T_reqtimestamp for that entry. It MUST compute theT_reqfor each such HistoryEntry according to the steps outlined in Determine T_req. - for each item in the
repair_requestfield:- the participant MUST remove entries matching the repair message ID from its own outgoing repair request buffer. This limits the number of participants that will request a common missing dependency.
- if the participant has the requested
Messagein its local history and is an eligible responder for the repair request, it SHOULD add the request to its incoming repair request buffer against a uniqueT_resptimestamp for that entry. It MUST compute theT_respfor each such repair request according to the steps outlined in Determine T_resp. It MUST determine if it's an eligible responder for a repair request according to the steps outlined in Determine response group.
Determine T_req
A participant determines the repair request timestamp, T_req,
for a missing HistoryEntry as follows:
T_req = current_time + hash(participant_id, message_id) % (T_max - T_min) + T_min
where current_time is the current timestamp,
participant_id is the participant's own participant ID
(not the sender_id in the missing HistoryEntry),
message_id is the missing HistoryEntry's message ID,
and T_min and T_max are as set out in SDS-R global state.
This allows T_req to be pseudorandomly and linearly distributed as a backoff of between T_min and T_max from current time.
Note: placing
T_reqvalues on an exponential backoff curve will likely be more appropriate and is left for a future improvement.
Determine T_resp
A participant determines the repair response timestamp, T_resp,
for a HistoryEntry that it could repair as follows:
distance = hash(participant_id) XOR hash(sender_id)
T_resp = current_time + distance*hash(message_id) % T_max
where current_time is the current timestamp,
participant_id is the participant's own (local) participant ID,
sender_id is the requested HistoryEntry sender ID,
message_id is the requested HistoryEntry message ID,
and T_max is as set out in SDS-R global state.
We first calculate the logical distance between the local participant_id and
the original sender_id.
If this participant is the original sender, the distance will be 0.
It should then be clear that the original participant will have a response backoff time of 0,
making it the most likely responder.
The T_resp values for other eligible participants will be pseudorandomly and
linearly distributed as a backoff of up to T_max from current time.
Note: placing
T_respvalues on an exponential backoff curve will likely be more appropriate and is left for a future improvement.
Determine response group
Given a message with sender_id and message_id,
a participant with participant_id is in the response group for that message if
hash(participant_id, message_id) % num_response_groups == hash(sender_id, message_id) % num_response_groups
where num_response_groups is as set out in SDS-R global state.
This ensures that a participant will always be in the response group for its own published messages.
It also allows participants to determine immediately on first reception of a message or
a history entry if they are in the associated response group.
SDS-R incoming repair request buffer sweep
An SDS-R participant MUST periodically check if there are any incoming requests in the incoming repair request buffer* that is due for a response.
For each item in the buffer,
the participant SHOULD broadcast the corresponding Message from local history
if its corresponding response timestamp, T_resp, has expired
(in other words, T_resp <= current_time).
SDS-R Periodic Sync Message
If the participant is due to send a periodic sync message, it SHOULD send the message according to SDS-R send message if there are any eligible items in the outgoing repair request buffer, regardless of whether other participants have also recently broadcast a Periodic Sync message.
Copyright
Copyright and related rights waived via CC0.
SERVICE-DISCOVERY-API
| Field | Value |
|---|---|
| Name | Service Discovery API |
| Slug | 160 |
| Status | raw |
| Category | Standards Track |
| Editor | Simon-Pierre Vivier [email protected] |
| Contributors | Hanno Cornelius [email protected] |
Timeline
- 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-05-07 —
48600b5— Migrate logos-messaging/specs into docs/messaging/ (#315) - 2026-05-05 —
ea3f24b— New logos service discovery API (#309)
Abstract
TODO
Motivation
TODO
Semantic
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in RFC 2119.
API Specification
The aim is to define an API that is compatible with most discovery protocols that supports service-specific discovery, maintaining similar function signatures even if the underlying protocol differs.
The API is defined in the form of C-style bindings. However, this simply serves to illustrate the exposed functions and can be adapted into the conventions of any strongly typed language. Although unspecified in the API below, all functions SHOULD return an error result type appropriate to the implementation language.
Type Definitions
typedef struct {
const uint8_t* bytes;
size_t len;
} Advertisement;
typedef struct {
const Advertisement* ads;
size_t len;
} AdvertisementList;
start()
Start the discovery protocol, including all tasks related to bootstrapping and maintenance of the underlying discovery protocol (such as initialising the routing table).
stop()
Stop the discovery protocol, including all tasks related to maintenance of the underlying discovery protocol (such as advertising or discovery loops).
start_advertising(const char* service_id, const Advertisement* advertisement)
Start advertising the encoded advertisement
against any service encoded as a service_id string.
For peer discovery,
the node MUST encode sufficient connection information in the Advertisement
for discoverers to connect to it.
stop_advertising(const char* service_id)
Stop advertising this node against the service
encoded in the input service_id string.
start_discovering(const char* service_id)
Start discovering and maintaining search tables
for the service encoded in the input service_id string.
stop_discovering(const char* service_id)
Stop discovering and maintenance of search tables
for the service encoded in the input service_id string.
AdvertisementList lookup(const char* service_id)
Lookup and return advertisements for peers supporting
the service encoded in the input service_id string,
using the underlying discovery protocol.
It is RECOMMENDED to use start_discovering
in advance of any lookup for each service_id
as a way to speed up search.
AdvertisementList lookup_random()
Unused, reserved for future use.
Copyright
Copyright and related rights waived via CC0.
References
STATUS-RLN-DEPLOYMENT
| Field | Value |
|---|---|
| Name | RLN deployment to the Status network for gasless L2 |
| Slug | 156 |
| Status | raw |
| Category | Standards Track |
| Editor | Ugur Sen [email protected] |
| Contributors | Sylvain [email protected] |
Timeline
- 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-01 —
b042c3e— docs: Initial PR for SN RLN deployment RFC (#286)
Abstract
This document specifies the Status L2 RLN deployment architecture for enabling gasless transactions with built-in spam resistance based on the RLN-V2 protocol. The specification defines system roles, on-chain and off-chain components, and the end-to-end transaction flow across users, smart contracts, Layer2 services, prover and verifier modules, and decentralized slashers. It describes Karma-based tier management, RLN membership registration, RLN proof generation and verification, deny-list enforcement, gas-aware message accounting, and decentralized slashing. The document further outlines storage requirements and synchronization mechanisms between on-chain events and off-chain state, providing a cohesive framework for scalable and abuse-resistant transaction processing on Status L2.
The architecture separates cryptographic soundness from operational deployment. While operational components may be centralized in this version, cryptographic enforcement of rate limits and slashing remains verifiable and non-custodial.
Roles
Status L2 RLN deployment consists of six roles: user, Karma contract,
RLN contract, Layer2, and Linea ecosystem, Slashers.
user: Uses the Status L2 in a gasless manner who MAY pay premium gas for the transaction (TX).Karma contract: The contract maintains user karma balances, enforces karma slashing, and manages updateable tier limits.RLN contract: The contract that stores the RLN memberships.Layer2: Trusted components that are operated by Status L2 team.Linea ecosystem:: Linea L2 componentsSlashers: External identities responsible for tracking RLN proofs and related metadata in order to identify spam and trigger slashing when applicable.
General Flow
Usercreates a TX send it to the network- The RPC node submits the TX to the mempool, where it is forwarded to the Prover via gRPC, before P2P propagation to the sequencer.
Prover modulebootstraps by querying theKarma contractfor current user tier limits, then listens to events and updates the local tier limit table upon any changes.Prover modulechecks user has enough KarmaminK(which equals theminKarmaof the first tier) for registration, if so prover module registers RLN membership on behalf of user, otherwise skips registration.- Prover creates the RLN proof using the Zerokit backend
prover moduleif user is registered and is in Tier limit and stores in a database. If registered user exceeds the tier limit, the user needs to pay premium gas. Then prover streams the proofs and metadata via gRPC. - RLN verifier module fetches the RLN proofs and metadata from prover module and try to find of RLN proof for each submitted Transaction (TX). The Sequencer forwards the transaction to the mempool if the RLN verifier module has not detected spam and the transaction is accompanied by a valid RLN proof.
- In parallel with the sequencer’s operation,
slashersindependently subscribe to and fetch RLN proofs from the prover and monitor them for spam behavior. Upon detecting spam,slashersextract correspondingsecret-hashfrom proofs and submit it to theRLN contract. As result, the spammer’s RLN membership is revoked on-chain by removing the registration, and the prover module updates its local state accordingly by removing the user based on the emitted slashing event. Finally, spammers Karma amount is mapped to theminK-1.
The tier table is as follows:
| Tier | Daily Quota (Tier limits) | Equivalent Rate | Karma Range |
|---|---|---|---|
| Entry | 1 tx/day | 1 tx every 24 hours | 0-1 |
| Newbie | 5 tx/day | 1 tx every ~5 hours | 2-49 |
| Basic | 15 tx/day | 1 tx every 90 minutes | 50-499 |
| Active | 96 tx/day | 1 tx every 15 minutes | 500-4999 |
| Regular | 480 tx/day | 1 tx every 3 minutes | 5000-19999 |
| Power User | 960 tx/day | 1 tx every 90 seconds | 20000-99999 |
| Pro User | 10080 tx/day | 1 tx every 9 seconds | 100000-499999 |
| High-Throughput | 108000 tx/day | 1 TPS | 500000-4999999 |
| S-Tier | 240000 tx/day | 5 TPS | 5000000-9999999 |
| Legendary | 480000 tx/day | 10 TPS | 10000000-∞ |
1. Prover module
Prover module is a stand-alone gRPC service module
that is mainly responsible for three functionality,
Karma service, RLN registration, creating RLN proofs.
This module is operated by Layer2.
1.1. Karma service
Prover module requires to amounts of Karma
of users to manage tier levels.
To this Karma service has two functionality with querying Karma contract,
- Get amount of Karma for a user
- Get Tier limits
Karma service query is triggered if the user has no more free TX right,
in case the user can move to higher tier without user interaction.
Otherwise, if the user has enough free TX, we don’t update user's tier.
Tier proto file for Tier Query info:
message GetUserTierInfoRequest {
Address user = 1;
}
message GetUserTierInfoReply {
oneof resp {
UserTierInfoResult res = 1;
UserTierInfoError error = 2;
}
}
message UserTierInfoResult {
sint64 current_epoch = 1;
sint64 current_epoch_slice = 2;
uint64 tx_count = 3;
optional Tier tier = 4;
}
message Tier {
string name = 1;
uint64 quota = 2;
}
message UserTierInfoError {
string message = 1;
}
1.2. RLN registration
Prover module MUST register the users who has at least minK Karma
to the RLN contract for corresponding global rate limit rateR automatically,
where minK and rateR are fixed for every user.
After setting this values, the registration as follows:
- Creates the
id-commitmentbased onrateRon behalf ofuser. - Sends the
id-commitmentto the RLN contract without Karma stake. - Receive and stores the membership proof information such as leaf index
from the RLN contract in
registeredUserslist.
Finally, registeredUsers consists of as follows:
- User address:
0xabc... - User
treeInfo: (treePath,treeIndex) sinceid-commitmentare stored in multiple tree in DB.
With the registration, user allows to use free gas transaction within its Tier
enum RegistrationStatus {
Success = 0;
Failure = 1;
AlreadyRegistered = 2;
}
message RegisterUserReply {
RegistrationStatus status = 1;
}
1.3. Proof generation
Prover module MUST create RLNproof for user who is in registeredUsers table,
upon a TX as shown in previous step for a gasless TX.
For RLNproof generation for the TX done by Prover module as follows:
- Receive the TX from the RPC node asynchronously, user is the owner of the TX
- Checks the user is indeed in
registeredUsers - Creates RLN proof on TX by using Zerokit with checking membership information
treeInfoinregisteredUsersthen streams the proof for a specific epoch. - Serializes then streams RLN proofs via gRPC.
- Outputs
RLNProofmetadata namedproof_valuecontainsyandinternal_nullifiervalue see the RLN specification for details.
message RlnProofFilter {
optional string address = 1;
}
message RlnProofReply {
oneof resp {
RlnProof proof = 1;
RlnProofError error = 2;
}
}
message RlnProof {
bytes sender = 1;
bytes tx_hash = 2;
bytes proof = 3;
}
message RlnProofError {
string error = 2;
}
Note that the prover module always creates an RLN proof upon user request,
regardless of whether the user exceeds tier or RLN limits.
Enforcement of tier limits is performed via deny-list interactions,
while RLN limits are enforced by revealing the secret-hash extracted
from spam proofs and submitting it to the RLN contract.
1.4. Storage
RLN proofs are stored in a persistent database (DB) with other informations as follows:
-
table “user”: Stores the
RlnUserIdentitywhich consists of three field elements:id-commitment,secret-hashandrateR.-
key = Serialized(
User address) -
value = Serialized (
RlnUserIdentity,TreeIndex,IndexInMerkleTree)Since
RlnUserIdentityare stored in multiple merkle tree, prover locates them withTreeIndexandIndexInMerkleTree.
-
-
table “idx”:
- there is only 1 key = “COUNT” and value = “Number of Merkle tree”
-
table “tx_counter”:
- key = Serialized (User adress)
- value = Serialized(EpochCounters structure) = Serialized(~
Epoch,tx_counter)
-
table “tier_limits”:
- Key = Only 2 keys
CURRENT‖NEXT - Value = Serialized
Tier Limit list
- Key = Only 2 keys
1.5. Tier List Management
Tiers list are stored on-chain in Karma contract and this is a dynamic list
that is adjusted by Status L2 team according to the inflation of Karma bound.
This section specifies the changes that initiates by Karma contract then affects prover module.
Each update starts by invoking the tier list in Karma contract with some requirements as follows:
- Each updates MUST be contiguous which means no gap or overlap between different tiers.
Other saying, the intersection of two sequential tiers’ maxKarma and minKarma range should be distinct,
where minKarma and MaxKarma values are the local values for each karma tier
unlike
minKis the minimum Karma amount for user can use gasless transaction. - For a tier, minKarma MUST less than maxKarma.
- First tier’s minKarma MUST be equal to
minK
struct Tier {
uint256 minKarma;
uint256 maxKarma;
string name;
uint32 txPerEpoch;
}
Updating tiers phase starts with updating tier list in Karma contract
which is static writing the new tiers that MAY be change the number of tiers and their bounds.
Then, the check method in Karma contract checks three requirements above.
As the second phase, prover module listen for a specific event then fetch
the new tier list from Karma contract and update the local list.
Note that, updating the contract require a delay till updating the local tier table of prover.
1.6 Gas Checking
Prover is also responsible for checking that the gas requirements of TXs are at the limit
since the RLN protects the network in terms of number of TXs not the total gas consumptions.
When a TX is submitted to the prover, it has a field named: estimated_gas_used (type uint64 - unit gas unit e.g. not in wei).
For now, prover has TX and its gas estimation , namely currentGas.
Prover checks that gasQuota cannot be larger than currentGas for a single proof.
If currentGas is equal or lower than the gasQuota,
the prover continues with the proof generation section.
Otherwise, prover calculates the txCounterIncrease as the number of ceil (==currentGas/gasQuota),
expecting a value greater than 2 since the currentGas > gasQuota.
Then the prover creates a proof burns txCounterIncrease many message allocation
for the TX due to the multi-message_id burn RLN.
2. Verifier Module
The verifier module is composed of an identity operating
in the sequencer environment together the decentralized external slashers.
Also verifier module manually conducts the slashing by invoking the Karma contract
with authorized callers as owner in case spamming.
Prover module outputs RLNproof with proof metadata named proof_values
that includes y and internal_nullifier value.
The verifier module MUST record and store all internal_nullifier to use them for detecting spam.
The detection of spam is requiring the internal_nullifier in an epoch.
In this case, when verifier module detects the recurring them,
verifier module MUST extracts the secret-hash from two different message with same message_id
(see RLN Specification), and invoke the Karma contract
for slashing which maps user’s Karma to MinK-1 then adds the user to denylist.
Note that, Zerokit contains a function named comput_id_secret
for extracting the secret-hash for a given two recurring internal_nullifier.
3. Smart Contracts
There are two contracts as Karma contract and RLN contract that former regulates
the tier management and slashing in case spam and later holds the RLN membership tree.
Prover is listening slashing event so that update its state by removing the slashed user
as spammer from the local DB. Prover also listening the tier-limits from karma contract to update local tier limits.
Karma contract:
- Modified ERC20 contract without transfer option.
- Can be queried to get any user’s Karma balance.
- Stored updatable tier table that shows min and max Karma that prover module fetches this information.
RLN contract:
- Stores the RLN membership tree that consists of
id-commitment - Does not store stake since Karma is non-transferable
- Contains the slashing function as mentioned in Decentralized Slashing section which takes a
secret-hashand get reward for invoker also spammersid-commitmentis dropped off from contract and prover.
4. Deny List
Deny list behaves a black list for a user who act maliciously in two ways:
- Exceeds the tier limit and still trying to use gasless TX. The prover module marked as this user as in deny list but still continue to create the RLN proof for the TX.
- Exceeds the global rate limit
rateRthat results with slashing by mapping user’s Karma toMinK-1.
The user who is on the deny list MUST NOT be able to submit gasless transactions.
A user can regain access to gasless transactions only after being removed from the deny list.
Escaping from the deny list is possible under the following conditions
- TTL expiration: Deny list entries MAY be configured with an expiration time. If a deny list participation is not intended to be permanent, the entry is assigned a predefined time window. Upon expiration of this period, the user address is automatically considered removed from the deny list. The sequencer is responsible for checking expiration timestamps and removing expired user addresses from the deny list accordingly.
- Explicit removal: In this type removel of deny list occurs in two cases: (i) when a user submits a transaction with a gas price exceeding the configured premium gas threshold, in which case the sequencer removes the user from the deny list, and (ii) through manual deletion performed by the Layer2 operator.
5. Decentralized Slashing
Decentralized slashing is a capability provided by specialized nodes,
called slashers, which operate alongside sequencer-side RLN verifiers
to externally detect RLN-based spam.
In RLN contract, the user id-commitment is stored as mapping.
The slashers receive all proofs by subscribing gRPC to the prover.
In the event of spam, any slasher can extract the secret-hash
from the proof and submit it to the RLN contract.
RLN Contract does as following:
- Receives the
secret-hashin plaintext - Calculates the
id-commitmentby hashingsecret-hashwith Poseidon hash. - Look up the list whether it includes the
id-commitmentreturns 1 if there is, returns 0 otherwise. - If it returns 1, the slasher who is the caller of the contract, is rewarded with Karma tokens.
- The prover module listens this activity (an event is sent by the smart contract when slashing)
and drop the particular
id-commitmentfrom its local DB. - Upon detecting spam, the
RLN Contractinvokes the slashing function in theKarma Contract, which burns the spammer’s Karma tokens.
Note that the secret-hash are derived by a high entropy randomness
that implies all id-commitment are unique.
Plus, the spammers’ id-commitment are dropped from the list.
Under this conditions, double slashing is not feasible.
5.1. Proof Aggregation Layer
Instead of having slashers connect directly to the prover,
an intermediate aggregation layer is introduced between the prover and the slashers.
An aggregator is an entity that subscribes to the prover via gRPC,
collects RLN proofs and associated metadata, and forwards them to slashers.
The aggregator MUST:
- Subscribe to the prover module via gRPC to receive all RLN proofs and metadata.
- Maintain an up-to-date list of active slashers and forward received proofs to each of them.
- Be stateless with respect to slashing decisions. The aggregator is responsible only for proof distribution, not detection or submission.
To avoid a single point of failure, multiple aggregator instances MAY be deployed. Each aggregator instance operates independently and subscribes to the prover separately. Slashers MAY connect to one or more aggregators to ensure redundant proof delivery.
The prover module MUST NOT impose a connection limit on aggregators. Any entity MAY act as a slasher by connecting to an aggregator without restrictions under normal operating conditions. In cases where slasher capacity limits are exceeded, access control MAY be enforced based on the Karma balance of the requesting entity, prioritizing slashers with higher Karma amounts.
References
Zerokit API
| Field | Value |
|---|---|
| Name | Zerokit API |
| Slug | 142 |
| Status | raw |
| Category | Standards Track |
| Editor | Vinh Trinh [email protected] |
| Contributors | Ekaterina Broslavskaya [email protected], Sylvain Delhomme [email protected] |
Timeline
- 2026-07-24 —
c6ee9bc— docs(anoncomms): update zerokit-api to match new upcoming v3.0.0 release (#378) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-01-21 —
70f3cfb— chore: mdbook font fix (#266)
Abstract
This document specifies the Zerokit API (version 3.0.0), an implementation of the RLN-V2 protocol. The specification covers the unified interface exposed through native Rust, C-compatible Foreign Function Interface (FFI) bindings, and WebAssembly (WASM) bindings.
Motivation
The main goal of this RFC is to define the API contract, serialization formats, and architectural guidance for integrating the Zerokit library across all supported platforms. Zerokit is the reference implementation of the RLN-V2 protocol.
Format Specification
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in 2119.
Important Note
All terms and parameters used remain the same as in RLN-V2 and RLN-V1.
Architecture Overview
Zerokit follows a layered architecture where the core RLN logic is implemented once in Rust and exposed through platform-specific bindings. The protocol layer handles zero-knowledge proof generation and verification, Merkle tree operations, and cryptographic primitives. This core is wrapped by three interface layers: native Rust for direct library integration, FFI for C-compatible bindings consumed by languages (such as C and Nim), and WASM for browser and Node.js environments. All three interfaces share identical serialization formats for inputs and outputs. Native Rust and FFI expose the full API surface, while WASM exposes the stateless subset (see WASM-Specific Notes).
┌─────────────────────────────────────────────────────┐
│ Application Layer │
└──────────┬───────────────┬───────────────┬──────────┘
│ │ │
┌──────▼───────┐ ┌─────▼─────┐ ┌───────▼─────┐
│ FFI API │ │ WASM API │ │ Rust API │
│ (C/Nim/..) │ │ (Browser) │ │ (Native) │
└──────┬───────┘ └─────┬─────┘ └───────┬─────┘
└───────────────┼───────────────┘
│
┌─────────▼─────────┐
│ RLN Protocol │
│ (Rust Core) │
└───────────────────┘
The workspace consists of four crates:
rln (protocol core, FFI bindings),
zerokit_utils (Merkle trees and Poseidon primitives),
rln-wasm (WASM bindings),
and rln-cli (example CLI, not published).
All published crates share the unified version 3.0.0.
Type-Level Configuration
The Merkle tree backend and the stateful/stateless operating mode are chosen at the type level in Rust (and through dedicated constructors in FFI/WASM):
RLN<Stateful<T>, ZkProof>embeds a Merkle tree of typeTand exposes the full tree management API.RLN<Stateless, ZkProof>carries no tree; applications MUST provide Merkle proofs and roots externally.
The core is also generic over the zkSNARK backend
(the RLNZkProof / RLNPartialZkProof traits) and,
through it, over the protocol hash (the ZerokitHasher trait);
custom backends and hashes are native-Rust-only extension points.
The shipped, proof-verifying implementation is
ArkGroth16Backend<PoseidonHash> (Groth16 over BN254 with Poseidon),
and the FFI and WASM bindings expose only this concrete combination.
A hash implementation without matching circuit resources (zkey and graph)
compiles but cannot produce valid proofs.
The available feature flags are:
parallel(rln,zerokit_utils,rln-wasm) enables rayon-based parallel computation for proof generation and tree operations.headers(rln) enables C header generation for the FFI surface.panic_hook(rln-wasm) enables theinitPanicHook()console panic hook.utils(rln-wasm) builds a utility-only WASM module (field elements, identity keys, hashing) without the proof surface.
Merkle Tree Backends
All backends are always compiled and implement the common
ZerokitMerkleTree trait; applications pick one by constructing it and
passing it to the builder.
FullMerkleTree allocates the complete tree structure in memory.
This backend provides the fastest performance but consumes the most memory.
OptimalMerkleTree uses sparse HashMap storage that only allocates nodes as needed.
This backend balances performance and memory efficiency.
PmTree<D, H> persists the tree to disk and
enables state durability across process restarts.
It is generic over the storage backend D;
SledDB (a sled database) is the provided backend,
configured through PmTreeSledConfig
(path, temporary flag, cache capacity, flush interval,
sled mode, compression, tree depth).
The backend set is open on the native Rust side.
Applications MAY plug in a fully custom tree
(any layout or storage strategy) by implementing the
ZerokitMerkleTree trait,
or keep PmTree and swap only its persistence layer
(PostgreSQL, RocksDB, or any other store)
by implementing the pmtree::Database trait for D.
The FFI constructors expose only the three built-in backends,
and WASM, being stateless, embeds no tree backend at all.
Proof Modes
Every RLN instance operates in one of two circuit modes, selected by the circuit resources (zkey and graph) loaded at construction:
- Single message-id mode: one
message_idper proof. This is the default circuit on native targets. - Multi message-id mode: a batch of message ids per proof.
The circuit has a fixed slot count
max_out(the embedded default circuit usesDEFAULT_MAX_OUT = 4);message_idsandselector_usedMUST match it in length, with the booleanselector_usedvector marking the active slots. Proof values carry vectorsysandnullifiersinstead of scalaryandnullifier. The Multi circuit is larger than the Single one, so proof generation is slower; choose it only when batching message ids per proof is needed.
Embedded circuit resources are exposed as
default_zkey_single() / default_graph_single() and
default_zkey_multi() / default_graph_multi().
The default tree depth is DEFAULT_TREE_DEPTH = 20.
Parallelization
parallel enables rayon-based parallel computation for
proof generation and tree operations.
This flag SHOULD be enabled for end-user clients where fastest individual proof generation time is required. For server-side proof services handling multiple concurrent requests, this flag SHOULD be disabled and applications SHOULD use dedicated worker threads per proof instead. The worker thread approach provides significantly higher throughput for concurrent proof generation.
The API
Overview
The API exposes strongly-typed interfaces. All three platform bindings share the same operations, differing only in language-specific conventions. Function signatures documented below are from the Rust perspective.
- Rust: https://github.com/vacp2p/zerokit/blob/master/rln/src/public.rs
- FFI: https://github.com/vacp2p/zerokit/tree/master/rln/src/ffi
- WASM: https://github.com/vacp2p/zerokit/tree/master/rln-wasm
Rust consumers SHOULD import from rln::prelude,
which re-exports the full public surface
(RLN types, protocol types, hashers, errors, and serialization traits).
Error Handling
Error handling differs across platform bindings.
For native Rust,
each operation returns a Result with a narrow, operation-specific error enum
whose variants are all reachable from that code path.
There is no top-level union error type.
The error enums map to operations as follows:
WitnessInputSingleError/WitnessInputMultiError/PartialWitnessInputError: structural validation in the witness builders.ProofValuesMultiError: structural validation of Multi-mode proof values.GenerateProofError: proof generation (witness/circuit mismatch or backend fault).VerifyProofError: verification input mismatch (InvalidSignal,InvalidRoot) or backend fault.RecoverSecretError: slashing recovery when the two proofs do not yield a matching nullifier.SerializationError: deserialization failures, including the construction-time validation errors surfaced through typed wrap variants.
For WASM and FFI bindings, errors are returned as human-readable string messages. This simplifies cross-language error propagation at the cost of type safety. Applications consuming these bindings SHOULD parse error strings or use error message prefixes to distinguish error types when needed.
Initialization
Native Rust construction goes exclusively through RLNBuilder,
a type-state builder that fixes the proof backend to
Groth16 over BN254 with the Poseidon hash
(ArkGroth16Backend<PoseidonHash>).
RLNBuilder::stateless().build() - Rust | Stateless mode
- Builds a stateless RLN instance.
- Optional setters
.zkey()and.graph()accept pre-loaded circuit resources; on native targets both default to the Single message-id circuit. - On
wasm32targets the resources MUST be supplied.
#![allow(unused)] fn main() { // A stateless instance; the embedded Single message-id circuit is used by default. let rln = RLNBuilder::stateless().build(); // A stateless instance using the embedded Multi message-id circuit instead. let rln = RLNBuilder::stateless() .graph(default_graph_multi().clone()) .zkey(default_zkey_multi().clone()) .build(); }
RLNBuilder::stateful().tree(tree).build() - Rust | Stateful mode
- Builds a stateful RLN instance around a caller-constructed Merkle tree
(
FullMerkleTree,OptimalMerkleTree, orPmTree). - The tree hasher MUST match the proof backend hash; a mismatch is a compile error.
- Optional
.zkey()/.graph()setters behave as instateless.
#![allow(unused)] fn main() { // A stateful instance owning a persistent PmTree; // the embedded Single message-id circuit is used by default. let config = PmTreeSledConfig::new() .path("./database") .temporary(false) .cache_capacity(1_073_741_824) .flush_every_ms(500) .build()?; let tree = PmTree::<SledDB, PoseidonHash>::new(DEFAULT_TREE_DEPTH, Fr::default(), config)?; let mut rln = RLNBuilder::stateful().tree(tree).build(); }
FFI exposes one constructor per backend and mode,
each with a _default variant that uses the embedded Single message-id
circuit and DEFAULT_TREE_DEPTH:
ffi_rln_new_stateless(zkey_data, graph_data)/ffi_rln_new_stateless_default()ffi_rln_new_with_full_merkle_tree(tree_depth, zkey_data, graph_data)/ffi_rln_new_with_full_merkle_tree_default()ffi_rln_new_with_optimal_merkle_tree(tree_depth, zkey_data, graph_data)/ffi_rln_new_with_optimal_merkle_tree_default()ffi_rln_new_with_pm_tree(tree_depth, zkey_data, graph_data, config_path)/ffi_rln_new_with_pm_tree_default()(an emptyconfig_pathselects the default sled configuration)
WASM is stateless only:
WasmRLN.newWithParams(zkey_data, graph_data) - WASM | Stateless mode
- Creates a stateless RLN instance from pre-loaded zkey and graph bytes.
- Unlike native targets, WASM ships no default circuit resources; both byte buffers are REQUIRED.
- Witness calculation is performed internally by the witness graph supplied at construction.
Key Generation
Identity material is represented by dedicated structs.
Secret components are wrapped in SecretFr,
a zeroize-on-drop field element with a redacted Debug representation
(see Security/Privacy Considerations).
IdentityKeys::generate::<PoseidonHash, R>(rng)
- Generates a random identity keypair using the caller-supplied
cryptographically secure RNG
R. - Accessors:
identity_secret() -> SecretFr,id_commitment() -> Fr.
IdentityKeys::generate_seeded::<PoseidonHash, R>(seed)
- Generates a deterministic identity keypair from a byte seed.
- The seed is expanded with Keccak-256 (an out-of-circuit hash;
see Hash Utilities) into the seed of the
type-level chosen seedable RNG
R.
ExtendedIdentityKeys::generate::<PoseidonHash, R>(rng)
- Generates a random extended identity keypair.
- Accessors:
identity_trapdoor(),identity_nullifier(),identity_secret()(allSecretFr), andid_commitment() -> Fr.
ExtendedIdentityKeys::generate_seeded::<PoseidonHash, R>(seed)
- Deterministic variant of the extended keypair generation.
Both the hash and the RNG are spelled at the call site; the Merkle leaf is the rate commitment derived from the identity commitment:
#![allow(unused)] fn main() { let identity_keys = IdentityKeys::generate::<PoseidonHash, ThreadRng>(&mut thread_rng()); let seeded_keys = IdentityKeys::generate_seeded::<PoseidonHash, ChaCha20Rng>(b"seed bytes"); let rate_commitment = Hasher::<PoseidonHash>::hash_pair(identity_keys.id_commitment(), user_message_limit); }
FFI and WASM wrappers pin concrete RNG defaults
(ThreadRng for random, ChaCha20Rng for seeded generation)
so seeded outputs are bit-identical across platforms:
ffi_identity_keys_generate() / ffi_identity_keys_generate_seeded(),
ffi_extended_identity_keys_generate() /
ffi_extended_identity_keys_generate_seeded(),
WasmIdentityKeys.generate() / generateSeeded(),
and WasmExtendedIdentityKeys.generate() / generateSeeded().
Merkle Tree Management
Tree management methods exist only on stateful instances
(RLN<Stateful<T>, _>); stateless instances do not expose them
(in FFI, calling a tree operation on a stateless handle returns an error).
tree_depth()
- Returns the depth of the internal Merkle tree.
leaves_set()
- Returns the number of leaves that have been set in the tree.
get_root()
- Returns the current Merkle tree root.
get_subtree_root(level, index)
- Returns the root of the subtree at the given
levelon the path to leafindex. level0 is the tree root;levelequal to the tree depth is the leaf itself.
set_leaf(index, leaf)
- Sets a leaf value at the specified index.
set_leaves_from(index, leaves)
- Sets multiple leaves starting from the specified index.
- Updates
next_indextomax(next_index, index + n). - If
nleaves are passed, they will be set at positionsindex,index + 1, ...,index + n - 1.
init_tree_with_leaves(leaves)
- Resets the tree state to default (keeping the current depth) and initializes it with the provided leaves starting from index 0.
- Resets the internal
next_indexto 0 before setting the leaves.
get_leaf(index)
- Returns the leaf value at the specified index.
get_empty_leaves_indices()
- Returns the indices of the leaves set to the default value, up to the last set leaf.
atomic_operation(index, leaves, indices)
- Atomically sets
leavesstarting fromindexand resets each entry ofindicesto the default value, in a single commit. - When a written position also appears in
indices, the write wins. - Updates
next_indextomax(next_index, index + n)wherenis the number of leaves inserted.
set_next_leaf(leaf)
- Sets a leaf at the next never-set index and increments
next_indexby one.
delete_leaf(index)
- Resets the leaf at the specified index to the default value.
- Does not change the internal
next_indexvalue.
get_merkle_proof(index)
- Returns the Merkle proof for the leaf at the specified index.
- Any backend proof converts into the canonical
RLNMerkleProofdata type (path_elements,identity_path_index) used by witness construction.
set_metadata(metadata) / get_metadata()
- Stores and retrieves arbitrary application metadata in the RLN object.
- This metadata is not used by the RLN module.
close()
- Closes the tree, flushing pending writes for persistent backends (a no-op for in-memory backends).
- Dropping the instance does not flush, so persistent-backend users
MUST call
close()before exit to guarantee durability.
Merkle Proof
RLNMerkleProof is the canonical Merkle proof data type
(path_elements, identity_path_index) consumed by witness construction.
RLNMerkleProof::new(path_elements, identity_path_index)
- Wraps externally supplied path data (stateless workflows).
- Tree proofs returned by
get_merkle_proof()convert into it automatically: a blanketFromimpl covers every type implementing theZerokitMerkleProoftrait, current and future backends alike. - The type carries its own LE and BE serde impls,
so a Merkle proof can be stored or transmitted on its own
(exposed over FFI as
ffi_rln_merkle_proof_to_bytes_le()/ffi_rln_merkle_proof_to_bytes_be()and the matchingfrom_bytesfunctions, and over WASM asWasmRLNMerkleProof.toBytesLE()/toBytesBE()/fromBytesLE()/fromBytesBE()).
Witness Construction
Witness inputs are built through validating builders and
are represented by the RLNWitnessInput enum
(Single / Multi variants).
Every builder takes its Merkle path through the merkle_proof setter,
which accepts the RLNMerkleProof data type
described above (or any tree proof convertible into it).
Single message-id witness:
#![allow(unused)] fn main() { let witness = RLNWitnessInput::new_single() .identity_secret(identity_secret) .user_message_limit(user_message_limit) .merkle_proof(&merkle_proof) .x(x) .external_nullifier(external_nullifier) .message_id(message_id) .build()?; }
build()checks the structural invariants (non-zerouser_message_limit, matchingpath_elements/identity_path_indexlengths,message_id < user_message_limit) and returnsWitnessInputSingleErroron violation.
Multi message-id witness:
#![allow(unused)] fn main() { let witness = RLNWitnessInput::new_multi() .identity_secret(identity_secret) .user_message_limit(user_message_limit) .merkle_proof(&merkle_proof) .x(x) .external_nullifier(external_nullifier) .message_ids(message_ids) .selector_used(selector_used) .build()?; }
build()checks the Multi-mode invariants (non-zerouser_message_limit, matching path lengths, non-emptymessage_ids,selector_usedmatchingmessage_idsin length, at least one active selector, and unique in-range activemessage_ids) and returnsWitnessInputMultiErroron violation.
Partial witness (the subset known ahead of time, used for two-step proof generation):
#![allow(unused)] fn main() { let partial_witness = RLNPartialWitnessInput::new() .identity_secret(identity_secret) .user_message_limit(user_message_limit) .merkle_proof(&merkle_proof) .build()?; }
build()checks the structural invariants and returnsPartialWitnessInputErroron violation.- A partial witness can also be converted from a full witness
(
From<&RLNWitnessInput>).
Witness calculation is handled internally on all platforms, including WASM, by the witness graph loaded at construction (the embedded default on native targets, caller-supplied bytes on WASM).
Proof Generation
generate_proof(witness)
- Generates a Groth16 zkSNARK proof and its public proof values from a witness.
- Returns
(proof, proof_values);proof_valuesis anRLNProofValuesenum (Single/Multi). - Fails with
GenerateProofErroron witness/graph inconsistency or backend fault.
generate_partial_proof(partial_witness)
- First step of two-step proof generation: precomputes a partial proof from the inputs known ahead of time (identity, message limit, Merkle path), before the signal and external nullifier are known.
finish_proof(partial_proof, witness)
- Second step: completes the partial proof with the full witness and
returns
(proof, proof_values). - This split lets latency-sensitive applications move the bulk of the proving work off the critical path.
Proof Verification
All verification methods return Result<bool>.
The Ok(bool) value is the zkSNARK verification verdict:
an invalid proof is reported as Ok(false), not as an error.
Err is reserved for caller-input mismatch
(InvalidSignal, InvalidRoot) and backend faults.
verify(proof, proof_values)
- Verifies only the zkSNARK proof without root or signal validation.
verify_with_signal(proof, proof_values, x)
- Checks that the signal
xmatches the value bound in the proof (Err(InvalidSignal)on mismatch), then returns the zkSNARK verdict.
verify_with_roots(proof, proof_values, x, roots)
- Additionally checks that the proof root is among
roots(Err(InvalidRoot)on mismatch). - If the
rootsslice is empty, root verification is skipped. - This is the RECOMMENDED verification entry point: pass the accepted root window when membership changes over time, or the externally obtained roots in stateless deployments.
End-to-end, proof generation and verification compose as:
#![allow(unused)] fn main() { let (proof, proof_values) = rln.generate_proof(&witness)?; let root = rln.get_root(); let verified = rln.verify_with_roots(&proof, &proof_values, &x, &[root])?; assert!(verified, "proof rejected"); }
The FFI and WASM boundaries preserve this shape:
an FFI FFI_BoolResult { ok: false, err: null } and
a WASM false return are real "proof invalid" verdicts,
not errors.
Slashing
RLNProofValues::recover_secret(other) (trait RecoverSecret)
- Recovers the identity secret from two proof values that share the same nullifier.
- Two proofs collide on a nullifier when they were generated with the same
external_nullifierand the samemessage_id(the nullifier is derived from both), i.e. amessage_idwas reused within an epoch. - Returns
RecoverSecretErrorwhen the two proofs do not yield a matching nullifier (no slashing possible). - Recovery works across modes: Single with Single, Multi with Multi, and Single combined with Multi.
compute_id_secret(share1, share2)
- Lower-level Shamir reconstruction from two
(x, y)shares.
FFI: ffi_rln_recover_id_secret(), ffi_rln_compute_id_secret()
(the recovered secret is returned as a plain field element deliberately,
since slashing is a reveal).
WASM: WasmRLNProofValues.recoverIdSecret() / computeIdSecret().
Hash Utilities
Hasher::<PoseidonHash>::hash_single(input) / hash_pair(left, right) / hash_list(inputs)
- Computes the Poseidon hash for one, two, or a list of inputs.
- All protocol hashes route through this facade.
hash_to_field_le(input) / hash_to_field_be(input)
- Hashes arbitrary bytes to a field element using Keccak-256, interpreting the digest with little-endian or big-endian byte order.
- Keccak-256 is used only for this out-of-circuit byte-to-field mapping (and for seed expansion in seeded key generation); Poseidon is the only hash evaluated inside the circuit.
Boundary equivalents: ffi_poseidon_hash_pair(),
ffi_hash_to_field_le() / ffi_hash_to_field_be(), and
ffi_uint_to_fr() (FFI);
poseidonHashPair() and hashToFieldLE() / hashToFieldBE() (WASM).
Serialization
Serialization is trait-based; there are no free serialization functions. Three trait pairs cover all protocol types (all re-exported by the prelude):
CanonicalSerialize/CanonicalDeserialize(arkworks): little-endian, the arkworks/circom native encoding.CanonicalSerializeBE/CanonicalDeserializeBE: big-endian, matching EVM smart contracts and other on-chain consumers. The zkSNARKProofandPartialProofare little-endian only and have no BE impls.CanonicalSerializeMixed/CanonicalDeserializeMixed: for types whose fields have conflicting encoding requirements.RLNProofis the one such type: it bundles the Groth16 proof, which only exists in arkworks compressed LE form, with the proof values, which are transmitted BE for on-chain consumers. Mixed writes both into a single buffer (proof in LE, then values in BE), so a complete proof can be sent as one payload.
Usage is uniform across types; endianness is chosen by the trait used:
#![allow(unused)] fn main() { // Little-endian (arkworks traits). let mut le_bytes = Vec::new(); witness.serialize_compressed(&mut le_bytes)?; let witness = RLNWitnessInput::deserialize_compressed(&le_bytes[..])?; // Big-endian (Zerokit BE traits). let mut be_bytes = Vec::new(); CanonicalSerializeBE::serialize(&witness, &mut be_bytes)?; let witness = <RLNWitnessInput as CanonicalDeserializeBE>::deserialize(&be_bytes[..])?; // Mixed: a complete RLN proof (Groth16 proof LE + proof values BE) in one buffer. let rln_proof = RLNProof::new(proof, proof_values); let mut mixed_bytes = Vec::new(); CanonicalSerializeMixed::serialize(&rln_proof, &mut mixed_bytes)?; let rln_proof = <RLNProof as CanonicalDeserializeMixed>::deserialize(&mixed_bytes[..])?; }
Deserialization enforces the same structural invariants as construction
and returns typed validation errors through SerializationError.
WASM-Specific Notes
WASM bindings wrap the Rust API with JavaScript-compatible types. Key differences:
- Field elements are wrapped as
WasmFr(zero(),one(),fromUint(),fromBytesLE()/fromBytesBE(),toBytesLE()/toBytesBE(),debug()). - Vectors of field elements use
VecWasmFrwithpush(),get(), andlength(). - Secrets are wrapped as
WasmSecretFr, which exposes ONLY a redacteddebug()and anequals()comparison; raw byte export of a bare secret is intentionally not available. Secret persistence goes throughWasmIdentityKeys.toBytesLE()/toBytesBE()(whole-struct). - Identity generation uses
WasmIdentityKeys.generate()/generateSeeded()andWasmExtendedIdentityKeysequivalents. - The Merkle path crosses the boundary as
WasmRLNMerkleProof(built withWasmRLNMerkleProof.new(pathElements, identityPathIndex), with its own getters and LE/BE serialization), mirroring the FFIFFI_RLNMerkleProofhandle. - Witness input uses
WasmRLNWitnessInput.newSingle()/newMulti()taking aWasmRLNMerkleProof; proof generation isWasmRLN.generateProof()with witness calculation handled internally. - Two-step proving:
generatePartialProof()/finishProof()withWasmRLNPartialWitnessInputandWasmRLNPartialProof; a partial witness reuseswitness.getMerkleProof(). - The WASM surface is stateless only and exposes no tree methods; JavaScript supplies the Merkle path data itself.
- When the
parallelfeature is enabled, callinitThreadPool()to initialize the rayon thread pool. initPanicHook()(with thepanic_hookfeature) installs a console panic hook for debugging.- Errors are returned as JavaScript strings that can be caught via try-catch blocks.
FFI-Specific Notes
FFI bindings use C-compatible types with the ffi_ function prefix
(pattern ffi_<type>_<action>_<variant>). Key differences:
- Field elements are wrapped as
FFI_Fr; secrets as the opaqueFFI_SecretFr(redacted debug viaffi_secret_fr_debug(), comparison viaffi_secret_fr_eq()). - Fallible functions return
FFI_Result<T>(heap pointer + error string), orFFI_BoolResult/FFI_UsizeResultfor bare values; errors are C strings in theerrfield. - All protocol types cross the boundary as opaque handles:
FFI_RLN,FFI_IdentityKeys,FFI_ExtendedIdentityKeys,FFI_RLNMerkleProof,FFI_RLNWitnessInput,FFI_RLNPartialWitnessInput,FFI_RLNProof,FFI_RLNPartialProof,FFI_RLNProofValues. - Memory MUST be explicitly freed with the matching
ffi_*_freefunction; every owned vector type has one (ffi_vec_fr_free(),ffi_vec_u8_free(),ffi_vec_bool_free(),ffi_vec_usize_free()); strings useffi_c_string_free(). - Returned strings and byte buffers are not NUL-terminated;
C callers MUST print them with an explicit length (
%.*s), never%s. - The C header
rln.his generated withcargo run --bin generate_headers --features=headers.
Usage Patterns
This section describes common deployment scenarios and the recommended API combinations for each.
Stateful with Changing Root
Applies when membership changes over time with members joining and slashing continuously.
Applications MUST maintain a sliding window of recent roots externally.
When members are added or removed via set_leaf(), delete_leaf(), or atomic_operation(),
capture the new root using get_root() and append it to the history buffer.
Verify incoming proofs using verify_with_roots() with the root history buffer,
accepting proofs valid against any recent root.
The window size depends on network propagation delays and epoch duration.
Stateful with Fixed Root
Applies when membership is established once and remains static during an operation period.
Initialize the tree using init_tree_with_leaves() with the complete membership set.
No root history is required.
Verify proofs using verify_with_signal(),
optionally combined with verify_with_roots() against the single internal root.
Stateless
Applies when membership state is managed externally, such as by a smart contract or relay network.
Construct the instance with RLNBuilder::stateless()
(or ffi_rln_new_stateless() / WasmRLN.newWithParams()).
Obtain Merkle proofs and valid roots from the external source.
Wrap externally provided path_elements and identity_path_index in
RLNMerkleProof::new() and pass it to the witness builder.
Verify using verify_with_roots() with externally provided roots.
Two-Step Proving
Applies when proof latency at message time matters.
Build an RLNPartialWitnessInput as soon as the identity and Merkle path
are known and call generate_partial_proof().
When the signal arrives, build the full witness and call finish_proof()
to obtain (proof, proof_values) with reduced critical-path latency.
Epoch and Rate Limit Configuration
The external nullifier is computed as poseidon_hash([epoch, rln_identifier]).
The rln_identifier is a field element that uniquely identifies your application (e.g., a hash of your app name).
All values that will be hashed MUST be represented as field elements.
For converting arbitrary data to field elements,
use the hash_to_field_le() or hash_to_field_be() functions,
which internally use Keccak-256.
Each application SHOULD use a unique rln_identifier to
prevent cross-application nullifier collisions.
The user_message_limit in the rate commitment determines messages allowed per epoch.
Each message_id MUST be less than user_message_limit and
SHOULD increment with each message.
In Multi message-id mode a single proof covers a batch of message ids,
with selector_used marking the active slots.
Applications MUST persist the message_id counter to avoid violations after restarts.
Security/Privacy Considerations
The security of Zerokit depends on the correct implementation of the RLN-V2 protocol and the underlying zero-knowledge proof system. Applications MUST ensure that:
- Identity secrets are kept confidential and never transmitted or logged
- The
message_idcounter is properly persisted to prevent accidental rate limit violations - External nullifiers are constructed correctly to prevent cross-application attacks
- Merkle tree roots are validated when using stateless mode
- Circuit parameters (zkey and graph data) are obtained from trusted sources; production deployments SHOULD run or verify their own trusted setup ceremony (Powers of Tau plus circuit-specific phase 2) for the circuit, rather than relying solely on the ceremony behind the embedded zkey
Zerokit handles secrets defensively in-process:
all secret field elements are carried as SecretFr,
which zeroizes its memory on drop,
cannot be implicitly copied,
and prints a redacted Debug representation so secrets never leak into logs.
The FFI boundary keeps secrets behind the opaque FFI_SecretFr handle,
and the WASM boundary exposes no raw byte export for a bare secret.
Note that WASM linear memory remains readable by the host page;
this hygiene is best-effort, not isolation.
When using the parallel feature in WASM,
applications MUST serve content with the
Cross-Origin-Opener-Policy: same-origin and
Cross-Origin-Embedder-Policy: require-corp HTTP response headers,
which browsers require before enabling SharedArrayBuffer.
The slashing mechanism exposes identity secrets when rate limits are violated. Applications SHOULD educate users about this risk and implement safeguards to prevent accidental violations.
References
Normative
- RLN-V1 Specification - Rate Limit Nullifier V1 protocol
Informative
- Zerokit GitHub Repository - Reference implementation
- RLN-V2 Specification - Rate Limit Nullifier V2 protocol
- Sled Database - Embedded database for persistent Merkle tree storage
Copyright
Copyright and related rights waived via CC0.
AnonComms Draft Specifications
AnonComms specifications that have reached draft status live here.
32/RLN-V1
| Field | Value |
|---|---|
| Name | Rate Limit Nullifier |
| Slug | 32 |
| Status | draft |
| Type | RFC |
| Category | Standards Track |
| Editor | Aaryamann Challani [email protected] |
| Contributors | Barry Whitehat [email protected], Sanaz Taheri [email protected], Oskar Thorén [email protected], Onur Kilic [email protected], Blagoj Dimovski [email protected], Rasul Ibragimov [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-08-05 —
eb25cd0— chore: replace email addresses (#86) - 2024-06-06 —
cbefa48— 32/RLN-V1: Move to Draft (#40) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-02-01 —
94db406— Update rln-v1.md - 2024-02-01 —
a23299f— Update and rename RLN-V1.md to rln-v1.md - 2024-01-27 —
539575b— Create RLN-V1.md
Abstract
The following specification covers the RLN construct as well as some auxiliary libraries useful for interacting with it. Rate limiting nullifier (RLN) is a construct based on zero-knowledge proofs that provides an anonymous rate-limited signaling/messaging framework suitable for decentralized (and centralized) environments. Anonymity refers to the unlinkability of messages to their owner.
Motivation
RLN guarantees a messaging rate is enforced cryptographically while preserving the anonymity of the message owners. A wide range of applications can benefit from RLN and provide desirable security features. For example, an e-voting system can integrate RLN to contain the voting rate while protecting the voters-vote unlinkability. Another use case is to protect an anonymous messaging system against DDoS and spam attacks by constraining messaging rate of users. This latter use case is explained in 17/WAKU2-RLN-RELAY RFC.
Wire Format Specification
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in 2119.
Flow
The users participate in the protocol by first registering to an application-defined group referred by the membership group. Registration to the group is mandatory for signaling in the application. After registration, group members can generate a zero-knowledge proof of membership for their signals and can participate in the application. Usually, the membership requires a financial or social stake which is beneficial for the prevention of inclusion of Sybils within the membership group. Group members are allowed to send one signal per external nullifier (an identifier that groups signals and can be thought of as a voting booth). If a user generates more signals than allowed, the user risks being slashed - by revealing his membership secret credentials. If the financial stake is put in place, the user also risks his stake being taken.
Generally the flow can be described by the following steps:
- Registration
- Signaling
- Verification and slashing
Registration
Depending on the application requirements, the registration can be implemented in different ways, for example:
- centralized registrations, by using a central server
- decentralized registrations, by using a smart contract
The users' identity commitments (explained in section User Identity) are stored in a Merkle tree, and the users can obtain a Merkle proof proving that they are part of the group.
Also depending on the application requirements, usually a financial or social stake is introduced. An example for financial stake is:
For each registration a certain amount of ETH is required. An example for social stake is using Interep as a registry, users need to prove that they have a highly reputable social media account.
Implementation notes
User identity
The user's identity is composed of:
{
identity_secret: [identity_nullifier, identity_trapdoor],
identity_secret_hash: poseidonHash(identity_secret),
identity_commitment: poseidonHash([identity_secret_hash])
}
For registration, the user MUST submit their identity_commitment
(along with any additional registration requirements) to the registry.
Upon registration, they SHOULD receive leaf_index value
which represents their position in the Merkle tree.
Receiving a leaf_index is not a hard requirement and is application specific.
The other way around is
the users calculating the leaf_index themselves upon successful registration.
Signaling
After registration, the users can participate in the application by sending signals to the other participants in a decentralised manner or to a centralised server. Along with their signal, they MUST generate a zero-knowledge proof by using the circuit with the specification described above.
For generating a proof, the users need to obtain the required parameters or compute them themselves, depending on the application implementation and client libraries supported by the application. For example, the users MAY store the membership Merkle tree on their end and generate a Merkle proof whenever they want to generate a signal.
Implementation Notes
Signal hash
The signal hash can be generated by hashing the raw signal (or content)
using the keccak256 hash function.
External nullifier
The external nullifier MUST be computed as the Poseidon hash of the current epoch (e.g. a value equal to or derived from the current UNIX timestamp divided by the epoch length) and the RLN identifier.
external_nullifier = poseidonHash([epoch, rln_identifier]);
Obtaining Merkle proof
The Merkle proof SHOULD be obtained locally or from a trusted third party.
By using the incremental Merkle tree algorithm,
the Merkle can be obtained by providing the leaf_index of the identity_commitment.
The proof (Merkle_proof) is composed of the following fields:
{
root: bigint,
indices: number[],
path_elements: bigint[][]
}
- root - The root of membership group Merkle tree at the time of publishing the message
- indices - The index fields of the leafs in the Merkle tree - used by the Merkle tree algorithm for verification
- path_elements - Auxiliary data structure used for storing the path to the leaf - used by the Merkle proof algorithm for verificaton
Generating proof
For proof generation, the user MUST submit the following fields to the circuit:
{
identity_secret: identity_secret_hash,
path_elements: Merkle_proof.path_elements,
identity_path_index: Merkle_proof.indices,
x: signal_hash,
external_nullifier: external_nullifier
}
Calculating output
The proof output is calculated locally,
in order for the required fields for proof verification
to be sent along with the proof.
The proof output is composed of the y share of the secret equation and the internal_nullifier.
The internal_nullifier represents a unique fingerprint of a user
for a given epoch and app.
The following fields are needed for proof output calculation:
{
identity_secret_hash: bigint,
external_nullifier: bigint,
x: bigint
}
The output [y, internal_nullifier] is calculated in the following way:
a_0 = identity_secret_hash;
a_1 = poseidonHash([a0, external_nullifier]);
y = a_0 + x * a_1;
internal_nullifier = poseidonHash([a_1]);
It relies on the properties of the Shamir's Secret sharing scheme.
Sending the output message
The user's output message (output_message),
containing the signal SHOULD contain the following fields at minimum:
{
signal: signal, # non-hashed signal,
proof: zk_proof,
internal_nullifier: internal_nullifier,
x: x, # signal_hash,
y: y,
rln_identifier: rln_identifier
}
Additionally depending on the application, the following fields MAY be required:
{
root: Merkle_proof.root,
epoch: epoch
}
Verification and slashing
The slashing implementation is dependent on the type of application. If the application is implemented in a centralised manner, and everything is stored on a single server, the slashing will be implemented only on the server. Otherwise if the application is distributed, the slashing will be implemented on each user's client.
Notes from Implementation
Each user of the protocol
(server or otherwise) MUST store metadata for each message received by each user,
for the given epoch.
The data can be deleted when the epoch passes.
Storing metadata is REQUIRED,
so that if a user sends more than one unique signal per epoch,
they can be slashed and removed from the protocol.
The metadata stored contains the x, y shares and
the internal_nullifier for the user for each message.
If enough such shares are present, the user's secret can be retreived.
One way of storing received metadata (messaging_metadata) is the following format:
{
[external_nullifier]: {
[internal_nullifier]: {
x_shares: [],
y_shares: []
}
}
}
Verification
The output message verification consists of the following steps:
external_nullifiercorrectness- non-duplicate message check
zk_proofzero-knowledge proof verification- spam verification
1. external_nullifier correctness
Upon received output_message,
first the epoch and rln_identifier fields are checked,
to ensure that the message matches the current external_nullifier.
If the external_nullifier is correct the verification continues, otherwise,
the message is discarded.
2. non-duplicate message check
The received message is checked to ensure it is not duplicate.
The duplicate message check is performed by verifying that the x and y
fields do not exist in the messaging_metadata object.
If the x and y fields exist in the x_shares and
y_shares array for the external_nullifier and
the internal_nullifier the message can be considered as a duplicate.
Duplicate messages are discarded.
3. zk_proof verification
The zk_proof SHOULD be verified by providing the zk_proof field
to the circuit verifier along with the public_signal:
[
y,
Merkle_proof.root,
internal_nullifier,
x, # signal_hash
external_nullifier
]
If the proof verification is correct, the verification continues, otherwise the message is discarded.
4. Double signaling verification
After the proof is verified the x, and
y fields are added to the x_shares and y_shares
arrays of the messaging_metadata external_nullifier and
internal_nullifier object.
If the length of the arrays is equal to the signaling threshold (limit),
the user can be slashed.
Slashing
After the verification,
the user SHOULD be slashed if two different shares are present
to reconstruct their identity_secret_hash from x_shares and
y_shares fields, for their internal_nullifier.
The secret can be retreived by the properties of the Shamir's secret sharing scheme.
In particular the secret (a_0) can be retrieved by computing Lagrange polynomials.
After the secret is retreived,
the user's identity_commitment SHOULD be generated from the secret and
it can be used for removing the user from the membership Merkle tree
(zeroing out the leaf that contains the user's identity_commitment).
Additionally, depending on the application the identity_secret_hash
MAY be used for taking the user's provided stake.
Technical overview
The main RLN construct is implemented using a ZK-SNARK circuit. However, it is helpful to describe the other necessary outside components for interaction with the circuit, which together with the ZK-SNARK circuit enable the above mentioned features.
Terminology
| Term | Description |
|---|---|
| ZK-SNARK | zksnarks |
| Stake | Financial or social stake required for registering in the RLN applications. Common stake examples are: locking cryptocurrency (financial), linking reputable social identity. |
| Identity secret | An array of two unique random components (identity nullifier and identity trapdoor), which must be kept private by the user. Secret hash and identity commitment are derived from this array. |
| Identity nullifier | Random 32 byte value used as component for identity secret generation. |
| Identity trapdoor | Random 32 byte value used as component for identity secret generation. |
| Identity secret hash | The hash of the identity secret, obtained using the Poseidon hash function. It is used for deriving the identity commitment of the user, and as a private input for zero-knowledge proof generation. The secret hash should be kept private by the user. |
| Identity commitment | Hash obtained from the Identity secret hash by using the poseidon hash function. It is used by the users for registering in the protocol. |
| Signal | The message generated by a user. It is an arbitrary bit string that may represent a chat message, a URL request, protobuf message, etc. |
| Signal hash | Keccak256 hash of the signal modulo circuit's field characteristic, used as an input in the RLN circuit. |
| RLN Identifier | Random finite field value unique per RLN app. It is used for additional cross-application security. The role of the RLN identifier is protection of the user secrets from being compromised when signals are being generated with the same credentials in different apps. |
| RLN membership tree | Merkle tree data structure, filled with identity commitments of the users. Serves as a data structure that ensures user registrations. |
| Merkle proof | Proof that a user is member of the RLN membership tree. |
RLN Zero-Knowledge Circuit specific terms
| Term | Description |
|---|---|
| x | Keccak hash of the signal, same as signal hash (Defined above). |
| A0 | The identity secret hash. |
| A1 | Poseidon hash of [A0, External nullifier] (see about External nullifier below). |
| y | The result of the polynomial equation (y = a0 + a1*x). The public output of the circuit. |
| External nullifier | Poseidon hash of [Epoch, RLN Identifier]. An identifier that groups signals and can be thought of as a voting booth. |
| Internal nullifier | Poseidon hash of [A1]. This field ensures that a user can send only one valid signal per external nullifier without risking being slashed. Public input of the circuit. |
Zero-Knowledge Circuits specification
Anonymous signaling with a controlled rate limit is enabled by proving that the user is part of a group which has high barriers to entry (form of stake) and enabling secret reveal if more than 1 unique signal is produced per external nullifier. The membership part is implemented using membership Merkle trees and Merkle proofs, while the secret reveal part is enabled by using the Shamir's Secret Sharing scheme. Essentially the protocol requires the users to generate zero-knowledge proof to be able to send signals and participate in the application. The zero knowledge proof proves that the user is member of a group, but also enforces the user to share part of their secret for each signal in an external nullifier. The external nullifier is usually represented by timestamp or a time interval. It can also be thought of as a voting booth in voting applications.
The zero-knowledge Circuit is implemented using a Groth-16 ZK-SNARK, using the circomlib library.
System parameters
DEPTH- Merkle tree depth
Circuit parameters
Public Inputs
xexternal_nullifier
Private Inputs
identity_secret_hashpath_elements- rln membership proof componentidentity_path_index- rln membership proof component
Outputs
yroot- the rln membership tree rootinternal_nullifier
Hash function
Canonical Poseidon hash implementation is used, as implemented in the circomlib library, according to the Poseidon paper. This Poseidon hash version (canonical implementation) uses the following parameters:
| Hash inputs | t | RF | RP |
|---|---|---|---|
| 1 | 2 | 8 | 56 |
| 2 | 3 | 8 | 57 |
| 3 | 4 | 8 | 56 |
| 4 | 5 | 8 | 60 |
| 5 | 6 | 8 | 60 |
| 6 | 7 | 8 | 63 |
| 7 | 8 | 8 | 64 |
| 8 | 9 | 8 | 63 |
Membership implementation
For a valid signal, a user's identity_commitment
(more on identity commitments below) must exist in identity membership tree.
Membership is proven by providing a membership proof (witness).
The fields from the membership proof REQUIRED for the verification are:
path_elements and identity_path_index.
IncrementalQuinTree algorithm is used for constructing the Membership Merkle tree. The circuits are reused from this repository. You can find out more details about the IncrementalQuinTree algorithm here.
Slashing and Shamir's Secret Sharing
Slashing is enabled by using polynomials and Shamir's Secret sharing.
In order to produce a valid proof,
identity_secret_hash as a private input to the circuit.
Then a secret equation is created in the form of:
y = a_0 + x * a_1;
where a_0 is the identity_secret_hash and a_1 = hash(a_0, external nullifier).
Along with the generated proof,
the users MUST provide a (x, y) share which satisfies the line equation,
in order for their proof to be verified.
x is the hashed signal, while the y is the circuit output.
With more than one pair of unique shares, anyone can derive a_0, i.e. the identity_secret_hash.
The hash of a signal will be the evaluation point x.
In this way,
a member who sends more than one unique signal per external_nullifier
risks their identity secret being revealed.
Note that shares used in different epochs and
different RLN apps cannot be used to derive the identity_secret_hash.
Thanks to the external_nullifier definition,
also shares computed from same secret within same epoch but
in different RLN apps cannot be used to derive the identity secret hash.
The rln_identifier is a random value from a finite field, unique per RLN app,
and is used for additional cross-application security -
to protect the user secrets being compromised if they use
the same credentials accross different RLN apps.
If rln_identifier is not present,
the user uses the same credentials and
sends a different message for two different RLN apps using the same external_nullifier,
then their user signals can be grouped by the internal_nullifier
which could lead the user's secret revealed.
This is because two separate signals under the same internal_nullifier
can be treated as rate limiting violation.
With adding the rln_identifier field we obscure the internal_nullifier,
so this kind of attack can be hardened because
we don't have the same internal_nullifier anymore.
Identity credentials generation
In order to be able to generate valid proofs,
the users MUST be part of the identity membership Merkle tree.
They are part of the identity membership Merkle tree if
their identity_commitment is placed in a leaf in the tree.
The identity credentials of a user are composed of:
identity_secretidentity_secret_hashidentity_commitment
identity_secret
The identity_secret is generated in the following way:
identity_nullifier = random_32_byte_buffer;
identity_trapdoor = random_32_byte_buffer;
identity_secret = [identity_nullifier, identity_trapdoor];
The same secret SHOULD NOT be used accross different protocols, because revealing the secret at one protocol could break privacy for the user in the other protocols.
identity_secret_hash
The identity_secret_hash is generated by obtaining a Poseidon hash
of the identity_secret array:
identity_secret_hash = poseidonHash(identity_secret);
identity_commitment
The identity_commitment is generated by obtaining a Poseidon hash of the identity_secret_hash:
identity_commitment = poseidonHash([identity_secret_hash]);
Appendix A: Security Considerations
RLN is an experimental and still un-audited technology. This means that the circuits have not been yet audited. Another consideration is the security of the underlying primitives. zk-SNARKS require a trusted setup for generating a prover and verifier keys. The standard for this is to use trusted Multi-Party Computation (MPC) ceremony, which requires two phases. Trusted MPC ceremony has not yet been performed for the RLN circuits.
SSS Security Assumptions
Shamir-Secret Sharing requires polynomial coefficients
to be independent of each other.
However, a_1 depends on a_0 through the Poseidon hash algorithm.
Due to the design of Poseidon,
it is possible to
attack
the protocol.
It was decided not to change the circuits design,
since at the moment the attack is infeasible.
Therefore, implementers must be aware that the current version
provides approximately 160-bit security and not 254.
Possible improvements:
- change the circuit to make coefficients independent;
- switch to other hash function (Keccak, SHA);
Appendix B: Identity Scheme Choice
The hashing scheme used is based on the design decisions which also include the Semaphore circuits. Our goal was to ensure compatibility of the secrets for apps that use Semaphore and RLN circuits while also not compromising on security because of using the same secrets.
For example, let's say there is a voting app that uses Semaphore, and also a chat app that uses RLN. The UX would be better if the users would not need to care about complicated identity management (secrets and commitments) they use for each app, and it would be much better if they could use a single id commitment for this. Also in some cases these kind of dependency is required - RLN chat app using Interep as a registry (instead of using financial stake). One potential concern about this interoperability is a slashed user on the RLN app side having their security compromised on the semaphore side apps as well. i.e. obtaining the user's secret, anyone would be able to generate valid semaphore proofs as the slashed user. We don't want that, and we should keep user's app specific security threats in the domain of that app alone.
To achieve the above interoperability UX while preventing the shared app security model (i.e slashing user on an RLN app having impact on Semaphore apps), we had to do the follow in regard the identity secret and identity commitment:
identity_secret = [identity_nullifier, identity_trapdoor];
identity_secret_hash = poseidonHash(identity_secret);
identity_commitment = poseidonHash([identity_secret_hash]);
Secret components for generating Semaphore proof:
identity_nullifieridentity_trapdoor
Secret components for generting RLN proof:
identity_secret_hash
When a user is slashed on the RLN app side, their identity_secret_hash is revealed.
However, a semaphore proof can't be generated because
we do not know the user's identity_nullifier and identity_trapdoor.
With this design we achieve:
identity_commitment (Semaphore) == identity_commitment (RLN)
secret (semaphore) != secret (RLN).
This is the only option we had for the scheme in order to satisfy the properties described above.
Also, for RLN we do a single secret component input for the circuit. Thus we need to hash the secret array (two components) to a secret hash, and we use that as a secret component input.
Appendix C: Auxiliary Tooling
There are few additional tools implemented for easier integrations and usage of the RLN protocol.
zerokit is a set of Zero Knowledge modules,
written in Rust and designed to be used in many different environments.
Among different modules, it supports Semaphore and RLN.
zk-kit
is a typescript library which exposes APIs for identity credentials generation,
as well as proof generation.
It supports various protocols (Semaphore, RLN).
zk-keeper
is a browser plugin which allows for safe credential storing and
proof generation.
You can think of MetaMask for zero-knowledge proofs.
It uses zk-kit under the hood.
Appendix D: Example Usage
The following examples are code snippets using the zerokit RLN module.
The examples are written in rust.
Creating a RLN Object
#![allow(unused)] fn main() { use rln::protocol::*; use rln::public::*; use std::io::Cursor; // We set the RLN parameters: // - the tree height; // - the circuit resource folder (requires a trailing "/"). let tree_height = 20; let resources = Cursor::new("../zerokit/rln/resources/tree_height_20/"); // We create a new RLN instance let mut rln = RLN::new(tree_height, resources); }
Generating Identity Credentials
#![allow(unused)] fn main() { // We generate an identity tuple let mut buffer = Cursor::new(Vec::<u8>::new()); rln.extended_key_gen(&mut buffer).unwrap(); // We deserialize the keygen output to obtain // the identiy_secret and id_commitment let (identity_trapdoor, identity_nullifier, identity_secret_hash, id_commitment) = deserialize_identity_tuple(buffer.into_inner()); }
Adding ID Commitment to the RLN Merkle Tree
#![allow(unused)] fn main() { // We define the tree index where id_commitment will be added let id_index = 10; // We serialize id_commitment and pass it to set_leaf let mut buffer = Cursor::new(serialize_field_element(id_commitment)); rln.set_leaf(id_index, &mut buffer).unwrap(); }
Setting Epoch and Signal
#![allow(unused)] fn main() { // We generate epoch from a date seed and we ensure is // mapped to a field element by hashing-to-field its content let epoch = hash_to_field(b"Today at noon, this year"); // We set our signal let signal = b"RLN is awesome"; }
Generating Proof
#![allow(unused)] fn main() { // We prepare input to the proof generation routine let proof_input = prepare_prove_input(identity_secret, id_index, epoch, signal); // We generate a RLN proof for proof_input let mut in_buffer = Cursor::new(proof_input); let mut out_buffer = Cursor::new(Vec::<u8>::new()); rln.generate_rln_proof(&mut in_buffer, &mut out_buffer) .unwrap(); // We get the public outputs returned by the circuit evaluation let proof_data = out_buffer.into_inner(); }
Verifiying Proof
#![allow(unused)] fn main() { // We prepare input to the proof verification routine let verify_data = prepare_verify_input(proof_data, signal); // We verify the zero-knowledge proof against the provided proof values let mut in_buffer = Cursor::new(verify_data); let verified = rln.verify(&mut in_buffer).unwrap(); // We ensure the proof is valid assert!(verified); }
For more details please visit the
zerokit library.
Copyright
Copyright and related rights waived via CC0
References
- 17/WAKU2-RLN-RELAY RFC
- Interep
- incremental Merkle tree algorithm
- Shamir's Secret sharing scheme
- Lagrange polynomials
- ZK-SNARK
- Merkle trees
- Groth-16 ZK-SNARK
- circomlib
- Poseidon hash implementation
- circomlib library
- IncrementalQuinTree
- IncrementalQuinTree algorithm
- Multi-Party Computation (MPC)
- Poseidon hash attack
- zerokit
- zk-kit
- zk-keeper
- rust
Informative
- [1] privacy-scaling-explorations
- [2] security-considerations-of-zk-snark-parameter-multi-party-computationsecurity-considerations-of-zk-snark-parameter-multi-party-computation/
- [3] rln-circuits
- [4] rln docs
AnonComms Deleted Specifications
AnonComms specifications that have been marked deleted live here.
25/LIBP2P-DNS-DISCOVERY
| Field | Value |
|---|---|
| Name | Libp2p Peer Discovery via DNS |
| Slug | 25 |
| Status | deleted |
| Type | RFC |
| Category | Standards Track |
| Editor | Hanno Cornelius [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-02-09 —
afd94c8— chore: add math support (#287) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-02-08 —
a3ad14e— Create libp2p-dns-discovery.md
25/LIBP2P-DNS-DISCOVERY specifies a scheme to implement libp2p
peer discovery via DNS for Waku v2.
The generalised purpose is to retrieve an arbitrarily long, authenticated,
updateable list of libp2p peers
to bootstrap connection to a libp2p network.
Since 10/WAKU2
currently specifies use of libp2p peer identities,
this method is suitable for a new Waku v2 node
to discover other Waku v2 nodes to connect to.
This specification is largely based on EIP-1459,
with the only deviation being the type of address being encoded (multiaddr vs enr).
Also see this earlier explainer
for more background on the suitability of DNS based discovery for Waku v2.
List encoding
The peer list MUST be encoded as a Merkle tree.
EIP-1459 specifies the URL scheme
to refer to such a DNS node list.
This specification uses the same approach, but with a matree scheme:
matree://<key>@<fqdn>
where
matreeis the selectedmultiaddrMerkle tree scheme<fqdn>is the fully qualified domain name on which the list can be found<key>is the base32 encoding of the compressed 32-byte binary public key that signed the list.
The example URL from EIP-1459, adapted to the above scheme becomes:
matree://AM5FCQLWIZX2QFPNJAP7VUERCCRNGRHWZG3YYHIUV7BVDQ5FDPRT2@peers.example.org
Each entry within the Merkle tree MUST be contained within a DNS TXT record
and stored in a subdomain (except for the base URL matree entry).
The content of any TXT record
MUST be small enough to fit into the 512-byte limit imposed on UDP DNS packets,
which limits the number of hashes that can be contained within a branch entry.
The subdomain name for each entry
is the base32 encoding of the abbreviated keccak256 hash of its text content.
See this example
of a fully populated tree for more information.
Entry types
The following entry types are derived from EIP-1459
and adapted for use with multiaddrs:
Root entry
The tree root entry MUST use the following format:
matree-root:v1 m=<ma-root> l=<link-root> seq=<sequence number> sig=<signature>
where
ma-rootandlink-rootrefer to the root hashes of subtrees containingmultiaddrsand links to other subtrees, respectivelysequence-numberis the tree's update sequence number. This number SHOULD increase with each update to the tree.signatureis a 65-byte secp256k1 EC signature over the keccak256 hash of the root record content, excluding thesig=part, encoded as URL-safe base64
Branch entry
Branch entries MUST take the format:
matree-branch:<h₁>,<h₂>,...,<hₙ>
where
<h₁>,<h₂>,...,<hₙ>are the hashes of other subtree entries
Leaf entries
There are two types of leaf entries:
Link entries
For the subtree pointed to by link-root,
leaf entries MUST take the format:
matree://<key>@<fqdn>
which links to a different list located in another domain.
multiaddr entries
For the subtree pointed to by ma-root,
leaf entries MUST take the format:
ma:<multiaddr>
which contains the multiaddr of a libp2p peer.
Client protocol
A client MUST adhere to the client protocol
as specified in EIP-1459,
and adapted for usage with multiaddr entry types below:
To find nodes at a given DNS name a client MUST perform the following steps:
- Resolve the TXT record of the DNS name and
check whether it contains a valid
matree-root:v1entry. - Verify the signature on the root against the known public key and check whether the sequence number is larger than or equal to any previous number seen for that name.
- Resolve the TXT record of a hash subdomain indicated in the record and verify that the content matches the hash.
- If the resolved entry is of type:
matree-branch: parse the list of hashes and continue resolving them (step 3).ma: import themultiaddrand add it to a local list of discovered nodes.
Copyright
Copyright and related rights waived via CC0.
References
10/WAKU2- EIP-1459: Client Protocol
- EIP-1459: Node Discovery via DNS
libp2plibp2ppeer identity- Merkle trees
ETH-SECPM
| Field | Value |
|---|---|
| Name | Secure channel setup using Ethereum accounts |
| Slug | 110 |
| Status | deleted |
| Type | RFC |
| Category | Standards Track |
| Editor | Ramses Fernandez [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-01-19 —
f24e567— Chore/updates mdbook (#262) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-06-05 —
36caaa6— Fix Errors rfc.vac.dev (#165) - 2025-06-02 —
db90adc— Fix LaTeX errors (#163) - 2025-04-04 —
517b639— Update the RFCs: Vac Raw RFC (#143) - 2024-08-29 —
13aaae3— Update eth-secpm.md (#84) - 2024-05-21 —
e234e9d— Update eth-secpm.md (#35) - 2024-03-21 —
2eaa794— Broken Links + Change Editors (#26) - 2024-02-28 —
b842725— Update eth-secpm.md - 2024-02-01 —
f2e1b4c— Rename ETH-SECPM.md to eth-secpm.md - 2024-02-01 —
22bb331— Update ETH-SECPM.md - 2024-01-27 —
5b8ce46— Create ETH-SECPM.md
NOTE
The content of this specification has been split between ETH-MLS-OFFCHAIN and NOISE-X3DH-DOUBLE-RATCHET LIPs.
Motivation
The need for secure communications has become paramount.
Traditional centralized messaging protocols are susceptible to various security threats,
including unauthorized access, data breaches, and single points of failure.
Therefore a decentralized approach to secure communication becomes increasingly relevant,
offering a robust solution to address these challenges.
This specification outlines a private messaging service using the Ethereum blockchain as authentication service. Rooted in the existing model, this proposal addresses the deficiencies related to forward privacy and authentication inherent in the current framework. The specification is divided into 3 sections:
- Private 1-to-1 communications protocol, based on Signal's double ratchet.
- Private group messaging protocol, based on the MLS protocol.
- Description of an Ethereum-based authentication protocol, based on SIWE.
Private 1-to-1 communications protocol
Theory
The specification is based on the noise protocol framework. It corresponds to the double ratchet scheme combined with the X3DH algorithm, which will be used to initialize the former. We chose to express the protocol in noise to be be able to use the noise streamlined implementation and proving features. The X3DH algorithm provides both authentication and forward secrecy, as stated in the X3DH specification.
This protocol will consist of several stages:
- Key setting for X3DH: this step will produce prekey bundles for Bob which will be fed into X3DH. It will also allow Alice to generate the keys required to run the X3DH algorithm correctly.
- Execution of X3DH: This step will output
a common secret key
SKtogether with an additional data vectorAD. Both will be used in the double ratchet algorithm initialization. - Execution of the double ratchet algorithm
for forward secure, authenticated communications,
using the common secret key
SK, obtained from X3DH, as a root key.
The protocol assumes the following requirements:
- Alice knows Bob’s Ethereum address.
- Bob is willing to participate in the protocol, and publishes his public key.
- Bob’s ownership of his public key is verifiable,
- Alice wants to send message M to Bob.
- An eavesdropper cannot read M’s content even if she is storing it or relaying it.
The inclusion of this first section devoted to secure 1-to-1 communications between users is motivated by the fact certain interactions between existing group members and prospective new members require secure communication channels.
Syntax
Cryptographic suite
The following cryptographic functions MUST be used:
X488as Diffie-Hellman functionDH.SHA256as KDF.AES256-GCMas AEAD algorithm.SHA512as hash function.XEd448for digital signatures.
X3DH initialization
This scheme MUST work on the curve curve448. The X3DH algorithm corresponds to the IX pattern in Noise.
Bob and Alice MUST define personal key pairs
(ik_B, IK_B) and (ik_A, IK_A) respectively where:
- The key
ikmust be kept secret, - and the key
IKis public.
Bob MUST generate new keys using
(ik_B, IK_B) = GENERATE_KEYPAIR(curve = curve448).
Bob MUST also generate a public key pair
(spk_B, SPK_B) = GENERATE_KEYPAIR(curve = curve448).
SPK is a public key generated and stored at medium-term.
Both signed prekey and the certificate MUST
undergo periodic replacement.
After replacing the key,
Bob keeps the old private key of SPK
for some interval, dependant on the implementation.
This allows Bob to decrypt delayed messages.
Bob MUST sign SPK for authentication:
SigSPK = XEd448(ik, Encode(SPK))
A final step requires the definition of
prekey_bundle = (IK, SPK, SigSPK, OPK_i)
One-time keys OPK MUST be generated as
(opk_B, OPK_B) = GENERATE_KEYPAIR(curve = curve448).
Before sending an initial message to Bob,
Alice MUST generate an AD: AD = Encode(IK_A) || Encode(IK_B).
Alice MUST generate ephemeral key pairs
(ek, EK) = GENERATE_KEYPAIR(curve = curve448).
The function Encode() transforms a
curve448 public key into a byte sequence.
This is specified in the RFC 7748
on elliptic curves for security.
One MUST consider q = 2^446 - 13818066809895115352007386748515426880336692474882178609894547503885
for digital signatures with (XEd448_sign, XEd448_verify):
XEd448_sign((ik, IK), message):
Z = randbytes(64)
r = SHA512(2^456 - 2 || ik || message || Z )
R = (r * convert_mont(5)) % q
h = SHA512(R || IK || M)
s = (r + h * ik) % q
return (R || s)
XEd448_verify(u, message, (R || s)):
if (R.y >= 2^448) or (s >= 2^446): return FALSE
h = (SHA512(R || 156326 || message)) % q
R_check = s * convert_mont(5) - h * 156326
if R == R_check: return TRUE
return FALSE
convert_mont(u):
u_masked = u % mod 2^448
inv = ((1 - u_masked)^(2^448 - 2^224 - 3)) % (2^448 - 2^224 - 1)
P.y = ((1 + u_masked) * inv)) % (2^448 - 2^224 - 1)
P.s = 0
return P
Use of X3DH
This specification combines the double ratchet with X3DH using the following data as initialization for the former:
- The
SKoutput from X3DH becomes theSKinput of the double ratchet. See section 3.3 of Signal Specification for a detailed description. - The
ADoutput from X3DH becomes theADinput of the double ratchet. See sections 3.4 and 3.5 of Signal Specification for a detailed description. - Bob’s signed prekey
SigSPKBfrom X3DH is used as Bob’s initial ratchet public key of the double ratchet.
X3DH has three phases:
- Bob publishes his identity key and prekeys to a server, a network, or dedicated smart contract.
- Alice fetches a prekey bundle from the server, and uses it to send an initial message to Bob.
- Bob receives and processes Alice's initial message.
Alice MUST perform the following computations:
dh1 = DH(IK_A, SPK_B, curve = curve448)
dh2 = DH(EK_A, IK_B, curve = curve448)
dh3 = DH(EK_A, SPK_B)
SK = KDF(dh1 || dh2 || dh3)
Alice MUST send to Bob a message containing:
IK_A, EK_A.- An identifier to Bob's prekeys used.
- A message encrypted with AES256-GCM using
ADandSK.
Upon reception of the initial message, Bob MUST:
- Perform the same computations above with the
DH()function. - Derive
SKand constructAD. - Decrypt the initial message encrypted with
AES256-GCM. - If decryption fails, abort the protocol.
Initialization of the double datchet
In this stage Bob and Alice have generated key pairs
and agreed a shared secret SK using X3DH.
Alice calls RatchetInitAlice() defined below:
RatchetInitAlice(SK, IK_B):
state.DHs = GENERATE_KEYPAIR(curve = curve448)
state.DHr = IK_B
state.RK, state.CKs = HKDF(SK, DH(state.DHs, state.DHr))
state.CKr = None
state.Ns, state.Nr, state.PN = 0
state.MKSKIPPED = {}
The HKDF function MUST be the proposal by
Krawczyk and Eronen.
In this proposal chaining_key and input_key_material
MUST be replaced with SK and the output of DH respectively.
Similarly, Bob calls the function RatchetInitBob() defined below:
RatchetInitBob(SK, (ik_B,IK_B)):
state.DHs = (ik_B, IK_B)
state.Dhr = None
state.RK = SK
state.CKs, state.CKr = None
state.Ns, state.Nr, state.PN = 0
state.MKSKIPPED = {}
Encryption
This function performs the symmetric key ratchet.
RatchetEncrypt(state, plaintext, AD):
state.CKs, mk = HMAC-SHA256(state.CKs)
header = HEADER(state.DHs, state.PN, state.Ns)
state.Ns = state.Ns + 1
return header, AES256-GCM_Enc(mk, plaintext, AD || header)
The HEADER function creates a new message header
containing the public key from the key pair output of the DHfunction.
It outputs the previous chain length pn,
and the message number n.
The returned header object contains ratchet public key
dh and integers pn and n.
Decryption
The function RatchetDecrypt() decrypts incoming messages:
RatchetDecrypt(state, header, ciphertext, AD):
plaintext = TrySkippedMessageKeys(state, header, ciphertext, AD)
if plaintext != None:
return plaintext
if header.dh != state.DHr:
SkipMessageKeys(state, header.pn)
DHRatchet(state, header)
SkipMessageKeys(state, header.n)
state.CKr, mk = HMAC-SHA256(state.CKr)
state.Nr = state.Nr + 1
return AES256-GCM_Dec(mk, ciphertext, AD || header)
Auxiliary functions follow:
DHRatchet(state, header):
state.PN = state.Ns
state.Ns = state.Nr = 0
state.DHr = header.dh
state.RK, state.CKr = HKDF(state.RK, DH(state.DHs, state.DHr))
state.DHs = GENERATE_KEYPAIR(curve = curve448)
state.RK, state.CKs = HKDF(state.RK, DH(state.DHs, state.DHr))
SkipMessageKeys(state, until):
if state.NR + MAX_SKIP < until:
raise Error
if state.CKr != none:
while state.Nr < until:
state.CKr, mk = HMAC-SHA256(state.CKr)
state.MKSKIPPED[state.DHr, state.Nr] = mk
state.Nr = state.Nr + 1
TrySkippedMessageKey(state, header, ciphertext, AD):
if (header.dh, header.n) in state.MKSKIPPED:
mk = state.MKSKIPPED[header.dh, header.n]
delete state.MKSKIPPED[header.dh, header.n]
return AES256-GCM_Dec(mk, ciphertext, AD || header)
else: return None
Information retrieval
Static data
Some data, such as the key pairs (ik, IK) for Alice and Bob,
MAY NOT be regenerated after a period of time.
Therefore the prekey bundle MAY be stored in long-term
storage solutions, such as a dedicated smart contract
which outputs such a key pair when receiving an Ethereum wallet
address.
Storing static data is done using a dedicated
smart contract PublicKeyStorage which associates
the Ethereum wallet address of a user with his public key.
This mapping is done by PublicKeyStorage
using a publicKeys function, or a setPublicKey function.
This mapping is done if the user passed an authorization process.
A user who wants to retrieve a public key associated
with a specific wallet address calls a function getPublicKey.
The user provides the wallet address as the only
input parameter for getPublicKey.
The function outputs the associated public key
from the smart contract.
Ephemeral data
Storing ephemeral data on Ethereum MAY be done using a combination of on-chain and off-chain solutions. This approach provides an efficient solution to the problem of storing updatable data in Ethereum.
- Ethereum stores a reference or a hash that points to the off-chain data.
- Off-chain solutions can include systems like IPFS, traditional cloud storage solutions, or decentralized storage networks such as a Swarm.
In any case, the user stores the associated IPFS hash, URL or reference in Ethereum.
The fact of a user not updating the ephemeral information can be understood as Bob not willing to participate in any communication.
This applies to KeyPackage,
which in the MLS specification are meant
o be stored in a directory provided by the delivery service.
If such an element does not exist,
KeyPackage MUST be stored according
to one of the two options outlined above.
Private group messaging protocol
Theoretical content
The Messaging Layer Security(MLS) protocol aims at providing a group of users with end-to-end encryption in an authenticated and asynchronous way. The main security characteristics of the protocol are: Message confidentiality and authentication, sender authentication, membership agreement, post-remove and post-update security, and forward secrecy and post-compromise security. The MLS protocol achieves: low-complexity, group integrity, synchronization and extensibility.
The extension to group chat described in forthcoming sections is built upon the MLS protocol.
Structure
Each MLS session uses a single cipher suite that specifies the primitives to be used in group key computations. The cipher suite MUST use:
X488as Diffie-Hellman function.SHA256as KDF.AES256-GCMas AEAD algorithm.SHA512as hash function.XEd448for digital signatures.
Formats for public keys, signatures and public-key encryption MUST follow Section 5.1 of RFC9420.
Hash-based identifiers
Some MLS messages refer to other MLS objects by hash. These identifiers MUST be computed according to Section 5.2 of RFC9420.
Credentials
Each member of a group presents a credential that provides one or more identities for the member and associates them with the member's signing key. The identities and signing key are verified by the Authentication Service in use for a group.
Credentials MUST follow the specifications of section 5.3 of RFC9420.
Below follows the flow diagram for the generation of credentials.
Users MUST generate key pairs by themselves.

Message framing
Handshake and application messages use a common framing structure providing encryption to ensure confidentiality within the group, and signing to authenticate the sender.
The structure is:
PublicMessage: represents a message that is only signed, and not encrypted. The definition and the encoding/decoding of aPublicMessageMUST follow the specification in section 6.2 of RFC9420.PrivateMessage: represents a signed and encrypted message, with protections for both the content of the message and related metadata.
The definition, and the encoding/decoding of a PrivateMessage MUST
follow the specification in section 6.3 of
RFC9420.
Applications MUST use PrivateMessage to encrypt application messages.
Applications SHOULD use PrivateMessage to encode handshake messages.
Each encrypted MLS message carries a "generation" number which is a per-sender incrementing counter. If a group member observes a gap in the generation sequence for a sender, then they know that they have missed a message from that sender.
Nodes contents
The nodes of a ratchet tree contain several types of data:
- Leaf nodes describe individual members.
- Parent nodes describe subgroups.
Contents of each kind of node, and its structure MUST follow the indications described in sections 7.1 and 7.2 of RFC9420.
Leaf node validation
KeyPackage objects describe the client's capabilities and provides
keys that can be used to add the client to a group.
The validity of a leaf node needs to be verified at the following stages:
- When a leaf node is downloaded in a
KeyPackage, before it is used to add the client to the group. - When a leaf node is received by a group member in an Add, Update, or Commit message.
- When a client validates a ratchet tree.
A client MUST verify the validity of a leaf node following the instructions of section 7.3 in RFC9420.
Ratchet tree evolution
Whenever a member initiates an epoch change, they MAY need to refresh the key pairs of their leaf and of the nodes on their direct path. This is done to keep forward secrecy and post-compromise security. The member initiating the epoch change MUST follow this procedure procedure. A member updates the nodes along its direct path as follows:
- Blank all the nodes on the direct path from the leaf to the root.
- Generate a fresh HPKE key pair for the leaf.
- Generate a sequence of path secrets, one for each node on the leaf's filtered direct path.
It MUST follow the procedure described in section 7.4 of [RFC9420 (https://datatracker.ietf.org/doc/rfc9420/).
- Compute the sequence of HPKE key pairs
(node_priv,node_pub), one for each node on the leaf's direct path.
It MUST follow the procedure described in section 7.4 of [RFC9420 (https://datatracker.ietf.org/doc/rfc9420/).
Views of the tree synchronization
After generating fresh key material and applying it to update their local tree state, the generator broadcasts this update to other members of the group. This operation MUST be done according to section 7.5 of [RFC9420 (https://datatracker.ietf.org/doc/rfc9420/).
Leaf synchronization
Changes to group memberships MUST be represented by adding and removing leaves of the tree. This corresponds to increasing or decreasing the depth of the tree, resulting in the number of leaves being doubled or halved. These operations MUST be done as described in section 7.7 of [RFC9420 (https://datatracker.ietf.org/doc/rfc9420/).
Tree and parent hashing
Group members can agree on the cryptographic state of the group by
generating a hash value that represents the contents of the group
ratchet tree and the member’s credentials.
The hash of the tree is the hash of its root node, defined recursively
from the leaves.
Tree hashes summarize the state of a tree at point in time.
The hash of a leaf is the hash of the LeafNodeHashInput object.
At the same time, the hash of a parent node including the root, is the
hash of a ParentNodeHashInput object.
Parent hashes capture information about how keys in the tree were
populated.
Tree and parent hashing MUST follow the directions in Sections 7.8 and 7.9 of RFC9420.
Key schedule
Group keys are derived using the Extract and Expand functions from
the KDF for the group's cipher suite, as well as the functions defined
below:
ExpandWithLabel(Secret, Label, Context, Length) = KDF.Expand(Secret,
KDFLabel, Length)
DeriveSecret(Secret, Label) = ExpandWithLabel(Secret, Label, "",
KDF.Nh)
KDFLabel MUST be specified as:
struct {
uint16 length;
opaque label<V>;
opaque context<V>;
} KDFLabel;
The fields of KDFLabel MUST be:
length = Length;
label = "MLS 1.0 " + Label;
context = Context;
Each member of the group MUST maintaint a GroupContext object
summarizing the state of the group.
The sturcture of such object MUST be:
struct {
ProtocolVersion version = mls10;
CipherSuite cipher_suite;
opaque group_id<V>;
uint64 epoch;
opaque tree_hash<V>;
opaque confirmed_trasncript_hash<V>;
Extension extension<V>;
} GroupContext;
The use of key scheduling MUST follow the indications in sections 8.1 - 8.7 in RFC9420.
Secret trees
For the generation of encryption keys and nonces, the key schedule
begins with the encryption_secret at the root and derives a tree of
secrets with the same structure as the group's ratchet tree.
Each leaf in the secret tree is associated with the same group member
as the corresponding leaf in the ratchet tree.
If N is a parent node in the secret tree, the secrets of the children
of N MUST be defined following section 9 of
RFC9420.
Encryption keys
MLS encrypts three different types of information:
- Metadata (sender information).
- Handshake messages (Proposal and Commit).
- Application messages.
For handshake and application messages, a sequence of keys is derived via a sender ratchet. Each sender has their own sender ratchet, and each step along the ratchet is called a generation. These procedures MUST follow section 9.1 of RFC9420.
Deletion schedule
All security-sensitive values MUST be deleted as soon as they are consumed.
A sensitive value S is consumed if:
- S was used to encrypt or (successfully) decrypt a message.
- A key, nonce, or secret derived from S has been consumed.
The deletion procedure MUST follow the instruction described in section 9.2 of RFC9420.
Key packages
KeyPackage objects are used to ease the addition of clients to a group asynchronously. A KeyPackage object specifies:
- Protocol version and cipher suite supported by the client.
- Public keys that can be used to encrypt Welcome messages. Welcome messages provide new members with the information to initialize their state for the epoch in which they were added or in which they want to add themselves to the group
- The content of the leaf node that should be added to the tree to represent this client.
KeyPackages are intended to be used only once and SHOULD NOT be reused.
Clients MAY generate and publish multiple KeyPackages to support multiple cipher suites.
The structure of the object MUST be:
struct {
ProtocolVersion version;
CipherSuite cipher_suite;
HPKEPublicKey init_key;
LeafNode leaf_node;
Extension extensions<V>;
/* SignWithLabel(., "KeyPackageTBS", KeyPackageTBS) */
opaque signature<V>;
}
struct {
ProtocolVersion version;
CipheSuite cipher_suite;
HPKEPublicKey init_key;
LeafNode leaf_node;
Extension extensions<V>;
}
KeyPackage object MUST be verified when:
- A
KeyPackageis downloaded by a group member, before it is used to add the client to the group. - When a
KeyPackageis received by a group member in anAddmessage.
Verification MUST be done as follows:
- Verify that the cipher suite and protocol version of the
KeyPackagematch those in theGroupContext. - Verify that the
leaf_nodeof theKeyPackageis valid for aKeyPackage. - Verify that the signature on the
KeyPackageis valid. - Verify that the value of
leaf_node.encryption_keyis different from the value of theinit_key field.
HPKE public keys are opaque values in a format defined by Section 4 of RFC9180.
Signature public keys are represented as opaque values in a format defined by the cipher suite's signature scheme.
Group creation
A group is always created with a single member. Other members are then added to the group using the usual Add/Commit mechanism. The creator of a group MUST set:
- the group ID.
- cipher suite.
- initial extensions for the group.
If the creator intends to add other members at the time of creation,
then it SHOULD fetch KeyPackages for those members, and select a
cipher suite and extensions according to their capabilities.
The creator MUST use the capabilities information in these
KeyPackages to verify that the chosen version and cipher suite is the
best option supported by all members.
Group IDs SHOULD be constructed so they are unique with high probability.
To initialize a group, the creator of the group MUST initialize a one member group with the following initial values:
- Ratchet tree: A tree with a single node, a leaf node containing an HPKE public key and credential for the creator.
- Group ID: A value set by the creator.
- Epoch:
0. - Tree hash: The root hash of the above ratchet tree.
- Confirmed transcript hash: The zero-length octet string.
- Epoch secret: A fresh random value of size
KDF.Nh. - Extensions: Any values of the creator's choosing.
The creator MUST also calculate the interim transcript hash:
- Derive the
confirmation_keyfor the epoch according to Section 8 of RFC9420. - Compute a
confirmation_tagover the emptyconfirmed_transcript_hashusing theconfirmation_keyas described in Section 8.1 of RFC9420. - Compute the updated
interim_transcript_hashfrom theconfirmed_transcript_hashand theconfirmation_tagas described in Section 8.2 RFC9420.
All members of a group MUST support the cipher suite and protocol
version in use. Additional requirements MAY be imposed by including a
required_capabilities extension in the GroupContext.
struct {
ExtensionType extension_types<V>;
ProposalType proposal_types<V>;
CredentialType credential_types<V>;
}
The flow diagram shows the procedure to fetch key material from other
users:

Below follows the flow diagram for the creation of a group:

Group evolution
Group membership can change, and existing members can change their keys in order to achieve post-compromise security. In MLS, each such change is accomplished by a two-step process:
- A proposal to make the change is broadcast to the group in a Proposal message.
- A member of the group or a new member broadcasts a Commit message that causes one or more proposed changes to enter into effect.
The group evolves from one cryptographic state to another each time a Commit message is sent and processed. These states are called epochs and are uniquely identified among states of the group by eight-octet epoch values.
Proposals are included in a FramedContent by way of a Proposal
structure that indicates their type:
struct {
ProposalType proposal_type;
select (Proposal.proposal_type) {
case add: Add:
case update: Update;
case remove: Remove;
case psk: PreSharedKey;
case reinit: ReInit;
case external_init: ExternalInit;
case group_context_extensions: GroupContextExtensions;
}
On receiving a FramedContent containing a Proposal, a client MUST
verify the signature inside FramedContentAuthData and that the epoch
field of the enclosing FramedContent is equal to the epoch field of the
current GroupContext object.
If the verification is successful, then the Proposal SHOULD be cached
in such a way that it can be retrieved by hash in a later Commit
message.
Proposals are organized as follows:
Add: requests that a client with a specified KeyPackage be added to the group.Update: similar to Add, it replaces the sender's LeafNode in the tree instead of adding a new leaf to the tree.Remove: requests that the member with the leaf index removed be removed from the group.ReInit: requests to reinitialize the group with different parameters.ExternalInit: used by new members that want to join a group by using an external commit.GroupContentExtensions: it is used to update the list of extensions in the GroupContext for the group.
Proposals structure and semantics MUST follow sections 12.1.1 - 12.1.7 of RFC9420.
Any list of commited proposals MUST be validated either by a the group member who created the commit, or any group member processing such commit. The validation MUST be done according to one of the procedures described in Section 12.2 of RFC9420.
When creating or processing a Commit, a client applies a list of
proposals to the ratchet tree and GroupContext.
The client MUST apply the proposals in the list in the order described
in Section 12.3 of RFC9420.
Below follows the flow diagram for the addition of a member to a group:

The diagram below shows the procedure to remove a group member:

The flow diagram below shows an update procedure:

Commit messages
Commit messages initiate new group epochs. It informs group members to update their representation of the state of the group by applying the proposals and advancing the key schedule.
Each proposal covered by the Commit is included by a ProposalOrRef
value.
ProposalOrRef identify the proposal to be applied by value or by
reference.
Commits that refer to new Proposals from the committer can be included
by value.
Commits for previously sent proposals from anyone can be sent by
reference.
Proposals sent by reference are specified by including the hash of the
AuthenticatedContent.
Group members that have observed one or more valid proposals within an epoch MUST send a Commit message before sending application data. A sender and a receiver of a Commit MUST verify that the committed list of proposals is valid. The sender of a Commit SHOULD include all valid proposals received during the current epoch.
Functioning of commits MUST follow the instructions of Section 12.4 of RFC9420.
Application messages
Handshake messages provide an authenticated group key exchange to
clients.
To protect application messages sent among the members of a group, the
encryption_secret provided by the key schedule is used to derive a
sequence of nonces and keys for message encryption.
Each client MUST maintain their local copy of the key schedule for each epoch during which they are a group member. They derive new keys, nonces, and secrets as needed. This data MUST be deleted as soon as they have been used.
Group members MUST use the AEAD algorithm associated with the negotiated MLS ciphersuite to encrypt and decrypt Application messages according to the Message Framing section. The group identifier and epoch allow a device to know which group secrets should be used and from which Epoch secret to start computing other secrets and keys. Application messages SHOULD be padded to provide resistance against traffic analysis techniques. This avoids additional information to be provided to an attacker in order to guess the length of the encrypted message. Padding SHOULD be used on messages with zero-valued bytes before AEAD encryption.
Functioning of application messages MUST follow the instructions of Section 15 of RFC9420.
Considerations with respect to decentralization
The MLS protocol assumes the existence on a (central, untrusted) delivery service, whose responsabilites include:
- Acting as a directory service providing the initial keying material for clients to use.
- Routing MLS messages among clients.
The central delivery service can be avoided in protocols using the publish/gossip approach, such as gossipsub.
Concerning keys, each node can generate and disseminate their encryption key among the other nodes, so they can create a local version of the tree that allows for the generation of the group key.
Another important component is the authentication service, which is replaced with SIWE in this specification.
Ethereum-based authentication protocol
Introduction
Sign-in with Ethereum describes how Ethereum accounts authenticate with off-chain services by signing a standard message format parameterized by scope, session details, and security mechanisms. Sign-in with Ethereum (SIWE), which is described in the [EIP 4361 (https://eips.ethereum.org/EIPS/eip-4361), MUST be the authentication method required.
Pattern
Message format (ABNF)
A SIWE Message MUST conform with the following Augmented Backus–Naur Form (RFC 5234) expression.
sign-in-with-ethereum =
[ scheme "://" ] domain %s" wants you to sign in with your
Ethereum account:" LF address LF
LF
[ statement LF ]
LF
%s"URI: " uri LF
%s"Version: " version LF
%s"Chain ID: " chain-id LF
%s"Nonce: " nonce LF
%s"Issued At: " issued-at
[ LF %s"Expiration Time: " expiration-time ]
[ LF %s"Not Before: " not-before ]
[ LF %s"Request ID: " request-id ]
[ LF %s"Resources:"
resources ]
scheme = ALPHA *( ALPHA / DIGIT / "+" / "-" / "." )
; See RFC 3986 for the fully contextualized
; definition of "scheme".
domain = authority
; From RFC 3986:
; authority = [ userinfo "@" ] host [ ":" port ]
; See RFC 3986 for the fully contextualized
; definition of "authority".
address = "0x" 40*40HEXDIG
; Must also conform to captilization
; checksum encoding specified in EIP-55
; where applicable (EOAs).
statement = *( reserved / unreserved / " " )
; See RFC 3986 for the definition
; of "reserved" and "unreserved".
; The purpose is to exclude LF (line break).
uri = URI
; See RFC 3986 for the definition of "URI".
version = "1"
chain-id = 1*DIGIT
; See EIP-155 for valid CHAIN_IDs.
nonce = 8*( ALPHA / DIGIT )
; See RFC 5234 for the definition
; of "ALPHA" and "DIGIT".
issued-at = date-time
expiration-time = date-time
not-before = date-time
; See RFC 3339 (ISO 8601) for the
; definition of "date-time".
request-id = *pchar
; See RFC 3986 for the definition of "pchar".
resources = *( LF resource )
resource = "- " URI
This specification defines the following SIWE Message fields that can be parsed from a SIWE Message by following the rules in ABNF Message Format:
-
schemeOPTIONAL. The URI scheme of the origin of the request. Its value MUST be a RFC 3986 URI scheme. -
domainREQUIRED. The domain that is requesting the signing. Its value MUST be a RFC 3986 authority. The authority includes an OPTIONAL port. If the port is not specified, the default port for the provided scheme is assumed.
If scheme is not specified, HTTPS is assumed by default.
-
addressREQUIRED. The Ethereum address performing the signing. Its value SHOULD be conformant to mixed-case checksum address encoding specified in ERC-55 where applicable. -
statementOPTIONAL. A human-readable ASCII assertion that the user will sign which MUST NOT include '\n' (the byte 0x0a). -
uriREQUIRED. An RFC 3986 URI referring to the resource that is the subject of the signing. -
versionREQUIRED. The current version of the SIWE Message, which MUST be 1 for this specification. -
chain-idREQUIRED. The EIP-155 Chain ID to which the session is bound, and the network where Contract Accounts MUST be resolved. -
nonceREQUIRED. A random string (minimum 8 alphanumeric characters) chosen by the relying party and used to prevent replay attacks. -
issued-atREQUIRED. The time when the message was generated, typically the current time.
Its value MUST be an ISO 8601 datetime string.
expiration-timeOPTIONAL. The time when the signed authentication message is no longer valid.
Its value MUST be an ISO 8601 datetime string.
not-beforeOPTIONAL. The time when the signed authentication message will become valid.
Its value MUST be an ISO 8601 datetime string.
-
request-idOPTIONAL. An system-specific identifier that MAY be used to uniquely refer to the sign-in request. -
resourcesOPTIONAL. A list of information or references to information the user wishes to have resolved as part of authentication by the relying party.
Every resource MUST be a RFC 3986 URI separated by "\n- " where \n is the byte 0x0a.
Signing and Verifying Messages with Ethereum Accounts
-
For Externally Owned Accounts, the verification method specified in ERC-191 MUST be used.
-
For Contract Accounts,
-
The verification method specified in ERC-1271 SHOULD be used. Otherwise, the implementer MUST clearly define the verification method to attain security and interoperability for both wallets and relying parties.
-
When performing ERC-1271 signature verification, the contract performing the verification MUST be resolved from the specified
chain-id. -
Implementers SHOULD take into consideration that [ERC-1271 (https://eips.ethereum.org/EIPS/eip-1271) implementations are not required to be pure functions. They can return different results for the same inputs depending on blockchain state. This can affect the security model and session validation rules.
-
Resolving Ethereum Name Service (ENS) Data
-
The relying party or wallet MAY additionally perform resolution of ENS data, as this can improve the user experience by displaying human friendly information that is related to the
address. Resolvable ENS data include:- The primary ENS name.
- The ENS avatar.
- Any other resolvable resources specified in the ENS documentation.
-
If resolution of ENS data is performed, implementers SHOULD take precautions to preserve user privacy and consent. Their
addresscould be forwarded to third party services as part of the resolution process.
Implementer steps: specifying the request origin
The domain and, if present, the scheme, in the SIWE Message MUST
correspond to the origin from where the signing request was made.
Implementer steps: verifying a signed message
The SIWE Message MUST be checked for conformance to the ABNF Message Format and its signature MUST be checked as defined in Signing and Verifying Messages with Ethereum Accounts.
Implementer steps: creating sessions
Sessions MUST be bound to the address and not to further resolved resources that can change.
Implementer steps: interpreting and resolving resources
Implementers SHOULD ensure that that URIs in the listed resources are human-friendly when expressed in plaintext form.
Wallet implementer steps: verifying the message format
The full SIWE message MUST be checked for conformance to the ABNF defined in ABNF Message Format.
Wallet implementers SHOULD warn users if the substring "wants you to sign in with your Ethereum account" appears anywhere in an [ERC-191
(https://eips.ethereum.org/EIPS/eip-191) message signing request unless
the message fully conforms to the format defined ABNF Message Format.
Wallet implementer steps: verifying the request origin
Wallet implementers MUST prevent phishing attacks by verifying the
origin of the request against the scheme and domain fields in the
SIWE Message.
The origin SHOULD be read from a trusted data source such as the browser window or over WalletConnect ERC-1328 sessions for comparison against the signing message contents.
Wallet implementers MAY warn instead of rejecting the verification if the origin is pointing to localhost.
The following is a RECOMMENDED algorithm for Wallets to conform with the requirements on request origin verification defined by this specification.
The algorithm takes the following input variables:
- fields from the SIWE message.
originof the signing request: the origin of the page which requested the signin via the provider.allowedSchemes: a list of schemes allowed by the Wallet.defaultScheme: a scheme to assume when none was provided. Wallet implementers in the browser SHOULD use https.- developer mode indication: a setting deciding if certain risks should
be a warning instead of rejection. Can be manually configured or
derived from
originbeing localhost.
The algorithm is described as follows:
- If
schemewas not provided, then assigndefaultSchemeas scheme. - If
schemeis not contained inallowedSchemes, then theschemeis not expected and the Wallet MUST reject the request. Wallet implementers in the browser SHOULD limit the list of allowedSchemes to just 'https' unless a developer mode is activated. - If
schemedoes not match the scheme of origin, the Wallet SHOULD reject the request. Wallet implementers MAY show a warning instead of rejecting the request if a developer mode is activated. In that case the Wallet continues processing the request. - If the
hostpart of thedomainandorigindo not match, the Wallet MUST reject the request unless the Wallet is in developer mode. In developer mode the Wallet MAY show a warning instead and continues procesing the request. - If
domainandoriginhave mismatching subdomains, the Wallet SHOULD reject the request unless the Wallet is in developer mode. In developer mode the Wallet MAY show a warning instead and continues procesing the request. - Let
portbe the port component ofdomain, and if no port is contained in domain, assign port the default port specified for the scheme. - If
portis not empty, then the Wallet SHOULD show a warning if theportdoes not match the port oforigin. - If
portis empty, then the Wallet MAY show a warning iforigincontains a specific port. - Return request origin verification completed.
Wallet implementer steps: creating SIWE interfaces
Wallet implementers MUST display to the user the following fields from
the SIWE Message request by default and prior to signing, if they are
present: scheme, domain, address, statement, and resources.
Other present fields MUST also be made available to the user prior to
signing either by default or through an extended interface.
Wallet implementers displaying a plaintext SIWE Message to the user SHOULD require the user to scroll to the bottom of the text area prior to signing.
Wallet implementers MAY construct a custom SIWE user interface by parsing the ABNF terms into data elements for use in the interface. The display rules above still apply to custom interfaces.
Wallet implementer steps: supporting internationalization (i18n)
After successfully parsing the message into ABNF terms, translation MAY happen at the UX level per human language.
Privacy and Security Considerations
- The double ratchet "recommends" using AES in CBC mode. Since encryption must be with an AEAD encryption scheme, we will use AES in GCM mode instead (supported by Noise).
- For the information retrieval, the algorithm MUST include a access control mechanisms to restrict who can call the set and get functions.
- One SHOULD include event logs to track changes in public keys.
- The curve vurve448 MUST be chosen due to its higher security level: 224-bit security instead of the 128-bit security provided by X25519.
- It is important that Bob MUST NOT reuse
SPK.
Considerations related to the use of Ethereum addresses
With respect to the Authentication Service
- If users used their Ethereum addresses as identifiers, they MUST generate their own credentials. These credentials MUST use the digital signature key pair associated to the Ethereum address.
- Other users can verify credentials.
- With this approach, there is no need to have a dedicated Authentication Service responsible for the issuance and verification of credentials.
- The interaction diagram showing the generation of credentials becomes obsolete.
With respect to the Delivery Service
- Users MUST generate their own KeyPackage.
- Other users can verify KeyPackages when required.
- A Delivery Service storage system MUST verify KeyPackages before storing them.
- Interaction diagrams involving the DS do not change.
Consideration related to the onchain component of the protocol
Assumptions
- Users have set a secure 1-1 communication channel.
- Each group is managed by a separate smart contract.
Addition of members to a group
Alice knows Bob’s Ethereum address
- Off-chain - Alice and Bob set a secure communication channel.
- Alice creates the smart contract associated to the group. This smart contract MUST include an ACL.
- Alice adds Bob’s Ethereum address to the ACL.
- Off-chain - Alice sends a request to join the group to Bob. The
request MUST include the contract’s address:
RequestMLSPayload {"You are joining the group with smart contract: 0xabcd"} - Off-chain - Bob responds the request with a digitally signed
response. This response includes Bob’s credentials and key package:
ResponseMLSPayload {sig: signature(ethereum_sk, message_to_sign), address: ethereum_address, credentials, keypackage} - Off-chain - Alice verifies the signature, using Bob’s
ethereum_pkand checks that it corresponds to an address contained in the ACL. - Off-chain - Alice sends a welcome message to Bob.
- Off-chain - Alice SHOULD broadcasts a message announcing the
addition of Bob to other users of the group.
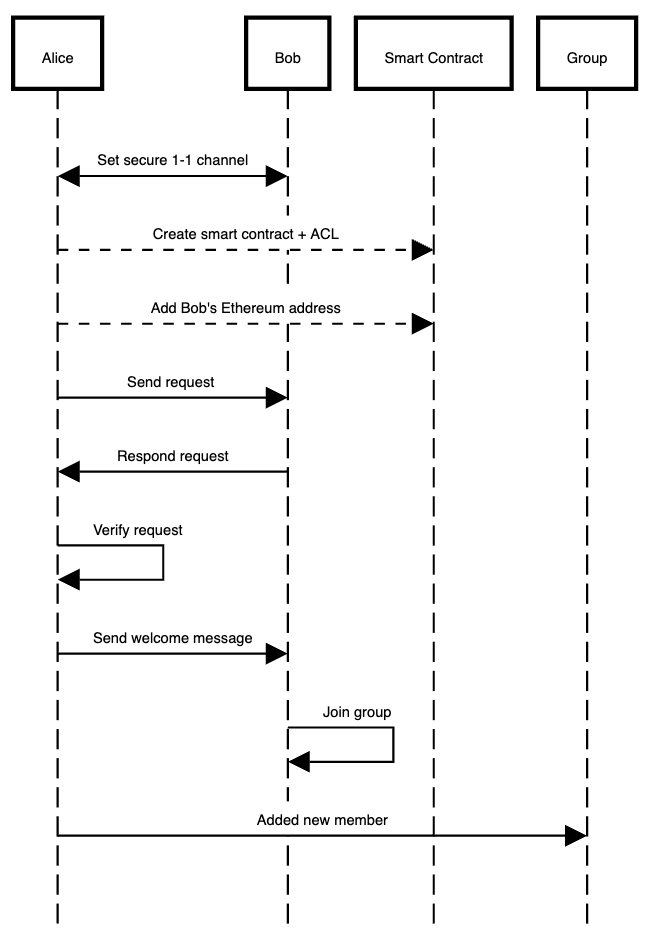
Alice does not know Bob’s Ethereum address
- Off-chain - Alice and Bob set a secure communication channel.
- Alice creates the smart contract associated to the group. This smart contract MUST include an ACL.
- Off-chain - Alice sends a request to join the group to Bob. The
request MUST include the contract’s address:
RequestMLSPayload{"You are joining the group with smart contract: 0xabcd"} - Off-chain - Bob responds the request with a digitally signed
response. This response includes Bob’s credentials, his Ethereum
address and key package:
ResponseMLSPayload {sig: signature(ethereum_sk, message_to_sign), address: ethereum_address, credentials, keypackage} - Off-chain - Alice verifies the signature using Bob’s
ethereum_pk. - Upon reception of Bob’s data, Alice registers data with the smart contract.
- Off-chain - Alice sends a welcome message to Bob.
- Off-chain - Alice SHOULD broadcasts a message announcing the addition of Bob to other users of the group.

Considerations regarding smart contracts
The role of the smart contract includes:
- Register user information and key packages: As described in the previous section.
- Updates of key material.
- Users MUST send any update in their key material to the other users of the group via off-chain messages.
- Upon reception of the new key material, the creator of the contract MUST update the state of the smart contract.
- Deletion of users.
- Any user can submit a proposal for the removal of a user via off-chain message.
- This proposal MUST be sent to the creator of the contract.
- The creator of the contract MUST update the ACL, and send messages to the group for key update.

It is important to note that both user removal and updates of any kind have a similar interaction flow.
- Queries of existing users.
- Any user can query the smart contract to know the state of the group, including existing users and removed ones.
- This aspect MUST be used when adding new members to verify that the prospective key package has not been already used.
Copyright
Copyright and related rights waived via CC0.
References
- Augmented BNF for Syntax Specifications
- Gossipsub
- HMAC-based Extract-and-Expand Key Derivation Function
- Hybrid Public Key Encryption
- Security Analysis and Improvements for the IETF MLS Standard for Group Messaging
- Signed Data Standard
- Sign-In with Ethereum
- Standard Signature Validation Method for Contracts
- The Double Ratchet Algorithm
- The Messaging Layer Security Protocol
- The X3DH Key Agreement Protocol
- Toy Ethereum Private Messaging Protocol
- Uniform Resource Identifier
- WalletConnect URI Format
Logos Research
Logos Research builds public good protocols for the decentralised web. Logos Research acts as a custodian for the protocols that live in the logos-lips repository. With the goal of widespread adoption, Logos Research will make sure the protocols adhere to a set of principles, including but not limited to liberty, security, privacy, decentralisation and inclusivity.
To learn more, visit Logos Research
Research Draft Specifications
Research specifications that have reached draft status live here.
1/COSS
| Field | Value |
|---|---|
| Name | Consensus-Oriented Specification System |
| Slug | 1 |
| Status | draft |
| Type | RFC |
| Category | Best Current Practice |
| Editor | Daniel Kaiser [email protected] |
| Contributors | Oskar Thoren [email protected], Pieter Hintjens [email protected], André Rebentisch [email protected], Alberto Barrionuevo [email protected], Chris Puttick [email protected], Yurii Rashkovskii [email protected], Jimmy Debe [email protected] |
Timeline
- 2026-06-16 —
16e8af1— Chore/separate messaging specs (#361) - 2026-06-12 —
124f895— chore: fix broken links (#357) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347) - 2026-05-11 —
1ac7689— chore: split ift ts specs (#334) - 2026-04-20 —
c3d15a9— COSS overhaul: new statuses, CFR type, raw-spec leniency (#308) - 2026-03-23 —
011eea8— docs(1/coss): add Approved/Verified statuses, CFR doc type, and raw-spec leniency (#301) - 2026-01-16 —
f01d5b9— chore: fix links (#260) - 2026-01-16 —
89f2ea8— Chore/mdbook updates (#258) - 2025-12-22 —
0f1855e— Chore/fix headers (#239) - 2025-12-22 —
b1a5783— Chore/mdbook updates (#237) - 2025-12-18 —
d03e699— ci: add mdBook configuration (#233) - 2025-11-04 —
dd397ad— Update Coss Date (#206) - 2024-10-09 —
d5e0072— cosmetic: fix external links in 1/COSS (#100) - 2024-09-13 —
3ab314d— Fix Files for Linting (#94) - 2024-08-09 —
ed2c68f— 1/COSS: New RFC Process (#4) - 2024-02-01 —
3eaccf9— Update and rename COSS.md to coss.md - 2024-01-30 —
990d940— Rename COSS.md to COSS.md - 2024-01-27 —
6495074— Rename vac/rfcs/01/README.md to vac/01/COSS.md - 2024-01-25 —
bab16a8— Rename README.md to README.md - 2024-01-25 —
a9162f2— Create README.md
This document describes a consensus-oriented specification system (COSS) for building interoperable technical specifications. COSS is based on a lightweight editorial process that seeks to engage the widest possible range of interested parties and move rapidly to consensus through working code.
This specification is based on Unprotocols 2/COSS, used by the ZeromMQ project. It is equivalent except for some areas:
- recommending the use of a permissive licenses, such as CC0 (with the exception of this document);
- miscellaneous metadata, editor, and format/link updates;
- more inheritance from the IETF Standards Process, e.g. using RFC categories: Standards Track, Informational, and Best Common Practice;
- standards track specifications SHOULD follow a specific structure that both streamlines editing, and helps implementers to quickly comprehend the specification
- specifications MUST feature a header providing specific meta information
- raw specifications will not be assigned numbers
- section explaining the IFT Request For Comments specification process managed by Logos Research
License
Copyright (c) 2008-26 the Editor and Contributors.
This Specification is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 3 of the License, or (at your option) any later version.
This specification is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program; if not, see gnu.org.
Change Process
This document is governed by the 1/COSS (COSS).
Language
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119.
Goals
The primary goal of COSS is to facilitate the process of writing, proving, and improving new technical specifications. A "technical specification" defines a protocol, a process, an API, a use of language, a methodology, or any other aspect of a technical environment that can usefully be documented for the purposes of technical or social interoperability.
COSS is intended to above all be economical and rapid, so that it is useful to small teams with little time to spend on more formal processes.
Principles:
- We aim for rough consensus and running code; inspired by the IETF Tao.
- Specifications are small pieces, made by small teams.
- Specifications should have a clearly responsible editor.
- The process should be visible, objective, and accessible to anyone.
- The process should clearly separate experiments from solutions.
- The process should allow deprecation of old specifications.
Specifications should take minutes to explain, hours to design, days to write, weeks to prove, months to become mature, and years to replace. Specifications have no special status except that accorded by the community.
Architecture
COSS is designed around fast, easy to use communications tools. Primarily, COSS uses a wiki model for editing and publishing specifications texts.
- The domain is the conservancy for a set of specifications.
- The domain is implemented as an Internet domain.
- Each specification is a document together with references and attached resources.
- A sub-domain is a initiative under a specific domain.
Individuals can become members of the domain by completing the necessary legal clearance. The copyright, patent, and trademark policies of the domain must be clarified in an Intellectual Property policy that applies to the domain.
Specifications exist as multiple pages, one page per version, (discussed below in "Branching and Merging"), which should be assigned URIs that MAY include an number identifier.
Thus, we refer to new specifications by specifying its domain, its sub-domain and short name. The syntax for a new specification reference is:
<domain>/<sub-domain>/<shortname>
For example, this specification should be lip.logos.co/research/draft/1/coss, if the status were raw.
A number will be assigned to the specification when obtaining draft status. New versions of the same specification will be assigned a new number. The syntax for a specification reference is:
<domain>/<sub-domain>/<number>/<shortname>
For example, this specification is lip.logos.co/research/draft/1/coss. The short form 1/COSS may be used when referring to the specification from other specifications in the same domain.
Specifications (excluding raw specifications) carries a different number including branches.
COSS Lifecycle
Every specification has an independent lifecycle that documents clearly its current status. For a specification to receive a lifecycle status, a new specification SHOULD be presented by the team of the sub-domain. After discussion amongst the contributors has reached a rough consensus, as described in RFC7282, the specification MAY begin the process to upgrade its status.
A specification has eight possible states that reflect its maturity and contractual weight:

Raw Specifications
All new specifications are raw specifications. Changes to raw specifications can be unilateral and arbitrary. A sub-domain MAY use the raw status for new specifications that live under their domain. Raw specifications have no contractual weight.
Draft Specifications
When raw specifications can be demonstrated, they become draft specifications and are assigned numbers. Changes to draft specifications should be done in consultation with users. Draft specifications are contracts between the editors and implementers.
Approved Specifications
When draft specifications have been reviewed and verified by the internal development team, they become approved specifications. Approved specifications are ready to be included in the specification index. Changes to approved specifications should be done in consultation with the development team. Approved specifications are contracts between the editors, the development team, and implementers.
Stable Specifications
When approved specifications are used by third parties, they become stable specifications. Changes to stable specifications should be restricted to cosmetic ones, errata and clarifications. Stable specifications are contracts between editors, implementers, and end-users.
Verified Specifications
When stable specifications have been implemented by a non-IFT entity, they become verified specifications. Verified status indicates external validation of the specification through independent implementation. Changes to verified specifications MUST be restricted to errata and clarifications. Verified specifications are contracts between editors, implementers, and external parties.
Deprecated Specifications
When stable or verified specifications are replaced by newer specifications, they become deprecated specifications. Deprecated specifications should not be changed except to indicate their replacements, if any. Deprecated specifications are contracts between editors, implementers, and end-users.
Retired Specifications
When deprecated specifications are no longer used in products, they become retired specifications. Retired specifications are part of the historical record. They should not be changed except to indicate their replacements, if any. Retired specifications have no contractual weight.
Deleted Specifications
Deleted specifications are those that have not reached maturity (stable) and were discarded. They should not be used and are only kept for their historical value. Only Raw and Draft specifications can be deleted.
Editorial control
A specification MUST have a single responsible editor, the only person who SHALL change the status of the specification through the lifecycle stages.
A specification MAY also have additional contributors who contribute changes to it. It is RECOMMENDED to use a process similar to C4 process to maximize the scale and diversity of contributions.
Unlike the original C4 process however, it is RECOMMENDED to use CC0 as a more permissive license alternative. We SHOULD NOT use GPL or GPL-like license. One exception is this specification, as this was the original license for this specification.
The editor is responsible for accurately maintaining the state of specifications, for retiring different versions that may live in other places and for handling all comments on the specification.
Branching and Merging
Any member of the domain MAY branch a specification at any point. This is done by copying the existing text, and creating a new specification with the same name and content, but a new number. Since raw specifications are not assigned a number, branching by any member of a sub-domain MAY differentiate specifications based on date, contributors, or version number within the document. The ability to branch a specification is necessary in these circumstances:
- To change the responsible editor for a specification, with or without the cooperation of the current responsible editor.
- To rejuvenate a specification that is stable but needs functional changes. This is the proper way to make a new version of a specification that is in stable or deprecated status.
- To resolve disputes between different technical opinions.
The responsible editor of a branched specification is the person who makes the branch.
Branches, including added contributions, are derived works and thus licensed under the same terms as the original specification. This means that contributors are guaranteed the right to merge changes made in branches back into their original specifications.
Technically speaking, a branch is a different specification, even if it carries the same name. Branches have no special status except that accorded by the community.
Conflict resolution
COSS resolves natural conflicts between teams and vendors by allowing anyone to define a new specification. There is no editorial control process except that practised by the editor of a new specification. The administrators of a domain (moderators) may choose to interfere in editorial conflicts, and may suspend or ban individuals for behaviour they consider inappropriate.
Specification Structure
Meta Information
Specifications MUST contain certain metadata fields. It is RECOMMENDED that specification metadata is specified as a YAML header (where possible). This will enable programmatic access to specification metadata.
Fields marked required MUST be present in all specifications at draft status or above. Fields marked optional MAY be omitted, particularly in raw specifications that are still being developed.
| Key | Required | Value | Type | Example |
|---|---|---|---|---|
| name | required | full name | string | Consensus-Oriented Specification System |
| slug | required | number | int | 1 |
| status | required | status | string | draft |
| type | required | document type | string | RFC |
| category | optional | category | string | Best Current Practice |
| tags | optional | 0 or several tags | list | waku-application, waku-core-protocol |
| editor | optional | editor name/email | string | Oskar Thoren [email protected] |
| contributors | optional | contributors | list | - Pieter Hintjens [email protected] - André Rebentisch [email protected] - Alberto Barrionuevo [email protected] - Chris Puttick [email protected] - Yurii Rashkovskii [email protected] |
For raw specifications,
only name and status are strictly required.
All other fields SHOULD be added before the specification is promoted to draft status.
IFT/Logos LIP Process
[!Note] This section is introduced to allow contributors to understand the IFT (Institute of Free Technology) Logos LIP specification process. Other organizations may make changes to this section according to their needs.
Logos Research is a department under the IFT organization that provides RFC (Request For Comments) specification services. This service works to help facilitate the RFC process, assuring standards are followed. Contributors within the service SHOULD assist a sub-domain in creating a new specification, editing a specification, and promoting the status of a specification along with other tasks. Once a specification reaches some level of maturity by rough consensus, the specification SHOULD enter the Logos LIP process. Similar to the IETF working group adoption described in RFC6174, the Logos LIP process SHOULD facilitate all updates to the specification.
Specifications are introduced by projects, under a specific domain, with the intention of becoming technically mature documents. The IFT domain currently houses the following projects:
- Messaging
- Storage
- Blockchain
- Annoncomms
When a specification is promoted to draft status, the number that is assigned MAY be incremental or by the sub-domain and the Logos LIP process. Standards track specifications MUST be based on the Logos LIP template before obtaining a new status. All changes, comments, and contributions SHOULD be documented.
Document Types
The IFT specification process recognizes two document types:
RFC (Request for Comments) is the primary document type for technical specifications. RFCs progress through the full COSS lifecycle (raw → draft → approved → stable → verified). All specifications described in this document are RFCs by default.
CFR (Change for Request) is a document type for proposing changes or amendments to existing specifications. A CFR describes a specific, bounded change to an existing RFC. CFRs follow the same lifecycle as RFCs but are scoped to a single change proposal. All eight lifecycle statuses apply to CFRs. A CFR that reaches stable or verified status MAY be merged back into the target RFC, after which the CFR transitions to deprecated.
Conventions
Where possible editors and contributors are encouraged to:
- Refer to and build on existing work when possible, especially IETF specifications.
- Contribute to existing specifications rather than reinvent their own.
- Use collaborative branching and merging as a tool for experimentation.
- Use Semantic Line Breaks: sembr.
Appendix A. Color Coding
It is RECOMMENDED to use color coding to indicate specification's status. Color coded specifications SHOULD use the following color scheme:








TEMPLATE
| Field | Value |
|---|---|
| Name | RFC Template |
| Slug | 72 |
| Status | raw/draft/approved/stable/verified/deprecated/retired/deleted |
| Type | RFC/CFR |
| Category | Standards Track/Informational/Best Current Practice |
| Editor | Daniel Kaiser [email protected] |
(Info, remove this section)
This section contains meta info about writing LIPs. This section (including its subsections) MUST be removed.
COSS explains the Logos LIP process.
Tags
The tags metadata SHOULD contain a list of tags if applicable.
Currently identified tags comprise
waku/core-protocolfor Waku protocol definitions (e.g. store, relay, light push),waku/applicationfor applications built on top of Waku protocol (e.g. eth-dm, toy-chat),
Abstract
Background / Rationale / Motivation
This section serves as an introduction providing background information and a motivation/rationale for why the specified protocol is useful.
Theory / Semantics
A standard track RFC in stable status MUST feature this section.
A standard track RFC in raw or draft status SHOULD feature this section.
This section SHOULD explain in detail how the proposed protocol works.
It may touch on the wire format where necessary for the explanation.
This section MAY also specify endpoint behaviour when receiving specific messages,
e.g. the behaviour of certain caches etc.
Wire Format Specification / Syntax
A standard track RFC in stable status MUST feature this section.
A standard track RFC in raw or draft status SHOULD feature this section.
This section SHOULD not contain explanations of semantics and
focus on concisely defining the wire format.
Implementations MUST adhere to these exact formats to interoperate with other implementations.
It is fine, if parts of the previous section that touch on the wire format are repeated.
The purpose of this section is having a concise definition
of what an implementation sends and accepts.
Parts that are not specified here are considered implementation details.
Implementors are free to decide on how to implement these details.
An optional implementation suggestions section may provide suggestions
on how to approach implementation details, and,
if available, point to existing implementations for reference.
Implementation Suggestions (optional)
(Further Optional Sections)
Security/Privacy Considerations
A standard track RFC in stable status MUST feature this section.
A standard track RFC in raw or draft status SHOULD feature this section.
Informational LIPs (in any state) may feature this section.
If there are none, this section MUST explicitly state that fact.
This section MAY contain additional relevant information,
e.g. an explanation as to why there are no security consideration
for the respective document.
Copyright
Copyright and related rights waived via CC0.
References
References MAY be subdivided into normative and informative.
normative
A list of references that MUST be read to fully understand and/or implement this protocol. See RFC3967 Section 1.1.
informative
A list of additional references.