ANALYSIS-IMPACT-OF-THE-SERVICE-DECLARATION-PROTOCOL-ON-THE-STATISTICAL-INFERENCE-OF-RELATIVE-STAKE
| Field | Value |
|---|---|
| Name | [Analysis] Impact of the Service Declaration Protocol on the Statistical Inference of Relative Stake |
| Slug | 192 |
| Status | raw |
| Category | Informational |
| Editor | Alexander Mozeika [email protected] |
| Contributors | Filip Dimitrijevic [email protected] |
Timeline
- 2026-05-29 —
67e498e— chore: fix math issues (#350) - 2026-05-28 —
d45eed2— Chore: mirror blochain specs into github/mdbook (#347)
Revision History
| Version | Changes | Date |
|---|---|---|
| 1.0.0 | Initial revision. | 2025-08-22 |
Introduction
The Service Declaration Protocol (SDP) introduces a piece of a priori information: the knowledge that a node's relative stake cannot be less than a known threshold, . Our research investigates the significance of the impact of this information on the statistical inference of relative stake. We propose a new estimator which explicitly utilises by setting any estimated stake below this threshold to .
Our new estimator works better because it fixes estimation errors at the lower end. When a node's true stake value () is close to the minimum threshold (), the standard maximum likelihood (ML) estimator often produces values that are too low. By automatically adjusting these too-low estimates up to the minimum threshold (), our new approach reduces errors. This improvement can be measured as a lower mean squared error (MSE) compared to the true stake value (). Thus any party, including potential adversaries, performing stake inference gains in accuracy by using the new estimator.
Numerical experiments demonstrate reduction in MSE of the new estimator compared to the ML estimator, particularly for stakes near . For example, for used in experiments, a reduction of MSE by a (approx.) factor of at most was observed. Furthermore, the probability, measured in the same experiment, that the inferred stake falls within a desired accuracy interval is higher (by factor of (approx.) at least) when the new estimator is used. While the advantage diminishes for much higher stake values where both estimators converge, the heightened accuracy near the critical threshold presents a meaningful enhancement for any party performing stake inference, including potential adversaries.
Key Findings
- Introduction of a priori information: The Service Declaration Protocol (SDP) introduces the knowledge that a node's relative stake cannot be less than a threshold (), which impacts statistical inference of relative stake.
- New estimator proposed: The research introduces a new estimator that explicitly uses α₀ by setting any estimated stake below this threshold to .
- Improved accuracy: The new estimator performs better because it corrects estimation errors at the lower end, particularly when a node's true stake value is close to the minimum threshold.
- Measurable improvements: Numerical experiments show:
- Reduction in Mean Squared Error (MSE) of the new estimator compared to the ML estimator, particularly for stakes near .
- For , MSE reduction by a factor of approximately was observed.
- Higher probability (by a factor of approximately 3) that inferred stake falls within desired accuracy intervals.
- Statistical significance: The advantage diminishes for much higher stake values where both estimators converge, but the enhanced accuracy near the critical α₀ threshold presents a meaningful improvement for any party performing stake inference.
- Security implications: This improvement benefits anyone performing stake inference, including potential adversaries.
The research provides mathematical proof and numerical simulations to validate these findings, showing that the proposed estimator is both unbiased and consistent in the limit of large number of observations.
Overview
This document examines the impact of minimum stake threshold, introduced in the SDP, on the statistical inference of relative stake along the following points:
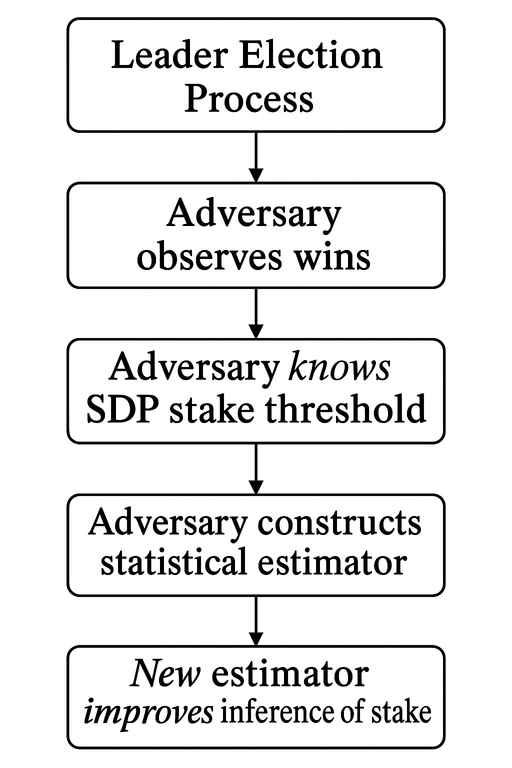
In particular:
- We consider the Leader Election Process where nodes allowed to participate only if their relative stake is no less than some prescribed by SDP threshold.
- We assume that the Adversary observes wins (and losses) of nodes and uses statistical inference to infer relative stake of nodes.
- The Adversary knows the SDP stake threshold, and using this information, the Adversary constructs a statistical estimator.
- This New estimator improves inference of stake when compared with an estimator which doesn’t use the SDP threshold. The simulation of adversarial inference shows that those most affected by this improvement are the nodes with values of relative stake close to the threshold.
Analysis
The Model
The relative stake of node , , is computed via the formula , where is the stake of node . We assume that the total stake can be inferred (with high accuracy) by using the total stake inference algorithm. We note that for the set , i.e. relative stakes of all nodes, it is possible that . It is known, through the declaration of the Service Declaration Protocol (SDP), that the relative stake of a node is at least . For , the relative stake of a node can be written as , where is unknown. Intuitively, this suggests that if, relative to the , the minimum stake is large, then then there is less “uncertainty” about the relative stake .
Node participates in the leader election and its probability of winning is given by the “lottery” function
where is the parameter of the consensus. Since the lottery function is a monotonically increasing function of relative stake, for the relative stake we have , i.e. the prob. of winning for nodes with relative stake greater than is higher.
Inference of relative stake
For the fractionof wins in the observations of the leader election process of a node the (naive) statistical estimator of , , is the solution of the equation given by
We note that for we have that . The estimator is biased because
where the average is defined in the Appendix. However, the average and the variance . If when then in this (”large number of observations”) limit we have
i.e. is consistent estimator of the relative stake .
Similarly to the estimator of, we construct new estimator of relative stake
The above can be written as follows
We note that from which follows that
but we showed that for a large number of observations, and hence in this limit.
Let us consider the (squared) distance
From the above follows the difference
Now, because , we have the following inequality
and hence
i.e. the mean squared error (MSE) of the estimator is greater than the MSE of the estimator . Furthermore, for the MSE of we have
Now is a consistent estimator of the relative stake and hence in the large number of observations limit, but , so is also a consistent estimator of the relative stake .
Simulations confirm that MSE of the estimator is greater than the MSE of the new estimator , as can be seen in the figures below.
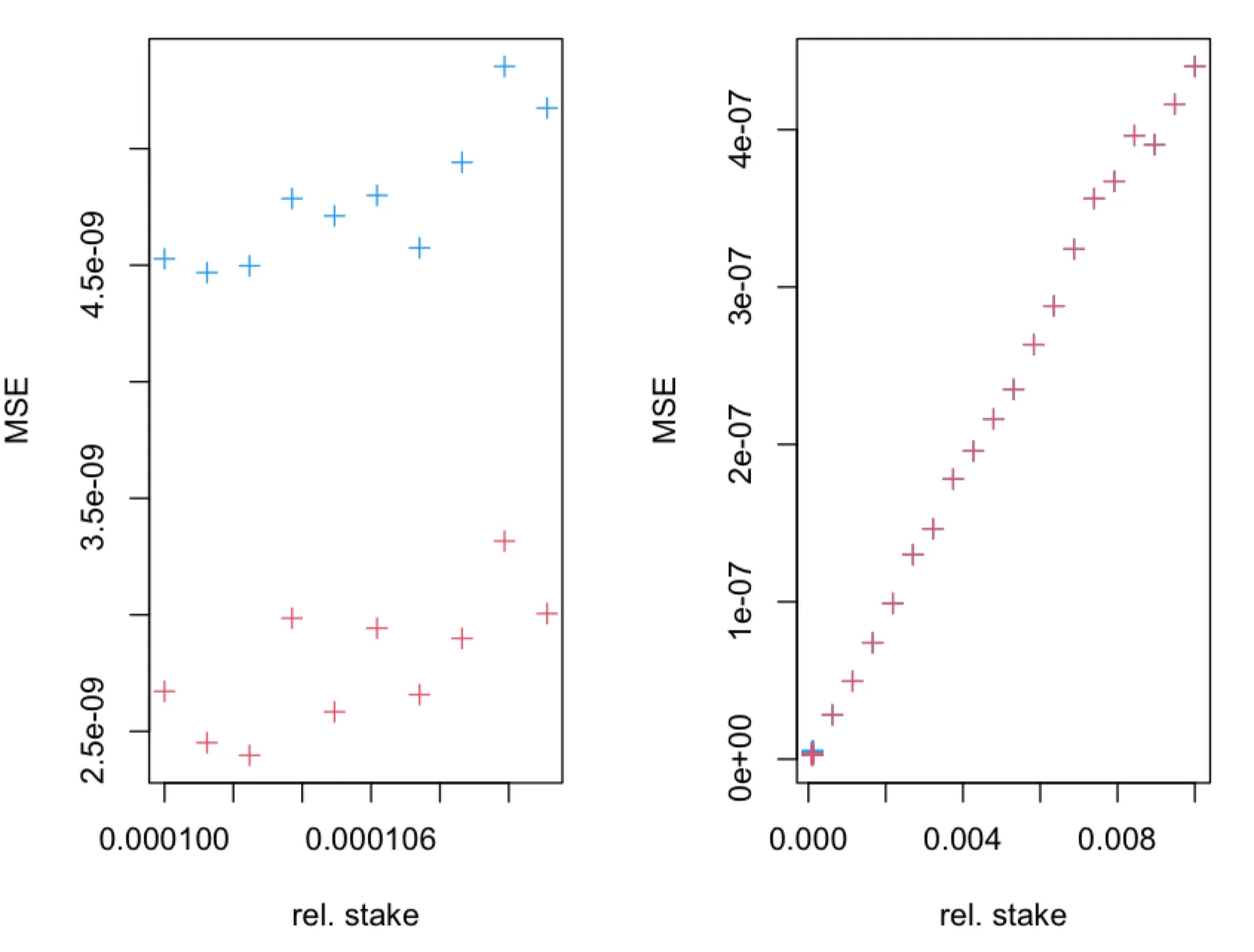
The MSE of the estimator (blue + symbols) and (red + symbols), obtained in simulations of leader election process, as a function of true relative stake , where . The leader election process, with parameter, was simulated for time-slots. The fraction of observed slots is .
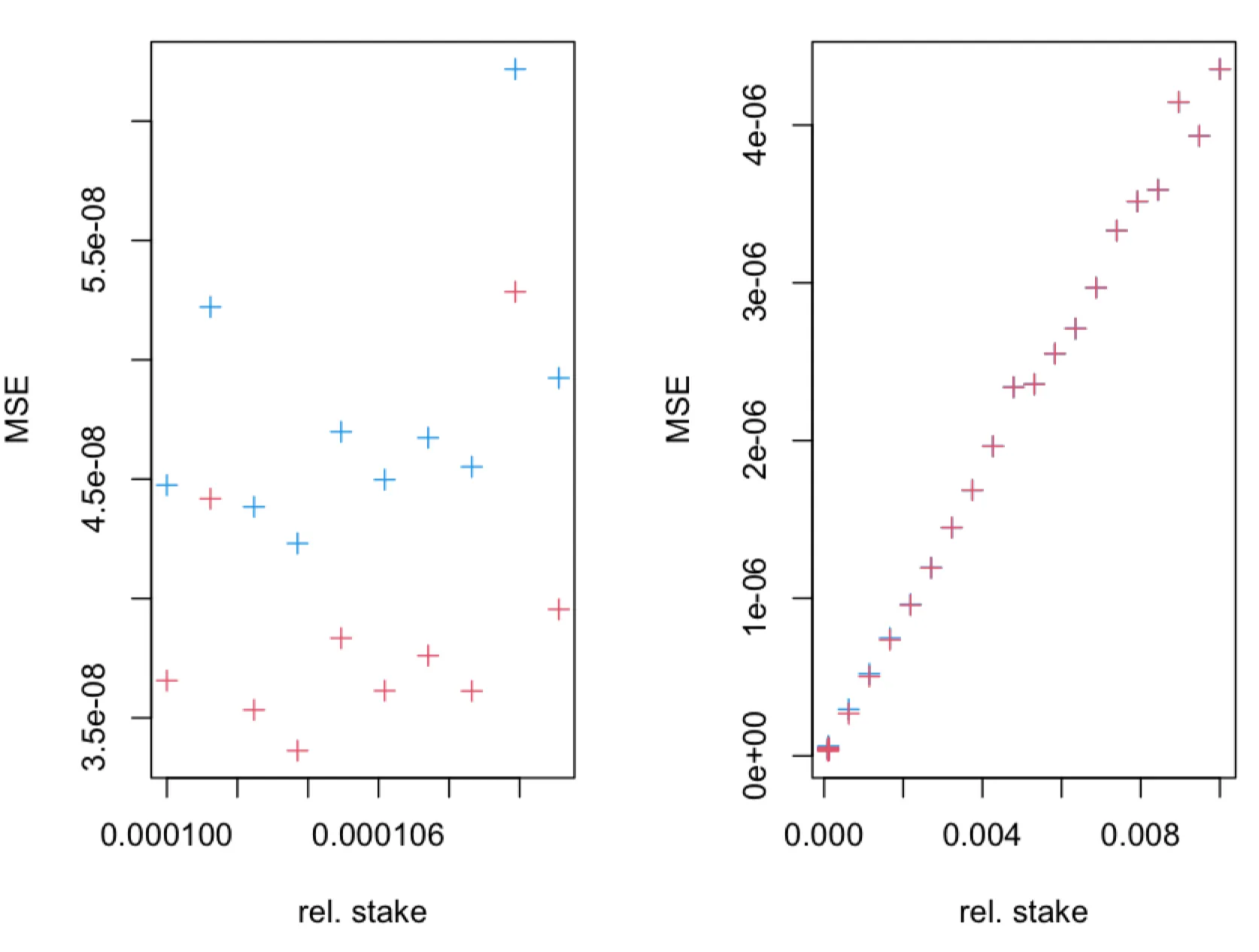
The MSE of the estimator (blue + symbols) and (red + symbols), obtained in simulations of leader election process, as a function of true relative stake , where . The leader election process, with parameter, was simulated for time-slots. The fraction of observed slots is .
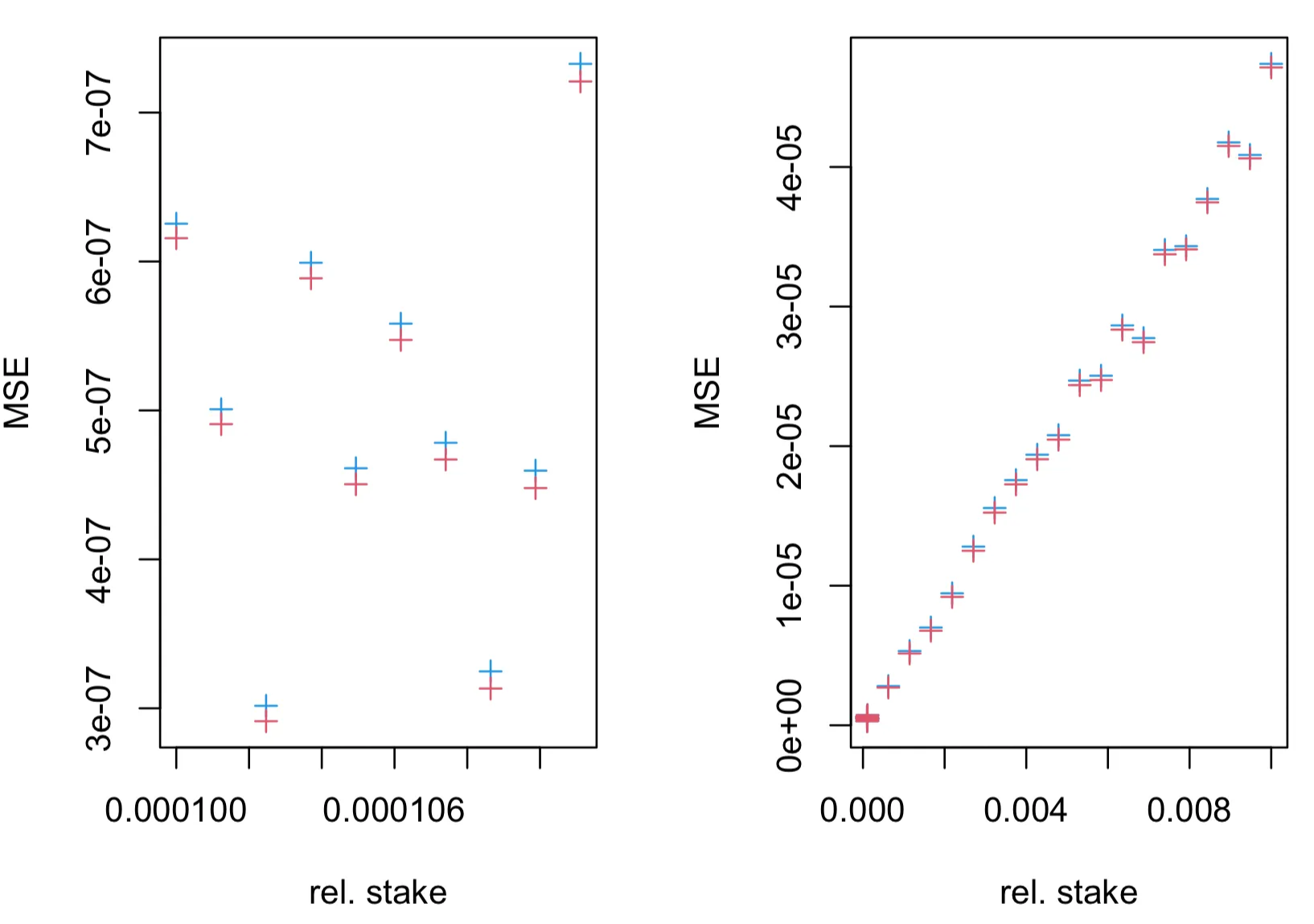
The MSE of the estimator (blue + symbols) and (red + symbols), obtained in simulations of leader election process, as a function of true relative stake , where . The leader election process, with parameter, was simulated for time-slots. The fraction of observed slots is .
We are interested in the probability which can be seen as adversarial "confidence". Here prescribes desired “accuracy” of the inference. We note that the probability can be estimated analytically for large . If for a given (accuracy) parameter we have that then the adversary has an advantage by using the new estimator, i.e. an adversary which knows that has a higher confidence than the adversary which doesn’t know the latter.
Recall that . We note that , provided . Let us assume (without loss of generality) that for some . Then, from follows that . Hence, if this inequality is satisfied, an adversary may have advantage. We compute the probabilities and using simulation and find that the adversary has advantage for the relative stake , as can be seen in figures below.
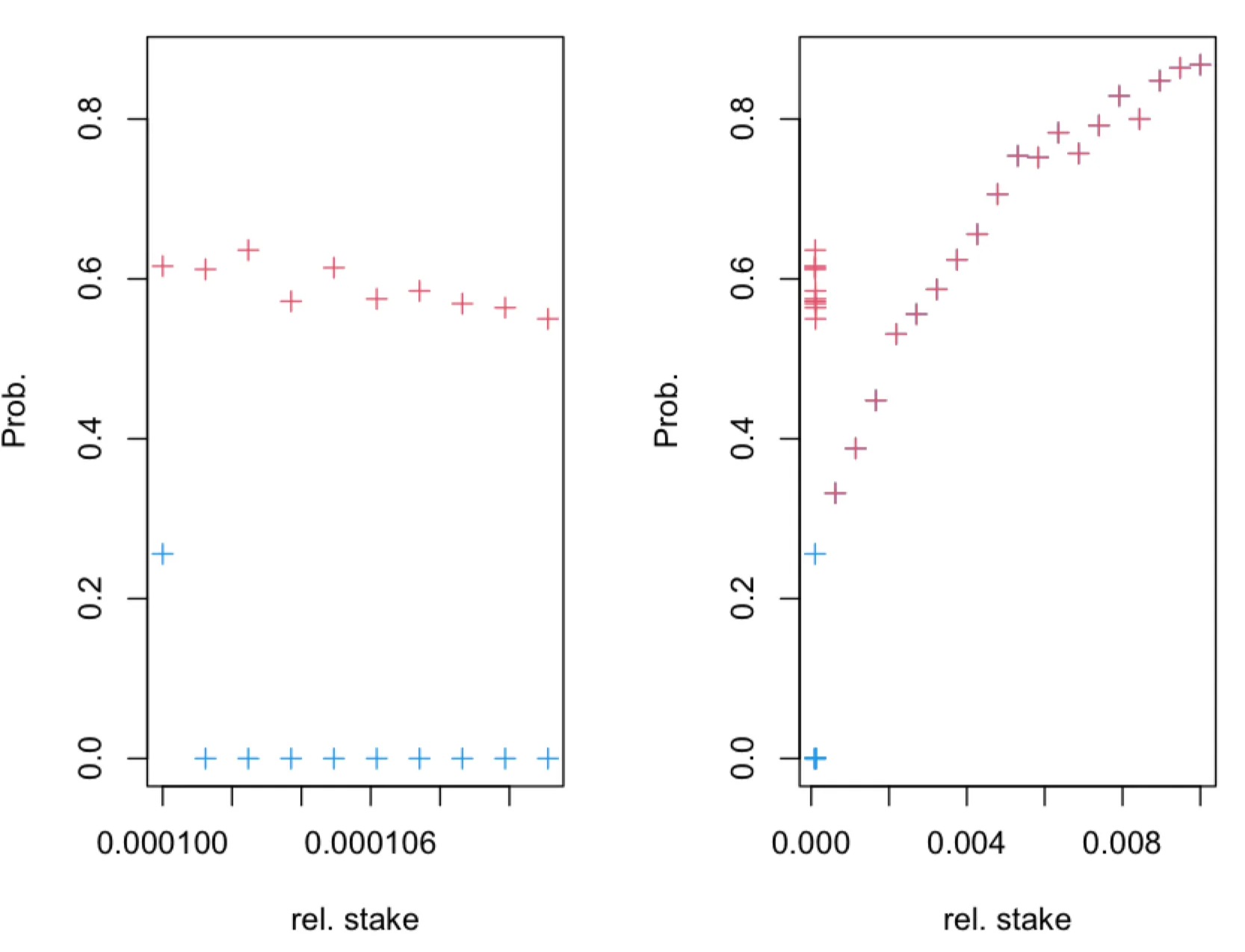
The probability (blue + symbols) and (red + symbols), obtained in simulations of leader election process for , as a function of true relative stake , where . The leader election process, with parameter, was simulated for time-slots. The fraction of observed slots is .
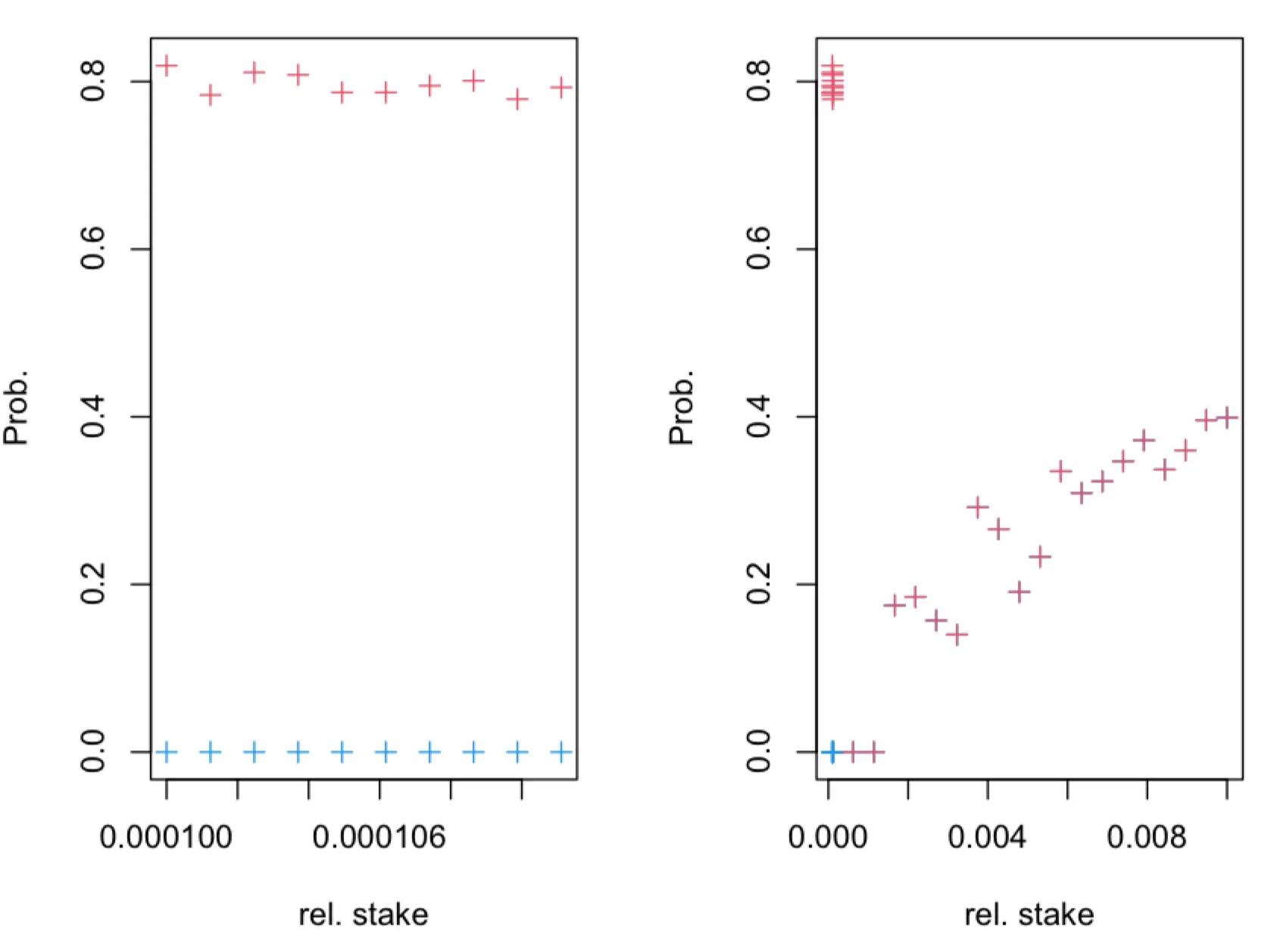
The probability (blue + symbols) and (red + symbols), obtained in simulations of leader election process for , as a function of true relative stake , where . The leader election process, with parameter, was simulated for time-slots. The fraction of observed slots is .
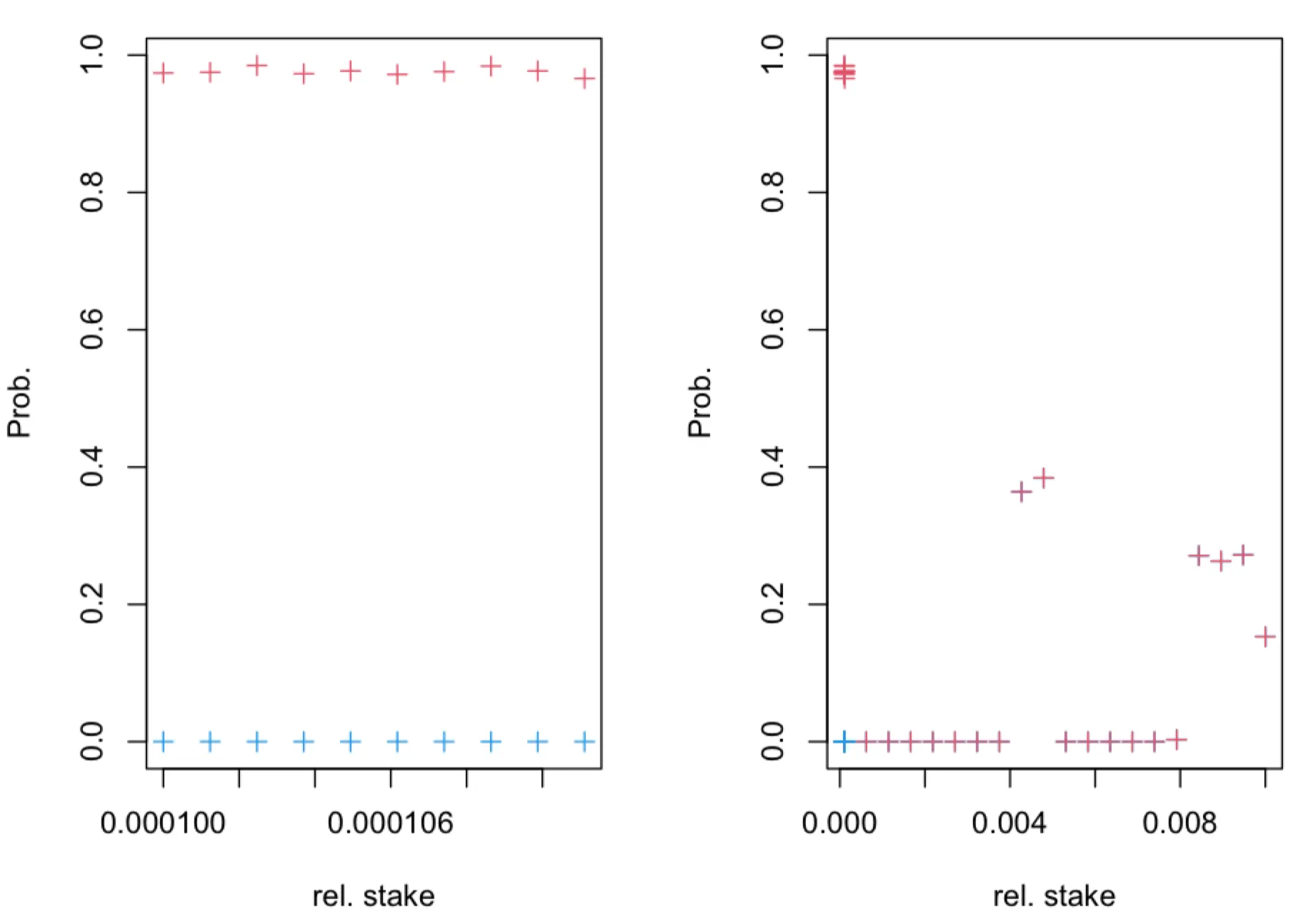
The probability (blue + symbols) and (red + symbols), obtained in simulations of leader election process for , as a function of true relative stake , where . The leader election process, with parameter, was simulated for time-slots. The fraction of observed slots is .
Numerical Experiments
In this section, we compare performance of the statistical estimators and in a single run of a simulation. This can be seen as a scenario where two adversaries collect the same data from the leader election process, but one of the adversaries knows and uses this in the statistical inference. To simulate the statistical inference of relative stake in one epoch ( time-slots) of the leader election process with parameter , we sampled random (stake) values from the Pareto distribution with shape parameter and scale parameter . The histogram of (relative) stake values is given below
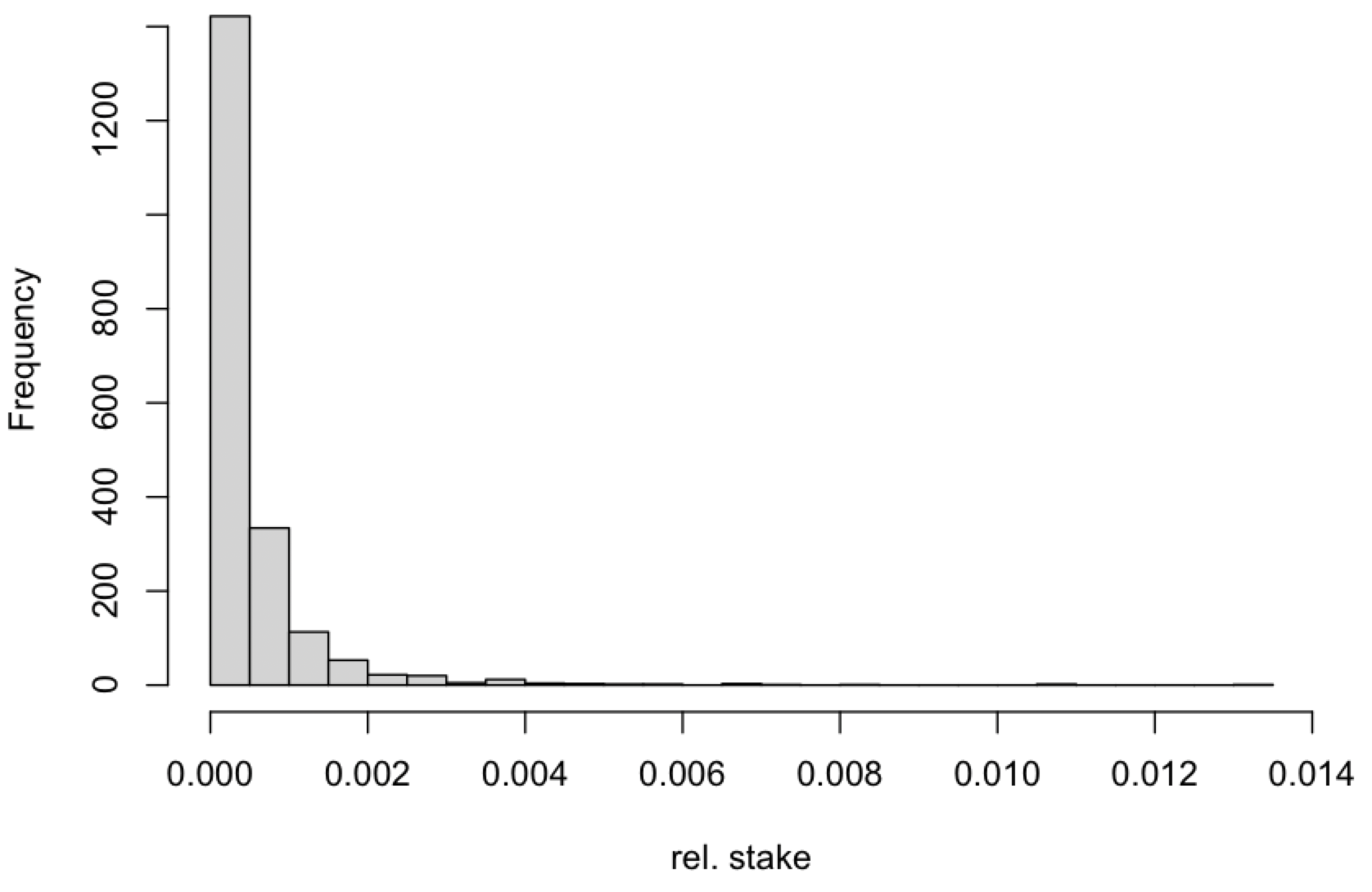
We consider inference only for nodes with the highest relative stake and for nodes with relative stake just above the threshold . We consider a scenario where fraction of time-slots of the leader election process are observed by adversary. Here we find differences between estimators only for nodes with relative stake close to as can be seen in the figures below.
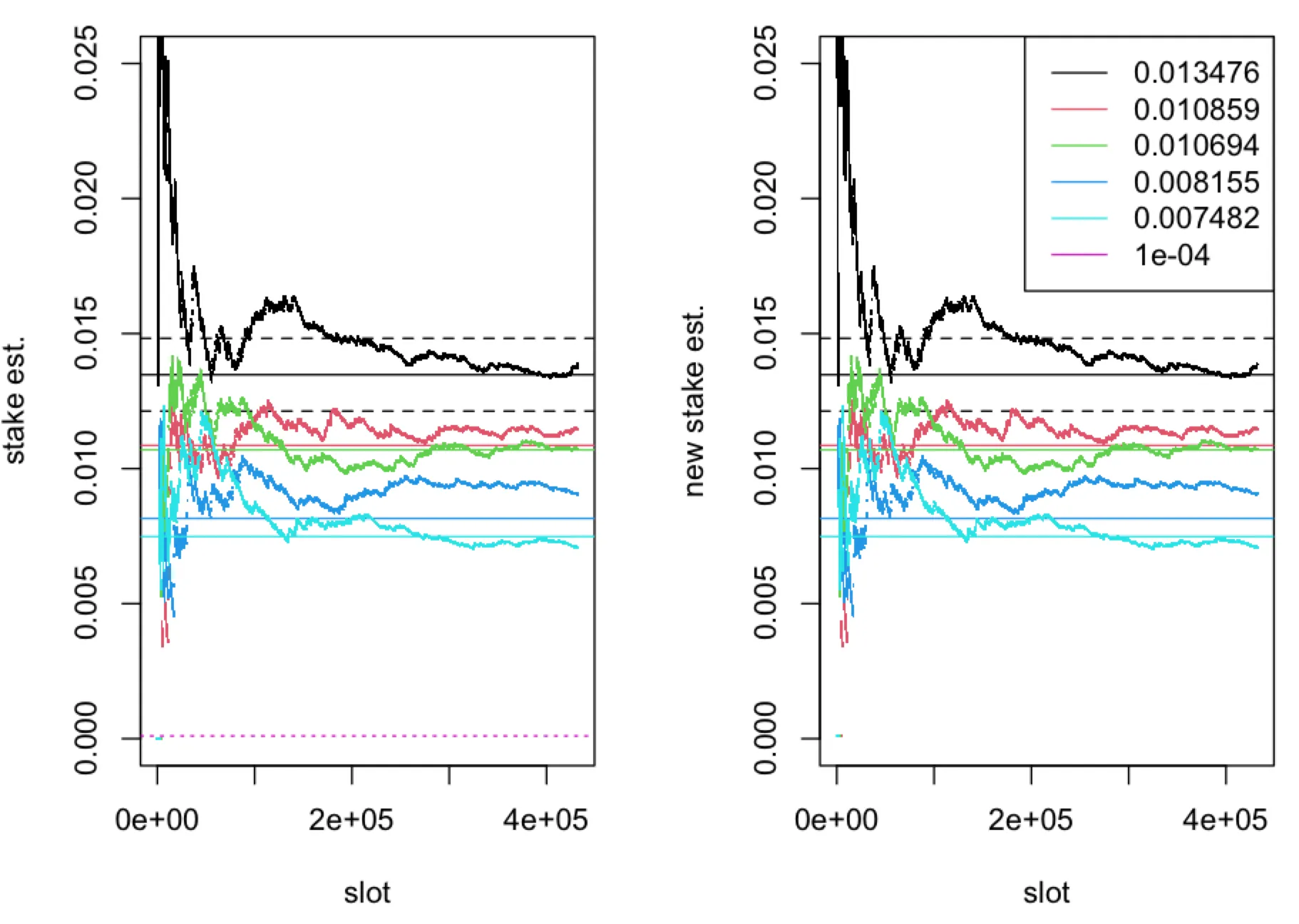
The (relative) stake estimator (left panel) and (right panel), computed in one epoch ( time-slots) of the leader election process with parameter , plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. The boundaries of the interval for and are represented by dashed horizontal lines. The dotted horizontal line corresponds to . The fraction of observed slots is .
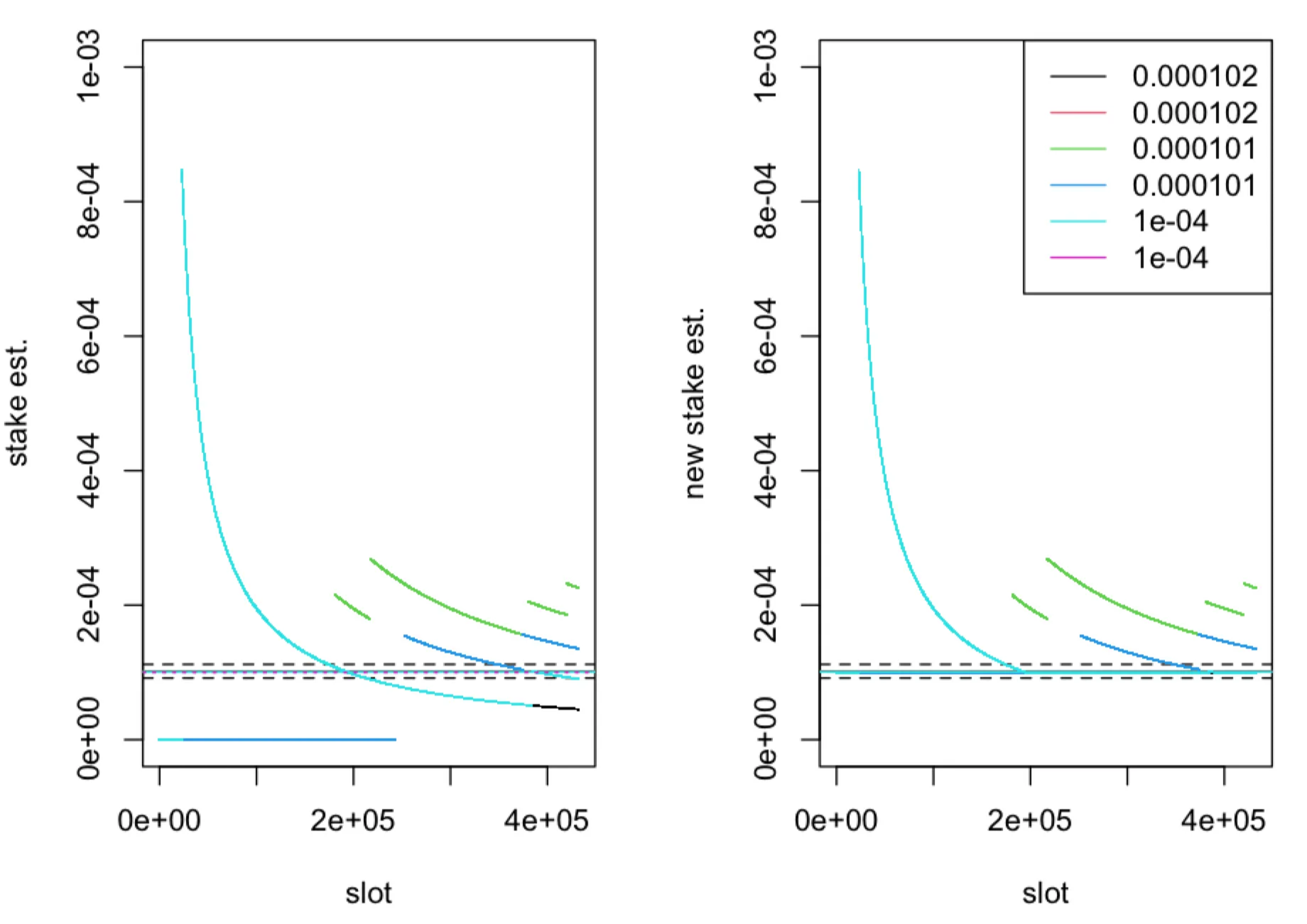
The (relative) stake estimator (left panel) and (right panel), computed in one epoch ( time-slots) of the leader election process with parameter , plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. The boundaries of the interval for and are represented by dashed horizontal lines. The dotted horizontal line corresponds to . The fraction of observed slots is .
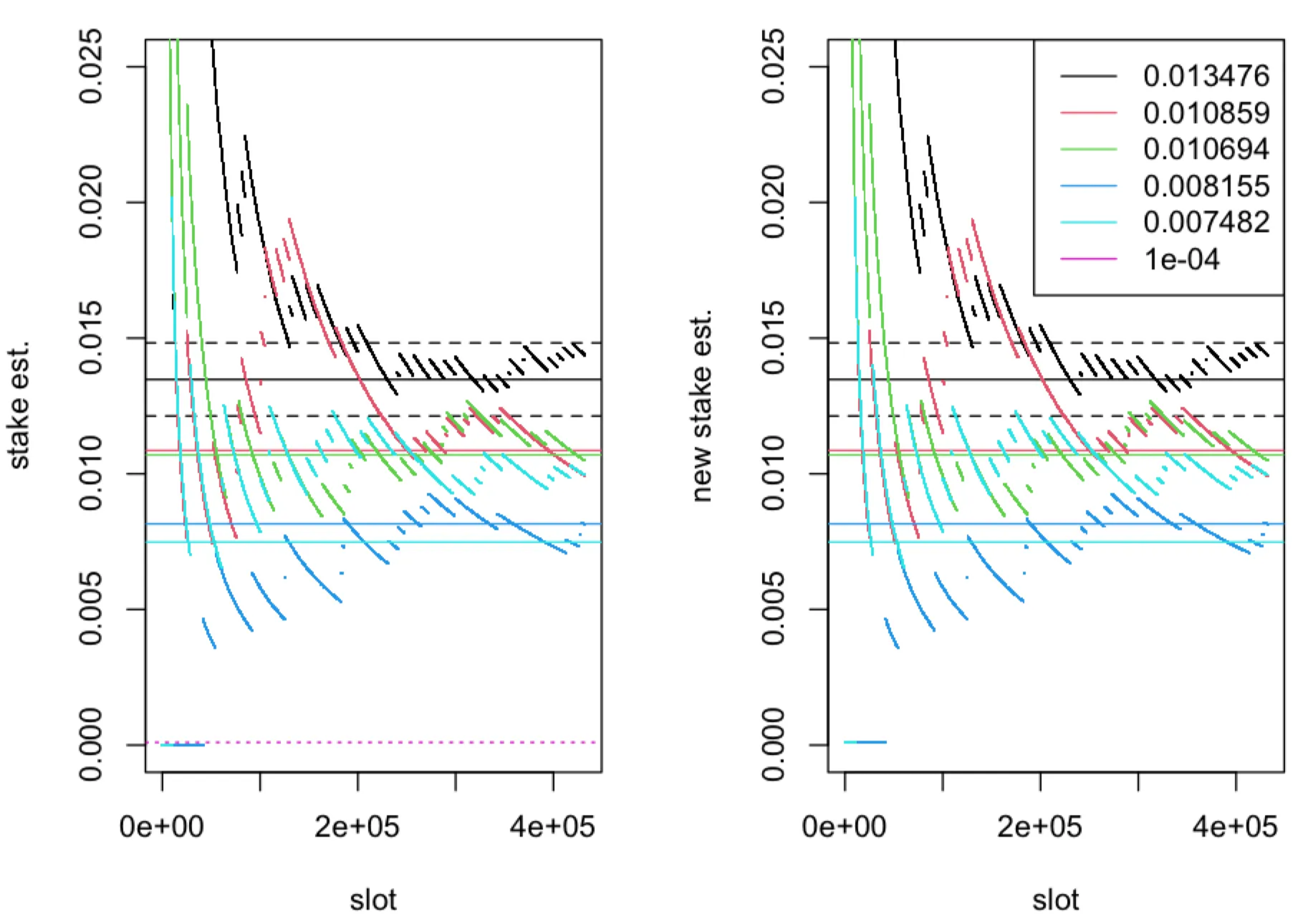
The (relative) stake estimator (left panel) and (right panel), computed in one epoch ( time-slots) of the leader election process with parameter , plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. The boundaries of the interval for and are represented by dashed horizontal lines. The dotted horizontal line corresponds to . The fraction of observed slots is .
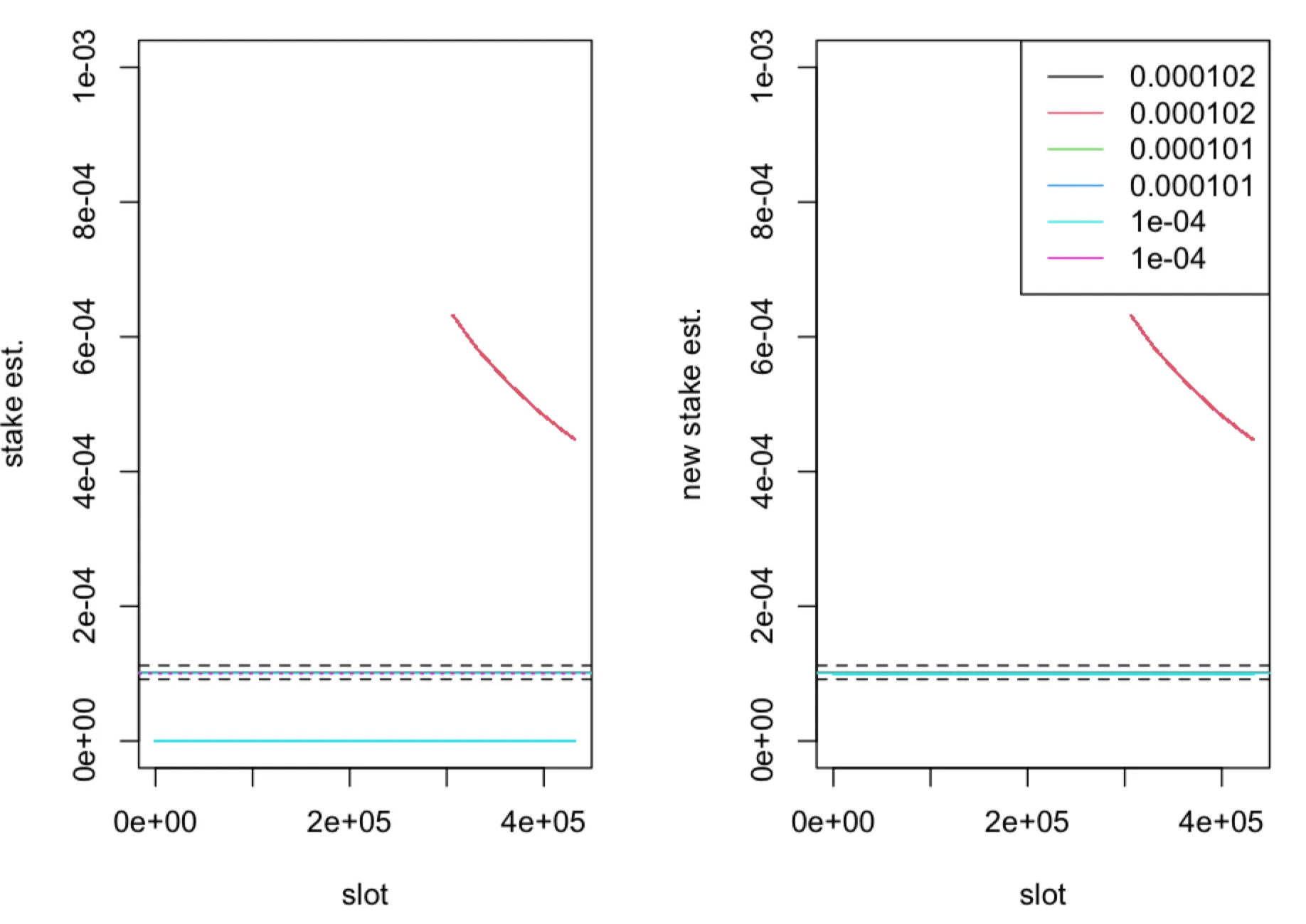
The (relative) stake estimator (left panel) and (right panel), computed in one epoch ( time-slots) of the leader election process with parameter , plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. The boundaries of the interval for and are represented by dashed horizontal lines. The dotted horizontal line corresponds to . The fraction of observed slots is .
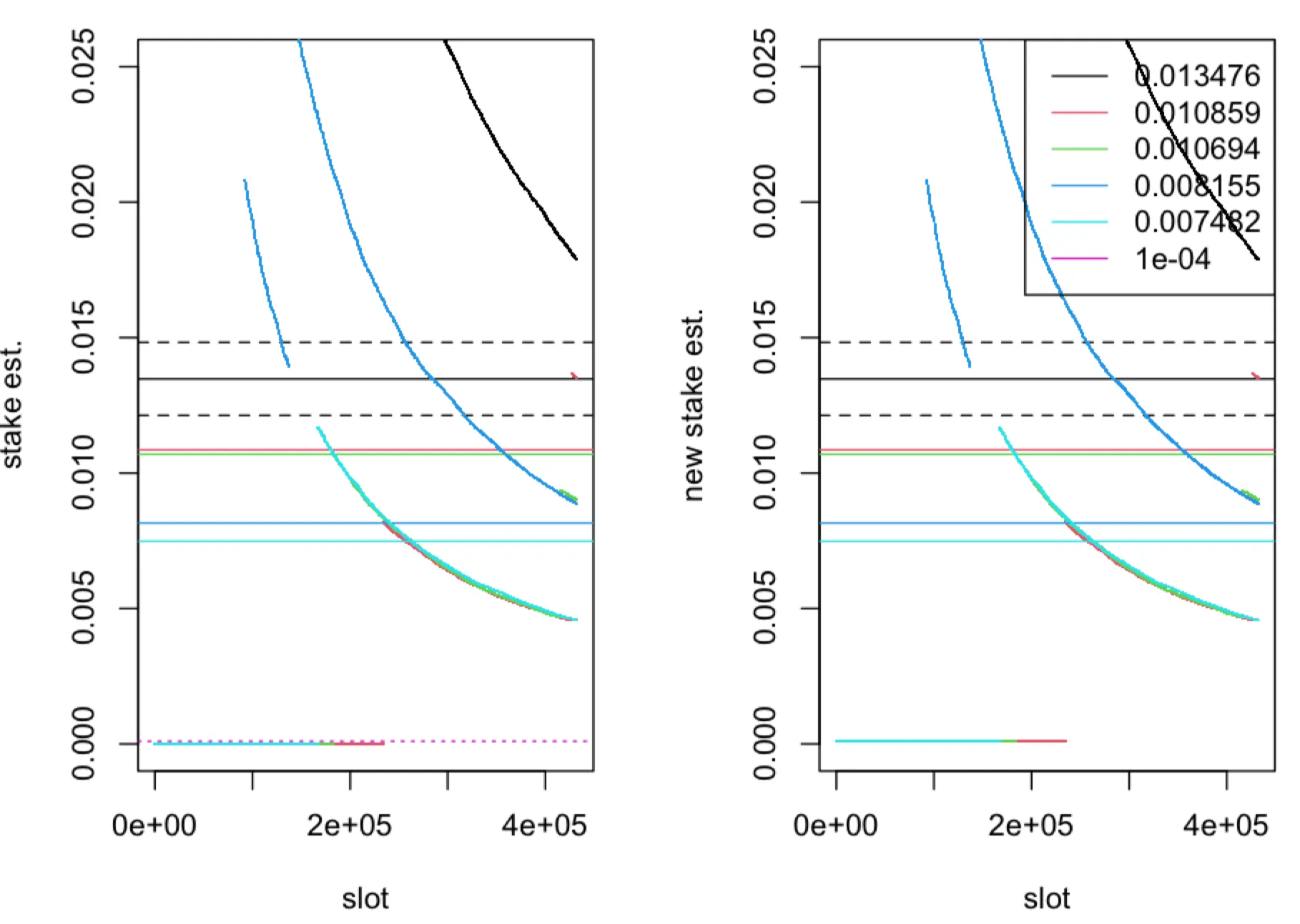
The (relative) stake estimator (left panel) and (right panel), computed in one epoch ( time-slots) of the leader election process with parameter , plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. The boundaries of the interval for and are represented by dashed horizontal lines. The dotted horizontal line corresponds to . The fraction of observed slots is .
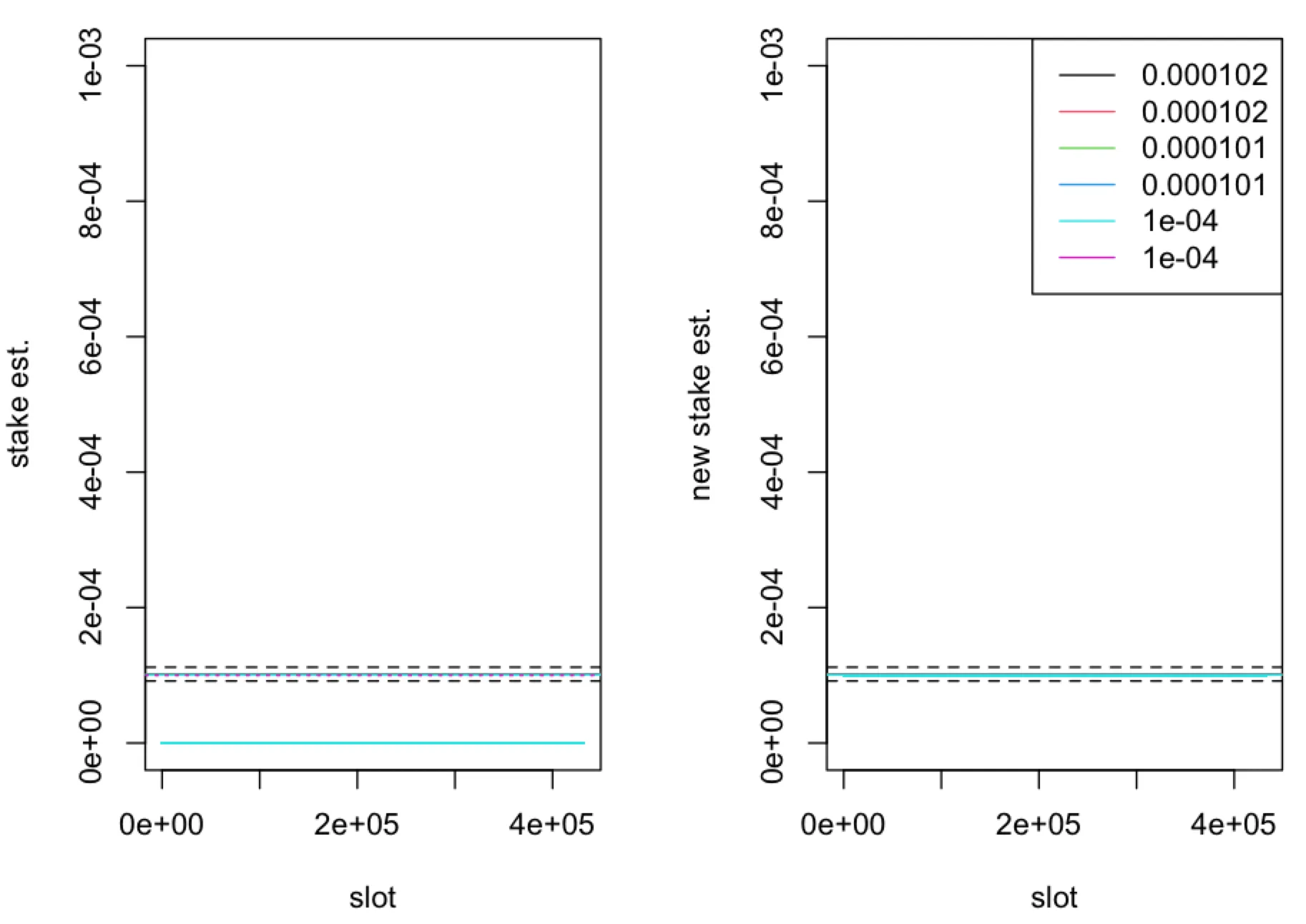
The (relative) stake estimator (left panel) and (right panel), computed in one epoch ( time-slots) of the leader election process with parameter , plotted as a function of time-slots for five nodes with true (relative stake) , represented by solid horizontal lines. The boundaries of the interval for and are represented by dashed horizontal lines. The dotted horizontal line corresponds to . The fraction of observed slots is .
Appendix
Inference of probability
The leader election process is governed by the probability distribution
of the outcome of election , where models outcome ( loss/win) for node in time-slot . The fraction of observed wins of node in one epoch is
where , with , is the total number of observations.
The average with respect to the leader election process gives us
i.e. is unbiased statistical estimator of prob. of winning . In the above is the averaging “operator” defines as
where . Since and , from above follows that .
The variance of is given by
If as , i.e. for a large number of observations, then , i.e. is a consistent estimator of the prob. .
Let us define the new estimator of as follows
The average with respect to leader election process gives us
i.e. the estimator has (positive) bias. We expect that in the limit as , i.e. for a large number of observations, the average . We note that since , we have that
and
Now, for by the Markov’s inequality we have
where . Using the definition, the average on the RHS of the above can be computed as follows
Using above result in the inequality we obtain
Furthermore, optimising the RHS in above with respect to we obtain the inequality
We note that is monotonic decreasing function of which is exactly zero when and hence this function is negative for . Hence we have the following inequality
where when .
From above follows that in the limit as , i.e. for a large number of observations. Using the latter in the upper bound gives us that in this limit. If in the limit of large number of observations we also have that the then is a consistent estimator of the prob. .
For , where we defined , the is given by
In the Variance section we show that
Hence in the limit of large number of observations .
Thus from above follows that
is unbiased and consistent estimator of the prob. in the limit of large number of observations as .
For the mean squared error (MSE) of the estimator is given by
Assuming that the variables are exactly the same as in the above, the MSE of the estimator is given by
Consider the difference as follows
Now the last line in the above can be bounded as follows
Hence
Thus, the MSE of the unbiased estimator is greater that the MSE of the biased, but consistent, estimator .
Variance of
For , where , we consider the variance
First, we consider the covariance
Because of , from the above it follows that .
Second, we consider the variance
Thus, from the above it follows that . The latter with implies which using the variance equation gives us that