NOMOSDA-CRYPTOGRAPHIC-PROTOCOL
| Field | Value |
|---|---|
| Name | NomosDA Cryptographic Protocol |
| Slug | 148 |
| Status | raw |
| Category | Standards Track |
| Editor | Mehmet Gonen [email protected] |
| Contributors | Álvaro Castro-Castilla [email protected], Thomas Lavaur [email protected], Daniel Kashepava [email protected], Marcin Pawlowski [email protected], Daniel Sanchez Quiros [email protected], Filip Dimitrijevic [email protected] |
Timeline
- 2026-01-30 —
0ef87b1— New RFC: CODEX-MANIFEST (#191) - 2026-01-30 —
25ebb3a— Replace nomosda-encoding with da-cryptographic-protocol (#264)
Abstract
This document describes the cryptographic protocol underlying NomosDA, the data availability (DA) layer for the Nomos blockchain. NomosDA ensures that all blob data submitted is made available and verifiable by all network participants, including sampling clients and validators. The protocol uses Reed–Solomon erasure coding for data redundancy and KZG polynomial commitments for cryptographic verification, enabling efficient and scalable data availability sampling.
Keywords: NomosDA, data availability, KZG, polynomial commitment, erasure coding, Reed-Solomon, sampling, BLS12-381
Semantics
The keywords "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119.
Definitions
| Terminology | Description |
|---|---|
| Blob | A unit of data submitted to NomosDA for availability guarantees. |
| Chunk | A 31-byte field element in the BLS12-381 scalar field. |
| DA Node | A node responsible for storing and serving column data. |
| Encoder | The entity that transforms blob data into encoded form with proofs. |
| Sampling Client | A client (e.g., light node) that verifies availability by sampling columns. |
| KZG Commitment | A polynomial commitment using the Kate-Zaverucha-Goldberg scheme. |
| Reed-Solomon Coding | An erasure coding scheme used for data redundancy. |
| Row Polynomial | A polynomial interpolated from chunks in a single row. |
| Combined Polynomial | A random linear combination of all row polynomials. |
Notations
| Symbol | Description |
|---|---|
| Polynomial interpolated from the chunks in row . | |
| KZG commitment of the row polynomial . | |
| Combined polynomial formed as a random linear combination of all row polynomials. | |
| KZG commitment of the combined polynomial . | |
| Primitive -th root of unity in the finite field. In this protocol, . | |
| Random scalar generated using the Fiat–Shamir heuristic from row commitments. | |
| KZG evaluation proof for column of the combined polynomial. | |
| Combined evaluation of column (i.e., ). | |
| Number of columns in the original data matrix. | |
| Number of rows in the data matrix. |
Background
To achieve data availability, the blob data is first encoded using Reed–Solomon erasure coding and arranged in a matrix format. Each row of the matrix is interpreted as a polynomial and then committed using a KZG polynomial commitment. The columns of this matrix are then distributed across a set of decentralized DA nodes.
Rather than requiring individual proofs for each chunk, NomosDA uses a random linear combination of all row polynomials to construct a single combined polynomial. This allows for generating one proof per column, which enables efficient and scalable verification without sacrificing soundness. Sampling clients verify availability by selecting random columns and checking that the data and proof they receive are consistent with the committed structure. Because each column intersects all rows, even a small number of sampled columns provides strong confidence that the entire blob is available.
Protocol Stages
The protocol is structured around three key stages:
- Encoding: Transform blob data into a matrix with commitments and proofs.
- Dispersal: Distribute columns to DA nodes for storage.
- Sampling: Verify data availability by sampling random columns.
Design Principles
The reason for expanding the original data row-wise is to ensure data availability by sending a column to each DA node and obtaining a sufficient number of responses from different DA nodes for sampling. Three core commitment types are used, and verification is done via column sampling:
-
Row commitment: Ensures the integrity of the original and RS-encoded data and binds the order of chunks within each row.
-
Combined commitment: Constructed by the verifier using a random linear combination of the row commitments. Used to verify the encoder's single proof per column and ensures that the column data is consistent with the committed row structure. Even if a single chunk is invalid, the combined evaluation will likely fail due to the unpredictability of the random coefficients.
-
Column sampling: Allows sampling clients to verify data availability efficiently by checking a small number of columns. With the combined commitment and a single proof, the sampling client can validate that an entire column is consistent with the committed data.
Protocol Specification
Encoding
In the NomosDA protocol, encoders perform the encoding process by dividing the blob data into chunks. Each chunk represents a 31-byte element in the scalar finite field used for the BLS12-381 elliptic curve. 31 bytes are chosen instead of 32 bytes because some 32-byte elements will exceed the BLS12-381 modulus, making it impossible to recover the data later.
The matrix representation has columns which include chunks each. The row and column numbers used in the representation are decided based on the size of the block data and the number of DA nodes.
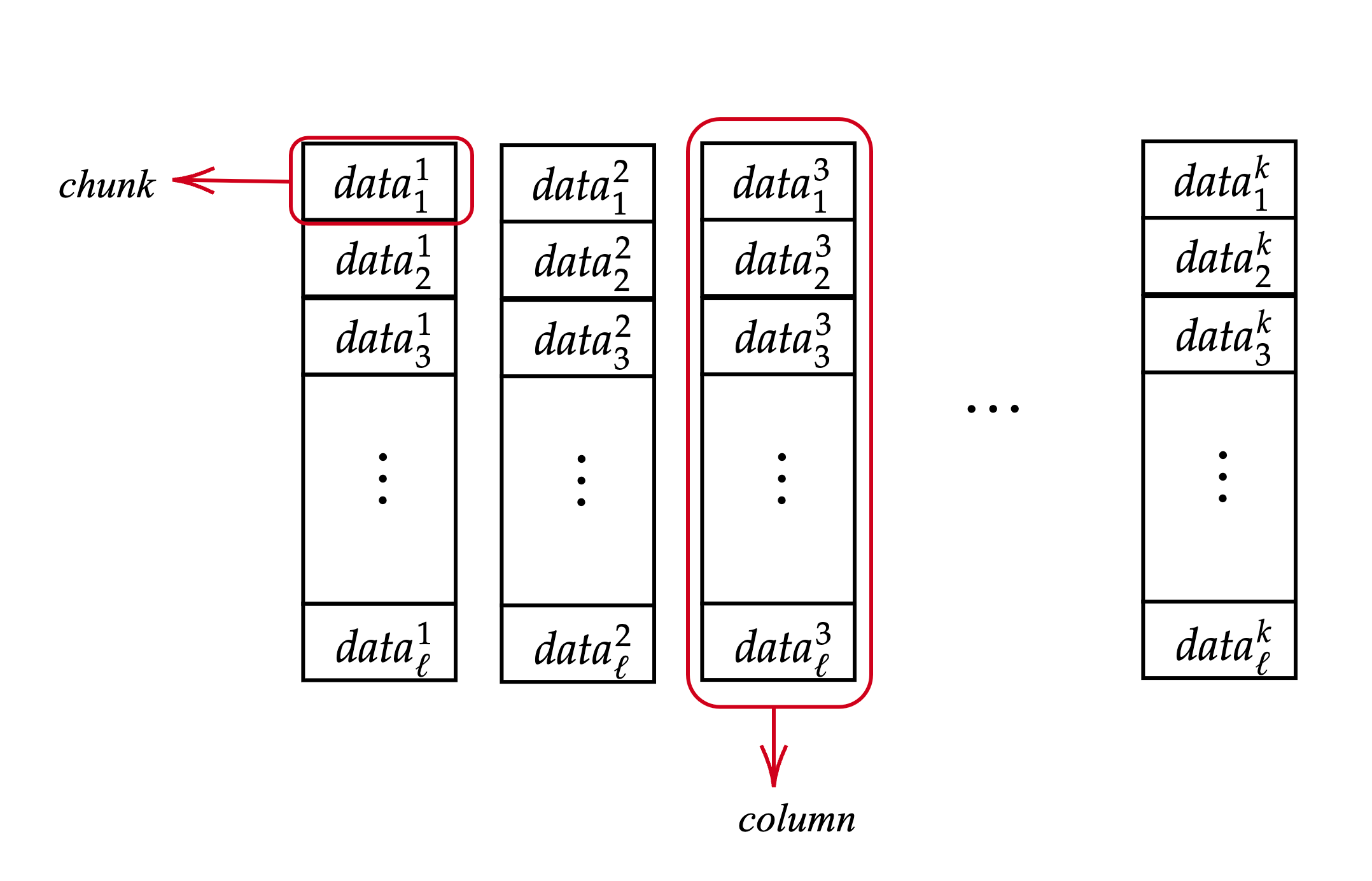
Figure 1: Data matrix structure showing chunks and columns. Each chunk is a 31-byte element, and each column contains chunks.
The encoding process consists of three steps:
- Calculating row commitments.
- Expanding the original data using RS coding.
- Computing the combined row polynomial and the combined column proofs.
Row Commitments
The original data chunks are considered in the evaluation form, and unique polynomials are interpolated for each row. For every row , the encoder interpolates a unique degree polynomial such that for row indices and column indices. Recall that is a primitive element of the field.
Subsequently, 48-byte row commitment values for these polynomials are computed by the encoder. These commitments ensure the correct ordering of chunks within each row.
Note: In this protocol, elliptic curves are used as a group, thus the entries of 's are also elliptic curve points. Let the -coordinate of be represented as and the -coordinate of as . If you have just and one bit of , then you can construct . Therefore, there is no need to use both coordinates of . However, for the sake of simplicity in this document, the value is used.
Reed-Solomon Expansion
Using RS coding, the encoder extends the original data row-wise to obtain the expanded data matrix. The expansion is calculated by evaluating the row polynomials at the new points where . The current design of NomosDA uses an expansion factor of 2, but it can also work with different factors. This expanded data matrix has rows of length .
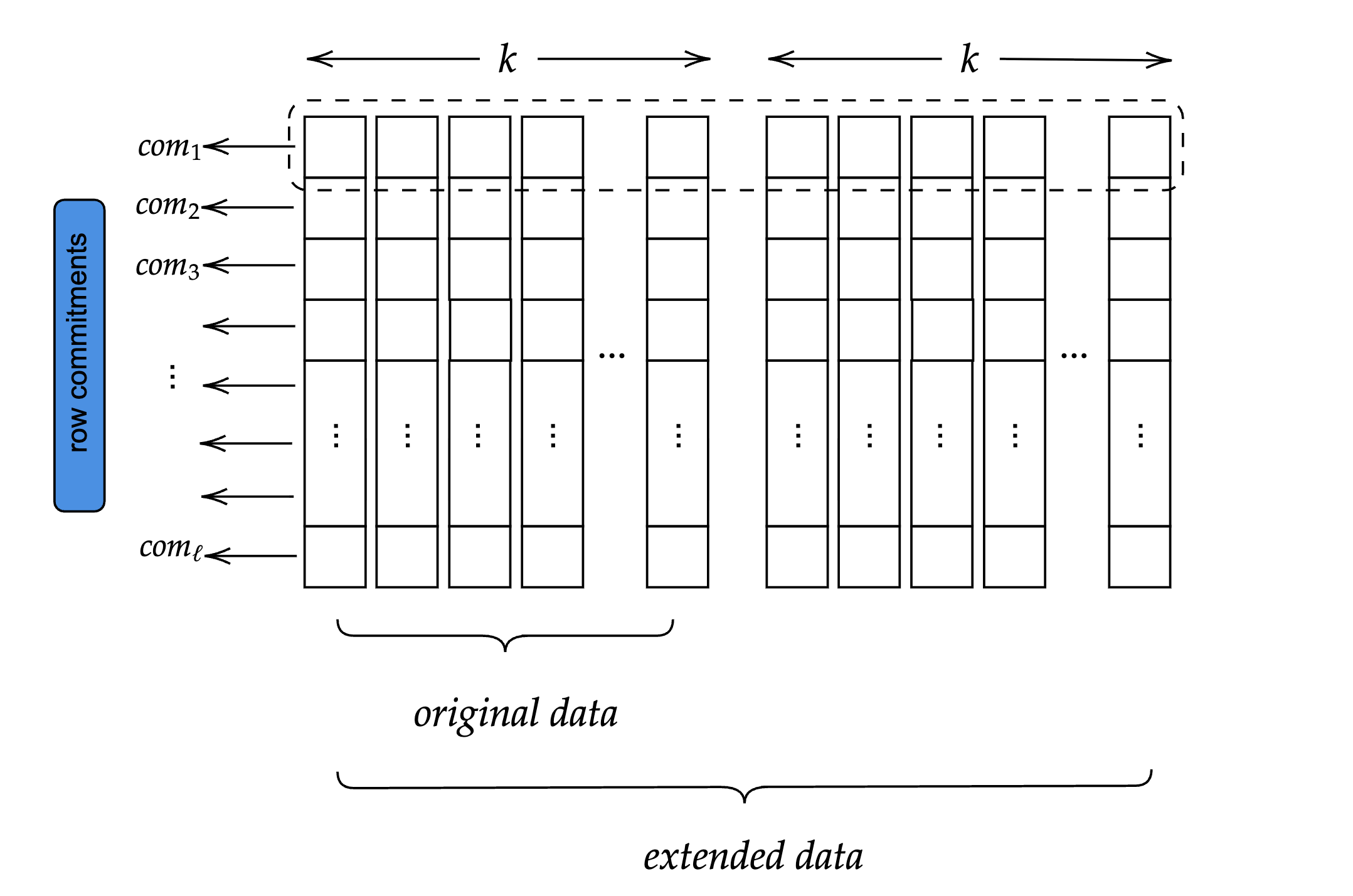
Figure 2: Extended data matrix showing original data ( columns) and extended data ( columns total) after Reed-Solomon expansion.
Due to the homomorphic property of KZG, the row commitment values calculated in the previous step are also valid for the row polynomials of the extended data.
Combined Row Commitment and Column Proofs
To eliminate the need for generating one proof per chunk, a more efficient technique using random linear combinations of row polynomials is used, allowing only one proof to be generated per column while still ensuring the validity of all underlying row data.
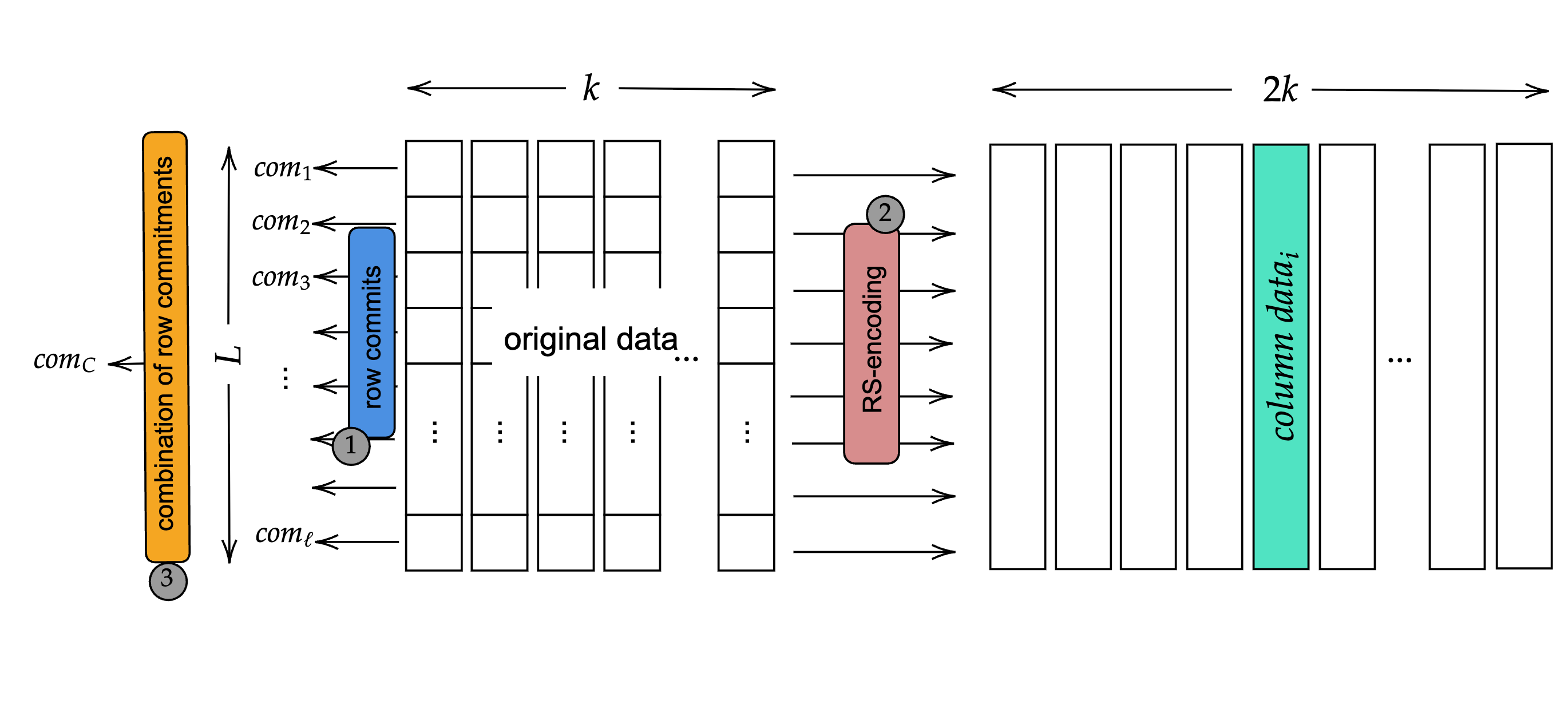
Figure 3: Complete encoding pipeline showing row commitments (step 1), RS-encoding (step 2), and combined row commitment with column data (step 3).
This process consists of the following steps:
Compute the Random Linear Combination Polynomial
Let each row have an associated polynomial and commitment .
The encoder computes random scalar using the Fiat–Shamir heuristic,
applying the BLAKE2b hash function with a 31-byte output,
over the row commitments with a domain separation tag DA_V1
to ensure uniqueness and prevent cross-protocol collisions:
The resulting digest is interpreted as a field element in the scalar field of BLS12-381.
Then, the encoder computes the combined polynomial , defined as:
The corresponding commitment to this polynomial is . This value does not need to be computed by the encoder, since the verifier can derive it directly from the row commitments using the same random scalar .
Compute Combined Evaluation Points per Column
For each column , the encoder has the set of column values , where each value corresponds to .
The encoder computes the combined evaluation value at column position directly:
Generate One Proof per Column
For each column index , the encoder computes a single KZG evaluation proof for the combined polynomial at the evaluation point :
The result is a set of evaluation proofs, one for each column, derived from the combined row structure.
Dispersal
The encoder sends the following information to a DA node in the subnet corresponding to the expanded column number :
- The row commitments .
- The column chunks .
- The combined proof of the column chunks .
This information is also replicated by the receiving node to every other node in the subnet.
Verification
A DA node that receives the column information described above performs the following checks:
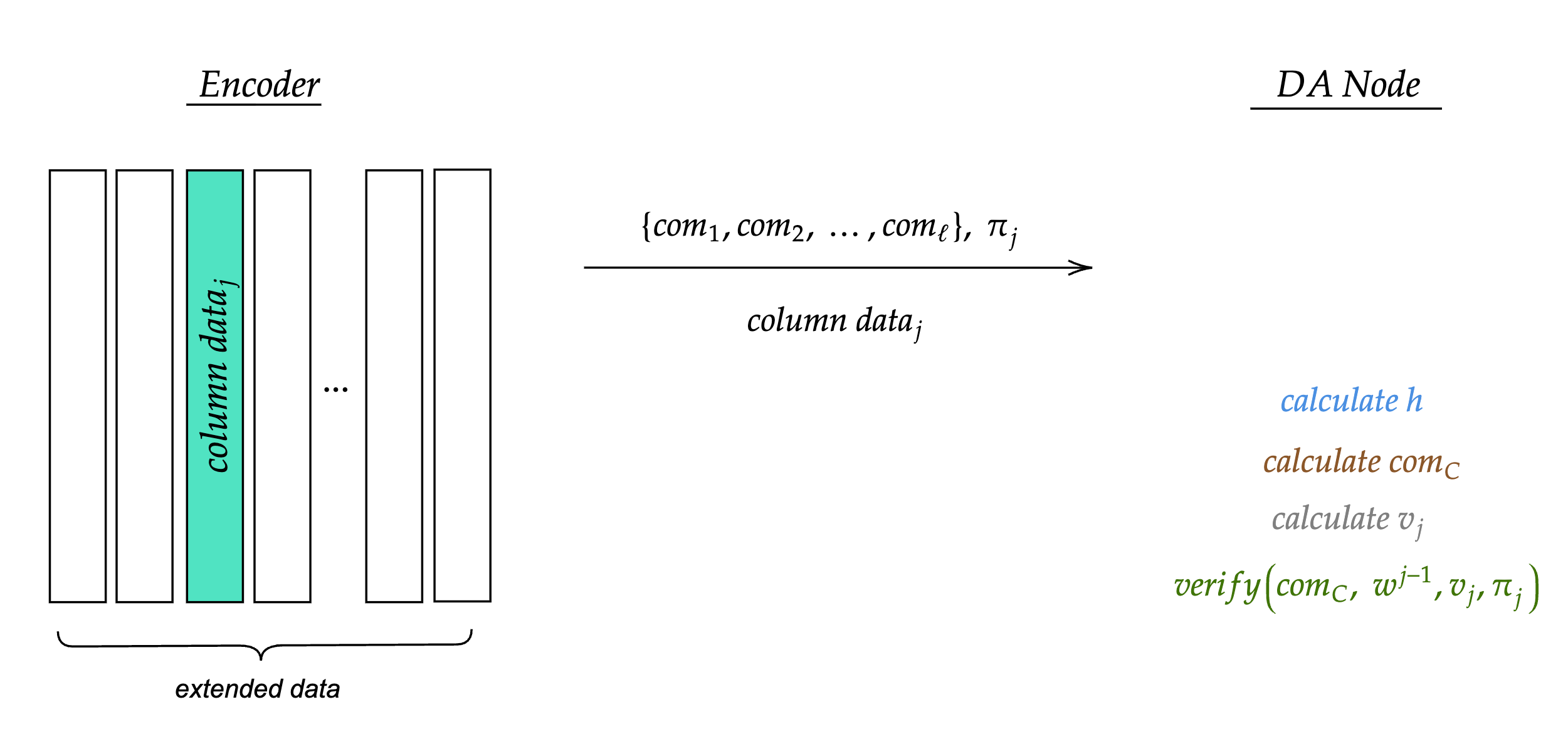
Figure 4: Dispersal and verification flow from Encoder to DA Node. The DA Node receives row commitments, column data, and combined proof, then verifies by calculating , , and .
-
The DA node computes the scalar challenge using a Fiat–Shamir hash over the row commitments with a domain separation tag:
-
The DA node computes the combined commitment :
This is the commitment of the following polynomial:
-
The DA node computes:
This represents , the evaluation of the combined polynomial at the corresponding column index.
-
The DA node verifies that is a valid proof:
Sampling
A sampling client, such as a light node, selects a random column index . It sends a request for column to a DA node hosting that column's data. The DA node sends the client the column data and the combined proof .
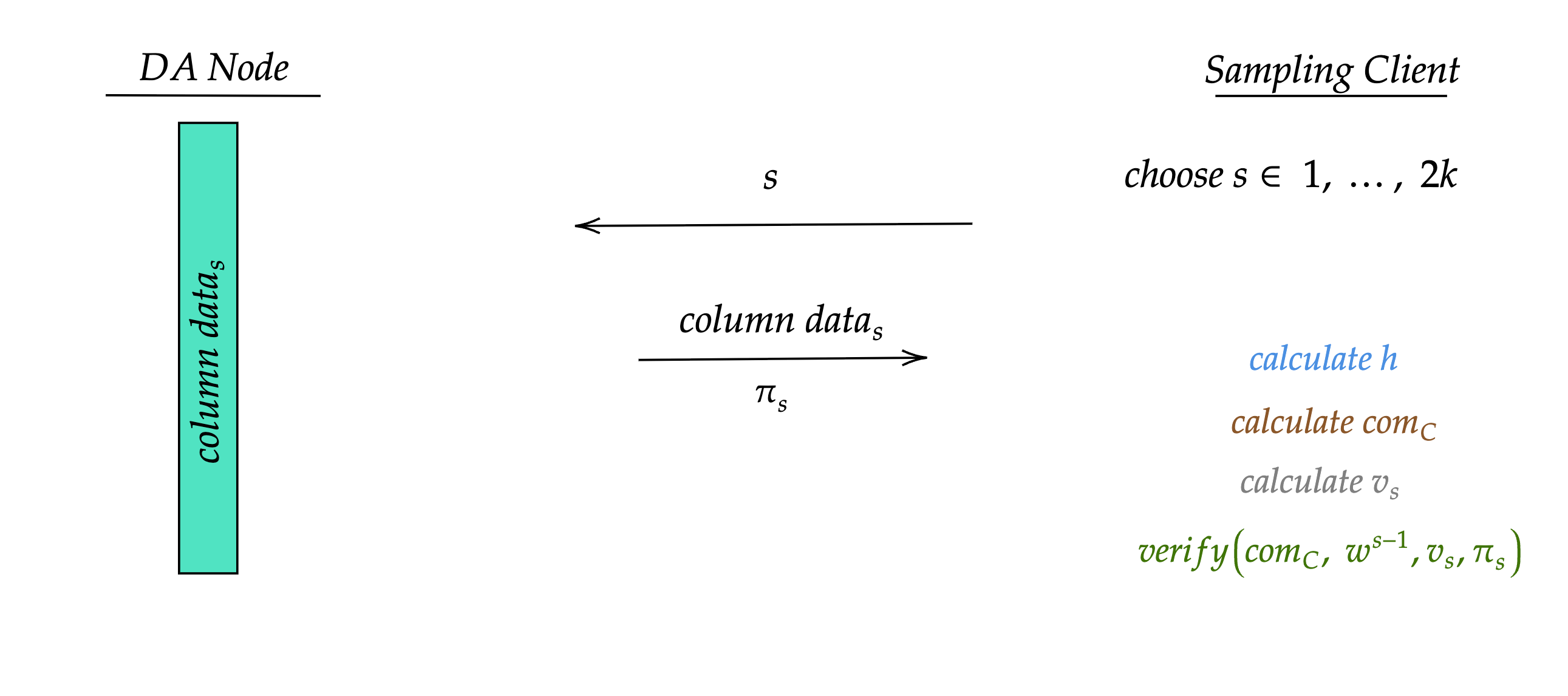
Figure 5: Sampling flow between DA Node and Sampling Client. The client requests a random column index , receives the column data and proof, then verifies by calculating , , and .
Note: The row commitments for a given blob are public and remain unchanged across multiple queries to that blob. If a sampling client has already obtained them, it does not need to request them again.
The verification process run by the sampling client proceeds as follows:
-
Compute the scalar using the domain-separated Fiat–Shamir hash:
-
Compute the combined commitment :
-
Compute the combined evaluation value using the received column data:
-
Verify the evaluation proof:
If these checks succeed, then this proves to the sampling client that the column is correctly encoded and matches the committed data. The sampling client can query several columns to reach a local opinion on the availability of the entire data.
Security Considerations
Fiat–Shamir Security
The random scalar MUST be computed using the Fiat–Shamir heuristic
with the domain separation tag DA_V1 to prevent cross-protocol attacks.
The hash function MUST be BLAKE2b with a 31-byte output.
Chunk Size
Chunks MUST be 31 bytes to ensure they fit within the BLS12-381 scalar field modulus. Using 32-byte chunks would cause some values to exceed the modulus, making data recovery impossible.
Column Sampling Confidence
The more columns a sampling client verifies, the higher confidence it has in the availability of the entire blob. Implementations SHOULD sample a sufficient number of columns to achieve the desired confidence level.
Proof Validity
If a single chunk is invalid, the combined evaluation will likely fail verification due to the unpredictability of the random coefficients. This provides strong guarantees against malicious encoders attempting to hide invalid data.
Part II: Implementation Considerations
IMPORTANT: The sections above define the normative protocol requirements. All implementations MUST comply with those requirements.
The sections below are non-normative. They provide mathematical background for implementers unfamiliar with the underlying cryptographic concepts.
Mathematical Background
Polynomial Interpolation
Polynomial interpolation is the process of creating a unique polynomial from a set of data. In NomosDA, univariate interpolation is used, where each polynomial is defined over a single variable. There are two main ways to represent polynomials:
Coefficient form: Given a set of coefficients , a unique polynomial of degree at most in coefficient form is:
If , then the degree of is exactly .
Evaluation form: Let be a primitive -th root of unity in the field, i.e., and for all . Given a dataset , there exists a unique polynomial in of degree less than such that:
This representation of a polynomial using its values at distinct points is called the evaluation form.
KZG Polynomial Commitment
The KZG polynomial commitment scheme provides a way to commit to a polynomial and provide a proof for an evaluation of this polynomial. This scheme has 4 steps: setup, polynomial commitment, proof evaluation, and proof verification.
The setup phase generates a structured reference string (SRS) and is required only once for all future uses of the scheme. The prover performs the polynomial commitment and proof generation steps, while the verifier checks the validity of the proof against the commitment and the evaluation point.
Setup:
- Choose a generator of a pairing-friendly elliptic curve group .
- Select the maximum degree of the polynomials to be committed to.
- Choose a secret parameter and compute global parameters . Delete and release the parameters publicly.
Note: The expression refers to elliptic curve point addition, i.e., where is the generator point of the group . This is known as multiplicative notation.
Polynomial Commitment: Given a polynomial , compute the commitment of as follows:
Proof Evaluation: Given an evaluation , compute the proof , where is called the quotient polynomial and it is a polynomial if and only if .
Proof Verification: Given commitment , the evaluation point , the evaluation , and proof , verify that:
where is a non-trivial bilinear pairing.
Note: The evaluation of the polynomial commitment to the function at the point , yielding the result and evaluation proof , is represented as: . The verification function is defined as: .
Random Linear Combination of Commitments and Evaluations
When multiple committed polynomials are evaluated at the same point, it's possible to verify all evaluations using a single combined proof, thanks to the homomorphic properties of KZG commitments. This technique improves efficiency by reducing multiple evaluation proofs to just one.
Suppose there are polynomials with corresponding commitments , and the goal is to verify that each .
Instead of generating separate proofs and performing pairing checks:
-
Use the Fiat–Shamir heuristic to derive deterministic random scalars from the commitments :
-
Form the combined polynomial:
-
Compute the combined evaluation:
-
Compute the proof for using the standard KZG method:
Verification: Given commitments , evaluation point and value , and proof :
The verifier calculates the combined commitment using random scalars :
and checks:
This ensures that all original evaluations are correct with a single proof and a single pairing check. Since the random scalars are generated via Fiat–Shamir, any incorrect will almost certainly cause the combined evaluation to fail verification.
Reed-Solomon Erasure Coding
Reed-Solomon coding, also known as RS coding, is an error-correcting code based on the fact that any -degree polynomial can be uniquely determined by points satisfying the polynomial equation. It uses the interpreted polynomial over the data set to produce more points in a process called expansion or encoding. Once the data is expanded, any elements of the total set of points can be used to reconstruct the original data.
Pairing Details
Let , , and be three cyclic groups of large prime order. A map is a pairing map such that:
Given and , a pairing can check that some element without knowing and .
For the KZG commitment scheme to work, a so-called trusted setup is needed, consisting of a structured reference string (SRS). This is a set of curve points in and . For a field element , define . The SRS consists of two sequences of group elements:
where is a secret field element, not known by either participant. is the generator point of and is the generator point of . is the upper bound for the degree of the polynomials that can be committed to, and is the maximum number of evaluations to be proven using a batched proof.
Verify Operation: To verify an evaluation proof, the verifier checks the following equation:
As the verifier does not have access to the actual polynomials and , the next best thing would be to check that:
Expanding the definition of :
For elliptic curve additive notation this is equivalent to:
Now there is a problem, namely, the multiplication on the left-hand side. Pairings allow us to get away with one multiplication. So the verifier actually checks:
i.e.,
This works because of the bilinearity property of elliptic curve pairings:
References
Normative
- BLS12-381 - BLS12-381 elliptic curve specification
Informative
- NomosDA Cryptographic Protocol - Original specification document
- Elliptic Curve Pairings - Background on elliptic curve pairings
Copyright
Copyright and related rights waived via CC0.